
gguf quantized version of mochi (test pack for gguf-node)
setup (once)
- drag mochi-q3_k_m.gguf [4.31GB] to > ./ComfyUI/models/diffusion_models
- drag t5xxl_fp16-q4_0.gguf [2.9GB] to > ./ComfyUI/models/text_encoders
- drag mochi_vae_fp8_e4m3fn.safetensors [460MB] to > ./ComfyUI/models/vae
run it straight (no installation needed way)
- run the .bat file in the main directory (assuming you are using the gguf-node pack below)
- drag the workflow json file (below) to > your browser
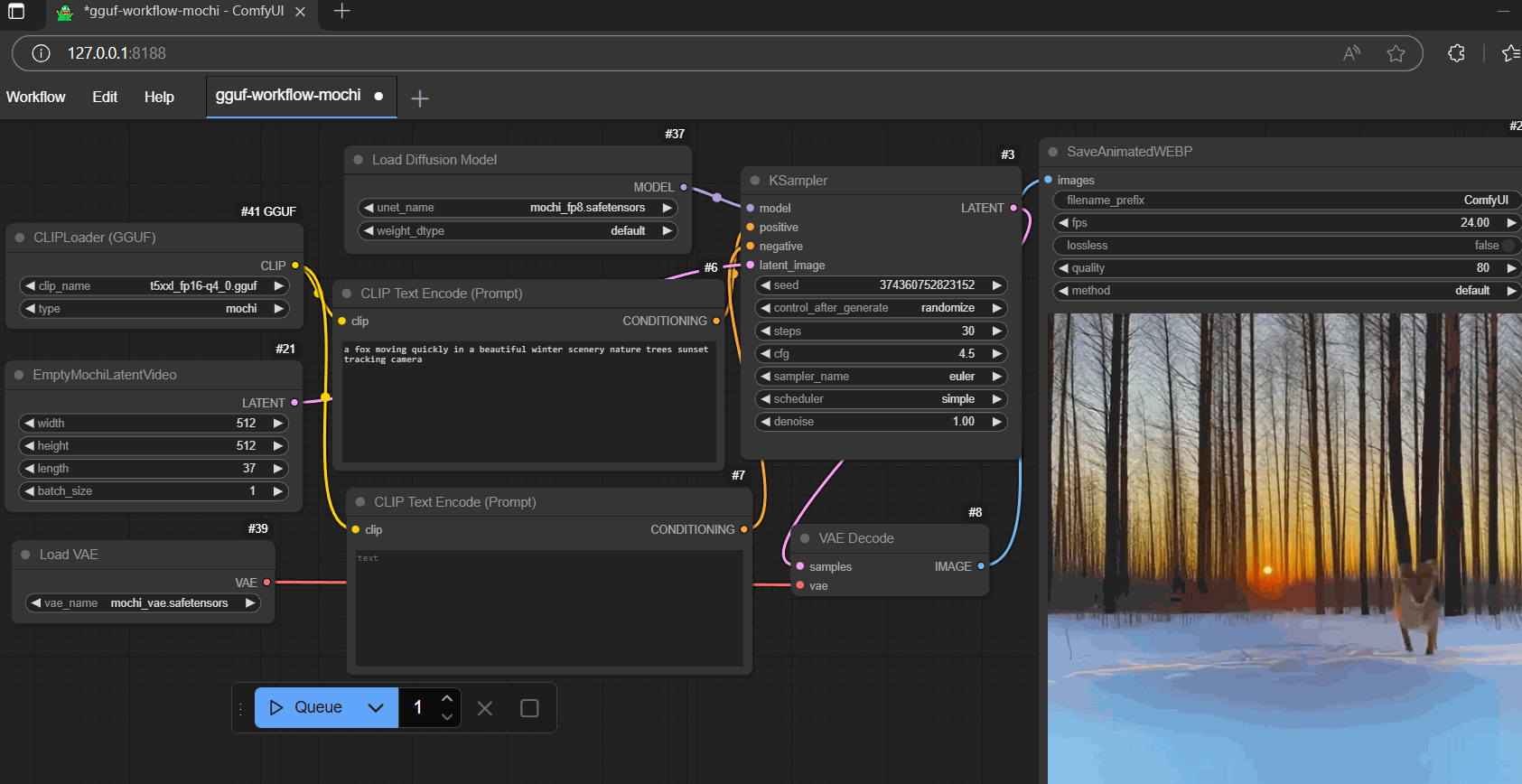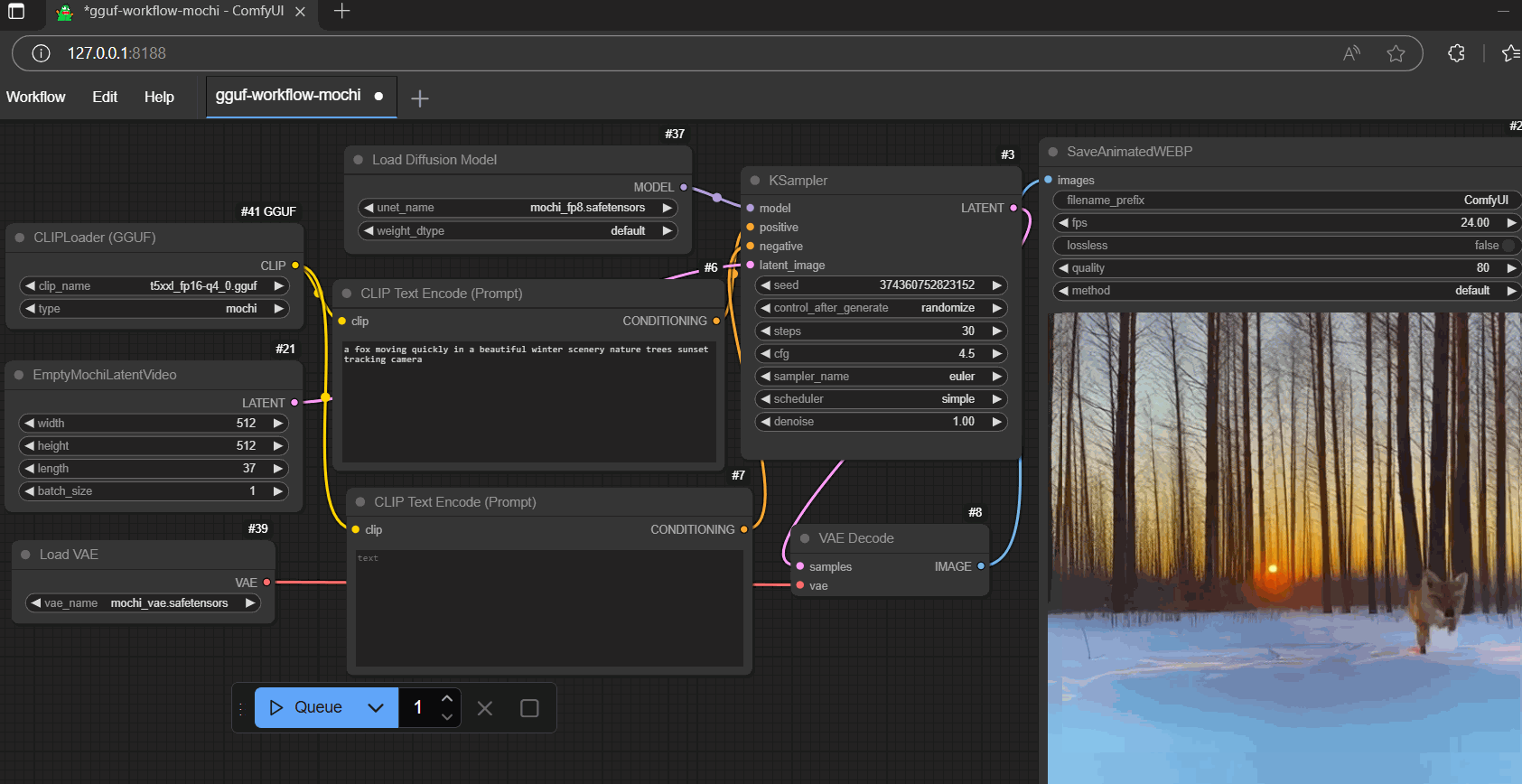
workflow
- example workflow (with gguf encoder)
- example workflow (safetensors)
review
- revised workflow to bypass oom issue and around 50% faster with the new fp8_e4m3fn file
- t5xxl works fine as text encoder; more quantized versions of t5xxl can be found here
- gguf with pig architecture is working right away; welcome to test
reference
- base model from genmo
- pig architecture from connector
- comfyui from comfyanonymous
- gguf-node (pypi|repo|pack)
prompt test#
 prompt: "a fox moving quickly in a beautiful winter scenery nature trees sunset tracking camera"
prompt: "a fox moving quickly in a beautiful winter scenery nature trees sunset tracking camera"

- Prompt
- a fox moving quickly in a beautiful winter scenery nature trees sunset tracking camera

- Prompt
- same prompt as 1st one <metadata inside>

- Prompt
- same prompt as 1st one; but with new workflow to bypass oom <metadata inside>
- Downloads last month
- 615
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.
The model cannot be deployed to the HF Inference API:
The model has no library tag.
Model tree for calcuis/mochi
Base model
genmo/mochi-1-preview