---
language:
- en
pretty_name: 'Comics: Pick-A-Panel'
tags:
- comics
dataset_info:
- config_name: char_coherence
features:
- name: sample_id
dtype: string
- name: context
sequence: image
- name: options
sequence: image
- name: index
dtype: int32
- name: solution_index
dtype: int32
- name: split
dtype: string
- name: task_type
dtype: string
- name: previous_panel_caption
dtype: string
splits:
- name: val
num_bytes: 379249617
num_examples: 143
- name: test
num_bytes: 1139813763
num_examples: 489
download_size: 1519137617
dataset_size: 1519063380
- config_name: caption_relevance
features:
- name: sample_id
dtype: string
- name: context
sequence: image
- name: options
sequence: image
- name: index
dtype: int32
- name: solution_index
dtype: int32
- name: split
dtype: string
- name: task_type
dtype: string
- name: previous_panel_caption
dtype: string
splits:
- name: val
num_bytes: 530485241
num_examples: 262
- name: test
num_bytes: 1670410617
num_examples: 932
download_size: 2200220497
dataset_size: 2200895858
- config_name: sequence_filling
features:
- name: sample_id
dtype: string
- name: context
sequence: image
- name: options
sequence: image
- name: index
dtype: int32
- name: solution_index
dtype: int32
- name: split
dtype: string
- name: task_type
dtype: string
- name: previous_panel_caption
dtype: string
splits:
- name: val
num_bytes: 1230082746
num_examples: 262
- name: test
num_bytes: 3889446893
num_examples: 932
download_size: 4961489402
dataset_size: 5119529639
- config_name: text_closure
features:
- name: sample_id
dtype: string
- name: context
sequence: image
- name: options
sequence: image
- name: index
dtype: int32
- name: solution_index
dtype: int32
- name: split
dtype: string
- name: task_type
dtype: string
- name: previous_panel_caption
dtype: string
splits:
- name: test
num_bytes: 2839781239
num_examples: 924
- name: val
num_bytes: 886890050
num_examples: 259
download_size: 4657519865
dataset_size: 3726671289
- config_name: visual_closure
features:
- name: sample_id
dtype: string
- name: context
sequence: image
- name: options
sequence: image
- name: index
dtype: int32
- name: solution_index
dtype: int32
- name: split
dtype: string
- name: task_type
dtype: string
- name: previous_panel_caption
dtype: string
splits:
- name: val
num_bytes: 1356539432
num_examples: 300
- name: test
num_bytes: 4020998551
num_examples: 1000
download_size: 10043154153
dataset_size: 5377537983
configs:
- config_name: char_coherence
data_files:
- split: val
path: char_coherence/val-*
- split: test
path: char_coherence/test-*
- config_name: caption_relevance
data_files:
- split: val
path: caption_relevance/val-*
- split: test
path: caption_relevance/test-*
- config_name: sequence_filling
data_files:
- split: val
path: sequence_filling/val-*
- split: test
path: sequence_filling/test-*
- config_name: text_closure
data_files:
- split: val
path: text_closure/val-*
- split: test
path: text_closure/test-*
- config_name: visual_closure
data_files:
- split: val
path: visual_closure/val-*
- split: test
path: visual_closure/test-*
license: cc-by-sa-4.0
---
# Comics: Pick-A-Panel
This is the dataset for the [ICDAR 2025 Competition on Comics Understanding in the Era of Foundational Models](https://rrc.cvc.uab.es/?ch=31&com=introduction)
The competition is hosted in the [Robust Reading Competition website](https://rrc.cvc.uab.es/?ch=31&com=introduction) and the leaderboard is available [here](https://rrc.cvc.uab.es/?ch=31&com=evaluation).
The dataset contains five subtask or skills:
Sequence Filling

Given a sequence of comic panels, a missing panel, and a set of option panels, the task is to pick the panel that best fits the sequence.
Character Coherence, Visual Closure, Text Closure
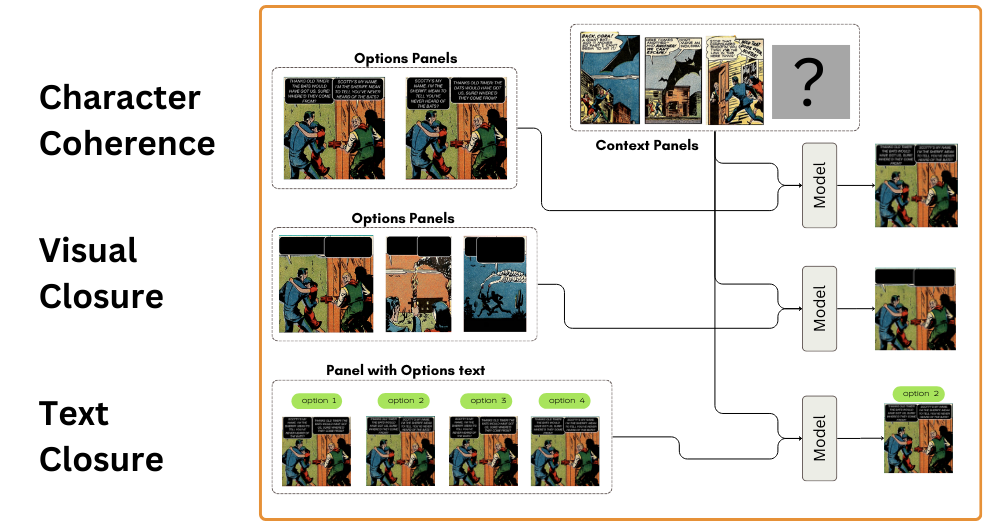
These skills require understanding the context sequence to then pick the best panel to continue the story, focusing on the characters, the visual elements, and the text:
- Character Coherence: Given a sequence of comic panels, pick the panel from the two options that best continues the story in a coherent with the characters. Both options are the same panel, but the text in the speech bubbles has been swapped.
- Visual Closure: Given a sequence of comic panels, pick the panel from the options that best continues the story in a coherent way with the visual elements.
- Text Closure: Given a sequence of comic panels, pick the panel from the options that best continues the story in a coherent way with the text. All options are the same panel, but with text in the speech retrieved from different panels.
Caption Relevance

Given a caption from the previous panel, select the panel that best continues the story.
## Loading the Data
```python
from datasets import load_dataset
skill = "sequence_filling" # "sequence_filling", "char_coherence", "visual_closure", "text_closure", "caption_relevance"
split = "val" # "val", "test"
dataset = load_dataset("VLR-CVC/ComicsPAP", skill, split=split)
```
Map to single images
If your model can only process single images, you can render each sample as a single image:

```python
from PIL import Image, ImageDraw, ImageFont
import numpy as np
from datasets import Features, Value, Image as ImageFeature
class SingleImagePickAPanel:
def __init__(self, max_size=500, margin=10, label_space=20, font_path=None):
if font_path is None:
raise ValueError("Font path must be provided. Testing was done with 'Arial.ttf'")
self.max_size = max_size
self.margin = margin
self.label_space = label_space
# Add separate font sizes
self.label_font_size = 20
self.number_font_size = 24
self.font_path = font_path
def resize_image(self, img):
"""Resize image keeping aspect ratio if longest edge > max_size"""
if max(img.size) > self.max_size:
ratio = self.max_size / max(img.size)
new_size = tuple(int(dim * ratio) for dim in img.size)
return img.resize(new_size, Image.Resampling.LANCZOS)
return img
def create_mask_panel(self, width, height):
"""Create a question mark panel"""
mask_panel = Image.new("RGB", (width, height), (200, 200, 200))
draw = ImageDraw.Draw(mask_panel)
font_size = int(height * 0.8)
try:
font = ImageFont.truetype(self.font_path, font_size)
except:
raise ValueError("Font file not found")
text = "?"
bbox = draw.textbbox((0, 0), text, font=font)
text_x = (width - (bbox[2] - bbox[0])) // 2
text_y = (height - (bbox[3] - bbox[1])) // 2
draw.text((text_x, text_y), text, fill="black", font=font)
return mask_panel
def draw_number_on_panel(self, panel, number, font):
"""Draw number on the bottom of the panel with background"""
draw = ImageDraw.Draw(panel)
# Get text size
bbox = draw.textbbox((0, 0), str(number), font=font)
text_width = bbox[2] - bbox[0]
text_height = bbox[3] - bbox[1]
# Calculate position (bottom-right corner)
padding = 2
text_x = panel.size[0] - text_width - padding
text_y = panel.size[1] - text_height - padding
# Draw semi-transparent background
bg_rect = [(text_x - padding, text_y - padding),
(text_x + text_width + padding, text_y + text_height + padding)]
draw.rectangle(bg_rect, fill=(255, 255, 255, 180))
# Draw text
draw.text((text_x, text_y), str(number), fill="black", font=font)
return panel
def map_to_single_image(self, examples):
"""Process a batch of examples from a HuggingFace dataset"""
single_images = []
for i in range(len(examples['sample_id'])):
# Get context and options for current example
context = examples['context'][i] if len(examples['context'][i]) > 0 else []
options = examples['options'][i]
# Resize all images
context = [self.resize_image(img) for img in context]
options = [self.resize_image(img) for img in options]
# Calculate common panel size (use median size to avoid outliers)
all_panels = context + options
if len(all_panels) > 0:
widths = [img.size[0] for img in all_panels]
heights = [img.size[1] for img in all_panels]
panel_width = int(np.median(widths))
panel_height = int(np.median(heights))
# Resize all panels to common size
context = [img.resize((panel_width, panel_height)) for img in context]
options = [img.resize((panel_width, panel_height)) for img in options]
# Create mask panel for sequence filling tasks if needed
if 'index' in examples and len(context) > 0:
mask_idx = examples['index'][i]
mask_panel = self.create_mask_panel(panel_width, panel_height)
context.insert(mask_idx, mask_panel)
# Calculate canvas dimensions based on whether we have context
if len(context) > 0:
context_row_width = panel_width * len(context) + self.margin * (len(context) - 1)
options_row_width = panel_width * len(options) + self.margin * (len(options) - 1)
canvas_width = max(context_row_width, options_row_width)
canvas_height = (panel_height * 2 +
self.label_space * 2)
else:
# Only options row for caption_relevance
canvas_width = panel_width * len(options) + self.margin * (len(options) - 1)
canvas_height = (panel_height +
self.label_space)
# Create canvas
final_image = Image.new("RGB", (canvas_width, canvas_height), "white")
draw = ImageDraw.Draw(final_image)
try:
label_font = ImageFont.truetype(self.font_path, self.label_font_size)
number_font = ImageFont.truetype(self.font_path, self.number_font_size)
except:
raise ValueError("Font file not found")
current_y = 0
# Add context section if it exists
if len(context) > 0:
# Draw "Context" label
bbox = draw.textbbox((0, 0), "Context", font=label_font)
text_x = (canvas_width - (bbox[2] - bbox[0])) // 2
draw.text((text_x, current_y), "Context", fill="black", font=label_font)
current_y += self.label_space
# Paste context panels
x_offset = (canvas_width - (panel_width * len(context) +
self.margin * (len(context) - 1))) // 2
for panel in context:
final_image.paste(panel, (x_offset, current_y))
x_offset += panel_width + self.margin
current_y += panel_height
# Add "Options" label
bbox = draw.textbbox((0, 0), "Options", font=label_font)
text_x = (canvas_width - (bbox[2] - bbox[0])) // 2
draw.text((text_x, current_y), "Options", fill="black", font=label_font)
current_y += self.label_space
# Paste options with numbers on panels
x_offset = (canvas_width - (panel_width * len(options) +
self.margin * (len(options) - 1))) // 2
for idx, panel in enumerate(options):
# Create a copy of the panel to draw on
panel_with_number = panel.copy()
if panel_with_number.mode != 'RGBA':
panel_with_number = panel_with_number.convert('RGBA')
# Draw number on panel
panel_with_number = self.draw_number_on_panel(
panel_with_number,
idx,
number_font
)
# Paste the panel with number
final_image.paste(panel_with_number, (x_offset, current_y), panel_with_number)
x_offset += panel_width + self.margin
# Convert final_image to PIL Image format (instead of numpy array)
single_images.append(final_image)
# Prepare batch output
examples['single_image'] = single_images
return examples
from datasets import load_dataset
skill = "sequence_filling" # "sequence_filling", "char_coherence", "visual_closure", "text_closure", "caption_relevance"
split = "val" # "val", "test"
dataset = load_dataset("VLR-CVC/ComicsPAP", skill, split=split)
processor = SingleImagePickAPanel()
dataset = dataset.map(
processor.map_to_single_image,
batched=True,
batch_size=32,
remove_columns=['context', 'options']
)
dataset.save_to_disk(f"ComicsPAP_{skill}_{split}_single_images")
```
## Evaluation
The evaluation metric for all tasks is the accuracy of the model's predictions. The overall accuracy is calculated as the weighted average of the accuracy of each subtask, with the weights being the number of examples in each subtask.
To evaluate on the test set you must submit your predictions to the [Robust Reading Competition website](https://rrc.cvc.uab.es/?ch=31&com=introduction), as a json file with the following structure:
```json
[
{ "sample_id" : "sample_id_0", "correct_panel_id" : 3},
{ "sample_id" : "sample_id_1", "correct_panel_id" : 1},
{ "sample_id" : "sample_id_2", "correct_panel_id" : 4},
...,
]
```
Where `sample_id` is the id of the sample, `correct_panel_id` is the prediction of your model as the index of the correct panel in the options.
Pseudocode for the evaluation on val set, adapt for your model:
```python
skills = {
"sequence_filling": {
"num_examples": 262
},
"char_coherence": {
"num_examples": 143
},
"visual_closure": {
"num_examples": 300
},
"text_closure": {
"num_examples": 259
},
"caption_relevance": {
"num_examples": 262
}
}
for skill in skills:
dataset = load_dataset("VLR-CVC/ComicsPAP", skill, split="val")
correct = 0
total = 0
for example in dataset:
# Your model prediction
prediction = model.generate(**example)
prediction = post_process(prediction)
if prediction == example["solution_index"]:
correct += 1
total += 1
accuracy = correct / total
print(f"Accuracy for {skill}: {accuracy}")
assert total == skills[skill]["num_examples"]
skills[skill]["accuracy"] = accuracy
# Calculate overall accuracy
total_examples = sum(skill["num_examples"] for skill in skills.values())
overall_accuracy = sum(skill["num_examples"] * skill["accuracy"] for skill in skills.values()) / total_examples
print(f"Overall accuracy: {overall_accuracy}")
```
## Baselines
_Results and Code for baselines coming on 25/02/2025_
## Citation
_coming soon_