
Add quantitative comparison of this model for dynamic input shapes and previous ones for input with fixed shapes.
c6a7fe9
verified
| library_name: birefnet | |
| tags: | |
| - background-removal | |
| - mask-generation | |
| - Dichotomous Image Segmentation | |
| - Camouflaged Object Detection | |
| - Salient Object Detection | |
| - pytorch_model_hub_mixin | |
| - model_hub_mixin | |
| - transformers | |
| - transformers.js | |
| repo_url: https://github.com/ZhengPeng7/BiRefNet | |
| pipeline_tag: image-segmentation | |
| license: mit | |
| <h1 align="center">Bilateral Reference for High-Resolution Dichotomous Image Segmentation</h1> | |
| > An arbitrary shape adaptable BiRefNet for matting. | |
| > This model was trained on arbitrary shapes (256x256 ~ 2304x2304) and shows great robustness on inputs with any shape. | |
| ### Performance | |
| > How it looks when compared with BiRefNet-matting and BiRefNet_HR-matting (fixed resolution, e.g., 1024x1024, 2048x2048). | |
| 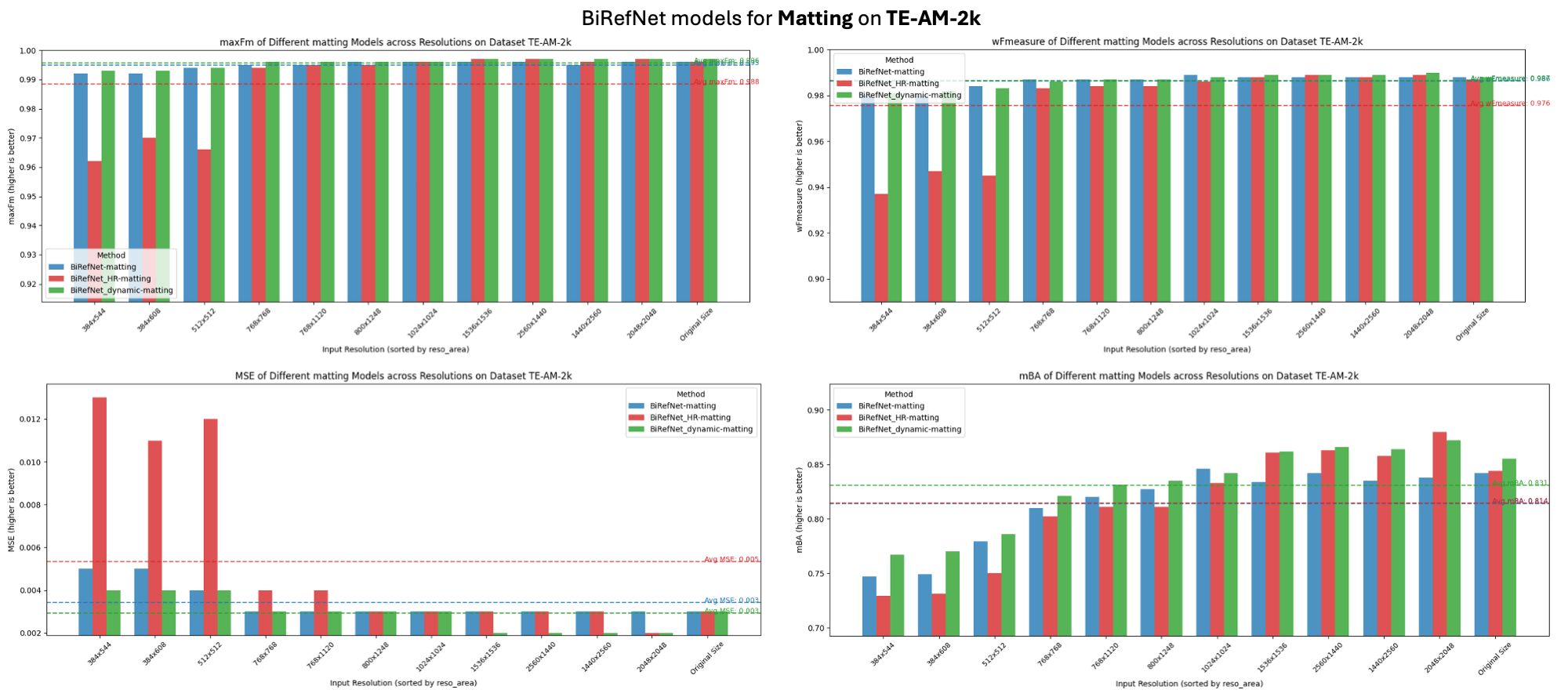 | |
| 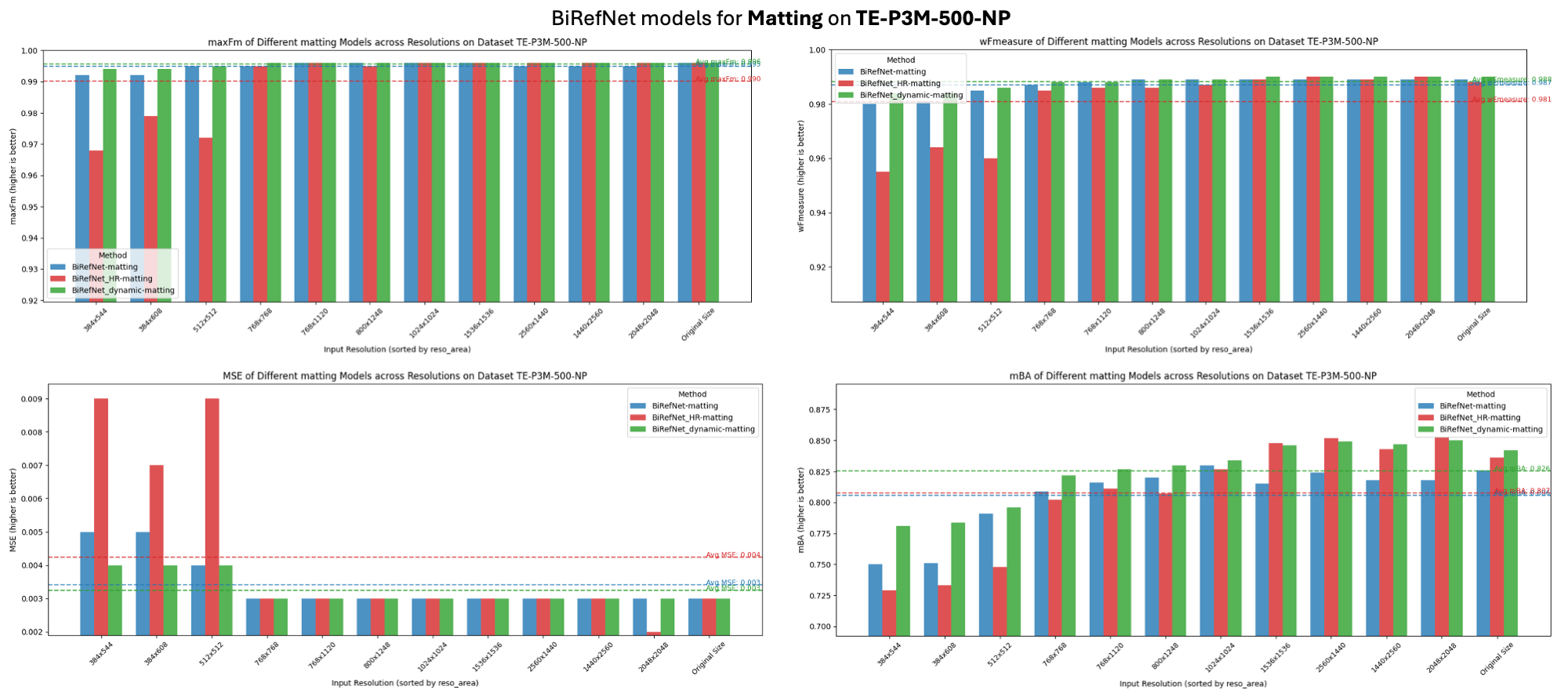 | |
| For performance of different epochs, check the [eval_results-xxx folder for it](https://drive.google.com/drive/u/0/folders/1wSOe0m98YJBRnOefQrC6iefFmeUPtVhn) on my google drive. | |
| <div align='center'> | |
| <a href='https://scholar.google.com/citations?user=TZRzWOsAAAAJ' target='_blank'><strong>Peng Zheng</strong></a><sup> 1,4,5,6</sup>,  | |
| <a href='https://scholar.google.com/citations?user=0uPb8MMAAAAJ' target='_blank'><strong>Dehong Gao</strong></a><sup> 2</sup>,  | |
| <a href='https://scholar.google.com/citations?user=kakwJ5QAAAAJ' target='_blank'><strong>Deng-Ping Fan</strong></a><sup> 1*</sup>,  | |
| <a href='https://scholar.google.com/citations?user=9cMQrVsAAAAJ' target='_blank'><strong>Li Liu</strong></a><sup> 3</sup>,  | |
| <a href='https://scholar.google.com/citations?user=qQP6WXIAAAAJ' target='_blank'><strong>Jorma Laaksonen</strong></a><sup> 4</sup>,  | |
| <a href='https://scholar.google.com/citations?user=pw_0Z_UAAAAJ' target='_blank'><strong>Wanli Ouyang</strong></a><sup> 5</sup>,  | |
| <a href='https://scholar.google.com/citations?user=stFCYOAAAAAJ' target='_blank'><strong>Nicu Sebe</strong></a><sup> 6</sup> | |
| </div> | |
| <div align='center'> | |
| <sup>1 </sup>Nankai University  <sup>2 </sup>Northwestern Polytechnical University  <sup>3 </sup>National University of Defense Technology  <sup>4 </sup>Aalto University  <sup>5 </sup>Shanghai AI Laboratory  <sup>6 </sup>University of Trento  | |
| </div> | |
| <div align="center" style="display: flex; justify-content: center; flex-wrap: wrap;"> | |
| <a href='https://www.sciopen.com/article/pdf/10.26599/AIR.2024.9150038.pdf'><img src='https://img.shields.io/badge/Journal-Paper-red'></a>  | |
| <a href='https://arxiv.org/pdf/2401.03407'><img src='https://img.shields.io/badge/arXiv-BiRefNet-red'></a>  | |
| <a href='https://drive.google.com/file/d/1aBnJ_R9lbnC2dm8dqD0-pzP2Cu-U1Xpt/view?usp=drive_link'><img src='https://img.shields.io/badge/中文版-BiRefNet-red'></a>  | |
| <a href='https://www.birefnet.top'><img src='https://img.shields.io/badge/Page-BiRefNet-red'></a>  | |
| <a href='https://drive.google.com/drive/folders/1s2Xe0cjq-2ctnJBR24563yMSCOu4CcxM'><img src='https://img.shields.io/badge/Drive-Stuff-green'></a>  | |
| <a href='LICENSE'><img src='https://img.shields.io/badge/License-MIT-yellow'></a>  | |
| <a href='https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Spaces-BiRefNet-blue'></a>  | |
| <a href='https://huggingface.co/ZhengPeng7/BiRefNet'><img src='https://img.shields.io/badge/%F0%9F%A4%97%20HF%20Models-BiRefNet-blue'></a>  | |
| <a href='https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link'><img src='https://img.shields.io/badge/Single_Image_Inference-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a>  | |
| <a href='https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S'><img src='https://img.shields.io/badge/Inference_&_Evaluation-F9AB00?style=for-the-badge&logo=googlecolab&color=525252'></a>  | |
| </div> | |
| | *DIS-Sample_1* | *DIS-Sample_2* | | |
| | :------------------------------: | :-------------------------------: | | |
| | <img src="https://drive.google.com/thumbnail?id=1ItXaA26iYnE8XQ_GgNLy71MOWePoS2-g&sz=w400" /> | <img src="https://drive.google.com/thumbnail?id=1Z-esCujQF_uEa_YJjkibc3NUrW4aR_d4&sz=w400" /> | | |
| This repo is the official implementation of "[**Bilateral Reference for High-Resolution Dichotomous Image Segmentation**](https://arxiv.org/pdf/2401.03407.pdf)" (___CAAI AIR 2024___). | |
| Visit our GitHub repo: [https://github.com/ZhengPeng7/BiRefNet](https://github.com/ZhengPeng7/BiRefNet) for more details -- **codes**, **docs**, and **model zoo**! | |
| ## How to use | |
| ### 0. Install Packages: | |
| ``` | |
| pip install -qr https://raw.githubusercontent.com/ZhengPeng7/BiRefNet/main/requirements.txt | |
| ``` | |
| ### 1. Load BiRefNet: | |
| #### Use codes + weights from HuggingFace | |
| > Only use the weights on HuggingFace -- Pro: No need to download BiRefNet codes manually; Con: Codes on HuggingFace might not be latest version (I'll try to keep them always latest). | |
| ```python | |
| # Load BiRefNet with weights | |
| from transformers import AutoModelForImageSegmentation | |
| birefnet = AutoModelForImageSegmentation.from_pretrained('ZhengPeng7/BiRefNet', trust_remote_code=True) | |
| ``` | |
| #### Use codes from GitHub + weights from HuggingFace | |
| > Only use the weights on HuggingFace -- Pro: codes are always latest; Con: Need to clone the BiRefNet repo from my GitHub. | |
| ```shell | |
| # Download codes | |
| git clone https://github.com/ZhengPeng7/BiRefNet.git | |
| cd BiRefNet | |
| ``` | |
| ```python | |
| # Use codes locally | |
| from models.birefnet import BiRefNet | |
| # Load weights from Hugging Face Models | |
| birefnet = BiRefNet.from_pretrained('ZhengPeng7/BiRefNet') | |
| ``` | |
| #### Use codes from GitHub + weights from local space | |
| > Only use the weights and codes both locally. | |
| ```python | |
| # Use codes and weights locally | |
| import torch | |
| from utils import check_state_dict | |
| birefnet = BiRefNet(bb_pretrained=False) | |
| state_dict = torch.load(PATH_TO_WEIGHT, map_location='cpu') | |
| state_dict = check_state_dict(state_dict) | |
| birefnet.load_state_dict(state_dict) | |
| ``` | |
| #### Use the loaded BiRefNet for inference | |
| ```python | |
| # Imports | |
| from PIL import Image | |
| import matplotlib.pyplot as plt | |
| import torch | |
| from torchvision import transforms | |
| from models.birefnet import BiRefNet | |
| birefnet = ... # -- BiRefNet should be loaded with codes above, either way. | |
| torch.set_float32_matmul_precision(['high', 'highest'][0]) | |
| birefnet.to('cuda') | |
| birefnet.eval() | |
| birefnet.half() | |
| def extract_object(birefnet, imagepath): | |
| # Data settings | |
| # image_size = (1024, 1024) | |
| # Since this model was trained on arbitrary shapes (256x256 ~ 2304x2304), the resizing is not necessary. | |
| transform_image = transforms.Compose([ | |
| # transforms.Resize(image_size), | |
| transforms.ToTensor(), | |
| transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) | |
| ]) | |
| image = Image.open(imagepath) | |
| input_images = transform_image(image).unsqueeze(0).to('cuda').half() | |
| # Prediction | |
| with torch.no_grad(): | |
| preds = birefnet(input_images)[-1].sigmoid().cpu() | |
| pred = preds[0].squeeze() | |
| pred_pil = transforms.ToPILImage()(pred) | |
| mask = pred_pil.resize(image.size) | |
| image.putalpha(mask) | |
| return image, mask | |
| # Visualization | |
| plt.axis("off") | |
| plt.imshow(extract_object(birefnet, imagepath='PATH-TO-YOUR_IMAGE.jpg')[0]) | |
| plt.show() | |
| ``` | |
| ### 2. Use inference endpoint locally: | |
| > You may need to click the *deploy* and set up the endpoint by yourself, which would make some costs. | |
| ``` | |
| import requests | |
| import base64 | |
| from io import BytesIO | |
| from PIL import Image | |
| YOUR_HF_TOKEN = 'xxx' | |
| API_URL = "xxx" | |
| headers = { | |
| "Authorization": "Bearer {}".format(YOUR_HF_TOKEN) | |
| } | |
| def base64_to_bytes(base64_string): | |
| # Remove the data URI prefix if present | |
| if "data:image" in base64_string: | |
| base64_string = base64_string.split(",")[1] | |
| # Decode the Base64 string into bytes | |
| image_bytes = base64.b64decode(base64_string) | |
| return image_bytes | |
| def bytes_to_base64(image_bytes): | |
| # Create a BytesIO object to handle the image data | |
| image_stream = BytesIO(image_bytes) | |
| # Open the image using Pillow (PIL) | |
| image = Image.open(image_stream) | |
| return image | |
| def query(payload): | |
| response = requests.post(API_URL, headers=headers, json=payload) | |
| return response.json() | |
| output = query({ | |
| "inputs": "https://hips.hearstapps.com/hmg-prod/images/gettyimages-1229892983-square.jpg", | |
| "parameters": {} | |
| }) | |
| output_image = bytes_to_base64(base64_to_bytes(output)) | |
| output_image | |
| ``` | |
| > This BiRefNet for standard dichotomous image segmentation (DIS) is trained on **DIS-TR** and validated on **DIS-TEs and DIS-VD**. | |
| ## This repo holds the official model weights of "[<ins>Bilateral Reference for High-Resolution Dichotomous Image Segmentation</ins>](https://arxiv.org/pdf/2401.03407)" (_CAAI AIR 2024_). | |
| This repo contains the weights of BiRefNet proposed in our paper, which has achieved the SOTA performance on three tasks (DIS, HRSOD, and COD). | |
| Go to my GitHub page for BiRefNet codes and the latest updates: https://github.com/ZhengPeng7/BiRefNet :) | |
| #### Try our online demos for inference: | |
| + Online **Image Inference** on Colab: [](https://colab.research.google.com/drive/14Dqg7oeBkFEtchaHLNpig2BcdkZEogba?usp=drive_link) | |
| + **Online Inference with GUI on Hugging Face** with adjustable resolutions: [](https://huggingface.co/spaces/ZhengPeng7/BiRefNet_demo) | |
| + **Inference and evaluation** of your given weights: [](https://colab.research.google.com/drive/1MaEiBfJ4xIaZZn0DqKrhydHB8X97hNXl#scrollTo=DJ4meUYjia6S) | |
| <img src="https://drive.google.com/thumbnail?id=12XmDhKtO1o2fEvBu4OE4ULVB2BK0ecWi&sz=w1080" /> | |
| ## Acknowledgement: | |
| + Many thanks to @Freepik for their generous support on GPU resources for training higher resolution BiRefNet models and more of my explorations. | |
| + Many thanks to @fal for their generous support on GPU resources for training better general BiRefNet models. | |
| + Many thanks to @not-lain for his help on the better deployment of our BiRefNet model on HuggingFace. | |
| ## Citation | |
| ``` | |
| @article{zheng2024birefnet, | |
| title={Bilateral Reference for High-Resolution Dichotomous Image Segmentation}, | |
| author={Zheng, Peng and Gao, Dehong and Fan, Deng-Ping and Liu, Li and Laaksonen, Jorma and Ouyang, Wanli and Sebe, Nicu}, | |
| journal={CAAI Artificial Intelligence Research}, | |
| volume = {3}, | |
| pages = {9150038}, | |
| year={2024} | |
| } | |
| ``` |