Qwen3-42B-A3B-2507-Thinking-TOTAL-RECALL-v2-Medium-MASTER-CODER [256k context]

This repo contains the full precision source code, in "safe tensors" format to generate GGUFs, GPTQ, EXL2, AWQ, HQQ and other formats.
The source code can also be used directly.
This model is for all use cases, but excels in CODING and programming in all major programming languages and many minor ones too.
This model is based on Qwen3-30B-A3B-Instruct-2507 (MOE, 128 experts, 8 activated), with Brainstorm 20X
(by DavidAU) - details at bottom of this page.
The Brainstorm adapter will improve general performance and "out of the box" thinking.
This creates a model of 42B parameters, 67 layers and 807 tensors.
This version has the NATIVE context of 256k.
This version (vs Brainstorm 40x, 53B version) can be used for both coding and creative use cases.
For coding, programming set expert to:
- 6-8 for general work.
- 10 for moderate work.
- 12-16 for complex work, long projects, complex coding.
- And for longer context, and/or multi-turn -> increase experts by 1-2 to help with longer context/multi turn understanding.
- Suggest min context 8k-16k for thinking/output.
Recommended settings - general:
- Rep pen 1.05 to 1.1 ; however rep pen of 1 will work well (may need to raise it for lower quants/fewer activated experts)
- Temp .3 to .6 (+- .2)
- Topk of 20, 40 or 100
- Topp of .95 / min p of .05
- System prompt (optional) to focus the model better.
- Suggest min context 8k-16k for thinking/output.
Creative Use Cases:
- Rep pen of 1.05 or higher, especially if using a lower quant / lower temps.
- Also use rep pen of 1.05 or higher with very short prompts.
- You can set active experts as low as "4" for creative use cases.
- Suggest min context 8k-16k for thinking/output.
This is the refined version -V1.4- from this project (see this repo for all settings, details, system prompts, example generations etc etc):
https://huggingface.co/DavidAU/Qwen3-55B-A3B-TOTAL-RECALL-Deep-40X-GGUF/
This version 2 is slightly smaller, with further refinements to the Brainstorm adapter and uses the new "Qwen3-30B-A3B-Instruct-2507".
Review and Specialized Settings for this model (V 1.4):
https://www.linkedin.com/posts/gchesler_davidauqwen3-53b-a3b-total-recall-v14-128k-activity-7344938636141858816-ILCM/
https://www.linkedin.com/posts/gchesler_haskell-postgres-agentic-activity-7347103276141596672-_zbo/
You may also want to see (root model of Total Recall series - Version 1):
https://huggingface.co/Qwen/Qwen3-30B-A3B
AND Version 2 root model:
https://huggingface.co/Qwen/Qwen3-30B-A3B-Thinking-2507
For additional settings, tool use, and other model settings.
Summary of root model below, followed by FULL HELP SECTION, then info on Brainstorm 40x.
QUANTS
Special Thanks to Team Mradermacher, and Nightmedia for the quants:
GGUF:
https://huggingface.co/mradermacher/Qwen3-42B-A3B-2507-Thinking-TOTAL-RECALL-v2-Medium-MASTER-CODE-GGUF
GGUF-IMATRIX:
https://huggingface.co/mradermacher/Qwen3-42B-A3B-2507-Thinking-TOTAL-RECALL-v2-Medium-MASTER-CODE-i1-GGUF
MLX:
https://huggingface.co/nightmedia/Qwen3-42B-A3B-2507-Thinking-TOTAL-RECALL-v2-Medium-MASTER-CODER-q6-hi-mlx
Qwen3-30B-A3B-Thinking-2507
Highlights
Over the past three months, we have continued to scale the thinking capability of Qwen3-30B-A3B, improving both the quality and depth of reasoning. We are pleased to introduce Qwen3-30B-A3B-Thinking-2507, featuring the following key enhancements:
- Significantly improved performance on reasoning tasks, including logical reasoning, mathematics, science, coding, and academic benchmarks that typically require human expertise.
- Markedly better general capabilities, such as instruction following, tool usage, text generation, and alignment with human preferences.
- Enhanced 256K long-context understanding capabilities.
NOTE: This version has an increased thinking length. We strongly recommend its use in highly complex reasoning tasks.
Model Overview
Qwen3-30B-A3B-Thinking-2507 has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: 262,144 natively.
NOTE: This model supports only thinking mode. Meanwhile, specifying enable_thinking=True is no longer required.
Additionally, to enforce model thinking, the default chat template automatically includes <think>. Therefore, it is normal for the model's output to contain only </think> without an explicit opening <think> tag.
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our blog, GitHub, and Documentation.
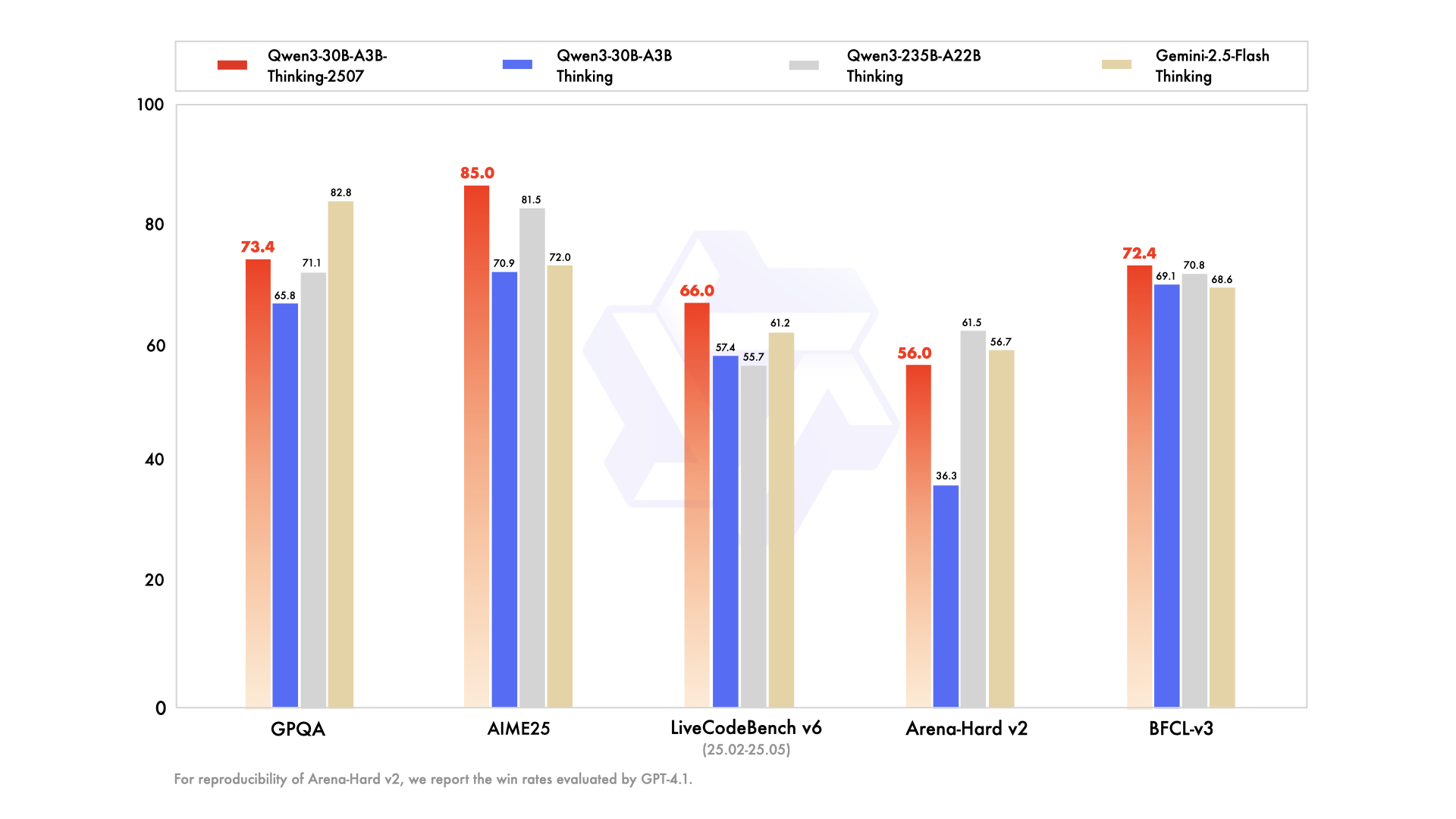
Performance
|
Gemini2.5-Flash-Thinking |
Qwen3-235B-A22B Thinking |
Qwen3-30B-A3B Thinking |
Qwen3-30B-A3B-Thinking-2507 |
| Knowledge |
|
|
|
|
| MMLU-Pro |
81.9 |
82.8 |
78.5 |
80.9 |
| MMLU-Redux |
92.1 |
92.7 |
89.5 |
91.4 |
| GPQA |
82.8 |
71.1 |
65.8 |
73.4 |
| SuperGPQA |
57.8 |
60.7 |
51.8 |
56.8 |
| Reasoning |
|
|
|
|
| AIME25 |
72.0 |
81.5 |
70.9 |
85.0 |
| HMMT25 |
64.2 |
62.5 |
49.8 |
71.4 |
| LiveBench 20241125 |
74.3 |
77.1 |
74.3 |
76.8 |
| Coding |
|
|
|
|
| LiveCodeBench v6 (25.02-25.05) |
61.2 |
55.7 |
57.4 |
66.0 |
| CFEval |
1995 |
2056 |
1940 |
2044 |
| OJBench |
23.5 |
25.6 |
20.7 |
25.1 |
| Alignment |
|
|
|
|
| IFEval |
89.8 |
83.4 |
86.5 |
88.9 |
| Arena-Hard v2$ |
56.7 |
61.5 |
36.3 |
56.0 |
| Creative Writing v3 |
85.0 |
84.6 |
79.1 |
84.4 |
| WritingBench |
83.9 |
80.3 |
77.0 |
85.0 |
| Agent |
|
|
|
|
| BFCL-v3 |
68.6 |
70.8 |
69.1 |
72.4 |
| TAU1-Retail |
65.2 |
54.8 |
61.7 |
67.8 |
| TAU1-Airline |
54.0 |
26.0 |
32.0 |
48.0 |
| TAU2-Retail |
66.7 |
40.4 |
34.2 |
58.8 |
| TAU2-Airline |
52.0 |
30.0 |
36.0 |
58.0 |
| TAU2-Telecom |
31.6 |
21.9 |
22.8 |
26.3 |
| Multilingualism |
|
|
|
|
| MultiIF |
74.4 |
71.9 |
72.2 |
76.4 |
| MMLU-ProX |
80.2 |
80.0 |
73.1 |
76.4 |
| INCLUDE |
83.9 |
78.7 |
71.9 |
74.4 |
| PolyMATH |
49.8 |
54.7 |
46.1 |
52.6 |
$ For reproducibility, we report the win rates evaluated by GPT-4.1.
& For highly challenging tasks (including PolyMATH and all reasoning and coding tasks), we use an output length of 81,920 tokens. For all other tasks, we set the output length to 32,768.
Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face transformers and we advise you to use the latest version of transformers.
With transformers<4.51.0, you will encounter the following error:
KeyError: 'qwen3_moe'
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Thinking-2507"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
For deployment, you can use sglang>=0.4.6.post1 or vllm>=0.8.5 or to create an OpenAI-compatible API endpoint:
- SGLang:
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Thinking-2507 --context-length 262144 --reasoning-parser deepseek-r1
- vLLM:
vllm serve Qwen/Qwen3-30B-A3B-Thinking-2507 --max-model-len 262144 --enable-reasoning --reasoning-parser deepseek_r1
Note: If you encounter out-of-memory (OOM) issues, you may consider reducing the context length to a smaller value. However, since the model may require longer token sequences for reasoning, we strongly recommend using a context length greater than 131,072 when possible.
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using Qwen-Agent to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
from qwen_agent.agents import Assistant
llm_cfg = {
'model': 'qwen3-30b-a3b-thinking-2507',
'model_type': 'qwen_dashscope',
}
tools = [
{'mcpServers': {
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter',
]
bot = Assistant(llm=llm_cfg, function_list=tools)
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
Best Practices
To achieve optimal performance, we recommend the following settings:
Sampling Parameters:
- We suggest using
Temperature=0.6, TopP=0.95, TopK=20, and MinP=0.
- For supported frameworks, you can adjust the
presence_penalty parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
Adequate Output Length: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 81,920 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
Standardize Output Format: We recommend using prompts to standardize model outputs when benchmarking.
- Math Problems: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- Multiple-Choice Questions: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the
answer field with only the choice letter, e.g., "answer": "C"."
No Thinking Content in History: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
Help, Adjustments, Samplers, Parameters and More
CHANGE THE NUMBER OF ACTIVE EXPERTS:
See this document:
https://huggingface.co/DavidAU/How-To-Set-and-Manage-MOE-Mix-of-Experts-Model-Activation-of-Experts
Settings: CHAT / ROLEPLAY and/or SMOOTHER operation of this model:
In "KoboldCpp" or "oobabooga/text-generation-webui" or "Silly Tavern" ;
Set the "Smoothing_factor" to 1.5
: in KoboldCpp -> Settings->Samplers->Advanced-> "Smooth_F"
: in text-generation-webui -> parameters -> lower right.
: In Silly Tavern this is called: "Smoothing"
NOTE: For "text-generation-webui"
-> if using GGUFs you need to use "llama_HF" (which involves downloading some config files from the SOURCE version of this model)
Source versions (and config files) of my models are here:
https://huggingface.co/collections/DavidAU/d-au-source-files-for-gguf-exl2-awq-gptq-hqq-etc-etc-66b55cb8ba25f914cbf210be
OTHER OPTIONS:
Increase rep pen to 1.1 to 1.15 (you don't need to do this if you use "smoothing_factor")
If the interface/program you are using to run AI MODELS supports "Quadratic Sampling" ("smoothing") just make the adjustment as noted.
Highest Quality Settings / Optimal Operation Guide / Parameters and Samplers
This a "Class 1" model:
For all settings used for this model (including specifics for its "class"), including example generation(s) and for advanced settings guide (which many times addresses any model issue(s)), including methods to improve model performance for all use case(s) as well as chat, roleplay and other use case(s) please see:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
You can see all parameters used for generation, in addition to advanced parameters and samplers to get the most out of this model here:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
What is Brainstorm?
Brainstorm 20x
The BRAINSTORM process was developed by David_AU.
Some of the core principals behind this process are discussed in this
scientific paper : Progressive LLaMA with Block Expansion .
However I went in a completely different direction from what was outlined in this paper.
What is "Brainstorm" ?
The reasoning center of an LLM is taken apart, reassembled, and expanded.
In this case for this model: 20 times
Then these centers are individually calibrated. These "centers" also interact with each other.
This introduces subtle changes into the reasoning process.
The calibrations further adjust - dial up or down - these "changes" further.
The number of centers (5x,10x etc) allow more "tuning points" to further customize how the model reasons so to speak.
The core aim of this process is to increase the model's detail, concept and connection to the "world",
general concept connections, prose quality and prose length without affecting instruction following.
This will also enhance any creative use case(s) of any kind, including "brainstorming", creative art form(s) and like case uses.
Here are some of the enhancements this process brings to the model's performance:
- Prose generation seems more focused on the moment to moment.
- Sometimes there will be "preamble" and/or foreshadowing present.
- Fewer or no "cliches"
- Better overall prose and/or more complex / nuanced prose.
- A greater sense of nuance on all levels.
- Coherence is stronger.
- Description is more detailed, and connected closer to the content.
- Simile and Metaphors are stronger and better connected to the prose, story, and character.
- Sense of "there" / in the moment is enhanced.
- Details are more vivid, and there are more of them.
- Prose generation length can be long to extreme.
- Emotional engagement is stronger.
- The model will take FEWER liberties vs a normal model: It will follow directives more closely but will "guess" less.
- The MORE instructions and/or details you provide the more strongly the model will respond.
- Depending on the model "voice" may be more "human" vs original model's "voice".
Other "lab" observations:
- This process does not, in my opinion, make the model 5x or 10x "smarter" - if only that was true!
- However, a change in "IQ" was not an issue / a priority, and was not tested or calibrated for so to speak.
- From lab testing it seems to ponder, and consider more carefully roughly speaking.
- You could say this process sharpens the model's focus on it's task(s) at a deeper level.
The process to modify the model occurs at the root level - source files level. The model can quanted as a GGUF, EXL2, AWQ etc etc.
