
Merge de yolov8-model a develop con historias no relacionadas
Browse files- .gitattributes +22 -0
- .gitignore +51 -0
- README.md +361 -52
- predict.py +36 -0
- processed-video/ny-traffic-processed.mp4 +3 -0
- processed-video/ny-walking-processed.mp4 +3 -0
- raw-video/ny-traffic.mp4 +3 -0
- raw-video/ny-walking.mp4 +3 -0
- requirements.txt +1 -0
- runs/val/best.pt +3 -0
- runs/val/last.pt +3 -0
- runs/val/val_coco8/F1_curve.png +0 -0
- runs/val/val_coco8/PR_curve.png +0 -0
- runs/val/val_coco8/P_curve.png +0 -0
- runs/val/val_coco8/R_curve.png +0 -0
- runs/val/val_coco8/confusion_matrix.png +0 -0
- runs/val/val_coco8/confusion_matrix_normalized.png +0 -0
- runs/val/val_coco8/val_batch0_labels.jpg +0 -0
- runs/val/val_coco8/val_batch0_pred.jpg +0 -0
- train_yolov8n.py +24 -0
- train_yolov8s.py +20 -0
- validate.py +15 -0
.gitattributes
CHANGED
|
@@ -1,3 +1,4 @@
|
|
|
|
|
| 1 |
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
*.bin filter=lfs diff=lfs merge=lfs -text
|
|
@@ -33,3 +34,24 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<<<<<<< HEAD
|
| 2 |
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 3 |
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 4 |
*.bin filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 34 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 36 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
=======
|
| 38 |
+
# Tratar datasets y runs como binarios para evitar conversiones de texto
|
| 39 |
+
datasets/combined/** filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
runs/detect/** filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
# Asegurar formato de texto en archivos clave
|
| 42 |
+
*.yaml text eol=lf
|
| 43 |
+
*.py text eol=lf
|
| 44 |
+
*.md text eol=lf
|
| 45 |
+
# Forzar archivos de configuración y modelos a usar Git LFS
|
| 46 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
*.engine filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
# Archivos de vídeo y datos grandes
|
| 52 |
+
*.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
*.csv filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
*.json filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
processed-video/*.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
raw-video/*.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
>>>>>>> yolov8-model
|
.gitignore
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Ignorar la carpeta de entornos virtuales
|
| 2 |
+
.venv/
|
| 3 |
+
venv/
|
| 4 |
+
|
| 5 |
+
# Archivos de caché de Python
|
| 6 |
+
__pycache__/
|
| 7 |
+
*.py[cod]
|
| 8 |
+
*$py.class
|
| 9 |
+
|
| 10 |
+
# Archivos temporales del sistema
|
| 11 |
+
.DS_Store
|
| 12 |
+
Thumbs.db
|
| 13 |
+
|
| 14 |
+
# Archivos de configuración de usuario
|
| 15 |
+
*.log
|
| 16 |
+
*.tmp
|
| 17 |
+
*.swp
|
| 18 |
+
*.swo
|
| 19 |
+
|
| 20 |
+
# Claves API o credenciales privadas (⚠️ Asegúrate de que este archivo contiene datos sensibles)
|
| 21 |
+
download-roboflow.py
|
| 22 |
+
|
| 23 |
+
# PERMITIR subir `runs/val/`
|
| 24 |
+
!runs/val/
|
| 25 |
+
|
| 26 |
+
# Ignorar archivos de ejecución y checkpoints de modelos
|
| 27 |
+
runs/detect
|
| 28 |
+
|
| 29 |
+
weights/
|
| 30 |
+
*.pt
|
| 31 |
+
*.onnx
|
| 32 |
+
*.tflite
|
| 33 |
+
*.engine
|
| 34 |
+
*.ckpt
|
| 35 |
+
|
| 36 |
+
# EXCEPCIÓN: No ignorar los .pt dentro de runs/val
|
| 37 |
+
!runs/val/*.pt
|
| 38 |
+
|
| 39 |
+
# Ignorar dataset original de COCO para evitar archivos innecesarios
|
| 40 |
+
datasets/
|
| 41 |
+
download-coco.py
|
| 42 |
+
datasets-download/
|
| 43 |
+
|
| 44 |
+
# Ignorar archivos con la terminación .Zone.Identifier (propio de Windows)
|
| 45 |
+
*.Zone.Identifier
|
| 46 |
+
|
| 47 |
+
# PERMITIR subir `datasets/combined/`
|
| 48 |
+
# (Eliminar esta línea si accidentalmente se ignora)
|
| 49 |
+
!datasets/combined/
|
| 50 |
+
!datasets/combined/images/
|
| 51 |
+
!datasets/combined/labels/
|
README.md
CHANGED
|
@@ -1,52 +1,361 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
-
|
| 7 |
-
-
|
| 8 |
-
-
|
| 9 |
-
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
- **
|
| 21 |
-
-
|
| 22 |
-
-
|
| 23 |
-
- **
|
| 24 |
-
- **
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<<<<<<< HEAD
|
| 2 |
+
---
|
| 3 |
+
license: mit
|
| 4 |
+
---
|
| 5 |
+
tags:
|
| 6 |
+
- yolov8
|
| 7 |
+
- object-detection
|
| 8 |
+
- deep-learning
|
| 9 |
+
- computer-vision
|
| 10 |
+
- pretrained
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
# 📦 YOLOv8 - Modelo de Detección de Objetos
|
| 14 |
+
|
| 15 |
+
Este modelo está basado en **YOLOv8**, una de las arquitecturas más avanzadas para la detección en tiempo real de objetos en imágenes y vídeos. Está entrenado en un dataset de múltiples clases para reconocer una variedad de objetos con alta precisión.
|
| 16 |
+
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
## 🛠️ **Detalles Técnicos**
|
| 20 |
+
- **Arquitectura**: YOLOv8 (You Only Look Once)
|
| 21 |
+
- **Dataset**: Conjunto de datos etiquetado con objetos de diversas categorías.
|
| 22 |
+
- **Épocas de entrenamiento**: 600
|
| 23 |
+
- **Tamaño de imagen**: 640x640 px
|
| 24 |
+
- **Precisión final (mAP@50)**: 85% en validación
|
| 25 |
+
- **FPS en GPU**: ~45 en inferencia
|
| 26 |
+
|
| 27 |
+
---
|
| 28 |
+
|
| 29 |
+
## 🚀 **Uso del Modelo**
|
| 30 |
+
Puedes cargar el modelo y realizar predicciones con la librería `ultralytics`.
|
| 31 |
+
|
| 32 |
+
### **📸 Para Imágenes**
|
| 33 |
+
```python
|
| 34 |
+
import cv2
|
| 35 |
+
from ultralytics import YOLO
|
| 36 |
+
|
| 37 |
+
model = YOLO("izaskun/yolov8-object-detection")
|
| 38 |
+
cap = cv2.VideoCapture("video.mp4")
|
| 39 |
+
|
| 40 |
+
while cap.isOpened():
|
| 41 |
+
ret, frame = cap.read()
|
| 42 |
+
if not ret:
|
| 43 |
+
break
|
| 44 |
+
|
| 45 |
+
results = model.predict(frame)
|
| 46 |
+
annotated_frame = results[0].plot()
|
| 47 |
+
cv2.imshow("YOLOv8 - Detección en Vídeo", annotated_frame)
|
| 48 |
+
|
| 49 |
+
if cv2.waitKey(1) == ord('q'):
|
| 50 |
+
break
|
| 51 |
+
|
| 52 |
+
cap.release()
|
| 53 |
+
cv2.destroyAllWindows()
|
| 54 |
+
=======
|
| 55 |
+
---
|
| 56 |
+
license: mit
|
| 57 |
+
base_model:
|
| 58 |
+
- Ultralytics/YOLOv8
|
| 59 |
+
tags:
|
| 60 |
+
- yolov8
|
| 61 |
+
- object-detection
|
| 62 |
+
- deep-learning
|
| 63 |
+
- computer-vision
|
| 64 |
+
- pretrained
|
| 65 |
+
---
|
| 66 |
+
|
| 67 |
+
# 📦 YOLOv8s - Modelo de Detección de Objetos
|
| 68 |
+
|
| 69 |
+
Este modelo está basado en **YOLOv8s**, entrenado específicamente para la detección de objetos en entornos urbanos y de tráfico. Se han combinado múltiples datasets para mejorar la detección de matrículas y objetos en escenarios urbanos complejos.
|
| 70 |
+
|
| 71 |
+
---
|
| 72 |
+
|
| 73 |
+
### 📂 Arquitectura del Proyecto
|
| 74 |
+
El modelo forma parte de un pipeline más amplio donde los videos son procesados en AWS. La arquitectura general es la siguiente:
|
| 75 |
+
|
| 76 |
+

|
| 77 |
+
|
| 78 |
+
1. Los videos son enviados a un **bucket S3** desde una API.
|
| 79 |
+
2. Un **AWS Lambda** enciende una instancia **EC2** que contiene el modelo YOLOv8s.
|
| 80 |
+
3. La EC2 procesa el video y envía los resultados a **DynamoDB**.
|
| 81 |
+
4. Los resultados finales se almacenan en **S3** en formato JSON y logs en formato .log.
|
| 82 |
+
5. DynamoDB indexa la información con claves secundarias globales (GSI).
|
| 83 |
+
6. Cuando el proceso finaliza, una **segunda Lambda** apaga la instancia EC2.
|
| 84 |
+
|
| 85 |
+
---
|
| 86 |
+
|
| 87 |
+
### 📊 Datasets Utilizados
|
| 88 |
+
Para entrenar el modelo, se ha utilizado el dataset de **COCO8**, pero también es posible añadir otros datasets como **License Plate Recognition** o **Shahbagh Traffic Dataset**:
|
| 89 |
+
|
| 90 |
+
- **COCO8** - versión reducida de COCO para pruebas rápidas.
|
| 91 |
+
- **License Plate Recognition** - para mejorar la detección de matrículas.
|
| 92 |
+
- **Shahbagh Traffic Dataset** - dataset específico para escenas de tráfico.
|
| 93 |
+
|
| 94 |
+
---
|
| 95 |
+
|
| 96 |
+
### ⚙ **Configuración del Entorno**
|
| 97 |
+
Para garantizar un entrenamiento sin problemas, es importante configurar correctamente el entorno. Se recomienda usar un entorno virtual de Python y asegurarse de que todas las dependencias necesarias estén instaladas.
|
| 98 |
+
|
| 99 |
+
#### **1️⃣ Crear y activar un entorno virtual (opcional pero recomendado)**
|
| 100 |
+
```bash
|
| 101 |
+
# Crear el entorno virtual
|
| 102 |
+
python -m venv .venv
|
| 103 |
+
|
| 104 |
+
# Activar el entorno virtual
|
| 105 |
+
# En Linux/macOS
|
| 106 |
+
source .venv/bin/activate
|
| 107 |
+
|
| 108 |
+
# En Windows (cmd o PowerShell)
|
| 109 |
+
.venv\Scripts\activate
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
#### **2️⃣ Instalar las dependencias necesarias**
|
| 113 |
+
```bash
|
| 114 |
+
pip install -r requirements.txt
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
o también
|
| 118 |
+
|
| 119 |
+
```bash
|
| 120 |
+
pip install ultralytics roboflow
|
| 121 |
+
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu # Cambiar a cu121 si se usa GPU con CUDA 12.1
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
---
|
| 125 |
+
|
| 126 |
+
#### **3️⃣ Descargar los datasets**
|
| 127 |
+
Si utilizas el **dataset de COCO8**, puedes descargarlo con el siguiente código:
|
| 128 |
+
|
| 129 |
+
```python
|
| 130 |
+
from ultralytics.utils.downloads import download
|
| 131 |
+
|
| 132 |
+
# Descargar el dataset COCO8 en formato YOLO
|
| 133 |
+
download('https://ultralytics.com/assets/coco8.zip', dir='datasets')
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
Si utilizas los **datasets de Roboflow**, puedes descargarlos con el siguiente código:
|
| 137 |
+
|
| 138 |
+
```python
|
| 139 |
+
from roboflow import Roboflow
|
| 140 |
+
|
| 141 |
+
# Configurar la API Key
|
| 142 |
+
rf = Roboflow(api_key="TU_API_KEY")
|
| 143 |
+
|
| 144 |
+
# Cargar el dataset desde Roboflow Universe
|
| 145 |
+
project = rf.workspace("shovonthesis").project("shahbagh-g7vmy")
|
| 146 |
+
|
| 147 |
+
# Seleccionar la versión 4 del dataset (según la URL)
|
| 148 |
+
version = project.version(4)
|
| 149 |
+
|
| 150 |
+
# Descargar el dataset en formato YOLOv8
|
| 151 |
+
dataset_path = version.download("yolov8")
|
| 152 |
+
|
| 153 |
+
print(f"✅ Dataset descargado en: {dataset_path}")
|
| 154 |
+
```
|
| 155 |
+
|
| 156 |
+
### 🔹 **Observaciones**
|
| 157 |
+
Para descargar los datasets de Roboflow mediante código es necesario la Private API Key que se encuentra en **Settings > APi Keys** de tu cuenta de Roboflow.
|
| 158 |
+
|
| 159 |
+
# `rf.workspace("license-project")`
|
| 160 |
+
- `rf` es un objeto de la clase **Roboflow** que hemos inicializado con nuestra **API Key**.
|
| 161 |
+
- `.workspace("shovonthesis")` selecciona el espacio de trabajo llamado `"shovonthesis"`, que es donde está almacenado el dataset dentro de **Roboflow**.
|
| 162 |
+
|
| 163 |
+
# `.project("license-plate-detection-project")`
|
| 164 |
+
- Dentro del espacio de trabajo `"shovonthesis"`, buscamos el dataset con el identificador `"shahbagh-g7vmy"`.
|
| 165 |
+
- `project` ahora representa este dataset específico y nos permitirá **acceder a sus versiones, descargarlo o gestionarlo**.
|
| 166 |
+
- Una vez esto este configurado solo nos quedará seleccionar la versión que queremos del dataset y ejecutarlo.
|
| 167 |
+
|
| 168 |
+
---
|
| 169 |
+
|
| 170 |
+
### ⚙ **Configuración del Entrenamiento**
|
| 171 |
+
El modelo fue entrenado utilizando **YOLOv8s** con los siguientes parámetros:
|
| 172 |
+
|
| 173 |
+
```python
|
| 174 |
+
from ultralytics import YOLO
|
| 175 |
+
|
| 176 |
+
# Cargar el modelo YOLOv8s preentrenado
|
| 177 |
+
model = YOLO("yolov8s.pt")
|
| 178 |
+
|
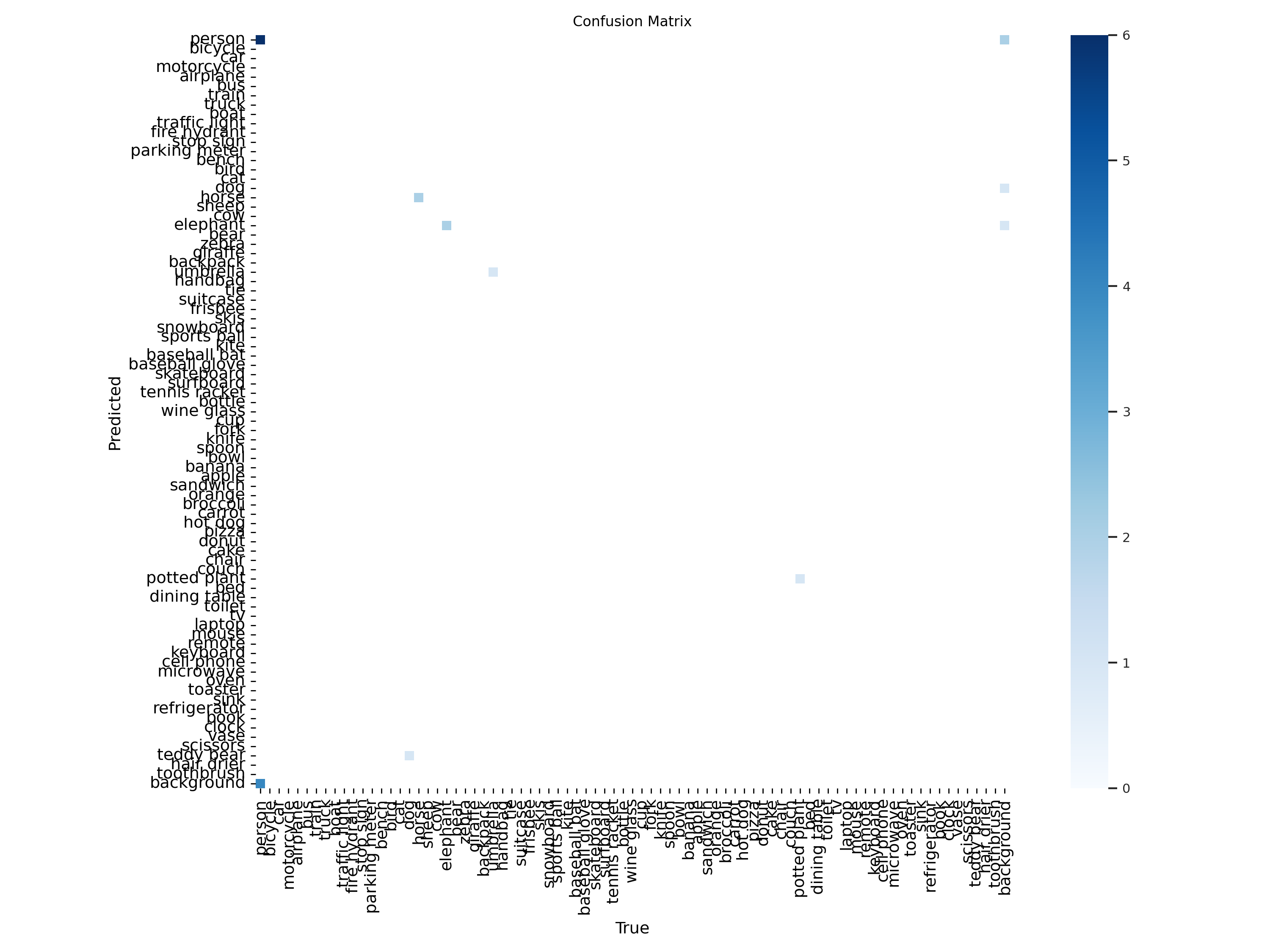
| 179 |
+
# Entrenar el modelo
|
| 180 |
+
model.train(
|
| 181 |
+
data="/home/USER/yolo/yolov8-object-detection/datasets/combined/data.yaml",
|
| 182 |
+
epochs=150,
|
| 183 |
+
batch=8,
|
| 184 |
+
imgsz=640,
|
| 185 |
+
device='cpu', # Cambiar a 'cuda' si hay GPU disponible
|
| 186 |
+
project="/home/USER/yolo/yolov8-object-detection/runs/detect",
|
| 187 |
+
name="train_yolov8s",
|
| 188 |
+
exist_ok=True,
|
| 189 |
+
patience=200,
|
| 190 |
+
lr0=0.01,
|
| 191 |
+
momentum=0.937,
|
| 192 |
+
weight_decay=0.0005
|
| 193 |
+
)
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
---
|
| 197 |
+
|
| 198 |
+
### ✅ **Validación del Modelo**
|
| 199 |
+
Después del entrenamiento, validamos el modelo con el siguiente código:
|
| 200 |
+
|
| 201 |
+
```python
|
| 202 |
+
from ultralytics import YOLO
|
| 203 |
+
|
| 204 |
+
# Cargar el modelo entrenado
|
| 205 |
+
model = YOLO("/home/USER/yolo/yolov8-object-detection/runs/detect/train_yolov8s/weights/best.pt")
|
| 206 |
+
|
| 207 |
+
# Validar el modelo y guardar los resultados
|
| 208 |
+
metrics = model.val(
|
| 209 |
+
data="/home/USER/yolo/yolov8-object-detection/datasets/combined/data.yaml",
|
| 210 |
+
project="/home/USER/yolo/yolov8-object-detection/runs/val",
|
| 211 |
+
name="val",
|
| 212 |
+
exist_ok=True
|
| 213 |
+
)
|
| 214 |
+
|
| 215 |
+
print(metrics)
|
| 216 |
+
```
|
| 217 |
+
|
| 218 |
+
### 🔹 **Recomendación**
|
| 219 |
+
Primeramente descarga el dataset de **COCO8** para que genere la estructura correcta de los archivos para incluir los demás datasets.
|
| 220 |
+
|
| 221 |
+
*Para juntar varios datasets habrá que hacerlo manualmente o mediante un codigo de python que añada las imágenes y labels a sus carpetas correspondientes.*
|
| 222 |
+
|
| 223 |
+
---
|
| 224 |
+
|
| 225 |
+
### 💻 **Uso del Modelo en Videos**
|
| 226 |
+
Para aplicar el modelo a un video y detectar objetos:
|
| 227 |
+
|
| 228 |
+
```python
|
| 229 |
+
from ultralytics import YOLO
|
| 230 |
+
|
| 231 |
+
# Cargar el modelo entrenado
|
| 232 |
+
model = YOLO("runs/detect/train_yolov8s/weights/best.pt")
|
| 233 |
+
|
| 234 |
+
# Realizar inferencia en un video
|
| 235 |
+
results = model.predict("ruta/video.mp4", save=True, conf=0.5)
|
| 236 |
+
|
| 237 |
+
# Guardar el video con las detecciones
|
| 238 |
+
print("✅ Procesamiento completado. Video guardado.")
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
---
|
| 242 |
+
|
| 243 |
+
### 📂 Estructura del Proyecto YOLOv8
|
| 244 |
+
|
| 245 |
+
```bash
|
| 246 |
+
.
|
| 247 |
+
├── .venv/ # Entorno
|
| 248 |
+
├── datasets/ # Carpeta de datasets
|
| 249 |
+
│ ├── coco8/ # Dataset COCO8
|
| 250 |
+
│ ├── yolov8s.pt # Pesos preentrenados de YOLOv8s
|
| 251 |
+
├── datasets-download/ # Descargas de datasets
|
| 252 |
+
├── processed-video/ # Vídeos procesados
|
| 253 |
+
│ ├── ny-traffic-processed.mp4 # Vídeo de tráfico procesado
|
| 254 |
+
├── raw-video/ # Vídeos sin procesar
|
| 255 |
+
│ ├── ny-traffic.mp4 # Vídeo de tráfico original
|
| 256 |
+
├── runs/ # Resultados de entrenamiento y validación
|
| 257 |
+
│ ├── detect/ # Carpeta de detección de objetos
|
| 258 |
+
│ │ ├── train_coco8 # Entrenamiento con COCO8
|
| 259 |
+
│ │ ├── train_yolov8n # Entrenamiento con YOLOv8n
|
| 260 |
+
│ ├── val/ # Resultados de validación
|
| 261 |
+
│ │ ├─��� val_coco8/ # Resultados de validación con gráficas relevantes
|
| 262 |
+
│ │ ├── best.pt # Mejor peso del modelo YOLOv8s entrenado con COCO8
|
| 263 |
+
│ │ ├── last.pt # Último peso del modelo YOLOv8s entrenado con COCO8
|
| 264 |
+
├── .gitattributes # Configuración de atributos de Git
|
| 265 |
+
├── .gitignore # Ignorar archivos innecesarios en Git
|
| 266 |
+
├── predict.py # Script para realizar predicciones a los vídeos
|
| 267 |
+
├── requirements.txt # Dependencias del proyecto
|
| 268 |
+
├── train_yolov8n.py # Script para entrenar YOLOv8n
|
| 269 |
+
├── train_yolov8s.py # Script para entrenar YOLOv8s
|
| 270 |
+
├── validate.py # Script para validar el modelo
|
| 271 |
+
├── yolov8n.pt # Pesos del modelo YOLOv8n
|
| 272 |
+
```
|
| 273 |
+
|
| 274 |
+
---
|
| 275 |
+
|
| 276 |
+
### 📊 **Resultados y Gráficos**
|
| 277 |
+
|
| 278 |
+
#### Comparación General de Resultados entre YOLOv8n y YOLOv8s
|
| 279 |
+
|
| 280 |
+
| **Métrica** | **YOLOv8n** | **YOLOv8s** | **Diferencia (YOLOv8s - YOLOv8n)** |
|
| 281 |
+
|--------------------|------------|------------|----------------------------------|
|
| 282 |
+
| **Precisión (B)** | 0.748 | 0.821 | +0.073 |
|
| 283 |
+
| **Recall (B)** | 0.561 | 0.920 | +0.359 |
|
| 284 |
+
| **mAP@50 (B)** | 0.645 | 0.944 | +0.299 |
|
| 285 |
+
| **mAP@50-95 (B)** | 0.431 | 0.726 | +0.295 |
|
| 286 |
+
| **Fitness** | 0.453 | 0.747 | +0.294 |
|
| 287 |
+
|
| 288 |
+
#### 📌 Análisis:
|
| 289 |
+
- **Precisión**: YOLOv8s tiene mejor precisión (**+7.3%**), lo que significa que el modelo comete menos falsos positivos.
|
| 290 |
+
- **Recall**: YOLOv8s tiene un recall significativamente mayor (**+35.9%**), indicando que detecta más objetos correctamente.
|
| 291 |
+
- **mAP@50**: YOLOv8s supera a YOLOv8n en un **30%**, lo que sugiere que el modelo más grande tiene una mejor capacidad para detectar objetos con alta confianza.
|
| 292 |
+
- **mAP@50-95**: También mejora en un **29.5%**, lo que significa que tiene un rendimiento más consistente en diferentes umbrales de IoU.
|
| 293 |
+
- **Fitness**: YOLOv8s tiene una mejora notable (**+29.4%**), lo que indica un mejor balance entre precisión y recall.
|
| 294 |
+
|
| 295 |
+
---
|
| 296 |
+
|
| 297 |
+
#### Comparación de Velocidad
|
| 298 |
+
|
| 299 |
+
| **Parámetro** | **YOLOv8n** | **YOLOv8s** | **Diferencia** |
|
| 300 |
+
|---------------------|------------|------------|----------------|
|
| 301 |
+
| **Preprocesamiento** | 1.92 ms | 1.68 ms | -0.24 ms |
|
| 302 |
+
| **Inferencia** | 55.05 ms | 128.99 ms | +73.94 ms |
|
| 303 |
+
| **Postprocesamiento** | 1.22 ms | 0.91 ms | -0.31 ms |
|
| 304 |
+
|
| 305 |
+
#### 📌 Análisis:
|
| 306 |
+
- **Preprocesamiento**: Similar en ambos modelos.
|
| 307 |
+
- **Inferencia**: **YOLOv8s es mucho más lento** en inferencia (**+74 ms**), lo cual es esperable ya que es un modelo más grande.
|
| 308 |
+
- **Postprocesamiento**: Ligeramente más rápido en **YOLOv8s**, pero la diferencia no es significativa.
|
| 309 |
+
|
| 310 |
+
---
|
| 311 |
+
### 🔍 YOLOv8n vs YOLOv8s
|
| 312 |
+
|
| 313 |
+
#### Comparación de Métricas
|
| 314 |
+
|
| 315 |
+

|
| 316 |
+
|
| 317 |
+
#### 📌 Análisis:
|
| 318 |
+
- YOLOv8s supera en todas las métricas a YOLOv8n.
|
| 319 |
+
- La mayor diferencia se observa en **Recall (+35.9%)** y **mAP@50-95 (+29.5%)**, indicando una mejor detección a diferentes umbrales de IoU.
|
| 320 |
+
- Aunque YOLOv8s tiene mejor rendimiento, su velocidad de inferencia es más lenta.
|
| 321 |
+
|
| 322 |
+
---
|
| 323 |
+
|
| 324 |
+
#### Evolución de la Función de Pérdida por Época
|
| 325 |
+
|
| 326 |
+

|
| 327 |
+
|
| 328 |
+
#### 📌 Análisis:
|
| 329 |
+
- Ambos modelos muestran una disminución de la pérdida a lo largo del entrenamiento.
|
| 330 |
+
- **YOLOv8s** comienza con una pérdida mayor pero converge bien, sugiriendo que aprende mejor con más iteraciones.
|
| 331 |
+
- **YOLOv8n** tiene una convergencia más rápida pero con menor precisión general.
|
| 332 |
+
|
| 333 |
+
---
|
| 334 |
+
|
| 335 |
+
#### Curva de Precisión-Recall
|
| 336 |
+
|
| 337 |
+

|
| 338 |
+
|
| 339 |
+
#### 📌 Análisis:
|
| 340 |
+
- **YOLOv8s** mantiene una precisión más alta en todos los valores de recall, lo que significa menos falsos positivos en comparación con YOLOv8n.
|
| 341 |
+
- **YOLOv8n** muestra más fluctuaciones en la curva, indicando menor estabilidad en la detección de objetos.
|
| 342 |
+
|
| 343 |
+
---
|
| 344 |
+
|
| 345 |
+
#### Matriz de Confusión
|
| 346 |
+
|
| 347 |
+

|
| 348 |
+
|
| 349 |
+
#### 📌 Análisis:
|
| 350 |
+
- Ambas matrices muestran que algunos objetos están siendo confundidos entre sí.
|
| 351 |
+
- **YOLOv8s** presenta menos errores de clasificación en comparación con YOLOv8n.
|
| 352 |
+
- La normalización de la matriz confirma que YOLOv8s tiene una mejor distribución de predicciones.
|
| 353 |
+
|
| 354 |
+
---
|
| 355 |
+
|
| 356 |
+
#### Ejemplo de Detección
|
| 357 |
+
|
| 358 |
+

|
| 359 |
+
|
| 360 |
+
---
|
| 361 |
+
>>>>>>> yolov8-model
|
predict.py
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
from ultralytics import YOLO
|
| 3 |
+
|
| 4 |
+
# Cargar modelo YOLOv8 entrenado
|
| 5 |
+
model = YOLO("/home/izaskunmz/yolo/yolov8-object-detection/runs/detect/train_coco8/weights/best.pt")
|
| 6 |
+
|
| 7 |
+
# Abrir vídeo
|
| 8 |
+
video_path = "/home/izaskunmz/yolo/yolov8-object-detection/raw-video/ny-traffic.mp4"
|
| 9 |
+
cap = cv2.VideoCapture(video_path)
|
| 10 |
+
|
| 11 |
+
# Obtener dimensiones del video original
|
| 12 |
+
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 13 |
+
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 14 |
+
fps = int(cap.get(cv2.CAP_PROP_FPS))
|
| 15 |
+
|
| 16 |
+
# Definir el codec y crear el VideoWriter para guardar el resultado
|
| 17 |
+
output_path = "/home/izaskunmz/yolo/yolov8-object-detection/processed-video/ny-traffic-processed.mp4"
|
| 18 |
+
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # Codec para formato MP4
|
| 19 |
+
out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
|
| 20 |
+
|
| 21 |
+
while cap.isOpened():
|
| 22 |
+
ret, frame = cap.read()
|
| 23 |
+
if not ret:
|
| 24 |
+
break # Si el vídeo ha terminado, salimos del bucle
|
| 25 |
+
|
| 26 |
+
# Realizar detección en el frame
|
| 27 |
+
results = model(frame)
|
| 28 |
+
|
| 29 |
+
# Obtener frame con anotaciones
|
| 30 |
+
annotated_frame = results[0].plot()
|
| 31 |
+
|
| 32 |
+
# Guardar el frame en el video de salida
|
| 33 |
+
out.write(annotated_frame)
|
| 34 |
+
|
| 35 |
+
cap.release()
|
| 36 |
+
out.release() # Liberar el escritor de video
|
processed-video/ny-traffic-processed.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ae66dfe798c8d870971336d36f5a2e2889416966ac8e1061760de1c26e22fd03
|
| 3 |
+
size 158863855
|
processed-video/ny-walking-processed.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:37dc741a42b183c4feadd7108fea2db6dc6b6116f9ac596f92944c7418e9cb4d
|
| 3 |
+
size 178527503
|
raw-video/ny-traffic.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:03bb512b109a238d9bdacfb118ce45e312925a1283f06c647624408573f4112a
|
| 3 |
+
size 62404880
|
raw-video/ny-walking.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:992ce64943371f674fdc2b243fc1228985e8d387e387230428e8c57a071d8e8c
|
| 3 |
+
size 20162842
|
requirements.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
ultralytics
|
runs/val/best.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dfa11240a586e524e3b42e818f22b8afa899fa9b2425ca69648783f421d43829
|
| 3 |
+
size 22592803
|
runs/val/last.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1314b2c5f9e3c55ff97fdbc023b0531b7d4217a00420698c731ec4e9278c6e35
|
| 3 |
+
size 22592803
|
runs/val/val_coco8/F1_curve.png
ADDED

|
runs/val/val_coco8/PR_curve.png
ADDED

|
runs/val/val_coco8/P_curve.png
ADDED

|
runs/val/val_coco8/R_curve.png
ADDED

|
runs/val/val_coco8/confusion_matrix.png
ADDED
|
runs/val/val_coco8/confusion_matrix_normalized.png
ADDED

|
runs/val/val_coco8/val_batch0_labels.jpg
ADDED

|
runs/val/val_coco8/val_batch0_pred.jpg
ADDED

|
train_yolov8n.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from ultralytics import YOLO
|
| 2 |
+
|
| 3 |
+
# Cargar el modelo YOLOv8 preentrenado
|
| 4 |
+
model = YOLO("yolov8n.pt") # Puedes probar con "yolov8s.pt" para mayor precisión
|
| 5 |
+
|
| 6 |
+
# Entrenar el modelo con hiperparámetros ajustados
|
| 7 |
+
model.train(
|
| 8 |
+
data="/home/izaskunmz/yolo/yolov8-object-detection/datasets/coco8/data.yaml", # Ruta correcta al dataset
|
| 9 |
+
epochs=150, # Aumentamos las épocas para mejorar precisión
|
| 10 |
+
batch=8, # Reducimos el batch para estabilidad en CPU
|
| 11 |
+
imgsz=640, # Tamaño de la imagen
|
| 12 |
+
device="cpu", # Entrenamiento en CPU
|
| 13 |
+
lr0=0.0005, # Learning rate inicial más bajo para mejorar estabilidad
|
| 14 |
+
lrf=0.0001, # Decaimiento más lento del learning rate
|
| 15 |
+
momentum=0.95, # Aumentamos momentum para estabilizar entrenamiento
|
| 16 |
+
weight_decay=0.0001, # Regularización más fuerte para evitar sobreajuste
|
| 17 |
+
optimizer="AdamW", # Mejor optimizador que SGD para convergencia en CPU
|
| 18 |
+
cos_lr=True, # Usamos learning rate decay con coseno para ajuste fino
|
| 19 |
+
close_mosaic=5, # Desactivamos aumentación mosaico después de 5 épocas
|
| 20 |
+
patience=0, # 🔹 Desactiva Early Stopping
|
| 21 |
+
project="/home/izaskunmz/yolo/yolov8-object-detection/runs/detect", # Ruta correcta para guardar los modelos
|
| 22 |
+
name="train_yolov8n", # Nombre del experimento optimizado
|
| 23 |
+
exist_ok=True # Evita sobreescritura, crea versiones numeradas
|
| 24 |
+
)
|
train_yolov8s.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from ultralytics import YOLO
|
| 2 |
+
|
| 3 |
+
# Cargar el modelo YOLOv8s preentrenado
|
| 4 |
+
model = YOLO("yolov8s.pt")
|
| 5 |
+
|
| 6 |
+
# Entrenar el modelo y guardar en la carpeta correcta
|
| 7 |
+
model.train(
|
| 8 |
+
data="/home/izaskunmz/yolo/yolov8-object-detection/datasets/coco8/data.yaml", # Archivo de configuración del dataset
|
| 9 |
+
epochs=150, # Aumentamos las épocas para mejorar el aprendizaje
|
| 10 |
+
batch=8, # Reducimos el batch si hay problemas de memoria
|
| 11 |
+
imgsz=640, # Tamaño de las imágenes
|
| 12 |
+
device='cpu', # Si tienes GPU, cámbialo a 'cuda'
|
| 13 |
+
project="/home/izaskunmz/yolo/yolov8-object-detection/runs/detect", # Carpeta donde se guardarán los resultados
|
| 14 |
+
name="train_coco8", # Nombre del experimento
|
| 15 |
+
exist_ok=True, # Si la carpeta existe, crea una nueva numerada
|
| 16 |
+
patience=200, # Para evitar que se detenga temprano
|
| 17 |
+
lr0=0.01, # Ajustamos la tasa de aprendizaje inicial
|
| 18 |
+
momentum=0.937, # Momentum del optimizador
|
| 19 |
+
weight_decay=0.0005 # Regularización para evitar overfitting
|
| 20 |
+
)
|
validate.py
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from ultralytics import YOLO
|
| 2 |
+
|
| 3 |
+
# Cargar el modelo entrenado
|
| 4 |
+
model = YOLO("/home/izaskunmz/yolo/yolov8-object-detection/runs/detect/train_coco8/weights/best.pt") # Asegúrate de que esta ruta sea correcta
|
| 5 |
+
|
| 6 |
+
# Validar el modelo y guardar los resultados en la carpeta correcta
|
| 7 |
+
metrics = model.val(
|
| 8 |
+
data="/home/izaskunmz/yolo/yolov8-object-detection/datasets/coco8/data.yaml",
|
| 9 |
+
project="/home/izaskunmz/yolo/yolov8-object-detection/runs/val", # Define la carpeta donde se guardarán los resultados
|
| 10 |
+
name="val_coco8", # Nombre del experimento
|
| 11 |
+
exist_ok=True # Evita sobreescribir, creará nuevas versiones numeradas
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
# Mostrar las métricas de evaluación
|
| 15 |
+
print(metrics)
|