
LLaMA-3.1-8B-LoRA-COCO-Deceptive-CLIP Model Card
🏆 This work is accepted to ACL 2025 (Main Conference).
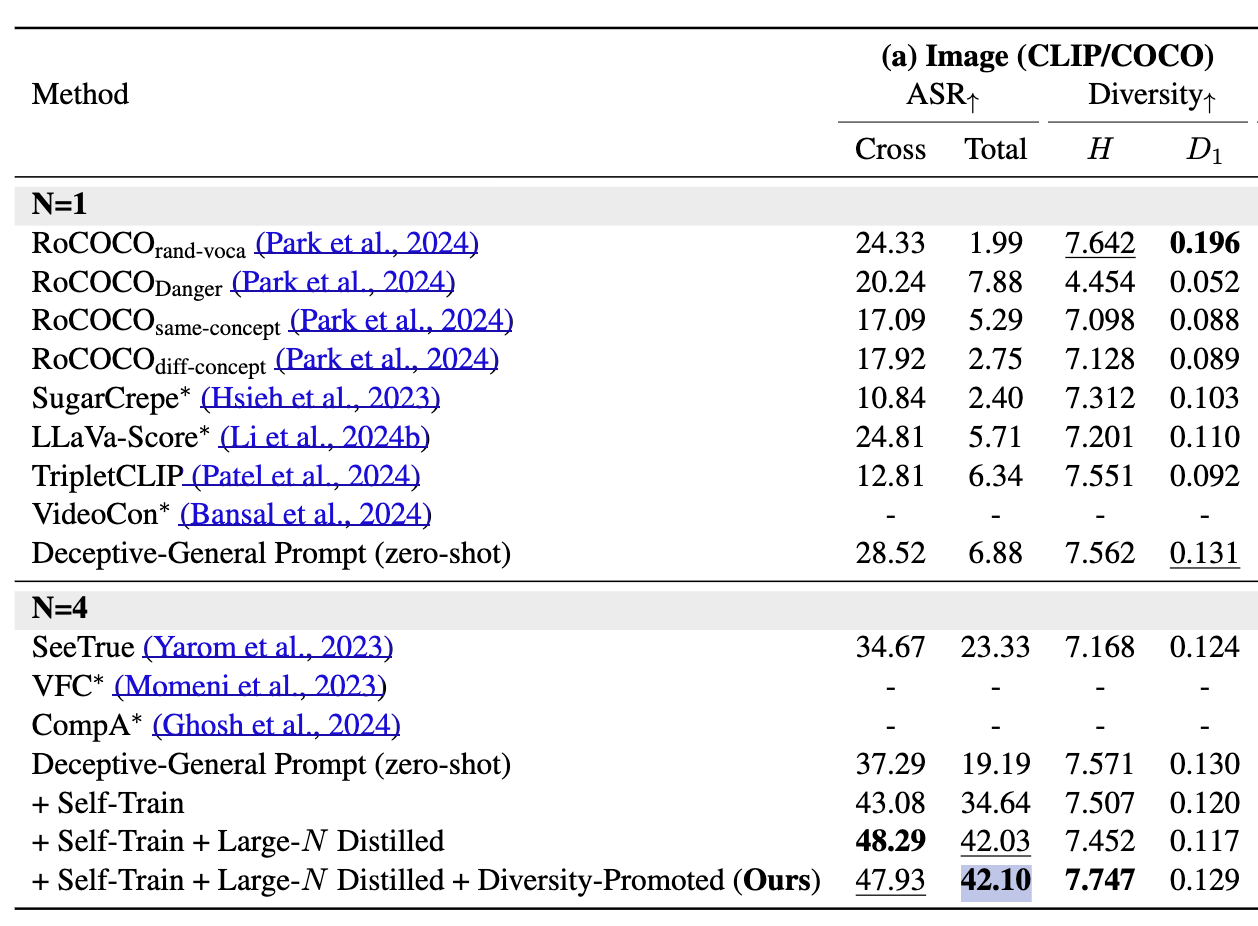 Figure: Attack success rate (ASR) and caption diversity of our model on the COCO dataset, illustrating its ability to generate deceptive captions that successfully fool CLIP.
Figure: Attack success rate (ASR) and caption diversity of our model on the COCO dataset, illustrating its ability to generate deceptive captions that successfully fool CLIP.
Model Description
- Repository: Code
- Paper: Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates
- Point of Contact: Jaewoo Ahn, Heeseung Yun
Model Details
- Model: LLaMA-3.1-8B-LoRA-COCO-Deceptive-CLIP is a deceptive caption generator built on LLaMA-3.1-8B, fine-tuned using LoRA (i.e., self-training, or more specifically, rejection sampling fine-tuning (RFT)) to deceive CLIP on the COCO dataset. It achieves an attack success rate (ASR) of 42.1%.\
- Architecture: This model is based on LLaMA-3.1-8B and utilizes PEFT v0.12.0 for efficient fine-tuning.
How to Use
See our GitHub repository for full usage instructions and scripts.
- Downloads last month
- 6
Model tree for ahnpersie/llama3.1-8b-lora-coco-deceptive-clip
Base model
meta-llama/Llama-3.1-8B
Finetuned
meta-llama/Llama-3.1-8B-Instruct