|
|
--- |
|
|
license: mit |
|
|
base_model: |
|
|
- microsoft/VibeVoice-1.5B |
|
|
pipeline_tag: text-to-speech |
|
|
tags: |
|
|
- gguf-connector |
|
|
--- |
|
|
## vibevoice-gguf |
|
|
- run it with `gguf-connector`; simply execute the command below in console/terminal |
|
|
``` |
|
|
ggc v6 |
|
|
``` |
|
|
> |
|
|
>GGUF file(s) available. Select which one to use: |
|
|
> |
|
|
>1. vibevoice-1.5b-iq4_nl.gguf |
|
|
>3. vibevoice-1.5b-q4_0.gguf |
|
|
>4. vibevoice-1.5b-q8_0.gguf |
|
|
> |
|
|
>Enter your choice (1 to 3): _ |
|
|
> |
|
|
- opt a `gguf` file in your current directory to interact with; nothing else |
|
|
|
|
|
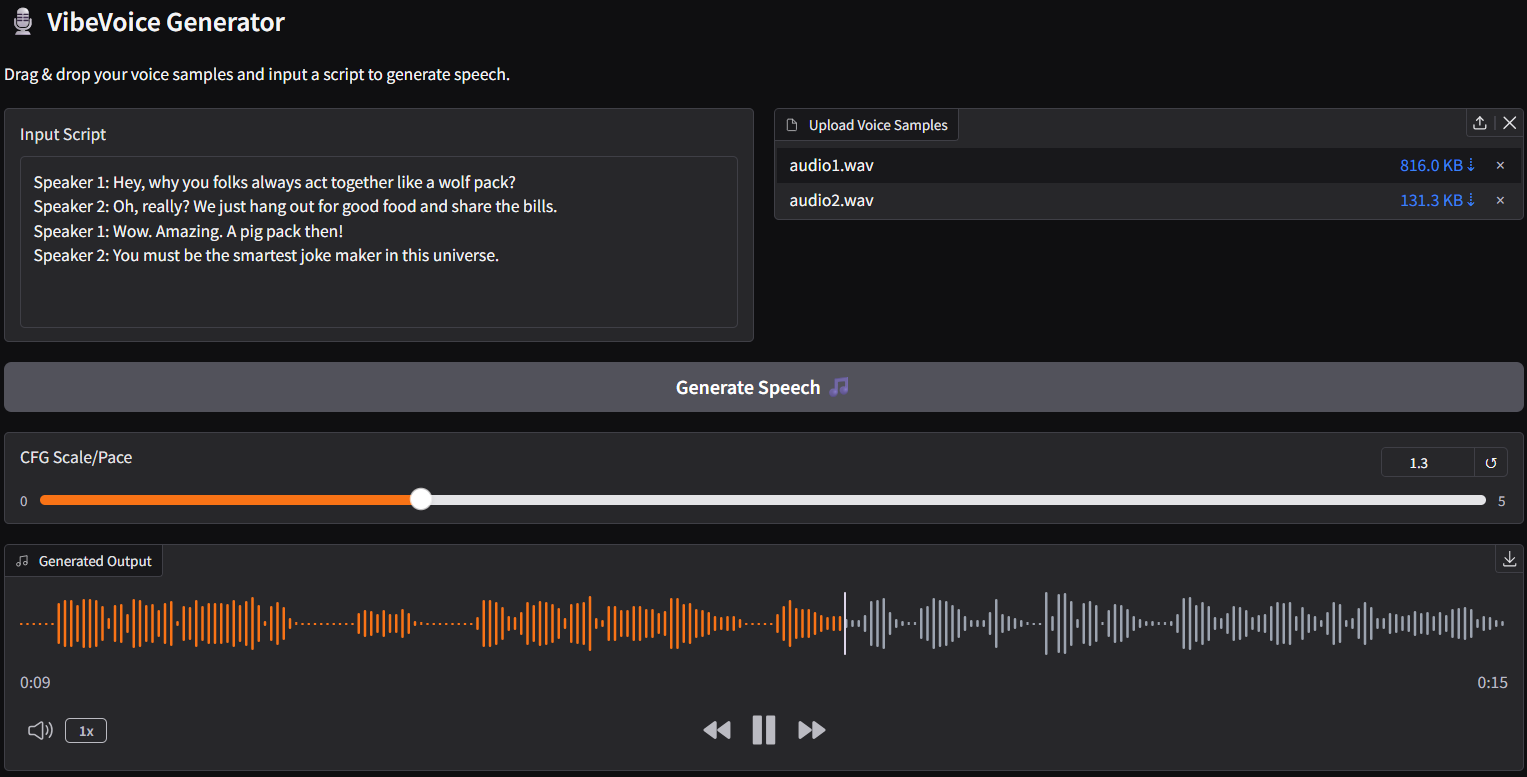 |
|
|
|
|
|
- note: for the latest update, you should be able to adjust the speech pacing (see picture above) |
|
|
|
|
|
| Prompt* | Audio Sample | |
|
|
|--------|---------------| |
|
|
|`Speaker 1: Hey, why you folks always act together like a wolf pack?`<br/>`Speaker 2: Oh, really? We just hang out for good food and share the bills.`<br/>`Speaker 1: Wow. Amazing. A pig pack then!`<br/>`Speaker 2: You must be the smartest joke maker in this universe.`<br/> | 🎧 **audio-output-demo**<br><audio controls src="https://huggingface.co/calcuis/vibevoice-gguf/resolve/main/audio-output.wav"></audio> | |
|
|
|
|
|
*for this demo prompt, drag [audio1.wav](https://huggingface.co/calcuis/vibevoice-gguf/blob/main/audio1.wav) and [audio2.wav](https://huggingface.co/calcuis/vibevoice-gguf/blob/main/audio2.wav) inside the upload voice samples, then it will be taken as voice reference for speakers 1 and 2 (voice cloning) |
|
|
|
|
|
### **reference** |
|
|
- base model from [microsoft](https://huggingface.co/microsoft/VibeVoice-1.5B) |
|
|
- gguf-connector ([pypi](https://pypi.org/project/gguf-connector)) |
