

Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- .mdl +0 -0
- .msc +0 -0
- .mv +1 -0
- README.md +103 -0
- chat_template.jinja +33 -0
- config.json +86 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +0 -0
- preprocessor_config.json +11 -0
- requirements.txt +10 -0
- tokenizer.json +3 -0
- tokenizer_config.json +218 -0
- video_preprocessor_config.json +11 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
.mdl
ADDED
|
Binary file (70 Bytes). View file
|
|
|
.msc
ADDED
|
Binary file (860 Bytes). View file
|
|
|
.mv
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Revision:master,CreatedAt:1751586428
|
README.md
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
pipeline_tag: text-generation
|
| 4 |
+
tags:
|
| 5 |
+
- glm4v
|
| 6 |
+
- GPTQ
|
| 7 |
+
- Int4-Int8Mix
|
| 8 |
+
- vLLM
|
| 9 |
+
base_model:
|
| 10 |
+
- ZhipuAI/GLM-4.1V-9B-Thinking
|
| 11 |
+
base_model_relation: quantized
|
| 12 |
+
---
|
| 13 |
+
# GLM-4.1V-9B-Thinking-GPTQ-Int4-Int8Mix
|
| 14 |
+
基础型 [ZhipuAI/GLM-4.1V-9B-Thinking](https://www.modelscope.cn/models/ZhipuAI/GLM-4.1V-9B-Thinking)
|
| 15 |
+
|
| 16 |
+
### 【模型更新日期】
|
| 17 |
+
```
|
| 18 |
+
2025-07-03
|
| 19 |
+
1. 首次commit
|
| 20 |
+
2. 确定支持1、2、4卡的`tensor-parallel-size`启动
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
### 【依赖】
|
| 24 |
+
|
| 25 |
+
```
|
| 26 |
+
vllm==0.9.2
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
<div style="
|
| 30 |
+
background: rgba(255, 193, 61, 0.15);
|
| 31 |
+
padding: 16px;
|
| 32 |
+
border-radius: 6px;
|
| 33 |
+
border: 1px solid rgba(255, 165, 0, 0.3);
|
| 34 |
+
margin: 16px 0;
|
| 35 |
+
">
|
| 36 |
+
### 【💡2025-07-03 临时安装命令💡】
|
| 37 |
+
|
| 38 |
+
```
|
| 39 |
+
pip3 install -r requirements.txt
|
| 40 |
+
git clone https://github.com/zRzRzRzRzRzRzR/vllm.git
|
| 41 |
+
cd vllm
|
| 42 |
+
git checkout glm4_1-v
|
| 43 |
+
VLLM_USE_PRECOMPILED=1 pip install --editable .
|
| 44 |
+
```
|
| 45 |
+
</div>
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
### 【模型列表】
|
| 49 |
+
|
| 50 |
+
| 文件大小 | 最近更新时间 |
|
| 51 |
+
|---------|--------------|
|
| 52 |
+
| `8.9GB` | `2025-07-03` |
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
### 【模型下载】
|
| 57 |
+
|
| 58 |
+
```python
|
| 59 |
+
from modelscope import snapshot_download
|
| 60 |
+
snapshot_download('tclf90/GLM-4.1V-9B-Thinking-GPTQ-Int4-Int8Mix', cache_dir="本地路径")
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
### 【介绍】
|
| 65 |
+
# GLM-4.1V-9B-Thinking
|
| 66 |
+
|
| 67 |
+
<div align="center">
|
| 68 |
+
<img src=https://raw.githubusercontent.com/THUDM/GLM-4.1V-Thinking/99c5eb6563236f0ff43605d91d107544da9863b2/resources/logo.svg width="40%"/>
|
| 69 |
+
</div>
|
| 70 |
+
<p align="center">
|
| 71 |
+
📖 查看 GLM-4.1V-9B-Thinking <a href="https://arxiv.org/abs/2507.01006" target="_blank">论文</a> 。
|
| 72 |
+
<br>
|
| 73 |
+
💡 立即在线体验 <a href="https://huggingface.co/spaces/THUDM/GLM-4.1V-9B-Thinking-Demo" target="_blank">Hugging Face</a> 或 <a href="https://modelscope.cn/studios/ZhipuAI/GLM-4.1V-9B-Thinking-Demo" target="_blank">ModelScope</a> 上的 GLM-4.1V-9B-Thinking。
|
| 74 |
+
<br>
|
| 75 |
+
📍 在 <a href="https://www.bigmodel.cn/dev/api/visual-reasoning-model/GLM-4.1V-Thinking">智谱大模型开放平台</a> 使用 GLM-4.1V-9B-Thinking 的API服务。
|
| 76 |
+
</p>
|
| 77 |
+
|
| 78 |
+
## 模型介绍
|
| 79 |
+
|
| 80 |
+
视觉语言大模型(VLM)已经成为智能系统的关键基石。随着真实世界的智能任务越来越复杂,VLM模型也亟需在基本的多模态感知之外,
|
| 81 |
+
逐渐增强复杂任务中的推理能力,提升自身的准确性、全面性和智能化程度,使得复杂问题解决、长上下文理解、多模态智能体等智能任务成为可能。
|
| 82 |
+
|
| 83 |
+
基于 [GLM-4-9B-0414](https://github.com/THUDM/GLM-4) 基座模型,我们推出新版VLM开源模型 **GLM-4.1V-9B-Thinking**
|
| 84 |
+
,引入思考范式,通过课程采样强化学习 RLCS(Reinforcement Learning with Curriculum Sampling)全面提升模型能力,
|
| 85 |
+
达到 10B 参数级别的视觉语言模型的最强性能,在18个榜单任务中持平甚至超过8倍参数量的 Qwen-2.5-VL-72B。
|
| 86 |
+
我们同步开源基座模型 **GLM-4.1V-9B-Base**,希望能够帮助更多研究者探索视觉语言模型的能力边界。
|
| 87 |
+
|
| 88 |
+
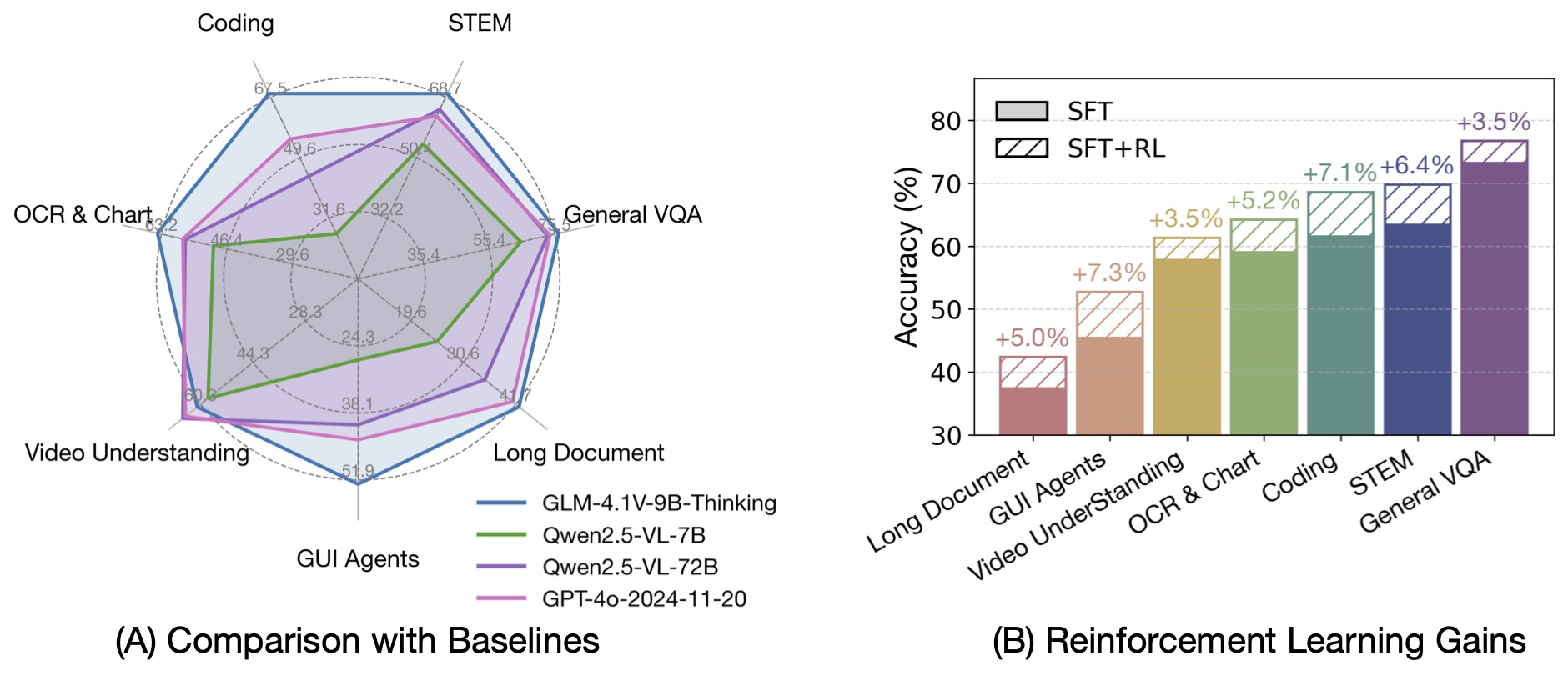
|
| 89 |
+
|
| 90 |
+
与上一代的 CogVLM2 及 GLM-4V 系列模型相比,**GLM-4.1V-Thinking** 有如下改进:
|
| 91 |
+
|
| 92 |
+
1. 系列中首个推理模型,不仅仅停留在数学领域,在多个子领域均达到世界前列的水平。
|
| 93 |
+
2. 支持 **64k** 上下长度。
|
| 94 |
+
3. 支持**任意长宽比**和高达 **4k** 的图像分辨率。
|
| 95 |
+
4. 提供支持**中英文双语**的开源模型版本。
|
| 96 |
+
|
| 97 |
+
## 榜单信息
|
| 98 |
+
|
| 99 |
+
GLM-4.1V-9B-Thinking 通过引入「思维链」(Chain-of-Thought)推理机制,在回答准确性、内容丰富度与可解释性方面,
|
| 100 |
+
全面超越传统的非推理式视觉模型。在28项评测任务中有23项达到10B级别模型最佳,甚至有18项任务超过8倍参数量的Qwen-2.5-VL-72B。
|
| 101 |
+
|
| 102 |
+

|
| 103 |
+
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[gMASK]<sop>
|
| 2 |
+
{%- for msg in messages %}
|
| 3 |
+
{%- if msg.role == 'system' %}
|
| 4 |
+
<|system|>
|
| 5 |
+
{{ msg.content }}
|
| 6 |
+
{%- elif msg.role == 'user' %}
|
| 7 |
+
<|user|>{{ '\n' }}
|
| 8 |
+
|
| 9 |
+
{%- if msg.content is string %}
|
| 10 |
+
{{ msg.content }}
|
| 11 |
+
{%- else %}
|
| 12 |
+
{%- for item in msg.content %}
|
| 13 |
+
{%- if item.type == 'video' or 'video' in item %}
|
| 14 |
+
<|begin_of_video|><|video|><|end_of_video|>
|
| 15 |
+
{%- elif item.type == 'image' or 'image' in item %}
|
| 16 |
+
<|begin_of_image|><|image|><|end_of_image|>
|
| 17 |
+
{%- elif item.type == 'text' %}
|
| 18 |
+
{{ item.text }}
|
| 19 |
+
{%- endif %}
|
| 20 |
+
{%- endfor %}
|
| 21 |
+
{%- endif %}
|
| 22 |
+
{%- elif msg.role == 'assistant' %}
|
| 23 |
+
{%- if msg.metadata %}
|
| 24 |
+
<|assistant|>{{ msg.metadata }}
|
| 25 |
+
{{ msg.content }}
|
| 26 |
+
{%- else %}
|
| 27 |
+
<|assistant|>
|
| 28 |
+
{{ msg.content }}
|
| 29 |
+
{%- endif %}
|
| 30 |
+
{%- endif %}
|
| 31 |
+
{%- endfor %}
|
| 32 |
+
{% if add_generation_prompt %}<|assistant|>
|
| 33 |
+
{% endif %}
|
config.json
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"name_or_path": "tclf90/GLM-4.1V-9B-Thinking-GPTQ-Int4-Int8Mix",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"Glm4vForConditionalGeneration"
|
| 5 |
+
],
|
| 6 |
+
"model_type": "glm4v",
|
| 7 |
+
"attention_bias": true,
|
| 8 |
+
"attention_dropout": 0.0,
|
| 9 |
+
"pad_token_id": 151329,
|
| 10 |
+
"eos_token_id": [
|
| 11 |
+
151329,
|
| 12 |
+
151336,
|
| 13 |
+
151338,
|
| 14 |
+
151348
|
| 15 |
+
],
|
| 16 |
+
"image_start_token_id": 151339,
|
| 17 |
+
"image_end_token_id": 151340,
|
| 18 |
+
"video_start_token_id": 151341,
|
| 19 |
+
"video_end_token_id": 151342,
|
| 20 |
+
"image_token_id": 151343,
|
| 21 |
+
"video_token_id": 151344,
|
| 22 |
+
"hidden_act": "silu",
|
| 23 |
+
"hidden_size": 4096,
|
| 24 |
+
"initializer_range": 0.02,
|
| 25 |
+
"intermediate_size": 13824,
|
| 26 |
+
"max_position_embeddings": 65536,
|
| 27 |
+
"num_attention_heads": 32,
|
| 28 |
+
"num_hidden_layers": 40,
|
| 29 |
+
"num_key_value_heads": 2,
|
| 30 |
+
"rms_norm_eps": 1e-05,
|
| 31 |
+
"rope_theta": 10000.0,
|
| 32 |
+
"tie_word_embeddings": false,
|
| 33 |
+
"torch_dtype": "float16",
|
| 34 |
+
"transformers_version": "4.53.0dev",
|
| 35 |
+
"use_cache": true,
|
| 36 |
+
"vocab_size": 151552,
|
| 37 |
+
"partial_rotary_factor": 0.5,
|
| 38 |
+
"vision_config": {
|
| 39 |
+
"hidden_size": 1536,
|
| 40 |
+
"depth": 24,
|
| 41 |
+
"num_heads": 12,
|
| 42 |
+
"attention_bias": false,
|
| 43 |
+
"intermediate_size": 13824,
|
| 44 |
+
"hidden_act": "silu",
|
| 45 |
+
"hidden_dropout_prob": 0.0,
|
| 46 |
+
"initializer_range": 0.02,
|
| 47 |
+
"image_size": 336,
|
| 48 |
+
"patch_size": 14,
|
| 49 |
+
"out_hidden_size": 4096,
|
| 50 |
+
"rms_norm_eps": 1e-05,
|
| 51 |
+
"spatial_merge_size": 2,
|
| 52 |
+
"temporal_patch_size": 2
|
| 53 |
+
},
|
| 54 |
+
"rope_scaling": {
|
| 55 |
+
"type": "default",
|
| 56 |
+
"mrope_section": [
|
| 57 |
+
8,
|
| 58 |
+
12,
|
| 59 |
+
12
|
| 60 |
+
]
|
| 61 |
+
},
|
| 62 |
+
"quantization_config": {
|
| 63 |
+
"quant_method": "gptq",
|
| 64 |
+
"bits": 4,
|
| 65 |
+
"group_size": 128,
|
| 66 |
+
"sym": false,
|
| 67 |
+
"desc_act": false,
|
| 68 |
+
"dynamic": {
|
| 69 |
+
"+:model.layers\\.([0-4]|3[6-9])\\..*": {
|
| 70 |
+
"bits": 8
|
| 71 |
+
},
|
| 72 |
+
"+:model.layers.*.self_attn.o_proj.*": {
|
| 73 |
+
"bits": 8
|
| 74 |
+
},
|
| 75 |
+
"+:model.layers.*.mlp.down_proj.*": {
|
| 76 |
+
"bits": 8
|
| 77 |
+
},
|
| 78 |
+
"+:visual.blocks.*.attn.proj.*": {
|
| 79 |
+
"bits": 8
|
| 80 |
+
},
|
| 81 |
+
"+:visual.blocks.*.mlp.down_proj.*": {
|
| 82 |
+
"bits": 8
|
| 83 |
+
}
|
| 84 |
+
}
|
| 85 |
+
}
|
| 86 |
+
}
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:83d28097498b6874a2291fc59dcf10c942590ae0db9a75076c046a31bea5cccd
|
| 3 |
+
size 4997139480
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cf7c2e19458408d368dac7c127d23c29e00dd8d7b08c0c9ba5147cb4b767195c
|
| 3 |
+
size 4479333632
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"size": {"shortest_edge": 12544, "longest_edge": 9633792},
|
| 3 |
+
"do_rescale": true,
|
| 4 |
+
"patch_size": 14,
|
| 5 |
+
"temporal_patch_size": 2,
|
| 6 |
+
"merge_size": 2,
|
| 7 |
+
"image_mean": [0.48145466, 0.4578275, 0.40821073],
|
| 8 |
+
"image_std": [0.26862954, 0.26130258, 0.27577711],
|
| 9 |
+
"image_processor_type": "Glm4vImageProcessor",
|
| 10 |
+
"processor_class": "Glm4vProcessor"
|
| 11 |
+
}
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
setuptools>=80.9.0
|
| 2 |
+
setuptools_scm>=8.3.1
|
| 3 |
+
git+https://github.com/huggingface/transformers.git@91221da2f1f68df9eb97c980a7206b14c4d3a9b0
|
| 4 |
+
torchvision>=0.22.0
|
| 5 |
+
gradio>=5.35.0
|
| 6 |
+
pre-commit>=4.2.0
|
| 7 |
+
PyMuPDF>=1.26.1
|
| 8 |
+
av>=14.4.0
|
| 9 |
+
accelerate>=1.6.0
|
| 10 |
+
spaces>=0.37.1
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:76ebeac0d8bd7879ead7b43c16b44981f277e47225de2bd7de9ae1a6cc664a8c
|
| 3 |
+
size 19966496
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"151329": {
|
| 4 |
+
"content": "<|endoftext|>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"151330": {
|
| 12 |
+
"content": "[MASK]",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"151331": {
|
| 20 |
+
"content": "[gMASK]",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"151332": {
|
| 28 |
+
"content": "[sMASK]",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"151333": {
|
| 36 |
+
"content": "<sop>",
|
| 37 |
+
"lstrip": false,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
},
|
| 43 |
+
"151334": {
|
| 44 |
+
"content": "<eop>",
|
| 45 |
+
"lstrip": false,
|
| 46 |
+
"normalized": false,
|
| 47 |
+
"rstrip": false,
|
| 48 |
+
"single_word": false,
|
| 49 |
+
"special": true
|
| 50 |
+
},
|
| 51 |
+
"151335": {
|
| 52 |
+
"content": "<|system|>",
|
| 53 |
+
"lstrip": false,
|
| 54 |
+
"normalized": false,
|
| 55 |
+
"rstrip": false,
|
| 56 |
+
"single_word": false,
|
| 57 |
+
"special": true
|
| 58 |
+
},
|
| 59 |
+
"151336": {
|
| 60 |
+
"content": "<|user|>",
|
| 61 |
+
"lstrip": false,
|
| 62 |
+
"normalized": false,
|
| 63 |
+
"rstrip": false,
|
| 64 |
+
"single_word": false,
|
| 65 |
+
"special": true
|
| 66 |
+
},
|
| 67 |
+
"151337": {
|
| 68 |
+
"content": "<|assistant|>",
|
| 69 |
+
"lstrip": false,
|
| 70 |
+
"normalized": false,
|
| 71 |
+
"rstrip": false,
|
| 72 |
+
"single_word": false,
|
| 73 |
+
"special": true
|
| 74 |
+
},
|
| 75 |
+
"151338": {
|
| 76 |
+
"content": "<|observation|>",
|
| 77 |
+
"lstrip": false,
|
| 78 |
+
"normalized": false,
|
| 79 |
+
"rstrip": false,
|
| 80 |
+
"single_word": false,
|
| 81 |
+
"special": true
|
| 82 |
+
},
|
| 83 |
+
"151339": {
|
| 84 |
+
"content": "<|begin_of_image|>",
|
| 85 |
+
"lstrip": false,
|
| 86 |
+
"normalized": false,
|
| 87 |
+
"rstrip": false,
|
| 88 |
+
"single_word": false,
|
| 89 |
+
"special": true
|
| 90 |
+
},
|
| 91 |
+
"151340": {
|
| 92 |
+
"content": "<|end_of_image|>",
|
| 93 |
+
"lstrip": false,
|
| 94 |
+
"normalized": false,
|
| 95 |
+
"rstrip": false,
|
| 96 |
+
"single_word": false,
|
| 97 |
+
"special": true
|
| 98 |
+
},
|
| 99 |
+
"151341": {
|
| 100 |
+
"content": "<|begin_of_video|>",
|
| 101 |
+
"lstrip": false,
|
| 102 |
+
"normalized": false,
|
| 103 |
+
"rstrip": false,
|
| 104 |
+
"single_word": false,
|
| 105 |
+
"special": true
|
| 106 |
+
},
|
| 107 |
+
"151342": {
|
| 108 |
+
"content": "<|end_of_video|>",
|
| 109 |
+
"lstrip": false,
|
| 110 |
+
"normalized": false,
|
| 111 |
+
"rstrip": false,
|
| 112 |
+
"single_word": false,
|
| 113 |
+
"special": true
|
| 114 |
+
},
|
| 115 |
+
"151343": {
|
| 116 |
+
"content": "<|image|>",
|
| 117 |
+
"lstrip": false,
|
| 118 |
+
"normalized": false,
|
| 119 |
+
"rstrip": false,
|
| 120 |
+
"single_word": false,
|
| 121 |
+
"special": true
|
| 122 |
+
},
|
| 123 |
+
"151344": {
|
| 124 |
+
"content": "<|video|>",
|
| 125 |
+
"lstrip": false,
|
| 126 |
+
"normalized": false,
|
| 127 |
+
"rstrip": false,
|
| 128 |
+
"single_word": false,
|
| 129 |
+
"special": true
|
| 130 |
+
},
|
| 131 |
+
"151345": {
|
| 132 |
+
"content": "<think>",
|
| 133 |
+
"lstrip": false,
|
| 134 |
+
"normalized": false,
|
| 135 |
+
"rstrip": false,
|
| 136 |
+
"single_word": false,
|
| 137 |
+
"special": false
|
| 138 |
+
},
|
| 139 |
+
"151346": {
|
| 140 |
+
"content": "</think>",
|
| 141 |
+
"lstrip": false,
|
| 142 |
+
"normalized": false,
|
| 143 |
+
"rstrip": false,
|
| 144 |
+
"single_word": false,
|
| 145 |
+
"special": false
|
| 146 |
+
},
|
| 147 |
+
"151347": {
|
| 148 |
+
"content": "<answer>",
|
| 149 |
+
"lstrip": false,
|
| 150 |
+
"normalized": false,
|
| 151 |
+
"rstrip": false,
|
| 152 |
+
"single_word": false,
|
| 153 |
+
"special": false
|
| 154 |
+
},
|
| 155 |
+
"151348": {
|
| 156 |
+
"content": "</answer>",
|
| 157 |
+
"lstrip": false,
|
| 158 |
+
"normalized": false,
|
| 159 |
+
"rstrip": false,
|
| 160 |
+
"single_word": false,
|
| 161 |
+
"special": false
|
| 162 |
+
},
|
| 163 |
+
"151349": {
|
| 164 |
+
"content": "<|begin_of_box|>",
|
| 165 |
+
"lstrip": false,
|
| 166 |
+
"normalized": false,
|
| 167 |
+
"rstrip": false,
|
| 168 |
+
"single_word": false,
|
| 169 |
+
"special": false
|
| 170 |
+
},
|
| 171 |
+
"151350": {
|
| 172 |
+
"content": "<|end_of_box|>",
|
| 173 |
+
"lstrip": false,
|
| 174 |
+
"normalized": false,
|
| 175 |
+
"rstrip": false,
|
| 176 |
+
"single_word": false,
|
| 177 |
+
"special": false
|
| 178 |
+
},
|
| 179 |
+
"151351": {
|
| 180 |
+
"content": "<|sep|>",
|
| 181 |
+
"lstrip": false,
|
| 182 |
+
"normalized": false,
|
| 183 |
+
"rstrip": false,
|
| 184 |
+
"single_word": false,
|
| 185 |
+
"special": false
|
| 186 |
+
}
|
| 187 |
+
},
|
| 188 |
+
"additional_special_tokens": [
|
| 189 |
+
"<|endoftext|>",
|
| 190 |
+
"[MASK]",
|
| 191 |
+
"[gMASK]",
|
| 192 |
+
"[sMASK]",
|
| 193 |
+
"<sop>",
|
| 194 |
+
"<eop>",
|
| 195 |
+
"<|system|>",
|
| 196 |
+
"<|user|>",
|
| 197 |
+
"<|assistant|>",
|
| 198 |
+
"<|observation|>",
|
| 199 |
+
"<|begin_of_image|>",
|
| 200 |
+
"<|end_of_image|>",
|
| 201 |
+
"<|begin_of_video|>",
|
| 202 |
+
"<|end_of_video|>",
|
| 203 |
+
"<|image|>",
|
| 204 |
+
"<|video|>"
|
| 205 |
+
],
|
| 206 |
+
"clean_up_tokenization_spaces": false,
|
| 207 |
+
"do_lower_case": false,
|
| 208 |
+
"eos_token": "<|endoftext|>",
|
| 209 |
+
"pad_token": "<|endoftext|>",
|
| 210 |
+
"model_input_names": [
|
| 211 |
+
"input_ids",
|
| 212 |
+
"attention_mask"
|
| 213 |
+
],
|
| 214 |
+
"model_max_length": 64000,
|
| 215 |
+
"padding_side": "left",
|
| 216 |
+
"remove_space": false,
|
| 217 |
+
"tokenizer_class": "PreTrainedTokenizer"
|
| 218 |
+
}
|
video_preprocessor_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"size": {"shortest_edge": 12544, "longest_edge": 47040000},
|
| 3 |
+
"do_rescale": true,
|
| 4 |
+
"patch_size": 14,
|
| 5 |
+
"temporal_patch_size": 2,
|
| 6 |
+
"merge_size": 2,
|
| 7 |
+
"image_mean": [0.48145466, 0.4578275, 0.40821073],
|
| 8 |
+
"image_std": [0.26862954, 0.26130258, 0.27577711],
|
| 9 |
+
"video_processor_type": "Glm4vVideoProcessor",
|
| 10 |
+
"processor_class": "Glm4vProcessor"
|
| 11 |
+
}
|