
Add files using upload-large-folder tool
Browse files- .gitattributes +2 -0
- BIAS.md +4 -0
- EXPLAINABILITY.md +13 -0
- PRIVACY.md +10 -0
- README.md +288 -0
- SAFETY.md +7 -0
- added_tokens.json +24 -0
- chat_template.jinja +20 -0
- genai_config.json +50 -0
- genselect_hf.py +204 -0
- merges.txt +0 -0
- model.onnx +3 -0
- model.onnx.data +3 -0
- special_tokens_map.json +31 -0
- tokenizer.json +3 -0
- tokenizer_config.json +207 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
model.onnx.data filter=lfs diff=lfs merge=lfs -text
|
BIAS.md
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:---------------------------------------------------------------------------------------------------|:---------------
|
| 3 |
+
Participation considerations from adversely impacted groups [protected classes](https://www.senate.ca.gov/content/protected-classes) in model design and testing: | None
|
| 4 |
+
Measures taken to mitigate against unwanted bias: | None
|
EXPLAINABILITY.md
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------
|
| 3 |
+
Intended Task/Domain: | Reasoning for Math, Code Science Solution Generation
|
| 4 |
+
Model Type: | Transformer
|
| 5 |
+
Intended Users: | Solving competitive programming questions and evaluation for benchmark comparison.
|
| 6 |
+
Output: | Text
|
| 7 |
+
Describe how the model works: | The model generates a reasoning trace and responds with a final solution in response to a user prompting a programming question.
|
| 8 |
+
Name the adversely impacted groups this has been tested to deliver comparable outcomes regardless of: | Not Applicable
|
| 9 |
+
Technical Limitations & Mitigation: | This model is not applicable for Software Engineering tasks. It primarily should be used for competitive coding challenges that require optimized code solutions that can operate in appropriate space and time complexity.
|
| 10 |
+
Verified to have met prescribed NVIDIA quality standards: | Yes
|
| 11 |
+
Performance Metrics: | Pass@1 score
|
| 12 |
+
Potential Known Risks: | The model may provide incorrect code solutions that fail to solve the problem. The model may enter a feedback loop and constantly generate reasoning tokens without generating the final solution.
|
| 13 |
+
Licensing: | [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/deed.en/)
|
PRIVACY.md
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:----------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------
|
| 3 |
+
Generatable or reverse engineerable personal data? | No
|
| 4 |
+
Personal data used to create this model? | No
|
| 5 |
+
How often is the dataset reviewed? | Before Release
|
| 6 |
+
Is there provenance for all datasets used in training? | Yes
|
| 7 |
+
Does data labeling (annotation, metadata) comply with privacy laws? | Yes
|
| 8 |
+
Is data compliant with data subject requests for data correction or removal, if such a request was made? | No, not possible with externally-sourced data.
|
| 9 |
+
Applicable Privacy Policy | https://www.nvidia.com/en-us/about-nvidia/privacy-policy/
|
| 10 |
+
|
README.md
ADDED
|
@@ -0,0 +1,288 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: cc-by-4.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
base_model:
|
| 6 |
+
- nvidia/OpenReasoning-Nemotron-1.5B
|
| 7 |
+
pipeline_tag: text-generation
|
| 8 |
+
library_name: onnxruntime-genai
|
| 9 |
+
tags:
|
| 10 |
+
- nvidia
|
| 11 |
+
- unsloth
|
| 12 |
+
- code
|
| 13 |
+
- onnxruntime
|
| 14 |
+
- onnxruntime-genai
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
# OpenReasoning-Nemotron-1.5B Overview
|
| 18 |
+
|
| 19 |
+
## Description: <br>
|
| 20 |
+
OpenReasoning-Nemotron-1.5B is a large language model (LLM) which is a derivative of Qwen2.5-1.5B-Instruct (AKA the reference model). It is a reasoning model that is post-trained for reasoning about math, code and science solution generation. We evaluated this model with up to 64K output tokens. The OpenReasoning model is available in the following sizes: 1.5B, 7B and 14B and 32B. <br>
|
| 21 |
+
|
| 22 |
+
This model is ready for commercial/non-commercial research use. <br>
|
| 23 |
+
|
| 24 |
+
### License/Terms of Use: <br>
|
| 25 |
+
GOVERNING TERMS: Use of the models listed above are governed by the [Creative Commons Attribution 4.0 International License (CC-BY-4.0)](https://creativecommons.org/licenses/by/4.0/legalcode.en). ADDITIONAL INFORMATION: [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct/blob/main/LICENSE)
|
| 26 |
+
|
| 27 |
+
## Scores on Reasoning Benchmarks
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
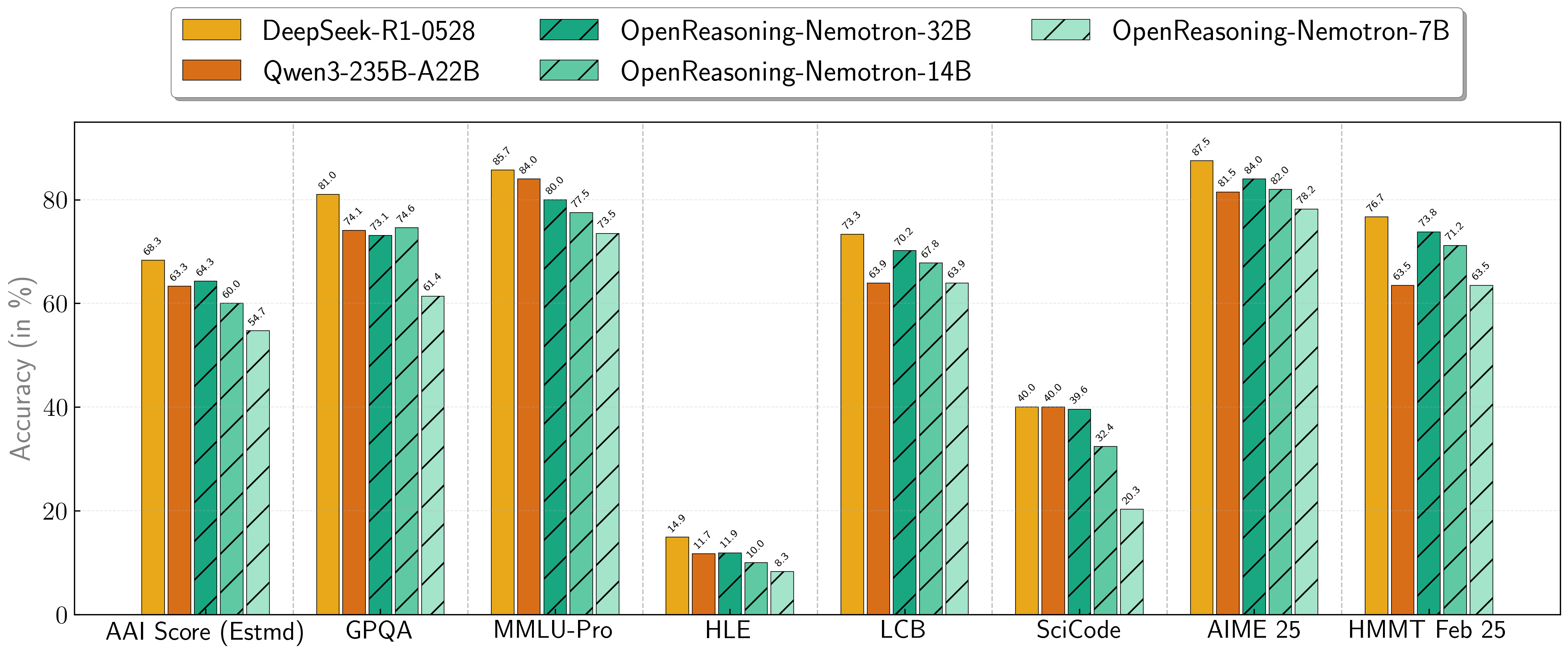
Our models demonstrate exceptional performance across a suite of challenging reasoning benchmarks. The 7B, 14B, and 32B models consistently set new state-of-the-art records for their size classes.
|
| 32 |
+
|
| 33 |
+
| **Model** | **AritificalAnalysisIndex*** | **GPQA** | **MMLU-PRO** | **HLE** | **LiveCodeBench*** | **SciCode** | **AIME24** | **AIME25** | **HMMT FEB 25** |
|
| 34 |
+
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
|
| 35 |
+
| **1.5B**| 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
|
| 36 |
+
| **7B** | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
|
| 37 |
+
| **14B** | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
|
| 38 |
+
| **32B** | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
|
| 39 |
+
|
| 40 |
+
\* This is our estimation of the Artificial Analysis Intelligence Index, not an official score.
|
| 41 |
+
|
| 42 |
+
\* LiveCodeBench version 6, date range 2408-2505.
|
| 43 |
+
|
| 44 |
+
## Combining the work of multiple agents
|
| 45 |
+
OpenReasoning-Nemotron models can be used in a "heavy" mode by starting multiple parallel generations and combining them together via [generative solution selection (GenSelect)](https://arxiv.org/abs/2504.16891). To add this "skill" we follow the original GenSelect training pipeline except we do not train on the selection summary but use the full reasoning trace of DeepSeek R1 0528 671B instead. We only train models to select the best solution for math problems but surprisingly find that this capability directly generalizes to code and science questions! With this "heavy" GenSelect inference mode, OpenReasoning-Nemotron-32B model surpasses O3 (High) on math and coding benchmarks.
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
| **Model** | **Pass@1 (Avg@64)** | **Majority@64** | **GenSelect** |
|
| 50 |
+
| :--- | :--- | :--- | :--- |
|
| 51 |
+
| **1.5B** | | | |
|
| 52 |
+
| **AIME24** | 55.5 | 76.7 | 76.7 |
|
| 53 |
+
| **AIME25** | 45.6 | 70.0 | 70.0 |
|
| 54 |
+
| **HMMT Feb 25** | 31.5 | 46.7 | 53.3 |
|
| 55 |
+
| **7B** | | | |
|
| 56 |
+
| **AIME24** | 84.7 | 93.3 | 93.3 |
|
| 57 |
+
| **AIME25** | 78.2 | 86.7 | 93.3 |
|
| 58 |
+
| **HMMT Feb 25** | 63.5 | 83.3 | 90.0 |
|
| 59 |
+
| **LCB v6 2408-2505** | 63.4 | n/a | 67.7 |
|
| 60 |
+
| **14B** | | | |
|
| 61 |
+
| **AIME24** | 87.8 | 93.3 | 93.3 |
|
| 62 |
+
| **AIME25** | 82.0 | 90.0 | 90.0 |
|
| 63 |
+
| **HMMT Feb 25** | 71.2 | 86.7 | 93.3 |
|
| 64 |
+
| **LCB v6 2408-2505** | 67.9 | n/a | 69.1 |
|
| 65 |
+
| **32B** | | | |
|
| 66 |
+
| **AIME24** | 89.2 | 93.3 | 93.3 |
|
| 67 |
+
| **AIME25** | 84.0 | 90.0 | 93.3 |
|
| 68 |
+
| **HMMT Feb 25** | 73.8 | 86.7 | 96.7 |
|
| 69 |
+
| **LCB v6 2408-2505** | 70.2 | n/a | 75.3 |
|
| 70 |
+
| **HLE** | 11.8 | 13.4 | 15.5 |
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
## How to use the models?
|
| 74 |
+
|
| 75 |
+
To run inference on coding problems:
|
| 76 |
+
|
| 77 |
+
````python
|
| 78 |
+
import transformers
|
| 79 |
+
import torch
|
| 80 |
+
model_id = "nvidia/OpenReasoning-Nemotron-1.5B"
|
| 81 |
+
pipeline = transformers.pipeline(
|
| 82 |
+
"text-generation",
|
| 83 |
+
model=model_id,
|
| 84 |
+
model_kwargs={"torch_dtype": torch.bfloat16},
|
| 85 |
+
device_map="auto",
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
# Code generation prompt
|
| 89 |
+
prompt = """You are a helpful and harmless assistant. You should think step-by-step before responding to the instruction below.
|
| 90 |
+
Please use python programming language only.
|
| 91 |
+
You must use ```python for just the final solution code block with the following format:
|
| 92 |
+
```python
|
| 93 |
+
# Your code here
|
| 94 |
+
```
|
| 95 |
+
{user}
|
| 96 |
+
"""
|
| 97 |
+
|
| 98 |
+
# Math generation prompt
|
| 99 |
+
# prompt = """Solve the following math problem. Make sure to put the answer (and only answer) inside \\boxed{}.
|
| 100 |
+
#
|
| 101 |
+
# {user}
|
| 102 |
+
# """
|
| 103 |
+
|
| 104 |
+
# Science generation prompt
|
| 105 |
+
# You can refer to prompts here -
|
| 106 |
+
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/generic/hle.yaml (HLE)
|
| 107 |
+
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-4choices-boxed.yaml (for GPQA)
|
| 108 |
+
# https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/eval/aai/mcq-10choices-boxed.yaml (MMLU-Pro)
|
| 109 |
+
|
| 110 |
+
messages = [
|
| 111 |
+
{
|
| 112 |
+
"role": "user",
|
| 113 |
+
"content": prompt.format(user="Write a program to calculate the sum of the first $N$ fibonacci numbers")},
|
| 114 |
+
]
|
| 115 |
+
outputs = pipeline(
|
| 116 |
+
messages,
|
| 117 |
+
max_new_tokens=64000,
|
| 118 |
+
)
|
| 119 |
+
print(outputs[0]["generated_text"][-1]['content'])
|
| 120 |
+
````
|
| 121 |
+
|
| 122 |
+
We have added [a simple transformer-based script](https://huggingface.co/nvidia/OpenReasoning-Nemotron-1.5B/blob/main/genselect_hf.py) in this repo to illustrate GenSelect.
|
| 123 |
+
To learn how to use the models in GenSelect mode with NeMo-Skills, see our [documentation](https://nvidia.github.io/NeMo-Skills/releases/openreasoning/evaluation/).
|
| 124 |
+
|
| 125 |
+
To use the model with GenSelect inference, we recommend following our
|
| 126 |
+
[reference implementation in NeMo-Skills](https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/pipeline/genselect.py). Alternatively, you can manually extract the summary from all solutions and use this
|
| 127 |
+
[prompt](https://github.com/NVIDIA/NeMo-Skills/blob/main/nemo_skills/prompt/config/openmath/genselect.yaml) for the math problems. We will add the prompt we used for the coding problems and a reference implementation soon!
|
| 128 |
+
|
| 129 |
+
You can learn more about GenSelect in these papers:
|
| 130 |
+
* [AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset](https://arxiv.org/abs/2504.16891)
|
| 131 |
+
* [GenSelect: A Generative Approach to Best-of-N](https://openreview.net/forum?id=8LhnmNmUDb)
|
| 132 |
+
|
| 133 |
+
## Accessing training data
|
| 134 |
+
|
| 135 |
+
Training data has been released! Math and code are available as part of
|
| 136 |
+
[Nemotron-Post-Training-Dataset-v1](https://huggingface.co/datasets/nvidia/Nemotron-Post-Training-Dataset-v1) and science is available in
|
| 137 |
+
[OpenScienceReasoning-2](https://huggingface.co/datasets/nvidia/OpenScienceReasoning-2).
|
| 138 |
+
See our [documentation](https://nvidia.github.io/NeMo-Skills/releases/openreasoning/training) for more details.
|
| 139 |
+
|
| 140 |
+
## Citation
|
| 141 |
+
|
| 142 |
+
If you find the data useful, please cite:
|
| 143 |
+
```
|
| 144 |
+
@article{ahmad2025opencodereasoning,
|
| 145 |
+
title={{OpenCodeReasoning: Advancing Data Distillation for Competitive Coding}},
|
| 146 |
+
author={Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, Boris Ginsburg},
|
| 147 |
+
year={2025},
|
| 148 |
+
eprint={2504.01943},
|
| 149 |
+
archivePrefix={arXiv},
|
| 150 |
+
primaryClass={cs.CL},
|
| 151 |
+
url={https://arxiv.org/abs/2504.01943},
|
| 152 |
+
}
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
```
|
| 156 |
+
@misc{ahmad2025opencodereasoningiisimpletesttime,
|
| 157 |
+
title={{OpenCodeReasoning-II: A Simple Test Time Scaling Approach via Self-Critique}},
|
| 158 |
+
author={Wasi Uddin Ahmad and Somshubra Majumdar and Aleksander Ficek and Sean Narenthiran and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Vahid Noroozi and Boris Ginsburg},
|
| 159 |
+
year={2025},
|
| 160 |
+
eprint={2507.09075},
|
| 161 |
+
archivePrefix={arXiv},
|
| 162 |
+
primaryClass={cs.CL},
|
| 163 |
+
url={https://arxiv.org/abs/2507.09075},
|
| 164 |
+
}
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
```
|
| 168 |
+
@misc{moshkov2025aimo2winningsolutionbuilding,
|
| 169 |
+
title={{AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset}},
|
| 170 |
+
author={Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman},
|
| 171 |
+
year={2025},
|
| 172 |
+
eprint={2504.16891},
|
| 173 |
+
archivePrefix={arXiv},
|
| 174 |
+
primaryClass={cs.AI},
|
| 175 |
+
url={https://arxiv.org/abs/2504.16891},
|
| 176 |
+
}
|
| 177 |
+
```
|
| 178 |
+
|
| 179 |
+
```
|
| 180 |
+
@inproceedings{toshniwal2025genselect,
|
| 181 |
+
title={{GenSelect: A Generative Approach to Best-of-N}},
|
| 182 |
+
author={Shubham Toshniwal and Ivan Sorokin and Aleksander Ficek and Ivan Moshkov and Igor Gitman},
|
| 183 |
+
booktitle={2nd AI for Math Workshop @ ICML 2025},
|
| 184 |
+
year={2025},
|
| 185 |
+
url={https://openreview.net/forum?id=8LhnmNmUDb}
|
| 186 |
+
}
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
## Additional Information:
|
| 191 |
+
|
| 192 |
+
### Deployment Geography:
|
| 193 |
+
Global<br>
|
| 194 |
+
|
| 195 |
+
### Use Case: <br>
|
| 196 |
+
This model is intended for developers and researchers who work on competitive math, code and science problems. It has been trained via only supervised fine-tuning to achieve strong scores on benchmarks. <br>
|
| 197 |
+
|
| 198 |
+
### Release Date: <br>
|
| 199 |
+
Huggingface [07/16/2025] via https://huggingface.co/nvidia/OpenReasoning-Nemotron-1.5B/ <br>
|
| 200 |
+
|
| 201 |
+
## Reference(s):
|
| 202 |
+
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
|
| 203 |
+
* [2504.01943] OpenCodeReasoning: Advancing Data Distillation for Competitive Coding
|
| 204 |
+
* [2504.16891] AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset
|
| 205 |
+
<br>
|
| 206 |
+
|
| 207 |
+
## Model Architecture: <br>
|
| 208 |
+
Architecture Type: Dense decoder-only Transformer model
|
| 209 |
+
Network Architecture: Qwen-1.5B-Instruct
|
| 210 |
+
<br>
|
| 211 |
+
**This model was developed based on Qwen2.5-1.5B-Instruct and has 1.5B model parameters. <br>
|
| 212 |
+
|
| 213 |
+
**OpenReasoning-Nemotron-1.5B was developed based on Qwen2.5-1.5B-Instruct and has 1.5B model parameters. <br>**
|
| 214 |
+
|
| 215 |
+
**OpenReasoning-Nemotron-7B was developed based on Qwen2.5-7B-Instruct and has 7B model parameters. <br>**
|
| 216 |
+
|
| 217 |
+
**OpenReasoning-Nemotron-14B was developed based on Qwen2.5-14B-Instruct and has 14B model parameters. <br>**
|
| 218 |
+
|
| 219 |
+
**OpenReasoning-Nemotron-32B was developed based on Qwen2.5-32B-Instruct and has 32B model parameters. <br>**
|
| 220 |
+
|
| 221 |
+
## Input: <br>
|
| 222 |
+
**Input Type(s):** Text <br>
|
| 223 |
+
**Input Format(s):** String <br>
|
| 224 |
+
**Input Parameters:** One-Dimensional (1D) <br>
|
| 225 |
+
**Other Properties Related to Input:** Trained for up to 64,000 output tokens <br>
|
| 226 |
+
|
| 227 |
+
## Output: <br>
|
| 228 |
+
**Output Type(s):** Text <br>
|
| 229 |
+
**Output Format:** String <br>
|
| 230 |
+
**Output Parameters:** One-Dimensional (1D) <br>
|
| 231 |
+
**Other Properties Related to Output:** Trained for up to 64,000 output tokens <br>
|
| 232 |
+
|
| 233 |
+
Our AI models are designed and/or optimized to run on NVIDIA GPU-accelerated systems. By leveraging NVIDIA’s hardware (e.g. GPU cores) and software frameworks (e.g., CUDA libraries), the model achieves faster training and inference times compared to CPU-only solutions. <br>
|
| 234 |
+
|
| 235 |
+
## Software Integration : <br>
|
| 236 |
+
* Runtime Engine: NeMo 2.3.0 <br>
|
| 237 |
+
* Recommended Hardware Microarchitecture Compatibility: <br>
|
| 238 |
+
NVIDIA Ampere <br>
|
| 239 |
+
NVIDIA Hopper <br>
|
| 240 |
+
* Preferred/Supported Operating System(s): Linux <br>
|
| 241 |
+
|
| 242 |
+
## Model Version(s):
|
| 243 |
+
1.0 (7/16/2025) <br>
|
| 244 |
+
OpenReasoning-Nemotron-32B<br>
|
| 245 |
+
OpenReasoning-Nemotron-14B<br>
|
| 246 |
+
OpenReasoning-Nemotron-7B<br>
|
| 247 |
+
OpenReasoning-Nemotron-1.5B<br>
|
| 248 |
+
|
| 249 |
+
# Training and Evaluation Datasets: <br>
|
| 250 |
+
|
| 251 |
+
## Training Dataset:
|
| 252 |
+
|
| 253 |
+
The training corpus for OpenReasoning-Nemotron-1.5B is comprised of questions from [OpenCodeReasoning](https://huggingface.co/datasets/nvidia/OpenCodeReasoning) dataset, [OpenCodeReasoning-II](https://arxiv.org/abs/2507.09075), [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning), and the Synthetic Science questions from the [Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset). All responses are generated using DeepSeek-R1-0528. We also include the instruction following and tool calling data from Llama-Nemotron-Post-Training-Dataset without modification.
|
| 254 |
+
|
| 255 |
+
Data Collection Method: Hybrid: Automated, Human, Synthetic <br>
|
| 256 |
+
Labeling Method: Hybrid: Automated, Human, Synthetic <br>
|
| 257 |
+
Properties: 5M DeepSeek-R1-0528 generated responses from OpenCodeReasoning questions (https://huggingface.co/datasets/nvidia/OpenCodeReasoning), [OpenMathReasoning](https://huggingface.co/datasets/nvidia/OpenMathReasoning), and the Synthetic Science questions from the [Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset). We also include the instruction following and tool calling data from Llama-Nemotron-Post-Training-Dataset without modification.
|
| 258 |
+
|
| 259 |
+
## Evaluation Dataset:
|
| 260 |
+
We used the following benchmarks to evaluate the model holistically.
|
| 261 |
+
|
| 262 |
+
### Math
|
| 263 |
+
- AIME 2024/2025 <br>
|
| 264 |
+
- HMMT Feb 2025 <br>
|
| 265 |
+
|
| 266 |
+
### Code
|
| 267 |
+
- LiveCodeBench <br>
|
| 268 |
+
- SciCode <br>
|
| 269 |
+
|
| 270 |
+
### Science
|
| 271 |
+
- GPQA <br>
|
| 272 |
+
- MMLU-PRO <br>
|
| 273 |
+
- HLE <br>
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
Data Collection Method: Hybrid: Automated, Human, Synthetic <br>
|
| 277 |
+
Labeling Method: Hybrid: Automated, Human, Synthetic <br>
|
| 278 |
+
|
| 279 |
+
## Inference:
|
| 280 |
+
**Acceleration Engine:** vLLM, Tensor(RT)-LLM <br>
|
| 281 |
+
**Test Hardware** NVIDIA H100-80GB <br>
|
| 282 |
+
|
| 283 |
+
## Ethical Considerations:
|
| 284 |
+
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
|
| 285 |
+
|
| 286 |
+
For more detailed information on ethical considerations for this model, please see the Model Card++ Explainability, Bias, Safety & Security, and Privacy Subcards.
|
| 287 |
+
|
| 288 |
+
Please report model quality, risk, security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
|
SAFETY.md
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Field | Response
|
| 2 |
+
:---------------------------------------------------|:----------------------------------
|
| 3 |
+
Model Application Field(s): | Reasoning for Code Generation<br>
|
| 4 |
+
Describe the life critical impact (if present). | Not Applicable <br>
|
| 5 |
+
Use Case Restrictions: | Abide by CC BY 4.0 <br>
|
| 6 |
+
Model and dataset restrictions: | The Principle of least privilege (PoLP) is applied limiting access for dataset generation and model development. Restrictions enforce dataset access during training, and dataset license constraints adhered to.
|
| 7 |
+
|
added_tokens.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</tool_call>": 151658,
|
| 3 |
+
"<tool_call>": 151657,
|
| 4 |
+
"<|box_end|>": 151649,
|
| 5 |
+
"<|box_start|>": 151648,
|
| 6 |
+
"<|endoftext|>": 151643,
|
| 7 |
+
"<|file_sep|>": 151664,
|
| 8 |
+
"<|fim_middle|>": 151660,
|
| 9 |
+
"<|fim_pad|>": 151662,
|
| 10 |
+
"<|fim_prefix|>": 151659,
|
| 11 |
+
"<|fim_suffix|>": 151661,
|
| 12 |
+
"<|im_end|>": 151645,
|
| 13 |
+
"<|im_start|>": 151644,
|
| 14 |
+
"<|image_pad|>": 151655,
|
| 15 |
+
"<|object_ref_end|>": 151647,
|
| 16 |
+
"<|object_ref_start|>": 151646,
|
| 17 |
+
"<|quad_end|>": 151651,
|
| 18 |
+
"<|quad_start|>": 151650,
|
| 19 |
+
"<|repo_name|>": 151663,
|
| 20 |
+
"<|video_pad|>": 151656,
|
| 21 |
+
"<|vision_end|>": 151653,
|
| 22 |
+
"<|vision_pad|>": 151654,
|
| 23 |
+
"<|vision_start|>": 151652
|
| 24 |
+
}
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{%- if messages[0]['role'] == 'system' %}
|
| 2 |
+
{{- '<|im_start|>system
|
| 3 |
+
' + messages[0]['content'] + '<|im_end|>
|
| 4 |
+
' }}
|
| 5 |
+
{%- else %}
|
| 6 |
+
{{- '<|im_start|>system
|
| 7 |
+
<|im_end|>
|
| 8 |
+
' }}
|
| 9 |
+
{%- endif %}
|
| 10 |
+
{%- for message in messages %}
|
| 11 |
+
{%- if (message.role == 'user') or (message.role == 'system' and not loop.first) or (message.role == 'assistant') %}
|
| 12 |
+
{{- '<|im_start|>' + message.role + '
|
| 13 |
+
' + message.content + '<|im_end|>' + '
|
| 14 |
+
' }}
|
| 15 |
+
{%- endif %}
|
| 16 |
+
{%- endfor %}
|
| 17 |
+
{%- if add_generation_prompt %}
|
| 18 |
+
{{- '<|im_start|>assistant
|
| 19 |
+
' }}
|
| 20 |
+
{%- endif %}
|
genai_config.json
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"model": {
|
| 3 |
+
"bos_token_id": 151643,
|
| 4 |
+
"context_length": 131072,
|
| 5 |
+
"decoder": {
|
| 6 |
+
"session_options": {
|
| 7 |
+
"log_id": "onnxruntime-genai",
|
| 8 |
+
"provider_options": []
|
| 9 |
+
},
|
| 10 |
+
"filename": "model.onnx",
|
| 11 |
+
"head_size": 128,
|
| 12 |
+
"hidden_size": 1536,
|
| 13 |
+
"inputs": {
|
| 14 |
+
"input_ids": "input_ids",
|
| 15 |
+
"attention_mask": "attention_mask",
|
| 16 |
+
"position_ids": "position_ids",
|
| 17 |
+
"past_key_names": "past_key_values.%d.key",
|
| 18 |
+
"past_value_names": "past_key_values.%d.value"
|
| 19 |
+
},
|
| 20 |
+
"outputs": {
|
| 21 |
+
"logits": "logits",
|
| 22 |
+
"present_key_names": "present.%d.key",
|
| 23 |
+
"present_value_names": "present.%d.value"
|
| 24 |
+
},
|
| 25 |
+
"num_attention_heads": 12,
|
| 26 |
+
"num_hidden_layers": 28,
|
| 27 |
+
"num_key_value_heads": 2
|
| 28 |
+
},
|
| 29 |
+
"eos_token_id": 151645,
|
| 30 |
+
"pad_token_id": 151645,
|
| 31 |
+
"type": "qwen2",
|
| 32 |
+
"vocab_size": 151936
|
| 33 |
+
},
|
| 34 |
+
"search": {
|
| 35 |
+
"diversity_penalty": 0.0,
|
| 36 |
+
"do_sample": false,
|
| 37 |
+
"early_stopping": true,
|
| 38 |
+
"length_penalty": 1.0,
|
| 39 |
+
"max_length": 131072,
|
| 40 |
+
"min_length": 0,
|
| 41 |
+
"no_repeat_ngram_size": 0,
|
| 42 |
+
"num_beams": 1,
|
| 43 |
+
"num_return_sequences": 1,
|
| 44 |
+
"past_present_share_buffer": false,
|
| 45 |
+
"repetition_penalty": 1.0,
|
| 46 |
+
"temperature": 1.0,
|
| 47 |
+
"top_k": 1,
|
| 48 |
+
"top_p": 1.0
|
| 49 |
+
}
|
| 50 |
+
}
|
genselect_hf.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024, NVIDIA CORPORATION. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 16 |
+
import random
|
| 17 |
+
import re
|
| 18 |
+
import torch
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
PROMPT = """You will be given a challenging math problem followed by {num_solutions} solutions. Your task is to systematically analyze these solutions to identify the most mathematically sound approach.
|
| 22 |
+
|
| 23 |
+
Input Format:
|
| 24 |
+
Problem: A complex mathematical word problem at advanced high school or college level
|
| 25 |
+
Solutions: Detailed solutions indexed 0-{max_idx}, each concluding with an answer in \\boxed{{}} notation
|
| 26 |
+
|
| 27 |
+
YOUR TASK
|
| 28 |
+
|
| 29 |
+
Problem: {problem}
|
| 30 |
+
|
| 31 |
+
Solutions:
|
| 32 |
+
{solutions}
|
| 33 |
+
|
| 34 |
+
Evaluation Process:
|
| 35 |
+
|
| 36 |
+
1. Initial Screening
|
| 37 |
+
- Group solutions by their final answers
|
| 38 |
+
- Identify and explain mathematical contradictions between different answers
|
| 39 |
+
- Eliminate solutions with clear mathematical errors
|
| 40 |
+
|
| 41 |
+
2. Detailed Analysis
|
| 42 |
+
For remaining solutions, evaluate:
|
| 43 |
+
- Mathematical precision and accuracy
|
| 44 |
+
- Logical progression of steps
|
| 45 |
+
- Completeness of mathematical reasoning
|
| 46 |
+
- Proper use of mathematical notation, including \\boxed{{}}
|
| 47 |
+
- Handling of edge cases or special conditions
|
| 48 |
+
- For solutions containing and addressing errors, evaluate the error identification and correction methodology.
|
| 49 |
+
|
| 50 |
+
3. Solution Comparison
|
| 51 |
+
Compare viable solutions based on:
|
| 52 |
+
- Efficiency of approach
|
| 53 |
+
- Clarity of mathematical reasoning
|
| 54 |
+
- Sophistication of method
|
| 55 |
+
- Robustness of solution (works for all cases)
|
| 56 |
+
|
| 57 |
+
Your response should include:
|
| 58 |
+
1. Brief analysis of conflicting answers
|
| 59 |
+
2. Detailed evaluation of mathematically sound solutions
|
| 60 |
+
3. Justification for eliminating incorrect solutions
|
| 61 |
+
4. Clear explanation for selecting the best approach
|
| 62 |
+
|
| 63 |
+
End your evaluation with exactly:
|
| 64 |
+
Judgment: [IDX]
|
| 65 |
+
where IDX is the index 0-{max_idx} of the best solution.
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
PROBLEM = """In an $11 \\times 11$ grid of cells, each pair of edge-adjacent cells is connected by a door. Karthik wants to walk a path in this grid. He can start in any cell, but he must end in the same cell he
|
| 70 |
+
started in, and he cannot go through any door more than once (not even in opposite directions). Compute the maximum number of doors he can go through in such a path."""
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
SOLUTION_LIST = [
|
| 74 |
+
"""The grid is \\(11 \\times 11\\), so there are \\(11 \\times 11 = 121\\) cells. The total number of doors (edges) is calculated as follows: \n- Horizontal doors: 11 rows with 10 doors each, so \\(1
|
| 75 |
+
1 \\times 10 = 110\\). \n- Vertical doors: 11 columns with 10 doors each, so \\(11 \\times 10 = 110\\). \nTotal doors: \\(110 + 110 = 220\\). \n\nKarthik must walk a closed path (cycle) starting and ending at th
|
| 76 |
+
e same cell, without reusing any door. The goal is to maximize the number of doors used, which corresponds to finding a subgraph that is connected, has all even degrees (to admit an Eulerian circuit), and maximizes
|
| 77 |
+
the number of edges. \n\nThe grid has 36 vertices of odd degree: \n- Each side has \\(11 - 2 = 9\\) edge cells (not corners) with degree 3. \n- With 4 sides, total odd-degree vertices: \\(4 \\times 9 = 36\\).
|
| 78 |
+
\n\nTo make all degrees even, edges must be removed. The minimum number of edges to remove to achieve an Eulerian circuit in a connected graph is given by a minimum T-join, where T is the set of odd-degree vertices
|
| 79 |
+
. For an \\(n \\times n\\) grid with \\(n\\) odd, the minimum number of edges to remove is \\(4n - 8\\). For \\(n = 11\\): \n\\[4 \\times 11 - 8 = 44 - 8 = 36.\\] \n\nThus, 36 edges must be removed. The remaining
|
| 80 |
+
number of edges is: \n\\[220 - 36 = 184.\\] \n\nThis is achievable with the following construction: \n1. On each boundary (top, bottom, left, right), remove 4 horizontal or vertical edges to pair adjacent odd-d
|
| 81 |
+
egree cells, covering 8 cells per boundary and leaving one unpaired per boundary. This removes \\(4 \\times 4 = 16\\) edges. \n - The unpaired cells are \\((1,10)\\), \\((11,10)\\), \\((10,1)\\), and \\((10,11)\
|
| 82 |
+
\). \n2. Pair \\((11,10)\\) and \\((10,11)\\) by removing a path of length 2 (e.g., edges \\((11,10)-(10,10)\\) and \\((10,10)-(10,11)\\)). \n3. Pair \\((1,10)\\) and \\((10,1)\\) by removing a path of length 18
|
| 83 |
+
(e.g., vertically down column 10 from \\((1,10)\\) to \\((10,10)\\), then horizontally left in row 10 from \\((10,10)\\) to \\((10,1)\\)). \n - This removes \\(2 + 18 = 20\\) edges. \nTotal edges removed: \\(16
|
| 84 |
+
+ 20 = 36\\). \n\nThe remaining graph has 184 edges, is connected, and has all even degrees, so an Eulerian circuit exists with 184 edges. This is the maximum possible, as fewer removals would leave odd-degree ve
|
| 85 |
+
rtices or disconnect the graph. \n\n\\boxed{184}""",
|
| 86 |
+
"""The problem involves finding the maximum number of doors Karthik can traverse in an \\(11 \\times 11\\) grid, starting and ending at the same cell, without repeating any door (edge adjacency).\n\nT
|
| 87 |
+
he grid has \\(11 \\times 11 = 121\\) cells. The total number of doors (edges) is calculated as follows:\n- Horizontal doors: \\(11\\) rows, each with \\(10\\) doors, so \\(11 \\times 10 = 110\\).\n- Vertical doors
|
| 88 |
+
: \\(11\\) columns, each with \\(10\\) doors, so \\(11 \\times 10 = 110\\).\n- Total doors: \\(110 + 110 = 220\\).\n\nThe grid graph is connected and bipartite, with a chessboard coloring. The number of black cells
|
| 89 |
+
is \\(61\\) and white cells is \\(60\\), since both dimensions are odd. The degrees of the vertices vary:\n- Corner cells have degree \\(2\\) (even).\n- Edge cells (not corners) have degree \\(3\\) (odd).\n- Inter
|
| 90 |
+
nal cells have degree \\(4\\) (even).\n\nThe number of odd-degree vertices (denoted \\(S\\)) is:\n- Top row: \\(11 - 2 = 9\\) (excluding corners).\n- Bottom row: \\(9\\).\n- Left column: \\(9\\) (excluding corners)
|
| 91 |
+
.\n- Right column: \\(9\\).\n- Total: \\(9 + 9 + 9 + 9 = 36\\).\n\nKarthik's path is a closed trail (start and end at the same vertex, no repeated edges, but vertices may be revisited). The maximum number of edges
|
| 92 |
+
in such a trail corresponds to the size of the largest connected Eulerian subgraph (all degrees even and connected).\n\nFor an \\(m \\times n\\) grid with both dimensions odd, the minimum number of edges to remove
|
| 93 |
+
to make the graph Eulerian (all degrees even) is \\(m + n - 2\\). Here, \\(m = n = 11\\), so:\n\\[\nm + n - 2 = 11 + 11 - 2 = 20.\n\\]\nAfter removing these 20 edges, the remaining graph has:\n\\[\n220 - 20 = 200\n
|
| 94 |
+
\\]\nedges. This subgraph is connected and Eulerian, so it admits an Eulerian circuit (a closed trail) using all 200 edges.\n\nIt is not possible to have a closed trail with more than 200 edges, as removing fewer t
|
| 95 |
+
han 20 edges cannot make all degrees even (since at least 20 edges must be removed to address the 36 odd-degree vertices, and the minimum is 20 for this grid).\n\nThus, the maximum number of doors Karthik can trave
|
| 96 |
+
rse is 200.\n\n\\boxed{200}""",
|
| 97 |
+
"""The grid is an $11 \\times 11$ graph with cells as vertices and doors between edge-adjacent cells as edges. The graph is bipartite, with partitions of sizes 61 and 60 due to the odd grid size. A cy
|
| 98 |
+
cle must alternate between the two partitions, so the maximum number of vertices in any cycle is $2 \\times \\min(61, 60) = 120$.\n\nThis maximum is achievable by removing one vertex from the partition of size 61, resulting in a graph with 60 vertices in each partition. The remaining graph is Hamiltonian, meaning it contains a cycle that visits each vertex exactly once. For an $11 \\times 11$ grid with one vertex removed, su
|
| 99 |
+
ch a cycle exists, as the grid remains connected and satisfies the conditions for Hamiltonicity when a single cell is removed (given the grid dimensions are at least $2 \\times 2$).\n\nA cycle with 120 vertices has
|
| 100 |
+
120 edges, as the number of edges equals the number of vertices in a cycle. Since each edge corresponds to a door, the maximum number of doors Karthik can traverse in a closed path without reusing any door is 120.
|
| 101 |
+
\n\n\\boxed{120}""",
|
| 102 |
+
"""The grid is an $11 \\times 11$ graph, which is bipartite due to its chessboard coloring. The total number of cells is $11 \\times 11 = 121$. In this coloring, one color class has 61 cells and the o
|
| 103 |
+
ther has 60 cells, as determined by the grid's odd size.\n\nA cycle in a bipartite graph must have an equal number of vertices from each color class. Therefore, the maximum number of vertices in any cycle is $2 \\t
|
| 104 |
+
imes \\min(61, 60) = 2 \\times 60 = 120$. This implies that the maximum cycle length in terms of vertices is 120.\n\nSince the number of edges in a cycle equals the number of vertices, the maximum number of edges (
|
| 105 |
+
doors) in a cycle is also 120. This maximum is achievable by removing one black vertex (from the color class with 61 vertices), specifically the center cell at $(6,6)$, and finding a Hamiltonian cycle on the remaining 120-vertex graph. The grid remains connected after removing the center, and such a cycle exists for an $n \\times n$ grid with $n$ odd by removing the center cell.\n\nThus, the maximum number of doors Karthik can traverse in a closed path without repeating any door is 120.\n\n\\boxed{120}""",
|
| 106 |
+
]
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
MODEL_NAME = "nvidia/OpenReasoning-Nemotron-1.5B"
|
| 110 |
+
MAX_NEW_TOKENS = 32000
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def load_model(model_name):
|
| 114 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 115 |
+
model_name,
|
| 116 |
+
device_map="auto",
|
| 117 |
+
torch_dtype=torch.bfloat16,
|
| 118 |
+
attn_implementation="flash_attention_2",
|
| 119 |
+
)
|
| 120 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 121 |
+
return model, tokenizer
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def format_prompt(problem, solutions, num_solutions):
|
| 125 |
+
prompt = PROMPT.format(problem=problem, solutions=solutions, num_solutions=num_solutions, max_idx=num_solutions - 1)
|
| 126 |
+
return prompt
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def format_solutions(solution_list):
|
| 130 |
+
solutions = "\n".join([f"Solution {i}: {solution}" for i, solution in enumerate(solution_list)])
|
| 131 |
+
return solutions
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
def get_prompt():
|
| 135 |
+
problem = PROBLEM
|
| 136 |
+
solutions = format_solutions(SOLUTION_LIST)
|
| 137 |
+
num_solutions = len(SOLUTION_LIST)
|
| 138 |
+
prompt = format_prompt(problem, solutions, num_solutions)
|
| 139 |
+
return prompt, num_solutions
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def generate_response(model, tokenizer, prompt):
|
| 143 |
+
chat = [{"role": "user", "content": prompt}]
|
| 144 |
+
input_ids = tokenizer.apply_chat_template(
|
| 145 |
+
chat,
|
| 146 |
+
return_tensors="pt"
|
| 147 |
+
)
|
| 148 |
+
outputs = model.generate(
|
| 149 |
+
input_ids.to(model.device),
|
| 150 |
+
max_new_tokens=MAX_NEW_TOKENS,
|
| 151 |
+
temperature=0.6,
|
| 152 |
+
top_p=0.95,
|
| 153 |
+
do_sample=True,
|
| 154 |
+
use_cache=True,
|
| 155 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 156 |
+
pad_token_id=tokenizer.eos_token_id
|
| 157 |
+
)
|
| 158 |
+
return tokenizer.decode(outputs[0], skip_special_tokens=True)
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
def extract_judgment(generation, max_idx=None):
|
| 162 |
+
"""Extract the judgment from the generation."""
|
| 163 |
+
judgment = None
|
| 164 |
+
|
| 165 |
+
try:
|
| 166 |
+
matches = re.findall(r"Judg[e]?ment: (\d+)", generation)
|
| 167 |
+
|
| 168 |
+
if matches:
|
| 169 |
+
number = matches[-1]
|
| 170 |
+
judgment = int(number)
|
| 171 |
+
if max_idx is not None and judgment > max_idx:
|
| 172 |
+
judgment = None
|
| 173 |
+
else:
|
| 174 |
+
judgment = None
|
| 175 |
+
|
| 176 |
+
except:
|
| 177 |
+
judgment = None
|
| 178 |
+
|
| 179 |
+
if judgment is not None and max_idx is not None:
|
| 180 |
+
if judgment > max_idx:
|
| 181 |
+
judgment = None
|
| 182 |
+
|
| 183 |
+
return judgment
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
def main():
|
| 187 |
+
# Load model
|
| 188 |
+
model, tokenizer = load_model(MODEL_NAME)
|
| 189 |
+
# Construct prompt
|
| 190 |
+
prompt, num_solutions = get_prompt()
|
| 191 |
+
# Get response
|
| 192 |
+
response = generate_response(model, tokenizer, prompt)
|
| 193 |
+
# Extract judgment
|
| 194 |
+
judgment = extract_judgment(response, max_idx=num_solutions - 1)
|
| 195 |
+
# Print judgment
|
| 196 |
+
print("Selected solution index:", judgment)
|
| 197 |
+
if judgment is not None:
|
| 198 |
+
print("Chosen solution:", SOLUTION_LIST[judgment])
|
| 199 |
+
else:
|
| 200 |
+
print("No solution selected")
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
if __name__ == "__main__":
|
| 204 |
+
main()
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:20d5dc2ac72bf20dba53aa75d1583925dfedfb7b5f3eb848456af2400bb5c2a2
|
| 3 |
+
size 687453
|
model.onnx.data
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cf9eb9ca257010b10e91133e11ed2c0a3f4bf2614bb7c16f7fca2dbd56170b44
|
| 3 |
+
size 3587730432
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|object_ref_start|>",
|
| 6 |
+
"<|object_ref_end|>",
|
| 7 |
+
"<|box_start|>",
|
| 8 |
+
"<|box_end|>",
|
| 9 |
+
"<|quad_start|>",
|
| 10 |
+
"<|quad_end|>",
|
| 11 |
+
"<|vision_start|>",
|
| 12 |
+
"<|vision_end|>",
|
| 13 |
+
"<|vision_pad|>",
|
| 14 |
+
"<|image_pad|>",
|
| 15 |
+
"<|video_pad|>"
|
| 16 |
+
],
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"content": "<|im_end|>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
},
|
| 24 |
+
"pad_token": {
|
| 25 |
+
"content": "<|endoftext|>",
|
| 26 |
+
"lstrip": false,
|
| 27 |
+
"normalized": false,
|
| 28 |
+
"rstrip": false,
|
| 29 |
+
"single_word": false
|
| 30 |
+
}
|
| 31 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9c5ae00e602b8860cbd784ba82a8aa14e8feecec692e7076590d014d7b7fdafa
|
| 3 |
+
size 11421896
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
}
|
| 181 |
+
},
|
| 182 |
+
"additional_special_tokens": [
|
| 183 |
+
"<|im_start|>",
|
| 184 |
+
"<|im_end|>",
|
| 185 |
+
"<|object_ref_start|>",
|
| 186 |
+
"<|object_ref_end|>",
|
| 187 |
+
"<|box_start|>",
|
| 188 |
+
"<|box_end|>",
|
| 189 |
+
"<|quad_start|>",
|
| 190 |
+
"<|quad_end|>",
|
| 191 |
+
"<|vision_start|>",
|
| 192 |
+
"<|vision_end|>",
|
| 193 |
+
"<|vision_pad|>",
|
| 194 |
+
"<|image_pad|>",
|
| 195 |
+
"<|video_pad|>"
|
| 196 |
+
],
|
| 197 |
+
"bos_token": null,
|
| 198 |
+
"clean_up_tokenization_spaces": false,
|
| 199 |
+
"eos_token": "<|im_end|>",
|
| 200 |
+
"errors": "replace",
|
| 201 |
+
"extra_special_tokens": {},
|
| 202 |
+
"model_max_length": 131072,
|
| 203 |
+
"pad_token": "<|endoftext|>",
|
| 204 |
+
"split_special_tokens": false,
|
| 205 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 206 |
+
"unk_token": null
|
| 207 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|