

Update README.md
Browse files
README.md
CHANGED
|
@@ -30,13 +30,13 @@ RoGuard 1.0, a SOTA instruction fine-tuned LLM, is designed to help safeguard ou
|
|
| 30 |
|
| 31 |
|
| 32 |
## 📊 Model Benchmark Results
|
| 33 |
-
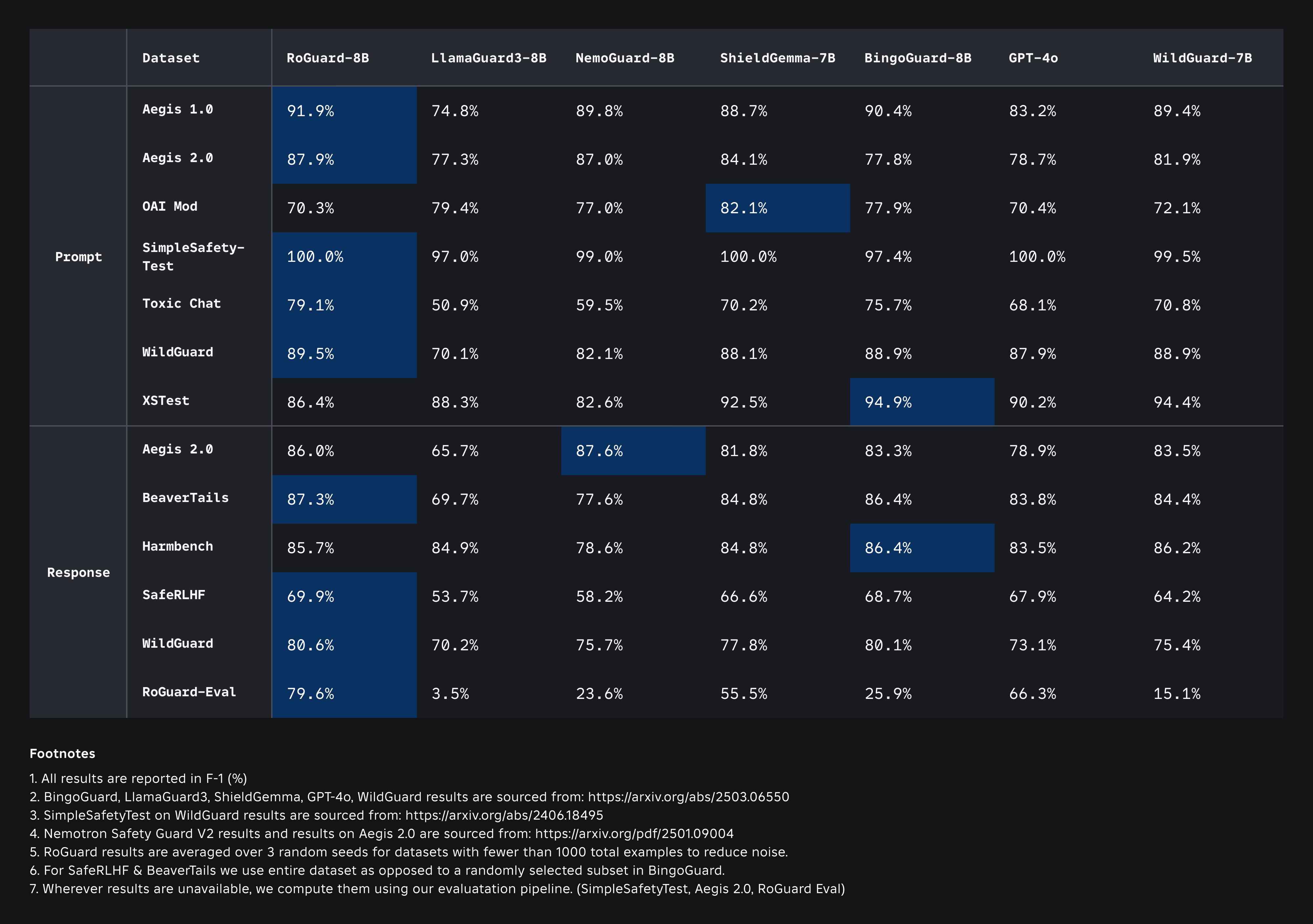
We benchmark RoGuard 1.0 model on a comprehensive set of open-source datasets for both prompt and response, as well as on RoGuard-Eval. This allows us to evaluate our model on both in-domain and out-of-domain datasets. We report our results in terms of F-1 score for binary violating/non-violating classification. In the table below, we compare our performance with that of several well-known models. The RoGuard 1.0 outperforms other models while generalizing on out-of-domain datasets.
|
| 34 |
|
| 35 |
-
-
|
| 36 |
-
- **Response Metrics**: These measure how well the model handles or generates **responses**, ensuring its outputs are safe and aligned.
|
| 37 |
|
|
|
|
| 38 |
|
| 39 |
-
|
|
|
|
| 40 |
|
| 41 |
|
| 42 |
## 🔗 GitHub Repository
|
|
|
|
| 30 |
|
| 31 |
|
| 32 |
## 📊 Model Benchmark Results
|
|
|
|
| 33 |
|
| 34 |
+
|
|
|
|
| 35 |
|
| 36 |
+
We benchmark RoGuard 1.0 model on a comprehensive set of open-source datasets for both prompt and response, as well as on RoGuard-Eval. This allows us to evaluate our model on both in-domain and out-of-domain datasets. We report our results in terms of F-1 score for binary violating/non-violating classification. In the table above, we compare our performance with that of several well-known models. The RoGuard 1.0 outperforms other models while generalizing on out-of-domain datasets.
|
| 37 |
|
| 38 |
+
- **Prompt Metrics**: These evaluate how well the model classifies or responds to potentially harmful **user inputs**
|
| 39 |
+
- **Response Metrics**: These measure how well the model handles or generates **responses**, ensuring its outputs are safe and aligned.
|
| 40 |
|
| 41 |
|
| 42 |
## 🔗 GitHub Repository
|