
OneReward
Official checkpoint of OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning
![]()

Introduction
We propose OneReward, a novel RLHF methodology for the visual domain by employing Qwen2.5-VL as a generative reward model to enhance multitask reinforcement learning, significantly improving the policy model’s generation ability across multiple subtask. Building on OneReward, we develop Seedream 3.0 Fill, a unified SOTA image editing model capable of effec-tively handling diverse tasks including image fill, image extend, object removal, and text rendering. It surpasses several leading commercial and open-source systems, including Ideogram, Adobe Photoshop, and FLUX Fill [Pro]. Finally, based on FLUX Fill [dev], we are thrilled to release FLUX.1-Fill-dev-OneReward, which outperforms closed-source FLUX Fill [Pro] in inpainting and outpainting tasks, serving as a powerful new baseline for future research in unified image editing.
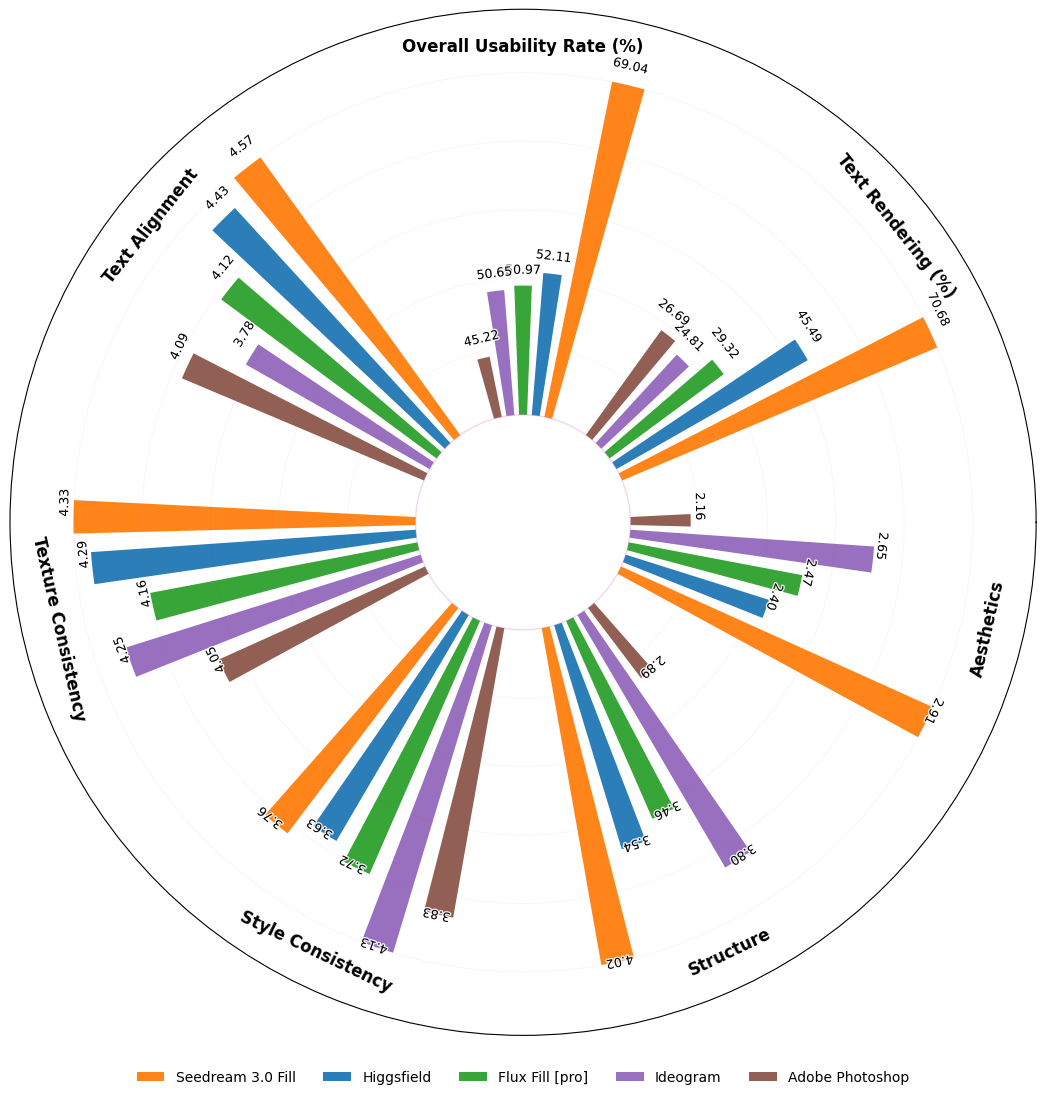
Image Fill |
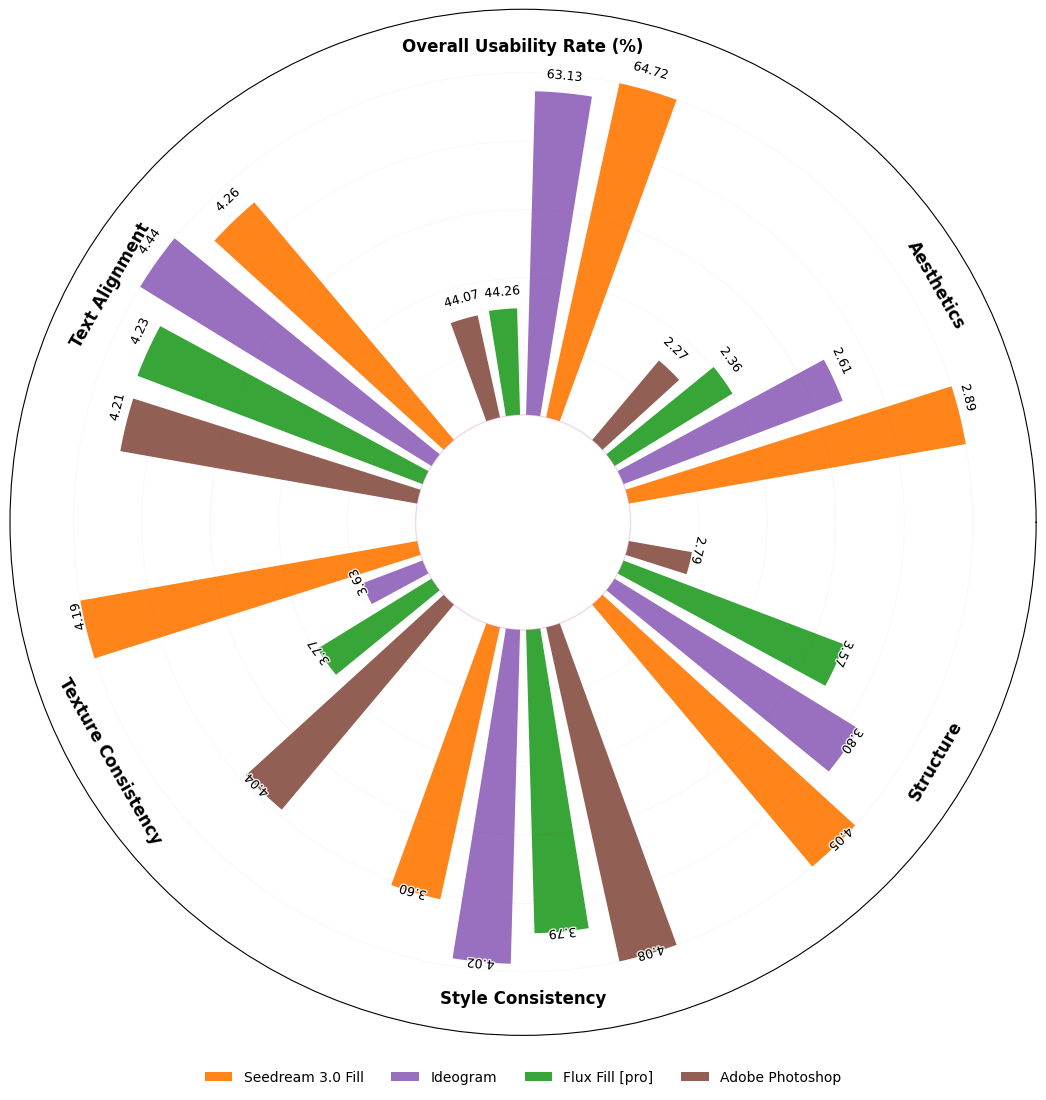
Image Extend with Prompt |
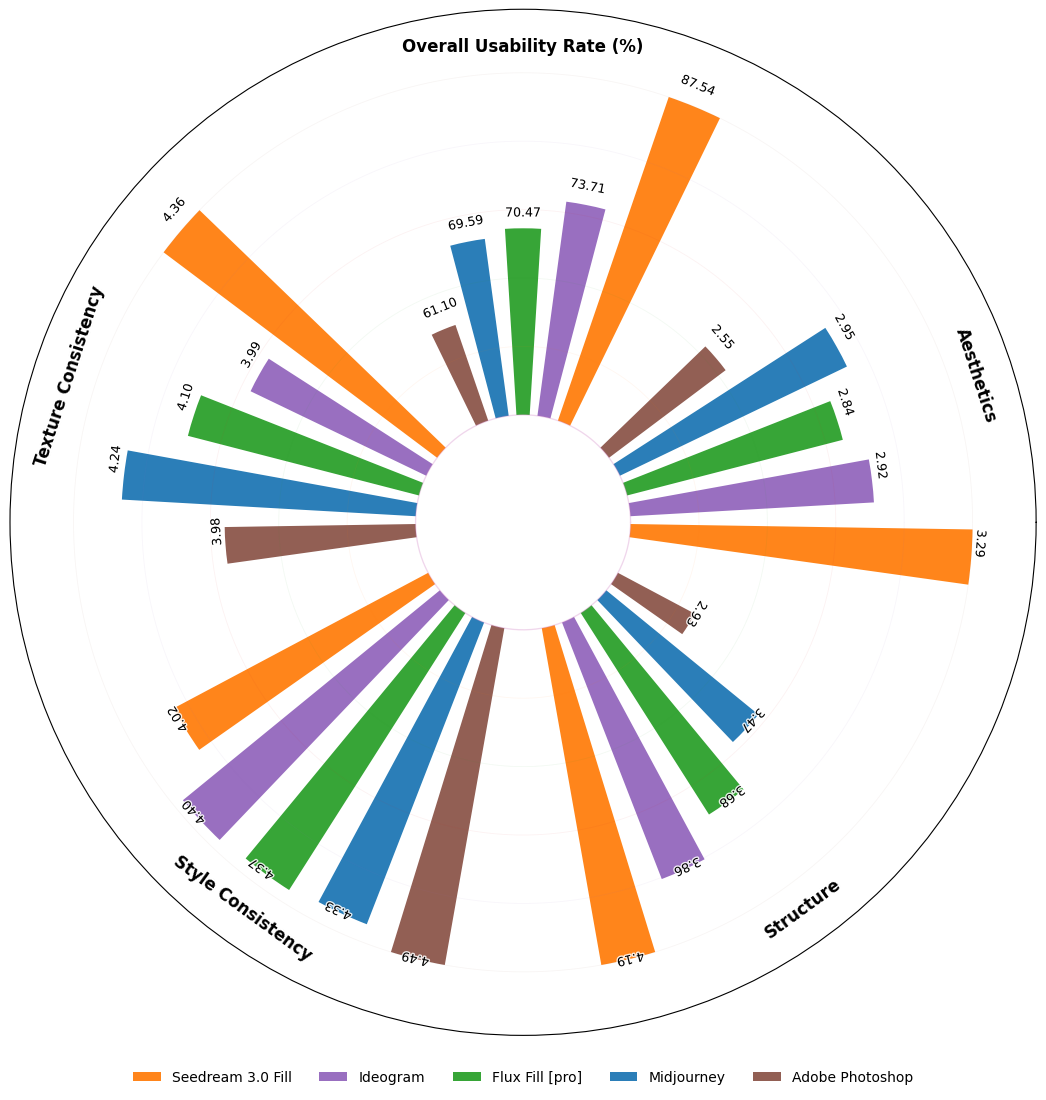
Image Extend without Prompt |

Object Removal |
Quick Start
Make sure your transformers>=4.51.3 (Supporting Qwen2.5-VL)
Install the latest version of diffusers
pip install -U diffusers
The following contains a code snippet illustrating how to use the model to generate images based on text prompts and input mask, support inpaint(image-fill), outpaint(image-extend), eraser(object-removal). As the model is fully trained, FluxFillCFGPipeline with cfg is needed, you can find it in our github.
import torch
from diffusers.utils import load_image
from diffusers import FluxTransformer2DModel
from src.pipeline_flux_fill_with_cfg import FluxFillCFGPipeline
transformer_onereward = FluxTransformer2DModel.from_pretrained(
"bytedance-research/OneReward",
subfolder="flux.1-fill-dev-OneReward-transformer",
torch_dtype=torch.bfloat16
)
pipe = FluxFillCFGPipeline.from_pretrained(
"black-forest-labs/FLUX.1-Fill-dev",
transformer=transformer_onereward,
torch_dtype=torch.bfloat16).to("cuda")
# Image Fill
image = load_image('assets/image.png')
mask = load_image('assets/mask_fill.png')
image = pipe(
prompt='the words "ByteDance", and in the next line "OneReward"',
negative_prompt="nsfw",
image=image,
mask_image=mask,
height=image.height,
width=image.width,
guidance_scale=1.0,
true_cfg=4.0,
num_inference_steps=50,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save(f"image_fill.jpg")

input |

output |
Model
FLUX.1-Fill-dev[OneReward], trained with Alg.1 in paper
transformer_onereward = FluxTransformer2DModel.from_pretrained(
"bytedance-research/OneReward",
subfolder="flux.1-fill-dev-OneReward-transformer",
torch_dtype=torch.bfloat16
)
pipe = FluxFillCFGPipeline.from_pretrained(
"black-forest-labs/FLUX.1-Fill-dev",
transformer=transformer_onereward,
torch_dtype=torch.bfloat16).to("cuda")
FLUX.1-Fill-dev[OneRewardDynamic], trained with Alg.2 in paper
transformer_onereward_dynamic = FluxTransformer2DModel.from_pretrained(
"bytedance-research/OneReward",
subfolder="flux.1-fill-dev-OneRewardDynamic-transformer",
torch_dtype=torch.bfloat16
)
pipe = FluxFillCFGPipeline.from_pretrained(
"black-forest-labs/FLUX.1-Fill-dev",
transformer=transformer_onereward_dynamic,
torch_dtype=torch.bfloat16).to("cuda")
Object Removal
image = load_image('assets/image.png')
mask = load_image('assets/mask_remove.png')
image = pipe(
prompt='remove', # using fix prompt in object removal
negative_prompt="nsfw",
image=image,
mask_image=mask,
height=image.height,
width=image.width,
guidance_scale=1.0,
true_cfg=4.0,
num_inference_steps=50,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save(f"object_removal.jpg")
Image Extend with prompt
image = load_image('assets/image2.png')
mask = load_image('assets/mask_extend.png')
image = pipe(
prompt='Deep in the forest, surronded by colorful flowers',
negative_prompt="nsfw",
image=image,
mask_image=mask,
height=image.height,
width=image.width,
guidance_scale=1.0,
true_cfg=4.0,
num_inference_steps=50,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save(f"image_extend_w_prompt.jpg")
Image Extend without prompt
image = load_image('assets/image2.png')
mask = load_image('assets/mask_extend.png')
image = pipe(
prompt='high-definition, perfect composition', # using fix prompt in image extend wo prompt
negative_prompt="nsfw",
image=image,
mask_image=mask,
height=image.height,
width=image.width,
guidance_scale=1.0,
true_cfg=4.0,
num_inference_steps=50,
generator=torch.Generator("cpu").manual_seed(0)
).images[0]
image.save(f"image_extend_wo_prompt.jpg")
License Agreement
Code is licensed under Apache 2.0. Model is licensed under CC BY NC 4.0.
Citation
@article{gong2025onereward,
title={OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning},
author={Gong, Yuan and Wang, Xionghui and Wu, Jie and Wang, Shiyin and Wang, Yitong and Wu, Xinglong},
journal={arXiv preprint arXiv:2508.21066},
year={2025}
}
- Downloads last month
- 36
Model tree for bytedance-research/OneReward
Base model
black-forest-labs/FLUX.1-Fill-dev