Datasets:


Paper Update
Browse files- README.md +13 -4
- benchmarks.png +3 -0
- fig1.png +3 -0
README.md
CHANGED
|
@@ -34,7 +34,7 @@ size_categories:
|
|
| 34 |
|
| 35 |
<div align="center">
|
| 36 |
|
| 37 |
-
<h1><a style="color:blue" href="https://daniel-cores.github.io/tvbench/">
|
| 38 |
|
| 39 |
[Daniel Cores](https://scholar.google.com/citations?user=pJqkUWgAAAAJ)\*,
|
| 40 |
[Michael Dorkenwald](https://scholar.google.com/citations?user=KY5nvLUAAAAJ)\*,
|
|
@@ -59,9 +59,18 @@ TVBench is a new benchmark specifically created to evaluate temporal understandi
|
|
| 59 |
|
| 60 |
We defined 10 temporally challenging tasks that either require repetition counting (Action Count), properties about moving objects (Object Shuffle, Object Count, Moving Direction), temporal localization (Action Localization, Unexpected Action), temporal sequential ordering (Action Sequence, Scene Transition, Egocentric Sequence) and distinguishing between temporally hard Action Antonyms such as "Standing up" and "Sitting down".
|
| 61 |
|
| 62 |
-
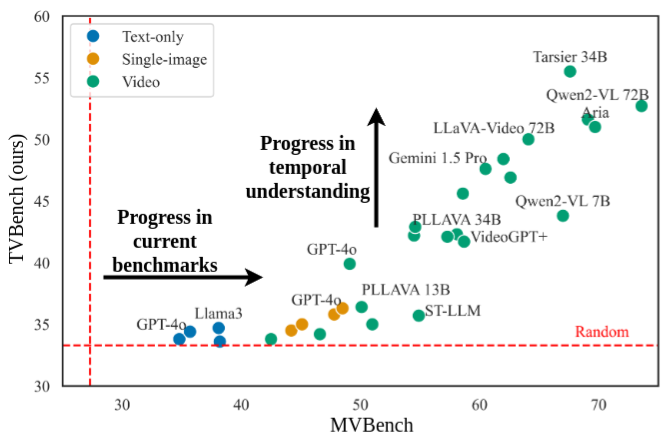
In TVBench, state-of-the-art text-only, image-based, and most video-language models perform close to random chance, with only the latest strong temporal models, such as Tarsier, outperforming the random baseline.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 63 |
|
| 64 |
-

|
| 65 |
|
| 66 |
### Dataset statistics:
|
| 67 |
The table below shows the number of samples and the average frame length for each task in TVBench.
|
|
@@ -84,7 +93,7 @@ If you find this benchmark useful, please consider citing:
|
|
| 84 |
|
| 85 |
@misc{cores2024tvbench,
|
| 86 |
author = {Daniel Cores and Michael Dorkenwald and Manuel Mucientes and Cees G. M. Snoek and Yuki M. Asano},
|
| 87 |
-
title = {
|
| 88 |
year = {2024},
|
| 89 |
eprint = {arXiv:2410.07752},
|
| 90 |
}
|
|
|
|
| 34 |
|
| 35 |
<div align="center">
|
| 36 |
|
| 37 |
+
<h1><a style="color:blue" href="https://daniel-cores.github.io/tvbench/">Lost in Time: A New Temporal Benchmark for Video LLMs</a></h1>
|
| 38 |
|
| 39 |
[Daniel Cores](https://scholar.google.com/citations?user=pJqkUWgAAAAJ)\*,
|
| 40 |
[Michael Dorkenwald](https://scholar.google.com/citations?user=KY5nvLUAAAAJ)\*,
|
|
|
|
| 59 |
|
| 60 |
We defined 10 temporally challenging tasks that either require repetition counting (Action Count), properties about moving objects (Object Shuffle, Object Count, Moving Direction), temporal localization (Action Localization, Unexpected Action), temporal sequential ordering (Action Sequence, Scene Transition, Egocentric Sequence) and distinguishing between temporally hard Action Antonyms such as "Standing up" and "Sitting down".
|
| 61 |
|
| 62 |
+
In TVBench, state-of-the-art text-only, image-based, and most video-language models perform close to random chance, with only the latest strong temporal models, such as Tarsier, outperforming the random baseline.
|
| 63 |
+
|
| 64 |
+
<center>
|
| 65 |
+
<img src="figs/fig1.png" alt="drawing" width="600"/>
|
| 66 |
+
</center>
|
| 67 |
+
|
| 68 |
+
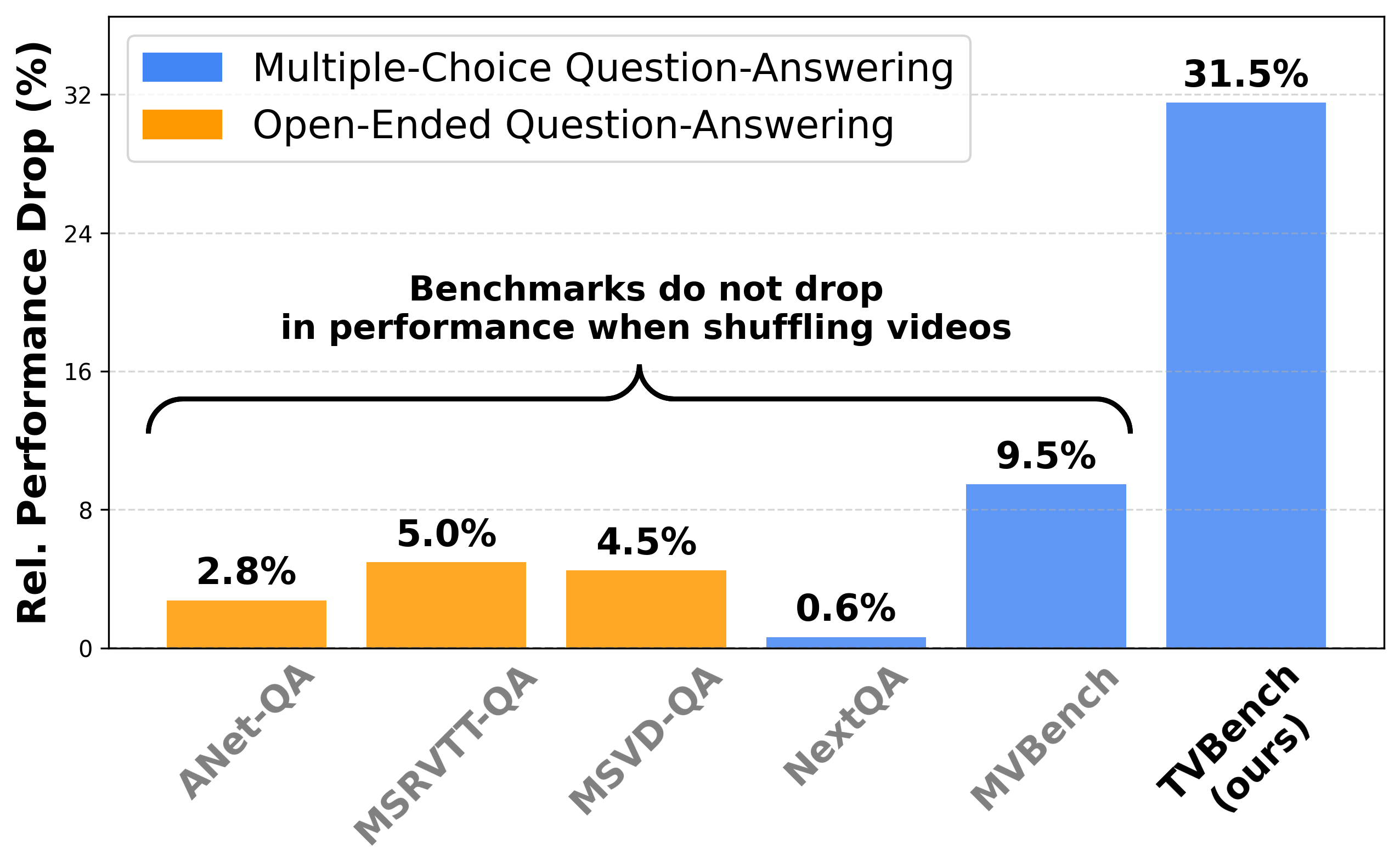
The performance of a SOTA models such as Tarsier on commonly used benchmarks hardly drops when shuffling the input videos. This suggests that these benchmarks do not effectively measure temporal understanding. In contrast, in our proposed TVBench, shuffling input frames results in random accuracy, as it should be.
|
| 69 |
+
|
| 70 |
+
<center>
|
| 71 |
+
<img src="figs/benchmarks.png" alt="drawing" width="600"/>
|
| 72 |
+
</center>
|
| 73 |
|
|
|
|
| 74 |
|
| 75 |
### Dataset statistics:
|
| 76 |
The table below shows the number of samples and the average frame length for each task in TVBench.
|
|
|
|
| 93 |
|
| 94 |
@misc{cores2024tvbench,
|
| 95 |
author = {Daniel Cores and Michael Dorkenwald and Manuel Mucientes and Cees G. M. Snoek and Yuki M. Asano},
|
| 96 |
+
title = {Lost in Time: A New Temporal Benchmark for Video LLMs},
|
| 97 |
year = {2024},
|
| 98 |
eprint = {arXiv:2410.07752},
|
| 99 |
}
|
benchmarks.png
ADDED
|
Git LFS Details
|
fig1.png
ADDED
|
Git LFS Details
|