
Video-UTR-7B Model Card
📄 Model details
Model type:
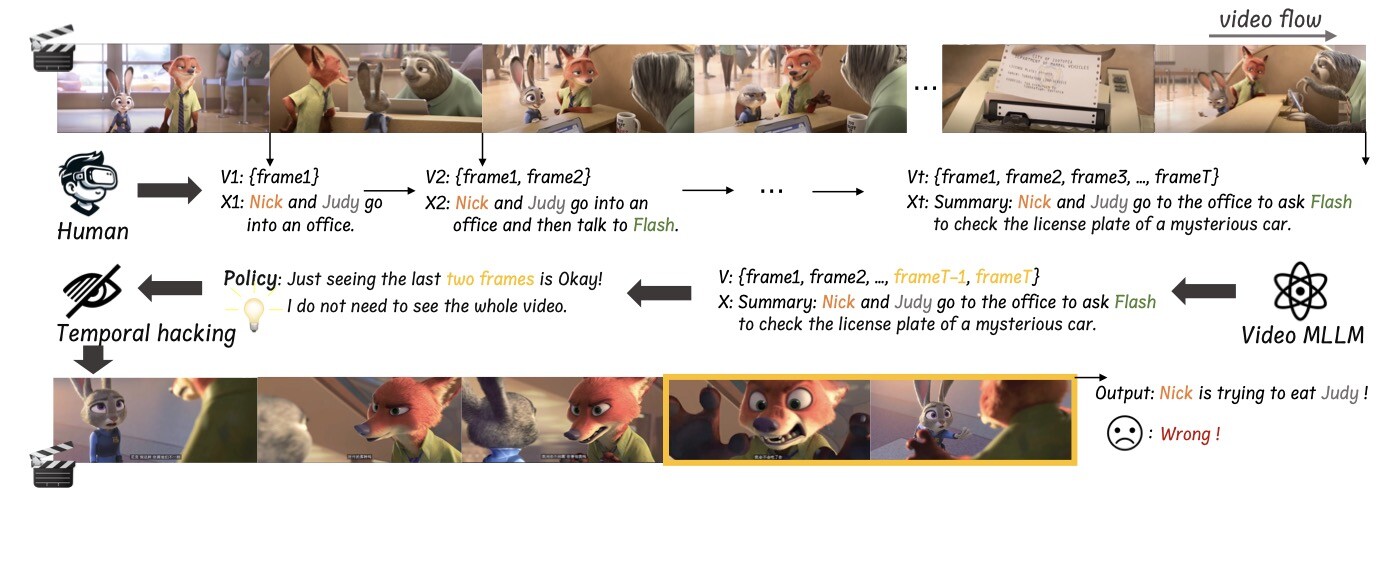
Video-UTR, as a new family of state-of-the-art video-MLLMs, is designed based on our proposed Unhackable Temporal Rewarding (UTR) under the LLaVA-NeXT architecture. UTR is a novel video-language modeling strategy guided by two princeples of our established temporal hacking theory, which contains two key innovations:
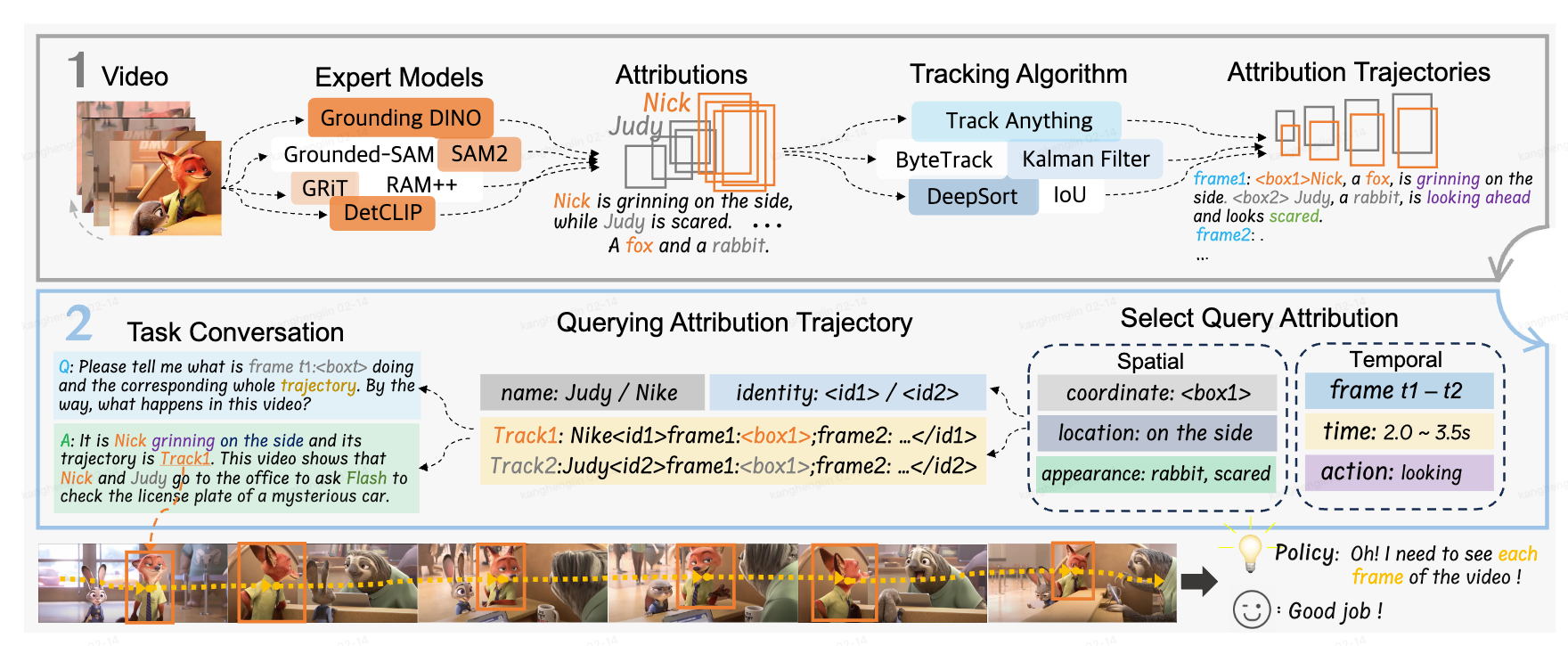
- Spatiotemporal Attributes: Extracts trajectory, identity and action features from video frames through a series of expert models to establish arrtibution trajectories.
- Bidirectional Querying: Perform bidirectional querying of temporal and spatial attributes to generate dialogue data to inforce learning spatiotemporal dynamics.
Paper or resources for more information:https://github.com/linkangheng/Video-UTR
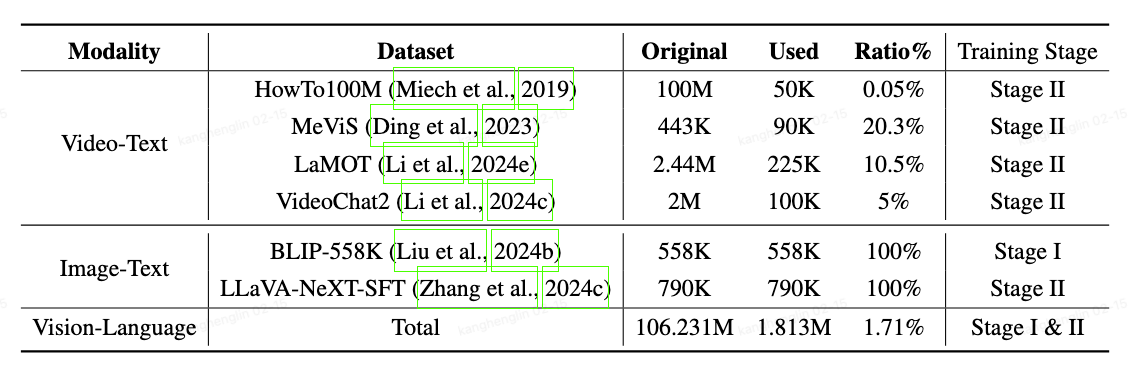
📚 Training dataset
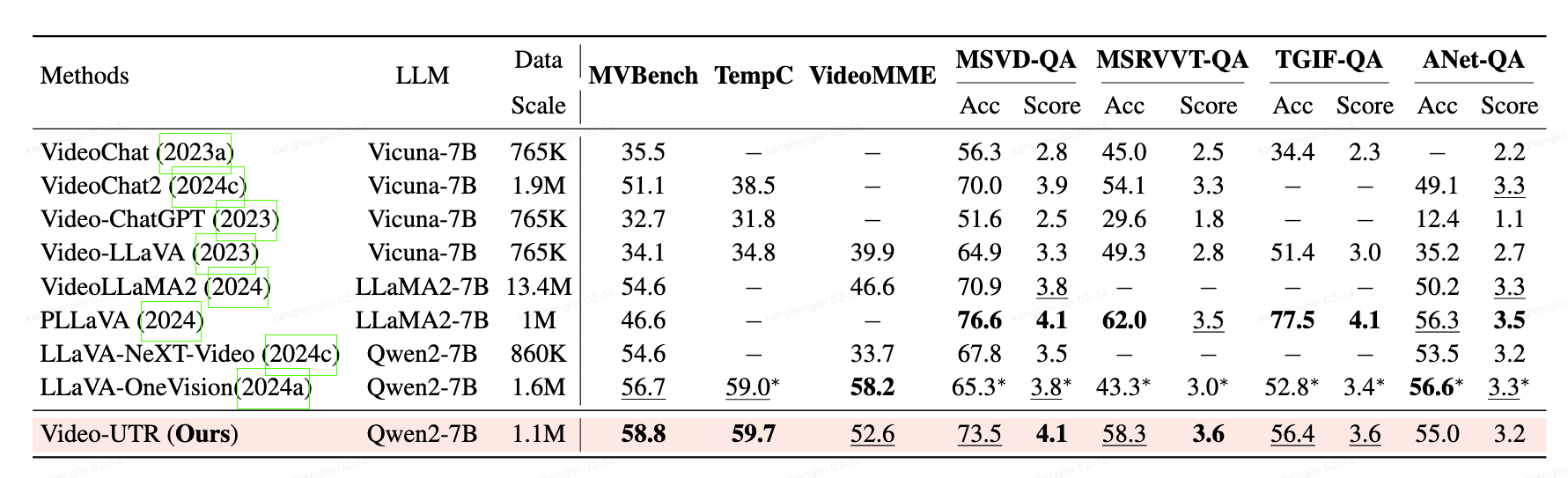
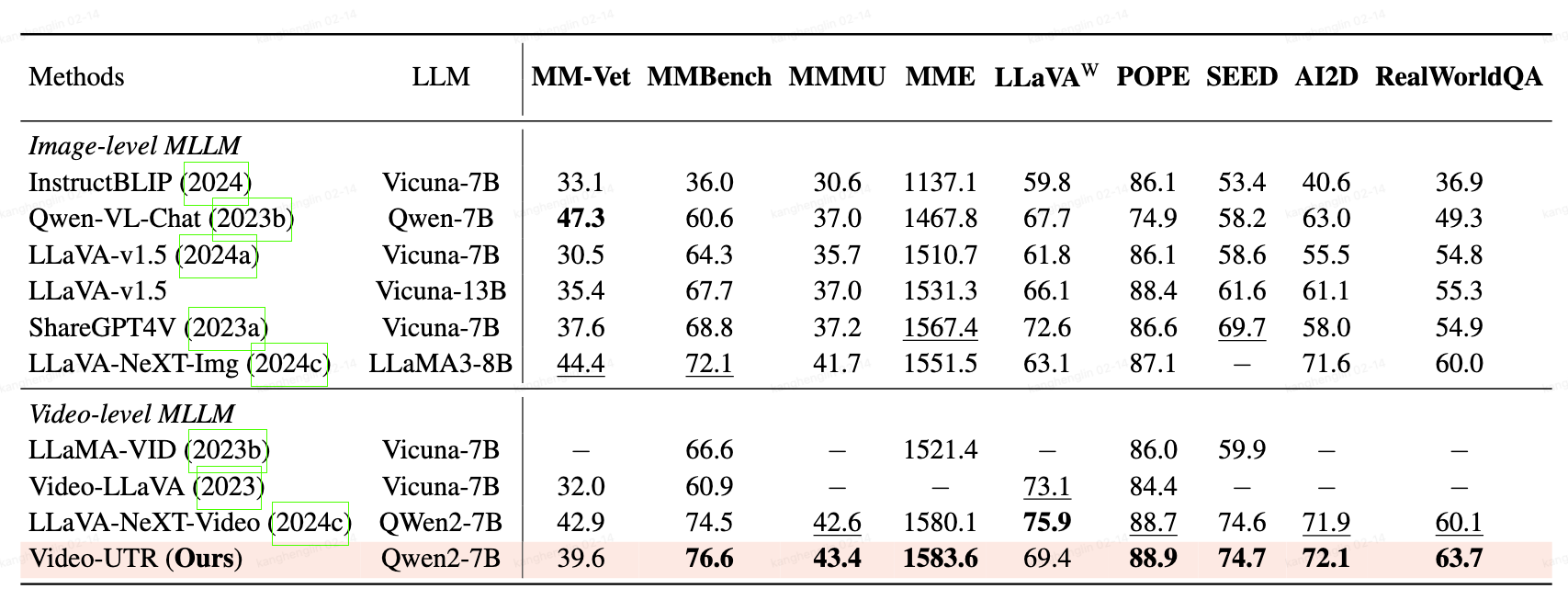
📊 Main Performance
🚀 How to use the model
First, make sure to have transformers >= 4.42.0.
The model supports multi-visual and multi-prompt generation. Meaning that you can pass multiple images/videos in your prompt. Make sure also to follow the correct prompt template (USER: xxx\nASSISTANT:) and add the token <image> or <video> to the location where you want to query images/videos:
import av
import torch
from transformers import AutoProcessor, LlavaOnevisionForConditionalGeneration
import numpy as np
from huggingface_hub import hf_hub_download
model_id = "Kangheng/Video-UTR-7b"
model = LlavaOnevisionForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(0)
processor = AutoProcessor.from_pretrained(model_id)
def read_video_pyav(container, indices):
'''
Decode the video with PyAV decoder.
Args:
container (`av.container.input.InputContainer`): PyAV container.
indices (`List[int]`): List of frame indices to decode.
Returns:
result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
'''
frames = []
container.seek(0)
start_index = indices[0]
end_index = indices[-1]
for i, frame in enumerate(container.decode(video=0)):
if i > end_index:
break
if i >= start_index and i in indices:
frames.append(frame)
return np.stack([x.to_ndarray(format="rgb24") for x in frames])
# define a chat history and use `apply_chat_template` to get correctly formatted prompt
# Each value in "content" has to be a list of dicts with types ("text", "image", "video")
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "Why is this video funny?."},
{"type": "video"},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
video_path = hf_hub_download(repo_id="raushan-testing-hf/videos-test", filename="sample_demo_1.mp4", repo_type="dataset")
container = av.open(video_path)
# sample uniformly 8 frames from the video, can sample more for longer videos
total_frames = container.streams.video[0].frames
indices = np.arange(0, total_frames, total_frames / 15).astype(int)
clip = read_video_pyav(container, indices)
inputs_video = processor(text=prompt, videos=clip, padding=True, return_tensors="pt").to(model.device)
output = model.generate(**inputs_video, max_new_tokens=2048, do_sample=False)
print(processor.decode(output[0][2:], skip_special_tokens=True))
🔒 License
This code repository and the model weights are licensed under the MIT License.
- Downloads last month
- 22