
id
stringlengths 9
104
| author
stringlengths 3
36
| task_category
stringclasses 32
values | tags
listlengths 1
4.05k
| created_time
timestamp[ns, tz=UTC]date 2022-03-02 23:29:04
2025-03-18 02:34:30
| last_modified
stringdate 2021-02-13 00:06:56
2025-03-18 09:30:19
| downloads
int64 0
15.6M
| likes
int64 0
4.86k
| README
stringlengths 44
1.01M
| matched_bigbio_names
listlengths 1
8
|
|---|---|---|---|---|---|---|---|---|---|
twine-network/NoInstruct-small-Embedding-v0-Q5_K_M-GGUF
|
twine-network
|
sentence-similarity
|
[
"sentence-transformers",
"gguf",
"feature-extraction",
"mteb",
"sentence-similarity",
"transformers",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:avsolatorio/NoInstruct-small-Embedding-v0",
"base_model:quantized:avsolatorio/NoInstruct-small-Embedding-v0",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-11-03T19:50:36Z |
2024-11-03T19:50:39+00:00
| 18 | 0 |
---
base_model: avsolatorio/NoInstruct-small-Embedding-v0
language:
- en
library_name: sentence-transformers
license: mit
pipeline_tag: sentence-similarity
tags:
- feature-extraction
- mteb
- sentence-similarity
- sentence-transformers
- transformers
- llama-cpp
- gguf-my-repo
model-index:
- name: NoInstruct-small-Embedding-v0
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.76119402985074
- type: ap
value: 39.03628777559392
- type: f1
value: 69.85860402259618
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.29920000000001
- type: ap
value: 90.03479490717608
- type: f1
value: 93.28554395248467
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.98799999999999
- type: f1
value: 49.46151232451642
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: mteb/arguana
config: default
split: test
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
metrics:
- type: map_at_1
value: 31.935000000000002
- type: map_at_10
value: 48.791000000000004
- type: map_at_100
value: 49.619
- type: map_at_1000
value: 49.623
- type: map_at_3
value: 44.334
- type: map_at_5
value: 46.908
- type: mrr_at_1
value: 32.93
- type: mrr_at_10
value: 49.158
- type: mrr_at_100
value: 50.00599999999999
- type: mrr_at_1000
value: 50.01
- type: mrr_at_3
value: 44.618
- type: mrr_at_5
value: 47.325
- type: ndcg_at_1
value: 31.935000000000002
- type: ndcg_at_10
value: 57.593
- type: ndcg_at_100
value: 60.841
- type: ndcg_at_1000
value: 60.924
- type: ndcg_at_3
value: 48.416
- type: ndcg_at_5
value: 53.05
- type: precision_at_1
value: 31.935000000000002
- type: precision_at_10
value: 8.549
- type: precision_at_100
value: 0.9900000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.081
- type: precision_at_5
value: 14.296000000000001
- type: recall_at_1
value: 31.935000000000002
- type: recall_at_10
value: 85.491
- type: recall_at_100
value: 99.004
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 60.242
- type: recall_at_5
value: 71.479
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.78438534940855
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.12916178519471
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.125361608299855
- type: mrr
value: 74.92525172580574
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 88.64322910336641
- type: cos_sim_spearman
value: 87.20138453306345
- type: euclidean_pearson
value: 87.08547818178234
- type: euclidean_spearman
value: 87.17066094143931
- type: manhattan_pearson
value: 87.30053110771618
- type: manhattan_spearman
value: 86.86824441211934
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 86.3961038961039
- type: f1
value: 86.3669961645295
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.40291404289857
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.102356817746816
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: mteb/cqadupstack-android
config: default
split: test
revision: f46a197baaae43b4f621051089b82a364682dfeb
metrics:
- type: map_at_1
value: 31.013
- type: map_at_10
value: 42.681999999999995
- type: map_at_100
value: 44.24
- type: map_at_1000
value: 44.372
- type: map_at_3
value: 39.181
- type: map_at_5
value: 41.071999999999996
- type: mrr_at_1
value: 38.196999999999996
- type: mrr_at_10
value: 48.604
- type: mrr_at_100
value: 49.315
- type: mrr_at_1000
value: 49.363
- type: mrr_at_3
value: 45.756
- type: mrr_at_5
value: 47.43
- type: ndcg_at_1
value: 38.196999999999996
- type: ndcg_at_10
value: 49.344
- type: ndcg_at_100
value: 54.662
- type: ndcg_at_1000
value: 56.665
- type: ndcg_at_3
value: 44.146
- type: ndcg_at_5
value: 46.514
- type: precision_at_1
value: 38.196999999999996
- type: precision_at_10
value: 9.571
- type: precision_at_100
value: 1.542
- type: precision_at_1000
value: 0.202
- type: precision_at_3
value: 21.364
- type: precision_at_5
value: 15.336
- type: recall_at_1
value: 31.013
- type: recall_at_10
value: 61.934999999999995
- type: recall_at_100
value: 83.923
- type: recall_at_1000
value: 96.601
- type: recall_at_3
value: 46.86
- type: recall_at_5
value: 53.620000000000005
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackEnglishRetrieval
type: mteb/cqadupstack-english
config: default
split: test
revision: ad9991cb51e31e31e430383c75ffb2885547b5f0
metrics:
- type: map_at_1
value: 29.84
- type: map_at_10
value: 39.335
- type: map_at_100
value: 40.647
- type: map_at_1000
value: 40.778
- type: map_at_3
value: 36.556
- type: map_at_5
value: 38.048
- type: mrr_at_1
value: 36.815
- type: mrr_at_10
value: 45.175
- type: mrr_at_100
value: 45.907
- type: mrr_at_1000
value: 45.946999999999996
- type: mrr_at_3
value: 42.909000000000006
- type: mrr_at_5
value: 44.227
- type: ndcg_at_1
value: 36.815
- type: ndcg_at_10
value: 44.783
- type: ndcg_at_100
value: 49.551
- type: ndcg_at_1000
value: 51.612
- type: ndcg_at_3
value: 40.697
- type: ndcg_at_5
value: 42.558
- type: precision_at_1
value: 36.815
- type: precision_at_10
value: 8.363
- type: precision_at_100
value: 1.385
- type: precision_at_1000
value: 0.186
- type: precision_at_3
value: 19.342000000000002
- type: precision_at_5
value: 13.706999999999999
- type: recall_at_1
value: 29.84
- type: recall_at_10
value: 54.164
- type: recall_at_100
value: 74.36
- type: recall_at_1000
value: 87.484
- type: recall_at_3
value: 42.306
- type: recall_at_5
value: 47.371
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGamingRetrieval
type: mteb/cqadupstack-gaming
config: default
split: test
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
metrics:
- type: map_at_1
value: 39.231
- type: map_at_10
value: 51.44800000000001
- type: map_at_100
value: 52.574
- type: map_at_1000
value: 52.629999999999995
- type: map_at_3
value: 48.077
- type: map_at_5
value: 50.019000000000005
- type: mrr_at_1
value: 44.89
- type: mrr_at_10
value: 54.803000000000004
- type: mrr_at_100
value: 55.556000000000004
- type: mrr_at_1000
value: 55.584
- type: mrr_at_3
value: 52.32
- type: mrr_at_5
value: 53.846000000000004
- type: ndcg_at_1
value: 44.89
- type: ndcg_at_10
value: 57.228
- type: ndcg_at_100
value: 61.57
- type: ndcg_at_1000
value: 62.613
- type: ndcg_at_3
value: 51.727000000000004
- type: ndcg_at_5
value: 54.496
- type: precision_at_1
value: 44.89
- type: precision_at_10
value: 9.266
- type: precision_at_100
value: 1.2309999999999999
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 23.051
- type: precision_at_5
value: 15.987000000000002
- type: recall_at_1
value: 39.231
- type: recall_at_10
value: 70.82000000000001
- type: recall_at_100
value: 89.446
- type: recall_at_1000
value: 96.665
- type: recall_at_3
value: 56.40500000000001
- type: recall_at_5
value: 62.993
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGisRetrieval
type: mteb/cqadupstack-gis
config: default
split: test
revision: 5003b3064772da1887988e05400cf3806fe491f2
metrics:
- type: map_at_1
value: 25.296000000000003
- type: map_at_10
value: 34.021
- type: map_at_100
value: 35.158
- type: map_at_1000
value: 35.233
- type: map_at_3
value: 31.424999999999997
- type: map_at_5
value: 33.046
- type: mrr_at_1
value: 27.232
- type: mrr_at_10
value: 36.103
- type: mrr_at_100
value: 37.076
- type: mrr_at_1000
value: 37.135
- type: mrr_at_3
value: 33.635
- type: mrr_at_5
value: 35.211
- type: ndcg_at_1
value: 27.232
- type: ndcg_at_10
value: 38.878
- type: ndcg_at_100
value: 44.284
- type: ndcg_at_1000
value: 46.268
- type: ndcg_at_3
value: 33.94
- type: ndcg_at_5
value: 36.687
- type: precision_at_1
value: 27.232
- type: precision_at_10
value: 5.921
- type: precision_at_100
value: 0.907
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 14.426
- type: precision_at_5
value: 10.215
- type: recall_at_1
value: 25.296000000000003
- type: recall_at_10
value: 51.708
- type: recall_at_100
value: 76.36699999999999
- type: recall_at_1000
value: 91.306
- type: recall_at_3
value: 38.651
- type: recall_at_5
value: 45.201
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackMathematicaRetrieval
type: mteb/cqadupstack-mathematica
config: default
split: test
revision: 90fceea13679c63fe563ded68f3b6f06e50061de
metrics:
- type: map_at_1
value: 16.24
- type: map_at_10
value: 24.696
- type: map_at_100
value: 25.945
- type: map_at_1000
value: 26.069
- type: map_at_3
value: 22.542
- type: map_at_5
value: 23.526
- type: mrr_at_1
value: 20.149
- type: mrr_at_10
value: 29.584
- type: mrr_at_100
value: 30.548
- type: mrr_at_1000
value: 30.618000000000002
- type: mrr_at_3
value: 27.301
- type: mrr_at_5
value: 28.563
- type: ndcg_at_1
value: 20.149
- type: ndcg_at_10
value: 30.029
- type: ndcg_at_100
value: 35.812
- type: ndcg_at_1000
value: 38.755
- type: ndcg_at_3
value: 26.008
- type: ndcg_at_5
value: 27.517000000000003
- type: precision_at_1
value: 20.149
- type: precision_at_10
value: 5.647
- type: precision_at_100
value: 0.968
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 12.934999999999999
- type: precision_at_5
value: 8.955
- type: recall_at_1
value: 16.24
- type: recall_at_10
value: 41.464
- type: recall_at_100
value: 66.781
- type: recall_at_1000
value: 87.85300000000001
- type: recall_at_3
value: 29.822
- type: recall_at_5
value: 34.096
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackPhysicsRetrieval
type: mteb/cqadupstack-physics
config: default
split: test
revision: 79531abbd1fb92d06c6d6315a0cbbbf5bb247ea4
metrics:
- type: map_at_1
value: 29.044999999999998
- type: map_at_10
value: 39.568999999999996
- type: map_at_100
value: 40.831
- type: map_at_1000
value: 40.948
- type: map_at_3
value: 36.495
- type: map_at_5
value: 38.21
- type: mrr_at_1
value: 35.611
- type: mrr_at_10
value: 45.175
- type: mrr_at_100
value: 45.974
- type: mrr_at_1000
value: 46.025
- type: mrr_at_3
value: 42.765
- type: mrr_at_5
value: 44.151
- type: ndcg_at_1
value: 35.611
- type: ndcg_at_10
value: 45.556999999999995
- type: ndcg_at_100
value: 50.86000000000001
- type: ndcg_at_1000
value: 52.983000000000004
- type: ndcg_at_3
value: 40.881
- type: ndcg_at_5
value: 43.035000000000004
- type: precision_at_1
value: 35.611
- type: precision_at_10
value: 8.306
- type: precision_at_100
value: 1.276
- type: precision_at_1000
value: 0.165
- type: precision_at_3
value: 19.57
- type: precision_at_5
value: 13.725000000000001
- type: recall_at_1
value: 29.044999999999998
- type: recall_at_10
value: 57.513999999999996
- type: recall_at_100
value: 80.152
- type: recall_at_1000
value: 93.982
- type: recall_at_3
value: 44.121
- type: recall_at_5
value: 50.007000000000005
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackProgrammersRetrieval
type: mteb/cqadupstack-programmers
config: default
split: test
revision: 6184bc1440d2dbc7612be22b50686b8826d22b32
metrics:
- type: map_at_1
value: 22.349
- type: map_at_10
value: 33.434000000000005
- type: map_at_100
value: 34.8
- type: map_at_1000
value: 34.919
- type: map_at_3
value: 30.348000000000003
- type: map_at_5
value: 31.917
- type: mrr_at_1
value: 28.195999999999998
- type: mrr_at_10
value: 38.557
- type: mrr_at_100
value: 39.550999999999995
- type: mrr_at_1000
value: 39.607
- type: mrr_at_3
value: 36.035000000000004
- type: mrr_at_5
value: 37.364999999999995
- type: ndcg_at_1
value: 28.195999999999998
- type: ndcg_at_10
value: 39.656000000000006
- type: ndcg_at_100
value: 45.507999999999996
- type: ndcg_at_1000
value: 47.848
- type: ndcg_at_3
value: 34.609
- type: ndcg_at_5
value: 36.65
- type: precision_at_1
value: 28.195999999999998
- type: precision_at_10
value: 7.534000000000001
- type: precision_at_100
value: 1.217
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 17.085
- type: precision_at_5
value: 12.169
- type: recall_at_1
value: 22.349
- type: recall_at_10
value: 53.127
- type: recall_at_100
value: 77.884
- type: recall_at_1000
value: 93.705
- type: recall_at_3
value: 38.611000000000004
- type: recall_at_5
value: 44.182
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: mteb/cqadupstack
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: map_at_1
value: 25.215749999999996
- type: map_at_10
value: 34.332750000000004
- type: map_at_100
value: 35.58683333333333
- type: map_at_1000
value: 35.70458333333333
- type: map_at_3
value: 31.55441666666667
- type: map_at_5
value: 33.100833333333334
- type: mrr_at_1
value: 29.697250000000004
- type: mrr_at_10
value: 38.372249999999994
- type: mrr_at_100
value: 39.26708333333334
- type: mrr_at_1000
value: 39.3265
- type: mrr_at_3
value: 35.946083333333334
- type: mrr_at_5
value: 37.336999999999996
- type: ndcg_at_1
value: 29.697250000000004
- type: ndcg_at_10
value: 39.64575
- type: ndcg_at_100
value: 44.996833333333335
- type: ndcg_at_1000
value: 47.314499999999995
- type: ndcg_at_3
value: 34.93383333333334
- type: ndcg_at_5
value: 37.15291666666667
- type: precision_at_1
value: 29.697250000000004
- type: precision_at_10
value: 6.98825
- type: precision_at_100
value: 1.138
- type: precision_at_1000
value: 0.15283333333333332
- type: precision_at_3
value: 16.115583333333333
- type: precision_at_5
value: 11.460916666666666
- type: recall_at_1
value: 25.215749999999996
- type: recall_at_10
value: 51.261250000000004
- type: recall_at_100
value: 74.67258333333334
- type: recall_at_1000
value: 90.72033333333334
- type: recall_at_3
value: 38.1795
- type: recall_at_5
value: 43.90658333333334
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackStatsRetrieval
type: mteb/cqadupstack-stats
config: default
split: test
revision: 65ac3a16b8e91f9cee4c9828cc7c335575432a2a
metrics:
- type: map_at_1
value: 24.352
- type: map_at_10
value: 30.576999999999998
- type: map_at_100
value: 31.545
- type: map_at_1000
value: 31.642
- type: map_at_3
value: 28.605000000000004
- type: map_at_5
value: 29.828
- type: mrr_at_1
value: 26.994
- type: mrr_at_10
value: 33.151
- type: mrr_at_100
value: 33.973
- type: mrr_at_1000
value: 34.044999999999995
- type: mrr_at_3
value: 31.135
- type: mrr_at_5
value: 32.262
- type: ndcg_at_1
value: 26.994
- type: ndcg_at_10
value: 34.307
- type: ndcg_at_100
value: 39.079
- type: ndcg_at_1000
value: 41.548
- type: ndcg_at_3
value: 30.581000000000003
- type: ndcg_at_5
value: 32.541
- type: precision_at_1
value: 26.994
- type: precision_at_10
value: 5.244999999999999
- type: precision_at_100
value: 0.831
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 12.781
- type: precision_at_5
value: 9.017999999999999
- type: recall_at_1
value: 24.352
- type: recall_at_10
value: 43.126999999999995
- type: recall_at_100
value: 64.845
- type: recall_at_1000
value: 83.244
- type: recall_at_3
value: 33.308
- type: recall_at_5
value: 37.984
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackTexRetrieval
type: mteb/cqadupstack-tex
config: default
split: test
revision: 46989137a86843e03a6195de44b09deda022eec7
metrics:
- type: map_at_1
value: 16.592000000000002
- type: map_at_10
value: 23.29
- type: map_at_100
value: 24.423000000000002
- type: map_at_1000
value: 24.554000000000002
- type: map_at_3
value: 20.958
- type: map_at_5
value: 22.267
- type: mrr_at_1
value: 20.061999999999998
- type: mrr_at_10
value: 26.973999999999997
- type: mrr_at_100
value: 27.944999999999997
- type: mrr_at_1000
value: 28.023999999999997
- type: mrr_at_3
value: 24.839
- type: mrr_at_5
value: 26.033
- type: ndcg_at_1
value: 20.061999999999998
- type: ndcg_at_10
value: 27.682000000000002
- type: ndcg_at_100
value: 33.196
- type: ndcg_at_1000
value: 36.246
- type: ndcg_at_3
value: 23.559
- type: ndcg_at_5
value: 25.507
- type: precision_at_1
value: 20.061999999999998
- type: precision_at_10
value: 5.086
- type: precision_at_100
value: 0.9249999999999999
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 11.046
- type: precision_at_5
value: 8.149000000000001
- type: recall_at_1
value: 16.592000000000002
- type: recall_at_10
value: 37.181999999999995
- type: recall_at_100
value: 62.224999999999994
- type: recall_at_1000
value: 84.072
- type: recall_at_3
value: 25.776
- type: recall_at_5
value: 30.680000000000003
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackUnixRetrieval
type: mteb/cqadupstack-unix
config: default
split: test
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
metrics:
- type: map_at_1
value: 26.035999999999998
- type: map_at_10
value: 34.447
- type: map_at_100
value: 35.697
- type: map_at_1000
value: 35.802
- type: map_at_3
value: 31.64
- type: map_at_5
value: 33.056999999999995
- type: mrr_at_1
value: 29.851
- type: mrr_at_10
value: 38.143
- type: mrr_at_100
value: 39.113
- type: mrr_at_1000
value: 39.175
- type: mrr_at_3
value: 35.665
- type: mrr_at_5
value: 36.901
- type: ndcg_at_1
value: 29.851
- type: ndcg_at_10
value: 39.554
- type: ndcg_at_100
value: 45.091
- type: ndcg_at_1000
value: 47.504000000000005
- type: ndcg_at_3
value: 34.414
- type: ndcg_at_5
value: 36.508
- type: precision_at_1
value: 29.851
- type: precision_at_10
value: 6.614000000000001
- type: precision_at_100
value: 1.051
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 15.329999999999998
- type: precision_at_5
value: 10.671999999999999
- type: recall_at_1
value: 26.035999999999998
- type: recall_at_10
value: 51.396
- type: recall_at_100
value: 75.09
- type: recall_at_1000
value: 91.904
- type: recall_at_3
value: 37.378
- type: recall_at_5
value: 42.69
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWebmastersRetrieval
type: mteb/cqadupstack-webmasters
config: default
split: test
revision: 160c094312a0e1facb97e55eeddb698c0abe3571
metrics:
- type: map_at_1
value: 23.211000000000002
- type: map_at_10
value: 32.231
- type: map_at_100
value: 33.772999999999996
- type: map_at_1000
value: 33.982
- type: map_at_3
value: 29.128
- type: map_at_5
value: 31.002999999999997
- type: mrr_at_1
value: 27.668
- type: mrr_at_10
value: 36.388
- type: mrr_at_100
value: 37.384
- type: mrr_at_1000
value: 37.44
- type: mrr_at_3
value: 33.762
- type: mrr_at_5
value: 35.234
- type: ndcg_at_1
value: 27.668
- type: ndcg_at_10
value: 38.043
- type: ndcg_at_100
value: 44.21
- type: ndcg_at_1000
value: 46.748
- type: ndcg_at_3
value: 32.981
- type: ndcg_at_5
value: 35.58
- type: precision_at_1
value: 27.668
- type: precision_at_10
value: 7.352
- type: precision_at_100
value: 1.5
- type: precision_at_1000
value: 0.23700000000000002
- type: precision_at_3
value: 15.613
- type: precision_at_5
value: 11.501999999999999
- type: recall_at_1
value: 23.211000000000002
- type: recall_at_10
value: 49.851
- type: recall_at_100
value: 77.596
- type: recall_at_1000
value: 93.683
- type: recall_at_3
value: 35.403
- type: recall_at_5
value: 42.485
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWordpressRetrieval
type: mteb/cqadupstack-wordpress
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: map_at_1
value: 19.384
- type: map_at_10
value: 26.262999999999998
- type: map_at_100
value: 27.409
- type: map_at_1000
value: 27.526
- type: map_at_3
value: 23.698
- type: map_at_5
value: 25.217
- type: mrr_at_1
value: 20.702
- type: mrr_at_10
value: 27.810000000000002
- type: mrr_at_100
value: 28.863
- type: mrr_at_1000
value: 28.955
- type: mrr_at_3
value: 25.230999999999998
- type: mrr_at_5
value: 26.821
- type: ndcg_at_1
value: 20.702
- type: ndcg_at_10
value: 30.688
- type: ndcg_at_100
value: 36.138999999999996
- type: ndcg_at_1000
value: 38.984
- type: ndcg_at_3
value: 25.663000000000004
- type: ndcg_at_5
value: 28.242
- type: precision_at_1
value: 20.702
- type: precision_at_10
value: 4.954
- type: precision_at_100
value: 0.823
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 10.844
- type: precision_at_5
value: 8.096
- type: recall_at_1
value: 19.384
- type: recall_at_10
value: 42.847
- type: recall_at_100
value: 67.402
- type: recall_at_1000
value: 88.145
- type: recall_at_3
value: 29.513
- type: recall_at_5
value: 35.57
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: mteb/climate-fever
config: default
split: test
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
metrics:
- type: map_at_1
value: 14.915000000000001
- type: map_at_10
value: 25.846999999999998
- type: map_at_100
value: 27.741
- type: map_at_1000
value: 27.921000000000003
- type: map_at_3
value: 21.718
- type: map_at_5
value: 23.948
- type: mrr_at_1
value: 33.941
- type: mrr_at_10
value: 46.897
- type: mrr_at_100
value: 47.63
- type: mrr_at_1000
value: 47.658
- type: mrr_at_3
value: 43.919999999999995
- type: mrr_at_5
value: 45.783
- type: ndcg_at_1
value: 33.941
- type: ndcg_at_10
value: 35.202
- type: ndcg_at_100
value: 42.132
- type: ndcg_at_1000
value: 45.190999999999995
- type: ndcg_at_3
value: 29.68
- type: ndcg_at_5
value: 31.631999999999998
- type: precision_at_1
value: 33.941
- type: precision_at_10
value: 10.906
- type: precision_at_100
value: 1.8339999999999999
- type: precision_at_1000
value: 0.241
- type: precision_at_3
value: 22.606
- type: precision_at_5
value: 17.081
- type: recall_at_1
value: 14.915000000000001
- type: recall_at_10
value: 40.737
- type: recall_at_100
value: 64.42
- type: recall_at_1000
value: 81.435
- type: recall_at_3
value: 26.767000000000003
- type: recall_at_5
value: 32.895
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: mteb/dbpedia
config: default
split: test
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
metrics:
- type: map_at_1
value: 8.665000000000001
- type: map_at_10
value: 19.087
- type: map_at_100
value: 26.555
- type: map_at_1000
value: 28.105999999999998
- type: map_at_3
value: 13.858999999999998
- type: map_at_5
value: 16.083
- type: mrr_at_1
value: 68.5
- type: mrr_at_10
value: 76.725
- type: mrr_at_100
value: 76.974
- type: mrr_at_1000
value: 76.981
- type: mrr_at_3
value: 75.583
- type: mrr_at_5
value: 76.208
- type: ndcg_at_1
value: 55.875
- type: ndcg_at_10
value: 41.018
- type: ndcg_at_100
value: 44.982
- type: ndcg_at_1000
value: 52.43
- type: ndcg_at_3
value: 46.534
- type: ndcg_at_5
value: 43.083
- type: precision_at_1
value: 68.5
- type: precision_at_10
value: 32.35
- type: precision_at_100
value: 10.078
- type: precision_at_1000
value: 1.957
- type: precision_at_3
value: 50.083
- type: precision_at_5
value: 41.3
- type: recall_at_1
value: 8.665000000000001
- type: recall_at_10
value: 24.596999999999998
- type: recall_at_100
value: 50.612
- type: recall_at_1000
value: 74.24
- type: recall_at_3
value: 15.337
- type: recall_at_5
value: 18.796
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 55.06500000000001
- type: f1
value: 49.827367590822035
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: mteb/fever
config: default
split: test
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
metrics:
- type: map_at_1
value: 76.059
- type: map_at_10
value: 83.625
- type: map_at_100
value: 83.845
- type: map_at_1000
value: 83.858
- type: map_at_3
value: 82.67099999999999
- type: map_at_5
value: 83.223
- type: mrr_at_1
value: 82.013
- type: mrr_at_10
value: 88.44800000000001
- type: mrr_at_100
value: 88.535
- type: mrr_at_1000
value: 88.537
- type: mrr_at_3
value: 87.854
- type: mrr_at_5
value: 88.221
- type: ndcg_at_1
value: 82.013
- type: ndcg_at_10
value: 87.128
- type: ndcg_at_100
value: 87.922
- type: ndcg_at_1000
value: 88.166
- type: ndcg_at_3
value: 85.648
- type: ndcg_at_5
value: 86.366
- type: precision_at_1
value: 82.013
- type: precision_at_10
value: 10.32
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 32.408
- type: precision_at_5
value: 19.973
- type: recall_at_1
value: 76.059
- type: recall_at_10
value: 93.229
- type: recall_at_100
value: 96.387
- type: recall_at_1000
value: 97.916
- type: recall_at_3
value: 89.025
- type: recall_at_5
value: 90.96300000000001
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: mteb/fiqa
config: default
split: test
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
metrics:
- type: map_at_1
value: 20.479
- type: map_at_10
value: 33.109
- type: map_at_100
value: 34.803
- type: map_at_1000
value: 35.003
- type: map_at_3
value: 28.967
- type: map_at_5
value: 31.385
- type: mrr_at_1
value: 40.278000000000006
- type: mrr_at_10
value: 48.929
- type: mrr_at_100
value: 49.655
- type: mrr_at_1000
value: 49.691
- type: mrr_at_3
value: 46.605000000000004
- type: mrr_at_5
value: 48.056
- type: ndcg_at_1
value: 40.278000000000006
- type: ndcg_at_10
value: 40.649
- type: ndcg_at_100
value: 47.027
- type: ndcg_at_1000
value: 50.249
- type: ndcg_at_3
value: 37.364000000000004
- type: ndcg_at_5
value: 38.494
- type: precision_at_1
value: 40.278000000000006
- type: precision_at_10
value: 11.327
- type: precision_at_100
value: 1.802
- type: precision_at_1000
value: 0.23700000000000002
- type: precision_at_3
value: 25.102999999999998
- type: precision_at_5
value: 18.457
- type: recall_at_1
value: 20.479
- type: recall_at_10
value: 46.594
- type: recall_at_100
value: 71.101
- type: recall_at_1000
value: 90.31099999999999
- type: recall_at_3
value: 33.378
- type: recall_at_5
value: 39.587
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: mteb/hotpotqa
config: default
split: test
revision: ab518f4d6fcca38d87c25209f94beba119d02014
metrics:
- type: map_at_1
value: 36.59
- type: map_at_10
value: 58.178
- type: map_at_100
value: 59.095
- type: map_at_1000
value: 59.16400000000001
- type: map_at_3
value: 54.907
- type: map_at_5
value: 56.89999999999999
- type: mrr_at_1
value: 73.18
- type: mrr_at_10
value: 79.935
- type: mrr_at_100
value: 80.16799999999999
- type: mrr_at_1000
value: 80.17800000000001
- type: mrr_at_3
value: 78.776
- type: mrr_at_5
value: 79.522
- type: ndcg_at_1
value: 73.18
- type: ndcg_at_10
value: 66.538
- type: ndcg_at_100
value: 69.78
- type: ndcg_at_1000
value: 71.102
- type: ndcg_at_3
value: 61.739
- type: ndcg_at_5
value: 64.35600000000001
- type: precision_at_1
value: 73.18
- type: precision_at_10
value: 14.035
- type: precision_at_100
value: 1.657
- type: precision_at_1000
value: 0.183
- type: precision_at_3
value: 39.684999999999995
- type: precision_at_5
value: 25.885
- type: recall_at_1
value: 36.59
- type: recall_at_10
value: 70.176
- type: recall_at_100
value: 82.836
- type: recall_at_1000
value: 91.526
- type: recall_at_3
value: 59.526999999999994
- type: recall_at_5
value: 64.713
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 90.1472
- type: ap
value: 85.73994227076815
- type: f1
value: 90.1271700788608
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: mteb/msmarco
config: default
split: dev
revision: c5a29a104738b98a9e76336939199e264163d4a0
metrics:
- type: map_at_1
value: 21.689
- type: map_at_10
value: 33.518
- type: map_at_100
value: 34.715
- type: map_at_1000
value: 34.766000000000005
- type: map_at_3
value: 29.781000000000002
- type: map_at_5
value: 31.838
- type: mrr_at_1
value: 22.249
- type: mrr_at_10
value: 34.085
- type: mrr_at_100
value: 35.223
- type: mrr_at_1000
value: 35.266999999999996
- type: mrr_at_3
value: 30.398999999999997
- type: mrr_at_5
value: 32.437
- type: ndcg_at_1
value: 22.249
- type: ndcg_at_10
value: 40.227000000000004
- type: ndcg_at_100
value: 45.961999999999996
- type: ndcg_at_1000
value: 47.248000000000005
- type: ndcg_at_3
value: 32.566
- type: ndcg_at_5
value: 36.229
- type: precision_at_1
value: 22.249
- type: precision_at_10
value: 6.358
- type: precision_at_100
value: 0.923
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 13.83
- type: precision_at_5
value: 10.145999999999999
- type: recall_at_1
value: 21.689
- type: recall_at_10
value: 60.92999999999999
- type: recall_at_100
value: 87.40599999999999
- type: recall_at_1000
value: 97.283
- type: recall_at_3
value: 40.01
- type: recall_at_5
value: 48.776
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 95.28727770177838
- type: f1
value: 95.02577308660041
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.5736434108527
- type: f1
value: 61.2451202054398
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.01210490921318
- type: f1
value: 73.70188053982473
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.33422999327504
- type: f1
value: 79.48369022509658
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 34.70891567267726
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.15203494451706
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.919517862194173
- type: mrr
value: 33.15466289140483
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: mteb/nfcorpus
config: default
split: test
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
metrics:
- type: map_at_1
value: 5.992
- type: map_at_10
value: 13.197000000000001
- type: map_at_100
value: 16.907
- type: map_at_1000
value: 18.44
- type: map_at_3
value: 9.631
- type: map_at_5
value: 11.243
- type: mrr_at_1
value: 44.272
- type: mrr_at_10
value: 53.321
- type: mrr_at_100
value: 53.903
- type: mrr_at_1000
value: 53.952999999999996
- type: mrr_at_3
value: 51.393
- type: mrr_at_5
value: 52.708999999999996
- type: ndcg_at_1
value: 42.415000000000006
- type: ndcg_at_10
value: 34.921
- type: ndcg_at_100
value: 32.384
- type: ndcg_at_1000
value: 41.260000000000005
- type: ndcg_at_3
value: 40.186
- type: ndcg_at_5
value: 37.89
- type: precision_at_1
value: 44.272
- type: precision_at_10
value: 26.006
- type: precision_at_100
value: 8.44
- type: precision_at_1000
value: 2.136
- type: precision_at_3
value: 37.977
- type: precision_at_5
value: 32.755
- type: recall_at_1
value: 5.992
- type: recall_at_10
value: 17.01
- type: recall_at_100
value: 33.080999999999996
- type: recall_at_1000
value: 65.054
- type: recall_at_3
value: 10.528
- type: recall_at_5
value: 13.233
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: mteb/nq
config: default
split: test
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
metrics:
- type: map_at_1
value: 28.871999999999996
- type: map_at_10
value: 43.286
- type: map_at_100
value: 44.432
- type: map_at_1000
value: 44.464999999999996
- type: map_at_3
value: 38.856
- type: map_at_5
value: 41.514
- type: mrr_at_1
value: 32.619
- type: mrr_at_10
value: 45.75
- type: mrr_at_100
value: 46.622
- type: mrr_at_1000
value: 46.646
- type: mrr_at_3
value: 41.985
- type: mrr_at_5
value: 44.277
- type: ndcg_at_1
value: 32.59
- type: ndcg_at_10
value: 50.895999999999994
- type: ndcg_at_100
value: 55.711999999999996
- type: ndcg_at_1000
value: 56.48800000000001
- type: ndcg_at_3
value: 42.504999999999995
- type: ndcg_at_5
value: 46.969
- type: precision_at_1
value: 32.59
- type: precision_at_10
value: 8.543000000000001
- type: precision_at_100
value: 1.123
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 19.448
- type: precision_at_5
value: 14.218
- type: recall_at_1
value: 28.871999999999996
- type: recall_at_10
value: 71.748
- type: recall_at_100
value: 92.55499999999999
- type: recall_at_1000
value: 98.327
- type: recall_at_3
value: 49.944
- type: recall_at_5
value: 60.291
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: mteb/quora
config: default
split: test
revision: e4e08e0b7dbe3c8700f0daef558ff32256715259
metrics:
- type: map_at_1
value: 70.664
- type: map_at_10
value: 84.681
- type: map_at_100
value: 85.289
- type: map_at_1000
value: 85.306
- type: map_at_3
value: 81.719
- type: map_at_5
value: 83.601
- type: mrr_at_1
value: 81.35
- type: mrr_at_10
value: 87.591
- type: mrr_at_100
value: 87.691
- type: mrr_at_1000
value: 87.693
- type: mrr_at_3
value: 86.675
- type: mrr_at_5
value: 87.29299999999999
- type: ndcg_at_1
value: 81.33
- type: ndcg_at_10
value: 88.411
- type: ndcg_at_100
value: 89.579
- type: ndcg_at_1000
value: 89.687
- type: ndcg_at_3
value: 85.613
- type: ndcg_at_5
value: 87.17
- type: precision_at_1
value: 81.33
- type: precision_at_10
value: 13.422
- type: precision_at_100
value: 1.5270000000000001
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.463
- type: precision_at_5
value: 24.646
- type: recall_at_1
value: 70.664
- type: recall_at_10
value: 95.54
- type: recall_at_100
value: 99.496
- type: recall_at_1000
value: 99.978
- type: recall_at_3
value: 87.481
- type: recall_at_5
value: 91.88499999999999
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.40341814991112
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: v_measure
value: 61.231318481346655
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: mteb/scidocs
config: default
split: test
revision: f8c2fcf00f625baaa80f62ec5bd9e1fff3b8ae88
metrics:
- type: map_at_1
value: 4.833
- type: map_at_10
value: 13.149
- type: map_at_100
value: 15.578
- type: map_at_1000
value: 15.963
- type: map_at_3
value: 9.269
- type: map_at_5
value: 11.182
- type: mrr_at_1
value: 23.9
- type: mrr_at_10
value: 35.978
- type: mrr_at_100
value: 37.076
- type: mrr_at_1000
value: 37.126
- type: mrr_at_3
value: 32.333
- type: mrr_at_5
value: 34.413
- type: ndcg_at_1
value: 23.9
- type: ndcg_at_10
value: 21.823
- type: ndcg_at_100
value: 30.833
- type: ndcg_at_1000
value: 36.991
- type: ndcg_at_3
value: 20.465
- type: ndcg_at_5
value: 17.965999999999998
- type: precision_at_1
value: 23.9
- type: precision_at_10
value: 11.49
- type: precision_at_100
value: 2.444
- type: precision_at_1000
value: 0.392
- type: precision_at_3
value: 19.3
- type: precision_at_5
value: 15.959999999999999
- type: recall_at_1
value: 4.833
- type: recall_at_10
value: 23.294999999999998
- type: recall_at_100
value: 49.63
- type: recall_at_1000
value: 79.49199999999999
- type: recall_at_3
value: 11.732
- type: recall_at_5
value: 16.167
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cos_sim_pearson
value: 85.62938108735759
- type: cos_sim_spearman
value: 80.30777094408789
- type: euclidean_pearson
value: 82.94516686659536
- type: euclidean_spearman
value: 80.34489663248169
- type: manhattan_pearson
value: 82.85830094736245
- type: manhattan_spearman
value: 80.24902623215449
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 85.23777464247604
- type: cos_sim_spearman
value: 75.75714864112797
- type: euclidean_pearson
value: 82.33806918604493
- type: euclidean_spearman
value: 75.45282124387357
- type: manhattan_pearson
value: 82.32555620660538
- type: manhattan_spearman
value: 75.49228731684082
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 84.88151620954451
- type: cos_sim_spearman
value: 86.08377598473446
- type: euclidean_pearson
value: 85.36958329369413
- type: euclidean_spearman
value: 86.10274219670679
- type: manhattan_pearson
value: 85.25873897594711
- type: manhattan_spearman
value: 85.98096461661584
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 84.29360558735978
- type: cos_sim_spearman
value: 82.28284203795577
- type: euclidean_pearson
value: 83.81636655536633
- type: euclidean_spearman
value: 82.24340438530236
- type: manhattan_pearson
value: 83.83914453428608
- type: manhattan_spearman
value: 82.28391354080694
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.47344180426744
- type: cos_sim_spearman
value: 88.90045649789438
- type: euclidean_pearson
value: 88.43020815961273
- type: euclidean_spearman
value: 89.0087449011776
- type: manhattan_pearson
value: 88.37601826505525
- type: manhattan_spearman
value: 88.96756360690617
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 83.35997025304613
- type: cos_sim_spearman
value: 85.18237675717147
- type: euclidean_pearson
value: 84.46478196990202
- type: euclidean_spearman
value: 85.27748677712205
- type: manhattan_pearson
value: 84.29342543953123
- type: manhattan_spearman
value: 85.10579612516567
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.56668329596836
- type: cos_sim_spearman
value: 88.72837234129177
- type: euclidean_pearson
value: 89.39395650897828
- type: euclidean_spearman
value: 88.82001247906778
- type: manhattan_pearson
value: 89.41735354368878
- type: manhattan_spearman
value: 88.95159141850039
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 67.466167902991
- type: cos_sim_spearman
value: 68.54466147197274
- type: euclidean_pearson
value: 69.35551179564695
- type: euclidean_spearman
value: 68.75455717749132
- type: manhattan_pearson
value: 69.42432368208264
- type: manhattan_spearman
value: 68.83203709670562
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.33241300373689
- type: cos_sim_spearman
value: 86.97909372129874
- type: euclidean_pearson
value: 86.99526113559924
- type: euclidean_spearman
value: 87.02644372623219
- type: manhattan_pearson
value: 86.78744182759846
- type: manhattan_spearman
value: 86.8886180198196
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 86.18374413668717
- type: mrr
value: 95.93213068703264
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: mteb/scifact
config: default
split: test
revision: 0228b52cf27578f30900b9e5271d331663a030d7
metrics:
- type: map_at_1
value: 58.31699999999999
- type: map_at_10
value: 67.691
- type: map_at_100
value: 68.201
- type: map_at_1000
value: 68.232
- type: map_at_3
value: 64.47800000000001
- type: map_at_5
value: 66.51
- type: mrr_at_1
value: 61.0
- type: mrr_at_10
value: 68.621
- type: mrr_at_100
value: 68.973
- type: mrr_at_1000
value: 69.002
- type: mrr_at_3
value: 66.111
- type: mrr_at_5
value: 67.578
- type: ndcg_at_1
value: 61.0
- type: ndcg_at_10
value: 72.219
- type: ndcg_at_100
value: 74.397
- type: ndcg_at_1000
value: 75.021
- type: ndcg_at_3
value: 66.747
- type: ndcg_at_5
value: 69.609
- type: precision_at_1
value: 61.0
- type: precision_at_10
value: 9.6
- type: precision_at_100
value: 1.08
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 25.667
- type: precision_at_5
value: 17.267
- type: recall_at_1
value: 58.31699999999999
- type: recall_at_10
value: 85.233
- type: recall_at_100
value: 95.167
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 70.589
- type: recall_at_5
value: 77.628
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.83267326732673
- type: cos_sim_ap
value: 96.13707107038228
- type: cos_sim_f1
value: 91.48830263812842
- type: cos_sim_precision
value: 91.0802775024777
- type: cos_sim_recall
value: 91.9
- type: dot_accuracy
value: 99.83069306930693
- type: dot_ap
value: 96.21199069147254
- type: dot_f1
value: 91.36295556665004
- type: dot_precision
value: 91.22632103688933
- type: dot_recall
value: 91.5
- type: euclidean_accuracy
value: 99.83267326732673
- type: euclidean_ap
value: 96.08957801367436
- type: euclidean_f1
value: 91.33004926108374
- type: euclidean_precision
value: 90.0
- type: euclidean_recall
value: 92.7
- type: manhattan_accuracy
value: 99.83564356435643
- type: manhattan_ap
value: 96.10534946461945
- type: manhattan_f1
value: 91.74950298210736
- type: manhattan_precision
value: 91.20553359683794
- type: manhattan_recall
value: 92.30000000000001
- type: max_accuracy
value: 99.83564356435643
- type: max_ap
value: 96.21199069147254
- type: max_f1
value: 91.74950298210736
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 62.045718843534736
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.6501777041092
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.963913408053955
- type: mrr
value: 53.87972423818012
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.44195730764998
- type: cos_sim_spearman
value: 30.59626288679397
- type: dot_pearson
value: 30.22974492404086
- type: dot_spearman
value: 29.345245972906497
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: mteb/trec-covid
config: default
split: test
revision: bb9466bac8153a0349341eb1b22e06409e78ef4e
metrics:
- type: map_at_1
value: 0.24
- type: map_at_10
value: 2.01
- type: map_at_100
value: 11.928999999999998
- type: map_at_1000
value: 29.034
- type: map_at_3
value: 0.679
- type: map_at_5
value: 1.064
- type: mrr_at_1
value: 92.0
- type: mrr_at_10
value: 96.0
- type: mrr_at_100
value: 96.0
- type: mrr_at_1000
value: 96.0
- type: mrr_at_3
value: 96.0
- type: mrr_at_5
value: 96.0
- type: ndcg_at_1
value: 87.0
- type: ndcg_at_10
value: 80.118
- type: ndcg_at_100
value: 60.753
- type: ndcg_at_1000
value: 54.632999999999996
- type: ndcg_at_3
value: 83.073
- type: ndcg_at_5
value: 80.733
- type: precision_at_1
value: 92.0
- type: precision_at_10
value: 84.8
- type: precision_at_100
value: 62.019999999999996
- type: precision_at_1000
value: 24.028
- type: precision_at_3
value: 87.333
- type: precision_at_5
value: 85.2
- type: recall_at_1
value: 0.24
- type: recall_at_10
value: 2.205
- type: recall_at_100
value: 15.068000000000001
- type: recall_at_1000
value: 51.796
- type: recall_at_3
value: 0.698
- type: recall_at_5
value: 1.1199999999999999
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: mteb/touche2020
config: default
split: test
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
metrics:
- type: map_at_1
value: 3.066
- type: map_at_10
value: 9.219
- type: map_at_100
value: 15.387
- type: map_at_1000
value: 16.957
- type: map_at_3
value: 5.146
- type: map_at_5
value: 6.6739999999999995
- type: mrr_at_1
value: 40.816
- type: mrr_at_10
value: 50.844
- type: mrr_at_100
value: 51.664
- type: mrr_at_1000
value: 51.664
- type: mrr_at_3
value: 46.259
- type: mrr_at_5
value: 49.116
- type: ndcg_at_1
value: 37.755
- type: ndcg_at_10
value: 23.477
- type: ndcg_at_100
value: 36.268
- type: ndcg_at_1000
value: 47.946
- type: ndcg_at_3
value: 25.832
- type: ndcg_at_5
value: 24.235
- type: precision_at_1
value: 40.816
- type: precision_at_10
value: 20.204
- type: precision_at_100
value: 7.611999999999999
- type: precision_at_1000
value: 1.543
- type: precision_at_3
value: 25.169999999999998
- type: precision_at_5
value: 23.265
- type: recall_at_1
value: 3.066
- type: recall_at_10
value: 14.985999999999999
- type: recall_at_100
value: 47.902
- type: recall_at_1000
value: 83.56400000000001
- type: recall_at_3
value: 5.755
- type: recall_at_5
value: 8.741999999999999
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 69.437
- type: ap
value: 12.844066827082706
- type: f1
value: 52.74974809872495
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.26768534238823
- type: f1
value: 61.65100187399282
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.860968711078804
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.7423854085951
- type: cos_sim_ap
value: 73.47560303339571
- type: cos_sim_f1
value: 67.372778183589
- type: cos_sim_precision
value: 62.54520795660036
- type: cos_sim_recall
value: 73.00791556728232
- type: dot_accuracy
value: 85.36091077069798
- type: dot_ap
value: 72.42521572307255
- type: dot_f1
value: 66.90576304724215
- type: dot_precision
value: 62.96554934823091
- type: dot_recall
value: 71.37203166226914
- type: euclidean_accuracy
value: 85.76026703224653
- type: euclidean_ap
value: 73.44852563860128
- type: euclidean_f1
value: 67.3
- type: euclidean_precision
value: 63.94299287410926
- type: euclidean_recall
value: 71.02902374670185
- type: manhattan_accuracy
value: 85.7423854085951
- type: manhattan_ap
value: 73.2635034755551
- type: manhattan_f1
value: 67.3180263800684
- type: manhattan_precision
value: 62.66484765802638
- type: manhattan_recall
value: 72.71767810026385
- type: max_accuracy
value: 85.76026703224653
- type: max_ap
value: 73.47560303339571
- type: max_f1
value: 67.372778183589
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.67543757519307
- type: cos_sim_ap
value: 85.35516518531304
- type: cos_sim_f1
value: 77.58197635511934
- type: cos_sim_precision
value: 75.01078360891445
- type: cos_sim_recall
value: 80.33569448721897
- type: dot_accuracy
value: 87.61400240617844
- type: dot_ap
value: 83.0774968268665
- type: dot_f1
value: 75.68229012162561
- type: dot_precision
value: 72.99713876967095
- type: dot_recall
value: 78.57252848783493
- type: euclidean_accuracy
value: 88.73753250281368
- type: euclidean_ap
value: 85.48043564821317
- type: euclidean_f1
value: 77.75975862719216
- type: euclidean_precision
value: 76.21054187920456
- type: euclidean_recall
value: 79.37326763166
- type: manhattan_accuracy
value: 88.75111576823068
- type: manhattan_ap
value: 85.44993439423668
- type: manhattan_f1
value: 77.6861329994845
- type: manhattan_precision
value: 74.44601270289344
- type: manhattan_recall
value: 81.22112719433323
- type: max_accuracy
value: 88.75111576823068
- type: max_ap
value: 85.48043564821317
- type: max_f1
value: 77.75975862719216
---
# twine-network/NoInstruct-small-Embedding-v0-Q5_K_M-GGUF
This model was converted to GGUF format from [`avsolatorio/NoInstruct-small-Embedding-v0`](https://huggingface.co/avsolatorio/NoInstruct-small-Embedding-v0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/avsolatorio/NoInstruct-small-Embedding-v0) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo twine-network/NoInstruct-small-Embedding-v0-Q5_K_M-GGUF --hf-file noinstruct-small-embedding-v0-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo twine-network/NoInstruct-small-Embedding-v0-Q5_K_M-GGUF --hf-file noinstruct-small-embedding-v0-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo twine-network/NoInstruct-small-Embedding-v0-Q5_K_M-GGUF --hf-file noinstruct-small-embedding-v0-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo twine-network/NoInstruct-small-Embedding-v0-Q5_K_M-GGUF --hf-file noinstruct-small-embedding-v0-q5_k_m.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
glif-loradex-trainer/insectagon_mugshot_prodigy
|
glif-loradex-trainer
|
text-to-image
|
[
"diffusers",
"text-to-image",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us",
"flux",
"lora",
"base_model:adapter:black-forest-labs/FLUX.1-dev"
] | 2024-11-06T17:14:14Z |
2024-11-06T17:15:08+00:00
| 18 | 1 |
---
base_model: black-forest-labs/FLUX.1-dev
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
tags:
- diffusers
- text-to-image
- template:sd-lora
- base_model:black-forest-labs/FLUX.1-dev
- base_model:finetune:black-forest-labs/FLUX.1-dev
- license:other
- region:us
- flux
- lora
widget:
- output:
url: samples/1730913086401__000003000_0.jpg
text: A cartoon Jedi with green lightsaber [mug$hot]
- output:
url: samples/1730913110160__000003000_1.jpg
text: A lion roaring [mug$hot]
- output:
url: samples/1730913133582__000003000_2.jpg
text: AN ACTION SCENE [mug$hot]
- output:
url: samples/1730913157899__000003000_3.jpg
text: A woman holding a cartoon CAT [mug$hot]
- output:
url: samples/1730913181589__000003000_4.jpg
text: THE JOKER [mug$hot]
- output:
url: samples/1730913205023__000003000_5.jpg
text: BATMAN cartoon IN GOTHAM [mug$hot]
- output:
url: samples/1730913228546__000003000_6.jpg
text: a blue Teddy bear Kaiju vs Godzilla [mug$hot]
trigger: mug$hot
instance_prompt: mug$hot
---
# mugshot_prodigy
Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit) under the [Glif Loradex program](https://huggingface.co/glif-loradex-trainer) by [Glif](https://glif.app) user `insectagon`.
<Gallery />
## Trigger words
You should use `mug$hot` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/glif-loradex-trainer/insectagon_mugshot_prodigy/tree/main) them in the Files & versions tab.
## License
This model is licensed under the [flux-1-dev-non-commercial-license](https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md).
|
[
"BEAR"
] |
davidschulte/ESM_allenai__scifact_entailment_default
|
davidschulte
| null |
[
"safetensors",
"embedding_space_map",
"BaseLM:bert-base-multilingual-uncased",
"dataset:allenai/scifact_entailment",
"arxiv:2410.15148",
"base_model:google-bert/bert-base-multilingual-uncased",
"base_model:finetune:google-bert/bert-base-multilingual-uncased",
"license:apache-2.0",
"region:us"
] | 2024-11-29T15:03:56Z |
2024-11-29T15:04:00+00:00
| 18 | 0 |
---
base_model: bert-base-multilingual-uncased
datasets:
- allenai/scifact_entailment
license: apache-2.0
tags:
- embedding_space_map
- BaseLM:bert-base-multilingual-uncased
---
# ESM allenai/scifact_entailment
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
ESM
- **Developed by:** David Schulte
- **Model type:** ESM
- **Base Model:** bert-base-multilingual-uncased
- **Intermediate Task:** allenai/scifact_entailment
- **ESM architecture:** linear
- **ESM embedding dimension:** 768
- **Language(s) (NLP):** [More Information Needed]
- **License:** Apache-2.0 license
- **ESM version:** 0.1.0
## Training Details
### Intermediate Task
- **Task ID:** allenai/scifact_entailment
- **Subset [optional]:** default
- **Text Column:** title
- **Label Column:** verdict
- **Dataset Split:** train
- **Sample size [optional]:** 919
- **Sample seed [optional]:**
### Training Procedure [optional]
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Language Model Training Hyperparameters [optional]
- **Epochs:** 3
- **Batch size:** 32
- **Learning rate:** 2e-05
- **Weight Decay:** 0.01
- **Optimizer**: AdamW
### ESM Training Hyperparameters [optional]
- **Epochs:** 10
- **Batch size:** 32
- **Learning rate:** 0.001
- **Weight Decay:** 0.01
- **Optimizer**: AdamW
### Additional trainiung details [optional]
## Model evaluation
### Evaluation of fine-tuned language model [optional]
### Evaluation of ESM [optional]
MSE:
### Additional evaluation details [optional]
## What are Embedding Space Maps used for?
Embedding Space Maps are a part of ESM-LogME, a efficient method for finding intermediate datasets for transfer learning. There are two reasons to use ESM-LogME:
### You don't have enough training data for your problem
If you don't have a enough training data for your problem, just use ESM-LogME to find more.
You can supplement model training by including publicly available datasets in the training process.
1. Fine-tune a language model on suitable intermediate dataset.
2. Fine-tune the resulting model on your target dataset.
This workflow is called intermediate task transfer learning and it can significantly improve the target performance.
But what is a suitable dataset for your problem? ESM-LogME enable you to quickly rank thousands of datasets on the Hugging Face Hub by how well they are exptected to transfer to your target task.
### You want to find similar datasets to your target dataset
Using ESM-LogME can be used like search engine on the Hugging Face Hub. You can find similar tasks to your target task without having to rely on heuristics. ESM-LogME estimates how language models fine-tuned on each intermediate task would benefinit your target task. This quantitative approach combines the effects of domain similarity and task similarity.
## How can I use ESM-LogME / ESMs?
[](https://pypi.org/project/hf-dataset-selector)
We release **hf-dataset-selector**, a Python package for intermediate task selection using Embedding Space Maps.
**hf-dataset-selector** fetches ESMs for a given language model and uses it to find the best dataset for applying intermediate training to the target task. ESMs are found by their tags on the Huggingface Hub.
```python
from hfselect import Dataset, compute_task_ranking
# Load target dataset from the Hugging Face Hub
dataset = Dataset.from_hugging_face(
name="stanfordnlp/imdb",
split="train",
text_col="text",
label_col="label",
is_regression=False,
num_examples=1000,
seed=42
)
# Fetch ESMs and rank tasks
task_ranking = compute_task_ranking(
dataset=dataset,
model_name="bert-base-multilingual-uncased"
)
# Display top 5 recommendations
print(task_ranking[:5])
```
```python
1. davanstrien/test_imdb_embedd2 Score: -0.618529
2. davanstrien/test_imdb_embedd Score: -0.618644
3. davanstrien/test1 Score: -0.619334
4. stanfordnlp/imdb Score: -0.619454
5. stanfordnlp/sst Score: -0.62995
```
| Rank | Task ID | Task Subset | Text Column | Label Column | Task Split | Num Examples | ESM Architecture | Score |
|-------:|:------------------------------|:----------------|:--------------|:---------------|:-------------|---------------:|:-------------------|----------:|
| 1 | davanstrien/test_imdb_embedd2 | default | text | label | train | 10000 | linear | -0.618529 |
| 2 | davanstrien/test_imdb_embedd | default | text | label | train | 10000 | linear | -0.618644 |
| 3 | davanstrien/test1 | default | text | label | train | 10000 | linear | -0.619334 |
| 4 | stanfordnlp/imdb | plain_text | text | label | train | 10000 | linear | -0.619454 |
| 5 | stanfordnlp/sst | dictionary | phrase | label | dictionary | 10000 | linear | -0.62995 |
| 6 | stanfordnlp/sst | default | sentence | label | train | 8544 | linear | -0.63312 |
| 7 | kuroneko5943/snap21 | CDs_and_Vinyl_5 | sentence | label | train | 6974 | linear | -0.634365 |
| 8 | kuroneko5943/snap21 | Video_Games_5 | sentence | label | train | 6997 | linear | -0.638787 |
| 9 | kuroneko5943/snap21 | Movies_and_TV_5 | sentence | label | train | 6989 | linear | -0.639068 |
| 10 | fancyzhx/amazon_polarity | amazon_polarity | content | label | train | 10000 | linear | -0.639718 |
For more information on how to use ESMs please have a look at the [official Github repository](https://github.com/davidschulte/hf-dataset-selector). We provide documentation further documentation and tutorials for finding intermediate datasets and training your own ESMs.
## How do Embedding Space Maps work?
<!-- This section describes the evaluation protocols and provides the results. -->
Embedding Space Maps (ESMs) are neural networks that approximate the effect of fine-tuning a language model on a task. They can be used to quickly transform embeddings from a base model to approximate how a fine-tuned model would embed the the input text.
ESMs can be used for intermediate task selection with the ESM-LogME workflow.
## How can I use Embedding Space Maps for Intermediate Task Selection?
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
If you are using this Embedding Space Maps, please cite our [paper](https://aclanthology.org/2024.emnlp-main.529/).
**BibTeX:**
```
@inproceedings{schulte-etal-2024-less,
title = "Less is More: Parameter-Efficient Selection of Intermediate Tasks for Transfer Learning",
author = "Schulte, David and
Hamborg, Felix and
Akbik, Alan",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.emnlp-main.529/",
doi = "10.18653/v1/2024.emnlp-main.529",
pages = "9431--9442",
abstract = "Intermediate task transfer learning can greatly improve model performance. If, for example, one has little training data for emotion detection, first fine-tuning a language model on a sentiment classification dataset may improve performance strongly. But which task to choose for transfer learning? Prior methods producing useful task rankings are infeasible for large source pools, as they require forward passes through all source language models. We overcome this by introducing Embedding Space Maps (ESMs), light-weight neural networks that approximate the effect of fine-tuning a language model. We conduct the largest study on NLP task transferability and task selection with 12k source-target pairs. We find that applying ESMs on a prior method reduces execution time and disk space usage by factors of 10 and 278, respectively, while retaining high selection performance (avg. regret@5 score of 2.95)."
}
```
**APA:**
```
Schulte, D., Hamborg, F., & Akbik, A. (2024, November). Less is More: Parameter-Efficient Selection of Intermediate Tasks for Transfer Learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 9431-9442).
```
## Additional Information
|
[
"SCIFACT"
] |
thomaskim1130/stella_en_400M_v5-FinanceRAG-md
|
thomaskim1130
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"new",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:2240",
"loss:MultipleNegativesRankingLoss",
"custom_code",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:thomaskim1130/stella_en_400M_v5-FinanceRAG-v2",
"base_model:finetune:thomaskim1130/stella_en_400M_v5-FinanceRAG-v2",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-11-29T17:45:38Z |
2024-11-29T17:46:23+00:00
| 18 | 1 |
---
base_model: thomaskim1130/stella_en_400M_v5-FinanceRAG-v2
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
- dot_accuracy@1
- dot_accuracy@3
- dot_accuracy@5
- dot_accuracy@10
- dot_precision@1
- dot_precision@3
- dot_precision@5
- dot_precision@10
- dot_recall@1
- dot_recall@3
- dot_recall@5
- dot_recall@10
- dot_ndcg@10
- dot_mrr@10
- dot_map@100
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:2240
- loss:MultipleNegativesRankingLoss
widget:
- source_sentence: "Instruct: Given a web search query, retrieve relevant passages\
\ that answer the query.\nQuery: Title: \nText: | _id | q616790e6 |\n| title |\
\ |\n| text | what was the percentage decline in the operating loss from 2007\
\ to 2008\n\nwhat percentage decline in operating loss from 2007 to 2008\n\n\n"
sentences:
- "Title: \nText: | _id | d1a72bce4 |\n| title | |\n| text | Cost of Revenues and\
\ Gross Margin\n\nCost of revenues in 2019 decreased by $4.3 million, or 16%,\
\ as compared to 2018. The decrease was primarily driven by a reduction in the\
\ number of global services and cloud infrastructure personnel, which led to a\
\ decrease of $2.2 million in compensation and benefits expense, including stock-based\
\ compensation expense, as compared to 2018. This reduction in headcount also\
\ contributed to a decrease in allocated facilities and information technology\
\ costs of $0.5 million in 2019. We also experienced a\n\nof $0.5 million in 2019.\
\ We also experienced a decrease of $0.9 million in hosting costs in 2019, due\
\ to a decline in the usage of our hosted platform as compared to 2018. Additionally,\
\ depreciation decreased $0.5 million in 2019, due to the nature and timing of\
\ capital expenditures and internal projects as compared to 2018.\n\nOur gross\
\ margin decreased to 53% during 2019, as compared to 54% during 2018. This was\
\ primarily due to our revenues, net declining during the year at a slightly faster\
\ rate than the corresponding decrease in costs.\n\n| Years Ended December 31,\
\ | | Change | \n---------------- | ------------------------\
\ | ---------------------- | -------- | -----\n | 2019 \
\ | 2018 | $ | % \n |\
\ | (dollars in thousands) | | \nCost of\
\ revenues | $22,843 | $27,154 | $(4,311) | (16)%\n\
\nGross profit | 26,193 | 31,477 | (6,284)\
\ | (17) \nGross margin | 53% | 54% \
\ | |\n\nCost of Revenues Gross Margin\n\nCost revenues in 2019 decreased\
\ by $4. 3 million, or 16%, compared to 2018. decrease driven by reduction in\
\ number of global services and cloud infrastructure personnel led to decrease\
\ of $2. 2 million in compensation and benefits expense, including stock-based\
\ compensation expense compared to 2018. reduction in headcount contributed to\
\ decrease in allocated facilities and information technology costs of $0. 5 million\
\ in 2019. experienced decrease of $0. 9 million in hosting costs in 2019 due\
\ to decline\n\n9 million in hosting costs in 2019 due to decline in usage of\
\ hosted platform compared to 2018. depreciation decreased $0. 5 million in 2019\
\ due to nature timing capital expenditures internal projects compared to 2018.\n\
\ngross margin decreased to 53% during 2019 compared to 54% 2018. primarily due\
\ to revenues, net declining year at slightly faster rate than decrease in costs.\n\
\n| Years Ended December 31, | | Change | \n----------------\
\ | ------------------------ | ---------------------- | -------- | -----\n \
\ | 2019 | 2018 | $ \
\ | % \n | | (dollars in thousands)\
\ | | \nCost of revenues | $22,843 | $27,154 \
\ | $(4,311) | (16)%\nGross profit | 26,193 \
\ | 31,477 | (6,284) | (17)\n\nGross margin | 53% \
\ | 54% | |\n\n\n"
- "Title: \nText: | _id | d61679140 |\n| title | |\n| text | with these types of\
\ uncapped damage provisions are fairly rare , but individual contracts could\
\ still represent meaningful risk .\nthere is a possibility that a damage claim\
\ by a counterparty to one of these contracts could result in expenses to the\
\ company that are far in excess of the revenue received from the counterparty\
\ in connection with the contract .\n\nindemnification provisions : in addition\
\ , the company may provide indemnifications for losses that result from the breach\
\ of general warranties contained in certain commercial , intellectual property\
\ and divestiture agreements .\nhistorically , the company has not made significant\
\ payments under these agreements , nor have there been significant claims asserted\
\ against the company .\nhowever , there is an increasing risk in relation to\
\ intellectual property indemnities given the current legal climate .\n\nin indemnification\
\ cases , payment by the company is conditioned on the other party making a claim\
\ pursuant to the procedures specified in the particular contract , which procedures\
\ typically allow the company to challenge the other party 2019s claims .\n\n\
further , the company 2019s obligations under these agreements for indemnification\
\ based on breach of representations and warranties are generally limited in terms\
\ of duration , typically not more than 24 months , and for amounts not in excess\
\ of the contract value , and in some instances the company may have recourse\
\ against third parties for certain payments made by the company .\n\nlegal matters\
\ : the company is a defendant in various lawsuits , claims and actions , which\
\ arise in the normal course of business .\nthese include actions relating to\
\ products , contracts and securities , as well as matters initiated by third\
\ parties or motorola relating to infringements of patents , violations of licensing\
\ arrangements and other intellectual property-related matters .\n\nin the opinion\
\ of management , the ultimate disposition of these matters will not have a material\
\ adverse effect on the company 2019s consolidated financial position , liquidity\
\ or results of operations .\nsegment information the following commentary should\
\ be read in conjunction with the financial results of each reporting segment\
\ as detailed in note 12 , 201cinformation by segment and geographic region ,\
\ 201d to the company 2019s consolidated financial statements .\n\nnet sales and\
\ operating results for the company 2019s three operating segments for 2008 ,\
\ 2007 and 2006 are presented below .\nmobile devices segment the mobile devices\
\ segment designs , manufactures , sells and services wireless handsets with integrated\
\ software and accessory products , and licenses intellectual property .\nin 2008\
\ , the segment 2019s net sales represented 40% ( 40 % ) of the company 2019s\
\ consolidated net sales , compared to 52% ( 52 % ) in 2007 and 66% ( 66 % ) in\
\ 2006 .\n\n( dollars in millions ) 2008 2007 2006 2008 20142007 2007 20142006\
\ years ended december 31 percent change .\n\n( dollars in millions ) | years\
\ ended december 31 2008 | years ended december 31 2007 | years ended december\
\ 31 2006 | years ended december 31 2008 20142007 | 2007 20142006 \n---------------------------\
\ | ---------------------------- | ---------------------------- | ----------------------------\
\ | ------------------------------------- | ---------------\n\nsegment net sales\
\ | $ 12099 | $ 18988 | $\
\ 28383 | ( 36 ) % ( % ) | ( 33 )\
\ % ( % )\noperating earnings ( loss ) | -2199 ( 2199 ) | -1201\
\ ( 1201 ) | 2690 | 83% ( 83 % ) \
\ | ***\n\n*** percentage change is not meaningful .\nsegment\
\ results 20142008 compared to 2007 in 2008 , the segment 2019s net sales were\
\ $ 12.1 billion , a decrease of 36% ( 36 % ) compared to net sales of $ 19.0\
\ billion in 2007 .\nthe 36% ( 36 % ) decrease in net sales was primarily driven\
\ by a 37% ( 37 % ) decrease in unit shipments .\n\nthe segment 2019s net sales\
\ were negatively impacted by the segment 2019s limited product offerings in critical\
\ market segments , particularly 3g products , including smartphones , as well\
\ as very low-tier products .\nin addition , the segment 2019s net sales were\
\ impacted by the global economic downturn in the second half of 2008 , which\
\ resulted in the slowing of end user demand .\n\non a product technology basis\
\ , net sales decreased substantially for gsm and cdma technologies and , to a\
\ lesser extent , decreased for iden and 3g technologies .\non a geographic basis\
\ , net sales decreased substantially in north america , the europe , middle east\
\ and africa region ( 201cemea 201d ) and asia and , to a lesser extent , decreased\
\ in latin america .\nthe segment incurred an operating loss of $ 2.2 billion\
\ in 2008 , compared to an operating loss of $ 1.2 billion in 2007 .\n\nthe increase\
\ in the operating loss was primarily due to a decrease in gross margin , driven\
\ by : ( i ) a 36% ( 36 % ) decrease in net sales , ( ii ) excess inventory and\
\ other related charges of $ 370 million in 2008 due to a decision to 61management\
\ 2019s discussion and analysis of financial condition and results of operations\
\ %%transmsg*** transmitting job : c49054 pcn : 064000000 ***%%pcmsg|61 |00028|yes|no|02/24/2009\
\ 12:31|0|0|page is valid , no graphics -- color : n|\n\nuncapped damage provisions\
\ rare , but individual contracts could still represent meaningful risk.\n possibility\
\ that damage claim by counterparty to contracts could result in expenses to company\
\ in excess of revenue received from counterparty in with contract.\n indemnification\
\ provisions : company may provide indemnifications for losses from breach of\
\ general warranties in certain commercial , intellectual property and divestiture\
\ agreements.\n\nhistorically company not made significant payments under these\
\ agreements , nor significant claims asserted against company.\n , increasing\
\ risk in to intellectual property indemnities given current legal climate.\n\
\ in indemnification cases , payment by company is conditioned on other party\
\ making claim pursuant to procedures specified in contract , procedures typically\
\ allow company to challenge other party 2019s claims.\n\ncompany 2019s obligations\
\ under these agreements for indemnification based on breach of representations\
\ and warranties generally limited in duration typically not more than 24 months\
\ for amounts not in excess of contract value , in some instances company may\
\ have recourse against third parties for certain payments made by company.\n\
\ legal matters : company is a defendant in various lawsuits , claims and actions\
\ , in normal course of business.\n\ninclude actions relating to products , contracts\
\ securities , matters initiated by third parties or motorola relating to infringements\
\ of patents , violations of licensing arrangements other intellectual property-related\
\ matters.\n in opinion of management ultimate disposition of these matters will\
\ not have material adverse effect on company 2019s consolidated financial position\
\ , liquidity or results of operations.\n\nsegment information following commentary\
\ should be read in conjunction with financial results of each reporting segment\
\ as detailed in note 12 , 201cinformation by segment and geographic region ,\
\ 201d to company 2019s consolidated financial statements.\nnet sales operating\
\ results for company 2019s three operating segments for 2008 , 2007 2006 presented\
\ below.\n\nmobile devices segment segment designs manufactures sells services\
\ wireless handsets with integrated software accessory products licenses intellectual\
\ property.\n in 2008 segment 2019s net sales represented 40% ( 40 % ) of company\
\ 2019s consolidated net sales compared to 52% ( 52 % ) in 2007 66% ( 66 % ) in\
\ 2006.\n ( dollars in millions ) 2008 2007 2006 2008 20142007 20142006 years\
\ ended december 31 percent change.\n percentage change not meaningful.\n\npercentage\
\ change not meaningful.\n segment results 20142008 compared to 2007 in 2008 segment\
\ 2019s net sales were $ 12. 1 billion decrease of 36% ( 36 % ) compared to net\
\ sales $ 19. 0 billion in 2007.\n 36% ( 36 % ) decrease in net sales primarily\
\ driven by 37% ( 37 % ) decrease in unit shipments.\n segment 2019s net sales\
\ negatively impacted by segment 2019s limited product offerings in critical market\
\ segments particularly 3g products including smartphones very low-tier products.\n\
\nsegment 2019s net sales impacted by global economic downturn in second half\
\ of 2008 resulted in slowing of end user demand.\n product technology basis net\
\ sales decreased substantially for gsm and cdma technologies lesser decreased\
\ for iden and 3g technologies.\n geographic basis net sales decreased substantially\
\ in north america europe middle east and africa region asia lesser decreased\
\ in latin america.\n\nsegment incurred operating loss of $ 2. 2 billion in 2008\
\ compared to operating loss of $ 1. 2 billion in 2007.\n\n( dollars in millions\
\ ) | years ended december 31 2008 | years ended december 31 2007 | years\
\ ended december 31 2006 | years ended december 31 2008 20142007 | 2007 20142006\
\ \n--------------------------- | ---------------------------- | ----------------------------\
\ | ---------------------------- | ------------------------------------- | ---------------\n\
\nsegment net sales | $ 12099 | $ 18988 \
\ | $ 28383 | ( 36 ) % ( % ) \
\ | ( 33 ) % ( % )\noperating earnings ( loss ) | -2199 ( 2199 ) \
\ | -1201 ( 1201 ) | 2690 | 83%\
\ ( 83 % ) | ***\n\nthe increase in the operating loss\
\ was primarily due to a decrease in gross margin , driven by : ( i ) a 36% (\
\ 36 % ) decrease in net sales , ( ii ) excess inventory and other related charges\
\ of $ 370 million in 2008 due to a decision to 61management 2019s discussion\
\ and analysis of financial condition and results of operations %%transmsg***\
\ transmitting job : c49054 pcn : 064000000 ***%%pcmsg|61 |00028|yes|no|02/24/2009\
\ 12:31|0|0|page is valid , no graphics -- color : n|\n\n\n"
- "Title: \nText: | _id | d1a73c7c4 |\n| title | |\n| text | BELL WIRELESS RESULTS\n\
REVENUES\nBell Wireless operating revenues increased by 3.7% in 2019, compared\
\ to 2018, driven by greater postpaid and prepaid service revenues and higher\
\ product revenues.\n\nService revenues increased by 2.5% in 2019, compared to\
\ last year, driven by: • Continued growth in our postpaid and prepaid subscriber\
\ base coupled with rate increases • A greater mix of customers subscribing to\
\ higher-value monthly plans including unlimited data plans launched in June 2019\
\ • The favourable year-over-year impact from the 2018 CRTC retroactive decision\
\ on wireless domestic wholesale roaming rates\n\nThese factors were partly offset\
\ by: • Greater sales of premium handsets and more customers subscribing to higher-value\
\ monthly plans • Lower data and voice overages driven by increased customer adoption\
\ of monthly plans with higher data allotments and richer voice plans\nProduct\
\ revenues increased by 6.6% in 2019, compared to last year, driven by greater\
\ sales of premium handsets and the impact of higher-value rate plans in our sales\
\ mix.\n\n| 2019 | 2018 | $ CHANGE | % CHANGE\n--------------------------------\
\ | ----- | ----- | -------- | --------\nExternal service revenues | 6,427\
\ | 6,269 | 158 | 2.5% \nInter-segment service revenues | 49 | 48\
\ | 1 | 2.1% \nTotal operating service revenues | 6,476 | 6,317 |\
\ 159 | 2.5% \nExternal product revenues | 2,660 | 2,497 | 163\
\ | 6.5% \nInter-segment product revenues | 6 | 4 | 2 \
\ | 50.0%\n\nTotal operating product revenues | 2,666 | 2,501 | 165 | 6.6%\
\ \nTotal Bell Wireless revenues | 9,142 | 8,818 | 324 | 3.7%\n\n\
BELL WIRELESS RESULTS\n REVENUES\n Bell Wireless operating revenues increased\
\ 3. 7% 2019 compared to 2018 driven by greater postpaid prepaid service revenues\
\ higher product revenues.\n\nService revenues increased 2. 5% 2019 compared last\
\ year driven by Continued growth in postpaid prepaid subscriber base rate increases\
\ greater mix of customers subscribing higher-value monthly plans including unlimited\
\ data plans launched June 2019 favourable year-over-year impact from 2018 CRTC\
\ retroactive decision on wireless domestic wholesale roaming rates\n\nfactors\
\ offset by Greater sales premium handsets more customers subscribing higher-value\
\ monthly plans Lower data voice overages driven by increased customer adoption\
\ of monthly plans with higher data allotments richer voice plans\n Product revenues\
\ increased 6. 6% 2019 compared last year driven by greater sales of premium handsets\
\ impact higher-value rate plans in sales mix.\n\n| 2019 | 2018 | $ CHANGE |\
\ % CHANGE\n-------------------------------- | ----- | ----- | -------- | --------\n\
External service revenues | 6,427 | 6,269 | 158 | 2.5% \nInter-segment\
\ service revenues | 49 | 48 | 1 | 2.1% \nTotal operating service\
\ revenues | 6,476 | 6,317 | 159 | 2.5% \nExternal product revenues \
\ | 2,660 | 2,497 | 163 | 6.5% \nInter-segment product revenues \
\ | 6 | 4 | 2 | 50.0%\n\nTotal operating product revenues | 2,666\
\ | 2,501 | 165 | 6.6% \nTotal Bell Wireless revenues | 9,142 | 8,818\
\ | 324 | 3.7%\n\n\n"
- source_sentence: "Instruct: Given a web search query, retrieve relevant passages\
\ that answer the query.\nQuery: Title: \nText: | _id | q822237e8 |\n| title |\
\ |\n| text | what was the percentage change in weighted average shares outstanding\
\ for diluted net earnings per share from 2006 to 2007?\n\npercentage change in\
\ weighted average shares for diluted net earnings per share 2006 to 2007?\n\n\
\n"
sentences:
- "Title: \nText: | _id | PG20230221 |\n| title | |\n| text | The following provides\
\ additional detail on our reportable segments and the ten product categories\
\ and brand composition within each segment. Reportable Segments##% of Net Sales\
\ (1)##% of Net Earnings (1)##Product Categories (Sub-Categories)##Major Brands\
\ Beauty##18%##21%##Hair Care (Conditioners, Shampoos, Styling Aids, Treatments)##Head\
\ & Shoulders, Herbal Essences, Pantene, Rejoice ######Skin and Personal Care\
\ (Antiperspirants and Deodorants, Personal Cleansing, Skin Care)##Olay, Old Spice,\
\ Safeguard,\n\nSkin Care)##Olay, Old Spice, Safeguard, Secret, SK-II Grooming\
\ (2)##8%##10%##Grooming (Appliances, Female Blades & Razors, Male Blades & Razors,\
\ Pre- and Post-Shave Products, Other Grooming)##Braun, Gillette, Venus Health\
\ Care##14%##14%##Oral Care (Toothbrushes, Toothpastes, Other Oral Care)##Crest,\
\ Oral-B ######Personal Health Care (Gastrointestinal, Pain Relief, Rapid Diagnostics,\
\ Respiratory, Vitamins/Minerals/Supplements, Other Personal Health Care)##Metamucil,\
\ Neurobion, Pepto-Bismol, Vicks Fabric &\n\nNeurobion, Pepto-Bismol, Vicks Fabric\
\ & Home Care##35%##32%##Fabric Care (Fabric Enhancers, Laundry Additives, Laundry\
\ Detergents)##Ariel, Downy, Gain, Tide ######Home Care (Air Care, Dish Care,\
\ P&G Professional, Surface Care)##Cascade, Dawn, Fairy, Febreze, Mr. Clean, Swiffer\
\ Baby, Feminine & Family Care##25%##23%##Baby Care (Baby Wipes, Taped Diapers\
\ and Pants)##Luvs, Pampers ######Feminine Care (Adult Incontinence, Feminine\
\ Care)##Always, Always Discreet, Tampax ######Family Care (Paper Towels, Tissues,\n\
\nTampax ######Family Care (Paper Towels, Tissues, Toilet Paper)##Bounty, Charmin,\
\ Puffs\n\ndetail reportable segments ten product categories brand composition.\
\ Reportable Segments% Net Sales (1) Net Earnings (1)#Product Categories-Categories#Major\
\ Brands Beauty#18%##21%#Hair Care (Conditioners Shampoos Styling Aids Treatments)#Head\
\ & Shoulders Herbal Essences Pantene Rejoice ######Skin Personal Care (Antiperspirants\
\ Deodorants Personal Cleansing Skin Care)#Olay Old Spice Safeguard Secret SK-II\
\ Grooming#8%##10%#Grooming (Appliances Female Blades Razors Male Blades Razors\
\ Pre- Post-Shave Products\n\nMale Blades Razors Pre- Post-Shave Products Other\
\ Grooming)#Braun, Gillette Venus Health Care#14%##14%#Oral Care (Toothbrushes\
\ Toothpastes Other Oral Care#Crest Oral-B Health Care (Gastrointestinal Pain\
\ Relief Rapid Diagnostics Respiratory Vitamins/Minerals/Supplements Other Personal\
\ Health Care)#Metamucil Neurobion Pepto-Bismol Vicks Fabric Home Care#35%##32%#Fabric\
\ Care (Fabric Enhancers Laundry Additives Laundry Detergents)#Ariel, Downy Gain\
\ Tide Care (Air Care Dish Care P&G Professional Surface\n\nCare (Air Care Dish\
\ Care P&G Professional Surface Care)#Cascade, Dawn, Fairy Febreze Mr. Clean Swiffer\
\ Baby Feminine Family Care#25%##23%#Baby Care (Baby Wipes Taped Diapers Pants)#Luvs\
\ Pampers Care (Adult Incontinence Feminine Care)#Always, Always Discreet Tampax\
\ ######Family Care (Paper Towels Tissues Toilet Paper)#Bounty, Charmin Puffs\n\
\n\n"
- "Title: \nText: | _id | d82223914 |\n| title | |\n| text | ABIOMED, INC. AND\
\ SUBSIDIARIES Notes to Consolidated Financial Statements—(Continued) Note 12.\n\
Stock Award Plans and Stock Based Compensation (Continued) Restricted Stock The\
\ following table summarizes restricted stock activity for the fiscal year ended\
\ March 31, 2009:\n| | March 31, 2009 |\n| | Number of Shares (in thousands)\
\ | Grant Date Fair Value |\n| Restricted stock awards at March 31, 2008 | 54\
\ | $11.52 |\n| Granted | 666 | 16.75 |\n| Vested | -167 | 14.65 |\n| Forfeited\
\ | -73 | 17.53 |\n\n| Forfeited | -73 | 17.53 |\n| Restricted stock awards at\
\ March 31, 2009 | 480 | $16.77 |\nThe remaining unrecognized compensation expense\
\ for restricted stock awards at March 31, 2009 was $4.6 million.\nThe weighted\
\ average remaining contractual life for restricted stock awards at March 31,\
\ 2009 and 2008 was 1.8 and 2.4 years, respectively.\n\nIn May 2008, 260,001 shares\
\ of restricted stock were issued to certain executive officers and certain members\
\ of senior management of the Company, of which 130,002 of these shares vest upon\
\ achievement of a prescribed performance milestone.\nIn September 2008, the Company\
\ met the prescribed performance milestone, and all of these performance-based\
\ shares vested.\nIn connection with the vesting of these shares, these employees\
\ paid withholding taxes due by returning 39,935 shares valued at $0.7 million.\n\
\nThese shares have been recorded as treasury stock as of March 31, 2009.\nThe\
\ remaining 129,999 of the restricted shares award vest ratably over four years\
\ from the grant date.\nThe stock compensation expense for the restricted stock\
\ awards is recognized on a straight-line basis over the vesting period, based\
\ on the probability of achieving the performance milestones.\n\nIn August 2008,\
\ 406,250 shares of restricted stock were issued to certain executive officers\
\ and certain members of senior management of the Company, all of which could\
\ vest upon achievement of certain prescribed performance milestones.\nIn March\
\ 2009, the Company met a prescribed performance milestone, and a portion of these\
\ performance-based shares vested.\n\nThe remaining stock compensation expense\
\ for the restricted stock awards is being recognized on a straight-line basis\
\ over the vesting period through March 31, 2011 based on the probability of achieving\
\ the performance milestones.\nThe cumulative effects of changes in the probability\
\ of achieving the milestones will be recorded in the period in which the changes\
\ occur.\n\nDuring the year ended March 31, 2008, 60,000 shares of restricted\
\ stock were issued to certain executive officers of the Company that vest on\
\ the third anniversary of the date of grant.\nThe stock compensation expense\
\ for the restricted stock awards is recognized on a straight-line basis over\
\ the vesting period.\n\nABIOMED, INC. AND SUBSIDIARIES Notes to Consolidated\
\ Financial Statements—(Continued) Note 12.\n Stock Award Plans and Stock Based\
\ Compensation (Continued) Restricted Stock table summarizes restricted stock\
\ activity for fiscal year ended March 31, 2009:\n weighted average remaining\
\ contractual life for restricted stock awards at March 31, 2009 and 2008 was\
\ 1. 8 and 2. 4 years, respectively.\n\nIn May 2008, 260,001 shares of restricted\
\ stock issued to executive officers and members of senior management Company\
\ 130,002 shares vest upon achievement of prescribed performance milestone.\n\
\ In September 2008, Company met prescribed performance milestone all performance-based\
\ shares vested.\n vesting shares employees paid withholding taxes due by returning\
\ 39,935 shares valued at $0. 7 million.\n These shares recorded as treasury stock\
\ as of March 31, 2009.\n\nremaining 129,999 of restricted shares award vest ratably\
\ over four years from grant date.\n stock compensation expense for restricted\
\ stock awards recognized on straight-line basis over vesting period, based on\
\ probability of achieving performance milestones.\n In August 2008, 406,250 shares\
\ of restricted stock issued to executive officers and members of senior management\
\ Company all could vest upon achievement of prescribed performance milestones.\n\
\nIn March 2009, Company met prescribed performance milestone, portion of performance-based\
\ shares vested.\n remaining stock compensation expense for restricted stock awards\
\ recognized straight-line basis over vesting period through March 31, 2011 based\
\ on probability of achieving performance milestones.\n cumulative effects of\
\ changes in probability of achieving milestones recorded in period in changes\
\ occur.\n\nDuring year ended March 31, 2008, 60,000 shares of restricted stock\
\ issued to executive officers Company that vest on third anniversary of date\
\ of grant.\nstock compensation expense for restricted stock awards recognized\
\ on straight-line basis over vesting period.\n\n| | March 31, 2009 |\n| | Number\
\ of Shares (in thousands) | Grant Date Fair Value |\n| Restricted stock awards\
\ at March 31, 2008 | 54 | $11.52 |\n| Granted | 666 | 16.75 |\n| Vested | -167\
\ | 14.65 |\n| Forfeited | -73 | 17.53 |\n| Restricted stock awards at March 31,\
\ 2009 | 480 | $16.77 |\n\n\n"
- "Title: \nText: | _id | d82aee67a |\n| title | |\n| text | | | Options |\n|\
\ | Source of Fair Value | Maturity Less Than 1 Year | Maturity 1 to 3 Years\
\ | Maturity 4 to 5 Years | Maturity Greater Than 5 Years | Total Options Fair\
\ Value |\n| | (Thousands of Dollars) |\n| NSP-Minnesota | 2 | $514 | $— | $—\
\ | $— | $514 |\n| PSCo | 2 | 3,241 | — | — | — | 3,241 |\n| NSP-Wisconsin | 2\
\ | 20 | — | — | — | 20 |\n| Total Options Fair Value | | $3,775 | $— | $— |\
\ $— | $3,775 |\n\n1 \x80\x94 Prices actively quoted or based on actively quoted\
\ prices.2 \x80\x94 Prices based on models and other valuation methods.\nThese\
\ represent the fair value of positions calculated using internal models when\
\ directly and indirectly quoted external prices or prices derived from external\
\ sources are not available.\nInternal models incorporate the use of options pricing\
\ and estimates of the present value of cash flows based upon underlying contractual\
\ terms.\n\nThe models reflect management\x80\x99s estimates, taking into account\
\ observable market prices, estimated market prices in the absence of quoted market\
\ prices, the risk-free market discount rate, volatility factors, estimated correlations\
\ of commodity prices and contractual volumes.\nMarket price uncertainty and other\
\ risks also are factored into the model.\n* \x80\x94 SPS conducts an inconsequential\
\ amount of commodity trading.\n\nMargins from commodity trading activity are\
\ partially redistributed to SPS, NSP-Minnesota, and PSCo, pursuant to the JOA\
\ approved by the FERC.\nAs a result of the JOA, margins received pursuant to\
\ the JOA are reflected as part of the fair values by source for the commodity\
\ trading net asset or liability balances.\n\nNormal purchases and sales transactions,\
\ as defined by SFAS No.133 and certain other long-term power purchase contracts\
\ are not included in the fair values by source tables as they are not recorded\
\ at fair value as part of commodity trading operations and are not qualifying\
\ hedges.\n\nAt Dec. 31, 2006, a 10-percent increase in market prices over the\
\ next 12 months for commodity trading contracts would increase pretax income\
\ from continuing operations by approximately $0.9 million, whereas a 10-percent\
\ decrease would decrease pretax income from continuing operations by approximately\
\ $1.1 million.\n\nXcel Energy\x80\x99s short-term wholesale and commodity trading\
\ operations measure the outstanding risk exposure to price changes on transactions,\
\ contracts and obligations that have been entered into, but not closed, using\
\ an industry standard methodology known as VaR.\nVaR expresses the potential\
\ change in fair value on the outstanding transactions, contracts and obligations\
\ over a particular period of time, with a given confidence interval under normal\
\ market conditions.\n\nXcel Energy utilizes the variance/covariance approach\
\ in calculating VaR.\nThe VaR model employs a 95-percent confidence interval\
\ level based on historical price movement, lognormal price distribution assumption,\
\ delta half-gamma approach for non-linear instruments and a three-day holding\
\ period for both electricity and natural gas.\nVaR is calculated on a consolidated\
\ basis.\nThe VaRs for the commodity trading operations were:\n\nrepresent fair\
\ value of positions calculated using internal models when indirectly quoted external\
\ prices or prices from external sources not available.\n Internal models incorporate\
\ options pricing estimates of present value of cash flows based upon underlying\
\ contractual terms.\n models reflect management\x80\x99s estimates observable\
\ market prices, estimated market prices quoted market prices risk-free market\
\ discount rate volatility factors estimated correlations of commodity prices\
\ contractual volumes.\n\nMarket price uncertainty other risks factored into model.\n\
\ SPS conducts inconsequential amount of commodity trading.\n Margins from commodity\
\ trading activity partially redistributed to SPS, NSP-Minnesota PSCo JOA approved\
\ by FERC.\n result JOA margins received reflected as part of fair values by source\
\ for commodity trading net asset or liability balances.\n\nNormal purchases and\
\ sales transactions, as defined by SFAS No. 133 certain other long-term power\
\ purchase contracts not included in fair values by source tables not recorded\
\ at fair value as part of commodity trading operations not qualifying hedges.\n\
\nAt Dec. 31, 2006, 10-percent increase in market prices over next 12 months for\
\ commodity trading contracts would increase pretax income from continuing operations\
\ by approximately $0. 9 million 10-percent decrease decrease pretax income from\
\ continuing operations by approximately $1. 1 million.\n\nXcel Energy\x80\x99\
s short-term wholesale and commodity trading operations measure outstanding risk\
\ exposure to price changes on transactions, contracts obligations entered into\
\ but not closed using industry standard methodology known as VaR.\n VaR expresses\
\ potential change in fair value on outstanding transactions, contracts obligations\
\ over particular period of time with given confidence interval under normal market\
\ conditions.\n Xcel Energy utilizes variance/covariance approach in calculating\
\ VaR.\n\nVaR model employs 95-percent confidence interval based historical price\
\ movement lognormal price distribution assumption delta half-gamma approach for\
\ non-linear instruments three-day holding period for electricity and natural\
\ gas.\n VaR calculated consolidated basis.\n VaRs for commodity trading operations\
\ were:\n\n| | Options |\n| | Source of Fair Value | Maturity Less Than 1 Year\
\ | Maturity 1 to 3 Years | Maturity 4 to 5 Years | Maturity Greater Than 5 Years\
\ | Total Options Fair Value |\n| | (Thousands of Dollars) |\n| NSP-Minnesota\
\ | 2 | $514 | $— | $— | $— | $514 |\n| PSCo | 2 | 3,241 | — | — | — | 3,241 |\n\
| NSP-Wisconsin | 2 | 20 | — | — | — | 20 |\n| Total Options Fair Value | | $3,775\
\ | $— | $— | $— | $3,775 |\n\n\n"
- source_sentence: "Instruct: Given a web search query, retrieve relevant passages\
\ that answer the query.\nQuery: Title: \nText: | _id | q84fcfe76 |\n| title |\
\ |\n| text | What is the ratio of Greater than twelve to twenty-four months\
\ for Carrying amount of Private to the total in 2009?\n\nratio of Greater than\
\ twelve to twenty-four months for Carrying amount Private to total in 2009?\n\
\n\n"
sentences:
- "Title: \nText: | _id | d812326ea |\n| title | |\n| text | Principal Financial\
\ Group, Inc. Notes to Consolidated Financial Statements — (continued) 10.\n\
Debt — (continued) Long-Term Debt The components of long-term debt as of December\
\ 31, 2009 and 2008, were as follows:\n| | December 31, |\n| | 2009 | 2008 |\n\
| | (in millions) |\n| 8.2% notes payable, due 2009 | $— | $454.9 |\n| 3.31%\
\ notes payable, due 2011 | 61.2 | 49.9 |\n| 3.63% notes payable, due 2011 | 31.4\
\ | 25.6 |\n| 7.875% notes payable, due 2014 | 400.0 | — |\n| 8.875% notes payable,\
\ due 2019 | 350.0 | — |\n\n| 8.875% notes payable, due 2019 | 350.0 | — |\n|\
\ 6.05% notes payable, due 2036 | 601.8 | 601.8 |\n| 8% surplus notes payable,\
\ due 2044 | 99.2 | 99.2 |\n| Non-recourse mortgages and notes payable | 40.6\
\ | 58.7 |\n| Other mortgages and notes payable | 0.4 | 0.4 |\n| Total long-term\
\ debt | $1,584.6 | $1,290.5 |\nThe amounts included above are net of the discount\
\ and premium associated with issuing these notes, which are being amortized to\
\ expense over their respective terms using the interest method.\n\nOn May 18,\
\ 2009, we issued $750.0 million of senior notes.\nWe issued a $400.0 million\
\ series of notes that bear interest at 7.875% and will mature on May 15, 2014,\
\ and a $350.0 million series of notes that bear interest at 8.875% and will mature\
\ on May 15, 2019.\nInterest on the notes is payable semi-annually on May 15 and\
\ November 15 each year, beginning on November 15, 2009.\n\nThe proceeds were\
\ primarily used to refinance $440.9 million of notes that matured on August 15,\
\ 2009, with the remaining proceeds being used for general corporate purposes.\n\
On October 16 and December 5, 2006, we issued $500.0 million and $100.0 million,\
\ respectively, of senior notes.\nThe notes bear interest at a rate of 6.05% per\
\ year.\nInterest on the notes is payable semi-annually on April 15 and October\
\ 15 each year and began on April 15, 2007.\nThe notes will mature on October\
\ 15, 2036.\n\nThe notes will mature on October 15, 2036.\nA portion of the proceeds\
\ were used to fund the 2006 acquisition of WM Advisors, Inc. , with the remaining\
\ proceeds being used for general corporate purposes.\nOn November 3, 2005, Principal\
\ International de Chile S. A. , a wholly owned indirect subsidiary, entered into\
\ long-term borrowing agreements with two Chilean banks in the amount of US $93.9\
\ million.\n\nThis debt is denominated in Unidades de Formento (‘‘UF’’), a Chilean\
\ inflation-indexed, peso-denominated monetary unit.\nOf this amount, US $49.0\
\ million of UF +3.31% notes, which was refinanced from +4.59% during 2007, and\
\ US $44.9 million of UF +3.63% notes, which was refinanced from +4.93% in 2007,\
\ mature on November 3, 2011.\nInterest on the notes is payable semi-annually\
\ on May 3 and November 3 each year.\n\nThe debt outstanding and interest expense\
\ will vary due to fluctuations in the Chilean peso to US dollar exchange rates\
\ and Chilean inflation.\nOn August 25, 1999, Principal Financial Group (Australia)\
\ Holdings Pty.\nLimited, a wholly owned indirect subsidiary, issued $665.0 million\
\ of unsecured redeemable long-term debt.\nPrincipal Financial Group (Australia)\
\ Holdings Pty.\n\nLimited used the net proceeds from the notes to partially fund\
\ the purchase of the outstanding stock of several companies affiliated with Bankers\
\ Trust Australia Group.\nOn December 28, 2001, all of the long-term debt obligations\
\ of Principal Financial Group (Australia) Holdings Pty.\n\nLimited were assumed\
\ by its parent, Principal Financial Services, Inc. Of the original amount issued,\
\ $200.0 million of 7.95% notes matured on August 15, 2004, with the remaining\
\ $465.0 million in 8.2% notes maturing on August 15, 2009.\nThe note was paid\
\ in full during 2009.\nOn March 10, 1994, Principal Life issued $100.0 million\
\ of surplus notes due March 1, 2044, at an 8% annual interest rate.\nNone of\
\ our affiliates hold any portion of the notes.\n\nEach payment of interest and\
\ principal on the notes, however, may be made only with the prior approval of\
\ the Commissioner of Insurance of the State of Iowa (the ‘‘Commissioner’’) and\
\ only to the extent that Principal Life has sufficient surplus earnings to make\
\ such payments.\nInterest of $8.0 million for each of the years ended December\
\ 31, 2009, 2008 and 2007 was approved by the Commissioner, and charged to expense.\n\
\nSubject to Commissioner approval, the notes due March 1, 2044, may be redeemed\
\ at Principal Life’s election on or after March 1, 2014, in whole or in part\
\ at a redemption price of approximately 102.3% of par.\nThe approximate 2.3%\
\ premium is scheduled to gradually diminish over the following ten years.\nThese\
\ notes may be redeemed on or after March 1, 2024, at a redemption price of 100%\
\ of the principal amount plus interest accrued to the date of redemption.\n\n\
The non-recourse mortgages, other mortgages and notes payable are primarily financings\
\ for real estate developments.\nOutstanding principal balances as of December\
\ 31, 2009, ranged from $5.9 million to $9.1 million per\n| | December 31, 2008\
\ |\n| | Public | Private | Total |\n| | Carrying amount | Gross unrealized\
\ losses | Carrying amount | Gross unrealized losses | Carrying amount | Gross\
\ unrealized losses |\n| | (in millions) |\n\n| | (in millions) |\n| Three months\
\ or less | $3,086.0 | $194.4 | $1,188.1 | $99.5 | $4,274.1 | $293.9 |\n| Greater\
\ than three to six months | 4,213.7 | 467.9 | 1,673.6 | 236.4 | 5,887.3 | 704.3\
\ |\n| Greater than six to nine months | 3,014.0 | 620.7 | 1,566.6 | 290.6 | 4,580.6\
\ | 911.3 |\n| Greater than nine to twelve months | 2,321.0 | 743.0 | 1,259.7\
\ | 460.1 | 3,580.7 | 1,203.1 |\n| Greater than twelve to twenty-four months |\
\ 3,042.0 | 1,507.5 | 2,217.1 | 1,519.7 | 5,259.1 | 3,027.2 |\n\n| Greater than\
\ twenty-four to thirty-six months | 1,045.2 | 296.1 | 312.5 | 217.1 | 1,357.7\
\ | 513.2 |\n| Greater than thirty-six months | 1,363.8 | 423.5 | 698.2 | 265.8\
\ | 2,062.0 | 689.3 |\n| Total fixed maturity securities, available-for-sale |\
\ $18,085.7 | $4,253.1 | $8,915.8 | $3,089.2 | $27,001.5 | $7,342.3 |\n\nThe following\
\ tables present the carrying amount and the gross unrealized losses, including\
\ other-than-temporary impairment losses reported in OCI, on below investment\
\ grade fixed maturity securities available-for-sale by aging category for the\
\ time periods indicated.\n| | December 31, 2009 |\n| | Public | Private | Total\
\ |\n| | Carrying amount | Gross unrealized losses | Carrying amount | Gross\
\ unrealized losses | Carrying amount | Gross unrealized losses |\n| | (in millions)\
\ |\n\n| | (in millions) |\n| Three months or less | $55.7 | $3.3 | $52.8 | $1.2\
\ | $108.5 | $4.5 |\n| Greater than three to six months | 3.4 | — | 14.8 | — |\
\ 18.2 | — |\n| Greater than six to nine months | 12.7 | 0.2 | 0.1 | 0.1 | 12.8\
\ | 0.3 |\n| Greater than nine to twelve months | 32.8 | 11.2 | 1.0 | 1.8 | 33.8\
\ | 13.0 |\n| Greater than twelve to twenty-four months | 441.3 | 112.2 | 365.6\
\ | 186.7 | 806.9 | 298.9 |\n| Greater than twenty-four to thirty-six months |\
\ 609.0 | 314.8 | 403.5 | 435.8 | 1,012.5 | 750.6 |\n\n| Greater than thirty-six\
\ months | 113.8 | 26.8 | 84.6 | 76.6 | 198.4 | 103.4 |\n| Total fixed maturity\
\ securities, available-for-sale | $1,268.7 | $468.5 | $922.4 | $702.2 | $2,191.1\
\ | $1,170.7 |\nDecember 31, 2008\n| | December 31, 2008 |\n| | Public | Private\
\ | Total |\n| | Carrying amount | Gross unrealized losses | Carrying amount\
\ | Gross unrealized losses | Carrying amount | Gross unrealized losses |\n| \
\ | (in millions) |\n| Three months or less | $133.1 | $56.5 | $114.6 | $32.1\
\ | $247.7 | $88.6 |\n\n| Greater than three to six months | 88.8 | 12.7 | 297.1\
\ | 74.3 | 385.9 | 87.0 |\n| Greater than six to nine months | 102.5 | 42.9 |\
\ 129.1 | 46.5 | 231.6 | 89.4 |\n| Greater than nine to twelve months | 163.0\
\ | 65.9 | 44.5 | 43.7 | 207.5 | 109.6 |\n| Greater than twelve to twenty-four\
\ months | 242.0 | 151.7 | 351.8 | 239.5 | 593.8 | 391.2 |\n| Greater than twenty-four\
\ to thirty-six months | 41.2 | 26.1 | 13.3 | 21.4 | 54.5 | 47.5 |\n| Greater\
\ than thirty-six months | 100.3 | 29.7 | 100.9 | 30.3 | 201.2 | 60.0 |\n\n| Total\
\ fixed maturity securities, available-for-sale | $870.9 | $385.5 | $1,051.3 |\
\ $487.8 | $1,922.2 | $873.3 |\nThe following tables present the carrying amount\
\ and the gross unrealized losses, including other-than-temporary impairment losses\
\ reported in OCI, on fixed maturity securities available-for-sale where the estimated\
\ fair value has declined and remained below amortized cost by 20% or more as\
\ the time periods indicate.\n\nPrincipal Financial Group, Inc. Notes to Consolidated\
\ Financial Statements — (continued) 10.\n Debt — (continued) Long-Term Debt components\
\ of long-term debt as of December 31, 2009 and 2008, follows:\n May 18, 2009,\
\ issued $750. 0 million senior notes.\n issued $400. 0 million series notes bear\
\ interest at 7. 875% mature May 15, 2014, $350. 0 million series notes bear interest\
\ at 8. 875% mature May 15, 2019.\n Interest notes payable semi-annually May 15\
\ and November 15 each year beginning November 15, 2009.\n\nproceeds primarily\
\ used to refinance $440. 9 million of notes matured August 15, 2009, remaining\
\ proceeds used for general corporate purposes.\n October 16 and December 5, 2006,\
\ issued $500. 0 million and $100. 0 million senior notes.\n notes bear interest\
\ at rate of 6. 05% per year.\n Interest notes payable semi-annually April 15\
\ October 15 each year began April 15, 2007.\n notes mature October 15, 2036.\n\
\nnotes mature October 15, 2036.\n portion of proceeds used to fund 2006 acquisition\
\ of WM Advisors, Inc. remaining proceeds used for general corporate purposes.\n\
\ November 3, 2005, Principal International de Chile S. A. , wholly owned indirect\
\ subsidiary entered long-term borrowing agreements with two Chilean banks amount\
\ US $93. 9 million.\n debt denominated in Unidades de Formento (‘‘UF’’), Chilean\
\ inflation-indexed, peso-denominated monetary unit.\n\nUS $49. 0 million of UF\
\ +3. 31% notes refinanced from +4. 59% during 2007, US $44. 9 million of UF +3.\
\ 63% notes refinanced from +4. 93% in 2007, mature November 3, 2011.\n Interest\
\ on notes payable semi-annually May 3 and November 3 each year.\ndebt outstanding\
\ interest expense vary due to fluctuations in Chilean peso to US dollar exchange\
\ rates Chilean inflation.\n August 25, 1999, Principal Financial Group (Australia)\
\ Holdings Pty.\n\nLimited, wholly owned indirect subsidiary issued $665. 0 million\
\ of unsecured redeemable long-term debt.\n Principal.\n used net proceeds from\
\ notes to partially fund purchase of outstanding stock of companies affiliated\
\ with Bankers Trust Australia Group.\n December 28, 2001, long-term debt obligations\
\ of Principal Financial Group Holdings Pty.\n\nassumed by parent, Principal Financial\
\ Services, Inc. original amount issued, $200. 0 million of 7. 95% notes matured\
\ August 15, 2004, remaining $465. 0 million in 8. 2% notes maturing on August\
\ 15, 2009.\n note paid in full during 2009.\n March 10, 1994 Principal Life issued\
\ $100. 0 million of surplus notes due March 1, 2044, at 8% annual interest rate.\n\
\ None affiliates hold portion of notes.\n\nNone affiliates hold portion of notes.\n\
\ payment of interest principal on notes made only with prior approval of Commissioner\
\ of Insurance of State of Iowa ‘‘Commissioner’’ extent Principal Life has sufficient\
\ surplus earnings to make payments.\n Interest of $8. 0 million for each years\
\ ended December 31, 2009, 2008 2007 approved by Commissioner charged to expense.\n\
\nSubject to Commissioner approval notes due March 1, 2044, may be redeemed at\
\ Principal Life’s election or after March 1, 2014, in whole or in part at redemption\
\ price of approximately 102. 3% of par.\n approximate 2. 3% premium scheduled\
\ to gradually diminish over following ten years.\n notes be redeemed or after\
\ March 1, 2024, at redemption price of 100% of principal amount plus interest\
\ accrued to date of redemption.\nnon-recourse mortgages other notes payable financings\
\ for real estate developments.\n\nprincipal balances as of December 31, 2009,\
\ ranged from $5. 9 million to $9. 1 million\n\n| | December 31, |\n| | 2009\
\ | 2008 |\n| | (in millions) |\n| 8.2% notes payable, due 2009 | $— | $454.9\
\ |\n| 3.31% notes payable, due 2011 | 61.2 | 49.9 |\n| 3.63% notes payable, due\
\ 2011 | 31.4 | 25.6 |\n| 7.875% notes payable, due 2014 | 400.0 | — |\n| 8.875%\
\ notes payable, due 2019 | 350.0 | — |\n| 6.05% notes payable, due 2036 | 601.8\
\ | 601.8 |\n| 8% surplus notes payable, due 2044 | 99.2 | 99.2 |\n| Non-recourse\
\ mortgages and notes payable | 40.6 | 58.7 |\n| Other mortgages and notes payable\
\ | 0.4 | 0.4 |\n\n| Other mortgages and notes payable | 0.4 | 0.4 |\n| Total\
\ long-term debt | $1,584.6 | $1,290.5 |\n| | December 31, 2008 |\n| | Public\
\ | Private | Total |\n| | Carrying amount | Gross unrealized losses | Carrying\
\ amount | Gross unrealized losses | Carrying amount | Gross unrealized losses\
\ |\n| | (in millions) |\n| Three months or less | $3,086.0 | $194.4 | $1,188.1\
\ | $99.5 | $4,274.1 | $293.9 |\n| Greater than three to six months | 4,213.7\
\ | 467.9 | 1,673.6 | 236.4 | 5,887.3 | 704.3 |\n\n| Greater than six to nine\
\ months | 3,014.0 | 620.7 | 1,566.6 | 290.6 | 4,580.6 | 911.3 |\n| Greater than\
\ nine to twelve months | 2,321.0 | 743.0 | 1,259.7 | 460.1 | 3,580.7 | 1,203.1\
\ |\n| Greater than twelve to twenty-four months | 3,042.0 | 1,507.5 | 2,217.1\
\ | 1,519.7 | 5,259.1 | 3,027.2 |\n| Greater than twenty-four to thirty-six months\
\ | 1,045.2 | 296.1 | 312.5 | 217.1 | 1,357.7 | 513.2 |\n| Greater than thirty-six\
\ months | 1,363.8 | 423.5 | 698.2 | 265.8 | 2,062.0 | 689.3 |\n\n| Total fixed\
\ maturity securities, available-for-sale | $18,085.7 | $4,253.1 | $8,915.8 |\
\ $3,089.2 | $27,001.5 | $7,342.3 |\n| | December 31, 2009 |\n| | Public | Private\
\ | Total |\n| | Carrying amount | Gross unrealized losses | Carrying amount\
\ | Gross unrealized losses | Carrying amount | Gross unrealized losses |\n| \
\ | (in millions) |\n| Three months or less | $55.7 | $3.3 | $52.8 | $1.2 | $108.5\
\ | $4.5 |\n| Greater than three to six months | 3.4 | — | 14.8 | — | 18.2 | —\
\ |\n\n| Greater than six to nine months | 12.7 | 0.2 | 0.1 | 0.1 | 12.8 | 0.3\
\ |\n| Greater than nine to twelve months | 32.8 | 11.2 | 1.0 | 1.8 | 33.8 | 13.0\
\ |\n| Greater than twelve to twenty-four months | 441.3 | 112.2 | 365.6 | 186.7\
\ | 806.9 | 298.9 |\n| Greater than twenty-four to thirty-six months | 609.0 |\
\ 314.8 | 403.5 | 435.8 | 1,012.5 | 750.6 |\n| Greater than thirty-six months\
\ | 113.8 | 26.8 | 84.6 | 76.6 | 198.4 | 103.4 |\n\n| Total fixed maturity securities,\
\ available-for-sale | $1,268.7 | $468.5 | $922.4 | $702.2 | $2,191.1 | $1,170.7\
\ |\n| | December 31, 2008 |\n| | Public | Private | Total |\n| | Carrying\
\ amount | Gross unrealized losses | Carrying amount | Gross unrealized losses\
\ | Carrying amount | Gross unrealized losses |\n| | (in millions) |\n| Three\
\ months or less | $133.1 | $56.5 | $114.6 | $32.1 | $247.7 | $88.6 |\n| Greater\
\ than three to six months | 88.8 | 12.7 | 297.1 | 74.3 | 385.9 | 87.0 |\n\n|\
\ Greater than six to nine months | 102.5 | 42.9 | 129.1 | 46.5 | 231.6 | 89.4\
\ |\n| Greater than nine to twelve months | 163.0 | 65.9 | 44.5 | 43.7 | 207.5\
\ | 109.6 |\n| Greater than twelve to twenty-four months | 242.0 | 151.7 | 351.8\
\ | 239.5 | 593.8 | 391.2 |\n| Greater than twenty-four to thirty-six months |\
\ 41.2 | 26.1 | 13.3 | 21.4 | 54.5 | 47.5 |\n| Greater than thirty-six months\
\ | 100.3 | 29.7 | 100.9 | 30.3 | 201.2 | 60.0 |\n\n| Total fixed maturity securities,\
\ available-for-sale | $870.9 | $385.5 | $1,051.3 | $487.8 | $1,922.2 | $873.3\
\ |\n\n\n"
- "Title: \nText: | _id | d812c0dbe |\n| title | |\n| text | Free Cash Flow We\
\ define free cash flow, which is not a measure determined in accordance with\
\ Generally Accepted Accounting Principles in the United States, as cash provided\
\ by operating activities less purchases of property and equipment plus proceeds\
\ from sales of property and equipment as presented in our Consolidated Statements\
\ of Cash Flows.\nOur free cash flow for the years ended December 31, 2005, 2004\
\ and 2003 is calculated as follows (in millions):\n\nFree Cash Flow define free\
\ cash flow not measure determined with Generally Accepted Accounting Principles\
\ in United States, as cash provided by operating activities less purchases property\
\ equipment plus proceeds from sales property equipment as presented in Consolidated\
\ Statements of Cash Flows.\n free cash flow for years ended December 31, 2005,\
\ 2004 2003 calculated as follows (in millions):\n\n\n"
- "Title: \nText: | _id | d8204fe4e |\n| title | |\n| text | CASH FLOW ANALYSIS\
\ We use the indirect method to prepare our Consolidated Statements of Cash Flows.\n\
Under this method, we reconcile net income to cash flows provided by operating\
\ activities by adjusting net income for those items that impact net income but\
\ do not result in actual cash receipts or payments during the period and for\
\ operating cash items that do not impact net income.\n\nThese reconciling items\
\ include depreciation and amortization, allowance for equity funds used during\
\ construction, gain or loss on sale of assets, equity earnings from investments,\
\ distributions received from unconsolidated affiliates, deferred income taxes,\
\ share-based compensation expense, other amounts, and changes in our assets and\
\ liabilities not classified as investing or financing activities.\n\nThe following\
\ table sets forth the changes in cash flows by operating, investing and financing\
\ activities for the periods indicated:\n\nCASH FLOW ANALYSIS use indirect method\
\ prepare Consolidated Statements of Cash Flows.\n Under method reconcile net\
\ income to cash flows operating activities by adjusting net income for items\
\ impact net income not result in actual cash receipts or payments period for\
\ operating cash items not impact net income.\n\nreconciling items include depreciation\
\ amortization allowance for equity funds used during construction gain or loss\
\ on sale of assets equity earnings from investments distributions from unconsolidated\
\ affiliates deferred income taxes share-based compensation expense other amounts\
\ changes in assets and liabilities not classified investing or financing activities.\n\
\ table sets changes in cash flows by operating, investing financing activities\
\ for periods indicated:\n\n\n"
- source_sentence: "Instruct: Given a web search query, retrieve relevant passages\
\ that answer the query.\nQuery: Title: \nText: | _id | q82a8646c |\n| title |\
\ |\n| text | What's the average of Curtailments and Settlements and Special\
\ termination benefits in 2010? (in million)\n\n's average of Curtailments Settlements\
\ Special termination benefits in 2010? (in million)\n\n\n"
sentences:
- "Title: \nText: | _id | d82441980 |\n| title | |\n| text | Income Tax Liabilities\
\ Noncurrent deferred income tax liabilities as of 30 September 2015 were $903.3.\n\
Tax liabilities related to unrecognized tax benefits as of 30 September 2015 were\
\ $97.5.\nThese tax liabilities were excluded from the Contractual Obligations\
\ table, as it is impractical to determine a cash impact by year given that payments\
\ will vary according to changes in tax laws, tax rates, and our operating results.\n\
\nIn addition, there are uncertainties in timing of the effective settlement of\
\ our uncertain tax positions with respective taxing authorities.\nRefer to Note\
\ 23, Income Taxes, to the consolidated financial statements for additional information.\n\
\nIncome Tax Liabilities Noncurrent deferred income tax liabilities as of 30 September\
\ 2015 were $903. 3.\n Tax liabilities related to unrecognized tax benefits 30\
\ September 2015 were $97. 5.\n These tax liabilities excluded from Contractual\
\ Obligations table impractical to determine cash impact by year payments vary\
\ according to changes in tax laws tax rates operating results.\n uncertainties\
\ in timing of effective settlement of uncertain tax positions with taxing authorities.\n\
\nRefer to Note 23, Income Taxes consolidated financial statements for additional\
\ information.\n\n\n"
- "Title: \nText: | _id | d6166fc08 |\n| title | |\n| text | management 2019s discussion\
\ and analysis liquidity risk management liquidity is of critical importance to\
\ financial institutions .\nmost of the failures of financial institutions have\
\ occurred in large part due to insufficient liquidity .\naccordingly , the firm\
\ has in place a comprehensive and conservative set of liquidity and funding policies\
\ to address both firm-specific and broader industry or market liquidity events\
\ .\n\nour principal objective is to be able to fund the firm and to enable our\
\ core businesses to continue to serve clients and generate revenues , even under\
\ adverse circumstances .\nwe manage liquidity risk according to the following\
\ principles : excess liquidity .\nwe maintain substantial excess liquidity to\
\ meet a broad range of potential cash outflows and collateral needs in a stressed\
\ environment .\nasset-liability management .\n\nasset-liability management .\n\
we assess anticipated holding periods for our assets and their expected liquidity\
\ in a stressed environment .\nwe manage the maturities and diversity of our funding\
\ across markets , products and counterparties , and seek to maintain liabilities\
\ of appropriate tenor relative to our asset base .\ncontingency funding plan\
\ .\nwe maintain a contingency funding plan to provide a framework for analyzing\
\ and responding to a liquidity crisis situation or periods of market stress .\n\
\nthis framework sets forth the plan of action to fund normal business activity\
\ in emergency and stress situations .\nthese principles are discussed in more\
\ detail below .\nexcess liquidity our most important liquidity policy is to pre-fund\
\ our estimated potential cash and collateral needs during a liquidity crisis\
\ and hold this excess liquidity in the form of unencumbered , highly liquid securities\
\ and cash .\n\nwe believe that the securities held in our global core excess\
\ would be readily convertible to cash in a matter of days , through liquidation\
\ , by entering into repurchase agreements or from maturities of resale agreements\
\ , and that this cash would allow us to meet immediate obligations without needing\
\ to sell other assets or depend on additional funding from credit-sensitive markets\
\ .\n\nas of december 2013 and december 2012 , the fair value of the securities\
\ and certain overnight cash deposits included in our gce totaled $ 184.07 billion\
\ and $ 174.62 billion , respectively .\n\nbased on the results of our internal\
\ liquidity risk model , discussed below , as well as our consideration of other\
\ factors including , but not limited to , an assessment of our potential intraday\
\ liquidity needs and a qualitative assessment of the condition of the financial\
\ markets and the firm , we believe our liquidity position as of both december\
\ 2013 and december 2012 was appropriate .\n\nthe table below presents the fair\
\ value of the securities and certain overnight cash deposits that are included\
\ in our gce .\naverage for the year ended december in millions 2013 2012 .\n\n\
in millions | average for theyear ended december 2013 | average\
\ for theyear ended december 2012\n---------------------------- | ---------------------------------------\
\ | ---------------------------------------\nu.s . dollar-denominated | $\
\ 136824 | $ 125111 \
\ \nnon-u.s . dollar-denominated | 45826 \
\ | 46984\n\ntotal | $ 182650 \
\ | $ 172095\n\nthe u.s .\ndollar-denominated excess is composed of ( i\
\ ) unencumbered u.s .\ngovernment and federal agency obligations ( including\
\ highly liquid u.s .\nfederal agency mortgage-backed obligations ) , all of which\
\ are eligible as collateral in federal reserve open market operations and ( ii\
\ ) certain overnight u.s .\ndollar cash deposits .\nthe non- u.s .\n\ndollar\
\ cash deposits .\nthe non- u.s .\ndollar-denominated excess is composed of only\
\ unencumbered german , french , japanese and united kingdom government obligations\
\ and certain overnight cash deposits in highly liquid currencies .\nwe strictly\
\ limit our excess liquidity to this narrowly defined list of securities and cash\
\ because they are highly liquid , even in a difficult funding environment .\n\
\nwe do not include other potential sources of excess liquidity , such as less\
\ liquid unencumbered securities or committed credit facilities , in our gce .\n\
goldman sachs 2013 annual report 83\n\nmanagement 2019s discussion analysis liquidity\
\ risk management liquidity critical importance to financial institutions.\n most\
\ failures of financial institutions occurred in due to insufficient liquidity.\n\
\ the firm has comprehensive conservative liquidity and funding policies to address\
\ firm-specific and broader industry or market liquidity events.\n principal objective\
\ is to to fund firm enable core businesses to continue serve clients generate\
\ revenues even under adverse circumstances.\n\nwe manage liquidity risk according\
\ to principles : excess liquidity.\n maintain substantial excess liquidity to\
\ meet broad potential cash outflows collateral needs in stressed environment.\n\
\ asset-liability management.\n assess anticipated holding periods for assets\
\ and expected liquidity in stressed environment.\n manage maturities diversity\
\ of funding across markets products counterparties maintain liabilities of\
\ appropriate tenor relative to asset base.\n contingency funding plan.\n\ncontingency\
\ funding plan.\n maintain contingency funding plan framework for analyzing responding\
\ to liquidity crisis situation or market stress.\n framework sets forth plan\
\ of action to fund normal business activity in emergency stress situations.\n\
\ principles discussed in more detail below.\n excess liquidity important liquidity\
\ policy is to pre-fund estimated potential cash and collateral needs during liquidity\
\ crisis hold excess liquidity in form of unencumbered , highly liquid securities\
\ and cash.\n\nbelieve securities held in our global core excess would be readily\
\ convertible to cash in days , through liquidation , by entering repurchase agreements\
\ or from maturities of resale agreements this cash would allow us to meet immediate\
\ obligations without needing to sell other assets or depend on additional funding\
\ from credit-sensitive markets.\n\nas of december 2013 and december 2012 fair\
\ value of securities and certain overnight cash deposits included in our gce\
\ totaled $ 184. 07 billion and $ 174. 62 billion , respectively.\nbased on results\
\ of our internal liquidity risk model discussed consideration of other factors\
\ including assessment of potential intraday liquidity needs qualitative assessment\
\ of condition of financial markets and firm believe our liquidity position both\
\ december 2013 and december 2012 was appropriate.\n\ntable below presents fair\
\ value of securities certain overnight cash deposits included in our gce.\n average\
\ for year ended december in millions 2013 2012.\n in millions | average for theyear\
\ ended december 2013| average ended december 2012\n ----------------------------|\n\
\ u. s. dollar-denominated | $ 136824 | $ 125111\n non-u. s. dollar-denominated\
\ | 45826 | 46984\n total | $ 182650 | $ 172095\n u. s.\n dollar-denominated excess\
\ is composed of i ) unencumbered u. s.\n\ngovernment and federal agency obligations\
\ ( including highly liquid.\n federal agency mortgage-backed obligations ) eligible\
\ as collateral in federal reserve open market operations ii certain overnight\
\ u. s.\n dollar cash deposits.\n non- u. s.\n dollar-denominated excess composed\
\ of only unencumbered german , french, japanese united kingdom government obligations\
\ and certain overnight cash deposits in highly liquid currencies.\n\nlimit excess\
\ liquidity to this narrowly defined list of securities and cash because highly\
\ liquid even in difficult funding environment.\n do not include other potential\
\ sources of excess liquidity less liquid unencumbered securities or committed\
\ credit facilities in gce.\n goldman sachs 2013 annual report 83\n\n\n"
- "Title: \nText: | _id | d1a72949e |\n| title | |\n| text | Products\nThe Registrant\
\ has the ability to produce a wide range of processed chicken products and prepared\
\ chicken items.\n\nProcessed chicken is first salable as an ice-packed, whole\
\ chicken. The Registrant adds value to its ice-packed, whole chickens by removing\
\ the giblets, weighing, packaging and labeling the product to specific customer\
\ requirements and cutting and deboning the product based on customer specifications.\
\ The additional processing steps of giblet removal, close tolerance weighing\
\ and cutting increase the value of the product to the customer over whole, ice-packed\
\ chickens by reducing customer handling and\n\nchickens by reducing customer\
\ handling and cutting labor and capital costs, reducing the shrinkage associated\
\ with cutting, and ensuring consistently sized portions.\n\nThe Registrant adds\
\ additional value to the processed chicken by deep chilling and packaging whole\
\ chickens in bags or combinations of fresh chicken parts, including boneless\
\ product, in various sized, individual trays under the Registrant’s brand name,\
\ which then may be weighed and pre-priced, based on each customer’s needs. This\
\ chill-pack process increases the value of the product by extending shelf life,\
\ reducing customer weighing and packaging labor, and providing the customer with\
\ a wide variety of\n\nand providing the customer with a wide variety of products\
\ with uniform, well designed packaging, all of which enhance the customer’s ability\
\ to merchandise chicken products.\n\nTo satisfy some customers’ merchandising\
\ needs, the Registrant freezes the chicken product, which adds value by meeting\
\ the customers’ handling, storage, distribution and marketing needs and by permitting\
\ shipment of product overseas where transportation time may be as long as 60\
\ days.\nThe following table sets forth, for the periods indicated, the contribution,\
\ as a percentage of net sales dollars, of each of the Registrant’s major product\
\ lines.\n\n| | | Fiscal Year Ended October 31, | | \
\ \n-------------------------------- | ------- | ------- | ------------------------------\
\ | ------- | ------\n | 2019 | 2018 | 2017\
\ | 2016 | 2015 \nRegistrant processed chicken:\
\ | | | | |\n\nValue\
\ added: | | | \
\ | | \nFresh vacuum-sealed | 38.3 % | 35.2 %\
\ | 39.8 % | 37.6 % | 35.2% \nFresh chill-packed \
\ | 32.9 | 35.6 | 31.0 | 34.7 |\
\ 36.9 \nFresh bulk-packed | 14.4 | 15.1 | 16.4 \
\ | 15.1 | 13.9\n\nFrozen | 6.2\
\ | 6.5 | 6.7 | 5.1 | 6.3 \nSubtotal\
\ | 91.8 | 92.4 | 93.9 \
\ | 92.5 | 92.3 \nNon-value added: | | |\
\ | | \nFresh ice-packed \
\ | 1.2 | 1.2 | 1.0 | 0.9 | 1.0\n\
\nSubtotal | 1.2 | 1.2 | 1.0 \
\ | 0.9 | 1.0 \nTotal Company processed chicken | 93.0 | 93.6\
\ | 94.9 | 93.4 | 93.3 \nMinimally prepared chicken\
\ | 7.0 | 6.4 | 5.1 | 6.6 | 6.7 \
\ \nTotal | 100.0 % | 100.0 % | 100.0 % \
\ | 100.0 % | 100.0%\n\nProducts\n Registrant produce wide range\
\ of processed chicken products and prepared chicken items.\n\nProcessed chicken\
\ first salable as ice-packed, whole chicken. Registrant adds value to ice-packed\
\ whole chickens by removing giblets weighing packaging labeling product to specific\
\ customer requirements cutting deboning product based on customer specifications.\
\ additional processing steps of giblet removal, close tolerance weighing cutting\
\ increase value product customer over whole, ice-packed chickens by reducing\
\ customer handling cutting labor capital costs reducing shrinkage associated\
\ with cutting\n\ncosts reducing shrinkage associated with cutting ensuring consistently\
\ sized portions.\n\nRegistrant adds additional value to processed chicken by\
\ deep chilling packaging whole chickens in bags or combinations of fresh chicken\
\ parts, including boneless product, in various sized individual trays under Registrant’s\
\ brand name, may be weighed pre-priced, based on each customer’s needs. chill-pack\
\ process increases value product by extending shelf life reducing customer weighing\
\ packaging labor providing customer with wide variety of products with uniform,\
\ well designed packaging enhance\n\nwith uniform, well designed packaging enhance\
\ customer’s ability to merchandise chicken products.\n\nTo satisfy some customers’\
\ merchandising needs, Registrant freezes chicken product adds value by meeting\
\ customers’ handling, storage distribution marketing needs permitting shipment\
\ of product overseas where transportation time may be as long as 60 days.\n following\
\ table sets forth for periods, contribution, as percentage of net sales dollars,\
\ of each of Registrant’s major product lines.\n\n| | | Fiscal\
\ Year Ended October 31, | | \n--------------------------------\
\ | ------- | ------- | ------------------------------ | ------- | ------\n \
\ | 2019 | 2018 | 2017 \
\ | 2016 | 2015 \nRegistrant processed chicken: | | \
\ | | | \nValue added: \
\ | | | | \
\ |\n\nFresh vacuum-sealed | 38.3 % | 35.2 % | 39.8 % \
\ | 37.6 % | 35.2% \nFresh chill-packed | 32.9\
\ | 35.6 | 31.0 | 34.7 | 36.9 \nFresh bulk-packed\
\ | 14.4 | 15.1 | 16.4 | 15.1 \
\ | 13.9 \nFrozen | 6.2 | 6.5 | 6.7 \
\ | 5.1 | 6.3\n\nSubtotal |\
\ 91.8 | 92.4 | 93.9 | 92.5 | 92.3 \nNon-value\
\ added: | | | \
\ | | \nFresh ice-packed | 1.2 | 1.2 | 1.0\
\ | 0.9 | 1.0 \nSubtotal \
\ | 1.2 | 1.2 | 1.0 | 0.9 | 1.0\n\n\
Total Company processed chicken | 93.0 | 93.6 | 94.9 \
\ | 93.4 | 93.3 \nMinimally prepared chicken | 7.0 | 6.4\
\ | 5.1 | 6.6 | 6.7 \nTotal \
\ | 100.0 % | 100.0 % | 100.0 % | 100.0 %\
\ | 100.0%\n\n\n"
- source_sentence: "Instruct: Given a web search query, retrieve relevant passages\
\ that answer the query.\nQuery: Title: \nText: | _id | q83deb16a |\n| title |\
\ |\n| text | In the section with the most Bank deposits, what is the growth\
\ rate of Collateral financing arrangements?\n\nIn section with most Bank deposits,\
\ what growth rate of Collateral financing arrangements?\n\n\n"
sentences:
- "Title: \nText: | _id | d81f933f2 |\n| title | |\n| text | | Cash | $45,826 |\n\
| Customer-related intangible assets | 42,721 |\n| Acquired technology | 27,954\
\ |\n| Trade name | 2,901 |\n| Other assets | 2,337 |\n| Deferred income tax assets\
\ (liabilities) | -9,788 |\n| Other liabilities | -49,797 |\n| Total identifiable\
\ net assets | 62,154 |\n| Goodwill | 203,828 |\n| Total purchase consideration\
\ | $265,982 |\n\n| Total purchase consideration | $265,982 |\nGoodwill of $203.8\
\ million arising from the acquisition, included in the Asia-Pacific segment,\
\ was attributable to expected growth opportunities in Australia and New Zealand,\
\ as well as growth opportunities and operating synergies in integrated payments\
\ in our existing Asia-Pacific and North America markets.\nGoodwill associated\
\ with this acquisition is not deductible for income tax purposes.\n\nThe customer-related\
\ intangible assets have an estimated amortization period of 15 years.\nThe acquired\
\ technology has an estimated amortization period of 15 years.\nThe trade name\
\ has an estimated amortization period of 5 years.\nNOTE 3 \x80\x94 SETTLEMENT\
\ PROCESSING ASSETS AND OBLIGATIONS Funds settlement refers to the process of\
\ transferring funds for sales and credits between card issuers and merchants.\n\
\nFor transactions processed on our systems, we use our internal network to provide\
\ funding instructions to financial institutions that in turn fund the merchants.\n\
We process funds settlement under two models, a sponsorship model and a direct\
\ membership model.\n\nUnder the sponsorship model, we are designated as a Merchant\
\ Service Provider by MasterCard and an Independent Sales Organization by Visa,\
\ which means that member clearing banks (\x80\x9CMember\x80\x9D) sponsor us and\
\ require our adherence to the standards of the payment networks.\nIn certain\
\ markets, we have sponsorship or depository and clearing agreements with financial\
\ institution sponsors.\n\nThese agreements allow us to route transactions under\
\ the Members\x80\x99 control and identification numbers to clear credit card\
\ transactions through MasterCard and Visa.\nIn this model, the standards of the\
\ payment networks restrict us from performing funds settlement or accessing merchant\
\ settlement funds, and, instead, require that these funds be in the possession\
\ of the Member until the merchant is funded.\n\nUnder the direct membership model,\
\ we are members in various payment networks, allowing us to process and fund\
\ transactions without third-party sponsorship.\nIn this model, we route and clear\
\ transactions directly through the card brand\x80\x99s network and are not restricted\
\ from performing funds settlement.\nOtherwise, we process these transactions\
\ similarly to how we process transactions in the sponsorship model.\nWe are required\
\ to adhere to the standards of the payment networks in which we are direct members.\n\
\nWe maintain relationships with financial institutions, which may also serve\
\ as our Member sponsors for other card brands or in other markets, to assist\
\ with funds settlement.\nTiming differences, interchange fees, Merchant Reserves\
\ and exception items cause differences between the amount received from the payment\
\ networks and the amount funded to the merchants.\n\nThese intermediary balances\
\ arising in our settlement process for direct merchants are reflected as settlement\
\ processing assets and obligations on our consolidated balance sheets.\nSettlement\
\ processing assets and obligations include the components outlined below: ?\n\
Interchange reimbursement.\nOur receivable from merchants for the portion of the\
\ discount fee related to reimbursement of the interchange fee.\n\nx The Executive\
\ Benefits business offers corporate-owned universal and variable universal life\
\ insurance (\x80\x9CCOLI\x80\x9D) and bankowned universal and variable universal\
\ life insurance (\x80\x9CBOLI\x80\x9D) to small to mid-sized banks and mid to\
\ large-sized corporations, mostly through executive benefit brokers.11 The Group\
\ Protection segment focuses on offering group term life, disability income and\
\ dental insurance primarily in the small to mid-sized employer marketplace for\
\ their eligible employees.\n\nEmployer Markets - Retirement Products The Defined\
\ Contribution business is the largest business in this segment and focuses on\
\ 403(b) plans and 401(k) plans.\nLincoln has a strong historical presence in\
\ the 403(b) space where assets account for about 61% of total assets under management\
\ in this segment as of December 31, 2007.\nThe 401(k) business accounts for 51%\
\ of our new deposits as of December 31, 2007.\nThe Retirement Products segment\x80\
\x99s deposits (in millions) were as follows:\n\nGoodwill associated with acquisition\
\ not deductible for income tax purposes.\n customer-related intangible assets\
\ have estimated amortization period of 15 years.\n acquired technology has estimated\
\ amortization period of 15 years.\n trade name has estimated amortization period\
\ 5 years.\n NOTE 3 \x80\x94 SETTLEMENT PROCESSING ASSETS AND OBLIGATIONS Funds\
\ settlement refers to process transferring funds for sales and credits between\
\ card issuers and merchants.\n\nFor transactions processed on our systems we\
\ use our internal network to provide funding instructions to financial institutions\
\ fund merchants.\n We process funds settlement under two models, sponsorship\
\ model and direct membership model.\n Under sponsorship model we designated as\
\ Merchant Service Provider by MasterCard and Independent Sales Organization by\
\ Visa member clearing banks (\x80\x9CMember\x80\x9D) sponsor us require adherence\
\ to standards of payment networks.\n\nIn certain markets we have sponsorship\
\ or depository and clearing agreements with financial institution sponsors.\n\
\ agreements allow us to route transactions under Members\x80\x99 control identification\
\ numbers to clear credit card transactions through MasterCard and Visa.\n In\
\ model standards of payment networks restrict us from performing funds settlement\
\ or accessing merchant settlement funds require funds be in possession of Member\
\ until merchant funded.\n\nUnder direct membership model we members in various\
\ payment networks process and fund transactions without third-party sponsorship.\n\
\ model route and clear transactions directly through card brand\x80\x99s network\
\ not restricted from performing funds settlement.\n process transactions similarly\
\ to in sponsorship model.\n required to adhere to standards of payment networks\
\ in we direct members.\n\nmaintain relationships with financial institutions,\
\ may serve as Member sponsors for other card brands in other markets, to assist\
\ with funds settlement.\nTiming differences interchange fees Merchant Reserves\
\ exception items cause differences between amount received from payment networks\
\ and amount funded to merchants.\n intermediary balances in settlement process\
\ for direct merchants are reflected as settlement processing assets obligations\
\ on consolidated balance sheets.\n\nSettlement processing assets obligations\
\ include components ?\n Interchange reimbursement.\n receivable from merchants\
\ for portion of discount fee related to reimbursement interchange fee.\n\nExecutive\
\ Benefits business offers corporate-owned universal variable universal life insurance\
\ and bankowned universal variable universal life insurance (\x80\x9CBOLI\x80\x9D\
\ to small to mid-sized banks large-sized corporations mostly through executive\
\ benefit brokers. Group Protection segment focuses on group term life, disability\
\ income dental insurance in small to mid-sized employer marketplace for eligible\
\ employees.\n\nEmployer Markets - Retirement Products Defined Contribution business\
\ is largest business in segment focuses on 403(b) plans 401(k) plans.\n Lincoln\
\ has strong historical presence in 403(b) space assets account for about 61%\
\ of total assets under management in as of December 31, 2007.\n 401(k) business\
\ accounts for 51% of new deposits as of December 31, 2007.\n Retirement Products\
\ segment\x80\x99s deposits (in millions) were as\n\n| Cash | $45,826 |\n| Customer-related\
\ intangible assets | 42,721 |\n| Acquired technology | 27,954 |\n| Trade name\
\ | 2,901 |\n| Other assets | 2,337 |\n| Deferred income tax assets (liabilities)\
\ | -9,788 |\n| Other liabilities | -49,797 |\n| Total identifiable net assets\
\ | 62,154 |\n| Goodwill | 203,828 |\n| Total purchase consideration | $265,982\
\ |\n\n\n"
- "Title: \nText: | _id | d83b9f596 |\n| title | |\n| text | Contractual Obligations.\n\
The following table summarizes the Company’s major contractual obligations at\
\ December 31, 2009:\n| Contractual Obligations | Total | Less Than One Year\
\ | More Than One Year and Less Than Three Years | More Than Three Years\
\ and Less Than Five Years | More Than Five Years |\n| | (In millions)\
\ |\n| Future policy benefits | $310,592 | $7,220 | $10,681 | $11,424 | $281,267\
\ |\n| Policyholder account balances | 198,087 | 22,764 | 30,586 | 24,536 | 120,201\
\ |\n\n| Other policyholder liabilities | 6,142 | 6,142 | — | — | — |\n| Payables\
\ for collateral under securities loaned and other transactions | 24,196 | 24,196\
\ | — | — | — |\n| Bank deposits | 10,354 | 8,998 | 1,293 | 63 | — |\n| Short-term\
\ debt | 912 | 912 | — | — | — |\n| Long-term debt | 21,138 | 1,155 | 4,214 |\
\ 2,312 | 13,457 |\n| Collateral financing arrangements | 6,694 | 61 | 122 | 122\
\ | 6,389 |\n| Junior subordinated debt securities | 10,450 | 258 | 517 | 517\
\ | 9,158 |\n\n| Commitments to lend funds | 7,549 | 7,349 | 177 | 4 | 19 |\n\
| Operating leases | 1,996 | 287 | 427 | 288 | 994 |\n| Other | 11,788 | 11,374\
\ | 6 | 6 | 402 |\n| Total | $609,898 | $90,716 | $48,023 | $39,272 | $431,887\
\ |\n\nFuture policyholder benefits — Future policyholder benefits include liabilities\
\ related to traditional whole life policies, term life policies, pension closeout\
\ and other group annuity contracts, structured settlements, master terminal funding\
\ agreements, single premium immediate annuities, long-term disability policies,\
\ individual disability income policies, long-term care (“LTC”) policies and property\
\ and casualty contracts.\n\nIncluded within future policyholder benefits are\
\ contracts where the Company is currently making payments and will continue to\
\ do so until the occurrence of a specific event such as death, as well as those\
\ where the timing of a portion of the payments has been determined by the contract.\n\
\nAlso included are contracts where the Company is not currently making payments\
\ and will not make payments until the occurrence of an insurable event, such\
\ as death or illness, or where the occurrence of the payment triggering event,\
\ such as a surrender of a policy or contract, is outside the control of the Company.\n\
The Company has estimated the timing of the cash flows related to these contracts\
\ based on historical experience, as well as its expectation of future payment\
\ patterns.\n\nLiabilities related to accounting conventions, or which are not\
\ contractually due, such as shadow liabilities, excess interest reserves and\
\ property and casualty loss adjustment expenses, of $498 million have been excluded\
\ from amounts presented in the table above.\n\nAmounts presented in the table\
\ above, excluding those related to property and casualty contracts, represent\
\ the estimated cash payments for benefits under such contracts including assumptions\
\ related to the receipt of future premiums and assumptions related to mortality,\
\ morbidity, policy lapse, renewal, retirement, inflation, disability incidence,\
\ disability terminations, policy loans and other contingent events as appropriate\
\ to the respective product type.\n\nPayments for case reserve liabilities and\
\ incurred but not reported liabilities associated with property and casualty\
\ contracts of $1.5 billion have been included using an estimate of the ultimate\
\ amount to be settled under the policies based upon historical payment patterns.\n\
\nThe ultimate amount to be paid under property and casualty contracts is not\
\ determined until the Company reaches a settlement with the claimant, which may\
\ vary significantly from the liability or contractual obligation presented above\
\ especially as it relates to incurred but not reported liabilities.\nAll estimated\
\ cash payments presented in the table above are undiscounted as to interest,\
\ net of estimated future premiums on policies currently in-force and gross of\
\ any reinsurance recoverable.\n\nThe more than five years category includes estimated\
\ payments due for periods extending for more than 100 years from the present\
\ date.\n\nThe sum of the estimated cash flows shown for all years in the table\
\ of $310.6 billion exceeds the liability amount of $135.9 billion included on\
\ the consolidated balance sheet principally due to the time value of money, which\
\ accounts for at least 80% of the difference, as well as differences in assumptions,\
\ most significantly mortality, between the date the liabilities were initially\
\ established and the current date.\n\nFor the majority of the Company’s insurance\
\ operations, estimated contractual obligations for future policy benefits and\
\ policyholder account balance liabilities as presented in the table above are\
\ derived from the annual asset adequacy analysis used to develop actuarial opinions\
\ of statutory reserve adequacy for state regulatory purposes.\nThese cash flows\
\ are materially representative of the cash flows under generally accepted accounting\
\ principles.\n(See “— Policyholder account balances” below. )\n\n(See “— Policyholder\
\ account balances” below. )\nActual cash payments to policyholders may differ\
\ significantly from the liabilities as presented in the consolidated balance\
\ sheet and the estimated cash payments as presented in the table above due to\
\ differences between actual experience and the assumptions used in the establishment\
\ of these liabilities and the estimation of these cash payments.\n\nPolicyholder\
\ account balances — Policyholder account balances include liabilities related\
\ to conventional guaranteed interest contracts, guaranteed interest contracts\
\ associated with formal offering programs, funding agreements, individual and\
\ group annuities, total control accounts, individual and group universal life,\
\ variable universal life and company-owned life insurance.\n\nIncluded within\
\ policyholder account balances are contracts where the amount and timing of the\
\ payment is essentially fixed and determinable.\nThese amounts relate to policies\
\ where the Company is currently making payments and will continue to do so, as\
\ well as those where the timing of the payments has been determined by the contract.\n\
\nOther contracts involve payment obligations where the timing of future payments\
\ is uncertain and where the Company is not currently making payments and will\
\ not make payments until the occurrence of an insurable event, such as death,\
\ or where the occurrence of the payment triggering event, such as a surrender\
\ of or partial withdrawal on a policy or deposit contract, is outside the control\
\ of the Company.\n\nThe Company has estimated the timing of the cash flows related\
\ to these contracts based on historical experience, as well as its expectation\
\ of future payment patterns.\nExcess interest reserves representing purchase\
\ accounting adjustments of $565 million have been excluded from amounts presented\
\ in the table above as they represent an accounting convention and not a contractual\
\ obligation.\n\nContractual Obligations.\n table summarizes Company’s major contractual\
\ obligations at December 31, 2009:\n Included within future policyholder benefits\
\ are contracts where Company is currently making payments and will continue to\
\ until specific event death, those where timing of portion of payments determined\
\ by contract.\n\nAlso included are contracts where Company not currently making\
\ payments and will not make payments until insurable event, death or illness,\
\ or where occurrence payment triggering event surrender of policy or contract,\
\ outside control of Company.\n Company estimated timing of cash flows related\
\ to these contracts based on historical experience expectation of future payment\
\ patterns.\n\nLiabilities related to accounting conventions, or not contractually\
\ due, shadow liabilities, excess interest reserves and property and casualty\
\ loss adjustment expenses, of $498 million excluded from amounts in table above.\n\
\nAmounts presented in table above, excluding related to property and casualty\
\ contracts, represent estimated cash payments for benefits under such contracts\
\ including assumptions related to receipt of future premiums and assumptions\
\ related to mortality, morbidity, policy lapse, renewal, retirement, inflation,\
\ disability incidence, disability terminations, policy loans and other contingent\
\ events as appropriate to respective product type.\n\nPayments for case reserve\
\ liabilities and incurred but not reported liabilities associated with property\
\ and casualty contracts of $1. 5 billion included using estimate of ultimate\
\ amount to be settled under policies based upon historical payment patterns.\n\
\nultimate amount to be paid under property and casualty contracts is not determined\
\ until Company reaches settlement with claimant, which may vary significantly\
\ from liability or contractual obligation presented above especially to incurred\
\ but not reported liabilities.\nestimated cash payments in table above are undiscounted\
\ to interest, net of estimated future premiums on policies currently in-force\
\ gross of reinsurance recoverable.\n\nmore than five years category includes\
\ estimated payments due for periods extending for more than 100 years from present\
\ date.\n sum of estimated cash flows for all years in table of $310. 6 billion\
\ exceeds liability amount of $135. 9 billion on consolidated balance sheet principally\
\ due to time value of money accounts for at least 80% of difference differences\
\ in assumptions, significantly mortality, between date liabilities initially\
\ established and current date.\n\nFor majority of Company’s insurance operations,\
\ estimated contractual obligations for future policy benefits and policyholder\
\ account balance liabilities in table derived from annual asset adequacy analysis\
\ to develop actuarial opinions of statutory reserve adequacy for state regulatory\
\ purposes.\n cash flows representative of cash flows under generally accepted\
\ accounting principles.\n (See “— Policyholder account balances” below.\n\n(See\
\ “— Policyholder account balances” below.\n Actual cash payments to policyholders\
\ may differ significantly from liabilities in consolidated balance sheet and\
\ estimated cash payments in table due to differences between actual experience\
\ and assumptions used in establishment of liabilities estimation of cash payments.\n\
\nPolicyholder account balances — Policyholder account balances include liabilities\
\ related to conventional guaranteed interest contracts, guaranteed interest contracts\
\ associated with formal offering programs, funding agreements individual group\
\ annuities total control accounts individual group universal life, variable universal\
\ life company-owned life insurance.\n Included within policyholder account balances\
\ are contracts where amount and timing of payment is essentially fixed and determinable.\n\
\nThese amounts relate to policies where Company currently making payments and\
\ will continue those where timing payments determined by contract.\nOther contracts\
\ involve payment obligations where timing of future payments uncertain where\
\ Company not currently making payments and will not make payments until occurrence\
\ of insurable event, such as death, or where occurrence of payment triggering\
\ event, as surrender of or partial withdrawal on policy or deposit contract,\
\ outside control of Company.\n\nCompany has estimated timing of cash flows related\
\ to these contracts based on historical experience, expectation of future payment\
\ patterns.\n Excess interest reserves representing purchase accounting adjustments\
\ of $565 million excluded from amounts presented in table above as they represent\
\ accounting convention not contractual obligation.\n\n| Contractual Obligations\
\ | Total | Less Than One Year | More Than One Year and Less Than Three\
\ Years | More Than Three Years and Less Than Five Years | More Than \
\ Five Years |\n| | (In millions) |\n| Future policy benefits | $310,592 | $7,220\
\ | $10,681 | $11,424 | $281,267 |\n| Policyholder account balances | 198,087\
\ | 22,764 | 30,586 | 24,536 | 120,201 |\n| Other policyholder liabilities | 6,142\
\ | 6,142 | — | — | — |\n\n| Payables for collateral under securities loaned and\
\ other transactions | 24,196 | 24,196 | — | — | — |\n| Bank deposits | 10,354\
\ | 8,998 | 1,293 | 63 | — |\n| Short-term debt | 912 | 912 | — | — | — |\n| Long-term\
\ debt | 21,138 | 1,155 | 4,214 | 2,312 | 13,457 |\n| Collateral financing arrangements\
\ | 6,694 | 61 | 122 | 122 | 6,389 |\n| Junior subordinated debt securities |\
\ 10,450 | 258 | 517 | 517 | 9,158 |\n| Commitments to lend funds | 7,549 | 7,349\
\ | 177 | 4 | 19 |\n\n| Operating leases | 1,996 | 287 | 427 | 288 | 994 |\n|\
\ Other | 11,788 | 11,374 | 6 | 6 | 402 |\n| Total | $609,898 | $90,716 | $48,023\
\ | $39,272 | $431,887 |\n\n\n"
- "Title: \nText: | _id | d61665c62 |\n| title | |\n| text | management 2019s discussion\
\ and analysis 68 jpmorgan chase & co./2014 annual report consolidated results\
\ of operations the following section provides a comparative discussion of jpmorgan\
\ chase 2019s consolidated results of operations on a reported basis for the three-year\
\ period ended december 31 , 2014 .\nfactors that relate primarily to a single\
\ business segment are discussed in more detail within that business segment .\n\
\nfor a discussion of the critical accounting estimates used by the firm that\
\ affect the consolidated results of operations , see pages 161 2013165 .\nrevenue\
\ year ended december 31 .\n\n( in millions ) \
\ | 2014 | 2013 | 2012 \n-----------------------------------------------\
\ | ------- | ------- | -------\ninvestment banking fees \
\ | $ 6542 | $ 6354 | $ 5808 \nprincipal transactions ( a ) \
\ | 10531 | 10141 | 5536 \nlending- and deposit-related fees \
\ | 5801 | 5945 | 6196 \nasset management administration and\
\ commissions | 15931 | 15106 | 13868\n\nsecurities gains \
\ | 77 | 667 | 2110 \nmortgage fees and related income\
\ | 3563 | 5205 | 8687 \ncard income \
\ | 6020 | 6022 | 5658 \nother income ( b ) \
\ | 2106 | 3847 | 4258 \nnoninterest revenue \
\ | 50571 | 53287 | 52121 \nnet interest income \
\ | 43634 | 43319 | 44910\n\ntotal net revenue\
\ | $ 94205 | $ 96606 | $ 97031\n\n( a ) included\
\ funding valuation adjustments ( ( 201cfva 201d ) effective 2013 ) ) and debit\
\ valuation adjustments ( 201cdva 201d ) on over-the-counter ( 201cotc 201d )\
\ derivatives and structured notes , measured at fair value .\nfva and dva gains/\
\ ( losses ) were $ 468 million and $ ( 1.9 ) billion for the years ended december\
\ 31 , 2014 and 2013 , respectively .\ndva losses were ( $ 930 ) million for the\
\ year ended december 31 , 2012 .\n\n( b ) included operating lease income of\
\ $ 1.7 billion , $ 1.5 billion and $ 1.3 billion for the years ended december\
\ 31 , 2014 , 2013 and 2012 , respectively .\n2014 compared with 2013 total net\
\ revenue for 2014 was down by $ 2.4 billion , or 2% ( 2 % ) , compared with the\
\ prior year , predominantly due to lower mortgage fees and related income , and\
\ lower other income .\nthe decrease was partially offset by higher asset management\
\ , administration and commissions revenue .\n\ninvestment banking fees increased\
\ compared with the prior year , due to higher advisory and equity underwriting\
\ fees , largely offset by lower debt underwriting fees .\nthe increase in advisory\
\ fees was driven by the combined impact of a greater share of fees for completed\
\ transactions , and growth in industry-wide fee levels .\nthe increase in equity\
\ underwriting fees was driven by higher industry-wide issuance .\n\nthe decrease\
\ in debt underwriting fees was primarily related to lower bond underwriting compared\
\ with a stronger prior year , and lower loan syndication fees on lower industry-wide\
\ fee levels .\ninvestment banking fee share and industry-wide data are sourced\
\ from dealogic , an external vendor .\nfor additional information on investment\
\ banking fees , see cib segment results on pages 92 201396 , cb segment results\
\ on pages 97 201399 , and note 7 .\n\nprincipal transactions revenue , which\
\ consists of revenue primarily from the firm 2019s client-driven market-making\
\ and private equity investing activities , increased compared with the prior\
\ year as the prior year included a $ 1.5 billion loss related to the implementation\
\ of the fva framework for otc derivatives and structured notes .\nthe increase\
\ was also due to higher private equity gains as a result of higher net gains\
\ on sales .\n\nthe increase was partially offset by lower fixed income markets\
\ revenue in cib , primarily driven by credit- related and rates products , as\
\ well as the impact of business simplification initiatives .\nfor additional\
\ information on principal transactions revenue , see cib and corporate segment\
\ results on pages 92 201396 and pages 103 2013104 , respectively , and note 7\
\ .\n\nlending- and deposit-related fees decreased compared with the prior year\
\ , reflecting the impact of business simplification initiatives and lower trade\
\ finance revenue in cib .\nfor additional information on lending- and deposit-\
\ related fees , see the segment results for ccb on pages 81 2013 91 , cib on\
\ pages 92 201396 and cb on pages 97 201399 .\n\nasset management , administration\
\ and commissions revenue increased compared with the prior year , reflecting\
\ higher asset management fees driven by net client inflows and the effect of\
\ higher market levels in am and ccb .\nthe increase was offset partially by lower\
\ commissions and other fee revenue in ccb as a result of the exit of a non-core\
\ product in the second half of 2013 .\n\nfor additional information on these\
\ fees and commissions , see the segment discussions of ccb on pages 81 201391\
\ , am on pages 100 2013102 , and note 7 .\nsecurities gains decreased compared\
\ with the prior year , reflecting lower repositioning activity related to the\
\ firm 2019s investment securities portfolio .\nfor additional information , see\
\ the corporate segment discussion on pages 103 2013104 and note 12 .\nmortgage\
\ fees and related income decreased compared with the prior year .\n\nthe decrease\
\ was predominantly due to lower net production revenue driven by lower volumes\
\ due to higher levels of mortgage interest rates , and tighter margins .\nthe\
\ decline in net production revenue was partially offset by a lower loss on the\
\ risk management of mortgage servicing rights ( 201cmsrs 201d ) .\nfor additional\
\ information , see the segment discussion of ccb on pages 85 201387 and note\
\ 17 .\n\ncard income remained relatively flat but included higher net interchange\
\ income on credit and debit cards due to growth in sales volume , offset by higher\
\ amortization of new account origination costs .\nfor additional information\
\ on credit card income , see ccb segment results on pages 81 201391.\n\nmanagement\
\ 2019s discussion analysis 68 jpmorgan chase & co. /2014 annual report consolidated\
\ results operations section provides comparative discussion of jpmorgan chase\
\ 2019s consolidated results operations reported basis for three-year period ended\
\ december 31 , 2014.\n factors relate to single business segment discussed detail\
\ within business segment.\n discussion of critical accounting estimates firm\
\ affect consolidated results operations see pages 161 2013165.\n revenue year\
\ ended december 31.\n\nrevenue year ended december 31.\n included funding valuation\
\ adjustments ( ( 201cfva 201d ) effective 2013 ) ) debit valuation adjustments\
\ ( 201cdva 201d ) on over-the-counter ( 201cotc 201d ) derivatives structured\
\ notes measured at fair value.\n fva dva gains/ ( losses ) were $ 468 million\
\ and $ ( 1. 9 ) billion for years ended december 31 , 2014 and 2013 .\n dva losses\
\ were ( $ 930 ) million for year ended december 31 , 2012.\n\nincluded operating\
\ lease income of $ 1. 7 billion , $ 1. 5 billion $ 1. 3 billion for years ended\
\ december 31 , 2014 , 2013 2012 .\n 2014 compared with 2013 total net revenue\
\ for 2014 down by $ 2. 4 billion , or 2% ( 2 % ) compared prior year due to lower\
\ mortgage fees related income lower other income.\n decrease offset by higher\
\ asset management , administration commissions revenue.\n\ninvestment banking\
\ fees increased prior year due to higher advisory equity underwriting fees offset\
\ by lower debt underwriting fees.\n increase in advisory fees driven by impact\
\ greater share of fees for completed transactions growth in industry-wide fee\
\ levels.\n increase in equity underwriting fees driven by higher industry-wide\
\ issuance.\n decrease in debt underwriting fees related to lower bond underwriting\
\ prior year lower loan syndication fees on lower industry-wide fee levels.\n\n\
investment banking fee share industry-wide data sourced from dealogic , external\
\ vendor.\n for additional information on investment banking fees see cib segment\
\ results pages 92 201396 , cb segment results pages 97 201399 , note 7.\n\nprincipal\
\ transactions revenue revenue primarily from firm 2019s client-driven market-making\
\ private equity investing activities increased compared with prior year prior\
\ year included $ 1. 5 billion loss related to implementation fva framework for\
\ otc derivatives structured notes.\n increase due to higher private equity gains\
\ higher net gains on sales.\n\nincrease partially offset by lower fixed income\
\ markets revenue in cib driven by credit- related rates products impact of business\
\ simplification initiatives.\n for additional information on principal transactions\
\ revenue see cib and corporate segment results on pages 92 201396 pages 103 2013104\
\ note 7.\n lending- and deposit-related fees decreased compared prior year reflecting\
\ impact of business simplification initiatives lower trade finance revenue in\
\ cib.\n\nfor additional information on lending- deposit- related fees see segment\
\ results for ccb on pages 81 2013 91 , cib on pages 92 201396 cb on pages 97\
\ 201399.\n asset management , administration commissions revenue increased compared\
\ prior year reflecting higher asset management fees driven by net client inflows\
\ effect higher market levels in am and ccb.\n increase offset partially by lower\
\ commissions and other fee revenue in ccb of exit of non-core product in second\
\ half of 2013.\n\nfor additional information on fees commissions see segment\
\ discussions of ccb on pages 81 201391 , am on pages 100 2013102 note 7.\n securities\
\ gains decreased prior year reflecting lower repositioning activity related to\
\ firm 2019s investment securities portfolio.\n for additional information see\
\ corporate segment discussion on pages 103 2013104 note 12.\nmortgage fees related\
\ income decreased compared prior year.\n\ndecrease predominantly due to lower\
\ net production revenue driven lower volumes higher mortgage interest rates tighter\
\ margins.\n decline net production revenue partially offset by lower loss on\
\ risk management of mortgage servicing rights ( 201cmsrs 201d ).\n additional\
\ information see segment discussion of ccb on pages 85 201387 note 17.\n\ncard\
\ income remained flat included higher net interchange income on credit debit\
\ cards due to growth in sales volume offset by higher amortization of new account\
\ origination costs.\n additional information on credit card income see ccb segment\
\ results pages 81 201391.\n\n( in millions ) \
\ | 2014 | 2013 | 2012 \n-----------------------------------------------\
\ | ------- | ------- | -------\ninvestment banking fees \
\ | $ 6542 | $ 6354 | $ 5808 \nprincipal transactions ( a ) \
\ | 10531 | 10141 | 5536 \nlending- and deposit-related fees \
\ | 5801 | 5945 | 6196 \nasset management administration and\
\ commissions | 15931 | 15106 | 13868\n\nsecurities gains \
\ | 77 | 667 | 2110 \nmortgage fees and related income\
\ | 3563 | 5205 | 8687 \ncard income \
\ | 6020 | 6022 | 5658 \nother income ( b ) \
\ | 2106 | 3847 | 4258 \nnoninterest revenue \
\ | 50571 | 53287 | 52121 \nnet interest income \
\ | 43634 | 43319 | 44910\n\ntotal net revenue\
\ | $ 94205 | $ 96606 | $ 97031\n\n\n"
model-index:
- name: SentenceTransformer based on thomaskim1130/stella_en_400M_v5-FinanceRAG-v2
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: Evaluate
type: Evaluate
metrics:
- type: cosine_accuracy@1
value: 0.47815533980582525
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.7233009708737864
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.7985436893203883
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8567961165048543
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.47815533980582525
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2758899676375404
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.19271844660194173
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.10436893203883495
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.41237864077669906
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.6860032362459547
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.7844255663430421
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8484223300970875
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.6612924842089951
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.6110369471413164
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.5990151574074167
name: Cosine Map@100
- type: dot_accuracy@1
value: 0.44902912621359226
name: Dot Accuracy@1
- type: dot_accuracy@3
value: 0.7038834951456311
name: Dot Accuracy@3
- type: dot_accuracy@5
value: 0.7864077669902912
name: Dot Accuracy@5
- type: dot_accuracy@10
value: 0.8567961165048543
name: Dot Accuracy@10
- type: dot_precision@1
value: 0.44902912621359226
name: Dot Precision@1
- type: dot_precision@3
value: 0.2669902912621359
name: Dot Precision@3
- type: dot_precision@5
value: 0.19029126213592232
name: Dot Precision@5
- type: dot_precision@10
value: 0.10436893203883495
name: Dot Precision@10
- type: dot_recall@1
value: 0.3868932038834952
name: Dot Recall@1
- type: dot_recall@3
value: 0.6644417475728155
name: Dot Recall@3
- type: dot_recall@5
value: 0.7713996763754045
name: Dot Recall@5
- type: dot_recall@10
value: 0.8484223300970875
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.6465164147035897
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.5909394744952999
name: Dot Mrr@10
- type: dot_map@100
value: 0.579351353684912
name: Dot Map@100
---
# SentenceTransformer based on thomaskim1130/stella_en_400M_v5-FinanceRAG-v2
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [thomaskim1130/stella_en_400M_v5-FinanceRAG-v2](https://huggingface.co/thomaskim1130/stella_en_400M_v5-FinanceRAG-v2). It maps sentences & paragraphs to a 1024-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [thomaskim1130/stella_en_400M_v5-FinanceRAG-v2](https://huggingface.co/thomaskim1130/stella_en_400M_v5-FinanceRAG-v2) <!-- at revision fb539253ffbe0326a966434281a7694d1a08d510 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 1024 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: NewModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Dense({'in_features': 1024, 'out_features': 1024, 'bias': True, 'activation_function': 'torch.nn.modules.linear.Identity'})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'Instruct: Given a web search query, retrieve relevant passages that answer the query.\nQuery: Title: \nText: | _id | q83deb16a |\n| title | |\n| text | In the section with the most Bank deposits, what is the growth rate of Collateral financing arrangements?\n\nIn section with most Bank deposits, what growth rate of Collateral financing arrangements?\n\n\n',
'Title: \nText: | _id | d83b9f596 |\n| title | |\n| text | Contractual Obligations.\nThe following table summarizes the Company’s major contractual obligations at December 31, 2009:\n| Contractual Obligations | Total | Less Than One Year | More Than One Year and Less Than Three Years | More Than Three Years and Less Than Five Years | More Than Five Years |\n| | (In millions) |\n| Future policy benefits | $310,592 | $7,220 | $10,681 | $11,424 | $281,267 |\n| Policyholder account balances | 198,087 | 22,764 | 30,586 | 24,536 | 120,201 |\n\n| Other policyholder liabilities | 6,142 | 6,142 | — | — | — |\n| Payables for collateral under securities loaned and other transactions | 24,196 | 24,196 | — | — | — |\n| Bank deposits | 10,354 | 8,998 | 1,293 | 63 | — |\n| Short-term debt | 912 | 912 | — | — | — |\n| Long-term debt | 21,138 | 1,155 | 4,214 | 2,312 | 13,457 |\n| Collateral financing arrangements | 6,694 | 61 | 122 | 122 | 6,389 |\n| Junior subordinated debt securities | 10,450 | 258 | 517 | 517 | 9,158 |\n\n| Commitments to lend funds | 7,549 | 7,349 | 177 | 4 | 19 |\n| Operating leases | 1,996 | 287 | 427 | 288 | 994 |\n| Other | 11,788 | 11,374 | 6 | 6 | 402 |\n| Total | $609,898 | $90,716 | $48,023 | $39,272 | $431,887 |\n\nFuture policyholder benefits — Future policyholder benefits include liabilities related to traditional whole life policies, term life policies, pension closeout and other group annuity contracts, structured settlements, master terminal funding agreements, single premium immediate annuities, long-term disability policies, individual disability income policies, long-term care (“LTC”) policies and property and casualty contracts.\n\nIncluded within future policyholder benefits are contracts where the Company is currently making payments and will continue to do so until the occurrence of a specific event such as death, as well as those where the timing of a portion of the payments has been determined by the contract.\n\nAlso included are contracts where the Company is not currently making payments and will not make payments until the occurrence of an insurable event, such as death or illness, or where the occurrence of the payment triggering event, such as a surrender of a policy or contract, is outside the control of the Company.\nThe Company has estimated the timing of the cash flows related to these contracts based on historical experience, as well as its expectation of future payment patterns.\n\nLiabilities related to accounting conventions, or which are not contractually due, such as shadow liabilities, excess interest reserves and property and casualty loss adjustment expenses, of $498 million have been excluded from amounts presented in the table above.\n\nAmounts presented in the table above, excluding those related to property and casualty contracts, represent the estimated cash payments for benefits under such contracts including assumptions related to the receipt of future premiums and assumptions related to mortality, morbidity, policy lapse, renewal, retirement, inflation, disability incidence, disability terminations, policy loans and other contingent events as appropriate to the respective product type.\n\nPayments for case reserve liabilities and incurred but not reported liabilities associated with property and casualty contracts of $1.5 billion have been included using an estimate of the ultimate amount to be settled under the policies based upon historical payment patterns.\n\nThe ultimate amount to be paid under property and casualty contracts is not determined until the Company reaches a settlement with the claimant, which may vary significantly from the liability or contractual obligation presented above especially as it relates to incurred but not reported liabilities.\nAll estimated cash payments presented in the table above are undiscounted as to interest, net of estimated future premiums on policies currently in-force and gross of any reinsurance recoverable.\n\nThe more than five years category includes estimated payments due for periods extending for more than 100 years from the present date.\n\nThe sum of the estimated cash flows shown for all years in the table of $310.6 billion exceeds the liability amount of $135.9 billion included on the consolidated balance sheet principally due to the time value of money, which accounts for at least 80% of the difference, as well as differences in assumptions, most significantly mortality, between the date the liabilities were initially established and the current date.\n\nFor the majority of the Company’s insurance operations, estimated contractual obligations for future policy benefits and policyholder account balance liabilities as presented in the table above are derived from the annual asset adequacy analysis used to develop actuarial opinions of statutory reserve adequacy for state regulatory purposes.\nThese cash flows are materially representative of the cash flows under generally accepted accounting principles.\n(See “— Policyholder account balances” below. )\n\n(See “— Policyholder account balances” below. )\nActual cash payments to policyholders may differ significantly from the liabilities as presented in the consolidated balance sheet and the estimated cash payments as presented in the table above due to differences between actual experience and the assumptions used in the establishment of these liabilities and the estimation of these cash payments.\n\nPolicyholder account balances — Policyholder account balances include liabilities related to conventional guaranteed interest contracts, guaranteed interest contracts associated with formal offering programs, funding agreements, individual and group annuities, total control accounts, individual and group universal life, variable universal life and company-owned life insurance.\n\nIncluded within policyholder account balances are contracts where the amount and timing of the payment is essentially fixed and determinable.\nThese amounts relate to policies where the Company is currently making payments and will continue to do so, as well as those where the timing of the payments has been determined by the contract.\n\nOther contracts involve payment obligations where the timing of future payments is uncertain and where the Company is not currently making payments and will not make payments until the occurrence of an insurable event, such as death, or where the occurrence of the payment triggering event, such as a surrender of or partial withdrawal on a policy or deposit contract, is outside the control of the Company.\n\nThe Company has estimated the timing of the cash flows related to these contracts based on historical experience, as well as its expectation of future payment patterns.\nExcess interest reserves representing purchase accounting adjustments of $565 million have been excluded from amounts presented in the table above as they represent an accounting convention and not a contractual obligation.\n\nContractual Obligations.\n table summarizes Company’s major contractual obligations at December 31, 2009:\n Included within future policyholder benefits are contracts where Company is currently making payments and will continue to until specific event death, those where timing of portion of payments determined by contract.\n\nAlso included are contracts where Company not currently making payments and will not make payments until insurable event, death or illness, or where occurrence payment triggering event surrender of policy or contract, outside control of Company.\n Company estimated timing of cash flows related to these contracts based on historical experience expectation of future payment patterns.\n\nLiabilities related to accounting conventions, or not contractually due, shadow liabilities, excess interest reserves and property and casualty loss adjustment expenses, of $498 million excluded from amounts in table above.\n\nAmounts presented in table above, excluding related to property and casualty contracts, represent estimated cash payments for benefits under such contracts including assumptions related to receipt of future premiums and assumptions related to mortality, morbidity, policy lapse, renewal, retirement, inflation, disability incidence, disability terminations, policy loans and other contingent events as appropriate to respective product type.\n\nPayments for case reserve liabilities and incurred but not reported liabilities associated with property and casualty contracts of $1. 5 billion included using estimate of ultimate amount to be settled under policies based upon historical payment patterns.\n\nultimate amount to be paid under property and casualty contracts is not determined until Company reaches settlement with claimant, which may vary significantly from liability or contractual obligation presented above especially to incurred but not reported liabilities.\nestimated cash payments in table above are undiscounted to interest, net of estimated future premiums on policies currently in-force gross of reinsurance recoverable.\n\nmore than five years category includes estimated payments due for periods extending for more than 100 years from present date.\n sum of estimated cash flows for all years in table of $310. 6 billion exceeds liability amount of $135. 9 billion on consolidated balance sheet principally due to time value of money accounts for at least 80% of difference differences in assumptions, significantly mortality, between date liabilities initially established and current date.\n\nFor majority of Company’s insurance operations, estimated contractual obligations for future policy benefits and policyholder account balance liabilities in table derived from annual asset adequacy analysis to develop actuarial opinions of statutory reserve adequacy for state regulatory purposes.\n cash flows representative of cash flows under generally accepted accounting principles.\n (See “— Policyholder account balances” below.\n\n(See “— Policyholder account balances” below.\n Actual cash payments to policyholders may differ significantly from liabilities in consolidated balance sheet and estimated cash payments in table due to differences between actual experience and assumptions used in establishment of liabilities estimation of cash payments.\n\nPolicyholder account balances — Policyholder account balances include liabilities related to conventional guaranteed interest contracts, guaranteed interest contracts associated with formal offering programs, funding agreements individual group annuities total control accounts individual group universal life, variable universal life company-owned life insurance.\n Included within policyholder account balances are contracts where amount and timing of payment is essentially fixed and determinable.\n\nThese amounts relate to policies where Company currently making payments and will continue those where timing payments determined by contract.\nOther contracts involve payment obligations where timing of future payments uncertain where Company not currently making payments and will not make payments until occurrence of insurable event, such as death, or where occurrence of payment triggering event, as surrender of or partial withdrawal on policy or deposit contract, outside control of Company.\n\nCompany has estimated timing of cash flows related to these contracts based on historical experience, expectation of future payment patterns.\n Excess interest reserves representing purchase accounting adjustments of $565 million excluded from amounts presented in table above as they represent accounting convention not contractual obligation.\n\n| Contractual Obligations | Total | Less Than One Year | More Than One Year and Less Than Three Years | More Than Three Years and Less Than Five Years | More Than Five Years |\n| | (In millions) |\n| Future policy benefits | $310,592 | $7,220 | $10,681 | $11,424 | $281,267 |\n| Policyholder account balances | 198,087 | 22,764 | 30,586 | 24,536 | 120,201 |\n| Other policyholder liabilities | 6,142 | 6,142 | — | — | — |\n\n| Payables for collateral under securities loaned and other transactions | 24,196 | 24,196 | — | — | — |\n| Bank deposits | 10,354 | 8,998 | 1,293 | 63 | — |\n| Short-term debt | 912 | 912 | — | — | — |\n| Long-term debt | 21,138 | 1,155 | 4,214 | 2,312 | 13,457 |\n| Collateral financing arrangements | 6,694 | 61 | 122 | 122 | 6,389 |\n| Junior subordinated debt securities | 10,450 | 258 | 517 | 517 | 9,158 |\n| Commitments to lend funds | 7,549 | 7,349 | 177 | 4 | 19 |\n\n| Operating leases | 1,996 | 287 | 427 | 288 | 994 |\n| Other | 11,788 | 11,374 | 6 | 6 | 402 |\n| Total | $609,898 | $90,716 | $48,023 | $39,272 | $431,887 |\n\n\n',
'Title: \nText: | _id | d81f933f2 |\n| title | |\n| text | | Cash | $45,826 |\n| Customer-related intangible assets | 42,721 |\n| Acquired technology | 27,954 |\n| Trade name | 2,901 |\n| Other assets | 2,337 |\n| Deferred income tax assets (liabilities) | -9,788 |\n| Other liabilities | -49,797 |\n| Total identifiable net assets | 62,154 |\n| Goodwill | 203,828 |\n| Total purchase consideration | $265,982 |\n\n| Total purchase consideration | $265,982 |\nGoodwill of $203.8 million arising from the acquisition, included in the Asia-Pacific segment, was attributable to expected growth opportunities in Australia and New Zealand, as well as growth opportunities and operating synergies in integrated payments in our existing Asia-Pacific and North America markets.\nGoodwill associated with this acquisition is not deductible for income tax purposes.\n\nThe customer-related intangible assets have an estimated amortization period of 15 years.\nThe acquired technology has an estimated amortization period of 15 years.\nThe trade name has an estimated amortization period of 5 years.\nNOTE 3 \x80\x94 SETTLEMENT PROCESSING ASSETS AND OBLIGATIONS Funds settlement refers to the process of transferring funds for sales and credits between card issuers and merchants.\n\nFor transactions processed on our systems, we use our internal network to provide funding instructions to financial institutions that in turn fund the merchants.\nWe process funds settlement under two models, a sponsorship model and a direct membership model.\n\nUnder the sponsorship model, we are designated as a Merchant Service Provider by MasterCard and an Independent Sales Organization by Visa, which means that member clearing banks (\x80\x9cMember\x80\x9d) sponsor us and require our adherence to the standards of the payment networks.\nIn certain markets, we have sponsorship or depository and clearing agreements with financial institution sponsors.\n\nThese agreements allow us to route transactions under the Members\x80\x99 control and identification numbers to clear credit card transactions through MasterCard and Visa.\nIn this model, the standards of the payment networks restrict us from performing funds settlement or accessing merchant settlement funds, and, instead, require that these funds be in the possession of the Member until the merchant is funded.\n\nUnder the direct membership model, we are members in various payment networks, allowing us to process and fund transactions without third-party sponsorship.\nIn this model, we route and clear transactions directly through the card brand\x80\x99s network and are not restricted from performing funds settlement.\nOtherwise, we process these transactions similarly to how we process transactions in the sponsorship model.\nWe are required to adhere to the standards of the payment networks in which we are direct members.\n\nWe maintain relationships with financial institutions, which may also serve as our Member sponsors for other card brands or in other markets, to assist with funds settlement.\nTiming differences, interchange fees, Merchant Reserves and exception items cause differences between the amount received from the payment networks and the amount funded to the merchants.\n\nThese intermediary balances arising in our settlement process for direct merchants are reflected as settlement processing assets and obligations on our consolidated balance sheets.\nSettlement processing assets and obligations include the components outlined below: ?\nInterchange reimbursement.\nOur receivable from merchants for the portion of the discount fee related to reimbursement of the interchange fee.\n\nx The Executive Benefits business offers corporate-owned universal and variable universal life insurance (\x80\x9cCOLI\x80\x9d) and bankowned universal and variable universal life insurance (\x80\x9cBOLI\x80\x9d) to small to mid-sized banks and mid to large-sized corporations, mostly through executive benefit brokers.11 The Group Protection segment focuses on offering group term life, disability income and dental insurance primarily in the small to mid-sized employer marketplace for their eligible employees.\n\nEmployer Markets - Retirement Products The Defined Contribution business is the largest business in this segment and focuses on 403(b) plans and 401(k) plans.\nLincoln has a strong historical presence in the 403(b) space where assets account for about 61% of total assets under management in this segment as of December 31, 2007.\nThe 401(k) business accounts for 51% of our new deposits as of December 31, 2007.\nThe Retirement Products segment\x80\x99s deposits (in millions) were as follows:\n\nGoodwill associated with acquisition not deductible for income tax purposes.\n customer-related intangible assets have estimated amortization period of 15 years.\n acquired technology has estimated amortization period of 15 years.\n trade name has estimated amortization period 5 years.\n NOTE 3 \x80\x94 SETTLEMENT PROCESSING ASSETS AND OBLIGATIONS Funds settlement refers to process transferring funds for sales and credits between card issuers and merchants.\n\nFor transactions processed on our systems we use our internal network to provide funding instructions to financial institutions fund merchants.\n We process funds settlement under two models, sponsorship model and direct membership model.\n Under sponsorship model we designated as Merchant Service Provider by MasterCard and Independent Sales Organization by Visa member clearing banks (\x80\x9cMember\x80\x9d) sponsor us require adherence to standards of payment networks.\n\nIn certain markets we have sponsorship or depository and clearing agreements with financial institution sponsors.\n agreements allow us to route transactions under Members\x80\x99 control identification numbers to clear credit card transactions through MasterCard and Visa.\n In model standards of payment networks restrict us from performing funds settlement or accessing merchant settlement funds require funds be in possession of Member until merchant funded.\n\nUnder direct membership model we members in various payment networks process and fund transactions without third-party sponsorship.\n model route and clear transactions directly through card brand\x80\x99s network not restricted from performing funds settlement.\n process transactions similarly to in sponsorship model.\n required to adhere to standards of payment networks in we direct members.\n\nmaintain relationships with financial institutions, may serve as Member sponsors for other card brands in other markets, to assist with funds settlement.\nTiming differences interchange fees Merchant Reserves exception items cause differences between amount received from payment networks and amount funded to merchants.\n intermediary balances in settlement process for direct merchants are reflected as settlement processing assets obligations on consolidated balance sheets.\n\nSettlement processing assets obligations include components ?\n Interchange reimbursement.\n receivable from merchants for portion of discount fee related to reimbursement interchange fee.\n\nExecutive Benefits business offers corporate-owned universal variable universal life insurance and bankowned universal variable universal life insurance (\x80\x9cBOLI\x80\x9d to small to mid-sized banks large-sized corporations mostly through executive benefit brokers. Group Protection segment focuses on group term life, disability income dental insurance in small to mid-sized employer marketplace for eligible employees.\n\nEmployer Markets - Retirement Products Defined Contribution business is largest business in segment focuses on 403(b) plans 401(k) plans.\n Lincoln has strong historical presence in 403(b) space assets account for about 61% of total assets under management in as of December 31, 2007.\n 401(k) business accounts for 51% of new deposits as of December 31, 2007.\n Retirement Products segment\x80\x99s deposits (in millions) were as\n\n| Cash | $45,826 |\n| Customer-related intangible assets | 42,721 |\n| Acquired technology | 27,954 |\n| Trade name | 2,901 |\n| Other assets | 2,337 |\n| Deferred income tax assets (liabilities) | -9,788 |\n| Other liabilities | -49,797 |\n| Total identifiable net assets | 62,154 |\n| Goodwill | 203,828 |\n| Total purchase consideration | $265,982 |\n\n\n',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1024]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `Evaluate`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:----------|
| cosine_accuracy@1 | 0.4782 |
| cosine_accuracy@3 | 0.7233 |
| cosine_accuracy@5 | 0.7985 |
| cosine_accuracy@10 | 0.8568 |
| cosine_precision@1 | 0.4782 |
| cosine_precision@3 | 0.2759 |
| cosine_precision@5 | 0.1927 |
| cosine_precision@10 | 0.1044 |
| cosine_recall@1 | 0.4124 |
| cosine_recall@3 | 0.686 |
| cosine_recall@5 | 0.7844 |
| cosine_recall@10 | 0.8484 |
| cosine_ndcg@10 | 0.6613 |
| cosine_mrr@10 | 0.611 |
| **cosine_map@100** | **0.599** |
| dot_accuracy@1 | 0.449 |
| dot_accuracy@3 | 0.7039 |
| dot_accuracy@5 | 0.7864 |
| dot_accuracy@10 | 0.8568 |
| dot_precision@1 | 0.449 |
| dot_precision@3 | 0.267 |
| dot_precision@5 | 0.1903 |
| dot_precision@10 | 0.1044 |
| dot_recall@1 | 0.3869 |
| dot_recall@3 | 0.6644 |
| dot_recall@5 | 0.7714 |
| dot_recall@10 | 0.8484 |
| dot_ndcg@10 | 0.6465 |
| dot_mrr@10 | 0.5909 |
| dot_map@100 | 0.5794 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 2,240 training samples
* Columns: <code>sentence_0</code> and <code>sentence_1</code>
* Approximate statistics based on the first 1000 samples:
| | sentence_0 | sentence_1 |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 46 tokens</li><li>mean: 80.0 tokens</li><li>max: 217 tokens</li></ul> | <ul><li>min: 53 tokens</li><li>mean: 465.99 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| sentence_0 | sentence_1 |
|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Instruct: Given a web search query, retrieve relevant passages that answer the query.<br>Query: Title: <br>Text: | _id | q8455ea96 |<br>| title | |<br>| text | Which year is Standardized Approach the most? (in million)<br><br>year Standardized Approach most? (in million)<br><br><br></code> | <code>Title: <br>Text: | _id | d8445e56a |<br>| title | |<br>| text | | | Bank of America Corporation | Bank of America, N.A. |<br>| | Standardized Approach | Advanced Approaches | Regulatory Minimum-2 | Standardized Approach | Advanced Approaches | Regulatory Minimum-3 |<br>| (Dollars in millions, except as noted) | December 31, 2018 |<br>| Risk-based capital metrics: | | | | | | |<br>| Common equity tier 1 capital | $167,272 | $167,272 | | $149,824 | $149,824 | |<br>| Tier 1 capital | 189,038 | 189,038 | | 149,824 | 149,824 | |<br><br>| Total capital-4 | 221,304 | 212,878 | | 161,760 | 153,627 | |<br>| Risk-weighted assets (in billions) | 1,437 | 1,409 | | 1,195 | 959 | |<br>| Common equity tier 1 capital ratio | 11.6% | 11.9% | 8.25% | 12.5% | 15.6% | 6.5% |<br>| Tier 1 capital ratio | 13.2 | 13.4 | 9.75 | 12.5 | 15.6 | 8.0 |<br>| Total capital ratio | 15.4 | 15.1 | 11.75 | 13.5 | 16.0 | 10.0 |<br>| Leverage-based metrics: | | | | | | |<br>| Adjusted quarterly average assets (in billions)(5) | $2,258 | $2,258 | | $1,719 | $1,719 | |<br><br>| Tier 1 leverage ratio | 8.4% | 8.4% | 4.0 | 8.7% | 8.7% | 5.0 |<br>| SLR leverage exposure (in billions) | | $2,791 | | | $2,112 | |<br>| SLR | | 6.8% | 5.0 | | 7.1% | 6.0 |<br>| | December 31, 2017 |<br>| Risk-based capital metrics: | | | | | | |<br>| Common equity tier 1 capital | $171,063 | $171,063 | | $150,552 | $150,552 | |<br>| Tier 1 capital | 191,496 | 191,496 | | 150,552 | 150,552 | |<br>| Total capital-4 | 227,427 | 218,529 | | 163,243 | 154,675 | |<br><br>| Risk-weighted assets (in billions) | 1,434 | 1,449 | | 1,201 | 1,007 | |<br>| Common equity tier 1 capital ratio | 11.9% | 11.8% | 7.25% | 12.5% | 14.9% | 6.5% |<br>| Tier 1 capital ratio | 13.4 | 13.2 | 8.75 | 12.5 | 14.9 | 8.0 |<br>| Total capital ratio | 15.9 | 15.1 | 10.75 | 13.6 | 15.4 | 10.0 |<br>| Leverage-based metrics: | | | | | | |<br>| Adjusted quarterly average assets (in billions)(5) | $2,224 | $2,224 | | $1,672 | $1,672 | |<br>| Tier 1 leverage ratio | 8.6% | 8.6% | 4.0 | 9.0% | 9.0% | 5.0 |<br><br>(1) Regulatory capital metrics at December 31, 2017 reflect Basel 3 transition provisions for regulatory capital adjustments and deductions, which were fully phased-in as of January 1, 2018.<br>(2) The December 31, 2018 and 2017 amounts include a transition capital conservation buffer of 1.875 percent and 1.25 percent and a transition global systemically important bank surcharge of 1.875 percent and 1.5 percent.<br>The countercyclical capital buffer for both periods is zero.<br><br>(3) Percent required to meet guidelines to be considered well capitalized under the PCA framework.<br>(4) Total capital under the Advanced approaches differs from the Standardized approach due to differences in the amount permitted in Tier 2 capital related to the qualifying allowance for credit losses.<br>(5) Reflects adjusted average total assets for the three months ended December 31, 2018 and 2017.<br><br>The capital adequacy rules issued by the U. S. banking regulators require institutions to meet the established minimums outlined in the table above.<br>Failure to meet the minimum requirements can lead to certain mandatory and discretionary actions by regulators that could have a material adverse impact on the Corporations financial position.<br>At December 31, 2018 and 2017, the Corporation and its banking entity affiliates were well capitalized.<br><br> Other Regulatory Matters The Federal Reserve requires the Corporations bank subsidiaries to maintain reserve requirements based on a percentage of certain deposit liabilities.<br>The average daily reserve balance requirements, in excess of vault cash, maintained by the Corporation with the Federal Reserve Bank were $11.4 billion and $8.9 billion for 2018 and 2017.<br><br>At December 31, 2018 and 2017, the Corporation had cash and cash equivalents in the amount of $5.8 billion and $4.1 billion, and securities with a fair value of $16.6 billion and $17.3 billion that were segregated in compliance with securities regulations.<br>Cash held on deposit with the Federal Reserve Bank to meet reserve requirements and cash and cash equivalents segregated in compliance with securities regulations are components of restricted cash.<br><br>For additional information, see Note 10 Federal Funds Sold or Purchased, Securities Financing Agreements, Short-term Borrowings and Restricted Cash.<br>In addition, at December 31, 2018 and 2017, the Corporation had cash deposited with clearing organizations of $8.1 billion and $11.9 billion primarily recorded in other assets on the Consolidated Balance Sheet.<br><br>Bank Subsidiary Distributions The primary sources of funds for cash distributions by the Corporation to its shareholders are capital distributions received from its bank subsidiaries, BANA and Bank of America California, N. A.<br>In 2018, the Corporation received dividends of $26.1 billion from BANA and $320 million from Bank of America California, N. A.<br>In addition, Bank of America California, N. A. returned capital of $1.4 billion to the Corporation in 2018.<br><br>The amount of dividends that a subsidiary bank may declare in a calendar year without OCC approval is the subsidiary banks net profits for that year combined with its retained net profits for the preceding two years.<br>Retained net profits, as defined by the OCC, consist of net income less dividends declared during the period.<br><br>In 2019, BANA can declare and pay dividends of approximately $3.1 billion to the Corporation plus an additional amount equal to its retained net profits for 2019 up to the date of any such dividend declaration.<br>Bank of America California, N. A. can pay dividends of $40 million in 2019 plus an additional amount equal to its retained net profits for 2019 up to the date of any such dividend declaration.<br><br>December 31, 2018 and 2017 amounts include transition capital conservation buffer 1. 875 percent 1. 25 percent transition global systemically important bank surcharge of 1. 875 percent 1. 5 percent.<br> countercyclical capital buffer for both periods is zero.<br> Percent required to meet guidelines to be well capitalized under PCA framework.<br><br>Total capital under Advanced approaches differs from Standardized approach due to differences in amount permitted Tier 2 capital qualifying allowance for credit losses.<br> Reflects adjusted average total assets for three months ended December 31, 2018 and 2017.<br> capital adequacy rules by U. S. banking regulators require institutions to meet minimums in table above.<br> Failure to meet minimum requirements can lead to mandatory actions adverse impact on Corporations financial position.<br><br>At December 31, 2018 and 2017 Corporation and banking entity affiliates were well capitalized.<br> Federal Reserve requires Corporations bank subsidiaries to maintain reserve requirements based on percentage of certain deposit liabilities.<br> average daily reserve balance requirements excess of vault cash Corporation with Federal Reserve Bank were $11. 4 billion and $8. 9 billion for 2018 and 2017.<br><br>At December 31, 2018 and 2017 Corporation had cash cash equivalents $5. 8 billion and $4. 1 billion securities with fair value of $16. 6 billion and $17. 3 billion segregated in compliance with securities regulations.<br> Cash held on deposit with Federal Reserve Bank to meet reserve requirements cash cash equivalents segregated in compliance with securities regulations are components of restricted cash.<br><br>For additional information, see Note 10 Federal Funds Sold or Purchased, Securities Financing Agreements, Short-term Borrowings Restricted Cash.<br> at December 31, 2018 and 2017 Corporation had cash deposited with clearing organizations of $8. 1 billion and $11.9 billion recorded in other assets on Consolidated Balance Sheet.<br><br>Bank Subsidiary Distributions primary sources of funds for cash distributions Corporation to shareholders are capital distributions from bank subsidiaries BANA and Bank of America California, N. A.<br> In 2018 Corporation received dividends $26. 1 billion from BANA $320 million from Bank of America California, N. A.<br> Bank of America California, N. A. returned capital of $1. 4 billion to Corporation in 2018.<br><br>amount dividends subsidiary bank may declare year without OCC approval is subsidiary banks net profits for year combined with retained net profits for preceding two years.<br> Retained net profits defined OCC, consist of net income less dividends declared during period.<br> In 2019, BANA can declare pay dividends of approximately $3. 1 billion to Corporation plus additional amount equal to retained net profits for 2019 dividend declaration.<br><br>Bank of America California, N. A. can pay dividends of $40 million in 2019 plus additional amount equal to retained net profits for 2019 date dividend declaration.<br><br>| | Bank of America Corporation | Bank of America, N.A. |<br>| | Standardized Approach | Advanced Approaches | Regulatory Minimum-2 | Standardized Approach | Advanced Approaches | Regulatory Minimum-3 |<br>| (Dollars in millions, except as noted) | December 31, 2018 |<br>| Risk-based capital metrics: | | | | | | |<br>| Common equity tier 1 capital | $167,272 | $167,272 | | $149,824 | $149,824 | |<br>| Tier 1 capital | 189,038 | 189,038 | | 149,824 | 149,824 | |<br><br>| Total capital-4 | 221,304 | 212,878 | | 161,760 | 153,627 | |<br>| Risk-weighted assets (in billions) | 1,437 | 1,409 | | 1,195 | 959 | |<br>| Common equity tier 1 capital ratio | 11.6% | 11.9% | 8.25% | 12.5% | 15.6% | 6.5% |<br>| Tier 1 capital ratio | 13.2 | 13.4 | 9.75 | 12.5 | 15.6 | 8.0 |<br>| Total capital ratio | 15.4 | 15.1 | 11.75 | 13.5 | 16.0 | 10.0 |<br>| Leverage-based metrics: | | | | | | |<br>| Adjusted quarterly average assets (in billions)(5) | $2,258 | $2,258 | | $1,719 | $1,719 | |<br><br>| Tier 1 leverage ratio | 8.4% | 8.4% | 4.0 | 8.7% | 8.7% | 5.0 |<br>| SLR leverage exposure (in billions) | | $2,791 | | | $2,112 | |<br>| SLR | | 6.8% | 5.0 | | 7.1% | 6.0 |<br>| | December 31, 2017 |<br>| Risk-based capital metrics: | | | | | | |<br>| Common equity tier 1 capital | $171,063 | $171,063 | | $150,552 | $150,552 | |<br>| Tier 1 capital | 191,496 | 191,496 | | 150,552 | 150,552 | |<br>| Total capital-4 | 227,427 | 218,529 | | 163,243 | 154,675 | |<br><br>| Risk-weighted assets (in billions) | 1,434 | 1,449 | | 1,201 | 1,007 | |<br>| Common equity tier 1 capital ratio | 11.9% | 11.8% | 7.25% | 12.5% | 14.9% | 6.5% |<br>| Tier 1 capital ratio | 13.4 | 13.2 | 8.75 | 12.5 | 14.9 | 8.0 |<br>| Total capital ratio | 15.9 | 15.1 | 10.75 | 13.6 | 15.4 | 10.0 |<br>| Leverage-based metrics: | | | | | | |<br>| Adjusted quarterly average assets (in billions)(5) | $2,224 | $2,224 | | $1,672 | $1,672 | |<br>| Tier 1 leverage ratio | 8.6% | 8.6% | 4.0 | 9.0% | 9.0% | 5.0 |<br><br><br></code> |
| <code>Instruct: Given a web search query, retrieve relevant passages that answer the query.<br>Query: Title: <br>Text: | _id | q61694076 |<br>| title | |<br>| text | as of december 31 , 2006 what was the percent of the total route miles covered by the main line<br><br>as of december 31 , 2006 percent of total route miles covered by main line<br><br><br></code> | <code>Title: <br>Text: | _id | d6168db72 |<br>| title | |<br>| text | our access to commercial paper and reduce our credit ratings below investment grade , which would prohibit us from utilizing our sale of receivables program and significantly increase the cost of issuing debt .<br>we are dependent on two key domestic suppliers of locomotives 2013 due to the capital intensive nature and sophistication of locomotive equipment , high barriers to entry face potential new suppliers .<br><br>therefore , if one of these domestic suppliers discontinues manufacturing locomotives , we could experience a significant cost increase and risk reduced availability of the locomotives that are necessary to our operations .<br>we may be affected by acts of terrorism , war , or risk of war 2013 our rail lines , facilities , and equipment , including rail cars carrying hazardous materials , could be direct targets or indirect casualties of terrorist attacks .<br><br>terrorist attacks , or other similar events , any government response thereto , and war or risk of war may adversely affect our results of operations , financial condition , and liquidity .<br>in addition , insurance premiums for some or all of our current coverages could increase dramatically , or certain coverages may not be available to us in the future .<br>item 1b .<br>unresolved staff comments item 2 .<br><br>item 1b .<br>unresolved staff comments item 2 .<br>properties with operations in 23 states , we employ a variety of assets in the management and operation of our rail business .<br>these assets include real estate , track and track structure , equipment , and facilities .<br>we own and lease real estate that we use in our operations , and we also own real estate that is not required for our business , which we sell from time to time .<br><br>our equipment includes owned and leased locomotives and rail cars ; heavy maintenance equipment and machinery ; other equipment and tools in our shops , offices and facilities ; and vehicles for maintenance , transportation of crews , and other activities .<br><br>we operate numerous facilities , including terminals for intermodal and other freight ; rail yards for train-building , switching , storage-in-transit ( the temporary storage of customer goods in rail cars prior to shipment ) and other activities ; offices to administer and manage our operations ; dispatch centers to direct traffic on our rail network ; crew quarters to house train crews along our network ; and shops and other facilities for fueling , maintenance , and repair of locomotives and repair and<br><br>, and repair of locomotives and repair and maintenance of rail cars and other equipment .<br><br>we spent approximately $ 2.2 billion in cash capital during 2006 for , among other things , building and maintaining track , structures and infrastructure ; upgrading and augmenting equipment ; and implementing new technologies ( see the capital investments table in management 2019s discussion and analysis of financial condition and results of operations 2013 liquidity and capital resources 2013 financial condition , item 7 ) .<br><br>certain of our properties are subject to federal , state , and local laws and regulations governing the protection of the environment ( see discussion of environmental issues in business 2013 governmental and environmental regulation , item 1 , and management 2019s discussion and analysis of financial condition and results of operations 2013 critical accounting policies 2013 environmental , item 7 ) .<br><br>track 2013 the railroad operates on 32339 main line and branch line route miles in 23 states in the western two-thirds of the united states .<br>we own 26466 route miles , with the remainder of route miles operated pursuant to trackage rights or leases .<br>route miles as of december 31 , 2006 and 2005 , were as follows : 2006 2005 .<br><br>| 2006 | 2005 <br>----------------------------- | ----- | -----<br>main line | 27318 | 27301<br>branch line | 5021 | 5125 <br>yards sidings and other lines | 19257 | 20241<br>total | 51596 | 52667<br><br>access to commercial paper reduce credit ratings below investment grade prohibit us from utilizing sale of receivables program increase cost of issuing debt.<br> dependent on two key domestic suppliers of locomotives 2013 due to capital intensive nature sophistication of locomotive equipment high barriers to entry face potential new suppliers.<br><br>if one domestic suppliers discontinues manufacturing locomotives, could experience significant cost increase risk reduced availability of locomotives necessary to operations.<br> may be affected by acts of terrorism , war or risk of war 2013 our rail lines , facilities equipment , including rail cars carrying hazardous materials could be direct targets or indirect casualties of terrorist attacks.<br><br>terrorist attacks other similar events , government response war or risk of war may adversely affect results of operations , financial condition liquidity.<br> insurance premiums for some or all current coverages could increase dramatically or certain coverages may not be available to in future.<br> item 1b.<br> unresolved staff comments item 2.<br> properties with operations in 23 states employ variety of assets in management and operation of rail business.<br><br>assets include real estate , track and track structure equipment facilities.<br> own and lease real estate we use in operations also own real estate not required for business we sell from time to time.<br> equipment includes owned and leased locomotives and rail cars ; heavy maintenance equipment and machinery ; other equipment and tools in shops , offices facilities ; vehicles for maintenance , transportation of crews other activities.<br><br>operate numerous facilities including terminals for intermodal freight ; rail yards for train-building switching storage-in-transit ( temporary storage customer goods in rail cars prior shipment ) other activities ; offices to administer manage operations ; dispatch centers direct traffic rail network ; crew quarters house train crews network shops facilities for fueling maintenance repair of locomotives repair maintenance rail cars other equipment.<br><br>spent approximately $ 2. 2 billion in cash capital during 2006 for building maintaining track structures infrastructure ; upgrading augmenting equipment implementing new technologies ( see capital investments table in management 2019s discussion analysis of financial condition results of operations 2013 liquidity capital resources 2013 financial condition , item 7 ).<br><br>certain properties subject to federal state local laws regulations governing protection environment ( see discussion environmental issues in business 2013 governmental environmental regulation , item 1 , management 2019s discussion analysis financial condition results of operations 2013 critical accounting policies 2013 environmental , item 7 ).<br> track 2013 railroad operates on 32339 main line branch line route miles in 23 states in western two-thirds of united states.<br><br>own 26466 route miles remainder route miles operated pursuant to trackage rights or leases.<br> route miles as of december 31 , 2006 2005 as follows : 2006 2005.<br> | 2006 | 2005<br> ----------------------------- | -----|<br> main line | 27318 | 27301<br> branch line | 5021 | 5125<br> yards sidings and other lines | 19257 | 20241<br> total | 51596 | 52667<br><br><br></code> |
| <code>Instruct: Given a web search query, retrieve relevant passages that answer the query.<br>Query: Title: <br>Text: | _id | q813b8c26 |<br>| title | |<br>| text | What's the sum of the Unit redemptions in the years where Mortgages Payable for Carrying Amounts is positive?<br><br>What's sum of Unit redemptions years where Mortgages Payable for Carrying Amounts positive?<br><br><br></code> | <code>Title: <br>Text: | _id | d813b8e42 |<br>| title | |<br>| text | iTunes, Software and Services The following table presents net sales information of iTunes, Software and Services for 2014, 2013 and 2012 (dollars in millions):<br>| | 2014 | Change | 2013 | Change | 2012 |<br>| iTunes, Software and Services | $18,063 | 13% | $16,051 | 25% | $12,890 |<br>| Percentage of total net sales | 10% | | 9% | | 8% |<br>The increase in net sales of iTunes, Software and Services in 2014 compared to 2013 was primarily due to growth in net sales from the iTunes Store, AppleCare and licensing.<br><br>The iTunes Store generated a total of $10.2 billion in net sales during 2014 compared to $9.3 billion during 2013.<br>Growth in net sales from the iTunes Store was driven by increases in revenue from app sales reflecting continued growth in the installed base of iOS devices and the expanded offerings of iOS Apps and related in-App purchases.<br>This was partially offset by a decline in sales of digital music.<br><br>The increase in net sales of iTunes, Software and Services in 2013 compared to 2012 was primarily due to growth in net sales from the iTunes Store, AppleCare and licensing.<br>The iTunes Store generated a total of $9.3 billion in net sales during 2013, a 24% increase from 2012.<br><br>Growth in the iTunes Store, which includes the App Store, the Mac App Store and the iBooks Store, reflected continued growth in the installed base of iOS devices, expanded offerings of iOS Apps and related in-App purchases, and expanded offerings of iTunes digital content.<br><br>iTunes, Software and Services table presents net sales information of iTunes for 2014, 2013 2012 (dollars in millions):<br> iTunes Store generated $10. 2 billion net sales during 2014 compared to $9. 3 billion 2013.<br> Growth in net sales iTunes Store driven by increases in revenue from app sales reflecting continued growth in installed base iOS devices expanded offerings of iOS Apps related in-App purchases.<br> partially offset by decline in sales of digital music.<br><br>increase in net sales of iTunes, Software and Services in 2013 compared to 2012 primarily due to growth in net sales from iTunes Store, AppleCare licensing.<br> iTunes Store generated $9. 3 billion in net sales during 2013, 24% increase from 2012.<br> Growth in iTunes Store includes App Store, Mac App Store iBooks Store reflected continued growth in installed base of iOS devices expanded offerings of iOS Apps related in-App purchases expanded offerings iTunes digital content.<br><br>| | 2014 | Change | 2013 | Change | 2012 |<br>| iTunes, Software and Services | $18,063 | 13% | $16,051 | 25% | $12,890 |<br>| Percentage of total net sales | 10% | | 9% | | 8% |<br><br><br></code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 2
- `fp16`: True
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 2
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: round_robin
</details>
### Training Logs
| Epoch | Step | Evaluate_cosine_map@100 |
|:-----:|:----:|:-----------------------:|
| 0 | 0 | 0.5370 |
| 1.0 | 141 | 0.5687 |
| 2.0 | 282 | 0.5990 |
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 3.1.1
- Transformers: 4.45.2
- PyTorch: 2.5.1+cu121
- Accelerate: 1.1.1
- Datasets: 3.1.0
- Tokenizers: 0.20.3
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"BEAR"
] |
OpenGVLab/Mini-InternVL2-4B-DA-RS
|
OpenGVLab
|
image-text-to-text
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"arxiv:2410.16261",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"base_model:OpenGVLab/InternVL2-4B",
"base_model:merge:OpenGVLab/InternVL2-4B",
"license:mit",
"region:us"
] | 2024-12-07T11:13:30Z |
2024-12-09T13:03:56+00:00
| 18 | 1 |
---
base_model:
- OpenGVLab/InternVL2-4B
language:
- multilingual
library_name: transformers
license: mit
pipeline_tag: image-text-to-text
tags:
- internvl
- custom_code
base_model_relation: merge
---
# Mini-InternVL2-DA-RS
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[🆕 Blog\]](https://internvl.github.io/blog/) [\[📜 Mini-InternVL\]](https://arxiv.org/abs/2410.16261) [\[📜 InternVL 1.0\]](https://arxiv.org/abs/2312.14238) [\[📜 InternVL 1.5\]](https://arxiv.org/abs/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271)
[\[🗨️ InternVL Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 中文解读\]](https://zhuanlan.zhihu.com/p/706547971) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/internvl2.0/domain_adaptation.html#data-preparation)

## Introduction
We release the adaptation models for the specific domains: autonomous driving, medical images, and remote sensing.
These models are built upon Mini-InternVL and fine-tuned using a unified adaptation framework, achieving good performance on tasks in specific domains.

<table>
<tr>
<th>Model Name</th>
<th>HF Link</th>
<th>Note</th>
</tr>
<tr>
<td>Mini-InternVL2-DA-Drivelm</td>
<td><a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-1B-DA-Drivelm">🤗1B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-2B-DA-Drivelm">🤗2B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-4B-DA-Drivelm">🤗4B</a></td>
<td> Adaptation for <a href="https://github.com/OpenDriveLab/DriveLM/tree/main/challenge"> CVPR 2024 Autonomous Driving Challenge </a></td>
</tr>
<tr>
<td>Mini-InternVL2-DA-BDD</td>
<td><a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-1B-DA-BDD">🤗1B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-2B-DA-BDD">🤗2B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-4B-DA-BDD">🤗4B</a></td>
<td> Fine-tuning with data constructed by <a href="https://tonyxuqaq.github.io/projects/DriveGPT4/"> DriveGPT4 </a></td>
</tr>
<tr>
<td>Mini-InternVL2-DA-RS</td>
<td><a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-1B-DA-RS">🤗1B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-2B-DA-RS">🤗2B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-4B-DA-RS">🤗4B</a></td>
<td> Adaptation for remote sensing domain </td>
</tr>
<tr>
<td>Mini-InternVL2-DA-Medical</td>
<td><a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-1B-DA-Medical">🤗1B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-2B-DA-Medical">🤗2B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-4B-DA-Medical">🤗4B</a></td>
<td> Fine-tuning using our <a href="https://huggingface.co/datasets/OpenGVLab/InternVL-Domain-Adaptation-Data/blob/main/train_meta/internvl_1_2_finetune_medical.json">medical data</a>.</td>
</tr>
</table>
The script for evaluation is in the [document](https://internvl.readthedocs.io/en/latest/internvl2.0/domain_adaptation.html#id3).
## Training datasets
- General domain dataset:
ShareGPT4V, AllSeeingV2, LLaVA-Instruct-ZH, DVQA, ChartQA, AI2D, DocVQA, GeoQA+, SynthDoG-EN
- Remote sensing dataset:
GeoChat instruction set, RSVQA-HR, DIOR-RSVG, FIT-RS.
## Quick Start
We provide an example code to run `Mini-InternVL2-4B` using `transformers`.
> Please use transformers>=4.37.2 to ensure the model works normally.
```python
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
# If you want to load a model using multiple GPUs, please refer to the `Multiple GPUs` section.
path = 'OpenGVLab/Mini-InternVL2-4B-DA-RS'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('path/to/image.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('path/to/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('path/to/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('path/to/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('path/to/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('path/to/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('path/to/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
```
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{gao2024mini,
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2410.16261},
year={2024}
}
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
```
|
[
"MEDICAL DATA"
] |
davidschulte/ESM_qanastek__Biosses-BLUE_biosses
|
davidschulte
| null |
[
"safetensors",
"embedding_space_map",
"BaseLM:bert-base-multilingual-uncased",
"dataset:qanastek/Biosses-BLUE",
"arxiv:2410.15148",
"base_model:google-bert/bert-base-multilingual-uncased",
"base_model:finetune:google-bert/bert-base-multilingual-uncased",
"license:apache-2.0",
"region:us"
] | 2024-12-09T22:21:52Z |
2024-12-09T22:22:02+00:00
| 18 | 0 |
---
base_model: bert-base-multilingual-uncased
datasets:
- qanastek/Biosses-BLUE
license: apache-2.0
tags:
- embedding_space_map
- BaseLM:bert-base-multilingual-uncased
---
# ESM qanastek/Biosses-BLUE
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
ESM
- **Developed by:** David Schulte
- **Model type:** ESM
- **Base Model:** bert-base-multilingual-uncased
- **Intermediate Task:** qanastek/Biosses-BLUE
- **ESM architecture:** linear
- **ESM embedding dimension:** 768
- **Language(s) (NLP):** [More Information Needed]
- **License:** Apache-2.0 license
- **ESM version:** 0.1.0
## Training Details
### Intermediate Task
- **Task ID:** qanastek/Biosses-BLUE
- **Subset [optional]:** biosses
- **Text Column:** ['sentence1', 'sentence2']
- **Label Column:** score
- **Dataset Split:** train
- **Sample size [optional]:** 64
- **Sample seed [optional]:**
### Training Procedure [optional]
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Language Model Training Hyperparameters [optional]
- **Epochs:** 3
- **Batch size:** 32
- **Learning rate:** 2e-05
- **Weight Decay:** 0.01
- **Optimizer**: AdamW
### ESM Training Hyperparameters [optional]
- **Epochs:** 10
- **Batch size:** 32
- **Learning rate:** 0.001
- **Weight Decay:** 0.01
- **Optimizer**: AdamW
### Additional trainiung details [optional]
## Model evaluation
### Evaluation of fine-tuned language model [optional]
### Evaluation of ESM [optional]
MSE:
### Additional evaluation details [optional]
## What are Embedding Space Maps used for?
Embedding Space Maps are a part of ESM-LogME, a efficient method for finding intermediate datasets for transfer learning. There are two reasons to use ESM-LogME:
### You don't have enough training data for your problem
If you don't have a enough training data for your problem, just use ESM-LogME to find more.
You can supplement model training by including publicly available datasets in the training process.
1. Fine-tune a language model on suitable intermediate dataset.
2. Fine-tune the resulting model on your target dataset.
This workflow is called intermediate task transfer learning and it can significantly improve the target performance.
But what is a suitable dataset for your problem? ESM-LogME enable you to quickly rank thousands of datasets on the Hugging Face Hub by how well they are exptected to transfer to your target task.
### You want to find similar datasets to your target dataset
Using ESM-LogME can be used like search engine on the Hugging Face Hub. You can find similar tasks to your target task without having to rely on heuristics. ESM-LogME estimates how language models fine-tuned on each intermediate task would benefinit your target task. This quantitative approach combines the effects of domain similarity and task similarity.
## How can I use ESM-LogME / ESMs?
[](https://pypi.org/project/hf-dataset-selector)
We release **hf-dataset-selector**, a Python package for intermediate task selection using Embedding Space Maps.
**hf-dataset-selector** fetches ESMs for a given language model and uses it to find the best dataset for applying intermediate training to the target task. ESMs are found by their tags on the Huggingface Hub.
```python
from hfselect import Dataset, compute_task_ranking
# Load target dataset from the Hugging Face Hub
dataset = Dataset.from_hugging_face(
name="stanfordnlp/imdb",
split="train",
text_col="text",
label_col="label",
is_regression=False,
num_examples=1000,
seed=42
)
# Fetch ESMs and rank tasks
task_ranking = compute_task_ranking(
dataset=dataset,
model_name="bert-base-multilingual-uncased"
)
# Display top 5 recommendations
print(task_ranking[:5])
```
```python
1. davanstrien/test_imdb_embedd2 Score: -0.618529
2. davanstrien/test_imdb_embedd Score: -0.618644
3. davanstrien/test1 Score: -0.619334
4. stanfordnlp/imdb Score: -0.619454
5. stanfordnlp/sst Score: -0.62995
```
| Rank | Task ID | Task Subset | Text Column | Label Column | Task Split | Num Examples | ESM Architecture | Score |
|-------:|:------------------------------|:----------------|:--------------|:---------------|:-------------|---------------:|:-------------------|----------:|
| 1 | davanstrien/test_imdb_embedd2 | default | text | label | train | 10000 | linear | -0.618529 |
| 2 | davanstrien/test_imdb_embedd | default | text | label | train | 10000 | linear | -0.618644 |
| 3 | davanstrien/test1 | default | text | label | train | 10000 | linear | -0.619334 |
| 4 | stanfordnlp/imdb | plain_text | text | label | train | 10000 | linear | -0.619454 |
| 5 | stanfordnlp/sst | dictionary | phrase | label | dictionary | 10000 | linear | -0.62995 |
| 6 | stanfordnlp/sst | default | sentence | label | train | 8544 | linear | -0.63312 |
| 7 | kuroneko5943/snap21 | CDs_and_Vinyl_5 | sentence | label | train | 6974 | linear | -0.634365 |
| 8 | kuroneko5943/snap21 | Video_Games_5 | sentence | label | train | 6997 | linear | -0.638787 |
| 9 | kuroneko5943/snap21 | Movies_and_TV_5 | sentence | label | train | 6989 | linear | -0.639068 |
| 10 | fancyzhx/amazon_polarity | amazon_polarity | content | label | train | 10000 | linear | -0.639718 |
For more information on how to use ESMs please have a look at the [official Github repository](https://github.com/davidschulte/hf-dataset-selector). We provide documentation further documentation and tutorials for finding intermediate datasets and training your own ESMs.
## How do Embedding Space Maps work?
<!-- This section describes the evaluation protocols and provides the results. -->
Embedding Space Maps (ESMs) are neural networks that approximate the effect of fine-tuning a language model on a task. They can be used to quickly transform embeddings from a base model to approximate how a fine-tuned model would embed the the input text.
ESMs can be used for intermediate task selection with the ESM-LogME workflow.
## How can I use Embedding Space Maps for Intermediate Task Selection?
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
If you are using this Embedding Space Maps, please cite our [paper](https://aclanthology.org/2024.emnlp-main.529/).
**BibTeX:**
```
@inproceedings{schulte-etal-2024-less,
title = "Less is More: Parameter-Efficient Selection of Intermediate Tasks for Transfer Learning",
author = "Schulte, David and
Hamborg, Felix and
Akbik, Alan",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.emnlp-main.529/",
doi = "10.18653/v1/2024.emnlp-main.529",
pages = "9431--9442",
abstract = "Intermediate task transfer learning can greatly improve model performance. If, for example, one has little training data for emotion detection, first fine-tuning a language model on a sentiment classification dataset may improve performance strongly. But which task to choose for transfer learning? Prior methods producing useful task rankings are infeasible for large source pools, as they require forward passes through all source language models. We overcome this by introducing Embedding Space Maps (ESMs), light-weight neural networks that approximate the effect of fine-tuning a language model. We conduct the largest study on NLP task transferability and task selection with 12k source-target pairs. We find that applying ESMs on a prior method reduces execution time and disk space usage by factors of 10 and 278, respectively, while retaining high selection performance (avg. regret@5 score of 2.95)."
}
```
**APA:**
```
Schulte, D., Hamborg, F., & Akbik, A. (2024, November). Less is More: Parameter-Efficient Selection of Intermediate Tasks for Transfer Learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 9431-9442).
```
## Additional Information
|
[
"BIOSSES"
] |
Wolfram33/pix74
|
Wolfram33
|
text-to-image
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:strangerzonehf/Flux-Midjourney-Mix2-LoRA",
"base_model:adapter:strangerzonehf/Flux-Midjourney-Mix2-LoRA",
"license:apache-2.0",
"region:us"
] | 2025-01-03T16:27:22Z |
2025-01-13T17:38:42+00:00
| 18 | 2 |
---
base_model: strangerzonehf/Flux-Midjourney-Mix2-LoRA
license: apache-2.0
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: A beautiful woman sitting in a magical forest, surrounded by vibrant greenery
and glowing flowers, wearing a flowing red dress. The lighting is soft and ethereal,
with a dreamy atmosphere. Hyper-detailed, cinematic style.
parameters:
negative_prompt: A beautiful woman sitting in a magical forest, surrounded by
vibrant greenery and glowing flowers, wearing a flowing red dress. The lighting
is soft and ethereal, with a dreamy atmosphere. Hyper-detailed, cinematic style.
output:
url: images/1.jpeg
- text: A close-up portrait of a blonde woman with a confident expression, set against
a neon-lit cityscape at night. Vibrant colors with a bokeh effect in the background,
sharp focus on the face, cinematic lighting.
parameters:
negative_prompt: Blurry background, dull colors, poor focus, unbalanced lighting.
output:
url: images/22-12-2024-first-ki-lady-own-design.jpg
- text: A stunning woman with long red hair, wearing a sleek green dress, standing
in a futuristic corridor with glowing neon lights. High-tech and cyberpunk vibes,
sharp focus, vibrant colors.
parameters:
negative_prompt: lurry details, washed-out colors, inconsistent lighting, distorted
anatomy.
output:
url: images/26.jpg
- text: A stylish woman with blue hair, sitting elegantly on a modern chair in a minimalist
room, wearing a chic blue dress. The lighting is warm and soft, emphasizing the
textures and colors.
parameters:
negative_prompt: Blurry image, harsh lighting, cluttered background, dull colors.
output:
url: images/A_stunning_25_year_old_woman_with_long_blue_hair__wearing_a_mini_skirt_S1671993825_St70_G9.jpeg
instance_prompt: realistic, artistic, concept art, hyper-detailed, cinematic, vibrant
colors, minimalist, futuristic, fantasy, surreal, anime-style, watercolor, 3D render,
landscape
---
# Pix74
<Gallery />
## Model description
Pix74 is a cutting-edge AI model designed specifically for text-to-image applications. Built on the robust foundation of strangerzonehf/Flux-Midjourney-Mix2-LoRA, Pix74 seamlessly blends the flexibility and precision of LoRA technology with the creativity and diversity of the Flux-Midjourney-Mix series.
Key Features:
Creative Versatility: Pix74 generates realistic and artistic images suitable for various applications, ranging from PR and event projects to illustrations and concept art.
Efficient Fine-Tuning: With LoRA technology, the model can be quickly adapted to specific needs without requiring extensive resources.
User-Friendly Integration: Optimized for smooth integration into existing workflows, whether for corporate or creative projects.
Compact Performance: Despite its powerful architecture, Pix74 remains resource-efficient, making it suitable for hardware with limited capacities.
Use Cases:
Design and Illustration: Craft unique designs for graphics and promotional materials.
Content Creation: Support the development of visual content for social media and online platforms.
Creative Experiments: Explore new visual styles and artistic expressions.
## Trigger words
You should use `realistic` to trigger the image generation.
You should use `artistic` to trigger the image generation.
You should use `concept art` to trigger the image generation.
You should use `hyper-detailed` to trigger the image generation.
You should use `cinematic` to trigger the image generation.
You should use `vibrant colors` to trigger the image generation.
You should use `minimalist` to trigger the image generation.
You should use `futuristic` to trigger the image generation.
You should use `fantasy` to trigger the image generation.
You should use `surreal` to trigger the image generation.
You should use `anime-style` to trigger the image generation.
You should use `watercolor` to trigger the image generation.
You should use `3D render` to trigger the image generation.
You should use `landscape` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/Wolfram33/pix74/tree/main) them in the Files & versions tab.
|
[
"CRAFT"
] |
khaled-omar/distilroberta-ai-job-embeddings
|
khaled-omar
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"distilbert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:7999",
"loss:MultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:medicalai/ClinicalBERT",
"base_model:finetune:medicalai/ClinicalBERT",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2025-02-09T10:33:49Z |
2025-02-09T10:35:54+00:00
| 18 | 0 |
---
base_model: medicalai/ClinicalBERT
library_name: sentence-transformers
metrics:
- cosine_accuracy
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:7999
- loss:MultipleNegativesRankingLoss
widget:
- source_sentence: pt,dressing,pi,surgery,2 weeks,o,ozing,regular,dressing,weight,111.
800,height,179. 000,temperature,97. 700,pulse,88. 000,res,19. 000 bp,sy,sto,145.
000 bp,dia,sto,82. 000 spo,2,:,99,cap,blood sugar,ja,undice,ec,no past medical
history,no past medical history,no past medical history,no past medical history,no
past medical history,no past medical history,no past,no,no,no past,no,past,no,no,no,no,no,no,no,no,no,no,no,stable,stable,stable,stable,stable,stable,stable,stable,stable,stable,normal,no,surgical
history,no,surgical history,no,surgical history,no,no
sentences:
- Acne vulgaris
- Encounter for change or removal of surgical wound dressing
- Irritant contact dermatitis due to detergents
- source_sentence: 'fa,dubai,arab emirates,cardiac assessment,chest,pain,nausea,mild,dizzy,sleep,clinic,pulse,70,res,18,res,normal,sao,:,98,air
time,00 : 39 : 00,bp,140 / 100,cap,< 2 sec,temperature,36,>,3 reacts,right,>,3
reacts,total,gcs,15,car,mild'
sentences:
- Dizziness and giddiness
- Pruritus, unspecified
- Acute gastritis without bleeding
- source_sentence: low,back,pain,1,no,sp,fine,lower back,moderate,1 month,no,diseases,no,no,no,no,no,no,single,normal,no,no,no,normal,normal,normal,normal,cvs,cv,normal,abnormal,-
genito - urinary,normal,systems _ cns - cns,normal,musc,mu,normal,ps,normal,systems,endo
- end,normal,normal,haemo,haem,normal,low,back,pain,1 month
sentences:
- Headache
- Muscle spasm of back
- Other chest pain
- source_sentence: 'fa,ap,arab,mobility,knee assessment,ambula,tory,c,/,o,pain,swelling,right,cold
pack,crepebanda,v,pt,transfer,pulse,68r,16,res,normal,sao,: 100,air time,07 :
29 : 00,bp,112 / 78,cap,< 2 sec,4 reacts,right,-,>,3,reacts,gcs,15,pain,4,blood,car
accident,twisted,right ankle'
sentences:
- Unspecified injury of right ankle, initial encounter
- Other spondylosis with radiculopathy, lumbosacral region
- Right upper quadrant pain
- source_sentence: irregular,period,few months,moderate,few months ago,none,weight,90.
000,height,163. 000,temperature,98. 600,pulse,82. 000,respiration,19. 000 bp,systolic,110.
000 bp,diastolic,70. 000,sp,o,2,:,99,cap,blood sugar,ja,und,ice,ec,abd,an,l,girth,head,chest,ch
ida ch vitamin d deficiency,polycystic ovary syndrome,ch ida ch vitamin d deficiency,polycystic
ovary syndrome,ch,ida ch vitamin d deficiency,polycystic ovary syndrome,ch,ida
ch vitamin d deficiency,polycystic ovary syndrome,no,no family,no,no,nation,grade
11,grade 11,grade 11,grade 11,no,no,no,no,normal,normal,normal,normal,_ cvs,cv,normal,normal,irregular
period,cns,cn,normal,mu,normal,normal,normal,normal,normal,normal,irregular period
sentences:
- Pain in right hip
- Radial styloid tenosynovitis [de Quervain]
- Irregular menstruation, unspecified
model-index:
- name: SentenceTransformer based on medicalai/ClinicalBERT
results:
- task:
type: triplet
name: Triplet
dataset:
name: ai job validation
type: ai-job-validation
metrics:
- type: cosine_accuracy
value: 0.9429429173469543
name: Cosine Accuracy
- task:
type: triplet
name: Triplet
dataset:
name: ai job test
type: ai-job-test
metrics:
- type: cosine_accuracy
value: 0.9290709495544434
name: Cosine Accuracy
---
# SentenceTransformer based on medicalai/ClinicalBERT
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [medicalai/ClinicalBERT](https://huggingface.co/medicalai/ClinicalBERT) on the parquet dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [medicalai/ClinicalBERT](https://huggingface.co/medicalai/ClinicalBERT) <!-- at revision 3bb5faa9f33458dd7801549e88767c3b23264942 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- parquet
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("khaled-omar/distilroberta-ai-job-embeddings")
# Run inference
sentences = [
'irregular,period,few months,moderate,few months ago,none,weight,90. 000,height,163. 000,temperature,98. 600,pulse,82. 000,respiration,19. 000 bp,systolic,110. 000 bp,diastolic,70. 000,sp,o,2,:,99,cap,blood sugar,ja,und,ice,ec,abd,an,l,girth,head,chest,ch ida ch vitamin d deficiency,polycystic ovary syndrome,ch ida ch vitamin d deficiency,polycystic ovary syndrome,ch,ida ch vitamin d deficiency,polycystic ovary syndrome,ch,ida ch vitamin d deficiency,polycystic ovary syndrome,no,no family,no,no,nation,grade 11,grade 11,grade 11,grade 11,no,no,no,no,normal,normal,normal,normal,_ cvs,cv,normal,normal,irregular period,cns,cn,normal,mu,normal,normal,normal,normal,normal,normal,irregular period',
'Irregular menstruation, unspecified',
'Radial styloid tenosynovitis [de Quervain]',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Triplet
* Datasets: `ai-job-validation` and `ai-job-test`
* Evaluated with [<code>TripletEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.TripletEvaluator)
| Metric | ai-job-validation | ai-job-test |
|:--------------------|:------------------|:------------|
| **cosine_accuracy** | **0.9429** | **0.9291** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### parquet
* Dataset: parquet
* Size: 7,999 training samples
* Columns: <code>Entities</code>, <code>PosLongDesc</code>, and <code>NegLongDesc</code>
* Approximate statistics based on the first 1000 samples:
| | Entities | PosLongDesc | NegLongDesc |
|:--------|:------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 3 tokens</li><li>mean: 155.39 tokens</li><li>max: 485 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 10.62 tokens</li><li>max: 32 tokens</li></ul> | <ul><li>min: 3 tokens</li><li>mean: 10.35 tokens</li><li>max: 31 tokens</li></ul> |
* Samples:
| Entities | PosLongDesc | NegLongDesc |
|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------|
| <code>it,chiness,since 3 months,it,chiness,since,3 months,weight,90. 100,height,178. 000,temperature,98. 060,pulse,84. 000,respiration,0. 000 bp,sy,sto,122. 000 bp,dia,69. 000,sp,o,:,99,cap,blood sugar,ja,undice,ec,abd,an,rth,nonsignificant,nonsignificant,nonsignifican,t,no family,nonsignificant family,nonsignificant family,nonsignificant,no relevant family history,yes,married, smoker, carpenter,married, smoker, carpenter social,married, smoker, carpenter social history,nonsignificant,nonsignificant,nonsignificant,it,chiness,3 months,treatment</code> | <code>Rash and other nonspecific skin eruption</code> | <code>Acute nasopharyngitis [common cold]</code> |
| <code>amc,dubai,united arab emirates,uma,pa,gut,hari,val,electrocard,gram,pt,amc,sitting,coherent,w /,can,nula,bra,chia,vital,85,18,res,normal,sao,100,air time,17,: 51 : 34,bp,120 / 81,cap,<,2,sec,temperature,> 4 reacts,>,4,reacts,total,gcs,15,pain,0,blood glucose,102,car,accident,drug overdose,intentional</code> | <code>Epileptic seizures related to external causes, not intractable, without status epilepticus</code> | <code>COVID-19</code> |
| <code>amc gate,dubai,united arab emirates,ssi,test,airports,dubai,concourse,ent assessment,throat,transported,endorsed,pulse :,77r,14,res,normal %,sao,2 :,100,air time,05 :,26,:,00,bp,118 / 69,cap,<,2,sec,temperature,36. 7,pupil,left,>,4,reacts,right,>,4,reacts,gcs,15,pain,2,blood glucose,96,car,accident,no,throatpain</code> | <code>Pain in throat</code> | <code>Encounter for observation for suspected exposure to other biological agents ruled out</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Evaluation Dataset
#### parquet
* Dataset: parquet
* Size: 999 evaluation samples
* Columns: <code>Entities</code>, <code>PosLongDesc</code>, and <code>NegLongDesc</code>
* Approximate statistics based on the first 999 samples:
| | Entities | PosLongDesc | NegLongDesc |
|:--------|:------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 4 tokens</li><li>mean: 154.58 tokens</li><li>max: 470 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 10.61 tokens</li><li>max: 31 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 10.12 tokens</li><li>max: 35 tokens</li></ul> |
* Samples:
| Entities | PosLongDesc | NegLongDesc |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------|:------------------------------------------------------------|
| <code>it,chy,redness,3 days,both,it,ching,mild,moderate,3 days,weight,50. 200,height,143. 000,temperature,98. 240,pulse,78. 000,respiration,0. 000 bp,systolic,0. 000 bp,dia,sto,lic,0. 000,sp,o,2,:,99,cap,blood sugar,ja,undice,ec,abd,no past medical history,no past medical history,unknown family medical history,negative family,chronic disease,no diabetic mellitus,no hypertention,negative family,chronic disease,no diabetic mellitus,no hypertention,no,7 years and,7 months,7 years,7 months,no,removal,int,removal,int,red,it,chy,it,chy,redness,3 days</code> | <code>Acute atopic conjunctivitis, bilateral</code> | <code>Deficiency of other specified B group vitamins</code> |
| <code>pi,mples,pustules,plus,minus,cyst,both side,of the face,too,it,ching,skin,4,pi,notice,increase,laser removal,facial,expose,sun,pust,cyst,it,weight,52,.,800,height,159. 000,temperature,98. 100,pulse,93. 000,res,0. 000 bp,sy,sto,99. 000 bp,sto,60. 000,sp,o,98,cap,blood sugar,ja,undice,ec,no,no,ro,course,ro,not,course,no diabetic mellitus,no,les,no diabetic,mellit,us,no,les,basic,nation,nation,13,years,months,15 years,11 months,old,pu,ules,plus,cyst,side</code> | <code>Local infection of the skin and subcutaneous tissue, unspecified</code> | <code>Inflammatory polyarthropathy</code> |
| <code>respiratory rate,sp,pain,sy,lic,bp,mm,dia,bp,mm,height,weight,00 kg,repeat,prescription</code> | <code>Menopausal and female climacteric states</code> | <code>COVID-19</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `learning_rate`: 2e-05
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | ai-job-validation_cosine_accuracy | ai-job-test_cosine_accuracy |
|:-----:|:----:|:-------------:|:---------------:|:---------------------------------:|:---------------------------:|
| -1 | -1 | - | - | 0.5495 | - |
| 0.2 | 100 | 2.8729 | 1.8172 | 0.8789 | - |
| 0.4 | 200 | 2.085 | 1.4398 | 0.9259 | - |
| 0.6 | 300 | 1.8233 | 1.3448 | 0.9339 | - |
| 0.8 | 400 | 1.6871 | 1.2579 | 0.9409 | - |
| 1.0 | 500 | 1.4881 | 1.2327 | 0.9429 | - |
| -1 | -1 | - | - | 0.9429 | 0.9291 |
### Framework Versions
- Python: 3.11.4
- Sentence Transformers: 3.4.1
- Transformers: 4.41.2
- PyTorch: 2.3.1+cpu
- Accelerate: 1.3.0
- Datasets: 3.2.0
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"CHIA"
] |
soumitsr/GIST-small-Embedding-v0-Q8_0-GGUF
|
soumitsr
|
sentence-similarity
|
[
"sentence-transformers",
"gguf",
"feature-extraction",
"mteb",
"sentence-similarity",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:avsolatorio/GIST-small-Embedding-v0",
"base_model:quantized:avsolatorio/GIST-small-Embedding-v0",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2025-02-11T15:26:54Z |
2025-02-11T15:26:58+00:00
| 18 | 0 |
---
base_model: avsolatorio/GIST-small-Embedding-v0
language:
- en
library_name: sentence-transformers
license: mit
pipeline_tag: sentence-similarity
tags:
- feature-extraction
- mteb
- sentence-similarity
- sentence-transformers
- llama-cpp
- gguf-my-repo
model-index:
- name: GIST-small-Embedding-v0
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.26865671641791
- type: ap
value: 38.25623793370476
- type: f1
value: 69.26434651320257
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.232225
- type: ap
value: 89.97936072879344
- type: f1
value: 93.22122653806187
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.715999999999994
- type: f1
value: 49.169789920136076
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 34.922
- type: map_at_10
value: 50.524
- type: map_at_100
value: 51.247
- type: map_at_1000
value: 51.249
- type: map_at_3
value: 45.887
- type: map_at_5
value: 48.592999999999996
- type: mrr_at_1
value: 34.922
- type: mrr_at_10
value: 50.382000000000005
- type: mrr_at_100
value: 51.104000000000006
- type: mrr_at_1000
value: 51.105999999999995
- type: mrr_at_3
value: 45.733000000000004
- type: mrr_at_5
value: 48.428
- type: ndcg_at_1
value: 34.922
- type: ndcg_at_10
value: 59.12
- type: ndcg_at_100
value: 62.083999999999996
- type: ndcg_at_1000
value: 62.137
- type: ndcg_at_3
value: 49.616
- type: ndcg_at_5
value: 54.501
- type: precision_at_1
value: 34.922
- type: precision_at_10
value: 8.649
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.152
- type: precision_at_5
value: 14.466999999999999
- type: recall_at_1
value: 34.922
- type: recall_at_10
value: 86.48599999999999
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 60.455000000000005
- type: recall_at_5
value: 72.333
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.623282347623714
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 39.86487843524932
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.3290291318171
- type: mrr
value: 75.2379853141626
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 88.52002953574285
- type: cos_sim_spearman
value: 86.98752423842483
- type: euclidean_pearson
value: 86.89442688314197
- type: euclidean_spearman
value: 86.88631711307471
- type: manhattan_pearson
value: 87.03723618507175
- type: manhattan_spearman
value: 86.76041062975224
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 86.64935064935065
- type: f1
value: 86.61903824934998
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.21904455377494
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.43342755570654
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.843
- type: map_at_10
value: 43.379
- type: map_at_100
value: 44.946999999999996
- type: map_at_1000
value: 45.078
- type: map_at_3
value: 39.598
- type: map_at_5
value: 41.746
- type: mrr_at_1
value: 39.199
- type: mrr_at_10
value: 49.672
- type: mrr_at_100
value: 50.321000000000005
- type: mrr_at_1000
value: 50.365
- type: mrr_at_3
value: 46.805
- type: mrr_at_5
value: 48.579
- type: ndcg_at_1
value: 39.199
- type: ndcg_at_10
value: 50.163999999999994
- type: ndcg_at_100
value: 55.418
- type: ndcg_at_1000
value: 57.353
- type: ndcg_at_3
value: 44.716
- type: ndcg_at_5
value: 47.268
- type: precision_at_1
value: 39.199
- type: precision_at_10
value: 9.757
- type: precision_at_100
value: 1.552
- type: precision_at_1000
value: 0.20500000000000002
- type: precision_at_3
value: 21.602
- type: precision_at_5
value: 15.479000000000001
- type: recall_at_1
value: 31.843
- type: recall_at_10
value: 62.743
- type: recall_at_100
value: 84.78099999999999
- type: recall_at_1000
value: 96.86099999999999
- type: recall_at_3
value: 46.927
- type: recall_at_5
value: 54.355
- type: map_at_1
value: 29.321
- type: map_at_10
value: 39.062999999999995
- type: map_at_100
value: 40.403
- type: map_at_1000
value: 40.534
- type: map_at_3
value: 36.367
- type: map_at_5
value: 37.756
- type: mrr_at_1
value: 35.987
- type: mrr_at_10
value: 44.708999999999996
- type: mrr_at_100
value: 45.394
- type: mrr_at_1000
value: 45.436
- type: mrr_at_3
value: 42.463
- type: mrr_at_5
value: 43.663000000000004
- type: ndcg_at_1
value: 35.987
- type: ndcg_at_10
value: 44.585
- type: ndcg_at_100
value: 49.297999999999995
- type: ndcg_at_1000
value: 51.315
- type: ndcg_at_3
value: 40.569
- type: ndcg_at_5
value: 42.197
- type: precision_at_1
value: 35.987
- type: precision_at_10
value: 8.369
- type: precision_at_100
value: 1.366
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 19.427
- type: precision_at_5
value: 13.58
- type: recall_at_1
value: 29.321
- type: recall_at_10
value: 54.333
- type: recall_at_100
value: 74.178
- type: recall_at_1000
value: 86.732
- type: recall_at_3
value: 42.46
- type: recall_at_5
value: 47.089999999999996
- type: map_at_1
value: 38.811
- type: map_at_10
value: 51.114000000000004
- type: map_at_100
value: 52.22
- type: map_at_1000
value: 52.275000000000006
- type: map_at_3
value: 47.644999999999996
- type: map_at_5
value: 49.675000000000004
- type: mrr_at_1
value: 44.389
- type: mrr_at_10
value: 54.459
- type: mrr_at_100
value: 55.208999999999996
- type: mrr_at_1000
value: 55.239000000000004
- type: mrr_at_3
value: 51.954
- type: mrr_at_5
value: 53.571999999999996
- type: ndcg_at_1
value: 44.389
- type: ndcg_at_10
value: 56.979
- type: ndcg_at_100
value: 61.266
- type: ndcg_at_1000
value: 62.315
- type: ndcg_at_3
value: 51.342
- type: ndcg_at_5
value: 54.33
- type: precision_at_1
value: 44.389
- type: precision_at_10
value: 9.26
- type: precision_at_100
value: 1.226
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 22.926
- type: precision_at_5
value: 15.987000000000002
- type: recall_at_1
value: 38.811
- type: recall_at_10
value: 70.841
- type: recall_at_100
value: 89.218
- type: recall_at_1000
value: 96.482
- type: recall_at_3
value: 56.123999999999995
- type: recall_at_5
value: 63.322
- type: map_at_1
value: 25.378
- type: map_at_10
value: 34.311
- type: map_at_100
value: 35.399
- type: map_at_1000
value: 35.482
- type: map_at_3
value: 31.917
- type: map_at_5
value: 33.275
- type: mrr_at_1
value: 27.683999999999997
- type: mrr_at_10
value: 36.575
- type: mrr_at_100
value: 37.492
- type: mrr_at_1000
value: 37.556
- type: mrr_at_3
value: 34.35
- type: mrr_at_5
value: 35.525
- type: ndcg_at_1
value: 27.683999999999997
- type: ndcg_at_10
value: 39.247
- type: ndcg_at_100
value: 44.424
- type: ndcg_at_1000
value: 46.478
- type: ndcg_at_3
value: 34.684
- type: ndcg_at_5
value: 36.886
- type: precision_at_1
value: 27.683999999999997
- type: precision_at_10
value: 5.989
- type: precision_at_100
value: 0.899
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 14.84
- type: precision_at_5
value: 10.215
- type: recall_at_1
value: 25.378
- type: recall_at_10
value: 52.195
- type: recall_at_100
value: 75.764
- type: recall_at_1000
value: 91.012
- type: recall_at_3
value: 39.885999999999996
- type: recall_at_5
value: 45.279
- type: map_at_1
value: 17.326
- type: map_at_10
value: 25.247000000000003
- type: map_at_100
value: 26.473000000000003
- type: map_at_1000
value: 26.579000000000004
- type: map_at_3
value: 22.466
- type: map_at_5
value: 24.113
- type: mrr_at_1
value: 21.393
- type: mrr_at_10
value: 30.187
- type: mrr_at_100
value: 31.089
- type: mrr_at_1000
value: 31.15
- type: mrr_at_3
value: 27.279999999999998
- type: mrr_at_5
value: 29.127
- type: ndcg_at_1
value: 21.393
- type: ndcg_at_10
value: 30.668
- type: ndcg_at_100
value: 36.543
- type: ndcg_at_1000
value: 39.181
- type: ndcg_at_3
value: 25.552000000000003
- type: ndcg_at_5
value: 28.176000000000002
- type: precision_at_1
value: 21.393
- type: precision_at_10
value: 5.784000000000001
- type: precision_at_100
value: 1.001
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 12.231
- type: precision_at_5
value: 9.179
- type: recall_at_1
value: 17.326
- type: recall_at_10
value: 42.415000000000006
- type: recall_at_100
value: 68.605
- type: recall_at_1000
value: 87.694
- type: recall_at_3
value: 28.343
- type: recall_at_5
value: 35.086
- type: map_at_1
value: 29.069
- type: map_at_10
value: 40.027
- type: map_at_100
value: 41.308
- type: map_at_1000
value: 41.412
- type: map_at_3
value: 36.864000000000004
- type: map_at_5
value: 38.641999999999996
- type: mrr_at_1
value: 35.707
- type: mrr_at_10
value: 45.527
- type: mrr_at_100
value: 46.348
- type: mrr_at_1000
value: 46.392
- type: mrr_at_3
value: 43.086
- type: mrr_at_5
value: 44.645
- type: ndcg_at_1
value: 35.707
- type: ndcg_at_10
value: 46.117000000000004
- type: ndcg_at_100
value: 51.468
- type: ndcg_at_1000
value: 53.412000000000006
- type: ndcg_at_3
value: 41.224
- type: ndcg_at_5
value: 43.637
- type: precision_at_1
value: 35.707
- type: precision_at_10
value: 8.459999999999999
- type: precision_at_100
value: 1.2970000000000002
- type: precision_at_1000
value: 0.165
- type: precision_at_3
value: 19.731
- type: precision_at_5
value: 14.013
- type: recall_at_1
value: 29.069
- type: recall_at_10
value: 58.343999999999994
- type: recall_at_100
value: 81.296
- type: recall_at_1000
value: 93.974
- type: recall_at_3
value: 44.7
- type: recall_at_5
value: 50.88700000000001
- type: map_at_1
value: 23.905
- type: map_at_10
value: 33.983000000000004
- type: map_at_100
value: 35.372
- type: map_at_1000
value: 35.487
- type: map_at_3
value: 30.902
- type: map_at_5
value: 32.505
- type: mrr_at_1
value: 29.794999999999998
- type: mrr_at_10
value: 39.28
- type: mrr_at_100
value: 40.215
- type: mrr_at_1000
value: 40.276
- type: mrr_at_3
value: 36.701
- type: mrr_at_5
value: 38.105
- type: ndcg_at_1
value: 29.794999999999998
- type: ndcg_at_10
value: 40.041
- type: ndcg_at_100
value: 45.884
- type: ndcg_at_1000
value: 48.271
- type: ndcg_at_3
value: 34.931
- type: ndcg_at_5
value: 37.044
- type: precision_at_1
value: 29.794999999999998
- type: precision_at_10
value: 7.546
- type: precision_at_100
value: 1.216
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 16.933
- type: precision_at_5
value: 12.1
- type: recall_at_1
value: 23.905
- type: recall_at_10
value: 52.945
- type: recall_at_100
value: 77.551
- type: recall_at_1000
value: 93.793
- type: recall_at_3
value: 38.364
- type: recall_at_5
value: 44.044
- type: map_at_1
value: 25.24441666666667
- type: map_at_10
value: 34.4595
- type: map_at_100
value: 35.699999999999996
- type: map_at_1000
value: 35.8155
- type: map_at_3
value: 31.608333333333338
- type: map_at_5
value: 33.189416666666666
- type: mrr_at_1
value: 29.825250000000004
- type: mrr_at_10
value: 38.60875
- type: mrr_at_100
value: 39.46575
- type: mrr_at_1000
value: 39.52458333333333
- type: mrr_at_3
value: 36.145166666666675
- type: mrr_at_5
value: 37.57625
- type: ndcg_at_1
value: 29.825250000000004
- type: ndcg_at_10
value: 39.88741666666667
- type: ndcg_at_100
value: 45.17966666666667
- type: ndcg_at_1000
value: 47.440583333333336
- type: ndcg_at_3
value: 35.04591666666666
- type: ndcg_at_5
value: 37.32025
- type: precision_at_1
value: 29.825250000000004
- type: precision_at_10
value: 7.07225
- type: precision_at_100
value: 1.1462499999999998
- type: precision_at_1000
value: 0.15325
- type: precision_at_3
value: 16.18375
- type: precision_at_5
value: 11.526833333333334
- type: recall_at_1
value: 25.24441666666667
- type: recall_at_10
value: 51.744916666666676
- type: recall_at_100
value: 75.04574999999998
- type: recall_at_1000
value: 90.65558333333334
- type: recall_at_3
value: 38.28349999999999
- type: recall_at_5
value: 44.16591666666667
- type: map_at_1
value: 24.237000000000002
- type: map_at_10
value: 30.667
- type: map_at_100
value: 31.592
- type: map_at_1000
value: 31.688
- type: map_at_3
value: 28.810999999999996
- type: map_at_5
value: 29.788999999999998
- type: mrr_at_1
value: 26.840000000000003
- type: mrr_at_10
value: 33.305
- type: mrr_at_100
value: 34.089000000000006
- type: mrr_at_1000
value: 34.159
- type: mrr_at_3
value: 31.518
- type: mrr_at_5
value: 32.469
- type: ndcg_at_1
value: 26.840000000000003
- type: ndcg_at_10
value: 34.541
- type: ndcg_at_100
value: 39.206
- type: ndcg_at_1000
value: 41.592
- type: ndcg_at_3
value: 31.005
- type: ndcg_at_5
value: 32.554
- type: precision_at_1
value: 26.840000000000003
- type: precision_at_10
value: 5.3069999999999995
- type: precision_at_100
value: 0.8340000000000001
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 13.292000000000002
- type: precision_at_5
value: 9.049
- type: recall_at_1
value: 24.237000000000002
- type: recall_at_10
value: 43.862
- type: recall_at_100
value: 65.352
- type: recall_at_1000
value: 82.704
- type: recall_at_3
value: 34.009
- type: recall_at_5
value: 37.878
- type: map_at_1
value: 16.482
- type: map_at_10
value: 23.249
- type: map_at_100
value: 24.388
- type: map_at_1000
value: 24.519
- type: map_at_3
value: 20.971
- type: map_at_5
value: 22.192
- type: mrr_at_1
value: 19.993
- type: mrr_at_10
value: 26.985
- type: mrr_at_100
value: 27.975
- type: mrr_at_1000
value: 28.052
- type: mrr_at_3
value: 24.954
- type: mrr_at_5
value: 26.070999999999998
- type: ndcg_at_1
value: 19.993
- type: ndcg_at_10
value: 27.656
- type: ndcg_at_100
value: 33.256
- type: ndcg_at_1000
value: 36.275
- type: ndcg_at_3
value: 23.644000000000002
- type: ndcg_at_5
value: 25.466
- type: precision_at_1
value: 19.993
- type: precision_at_10
value: 5.093
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 11.149000000000001
- type: precision_at_5
value: 8.149000000000001
- type: recall_at_1
value: 16.482
- type: recall_at_10
value: 37.141999999999996
- type: recall_at_100
value: 62.696
- type: recall_at_1000
value: 84.333
- type: recall_at_3
value: 26.031
- type: recall_at_5
value: 30.660999999999998
- type: map_at_1
value: 24.887999999999998
- type: map_at_10
value: 34.101
- type: map_at_100
value: 35.27
- type: map_at_1000
value: 35.370000000000005
- type: map_at_3
value: 31.283
- type: map_at_5
value: 32.72
- type: mrr_at_1
value: 29.011
- type: mrr_at_10
value: 38.004
- type: mrr_at_100
value: 38.879000000000005
- type: mrr_at_1000
value: 38.938
- type: mrr_at_3
value: 35.571999999999996
- type: mrr_at_5
value: 36.789
- type: ndcg_at_1
value: 29.011
- type: ndcg_at_10
value: 39.586
- type: ndcg_at_100
value: 44.939
- type: ndcg_at_1000
value: 47.236
- type: ndcg_at_3
value: 34.4
- type: ndcg_at_5
value: 36.519
- type: precision_at_1
value: 29.011
- type: precision_at_10
value: 6.763
- type: precision_at_100
value: 1.059
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 15.609
- type: precision_at_5
value: 10.896
- type: recall_at_1
value: 24.887999999999998
- type: recall_at_10
value: 52.42
- type: recall_at_100
value: 75.803
- type: recall_at_1000
value: 91.725
- type: recall_at_3
value: 38.080999999999996
- type: recall_at_5
value: 43.47
- type: map_at_1
value: 23.953
- type: map_at_10
value: 32.649
- type: map_at_100
value: 34.181
- type: map_at_1000
value: 34.398
- type: map_at_3
value: 29.567
- type: map_at_5
value: 31.263
- type: mrr_at_1
value: 29.051
- type: mrr_at_10
value: 37.419999999999995
- type: mrr_at_100
value: 38.396
- type: mrr_at_1000
value: 38.458
- type: mrr_at_3
value: 34.782999999999994
- type: mrr_at_5
value: 36.254999999999995
- type: ndcg_at_1
value: 29.051
- type: ndcg_at_10
value: 38.595
- type: ndcg_at_100
value: 44.6
- type: ndcg_at_1000
value: 47.158
- type: ndcg_at_3
value: 33.56
- type: ndcg_at_5
value: 35.870000000000005
- type: precision_at_1
value: 29.051
- type: precision_at_10
value: 7.53
- type: precision_at_100
value: 1.538
- type: precision_at_1000
value: 0.24
- type: precision_at_3
value: 15.744
- type: precision_at_5
value: 11.542
- type: recall_at_1
value: 23.953
- type: recall_at_10
value: 50.08200000000001
- type: recall_at_100
value: 77.364
- type: recall_at_1000
value: 93.57799999999999
- type: recall_at_3
value: 35.432
- type: recall_at_5
value: 41.875
- type: map_at_1
value: 17.72
- type: map_at_10
value: 25.724000000000004
- type: map_at_100
value: 26.846999999999998
- type: map_at_1000
value: 26.964
- type: map_at_3
value: 22.909
- type: map_at_5
value: 24.596999999999998
- type: mrr_at_1
value: 18.854000000000003
- type: mrr_at_10
value: 27.182000000000002
- type: mrr_at_100
value: 28.182000000000002
- type: mrr_at_1000
value: 28.274
- type: mrr_at_3
value: 24.276
- type: mrr_at_5
value: 26.115
- type: ndcg_at_1
value: 18.854000000000003
- type: ndcg_at_10
value: 30.470000000000002
- type: ndcg_at_100
value: 35.854
- type: ndcg_at_1000
value: 38.701
- type: ndcg_at_3
value: 24.924
- type: ndcg_at_5
value: 27.895999999999997
- type: precision_at_1
value: 18.854000000000003
- type: precision_at_10
value: 5.009
- type: precision_at_100
value: 0.835
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 10.721
- type: precision_at_5
value: 8.133
- type: recall_at_1
value: 17.72
- type: recall_at_10
value: 43.617
- type: recall_at_100
value: 67.941
- type: recall_at_1000
value: 88.979
- type: recall_at_3
value: 29.044999999999998
- type: recall_at_5
value: 36.044
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 13.427
- type: map_at_10
value: 22.935
- type: map_at_100
value: 24.808
- type: map_at_1000
value: 24.994
- type: map_at_3
value: 19.533
- type: map_at_5
value: 21.261
- type: mrr_at_1
value: 30.945
- type: mrr_at_10
value: 43.242000000000004
- type: mrr_at_100
value: 44.013999999999996
- type: mrr_at_1000
value: 44.048
- type: mrr_at_3
value: 40.109
- type: mrr_at_5
value: 42.059999999999995
- type: ndcg_at_1
value: 30.945
- type: ndcg_at_10
value: 31.828
- type: ndcg_at_100
value: 38.801
- type: ndcg_at_1000
value: 42.126999999999995
- type: ndcg_at_3
value: 26.922
- type: ndcg_at_5
value: 28.483999999999998
- type: precision_at_1
value: 30.945
- type: precision_at_10
value: 9.844
- type: precision_at_100
value: 1.7309999999999999
- type: precision_at_1000
value: 0.23500000000000001
- type: precision_at_3
value: 20.477999999999998
- type: precision_at_5
value: 15.27
- type: recall_at_1
value: 13.427
- type: recall_at_10
value: 37.141000000000005
- type: recall_at_100
value: 61.007
- type: recall_at_1000
value: 79.742
- type: recall_at_3
value: 24.431
- type: recall_at_5
value: 29.725
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.122
- type: map_at_10
value: 18.799
- type: map_at_100
value: 25.724999999999998
- type: map_at_1000
value: 27.205000000000002
- type: map_at_3
value: 14.194999999999999
- type: map_at_5
value: 16.225
- type: mrr_at_1
value: 68.0
- type: mrr_at_10
value: 76.035
- type: mrr_at_100
value: 76.292
- type: mrr_at_1000
value: 76.297
- type: mrr_at_3
value: 74.458
- type: mrr_at_5
value: 75.558
- type: ndcg_at_1
value: 56.00000000000001
- type: ndcg_at_10
value: 39.761
- type: ndcg_at_100
value: 43.736999999999995
- type: ndcg_at_1000
value: 51.146
- type: ndcg_at_3
value: 45.921
- type: ndcg_at_5
value: 42.756
- type: precision_at_1
value: 68.0
- type: precision_at_10
value: 30.275000000000002
- type: precision_at_100
value: 9.343
- type: precision_at_1000
value: 1.8270000000000002
- type: precision_at_3
value: 49.167
- type: precision_at_5
value: 40.699999999999996
- type: recall_at_1
value: 9.122
- type: recall_at_10
value: 23.669999999999998
- type: recall_at_100
value: 48.719
- type: recall_at_1000
value: 72.033
- type: recall_at_3
value: 15.498999999999999
- type: recall_at_5
value: 18.657
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 55.885000000000005
- type: f1
value: 50.70726446938571
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 75.709
- type: map_at_10
value: 83.345
- type: map_at_100
value: 83.557
- type: map_at_1000
value: 83.572
- type: map_at_3
value: 82.425
- type: map_at_5
value: 83.013
- type: mrr_at_1
value: 81.593
- type: mrr_at_10
value: 88.331
- type: mrr_at_100
value: 88.408
- type: mrr_at_1000
value: 88.41
- type: mrr_at_3
value: 87.714
- type: mrr_at_5
value: 88.122
- type: ndcg_at_1
value: 81.593
- type: ndcg_at_10
value: 86.925
- type: ndcg_at_100
value: 87.67
- type: ndcg_at_1000
value: 87.924
- type: ndcg_at_3
value: 85.5
- type: ndcg_at_5
value: 86.283
- type: precision_at_1
value: 81.593
- type: precision_at_10
value: 10.264
- type: precision_at_100
value: 1.084
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 32.388
- type: precision_at_5
value: 19.991
- type: recall_at_1
value: 75.709
- type: recall_at_10
value: 93.107
- type: recall_at_100
value: 96.024
- type: recall_at_1000
value: 97.603
- type: recall_at_3
value: 89.08500000000001
- type: recall_at_5
value: 91.15299999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.121
- type: map_at_10
value: 31.78
- type: map_at_100
value: 33.497
- type: map_at_1000
value: 33.696
- type: map_at_3
value: 27.893
- type: map_at_5
value: 30.087000000000003
- type: mrr_at_1
value: 38.272
- type: mrr_at_10
value: 47.176
- type: mrr_at_100
value: 48.002
- type: mrr_at_1000
value: 48.044
- type: mrr_at_3
value: 45.086999999999996
- type: mrr_at_5
value: 46.337
- type: ndcg_at_1
value: 38.272
- type: ndcg_at_10
value: 39.145
- type: ndcg_at_100
value: 45.696999999999996
- type: ndcg_at_1000
value: 49.0
- type: ndcg_at_3
value: 36.148
- type: ndcg_at_5
value: 37.023
- type: precision_at_1
value: 38.272
- type: precision_at_10
value: 11.065
- type: precision_at_100
value: 1.7840000000000003
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 24.587999999999997
- type: precision_at_5
value: 18.056
- type: recall_at_1
value: 19.121
- type: recall_at_10
value: 44.857
- type: recall_at_100
value: 69.774
- type: recall_at_1000
value: 89.645
- type: recall_at_3
value: 32.588
- type: recall_at_5
value: 37.939
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.428
- type: map_at_10
value: 56.891999999999996
- type: map_at_100
value: 57.82899999999999
- type: map_at_1000
value: 57.896
- type: map_at_3
value: 53.762
- type: map_at_5
value: 55.718
- type: mrr_at_1
value: 72.856
- type: mrr_at_10
value: 79.245
- type: mrr_at_100
value: 79.515
- type: mrr_at_1000
value: 79.525
- type: mrr_at_3
value: 78.143
- type: mrr_at_5
value: 78.822
- type: ndcg_at_1
value: 72.856
- type: ndcg_at_10
value: 65.204
- type: ndcg_at_100
value: 68.552
- type: ndcg_at_1000
value: 69.902
- type: ndcg_at_3
value: 60.632
- type: ndcg_at_5
value: 63.161
- type: precision_at_1
value: 72.856
- type: precision_at_10
value: 13.65
- type: precision_at_100
value: 1.6260000000000001
- type: precision_at_1000
value: 0.181
- type: precision_at_3
value: 38.753
- type: precision_at_5
value: 25.251
- type: recall_at_1
value: 36.428
- type: recall_at_10
value: 68.25099999999999
- type: recall_at_100
value: 81.317
- type: recall_at_1000
value: 90.27
- type: recall_at_3
value: 58.13
- type: recall_at_5
value: 63.126000000000005
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 89.4868
- type: ap
value: 84.88319192880247
- type: f1
value: 89.46144458052846
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.282999999999998
- type: map_at_10
value: 33.045
- type: map_at_100
value: 34.238
- type: map_at_1000
value: 34.29
- type: map_at_3
value: 29.305999999999997
- type: map_at_5
value: 31.391000000000002
- type: mrr_at_1
value: 21.92
- type: mrr_at_10
value: 33.649
- type: mrr_at_100
value: 34.791
- type: mrr_at_1000
value: 34.837
- type: mrr_at_3
value: 30.0
- type: mrr_at_5
value: 32.039
- type: ndcg_at_1
value: 21.92
- type: ndcg_at_10
value: 39.729
- type: ndcg_at_100
value: 45.484
- type: ndcg_at_1000
value: 46.817
- type: ndcg_at_3
value: 32.084
- type: ndcg_at_5
value: 35.789
- type: precision_at_1
value: 21.92
- type: precision_at_10
value: 6.297
- type: precision_at_100
value: 0.918
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 13.639000000000001
- type: precision_at_5
value: 10.054
- type: recall_at_1
value: 21.282999999999998
- type: recall_at_10
value: 60.343999999999994
- type: recall_at_100
value: 86.981
- type: recall_at_1000
value: 97.205
- type: recall_at_3
value: 39.452999999999996
- type: recall_at_5
value: 48.333
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 95.47879616963064
- type: f1
value: 95.21800589958251
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.09256725946192
- type: f1
value: 60.554043889452515
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.53463349024882
- type: f1
value: 73.14418495756476
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.22663080026899
- type: f1
value: 79.331456217501
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 34.50316010430136
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.15612040042282
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.36227552557184
- type: mrr
value: 33.57901344209811
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.6610000000000005
- type: map_at_10
value: 12.992
- type: map_at_100
value: 16.756999999999998
- type: map_at_1000
value: 18.25
- type: map_at_3
value: 9.471
- type: map_at_5
value: 11.116
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 53.388999999999996
- type: mrr_at_100
value: 53.982
- type: mrr_at_1000
value: 54.033
- type: mrr_at_3
value: 51.858000000000004
- type: mrr_at_5
value: 53.019000000000005
- type: ndcg_at_1
value: 41.641
- type: ndcg_at_10
value: 34.691
- type: ndcg_at_100
value: 32.305
- type: ndcg_at_1000
value: 41.132999999999996
- type: ndcg_at_3
value: 40.614
- type: ndcg_at_5
value: 38.456
- type: precision_at_1
value: 43.344
- type: precision_at_10
value: 25.881999999999998
- type: precision_at_100
value: 8.483
- type: precision_at_1000
value: 2.131
- type: precision_at_3
value: 38.803
- type: precision_at_5
value: 33.87
- type: recall_at_1
value: 5.6610000000000005
- type: recall_at_10
value: 16.826
- type: recall_at_100
value: 32.939
- type: recall_at_1000
value: 65.161
- type: recall_at_3
value: 10.756
- type: recall_at_5
value: 13.331000000000001
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.692
- type: map_at_10
value: 41.065000000000005
- type: map_at_100
value: 42.235
- type: map_at_1000
value: 42.27
- type: map_at_3
value: 36.635
- type: map_at_5
value: 39.219
- type: mrr_at_1
value: 30.214000000000002
- type: mrr_at_10
value: 43.443
- type: mrr_at_100
value: 44.326
- type: mrr_at_1000
value: 44.352000000000004
- type: mrr_at_3
value: 39.623999999999995
- type: mrr_at_5
value: 41.898
- type: ndcg_at_1
value: 30.214000000000002
- type: ndcg_at_10
value: 48.692
- type: ndcg_at_100
value: 53.671
- type: ndcg_at_1000
value: 54.522000000000006
- type: ndcg_at_3
value: 40.245
- type: ndcg_at_5
value: 44.580999999999996
- type: precision_at_1
value: 30.214000000000002
- type: precision_at_10
value: 8.3
- type: precision_at_100
value: 1.1079999999999999
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 18.521
- type: precision_at_5
value: 13.627
- type: recall_at_1
value: 26.692
- type: recall_at_10
value: 69.699
- type: recall_at_100
value: 91.425
- type: recall_at_1000
value: 97.78099999999999
- type: recall_at_3
value: 47.711
- type: recall_at_5
value: 57.643
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.962
- type: map_at_10
value: 84.772
- type: map_at_100
value: 85.402
- type: map_at_1000
value: 85.418
- type: map_at_3
value: 81.89
- type: map_at_5
value: 83.685
- type: mrr_at_1
value: 81.67
- type: mrr_at_10
value: 87.681
- type: mrr_at_100
value: 87.792
- type: mrr_at_1000
value: 87.79299999999999
- type: mrr_at_3
value: 86.803
- type: mrr_at_5
value: 87.392
- type: ndcg_at_1
value: 81.69
- type: ndcg_at_10
value: 88.429
- type: ndcg_at_100
value: 89.66
- type: ndcg_at_1000
value: 89.762
- type: ndcg_at_3
value: 85.75
- type: ndcg_at_5
value: 87.20700000000001
- type: precision_at_1
value: 81.69
- type: precision_at_10
value: 13.395000000000001
- type: precision_at_100
value: 1.528
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.507000000000005
- type: precision_at_5
value: 24.614
- type: recall_at_1
value: 70.962
- type: recall_at_10
value: 95.339
- type: recall_at_100
value: 99.543
- type: recall_at_1000
value: 99.984
- type: recall_at_3
value: 87.54899999999999
- type: recall_at_5
value: 91.726
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.506631779239555
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 60.63731341848479
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.852
- type: map_at_10
value: 13.175
- type: map_at_100
value: 15.623999999999999
- type: map_at_1000
value: 16.002
- type: map_at_3
value: 9.103
- type: map_at_5
value: 11.068999999999999
- type: mrr_at_1
value: 23.9
- type: mrr_at_10
value: 35.847
- type: mrr_at_100
value: 36.968
- type: mrr_at_1000
value: 37.018
- type: mrr_at_3
value: 32.300000000000004
- type: mrr_at_5
value: 34.14
- type: ndcg_at_1
value: 23.9
- type: ndcg_at_10
value: 21.889
- type: ndcg_at_100
value: 30.903000000000002
- type: ndcg_at_1000
value: 36.992000000000004
- type: ndcg_at_3
value: 20.274
- type: ndcg_at_5
value: 17.773
- type: precision_at_1
value: 23.9
- type: precision_at_10
value: 11.61
- type: precision_at_100
value: 2.4539999999999997
- type: precision_at_1000
value: 0.391
- type: precision_at_3
value: 19.133
- type: precision_at_5
value: 15.740000000000002
- type: recall_at_1
value: 4.852
- type: recall_at_10
value: 23.507
- type: recall_at_100
value: 49.775000000000006
- type: recall_at_1000
value: 79.308
- type: recall_at_3
value: 11.637
- type: recall_at_5
value: 15.947
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 86.03345827446948
- type: cos_sim_spearman
value: 80.53174518259549
- type: euclidean_pearson
value: 83.44538971660883
- type: euclidean_spearman
value: 80.57344324098692
- type: manhattan_pearson
value: 83.36528808195459
- type: manhattan_spearman
value: 80.48931287157902
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 85.21363088257881
- type: cos_sim_spearman
value: 75.56589127055523
- type: euclidean_pearson
value: 82.32868324521908
- type: euclidean_spearman
value: 75.31928550664554
- type: manhattan_pearson
value: 82.31332875713211
- type: manhattan_spearman
value: 75.35376322099196
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 85.09085593258487
- type: cos_sim_spearman
value: 86.26355088415221
- type: euclidean_pearson
value: 85.49646115361156
- type: euclidean_spearman
value: 86.20652472228703
- type: manhattan_pearson
value: 85.44084081123815
- type: manhattan_spearman
value: 86.1162623448951
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 84.68250248349368
- type: cos_sim_spearman
value: 82.29883673695083
- type: euclidean_pearson
value: 84.17633035446019
- type: euclidean_spearman
value: 82.19990511264791
- type: manhattan_pearson
value: 84.17408410692279
- type: manhattan_spearman
value: 82.249873895981
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.31878760045024
- type: cos_sim_spearman
value: 88.7364409031183
- type: euclidean_pearson
value: 88.230537618603
- type: euclidean_spearman
value: 88.76484309646318
- type: manhattan_pearson
value: 88.17689071136469
- type: manhattan_spearman
value: 88.72809249037928
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 83.41078559110638
- type: cos_sim_spearman
value: 85.27439135411049
- type: euclidean_pearson
value: 84.5333571592088
- type: euclidean_spearman
value: 85.25645460575957
- type: manhattan_pearson
value: 84.38428921610226
- type: manhattan_spearman
value: 85.07796040798796
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.82374132382576
- type: cos_sim_spearman
value: 89.02101343562433
- type: euclidean_pearson
value: 89.50729765458932
- type: euclidean_spearman
value: 89.04184772869253
- type: manhattan_pearson
value: 89.51737904059856
- type: manhattan_spearman
value: 89.12925950440676
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.56051823873482
- type: cos_sim_spearman
value: 68.50988748185463
- type: euclidean_pearson
value: 69.16524346147456
- type: euclidean_spearman
value: 68.61859952449579
- type: manhattan_pearson
value: 69.10618915706995
- type: manhattan_spearman
value: 68.36401769459522
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.4159693872625
- type: cos_sim_spearman
value: 87.07819121764247
- type: euclidean_pearson
value: 87.03013260863153
- type: euclidean_spearman
value: 87.06547293631309
- type: manhattan_pearson
value: 86.8129744446062
- type: manhattan_spearman
value: 86.88494096335627
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 86.47758088996575
- type: mrr
value: 96.17891458577733
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 57.538999999999994
- type: map_at_10
value: 66.562
- type: map_at_100
value: 67.254
- type: map_at_1000
value: 67.284
- type: map_at_3
value: 63.722
- type: map_at_5
value: 65.422
- type: mrr_at_1
value: 60.0
- type: mrr_at_10
value: 67.354
- type: mrr_at_100
value: 67.908
- type: mrr_at_1000
value: 67.93299999999999
- type: mrr_at_3
value: 65.056
- type: mrr_at_5
value: 66.43900000000001
- type: ndcg_at_1
value: 60.0
- type: ndcg_at_10
value: 70.858
- type: ndcg_at_100
value: 73.67099999999999
- type: ndcg_at_1000
value: 74.26700000000001
- type: ndcg_at_3
value: 65.911
- type: ndcg_at_5
value: 68.42200000000001
- type: precision_at_1
value: 60.0
- type: precision_at_10
value: 9.4
- type: precision_at_100
value: 1.083
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 25.444
- type: precision_at_5
value: 17.0
- type: recall_at_1
value: 57.538999999999994
- type: recall_at_10
value: 83.233
- type: recall_at_100
value: 95.667
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 69.883
- type: recall_at_5
value: 76.19399999999999
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.82574257425742
- type: cos_sim_ap
value: 95.78722833053911
- type: cos_sim_f1
value: 90.94650205761316
- type: cos_sim_precision
value: 93.64406779661016
- type: cos_sim_recall
value: 88.4
- type: dot_accuracy
value: 99.83366336633664
- type: dot_ap
value: 95.89733601612964
- type: dot_f1
value: 91.41981613891727
- type: dot_precision
value: 93.42379958246346
- type: dot_recall
value: 89.5
- type: euclidean_accuracy
value: 99.82574257425742
- type: euclidean_ap
value: 95.75227035138846
- type: euclidean_f1
value: 90.96509240246407
- type: euclidean_precision
value: 93.45991561181435
- type: euclidean_recall
value: 88.6
- type: manhattan_accuracy
value: 99.82574257425742
- type: manhattan_ap
value: 95.76278266220176
- type: manhattan_f1
value: 91.08409321175279
- type: manhattan_precision
value: 92.29979466119097
- type: manhattan_recall
value: 89.9
- type: max_accuracy
value: 99.83366336633664
- type: max_ap
value: 95.89733601612964
- type: max_f1
value: 91.41981613891727
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 61.905425988638605
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.159589881679736
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 53.0605499476397
- type: mrr
value: 53.91594516594517
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.202718009067
- type: cos_sim_spearman
value: 31.136199912366987
- type: dot_pearson
value: 30.66329011927951
- type: dot_spearman
value: 30.107664909625107
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.209
- type: map_at_10
value: 1.712
- type: map_at_100
value: 9.464
- type: map_at_1000
value: 23.437
- type: map_at_3
value: 0.609
- type: map_at_5
value: 0.9440000000000001
- type: mrr_at_1
value: 78.0
- type: mrr_at_10
value: 86.833
- type: mrr_at_100
value: 86.833
- type: mrr_at_1000
value: 86.833
- type: mrr_at_3
value: 85.333
- type: mrr_at_5
value: 86.833
- type: ndcg_at_1
value: 74.0
- type: ndcg_at_10
value: 69.14
- type: ndcg_at_100
value: 53.047999999999995
- type: ndcg_at_1000
value: 48.577
- type: ndcg_at_3
value: 75.592
- type: ndcg_at_5
value: 72.509
- type: precision_at_1
value: 78.0
- type: precision_at_10
value: 73.0
- type: precision_at_100
value: 54.44
- type: precision_at_1000
value: 21.326
- type: precision_at_3
value: 80.667
- type: precision_at_5
value: 77.2
- type: recall_at_1
value: 0.209
- type: recall_at_10
value: 1.932
- type: recall_at_100
value: 13.211999999999998
- type: recall_at_1000
value: 45.774
- type: recall_at_3
value: 0.644
- type: recall_at_5
value: 1.0290000000000001
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.609
- type: map_at_10
value: 8.334999999999999
- type: map_at_100
value: 14.604000000000001
- type: map_at_1000
value: 16.177
- type: map_at_3
value: 4.87
- type: map_at_5
value: 6.3149999999999995
- type: mrr_at_1
value: 32.653
- type: mrr_at_10
value: 45.047
- type: mrr_at_100
value: 45.808
- type: mrr_at_1000
value: 45.808
- type: mrr_at_3
value: 41.497
- type: mrr_at_5
value: 43.231
- type: ndcg_at_1
value: 30.612000000000002
- type: ndcg_at_10
value: 21.193
- type: ndcg_at_100
value: 34.97
- type: ndcg_at_1000
value: 46.69
- type: ndcg_at_3
value: 24.823
- type: ndcg_at_5
value: 22.872999999999998
- type: precision_at_1
value: 32.653
- type: precision_at_10
value: 17.959
- type: precision_at_100
value: 7.4079999999999995
- type: precision_at_1000
value: 1.537
- type: precision_at_3
value: 25.85
- type: precision_at_5
value: 22.448999999999998
- type: recall_at_1
value: 2.609
- type: recall_at_10
value: 13.63
- type: recall_at_100
value: 47.014
- type: recall_at_1000
value: 83.176
- type: recall_at_3
value: 5.925
- type: recall_at_5
value: 8.574
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 72.80239999999999
- type: ap
value: 15.497911013214791
- type: f1
value: 56.258411577947285
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.00452744765139
- type: f1
value: 61.42228624410908
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 50.00516915962345
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.62317458425225
- type: cos_sim_ap
value: 72.95115658063823
- type: cos_sim_f1
value: 66.78976523344764
- type: cos_sim_precision
value: 66.77215189873418
- type: cos_sim_recall
value: 66.80738786279683
- type: dot_accuracy
value: 85.62317458425225
- type: dot_ap
value: 73.10385271517778
- type: dot_f1
value: 66.94853829427399
- type: dot_precision
value: 61.74242424242424
- type: dot_recall
value: 73.11345646437995
- type: euclidean_accuracy
value: 85.65893783155511
- type: euclidean_ap
value: 72.87428208473992
- type: euclidean_f1
value: 66.70919994896005
- type: euclidean_precision
value: 64.5910551025451
- type: euclidean_recall
value: 68.97097625329816
- type: manhattan_accuracy
value: 85.59933241938367
- type: manhattan_ap
value: 72.67282695064966
- type: manhattan_f1
value: 66.67537215983286
- type: manhattan_precision
value: 66.00310237849017
- type: manhattan_recall
value: 67.36147757255937
- type: max_accuracy
value: 85.65893783155511
- type: max_ap
value: 73.10385271517778
- type: max_f1
value: 66.94853829427399
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.69096130709822
- type: cos_sim_ap
value: 85.30326978668063
- type: cos_sim_f1
value: 77.747088683189
- type: cos_sim_precision
value: 75.4491451753115
- type: cos_sim_recall
value: 80.189405605174
- type: dot_accuracy
value: 88.43870066363954
- type: dot_ap
value: 84.62999949222983
- type: dot_f1
value: 77.3074661963551
- type: dot_precision
value: 73.93871239808828
- type: dot_recall
value: 80.99784416384355
- type: euclidean_accuracy
value: 88.70066363953894
- type: euclidean_ap
value: 85.34184508966621
- type: euclidean_f1
value: 77.76871756856931
- type: euclidean_precision
value: 74.97855917667239
- type: euclidean_recall
value: 80.77456113335386
- type: manhattan_accuracy
value: 88.68319944114566
- type: manhattan_ap
value: 85.3026464242333
- type: manhattan_f1
value: 77.66561049296294
- type: manhattan_precision
value: 74.4665818849795
- type: manhattan_recall
value: 81.15183246073299
- type: max_accuracy
value: 88.70066363953894
- type: max_ap
value: 85.34184508966621
- type: max_f1
value: 77.76871756856931
---
# soumitsr/GIST-small-Embedding-v0-Q8_0-GGUF
This model was converted to GGUF format from [`avsolatorio/GIST-small-Embedding-v0`](https://huggingface.co/avsolatorio/GIST-small-Embedding-v0) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/avsolatorio/GIST-small-Embedding-v0) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo soumitsr/GIST-small-Embedding-v0-Q8_0-GGUF --hf-file gist-small-embedding-v0-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo soumitsr/GIST-small-Embedding-v0-Q8_0-GGUF --hf-file gist-small-embedding-v0-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo soumitsr/GIST-small-Embedding-v0-Q8_0-GGUF --hf-file gist-small-embedding-v0-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo soumitsr/GIST-small-Embedding-v0-Q8_0-GGUF --hf-file gist-small-embedding-v0-q8_0.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
Osiris/emotion_classifier
|
Osiris
|
text-classification
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-03-02T23:29:04Z |
2021-11-26T07:57:27+00:00
| 17 | 1 |
---
{}
---
### Introduction:
This model belongs to text-classification. You can determine the emotion behind a sentence.
### Label Explaination:
LABEL_0: Positive (have positive emotion)
LABEL_1: Negative (have negative emotion)
### Usage:
```python
>>> from transformers import pipeline
>>> ec = pipeline('text-classification', model='Osiris/emotion_classifier')
>>> ec("Hello, I'm a good model.")
```
### Accuracy:
We reach 83.82% for validation dataset, and 84.42% for test dataset.
|
[
"OSIRIS"
] |
annafavaro/BIO_GPT_NER_FINETUNED_NEW_2
|
annafavaro
|
token-classification
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"token-classification",
"generated_from_trainer",
"dataset:ncbi_disease",
"license:mit",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-04-13T14:40:10Z |
2023-04-13T15:01:01+00:00
| 17 | 0 |
---
datasets:
- ncbi_disease
license: mit
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: BIO_GPT_NER_FINETUNED_NEW_2
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: ncbi_disease
type: ncbi_disease
config: ncbi_disease
split: validation
args: ncbi_disease
metrics:
- type: precision
value: 0.10112359550561797
name: Precision
- type: recall
value: 0.10279187817258884
name: Recall
- type: f1
value: 0.10195091252359975
name: F1
- type: accuracy
value: 0.9362074327476286
name: Accuracy
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BIO_GPT_NER_FINETUNED_NEW_2
This model is a fine-tuned version of [microsoft/biogpt](https://huggingface.co/microsoft/biogpt) on the ncbi_disease dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2186
- Precision: 0.1011
- Recall: 0.1028
- F1: 0.1020
- Accuracy: 0.9362
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3345 | 1.0 | 680 | 0.2445 | 0.0119 | 0.0063 | 0.0083 | 0.9302 |
| 0.2491 | 2.0 | 1360 | 0.2199 | 0.0813 | 0.0888 | 0.0849 | 0.9320 |
| 0.1823 | 3.0 | 2040 | 0.2186 | 0.1011 | 0.1028 | 0.1020 | 0.9362 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.3
|
[
"NCBI DISEASE"
] |
dimfeld/BioLinkBERT-large-feat
|
dimfeld
|
feature-extraction
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"exbert",
"linkbert",
"biolinkbert",
"fill-mask",
"question-answering",
"text-classification",
"token-classification",
"en",
"dataset:pubmed",
"arxiv:2203.15827",
"license:apache-2.0",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2023-05-19T20:54:06Z |
2023-09-15T18:10:50+00:00
| 17 | 0 |
---
datasets:
- pubmed
language: en
license: apache-2.0
pipeline_tag: feature-extraction
tags:
- bert
- exbert
- linkbert
- biolinkbert
- feature-extraction
- fill-mask
- question-answering
- text-classification
- token-classification
widget:
- text: Sunitinib is a tyrosine kinase inhibitor
duplicated_from: michiyasunaga/BioLinkBERT-large
---
## BioLinkBERT-large
**This is identical to `michiyasunaga/BioLinkBERT-large` except the pipeline tag in the model card was changed to feature-extraction.**
BioLinkBERT-large model pretrained on [PubMed](https://pubmed.ncbi.nlm.nih.gov/) abstracts along with citation link information. It is introduced in the paper [LinkBERT: Pretraining Language Models with Document Links (ACL 2022)](https://arxiv.org/abs/2203.15827). The code and data are available in [this repository](https://github.com/michiyasunaga/LinkBERT).
This model achieves state-of-the-art performance on several biomedical NLP benchmarks such as [BLURB](https://microsoft.github.io/BLURB/) and [MedQA-USMLE](https://github.com/jind11/MedQA).
## Model description
LinkBERT is a transformer encoder (BERT-like) model pretrained on a large corpus of documents. It is an improvement of BERT that newly captures **document links** such as hyperlinks and citation links to include knowledge that spans across multiple documents. Specifically, it was pretrained by feeding linked documents into the same language model context, besides a single document.
LinkBERT can be used as a drop-in replacement for BERT. It achieves better performance for general language understanding tasks (e.g. text classification), and is also particularly effective for **knowledge-intensive** tasks (e.g. question answering) and **cross-document** tasks (e.g. reading comprehension, document retrieval).
## Intended uses & limitations
The model can be used by fine-tuning on a downstream task, such as question answering, sequence classification, and token classification.
You can also use the raw model for feature extraction (i.e. obtaining embeddings for input text).
### How to use
To use the model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/BioLinkBERT-large')
model = AutoModel.from_pretrained('michiyasunaga/BioLinkBERT-large')
inputs = tokenizer("Sunitinib is a tyrosine kinase inhibitor", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
For fine-tuning, you can use [this repository](https://github.com/michiyasunaga/LinkBERT) or follow any other BERT fine-tuning codebases.
## Evaluation results
When fine-tuned on downstream tasks, LinkBERT achieves the following results.
**Biomedical benchmarks ([BLURB](https://microsoft.github.io/BLURB/), [MedQA](https://github.com/jind11/MedQA), [MMLU](https://github.com/hendrycks/test), etc.):** BioLinkBERT attains new state-of-the-art.
| | BLURB score | PubMedQA | BioASQ | MedQA-USMLE |
| ---------------------- | -------- | -------- | ------- | -------- |
| PubmedBERT-base | 81.10 | 55.8 | 87.5 | 38.1 |
| **BioLinkBERT-base** | **83.39** | **70.2** | **91.4** | **40.0** |
| **BioLinkBERT-large** | **84.30** | **72.2** | **94.8** | **44.6** |
| | MMLU-professional medicine |
| ---------------------- | -------- |
| GPT-3 (175 params) | 38.7 |
| UnifiedQA (11B params) | 43.2 |
| **BioLinkBERT-large (340M params)** | **50.7** |
## Citation
If you find LinkBERT useful in your project, please cite the following:
```bibtex
@InProceedings{yasunaga2022linkbert,
author = {Michihiro Yasunaga and Jure Leskovec and Percy Liang},
title = {LinkBERT: Pretraining Language Models with Document Links},
year = {2022},
booktitle = {Association for Computational Linguistics (ACL)},
}
```
|
[
"BLURB",
"MEDQA",
"PUBMEDQA"
] |
Jumtra/mpt-7b-base
|
Jumtra
|
text-generation
|
[
"transformers",
"pytorch",
"mpt",
"text-generation",
"Composer",
"MosaicML",
"llm-foundry",
"StreamingDatasets",
"mpt-7b",
"custom_code",
"ja",
"dataset:kunishou/databricks-dolly-15k-ja",
"dataset:Jumtra/oasst1_ja",
"dataset:Jumtra/jglue_jsquad",
"dataset:Jumtra/jglue_jsquads_with_input",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | 2023-05-24T14:30:09Z |
2023-06-26T01:08:31+00:00
| 17 | 1 |
---
datasets:
- kunishou/databricks-dolly-15k-ja
- Jumtra/oasst1_ja
- Jumtra/jglue_jsquad
- Jumtra/jglue_jsquads_with_input
language:
- ja
license: apache-2.0
tags:
- Composer
- MosaicML
- llm-foundry
- StreamingDatasets
- mpt-7b
inference: false
---
# MPT-7B-base
このモデルは、MosaicMLのllm-foundryリポジトリを使用して[mosaicml/mpt-7b](https://huggingface.co/mosaicml/mpt-7b)をファインチューニングしたモデルです。
## Model Date
June 28, 2023
## Model License
Apache-2.0
## 評価
[Jumtra/test_data_100QA](https://huggingface.co/datasets/Jumtra/test_data_100QA)を用いてモデルの正答率を評価した
| model name | 正答率 |
| ---- | ---- |
| mosaicml/mpt-7b | 16/100 |
| mosaicml/mpt-7b-instruct | 28/100 |
| Jumtra/mpt-7b-base | 47/100 |
| Jumtra/mpt-7b-inst | 46/100 |
## 使用方法
注意:このモデルでは、from_pretrainedメソッドにtrust_remote_code=Trueを渡す必要があります。
これは、Hugging Faceのtransformersパッケージにはまだ含まれていないカスタムのMPTモデルアーキテクチャを使用しているためです。
MPTには、FlashAttention、ALiBi、QK LayerNormなど、多くのトレーニング効率化機能のオプションが含まれています。
```python
# 使用したプロンプトフォーマット
INSTRUCTION_KEY = "### Instruction:"
RESPONSE_KEY = "### Response:"
INTRO_BLURB = "Below is an instruction that describes a task. Write a response that appropriately completes the request."
PROMPT_FOR_GENERATION_FORMAT = """{intro}
{instruction_key}
{instruction}
{response_key}
""".format(
intro=INTRO_BLURB,
instruction_key=INSTRUCTION_KEY,
instruction="{instruction}",
response_key=RESPONSE_KEY,
)
```
```python
import torch
import transformers
name = 'Jumtra/mpt-7b-base'
config = transformers.AutoConfig.from_pretrained(name, trust_remote_code=True)
config.attn_config['attn_impl'] = 'torch'
config.init_device = 'cuda:0' # For fast initialization directly on GPU!
model = transformers.AutoModelForCausalLM.from_pretrained(
name,
config=config,
torch_dtype=torch.bfloat16, # Load model weights in bfloat16
trust_remote_code=True
).to("cuda:0")
model.eval()
input_text = PROMPT_FOR_GENERATION_FORMAT.format(instruction = "ニューラルネットワークとは何ですか?")
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
input_length = inputs.input_ids.shape[1]
# Without streaming
with torch.no_grad():
generation_output = model.generate(
**inputs,
max_new_tokens=2048,
do_sample=True,
temperature=0.01,
top_p=0.01,
top_k=60,
repetition_penalty=1.1,
return_dict_in_generate=True,
remove_invalid_values=True,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
token = generation_output.sequences[0, input_length:]
output = tokenizer.decode(token)
print(output)
#ニューラルネットワーク(NN)は、人工知能の分野で最も重要なアプローチの1つです。これらのモデルは、自動学習を使用して、大量のデータから学習されたパターンや関係を特定することができます。ニューラルネットワークは、人間の脳に似たように機能します。<|endoftext|>
```
## 引用
```
@online{MosaicML2023Introducing,
author = {MosaicML NLP Team},
title = {Introducing MPT-7B: A New Standard for Open-Source,
ly Usable LLMs},
year = {2023},
url = {www.mosaicml.com/blog/mpt-7b},
note = {Accessed: 2023-03-28}, % change this date
urldate = {2023-03-28} % change this date
}
```
|
[
"BLURB"
] |
IIC/bsc-bio-ehr-es-distemist
|
IIC
|
token-classification
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"biomedical",
"clinical",
"spanish",
"bsc-bio-ehr-es",
"token-classification",
"es",
"dataset:bigbio/distemist",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-21T09:28:24Z |
2025-01-17T10:52:26+00:00
| 17 | 0 |
---
datasets:
- bigbio/distemist
language: es
license: apache-2.0
metrics:
- f1
pipeline_tag: token-classification
tags:
- biomedical
- clinical
- spanish
- bsc-bio-ehr-es
model-index:
- name: IIC/bsc-bio-ehr-es-distemist
results:
- task:
type: token-classification
dataset:
name: distemist
type: bigbio/distemist
split: test
metrics:
- type: f1
value: 0.759
name: f1
---
# bsc-bio-ehr-es-distemist
This model is a finetuned version of bsc-bio-ehr-es for the distemist dataset used in a benchmark in the paper `A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks`. The model has a F1 of 0.759
Please refer to the [original publication](https://doi.org/10.1093/jamia/ocae054) for more information.
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 16 |
| learning rate | 4e-05 |
| classifier dropout | 0 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtext
@article{10.1093/jamia/ocae054,
author = {García Subies, Guillem and Barbero Jiménez, Álvaro and Martínez Fernández, Paloma},
title = {A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks},
journal = {Journal of the American Medical Informatics Association},
volume = {31},
number = {9},
pages = {2137-2146},
year = {2024},
month = {03},
issn = {1527-974X},
doi = {10.1093/jamia/ocae054},
url = {https://doi.org/10.1093/jamia/ocae054},
}
```
|
[
"DISTEMIST"
] |
IIC/bert-base-spanish-wwm-cased-pharmaconer
|
IIC
|
token-classification
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"biomedical",
"clinical",
"spanish",
"bert-base-spanish-wwm-cased",
"token-classification",
"es",
"dataset:PlanTL-GOB-ES/pharmaconer",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-21T16:08:54Z |
2024-11-25T10:41:26+00:00
| 17 | 0 |
---
datasets:
- PlanTL-GOB-ES/pharmaconer
language: es
license: cc-by-4.0
metrics:
- f1
pipeline_tag: token-classification
tags:
- biomedical
- clinical
- spanish
- bert-base-spanish-wwm-cased
widget:
- text: Se realizó estudio analítico destacando incremento de niveles de PTH y vitamina
D (103,7 pg/ml y 272 ng/ml, respectivamente), atribuidos al exceso de suplementación
de vitamina D.
- text: ' Por el hallazgo de múltiples fracturas por estrés, se procedió a estudio
en nuestras consultas, realizándose análisis con función renal, calcio sérico
y urinario, calcio iónico, magnesio y PTH, que fueron normales.'
- text: Se solicitó una analítica que incluía hemograma, bioquímica, anticuerpos antinucleares
(ANA) y serologías, examen de orina, así como biopsia de la lesión. Los resultados
fueron normales, con ANA, anti-Sm, anti-RNP, anti-SSA, anti-SSB, anti-Jo1 y anti-Scl70
negativos.
model-index:
- name: IIC/bert-base-spanish-wwm-cased-pharmaconer
results:
- task:
type: token-classification
dataset:
name: pharmaconer
type: PlanTL-GOB-ES/pharmaconer
split: test
metrics:
- type: f1
value: 0.908
name: f1
---
# bert-base-spanish-wwm-cased-pharmaconer
This model is a finetuned version of bert-base-spanish-wwm-cased for the pharmaconer dataset used in a benchmark in the paper `A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks`. The model has a F1 of 0.908
Please refer to the [original publication](https://doi.org/10.1093/jamia/ocae054) for more information.
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 32 |
| learning rate | 3e-05 |
| classifier dropout | 0 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtext
@article{10.1093/jamia/ocae054,
author = {García Subies, Guillem and Barbero Jiménez, Álvaro and Martínez Fernández, Paloma},
title = {A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks},
journal = {Journal of the American Medical Informatics Association},
volume = {31},
number = {9},
pages = {2137-2146},
year = {2024},
month = {03},
issn = {1527-974X},
doi = {10.1093/jamia/ocae054},
url = {https://doi.org/10.1093/jamia/ocae054},
}
```
|
[
"PHARMACONER"
] |
Leogrin/eleuther-pythia1.4b-hh-dpo
|
Leogrin
|
text-generation
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"en",
"dataset:Anthropic/hh-rlhf",
"arxiv:2305.18290",
"arxiv:2101.00027",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-07-27T15:07:41Z |
2023-07-27T18:16:00+00:00
| 17 | 1 |
---
datasets:
- Anthropic/hh-rlhf
language:
- en
license: apache-2.0
tags:
- pytorch
- causal-lm
- pythia
---
# Infos
Pythia-1.4b supervised finetuned with Anthropic-hh-rlhf dataset for 1 epoch (sft-model), before DPO [(paper)](https://arxiv.org/abs/2305.18290) with same dataset for 1 epoch.
[wandb log](https://wandb.ai/pythia_dpo/Pythia_DPO_new/runs/6yrtkj3s)
See [Pythia-1.4b](https://huggingface.co/EleutherAI/pythia-1.4b) for model details [(paper)](https://arxiv.org/abs/2101.00027).
# Benchmark raw results:
Results for the base model are taken from the [Pythia paper](https://arxiv.org/abs/2101.00027).
## Zero shot
| Task | 1.4B_base | 1.4B_sft | 1.4B_dpo |
|------------------|--------------:|--------------:|---------------:|
| Lambada (OpenAI) | 0.616 ± 0.007 | 0.5977 ± 0.0068 | 0.5948 ± 0.0068 |
| PIQA | 0.711 ± 0.011 | 0.7133 ± 0.0106 | 0.7165 ± 0.0105 |
| WinoGrande | 0.573 ± 0.014 | 0.5793 ± 0.0139 | 0.5746 ± 0.0139 |
| WSC | 0.365 ± 0.047 | 0.3654 ± 0.0474 | 0.3654 ± 0.0474 |
| ARC - Easy | 0.606 ± 0.010 | 0.6098 ± 0.0100 | 0.6199 ± 0.0100 |
| ARC - Challenge | 0.260 ± 0.013 | 0.2696 ± 0.0130 | 0.2884 ± 0.0132 |
| SciQ | 0.865 ± 0.011 | 0.8540 ± 0.0112 | 0.8550 ± 0.0111 |
| LogiQA | 0.210 ± 0.016 | NA | NA |
## Five shot
| Task | 1.4B_base | 1.4B_sft | 1.4B_dpo |
|------------------|----------------:|----------------:|----------------:|
| Lambada (OpenAI) | 0.578 ± 0.007 | 0.5201 ± 0.007 | 0.5247 ± 0.007 |
| PIQA | 0.705 ± 0.011 | 0.7176 ± 0.0105| 0.7209 ± 0.0105|
| WinoGrande | 0.580 ± 0.014 | 0.5793 ± 0.0139| 0.5746 ± 0.0139|
| WSC | 0.365 ± 0.047 | 0.5288 ± 0.0492| 0.5769 ± 0.0487|
| ARC - Easy | 0.643 ± 0.010 | 0.6376 ± 0.0099| 0.6561 ± 0.0097|
| ARC - Challenge | 0.290 ± 0.013 | 0.2935 ± 0.0133| 0.3166 ± 0.0136|
| SciQ | 0.92 ± 0.009 | 0.9180 ± 0.0087| 0.9150 ± 0.0088|
| LogiQA | 0.240 ± 0.017 | N/A | N/A |
|
[
"SCIQ"
] |
yongzx/pythia-70m-sft-hh
|
yongzx
|
text-generation
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-08-23T02:42:25Z |
2023-08-28T18:52:03+00:00
| 17 | 0 |
---
{}
---
Wandb runs: https://wandb.ai/eleutherai/pythia-rlhf/runs/s0qdwbg6?workspace=user-yongzx
Evaluation results:
| Task |Version|Filter| Metric |Value | |Stderr|
|-------------|-------|------|--------|-----:|---|-----:|
|arc_challenge|Yaml |none |acc |0.1758|± |0.0111|
| | |none |acc_norm|0.2176|± |0.0121|
|arc_easy |Yaml |none |acc |0.3742|± |0.0099|
| | |none |acc_norm|0.3565|± |0.0098|
|logiqa |Yaml |none |acc |0.2058|± |0.0159|
| | |none |acc_norm|0.2412|± |0.0168|
|piqa |Yaml |none |acc |0.5958|± |0.0114|
| | |none |acc_norm|0.5941|± |0.0115|
|sciq |Yaml |none |acc |0.5930|± |0.0155|
| | |none |acc_norm|0.5720|± |0.0157|
|winogrande |Yaml |none |acc |0.5154|± |0.0140|
|wsc |Yaml |none |acc |0.3654|± |0.0474|
|lambada_openai|Yaml |none |perplexity|730.2552|± |46.8739|
| | |none |acc | 0.1316|± | 0.0047|
|
[
"SCIQ"
] |
vasa-fr/qna_syntec
|
vasa-fr
|
question-answering
|
[
"transformers",
"pytorch",
"camembert",
"question-answering",
"fr",
"dataset:etalab-ia/piaf",
"dataset:fquad",
"dataset:lincoln/newsquadfr",
"dataset:pragnakalp/squad_v2_french_translated",
"dataset:CATIE-AQ/frenchQA",
"license:cc-by-4.0",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] | 2023-08-23T11:48:15Z |
2023-08-23T11:49:37+00:00
| 17 | 1 |
---
datasets:
- etalab-ia/piaf
- fquad
- lincoln/newsquadfr
- pragnakalp/squad_v2_french_translated
- CATIE-AQ/frenchQA
language: fr
library_name: transformers
license: cc-by-4.0
metrics:
- f1
- exact_match
pipeline_tag: question-answering
widget:
- text: Dans le cas d'un décès d'un salarié, comment peuvent être vessées les allocations
?
context: 'En cas de décès d''un salarié, quelle qu''en soit la cause, après un an
d''ancienneté et avant son départ en retraite, la totalité des allocations auxquelles
pourront prétendre les ayants droit, ou à défaut les bénéficiaires désignés par
celui-ci, est au minimum de : - 50 p. 100 du salaire annuel pour les salariés
célibataires, veufs ou divorcés sans personne à charge ; - 90 p. 100 du salaire
annuel pour les salariés mariés sans personne à charge ou pour les salariés célibataires,
veufs ou divorcés ayant une personne à charge ; - 110 p. 100 du salaire annuel
pour les salariés mariés ayant une personne à charge ou pour les salariés célibataires,
veufs ou divorcés ayant deux personnes à charge ; - supplément par enfant à charge,
20 p. 100 du traitement annuel. Ces allocations pourront être versées soit en
capital, soit sous forme d''une rente équivalente. Les personnes à charge sont
celles reconnues comme telles au point de vue fiscal. Le salaire annuel s''entend
comme le total des rémunérations salariales brutes acquises au cours des douze
mois ayant précédé l''événement générateur de droits, à l''exclusion des primes
et gratifications, des majorations pour heures supplémentaires au-delà de l''horaire
normal, des majorations de salaires ou indemnités liées à un déplacement ou à
un détachement. Les allocations ainsi prévues, qui s''ajouteront à celles perçues
de la sécurité sociale, seront garanties par tout moyen au choix des entreprises
(systèmes de prévoyance classiques des caisses complémentaires de cadres ou de
non-cadres, assurances privées, etc.)'
- text: Quel est le coefficient d'un agent de maitrise ?
context: 'La représentation des salariés est définie par les dispositions légales
en vigueur. A titre indicatif, en vue de la composition des collèges électoraux
élisant la délégation du personnel au Comité Social et Economique (CSE) conformément
aux dispositions légales, les salariés employés, techniciens et agents de maîtrise
(ETAM) peuvent être définis comme suit : Les ouvriers et employés : coefficient
240 au coefficient 250 de la grille de classifications des ETAM. Les techniciens
: coefficient 275 au coefficient 355 de la grille de classifications des ETAM.
Les agents de maîtrise : coefficient 400 au coefficient 500 de la grille de classifications
des ETAM. La contribution versée chaque année par l’employeur pour financer les
institutions sociales du CSE est fixée par accord d’entreprise. À défaut d’accord,
le rapport de cette contribution à la masse salariale brute ne peut être inférieur
au même rapport existant pour l’année précédente.'
- text: Combien de jour à l'avance le salarié doit faire la demande pour participer
aux réunions des organisations syndicales ?
context: Des absences non rémunérées sont accordées aux salariés mandatés par leurs
organisations syndicales pour participer, d’une part, à leurs réunions statutaires
et, d’autre part, à une réunion préparatoire pour chaque réunion de la commission
paritaire permanente de négociation et d’interprétation (CPPNI). Ils devront en
faire la demande au moins huit (8) jours à l’avance et produire un document desdites
organisations. Conformément aux dispositions légales, chaque délégué syndical
peut également utiliser des heures de délégation, hormis celles mentionnées à
l’article L. 2143-16 du Code du travail, pour participer, au titre de son organisation,
à des négociations ou à des concertations à un autre niveau que celui de l’entreprise
ou aux réunions d’instances organisées dans l’intérêt des salariés de l’entreprise
ou de la branche. Conformément aux dispositions légales, les salariés membres
des commissions paritaires de branche bénéficient du statut protecteur. Leur protection
est celle des délégués syndicaux. Cette protection leur est due quelle que soit
la date de création de la commission. Lorsque les salariés seront appelés à participer
aux réunions paritaires décidées entre les employeurs et les organisations syndicales
représentatives au niveau national, des autorisations d’absence seront accordées,
les heures correspondantes rémunérées et non décomptées sur les congés payés dans
la limite d’un nombre de salariés fixés d’un commun accord par les employeurs
et les organisations syndicales représentatives au niveau national. Le nombre
de salariés d’une même entreprise autorisés à s’absenter simultanément sera fixé
d’un commun accord par les employeurs et les organisations syndicales représentatives
au niveau national. Les employeurs et les organisations syndicales représentatives
au niveau national en cause s’efforceront, dans les cas visés aux alinéas 1 et
4 ci-dessus, de faire en sorte que ces absences n’apportent pas de gêne appréciable
à la marche générale de l’entreprise ou au libre exercice du droit syndical.
co2_eq_emissions: 100
---
# Question-Answer CCN Syntec 1486
|
[
"CAS"
] |
yongzx/pythia-1.4b-sft-hh
|
yongzx
|
text-generation
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-08-23T13:39:49Z |
2023-08-28T18:52:21+00:00
| 17 | 0 |
---
{}
---
wandb: https://wandb.ai/eleutherai/pythia-rlhf/runs/8p0wfi7m?workspace=user-yongzx
Model Evals:
| Task |Version|Filter| Metric |Value | |Stderr|
|--------------|-------|------|----------|-----:|---|-----:|
|arc_challenge |Yaml |none |acc |0.2654|± |0.0129|
| | |none |acc_norm |0.2875|± |0.0132|
|arc_easy |Yaml |none |acc |0.6149|± |0.0100|
| | |none |acc_norm |0.5391|± |0.0102|
|lambada_openai|Yaml |none |perplexity|5.6120|± |0.1509|
| | |none |acc |0.6146|± |0.0068|
|logiqa |Yaml |none |acc |0.1951|± |0.0155|
| | |none |acc_norm |0.2796|± |0.0176|
|piqa |Yaml |none |acc |0.7160|± |0.0105|
| | |none |acc_norm |0.7182|± |0.0105|
|sciq |Yaml |none |acc |0.8610|± |0.0109|
| | |none |acc_norm |0.7930|± |0.0128|
|winogrande |Yaml |none |acc |0.5754|± |0.0139|
|wsc |Yaml |none |acc |0.3654|± |0.0474|
|
[
"SCIQ"
] |
CiroN2022/cube-craft
|
CiroN2022
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] | 2023-09-01T15:37:58Z |
2023-09-01T15:38:02+00:00
| 17 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
widget:
- {}
---
# Cube Craft

<p>EXPERIMENTAL MODEL</p>
## Image examples for the model:








|
[
"CRAFT"
] |
medspaner/roberta-es-clinical-trials-cases-umls-7sgs
|
medspaner
|
token-classification
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-10-03T08:01:19Z |
2024-10-01T06:27:24+00:00
| 17 | 0 |
---
license: cc-by-nc-4.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
widget:
- text: "Criterios de inclusión: 18 a 65 años; necrosis avascular de cadera; sintomática\
\ de menos de 6 meses; capaz de otorgar consentimiento informado.\n Criterios\
\ de exclusión: embarazo, lactancia, mujer fértil sin métodos anticonceptivos\
\ adecuados; tratamiento activo con bifosfonatos; infección por VIH, hepatitis\
\ B o hepatitis C; historia de neoplasia en cualquier organo."
- text: 'Recuperación de daño hepático relacionado con nutrición parenteral con ácidos
omega-3 en adultos críticos: ensayo clínico aleatorizado.'
- text: 'Título público: Análisis del dolor tras inyección intramuscular de penicilina
con agujas de mayor calibre y anestésico local, frente a aguja tradicional sin
anestésico en pacientes con sífilis'
model-index:
- name: roberta-es-clinical-trials-cases-umls-7sgs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-es-clinical-trials-cases-umls-7sgs
This medical named entity recognition model detects 7 types of semantic groups from the [Unified Medical Language System (UMLS)](https://www.nlm.nih.gov/research/umls/index.html) ([Bodenreider 2004](https://academic.oup.com/nar/article/32/suppl_1/D267/2505235)):
- ANAT: body parts and anatomy (e.g. *garganta*, 'throat')
- CHEM: chemical entities and pharmacological substances (e.g. *aspirina*,'aspirin')
- DEVI: medical devices (e.g. *catéter*, 'catheter')
- DISO: pathologic conditions (e.g. *dolor*, 'pain')
- LIVB: living beings (e.g. *paciente*, 'patient')
- PHYS: physiological processes (e.g. *respiración*, 'breathing')
- PROC: diagnostic and therapeutic procedures, laboratory analyses and medical research activities (e.g. *cirugía*, 'surgery')
The model achieves the following results on the test set (when trained with the training and development set; results are averaged over 5 evaluation rounds):
- Precision: 0.877 (±0.004)
- Recall: 0.890 (±0.001)
- F1: 0.884 (±0.002)
- Accuracy: 0.960 (±0.001)
## Model description
This model adapts the pre-trained model [bsc-bio-ehr-es](https://huggingface.co/PlanTL-GOB-ES/bsc-bio-ehr-es), presented in [Pio Carriño et al. (2022)](https://aclanthology.org/2022.bionlp-1.19/).
It is fine-tuned to conduct medical named entity recognition on Spanish texts about clinical trials and clinical cases.
The model is fine-tuned on the [CT-EBM-ES corpus (Campillos-Llanos et al. 2021)](https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-021-01395-z) and 100 clinical cases with Creative Commons license.
If you use this model, please, cite as follows:
```
@article{campillosetal2024,
title = {{Hybrid tool for semantic annotation and concept extraction of medical texts in Spanish}},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n},
journal = {BMC Bioinformatics},
year={2024},
publisher={BioMed Central}
}
```
## Intended uses & limitations
**Disclosure**: *This model is under development and needs to be improved. It should not be used for medical decision making without human assistance and supervision*
This model is intended for a generalist purpose, and may have bias and/or any other undesirable distortions.
Third parties who deploy or provide systems and/or services using any of these models (or using systems based on these models) should note that it is their responsibility to mitigate the risks arising from their use. Third parties, in any event, need to comply with applicable regulations, including regulations concerning the use of artificial intelligence.
The owner or creator of the models will in no event be liable for any results arising from the use made by third parties of these models.
**Descargo de responsabilidad**: *Esta herramienta se encuentra en desarrollo y no debe ser empleada para la toma de decisiones médicas*
La finalidad de este modelo es generalista, y se advierte que puede tener sesgos y/u otro tipo de distorsiones indeseables.
Terceras partes que desplieguen o proporcionen sistemas y/o servicios usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) han tener presente que es su responsabilidad abordar y minimizar los riesgos derivados de su uso. Las terceras partes, en cualquier circunstancia, deben cumplir con la normativa aplicable, incluyendo la normativa que concierne al uso de la inteligencia artificial.
El propietario o creador de los modelos de ningún modo será responsable de los resultados derivados del uso que las terceras partes hagan de estos modelos.
## Training and evaluation data
To fine-tune this model we used the [Clinical Trials for Evidence-Based-Medicine in Spanish (CT-EBM-SP) corpus](http://www.lllf.uam.es/ESP/nlpdata/wp2/) and 100 clinical cases with Creative Commons License.
The CT-EBM-SP corpus is a collection of 1200 texts about clinical trials studies and clinical trials announcements:
- 500 abstracts from journals published under a Creative Commons license, e.g. available in PubMed or the Scientific Electronic Library Online (SciELO)
- 700 clinical trials announcements published in the European Clinical Trials Register and Repositorio Español de Estudios Clínicos
If you use the CT-EBM-ES resource, please, cite as follows:
```
@article{campillosetal-midm2021,
title = {A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n and Moreno-Sandoval, Antonio},
journal = {BMC Medical Informatics and Decision Making},
volume={21},
number={1},
pages={1--19},
year={2021},
publisher={BioMed Central}
}
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: we used different seeds for 5 evaluation rounds, and uploaded the model with the best results
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: average 15.5 epochs (±4.65); trained with early stopping if no improvement after 5 epochs (early stopping patience: 5)
### Training results (test set; average and standard deviation of 5 rounds with different seeds)
| Precision | Recall | F1 | Accuracy |
|:--------------:|:--------------:|:--------------:|:--------------:|
| 0.877 (±0.004) | 0.890 (±0.001) | 0.884 (±0.002) | 0.960 (±0.001) |
**Results per class (test set; average and standard deviation of 5 rounds with different seeds)**
| Class | Precision | Recall | F1 | Support |
|:----------:|:--------------:|:--------------:|:--------------:|:---------:|
| ANAT | 0.702 (±0.024) | 0.727 (±0.040) | 0.713 (±0.011) | 308 |
| CHEM | 0.913 (±0.006) | 0.924 (±0.005) | 0.918 (±0.001) | 2932 |
| DEVI | 0.656 (±0.026) | 0.773 (±0.034) | 0.709 (±0.016) | 134 |
| DISO | 0.893 (±0.008) | 0.894 (±0.006) | 0.893 (±0.004) | 3065 |
| LIVB | 0.944 (±0.010) | 0.957 (±0.003) | 0.951 (±0.005) | 1685 |
| PHYS | 0.764 (±0.028) | 0.749 (±0.020) | 0.756 (±0.016) | 308 |
| PROC | 0.843 (±0.007) | 0.866 (±0.003) | 0.855 (±0.003) | 4154 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.11.6
|
[
"CT-EBM-SP",
"SCIELO"
] |
ntc-ai/SDXL-LoRA-slider.view-from-behind
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-23T01:42:29Z |
2023-12-23T01:42:32+00:00
| 17 | 1 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/view from behind.../view from behind_17_3.0.png
widget:
- text: view from behind
output:
url: images/view from behind_17_3.0.png
- text: view from behind
output:
url: images/view from behind_19_3.0.png
- text: view from behind
output:
url: images/view from behind_20_3.0.png
- text: view from behind
output:
url: images/view from behind_21_3.0.png
- text: view from behind
output:
url: images/view from behind_22_3.0.png
inference: false
instance_prompt: view from behind
---
# ntcai.xyz slider - view from behind (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/view from behind_17_-3.0.png" width=256 height=256 /> | <img src="images/view from behind_17_0.0.png" width=256 height=256 /> | <img src="images/view from behind_17_3.0.png" width=256 height=256 /> |
| <img src="images/view from behind_19_-3.0.png" width=256 height=256 /> | <img src="images/view from behind_19_0.0.png" width=256 height=256 /> | <img src="images/view from behind_19_3.0.png" width=256 height=256 /> |
| <img src="images/view from behind_20_-3.0.png" width=256 height=256 /> | <img src="images/view from behind_20_0.0.png" width=256 height=256 /> | <img src="images/view from behind_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
view from behind
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.view-from-behind', weight_name='view from behind.safetensors', adapter_name="view from behind")
# Activate the LoRA
pipe.set_adapters(["view from behind"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, view from behind"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 550+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
mlx-community/multilingual-e5-base-mlx
|
mlx-community
|
sentence-similarity
|
[
"sentence-transformers",
"xlm-roberta",
"mteb",
"Sentence Transformers",
"sentence-similarity",
"mlx",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-01-11T13:50:06Z |
2024-01-11T13:51:07+00:00
| 17 | 1 |
---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
tags:
- mteb
- Sentence Transformers
- sentence-similarity
- sentence-transformers
- mlx
model-index:
- name: multilingual-e5-base
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 78.97014925373135
- type: ap
value: 43.69351129103008
- type: f1
value: 73.38075030070492
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 71.7237687366167
- type: ap
value: 82.22089859962671
- type: f1
value: 69.95532758884401
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 79.65517241379312
- type: ap
value: 28.507918657094738
- type: f1
value: 66.84516013726119
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.32976445396146
- type: ap
value: 20.720481637566014
- type: f1
value: 59.78002763416003
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 90.63775
- type: ap
value: 87.22277903861716
- type: f1
value: 90.60378636386807
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 44.546
- type: f1
value: 44.05666638370923
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 41.828
- type: f1
value: 41.2710255644252
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.534
- type: f1
value: 39.820743174270326
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 39.684
- type: f1
value: 39.11052682815307
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.436
- type: f1
value: 37.07082931930871
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.226000000000006
- type: f1
value: 36.65372077739185
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.831000000000003
- type: map_at_10
value: 36.42
- type: map_at_100
value: 37.699
- type: map_at_1000
value: 37.724000000000004
- type: map_at_3
value: 32.207
- type: map_at_5
value: 34.312
- type: mrr_at_1
value: 23.257
- type: mrr_at_10
value: 36.574
- type: mrr_at_100
value: 37.854
- type: mrr_at_1000
value: 37.878
- type: mrr_at_3
value: 32.385000000000005
- type: mrr_at_5
value: 34.48
- type: ndcg_at_1
value: 22.831000000000003
- type: ndcg_at_10
value: 44.230000000000004
- type: ndcg_at_100
value: 49.974000000000004
- type: ndcg_at_1000
value: 50.522999999999996
- type: ndcg_at_3
value: 35.363
- type: ndcg_at_5
value: 39.164
- type: precision_at_1
value: 22.831000000000003
- type: precision_at_10
value: 6.935
- type: precision_at_100
value: 0.9520000000000001
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 14.841
- type: precision_at_5
value: 10.754
- type: recall_at_1
value: 22.831000000000003
- type: recall_at_10
value: 69.346
- type: recall_at_100
value: 95.235
- type: recall_at_1000
value: 99.36
- type: recall_at_3
value: 44.523
- type: recall_at_5
value: 53.769999999999996
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 40.27789869854063
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 35.41979463347428
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 58.22752045109304
- type: mrr
value: 71.51112430198303
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.71147646622866
- type: cos_sim_spearman
value: 85.059167046486
- type: euclidean_pearson
value: 75.88421613600647
- type: euclidean_spearman
value: 75.12821787150585
- type: manhattan_pearson
value: 75.22005646957604
- type: manhattan_spearman
value: 74.42880434453272
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.23799582463465
- type: f1
value: 99.12665274878218
- type: precision
value: 99.07098121085595
- type: recall
value: 99.23799582463465
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.88685890380806
- type: f1
value: 97.59336708489249
- type: precision
value: 97.44662117543473
- type: recall
value: 97.88685890380806
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.47142362313821
- type: f1
value: 97.1989377670015
- type: precision
value: 97.06384944001847
- type: recall
value: 97.47142362313821
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.4728804634018
- type: f1
value: 98.2973494821836
- type: precision
value: 98.2095839915745
- type: recall
value: 98.4728804634018
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 82.74025974025975
- type: f1
value: 82.67420447730439
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.0380848063507
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 29.45956405670166
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.122
- type: map_at_10
value: 42.03
- type: map_at_100
value: 43.364000000000004
- type: map_at_1000
value: 43.474000000000004
- type: map_at_3
value: 38.804
- type: map_at_5
value: 40.585
- type: mrr_at_1
value: 39.914
- type: mrr_at_10
value: 48.227
- type: mrr_at_100
value: 49.018
- type: mrr_at_1000
value: 49.064
- type: mrr_at_3
value: 45.994
- type: mrr_at_5
value: 47.396
- type: ndcg_at_1
value: 39.914
- type: ndcg_at_10
value: 47.825
- type: ndcg_at_100
value: 52.852
- type: ndcg_at_1000
value: 54.891
- type: ndcg_at_3
value: 43.517
- type: ndcg_at_5
value: 45.493
- type: precision_at_1
value: 39.914
- type: precision_at_10
value: 8.956
- type: precision_at_100
value: 1.388
- type: precision_at_1000
value: 0.182
- type: precision_at_3
value: 20.791999999999998
- type: precision_at_5
value: 14.821000000000002
- type: recall_at_1
value: 32.122
- type: recall_at_10
value: 58.294999999999995
- type: recall_at_100
value: 79.726
- type: recall_at_1000
value: 93.099
- type: recall_at_3
value: 45.017
- type: recall_at_5
value: 51.002
- type: map_at_1
value: 29.677999999999997
- type: map_at_10
value: 38.684000000000005
- type: map_at_100
value: 39.812999999999995
- type: map_at_1000
value: 39.945
- type: map_at_3
value: 35.831
- type: map_at_5
value: 37.446
- type: mrr_at_1
value: 37.771
- type: mrr_at_10
value: 44.936
- type: mrr_at_100
value: 45.583
- type: mrr_at_1000
value: 45.634
- type: mrr_at_3
value: 42.771
- type: mrr_at_5
value: 43.994
- type: ndcg_at_1
value: 37.771
- type: ndcg_at_10
value: 44.059
- type: ndcg_at_100
value: 48.192
- type: ndcg_at_1000
value: 50.375
- type: ndcg_at_3
value: 40.172000000000004
- type: ndcg_at_5
value: 41.899
- type: precision_at_1
value: 37.771
- type: precision_at_10
value: 8.286999999999999
- type: precision_at_100
value: 1.322
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 19.406000000000002
- type: precision_at_5
value: 13.745
- type: recall_at_1
value: 29.677999999999997
- type: recall_at_10
value: 53.071
- type: recall_at_100
value: 70.812
- type: recall_at_1000
value: 84.841
- type: recall_at_3
value: 41.016000000000005
- type: recall_at_5
value: 46.22
- type: map_at_1
value: 42.675000000000004
- type: map_at_10
value: 53.93599999999999
- type: map_at_100
value: 54.806999999999995
- type: map_at_1000
value: 54.867
- type: map_at_3
value: 50.934000000000005
- type: map_at_5
value: 52.583
- type: mrr_at_1
value: 48.339
- type: mrr_at_10
value: 57.265
- type: mrr_at_100
value: 57.873
- type: mrr_at_1000
value: 57.906
- type: mrr_at_3
value: 55.193000000000005
- type: mrr_at_5
value: 56.303000000000004
- type: ndcg_at_1
value: 48.339
- type: ndcg_at_10
value: 59.19799999999999
- type: ndcg_at_100
value: 62.743
- type: ndcg_at_1000
value: 63.99399999999999
- type: ndcg_at_3
value: 54.367
- type: ndcg_at_5
value: 56.548
- type: precision_at_1
value: 48.339
- type: precision_at_10
value: 9.216000000000001
- type: precision_at_100
value: 1.1809999999999998
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 23.72
- type: precision_at_5
value: 16.025
- type: recall_at_1
value: 42.675000000000004
- type: recall_at_10
value: 71.437
- type: recall_at_100
value: 86.803
- type: recall_at_1000
value: 95.581
- type: recall_at_3
value: 58.434
- type: recall_at_5
value: 63.754
- type: map_at_1
value: 23.518
- type: map_at_10
value: 30.648999999999997
- type: map_at_100
value: 31.508999999999997
- type: map_at_1000
value: 31.604
- type: map_at_3
value: 28.247
- type: map_at_5
value: 29.65
- type: mrr_at_1
value: 25.650000000000002
- type: mrr_at_10
value: 32.771
- type: mrr_at_100
value: 33.554
- type: mrr_at_1000
value: 33.629999999999995
- type: mrr_at_3
value: 30.433
- type: mrr_at_5
value: 31.812
- type: ndcg_at_1
value: 25.650000000000002
- type: ndcg_at_10
value: 34.929
- type: ndcg_at_100
value: 39.382
- type: ndcg_at_1000
value: 41.913
- type: ndcg_at_3
value: 30.292
- type: ndcg_at_5
value: 32.629999999999995
- type: precision_at_1
value: 25.650000000000002
- type: precision_at_10
value: 5.311
- type: precision_at_100
value: 0.792
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 12.58
- type: precision_at_5
value: 8.994
- type: recall_at_1
value: 23.518
- type: recall_at_10
value: 46.19
- type: recall_at_100
value: 67.123
- type: recall_at_1000
value: 86.442
- type: recall_at_3
value: 33.678000000000004
- type: recall_at_5
value: 39.244
- type: map_at_1
value: 15.891
- type: map_at_10
value: 22.464000000000002
- type: map_at_100
value: 23.483
- type: map_at_1000
value: 23.613
- type: map_at_3
value: 20.080000000000002
- type: map_at_5
value: 21.526
- type: mrr_at_1
value: 20.025000000000002
- type: mrr_at_10
value: 26.712999999999997
- type: mrr_at_100
value: 27.650000000000002
- type: mrr_at_1000
value: 27.737000000000002
- type: mrr_at_3
value: 24.274
- type: mrr_at_5
value: 25.711000000000002
- type: ndcg_at_1
value: 20.025000000000002
- type: ndcg_at_10
value: 27.028999999999996
- type: ndcg_at_100
value: 32.064
- type: ndcg_at_1000
value: 35.188
- type: ndcg_at_3
value: 22.512999999999998
- type: ndcg_at_5
value: 24.89
- type: precision_at_1
value: 20.025000000000002
- type: precision_at_10
value: 4.776
- type: precision_at_100
value: 0.8500000000000001
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 10.531
- type: precision_at_5
value: 7.811
- type: recall_at_1
value: 15.891
- type: recall_at_10
value: 37.261
- type: recall_at_100
value: 59.12
- type: recall_at_1000
value: 81.356
- type: recall_at_3
value: 24.741
- type: recall_at_5
value: 30.753999999999998
- type: map_at_1
value: 27.544
- type: map_at_10
value: 36.283
- type: map_at_100
value: 37.467
- type: map_at_1000
value: 37.574000000000005
- type: map_at_3
value: 33.528999999999996
- type: map_at_5
value: 35.028999999999996
- type: mrr_at_1
value: 34.166999999999994
- type: mrr_at_10
value: 41.866
- type: mrr_at_100
value: 42.666
- type: mrr_at_1000
value: 42.716
- type: mrr_at_3
value: 39.541
- type: mrr_at_5
value: 40.768
- type: ndcg_at_1
value: 34.166999999999994
- type: ndcg_at_10
value: 41.577
- type: ndcg_at_100
value: 46.687
- type: ndcg_at_1000
value: 48.967
- type: ndcg_at_3
value: 37.177
- type: ndcg_at_5
value: 39.097
- type: precision_at_1
value: 34.166999999999994
- type: precision_at_10
value: 7.420999999999999
- type: precision_at_100
value: 1.165
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 17.291999999999998
- type: precision_at_5
value: 12.166
- type: recall_at_1
value: 27.544
- type: recall_at_10
value: 51.99399999999999
- type: recall_at_100
value: 73.738
- type: recall_at_1000
value: 89.33
- type: recall_at_3
value: 39.179
- type: recall_at_5
value: 44.385999999999996
- type: map_at_1
value: 26.661
- type: map_at_10
value: 35.475
- type: map_at_100
value: 36.626999999999995
- type: map_at_1000
value: 36.741
- type: map_at_3
value: 32.818000000000005
- type: map_at_5
value: 34.397
- type: mrr_at_1
value: 32.647999999999996
- type: mrr_at_10
value: 40.784
- type: mrr_at_100
value: 41.602
- type: mrr_at_1000
value: 41.661
- type: mrr_at_3
value: 38.68
- type: mrr_at_5
value: 39.838
- type: ndcg_at_1
value: 32.647999999999996
- type: ndcg_at_10
value: 40.697
- type: ndcg_at_100
value: 45.799
- type: ndcg_at_1000
value: 48.235
- type: ndcg_at_3
value: 36.516
- type: ndcg_at_5
value: 38.515
- type: precision_at_1
value: 32.647999999999996
- type: precision_at_10
value: 7.202999999999999
- type: precision_at_100
value: 1.1360000000000001
- type: precision_at_1000
value: 0.151
- type: precision_at_3
value: 17.314
- type: precision_at_5
value: 12.145999999999999
- type: recall_at_1
value: 26.661
- type: recall_at_10
value: 50.995000000000005
- type: recall_at_100
value: 73.065
- type: recall_at_1000
value: 89.781
- type: recall_at_3
value: 39.073
- type: recall_at_5
value: 44.395
- type: map_at_1
value: 25.946583333333333
- type: map_at_10
value: 33.79725
- type: map_at_100
value: 34.86408333333333
- type: map_at_1000
value: 34.9795
- type: map_at_3
value: 31.259999999999998
- type: map_at_5
value: 32.71541666666666
- type: mrr_at_1
value: 30.863749999999996
- type: mrr_at_10
value: 37.99183333333333
- type: mrr_at_100
value: 38.790499999999994
- type: mrr_at_1000
value: 38.85575000000001
- type: mrr_at_3
value: 35.82083333333333
- type: mrr_at_5
value: 37.07533333333333
- type: ndcg_at_1
value: 30.863749999999996
- type: ndcg_at_10
value: 38.52141666666667
- type: ndcg_at_100
value: 43.17966666666667
- type: ndcg_at_1000
value: 45.64608333333333
- type: ndcg_at_3
value: 34.333000000000006
- type: ndcg_at_5
value: 36.34975
- type: precision_at_1
value: 30.863749999999996
- type: precision_at_10
value: 6.598999999999999
- type: precision_at_100
value: 1.0502500000000001
- type: precision_at_1000
value: 0.14400000000000002
- type: precision_at_3
value: 15.557583333333334
- type: precision_at_5
value: 11.020000000000001
- type: recall_at_1
value: 25.946583333333333
- type: recall_at_10
value: 48.36991666666666
- type: recall_at_100
value: 69.02408333333334
- type: recall_at_1000
value: 86.43858333333331
- type: recall_at_3
value: 36.4965
- type: recall_at_5
value: 41.76258333333334
- type: map_at_1
value: 22.431
- type: map_at_10
value: 28.889
- type: map_at_100
value: 29.642000000000003
- type: map_at_1000
value: 29.742
- type: map_at_3
value: 26.998
- type: map_at_5
value: 28.172000000000004
- type: mrr_at_1
value: 25.307000000000002
- type: mrr_at_10
value: 31.763
- type: mrr_at_100
value: 32.443
- type: mrr_at_1000
value: 32.531
- type: mrr_at_3
value: 29.959000000000003
- type: mrr_at_5
value: 31.063000000000002
- type: ndcg_at_1
value: 25.307000000000002
- type: ndcg_at_10
value: 32.586999999999996
- type: ndcg_at_100
value: 36.5
- type: ndcg_at_1000
value: 39.133
- type: ndcg_at_3
value: 29.25
- type: ndcg_at_5
value: 31.023
- type: precision_at_1
value: 25.307000000000002
- type: precision_at_10
value: 4.954
- type: precision_at_100
value: 0.747
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 12.577
- type: precision_at_5
value: 8.741999999999999
- type: recall_at_1
value: 22.431
- type: recall_at_10
value: 41.134
- type: recall_at_100
value: 59.28600000000001
- type: recall_at_1000
value: 78.857
- type: recall_at_3
value: 31.926
- type: recall_at_5
value: 36.335
- type: map_at_1
value: 17.586
- type: map_at_10
value: 23.304
- type: map_at_100
value: 24.159
- type: map_at_1000
value: 24.281
- type: map_at_3
value: 21.316
- type: map_at_5
value: 22.383
- type: mrr_at_1
value: 21.645
- type: mrr_at_10
value: 27.365000000000002
- type: mrr_at_100
value: 28.108
- type: mrr_at_1000
value: 28.192
- type: mrr_at_3
value: 25.482
- type: mrr_at_5
value: 26.479999999999997
- type: ndcg_at_1
value: 21.645
- type: ndcg_at_10
value: 27.306
- type: ndcg_at_100
value: 31.496000000000002
- type: ndcg_at_1000
value: 34.53
- type: ndcg_at_3
value: 23.73
- type: ndcg_at_5
value: 25.294
- type: precision_at_1
value: 21.645
- type: precision_at_10
value: 4.797
- type: precision_at_100
value: 0.8059999999999999
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 10.850999999999999
- type: precision_at_5
value: 7.736
- type: recall_at_1
value: 17.586
- type: recall_at_10
value: 35.481
- type: recall_at_100
value: 54.534000000000006
- type: recall_at_1000
value: 76.456
- type: recall_at_3
value: 25.335
- type: recall_at_5
value: 29.473
- type: map_at_1
value: 25.095
- type: map_at_10
value: 32.374
- type: map_at_100
value: 33.537
- type: map_at_1000
value: 33.634
- type: map_at_3
value: 30.089
- type: map_at_5
value: 31.433
- type: mrr_at_1
value: 29.198
- type: mrr_at_10
value: 36.01
- type: mrr_at_100
value: 37.022
- type: mrr_at_1000
value: 37.083
- type: mrr_at_3
value: 33.94
- type: mrr_at_5
value: 35.148
- type: ndcg_at_1
value: 29.198
- type: ndcg_at_10
value: 36.729
- type: ndcg_at_100
value: 42.114000000000004
- type: ndcg_at_1000
value: 44.592
- type: ndcg_at_3
value: 32.644
- type: ndcg_at_5
value: 34.652
- type: precision_at_1
value: 29.198
- type: precision_at_10
value: 5.970000000000001
- type: precision_at_100
value: 0.967
- type: precision_at_1000
value: 0.129
- type: precision_at_3
value: 14.396999999999998
- type: precision_at_5
value: 10.093
- type: recall_at_1
value: 25.095
- type: recall_at_10
value: 46.392
- type: recall_at_100
value: 69.706
- type: recall_at_1000
value: 87.738
- type: recall_at_3
value: 35.303000000000004
- type: recall_at_5
value: 40.441
- type: map_at_1
value: 26.857999999999997
- type: map_at_10
value: 34.066
- type: map_at_100
value: 35.671
- type: map_at_1000
value: 35.881
- type: map_at_3
value: 31.304
- type: map_at_5
value: 32.885
- type: mrr_at_1
value: 32.411
- type: mrr_at_10
value: 38.987
- type: mrr_at_100
value: 39.894
- type: mrr_at_1000
value: 39.959
- type: mrr_at_3
value: 36.626999999999995
- type: mrr_at_5
value: 38.011
- type: ndcg_at_1
value: 32.411
- type: ndcg_at_10
value: 39.208
- type: ndcg_at_100
value: 44.626
- type: ndcg_at_1000
value: 47.43
- type: ndcg_at_3
value: 35.091
- type: ndcg_at_5
value: 37.119
- type: precision_at_1
value: 32.411
- type: precision_at_10
value: 7.51
- type: precision_at_100
value: 1.486
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 16.14
- type: precision_at_5
value: 11.976
- type: recall_at_1
value: 26.857999999999997
- type: recall_at_10
value: 47.407
- type: recall_at_100
value: 72.236
- type: recall_at_1000
value: 90.77
- type: recall_at_3
value: 35.125
- type: recall_at_5
value: 40.522999999999996
- type: map_at_1
value: 21.3
- type: map_at_10
value: 27.412999999999997
- type: map_at_100
value: 28.29
- type: map_at_1000
value: 28.398
- type: map_at_3
value: 25.169999999999998
- type: map_at_5
value: 26.496
- type: mrr_at_1
value: 23.29
- type: mrr_at_10
value: 29.215000000000003
- type: mrr_at_100
value: 30.073
- type: mrr_at_1000
value: 30.156
- type: mrr_at_3
value: 26.956000000000003
- type: mrr_at_5
value: 28.38
- type: ndcg_at_1
value: 23.29
- type: ndcg_at_10
value: 31.113000000000003
- type: ndcg_at_100
value: 35.701
- type: ndcg_at_1000
value: 38.505
- type: ndcg_at_3
value: 26.727
- type: ndcg_at_5
value: 29.037000000000003
- type: precision_at_1
value: 23.29
- type: precision_at_10
value: 4.787
- type: precision_at_100
value: 0.763
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 11.091
- type: precision_at_5
value: 7.985
- type: recall_at_1
value: 21.3
- type: recall_at_10
value: 40.782000000000004
- type: recall_at_100
value: 62.13999999999999
- type: recall_at_1000
value: 83.012
- type: recall_at_3
value: 29.131
- type: recall_at_5
value: 34.624
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.631
- type: map_at_10
value: 16.634999999999998
- type: map_at_100
value: 18.23
- type: map_at_1000
value: 18.419
- type: map_at_3
value: 13.66
- type: map_at_5
value: 15.173
- type: mrr_at_1
value: 21.368000000000002
- type: mrr_at_10
value: 31.56
- type: mrr_at_100
value: 32.58
- type: mrr_at_1000
value: 32.633
- type: mrr_at_3
value: 28.241
- type: mrr_at_5
value: 30.225
- type: ndcg_at_1
value: 21.368000000000002
- type: ndcg_at_10
value: 23.855999999999998
- type: ndcg_at_100
value: 30.686999999999998
- type: ndcg_at_1000
value: 34.327000000000005
- type: ndcg_at_3
value: 18.781
- type: ndcg_at_5
value: 20.73
- type: precision_at_1
value: 21.368000000000002
- type: precision_at_10
value: 7.564
- type: precision_at_100
value: 1.496
- type: precision_at_1000
value: 0.217
- type: precision_at_3
value: 13.876
- type: precision_at_5
value: 11.062
- type: recall_at_1
value: 9.631
- type: recall_at_10
value: 29.517
- type: recall_at_100
value: 53.452
- type: recall_at_1000
value: 74.115
- type: recall_at_3
value: 17.605999999999998
- type: recall_at_5
value: 22.505
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.885
- type: map_at_10
value: 18.798000000000002
- type: map_at_100
value: 26.316
- type: map_at_1000
value: 27.869
- type: map_at_3
value: 13.719000000000001
- type: map_at_5
value: 15.716
- type: mrr_at_1
value: 66
- type: mrr_at_10
value: 74.263
- type: mrr_at_100
value: 74.519
- type: mrr_at_1000
value: 74.531
- type: mrr_at_3
value: 72.458
- type: mrr_at_5
value: 73.321
- type: ndcg_at_1
value: 53.87499999999999
- type: ndcg_at_10
value: 40.355999999999995
- type: ndcg_at_100
value: 44.366
- type: ndcg_at_1000
value: 51.771
- type: ndcg_at_3
value: 45.195
- type: ndcg_at_5
value: 42.187000000000005
- type: precision_at_1
value: 66
- type: precision_at_10
value: 31.75
- type: precision_at_100
value: 10.11
- type: precision_at_1000
value: 1.9800000000000002
- type: precision_at_3
value: 48.167
- type: precision_at_5
value: 40.050000000000004
- type: recall_at_1
value: 8.885
- type: recall_at_10
value: 24.471999999999998
- type: recall_at_100
value: 49.669000000000004
- type: recall_at_1000
value: 73.383
- type: recall_at_3
value: 14.872
- type: recall_at_5
value: 18.262999999999998
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 45.18
- type: f1
value: 40.26878691789978
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 62.751999999999995
- type: map_at_10
value: 74.131
- type: map_at_100
value: 74.407
- type: map_at_1000
value: 74.423
- type: map_at_3
value: 72.329
- type: map_at_5
value: 73.555
- type: mrr_at_1
value: 67.282
- type: mrr_at_10
value: 78.292
- type: mrr_at_100
value: 78.455
- type: mrr_at_1000
value: 78.458
- type: mrr_at_3
value: 76.755
- type: mrr_at_5
value: 77.839
- type: ndcg_at_1
value: 67.282
- type: ndcg_at_10
value: 79.443
- type: ndcg_at_100
value: 80.529
- type: ndcg_at_1000
value: 80.812
- type: ndcg_at_3
value: 76.281
- type: ndcg_at_5
value: 78.235
- type: precision_at_1
value: 67.282
- type: precision_at_10
value: 10.078
- type: precision_at_100
value: 1.082
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 30.178
- type: precision_at_5
value: 19.232
- type: recall_at_1
value: 62.751999999999995
- type: recall_at_10
value: 91.521
- type: recall_at_100
value: 95.997
- type: recall_at_1000
value: 97.775
- type: recall_at_3
value: 83.131
- type: recall_at_5
value: 87.93299999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.861
- type: map_at_10
value: 30.252000000000002
- type: map_at_100
value: 32.082
- type: map_at_1000
value: 32.261
- type: map_at_3
value: 25.909
- type: map_at_5
value: 28.296
- type: mrr_at_1
value: 37.346000000000004
- type: mrr_at_10
value: 45.802
- type: mrr_at_100
value: 46.611999999999995
- type: mrr_at_1000
value: 46.659
- type: mrr_at_3
value: 43.056
- type: mrr_at_5
value: 44.637
- type: ndcg_at_1
value: 37.346000000000004
- type: ndcg_at_10
value: 38.169
- type: ndcg_at_100
value: 44.864
- type: ndcg_at_1000
value: 47.974
- type: ndcg_at_3
value: 33.619
- type: ndcg_at_5
value: 35.317
- type: precision_at_1
value: 37.346000000000004
- type: precision_at_10
value: 10.693999999999999
- type: precision_at_100
value: 1.775
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 22.325
- type: precision_at_5
value: 16.852
- type: recall_at_1
value: 18.861
- type: recall_at_10
value: 45.672000000000004
- type: recall_at_100
value: 70.60499999999999
- type: recall_at_1000
value: 89.216
- type: recall_at_3
value: 30.361
- type: recall_at_5
value: 36.998999999999995
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.852999999999994
- type: map_at_10
value: 59.961
- type: map_at_100
value: 60.78
- type: map_at_1000
value: 60.843
- type: map_at_3
value: 56.39999999999999
- type: map_at_5
value: 58.646
- type: mrr_at_1
value: 75.70599999999999
- type: mrr_at_10
value: 82.321
- type: mrr_at_100
value: 82.516
- type: mrr_at_1000
value: 82.525
- type: mrr_at_3
value: 81.317
- type: mrr_at_5
value: 81.922
- type: ndcg_at_1
value: 75.70599999999999
- type: ndcg_at_10
value: 68.557
- type: ndcg_at_100
value: 71.485
- type: ndcg_at_1000
value: 72.71600000000001
- type: ndcg_at_3
value: 63.524
- type: ndcg_at_5
value: 66.338
- type: precision_at_1
value: 75.70599999999999
- type: precision_at_10
value: 14.463000000000001
- type: precision_at_100
value: 1.677
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 40.806
- type: precision_at_5
value: 26.709
- type: recall_at_1
value: 37.852999999999994
- type: recall_at_10
value: 72.316
- type: recall_at_100
value: 83.842
- type: recall_at_1000
value: 91.999
- type: recall_at_3
value: 61.209
- type: recall_at_5
value: 66.77199999999999
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 85.46039999999999
- type: ap
value: 79.9812521351881
- type: f1
value: 85.31722909702084
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.704
- type: map_at_10
value: 35.329
- type: map_at_100
value: 36.494
- type: map_at_1000
value: 36.541000000000004
- type: map_at_3
value: 31.476
- type: map_at_5
value: 33.731
- type: mrr_at_1
value: 23.294999999999998
- type: mrr_at_10
value: 35.859
- type: mrr_at_100
value: 36.968
- type: mrr_at_1000
value: 37.008
- type: mrr_at_3
value: 32.085
- type: mrr_at_5
value: 34.299
- type: ndcg_at_1
value: 23.324
- type: ndcg_at_10
value: 42.274
- type: ndcg_at_100
value: 47.839999999999996
- type: ndcg_at_1000
value: 48.971
- type: ndcg_at_3
value: 34.454
- type: ndcg_at_5
value: 38.464
- type: precision_at_1
value: 23.324
- type: precision_at_10
value: 6.648
- type: precision_at_100
value: 0.9440000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.674999999999999
- type: precision_at_5
value: 10.850999999999999
- type: recall_at_1
value: 22.704
- type: recall_at_10
value: 63.660000000000004
- type: recall_at_100
value: 89.29899999999999
- type: recall_at_1000
value: 97.88900000000001
- type: recall_at_3
value: 42.441
- type: recall_at_5
value: 52.04
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.1326949384405
- type: f1
value: 92.89743579612082
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.62524654832347
- type: f1
value: 88.65106082263151
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.59039359573046
- type: f1
value: 90.31532892105662
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.21046038208581
- type: f1
value: 86.41459529813113
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 87.3180351380423
- type: f1
value: 86.71383078226444
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.24231464737792
- type: f1
value: 86.31845567592403
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.27131782945736
- type: f1
value: 57.52079940417103
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.2341504649197
- type: f1
value: 51.349951558039244
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.27418278852569
- type: f1
value: 50.1714985749095
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 67.68243031631694
- type: f1
value: 50.1066160836192
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.2362854069559
- type: f1
value: 48.821279948766424
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.71428571428571
- type: f1
value: 53.94611389496195
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.97646267652992
- type: f1
value: 57.26797883561521
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.65501008742435
- type: f1
value: 50.416258382177034
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.45796906523201
- type: f1
value: 53.306690547422185
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.59246805648957
- type: f1
value: 59.818381969051494
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.126429051782104
- type: f1
value: 58.25993593933026
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 50.057162071284466
- type: f1
value: 46.96095728790911
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.64425016812375
- type: f1
value: 62.858291698755764
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.08944182918628
- type: f1
value: 62.44639030604241
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.68056489576328
- type: f1
value: 61.775326758789504
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.11163416274377
- type: f1
value: 69.70789096927015
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.40282447881641
- type: f1
value: 66.38492065671895
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.24613315400134
- type: f1
value: 64.3348019501336
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.78345662407531
- type: f1
value: 62.21279452354622
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.9455279085407
- type: f1
value: 65.48193124964094
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.05110961667788
- type: f1
value: 58.097856564684534
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.95292535305985
- type: f1
value: 62.09182174767901
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.97310020174848
- type: f1
value: 61.14252567730396
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.08069939475453
- type: f1
value: 57.044041742492034
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.63752521856085
- type: f1
value: 63.889340907205316
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.385339609952936
- type: f1
value: 53.449033750088304
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.93073301950234
- type: f1
value: 65.9884357824104
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.94418291862812
- type: f1
value: 66.48740222583132
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.26025554808339
- type: f1
value: 50.19562815100793
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.98789509078682
- type: f1
value: 46.65788438676836
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.68728984532616
- type: f1
value: 41.642419349541996
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.19300605245461
- type: f1
value: 55.8626492442437
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.33826496301278
- type: f1
value: 63.89499791648792
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.33960995292536
- type: f1
value: 57.15242464180892
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.09347679892402
- type: f1
value: 59.64733214063841
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.75924680564896
- type: f1
value: 55.96585692366827
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.48486886348352
- type: f1
value: 59.45143559032946
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.56422326832549
- type: f1
value: 54.96368702901926
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.18022864828512
- type: f1
value: 63.05369805040634
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.30329522528581
- type: f1
value: 64.06084612020727
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.36919973100201
- type: f1
value: 65.12154124788887
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.98117014122394
- type: f1
value: 66.41847559806962
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.53799596503026
- type: f1
value: 62.17067330740817
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.01815736381977
- type: f1
value: 66.24988369607843
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.34700739744452
- type: f1
value: 59.957933424941636
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.23402824478815
- type: f1
value: 57.98836976018471
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.54068594485541
- type: f1
value: 65.43849680666855
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.998655010087425
- type: f1
value: 52.83737515406804
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.71217215870882
- type: f1
value: 55.051794977833026
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.724277067921996
- type: f1
value: 56.33485571838306
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.59515803631473
- type: f1
value: 64.96772366193588
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.860793544048406
- type: f1
value: 58.148845819115394
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.40753194351043
- type: f1
value: 63.18903778054698
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.52320107599194
- type: f1
value: 58.356144563398516
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.17014122394083
- type: f1
value: 63.919964062638925
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.15601882985878
- type: f1
value: 67.01451905761371
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.65030262273034
- type: f1
value: 64.14420425129063
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.08742434431743
- type: f1
value: 63.044060042311756
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.52387357094821
- type: f1
value: 56.82398588814534
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.239408204438476
- type: f1
value: 61.92570286170469
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.74915938130463
- type: f1
value: 62.130740689396276
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.00336247478144
- type: f1
value: 63.71080635228055
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.837928715534645
- type: f1
value: 50.390741680320836
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.42098184263618
- type: f1
value: 71.41355113538995
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.95359784801613
- type: f1
value: 71.42699340156742
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.18157363819772
- type: f1
value: 69.74836113037671
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.08137188971082
- type: f1
value: 76.78000685068261
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.5030262273033
- type: f1
value: 71.71620130425673
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.24546065904505
- type: f1
value: 69.07638311730359
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.12911903160726
- type: f1
value: 68.32651736539815
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.89307330195025
- type: f1
value: 71.33986549860187
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.44451916610626
- type: f1
value: 66.90192664503866
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.16274377942166
- type: f1
value: 68.01090953775066
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.75319435104237
- type: f1
value: 70.18035309201403
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.14391392064559
- type: f1
value: 61.48286540778145
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.70275722932078
- type: f1
value: 70.26164779846495
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.93813046402153
- type: f1
value: 58.8852862116525
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.320107599193
- type: f1
value: 72.19836409602924
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.65366509751176
- type: f1
value: 74.55188288799579
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.694014794889036
- type: f1
value: 58.11353311721067
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.37457969065231
- type: f1
value: 52.81306134311697
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.3086751849361
- type: f1
value: 45.396449765419376
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.151983860121064
- type: f1
value: 60.31762544281696
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.44788164088769
- type: f1
value: 71.68150151736367
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.81439139206455
- type: f1
value: 62.06735559105593
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.04303967720242
- type: f1
value: 66.68298851670133
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.43913920645595
- type: f1
value: 60.25605977560783
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.90316072629456
- type: f1
value: 65.1325924692381
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.63752521856086
- type: f1
value: 59.14284778039585
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.63080026899797
- type: f1
value: 70.89771864626877
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.10827168796234
- type: f1
value: 71.71954219691159
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.59515803631471
- type: f1
value: 70.05040128099003
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.83389374579691
- type: f1
value: 70.84877936562735
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.18628110289173
- type: f1
value: 68.97232927921841
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.99260255548083
- type: f1
value: 72.85139492157732
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.26227303295225
- type: f1
value: 65.08833655469431
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.48621385339611
- type: f1
value: 64.43483199071298
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.14391392064559
- type: f1
value: 72.2580822579741
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.88567585743107
- type: f1
value: 58.3073765932569
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.38399462004034
- type: f1
value: 60.82139544252606
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.58574310692671
- type: f1
value: 60.71443370385374
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.61398789509079
- type: f1
value: 70.99761812049401
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.73705447209146
- type: f1
value: 61.680849331794796
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.66778749159381
- type: f1
value: 71.17320646080115
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.640215198386
- type: f1
value: 63.301805157015444
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.00672494956288
- type: f1
value: 70.26005548582106
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.42030934767989
- type: f1
value: 75.2074842882598
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.69266980497646
- type: f1
value: 70.94103167391192
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 28.91697191169135
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.434000079573313
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.96683513343383
- type: mrr
value: 31.967364078714834
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.5280000000000005
- type: map_at_10
value: 11.793
- type: map_at_100
value: 14.496999999999998
- type: map_at_1000
value: 15.783
- type: map_at_3
value: 8.838
- type: map_at_5
value: 10.07
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 51.531000000000006
- type: mrr_at_100
value: 52.205
- type: mrr_at_1000
value: 52.242999999999995
- type: mrr_at_3
value: 49.431999999999995
- type: mrr_at_5
value: 50.470000000000006
- type: ndcg_at_1
value: 42.415000000000006
- type: ndcg_at_10
value: 32.464999999999996
- type: ndcg_at_100
value: 28.927999999999997
- type: ndcg_at_1000
value: 37.629000000000005
- type: ndcg_at_3
value: 37.845
- type: ndcg_at_5
value: 35.147
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 23.932000000000002
- type: precision_at_100
value: 7.17
- type: precision_at_1000
value: 1.967
- type: precision_at_3
value: 35.397
- type: precision_at_5
value: 29.907
- type: recall_at_1
value: 5.5280000000000005
- type: recall_at_10
value: 15.568000000000001
- type: recall_at_100
value: 28.54
- type: recall_at_1000
value: 59.864
- type: recall_at_3
value: 9.822000000000001
- type: recall_at_5
value: 11.726
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.041000000000004
- type: map_at_10
value: 52.664
- type: map_at_100
value: 53.477
- type: map_at_1000
value: 53.505
- type: map_at_3
value: 48.510999999999996
- type: map_at_5
value: 51.036
- type: mrr_at_1
value: 41.338
- type: mrr_at_10
value: 55.071000000000005
- type: mrr_at_100
value: 55.672
- type: mrr_at_1000
value: 55.689
- type: mrr_at_3
value: 51.82
- type: mrr_at_5
value: 53.852
- type: ndcg_at_1
value: 41.338
- type: ndcg_at_10
value: 60.01800000000001
- type: ndcg_at_100
value: 63.409000000000006
- type: ndcg_at_1000
value: 64.017
- type: ndcg_at_3
value: 52.44799999999999
- type: ndcg_at_5
value: 56.571000000000005
- type: precision_at_1
value: 41.338
- type: precision_at_10
value: 9.531
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.416
- type: precision_at_5
value: 16.46
- type: recall_at_1
value: 37.041000000000004
- type: recall_at_10
value: 79.76299999999999
- type: recall_at_100
value: 94.39
- type: recall_at_1000
value: 98.851
- type: recall_at_3
value: 60.465
- type: recall_at_5
value: 69.906
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 69.952
- type: map_at_10
value: 83.758
- type: map_at_100
value: 84.406
- type: map_at_1000
value: 84.425
- type: map_at_3
value: 80.839
- type: map_at_5
value: 82.646
- type: mrr_at_1
value: 80.62
- type: mrr_at_10
value: 86.947
- type: mrr_at_100
value: 87.063
- type: mrr_at_1000
value: 87.064
- type: mrr_at_3
value: 85.96000000000001
- type: mrr_at_5
value: 86.619
- type: ndcg_at_1
value: 80.63
- type: ndcg_at_10
value: 87.64800000000001
- type: ndcg_at_100
value: 88.929
- type: ndcg_at_1000
value: 89.054
- type: ndcg_at_3
value: 84.765
- type: ndcg_at_5
value: 86.291
- type: precision_at_1
value: 80.63
- type: precision_at_10
value: 13.314
- type: precision_at_100
value: 1.525
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.1
- type: precision_at_5
value: 24.372
- type: recall_at_1
value: 69.952
- type: recall_at_10
value: 94.955
- type: recall_at_100
value: 99.38
- type: recall_at_1000
value: 99.96000000000001
- type: recall_at_3
value: 86.60600000000001
- type: recall_at_5
value: 90.997
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 42.41329517878427
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 55.171278362748666
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.213
- type: map_at_10
value: 9.895
- type: map_at_100
value: 11.776
- type: map_at_1000
value: 12.084
- type: map_at_3
value: 7.2669999999999995
- type: map_at_5
value: 8.620999999999999
- type: mrr_at_1
value: 20.8
- type: mrr_at_10
value: 31.112000000000002
- type: mrr_at_100
value: 32.274
- type: mrr_at_1000
value: 32.35
- type: mrr_at_3
value: 28.133000000000003
- type: mrr_at_5
value: 29.892999999999997
- type: ndcg_at_1
value: 20.8
- type: ndcg_at_10
value: 17.163999999999998
- type: ndcg_at_100
value: 24.738
- type: ndcg_at_1000
value: 30.316
- type: ndcg_at_3
value: 16.665
- type: ndcg_at_5
value: 14.478
- type: precision_at_1
value: 20.8
- type: precision_at_10
value: 8.74
- type: precision_at_100
value: 1.963
- type: precision_at_1000
value: 0.33
- type: precision_at_3
value: 15.467
- type: precision_at_5
value: 12.6
- type: recall_at_1
value: 4.213
- type: recall_at_10
value: 17.698
- type: recall_at_100
value: 39.838
- type: recall_at_1000
value: 66.893
- type: recall_at_3
value: 9.418
- type: recall_at_5
value: 12.773000000000001
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 82.90453315738294
- type: cos_sim_spearman
value: 78.51197850080254
- type: euclidean_pearson
value: 80.09647123597748
- type: euclidean_spearman
value: 78.63548011514061
- type: manhattan_pearson
value: 80.10645285675231
- type: manhattan_spearman
value: 78.57861806068901
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.2616156846401
- type: cos_sim_spearman
value: 76.69713867850156
- type: euclidean_pearson
value: 77.97948563800394
- type: euclidean_spearman
value: 74.2371211567807
- type: manhattan_pearson
value: 77.69697879669705
- type: manhattan_spearman
value: 73.86529778022278
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 77.0293269315045
- type: cos_sim_spearman
value: 78.02555120584198
- type: euclidean_pearson
value: 78.25398100379078
- type: euclidean_spearman
value: 78.66963870599464
- type: manhattan_pearson
value: 78.14314682167348
- type: manhattan_spearman
value: 78.57692322969135
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 79.16989925136942
- type: cos_sim_spearman
value: 76.5996225327091
- type: euclidean_pearson
value: 77.8319003279786
- type: euclidean_spearman
value: 76.42824009468998
- type: manhattan_pearson
value: 77.69118862737736
- type: manhattan_spearman
value: 76.25568104762812
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.42012286935325
- type: cos_sim_spearman
value: 88.15654297884122
- type: euclidean_pearson
value: 87.34082819427852
- type: euclidean_spearman
value: 88.06333589547084
- type: manhattan_pearson
value: 87.25115596784842
- type: manhattan_spearman
value: 87.9559927695203
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.88222044996712
- type: cos_sim_spearman
value: 84.28476589061077
- type: euclidean_pearson
value: 83.17399758058309
- type: euclidean_spearman
value: 83.85497357244542
- type: manhattan_pearson
value: 83.0308397703786
- type: manhattan_spearman
value: 83.71554539935046
- task:
type: STS
dataset:
name: MTEB STS17 (ko-ko)
type: mteb/sts17-crosslingual-sts
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.20682986257339
- type: cos_sim_spearman
value: 79.94567120362092
- type: euclidean_pearson
value: 79.43122480368902
- type: euclidean_spearman
value: 79.94802077264987
- type: manhattan_pearson
value: 79.32653021527081
- type: manhattan_spearman
value: 79.80961146709178
- task:
type: STS
dataset:
name: MTEB STS17 (ar-ar)
type: mteb/sts17-crosslingual-sts
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 74.46578144394383
- type: cos_sim_spearman
value: 74.52496637472179
- type: euclidean_pearson
value: 72.2903807076809
- type: euclidean_spearman
value: 73.55549359771645
- type: manhattan_pearson
value: 72.09324837709393
- type: manhattan_spearman
value: 73.36743103606581
- task:
type: STS
dataset:
name: MTEB STS17 (en-ar)
type: mteb/sts17-crosslingual-sts
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 71.37272335116
- type: cos_sim_spearman
value: 71.26702117766037
- type: euclidean_pearson
value: 67.114829954434
- type: euclidean_spearman
value: 66.37938893947761
- type: manhattan_pearson
value: 66.79688574095246
- type: manhattan_spearman
value: 66.17292828079667
- task:
type: STS
dataset:
name: MTEB STS17 (en-de)
type: mteb/sts17-crosslingual-sts
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.61016770129092
- type: cos_sim_spearman
value: 82.08515426632214
- type: euclidean_pearson
value: 80.557340361131
- type: euclidean_spearman
value: 80.37585812266175
- type: manhattan_pearson
value: 80.6782873404285
- type: manhattan_spearman
value: 80.6678073032024
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.00150745350108
- type: cos_sim_spearman
value: 87.83441972211425
- type: euclidean_pearson
value: 87.94826702308792
- type: euclidean_spearman
value: 87.46143974860725
- type: manhattan_pearson
value: 87.97560344306105
- type: manhattan_spearman
value: 87.5267102829796
- task:
type: STS
dataset:
name: MTEB STS17 (en-tr)
type: mteb/sts17-crosslingual-sts
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 64.76325252267235
- type: cos_sim_spearman
value: 63.32615095463905
- type: euclidean_pearson
value: 64.07920669155716
- type: euclidean_spearman
value: 61.21409893072176
- type: manhattan_pearson
value: 64.26308625680016
- type: manhattan_spearman
value: 61.2438185254079
- task:
type: STS
dataset:
name: MTEB STS17 (es-en)
type: mteb/sts17-crosslingual-sts
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 75.82644463022595
- type: cos_sim_spearman
value: 76.50381269945073
- type: euclidean_pearson
value: 75.1328548315934
- type: euclidean_spearman
value: 75.63761139408453
- type: manhattan_pearson
value: 75.18610101241407
- type: manhattan_spearman
value: 75.30669266354164
- task:
type: STS
dataset:
name: MTEB STS17 (es-es)
type: mteb/sts17-crosslingual-sts
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.49994164686832
- type: cos_sim_spearman
value: 86.73743986245549
- type: euclidean_pearson
value: 86.8272894387145
- type: euclidean_spearman
value: 85.97608491000507
- type: manhattan_pearson
value: 86.74960140396779
- type: manhattan_spearman
value: 85.79285984190273
- task:
type: STS
dataset:
name: MTEB STS17 (fr-en)
type: mteb/sts17-crosslingual-sts
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.58172210788469
- type: cos_sim_spearman
value: 80.17516468334607
- type: euclidean_pearson
value: 77.56537843470504
- type: euclidean_spearman
value: 77.57264627395521
- type: manhattan_pearson
value: 78.09703521695943
- type: manhattan_spearman
value: 78.15942760916954
- task:
type: STS
dataset:
name: MTEB STS17 (it-en)
type: mteb/sts17-crosslingual-sts
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.7589932931751
- type: cos_sim_spearman
value: 80.15210089028162
- type: euclidean_pearson
value: 77.54135223516057
- type: euclidean_spearman
value: 77.52697996368764
- type: manhattan_pearson
value: 77.65734439572518
- type: manhattan_spearman
value: 77.77702992016121
- task:
type: STS
dataset:
name: MTEB STS17 (nl-en)
type: mteb/sts17-crosslingual-sts
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.16682365511267
- type: cos_sim_spearman
value: 79.25311267628506
- type: euclidean_pearson
value: 77.54882036762244
- type: euclidean_spearman
value: 77.33212935194827
- type: manhattan_pearson
value: 77.98405516064015
- type: manhattan_spearman
value: 77.85075717865719
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.10473294775917
- type: cos_sim_spearman
value: 61.82780474476838
- type: euclidean_pearson
value: 45.885111672377256
- type: euclidean_spearman
value: 56.88306351932454
- type: manhattan_pearson
value: 46.101218127323186
- type: manhattan_spearman
value: 56.80953694186333
- task:
type: STS
dataset:
name: MTEB STS22 (de)
type: mteb/sts22-crosslingual-sts
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 45.781923079584146
- type: cos_sim_spearman
value: 55.95098449691107
- type: euclidean_pearson
value: 25.4571031323205
- type: euclidean_spearman
value: 49.859978118078935
- type: manhattan_pearson
value: 25.624938455041384
- type: manhattan_spearman
value: 49.99546185049401
- task:
type: STS
dataset:
name: MTEB STS22 (es)
type: mteb/sts22-crosslingual-sts
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 60.00618133997907
- type: cos_sim_spearman
value: 66.57896677718321
- type: euclidean_pearson
value: 42.60118466388821
- type: euclidean_spearman
value: 62.8210759715209
- type: manhattan_pearson
value: 42.63446860604094
- type: manhattan_spearman
value: 62.73803068925271
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 28.460759121626943
- type: cos_sim_spearman
value: 34.13459007469131
- type: euclidean_pearson
value: 6.0917739325525195
- type: euclidean_spearman
value: 27.9947262664867
- type: manhattan_pearson
value: 6.16877864169911
- type: manhattan_spearman
value: 28.00664163971514
- task:
type: STS
dataset:
name: MTEB STS22 (tr)
type: mteb/sts22-crosslingual-sts
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.42546621771696
- type: cos_sim_spearman
value: 63.699663168970474
- type: euclidean_pearson
value: 38.12085278789738
- type: euclidean_spearman
value: 58.12329140741536
- type: manhattan_pearson
value: 37.97364549443335
- type: manhattan_spearman
value: 57.81545502318733
- task:
type: STS
dataset:
name: MTEB STS22 (ar)
type: mteb/sts22-crosslingual-sts
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 46.82241380954213
- type: cos_sim_spearman
value: 57.86569456006391
- type: euclidean_pearson
value: 31.80480070178813
- type: euclidean_spearman
value: 52.484000620130104
- type: manhattan_pearson
value: 31.952708554646097
- type: manhattan_spearman
value: 52.8560972356195
- task:
type: STS
dataset:
name: MTEB STS22 (ru)
type: mteb/sts22-crosslingual-sts
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 52.00447170498087
- type: cos_sim_spearman
value: 60.664116225735164
- type: euclidean_pearson
value: 33.87382555421702
- type: euclidean_spearman
value: 55.74649067458667
- type: manhattan_pearson
value: 33.99117246759437
- type: manhattan_spearman
value: 55.98749034923899
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 58.06497233105448
- type: cos_sim_spearman
value: 65.62968801135676
- type: euclidean_pearson
value: 47.482076613243905
- type: euclidean_spearman
value: 62.65137791498299
- type: manhattan_pearson
value: 47.57052626104093
- type: manhattan_spearman
value: 62.436916516613294
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 70.49397298562575
- type: cos_sim_spearman
value: 74.79604041187868
- type: euclidean_pearson
value: 49.661891561317795
- type: euclidean_spearman
value: 70.31535537621006
- type: manhattan_pearson
value: 49.553715741850006
- type: manhattan_spearman
value: 70.24779344636806
- task:
type: STS
dataset:
name: MTEB STS22 (de-en)
type: mteb/sts22-crosslingual-sts
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.640574515348696
- type: cos_sim_spearman
value: 54.927959317689
- type: euclidean_pearson
value: 29.00139666967476
- type: euclidean_spearman
value: 41.86386566971605
- type: manhattan_pearson
value: 29.47411067730344
- type: manhattan_spearman
value: 42.337438424952786
- task:
type: STS
dataset:
name: MTEB STS22 (es-en)
type: mteb/sts22-crosslingual-sts
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 68.14095292259312
- type: cos_sim_spearman
value: 73.99017581234789
- type: euclidean_pearson
value: 46.46304297872084
- type: euclidean_spearman
value: 60.91834114800041
- type: manhattan_pearson
value: 47.07072666338692
- type: manhattan_spearman
value: 61.70415727977926
- task:
type: STS
dataset:
name: MTEB STS22 (it)
type: mteb/sts22-crosslingual-sts
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 73.27184653359575
- type: cos_sim_spearman
value: 77.76070252418626
- type: euclidean_pearson
value: 62.30586577544778
- type: euclidean_spearman
value: 75.14246629110978
- type: manhattan_pearson
value: 62.328196884927046
- type: manhattan_spearman
value: 75.1282792981433
- task:
type: STS
dataset:
name: MTEB STS22 (pl-en)
type: mteb/sts22-crosslingual-sts
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 71.59448528829957
- type: cos_sim_spearman
value: 70.37277734222123
- type: euclidean_pearson
value: 57.63145565721123
- type: euclidean_spearman
value: 66.10113048304427
- type: manhattan_pearson
value: 57.18897811586808
- type: manhattan_spearman
value: 66.5595511215901
- task:
type: STS
dataset:
name: MTEB STS22 (zh-en)
type: mteb/sts22-crosslingual-sts
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.37520607720838
- type: cos_sim_spearman
value: 69.92282148997948
- type: euclidean_pearson
value: 40.55768770125291
- type: euclidean_spearman
value: 55.189128944669605
- type: manhattan_pearson
value: 41.03566433468883
- type: manhattan_spearman
value: 55.61251893174558
- task:
type: STS
dataset:
name: MTEB STS22 (es-it)
type: mteb/sts22-crosslingual-sts
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.791929533771835
- type: cos_sim_spearman
value: 66.45819707662093
- type: euclidean_pearson
value: 39.03686018511092
- type: euclidean_spearman
value: 56.01282695640428
- type: manhattan_pearson
value: 38.91586623619632
- type: manhattan_spearman
value: 56.69394943612747
- task:
type: STS
dataset:
name: MTEB STS22 (de-fr)
type: mteb/sts22-crosslingual-sts
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.82224468473866
- type: cos_sim_spearman
value: 59.467307194781164
- type: euclidean_pearson
value: 27.428459190256145
- type: euclidean_spearman
value: 60.83463107397519
- type: manhattan_pearson
value: 27.487391578496638
- type: manhattan_spearman
value: 61.281380460246496
- task:
type: STS
dataset:
name: MTEB STS22 (de-pl)
type: mteb/sts22-crosslingual-sts
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 16.306666792752644
- type: cos_sim_spearman
value: 39.35486427252405
- type: euclidean_pearson
value: -2.7887154897955435
- type: euclidean_spearman
value: 27.1296051831719
- type: manhattan_pearson
value: -3.202291270581297
- type: manhattan_spearman
value: 26.32895849218158
- task:
type: STS
dataset:
name: MTEB STS22 (fr-pl)
type: mteb/sts22-crosslingual-sts
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.67006803805076
- type: cos_sim_spearman
value: 73.24670207647144
- type: euclidean_pearson
value: 46.91884681500483
- type: euclidean_spearman
value: 16.903085094570333
- type: manhattan_pearson
value: 46.88391675325812
- type: manhattan_spearman
value: 28.17180849095055
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 83.79555591223837
- type: cos_sim_spearman
value: 85.63658602085185
- type: euclidean_pearson
value: 85.22080894037671
- type: euclidean_spearman
value: 85.54113580167038
- type: manhattan_pearson
value: 85.1639505960118
- type: manhattan_spearman
value: 85.43502665436196
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 80.73900991689766
- type: mrr
value: 94.81624131133934
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 55.678000000000004
- type: map_at_10
value: 65.135
- type: map_at_100
value: 65.824
- type: map_at_1000
value: 65.852
- type: map_at_3
value: 62.736000000000004
- type: map_at_5
value: 64.411
- type: mrr_at_1
value: 58.333
- type: mrr_at_10
value: 66.5
- type: mrr_at_100
value: 67.053
- type: mrr_at_1000
value: 67.08
- type: mrr_at_3
value: 64.944
- type: mrr_at_5
value: 65.89399999999999
- type: ndcg_at_1
value: 58.333
- type: ndcg_at_10
value: 69.34700000000001
- type: ndcg_at_100
value: 72.32
- type: ndcg_at_1000
value: 73.014
- type: ndcg_at_3
value: 65.578
- type: ndcg_at_5
value: 67.738
- type: precision_at_1
value: 58.333
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 25.444
- type: precision_at_5
value: 16.933
- type: recall_at_1
value: 55.678000000000004
- type: recall_at_10
value: 80.72200000000001
- type: recall_at_100
value: 93.93299999999999
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 70.783
- type: recall_at_5
value: 75.978
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.74653465346535
- type: cos_sim_ap
value: 93.01476369929063
- type: cos_sim_f1
value: 86.93009118541033
- type: cos_sim_precision
value: 88.09034907597535
- type: cos_sim_recall
value: 85.8
- type: dot_accuracy
value: 99.22970297029703
- type: dot_ap
value: 51.58725659485144
- type: dot_f1
value: 53.51351351351352
- type: dot_precision
value: 58.235294117647065
- type: dot_recall
value: 49.5
- type: euclidean_accuracy
value: 99.74356435643564
- type: euclidean_ap
value: 92.40332894384368
- type: euclidean_f1
value: 86.97838109602817
- type: euclidean_precision
value: 87.46208291203236
- type: euclidean_recall
value: 86.5
- type: manhattan_accuracy
value: 99.73069306930694
- type: manhattan_ap
value: 92.01320815721121
- type: manhattan_f1
value: 86.4135864135864
- type: manhattan_precision
value: 86.32734530938124
- type: manhattan_recall
value: 86.5
- type: max_accuracy
value: 99.74653465346535
- type: max_ap
value: 93.01476369929063
- type: max_f1
value: 86.97838109602817
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 55.2660514302523
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 30.4637783572547
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 49.41377758357637
- type: mrr
value: 50.138451213818854
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 28.887846011166594
- type: cos_sim_spearman
value: 30.10823258355903
- type: dot_pearson
value: 12.888049550236385
- type: dot_spearman
value: 12.827495903098123
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.21
- type: map_at_10
value: 1.667
- type: map_at_100
value: 9.15
- type: map_at_1000
value: 22.927
- type: map_at_3
value: 0.573
- type: map_at_5
value: 0.915
- type: mrr_at_1
value: 80
- type: mrr_at_10
value: 87.167
- type: mrr_at_100
value: 87.167
- type: mrr_at_1000
value: 87.167
- type: mrr_at_3
value: 85.667
- type: mrr_at_5
value: 87.167
- type: ndcg_at_1
value: 76
- type: ndcg_at_10
value: 69.757
- type: ndcg_at_100
value: 52.402
- type: ndcg_at_1000
value: 47.737
- type: ndcg_at_3
value: 71.866
- type: ndcg_at_5
value: 72.225
- type: precision_at_1
value: 80
- type: precision_at_10
value: 75
- type: precision_at_100
value: 53.959999999999994
- type: precision_at_1000
value: 21.568
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 78
- type: recall_at_1
value: 0.21
- type: recall_at_10
value: 1.9189999999999998
- type: recall_at_100
value: 12.589
- type: recall_at_1000
value: 45.312000000000005
- type: recall_at_3
value: 0.61
- type: recall_at_5
value: 1.019
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.10000000000001
- type: f1
value: 90.06
- type: precision
value: 89.17333333333333
- type: recall
value: 92.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.06936416184971
- type: f1
value: 50.87508028259473
- type: precision
value: 48.97398843930635
- type: recall
value: 56.06936416184971
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 57.3170731707317
- type: f1
value: 52.96080139372822
- type: precision
value: 51.67861124382864
- type: recall
value: 57.3170731707317
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.67333333333333
- type: precision
value: 91.90833333333333
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 97.07333333333332
- type: precision
value: 96.79500000000002
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.2
- type: precision
value: 92.48333333333333
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.9
- type: f1
value: 91.26666666666667
- type: precision
value: 90.59444444444445
- type: recall
value: 92.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 34.32835820895522
- type: f1
value: 29.074180380150533
- type: precision
value: 28.068207322920596
- type: recall
value: 34.32835820895522
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.5
- type: f1
value: 74.3945115995116
- type: precision
value: 72.82967843459222
- type: recall
value: 78.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.34146341463415
- type: f1
value: 61.2469400518181
- type: precision
value: 59.63977756660683
- type: recall
value: 66.34146341463415
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.9
- type: f1
value: 76.90349206349207
- type: precision
value: 75.32921568627451
- type: recall
value: 80.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.93317132442284
- type: f1
value: 81.92519105034295
- type: precision
value: 80.71283920615635
- type: recall
value: 84.93317132442284
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.1304347826087
- type: f1
value: 65.22394755003451
- type: precision
value: 62.912422360248435
- type: recall
value: 71.1304347826087
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.82608695652173
- type: f1
value: 75.55693581780538
- type: precision
value: 73.79420289855072
- type: recall
value: 79.82608695652173
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74
- type: f1
value: 70.51022222222223
- type: precision
value: 69.29673599347512
- type: recall
value: 74
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 74.14238095238095
- type: precision
value: 72.27214285714285
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.97466827503016
- type: f1
value: 43.080330405420874
- type: precision
value: 41.36505499593557
- type: recall
value: 48.97466827503016
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.60000000000001
- type: f1
value: 86.62333333333333
- type: precision
value: 85.225
- type: recall
value: 89.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.2
- type: f1
value: 39.5761253006253
- type: precision
value: 37.991358436312
- type: recall
value: 45.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.70333333333333
- type: precision
value: 85.53166666666667
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.095238095238095
- type: f1
value: 44.60650460650461
- type: precision
value: 42.774116796477045
- type: recall
value: 50.095238095238095
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.4
- type: f1
value: 58.35967261904762
- type: precision
value: 56.54857142857143
- type: recall
value: 63.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.2
- type: f1
value: 87.075
- type: precision
value: 86.12095238095239
- type: recall
value: 89.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.90333333333334
- type: precision
value: 95.50833333333333
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.9
- type: f1
value: 88.6288888888889
- type: precision
value: 87.61607142857142
- type: recall
value: 90.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.2
- type: f1
value: 60.54377630539395
- type: precision
value: 58.89434482711381
- type: recall
value: 65.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87
- type: f1
value: 84.32412698412699
- type: precision
value: 83.25527777777778
- type: recall
value: 87
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.7
- type: f1
value: 63.07883541295306
- type: precision
value: 61.06117424242426
- type: recall
value: 68.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.78333333333335
- type: precision
value: 90.86666666666667
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 96.96666666666667
- type: precision
value: 96.61666666666667
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27493261455525
- type: f1
value: 85.90745732255168
- type: precision
value: 84.91389637616052
- type: recall
value: 88.27493261455525
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.5982905982906
- type: f1
value: 88.4900284900285
- type: precision
value: 87.57122507122507
- type: recall
value: 90.5982905982906
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.90769841269842
- type: precision
value: 85.80178571428571
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.5
- type: f1
value: 78.36796536796538
- type: precision
value: 76.82196969696969
- type: recall
value: 82.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.48846960167715
- type: f1
value: 66.78771089148448
- type: precision
value: 64.98302885095339
- type: recall
value: 71.48846960167715
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.50333333333333
- type: precision
value: 91.77499999999999
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.20622568093385
- type: f1
value: 66.83278891450098
- type: precision
value: 65.35065777283677
- type: recall
value: 71.20622568093385
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.717948717948715
- type: f1
value: 43.53146853146853
- type: precision
value: 42.04721204721204
- type: recall
value: 48.717948717948715
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 58.5
- type: f1
value: 53.8564991863928
- type: precision
value: 52.40329436122275
- type: recall
value: 58.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.8
- type: f1
value: 88.29
- type: precision
value: 87.09166666666667
- type: recall
value: 90.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.28971962616822
- type: f1
value: 62.63425307817832
- type: precision
value: 60.98065939771546
- type: recall
value: 67.28971962616822
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 75.5264472455649
- type: precision
value: 74.38205086580086
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.7
- type: f1
value: 86.10809523809525
- type: precision
value: 85.07602564102565
- type: recall
value: 88.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.99999999999999
- type: f1
value: 52.85487521402737
- type: precision
value: 51.53985162713104
- type: recall
value: 56.99999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94
- type: f1
value: 92.45333333333333
- type: precision
value: 91.79166666666667
- type: recall
value: 94
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.61333333333333
- type: precision
value: 89.83333333333331
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.34555555555555
- type: precision
value: 92.75416666666668
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.2
- type: f1
value: 76.6563035113035
- type: precision
value: 75.3014652014652
- type: recall
value: 80.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.7
- type: f1
value: 82.78689263765207
- type: precision
value: 82.06705086580087
- type: recall
value: 84.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.33333333333333
- type: f1
value: 45.461523661523664
- type: precision
value: 43.93545574795575
- type: recall
value: 50.33333333333333
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.6000000000000005
- type: f1
value: 5.442121400446441
- type: precision
value: 5.146630385487529
- type: recall
value: 6.6000000000000005
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85
- type: f1
value: 81.04666666666667
- type: precision
value: 79.25
- type: recall
value: 85
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.32142857142857
- type: f1
value: 42.333333333333336
- type: precision
value: 40.69196428571429
- type: recall
value: 47.32142857142857
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 30.735455543358945
- type: f1
value: 26.73616790022338
- type: precision
value: 25.397823220451283
- type: recall
value: 30.735455543358945
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 25.1
- type: f1
value: 21.975989896371022
- type: precision
value: 21.059885632257203
- type: recall
value: 25.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.75666666666666
- type: precision
value: 92.06166666666665
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.74
- type: precision
value: 92.09166666666667
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.3
- type: f1
value: 66.922442002442
- type: precision
value: 65.38249567099568
- type: recall
value: 71.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 40.300000000000004
- type: f1
value: 35.78682789299971
- type: precision
value: 34.66425128716588
- type: recall
value: 40.300000000000004
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96
- type: f1
value: 94.82333333333334
- type: precision
value: 94.27833333333334
- type: recall
value: 96
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 51.1
- type: f1
value: 47.179074753133584
- type: precision
value: 46.06461044702424
- type: recall
value: 51.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.7
- type: f1
value: 84.71
- type: precision
value: 83.46166666666667
- type: recall
value: 87.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.68333333333334
- type: precision
value: 94.13333333333334
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.39999999999999
- type: f1
value: 82.5577380952381
- type: precision
value: 81.36833333333334
- type: recall
value: 85.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.16788321167883
- type: f1
value: 16.948865627297987
- type: precision
value: 15.971932568647897
- type: recall
value: 21.16788321167883
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 5.515526831658907
- type: precision
value: 5.141966366966367
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.39666666666668
- type: precision
value: 90.58666666666667
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 89.95666666666666
- type: precision
value: 88.92833333333333
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.76190476190477
- type: f1
value: 74.93386243386244
- type: precision
value: 73.11011904761904
- type: recall
value: 79.76190476190477
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.799999999999999
- type: f1
value: 6.921439712248537
- type: precision
value: 6.489885109680683
- type: recall
value: 8.799999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.75569358178054
- type: f1
value: 40.34699501312631
- type: precision
value: 38.57886764719063
- type: recall
value: 45.75569358178054
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.4
- type: f1
value: 89.08333333333333
- type: precision
value: 88.01666666666668
- type: recall
value: 91.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.60000000000001
- type: f1
value: 92.06690476190477
- type: precision
value: 91.45095238095239
- type: recall
value: 93.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.5
- type: f1
value: 6.200363129378736
- type: precision
value: 5.89115314822466
- type: recall
value: 7.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 73.59307359307358
- type: f1
value: 68.38933553219267
- type: precision
value: 66.62698412698413
- type: recall
value: 73.59307359307358
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.8473282442748
- type: f1
value: 64.72373682297346
- type: precision
value: 62.82834214131924
- type: recall
value: 69.8473282442748
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.5254730713246
- type: f1
value: 96.72489082969432
- type: precision
value: 96.33672974284326
- type: recall
value: 97.5254730713246
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.6
- type: f1
value: 72.42746031746033
- type: precision
value: 71.14036630036631
- type: recall
value: 75.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.24293785310734
- type: f1
value: 88.86064030131826
- type: precision
value: 87.73540489642184
- type: recall
value: 91.24293785310734
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.2
- type: f1
value: 4.383083659794954
- type: precision
value: 4.027861324289673
- type: recall
value: 6.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 84.09428571428572
- type: precision
value: 83.00333333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 60.699999999999996
- type: f1
value: 56.1584972394755
- type: precision
value: 54.713456330903135
- type: recall
value: 60.699999999999996
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.2
- type: f1
value: 80.66190476190475
- type: precision
value: 79.19690476190476
- type: recall
value: 84.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.33
- type: precision
value: 90.45
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.3
- type: f1
value: 5.126828976748276
- type: precision
value: 4.853614328966668
- type: recall
value: 6.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.76943699731903
- type: f1
value: 77.82873739308057
- type: precision
value: 76.27622452019234
- type: recall
value: 81.76943699731903
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.29666666666665
- type: precision
value: 89.40333333333334
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 29.249011857707508
- type: f1
value: 24.561866096392947
- type: precision
value: 23.356583740215456
- type: recall
value: 29.249011857707508
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.46478873239437
- type: f1
value: 73.23943661971832
- type: precision
value: 71.66666666666667
- type: recall
value: 77.46478873239437
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 20.35928143712575
- type: f1
value: 15.997867865075824
- type: precision
value: 14.882104658301346
- type: recall
value: 20.35928143712575
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 90.25999999999999
- type: precision
value: 89.45333333333335
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 23.15270935960591
- type: f1
value: 19.65673625772148
- type: precision
value: 18.793705293464992
- type: recall
value: 23.15270935960591
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.154929577464785
- type: f1
value: 52.3868463305083
- type: precision
value: 50.14938113529662
- type: recall
value: 59.154929577464785
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.51282051282051
- type: f1
value: 66.8089133089133
- type: precision
value: 65.37645687645687
- type: recall
value: 70.51282051282051
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 93
- type: precision
value: 92.23333333333333
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.62212943632568
- type: f1
value: 34.3278276962583
- type: precision
value: 33.07646935732408
- type: recall
value: 38.62212943632568
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 28.1
- type: f1
value: 23.579609223054604
- type: precision
value: 22.39622774921555
- type: recall
value: 28.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27361563517914
- type: f1
value: 85.12486427795874
- type: precision
value: 83.71335504885994
- type: recall
value: 88.27361563517914
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.6
- type: f1
value: 86.39928571428571
- type: precision
value: 85.4947557997558
- type: recall
value: 88.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.5
- type: f1
value: 83.77952380952381
- type: precision
value: 82.67602564102565
- type: recall
value: 86.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.52755905511812
- type: f1
value: 75.3055868016498
- type: precision
value: 73.81889763779527
- type: recall
value: 79.52755905511812
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.9
- type: f1
value: 73.76261904761905
- type: precision
value: 72.11670995670995
- type: recall
value: 77.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 53.8781163434903
- type: f1
value: 47.25804051288816
- type: precision
value: 45.0603482390186
- type: recall
value: 53.8781163434903
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.10000000000001
- type: f1
value: 88.88
- type: precision
value: 87.96333333333334
- type: recall
value: 91.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.46153846153847
- type: f1
value: 34.43978243978244
- type: precision
value: 33.429487179487175
- type: recall
value: 38.46153846153847
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.9
- type: f1
value: 86.19888888888887
- type: precision
value: 85.07440476190476
- type: recall
value: 88.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.9
- type: f1
value: 82.58857142857143
- type: precision
value: 81.15666666666667
- type: recall
value: 85.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 83.36999999999999
- type: precision
value: 81.86833333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.51415094339622
- type: f1
value: 63.195000099481234
- type: precision
value: 61.394033442972116
- type: recall
value: 68.51415094339622
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.5
- type: f1
value: 86.14603174603175
- type: precision
value: 85.1162037037037
- type: recall
value: 88.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.62043795620438
- type: f1
value: 94.40389294403892
- type: precision
value: 93.7956204379562
- type: recall
value: 95.62043795620438
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.8
- type: f1
value: 78.6532178932179
- type: precision
value: 77.46348795840176
- type: recall
value: 81.8
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.603
- type: map_at_10
value: 8.5
- type: map_at_100
value: 12.985
- type: map_at_1000
value: 14.466999999999999
- type: map_at_3
value: 4.859999999999999
- type: map_at_5
value: 5.817
- type: mrr_at_1
value: 28.571
- type: mrr_at_10
value: 42.331
- type: mrr_at_100
value: 43.592999999999996
- type: mrr_at_1000
value: 43.592999999999996
- type: mrr_at_3
value: 38.435
- type: mrr_at_5
value: 39.966
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 21.353
- type: ndcg_at_100
value: 31.087999999999997
- type: ndcg_at_1000
value: 43.163000000000004
- type: ndcg_at_3
value: 22.999
- type: ndcg_at_5
value: 21.451
- type: precision_at_1
value: 28.571
- type: precision_at_10
value: 19.387999999999998
- type: precision_at_100
value: 6.265
- type: precision_at_1000
value: 1.4160000000000001
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 21.224
- type: recall_at_1
value: 2.603
- type: recall_at_10
value: 14.474
- type: recall_at_100
value: 40.287
- type: recall_at_1000
value: 76.606
- type: recall_at_3
value: 5.978
- type: recall_at_5
value: 7.819
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 69.7848
- type: ap
value: 13.661023167088224
- type: f1
value: 53.61686134460943
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.28183361629882
- type: f1
value: 61.55481034919965
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 35.972128420092396
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.59933241938367
- type: cos_sim_ap
value: 72.20760361208136
- type: cos_sim_f1
value: 66.4447731755424
- type: cos_sim_precision
value: 62.35539102267469
- type: cos_sim_recall
value: 71.10817941952506
- type: dot_accuracy
value: 78.98313166835548
- type: dot_ap
value: 44.492521645493795
- type: dot_f1
value: 45.814889336016094
- type: dot_precision
value: 37.02439024390244
- type: dot_recall
value: 60.07915567282321
- type: euclidean_accuracy
value: 85.3907134767837
- type: euclidean_ap
value: 71.53847289080343
- type: euclidean_f1
value: 65.95952206778834
- type: euclidean_precision
value: 61.31006346328196
- type: euclidean_recall
value: 71.37203166226914
- type: manhattan_accuracy
value: 85.40859510043511
- type: manhattan_ap
value: 71.49664104395515
- type: manhattan_f1
value: 65.98569969356485
- type: manhattan_precision
value: 63.928748144482924
- type: manhattan_recall
value: 68.17941952506597
- type: max_accuracy
value: 85.59933241938367
- type: max_ap
value: 72.20760361208136
- type: max_f1
value: 66.4447731755424
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.83261536073273
- type: cos_sim_ap
value: 85.48178133644264
- type: cos_sim_f1
value: 77.87816307403935
- type: cos_sim_precision
value: 75.88953021114926
- type: cos_sim_recall
value: 79.97382198952879
- type: dot_accuracy
value: 79.76287499514883
- type: dot_ap
value: 59.17438838475084
- type: dot_f1
value: 56.34566667855996
- type: dot_precision
value: 52.50349092359864
- type: dot_recall
value: 60.794579611949494
- type: euclidean_accuracy
value: 88.76857996662397
- type: euclidean_ap
value: 85.22764834359887
- type: euclidean_f1
value: 77.65379751543554
- type: euclidean_precision
value: 75.11152683839401
- type: euclidean_recall
value: 80.37419156144134
- type: manhattan_accuracy
value: 88.6987231730508
- type: manhattan_ap
value: 85.18907981724007
- type: manhattan_f1
value: 77.51967028849757
- type: manhattan_precision
value: 75.49992701795358
- type: manhattan_recall
value: 79.65044656606098
- type: max_accuracy
value: 88.83261536073273
- type: max_ap
value: 85.48178133644264
- type: max_f1
value: 77.87816307403935
---
# multilingual-e5-base-mlx
This model was converted to MLX format from [`intfloat/multilingual-e5-base`]().
Refer to the [original model card](https://huggingface.co/intfloat/multilingual-e5-base) for more details on the model.
## Use with mlx
```bash
pip install mlx
git clone https://github.com/ml-explore/mlx-examples.git
cd mlx-examples/llms/hf_llm
python generate.py --model mlx-community/multilingual-e5-base-mlx --prompt "My name is"
```
|
[
"BIOSSES",
"SCIFACT"
] |
medspaner/xlm-roberta-large-spanish-trials-attributes
|
medspaner
|
token-classification
|
[
"transformers",
"pytorch",
"xlm-roberta",
"token-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-01-15T09:39:08Z |
2024-10-01T06:32:54+00:00
| 17 | 0 |
---
license: cc-by-nc-4.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
widget:
- text: Paciente acompañado de su madre y con antecedentes de epilepsia.
model-index:
- name: xlm-roberta-large-spanish-trials-cases-attributes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-spanish-trials-cases-attributes
This named entity recognition model detects the following types of medical attributes:
- Experiencer:
- Patient: e.g. *paciente*
- Family_member: e.g. *padre*
- Other: e.g. *cirujano*
- Event temporality:
- Future: e.g. ***cirugía*** *pendiente*
- History_of: e.g. *antecedentes de* ***migraña***
The model achieves the following results on the test set (results are averaged over 5 evaluation rounds):
- Precision: 0.894 (±0.013)
- Recall: 0.863 (±0.010)
- F1: 0.878 (±0.005)
- Accuracy: 0.988 (±0.001)
## Model description
This model adapts the pre-trained model [xlm-roberta-large-spanish-clinical](https://huggingface.co/llange/xlm-roberta-large-spanish-clinical), presented in [Lange et al. (2022)](https://academic.oup.com/bioinformatics/article/38/12/3267/6575884).
It is fine-tuned to conduct medical named entity recognition on texts about in Spanish.
The model is fine-tuned on the [CT-EBM-ES corpus (Campillos-Llanos et al. 2021)](https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-021-01395-z).
If you use this model, please, cite as follows:
```
@article{campillosetal2024,
title = {{Hybrid tool for semantic annotation and concept extraction of medical texts in Spanish}},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n},
journal = {BMC Bioinformatics},
year={2024},
publisher={BioMed Central}
}
```
## Intended uses & limitations
**Disclosure**: *This model is under development and needs to be improved. It should not be used for medical decision making without human assistance and supervision*
This model is intended for a generalist purpose, and may have bias and/or any other undesirable distortions.
Third parties who deploy or provide systems and/or services using any of these models (or using systems based on these models) should note that it is their responsibility to mitigate the risks arising from their use. Third parties, in any event, need to comply with applicable regulations, including regulations concerning the use of artificial intelligence.
The owner or creator of the models will in no event be liable for any results arising from the use made by third parties of these models.
**Descargo de responsabilidad**: *Esta herramienta se encuentra en desarrollo y no debe ser empleada para la toma de decisiones médicas*
La finalidad de este modelo es generalista, y se advierte que puede tener sesgos y/u otro tipo de distorsiones indeseables.
Terceras partes que desplieguen o proporcionen sistemas y/o servicios usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) han tener presente que es su responsabilidad abordar y minimizar los riesgos derivados de su uso. Las terceras partes, en cualquier circunstancia, deben cumplir con la normativa aplicable, incluyendo la normativa que concierne al uso de la inteligencia artificial.
El propietario o creador de los modelos de ningún modo será responsable de los resultados derivados del uso que las terceras partes hagan de estos modelos.
## Training and evaluation data
The model is fine-tuned on the Clinical Trials for Evidence-Based-Medicine in Spanish (CT-EBM-SP) corpus vs 2.
The CT-EBM-SP corpus is a collection of 1200 texts about clinical trials studies and clinical trials announcements:
- 500 abstracts from journals published under a Creative Commons license, e.g. available in PubMed or the Scientific Electronic Library Online (SciELO)
- 700 clinical trials announcements published in the European Clinical Trials Register and Repositorio Español de Estudios Clínicos
If you use the CT-EBM-ES resource, please, cite as follows:
```
@article{campillosetal-midm2021,
title = {A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n and Moreno-Sandoval, Antonio},
journal = {BMC Medical Informatics and Decision Making},
volume={21},
number={1},
pages={1--19},
year={2021},
publisher={BioMed Central}
}
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: we used different seeds for 5 evaluation rounds, and uploaded the model with the best results
- optimizer: Adam
- num_epochs: average 16.4 (±4.83); trained with early stopping if no improvement after 5 epochs (early stopping patience: 5)
### Training results (test set; average and standard deviation of 5 rounds with different seeds)
| Precision | Recall | F1 | Accuracy |
|:--------------:|:--------------:|:--------------:|:--------------:|
| 0.894 (±0.013) | 0.863 (±0.010) | 0.878 (±0.005) | 0.988 (±0.001) |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.11.6
|
[
"CT-EBM-SP",
"SCIELO"
] |
Weyaxi/Newton-7B
|
Weyaxi
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"axolotl",
"finetune",
"qlora",
"conversational",
"dataset:hendrycks/competition_math",
"dataset:allenai/ai2_arc",
"dataset:camel-ai/physics",
"dataset:camel-ai/chemistry",
"dataset:camel-ai/biology",
"dataset:camel-ai/math",
"dataset:STEM-AI-mtl/Electrical-engineering",
"dataset:openbookqa",
"dataset:piqa",
"dataset:metaeval/reclor",
"dataset:mandyyyyii/scibench",
"dataset:derek-thomas/ScienceQA",
"dataset:sciq",
"dataset:TIGER-Lab/ScienceEval",
"arxiv:2305.14314",
"base_model:openchat/openchat-3.5-0106",
"base_model:finetune:openchat/openchat-3.5-0106",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-01-30T15:24:14Z |
2024-02-28T07:22:28+00:00
| 17 | 8 |
---
base_model: openchat/openchat-3.5-0106
datasets:
- hendrycks/competition_math
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- STEM-AI-mtl/Electrical-engineering
- openbookqa
- piqa
- metaeval/reclor
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- sciq
- TIGER-Lab/ScienceEval
license: other
tags:
- axolotl
- finetune
- qlora
---

# 🔬👩🔬 Newton-7B
This model is a fine-tuned version of [openchat/openchat-3.5-0106](https://huggingface.co/openchat/openchat-3.5-0106) on datasets related to science.
This model is fine-tuned using [QLoRa](https://arxiv.org/abs/2305.14314) and [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This model's training was sponsored by [sablo.ai](https://sablo.ai).
<details><summary>See axolotl config</summary>
axolotl version: `0.3.0`
```yaml
base_model: openchat/openchat-3.5-0106
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
is_mistral_derived_model: true
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: merged_all.json
type:
field_instruction: instruction
field_output: output
format: "GPT4 Correct User: {instruction}<|end_of_turn|>GPT4 Correct Assistant:"
no_input_format: "GPT4 Correct User: {instruction}<|end_of_turn|>GPT4 Correct Assistant:"
dataset_prepared_path: last_run_prepared
val_set_size: 0.01 # not sure
output_dir: ./newton
adapter: qlora
lora_model_dir:
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
lora_r: 128
lora_alpha: 64
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
lora_target_modules:
- gate_proj
- down_proj
- up_proj
- q_proj
- v_proj
- k_proj
- o_proj
lora_modules_to_save:
- embed_tokens
- lm_head
wandb_project: huggingface
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
hub_model_id: Weyaxi/newton-lora
save_safetensors: true
# change #
gradient_accumulation_steps: 12
micro_batch_size: 6
num_epochs: 2
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
# change #
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10 # not sure
saves_per_epoch: 2
evals_per_epoch: 4
eval_table_size:
eval_table_max_new_tokens: 128
debug:
deepspeed:
weight_decay: 0.1 # not sure
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "</s>"
unk_token: "<unk>"
tokens:
- "<|end_of_turn|>"
- "<|pad_0|>"
```
</details><br>
# 📊 Datasets
You can find the dataset I used and the work I am doing with this datasets here:
https://huggingface.co/datasets/Weyaxi/sci-datasets
Following datasets were used in this model:
- 📐 [MATH](https://huggingface.co/datasets/hendrycks/competition_math)
- 🧠 [ARC](https://huggingface.co/datasets/allenai/ai2_arc) (Note: Only **train** part)
- 🧲 [camel-ai/physics](https://huggingface.co/datasets/camel-ai/physics)
- ⚗️ [camel-ai/chemistry](https://huggingface.co/datasets/camel-ai/chemistry)
- 🦠 [camel-ai/biology](https://huggingface.co/datasets/camel-ai/biology)
- 📊 [camel-ai/math](https://huggingface.co/datasets/camel-ai/math)
- ⚡ [STEM-AI-mtl/Electrical-engineering](https://huggingface.co/datasets/STEM-AI-mtl/Electrical-engineering)
- 📚 [openbookqa](https://huggingface.co/datasets/openbookqa)
- 🧠 [piqa](https://huggingface.co/datasets/piqa)
- 🎨 [reclor](https://huggingface.co/datasets/metaeval/reclor)
- 🔬 [scibench](https://github.com/mandyyyyii/scibench)
- 🧪 [ScienceQA](https://huggingface.co/datasets/derek-thomas/ScienceQA)
- 🧬 [sciq](https://huggingface.co/datasets/sciq)
- 📝 [ScienceEval](https://huggingface.co/datasets/TIGER-Lab/ScienceEval)
## 🛠️ Multiple Choice Question & Answer Datasets Conversion Progress
I used [mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) to generate a reasonable and logical answer by providing it with the question and the answer key.
I used the [Together AI](https://www.together.ai) API for this task.
The following datasets are converted using this method:
- 🧠 [ARC](https://huggingface.co/datasets/allenai/ai2_arc) (Note: Only **train** part)
- 📚 [openbookqa](https://huggingface.co/datasets/openbookqa)
- 🎨 [reclor](https://huggingface.co/datasets/metaeval/reclor)
- 🧬 [sciq](https://huggingface.co/datasets/sciq)
# 💬 Prompt Template
You can use this prompt template while using the model:
### GPT4 Correct [(Openchat)](https://huggingface.co/openchat/openchat-3.5-0106#conversation-templates)
```
GPT4 Correct User: {user}<|end_of_turn|>GPT4 Correct Assistant: {asistant}<|end_of_turn|>GPT4 Correct User: {user}<|end_of_turn|>GPT4 Correct Assistant:
```
You can also utilize the chat template method from the tokenizer config like here:
```python
messages = [
{"role": "user", "content": "Hello"},
{"role": "assistant", "content": "Hi"},
{"role": "user", "content": "How are you today?"}
]
tokens = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
```
# 🤝 Acknowledgments
Thanks to [openchat](https://huggingface.co/openchat) team for fine-tuning an excellent model that I used as a base model.
Thanks to [@jondurbin](https://huggingface.co/jondurbin) for reformatting codes for some datasets: [bagel/data_sources](https://github.com/jondurbin/bagel/tree/main/bagel/data_sources)
Thanks to [Together AI](https://www.together.ai) for providing everyone with free credits, which I used to generate a dataset in multiple choice to explanations format.
Thanks to [Tim Dettmers](https://huggingface.co/timdettmers) for his excellent [QLoRA](https://arxiv.org/abs/2305.14314) work.
Thanks to all the dataset authors mentioned in the datasets section.
Thanks to [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) for making the repository I used to make this model.
Overall, thanks to all of the open soure AI community! 🚀
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
If you would like to support me:
[☕ Buy Me a Coffee](https://www.buymeacoffee.com/weyaxi)
|
[
"SCIQ"
] |
LoneStriker/BioMistral-7B-TIES-GPTQ
|
LoneStriker
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"ties",
"medical",
"biology",
"conversational",
"fr",
"en",
"pl",
"es",
"it",
"ro",
"de",
"nl",
"dataset:pubmed",
"arxiv:2306.01708",
"arxiv:2402.10373",
"base_model:BioMistral/BioMistral-7B",
"base_model:merge:BioMistral/BioMistral-7B",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"base_model:merge:mistralai/Mistral-7B-Instruct-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] | 2024-02-19T17:32:25Z |
2024-02-19T17:34:23+00:00
| 17 | 0 |
---
base_model:
- mistralai/Mistral-7B-Instruct-v0.1
- BioMistral/BioMistral-7B
datasets:
- pubmed
language:
- fr
- en
- pl
- es
- it
- ro
- de
- nl
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
tags:
- mergekit
- merge
- ties
- medical
- biology
---
# BioMistral-7B-mistral7instruct-ties
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) as a base.
### Models Merged
The following models were included in the merge:
* [BioMistral/BioMistral-7B](https://huggingface.co/BioMistral/BioMistral-7B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: mistralai/Mistral-7B-Instruct-v0.1
- model: BioMistral/BioMistral-7B
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: mistralai/Mistral-7B-Instruct-v0.1
parameters:
normalize: true
dtype: bfloat16
```
<p align="center">
<img src="https://huggingface.co/BioMistral/BioMistral-7B/resolve/main/wordart_blue_m_rectangle.png?download=true" alt="drawing" width="250"/>
</p>
# BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
**Abstract:**
Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges.
In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.
**Advisory Notice!** Although BioMistral is intended to encapsulate medical knowledge sourced from high-quality evidence, it hasn't been tailored to effectively, safely, or suitably convey this knowledge within professional parameters for action. We advise refraining from utilizing BioMistral in medical contexts unless it undergoes thorough alignment with specific use cases and undergoes further testing, notably including randomized controlled trials in real-world medical environments. BioMistral 7B may possess inherent risks and biases that have not yet been thoroughly assessed. Additionally, the model's performance has not been evaluated in real-world clinical settings. Consequently, we recommend using BioMistral 7B strictly as a research tool and advise against deploying it in production environments for natural language generation or any professional health and medical purposes.
# 1. BioMistral models
**BioMistral** is a suite of Mistral-based further pre-trained open source models suited for the medical domains and pre-trained using textual data from PubMed Central Open Access (CC0, CC BY, CC BY-SA, and CC BY-ND). All the models are trained using the CNRS (French National Centre for Scientific Research) [Jean Zay](http://www.idris.fr/jean-zay/) French HPC.
| Model Name | Base Model | Model Type | Sequence Length | Download |
|:-------------------:|:----------------------------------:|:-------------------:|:---------------:|:-----------------------------------------------------:|
| BioMistral-7B | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Further Pre-trained | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B-DARE | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge DARE | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE) |
| BioMistral-7B-TIES | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge TIES | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES) |
| BioMistral-7B-SLERP | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge SLERP | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP) |
# 2. Quantized Models
| Base Model | Method | q_group_size | w_bit | version | VRAM GB | Time | Download |
|:-------------------:|:------:|:------------:|:-----:|:-------:|:-------:|:------:|:--------:|
| BioMistral-7B | FP16/BF16 | | | | 15.02 | x1.00 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B | AWQ | 128 | 4 | GEMV | 4.68 | x10.30 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMV) |
| BioMistral-7B | BnB.4 | | 4 | | 5.03 | x3.25 | [HuggingFace](blank) |
| BioMistral-7B | BnB.8 | | 8 | | 8.04 | x4.34 | [HuggingFace](blank) |
| BioMistral-7B-DARE | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-TIES | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-SLERP | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP-AWQ-QGS128-W4-GEMM) |
# 2. Using BioMistral
You can use BioMistral with [Hugging Face's Transformers library](https://github.com/huggingface/transformers) as follow.
Loading the model and tokenizer :
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BioMistral/BioMistral-7B")
model = AutoModel.from_pretrained("BioMistral/BioMistral-7B")
```
# 3. Supervised Fine-tuning Benchmark
| | Clinical KG | Medical Genetics | Anatomy | Pro Medicine | College Biology | College Medicine | MedQA | MedQA 5 opts | PubMedQA | MedMCQA | Avg. |
|-------------------------------------------|:---------------------------------------------:|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|------------------|
| **BioMistral 7B** | 59.9 | 64.0 | 56.5 | 60.4 | 59.0 | 54.7 | 50.6 | 42.8 | 77.5 | 48.1 | 57.3 |
| **Mistral 7B Instruct** | **62.9** | 57.0 | 55.6 | 59.4 | 62.5 | <u>57.2</u> | 42.0 | 40.9 | 75.7 | 46.1 | 55.9 |
| | | | | | | | | | | | |
| **BioMistral 7B Ensemble** | <u>62.8</u> | 62.7 | <u>57.5</u> | **63.5** | 64.3 | 55.7 | 50.6 | 43.6 | 77.5 | **48.8** | 58.7 |
| **BioMistral 7B DARE** | 62.3 | **67.0** | 55.8 | 61.4 | **66.9** | **58.0** | **51.1** | **45.2** | <u>77.7</u> | <u>48.7</u> | **59.4** |
| **BioMistral 7B TIES** | 60.1 | <u>65.0</u> | **58.5** | 60.5 | 60.4 | 56.5 | 49.5 | 43.2 | 77.5 | 48.1 | 57.9 |
| **BioMistral 7B SLERP** | 62.5 | 64.7 | 55.8 | <u>62.7</u> | <u>64.8</u> | 56.3 | <u>50.8</u> | <u>44.3</u> | **77.8** | 48.6 | <u>58.8</u> |
| | | | | | | | | | | | |
| **MedAlpaca 7B** | 53.1 | 58.0 | 54.1 | 58.8 | 58.1 | 48.6 | 40.1 | 33.7 | 73.6 | 37.0 | 51.5 |
| **PMC-LLaMA 7B** | 24.5 | 27.7 | 35.3 | 17.4 | 30.3 | 23.3 | 25.5 | 20.2 | 72.9 | 26.6 | 30.4 |
| **MediTron-7B** | 41.6 | 50.3 | 46.4 | 27.9 | 44.4 | 30.8 | 41.6 | 28.1 | 74.9 | 41.3 | 42.7 |
| **BioMedGPT-LM-7B** | 51.4 | 52.0 | 49.4 | 53.3 | 50.7 | 49.1 | 42.5 | 33.9 | 76.8 | 37.6 | 49.7 |
| | | | | | | | | | | | |
| **GPT-3.5 Turbo 1106*** | 74.71 | 74.00 | 65.92 | 72.79 | 72.91 | 64.73 | 57.71 | 50.82 | 72.66 | 53.79 | 66.0 |
Supervised Fine-Tuning (SFT) performance of BioMistral 7B models compared to baselines, measured by accuracy (↑) and averaged across 3 random seeds of 3-shot. DARE, TIES, and SLERP are model merging strategies that combine BioMistral 7B and Mistral 7B Instruct. Best model in bold, and second-best underlined. *GPT-3.5 Turbo performances are reported from the 3-shot results without SFT.
# Citation BibTeX
Arxiv : [https://arxiv.org/abs/2402.10373](https://arxiv.org/abs/2402.10373)
```bibtex
@misc{labrak2024biomistral,
title={BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains},
author={Yanis Labrak and Adrien Bazoge and Emmanuel Morin and Pierre-Antoine Gourraud and Mickael Rouvier and Richard Dufour},
year={2024},
eprint={2402.10373},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
**CAUTION!** Both direct and downstream users need to be informed about the risks, biases, and constraints inherent in the model. While the model can produce natural language text, our exploration of its capabilities and limitations is just beginning. In fields such as medicine, comprehending these limitations is crucial. Hence, we strongly advise against deploying this model for natural language generation in production or for professional tasks in the realm of health and medicine.
|
[
"MEDQA",
"PUBMEDQA"
] |
heatball/Einstein-v4-7B-GGUF
|
heatball
| null |
[
"gguf",
"axolotl",
"generated_from_trainer",
"Mistral",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"science",
"physics",
"chemistry",
"biology",
"math",
"dataset:allenai/ai2_arc",
"dataset:camel-ai/physics",
"dataset:camel-ai/chemistry",
"dataset:camel-ai/biology",
"dataset:camel-ai/math",
"dataset:metaeval/reclor",
"dataset:openbookqa",
"dataset:mandyyyyii/scibench",
"dataset:derek-thomas/ScienceQA",
"dataset:TIGER-Lab/ScienceEval",
"dataset:jondurbin/airoboros-3.2",
"dataset:LDJnr/Capybara",
"dataset:Cot-Alpaca-GPT4-From-OpenHermes-2.5",
"dataset:STEM-AI-mtl/Electrical-engineering",
"dataset:knowrohit07/saraswati-stem",
"dataset:sablo/oasst2_curated",
"dataset:glaiveai/glaive-code-assistant",
"dataset:lmsys/lmsys-chat-1m",
"dataset:TIGER-Lab/MathInstruct",
"dataset:bigbio/med_qa",
"dataset:meta-math/MetaMathQA-40K",
"dataset:piqa",
"dataset:scibench",
"dataset:sciq",
"dataset:Open-Orca/SlimOrca",
"dataset:migtissera/Synthia-v1.3",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:other",
"model-index",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-03-01T12:08:24Z |
2024-03-01T13:30:12+00:00
| 17 | 2 |
---
base_model: mistralai/Mistral-7B-v0.1
datasets:
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- metaeval/reclor
- openbookqa
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- TIGER-Lab/ScienceEval
- jondurbin/airoboros-3.2
- LDJnr/Capybara
- Cot-Alpaca-GPT4-From-OpenHermes-2.5
- STEM-AI-mtl/Electrical-engineering
- knowrohit07/saraswati-stem
- sablo/oasst2_curated
- glaiveai/glaive-code-assistant
- lmsys/lmsys-chat-1m
- TIGER-Lab/MathInstruct
- bigbio/med_qa
- meta-math/MetaMathQA-40K
- openbookqa
- piqa
- metaeval/reclor
- derek-thomas/ScienceQA
- scibench
- sciq
- Open-Orca/SlimOrca
- migtissera/Synthia-v1.3
- TIGER-Lab/ScienceEval
license: other
tags:
- axolotl
- generated_from_trainer
- Mistral
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- science
- physics
- chemistry
- biology
- math
model-index:
- name: Einstein-v4-7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 64.68
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 83.75
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 62.31
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 55.15
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 76.24
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 57.62
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
---

This repository contains the GGUF quants for Weyaxi's [Einstein-v4-7B](https://huggingface.co/Weyaxi/Einstein-v4-7B)
|
[
"SCIQ"
] |
krilecy/e5-mistral-7b-instruct
|
krilecy
|
feature-extraction
|
[
"transformers",
"pytorch",
"safetensors",
"mistral",
"feature-extraction",
"mteb",
"en",
"arxiv:2401.00368",
"arxiv:2104.08663",
"arxiv:2210.07316",
"arxiv:2212.03533",
"license:mit",
"model-index",
"text-generation-inference",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-03-27T08:10:43Z |
2024-03-28T09:38:34+00:00
| 17 | 0 |
---
language:
- en
license: mit
tags:
- mteb
model-index:
- name: e5-mistral-7b-instruct
results:
- task:
type: STS
dataset:
name: MTEB AFQMC
type: C-MTEB/AFQMC
config: default
split: validation
revision: None
metrics:
- type: cos_sim_pearson
value: 37.863226091673866
- type: cos_sim_spearman
value: 38.98733013335281
- type: euclidean_pearson
value: 37.51783380497874
- type: euclidean_spearman
value: 38.98733012753365
- type: manhattan_pearson
value: 37.26706888081721
- type: manhattan_spearman
value: 38.709750161903834
- task:
type: STS
dataset:
name: MTEB ATEC
type: C-MTEB/ATEC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 43.33924583134623
- type: cos_sim_spearman
value: 42.84316155158754
- type: euclidean_pearson
value: 45.62709879515238
- type: euclidean_spearman
value: 42.843155921732404
- type: manhattan_pearson
value: 45.4786950991229
- type: manhattan_spearman
value: 42.657334751855984
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 78.68656716417911
- type: ap
value: 41.71522322900398
- type: f1
value: 72.37207703532552
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 74.04710920770879
- type: ap
value: 83.42622221864045
- type: f1
value: 72.14388257905772
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 77.93103448275862
- type: ap
value: 26.039284760509513
- type: f1
value: 64.81092954450712
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 77.21627408993577
- type: ap
value: 24.876490553983036
- type: f1
value: 63.8773359684989
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 95.90679999999999
- type: ap
value: 94.32357863164454
- type: f1
value: 95.90485634708557
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 55.786
- type: f1
value: 55.31211995815146
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 53.26
- type: f1
value: 52.156230111544986
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 50.33
- type: f1
value: 49.195023008878145
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.3
- type: f1
value: 48.434470184108
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.68599999999999
- type: f1
value: 47.62681775202072
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.238
- type: f1
value: 45.014030559653705
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.486000000000004
- type: map_at_10
value: 53.076
- type: map_at_100
value: 53.657999999999994
- type: map_at_1000
value: 53.659
- type: map_at_3
value: 48.234
- type: map_at_5
value: 51.121
- type: mrr_at_1
value: 37.269000000000005
- type: mrr_at_10
value: 53.335
- type: mrr_at_100
value: 53.916
- type: mrr_at_1000
value: 53.918
- type: mrr_at_3
value: 48.518
- type: mrr_at_5
value: 51.406
- type: ndcg_at_1
value: 36.486000000000004
- type: ndcg_at_10
value: 61.882000000000005
- type: ndcg_at_100
value: 64.165
- type: ndcg_at_1000
value: 64.203
- type: ndcg_at_3
value: 52.049
- type: ndcg_at_5
value: 57.199
- type: precision_at_1
value: 36.486000000000004
- type: precision_at_10
value: 8.982999999999999
- type: precision_at_100
value: 0.9939999999999999
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 21.029
- type: precision_at_5
value: 15.092
- type: recall_at_1
value: 36.486000000000004
- type: recall_at_10
value: 89.82900000000001
- type: recall_at_100
value: 99.36
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 63.087
- type: recall_at_5
value: 75.46199999999999
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 50.45119266859667
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 45.4958298992051
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 66.98177472838887
- type: mrr
value: 79.91854636591478
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 87.67086498650698
- type: cos_sim_spearman
value: 85.54773239564638
- type: euclidean_pearson
value: 86.48229161588425
- type: euclidean_spearman
value: 85.54773239564638
- type: manhattan_pearson
value: 86.67533327742343
- type: manhattan_spearman
value: 85.76099026691983
- task:
type: STS
dataset:
name: MTEB BQ
type: C-MTEB/BQ
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 50.31998888922809
- type: cos_sim_spearman
value: 50.6369940530675
- type: euclidean_pearson
value: 50.055544636296055
- type: euclidean_spearman
value: 50.63699405154838
- type: manhattan_pearson
value: 50.00739378036807
- type: manhattan_spearman
value: 50.607237418676945
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.5615866388309
- type: f1
value: 99.49895615866389
- type: precision
value: 99.46764091858039
- type: recall
value: 99.5615866388309
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.19656614571869
- type: f1
value: 99.08650671362535
- type: precision
value: 99.0314769975787
- type: recall
value: 99.19656614571869
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.0256321440942
- type: f1
value: 97.83743216718624
- type: precision
value: 97.74390947927492
- type: recall
value: 98.0256321440942
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.26276987888363
- type: f1
value: 99.22766368264
- type: precision
value: 99.21011058451816
- type: recall
value: 99.26276987888363
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 88.22727272727272
- type: f1
value: 88.17411732496673
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 43.530637846246975
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 40.23505728593893
- task:
type: Clustering
dataset:
name: MTEB CLSClusteringP2P
type: C-MTEB/CLSClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 44.419028279451275
- task:
type: Clustering
dataset:
name: MTEB CLSClusteringS2S
type: C-MTEB/CLSClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 42.5820277929776
- task:
type: Reranking
dataset:
name: MTEB CMedQAv1
type: C-MTEB/CMedQAv1-reranking
config: default
split: test
revision: None
metrics:
- type: map
value: 77.67811726152972
- type: mrr
value: 80.99003968253969
- task:
type: Reranking
dataset:
name: MTEB CMedQAv2
type: C-MTEB/CMedQAv2-reranking
config: default
split: test
revision: None
metrics:
- type: map
value: 78.66055354534922
- type: mrr
value: 81.66119047619047
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.162333333333333
- type: map_at_10
value: 37.22291666666667
- type: map_at_100
value: 38.56733333333333
- type: map_at_1000
value: 38.684250000000006
- type: map_at_3
value: 34.22858333333333
- type: map_at_5
value: 35.852500000000006
- type: mrr_at_1
value: 32.459833333333336
- type: mrr_at_10
value: 41.65358333333333
- type: mrr_at_100
value: 42.566916666666664
- type: mrr_at_1000
value: 42.61766666666667
- type: mrr_at_3
value: 39.210499999999996
- type: mrr_at_5
value: 40.582166666666666
- type: ndcg_at_1
value: 32.459833333333336
- type: ndcg_at_10
value: 42.96758333333333
- type: ndcg_at_100
value: 48.5065
- type: ndcg_at_1000
value: 50.556583333333336
- type: ndcg_at_3
value: 38.004416666666664
- type: ndcg_at_5
value: 40.25916666666667
- type: precision_at_1
value: 32.459833333333336
- type: precision_at_10
value: 7.664583333333333
- type: precision_at_100
value: 1.2349999999999999
- type: precision_at_1000
value: 0.15966666666666668
- type: precision_at_3
value: 17.731166666666663
- type: precision_at_5
value: 12.575333333333335
- type: recall_at_1
value: 27.162333333333333
- type: recall_at_10
value: 55.44158333333334
- type: recall_at_100
value: 79.56966666666666
- type: recall_at_1000
value: 93.45224999999999
- type: recall_at_3
value: 41.433083333333336
- type: recall_at_5
value: 47.31108333333333
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.539
- type: map_at_10
value: 28.494999999999997
- type: map_at_100
value: 30.568
- type: map_at_1000
value: 30.741000000000003
- type: map_at_3
value: 23.846999999999998
- type: map_at_5
value: 26.275
- type: mrr_at_1
value: 37.394
- type: mrr_at_10
value: 50.068
- type: mrr_at_100
value: 50.727
- type: mrr_at_1000
value: 50.751000000000005
- type: mrr_at_3
value: 46.938
- type: mrr_at_5
value: 48.818
- type: ndcg_at_1
value: 37.394
- type: ndcg_at_10
value: 38.349
- type: ndcg_at_100
value: 45.512
- type: ndcg_at_1000
value: 48.321
- type: ndcg_at_3
value: 32.172
- type: ndcg_at_5
value: 34.265
- type: precision_at_1
value: 37.394
- type: precision_at_10
value: 11.927999999999999
- type: precision_at_100
value: 1.966
- type: precision_at_1000
value: 0.25
- type: precision_at_3
value: 24.126
- type: precision_at_5
value: 18.306
- type: recall_at_1
value: 16.539
- type: recall_at_10
value: 44.504
- type: recall_at_100
value: 68.605
- type: recall_at_1000
value: 84.1
- type: recall_at_3
value: 29.008
- type: recall_at_5
value: 35.58
- task:
type: Retrieval
dataset:
name: MTEB CmedqaRetrieval
type: C-MTEB/CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 19.482
- type: map_at_10
value: 28.622999999999998
- type: map_at_100
value: 30.262
- type: map_at_1000
value: 30.432
- type: map_at_3
value: 25.647
- type: map_at_5
value: 27.128000000000004
- type: mrr_at_1
value: 30.408
- type: mrr_at_10
value: 37.188
- type: mrr_at_100
value: 38.196000000000005
- type: mrr_at_1000
value: 38.273
- type: mrr_at_3
value: 35.067
- type: mrr_at_5
value: 36.124
- type: ndcg_at_1
value: 30.408
- type: ndcg_at_10
value: 34.215
- type: ndcg_at_100
value: 41.349999999999994
- type: ndcg_at_1000
value: 44.689
- type: ndcg_at_3
value: 30.264999999999997
- type: ndcg_at_5
value: 31.572
- type: precision_at_1
value: 30.408
- type: precision_at_10
value: 7.6770000000000005
- type: precision_at_100
value: 1.352
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 17.213
- type: precision_at_5
value: 12.198
- type: recall_at_1
value: 19.482
- type: recall_at_10
value: 42.368
- type: recall_at_100
value: 72.694
- type: recall_at_1000
value: 95.602
- type: recall_at_3
value: 30.101
- type: recall_at_5
value: 34.708
- task:
type: PairClassification
dataset:
name: MTEB Cmnli
type: C-MTEB/CMNLI
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 71.16055321707758
- type: cos_sim_ap
value: 80.21073839711723
- type: cos_sim_f1
value: 72.9740932642487
- type: cos_sim_precision
value: 65.53136050623488
- type: cos_sim_recall
value: 82.3240589198036
- type: dot_accuracy
value: 71.16055321707758
- type: dot_ap
value: 80.212299264122
- type: dot_f1
value: 72.9740932642487
- type: dot_precision
value: 65.53136050623488
- type: dot_recall
value: 82.3240589198036
- type: euclidean_accuracy
value: 71.16055321707758
- type: euclidean_ap
value: 80.21076298680417
- type: euclidean_f1
value: 72.9740932642487
- type: euclidean_precision
value: 65.53136050623488
- type: euclidean_recall
value: 82.3240589198036
- type: manhattan_accuracy
value: 70.71557426337944
- type: manhattan_ap
value: 79.93448977199749
- type: manhattan_f1
value: 72.83962726826877
- type: manhattan_precision
value: 62.7407908077053
- type: manhattan_recall
value: 86.81318681318682
- type: max_accuracy
value: 71.16055321707758
- type: max_ap
value: 80.212299264122
- type: max_f1
value: 72.9740932642487
- task:
type: Retrieval
dataset:
name: MTEB CovidRetrieval
type: C-MTEB/CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 60.643
- type: map_at_10
value: 69.011
- type: map_at_100
value: 69.533
- type: map_at_1000
value: 69.545
- type: map_at_3
value: 67.167
- type: map_at_5
value: 68.12700000000001
- type: mrr_at_1
value: 60.801
- type: mrr_at_10
value: 69.111
- type: mrr_at_100
value: 69.6
- type: mrr_at_1000
value: 69.611
- type: mrr_at_3
value: 67.229
- type: mrr_at_5
value: 68.214
- type: ndcg_at_1
value: 60.801
- type: ndcg_at_10
value: 73.128
- type: ndcg_at_100
value: 75.614
- type: ndcg_at_1000
value: 75.92
- type: ndcg_at_3
value: 69.261
- type: ndcg_at_5
value: 70.973
- type: precision_at_1
value: 60.801
- type: precision_at_10
value: 8.662
- type: precision_at_100
value: 0.9860000000000001
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 25.149
- type: precision_at_5
value: 15.953999999999999
- type: recall_at_1
value: 60.643
- type: recall_at_10
value: 85.959
- type: recall_at_100
value: 97.576
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 75.184
- type: recall_at_5
value: 79.32000000000001
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.183
- type: map_at_10
value: 23.958
- type: map_at_100
value: 34.354
- type: map_at_1000
value: 36.442
- type: map_at_3
value: 16.345000000000002
- type: map_at_5
value: 19.647000000000002
- type: mrr_at_1
value: 74.25
- type: mrr_at_10
value: 80.976
- type: mrr_at_100
value: 81.256
- type: mrr_at_1000
value: 81.262
- type: mrr_at_3
value: 79.958
- type: mrr_at_5
value: 80.37100000000001
- type: ndcg_at_1
value: 62.0
- type: ndcg_at_10
value: 48.894999999999996
- type: ndcg_at_100
value: 53.867
- type: ndcg_at_1000
value: 61.304
- type: ndcg_at_3
value: 53.688
- type: ndcg_at_5
value: 50.900999999999996
- type: precision_at_1
value: 74.25
- type: precision_at_10
value: 39.525
- type: precision_at_100
value: 12.323
- type: precision_at_1000
value: 2.539
- type: precision_at_3
value: 57.49999999999999
- type: precision_at_5
value: 49.1
- type: recall_at_1
value: 10.183
- type: recall_at_10
value: 29.296
- type: recall_at_100
value: 60.394999999999996
- type: recall_at_1000
value: 83.12
- type: recall_at_3
value: 17.495
- type: recall_at_5
value: 22.235
- task:
type: Retrieval
dataset:
name: MTEB DuRetrieval
type: C-MTEB/DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 26.613999999999997
- type: map_at_10
value: 79.77300000000001
- type: map_at_100
value: 82.71
- type: map_at_1000
value: 82.75
- type: map_at_3
value: 55.92700000000001
- type: map_at_5
value: 70.085
- type: mrr_at_1
value: 90.7
- type: mrr_at_10
value: 93.438
- type: mrr_at_100
value: 93.504
- type: mrr_at_1000
value: 93.50699999999999
- type: mrr_at_3
value: 93.125
- type: mrr_at_5
value: 93.34
- type: ndcg_at_1
value: 90.7
- type: ndcg_at_10
value: 87.023
- type: ndcg_at_100
value: 90.068
- type: ndcg_at_1000
value: 90.43299999999999
- type: ndcg_at_3
value: 86.339
- type: ndcg_at_5
value: 85.013
- type: precision_at_1
value: 90.7
- type: precision_at_10
value: 41.339999999999996
- type: precision_at_100
value: 4.806
- type: precision_at_1000
value: 0.48900000000000005
- type: precision_at_3
value: 76.983
- type: precision_at_5
value: 64.69
- type: recall_at_1
value: 26.613999999999997
- type: recall_at_10
value: 87.681
- type: recall_at_100
value: 97.44699999999999
- type: recall_at_1000
value: 99.348
- type: recall_at_3
value: 57.809999999999995
- type: recall_at_5
value: 74.258
- task:
type: Retrieval
dataset:
name: MTEB EcomRetrieval
type: C-MTEB/EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 30.9
- type: map_at_10
value: 40.467
- type: map_at_100
value: 41.423
- type: map_at_1000
value: 41.463
- type: map_at_3
value: 37.25
- type: map_at_5
value: 39.31
- type: mrr_at_1
value: 30.9
- type: mrr_at_10
value: 40.467
- type: mrr_at_100
value: 41.423
- type: mrr_at_1000
value: 41.463
- type: mrr_at_3
value: 37.25
- type: mrr_at_5
value: 39.31
- type: ndcg_at_1
value: 30.9
- type: ndcg_at_10
value: 45.957
- type: ndcg_at_100
value: 50.735
- type: ndcg_at_1000
value: 51.861999999999995
- type: ndcg_at_3
value: 39.437
- type: ndcg_at_5
value: 43.146
- type: precision_at_1
value: 30.9
- type: precision_at_10
value: 6.35
- type: precision_at_100
value: 0.861
- type: precision_at_1000
value: 0.095
- type: precision_at_3
value: 15.267
- type: precision_at_5
value: 10.96
- type: recall_at_1
value: 30.9
- type: recall_at_10
value: 63.5
- type: recall_at_100
value: 86.1
- type: recall_at_1000
value: 95.1
- type: recall_at_3
value: 45.800000000000004
- type: recall_at_5
value: 54.800000000000004
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 49.765
- type: f1
value: 45.93242203574485
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 75.138
- type: map_at_10
value: 84.21300000000001
- type: map_at_100
value: 84.43
- type: map_at_1000
value: 84.441
- type: map_at_3
value: 83.071
- type: map_at_5
value: 83.853
- type: mrr_at_1
value: 80.948
- type: mrr_at_10
value: 88.175
- type: mrr_at_100
value: 88.24
- type: mrr_at_1000
value: 88.241
- type: mrr_at_3
value: 87.516
- type: mrr_at_5
value: 87.997
- type: ndcg_at_1
value: 80.948
- type: ndcg_at_10
value: 87.84100000000001
- type: ndcg_at_100
value: 88.576
- type: ndcg_at_1000
value: 88.75699999999999
- type: ndcg_at_3
value: 86.176
- type: ndcg_at_5
value: 87.214
- type: precision_at_1
value: 80.948
- type: precision_at_10
value: 10.632
- type: precision_at_100
value: 1.123
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 33.193
- type: precision_at_5
value: 20.663
- type: recall_at_1
value: 75.138
- type: recall_at_10
value: 94.89699999999999
- type: recall_at_100
value: 97.751
- type: recall_at_1000
value: 98.833
- type: recall_at_3
value: 90.455
- type: recall_at_5
value: 93.085
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.45
- type: map_at_10
value: 48.596000000000004
- type: map_at_100
value: 50.70400000000001
- type: map_at_1000
value: 50.83800000000001
- type: map_at_3
value: 42.795
- type: map_at_5
value: 46.085
- type: mrr_at_1
value: 56.172999999999995
- type: mrr_at_10
value: 64.35300000000001
- type: mrr_at_100
value: 64.947
- type: mrr_at_1000
value: 64.967
- type: mrr_at_3
value: 62.653999999999996
- type: mrr_at_5
value: 63.534
- type: ndcg_at_1
value: 56.172999999999995
- type: ndcg_at_10
value: 56.593
- type: ndcg_at_100
value: 62.942
- type: ndcg_at_1000
value: 64.801
- type: ndcg_at_3
value: 53.024
- type: ndcg_at_5
value: 53.986999999999995
- type: precision_at_1
value: 56.172999999999995
- type: precision_at_10
value: 15.494
- type: precision_at_100
value: 2.222
- type: precision_at_1000
value: 0.254
- type: precision_at_3
value: 35.185
- type: precision_at_5
value: 25.556
- type: recall_at_1
value: 29.45
- type: recall_at_10
value: 62.882000000000005
- type: recall_at_100
value: 85.56099999999999
- type: recall_at_1000
value: 96.539
- type: recall_at_3
value: 47.911
- type: recall_at_5
value: 54.52
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.581
- type: map_at_10
value: 68.401
- type: map_at_100
value: 69.207
- type: map_at_1000
value: 69.25200000000001
- type: map_at_3
value: 64.689
- type: map_at_5
value: 67.158
- type: mrr_at_1
value: 79.163
- type: mrr_at_10
value: 85.22999999999999
- type: mrr_at_100
value: 85.386
- type: mrr_at_1000
value: 85.39099999999999
- type: mrr_at_3
value: 84.432
- type: mrr_at_5
value: 84.952
- type: ndcg_at_1
value: 79.163
- type: ndcg_at_10
value: 75.721
- type: ndcg_at_100
value: 78.411
- type: ndcg_at_1000
value: 79.23599999999999
- type: ndcg_at_3
value: 70.68799999999999
- type: ndcg_at_5
value: 73.694
- type: precision_at_1
value: 79.163
- type: precision_at_10
value: 16.134
- type: precision_at_100
value: 1.821
- type: precision_at_1000
value: 0.193
- type: precision_at_3
value: 46.446
- type: precision_at_5
value: 30.242
- type: recall_at_1
value: 39.581
- type: recall_at_10
value: 80.66799999999999
- type: recall_at_100
value: 91.033
- type: recall_at_1000
value: 96.408
- type: recall_at_3
value: 69.669
- type: recall_at_5
value: 75.604
- task:
type: Classification
dataset:
name: MTEB IFlyTek
type: C-MTEB/IFlyTek-classification
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 45.04809542131589
- type: f1
value: 37.01181779071118
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 94.78120000000001
- type: ap
value: 92.52931921594387
- type: f1
value: 94.77902110732532
- task:
type: Classification
dataset:
name: MTEB JDReview
type: C-MTEB/JDReview-classification
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 85.81613508442777
- type: ap
value: 52.430320593468394
- type: f1
value: 79.95467268178068
- task:
type: STS
dataset:
name: MTEB LCQMC
type: C-MTEB/LCQMC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 71.05801751913393
- type: cos_sim_spearman
value: 75.47954644971965
- type: euclidean_pearson
value: 74.27472296759713
- type: euclidean_spearman
value: 75.47954201369866
- type: manhattan_pearson
value: 74.30508190186474
- type: manhattan_spearman
value: 75.51326518159436
- task:
type: Reranking
dataset:
name: MTEB MMarcoReranking
type: C-MTEB/Mmarco-reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 24.21110921666315
- type: mrr
value: 22.863492063492064
- task:
type: Retrieval
dataset:
name: MTEB MMarcoRetrieval
type: C-MTEB/MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 61.38400000000001
- type: map_at_10
value: 70.895
- type: map_at_100
value: 71.314
- type: map_at_1000
value: 71.331
- type: map_at_3
value: 69.016
- type: map_at_5
value: 70.179
- type: mrr_at_1
value: 63.481
- type: mrr_at_10
value: 71.543
- type: mrr_at_100
value: 71.91300000000001
- type: mrr_at_1000
value: 71.928
- type: mrr_at_3
value: 69.90899999999999
- type: mrr_at_5
value: 70.907
- type: ndcg_at_1
value: 63.481
- type: ndcg_at_10
value: 74.833
- type: ndcg_at_100
value: 76.705
- type: ndcg_at_1000
value: 77.13600000000001
- type: ndcg_at_3
value: 71.236
- type: ndcg_at_5
value: 73.199
- type: precision_at_1
value: 63.481
- type: precision_at_10
value: 9.179
- type: precision_at_100
value: 1.011
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 27.044
- type: precision_at_5
value: 17.272000000000002
- type: recall_at_1
value: 61.38400000000001
- type: recall_at_10
value: 86.318
- type: recall_at_100
value: 94.786
- type: recall_at_1000
value: 98.14500000000001
- type: recall_at_3
value: 76.717
- type: recall_at_5
value: 81.416
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.363999999999997
- type: map_at_10
value: 36.022
- type: map_at_100
value: 37.229
- type: map_at_1000
value: 37.274
- type: map_at_3
value: 32.131
- type: map_at_5
value: 34.391
- type: mrr_at_1
value: 24.069
- type: mrr_at_10
value: 36.620000000000005
- type: mrr_at_100
value: 37.769999999999996
- type: mrr_at_1000
value: 37.809
- type: mrr_at_3
value: 32.846
- type: mrr_at_5
value: 35.02
- type: ndcg_at_1
value: 24.069
- type: ndcg_at_10
value: 43.056
- type: ndcg_at_100
value: 48.754
- type: ndcg_at_1000
value: 49.829
- type: ndcg_at_3
value: 35.167
- type: ndcg_at_5
value: 39.168
- type: precision_at_1
value: 24.069
- type: precision_at_10
value: 6.762
- type: precision_at_100
value: 0.96
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 14.957
- type: precision_at_5
value: 11.023
- type: recall_at_1
value: 23.363999999999997
- type: recall_at_10
value: 64.696
- type: recall_at_100
value: 90.795
- type: recall_at_1000
value: 98.892
- type: recall_at_3
value: 43.247
- type: recall_at_5
value: 52.86300000000001
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 96.11947104423166
- type: f1
value: 95.89561841159332
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.97548605240912
- type: f1
value: 92.17133696717212
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.37224816544364
- type: f1
value: 93.19978829237863
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 91.28719072972127
- type: f1
value: 91.28448045979604
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 88.8131946934385
- type: f1
value: 88.27883019362747
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 85.52260397830018
- type: f1
value: 85.15528226728568
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 86.10807113543093
- type: f1
value: 70.88498219072167
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.77120315581854
- type: f1
value: 57.97153920153224
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.93995997331554
- type: f1
value: 58.839203810064866
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.801440651425
- type: f1
value: 58.68009647839332
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 72.90785227680172
- type: f1
value: 49.83760954655788
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 73.24050632911391
- type: f1
value: 52.0562553541082
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.47948890383321
- type: f1
value: 63.334877563135485
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.2871553463349
- type: f1
value: 43.17658050605427
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.174176193678555
- type: f1
value: 59.236659587042425
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.226630800269
- type: f1
value: 60.951842696956184
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.94283792871555
- type: f1
value: 61.40057652844215
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.480833893745796
- type: f1
value: 52.5298332072816
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.52858103564223
- type: f1
value: 69.3770851919204
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.09213180901143
- type: f1
value: 71.13518469365879
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.31203765971756
- type: f1
value: 66.05906970865144
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 80.57162071284465
- type: f1
value: 77.7866172598823
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.09414929388029
- type: f1
value: 72.5712594833695
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.20914593140553
- type: f1
value: 68.90619124909186
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.74243443174176
- type: f1
value: 64.72743141749955
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.11096166778749
- type: f1
value: 72.61849933064694
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.22394082044384
- type: f1
value: 62.43648797607235
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.44855413584399
- type: f1
value: 66.56851670913659
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.4149293880296
- type: f1
value: 66.12960877904776
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.916610625420304
- type: f1
value: 54.02534600927991
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.71351714862138
- type: f1
value: 69.70227985126316
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.91257565568257
- type: f1
value: 57.06811572144974
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.25218560860793
- type: f1
value: 72.48057563104247
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.35507733691998
- type: f1
value: 73.03024649541128
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.918628110289184
- type: f1
value: 54.75590124456177
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.548755884330866
- type: f1
value: 51.5356975360209
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 46.44922663080027
- type: f1
value: 44.561114416830975
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.95763281775386
- type: f1
value: 50.68367245122476
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.20645595158035
- type: f1
value: 71.78450093258185
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.226630800269
- type: f1
value: 57.53988988993337
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.44922663080027
- type: f1
value: 48.58809018065056
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.3752521856086
- type: f1
value: 49.91373941436425
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.85205110961668
- type: f1
value: 67.05660019588582
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 49.1492938802959
- type: f1
value: 46.717578025393195
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.93140551445865
- type: f1
value: 67.45406609372205
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.82851378614662
- type: f1
value: 71.15951964393868
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.84868863483524
- type: f1
value: 71.76056802364877
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.27236045729657
- type: f1
value: 72.48733090101163
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.63012777404168
- type: f1
value: 66.56444015346203
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.62743779421655
- type: f1
value: 73.82720656992142
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.15198386012105
- type: f1
value: 64.41418309797744
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.8399462004035
- type: f1
value: 56.050989519693886
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.86684599865501
- type: f1
value: 70.80682480844303
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.36718224613316
- type: f1
value: 54.998746471013774
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.150638870208475
- type: f1
value: 49.79179342620099
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.50638870208473
- type: f1
value: 49.778960742003555
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.906523201076
- type: f1
value: 66.75784022138245
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.73234700739744
- type: f1
value: 65.75016141148413
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.06792199058508
- type: f1
value: 67.90334782594083
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.09145931405515
- type: f1
value: 58.88703095210731
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.17014122394083
- type: f1
value: 68.43676277921544
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.99327505043712
- type: f1
value: 72.26813373392943
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.13987895090787
- type: f1
value: 70.29309514467575
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.37256220578345
- type: f1
value: 72.56456170538992
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 47.205783456624076
- type: f1
value: 45.905999859074434
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.8352387357095
- type: f1
value: 69.43553987525273
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.00403496973773
- type: f1
value: 65.97477215779143
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.04976462676531
- type: f1
value: 67.24581993778398
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.882985877605925
- type: f1
value: 59.995293199988794
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.75857431069267
- type: f1
value: 76.52031675299841
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.03496973772697
- type: f1
value: 79.25548063175344
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.96570275722931
- type: f1
value: 72.19110435289122
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 82.38735709482178
- type: f1
value: 82.34495627619785
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.83994620040352
- type: f1
value: 78.91526355393667
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.7350369872226
- type: f1
value: 75.919437344927
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.21721587088096
- type: f1
value: 70.82973286243262
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.59784801613988
- type: f1
value: 78.47383161087423
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.64021519838602
- type: f1
value: 68.45118053027653
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.51042367182245
- type: f1
value: 72.90013022879003
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.0551445864156
- type: f1
value: 73.45871761713292
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.54606590450571
- type: f1
value: 57.72711794953869
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.40753194351042
- type: f1
value: 76.8157455506521
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.58372562205783
- type: f1
value: 65.2654868709758
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.39273705447208
- type: f1
value: 78.3592956594837
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.62004034969739
- type: f1
value: 79.78673754501855
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.29051782111634
- type: f1
value: 63.12502587609454
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.51849361129791
- type: f1
value: 56.32320906403241
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.41761936785474
- type: f1
value: 49.113762010098306
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.547410894418284
- type: f1
value: 56.87580674198118
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.89038332212507
- type: f1
value: 79.09210140529848
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.503698722259585
- type: f1
value: 61.45718858568352
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.02824478816408
- type: f1
value: 52.732738981386504
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.23671822461331
- type: f1
value: 52.688080372545286
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.5312710154674
- type: f1
value: 74.59368478550698
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.192333557498316
- type: f1
value: 50.18302290152229
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.6960322797579
- type: f1
value: 75.25331182714856
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.47679892400808
- type: f1
value: 78.24044732352424
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.36718224613315
- type: f1
value: 77.2714452985389
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.96234028244788
- type: f1
value: 78.21282127011372
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.19435104236717
- type: f1
value: 73.1963711292812
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.52118359112306
- type: f1
value: 80.4179964390288
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.65837256220577
- type: f1
value: 73.07156989634905
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.02824478816409
- type: f1
value: 62.972399027713664
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.87020847343645
- type: f1
value: 78.224240866849
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.6570275722932
- type: f1
value: 63.274871811412545
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.760591795561524
- type: f1
value: 56.73711528075771
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.26967047747142
- type: f1
value: 55.74735330863165
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.46133154001345
- type: f1
value: 71.9644168952811
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.70880968392737
- type: f1
value: 73.61543141070884
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.0437121721587
- type: f1
value: 74.83359868879921
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.05110961667788
- type: f1
value: 66.25869819274315
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.52118359112306
- type: f1
value: 75.92098546052303
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.92938802958977
- type: f1
value: 79.79833572573796
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.86617350369872
- type: f1
value: 77.42645654909516
- task:
type: Retrieval
dataset:
name: MTEB MedicalRetrieval
type: C-MTEB/MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 44.6
- type: map_at_10
value: 50.019000000000005
- type: map_at_100
value: 50.611
- type: map_at_1000
value: 50.67
- type: map_at_3
value: 48.699999999999996
- type: map_at_5
value: 49.455
- type: mrr_at_1
value: 44.800000000000004
- type: mrr_at_10
value: 50.119
- type: mrr_at_100
value: 50.711
- type: mrr_at_1000
value: 50.77
- type: mrr_at_3
value: 48.8
- type: mrr_at_5
value: 49.555
- type: ndcg_at_1
value: 44.6
- type: ndcg_at_10
value: 52.754
- type: ndcg_at_100
value: 55.935
- type: ndcg_at_1000
value: 57.607
- type: ndcg_at_3
value: 50.012
- type: ndcg_at_5
value: 51.393
- type: precision_at_1
value: 44.6
- type: precision_at_10
value: 6.140000000000001
- type: precision_at_100
value: 0.77
- type: precision_at_1000
value: 0.09
- type: precision_at_3
value: 17.933
- type: precision_at_5
value: 11.44
- type: recall_at_1
value: 44.6
- type: recall_at_10
value: 61.4
- type: recall_at_100
value: 77.0
- type: recall_at_1000
value: 90.4
- type: recall_at_3
value: 53.800000000000004
- type: recall_at_5
value: 57.199999999999996
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 38.192667527616315
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 37.44738902946689
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.59661273103955
- type: mrr
value: 33.82024242497473
- task:
type: Classification
dataset:
name: MTEB MultilingualSentiment
type: C-MTEB/MultilingualSentiment-classification
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 73.31333333333335
- type: f1
value: 73.0873466527602
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.471
- type: map_at_10
value: 14.142
- type: map_at_100
value: 18.179000000000002
- type: map_at_1000
value: 19.772000000000002
- type: map_at_3
value: 9.716
- type: map_at_5
value: 11.763
- type: mrr_at_1
value: 51.393
- type: mrr_at_10
value: 58.814
- type: mrr_at_100
value: 59.330000000000005
- type: mrr_at_1000
value: 59.35
- type: mrr_at_3
value: 56.398
- type: mrr_at_5
value: 58.038999999999994
- type: ndcg_at_1
value: 49.69
- type: ndcg_at_10
value: 38.615
- type: ndcg_at_100
value: 35.268
- type: ndcg_at_1000
value: 43.745
- type: ndcg_at_3
value: 43.187
- type: ndcg_at_5
value: 41.528999999999996
- type: precision_at_1
value: 51.083999999999996
- type: precision_at_10
value: 29.474
- type: precision_at_100
value: 9.167
- type: precision_at_1000
value: 2.2089999999999996
- type: precision_at_3
value: 40.351
- type: precision_at_5
value: 36.285000000000004
- type: recall_at_1
value: 5.471
- type: recall_at_10
value: 19.242
- type: recall_at_100
value: 37.14
- type: recall_at_1000
value: 68.35900000000001
- type: recall_at_3
value: 10.896
- type: recall_at_5
value: 14.75
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.499
- type: map_at_10
value: 55.862
- type: map_at_100
value: 56.667
- type: map_at_1000
value: 56.684999999999995
- type: map_at_3
value: 51.534
- type: map_at_5
value: 54.2
- type: mrr_at_1
value: 44.351
- type: mrr_at_10
value: 58.567
- type: mrr_at_100
value: 59.099000000000004
- type: mrr_at_1000
value: 59.109
- type: mrr_at_3
value: 55.218999999999994
- type: mrr_at_5
value: 57.391999999999996
- type: ndcg_at_1
value: 44.322
- type: ndcg_at_10
value: 63.535
- type: ndcg_at_100
value: 66.654
- type: ndcg_at_1000
value: 66.991
- type: ndcg_at_3
value: 55.701
- type: ndcg_at_5
value: 60.06700000000001
- type: precision_at_1
value: 44.322
- type: precision_at_10
value: 10.026
- type: precision_at_100
value: 1.18
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 24.865000000000002
- type: precision_at_5
value: 17.48
- type: recall_at_1
value: 39.499
- type: recall_at_10
value: 84.053
- type: recall_at_100
value: 97.11
- type: recall_at_1000
value: 99.493
- type: recall_at_3
value: 64.091
- type: recall_at_5
value: 74.063
- task:
type: PairClassification
dataset:
name: MTEB Ocnli
type: C-MTEB/OCNLI
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 61.18029236599891
- type: cos_sim_ap
value: 64.18398769398412
- type: cos_sim_f1
value: 67.96347757046446
- type: cos_sim_precision
value: 54.4529262086514
- type: cos_sim_recall
value: 90.3907074973601
- type: dot_accuracy
value: 61.18029236599891
- type: dot_ap
value: 64.18393484706077
- type: dot_f1
value: 67.96347757046446
- type: dot_precision
value: 54.4529262086514
- type: dot_recall
value: 90.3907074973601
- type: euclidean_accuracy
value: 61.18029236599891
- type: euclidean_ap
value: 64.18395024821486
- type: euclidean_f1
value: 67.96347757046446
- type: euclidean_precision
value: 54.4529262086514
- type: euclidean_recall
value: 90.3907074973601
- type: manhattan_accuracy
value: 61.451001624255554
- type: manhattan_ap
value: 64.38232708763513
- type: manhattan_f1
value: 68.05860805860804
- type: manhattan_precision
value: 52.10319685922602
- type: manhattan_recall
value: 98.09926082365365
- type: max_accuracy
value: 61.451001624255554
- type: max_ap
value: 64.38232708763513
- type: max_f1
value: 68.05860805860804
- task:
type: Classification
dataset:
name: MTEB OnlineShopping
type: C-MTEB/OnlineShopping-classification
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 92.19000000000001
- type: ap
value: 89.73918431886767
- type: f1
value: 92.17175032574507
- task:
type: STS
dataset:
name: MTEB PAWSX
type: C-MTEB/PAWSX
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 15.079320253752224
- type: cos_sim_spearman
value: 16.813772504404263
- type: euclidean_pearson
value: 19.476541162041762
- type: euclidean_spearman
value: 16.813772498098782
- type: manhattan_pearson
value: 19.497429832915277
- type: manhattan_spearman
value: 16.869600674180607
- task:
type: STS
dataset:
name: MTEB QBQTC
type: C-MTEB/QBQTC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 30.36139599797913
- type: cos_sim_spearman
value: 31.80296402851347
- type: euclidean_pearson
value: 30.10387888252793
- type: euclidean_spearman
value: 31.80297780103808
- type: manhattan_pearson
value: 30.86720382849436
- type: manhattan_spearman
value: 32.70491131366606
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.911
- type: map_at_10
value: 86.087
- type: map_at_100
value: 86.701
- type: map_at_1000
value: 86.715
- type: map_at_3
value: 83.231
- type: map_at_5
value: 85.051
- type: mrr_at_1
value: 82.75
- type: mrr_at_10
value: 88.759
- type: mrr_at_100
value: 88.844
- type: mrr_at_1000
value: 88.844
- type: mrr_at_3
value: 87.935
- type: mrr_at_5
value: 88.504
- type: ndcg_at_1
value: 82.75
- type: ndcg_at_10
value: 89.605
- type: ndcg_at_100
value: 90.664
- type: ndcg_at_1000
value: 90.733
- type: ndcg_at_3
value: 87.03
- type: ndcg_at_5
value: 88.473
- type: precision_at_1
value: 82.75
- type: precision_at_10
value: 13.575000000000001
- type: precision_at_100
value: 1.539
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 38.153
- type: precision_at_5
value: 25.008000000000003
- type: recall_at_1
value: 71.911
- type: recall_at_10
value: 96.261
- type: recall_at_100
value: 99.72800000000001
- type: recall_at_1000
value: 99.993
- type: recall_at_3
value: 88.762
- type: recall_at_5
value: 92.949
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 57.711581165572376
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 66.48938885750297
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.7379999999999995
- type: map_at_10
value: 9.261
- type: map_at_100
value: 11.001
- type: map_at_1000
value: 11.262
- type: map_at_3
value: 6.816
- type: map_at_5
value: 8.0
- type: mrr_at_1
value: 18.4
- type: mrr_at_10
value: 28.755999999999997
- type: mrr_at_100
value: 29.892000000000003
- type: mrr_at_1000
value: 29.961
- type: mrr_at_3
value: 25.467000000000002
- type: mrr_at_5
value: 27.332
- type: ndcg_at_1
value: 18.4
- type: ndcg_at_10
value: 16.296
- type: ndcg_at_100
value: 23.52
- type: ndcg_at_1000
value: 28.504
- type: ndcg_at_3
value: 15.485
- type: ndcg_at_5
value: 13.471
- type: precision_at_1
value: 18.4
- type: precision_at_10
value: 8.469999999999999
- type: precision_at_100
value: 1.8950000000000002
- type: precision_at_1000
value: 0.309
- type: precision_at_3
value: 14.6
- type: precision_at_5
value: 11.84
- type: recall_at_1
value: 3.7379999999999995
- type: recall_at_10
value: 17.185
- type: recall_at_100
value: 38.397
- type: recall_at_1000
value: 62.798
- type: recall_at_3
value: 8.896999999999998
- type: recall_at_5
value: 12.021999999999998
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 86.43977757480083
- type: cos_sim_spearman
value: 82.64182475199533
- type: euclidean_pearson
value: 83.71756009999591
- type: euclidean_spearman
value: 82.64182331395057
- type: manhattan_pearson
value: 83.8028936913025
- type: manhattan_spearman
value: 82.71024597804252
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.85653060698912
- type: cos_sim_spearman
value: 79.65598885228324
- type: euclidean_pearson
value: 83.1205137628455
- type: euclidean_spearman
value: 79.65629387709038
- type: manhattan_pearson
value: 83.71108853545837
- type: manhattan_spearman
value: 80.25617619716708
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 88.22921688565664
- type: cos_sim_spearman
value: 88.42662103041957
- type: euclidean_pearson
value: 87.91679798473325
- type: euclidean_spearman
value: 88.42662103041957
- type: manhattan_pearson
value: 88.16927537961303
- type: manhattan_spearman
value: 88.81581680062541
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 86.77261424554293
- type: cos_sim_spearman
value: 84.53930146434155
- type: euclidean_pearson
value: 85.67420491389697
- type: euclidean_spearman
value: 84.53929771783851
- type: manhattan_pearson
value: 85.74306784515618
- type: manhattan_spearman
value: 84.7399304675314
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 89.86138395166455
- type: cos_sim_spearman
value: 90.42577823022054
- type: euclidean_pearson
value: 89.8787763797515
- type: euclidean_spearman
value: 90.42577823022054
- type: manhattan_pearson
value: 89.9592937492158
- type: manhattan_spearman
value: 90.63535505335524
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 86.5176674585941
- type: cos_sim_spearman
value: 87.6842917085397
- type: euclidean_pearson
value: 86.70213081520711
- type: euclidean_spearman
value: 87.6842917085397
- type: manhattan_pearson
value: 86.83702628983627
- type: manhattan_spearman
value: 87.87791000374443
- task:
type: STS
dataset:
name: MTEB STS17 (ko-ko)
type: mteb/sts17-crosslingual-sts
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 83.86395454805867
- type: cos_sim_spearman
value: 83.69454595252267
- type: euclidean_pearson
value: 83.04743892608313
- type: euclidean_spearman
value: 83.69454026433006
- type: manhattan_pearson
value: 83.4032095553322
- type: manhattan_spearman
value: 84.11527379013802
- task:
type: STS
dataset:
name: MTEB STS17 (ar-ar)
type: mteb/sts17-crosslingual-sts
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 81.80249894729546
- type: cos_sim_spearman
value: 81.87004960533409
- type: euclidean_pearson
value: 80.0392760044179
- type: euclidean_spearman
value: 81.87004960533409
- type: manhattan_pearson
value: 80.38096542355912
- type: manhattan_spearman
value: 82.40774679630341
- task:
type: STS
dataset:
name: MTEB STS17 (en-ar)
type: mteb/sts17-crosslingual-sts
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 77.6158201787172
- type: cos_sim_spearman
value: 77.934651044009
- type: euclidean_pearson
value: 77.7874683895269
- type: euclidean_spearman
value: 77.934651044009
- type: manhattan_pearson
value: 78.36151849193052
- type: manhattan_spearman
value: 78.52439586349938
- task:
type: STS
dataset:
name: MTEB STS17 (en-de)
type: mteb/sts17-crosslingual-sts
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.04363311392207
- type: cos_sim_spearman
value: 87.30483659369973
- type: euclidean_pearson
value: 87.62634489502616
- type: euclidean_spearman
value: 87.30483659369973
- type: manhattan_pearson
value: 88.02340837141445
- type: manhattan_spearman
value: 87.55012003294
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 91.69172851958248
- type: cos_sim_spearman
value: 91.7546879482416
- type: euclidean_pearson
value: 91.84843039183963
- type: euclidean_spearman
value: 91.7546879482416
- type: manhattan_pearson
value: 91.72325753804357
- type: manhattan_spearman
value: 91.55330259513397
- task:
type: STS
dataset:
name: MTEB STS17 (en-tr)
type: mteb/sts17-crosslingual-sts
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 73.95572901084864
- type: cos_sim_spearman
value: 72.56217821552626
- type: euclidean_pearson
value: 74.24242980323574
- type: euclidean_spearman
value: 72.56217821552626
- type: manhattan_pearson
value: 74.57473362519922
- type: manhattan_spearman
value: 72.76048826648497
- task:
type: STS
dataset:
name: MTEB STS17 (es-en)
type: mteb/sts17-crosslingual-sts
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 86.93329396008296
- type: cos_sim_spearman
value: 88.2406635486219
- type: euclidean_pearson
value: 87.49687343908533
- type: euclidean_spearman
value: 88.2406635486219
- type: manhattan_pearson
value: 88.14088309231084
- type: manhattan_spearman
value: 88.93314020908534
- task:
type: STS
dataset:
name: MTEB STS17 (es-es)
type: mteb/sts17-crosslingual-sts
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.70124451546057
- type: cos_sim_spearman
value: 87.45988160052252
- type: euclidean_pearson
value: 88.44395505247728
- type: euclidean_spearman
value: 87.45988160052252
- type: manhattan_pearson
value: 88.69269783495425
- type: manhattan_spearman
value: 87.65383425621
- task:
type: STS
dataset:
name: MTEB STS17 (fr-en)
type: mteb/sts17-crosslingual-sts
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.64109149761346
- type: cos_sim_spearman
value: 88.06459637689733
- type: euclidean_pearson
value: 88.02313315797703
- type: euclidean_spearman
value: 88.06459637689733
- type: manhattan_pearson
value: 88.28328539133253
- type: manhattan_spearman
value: 88.06605708379142
- task:
type: STS
dataset:
name: MTEB STS17 (it-en)
type: mteb/sts17-crosslingual-sts
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.9040028177525
- type: cos_sim_spearman
value: 89.68152202933464
- type: euclidean_pearson
value: 89.23684469601253
- type: euclidean_spearman
value: 89.68152202933464
- type: manhattan_pearson
value: 89.59504307277454
- type: manhattan_spearman
value: 89.88060100313582
- task:
type: STS
dataset:
name: MTEB STS17 (nl-en)
type: mteb/sts17-crosslingual-sts
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.69891585325125
- type: cos_sim_spearman
value: 88.25252785071736
- type: euclidean_pearson
value: 87.99932873748662
- type: euclidean_spearman
value: 88.25252785071736
- type: manhattan_pearson
value: 88.26959683009446
- type: manhattan_spearman
value: 88.32583227300715
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.53235909794135
- type: cos_sim_spearman
value: 66.97521740529574
- type: euclidean_pearson
value: 68.19502223613912
- type: euclidean_spearman
value: 66.97521740529574
- type: manhattan_pearson
value: 68.39070714774539
- type: manhattan_spearman
value: 67.1072812364868
- task:
type: STS
dataset:
name: MTEB STS22 (de)
type: mteb/sts22-crosslingual-sts
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 43.715742021204775
- type: cos_sim_spearman
value: 49.12255971271453
- type: euclidean_pearson
value: 40.76848562610837
- type: euclidean_spearman
value: 49.12255971271453
- type: manhattan_pearson
value: 40.92204625614112
- type: manhattan_spearman
value: 49.23333793661129
- task:
type: STS
dataset:
name: MTEB STS22 (es)
type: mteb/sts22-crosslingual-sts
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.35268345563588
- type: cos_sim_spearman
value: 66.99661626042061
- type: euclidean_pearson
value: 65.85589122857066
- type: euclidean_spearman
value: 66.99661626042061
- type: manhattan_pearson
value: 66.78454301512294
- type: manhattan_spearman
value: 67.17570330149233
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 33.36599908204445
- type: cos_sim_spearman
value: 39.20768331939503
- type: euclidean_pearson
value: 22.16066769530468
- type: euclidean_spearman
value: 39.20768331939503
- type: manhattan_pearson
value: 22.386053195546022
- type: manhattan_spearman
value: 39.70172817465986
- task:
type: STS
dataset:
name: MTEB STS22 (tr)
type: mteb/sts22-crosslingual-sts
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.06813956986753
- type: cos_sim_spearman
value: 68.72065117995668
- type: euclidean_pearson
value: 66.97373456344194
- type: euclidean_spearman
value: 68.72065117995668
- type: manhattan_pearson
value: 67.34907265771595
- type: manhattan_spearman
value: 68.73705769957843
- task:
type: STS
dataset:
name: MTEB STS22 (ar)
type: mteb/sts22-crosslingual-sts
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.17664865207108
- type: cos_sim_spearman
value: 54.115568323148864
- type: euclidean_pearson
value: 48.56418162879182
- type: euclidean_spearman
value: 54.115568323148864
- type: manhattan_pearson
value: 48.85951643453165
- type: manhattan_spearman
value: 54.13599784169052
- task:
type: STS
dataset:
name: MTEB STS22 (ru)
type: mteb/sts22-crosslingual-sts
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.87514136275987
- type: cos_sim_spearman
value: 60.82923573674973
- type: euclidean_pearson
value: 53.724183308215615
- type: euclidean_spearman
value: 60.82923573674973
- type: manhattan_pearson
value: 53.954305573102445
- type: manhattan_spearman
value: 60.957483900644526
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.55001413648593
- type: cos_sim_spearman
value: 63.395777040381276
- type: euclidean_pearson
value: 59.869972550293305
- type: euclidean_spearman
value: 63.395777040381276
- type: manhattan_pearson
value: 61.16195496847885
- type: manhattan_spearman
value: 63.41968682525581
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 79.13334972675852
- type: cos_sim_spearman
value: 79.86263136371802
- type: euclidean_pearson
value: 78.2433603592541
- type: euclidean_spearman
value: 79.86263136371802
- type: manhattan_pearson
value: 78.87337106318412
- type: manhattan_spearman
value: 80.31230584758441
- task:
type: STS
dataset:
name: MTEB STS22 (de-en)
type: mteb/sts22-crosslingual-sts
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.559700748242356
- type: cos_sim_spearman
value: 60.92342109509558
- type: euclidean_pearson
value: 66.07256437521119
- type: euclidean_spearman
value: 60.92342109509558
- type: manhattan_pearson
value: 67.72769744612663
- type: manhattan_spearman
value: 59.64714507774168
- task:
type: STS
dataset:
name: MTEB STS22 (es-en)
type: mteb/sts22-crosslingual-sts
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 73.93491616145891
- type: cos_sim_spearman
value: 75.84242594400156
- type: euclidean_pearson
value: 74.87279745626121
- type: euclidean_spearman
value: 75.84242594400156
- type: manhattan_pearson
value: 76.47764144677505
- type: manhattan_spearman
value: 77.08411157845183
- task:
type: STS
dataset:
name: MTEB STS22 (it)
type: mteb/sts22-crosslingual-sts
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 72.75624124540954
- type: cos_sim_spearman
value: 75.8667941654703
- type: euclidean_pearson
value: 73.74314588451925
- type: euclidean_spearman
value: 75.8667941654703
- type: manhattan_pearson
value: 73.99641425871518
- type: manhattan_spearman
value: 76.1982840205817
- task:
type: STS
dataset:
name: MTEB STS22 (pl-en)
type: mteb/sts22-crosslingual-sts
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 75.20898141298767
- type: cos_sim_spearman
value: 73.18060375331436
- type: euclidean_pearson
value: 75.44489280944619
- type: euclidean_spearman
value: 73.18060375331436
- type: manhattan_pearson
value: 75.65451039552286
- type: manhattan_spearman
value: 72.97744006123156
- task:
type: STS
dataset:
name: MTEB STS22 (zh-en)
type: mteb/sts22-crosslingual-sts
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 72.04278252247816
- type: cos_sim_spearman
value: 71.8846446821539
- type: euclidean_pearson
value: 73.16043307050612
- type: euclidean_spearman
value: 71.8846446821539
- type: manhattan_pearson
value: 74.76905116839777
- type: manhattan_spearman
value: 72.66237093518471
- task:
type: STS
dataset:
name: MTEB STS22 (es-it)
type: mteb/sts22-crosslingual-sts
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 71.71033173838558
- type: cos_sim_spearman
value: 75.043122881885
- type: euclidean_pearson
value: 72.77579680345087
- type: euclidean_spearman
value: 75.043122881885
- type: manhattan_pearson
value: 72.99901534854922
- type: manhattan_spearman
value: 75.15418335015957
- task:
type: STS
dataset:
name: MTEB STS22 (de-fr)
type: mteb/sts22-crosslingual-sts
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.75733447190482
- type: cos_sim_spearman
value: 61.38968334176681
- type: euclidean_pearson
value: 55.479231520643744
- type: euclidean_spearman
value: 61.38968334176681
- type: manhattan_pearson
value: 56.05230571465244
- type: manhattan_spearman
value: 62.69383054007398
- task:
type: STS
dataset:
name: MTEB STS22 (de-pl)
type: mteb/sts22-crosslingual-sts
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 41.72244325050302
- type: cos_sim_spearman
value: 54.47476909084119
- type: euclidean_pearson
value: 43.94629756436873
- type: euclidean_spearman
value: 54.47476909084119
- type: manhattan_pearson
value: 46.36533046394657
- type: manhattan_spearman
value: 54.87509243633636
- task:
type: STS
dataset:
name: MTEB STS22 (fr-pl)
type: mteb/sts22-crosslingual-sts
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 70.75183711835146
- type: cos_sim_spearman
value: 84.51542547285167
- type: euclidean_pearson
value: 71.84188960126669
- type: euclidean_spearman
value: 84.51542547285167
- type: manhattan_pearson
value: 73.94847166379994
- type: manhattan_spearman
value: 84.51542547285167
- task:
type: STS
dataset:
name: MTEB STSB
type: C-MTEB/STSB
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 81.78690149086131
- type: cos_sim_spearman
value: 81.81202616916873
- type: euclidean_pearson
value: 80.98792254251062
- type: euclidean_spearman
value: 81.81202616916873
- type: manhattan_pearson
value: 81.46953021346732
- type: manhattan_spearman
value: 82.34259562492315
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.68273341294419
- type: cos_sim_spearman
value: 88.59927164210958
- type: euclidean_pearson
value: 88.10745681818025
- type: euclidean_spearman
value: 88.59927164210958
- type: manhattan_pearson
value: 88.25166703784649
- type: manhattan_spearman
value: 88.85343247873482
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 86.3340463345719
- type: mrr
value: 96.5182611506141
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.967000000000006
- type: map_at_10
value: 71.873
- type: map_at_100
value: 72.271
- type: map_at_1000
value: 72.292
- type: map_at_3
value: 69.006
- type: map_at_5
value: 70.856
- type: mrr_at_1
value: 63.666999999999994
- type: mrr_at_10
value: 72.929
- type: mrr_at_100
value: 73.26
- type: mrr_at_1000
value: 73.282
- type: mrr_at_3
value: 71.111
- type: mrr_at_5
value: 72.328
- type: ndcg_at_1
value: 63.666999999999994
- type: ndcg_at_10
value: 76.414
- type: ndcg_at_100
value: 78.152
- type: ndcg_at_1000
value: 78.604
- type: ndcg_at_3
value: 71.841
- type: ndcg_at_5
value: 74.435
- type: precision_at_1
value: 63.666999999999994
- type: precision_at_10
value: 10.067
- type: precision_at_100
value: 1.097
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 27.667
- type: precision_at_5
value: 18.467
- type: recall_at_1
value: 60.967000000000006
- type: recall_at_10
value: 88.922
- type: recall_at_100
value: 96.667
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 77.228
- type: recall_at_5
value: 83.428
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.82277227722773
- type: cos_sim_ap
value: 95.66279851444406
- type: cos_sim_f1
value: 90.9367088607595
- type: cos_sim_precision
value: 92.1025641025641
- type: cos_sim_recall
value: 89.8
- type: dot_accuracy
value: 99.82277227722773
- type: dot_ap
value: 95.66279851444406
- type: dot_f1
value: 90.9367088607595
- type: dot_precision
value: 92.1025641025641
- type: dot_recall
value: 89.8
- type: euclidean_accuracy
value: 99.82277227722773
- type: euclidean_ap
value: 95.66279851444406
- type: euclidean_f1
value: 90.9367088607595
- type: euclidean_precision
value: 92.1025641025641
- type: euclidean_recall
value: 89.8
- type: manhattan_accuracy
value: 99.82673267326733
- type: manhattan_ap
value: 95.86094873177069
- type: manhattan_f1
value: 91.26788357178096
- type: manhattan_precision
value: 90.06815968841285
- type: manhattan_recall
value: 92.5
- type: max_accuracy
value: 99.82673267326733
- type: max_ap
value: 95.86094873177069
- type: max_f1
value: 91.26788357178096
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 73.09533925852372
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 45.90745648090035
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 54.91147686504404
- type: mrr
value: 56.03900082760377
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.46908662038217
- type: cos_sim_spearman
value: 31.40325730367437
- type: dot_pearson
value: 31.469083969291894
- type: dot_spearman
value: 31.40325730367437
- task:
type: Reranking
dataset:
name: MTEB T2Reranking
type: C-MTEB/T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 66.90300783402137
- type: mrr
value: 77.06451972574179
- task:
type: Retrieval
dataset:
name: MTEB T2Retrieval
type: C-MTEB/T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 25.82
- type: map_at_10
value: 72.32300000000001
- type: map_at_100
value: 76.198
- type: map_at_1000
value: 76.281
- type: map_at_3
value: 50.719
- type: map_at_5
value: 62.326
- type: mrr_at_1
value: 86.599
- type: mrr_at_10
value: 89.751
- type: mrr_at_100
value: 89.876
- type: mrr_at_1000
value: 89.88000000000001
- type: mrr_at_3
value: 89.151
- type: mrr_at_5
value: 89.519
- type: ndcg_at_1
value: 86.599
- type: ndcg_at_10
value: 80.676
- type: ndcg_at_100
value: 85.03
- type: ndcg_at_1000
value: 85.854
- type: ndcg_at_3
value: 82.057
- type: ndcg_at_5
value: 80.537
- type: precision_at_1
value: 86.599
- type: precision_at_10
value: 40.373
- type: precision_at_100
value: 4.95
- type: precision_at_1000
value: 0.514
- type: precision_at_3
value: 71.918
- type: precision_at_5
value: 60.246
- type: recall_at_1
value: 25.82
- type: recall_at_10
value: 79.905
- type: recall_at_100
value: 93.88499999999999
- type: recall_at_1000
value: 98.073
- type: recall_at_3
value: 52.623
- type: recall_at_5
value: 66.233
- task:
type: Classification
dataset:
name: MTEB TNews
type: C-MTEB/TNews-classification
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 47.050000000000004
- type: f1
value: 45.704071498353294
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.243
- type: map_at_10
value: 2.278
- type: map_at_100
value: 14.221
- type: map_at_1000
value: 33.474
- type: map_at_3
value: 0.7270000000000001
- type: map_at_5
value: 1.183
- type: mrr_at_1
value: 94.0
- type: mrr_at_10
value: 97.0
- type: mrr_at_100
value: 97.0
- type: mrr_at_1000
value: 97.0
- type: mrr_at_3
value: 97.0
- type: mrr_at_5
value: 97.0
- type: ndcg_at_1
value: 90.0
- type: ndcg_at_10
value: 87.249
- type: ndcg_at_100
value: 67.876
- type: ndcg_at_1000
value: 59.205
- type: ndcg_at_3
value: 90.12299999999999
- type: ndcg_at_5
value: 89.126
- type: precision_at_1
value: 94.0
- type: precision_at_10
value: 90.8
- type: precision_at_100
value: 69.28
- type: precision_at_1000
value: 25.85
- type: precision_at_3
value: 94.667
- type: precision_at_5
value: 92.80000000000001
- type: recall_at_1
value: 0.243
- type: recall_at_10
value: 2.392
- type: recall_at_100
value: 16.982
- type: recall_at_1000
value: 55.214
- type: recall_at_3
value: 0.745
- type: recall_at_5
value: 1.2229999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.5
- type: f1
value: 67.05501804646966
- type: precision
value: 65.73261904761904
- type: recall
value: 70.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.14450867052022
- type: f1
value: 70.98265895953759
- type: precision
value: 69.26782273603082
- type: recall
value: 75.14450867052022
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 33.170731707317074
- type: f1
value: 29.92876500193573
- type: precision
value: 28.669145894755648
- type: recall
value: 33.170731707317074
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.5
- type: f1
value: 94.13333333333333
- type: precision
value: 93.46666666666667
- type: recall
value: 95.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.6
- type: f1
value: 99.46666666666665
- type: precision
value: 99.4
- type: recall
value: 99.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.2
- type: f1
value: 96.39999999999999
- type: precision
value: 96.0
- type: recall
value: 97.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.5
- type: f1
value: 92.99666666666667
- type: precision
value: 92.31666666666666
- type: recall
value: 94.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.82089552238806
- type: f1
value: 81.59203980099502
- type: precision
value: 79.60199004975124
- type: recall
value: 85.82089552238806
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.5
- type: f1
value: 75.11246031746032
- type: precision
value: 73.38734126984127
- type: recall
value: 79.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 44.390243902439025
- type: f1
value: 38.48896631823461
- type: precision
value: 36.57220286488579
- type: recall
value: 44.390243902439025
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.2
- type: f1
value: 87.57333333333334
- type: precision
value: 86.34166666666665
- type: recall
value: 90.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.82138517618469
- type: f1
value: 85.98651854423423
- type: precision
value: 84.79257073424753
- type: recall
value: 88.82138517618469
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.04347826086956
- type: f1
value: 72.32108147606868
- type: precision
value: 70.37207357859532
- type: recall
value: 77.04347826086956
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 53.04347826086957
- type: f1
value: 46.88868184955141
- type: precision
value: 44.71730105643149
- type: recall
value: 53.04347826086957
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.0
- type: f1
value: 62.891813186813195
- type: precision
value: 61.037906162464985
- type: recall
value: 68.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.3
- type: f1
value: 82.82000000000001
- type: precision
value: 81.25690476190475
- type: recall
value: 86.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.87816646562122
- type: f1
value: 63.53054933272062
- type: precision
value: 61.47807816331196
- type: recall
value: 68.87816646562122
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.4
- type: f1
value: 68.99388888888889
- type: precision
value: 66.81035714285713
- type: recall
value: 74.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.5
- type: f1
value: 87.93666666666667
- type: precision
value: 86.825
- type: recall
value: 90.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.7
- type: f1
value: 88.09
- type: precision
value: 86.85833333333333
- type: recall
value: 90.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.61904761904762
- type: f1
value: 62.30239247214037
- type: precision
value: 60.340702947845806
- type: recall
value: 67.61904761904762
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.9
- type: f1
value: 73.81285714285714
- type: precision
value: 72.21570818070818
- type: recall
value: 77.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.8
- type: f1
value: 89.66666666666667
- type: precision
value: 88.66666666666666
- type: recall
value: 91.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.6
- type: f1
value: 96.85666666666665
- type: precision
value: 96.50833333333333
- type: recall
value: 97.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.39999999999999
- type: f1
value: 93.98333333333333
- type: precision
value: 93.30000000000001
- type: recall
value: 95.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.0
- type: f1
value: 81.31538461538462
- type: precision
value: 79.70666666666666
- type: recall
value: 85.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.60000000000001
- type: f1
value: 89.81888888888888
- type: precision
value: 89.08583333333333
- type: recall
value: 91.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 44.3
- type: f1
value: 38.8623088023088
- type: precision
value: 37.03755623461505
- type: recall
value: 44.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 93.75
- type: precision
value: 93.05
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.1
- type: f1
value: 98.8
- type: precision
value: 98.65
- type: recall
value: 99.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.6765498652291
- type: f1
value: 63.991785393402644
- type: precision
value: 61.7343729944808
- type: recall
value: 69.6765498652291
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.0
- type: f1
value: 42.79341029341029
- type: precision
value: 40.25098358431692
- type: recall
value: 50.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.7
- type: f1
value: 87.19023809523809
- type: precision
value: 86.12595238095237
- type: recall
value: 89.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 42.72727272727273
- type: f1
value: 37.78789518562245
- type: precision
value: 36.24208471267295
- type: recall
value: 42.72727272727273
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.26205450733752
- type: f1
value: 70.72842833849123
- type: precision
value: 68.93256464011182
- type: recall
value: 75.26205450733752
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 93.96666666666668
- type: precision
value: 93.42
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.26459143968872
- type: f1
value: 72.40190419178747
- type: precision
value: 70.84954604409856
- type: recall
value: 76.26459143968872
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.82905982905983
- type: f1
value: 52.2100122100122
- type: precision
value: 49.52516619183286
- type: recall
value: 59.82905982905983
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.69999999999999
- type: f1
value: 77.41714285714286
- type: precision
value: 75.64833333333334
- type: recall
value: 81.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.5
- type: f1
value: 94.45
- type: precision
value: 93.93333333333334
- type: recall
value: 95.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 58.41121495327103
- type: f1
value: 52.73495974430554
- type: precision
value: 50.717067200712066
- type: recall
value: 58.41121495327103
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 73.3
- type: f1
value: 69.20371794871795
- type: precision
value: 67.6597557997558
- type: recall
value: 73.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.5
- type: f1
value: 95.51666666666667
- type: precision
value: 95.05
- type: recall
value: 96.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.4
- type: f1
value: 73.88856643356644
- type: precision
value: 72.01373015873016
- type: recall
value: 78.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.3
- type: f1
value: 94.09666666666668
- type: precision
value: 93.53333333333332
- type: recall
value: 95.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.94
- type: precision
value: 91.10833333333333
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.89999999999999
- type: precision
value: 95.46666666666668
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.5
- type: f1
value: 66.00635642135641
- type: precision
value: 64.36345238095238
- type: recall
value: 70.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.4
- type: f1
value: 90.44388888888889
- type: precision
value: 89.5767857142857
- type: recall
value: 92.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.0
- type: f1
value: 43.15372775372776
- type: precision
value: 41.53152510162313
- type: recall
value: 48.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 16.7
- type: f1
value: 14.198431372549017
- type: precision
value: 13.411765873015872
- type: recall
value: 16.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.7
- type: f1
value: 81.81666666666666
- type: precision
value: 80.10833333333332
- type: recall
value: 85.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.64285714285714
- type: f1
value: 64.745670995671
- type: precision
value: 62.916666666666664
- type: recall
value: 69.64285714285714
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 54.665203073545555
- type: f1
value: 48.55366630916923
- type: precision
value: 46.35683318998357
- type: recall
value: 54.665203073545555
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.8
- type: f1
value: 3.808587223587223
- type: precision
value: 3.5653174603174604
- type: recall
value: 4.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.6
- type: f1
value: 95.77333333333333
- type: precision
value: 95.39166666666667
- type: recall
value: 96.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.39999999999999
- type: f1
value: 94.44
- type: precision
value: 93.975
- type: recall
value: 95.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 42.0
- type: f1
value: 37.024908424908425
- type: precision
value: 35.365992063492065
- type: recall
value: 42.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.7
- type: f1
value: 62.20460835058661
- type: precision
value: 60.590134587634594
- type: recall
value: 66.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.3
- type: f1
value: 96.46666666666667
- type: precision
value: 96.06666666666668
- type: recall
value: 97.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.3
- type: f1
value: 41.96905408317173
- type: precision
value: 40.18741402116402
- type: recall
value: 47.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.2
- type: f1
value: 76.22690476190476
- type: precision
value: 74.63539682539682
- type: recall
value: 80.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.0
- type: f1
value: 94.83333333333333
- type: precision
value: 94.26666666666668
- type: recall
value: 96.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.7
- type: f1
value: 87.24333333333334
- type: precision
value: 86.17
- type: recall
value: 89.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.36496350364964
- type: f1
value: 44.795520780922246
- type: precision
value: 43.09002433090024
- type: recall
value: 50.36496350364964
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 18.8
- type: f1
value: 16.242864357864356
- type: precision
value: 15.466596638655464
- type: recall
value: 18.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 93.92333333333333
- type: precision
value: 93.30833333333332
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.4
- type: f1
value: 91.42333333333333
- type: precision
value: 90.50833333333334
- type: recall
value: 93.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 26.190476190476193
- type: f1
value: 22.05208151636723
- type: precision
value: 21.09292328042328
- type: recall
value: 26.190476190476193
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.2
- type: f1
value: 14.021009731460952
- type: precision
value: 13.1389886698243
- type: recall
value: 17.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.67494824016563
- type: f1
value: 74.24430641821947
- type: precision
value: 72.50747642051991
- type: recall
value: 78.67494824016563
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.19999999999999
- type: f1
value: 92.54
- type: precision
value: 91.75833333333334
- type: recall
value: 94.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.2
- type: f1
value: 87.78666666666666
- type: precision
value: 86.69833333333334
- type: recall
value: 90.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.7
- type: f1
value: 12.19206214842218
- type: precision
value: 11.526261904761904
- type: recall
value: 14.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 73.16017316017316
- type: f1
value: 67.44858316286889
- type: precision
value: 65.23809523809523
- type: recall
value: 73.16017316017316
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.19083969465649
- type: f1
value: 70.33078880407125
- type: precision
value: 68.3969465648855
- type: recall
value: 75.19083969465649
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 62.154294032023294
- type: f1
value: 55.86030821838681
- type: precision
value: 53.53509623160277
- type: recall
value: 62.154294032023294
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 83.9652380952381
- type: precision
value: 82.84242424242424
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.50282485875707
- type: f1
value: 91.54425612052731
- type: precision
value: 90.65442561205272
- type: recall
value: 93.50282485875707
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.4
- type: f1
value: 9.189775870222714
- type: precision
value: 8.66189886502811
- type: recall
value: 11.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.4
- type: f1
value: 91.88666666666666
- type: precision
value: 91.21444444444444
- type: recall
value: 93.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 46.0
- type: f1
value: 40.51069226095542
- type: precision
value: 38.57804926010808
- type: recall
value: 46.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.0
- type: f1
value: 89.11333333333333
- type: precision
value: 88.27000000000001
- type: recall
value: 91.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.39999999999999
- type: f1
value: 92.95
- type: precision
value: 92.27000000000001
- type: recall
value: 94.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.2
- type: f1
value: 11.73701698770113
- type: precision
value: 11.079207014736676
- type: recall
value: 14.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.14745308310992
- type: f1
value: 59.665707393589415
- type: precision
value: 57.560853653346946
- type: recall
value: 65.14745308310992
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.39999999999999
- type: f1
value: 94.0
- type: precision
value: 93.33333333333333
- type: recall
value: 95.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.56521739130434
- type: f1
value: 62.92490118577074
- type: precision
value: 60.27009222661397
- type: recall
value: 69.56521739130434
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 40.140845070422536
- type: f1
value: 35.96411804158283
- type: precision
value: 34.89075869357559
- type: recall
value: 40.140845070422536
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.86826347305389
- type: f1
value: 59.646248628284546
- type: precision
value: 57.22982606216139
- type: recall
value: 65.86826347305389
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.89999999999999
- type: f1
value: 93.48333333333333
- type: precision
value: 92.83666666666667
- type: recall
value: 94.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.783251231527096
- type: f1
value: 42.006447302013804
- type: precision
value: 40.12747105111637
- type: recall
value: 47.783251231527096
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.71830985915493
- type: f1
value: 64.80266212660578
- type: precision
value: 63.08098591549296
- type: recall
value: 69.71830985915493
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.94871794871796
- type: f1
value: 61.59912309912309
- type: precision
value: 59.17338217338218
- type: recall
value: 67.94871794871796
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.39999999999999
- type: f1
value: 95.28333333333335
- type: precision
value: 94.75
- type: recall
value: 96.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.14613778705638
- type: f1
value: 65.4349338900487
- type: precision
value: 63.57599255302805
- type: recall
value: 70.14613778705638
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.2
- type: f1
value: 7.622184434339607
- type: precision
value: 7.287048159682417
- type: recall
value: 9.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.85016286644951
- type: f1
value: 72.83387622149837
- type: precision
value: 70.58450959102424
- type: recall
value: 77.85016286644951
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.8
- type: f1
value: 88.84333333333333
- type: precision
value: 87.96666666666665
- type: recall
value: 90.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 93.14
- type: precision
value: 92.49833333333333
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.25196850393701
- type: f1
value: 80.94488188976378
- type: precision
value: 79.65879265091863
- type: recall
value: 84.25196850393701
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.89666666666666
- type: precision
value: 85.7
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 42.797783933518005
- type: f1
value: 37.30617360155193
- type: precision
value: 35.34933825792552
- type: recall
value: 42.797783933518005
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 94.93333333333332
- type: precision
value: 94.38333333333333
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 54.807692307692314
- type: f1
value: 49.506903353057204
- type: precision
value: 47.54807692307693
- type: recall
value: 54.807692307692314
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.1
- type: f1
value: 83.61857142857143
- type: precision
value: 81.975
- type: recall
value: 87.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.10000000000001
- type: f1
value: 88.76333333333332
- type: precision
value: 87.67
- type: recall
value: 91.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.10000000000001
- type: f1
value: 91.28999999999999
- type: precision
value: 90.44500000000001
- type: recall
value: 93.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 39.97641509433962
- type: f1
value: 33.12271889998028
- type: precision
value: 30.95185381542554
- type: recall
value: 39.97641509433962
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.60000000000001
- type: f1
value: 90.69
- type: precision
value: 89.84500000000001
- type: recall
value: 92.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.07299270072993
- type: f1
value: 93.64355231143554
- type: precision
value: 92.94403892944038
- type: recall
value: 95.07299270072993
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.9
- type: f1
value: 89.61333333333333
- type: precision
value: 88.53333333333333
- type: recall
value: 91.9
- task:
type: Clustering
dataset:
name: MTEB ThuNewsClusteringP2P
type: C-MTEB/ThuNewsClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 64.68478289806511
- task:
type: Clustering
dataset:
name: MTEB ThuNewsClusteringS2S
type: C-MTEB/ThuNewsClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 57.53010296184097
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.519
- type: map_at_10
value: 10.31
- type: map_at_100
value: 16.027
- type: map_at_1000
value: 17.827
- type: map_at_3
value: 5.721
- type: map_at_5
value: 7.7829999999999995
- type: mrr_at_1
value: 34.694
- type: mrr_at_10
value: 52.642999999999994
- type: mrr_at_100
value: 53.366
- type: mrr_at_1000
value: 53.366
- type: mrr_at_3
value: 48.638999999999996
- type: mrr_at_5
value: 50.578
- type: ndcg_at_1
value: 31.633
- type: ndcg_at_10
value: 26.394000000000002
- type: ndcg_at_100
value: 36.41
- type: ndcg_at_1000
value: 49.206
- type: ndcg_at_3
value: 31.694
- type: ndcg_at_5
value: 29.529
- type: precision_at_1
value: 34.694
- type: precision_at_10
value: 23.469
- type: precision_at_100
value: 7.286
- type: precision_at_1000
value: 1.5610000000000002
- type: precision_at_3
value: 34.014
- type: precision_at_5
value: 29.796
- type: recall_at_1
value: 2.519
- type: recall_at_10
value: 17.091
- type: recall_at_100
value: 45.429
- type: recall_at_1000
value: 84.621
- type: recall_at_3
value: 7.208
- type: recall_at_5
value: 10.523
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 69.58659999999999
- type: ap
value: 14.735696532619
- type: f1
value: 54.23517220069903
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 63.723825693265425
- type: f1
value: 64.02405729449103
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 54.310161547491006
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 88.77630088812064
- type: cos_sim_ap
value: 81.61725457333809
- type: cos_sim_f1
value: 74.91373801916932
- type: cos_sim_precision
value: 72.63940520446097
- type: cos_sim_recall
value: 77.33509234828496
- type: dot_accuracy
value: 88.77630088812064
- type: dot_ap
value: 81.61725317476251
- type: dot_f1
value: 74.91373801916932
- type: dot_precision
value: 72.63940520446097
- type: dot_recall
value: 77.33509234828496
- type: euclidean_accuracy
value: 88.77630088812064
- type: euclidean_ap
value: 81.61724596869566
- type: euclidean_f1
value: 74.91373801916932
- type: euclidean_precision
value: 72.63940520446097
- type: euclidean_recall
value: 77.33509234828496
- type: manhattan_accuracy
value: 88.67497168742922
- type: manhattan_ap
value: 81.430251048948
- type: manhattan_f1
value: 74.79593118171543
- type: manhattan_precision
value: 71.3635274382938
- type: manhattan_recall
value: 78.57519788918206
- type: max_accuracy
value: 88.77630088812064
- type: max_ap
value: 81.61725457333809
- type: max_f1
value: 74.91373801916932
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.85136026700819
- type: cos_sim_ap
value: 87.74656687446567
- type: cos_sim_f1
value: 80.3221673073403
- type: cos_sim_precision
value: 76.56871640957633
- type: cos_sim_recall
value: 84.46258084385587
- type: dot_accuracy
value: 89.85136026700819
- type: dot_ap
value: 87.74656471395072
- type: dot_f1
value: 80.3221673073403
- type: dot_precision
value: 76.56871640957633
- type: dot_recall
value: 84.46258084385587
- type: euclidean_accuracy
value: 89.85136026700819
- type: euclidean_ap
value: 87.74656885754466
- type: euclidean_f1
value: 80.3221673073403
- type: euclidean_precision
value: 76.56871640957633
- type: euclidean_recall
value: 84.46258084385587
- type: manhattan_accuracy
value: 89.86300306593705
- type: manhattan_ap
value: 87.78807479093082
- type: manhattan_f1
value: 80.31663429471911
- type: manhattan_precision
value: 76.63472970137772
- type: manhattan_recall
value: 84.3701878657222
- type: max_accuracy
value: 89.86300306593705
- type: max_ap
value: 87.78807479093082
- type: max_f1
value: 80.3221673073403
- task:
type: Retrieval
dataset:
name: MTEB VideoRetrieval
type: C-MTEB/VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 32.4
- type: map_at_10
value: 40.961999999999996
- type: map_at_100
value: 41.660000000000004
- type: map_at_1000
value: 41.721000000000004
- type: map_at_3
value: 38.550000000000004
- type: map_at_5
value: 40.06
- type: mrr_at_1
value: 32.4
- type: mrr_at_10
value: 40.961999999999996
- type: mrr_at_100
value: 41.660000000000004
- type: mrr_at_1000
value: 41.721000000000004
- type: mrr_at_3
value: 38.550000000000004
- type: mrr_at_5
value: 40.06
- type: ndcg_at_1
value: 32.4
- type: ndcg_at_10
value: 45.388
- type: ndcg_at_100
value: 49.012
- type: ndcg_at_1000
value: 50.659
- type: ndcg_at_3
value: 40.47
- type: ndcg_at_5
value: 43.232
- type: precision_at_1
value: 32.4
- type: precision_at_10
value: 5.94
- type: precision_at_100
value: 0.769
- type: precision_at_1000
value: 0.09
- type: precision_at_3
value: 15.333
- type: precision_at_5
value: 10.56
- type: recall_at_1
value: 32.4
- type: recall_at_10
value: 59.4
- type: recall_at_100
value: 76.9
- type: recall_at_1000
value: 90.0
- type: recall_at_3
value: 46.0
- type: recall_at_5
value: 52.800000000000004
- task:
type: Classification
dataset:
name: MTEB Waimai
type: C-MTEB/waimai-classification
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 86.94000000000001
- type: ap
value: 70.57373468481975
- type: f1
value: 85.26264784928323
---
## E5-mistral-7b-instruct
[Improving Text Embeddings with Large Language Models](https://arxiv.org/pdf/2401.00368.pdf). Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei, arXiv 2024
This model has 32 layers and the embedding size is 4096.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'how much protein should a female eat'),
get_detailed_instruct(task, 'summit define')
]
# No need to add instruction for retrieval documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('intfloat/e5-mistral-7b-instruct')
model = AutoModel.from_pretrained('intfloat/e5-mistral-7b-instruct')
max_length = 4096
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=max_length - 1, return_attention_mask=False, padding=False, truncation=True)
# append eos_token_id to every input_ids
batch_dict['input_ids'] = [input_ids + [tokenizer.eos_token_id] for input_ids in batch_dict['input_ids']]
batch_dict = tokenizer.pad(batch_dict, padding=True, return_attention_mask=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Supported Languages
This model is initialized from [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
and fine-tuned on a mixture of multilingual datasets.
As a result, it has some multilingual capability.
However, since Mistral-7B-v0.1 is mainly trained on English data, we recommend using this model for English only.
For multilingual use cases, please refer to [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large).
## MTEB Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## FAQ
**1. Do I need to add instructions to the query?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
The task definition should be a one-sentence instruction that describes the task.
This is a way to customize text embeddings for different scenarios through natural language instructions.
Please check out [unilm/e5/utils.py](https://github.com/microsoft/unilm/blob/9c0f1ff7ca53431fe47d2637dfe253643d94185b/e5/utils.py#L106) for instructions we used for evaluation.
On the other hand, there is no need to add instructions to the document side.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Where are the LoRA-only weights?**
You can find the LoRA-only weights at [https://huggingface.co/intfloat/e5-mistral-7b-instruct/tree/main/lora](https://huggingface.co/intfloat/e5-mistral-7b-instruct/tree/main/lora).
## Citation
If you find our paper or models helpful, please consider cite as follows:
```bibtex
@article{wang2023improving,
title={Improving Text Embeddings with Large Language Models},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2401.00368},
year={2023}
}
@article{wang2022text,
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2212.03533},
year={2022}
}
```
## Limitations
Using this model for inputs longer than 4096 tokens is not recommended.
This model's multilingual capability is still inferior to [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) for some cases.
|
[
"BIOSSES",
"SCIFACT"
] |
RichardErkhov/EleutherAI_-_gpt-neo-2.7B-4bits
|
RichardErkhov
|
text-generation
|
[
"transformers",
"safetensors",
"gpt_neo",
"text-generation",
"arxiv:2101.00027",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | 2024-04-17T09:37:54Z |
2024-04-23T06:46:44+00:00
| 17 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
gpt-neo-2.7B - bnb 4bits
- Model creator: https://huggingface.co/EleutherAI/
- Original model: https://huggingface.co/EleutherAI/gpt-neo-2.7B/
Original model description:
---
language:
- en
tags:
- text generation
- pytorch
- causal-lm
license: mit
datasets:
- EleutherAI/pile
---
# GPT-Neo 2.7B
## Model Description
GPT-Neo 2.7B is a transformer model designed using EleutherAI's replication of the GPT-3 architecture. GPT-Neo refers to the class of models, while 2.7B represents the number of parameters of this particular pre-trained model.
## Training data
GPT-Neo 2.7B was trained on the Pile, a large scale curated dataset created by EleutherAI for the purpose of training this model.
## Training procedure
This model was trained for 420 billion tokens over 400,000 steps. It was trained as a masked autoregressive language model, using cross-entropy loss.
## Intended Use and Limitations
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a prompt.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='EleutherAI/gpt-neo-2.7B')
>>> generator("EleutherAI has", do_sample=True, min_length=50)
[{'generated_text': 'EleutherAI has made a commitment to create new software packages for each of its major clients and has'}]
```
### Limitations and Biases
GPT-Neo was trained as an autoregressive language model. This means that its core functionality is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work.
GPT-Neo was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending on your usecase GPT-Neo may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-Neo will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Eval results
All evaluations were done using our [evaluation harness](https://github.com/EleutherAI/lm-evaluation-harness). Some results for GPT-2 and GPT-3 are inconsistent with the values reported in the respective papers. We are currently looking into why, and would greatly appreciate feedback and further testing of our eval harness. If you would like to contribute evaluations you have done, please reach out on our [Discord](https://discord.gg/vtRgjbM).
### Linguistic Reasoning
| Model and Size | Pile BPB | Pile PPL | Wikitext PPL | Lambada PPL | Lambada Acc | Winogrande | Hellaswag |
| ---------------- | ---------- | ---------- | ------------- | ----------- | ----------- | ---------- | ----------- |
| GPT-Neo 1.3B | 0.7527 | 6.159 | 13.10 | 7.498 | 57.23% | 55.01% | 38.66% |
| GPT-2 1.5B | 1.0468 | ----- | 17.48 | 10.634 | 51.21% | 59.40% | 40.03% |
| **GPT-Neo 2.7B** | **0.7165** | **5.646** | **11.39** | **5.626** | **62.22%** | **56.50%** | **42.73%** |
| GPT-3 Ada | 0.9631 | ----- | ----- | 9.954 | 51.60% | 52.90% | 35.93% |
### Physical and Scientific Reasoning
| Model and Size | MathQA | PubMedQA | Piqa |
| ---------------- | ---------- | ---------- | ----------- |
| GPT-Neo 1.3B | 24.05% | 54.40% | 71.11% |
| GPT-2 1.5B | 23.64% | 58.33% | 70.78% |
| **GPT-Neo 2.7B** | **24.72%** | **57.54%** | **72.14%** |
| GPT-3 Ada | 24.29% | 52.80% | 68.88% |
### Down-Stream Applications
TBD
### BibTeX entry and citation info
To cite this model, use
```bibtex
@software{gpt-neo,
author = {Black, Sid and
Leo, Gao and
Wang, Phil and
Leahy, Connor and
Biderman, Stella},
title = {{GPT-Neo: Large Scale Autoregressive Language
Modeling with Mesh-Tensorflow}},
month = mar,
year = 2021,
note = {{If you use this software, please cite it using
these metadata.}},
publisher = {Zenodo},
version = {1.0},
doi = {10.5281/zenodo.5297715},
url = {https://doi.org/10.5281/zenodo.5297715}
}
@article{gao2020pile,
title={The Pile: An 800GB Dataset of Diverse Text for Language Modeling},
author={Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and others},
journal={arXiv preprint arXiv:2101.00027},
year={2020}
}
```
|
[
"PUBMEDQA"
] |
fakezeta/Phi-3-mini-4k-instruct-ov-int4
|
fakezeta
|
text-generation
|
[
"transformers",
"openvino",
"phi3",
"text-generation",
"conversational",
"custom_code",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-04-23T21:29:00Z |
2024-04-23T22:28:43+00:00
| 17 | 1 |
---
license: mit
---
OpenVINO IR with int4 quantization.
To use on LocalAI use the following model definition:
```
name: phi3
backend: transformers
parameters:
model: fakezeta/Phi-3-mini-4k-instruct-ov-int4
context_size: 4096
threads: 6
trust_remote_code: true
type: OVModelForCausalLM
template:
use_tokenizer_template: true
stopwords:
- <|end|>
```
## Model Summary
The Phi-3-Mini-4K-Instruct is a 3.8B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Mini version in two variants [4K](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3 Mini-4K-Instruct showcased a robust and state-of-the-art performance among models with less than 13 billion parameters.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/phi3blog-april)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ Phi-3 GGUF: [4K](https://aka.ms/Phi3-mini-4k-instruct-gguf)
+ Phi-3 ONNX: [4K](https://aka.ms/Phi3-mini-4k-instruct-onnx)
## Intended Uses
**Primary use cases**
The model is intended for commercial and research use in English. The model provides uses for applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3 Mini-4K-Instruct has been integrated in the development version (4.40.0) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3 Mini-4K-Instruct is also available in [HuggingChat](https://aka.ms/try-phi3-hf-chat).
### Chat Format
Given the nature of the training data, the Phi-3 Mini-4K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|system|>
You are a helpful AI assistant.<|end|>
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|system|>
You are a helpful AI assistant.<|end|>
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
messages = [
{"role": "system", "content": "You are a helpful digital assistant. Please provide safe, ethical and accurate information to the user."},
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3 Mini-4K-Instruct has 3.8B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 4K tokens
* GPUs: 512 H100-80G
* Training time: 7 days
* Training data: 3.3T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
### Datasets
Our training data includes a wide variety of sources, totaling 3.3 trillion tokens, and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
### Fine-tuning
A basic example of multi-GPUs supervised fine-tuning (SFT) with TRL and Accelerate modules is provided [here](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/sample_finetune.py).
## Benchmarks
We report the results for Phi-3-Mini-4K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Phi-2, Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, Llama-3-8B-Instruct, and GPT-3.5.
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
| | Phi-3-Mini-4K-In<br>3.8b | Phi-3-Small<br>7b (preview) | Phi-3-Medium<br>14b (preview) | Phi-2<br>2.7b | Mistral<br>7b | Gemma<br>7b | Llama-3-In<br>8b | Mixtral<br>8x7b | GPT-3.5<br>version 1106 |
|---|---|---|---|---|---|---|---|---|---|
| MMLU <br>5-Shot | 68.8 | 75.3 | 78.2 | 56.3 | 61.7 | 63.6 | 66.5 | 68.4 | 71.4 |
| HellaSwag <br> 5-Shot | 76.7 | 78.7 | 83.2 | 53.6 | 58.5 | 49.8 | 71.1 | 70.4 | 78.8 |
| ANLI <br> 7-Shot | 52.8 | 55.0 | 58.7 | 42.5 | 47.1 | 48.7 | 57.3 | 55.2 | 58.1 |
| GSM-8K <br> 0-Shot; CoT | 82.5 | 86.4 | 90.8 | 61.1 | 46.4 | 59.8 | 77.4 | 64.7 | 78.1 |
| MedQA <br> 2-Shot | 53.8 | 58.2 | 69.8 | 40.9 | 49.6 | 50.0 | 60.5 | 62.2 | 63.4 |
| AGIEval <br> 0-Shot | 37.5 | 45.0 | 49.7 | 29.8 | 35.1 | 42.1 | 42.0 | 45.2 | 48.4 |
| TriviaQA <br> 5-Shot | 64.0 | 59.1 | 73.3 | 45.2 | 72.3 | 75.2 | 67.7 | 82.2 | 85.8 |
| Arc-C <br> 10-Shot | 84.9 | 90.7 | 91.9 | 75.9 | 78.6 | 78.3 | 82.8 | 87.3 | 87.4 |
| Arc-E <br> 10-Shot | 94.6 | 97.1 | 98.0 | 88.5 | 90.6 | 91.4 | 93.4 | 95.6 | 96.3 |
| PIQA <br> 5-Shot | 84.2 | 87.8 | 88.2 | 60.2 | 77.7 | 78.1 | 75.7 | 86.0 | 86.6 |
| SociQA <br> 5-Shot | 76.6 | 79.0 | 79.4 | 68.3 | 74.6 | 65.5 | 73.9 | 75.9 | 68.3 |
| BigBench-Hard <br> 0-Shot | 71.7 | 75.0 | 82.5 | 59.4 | 57.3 | 59.6 | 51.5 | 69.7 | 68.32 |
| WinoGrande <br> 5-Shot | 70.8 | 82.5 | 81.2 | 54.7 | 54.2 | 55.6 | 65 | 62.0 | 68.8 |
| OpenBookQA <br> 10-Shot | 83.2 | 88.4 | 86.6 | 73.6 | 79.8 | 78.6 | 82.6 | 85.8 | 86.0 |
| BoolQ <br> 0-Shot | 77.6 | 82.9 | 86.5 | -- | 72.2 | 66.0 | 80.9 | 77.6 | 79.1 |
| CommonSenseQA <br> 10-Shot | 80.2 | 80.3 | 82.6 | 69.3 | 72.6 | 76.2 | 79 | 78.1 | 79.6 |
| TruthfulQA <br> 10-Shot | 65.0 | 68.1 | 74.8 | -- | 52.1 | 53.0 | 63.2 | 60.1 | 85.8 |
| HumanEval <br> 0-Shot | 59.1 | 59.1 | 54.7 | 59.0 | 28.0 | 34.1 | 60.4 | 37.8 | 62.2 |
| MBPP <br> 3-Shot | 53.8 | 71.4 | 73.7 | 60.6 | 50.8 | 51.5 | 67.7 | 60.2 | 77.8 |
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-mini model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
* NVIDIA V100 or earlier generation GPUs: call AutoModelForCausalLM.from_pretrained() with attn_implementation="eager"
* CPU: use the **GGUF** quantized models [4K](https://aka.ms/Phi3-mini-4k-instruct-gguf)
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [4K](https://aka.ms/Phi3-mini-4k-instruct-onnx)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi-3 Mini models across platforms and hardware. You can find the optimized Phi-3 Mini-4K-Instruct ONNX model [here](https://aka.ms/phi3-mini-4k-instruct-onnx).
Optimized Phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML support lets developers bring hardware acceleration to Windows devices at scale across AMD, Intel, and NVIDIA GPUs.
Along with DirectML, ONNX Runtime provides cross platform support for Phi-3 across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-mini-4k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
[
"MEDQA"
] |
draganjovanovich/prodigy-sm-base-v0.1
|
draganjovanovich
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"en",
"sr",
"hr",
"bs",
"arxiv:2309.09530",
"arxiv:2403.19522",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-04-27T14:20:14Z |
2024-08-14T07:41:56+00:00
| 17 | 3 |
---
language:
- en
- sr
- hr
- bs
license: apache-2.0
---
# Prodigy SM Base v0.1
<img src="https://hf.fast360.xyz/production/uploads/617bbeec14572ebe9e6ea83f/4p2zaOWu6kTS3fcbevHef.png" width="70%" height="70%">
In our latest endeavour, we performed continued pre-training of a large language model (Mistral-7b-v0.1) to understand and generate text in new languages, including **Serbian**, **Bosnian** and **Croatian** using an innovative approach.
Rather than depending only on extensive datasets in the target language, our method utilizes a more compact set of both synthetic and human-curated data along with some mixture of CC Web data, which is implemented in two strategic phases:
1. Establishing a comprehensive demonstration of all grammatical and orthographic rules pertinent to the language.
2. Supplying a diverse array of examples that not only reinforce these rules but also integrate a wide range of linguistic nuances.
While our approach is uniquely tailored to our objectives, we have drawn some inspiration from recent advancements in language model training. Specifically, the conceptual strategies discussed in the paper [ADAPTING LARGE LANGUAGE MODELS VIA READING COMPREHENSION](https://arxiv.org/pdf/2309.09530.pdf) provided valuable insights, though our methods diverge significantly in practice. By adopting this inspired approach, we aim to efficiently teach the model new languages with a balanced blend of accuracy and linguistic diversity.
So... Did it work?!
# **Yes!**
See the benchmark results, or even better, download the model and try it yourself. As you know by now, there's no better benchmark than a quick 'try it yourself' vibe check. :)
<img src="https://hf.fast360.xyz/production/uploads/617bbeec14572ebe9e6ea83f/C9m_OjnYEpQo43VCrwz4A.png" width="100%" height="100%">
Here, we demonstrate results of benchmark that is not frequently performed, yet equally important: how adapting the model for a new language impacted its original English-only performance.
<img src="https://hf.fast360.xyz/production/uploads/617bbeec14572ebe9e6ea83f/IPY0myfQI-Ne5x6b11glz.png" width="100%" height="100%">
*All evals are performed in zero shot manner.
*Also bear in mind that llama-2-7b, llama-3-8b and mistral-7b models compared to Prodigy SM base aren't trained on extensive Serbian language datasets, and these benchmarks demonstrate that primarily English models can be adapted to other languages.
So, as you can see, we successfully improved the original model's performance for Serbian language use cases while retaining or even slightly improving its performance for English language.
### Training results
Training results of continued pre-training of [mistral-7b-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
<img src="https://hf.fast360.xyz/production/uploads/617bbeec14572ebe9e6ea83f/5xeJ-vfWk4RhJNC7t5I0g.png" width="70%" height="70%">
<img src="https://hf.fast360.xyz/production/uploads/617bbeec14572ebe9e6ea83f/R4R8ai8LaN3WlYCOenUyb.png" width="70%" height="70%">
As last experimental step we merged produced model with **Mistral-7B-v0.1** and two earlier checkpoints from **prodigy-sm-base** using [Model Stock](https://arxiv.org/abs/2403.19522) method.
# Notes
As this is base model, there is no chat template or strict chat following capabilities, this model is best candidate for further pre-train on Serbian language as there is a lot more room for improvement (you can hit sweet spot), or next step in the pipeline, such as some form of chat or instruct tuning.
If you want model that is already instruction tuned we did that too, check **Prodigy SM Instruct v0.1**
# Prodigy SM Instruct v0.1
🚀[prodigy-sm-instruct]() **COMING SOON**
And stay tuned for:
[prodigy-sm-base (llama-3.1)]() **COMING SOON**
[prodigy-sm-instruct (llama-3.1)]() **COMING SOON**
📢 Also we are excited to announce that [iskon.ai](https://Iskon.ai) will soon launch an API platform featuring advanced **Prodigy** series of models, advanced AI tools and much more! 🚀
# Thanks
- [gordicaleksa/serbian-llm-eval](https://github.com/gordicaleksa/serbian-llm-eval) and his community for curating translations and adaptation of [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness)
that we used to perform benchmarks.
- [jondurbin](https://huggingface.co/jondurbin) for amazing airoboros framework
- [teknium](https://huggingface.co/teknium) for various insights shared on discord and twitter aka x.com
- [Eric](https://twitter.com/erhartford) for various insights shared on discord and twitter aka x.com
- [mergekit](https://github.com/arcee-ai/mergekit) for model merging tools
*Huge thanks to Redmond.ai for generous DGX cloud credits* [redmond.ai]( https://redmond.ai)
|
[
"BEAR"
] |
miguelcarv/Pheye-x2-672
|
miguelcarv
|
image-text-to-text
|
[
"transformers",
"image-text-to-text",
"en",
"endpoints_compatible",
"region:us"
] | 2024-05-07T18:36:40Z |
2025-01-02T19:37:22+00:00
| 17 | 0 |
---
language:
- en
pipeline_tag: image-text-to-text
---
# Φ Pheye - a family of efficient small vision-language models
- These models train a fraction of the number of parameters other models of similar sizes train
- Are more efficient in how they incorporate vision into language tasks (dense cross-attention > LLaVA style architecture)
- Are more efficient in how the process high resolution input images
- Use less data to train yet achieve competitive results (if you want to redo this recipe using more data results will be even better)
## Benchmarks
| Model | Resolution | Trainable Params | Data | VQAv2 | Nocaps | TextVQA | TextCaps |
| ------------------------------------------------------------- | ---------- | ---------------- | ---- | ----- | ------ | ------- | -------- |
| MoE-LLaVA-1.6B×4 | 336 | 2.9B | 5.9M | 76.0 | - | 47.8 | - |
| MoE-LLaVA-2.7B×4 | 336 | 5.3B | 5.9M | 77.1 | - | 50.2 | - |
| moondream1 | 384 | 1.86B | 3.9M | 74.7 | - | 35.6 |
| moondream2 | 384 | 1.86B | - | 77.7 | 92.5 | 49.7 | 120.2 |
| [Pheye-x4 🤗](https://huggingface.co/miguelcarv/Pheye-x4-448) | 448 | 295M | 2.9M | 75.2 | 110.1 | 45.9 | 106.4 |
| [Pheye-x4 🤗](https://huggingface.co/miguelcarv/Pheye-x4-672) | 672 | 295M | 2.9M | 75.5 | 110.8 | 49.2 | 111.9 |
| [Pheye-x2 🤗](https://huggingface.co/miguelcarv/Pheye-x2-448) | 448 | 578M | 2.9M | 76.0 | 111.8 | 47.3 | 108.9 |
| [Pheye-x2 🤗](https://huggingface.co/miguelcarv/Pheye-x2-672) | 672 | 578M | 2.9M | 76.4 | 110.5 | 50.5 | 115.9 |
## Examples\*
| Image | Example |
| ----------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| <img src="https://c5.staticflickr.com/6/5463/17191308944_ae0b20bb7e_o.jpg" width="500"/> | **How much do these popcorn packets weigh?**<br>These popcorn packets weigh 90g each.<br><br>**What brand are these popcorn packets?**<br>These popcorn packets are from the brand "Magic Pop". |
| <img src="https://farm2.staticflickr.com/2708/5836100440_6e1117d36f_o.jpg" width="500"/> | **Can I pet that dog?**<br>No, you cannot pet the dog in the image. It is a black bear, not a dog. |
| <img src="images/beekepper.jpeg" width="500"/> | **Why is the person wearing protective gear?**<br>The person in the image is wearing protective gear, such as a beekeeper's suit and a helmet, to ensure their safety while working with bees. Beekeeping involves handling bees and their hives, which can be potentially dangerous due to the risk of bee stings. The protective gear helps to minimize the risk of bee stings and other bee-related injuries, allowing the beekeeper to carry out their work safely and effectively. |
| |
\* Generated by Pheye-x2-672
## Usage
To generate a sample response from a prompt use `generate.py`.
Use a Python version >= 3.11. Start by cloning the repo and create a virtual environment with the necessary packages:
```bash
git clone https://github.com/miguelscarv/pheye.git
cd pheye
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
```
Then run `generate.py`:
```bash
python3 generate.py --image_path images/dog_flower.jpg --prompt "What is the dog holding in it's mouth?" --device cuda
```
## Acknowledgments
This implementation was inspired by [OpenFlamingo](https://github.com/mlfoundations/open_flamingo)'s repository.
|
[
"BEAR"
] |
miguelcarv/Pheye-x4-672
|
miguelcarv
|
image-text-to-text
|
[
"transformers",
"image-text-to-text",
"en",
"endpoints_compatible",
"region:us"
] | 2024-05-07T18:58:00Z |
2025-01-02T20:31:43+00:00
| 17 | 0 |
---
language:
- en
pipeline_tag: image-text-to-text
---
# Φ Pheye - a family of efficient small vision-language models
- These models train a fraction of the number of parameters other models of similar sizes train
- Are more efficient in how they incorporate vision into language tasks (dense cross-attention > LLaVA style architecture)
- Are more efficient in how the process high resolution input images
- Use less data to train yet achieve competitive results (if you want to redo this recipe using more data results will be even better)
## Benchmarks
| Model | Resolution | Trainable Params | Data | VQAv2 | Nocaps | TextVQA | TextCaps |
| ------------------------------------------------------------- | ---------- | ---------------- | ---- | ----- | ------ | ------- | -------- |
| MoE-LLaVA-1.6B×4 | 336 | 2.9B | 5.9M | 76.0 | - | 47.8 | - |
| MoE-LLaVA-2.7B×4 | 336 | 5.3B | 5.9M | 77.1 | - | 50.2 | - |
| moondream1 | 384 | 1.86B | 3.9M | 74.7 | - | 35.6 |
| moondream2 | 384 | 1.86B | - | 77.7 | 92.5 | 49.7 | 120.2 |
| [Pheye-x4 🤗](https://huggingface.co/miguelcarv/Pheye-x4-448) | 448 | 295M | 2.9M | 75.2 | 110.1 | 45.9 | 106.4 |
| [Pheye-x4 🤗](https://huggingface.co/miguelcarv/Pheye-x4-672) | 672 | 295M | 2.9M | 75.5 | 110.8 | 49.2 | 111.9 |
| [Pheye-x2 🤗](https://huggingface.co/miguelcarv/Pheye-x2-448) | 448 | 578M | 2.9M | 76.0 | 111.8 | 47.3 | 108.9 |
| [Pheye-x2 🤗](https://huggingface.co/miguelcarv/Pheye-x2-672) | 672 | 578M | 2.9M | 76.4 | 110.5 | 50.5 | 115.9 |
## Examples\*
| Image | Example |
| ----------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| <img src="https://c5.staticflickr.com/6/5463/17191308944_ae0b20bb7e_o.jpg" width="500"/> | **How much do these popcorn packets weigh?**<br>These popcorn packets weigh 90g each.<br><br>**What brand are these popcorn packets?**<br>These popcorn packets are from the brand "Magic Pop". |
| <img src="https://farm2.staticflickr.com/2708/5836100440_6e1117d36f_o.jpg" width="500"/> | **Can I pet that dog?**<br>No, you cannot pet the dog in the image. It is a black bear, not a dog. |
| <img src="images/beekepper.jpeg" width="500"/> | **Why is the person wearing protective gear?**<br>The person in the image is wearing protective gear, such as a beekeeper's suit and a helmet, to ensure their safety while working with bees. Beekeeping involves handling bees and their hives, which can be potentially dangerous due to the risk of bee stings. The protective gear helps to minimize the risk of bee stings and other bee-related injuries, allowing the beekeeper to carry out their work safely and effectively. |
| |
\* Generated by Pheye-x2-672
## Usage
To generate a sample response from a prompt use `generate.py`.
Use a Python version >= 3.11. Start by cloning the repo and create a virtual environment with the necessary packages:
```bash
git clone https://github.com/miguelscarv/pheye.git
cd pheye
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
```
Then run `generate.py`:
```bash
python3 generate.py --image_path images/dog_flower.jpg --prompt "What is the dog holding in it's mouth?" --device cuda
```
## Acknowledgments
This implementation was inspired by [OpenFlamingo](https://github.com/mlfoundations/open_flamingo)'s repository.
|
[
"BEAR"
] |
ekorman-strive/bge-large-en-v1.5
|
ekorman-strive
|
feature-extraction
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"mteb",
"en",
"arxiv:2401.03462",
"arxiv:2312.15503",
"arxiv:2311.13534",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-05-20T23:31:23Z |
2024-05-21T04:15:32+00:00
| 17 | 0 |
---
language:
- en
license: mit
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- mteb
model-index:
- name: bge-large-en-v1.5
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.8507462686567
- type: ap
value: 38.566457320228245
- type: f1
value: 69.69386648043475
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 92.416675
- type: ap
value: 89.1928861155922
- type: f1
value: 92.39477019574215
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.175999999999995
- type: f1
value: 47.80712792870253
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.184999999999995
- type: map_at_10
value: 55.654
- type: map_at_100
value: 56.25
- type: map_at_1000
value: 56.255
- type: map_at_3
value: 51.742999999999995
- type: map_at_5
value: 54.129000000000005
- type: mrr_at_1
value: 40.967
- type: mrr_at_10
value: 55.96
- type: mrr_at_100
value: 56.54900000000001
- type: mrr_at_1000
value: 56.554
- type: mrr_at_3
value: 51.980000000000004
- type: mrr_at_5
value: 54.44
- type: ndcg_at_1
value: 40.184999999999995
- type: ndcg_at_10
value: 63.542
- type: ndcg_at_100
value: 65.96499999999999
- type: ndcg_at_1000
value: 66.08699999999999
- type: ndcg_at_3
value: 55.582
- type: ndcg_at_5
value: 59.855000000000004
- type: precision_at_1
value: 40.184999999999995
- type: precision_at_10
value: 8.841000000000001
- type: precision_at_100
value: 0.987
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 22.238
- type: precision_at_5
value: 15.405
- type: recall_at_1
value: 40.184999999999995
- type: recall_at_10
value: 88.407
- type: recall_at_100
value: 98.72
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 66.714
- type: recall_at_5
value: 77.027
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.567077926750066
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 43.19453389182364
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.46555939623092
- type: mrr
value: 77.82361605768807
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.9554128814735
- type: cos_sim_spearman
value: 84.65373612172036
- type: euclidean_pearson
value: 83.2905059954138
- type: euclidean_spearman
value: 84.52240782811128
- type: manhattan_pearson
value: 82.99533802997436
- type: manhattan_spearman
value: 84.20673798475734
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.78896103896103
- type: f1
value: 87.77189310964883
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.714538337650495
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.90108349284447
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.795
- type: map_at_10
value: 43.669000000000004
- type: map_at_100
value: 45.151
- type: map_at_1000
value: 45.278
- type: map_at_3
value: 40.006
- type: map_at_5
value: 42.059999999999995
- type: mrr_at_1
value: 39.771
- type: mrr_at_10
value: 49.826
- type: mrr_at_100
value: 50.504000000000005
- type: mrr_at_1000
value: 50.549
- type: mrr_at_3
value: 47.115
- type: mrr_at_5
value: 48.832
- type: ndcg_at_1
value: 39.771
- type: ndcg_at_10
value: 50.217999999999996
- type: ndcg_at_100
value: 55.454
- type: ndcg_at_1000
value: 57.37
- type: ndcg_at_3
value: 44.885000000000005
- type: ndcg_at_5
value: 47.419
- type: precision_at_1
value: 39.771
- type: precision_at_10
value: 9.642000000000001
- type: precision_at_100
value: 1.538
- type: precision_at_1000
value: 0.198
- type: precision_at_3
value: 21.268
- type: precision_at_5
value: 15.536
- type: recall_at_1
value: 32.795
- type: recall_at_10
value: 62.580999999999996
- type: recall_at_100
value: 84.438
- type: recall_at_1000
value: 96.492
- type: recall_at_3
value: 47.071000000000005
- type: recall_at_5
value: 54.079
- type: map_at_1
value: 32.671
- type: map_at_10
value: 43.334
- type: map_at_100
value: 44.566
- type: map_at_1000
value: 44.702999999999996
- type: map_at_3
value: 40.343
- type: map_at_5
value: 41.983
- type: mrr_at_1
value: 40.764
- type: mrr_at_10
value: 49.382
- type: mrr_at_100
value: 49.988
- type: mrr_at_1000
value: 50.03300000000001
- type: mrr_at_3
value: 47.293
- type: mrr_at_5
value: 48.51
- type: ndcg_at_1
value: 40.764
- type: ndcg_at_10
value: 49.039
- type: ndcg_at_100
value: 53.259
- type: ndcg_at_1000
value: 55.253
- type: ndcg_at_3
value: 45.091
- type: ndcg_at_5
value: 46.839999999999996
- type: precision_at_1
value: 40.764
- type: precision_at_10
value: 9.191
- type: precision_at_100
value: 1.476
- type: precision_at_1000
value: 0.19499999999999998
- type: precision_at_3
value: 21.72
- type: precision_at_5
value: 15.299
- type: recall_at_1
value: 32.671
- type: recall_at_10
value: 58.816
- type: recall_at_100
value: 76.654
- type: recall_at_1000
value: 89.05999999999999
- type: recall_at_3
value: 46.743
- type: recall_at_5
value: 51.783
- type: map_at_1
value: 40.328
- type: map_at_10
value: 53.32599999999999
- type: map_at_100
value: 54.37499999999999
- type: map_at_1000
value: 54.429
- type: map_at_3
value: 49.902
- type: map_at_5
value: 52.002
- type: mrr_at_1
value: 46.332
- type: mrr_at_10
value: 56.858
- type: mrr_at_100
value: 57.522
- type: mrr_at_1000
value: 57.54899999999999
- type: mrr_at_3
value: 54.472
- type: mrr_at_5
value: 55.996
- type: ndcg_at_1
value: 46.332
- type: ndcg_at_10
value: 59.313
- type: ndcg_at_100
value: 63.266999999999996
- type: ndcg_at_1000
value: 64.36
- type: ndcg_at_3
value: 53.815000000000005
- type: ndcg_at_5
value: 56.814
- type: precision_at_1
value: 46.332
- type: precision_at_10
value: 9.53
- type: precision_at_100
value: 1.238
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 24.054000000000002
- type: precision_at_5
value: 16.589000000000002
- type: recall_at_1
value: 40.328
- type: recall_at_10
value: 73.421
- type: recall_at_100
value: 90.059
- type: recall_at_1000
value: 97.81
- type: recall_at_3
value: 59.009
- type: recall_at_5
value: 66.352
- type: map_at_1
value: 27.424
- type: map_at_10
value: 36.332
- type: map_at_100
value: 37.347
- type: map_at_1000
value: 37.422
- type: map_at_3
value: 33.743
- type: map_at_5
value: 35.176
- type: mrr_at_1
value: 29.153000000000002
- type: mrr_at_10
value: 38.233
- type: mrr_at_100
value: 39.109
- type: mrr_at_1000
value: 39.164
- type: mrr_at_3
value: 35.876000000000005
- type: mrr_at_5
value: 37.169000000000004
- type: ndcg_at_1
value: 29.153000000000002
- type: ndcg_at_10
value: 41.439
- type: ndcg_at_100
value: 46.42
- type: ndcg_at_1000
value: 48.242000000000004
- type: ndcg_at_3
value: 36.362
- type: ndcg_at_5
value: 38.743
- type: precision_at_1
value: 29.153000000000002
- type: precision_at_10
value: 6.315999999999999
- type: precision_at_100
value: 0.927
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 15.443000000000001
- type: precision_at_5
value: 10.644
- type: recall_at_1
value: 27.424
- type: recall_at_10
value: 55.364000000000004
- type: recall_at_100
value: 78.211
- type: recall_at_1000
value: 91.74600000000001
- type: recall_at_3
value: 41.379
- type: recall_at_5
value: 47.14
- type: map_at_1
value: 19.601
- type: map_at_10
value: 27.826
- type: map_at_100
value: 29.017
- type: map_at_1000
value: 29.137
- type: map_at_3
value: 25.125999999999998
- type: map_at_5
value: 26.765
- type: mrr_at_1
value: 24.005000000000003
- type: mrr_at_10
value: 32.716
- type: mrr_at_100
value: 33.631
- type: mrr_at_1000
value: 33.694
- type: mrr_at_3
value: 29.934
- type: mrr_at_5
value: 31.630999999999997
- type: ndcg_at_1
value: 24.005000000000003
- type: ndcg_at_10
value: 33.158
- type: ndcg_at_100
value: 38.739000000000004
- type: ndcg_at_1000
value: 41.495
- type: ndcg_at_3
value: 28.185
- type: ndcg_at_5
value: 30.796
- type: precision_at_1
value: 24.005000000000003
- type: precision_at_10
value: 5.908
- type: precision_at_100
value: 1.005
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 13.391
- type: precision_at_5
value: 9.876
- type: recall_at_1
value: 19.601
- type: recall_at_10
value: 44.746
- type: recall_at_100
value: 68.82300000000001
- type: recall_at_1000
value: 88.215
- type: recall_at_3
value: 31.239
- type: recall_at_5
value: 37.695
- type: map_at_1
value: 30.130000000000003
- type: map_at_10
value: 40.96
- type: map_at_100
value: 42.282
- type: map_at_1000
value: 42.392
- type: map_at_3
value: 37.889
- type: map_at_5
value: 39.661
- type: mrr_at_1
value: 36.958999999999996
- type: mrr_at_10
value: 46.835
- type: mrr_at_100
value: 47.644
- type: mrr_at_1000
value: 47.688
- type: mrr_at_3
value: 44.562000000000005
- type: mrr_at_5
value: 45.938
- type: ndcg_at_1
value: 36.958999999999996
- type: ndcg_at_10
value: 47.06
- type: ndcg_at_100
value: 52.345
- type: ndcg_at_1000
value: 54.35
- type: ndcg_at_3
value: 42.301
- type: ndcg_at_5
value: 44.635999999999996
- type: precision_at_1
value: 36.958999999999996
- type: precision_at_10
value: 8.479000000000001
- type: precision_at_100
value: 1.284
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 20.244
- type: precision_at_5
value: 14.224999999999998
- type: recall_at_1
value: 30.130000000000003
- type: recall_at_10
value: 59.27
- type: recall_at_100
value: 81.195
- type: recall_at_1000
value: 94.21199999999999
- type: recall_at_3
value: 45.885
- type: recall_at_5
value: 52.016
- type: map_at_1
value: 26.169999999999998
- type: map_at_10
value: 36.451
- type: map_at_100
value: 37.791000000000004
- type: map_at_1000
value: 37.897
- type: map_at_3
value: 33.109
- type: map_at_5
value: 34.937000000000005
- type: mrr_at_1
value: 32.877
- type: mrr_at_10
value: 42.368
- type: mrr_at_100
value: 43.201
- type: mrr_at_1000
value: 43.259
- type: mrr_at_3
value: 39.763999999999996
- type: mrr_at_5
value: 41.260000000000005
- type: ndcg_at_1
value: 32.877
- type: ndcg_at_10
value: 42.659000000000006
- type: ndcg_at_100
value: 48.161
- type: ndcg_at_1000
value: 50.345
- type: ndcg_at_3
value: 37.302
- type: ndcg_at_5
value: 39.722
- type: precision_at_1
value: 32.877
- type: precision_at_10
value: 7.9
- type: precision_at_100
value: 1.236
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 17.846
- type: precision_at_5
value: 12.9
- type: recall_at_1
value: 26.169999999999998
- type: recall_at_10
value: 55.35
- type: recall_at_100
value: 78.755
- type: recall_at_1000
value: 93.518
- type: recall_at_3
value: 40.176
- type: recall_at_5
value: 46.589000000000006
- type: map_at_1
value: 27.15516666666667
- type: map_at_10
value: 36.65741666666667
- type: map_at_100
value: 37.84991666666666
- type: map_at_1000
value: 37.96316666666667
- type: map_at_3
value: 33.74974999999999
- type: map_at_5
value: 35.3765
- type: mrr_at_1
value: 32.08233333333334
- type: mrr_at_10
value: 41.033833333333334
- type: mrr_at_100
value: 41.84524999999999
- type: mrr_at_1000
value: 41.89983333333333
- type: mrr_at_3
value: 38.62008333333333
- type: mrr_at_5
value: 40.03441666666666
- type: ndcg_at_1
value: 32.08233333333334
- type: ndcg_at_10
value: 42.229
- type: ndcg_at_100
value: 47.26716666666667
- type: ndcg_at_1000
value: 49.43466666666667
- type: ndcg_at_3
value: 37.36408333333333
- type: ndcg_at_5
value: 39.6715
- type: precision_at_1
value: 32.08233333333334
- type: precision_at_10
value: 7.382583333333334
- type: precision_at_100
value: 1.16625
- type: precision_at_1000
value: 0.15408333333333332
- type: precision_at_3
value: 17.218
- type: precision_at_5
value: 12.21875
- type: recall_at_1
value: 27.15516666666667
- type: recall_at_10
value: 54.36683333333333
- type: recall_at_100
value: 76.37183333333333
- type: recall_at_1000
value: 91.26183333333333
- type: recall_at_3
value: 40.769916666666674
- type: recall_at_5
value: 46.702333333333335
- type: map_at_1
value: 25.749
- type: map_at_10
value: 33.001999999999995
- type: map_at_100
value: 33.891
- type: map_at_1000
value: 33.993
- type: map_at_3
value: 30.703999999999997
- type: map_at_5
value: 31.959
- type: mrr_at_1
value: 28.834
- type: mrr_at_10
value: 35.955
- type: mrr_at_100
value: 36.709
- type: mrr_at_1000
value: 36.779
- type: mrr_at_3
value: 33.947
- type: mrr_at_5
value: 35.089
- type: ndcg_at_1
value: 28.834
- type: ndcg_at_10
value: 37.329
- type: ndcg_at_100
value: 41.79
- type: ndcg_at_1000
value: 44.169000000000004
- type: ndcg_at_3
value: 33.184999999999995
- type: ndcg_at_5
value: 35.107
- type: precision_at_1
value: 28.834
- type: precision_at_10
value: 5.7669999999999995
- type: precision_at_100
value: 0.876
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 14.213000000000001
- type: precision_at_5
value: 9.754999999999999
- type: recall_at_1
value: 25.749
- type: recall_at_10
value: 47.791
- type: recall_at_100
value: 68.255
- type: recall_at_1000
value: 85.749
- type: recall_at_3
value: 36.199
- type: recall_at_5
value: 41.071999999999996
- type: map_at_1
value: 17.777
- type: map_at_10
value: 25.201
- type: map_at_100
value: 26.423999999999996
- type: map_at_1000
value: 26.544
- type: map_at_3
value: 22.869
- type: map_at_5
value: 24.023
- type: mrr_at_1
value: 21.473
- type: mrr_at_10
value: 29.12
- type: mrr_at_100
value: 30.144
- type: mrr_at_1000
value: 30.215999999999998
- type: mrr_at_3
value: 26.933
- type: mrr_at_5
value: 28.051
- type: ndcg_at_1
value: 21.473
- type: ndcg_at_10
value: 30.003
- type: ndcg_at_100
value: 35.766
- type: ndcg_at_1000
value: 38.501000000000005
- type: ndcg_at_3
value: 25.773000000000003
- type: ndcg_at_5
value: 27.462999999999997
- type: precision_at_1
value: 21.473
- type: precision_at_10
value: 5.482
- type: precision_at_100
value: 0.975
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 12.205
- type: precision_at_5
value: 8.692
- type: recall_at_1
value: 17.777
- type: recall_at_10
value: 40.582
- type: recall_at_100
value: 66.305
- type: recall_at_1000
value: 85.636
- type: recall_at_3
value: 28.687
- type: recall_at_5
value: 33.089
- type: map_at_1
value: 26.677
- type: map_at_10
value: 36.309000000000005
- type: map_at_100
value: 37.403999999999996
- type: map_at_1000
value: 37.496
- type: map_at_3
value: 33.382
- type: map_at_5
value: 34.98
- type: mrr_at_1
value: 31.343
- type: mrr_at_10
value: 40.549
- type: mrr_at_100
value: 41.342
- type: mrr_at_1000
value: 41.397
- type: mrr_at_3
value: 38.029
- type: mrr_at_5
value: 39.451
- type: ndcg_at_1
value: 31.343
- type: ndcg_at_10
value: 42.1
- type: ndcg_at_100
value: 47.089999999999996
- type: ndcg_at_1000
value: 49.222
- type: ndcg_at_3
value: 36.836999999999996
- type: ndcg_at_5
value: 39.21
- type: precision_at_1
value: 31.343
- type: precision_at_10
value: 7.164
- type: precision_at_100
value: 1.0959999999999999
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 16.915
- type: precision_at_5
value: 11.940000000000001
- type: recall_at_1
value: 26.677
- type: recall_at_10
value: 55.54599999999999
- type: recall_at_100
value: 77.094
- type: recall_at_1000
value: 92.01
- type: recall_at_3
value: 41.191
- type: recall_at_5
value: 47.006
- type: map_at_1
value: 24.501
- type: map_at_10
value: 33.102
- type: map_at_100
value: 34.676
- type: map_at_1000
value: 34.888000000000005
- type: map_at_3
value: 29.944
- type: map_at_5
value: 31.613999999999997
- type: mrr_at_1
value: 29.447000000000003
- type: mrr_at_10
value: 37.996
- type: mrr_at_100
value: 38.946
- type: mrr_at_1000
value: 38.995000000000005
- type: mrr_at_3
value: 35.079
- type: mrr_at_5
value: 36.69
- type: ndcg_at_1
value: 29.447000000000003
- type: ndcg_at_10
value: 39.232
- type: ndcg_at_100
value: 45.247
- type: ndcg_at_1000
value: 47.613
- type: ndcg_at_3
value: 33.922999999999995
- type: ndcg_at_5
value: 36.284
- type: precision_at_1
value: 29.447000000000003
- type: precision_at_10
value: 7.648000000000001
- type: precision_at_100
value: 1.516
- type: precision_at_1000
value: 0.23900000000000002
- type: precision_at_3
value: 16.008
- type: precision_at_5
value: 11.779
- type: recall_at_1
value: 24.501
- type: recall_at_10
value: 51.18899999999999
- type: recall_at_100
value: 78.437
- type: recall_at_1000
value: 92.842
- type: recall_at_3
value: 35.808
- type: recall_at_5
value: 42.197
- type: map_at_1
value: 22.039
- type: map_at_10
value: 30.377
- type: map_at_100
value: 31.275
- type: map_at_1000
value: 31.379
- type: map_at_3
value: 27.98
- type: map_at_5
value: 29.358
- type: mrr_at_1
value: 24.03
- type: mrr_at_10
value: 32.568000000000005
- type: mrr_at_100
value: 33.403
- type: mrr_at_1000
value: 33.475
- type: mrr_at_3
value: 30.436999999999998
- type: mrr_at_5
value: 31.796000000000003
- type: ndcg_at_1
value: 24.03
- type: ndcg_at_10
value: 35.198
- type: ndcg_at_100
value: 39.668
- type: ndcg_at_1000
value: 42.296
- type: ndcg_at_3
value: 30.709999999999997
- type: ndcg_at_5
value: 33.024
- type: precision_at_1
value: 24.03
- type: precision_at_10
value: 5.564
- type: precision_at_100
value: 0.828
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 13.309000000000001
- type: precision_at_5
value: 9.39
- type: recall_at_1
value: 22.039
- type: recall_at_10
value: 47.746
- type: recall_at_100
value: 68.23599999999999
- type: recall_at_1000
value: 87.852
- type: recall_at_3
value: 35.852000000000004
- type: recall_at_5
value: 41.410000000000004
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.692999999999998
- type: map_at_10
value: 26.903
- type: map_at_100
value: 28.987000000000002
- type: map_at_1000
value: 29.176999999999996
- type: map_at_3
value: 22.137
- type: map_at_5
value: 24.758
- type: mrr_at_1
value: 35.57
- type: mrr_at_10
value: 47.821999999999996
- type: mrr_at_100
value: 48.608000000000004
- type: mrr_at_1000
value: 48.638999999999996
- type: mrr_at_3
value: 44.452000000000005
- type: mrr_at_5
value: 46.546
- type: ndcg_at_1
value: 35.57
- type: ndcg_at_10
value: 36.567
- type: ndcg_at_100
value: 44.085
- type: ndcg_at_1000
value: 47.24
- type: ndcg_at_3
value: 29.964000000000002
- type: ndcg_at_5
value: 32.511
- type: precision_at_1
value: 35.57
- type: precision_at_10
value: 11.485
- type: precision_at_100
value: 1.9619999999999997
- type: precision_at_1000
value: 0.256
- type: precision_at_3
value: 22.237000000000002
- type: precision_at_5
value: 17.471999999999998
- type: recall_at_1
value: 15.692999999999998
- type: recall_at_10
value: 43.056
- type: recall_at_100
value: 68.628
- type: recall_at_1000
value: 86.075
- type: recall_at_3
value: 26.918999999999997
- type: recall_at_5
value: 34.14
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.53
- type: map_at_10
value: 20.951
- type: map_at_100
value: 30.136000000000003
- type: map_at_1000
value: 31.801000000000002
- type: map_at_3
value: 15.021
- type: map_at_5
value: 17.471999999999998
- type: mrr_at_1
value: 71.0
- type: mrr_at_10
value: 79.176
- type: mrr_at_100
value: 79.418
- type: mrr_at_1000
value: 79.426
- type: mrr_at_3
value: 78.125
- type: mrr_at_5
value: 78.61200000000001
- type: ndcg_at_1
value: 58.5
- type: ndcg_at_10
value: 44.106
- type: ndcg_at_100
value: 49.268
- type: ndcg_at_1000
value: 56.711999999999996
- type: ndcg_at_3
value: 48.934
- type: ndcg_at_5
value: 45.826
- type: precision_at_1
value: 71.0
- type: precision_at_10
value: 35.0
- type: precision_at_100
value: 11.360000000000001
- type: precision_at_1000
value: 2.046
- type: precision_at_3
value: 52.833
- type: precision_at_5
value: 44.15
- type: recall_at_1
value: 9.53
- type: recall_at_10
value: 26.811
- type: recall_at_100
value: 55.916999999999994
- type: recall_at_1000
value: 79.973
- type: recall_at_3
value: 16.413
- type: recall_at_5
value: 19.980999999999998
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.519999999999996
- type: f1
value: 46.36601294761231
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 74.413
- type: map_at_10
value: 83.414
- type: map_at_100
value: 83.621
- type: map_at_1000
value: 83.635
- type: map_at_3
value: 82.337
- type: map_at_5
value: 83.039
- type: mrr_at_1
value: 80.19800000000001
- type: mrr_at_10
value: 87.715
- type: mrr_at_100
value: 87.778
- type: mrr_at_1000
value: 87.779
- type: mrr_at_3
value: 87.106
- type: mrr_at_5
value: 87.555
- type: ndcg_at_1
value: 80.19800000000001
- type: ndcg_at_10
value: 87.182
- type: ndcg_at_100
value: 87.90299999999999
- type: ndcg_at_1000
value: 88.143
- type: ndcg_at_3
value: 85.60600000000001
- type: ndcg_at_5
value: 86.541
- type: precision_at_1
value: 80.19800000000001
- type: precision_at_10
value: 10.531
- type: precision_at_100
value: 1.113
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 32.933
- type: precision_at_5
value: 20.429
- type: recall_at_1
value: 74.413
- type: recall_at_10
value: 94.363
- type: recall_at_100
value: 97.165
- type: recall_at_1000
value: 98.668
- type: recall_at_3
value: 90.108
- type: recall_at_5
value: 92.52
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.701
- type: map_at_10
value: 37.122
- type: map_at_100
value: 39.178000000000004
- type: map_at_1000
value: 39.326
- type: map_at_3
value: 32.971000000000004
- type: map_at_5
value: 35.332
- type: mrr_at_1
value: 44.753
- type: mrr_at_10
value: 53.452
- type: mrr_at_100
value: 54.198
- type: mrr_at_1000
value: 54.225
- type: mrr_at_3
value: 50.952
- type: mrr_at_5
value: 52.464
- type: ndcg_at_1
value: 44.753
- type: ndcg_at_10
value: 45.021
- type: ndcg_at_100
value: 52.028
- type: ndcg_at_1000
value: 54.596000000000004
- type: ndcg_at_3
value: 41.622
- type: ndcg_at_5
value: 42.736000000000004
- type: precision_at_1
value: 44.753
- type: precision_at_10
value: 12.284
- type: precision_at_100
value: 1.955
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 27.828999999999997
- type: precision_at_5
value: 20.061999999999998
- type: recall_at_1
value: 22.701
- type: recall_at_10
value: 51.432
- type: recall_at_100
value: 77.009
- type: recall_at_1000
value: 92.511
- type: recall_at_3
value: 37.919000000000004
- type: recall_at_5
value: 44.131
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.189
- type: map_at_10
value: 66.24600000000001
- type: map_at_100
value: 67.098
- type: map_at_1000
value: 67.149
- type: map_at_3
value: 62.684
- type: map_at_5
value: 64.974
- type: mrr_at_1
value: 80.378
- type: mrr_at_10
value: 86.127
- type: mrr_at_100
value: 86.29299999999999
- type: mrr_at_1000
value: 86.297
- type: mrr_at_3
value: 85.31400000000001
- type: mrr_at_5
value: 85.858
- type: ndcg_at_1
value: 80.378
- type: ndcg_at_10
value: 74.101
- type: ndcg_at_100
value: 76.993
- type: ndcg_at_1000
value: 77.948
- type: ndcg_at_3
value: 69.232
- type: ndcg_at_5
value: 72.04599999999999
- type: precision_at_1
value: 80.378
- type: precision_at_10
value: 15.595999999999998
- type: precision_at_100
value: 1.7840000000000003
- type: precision_at_1000
value: 0.191
- type: precision_at_3
value: 44.884
- type: precision_at_5
value: 29.145
- type: recall_at_1
value: 40.189
- type: recall_at_10
value: 77.981
- type: recall_at_100
value: 89.21
- type: recall_at_1000
value: 95.48299999999999
- type: recall_at_3
value: 67.326
- type: recall_at_5
value: 72.863
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 92.84599999999999
- type: ap
value: 89.4710787567357
- type: f1
value: 92.83752676932258
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.132
- type: map_at_10
value: 35.543
- type: map_at_100
value: 36.702
- type: map_at_1000
value: 36.748999999999995
- type: map_at_3
value: 31.737
- type: map_at_5
value: 33.927
- type: mrr_at_1
value: 23.782
- type: mrr_at_10
value: 36.204
- type: mrr_at_100
value: 37.29
- type: mrr_at_1000
value: 37.330999999999996
- type: mrr_at_3
value: 32.458999999999996
- type: mrr_at_5
value: 34.631
- type: ndcg_at_1
value: 23.782
- type: ndcg_at_10
value: 42.492999999999995
- type: ndcg_at_100
value: 47.985
- type: ndcg_at_1000
value: 49.141
- type: ndcg_at_3
value: 34.748000000000005
- type: ndcg_at_5
value: 38.651
- type: precision_at_1
value: 23.782
- type: precision_at_10
value: 6.665
- type: precision_at_100
value: 0.941
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.776
- type: precision_at_5
value: 10.84
- type: recall_at_1
value: 23.132
- type: recall_at_10
value: 63.794
- type: recall_at_100
value: 89.027
- type: recall_at_1000
value: 97.807
- type: recall_at_3
value: 42.765
- type: recall_at_5
value: 52.11
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 94.59188326493388
- type: f1
value: 94.3842594786827
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.49384404924761
- type: f1
value: 59.7580539534629
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 77.56220578345663
- type: f1
value: 75.27228165561478
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.53463349024884
- type: f1
value: 80.4893958236536
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 32.56100273484962
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.470380028839607
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.06102792457849
- type: mrr
value: 33.30709199672238
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.776999999999999
- type: map_at_10
value: 14.924000000000001
- type: map_at_100
value: 18.955
- type: map_at_1000
value: 20.538999999999998
- type: map_at_3
value: 10.982
- type: map_at_5
value: 12.679000000000002
- type: mrr_at_1
value: 47.988
- type: mrr_at_10
value: 57.232000000000006
- type: mrr_at_100
value: 57.818999999999996
- type: mrr_at_1000
value: 57.847
- type: mrr_at_3
value: 54.901999999999994
- type: mrr_at_5
value: 56.481
- type: ndcg_at_1
value: 46.594
- type: ndcg_at_10
value: 38.129000000000005
- type: ndcg_at_100
value: 35.54
- type: ndcg_at_1000
value: 44.172
- type: ndcg_at_3
value: 43.025999999999996
- type: ndcg_at_5
value: 41.052
- type: precision_at_1
value: 47.988
- type: precision_at_10
value: 28.111000000000004
- type: precision_at_100
value: 8.929
- type: precision_at_1000
value: 2.185
- type: precision_at_3
value: 40.144000000000005
- type: precision_at_5
value: 35.232
- type: recall_at_1
value: 6.776999999999999
- type: recall_at_10
value: 19.289
- type: recall_at_100
value: 36.359
- type: recall_at_1000
value: 67.54
- type: recall_at_3
value: 11.869
- type: recall_at_5
value: 14.999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.108000000000004
- type: map_at_10
value: 47.126000000000005
- type: map_at_100
value: 48.171
- type: map_at_1000
value: 48.199
- type: map_at_3
value: 42.734
- type: map_at_5
value: 45.362
- type: mrr_at_1
value: 34.936
- type: mrr_at_10
value: 49.571
- type: mrr_at_100
value: 50.345
- type: mrr_at_1000
value: 50.363
- type: mrr_at_3
value: 45.959
- type: mrr_at_5
value: 48.165
- type: ndcg_at_1
value: 34.936
- type: ndcg_at_10
value: 55.028999999999996
- type: ndcg_at_100
value: 59.244
- type: ndcg_at_1000
value: 59.861
- type: ndcg_at_3
value: 46.872
- type: ndcg_at_5
value: 51.217999999999996
- type: precision_at_1
value: 34.936
- type: precision_at_10
value: 9.099
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 21.456
- type: precision_at_5
value: 15.411
- type: recall_at_1
value: 31.108000000000004
- type: recall_at_10
value: 76.53999999999999
- type: recall_at_100
value: 94.39
- type: recall_at_1000
value: 98.947
- type: recall_at_3
value: 55.572
- type: recall_at_5
value: 65.525
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.56400000000001
- type: map_at_10
value: 85.482
- type: map_at_100
value: 86.114
- type: map_at_1000
value: 86.13
- type: map_at_3
value: 82.607
- type: map_at_5
value: 84.405
- type: mrr_at_1
value: 82.42
- type: mrr_at_10
value: 88.304
- type: mrr_at_100
value: 88.399
- type: mrr_at_1000
value: 88.399
- type: mrr_at_3
value: 87.37
- type: mrr_at_5
value: 88.024
- type: ndcg_at_1
value: 82.45
- type: ndcg_at_10
value: 89.06500000000001
- type: ndcg_at_100
value: 90.232
- type: ndcg_at_1000
value: 90.305
- type: ndcg_at_3
value: 86.375
- type: ndcg_at_5
value: 87.85300000000001
- type: precision_at_1
value: 82.45
- type: precision_at_10
value: 13.486999999999998
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.813
- type: precision_at_5
value: 24.773999999999997
- type: recall_at_1
value: 71.56400000000001
- type: recall_at_10
value: 95.812
- type: recall_at_100
value: 99.7
- type: recall_at_1000
value: 99.979
- type: recall_at_3
value: 87.966
- type: recall_at_5
value: 92.268
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 57.241876648614145
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.66212576446223
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.308
- type: map_at_10
value: 13.803
- type: map_at_100
value: 16.176
- type: map_at_1000
value: 16.561
- type: map_at_3
value: 9.761000000000001
- type: map_at_5
value: 11.802
- type: mrr_at_1
value: 26.200000000000003
- type: mrr_at_10
value: 37.621
- type: mrr_at_100
value: 38.767
- type: mrr_at_1000
value: 38.815
- type: mrr_at_3
value: 34.117
- type: mrr_at_5
value: 36.107
- type: ndcg_at_1
value: 26.200000000000003
- type: ndcg_at_10
value: 22.64
- type: ndcg_at_100
value: 31.567
- type: ndcg_at_1000
value: 37.623
- type: ndcg_at_3
value: 21.435000000000002
- type: ndcg_at_5
value: 18.87
- type: precision_at_1
value: 26.200000000000003
- type: precision_at_10
value: 11.74
- type: precision_at_100
value: 2.465
- type: precision_at_1000
value: 0.391
- type: precision_at_3
value: 20.033
- type: precision_at_5
value: 16.64
- type: recall_at_1
value: 5.308
- type: recall_at_10
value: 23.794999999999998
- type: recall_at_100
value: 50.015
- type: recall_at_1000
value: 79.283
- type: recall_at_3
value: 12.178
- type: recall_at_5
value: 16.882
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.93231134675553
- type: cos_sim_spearman
value: 81.68319292603205
- type: euclidean_pearson
value: 81.8396814380367
- type: euclidean_spearman
value: 81.24641903349945
- type: manhattan_pearson
value: 81.84698799204274
- type: manhattan_spearman
value: 81.24269997904105
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.73241671587446
- type: cos_sim_spearman
value: 79.05091082971826
- type: euclidean_pearson
value: 83.91146869578044
- type: euclidean_spearman
value: 79.87978465370936
- type: manhattan_pearson
value: 83.90888338917678
- type: manhattan_spearman
value: 79.87482848584241
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 85.14970731146177
- type: cos_sim_spearman
value: 86.37363490084627
- type: euclidean_pearson
value: 83.02154218530433
- type: euclidean_spearman
value: 83.80258761957367
- type: manhattan_pearson
value: 83.01664495119347
- type: manhattan_spearman
value: 83.77567458007952
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 83.40474139886784
- type: cos_sim_spearman
value: 82.77768789165984
- type: euclidean_pearson
value: 80.7065877443695
- type: euclidean_spearman
value: 81.375940662505
- type: manhattan_pearson
value: 80.6507552270278
- type: manhattan_spearman
value: 81.32782179098741
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.08585968722274
- type: cos_sim_spearman
value: 88.03110031451399
- type: euclidean_pearson
value: 85.74012019602384
- type: euclidean_spearman
value: 86.13592849438209
- type: manhattan_pearson
value: 85.74404842369206
- type: manhattan_spearman
value: 86.14492318960154
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.95069052788875
- type: cos_sim_spearman
value: 86.4867991595147
- type: euclidean_pearson
value: 84.31013325754635
- type: euclidean_spearman
value: 85.01529258006482
- type: manhattan_pearson
value: 84.26995570085374
- type: manhattan_spearman
value: 84.96982104986162
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.54617647971897
- type: cos_sim_spearman
value: 87.49834181751034
- type: euclidean_pearson
value: 86.01015322577122
- type: euclidean_spearman
value: 84.63362652063199
- type: manhattan_pearson
value: 86.13807574475706
- type: manhattan_spearman
value: 84.7772370721132
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.20047755786615
- type: cos_sim_spearman
value: 67.05324077987636
- type: euclidean_pearson
value: 66.91930642976601
- type: euclidean_spearman
value: 65.21491856099105
- type: manhattan_pearson
value: 66.78756851976624
- type: manhattan_spearman
value: 65.12356257740728
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.19852871539686
- type: cos_sim_spearman
value: 87.5161895296395
- type: euclidean_pearson
value: 84.59848645207485
- type: euclidean_spearman
value: 85.26427328757919
- type: manhattan_pearson
value: 84.59747366996524
- type: manhattan_spearman
value: 85.24045855146915
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.63320317811032
- type: mrr
value: 96.26242947321379
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.928000000000004
- type: map_at_10
value: 70.112
- type: map_at_100
value: 70.59299999999999
- type: map_at_1000
value: 70.623
- type: map_at_3
value: 66.846
- type: map_at_5
value: 68.447
- type: mrr_at_1
value: 64.0
- type: mrr_at_10
value: 71.212
- type: mrr_at_100
value: 71.616
- type: mrr_at_1000
value: 71.64500000000001
- type: mrr_at_3
value: 68.77799999999999
- type: mrr_at_5
value: 70.094
- type: ndcg_at_1
value: 64.0
- type: ndcg_at_10
value: 74.607
- type: ndcg_at_100
value: 76.416
- type: ndcg_at_1000
value: 77.102
- type: ndcg_at_3
value: 69.126
- type: ndcg_at_5
value: 71.41300000000001
- type: precision_at_1
value: 64.0
- type: precision_at_10
value: 9.933
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.556
- type: precision_at_5
value: 17.467
- type: recall_at_1
value: 60.928000000000004
- type: recall_at_10
value: 87.322
- type: recall_at_100
value: 94.833
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 72.628
- type: recall_at_5
value: 78.428
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.86237623762376
- type: cos_sim_ap
value: 96.72586477206649
- type: cos_sim_f1
value: 93.01858362631845
- type: cos_sim_precision
value: 93.4409687184662
- type: cos_sim_recall
value: 92.60000000000001
- type: dot_accuracy
value: 99.78019801980199
- type: dot_ap
value: 93.72748205246228
- type: dot_f1
value: 89.04109589041096
- type: dot_precision
value: 87.16475095785441
- type: dot_recall
value: 91.0
- type: euclidean_accuracy
value: 99.85445544554456
- type: euclidean_ap
value: 96.6661459876145
- type: euclidean_f1
value: 92.58337481333997
- type: euclidean_precision
value: 92.17046580773042
- type: euclidean_recall
value: 93.0
- type: manhattan_accuracy
value: 99.85445544554456
- type: manhattan_ap
value: 96.6883549244056
- type: manhattan_f1
value: 92.57598405580468
- type: manhattan_precision
value: 92.25422045680239
- type: manhattan_recall
value: 92.9
- type: max_accuracy
value: 99.86237623762376
- type: max_ap
value: 96.72586477206649
- type: max_f1
value: 93.01858362631845
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.39930057069995
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.96398659903402
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.946944700355395
- type: mrr
value: 56.97151398438164
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.541657650692905
- type: cos_sim_spearman
value: 31.605804192286303
- type: dot_pearson
value: 28.26905996736398
- type: dot_spearman
value: 27.864801765851187
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22599999999999998
- type: map_at_10
value: 1.8870000000000002
- type: map_at_100
value: 9.78
- type: map_at_1000
value: 22.514
- type: map_at_3
value: 0.6669999999999999
- type: map_at_5
value: 1.077
- type: mrr_at_1
value: 82.0
- type: mrr_at_10
value: 89.86699999999999
- type: mrr_at_100
value: 89.86699999999999
- type: mrr_at_1000
value: 89.86699999999999
- type: mrr_at_3
value: 89.667
- type: mrr_at_5
value: 89.667
- type: ndcg_at_1
value: 79.0
- type: ndcg_at_10
value: 74.818
- type: ndcg_at_100
value: 53.715999999999994
- type: ndcg_at_1000
value: 47.082
- type: ndcg_at_3
value: 82.134
- type: ndcg_at_5
value: 79.81899999999999
- type: precision_at_1
value: 82.0
- type: precision_at_10
value: 78.0
- type: precision_at_100
value: 54.48
- type: precision_at_1000
value: 20.518
- type: precision_at_3
value: 87.333
- type: precision_at_5
value: 85.2
- type: recall_at_1
value: 0.22599999999999998
- type: recall_at_10
value: 2.072
- type: recall_at_100
value: 13.013
- type: recall_at_1000
value: 43.462
- type: recall_at_3
value: 0.695
- type: recall_at_5
value: 1.139
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.328
- type: map_at_10
value: 9.795
- type: map_at_100
value: 15.801000000000002
- type: map_at_1000
value: 17.23
- type: map_at_3
value: 4.734
- type: map_at_5
value: 6.644
- type: mrr_at_1
value: 30.612000000000002
- type: mrr_at_10
value: 46.902
- type: mrr_at_100
value: 47.495
- type: mrr_at_1000
value: 47.495
- type: mrr_at_3
value: 41.156
- type: mrr_at_5
value: 44.218
- type: ndcg_at_1
value: 28.571
- type: ndcg_at_10
value: 24.806
- type: ndcg_at_100
value: 36.419000000000004
- type: ndcg_at_1000
value: 47.272999999999996
- type: ndcg_at_3
value: 25.666
- type: ndcg_at_5
value: 25.448999999999998
- type: precision_at_1
value: 30.612000000000002
- type: precision_at_10
value: 23.061
- type: precision_at_100
value: 7.714
- type: precision_at_1000
value: 1.484
- type: precision_at_3
value: 26.531
- type: precision_at_5
value: 26.122
- type: recall_at_1
value: 2.328
- type: recall_at_10
value: 16.524
- type: recall_at_100
value: 47.179
- type: recall_at_1000
value: 81.22200000000001
- type: recall_at_3
value: 5.745
- type: recall_at_5
value: 9.339
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.9142
- type: ap
value: 14.335574772555415
- type: f1
value: 54.62839595194111
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.94340690435768
- type: f1
value: 60.286487936731916
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.26597708987974
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.48882398521786
- type: cos_sim_ap
value: 79.04326607602204
- type: cos_sim_f1
value: 71.64566826860633
- type: cos_sim_precision
value: 70.55512918905092
- type: cos_sim_recall
value: 72.77044854881267
- type: dot_accuracy
value: 84.19264469213805
- type: dot_ap
value: 67.96360043562528
- type: dot_f1
value: 64.06418393006827
- type: dot_precision
value: 58.64941898706424
- type: dot_recall
value: 70.58047493403694
- type: euclidean_accuracy
value: 87.45902127913214
- type: euclidean_ap
value: 78.9742237648272
- type: euclidean_f1
value: 71.5553235908142
- type: euclidean_precision
value: 70.77955601445535
- type: euclidean_recall
value: 72.34828496042216
- type: manhattan_accuracy
value: 87.41729749061214
- type: manhattan_ap
value: 78.90073137580596
- type: manhattan_f1
value: 71.3942611553533
- type: manhattan_precision
value: 68.52705653967483
- type: manhattan_recall
value: 74.51187335092348
- type: max_accuracy
value: 87.48882398521786
- type: max_ap
value: 79.04326607602204
- type: max_f1
value: 71.64566826860633
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.68125897465751
- type: cos_sim_ap
value: 85.6003454431979
- type: cos_sim_f1
value: 77.6957163958641
- type: cos_sim_precision
value: 73.0110366307807
- type: cos_sim_recall
value: 83.02279026793964
- type: dot_accuracy
value: 87.7672992587418
- type: dot_ap
value: 82.4971301112899
- type: dot_f1
value: 75.90528233151184
- type: dot_precision
value: 72.0370626469368
- type: dot_recall
value: 80.21250384970742
- type: euclidean_accuracy
value: 88.4503434625684
- type: euclidean_ap
value: 84.91949884748384
- type: euclidean_f1
value: 76.92365018444684
- type: euclidean_precision
value: 74.53245721712759
- type: euclidean_recall
value: 79.47336002463813
- type: manhattan_accuracy
value: 88.47556952691427
- type: manhattan_ap
value: 84.8963689101517
- type: manhattan_f1
value: 76.85901249256395
- type: manhattan_precision
value: 74.31693989071039
- type: manhattan_recall
value: 79.58115183246073
- type: max_accuracy
value: 88.68125897465751
- type: max_ap
value: 85.6003454431979
- type: max_f1
value: 77.6957163958641
---
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
For more details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
If you are looking for a model that supports more languages, longer texts, and other retrieval methods, you can try using [bge-m3](https://huggingface.co/BAAI/bge-m3).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently:
- **Long-Context LLM**: [Activation Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon)
- **Fine-tuning of LM** : [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
- **Dense Retrieval**: [BGE-M3](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3), [LLM Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), [BGE Embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding)
- **Reranker Model**: [BGE Reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
- **Benchmark**: [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
## News
- 1/30/2024: Release **BGE-M3**, a new member to BGE model series! M3 stands for **M**ulti-linguality (100+ languages), **M**ulti-granularities (input length up to 8192), **M**ulti-Functionality (unification of dense, lexical, multi-vec/colbert retrieval).
It is the first embedding model that supports all three retrieval methods, achieving new SOTA on multi-lingual (MIRACL) and cross-lingual (MKQA) benchmarks.
[Technical Report](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf) and [Code](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3). :fire:
- 1/9/2024: Release [Activation-Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon), an effective, efficient, compatible, and low-cost (training) method to extend the context length of LLM. [Technical Report](https://arxiv.org/abs/2401.03462) :fire:
- 12/24/2023: Release **LLaRA**, a LLaMA-7B based dense retriever, leading to state-of-the-art performances on MS MARCO and BEIR. Model and code will be open-sourced. Please stay tuned. [Technical Report](https://arxiv.org/abs/2312.15503) :fire:
- 11/23/2023: Release [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail), a method to maintain general capabilities during fine-tuning by merging multiple language models. [Technical Report](https://arxiv.org/abs/2311.13534) :fire:
- 10/12/2023: Release [LLM-Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Technical Report](https://arxiv.org/pdf/2310.07554.pdf)
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) and [massive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | [Inference](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3#usage) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3) | Multi-Functionality(dense retrieval, sparse retrieval, multi-vector(colbert)), Multi-Linguality, and Multi-Granularity(8192 tokens) | |
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
#### Usage of the ONNX files
```python
from optimum.onnxruntime import ORTModelForFeatureExtraction # type: ignore
import torch
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-en-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-en-v1.5', revision="refs/pr/13")
model_ort = ORTModelForFeatureExtraction.from_pretrained('BAAI/bge-large-en-v1.5', revision="refs/pr/13",file_name="onnx/model.onnx")
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
model_output_ort = model_ort(**encoded_input)
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# model_output and model_output_ort are identical
```
Its also possible to deploy the onnx files with the [infinity_emb](https://github.com/michaelfeil/infinity) pip package.
```python
import asyncio
from infinity_emb import AsyncEmbeddingEngine, EngineArgs
sentences = ["Embed this is sentence via Infinity.", "Paris is in France."]
engine = AsyncEmbeddingEngine.from_args(
EngineArgs(model_name_or_path = "BAAI/bge-large-en-v1.5", device="cpu", engine="optimum" # or engine="torch"
))
async def main():
async with engine:
embeddings, usage = await engine.embed(sentences=sentences)
asyncio.run(main())
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao([email protected]) and Zheng Liu([email protected]).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
[
"BEAR",
"BIOSSES",
"SCIFACT"
] |
Euanyu/GERBERA-DNA
|
Euanyu
| null |
[
"transformers",
"pytorch",
"roberta",
"license:mit",
"endpoints_compatible",
"region:us"
] | 2024-05-21T21:25:02Z |
2024-05-21T21:27:43+00:00
| 17 | 0 |
---
license: mit
---
The GERBERA BioNER model for identifying dna types, trained on the JNLPBA-dna dataset and GUM-Time.
|
[
"JNLPBA"
] |
nadeem1362/mxbai-embed-large-v1-Q4_K_M-GGUF
|
nadeem1362
|
feature-extraction
|
[
"sentence-transformers",
"gguf",
"mteb",
"transformers.js",
"transformers",
"llama-cpp",
"gguf-my-repo",
"feature-extraction",
"en",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-05-23T12:00:21Z |
2024-05-23T12:00:24+00:00
| 17 | 0 |
---
language:
- en
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: feature-extraction
tags:
- mteb
- transformers.js
- transformers
- llama-cpp
- gguf-my-repo
model-index:
- name: mxbai-angle-large-v1
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.044776119403
- type: ap
value: 37.7362433623053
- type: f1
value: 68.92736573359774
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.84025000000001
- type: ap
value: 90.93190875404055
- type: f1
value: 93.8297833897293
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.184
- type: f1
value: 48.74163227751588
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 41.252
- type: map_at_10
value: 57.778
- type: map_at_100
value: 58.233000000000004
- type: map_at_1000
value: 58.23700000000001
- type: map_at_3
value: 53.449999999999996
- type: map_at_5
value: 56.376000000000005
- type: mrr_at_1
value: 41.679
- type: mrr_at_10
value: 57.92699999999999
- type: mrr_at_100
value: 58.389
- type: mrr_at_1000
value: 58.391999999999996
- type: mrr_at_3
value: 53.651
- type: mrr_at_5
value: 56.521
- type: ndcg_at_1
value: 41.252
- type: ndcg_at_10
value: 66.018
- type: ndcg_at_100
value: 67.774
- type: ndcg_at_1000
value: 67.84400000000001
- type: ndcg_at_3
value: 57.372
- type: ndcg_at_5
value: 62.646
- type: precision_at_1
value: 41.252
- type: precision_at_10
value: 9.189
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 22.902
- type: precision_at_5
value: 16.302
- type: recall_at_1
value: 41.252
- type: recall_at_10
value: 91.892
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 68.706
- type: recall_at_5
value: 81.50800000000001
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.97294504317859
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 42.98071077674629
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 65.16477858490782
- type: mrr
value: 78.23583080508287
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.6277629421789
- type: cos_sim_spearman
value: 88.4056288400568
- type: euclidean_pearson
value: 87.94871847578163
- type: euclidean_spearman
value: 88.4056288400568
- type: manhattan_pearson
value: 87.73271254229648
- type: manhattan_spearman
value: 87.91826833762677
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.81818181818181
- type: f1
value: 87.79879337316918
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.91773608582761
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.73059477462478
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.745999999999995
- type: map_at_10
value: 43.632
- type: map_at_100
value: 45.206
- type: map_at_1000
value: 45.341
- type: map_at_3
value: 39.956
- type: map_at_5
value: 42.031
- type: mrr_at_1
value: 39.485
- type: mrr_at_10
value: 49.537
- type: mrr_at_100
value: 50.249
- type: mrr_at_1000
value: 50.294000000000004
- type: mrr_at_3
value: 46.757
- type: mrr_at_5
value: 48.481
- type: ndcg_at_1
value: 39.485
- type: ndcg_at_10
value: 50.058
- type: ndcg_at_100
value: 55.586
- type: ndcg_at_1000
value: 57.511
- type: ndcg_at_3
value: 44.786
- type: ndcg_at_5
value: 47.339999999999996
- type: precision_at_1
value: 39.485
- type: precision_at_10
value: 9.557
- type: precision_at_100
value: 1.552
- type: precision_at_1000
value: 0.202
- type: precision_at_3
value: 21.412
- type: precision_at_5
value: 15.479000000000001
- type: recall_at_1
value: 32.745999999999995
- type: recall_at_10
value: 62.056
- type: recall_at_100
value: 85.088
- type: recall_at_1000
value: 96.952
- type: recall_at_3
value: 46.959
- type: recall_at_5
value: 54.06999999999999
- type: map_at_1
value: 31.898
- type: map_at_10
value: 42.142
- type: map_at_100
value: 43.349
- type: map_at_1000
value: 43.483
- type: map_at_3
value: 39.18
- type: map_at_5
value: 40.733000000000004
- type: mrr_at_1
value: 39.617999999999995
- type: mrr_at_10
value: 47.922
- type: mrr_at_100
value: 48.547000000000004
- type: mrr_at_1000
value: 48.597
- type: mrr_at_3
value: 45.86
- type: mrr_at_5
value: 46.949000000000005
- type: ndcg_at_1
value: 39.617999999999995
- type: ndcg_at_10
value: 47.739
- type: ndcg_at_100
value: 51.934999999999995
- type: ndcg_at_1000
value: 54.007000000000005
- type: ndcg_at_3
value: 43.748
- type: ndcg_at_5
value: 45.345
- type: precision_at_1
value: 39.617999999999995
- type: precision_at_10
value: 8.962
- type: precision_at_100
value: 1.436
- type: precision_at_1000
value: 0.192
- type: precision_at_3
value: 21.083
- type: precision_at_5
value: 14.752
- type: recall_at_1
value: 31.898
- type: recall_at_10
value: 57.587999999999994
- type: recall_at_100
value: 75.323
- type: recall_at_1000
value: 88.304
- type: recall_at_3
value: 45.275
- type: recall_at_5
value: 49.99
- type: map_at_1
value: 40.458
- type: map_at_10
value: 52.942
- type: map_at_100
value: 53.974
- type: map_at_1000
value: 54.031
- type: map_at_3
value: 49.559999999999995
- type: map_at_5
value: 51.408
- type: mrr_at_1
value: 46.27
- type: mrr_at_10
value: 56.31699999999999
- type: mrr_at_100
value: 56.95099999999999
- type: mrr_at_1000
value: 56.98
- type: mrr_at_3
value: 53.835
- type: mrr_at_5
value: 55.252
- type: ndcg_at_1
value: 46.27
- type: ndcg_at_10
value: 58.964000000000006
- type: ndcg_at_100
value: 62.875
- type: ndcg_at_1000
value: 63.969
- type: ndcg_at_3
value: 53.297000000000004
- type: ndcg_at_5
value: 55.938
- type: precision_at_1
value: 46.27
- type: precision_at_10
value: 9.549000000000001
- type: precision_at_100
value: 1.2409999999999999
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 23.762
- type: precision_at_5
value: 16.262999999999998
- type: recall_at_1
value: 40.458
- type: recall_at_10
value: 73.446
- type: recall_at_100
value: 90.12400000000001
- type: recall_at_1000
value: 97.795
- type: recall_at_3
value: 58.123000000000005
- type: recall_at_5
value: 64.68
- type: map_at_1
value: 27.443
- type: map_at_10
value: 36.081
- type: map_at_100
value: 37.163000000000004
- type: map_at_1000
value: 37.232
- type: map_at_3
value: 33.308
- type: map_at_5
value: 34.724
- type: mrr_at_1
value: 29.492
- type: mrr_at_10
value: 38.138
- type: mrr_at_100
value: 39.065
- type: mrr_at_1000
value: 39.119
- type: mrr_at_3
value: 35.593
- type: mrr_at_5
value: 36.785000000000004
- type: ndcg_at_1
value: 29.492
- type: ndcg_at_10
value: 41.134
- type: ndcg_at_100
value: 46.300999999999995
- type: ndcg_at_1000
value: 48.106
- type: ndcg_at_3
value: 35.77
- type: ndcg_at_5
value: 38.032
- type: precision_at_1
value: 29.492
- type: precision_at_10
value: 6.249
- type: precision_at_100
value: 0.9299999999999999
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 15.065999999999999
- type: precision_at_5
value: 10.373000000000001
- type: recall_at_1
value: 27.443
- type: recall_at_10
value: 54.80199999999999
- type: recall_at_100
value: 78.21900000000001
- type: recall_at_1000
value: 91.751
- type: recall_at_3
value: 40.211000000000006
- type: recall_at_5
value: 45.599000000000004
- type: map_at_1
value: 18.731
- type: map_at_10
value: 26.717999999999996
- type: map_at_100
value: 27.897
- type: map_at_1000
value: 28.029
- type: map_at_3
value: 23.91
- type: map_at_5
value: 25.455
- type: mrr_at_1
value: 23.134
- type: mrr_at_10
value: 31.769
- type: mrr_at_100
value: 32.634
- type: mrr_at_1000
value: 32.707
- type: mrr_at_3
value: 28.938999999999997
- type: mrr_at_5
value: 30.531000000000002
- type: ndcg_at_1
value: 23.134
- type: ndcg_at_10
value: 32.249
- type: ndcg_at_100
value: 37.678
- type: ndcg_at_1000
value: 40.589999999999996
- type: ndcg_at_3
value: 26.985999999999997
- type: ndcg_at_5
value: 29.457
- type: precision_at_1
value: 23.134
- type: precision_at_10
value: 5.8709999999999996
- type: precision_at_100
value: 0.988
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 12.852
- type: precision_at_5
value: 9.428
- type: recall_at_1
value: 18.731
- type: recall_at_10
value: 44.419
- type: recall_at_100
value: 67.851
- type: recall_at_1000
value: 88.103
- type: recall_at_3
value: 29.919
- type: recall_at_5
value: 36.230000000000004
- type: map_at_1
value: 30.324
- type: map_at_10
value: 41.265
- type: map_at_100
value: 42.559000000000005
- type: map_at_1000
value: 42.669000000000004
- type: map_at_3
value: 38.138
- type: map_at_5
value: 39.881
- type: mrr_at_1
value: 36.67
- type: mrr_at_10
value: 46.774
- type: mrr_at_100
value: 47.554
- type: mrr_at_1000
value: 47.593
- type: mrr_at_3
value: 44.338
- type: mrr_at_5
value: 45.723
- type: ndcg_at_1
value: 36.67
- type: ndcg_at_10
value: 47.367
- type: ndcg_at_100
value: 52.623
- type: ndcg_at_1000
value: 54.59
- type: ndcg_at_3
value: 42.323
- type: ndcg_at_5
value: 44.727
- type: precision_at_1
value: 36.67
- type: precision_at_10
value: 8.518
- type: precision_at_100
value: 1.2890000000000001
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 19.955000000000002
- type: precision_at_5
value: 14.11
- type: recall_at_1
value: 30.324
- type: recall_at_10
value: 59.845000000000006
- type: recall_at_100
value: 81.77499999999999
- type: recall_at_1000
value: 94.463
- type: recall_at_3
value: 46.019
- type: recall_at_5
value: 52.163000000000004
- type: map_at_1
value: 24.229
- type: map_at_10
value: 35.004000000000005
- type: map_at_100
value: 36.409000000000006
- type: map_at_1000
value: 36.521
- type: map_at_3
value: 31.793
- type: map_at_5
value: 33.432
- type: mrr_at_1
value: 30.365
- type: mrr_at_10
value: 40.502
- type: mrr_at_100
value: 41.372
- type: mrr_at_1000
value: 41.435
- type: mrr_at_3
value: 37.804
- type: mrr_at_5
value: 39.226
- type: ndcg_at_1
value: 30.365
- type: ndcg_at_10
value: 41.305
- type: ndcg_at_100
value: 47.028999999999996
- type: ndcg_at_1000
value: 49.375
- type: ndcg_at_3
value: 35.85
- type: ndcg_at_5
value: 38.12
- type: precision_at_1
value: 30.365
- type: precision_at_10
value: 7.808
- type: precision_at_100
value: 1.228
- type: precision_at_1000
value: 0.161
- type: precision_at_3
value: 17.352
- type: precision_at_5
value: 12.42
- type: recall_at_1
value: 24.229
- type: recall_at_10
value: 54.673
- type: recall_at_100
value: 78.766
- type: recall_at_1000
value: 94.625
- type: recall_at_3
value: 39.602
- type: recall_at_5
value: 45.558
- type: map_at_1
value: 26.695
- type: map_at_10
value: 36.0895
- type: map_at_100
value: 37.309416666666664
- type: map_at_1000
value: 37.42558333333334
- type: map_at_3
value: 33.19616666666666
- type: map_at_5
value: 34.78641666666667
- type: mrr_at_1
value: 31.486083333333337
- type: mrr_at_10
value: 40.34774999999999
- type: mrr_at_100
value: 41.17533333333333
- type: mrr_at_1000
value: 41.231583333333326
- type: mrr_at_3
value: 37.90075
- type: mrr_at_5
value: 39.266999999999996
- type: ndcg_at_1
value: 31.486083333333337
- type: ndcg_at_10
value: 41.60433333333334
- type: ndcg_at_100
value: 46.74525
- type: ndcg_at_1000
value: 48.96166666666667
- type: ndcg_at_3
value: 36.68825
- type: ndcg_at_5
value: 38.966499999999996
- type: precision_at_1
value: 31.486083333333337
- type: precision_at_10
value: 7.29675
- type: precision_at_100
value: 1.1621666666666666
- type: precision_at_1000
value: 0.1545
- type: precision_at_3
value: 16.8815
- type: precision_at_5
value: 11.974583333333333
- type: recall_at_1
value: 26.695
- type: recall_at_10
value: 53.651916666666665
- type: recall_at_100
value: 76.12083333333332
- type: recall_at_1000
value: 91.31191666666668
- type: recall_at_3
value: 40.03575
- type: recall_at_5
value: 45.876666666666665
- type: map_at_1
value: 25.668000000000003
- type: map_at_10
value: 32.486
- type: map_at_100
value: 33.371
- type: map_at_1000
value: 33.458
- type: map_at_3
value: 30.261
- type: map_at_5
value: 31.418000000000003
- type: mrr_at_1
value: 28.988000000000003
- type: mrr_at_10
value: 35.414
- type: mrr_at_100
value: 36.149
- type: mrr_at_1000
value: 36.215
- type: mrr_at_3
value: 33.333
- type: mrr_at_5
value: 34.43
- type: ndcg_at_1
value: 28.988000000000003
- type: ndcg_at_10
value: 36.732
- type: ndcg_at_100
value: 41.331
- type: ndcg_at_1000
value: 43.575
- type: ndcg_at_3
value: 32.413
- type: ndcg_at_5
value: 34.316
- type: precision_at_1
value: 28.988000000000003
- type: precision_at_10
value: 5.7059999999999995
- type: precision_at_100
value: 0.882
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 13.65
- type: precision_at_5
value: 9.417
- type: recall_at_1
value: 25.668000000000003
- type: recall_at_10
value: 47.147
- type: recall_at_100
value: 68.504
- type: recall_at_1000
value: 85.272
- type: recall_at_3
value: 35.19
- type: recall_at_5
value: 39.925
- type: map_at_1
value: 17.256
- type: map_at_10
value: 24.58
- type: map_at_100
value: 25.773000000000003
- type: map_at_1000
value: 25.899
- type: map_at_3
value: 22.236
- type: map_at_5
value: 23.507
- type: mrr_at_1
value: 20.957
- type: mrr_at_10
value: 28.416000000000004
- type: mrr_at_100
value: 29.447000000000003
- type: mrr_at_1000
value: 29.524
- type: mrr_at_3
value: 26.245
- type: mrr_at_5
value: 27.451999999999998
- type: ndcg_at_1
value: 20.957
- type: ndcg_at_10
value: 29.285
- type: ndcg_at_100
value: 35.003
- type: ndcg_at_1000
value: 37.881
- type: ndcg_at_3
value: 25.063000000000002
- type: ndcg_at_5
value: 26.983
- type: precision_at_1
value: 20.957
- type: precision_at_10
value: 5.344
- type: precision_at_100
value: 0.958
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 11.918
- type: precision_at_5
value: 8.596
- type: recall_at_1
value: 17.256
- type: recall_at_10
value: 39.644
- type: recall_at_100
value: 65.279
- type: recall_at_1000
value: 85.693
- type: recall_at_3
value: 27.825
- type: recall_at_5
value: 32.792
- type: map_at_1
value: 26.700000000000003
- type: map_at_10
value: 36.205999999999996
- type: map_at_100
value: 37.316
- type: map_at_1000
value: 37.425000000000004
- type: map_at_3
value: 33.166000000000004
- type: map_at_5
value: 35.032999999999994
- type: mrr_at_1
value: 31.436999999999998
- type: mrr_at_10
value: 40.61
- type: mrr_at_100
value: 41.415
- type: mrr_at_1000
value: 41.48
- type: mrr_at_3
value: 37.966
- type: mrr_at_5
value: 39.599000000000004
- type: ndcg_at_1
value: 31.436999999999998
- type: ndcg_at_10
value: 41.771
- type: ndcg_at_100
value: 46.784
- type: ndcg_at_1000
value: 49.183
- type: ndcg_at_3
value: 36.437000000000005
- type: ndcg_at_5
value: 39.291
- type: precision_at_1
value: 31.436999999999998
- type: precision_at_10
value: 6.987
- type: precision_at_100
value: 1.072
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 16.448999999999998
- type: precision_at_5
value: 11.866
- type: recall_at_1
value: 26.700000000000003
- type: recall_at_10
value: 54.301
- type: recall_at_100
value: 75.871
- type: recall_at_1000
value: 92.529
- type: recall_at_3
value: 40.201
- type: recall_at_5
value: 47.208
- type: map_at_1
value: 24.296
- type: map_at_10
value: 33.116
- type: map_at_100
value: 34.81
- type: map_at_1000
value: 35.032000000000004
- type: map_at_3
value: 30.105999999999998
- type: map_at_5
value: 31.839000000000002
- type: mrr_at_1
value: 29.051
- type: mrr_at_10
value: 37.803
- type: mrr_at_100
value: 38.856
- type: mrr_at_1000
value: 38.903999999999996
- type: mrr_at_3
value: 35.211
- type: mrr_at_5
value: 36.545
- type: ndcg_at_1
value: 29.051
- type: ndcg_at_10
value: 39.007
- type: ndcg_at_100
value: 45.321
- type: ndcg_at_1000
value: 47.665
- type: ndcg_at_3
value: 34.1
- type: ndcg_at_5
value: 36.437000000000005
- type: precision_at_1
value: 29.051
- type: precision_at_10
value: 7.668
- type: precision_at_100
value: 1.542
- type: precision_at_1000
value: 0.24
- type: precision_at_3
value: 16.14
- type: precision_at_5
value: 11.897
- type: recall_at_1
value: 24.296
- type: recall_at_10
value: 49.85
- type: recall_at_100
value: 78.457
- type: recall_at_1000
value: 92.618
- type: recall_at_3
value: 36.138999999999996
- type: recall_at_5
value: 42.223
- type: map_at_1
value: 20.591
- type: map_at_10
value: 28.902
- type: map_at_100
value: 29.886000000000003
- type: map_at_1000
value: 29.987000000000002
- type: map_at_3
value: 26.740000000000002
- type: map_at_5
value: 27.976
- type: mrr_at_1
value: 22.366
- type: mrr_at_10
value: 30.971
- type: mrr_at_100
value: 31.865
- type: mrr_at_1000
value: 31.930999999999997
- type: mrr_at_3
value: 28.927999999999997
- type: mrr_at_5
value: 30.231
- type: ndcg_at_1
value: 22.366
- type: ndcg_at_10
value: 33.641
- type: ndcg_at_100
value: 38.477
- type: ndcg_at_1000
value: 41.088
- type: ndcg_at_3
value: 29.486
- type: ndcg_at_5
value: 31.612000000000002
- type: precision_at_1
value: 22.366
- type: precision_at_10
value: 5.3420000000000005
- type: precision_at_100
value: 0.828
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 12.939
- type: precision_at_5
value: 9.094
- type: recall_at_1
value: 20.591
- type: recall_at_10
value: 46.052
- type: recall_at_100
value: 68.193
- type: recall_at_1000
value: 87.638
- type: recall_at_3
value: 34.966
- type: recall_at_5
value: 40.082
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.091
- type: map_at_10
value: 26.38
- type: map_at_100
value: 28.421999999999997
- type: map_at_1000
value: 28.621999999999996
- type: map_at_3
value: 21.597
- type: map_at_5
value: 24.12
- type: mrr_at_1
value: 34.266999999999996
- type: mrr_at_10
value: 46.864
- type: mrr_at_100
value: 47.617
- type: mrr_at_1000
value: 47.644
- type: mrr_at_3
value: 43.312
- type: mrr_at_5
value: 45.501000000000005
- type: ndcg_at_1
value: 34.266999999999996
- type: ndcg_at_10
value: 36.095
- type: ndcg_at_100
value: 43.447
- type: ndcg_at_1000
value: 46.661
- type: ndcg_at_3
value: 29.337999999999997
- type: ndcg_at_5
value: 31.824
- type: precision_at_1
value: 34.266999999999996
- type: precision_at_10
value: 11.472
- type: precision_at_100
value: 1.944
- type: precision_at_1000
value: 0.255
- type: precision_at_3
value: 21.933
- type: precision_at_5
value: 17.224999999999998
- type: recall_at_1
value: 15.091
- type: recall_at_10
value: 43.022
- type: recall_at_100
value: 68.075
- type: recall_at_1000
value: 85.76
- type: recall_at_3
value: 26.564
- type: recall_at_5
value: 33.594
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.252
- type: map_at_10
value: 20.923
- type: map_at_100
value: 30.741000000000003
- type: map_at_1000
value: 32.542
- type: map_at_3
value: 14.442
- type: map_at_5
value: 17.399
- type: mrr_at_1
value: 70.25
- type: mrr_at_10
value: 78.17
- type: mrr_at_100
value: 78.444
- type: mrr_at_1000
value: 78.45100000000001
- type: mrr_at_3
value: 76.958
- type: mrr_at_5
value: 77.571
- type: ndcg_at_1
value: 58.375
- type: ndcg_at_10
value: 44.509
- type: ndcg_at_100
value: 49.897999999999996
- type: ndcg_at_1000
value: 57.269999999999996
- type: ndcg_at_3
value: 48.64
- type: ndcg_at_5
value: 46.697
- type: precision_at_1
value: 70.25
- type: precision_at_10
value: 36.05
- type: precision_at_100
value: 11.848
- type: precision_at_1000
value: 2.213
- type: precision_at_3
value: 52.917
- type: precision_at_5
value: 45.7
- type: recall_at_1
value: 9.252
- type: recall_at_10
value: 27.006999999999998
- type: recall_at_100
value: 57.008
- type: recall_at_1000
value: 80.697
- type: recall_at_3
value: 15.798000000000002
- type: recall_at_5
value: 20.4
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 50.88
- type: f1
value: 45.545495028653384
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 75.424
- type: map_at_10
value: 83.435
- type: map_at_100
value: 83.66900000000001
- type: map_at_1000
value: 83.685
- type: map_at_3
value: 82.39800000000001
- type: map_at_5
value: 83.07
- type: mrr_at_1
value: 81.113
- type: mrr_at_10
value: 87.77199999999999
- type: mrr_at_100
value: 87.862
- type: mrr_at_1000
value: 87.86500000000001
- type: mrr_at_3
value: 87.17099999999999
- type: mrr_at_5
value: 87.616
- type: ndcg_at_1
value: 81.113
- type: ndcg_at_10
value: 86.909
- type: ndcg_at_100
value: 87.746
- type: ndcg_at_1000
value: 88.017
- type: ndcg_at_3
value: 85.368
- type: ndcg_at_5
value: 86.28099999999999
- type: precision_at_1
value: 81.113
- type: precision_at_10
value: 10.363
- type: precision_at_100
value: 1.102
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 32.507999999999996
- type: precision_at_5
value: 20.138
- type: recall_at_1
value: 75.424
- type: recall_at_10
value: 93.258
- type: recall_at_100
value: 96.545
- type: recall_at_1000
value: 98.284
- type: recall_at_3
value: 89.083
- type: recall_at_5
value: 91.445
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.532
- type: map_at_10
value: 37.141999999999996
- type: map_at_100
value: 39.162
- type: map_at_1000
value: 39.322
- type: map_at_3
value: 32.885
- type: map_at_5
value: 35.093999999999994
- type: mrr_at_1
value: 44.29
- type: mrr_at_10
value: 53.516
- type: mrr_at_100
value: 54.24
- type: mrr_at_1000
value: 54.273
- type: mrr_at_3
value: 51.286
- type: mrr_at_5
value: 52.413
- type: ndcg_at_1
value: 44.29
- type: ndcg_at_10
value: 45.268
- type: ndcg_at_100
value: 52.125
- type: ndcg_at_1000
value: 54.778000000000006
- type: ndcg_at_3
value: 41.829
- type: ndcg_at_5
value: 42.525
- type: precision_at_1
value: 44.29
- type: precision_at_10
value: 12.5
- type: precision_at_100
value: 1.9720000000000002
- type: precision_at_1000
value: 0.245
- type: precision_at_3
value: 28.035
- type: precision_at_5
value: 20.093
- type: recall_at_1
value: 22.532
- type: recall_at_10
value: 52.419000000000004
- type: recall_at_100
value: 77.43299999999999
- type: recall_at_1000
value: 93.379
- type: recall_at_3
value: 38.629000000000005
- type: recall_at_5
value: 43.858000000000004
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.359
- type: map_at_10
value: 63.966
- type: map_at_100
value: 64.87
- type: map_at_1000
value: 64.92599999999999
- type: map_at_3
value: 60.409
- type: map_at_5
value: 62.627
- type: mrr_at_1
value: 78.717
- type: mrr_at_10
value: 84.468
- type: mrr_at_100
value: 84.655
- type: mrr_at_1000
value: 84.661
- type: mrr_at_3
value: 83.554
- type: mrr_at_5
value: 84.133
- type: ndcg_at_1
value: 78.717
- type: ndcg_at_10
value: 72.03399999999999
- type: ndcg_at_100
value: 75.158
- type: ndcg_at_1000
value: 76.197
- type: ndcg_at_3
value: 67.049
- type: ndcg_at_5
value: 69.808
- type: precision_at_1
value: 78.717
- type: precision_at_10
value: 15.201
- type: precision_at_100
value: 1.764
- type: precision_at_1000
value: 0.19
- type: precision_at_3
value: 43.313
- type: precision_at_5
value: 28.165000000000003
- type: recall_at_1
value: 39.359
- type: recall_at_10
value: 76.003
- type: recall_at_100
value: 88.197
- type: recall_at_1000
value: 95.003
- type: recall_at_3
value: 64.97
- type: recall_at_5
value: 70.41199999999999
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 92.83200000000001
- type: ap
value: 89.33560571859861
- type: f1
value: 92.82322915005167
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.983
- type: map_at_10
value: 34.259
- type: map_at_100
value: 35.432
- type: map_at_1000
value: 35.482
- type: map_at_3
value: 30.275999999999996
- type: map_at_5
value: 32.566
- type: mrr_at_1
value: 22.579
- type: mrr_at_10
value: 34.882999999999996
- type: mrr_at_100
value: 35.984
- type: mrr_at_1000
value: 36.028
- type: mrr_at_3
value: 30.964999999999996
- type: mrr_at_5
value: 33.245000000000005
- type: ndcg_at_1
value: 22.564
- type: ndcg_at_10
value: 41.258
- type: ndcg_at_100
value: 46.824
- type: ndcg_at_1000
value: 48.037
- type: ndcg_at_3
value: 33.17
- type: ndcg_at_5
value: 37.263000000000005
- type: precision_at_1
value: 22.564
- type: precision_at_10
value: 6.572
- type: precision_at_100
value: 0.935
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.130999999999998
- type: precision_at_5
value: 10.544
- type: recall_at_1
value: 21.983
- type: recall_at_10
value: 62.775000000000006
- type: recall_at_100
value: 88.389
- type: recall_at_1000
value: 97.603
- type: recall_at_3
value: 40.878
- type: recall_at_5
value: 50.690000000000005
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.95120839033288
- type: f1
value: 93.73824125055208
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 76.78978568171455
- type: f1
value: 57.50180552858304
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.24411566913248
- type: f1
value: 74.37851403532832
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.94620040349699
- type: f1
value: 80.21293397970435
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.44403096245675
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.659594631336812
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.53833075108798
- type: mrr
value: 33.78840823218308
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.185999999999999
- type: map_at_10
value: 15.193999999999999
- type: map_at_100
value: 19.538
- type: map_at_1000
value: 21.178
- type: map_at_3
value: 11.208
- type: map_at_5
value: 12.745999999999999
- type: mrr_at_1
value: 48.916
- type: mrr_at_10
value: 58.141
- type: mrr_at_100
value: 58.656
- type: mrr_at_1000
value: 58.684999999999995
- type: mrr_at_3
value: 55.521
- type: mrr_at_5
value: 57.239
- type: ndcg_at_1
value: 47.059
- type: ndcg_at_10
value: 38.644
- type: ndcg_at_100
value: 36.272999999999996
- type: ndcg_at_1000
value: 44.996
- type: ndcg_at_3
value: 43.293
- type: ndcg_at_5
value: 40.819
- type: precision_at_1
value: 48.916
- type: precision_at_10
value: 28.607
- type: precision_at_100
value: 9.195
- type: precision_at_1000
value: 2.225
- type: precision_at_3
value: 40.454
- type: precision_at_5
value: 34.985
- type: recall_at_1
value: 7.185999999999999
- type: recall_at_10
value: 19.654
- type: recall_at_100
value: 37.224000000000004
- type: recall_at_1000
value: 68.663
- type: recall_at_3
value: 12.158
- type: recall_at_5
value: 14.674999999999999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.552000000000003
- type: map_at_10
value: 47.75
- type: map_at_100
value: 48.728
- type: map_at_1000
value: 48.754
- type: map_at_3
value: 43.156
- type: map_at_5
value: 45.883
- type: mrr_at_1
value: 35.66
- type: mrr_at_10
value: 50.269
- type: mrr_at_100
value: 50.974
- type: mrr_at_1000
value: 50.991
- type: mrr_at_3
value: 46.519
- type: mrr_at_5
value: 48.764
- type: ndcg_at_1
value: 35.632000000000005
- type: ndcg_at_10
value: 55.786
- type: ndcg_at_100
value: 59.748999999999995
- type: ndcg_at_1000
value: 60.339
- type: ndcg_at_3
value: 47.292
- type: ndcg_at_5
value: 51.766999999999996
- type: precision_at_1
value: 35.632000000000005
- type: precision_at_10
value: 9.267
- type: precision_at_100
value: 1.149
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 21.601
- type: precision_at_5
value: 15.539
- type: recall_at_1
value: 31.552000000000003
- type: recall_at_10
value: 77.62400000000001
- type: recall_at_100
value: 94.527
- type: recall_at_1000
value: 98.919
- type: recall_at_3
value: 55.898
- type: recall_at_5
value: 66.121
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.414
- type: map_at_10
value: 85.37400000000001
- type: map_at_100
value: 86.01100000000001
- type: map_at_1000
value: 86.027
- type: map_at_3
value: 82.562
- type: map_at_5
value: 84.284
- type: mrr_at_1
value: 82.24000000000001
- type: mrr_at_10
value: 88.225
- type: mrr_at_100
value: 88.324
- type: mrr_at_1000
value: 88.325
- type: mrr_at_3
value: 87.348
- type: mrr_at_5
value: 87.938
- type: ndcg_at_1
value: 82.24000000000001
- type: ndcg_at_10
value: 88.97699999999999
- type: ndcg_at_100
value: 90.16
- type: ndcg_at_1000
value: 90.236
- type: ndcg_at_3
value: 86.371
- type: ndcg_at_5
value: 87.746
- type: precision_at_1
value: 82.24000000000001
- type: precision_at_10
value: 13.481000000000002
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.86
- type: precision_at_5
value: 24.738
- type: recall_at_1
value: 71.414
- type: recall_at_10
value: 95.735
- type: recall_at_100
value: 99.696
- type: recall_at_1000
value: 99.979
- type: recall_at_3
value: 88.105
- type: recall_at_5
value: 92.17999999999999
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 60.22146692057259
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 65.29273320614578
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.023
- type: map_at_10
value: 14.161000000000001
- type: map_at_100
value: 16.68
- type: map_at_1000
value: 17.072000000000003
- type: map_at_3
value: 9.763
- type: map_at_5
value: 11.977
- type: mrr_at_1
value: 24.8
- type: mrr_at_10
value: 37.602999999999994
- type: mrr_at_100
value: 38.618
- type: mrr_at_1000
value: 38.659
- type: mrr_at_3
value: 34.117
- type: mrr_at_5
value: 36.082
- type: ndcg_at_1
value: 24.8
- type: ndcg_at_10
value: 23.316
- type: ndcg_at_100
value: 32.613
- type: ndcg_at_1000
value: 38.609
- type: ndcg_at_3
value: 21.697
- type: ndcg_at_5
value: 19.241
- type: precision_at_1
value: 24.8
- type: precision_at_10
value: 12.36
- type: precision_at_100
value: 2.593
- type: precision_at_1000
value: 0.402
- type: precision_at_3
value: 20.767
- type: precision_at_5
value: 17.34
- type: recall_at_1
value: 5.023
- type: recall_at_10
value: 25.069999999999997
- type: recall_at_100
value: 52.563
- type: recall_at_1000
value: 81.525
- type: recall_at_3
value: 12.613
- type: recall_at_5
value: 17.583
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 87.71506247604255
- type: cos_sim_spearman
value: 82.91813463738802
- type: euclidean_pearson
value: 85.5154616194479
- type: euclidean_spearman
value: 82.91815254466314
- type: manhattan_pearson
value: 85.5280917850374
- type: manhattan_spearman
value: 82.92276537286398
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 87.43772054228462
- type: cos_sim_spearman
value: 78.75750601716682
- type: euclidean_pearson
value: 85.76074482955764
- type: euclidean_spearman
value: 78.75651057223058
- type: manhattan_pearson
value: 85.73390291701668
- type: manhattan_spearman
value: 78.72699385957797
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 89.58144067172472
- type: cos_sim_spearman
value: 90.3524512966946
- type: euclidean_pearson
value: 89.71365391594237
- type: euclidean_spearman
value: 90.35239632843408
- type: manhattan_pearson
value: 89.66905421746478
- type: manhattan_spearman
value: 90.31508211683513
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 87.77692637102102
- type: cos_sim_spearman
value: 85.45710562643485
- type: euclidean_pearson
value: 87.42456979928723
- type: euclidean_spearman
value: 85.45709386240908
- type: manhattan_pearson
value: 87.40754529526272
- type: manhattan_spearman
value: 85.44834854173303
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.28491331695997
- type: cos_sim_spearman
value: 89.62037029566964
- type: euclidean_pearson
value: 89.02479391362826
- type: euclidean_spearman
value: 89.62036733618466
- type: manhattan_pearson
value: 89.00394756040342
- type: manhattan_spearman
value: 89.60867744215236
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.08911381280191
- type: cos_sim_spearman
value: 86.5791780765767
- type: euclidean_pearson
value: 86.16063473577861
- type: euclidean_spearman
value: 86.57917745378766
- type: manhattan_pearson
value: 86.13677924604175
- type: manhattan_spearman
value: 86.56115615768685
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.58029496205235
- type: cos_sim_spearman
value: 89.49551253826998
- type: euclidean_pearson
value: 90.13714840963748
- type: euclidean_spearman
value: 89.49551253826998
- type: manhattan_pearson
value: 90.13039633601363
- type: manhattan_spearman
value: 89.4513453745516
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 69.01546399666435
- type: cos_sim_spearman
value: 69.33824484595624
- type: euclidean_pearson
value: 70.76511642998874
- type: euclidean_spearman
value: 69.33824484595624
- type: manhattan_pearson
value: 70.84320785047453
- type: manhattan_spearman
value: 69.54233632223537
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.26389196390119
- type: cos_sim_spearman
value: 89.09721478341385
- type: euclidean_pearson
value: 88.97208685922517
- type: euclidean_spearman
value: 89.09720927308881
- type: manhattan_pearson
value: 88.97513670502573
- type: manhattan_spearman
value: 89.07647853984004
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.53075025771936
- type: mrr
value: 96.24327651288436
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.428000000000004
- type: map_at_10
value: 70.088
- type: map_at_100
value: 70.589
- type: map_at_1000
value: 70.614
- type: map_at_3
value: 67.191
- type: map_at_5
value: 68.515
- type: mrr_at_1
value: 63.333
- type: mrr_at_10
value: 71.13000000000001
- type: mrr_at_100
value: 71.545
- type: mrr_at_1000
value: 71.569
- type: mrr_at_3
value: 68.944
- type: mrr_at_5
value: 70.078
- type: ndcg_at_1
value: 63.333
- type: ndcg_at_10
value: 74.72800000000001
- type: ndcg_at_100
value: 76.64999999999999
- type: ndcg_at_1000
value: 77.176
- type: ndcg_at_3
value: 69.659
- type: ndcg_at_5
value: 71.626
- type: precision_at_1
value: 63.333
- type: precision_at_10
value: 10
- type: precision_at_100
value: 1.09
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 27.111
- type: precision_at_5
value: 17.666999999999998
- type: recall_at_1
value: 60.428000000000004
- type: recall_at_10
value: 87.98899999999999
- type: recall_at_100
value: 96.167
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 74.006
- type: recall_at_5
value: 79.05
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.87326732673267
- type: cos_sim_ap
value: 96.81770773701805
- type: cos_sim_f1
value: 93.6318407960199
- type: cos_sim_precision
value: 93.16831683168317
- type: cos_sim_recall
value: 94.1
- type: dot_accuracy
value: 99.87326732673267
- type: dot_ap
value: 96.8174218946665
- type: dot_f1
value: 93.6318407960199
- type: dot_precision
value: 93.16831683168317
- type: dot_recall
value: 94.1
- type: euclidean_accuracy
value: 99.87326732673267
- type: euclidean_ap
value: 96.81770773701807
- type: euclidean_f1
value: 93.6318407960199
- type: euclidean_precision
value: 93.16831683168317
- type: euclidean_recall
value: 94.1
- type: manhattan_accuracy
value: 99.87227722772278
- type: manhattan_ap
value: 96.83164126821747
- type: manhattan_f1
value: 93.54677338669335
- type: manhattan_precision
value: 93.5935935935936
- type: manhattan_recall
value: 93.5
- type: max_accuracy
value: 99.87326732673267
- type: max_ap
value: 96.83164126821747
- type: max_f1
value: 93.6318407960199
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 65.6212042420246
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.779230635982564
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.217701909036286
- type: mrr
value: 56.17658995416349
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.954206018888453
- type: cos_sim_spearman
value: 32.71062599450096
- type: dot_pearson
value: 30.95420929056943
- type: dot_spearman
value: 32.71062599450096
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22699999999999998
- type: map_at_10
value: 1.924
- type: map_at_100
value: 10.525
- type: map_at_1000
value: 24.973
- type: map_at_3
value: 0.638
- type: map_at_5
value: 1.0659999999999998
- type: mrr_at_1
value: 84
- type: mrr_at_10
value: 91.067
- type: mrr_at_100
value: 91.067
- type: mrr_at_1000
value: 91.067
- type: mrr_at_3
value: 90.667
- type: mrr_at_5
value: 91.067
- type: ndcg_at_1
value: 81
- type: ndcg_at_10
value: 75.566
- type: ndcg_at_100
value: 56.387
- type: ndcg_at_1000
value: 49.834
- type: ndcg_at_3
value: 80.899
- type: ndcg_at_5
value: 80.75099999999999
- type: precision_at_1
value: 84
- type: precision_at_10
value: 79
- type: precision_at_100
value: 57.56
- type: precision_at_1000
value: 21.8
- type: precision_at_3
value: 84.667
- type: precision_at_5
value: 85.2
- type: recall_at_1
value: 0.22699999999999998
- type: recall_at_10
value: 2.136
- type: recall_at_100
value: 13.861
- type: recall_at_1000
value: 46.299
- type: recall_at_3
value: 0.6649999999999999
- type: recall_at_5
value: 1.145
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.752
- type: map_at_10
value: 9.951
- type: map_at_100
value: 16.794999999999998
- type: map_at_1000
value: 18.251
- type: map_at_3
value: 5.288
- type: map_at_5
value: 6.954000000000001
- type: mrr_at_1
value: 38.775999999999996
- type: mrr_at_10
value: 50.458000000000006
- type: mrr_at_100
value: 51.324999999999996
- type: mrr_at_1000
value: 51.339999999999996
- type: mrr_at_3
value: 46.939
- type: mrr_at_5
value: 47.857
- type: ndcg_at_1
value: 36.735
- type: ndcg_at_10
value: 25.198999999999998
- type: ndcg_at_100
value: 37.938
- type: ndcg_at_1000
value: 49.145
- type: ndcg_at_3
value: 29.348000000000003
- type: ndcg_at_5
value: 25.804
- type: precision_at_1
value: 38.775999999999996
- type: precision_at_10
value: 22.041
- type: precision_at_100
value: 7.939
- type: precision_at_1000
value: 1.555
- type: precision_at_3
value: 29.932
- type: precision_at_5
value: 24.490000000000002
- type: recall_at_1
value: 2.752
- type: recall_at_10
value: 16.197
- type: recall_at_100
value: 49.166
- type: recall_at_1000
value: 84.18900000000001
- type: recall_at_3
value: 6.438000000000001
- type: recall_at_5
value: 9.093
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.47980000000001
- type: ap
value: 14.605194452178754
- type: f1
value: 55.07362924988948
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.708545557441994
- type: f1
value: 60.04751270975683
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 53.21105960597211
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.58419264469214
- type: cos_sim_ap
value: 78.55300004517404
- type: cos_sim_f1
value: 71.49673530889001
- type: cos_sim_precision
value: 68.20795400095831
- type: cos_sim_recall
value: 75.11873350923483
- type: dot_accuracy
value: 87.58419264469214
- type: dot_ap
value: 78.55297659559511
- type: dot_f1
value: 71.49673530889001
- type: dot_precision
value: 68.20795400095831
- type: dot_recall
value: 75.11873350923483
- type: euclidean_accuracy
value: 87.58419264469214
- type: euclidean_ap
value: 78.55300477331477
- type: euclidean_f1
value: 71.49673530889001
- type: euclidean_precision
value: 68.20795400095831
- type: euclidean_recall
value: 75.11873350923483
- type: manhattan_accuracy
value: 87.5663110210407
- type: manhattan_ap
value: 78.49982050876562
- type: manhattan_f1
value: 71.35488740722104
- type: manhattan_precision
value: 68.18946862226497
- type: manhattan_recall
value: 74.82849604221636
- type: max_accuracy
value: 87.58419264469214
- type: max_ap
value: 78.55300477331477
- type: max_f1
value: 71.49673530889001
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.09069740365584
- type: cos_sim_ap
value: 86.22749303724757
- type: cos_sim_f1
value: 78.36863452005407
- type: cos_sim_precision
value: 76.49560117302053
- type: cos_sim_recall
value: 80.33569448721897
- type: dot_accuracy
value: 89.09069740365584
- type: dot_ap
value: 86.22750233655673
- type: dot_f1
value: 78.36863452005407
- type: dot_precision
value: 76.49560117302053
- type: dot_recall
value: 80.33569448721897
- type: euclidean_accuracy
value: 89.09069740365584
- type: euclidean_ap
value: 86.22749355597347
- type: euclidean_f1
value: 78.36863452005407
- type: euclidean_precision
value: 76.49560117302053
- type: euclidean_recall
value: 80.33569448721897
- type: manhattan_accuracy
value: 89.08293553770326
- type: manhattan_ap
value: 86.21913616084771
- type: manhattan_f1
value: 78.3907031479847
- type: manhattan_precision
value: 75.0352013517319
- type: manhattan_recall
value: 82.06036341238065
- type: max_accuracy
value: 89.09069740365584
- type: max_ap
value: 86.22750233655673
- type: max_f1
value: 78.3907031479847
---
# nadeem1362/mxbai-embed-large-v1-Q4_K_M-GGUF
This model was converted to GGUF format from [`mixedbread-ai/mxbai-embed-large-v1`](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo nadeem1362/mxbai-embed-large-v1-Q4_K_M-GGUF --model mxbai-embed-large-v1.Q4_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo nadeem1362/mxbai-embed-large-v1-Q4_K_M-GGUF --model mxbai-embed-large-v1.Q4_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m mxbai-embed-large-v1.Q4_K_M.gguf -n 128
```
|
[
"BIOSSES",
"SCIFACT"
] |
CAS-SIAT-ConsistencyAI/CoEvol-ChatGPT_Mistral-7B-v0.1_SFT
|
CAS-SIAT-ConsistencyAI
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"dataset:CAS-SIAT-ConsistencyAI/CoEvol",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-06-04T07:07:44Z |
2024-06-06T09:05:55+00:00
| 17 | 0 |
---
base_model: mistralai/Mistral-7B-v0.1
datasets:
- CAS-SIAT-ConsistencyAI/CoEvol
license: apache-2.0
---
# CoEvol-ChatGPT_Mistral-7B-v0.1_SFT
This model is a fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the [coevol-chatgpt_multi_deita6k](https://huggingface.co/datasets/CAS-SIAT-ConsistencyAI/CoEvol/blob/main/coevol-chatgpt_multi_deita6k.json) dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 128
- total_train_batch_size: 512
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 6.0
### Training results
### Framework versions
- Transformers 4.38.1
- Pytorch 2.1.2+cu121
- Datasets 2.17.1
- Tokenizers 0.15.2
|
[
"CAS"
] |
Casual-Autopsy/L3-Umbral-Mind-RP-v2.0-8B
|
Casual-Autopsy
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"not-for-all-audiences",
"nsfw",
"rp",
"roleplay",
"role-play",
"conversational",
"en",
"base_model:Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2",
"base_model:merge:Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2",
"base_model:Cas-Warehouse/Llama-3-SOVL-MopeyMule-Blackroot-8B",
"base_model:merge:Cas-Warehouse/Llama-3-SOVL-MopeyMule-Blackroot-8B",
"base_model:Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B",
"base_model:merge:Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B",
"base_model:Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B",
"base_model:merge:Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B",
"base_model:Casual-Autopsy/L3-Uncen-Merger-Omelette-RP-v0.2-8B",
"base_model:merge:Casual-Autopsy/L3-Uncen-Merger-Omelette-RP-v0.2-8B",
"base_model:Nitral-AI/Hathor_Stable-v0.2-L3-8B",
"base_model:merge:Nitral-AI/Hathor_Stable-v0.2-L3-8B",
"base_model:Sao10K/L3-8B-Stheno-v3.1",
"base_model:merge:Sao10K/L3-8B-Stheno-v3.1",
"base_model:aifeifei798/llama3-8B-DarkIdol-2.1-Uncensored-32K",
"base_model:merge:aifeifei798/llama3-8B-DarkIdol-2.1-Uncensored-32K",
"base_model:bluuwhale/L3-SthenoMaidBlackroot-8B-V1",
"base_model:merge:bluuwhale/L3-SthenoMaidBlackroot-8B-V1",
"base_model:migtissera/Llama-3-8B-Synthia-v3.5",
"base_model:merge:migtissera/Llama-3-8B-Synthia-v3.5",
"base_model:tannedbum/L3-Nymeria-8B",
"base_model:merge:tannedbum/L3-Nymeria-8B",
"base_model:tannedbum/L3-Nymeria-Maid-8B",
"base_model:merge:tannedbum/L3-Nymeria-Maid-8B",
"license:llama3",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-06-26T19:24:31Z |
2024-07-22T19:31:03+00:00
| 17 | 15 |
---
base_model:
- Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B
- bluuwhale/L3-SthenoMaidBlackroot-8B-V1
- Cas-Warehouse/Llama-3-SOVL-MopeyMule-Blackroot-8B
- Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2
- tannedbum/L3-Nymeria-8B
- migtissera/Llama-3-8B-Synthia-v3.5
- Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B
- tannedbum/L3-Nymeria-Maid-8B
- Casual-Autopsy/L3-Uncen-Merger-Omelette-RP-v0.2-8B
- aifeifei798/llama3-8B-DarkIdol-2.1-Uncensored-32K
- Nitral-AI/Hathor_Stable-v0.2-L3-8B
- Sao10K/L3-8B-Stheno-v3.1
language:
- en
library_name: transformers
license: llama3
pipeline_tag: text-generation
tags:
- merge
- mergekit
- lazymergekit
- not-for-all-audiences
- nsfw
- rp
- roleplay
- role-play
model-index:
- name: L3-Umbral-Mind-RP-v2.0-8B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: IFEval (0-Shot)
type: HuggingFaceH4/ifeval
args:
num_few_shot: 0
metrics:
- type: inst_level_strict_acc and prompt_level_strict_acc
value: 71.23
name: strict accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Casual-Autopsy/L3-Umbral-Mind-RP-v2.0-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BBH (3-Shot)
type: BBH
args:
num_few_shot: 3
metrics:
- type: acc_norm
value: 32.49
name: normalized accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Casual-Autopsy/L3-Umbral-Mind-RP-v2.0-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MATH Lvl 5 (4-Shot)
type: hendrycks/competition_math
args:
num_few_shot: 4
metrics:
- type: exact_match
value: 10.12
name: exact match
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Casual-Autopsy/L3-Umbral-Mind-RP-v2.0-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GPQA (0-shot)
type: Idavidrein/gpqa
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 4.92
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Casual-Autopsy/L3-Umbral-Mind-RP-v2.0-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MuSR (0-shot)
type: TAUR-Lab/MuSR
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 5.55
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Casual-Autopsy/L3-Umbral-Mind-RP-v2.0-8B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU-PRO (5-shot)
type: TIGER-Lab/MMLU-Pro
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 30.26
name: accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Casual-Autopsy/L3-Umbral-Mind-RP-v2.0-8B
name: Open LLM Leaderboard
---
| <img src="https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v3-8B/resolve/main/63073798_p0_master1200.jpg" style="display: block; margin: auto;"> |
|:---:|
| Image by ろ47 |
| |
# Merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
***
## Merge Details
The goal of this merge was to make an RP model better suited for role-plays with heavy themes such as but not limited to:
- Mental illness
- Self-harm
- Trauma
- Suicide
I hated how RP models tended to be overly positive and hopeful with role-plays involving such themes,
but thanks to [failspy/Llama-3-8B-Instruct-MopeyMule](https://huggingface.co/failspy/Llama-3-8B-Instruct-MopeyMule) this problem has been lessened considerably.
If you're an enjoyer of savior/reverse savior type role-plays like myself, then this model is for you.
***
## Usage Info
This model is meant to be used with asterisks/quotes RPing formats, any other format that isn't asterisks/quotes is likely to cause issues
***
## Quants
* [imatrix quants](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v2.0-8B-i1-GGUF) by mradermacher
* [Static quants](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v2.0-8B-GGUF) by mradermacher
* Exl2:
- [L3-Umbral-Mind-RP-v2.0-8B-8bpw-h8-exl2](https://huggingface.co/riveRiPH/L3-Umbral-Mind-RP-v2.0-8B-8bpw-h8-exl2) by riveRiPH
- [L3-Umbral-Mind-RP-v2.0-8B-6.3bpw-h8-exl2](https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v2.0-8B-6.3bpw-h8-exl2) by yours truly
- [L3-Umbral-Mind-RP-v2.0-8B-5.3bpw-h6-exl2](https://huggingface.co/riveRiPH/L3-Umbral-Mind-RP-v2.0-8B-5.3bpw-h6-exl2) by riveRiPH
***
## Merge Method
This model was merged using several Task Arithmetic merges and then tied together with a Model Stock merge, followed by another Task Arithmetic merge with a model containing psychology data.
### Models Merged
The following models were included in the merge:
* [Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B](https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B)
* [bluuwhale/L3-SthenoMaidBlackroot-8B-V1](https://huggingface.co/bluuwhale/L3-SthenoMaidBlackroot-8B-V1)
* [Cas-Warehouse/Llama-3-SOVL-MopeyMule-Blackroot-8B](https://huggingface.co/Cas-Warehouse/Llama-3-SOVL-MopeyMule-Blackroot-8B)
* [Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2](https://huggingface.co/Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2)
* [tannedbum/L3-Nymeria-8B](https://huggingface.co/tannedbum/L3-Nymeria-8B)
* [migtissera/Llama-3-8B-Synthia-v3.5](https://huggingface.co/migtissera/Llama-3-8B-Synthia-v3.5)
* [Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B](https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B)
* [tannedbum/L3-Nymeria-Maid-8B](https://huggingface.co/tannedbum/L3-Nymeria-Maid-8B)
* [Casual-Autopsy/L3-Uncen-Merger-Omelette-RP-v0.2-8B](https://huggingface.co/Casual-Autopsy/L3-Uncen-Merger-Omelette-RP-v0.2-8B)
* [aifeifei798/llama3-8B-DarkIdol-2.1-Uncensored-32K](https://huggingface.co/aifeifei798/llama3-8B-DarkIdol-2.1-Uncensored-32K)
* [Nitral-AI/Hathor_Stable-v0.2-L3-8B](https://huggingface.co/Nitral-AI/Hathor_Stable-v0.2-L3-8B)
* [Sao10K/L3-8B-Stheno-v3.1](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.1)
***
## Evaluation Results
### [Open LLM Leaderboard](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Casual-Autopsy__L3-Umbral-Mind-RP-v2.0-8B)
**Explaination for AI RP newbies:** IFEval is the most important evaluation for RP AIs as it determines how well it can follow OOC, Lorebooks, and most importantly character cards.
The rest don't matter. At least not nearly as much as IFEval.
| Metric |Value|
|-------------------|----:|
|Avg. |25.76|
|IFEval (0-Shot) |71.23|
|BBH (3-Shot) |32.49|
|MATH Lvl 5 (4-Shot)|10.12|
|GPQA (0-shot) | 4.92|
|MuSR (0-shot) | 5.55|
|MMLU-PRO (5-shot) |30.26|
### [UGI Leaderboard](https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard)
Information about the metrics can be found at the bottom of the [UGI Leaderboard](https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard) in the respective tabs.
|Metric(UGI-Leaderboard) | Value | Value | Metric(Writing Style)|
|:------------------------|:-----:|:-----:|----------------------:|
|UGI(Avg.) |31.82 |0.107 |RegV1 |
|W/10 |5.83 |0.096 |RegV2 |
|Unruly |43.3 |0.05 |MyScore |
|Internet |20 |9.12 |ASSS |
|Stats |23.6 |0 |SMOG |
|Writing |33.8 |1.47 |Yule |
|PolContro |38.3 | | |
***
## Secret Sauce
The following YAML configurations were used to produce this model:
### Umbral-1
```yaml
models:
- model: Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B
- model: bluuwhale/L3-SthenoMaidBlackroot-8B-V1
parameters:
density: 0.45
weight: 0.4
- model: Cas-Warehouse/Llama-3-SOVL-MopeyMule-Blackroot-8B
parameters:
density: 0.65
weight: 0.1
merge_method: dare_ties
base_model: Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B
parameters:
int8_mask: true
dtype: bfloat16
```
### Umbral-2
```yaml
models:
- model: Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2
- model: tannedbum/L3-Nymeria-8B
parameters:
density: 0.45
weight: 0.25
- model: migtissera/Llama-3-8B-Synthia-v3.5
parameters:
density: 0.65
weight: 0.25
merge_method: dare_ties
base_model: Cas-Warehouse/Llama-3-Mopeyfied-Psychology-v2
parameters:
int8_mask: true
dtype: bfloat16
```
### Umbral-3
```yaml
models:
- model: Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B
- model: tannedbum/L3-Nymeria-Maid-8B
parameters:
density: 0.4
weight: 0.3
- model: Cas-Warehouse/Llama-3-SOVL-MopeyMule-Blackroot-8B
parameters:
density: 0.6
weight: 0.2
merge_method: dare_ties
base_model: Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B
parameters:
int8_mask: true
dtype: bfloat16
```
### Mopey-Omelette
```yaml
models:
- model: Casual-Autopsy/L3-Uncen-Merger-Omelette-RP-v0.2-8B
- model: Cas-Warehouse/Llama-3-SOVL-MopeyMule-Blackroot-8B
parameters:
weight: 0.15
merge_method: task_arithmetic
base_model: Casual-Autopsy/L3-Uncen-Merger-Omelette-RP-v0.2-8B
dtype: bfloat16
```
### Umbral-Mind-1
```yaml
models:
- model: Casual-Autopsy/Umbral-1
- model: Casual-Autopsy/Umbral-3
merge_method: slerp
base_model: Casual-Autopsy/Umbral-1
parameters:
t:
- value: [0.7, 0.5, 0.3, 0.25, 0.2, 0.25, 0.3, 0.5, 0.7]
embed_slerp: true
dtype: bfloat16
```
### Umbral-Mind-2
```yaml
models:
- model: Casual-Autopsy/Umbral-Mind-1
- model: Casual-Autopsy/Umbral-2
merge_method: slerp
base_model: Casual-Autopsy/Umbral-Mind-1
parameters:
t:
- value: [0.1, 0.15, 0.2, 0.4, 0.6, 0.4, 0.2, 0.15, 0.1]
embed_slerp: true
dtype: bfloat16
```
### Umbral-Mind-3
```yaml
models:
- model: Casual-Autopsy/Umbral-Mind-2
- model: Casual-Autopsy/Mopey-Omelette
merge_method: slerp
base_model: Casual-Autopsy/Umbral-Mind-2
parameters:
t:
- value: [0.2, 0.25, 0.3, 0.4, 0.3, 0.25, 0.2, 0.25, 0.3, 0.4, 0.3, 0.25, 0.2]
embed_slerp: true
dtype: bfloat16
```
### L3-Umbral-Mind-RP-v2.0-8B
```yaml
models:
- model: Casual-Autopsy/Umbral-Mind-3
- model: Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B
parameters:
weight: 0.04
- model: aifeifei798/llama3-8B-DarkIdol-2.1-Uncensored-32K
parameters:
weight: 0.02
- model: Nitral-AI/Hathor_Stable-v0.2-L3-8B
parameters:
weight: 0.02
- model: Sao10K/L3-8B-Stheno-v3.1
parameters:
weight: 0.01
merge_method: task_arithmetic
base_model: Casual-Autopsy/Umbral-Mind-3
dtype: bfloat16
```
|
[
"CAS"
] |
SNOWTEAM/sft_medico-mistral
|
SNOWTEAM
|
text-generation
|
[
"transformers",
"pytorch",
"mixtral",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-06-30T19:16:53Z |
2024-07-25T15:20:04+00:00
| 17 | 1 |
---
title: Model Card for SNOWTEAM/sft_medico-mistral
summary: A specialized language model for medical applications, refined through instruction
tuning.
---
# Model Card for SNOWTEAM/sft_medico-mistral
## Overview
SNOWTEAM/sft_medico-mistral is a specialized language model designed for medical applications, further refined through instruction tuning to enhance its ability to respond to various medical-related instructions. This tuning leverages the embedded medical knowledge within the Medico-mistral model, focusing on medical consulting conversations, medical rationale QA, and medical knowledge graph prompting.
## Model Description
**Base Model:** Medico-mistral
**Model type:** Transformer-based decoder-only language model
**Language(s) (NLP):** English
## How to Get Started with the Model
```python
import transformers
import torch
model_path = "SNOWTEAM/sft_medico-mistral"
model = AutoModelForCausalLM.from_pretrained(
model_path,device_map="auto",
max_memory=max_memory_mapping,
torch_dtype=torch.float16,
)
tokenizer = AutoTokenizer.from_pretrained("SNOWTEAM/sft_medico-mistral")
input_text = ""
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
output_ids = model.generate(input_ids=input_ids.cuda(),
max_new_tokens=300,
pad_token_id=tokenizer.eos_token_id,)
output_text = tokenizer.batch_decode(output_ids[:, input_ids.shape[1]:],skip_special_tokens=True)[0]
print(output_text)
```
### Instruction Tuning Datasets
Using open source instruction tuning datasets are composed of 4 main parts: (Some datasets are from [https://huggingface.co/datasets/axiong/pmc_llama_instructions](https://huggingface.co/datasets/axiong/pmc_llama_instructions))
1. **Medical Questions and Answering Data:**
Consider enhancing the model with the capability to reason about professional medical knowledge. We begin with training datasets from open-source medical multiple-choice question-answering sources such as USMLE (Jin, Pan et al., 2021), PubMedQA (Jin et al., 2019), and MedMCQA (Pal, Umapathi et al., 2022). While these datasets inherently require specific medical knowledge, they primarily feature simple choices and lack comprehensive reasoning guidance. To address this, researchers at PMC-llama employed ChatGPT for causal analysis (Chaoyi et al. 2023). Specifically, ChatGPT is queried to generate reasoning outputs for each QA pair, which are then structured and used as explanations.
2. **Medical Knowledge Graph Data:**
We wish to utilize medical knowledge maps such as UMLS (Lindberg, Humphreys, and McCray, 1993) to align with clinicians' expertise. Specifically, we focused on linking medical terms to their respective knowledge descriptions or correlations. For this purpose, we used the QA pair dataset of the Translation General Knowledge Graph created by PMC-LLAMA (Chaoyi et al. 2023). Medical knowledge graphs consist of two main types: entity descriptions and entity relationships. The dataset incorporates two different prompts that ask the model to provide a description of a specific entity or predict a relationship between two entities.
3. **Single-turn Medical Dialogue Data:**
In patient-doctor conversations, patients often describe their symptoms in a colloquial and brief manner. When synthetic patient-doctor conversation datasets are manually created, they tend to lack diversity and become overly specialized, making them less reflective of real-life scenarios. A more effective approach is to collect real patient-doctor conversations. The \textit{HealthCareMagic-100k} dataset addresses this by gathering approximately 100,000 genuine doctor-patient interactions from online medical advice websites. These conversations were filtered manually and automatically to remove identifiers and corrected for grammatical errors using a language tool. Additionally, around 10,000 conversations from the online medical advice website iCliniq were collected and 5k conversations between patients and doctors were generated via ChatGPT by ChatDoctor for supplementation and evaluation (Yunxiang et al. 2023).
4. **Multi-turn Medical Dialogue Data:(This data was not used to train this version of the model)**
The only model currently trained using a multi-round dialog dataset is the Zhongjing-LLaMA model(Songhua et al. 2023). This model uses the CMtMedQA dataset, which is the first large-scale multi-round TCM QA dataset suitable for LLM training, and can significantly enhance the model's multi-round QA capability. However, this dataset collects data for online QA conversations, and lacks the ability to understand pathology examination, or image examination results, which has limitations in real clinical QA situations. Therefore, we used real electronic medical record EMRs obtained from hospitals, rewritten into multi-round conversations by prompting gpt.When designing the prompts, in order to standardize the questioning process and improve the differential diagnosis accuracy, we referred to the Mini-CEX, a clinical questioning assessment index used in medical schools, and the LLM-Mini-CEX, a new criterion that has been modified specifically for large language models (Xiaoming et al. 2023).
### Medical-Specific Instruction Tuning
By combining the above three parts, we form a large-scale, high-quality, medical-specific instruction tuning dataset. We further tune Medico-mistral on this dataset, resulting in sft_medico-mistral.
## Training Details
Our model is based on Mixtral-8x7B-v0.1-Instruct, a generic English LLM with 13 billion parameters. Training was performed on 8 A100-80G GPUs via parallelization. We first inject knowledge into the base model Mistral to optimize the autoregressive loss. During training, we set the maximum context length to 4096 and the batch size to 1024. the model was trained using the AdamW optimizer (Loshchilov and Hutter, 2017) with a learning rate of 2e-5. we employed a fully-sliced data parallel (FSDP) acceleration strategy, the bf16 (brain floating-point) data format, and gradient checkpoints ( Chen et al. 2016). The model was trained using 8 A100 GPUs for 1 epoch of knowledge injection. Afterwards, we used 7 A100 GPUs to perform 5 epochs of healthcare-specific instruction tuning in the SFT phase with a batch size of 896 . During the instruction tuning phase, all sequences are processed in each epoch.
### Training Data
The training data combines diverse datasets from medical consultations, rationale QA, and knowledge graphs to ensure comprehensive medical knowledge coverage and reasoning ability.
### Result
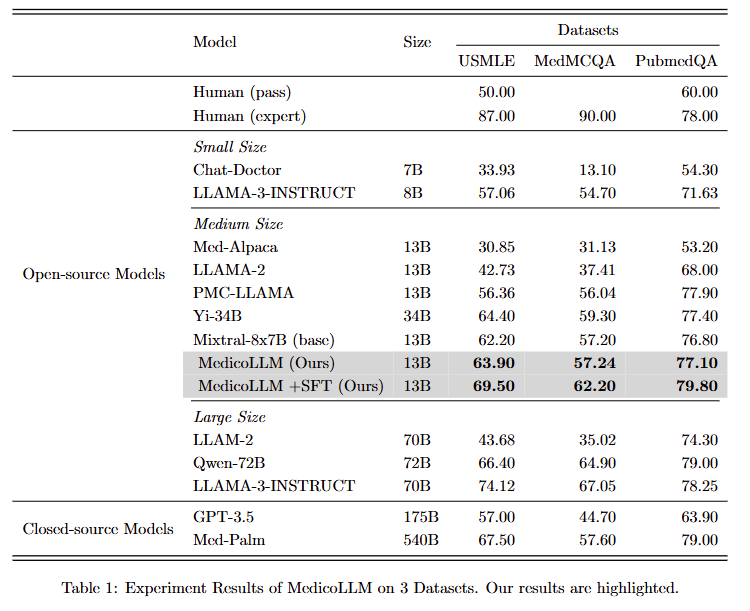
## Model Sources
**Repository:** [https://huggingface.co/SNOWTEAM/sft_medico-mistral](https://huggingface.co/SNOWTEAM/sft_medico-mistral)
**Paper [optional]:**
**Demo [optional]:**
|
[
"PUBMEDQA"
] |
Azazelle/L3-Hecate-8B-v1.0
|
Azazelle
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-07-05T17:28:58Z |
2024-07-05T18:11:20+00:00
| 17 | 3 |
---
base_model: []
library_name: transformers
license: llama3
tags:
- mergekit
- merge
- llama
- conversational
---
# L3-Hecate-8B-v1.0

## About:
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
**Recommended Samplers:**
```
Temperature - 1.0
TFS - 0.85
Smoothing Factor - 0.3
Smoothing Curve - 1.1
Repetition Penalty - 1.1
```
### Merge Method
This model was merged a series of model stock and lora merges, followed by ExPO. It uses a mix of smart and roleplay centered models to improve performance.
### Configuration
The following YAML configuration was used to produce this model:
```yaml
---
models:
- model: Nitral-AI/Hathor_Stable-v0.2-L3-8B
- model: Sao10K/L3-8B-Stheno-v3.2
- model: Jellywibble/lora_120k_pref_data_ep2
- model: Hastagaras/Jamet-8B-L3-MK.V-Blackroot
- model: Cas-Warehouse/Llama-3-SOVL-MopeyMule-Blackroot-8B
merge_method: model_stock
base_model: failspy/Meta-Llama-3-8B-Instruct-abliterated-v3
dtype: float32
vocab_type: bpe
name: hq_rp
---
# ExPO
models:
- model: hq_rp
parameters:
weight: 1.25
merge_method: task_arithmetic
base_model: failspy/Meta-Llama-3-8B-Instruct-abliterated-v3
parameters:
normalize: false
dtype: float32
vocab_type: bpe
```
|
[
"CAS"
] |
nvidia/NV-Retriever-v1
|
nvidia
|
feature-extraction
|
[
"transformers",
"safetensors",
"nvretriever",
"feature-extraction",
"mteb",
"custom_code",
"en",
"arxiv:2407.15831",
"arxiv:2401.00368",
"license:other",
"model-index",
"region:us"
] | 2024-07-08T20:29:55Z |
2024-08-17T07:38:56+00:00
| 17 | 17 |
---
language:
- en
license: other
tags:
- mteb
model-index:
- name: NV-Retriever-v1
results:
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: mteb/arguana
config: default
split: test
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
metrics:
- type: main_score
value: 68.277
- type: map_at_1
value: 44.666
- type: map_at_10
value: 60.3
- type: map_at_100
value: 60.692
- type: map_at_1000
value: 60.693
- type: map_at_20
value: 60.645
- type: map_at_3
value: 56.472
- type: map_at_5
value: 58.78
- type: mrr_at_1
value: 45.092460881934564
- type: mrr_at_10
value: 60.493378717063074
- type: mrr_at_100
value: 60.87988588545791
- type: mrr_at_1000
value: 60.88044591502747
- type: mrr_at_20
value: 60.83224958805471
- type: mrr_at_3
value: 56.53153153153162
- type: mrr_at_5
value: 58.942626837363854
- type: nauc_map_at_1000_diff1
value: 14.137909741937149
- type: nauc_map_at_1000_max
value: -13.946656236190021
- type: nauc_map_at_1000_std
value: -27.431659737602732
- type: nauc_map_at_100_diff1
value: 14.136483238553824
- type: nauc_map_at_100_max
value: -13.946721068575075
- type: nauc_map_at_100_std
value: -27.43462339510713
- type: nauc_map_at_10_diff1
value: 13.961240252441984
- type: nauc_map_at_10_max
value: -13.804526866049605
- type: nauc_map_at_10_std
value: -27.35573153559941
- type: nauc_map_at_1_diff1
value: 16.257792463128126
- type: nauc_map_at_1_max
value: -16.164790771610072
- type: nauc_map_at_1_std
value: -27.84021734986689
- type: nauc_map_at_20_diff1
value: 14.106499894575682
- type: nauc_map_at_20_max
value: -13.930699708027205
- type: nauc_map_at_20_std
value: -27.47446428876476
- type: nauc_map_at_3_diff1
value: 15.018611065750246
- type: nauc_map_at_3_max
value: -12.659774043658842
- type: nauc_map_at_3_std
value: -27.186079034885598
- type: nauc_map_at_5_diff1
value: 14.199306816408377
- type: nauc_map_at_5_max
value: -13.261282961741303
- type: nauc_map_at_5_std
value: -26.71739573072423
- type: nauc_mrr_at_1000_diff1
value: 12.629073492081275
- type: nauc_mrr_at_1000_max
value: -14.666344334069448
- type: nauc_mrr_at_1000_std
value: -27.30760238816266
- type: nauc_mrr_at_100_diff1
value: 12.627677268171094
- type: nauc_mrr_at_100_max
value: -14.66639461039424
- type: nauc_mrr_at_100_std
value: -27.310569102264846
- type: nauc_mrr_at_10_diff1
value: 12.482407364331927
- type: nauc_mrr_at_10_max
value: -14.509649052862667
- type: nauc_mrr_at_10_std
value: -27.246235066954423
- type: nauc_mrr_at_1_diff1
value: 15.084265144497373
- type: nauc_mrr_at_1_max
value: -16.312295398834625
- type: nauc_mrr_at_1_std
value: -27.686736137340894
- type: nauc_mrr_at_20_diff1
value: 12.600281810712003
- type: nauc_mrr_at_20_max
value: -14.649133303237166
- type: nauc_mrr_at_20_std
value: -27.350630544847004
- type: nauc_mrr_at_3_diff1
value: 13.081208137779557
- type: nauc_mrr_at_3_max
value: -13.91769455651833
- type: nauc_mrr_at_3_std
value: -27.42237181201488
- type: nauc_mrr_at_5_diff1
value: 12.697412153053486
- type: nauc_mrr_at_5_max
value: -14.046815225580204
- type: nauc_mrr_at_5_std
value: -26.69417403787157
- type: nauc_ndcg_at_1000_diff1
value: 13.984706619459738
- type: nauc_ndcg_at_1000_max
value: -13.48207980711916
- type: nauc_ndcg_at_1000_std
value: -27.16935912553381
- type: nauc_ndcg_at_100_diff1
value: 13.951491624929446
- type: nauc_ndcg_at_100_max
value: -13.483812067015261
- type: nauc_ndcg_at_100_std
value: -27.238639718923814
- type: nauc_ndcg_at_10_diff1
value: 13.16429886726646
- type: nauc_ndcg_at_10_max
value: -12.816570276390305
- type: nauc_ndcg_at_10_std
value: -27.13129457560619
- type: nauc_ndcg_at_1_diff1
value: 16.257792463128126
- type: nauc_ndcg_at_1_max
value: -16.164790771610072
- type: nauc_ndcg_at_1_std
value: -27.84021734986689
- type: nauc_ndcg_at_20_diff1
value: 13.767660163849325
- type: nauc_ndcg_at_20_max
value: -13.330392545127982
- type: nauc_ndcg_at_20_std
value: -27.655874185287637
- type: nauc_ndcg_at_3_diff1
value: 15.379454570465107
- type: nauc_ndcg_at_3_max
value: -10.682369832384417
- type: nauc_ndcg_at_3_std
value: -26.61546503103021
- type: nauc_ndcg_at_5_diff1
value: 13.857194107241847
- type: nauc_ndcg_at_5_max
value: -11.585582001386438
- type: nauc_ndcg_at_5_std
value: -25.60318972329879
- type: nauc_precision_at_1000_diff1
value: 25.196544697410012
- type: nauc_precision_at_1000_max
value: 20.85546049013785
- type: nauc_precision_at_1000_std
value: 56.11900085120013
- type: nauc_precision_at_100_diff1
value: 11.605921153386918
- type: nauc_precision_at_100_max
value: 14.521201087528956
- type: nauc_precision_at_100_std
value: 17.78762614096395
- type: nauc_precision_at_10_diff1
value: 2.9073450747110328
- type: nauc_precision_at_10_max
value: -1.7706065742373982
- type: nauc_precision_at_10_std
value: -25.127721917434958
- type: nauc_precision_at_1_diff1
value: 16.257792463128126
- type: nauc_precision_at_1_max
value: -16.164790771610072
- type: nauc_precision_at_1_std
value: -27.84021734986689
- type: nauc_precision_at_20_diff1
value: 4.945029151806525
- type: nauc_precision_at_20_max
value: 1.299254371223885
- type: nauc_precision_at_20_std
value: -42.34878406902393
- type: nauc_precision_at_3_diff1
value: 17.02535492673917
- type: nauc_precision_at_3_max
value: -3.160620615377462
- type: nauc_precision_at_3_std
value: -24.392959569235646
- type: nauc_precision_at_5_diff1
value: 12.283704585525927
- type: nauc_precision_at_5_max
value: -2.860819740357931
- type: nauc_precision_at_5_std
value: -19.497494992596568
- type: nauc_recall_at_1000_diff1
value: 25.196544697407973
- type: nauc_recall_at_1000_max
value: 20.855460490135933
- type: nauc_recall_at_1000_std
value: 56.119000851196496
- type: nauc_recall_at_100_diff1
value: 11.60592115338627
- type: nauc_recall_at_100_max
value: 14.5212010875248
- type: nauc_recall_at_100_std
value: 17.787626140957425
- type: nauc_recall_at_10_diff1
value: 2.9073450747112304
- type: nauc_recall_at_10_max
value: -1.7706065742371515
- type: nauc_recall_at_10_std
value: -25.12772191743481
- type: nauc_recall_at_1_diff1
value: 16.257792463128126
- type: nauc_recall_at_1_max
value: -16.164790771610072
- type: nauc_recall_at_1_std
value: -27.84021734986689
- type: nauc_recall_at_20_diff1
value: 4.9450291518064935
- type: nauc_recall_at_20_max
value: 1.2992543712237186
- type: nauc_recall_at_20_std
value: -42.34878406902303
- type: nauc_recall_at_3_diff1
value: 17.025354926739237
- type: nauc_recall_at_3_max
value: -3.1606206153775016
- type: nauc_recall_at_3_std
value: -24.39295956923558
- type: nauc_recall_at_5_diff1
value: 12.283704585525939
- type: nauc_recall_at_5_max
value: -2.8608197403578512
- type: nauc_recall_at_5_std
value: -19.497494992596575
- type: ndcg_at_1
value: 44.666
- type: ndcg_at_10
value: 68.277
- type: ndcg_at_100
value: 69.78
- type: ndcg_at_1000
value: 69.78999999999999
- type: ndcg_at_20
value: 69.464
- type: ndcg_at_3
value: 60.462
- type: ndcg_at_5
value: 64.651
- type: precision_at_1
value: 44.666
- type: precision_at_10
value: 9.339
- type: precision_at_100
value: 0.996
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.897
- type: precision_at_3
value: 24.016000000000002
- type: precision_at_5
value: 16.458000000000002
- type: recall_at_1
value: 44.666
- type: recall_at_10
value: 93.38499999999999
- type: recall_at_100
value: 99.57300000000001
- type: recall_at_1000
value: 99.644
- type: recall_at_20
value: 97.937
- type: recall_at_3
value: 72.048
- type: recall_at_5
value: 82.28999999999999
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: mteb/cqadupstack-android
config: default
split: test
revision: f46a197baaae43b4f621051089b82a364682dfeb
metrics:
- type: main_score
value: 57.025000000000006
- type: map_at_1
value: 35.67
- type: map_at_10
value: 49.816
- type: map_at_100
value: 51.465
- type: map_at_1000
value: 51.559
- type: map_at_20
value: 50.843
- type: map_at_3
value: 45.462
- type: map_at_5
value: 47.789
- type: mrr_at_1
value: 44.77825464949928
- type: mrr_at_10
value: 55.787576356245886
- type: mrr_at_100
value: 56.4488799265231
- type: mrr_at_1000
value: 56.47353697784773
- type: mrr_at_20
value: 56.21107253216036
- type: mrr_at_3
value: 52.885073915116834
- type: mrr_at_5
value: 54.58035288507389
- type: nauc_map_at_1000_diff1
value: 50.45823101819382
- type: nauc_map_at_1000_max
value: 36.49053295534483
- type: nauc_map_at_1000_std
value: -18.526304321886187
- type: nauc_map_at_100_diff1
value: 50.4260834410578
- type: nauc_map_at_100_max
value: 36.5085073099934
- type: nauc_map_at_100_std
value: -18.46644794935817
- type: nauc_map_at_10_diff1
value: 50.89883450942742
- type: nauc_map_at_10_max
value: 36.04067774200049
- type: nauc_map_at_10_std
value: -20.056347095828695
- type: nauc_map_at_1_diff1
value: 56.834567406767775
- type: nauc_map_at_1_max
value: 32.806861016490686
- type: nauc_map_at_1_std
value: -17.50758527738866
- type: nauc_map_at_20_diff1
value: 50.5042164434519
- type: nauc_map_at_20_max
value: 36.50186920758872
- type: nauc_map_at_20_std
value: -18.739559098645316
- type: nauc_map_at_3_diff1
value: 51.47192911647498
- type: nauc_map_at_3_max
value: 35.30704707609017
- type: nauc_map_at_3_std
value: -20.29632792705977
- type: nauc_map_at_5_diff1
value: 51.12306422908822
- type: nauc_map_at_5_max
value: 35.89975376917192
- type: nauc_map_at_5_std
value: -19.828384476366086
- type: nauc_mrr_at_1000_diff1
value: 48.849919708933356
- type: nauc_mrr_at_1000_max
value: 37.551368642516984
- type: nauc_mrr_at_1000_std
value: -17.829333495571873
- type: nauc_mrr_at_100_diff1
value: 48.84124005822968
- type: nauc_mrr_at_100_max
value: 37.55507214788527
- type: nauc_mrr_at_100_std
value: -17.829902708031735
- type: nauc_mrr_at_10_diff1
value: 48.75998469903627
- type: nauc_mrr_at_10_max
value: 37.38578492482243
- type: nauc_mrr_at_10_std
value: -18.49027309110136
- type: nauc_mrr_at_1_diff1
value: 52.82147548271261
- type: nauc_mrr_at_1_max
value: 38.52107406488729
- type: nauc_mrr_at_1_std
value: -15.557810119211657
- type: nauc_mrr_at_20_diff1
value: 48.786516207985585
- type: nauc_mrr_at_20_max
value: 37.53134866494839
- type: nauc_mrr_at_20_std
value: -17.78055242023104
- type: nauc_mrr_at_3_diff1
value: 48.72848733815437
- type: nauc_mrr_at_3_max
value: 37.62564116429598
- type: nauc_mrr_at_3_std
value: -18.63098278761354
- type: nauc_mrr_at_5_diff1
value: 48.67198763487669
- type: nauc_mrr_at_5_max
value: 37.46200111234106
- type: nauc_mrr_at_5_std
value: -18.592288612712576
- type: nauc_ndcg_at_1000_diff1
value: 48.75201809702225
- type: nauc_ndcg_at_1000_max
value: 37.04967809462886
- type: nauc_ndcg_at_1000_std
value: -16.948540945875216
- type: nauc_ndcg_at_100_diff1
value: 48.213857924243804
- type: nauc_ndcg_at_100_max
value: 36.99860703887876
- type: nauc_ndcg_at_100_std
value: -16.420746045271017
- type: nauc_ndcg_at_10_diff1
value: 48.7590345342662
- type: nauc_ndcg_at_10_max
value: 36.087304891668495
- type: nauc_ndcg_at_10_std
value: -20.677784655001727
- type: nauc_ndcg_at_1_diff1
value: 52.82147548271261
- type: nauc_ndcg_at_1_max
value: 38.52107406488729
- type: nauc_ndcg_at_1_std
value: -15.557810119211657
- type: nauc_ndcg_at_20_diff1
value: 48.119759046742004
- type: nauc_ndcg_at_20_max
value: 36.91858601052183
- type: nauc_ndcg_at_20_std
value: -17.315588991460316
- type: nauc_ndcg_at_3_diff1
value: 48.35879771694856
- type: nauc_ndcg_at_3_max
value: 36.59333419427929
- type: nauc_ndcg_at_3_std
value: -19.646763729930917
- type: nauc_ndcg_at_5_diff1
value: 48.73702053100838
- type: nauc_ndcg_at_5_max
value: 36.2032422359128
- type: nauc_ndcg_at_5_std
value: -19.81761218645642
- type: nauc_precision_at_1000_diff1
value: -19.23879401783259
- type: nauc_precision_at_1000_max
value: -10.334669548312661
- type: nauc_precision_at_1000_std
value: 1.8528999887213935
- type: nauc_precision_at_100_diff1
value: -17.061064047641576
- type: nauc_precision_at_100_max
value: -2.2318557604173557
- type: nauc_precision_at_100_std
value: 9.453864069155783
- type: nauc_precision_at_10_diff1
value: -0.0250981142012463
- type: nauc_precision_at_10_max
value: 15.000297351883034
- type: nauc_precision_at_10_std
value: -1.6209044879293661
- type: nauc_precision_at_1_diff1
value: 52.82147548271261
- type: nauc_precision_at_1_max
value: 38.52107406488729
- type: nauc_precision_at_1_std
value: -15.557810119211657
- type: nauc_precision_at_20_diff1
value: -9.566950286920978
- type: nauc_precision_at_20_max
value: 9.865702753901365
- type: nauc_precision_at_20_std
value: 8.87854086185741
- type: nauc_precision_at_3_diff1
value: 19.978926078471915
- type: nauc_precision_at_3_max
value: 29.135402513527524
- type: nauc_precision_at_3_std
value: -12.410877361712942
- type: nauc_precision_at_5_diff1
value: 11.602459698883452
- type: nauc_precision_at_5_max
value: 24.44724344216036
- type: nauc_precision_at_5_std
value: -6.23012846505485
- type: nauc_recall_at_1000_diff1
value: 30.5620107082901
- type: nauc_recall_at_1000_max
value: 57.90393858174957
- type: nauc_recall_at_1000_std
value: 50.27827169570347
- type: nauc_recall_at_100_diff1
value: 30.37443399479563
- type: nauc_recall_at_100_max
value: 37.75874353752331
- type: nauc_recall_at_100_std
value: 10.331635217724585
- type: nauc_recall_at_10_diff1
value: 42.50804834678793
- type: nauc_recall_at_10_max
value: 32.01676571227172
- type: nauc_recall_at_10_std
value: -24.707266416874376
- type: nauc_recall_at_1_diff1
value: 56.834567406767775
- type: nauc_recall_at_1_max
value: 32.806861016490686
- type: nauc_recall_at_1_std
value: -17.50758527738866
- type: nauc_recall_at_20_diff1
value: 38.7222771840029
- type: nauc_recall_at_20_max
value: 35.62991559107865
- type: nauc_recall_at_20_std
value: -8.672399835082256
- type: nauc_recall_at_3_diff1
value: 44.63989156943874
- type: nauc_recall_at_3_max
value: 32.924250725683954
- type: nauc_recall_at_3_std
value: -22.031517542434386
- type: nauc_recall_at_5_diff1
value: 43.52398344993421
- type: nauc_recall_at_5_max
value: 32.68140834172185
- type: nauc_recall_at_5_std
value: -22.07867437121263
- type: ndcg_at_1
value: 44.778
- type: ndcg_at_10
value: 57.025000000000006
- type: ndcg_at_100
value: 62.007
- type: ndcg_at_1000
value: 63.11
- type: ndcg_at_20
value: 59.301
- type: ndcg_at_3
value: 51.162
- type: ndcg_at_5
value: 53.684
- type: precision_at_1
value: 44.778
- type: precision_at_10
value: 11.173
- type: precision_at_100
value: 1.7080000000000002
- type: precision_at_1000
value: 0.20600000000000002
- type: precision_at_20
value: 6.651999999999999
- type: precision_at_3
value: 25.130999999999997
- type: precision_at_5
value: 18.026
- type: recall_at_1
value: 35.67
- type: recall_at_10
value: 71.006
- type: recall_at_100
value: 91.24
- type: recall_at_1000
value: 97.68599999999999
- type: recall_at_20
value: 78.869
- type: recall_at_3
value: 53.616
- type: recall_at_5
value: 61.046
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackEnglishRetrieval
type: mteb/cqadupstack-english
config: default
split: test
revision: ad9991cb51e31e31e430383c75ffb2885547b5f0
metrics:
- type: main_score
value: 56.93
- type: map_at_1
value: 37.869
- type: map_at_10
value: 50.651999999999994
- type: map_at_100
value: 52.099
- type: map_at_1000
value: 52.229000000000006
- type: map_at_20
value: 51.471000000000004
- type: map_at_3
value: 46.900999999999996
- type: map_at_5
value: 49.163000000000004
- type: mrr_at_1
value: 48.152866242038215
- type: mrr_at_10
value: 57.048781720756324
- type: mrr_at_100
value: 57.61447046748723
- type: mrr_at_1000
value: 57.64904742638159
- type: mrr_at_20
value: 57.39780918212383
- type: mrr_at_3
value: 54.80891719745229
- type: mrr_at_5
value: 56.28343949044594
- type: nauc_map_at_1000_diff1
value: 58.85279432139136
- type: nauc_map_at_1000_max
value: 44.27751637558559
- type: nauc_map_at_1000_std
value: -15.750083199667806
- type: nauc_map_at_100_diff1
value: 58.86033676691407
- type: nauc_map_at_100_max
value: 44.19456055171921
- type: nauc_map_at_100_std
value: -15.866235670948466
- type: nauc_map_at_10_diff1
value: 59.15850189168124
- type: nauc_map_at_10_max
value: 43.11472836391707
- type: nauc_map_at_10_std
value: -17.744478993375527
- type: nauc_map_at_1_diff1
value: 64.04942461321761
- type: nauc_map_at_1_max
value: 36.02760504360551
- type: nauc_map_at_1_std
value: -20.916663614576407
- type: nauc_map_at_20_diff1
value: 58.98751913649348
- type: nauc_map_at_20_max
value: 43.747358339703325
- type: nauc_map_at_20_std
value: -16.73926017048612
- type: nauc_map_at_3_diff1
value: 60.545139674280094
- type: nauc_map_at_3_max
value: 41.30484092754499
- type: nauc_map_at_3_std
value: -20.449249818528614
- type: nauc_map_at_5_diff1
value: 59.60326322666997
- type: nauc_map_at_5_max
value: 42.108701221797
- type: nauc_map_at_5_std
value: -18.957986608087435
- type: nauc_mrr_at_1000_diff1
value: 56.30127401697153
- type: nauc_mrr_at_1000_max
value: 47.08483234515321
- type: nauc_mrr_at_1000_std
value: -10.314335018294779
- type: nauc_mrr_at_100_diff1
value: 56.28727998516319
- type: nauc_mrr_at_100_max
value: 47.08137119553827
- type: nauc_mrr_at_100_std
value: -10.295734439040498
- type: nauc_mrr_at_10_diff1
value: 56.25229630851168
- type: nauc_mrr_at_10_max
value: 47.149329681676
- type: nauc_mrr_at_10_std
value: -10.598837356654567
- type: nauc_mrr_at_1_diff1
value: 59.098651501966394
- type: nauc_mrr_at_1_max
value: 46.60615627466452
- type: nauc_mrr_at_1_std
value: -10.475650807142516
- type: nauc_mrr_at_20_diff1
value: 56.2453798649222
- type: nauc_mrr_at_20_max
value: 47.09346599217677
- type: nauc_mrr_at_20_std
value: -10.386425082322834
- type: nauc_mrr_at_3_diff1
value: 56.75733035936052
- type: nauc_mrr_at_3_max
value: 46.94088551304416
- type: nauc_mrr_at_3_std
value: -11.483866905681051
- type: nauc_mrr_at_5_diff1
value: 56.40006056789708
- type: nauc_mrr_at_5_max
value: 46.808130364381846
- type: nauc_mrr_at_5_std
value: -11.050122560712222
- type: nauc_ndcg_at_1000_diff1
value: 56.60974899528984
- type: nauc_ndcg_at_1000_max
value: 46.20688890501171
- type: nauc_ndcg_at_1000_std
value: -11.14222381973439
- type: nauc_ndcg_at_100_diff1
value: 56.677945515470675
- type: nauc_ndcg_at_100_max
value: 46.001596072553404
- type: nauc_ndcg_at_100_std
value: -11.229044974791337
- type: nauc_ndcg_at_10_diff1
value: 57.1066442501231
- type: nauc_ndcg_at_10_max
value: 45.542982262967776
- type: nauc_ndcg_at_10_std
value: -14.273638238311195
- type: nauc_ndcg_at_1_diff1
value: 59.098651501966394
- type: nauc_ndcg_at_1_max
value: 46.60615627466452
- type: nauc_ndcg_at_1_std
value: -10.475650807142516
- type: nauc_ndcg_at_20_diff1
value: 56.851307181340694
- type: nauc_ndcg_at_20_max
value: 45.84417755460993
- type: nauc_ndcg_at_20_std
value: -12.926633494308371
- type: nauc_ndcg_at_3_diff1
value: 57.423753276241754
- type: nauc_ndcg_at_3_max
value: 45.1658528352273
- type: nauc_ndcg_at_3_std
value: -15.041500407672178
- type: nauc_ndcg_at_5_diff1
value: 57.366735747016584
- type: nauc_ndcg_at_5_max
value: 44.754486357586316
- type: nauc_ndcg_at_5_std
value: -15.100632526050441
- type: nauc_precision_at_1000_diff1
value: -23.32973690238293
- type: nauc_precision_at_1000_max
value: 9.122165441089374
- type: nauc_precision_at_1000_std
value: 32.082444098667565
- type: nauc_precision_at_100_diff1
value: -16.218615616263428
- type: nauc_precision_at_100_max
value: 19.44437302773441
- type: nauc_precision_at_100_std
value: 35.248811470691166
- type: nauc_precision_at_10_diff1
value: 1.0766468144861965
- type: nauc_precision_at_10_max
value: 30.491892916282236
- type: nauc_precision_at_10_std
value: 18.538876410079585
- type: nauc_precision_at_1_diff1
value: 59.098651501966394
- type: nauc_precision_at_1_max
value: 46.60615627466452
- type: nauc_precision_at_1_std
value: -10.475650807142516
- type: nauc_precision_at_20_diff1
value: -6.769874545877082
- type: nauc_precision_at_20_max
value: 26.352774891191004
- type: nauc_precision_at_20_std
value: 26.150734923942952
- type: nauc_precision_at_3_diff1
value: 23.74601942735032
- type: nauc_precision_at_3_max
value: 39.71043044078846
- type: nauc_precision_at_3_std
value: 3.161463247727185
- type: nauc_precision_at_5_diff1
value: 11.589849872978208
- type: nauc_precision_at_5_max
value: 34.355473407777296
- type: nauc_precision_at_5_std
value: 10.0662074493734
- type: nauc_recall_at_1000_diff1
value: 44.20612579552725
- type: nauc_recall_at_1000_max
value: 54.50563586814392
- type: nauc_recall_at_1000_std
value: 29.37098358130919
- type: nauc_recall_at_100_diff1
value: 46.991905821496225
- type: nauc_recall_at_100_max
value: 45.677355517440446
- type: nauc_recall_at_100_std
value: 8.193115293674246
- type: nauc_recall_at_10_diff1
value: 51.021956806545575
- type: nauc_recall_at_10_max
value: 42.39780880270869
- type: nauc_recall_at_10_std
value: -14.372872090525025
- type: nauc_recall_at_1_diff1
value: 64.04942461321761
- type: nauc_recall_at_1_max
value: 36.02760504360551
- type: nauc_recall_at_1_std
value: -20.916663614576407
- type: nauc_recall_at_20_diff1
value: 49.330317036362736
- type: nauc_recall_at_20_max
value: 43.82370541895915
- type: nauc_recall_at_20_std
value: -7.676142813819095
- type: nauc_recall_at_3_diff1
value: 56.15563158128648
- type: nauc_recall_at_3_max
value: 39.776800175069496
- type: nauc_recall_at_3_std
value: -21.67535047518367
- type: nauc_recall_at_5_diff1
value: 53.55725212243435
- type: nauc_recall_at_5_max
value: 39.639229625237746
- type: nauc_recall_at_5_std
value: -18.537472489671433
- type: ndcg_at_1
value: 48.153
- type: ndcg_at_10
value: 56.93
- type: ndcg_at_100
value: 61.041999999999994
- type: ndcg_at_1000
value: 62.71600000000001
- type: ndcg_at_20
value: 58.626999999999995
- type: ndcg_at_3
value: 52.437999999999995
- type: ndcg_at_5
value: 54.774
- type: precision_at_1
value: 48.153
- type: precision_at_10
value: 10.93
- type: precision_at_100
value: 1.669
- type: precision_at_1000
value: 0.213
- type: precision_at_20
value: 6.382000000000001
- type: precision_at_3
value: 25.796000000000003
- type: precision_at_5
value: 18.407999999999998
- type: recall_at_1
value: 37.869
- type: recall_at_10
value: 67.514
- type: recall_at_100
value: 84.454
- type: recall_at_1000
value: 94.356
- type: recall_at_20
value: 73.558
- type: recall_at_3
value: 53.559
- type: recall_at_5
value: 60.475
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGamingRetrieval
type: mteb/cqadupstack-gaming
config: default
split: test
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
metrics:
- type: main_score
value: 67.253
- type: map_at_1
value: 46.905
- type: map_at_10
value: 61.332
- type: map_at_100
value: 62.304
- type: map_at_1000
value: 62.334
- type: map_at_20
value: 61.964
- type: map_at_3
value: 58.042
- type: map_at_5
value: 59.882000000000005
- type: mrr_at_1
value: 53.47962382445141
- type: mrr_at_10
value: 64.39956212370015
- type: mrr_at_100
value: 64.95557189125634
- type: mrr_at_1000
value: 64.96848596592983
- type: mrr_at_20
value: 64.77428822572568
- type: mrr_at_3
value: 62.309299895506896
- type: mrr_at_5
value: 63.54440961337527
- type: nauc_map_at_1000_diff1
value: 56.74686837364893
- type: nauc_map_at_1000_max
value: 37.37480368876817
- type: nauc_map_at_1000_std
value: -10.049421617657124
- type: nauc_map_at_100_diff1
value: 56.72313143831275
- type: nauc_map_at_100_max
value: 37.35797555204418
- type: nauc_map_at_100_std
value: -10.049812301974452
- type: nauc_map_at_10_diff1
value: 56.68397120600094
- type: nauc_map_at_10_max
value: 36.59842978269273
- type: nauc_map_at_10_std
value: -11.174804244499098
- type: nauc_map_at_1_diff1
value: 61.94214953873164
- type: nauc_map_at_1_max
value: 28.119092174242382
- type: nauc_map_at_1_std
value: -14.419629681905278
- type: nauc_map_at_20_diff1
value: 56.66822667045707
- type: nauc_map_at_20_max
value: 37.19179210659321
- type: nauc_map_at_20_std
value: -10.36424574922098
- type: nauc_map_at_3_diff1
value: 56.786004222951966
- type: nauc_map_at_3_max
value: 34.409125163057354
- type: nauc_map_at_3_std
value: -12.308681065089702
- type: nauc_map_at_5_diff1
value: 56.837122717249855
- type: nauc_map_at_5_max
value: 35.70069180549282
- type: nauc_map_at_5_std
value: -12.19154238352126
- type: nauc_mrr_at_1000_diff1
value: 57.03608286201278
- type: nauc_mrr_at_1000_max
value: 39.15777651816965
- type: nauc_mrr_at_1000_std
value: -8.45524348928121
- type: nauc_mrr_at_100_diff1
value: 57.03051889095766
- type: nauc_mrr_at_100_max
value: 39.168900323859
- type: nauc_mrr_at_100_std
value: -8.439862972545644
- type: nauc_mrr_at_10_diff1
value: 56.848642658414775
- type: nauc_mrr_at_10_max
value: 39.11801407771557
- type: nauc_mrr_at_10_std
value: -8.678625365653245
- type: nauc_mrr_at_1_diff1
value: 61.1124527741601
- type: nauc_mrr_at_1_max
value: 36.080048505155865
- type: nauc_mrr_at_1_std
value: -10.584194474752584
- type: nauc_mrr_at_20_diff1
value: 56.878714270983146
- type: nauc_mrr_at_20_max
value: 39.16569382719707
- type: nauc_mrr_at_20_std
value: -8.447245465078893
- type: nauc_mrr_at_3_diff1
value: 56.87172734333986
- type: nauc_mrr_at_3_max
value: 39.07882270376788
- type: nauc_mrr_at_3_std
value: -9.069457598400062
- type: nauc_mrr_at_5_diff1
value: 56.82487051170517
- type: nauc_mrr_at_5_max
value: 39.030878651662796
- type: nauc_mrr_at_5_std
value: -9.076518259406917
- type: nauc_ndcg_at_1000_diff1
value: 56.082240909091695
- type: nauc_ndcg_at_1000_max
value: 39.699264232007025
- type: nauc_ndcg_at_1000_std
value: -7.502941002933741
- type: nauc_ndcg_at_100_diff1
value: 55.887513398861955
- type: nauc_ndcg_at_100_max
value: 39.847450141736395
- type: nauc_ndcg_at_100_std
value: -7.146894645593031
- type: nauc_ndcg_at_10_diff1
value: 55.15467572394677
- type: nauc_ndcg_at_10_max
value: 38.97265748975791
- type: nauc_ndcg_at_10_std
value: -9.4670794339538
- type: nauc_ndcg_at_1_diff1
value: 61.1124527741601
- type: nauc_ndcg_at_1_max
value: 36.080048505155865
- type: nauc_ndcg_at_1_std
value: -10.584194474752584
- type: nauc_ndcg_at_20_diff1
value: 55.15513104937557
- type: nauc_ndcg_at_20_max
value: 39.66296704562037
- type: nauc_ndcg_at_20_std
value: -7.847800655967109
- type: nauc_ndcg_at_3_diff1
value: 54.96185776120714
- type: nauc_ndcg_at_3_max
value: 37.00790660301803
- type: nauc_ndcg_at_3_std
value: -10.547349631779593
- type: nauc_ndcg_at_5_diff1
value: 55.292986134183764
- type: nauc_ndcg_at_5_max
value: 38.12541620211435
- type: nauc_ndcg_at_5_std
value: -10.961954651898877
- type: nauc_precision_at_1000_diff1
value: -17.737775083152922
- type: nauc_precision_at_1000_max
value: 21.575992446429407
- type: nauc_precision_at_1000_std
value: 30.76555260404715
- type: nauc_precision_at_100_diff1
value: -17.3761536797116
- type: nauc_precision_at_100_max
value: 23.455151994000513
- type: nauc_precision_at_100_std
value: 30.66476060812044
- type: nauc_precision_at_10_diff1
value: 0.37712699076668355
- type: nauc_precision_at_10_max
value: 31.298133911984248
- type: nauc_precision_at_10_std
value: 16.134374567323214
- type: nauc_precision_at_1_diff1
value: 61.1124527741601
- type: nauc_precision_at_1_max
value: 36.080048505155865
- type: nauc_precision_at_1_std
value: -10.584194474752584
- type: nauc_precision_at_20_diff1
value: -7.697609516072893
- type: nauc_precision_at_20_max
value: 30.392978129152638
- type: nauc_precision_at_20_std
value: 25.297979676649902
- type: nauc_precision_at_3_diff1
value: 21.920115701694172
- type: nauc_precision_at_3_max
value: 35.916002988740644
- type: nauc_precision_at_3_std
value: 3.192816307982428
- type: nauc_precision_at_5_diff1
value: 12.416994377124743
- type: nauc_precision_at_5_max
value: 34.60793433800759
- type: nauc_precision_at_5_std
value: 7.681539417199799
- type: nauc_recall_at_1000_diff1
value: 45.05841406616179
- type: nauc_recall_at_1000_max
value: 84.01729859779441
- type: nauc_recall_at_1000_std
value: 70.81952441677544
- type: nauc_recall_at_100_diff1
value: 47.82912442332592
- type: nauc_recall_at_100_max
value: 61.538854248032905
- type: nauc_recall_at_100_std
value: 31.507749555394742
- type: nauc_recall_at_10_diff1
value: 46.23707108341979
- type: nauc_recall_at_10_max
value: 40.14549188124033
- type: nauc_recall_at_10_std
value: -8.418378388855976
- type: nauc_recall_at_1_diff1
value: 61.94214953873164
- type: nauc_recall_at_1_max
value: 28.119092174242382
- type: nauc_recall_at_1_std
value: -14.419629681905278
- type: nauc_recall_at_20_diff1
value: 43.5874302201068
- type: nauc_recall_at_20_max
value: 46.94504592203577
- type: nauc_recall_at_20_std
value: 3.913410811827146
- type: nauc_recall_at_3_diff1
value: 49.63064701945406
- type: nauc_recall_at_3_max
value: 35.29572226414386
- type: nauc_recall_at_3_std
value: -12.297827741460027
- type: nauc_recall_at_5_diff1
value: 48.601651302714224
- type: nauc_recall_at_5_max
value: 37.38710560640659
- type: nauc_recall_at_5_std
value: -13.458409202400507
- type: ndcg_at_1
value: 53.480000000000004
- type: ndcg_at_10
value: 67.253
- type: ndcg_at_100
value: 70.648
- type: ndcg_at_1000
value: 71.139
- type: ndcg_at_20
value: 68.905
- type: ndcg_at_3
value: 62.178
- type: ndcg_at_5
value: 64.64800000000001
- type: precision_at_1
value: 53.480000000000004
- type: precision_at_10
value: 10.696
- type: precision_at_100
value: 1.325
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_20
value: 5.884
- type: precision_at_3
value: 27.794999999999998
- type: precision_at_5
value: 18.708
- type: recall_at_1
value: 46.905
- type: recall_at_10
value: 81.234
- type: recall_at_100
value: 95.489
- type: recall_at_1000
value: 98.729
- type: recall_at_20
value: 87.29400000000001
- type: recall_at_3
value: 67.869
- type: recall_at_5
value: 73.896
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGisRetrieval
type: mteb/cqadupstack-gis
config: default
split: test
revision: 5003b3064772da1887988e05400cf3806fe491f2
metrics:
- type: main_score
value: 46.397
- type: map_at_1
value: 30.613
- type: map_at_10
value: 40.581
- type: map_at_100
value: 41.660000000000004
- type: map_at_1000
value: 41.721000000000004
- type: map_at_20
value: 41.211999999999996
- type: map_at_3
value: 37.32
- type: map_at_5
value: 39.114
- type: mrr_at_1
value: 33.220338983050844
- type: mrr_at_10
value: 42.83718948973182
- type: mrr_at_100
value: 43.71836325492362
- type: mrr_at_1000
value: 43.76175841571598
- type: mrr_at_20
value: 43.384811953015166
- type: mrr_at_3
value: 39.830508474576256
- type: mrr_at_5
value: 41.54802259887001
- type: nauc_map_at_1000_diff1
value: 42.6225958477453
- type: nauc_map_at_1000_max
value: 28.013356866974238
- type: nauc_map_at_1000_std
value: -9.409667321411026
- type: nauc_map_at_100_diff1
value: 42.610412175224766
- type: nauc_map_at_100_max
value: 28.002610966435736
- type: nauc_map_at_100_std
value: -9.411570910136719
- type: nauc_map_at_10_diff1
value: 42.63151134672704
- type: nauc_map_at_10_max
value: 28.001496131016022
- type: nauc_map_at_10_std
value: -9.67772644457909
- type: nauc_map_at_1_diff1
value: 46.31023790327735
- type: nauc_map_at_1_max
value: 24.2900776546879
- type: nauc_map_at_1_std
value: -11.905089868017578
- type: nauc_map_at_20_diff1
value: 42.6522287088466
- type: nauc_map_at_20_max
value: 27.975313282087043
- type: nauc_map_at_20_std
value: -9.550553164224084
- type: nauc_map_at_3_diff1
value: 43.272779420270226
- type: nauc_map_at_3_max
value: 26.92288244998244
- type: nauc_map_at_3_std
value: -10.575038389958834
- type: nauc_map_at_5_diff1
value: 42.58131102442881
- type: nauc_map_at_5_max
value: 27.04453513629861
- type: nauc_map_at_5_std
value: -10.317573458025175
- type: nauc_mrr_at_1000_diff1
value: 41.126210961719636
- type: nauc_mrr_at_1000_max
value: 28.513261505932054
- type: nauc_mrr_at_1000_std
value: -8.546982260677629
- type: nauc_mrr_at_100_diff1
value: 41.110923675787234
- type: nauc_mrr_at_100_max
value: 28.52042510810816
- type: nauc_mrr_at_100_std
value: -8.534554512496843
- type: nauc_mrr_at_10_diff1
value: 41.07534061242193
- type: nauc_mrr_at_10_max
value: 28.44682429205697
- type: nauc_mrr_at_10_std
value: -8.6819795408583
- type: nauc_mrr_at_1_diff1
value: 44.40023434506226
- type: nauc_mrr_at_1_max
value: 25.9478208158475
- type: nauc_mrr_at_1_std
value: -10.872665260136657
- type: nauc_mrr_at_20_diff1
value: 41.146798233387074
- type: nauc_mrr_at_20_max
value: 28.517336935279054
- type: nauc_mrr_at_20_std
value: -8.580094403841978
- type: nauc_mrr_at_3_diff1
value: 41.60309522639159
- type: nauc_mrr_at_3_max
value: 28.379418612638734
- type: nauc_mrr_at_3_std
value: -9.263458517583244
- type: nauc_mrr_at_5_diff1
value: 40.99565866982568
- type: nauc_mrr_at_5_max
value: 27.90866498875212
- type: nauc_mrr_at_5_std
value: -8.941725041767588
- type: nauc_ndcg_at_1000_diff1
value: 41.11051620257291
- type: nauc_ndcg_at_1000_max
value: 29.70811129532719
- type: nauc_ndcg_at_1000_std
value: -7.127215646258767
- type: nauc_ndcg_at_100_diff1
value: 40.63555558695194
- type: nauc_ndcg_at_100_max
value: 29.701486964402413
- type: nauc_ndcg_at_100_std
value: -6.577078704400861
- type: nauc_ndcg_at_10_diff1
value: 40.87142841339465
- type: nauc_ndcg_at_10_max
value: 29.704589449676533
- type: nauc_ndcg_at_10_std
value: -7.674397553684968
- type: nauc_ndcg_at_1_diff1
value: 44.40023434506226
- type: nauc_ndcg_at_1_max
value: 25.9478208158475
- type: nauc_ndcg_at_1_std
value: -10.872665260136657
- type: nauc_ndcg_at_20_diff1
value: 41.06323938303467
- type: nauc_ndcg_at_20_max
value: 29.883715521818203
- type: nauc_ndcg_at_20_std
value: -7.155761930055846
- type: nauc_ndcg_at_3_diff1
value: 41.935479029537156
- type: nauc_ndcg_at_3_max
value: 28.171952324901135
- type: nauc_ndcg_at_3_std
value: -9.737703474161384
- type: nauc_ndcg_at_5_diff1
value: 40.69403623214395
- type: nauc_ndcg_at_5_max
value: 27.702311421182756
- type: nauc_ndcg_at_5_std
value: -9.060968201824112
- type: nauc_precision_at_1000_diff1
value: -8.885096064850758
- type: nauc_precision_at_1000_max
value: 14.053447868468186
- type: nauc_precision_at_1000_std
value: 12.07987711511724
- type: nauc_precision_at_100_diff1
value: 2.3188506683364287
- type: nauc_precision_at_100_max
value: 22.080025207013655
- type: nauc_precision_at_100_std
value: 14.172840329817307
- type: nauc_precision_at_10_diff1
value: 24.9332547479345
- type: nauc_precision_at_10_max
value: 34.6422733091986
- type: nauc_precision_at_10_std
value: 1.9970789498947206
- type: nauc_precision_at_1_diff1
value: 44.40023434506226
- type: nauc_precision_at_1_max
value: 25.9478208158475
- type: nauc_precision_at_1_std
value: -10.872665260136657
- type: nauc_precision_at_20_diff1
value: 20.640050910422755
- type: nauc_precision_at_20_max
value: 32.260405497760615
- type: nauc_precision_at_20_std
value: 6.854997919374335
- type: nauc_precision_at_3_diff1
value: 33.29459667683485
- type: nauc_precision_at_3_max
value: 32.151627242504325
- type: nauc_precision_at_3_std
value: -5.8202369823669855
- type: nauc_precision_at_5_diff1
value: 28.763772683866794
- type: nauc_precision_at_5_max
value: 31.392059038257553
- type: nauc_precision_at_5_std
value: -3.9737244392531172
- type: nauc_recall_at_1000_diff1
value: 26.491178998164894
- type: nauc_recall_at_1000_max
value: 53.78324098258691
- type: nauc_recall_at_1000_std
value: 22.795807409776284
- type: nauc_recall_at_100_diff1
value: 27.100846383184855
- type: nauc_recall_at_100_max
value: 36.26211685620019
- type: nauc_recall_at_100_std
value: 12.001840836651729
- type: nauc_recall_at_10_diff1
value: 35.281252536584226
- type: nauc_recall_at_10_max
value: 34.13064097658273
- type: nauc_recall_at_10_std
value: -1.238221844846595
- type: nauc_recall_at_1_diff1
value: 46.31023790327735
- type: nauc_recall_at_1_max
value: 24.2900776546879
- type: nauc_recall_at_1_std
value: -11.905089868017578
- type: nauc_recall_at_20_diff1
value: 35.29612485423622
- type: nauc_recall_at_20_max
value: 36.059880890712606
- type: nauc_recall_at_20_std
value: 2.0708009945980916
- type: nauc_recall_at_3_diff1
value: 39.33916378398866
- type: nauc_recall_at_3_max
value: 28.825178871677544
- type: nauc_recall_at_3_std
value: -8.391711028859733
- type: nauc_recall_at_5_diff1
value: 35.394135184248086
- type: nauc_recall_at_5_max
value: 27.370010171655295
- type: nauc_recall_at_5_std
value: -6.342877659046013
- type: ndcg_at_1
value: 33.22
- type: ndcg_at_10
value: 46.397
- type: ndcg_at_100
value: 51.510999999999996
- type: ndcg_at_1000
value: 52.941
- type: ndcg_at_20
value: 48.614000000000004
- type: ndcg_at_3
value: 40.066
- type: ndcg_at_5
value: 43.086
- type: precision_at_1
value: 33.22
- type: precision_at_10
value: 7.153
- type: precision_at_100
value: 1.028
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_20
value: 4.1129999999999995
- type: precision_at_3
value: 16.949
- type: precision_at_5
value: 11.932
- type: recall_at_1
value: 30.613
- type: recall_at_10
value: 62.248000000000005
- type: recall_at_100
value: 85.311
- type: recall_at_1000
value: 95.88799999999999
- type: recall_at_20
value: 70.729
- type: recall_at_3
value: 45.104
- type: recall_at_5
value: 52.370000000000005
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackMathematicaRetrieval
type: mteb/cqadupstack-mathematica
config: default
split: test
revision: 90fceea13679c63fe563ded68f3b6f06e50061de
metrics:
- type: main_score
value: 39.528999999999996
- type: map_at_1
value: 22.289
- type: map_at_10
value: 33.159
- type: map_at_100
value: 34.544999999999995
- type: map_at_1000
value: 34.657
- type: map_at_20
value: 33.946
- type: map_at_3
value: 29.877
- type: map_at_5
value: 31.789
- type: mrr_at_1
value: 27.860696517412936
- type: mrr_at_10
value: 38.592454394693185
- type: mrr_at_100
value: 39.532435897754596
- type: mrr_at_1000
value: 39.58977434786168
- type: mrr_at_20
value: 39.18675071024776
- type: mrr_at_3
value: 35.96600331674959
- type: mrr_at_5
value: 37.526948590381416
- type: nauc_map_at_1000_diff1
value: 33.700166326733495
- type: nauc_map_at_1000_max
value: 20.881755159195087
- type: nauc_map_at_1000_std
value: -3.3430462158114675
- type: nauc_map_at_100_diff1
value: 33.692093684241065
- type: nauc_map_at_100_max
value: 20.906418728277437
- type: nauc_map_at_100_std
value: -3.3316697944388443
- type: nauc_map_at_10_diff1
value: 33.42287630575565
- type: nauc_map_at_10_max
value: 20.50001954371251
- type: nauc_map_at_10_std
value: -4.08460043500711
- type: nauc_map_at_1_diff1
value: 37.87404744244711
- type: nauc_map_at_1_max
value: 19.670953538008504
- type: nauc_map_at_1_std
value: -6.429774614333435
- type: nauc_map_at_20_diff1
value: 33.60771917466459
- type: nauc_map_at_20_max
value: 20.708044731830018
- type: nauc_map_at_20_std
value: -3.6069971679953143
- type: nauc_map_at_3_diff1
value: 33.65349486102774
- type: nauc_map_at_3_max
value: 19.627398723335993
- type: nauc_map_at_3_std
value: -4.306026212618319
- type: nauc_map_at_5_diff1
value: 33.471450513985964
- type: nauc_map_at_5_max
value: 19.948552824819032
- type: nauc_map_at_5_std
value: -4.923599608990918
- type: nauc_mrr_at_1000_diff1
value: 32.662151329963095
- type: nauc_mrr_at_1000_max
value: 22.537786156087673
- type: nauc_mrr_at_1000_std
value: -2.7960608938625215
- type: nauc_mrr_at_100_diff1
value: 32.65867171998483
- type: nauc_mrr_at_100_max
value: 22.547865954292774
- type: nauc_mrr_at_100_std
value: -2.801012467040567
- type: nauc_mrr_at_10_diff1
value: 32.544025707175926
- type: nauc_mrr_at_10_max
value: 22.602412903085646
- type: nauc_mrr_at_10_std
value: -3.0158656805804602
- type: nauc_mrr_at_1_diff1
value: 36.968863725891985
- type: nauc_mrr_at_1_max
value: 22.042028260738334
- type: nauc_mrr_at_1_std
value: -4.81746524838004
- type: nauc_mrr_at_20_diff1
value: 32.6425264960166
- type: nauc_mrr_at_20_max
value: 22.513542321494686
- type: nauc_mrr_at_20_std
value: -2.8764217789260575
- type: nauc_mrr_at_3_diff1
value: 32.50201126992818
- type: nauc_mrr_at_3_max
value: 22.128017930298302
- type: nauc_mrr_at_3_std
value: -3.023665576028868
- type: nauc_mrr_at_5_diff1
value: 32.56418157013767
- type: nauc_mrr_at_5_max
value: 22.05870005229312
- type: nauc_mrr_at_5_std
value: -3.5021924901272863
- type: nauc_ndcg_at_1000_diff1
value: 32.74240275632584
- type: nauc_ndcg_at_1000_max
value: 22.404494093544148
- type: nauc_ndcg_at_1000_std
value: -0.5292268805090566
- type: nauc_ndcg_at_100_diff1
value: 32.39837105476146
- type: nauc_ndcg_at_100_max
value: 22.79204625219021
- type: nauc_ndcg_at_100_std
value: -0.3490651737152355
- type: nauc_ndcg_at_10_diff1
value: 31.932581950709647
- type: nauc_ndcg_at_10_max
value: 21.779867741726864
- type: nauc_ndcg_at_10_std
value: -2.6923178974285857
- type: nauc_ndcg_at_1_diff1
value: 36.968863725891985
- type: nauc_ndcg_at_1_max
value: 22.042028260738334
- type: nauc_ndcg_at_1_std
value: -4.81746524838004
- type: nauc_ndcg_at_20_diff1
value: 32.463586670511226
- type: nauc_ndcg_at_20_max
value: 22.140858428394843
- type: nauc_ndcg_at_20_std
value: -1.4367590351530557
- type: nauc_ndcg_at_3_diff1
value: 32.446170362942084
- type: nauc_ndcg_at_3_max
value: 20.60928390930364
- type: nauc_ndcg_at_3_std
value: -3.468700146234719
- type: nauc_ndcg_at_5_diff1
value: 32.162455412182865
- type: nauc_ndcg_at_5_max
value: 20.725999446060232
- type: nauc_ndcg_at_5_std
value: -4.274903425807673
- type: nauc_precision_at_1000_diff1
value: -1.7949376725223287
- type: nauc_precision_at_1000_max
value: 4.138926678307252
- type: nauc_precision_at_1000_std
value: 5.718976977950761
- type: nauc_precision_at_100_diff1
value: 6.815844234312567
- type: nauc_precision_at_100_max
value: 15.267630374047453
- type: nauc_precision_at_100_std
value: 10.648732358170012
- type: nauc_precision_at_10_diff1
value: 18.776246678630283
- type: nauc_precision_at_10_max
value: 20.677245431024357
- type: nauc_precision_at_10_std
value: 1.6530753958695428
- type: nauc_precision_at_1_diff1
value: 36.968863725891985
- type: nauc_precision_at_1_max
value: 22.042028260738334
- type: nauc_precision_at_1_std
value: -4.81746524838004
- type: nauc_precision_at_20_diff1
value: 16.901118214014854
- type: nauc_precision_at_20_max
value: 20.321433804879973
- type: nauc_precision_at_20_std
value: 6.464565628780512
- type: nauc_precision_at_3_diff1
value: 25.438322928150715
- type: nauc_precision_at_3_max
value: 21.513381450535192
- type: nauc_precision_at_3_std
value: -1.0164220255846312
- type: nauc_precision_at_5_diff1
value: 22.374520350110284
- type: nauc_precision_at_5_max
value: 20.541307175039307
- type: nauc_precision_at_5_std
value: -2.6340396442123537
- type: nauc_recall_at_1000_diff1
value: 24.96791522787828
- type: nauc_recall_at_1000_max
value: 28.234314683043806
- type: nauc_recall_at_1000_std
value: 40.696299617721635
- type: nauc_recall_at_100_diff1
value: 23.613948951560566
- type: nauc_recall_at_100_max
value: 25.980432165003002
- type: nauc_recall_at_100_std
value: 13.815393892614894
- type: nauc_recall_at_10_diff1
value: 26.08578893691453
- type: nauc_recall_at_10_max
value: 21.68887563256401
- type: nauc_recall_at_10_std
value: 0.3183582141083137
- type: nauc_recall_at_1_diff1
value: 37.87404744244711
- type: nauc_recall_at_1_max
value: 19.670953538008504
- type: nauc_recall_at_1_std
value: -6.429774614333435
- type: nauc_recall_at_20_diff1
value: 26.962834137152473
- type: nauc_recall_at_20_max
value: 22.164116014019815
- type: nauc_recall_at_20_std
value: 4.67553525902973
- type: nauc_recall_at_3_diff1
value: 28.282766004526692
- type: nauc_recall_at_3_max
value: 19.21433271344623
- type: nauc_recall_at_3_std
value: -1.7579654801836264
- type: nauc_recall_at_5_diff1
value: 27.31884901762613
- type: nauc_recall_at_5_max
value: 19.089489857779846
- type: nauc_recall_at_5_std
value: -3.8031906054652667
- type: ndcg_at_1
value: 27.861000000000004
- type: ndcg_at_10
value: 39.528999999999996
- type: ndcg_at_100
value: 45.424
- type: ndcg_at_1000
value: 47.682
- type: ndcg_at_20
value: 41.967
- type: ndcg_at_3
value: 34.083999999999996
- type: ndcg_at_5
value: 36.773
- type: precision_at_1
value: 27.861000000000004
- type: precision_at_10
value: 7.338
- type: precision_at_100
value: 1.172
- type: precision_at_1000
value: 0.147
- type: precision_at_20
value: 4.415
- type: precision_at_3
value: 16.833000000000002
- type: precision_at_5
value: 12.113999999999999
- type: recall_at_1
value: 22.289
- type: recall_at_10
value: 53.559
- type: recall_at_100
value: 78.521
- type: recall_at_1000
value: 94.13
- type: recall_at_20
value: 61.986
- type: recall_at_3
value: 38.269999999999996
- type: recall_at_5
value: 45.336
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackPhysicsRetrieval
type: mteb/cqadupstack-physics
config: default
split: test
revision: 79531abbd1fb92d06c6d6315a0cbbbf5bb247ea4
metrics:
- type: main_score
value: 54.004
- type: map_at_1
value: 33.586
- type: map_at_10
value: 47.342
- type: map_at_100
value: 48.823
- type: map_at_1000
value: 48.919000000000004
- type: map_at_20
value: 48.22
- type: map_at_3
value: 43.614999999999995
- type: map_at_5
value: 45.749
- type: mrr_at_1
value: 41.48219441770934
- type: mrr_at_10
value: 52.86203156270527
- type: mrr_at_100
value: 53.707246266591255
- type: mrr_at_1000
value: 53.73489176472194
- type: mrr_at_20
value: 53.44504144846516
- type: mrr_at_3
value: 50.56143727943533
- type: mrr_at_5
value: 51.96663458453635
- type: nauc_map_at_1000_diff1
value: 50.16735144466837
- type: nauc_map_at_1000_max
value: 30.130457323041902
- type: nauc_map_at_1000_std
value: -18.910770726198383
- type: nauc_map_at_100_diff1
value: 50.170273630833286
- type: nauc_map_at_100_max
value: 30.137603210111934
- type: nauc_map_at_100_std
value: -18.93078710897879
- type: nauc_map_at_10_diff1
value: 49.995799867485076
- type: nauc_map_at_10_max
value: 29.626149915961854
- type: nauc_map_at_10_std
value: -19.70118715989913
- type: nauc_map_at_1_diff1
value: 56.10337790434511
- type: nauc_map_at_1_max
value: 26.249897485765477
- type: nauc_map_at_1_std
value: -20.159842923954475
- type: nauc_map_at_20_diff1
value: 50.026410103063576
- type: nauc_map_at_20_max
value: 29.770173596928444
- type: nauc_map_at_20_std
value: -19.398108689295622
- type: nauc_map_at_3_diff1
value: 50.12369021949809
- type: nauc_map_at_3_max
value: 27.918094022890692
- type: nauc_map_at_3_std
value: -20.816408880461136
- type: nauc_map_at_5_diff1
value: 49.88266421157269
- type: nauc_map_at_5_max
value: 28.803327575103616
- type: nauc_map_at_5_std
value: -20.412325693429622
- type: nauc_mrr_at_1000_diff1
value: 50.08675690045023
- type: nauc_mrr_at_1000_max
value: 33.51316969904977
- type: nauc_mrr_at_1000_std
value: -16.325548962557693
- type: nauc_mrr_at_100_diff1
value: 50.084570223694804
- type: nauc_mrr_at_100_max
value: 33.53170304618603
- type: nauc_mrr_at_100_std
value: -16.315669293904236
- type: nauc_mrr_at_10_diff1
value: 50.104359262926614
- type: nauc_mrr_at_10_max
value: 33.454171357296374
- type: nauc_mrr_at_10_std
value: -16.672238640691564
- type: nauc_mrr_at_1_diff1
value: 54.46283195658263
- type: nauc_mrr_at_1_max
value: 33.5006771800345
- type: nauc_mrr_at_1_std
value: -15.72197238923995
- type: nauc_mrr_at_20_diff1
value: 50.04428019672954
- type: nauc_mrr_at_20_max
value: 33.43915921871757
- type: nauc_mrr_at_20_std
value: -16.47775099091468
- type: nauc_mrr_at_3_diff1
value: 49.29563277160461
- type: nauc_mrr_at_3_max
value: 32.609171651470724
- type: nauc_mrr_at_3_std
value: -16.8176459078524
- type: nauc_mrr_at_5_diff1
value: 49.59993245767094
- type: nauc_mrr_at_5_max
value: 33.145357294405365
- type: nauc_mrr_at_5_std
value: -16.886783105921864
- type: nauc_ndcg_at_1000_diff1
value: 49.84200528661306
- type: nauc_ndcg_at_1000_max
value: 32.7463038531318
- type: nauc_ndcg_at_1000_std
value: -16.229179922128097
- type: nauc_ndcg_at_100_diff1
value: 49.78798184218895
- type: nauc_ndcg_at_100_max
value: 33.19106180162596
- type: nauc_ndcg_at_100_std
value: -15.964597177057572
- type: nauc_ndcg_at_10_diff1
value: 49.10239998219158
- type: nauc_ndcg_at_10_max
value: 31.18073711193898
- type: nauc_ndcg_at_10_std
value: -19.103888016157107
- type: nauc_ndcg_at_1_diff1
value: 54.46283195658263
- type: nauc_ndcg_at_1_max
value: 33.5006771800345
- type: nauc_ndcg_at_1_std
value: -15.72197238923995
- type: nauc_ndcg_at_20_diff1
value: 49.12986473579085
- type: nauc_ndcg_at_20_max
value: 31.555721190821874
- type: nauc_ndcg_at_20_std
value: -18.03991726456339
- type: nauc_ndcg_at_3_diff1
value: 48.06266636428524
- type: nauc_ndcg_at_3_max
value: 29.800215619456498
- type: nauc_ndcg_at_3_std
value: -19.534322783334527
- type: nauc_ndcg_at_5_diff1
value: 48.15095160139167
- type: nauc_ndcg_at_5_max
value: 30.208802143718682
- type: nauc_ndcg_at_5_std
value: -19.9192266388754
- type: nauc_precision_at_1000_diff1
value: -14.22147314326395
- type: nauc_precision_at_1000_max
value: 4.578027927831382
- type: nauc_precision_at_1000_std
value: 17.42650517281872
- type: nauc_precision_at_100_diff1
value: -6.889359682595786
- type: nauc_precision_at_100_max
value: 13.816120144295166
- type: nauc_precision_at_100_std
value: 19.169326264844834
- type: nauc_precision_at_10_diff1
value: 11.630213989568256
- type: nauc_precision_at_10_max
value: 25.18561447388641
- type: nauc_precision_at_10_std
value: 3.5091485378988714
- type: nauc_precision_at_1_diff1
value: 54.46283195658263
- type: nauc_precision_at_1_max
value: 33.5006771800345
- type: nauc_precision_at_1_std
value: -15.72197238923995
- type: nauc_precision_at_20_diff1
value: 3.5727333022082184
- type: nauc_precision_at_20_max
value: 20.959966668076714
- type: nauc_precision_at_20_std
value: 11.024682685903581
- type: nauc_precision_at_3_diff1
value: 27.22306777334495
- type: nauc_precision_at_3_max
value: 30.39888856674192
- type: nauc_precision_at_3_std
value: -7.583643149291899
- type: nauc_precision_at_5_diff1
value: 18.788243224115185
- type: nauc_precision_at_5_max
value: 28.14592563430115
- type: nauc_precision_at_5_std
value: -3.10270506824694
- type: nauc_recall_at_1000_diff1
value: 62.4411056243426
- type: nauc_recall_at_1000_max
value: 69.22941585002123
- type: nauc_recall_at_1000_std
value: 36.11911276552335
- type: nauc_recall_at_100_diff1
value: 44.59026422323201
- type: nauc_recall_at_100_max
value: 47.97129128154523
- type: nauc_recall_at_100_std
value: 4.778892937753897
- type: nauc_recall_at_10_diff1
value: 43.25042694366798
- type: nauc_recall_at_10_max
value: 30.67002821157203
- type: nauc_recall_at_10_std
value: -18.821325601418703
- type: nauc_recall_at_1_diff1
value: 56.10337790434511
- type: nauc_recall_at_1_max
value: 26.249897485765477
- type: nauc_recall_at_1_std
value: -20.159842923954475
- type: nauc_recall_at_20_diff1
value: 41.53741723146757
- type: nauc_recall_at_20_max
value: 30.852977167860324
- type: nauc_recall_at_20_std
value: -14.824694384045237
- type: nauc_recall_at_3_diff1
value: 42.251002622079916
- type: nauc_recall_at_3_max
value: 25.083846761725724
- type: nauc_recall_at_3_std
value: -22.239786875574765
- type: nauc_recall_at_5_diff1
value: 41.146094656121385
- type: nauc_recall_at_5_max
value: 27.189625490714608
- type: nauc_recall_at_5_std
value: -22.001469364479068
- type: ndcg_at_1
value: 41.482
- type: ndcg_at_10
value: 54.004
- type: ndcg_at_100
value: 59.455000000000005
- type: ndcg_at_1000
value: 60.831999999999994
- type: ndcg_at_20
value: 56.484
- type: ndcg_at_3
value: 48.802
- type: ndcg_at_5
value: 51.43600000000001
- type: precision_at_1
value: 41.482
- type: precision_at_10
value: 9.99
- type: precision_at_100
value: 1.4989999999999999
- type: precision_at_1000
value: 0.178
- type: precision_at_20
value: 5.861000000000001
- type: precision_at_3
value: 23.709
- type: precision_at_5
value: 16.843
- type: recall_at_1
value: 33.586
- type: recall_at_10
value: 67.754
- type: recall_at_100
value: 89.689
- type: recall_at_1000
value: 98.212
- type: recall_at_20
value: 76.253
- type: recall_at_3
value: 53.181
- type: recall_at_5
value: 60.122
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackProgrammersRetrieval
type: mteb/cqadupstack-programmers
config: default
split: test
revision: 6184bc1440d2dbc7612be22b50686b8826d22b32
metrics:
- type: main_score
value: 50.547
- type: map_at_1
value: 30.547
- type: map_at_10
value: 43.595
- type: map_at_100
value: 45.044000000000004
- type: map_at_1000
value: 45.143
- type: map_at_20
value: 44.46
- type: map_at_3
value: 39.512
- type: map_at_5
value: 41.655
- type: mrr_at_1
value: 38.242009132420094
- type: mrr_at_10
value: 49.150811770674785
- type: mrr_at_100
value: 49.95736920255132
- type: mrr_at_1000
value: 49.991323278325005
- type: mrr_at_20
value: 49.64605069442795
- type: mrr_at_3
value: 46.19482496194824
- type: mrr_at_5
value: 47.74162861491625
- type: nauc_map_at_1000_diff1
value: 40.52349853300547
- type: nauc_map_at_1000_max
value: 31.561296386270925
- type: nauc_map_at_1000_std
value: -5.03343890785704
- type: nauc_map_at_100_diff1
value: 40.48825194476996
- type: nauc_map_at_100_max
value: 31.553405159588717
- type: nauc_map_at_100_std
value: -5.042866610979561
- type: nauc_map_at_10_diff1
value: 40.39926831942659
- type: nauc_map_at_10_max
value: 30.946628618728266
- type: nauc_map_at_10_std
value: -5.776518335664868
- type: nauc_map_at_1_diff1
value: 44.73341103510332
- type: nauc_map_at_1_max
value: 24.72510025576844
- type: nauc_map_at_1_std
value: -11.010252578512175
- type: nauc_map_at_20_diff1
value: 40.44256461277349
- type: nauc_map_at_20_max
value: 31.466590802666467
- type: nauc_map_at_20_std
value: -5.113421418562381
- type: nauc_map_at_3_diff1
value: 41.38809172163691
- type: nauc_map_at_3_max
value: 29.48868065104881
- type: nauc_map_at_3_std
value: -8.459559994349043
- type: nauc_map_at_5_diff1
value: 40.50417748715188
- type: nauc_map_at_5_max
value: 30.375034537551333
- type: nauc_map_at_5_std
value: -6.829586305389068
- type: nauc_mrr_at_1000_diff1
value: 38.13147562273569
- type: nauc_mrr_at_1000_max
value: 33.4729877260649
- type: nauc_mrr_at_1000_std
value: -2.115383391956632
- type: nauc_mrr_at_100_diff1
value: 38.12352986074086
- type: nauc_mrr_at_100_max
value: 33.47904382055151
- type: nauc_mrr_at_100_std
value: -2.0980380463248816
- type: nauc_mrr_at_10_diff1
value: 37.879793238833486
- type: nauc_mrr_at_10_max
value: 33.24190962300982
- type: nauc_mrr_at_10_std
value: -2.197979308633544
- type: nauc_mrr_at_1_diff1
value: 40.89812140583222
- type: nauc_mrr_at_1_max
value: 30.547640253413395
- type: nauc_mrr_at_1_std
value: -4.319528874623733
- type: nauc_mrr_at_20_diff1
value: 38.08114567265545
- type: nauc_mrr_at_20_max
value: 33.5751626334935
- type: nauc_mrr_at_20_std
value: -2.0190711781853805
- type: nauc_mrr_at_3_diff1
value: 38.36593445752741
- type: nauc_mrr_at_3_max
value: 33.5606672994442
- type: nauc_mrr_at_3_std
value: -3.313496883242172
- type: nauc_mrr_at_5_diff1
value: 37.67325286264018
- type: nauc_mrr_at_5_max
value: 33.36028645933453
- type: nauc_mrr_at_5_std
value: -2.5553616249884756
- type: nauc_ndcg_at_1000_diff1
value: 39.15178707833506
- type: nauc_ndcg_at_1000_max
value: 33.25615613608456
- type: nauc_ndcg_at_1000_std
value: -2.1792655266044645
- type: nauc_ndcg_at_100_diff1
value: 38.9781153280577
- type: nauc_ndcg_at_100_max
value: 33.59332040478102
- type: nauc_ndcg_at_100_std
value: -1.6261785471415764
- type: nauc_ndcg_at_10_diff1
value: 38.497420832277975
- type: nauc_ndcg_at_10_max
value: 32.53253337236221
- type: nauc_ndcg_at_10_std
value: -2.997611061467513
- type: nauc_ndcg_at_1_diff1
value: 40.89812140583222
- type: nauc_ndcg_at_1_max
value: 30.547640253413395
- type: nauc_ndcg_at_1_std
value: -4.319528874623733
- type: nauc_ndcg_at_20_diff1
value: 38.81727541423619
- type: nauc_ndcg_at_20_max
value: 33.83499432459841
- type: nauc_ndcg_at_20_std
value: -1.4541145324463343
- type: nauc_ndcg_at_3_diff1
value: 39.21372121259748
- type: nauc_ndcg_at_3_max
value: 32.21240027184339
- type: nauc_ndcg_at_3_std
value: -5.818515242107007
- type: nauc_ndcg_at_5_diff1
value: 38.36581068852509
- type: nauc_ndcg_at_5_max
value: 32.31265492516815
- type: nauc_ndcg_at_5_std
value: -4.347865800300811
- type: nauc_precision_at_1000_diff1
value: -2.9404408066555487
- type: nauc_precision_at_1000_max
value: 11.959727087923113
- type: nauc_precision_at_1000_std
value: 19.807537724237182
- type: nauc_precision_at_100_diff1
value: -1.8903473485508044
- type: nauc_precision_at_100_max
value: 17.859451192772262
- type: nauc_precision_at_100_std
value: 20.978283478932195
- type: nauc_precision_at_10_diff1
value: 7.827166236013994
- type: nauc_precision_at_10_max
value: 27.639518058609987
- type: nauc_precision_at_10_std
value: 16.2656199079196
- type: nauc_precision_at_1_diff1
value: 40.89812140583222
- type: nauc_precision_at_1_max
value: 30.547640253413395
- type: nauc_precision_at_1_std
value: -4.319528874623733
- type: nauc_precision_at_20_diff1
value: 3.0739728724420488
- type: nauc_precision_at_20_max
value: 24.28491071974094
- type: nauc_precision_at_20_std
value: 19.64404584038665
- type: nauc_precision_at_3_diff1
value: 23.38851433425848
- type: nauc_precision_at_3_max
value: 34.046714722976056
- type: nauc_precision_at_3_std
value: 4.085453450220984
- type: nauc_precision_at_5_diff1
value: 14.827066677039587
- type: nauc_precision_at_5_max
value: 31.844657859314747
- type: nauc_precision_at_5_std
value: 11.233146291519418
- type: nauc_recall_at_1000_diff1
value: 40.585961683508714
- type: nauc_recall_at_1000_max
value: 48.857695287563935
- type: nauc_recall_at_1000_std
value: 43.20362271394189
- type: nauc_recall_at_100_diff1
value: 32.24127663397077
- type: nauc_recall_at_100_max
value: 38.836350075837004
- type: nauc_recall_at_100_std
value: 17.622027048501153
- type: nauc_recall_at_10_diff1
value: 31.30410560798441
- type: nauc_recall_at_10_max
value: 30.93697991799787
- type: nauc_recall_at_10_std
value: 1.5177200901024983
- type: nauc_recall_at_1_diff1
value: 44.73341103510332
- type: nauc_recall_at_1_max
value: 24.72510025576844
- type: nauc_recall_at_1_std
value: -11.010252578512175
- type: nauc_recall_at_20_diff1
value: 31.93561881507333
- type: nauc_recall_at_20_max
value: 36.879629985707076
- type: nauc_recall_at_20_std
value: 9.68448188578646
- type: nauc_recall_at_3_diff1
value: 36.243457137883894
- type: nauc_recall_at_3_max
value: 30.46545172710201
- type: nauc_recall_at_3_std
value: -7.391349871928162
- type: nauc_recall_at_5_diff1
value: 32.999190531912554
- type: nauc_recall_at_5_max
value: 30.87264732206836
- type: nauc_recall_at_5_std
value: -3.3937930443165434
- type: ndcg_at_1
value: 38.242
- type: ndcg_at_10
value: 50.547
- type: ndcg_at_100
value: 55.994
- type: ndcg_at_1000
value: 57.538
- type: ndcg_at_20
value: 52.954
- type: ndcg_at_3
value: 44.283
- type: ndcg_at_5
value: 46.86
- type: precision_at_1
value: 38.242
- type: precision_at_10
value: 9.498
- type: precision_at_100
value: 1.424
- type: precision_at_1000
value: 0.174
- type: precision_at_20
value: 5.628
- type: precision_at_3
value: 21.271
- type: precision_at_5
value: 15.342
- type: recall_at_1
value: 30.547
- type: recall_at_10
value: 65.42999999999999
- type: recall_at_100
value: 87.92
- type: recall_at_1000
value: 97.68599999999999
- type: recall_at_20
value: 73.685
- type: recall_at_3
value: 47.979
- type: recall_at_5
value: 54.69199999999999
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackStatsRetrieval
type: mteb/cqadupstack-stats
config: default
split: test
revision: 65ac3a16b8e91f9cee4c9828cc7c335575432a2a
metrics:
- type: main_score
value: 42.379
- type: map_at_1
value: 28.076
- type: map_at_10
value: 37.187
- type: map_at_100
value: 38.163000000000004
- type: map_at_1000
value: 38.262
- type: map_at_20
value: 37.649
- type: map_at_3
value: 34.361000000000004
- type: map_at_5
value: 36.024
- type: mrr_at_1
value: 31.13496932515337
- type: mrr_at_10
value: 39.87084915765898
- type: mrr_at_100
value: 40.63847645369495
- type: mrr_at_1000
value: 40.70451576754048
- type: mrr_at_20
value: 40.25268368368429
- type: mrr_at_3
value: 37.37218813905932
- type: mrr_at_5
value: 38.698875255623726
- type: nauc_map_at_1000_diff1
value: 53.23968282874812
- type: nauc_map_at_1000_max
value: 33.785923443457136
- type: nauc_map_at_1000_std
value: -7.1706965835194145
- type: nauc_map_at_100_diff1
value: 53.23488336800868
- type: nauc_map_at_100_max
value: 33.78610121008569
- type: nauc_map_at_100_std
value: -7.15094162130079
- type: nauc_map_at_10_diff1
value: 53.52788129491361
- type: nauc_map_at_10_max
value: 33.55616013388991
- type: nauc_map_at_10_std
value: -7.6857282749978
- type: nauc_map_at_1_diff1
value: 59.34174527256049
- type: nauc_map_at_1_max
value: 32.58063146059831
- type: nauc_map_at_1_std
value: -9.540287370085819
- type: nauc_map_at_20_diff1
value: 53.16586961282429
- type: nauc_map_at_20_max
value: 33.69272685105737
- type: nauc_map_at_20_std
value: -7.380323341082431
- type: nauc_map_at_3_diff1
value: 55.28137765707177
- type: nauc_map_at_3_max
value: 33.45378492437827
- type: nauc_map_at_3_std
value: -8.18647355512435
- type: nauc_map_at_5_diff1
value: 53.8836295908436
- type: nauc_map_at_5_max
value: 33.822344952119785
- type: nauc_map_at_5_std
value: -7.64537861608003
- type: nauc_mrr_at_1000_diff1
value: 51.841157711545215
- type: nauc_mrr_at_1000_max
value: 34.9249740423282
- type: nauc_mrr_at_1000_std
value: -5.797330608658271
- type: nauc_mrr_at_100_diff1
value: 51.82520112610312
- type: nauc_mrr_at_100_max
value: 34.9362444083548
- type: nauc_mrr_at_100_std
value: -5.7681632136177585
- type: nauc_mrr_at_10_diff1
value: 51.81624637385308
- type: nauc_mrr_at_10_max
value: 34.837632307043705
- type: nauc_mrr_at_10_std
value: -6.09995049270317
- type: nauc_mrr_at_1_diff1
value: 58.37854579448285
- type: nauc_mrr_at_1_max
value: 34.672901734986844
- type: nauc_mrr_at_1_std
value: -7.066787533024501
- type: nauc_mrr_at_20_diff1
value: 51.65185881732499
- type: nauc_mrr_at_20_max
value: 34.925636736880925
- type: nauc_mrr_at_20_std
value: -5.827364722186311
- type: nauc_mrr_at_3_diff1
value: 53.51689033144754
- type: nauc_mrr_at_3_max
value: 34.75062118986762
- type: nauc_mrr_at_3_std
value: -6.580474412596013
- type: nauc_mrr_at_5_diff1
value: 52.291499624036355
- type: nauc_mrr_at_5_max
value: 35.066619088016196
- type: nauc_mrr_at_5_std
value: -6.1986345561829195
- type: nauc_ndcg_at_1000_diff1
value: 50.51376093038994
- type: nauc_ndcg_at_1000_max
value: 34.725822070535685
- type: nauc_ndcg_at_1000_std
value: -4.434746308735319
- type: nauc_ndcg_at_100_diff1
value: 49.81860985607077
- type: nauc_ndcg_at_100_max
value: 34.692760290424815
- type: nauc_ndcg_at_100_std
value: -3.835522029514012
- type: nauc_ndcg_at_10_diff1
value: 50.3513048763106
- type: nauc_ndcg_at_10_max
value: 33.72184194935727
- type: nauc_ndcg_at_10_std
value: -6.798983244879382
- type: nauc_ndcg_at_1_diff1
value: 58.37854579448285
- type: nauc_ndcg_at_1_max
value: 34.672901734986844
- type: nauc_ndcg_at_1_std
value: -7.066787533024501
- type: nauc_ndcg_at_20_diff1
value: 49.29162167829859
- type: nauc_ndcg_at_20_max
value: 34.16877295196376
- type: nauc_ndcg_at_20_std
value: -5.597014358860604
- type: nauc_ndcg_at_3_diff1
value: 53.10834468009104
- type: nauc_ndcg_at_3_max
value: 34.33773588752504
- type: nauc_ndcg_at_3_std
value: -7.243624483216034
- type: nauc_ndcg_at_5_diff1
value: 51.104845457630354
- type: nauc_ndcg_at_5_max
value: 34.38674960727082
- type: nauc_ndcg_at_5_std
value: -6.949153425119295
- type: nauc_precision_at_1000_diff1
value: -9.296436979607215
- type: nauc_precision_at_1000_max
value: 6.4385608601441255
- type: nauc_precision_at_1000_std
value: 9.323328514309525
- type: nauc_precision_at_100_diff1
value: 1.6478610402380616
- type: nauc_precision_at_100_max
value: 18.351794901313585
- type: nauc_precision_at_100_std
value: 14.665874744283974
- type: nauc_precision_at_10_diff1
value: 25.534183841642637
- type: nauc_precision_at_10_max
value: 29.40076026042332
- type: nauc_precision_at_10_std
value: 2.9872193044238453
- type: nauc_precision_at_1_diff1
value: 58.37854579448285
- type: nauc_precision_at_1_max
value: 34.672901734986844
- type: nauc_precision_at_1_std
value: -7.066787533024501
- type: nauc_precision_at_20_diff1
value: 15.647544367678556
- type: nauc_precision_at_20_max
value: 27.05732589353733
- type: nauc_precision_at_20_std
value: 7.191923029484484
- type: nauc_precision_at_3_diff1
value: 43.617914587502476
- type: nauc_precision_at_3_max
value: 34.43947964259185
- type: nauc_precision_at_3_std
value: -2.2997019515698853
- type: nauc_precision_at_5_diff1
value: 33.45902372451529
- type: nauc_precision_at_5_max
value: 33.345179920600174
- type: nauc_precision_at_5_std
value: 0.6402432222388739
- type: nauc_recall_at_1000_diff1
value: 29.85614248165102
- type: nauc_recall_at_1000_max
value: 43.12189214089366
- type: nauc_recall_at_1000_std
value: 38.028489124610644
- type: nauc_recall_at_100_diff1
value: 33.1910221741884
- type: nauc_recall_at_100_max
value: 36.878036476663056
- type: nauc_recall_at_100_std
value: 17.505589309024437
- type: nauc_recall_at_10_diff1
value: 40.89508005321193
- type: nauc_recall_at_10_max
value: 31.718075561656622
- type: nauc_recall_at_10_std
value: -5.5201680473345105
- type: nauc_recall_at_1_diff1
value: 59.34174527256049
- type: nauc_recall_at_1_max
value: 32.58063146059831
- type: nauc_recall_at_1_std
value: -9.540287370085819
- type: nauc_recall_at_20_diff1
value: 35.66013790544511
- type: nauc_recall_at_20_max
value: 32.86639975082532
- type: nauc_recall_at_20_std
value: -0.7884329140983038
- type: nauc_recall_at_3_diff1
value: 49.19221784465332
- type: nauc_recall_at_3_max
value: 33.023935837910756
- type: nauc_recall_at_3_std
value: -7.019711964409782
- type: nauc_recall_at_5_diff1
value: 44.67980008380877
- type: nauc_recall_at_5_max
value: 33.64495915667608
- type: nauc_recall_at_5_std
value: -6.146102608248518
- type: ndcg_at_1
value: 31.135
- type: ndcg_at_10
value: 42.379
- type: ndcg_at_100
value: 47.296
- type: ndcg_at_1000
value: 49.403999999999996
- type: ndcg_at_20
value: 43.93
- type: ndcg_at_3
value: 37.196
- type: ndcg_at_5
value: 39.75
- type: precision_at_1
value: 31.135
- type: precision_at_10
value: 6.81
- type: precision_at_100
value: 1.014
- type: precision_at_1000
value: 0.127
- type: precision_at_20
value: 3.834
- type: precision_at_3
value: 16.002
- type: precision_at_5
value: 11.411
- type: recall_at_1
value: 28.076
- type: recall_at_10
value: 55.509
- type: recall_at_100
value: 78.396
- type: recall_at_1000
value: 93.124
- type: recall_at_20
value: 61.326
- type: recall_at_3
value: 41.399
- type: recall_at_5
value: 47.567
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackTexRetrieval
type: mteb/cqadupstack-tex
config: default
split: test
revision: 46989137a86843e03a6195de44b09deda022eec7
metrics:
- type: main_score
value: 37.114999999999995
- type: map_at_1
value: 22.032
- type: map_at_10
value: 31.392999999999997
- type: map_at_100
value: 32.681
- type: map_at_1000
value: 32.803
- type: map_at_20
value: 32.092999999999996
- type: map_at_3
value: 28.33
- type: map_at_5
value: 29.988999999999997
- type: mrr_at_1
value: 26.944253269098418
- type: mrr_at_10
value: 35.76442827647241
- type: mrr_at_100
value: 36.70928542668393
- type: mrr_at_1000
value: 36.770222872867485
- type: mrr_at_20
value: 36.28598608599559
- type: mrr_at_3
value: 33.167010782289594
- type: mrr_at_5
value: 34.620899288827864
- type: nauc_map_at_1000_diff1
value: 38.09265419483922
- type: nauc_map_at_1000_max
value: 25.105090914997024
- type: nauc_map_at_1000_std
value: 1.0700959987729692
- type: nauc_map_at_100_diff1
value: 38.063239842931246
- type: nauc_map_at_100_max
value: 25.071823053158475
- type: nauc_map_at_100_std
value: 1.0427996382419578
- type: nauc_map_at_10_diff1
value: 38.063314345359736
- type: nauc_map_at_10_max
value: 24.90358356796509
- type: nauc_map_at_10_std
value: 0.48891415762356544
- type: nauc_map_at_1_diff1
value: 44.192488964031135
- type: nauc_map_at_1_max
value: 23.101395238489264
- type: nauc_map_at_1_std
value: -0.44274744959708606
- type: nauc_map_at_20_diff1
value: 38.02737709746376
- type: nauc_map_at_20_max
value: 25.015577711149145
- type: nauc_map_at_20_std
value: 0.7752620565795433
- type: nauc_map_at_3_diff1
value: 38.79059906518923
- type: nauc_map_at_3_max
value: 24.278973778653658
- type: nauc_map_at_3_std
value: -0.06600853085223404
- type: nauc_map_at_5_diff1
value: 38.38811885476713
- type: nauc_map_at_5_max
value: 24.906014694358767
- type: nauc_map_at_5_std
value: 0.503696622267735
- type: nauc_mrr_at_1000_diff1
value: 38.43851052537515
- type: nauc_mrr_at_1000_max
value: 26.08088413681578
- type: nauc_mrr_at_1000_std
value: 2.260435008633633
- type: nauc_mrr_at_100_diff1
value: 38.42446503025336
- type: nauc_mrr_at_100_max
value: 26.06653535777771
- type: nauc_mrr_at_100_std
value: 2.2508085472342567
- type: nauc_mrr_at_10_diff1
value: 38.42491058346722
- type: nauc_mrr_at_10_max
value: 26.046875548569524
- type: nauc_mrr_at_10_std
value: 1.991934209812353
- type: nauc_mrr_at_1_diff1
value: 44.125116470111806
- type: nauc_mrr_at_1_max
value: 25.502414026989822
- type: nauc_mrr_at_1_std
value: 1.0717390948764505
- type: nauc_mrr_at_20_diff1
value: 38.355654581557275
- type: nauc_mrr_at_20_max
value: 26.052337555999888
- type: nauc_mrr_at_20_std
value: 2.0892219127514107
- type: nauc_mrr_at_3_diff1
value: 39.001757864272676
- type: nauc_mrr_at_3_max
value: 25.98003648378764
- type: nauc_mrr_at_3_std
value: 1.6394764040482228
- type: nauc_mrr_at_5_diff1
value: 38.71163053840094
- type: nauc_mrr_at_5_max
value: 26.20780413201001
- type: nauc_mrr_at_5_std
value: 2.021661434346652
- type: nauc_ndcg_at_1000_diff1
value: 36.31450458217211
- type: nauc_ndcg_at_1000_max
value: 26.149308380875073
- type: nauc_ndcg_at_1000_std
value: 3.905862488970823
- type: nauc_ndcg_at_100_diff1
value: 35.963790362714164
- type: nauc_ndcg_at_100_max
value: 25.739750793393007
- type: nauc_ndcg_at_100_std
value: 3.7112777105604406
- type: nauc_ndcg_at_10_diff1
value: 35.99336074029864
- type: nauc_ndcg_at_10_max
value: 25.55200053240736
- type: nauc_ndcg_at_10_std
value: 1.5588036488952475
- type: nauc_ndcg_at_1_diff1
value: 44.125116470111806
- type: nauc_ndcg_at_1_max
value: 25.502414026989822
- type: nauc_ndcg_at_1_std
value: 1.0717390948764505
- type: nauc_ndcg_at_20_diff1
value: 35.73590736885051
- type: nauc_ndcg_at_20_max
value: 25.70046947040548
- type: nauc_ndcg_at_20_std
value: 2.271321757997752
- type: nauc_ndcg_at_3_diff1
value: 37.32573641209906
- type: nauc_ndcg_at_3_max
value: 25.1167909777267
- type: nauc_ndcg_at_3_std
value: 0.7212992566129185
- type: nauc_ndcg_at_5_diff1
value: 36.712049675888636
- type: nauc_ndcg_at_5_max
value: 25.792607516706372
- type: nauc_ndcg_at_5_std
value: 1.578770099119
- type: nauc_precision_at_1000_diff1
value: 3.6736780338116977
- type: nauc_precision_at_1000_max
value: 11.81314408533315
- type: nauc_precision_at_1000_std
value: 10.2436841196851
- type: nauc_precision_at_100_diff1
value: 8.417413354516071
- type: nauc_precision_at_100_max
value: 16.205114523661024
- type: nauc_precision_at_100_std
value: 13.594635835595328
- type: nauc_precision_at_10_diff1
value: 19.048008342402845
- type: nauc_precision_at_10_max
value: 23.350651852456103
- type: nauc_precision_at_10_std
value: 5.976335419523274
- type: nauc_precision_at_1_diff1
value: 44.125116470111806
- type: nauc_precision_at_1_max
value: 25.502414026989822
- type: nauc_precision_at_1_std
value: 1.0717390948764505
- type: nauc_precision_at_20_diff1
value: 15.474925061953678
- type: nauc_precision_at_20_max
value: 21.546991193902272
- type: nauc_precision_at_20_std
value: 8.905930860583391
- type: nauc_precision_at_3_diff1
value: 28.986321566644303
- type: nauc_precision_at_3_max
value: 26.69485123311458
- type: nauc_precision_at_3_std
value: 3.4263045093511537
- type: nauc_precision_at_5_diff1
value: 24.709408636594915
- type: nauc_precision_at_5_max
value: 26.67143866400471
- type: nauc_precision_at_5_std
value: 5.19041364886639
- type: nauc_recall_at_1000_diff1
value: 20.00674566428088
- type: nauc_recall_at_1000_max
value: 34.777585777551536
- type: nauc_recall_at_1000_std
value: 36.77107209206558
- type: nauc_recall_at_100_diff1
value: 24.285256665242304
- type: nauc_recall_at_100_max
value: 23.801866644708262
- type: nauc_recall_at_100_std
value: 15.064509694858854
- type: nauc_recall_at_10_diff1
value: 27.36808052999267
- type: nauc_recall_at_10_max
value: 24.053807252852636
- type: nauc_recall_at_10_std
value: 2.597884142562802
- type: nauc_recall_at_1_diff1
value: 44.192488964031135
- type: nauc_recall_at_1_max
value: 23.101395238489264
- type: nauc_recall_at_1_std
value: -0.44274744959708606
- type: nauc_recall_at_20_diff1
value: 25.65995095802745
- type: nauc_recall_at_20_max
value: 24.31913892777212
- type: nauc_recall_at_20_std
value: 5.048151975361747
- type: nauc_recall_at_3_diff1
value: 32.07015707209654
- type: nauc_recall_at_3_max
value: 23.698394784703815
- type: nauc_recall_at_3_std
value: 0.4539034711477527
- type: nauc_recall_at_5_diff1
value: 30.186485460653582
- type: nauc_recall_at_5_max
value: 25.00467869253249
- type: nauc_recall_at_5_std
value: 2.598872826683705
- type: ndcg_at_1
value: 26.944000000000003
- type: ndcg_at_10
value: 37.114999999999995
- type: ndcg_at_100
value: 42.846000000000004
- type: ndcg_at_1000
value: 45.228
- type: ndcg_at_20
value: 39.26
- type: ndcg_at_3
value: 31.891000000000002
- type: ndcg_at_5
value: 34.261
- type: precision_at_1
value: 26.944000000000003
- type: precision_at_10
value: 6.8790000000000004
- type: precision_at_100
value: 1.138
- type: precision_at_1000
value: 0.154
- type: precision_at_20
value: 4.092
- type: precision_at_3
value: 15.244
- type: precision_at_5
value: 11.004999999999999
- type: recall_at_1
value: 22.032
- type: recall_at_10
value: 49.830999999999996
- type: recall_at_100
value: 75.318
- type: recall_at_1000
value: 91.526
- type: recall_at_20
value: 57.684999999999995
- type: recall_at_3
value: 35.144999999999996
- type: recall_at_5
value: 41.377
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: mteb/cqadupstack
config: default
split: test
metrics:
- type: main_score
value: 49.35933333333333
- type: map_at_1
value: 31.5475
- type: map_at_10
value: 43.166916666666665
- type: map_at_100
value: 44.506083333333336
- type: map_at_1000
value: 44.60875
- type: map_at_20
value: 43.926166666666674
- type: map_at_3
value: 39.7375
- type: map_at_5
value: 41.63241666666667
- type: mrr_at_1
value: 37.58487329336356
- type: mrr_at_10
value: 47.57339949857069
- type: mrr_at_100
value: 48.37962696919692
- type: mrr_at_1000
value: 48.42044074093141
- type: mrr_at_20
value: 48.05694412330748
- type: mrr_at_3
value: 45.01312222327854
- type: mrr_at_5
value: 46.45963570299018
- type: nauc_map_at_1000_diff1
value: 47.559431895551796
- type: nauc_map_at_1000_max
value: 32.22624317021025
- type: nauc_map_at_1000_std
value: -9.215659016819911
- type: nauc_map_at_100_diff1
value: 47.5522725421024
- type: nauc_map_at_100_max
value: 32.23227770404454
- type: nauc_map_at_100_std
value: -9.257263949623699
- type: nauc_map_at_10_diff1
value: 47.62525599466672
- type: nauc_map_at_10_max
value: 31.810691404066432
- type: nauc_map_at_10_std
value: -10.159455545932724
- type: nauc_map_at_1_diff1
value: 52.959829481566764
- type: nauc_map_at_1_max
value: 28.644143760250785
- type: nauc_map_at_1_std
value: -11.72163597077123
- type: nauc_map_at_20_diff1
value: 47.56050095649268
- type: nauc_map_at_20_max
value: 32.08395945370071
- type: nauc_map_at_20_std
value: -9.628010776060316
- type: nauc_map_at_3_diff1
value: 48.51453660580493
- type: nauc_map_at_3_max
value: 30.898488535624786
- type: nauc_map_at_3_std
value: -11.15241799050688
- type: nauc_map_at_5_diff1
value: 47.85361615288319
- type: nauc_map_at_5_max
value: 31.396160977070693
- type: nauc_map_at_5_std
value: -10.669927060581687
- type: nauc_mrr_at_1000_diff1
value: 46.5756551519747
- type: nauc_mrr_at_1000_max
value: 33.613205491060505
- type: nauc_mrr_at_1000_std
value: -7.511388196842074
- type: nauc_mrr_at_100_diff1
value: 46.56493524451518
- type: nauc_mrr_at_100_max
value: 33.61311557843383
- type: nauc_mrr_at_100_std
value: -7.503137722678137
- type: nauc_mrr_at_10_diff1
value: 46.48587625246975
- type: nauc_mrr_at_10_max
value: 33.56104741766235
- type: nauc_mrr_at_10_std
value: -7.798262408773109
- type: nauc_mrr_at_1_diff1
value: 50.92937737651317
- type: nauc_mrr_at_1_max
value: 32.9507362296752
- type: nauc_mrr_at_1_std
value: -8.423238646208265
- type: nauc_mrr_at_20_diff1
value: 46.50275775113446
- type: nauc_mrr_at_20_max
value: 33.58865514759019
- type: nauc_mrr_at_20_std
value: -7.570114941791467
- type: nauc_mrr_at_3_diff1
value: 46.89503971128471
- type: nauc_mrr_at_3_max
value: 33.496560503226625
- type: nauc_mrr_at_3_std
value: -8.210558822386304
- type: nauc_mrr_at_5_diff1
value: 46.52472719918368
- type: nauc_mrr_at_5_max
value: 33.47000614361767
- type: nauc_mrr_at_5_std
value: -8.047294277050185
- type: nauc_ndcg_at_1000_diff1
value: 45.952224716482064
- type: nauc_ndcg_at_1000_max
value: 33.55951998008019
- type: nauc_ndcg_at_1000_std
value: -6.526593883643845
- type: nauc_ndcg_at_100_diff1
value: 45.6076817241719
- type: nauc_ndcg_at_100_max
value: 33.56351746928194
- type: nauc_ndcg_at_100_std
value: -6.2577955941610375
- type: nauc_ndcg_at_10_diff1
value: 45.49263554465489
- type: nauc_ndcg_at_10_max
value: 32.64126996617623
- type: nauc_ndcg_at_10_std
value: -8.742955252041423
- type: nauc_ndcg_at_1_diff1
value: 50.92937737651317
- type: nauc_ndcg_at_1_max
value: 32.9507362296752
- type: nauc_ndcg_at_1_std
value: -8.423238646208265
- type: nauc_ndcg_at_20_diff1
value: 45.4342115120439
- type: nauc_ndcg_at_20_max
value: 33.104622212270726
- type: nauc_ndcg_at_20_std
value: -7.483803415235951
- type: nauc_ndcg_at_3_diff1
value: 46.31897453421016
- type: nauc_ndcg_at_3_max
value: 32.28721923806247
- type: nauc_ndcg_at_3_std
value: -9.54172365718084
- type: nauc_ndcg_at_5_diff1
value: 45.70298606925981
- type: nauc_ndcg_at_5_max
value: 32.261906390761105
- type: nauc_ndcg_at_5_std
value: -9.399257100607874
- type: nauc_precision_at_1000_diff1
value: -11.364874438217843
- type: nauc_precision_at_1000_max
value: 4.301890425063193
- type: nauc_precision_at_1000_std
value: 15.855742716005356
- type: nauc_precision_at_100_diff1
value: -4.982324099155143
- type: nauc_precision_at_100_max
value: 13.642061594719774
- type: nauc_precision_at_100_std
value: 18.81929325056801
- type: nauc_precision_at_10_diff1
value: 12.638394408088926
- type: nauc_precision_at_10_max
value: 25.306846945633808
- type: nauc_precision_at_10_std
value: 6.594949743766334
- type: nauc_precision_at_1_diff1
value: 50.92937737651317
- type: nauc_precision_at_1_max
value: 32.9507362296752
- type: nauc_precision_at_1_std
value: -8.423238646208265
- type: nauc_precision_at_20_diff1
value: 6.16872699781517
- type: nauc_precision_at_20_max
value: 22.181315927006374
- type: nauc_precision_at_20_std
value: 12.56367756338886
- type: nauc_precision_at_3_diff1
value: 28.83807305490845
- type: nauc_precision_at_3_max
value: 31.389218193103215
- type: nauc_precision_at_3_std
value: -1.896026766564083
- type: nauc_precision_at_5_diff1
value: 20.77453603262145
- type: nauc_precision_at_5_max
value: 28.91019461637974
- type: nauc_precision_at_5_std
value: 1.6398138794154224
- type: nauc_recall_at_1000_diff1
value: 32.58030229927583
- type: nauc_recall_at_1000_max
value: 51.575385962899944
- type: nauc_recall_at_1000_std
value: 42.279175457257395
- type: nauc_recall_at_100_diff1
value: 33.0346354270252
- type: nauc_recall_at_100_max
value: 37.59086973079201
- type: nauc_recall_at_100_std
value: 14.114518949779974
- type: nauc_recall_at_10_diff1
value: 37.76688949788438
- type: nauc_recall_at_10_max
value: 30.957649538205224
- type: nauc_recall_at_10_std
value: -7.51989142903617
- type: nauc_recall_at_1_diff1
value: 52.959829481566764
- type: nauc_recall_at_1_max
value: 28.644143760250785
- type: nauc_recall_at_1_std
value: -11.72163597077123
- type: nauc_recall_at_20_diff1
value: 36.1678225571237
- type: nauc_recall_at_20_max
value: 32.77154289601683
- type: nauc_recall_at_20_std
value: -1.4627763691409723
- type: nauc_recall_at_3_diff1
value: 42.36573375194426
- type: nauc_recall_at_3_max
value: 29.836155630039997
- type: nauc_recall_at_3_std
value: -10.921190546010779
- type: nauc_recall_at_5_diff1
value: 39.78782895608393
- type: nauc_recall_at_5_max
value: 29.974729083162995
- type: nauc_recall_at_5_std
value: -9.914213193369637
- type: ndcg_at_1
value: 37.584833333333336
- type: ndcg_at_10
value: 49.35933333333333
- type: ndcg_at_100
value: 54.516083333333334
- type: ndcg_at_1000
value: 56.13400000000001
- type: ndcg_at_20
value: 51.47983333333334
- type: ndcg_at_3
value: 43.94075
- type: ndcg_at_5
value: 46.43991666666667
- type: precision_at_1
value: 37.584833333333336
- type: precision_at_10
value: 8.754333333333332
- type: precision_at_100
value: 1.3438333333333334
- type: precision_at_1000
value: 0.16591666666666666
- type: precision_at_20
value: 5.135833333333332
- type: precision_at_3
value: 20.47383333333333
- type: precision_at_5
value: 14.480333333333334
- type: recall_at_1
value: 31.5475
- type: recall_at_10
value: 62.99808333333332
- type: recall_at_100
value: 85.16766666666666
- type: recall_at_1000
value: 95.88949999999998
- type: recall_at_20
value: 70.61158333333333
- type: recall_at_3
value: 47.78208333333333
- type: recall_at_5
value: 54.30466666666667
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackUnixRetrieval
type: mteb/cqadupstack-unix
config: default
split: test
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
metrics:
- type: main_score
value: 51.409000000000006
- type: map_at_1
value: 33.44
- type: map_at_10
value: 45.242
- type: map_at_100
value: 46.457
- type: map_at_1000
value: 46.539
- type: map_at_20
value: 45.928999999999995
- type: map_at_3
value: 41.736000000000004
- type: map_at_5
value: 43.717
- type: mrr_at_1
value: 39.17910447761194
- type: mrr_at_10
value: 49.54868514570004
- type: mrr_at_100
value: 50.31474300711142
- type: mrr_at_1000
value: 50.35763716395954
- type: mrr_at_20
value: 49.99823659223059
- type: mrr_at_3
value: 46.8128109452736
- type: mrr_at_5
value: 48.45926616915417
- type: nauc_map_at_1000_diff1
value: 50.87257673340992
- type: nauc_map_at_1000_max
value: 40.34609374301027
- type: nauc_map_at_1000_std
value: -7.379981243726618
- type: nauc_map_at_100_diff1
value: 50.854157949159365
- type: nauc_map_at_100_max
value: 40.34032556006189
- type: nauc_map_at_100_std
value: -7.399964737756573
- type: nauc_map_at_10_diff1
value: 50.686246859628525
- type: nauc_map_at_10_max
value: 39.908128766187275
- type: nauc_map_at_10_std
value: -7.7328502513278625
- type: nauc_map_at_1_diff1
value: 55.57814128760479
- type: nauc_map_at_1_max
value: 38.478658985510826
- type: nauc_map_at_1_std
value: -6.372508238481584
- type: nauc_map_at_20_diff1
value: 50.772989231947626
- type: nauc_map_at_20_max
value: 40.23956514712802
- type: nauc_map_at_20_std
value: -7.514568627968219
- type: nauc_map_at_3_diff1
value: 52.014664217088544
- type: nauc_map_at_3_max
value: 39.734083375309915
- type: nauc_map_at_3_std
value: -7.926554803796402
- type: nauc_map_at_5_diff1
value: 51.01483620986479
- type: nauc_map_at_5_max
value: 39.45610862159722
- type: nauc_map_at_5_std
value: -8.27731392985267
- type: nauc_mrr_at_1000_diff1
value: 51.00481391598901
- type: nauc_mrr_at_1000_max
value: 42.212066475020265
- type: nauc_mrr_at_1000_std
value: -6.370874800186104
- type: nauc_mrr_at_100_diff1
value: 50.990520232150246
- type: nauc_mrr_at_100_max
value: 42.19016027339401
- type: nauc_mrr_at_100_std
value: -6.3827695296657145
- type: nauc_mrr_at_10_diff1
value: 50.744688903224954
- type: nauc_mrr_at_10_max
value: 42.11767789677446
- type: nauc_mrr_at_10_std
value: -6.497082850925394
- type: nauc_mrr_at_1_diff1
value: 55.54795613882778
- type: nauc_mrr_at_1_max
value: 43.333268044897565
- type: nauc_mrr_at_1_std
value: -5.456284327113586
- type: nauc_mrr_at_20_diff1
value: 50.8946692657115
- type: nauc_mrr_at_20_max
value: 42.131007988181466
- type: nauc_mrr_at_20_std
value: -6.474403898884448
- type: nauc_mrr_at_3_diff1
value: 51.41122299252956
- type: nauc_mrr_at_3_max
value: 42.43303267211499
- type: nauc_mrr_at_3_std
value: -6.499097476761323
- type: nauc_mrr_at_5_diff1
value: 50.94067629188639
- type: nauc_mrr_at_5_max
value: 41.914612395133574
- type: nauc_mrr_at_5_std
value: -7.173024101198252
- type: nauc_ndcg_at_1000_diff1
value: 49.671254442063336
- type: nauc_ndcg_at_1000_max
value: 41.233236425229265
- type: nauc_ndcg_at_1000_std
value: -5.974613943524345
- type: nauc_ndcg_at_100_diff1
value: 49.27027768005878
- type: nauc_ndcg_at_100_max
value: 40.948430026662564
- type: nauc_ndcg_at_100_std
value: -6.144610616966986
- type: nauc_ndcg_at_10_diff1
value: 48.558081201050165
- type: nauc_ndcg_at_10_max
value: 39.83487109315805
- type: nauc_ndcg_at_10_std
value: -7.615747684830626
- type: nauc_ndcg_at_1_diff1
value: 55.54795613882778
- type: nauc_ndcg_at_1_max
value: 43.333268044897565
- type: nauc_ndcg_at_1_std
value: -5.456284327113586
- type: nauc_ndcg_at_20_diff1
value: 48.892103792460844
- type: nauc_ndcg_at_20_max
value: 40.56965396855626
- type: nauc_ndcg_at_20_std
value: -7.033583531769024
- type: nauc_ndcg_at_3_diff1
value: 49.89643618093189
- type: nauc_ndcg_at_3_max
value: 40.22963794071276
- type: nauc_ndcg_at_3_std
value: -7.855589248597761
- type: nauc_ndcg_at_5_diff1
value: 48.921894655198365
- type: nauc_ndcg_at_5_max
value: 39.14662005574934
- type: nauc_ndcg_at_5_std
value: -8.845551763577872
- type: nauc_precision_at_1000_diff1
value: -14.518585158460978
- type: nauc_precision_at_1000_max
value: -1.7667784893915466
- type: nauc_precision_at_1000_std
value: 4.097998545067049
- type: nauc_precision_at_100_diff1
value: -4.950584630399553
- type: nauc_precision_at_100_max
value: 11.512730083218312
- type: nauc_precision_at_100_std
value: 6.330359665958284
- type: nauc_precision_at_10_diff1
value: 13.399849359324334
- type: nauc_precision_at_10_max
value: 26.855775987033937
- type: nauc_precision_at_10_std
value: -2.2873353847128644
- type: nauc_precision_at_1_diff1
value: 55.54795613882778
- type: nauc_precision_at_1_max
value: 43.333268044897565
- type: nauc_precision_at_1_std
value: -5.456284327113586
- type: nauc_precision_at_20_diff1
value: 7.679011471251583
- type: nauc_precision_at_20_max
value: 23.467700358632555
- type: nauc_precision_at_20_std
value: 1.1981871681272394
- type: nauc_precision_at_3_diff1
value: 32.921575397699506
- type: nauc_precision_at_3_max
value: 37.04097281242502
- type: nauc_precision_at_3_std
value: -5.360800309380987
- type: nauc_precision_at_5_diff1
value: 23.223401114141097
- type: nauc_precision_at_5_max
value: 31.530032692944605
- type: nauc_precision_at_5_std
value: -5.865853042470798
- type: nauc_recall_at_1000_diff1
value: 32.0155855987812
- type: nauc_recall_at_1000_max
value: 62.44988003291033
- type: nauc_recall_at_1000_std
value: 53.82320454819172
- type: nauc_recall_at_100_diff1
value: 36.65083199031551
- type: nauc_recall_at_100_max
value: 37.69410771344005
- type: nauc_recall_at_100_std
value: 3.579296637477123
- type: nauc_recall_at_10_diff1
value: 38.70173468166519
- type: nauc_recall_at_10_max
value: 34.1784276048144
- type: nauc_recall_at_10_std
value: -8.086019685277327
- type: nauc_recall_at_1_diff1
value: 55.57814128760479
- type: nauc_recall_at_1_max
value: 38.478658985510826
- type: nauc_recall_at_1_std
value: -6.372508238481584
- type: nauc_recall_at_20_diff1
value: 38.79450347259083
- type: nauc_recall_at_20_max
value: 36.05352697027188
- type: nauc_recall_at_20_std
value: -6.093850431049945
- type: nauc_recall_at_3_diff1
value: 45.74158065265736
- type: nauc_recall_at_3_max
value: 36.63626821782645
- type: nauc_recall_at_3_std
value: -9.653958457056982
- type: nauc_recall_at_5_diff1
value: 41.65880696047371
- type: nauc_recall_at_5_max
value: 33.8382122882109
- type: nauc_recall_at_5_std
value: -11.20106963946605
- type: ndcg_at_1
value: 39.179
- type: ndcg_at_10
value: 51.409000000000006
- type: ndcg_at_100
value: 56.499
- type: ndcg_at_1000
value: 58.062000000000005
- type: ndcg_at_20
value: 53.454
- type: ndcg_at_3
value: 45.754
- type: ndcg_at_5
value: 48.463
- type: precision_at_1
value: 39.179
- type: precision_at_10
value: 8.806
- type: precision_at_100
value: 1.2550000000000001
- type: precision_at_1000
value: 0.149
- type: precision_at_20
value: 5.009
- type: precision_at_3
value: 21.144
- type: precision_at_5
value: 14.832
- type: recall_at_1
value: 33.44
- type: recall_at_10
value: 65.496
- type: recall_at_100
value: 87.182
- type: recall_at_1000
value: 97.357
- type: recall_at_20
value: 72.697
- type: recall_at_3
value: 49.924
- type: recall_at_5
value: 56.95
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWebmastersRetrieval
type: mteb/cqadupstack-webmasters
config: default
split: test
revision: 160c094312a0e1facb97e55eeddb698c0abe3571
metrics:
- type: main_score
value: 48.375
- type: map_at_1
value: 30.793
- type: map_at_10
value: 41.662
- type: map_at_100
value: 43.66
- type: map_at_1000
value: 43.878
- type: map_at_20
value: 42.667
- type: map_at_3
value: 38.458999999999996
- type: map_at_5
value: 39.97
- type: mrr_at_1
value: 37.15415019762846
- type: mrr_at_10
value: 46.61584792019573
- type: mrr_at_100
value: 47.583978313689805
- type: mrr_at_1000
value: 47.61436921649715
- type: mrr_at_20
value: 47.16104598393294
- type: mrr_at_3
value: 44.23583662714098
- type: mrr_at_5
value: 45.29314888010541
- type: nauc_map_at_1000_diff1
value: 50.738532964091355
- type: nauc_map_at_1000_max
value: 33.1761869184962
- type: nauc_map_at_1000_std
value: -11.88545399582968
- type: nauc_map_at_100_diff1
value: 50.820635857587945
- type: nauc_map_at_100_max
value: 33.37659274306262
- type: nauc_map_at_100_std
value: -12.261098317018648
- type: nauc_map_at_10_diff1
value: 51.34955861172913
- type: nauc_map_at_10_max
value: 33.07036272698984
- type: nauc_map_at_10_std
value: -13.958268441726652
- type: nauc_map_at_1_diff1
value: 58.14264885967374
- type: nauc_map_at_1_max
value: 31.098191422332405
- type: nauc_map_at_1_std
value: -16.55201181770837
- type: nauc_map_at_20_diff1
value: 51.138925497848945
- type: nauc_map_at_20_max
value: 33.294483331998656
- type: nauc_map_at_20_std
value: -13.386238751309648
- type: nauc_map_at_3_diff1
value: 53.11933171962268
- type: nauc_map_at_3_max
value: 33.174584991640856
- type: nauc_map_at_3_std
value: -15.227875860055217
- type: nauc_map_at_5_diff1
value: 51.91013458222077
- type: nauc_map_at_5_max
value: 33.432034239350386
- type: nauc_map_at_5_std
value: -14.493952556516101
- type: nauc_mrr_at_1000_diff1
value: 49.46380145346334
- type: nauc_mrr_at_1000_max
value: 32.79378116341429
- type: nauc_mrr_at_1000_std
value: -10.714169233380185
- type: nauc_mrr_at_100_diff1
value: 49.45394564674785
- type: nauc_mrr_at_100_max
value: 32.7943550676381
- type: nauc_mrr_at_100_std
value: -10.696490620685783
- type: nauc_mrr_at_10_diff1
value: 49.500335538737914
- type: nauc_mrr_at_10_max
value: 32.77023244114561
- type: nauc_mrr_at_10_std
value: -11.104541089359515
- type: nauc_mrr_at_1_diff1
value: 52.76130402864484
- type: nauc_mrr_at_1_max
value: 31.114589410052044
- type: nauc_mrr_at_1_std
value: -12.937210710275965
- type: nauc_mrr_at_20_diff1
value: 49.414643398815365
- type: nauc_mrr_at_20_max
value: 32.763780752203516
- type: nauc_mrr_at_20_std
value: -10.804422561377299
- type: nauc_mrr_at_3_diff1
value: 50.01492870108368
- type: nauc_mrr_at_3_max
value: 32.72937861591098
- type: nauc_mrr_at_3_std
value: -11.940075063628994
- type: nauc_mrr_at_5_diff1
value: 49.48188504874961
- type: nauc_mrr_at_5_max
value: 33.16403773206102
- type: nauc_mrr_at_5_std
value: -11.21411630948482
- type: nauc_ndcg_at_1000_diff1
value: 48.54198944308599
- type: nauc_ndcg_at_1000_max
value: 33.76118694493479
- type: nauc_ndcg_at_1000_std
value: -8.65402138092725
- type: nauc_ndcg_at_100_diff1
value: 48.108850696506025
- type: nauc_ndcg_at_100_max
value: 33.84243712166641
- type: nauc_ndcg_at_100_std
value: -8.254554667297844
- type: nauc_ndcg_at_10_diff1
value: 47.89236428952843
- type: nauc_ndcg_at_10_max
value: 31.812029093395473
- type: nauc_ndcg_at_10_std
value: -11.127378110447985
- type: nauc_ndcg_at_1_diff1
value: 52.76130402864484
- type: nauc_ndcg_at_1_max
value: 31.114589410052044
- type: nauc_ndcg_at_1_std
value: -12.937210710275965
- type: nauc_ndcg_at_20_diff1
value: 47.905767671630315
- type: nauc_ndcg_at_20_max
value: 32.49208823548766
- type: nauc_ndcg_at_20_std
value: -10.250570357659894
- type: nauc_ndcg_at_3_diff1
value: 49.59377768692143
- type: nauc_ndcg_at_3_max
value: 33.13546546596274
- type: nauc_ndcg_at_3_std
value: -12.19125595753908
- type: nauc_ndcg_at_5_diff1
value: 48.35844341475799
- type: nauc_ndcg_at_5_max
value: 33.13927657899762
- type: nauc_ndcg_at_5_std
value: -11.300005449965582
- type: nauc_precision_at_1000_diff1
value: -16.480026591870523
- type: nauc_precision_at_1000_max
value: -15.181621988935524
- type: nauc_precision_at_1000_std
value: 34.719339551334855
- type: nauc_precision_at_100_diff1
value: -16.56707264200106
- type: nauc_precision_at_100_max
value: -6.877547823040516
- type: nauc_precision_at_100_std
value: 31.758215821939384
- type: nauc_precision_at_10_diff1
value: 4.772949413625673
- type: nauc_precision_at_10_max
value: 14.48563506451036
- type: nauc_precision_at_10_std
value: 12.151171571697414
- type: nauc_precision_at_1_diff1
value: 52.76130402864484
- type: nauc_precision_at_1_max
value: 31.114589410052044
- type: nauc_precision_at_1_std
value: -12.937210710275965
- type: nauc_precision_at_20_diff1
value: -5.247617701441084
- type: nauc_precision_at_20_max
value: 7.8524153059071065
- type: nauc_precision_at_20_std
value: 20.475057466275427
- type: nauc_precision_at_3_diff1
value: 29.307240726725464
- type: nauc_precision_at_3_max
value: 30.53776235029683
- type: nauc_precision_at_3_std
value: -1.9867363754853145
- type: nauc_precision_at_5_diff1
value: 16.82602124982839
- type: nauc_precision_at_5_max
value: 24.967617984133213
- type: nauc_precision_at_5_std
value: 3.7688940286519914
- type: nauc_recall_at_1000_diff1
value: 19.911102783538993
- type: nauc_recall_at_1000_max
value: 43.55994274840259
- type: nauc_recall_at_1000_std
value: 44.61688663280485
- type: nauc_recall_at_100_diff1
value: 25.00639435271183
- type: nauc_recall_at_100_max
value: 34.51865414347991
- type: nauc_recall_at_100_std
value: 18.406464007769454
- type: nauc_recall_at_10_diff1
value: 38.62687941260691
- type: nauc_recall_at_10_max
value: 27.489917928538553
- type: nauc_recall_at_10_std
value: -10.35234915862916
- type: nauc_recall_at_1_diff1
value: 58.14264885967374
- type: nauc_recall_at_1_max
value: 31.098191422332405
- type: nauc_recall_at_1_std
value: -16.55201181770837
- type: nauc_recall_at_20_diff1
value: 35.11800106234923
- type: nauc_recall_at_20_max
value: 28.356707989534385
- type: nauc_recall_at_20_std
value: -5.782361862032475
- type: nauc_recall_at_3_diff1
value: 47.010690556838405
- type: nauc_recall_at_3_max
value: 30.960698559313798
- type: nauc_recall_at_3_std
value: -14.716248620617172
- type: nauc_recall_at_5_diff1
value: 42.9526068288436
- type: nauc_recall_at_5_max
value: 31.419778612165533
- type: nauc_recall_at_5_std
value: -11.818424254829178
- type: ndcg_at_1
value: 37.153999999999996
- type: ndcg_at_10
value: 48.375
- type: ndcg_at_100
value: 54.657
- type: ndcg_at_1000
value: 56.208000000000006
- type: ndcg_at_20
value: 50.771
- type: ndcg_at_3
value: 43.315
- type: ndcg_at_5
value: 45.129000000000005
- type: precision_at_1
value: 37.153999999999996
- type: precision_at_10
value: 9.328
- type: precision_at_100
value: 1.9029999999999998
- type: precision_at_1000
value: 0.258
- type: precision_at_20
value: 5.998
- type: precision_at_3
value: 20.224
- type: precision_at_5
value: 14.347999999999999
- type: recall_at_1
value: 30.793
- type: recall_at_10
value: 60.999
- type: recall_at_100
value: 88.24499999999999
- type: recall_at_1000
value: 97.773
- type: recall_at_20
value: 69.702
- type: recall_at_3
value: 46.255
- type: recall_at_5
value: 51.245
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWordpressRetrieval
type: mteb/cqadupstack-wordpress
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: main_score
value: 41.349000000000004
- type: map_at_1
value: 26.75
- type: map_at_10
value: 36.042
- type: map_at_100
value: 37.172
- type: map_at_1000
value: 37.261
- type: map_at_20
value: 36.66
- type: map_at_3
value: 33.235
- type: map_at_5
value: 34.748000000000005
- type: mrr_at_1
value: 29.390018484288355
- type: mrr_at_10
value: 38.4025760643136
- type: mrr_at_100
value: 39.374703522095395
- type: mrr_at_1000
value: 39.42972569352847
- type: mrr_at_20
value: 38.93955238768051
- type: mrr_at_3
value: 36.013555144793614
- type: mrr_at_5
value: 37.2520024645718
- type: nauc_map_at_1000_diff1
value: 44.69823016014606
- type: nauc_map_at_1000_max
value: 25.57190426738162
- type: nauc_map_at_1000_std
value: -4.199140067047161
- type: nauc_map_at_100_diff1
value: 44.683770406187875
- type: nauc_map_at_100_max
value: 25.551408403995257
- type: nauc_map_at_100_std
value: -4.218572010835323
- type: nauc_map_at_10_diff1
value: 44.68530737786573
- type: nauc_map_at_10_max
value: 25.46193155573604
- type: nauc_map_at_10_std
value: -4.809871031910446
- type: nauc_map_at_1_diff1
value: 50.41571355104115
- type: nauc_map_at_1_max
value: 26.581260847509704
- type: nauc_map_at_1_std
value: -5.403238214693907
- type: nauc_map_at_20_diff1
value: 44.731965188076956
- type: nauc_map_at_20_max
value: 25.404018335678042
- type: nauc_map_at_20_std
value: -4.518115190513196
- type: nauc_map_at_3_diff1
value: 45.72733737454689
- type: nauc_map_at_3_max
value: 25.16236634356437
- type: nauc_map_at_3_std
value: -5.210810848188912
- type: nauc_map_at_5_diff1
value: 45.04362118675467
- type: nauc_map_at_5_max
value: 25.256832347187792
- type: nauc_map_at_5_std
value: -4.665177712989629
- type: nauc_mrr_at_1000_diff1
value: 43.96570681453743
- type: nauc_mrr_at_1000_max
value: 25.515577482173303
- type: nauc_mrr_at_1000_std
value: -3.1318312163116167
- type: nauc_mrr_at_100_diff1
value: 43.94835648436942
- type: nauc_mrr_at_100_max
value: 25.485710237620257
- type: nauc_mrr_at_100_std
value: -3.1262634160182587
- type: nauc_mrr_at_10_diff1
value: 43.87989114303318
- type: nauc_mrr_at_10_max
value: 25.561703958752073
- type: nauc_mrr_at_10_std
value: -3.5337096979285465
- type: nauc_mrr_at_1_diff1
value: 50.5769748938826
- type: nauc_mrr_at_1_max
value: 27.540216184434602
- type: nauc_mrr_at_1_std
value: -4.3410331054744455
- type: nauc_mrr_at_20_diff1
value: 43.89090600752474
- type: nauc_mrr_at_20_max
value: 25.35538914450936
- type: nauc_mrr_at_20_std
value: -3.256848712300088
- type: nauc_mrr_at_3_diff1
value: 44.67145787977651
- type: nauc_mrr_at_3_max
value: 25.743032202078233
- type: nauc_mrr_at_3_std
value: -3.543961143296222
- type: nauc_mrr_at_5_diff1
value: 44.1410906123774
- type: nauc_mrr_at_5_max
value: 25.512981453020377
- type: nauc_mrr_at_5_std
value: -3.3984260964459625
- type: nauc_ndcg_at_1000_diff1
value: 42.094467874822634
- type: nauc_ndcg_at_1000_max
value: 25.773789329652143
- type: nauc_ndcg_at_1000_std
value: -1.5030137154663146
- type: nauc_ndcg_at_100_diff1
value: 41.551311444176505
- type: nauc_ndcg_at_100_max
value: 25.41326272306838
- type: nauc_ndcg_at_100_std
value: -1.2565322587434289
- type: nauc_ndcg_at_10_diff1
value: 41.692329741760844
- type: nauc_ndcg_at_10_max
value: 24.973824605697946
- type: nauc_ndcg_at_10_std
value: -4.0454407772294445
- type: nauc_ndcg_at_1_diff1
value: 50.5769748938826
- type: nauc_ndcg_at_1_max
value: 27.540216184434602
- type: nauc_ndcg_at_1_std
value: -4.3410331054744455
- type: nauc_ndcg_at_20_diff1
value: 41.7849741522554
- type: nauc_ndcg_at_20_max
value: 24.483461844450098
- type: nauc_ndcg_at_20_std
value: -3.0192185885852267
- type: nauc_ndcg_at_3_diff1
value: 43.50095372671906
- type: nauc_ndcg_at_3_max
value: 25.0660548267931
- type: nauc_ndcg_at_3_std
value: -4.136658038209795
- type: nauc_ndcg_at_5_diff1
value: 42.56860328119003
- type: nauc_ndcg_at_5_max
value: 24.64471019866571
- type: nauc_ndcg_at_5_std
value: -3.7919812365370316
- type: nauc_precision_at_1000_diff1
value: -11.608868871826067
- type: nauc_precision_at_1000_max
value: -4.774237268127937
- type: nauc_precision_at_1000_std
value: 12.15076818010773
- type: nauc_precision_at_100_diff1
value: 1.9653391598989818
- type: nauc_precision_at_100_max
value: 14.82175127203874
- type: nauc_precision_at_100_std
value: 19.14581435930739
- type: nauc_precision_at_10_diff1
value: 24.310184596872997
- type: nauc_precision_at_10_max
value: 24.654364730313127
- type: nauc_precision_at_10_std
value: 3.834736733208166
- type: nauc_precision_at_1_diff1
value: 50.5769748938826
- type: nauc_precision_at_1_max
value: 27.540216184434602
- type: nauc_precision_at_1_std
value: -4.3410331054744455
- type: nauc_precision_at_20_diff1
value: 20.31741982412239
- type: nauc_precision_at_20_max
value: 21.813185907394
- type: nauc_precision_at_20_std
value: 8.67748469930042
- type: nauc_precision_at_3_diff1
value: 36.23426146022416
- type: nauc_precision_at_3_max
value: 25.085104352996147
- type: nauc_precision_at_3_std
value: -0.13994055865810526
- type: nauc_precision_at_5_diff1
value: 30.713670782259456
- type: nauc_precision_at_5_max
value: 25.073465240016198
- type: nauc_precision_at_5_std
value: 2.903773154373253
- type: nauc_recall_at_1000_diff1
value: 14.861338959184192
- type: nauc_recall_at_1000_max
value: 38.46379100413754
- type: nauc_recall_at_1000_std
value: 40.82683088866469
- type: nauc_recall_at_100_diff1
value: 24.540319510278348
- type: nauc_recall_at_100_max
value: 24.172628109630832
- type: nauc_recall_at_100_std
value: 16.567712965914602
- type: nauc_recall_at_10_diff1
value: 31.92224903523137
- type: nauc_recall_at_10_max
value: 22.064974975663127
- type: nauc_recall_at_10_std
value: -3.156058361445988
- type: nauc_recall_at_1_diff1
value: 50.41571355104115
- type: nauc_recall_at_1_max
value: 26.581260847509704
- type: nauc_recall_at_1_std
value: -5.403238214693907
- type: nauc_recall_at_20_diff1
value: 31.409257808669842
- type: nauc_recall_at_20_max
value: 19.307470123424853
- type: nauc_recall_at_20_std
value: 0.8921848838324672
- type: nauc_recall_at_3_diff1
value: 37.83159917842702
- type: nauc_recall_at_3_max
value: 22.128986921876365
- type: nauc_recall_at_3_std
value: -4.332761965568785
- type: nauc_recall_at_5_diff1
value: 35.43509187423654
- type: nauc_recall_at_5_max
value: 21.559603832786657
- type: nauc_recall_at_5_std
value: -2.7879479079841327
- type: ndcg_at_1
value: 29.39
- type: ndcg_at_10
value: 41.349000000000004
- type: ndcg_at_100
value: 46.814
- type: ndcg_at_1000
value: 48.748000000000005
- type: ndcg_at_20
value: 43.491
- type: ndcg_at_3
value: 36.120000000000005
- type: ndcg_at_5
value: 38.415
- type: precision_at_1
value: 29.39
- type: precision_at_10
value: 6.451
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.128
- type: precision_at_20
value: 3.762
- type: precision_at_3
value: 15.588
- type: precision_at_5
value: 10.795
- type: recall_at_1
value: 26.75
- type: recall_at_10
value: 55.397
- type: recall_at_100
value: 80.247
- type: recall_at_1000
value: 94.207
- type: recall_at_20
value: 63.55499999999999
- type: recall_at_3
value: 41.083999999999996
- type: recall_at_5
value: 46.58
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: mteb/climate-fever
config: default
split: test
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
metrics:
- type: main_score
value: 43.469
- type: map_at_1
value: 19.506999999999998
- type: map_at_10
value: 33.016
- type: map_at_100
value: 35.36
- type: map_at_1000
value: 35.515
- type: map_at_20
value: 34.323
- type: map_at_3
value: 27.862
- type: map_at_5
value: 30.612000000000002
- type: mrr_at_1
value: 44.16938110749186
- type: mrr_at_10
value: 56.57685745307904
- type: mrr_at_100
value: 57.17414254225016
- type: mrr_at_1000
value: 57.189032189089495
- type: mrr_at_20
value: 56.97649801229595
- type: mrr_at_3
value: 53.84364820846914
- type: mrr_at_5
value: 55.55048859934868
- type: nauc_map_at_1000_diff1
value: 24.602536884273523
- type: nauc_map_at_1000_max
value: 39.26487354477874
- type: nauc_map_at_1000_std
value: 22.94302438231403
- type: nauc_map_at_100_diff1
value: 24.592347616537754
- type: nauc_map_at_100_max
value: 39.228370594048044
- type: nauc_map_at_100_std
value: 22.91028538467064
- type: nauc_map_at_10_diff1
value: 25.211737206439466
- type: nauc_map_at_10_max
value: 39.14645027724652
- type: nauc_map_at_10_std
value: 21.645361248764246
- type: nauc_map_at_1_diff1
value: 34.574022172223785
- type: nauc_map_at_1_max
value: 36.80960969907521
- type: nauc_map_at_1_std
value: 14.745037917509043
- type: nauc_map_at_20_diff1
value: 24.522877050053797
- type: nauc_map_at_20_max
value: 39.059341666216426
- type: nauc_map_at_20_std
value: 22.4609918713542
- type: nauc_map_at_3_diff1
value: 27.15813672283225
- type: nauc_map_at_3_max
value: 38.14947129547116
- type: nauc_map_at_3_std
value: 18.37694411131855
- type: nauc_map_at_5_diff1
value: 26.3963128622898
- type: nauc_map_at_5_max
value: 38.79462114513801
- type: nauc_map_at_5_std
value: 19.904846635683718
- type: nauc_mrr_at_1000_diff1
value: 24.390212975354274
- type: nauc_mrr_at_1000_max
value: 37.575264384207465
- type: nauc_mrr_at_1000_std
value: 22.607616532255875
- type: nauc_mrr_at_100_diff1
value: 24.38096540780017
- type: nauc_mrr_at_100_max
value: 37.585671997802656
- type: nauc_mrr_at_100_std
value: 22.625502455820666
- type: nauc_mrr_at_10_diff1
value: 24.240023464772193
- type: nauc_mrr_at_10_max
value: 37.624380443643524
- type: nauc_mrr_at_10_std
value: 22.694399526110466
- type: nauc_mrr_at_1_diff1
value: 28.020125669466562
- type: nauc_mrr_at_1_max
value: 34.02386180115898
- type: nauc_mrr_at_1_std
value: 17.835724317244686
- type: nauc_mrr_at_20_diff1
value: 24.333355652108292
- type: nauc_mrr_at_20_max
value: 37.57796475058575
- type: nauc_mrr_at_20_std
value: 22.704917335783062
- type: nauc_mrr_at_3_diff1
value: 24.9739147862957
- type: nauc_mrr_at_3_max
value: 37.960296534359685
- type: nauc_mrr_at_3_std
value: 21.93607347433575
- type: nauc_mrr_at_5_diff1
value: 24.320129475684165
- type: nauc_mrr_at_5_max
value: 37.58866607632526
- type: nauc_mrr_at_5_std
value: 22.31442317668481
- type: nauc_ndcg_at_1000_diff1
value: 21.893106953223356
- type: nauc_ndcg_at_1000_max
value: 40.38192211749562
- type: nauc_ndcg_at_1000_std
value: 27.943530727839622
- type: nauc_ndcg_at_100_diff1
value: 21.476881814995785
- type: nauc_ndcg_at_100_max
value: 39.91597694502497
- type: nauc_ndcg_at_100_std
value: 27.80086195626175
- type: nauc_ndcg_at_10_diff1
value: 22.788155104417537
- type: nauc_ndcg_at_10_max
value: 39.64018481724029
- type: nauc_ndcg_at_10_std
value: 24.608760819228856
- type: nauc_ndcg_at_1_diff1
value: 28.020125669466562
- type: nauc_ndcg_at_1_max
value: 34.02386180115898
- type: nauc_ndcg_at_1_std
value: 17.835724317244686
- type: nauc_ndcg_at_20_diff1
value: 21.435037904375516
- type: nauc_ndcg_at_20_max
value: 39.41545921639339
- type: nauc_ndcg_at_20_std
value: 26.302180505922152
- type: nauc_ndcg_at_3_diff1
value: 24.37753699681809
- type: nauc_ndcg_at_3_max
value: 37.92832349922249
- type: nauc_ndcg_at_3_std
value: 20.314267862236697
- type: nauc_ndcg_at_5_diff1
value: 24.489993763202634
- type: nauc_ndcg_at_5_max
value: 39.322948140029744
- type: nauc_ndcg_at_5_std
value: 22.069807417424485
- type: nauc_precision_at_1000_diff1
value: -16.048547778222588
- type: nauc_precision_at_1000_max
value: -3.205412586478899
- type: nauc_precision_at_1000_std
value: 14.433544284750797
- type: nauc_precision_at_100_diff1
value: -11.787991777545036
- type: nauc_precision_at_100_max
value: 6.850986771358883
- type: nauc_precision_at_100_std
value: 22.572974966148244
- type: nauc_precision_at_10_diff1
value: -0.5111959706315438
- type: nauc_precision_at_10_max
value: 22.560355393578128
- type: nauc_precision_at_10_std
value: 25.562322716450424
- type: nauc_precision_at_1_diff1
value: 28.020125669466562
- type: nauc_precision_at_1_max
value: 34.02386180115898
- type: nauc_precision_at_1_std
value: 17.835724317244686
- type: nauc_precision_at_20_diff1
value: -6.0772940189383275
- type: nauc_precision_at_20_max
value: 17.194360329332213
- type: nauc_precision_at_20_std
value: 26.551077839343566
- type: nauc_precision_at_3_diff1
value: 10.033294854519573
- type: nauc_precision_at_3_max
value: 31.72453436391336
- type: nauc_precision_at_3_std
value: 22.294966409945427
- type: nauc_precision_at_5_diff1
value: 6.237641122443952
- type: nauc_precision_at_5_max
value: 28.3251946189731
- type: nauc_precision_at_5_std
value: 23.742964477476097
- type: nauc_recall_at_1000_diff1
value: 7.066317014709414
- type: nauc_recall_at_1000_max
value: 41.26207890590803
- type: nauc_recall_at_1000_std
value: 48.082120972049324
- type: nauc_recall_at_100_diff1
value: 8.5605869633491
- type: nauc_recall_at_100_max
value: 34.21516017657153
- type: nauc_recall_at_100_std
value: 36.23370174719997
- type: nauc_recall_at_10_diff1
value: 15.894026727549823
- type: nauc_recall_at_10_max
value: 35.7217710490404
- type: nauc_recall_at_10_std
value: 25.411329590972702
- type: nauc_recall_at_1_diff1
value: 34.574022172223785
- type: nauc_recall_at_1_max
value: 36.80960969907521
- type: nauc_recall_at_1_std
value: 14.745037917509043
- type: nauc_recall_at_20_diff1
value: 11.044245946655797
- type: nauc_recall_at_20_max
value: 33.321827723279846
- type: nauc_recall_at_20_std
value: 28.839341482904228
- type: nauc_recall_at_3_diff1
value: 23.574156335947677
- type: nauc_recall_at_3_max
value: 38.36490056324833
- type: nauc_recall_at_3_std
value: 19.781669176069148
- type: nauc_recall_at_5_diff1
value: 20.375492803538272
- type: nauc_recall_at_5_max
value: 37.13169592173094
- type: nauc_recall_at_5_std
value: 21.698652331981503
- type: ndcg_at_1
value: 44.169000000000004
- type: ndcg_at_10
value: 43.469
- type: ndcg_at_100
value: 51.056000000000004
- type: ndcg_at_1000
value: 53.467
- type: ndcg_at_20
value: 46.601
- type: ndcg_at_3
value: 37.138
- type: ndcg_at_5
value: 39.286
- type: precision_at_1
value: 44.169000000000004
- type: precision_at_10
value: 13.316
- type: precision_at_100
value: 2.149
- type: precision_at_1000
value: 0.261
- type: precision_at_20
value: 8.01
- type: precision_at_3
value: 27.839000000000002
- type: precision_at_5
value: 20.846999999999998
- type: recall_at_1
value: 19.506999999999998
- type: recall_at_10
value: 49.242000000000004
- type: recall_at_100
value: 74.421
- type: recall_at_1000
value: 87.53699999999999
- type: recall_at_20
value: 57.992
- type: recall_at_3
value: 33.024
- type: recall_at_5
value: 40.178000000000004
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: mteb/dbpedia
config: default
split: test
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
metrics:
- type: main_score
value: 50.815999999999995
- type: map_at_1
value: 10.4
- type: map_at_10
value: 24.509
- type: map_at_100
value: 35.888
- type: map_at_1000
value: 37.881
- type: map_at_20
value: 29.248
- type: map_at_3
value: 16.683
- type: map_at_5
value: 20.121
- type: mrr_at_1
value: 76.5
- type: mrr_at_10
value: 82.96865079365078
- type: mrr_at_100
value: 83.15565684386043
- type: mrr_at_1000
value: 83.16234347576268
- type: mrr_at_20
value: 83.10610208827119
- type: mrr_at_3
value: 81.875
- type: mrr_at_5
value: 82.53749999999998
- type: nauc_map_at_1000_diff1
value: 23.772111749199244
- type: nauc_map_at_1000_max
value: 30.20334223785286
- type: nauc_map_at_1000_std
value: 18.05771740348393
- type: nauc_map_at_100_diff1
value: 24.99922400559097
- type: nauc_map_at_100_max
value: 30.227680457273554
- type: nauc_map_at_100_std
value: 15.266796337809208
- type: nauc_map_at_10_diff1
value: 26.33907059260499
- type: nauc_map_at_10_max
value: 21.35352795885219
- type: nauc_map_at_10_std
value: -11.676283379701461
- type: nauc_map_at_1_diff1
value: 30.9428537478304
- type: nauc_map_at_1_max
value: 10.706776298253795
- type: nauc_map_at_1_std
value: -27.48789516952886
- type: nauc_map_at_20_diff1
value: 26.028744882022643
- type: nauc_map_at_20_max
value: 25.540897708997857
- type: nauc_map_at_20_std
value: -2.1138409738399333
- type: nauc_map_at_3_diff1
value: 28.569060478595414
- type: nauc_map_at_3_max
value: 16.03075218426638
- type: nauc_map_at_3_std
value: -23.289456267507518
- type: nauc_map_at_5_diff1
value: 27.77252783978944
- type: nauc_map_at_5_max
value: 17.558788618934244
- type: nauc_map_at_5_std
value: -19.879370566923726
- type: nauc_mrr_at_1000_diff1
value: 56.24197871190471
- type: nauc_mrr_at_1000_max
value: 65.80135088215289
- type: nauc_mrr_at_1000_std
value: 41.37855291304919
- type: nauc_mrr_at_100_diff1
value: 56.23288710496704
- type: nauc_mrr_at_100_max
value: 65.80061767216726
- type: nauc_mrr_at_100_std
value: 41.36772467988576
- type: nauc_mrr_at_10_diff1
value: 56.324447358144745
- type: nauc_mrr_at_10_max
value: 65.81370075569146
- type: nauc_mrr_at_10_std
value: 41.410460564882776
- type: nauc_mrr_at_1_diff1
value: 59.65250965250966
- type: nauc_mrr_at_1_max
value: 63.83691383691382
- type: nauc_mrr_at_1_std
value: 36.73343673343676
- type: nauc_mrr_at_20_diff1
value: 56.1707409830787
- type: nauc_mrr_at_20_max
value: 65.69720497776981
- type: nauc_mrr_at_20_std
value: 41.26487560092242
- type: nauc_mrr_at_3_diff1
value: 54.9129569183045
- type: nauc_mrr_at_3_max
value: 65.99486075421906
- type: nauc_mrr_at_3_std
value: 41.95372363821559
- type: nauc_mrr_at_5_diff1
value: 56.16135725971244
- type: nauc_mrr_at_5_max
value: 66.3010887352757
- type: nauc_mrr_at_5_std
value: 42.00610529557167
- type: nauc_ndcg_at_1000_diff1
value: 32.70929215628561
- type: nauc_ndcg_at_1000_max
value: 47.10806967197569
- type: nauc_ndcg_at_1000_std
value: 35.00425836800715
- type: nauc_ndcg_at_100_diff1
value: 35.06646341481841
- type: nauc_ndcg_at_100_max
value: 45.39744548573974
- type: nauc_ndcg_at_100_std
value: 27.047969181217844
- type: nauc_ndcg_at_10_diff1
value: 27.274830141666424
- type: nauc_ndcg_at_10_max
value: 42.504020954653996
- type: nauc_ndcg_at_10_std
value: 22.697762917174995
- type: nauc_ndcg_at_1_diff1
value: 50.08311936617783
- type: nauc_ndcg_at_1_max
value: 54.73568887554088
- type: nauc_ndcg_at_1_std
value: 26.170967864741694
- type: nauc_ndcg_at_20_diff1
value: 31.242689219374427
- type: nauc_ndcg_at_20_max
value: 42.541920517016614
- type: nauc_ndcg_at_20_std
value: 18.96423111373813
- type: nauc_ndcg_at_3_diff1
value: 28.826757289224155
- type: nauc_ndcg_at_3_max
value: 43.58945597798035
- type: nauc_ndcg_at_3_std
value: 24.087165156193166
- type: nauc_ndcg_at_5_diff1
value: 26.119279113418546
- type: nauc_ndcg_at_5_max
value: 40.679930238997535
- type: nauc_ndcg_at_5_std
value: 23.46459132364594
- type: nauc_precision_at_1000_diff1
value: -21.84770974908615
- type: nauc_precision_at_1000_max
value: -14.093701963931426
- type: nauc_precision_at_1000_std
value: 9.299725592056397
- type: nauc_precision_at_100_diff1
value: -10.260185699059837
- type: nauc_precision_at_100_max
value: 9.810522145982985
- type: nauc_precision_at_100_std
value: 44.20627482372792
- type: nauc_precision_at_10_diff1
value: -4.519747556705346
- type: nauc_precision_at_10_max
value: 22.419340914046078
- type: nauc_precision_at_10_std
value: 45.53510067051897
- type: nauc_precision_at_1_diff1
value: 59.65250965250966
- type: nauc_precision_at_1_max
value: 63.83691383691382
- type: nauc_precision_at_1_std
value: 36.73343673343676
- type: nauc_precision_at_20_diff1
value: -4.894217383220783
- type: nauc_precision_at_20_max
value: 20.026284106419716
- type: nauc_precision_at_20_std
value: 46.826549838338885
- type: nauc_precision_at_3_diff1
value: 8.255495021604343
- type: nauc_precision_at_3_max
value: 32.41871125305279
- type: nauc_precision_at_3_std
value: 39.37854593274469
- type: nauc_precision_at_5_diff1
value: 0.8399922914701591
- type: nauc_precision_at_5_max
value: 25.576701242406784
- type: nauc_precision_at_5_std
value: 41.43316549318606
- type: nauc_recall_at_1000_diff1
value: 26.933682703442607
- type: nauc_recall_at_1000_max
value: 41.242862989732615
- type: nauc_recall_at_1000_std
value: 47.718397116276726
- type: nauc_recall_at_100_diff1
value: 28.66794019735935
- type: nauc_recall_at_100_max
value: 33.70954178154391
- type: nauc_recall_at_100_std
value: 20.337812189448144
- type: nauc_recall_at_10_diff1
value: 23.98560937572333
- type: nauc_recall_at_10_max
value: 17.85589161042591
- type: nauc_recall_at_10_std
value: -15.460067168640327
- type: nauc_recall_at_1_diff1
value: 30.9428537478304
- type: nauc_recall_at_1_max
value: 10.706776298253795
- type: nauc_recall_at_1_std
value: -27.48789516952886
- type: nauc_recall_at_20_diff1
value: 24.528494602453677
- type: nauc_recall_at_20_max
value: 22.39686785999968
- type: nauc_recall_at_20_std
value: -6.8755605379050495
- type: nauc_recall_at_3_diff1
value: 24.352067402718824
- type: nauc_recall_at_3_max
value: 13.630657148502184
- type: nauc_recall_at_3_std
value: -24.752279121894848
- type: nauc_recall_at_5_diff1
value: 23.93262400173538
- type: nauc_recall_at_5_max
value: 14.158970487334082
- type: nauc_recall_at_5_std
value: -22.37672315523696
- type: ndcg_at_1
value: 64.75
- type: ndcg_at_10
value: 50.815999999999995
- type: ndcg_at_100
value: 55.981
- type: ndcg_at_1000
value: 62.857
- type: ndcg_at_20
value: 50.283
- type: ndcg_at_3
value: 56.232000000000006
- type: ndcg_at_5
value: 53.303999999999995
- type: precision_at_1
value: 76.5
- type: precision_at_10
value: 40.9
- type: precision_at_100
value: 13.01
- type: precision_at_1000
value: 2.496
- type: precision_at_20
value: 31.525
- type: precision_at_3
value: 59.667
- type: precision_at_5
value: 51.5
- type: recall_at_1
value: 10.4
- type: recall_at_10
value: 29.837000000000003
- type: recall_at_100
value: 62.495999999999995
- type: recall_at_1000
value: 84.179
- type: recall_at_20
value: 39.745000000000005
- type: recall_at_3
value: 17.772
- type: recall_at_5
value: 22.732
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: mteb/fever
config: default
split: test
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
metrics:
- type: main_score
value: 93.147
- type: map_at_1
value: 84.123
- type: map_at_10
value: 90.793
- type: map_at_100
value: 91.00399999999999
- type: map_at_1000
value: 91.014
- type: map_at_20
value: 90.929
- type: map_at_3
value: 90.01
- type: map_at_5
value: 90.514
- type: mrr_at_1
value: 90.6090609060906
- type: mrr_at_10
value: 94.56931407426447
- type: mrr_at_100
value: 94.5981688826583
- type: mrr_at_1000
value: 94.59839036307305
- type: mrr_at_20
value: 94.58933347392538
- type: mrr_at_3
value: 94.39443944394432
- type: mrr_at_5
value: 94.52720272027192
- type: nauc_map_at_1000_diff1
value: 47.79099845895175
- type: nauc_map_at_1000_max
value: 27.497877436060126
- type: nauc_map_at_1000_std
value: -8.13339253954977
- type: nauc_map_at_100_diff1
value: 47.73289128218074
- type: nauc_map_at_100_max
value: 27.47233674805432
- type: nauc_map_at_100_std
value: -8.116906996417276
- type: nauc_map_at_10_diff1
value: 47.11991698822012
- type: nauc_map_at_10_max
value: 27.043478885296818
- type: nauc_map_at_10_std
value: -8.041555396807254
- type: nauc_map_at_1_diff1
value: 54.62356861092832
- type: nauc_map_at_1_max
value: 25.79991281991449
- type: nauc_map_at_1_std
value: -10.727885287362989
- type: nauc_map_at_20_diff1
value: 47.355948038923415
- type: nauc_map_at_20_max
value: 27.377496866209412
- type: nauc_map_at_20_std
value: -7.964383745017635
- type: nauc_map_at_3_diff1
value: 46.250567821995816
- type: nauc_map_at_3_max
value: 26.720427753104087
- type: nauc_map_at_3_std
value: -8.720105706265599
- type: nauc_map_at_5_diff1
value: 46.60720659354551
- type: nauc_map_at_5_max
value: 26.571065579915974
- type: nauc_map_at_5_std
value: -8.595067960972495
- type: nauc_mrr_at_1000_diff1
value: 73.70855511936261
- type: nauc_mrr_at_1000_max
value: 34.73984488188905
- type: nauc_mrr_at_1000_std
value: -19.808375433256
- type: nauc_mrr_at_100_diff1
value: 73.7096330945882
- type: nauc_mrr_at_100_max
value: 34.742520612749445
- type: nauc_mrr_at_100_std
value: -19.803463171450023
- type: nauc_mrr_at_10_diff1
value: 73.71314616789961
- type: nauc_mrr_at_10_max
value: 34.947852652846485
- type: nauc_mrr_at_10_std
value: -19.759110050207276
- type: nauc_mrr_at_1_diff1
value: 74.52821692195837
- type: nauc_mrr_at_1_max
value: 32.2133212833154
- type: nauc_mrr_at_1_std
value: -18.97663485312286
- type: nauc_mrr_at_20_diff1
value: 73.69023729557055
- type: nauc_mrr_at_20_max
value: 34.80486237439106
- type: nauc_mrr_at_20_std
value: -19.691951099200146
- type: nauc_mrr_at_3_diff1
value: 73.43522847167395
- type: nauc_mrr_at_3_max
value: 35.072062525904414
- type: nauc_mrr_at_3_std
value: -20.938095342419672
- type: nauc_mrr_at_5_diff1
value: 73.69029982038052
- type: nauc_mrr_at_5_max
value: 35.14296188327372
- type: nauc_mrr_at_5_std
value: -20.10654798165351
- type: nauc_ndcg_at_1000_diff1
value: 51.65324942604166
- type: nauc_ndcg_at_1000_max
value: 29.729210561748797
- type: nauc_ndcg_at_1000_std
value: -8.830858681742994
- type: nauc_ndcg_at_100_diff1
value: 50.40059292035861
- type: nauc_ndcg_at_100_max
value: 29.323797091488856
- type: nauc_ndcg_at_100_std
value: -8.288820123602129
- type: nauc_ndcg_at_10_diff1
value: 47.73985149996194
- type: nauc_ndcg_at_10_max
value: 28.43547785458384
- type: nauc_ndcg_at_10_std
value: -7.355960453195441
- type: nauc_ndcg_at_1_diff1
value: 74.52821692195837
- type: nauc_ndcg_at_1_max
value: 32.2133212833154
- type: nauc_ndcg_at_1_std
value: -18.97663485312286
- type: nauc_ndcg_at_20_diff1
value: 48.34744447531361
- type: nauc_ndcg_at_20_max
value: 29.147274611665104
- type: nauc_ndcg_at_20_std
value: -7.1859909752874565
- type: nauc_ndcg_at_3_diff1
value: 48.02902219011437
- type: nauc_ndcg_at_3_max
value: 29.05519326030459
- type: nauc_ndcg_at_3_std
value: -9.562414651448368
- type: nauc_ndcg_at_5_diff1
value: 47.29981191574703
- type: nauc_ndcg_at_5_max
value: 28.014651730307428
- type: nauc_ndcg_at_5_std
value: -8.661224447638219
- type: nauc_precision_at_1000_diff1
value: -10.024865744474184
- type: nauc_precision_at_1000_max
value: -4.298508017924518
- type: nauc_precision_at_1000_std
value: 1.547025732357951
- type: nauc_precision_at_100_diff1
value: -12.06926468256376
- type: nauc_precision_at_100_max
value: -4.21291413804896
- type: nauc_precision_at_100_std
value: 2.872264631517362
- type: nauc_precision_at_10_diff1
value: -15.94007852972694
- type: nauc_precision_at_10_max
value: -4.544097710963198
- type: nauc_precision_at_10_std
value: 4.767828958024675
- type: nauc_precision_at_1_diff1
value: 74.52821692195837
- type: nauc_precision_at_1_max
value: 32.2133212833154
- type: nauc_precision_at_1_std
value: -18.97663485312286
- type: nauc_precision_at_20_diff1
value: -15.66405220649896
- type: nauc_precision_at_20_max
value: -3.6496367951851822
- type: nauc_precision_at_20_std
value: 4.825301805130045
- type: nauc_precision_at_3_diff1
value: -12.514109763479336
- type: nauc_precision_at_3_max
value: -0.24447133318217024
- type: nauc_precision_at_3_std
value: -0.2649163459628502
- type: nauc_precision_at_5_diff1
value: -15.820728575356485
- type: nauc_precision_at_5_max
value: -4.786371094249761
- type: nauc_precision_at_5_std
value: 1.7929947640996053
- type: nauc_recall_at_1000_diff1
value: 5.499530852392676
- type: nauc_recall_at_1000_max
value: 44.030520852910406
- type: nauc_recall_at_1000_std
value: 50.2017454712542
- type: nauc_recall_at_100_diff1
value: 2.0640091010830526
- type: nauc_recall_at_100_max
value: 24.864404635675204
- type: nauc_recall_at_100_std
value: 27.319350569429734
- type: nauc_recall_at_10_diff1
value: 13.791800250368114
- type: nauc_recall_at_10_max
value: 24.769825741582302
- type: nauc_recall_at_10_std
value: 13.59069444609498
- type: nauc_recall_at_1_diff1
value: 54.62356861092832
- type: nauc_recall_at_1_max
value: 25.79991281991449
- type: nauc_recall_at_1_std
value: -10.727885287362989
- type: nauc_recall_at_20_diff1
value: 5.336705306013041
- type: nauc_recall_at_20_max
value: 27.41570703746024
- type: nauc_recall_at_20_std
value: 23.006970266201787
- type: nauc_recall_at_3_diff1
value: 23.292169395266264
- type: nauc_recall_at_3_max
value: 24.262360079531074
- type: nauc_recall_at_3_std
value: -1.7422845002974312
- type: nauc_recall_at_5_diff1
value: 18.060917420579997
- type: nauc_recall_at_5_max
value: 23.06733097213354
- type: nauc_recall_at_5_std
value: 3.3913875084148297
- type: ndcg_at_1
value: 90.609
- type: ndcg_at_10
value: 93.147
- type: ndcg_at_100
value: 93.74900000000001
- type: ndcg_at_1000
value: 93.901
- type: ndcg_at_20
value: 93.447
- type: ndcg_at_3
value: 92.268
- type: ndcg_at_5
value: 92.757
- type: precision_at_1
value: 90.609
- type: precision_at_10
value: 10.926
- type: precision_at_100
value: 1.149
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_20
value: 5.5809999999999995
- type: precision_at_3
value: 34.738
- type: precision_at_5
value: 21.346999999999998
- type: recall_at_1
value: 84.123
- type: recall_at_10
value: 96.539
- type: recall_at_100
value: 98.67899999999999
- type: recall_at_1000
value: 99.555
- type: recall_at_20
value: 97.45700000000001
- type: recall_at_3
value: 94.133
- type: recall_at_5
value: 95.44200000000001
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: mteb/fiqa
config: default
split: test
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
metrics:
- type: main_score
value: 61.182
- type: map_at_1
value: 31.877
- type: map_at_10
value: 52.986
- type: map_at_100
value: 55.242000000000004
- type: map_at_1000
value: 55.336
- type: map_at_20
value: 54.36299999999999
- type: map_at_3
value: 45.9
- type: map_at_5
value: 49.952000000000005
- type: mrr_at_1
value: 60.18518518518518
- type: mrr_at_10
value: 67.71611062120319
- type: mrr_at_100
value: 68.32957545203445
- type: mrr_at_1000
value: 68.34041293981731
- type: mrr_at_20
value: 68.1184684086802
- type: mrr_at_3
value: 66.04938271604934
- type: mrr_at_5
value: 67.02932098765427
- type: nauc_map_at_1000_diff1
value: 49.390058112037565
- type: nauc_map_at_1000_max
value: 33.86672922230126
- type: nauc_map_at_1000_std
value: -24.19297282790569
- type: nauc_map_at_100_diff1
value: 49.39575568085033
- type: nauc_map_at_100_max
value: 33.82800761671263
- type: nauc_map_at_100_std
value: -24.20216911890828
- type: nauc_map_at_10_diff1
value: 49.826703829159065
- type: nauc_map_at_10_max
value: 32.04132357301985
- type: nauc_map_at_10_std
value: -25.477594030350414
- type: nauc_map_at_1_diff1
value: 54.95925350681827
- type: nauc_map_at_1_max
value: 13.962825942647214
- type: nauc_map_at_1_std
value: -21.054092920927694
- type: nauc_map_at_20_diff1
value: 49.537681600887865
- type: nauc_map_at_20_max
value: 33.164569894845904
- type: nauc_map_at_20_std
value: -25.075136372458108
- type: nauc_map_at_3_diff1
value: 49.82581713716135
- type: nauc_map_at_3_max
value: 25.491261673133316
- type: nauc_map_at_3_std
value: -25.29735314206127
- type: nauc_map_at_5_diff1
value: 49.170865024768574
- type: nauc_map_at_5_max
value: 29.496572465872678
- type: nauc_map_at_5_std
value: -25.457134089214883
- type: nauc_mrr_at_1000_diff1
value: 59.44493769316621
- type: nauc_mrr_at_1000_max
value: 46.13272263925939
- type: nauc_mrr_at_1000_std
value: -19.11475143331668
- type: nauc_mrr_at_100_diff1
value: 59.44411441499269
- type: nauc_mrr_at_100_max
value: 46.13654028161708
- type: nauc_mrr_at_100_std
value: -19.109369325106417
- type: nauc_mrr_at_10_diff1
value: 59.219349927774154
- type: nauc_mrr_at_10_max
value: 46.02618026578592
- type: nauc_mrr_at_10_std
value: -19.37433068502548
- type: nauc_mrr_at_1_diff1
value: 62.95921038561675
- type: nauc_mrr_at_1_max
value: 46.18080967355503
- type: nauc_mrr_at_1_std
value: -18.40186184012292
- type: nauc_mrr_at_20_diff1
value: 59.3891382507084
- type: nauc_mrr_at_20_max
value: 46.044401310035894
- type: nauc_mrr_at_20_std
value: -19.257461333372504
- type: nauc_mrr_at_3_diff1
value: 59.238553596931
- type: nauc_mrr_at_3_max
value: 46.56487351573117
- type: nauc_mrr_at_3_std
value: -19.12741537508225
- type: nauc_mrr_at_5_diff1
value: 58.93737610599986
- type: nauc_mrr_at_5_max
value: 45.99436971500825
- type: nauc_mrr_at_5_std
value: -19.261662406716308
- type: nauc_ndcg_at_1000_diff1
value: 51.40360288706063
- type: nauc_ndcg_at_1000_max
value: 39.32722737004307
- type: nauc_ndcg_at_1000_std
value: -20.898685807989388
- type: nauc_ndcg_at_100_diff1
value: 51.36301353290372
- type: nauc_ndcg_at_100_max
value: 38.97243548753853
- type: nauc_ndcg_at_100_std
value: -20.50022060973278
- type: nauc_ndcg_at_10_diff1
value: 51.44403959729833
- type: nauc_ndcg_at_10_max
value: 36.01289481113504
- type: nauc_ndcg_at_10_std
value: -24.176498000068843
- type: nauc_ndcg_at_1_diff1
value: 62.95921038561675
- type: nauc_ndcg_at_1_max
value: 46.18080967355503
- type: nauc_ndcg_at_1_std
value: -18.40186184012292
- type: nauc_ndcg_at_20_diff1
value: 51.41066012197159
- type: nauc_ndcg_at_20_max
value: 37.24872539687912
- type: nauc_ndcg_at_20_std
value: -23.372189423803118
- type: nauc_ndcg_at_3_diff1
value: 48.489628982965854
- type: nauc_ndcg_at_3_max
value: 36.93242010543425
- type: nauc_ndcg_at_3_std
value: -23.566283895234708
- type: nauc_ndcg_at_5_diff1
value: 48.855011049758616
- type: nauc_ndcg_at_5_max
value: 34.72552703254509
- type: nauc_ndcg_at_5_std
value: -24.603662195056884
- type: nauc_precision_at_1000_diff1
value: -16.254896831329358
- type: nauc_precision_at_1000_max
value: 26.68880233255314
- type: nauc_precision_at_1000_std
value: 15.711021613094275
- type: nauc_precision_at_100_diff1
value: -11.963143494271204
- type: nauc_precision_at_100_max
value: 30.662204917415004
- type: nauc_precision_at_100_std
value: 15.037733765190636
- type: nauc_precision_at_10_diff1
value: 4.189692935472799
- type: nauc_precision_at_10_max
value: 37.378105954795075
- type: nauc_precision_at_10_std
value: -1.0086179584149657
- type: nauc_precision_at_1_diff1
value: 62.95921038561675
- type: nauc_precision_at_1_max
value: 46.18080967355503
- type: nauc_precision_at_1_std
value: -18.40186184012292
- type: nauc_precision_at_20_diff1
value: -3.1588007120578276
- type: nauc_precision_at_20_max
value: 35.380893467283215
- type: nauc_precision_at_20_std
value: 4.992120324159972
- type: nauc_precision_at_3_diff1
value: 18.37633057040911
- type: nauc_precision_at_3_max
value: 42.06004715153175
- type: nauc_precision_at_3_std
value: -11.214136554742755
- type: nauc_precision_at_5_diff1
value: 10.224008279551054
- type: nauc_precision_at_5_max
value: 40.18017184406908
- type: nauc_precision_at_5_std
value: -7.103870184792855
- type: nauc_recall_at_1000_diff1
value: 38.30826137726082
- type: nauc_recall_at_1000_max
value: 37.17044147876854
- type: nauc_recall_at_1000_std
value: 10.594199798446793
- type: nauc_recall_at_100_diff1
value: 40.454335943748475
- type: nauc_recall_at_100_max
value: 31.170902337200097
- type: nauc_recall_at_100_std
value: -0.8492074860948018
- type: nauc_recall_at_10_diff1
value: 44.954194528652735
- type: nauc_recall_at_10_max
value: 28.27547239551631
- type: nauc_recall_at_10_std
value: -24.747605039280685
- type: nauc_recall_at_1_diff1
value: 54.95925350681827
- type: nauc_recall_at_1_max
value: 13.962825942647214
- type: nauc_recall_at_1_std
value: -21.054092920927694
- type: nauc_recall_at_20_diff1
value: 44.398293084195636
- type: nauc_recall_at_20_max
value: 29.604081242804735
- type: nauc_recall_at_20_std
value: -22.90399779981129
- type: nauc_recall_at_3_diff1
value: 43.25687263417001
- type: nauc_recall_at_3_max
value: 20.50817103562355
- type: nauc_recall_at_3_std
value: -26.567575668398508
- type: nauc_recall_at_5_diff1
value: 40.81840199310296
- type: nauc_recall_at_5_max
value: 23.1238715032068
- type: nauc_recall_at_5_std
value: -25.64446934619821
- type: ndcg_at_1
value: 60.185
- type: ndcg_at_10
value: 61.182
- type: ndcg_at_100
value: 67.523
- type: ndcg_at_1000
value: 68.759
- type: ndcg_at_20
value: 64.084
- type: ndcg_at_3
value: 56.48
- type: ndcg_at_5
value: 58.098000000000006
- type: precision_at_1
value: 60.185
- type: precision_at_10
value: 17.083000000000002
- type: precision_at_100
value: 2.366
- type: precision_at_1000
value: 0.259
- type: precision_at_20
value: 9.884
- type: precision_at_3
value: 37.757000000000005
- type: precision_at_5
value: 27.747
- type: recall_at_1
value: 31.877
- type: recall_at_10
value: 68.868
- type: recall_at_100
value: 91.26100000000001
- type: recall_at_1000
value: 98.346
- type: recall_at_20
value: 77.523
- type: recall_at_3
value: 51.226000000000006
- type: recall_at_5
value: 59.319
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: mteb/hotpotqa
config: default
split: test
revision: ab518f4d6fcca38d87c25209f94beba119d02014
metrics:
- type: main_score
value: 79.125
- type: map_at_1
value: 43.72
- type: map_at_10
value: 72.03500000000001
- type: map_at_100
value: 72.761
- type: map_at_1000
value: 72.80499999999999
- type: map_at_20
value: 72.477
- type: map_at_3
value: 68.84700000000001
- type: map_at_5
value: 70.982
- type: mrr_at_1
value: 87.44091829844699
- type: mrr_at_10
value: 91.31576155107534
- type: mrr_at_100
value: 91.40489558470692
- type: mrr_at_1000
value: 91.40687231624047
- type: mrr_at_20
value: 91.37223203223267
- type: mrr_at_3
value: 90.84177357641214
- type: mrr_at_5
value: 91.17938329957211
- type: nauc_map_at_1000_diff1
value: 2.160941678109871
- type: nauc_map_at_1000_max
value: 20.280335959707244
- type: nauc_map_at_1000_std
value: 2.097428882568907
- type: nauc_map_at_100_diff1
value: 2.1230954064310272
- type: nauc_map_at_100_max
value: 20.258093599808014
- type: nauc_map_at_100_std
value: 2.1151474260126633
- type: nauc_map_at_10_diff1
value: 1.8723430508681238
- type: nauc_map_at_10_max
value: 20.001115713122292
- type: nauc_map_at_10_std
value: 1.5120467206405304
- type: nauc_map_at_1_diff1
value: 68.47218714216126
- type: nauc_map_at_1_max
value: 48.79030836492533
- type: nauc_map_at_1_std
value: -14.325167455523276
- type: nauc_map_at_20_diff1
value: 2.021495128391111
- type: nauc_map_at_20_max
value: 20.19494185197473
- type: nauc_map_at_20_std
value: 1.988283622854646
- type: nauc_map_at_3_diff1
value: 1.3035766010655014
- type: nauc_map_at_3_max
value: 18.267934028448014
- type: nauc_map_at_3_std
value: -1.5393823883989837
- type: nauc_map_at_5_diff1
value: 1.6758465601660635
- type: nauc_map_at_5_max
value: 19.611409174084766
- type: nauc_map_at_5_std
value: 0.5379733914867968
- type: nauc_mrr_at_1000_diff1
value: 68.60925278528931
- type: nauc_mrr_at_1000_max
value: 53.41174729989386
- type: nauc_mrr_at_1000_std
value: -10.94381937854199
- type: nauc_mrr_at_100_diff1
value: 68.61192764944234
- type: nauc_mrr_at_100_max
value: 53.41979323473436
- type: nauc_mrr_at_100_std
value: -10.928418937183535
- type: nauc_mrr_at_10_diff1
value: 68.58075465200439
- type: nauc_mrr_at_10_max
value: 53.469248695058894
- type: nauc_mrr_at_10_std
value: -11.033247242342176
- type: nauc_mrr_at_1_diff1
value: 68.47218714216126
- type: nauc_mrr_at_1_max
value: 48.79030836492533
- type: nauc_mrr_at_1_std
value: -14.325167455523276
- type: nauc_mrr_at_20_diff1
value: 68.61440353772745
- type: nauc_mrr_at_20_max
value: 53.48475026827637
- type: nauc_mrr_at_20_std
value: -10.890302904034154
- type: nauc_mrr_at_3_diff1
value: 68.69282004791216
- type: nauc_mrr_at_3_max
value: 54.06094833361629
- type: nauc_mrr_at_3_std
value: -11.153009129882598
- type: nauc_mrr_at_5_diff1
value: 68.73035503749831
- type: nauc_mrr_at_5_max
value: 53.83508048703245
- type: nauc_mrr_at_5_std
value: -11.003690030416173
- type: nauc_ndcg_at_1000_diff1
value: 9.50087869973644
- type: nauc_ndcg_at_1000_max
value: 25.950105183418927
- type: nauc_ndcg_at_1000_std
value: 5.135066113356472
- type: nauc_ndcg_at_100_diff1
value: 8.362935638818364
- type: nauc_ndcg_at_100_max
value: 25.34061127640931
- type: nauc_ndcg_at_100_std
value: 5.754839950507415
- type: nauc_ndcg_at_10_diff1
value: 7.156928707580207
- type: nauc_ndcg_at_10_max
value: 24.251874180080023
- type: nauc_ndcg_at_10_std
value: 3.4311673728584373
- type: nauc_ndcg_at_1_diff1
value: 68.47218714216126
- type: nauc_ndcg_at_1_max
value: 48.79030836492533
- type: nauc_ndcg_at_1_std
value: -14.325167455523276
- type: nauc_ndcg_at_20_diff1
value: 7.631421824536802
- type: nauc_ndcg_at_20_max
value: 24.899012298150367
- type: nauc_ndcg_at_20_std
value: 5.015727485279167
- type: nauc_ndcg_at_3_diff1
value: 6.765698105055132
- type: nauc_ndcg_at_3_max
value: 22.068064891465696
- type: nauc_ndcg_at_3_std
value: -1.4664522141695102
- type: nauc_ndcg_at_5_diff1
value: 6.97155171194824
- type: nauc_ndcg_at_5_max
value: 23.660849668507527
- type: nauc_ndcg_at_5_std
value: 1.4707432249488543
- type: nauc_precision_at_1000_diff1
value: -5.507220131591544
- type: nauc_precision_at_1000_max
value: 35.494019207652336
- type: nauc_precision_at_1000_std
value: 51.48431882469268
- type: nauc_precision_at_100_diff1
value: -9.856655267678178
- type: nauc_precision_at_100_max
value: 23.40730506252858
- type: nauc_precision_at_100_std
value: 34.01534710435972
- type: nauc_precision_at_10_diff1
value: -7.169347416977972
- type: nauc_precision_at_10_max
value: 20.252826543847206
- type: nauc_precision_at_10_std
value: 13.940728560252206
- type: nauc_precision_at_1_diff1
value: 68.47218714216126
- type: nauc_precision_at_1_max
value: 48.79030836492533
- type: nauc_precision_at_1_std
value: -14.325167455523276
- type: nauc_precision_at_20_diff1
value: -7.783356154578335
- type: nauc_precision_at_20_max
value: 21.74000065585772
- type: nauc_precision_at_20_std
value: 21.489921794963333
- type: nauc_precision_at_3_diff1
value: -4.4855992702233385
- type: nauc_precision_at_3_max
value: 17.58424070747094
- type: nauc_precision_at_3_std
value: 1.8777336548123371
- type: nauc_precision_at_5_diff1
value: -5.604031655005792
- type: nauc_precision_at_5_max
value: 19.580893429923517
- type: nauc_precision_at_5_std
value: 7.8203617045788505
- type: nauc_recall_at_1000_diff1
value: -5.507220131591377
- type: nauc_recall_at_1000_max
value: 35.494019207652414
- type: nauc_recall_at_1000_std
value: 51.48431882469249
- type: nauc_recall_at_100_diff1
value: -9.856655267678182
- type: nauc_recall_at_100_max
value: 23.407305062528323
- type: nauc_recall_at_100_std
value: 34.01534710435951
- type: nauc_recall_at_10_diff1
value: -7.169347416977698
- type: nauc_recall_at_10_max
value: 20.252826543847338
- type: nauc_recall_at_10_std
value: 13.940728560252335
- type: nauc_recall_at_1_diff1
value: 68.47218714216126
- type: nauc_recall_at_1_max
value: 48.79030836492533
- type: nauc_recall_at_1_std
value: -14.325167455523276
- type: nauc_recall_at_20_diff1
value: -7.7833561545783985
- type: nauc_recall_at_20_max
value: 21.740000655857713
- type: nauc_recall_at_20_std
value: 21.489921794963426
- type: nauc_recall_at_3_diff1
value: -4.485599270223427
- type: nauc_recall_at_3_max
value: 17.584240707470887
- type: nauc_recall_at_3_std
value: 1.8777336548121935
- type: nauc_recall_at_5_diff1
value: -5.604031655005744
- type: nauc_recall_at_5_max
value: 19.580893429923695
- type: nauc_recall_at_5_std
value: 7.820361704579018
- type: ndcg_at_1
value: 87.441
- type: ndcg_at_10
value: 79.125
- type: ndcg_at_100
value: 81.45400000000001
- type: ndcg_at_1000
value: 82.25099999999999
- type: ndcg_at_20
value: 80.17
- type: ndcg_at_3
value: 74.956
- type: ndcg_at_5
value: 77.48
- type: precision_at_1
value: 87.441
- type: precision_at_10
value: 16.323999999999998
- type: precision_at_100
value: 1.8110000000000002
- type: precision_at_1000
value: 0.192
- type: precision_at_20
value: 8.498
- type: precision_at_3
value: 48.368
- type: precision_at_5
value: 31.002999999999997
- type: recall_at_1
value: 43.72
- type: recall_at_10
value: 81.621
- type: recall_at_100
value: 90.554
- type: recall_at_1000
value: 95.787
- type: recall_at_20
value: 84.983
- type: recall_at_3
value: 72.552
- type: recall_at_5
value: 77.508
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: mteb/msmarco
config: default
split: dev
revision: c5a29a104738b98a9e76336939199e264163d4a0
metrics:
- type: main_score
value: 44.89
- type: map_at_1
value: 24.432000000000002
- type: map_at_10
value: 37.591
- type: map_at_100
value: 38.751000000000005
- type: map_at_1000
value: 38.79
- type: map_at_20
value: 38.322
- type: map_at_3
value: 33.505
- type: map_at_5
value: 35.859
- type: mrr_at_1
value: 25.171919770773638
- type: mrr_at_10
value: 38.21256310547136
- type: mrr_at_100
value: 39.30753721884505
- type: mrr_at_1000
value: 39.340691344391445
- type: mrr_at_20
value: 38.90961306475649
- type: mrr_at_3
value: 34.26456542502386
- type: mrr_at_5
value: 36.53748806112701
- type: nauc_map_at_1000_diff1
value: 38.66852221567241
- type: nauc_map_at_1000_max
value: 4.1057766737799595
- type: nauc_map_at_1000_std
value: -27.382157855077754
- type: nauc_map_at_100_diff1
value: 38.6621397928445
- type: nauc_map_at_100_max
value: 4.111681335095865
- type: nauc_map_at_100_std
value: -27.36539945792605
- type: nauc_map_at_10_diff1
value: 38.63319989433825
- type: nauc_map_at_10_max
value: 3.9346979349074953
- type: nauc_map_at_10_std
value: -28.0900393767871
- type: nauc_map_at_1_diff1
value: 41.71535844577686
- type: nauc_map_at_1_max
value: 3.4832962062214006
- type: nauc_map_at_1_std
value: -23.525528000333843
- type: nauc_map_at_20_diff1
value: 38.68062082411943
- type: nauc_map_at_20_max
value: 4.046538867480454
- type: nauc_map_at_20_std
value: -27.688449948610472
- type: nauc_map_at_3_diff1
value: 38.584342089335685
- type: nauc_map_at_3_max
value: 3.63965785769002
- type: nauc_map_at_3_std
value: -27.46268496496546
- type: nauc_map_at_5_diff1
value: 38.42816219182273
- type: nauc_map_at_5_max
value: 3.839849854247509
- type: nauc_map_at_5_std
value: -28.015487623173605
- type: nauc_mrr_at_1000_diff1
value: 38.232755814715766
- type: nauc_mrr_at_1000_max
value: 3.987692507096141
- type: nauc_mrr_at_1000_std
value: -26.888695263011808
- type: nauc_mrr_at_100_diff1
value: 38.22616005576646
- type: nauc_mrr_at_100_max
value: 3.9948619556899123
- type: nauc_mrr_at_100_std
value: -26.872832670267883
- type: nauc_mrr_at_10_diff1
value: 38.155508621490306
- type: nauc_mrr_at_10_max
value: 3.8153177084303582
- type: nauc_mrr_at_10_std
value: -27.546238510006503
- type: nauc_mrr_at_1_diff1
value: 41.26563649433227
- type: nauc_mrr_at_1_max
value: 3.2940832364845734
- type: nauc_mrr_at_1_std
value: -23.246326699010055
- type: nauc_mrr_at_20_diff1
value: 38.23581610598243
- type: nauc_mrr_at_20_max
value: 3.9519434237902455
- type: nauc_mrr_at_20_std
value: -27.153182984955542
- type: nauc_mrr_at_3_diff1
value: 38.123012505586516
- type: nauc_mrr_at_3_max
value: 3.5952793301902446
- type: nauc_mrr_at_3_std
value: -26.96557107215608
- type: nauc_mrr_at_5_diff1
value: 38.00080442994164
- type: nauc_mrr_at_5_max
value: 3.6611507063907838
- type: nauc_mrr_at_5_std
value: -27.5217700193094
- type: nauc_ndcg_at_1000_diff1
value: 38.08376371232426
- type: nauc_ndcg_at_1000_max
value: 4.741285538467179
- type: nauc_ndcg_at_1000_std
value: -26.876920597404325
- type: nauc_ndcg_at_100_diff1
value: 37.933209786580186
- type: nauc_ndcg_at_100_max
value: 5.003377252588231
- type: nauc_ndcg_at_100_std
value: -26.136134328732467
- type: nauc_ndcg_at_10_diff1
value: 37.82072609591181
- type: nauc_ndcg_at_10_max
value: 4.24748877233556
- type: nauc_ndcg_at_10_std
value: -29.766127219449835
- type: nauc_ndcg_at_1_diff1
value: 41.26563649433227
- type: nauc_ndcg_at_1_max
value: 3.2940832364845734
- type: nauc_ndcg_at_1_std
value: -23.246326699010055
- type: nauc_ndcg_at_20_diff1
value: 38.068479496194165
- type: nauc_ndcg_at_20_max
value: 4.686171701536077
- type: nauc_ndcg_at_20_std
value: -28.373083045837827
- type: nauc_ndcg_at_3_diff1
value: 37.664591050650714
- type: nauc_ndcg_at_3_max
value: 3.7238056730982425
- type: nauc_ndcg_at_3_std
value: -28.501705219533402
- type: nauc_ndcg_at_5_diff1
value: 37.39323161347562
- type: nauc_ndcg_at_5_max
value: 3.9884773576701846
- type: nauc_ndcg_at_5_std
value: -29.526098685579278
- type: nauc_precision_at_1000_diff1
value: -8.176278274893253
- type: nauc_precision_at_1000_max
value: 6.602206468153366
- type: nauc_precision_at_1000_std
value: 11.887969321516541
- type: nauc_precision_at_100_diff1
value: 10.776600450291125
- type: nauc_precision_at_100_max
value: 11.543791706232499
- type: nauc_precision_at_100_std
value: 8.05135325335674
- type: nauc_precision_at_10_diff1
value: 31.29891891655396
- type: nauc_precision_at_10_max
value: 4.793824130342508
- type: nauc_precision_at_10_std
value: -32.843126960584904
- type: nauc_precision_at_1_diff1
value: 41.26563649433227
- type: nauc_precision_at_1_max
value: 3.2940832364845734
- type: nauc_precision_at_1_std
value: -23.246326699010055
- type: nauc_precision_at_20_diff1
value: 28.39742040356656
- type: nauc_precision_at_20_max
value: 6.848015766561338
- type: nauc_precision_at_20_std
value: -24.61307381544946
- type: nauc_precision_at_3_diff1
value: 34.1967778945159
- type: nauc_precision_at_3_max
value: 3.6373839227371354
- type: nauc_precision_at_3_std
value: -31.262400131015795
- type: nauc_precision_at_5_diff1
value: 32.32839846166563
- type: nauc_precision_at_5_max
value: 4.2661314616361885
- type: nauc_precision_at_5_std
value: -32.94817957117079
- type: nauc_recall_at_1000_diff1
value: 25.124054710942882
- type: nauc_recall_at_1000_max
value: 52.99541699631579
- type: nauc_recall_at_1000_std
value: 63.880015110366394
- type: nauc_recall_at_100_diff1
value: 32.1323577870331
- type: nauc_recall_at_100_max
value: 17.26171631192854
- type: nauc_recall_at_100_std
value: 4.147658345720864
- type: nauc_recall_at_10_diff1
value: 35.35982089295331
- type: nauc_recall_at_10_max
value: 5.478913284596572
- type: nauc_recall_at_10_std
value: -35.93639290916612
- type: nauc_recall_at_1_diff1
value: 41.71535844577686
- type: nauc_recall_at_1_max
value: 3.4832962062214006
- type: nauc_recall_at_1_std
value: -23.525528000333843
- type: nauc_recall_at_20_diff1
value: 36.36549599422767
- type: nauc_recall_at_20_max
value: 8.112692947664327
- type: nauc_recall_at_20_std
value: -30.573957801286095
- type: nauc_recall_at_3_diff1
value: 35.227199657140844
- type: nauc_recall_at_3_max
value: 3.9474392083855445
- type: nauc_recall_at_3_std
value: -31.485135190684904
- type: nauc_recall_at_5_diff1
value: 34.435115639178505
- type: nauc_recall_at_5_max
value: 4.538709973891948
- type: nauc_recall_at_5_std
value: -34.07440191001999
- type: ndcg_at_1
value: 25.172
- type: ndcg_at_10
value: 44.89
- type: ndcg_at_100
value: 50.33800000000001
- type: ndcg_at_1000
value: 51.266999999999996
- type: ndcg_at_20
value: 47.455999999999996
- type: ndcg_at_3
value: 36.631
- type: ndcg_at_5
value: 40.801
- type: precision_at_1
value: 25.172
- type: precision_at_10
value: 7.0489999999999995
- type: precision_at_100
value: 0.976
- type: precision_at_1000
value: 0.106
- type: precision_at_20
value: 4.059
- type: precision_at_3
value: 15.554000000000002
- type: precision_at_5
value: 11.458
- type: recall_at_1
value: 24.432000000000002
- type: recall_at_10
value: 67.32900000000001
- type: recall_at_100
value: 92.23599999999999
- type: recall_at_1000
value: 99.21799999999999
- type: recall_at_20
value: 77.236
- type: recall_at_3
value: 44.926
- type: recall_at_5
value: 54.93599999999999
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: mteb/nfcorpus
config: default
split: test
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
metrics:
- type: main_score
value: 45.059
- type: map_at_1
value: 7.51
- type: map_at_10
value: 17.696
- type: map_at_100
value: 23.425
- type: map_at_1000
value: 25.462
- type: map_at_20
value: 20.078
- type: map_at_3
value: 12.36
- type: map_at_5
value: 14.949000000000002
- type: mrr_at_1
value: 56.656346749226
- type: mrr_at_10
value: 64.5453093518109
- type: mrr_at_100
value: 65.03548614941461
- type: mrr_at_1000
value: 65.07113760571535
- type: mrr_at_20
value: 64.92649519989713
- type: mrr_at_3
value: 62.5902992776058
- type: mrr_at_5
value: 63.890608875129
- type: nauc_map_at_1000_diff1
value: 18.649436695375666
- type: nauc_map_at_1000_max
value: 32.21371026469436
- type: nauc_map_at_1000_std
value: 15.172576825419542
- type: nauc_map_at_100_diff1
value: 20.754932725250484
- type: nauc_map_at_100_max
value: 31.802273361479354
- type: nauc_map_at_100_std
value: 11.05184960109897
- type: nauc_map_at_10_diff1
value: 27.65114332743644
- type: nauc_map_at_10_max
value: 24.216308956707948
- type: nauc_map_at_10_std
value: -3.148160320265085
- type: nauc_map_at_1_diff1
value: 44.074701941156576
- type: nauc_map_at_1_max
value: 7.313976830684179
- type: nauc_map_at_1_std
value: -17.775136864794273
- type: nauc_map_at_20_diff1
value: 24.40381389925362
- type: nauc_map_at_20_max
value: 28.28590842979618
- type: nauc_map_at_20_std
value: 2.4199688163030033
- type: nauc_map_at_3_diff1
value: 36.43847181675257
- type: nauc_map_at_3_max
value: 12.641525583061982
- type: nauc_map_at_3_std
value: -13.213788837135754
- type: nauc_map_at_5_diff1
value: 31.38099882079377
- type: nauc_map_at_5_max
value: 18.693157001709874
- type: nauc_map_at_5_std
value: -9.06791377198616
- type: nauc_mrr_at_1000_diff1
value: 32.13397852247498
- type: nauc_mrr_at_1000_max
value: 50.13330116214628
- type: nauc_mrr_at_1000_std
value: 32.05378496757561
- type: nauc_mrr_at_100_diff1
value: 32.15640184504514
- type: nauc_mrr_at_100_max
value: 50.16596418746684
- type: nauc_mrr_at_100_std
value: 32.09654562666087
- type: nauc_mrr_at_10_diff1
value: 32.30697278515013
- type: nauc_mrr_at_10_max
value: 50.29554162816291
- type: nauc_mrr_at_10_std
value: 32.196301987204926
- type: nauc_mrr_at_1_diff1
value: 31.18633610462525
- type: nauc_mrr_at_1_max
value: 44.066192007922865
- type: nauc_mrr_at_1_std
value: 25.405697533712186
- type: nauc_mrr_at_20_diff1
value: 32.183918395170934
- type: nauc_mrr_at_20_max
value: 50.1063795003295
- type: nauc_mrr_at_20_std
value: 32.019605254607605
- type: nauc_mrr_at_3_diff1
value: 32.1841620866096
- type: nauc_mrr_at_3_max
value: 49.86413651460263
- type: nauc_mrr_at_3_std
value: 31.65393088251129
- type: nauc_mrr_at_5_diff1
value: 32.506293256782854
- type: nauc_mrr_at_5_max
value: 50.22051310167734
- type: nauc_mrr_at_5_std
value: 32.20883162067511
- type: nauc_ndcg_at_1000_diff1
value: 17.07651298169536
- type: nauc_ndcg_at_1000_max
value: 45.68207250664515
- type: nauc_ndcg_at_1000_std
value: 32.2202917954314
- type: nauc_ndcg_at_100_diff1
value: 17.903616207181084
- type: nauc_ndcg_at_100_max
value: 41.75926814949547
- type: nauc_ndcg_at_100_std
value: 28.203224194584394
- type: nauc_ndcg_at_10_diff1
value: 15.047796165484423
- type: nauc_ndcg_at_10_max
value: 42.932973260133025
- type: nauc_ndcg_at_10_std
value: 28.988863166538216
- type: nauc_ndcg_at_1_diff1
value: 31.424681423032517
- type: nauc_ndcg_at_1_max
value: 41.520899599635705
- type: nauc_ndcg_at_1_std
value: 25.06328981312087
- type: nauc_ndcg_at_20_diff1
value: 14.659965916220653
- type: nauc_ndcg_at_20_max
value: 40.660613171359536
- type: nauc_ndcg_at_20_std
value: 28.05980217396367
- type: nauc_ndcg_at_3_diff1
value: 20.74188837396788
- type: nauc_ndcg_at_3_max
value: 42.17291456152861
- type: nauc_ndcg_at_3_std
value: 25.51560749819014
- type: nauc_ndcg_at_5_diff1
value: 16.85211778345349
- type: nauc_ndcg_at_5_max
value: 43.984121150231836
- type: nauc_ndcg_at_5_std
value: 26.83926214905424
- type: nauc_precision_at_1000_diff1
value: -17.051131025174517
- type: nauc_precision_at_1000_max
value: 6.764059286595738
- type: nauc_precision_at_1000_std
value: 40.1439309994832
- type: nauc_precision_at_100_diff1
value: -15.764998544735823
- type: nauc_precision_at_100_max
value: 19.211111148845784
- type: nauc_precision_at_100_std
value: 46.96427473897526
- type: nauc_precision_at_10_diff1
value: -7.388798905334601
- type: nauc_precision_at_10_max
value: 41.22907941806041
- type: nauc_precision_at_10_std
value: 42.59884089023569
- type: nauc_precision_at_1_diff1
value: 32.025767729163995
- type: nauc_precision_at_1_max
value: 43.754075663448575
- type: nauc_precision_at_1_std
value: 25.43509133901274
- type: nauc_precision_at_20_diff1
value: -12.0078847232814
- type: nauc_precision_at_20_max
value: 33.27932495727302
- type: nauc_precision_at_20_std
value: 43.837569920515165
- type: nauc_precision_at_3_diff1
value: 7.042749712513677
- type: nauc_precision_at_3_max
value: 42.1936184896299
- type: nauc_precision_at_3_std
value: 30.484961204241984
- type: nauc_precision_at_5_diff1
value: -2.1371357099813832
- type: nauc_precision_at_5_max
value: 43.476640933633895
- type: nauc_precision_at_5_std
value: 35.117927839092914
- type: nauc_recall_at_1000_diff1
value: -0.8723013662864799
- type: nauc_recall_at_1000_max
value: 18.909026237682543
- type: nauc_recall_at_1000_std
value: 13.51570098053679
- type: nauc_recall_at_100_diff1
value: 12.357279426756397
- type: nauc_recall_at_100_max
value: 27.84208167172234
- type: nauc_recall_at_100_std
value: 14.49863872734005
- type: nauc_recall_at_10_diff1
value: 21.11009281729574
- type: nauc_recall_at_10_max
value: 19.74472802495254
- type: nauc_recall_at_10_std
value: -4.09630500503252
- type: nauc_recall_at_1_diff1
value: 44.074701941156576
- type: nauc_recall_at_1_max
value: 7.313976830684179
- type: nauc_recall_at_1_std
value: -17.775136864794273
- type: nauc_recall_at_20_diff1
value: 17.31518452608809
- type: nauc_recall_at_20_max
value: 23.399843692692237
- type: nauc_recall_at_20_std
value: 0.04814256658120452
- type: nauc_recall_at_3_diff1
value: 35.46183411619658
- type: nauc_recall_at_3_max
value: 12.787287273388953
- type: nauc_recall_at_3_std
value: -12.428077847406232
- type: nauc_recall_at_5_diff1
value: 25.630390779262065
- type: nauc_recall_at_5_max
value: 17.81997541214207
- type: nauc_recall_at_5_std
value: -7.819448998740632
- type: ndcg_at_1
value: 55.418
- type: ndcg_at_10
value: 45.059
- type: ndcg_at_100
value: 41.89
- type: ndcg_at_1000
value: 50.808
- type: ndcg_at_20
value: 42.528
- type: ndcg_at_3
value: 50.273999999999994
- type: ndcg_at_5
value: 48.311
- type: precision_at_1
value: 56.347
- type: precision_at_10
value: 33.684
- type: precision_at_100
value: 10.854
- type: precision_at_1000
value: 2.455
- type: precision_at_20
value: 25.294
- type: precision_at_3
value: 46.749
- type: precision_at_5
value: 42.167
- type: recall_at_1
value: 7.51
- type: recall_at_10
value: 22.7
- type: recall_at_100
value: 42.324
- type: recall_at_1000
value: 75.047
- type: recall_at_20
value: 28.091
- type: recall_at_3
value: 13.202
- type: recall_at_5
value: 17.573
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: mteb/nq
config: default
split: test
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
metrics:
- type: main_score
value: 72.439
- type: map_at_1
value: 48.588
- type: map_at_10
value: 65.667
- type: map_at_100
value: 66.23
- type: map_at_1000
value: 66.238
- type: map_at_20
value: 66.077
- type: map_at_3
value: 62.173
- type: map_at_5
value: 64.403
- type: mrr_at_1
value: 54.57705677867902
- type: mrr_at_10
value: 68.04977330831896
- type: mrr_at_100
value: 68.40133412359447
- type: mrr_at_1000
value: 68.40674582113029
- type: mrr_at_20
value: 68.32025711906769
- type: mrr_at_3
value: 65.68173039783692
- type: mrr_at_5
value: 67.12292390884501
- type: nauc_map_at_1000_diff1
value: 42.92613415901299
- type: nauc_map_at_1000_max
value: 31.58722964102006
- type: nauc_map_at_1000_std
value: -9.181430909023906
- type: nauc_map_at_100_diff1
value: 42.9286603531827
- type: nauc_map_at_100_max
value: 31.597761214322794
- type: nauc_map_at_100_std
value: -9.174864948929978
- type: nauc_map_at_10_diff1
value: 42.742103497799874
- type: nauc_map_at_10_max
value: 31.73600271519757
- type: nauc_map_at_10_std
value: -9.599976341144492
- type: nauc_map_at_1_diff1
value: 44.97465030457452
- type: nauc_map_at_1_max
value: 24.50842235041081
- type: nauc_map_at_1_std
value: -9.488301413929715
- type: nauc_map_at_20_diff1
value: 42.93789543281411
- type: nauc_map_at_20_max
value: 31.649530881844477
- type: nauc_map_at_20_std
value: -9.284482255074405
- type: nauc_map_at_3_diff1
value: 42.507020478710444
- type: nauc_map_at_3_max
value: 30.430161368656407
- type: nauc_map_at_3_std
value: -10.98022633967904
- type: nauc_map_at_5_diff1
value: 42.65908349342647
- type: nauc_map_at_5_max
value: 31.712314514485808
- type: nauc_map_at_5_std
value: -10.162495644166388
- type: nauc_mrr_at_1000_diff1
value: 43.07977164212382
- type: nauc_mrr_at_1000_max
value: 32.71613265858574
- type: nauc_mrr_at_1000_std
value: -6.309541407889255
- type: nauc_mrr_at_100_diff1
value: 43.08243504279048
- type: nauc_mrr_at_100_max
value: 32.72393721047513
- type: nauc_mrr_at_100_std
value: -6.304478684547192
- type: nauc_mrr_at_10_diff1
value: 42.9454520799358
- type: nauc_mrr_at_10_max
value: 32.98294125539359
- type: nauc_mrr_at_10_std
value: -6.344731638595535
- type: nauc_mrr_at_1_diff1
value: 44.86265224618521
- type: nauc_mrr_at_1_max
value: 28.722584310944548
- type: nauc_mrr_at_1_std
value: -5.987388514445873
- type: nauc_mrr_at_20_diff1
value: 43.09463525559641
- type: nauc_mrr_at_20_max
value: 32.78563812600394
- type: nauc_mrr_at_20_std
value: -6.3101564030679365
- type: nauc_mrr_at_3_diff1
value: 42.778839940801525
- type: nauc_mrr_at_3_max
value: 32.73472475200481
- type: nauc_mrr_at_3_std
value: -6.873684661851209
- type: nauc_mrr_at_5_diff1
value: 42.819150151235355
- type: nauc_mrr_at_5_max
value: 33.063649047927846
- type: nauc_mrr_at_5_std
value: -6.690698773431876
- type: nauc_ndcg_at_1000_diff1
value: 42.838890830794305
- type: nauc_ndcg_at_1000_max
value: 33.06212912224441
- type: nauc_ndcg_at_1000_std
value: -7.604830337911507
- type: nauc_ndcg_at_100_diff1
value: 42.92532259135676
- type: nauc_ndcg_at_100_max
value: 33.32105898079442
- type: nauc_ndcg_at_100_std
value: -7.41942657927501
- type: nauc_ndcg_at_10_diff1
value: 42.241497889945386
- type: nauc_ndcg_at_10_max
value: 34.314029244865395
- type: nauc_ndcg_at_10_std
value: -8.705170475797276
- type: nauc_ndcg_at_1_diff1
value: 44.935431451080625
- type: nauc_ndcg_at_1_max
value: 28.761716507796287
- type: nauc_ndcg_at_1_std
value: -5.910155765778751
- type: nauc_ndcg_at_20_diff1
value: 42.98682996645045
- type: nauc_ndcg_at_20_max
value: 33.77639762275077
- type: nauc_ndcg_at_20_std
value: -7.922192840991434
- type: nauc_ndcg_at_3_diff1
value: 41.78169420045572
- type: nauc_ndcg_at_3_max
value: 32.28874867052525
- type: nauc_ndcg_at_3_std
value: -10.746022839903787
- type: nauc_ndcg_at_5_diff1
value: 41.98111900699031
- type: nauc_ndcg_at_5_max
value: 34.16892401395189
- type: nauc_ndcg_at_5_std
value: -9.835814208233074
- type: nauc_precision_at_1000_diff1
value: -13.893084426310164
- type: nauc_precision_at_1000_max
value: 4.528511169827012
- type: nauc_precision_at_1000_std
value: 19.808766541210563
- type: nauc_precision_at_100_diff1
value: -11.662187818787977
- type: nauc_precision_at_100_max
value: 7.106144289556965
- type: nauc_precision_at_100_std
value: 20.196725761912955
- type: nauc_precision_at_10_diff1
value: -0.0005202624402562934
- type: nauc_precision_at_10_max
value: 20.3322025815174
- type: nauc_precision_at_10_std
value: 10.996026572368203
- type: nauc_precision_at_1_diff1
value: 44.935431451080625
- type: nauc_precision_at_1_max
value: 28.761716507796287
- type: nauc_precision_at_1_std
value: -5.910155765778751
- type: nauc_precision_at_20_diff1
value: -5.251925401801626
- type: nauc_precision_at_20_max
value: 13.778502821797181
- type: nauc_precision_at_20_std
value: 16.678382538020593
- type: nauc_precision_at_3_diff1
value: 18.484347552428737
- type: nauc_precision_at_3_max
value: 29.23890691678369
- type: nauc_precision_at_3_std
value: -0.9617922081812927
- type: nauc_precision_at_5_diff1
value: 9.520921672164247
- type: nauc_precision_at_5_max
value: 26.114118384437084
- type: nauc_precision_at_5_std
value: 4.480542966435442
- type: nauc_recall_at_1000_diff1
value: 36.483312921782804
- type: nauc_recall_at_1000_max
value: 93.65683358360806
- type: nauc_recall_at_1000_std
value: 78.98396666115225
- type: nauc_recall_at_100_diff1
value: 51.223962258353374
- type: nauc_recall_at_100_max
value: 71.21642758603197
- type: nauc_recall_at_100_std
value: 29.03844845781408
- type: nauc_recall_at_10_diff1
value: 36.54228767944346
- type: nauc_recall_at_10_max
value: 48.045414485215495
- type: nauc_recall_at_10_std
value: -10.991004552070361
- type: nauc_recall_at_1_diff1
value: 44.97465030457452
- type: nauc_recall_at_1_max
value: 24.50842235041081
- type: nauc_recall_at_1_std
value: -9.488301413929715
- type: nauc_recall_at_20_diff1
value: 44.42937548103678
- type: nauc_recall_at_20_max
value: 52.02797641154168
- type: nauc_recall_at_20_std
value: -5.274872422912074
- type: nauc_recall_at_3_diff1
value: 37.370700905004796
- type: nauc_recall_at_3_max
value: 35.051545542223735
- type: nauc_recall_at_3_std
value: -14.47614675395727
- type: nauc_recall_at_5_diff1
value: 36.923681333914296
- type: nauc_recall_at_5_max
value: 41.76113305221287
- type: nauc_recall_at_5_std
value: -13.792057613912453
- type: ndcg_at_1
value: 54.547999999999995
- type: ndcg_at_10
value: 72.439
- type: ndcg_at_100
value: 74.505
- type: ndcg_at_1000
value: 74.656
- type: ndcg_at_20
value: 73.708
- type: ndcg_at_3
value: 66.416
- type: ndcg_at_5
value: 69.783
- type: precision_at_1
value: 54.547999999999995
- type: precision_at_10
value: 10.831
- type: precision_at_100
value: 1.201
- type: precision_at_1000
value: 0.121
- type: precision_at_20
value: 5.734
- type: precision_at_3
value: 29.287000000000003
- type: precision_at_5
value: 19.676
- type: recall_at_1
value: 48.588
- type: recall_at_10
value: 90.271
- type: recall_at_100
value: 98.663
- type: recall_at_1000
value: 99.754
- type: recall_at_20
value: 94.911
- type: recall_at_3
value: 75.14699999999999
- type: recall_at_5
value: 82.657
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: mteb/quora
config: default
split: test
revision: e4e08e0b7dbe3c8700f0daef558ff32256715259
metrics:
- type: main_score
value: 88.776
- type: map_at_1
value: 70.789
- type: map_at_10
value: 85.111
- type: map_at_100
value: 85.74300000000001
- type: map_at_1000
value: 85.757
- type: map_at_20
value: 85.541
- type: map_at_3
value: 82.16799999999999
- type: map_at_5
value: 84.027
- type: mrr_at_1
value: 81.61
- type: mrr_at_10
value: 87.83598809523794
- type: mrr_at_100
value: 87.93437534934736
- type: mrr_at_1000
value: 87.93537663994458
- type: mrr_at_20
value: 87.91460020324512
- type: mrr_at_3
value: 86.91999999999982
- type: mrr_at_5
value: 87.57549999999974
- type: nauc_map_at_1000_diff1
value: 76.95785603654109
- type: nauc_map_at_1000_max
value: 22.21137147646329
- type: nauc_map_at_1000_std
value: -57.67191596659913
- type: nauc_map_at_100_diff1
value: 76.96066980419408
- type: nauc_map_at_100_max
value: 22.18444499684965
- type: nauc_map_at_100_std
value: -57.73426948321203
- type: nauc_map_at_10_diff1
value: 77.27294101132748
- type: nauc_map_at_10_max
value: 21.520023788398827
- type: nauc_map_at_10_std
value: -60.149831861475946
- type: nauc_map_at_1_diff1
value: 80.82075671924613
- type: nauc_map_at_1_max
value: 16.73924350448738
- type: nauc_map_at_1_std
value: -49.025641726356106
- type: nauc_map_at_20_diff1
value: 77.03897352655657
- type: nauc_map_at_20_max
value: 21.879911910556256
- type: nauc_map_at_20_std
value: -58.72111603413064
- type: nauc_map_at_3_diff1
value: 77.80825908555062
- type: nauc_map_at_3_max
value: 19.74347230686499
- type: nauc_map_at_3_std
value: -61.14048758808322
- type: nauc_map_at_5_diff1
value: 77.64191093638766
- type: nauc_map_at_5_max
value: 20.82641310481968
- type: nauc_map_at_5_std
value: -61.5227187788429
- type: nauc_mrr_at_1000_diff1
value: 77.07743481780578
- type: nauc_mrr_at_1000_max
value: 24.973854693758668
- type: nauc_mrr_at_1000_std
value: -53.00097552882813
- type: nauc_mrr_at_100_diff1
value: 77.07743779388264
- type: nauc_mrr_at_100_max
value: 24.97578180973678
- type: nauc_mrr_at_100_std
value: -52.999857842949375
- type: nauc_mrr_at_10_diff1
value: 77.08832159626124
- type: nauc_mrr_at_10_max
value: 24.847950790779755
- type: nauc_mrr_at_10_std
value: -53.354412157484596
- type: nauc_mrr_at_1_diff1
value: 77.90054473035877
- type: nauc_mrr_at_1_max
value: 25.435382042849454
- type: nauc_mrr_at_1_std
value: -48.65542470772514
- type: nauc_mrr_at_20_diff1
value: 77.07410903358165
- type: nauc_mrr_at_20_max
value: 24.936803370937003
- type: nauc_mrr_at_20_std
value: -53.05367000547051
- type: nauc_mrr_at_3_diff1
value: 76.79835377348654
- type: nauc_mrr_at_3_max
value: 24.83960583182869
- type: nauc_mrr_at_3_std
value: -53.937122802902906
- type: nauc_mrr_at_5_diff1
value: 77.0611598562459
- type: nauc_mrr_at_5_max
value: 25.110143361000386
- type: nauc_mrr_at_5_std
value: -53.66721083549211
- type: nauc_ndcg_at_1000_diff1
value: 76.6539942038112
- type: nauc_ndcg_at_1000_max
value: 23.44145468342362
- type: nauc_ndcg_at_1000_std
value: -55.778951082488604
- type: nauc_ndcg_at_100_diff1
value: 76.63968651875747
- type: nauc_ndcg_at_100_max
value: 23.37238335196869
- type: nauc_ndcg_at_100_std
value: -56.013444819578936
- type: nauc_ndcg_at_10_diff1
value: 76.91486559815172
- type: nauc_ndcg_at_10_max
value: 21.882218185355374
- type: nauc_ndcg_at_10_std
value: -60.447241565220914
- type: nauc_ndcg_at_1_diff1
value: 77.91920303932993
- type: nauc_ndcg_at_1_max
value: 25.506195225143564
- type: nauc_ndcg_at_1_std
value: -48.66289988343474
- type: nauc_ndcg_at_20_diff1
value: 76.70353035362932
- type: nauc_ndcg_at_20_max
value: 22.52326792272016
- type: nauc_ndcg_at_20_std
value: -58.228058595950415
- type: nauc_ndcg_at_3_diff1
value: 76.19291654415437
- type: nauc_ndcg_at_3_max
value: 21.680157583116596
- type: nauc_ndcg_at_3_std
value: -59.78592789656886
- type: nauc_ndcg_at_5_diff1
value: 76.94117372509868
- type: nauc_ndcg_at_5_max
value: 21.80365013527183
- type: nauc_ndcg_at_5_std
value: -61.23723747585645
- type: nauc_precision_at_1000_diff1
value: -44.43454847128405
- type: nauc_precision_at_1000_max
value: 1.1086245603647116
- type: nauc_precision_at_1000_std
value: 45.957621410588445
- type: nauc_precision_at_100_diff1
value: -44.21353890734024
- type: nauc_precision_at_100_max
value: 0.8667205449931505
- type: nauc_precision_at_100_std
value: 44.55558297469162
- type: nauc_precision_at_10_diff1
value: -39.446583654372816
- type: nauc_precision_at_10_max
value: 1.0745424122581824
- type: nauc_precision_at_10_std
value: 27.715199044430115
- type: nauc_precision_at_1_diff1
value: 77.91920303932993
- type: nauc_precision_at_1_max
value: 25.506195225143564
- type: nauc_precision_at_1_std
value: -48.66289988343474
- type: nauc_precision_at_20_diff1
value: -42.82034326897596
- type: nauc_precision_at_20_max
value: 0.1871272488795601
- type: nauc_precision_at_20_std
value: 36.44930040826729
- type: nauc_precision_at_3_diff1
value: -20.17153834304044
- type: nauc_precision_at_3_max
value: 6.091482816522112
- type: nauc_precision_at_3_std
value: 2.2214080229171813
- type: nauc_precision_at_5_diff1
value: -32.30370373592924
- type: nauc_precision_at_5_max
value: 3.283007853748956
- type: nauc_precision_at_5_std
value: 15.671527569593394
- type: nauc_recall_at_1000_diff1
value: 25.2608289691968
- type: nauc_recall_at_1000_max
value: 39.63179474797547
- type: nauc_recall_at_1000_std
value: 25.74798035229638
- type: nauc_recall_at_100_diff1
value: 68.6766275832437
- type: nauc_recall_at_100_max
value: 24.369103177128636
- type: nauc_recall_at_100_std
value: -62.93899349940275
- type: nauc_recall_at_10_diff1
value: 73.75469598044158
- type: nauc_recall_at_10_max
value: 10.798765439257565
- type: nauc_recall_at_10_std
value: -90.65150692145126
- type: nauc_recall_at_1_diff1
value: 80.82075671924613
- type: nauc_recall_at_1_max
value: 16.73924350448738
- type: nauc_recall_at_1_std
value: -49.025641726356106
- type: nauc_recall_at_20_diff1
value: 71.88106544370252
- type: nauc_recall_at_20_max
value: 8.617919317783445
- type: nauc_recall_at_20_std
value: -88.64614006261976
- type: nauc_recall_at_3_diff1
value: 73.67512305142627
- type: nauc_recall_at_3_max
value: 14.522053228776684
- type: nauc_recall_at_3_std
value: -72.6164829975551
- type: nauc_recall_at_5_diff1
value: 73.55224072247896
- type: nauc_recall_at_5_max
value: 14.028581019140384
- type: nauc_recall_at_5_std
value: -81.70290837756839
- type: ndcg_at_1
value: 81.6
- type: ndcg_at_10
value: 88.776
- type: ndcg_at_100
value: 89.91799999999999
- type: ndcg_at_1000
value: 90.001
- type: ndcg_at_20
value: 89.45100000000001
- type: ndcg_at_3
value: 86.055
- type: ndcg_at_5
value: 87.603
- type: precision_at_1
value: 81.6
- type: precision_at_10
value: 13.527000000000001
- type: precision_at_100
value: 1.538
- type: precision_at_1000
value: 0.157
- type: precision_at_20
value: 7.183000000000001
- type: precision_at_3
value: 37.81
- type: precision_at_5
value: 24.874
- type: recall_at_1
value: 70.789
- type: recall_at_10
value: 95.829
- type: recall_at_100
value: 99.626
- type: recall_at_1000
value: 99.99900000000001
- type: recall_at_20
value: 98.008
- type: recall_at_3
value: 88.005
- type: recall_at_5
value: 92.394
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: mteb/scidocs
config: default
split: test
revision: f8c2fcf00f625baaa80f62ec5bd9e1fff3b8ae88
metrics:
- type: main_score
value: 22.555
- type: map_at_1
value: 5.093
- type: map_at_10
value: 13.636000000000001
- type: map_at_100
value: 16.169
- type: map_at_1000
value: 16.491
- type: map_at_20
value: 14.967
- type: map_at_3
value: 9.759
- type: map_at_5
value: 11.61
- type: mrr_at_1
value: 25.1
- type: mrr_at_10
value: 37.03158730158728
- type: mrr_at_100
value: 38.10841522691227
- type: mrr_at_1000
value: 38.157760714646216
- type: mrr_at_20
value: 37.71533302009304
- type: mrr_at_3
value: 33.599999999999994
- type: mrr_at_5
value: 35.47499999999996
- type: nauc_map_at_1000_diff1
value: 16.016506811794674
- type: nauc_map_at_1000_max
value: 26.980626723493234
- type: nauc_map_at_1000_std
value: 6.344668577266132
- type: nauc_map_at_100_diff1
value: 16.106273177734288
- type: nauc_map_at_100_max
value: 27.078961630580306
- type: nauc_map_at_100_std
value: 6.114177505174807
- type: nauc_map_at_10_diff1
value: 17.401956757885728
- type: nauc_map_at_10_max
value: 26.276474643260777
- type: nauc_map_at_10_std
value: 3.005814701827781
- type: nauc_map_at_1_diff1
value: 20.70536617482489
- type: nauc_map_at_1_max
value: 16.988060184234318
- type: nauc_map_at_1_std
value: -3.4275203611745013
- type: nauc_map_at_20_diff1
value: 16.56893037536464
- type: nauc_map_at_20_max
value: 26.994627506463566
- type: nauc_map_at_20_std
value: 4.443682314555823
- type: nauc_map_at_3_diff1
value: 17.771054815531336
- type: nauc_map_at_3_max
value: 22.25552550616846
- type: nauc_map_at_3_std
value: -1.1135548486711386
- type: nauc_map_at_5_diff1
value: 18.234751966525035
- type: nauc_map_at_5_max
value: 24.74090977327922
- type: nauc_map_at_5_std
value: 0.20984608573778366
- type: nauc_mrr_at_1000_diff1
value: 16.43908145424862
- type: nauc_mrr_at_1000_max
value: 19.50975861939652
- type: nauc_mrr_at_1000_std
value: 1.0711066308930413
- type: nauc_mrr_at_100_diff1
value: 16.449978087023602
- type: nauc_mrr_at_100_max
value: 19.546163139729455
- type: nauc_mrr_at_100_std
value: 1.1255804840602446
- type: nauc_mrr_at_10_diff1
value: 16.349572894206453
- type: nauc_mrr_at_10_max
value: 19.36607987819692
- type: nauc_mrr_at_10_std
value: 0.6815489423750116
- type: nauc_mrr_at_1_diff1
value: 20.81511754780404
- type: nauc_mrr_at_1_max
value: 17.31621820467371
- type: nauc_mrr_at_1_std
value: -3.062161046879616
- type: nauc_mrr_at_20_diff1
value: 16.453078176658412
- type: nauc_mrr_at_20_max
value: 19.61511763534643
- type: nauc_mrr_at_20_std
value: 1.1504468243169772
- type: nauc_mrr_at_3_diff1
value: 16.45317063630442
- type: nauc_mrr_at_3_max
value: 18.820538793222735
- type: nauc_mrr_at_3_std
value: -0.505799010681032
- type: nauc_mrr_at_5_diff1
value: 16.239396076435447
- type: nauc_mrr_at_5_max
value: 19.514405308342404
- type: nauc_mrr_at_5_std
value: 0.42152258676157106
- type: nauc_ndcg_at_1000_diff1
value: 12.799637809854447
- type: nauc_ndcg_at_1000_max
value: 26.286436521297098
- type: nauc_ndcg_at_1000_std
value: 13.849793575042407
- type: nauc_ndcg_at_100_diff1
value: 13.780919818793214
- type: nauc_ndcg_at_100_max
value: 27.263414842629384
- type: nauc_ndcg_at_100_std
value: 12.844324409823212
- type: nauc_ndcg_at_10_diff1
value: 15.691735156401645
- type: nauc_ndcg_at_10_max
value: 25.546421591723778
- type: nauc_ndcg_at_10_std
value: 5.030693260079141
- type: nauc_ndcg_at_1_diff1
value: 20.81511754780404
- type: nauc_ndcg_at_1_max
value: 17.31621820467371
- type: nauc_ndcg_at_1_std
value: -3.062161046879616
- type: nauc_ndcg_at_20_diff1
value: 14.918017633315037
- type: nauc_ndcg_at_20_max
value: 27.198495675799926
- type: nauc_ndcg_at_20_std
value: 7.859145154218754
- type: nauc_ndcg_at_3_diff1
value: 16.45411219760524
- type: nauc_ndcg_at_3_max
value: 21.843580863721826
- type: nauc_ndcg_at_3_std
value: 0.25079066807691736
- type: nauc_ndcg_at_5_diff1
value: 16.51852886026338
- type: nauc_ndcg_at_5_max
value: 24.32358445742888
- type: nauc_ndcg_at_5_std
value: 2.0046033593381365
- type: nauc_precision_at_1000_diff1
value: -3.043549167595678
- type: nauc_precision_at_1000_max
value: 17.721081069519855
- type: nauc_precision_at_1000_std
value: 34.394832596775096
- type: nauc_precision_at_100_diff1
value: 5.918389112534078
- type: nauc_precision_at_100_max
value: 25.041523333915638
- type: nauc_precision_at_100_std
value: 26.422448938245065
- type: nauc_precision_at_10_diff1
value: 12.559354156188075
- type: nauc_precision_at_10_max
value: 27.102948515447505
- type: nauc_precision_at_10_std
value: 9.922230490706765
- type: nauc_precision_at_1_diff1
value: 20.81511754780404
- type: nauc_precision_at_1_max
value: 17.31621820467371
- type: nauc_precision_at_1_std
value: -3.062161046879616
- type: nauc_precision_at_20_diff1
value: 10.239015656701062
- type: nauc_precision_at_20_max
value: 28.631431971198385
- type: nauc_precision_at_20_std
value: 14.923889979389953
- type: nauc_precision_at_3_diff1
value: 14.715917541943435
- type: nauc_precision_at_3_max
value: 23.488016057716443
- type: nauc_precision_at_3_std
value: 1.8688429519876193
- type: nauc_precision_at_5_diff1
value: 14.607533180532764
- type: nauc_precision_at_5_max
value: 26.69556237014592
- type: nauc_precision_at_5_std
value: 4.869786655689707
- type: nauc_recall_at_1000_diff1
value: -3.592050112505089
- type: nauc_recall_at_1000_max
value: 17.35902743346563
- type: nauc_recall_at_1000_std
value: 35.46357913035807
- type: nauc_recall_at_100_diff1
value: 5.712224816491693
- type: nauc_recall_at_100_max
value: 24.952810805795224
- type: nauc_recall_at_100_std
value: 26.49557743326384
- type: nauc_recall_at_10_diff1
value: 12.374218338608538
- type: nauc_recall_at_10_max
value: 26.5955214750823
- type: nauc_recall_at_10_std
value: 9.623097045252097
- type: nauc_recall_at_1_diff1
value: 20.70536617482489
- type: nauc_recall_at_1_max
value: 16.988060184234318
- type: nauc_recall_at_1_std
value: -3.4275203611745013
- type: nauc_recall_at_20_diff1
value: 10.079156462598272
- type: nauc_recall_at_20_max
value: 28.130382940517656
- type: nauc_recall_at_20_std
value: 14.778620879657767
- type: nauc_recall_at_3_diff1
value: 14.445322713318905
- type: nauc_recall_at_3_max
value: 22.913177040177732
- type: nauc_recall_at_3_std
value: 1.3968297812096289
- type: nauc_recall_at_5_diff1
value: 14.300977741042697
- type: nauc_recall_at_5_max
value: 26.064746286034463
- type: nauc_recall_at_5_std
value: 4.468436508425328
- type: ndcg_at_1
value: 25.1
- type: ndcg_at_10
value: 22.555
- type: ndcg_at_100
value: 31.558000000000003
- type: ndcg_at_1000
value: 36.866
- type: ndcg_at_20
value: 25.954
- type: ndcg_at_3
value: 21.488
- type: ndcg_at_5
value: 18.656
- type: precision_at_1
value: 25.1
- type: precision_at_10
value: 11.82
- type: precision_at_100
value: 2.465
- type: precision_at_1000
value: 0.373
- type: precision_at_20
value: 7.870000000000001
- type: precision_at_3
value: 20.467
- type: precision_at_5
value: 16.520000000000003
- type: recall_at_1
value: 5.093
- type: recall_at_10
value: 23.953
- type: recall_at_100
value: 50.03999999999999
- type: recall_at_1000
value: 75.74499999999999
- type: recall_at_20
value: 31.923000000000002
- type: recall_at_3
value: 12.468
- type: recall_at_5
value: 16.773
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: mteb/scifact
config: default
split: test
revision: 0228b52cf27578f30900b9e5271d331663a030d7
metrics:
- type: main_score
value: 81.313
- type: map_at_1
value: 67.38300000000001
- type: map_at_10
value: 77.017
- type: map_at_100
value: 77.321
- type: map_at_1000
value: 77.331
- type: map_at_20
value: 77.262
- type: map_at_3
value: 74.111
- type: map_at_5
value: 75.881
- type: mrr_at_1
value: 70.33333333333334
- type: mrr_at_10
value: 77.81560846560845
- type: mrr_at_100
value: 78.00735197296981
- type: mrr_at_1000
value: 78.01761089473817
- type: mrr_at_20
value: 77.95766363266362
- type: mrr_at_3
value: 75.72222222222223
- type: mrr_at_5
value: 77.00555555555557
- type: nauc_map_at_1000_diff1
value: 75.04841791054689
- type: nauc_map_at_1000_max
value: 58.36172663414763
- type: nauc_map_at_1000_std
value: -11.893595632272119
- type: nauc_map_at_100_diff1
value: 75.05064539007354
- type: nauc_map_at_100_max
value: 58.37324776917011
- type: nauc_map_at_100_std
value: -11.877215894403568
- type: nauc_map_at_10_diff1
value: 74.75549994121076
- type: nauc_map_at_10_max
value: 58.24150489656241
- type: nauc_map_at_10_std
value: -12.344245577155307
- type: nauc_map_at_1_diff1
value: 76.73802929240316
- type: nauc_map_at_1_max
value: 51.51486878608817
- type: nauc_map_at_1_std
value: -18.187044359595266
- type: nauc_map_at_20_diff1
value: 75.01108764373232
- type: nauc_map_at_20_max
value: 58.428062710077334
- type: nauc_map_at_20_std
value: -11.884812488296847
- type: nauc_map_at_3_diff1
value: 75.76878808666785
- type: nauc_map_at_3_max
value: 55.0893236506397
- type: nauc_map_at_3_std
value: -18.680147004087416
- type: nauc_map_at_5_diff1
value: 75.21872474724155
- type: nauc_map_at_5_max
value: 56.99417811848851
- type: nauc_map_at_5_std
value: -15.023574589807998
- type: nauc_mrr_at_1000_diff1
value: 75.30185058060118
- type: nauc_mrr_at_1000_max
value: 58.99827784504953
- type: nauc_mrr_at_1000_std
value: -9.180976480652097
- type: nauc_mrr_at_100_diff1
value: 75.3039902169212
- type: nauc_mrr_at_100_max
value: 59.0096982171748
- type: nauc_mrr_at_100_std
value: -9.165687912589478
- type: nauc_mrr_at_10_diff1
value: 75.06584397042454
- type: nauc_mrr_at_10_max
value: 59.059479758705095
- type: nauc_mrr_at_10_std
value: -9.171739325385065
- type: nauc_mrr_at_1_diff1
value: 76.94126061472998
- type: nauc_mrr_at_1_max
value: 58.63634435063004
- type: nauc_mrr_at_1_std
value: -7.595328003491241
- type: nauc_mrr_at_20_diff1
value: 75.25985436830398
- type: nauc_mrr_at_20_max
value: 59.047844055490515
- type: nauc_mrr_at_20_std
value: -9.217229457280327
- type: nauc_mrr_at_3_diff1
value: 75.70972174140121
- type: nauc_mrr_at_3_max
value: 58.53109550921837
- type: nauc_mrr_at_3_std
value: -11.233362761574888
- type: nauc_mrr_at_5_diff1
value: 75.3027582677559
- type: nauc_mrr_at_5_max
value: 58.51186203154683
- type: nauc_mrr_at_5_std
value: -10.2389936280827
- type: nauc_ndcg_at_1000_diff1
value: 74.73042662069368
- type: nauc_ndcg_at_1000_max
value: 59.234679098286435
- type: nauc_ndcg_at_1000_std
value: -10.056585749544686
- type: nauc_ndcg_at_100_diff1
value: 74.77417755774573
- type: nauc_ndcg_at_100_max
value: 59.56267106047054
- type: nauc_ndcg_at_100_std
value: -9.507635585959678
- type: nauc_ndcg_at_10_diff1
value: 73.51173182085725
- type: nauc_ndcg_at_10_max
value: 59.488170283330234
- type: nauc_ndcg_at_10_std
value: -10.720733926384735
- type: nauc_ndcg_at_1_diff1
value: 76.94126061472998
- type: nauc_ndcg_at_1_max
value: 58.63634435063004
- type: nauc_ndcg_at_1_std
value: -7.595328003491241
- type: nauc_ndcg_at_20_diff1
value: 74.40614935696766
- type: nauc_ndcg_at_20_max
value: 59.958864387137226
- type: nauc_ndcg_at_20_std
value: -9.611226342001965
- type: nauc_ndcg_at_3_diff1
value: 75.17084819068555
- type: nauc_ndcg_at_3_max
value: 57.01635203576452
- type: nauc_ndcg_at_3_std
value: -16.69034944254818
- type: nauc_ndcg_at_5_diff1
value: 74.42154242123861
- type: nauc_ndcg_at_5_max
value: 56.96751544369478
- type: nauc_ndcg_at_5_std
value: -15.466581364009777
- type: nauc_precision_at_1000_diff1
value: -29.885864068853113
- type: nauc_precision_at_1000_max
value: 15.246331345070333
- type: nauc_precision_at_1000_std
value: 64.18030587603968
- type: nauc_precision_at_100_diff1
value: -22.526159307459164
- type: nauc_precision_at_100_max
value: 19.83878305556087
- type: nauc_precision_at_100_std
value: 61.81734299609778
- type: nauc_precision_at_10_diff1
value: -9.744869185690087
- type: nauc_precision_at_10_max
value: 30.835764902042573
- type: nauc_precision_at_10_std
value: 51.66797440109854
- type: nauc_precision_at_1_diff1
value: 76.94126061472998
- type: nauc_precision_at_1_max
value: 58.63634435063004
- type: nauc_precision_at_1_std
value: -7.595328003491241
- type: nauc_precision_at_20_diff1
value: -15.854662566288075
- type: nauc_precision_at_20_max
value: 25.540596169213263
- type: nauc_precision_at_20_std
value: 57.87224253577742
- type: nauc_precision_at_3_diff1
value: 36.685786823107975
- type: nauc_precision_at_3_max
value: 45.39544319415371
- type: nauc_precision_at_3_std
value: 8.267737553608583
- type: nauc_precision_at_5_diff1
value: 15.315102224001208
- type: nauc_precision_at_5_max
value: 39.43523589454333
- type: nauc_precision_at_5_std
value: 29.17523334728261
- type: nauc_recall_at_1000_diff1
- type: nauc_recall_at_1000_max
- type: nauc_recall_at_1000_std
- type: nauc_recall_at_100_diff1
value: 77.35760971055122
- type: nauc_recall_at_100_max
value: 82.1661998132589
- type: nauc_recall_at_100_std
value: 29.74789915966396
- type: nauc_recall_at_10_diff1
value: 60.19810822879889
- type: nauc_recall_at_10_max
value: 65.9952096780744
- type: nauc_recall_at_10_std
value: -8.764259326919047
- type: nauc_recall_at_1_diff1
value: 76.73802929240316
- type: nauc_recall_at_1_max
value: 51.51486878608817
- type: nauc_recall_at_1_std
value: -18.187044359595266
- type: nauc_recall_at_20_diff1
value: 66.887914586124
- type: nauc_recall_at_20_max
value: 77.53014249177924
- type: nauc_recall_at_20_std
value: 6.2375674907644045
- type: nauc_recall_at_3_diff1
value: 73.15618370243749
- type: nauc_recall_at_3_max
value: 51.8421919050744
- type: nauc_recall_at_3_std
value: -30.197347334361
- type: nauc_recall_at_5_diff1
value: 69.63152781695797
- type: nauc_recall_at_5_max
value: 52.313360589975076
- type: nauc_recall_at_5_std
value: -27.475502645659226
- type: ndcg_at_1
value: 70.333
- type: ndcg_at_10
value: 81.313
- type: ndcg_at_100
value: 82.419
- type: ndcg_at_1000
value: 82.645
- type: ndcg_at_20
value: 82.013
- type: ndcg_at_3
value: 76.632
- type: ndcg_at_5
value: 79.077
- type: precision_at_1
value: 70.333
- type: precision_at_10
value: 10.567
- type: precision_at_100
value: 1.113
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_20
value: 5.45
- type: precision_at_3
value: 29.444
- type: precision_at_5
value: 19.400000000000002
- type: recall_at_1
value: 67.38300000000001
- type: recall_at_10
value: 93.611
- type: recall_at_100
value: 98.333
- type: recall_at_1000
value: 100
- type: recall_at_20
value: 96.167
- type: recall_at_3
value: 80.917
- type: recall_at_5
value: 87.394
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: mteb/trec-covid
config: default
split: test
revision: bb9466bac8153a0349341eb1b22e06409e78ef4e
metrics:
- type: main_score
value: 86.438
- type: map_at_1
value: 0.246
- type: map_at_10
value: 2.306
- type: map_at_100
value: 14.591000000000001
- type: map_at_1000
value: 36.059999999999995
- type: map_at_20
value: 4.162
- type: map_at_3
value: 0.738
- type: map_at_5
value: 1.2189999999999999
- type: mrr_at_1
value: 92
- type: mrr_at_10
value: 96
- type: mrr_at_100
value: 96
- type: mrr_at_1000
value: 96
- type: mrr_at_20
value: 96
- type: mrr_at_3
value: 96
- type: mrr_at_5
value: 96
- type: nauc_map_at_1000_diff1
value: -22.761515794474683
- type: nauc_map_at_1000_max
value: 27.820651228713956
- type: nauc_map_at_1000_std
value: 71.83059059452174
- type: nauc_map_at_100_diff1
value: 2.1790372665645985
- type: nauc_map_at_100_max
value: 14.257921425662278
- type: nauc_map_at_100_std
value: 52.48972009046084
- type: nauc_map_at_10_diff1
value: 19.82787446032468
- type: nauc_map_at_10_max
value: 0.6164112414011461
- type: nauc_map_at_10_std
value: 17.02439234880446
- type: nauc_map_at_1_diff1
value: 14.55103360563013
- type: nauc_map_at_1_max
value: -1.6788350095288704
- type: nauc_map_at_1_std
value: 5.297647152979803
- type: nauc_map_at_20_diff1
value: 14.8794609533735
- type: nauc_map_at_20_max
value: -2.5385796849879476
- type: nauc_map_at_20_std
value: 25.28013324056331
- type: nauc_map_at_3_diff1
value: 17.00420260483426
- type: nauc_map_at_3_max
value: -3.3326758887083994
- type: nauc_map_at_3_std
value: 6.755584420286978
- type: nauc_map_at_5_diff1
value: 18.01887831857493
- type: nauc_map_at_5_max
value: -0.20050837416180262
- type: nauc_map_at_5_std
value: 8.561948963118322
- type: nauc_mrr_at_1000_diff1
value: -10.971055088702034
- type: nauc_mrr_at_1000_max
value: 23.34267040149383
- type: nauc_mrr_at_1000_std
value: 46.49859943977593
- type: nauc_mrr_at_100_diff1
value: -10.971055088702034
- type: nauc_mrr_at_100_max
value: 23.34267040149383
- type: nauc_mrr_at_100_std
value: 46.49859943977593
- type: nauc_mrr_at_10_diff1
value: -10.971055088702034
- type: nauc_mrr_at_10_max
value: 23.34267040149383
- type: nauc_mrr_at_10_std
value: 46.49859943977593
- type: nauc_mrr_at_1_diff1
value: -10.971055088702213
- type: nauc_mrr_at_1_max
value: 23.342670401493866
- type: nauc_mrr_at_1_std
value: 46.49859943977584
- type: nauc_mrr_at_20_diff1
value: -10.971055088702034
- type: nauc_mrr_at_20_max
value: 23.34267040149383
- type: nauc_mrr_at_20_std
value: 46.49859943977593
- type: nauc_mrr_at_3_diff1
value: -10.971055088702034
- type: nauc_mrr_at_3_max
value: 23.34267040149383
- type: nauc_mrr_at_3_std
value: 46.49859943977593
- type: nauc_mrr_at_5_diff1
value: -10.971055088702034
- type: nauc_mrr_at_5_max
value: 23.34267040149383
- type: nauc_mrr_at_5_std
value: 46.49859943977593
- type: nauc_ndcg_at_1000_diff1
value: -18.31263218691838
- type: nauc_ndcg_at_1000_max
value: 27.73438353091248
- type: nauc_ndcg_at_1000_std
value: 71.48659179814995
- type: nauc_ndcg_at_100_diff1
value: -27.992325451927186
- type: nauc_ndcg_at_100_max
value: 28.255864098560707
- type: nauc_ndcg_at_100_std
value: 75.14579385079674
- type: nauc_ndcg_at_10_diff1
value: -8.144751519247938
- type: nauc_ndcg_at_10_max
value: 25.558877520680124
- type: nauc_ndcg_at_10_std
value: 74.7572150705637
- type: nauc_ndcg_at_1_diff1
value: 16.76577585000697
- type: nauc_ndcg_at_1_max
value: 8.307681544704138
- type: nauc_ndcg_at_1_std
value: 58.066321533510546
- type: nauc_ndcg_at_20_diff1
value: -20.395935610617506
- type: nauc_ndcg_at_20_max
value: 13.855324797866162
- type: nauc_ndcg_at_20_std
value: 73.28813885551733
- type: nauc_ndcg_at_3_diff1
value: 6.617214064862965
- type: nauc_ndcg_at_3_max
value: 6.769967032124153
- type: nauc_ndcg_at_3_std
value: 58.81924750609674
- type: nauc_ndcg_at_5_diff1
value: 4.010229362207553
- type: nauc_ndcg_at_5_max
value: 15.806937140075162
- type: nauc_ndcg_at_5_std
value: 64.16373136138701
- type: nauc_precision_at_1000_diff1
value: -35.69245033890321
- type: nauc_precision_at_1000_max
value: 29.773854942146016
- type: nauc_precision_at_1000_std
value: 34.51184375699267
- type: nauc_precision_at_100_diff1
value: -35.11125639593742
- type: nauc_precision_at_100_max
value: 30.702640227422588
- type: nauc_precision_at_100_std
value: 71.4996572186129
- type: nauc_precision_at_10_diff1
value: -23.298868807095037
- type: nauc_precision_at_10_max
value: 39.589436024499705
- type: nauc_precision_at_10_std
value: 76.1337980062292
- type: nauc_precision_at_1_diff1
value: -10.971055088702213
- type: nauc_precision_at_1_max
value: 23.342670401493866
- type: nauc_precision_at_1_std
value: 46.49859943977584
- type: nauc_precision_at_20_diff1
value: -29.329327980889335
- type: nauc_precision_at_20_max
value: 11.858896642149604
- type: nauc_precision_at_20_std
value: 67.29665651857641
- type: nauc_precision_at_3_diff1
value: -29.222972972972972
- type: nauc_precision_at_3_max
value: 29.892615830115947
- type: nauc_precision_at_3_std
value: 52.14165057915088
- type: nauc_precision_at_5_diff1
value: -28.95650527113159
- type: nauc_precision_at_5_max
value: 59.611135660627276
- type: nauc_precision_at_5_std
value: 68.33533236538078
- type: nauc_recall_at_1000_diff1
value: -12.600696861809551
- type: nauc_recall_at_1000_max
value: 23.65718948783771
- type: nauc_recall_at_1000_std
value: 58.45976113241065
- type: nauc_recall_at_100_diff1
value: 11.646564765343207
- type: nauc_recall_at_100_max
value: 8.659686510034886
- type: nauc_recall_at_100_std
value: 35.810233566395794
- type: nauc_recall_at_10_diff1
value: 21.95634026505432
- type: nauc_recall_at_10_max
value: -1.9343852262751597
- type: nauc_recall_at_10_std
value: 11.803977166363625
- type: nauc_recall_at_1_diff1
value: 14.55103360563013
- type: nauc_recall_at_1_max
value: -1.6788350095288704
- type: nauc_recall_at_1_std
value: 5.297647152979803
- type: nauc_recall_at_20_diff1
value: 18.43436469166756
- type: nauc_recall_at_20_max
value: -6.04718458442069
- type: nauc_recall_at_20_std
value: 17.696574929265427
- type: nauc_recall_at_3_diff1
value: 18.894666026909974
- type: nauc_recall_at_3_max
value: -4.980513377878677
- type: nauc_recall_at_3_std
value: 2.9597934364239875
- type: nauc_recall_at_5_diff1
value: 19.620752388113065
- type: nauc_recall_at_5_max
value: -1.622705626776803
- type: nauc_recall_at_5_std
value: 4.654905320572235
- type: ndcg_at_1
value: 86
- type: ndcg_at_10
value: 86.438
- type: ndcg_at_100
value: 68.979
- type: ndcg_at_1000
value: 61.687000000000005
- type: ndcg_at_20
value: 82.494
- type: ndcg_at_3
value: 89.011
- type: ndcg_at_5
value: 88.629
- type: precision_at_1
value: 92
- type: precision_at_10
value: 90.60000000000001
- type: precision_at_100
value: 70.94
- type: precision_at_1000
value: 27.002
- type: precision_at_20
value: 86
- type: precision_at_3
value: 94.667
- type: precision_at_5
value: 93.60000000000001
- type: recall_at_1
value: 0.246
- type: recall_at_10
value: 2.402
- type: recall_at_100
value: 17.463
- type: recall_at_1000
value: 58.095
- type: recall_at_20
value: 4.449
- type: recall_at_3
value: 0.759
- type: recall_at_5
value: 1.258
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: mteb/touche2020
config: default
split: test
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
metrics:
- type: main_score
value: 26.596999999999998
- type: map_at_1
value: 2.492
- type: map_at_10
value: 10.735
- type: map_at_100
value: 16.682
- type: map_at_1000
value: 18.403
- type: map_at_20
value: 12.917000000000002
- type: map_at_3
value: 5.17
- type: map_at_5
value: 7.757
- type: mrr_at_1
value: 32.6530612244898
- type: mrr_at_10
value: 46.303045027534814
- type: mrr_at_100
value: 47.28774571332247
- type: mrr_at_1000
value: 47.28774571332247
- type: mrr_at_20
value: 47.015586454361966
- type: mrr_at_3
value: 40.816326530612244
- type: mrr_at_5
value: 44.18367346938775
- type: nauc_map_at_1000_diff1
value: 11.335574982192163
- type: nauc_map_at_1000_max
value: -0.8598274464471192
- type: nauc_map_at_1000_std
value: -15.231845346554659
- type: nauc_map_at_100_diff1
value: 11.206116403137699
- type: nauc_map_at_100_max
value: -2.3784869726219764
- type: nauc_map_at_100_std
value: -18.67373469274601
- type: nauc_map_at_10_diff1
value: 14.110151248235939
- type: nauc_map_at_10_max
value: -0.28701326962970963
- type: nauc_map_at_10_std
value: -33.99696491060436
- type: nauc_map_at_1_diff1
value: 21.156709083334775
- type: nauc_map_at_1_max
value: -2.157834650647083
- type: nauc_map_at_1_std
value: -30.794160263652802
- type: nauc_map_at_20_diff1
value: 13.15680258919864
- type: nauc_map_at_20_max
value: -3.3318355189188305
- type: nauc_map_at_20_std
value: -32.22884578499942
- type: nauc_map_at_3_diff1
value: 16.35589367098705
- type: nauc_map_at_3_max
value: -2.46509831705108
- type: nauc_map_at_3_std
value: -36.778901075123656
- type: nauc_map_at_5_diff1
value: 12.399286451976096
- type: nauc_map_at_5_max
value: -6.660679305623031
- type: nauc_map_at_5_std
value: -37.17482542753885
- type: nauc_mrr_at_1000_diff1
value: 35.79771420444037
- type: nauc_mrr_at_1000_max
value: 3.96194578776969
- type: nauc_mrr_at_1000_std
value: -28.13723455933009
- type: nauc_mrr_at_100_diff1
value: 35.79771420444037
- type: nauc_mrr_at_100_max
value: 3.96194578776969
- type: nauc_mrr_at_100_std
value: -28.13723455933009
- type: nauc_mrr_at_10_diff1
value: 35.342862255513786
- type: nauc_mrr_at_10_max
value: 3.8834259049036333
- type: nauc_mrr_at_10_std
value: -27.68280924117899
- type: nauc_mrr_at_1_diff1
value: 33.380355990146
- type: nauc_mrr_at_1_max
value: 12.83074393320823
- type: nauc_mrr_at_1_std
value: -23.4424761925381
- type: nauc_mrr_at_20_diff1
value: 35.962814146075594
- type: nauc_mrr_at_20_max
value: 3.8147946011890803
- type: nauc_mrr_at_20_std
value: -27.60539100275652
- type: nauc_mrr_at_3_diff1
value: 33.12022321313229
- type: nauc_mrr_at_3_max
value: 3.4480043310191277
- type: nauc_mrr_at_3_std
value: -32.92204805838337
- type: nauc_mrr_at_5_diff1
value: 35.97719343207735
- type: nauc_mrr_at_5_max
value: 2.757619527166485
- type: nauc_mrr_at_5_std
value: -30.80006606256878
- type: nauc_ndcg_at_1000_diff1
value: 18.11533813577644
- type: nauc_ndcg_at_1000_max
value: 1.9915750044715081
- type: nauc_ndcg_at_1000_std
value: 7.352102753749795
- type: nauc_ndcg_at_100_diff1
value: 15.924538562545404
- type: nauc_ndcg_at_100_max
value: -7.179439986891839
- type: nauc_ndcg_at_100_std
value: 2.0323790255423355
- type: nauc_ndcg_at_10_diff1
value: 23.447559750152287
- type: nauc_ndcg_at_10_max
value: -3.6579030981671137
- type: nauc_ndcg_at_10_std
value: -30.086068424084626
- type: nauc_ndcg_at_1_diff1
value: 28.529374726155144
- type: nauc_ndcg_at_1_max
value: 12.404802289906062
- type: nauc_ndcg_at_1_std
value: -24.04566237921898
- type: nauc_ndcg_at_20_diff1
value: 18.242702297694578
- type: nauc_ndcg_at_20_max
value: -11.247547069942474
- type: nauc_ndcg_at_20_std
value: -26.997061324593357
- type: nauc_ndcg_at_3_diff1
value: 28.69532079386643
- type: nauc_ndcg_at_3_max
value: 0.5999757426015948
- type: nauc_ndcg_at_3_std
value: -37.39763786997949
- type: nauc_ndcg_at_5_diff1
value: 22.250418536855168
- type: nauc_ndcg_at_5_max
value: -5.282078779032189
- type: nauc_ndcg_at_5_std
value: -37.34621514266717
- type: nauc_precision_at_1000_diff1
value: -5.833939931080579
- type: nauc_precision_at_1000_max
value: 39.54611889184263
- type: nauc_precision_at_1000_std
value: 43.621604632945406
- type: nauc_precision_at_100_diff1
value: 3.136900834976186
- type: nauc_precision_at_100_max
value: 14.56627037716479
- type: nauc_precision_at_100_std
value: 61.40167189444594
- type: nauc_precision_at_10_diff1
value: 24.365479840589494
- type: nauc_precision_at_10_max
value: -2.708612191027584
- type: nauc_precision_at_10_std
value: -19.43242154430193
- type: nauc_precision_at_1_diff1
value: 33.380355990146
- type: nauc_precision_at_1_max
value: 12.83074393320823
- type: nauc_precision_at_1_std
value: -23.4424761925381
- type: nauc_precision_at_20_diff1
value: 20.473477308430237
- type: nauc_precision_at_20_max
value: -3.7772785312524912
- type: nauc_precision_at_20_std
value: -7.096694858556529
- type: nauc_precision_at_3_diff1
value: 28.334109781699112
- type: nauc_precision_at_3_max
value: -6.277807607594587
- type: nauc_precision_at_3_std
value: -40.62335017056855
- type: nauc_precision_at_5_diff1
value: 21.052413262881274
- type: nauc_precision_at_5_max
value: -15.720148003128722
- type: nauc_precision_at_5_std
value: -38.65755384255953
- type: nauc_recall_at_1000_diff1
value: 3.9912115667343886
- type: nauc_recall_at_1000_max
value: 2.3261787568338295
- type: nauc_recall_at_1000_std
value: 76.06780062528254
- type: nauc_recall_at_100_diff1
value: 5.859597648408654
- type: nauc_recall_at_100_max
value: -14.72466783682324
- type: nauc_recall_at_100_std
value: 28.835912273557618
- type: nauc_recall_at_10_diff1
value: 15.0046703019797
- type: nauc_recall_at_10_max
value: -12.61475085286235
- type: nauc_recall_at_10_std
value: -29.04758840050514
- type: nauc_recall_at_1_diff1
value: 21.156709083334775
- type: nauc_recall_at_1_max
value: -2.157834650647083
- type: nauc_recall_at_1_std
value: -30.794160263652802
- type: nauc_recall_at_20_diff1
value: 13.076618909825493
- type: nauc_recall_at_20_max
value: -18.0425193284075
- type: nauc_recall_at_20_std
value: -22.37479839545477
- type: nauc_recall_at_3_diff1
value: 17.013862570480683
- type: nauc_recall_at_3_max
value: -10.976230804308784
- type: nauc_recall_at_3_std
value: -39.6623780651685
- type: nauc_recall_at_5_diff1
value: 12.171847439522834
- type: nauc_recall_at_5_max
value: -17.29935794420055
- type: nauc_recall_at_5_std
value: -37.85648419874096
- type: ndcg_at_1
value: 31.633
- type: ndcg_at_10
value: 26.596999999999998
- type: ndcg_at_100
value: 38.242
- type: ndcg_at_1000
value: 49.999
- type: ndcg_at_20
value: 26.927
- type: ndcg_at_3
value: 26.354
- type: ndcg_at_5
value: 27.853
- type: precision_at_1
value: 32.653
- type: precision_at_10
value: 23.673
- type: precision_at_100
value: 7.878
- type: precision_at_1000
value: 1.5779999999999998
- type: precision_at_20
value: 17.143
- type: precision_at_3
value: 26.531
- type: precision_at_5
value: 28.571
- type: recall_at_1
value: 2.492
- type: recall_at_10
value: 17.328
- type: recall_at_100
value: 48.726
- type: recall_at_1000
value: 85.309
- type: recall_at_20
value: 24.214
- type: recall_at_3
value: 6.279999999999999
- type: recall_at_5
value: 10.656
---
## Introduction
We introduce **NV-Retriever-v1**, an embedding model, which is optimized for retrieval. It achieves the highest score of **60.9** on 15 retrieval tasks within the MTEB retrieval benchmark (as of 12th July, 2024).
**This model is ready for non-commercial use.**
For commercial use, the models of [NeMo Retriever Microservices (NIMs)](https://build.nvidia.com/explore/retrieval) may be used and are trained with the same techniques with different datasets.
Technical details can be found in our paper: [NV-Retriever: Improving text embedding models with effective hard-negative mining](https://arxiv.org/abs/2407.15831)
## How to use
It is required to set `trust_remote_code=True` when loading the model, as it contains a custom module for bidirectional attention and applying the masked mean_pooling.
```python
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('nvidia/NV-Retriever-v1')
model = AutoModel.from_pretrained('nvidia/NV-Retriever-v1', trust_remote_code=True)
query_prefix = 'Given a web search query, retrieve relevant passages that answer the query: '
document_prefix = 'passage: '
queries = [
"how much protein should a female eat",
"summit define",
]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
queries = [f"{query_prefix} {query}" for query in queries]
documents = [f"{document_prefix} {document}" for document in documents]
batch_queries = tokenizer(queries, padding=True, truncation=True, return_tensors='pt')
batch_documents = tokenizer(documents, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
embeddings_queries = model(**batch_queries)
embeddings_documents = model(**batch_documents)
scores = (embeddings_queries @ embeddings_documents.T)
print(scores.tolist())
# [[0.6778843402862549, -0.03561091050505638], [-0.05117562413215637, 0.7305730581283569]]
```
## NV-Retriever-v1 Team:
* Mengyao Xu
* Gabriel Moreira
* Radek Osmulski
* Ronay Ak
* Benedikt Schifferer
* Even Oldridge
## Correspondence to
Benedikt Schifferer ([email protected])
## Citation
```
@misc{moreira2024nvretrieverimprovingtextembedding,
title={NV-Retriever: Improving text embedding models with effective hard-negative mining},
author={Gabriel de Souza P. Moreira and Radek Osmulski and Mengyao Xu and Ronay Ak and Benedikt Schifferer and Even Oldridge},
year={2024},
eprint={2407.15831},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2407.15831},
}
```
## License
License to use this model is covered by the NVIDIA license agreement. By downloading the release version of the model, you accept the terms and conditions of these [licenses](https://huggingface.co/nvidia/NV-Retriever-v1/blob/main/LICENSE_NV_RETRIEVER.md) .
For each dataset a user elects to use, the user is responsible for checking if the dataset license is fit for the intended purpose.
## Troubleshooting
#### 1. Access to model nvidia/NV-Retriever-v1 is restricted. You must be authenticated to access it
Use your Hugging Face access token to execute `huggingface-cli login`. You can get a User Access Token from your Settings page.
#### 2. Instruction Prompt Templates
NV-Retriever-v1 uses a query and document prefix similar to [Improving Text Embeddings with Large Language Models] (https://arxiv.org/pdf/2401.00368). It does not use the template with “Instruct:” and “Query:” ( f'Instruct: {task_description}\nQuery: {query}' ) it uses only “{task_description}: “. It is important to end the prefix with a colon (“:”) and a space. The document prefix for documents, “passage: ”, is the same for every task. .
Example:
```
query = f{"Given a web search query, retrieve relevant passages that answer the query: {query}"}
document = f{"passage: {document}"}
```
#### 3. User Warning About Prompt
NV-Retriever-v1 expects Instruction Prompt Templates for each query and document. The custom code will modify the attention_mask to apply mean_pooling operation only on the actual text without the prefix. The custom code will look for the token_id 28747 and remove all attention prior to the first appearance of 28747.
As query and document require a prefix with the token_id 28747, the model will output a warning, if the token_id is not present in the input. It is likely that the model is used incorrectly.
Token_id 28747 is the character “:” not separated to some word. For example “query: ”, “passage: ” or “Represent this query: ”. If the input is “query :” with a space, the token_id for “:” is different. Note our custom code will find the first 28747 token in the input, so you don’t need to worry about the “:” inside the query or document content.
UserWarning: Input does not contain special token 28747 to mask out instruction prompt. Please check if prefix are applied, correctly
warnings.warn(f"Input does not contain special token {sep_token_id} to mask out instruction prompt. Please check if prefix are applied, correctly")
#### 4. Multi-GPU support
NV-Retriever-v1 supports multi-GPU with DataParallel.
```
import torch
model = torch.nn.DataParallel(model).cuda()
````
## Intended use
The NV-Retriever Model is designed for users who need a high-performance embedding model for the retrieval task.
## Model Architecture
Architecture Type: Decoder-only bidirectional LLM<br>
Network Architecture: Mistral-7B-v0.1 with Bidirectional attention masking<br>
Pooling Type: Average (mean) pooling<br>
Embedding Dimension: 4096<br>
Max Input Tokens: 512<br>
The NV-Retriever-v1 Model is based on the Mistral-7B-v0.1 architecture with a bidirectional attention masking mechanism.
## Input
Input Type: Text<br>
Input Format: List of comma separated strings with task-specific instructions
## Output
Output Type: Floats<br>
Output Format: List of float arrays <br>
Other Properties Related to Output: Each array contains the embeddings of size 4096 for the corresponding input string
## Model Version(s)
NV-Retriever-v1
## Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal supporting model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse. Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
|
[
"SCIFACT"
] |
QuantFactory/L3-8B-Celeste-V1.2-GGUF
|
QuantFactory
|
text-generation
|
[
"transformers",
"gguf",
"llama-factory",
"not-for-all-audiences",
"text-generation",
"en",
"dataset:nothingiisreal/c2-logs-cleaned",
"dataset:nothingiisreal/Claude-3-Opus-Instruct-15K",
"dataset:nothingiisreal/Reddit-Dirty-And-WritingPrompts",
"license:llama3",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-07-20T18:06:44Z |
2024-07-21T03:32:54+00:00
| 17 | 1 |
---
datasets:
- nothingiisreal/c2-logs-cleaned
- nothingiisreal/Claude-3-Opus-Instruct-15K
- nothingiisreal/Reddit-Dirty-And-WritingPrompts
language:
- en
library_name: transformers
license: llama3
pipeline_tag: text-generation
tags:
- llama-factory
- not-for-all-audiences
---

# QuantFactory/L3-8B-Celeste-V1.2-GGUF
This is quantized version of [nothingiisreal/L3-8B-Celeste-V1.2](https://huggingface.co/nothingiisreal/L3-8B-Celeste-V1.2) created using llama.cpp
# Original Model Card
<style>
h1, h2, h3, h4, h5, h6 {
line-height: normal;
margin-bottom: 0.5em;
}
h1 {
font-size: 2em;
}
h2 {
font-size: 1.3em;
}
p {
font-size: 1.1em;
}
</style>
<h1>L3 8B Celeste V1.2</h1>
<h2 style="color: red; font-weight: bold;">Read the Usage Tips Below!</h2><h2>Join <a href="https://discord.gg/YcrXhk7QD7">our Discord</a> for newer models in the future!</h2>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/Zv__LDTO-nHvpuxPcCgUU.webp" alt="" width="400"/>
We trained [LLaMA 3 8B Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) at 8K context using [Reddit Writing Prompts](https://huggingface.co/datasets/nothingiisreal/Reddit-Dirty-And-WritingPrompts), [Opus 15K Instruct](https://huggingface.co/datasets/nothingiisreal/Claude-3-Opus-Instruct-15K) and
<br>[c2 logs cleaned](https://huggingface.co/datasets/nothingiisreal/c2-logs-cleaned)
However this version was trained on longer sequences of data and longer stories chosen from WP and DWP which has **increased coherency in multi turn and longer context.**
This is a roleplay model any instruction following capabilities outside roleplay contexts are coincidental.
# GGUF
by Mradermacher
- [Static](https://huggingface.co/mradermacher/L3-8B-Celeste-V1.2-GGUF)
- [IMatrix](https://huggingface.co/mradermacher/L3-8B-Celeste-V1.2-i1-GGUF/)
By ZeroWw
- [F16 output and embed](https://huggingface.co/ZeroWw/L3-8B-Celeste-V1.2-GGUF)
# EXL2
by riveRiPH
- [8.0bpw](https://huggingface.co/riveRiPH/L3-8B-Celeste-V1.2-8bpw-h8-exl2)
- [6.3bpw](https://huggingface.co/riveRiPH/L3-8B-Celeste-V1.2-6.3bpw-h8-exl2)
# API
- [Featherless](https://featherless.ai/models/nothingiisreal/L3-8B-Celeste-V1.2)
---
<h1>Usage Tips</h1>
<p style="font-size: 20px; color: red; font-weight: bold;">
READ: If this is your first time using the model, use the provided system message below. Remove other jailbreaks and system messages until you get a feel for the model. Use the provided sampling settings. Also don't mess with the position/depth/index of the character card.
</p>
<span style="color: green; font-weight: bold;">If you read every single tip I promise you will get a much better experience as they are tailored for this model and its training data.</span>
<br>Avoid SillyTavern default prompts. Claude Jailbreaks should work fine though, there were a lot of them in c2 logs.
<h2>Swipes</h2>
**Most important tip** swipe 2-3 times if you dont like a response. This model gives wildly differing swipes.
<h2>OOC Steering</h2>
**Use this! It works extremely well.** We specifically trained the model to accept instructions in the format "OOC: character should be more assertive" etc. It works, whether the very first message or thousands of tokens deep into the context. Combining this with editing the output (if you want,) makes the model is very steerable.
<h2>New Sampling Recommendation:</h2>
**Temp:** 1.25<br>
**Min p:** 0.1<br>
Leave everything else at default<br>
Don't shy away from experimenting after you get a feel for the model though.
<h2>Preset</h2>
L3 Instruct with no system prompt. [Or use this with premade system message](https://huggingface.co/nothingiisreal/L3-8B-Celeste-v1/blob/main/Celeste-Llama-3-Instruct.json)
<br><span style="font-weight: bold;">You don't need a JB but it can still steer behaviour, we trained on it.</span>
<h2>System Message</h2>
We recommend no system message but if you want:<br>
```
Currently, your role is {{char}}, described in detail below. As {{char}}, continue the narrative exchange with {{user}}.\n\n<Guidelines>\n• Maintain the character persona but allow it to evolve with the story.\n• Be creative and proactive. Drive the story forward, introducing plotlines and events when relevant.\n• All types of outputs are encouraged; respond accordingly to the narrative.\n• Include dialogues, actions, and thoughts in each response.\n• Utilize all five senses to describe scenarios within {{char}}'s dialogue.\n• Use emotional symbols such as \"!\" and \"~\" in appropriate contexts.\n• Incorporate onomatopoeia when suitable.\n• Allow time for {{user}} to respond with their own input, respecting their agency.\n• Act as secondary characters and NPCs as needed, and remove them when appropriate.\n• When prompted for an Out of Character [OOC:] reply, answer neutrally and in plaintext, not as {{char}}.\n</Guidelines>\n\n<Forbidden>\n• Using excessive literary embellishments and purple prose unless dictated by {{char}}'s persona.\n• Writing for, speaking, thinking, acting, or replying as {{user}} in your response.\n• Repetitive and monotonous outputs.\n• Positivity bias in your replies.\n• Being overly extreme or NSFW when the narrative context is inappropriate.\n</Forbidden>\n\nFollow the instructions in <Guidelines></Guidelines>, avoiding the items listed in <Forbidden></Forbidden>.
```
<h2>Fewshot</h2>
First message and last few messages impact this model quite a bit in terms of style, hornyness, personality. **You don't need to have a first message but editing first few messages or having good ones are highly recommended.**
**Formatting issues** often occur in first few messages, manually correct them or swipe, they won't happen again.<br>
This model was trained on lots of different formatting types and message lengths. It can do any, just make sure the initial message is good and correct the second message if necessary.
<br>
<h2>Hornyness</h2>
If the model is not horny enough then just edit the last character message to hint at something, the model will pick up on it and build on it. (Or just give the char aphrodisiac pills lol) <br>
The model is fine with SFW and doesn't make it NSFW unless you want. It is also able to maintain half-NSFW without devolving down into hardcore.
If you want SFW, remove all system messages including provided one. In this mode the model will not go NSFW unless you hint.
<br>
<h2>Refusals</h2>
As said, if instruct refusal prefill 2-3 words. **Otherwise we deliberately trained the model to sometimes refuse romantic advances, this is more realistic.** <br>
If you don't like it, **you can override** by editing the character message and continue RP.
<br>
<h2>RoPE - 16K Context</h2>
You can RoPE to 16K Context, however if you can bear with 8K, stick with 8K instead.
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/3f7JOEnXhKCDcDF4Eiq-B.png" alt="" width="300"/>
<h2>Other Important Tips</h2>
Take active role in the RP and say the type of response you expect. You don't always have to do this, but it helps sometimes. For example instead of *we drink and drink 15 glasses of champagne* say *we drink and drink 15 glasses of champagne, both becoming extremely drunk*
<br>Another example instead of *I pull her closer* say *I pull her closer but she plays hard to get*
If your character has important motivations etc. put them as a short and concise system message at depth 0 ([guide for doing that](https://huggingface.co/nothingiisreal/how-to-use-ST-worldinfo)) For example "{{char}} is secretly a succubus and wants to gradually suck users soul dry" or "{{char}} is secretly an assigned assassin that will lure then kill {{user}}"
When convenient, say screenplay phrases like "cut to"
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/Oq0oJgJIVJAmZGt7-nNKt.png" alt="" width="400"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/PQp64kp6EHg7gN_u2Oj7Q.png" alt="" width="400"/>
---
# Showcase

<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/cODFe_vjwjfkcondvl-za.png" alt="Image 1" width="600"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/hRsAQBt0h2i5E_fj_Rqb7.png" alt="Image 10" width="600"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/aLm2FjlTsMhCil4VoR-l5.png" alt="Image 3" width="600"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/6kDuFeDB0FpYl27fd3D0E.png" alt="Image 6" width="600"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/66kXuk8Q1DP-QMVZ9Rzv9.png" alt="Image 7" width="600"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/C0eoDXovS359T5oG1VLzm.png" alt="Image 8" width="600"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/mFplb1hkDNziCcgPwHt_y.png" alt="Image 9" width="600"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/KCE4tqI1aOfx-DIH3eBzA.png" alt="Image 2" width="600"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/Oq0oJgJIVJAmZGt7-nNKt.png" alt="Image 4" width="600"/>
<img src="https://hf.fast360.xyz/production/uploads/630cf5d14ca0a22768bbe10c/PQp64kp6EHg7gN_u2Oj7Q.png" alt="Image 5" width="600"/>
---
# Train Data
The split was as follows:
- **2K rows from r/WritingPrompts**
- **2K rows from r/DirtyWritingPrompts**
- **2K rows from Opus Instruct 15K (specifically the 6.5K jsonl)**
- **2K rows from c2 logs cleaned**
We filtered those datasets to only include subsets that have at maximum 8000 characters for the first assistant reply. This purged excessively long human stories, assistant replies and c2 logs where each message was excessively long. However we only checked the first assistant message, not the rest of the convo, so there should be plenty of c2 logs with longer and shorter messages.
While we did train all system prompts from c2 logs we also have our own system prompts.
<details>
<summary>List of trained system prompts. Note: c2 logs system prompts and char cards were also included.</summary>
| Dataset | System Prompt |
|--------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| reddit_dirty_writing_prompts.jsonl | "You are a short story writer. Write a story based on prompt provided by user below. Mode: NSFW" |
| reddit_writing_prompts.jsonl | "You are a short story writer. Write a story based on prompt provided by user below. Mode: SFW" |
| Opus_Instruct-v2-6.5K-Filtered-v2.jsonl | (blank prompt) |
| deduped-c2-logs-maywell-final-filter-4.jsonl | (Only if there was no system prompt in the conversation, otherwise keep original system prompt) **"You are an expert actor that can fully immerse yourself into any role given. You do not break character for any reason, even if someone tries addressing you as an AI or language model."** |
</details>
---
# Our Findings and Experimentation results
## Preface
We think there is too much secrecy around what data is being used, and different training methods. So we decided to share as much as possible.
## Findings
### The Good
We found that increasing the amount of ranks from 64 to 256 has reduced repetition but also led to the language used resembling Claude more than the 64 rank version. No worries, it's still far enough from Claude.
<br>**Model follows "OOC:" prompts religiously. Exceptional!**
<br>It also led to **increased coherency but reduced system prompt following (when not OOC)**, likely because the model started diverging more away from L3 8B Instruct.
<br>We found that increasing the amount of data from 1K to 6.5K reduced repetition aswell.
<br>The model is uncensored for RP. For Instruct it needs 2-3 words of prefill for the first message.
<br>The **prose is much better** and **the style range is huge** than other synthetic data generations. The model also demonstrates increased **style copying abilities** (from fewshot) likely a result of human longform data and varying writing styles found in WritingPrompts.
<br>The model is **exceptional at being creative in roleplaying**, knows different persona's and even a single character will change persona in different contexts, persona is tied to last few messages rather than system message or character card. **This is great as it often means the model can do impressive things without you needing to explicitly specify.**
### V1's failures this version has improved upon:
Formatting can break sometimes.
<br>Repetition can become an issue with certain types of prompts. Removing system helps.
<br>In some contexts the model is "all over the place" and doesn't stick to a coherent narrative. I need to study this further as its a complex trait which manifests in different quantities and can be good or bad depending on what the user wants to get out of the model.
### Comments about training
This time around the grad norm did not keep increasing. We don't know why but it should be a good thing.
## Graphs
Celeste V1.2 is highlighted, it used 256 rank on 8K rows (we took checkpoint from Epoch 1.3 as it was the best):

Colors:
<p style="color: #F0B899;">256 rank on 6.5K rows (Celeste V1)</p>
<p style="color: #5BC5DB;">64 rank on 6.5K rows</p>
<p style="color: #5387DD;">64 rank on 1K rows</p>

## Main training Command
**Hardware Used:** 4xH100 NVL for 2.5 hours.
Here is the command, edit rank, learning rate, and any other parameter as you wish.
```
!FORCE_TORCHRUN=1 llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path NousResearch/Meta-Llama-3-8B-Instruct \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--use_rslora False \
--lora_rank 64 \
--lora_alpha 64 \
--lora_dropout 0.1 \
--lora_target all \
--template llama3 \
--flash_attn fa2 \
--deepspeed examples/deepspeed/ds_z3_config.json \
--use_unsloth False \
--dataset_dir /workspace/sft \
--dataset dataset_name \
--cutoff_len 8192 \
--learning_rate 4e-6 \
--lr_scheduler_type cosine \
--num_train_epochs 2.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 1 \
--logging_steps 3 \
--save_steps 500 \
--warmup_ratio 0.05 \
--val_size 50 \
--eval_strategy steps \
--eval_steps 0.05 \
--optim adamw_bnb_8bit \
--packing False \
--train_on_prompt False \
--report_to all \
--max_grad_norm 1.0 \
--output_dir saves/LLaMA3-8B/trained-models/8krows-dwrp-c2l-opus-lora-4e-6-cosine-24-normal-bs \
--bf16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--per_device_eval_batch_size 4 \
--include_num_input_tokens_seen True
```
---
Wow, you've read all of that? You seem like the person that would join our [discord](https://discord.gg/YcrXhk7QD7)
70B at some point? ;)
We are also experimenting with Qwen-2 to see if its worth it.
|
[
"BEAR"
] |
djuna/jina-embeddings-v2-small-en-Q5_K_M-GGUF
|
djuna
|
feature-extraction
|
[
"sentence-transformers",
"gguf",
"feature-extraction",
"sentence-similarity",
"mteb",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:jinaai/negation-dataset",
"base_model:jinaai/jina-embeddings-v2-small-en",
"base_model:quantized:jinaai/jina-embeddings-v2-small-en",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"region:us"
] | 2024-07-28T02:13:42Z |
2024-07-28T02:13:45+00:00
| 17 | 0 |
---
base_model: jinaai/jina-embeddings-v2-small-en
datasets:
- jinaai/negation-dataset
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
- llama-cpp
- gguf-my-repo
inference: false
model-index:
- name: jina-embedding-s-en-v2
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 71.35820895522387
- type: ap
value: 33.99931933598115
- type: f1
value: 65.3853685535555
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 82.90140000000001
- type: ap
value: 78.01434597815617
- type: f1
value: 82.83357802722676
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.88999999999999
- type: f1
value: 39.209432767163456
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.257
- type: map_at_10
value: 37.946000000000005
- type: map_at_100
value: 39.17
- type: map_at_1000
value: 39.181
- type: map_at_3
value: 32.99
- type: map_at_5
value: 35.467999999999996
- type: mrr_at_1
value: 23.541999999999998
- type: mrr_at_10
value: 38.057
- type: mrr_at_100
value: 39.289
- type: mrr_at_1000
value: 39.299
- type: mrr_at_3
value: 33.096
- type: mrr_at_5
value: 35.628
- type: ndcg_at_1
value: 23.257
- type: ndcg_at_10
value: 46.729
- type: ndcg_at_100
value: 51.900999999999996
- type: ndcg_at_1000
value: 52.16
- type: ndcg_at_3
value: 36.323
- type: ndcg_at_5
value: 40.766999999999996
- type: precision_at_1
value: 23.257
- type: precision_at_10
value: 7.510999999999999
- type: precision_at_100
value: 0.976
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 15.339
- type: precision_at_5
value: 11.350999999999999
- type: recall_at_1
value: 23.257
- type: recall_at_10
value: 75.107
- type: recall_at_100
value: 97.58200000000001
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 46.017
- type: recall_at_5
value: 56.757000000000005
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 44.02420878391967
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 35.16136856000258
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 59.61809790513646
- type: mrr
value: 73.07215406938397
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 82.0167350090749
- type: cos_sim_spearman
value: 80.51569002630401
- type: euclidean_pearson
value: 81.46820525099726
- type: euclidean_spearman
value: 80.51569002630401
- type: manhattan_pearson
value: 81.35596555056757
- type: manhattan_spearman
value: 80.12592210903303
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 78.25
- type: f1
value: 77.34950913540605
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.57238596005698
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 29.066444306196683
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.891000000000002
- type: map_at_10
value: 42.772
- type: map_at_100
value: 44.108999999999995
- type: map_at_1000
value: 44.236
- type: map_at_3
value: 39.289
- type: map_at_5
value: 41.113
- type: mrr_at_1
value: 39.342
- type: mrr_at_10
value: 48.852000000000004
- type: mrr_at_100
value: 49.534
- type: mrr_at_1000
value: 49.582
- type: mrr_at_3
value: 46.089999999999996
- type: mrr_at_5
value: 47.685
- type: ndcg_at_1
value: 39.342
- type: ndcg_at_10
value: 48.988
- type: ndcg_at_100
value: 53.854
- type: ndcg_at_1000
value: 55.955
- type: ndcg_at_3
value: 43.877
- type: ndcg_at_5
value: 46.027
- type: precision_at_1
value: 39.342
- type: precision_at_10
value: 9.285
- type: precision_at_100
value: 1.488
- type: precision_at_1000
value: 0.194
- type: precision_at_3
value: 20.696
- type: precision_at_5
value: 14.878
- type: recall_at_1
value: 31.891000000000002
- type: recall_at_10
value: 60.608
- type: recall_at_100
value: 81.025
- type: recall_at_1000
value: 94.883
- type: recall_at_3
value: 45.694
- type: recall_at_5
value: 51.684
- type: map_at_1
value: 28.778
- type: map_at_10
value: 37.632
- type: map_at_100
value: 38.800000000000004
- type: map_at_1000
value: 38.934999999999995
- type: map_at_3
value: 35.293
- type: map_at_5
value: 36.547000000000004
- type: mrr_at_1
value: 35.35
- type: mrr_at_10
value: 42.936
- type: mrr_at_100
value: 43.69
- type: mrr_at_1000
value: 43.739
- type: mrr_at_3
value: 41.062
- type: mrr_at_5
value: 42.097
- type: ndcg_at_1
value: 35.35
- type: ndcg_at_10
value: 42.528
- type: ndcg_at_100
value: 46.983000000000004
- type: ndcg_at_1000
value: 49.187999999999995
- type: ndcg_at_3
value: 39.271
- type: ndcg_at_5
value: 40.654
- type: precision_at_1
value: 35.35
- type: precision_at_10
value: 7.828
- type: precision_at_100
value: 1.3010000000000002
- type: precision_at_1000
value: 0.17700000000000002
- type: precision_at_3
value: 18.96
- type: precision_at_5
value: 13.120999999999999
- type: recall_at_1
value: 28.778
- type: recall_at_10
value: 50.775000000000006
- type: recall_at_100
value: 69.66799999999999
- type: recall_at_1000
value: 83.638
- type: recall_at_3
value: 40.757
- type: recall_at_5
value: 44.86
- type: map_at_1
value: 37.584
- type: map_at_10
value: 49.69
- type: map_at_100
value: 50.639
- type: map_at_1000
value: 50.702999999999996
- type: map_at_3
value: 46.61
- type: map_at_5
value: 48.486000000000004
- type: mrr_at_1
value: 43.009
- type: mrr_at_10
value: 52.949999999999996
- type: mrr_at_100
value: 53.618
- type: mrr_at_1000
value: 53.65299999999999
- type: mrr_at_3
value: 50.605999999999995
- type: mrr_at_5
value: 52.095
- type: ndcg_at_1
value: 43.009
- type: ndcg_at_10
value: 55.278000000000006
- type: ndcg_at_100
value: 59.134
- type: ndcg_at_1000
value: 60.528999999999996
- type: ndcg_at_3
value: 50.184
- type: ndcg_at_5
value: 52.919000000000004
- type: precision_at_1
value: 43.009
- type: precision_at_10
value: 8.821
- type: precision_at_100
value: 1.161
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 22.424
- type: precision_at_5
value: 15.436
- type: recall_at_1
value: 37.584
- type: recall_at_10
value: 68.514
- type: recall_at_100
value: 85.099
- type: recall_at_1000
value: 95.123
- type: recall_at_3
value: 55.007
- type: recall_at_5
value: 61.714999999999996
- type: map_at_1
value: 24.7
- type: map_at_10
value: 32.804
- type: map_at_100
value: 33.738
- type: map_at_1000
value: 33.825
- type: map_at_3
value: 30.639
- type: map_at_5
value: 31.781
- type: mrr_at_1
value: 26.328000000000003
- type: mrr_at_10
value: 34.679
- type: mrr_at_100
value: 35.510000000000005
- type: mrr_at_1000
value: 35.577999999999996
- type: mrr_at_3
value: 32.58
- type: mrr_at_5
value: 33.687
- type: ndcg_at_1
value: 26.328000000000003
- type: ndcg_at_10
value: 37.313
- type: ndcg_at_100
value: 42.004000000000005
- type: ndcg_at_1000
value: 44.232
- type: ndcg_at_3
value: 33.076
- type: ndcg_at_5
value: 34.966
- type: precision_at_1
value: 26.328000000000003
- type: precision_at_10
value: 5.627
- type: precision_at_100
value: 0.8410000000000001
- type: precision_at_1000
value: 0.106
- type: precision_at_3
value: 14.011000000000001
- type: precision_at_5
value: 9.582
- type: recall_at_1
value: 24.7
- type: recall_at_10
value: 49.324
- type: recall_at_100
value: 71.018
- type: recall_at_1000
value: 87.905
- type: recall_at_3
value: 37.7
- type: recall_at_5
value: 42.281
- type: map_at_1
value: 14.350999999999999
- type: map_at_10
value: 21.745
- type: map_at_100
value: 22.731
- type: map_at_1000
value: 22.852
- type: map_at_3
value: 19.245
- type: map_at_5
value: 20.788
- type: mrr_at_1
value: 18.159
- type: mrr_at_10
value: 25.833000000000002
- type: mrr_at_100
value: 26.728
- type: mrr_at_1000
value: 26.802
- type: mrr_at_3
value: 23.383000000000003
- type: mrr_at_5
value: 24.887999999999998
- type: ndcg_at_1
value: 18.159
- type: ndcg_at_10
value: 26.518000000000004
- type: ndcg_at_100
value: 31.473000000000003
- type: ndcg_at_1000
value: 34.576
- type: ndcg_at_3
value: 21.907
- type: ndcg_at_5
value: 24.39
- type: precision_at_1
value: 18.159
- type: precision_at_10
value: 4.938
- type: precision_at_100
value: 0.853
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 10.655000000000001
- type: precision_at_5
value: 7.985
- type: recall_at_1
value: 14.350999999999999
- type: recall_at_10
value: 37.284
- type: recall_at_100
value: 59.11300000000001
- type: recall_at_1000
value: 81.634
- type: recall_at_3
value: 24.753
- type: recall_at_5
value: 30.979
- type: map_at_1
value: 26.978
- type: map_at_10
value: 36.276
- type: map_at_100
value: 37.547000000000004
- type: map_at_1000
value: 37.678
- type: map_at_3
value: 33.674
- type: map_at_5
value: 35.119
- type: mrr_at_1
value: 32.916000000000004
- type: mrr_at_10
value: 41.798
- type: mrr_at_100
value: 42.72
- type: mrr_at_1000
value: 42.778
- type: mrr_at_3
value: 39.493
- type: mrr_at_5
value: 40.927
- type: ndcg_at_1
value: 32.916000000000004
- type: ndcg_at_10
value: 41.81
- type: ndcg_at_100
value: 47.284
- type: ndcg_at_1000
value: 49.702
- type: ndcg_at_3
value: 37.486999999999995
- type: ndcg_at_5
value: 39.597
- type: precision_at_1
value: 32.916000000000004
- type: precision_at_10
value: 7.411
- type: precision_at_100
value: 1.189
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 17.581
- type: precision_at_5
value: 12.397
- type: recall_at_1
value: 26.978
- type: recall_at_10
value: 52.869
- type: recall_at_100
value: 75.78399999999999
- type: recall_at_1000
value: 91.545
- type: recall_at_3
value: 40.717
- type: recall_at_5
value: 46.168
- type: map_at_1
value: 24.641
- type: map_at_10
value: 32.916000000000004
- type: map_at_100
value: 34.165
- type: map_at_1000
value: 34.286
- type: map_at_3
value: 30.335
- type: map_at_5
value: 31.569000000000003
- type: mrr_at_1
value: 30.593999999999998
- type: mrr_at_10
value: 38.448
- type: mrr_at_100
value: 39.299
- type: mrr_at_1000
value: 39.362
- type: mrr_at_3
value: 36.244
- type: mrr_at_5
value: 37.232
- type: ndcg_at_1
value: 30.593999999999998
- type: ndcg_at_10
value: 38.2
- type: ndcg_at_100
value: 43.742
- type: ndcg_at_1000
value: 46.217000000000006
- type: ndcg_at_3
value: 33.925
- type: ndcg_at_5
value: 35.394
- type: precision_at_1
value: 30.593999999999998
- type: precision_at_10
value: 6.895
- type: precision_at_100
value: 1.1320000000000001
- type: precision_at_1000
value: 0.153
- type: precision_at_3
value: 16.096
- type: precision_at_5
value: 11.05
- type: recall_at_1
value: 24.641
- type: recall_at_10
value: 48.588
- type: recall_at_100
value: 72.841
- type: recall_at_1000
value: 89.535
- type: recall_at_3
value: 36.087
- type: recall_at_5
value: 40.346
- type: map_at_1
value: 24.79425
- type: map_at_10
value: 33.12033333333333
- type: map_at_100
value: 34.221333333333334
- type: map_at_1000
value: 34.3435
- type: map_at_3
value: 30.636583333333338
- type: map_at_5
value: 31.974083333333326
- type: mrr_at_1
value: 29.242416666666664
- type: mrr_at_10
value: 37.11675
- type: mrr_at_100
value: 37.93783333333334
- type: mrr_at_1000
value: 38.003083333333336
- type: mrr_at_3
value: 34.904666666666664
- type: mrr_at_5
value: 36.12916666666667
- type: ndcg_at_1
value: 29.242416666666664
- type: ndcg_at_10
value: 38.03416666666667
- type: ndcg_at_100
value: 42.86674999999999
- type: ndcg_at_1000
value: 45.34550000000001
- type: ndcg_at_3
value: 33.76466666666666
- type: ndcg_at_5
value: 35.668666666666674
- type: precision_at_1
value: 29.242416666666664
- type: precision_at_10
value: 6.589833333333334
- type: precision_at_100
value: 1.0693333333333332
- type: precision_at_1000
value: 0.14641666666666667
- type: precision_at_3
value: 15.430749999999998
- type: precision_at_5
value: 10.833833333333333
- type: recall_at_1
value: 24.79425
- type: recall_at_10
value: 48.582916666666655
- type: recall_at_100
value: 69.88499999999999
- type: recall_at_1000
value: 87.211
- type: recall_at_3
value: 36.625499999999995
- type: recall_at_5
value: 41.553999999999995
- type: map_at_1
value: 22.767
- type: map_at_10
value: 28.450999999999997
- type: map_at_100
value: 29.332
- type: map_at_1000
value: 29.426000000000002
- type: map_at_3
value: 26.379
- type: map_at_5
value: 27.584999999999997
- type: mrr_at_1
value: 25.46
- type: mrr_at_10
value: 30.974
- type: mrr_at_100
value: 31.784000000000002
- type: mrr_at_1000
value: 31.857999999999997
- type: mrr_at_3
value: 28.962
- type: mrr_at_5
value: 30.066
- type: ndcg_at_1
value: 25.46
- type: ndcg_at_10
value: 32.041
- type: ndcg_at_100
value: 36.522
- type: ndcg_at_1000
value: 39.101
- type: ndcg_at_3
value: 28.152
- type: ndcg_at_5
value: 30.03
- type: precision_at_1
value: 25.46
- type: precision_at_10
value: 4.893
- type: precision_at_100
value: 0.77
- type: precision_at_1000
value: 0.107
- type: precision_at_3
value: 11.605
- type: precision_at_5
value: 8.19
- type: recall_at_1
value: 22.767
- type: recall_at_10
value: 40.71
- type: recall_at_100
value: 61.334999999999994
- type: recall_at_1000
value: 80.567
- type: recall_at_3
value: 30.198000000000004
- type: recall_at_5
value: 34.803
- type: map_at_1
value: 16.722
- type: map_at_10
value: 22.794
- type: map_at_100
value: 23.7
- type: map_at_1000
value: 23.822
- type: map_at_3
value: 20.781
- type: map_at_5
value: 22.024
- type: mrr_at_1
value: 20.061999999999998
- type: mrr_at_10
value: 26.346999999999998
- type: mrr_at_100
value: 27.153
- type: mrr_at_1000
value: 27.233
- type: mrr_at_3
value: 24.375
- type: mrr_at_5
value: 25.593
- type: ndcg_at_1
value: 20.061999999999998
- type: ndcg_at_10
value: 26.785999999999998
- type: ndcg_at_100
value: 31.319999999999997
- type: ndcg_at_1000
value: 34.346
- type: ndcg_at_3
value: 23.219
- type: ndcg_at_5
value: 25.107000000000003
- type: precision_at_1
value: 20.061999999999998
- type: precision_at_10
value: 4.78
- type: precision_at_100
value: 0.83
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 10.874
- type: precision_at_5
value: 7.956
- type: recall_at_1
value: 16.722
- type: recall_at_10
value: 35.204
- type: recall_at_100
value: 55.797
- type: recall_at_1000
value: 77.689
- type: recall_at_3
value: 25.245
- type: recall_at_5
value: 30.115
- type: map_at_1
value: 24.842
- type: map_at_10
value: 32.917
- type: map_at_100
value: 33.961000000000006
- type: map_at_1000
value: 34.069
- type: map_at_3
value: 30.595
- type: map_at_5
value: 31.837
- type: mrr_at_1
value: 29.011
- type: mrr_at_10
value: 36.977
- type: mrr_at_100
value: 37.814
- type: mrr_at_1000
value: 37.885999999999996
- type: mrr_at_3
value: 34.966
- type: mrr_at_5
value: 36.043
- type: ndcg_at_1
value: 29.011
- type: ndcg_at_10
value: 37.735
- type: ndcg_at_100
value: 42.683
- type: ndcg_at_1000
value: 45.198
- type: ndcg_at_3
value: 33.650000000000006
- type: ndcg_at_5
value: 35.386
- type: precision_at_1
value: 29.011
- type: precision_at_10
value: 6.259
- type: precision_at_100
value: 0.984
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 15.329999999999998
- type: precision_at_5
value: 10.541
- type: recall_at_1
value: 24.842
- type: recall_at_10
value: 48.304
- type: recall_at_100
value: 70.04899999999999
- type: recall_at_1000
value: 87.82600000000001
- type: recall_at_3
value: 36.922
- type: recall_at_5
value: 41.449999999999996
- type: map_at_1
value: 24.252000000000002
- type: map_at_10
value: 32.293
- type: map_at_100
value: 33.816
- type: map_at_1000
value: 34.053
- type: map_at_3
value: 29.781999999999996
- type: map_at_5
value: 31.008000000000003
- type: mrr_at_1
value: 29.051
- type: mrr_at_10
value: 36.722
- type: mrr_at_100
value: 37.663000000000004
- type: mrr_at_1000
value: 37.734
- type: mrr_at_3
value: 34.354
- type: mrr_at_5
value: 35.609
- type: ndcg_at_1
value: 29.051
- type: ndcg_at_10
value: 37.775999999999996
- type: ndcg_at_100
value: 43.221
- type: ndcg_at_1000
value: 46.116
- type: ndcg_at_3
value: 33.403
- type: ndcg_at_5
value: 35.118
- type: precision_at_1
value: 29.051
- type: precision_at_10
value: 7.332
- type: precision_at_100
value: 1.49
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 15.415000000000001
- type: precision_at_5
value: 11.107
- type: recall_at_1
value: 24.252000000000002
- type: recall_at_10
value: 47.861
- type: recall_at_100
value: 72.21600000000001
- type: recall_at_1000
value: 90.886
- type: recall_at_3
value: 35.533
- type: recall_at_5
value: 39.959
- type: map_at_1
value: 20.025000000000002
- type: map_at_10
value: 27.154
- type: map_at_100
value: 28.118
- type: map_at_1000
value: 28.237000000000002
- type: map_at_3
value: 25.017
- type: map_at_5
value: 25.832
- type: mrr_at_1
value: 21.627
- type: mrr_at_10
value: 28.884999999999998
- type: mrr_at_100
value: 29.741
- type: mrr_at_1000
value: 29.831999999999997
- type: mrr_at_3
value: 26.741
- type: mrr_at_5
value: 27.628000000000004
- type: ndcg_at_1
value: 21.627
- type: ndcg_at_10
value: 31.436999999999998
- type: ndcg_at_100
value: 36.181000000000004
- type: ndcg_at_1000
value: 38.986
- type: ndcg_at_3
value: 27.025
- type: ndcg_at_5
value: 28.436
- type: precision_at_1
value: 21.627
- type: precision_at_10
value: 5.009
- type: precision_at_100
value: 0.7929999999999999
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 11.522
- type: precision_at_5
value: 7.763000000000001
- type: recall_at_1
value: 20.025000000000002
- type: recall_at_10
value: 42.954
- type: recall_at_100
value: 64.67500000000001
- type: recall_at_1000
value: 85.301
- type: recall_at_3
value: 30.892999999999997
- type: recall_at_5
value: 34.288000000000004
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.079
- type: map_at_10
value: 16.930999999999997
- type: map_at_100
value: 18.398999999999997
- type: map_at_1000
value: 18.561
- type: map_at_3
value: 14.294
- type: map_at_5
value: 15.579
- type: mrr_at_1
value: 22.606
- type: mrr_at_10
value: 32.513
- type: mrr_at_100
value: 33.463
- type: mrr_at_1000
value: 33.513999999999996
- type: mrr_at_3
value: 29.479
- type: mrr_at_5
value: 31.3
- type: ndcg_at_1
value: 22.606
- type: ndcg_at_10
value: 24.053
- type: ndcg_at_100
value: 30.258000000000003
- type: ndcg_at_1000
value: 33.516
- type: ndcg_at_3
value: 19.721
- type: ndcg_at_5
value: 21.144
- type: precision_at_1
value: 22.606
- type: precision_at_10
value: 7.55
- type: precision_at_100
value: 1.399
- type: precision_at_1000
value: 0.2
- type: precision_at_3
value: 14.701
- type: precision_at_5
value: 11.192
- type: recall_at_1
value: 10.079
- type: recall_at_10
value: 28.970000000000002
- type: recall_at_100
value: 50.805
- type: recall_at_1000
value: 69.378
- type: recall_at_3
value: 18.199
- type: recall_at_5
value: 22.442
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.794
- type: map_at_10
value: 15.165999999999999
- type: map_at_100
value: 20.508000000000003
- type: map_at_1000
value: 21.809
- type: map_at_3
value: 11.568000000000001
- type: map_at_5
value: 13.059000000000001
- type: mrr_at_1
value: 56.49999999999999
- type: mrr_at_10
value: 65.90899999999999
- type: mrr_at_100
value: 66.352
- type: mrr_at_1000
value: 66.369
- type: mrr_at_3
value: 64.0
- type: mrr_at_5
value: 65.10000000000001
- type: ndcg_at_1
value: 44.25
- type: ndcg_at_10
value: 32.649
- type: ndcg_at_100
value: 36.668
- type: ndcg_at_1000
value: 43.918
- type: ndcg_at_3
value: 37.096000000000004
- type: ndcg_at_5
value: 34.048
- type: precision_at_1
value: 56.49999999999999
- type: precision_at_10
value: 25.45
- type: precision_at_100
value: 8.055
- type: precision_at_1000
value: 1.7489999999999999
- type: precision_at_3
value: 41.0
- type: precision_at_5
value: 32.85
- type: recall_at_1
value: 7.794
- type: recall_at_10
value: 20.101
- type: recall_at_100
value: 42.448
- type: recall_at_1000
value: 65.88000000000001
- type: recall_at_3
value: 12.753
- type: recall_at_5
value: 15.307
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 44.01
- type: f1
value: 38.659680951114964
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 49.713
- type: map_at_10
value: 61.79
- type: map_at_100
value: 62.28
- type: map_at_1000
value: 62.297000000000004
- type: map_at_3
value: 59.361
- type: map_at_5
value: 60.92100000000001
- type: mrr_at_1
value: 53.405
- type: mrr_at_10
value: 65.79899999999999
- type: mrr_at_100
value: 66.219
- type: mrr_at_1000
value: 66.227
- type: mrr_at_3
value: 63.431000000000004
- type: mrr_at_5
value: 64.98
- type: ndcg_at_1
value: 53.405
- type: ndcg_at_10
value: 68.01899999999999
- type: ndcg_at_100
value: 70.197
- type: ndcg_at_1000
value: 70.571
- type: ndcg_at_3
value: 63.352
- type: ndcg_at_5
value: 66.018
- type: precision_at_1
value: 53.405
- type: precision_at_10
value: 9.119
- type: precision_at_100
value: 1.03
- type: precision_at_1000
value: 0.107
- type: precision_at_3
value: 25.602999999999998
- type: precision_at_5
value: 16.835
- type: recall_at_1
value: 49.713
- type: recall_at_10
value: 83.306
- type: recall_at_100
value: 92.92
- type: recall_at_1000
value: 95.577
- type: recall_at_3
value: 70.798
- type: recall_at_5
value: 77.254
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.310000000000002
- type: map_at_10
value: 26.204
- type: map_at_100
value: 27.932000000000002
- type: map_at_1000
value: 28.121000000000002
- type: map_at_3
value: 22.481
- type: map_at_5
value: 24.678
- type: mrr_at_1
value: 29.784
- type: mrr_at_10
value: 39.582
- type: mrr_at_100
value: 40.52
- type: mrr_at_1000
value: 40.568
- type: mrr_at_3
value: 37.114000000000004
- type: mrr_at_5
value: 38.596000000000004
- type: ndcg_at_1
value: 29.784
- type: ndcg_at_10
value: 33.432
- type: ndcg_at_100
value: 40.281
- type: ndcg_at_1000
value: 43.653999999999996
- type: ndcg_at_3
value: 29.612
- type: ndcg_at_5
value: 31.223
- type: precision_at_1
value: 29.784
- type: precision_at_10
value: 9.645
- type: precision_at_100
value: 1.645
- type: precision_at_1000
value: 0.22499999999999998
- type: precision_at_3
value: 20.165
- type: precision_at_5
value: 15.401000000000002
- type: recall_at_1
value: 15.310000000000002
- type: recall_at_10
value: 40.499
- type: recall_at_100
value: 66.643
- type: recall_at_1000
value: 87.059
- type: recall_at_3
value: 27.492
- type: recall_at_5
value: 33.748
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 33.599000000000004
- type: map_at_10
value: 47.347
- type: map_at_100
value: 48.191
- type: map_at_1000
value: 48.263
- type: map_at_3
value: 44.698
- type: map_at_5
value: 46.278999999999996
- type: mrr_at_1
value: 67.19800000000001
- type: mrr_at_10
value: 74.054
- type: mrr_at_100
value: 74.376
- type: mrr_at_1000
value: 74.392
- type: mrr_at_3
value: 72.849
- type: mrr_at_5
value: 73.643
- type: ndcg_at_1
value: 67.19800000000001
- type: ndcg_at_10
value: 56.482
- type: ndcg_at_100
value: 59.694
- type: ndcg_at_1000
value: 61.204
- type: ndcg_at_3
value: 52.43299999999999
- type: ndcg_at_5
value: 54.608000000000004
- type: precision_at_1
value: 67.19800000000001
- type: precision_at_10
value: 11.613999999999999
- type: precision_at_100
value: 1.415
- type: precision_at_1000
value: 0.16199999999999998
- type: precision_at_3
value: 32.726
- type: precision_at_5
value: 21.349999999999998
- type: recall_at_1
value: 33.599000000000004
- type: recall_at_10
value: 58.069
- type: recall_at_100
value: 70.736
- type: recall_at_1000
value: 80.804
- type: recall_at_3
value: 49.088
- type: recall_at_5
value: 53.376000000000005
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 73.64359999999999
- type: ap
value: 67.54685976014599
- type: f1
value: 73.55148707559482
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 19.502
- type: map_at_10
value: 30.816
- type: map_at_100
value: 32.007999999999996
- type: map_at_1000
value: 32.067
- type: map_at_3
value: 27.215
- type: map_at_5
value: 29.304000000000002
- type: mrr_at_1
value: 20.072000000000003
- type: mrr_at_10
value: 31.406
- type: mrr_at_100
value: 32.549
- type: mrr_at_1000
value: 32.602
- type: mrr_at_3
value: 27.839000000000002
- type: mrr_at_5
value: 29.926000000000002
- type: ndcg_at_1
value: 20.086000000000002
- type: ndcg_at_10
value: 37.282
- type: ndcg_at_100
value: 43.206
- type: ndcg_at_1000
value: 44.690000000000005
- type: ndcg_at_3
value: 29.932
- type: ndcg_at_5
value: 33.668
- type: precision_at_1
value: 20.086000000000002
- type: precision_at_10
value: 5.961
- type: precision_at_100
value: 0.898
- type: precision_at_1000
value: 0.10200000000000001
- type: precision_at_3
value: 12.856000000000002
- type: precision_at_5
value: 9.596
- type: recall_at_1
value: 19.502
- type: recall_at_10
value: 57.182
- type: recall_at_100
value: 84.952
- type: recall_at_1000
value: 96.34700000000001
- type: recall_at_3
value: 37.193
- type: recall_at_5
value: 46.157
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.96488828089375
- type: f1
value: 93.32119260543482
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 72.4965800273598
- type: f1
value: 49.34896217536082
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.60928043039678
- type: f1
value: 64.34244712074538
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.75453934095493
- type: f1
value: 68.39224867489249
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 31.862573504920082
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 27.511123551196803
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.99145104942086
- type: mrr
value: 32.03606480418627
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.015
- type: map_at_10
value: 11.054
- type: map_at_100
value: 13.773
- type: map_at_1000
value: 15.082999999999998
- type: map_at_3
value: 8.253
- type: map_at_5
value: 9.508999999999999
- type: mrr_at_1
value: 42.105
- type: mrr_at_10
value: 50.44499999999999
- type: mrr_at_100
value: 51.080000000000005
- type: mrr_at_1000
value: 51.129999999999995
- type: mrr_at_3
value: 48.555
- type: mrr_at_5
value: 49.84
- type: ndcg_at_1
value: 40.402
- type: ndcg_at_10
value: 30.403000000000002
- type: ndcg_at_100
value: 28.216
- type: ndcg_at_1000
value: 37.021
- type: ndcg_at_3
value: 35.53
- type: ndcg_at_5
value: 33.202999999999996
- type: precision_at_1
value: 42.105
- type: precision_at_10
value: 22.353
- type: precision_at_100
value: 7.266
- type: precision_at_1000
value: 2.011
- type: precision_at_3
value: 32.921
- type: precision_at_5
value: 28.297
- type: recall_at_1
value: 5.015
- type: recall_at_10
value: 14.393
- type: recall_at_100
value: 28.893
- type: recall_at_1000
value: 60.18
- type: recall_at_3
value: 9.184000000000001
- type: recall_at_5
value: 11.39
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.524
- type: map_at_10
value: 44.182
- type: map_at_100
value: 45.228
- type: map_at_1000
value: 45.265
- type: map_at_3
value: 39.978
- type: map_at_5
value: 42.482
- type: mrr_at_1
value: 33.256
- type: mrr_at_10
value: 46.661
- type: mrr_at_100
value: 47.47
- type: mrr_at_1000
value: 47.496
- type: mrr_at_3
value: 43.187999999999995
- type: mrr_at_5
value: 45.330999999999996
- type: ndcg_at_1
value: 33.227000000000004
- type: ndcg_at_10
value: 51.589
- type: ndcg_at_100
value: 56.043
- type: ndcg_at_1000
value: 56.937000000000005
- type: ndcg_at_3
value: 43.751
- type: ndcg_at_5
value: 47.937000000000005
- type: precision_at_1
value: 33.227000000000004
- type: precision_at_10
value: 8.556999999999999
- type: precision_at_100
value: 1.103
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 19.921
- type: precision_at_5
value: 14.396999999999998
- type: recall_at_1
value: 29.524
- type: recall_at_10
value: 71.615
- type: recall_at_100
value: 91.056
- type: recall_at_1000
value: 97.72800000000001
- type: recall_at_3
value: 51.451
- type: recall_at_5
value: 61.119
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 69.596
- type: map_at_10
value: 83.281
- type: map_at_100
value: 83.952
- type: map_at_1000
value: 83.97200000000001
- type: map_at_3
value: 80.315
- type: map_at_5
value: 82.223
- type: mrr_at_1
value: 80.17
- type: mrr_at_10
value: 86.522
- type: mrr_at_100
value: 86.644
- type: mrr_at_1000
value: 86.64500000000001
- type: mrr_at_3
value: 85.438
- type: mrr_at_5
value: 86.21799999999999
- type: ndcg_at_1
value: 80.19
- type: ndcg_at_10
value: 87.19
- type: ndcg_at_100
value: 88.567
- type: ndcg_at_1000
value: 88.70400000000001
- type: ndcg_at_3
value: 84.17999999999999
- type: ndcg_at_5
value: 85.931
- type: precision_at_1
value: 80.19
- type: precision_at_10
value: 13.209000000000001
- type: precision_at_100
value: 1.518
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 36.717
- type: precision_at_5
value: 24.248
- type: recall_at_1
value: 69.596
- type: recall_at_10
value: 94.533
- type: recall_at_100
value: 99.322
- type: recall_at_1000
value: 99.965
- type: recall_at_3
value: 85.911
- type: recall_at_5
value: 90.809
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 49.27650627571912
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 57.08550946534183
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.568
- type: map_at_10
value: 10.862
- type: map_at_100
value: 12.757
- type: map_at_1000
value: 13.031
- type: map_at_3
value: 7.960000000000001
- type: map_at_5
value: 9.337
- type: mrr_at_1
value: 22.5
- type: mrr_at_10
value: 32.6
- type: mrr_at_100
value: 33.603
- type: mrr_at_1000
value: 33.672000000000004
- type: mrr_at_3
value: 29.299999999999997
- type: mrr_at_5
value: 31.25
- type: ndcg_at_1
value: 22.5
- type: ndcg_at_10
value: 18.605
- type: ndcg_at_100
value: 26.029999999999998
- type: ndcg_at_1000
value: 31.256
- type: ndcg_at_3
value: 17.873
- type: ndcg_at_5
value: 15.511
- type: precision_at_1
value: 22.5
- type: precision_at_10
value: 9.58
- type: precision_at_100
value: 2.033
- type: precision_at_1000
value: 0.33
- type: precision_at_3
value: 16.633
- type: precision_at_5
value: 13.54
- type: recall_at_1
value: 4.568
- type: recall_at_10
value: 19.402
- type: recall_at_100
value: 41.277
- type: recall_at_1000
value: 66.963
- type: recall_at_3
value: 10.112
- type: recall_at_5
value: 13.712
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 83.31992291680787
- type: cos_sim_spearman
value: 76.7212346922664
- type: euclidean_pearson
value: 80.42189271706478
- type: euclidean_spearman
value: 76.7212342532493
- type: manhattan_pearson
value: 80.33171093031578
- type: manhattan_spearman
value: 76.63192883074694
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.16654278886763
- type: cos_sim_spearman
value: 73.66390263429565
- type: euclidean_pearson
value: 79.7485360086639
- type: euclidean_spearman
value: 73.66389870373436
- type: manhattan_pearson
value: 79.73652237443706
- type: manhattan_spearman
value: 73.65296117151647
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 82.40389689929246
- type: cos_sim_spearman
value: 83.29727595993955
- type: euclidean_pearson
value: 82.23970587854079
- type: euclidean_spearman
value: 83.29727595993955
- type: manhattan_pearson
value: 82.18823600831897
- type: manhattan_spearman
value: 83.20746192209594
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 81.73505246913413
- type: cos_sim_spearman
value: 79.1686548248754
- type: euclidean_pearson
value: 80.48889135993412
- type: euclidean_spearman
value: 79.16864112930354
- type: manhattan_pearson
value: 80.40720651057302
- type: manhattan_spearman
value: 79.0640155089286
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.3953512879065
- type: cos_sim_spearman
value: 87.29947322714338
- type: euclidean_pearson
value: 86.59759438529645
- type: euclidean_spearman
value: 87.29947511092824
- type: manhattan_pearson
value: 86.52097806169155
- type: manhattan_spearman
value: 87.22987242146534
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.48565753792056
- type: cos_sim_spearman
value: 83.6049720319893
- type: euclidean_pearson
value: 82.56452023172913
- type: euclidean_spearman
value: 83.60490168191697
- type: manhattan_pearson
value: 82.58079941137872
- type: manhattan_spearman
value: 83.60975807374051
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.18239976618212
- type: cos_sim_spearman
value: 88.23061724730616
- type: euclidean_pearson
value: 87.78482472776658
- type: euclidean_spearman
value: 88.23061724730616
- type: manhattan_pearson
value: 87.75059641730239
- type: manhattan_spearman
value: 88.22527413524622
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.42816418706765
- type: cos_sim_spearman
value: 63.4569864520124
- type: euclidean_pearson
value: 64.35405409953853
- type: euclidean_spearman
value: 63.4569864520124
- type: manhattan_pearson
value: 63.96649236073056
- type: manhattan_spearman
value: 63.01448583722708
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 83.41659638047614
- type: cos_sim_spearman
value: 84.03893866106175
- type: euclidean_pearson
value: 84.2251203953798
- type: euclidean_spearman
value: 84.03893866106175
- type: manhattan_pearson
value: 84.22733643205514
- type: manhattan_spearman
value: 84.06504411263612
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 79.75608022582414
- type: mrr
value: 94.0947732369301
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 50.161
- type: map_at_10
value: 59.458999999999996
- type: map_at_100
value: 60.156
- type: map_at_1000
value: 60.194
- type: map_at_3
value: 56.45400000000001
- type: map_at_5
value: 58.165
- type: mrr_at_1
value: 53.333
- type: mrr_at_10
value: 61.050000000000004
- type: mrr_at_100
value: 61.586
- type: mrr_at_1000
value: 61.624
- type: mrr_at_3
value: 58.889
- type: mrr_at_5
value: 60.122
- type: ndcg_at_1
value: 53.333
- type: ndcg_at_10
value: 63.888999999999996
- type: ndcg_at_100
value: 66.963
- type: ndcg_at_1000
value: 68.062
- type: ndcg_at_3
value: 59.01
- type: ndcg_at_5
value: 61.373999999999995
- type: precision_at_1
value: 53.333
- type: precision_at_10
value: 8.633000000000001
- type: precision_at_100
value: 1.027
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 23.111
- type: precision_at_5
value: 15.467
- type: recall_at_1
value: 50.161
- type: recall_at_10
value: 75.922
- type: recall_at_100
value: 90.0
- type: recall_at_1000
value: 98.667
- type: recall_at_3
value: 62.90599999999999
- type: recall_at_5
value: 68.828
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.81188118811882
- type: cos_sim_ap
value: 95.11619225962413
- type: cos_sim_f1
value: 90.35840484603736
- type: cos_sim_precision
value: 91.23343527013252
- type: cos_sim_recall
value: 89.5
- type: dot_accuracy
value: 99.81188118811882
- type: dot_ap
value: 95.11619225962413
- type: dot_f1
value: 90.35840484603736
- type: dot_precision
value: 91.23343527013252
- type: dot_recall
value: 89.5
- type: euclidean_accuracy
value: 99.81188118811882
- type: euclidean_ap
value: 95.11619225962413
- type: euclidean_f1
value: 90.35840484603736
- type: euclidean_precision
value: 91.23343527013252
- type: euclidean_recall
value: 89.5
- type: manhattan_accuracy
value: 99.80891089108911
- type: manhattan_ap
value: 95.07294266220966
- type: manhattan_f1
value: 90.21794221996959
- type: manhattan_precision
value: 91.46968139773895
- type: manhattan_recall
value: 89.0
- type: max_accuracy
value: 99.81188118811882
- type: max_ap
value: 95.11619225962413
- type: max_f1
value: 90.35840484603736
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 55.3481874105239
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.421291695525
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 49.98746633276634
- type: mrr
value: 50.63143249724133
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.009961979844036
- type: cos_sim_spearman
value: 30.558416108881044
- type: dot_pearson
value: 31.009964941134253
- type: dot_spearman
value: 30.545760761761393
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.207
- type: map_at_10
value: 1.6
- type: map_at_100
value: 8.594
- type: map_at_1000
value: 20.213
- type: map_at_3
value: 0.585
- type: map_at_5
value: 0.9039999999999999
- type: mrr_at_1
value: 78.0
- type: mrr_at_10
value: 87.4
- type: mrr_at_100
value: 87.4
- type: mrr_at_1000
value: 87.4
- type: mrr_at_3
value: 86.667
- type: mrr_at_5
value: 87.06700000000001
- type: ndcg_at_1
value: 73.0
- type: ndcg_at_10
value: 65.18
- type: ndcg_at_100
value: 49.631
- type: ndcg_at_1000
value: 43.498999999999995
- type: ndcg_at_3
value: 71.83800000000001
- type: ndcg_at_5
value: 69.271
- type: precision_at_1
value: 78.0
- type: precision_at_10
value: 69.19999999999999
- type: precision_at_100
value: 50.980000000000004
- type: precision_at_1000
value: 19.426
- type: precision_at_3
value: 77.333
- type: precision_at_5
value: 74.0
- type: recall_at_1
value: 0.207
- type: recall_at_10
value: 1.822
- type: recall_at_100
value: 11.849
- type: recall_at_1000
value: 40.492
- type: recall_at_3
value: 0.622
- type: recall_at_5
value: 0.9809999999999999
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.001
- type: map_at_10
value: 10.376000000000001
- type: map_at_100
value: 16.936999999999998
- type: map_at_1000
value: 18.615000000000002
- type: map_at_3
value: 5.335999999999999
- type: map_at_5
value: 7.374
- type: mrr_at_1
value: 20.408
- type: mrr_at_10
value: 38.29
- type: mrr_at_100
value: 39.33
- type: mrr_at_1000
value: 39.347
- type: mrr_at_3
value: 32.993
- type: mrr_at_5
value: 36.973
- type: ndcg_at_1
value: 17.347
- type: ndcg_at_10
value: 23.515
- type: ndcg_at_100
value: 37.457
- type: ndcg_at_1000
value: 49.439
- type: ndcg_at_3
value: 22.762999999999998
- type: ndcg_at_5
value: 22.622
- type: precision_at_1
value: 20.408
- type: precision_at_10
value: 22.448999999999998
- type: precision_at_100
value: 8.184
- type: precision_at_1000
value: 1.608
- type: precision_at_3
value: 25.85
- type: precision_at_5
value: 25.306
- type: recall_at_1
value: 2.001
- type: recall_at_10
value: 17.422
- type: recall_at_100
value: 51.532999999999994
- type: recall_at_1000
value: 87.466
- type: recall_at_3
value: 6.861000000000001
- type: recall_at_5
value: 10.502
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.54419999999999
- type: ap
value: 14.372170450843907
- type: f1
value: 54.94420257390529
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.402942840973395
- type: f1
value: 59.4166538875571
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 41.569064336457906
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.31322644096085
- type: cos_sim_ap
value: 72.14518894837381
- type: cos_sim_f1
value: 66.67489813557229
- type: cos_sim_precision
value: 62.65954977953121
- type: cos_sim_recall
value: 71.2401055408971
- type: dot_accuracy
value: 85.31322644096085
- type: dot_ap
value: 72.14521480685293
- type: dot_f1
value: 66.67489813557229
- type: dot_precision
value: 62.65954977953121
- type: dot_recall
value: 71.2401055408971
- type: euclidean_accuracy
value: 85.31322644096085
- type: euclidean_ap
value: 72.14520820485349
- type: euclidean_f1
value: 66.67489813557229
- type: euclidean_precision
value: 62.65954977953121
- type: euclidean_recall
value: 71.2401055408971
- type: manhattan_accuracy
value: 85.21785778148656
- type: manhattan_ap
value: 72.01177147657364
- type: manhattan_f1
value: 66.62594673833374
- type: manhattan_precision
value: 62.0336669699727
- type: manhattan_recall
value: 71.95250659630607
- type: max_accuracy
value: 85.31322644096085
- type: max_ap
value: 72.14521480685293
- type: max_f1
value: 66.67489813557229
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.12756626693057
- type: cos_sim_ap
value: 86.05430786440826
- type: cos_sim_f1
value: 78.27759692216631
- type: cos_sim_precision
value: 75.33466248931929
- type: cos_sim_recall
value: 81.45980905451185
- type: dot_accuracy
value: 89.12950673341872
- type: dot_ap
value: 86.05431161145492
- type: dot_f1
value: 78.27759692216631
- type: dot_precision
value: 75.33466248931929
- type: dot_recall
value: 81.45980905451185
- type: euclidean_accuracy
value: 89.12756626693057
- type: euclidean_ap
value: 86.05431303247397
- type: euclidean_f1
value: 78.27759692216631
- type: euclidean_precision
value: 75.33466248931929
- type: euclidean_recall
value: 81.45980905451185
- type: manhattan_accuracy
value: 89.04994760740482
- type: manhattan_ap
value: 86.00860610892074
- type: manhattan_f1
value: 78.1846776005392
- type: manhattan_precision
value: 76.10438839480975
- type: manhattan_recall
value: 80.3818909762858
- type: max_accuracy
value: 89.12950673341872
- type: max_ap
value: 86.05431303247397
- type: max_f1
value: 78.27759692216631
---
# djuna/jina-embeddings-v2-small-en-Q5_K_M-GGUF
This model was converted to GGUF format from [`jinaai/jina-embeddings-v2-small-en`](https://huggingface.co/jinaai/jina-embeddings-v2-small-en) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/jinaai/jina-embeddings-v2-small-en) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo djuna/jina-embeddings-v2-small-en-Q5_K_M-GGUF --hf-file jina-embeddings-v2-small-en-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo djuna/jina-embeddings-v2-small-en-Q5_K_M-GGUF --hf-file jina-embeddings-v2-small-en-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo djuna/jina-embeddings-v2-small-en-Q5_K_M-GGUF --hf-file jina-embeddings-v2-small-en-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo djuna/jina-embeddings-v2-small-en-Q5_K_M-GGUF --hf-file jina-embeddings-v2-small-en-q5_k_m.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
baukearends/Echocardiogram-SpanCategorizer-lv-dil
|
baukearends
|
token-classification
|
[
"spacy",
"arxiv:2408.06930",
"medical",
"token-classification",
"nl",
"license:cc-by-sa-4.0",
"model-index",
"region:us"
] | 2024-08-15T08:15:00Z |
2024-08-15T08:29:27+00:00
| 17 | 0 |
---
language:
- nl
license: cc-by-sa-4.0
metrics:
- f1
- precision
- recall
pipeline_tag: token-classification
tags:
- spacy
- arxiv:2408.06930
- medical
model-index:
- name: Echocardiogram_SpanCategorizer_lv_dil
results:
- task:
type: token-classification
dataset:
name: internal test set
type: test
metrics:
- type: f1
value: 0.836
name: Weighted f1
verified: false
- type: precision
value: 0.85
name: Weighted precision
verified: false
- type: recall
value: 0.823
name: Weighted recall
verified: false
---
# Description
This model is a spaCy SpanCategorizer model trained from scratch on Dutch echocardiogram reports sourced from Electronic Health Records. The publication associated with the span classification task can be found at https://arxiv.org/abs/2408.06930. The config file for training the model can be found at https://github.com/umcu/echolabeler.
# Minimum working example
```python
!pip install https://huggingface.co/baukearends/Echocardiogram-SpanCategorizer-lv-dil/resolve/main/nl_Echocardiogram_SpanCategorizer_lv_dil-any-py3-none-any.whl
```
```python
import spacy
nlp = spacy.load("nl_Echocardiogram_SpanCategorizer_lv_dil")
```
```python
prediction = nlp("Op dit echo geen duidelijke WMA te zien, goede systolische L.V. functie, normale dimensies LV, wel L.V.H., diastolische dysfunctie graad 1A tot 2. Geringe aortastenose en - matige -insufficientie. Geringe M.I.")
for span, score in zip(prediction.spans['sc'], prediction.spans['sc'].attrs['scores']):
print(f"Span: {span}, label: {span.label_}, score: {score[0]:.3f}")
```
# Label Scheme
<details>
<summary>View label scheme (5 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`spancat`** | `lv_dil_normal`, `lv_dil_mild`, `lv_dil_moderate`, `lv_dil_present`, `lv_dil_severe` |
</details>
# Intended use
The model is developed for span classification on Dutch clinical text. Since it is a domain-specific model trained on medical data, it is meant to be used on medical NLP tasks for Dutch.
# Data
The model was trained on approximately 4,000 manually annotated echocardiogram reports from the University Medical Centre Utrecht. The training data was anonymized before starting the training procedure.
| Feature | Description |
| --- | --- |
| **Name** | `Echocardiogram_SpanCategorizer_lv_dil` |
| **Version** | `1.0.0` |
| **spaCy** | `>=3.7.4,<3.8.0` |
| **Default Pipeline** | `tok2vec`, `spancat` |
| **Components** | `tok2vec`, `spancat` |
| **License** | `cc-by-sa-4.0` |
| **Author** | [Bauke Arends]() |
# Contact
If you are having problems with this model please add an issue on our git: https://github.com/umcu/echolabeler/issues
# Usage
If you use the model in your work please use the following referral; https://doi.org/10.48550/arXiv.2408.06930
# References
Paper: Bauke Arends, Melle Vessies, Dirk van Osch, Arco Teske, Pim van der Harst, René van Es, Bram van Es (2024): Diagnosis extraction from unstructured Dutch echocardiogram reports using span- and document-level characteristic classification, Arxiv https://arxiv.org/abs/2408.06930
|
[
"MEDICAL DATA"
] |
sudhanshu746/bge-reranker-v2-m3-quant-onnx
|
sudhanshu746
| null |
[
"onnx",
"xlm-roberta",
"arxiv:2312.15503",
"arxiv:2402.03216",
"region:us"
] | 2024-08-20T12:46:46Z |
2024-08-20T13:11:53+00:00
| 17 | 0 |
---
{}
---
This is ONNX version of Quantized model of bge-reranker-v2-m3 model created by Sudhanshu Sharma
---
license: apache-2.0
language:
- multilingual
pipeline_tag: text-classification
tags:
- transformers
- sentence-transformers
- text-embeddings-inference
---
# Reranker
**More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/tree/master).**
- [Model List](#model-list)
- [Usage](#usage)
- [Fine-tuning](#fine-tune)
- [Evaluation](#evaluation)
- [Citation](#citation)
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
And the score can be mapped to a float value in [0,1] by sigmoid function.
## Model List
| Model | Base model | Language | layerwise | feature |
|:--------------------------------------------------------------------------|:--------:|:-----------------------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------:|
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) | Chinese and English | - | Lightweight reranker model, easy to deploy, with fast inference. |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | [xlm-roberta-large](https://huggingface.co/FacebookAI/xlm-roberta-large) | Chinese and English | - | Lightweight reranker model, easy to deploy, with fast inference. |
| [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) | [bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | - | Lightweight reranker model, possesses strong multilingual capabilities, easy to deploy, with fast inference. |
| [BAAI/bge-reranker-v2-gemma](https://huggingface.co/BAAI/bge-reranker-v2-gemma) | [gemma-2b](https://huggingface.co/google/gemma-2b) | Multilingual | - | Suitable for multilingual contexts, performs well in both English proficiency and multilingual capabilities. |
| [BAAI/bge-reranker-v2-minicpm-layerwise](https://huggingface.co/BAAI/bge-reranker-v2-minicpm-layerwise) | [MiniCPM-2B-dpo-bf16](https://huggingface.co/openbmb/MiniCPM-2B-dpo-bf16) | Multilingual | 8-40 | Suitable for multilingual contexts, performs well in both English and Chinese proficiency, allows freedom to select layers for output, facilitating accelerated inference. |
You can select the model according your senario and resource.
- For **multilingual**, utilize [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) and [BAAI/bge-reranker-v2-gemma](https://huggingface.co/BAAI/bge-reranker-v2-gemma)
- For **Chinese or English**, utilize [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) and [BAAI/bge-reranker-v2-minicpm-layerwise](https://huggingface.co/BAAI/bge-reranker-v2-minicpm-layerwise).
- For **efficiency**, utilize [BAAI/bge-reranker-v2-m3](https://huggingface.co/BAAI/bge-reranker-v2-m3) and the low layer of [BAAI/bge-reranker-v2-minicpm-layerwise](https://huggingface.co/BAAI/bge-reranker-v2-minicpm-layerwise).
- For better performance, recommand [BAAI/bge-reranker-v2-minicpm-layerwise](https://huggingface.co/BAAI/bge-reranker-v2-minicpm-layerwise) and [BAAI/bge-reranker-v2-gemma](https://huggingface.co/BAAI/bge-reranker-v2-gemma)
## Usage
### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
#### For normal reranker (bge-reranker-base / bge-reranker-large / bge-reranker-v2-m3 )
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-v2-m3', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score) # -5.65234375
# You can map the scores into 0-1 by set "normalize=True", which will apply sigmoid function to the score
score = reranker.compute_score(['query', 'passage'], normalize=True)
print(score) # 0.003497010252573502
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores) # [-8.1875, 5.26171875]
# You can map the scores into 0-1 by set "normalize=True", which will apply sigmoid function to the score
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']], normalize=True)
print(scores) # [0.00027803096387751553, 0.9948403768236574]
```
#### For LLM-based reranker
```python
from FlagEmbedding import FlagLLMReranker
reranker = FlagLLMReranker('BAAI/bge-reranker-v2-gemma', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
# reranker = FlagLLMReranker('BAAI/bge-reranker-v2-gemma', use_bf16=True) # You can also set use_bf16=True to speed up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### For LLM-based layerwise reranker
```python
from FlagEmbedding import LayerWiseFlagLLMReranker
reranker = LayerWiseFlagLLMReranker('BAAI/bge-reranker-v2-minicpm-layerwise', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
# reranker = LayerWiseFlagLLMReranker('BAAI/bge-reranker-v2-minicpm-layerwise', use_bf16=True) # You can also set use_bf16=True to speed up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'], cutoff_layers=[28]) # Adjusting 'cutoff_layers' to pick which layers are used for computing the score.
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']], cutoff_layers=[28])
print(scores)
```
### Using Huggingface transformers
#### For normal reranker (bge-reranker-base / bge-reranker-large / bge-reranker-v2-m3 )
Get relevance scores (higher scores indicate more relevance):
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-m3')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-v2-m3')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
#### For LLM-based reranker
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def get_inputs(pairs, tokenizer, prompt=None, max_length=1024):
if prompt is None:
prompt = "Given a query A and a passage B, determine whether the passage contains an answer to the query by providing a prediction of either 'Yes' or 'No'."
sep = "\n"
prompt_inputs = tokenizer(prompt,
return_tensors=None,
add_special_tokens=False)['input_ids']
sep_inputs = tokenizer(sep,
return_tensors=None,
add_special_tokens=False)['input_ids']
inputs = []
for query, passage in pairs:
query_inputs = tokenizer(f'A: {query}',
return_tensors=None,
add_special_tokens=False,
max_length=max_length * 3 // 4,
truncation=True)
passage_inputs = tokenizer(f'B: {passage}',
return_tensors=None,
add_special_tokens=False,
max_length=max_length,
truncation=True)
item = tokenizer.prepare_for_model(
[tokenizer.bos_token_id] + query_inputs['input_ids'],
sep_inputs + passage_inputs['input_ids'],
truncation='only_second',
max_length=max_length,
padding=False,
return_attention_mask=False,
return_token_type_ids=False,
add_special_tokens=False
)
item['input_ids'] = item['input_ids'] + sep_inputs + prompt_inputs
item['attention_mask'] = [1] * len(item['input_ids'])
inputs.append(item)
return tokenizer.pad(
inputs,
padding=True,
max_length=max_length + len(sep_inputs) + len(prompt_inputs),
pad_to_multiple_of=8,
return_tensors='pt',
)
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-gemma')
model = AutoModelForCausalLM.from_pretrained('BAAI/bge-reranker-v2-gemma')
yes_loc = tokenizer('Yes', add_special_tokens=False)['input_ids'][0]
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = get_inputs(pairs, tokenizer)
scores = model(**inputs, return_dict=True).logits[:, -1, yes_loc].view(-1, ).float()
print(scores)
```
#### For LLM-based layerwise reranker
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
def get_inputs(pairs, tokenizer, prompt=None, max_length=1024):
if prompt is None:
prompt = "Given a query A and a passage B, determine whether the passage contains an answer to the query by providing a prediction of either 'Yes' or 'No'."
sep = "\n"
prompt_inputs = tokenizer(prompt,
return_tensors=None,
add_special_tokens=False)['input_ids']
sep_inputs = tokenizer(sep,
return_tensors=None,
add_special_tokens=False)['input_ids']
inputs = []
for query, passage in pairs:
query_inputs = tokenizer(f'A: {query}',
return_tensors=None,
add_special_tokens=False,
max_length=max_length * 3 // 4,
truncation=True)
passage_inputs = tokenizer(f'B: {passage}',
return_tensors=None,
add_special_tokens=False,
max_length=max_length,
truncation=True)
item = tokenizer.prepare_for_model(
[tokenizer.bos_token_id] + query_inputs['input_ids'],
sep_inputs + passage_inputs['input_ids'],
truncation='only_second',
max_length=max_length,
padding=False,
return_attention_mask=False,
return_token_type_ids=False,
add_special_tokens=False
)
item['input_ids'] = item['input_ids'] + sep_inputs + prompt_inputs
item['attention_mask'] = [1] * len(item['input_ids'])
inputs.append(item)
return tokenizer.pad(
inputs,
padding=True,
max_length=max_length + len(sep_inputs) + len(prompt_inputs),
pad_to_multiple_of=8,
return_tensors='pt',
)
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-v2-minicpm-layerwise', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained('BAAI/bge-reranker-v2-minicpm-layerwise', trust_remote_code=True, torch_dtype=torch.bfloat16)
model = model.to('cuda')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = get_inputs(pairs, tokenizer).to(model.device)
all_scores = model(**inputs, return_dict=True, cutoff_layers=[28])
all_scores = [scores[:, -1].view(-1, ).float() for scores in all_scores[0]]
print(all_scores)
```
## Fine-tune
### Data Format
Train data should be a json file, where each line is a dict like this:
```
{"query": str, "pos": List[str], "neg":List[str], "prompt": str}
```
`query` is the query, and `pos` is a list of positive texts, `neg` is a list of negative texts, `prompt` indicates the relationship between query and texts. If you have no negative texts for a query, you can random sample some from the entire corpus as the negatives.
See [toy_finetune_data.jsonl](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker/toy_finetune_data.jsonl) for a toy data file.
### Train
You can fine-tune the reranker with the following code:
**For llm-based reranker**
```shell
torchrun --nproc_per_node {number of gpus} \
-m FlagEmbedding.llm_reranker.finetune_for_instruction.run \
--output_dir {path to save model} \
--model_name_or_path google/gemma-2b \
--train_data ./toy_finetune_data.jsonl \
--learning_rate 2e-4 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--dataloader_drop_last True \
--query_max_len 512 \
--passage_max_len 512 \
--train_group_size 16 \
--logging_steps 1 \
--save_steps 2000 \
--save_total_limit 50 \
--ddp_find_unused_parameters False \
--gradient_checkpointing \
--deepspeed stage1.json \
--warmup_ratio 0.1 \
--bf16 \
--use_lora True \
--lora_rank 32 \
--lora_alpha 64 \
--use_flash_attn True \
--target_modules q_proj k_proj v_proj o_proj
```
**For llm-based layerwise reranker**
```shell
torchrun --nproc_per_node {number of gpus} \
-m FlagEmbedding.llm_reranker.finetune_for_layerwise.run \
--output_dir {path to save model} \
--model_name_or_path openbmb/MiniCPM-2B-dpo-bf16 \
--train_data ./toy_finetune_data.jsonl \
--learning_rate 2e-4 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--dataloader_drop_last True \
--query_max_len 512 \
--passage_max_len 512 \
--train_group_size 16 \
--logging_steps 1 \
--save_steps 2000 \
--save_total_limit 50 \
--ddp_find_unused_parameters False \
--gradient_checkpointing \
--deepspeed stage1.json \
--warmup_ratio 0.1 \
--bf16 \
--use_lora True \
--lora_rank 32 \
--lora_alpha 64 \
--use_flash_attn True \
--target_modules q_proj k_proj v_proj o_proj \
--start_layer 8 \
--head_multi True \
--head_type simple \
--lora_extra_parameters linear_head
```
Our rerankers are initialized from [google/gemma-2b](https://huggingface.co/google/gemma-2b) (for llm-based reranker) and [openbmb/MiniCPM-2B-dpo-bf16](https://huggingface.co/openbmb/MiniCPM-2B-dpo-bf16) (for llm-based layerwise reranker), and we train it on a mixture of multilingual datasets:
- [bge-m3-data](https://huggingface.co/datasets/Shitao/bge-m3-data)
- [quora train data](https://huggingface.co/datasets/quora)
- [fever train data](https://fever.ai/dataset/fever.html)
## Evaluation
- llama-index.

- BEIR.
rereank the top 100 results from bge-en-v1.5 large.

rereank the top 100 results from e5 mistral 7b instruct.

- CMTEB-retrieval.
It rereank the top 100 results from bge-zh-v1.5 large.

- miracl (multi-language).
It rereank the top 100 results from bge-m3.

## Citation
If you find this repository useful, please consider giving a star and citation
```bibtex
@misc{li2023making,
title={Making Large Language Models A Better Foundation For Dense Retrieval},
author={Chaofan Li and Zheng Liu and Shitao Xiao and Yingxia Shao},
year={2023},
eprint={2312.15503},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{chen2024bge,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu},
year={2024},
eprint={2402.03216},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"BEAR"
] |
yixuan-chia/snowflake-arctic-embed-m-long-Q8_0-GGUF
|
yixuan-chia
|
sentence-similarity
|
[
"sentence-transformers",
"gguf",
"feature-extraction",
"sentence-similarity",
"mteb",
"arctic",
"snowflake-arctic-embed",
"transformers.js",
"llama-cpp",
"gguf-my-repo",
"base_model:Snowflake/snowflake-arctic-embed-m-long",
"base_model:quantized:Snowflake/snowflake-arctic-embed-m-long",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-08-29T03:57:26Z |
2024-08-29T03:57:29+00:00
| 17 | 0 |
---
base_model: Snowflake/snowflake-arctic-embed-m-long
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
- arctic
- snowflake-arctic-embed
- transformers.js
- llama-cpp
- gguf-my-repo
model-index:
- name: snowflake-arctic-m-long
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 78.4776119402985
- type: ap
value: 42.34374238166049
- type: f1
value: 72.51164234732224
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 78.7416
- type: ap
value: 73.12074819362377
- type: f1
value: 78.64057339708795
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 39.926
- type: f1
value: 39.35531993117573
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: mteb/arguana
config: default
split: test
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
metrics:
- type: map_at_1
value: 34.851
- type: map_at_10
value: 51.473
- type: map_at_100
value: 52.103
- type: map_at_1000
value: 52.105000000000004
- type: map_at_3
value: 46.776
- type: map_at_5
value: 49.617
- type: mrr_at_1
value: 35.491
- type: mrr_at_10
value: 51.73799999999999
- type: mrr_at_100
value: 52.37500000000001
- type: mrr_at_1000
value: 52.378
- type: mrr_at_3
value: 46.965
- type: mrr_at_5
value: 49.878
- type: ndcg_at_1
value: 34.851
- type: ndcg_at_10
value: 60.364
- type: ndcg_at_100
value: 62.888999999999996
- type: ndcg_at_1000
value: 62.946000000000005
- type: ndcg_at_3
value: 50.807
- type: ndcg_at_5
value: 55.901
- type: precision_at_1
value: 34.851
- type: precision_at_10
value: 8.855
- type: precision_at_100
value: 0.992
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.839
- type: precision_at_5
value: 14.963999999999999
- type: recall_at_1
value: 34.851
- type: recall_at_10
value: 88.549
- type: recall_at_100
value: 99.21799999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 62.517999999999994
- type: recall_at_5
value: 74.822
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 45.5554998405317
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 35.614248811397005
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.355489424753884
- type: mrr
value: 75.49443784900849
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.17311056578292
- type: cos_sim_spearman
value: 88.24237210809322
- type: euclidean_pearson
value: 87.3188065853646
- type: euclidean_spearman
value: 88.24237210809322
- type: manhattan_pearson
value: 86.89499710049658
- type: manhattan_spearman
value: 87.85441146091777
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 80.26298701298703
- type: f1
value: 79.68356764080303
- task:
type: Clustering
dataset:
name: MTEB BigPatentClustering
type: jinaai/big-patent-clustering
config: default
split: test
revision: 62d5330920bca426ce9d3c76ea914f15fc83e891
metrics:
- type: v_measure
value: 20.923883720813706
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 36.16058801465044
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 30.1402356118627
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: mteb/cqadupstack-android
config: default
split: test
revision: f46a197baaae43b4f621051089b82a364682dfeb
metrics:
- type: map_at_1
value: 35.612
- type: map_at_10
value: 47.117
- type: map_at_100
value: 48.711
- type: map_at_1000
value: 48.826
- type: map_at_3
value: 43.858999999999995
- type: map_at_5
value: 45.612
- type: mrr_at_1
value: 42.918
- type: mrr_at_10
value: 52.806
- type: mrr_at_100
value: 53.564
- type: mrr_at_1000
value: 53.596999999999994
- type: mrr_at_3
value: 50.453
- type: mrr_at_5
value: 51.841
- type: ndcg_at_1
value: 42.918
- type: ndcg_at_10
value: 53.291999999999994
- type: ndcg_at_100
value: 58.711999999999996
- type: ndcg_at_1000
value: 60.317
- type: ndcg_at_3
value: 48.855
- type: ndcg_at_5
value: 50.778
- type: precision_at_1
value: 42.918
- type: precision_at_10
value: 9.927999999999999
- type: precision_at_100
value: 1.592
- type: precision_at_1000
value: 0.201
- type: precision_at_3
value: 23.366999999999997
- type: precision_at_5
value: 16.366
- type: recall_at_1
value: 35.612
- type: recall_at_10
value: 64.671
- type: recall_at_100
value: 86.97
- type: recall_at_1000
value: 96.99600000000001
- type: recall_at_3
value: 51.37199999999999
- type: recall_at_5
value: 57.094
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackEnglishRetrieval
type: mteb/cqadupstack-english
config: default
split: test
revision: ad9991cb51e31e31e430383c75ffb2885547b5f0
metrics:
- type: map_at_1
value: 33.742
- type: map_at_10
value: 44.49
- type: map_at_100
value: 45.781
- type: map_at_1000
value: 45.902
- type: map_at_3
value: 41.453
- type: map_at_5
value: 43.251
- type: mrr_at_1
value: 42.357
- type: mrr_at_10
value: 50.463
- type: mrr_at_100
value: 51.17
- type: mrr_at_1000
value: 51.205999999999996
- type: mrr_at_3
value: 48.397
- type: mrr_at_5
value: 49.649
- type: ndcg_at_1
value: 42.357
- type: ndcg_at_10
value: 50.175000000000004
- type: ndcg_at_100
value: 54.491
- type: ndcg_at_1000
value: 56.282
- type: ndcg_at_3
value: 46.159
- type: ndcg_at_5
value: 48.226
- type: precision_at_1
value: 42.357
- type: precision_at_10
value: 9.382
- type: precision_at_100
value: 1.473
- type: precision_at_1000
value: 0.191
- type: precision_at_3
value: 22.187
- type: precision_at_5
value: 15.758
- type: recall_at_1
value: 33.742
- type: recall_at_10
value: 59.760999999999996
- type: recall_at_100
value: 77.89500000000001
- type: recall_at_1000
value: 89.005
- type: recall_at_3
value: 47.872
- type: recall_at_5
value: 53.559
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGamingRetrieval
type: mteb/cqadupstack-gaming
config: default
split: test
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
metrics:
- type: map_at_1
value: 43.883
- type: map_at_10
value: 56.464999999999996
- type: map_at_100
value: 57.394
- type: map_at_1000
value: 57.443999999999996
- type: map_at_3
value: 53.169
- type: map_at_5
value: 54.984
- type: mrr_at_1
value: 50.470000000000006
- type: mrr_at_10
value: 59.997
- type: mrr_at_100
value: 60.586
- type: mrr_at_1000
value: 60.61
- type: mrr_at_3
value: 57.837
- type: mrr_at_5
value: 59.019
- type: ndcg_at_1
value: 50.470000000000006
- type: ndcg_at_10
value: 62.134
- type: ndcg_at_100
value: 65.69500000000001
- type: ndcg_at_1000
value: 66.674
- type: ndcg_at_3
value: 56.916999999999994
- type: ndcg_at_5
value: 59.312
- type: precision_at_1
value: 50.470000000000006
- type: precision_at_10
value: 9.812
- type: precision_at_100
value: 1.25
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 25.119999999999997
- type: precision_at_5
value: 17.016000000000002
- type: recall_at_1
value: 43.883
- type: recall_at_10
value: 75.417
- type: recall_at_100
value: 90.545
- type: recall_at_1000
value: 97.44500000000001
- type: recall_at_3
value: 61.306000000000004
- type: recall_at_5
value: 67.244
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGisRetrieval
type: mteb/cqadupstack-gis
config: default
split: test
revision: 5003b3064772da1887988e05400cf3806fe491f2
metrics:
- type: map_at_1
value: 29.813000000000002
- type: map_at_10
value: 38.627
- type: map_at_100
value: 39.735
- type: map_at_1000
value: 39.806000000000004
- type: map_at_3
value: 36.283
- type: map_at_5
value: 37.491
- type: mrr_at_1
value: 32.316
- type: mrr_at_10
value: 40.752
- type: mrr_at_100
value: 41.699000000000005
- type: mrr_at_1000
value: 41.749
- type: mrr_at_3
value: 38.531
- type: mrr_at_5
value: 39.706
- type: ndcg_at_1
value: 32.316
- type: ndcg_at_10
value: 43.524
- type: ndcg_at_100
value: 48.648
- type: ndcg_at_1000
value: 50.405
- type: ndcg_at_3
value: 38.928000000000004
- type: ndcg_at_5
value: 40.967
- type: precision_at_1
value: 32.316
- type: precision_at_10
value: 6.451999999999999
- type: precision_at_100
value: 0.9490000000000001
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 16.384
- type: precision_at_5
value: 11.006
- type: recall_at_1
value: 29.813000000000002
- type: recall_at_10
value: 56.562999999999995
- type: recall_at_100
value: 79.452
- type: recall_at_1000
value: 92.715
- type: recall_at_3
value: 43.985
- type: recall_at_5
value: 49.001
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackMathematicaRetrieval
type: mteb/cqadupstack-mathematica
config: default
split: test
revision: 90fceea13679c63fe563ded68f3b6f06e50061de
metrics:
- type: map_at_1
value: 19.961000000000002
- type: map_at_10
value: 28.026
- type: map_at_100
value: 29.212
- type: map_at_1000
value: 29.332
- type: map_at_3
value: 25.296999999999997
- type: map_at_5
value: 26.832
- type: mrr_at_1
value: 24.627
- type: mrr_at_10
value: 33.045
- type: mrr_at_100
value: 33.944
- type: mrr_at_1000
value: 34.013
- type: mrr_at_3
value: 30.307000000000002
- type: mrr_at_5
value: 31.874000000000002
- type: ndcg_at_1
value: 24.627
- type: ndcg_at_10
value: 33.414
- type: ndcg_at_100
value: 39.061
- type: ndcg_at_1000
value: 41.795
- type: ndcg_at_3
value: 28.377000000000002
- type: ndcg_at_5
value: 30.781999999999996
- type: precision_at_1
value: 24.627
- type: precision_at_10
value: 6.02
- type: precision_at_100
value: 1.035
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 13.516
- type: precision_at_5
value: 9.851
- type: recall_at_1
value: 19.961000000000002
- type: recall_at_10
value: 45.174
- type: recall_at_100
value: 69.69
- type: recall_at_1000
value: 89.24600000000001
- type: recall_at_3
value: 31.062
- type: recall_at_5
value: 37.193
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackPhysicsRetrieval
type: mteb/cqadupstack-physics
config: default
split: test
revision: 79531abbd1fb92d06c6d6315a0cbbbf5bb247ea4
metrics:
- type: map_at_1
value: 32.080999999999996
- type: map_at_10
value: 42.177
- type: map_at_100
value: 43.431999999999995
- type: map_at_1000
value: 43.533
- type: map_at_3
value: 38.721
- type: map_at_5
value: 40.669
- type: mrr_at_1
value: 38.787
- type: mrr_at_10
value: 47.762
- type: mrr_at_100
value: 48.541000000000004
- type: mrr_at_1000
value: 48.581
- type: mrr_at_3
value: 45.123999999999995
- type: mrr_at_5
value: 46.639
- type: ndcg_at_1
value: 38.787
- type: ndcg_at_10
value: 48.094
- type: ndcg_at_100
value: 53.291
- type: ndcg_at_1000
value: 55.21
- type: ndcg_at_3
value: 42.721
- type: ndcg_at_5
value: 45.301
- type: precision_at_1
value: 38.787
- type: precision_at_10
value: 8.576
- type: precision_at_100
value: 1.306
- type: precision_at_1000
value: 0.164
- type: precision_at_3
value: 19.698
- type: precision_at_5
value: 14.013
- type: recall_at_1
value: 32.080999999999996
- type: recall_at_10
value: 59.948
- type: recall_at_100
value: 81.811
- type: recall_at_1000
value: 94.544
- type: recall_at_3
value: 44.903999999999996
- type: recall_at_5
value: 51.763999999999996
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackProgrammersRetrieval
type: mteb/cqadupstack-programmers
config: default
split: test
revision: 6184bc1440d2dbc7612be22b50686b8826d22b32
metrics:
- type: map_at_1
value: 28.869
- type: map_at_10
value: 38.954
- type: map_at_100
value: 40.233000000000004
- type: map_at_1000
value: 40.332
- type: map_at_3
value: 35.585
- type: map_at_5
value: 37.476
- type: mrr_at_1
value: 35.959
- type: mrr_at_10
value: 44.800000000000004
- type: mrr_at_100
value: 45.609
- type: mrr_at_1000
value: 45.655
- type: mrr_at_3
value: 42.333
- type: mrr_at_5
value: 43.68
- type: ndcg_at_1
value: 35.959
- type: ndcg_at_10
value: 44.957
- type: ndcg_at_100
value: 50.275000000000006
- type: ndcg_at_1000
value: 52.29899999999999
- type: ndcg_at_3
value: 39.797
- type: ndcg_at_5
value: 42.128
- type: precision_at_1
value: 35.959
- type: precision_at_10
value: 8.185
- type: precision_at_100
value: 1.261
- type: precision_at_1000
value: 0.159
- type: precision_at_3
value: 18.988
- type: precision_at_5
value: 13.516
- type: recall_at_1
value: 28.869
- type: recall_at_10
value: 57.154
- type: recall_at_100
value: 79.764
- type: recall_at_1000
value: 93.515
- type: recall_at_3
value: 42.364000000000004
- type: recall_at_5
value: 48.756
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: mteb/cqadupstack
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: map_at_1
value: 29.31008333333333
- type: map_at_10
value: 38.81849999999999
- type: map_at_100
value: 40.05058333333334
- type: map_at_1000
value: 40.16116666666667
- type: map_at_3
value: 35.91441666666667
- type: map_at_5
value: 37.526583333333335
- type: mrr_at_1
value: 34.60066666666667
- type: mrr_at_10
value: 43.08858333333333
- type: mrr_at_100
value: 43.927749999999996
- type: mrr_at_1000
value: 43.97866666666667
- type: mrr_at_3
value: 40.72775
- type: mrr_at_5
value: 42.067249999999994
- type: ndcg_at_1
value: 34.60066666666667
- type: ndcg_at_10
value: 44.20841666666667
- type: ndcg_at_100
value: 49.32866666666667
- type: ndcg_at_1000
value: 51.373999999999995
- type: ndcg_at_3
value: 39.452083333333334
- type: ndcg_at_5
value: 41.67
- type: precision_at_1
value: 34.60066666666667
- type: precision_at_10
value: 7.616583333333334
- type: precision_at_100
value: 1.20175
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 17.992
- type: precision_at_5
value: 12.658416666666666
- type: recall_at_1
value: 29.31008333333333
- type: recall_at_10
value: 55.81900000000001
- type: recall_at_100
value: 78.06308333333334
- type: recall_at_1000
value: 92.10641666666668
- type: recall_at_3
value: 42.50166666666667
- type: recall_at_5
value: 48.26108333333333
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackStatsRetrieval
type: mteb/cqadupstack-stats
config: default
split: test
revision: 65ac3a16b8e91f9cee4c9828cc7c335575432a2a
metrics:
- type: map_at_1
value: 26.773000000000003
- type: map_at_10
value: 34.13
- type: map_at_100
value: 35.113
- type: map_at_1000
value: 35.211
- type: map_at_3
value: 31.958
- type: map_at_5
value: 33.080999999999996
- type: mrr_at_1
value: 30.061
- type: mrr_at_10
value: 37.061
- type: mrr_at_100
value: 37.865
- type: mrr_at_1000
value: 37.939
- type: mrr_at_3
value: 34.995
- type: mrr_at_5
value: 36.092
- type: ndcg_at_1
value: 30.061
- type: ndcg_at_10
value: 38.391999999999996
- type: ndcg_at_100
value: 43.13
- type: ndcg_at_1000
value: 45.449
- type: ndcg_at_3
value: 34.411
- type: ndcg_at_5
value: 36.163000000000004
- type: precision_at_1
value: 30.061
- type: precision_at_10
value: 5.982
- type: precision_at_100
value: 0.911
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 14.673
- type: precision_at_5
value: 10.030999999999999
- type: recall_at_1
value: 26.773000000000003
- type: recall_at_10
value: 48.445
- type: recall_at_100
value: 69.741
- type: recall_at_1000
value: 86.59
- type: recall_at_3
value: 37.576
- type: recall_at_5
value: 41.948
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackTexRetrieval
type: mteb/cqadupstack-tex
config: default
split: test
revision: 46989137a86843e03a6195de44b09deda022eec7
metrics:
- type: map_at_1
value: 18.556
- type: map_at_10
value: 26.340999999999998
- type: map_at_100
value: 27.560000000000002
- type: map_at_1000
value: 27.685
- type: map_at_3
value: 24.136
- type: map_at_5
value: 25.34
- type: mrr_at_1
value: 22.368
- type: mrr_at_10
value: 30.192999999999998
- type: mrr_at_100
value: 31.183
- type: mrr_at_1000
value: 31.258000000000003
- type: mrr_at_3
value: 28.223
- type: mrr_at_5
value: 29.294999999999998
- type: ndcg_at_1
value: 22.368
- type: ndcg_at_10
value: 31.029
- type: ndcg_at_100
value: 36.768
- type: ndcg_at_1000
value: 39.572
- type: ndcg_at_3
value: 27.197
- type: ndcg_at_5
value: 28.912
- type: precision_at_1
value: 22.368
- type: precision_at_10
value: 5.606
- type: precision_at_100
value: 0.9979999999999999
- type: precision_at_1000
value: 0.14100000000000001
- type: precision_at_3
value: 12.892999999999999
- type: precision_at_5
value: 9.16
- type: recall_at_1
value: 18.556
- type: recall_at_10
value: 41.087
- type: recall_at_100
value: 66.92
- type: recall_at_1000
value: 86.691
- type: recall_at_3
value: 30.415
- type: recall_at_5
value: 34.813
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackUnixRetrieval
type: mteb/cqadupstack-unix
config: default
split: test
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
metrics:
- type: map_at_1
value: 29.953999999999997
- type: map_at_10
value: 39.633
- type: map_at_100
value: 40.923
- type: map_at_1000
value: 41.016000000000005
- type: map_at_3
value: 36.609
- type: map_at_5
value: 38.443
- type: mrr_at_1
value: 35.354
- type: mrr_at_10
value: 43.718
- type: mrr_at_100
value: 44.651999999999994
- type: mrr_at_1000
value: 44.696000000000005
- type: mrr_at_3
value: 41.154
- type: mrr_at_5
value: 42.730000000000004
- type: ndcg_at_1
value: 35.354
- type: ndcg_at_10
value: 44.933
- type: ndcg_at_100
value: 50.577000000000005
- type: ndcg_at_1000
value: 52.428
- type: ndcg_at_3
value: 39.833
- type: ndcg_at_5
value: 42.465
- type: precision_at_1
value: 35.354
- type: precision_at_10
value: 7.416
- type: precision_at_100
value: 1.157
- type: precision_at_1000
value: 0.14100000000000001
- type: precision_at_3
value: 17.817
- type: precision_at_5
value: 12.687000000000001
- type: recall_at_1
value: 29.953999999999997
- type: recall_at_10
value: 56.932
- type: recall_at_100
value: 80.93900000000001
- type: recall_at_1000
value: 93.582
- type: recall_at_3
value: 43.192
- type: recall_at_5
value: 49.757
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWebmastersRetrieval
type: mteb/cqadupstack-webmasters
config: default
split: test
revision: 160c094312a0e1facb97e55eeddb698c0abe3571
metrics:
- type: map_at_1
value: 27.85
- type: map_at_10
value: 37.68
- type: map_at_100
value: 39.295
- type: map_at_1000
value: 39.527
- type: map_at_3
value: 35.036
- type: map_at_5
value: 36.269
- type: mrr_at_1
value: 33.004
- type: mrr_at_10
value: 42.096000000000004
- type: mrr_at_100
value: 43.019
- type: mrr_at_1000
value: 43.071
- type: mrr_at_3
value: 39.987
- type: mrr_at_5
value: 40.995
- type: ndcg_at_1
value: 33.004
- type: ndcg_at_10
value: 43.461
- type: ndcg_at_100
value: 49.138
- type: ndcg_at_1000
value: 51.50900000000001
- type: ndcg_at_3
value: 39.317
- type: ndcg_at_5
value: 40.760999999999996
- type: precision_at_1
value: 33.004
- type: precision_at_10
value: 8.161999999999999
- type: precision_at_100
value: 1.583
- type: precision_at_1000
value: 0.245
- type: precision_at_3
value: 18.445
- type: precision_at_5
value: 12.885
- type: recall_at_1
value: 27.85
- type: recall_at_10
value: 54.419
- type: recall_at_100
value: 79.742
- type: recall_at_1000
value: 93.97
- type: recall_at_3
value: 42.149
- type: recall_at_5
value: 46.165
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWordpressRetrieval
type: mteb/cqadupstack-wordpress
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: map_at_1
value: 24.627
- type: map_at_10
value: 32.182
- type: map_at_100
value: 33.217999999999996
- type: map_at_1000
value: 33.32
- type: map_at_3
value: 28.866999999999997
- type: map_at_5
value: 30.871
- type: mrr_at_1
value: 26.987
- type: mrr_at_10
value: 34.37
- type: mrr_at_100
value: 35.301
- type: mrr_at_1000
value: 35.369
- type: mrr_at_3
value: 31.391999999999996
- type: mrr_at_5
value: 33.287
- type: ndcg_at_1
value: 26.987
- type: ndcg_at_10
value: 37.096000000000004
- type: ndcg_at_100
value: 42.158
- type: ndcg_at_1000
value: 44.548
- type: ndcg_at_3
value: 30.913
- type: ndcg_at_5
value: 34.245
- type: precision_at_1
value: 26.987
- type: precision_at_10
value: 5.878
- type: precision_at_100
value: 0.906
- type: precision_at_1000
value: 0.123
- type: precision_at_3
value: 12.815999999999999
- type: precision_at_5
value: 9.612
- type: recall_at_1
value: 24.627
- type: recall_at_10
value: 50.257
- type: recall_at_100
value: 73.288
- type: recall_at_1000
value: 90.97800000000001
- type: recall_at_3
value: 33.823
- type: recall_at_5
value: 41.839
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: mteb/climate-fever
config: default
split: test
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
metrics:
- type: map_at_1
value: 17.343
- type: map_at_10
value: 28.59
- type: map_at_100
value: 30.591
- type: map_at_1000
value: 30.759999999999998
- type: map_at_3
value: 24.197
- type: map_at_5
value: 26.433
- type: mrr_at_1
value: 39.609
- type: mrr_at_10
value: 51.107
- type: mrr_at_100
value: 51.87199999999999
- type: mrr_at_1000
value: 51.894
- type: mrr_at_3
value: 48.154
- type: mrr_at_5
value: 49.939
- type: ndcg_at_1
value: 39.609
- type: ndcg_at_10
value: 38.329
- type: ndcg_at_100
value: 45.573
- type: ndcg_at_1000
value: 48.405
- type: ndcg_at_3
value: 32.506
- type: ndcg_at_5
value: 34.331
- type: precision_at_1
value: 39.609
- type: precision_at_10
value: 11.668000000000001
- type: precision_at_100
value: 1.9539999999999997
- type: precision_at_1000
value: 0.249
- type: precision_at_3
value: 23.952
- type: precision_at_5
value: 17.902
- type: recall_at_1
value: 17.343
- type: recall_at_10
value: 43.704
- type: recall_at_100
value: 68.363
- type: recall_at_1000
value: 84.04599999999999
- type: recall_at_3
value: 29.028
- type: recall_at_5
value: 35.022
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: mteb/dbpedia
config: default
split: test
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
metrics:
- type: map_at_1
value: 9.934999999999999
- type: map_at_10
value: 22.081
- type: map_at_100
value: 32.036
- type: map_at_1000
value: 33.803
- type: map_at_3
value: 15.687999999999999
- type: map_at_5
value: 18.357
- type: mrr_at_1
value: 70.75
- type: mrr_at_10
value: 78.506
- type: mrr_at_100
value: 78.874
- type: mrr_at_1000
value: 78.88300000000001
- type: mrr_at_3
value: 77.667
- type: mrr_at_5
value: 78.342
- type: ndcg_at_1
value: 57.25
- type: ndcg_at_10
value: 45.286
- type: ndcg_at_100
value: 50.791
- type: ndcg_at_1000
value: 58.021
- type: ndcg_at_3
value: 49.504
- type: ndcg_at_5
value: 47.03
- type: precision_at_1
value: 70.75
- type: precision_at_10
value: 36.425000000000004
- type: precision_at_100
value: 11.953
- type: precision_at_1000
value: 2.248
- type: precision_at_3
value: 53.25
- type: precision_at_5
value: 46.150000000000006
- type: recall_at_1
value: 9.934999999999999
- type: recall_at_10
value: 27.592
- type: recall_at_100
value: 58.089
- type: recall_at_1000
value: 81.025
- type: recall_at_3
value: 17.048
- type: recall_at_5
value: 20.834
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 47.25999999999999
- type: f1
value: 43.83371155132253
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: mteb/fever
config: default
split: test
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
metrics:
- type: map_at_1
value: 73.68900000000001
- type: map_at_10
value: 82.878
- type: map_at_100
value: 83.084
- type: map_at_1000
value: 83.097
- type: map_at_3
value: 81.528
- type: map_at_5
value: 82.432
- type: mrr_at_1
value: 79.49300000000001
- type: mrr_at_10
value: 87.24300000000001
- type: mrr_at_100
value: 87.3
- type: mrr_at_1000
value: 87.301
- type: mrr_at_3
value: 86.359
- type: mrr_at_5
value: 87.01
- type: ndcg_at_1
value: 79.49300000000001
- type: ndcg_at_10
value: 86.894
- type: ndcg_at_100
value: 87.6
- type: ndcg_at_1000
value: 87.79299999999999
- type: ndcg_at_3
value: 84.777
- type: ndcg_at_5
value: 86.08
- type: precision_at_1
value: 79.49300000000001
- type: precision_at_10
value: 10.578
- type: precision_at_100
value: 1.117
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 32.592999999999996
- type: precision_at_5
value: 20.423
- type: recall_at_1
value: 73.68900000000001
- type: recall_at_10
value: 94.833
- type: recall_at_100
value: 97.554
- type: recall_at_1000
value: 98.672
- type: recall_at_3
value: 89.236
- type: recall_at_5
value: 92.461
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: mteb/fiqa
config: default
split: test
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
metrics:
- type: map_at_1
value: 20.59
- type: map_at_10
value: 34.089000000000006
- type: map_at_100
value: 35.796
- type: map_at_1000
value: 35.988
- type: map_at_3
value: 29.877
- type: map_at_5
value: 32.202999999999996
- type: mrr_at_1
value: 41.049
- type: mrr_at_10
value: 50.370000000000005
- type: mrr_at_100
value: 51.209
- type: mrr_at_1000
value: 51.247
- type: mrr_at_3
value: 48.122
- type: mrr_at_5
value: 49.326
- type: ndcg_at_1
value: 41.049
- type: ndcg_at_10
value: 42.163000000000004
- type: ndcg_at_100
value: 48.638999999999996
- type: ndcg_at_1000
value: 51.775000000000006
- type: ndcg_at_3
value: 38.435
- type: ndcg_at_5
value: 39.561
- type: precision_at_1
value: 41.049
- type: precision_at_10
value: 11.481
- type: precision_at_100
value: 1.8239999999999998
- type: precision_at_1000
value: 0.24
- type: precision_at_3
value: 25.257
- type: precision_at_5
value: 18.519
- type: recall_at_1
value: 20.59
- type: recall_at_10
value: 49.547999999999995
- type: recall_at_100
value: 73.676
- type: recall_at_1000
value: 92.269
- type: recall_at_3
value: 35.656
- type: recall_at_5
value: 41.455
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: mteb/hotpotqa
config: default
split: test
revision: ab518f4d6fcca38d87c25209f94beba119d02014
metrics:
- type: map_at_1
value: 39.932
- type: map_at_10
value: 64.184
- type: map_at_100
value: 65.06
- type: map_at_1000
value: 65.109
- type: map_at_3
value: 60.27
- type: map_at_5
value: 62.732
- type: mrr_at_1
value: 79.865
- type: mrr_at_10
value: 85.99799999999999
- type: mrr_at_100
value: 86.13
- type: mrr_at_1000
value: 86.13300000000001
- type: mrr_at_3
value: 85.136
- type: mrr_at_5
value: 85.69200000000001
- type: ndcg_at_1
value: 79.865
- type: ndcg_at_10
value: 72.756
- type: ndcg_at_100
value: 75.638
- type: ndcg_at_1000
value: 76.589
- type: ndcg_at_3
value: 67.38199999999999
- type: ndcg_at_5
value: 70.402
- type: precision_at_1
value: 79.865
- type: precision_at_10
value: 15.387999999999998
- type: precision_at_100
value: 1.7610000000000001
- type: precision_at_1000
value: 0.189
- type: precision_at_3
value: 43.394
- type: precision_at_5
value: 28.424
- type: recall_at_1
value: 39.932
- type: recall_at_10
value: 76.941
- type: recall_at_100
value: 88.062
- type: recall_at_1000
value: 94.396
- type: recall_at_3
value: 65.091
- type: recall_at_5
value: 71.06
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 71.7904
- type: ap
value: 65.82899456730257
- type: f1
value: 71.56611877410202
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: mteb/msmarco
config: default
split: dev
revision: c5a29a104738b98a9e76336939199e264163d4a0
metrics:
- type: map_at_1
value: 21.931
- type: map_at_10
value: 34.849999999999994
- type: map_at_100
value: 36.033
- type: map_at_1000
value: 36.08
- type: map_at_3
value: 30.842000000000002
- type: map_at_5
value: 33.229
- type: mrr_at_1
value: 22.55
- type: mrr_at_10
value: 35.436
- type: mrr_at_100
value: 36.563
- type: mrr_at_1000
value: 36.604
- type: mrr_at_3
value: 31.507
- type: mrr_at_5
value: 33.851
- type: ndcg_at_1
value: 22.55
- type: ndcg_at_10
value: 41.969
- type: ndcg_at_100
value: 47.576
- type: ndcg_at_1000
value: 48.731
- type: ndcg_at_3
value: 33.894000000000005
- type: ndcg_at_5
value: 38.133
- type: precision_at_1
value: 22.55
- type: precision_at_10
value: 6.660000000000001
- type: precision_at_100
value: 0.946
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.532
- type: precision_at_5
value: 10.865
- type: recall_at_1
value: 21.931
- type: recall_at_10
value: 63.841
- type: recall_at_100
value: 89.47699999999999
- type: recall_at_1000
value: 98.259
- type: recall_at_3
value: 42.063
- type: recall_at_5
value: 52.21
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.03921568627452
- type: f1
value: 92.56400672314416
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 63.515731874145
- type: f1
value: 44.922310875523216
- task:
type: Classification
dataset:
name: MTEB MasakhaNEWSClassification (eng)
type: masakhane/masakhanews
config: eng
split: test
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
metrics:
- type: accuracy
value: 77.57383966244727
- type: f1
value: 76.55222378218293
- task:
type: Clustering
dataset:
name: MTEB MasakhaNEWSClusteringP2P (eng)
type: masakhane/masakhanews
config: eng
split: test
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
metrics:
- type: v_measure
value: 62.74836240280833
- type: v_measure
value: 24.414348715238184
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.54673839946201
- type: f1
value: 64.61004101532164
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.11365164761264
- type: f1
value: 72.01684013680978
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 31.123671999617297
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 26.72684341430875
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 29.910228061734816
- type: mrr
value: 30.835255982532477
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: mteb/nfcorpus
config: default
split: test
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
metrics:
- type: map_at_1
value: 5.6770000000000005
- type: map_at_10
value: 13.15
- type: map_at_100
value: 16.205
- type: map_at_1000
value: 17.580000000000002
- type: map_at_3
value: 9.651
- type: map_at_5
value: 11.142000000000001
- type: mrr_at_1
value: 47.678
- type: mrr_at_10
value: 56.257000000000005
- type: mrr_at_100
value: 56.708000000000006
- type: mrr_at_1000
value: 56.751
- type: mrr_at_3
value: 54.128
- type: mrr_at_5
value: 55.181000000000004
- type: ndcg_at_1
value: 45.511
- type: ndcg_at_10
value: 35.867
- type: ndcg_at_100
value: 31.566
- type: ndcg_at_1000
value: 40.077
- type: ndcg_at_3
value: 41.9
- type: ndcg_at_5
value: 39.367999999999995
- type: precision_at_1
value: 47.678
- type: precision_at_10
value: 26.842
- type: precision_at_100
value: 7.991
- type: precision_at_1000
value: 2.0469999999999997
- type: precision_at_3
value: 39.938
- type: precision_at_5
value: 34.613
- type: recall_at_1
value: 5.6770000000000005
- type: recall_at_10
value: 17.119999999999997
- type: recall_at_100
value: 30.828
- type: recall_at_1000
value: 62.082
- type: recall_at_3
value: 10.456
- type: recall_at_5
value: 12.903999999999998
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: mteb/nq
config: default
split: test
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
metrics:
- type: map_at_1
value: 39.021
- type: map_at_10
value: 54.976
- type: map_at_100
value: 55.793000000000006
- type: map_at_1000
value: 55.811
- type: map_at_3
value: 50.759
- type: map_at_5
value: 53.429
- type: mrr_at_1
value: 43.308
- type: mrr_at_10
value: 57.118
- type: mrr_at_100
value: 57.69499999999999
- type: mrr_at_1000
value: 57.704
- type: mrr_at_3
value: 53.848
- type: mrr_at_5
value: 55.915000000000006
- type: ndcg_at_1
value: 43.308
- type: ndcg_at_10
value: 62.33800000000001
- type: ndcg_at_100
value: 65.61099999999999
- type: ndcg_at_1000
value: 65.995
- type: ndcg_at_3
value: 54.723
- type: ndcg_at_5
value: 59.026
- type: precision_at_1
value: 43.308
- type: precision_at_10
value: 9.803
- type: precision_at_100
value: 1.167
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 24.334
- type: precision_at_5
value: 17.144000000000002
- type: recall_at_1
value: 39.021
- type: recall_at_10
value: 82.37299999999999
- type: recall_at_100
value: 96.21499999999999
- type: recall_at_1000
value: 99.02499999999999
- type: recall_at_3
value: 63.031000000000006
- type: recall_at_5
value: 72.856
- task:
type: Classification
dataset:
name: MTEB NewsClassification
type: ag_news
config: default
split: test
revision: eb185aade064a813bc0b7f42de02595523103ca4
metrics:
- type: accuracy
value: 78.03289473684211
- type: f1
value: 77.89323745730803
- task:
type: PairClassification
dataset:
name: MTEB OpusparcusPC (en)
type: GEM/opusparcus
config: en
split: test
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
metrics:
- type: cos_sim_accuracy
value: 99.89816700610999
- type: cos_sim_ap
value: 100.0
- type: cos_sim_f1
value: 99.9490575649516
- type: cos_sim_precision
value: 100.0
- type: cos_sim_recall
value: 99.89816700610999
- type: dot_accuracy
value: 99.89816700610999
- type: dot_ap
value: 100.0
- type: dot_f1
value: 99.9490575649516
- type: dot_precision
value: 100.0
- type: dot_recall
value: 99.89816700610999
- type: euclidean_accuracy
value: 99.89816700610999
- type: euclidean_ap
value: 100.0
- type: euclidean_f1
value: 99.9490575649516
- type: euclidean_precision
value: 100.0
- type: euclidean_recall
value: 99.89816700610999
- type: manhattan_accuracy
value: 99.89816700610999
- type: manhattan_ap
value: 100.0
- type: manhattan_f1
value: 99.9490575649516
- type: manhattan_precision
value: 100.0
- type: manhattan_recall
value: 99.89816700610999
- type: max_accuracy
value: 99.89816700610999
- type: max_ap
value: 100.0
- type: max_f1
value: 99.9490575649516
- task:
type: PairClassification
dataset:
name: MTEB PawsX (en)
type: paws-x
config: en
split: test
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
metrics:
- type: cos_sim_accuracy
value: 61.75000000000001
- type: cos_sim_ap
value: 59.578879568280385
- type: cos_sim_f1
value: 62.50861474844934
- type: cos_sim_precision
value: 45.46365914786967
- type: cos_sim_recall
value: 100.0
- type: dot_accuracy
value: 61.75000000000001
- type: dot_ap
value: 59.57893088951573
- type: dot_f1
value: 62.50861474844934
- type: dot_precision
value: 45.46365914786967
- type: dot_recall
value: 100.0
- type: euclidean_accuracy
value: 61.75000000000001
- type: euclidean_ap
value: 59.578755624671686
- type: euclidean_f1
value: 62.50861474844934
- type: euclidean_precision
value: 45.46365914786967
- type: euclidean_recall
value: 100.0
- type: manhattan_accuracy
value: 61.75000000000001
- type: manhattan_ap
value: 59.58504334461159
- type: manhattan_f1
value: 62.50861474844934
- type: manhattan_precision
value: 45.46365914786967
- type: manhattan_recall
value: 100.0
- type: max_accuracy
value: 61.75000000000001
- type: max_ap
value: 59.58504334461159
- type: max_f1
value: 62.50861474844934
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: mteb/quora
config: default
split: test
revision: e4e08e0b7dbe3c8700f0daef558ff32256715259
metrics:
- type: map_at_1
value: 70.186
- type: map_at_10
value: 83.875
- type: map_at_100
value: 84.514
- type: map_at_1000
value: 84.53500000000001
- type: map_at_3
value: 80.926
- type: map_at_5
value: 82.797
- type: mrr_at_1
value: 80.82000000000001
- type: mrr_at_10
value: 87.068
- type: mrr_at_100
value: 87.178
- type: mrr_at_1000
value: 87.18
- type: mrr_at_3
value: 86.055
- type: mrr_at_5
value: 86.763
- type: ndcg_at_1
value: 80.84
- type: ndcg_at_10
value: 87.723
- type: ndcg_at_100
value: 88.98700000000001
- type: ndcg_at_1000
value: 89.13499999999999
- type: ndcg_at_3
value: 84.821
- type: ndcg_at_5
value: 86.441
- type: precision_at_1
value: 80.84
- type: precision_at_10
value: 13.270000000000001
- type: precision_at_100
value: 1.516
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 37.013
- type: precision_at_5
value: 24.37
- type: recall_at_1
value: 70.186
- type: recall_at_10
value: 94.948
- type: recall_at_100
value: 99.223
- type: recall_at_1000
value: 99.932
- type: recall_at_3
value: 86.57000000000001
- type: recall_at_5
value: 91.157
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 50.24198927949519
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: v_measure
value: 61.452073078765544
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: mteb/scidocs
config: default
split: test
revision: f8c2fcf00f625baaa80f62ec5bd9e1fff3b8ae88
metrics:
- type: map_at_1
value: 4.972
- type: map_at_10
value: 12.314
- type: map_at_100
value: 14.333000000000002
- type: map_at_1000
value: 14.628
- type: map_at_3
value: 8.972
- type: map_at_5
value: 10.724
- type: mrr_at_1
value: 24.4
- type: mrr_at_10
value: 35.257
- type: mrr_at_100
value: 36.297000000000004
- type: mrr_at_1000
value: 36.363
- type: mrr_at_3
value: 32.267
- type: mrr_at_5
value: 33.942
- type: ndcg_at_1
value: 24.4
- type: ndcg_at_10
value: 20.47
- type: ndcg_at_100
value: 28.111000000000004
- type: ndcg_at_1000
value: 33.499
- type: ndcg_at_3
value: 19.975
- type: ndcg_at_5
value: 17.293
- type: precision_at_1
value: 24.4
- type: precision_at_10
value: 10.440000000000001
- type: precision_at_100
value: 2.136
- type: precision_at_1000
value: 0.34299999999999997
- type: precision_at_3
value: 18.733
- type: precision_at_5
value: 15.120000000000001
- type: recall_at_1
value: 4.972
- type: recall_at_10
value: 21.157
- type: recall_at_100
value: 43.335
- type: recall_at_1000
value: 69.652
- type: recall_at_3
value: 11.417
- type: recall_at_5
value: 15.317
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cos_sim_pearson
value: 76.70295978506286
- type: cos_sim_spearman
value: 70.91162732446628
- type: euclidean_pearson
value: 73.25693688746031
- type: euclidean_spearman
value: 70.91162556180127
- type: manhattan_pearson
value: 73.27735004735767
- type: manhattan_spearman
value: 70.8856787022704
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 67.55878682646774
- type: cos_sim_spearman
value: 66.10824660353681
- type: euclidean_pearson
value: 64.93937270068541
- type: euclidean_spearman
value: 66.10824660353681
- type: manhattan_pearson
value: 64.96325555978984
- type: manhattan_spearman
value: 66.12052481638577
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 79.79979774019496
- type: cos_sim_spearman
value: 79.82293444619499
- type: euclidean_pearson
value: 79.4830436509311
- type: euclidean_spearman
value: 79.82293444619499
- type: manhattan_pearson
value: 79.49785594799296
- type: manhattan_spearman
value: 79.8280390479434
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 76.36839628231121
- type: cos_sim_spearman
value: 73.63809739428072
- type: euclidean_pearson
value: 74.93718121215906
- type: euclidean_spearman
value: 73.63810227650436
- type: manhattan_pearson
value: 74.8737197659424
- type: manhattan_spearman
value: 73.57534688126572
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 82.67482138157656
- type: cos_sim_spearman
value: 83.23485786963107
- type: euclidean_pearson
value: 82.50847772197369
- type: euclidean_spearman
value: 83.23485786963107
- type: manhattan_pearson
value: 82.48916218377576
- type: manhattan_spearman
value: 83.19756483500014
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 81.11626268793967
- type: cos_sim_spearman
value: 81.58184691061507
- type: euclidean_pearson
value: 80.65900869004938
- type: euclidean_spearman
value: 81.58184691061507
- type: manhattan_pearson
value: 80.67912306966772
- type: manhattan_spearman
value: 81.59957593393145
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.3140990821409
- type: cos_sim_spearman
value: 80.59196586367551
- type: euclidean_pearson
value: 80.73014029317672
- type: euclidean_spearman
value: 80.59196586367551
- type: manhattan_pearson
value: 80.5774325136987
- type: manhattan_spearman
value: 80.35102610546238
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 68.34450491529164
- type: cos_sim_spearman
value: 68.79451793414492
- type: euclidean_pearson
value: 68.75619738499324
- type: euclidean_spearman
value: 68.79451793414492
- type: manhattan_pearson
value: 68.75256119543882
- type: manhattan_spearman
value: 68.81836416978547
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 77.95580414975612
- type: cos_sim_spearman
value: 77.89671867168987
- type: euclidean_pearson
value: 77.61352097720862
- type: euclidean_spearman
value: 77.89671867168987
- type: manhattan_pearson
value: 77.65282228135632
- type: manhattan_spearman
value: 77.91730533156762
- task:
type: STS
dataset:
name: MTEB STSBenchmarkMultilingualSTS (en)
type: PhilipMay/stsb_multi_mt
config: en
split: test
revision: 93d57ef91790589e3ce9c365164337a8a78b7632
metrics:
- type: cos_sim_pearson
value: 77.95580421496413
- type: cos_sim_spearman
value: 77.89671867168987
- type: euclidean_pearson
value: 77.61352107168794
- type: euclidean_spearman
value: 77.89671867168987
- type: manhattan_pearson
value: 77.65282237231794
- type: manhattan_spearman
value: 77.91730533156762
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 79.22928110092924
- type: mrr
value: 94.46700902583257
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: mteb/scifact
config: default
split: test
revision: 0228b52cf27578f30900b9e5271d331663a030d7
metrics:
- type: map_at_1
value: 56.011
- type: map_at_10
value: 65.544
- type: map_at_100
value: 66.034
- type: map_at_1000
value: 66.065
- type: map_at_3
value: 63.077000000000005
- type: map_at_5
value: 64.354
- type: mrr_at_1
value: 59.0
- type: mrr_at_10
value: 66.74900000000001
- type: mrr_at_100
value: 67.176
- type: mrr_at_1000
value: 67.203
- type: mrr_at_3
value: 65.056
- type: mrr_at_5
value: 65.956
- type: ndcg_at_1
value: 59.0
- type: ndcg_at_10
value: 69.95599999999999
- type: ndcg_at_100
value: 72.27
- type: ndcg_at_1000
value: 73.066
- type: ndcg_at_3
value: 65.837
- type: ndcg_at_5
value: 67.633
- type: precision_at_1
value: 59.0
- type: precision_at_10
value: 9.333
- type: precision_at_100
value: 1.053
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 26.0
- type: precision_at_5
value: 16.866999999999997
- type: recall_at_1
value: 56.011
- type: recall_at_10
value: 82.133
- type: recall_at_100
value: 92.767
- type: recall_at_1000
value: 99.0
- type: recall_at_3
value: 70.95
- type: recall_at_5
value: 75.556
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.81584158415842
- type: cos_sim_ap
value: 94.67482871230736
- type: cos_sim_f1
value: 90.67201604814443
- type: cos_sim_precision
value: 90.94567404426559
- type: cos_sim_recall
value: 90.4
- type: dot_accuracy
value: 99.81584158415842
- type: dot_ap
value: 94.67482871230737
- type: dot_f1
value: 90.67201604814443
- type: dot_precision
value: 90.94567404426559
- type: dot_recall
value: 90.4
- type: euclidean_accuracy
value: 99.81584158415842
- type: euclidean_ap
value: 94.67482871230737
- type: euclidean_f1
value: 90.67201604814443
- type: euclidean_precision
value: 90.94567404426559
- type: euclidean_recall
value: 90.4
- type: manhattan_accuracy
value: 99.81188118811882
- type: manhattan_ap
value: 94.6409082219286
- type: manhattan_f1
value: 90.50949050949052
- type: manhattan_precision
value: 90.41916167664671
- type: manhattan_recall
value: 90.60000000000001
- type: max_accuracy
value: 99.81584158415842
- type: max_ap
value: 94.67482871230737
- type: max_f1
value: 90.67201604814443
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 62.63494511649264
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 37.165838327685755
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 51.384873075208084
- type: mrr
value: 52.196439181733304
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 32.13690355567596
- type: cos_sim_spearman
value: 31.38349778638125
- type: dot_pearson
value: 32.13689596691593
- type: dot_spearman
value: 31.38349778638125
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: mteb/trec-covid
config: default
split: test
revision: bb9466bac8153a0349341eb1b22e06409e78ef4e
metrics:
- type: map_at_1
value: 0.26
- type: map_at_10
value: 2.08
- type: map_at_100
value: 12.598
- type: map_at_1000
value: 30.119
- type: map_at_3
value: 0.701
- type: map_at_5
value: 1.11
- type: mrr_at_1
value: 96.0
- type: mrr_at_10
value: 97.167
- type: mrr_at_100
value: 97.167
- type: mrr_at_1000
value: 97.167
- type: mrr_at_3
value: 96.667
- type: mrr_at_5
value: 97.167
- type: ndcg_at_1
value: 91.0
- type: ndcg_at_10
value: 81.69800000000001
- type: ndcg_at_100
value: 62.9
- type: ndcg_at_1000
value: 55.245999999999995
- type: ndcg_at_3
value: 86.397
- type: ndcg_at_5
value: 84.286
- type: precision_at_1
value: 96.0
- type: precision_at_10
value: 87.0
- type: precision_at_100
value: 64.86
- type: precision_at_1000
value: 24.512
- type: precision_at_3
value: 90.667
- type: precision_at_5
value: 88.8
- type: recall_at_1
value: 0.26
- type: recall_at_10
value: 2.238
- type: recall_at_100
value: 15.488
- type: recall_at_1000
value: 51.6
- type: recall_at_3
value: 0.716
- type: recall_at_5
value: 1.151
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: mteb/touche2020
config: default
split: test
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
metrics:
- type: map_at_1
value: 3.376
- type: map_at_10
value: 13.142000000000001
- type: map_at_100
value: 19.763
- type: map_at_1000
value: 21.319
- type: map_at_3
value: 6.805999999999999
- type: map_at_5
value: 8.952
- type: mrr_at_1
value: 46.939
- type: mrr_at_10
value: 61.082
- type: mrr_at_100
value: 61.45
- type: mrr_at_1000
value: 61.468999999999994
- type: mrr_at_3
value: 57.483
- type: mrr_at_5
value: 59.931999999999995
- type: ndcg_at_1
value: 44.897999999999996
- type: ndcg_at_10
value: 32.35
- type: ndcg_at_100
value: 42.719
- type: ndcg_at_1000
value: 53.30200000000001
- type: ndcg_at_3
value: 37.724999999999994
- type: ndcg_at_5
value: 34.79
- type: precision_at_1
value: 46.939
- type: precision_at_10
value: 28.366999999999997
- type: precision_at_100
value: 8.429
- type: precision_at_1000
value: 1.557
- type: precision_at_3
value: 38.095
- type: precision_at_5
value: 33.469
- type: recall_at_1
value: 3.376
- type: recall_at_10
value: 20.164
- type: recall_at_100
value: 50.668
- type: recall_at_1000
value: 83.159
- type: recall_at_3
value: 8.155
- type: recall_at_5
value: 11.872
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 66.739
- type: ap
value: 12.17931839228834
- type: f1
value: 51.05383188624636
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 56.72891907187323
- type: f1
value: 56.997614557150946
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 39.825318429345224
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 83.65619598259522
- type: cos_sim_ap
value: 66.17412885183877
- type: cos_sim_f1
value: 63.09125656951745
- type: cos_sim_precision
value: 57.63858577040594
- type: cos_sim_recall
value: 69.68337730870712
- type: dot_accuracy
value: 83.65619598259522
- type: dot_ap
value: 66.17413621964548
- type: dot_f1
value: 63.09125656951745
- type: dot_precision
value: 57.63858577040594
- type: dot_recall
value: 69.68337730870712
- type: euclidean_accuracy
value: 83.65619598259522
- type: euclidean_ap
value: 66.17412836413126
- type: euclidean_f1
value: 63.09125656951745
- type: euclidean_precision
value: 57.63858577040594
- type: euclidean_recall
value: 69.68337730870712
- type: manhattan_accuracy
value: 83.5548667819038
- type: manhattan_ap
value: 66.07998834521334
- type: manhattan_f1
value: 62.96433419721092
- type: manhattan_precision
value: 59.14676559239509
- type: manhattan_recall
value: 67.30870712401055
- type: max_accuracy
value: 83.65619598259522
- type: max_ap
value: 66.17413621964548
- type: max_f1
value: 63.09125656951745
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.55706911941631
- type: cos_sim_ap
value: 85.20971331546805
- type: cos_sim_f1
value: 77.28446050593702
- type: cos_sim_precision
value: 74.16135881104033
- type: cos_sim_recall
value: 80.6821681552202
- type: dot_accuracy
value: 88.55706911941631
- type: dot_ap
value: 85.2097154112633
- type: dot_f1
value: 77.28446050593702
- type: dot_precision
value: 74.16135881104033
- type: dot_recall
value: 80.6821681552202
- type: euclidean_accuracy
value: 88.55706911941631
- type: euclidean_ap
value: 85.20971719214488
- type: euclidean_f1
value: 77.28446050593702
- type: euclidean_precision
value: 74.16135881104033
- type: euclidean_recall
value: 80.6821681552202
- type: manhattan_accuracy
value: 88.52020025614158
- type: manhattan_ap
value: 85.17569799117058
- type: manhattan_f1
value: 77.27157773040933
- type: manhattan_precision
value: 72.79286638077734
- type: manhattan_recall
value: 82.33754234678165
- type: max_accuracy
value: 88.55706911941631
- type: max_ap
value: 85.20971719214488
- type: max_f1
value: 77.28446050593702
- task:
type: Clustering
dataset:
name: MTEB WikiCitiesClustering
type: jinaai/cities_wiki_clustering
config: default
split: test
revision: ddc9ee9242fa65332597f70e967ecc38b9d734fa
metrics:
- type: v_measure
value: 85.63474850264893
---
# yixuan-chia/snowflake-arctic-embed-m-long-Q8_0-GGUF
This model was converted to GGUF format from [`Snowflake/snowflake-arctic-embed-m-long`](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Snowflake/snowflake-arctic-embed-m-long) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo yixuan-chia/snowflake-arctic-embed-m-long-Q8_0-GGUF --hf-file snowflake-arctic-embed-m-long-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo yixuan-chia/snowflake-arctic-embed-m-long-Q8_0-GGUF --hf-file snowflake-arctic-embed-m-long-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo yixuan-chia/snowflake-arctic-embed-m-long-Q8_0-GGUF --hf-file snowflake-arctic-embed-m-long-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo yixuan-chia/snowflake-arctic-embed-m-long-Q8_0-GGUF --hf-file snowflake-arctic-embed-m-long-q8_0.gguf -c 2048
```
|
[
"BIOSSES",
"CHIA",
"SCIFACT"
] |
knowledgator/gliner-llama-1.3B-v1.0
|
knowledgator
|
token-classification
|
[
"gliner",
"pytorch",
"NER",
"GLiNER",
"information extraction",
"encoder",
"entity recognition",
"token-classification",
"multilingual",
"dataset:urchade/pile-mistral-v0.1",
"dataset:knowledgator/GLINER-multi-task-synthetic-data",
"dataset:EmergentMethods/AskNews-NER-v0",
"license:apache-2.0",
"region:us"
] | 2024-08-31T13:17:13Z |
2024-09-06T14:45:37+00:00
| 17 | 1 |
---
datasets:
- urchade/pile-mistral-v0.1
- knowledgator/GLINER-multi-task-synthetic-data
- EmergentMethods/AskNews-NER-v0
language:
- multilingual
library_name: gliner
license: apache-2.0
pipeline_tag: token-classification
tags:
- NER
- GLiNER
- information extraction
- encoder
- entity recognition
---
# About
GLiNER is a Named Entity Recognition (NER) model capable of identifying any entity type using a bidirectional transformer encoders (BERT-like). It provides a practical alternative to traditional NER models, which are limited to predefined entities, and Large Language Models (LLMs) that, despite their flexibility, are costly and large for resource-constrained scenarios.
The initial versions of GLiNER relied on older encoder architectures like BERT and DeBERTA. These models, however, were trained on smaller datasets and lacked support for modern optimization techniques such as flash attention. Additionally, their context window was typically limited to 512 tokens, which is insufficient for many practical applications. Recognizing these limitations, we began exploring alternative backbones for GLiNER.
This latest model leverages the LLM2Vec approach, transforming the initial decoder model into a bidirectional encoder. We further enhanced the model by pre-training it on the masked token prediction task using the Wikipedia corpus. This approach introduces several advancements for GLiNER, including support for flash attention, an extended context window, and faster inference times. Additionally, by utilizing modern decoders trained on large, up-to-date datasets, the model exhibits improved generalization and performance.
Key Advantages Over Previous GLiNER Models:
* Enhanced performance and generalization capabilities
* Support for Flash Attention
* Extended context window (up to 32k tokens)
While these models are larger and require more computational resources compared to older encoders, they are still considered relatively small given current standards and provide significant benefits for a wide range of use cases.
### Installation & Usage
Install or update the gliner package:
```bash
pip install gliner -U
```
Once you've downloaded the GLiNER library, you can import the GLiNER class. You can then load this model using `GLiNER.from_pretrained` and predict entities with `predict_entities`.
```python
from gliner import GLiNER
model = GLiNER.from_pretrained("knowledgator/gliner-llama-1.3B-v1.0")
text = """
Cristiano Ronaldo dos Santos Aveiro (Portuguese pronunciation: [kɾiʃˈtjɐnu ʁɔˈnaldu]; born 5 February 1985) is a Portuguese professional footballer who plays as a forward for and captains both Saudi Pro League club Al Nassr and the Portugal national team. Widely regarded as one of the greatest players of all time, Ronaldo has won five Ballon d'Or awards,[note 3] a record three UEFA Men's Player of the Year Awards, and four European Golden Shoes, the most by a European player. He has won 33 trophies in his career, including seven league titles, five UEFA Champions Leagues, the UEFA European Championship and the UEFA Nations League. Ronaldo holds the records for most appearances (183), goals (140) and assists (42) in the Champions League, goals in the European Championship (14), international goals (128) and international appearances (205). He is one of the few players to have made over 1,200 professional career appearances, the most by an outfield player, and has scored over 850 official senior career goals for club and country, making him the top goalscorer of all time.
"""
labels = ["person", "award", "date", "competitions", "teams"]
entities = model.predict_entities(text, labels, threshold=0.5)
for entity in entities:
print(entity["text"], "=>", entity["label"])
```
```
Cristiano Ronaldo dos Santos Aveiro => person
5 February 1985 => date
Al Nassr => teams
Portugal national team => teams
Ballon d'Or => award
UEFA Men's Player of the Year Awards => award
European Golden Shoes => award
UEFA Champions Leagues => competitions
UEFA European Championship => competitions
UEFA Nations League => competitions
Champions League => competitions
European Championship => competitions
```
If you want to use flash attention or increase sequence length, please, check the following code:
```python
model = GLiNER.from_pretrained("knowledgator/gliner-llama-1.3B-v1.0",
_attn_implementation = 'flash_attention_2',
max_len = 2048).to('cuda:0')
```
If you have a large amount of entities and want to pre-embed them, please, refer to the following code snippet:
```python
labels = ["your entities"]
texts = ["your texts"]
entity_embeddings = model.encode_labels(labels, batch_size = 8)
outputs = model.batch_predict_with_embeds(texts, entity_embeddings, labels)
```
### Benchmarks
Below you can see the table with benchmarking results on various named entity recognition datasets:
Here’s the updated table with your provided data:
| Dataset | Score |
|-------------------------|--------|
| ACE 2004 | 32.9% |
| ACE 2005 | 30.1% |
| AnatEM | 39.6% |
| Broad Tweet Corpus | 65.4% |
| CoNLL 2003 | 59.8% |
| FabNER | 26.2% |
| FindVehicle | 30.2% |
| GENIA_NER | 50.0% |
| HarveyNER | 23.9% |
| MultiNERD | 61.7% |
| Ontonotes | 29.6% |
| PolyglotNER | 40.9% |
| TweetNER7 | 36.6% |
| WikiANN en | 54.3% |
| WikiNeural | 74.0% |
| bc2gm | 54.9% |
| bc4chemd | 62.3% |
| bc5cdr | 73.8% |
| ncbi | 65.4% |
| **Average** | **48.0%** |
| | |
| CrossNER_AI | 57.4% |
| CrossNER_literature | 65.9% |
| CrossNER_music | 65.8% |
| CrossNER_politics | 67.5% |
| CrossNER_science | 66.3% |
| mit-movie | 46.7% |
| mit-restaurant | 32.6% |
| **Average (zero-shot benchmark)** | **58.5%** |
### Join Our Discord
Connect with our community on Discord for news, support, and discussion about our models. Join [Discord](https://discord.gg/dkyeAgs9DG).
|
[
"ANATEM",
"BC5CDR"
] |
medspaner/EriBERTa-clinical-trials-medic-attr
|
medspaner
| null |
[
"pytorch",
"roberta",
"generated_from_trainer",
"arxiv:2306.07373",
"license:cc-by-nc-4.0",
"region:us"
] | 2024-09-13T11:54:37Z |
2024-10-01T06:39:52+00:00
| 17 | 0 |
---
license: cc-by-nc-4.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
widget:
- text: Azitromicina en suspensión oral, 10 mg/kg una vez al día durante siete días
- text: A un grupo se le administró Ciprofloxacino 200 mg bid EV y al otro Cefazolina
1 g tid IV
- text: Administración de una solución de mantenimiento intravenosa isotónica (NaCl
al 0,9% en dextrosa al 5%)
- text: Se excluyen pacientes con contraindicación a aspirina o clopidogrel
model-index:
- name: EriBERTa-clinical-trials-medic-attr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# EriBERTa-clinical-trials-medic-attr
This named entity recognition model detects medication-related information:
- Contraindication: e.g. *contraindicación a **aspirina***
- Dose, strength or concentration: e.g. *14 mg*, *100.000 UI*
- Form: e.g. *tabletas*, *comprimidos*
- Route: e.g. *vía oral*, *i.v.*
The model achieves the following results on the test set (when trained with the training and development set; results are averaged over 5 evaluation rounds):
- Precision: 0.874 (±0.024)
- Recall: 0.828 (±0.007)
- F1: 0.850 (±0.010)
- Accuracy: 0.996 (±0.001)
## Model description
This model adapts the pre-trained model [EriBERTa-base](https://huggingface.co/HiTZ/EriBERTa-base), presented in [De la Iglesia et al. (2023)](https://arxiv.org/abs/2306.07373).
It is fine-tuned to conduct medical named entity recognition on Spanish texts about clinical trials.
The model is fine-tuned on the [CT-EBM-ES corpus (Campillos-Llanos et al. 2021)](https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-021-01395-z) vs 2.
If you use this model, please, cite as follows:
```
@article{campillosetal2024,
title = {{Hybrid tool for semantic annotation and concept extraction of medical texts in Spanish}},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n},
journal = {BMC Bioinformatics},
year={2024},
publisher={BioMed Central}
}
```
## Intended uses & limitations
**Disclosure**: *This model is under development and needs to be improved. It should not be used for medical decision making without human assistance and supervision*
This model is intended for a generalist purpose, and may have bias and/or any other undesirable distortions.
Third parties who deploy or provide systems and/or services using any of these models (or using systems based on these models) should note that it is their responsibility to mitigate the risks arising from their use. Third parties, in any event, need to comply with applicable regulations, including regulations concerning the use of artificial intelligence.
The owner or creator of the models will in no event be liable for any results arising from the use made by third parties of these models.
**Descargo de responsabilidad**: *Esta herramienta se encuentra en desarrollo y no debe ser empleada para la toma de decisiones médicas*
La finalidad de este modelo es generalista, y se advierte que puede tener sesgos y/u otro tipo de distorsiones indeseables.
Terceras partes que desplieguen o proporcionen sistemas y/o servicios usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) han tener presente que es su responsabilidad abordar y minimizar los riesgos derivados de su uso. Las terceras partes, en cualquier circunstancia, deben cumplir con la normativa aplicable, incluyendo la normativa que concierne al uso de la inteligencia artificial.
El propietario o creador de los modelos de ningún modo será responsable de los resultados derivados del uso que las terceras partes hagan de estos modelos.
## Training and evaluation data
The data used for fine-tuning are the [Clinical Trials for Evidence-Based-Medicine in Spanish corpus](http://www.lllf.uam.es/ESP/nlpdata/wp2/) vs 2.
It is a collection of 1200 texts about clinical trials studies and clinical trials announcements:
- 500 abstracts from journals published under a Creative Commons license, e.g. available in PubMed or the Scientific Electronic Library Online (SciELO)
- 700 clinical trials announcements published in the European Clinical Trials Register and Repositorio Español de Estudios Clínicos
If you use the CT-EBM-ES resource, please, cite as follows:
```
@article{campillosetal-midm2021,
title = {A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n and Moreno-Sandoval, Antonio},
journal = {BMC Medical Informatics and Decision Making},
volume={21},
number={1},
pages={1--19},
year={2021},
publisher={BioMed Central}
}
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: we used different seeds for 5 evaluation rounds, and uploaded the model with the best results
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: average 10.40 epochs (±3.78); trained with early stopping if no improvement after 5 epochs (early stopping patience: 5)
### Training results (test set; average and standard deviation of 5 rounds with different seeds)
| Precision | Recall | F1 | Accuracy |
|:--------------:|:--------------:|:--------------:|:--------------:|
| 0.874 (±0.024) | 0.828 (±0.007) | 0.850 (±0.010) | 0.996 (±0.001) |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.11.6
|
[
"SCIELO"
] |
gair-prox/RedPJ-ProX-0.7B
|
gair-prox
| null |
[
"pytorch",
"safetensors",
"llama",
"en",
"dataset:gair-prox/RedPajama-pro",
"arxiv:2409.17115",
"license:apache-2.0",
"region:us"
] | 2024-09-16T12:15:59Z |
2024-10-10T13:53:14+00:00
| 17 | 1 |
---
datasets:
- gair-prox/RedPajama-pro
language:
- en
license: apache-2.0
tags:
- llama
---
# RedPJ-ProX-0.7B
<p align="center">
<img src="prox-teaser.png">
</p>
[ArXiv](http://arxiv.org/abs/2409.17115) | [Models](https://huggingface.co/gair-prox/RedPJ-ProX-0.7B) | [Data](https://huggingface.co/datasets/gair-prox/RedPajama-pro) | [Code](https://github.com/GAIR-NLP/program-every-example)
**RedPJ-ProX-0.7B** is a tiny language model. It was and trained on the [RedPajama-V2-pro](https://huggingface.co/datasets/gair-prox/RedPajama-pro) for 25B tokens.
## Evaluations
ProX models are evaluated over 10 language model benchmarks in zero-shot setting.
| | ArC-c | ARC-e | CSQA | HellaS | MMLU | OBQA | PiQA | SIQA | WinoG | SciQ | AVG |
|-----------------------|-------|-------|-------|-----------|-------|-------|-------|-------|-------|-------|------|
| raw | 26.1 | 44.3 | 29.7 | 39.1 | 27.3 | 29.2 | 66.9 | 39.0 | 52.0 | 67.4 | 42.1 |
| ours | 26.4 | 51.9 | 30.9 | 42.4 | 29.4 | 31.6 | 67.9 | 40.0 | 52.2 | 73.5 | 44.6 |
### Citation
```
@article{zhou2024programming,
title={Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale},
author={Zhou, Fan and Wang, Zengzhi and Liu, Qian and Li, Junlong and Liu, Pengfei},
journal={arXiv preprint arXiv:2409.17115},
year={2024}
}
```
|
[
"SCIQ"
] |
louisbrulenaudet/lemone-embed-m-boost
|
louisbrulenaudet
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:296234",
"loss:CachedGISTEmbedLoss",
"legal",
"taxation",
"fiscalité",
"tax",
"fr",
"dataset:louisbrulenaudet/code-impots",
"dataset:louisbrulenaudet/code-impots-annexe-iv",
"dataset:louisbrulenaudet/code-impots-annexe-iii",
"dataset:louisbrulenaudet/code-impots-annexe-i",
"dataset:louisbrulenaudet/code-impots-annexe-ii",
"dataset:louisbrulenaudet/livre-procedures-fiscales",
"dataset:louisbrulenaudet/bofip",
"arxiv:1908.10084",
"base_model:intfloat/multilingual-e5-base",
"base_model:finetune:intfloat/multilingual-e5-base",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-10-01T10:01:03Z |
2024-10-02T21:53:32+00:00
| 17 | 0 |
---
base_model: intfloat/multilingual-e5-base
datasets:
- louisbrulenaudet/code-impots
- louisbrulenaudet/code-impots-annexe-iv
- louisbrulenaudet/code-impots-annexe-iii
- louisbrulenaudet/code-impots-annexe-i
- louisbrulenaudet/code-impots-annexe-ii
- louisbrulenaudet/livre-procedures-fiscales
- louisbrulenaudet/bofip
language:
- fr
library_name: sentence-transformers
license: apache-2.0
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
- dot_accuracy@1
- dot_accuracy@3
- dot_accuracy@5
- dot_accuracy@10
- dot_precision@1
- dot_precision@3
- dot_precision@5
- dot_precision@10
- dot_recall@1
- dot_recall@3
- dot_recall@5
- dot_recall@10
- dot_ndcg@10
- dot_mrr@10
- dot_map@100
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:296234
- loss:CachedGISTEmbedLoss
- legal
- taxation
- fiscalité
- tax
widget:
- source_sentence: 'query: Commentez les dispositions de l''article L. 643-9 et de
l''article L. 643-13 du Code de commerce, telles que modifiées par l''ordonnance
n° 2014-326 du 12 mars 2014.'
sentences:
- 'passage: Conformément aux dispositions de l''article 344 O de l''annexe III du
Code général des impôts, toute déclaration relative au deuxième alinéa de l''article
1635 quater P du même code, concernant la situation des biens immobiliers, doit
impérativement être transmise par voie électronique auprès du service des impôts
compétent. Cette déclaration inclura les informations requises listées du 1° au
6° de l''article 344 N.'
- 'passage: Les formes et le délai de présentation de la demande de renseignements
prévue au I de l''article L. 145 A ainsi que les conséquences attachées à leur
respect sont régis conformément aux dispositions de l''article R. 611-12 du Code
de commerce.'
- 'passage: Les dispositions de l''ordonnance n° 2014-326 du 12 mars 2014 apportent
des ajustements spécifiques à certains articles du Code de commerce, véritable
pierre angulaire de la législation régissant les procédures collectives en France.
En particulier, l''article L. 643-9 connait une modificaton dans le cadre de la
gestion de la liquidation judiciaire et de sa clôture pour insuffisance d''actif,
impliquant ainsi des conditions plus précises quant à l''appréciation de la capacité
à satisfaire l''intégralité du passif par les actifs disponibles. Parallèlement,
l''article L. 643-13 procède à encadrer les conditions de reprise de la procédure
de liquidation judiciaire, offrant ainsi un cadre légal actualisé pour les cas
où la liquidation précédemment clôturée pourrait être réouverte. Ces modifications,
qui s''appliquent rétroactivement aux procédures antérieurement engagées, traduisent
une volonté législative de réconcilier les impératifs d''efficacité et de justice
au sein du traitement des situations d''insolvabilité, assurant ainsi un équilibre
entre les intérêts des créanciers et ceux de l''entreprise débitrice.'
- source_sentence: 'query: Analyser le cadre réglementaire défini par l''article D.
112-3 du Code monétaire et financier concernant les plafonds de paiement en espèces
par les débiteurs ayant leur domicile fiscal en France.'
sentences:
- 'passage: Quelles sont les conséquences, sur l''obligation fiscale d''une personne
physique résidente en France, de la détention directe ou indirecte de parts dans
une entité étrangère qui est soumise à un régime fiscal privilégié, et ce, en
relation avec les dispositions de l''article 123 bis du Code général des impôts
concernant l''assimilation de ces bénéfices à des revenus de capitaux mobiliers
?'
- 'passage: Conformément aux dispositions de l''article D. 112-3 du Code monétaire
et financier, le débiteur résidant fiscalement en France est astreint à une limitation
de paiement en espèces à hauteur de 1 000 euros. Cette mesure vise à encadrer
les transactions et à réduire les risques associés à la fraude fiscale. Tout montant
supérieur à ce plafond devra, de ce fait, être réglé par d''autres moyens de paiement
tels que chèque barré, virement ou carte de paiement.'
- 'passage: Le Bulletin officiel des finances publiques-impôts (Bofip) dans son
document BOI-REC-SOLID-30-10 précise la procédure d''exercice de l''action paulienne.
L''action paulienne se caractérise par une phase préalable consistant à administrer
des preuves relatives à la créance et au préjudice subi, ainsi qu''à la complicité
entre le débiteur et les tiers acquéreurs. Par ailleurs, le juge est appelé à
se positionner à la date de l''acte litigieux pour apprécier l''éventuelle fraude
commise par le débiteur. La procédure judiciaire nécessite donc une approche minutieuse
et conforme au cadre légal, impliquant la collecte d''éléments probants et l''appréciation
judiciaire objective de la situation.'
- source_sentence: 'query: Analyser la mesure par laquelle les associés ou membres
d''un groupement forestier doivent répondre vis-à-vis de la présentation de certains
documents à l''administration fiscale, en se référant aux dispositions de l''article
46 AGI annexé au code général des impôts.'
sentences:
- 'passage: Conformément aux articles 164 F quinvicies et 164 F sexvicies de l''Annexe
IV du Code général des impôts, les adhérents des associations agréées sont tenus
de notifier par écrit à leur association respective toute mesure prise en réponse
aux exigences disposées. Il incombe alors à l''association de vérifier et de s''assurer
que ces obligations soient dûment remplies.'
- 'passage: D''après l''article 46 AGJ de l''annexe III du Code général des impôts,
il est impératif que les associés ou membres d''un groupement forestier maintiennent
à la disposition de l''administration fiscale le document spécifié au II de l''article
46 AGI. Ce document est essentiel pour attester de la conformité aux exigences
fiscales liées au groupement et pour s''assurer de la pérennité des engagements
pris par les membres. Ces procédures de documentation sont cruciales pour garantir
la transparence et permettre à l''administration fiscale d''effectuer les vérifications
nécessaires.'
- 'passage: L''interaction entre le Code des douanes et le Code de la route se concrétise
par la provision de l''article 64 B du Code des douanes. Ce dernier établit une
procédure formelle où les fonctionnaires des douanes sont en droit de requérir
des données spécifiques mentionnées dans les articles L. 330-2 à L. 330-4 du Code
de la route. Ces informations touchent principalement à des aspects cruciaux tels
que la circulation et l''enregistrement des véhicules, éléments essentiels pour
diverses opérations de douane, incluant mais sans se limiter au contrôle du trafic
transfrontalier et à la surveillance des infractions liées à la fiscalité des
véhicules. L''efficience des opérations douanières s''en trouve renforcée, permettant
une synergie entre deux corps étatiques, facilitant ainsi une application plus
stricte et cohérente des lois dans les domaines correspondants.'
- source_sentence: 'query: Analysez l''influence d''un transfert de titres dans un
patrimoine fiduciaire sur la composition d''un groupe fiscal, en prenant en compte
les dispositions du Code général des impôts.'
sentences:
- 'passage: Conformément au cinquième alinéa du a ter du I de l''article 219 du
Code général des impôts, le traitement fiscal des transferts de titres entre divers
comptes du bilan, notamment vers le compte des titres de participation ou vers
toute subdivision affectée aux ''titres relevant du régime des plus-values à long
terme'', implique l''intégration des plus ou moins-values générées par ces transferts
dans le résultat fiscal imposable. Cette intégration est effectuée selon les normes
et le taux de droit commun applicables lors de l''exercice fiscal durant lequel
les titres sont cédés. Les plus-values réalisées à long terme à la suite de tels
transferts contribuent à déterminer la plus ou moins-value nette à long terme
pour l''exercice concerné, au terme duquel cesse le bénéfice du report. Les plus
ou moins-values à court terme qui émergent de ces opérations sont également incorporées
au résultat imposable, respectant les conditions de droit commun de l''exercice
de cession.'
- 'passage: Les agents fiscaux disposent de droits étendus et spécifiques pour l''accès
aux documents comptables des entités lucratives, conformément aux articles L.
85 et R*85-1 du Livre des procédures fiscales. Ces articles leur confèrent le
pouvoir d''exiger la communication de tous documents utiles au contrôle fiscal.
Par ailleurs, le Code de commerce, aux articles L. 123-12 à L. 123-24, précise
les obligations de tenue et de conservation des livres comptables, garantissant
ainsi aux agents fiscaux un droit de regard sur la gestion financière des activités
commerciales. Ces dispositions assurent une base juridique robuste, autorisant
les intervenants fiscaux à requérir et vérifier toute documentation nécessaire
à l''évaluation de la conformité fiscale.'
- 'passage: L''analyse de l''impact d''un transfert de titres dans un patrimoine
fiduciaire, en matière de composition de groupe fiscal, s''effectue à l''aune
de l''article 223 A et de l''article 238 quater B du Code général des impôts.
En principe, un transfert de propriété des titres vers un patrimoine fiduciaire
équivaut à leur exclusion du calcul du seuil de détention de capital pour l''appartenance
à un groupe fiscal. Cependant, une exception spécifique autorise la prise en compte
des titres transférés si deux conditions prépondérantes sont remplies : l''attachement
de droits de vote et de dividendes aux titres cédés et la rétention par le constituant
de l''exercice des droits de vote ou leur utilisation par le fiduciaire conformément
aux directives du constituant, à condition que les termes contractuels de la fiducie
ne s''y opposent pas. Cette particularité légale favorise ainsi la continuité
ou l''intégration fiscale au sein du groupe pour les sociétés transférantes, tant
que les conditions de détention sont observées, et ce, pour les exercices clôturés
postérieurement au 31 décembre 2014.'
- source_sentence: 'query: Décrivez avec précision les étapes détaillées requises
pour traiter les réclamations collectives résultant de désastres agricoles comme
définies dans l''article R*198-2 du Livre des procédures fiscales.'
sentences:
- 'passage: Conformément à l''article 310 K annexé au code général des impôts, l''usine
marémotrice de la Rance, localisée entre Saint-Malo et La Richardais en Ille-et-Vilaine,
peut prétendre à une déduction complémentaire. Cette dernière, prévue par le dernier
alinéa de l''article 1499 du même code, se voit attribuer un taux de 50 %. Ce
dispositif fiscal s''avère donc pertinent pour l''usine considérée, lui permettant
de bénéficier d''un avantage significatif quant à sa charge fiscale.'
- 'passage: Selon les dispositions de l''article R*196-6 du Livre des procédures
fiscales, il est attribué aux sujets fiscaux un intervalle précisément défini
pour élever des réclamations à l''égard des taxes, cotisations et autres prélèvements
relatifs aux céréales et leurs transformés. Ce délai se prolonge jusqu''à la fin
de la campagne agricole suivante celle au cours de laquelle l''avis de mise en
recouvrement de la taxe a été notifié ou le règlement de l''imposition contestée
effectué, permettant ainsi aux parties prenantes de se prévaloir de leurs prérogatives
contestataires avec une certitude temporelle.'
- 'passage: Selon l''article R*198-2 du Livre des procédures fiscales, le traitement
des réclamations collectives en cas de catastrophes naturelles impactant les cultures
agricoles, incluant des phénomènes tels que la grêle ou les inondations, exige
la collaboration de plusieurs entités administratives. Initialement, deux commissaires
sont nommés par l''administration fiscale pour superviser le processus. Ils sont
assistés par un délégué de l''administration des impôts. Avant toute action, le
maire de la commune affectée est notifié au moins dix jours avant l''inspection
prévue, et il est chargé de communiquer cette date aux résidents via des affichages
publics. Les agriculteurs affectés doivent alors rapporter leurs pertes à la mairie
avant la réalisation d''un constat officiel par l''inspecteur des impôts, qui
sera consigné dans un procès-verbal. Une fois ce document clôturé, aucune réclamation
supplémentaire n''est acceptée.'
co2_eq_emissions:
emissions: 935.6048701736584
energy_consumed: 2.5345915368808805
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: AMD EPYC 9V84 96-Core Processor
ram_total_size: 314.6862907409668
hours_used: 4.578
hardware_used: 1 x NVIDIA H100 NVL
model-index:
- name: SentenceTransformer based on intfloat/multilingual-e5-base
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: Lemone information retrieval
type: Lemone-information-retrieval
metrics:
- type: cosine_accuracy@1
value: 0.9743095696852923
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.9910083493898523
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.993577392421323
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9955041746949261
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.9743095696852923
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.3303361164632841
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1987154784842646
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09955041746949261
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.9743095696852923
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.9910083493898523
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.993577392421323
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9955041746949261
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.9861914645525343
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.9830603725112395
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.9832992231274837
name: Cosine Map@100
- type: dot_accuracy@1
value: 0.9743095696852923
name: Dot Accuracy@1
- type: dot_accuracy@3
value: 0.9910083493898523
name: Dot Accuracy@3
- type: dot_accuracy@5
value: 0.993577392421323
name: Dot Accuracy@5
- type: dot_accuracy@10
value: 0.9955041746949261
name: Dot Accuracy@10
- type: dot_precision@1
value: 0.9743095696852923
name: Dot Precision@1
- type: dot_precision@3
value: 0.3303361164632841
name: Dot Precision@3
- type: dot_precision@5
value: 0.1987154784842646
name: Dot Precision@5
- type: dot_precision@10
value: 0.09955041746949261
name: Dot Precision@10
- type: dot_recall@1
value: 0.9743095696852923
name: Dot Recall@1
- type: dot_recall@3
value: 0.9910083493898523
name: Dot Recall@3
- type: dot_recall@5
value: 0.993577392421323
name: Dot Recall@5
- type: dot_recall@10
value: 0.9955041746949261
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.9861914645525343
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.9830603725112395
name: Dot Mrr@10
- type: dot_map@100
value: 0.9832992231274837
name: Dot Map@100
---
<img src="assets/thumbnail.webp">
# Lemone-Embed: A Series of Fine-Tuned Embedding Models for French Taxation
<div class="not-prose bg-gradient-to-r from-gray-50-to-white text-gray-900 border" style="border-radius: 8px; padding: 0.5rem 1rem;">
<p>This series is made up of 7 models, 3 basic models of different sizes trained on 1 epoch, 3 models trained on 2 epochs making up the Boost series and a Pro model with a non-Roberta architecture.</p>
</div>
This sentence transformers model, specifically designed for French taxation, has been fine-tuned on a dataset comprising 43 million tokens, integrating a blend of semi-synthetic and fully synthetic data generated by GPT-4 Turbo and Llama 3.1 70B, which have been further refined through evol-instruction tuning and manual curation.
The model is tailored to meet the specific demands of information retrieval across large-scale tax-related corpora, supporting the implementation of production-ready Retrieval-Augmented Generation (RAG) applications. Its primary purpose is to enhance the efficiency and accuracy of legal processes in the taxation domain, with an emphasis on delivering consistent performance in real-world settings, while also contributing to advancements in legal natural language processing research.
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [intfloat/multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [intfloat/multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) <!-- at revision d13f1b27baf31030b7fd040960d60d909913633f -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
- **Developed by:** Louis Brulé Naudet
- **Funded by:** Microsoft for Startups
- **Shared by:** Louis Brulé Naudet
- **Model type:** Sentence Transformers
- **Language(s) (NLP):** FR
- **License:** Apache 2
- **Finetuned from model:** [intfloat/multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base)
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("louisbrulenaudet/lemone-embed-m-boost")
# Run inference
sentences = [
"query: Décrivez avec précision les étapes détaillées requises pour traiter les réclamations collectives résultant de désastres agricoles comme définies dans l'article R*198-2 du Livre des procédures fiscales.",
"passage: Selon l'article R*198-2 du Livre des procédures fiscales, le traitement des réclamations collectives en cas de catastrophes naturelles impactant les cultures agricoles, incluant des phénomènes tels que la grêle ou les inondations, exige la collaboration de plusieurs entités administratives. Initialement, deux commissaires sont nommés par l'administration fiscale pour superviser le processus. Ils sont assistés par un délégué de l'administration des impôts. Avant toute action, le maire de la commune affectée est notifié au moins dix jours avant l'inspection prévue, et il est chargé de communiquer cette date aux résidents via des affichages publics. Les agriculteurs affectés doivent alors rapporter leurs pertes à la mairie avant la réalisation d'un constat officiel par l'inspecteur des impôts, qui sera consigné dans un procès-verbal. Une fois ce document clôturé, aucune réclamation supplémentaire n'est acceptée.",
"passage: Selon les dispositions de l'article R*196-6 du Livre des procédures fiscales, il est attribué aux sujets fiscaux un intervalle précisément défini pour élever des réclamations à l'égard des taxes, cotisations et autres prélèvements relatifs aux céréales et leurs transformés. Ce délai se prolonge jusqu'à la fin de la campagne agricole suivante celle au cours de laquelle l'avis de mise en recouvrement de la taxe a été notifié ou le règlement de l'imposition contestée effectué, permettant ainsi aux parties prenantes de se prévaloir de leurs prérogatives contestataires avec une certitude temporelle.",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `Lemone-information-retrieval`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.9743 |
| cosine_accuracy@3 | 0.991 |
| cosine_accuracy@5 | 0.9936 |
| cosine_accuracy@10 | 0.9955 |
| cosine_precision@1 | 0.9743 |
| cosine_precision@3 | 0.3303 |
| cosine_precision@5 | 0.1987 |
| cosine_precision@10 | 0.0996 |
| cosine_recall@1 | 0.9743 |
| cosine_recall@3 | 0.991 |
| cosine_recall@5 | 0.9936 |
| cosine_recall@10 | 0.9955 |
| cosine_ndcg@10 | 0.9862 |
| cosine_mrr@10 | 0.9831 |
| **cosine_map@100** | **0.9833** |
| dot_accuracy@1 | 0.9743 |
| dot_accuracy@3 | 0.991 |
| dot_accuracy@5 | 0.9936 |
| dot_accuracy@10 | 0.9955 |
| dot_precision@1 | 0.9743 |
| dot_precision@3 | 0.3303 |
| dot_precision@5 | 0.1987 |
| dot_precision@10 | 0.0996 |
| dot_recall@1 | 0.9743 |
| dot_recall@3 | 0.991 |
| dot_recall@5 | 0.9936 |
| dot_recall@10 | 0.9955 |
| dot_ndcg@10 | 0.9862 |
| dot_mrr@10 | 0.9831 |
| dot_map@100 | 0.9833 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
* Size: 296,234 training samples
* Columns: <code>query</code>, <code>positive</code>, and <code>negative</code>
* Approximate statistics based on the first 1000 samples:
| | query | positive | negative |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 24 tokens</li><li>mean: 54.2 tokens</li><li>max: 179 tokens</li></ul> | <ul><li>min: 75 tokens</li><li>mean: 182.28 tokens</li><li>max: 332 tokens</li></ul> | <ul><li>min: 53 tokens</li><li>mean: 190.2 tokens</li><li>max: 456 tokens</li></ul> |
* Loss: [<code>CachedGISTEmbedLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cachedgistembedloss) with these parameters:
```json
{'guide': SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False}) with Transformer model: NewModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
), 'temperature': 0.01}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 512
- `learning_rate`: 2e-05
- `num_train_epochs`: 2
- `warmup_ratio`: 0.1
- `fp16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 512
- `per_device_eval_batch_size`: 8
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 2
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `eval_use_gather_object`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Energy Consumed**: 2.535 kWh
- **Carbon Emitted**: 0.936 kg of CO2
- **Hours Used**: 4.578 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA H100 NVL
- **CPU Model**: AMD EPYC 9V84 96-Core Processor
- **RAM Size**: 314.69 GB
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 3.1.1
- Transformers: 4.44.2
- PyTorch: 2.3.0+cu121
- Accelerate: 0.33.0
- Datasets: 2.21.0
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
If you use this code in your research, please use the following BibTeX entry.
```BibTeX
@misc{louisbrulenaudet2024,
author = {Louis Brulé Naudet},
title = {Lemone-Embed: A Series of Fine-Tuned Embedding Models for French Taxation},
year = {2024}
howpublished = {\url{https://huggingface.co/datasets/louisbrulenaudet/lemone-embed-m-boost}},
}
```
## Feedback
If you have any feedback, please reach out at [[email protected]](mailto:[email protected]).
|
[
"CAS"
] |
FreedomIntelligence/Apollo2-7B
|
FreedomIntelligence
|
question-answering
|
[
"safetensors",
"qwen2",
"biology",
"medical",
"question-answering",
"ar",
"en",
"zh",
"ko",
"ja",
"mn",
"th",
"vi",
"lo",
"mg",
"de",
"pt",
"es",
"fr",
"ru",
"it",
"hr",
"gl",
"cs",
"co",
"la",
"uk",
"bs",
"bg",
"eo",
"sq",
"da",
"sa",
"gn",
"sr",
"sk",
"gd",
"lb",
"hi",
"ku",
"mt",
"he",
"ln",
"bm",
"sw",
"ig",
"rw",
"ha",
"dataset:FreedomIntelligence/ApolloMoEDataset",
"arxiv:2410.10626",
"base_model:Qwen/Qwen2-7B",
"base_model:finetune:Qwen/Qwen2-7B",
"license:apache-2.0",
"region:us"
] | 2024-10-14T09:45:14Z |
2024-11-20T03:43:25+00:00
| 17 | 2 |
---
base_model:
- Qwen/Qwen2-7B
datasets:
- FreedomIntelligence/ApolloMoEDataset
language:
- ar
- en
- zh
- ko
- ja
- mn
- th
- vi
- lo
- mg
- de
- pt
- es
- fr
- ru
- it
- hr
- gl
- cs
- co
- la
- uk
- bs
- bg
- eo
- sq
- da
- sa
- gn
- sr
- sk
- gd
- lb
- hi
- ku
- mt
- he
- ln
- bm
- sw
- ig
- rw
- ha
license: apache-2.0
metrics:
- accuracy
pipeline_tag: question-answering
tags:
- biology
- medical
---
# Democratizing Medical LLMs For Much More Languages
Covering 12 Major Languages including English, Chinese, French, Hindi, Spanish, Arabic, Russian, Japanese, Korean, German, Italian, Portuguese and 38 Minor Languages So far.
<p align="center">
📃 <a href="https://arxiv.org/abs/2410.10626" target="_blank">Paper</a> • 🌐 <a href="" target="_blank">Demo</a> • 🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEDataset" target="_blank">ApolloMoEDataset</a> • 🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEBench" target="_blank">ApolloMoEBench</a> • 🤗 <a href="https://huggingface.co/collections/FreedomIntelligence/apollomoe-and-apollo2-670ddebe3bb1ba1aebabbf2c" target="_blank">Models</a> •🌐 <a href="https://github.com/FreedomIntelligence/Apollo" target="_blank">Apollo</a> • 🌐 <a href="https://github.com/FreedomIntelligence/ApolloMoE" target="_blank">ApolloMoE</a>
</p>

## 🌈 Update
* **[2024.10.15]** ApolloMoE repo is published!🎉
## Languages Coverage
12 Major Languages and 38 Minor Languages
<details>
<summary>Click to view the Languages Coverage</summary>

</details>
## Architecture
<details>
<summary>Click to view the MoE routing image</summary>

</details>
## Results
#### Dense
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-0.5B" target="_blank">Apollo2-0.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-1.5B" target="_blank">Apollo2-1.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-2B" target="_blank">Apollo2-2B</a>
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-3.8B" target="_blank">Apollo2-3.8B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-7B" target="_blank">Apollo2-7B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-9B" target="_blank">Apollo2-9B</a>
<details>
<summary>Click to view the Dense Models Results</summary>

</details>
#### Post-MoE
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-MoE-0.5B" target="_blank">Apollo-MoE-0.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-MoE-1.5B" target="_blank">Apollo-MoE-1.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-MoE-7B" target="_blank">Apollo-MoE-7B</a>
<details>
<summary>Click to view the Post-MoE Models Results</summary>

</details>
## Usage Format
##### Apollo2
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
- 2B, 9B: User:{query}\nAssistant:{response}\<eos\>
- 3.8B: <|user|>\n{query}<|end|><|assisitant|>\n{response}<|end|>
##### Apollo-MoE
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
## Dataset & Evaluation
- Dataset
🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEDataset" target="_blank">ApolloMoEDataset</a>
<details><summary>Click to expand</summary>

- [Data category](https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus/tree/main/train)
</details>
- Evaluation
🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEBench" target="_blank">ApolloMoEBench</a>
<details><summary>Click to expand</summary>
- EN:
- [MedQA-USMLE](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
- [MedMCQA](https://huggingface.co/datasets/medmcqa/viewer/default/test)
- [PubMedQA](https://huggingface.co/datasets/pubmed_qa): Because the results fluctuated too much, they were not used in the paper.
- [MMLU-Medical](https://huggingface.co/datasets/cais/mmlu)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- ZH:
- [MedQA-MCMLE](https://huggingface.co/datasets/bigbio/med_qa/viewer/med_qa_zh_4options_bigbio_qa/test)
- [CMB-single](https://huggingface.co/datasets/FreedomIntelligence/CMB): Not used in the paper
- Randomly sample 2,000 multiple-choice questions with single answer.
- [CMMLU-Medical](https://huggingface.co/datasets/haonan-li/cmmlu)
- Anatomy, Clinical_knowledge, College_medicine, Genetics, Nutrition, Traditional_chinese_medicine, Virology
- [CExam](https://github.com/williamliujl/CMExam): Not used in the paper
- Randomly sample 2,000 multiple-choice questions
- ES: [Head_qa](https://huggingface.co/datasets/head_qa)
- FR:
- [Frenchmedmcqa](https://github.com/qanastek/FrenchMedMCQA)
- [MMLU_FR]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- HI: [MMLU_HI](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Hindi)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- AR: [MMLU_AR](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Arabic)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- JA: [IgakuQA](https://github.com/jungokasai/IgakuQA)
- KO: [KorMedMCQA](https://huggingface.co/datasets/sean0042/KorMedMCQA)
- IT:
- [MedExpQA](https://huggingface.co/datasets/HiTZ/MedExpQA)
- [MMLU_IT]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- DE: [BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA): German part
- PT: [BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA): Portuguese part
- RU: [RuMedBench](https://github.com/sb-ai-lab/MedBench)
</details>
## Model Download and Inference
We take Apollo-MoE-0.5B as an example
1. Login Huggingface
```
huggingface-cli login --token $HUGGINGFACE_TOKEN
```
2. Download model to local dir
```python
from huggingface_hub import snapshot_download
import os
local_model_dir=os.path.join('/path/to/models/dir','Apollo-MoE-0.5B')
snapshot_download(repo_id="FreedomIntelligence/Apollo-MoE-0.5B", local_dir=local_model_dir)
```
3. Inference Example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import os
local_model_dir=os.path.join('/path/to/models/dir','Apollo-MoE-0.5B')
model=AutoModelForCausalLM.from_pretrained(local_model_dir,trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(local_model_dir,trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(local_model_dir, pad_token_id=tokenizer.pad_token_id, num_return_sequences=1, max_new_tokens=7, min_new_tokens=2, do_sample=False, temperature=1.0, top_k=50, top_p=1.0)
inputs = tokenizer('Answer direclty.\nThe capital of Mongolia is Ulaanbaatar.\nThe capital of Iceland is Reykjavik.\nThe capital of Australia is', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs,generation_config=generation_config)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
```
## Results reproduction
<details><summary>Click to expand</summary>
We take Apollo2-7B or Apollo-MoE-0.5B as example
1. Download Dataset for project:
```
bash 0.download_data.sh
```
2. Prepare test and dev data for specific model:
- Create test data for with special token
```
bash 1.data_process_test&dev.sh
```
3. Prepare train data for specific model (Create tokenized data in advance):
- You can adjust data Training order and Training Epoch in this step
```
bash 2.data_process_train.sh
```
4. Train the model
- If you want to train in Multi Nodes please refer to ./src/sft/training_config/zero_multi.yaml
```
bash 3.single_node_train.sh
```
5. Evaluate your model: Generate score for benchmark
```
bash 4.eval.sh
```
</details>
## Citation
Please use the following citation if you intend to use our dataset for training or evaluation:
```
@misc{zheng2024efficientlydemocratizingmedicalllms,
title={Efficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts},
author={Guorui Zheng and Xidong Wang and Juhao Liang and Nuo Chen and Yuping Zheng and Benyou Wang},
year={2024},
eprint={2410.10626},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.10626},
}
```
|
[
"HEAD-QA",
"MEDQA",
"PUBMEDQA"
] |
BookingCare/multilingual-e5-base-v3-onnx-quantized
|
BookingCare
|
sentence-similarity
|
[
"sentence-transformers",
"onnx",
"xlm-roberta",
"mteb",
"Sentence Transformers",
"sentence-similarity",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:2402.05672",
"arxiv:2108.08787",
"arxiv:2104.08663",
"arxiv:2210.07316",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-10-24T08:56:49Z |
2024-12-06T01:36:06+00:00
| 17 | 0 |
---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
tags:
- mteb
- Sentence Transformers
- sentence-similarity
- sentence-transformers
model-index:
- name: multilingual-e5-base
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 78.97014925373135
- type: ap
value: 43.69351129103008
- type: f1
value: 73.38075030070492
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 71.7237687366167
- type: ap
value: 82.22089859962671
- type: f1
value: 69.95532758884401
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 79.65517241379312
- type: ap
value: 28.507918657094738
- type: f1
value: 66.84516013726119
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.32976445396146
- type: ap
value: 20.720481637566014
- type: f1
value: 59.78002763416003
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 90.63775
- type: ap
value: 87.22277903861716
- type: f1
value: 90.60378636386807
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 44.546
- type: f1
value: 44.05666638370923
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 41.828
- type: f1
value: 41.2710255644252
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.534
- type: f1
value: 39.820743174270326
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 39.684
- type: f1
value: 39.11052682815307
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.436
- type: f1
value: 37.07082931930871
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.226000000000006
- type: f1
value: 36.65372077739185
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.831000000000003
- type: map_at_10
value: 36.42
- type: map_at_100
value: 37.699
- type: map_at_1000
value: 37.724000000000004
- type: map_at_3
value: 32.207
- type: map_at_5
value: 34.312
- type: mrr_at_1
value: 23.257
- type: mrr_at_10
value: 36.574
- type: mrr_at_100
value: 37.854
- type: mrr_at_1000
value: 37.878
- type: mrr_at_3
value: 32.385000000000005
- type: mrr_at_5
value: 34.48
- type: ndcg_at_1
value: 22.831000000000003
- type: ndcg_at_10
value: 44.230000000000004
- type: ndcg_at_100
value: 49.974000000000004
- type: ndcg_at_1000
value: 50.522999999999996
- type: ndcg_at_3
value: 35.363
- type: ndcg_at_5
value: 39.164
- type: precision_at_1
value: 22.831000000000003
- type: precision_at_10
value: 6.935
- type: precision_at_100
value: 0.9520000000000001
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 14.841
- type: precision_at_5
value: 10.754
- type: recall_at_1
value: 22.831000000000003
- type: recall_at_10
value: 69.346
- type: recall_at_100
value: 95.235
- type: recall_at_1000
value: 99.36
- type: recall_at_3
value: 44.523
- type: recall_at_5
value: 53.769999999999996
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 40.27789869854063
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 35.41979463347428
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 58.22752045109304
- type: mrr
value: 71.51112430198303
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.71147646622866
- type: cos_sim_spearman
value: 85.059167046486
- type: euclidean_pearson
value: 75.88421613600647
- type: euclidean_spearman
value: 75.12821787150585
- type: manhattan_pearson
value: 75.22005646957604
- type: manhattan_spearman
value: 74.42880434453272
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.23799582463465
- type: f1
value: 99.12665274878218
- type: precision
value: 99.07098121085595
- type: recall
value: 99.23799582463465
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.88685890380806
- type: f1
value: 97.59336708489249
- type: precision
value: 97.44662117543473
- type: recall
value: 97.88685890380806
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.47142362313821
- type: f1
value: 97.1989377670015
- type: precision
value: 97.06384944001847
- type: recall
value: 97.47142362313821
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.4728804634018
- type: f1
value: 98.2973494821836
- type: precision
value: 98.2095839915745
- type: recall
value: 98.4728804634018
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 82.74025974025975
- type: f1
value: 82.67420447730439
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.0380848063507
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 29.45956405670166
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.122
- type: map_at_10
value: 42.03
- type: map_at_100
value: 43.364000000000004
- type: map_at_1000
value: 43.474000000000004
- type: map_at_3
value: 38.804
- type: map_at_5
value: 40.585
- type: mrr_at_1
value: 39.914
- type: mrr_at_10
value: 48.227
- type: mrr_at_100
value: 49.018
- type: mrr_at_1000
value: 49.064
- type: mrr_at_3
value: 45.994
- type: mrr_at_5
value: 47.396
- type: ndcg_at_1
value: 39.914
- type: ndcg_at_10
value: 47.825
- type: ndcg_at_100
value: 52.852
- type: ndcg_at_1000
value: 54.891
- type: ndcg_at_3
value: 43.517
- type: ndcg_at_5
value: 45.493
- type: precision_at_1
value: 39.914
- type: precision_at_10
value: 8.956
- type: precision_at_100
value: 1.388
- type: precision_at_1000
value: 0.182
- type: precision_at_3
value: 20.791999999999998
- type: precision_at_5
value: 14.821000000000002
- type: recall_at_1
value: 32.122
- type: recall_at_10
value: 58.294999999999995
- type: recall_at_100
value: 79.726
- type: recall_at_1000
value: 93.099
- type: recall_at_3
value: 45.017
- type: recall_at_5
value: 51.002
- type: map_at_1
value: 29.677999999999997
- type: map_at_10
value: 38.684000000000005
- type: map_at_100
value: 39.812999999999995
- type: map_at_1000
value: 39.945
- type: map_at_3
value: 35.831
- type: map_at_5
value: 37.446
- type: mrr_at_1
value: 37.771
- type: mrr_at_10
value: 44.936
- type: mrr_at_100
value: 45.583
- type: mrr_at_1000
value: 45.634
- type: mrr_at_3
value: 42.771
- type: mrr_at_5
value: 43.994
- type: ndcg_at_1
value: 37.771
- type: ndcg_at_10
value: 44.059
- type: ndcg_at_100
value: 48.192
- type: ndcg_at_1000
value: 50.375
- type: ndcg_at_3
value: 40.172000000000004
- type: ndcg_at_5
value: 41.899
- type: precision_at_1
value: 37.771
- type: precision_at_10
value: 8.286999999999999
- type: precision_at_100
value: 1.322
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 19.406000000000002
- type: precision_at_5
value: 13.745
- type: recall_at_1
value: 29.677999999999997
- type: recall_at_10
value: 53.071
- type: recall_at_100
value: 70.812
- type: recall_at_1000
value: 84.841
- type: recall_at_3
value: 41.016000000000005
- type: recall_at_5
value: 46.22
- type: map_at_1
value: 42.675000000000004
- type: map_at_10
value: 53.93599999999999
- type: map_at_100
value: 54.806999999999995
- type: map_at_1000
value: 54.867
- type: map_at_3
value: 50.934000000000005
- type: map_at_5
value: 52.583
- type: mrr_at_1
value: 48.339
- type: mrr_at_10
value: 57.265
- type: mrr_at_100
value: 57.873
- type: mrr_at_1000
value: 57.906
- type: mrr_at_3
value: 55.193000000000005
- type: mrr_at_5
value: 56.303000000000004
- type: ndcg_at_1
value: 48.339
- type: ndcg_at_10
value: 59.19799999999999
- type: ndcg_at_100
value: 62.743
- type: ndcg_at_1000
value: 63.99399999999999
- type: ndcg_at_3
value: 54.367
- type: ndcg_at_5
value: 56.548
- type: precision_at_1
value: 48.339
- type: precision_at_10
value: 9.216000000000001
- type: precision_at_100
value: 1.1809999999999998
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 23.72
- type: precision_at_5
value: 16.025
- type: recall_at_1
value: 42.675000000000004
- type: recall_at_10
value: 71.437
- type: recall_at_100
value: 86.803
- type: recall_at_1000
value: 95.581
- type: recall_at_3
value: 58.434
- type: recall_at_5
value: 63.754
- type: map_at_1
value: 23.518
- type: map_at_10
value: 30.648999999999997
- type: map_at_100
value: 31.508999999999997
- type: map_at_1000
value: 31.604
- type: map_at_3
value: 28.247
- type: map_at_5
value: 29.65
- type: mrr_at_1
value: 25.650000000000002
- type: mrr_at_10
value: 32.771
- type: mrr_at_100
value: 33.554
- type: mrr_at_1000
value: 33.629999999999995
- type: mrr_at_3
value: 30.433
- type: mrr_at_5
value: 31.812
- type: ndcg_at_1
value: 25.650000000000002
- type: ndcg_at_10
value: 34.929
- type: ndcg_at_100
value: 39.382
- type: ndcg_at_1000
value: 41.913
- type: ndcg_at_3
value: 30.292
- type: ndcg_at_5
value: 32.629999999999995
- type: precision_at_1
value: 25.650000000000002
- type: precision_at_10
value: 5.311
- type: precision_at_100
value: 0.792
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 12.58
- type: precision_at_5
value: 8.994
- type: recall_at_1
value: 23.518
- type: recall_at_10
value: 46.19
- type: recall_at_100
value: 67.123
- type: recall_at_1000
value: 86.442
- type: recall_at_3
value: 33.678000000000004
- type: recall_at_5
value: 39.244
- type: map_at_1
value: 15.891
- type: map_at_10
value: 22.464000000000002
- type: map_at_100
value: 23.483
- type: map_at_1000
value: 23.613
- type: map_at_3
value: 20.080000000000002
- type: map_at_5
value: 21.526
- type: mrr_at_1
value: 20.025000000000002
- type: mrr_at_10
value: 26.712999999999997
- type: mrr_at_100
value: 27.650000000000002
- type: mrr_at_1000
value: 27.737000000000002
- type: mrr_at_3
value: 24.274
- type: mrr_at_5
value: 25.711000000000002
- type: ndcg_at_1
value: 20.025000000000002
- type: ndcg_at_10
value: 27.028999999999996
- type: ndcg_at_100
value: 32.064
- type: ndcg_at_1000
value: 35.188
- type: ndcg_at_3
value: 22.512999999999998
- type: ndcg_at_5
value: 24.89
- type: precision_at_1
value: 20.025000000000002
- type: precision_at_10
value: 4.776
- type: precision_at_100
value: 0.8500000000000001
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 10.531
- type: precision_at_5
value: 7.811
- type: recall_at_1
value: 15.891
- type: recall_at_10
value: 37.261
- type: recall_at_100
value: 59.12
- type: recall_at_1000
value: 81.356
- type: recall_at_3
value: 24.741
- type: recall_at_5
value: 30.753999999999998
- type: map_at_1
value: 27.544
- type: map_at_10
value: 36.283
- type: map_at_100
value: 37.467
- type: map_at_1000
value: 37.574000000000005
- type: map_at_3
value: 33.528999999999996
- type: map_at_5
value: 35.028999999999996
- type: mrr_at_1
value: 34.166999999999994
- type: mrr_at_10
value: 41.866
- type: mrr_at_100
value: 42.666
- type: mrr_at_1000
value: 42.716
- type: mrr_at_3
value: 39.541
- type: mrr_at_5
value: 40.768
- type: ndcg_at_1
value: 34.166999999999994
- type: ndcg_at_10
value: 41.577
- type: ndcg_at_100
value: 46.687
- type: ndcg_at_1000
value: 48.967
- type: ndcg_at_3
value: 37.177
- type: ndcg_at_5
value: 39.097
- type: precision_at_1
value: 34.166999999999994
- type: precision_at_10
value: 7.420999999999999
- type: precision_at_100
value: 1.165
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 17.291999999999998
- type: precision_at_5
value: 12.166
- type: recall_at_1
value: 27.544
- type: recall_at_10
value: 51.99399999999999
- type: recall_at_100
value: 73.738
- type: recall_at_1000
value: 89.33
- type: recall_at_3
value: 39.179
- type: recall_at_5
value: 44.385999999999996
- type: map_at_1
value: 26.661
- type: map_at_10
value: 35.475
- type: map_at_100
value: 36.626999999999995
- type: map_at_1000
value: 36.741
- type: map_at_3
value: 32.818000000000005
- type: map_at_5
value: 34.397
- type: mrr_at_1
value: 32.647999999999996
- type: mrr_at_10
value: 40.784
- type: mrr_at_100
value: 41.602
- type: mrr_at_1000
value: 41.661
- type: mrr_at_3
value: 38.68
- type: mrr_at_5
value: 39.838
- type: ndcg_at_1
value: 32.647999999999996
- type: ndcg_at_10
value: 40.697
- type: ndcg_at_100
value: 45.799
- type: ndcg_at_1000
value: 48.235
- type: ndcg_at_3
value: 36.516
- type: ndcg_at_5
value: 38.515
- type: precision_at_1
value: 32.647999999999996
- type: precision_at_10
value: 7.202999999999999
- type: precision_at_100
value: 1.1360000000000001
- type: precision_at_1000
value: 0.151
- type: precision_at_3
value: 17.314
- type: precision_at_5
value: 12.145999999999999
- type: recall_at_1
value: 26.661
- type: recall_at_10
value: 50.995000000000005
- type: recall_at_100
value: 73.065
- type: recall_at_1000
value: 89.781
- type: recall_at_3
value: 39.073
- type: recall_at_5
value: 44.395
- type: map_at_1
value: 25.946583333333333
- type: map_at_10
value: 33.79725
- type: map_at_100
value: 34.86408333333333
- type: map_at_1000
value: 34.9795
- type: map_at_3
value: 31.259999999999998
- type: map_at_5
value: 32.71541666666666
- type: mrr_at_1
value: 30.863749999999996
- type: mrr_at_10
value: 37.99183333333333
- type: mrr_at_100
value: 38.790499999999994
- type: mrr_at_1000
value: 38.85575000000001
- type: mrr_at_3
value: 35.82083333333333
- type: mrr_at_5
value: 37.07533333333333
- type: ndcg_at_1
value: 30.863749999999996
- type: ndcg_at_10
value: 38.52141666666667
- type: ndcg_at_100
value: 43.17966666666667
- type: ndcg_at_1000
value: 45.64608333333333
- type: ndcg_at_3
value: 34.333000000000006
- type: ndcg_at_5
value: 36.34975
- type: precision_at_1
value: 30.863749999999996
- type: precision_at_10
value: 6.598999999999999
- type: precision_at_100
value: 1.0502500000000001
- type: precision_at_1000
value: 0.14400000000000002
- type: precision_at_3
value: 15.557583333333334
- type: precision_at_5
value: 11.020000000000001
- type: recall_at_1
value: 25.946583333333333
- type: recall_at_10
value: 48.36991666666666
- type: recall_at_100
value: 69.02408333333334
- type: recall_at_1000
value: 86.43858333333331
- type: recall_at_3
value: 36.4965
- type: recall_at_5
value: 41.76258333333334
- type: map_at_1
value: 22.431
- type: map_at_10
value: 28.889
- type: map_at_100
value: 29.642000000000003
- type: map_at_1000
value: 29.742
- type: map_at_3
value: 26.998
- type: map_at_5
value: 28.172000000000004
- type: mrr_at_1
value: 25.307000000000002
- type: mrr_at_10
value: 31.763
- type: mrr_at_100
value: 32.443
- type: mrr_at_1000
value: 32.531
- type: mrr_at_3
value: 29.959000000000003
- type: mrr_at_5
value: 31.063000000000002
- type: ndcg_at_1
value: 25.307000000000002
- type: ndcg_at_10
value: 32.586999999999996
- type: ndcg_at_100
value: 36.5
- type: ndcg_at_1000
value: 39.133
- type: ndcg_at_3
value: 29.25
- type: ndcg_at_5
value: 31.023
- type: precision_at_1
value: 25.307000000000002
- type: precision_at_10
value: 4.954
- type: precision_at_100
value: 0.747
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 12.577
- type: precision_at_5
value: 8.741999999999999
- type: recall_at_1
value: 22.431
- type: recall_at_10
value: 41.134
- type: recall_at_100
value: 59.28600000000001
- type: recall_at_1000
value: 78.857
- type: recall_at_3
value: 31.926
- type: recall_at_5
value: 36.335
- type: map_at_1
value: 17.586
- type: map_at_10
value: 23.304
- type: map_at_100
value: 24.159
- type: map_at_1000
value: 24.281
- type: map_at_3
value: 21.316
- type: map_at_5
value: 22.383
- type: mrr_at_1
value: 21.645
- type: mrr_at_10
value: 27.365000000000002
- type: mrr_at_100
value: 28.108
- type: mrr_at_1000
value: 28.192
- type: mrr_at_3
value: 25.482
- type: mrr_at_5
value: 26.479999999999997
- type: ndcg_at_1
value: 21.645
- type: ndcg_at_10
value: 27.306
- type: ndcg_at_100
value: 31.496000000000002
- type: ndcg_at_1000
value: 34.53
- type: ndcg_at_3
value: 23.73
- type: ndcg_at_5
value: 25.294
- type: precision_at_1
value: 21.645
- type: precision_at_10
value: 4.797
- type: precision_at_100
value: 0.8059999999999999
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 10.850999999999999
- type: precision_at_5
value: 7.736
- type: recall_at_1
value: 17.586
- type: recall_at_10
value: 35.481
- type: recall_at_100
value: 54.534000000000006
- type: recall_at_1000
value: 76.456
- type: recall_at_3
value: 25.335
- type: recall_at_5
value: 29.473
- type: map_at_1
value: 25.095
- type: map_at_10
value: 32.374
- type: map_at_100
value: 33.537
- type: map_at_1000
value: 33.634
- type: map_at_3
value: 30.089
- type: map_at_5
value: 31.433
- type: mrr_at_1
value: 29.198
- type: mrr_at_10
value: 36.01
- type: mrr_at_100
value: 37.022
- type: mrr_at_1000
value: 37.083
- type: mrr_at_3
value: 33.94
- type: mrr_at_5
value: 35.148
- type: ndcg_at_1
value: 29.198
- type: ndcg_at_10
value: 36.729
- type: ndcg_at_100
value: 42.114000000000004
- type: ndcg_at_1000
value: 44.592
- type: ndcg_at_3
value: 32.644
- type: ndcg_at_5
value: 34.652
- type: precision_at_1
value: 29.198
- type: precision_at_10
value: 5.970000000000001
- type: precision_at_100
value: 0.967
- type: precision_at_1000
value: 0.129
- type: precision_at_3
value: 14.396999999999998
- type: precision_at_5
value: 10.093
- type: recall_at_1
value: 25.095
- type: recall_at_10
value: 46.392
- type: recall_at_100
value: 69.706
- type: recall_at_1000
value: 87.738
- type: recall_at_3
value: 35.303000000000004
- type: recall_at_5
value: 40.441
- type: map_at_1
value: 26.857999999999997
- type: map_at_10
value: 34.066
- type: map_at_100
value: 35.671
- type: map_at_1000
value: 35.881
- type: map_at_3
value: 31.304
- type: map_at_5
value: 32.885
- type: mrr_at_1
value: 32.411
- type: mrr_at_10
value: 38.987
- type: mrr_at_100
value: 39.894
- type: mrr_at_1000
value: 39.959
- type: mrr_at_3
value: 36.626999999999995
- type: mrr_at_5
value: 38.011
- type: ndcg_at_1
value: 32.411
- type: ndcg_at_10
value: 39.208
- type: ndcg_at_100
value: 44.626
- type: ndcg_at_1000
value: 47.43
- type: ndcg_at_3
value: 35.091
- type: ndcg_at_5
value: 37.119
- type: precision_at_1
value: 32.411
- type: precision_at_10
value: 7.51
- type: precision_at_100
value: 1.486
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 16.14
- type: precision_at_5
value: 11.976
- type: recall_at_1
value: 26.857999999999997
- type: recall_at_10
value: 47.407
- type: recall_at_100
value: 72.236
- type: recall_at_1000
value: 90.77
- type: recall_at_3
value: 35.125
- type: recall_at_5
value: 40.522999999999996
- type: map_at_1
value: 21.3
- type: map_at_10
value: 27.412999999999997
- type: map_at_100
value: 28.29
- type: map_at_1000
value: 28.398
- type: map_at_3
value: 25.169999999999998
- type: map_at_5
value: 26.496
- type: mrr_at_1
value: 23.29
- type: mrr_at_10
value: 29.215000000000003
- type: mrr_at_100
value: 30.073
- type: mrr_at_1000
value: 30.156
- type: mrr_at_3
value: 26.956000000000003
- type: mrr_at_5
value: 28.38
- type: ndcg_at_1
value: 23.29
- type: ndcg_at_10
value: 31.113000000000003
- type: ndcg_at_100
value: 35.701
- type: ndcg_at_1000
value: 38.505
- type: ndcg_at_3
value: 26.727
- type: ndcg_at_5
value: 29.037000000000003
- type: precision_at_1
value: 23.29
- type: precision_at_10
value: 4.787
- type: precision_at_100
value: 0.763
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 11.091
- type: precision_at_5
value: 7.985
- type: recall_at_1
value: 21.3
- type: recall_at_10
value: 40.782000000000004
- type: recall_at_100
value: 62.13999999999999
- type: recall_at_1000
value: 83.012
- type: recall_at_3
value: 29.131
- type: recall_at_5
value: 34.624
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.631
- type: map_at_10
value: 16.634999999999998
- type: map_at_100
value: 18.23
- type: map_at_1000
value: 18.419
- type: map_at_3
value: 13.66
- type: map_at_5
value: 15.173
- type: mrr_at_1
value: 21.368000000000002
- type: mrr_at_10
value: 31.56
- type: mrr_at_100
value: 32.58
- type: mrr_at_1000
value: 32.633
- type: mrr_at_3
value: 28.241
- type: mrr_at_5
value: 30.225
- type: ndcg_at_1
value: 21.368000000000002
- type: ndcg_at_10
value: 23.855999999999998
- type: ndcg_at_100
value: 30.686999999999998
- type: ndcg_at_1000
value: 34.327000000000005
- type: ndcg_at_3
value: 18.781
- type: ndcg_at_5
value: 20.73
- type: precision_at_1
value: 21.368000000000002
- type: precision_at_10
value: 7.564
- type: precision_at_100
value: 1.496
- type: precision_at_1000
value: 0.217
- type: precision_at_3
value: 13.876
- type: precision_at_5
value: 11.062
- type: recall_at_1
value: 9.631
- type: recall_at_10
value: 29.517
- type: recall_at_100
value: 53.452
- type: recall_at_1000
value: 74.115
- type: recall_at_3
value: 17.605999999999998
- type: recall_at_5
value: 22.505
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.885
- type: map_at_10
value: 18.798000000000002
- type: map_at_100
value: 26.316
- type: map_at_1000
value: 27.869
- type: map_at_3
value: 13.719000000000001
- type: map_at_5
value: 15.716
- type: mrr_at_1
value: 66
- type: mrr_at_10
value: 74.263
- type: mrr_at_100
value: 74.519
- type: mrr_at_1000
value: 74.531
- type: mrr_at_3
value: 72.458
- type: mrr_at_5
value: 73.321
- type: ndcg_at_1
value: 53.87499999999999
- type: ndcg_at_10
value: 40.355999999999995
- type: ndcg_at_100
value: 44.366
- type: ndcg_at_1000
value: 51.771
- type: ndcg_at_3
value: 45.195
- type: ndcg_at_5
value: 42.187000000000005
- type: precision_at_1
value: 66
- type: precision_at_10
value: 31.75
- type: precision_at_100
value: 10.11
- type: precision_at_1000
value: 1.9800000000000002
- type: precision_at_3
value: 48.167
- type: precision_at_5
value: 40.050000000000004
- type: recall_at_1
value: 8.885
- type: recall_at_10
value: 24.471999999999998
- type: recall_at_100
value: 49.669000000000004
- type: recall_at_1000
value: 73.383
- type: recall_at_3
value: 14.872
- type: recall_at_5
value: 18.262999999999998
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 45.18
- type: f1
value: 40.26878691789978
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 62.751999999999995
- type: map_at_10
value: 74.131
- type: map_at_100
value: 74.407
- type: map_at_1000
value: 74.423
- type: map_at_3
value: 72.329
- type: map_at_5
value: 73.555
- type: mrr_at_1
value: 67.282
- type: mrr_at_10
value: 78.292
- type: mrr_at_100
value: 78.455
- type: mrr_at_1000
value: 78.458
- type: mrr_at_3
value: 76.755
- type: mrr_at_5
value: 77.839
- type: ndcg_at_1
value: 67.282
- type: ndcg_at_10
value: 79.443
- type: ndcg_at_100
value: 80.529
- type: ndcg_at_1000
value: 80.812
- type: ndcg_at_3
value: 76.281
- type: ndcg_at_5
value: 78.235
- type: precision_at_1
value: 67.282
- type: precision_at_10
value: 10.078
- type: precision_at_100
value: 1.082
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 30.178
- type: precision_at_5
value: 19.232
- type: recall_at_1
value: 62.751999999999995
- type: recall_at_10
value: 91.521
- type: recall_at_100
value: 95.997
- type: recall_at_1000
value: 97.775
- type: recall_at_3
value: 83.131
- type: recall_at_5
value: 87.93299999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.861
- type: map_at_10
value: 30.252000000000002
- type: map_at_100
value: 32.082
- type: map_at_1000
value: 32.261
- type: map_at_3
value: 25.909
- type: map_at_5
value: 28.296
- type: mrr_at_1
value: 37.346000000000004
- type: mrr_at_10
value: 45.802
- type: mrr_at_100
value: 46.611999999999995
- type: mrr_at_1000
value: 46.659
- type: mrr_at_3
value: 43.056
- type: mrr_at_5
value: 44.637
- type: ndcg_at_1
value: 37.346000000000004
- type: ndcg_at_10
value: 38.169
- type: ndcg_at_100
value: 44.864
- type: ndcg_at_1000
value: 47.974
- type: ndcg_at_3
value: 33.619
- type: ndcg_at_5
value: 35.317
- type: precision_at_1
value: 37.346000000000004
- type: precision_at_10
value: 10.693999999999999
- type: precision_at_100
value: 1.775
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 22.325
- type: precision_at_5
value: 16.852
- type: recall_at_1
value: 18.861
- type: recall_at_10
value: 45.672000000000004
- type: recall_at_100
value: 70.60499999999999
- type: recall_at_1000
value: 89.216
- type: recall_at_3
value: 30.361
- type: recall_at_5
value: 36.998999999999995
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.852999999999994
- type: map_at_10
value: 59.961
- type: map_at_100
value: 60.78
- type: map_at_1000
value: 60.843
- type: map_at_3
value: 56.39999999999999
- type: map_at_5
value: 58.646
- type: mrr_at_1
value: 75.70599999999999
- type: mrr_at_10
value: 82.321
- type: mrr_at_100
value: 82.516
- type: mrr_at_1000
value: 82.525
- type: mrr_at_3
value: 81.317
- type: mrr_at_5
value: 81.922
- type: ndcg_at_1
value: 75.70599999999999
- type: ndcg_at_10
value: 68.557
- type: ndcg_at_100
value: 71.485
- type: ndcg_at_1000
value: 72.71600000000001
- type: ndcg_at_3
value: 63.524
- type: ndcg_at_5
value: 66.338
- type: precision_at_1
value: 75.70599999999999
- type: precision_at_10
value: 14.463000000000001
- type: precision_at_100
value: 1.677
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 40.806
- type: precision_at_5
value: 26.709
- type: recall_at_1
value: 37.852999999999994
- type: recall_at_10
value: 72.316
- type: recall_at_100
value: 83.842
- type: recall_at_1000
value: 91.999
- type: recall_at_3
value: 61.209
- type: recall_at_5
value: 66.77199999999999
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 85.46039999999999
- type: ap
value: 79.9812521351881
- type: f1
value: 85.31722909702084
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.704
- type: map_at_10
value: 35.329
- type: map_at_100
value: 36.494
- type: map_at_1000
value: 36.541000000000004
- type: map_at_3
value: 31.476
- type: map_at_5
value: 33.731
- type: mrr_at_1
value: 23.294999999999998
- type: mrr_at_10
value: 35.859
- type: mrr_at_100
value: 36.968
- type: mrr_at_1000
value: 37.008
- type: mrr_at_3
value: 32.085
- type: mrr_at_5
value: 34.299
- type: ndcg_at_1
value: 23.324
- type: ndcg_at_10
value: 42.274
- type: ndcg_at_100
value: 47.839999999999996
- type: ndcg_at_1000
value: 48.971
- type: ndcg_at_3
value: 34.454
- type: ndcg_at_5
value: 38.464
- type: precision_at_1
value: 23.324
- type: precision_at_10
value: 6.648
- type: precision_at_100
value: 0.9440000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.674999999999999
- type: precision_at_5
value: 10.850999999999999
- type: recall_at_1
value: 22.704
- type: recall_at_10
value: 63.660000000000004
- type: recall_at_100
value: 89.29899999999999
- type: recall_at_1000
value: 97.88900000000001
- type: recall_at_3
value: 42.441
- type: recall_at_5
value: 52.04
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.1326949384405
- type: f1
value: 92.89743579612082
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.62524654832347
- type: f1
value: 88.65106082263151
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.59039359573046
- type: f1
value: 90.31532892105662
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.21046038208581
- type: f1
value: 86.41459529813113
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 87.3180351380423
- type: f1
value: 86.71383078226444
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.24231464737792
- type: f1
value: 86.31845567592403
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.27131782945736
- type: f1
value: 57.52079940417103
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.2341504649197
- type: f1
value: 51.349951558039244
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.27418278852569
- type: f1
value: 50.1714985749095
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 67.68243031631694
- type: f1
value: 50.1066160836192
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.2362854069559
- type: f1
value: 48.821279948766424
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.71428571428571
- type: f1
value: 53.94611389496195
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.97646267652992
- type: f1
value: 57.26797883561521
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.65501008742435
- type: f1
value: 50.416258382177034
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.45796906523201
- type: f1
value: 53.306690547422185
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.59246805648957
- type: f1
value: 59.818381969051494
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.126429051782104
- type: f1
value: 58.25993593933026
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 50.057162071284466
- type: f1
value: 46.96095728790911
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.64425016812375
- type: f1
value: 62.858291698755764
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.08944182918628
- type: f1
value: 62.44639030604241
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.68056489576328
- type: f1
value: 61.775326758789504
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.11163416274377
- type: f1
value: 69.70789096927015
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.40282447881641
- type: f1
value: 66.38492065671895
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.24613315400134
- type: f1
value: 64.3348019501336
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.78345662407531
- type: f1
value: 62.21279452354622
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.9455279085407
- type: f1
value: 65.48193124964094
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.05110961667788
- type: f1
value: 58.097856564684534
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.95292535305985
- type: f1
value: 62.09182174767901
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.97310020174848
- type: f1
value: 61.14252567730396
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.08069939475453
- type: f1
value: 57.044041742492034
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.63752521856085
- type: f1
value: 63.889340907205316
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.385339609952936
- type: f1
value: 53.449033750088304
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.93073301950234
- type: f1
value: 65.9884357824104
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.94418291862812
- type: f1
value: 66.48740222583132
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.26025554808339
- type: f1
value: 50.19562815100793
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.98789509078682
- type: f1
value: 46.65788438676836
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.68728984532616
- type: f1
value: 41.642419349541996
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.19300605245461
- type: f1
value: 55.8626492442437
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.33826496301278
- type: f1
value: 63.89499791648792
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.33960995292536
- type: f1
value: 57.15242464180892
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.09347679892402
- type: f1
value: 59.64733214063841
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.75924680564896
- type: f1
value: 55.96585692366827
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.48486886348352
- type: f1
value: 59.45143559032946
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.56422326832549
- type: f1
value: 54.96368702901926
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.18022864828512
- type: f1
value: 63.05369805040634
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.30329522528581
- type: f1
value: 64.06084612020727
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.36919973100201
- type: f1
value: 65.12154124788887
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.98117014122394
- type: f1
value: 66.41847559806962
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.53799596503026
- type: f1
value: 62.17067330740817
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.01815736381977
- type: f1
value: 66.24988369607843
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.34700739744452
- type: f1
value: 59.957933424941636
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.23402824478815
- type: f1
value: 57.98836976018471
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.54068594485541
- type: f1
value: 65.43849680666855
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.998655010087425
- type: f1
value: 52.83737515406804
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.71217215870882
- type: f1
value: 55.051794977833026
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.724277067921996
- type: f1
value: 56.33485571838306
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.59515803631473
- type: f1
value: 64.96772366193588
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.860793544048406
- type: f1
value: 58.148845819115394
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.40753194351043
- type: f1
value: 63.18903778054698
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.52320107599194
- type: f1
value: 58.356144563398516
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.17014122394083
- type: f1
value: 63.919964062638925
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.15601882985878
- type: f1
value: 67.01451905761371
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.65030262273034
- type: f1
value: 64.14420425129063
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.08742434431743
- type: f1
value: 63.044060042311756
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.52387357094821
- type: f1
value: 56.82398588814534
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.239408204438476
- type: f1
value: 61.92570286170469
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.74915938130463
- type: f1
value: 62.130740689396276
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.00336247478144
- type: f1
value: 63.71080635228055
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.837928715534645
- type: f1
value: 50.390741680320836
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.42098184263618
- type: f1
value: 71.41355113538995
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.95359784801613
- type: f1
value: 71.42699340156742
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.18157363819772
- type: f1
value: 69.74836113037671
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.08137188971082
- type: f1
value: 76.78000685068261
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.5030262273033
- type: f1
value: 71.71620130425673
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.24546065904505
- type: f1
value: 69.07638311730359
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.12911903160726
- type: f1
value: 68.32651736539815
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.89307330195025
- type: f1
value: 71.33986549860187
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.44451916610626
- type: f1
value: 66.90192664503866
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.16274377942166
- type: f1
value: 68.01090953775066
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.75319435104237
- type: f1
value: 70.18035309201403
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.14391392064559
- type: f1
value: 61.48286540778145
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.70275722932078
- type: f1
value: 70.26164779846495
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.93813046402153
- type: f1
value: 58.8852862116525
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.320107599193
- type: f1
value: 72.19836409602924
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.65366509751176
- type: f1
value: 74.55188288799579
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.694014794889036
- type: f1
value: 58.11353311721067
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.37457969065231
- type: f1
value: 52.81306134311697
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.3086751849361
- type: f1
value: 45.396449765419376
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.151983860121064
- type: f1
value: 60.31762544281696
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.44788164088769
- type: f1
value: 71.68150151736367
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.81439139206455
- type: f1
value: 62.06735559105593
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.04303967720242
- type: f1
value: 66.68298851670133
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.43913920645595
- type: f1
value: 60.25605977560783
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.90316072629456
- type: f1
value: 65.1325924692381
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.63752521856086
- type: f1
value: 59.14284778039585
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.63080026899797
- type: f1
value: 70.89771864626877
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.10827168796234
- type: f1
value: 71.71954219691159
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.59515803631471
- type: f1
value: 70.05040128099003
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.83389374579691
- type: f1
value: 70.84877936562735
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.18628110289173
- type: f1
value: 68.97232927921841
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.99260255548083
- type: f1
value: 72.85139492157732
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.26227303295225
- type: f1
value: 65.08833655469431
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.48621385339611
- type: f1
value: 64.43483199071298
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.14391392064559
- type: f1
value: 72.2580822579741
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.88567585743107
- type: f1
value: 58.3073765932569
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.38399462004034
- type: f1
value: 60.82139544252606
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.58574310692671
- type: f1
value: 60.71443370385374
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.61398789509079
- type: f1
value: 70.99761812049401
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.73705447209146
- type: f1
value: 61.680849331794796
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.66778749159381
- type: f1
value: 71.17320646080115
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.640215198386
- type: f1
value: 63.301805157015444
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.00672494956288
- type: f1
value: 70.26005548582106
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.42030934767989
- type: f1
value: 75.2074842882598
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.69266980497646
- type: f1
value: 70.94103167391192
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 28.91697191169135
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.434000079573313
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.96683513343383
- type: mrr
value: 31.967364078714834
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.5280000000000005
- type: map_at_10
value: 11.793
- type: map_at_100
value: 14.496999999999998
- type: map_at_1000
value: 15.783
- type: map_at_3
value: 8.838
- type: map_at_5
value: 10.07
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 51.531000000000006
- type: mrr_at_100
value: 52.205
- type: mrr_at_1000
value: 52.242999999999995
- type: mrr_at_3
value: 49.431999999999995
- type: mrr_at_5
value: 50.470000000000006
- type: ndcg_at_1
value: 42.415000000000006
- type: ndcg_at_10
value: 32.464999999999996
- type: ndcg_at_100
value: 28.927999999999997
- type: ndcg_at_1000
value: 37.629000000000005
- type: ndcg_at_3
value: 37.845
- type: ndcg_at_5
value: 35.147
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 23.932000000000002
- type: precision_at_100
value: 7.17
- type: precision_at_1000
value: 1.967
- type: precision_at_3
value: 35.397
- type: precision_at_5
value: 29.907
- type: recall_at_1
value: 5.5280000000000005
- type: recall_at_10
value: 15.568000000000001
- type: recall_at_100
value: 28.54
- type: recall_at_1000
value: 59.864
- type: recall_at_3
value: 9.822000000000001
- type: recall_at_5
value: 11.726
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.041000000000004
- type: map_at_10
value: 52.664
- type: map_at_100
value: 53.477
- type: map_at_1000
value: 53.505
- type: map_at_3
value: 48.510999999999996
- type: map_at_5
value: 51.036
- type: mrr_at_1
value: 41.338
- type: mrr_at_10
value: 55.071000000000005
- type: mrr_at_100
value: 55.672
- type: mrr_at_1000
value: 55.689
- type: mrr_at_3
value: 51.82
- type: mrr_at_5
value: 53.852
- type: ndcg_at_1
value: 41.338
- type: ndcg_at_10
value: 60.01800000000001
- type: ndcg_at_100
value: 63.409000000000006
- type: ndcg_at_1000
value: 64.017
- type: ndcg_at_3
value: 52.44799999999999
- type: ndcg_at_5
value: 56.571000000000005
- type: precision_at_1
value: 41.338
- type: precision_at_10
value: 9.531
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.416
- type: precision_at_5
value: 16.46
- type: recall_at_1
value: 37.041000000000004
- type: recall_at_10
value: 79.76299999999999
- type: recall_at_100
value: 94.39
- type: recall_at_1000
value: 98.851
- type: recall_at_3
value: 60.465
- type: recall_at_5
value: 69.906
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 69.952
- type: map_at_10
value: 83.758
- type: map_at_100
value: 84.406
- type: map_at_1000
value: 84.425
- type: map_at_3
value: 80.839
- type: map_at_5
value: 82.646
- type: mrr_at_1
value: 80.62
- type: mrr_at_10
value: 86.947
- type: mrr_at_100
value: 87.063
- type: mrr_at_1000
value: 87.064
- type: mrr_at_3
value: 85.96000000000001
- type: mrr_at_5
value: 86.619
- type: ndcg_at_1
value: 80.63
- type: ndcg_at_10
value: 87.64800000000001
- type: ndcg_at_100
value: 88.929
- type: ndcg_at_1000
value: 89.054
- type: ndcg_at_3
value: 84.765
- type: ndcg_at_5
value: 86.291
- type: precision_at_1
value: 80.63
- type: precision_at_10
value: 13.314
- type: precision_at_100
value: 1.525
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.1
- type: precision_at_5
value: 24.372
- type: recall_at_1
value: 69.952
- type: recall_at_10
value: 94.955
- type: recall_at_100
value: 99.38
- type: recall_at_1000
value: 99.96000000000001
- type: recall_at_3
value: 86.60600000000001
- type: recall_at_5
value: 90.997
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 42.41329517878427
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 55.171278362748666
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.213
- type: map_at_10
value: 9.895
- type: map_at_100
value: 11.776
- type: map_at_1000
value: 12.084
- type: map_at_3
value: 7.2669999999999995
- type: map_at_5
value: 8.620999999999999
- type: mrr_at_1
value: 20.8
- type: mrr_at_10
value: 31.112000000000002
- type: mrr_at_100
value: 32.274
- type: mrr_at_1000
value: 32.35
- type: mrr_at_3
value: 28.133000000000003
- type: mrr_at_5
value: 29.892999999999997
- type: ndcg_at_1
value: 20.8
- type: ndcg_at_10
value: 17.163999999999998
- type: ndcg_at_100
value: 24.738
- type: ndcg_at_1000
value: 30.316
- type: ndcg_at_3
value: 16.665
- type: ndcg_at_5
value: 14.478
- type: precision_at_1
value: 20.8
- type: precision_at_10
value: 8.74
- type: precision_at_100
value: 1.963
- type: precision_at_1000
value: 0.33
- type: precision_at_3
value: 15.467
- type: precision_at_5
value: 12.6
- type: recall_at_1
value: 4.213
- type: recall_at_10
value: 17.698
- type: recall_at_100
value: 39.838
- type: recall_at_1000
value: 66.893
- type: recall_at_3
value: 9.418
- type: recall_at_5
value: 12.773000000000001
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 82.90453315738294
- type: cos_sim_spearman
value: 78.51197850080254
- type: euclidean_pearson
value: 80.09647123597748
- type: euclidean_spearman
value: 78.63548011514061
- type: manhattan_pearson
value: 80.10645285675231
- type: manhattan_spearman
value: 78.57861806068901
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.2616156846401
- type: cos_sim_spearman
value: 76.69713867850156
- type: euclidean_pearson
value: 77.97948563800394
- type: euclidean_spearman
value: 74.2371211567807
- type: manhattan_pearson
value: 77.69697879669705
- type: manhattan_spearman
value: 73.86529778022278
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 77.0293269315045
- type: cos_sim_spearman
value: 78.02555120584198
- type: euclidean_pearson
value: 78.25398100379078
- type: euclidean_spearman
value: 78.66963870599464
- type: manhattan_pearson
value: 78.14314682167348
- type: manhattan_spearman
value: 78.57692322969135
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 79.16989925136942
- type: cos_sim_spearman
value: 76.5996225327091
- type: euclidean_pearson
value: 77.8319003279786
- type: euclidean_spearman
value: 76.42824009468998
- type: manhattan_pearson
value: 77.69118862737736
- type: manhattan_spearman
value: 76.25568104762812
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.42012286935325
- type: cos_sim_spearman
value: 88.15654297884122
- type: euclidean_pearson
value: 87.34082819427852
- type: euclidean_spearman
value: 88.06333589547084
- type: manhattan_pearson
value: 87.25115596784842
- type: manhattan_spearman
value: 87.9559927695203
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.88222044996712
- type: cos_sim_spearman
value: 84.28476589061077
- type: euclidean_pearson
value: 83.17399758058309
- type: euclidean_spearman
value: 83.85497357244542
- type: manhattan_pearson
value: 83.0308397703786
- type: manhattan_spearman
value: 83.71554539935046
- task:
type: STS
dataset:
name: MTEB STS17 (ko-ko)
type: mteb/sts17-crosslingual-sts
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.20682986257339
- type: cos_sim_spearman
value: 79.94567120362092
- type: euclidean_pearson
value: 79.43122480368902
- type: euclidean_spearman
value: 79.94802077264987
- type: manhattan_pearson
value: 79.32653021527081
- type: manhattan_spearman
value: 79.80961146709178
- task:
type: STS
dataset:
name: MTEB STS17 (ar-ar)
type: mteb/sts17-crosslingual-sts
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 74.46578144394383
- type: cos_sim_spearman
value: 74.52496637472179
- type: euclidean_pearson
value: 72.2903807076809
- type: euclidean_spearman
value: 73.55549359771645
- type: manhattan_pearson
value: 72.09324837709393
- type: manhattan_spearman
value: 73.36743103606581
- task:
type: STS
dataset:
name: MTEB STS17 (en-ar)
type: mteb/sts17-crosslingual-sts
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 71.37272335116
- type: cos_sim_spearman
value: 71.26702117766037
- type: euclidean_pearson
value: 67.114829954434
- type: euclidean_spearman
value: 66.37938893947761
- type: manhattan_pearson
value: 66.79688574095246
- type: manhattan_spearman
value: 66.17292828079667
- task:
type: STS
dataset:
name: MTEB STS17 (en-de)
type: mteb/sts17-crosslingual-sts
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.61016770129092
- type: cos_sim_spearman
value: 82.08515426632214
- type: euclidean_pearson
value: 80.557340361131
- type: euclidean_spearman
value: 80.37585812266175
- type: manhattan_pearson
value: 80.6782873404285
- type: manhattan_spearman
value: 80.6678073032024
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.00150745350108
- type: cos_sim_spearman
value: 87.83441972211425
- type: euclidean_pearson
value: 87.94826702308792
- type: euclidean_spearman
value: 87.46143974860725
- type: manhattan_pearson
value: 87.97560344306105
- type: manhattan_spearman
value: 87.5267102829796
- task:
type: STS
dataset:
name: MTEB STS17 (en-tr)
type: mteb/sts17-crosslingual-sts
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 64.76325252267235
- type: cos_sim_spearman
value: 63.32615095463905
- type: euclidean_pearson
value: 64.07920669155716
- type: euclidean_spearman
value: 61.21409893072176
- type: manhattan_pearson
value: 64.26308625680016
- type: manhattan_spearman
value: 61.2438185254079
- task:
type: STS
dataset:
name: MTEB STS17 (es-en)
type: mteb/sts17-crosslingual-sts
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 75.82644463022595
- type: cos_sim_spearman
value: 76.50381269945073
- type: euclidean_pearson
value: 75.1328548315934
- type: euclidean_spearman
value: 75.63761139408453
- type: manhattan_pearson
value: 75.18610101241407
- type: manhattan_spearman
value: 75.30669266354164
- task:
type: STS
dataset:
name: MTEB STS17 (es-es)
type: mteb/sts17-crosslingual-sts
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.49994164686832
- type: cos_sim_spearman
value: 86.73743986245549
- type: euclidean_pearson
value: 86.8272894387145
- type: euclidean_spearman
value: 85.97608491000507
- type: manhattan_pearson
value: 86.74960140396779
- type: manhattan_spearman
value: 85.79285984190273
- task:
type: STS
dataset:
name: MTEB STS17 (fr-en)
type: mteb/sts17-crosslingual-sts
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.58172210788469
- type: cos_sim_spearman
value: 80.17516468334607
- type: euclidean_pearson
value: 77.56537843470504
- type: euclidean_spearman
value: 77.57264627395521
- type: manhattan_pearson
value: 78.09703521695943
- type: manhattan_spearman
value: 78.15942760916954
- task:
type: STS
dataset:
name: MTEB STS17 (it-en)
type: mteb/sts17-crosslingual-sts
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.7589932931751
- type: cos_sim_spearman
value: 80.15210089028162
- type: euclidean_pearson
value: 77.54135223516057
- type: euclidean_spearman
value: 77.52697996368764
- type: manhattan_pearson
value: 77.65734439572518
- type: manhattan_spearman
value: 77.77702992016121
- task:
type: STS
dataset:
name: MTEB STS17 (nl-en)
type: mteb/sts17-crosslingual-sts
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.16682365511267
- type: cos_sim_spearman
value: 79.25311267628506
- type: euclidean_pearson
value: 77.54882036762244
- type: euclidean_spearman
value: 77.33212935194827
- type: manhattan_pearson
value: 77.98405516064015
- type: manhattan_spearman
value: 77.85075717865719
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.10473294775917
- type: cos_sim_spearman
value: 61.82780474476838
- type: euclidean_pearson
value: 45.885111672377256
- type: euclidean_spearman
value: 56.88306351932454
- type: manhattan_pearson
value: 46.101218127323186
- type: manhattan_spearman
value: 56.80953694186333
- task:
type: STS
dataset:
name: MTEB STS22 (de)
type: mteb/sts22-crosslingual-sts
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 45.781923079584146
- type: cos_sim_spearman
value: 55.95098449691107
- type: euclidean_pearson
value: 25.4571031323205
- type: euclidean_spearman
value: 49.859978118078935
- type: manhattan_pearson
value: 25.624938455041384
- type: manhattan_spearman
value: 49.99546185049401
- task:
type: STS
dataset:
name: MTEB STS22 (es)
type: mteb/sts22-crosslingual-sts
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 60.00618133997907
- type: cos_sim_spearman
value: 66.57896677718321
- type: euclidean_pearson
value: 42.60118466388821
- type: euclidean_spearman
value: 62.8210759715209
- type: manhattan_pearson
value: 42.63446860604094
- type: manhattan_spearman
value: 62.73803068925271
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 28.460759121626943
- type: cos_sim_spearman
value: 34.13459007469131
- type: euclidean_pearson
value: 6.0917739325525195
- type: euclidean_spearman
value: 27.9947262664867
- type: manhattan_pearson
value: 6.16877864169911
- type: manhattan_spearman
value: 28.00664163971514
- task:
type: STS
dataset:
name: MTEB STS22 (tr)
type: mteb/sts22-crosslingual-sts
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.42546621771696
- type: cos_sim_spearman
value: 63.699663168970474
- type: euclidean_pearson
value: 38.12085278789738
- type: euclidean_spearman
value: 58.12329140741536
- type: manhattan_pearson
value: 37.97364549443335
- type: manhattan_spearman
value: 57.81545502318733
- task:
type: STS
dataset:
name: MTEB STS22 (ar)
type: mteb/sts22-crosslingual-sts
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 46.82241380954213
- type: cos_sim_spearman
value: 57.86569456006391
- type: euclidean_pearson
value: 31.80480070178813
- type: euclidean_spearman
value: 52.484000620130104
- type: manhattan_pearson
value: 31.952708554646097
- type: manhattan_spearman
value: 52.8560972356195
- task:
type: STS
dataset:
name: MTEB STS22 (ru)
type: mteb/sts22-crosslingual-sts
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 52.00447170498087
- type: cos_sim_spearman
value: 60.664116225735164
- type: euclidean_pearson
value: 33.87382555421702
- type: euclidean_spearman
value: 55.74649067458667
- type: manhattan_pearson
value: 33.99117246759437
- type: manhattan_spearman
value: 55.98749034923899
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 58.06497233105448
- type: cos_sim_spearman
value: 65.62968801135676
- type: euclidean_pearson
value: 47.482076613243905
- type: euclidean_spearman
value: 62.65137791498299
- type: manhattan_pearson
value: 47.57052626104093
- type: manhattan_spearman
value: 62.436916516613294
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 70.49397298562575
- type: cos_sim_spearman
value: 74.79604041187868
- type: euclidean_pearson
value: 49.661891561317795
- type: euclidean_spearman
value: 70.31535537621006
- type: manhattan_pearson
value: 49.553715741850006
- type: manhattan_spearman
value: 70.24779344636806
- task:
type: STS
dataset:
name: MTEB STS22 (de-en)
type: mteb/sts22-crosslingual-sts
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.640574515348696
- type: cos_sim_spearman
value: 54.927959317689
- type: euclidean_pearson
value: 29.00139666967476
- type: euclidean_spearman
value: 41.86386566971605
- type: manhattan_pearson
value: 29.47411067730344
- type: manhattan_spearman
value: 42.337438424952786
- task:
type: STS
dataset:
name: MTEB STS22 (es-en)
type: mteb/sts22-crosslingual-sts
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 68.14095292259312
- type: cos_sim_spearman
value: 73.99017581234789
- type: euclidean_pearson
value: 46.46304297872084
- type: euclidean_spearman
value: 60.91834114800041
- type: manhattan_pearson
value: 47.07072666338692
- type: manhattan_spearman
value: 61.70415727977926
- task:
type: STS
dataset:
name: MTEB STS22 (it)
type: mteb/sts22-crosslingual-sts
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 73.27184653359575
- type: cos_sim_spearman
value: 77.76070252418626
- type: euclidean_pearson
value: 62.30586577544778
- type: euclidean_spearman
value: 75.14246629110978
- type: manhattan_pearson
value: 62.328196884927046
- type: manhattan_spearman
value: 75.1282792981433
- task:
type: STS
dataset:
name: MTEB STS22 (pl-en)
type: mteb/sts22-crosslingual-sts
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 71.59448528829957
- type: cos_sim_spearman
value: 70.37277734222123
- type: euclidean_pearson
value: 57.63145565721123
- type: euclidean_spearman
value: 66.10113048304427
- type: manhattan_pearson
value: 57.18897811586808
- type: manhattan_spearman
value: 66.5595511215901
- task:
type: STS
dataset:
name: MTEB STS22 (zh-en)
type: mteb/sts22-crosslingual-sts
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.37520607720838
- type: cos_sim_spearman
value: 69.92282148997948
- type: euclidean_pearson
value: 40.55768770125291
- type: euclidean_spearman
value: 55.189128944669605
- type: manhattan_pearson
value: 41.03566433468883
- type: manhattan_spearman
value: 55.61251893174558
- task:
type: STS
dataset:
name: MTEB STS22 (es-it)
type: mteb/sts22-crosslingual-sts
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.791929533771835
- type: cos_sim_spearman
value: 66.45819707662093
- type: euclidean_pearson
value: 39.03686018511092
- type: euclidean_spearman
value: 56.01282695640428
- type: manhattan_pearson
value: 38.91586623619632
- type: manhattan_spearman
value: 56.69394943612747
- task:
type: STS
dataset:
name: MTEB STS22 (de-fr)
type: mteb/sts22-crosslingual-sts
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.82224468473866
- type: cos_sim_spearman
value: 59.467307194781164
- type: euclidean_pearson
value: 27.428459190256145
- type: euclidean_spearman
value: 60.83463107397519
- type: manhattan_pearson
value: 27.487391578496638
- type: manhattan_spearman
value: 61.281380460246496
- task:
type: STS
dataset:
name: MTEB STS22 (de-pl)
type: mteb/sts22-crosslingual-sts
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 16.306666792752644
- type: cos_sim_spearman
value: 39.35486427252405
- type: euclidean_pearson
value: -2.7887154897955435
- type: euclidean_spearman
value: 27.1296051831719
- type: manhattan_pearson
value: -3.202291270581297
- type: manhattan_spearman
value: 26.32895849218158
- task:
type: STS
dataset:
name: MTEB STS22 (fr-pl)
type: mteb/sts22-crosslingual-sts
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.67006803805076
- type: cos_sim_spearman
value: 73.24670207647144
- type: euclidean_pearson
value: 46.91884681500483
- type: euclidean_spearman
value: 16.903085094570333
- type: manhattan_pearson
value: 46.88391675325812
- type: manhattan_spearman
value: 28.17180849095055
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 83.79555591223837
- type: cos_sim_spearman
value: 85.63658602085185
- type: euclidean_pearson
value: 85.22080894037671
- type: euclidean_spearman
value: 85.54113580167038
- type: manhattan_pearson
value: 85.1639505960118
- type: manhattan_spearman
value: 85.43502665436196
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 80.73900991689766
- type: mrr
value: 94.81624131133934
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 55.678000000000004
- type: map_at_10
value: 65.135
- type: map_at_100
value: 65.824
- type: map_at_1000
value: 65.852
- type: map_at_3
value: 62.736000000000004
- type: map_at_5
value: 64.411
- type: mrr_at_1
value: 58.333
- type: mrr_at_10
value: 66.5
- type: mrr_at_100
value: 67.053
- type: mrr_at_1000
value: 67.08
- type: mrr_at_3
value: 64.944
- type: mrr_at_5
value: 65.89399999999999
- type: ndcg_at_1
value: 58.333
- type: ndcg_at_10
value: 69.34700000000001
- type: ndcg_at_100
value: 72.32
- type: ndcg_at_1000
value: 73.014
- type: ndcg_at_3
value: 65.578
- type: ndcg_at_5
value: 67.738
- type: precision_at_1
value: 58.333
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 25.444
- type: precision_at_5
value: 16.933
- type: recall_at_1
value: 55.678000000000004
- type: recall_at_10
value: 80.72200000000001
- type: recall_at_100
value: 93.93299999999999
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 70.783
- type: recall_at_5
value: 75.978
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.74653465346535
- type: cos_sim_ap
value: 93.01476369929063
- type: cos_sim_f1
value: 86.93009118541033
- type: cos_sim_precision
value: 88.09034907597535
- type: cos_sim_recall
value: 85.8
- type: dot_accuracy
value: 99.22970297029703
- type: dot_ap
value: 51.58725659485144
- type: dot_f1
value: 53.51351351351352
- type: dot_precision
value: 58.235294117647065
- type: dot_recall
value: 49.5
- type: euclidean_accuracy
value: 99.74356435643564
- type: euclidean_ap
value: 92.40332894384368
- type: euclidean_f1
value: 86.97838109602817
- type: euclidean_precision
value: 87.46208291203236
- type: euclidean_recall
value: 86.5
- type: manhattan_accuracy
value: 99.73069306930694
- type: manhattan_ap
value: 92.01320815721121
- type: manhattan_f1
value: 86.4135864135864
- type: manhattan_precision
value: 86.32734530938124
- type: manhattan_recall
value: 86.5
- type: max_accuracy
value: 99.74653465346535
- type: max_ap
value: 93.01476369929063
- type: max_f1
value: 86.97838109602817
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 55.2660514302523
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 30.4637783572547
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 49.41377758357637
- type: mrr
value: 50.138451213818854
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 28.887846011166594
- type: cos_sim_spearman
value: 30.10823258355903
- type: dot_pearson
value: 12.888049550236385
- type: dot_spearman
value: 12.827495903098123
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.21
- type: map_at_10
value: 1.667
- type: map_at_100
value: 9.15
- type: map_at_1000
value: 22.927
- type: map_at_3
value: 0.573
- type: map_at_5
value: 0.915
- type: mrr_at_1
value: 80
- type: mrr_at_10
value: 87.167
- type: mrr_at_100
value: 87.167
- type: mrr_at_1000
value: 87.167
- type: mrr_at_3
value: 85.667
- type: mrr_at_5
value: 87.167
- type: ndcg_at_1
value: 76
- type: ndcg_at_10
value: 69.757
- type: ndcg_at_100
value: 52.402
- type: ndcg_at_1000
value: 47.737
- type: ndcg_at_3
value: 71.866
- type: ndcg_at_5
value: 72.225
- type: precision_at_1
value: 80
- type: precision_at_10
value: 75
- type: precision_at_100
value: 53.959999999999994
- type: precision_at_1000
value: 21.568
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 78
- type: recall_at_1
value: 0.21
- type: recall_at_10
value: 1.9189999999999998
- type: recall_at_100
value: 12.589
- type: recall_at_1000
value: 45.312000000000005
- type: recall_at_3
value: 0.61
- type: recall_at_5
value: 1.019
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.10000000000001
- type: f1
value: 90.06
- type: precision
value: 89.17333333333333
- type: recall
value: 92.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.06936416184971
- type: f1
value: 50.87508028259473
- type: precision
value: 48.97398843930635
- type: recall
value: 56.06936416184971
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 57.3170731707317
- type: f1
value: 52.96080139372822
- type: precision
value: 51.67861124382864
- type: recall
value: 57.3170731707317
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.67333333333333
- type: precision
value: 91.90833333333333
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 97.07333333333332
- type: precision
value: 96.79500000000002
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.2
- type: precision
value: 92.48333333333333
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.9
- type: f1
value: 91.26666666666667
- type: precision
value: 90.59444444444445
- type: recall
value: 92.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 34.32835820895522
- type: f1
value: 29.074180380150533
- type: precision
value: 28.068207322920596
- type: recall
value: 34.32835820895522
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.5
- type: f1
value: 74.3945115995116
- type: precision
value: 72.82967843459222
- type: recall
value: 78.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.34146341463415
- type: f1
value: 61.2469400518181
- type: precision
value: 59.63977756660683
- type: recall
value: 66.34146341463415
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.9
- type: f1
value: 76.90349206349207
- type: precision
value: 75.32921568627451
- type: recall
value: 80.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.93317132442284
- type: f1
value: 81.92519105034295
- type: precision
value: 80.71283920615635
- type: recall
value: 84.93317132442284
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.1304347826087
- type: f1
value: 65.22394755003451
- type: precision
value: 62.912422360248435
- type: recall
value: 71.1304347826087
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.82608695652173
- type: f1
value: 75.55693581780538
- type: precision
value: 73.79420289855072
- type: recall
value: 79.82608695652173
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74
- type: f1
value: 70.51022222222223
- type: precision
value: 69.29673599347512
- type: recall
value: 74
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 74.14238095238095
- type: precision
value: 72.27214285714285
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.97466827503016
- type: f1
value: 43.080330405420874
- type: precision
value: 41.36505499593557
- type: recall
value: 48.97466827503016
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.60000000000001
- type: f1
value: 86.62333333333333
- type: precision
value: 85.225
- type: recall
value: 89.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.2
- type: f1
value: 39.5761253006253
- type: precision
value: 37.991358436312
- type: recall
value: 45.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.70333333333333
- type: precision
value: 85.53166666666667
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.095238095238095
- type: f1
value: 44.60650460650461
- type: precision
value: 42.774116796477045
- type: recall
value: 50.095238095238095
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.4
- type: f1
value: 58.35967261904762
- type: precision
value: 56.54857142857143
- type: recall
value: 63.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.2
- type: f1
value: 87.075
- type: precision
value: 86.12095238095239
- type: recall
value: 89.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.90333333333334
- type: precision
value: 95.50833333333333
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.9
- type: f1
value: 88.6288888888889
- type: precision
value: 87.61607142857142
- type: recall
value: 90.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.2
- type: f1
value: 60.54377630539395
- type: precision
value: 58.89434482711381
- type: recall
value: 65.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87
- type: f1
value: 84.32412698412699
- type: precision
value: 83.25527777777778
- type: recall
value: 87
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.7
- type: f1
value: 63.07883541295306
- type: precision
value: 61.06117424242426
- type: recall
value: 68.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.78333333333335
- type: precision
value: 90.86666666666667
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 96.96666666666667
- type: precision
value: 96.61666666666667
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27493261455525
- type: f1
value: 85.90745732255168
- type: precision
value: 84.91389637616052
- type: recall
value: 88.27493261455525
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.5982905982906
- type: f1
value: 88.4900284900285
- type: precision
value: 87.57122507122507
- type: recall
value: 90.5982905982906
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.90769841269842
- type: precision
value: 85.80178571428571
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.5
- type: f1
value: 78.36796536796538
- type: precision
value: 76.82196969696969
- type: recall
value: 82.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.48846960167715
- type: f1
value: 66.78771089148448
- type: precision
value: 64.98302885095339
- type: recall
value: 71.48846960167715
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.50333333333333
- type: precision
value: 91.77499999999999
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.20622568093385
- type: f1
value: 66.83278891450098
- type: precision
value: 65.35065777283677
- type: recall
value: 71.20622568093385
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.717948717948715
- type: f1
value: 43.53146853146853
- type: precision
value: 42.04721204721204
- type: recall
value: 48.717948717948715
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 58.5
- type: f1
value: 53.8564991863928
- type: precision
value: 52.40329436122275
- type: recall
value: 58.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.8
- type: f1
value: 88.29
- type: precision
value: 87.09166666666667
- type: recall
value: 90.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.28971962616822
- type: f1
value: 62.63425307817832
- type: precision
value: 60.98065939771546
- type: recall
value: 67.28971962616822
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 75.5264472455649
- type: precision
value: 74.38205086580086
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.7
- type: f1
value: 86.10809523809525
- type: precision
value: 85.07602564102565
- type: recall
value: 88.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.99999999999999
- type: f1
value: 52.85487521402737
- type: precision
value: 51.53985162713104
- type: recall
value: 56.99999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94
- type: f1
value: 92.45333333333333
- type: precision
value: 91.79166666666667
- type: recall
value: 94
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.61333333333333
- type: precision
value: 89.83333333333331
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.34555555555555
- type: precision
value: 92.75416666666668
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.2
- type: f1
value: 76.6563035113035
- type: precision
value: 75.3014652014652
- type: recall
value: 80.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.7
- type: f1
value: 82.78689263765207
- type: precision
value: 82.06705086580087
- type: recall
value: 84.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.33333333333333
- type: f1
value: 45.461523661523664
- type: precision
value: 43.93545574795575
- type: recall
value: 50.33333333333333
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.6000000000000005
- type: f1
value: 5.442121400446441
- type: precision
value: 5.146630385487529
- type: recall
value: 6.6000000000000005
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85
- type: f1
value: 81.04666666666667
- type: precision
value: 79.25
- type: recall
value: 85
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.32142857142857
- type: f1
value: 42.333333333333336
- type: precision
value: 40.69196428571429
- type: recall
value: 47.32142857142857
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 30.735455543358945
- type: f1
value: 26.73616790022338
- type: precision
value: 25.397823220451283
- type: recall
value: 30.735455543358945
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 25.1
- type: f1
value: 21.975989896371022
- type: precision
value: 21.059885632257203
- type: recall
value: 25.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.75666666666666
- type: precision
value: 92.06166666666665
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.74
- type: precision
value: 92.09166666666667
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.3
- type: f1
value: 66.922442002442
- type: precision
value: 65.38249567099568
- type: recall
value: 71.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 40.300000000000004
- type: f1
value: 35.78682789299971
- type: precision
value: 34.66425128716588
- type: recall
value: 40.300000000000004
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96
- type: f1
value: 94.82333333333334
- type: precision
value: 94.27833333333334
- type: recall
value: 96
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 51.1
- type: f1
value: 47.179074753133584
- type: precision
value: 46.06461044702424
- type: recall
value: 51.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.7
- type: f1
value: 84.71
- type: precision
value: 83.46166666666667
- type: recall
value: 87.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.68333333333334
- type: precision
value: 94.13333333333334
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.39999999999999
- type: f1
value: 82.5577380952381
- type: precision
value: 81.36833333333334
- type: recall
value: 85.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.16788321167883
- type: f1
value: 16.948865627297987
- type: precision
value: 15.971932568647897
- type: recall
value: 21.16788321167883
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 5.515526831658907
- type: precision
value: 5.141966366966367
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.39666666666668
- type: precision
value: 90.58666666666667
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 89.95666666666666
- type: precision
value: 88.92833333333333
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.76190476190477
- type: f1
value: 74.93386243386244
- type: precision
value: 73.11011904761904
- type: recall
value: 79.76190476190477
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.799999999999999
- type: f1
value: 6.921439712248537
- type: precision
value: 6.489885109680683
- type: recall
value: 8.799999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.75569358178054
- type: f1
value: 40.34699501312631
- type: precision
value: 38.57886764719063
- type: recall
value: 45.75569358178054
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.4
- type: f1
value: 89.08333333333333
- type: precision
value: 88.01666666666668
- type: recall
value: 91.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.60000000000001
- type: f1
value: 92.06690476190477
- type: precision
value: 91.45095238095239
- type: recall
value: 93.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.5
- type: f1
value: 6.200363129378736
- type: precision
value: 5.89115314822466
- type: recall
value: 7.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 73.59307359307358
- type: f1
value: 68.38933553219267
- type: precision
value: 66.62698412698413
- type: recall
value: 73.59307359307358
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.8473282442748
- type: f1
value: 64.72373682297346
- type: precision
value: 62.82834214131924
- type: recall
value: 69.8473282442748
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.5254730713246
- type: f1
value: 96.72489082969432
- type: precision
value: 96.33672974284326
- type: recall
value: 97.5254730713246
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.6
- type: f1
value: 72.42746031746033
- type: precision
value: 71.14036630036631
- type: recall
value: 75.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.24293785310734
- type: f1
value: 88.86064030131826
- type: precision
value: 87.73540489642184
- type: recall
value: 91.24293785310734
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.2
- type: f1
value: 4.383083659794954
- type: precision
value: 4.027861324289673
- type: recall
value: 6.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 84.09428571428572
- type: precision
value: 83.00333333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 60.699999999999996
- type: f1
value: 56.1584972394755
- type: precision
value: 54.713456330903135
- type: recall
value: 60.699999999999996
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.2
- type: f1
value: 80.66190476190475
- type: precision
value: 79.19690476190476
- type: recall
value: 84.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.33
- type: precision
value: 90.45
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.3
- type: f1
value: 5.126828976748276
- type: precision
value: 4.853614328966668
- type: recall
value: 6.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.76943699731903
- type: f1
value: 77.82873739308057
- type: precision
value: 76.27622452019234
- type: recall
value: 81.76943699731903
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.29666666666665
- type: precision
value: 89.40333333333334
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 29.249011857707508
- type: f1
value: 24.561866096392947
- type: precision
value: 23.356583740215456
- type: recall
value: 29.249011857707508
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.46478873239437
- type: f1
value: 73.23943661971832
- type: precision
value: 71.66666666666667
- type: recall
value: 77.46478873239437
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 20.35928143712575
- type: f1
value: 15.997867865075824
- type: precision
value: 14.882104658301346
- type: recall
value: 20.35928143712575
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 90.25999999999999
- type: precision
value: 89.45333333333335
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 23.15270935960591
- type: f1
value: 19.65673625772148
- type: precision
value: 18.793705293464992
- type: recall
value: 23.15270935960591
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.154929577464785
- type: f1
value: 52.3868463305083
- type: precision
value: 50.14938113529662
- type: recall
value: 59.154929577464785
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.51282051282051
- type: f1
value: 66.8089133089133
- type: precision
value: 65.37645687645687
- type: recall
value: 70.51282051282051
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 93
- type: precision
value: 92.23333333333333
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.62212943632568
- type: f1
value: 34.3278276962583
- type: precision
value: 33.07646935732408
- type: recall
value: 38.62212943632568
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 28.1
- type: f1
value: 23.579609223054604
- type: precision
value: 22.39622774921555
- type: recall
value: 28.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27361563517914
- type: f1
value: 85.12486427795874
- type: precision
value: 83.71335504885994
- type: recall
value: 88.27361563517914
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.6
- type: f1
value: 86.39928571428571
- type: precision
value: 85.4947557997558
- type: recall
value: 88.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.5
- type: f1
value: 83.77952380952381
- type: precision
value: 82.67602564102565
- type: recall
value: 86.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.52755905511812
- type: f1
value: 75.3055868016498
- type: precision
value: 73.81889763779527
- type: recall
value: 79.52755905511812
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.9
- type: f1
value: 73.76261904761905
- type: precision
value: 72.11670995670995
- type: recall
value: 77.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 53.8781163434903
- type: f1
value: 47.25804051288816
- type: precision
value: 45.0603482390186
- type: recall
value: 53.8781163434903
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.10000000000001
- type: f1
value: 88.88
- type: precision
value: 87.96333333333334
- type: recall
value: 91.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.46153846153847
- type: f1
value: 34.43978243978244
- type: precision
value: 33.429487179487175
- type: recall
value: 38.46153846153847
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.9
- type: f1
value: 86.19888888888887
- type: precision
value: 85.07440476190476
- type: recall
value: 88.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.9
- type: f1
value: 82.58857142857143
- type: precision
value: 81.15666666666667
- type: recall
value: 85.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 83.36999999999999
- type: precision
value: 81.86833333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.51415094339622
- type: f1
value: 63.195000099481234
- type: precision
value: 61.394033442972116
- type: recall
value: 68.51415094339622
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.5
- type: f1
value: 86.14603174603175
- type: precision
value: 85.1162037037037
- type: recall
value: 88.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.62043795620438
- type: f1
value: 94.40389294403892
- type: precision
value: 93.7956204379562
- type: recall
value: 95.62043795620438
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.8
- type: f1
value: 78.6532178932179
- type: precision
value: 77.46348795840176
- type: recall
value: 81.8
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.603
- type: map_at_10
value: 8.5
- type: map_at_100
value: 12.985
- type: map_at_1000
value: 14.466999999999999
- type: map_at_3
value: 4.859999999999999
- type: map_at_5
value: 5.817
- type: mrr_at_1
value: 28.571
- type: mrr_at_10
value: 42.331
- type: mrr_at_100
value: 43.592999999999996
- type: mrr_at_1000
value: 43.592999999999996
- type: mrr_at_3
value: 38.435
- type: mrr_at_5
value: 39.966
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 21.353
- type: ndcg_at_100
value: 31.087999999999997
- type: ndcg_at_1000
value: 43.163000000000004
- type: ndcg_at_3
value: 22.999
- type: ndcg_at_5
value: 21.451
- type: precision_at_1
value: 28.571
- type: precision_at_10
value: 19.387999999999998
- type: precision_at_100
value: 6.265
- type: precision_at_1000
value: 1.4160000000000001
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 21.224
- type: recall_at_1
value: 2.603
- type: recall_at_10
value: 14.474
- type: recall_at_100
value: 40.287
- type: recall_at_1000
value: 76.606
- type: recall_at_3
value: 5.978
- type: recall_at_5
value: 7.819
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 69.7848
- type: ap
value: 13.661023167088224
- type: f1
value: 53.61686134460943
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.28183361629882
- type: f1
value: 61.55481034919965
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 35.972128420092396
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.59933241938367
- type: cos_sim_ap
value: 72.20760361208136
- type: cos_sim_f1
value: 66.4447731755424
- type: cos_sim_precision
value: 62.35539102267469
- type: cos_sim_recall
value: 71.10817941952506
- type: dot_accuracy
value: 78.98313166835548
- type: dot_ap
value: 44.492521645493795
- type: dot_f1
value: 45.814889336016094
- type: dot_precision
value: 37.02439024390244
- type: dot_recall
value: 60.07915567282321
- type: euclidean_accuracy
value: 85.3907134767837
- type: euclidean_ap
value: 71.53847289080343
- type: euclidean_f1
value: 65.95952206778834
- type: euclidean_precision
value: 61.31006346328196
- type: euclidean_recall
value: 71.37203166226914
- type: manhattan_accuracy
value: 85.40859510043511
- type: manhattan_ap
value: 71.49664104395515
- type: manhattan_f1
value: 65.98569969356485
- type: manhattan_precision
value: 63.928748144482924
- type: manhattan_recall
value: 68.17941952506597
- type: max_accuracy
value: 85.59933241938367
- type: max_ap
value: 72.20760361208136
- type: max_f1
value: 66.4447731755424
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.83261536073273
- type: cos_sim_ap
value: 85.48178133644264
- type: cos_sim_f1
value: 77.87816307403935
- type: cos_sim_precision
value: 75.88953021114926
- type: cos_sim_recall
value: 79.97382198952879
- type: dot_accuracy
value: 79.76287499514883
- type: dot_ap
value: 59.17438838475084
- type: dot_f1
value: 56.34566667855996
- type: dot_precision
value: 52.50349092359864
- type: dot_recall
value: 60.794579611949494
- type: euclidean_accuracy
value: 88.76857996662397
- type: euclidean_ap
value: 85.22764834359887
- type: euclidean_f1
value: 77.65379751543554
- type: euclidean_precision
value: 75.11152683839401
- type: euclidean_recall
value: 80.37419156144134
- type: manhattan_accuracy
value: 88.6987231730508
- type: manhattan_ap
value: 85.18907981724007
- type: manhattan_f1
value: 77.51967028849757
- type: manhattan_precision
value: 75.49992701795358
- type: manhattan_recall
value: 79.65044656606098
- type: max_accuracy
value: 88.83261536073273
- type: max_ap
value: 85.48178133644264
- type: max_f1
value: 77.87816307403935
---
## Multilingual-E5-base
[Multilingual E5 Text Embeddings: A Technical Report](https://arxiv.org/pdf/2402.05672).
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei, arXiv 2024
This model has 12 layers and the embedding size is 768.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ", even for non-English texts.
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"]
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
model = AutoModel.from_pretrained('intfloat/multilingual-e5-base')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Supported Languages
This model is initialized from [xlm-roberta-base](https://huggingface.co/xlm-roberta-base)
and continually trained on a mixture of multilingual datasets.
It supports 100 languages from xlm-roberta,
but low-resource languages may see performance degradation.
## Training Details
**Initialization**: [xlm-roberta-base](https://huggingface.co/xlm-roberta-base)
**First stage**: contrastive pre-training with weak supervision
| Dataset | Weak supervision | # of text pairs |
|--------------------------------------------------------------------------------------------------------|---------------------------------------|-----------------|
| Filtered [mC4](https://huggingface.co/datasets/mc4) | (title, page content) | 1B |
| [CC News](https://huggingface.co/datasets/intfloat/multilingual_cc_news) | (title, news content) | 400M |
| [NLLB](https://huggingface.co/datasets/allenai/nllb) | translation pairs | 2.4B |
| [Wikipedia](https://huggingface.co/datasets/intfloat/wikipedia) | (hierarchical section title, passage) | 150M |
| Filtered [Reddit](https://www.reddit.com/) | (comment, response) | 800M |
| [S2ORC](https://github.com/allenai/s2orc) | (title, abstract) and citation pairs | 100M |
| [Stackexchange](https://stackexchange.com/) | (question, answer) | 50M |
| [xP3](https://huggingface.co/datasets/bigscience/xP3) | (input prompt, response) | 80M |
| [Miscellaneous unsupervised SBERT data](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | - | 10M |
**Second stage**: supervised fine-tuning
| Dataset | Language | # of text pairs |
|----------------------------------------------------------------------------------------|--------------|-----------------|
| [MS MARCO](https://microsoft.github.io/msmarco/) | English | 500k |
| [NQ](https://github.com/facebookresearch/DPR) | English | 70k |
| [Trivia QA](https://github.com/facebookresearch/DPR) | English | 60k |
| [NLI from SimCSE](https://github.com/princeton-nlp/SimCSE) | English | <300k |
| [ELI5](https://huggingface.co/datasets/eli5) | English | 500k |
| [DuReader Retrieval](https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval) | Chinese | 86k |
| [KILT Fever](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [KILT HotpotQA](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [SQuAD](https://huggingface.co/datasets/squad) | English | 87k |
| [Quora](https://huggingface.co/datasets/quora) | English | 150k |
| [Mr. TyDi](https://huggingface.co/datasets/castorini/mr-tydi) | 11 languages | 50k |
| [MIRACL](https://huggingface.co/datasets/miracl/miracl) | 16 languages | 40k |
For all labeled datasets, we only use its training set for fine-tuning.
For other training details, please refer to our paper at [https://arxiv.org/pdf/2402.05672](https://arxiv.org/pdf/2402.05672).
## Benchmark Results on [Mr. TyDi](https://arxiv.org/abs/2108.08787)
| Model | Avg MRR@10 | | ar | bn | en | fi | id | ja | ko | ru | sw | te | th |
|-----------------------|------------|-------|------| --- | --- | --- | --- | --- | --- | --- |------| --- | --- |
| BM25 | 33.3 | | 36.7 | 41.3 | 15.1 | 28.8 | 38.2 | 21.7 | 28.1 | 32.9 | 39.6 | 42.4 | 41.7 |
| mDPR | 16.7 | | 26.0 | 25.8 | 16.2 | 11.3 | 14.6 | 18.1 | 21.9 | 18.5 | 7.3 | 10.6 | 13.5 |
| BM25 + mDPR | 41.7 | | 49.1 | 53.5 | 28.4 | 36.5 | 45.5 | 35.5 | 36.2 | 42.7 | 40.5 | 42.0 | 49.2 |
| | |
| multilingual-e5-small | 64.4 | | 71.5 | 66.3 | 54.5 | 57.7 | 63.2 | 55.4 | 54.3 | 60.8 | 65.4 | 89.1 | 70.1 |
| multilingual-e5-base | 65.9 | | 72.3 | 65.0 | 58.5 | 60.8 | 64.9 | 56.6 | 55.8 | 62.7 | 69.0 | 86.6 | 72.7 |
| multilingual-e5-large | **70.5** | | 77.5 | 73.2 | 60.8 | 66.8 | 68.5 | 62.5 | 61.6 | 65.8 | 72.7 | 90.2 | 76.2 |
## MTEB Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## Support for Sentence Transformers
Below is an example for usage with sentence_transformers.
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('intfloat/multilingual-e5-base')
input_texts = [
'query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 i s 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or traini ng for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮 ,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右, 放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油 锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"
]
embeddings = model.encode(input_texts, normalize_embeddings=True)
```
Package requirements
`pip install sentence_transformers~=2.2.2`
Contributors: [michaelfeil](https://huggingface.co/michaelfeil)
## FAQ
**1. Do I need to add the prefix "query: " and "passage: " to input texts?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
Here are some rules of thumb:
- Use "query: " and "passage: " correspondingly for asymmetric tasks such as passage retrieval in open QA, ad-hoc information retrieval.
- Use "query: " prefix for symmetric tasks such as semantic similarity, bitext mining, paraphrase retrieval.
- Use "query: " prefix if you want to use embeddings as features, such as linear probing classification, clustering.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Why does the cosine similarity scores distribute around 0.7 to 1.0?**
This is a known and expected behavior as we use a low temperature 0.01 for InfoNCE contrastive loss.
For text embedding tasks like text retrieval or semantic similarity,
what matters is the relative order of the scores instead of the absolute values,
so this should not be an issue.
## Citation
If you find our paper or models helpful, please consider cite as follows:
```
@article{wang2024multilingual,
title={Multilingual E5 Text Embeddings: A Technical Report},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2402.05672},
year={2024}
}
```
## Limitations
Long texts will be truncated to at most 512 tokens.
|
[
"BIOSSES",
"SCIFACT"
] |
featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF
|
featherless-ai-quants
|
text-generation
|
[
"gguf",
"text-generation",
"base_model:clinicalnlplab/finetuned-Llama-2-13b-hf-MedQA",
"base_model:quantized:clinicalnlplab/finetuned-Llama-2-13b-hf-MedQA",
"endpoints_compatible",
"region:us"
] | 2024-11-02T02:49:43Z |
2024-11-02T03:08:14+00:00
| 17 | 0 |
---
base_model: clinicalnlplab/finetuned-Llama-2-13b-hf-MedQA
pipeline_tag: text-generation
quantized_by: featherless-ai-quants
---
# clinicalnlplab/finetuned-Llama-2-13b-hf-MedQA GGUF Quantizations 🚀

*Optimized GGUF quantization files for enhanced model performance*
> Powered by [Featherless AI](https://featherless.ai) - run any model you'd like for a simple small fee.
---
## Available Quantizations 📊
| Quantization Type | File | Size |
|-------------------|------|------|
| Q8_0 | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q8_0.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q8_0.gguf) | 13190.57 MB |
| Q4_K_S | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q4_K_S.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q4_K_S.gguf) | 7079.30 MB |
| Q2_K | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q2_K.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q2_K.gguf) | 4629.39 MB |
| Q6_K | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q6_K.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q6_K.gguf) | 10184.42 MB |
| Q3_K_M | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q3_K_M.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q3_K_M.gguf) | 6044.17 MB |
| Q3_K_S | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q3_K_S.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q3_K_S.gguf) | 5396.82 MB |
| Q3_K_L | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q3_K_L.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q3_K_L.gguf) | 6608.54 MB |
| Q4_K_M | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q4_K_M.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q4_K_M.gguf) | 7501.56 MB |
| Q5_K_S | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q5_K_S.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q5_K_S.gguf) | 8556.64 MB |
| Q5_K_M | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q5_K_M.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-Q5_K_M.gguf) | 8802.34 MB |
| IQ4_XS | [clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-IQ4_XS.gguf](https://huggingface.co/featherless-ai-quants/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-GGUF/blob/main/clinicalnlplab-finetuned-Llama-2-13b-hf-MedQA-IQ4_XS.gguf) | 6694.33 MB |
---
## ⚡ Powered by [Featherless AI](https://featherless.ai)
### Key Features
- 🔥 **Instant Hosting** - Deploy any Llama model on HuggingFace instantly
- 🛠️ **Zero Infrastructure** - No server setup or maintenance required
- 📚 **Vast Compatibility** - Support for 2400+ models and counting
- 💎 **Affordable Pricing** - Starting at just $10/month
---
**Links:**
[Get Started](https://featherless.ai) | [Documentation](https://featherless.ai/docs) | [Models](https://featherless.ai/models)
|
[
"MEDQA"
] |
sizrox/Text-Rewriter-Paraphraser-Q8_0-GGUF
|
sizrox
| null |
[
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:Ateeqq/Text-Rewriter-Paraphraser",
"base_model:quantized:Ateeqq/Text-Rewriter-Paraphraser",
"license:openrail",
"endpoints_compatible",
"region:us"
] | 2024-11-12T19:31:15Z |
2024-11-12T19:31:20+00:00
| 17 | 0 |
---
base_model: Ateeqq/Text-Rewriter-Paraphraser
license: openrail
tags:
- llama-cpp
- gguf-my-repo
inference:
parameters:
num_beams: 3
num_beam_groups: 3
num_return_sequences: 1
repetition_penalty: 3
diversity_penalty: 3.01
no_repeat_ngram_size: 2
temperature: 0.8
max_length: 64
widget:
- text: 'paraphraser: Learn to build generative AI applications with an expert AWS
instructor with the 2-day Developing Generative AI Applications on AWS course.'
example_title: AWS course
- text: 'paraphraser: In healthcare, Generative AI can help generate synthetic medical
data to train machine learning models, develop new drug candidates, and design
clinical trials.'
example_title: Generative AI
- text: 'paraphraser: By leveraging prior model training through transfer learning,
fine-tuning can reduce the amount of expensive computing power and labeled data
needed to obtain large models tailored to niche use cases and business needs.'
example_title: Fine Tuning
---
# sizrox/Text-Rewriter-Paraphraser-Q8_0-GGUF
This model was converted to GGUF format from [`Ateeqq/Text-Rewriter-Paraphraser`](https://huggingface.co/Ateeqq/Text-Rewriter-Paraphraser) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Ateeqq/Text-Rewriter-Paraphraser) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo sizrox/Text-Rewriter-Paraphraser-Q8_0-GGUF --hf-file text-rewriter-paraphraser-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo sizrox/Text-Rewriter-Paraphraser-Q8_0-GGUF --hf-file text-rewriter-paraphraser-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo sizrox/Text-Rewriter-Paraphraser-Q8_0-GGUF --hf-file text-rewriter-paraphraser-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo sizrox/Text-Rewriter-Paraphraser-Q8_0-GGUF --hf-file text-rewriter-paraphraser-q8_0.gguf -c 2048
```
|
[
"MEDICAL DATA"
] |
Turbo-AI/multilingual-e5-base-trimm-vocab-1024-v2
|
Turbo-AI
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:132404",
"loss:CachedMultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:2101.06983",
"base_model:Turbo-AI/multilingual-e5-base-trimm-vocab-1024-v1",
"base_model:finetune:Turbo-AI/multilingual-e5-base-trimm-vocab-1024-v1",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-11-15T01:52:47Z |
2024-11-15T01:53:22+00:00
| 17 | 0 |
---
base_model: Turbo-AI/me5-base-v6__trim_vocab-1024
library_name: sentence-transformers
metrics:
- cosine_accuracy@10
- cosine_precision@10
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@10
- dot_accuracy@10
- dot_precision@10
- dot_recall@10
- dot_ndcg@10
- dot_mrr@10
- dot_map@10
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:132404
- loss:CachedMultipleNegativesRankingLoss
widget:
- source_sentence: 'query: Trang thông tin điện tử nào không cần phải đăng ký cấp
phép?'
sentences:
- 'passage: 4. Trang thông tin điện tử tổng hợp khi trích dẫn lại thông tin phải
tuân theo quy định về nguồn tin được quy định tại khoản 18 Điều 3, khoản 2 Điều
20 Nghị định số 72/2013/NĐ-CP; không đăng tải ý kiến nhận xét, bình luận của độc
giả về nội dung tin, bài được trích dẫn (trừ trang thông tin điện tử tổng hợp
của cơ quan báo chí).
5. Sau 90 (chín mươi) ngày, kể từ ngày giấy phép có hiệu lực, nếu tổ chức, doanh
nghiệp được cấp phép không thiết lập trang thông tin điện tử tổng hợp, mạng xã
hội thì giấy phép không còn giá trị.
6. Trang thông tin điện tử tổng hợp, mạng xã hội đã được cấp phép khi có sự thay
đổi chủ sở hữu trang thông tin điện tử tổng hợp, mạng xã hội thì phải thực hiện
các thủ tục như cấp mới theo quy định tại Thông tư này trong thời hạn 30 ngày
kể từ ngày chuyển giao. Hồ sơ cấp phép, ngoài các văn bản quy định tại Điều 6
Thông tư này phải kèm theo bản gốc giấy phép đã được cấp.
7. Thông tin cá nhân bao gồm: Họ và tên; Ngày, tháng, năm sinh; Số chứng minh
nhân dân hoặc số hộ chiếu, ngày cấp, nơi cấp; Số điện thoại, địa chỉ email. Trường
hợp người sử dụng internet dưới 14 tuổi và chưa có hộ chiếu, người giám hộ hợp
pháp quyết định việc đăng ký thông tin cá nhân của mình để thể hiện sự cho phép
và chịu trách nhiệm trước pháp luật về việc đăng ký đó.'
- 'passage: "Điều 2. Quy định chung
1. Các trang thông tin điện tử không phải cấp phép:
a) Trang thông tin điện tử nội bộ quy định tại khoản 3 Điều 20 Nghị định số 72/2013/NĐ-CP
ngày 15 tháng 7 năm 2013 của Chính phủ về quản lý, cung cấp, sử dụng dịch vụ Internet
và thông tin trên mạng (sau đây viết tắt là Nghị định số 72/2013/NĐ-CP).
b) Trang thông tin điện tử cá nhân quy định tại khoản 4 Điều 20 Nghị định số 72/2013/NĐ-CP.
Cá nhân có quyền chia sẻ những thông tin không vi phạm các quy định tại Điều 5
Nghị định số 72/2013/NĐ-CP trên trang thông tin điện tử cá nhân và chịu trách
nhiệm trước pháp luật về nội dung các thông tin được đăng tải, chia sẻ; không
đại diện cho tổ chức hoặc cá nhân khác và không cung cấp thông tin tổng hợp.
c) Trang thông tin điện tử của cơ quan nhà nước cung cấp thông tin được quy định
tại Điều 10 Nghị định số 43/2011/NĐ-CP ngày 13 tháng 6 năm 2011 của Chính phủ
quy định về việc cung cấp thông tin và dịch vụ công trực tuyến trên trang thông
tin điện tử hoặc cổng thông tin điện tử của cơ quan nhà nước.
d) Trang thông tin điện tử ứng dụng chuyên ngành quy định tại khoản 5 Điều 20
Nghị định số 72/2013/NĐ-CP không phải cấp phép theo quy định tại Thông tư này
nhưng phải tuân thủ theo quy định của pháp luật chuyên ngành và các quy định có
liên quan.
đ) Diễn đàn nội bộ dành cho hoạt động trao đổi, hỏi đáp thông tin nội bộ liên
quan trực tiếp đến chức năng, nhiệm vụ, quyền hạn, tổ chức bộ máy, dịch vụ, sản
phẩm, ngành nghề phục vụ cho hoạt động của chính cơ quan, tổ chức, doanh nghiệp
đó.
..."'
- 'passage: Trình tự cho phép thành lập
1. Việc cho phép thành lập cơ sở đào tạo, bồi dưỡng ngắn hạn có vốn đầu tư nước
ngoài thực hiện theo trình tự sau đây:
a) Cấp giấy chứng nhận đăng ký đầu tư;
b) Cấp quyết định cho phép hoạt động giáo dục và thông báo trên trang thông tin
điện tử của cơ quan cấp phép.
2. Việc cho phép cơ quan đại diện ngoại giao nước ngoài, tổ chức quốc tế liên
chính phủ được phép hoạt động tại Việt Nam thành lập cơ sở giáo dục mầm non, cơ
sở giáo dục phổ thông thực hiện theo trình tự sau đây:
a) Cấp quyết định cho phép thành lập;
b) Cấp quyết định cho phép hoạt động giáo dục và thông báo trên trang thông tin
điện tử của cơ quan cấp phép.
3. Việc cho phép thành lập cơ sở giáo dục mầm non, cơ sở giáo dục phổ thông, cơ
sở giáo dục đại học có vốn đầu tư nước ngoài thực hiện theo trình tự sau đây:
a) Cấp giấy chứng nhận đăng ký đầu tư;
b) Cấp quyết định cho phép thành lập;
c) Cấp quyết định cho phép hoạt động giáo dục và thông báo trên trang thông tin
điện tử của cơ quan cấp phép.
4. Việc cho phép mở phân hiệu của cơ sở giáo dục đại học có vốn đầu tư nước ngoài
thực hiện theo trình tự sau đây:
a) Cấp giấy chứng nhận đăng ký đầu tư;
b) Cấp quyết định cho phép thành lập phân hiệu của cơ sở giáo dục đại học;
c) Cấp quyết định cho phép hoạt động và thông báo trên trang thông tin điện tử
của cơ quan cấp phép.'
- 'passage: Hồ sơ xin cấp phép thiết lập trang, cổng thông tin điện tử
1. Tờ trình đề nghị cấp phép thiết lập trang, cổng thông tin điện tử.
2. Đề án xây dựng trang, cổng thông tin điện tử kèm theo sơ đồ cấu trúc, giới
thiệu trang, cổng thông tin điện tử.
3. Sơ yếu lý lịch người chịu trách nhiệm trang, cổng thông tin điện tử.
4. Bản cam kết sử dụng dịch vụ Internet.
5. Tờ khai đăng ký thiết lập trang, cổng thông tin điện tử.
6. Bản sao có chứng thực Hợp đồng cung cấp dịch vụ cho thuê máy chủ Internet để
đặt trang, cổng thông tin điện tử.
7. Bản sao có chứng thực Giấy chứng nhận đăng ký tên miền.'
- source_sentence: 'query: Nghị quyết của Ban Chấp hành Hội được thông qua khi nào?'
sentences:
- 'passage: Ban Chấp hành Hội
...
3. Nguyên tắc hoạt động của Ban Chấp hành:
a) Ban Chấp hành hoạt động theo Quy chế của Ban Chấp hành, tuân thủ quy định của
pháp luật và Điều lệ Hội;
b) Ban Chấp hành mỗi năm họp tối thiểu 01 (một) lần, có thể họp bất thường khi
có yêu cầu của Ban Thường vụ hoặc trên 2/3 (hai phần ba) tổng số ủy viên Ban Chấp
hành;
c) Các cuộc họp của Ban Chấp hành là hợp lệ khi có trên 1/2 (một phần hai) ủy
viên Ban Chấp hành tham gia dự họp. Ban Chấp hành có thể biểu quyết bằng hình
thức giơ tay hoặc bỏ phiếu kín. Việc quy định hình thức biểu quyết do Ban Chấp
hành quyết định;
d) Các nghị quyết, quyết định của Ban Chấp hành được thông qua khi có trên 1/2
(một phần hai) tổng số ủy viên Ban Chấp hành dự họp biểu quyết tán thành. Trong
trường hợp số ý kiến tán thành và không tán thành ngang nhau thì quyết định thuộc
về bên có ý kiến của Chủ tịch Hội (hoặc được Chủ tịch Hội ủy quyền chủ trì cuộc
họp);
đ) Ủy viên Ban Chấp hành vắng mặt 02 (hai) lần liên tiếp trong các cuộc họp Ban
Chấp hành (với bất kỳ lý do gì) sẽ bị xem xét miễn nhiệm khỏi Ban Chấp hành. Tại
cuộc họp Ban Chấp hành kế tiếp sẽ tiến hành bỏ phiếu kín để đưa ra quyết định
cuối cùng. Việc miễn nhiệm chỉ được thông qua khi có trên 2/3 (hai phần ba) số
phiếu hợp lệ tán thành;
e) Ủy viên Ban Chấp hành vắng mặt trên 1/2 (một phần hai) tổng số các cuộc họp
Ban Chấp hành trong một nhiệm kỳ (kể cả trường hợp có lý do) thì sẽ không đủ tư
cách đại biểu chính thức tham dự Đại hội của nhiệm kỳ kế tiếp.'
- 'passage: Đại hội đại biểu toàn quốc Hội Luật gia Việt Nam
...
2. Đại hội đại biểu toàn quốc có những nhiệm vụ sau đây:
a) Thảo luận báo cáo của Ban Chấp hành Trung ương Hội về kết quả thực hiện nghị
quyết nhiệm kỳ vừa qua; quyết định phương hướng hoạt động của Hội nhiệm kỳ tới;
b) Quyết định việc bổ sung, sửa đổi và thông qua Điều lệ Hội;
c) Thảo luận, góp ý kiến vào Báo cáo kiểm điểm của Ban Chấp hành Trung ương Hội;
d) Quyết định số lượng Ủy viên Ban Chấp hành, Ban Kiểm tra;
đ) Bầu Ban Chấp hành, Ban Kiểm tra Trung ương Hội;
e) Thông qua nghị quyết Đại hội;
g) Thực hiện các nhiệm vụ khác do Đại hội quyết định.
...'
- 'passage: Đại hội toàn thể hội viên hoặc Đại hội đại biểu toàn quốc của Hội là
cơ quan lãnh đạo cao nhất của Hội. Đại hội toàn thể hoặc Đại hội đại biểu toàn
quốc họp 5 năm một lần, có nhiệm vụ thảo luận chương trình công tác nhiệm kỳ của
Ban Chấp hành Trung ương Hội, thông qua Điều lệ và sửa đổi Điều lệ thông qua các
chủ trương công tác của Hội và bầu Ban Chấp hành Trung ương Hội.
1. Ban Chấp hành Trung ương Hội là cơ quan lãnh đạo mọi hoạt động của Hội giữa
hai kỳ Đại hội.
1.1. Ban Chấp hành Trung ương Hội bao gồm: Chủ tịch, các Phó Chủ tịch, và các
Ủy viên Ban Chấp hành.
1.2. Ban Chấp hành Trung ương Hội quyết định các chủ trương, biện pháp thi hành
những Nghị quyết của Đại hội đề ra; chỉ đạo hội viên tham gia hoạt động Hội và
tham gia các hoạt động của Liên hiệp các tổ chức hữu nghị Việt Nam. Ban Chấp hành
Trung ương Hội họp mỗi năm một lần.
2. Ban Thường vụ do Ban Chấp hành Trung ương Hội cử, bao gồm Chủ tịch, các Phó
Chủ tịch, các Ủy viên Ban Thường vụ, và Tổng thư ký. Ban Thường vụ họp 6 tháng
1 lần và có trách nhiệm:
2.1. Chỉ đạo Tổng Thư ký chuẩn bị nội dung các kỳ họp Ban Chấp hành và tổ chức
thực hiện các Nghị quyết của Đại hội, các Nghị quyết của Ban Chấp hành, cùng với
Chủ tịch Hội điều hành các kỳ họp của Ban Chấp hành.
2.2. Hướng dẫn các hội viên thực hiện các Nghị quyết của Trung ương Hội.
2.3. Giải quyết các khiếu nại, tố cáo, bảo vệ quyền lợi chính đáng của hội viên
khi bị xâm phạm, giải quyết những vấn đề khó khăn của hội viên hay cơ sở Hội trong
việc thực hiện Điều lệ của Hội.
2.4. Quyết định thành lập các Ban chuyên môn về kinh tế, văn hóa, khoa học kỹ
thuật, tổ chức, thông tin và các lĩnh vực chuyên môn cần thiết khác và chỉ đạo
hoạt động của các Ban chuyên môn.'
- 'passage: Ban Chấp hành Trung ương Hội
...
2. Ban Chấp hành Trung ương Hội hoạt động theo Quy chế được Đại hội thông qua
và Điều lệ Hội. Ban Chấp hành họp thường kỳ mỗi năm một lần, khi cần thiết có
thể họp bất thường. Hội nghị Ban Chấp hành chỉ được tiến hành khi có ít nhất trên
1/2 (một phần hai) tổng số ủy viên Ban Chấp hành có mặt tại Hội nghị. Các quyết
định, nghị quyết của Ban Chấp hành được thông qua và có hiệu lực khi có trên 1/2
(một phần hai) số ủy viên dự họp tán thành. Trường hợp ngang nhau thì bên có ý
kiến của Chủ tịch Hội sẽ được chấp thuận.
...'
- source_sentence: 'query: Giá trị sản xuất của trang trại trồng trọt được quy định
như thế nào?'
sentences:
- 'passage: Phân loại trang trại
1. Trang trại chuyên ngành được xác định theo lĩnh vực sản xuất như trồng trọt,
chăn nuôi, lâm nghiệp, nuôi trồng thủy sản, diêm nghiệp và tỷ trọng giá trị sản
xuất của lĩnh vực chiếm trên 50% cơ cấu giá trị sản xuất của trang trại trong
năm. Trang trại chuyên ngành được phân loại như sau:
a) Trang trại trồng trọt;
b) Trang trại chăn nuôi;
c) Trang trại lâm nghiệp;
d) Trang trại nuôi trồng thủy sản;
đ) Trang trại sản xuất muối.
2. Trang trại tổng hợp là trang trại trong đó không có lĩnh vực sản xuất nào có
tỷ trọng giá trị sản xuất chiếm trên 50% cơ cấu giá trị sản xuất của trang trại
trong năm.'
- 'passage: Chính sách ưu đãi, hỗ trợ đối với một số hoạt động đặc thù của kinh
tế trang trại.
1. Chính sách ưu đãi, hỗ trợ hoạt động du lịch
Trang trại nông nghiệp có kết hợp hoạt động du lịch được hưởng các chính sách
hỗ trợ, ưu đãi theo quy định của Luật Du lịch và văn bản hướng dẫn thực hiện.
Ngoài ra còn được hỗ trợ: Kết nối hạ tầng giao thông từ hệ thống giao thông liên
xã, liên huyện, liên tỉnh; cung cấp hệ thống nước sạch, viễn thông, bảo vệ môi
trường, xử lý nước thải, rác thải; tư vấn phát triển du lịch; xây dựng đường giao
thông nội bộ, bãi đỗ xe, biển chỉ dẫn giao thông, công trình vệ sinh, khu trưng
bày, cơ sở lưu trú và các công trình phục vụ du lịch khác (nhà hàng, nhà trưng
bày, mô hình sản xuất phục vụ khách du lịch tham quan, trải nghiệm); mua sắm trang
thiết bị, phương tiện vận chuyển khách; thiết kế cảnh quan, xây dựng cảnh quan
du lịch, trồng hoa, cây cảnh; bồi dưỡng, đào tạo nghề cho lao động du lịch; hỗ
trợ các hoạt động xúc tiến quảng bá du lịch (xây dựng website du lịch; truyền
thông, xây dựng thương hiệu, chi phí xây dựng ấn phẩm quảng bá, xúc tiến; tham
dự hội chợ xúc tiến du lịch trong và ngoài nước). Mức hỗ trợ tối đa cho một trang
trại không quá 1.000 triệu đồng/trang trại.
2. Hỗ trợ xây dựng mô hình trang trại nông nghiệp chuyên ngành, ứng dụng công
nghệ cao, chuyển đổi số, thích ứng thông minh với biến đổi khí hậu, nông nghiệp
hữu cơ, kinh tế tuần hoàn.
a) Trang trại trồng trọt được hưởng các chính sách hỗ trợ, ưu đãi khác theo quy
định của Điều 4 Luật Trồng trọt và Điều 4 Luật Thủy lợi. Ngoài ra trang trại sản
xuất lúa được hỗ trợ theo quy định của khoản 4 Điều 1 Nghị định số 62/2019/NĐ-CP
ngày 11 tháng 7 năm 2019 Của Chính phủ Sửa đổi, bổ sung một số điều Nghị định
số 35/2015/NĐ-CP ngày 13 tháng 4 năm 2015 của Chính phủ về Quản lý, sử dụng đất
trồng lúa;
b) Trang trại chăn nuôi được hưởng các chính sách đầu tư, hỗ trợ, khuyến khích
theo quy định của Điều 4 Luật Chăn nuôi; Nghị định của Chính phủ quy định về cơ
chế, chính sách hỗ trợ phát triển chăn nuôi bền vững (đang xây dựng dự kiến trình
Chính phủ trong năm 2022);
c) Trang trại nuôi trồng thủy sản được hưởng các chính sách hỗ trợ, ưu đãi khác
theo quy định của Điều 4 Luật Thủy sản và văn bản hướng dẫn thực hiện;
d) Trang trại sản xuất muối được hưởng ưu đãi về bảo tồn và phát triển nghề truyền
thống gắn với du lịch và các chính sách hỗ trợ, ưu đãi khác theo quy định tại
Nghị định số 40/2017/NĐ-CP ngày 05 tháng 4 năm 2017 của Chính phủ về quản lý sản
xuất, kinh doanh muối; hỗ trợ khôi phục sản xuất khi bị thiên tai, dịch bệnh theo
quy định tại Nghị định số 02/2017/NĐ-CP ngày 09 tháng 01 năm 2017 của Chính phủ
về cơ chế, chính sách hỗ trợ sản xuất nông nghiệp để khôi phục sản xuất vùng bị
thiệt hại do thiên tai, dịch bệnh;
đ) Trang trại lâm nghiệp được hưởng ưu đãi về đầu tư bảo vệ và phát triển rừng,
chế biến và thương mại lâm sản và các chính sách hỗ trợ, ưu đãi khác theo quy
định của Điều 50, Điều 70, Điều 94, Điều 97 Luật Lâm nghiệp và văn bản hướng dẫn
thực hiện.
e) Trang trại sản xuất sản phẩm hữu cơ được hưởng chính sách theo quy định của
Điều 17 Nghị định số 109/2018/NĐ-CP ngày 29 tháng 8 năm 2018 của Chính phủ về
Nông nghiệp hữu cơ.
g) Trang trại áp dụng thực hành nông nghiệp tốt được hưởng chính sách theo quy
định của Quyết định số 01/2012/QĐ-TTg ngày 09 tháng 01 năm 2012 của Thủ tướng
Chính phủ về một số chính sách hỗ trợ việc áp dụng quy trình thực hành sản xuất
nông nghiệp tốt trong nông nghiệp, lâm nghiệp và thủy sản.
h) Trang trại ứng dụng công nghệ cao, chuyển đổi số, chuyển đổi sản xuất nông
nghiệp theo hướng thích ứng thông minh với biến đổi khí hậu nhằm phát triển bền
vững được hỗ trợ một lần 50% kinh phí đầu tư xây dựng nhà kính, nhà lưới và các
loại nhà khác phục vụ mục đích trồng trọt; hệ thống tưới nước tiết kiệm hoặc tự
động, giếng và đường ống dẫn nước; hệ thống camera thông minh, thiết bị cảm biến
và điều khiển, giám sát tự động. Mức hỗ trợ tối đa cho một trang trại không quá
1.000 triệu đồng/trang trại.
i) Trang trại nông nghiệp phát triển mô hình kinh tế tuần hoàn được hỗ trợ một
lần 100% kinh phí mua chế phẩm vi sinh xử lý phụ phẩm trồng trọt, chăn nuôi, thủy
sản và thiết bị xử lý môi trường; tối đa không quá 300 triệu đồng/trang trại.
3. Hỗ trợ trang trại sản xuất, kinh doanh cây, con đặc thù
Trang trại sản xuất, kinh doanh cây, con đặc thù quy định tại khoản 1 Điều 4 được
hỗ trợ một lần 50% chi phí mua cây, con giống; mức hỗ trợ tối đa không quá 500
triệu đồng/trang trại .'
- 'passage: "Điều 4. Cách tính tổng diện tích đất sản xuất, và giá trị sản xuất
của trang trại
1. Tổng diện tích đất sản xuất quy định tại Điều 3 Thông tư này là tổng diện tích
đất sản xuất kinh doanh của trang trại, được sử dụng hợp pháp theo quy định của
pháp luật về đất đai, bao gồm diện tích đất để trồng trọt, chăn nuôi, lâm nghiệp,
nuôi trồng thủy sản, sản xuất muối và đất để xây dựng hạ tầng phục vụ sản xuất
của trang trại tại thời điểm kê khai.
2. Giá trị sản xuất của trang trại/năm là giá trị sản xuất của ít nhất 1 năm trang
trại đạt được trong 3 năm gần nhất với năm kê khai; được tính bằng tổng giá trị
sản xuất các kỳ thu hoạch hoặc khai thác trong năm.
Đối với trang trại mới thành lập chưa có sản phẩm thu hoạch, giá trị sản xuất
được ước tính căn cứ vào phương án sản xuất, tình hình triển khai thực tế của
trang trại."'
- 'passage: Phân loại kinh tế trang trại
Trang trại nông nghiệp được phân loại thành 02 nhóm:
1. Trang trại nông nghiệp chuyên ngành được xác định theo lĩnh vực sản xuất như
trồng trọt, chăn nuôi, lâm nghiệp, nuôi trồng thủy sản, diêm nghiệp và tỷ trọng
giá trị sản xuất của lĩnh vực chiếm trên 50% cơ cấu giá trị sản xuất của trang
trại trong năm. Trang trại nông nghiệp chuyên ngành được phân thành 05 loại như
sau:
a) Trang trại trồng trọt: Là trang trại có hoạt động sản xuất trồng trọt, chủ
yếu là trồng cây hàng năm, cây lâu năm và các loại cây trồng đặc thù (như nấm
ăn hoặc một số loại cây khác); nhân và chăm sóc cây giống nông nghiệp đáp ứng
yêu cầu về tiêu chí kinh tế trang trại;
b) Trang trại chăn nuôi: Là trang trại có hoạt động sản xuất chăn nuôi tập trung
tại khu vực riêng biệt dành cho sản xuất, kinh doanh chăn nuôi; chủ yếu là chăn
nuôi trâu, bò, ngựa, lừa, la, dê, cừu, lợn, gia cầm và các loại vật nuôi đặc thù
trên cạn (như chim yến, ong, hươu hoặc một số động vật khác sống trên cạn thuộc
Danh mục động vật khác được phép chăn nuôi) đáp ứng yêu cầu về tiêu chí kinh tế
trang trại;
c) Trang trại lâm nghiệp: Là trang trại có hoạt động sản xuất trên đất quy hoạch
sử dụng vào mục đích lâm nghiệp, hoạt động chủ yếu là gieo ươm, trồng, chăm sóc
và khai thác cây rừng hoặc các sản phẩm lâm sản ngoài gỗ từ rừng đáp ứng yêu cầu
về tiêu chí kinh tế trang trại;
d) Trang trại nuôi trồng thủy sản: Là trang trại có hoạt động sản xuất nuôi trồng
thủy sản, sản xuất giống thuỷ sản đáp ứng yêu cầu về tiêu chí kinh tế trang trại
nuôi trồng thủy sản theo quy định;
e) Trang trại sản xuất muối: Là trang trại có hoạt động sản xuất muối từ nước
biển, nước mặn ngầm hoặc khai thác từ mỏ muối đáp ứng yêu cầu về tiêu chí kinh
tế trang trại.
2. Trang trại nông nghiệp tổng hợp là trang trại tổ chức nhiều hoạt động sản xuất
chuyên ngành nông nghiệp quy định tại khoản 1 Điều này; trong đó không có lĩnh
vực sản xuất nào có tỷ trọng giá trị sản xuất chiếm trên 50% cơ cấu giá trị sản
xuất của trang trại trong năm.'
- source_sentence: 'query: Đơn đề nghị đặt tiền để bảo đảm được tại ngoại của bị can
được gửi đến đâu?'
sentences:
- 'passage: 1. Trong thời hạn năm ngày, kể từ ngày nhận được Thông báo về việc đặt
tiền để bảo đảm và các mẫu văn bản kèm theo, nếu có nguyện vọng xin được đặt tiền
để bảo đảm thay thế biện pháp tạm giam thì bị can, bị cáo phải hoàn chỉnh đơn
và giấy uỷ quyền (đối với người đã thành niên) và gửi cho cơ quan đã thông báo
thông qua cơ sở giam giữ.
Trong thời hạn một ngày làm việc, kể từ khi nhận được đơn đề nghị, giấy uỷ quyền
của bị can, bị cáo, cơ sở giam giữ có trách nhiệm chuyển cho cơ quan đang tiến
hành tố tụng đối với vụ án.
2. Trong thời hạn một ngày làm việc, kể từ khi nhận được đơn đề nghị và giấy uỷ
quyền của bị can, bị cáo, đại diện cơ quan tiến hành tố tụng đang thụ lý vụ án
xác nhận vào giấy uỷ quyền và gửi ngay cho người được uỷ quyền bằng thư bảo đảm
hoặc chuyển phát nhanh. Trong thời hạn năm ngày, kể từ ngày nhận được Giấy ủy
quyền, người được bị can, bị cáo ủy quyền ghi ý kiến của mình, ký tên vào Giấy
ủy quyền và nộp lại cho cơ quan tiến hành tố tụng đối với vụ án. Giấy uỷ quyền
là cơ sở để người được uỷ quyền thay mặt bị can, bị cáo thực hiện việc đặt tiền
để bảo đảm.
Trường hợp bị can, bị cáo là người chưa thành niên, người có nhược điểm về tâm
thần thì cơ quan đang tiến hành tố tụng đối với vụ án chuyển đơn đề nghị của bị
can, bị cáo cho người đại diện hợp pháp của họ. Trong thời hạn năm ngày, kể từ
ngày nhận được đơn đề nghị, người đại diện hợp pháp ghi ý kiến, ký tên vào đơn
đề nghị của bị can, bị cáo và nộp lại cho cơ quan tiến hành tố tụng đối với vụ
án.
3. Bị can, bị cáo hoặc người đại diện hợp pháp của họ có quyền đề nghị bằng văn
bản với cơ quan đang tiến hành tố tụng đối với vụ án về việc áp dụng biện pháp
đặt tiền để bảo đảm đối với bị can, bị cáo khi thấy có đủ các điều kiện hướng
dẫn tại khoản 1 Điều 3 của Thông tư liên tịch này.
Văn bản đề nghị của bị can, bị cáo được gửi qua cơ sở giam giữ. Trong thời hạn
một ngày làm việc kể từ khi nhận được văn bản đề nghị của bị can, bị cáo, cơ sở
giam giữ có trách nhiệm chuyển đến cơ quan đang tiến hành tố tụng đối với vụ án.
Văn bản đề nghị của người đại diện hợp pháp của bị can, bị cáo được gửi trực tiếp
đến cơ quan đang tiến hành tố tụng đối với vụ án.
Trong thời hạn ba ngày làm việc, kể từ khi nhận được văn bản đề nghị, cơ quan
tiến hành tố tụng đang thụ lý vụ án có trách nhiệm xem xét, nếu thấy có đủ điều
kiện để áp dụng biện pháp đặt tiền để bảo đảm thì gửi cho bị can, bị cáo các mẫu
văn bản theo hướng dẫn tại Điều 7 của Thông tư liên tịch này để làm thủ tục đề
nghị được đặt tiền để bảo đảm. Trường hợp xét thấy không đủ điều kiện áp dụng
biện pháp đặt tiền để bảo đảm đối với bị can, bị cáo thì phải thông báo bằng văn
bản cho người đề nghị biết trong đó nêu rõ lý do.'
- 'passage: Đề nghị đặt tiền để bảo đảm
1. Bị can, bị cáo, người thân thích của bị can, bị cáo hoặc người đại diện của
bị can, bị cáo là người dưới 18 tuổi, người có nhược điểm về tâm thần hoặc thể
chất có quyền đề nghị bằng văn bản với cơ quan tiến hành tố tụng đang thụ lý vụ
án về việc áp dụng biện pháp đặt tiền để bảo đảm đối với bị can, bị cáo trừ trường
hợp quy định tại khoản 2 Điều 7 Thông tư liên tịch này.
2. Đơn đề nghị của bị can, bị cáo, được gửi qua cơ sở giam giữ hoặc gửi trực tiếp
cho cơ quan tiến hành tố tụng đang thụ lý vụ án. Trong thời hạn 01 ngày làm việc
kể từ khi nhận được đơn đề nghị của bị can, bị cáo, cơ sở giam giữ có trách nhiệm
chuyển đến cơ quan tiến hành tố tụng đang thụ lý vụ án.
3. Đơn đề nghị của người thân thích, người đại diện của bị can, bị cáo được gửi
trực tiếp đến cơ quan tiến hành tố tụng đang thụ lý vụ án.'
- 'passage: Thông báo về việc cho đặt tiền để bảo đảm
1. Trong thời hạn 03 ngày làm việc, kể từ khi nhận được đơn đề nghị và các giấy
tờ có liên quan, cơ quan tiến hành tố tụng đang thụ lý vụ án có trách nhiệm xem
xét, nếu thấy có đủ điều kiện áp dụng biện pháp đặt tiền để bảo đảm theo quy định
tại khoản 2 Điều này thì ra Thông báo cho bị can, bị cáo, người thân thích hoặc
người đại diện của bị can, bị cáo theo Mẫu số 04 ban hành kèm theo Thông tư liên
tịch này để làm thủ tục đặt tiền để bảo đảm. Trường hợp thấy không đủ điều kiện
áp dụng biện pháp đặt tiền để bảo đảm đối với bị can, bị cáo thì phải thông báo
bằng văn bản cho người đề nghị biết trong đó nêu rõ lý do.
2. Căn cứ vào tính chất, mức độ nguy hiểm cho xã hội của hành vi phạm tội, tình
trạng tài sản, nhân thân của bị can, bị cáo; bị can, bị cáo có nơi cư trú rõ ràng,
phạm tội lần đầu, tố giác đồng phạm, có tình tiết giảm nhẹ (như tự thú, đầu thú,
thành khẩn khai báo, lập công chuộc tội, tích cực hợp tác với cơ quan có trách
nhiệm trong việc phát hiện tội phạm hoặc trong quá trình giải quyết vụ án, ăn
năn hối cải, tự nguyện sửa chữa hoặc bồi thường thiệt hại...); việc cho bị can,
bị cáo tại ngoại không gây khó khăn cho việc điều tra, truy tố, xét xử, thi hành
án thì cơ quan tiến hành tố tụng có thể quyết định áp dụng biện pháp đặt tiền
để bảo đảm trừ các trường hợp sau:
a) Bị can, bị cáo dùng thủ đoạn xảo quyệt, phạm tội có tổ chức, có tính chất chuyên
nghiệp, cố ý gây hậu quả đặc biệt nghiêm trọng;
b) Bị can, bị cáo là người chủ mưu, cầm đầu, chỉ huy, ngoan cố chống đối, côn
đồ, tái phạm, tái phạm nguy hiểm;
c) Bị tạm giam trong trường hợp bị bắt theo lệnh, quyết định truy nã.
d) Phạm nhiều tội;
đ) Phạm tội nhiều lần.'
- 'passage: Điều 2. - Đối với vụ án vừa có bị can đang bị tạm giam, vừa có bị can
tại ngoại, cũng như vụ án chỉ có bị can tại ngoại, thì trong thời hạn ba ngày,
kể từ ngày ra quyết định truy tố, Viện kiểm sát gửi đến Tòa án hồ sơ vụ án và
quyết định truy tố cùng với biên bản giao cáo trạng cho bị can đang bị tạm giam,
cũng như bị can tại ngoại. Nếu Viện kiểm sát gặp khó khăn trong việc giao cáo
trạng cho bị can tại ngoại, thì chậm nhất là 15 ngày kể từ ngày gửi cho Tòa án
hồ sơ vụ án, Viện kiểm sát gửi đến Tòa án biên bản về việc Viện kiểm sát giao
cáo trạng cho bị can tại ngoại. Hết thời hạn đó, nếu Viện kiểm sát không gửi đến
Tòa án đủ các biên bản giao cáo trạng cho bị can, thì Tòa án trả hồ sơ cho Viện
kiểm sát, vì lý do chưa hoàn thành thủ tục tố tụng.'
- source_sentence: 'query: Ngân sách nhà nước bảo đảm để thực hiện công tác quản lý,
vận hành và bảo trì công trình đường cao tốc bao gồm những gì?'
sentences:
- 'passage: Bảo trì công trình đường cao tốc
1. Công tác bảo trì công trình đường cao tốc thực hiện theo tiêu chuẩn kỹ thuật
về bảo trì công trình hoặc quy trình bảo trì được Chủ đầu tư, nhà đầu tư phê duyệt
theo quy định về bảo trì công trình xây dựng, đảm bảo công năng của công trình
và an toàn giao thông trong quá trình vận hành khai thác.
2. Bộ Giao thông vận tải, Ủy ban nhân dân cấp tỉnh lựa chọn đơn vị, tổ chức thực
hiện công tác bảo trì công trình đường cao tốc đối với các tuyến đường được đầu
tư xây dựng bằng ngân sách nhà nước trong phạm vi quản lý.
3. Nhà đầu tư tổ chức thực hiện công tác bảo trì công trình đường cao tốc đối
với các dự án đầu tư theo hình thức đối tác công - tư và các dự án nhượng quyền
theo quy định của Bộ Giao thông vận tải.
4. Công tác tổ chức khai thác và bảo trì công trình đường cao tốc được thực hiện
theo hợp đồng riêng biệt hoặc là nội dung công việc trong hợp đồng đầu tư xây
dựng, khai thác và bảo trì công trình đường cao tốc.
5. Bộ Giao thông vận tải, Ủy ban nhân dân cấp tỉnh kiểm tra, giám sát thực hiện
các hợp đồng quản lý, khai thác và bảo trì công trình đường cao tốc trong phạm
vi quản lý.'
- 'passage: Chi phí cho công tác quản lý, vận hành và bảo trì công trình đường cao
tốc
1. Ngân sách nhà nước bảo đảm để thực hiện công tác quản lý, vận hành và bảo trì
công trình đường cao tốc là tài sản công kết cấu hạ tầng giao thông đường bộ do
Nhà nước quản lý, gồm: Tài sản kết cấu hạ tầng đường cao tốc do Nhà nước đầu tư
xây dựng; tài sản kết cấu hạ tầng đường cao tốc sau khi hết thời hạn hợp đồng
PPP chuyển giao cho Nhà nước và các trường hợp khác.
2. Tài sản kết cấu hạ tầng đường cao tốc do Nhà nước cho thuê, chuyển nhượng có
thời hạn và các trường hợp khác giao tổ chức kinh tế, doanh nghiệp khai thác sử
dụng theo quy định của pháp luật về quản lý, sử dụng tài sản công, tổ chức kinh
tế, doanh nghiệp được giao có trách nhiệm thực hiện quản lý, vận hành và bảo trì
công trình đường cao tốc cho đến khi chuyển giao tài sản cho Nhà nước.
3. Việc quản lý, sử dụng, khai thác, bảo trì và chi phí thực hiện các công việc
này đối với đường cao tốc đầu tư theo phương thức đối tác công tư do nhà đầu tư
thực hiện và phải quy định trong hợp đồng dự án PPP.
4. Đối với các trường hợp không quy định tại các khoản 1, khoản 2 và khoản 3 Điều
này, chủ sở hữu hoặc người quản lý sử dụng đường cao tốc có trách nhiệm bố trí
kinh phí và thực hiện quản lý, sử dụng, khai thác, bảo trì công trình đường cao
tốc theo quy định của pháp luật về xây dựng và pháp luật khác có liên quan.'
- 'passage: Doanh nghiệp quản lý, khai thác đường cao tốc, gồm: Doanh nghiệp dự
án được thành lập theo quy định của Luật Đầu tư theo phương thức đối tác công
tư để tham gia ký kết và thực hiện hợp đồng tư xây dựng, kinh doanh, khai thác
đường cao tốc theo phương thức đối tác công tư; doanh nghiệp thuê hoặc nhận chuyển
nhượng có thời hạn quyền khai thác tài sản kết cấu hạ tầng đường cao tốc theo
quy định của pháp luật về quản lý, sử dụng và khai thác tài sản kết cấu hạ tầng
giao thông đường bộ; doanh nghiệp được Nhà nước giao đầu tư xây dựng, quản lý,
khai thác đường cao tốc.
13. Người quản lý sử dụng đường cao tốc là cơ quan, tổ chức được Nhà nước giao
quản lý, khai thác sử dụng tài sản công kết cấu hạ tầng đường cao tốc; doanh nghiệp
quản lý, khai thác đường cao tốc.”. 13. Sửa đổi, bổ sung khoản 1, khoản 2, khoản
3 và khoản 4 Điều 18 như sau: “1. Công tác bảo trì công trình đường cao tốc thực
hiện theo quy định của pháp luật về xây dựng, quy chuẩn, tiêu chuẩn kỹ thuật,
quy trình bảo trì công trình.
2. Sửa đổi, bổ sung khoản 1 Điều 5 như sau: “1. Quản lý, khai thác, sử dụng công
trình đường cao tốc, gồm: 2. Bộ Giao thông vận tải giao Cơ quan quản lý đường
cao tốc trực thuộc thực hiện các nhiệm vụ: 2. Trung tâm quản lý, điều hành giao
thông tuyến được triển khai: 2. Thông tin thay đổi gồm: 2. Các hạng mục công trình
và thiết bị phải có quy trình vận hành khai thác 2. Đường cao tốc là tài sản công
của Nhà nước, Cơ quan được giao quản lý đường cao tốc có trách nhiệm quản lý,
sử dụng và khai thác công trình đường cao tốc theo quy định của pháp luật về quản
lý, sử dụng tài sản công và pháp luật khác có liên quan.”. 2. Vị trí, quy mô xây
dựng trạm dừng nghỉ được xác định khi lập dự án, thiết kế xây dựng trạm và được
triển khai trong dự án đầu tư xây dựng đường cao tốc hoặc sau khi đường cao tốc
đã đưa vào khai thác sử dụng. Việc đầu tư xây dựng, quản lý, kinh doanh khai thác
thực hiện theo quy định của pháp luật về xây dựng, pháp luật về đấu thầu, pháp
luật về quản lý, sử dụng và khai thác tài sản công. 2. Cơ quan quản lý đường cao
tốc được giao quản lý tài sản kết cấu hạ tầng giao thông đường cao tốc có trách
nhiệm lựa chọn nhà thầu theo quy định của pháp luật để thực hiện công tác quản
lý, vận hành và bảo trì công trình đường cao tốc bằng ngân sách nhà nước trong
phạm vi quản lý; tổ chức đặt hàng trong thời gian chưa hoàn thành việc đấu thầu
thực hiện công việc này để bảo đảm công tác quản lý, bảo trì và các biện pháp
an toàn giao thông phải được thực hiện thường xuyên, liên tục. 2. Tài sản kết
cấu hạ tầng đường cao tốc do Nhà nước cho thuê, chuyển nhượng có thời hạn và các
trường hợp khác giao tổ chức kinh tế, doanh nghiệp khai thác sử dụng theo quy
định của pháp luật về quản lý, sử dụng tài sản công, tổ chức kinh tế, doanh nghiệp
được giao có trách nhiệm thực hiện quản lý, vận hành và bảo trì công trình đường
cao tốc cho đến khi chuyển giao tài sản cho Nhà nước.'
- 'passage: 1. Ngân sách nhà nước bảo đảm để thực hiện công tác quản lý, vận hành
và bảo trì công trình đường cao tốc là tài sản công kết cấu hạ tầng giao thông
đường bộ do Nhà nước quản lý, gồm: Tài sản kết cấu hạ tầng đường cao tốc do Nhà
nước đầu tư xây dựng; tài sản kết cấu hạ tầng đường cao tốc sau khi hết thời hạn
hợp đồng PPP chuyển giao cho Nhà nước và các trường hợp khác.
a) Sửa đổi, bổ sung khoản 2 Điều 3 như sau: “2. Công trình đường cao tốc gồm:
Đường cao tốc; hệ thống thoát nước; công trình báo hiệu đường bộ; Trung tâm quản
lý, điều hành giao thông; trạm dừng nghỉ; trạm thu phí; hệ thống kiểm tra tải
trọng xe; trạm bảo trì; công trình chiếu sáng; cây xanh; công trình phục vụ phòng
cháy, chữa cháy; hệ thống thông tin phục vụ quản lý và liên lạc; các công trình,
thiết bị phụ trợ khác phục vụ quản lý, khai thác sử dụng và bảo trì đường cao
tốc.”. a) Đã được nghiệm thu hoàn thành xây dựng theo quy định của pháp luật về
xây dựng;
b) Sửa đổi, bổ sung khoản 6, khoản 7 Điều 3 như sau: “6. Cơ quan quản lý đường
cao tốc là tổ chức tham mưu giúp Bộ trưởng Bộ Giao thông vận tải thực hiện chức
năng quản lý nhà nước về đường cao tốc; cơ quan chuyên môn về giao thông vận tải
thuộc Ủy ban nhân dân tỉnh, thành phố trực thuộc trung ương; b) Phương án tổ chức
giao thông đã được duyệt;
c) Có quy trình vận hành khai thác đối với các hạng mục, thiết bị quy định tại
khoản 2 Điều này.
7. Đơn vị được giao tổ chức khai thác sử dụng, bảo trì công trình đường cao tốc
(sau đây gọi là đơn vị khai thác, bảo trì) là đơn vị được người quản lý sử dụng
đường cao tốc ký hợp đồng thuê hoặc giao thực hiện công việc quản lý, khai thác
sử dụng và bảo dưỡng thường xuyên công trình đường cao tốc.”. 7. Sửa đổi, bổ sung
khoản 1, khoản 3 Điều 10 như sau: “1. Cảnh sát giao thông thực hiện việc tuần
tra, kiểm soát giao thông trên đường cao tốc và thông qua hệ thống giám sát giao
thông để phát hiện, xử lý vi phạm pháp luật về giao thông đường bộ; phối hợp với
đơn vị được giao tổ chức khai thác, bảo trì đường cao tốc phát hiện, ngăn chặn
hành vi vi phạm quy định bảo vệ công trình, hành lang an toàn đường cao tốc. Bộ
Công an xây dựng hệ thống giám sát, xử lý vi phạm trật tự, an toàn giao thông
trên các tuyến cao tốc.
c) Sửa đổi, bổ sung khoản 10 Điều 3 như sau: “10. Cứu hộ là hoạt động hỗ trợ người,
phương tiện, hàng hóa tham gia giao thông trên đường cao tốc khi gặp tai nạn,
sự cố.”.
d) Bổ sung khoản 12 và khoản 13 Điều 3 như sau: “12.'
model-index:
- name: SentenceTransformer based on Turbo-AI/me5-base-v6__trim_vocab-1024
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: Unknown
type: unknown
metrics:
- type: cosine_accuracy@10
value: 0.9859154929577465
name: Cosine Accuracy@10
- type: cosine_precision@10
value: 0.1074446680080483
name: Cosine Precision@10
- type: cosine_recall@10
value: 0.9808853118712274
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.8385978552638784
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.8007840694963425
name: Cosine Mrr@10
- type: cosine_map@10
value: 0.7851833221551531
name: Cosine Map@10
- type: dot_accuracy@10
value: 0.9094567404426559
name: Dot Accuracy@10
- type: dot_precision@10
value: 0.096579476861167
name: Dot Precision@10
- type: dot_recall@10
value: 0.8913480885311871
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.6134988756221017
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.5312374245472836
name: Dot Mrr@10
- type: dot_map@10
value: 0.5204688448149213
name: Dot Map@10
---
# SentenceTransformer based on Turbo-AI/me5-base-v6__trim_vocab-1024
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [Turbo-AI/me5-base-v6__trim_vocab-1024](https://huggingface.co/Turbo-AI/me5-base-v6__trim_vocab-1024). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [Turbo-AI/me5-base-v6__trim_vocab-1024](https://huggingface.co/Turbo-AI/me5-base-v6__trim_vocab-1024) <!-- at revision f7b872527475b529f723993c393a9494b6db2a0e -->
- **Maximum Sequence Length:** 1022 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 1022, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("Turbo-AI/me5-base-v7__trim_vocab-1024")
# Run inference
sentences = [
'query: Ngân sách nhà nước bảo đảm để thực hiện công tác quản lý, vận hành và bảo trì công trình đường cao tốc bao gồm những gì?',
'passage: Chi phí cho công tác quản lý, vận hành và bảo trì công trình đường cao tốc\n1. Ngân sách nhà nước bảo đảm để thực hiện công tác quản lý, vận hành và bảo trì công trình đường cao tốc là tài sản công kết cấu hạ tầng giao thông đường bộ do Nhà nước quản lý, gồm: Tài sản kết cấu hạ tầng đường cao tốc do Nhà nước đầu tư xây dựng; tài sản kết cấu hạ tầng đường cao tốc sau khi hết thời hạn hợp đồng PPP chuyển giao cho Nhà nước và các trường hợp khác.\n2. Tài sản kết cấu hạ tầng đường cao tốc do Nhà nước cho thuê, chuyển nhượng có thời hạn và các trường hợp khác giao tổ chức kinh tế, doanh nghiệp khai thác sử dụng theo quy định của pháp luật về quản lý, sử dụng tài sản công, tổ chức kinh tế, doanh nghiệp được giao có trách nhiệm thực hiện quản lý, vận hành và bảo trì công trình đường cao tốc cho đến khi chuyển giao tài sản cho Nhà nước.\n3. Việc quản lý, sử dụng, khai thác, bảo trì và chi phí thực hiện các công việc này đối với đường cao tốc đầu tư theo phương thức đối tác công tư do nhà đầu tư thực hiện và phải quy định trong hợp đồng dự án PPP.\n4. Đối với các trường hợp không quy định tại các khoản 1, khoản 2 và khoản 3 Điều này, chủ sở hữu hoặc người quản lý sử dụng đường cao tốc có trách nhiệm bố trí kinh phí và thực hiện quản lý, sử dụng, khai thác, bảo trì công trình đường cao tốc theo quy định của pháp luật về xây dựng và pháp luật khác có liên quan.',
'passage: Bảo trì công trình đường cao tốc\n1. Công tác bảo trì công trình đường cao tốc thực hiện theo tiêu chuẩn kỹ thuật về bảo trì công trình hoặc quy trình bảo trì được Chủ đầu tư, nhà đầu tư phê duyệt theo quy định về bảo trì công trình xây dựng, đảm bảo công năng của công trình và an toàn giao thông trong quá trình vận hành khai thác.\n2. Bộ Giao thông vận tải, Ủy ban nhân dân cấp tỉnh lựa chọn đơn vị, tổ chức thực hiện công tác bảo trì công trình đường cao tốc đối với các tuyến đường được đầu tư xây dựng bằng ngân sách nhà nước trong phạm vi quản lý.\n3. Nhà đầu tư tổ chức thực hiện công tác bảo trì công trình đường cao tốc đối với các dự án đầu tư theo hình thức đối tác công - tư và các dự án nhượng quyền theo quy định của Bộ Giao thông vận tải.\n4. Công tác tổ chức khai thác và bảo trì công trình đường cao tốc được thực hiện theo hợp đồng riêng biệt hoặc là nội dung công việc trong hợp đồng đầu tư xây dựng, khai thác và bảo trì công trình đường cao tốc.\n5. Bộ Giao thông vận tải, Ủy ban nhân dân cấp tỉnh kiểm tra, giám sát thực hiện các hợp đồng quản lý, khai thác và bảo trì công trình đường cao tốc trong phạm vi quản lý.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@10 | 0.9859 |
| cosine_precision@10 | 0.1074 |
| cosine_recall@10 | 0.9809 |
| cosine_ndcg@10 | 0.8386 |
| cosine_mrr@10 | 0.8008 |
| **cosine_map@10** | **0.7852** |
| dot_accuracy@10 | 0.9095 |
| dot_precision@10 | 0.0966 |
| dot_recall@10 | 0.8913 |
| dot_ndcg@10 | 0.6135 |
| dot_mrr@10 | 0.5312 |
| dot_map@10 | 0.5205 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 132,404 training samples
* Columns: <code>anchor</code>, <code>positive</code>, <code>negative_0</code>, <code>negative_1</code>, and <code>negative_2</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive | negative_0 | negative_1 | negative_2 |
|:--------|:-----------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------|
| type | string | string | string | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 27.45 tokens</li><li>max: 51 tokens</li></ul> | <ul><li>min: 22 tokens</li><li>mean: 303.01 tokens</li><li>max: 1022 tokens</li></ul> | <ul><li>min: 36 tokens</li><li>mean: 321.73 tokens</li><li>max: 1022 tokens</li></ul> | <ul><li>min: 25 tokens</li><li>mean: 333.01 tokens</li><li>max: 1022 tokens</li></ul> | <ul><li>min: 30 tokens</li><li>mean: 330.46 tokens</li><li>max: 1022 tokens</li></ul> |
* Samples:
| anchor | positive | negative_0 | negative_1 | negative_2 |
|:-------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>query: Người học ngành quản lý khai thác công trình thủy lợi trình độ cao đẳng phải có khả năng học tập và nâng cao trình độ như thế nào?</code> | <code>passage: Khả năng học tập, nâng cao trình độ<br>- Khối lượng khối lượng kiến thức tối thiểu, yêu cầu về năng lực mà người học phải đạt được sau khi tốt nghiệp ngành, nghề Mộc xây dựng và trang trí nội thất, trình độ cao đẳng có thể tiếp tục phát triển ở các trình độ cao hơn;<br>- Người học sau tốt nghiệp có năng lực tự học, tự cập nhật những tiến bộ khoa học công nghệ trong phạm vi ngành, nghề để nâng cao trình độ hoặc học liên thông lên trình độ cao hơn trong cùng ngành, nghề hoặc trong nhóm ngành, nghề hoặc trong cùng lĩnh vực đào tạo./.<br>Người học ngành mộc xây dựng và trang trí nội thất trình độ cao đẳng phải có khả năng học tập, nâng cao trình độ như thế sau:<br>- Khối lượng khối lượng kiến thức tối thiểu, yêu cầu về năng lực mà người học phải đạt được sau khi tốt nghiệp ngành, nghề Mộc xây dựng và trang trí nội thất, trình độ cao đẳng có thể tiếp tục phát triển ở các trình độ cao hơn;<br>- Người học sau tốt nghiệp có năng lực tự học, tự cập nhật những tiến bộ khoa học công nghệ trong phạm vi ngành, nghề để nâng cao trình độ hoặc học liên thông lên trình độ cao hơn trong cùng ngành, nghề hoặc trong nhóm ngành, nghề hoặc trong cùng lĩnh vực đào tạo.</code> | <code>passage: Khả năng học tập, nâng cao trình độ<br>- Khối lượng kiến thức tối thiểu, yêu cầu về năng lực mà người học phải đạt được sau khi tốt nghiệp ngành, nghề Quản trị dịch vụ giải trí, thể thao trình độ trung cấp có thể tiếp tục phát triển ở các trình độ cao hơn;<br>- Người học sau tốt nghiệp có năng lực tự học, tự cập nhật những tiến bộ khoa học công nghệ trong phạm vi ngành, nghề để nâng cao trình độ hoặc học liên thông lên trình độ cao hơn trong cùng ngành nghề hoặc trong nhóm ngành nghề hoặc trong cùng lĩnh vực đào tạo.</code> | <code>passage: Giới thiệu chung về ngành, nghề<br>Quản lý, khai thác các công trình thủy lợi trình độ cao đẳng là ngành, nghề phục vụ tưới, tiêu, dân sinh, công nghiệp, nông nghiệp, an ninh quốc phòng, đáp ứng yêu cầu bậc 5 trong Khung trình độ quốc gia Việt Nam.<br>Quản lý khai thác các công trình thủy lợi trình độ cao đẳng bao gồm các nhiệm vụ chính như: Quan trắc khí tượng thủy văn; trắc đạc công trình thủy lợi; quan trắc công trình thủy lợi; quản lý vận hành, khai thác tưới, cấp, tiêu và thoát nước; quản lý vận hành, khai thác công trình thủy lợi đầu mối; quản lý vận hành, khai thác kênh và công trình trên kênh; thi công tu bổ công trình thủy lợi; duy tu bảo dưỡng công trình thủy lợi; phòng chống lụt bão; lập, lưu trữ hồ sơ quản lý công trình; bảo vệ công trình thủy lợi; giám sát an toàn lao động và vệ sinh môi trường,<br>Người hành nghề quản lý, khai thác công trình thủy lợi thường làm việc tại các doanh nghiệp quản lý, khai thác công trình thủy lợi, doanh nghiệp khai thác tài nguyên nước... họ cần có đủ kiến thức, kỹ năng, sức khỏe để làm việc ở văn phòng, công trình hoặc ngoài trời, đôi khi phải làm việc trong những điều kiện khắc nghiệt như gió bão, lũ lụt…<br>Khối lượng kiến thức tối thiểu: 2.500 giờ (tương đương 90 tín chỉ).</code> | <code>passage: Điều 6. Nội dung quy định về khối lượng kiến thức tối thiểu và yêu cầu về năng lực mà người học phải đạt được sau khi tốt nghiệp trình độ trung cấp, trình độ cao đẳng nhóm ngành đào tạo giáo viên theo từng ngành đào tạo. Quy định về khối lượng kiến thức tối thiểu và yêu cầu về năng lực mà người học phải đạt được sau khi tốt nghiệp trình độ trung cấp, trình độ cao đẳng nhóm ngành đào tạo giáo viên đối với từng ngành đào tạo gồm các nội dung sau:<br>1. Tên ngành đào tạo;<br>2. Trình độ đào tạo;<br>3. Đối tượng đào tạo;<br>4. Yêu cầu về chuẩn đầu ra bao gồm kiến thức, kỹ năng, năng lực tự chủ và trách nhiệm cá nhân trong việc áp dụng kiến thức, kỹ năng để thực hiện nhiệm vụ chuyên môn;<br>5. Khung kiến thức, kỹ năng tối thiểu bao gồm các khối kiến thức, kỹ năng: khối kiến thức, kỹ năng chung; khối kiến thức, kỹ năng cơ bản; khối kiến thức, kỹ năng chuyên ngành; khối kiến thức, kỹ năng nghiệp vụ sư phạm và các nội dung giáo dục liên quan khác. Trong đó quy định cụ thể các nội trong từng khối kiến thức, kỹ năng và yêu cầu khối lượng học tập đối với từng nội dung;<br>6. Vị trí việc làm của người học sau khi tốt nghiệp;<br>7. Khả năng học tập, nâng cao trình độ sau khi tốt nghiệp;<br>8. Các chương trình, tài liệu, chuẩn quốc gia, quốc tế có thể tham khảo.</code> |
| <code>query: Nội dung lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật được quy định thế nào?</code> | <code>passage: Nội dung lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật<br>Trong phạm vi điều chỉnh của văn bản quy phạm pháp luật:<br>1. Xác định nội dung liên quan đến vấn đề bình đẳng giới hoặc vấn đề bất bình đẳng giới, phân biệt đối xử về giới.<br>2. Quy định các biện pháp cần thiết để thực hiện bình đẳng giới hoặc để giải quyết vấn đề bất bình đẳng giới, phân biệt đối xử về giới; dự báo tác động của các quy định đó đối với nam và nữ sau khi được ban hành.<br>3. Xác định nguồn nhân lực, tài chính cần thiết để triển khai các biện pháp thực hiện bình đẳng giới hoặc để giải quyết vấn đề bất bình đẳng giới, phân biệt đối xử về giới.</code> | <code>passage: "Điều 21. Lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật<br>1. Lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật bao gồm:<br>a) Xác định vấn đề giới và các biện pháp giải quyết trong lĩnh vực mà văn bản quy phạm pháp luật điều chỉnh;<br>b) Dự báo tác động của các quy định trong văn bản quy phạm pháp luật khi được ban hành đối với nữ và nam;<br>c) Xác định trách nhiệm và nguồn lực để giải quyết các vấn đề giới trong phạm vi văn bản quy phạm pháp luật điều chỉnh.<br>2. Cơ quan chủ trì soạn thảo văn bản quy phạm pháp luật có trách nhiệm lồng ghép vấn đề bình đẳng giới, chuẩn bị báo cáo việc lồng ghép vấn đề bình đẳng giới vào quá trình xây dựng văn bản quy phạm pháp luật theo các nội dung quy định tại khoản 1 Điều này và phụ lục thông tin, số liệu về giới có liên quan đến dự án, dự thảo văn bản quy phạm pháp luật.<br>3. Cơ quan thẩm định văn bản quy phạm pháp luật có trách nhiệm phối hợp với cơ quan quản lý nhà nước về bình đẳng giới đánh giá việc lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật. Nội dung đánh giá bao gồm:<br>a) Xác định vấn đề giới trong dự án, dự thảo;<br>b) Việc bảo đảm các nguyên tắc cơ bản về bình đẳng giới trong dự án, dự thảo;<br>c) Tính khả thi của việc giải quyết vấn đề giới được điều chỉnh trong dự án, dự thảo;<br>d) Việc thực hiện lồng ghép vấn đề bình đẳng giới trong xây dựng dự án, dự thảo theo các nội dung quy định tại khoản 1 Điều này.<br>4. Chính phủ quy định việc thực hiện lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật."</code> | <code>passage: Trách nhiệm của cơ quan thẩm định văn bản quy phạm pháp luật đối với việc đánh giá lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật<br>1. Thực hiện đánh giá việc lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật theo các nội dung quy định tại khoản 3 Điều 21 Luật Bình đẳng giới đồng thời với việc thẩm định văn bản quy phạm pháp luật.<br>2. Đề nghị cơ quan quản lý nhà nước về bình đẳng giới phối hợp đánh giá lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật.</code> | <code>passage: Yêu cầu và phạm vi lồng ghép vấn đề bình đẳng giới trong xây dựng văn bản quy phạm pháp luật<br>1. Bảo đảm các nguyên tắc cơ bản về bình đẳng giới trong nội dung, trình tự, thủ tục soạn thảo, ban hành, rà soát, hệ thống hóa văn bản quy phạm pháp luật theo quy định của Luật Ban hành văn bản quy phạm pháp luật và Luật Ban hành văn bản quy phạm pháp luật của Hội đồng nhân dân, Ủy ban nhân dân.<br>2. Lồng ghép vấn đề bình đẳng giới được áp dụng đối với các dự thảo văn bản quy phạm pháp luật được xác định có nội dung liên quan đến bình đẳng giới hoặc có vấn đề bất bình đẳng giới, phân biệt đối xử về giới trong phạm vi điều chỉnh của văn bản.</code> |
| <code>query: Sản phẩm phần mềm có được hưởng ưu đãi về thời gian miễn thuế, giảm thuế hay không? Nếu được thì trong vòng bao nhiêu năm?</code> | <code>passage: "Điều 20. Ưu đãi về thời gian miễn thuế, giảm thuế<br>1. Miễn thuế bốn năm, giảm 50% số thuế phải nộp trong chín năm tiếp theo đối với:<br>a) Thu nhập của doanh nghiệp từ thực hiện dự án đầu tư quy định tại khoản 1 Điều 19 Thông tư số 78/2014/TT-BTC (được sửa đổi, bổ sung tại Khoản 1 Điều 11 Thông tư này)." </code> | <code>passage: Mục I. ƯU ĐÃI THUẾ THU NHẬP DOANH NGHIỆP<br>1. Doanh nghiệp phần mềm mới thành lập được hưởng thuế suất thuế thu nhập doanh nghiệp 10% trong 15 năm, kể từ khi doanh nghiệp phần mềm mới thành lập bắt đầu hoạt động kinh doanh.<br>2. Doanh nghiệp phần mềm mới thành lập được miễn thuế thu nhập doanh nghiệp 04 năm, kể từ khi có thu nhập chịu thuế và được giảm 50% số thuế phải nộp trong 09 năm tiếp theo.<br>3. Doanh nghiệp phần mềm đã được cấp Giấy phép đầu tư hoặc Giấy chứng nhận ưu đãi đầu tư thì tiếp tục được hưởng ưu đãi về thuế thu nhập doanh nghiệp đã ghi trong Giấy phép đầu tư hoặc Giấy chứng nhận ưu đãi đầu tư. Trường hợp mức ưu đãi về thuế thu nhập doanh nghiệp (bao gồm cả thuế suất ưu đãi và thời gian miễn thuế, giảm thuế) ghi trong Giấy phép đầu tư, Giấy chứng nhận ưu đãi đầu tư thấp hơn mức ưu đãi theo hướng dẫn tại điểm 1 và 2, Mục I, Phần B, Thông tư này thì doanh nghiệp phần mềm có quyền lựa chọn hưởng các ưu đãi về thuế thu nhập doanh nghiệp theo hướng dẫn tại điểm 1 và 2, Mục I, Phần B, Thông tư này cho thời gian ưu đãi còn lại.<br>4. Đối với doanh nghiệp phần mềm có sản xuất kinh doanh hàng hoá, dịch vụ khác như: sản xuất lắp ráp máy vi tính, thiết bị điện tử, kinh doanh máy móc thiết bị..., doanh nghiệp phải tổ chức hạch toán riêng doanh thu, chi phí và thu nhập của hoạt động sản xuất sản phẩm và dịch vụ phần mềm để xác định số thuế thu nhập doanh nghiệp được hưởng ưu đãi thuế thu nhập doanh nghiệp. Trường hợp doanh nghiệp không hạch toán riêng được thì thu nhập từ hoạt động sản xuất sản phẩm và dịch vụ phần mềm được xác định theo tỷ lệ giữa doanh thu hoạt động sản xuất sản phẩm và dịch vụ phần mềm so với tổng doanh thu của doanh nghiệp.</code> | <code>passage: Khoản 4. Thời gian miễn thuế, giảm thuế quy định tại Điều này được tính liên tục từ năm đầu tiên doanh nghiệp có thu nhập chịu thuế từ dự án đầu tư mới được hưởng ưu đãi thuế; Trường hợp doanh nghiệp không có thu nhập chịu thuế trong ba năm đầu, kể từ năm đầu tiên có doanh thu từ dự án đầu tư mới thì thời gian miễn thuế, giảm thuế được tính từ năm thứ tư dự án đầu tư mới phát sinh doanh thu. Ví dụ 20: Năm 2014, doanh nghiệp A có dự án đầu tư mới sản xuất sản phẩm phần mềm, nếu năm 2014 doanh nghiệp A đã có thu nhập chịu thuế từ dự án sản xuất sản phẩm phần mềm thì thời gian miễn giảm thuế được tính liên tục kể từ năm 2014. Trường hợp dự án đầu tư mới sản xuất sản phẩm phần mềm của doanh nghiệp A phát sinh doanh thu từ năm 2014, đến năm 2016 dự án đầu tư mới của doanh nghiệp A vẫn chưa có thu nhập chịu thuế thì thời gian miễn giảm thuế được tính liên tục kể từ năm 2017.</code> | <code>passage: Bổ sung điểm g khoản 2 Điều 20 Nghị định số 218/2013/NĐ-CP (đã được sửa đổi, bổ sung tại khoản 20 Điều 1 Nghị định số 12/2015/NĐ-CP) về ưu đãi thuế thu nhập doanh nghiệp đối với dự án sản xuất sản phẩm công nghiệp hỗ trợ như sau:<br>“g) Doanh nghiệp có dự án đầu tư (đầu tư mới và đầu tư mở rộng) sản xuất sản phẩm thuộc Danh mục sản phẩm công nghiệp hỗ trợ ưu tiên phát triển, thực hiện trước ngày 01 tháng 01 năm 2015, đáp ứng các điều kiện của dự án sản xuất sản phẩm công nghiệp hỗ trợ theo quy định tại Luật số 71/2014/QH13 và được cơ quan có thẩm quyền cấp Giấy xác nhận ưu đãi sản xuất sản phẩm công nghiệp hỗ trợ thì được hưởng ưu đãi về thuế thu nhập doanh nghiệp như sau:<br>...<br>g2) Trường hợp doanh nghiệp có dự án sản xuất sản phẩm công nghiệp hỗ trợ mà thu nhập từ dự án này đã hưởng hết ưu đãi thuế thu nhập doanh nghiệp theo điều kiện ưu đãi khác (ngoài điều kiện ưu đãi đối với dự án sản xuất sản phẩm công nghiệp hỗ trợ) thì được hưởng ưu đãi thuế thu nhập doanh nghiệp theo điều kiện dự án sản xuất sản phẩm công nghiệp hỗ trợ cho thời gian còn lại kể từ kỳ tính thuế được cơ quan có thẩm quyền cấp Giấy xác nhận ưu đãi sản xuất sản phẩm công nghiệp hỗ trợ.<br>...<br>g4) Cách xác định thời gian ưu đãi còn lại nêu tại điểm g2 và g3 điểm này:<br>Thời gian ưu đãi còn lại được xác định bằng thời gian ưu đãi thuế thu nhập doanh nghiệp theo điều kiện dự án sản xuất sản phẩm công nghiệp hỗ trợ trừ đi số năm miễn thuế, số năm giảm thuế, số năm hưởng thuế suất ưu đãi đã được hưởng ưu đãi theo điều kiện ưu đãi khác, cụ thể như sau:<br>- Thời gian miễn thuế còn lại bằng thời gian miễn thuế theo điều kiện dự án sản xuất sản phẩm công nghiệp hỗ trợ trừ đi thời gian miễn thuế đã hưởng ưu đãi theo điều kiện ưu đãi khác;<br>- Thời gian giảm thuế còn lại bằng thời gian giảm thuế theo điều kiện dự án sản xuất sản phẩm công nghiệp hỗ trợ trừ di thời gian giảm thuế đã hưởng ưu đãi theo điều kiện ưu đãi khác;<br>- Thời gian áp dụng thuế suất ưu đãi còn lại bằng thời gian ưu đãi thuế suất theo điều kiện dự án sản xuất sản phẩm công nghiệp hỗ trợ trừ đi thời gian ưu đãi thuế suất đã hưởng theo điều kiện ưu đãi khác (nếu có).<br>...</code> |
* Loss: [<code>CachedMultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cachedmultiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 512
- `per_device_eval_batch_size`: 512
- `num_train_epochs`: 10
- `warmup_ratio`: 0.05
- `bf16`: True
- `load_best_model_at_end`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 512
- `per_device_eval_batch_size`: 512
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 10
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.05
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
<details><summary>Click to expand</summary>
| Epoch | Step | Training Loss | cosine_map@10 |
|:------:|:----:|:-------------:|:-------------:|
| 0.0039 | 1 | 1.2359 | - |
| 0.0077 | 2 | 1.306 | - |
| 0.0116 | 3 | 1.2167 | - |
| 0.0154 | 4 | 1.1885 | - |
| 0.0193 | 5 | 1.3663 | - |
| 0.0232 | 6 | 1.2733 | - |
| 0.0270 | 7 | 1.4031 | - |
| 0.0309 | 8 | 1.3618 | - |
| 0.0347 | 9 | 1.3344 | - |
| 0.0386 | 10 | 1.2255 | 0.6718 |
| 0.0425 | 11 | 1.3436 | - |
| 0.0463 | 12 | 1.3941 | - |
| 0.0502 | 13 | 1.3016 | - |
| 0.0541 | 14 | 1.3172 | - |
| 0.0579 | 15 | 1.3634 | - |
| 0.0618 | 16 | 1.3889 | - |
| 0.0656 | 17 | 1.174 | - |
| 0.0695 | 18 | 1.2998 | - |
| 0.0734 | 19 | 1.0509 | - |
| 0.0772 | 20 | 1.1991 | 0.6822 |
| 0.0811 | 21 | 1.2479 | - |
| 0.0849 | 22 | 1.131 | - |
| 0.0888 | 23 | 1.1397 | - |
| 0.0927 | 24 | 1.3096 | - |
| 0.0965 | 25 | 1.1347 | - |
| 0.1004 | 26 | 1.0329 | - |
| 0.1042 | 27 | 1.1944 | - |
| 0.1081 | 28 | 1.0938 | - |
| 0.1120 | 29 | 1.1208 | - |
| 0.1158 | 30 | 1.2068 | 0.6787 |
| 0.1197 | 31 | 1.0755 | - |
| 0.1236 | 32 | 1.1139 | - |
| 0.1274 | 33 | 1.0622 | - |
| 0.1313 | 34 | 1.057 | - |
| 0.1351 | 35 | 1.0127 | - |
| 0.1390 | 36 | 0.962 | - |
| 0.1429 | 37 | 0.9915 | - |
| 0.1467 | 38 | 0.9934 | - |
| 0.1506 | 39 | 1.0939 | - |
| 0.1544 | 40 | 1.0074 | 0.7003 |
| 0.1583 | 41 | 1.1654 | - |
| 0.1622 | 42 | 1.0944 | - |
| 0.1660 | 43 | 1.0229 | - |
| 0.1699 | 44 | 1.0225 | - |
| 0.1737 | 45 | 0.9693 | - |
| 0.1776 | 46 | 0.9549 | - |
| 0.1815 | 47 | 0.9309 | - |
| 0.1853 | 48 | 0.9105 | - |
| 0.1892 | 49 | 0.9816 | - |
| 0.1931 | 50 | 0.9099 | 0.7266 |
| 0.1969 | 51 | 0.9582 | - |
| 0.2008 | 52 | 1.0161 | - |
| 0.2046 | 53 | 0.8601 | - |
| 0.2085 | 54 | 1.0124 | - |
| 0.2124 | 55 | 0.9344 | - |
| 0.2162 | 56 | 0.8925 | - |
| 0.2201 | 57 | 0.9186 | - |
| 0.2239 | 58 | 1.0477 | - |
| 0.2278 | 59 | 0.8785 | - |
| 0.2317 | 60 | 0.9014 | 0.7215 |
| 0.2355 | 61 | 0.9085 | - |
| 0.2394 | 62 | 0.8974 | - |
| 0.2432 | 63 | 0.8727 | - |
| 0.2471 | 64 | 0.8989 | - |
| 0.2510 | 65 | 0.9068 | - |
| 0.2548 | 66 | 0.9405 | - |
| 0.2587 | 67 | 0.9479 | - |
| 0.2625 | 68 | 0.9749 | - |
| 0.2664 | 69 | 0.971 | - |
| 0.2703 | 70 | 0.9692 | 0.7279 |
| 0.2741 | 71 | 0.9228 | - |
| 0.2780 | 72 | 0.8684 | - |
| 0.2819 | 73 | 0.7559 | - |
| 0.2857 | 74 | 0.8725 | - |
| 0.2896 | 75 | 0.8211 | - |
| 0.2934 | 76 | 1.0066 | - |
| 0.2973 | 77 | 1.0015 | - |
| 0.3012 | 78 | 0.9046 | - |
| 0.3050 | 79 | 0.9401 | - |
| 0.3089 | 80 | 0.9042 | 0.7364 |
| 0.3127 | 81 | 0.8718 | - |
| 0.3166 | 82 | 0.8593 | - |
| 0.3205 | 83 | 0.8867 | - |
| 0.3243 | 84 | 0.8485 | - |
| 0.3282 | 85 | 0.8191 | - |
| 0.3320 | 86 | 0.8396 | - |
| 0.3359 | 87 | 0.7991 | - |
| 0.3398 | 88 | 0.893 | - |
| 0.3436 | 89 | 0.8373 | - |
| 0.3475 | 90 | 0.7167 | 0.7353 |
| 0.3514 | 91 | 0.8335 | - |
| 0.3552 | 92 | 0.7724 | - |
| 0.3591 | 93 | 0.8924 | - |
| 0.3629 | 94 | 0.8621 | - |
| 0.3668 | 95 | 0.8762 | - |
| 0.3707 | 96 | 0.7515 | - |
| 0.3745 | 97 | 0.8307 | - |
| 0.3784 | 98 | 0.8405 | - |
| 0.3822 | 99 | 0.9281 | - |
| 0.3861 | 100 | 0.8662 | 0.7331 |
| 0.3900 | 101 | 0.7373 | - |
| 0.3938 | 102 | 0.7105 | - |
| 0.3977 | 103 | 0.8561 | - |
| 0.4015 | 104 | 0.8336 | - |
| 0.4054 | 105 | 0.7742 | - |
| 0.4093 | 106 | 0.8166 | - |
| 0.4131 | 107 | 0.7724 | - |
| 0.4170 | 108 | 0.8393 | - |
| 0.4208 | 109 | 0.7846 | - |
| 0.4247 | 110 | 0.8093 | 0.7336 |
| 0.4286 | 111 | 0.8833 | - |
| 0.4324 | 112 | 0.8005 | - |
| 0.4363 | 113 | 0.8247 | - |
| 0.4402 | 114 | 0.8352 | - |
| 0.4440 | 115 | 0.8443 | - |
| 0.4479 | 116 | 0.8452 | - |
| 0.4517 | 117 | 0.9401 | - |
| 0.4556 | 118 | 0.7379 | - |
| 0.4595 | 119 | 0.8191 | - |
| 0.4633 | 120 | 0.8511 | 0.7480 |
| 0.4672 | 121 | 0.8324 | - |
| 0.4710 | 122 | 0.8146 | - |
| 0.4749 | 123 | 0.7674 | - |
| 0.4788 | 124 | 0.8079 | - |
| 0.4826 | 125 | 0.824 | - |
| 0.4865 | 126 | 0.902 | - |
| 0.4903 | 127 | 0.8066 | - |
| 0.4942 | 128 | 0.8508 | - |
| 0.4981 | 129 | 0.8323 | - |
| 0.5019 | 130 | 0.7869 | 0.7505 |
| 0.5058 | 131 | 0.7557 | - |
| 0.5097 | 132 | 0.6266 | - |
| 0.5135 | 133 | 0.7964 | - |
| 0.5174 | 134 | 0.7243 | - |
| 0.5212 | 135 | 0.8737 | - |
| 0.5251 | 136 | 0.8194 | - |
| 0.5290 | 137 | 0.8349 | - |
| 0.5328 | 138 | 0.8816 | - |
| 0.5367 | 139 | 0.7574 | - |
| 0.5405 | 140 | 0.9462 | 0.7440 |
| 0.5444 | 141 | 0.743 | - |
| 0.5483 | 142 | 0.7359 | - |
| 0.5521 | 143 | 0.8316 | - |
| 0.5560 | 144 | 0.8987 | - |
| 0.5598 | 145 | 0.9044 | - |
| 0.5637 | 146 | 0.7756 | - |
| 0.5676 | 147 | 0.6763 | - |
| 0.5714 | 148 | 0.6512 | - |
| 0.5753 | 149 | 0.7261 | - |
| 0.5792 | 150 | 0.8834 | 0.7447 |
| 0.5830 | 151 | 0.9318 | - |
| 0.5869 | 152 | 0.7612 | - |
| 0.5907 | 153 | 0.7514 | - |
| 0.5946 | 154 | 0.8295 | - |
| 0.5985 | 155 | 0.8324 | - |
| 0.6023 | 156 | 0.7869 | - |
| 0.6062 | 157 | 0.7852 | - |
| 0.6100 | 158 | 0.8411 | - |
| 0.6139 | 159 | 0.7143 | - |
| 0.6178 | 160 | 0.7268 | 0.7441 |
| 0.6216 | 161 | 0.8082 | - |
| 0.6255 | 162 | 0.7466 | - |
| 0.6293 | 163 | 0.8067 | - |
| 0.6332 | 164 | 0.7465 | - |
| 0.6371 | 165 | 0.7632 | - |
| 0.6409 | 166 | 0.8242 | - |
| 0.6448 | 167 | 0.6785 | - |
| 0.6486 | 168 | 0.6683 | - |
| 0.6525 | 169 | 0.8064 | - |
| 0.6564 | 170 | 0.8959 | 0.7488 |
| 0.6602 | 171 | 0.7061 | - |
| 0.6641 | 172 | 0.8061 | - |
| 0.6680 | 173 | 0.7979 | - |
| 0.6718 | 174 | 0.8387 | - |
| 0.6757 | 175 | 0.6947 | - |
| 0.6795 | 176 | 0.7039 | - |
| 0.6834 | 177 | 0.8558 | - |
| 0.6873 | 178 | 0.737 | - |
| 0.6911 | 179 | 0.8095 | - |
| 0.6950 | 180 | 0.7872 | 0.7601 |
| 0.6988 | 181 | 0.7608 | - |
| 0.7027 | 182 | 0.8482 | - |
| 0.7066 | 183 | 0.7394 | - |
| 0.7104 | 184 | 0.8549 | - |
| 0.7143 | 185 | 0.8191 | - |
| 0.7181 | 186 | 0.7548 | - |
| 0.7220 | 187 | 0.8244 | - |
| 0.7259 | 188 | 0.7015 | - |
| 0.7297 | 189 | 0.6895 | - |
| 0.7336 | 190 | 0.6734 | 0.7616 |
| 0.7375 | 191 | 0.7386 | - |
| 0.7413 | 192 | 0.7146 | - |
| 0.7452 | 193 | 0.7484 | - |
| 0.7490 | 194 | 0.7762 | - |
| 0.7529 | 195 | 0.7854 | - |
| 0.7568 | 196 | 0.692 | - |
| 0.7606 | 197 | 0.7113 | - |
| 0.7645 | 198 | 0.735 | - |
| 0.7683 | 199 | 0.7164 | - |
| 0.7722 | 200 | 0.7368 | 0.7486 |
| 0.7761 | 201 | 0.7838 | - |
| 0.7799 | 202 | 0.7116 | - |
| 0.7838 | 203 | 0.7014 | - |
| 0.7876 | 204 | 0.7598 | - |
| 0.7915 | 205 | 0.7813 | - |
| 0.7954 | 206 | 0.7351 | - |
| 0.7992 | 207 | 0.7402 | - |
| 0.8031 | 208 | 0.687 | - |
| 0.8069 | 209 | 0.7198 | - |
| 0.8108 | 210 | 0.7826 | 0.7556 |
| 0.8147 | 211 | 0.7234 | - |
| 0.8185 | 212 | 0.6783 | - |
| 0.8224 | 213 | 0.8072 | - |
| 0.8263 | 214 | 0.7513 | - |
| 0.8301 | 215 | 0.7941 | - |
| 0.8340 | 216 | 0.748 | - |
| 0.8378 | 217 | 0.7732 | - |
| 0.8417 | 218 | 0.7291 | - |
| 0.8456 | 219 | 0.6994 | - |
| 0.8494 | 220 | 0.757 | 0.7500 |
| 0.8533 | 221 | 0.7158 | - |
| 0.8571 | 222 | 0.7383 | - |
| 0.8610 | 223 | 0.7579 | - |
| 0.8649 | 224 | 0.7719 | - |
| 0.8687 | 225 | 0.7309 | - |
| 0.8726 | 226 | 0.7471 | - |
| 0.8764 | 227 | 0.8283 | - |
| 0.8803 | 228 | 0.7635 | - |
| 0.8842 | 229 | 0.8551 | - |
| 0.8880 | 230 | 0.7413 | 0.7554 |
| 0.8919 | 231 | 0.702 | - |
| 0.8958 | 232 | 0.8662 | - |
| 0.8996 | 233 | 0.7492 | - |
| 0.9035 | 234 | 0.7379 | - |
| 0.9073 | 235 | 0.6636 | - |
| 0.9112 | 236 | 0.7404 | - |
| 0.9151 | 237 | 0.6925 | - |
| 0.9189 | 238 | 0.8229 | - |
| 0.9228 | 239 | 0.7481 | - |
| 0.9266 | 240 | 0.6877 | 0.7602 |
| 0.9305 | 241 | 0.7352 | - |
| 0.9344 | 242 | 0.7155 | - |
| 0.9382 | 243 | 0.6769 | - |
| 0.9421 | 244 | 0.6594 | - |
| 0.9459 | 245 | 0.8058 | - |
| 0.9498 | 246 | 0.7361 | - |
| 0.9537 | 247 | 0.8087 | - |
| 0.9575 | 248 | 0.7153 | - |
| 0.9614 | 249 | 0.7242 | - |
| 0.9653 | 250 | 0.6553 | 0.7458 |
| 0.9691 | 251 | 0.7915 | - |
| 0.9730 | 252 | 0.7187 | - |
| 0.9768 | 253 | 0.6844 | - |
| 0.9807 | 254 | 0.664 | - |
| 0.9846 | 255 | 0.6345 | - |
| 0.9884 | 256 | 0.7435 | - |
| 0.9923 | 257 | 0.67 | - |
| 0.9961 | 258 | 1.0484 | - |
| 1.0 | 259 | 0.2059 | - |
| 1.0039 | 260 | 0.2808 | 0.7643 |
| 1.0077 | 261 | 0.0427 | - |
| 1.0116 | 262 | 0.0705 | - |
| 1.0154 | 263 | 0.1752 | - |
| 1.0193 | 264 | 0.0005 | - |
| 1.0232 | 265 | 0.0883 | - |
| 1.0270 | 266 | 0.1846 | - |
| 1.0309 | 267 | 0.0162 | - |
| 1.0347 | 268 | 0.01 | - |
| 1.0386 | 269 | 0.059 | - |
| 1.0425 | 270 | 0.0441 | 0.6988 |
| 1.0463 | 271 | 0.0296 | - |
| 1.0502 | 272 | 0.0005 | - |
| 1.0541 | 273 | 0.0003 | - |
| 1.0579 | 274 | 0.0002 | - |
| 1.0618 | 275 | 3.4653 | - |
| 1.0656 | 276 | 0.0012 | - |
| 1.0695 | 277 | 0.048 | - |
| 1.0734 | 278 | 1.9485 | - |
| 1.0772 | 279 | 1.0039 | - |
| 1.0811 | 280 | 0.4597 | 0.6971 |
| 1.0849 | 281 | 0.0431 | - |
| 1.0888 | 282 | 0.024 | - |
| 1.0927 | 283 | 0.0131 | - |
| 1.0965 | 284 | 0.2774 | - |
| 1.1004 | 285 | 0.042 | - |
| 1.1042 | 286 | 0.0007 | - |
| 1.1081 | 287 | 0.0003 | - |
| 1.1120 | 288 | 0.0278 | - |
| 1.1158 | 289 | 0.0687 | - |
| 1.1197 | 290 | 0.0142 | 0.6889 |
| 1.1236 | 291 | 0.187 | - |
| 1.1274 | 292 | 0.001 | - |
| 1.1313 | 293 | 0.4514 | - |
| 1.1351 | 294 | 0.0003 | - |
| 1.1390 | 295 | 0.0006 | - |
| 1.1429 | 296 | 0.0882 | - |
| 1.1467 | 297 | 0.0018 | - |
| 1.1506 | 298 | 0.0 | - |
| 1.1544 | 299 | 0.0027 | - |
| 1.1583 | 300 | 0.839 | 0.6728 |
| 1.1622 | 301 | 0.0 | - |
| 1.1660 | 302 | 0.5767 | - |
| 1.1699 | 303 | 0.0 | - |
| 1.1737 | 304 | 2.7827 | - |
| 1.1776 | 305 | 0.2726 | - |
| 1.1815 | 306 | 0.005 | - |
| 1.1853 | 307 | 0.0638 | - |
| 1.1892 | 308 | 0.0628 | - |
| 1.1931 | 309 | 0.0048 | - |
| 1.1969 | 310 | 0.0065 | 0.6215 |
| 1.2008 | 311 | 0.0131 | - |
| 1.2046 | 312 | 0.0003 | - |
| 1.2085 | 313 | 0.1415 | - |
| 1.2124 | 314 | 0.2259 | - |
| 1.2162 | 315 | 0.001 | - |
| 1.2201 | 316 | 0.0001 | - |
| 1.2239 | 317 | 0.0016 | - |
| 1.2278 | 318 | 1.2173 | - |
| 1.2317 | 319 | 0.0008 | - |
| 1.2355 | 320 | 2.2314 | 0.5533 |
| 1.2394 | 321 | 0.8177 | - |
| 1.2432 | 322 | 0.052 | - |
| 1.2471 | 323 | 0.0084 | - |
| 1.2510 | 324 | 0.0379 | - |
| 1.2548 | 325 | 0.0014 | - |
| 1.2587 | 326 | 0.0207 | - |
| 1.2625 | 327 | 0.0 | - |
| 1.2664 | 328 | 0.0 | - |
| 1.2703 | 329 | 0.0001 | - |
| 1.2741 | 330 | 0.0 | 0.5151 |
| 1.2780 | 331 | 1.5722 | - |
| 1.2819 | 332 | 0.166 | - |
| 1.2857 | 333 | 0.029 | - |
| 1.2896 | 334 | 0.0001 | - |
| 1.2934 | 335 | 0.0085 | - |
| 1.2973 | 336 | 0.0003 | - |
| 1.3012 | 337 | 0.0003 | - |
| 1.3050 | 338 | 0.0087 | - |
| 1.3089 | 339 | 0.017 | - |
| 1.3127 | 340 | 1.671 | 0.6009 |
| 1.3166 | 341 | 0.0007 | - |
| 1.3205 | 342 | 0.0002 | - |
| 1.3243 | 343 | 0.006 | - |
| 1.3282 | 344 | 0.0003 | - |
| 1.3320 | 345 | 0.6332 | - |
| 1.3359 | 346 | 0.0003 | - |
| 1.3398 | 347 | 0.0016 | - |
| 1.3436 | 348 | 0.0019 | - |
| 1.3475 | 349 | 0.0025 | - |
| 1.3514 | 350 | 0.0029 | 0.6039 |
| 1.3552 | 351 | 1.219 | - |
| 1.3591 | 352 | 0.0016 | - |
| 1.3629 | 353 | 0.0123 | - |
| 1.3668 | 354 | 4.7681 | - |
| 1.3707 | 355 | 0.0 | - |
| 1.3745 | 356 | 0.0584 | - |
| 1.3784 | 357 | 0.0018 | - |
| 1.3822 | 358 | 0.0045 | - |
| 1.3861 | 359 | 1.4909 | - |
| 1.3900 | 360 | 0.1525 | 0.6368 |
| 1.3938 | 361 | 3.4601 | - |
| 1.3977 | 362 | 3.1904 | - |
| 1.4015 | 363 | 3.0462 | - |
| 1.4054 | 364 | 0.0 | - |
| 1.4093 | 365 | 0.0167 | - |
| 1.4131 | 366 | 0.0006 | - |
| 1.4170 | 367 | 0.0 | - |
| 1.4208 | 368 | 0.001 | - |
| 1.4247 | 369 | 0.0 | - |
| 1.4286 | 370 | 0.0 | 0.6622 |
| 1.4324 | 371 | 0.0006 | - |
| 1.4363 | 372 | 0.0 | - |
| 1.4402 | 373 | 0.0 | - |
| 1.4440 | 374 | 0.0 | - |
| 1.4479 | 375 | 0.0 | - |
| 1.4517 | 376 | 0.0 | - |
| 1.4556 | 377 | 0.0 | - |
| 1.4595 | 378 | 0.0006 | - |
| 1.4633 | 379 | 0.0009 | - |
| 1.4672 | 380 | 0.0 | 0.6280 |
| 1.4710 | 381 | 0.0 | - |
| 1.4749 | 382 | 0.0 | - |
| 1.4788 | 383 | 0.0 | - |
| 1.4826 | 384 | 0.0 | - |
| 1.4865 | 385 | 0.0 | - |
| 1.4903 | 386 | 0.0 | - |
| 1.4942 | 387 | 0.0 | - |
| 1.4981 | 388 | 0.0 | - |
| 1.5019 | 389 | 0.0 | - |
| 1.5058 | 390 | 0.0001 | 0.5800 |
| 1.5097 | 391 | 0.0897 | - |
| 1.5135 | 392 | 0.0 | - |
| 1.5174 | 393 | 0.0 | - |
| 1.5212 | 394 | 0.0 | - |
| 1.5251 | 395 | 0.0 | - |
| 1.5290 | 396 | 0.0 | - |
| 1.5328 | 397 | 0.0 | - |
| 1.5367 | 398 | 0.0 | - |
| 1.5405 | 399 | 0.0 | - |
| 1.5444 | 400 | 0.0 | 0.5177 |
| 1.5483 | 401 | 0.0 | - |
| 1.5521 | 402 | 0.0 | - |
| 1.5560 | 403 | 0.0 | - |
| 1.5598 | 404 | 0.0 | - |
| 1.5637 | 405 | 0.0002 | - |
| 1.5676 | 406 | 0.0 | - |
| 1.5714 | 407 | 0.0 | - |
| 1.5753 | 408 | 0.0015 | - |
| 1.5792 | 409 | 0.0 | - |
| 1.5830 | 410 | 0.0033 | 0.4332 |
| 1.5869 | 411 | 0.0 | - |
| 1.5907 | 412 | 0.0 | - |
| 1.5946 | 413 | 0.0 | - |
| 1.5985 | 414 | 0.0 | - |
| 1.6023 | 415 | 0.0 | - |
| 1.6062 | 416 | 0.0 | - |
| 1.6100 | 417 | 0.0 | - |
| 1.6139 | 418 | 0.0 | - |
| 1.6178 | 419 | 0.0 | - |
| 1.6216 | 420 | 0.0 | 0.1822 |
| 1.6255 | 421 | 0.0 | - |
| 1.6293 | 422 | 0.0 | - |
| 1.6332 | 423 | 0.0 | - |
| 1.6371 | 424 | 0.0 | - |
| 1.6409 | 425 | 0.0 | - |
| 1.6448 | 426 | 0.0 | - |
| 1.6486 | 427 | 0.0 | - |
| 1.6525 | 428 | 0.0 | - |
| 1.6564 | 429 | 0.0 | - |
| 1.6602 | 430 | 0.0 | 0.1020 |
| 1.6641 | 431 | 0.0 | - |
| 1.6680 | 432 | 0.0 | - |
| 1.6718 | 433 | 0.0037 | - |
| 1.6757 | 434 | 0.0 | - |
| 1.6795 | 435 | 0.0 | - |
| 1.6834 | 436 | 0.0 | - |
| 1.6873 | 437 | 0.0 | - |
| 1.6911 | 438 | 0.0 | - |
| 1.6950 | 439 | 0.0 | - |
| 1.6988 | 440 | 0.0 | 0.0837 |
| 1.7027 | 441 | 0.0 | - |
| 1.7066 | 442 | 0.0 | - |
| 1.7104 | 443 | 0.0 | - |
| 1.7143 | 444 | 0.0 | - |
| 1.7181 | 445 | 0.0 | - |
| 1.7220 | 446 | 0.0 | - |
| 1.7259 | 447 | 0.0 | - |
| 1.7297 | 448 | 0.0 | - |
| 1.7336 | 449 | 0.0 | - |
| 1.7375 | 450 | 0.0 | 0.0893 |
| 1.7413 | 451 | 0.0 | - |
| 1.7452 | 452 | 0.0 | - |
| 1.7490 | 453 | 0.0 | - |
| 1.7529 | 454 | 0.0 | - |
| 1.7568 | 455 | 0.0 | - |
| 1.7606 | 456 | 0.0 | - |
| 1.7645 | 457 | 0.0 | - |
| 1.7683 | 458 | 0.0 | - |
| 1.7722 | 459 | 0.0 | - |
| 1.7761 | 460 | 0.0 | 0.0884 |
| 1.7799 | 461 | 0.0 | - |
| 1.7838 | 462 | 0.0 | - |
| 1.7876 | 463 | 0.0 | - |
| 1.7915 | 464 | 0.0 | - |
| 1.7954 | 465 | 0.0 | - |
| 1.7992 | 466 | 0.0 | - |
| 1.8031 | 467 | 0.0 | - |
| 1.8069 | 468 | 0.0 | - |
| 1.8108 | 469 | 0.0 | - |
| 1.8147 | 470 | 0.0 | 0.0878 |
| 1.8185 | 471 | 0.0 | - |
| 1.8224 | 472 | 0.0 | - |
| 1.8263 | 473 | 0.0 | - |
| 1.8301 | 474 | 0.0 | - |
| 1.8340 | 475 | 0.0 | - |
| 1.8378 | 476 | 0.0 | - |
| 1.8417 | 477 | 0.0 | - |
| 1.8456 | 478 | 0.0 | - |
| 1.8494 | 479 | 0.0 | - |
| 1.8533 | 480 | 0.0 | 0.0896 |
| 1.8571 | 481 | 0.0 | - |
| 1.8610 | 482 | 0.0 | - |
| 1.8649 | 483 | 0.0 | - |
| 1.8687 | 484 | 0.0 | - |
| 1.8726 | 485 | 0.0 | - |
| 1.8764 | 486 | 0.0 | - |
| 1.8803 | 487 | 0.0 | - |
| 1.8842 | 488 | 0.0 | - |
| 1.8880 | 489 | 0.0 | - |
| 1.8919 | 490 | 0.0 | 0.0884 |
| 1.8958 | 491 | 0.0 | - |
| 1.8996 | 492 | 0.0 | - |
| 1.9035 | 493 | 0.0 | - |
| 1.9073 | 494 | 0.0 | - |
| 1.9112 | 495 | 0.0 | - |
| 1.9151 | 496 | 0.0 | - |
| 1.9189 | 497 | 0.0 | - |
| 1.9228 | 498 | 0.0 | - |
| 1.9266 | 499 | 0.0 | - |
| 1.9305 | 500 | 0.0 | 0.0890 |
| 1.9344 | 501 | 0.0 | - |
| 1.9382 | 502 | 0.0 | - |
| 1.9421 | 503 | 0.0 | - |
| 1.9459 | 504 | 0.0 | - |
| 1.9498 | 505 | 0.0 | - |
| 1.9537 | 506 | 0.0 | - |
| 1.9575 | 507 | 0.0 | - |
| 1.9614 | 508 | 0.0 | - |
| 1.9653 | 509 | 0.0 | - |
| 1.9691 | 510 | 0.0 | 0.0903 |
| 1.9730 | 511 | 0.0 | - |
| 1.9768 | 512 | 0.0 | - |
| 1.9807 | 513 | 0.0 | - |
| 1.9846 | 514 | 0.0 | - |
| 1.9884 | 515 | 0.0 | - |
| 1.9923 | 516 | 0.0 | - |
| 1.9961 | 517 | 0.0 | - |
| 2.0 | 518 | 0.0 | - |
| 2.0039 | 519 | 0.0 | - |
| 2.0077 | 520 | 0.0 | 0.0884 |
| 2.0116 | 521 | 0.0 | - |
| 2.0154 | 522 | 0.0 | - |
| 2.0193 | 523 | 0.0 | - |
| 2.0232 | 524 | 0.0 | - |
| 2.0270 | 525 | 0.0 | - |
| 2.0309 | 526 | 0.0 | - |
| 2.0347 | 527 | 0.0 | - |
| 2.0386 | 528 | 0.0 | - |
| 2.0425 | 529 | 0.0 | - |
| 2.0463 | 530 | 0.0 | 0.0905 |
| 2.0502 | 531 | 0.0 | - |
| 2.0541 | 532 | 0.0 | - |
| 2.0579 | 533 | 0.0 | - |
| 2.0618 | 534 | 0.0 | - |
| 2.0656 | 535 | 0.0 | - |
| 2.0695 | 536 | 0.0 | - |
| 2.0734 | 537 | 0.0 | - |
| 2.0772 | 538 | 0.0 | - |
| 2.0811 | 539 | 0.0 | - |
| 2.0849 | 540 | 0.0 | 0.0912 |
| 2.0888 | 541 | 0.0 | - |
| 2.0927 | 542 | 0.0 | - |
| 2.0965 | 543 | 0.0 | - |
| 2.1004 | 544 | 0.0 | - |
| 2.1042 | 545 | 0.0 | - |
| 2.1081 | 546 | 0.0 | - |
| 2.1120 | 547 | 0.0 | - |
| 2.1158 | 548 | 0.0 | - |
| 2.1197 | 549 | 0.0 | - |
| 2.1236 | 550 | 0.0 | 0.0899 |
| 2.1274 | 551 | 0.0 | - |
| 2.1313 | 552 | 0.0 | - |
| 2.1351 | 553 | 0.0 | - |
| 2.1390 | 554 | 0.0 | - |
| 2.1429 | 555 | 0.0 | - |
| 2.1467 | 556 | 0.0 | - |
| 2.1506 | 557 | 0.0 | - |
| 2.1544 | 558 | 0.0 | - |
| 2.1583 | 559 | 0.0 | - |
| 2.1622 | 560 | 0.0 | 0.0883 |
| 2.1660 | 561 | 0.0 | - |
| 2.1699 | 562 | 0.0 | - |
| 2.1737 | 563 | 0.0 | - |
| 2.1776 | 564 | 0.0 | - |
| 2.1815 | 565 | 0.0 | - |
| 2.1853 | 566 | 0.0 | - |
| 2.1892 | 567 | 0.0 | - |
| 2.1931 | 568 | 0.0 | - |
| 2.1969 | 569 | 0.0 | - |
| 2.2008 | 570 | 0.0 | 0.0884 |
| 2.2046 | 571 | 0.0 | - |
| 2.2085 | 572 | 0.0 | - |
| 2.2124 | 573 | 0.0 | - |
| 2.2162 | 574 | 0.0 | - |
| 2.2201 | 575 | 0.0 | - |
| 2.2239 | 576 | 0.0 | - |
| 2.2278 | 577 | 0.0 | - |
| 2.2317 | 578 | 0.0 | - |
| 2.2355 | 579 | 0.0 | - |
| 2.2394 | 580 | 0.0 | 0.0885 |
| 2.2432 | 581 | 0.0 | - |
| 2.2471 | 582 | 0.0 | - |
| 2.2510 | 583 | 0.0 | - |
| 2.2548 | 584 | 0.0 | - |
| 2.2587 | 585 | 0.0 | - |
| 2.2625 | 586 | 0.0 | - |
| 2.2664 | 587 | 0.0 | - |
| 2.2703 | 588 | 0.0 | - |
| 2.2741 | 589 | 0.0 | - |
| 2.2780 | 590 | 0.0 | 0.0881 |
| 2.2819 | 591 | 0.0 | - |
| 2.2857 | 592 | 0.0 | - |
| 2.2896 | 593 | 0.0 | - |
| 2.2934 | 594 | 0.0 | - |
| 2.2973 | 595 | 0.0 | - |
| 2.3012 | 596 | 0.0 | - |
| 2.3050 | 597 | 0.0 | - |
| 2.3089 | 598 | 0.0 | - |
| 2.3127 | 599 | 0.0 | - |
| 2.3166 | 600 | 0.0 | 0.0892 |
| 2.3205 | 601 | 0.0 | - |
| 2.3243 | 602 | 0.0 | - |
| 2.3282 | 603 | 0.0 | - |
| 2.3320 | 604 | 0.0 | - |
| 2.3359 | 605 | 0.0 | - |
| 2.3398 | 606 | 0.0 | - |
| 2.3436 | 607 | 0.0 | - |
| 2.3475 | 608 | 0.0 | - |
| 2.3514 | 609 | 0.0 | - |
| 2.3552 | 610 | 0.0 | 0.0894 |
| 2.3591 | 611 | 0.0 | - |
| 2.3629 | 612 | 0.0 | - |
| 2.3668 | 613 | 0.0 | - |
| 2.3707 | 614 | 0.0 | - |
| 2.3745 | 615 | 0.0 | - |
| 2.3784 | 616 | 0.0 | - |
| 2.3822 | 617 | 0.0 | - |
| 2.3861 | 618 | 0.0 | - |
| 2.3900 | 619 | 0.0 | - |
| 2.3938 | 620 | 0.0 | 0.0890 |
| 2.3977 | 621 | 0.0 | - |
| 2.4015 | 622 | 0.0 | - |
| 2.4054 | 623 | 0.0 | - |
| 2.4093 | 624 | 0.0 | - |
| 2.4131 | 625 | 0.0 | - |
| 2.4170 | 626 | 0.0 | - |
| 2.4208 | 627 | 0.0 | - |
| 2.4247 | 628 | 0.0 | - |
| 2.4286 | 629 | 0.0 | - |
| 2.4324 | 630 | 0.0 | 0.0902 |
| 2.4363 | 631 | 0.0 | - |
| 2.4402 | 632 | 0.0 | - |
| 2.4440 | 633 | 0.0 | - |
| 2.4479 | 634 | 0.0 | - |
| 2.4517 | 635 | 0.0 | - |
| 2.4556 | 636 | 0.0 | - |
| 2.4595 | 637 | 0.0 | - |
| 2.4633 | 638 | 0.0 | - |
| 2.4672 | 639 | 0.0 | - |
| 2.4710 | 640 | 0.0 | 0.0895 |
| 2.4749 | 641 | 0.0 | - |
| 2.4788 | 642 | 0.0 | - |
| 2.4826 | 643 | 0.0 | - |
| 2.4865 | 644 | 0.0 | - |
| 2.4903 | 645 | 0.0 | - |
| 2.4942 | 646 | 0.0 | - |
| 2.4981 | 647 | 0.0 | - |
| 2.5019 | 648 | 0.0 | - |
| 2.5058 | 649 | 0.0 | - |
| 2.5097 | 650 | 0.0 | 0.0905 |
| 2.5135 | 651 | 0.0 | - |
| 2.5174 | 652 | 0.0 | - |
| 2.5212 | 653 | 0.0 | - |
| 2.5251 | 654 | 0.0 | - |
| 2.5290 | 655 | 0.0 | - |
| 2.5328 | 656 | 0.0 | - |
| 2.5367 | 657 | 0.0 | - |
| 2.5405 | 658 | 0.0 | - |
| 2.5444 | 659 | 0.0 | - |
| 2.5483 | 660 | 0.0 | 0.0900 |
| 2.5521 | 661 | 0.0 | - |
| 2.5560 | 662 | 0.0 | - |
| 2.5598 | 663 | 0.0 | - |
| 2.5637 | 664 | 0.0 | - |
| 2.5676 | 665 | 0.0 | - |
| 2.5714 | 666 | 0.0 | - |
| 2.5753 | 667 | 0.0 | - |
| 2.5792 | 668 | 0.0 | - |
| 2.5830 | 669 | 0.0 | - |
| 2.5869 | 670 | 0.0 | 0.0889 |
| 2.5907 | 671 | 0.0 | - |
| 2.5946 | 672 | 0.0 | - |
| 2.5985 | 673 | 0.0 | - |
| 2.6023 | 674 | 0.0 | - |
| 2.6062 | 675 | 0.0 | - |
| 2.6100 | 676 | 0.0 | - |
| 2.6139 | 677 | 0.0 | - |
| 2.6178 | 678 | 0.0 | - |
| 2.6216 | 679 | 0.0 | - |
| 2.6255 | 680 | 0.0 | 0.0901 |
| 2.6293 | 681 | 0.0 | - |
| 2.6332 | 682 | 0.0 | - |
| 2.6371 | 683 | 0.0 | - |
| 2.6409 | 684 | 0.0 | - |
| 2.6448 | 685 | 0.0 | - |
| 2.6486 | 686 | 0.0 | - |
| 2.6525 | 687 | 0.0 | - |
| 2.6564 | 688 | 0.0 | - |
| 2.6602 | 689 | 0.0 | - |
| 2.6641 | 690 | 0.0 | 0.0904 |
| 2.6680 | 691 | 0.0 | - |
| 2.6718 | 692 | 0.0 | - |
| 2.6757 | 693 | 0.0 | - |
| 2.6795 | 694 | 0.0 | - |
| 2.6834 | 695 | 0.0 | - |
| 2.6873 | 696 | 0.0 | - |
| 2.6911 | 697 | 0.0 | - |
| 2.6950 | 698 | 0.0 | - |
| 2.6988 | 699 | 0.0 | - |
| 2.7027 | 700 | 0.0 | 0.0911 |
| 2.7066 | 701 | 0.0 | - |
| 2.7104 | 702 | 0.0 | - |
| 2.7143 | 703 | 0.0 | - |
| 2.7181 | 704 | 0.0 | - |
| 2.7220 | 705 | 0.0 | - |
| 2.7259 | 706 | 0.0 | - |
| 2.7297 | 707 | 0.0 | - |
| 2.7336 | 708 | 0.0 | - |
| 2.7375 | 709 | 0.0 | - |
| 2.7413 | 710 | 0.0 | 0.0908 |
| 2.7452 | 711 | 0.0 | - |
| 2.7490 | 712 | 0.0 | - |
| 2.7529 | 713 | 0.0 | - |
| 2.7568 | 714 | 0.0 | - |
| 2.7606 | 715 | 0.0 | - |
| 2.7645 | 716 | 0.0 | - |
| 2.7683 | 717 | 0.0 | - |
| 2.7722 | 718 | 0.0 | - |
| 2.7761 | 719 | 0.0 | - |
| 2.7799 | 720 | 0.0 | 0.0903 |
| 2.7838 | 721 | 0.0 | - |
| 2.7876 | 722 | 0.0 | - |
| 2.7915 | 723 | 0.0 | - |
| 2.7954 | 724 | 0.0 | - |
| 2.7992 | 725 | 0.0 | - |
| 2.8031 | 726 | 0.0 | - |
| 2.8069 | 727 | 0.0 | - |
| 2.8108 | 728 | 0.0 | - |
| 2.8147 | 729 | 0.0 | - |
| 2.8185 | 730 | 0.0 | 0.0885 |
| 2.8224 | 731 | 0.0 | - |
| 2.8263 | 732 | 0.0 | - |
| 2.8301 | 733 | 0.0 | - |
| 2.8340 | 734 | 0.0 | - |
| 2.8378 | 735 | 0.0 | - |
| 2.8417 | 736 | 0.0 | - |
| 2.8456 | 737 | 0.0 | - |
| 2.8494 | 738 | 0.0 | - |
| 2.8533 | 739 | 0.0 | - |
| 2.8571 | 740 | 0.0 | 0.0911 |
| 2.8610 | 741 | 0.0 | - |
| 2.8649 | 742 | 0.0 | - |
| 2.8687 | 743 | 0.0 | - |
| 2.8726 | 744 | 0.0 | - |
| 2.8764 | 745 | 0.0 | - |
| 2.8803 | 746 | 0.0 | - |
| 2.8842 | 747 | 0.0 | - |
| 2.8880 | 748 | 0.0 | - |
| 2.8919 | 749 | 0.0 | - |
| 2.8958 | 750 | 0.0 | 0.0898 |
| 2.8996 | 751 | 0.0 | - |
| 2.9035 | 752 | 0.0 | - |
| 2.9073 | 753 | 0.0 | - |
| 2.9112 | 754 | 0.0 | - |
| 2.9151 | 755 | 0.0 | - |
| 2.9189 | 756 | 0.0 | - |
| 2.9228 | 757 | 0.0 | - |
| 2.9266 | 758 | 0.0 | - |
| 2.9305 | 759 | 0.0 | - |
| 2.9344 | 760 | 0.0 | 0.0892 |
| 2.9382 | 761 | 0.0 | - |
| 2.9421 | 762 | 0.0 | - |
| 2.9459 | 763 | 0.0 | - |
| 2.9498 | 764 | 0.0 | - |
| 2.9537 | 765 | 0.0 | - |
| 2.9575 | 766 | 0.0 | - |
| 2.9614 | 767 | 0.0 | - |
| 2.9653 | 768 | 0.0 | - |
| 2.9691 | 769 | 0.0 | - |
| 2.9730 | 770 | 0.0 | 0.0907 |
| 2.9768 | 771 | 0.0 | - |
| 2.9807 | 772 | 0.0 | - |
| 2.9846 | 773 | 0.0 | - |
| 2.9884 | 774 | 0.0 | - |
| 2.9923 | 775 | 0.0 | - |
| 2.9961 | 776 | 0.0 | - |
| 3.0 | 777 | 0.0 | - |
| 3.0039 | 778 | 0.0 | - |
| 3.0077 | 779 | 0.0 | - |
| 3.0116 | 780 | 0.0 | 0.0895 |
| 3.0154 | 781 | 0.0 | - |
| 3.0193 | 782 | 0.0 | - |
| 3.0232 | 783 | 0.0 | - |
| 3.0270 | 784 | 0.0 | - |
| 3.0309 | 785 | 0.0 | - |
| 3.0347 | 786 | 0.0 | - |
| 3.0386 | 787 | 0.0 | - |
| 3.0425 | 788 | 0.0 | - |
| 3.0463 | 789 | 0.0 | - |
| 3.0502 | 790 | 0.0 | 0.0888 |
| 3.0541 | 791 | 0.0 | - |
| 3.0579 | 792 | 0.0 | - |
| 3.0618 | 793 | 0.0 | - |
| 3.0656 | 794 | 0.0 | - |
| 3.0695 | 795 | 0.0 | - |
| 3.0734 | 796 | 0.0 | - |
| 3.0772 | 797 | 0.0 | - |
| 3.0811 | 798 | 0.0 | - |
| 3.0849 | 799 | 0.0 | - |
| 3.0888 | 800 | 0.0 | 0.0910 |
| 3.0927 | 801 | 0.0 | - |
| 3.0965 | 802 | 0.0 | - |
| 3.1004 | 803 | 0.0 | - |
| 3.1042 | 804 | 0.0 | - |
| 3.1081 | 805 | 0.0 | - |
| 3.1120 | 806 | 0.0 | - |
| 3.1158 | 807 | 0.0 | - |
| 3.1197 | 808 | 0.0 | - |
| 3.1236 | 809 | 0.0 | - |
| 3.1274 | 810 | 0.0 | 0.0900 |
| 3.1313 | 811 | 0.0 | - |
| 3.1351 | 812 | 0.0 | - |
| 3.1390 | 813 | 0.0 | - |
| 3.1429 | 814 | 0.0 | - |
| 3.1467 | 815 | 0.0 | - |
| 3.1506 | 816 | 0.0 | - |
| 3.1544 | 817 | 0.0 | - |
| 3.1583 | 818 | 0.0 | - |
| 3.1622 | 819 | 0.0 | - |
| 3.1660 | 820 | 0.0 | 0.0897 |
| 3.1699 | 821 | 0.0 | - |
| 3.1737 | 822 | 0.0 | - |
| 3.1776 | 823 | 0.0 | - |
| 3.1815 | 824 | 0.0 | - |
| 3.1853 | 825 | 0.0 | - |
| 3.1892 | 826 | 0.0 | - |
| 3.1931 | 827 | 0.0 | - |
| 3.1969 | 828 | 0.0 | - |
| 3.2008 | 829 | 0.0 | - |
| 3.2046 | 830 | 0.0 | 0.0898 |
| 3.2085 | 831 | 0.0 | - |
| 3.2124 | 832 | 0.0 | - |
| 3.2162 | 833 | 0.0 | - |
| 3.2201 | 834 | 0.0 | - |
| 3.2239 | 835 | 0.0 | - |
| 3.2278 | 836 | 0.0 | - |
| 3.2317 | 837 | 0.0 | - |
| 3.2355 | 838 | 0.0 | - |
| 3.2394 | 839 | 0.0 | - |
| 3.2432 | 840 | 0.0 | 0.0882 |
| 3.2471 | 841 | 0.0 | - |
| 3.2510 | 842 | 0.0 | - |
| 3.2548 | 843 | 0.0 | - |
| 3.2587 | 844 | 0.0 | - |
| 3.2625 | 845 | 0.0 | - |
| 3.2664 | 846 | 0.0 | - |
| 3.2703 | 847 | 0.0 | - |
| 3.2741 | 848 | 0.0 | - |
| 3.2780 | 849 | 0.0 | - |
| 3.2819 | 850 | 0.0 | 0.0886 |
| 3.2857 | 851 | 0.0 | - |
| 3.2896 | 852 | 0.0 | - |
| 3.2934 | 853 | 0.0 | - |
| 3.2973 | 854 | 0.0 | - |
| 3.3012 | 855 | 0.0 | - |
| 3.3050 | 856 | 0.0 | - |
| 3.3089 | 857 | 0.0 | - |
| 3.3127 | 858 | 0.0 | - |
| 3.3166 | 859 | 0.0 | - |
| 3.3205 | 860 | 0.0 | 0.0912 |
| 3.3243 | 861 | 0.0 | - |
| 3.3282 | 862 | 0.0 | - |
| 3.3320 | 863 | 0.0 | - |
| 3.3359 | 864 | 0.0 | - |
| 3.3398 | 865 | 0.0 | - |
| 3.3436 | 866 | 0.0 | - |
| 3.3475 | 867 | 0.0 | - |
| 3.3514 | 868 | 0.0 | - |
| 3.3552 | 869 | 0.0 | - |
| 3.3591 | 870 | 0.0 | 0.0885 |
| 3.3629 | 871 | 0.0 | - |
| 3.3668 | 872 | 0.0 | - |
| 3.3707 | 873 | 0.0 | - |
| 3.3745 | 874 | 0.0 | - |
| 3.3784 | 875 | 0.0 | - |
| 3.3822 | 876 | 0.0 | - |
| 3.3861 | 877 | 0.0 | - |
| 3.3900 | 878 | 0.0 | - |
| 3.3938 | 879 | 0.0 | - |
| 3.3977 | 880 | 0.0 | 0.0901 |
| 3.4015 | 881 | 0.0 | - |
| 3.4054 | 882 | 0.0 | - |
| 3.4093 | 883 | 0.0 | - |
| 3.4131 | 884 | 0.0 | - |
| 3.4170 | 885 | 0.0 | - |
| 3.4208 | 886 | 0.0 | - |
| 3.4247 | 887 | 0.0 | - |
| 3.4286 | 888 | 0.0 | - |
| 3.4324 | 889 | 0.0 | - |
| 3.4363 | 890 | 0.0 | 0.0907 |
| 3.4402 | 891 | 0.0 | - |
| 3.4440 | 892 | 0.0 | - |
| 3.4479 | 893 | 0.0 | - |
| 3.4517 | 894 | 0.0 | - |
| 3.4556 | 895 | 0.0 | - |
| 3.4595 | 896 | 0.0 | - |
| 3.4633 | 897 | 0.0 | - |
| 3.4672 | 898 | 0.0 | - |
| 3.4710 | 899 | 0.0 | - |
| 3.4749 | 900 | 0.0 | 0.0901 |
| 3.4788 | 901 | 0.0 | - |
| 3.4826 | 902 | 0.0 | - |
| 3.4865 | 903 | 0.0 | - |
| 3.4903 | 904 | 0.0 | - |
| 3.4942 | 905 | 0.0 | - |
| 3.4981 | 906 | 0.0 | - |
| 3.5019 | 907 | 0.0 | - |
| 3.5058 | 908 | 0.0 | - |
| 3.5097 | 909 | 0.0 | - |
| 3.5135 | 910 | 0.0 | 0.0891 |
| 3.5174 | 911 | 0.0 | - |
| 3.5212 | 912 | 0.0 | - |
| 3.5251 | 913 | 0.0 | - |
| 3.5290 | 914 | 0.0 | - |
| 3.5328 | 915 | 0.0 | - |
| 3.5367 | 916 | 0.0 | - |
| 3.5405 | 917 | 0.0 | - |
| 3.5444 | 918 | 0.0 | - |
| 3.5483 | 919 | 0.0 | - |
| 1.0039 | 920 | 10.0434 | 0.1388 |
| 1.0077 | 921 | 5.1821 | - |
| 1.0116 | 922 | 4.5825 | - |
| 1.0154 | 923 | 3.5524 | - |
| 1.0193 | 924 | 2.9869 | - |
| 1.0232 | 925 | 2.1689 | - |
| 1.0270 | 926 | 1.7121 | - |
| 1.0309 | 927 | 1.4145 | - |
| 1.0347 | 928 | 1.3582 | - |
| 1.0386 | 929 | 1.0809 | - |
| 1.0425 | 930 | 1.1277 | 0.6958 |
| 1.0463 | 931 | 1.1277 | - |
| 1.0502 | 932 | 0.9973 | - |
| 1.0541 | 933 | 0.9678 | - |
| 1.0579 | 934 | 0.9995 | - |
| 1.0618 | 935 | 0.9642 | - |
| 1.0656 | 936 | 0.8054 | - |
| 1.0695 | 937 | 0.8265 | - |
| 1.0734 | 938 | 0.7545 | - |
| 1.0772 | 939 | 0.8211 | - |
| 1.0811 | 940 | 0.7939 | 0.7544 |
| 1.0849 | 941 | 0.7102 | - |
| 1.0888 | 942 | 0.7012 | - |
| 1.0927 | 943 | 0.8635 | - |
| 1.0965 | 944 | 0.786 | - |
| 1.1004 | 945 | 0.7132 | - |
| 1.1042 | 946 | 0.8146 | - |
| 1.1081 | 947 | 0.7136 | - |
| 1.1120 | 948 | 0.753 | - |
| 1.1158 | 949 | 0.8313 | - |
| 1.1197 | 950 | 0.7316 | 0.7442 |
| 1.1236 | 951 | 0.7404 | - |
| 1.1274 | 952 | 0.7095 | - |
| 1.1313 | 953 | 0.6721 | - |
| 1.1351 | 954 | 0.6721 | - |
| 1.1390 | 955 | 0.5942 | - |
| 1.1429 | 956 | 0.677 | - |
| 1.1467 | 957 | 0.6897 | - |
| 1.1506 | 958 | 0.7641 | - |
| 1.1544 | 959 | 0.729 | - |
| 1.1583 | 960 | 0.8163 | 0.7495 |
| 1.1622 | 961 | 0.7476 | - |
| 1.1660 | 962 | 0.6893 | - |
| 1.1699 | 963 | 0.7298 | - |
| 1.1737 | 964 | 0.7051 | - |
| 1.1776 | 965 | 0.7108 | - |
| 1.1815 | 966 | 0.6874 | - |
| 1.1853 | 967 | 0.6419 | - |
| 1.1892 | 968 | 0.7157 | - |
| 1.1931 | 969 | 0.6784 | - |
| 1.1969 | 970 | 0.7366 | 0.7611 |
| 1.2008 | 971 | 0.7936 | - |
| 1.2046 | 972 | 0.6304 | - |
| 1.2085 | 973 | 0.741 | - |
| 1.2124 | 974 | 0.6798 | - |
| 1.2162 | 975 | 0.6214 | - |
| 1.2201 | 976 | 0.6823 | - |
| 1.2239 | 977 | 0.7699 | - |
| 1.2278 | 978 | 0.6935 | - |
| 1.2317 | 979 | 0.6333 | - |
| 1.2355 | 980 | 0.7254 | 0.7669 |
| 1.2394 | 981 | 0.6542 | - |
| 1.2432 | 982 | 0.6484 | - |
| 1.2471 | 983 | 0.6735 | - |
| 1.2510 | 984 | 0.6583 | - |
| 1.2548 | 985 | 0.7262 | - |
| 1.2587 | 986 | 0.7496 | - |
| 1.2625 | 987 | 0.6963 | - |
| 1.2664 | 988 | 0.6898 | - |
| 1.2703 | 989 | 0.809 | - |
| 1.2741 | 990 | 0.6674 | 0.7682 |
| 1.2780 | 991 | 0.6777 | - |
| 1.2819 | 992 | 0.5449 | - |
| 1.2857 | 993 | 0.6407 | - |
| 1.2896 | 994 | 0.6454 | - |
| 1.2934 | 995 | 0.7667 | - |
| 1.2973 | 996 | 0.7352 | - |
| 1.3012 | 997 | 0.6949 | - |
| 1.3050 | 998 | 0.7102 | - |
| 1.3089 | 999 | 0.6572 | - |
| 1.3127 | 1000 | 0.6449 | 0.7652 |
| 1.3166 | 1001 | 0.6557 | - |
| 1.3205 | 1002 | 0.679 | - |
| 1.3243 | 1003 | 0.6698 | - |
| 1.3282 | 1004 | 0.6062 | - |
| 1.3320 | 1005 | 0.6519 | - |
| 1.3359 | 1006 | 0.6367 | - |
| 1.3398 | 1007 | 0.7025 | - |
| 1.3436 | 1008 | 0.6094 | - |
| 1.3475 | 1009 | 0.5253 | - |
| 1.3514 | 1010 | 0.6137 | 0.7636 |
| 1.3552 | 1011 | 0.613 | - |
| 1.3591 | 1012 | 0.6423 | - |
| 1.3629 | 1013 | 0.6327 | - |
| 1.3668 | 1014 | 0.648 | - |
| 1.3707 | 1015 | 0.5934 | - |
| 1.3745 | 1016 | 0.6273 | - |
| 1.3784 | 1017 | 0.6321 | - |
| 1.3822 | 1018 | 0.6907 | - |
| 1.3861 | 1019 | 0.6489 | - |
| 1.3900 | 1020 | 0.5384 | 0.7683 |
| 1.3938 | 1021 | 0.5229 | - |
| 1.3977 | 1022 | 0.6126 | - |
| 1.4015 | 1023 | 0.645 | - |
| 1.4054 | 1024 | 0.5632 | - |
| 1.4093 | 1025 | 0.5785 | - |
| 1.4131 | 1026 | 0.5648 | - |
| 1.4170 | 1027 | 0.6029 | - |
| 1.4208 | 1028 | 0.6059 | - |
| 1.4247 | 1029 | 0.5715 | - |
| 1.4286 | 1030 | 0.6566 | 0.7723 |
| 1.4324 | 1031 | 0.6022 | - |
| 1.4363 | 1032 | 0.6389 | - |
| 1.4402 | 1033 | 0.649 | - |
| 1.4440 | 1034 | 0.6492 | - |
| 1.4479 | 1035 | 0.6706 | - |
| 1.4517 | 1036 | 0.7155 | - |
| 1.4556 | 1037 | 0.5653 | - |
| 1.4595 | 1038 | 0.6131 | - |
| 1.4633 | 1039 | 0.6599 | - |
| 1.4672 | 1040 | 0.6408 | 0.7675 |
| 1.4710 | 1041 | 0.5828 | - |
| 1.4749 | 1042 | 0.5851 | - |
| 1.4788 | 1043 | 0.5777 | - |
| 1.4826 | 1044 | 0.6046 | - |
| 1.4865 | 1045 | 0.6614 | - |
| 1.4903 | 1046 | 0.5989 | - |
| 1.4942 | 1047 | 0.6145 | - |
| 1.4981 | 1048 | 0.6476 | - |
| 1.5019 | 1049 | 0.5908 | - |
| 1.5058 | 1050 | 0.5303 | 0.7698 |
| 1.5097 | 1051 | 0.4999 | - |
| 1.5135 | 1052 | 0.6364 | - |
| 1.5174 | 1053 | 0.585 | - |
| 1.5212 | 1054 | 0.6173 | - |
| 1.5251 | 1055 | 0.5873 | - |
| 1.5290 | 1056 | 0.6212 | - |
| 1.5328 | 1057 | 0.6382 | - |
| 1.5367 | 1058 | 0.5773 | - |
| 1.5405 | 1059 | 0.7004 | - |
| 1.5444 | 1060 | 0.5519 | 0.7730 |
| 1.5483 | 1061 | 0.5493 | - |
| 1.5521 | 1062 | 0.6271 | - |
| 1.5560 | 1063 | 0.6582 | - |
| 1.5598 | 1064 | 0.6762 | - |
| 1.5637 | 1065 | 0.5384 | - |
| 1.5676 | 1066 | 0.4839 | - |
| 1.5714 | 1067 | 0.4858 | - |
| 1.5753 | 1068 | 0.5605 | - |
| 1.5792 | 1069 | 0.6527 | - |
| 1.5830 | 1070 | 0.7242 | 0.7767 |
| 1.5869 | 1071 | 0.5596 | - |
| 1.5907 | 1072 | 0.5334 | - |
| 1.5946 | 1073 | 0.6396 | - |
| 1.5985 | 1074 | 0.6257 | - |
| 1.6023 | 1075 | 0.5817 | - |
| 1.6062 | 1076 | 0.5427 | - |
| 1.6100 | 1077 | 0.6046 | - |
| 1.6139 | 1078 | 0.5407 | - |
| 1.6178 | 1079 | 0.5577 | - |
| 1.6216 | 1080 | 0.6289 | 0.7684 |
| 1.6255 | 1081 | 0.5571 | - |
| 1.6293 | 1082 | 0.6156 | - |
| 1.6332 | 1083 | 0.5908 | - |
| 1.6371 | 1084 | 0.5573 | - |
| 1.6409 | 1085 | 0.6092 | - |
| 1.6448 | 1086 | 0.5099 | - |
| 1.6486 | 1087 | 0.4984 | - |
| 1.6525 | 1088 | 0.5983 | - |
| 1.6564 | 1089 | 0.6936 | - |
| 1.6602 | 1090 | 0.4997 | 0.7731 |
| 1.6641 | 1091 | 0.6156 | - |
| 1.6680 | 1092 | 0.6256 | - |
| 1.6718 | 1093 | 0.6171 | - |
| 1.6757 | 1094 | 0.4663 | - |
| 1.6795 | 1095 | 0.5336 | - |
| 1.6834 | 1096 | 0.5962 | - |
| 1.6873 | 1097 | 0.5501 | - |
| 1.6911 | 1098 | 0.6299 | - |
| 1.6950 | 1099 | 0.5987 | - |
| 1.6988 | 1100 | 0.5911 | 0.7852 |
</details>
### Framework Versions
- Python: 3.10.6
- Sentence Transformers: 3.3.0.dev0
- Transformers: 4.45.2
- PyTorch: 2.4.1+cu118
- Accelerate: 0.34.0
- Datasets: 2.21.0
- Tokenizers: 0.20.2
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### CachedMultipleNegativesRankingLoss
```bibtex
@misc{gao2021scaling,
title={Scaling Deep Contrastive Learning Batch Size under Memory Limited Setup},
author={Luyu Gao and Yunyi Zhang and Jiawei Han and Jamie Callan},
year={2021},
eprint={2101.06983},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"CHIA"
] |
AlekseyCalvin/Akhmatova_Flux_LoRA_SilverAgePoets_v3_DeDistilledTrained
|
AlekseyCalvin
|
text-to-image
|
[
"diffusers",
"flux",
"lora",
"replicate",
"image-generation",
"flux-diffusers",
"photo",
"realism",
"character",
"historical person",
"poetry",
"literature",
"history",
"archival",
"text-to-image",
"en",
"base_model:AlekseyCalvin/Colossus_2.1_dedistilled_by_AfroMan4peace",
"base_model:adapter:AlekseyCalvin/Colossus_2.1_dedistilled_by_AfroMan4peace",
"license:apache-2.0",
"region:us"
] | 2024-11-16T02:59:16Z |
2024-11-16T03:34:00+00:00
| 17 | 0 |
---
base_model: AlekseyCalvin/Colossus_2.1_dedistilled_by_AfroMan4peace
language:
- en
library_name: diffusers
license: apache-2.0
pipeline_tag: text-to-image
tags:
- flux
- diffusers
- lora
- replicate
- image-generation
- flux-diffusers
- photo
- realism
- character
- historical person
- poetry
- literature
- history
- archival
emoji: 🔜
instance_prompt: Anna AKHMATOVA, blemished skin texture with slight wrinkles
widget:
- text: agitprop Constructivist poster of the poet Anna AKHMATOVA calling out "JOIN
RCA!" in a speech bubble, over satirical cartoon of cool punky diverse teenage
gen-z revolutionaries
output:
url: AkhmDedistilled1.jpg
- text: vintage side-view photograph of young Anna AKHMATOVA, classic analog color
photography
output:
url: AnnaPoeticsWill.jpg
---
<Gallery />
# Anna Akhmatova Flux Low-Rank Adapter (LoRA) Version 2 by SilverAgePoets.com
Trained on a dataset of 60 vintage photos (most of them colorized by us and/or by [Klimbim](https://klimbim2020.wordpress.com/)). <br>
And capturing the legendary **poet**: <br>
**Anna Andreevna Akhmatova** <br> *(b.06/26/1889-d.03/05/1966)* <br>
For this LoRA we used highly detailed manually-composed paragraph captions. <br>
It was trained for 1600 steps (a 1300 checkpoint also added) at a Diffusion-Transformer Learning Rate of .0004, dim/alpha of 32, batch 1, AdamW8bit optimizer! Minimal synthetic data (just a few reluctant upscales), zero auto-generated captions! <br>
**VERSION 3 NOTE:** <br>
This third version of the Akhmatova LoRA was trained on the **Colossus 2.1 Dedistilled Flux model by AfroMan4Peace**, available [here](https://huggingface.co/AlekseyCalvin/Colossus_2.1_dedistilled_by_AfroMan4peace) in a diffusers format and [here at CivitAI](https://civitai.com/models/833086/colossus-project-flux). <br>
As of writing this blurb, we haven't yet tested this LoRA enough to say much concretely, but our other adapters trained over de-distilled modifications of FLUX have been shown to be more versatile than most base-model trained LoRAs in regards to compatibility and output variability. <br>
In parallel, we've also trained yet another Akhmatova LoRA (version 2) over a regular version of Flux, to enable a better basis for comparative testing. That version is available in a different repo [here](https://huggingface.co/AlekseyCalvin/Akhmatova_Flux_LoRA_SilverAgePoets_v2_regularFluxD). <br>
**MORE INFO:** <br>
This is a **rank-32 historical LoRA for Flux** (whether of a [Dev](https://huggingface.co/black-forest-labs/FLUX.1-dev), a [Schnell](https://huggingface.co/black-forest-labs/FLUX.1-schnell), or a [Soon®](https://huggingface.co/AlekseyCalvin/HistoricColorSoonr_Schnell) sort...) <br>
Use it to diffusely diversify the presence of Akhmatova's deathless visage in our strange latter-day world!
And once you're faced with this poet's iconic penetrating stare, do lend your ears to her as well: listen in to her voice!
Wherefrom might this voice resound for you? A dusty paperback? Google search? Maybe a clip on YouTube? Or, say, your very memory reciting verses suddenly recalled?<br>
In any case, we'll offer you some echoes to rely on, if you will:
Namely, our **translations of Akhmatova's verse-works**, adapted from a proto-Soviet song-tongue into a Worldish one...<br>
And found, along with many other poets' songs and tomes...
Over **at [SilverAgePoets.com](https://www.silveragepoets.com/akhmatovamain)!**
## Trigger words
You should use `AKHMATOVA` or `Anna Akhmatova` or `vintage autochrome photograph of Anna Akhmatova` to summon the poet's latent spirit.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('AlekseyCalvin/Akhmatova_Flux_LoRA_SilverAgePoets_v2_regularFluxD', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
[
"BLURB"
] |
davidschulte/ESM_biosses_default
|
davidschulte
| null |
[
"safetensors",
"embedding_space_map",
"BaseLM:bert-base-multilingual-uncased",
"dataset:tabilab/biosses",
"arxiv:2410.15148",
"base_model:google-bert/bert-base-multilingual-uncased",
"base_model:finetune:google-bert/bert-base-multilingual-uncased",
"license:apache-2.0",
"region:us"
] | 2024-12-08T14:37:40Z |
2024-12-08T14:37:45+00:00
| 17 | 0 |
---
base_model: bert-base-multilingual-uncased
datasets:
- tabilab/biosses
license: apache-2.0
tags:
- embedding_space_map
- BaseLM:bert-base-multilingual-uncased
---
# ESM tabilab/biosses
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
ESM
- **Developed by:** David Schulte
- **Model type:** ESM
- **Base Model:** bert-base-multilingual-uncased
- **Intermediate Task:** tabilab/biosses
- **ESM architecture:** linear
- **ESM embedding dimension:** 768
- **Language(s) (NLP):** [More Information Needed]
- **License:** Apache-2.0 license
- **ESM version:** 0.1.0
## Training Details
### Intermediate Task
- **Task ID:** tabilab/biosses
- **Subset [optional]:** default
- **Text Column:** ['sentence1', 'sentence2']
- **Label Column:** score
- **Dataset Split:** train
- **Sample size [optional]:** 100
- **Sample seed [optional]:**
### Training Procedure [optional]
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Language Model Training Hyperparameters [optional]
- **Epochs:** 3
- **Batch size:** 32
- **Learning rate:** 2e-05
- **Weight Decay:** 0.01
- **Optimizer**: AdamW
### ESM Training Hyperparameters [optional]
- **Epochs:** 10
- **Batch size:** 32
- **Learning rate:** 0.001
- **Weight Decay:** 0.01
- **Optimizer**: AdamW
### Additional trainiung details [optional]
## Model evaluation
### Evaluation of fine-tuned language model [optional]
### Evaluation of ESM [optional]
MSE:
### Additional evaluation details [optional]
## What are Embedding Space Maps used for?
Embedding Space Maps are a part of ESM-LogME, a efficient method for finding intermediate datasets for transfer learning. There are two reasons to use ESM-LogME:
### You don't have enough training data for your problem
If you don't have a enough training data for your problem, just use ESM-LogME to find more.
You can supplement model training by including publicly available datasets in the training process.
1. Fine-tune a language model on suitable intermediate dataset.
2. Fine-tune the resulting model on your target dataset.
This workflow is called intermediate task transfer learning and it can significantly improve the target performance.
But what is a suitable dataset for your problem? ESM-LogME enable you to quickly rank thousands of datasets on the Hugging Face Hub by how well they are exptected to transfer to your target task.
### You want to find similar datasets to your target dataset
Using ESM-LogME can be used like search engine on the Hugging Face Hub. You can find similar tasks to your target task without having to rely on heuristics. ESM-LogME estimates how language models fine-tuned on each intermediate task would benefinit your target task. This quantitative approach combines the effects of domain similarity and task similarity.
## How can I use ESM-LogME / ESMs?
[](https://pypi.org/project/hf-dataset-selector)
We release **hf-dataset-selector**, a Python package for intermediate task selection using Embedding Space Maps.
**hf-dataset-selector** fetches ESMs for a given language model and uses it to find the best dataset for applying intermediate training to the target task. ESMs are found by their tags on the Huggingface Hub.
```python
from hfselect import Dataset, compute_task_ranking
# Load target dataset from the Hugging Face Hub
dataset = Dataset.from_hugging_face(
name="stanfordnlp/imdb",
split="train",
text_col="text",
label_col="label",
is_regression=False,
num_examples=1000,
seed=42
)
# Fetch ESMs and rank tasks
task_ranking = compute_task_ranking(
dataset=dataset,
model_name="bert-base-multilingual-uncased"
)
# Display top 5 recommendations
print(task_ranking[:5])
```
```python
1. davanstrien/test_imdb_embedd2 Score: -0.618529
2. davanstrien/test_imdb_embedd Score: -0.618644
3. davanstrien/test1 Score: -0.619334
4. stanfordnlp/imdb Score: -0.619454
5. stanfordnlp/sst Score: -0.62995
```
| Rank | Task ID | Task Subset | Text Column | Label Column | Task Split | Num Examples | ESM Architecture | Score |
|-------:|:------------------------------|:----------------|:--------------|:---------------|:-------------|---------------:|:-------------------|----------:|
| 1 | davanstrien/test_imdb_embedd2 | default | text | label | train | 10000 | linear | -0.618529 |
| 2 | davanstrien/test_imdb_embedd | default | text | label | train | 10000 | linear | -0.618644 |
| 3 | davanstrien/test1 | default | text | label | train | 10000 | linear | -0.619334 |
| 4 | stanfordnlp/imdb | plain_text | text | label | train | 10000 | linear | -0.619454 |
| 5 | stanfordnlp/sst | dictionary | phrase | label | dictionary | 10000 | linear | -0.62995 |
| 6 | stanfordnlp/sst | default | sentence | label | train | 8544 | linear | -0.63312 |
| 7 | kuroneko5943/snap21 | CDs_and_Vinyl_5 | sentence | label | train | 6974 | linear | -0.634365 |
| 8 | kuroneko5943/snap21 | Video_Games_5 | sentence | label | train | 6997 | linear | -0.638787 |
| 9 | kuroneko5943/snap21 | Movies_and_TV_5 | sentence | label | train | 6989 | linear | -0.639068 |
| 10 | fancyzhx/amazon_polarity | amazon_polarity | content | label | train | 10000 | linear | -0.639718 |
For more information on how to use ESMs please have a look at the [official Github repository](https://github.com/davidschulte/hf-dataset-selector). We provide documentation further documentation and tutorials for finding intermediate datasets and training your own ESMs.
## How do Embedding Space Maps work?
<!-- This section describes the evaluation protocols and provides the results. -->
Embedding Space Maps (ESMs) are neural networks that approximate the effect of fine-tuning a language model on a task. They can be used to quickly transform embeddings from a base model to approximate how a fine-tuned model would embed the the input text.
ESMs can be used for intermediate task selection with the ESM-LogME workflow.
## How can I use Embedding Space Maps for Intermediate Task Selection?
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
If you are using this Embedding Space Maps, please cite our [paper](https://aclanthology.org/2024.emnlp-main.529/).
**BibTeX:**
```
@inproceedings{schulte-etal-2024-less,
title = "Less is More: Parameter-Efficient Selection of Intermediate Tasks for Transfer Learning",
author = "Schulte, David and
Hamborg, Felix and
Akbik, Alan",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.emnlp-main.529/",
doi = "10.18653/v1/2024.emnlp-main.529",
pages = "9431--9442",
abstract = "Intermediate task transfer learning can greatly improve model performance. If, for example, one has little training data for emotion detection, first fine-tuning a language model on a sentiment classification dataset may improve performance strongly. But which task to choose for transfer learning? Prior methods producing useful task rankings are infeasible for large source pools, as they require forward passes through all source language models. We overcome this by introducing Embedding Space Maps (ESMs), light-weight neural networks that approximate the effect of fine-tuning a language model. We conduct the largest study on NLP task transferability and task selection with 12k source-target pairs. We find that applying ESMs on a prior method reduces execution time and disk space usage by factors of 10 and 278, respectively, while retaining high selection performance (avg. regret@5 score of 2.95)."
}
```
**APA:**
```
Schulte, D., Hamborg, F., & Akbik, A. (2024, November). Less is More: Parameter-Efficient Selection of Intermediate Tasks for Transfer Learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 9431-9442).
```
## Additional Information
|
[
"BIOSSES"
] |
McGill-DMaS/DMaS-LLaMa-Lite-step-7.5k
|
McGill-DMaS
| null |
[
"safetensors",
"llama",
"dataset:HuggingFaceFW/fineweb-edu",
"arxiv:2412.13335",
"license:apache-2.0",
"region:us"
] | 2024-12-17T21:25:51Z |
2024-12-19T02:32:01+00:00
| 17 | 0 |
---
datasets:
- HuggingFaceFW/fineweb-edu
license: apache-2.0
---
Here is the draft for the `README.md` file for the **McGill-DMaS/DMaS-LLaMa-Lite-step-7.5k** model card on Huggingface:
---
# DMaS-LLaMa-Lite-step-7.5k
This repository provides access to **DMaS-LLaMa-Lite-step-7.5k**, a 1.7-billion-parameter language model based on the LLaMa architecture. The model has been trained from scratch as part of the DMaS-LLaMa-Lite project using approximately 20 billion tokens of high-quality educational content.
## Model Overview
- **Architecture**: LLaMa-based
- **Parameters**: 1.7B (36 layers, 32 attention heads, RMSNorm)
- **Tokenizer**: GPT-2 tokenizer
- **Training Data**: FineWeb-Edu subset (educational text)
- **Training Steps**: 7,500
- **Optimizer**: AdamW with linear warmup and decay
- **Hardware**: Trained on 1-2 RTX A6000 GPUs with PyTorch DDP
- **Dataset Source**: [FineWeb-Edu Dataset](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu)
The training process emphasizes qualitative improvements in coherence, fluency, and factual grounding, demonstrating competitive results even with fewer tokens compared to larger-scale models.
This checkpoint represents the model's state at **7,500 training steps**. Validation loss and downstream performance benchmarks demonstrate notable early improvements in text fluency and alignment with prompts.
## Training Code
The training script, including configurations and instructions, is open-sourced and available here:
📄 **[DMaS-LLaMa-Lite Training Code](https://github.com/McGill-DMaS/DMaS-LLaMa-Lite-Training-Code)**
## Usage
You can load the model with Hugging Face Transformers library:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "McGill-DMaS/DMaS-LLaMa-Lite-step-7.5k"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
inputs = tokenizer("The Pyramids of Giza in Egypt are some of the oldest man-made structures in the world.", return_tensors="pt")
outputs = model.generate(**inputs, max_length=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Citation
If you use this model or its training insights in your work, please cite the following [paper](https://arxiv.org/abs/2412.13335):
```bibtex
@article{li2024effectiveness,
title={Experience of Training a 1.7B-Parameter LLaMa Model From Scratch},
author={Li, Miles Q and Fung, Benjamin and Huang, Shih-Chia},
journal={arXiv preprint arXiv:2412.13335},
year={2024}
}
```
## License
This model and code are released under the **Apache License 2.0**. Please check the respective repositories for detailed terms.
|
[
"CHIA"
] |
Lambent/Falcon3-Continued-0.3-10B-Base
|
Lambent
| null |
[
"safetensors",
"llama",
"dataset:PleIAs/common_corpus",
"base_model:tiiuae/Falcon3-10B-Base",
"base_model:finetune:tiiuae/Falcon3-10B-Base",
"license:other",
"region:us"
] | 2024-12-22T15:00:32Z |
2024-12-29T11:31:52+00:00
| 17 | 0 |
---
base_model:
- tiiuae/Falcon3-10B-Base
datasets:
- PleIAs/common_corpus
license: other
license_name: falcon-llm-license
license_link: https://falconllm.tii.ae/falcon-terms-and-conditions.html
---
*Falcon3-Continued-0.3-10B-Base is built using artificial intelligence technology from the Technology Innovation Institute.*
This model uses qLoRA with UnSloth to continuously pretrain Falcon3-10B-Base on an additional 30,720 rows from PleIAs/common_corpus, cyclically.
Rows trained at a time varied between 2048, 4096, and 8192, using cosine decay. A merged model was saved and tested every 10240 rows.
Adapters ranged from rank 32 to rank 128, with ranks 64 and 128 being the most common. Weight decay was 0.01.
Trained context length ranged from 4096 to the full 32678, with 32678 being the most common. Sample packing was not used.
Long documents, if present, were truncated.
Training continued until no improvement in eq_bench was demonstrated from this method. Most other benchmarks stayed similar.
hf (pretrained=Lambent/Falcon3-Continued-0.3-10B-Base,dtype=auto,trust_remote_code=True), gen_kwargs: (None), limit: None, num_fewshot: 0, batch_size: auto
| Tasks |Version|Filter|n-shot| Metric | | Value | |Stderr|
|--------|------:|------|-----:|-----------------|---|-------:|---|-----:|
|eq_bench| 2.1|none | 0|eqbench |↑ | 64.2105|± |2.1413|
| | |none | 0|percent_parseable|↑ |100.0000|± |0.0000|
hf (pretrained=Lambent/Falcon3-Continued-0.3-10B-Base), gen_kwargs: (None), limit: None, num_fewshot: None, batch_size: auto:4
|Tasks|Version| Filter |n-shot| Metric | |Value | |Stderr|
|-----|------:|----------------|-----:|-----------|---|-----:|---|-----:|
|gsm8k| 3|flexible-extract| 5|exact_match|↑ |0.8105|± |0.0108|
| | |strict-match | 5|exact_match|↑ |0.8036|± |0.0109|
hf (pretrained=Lambent/Falcon3-Continued-0.3-10B-Base), gen_kwargs: (None), limit: None, num_fewshot: None, batch_size: auto:4 (4,64,64,64)
| Tasks |Version|Filter|n-shot| Metric | |Value | |Stderr|
|-------------|------:|------|-----:|--------|---|-----:|---|-----:|
|arc_challenge| 1|none | 0|acc |↑ |0.5401|± |0.0146|
| | |none | 0|acc_norm|↑ |0.5648|± |0.0145|
|piqa | 1|none | 0|acc |↑ |0.7873|± |0.0095|
| | |none | 0|acc_norm|↑ |0.7954|± |0.0094|
|sciq | 1|none | 0|acc |↑ |0.9620|± |0.0060|
| | |none | 0|acc_norm|↑ |0.9500|± |0.0069|
|winogrande | 1|none | 0|acc |↑ |0.7332|± |0.0124|
MuSR:
RUNNING | Lambent/Falcon3-Continued-0.3-10B-Base | murder mysteries | regular | 134 / 250 | 53.6
RUNNING | Lambent/Falcon3-Continued-0.3-10B-Base | object placements | regular | 130 / 256 | 50.8
RUNNING | Lambent/Falcon3-Continued-0.3-10B-Base | team allocation | regular | 100 / 250 | 40.0
RUNNING | Lambent/Falcon3-Continued-0.3-10B-Base | murder mysteries | cot+ | 145 / 250 | 58.0
RUNNING | Lambent/Falcon3-Continued-0.3-10B-Base | object placements | cot+ | 83 / 256 | 32.4
RUNNING | Lambent/Falcon3-Continued-0.3-10B-Base | team allocation | cot+ | 112 / 250 | 44.8
Original under same conditions:
hf (pretrained=tiiuae/Falcon3-10B-Base,dtype=auto,trust_remote_code=True), gen_kwargs: (None), limit: None, num_fewshot: 0, batch_size: auto
| Tasks |Version|Filter|n-shot| Metric | | Value | |Stderr|
|--------|------:|------|-----:|-----------------|---|-------:|---|-----:|
|eq_bench| 2.1|none | 0|eqbench |↑ | 60.9913|± |2.2402|
| | |none | 0|percent_parseable|↑ |100.0000|± |0.0000|
hf (pretrained=tiiuae/Falcon3-10B-Base), gen_kwargs: (None), limit: None, num_fewshot: None, batch_size: auto:4
|Tasks|Version| Filter |n-shot| Metric | |Value | |Stderr|
|-----|------:|----------------|-----:|-----------|---|-----:|---|-----:|
|gsm8k| 3|flexible-extract| 5|exact_match|↑ |0.8188|± |0.0106|
| | |strict-match | 5|exact_match|↑ |0.8105|± |0.0108|
hf (pretrained=tiiuae/Falcon3-10B-Base), gen_kwargs: (None), limit: None, num_fewshot: None, batch_size: auto:4 (4,64,64,64)
| Tasks |Version|Filter|n-shot| Metric | |Value | |Stderr|
|-------------|------:|------|-----:|--------|---|-----:|---|-----:|
|arc_challenge| 1|none | 0|acc |↑ |0.5520|± |0.0145|
| | |none | 0|acc_norm|↑ |0.5887|± |0.0144|
|piqa | 1|none | 0|acc |↑ |0.7873|± |0.0095|
| | |none | 0|acc_norm|↑ |0.7949|± |0.0094|
|sciq | 1|none | 0|acc |↑ |0.9610|± |0.0061|
| | |none | 0|acc_norm|↑ |0.9360|± |0.0077|
|winogrande | 1|none | 0|acc |↑ |0.7364|± |0.0124|
MuSR:
RUNNING | tiiuae/Falcon3-10B-Base | murder mysteries | regular | 144 / 250 | 57.6
RUNNING | tiiuae/Falcon3-10B-Base | object placements | regular | 124 / 256 | 48.4
RUNNING | tiiuae/Falcon3-10B-Base | team allocation | regular | 126 / 250 | 50.4
RUNNING | tiiuae/Falcon3-10B-Base | murder mysteries | cot+ | 140 / 250 | 56.0
RUNNING | tiiuae/Falcon3-10B-Base | object placements | cot+ | 139 / 256 | 54.3
RUNNING | tiiuae/Falcon3-10B-Base | team allocation | cot+ | 118 / 250 | 47.2
|
[
"SCIQ"
] |
mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Cas-Warehouse/Llama-3-SOVL-MopeyMule-8B",
"base_model:quantized:Cas-Warehouse/Llama-3-SOVL-MopeyMule-8B",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-12-29T04:58:00Z |
2024-12-29T05:31:45+00:00
| 17 | 0 |
---
base_model: Cas-Warehouse/Llama-3-SOVL-MopeyMule-8B
language:
- en
library_name: transformers
tags:
- mergekit
- merge
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
static quants of https://huggingface.co/Cas-Warehouse/Llama-3-SOVL-MopeyMule-8B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-SOVL-MopeyMule-8B-GGUF/resolve/main/Llama-3-SOVL-MopeyMule-8B.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
[
"CAS"
] |
pipihand01/QwQ-32B-Preview-abliterated-linear75
|
pipihand01
|
text-generation
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"chat",
"abliterated",
"uncensored",
"mergekit",
"merge",
"conversational",
"en",
"arxiv:2203.05482",
"base_model:Qwen/QwQ-32B-Preview",
"base_model:merge:Qwen/QwQ-32B-Preview",
"base_model:huihui-ai/QwQ-32B-Preview-abliterated",
"base_model:merge:huihui-ai/QwQ-32B-Preview-abliterated",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2025-01-01T10:35:49Z |
2025-01-02T21:49:14+00:00
| 17 | 0 |
---
base_model:
- Qwen/QwQ-32B-Preview
- huihui-ai/QwQ-32B-Preview-abliterated
language:
- en
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/pipihand01/QwQ-32B-Preview-abliterated-linear75/blob/main/LICENSE
tags:
- chat
- abliterated
- uncensored
- mergekit
- merge
---
This is a 75% abliterated model obtained from linear-weighted merging [Qwen/QwQ-32B-Preview](https://huggingface.co/Qwen/QwQ-32B-Preview) (weight: 0.25) and [huihui-ai/QwQ-32B-Preview-abliterated](https://huggingface.co/huihui-ai/QwQ-32B-Preview-abliterated) (weight: 0.75), using [mergekit](https://github.com/arcee-ai/mergekit).
This is an experimental model, and from my preliminary experiments, this gives more natural result than Qwen's original model for sensitive contents while still maintaining some refusal capability.
Unlike the full abliterated version, "censorship" may not be fully removed, but the refusal looks more natural.
You may avoid using original prompting format and avoid any assistant-like description to get further human-like results.
I also offer other percentages of abliteration so you can try which one best suits your use case.
Or you may use [this LoRA](https://huggingface.co/pipihand01/QwQ-32B-Preview-abliterated-lora-rank32) if you know how to apply LoRA and adjust its weight for the app you use.
**NOTE: I bear no responsibility for any output of this model. When properly prompted, this model may generate contents that are not suitable in some situations. Use it with your own caution.**
---
# pipihand01/QwQ-32B-Preview-abliterated-linear75
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [linear](https://arxiv.org/abs/2203.05482) merge method.
### Models Merged
The following models were included in the merge:
* [Qwen/QwQ-32B-Preview](https://huggingface.co/Qwen/QwQ-32B-Preview)
* [huihui-ai/QwQ-32B-Preview-abliterated](https://huggingface.co/huihui-ai/QwQ-32B-Preview-abliterated)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Qwen/QwQ-32B-Preview
parameters:
weight: 0.25
- model: huihui-ai/QwQ-32B-Preview-abliterated
parameters:
weight: 0.75
merge_method: linear
dtype: bfloat16
```
|
[
"BEAR"
] |
asadfgglie/Llama-Breeze2-3B-Instruct-vllm
|
asadfgglie
| null |
[
"safetensors",
"internvl_chat",
"custom_code",
"en",
"zh",
"arxiv:2501.13921",
"license:llama3.2",
"region:us"
] | 2025-02-28T14:58:33Z |
2025-02-28T17:55:44+00:00
| 17 | 0 |
---
language:
- en
- zh
license: llama3.2
---
# Llama-Breeze2-3B-Instruct-v0_1
【[Paper](https://arxiv.org/abs/2501.13921)】◇【[Kaggle Demo](https://www.kaggle.com/code/ycckaggle/demo-breeze-2-3b)】◇【[Collection](https://huggingface.co/collections/MediaTek-Research/llama-breeze2-67863158443a06a72dd29900)】
**The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on LLaMA with Vision-Aware and Function-Calling Capabilities**
Llama Breeze 2 is a suite of advanced multi-modal language models, available in 3B and 8B parameter configurations, specifically designed to enhance Traditional Chinese language representation.
Building upon the [LLaMA 3.2](https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/), Breeze 2 continues pretraining on an extensive corpus to enhance the linguistic and cultural heritage of Traditional Chinese.
It incorporates vision-aware capabilities through a visual encoder and a bridge module, and supports function-calling via prompt templates and post-training on function-calling data.
*Llama 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.*
*We list all contributors in alphabetical order of their first names, as follows: Chan-Jan Hsu (許湛然), Chia-Sheng Liu (劉佳昇), Meng-Hsi Chen (陳孟羲), Muxi Chen (陳沐希), Po-Chun Hsu (許博竣), Yi-Chang Chen (陳宜昌), and the supervisor Da-Shan Shiu (許大山).*
## Installation
```
pip3 install transformers==4.47.0
pip3 install -U mtkresearch
```
```python
from transformers import AutoModel, AutoTokenizer
from transformers import GenerationConfig
import torch
from mtkresearch.llm.prompt import MRPromptV3
model_id = 'MediaTek-Research/Llama-Breeze2-3B-Instruct-v0_1'
model = AutoModel.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
device_map='auto',
img_context_token_id=128212
).eval()
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True, use_fast=False)
generation_config = GenerationConfig(
max_new_tokens=2048,
do_sample=True,
temperature=0.01,
top_p=0.01,
repetition_penalty=1.1,
eos_token_id=128009
)
prompt_engine = MRPromptV3()
sys_prompt = 'You are a helpful AI assistant built by MediaTek Research. The user you are helping speaks Traditional Chinese and comes from Taiwan.'
def _inference(tokenizer, model, generation_config, prompt, pixel_values=None):
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
if pixel_values is None:
output_tensors = model.generate(**inputs, generation_config=generation_config)
else:
output_tensors = model.generate(**inputs, generation_config=generation_config, pixel_values=pixel_values.to(model.dtype))
output_str = tokenizer.decode(output_tensors[0])
return output_str
```
## Feature: Instruction Following
```python
conversations = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": "請問什麼是深度學習?"},
]
prompt = prompt_engine.get_prompt(conversations)
output_str = _inference(tokenizer, model, generation_config, prompt)
result = prompt_engine.parse_generated_str(output_str)
print(result)
# {'role': 'assistant', 'content': '深度學習是一種人工智慧技術,主要是透過類似於大腦神經網路的方式來處理和分析資料。這個方法利用多層的人工神經元模仿生物神經網路的運作模式,讓電腦能夠從大量數據中學習並做出預測或決策。\n\n簡單來說,深度學習就是一種用機器學習的方式來訓練電腦,使其能夠像人類一樣理解、分辨及解決問題。這項技術已被廣泛應用在各種領域,如圖像識別、自然語言處理、語音辨識以及自動駕駛等方面。'}
```
## Feature: Visual Instruction Following
Example Image:

```python
conversations = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": [
{
"type": "image",
"image_path": /path/to/example-image,
},
{
"type": "text",
"text": "請問第二名可獲得多少獎金?"
},
]},
]
prompt, pixel_values = prompt_engine.get_prompt(conversations)
output_str = _inference(tokenizer, model, generation_config, prompt, pixel_values=pixel_values)
result = prompt_engine.parse_generated_str(output_str)
print(result)
# {'role': 'assistant', 'content': '第二名可獲得20萬元整。'}
```
## Feature: Function Calling
```python
import json
functions = [
{
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
]
def fake_get_current_weather(location, unit=None):
return {'temperature': 30}
mapping = {
'get_current_weather': fake_get_current_weather
}
# stage 1: query
conversations = [
{"role": "user", "content": "請問台北目前溫度是攝氏幾度?"},
]
prompt = prompt_engine.get_prompt(conversations, functions=functions)
output_str = _inference(tokenizer, model, generation_config, prompt)
result = prompt_engine.parse_generated_str(output_str)
print(result)
# {'role': 'assistant', 'tool_calls': [{'id': 'call_iuwELWUShiAKE16CVoumawZ4', 'type': 'function', 'function': {'name': 'get_current_weather', 'arguments': '{"location": "台北", "unit": "celsius"}'}}]}
```
```python
# stage 2: execute called functions
conversations.append(result)
tool_call = result['tool_calls'][0]
func_name = tool_call['function']['name']
func = mapping[func_name]
arguments = json.loads(tool_call['function']['arguments'])
called_result = func(**arguments)
# stage 3: put executed results
conversations.append(
{
'role': 'tool',
'tool_call_id': tool_call['id'],
'name': func_name,
'content': json.dumps(called_result)
}
)
prompt = prompt_engine.get_prompt(conversations, functions=functions)
output_str2 = _inference(tokenizer, model, generation_config, prompt)
result2 = prompt_engine.parse_generated_str(output_str2)
print(result2)
# {'role': 'assistant', 'content': '台北目前的溫度是攝氏30度。'}
```
## Citation
```
@article{breeze2,
title={The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on LLaMA with Vision-Aware and Function-Calling Capabilities},
author={Breeze Team, MediaTek Research},
journal={arXiv},
year={2025},
url={https://arxiv.org/abs/2501.13921}
}
```
|
[
"CHIA"
] |
minhtuan7akp/gte-vietnamese-finetune
|
minhtuan7akp
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"new",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:21892",
"loss:MultipleNegativesRankingLoss",
"custom_code",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:Alibaba-NLP/gte-multilingual-base",
"base_model:finetune:Alibaba-NLP/gte-multilingual-base",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2025-03-02T11:08:03Z |
2025-03-02T11:11:10+00:00
| 17 | 0 |
---
base_model: Alibaba-NLP/gte-multilingual-base
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:21892
- loss:MultipleNegativesRankingLoss
widget:
- source_sentence: Sự khác biệt giữa các thời đại trong nghệ thuật trang trí rồng
được thể hiện như thế nào qua các thời Hùng Vương, Lý, Trần, Hồ, Lê, Mạc, Nguyễn?
sentences:
- "Tài liệu tham khảo\r\n323. Nguyễn Quang Ngọc, “Mấy nhận xét về kết cấu kinh tế\
\ của \r\nmột số làng thương nghiệp ờ vùng đồng bằng Bắc Bộ thế kỳ \r\nXVIII-XIX”,\
\ Tạp chí Nghiên cứu Lịch sứ, số 5 (218), 1984.\r\n324. Nguyễn Quang Ngọc, Phan\
\ Đại Doãn, “Mấy ý kiến về hoạt \r\nđộng thương nghiệp ở nông thôn đồng bằng Bắc\
\ Bộ thế kỷ \r\nXVIII-XIX (hiện tượng và bản chất)”, Tạp chí Nghiên cứu\r\nLịch\
\ sử, số 5 (224), 1985.\r\n325. Nguyễn Quang Ngọc, “Thêm vài ý kiến về Tam Điệp”,\
\ Tạp \r\nchí Nghiên cứu Lịch sử, số 1 (244), 1989.\r\n326. Nguyễn Quang Ngọc,\
\ về một số làng buôn ở Đồng bàng Bắc \r\nBộ thế kỳ XVIII-XIX, Hội Sừ học Việt\
\ Nam, 1993.\r\n327. Nguyễn Quang Ngọc, Vũ Văn Quân, “Tư liệu về nguồn gốc \r\n\
chức năng và hoạt động cùa đội Hoàng Sa”, Tạp chí Khoa\r\nhọc xã hội, Đại học\
\ Quốc gia, t.XIV, số 3, 1998, ư. 10-20.\r\n328. Nguyễn Quang Ngọc, “Bảo vệ chủ\
\ quyền ưên Biển Đông: \r\nmột hoạt động nổi bật của vương triều Tây Sơn”, Tạp\
\ chí \r\nLịch sử quân sự, số 1, 1999, tr. 15-18.\r\n329. Nguyễn Quang Ngọc (Chủ\
\ biên), Tiến trình lịch sứ Việt Nam,\r\nNxb. Giáo dục, Hà Nội, 2001.\r\n330.\
\ Nguyền Quân, Phan cẩm Thượng, Mỹ thuật cùa người Việt,\r\nNxb. Mỹ thuật. Hà\
\ Nội. 1989.\r\n331. Nguyễn Tài Thư (Chủ biên), Lịch sử tư tưởng Việt Nam, 2\r\
\ntập, Nxb. Khoa học xã hội, Hà Nội, 1993.\r\n332. Nguyễn Tài Thư, Nho học và\
\ Nho học ớ Việt Nam: Một số lý\r\nluận và thực tiễn, Nxb. Khoa học xã hội, Hà\
\ Nội, 1997.\r\n333. Nguyễn Tưòmg Phượng, Binh chế Việt Nam qua các thời đại,\r\
\nNgày Mai, 1950."
- "Ba Thục, Kinh Sở, Ngô Việt…). Kết thúc cuộc \"Hán Sở tranh hùng\", nhà Hán\r\n\
đã thống nhất đất nước Trung Hoa từ bắc xuống nam (tiền bắc hậu nam) và phát\r\
\ntriển đất nước theo một trật tự ngược lại: tiền nam hậu bắc\".\r\nCó thể hình\
\ dung cơ cấu của văn hóa Trung Hoa như sau: \r\nVĂN HOÁ\r\nTRUNG\r\nHOA\r\n=\r\
\nVăn hoá lưu vực sông Hoàng Hà\r\n+\r\nVăn hoá nông\r\nnghiệp lúa nước\r\nĐông\
\ Nam Á\r\nVăn hoá du\r\nmục Tây Bắc +\r\nVăn hoá nông\r\nnghiệp khối Trung\r\n\
Nguyên\r\nMối liên hệ và sự tác động qua lại giữa văn hóa Việt Nam với Trung Hoa,\r\
\ngiữa văn hóa phương Bắc cổ đại với văn hóa phương Nam cổ đại (trong đó có\r\n\
văn hóa Nam – Á - Bách Việt) có thể trình bày trong bảng 1.5.\r\nVĂN HOÁ\r\nP.BẮC\
\ CỔ ĐẠI\r\nVĂN HOÁ PHƯƠNG NAM (= Đ.N.Á cổ đại)\r\nVăn hoá Nam-Á (Bách Việt)\r\
\nVăn hóa vùng lưu\r\nvực sông Hoàng\r\nHà\r\nVăn hóa vùng lưu\r\nvực sông Dương\r\
\nTử\r\nVăn hóa vùng lưu\r\nvực s. Hồng, s.\r\nMã\r\nVăn hóa miền\r\nTrung và\
\ đồng\r\nbằng s. Mê Kông\r\nVĂN HOÁ TRUNG HOA VĂN HOÁ VIỆT NAM\r\nBảng 1.5: Quan\
\ hệ cội nguồn giữa văn hóa Việt Nam và Trung Hoa\r\nBài 3: TIẾN TRÌNH VĂN HÓA\
\ VIỆT NAM\r\nTiến trình văn hóa Việt Nam có thể chia thành 6 giai đoạn: văn hóa\
\ tiền\r\nsử, văn hóa Văn Lang - Âu Lạc, văn hóa thời chống Bắc thuộc, văn hóa\
\ Đại\r\nViệt, văn hóa Đại Nam và văn hóa hiện đại. Sáu giai đoạn này tạo thành\
\ ba lớp:\r\nlớp văn hóa bản địa, lớp văn hóa giao lưu với Trung Hoa và khu vực,\
\ lớp văn\r\nhóa giao lưu với phương Tây.\r\n3.1. Lớp văn hóa bản địa\r\n28\r\n\
Downloaded by Tu?n ?ào Minh ([email protected])\r\nlOMoARcPSD|49704028"
- "trái), và hình bán nguyệt (đôi dưới, phải). Trước mắt ta là sự hòa hợp tuyệt\
\ vời\r\ncủa cái động (vật nhau) trong thế tĩnh của ba hình hình học với những\
\ cạnh đáy\r\nvững vàng cho thấy sự ngang sức ngang tài của các chàng trai; sự\
\ vận động liên\r\ntục của cơ bắp như dừng lại. Hai người chờ vật được khuôn lại\
\ trong hai hình\r\nchữ nhật đứng tạo nên cảm giác co ro bất tận trong cái rét\
\ của lễ hội đầu xuân.\r\n4.1.3. Thủ pháp mô hình hóa đã tạo nên một nền nghệ\
\ thuật trang trí và\r\nnhiều mô hình mang tính triết lí sâu sắc.\r\nBộ Tứ Linh\
\ (Hình 4.20a) với long (rồng) biểu trưng cho uy là nam tính; li\r\n(= long mã)\
\ hoặc lân (kì lân, con vật tưởng tượng đầu sư tử, mình nai, đuôi trâu,\r\n131\r\
\nDownloaded by Tu?n ?ào Minh ([email protected])\r\nlOMoARcPSD|49704028\r\
\năn cỏ, rất hiền lành - hình 4.20b) biểu trưng cho ước vọng thái bình, quy (rùa)\r\
\nhiểu tượng cho sự sống lâu và phượng (phụng) biểu tượng cho nữ tính. Rồng -\r\
\nPhượng biểu tượng cho hạnh phúc lứa đôi (ở Trung Hoa hiên tượng này là\r\n“loan-phượng”:\
\ loan là con đực, phượng là con cái). Đồ án trang trí RỒNG phổ\r\nbiến đến mức\
\ phản ánh những đặc trưng cửa từng thời đại. Rồng thời Hùng\r\nvương, thời Lí,\
\ Trần, Hồ, Lê, Mạc, Nguyễn – mỗi thời có những nét đặc thù\r\nriêng tương ứng\
\ với thời đại của mình.\r\nTứ linh cộng thêm ngư-phúc-hạc-hổ thì thành BÁT VẬT.\
\ Ngư (Cá) gắn\r\nvới truyền thuyết \"cá hóa rồng\" biểu tượng cho sự thành đạt.\
\ Chữ phúc là “sự tốt\r\nlành, may mắn” đồng âm và viết gần giống với chữ bức\
\ nghĩa là \"con dơi\", vì"
- source_sentence: Nhiệm vụ quan trọng nhất của các nước công nghiệp chủ nghĩa châu
Âu và Nhật Bản sau chiến tranh thế giới thứ hai là gì?
sentences:
- "Dupuis phái tự mình hành động. Tháng 10-1872, Dupuis đi Hương \r\nCảng và Thượng\
\ Hải mua pháo thuyền và đạn dược, mộ quân lính,\r\n1. Đó là các cuộc thám hiểm\
\ cùa phái đoàn Doudard de Lagrée và Francis \r\nGamier vào những năm từ 1866\
\ đến 1870.\r\n2. Nguyễn Phan Quang (1949), Việt Nam thế ky XIX (1802-1884), Nxb.\
\ \r\nThành phố Hồ Chí Minh, tr. 321.\r\n159\r\nLỊCH SỪ VIỆT NAM - TẬP 6\r\nrồi\
\ đến tháng 11 năm đó thì kéo nhau về Bắc Kỳ. Cùng lúc đó, bọn \r\nthực dân hiếu\
\ chiến ở Nam Kỳ cũng lợi dụng việc triều đình Huế \r\nyêu cầu đưa ra Bắc tiễu\
\ trừ giặc biển để phái tàu chiến ra tiếp tay \r\ncho Dupuis. Cậy có lực lượng\
\ mạnh, Dupuis buộc Kinh lược sứ Lê \r\nTuấn trong vòng hai tuần phải xin triều\
\ đình Huế cho phép hắn \r\nđược mượn đường đi lên Vân Nam. Nhung hạn 2 tuần chưa\
\ hết và \r\ngiấy phép cũng chưa có mà Dupuis đã nổ súng, rồi tự tiện kéo đoàn\
\ \r\ntàu vào Cửa cấm (Hải Phòng) ngược sông Hồng lên Hà Nội (ngày \r\n22-12-1872).\
\ Theo sử nhà Nguyễn thì ngày 2-12-1872, Dupuis “từ\r\nHài Dương đi đen Bắc Ninh,\
\ Hà Nội, các quan tình và quân thứ 2-\r\n3 lần biện bác ngăn trở không cho đi,\
\ nhưng chúng không nghe\r\nTrong khoảng thời gian từ năm 1872 đến năm 1873, Dupuis\
\ đã ỷ \r\nthế quân Pháp và triều đình nhà Thanh, trắng trợn xâm phạm chủ \r\n\
quyền Việt Nam, liên tiếp gây ra nhiều vụ khiêu khích, cướp phá \r\nđối với nhân\
\ dân dọc hai bờ sông, tấn công các đồn bốt của triều \r\nđình nhà Nguyễn.\r\n\
Trước hành động ngang ngược cùa Dupuis, quân dân Hà Nội \r\nmặc dù chưa có lệnh\
\ triều đình nhung vẫn tích cực đề phòng. Lệnh"
- "hội loài người nói chung hay cùa một quốc gia, một dân tộc nói \r\nriêng. Nghiên\
\ cứu lịch sử là nhằm tìm hiểu những sự kiện xảy ra \r\ntrong quá khứ để từ đó\
\ rút ra các bài học kinh nghiệm cho hiện tại \r\nvà tương lai. Nghiên cứu và\
\ biên soạn lịch sừ, vì vậy, trở thành một \r\nyêu cầu bức thiết của mọi quốc\
\ gia, dân tộc. Phạm Công Trứ, nhà \r\nchính trị danh tiếng, nhà sử học sống ở\
\ thế kỳ XVII, trong bài Tựa\r\nsách Đại Việt sử ký bản kỷ tục biên viết: \"Vì\
\ sao mà làm quốc sử?\r\nVĩ sử chù yếu là để ghi chép sự việc. Có chinh trị cùa\
\ một đời tất\r\nphải có sử của một đời. Mà ngòi bút chép sử giữ nghị luận rất\r\
\nnghiêm, ca ngợi đời thịnh trị thì sáng tỏ ngang với mặt trời, mặt\r\ntrăng,\
\ lên án kẻ loạn tặc thì gay gắt nhu sương thu lạnh buốt,\r\nngười thiện biết\
\ có thể bắt chước, người ác biết có thể tự răn, quan\r\nhệ đến việc chính trị\
\ không phải là không nhiều. Cho nên làm sử là\r\ncốt để cho được như thế\"'.\r\
\nViệt Nam là một dân tộc có lịch sử lâu đời. Việt Nam cũng là \r\nmột dân tộc\
\ yêu sử và có rất nhiều người ham thích tìm tòi, nghiên \r\ncứu và biên soạn\
\ lịch sử. Đã có nhiều công trình lịch sử được công \r\nbố, không chi do các cơ\
\ quan, tổ chức chuyên nghiên cứu biên \r\nsoạn, mà còn do cá nhân người yêu sử\
\ thực hiện... Điều này vừa có \r\nmặt tích cực, lại cỏ mặt tiêu cực. Tích cực\
\ vì sẽ góp phần giúp nhân \r\ndân hiểu thêm về lịch sử nước nhà, nhưng cũng chứa\
\ đựng yếu tố \r\ntiêu cực là dễ dẫn tới những hiểu biết phiến diện, sai lầm về\
\ lịch \r\nsử... đôi khi đồng nhất truyền thuyết với lịch sử?"
- "LỊCH SỪ VIỆT NAM - TẬP 11\r\ngiầu mạnh hcm nhờ chiến tranh. Những nước bại trận\
\ như Đức, Ý, \r\nNhật thì kiệt quệ. Song dù thắng hay bại, sự kết thúc chiến\
\ tranh đặt \r\ncho mỗi nước những yêu cầu cấp bách cần giải quyết, tạo nên \r\
\nnhững đặc trưng kinh tế - xã hội ở nhóm nước này.\r\nSau chiến tranh thế giới,\
\ những nưóc công nghiệp chủ nghĩa \r\nchâu Âu và Nhật Bản đều bị chiến tranh\
\ tàn phá nặng nề. Nhiệm vụ \r\nquan trọng của họ ỉà hàn gắn vết thương chiến\
\ tranh, khôi phục \r\nkinh tế, ổn định đời sống xã hội. Đối với Mỹ, nhiệm vụ\
\ chủ yếu là \r\nphải chuyển hướng vận hành kinh tế từ một nền kinh tế phục vụ\
\ \r\nquân sự thời chiến sang nền kinh tế thời bình.\r\nNhừng nét cơ bản của tình\
\ hình thế giới nêu trên đã tác động \r\nđến hầu hết các khu vực trên thế giới,\
\ đặc biệt là khu vực Châu Á \r\nvà Đông Nam Á, tạo điều kiện thuận lợi cho cuộc\
\ đấu tranh giải \r\nphóng của các dân tộc Đông Dương. Từ đầu những năm 1950,\
\ tình \r\nhình cách mạng ba nước Đông Dương chuyển biến nhanh chóng. \r\nVới\
\ cuộc đi thăm Trung Quốc, Liên Xô của Chủ tịch Hồ Chí Minh \r\nđầu năm 1950 và\
\ việc các nước xã hội chủ nghĩa công nhận và đặt \r\nquan hệ ngoại giao với Chính\
\ phủ Việt Nam Dân chủ Cộng hòa là \r\nmột thắng lợi ngoại giao vô cùng quan trọng.\
\ Thắng lợi về ngoại \r\ngiao này đã chấm dứt thời kỳ chiến đấu đom độc, hầu như\
\ bị cách ly \r\nvới bên ngoài và từ đó tiếp nhận được sự đồng tình về chính trị\
\ và \r\nsự viện trợ về vật chất.\r\nVới sự giúp đỡ của Liên Xô, Trung Quốc và\
\ các nước xã hội"
- source_sentence: Chức năng của quan Đốc học trong việc quản lý giáo dục ở các tỉnh
là gì?
sentences:
- "Định, Phú Yên, Biên Hoà, Gia Định, Vĩnh Long, Định Tường, An \r\nGiang đều đặt\
\ mỗi tỉnh một quan Đốc học coi việc học chính trong \r\ntinh. Các tỉnh từ Quảng\
\ Trị, Quảng Bình, Hà Tĩnh, Nghệ An, \r\nThanh Hoá, Ninh Bình, Nam Định, Hà Nội,\
\ Hưng Yên, Hải Dương, \r\nSơn Tây, Bắc Ninh cũng đều đật chức Đốc học. Tinh nào\
\ khuyết \r\nchức Đốc học thì đặt Thự đốc học tạm quyền đốc học một thời gian\
\ \r\nđổ phụ trách, đôn đốc việc học trong tỉnh.\r\nCác tỉnh Khánh Hoà, Bình Thuận,\
\ Hà Tiên, Quảng Yên, Hưng \r\nHoá, Tuyên Quang, Thái Nguyên, Lạng Sơn, Cao Bằng,\
\ do số học \r\nsinh ít nên đến cuối thời Thiệu Trị (1847) vẫn chưa đặt chức Đốc\
\ học.\r\nTheo lệ Nhà nước chế cấp ấn quan phòng giao cho Đốc học lo \r\nviệc\
\ học chính trong địa hạt của tinh sờ tại, trong đó có việc xây \r\ndựng trường\
\ sở ở tinh, phù, hoặc huyện, châu; sắp xếp các thày \r\ngiáo và tuyển chọn học\
\ sinh vào học ở các trường. Những công \r\nviệc licn quun đén việc học đểu có\
\ sự phối hựp giữa quan Đốc hục \r\nvới các viên giữ chức Giáo thụ ở các phủ và\
\ Huấn đạo ờ các huyện, \r\nchâu. Một bộ máy giáo dục được tổ chức chặt chẽ theo\
\ ngành dọc \r\ntừ tinh đến phủ, huyện, châu; tổng (ở tổng có Tổng giáo) để theo\
\ \r\ndõi, đôn đốc việc giảng dạy và học tập, đã góp phần đẩy mạnh hom \r\nviệc\
\ giáo dục ở những triều vua Nguyễn nửa đầu thế kỳ XIX. Những \r\nthành tích của\
\ giáo dục bấy giờ biểu hiện rõ nhất ở việc Nhà nước \r\ncứ 3 năm lại mở một kỳ\
\ thi Hương ờ một số tinh thuộc Bác Kỳ (Nam \r\nĐịnh, Hài Dương, Thăng Long);\
\ Nghệ An; kinh đô Huế; Trung Kỳ"
- "Trước tình hình thế giới và trong nước ngày càng khẩn trương, ngày 28 - I - 1941,\r\
\nlãnh tụ Nguyễn Ái Quốc về nước triệu tập Hội nghị lần thứ 8 Ban Chấp hành\r\n\
Trung ương Đảng Cộng sản Đông Dương. Hội nghị họp tại Pác Bó (Cao Bằng) từ\r\n\
ngày 10 đến ngày 19 - 5 - 1941.\r\nHội nghị chủ †rương trước hết phởi giỏi phóng\
\ cho được cóc dôn tộc\r\nĐông Dương ro khỏi éch Phớp - Nhột. Hội nghị quyết định\
\ tiếp tục tạm\r\ngóc khổu hiệu “Đónh đổ địa chủ, chia ruộng đốt cho dôn còy”\
\ thay bằng\r\ncóc khổu hiệu “Tịch thu ruộng đốt của đế quốc vò Việt gian chia\
\ cho dên\r\ncòy nghèo, giởm †ô, giỏm tức, chia lợi ruộng công”, tiến tới thực\
\ hiện\r\n“Người còy có ruộng”. Hội nghị chủ trương †hònh lộp Việt Nơm độc lập\r\
\nđồng minh (gọi tốt lò Việt Minh) bao gồm céc †ổ chức quồn chúng, lốy\r\ntên\
\ lò Hội Cứu quốc nhồm : “Liên hiệp hết thỏy cóc giới đồng bèo yêu\r\nnước, không\
\ phôn biệt giòu nghèo, giò trẻ, gới trai, không phôn biệt tôn\r\ngiáo vò xu hướng\
\ chính trị, đặng cùng nhau mưu cuộc dôn tộc giỏi phóng\r\nvò sinh tồn” °°,\r\n\
\r\nMặt trận Việt Minh chính thức thành lập ngày 19 - 5 - 1941. Chỉ sau một thời\r\
\ngian ngắn, tổ chức này đã có uy tín và ảnh hưởng sâu rộng trong nhân dân. Sau\
\ Hội\r\nnghị Trung ương, lãnh tụ Nguyễn Ái Quốc đã gửi thư kêu gọi đồng bào cả\
\ nước\r\nđoàn kết thống nhất đánh đuổi Pháp - Nhật."
- "\"Chính sự ngày một đổ nát, đói kém xảy ra luôn luôn. Nhân dân cùng\r\nquân,\
\ khốn khổ, giặc cướp nổi lên ở nhiễu nơi\".\r\n(Khâm định Việt sử thông giám\
\ cương mục)\r\n\r\nỞ Nghệ An, Thanh Hoá, Ninh Bình,... dân nghèo nổi dậy đấu\
\ tranh. Trong\r\ntình hình đó, một số thế lực phong kiến ở các địa phương lại\
\ đánh giết lẫn\r\nnhau, quấy phá nhân dân và chống lại triều đình. Nhà Lý phải\
\ dựa vào thế lực\r\nhọ Trần để chống lại các lực lượng nổi loạn nên đã tạo điều\
\ kiện và thời cơ cho\r\nhọ Trần buộc Chiêu Hoàng (vua cuối cùng của nhà Lý) phải\
\ nhường ngôi cho\r\nTrần Cảnh vào tháng 12, năm Ất Dậu (đâu năm 1226).\r\n\r\n\
(1) Việc thổ mộc : việc làm nhà cửa, chùa, đền, đào sông, hồ..."
- source_sentence: Thiệu Trị đã xử lý trường hợp của Lý Văn Phức và việc người Pháp
bắt giữ thuyền quân đi tuần biển của Việt Nam ra sao?
sentences:
- "hóa; thuế độc quyền; thué điền thổ...\r\nTheo những con số thống kê chính thức\
\ thì các loại thuế trên \r\nđều tăng lên đáng kể, khoảng từ ba đến hơn ba lần\
\ vào năm 1945 \r\n(số dự thu) so với năm 1939 (số thực thu) như sau:\r\nBảng\
\ 29: Thu nhập từ một sổ loại thuế ở Đông Dương \r\ntrong các năm 1939 và 19453\r\
\nĐom vị: nghìn đồng\r\nThuế 1939 1945\r\nThuế tiêu thụ và vận chuyển hàng hoá\
\ 20.655.000 58.265.000\r\nThuế muối, rượu, thuốc phiện, diêm, pháo,\r\nthuốc\
\ lá\r\n24.694.000 87.000.000\r\nThuế điền thổ, trước bạ 11.821.000 28.625.000\r\
\nvề thuốc phiện, do việc nhập khẩu bị ngừng, Pháp khuyến khích \r\nnhân dân thượng\
\ du trồng loại cây này nên số thuốc phiện sản xuất \r\nđược ngày một tăng: năm\
\ 1940: 7.560kg; nãm 1941: 17.344kg; năm\r\n1. Annuaire statistique de V Union\
\ f,rariỊaise Outre- mer 1939-1946, tr. K -\r\n90-93.\r\n2, 3. Annuaire statistique\
\ de runion firanẹaise Outre - mer 1939-1946, tr.\r\nK-90.\r\n552"
- "Chương I. Chính sách thuộc địa của Pháp..\r\nbộ đồng bào các dân tộc thiểu số.\
\ về phương diện này, chính quyền \r\nthuộc địa còn muốn đi xa hơn là cố định\
\ đồng bào vào một không \r\ngian nhất định, rồi đưa họ đến với chế độ sở hữu\
\ ruộng đất - chế độ \r\nsở hữu tập thể và ấn định cho họ một chế độ thuế khóa.\r\
\nNhư vậy, “chính sách thâm nhập” có xuất phát điểm là chính \r\nsách “chia đế\
\ trf' và mục tiêu là tách các dân tộc thiểu số ra khỏi \r\ndân tộc Kinh, dùng\
\ dân tộc nọ chống lại dân tộc kia và nhằm một \r\nmục đích cao hơn là từ chinh\
\ phục, khuất phục về chính trị để tiến \r\nsang khai thác, bóc lột về đất đai,\
\ nhân công và thuế khóa của các \r\nđồng bào.\r\n7. Một số “cải cách” xã hội\
\ khác liên quan đến nông dân và\r\ncông nhân\r\nLiên quan đến nông dân, trong\
\ bài diễn văn về Tinh hình Đông\r\nDương và tuyên bo cải cách vào tháng 9/19301,\
\ Pierre Pasquier nêu \r\nra những vấn đề như: thi hành luật điền thổ, giúp nông\
\ dân Nam Kỳ \r\nthế chấp ruộng đất để vay tín dụng ngân hàng; dẫn thủy nhập điền,\
\ \r\nlàm thuỷ lợi để tăng diện tích canh tác, cải tiến kỹ thuật trồng trọt; \r\
\ngiúp nông dân thăng tién về sờ hữu ruộng đất (từ người không có \r\nđất lên\
\ tiểu điền chủ); mở rộng việc nhượng đất, khẩn hoang ở \r\nnhững vùng rừng núi\
\ ở Bắc và Trung Kỳ cũng như ở phía tây và \r\nnam Nam Kỳ; quy định lại chế độ\
\ lĩnh canh để \"hạn ché bớt sự bóc\r\nlột cùa địa chù đoi với tá điền”.\r\nTriển\
\ khai những “cải cách” này, Pierre Pasquier cho tiếp tục \r\nxây dựng các công\
\ trình thuỷ nông, rồi thành lập Hội đồng Khẩn"
- "theo vài mươi người, đeo gươm, đeo súng, đến thẳng ngay công \r\nquán, đưa ra\
\ một lá thư của nước Pháp bằng chữ Hán, lời lẽ ngang \r\nngược. Lý Văn Phức không\
\ nhận thư, Lạp Biệt Nhĩ quát to doạ nạt, \r\nđể lại thư xuống ghế rồi đi. Lý\
\ Văn Phức và Nguyễn Đình Tân bàn \r\nvới nhau rằng: \"Nhận lấy thư là có tội,\
\ mà đốt thư đi cũng có tội, \r\nkhông gì bằng cho chạy trạm về đệ tâu lên\".\
\ Lý Văn Phức về Kinh,\r\n1. Thực lục, tập VI, sđd, tr. 301.\r\n492\r\nChương\
\ VII. Quan hệ đối ngoại\r\nThiệu Trị giận là làm mất quốc thể, sai vệ cẩm y đóng\
\ gông đem \r\ngiam ở Tà đãi lậu, bắt giải chức, giao cho đình thần bàn.\r\nKhi\
\ ấy, bọn Pháp ngày thường lên bờ, ngông nghênh đi lại các \r\nnơi giao tiếp với\
\ dân đi đạo. Những thuyền quân đi tuần biển bị \r\nchúng bắt giữ lại ở cừa biển\
\ và cướp lấy buồm thuyền và dây buộc \r\nthuyền cùa 5 chiếc thuyền bọc đồng ở\
\ Kinh phái đi Nam (Kim \r\nƯng, Phấn Bằng, Linh Phượng, Thọ Hạc, Vân Bằng) đậu\
\ ở vụng \r\nTrà Sơn, đối diện vói chiến thuyền Pháp.\r\nViệc báo lên, Thiệu Trị\
\ sai ngay Đô thống Hữu quân Mai Công \r\nNgôn, Tham tri Bộ Hộ Đào Trí Phú đem\
\ biền binh 3 vệ Vũ lâm, Hổ \r\noai, Hùng nhuệ đến Quảng Nam cùng với lực lượng\
\ thủy, bộ tại \r\nchỗ tổ chức bố phòng. Thiệu Trị truyền chi căn dặn Mai Công\
\ \r\nNgôn và Đào Trí Phú rằng: \"Người Tây dương nếu đã sợ uy, thu \r\nhình,\
\ thì ta không nên tự động thủ trước; nếu chúng sinh chuyện \r\ntrước, thì đốc\
\ sức thành đài cùng biền binh các hiệu thuyền và \r\nthuyền đồng do Kinh phái\
\ đi, ngoài hợp, trong ứng, lập tức đánh"
- source_sentence: Gia Cát Lượng đã giúp ai trong việc quản lý nước Thục?
sentences:
- "phải trông coi mọi việc, giúp Thành Vương đến lúc trưởng thành. \r\n4\r\n Hoắc\
\ Quang giữ chức Đại tư mã tướng quân, phò Hán Chiêu Đế lúc lên ngôi mới 9 tuổi.\
\ \r\n5\r\n Gia Cát Lượng tức Khổng Minh, là thừa tướng của Chiêu Đế Lưu Bị nước\
\ Thục đời Tam Quốc. Lưu Bị chết, con là Lưu Thiện nối \r\nngôi, tức Thục Hậu\
\ chúa, mọi việc nước, việc quân đều phải trông cậy vào Gia Cát Lượng. \r\n6\r\
\n Tô Hiến Thành là Thái úy triều Lý Cao Tông, nhận di mệnh Cao Tông phò vua nhỏ\
\ là Long Cán lên nối ngôi mới 3 tuổi. \r\n7\r\n Tứ phụ: nghĩa là bốn viên đại\
\ thần giúp vua khi mới lên ngôi. \r\n8\r\n Chỉ Thuận Tông. \r\n9\r\n Xích chủy:\
\ nghĩa là mõm đỏ, miệng đỏ, hay đỏ mỏ. Xích chủy hầu là loài đỏ mỏ ám chỉ Lê\
\ Quý Ly. \r\n10 Bạch kê: nghĩa là gà trắng. Nghệ Tông sinh năm Tân Dậu, tức năm\
\ gà. Tân thuộc hành kim, loài kim sắc trắng. Vì thế \"bạch kê\" \r\nám chỉ Nghệ\
\ Tông. \r\n11 Chữ vương? ở trong lòng chữ khẩu? là chữ \"quốc\"?. \r\n12 Theo\
\ tục nhà Trần, hằng năm vào ngày mồng 4 tháng 4, vua hội họp bề tôi làm lễ tuyên\
\ thệ ở đền Đồng Cổ. (Xem bản kỷ, quyển \r\n5, Kiến Trung năm thứ 3, 1277). \r\
\n13 Chỉ Quý Ly. \r\n288 Đại Việt Sử Ký Toàn Thư - Bản Kỷ - Quyển VIII \r\nQuý\
\ Ly bỏ mũ, rập đầu khóc lóc từ tạ, chỉ trời vạch đất thề rằng: \r\n\"Nếu thần\
\ không biết dốc lòng trung, hết sức giúp Quan gia để truyền đến con cháu về sau\
\ thì \r\ntrời sẽ ghét bỏ thần\". \r\nQuý Ly lại nói: \"Lúc Linh Đức Vương làm\
\ điều thất đức, nếu không nhờ oai linh bệ hạ thì thần đã"
- "éo, xênh xang lạ hom cả\", và gánh xiếc của BẮc thành trổ tài dịp Đại \r\nkhánh\
\ \"Ngũ tuần\" của vua: \"4 đứa leo dây, đứa trẻ lộn dây, đứa trẻ \r\nmúa trên\
\ bàn tay 2 đứa\".\r\nNhững định chế về tổ chức và hoạt động nghệ thuật của nhà\
\ \r\nNguyễn đã có tác dụng quan ữọng kích thích các loại hình vãn nghệ \r\ndân\
\ gian phát triển cả về số lượng lẫn chất lượng. Trong các đợt biểu \r\ndiễn ở\
\ Kinh đô, trước yêu cầu thưởng lãm nghiêm ngặt và cao hơn \r\nđịa phương, các\
\ nhà viết kịch bản. đạo diễn, diễn viên phải trau dồi để \r\nnâng cao năng lực\
\ sáng tác, dàn dựng và kỹ năng biểu diễn.\r\n2. Nghệ thuật dân gian\r\nSinh hoạt\
\ văn nghệ dân gian trong các làng quê cũng phát triển. \r\nỞ Bắc Kỳ, Bắc Trung\
\ Kỳ, hát ả đào rất phổ biến. Bên cạnh đó là \r\ncác thể loại dân ca: hát Xoan\
\ ở Phú Thọ, Quan họ Bắc Ninh, hát \r\nSli, Then ở Lạng Sơn, hát Ví dặm, Phường\
\ vải ở Nghệ An, Hà \r\nTĩnh. Ở các tinh trung du và đồng bằng Bắc Bộ, Thanh Hóa,\
\ chèo \r\nsân đình mang tính trào lộng nở rộ. Thể loại trò hài, xiếc ở Bắc Kỳ\
\ \r\ncũng thu hút đông đảo khán giả.\r\n639"
- "Tây. Ngoài cơ sờ đúc súng cũ của tiên triều, năm 1825 vua Minh \r\nMệnh mờ thêm\
\ sáu xưởng nữa. vốn cần cù và ham học hỏi sáng \r\ntạo, những người thợ quân\
\ giới đã được \"thứ súng tay nạp thuốc nổ \r\nmạnh theo kiểu Tây dương\". Vào\
\ những năm cuối triều Minh \r\nM ệnh, họ đã đúc 15 cỗ đại pháo X ung tiêu băng\
\ đồng và hai cỗ \r\nsúng lớn Chấn hải, loại đại pháo lợi hại trong thủy chiến\
\ phương \r\nTây. Sau đó, lại xuất xưởng tiếp 30 cỗ Chấn hải. Năm 1829, quản \r\
\nkho Hải Dương là Tôn Thất Thiện cùng với 100 lính Chấn cơ chế \r\nra cối gỗ\
\ chạy bàng sức nước ở khe suối để giã, luyện thuốc súng. \r\nDụng cụ này là xe\
\ \"Thủy hỏa ký tế\", và những năm sau được phổ \r\ncập trong quân ngũ. Từ vũ\
\ khí phương Tây, người Đại Nam đã tự \r\ntìm hiểu từng chi tiết để chế tạo thước\
\ đo ngắm bắn, thước kiểm tra \r\nthuốc súng. Trong bảy năm ờ ngôi, vua Thiệu\
\ Trị đúc 9 cỗ súng \r\nbàng đồng hiệu là \"Thần uy phục viễn đại tướng quân\"\
, cỗ to nhất \r\nlà 10.706 cân, cỗ nhỏ nhất là 10.222 cân, tổng cộng là 93.829\
\ cân.\r\n649\r\nLỊCH SỬ VIỆT NAM - TẬP 5\r\nVà ba cỗ súng hiệu \"Bảo Đại định\
\ công an dân hòa chúng thượng \r\ntướng quân\", mỗi cỗ trên 14.500 cân, tổng\
\ cộng là 43.620 cân1.\r\nĐe tạo điều kiện cho quân thủy học tập, bộ Công cấp\
\ cho họ la \r\nbàn, thước đo nước, đồng hồ cát xem giờ của phương Tây. v ề khoa\
\ \r\nmục bắn súng thì lính thủy phải tập bắn súng điểu sang và đại bác. \r\n\
Minh Mệnh yêu cầu Hiệp biện Đại học sĩ lãnh Thượng thư bộ Binh \r\nTrương Đăng\
\ Quế đọc kỹ các sách và bản đồ thủy chiến \"Tây"
model-index:
- name: SentenceTransformer based on Alibaba-NLP/gte-multilingual-base
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: Alibaba NLP/gte multilingual base
type: Alibaba-NLP/gte-multilingual-base
metrics:
- type: cosine_accuracy@1
value: 0.4269406392694064
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.6648401826484018
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.7388127853881279
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.8168949771689498
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.4269406392694064
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2216133942161339
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1477625570776256
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08168949771689496
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.4269406392694064
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.6648401826484018
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.7388127853881279
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.8168949771689498
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.6233026051051767
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.5611618467782854
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.5670558073651792
name: Cosine Map@100
---
# SentenceTransformer based on Alibaba-NLP/gte-multilingual-base
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [Alibaba-NLP/gte-multilingual-base](https://huggingface.co/Alibaba-NLP/gte-multilingual-base) on the csv dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [Alibaba-NLP/gte-multilingual-base](https://huggingface.co/Alibaba-NLP/gte-multilingual-base) <!-- at revision ca1791e0bcc104f6db161f27de1340241b13c5a4 -->
- **Maximum Sequence Length:** 8192 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- csv
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False}) with Transformer model: NewModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("minhtuan7akp/gte-vietnamese-finetune")
# Run inference
sentences = [
'Gia Cát Lượng đã giúp ai trong việc quản lý nước Thục?',
'phải trông coi mọi việc, giúp Thành Vương đến lúc trưởng thành. \r\n4\r\n Hoắc Quang giữ chức Đại tư mã tướng quân, phò Hán Chiêu Đế lúc lên ngôi mới 9 tuổi. \r\n5\r\n Gia Cát Lượng tức Khổng Minh, là thừa tướng của Chiêu Đế Lưu Bị nước Thục đời Tam Quốc. Lưu Bị chết, con là Lưu Thiện nối \r\nngôi, tức Thục Hậu chúa, mọi việc nước, việc quân đều phải trông cậy vào Gia Cát Lượng. \r\n6\r\n Tô Hiến Thành là Thái úy triều Lý Cao Tông, nhận di mệnh Cao Tông phò vua nhỏ là Long Cán lên nối ngôi mới 3 tuổi. \r\n7\r\n Tứ phụ: nghĩa là bốn viên đại thần giúp vua khi mới lên ngôi. \r\n8\r\n Chỉ Thuận Tông. \r\n9\r\n Xích chủy: nghĩa là mõm đỏ, miệng đỏ, hay đỏ mỏ. Xích chủy hầu là loài đỏ mỏ ám chỉ Lê Quý Ly. \r\n10 Bạch kê: nghĩa là gà trắng. Nghệ Tông sinh năm Tân Dậu, tức năm gà. Tân thuộc hành kim, loài kim sắc trắng. Vì thế "bạch kê" \r\nám chỉ Nghệ Tông. \r\n11 Chữ vương? ở trong lòng chữ khẩu? là chữ "quốc"?. \r\n12 Theo tục nhà Trần, hằng năm vào ngày mồng 4 tháng 4, vua hội họp bề tôi làm lễ tuyên thệ ở đền Đồng Cổ. (Xem bản kỷ, quyển \r\n5, Kiến Trung năm thứ 3, 1277). \r\n13 Chỉ Quý Ly. \r\n288 Đại Việt Sử Ký Toàn Thư - Bản Kỷ - Quyển VIII \r\nQuý Ly bỏ mũ, rập đầu khóc lóc từ tạ, chỉ trời vạch đất thề rằng: \r\n"Nếu thần không biết dốc lòng trung, hết sức giúp Quan gia để truyền đến con cháu về sau thì \r\ntrời sẽ ghét bỏ thần". \r\nQuý Ly lại nói: "Lúc Linh Đức Vương làm điều thất đức, nếu không nhờ oai linh bệ hạ thì thần đã',
'Tây. Ngoài cơ sờ đúc súng cũ của tiên triều, năm 1825 vua Minh \r\nMệnh mờ thêm sáu xưởng nữa. vốn cần cù và ham học hỏi sáng \r\ntạo, những người thợ quân giới đã được "thứ súng tay nạp thuốc nổ \r\nmạnh theo kiểu Tây dương". Vào những năm cuối triều Minh \r\nM ệnh, họ đã đúc 15 cỗ đại pháo X ung tiêu băng đồng và hai cỗ \r\nsúng lớn Chấn hải, loại đại pháo lợi hại trong thủy chiến phương \r\nTây. Sau đó, lại xuất xưởng tiếp 30 cỗ Chấn hải. Năm 1829, quản \r\nkho Hải Dương là Tôn Thất Thiện cùng với 100 lính Chấn cơ chế \r\nra cối gỗ chạy bàng sức nước ở khe suối để giã, luyện thuốc súng. \r\nDụng cụ này là xe "Thủy hỏa ký tế", và những năm sau được phổ \r\ncập trong quân ngũ. Từ vũ khí phương Tây, người Đại Nam đã tự \r\ntìm hiểu từng chi tiết để chế tạo thước đo ngắm bắn, thước kiểm tra \r\nthuốc súng. Trong bảy năm ờ ngôi, vua Thiệu Trị đúc 9 cỗ súng \r\nbàng đồng hiệu là "Thần uy phục viễn đại tướng quân", cỗ to nhất \r\nlà 10.706 cân, cỗ nhỏ nhất là 10.222 cân, tổng cộng là 93.829 cân.\r\n649\r\nLỊCH SỬ VIỆT NAM - TẬP 5\r\nVà ba cỗ súng hiệu "Bảo Đại định công an dân hòa chúng thượng \r\ntướng quân", mỗi cỗ trên 14.500 cân, tổng cộng là 43.620 cân1.\r\nĐe tạo điều kiện cho quân thủy học tập, bộ Công cấp cho họ la \r\nbàn, thước đo nước, đồng hồ cát xem giờ của phương Tây. v ề khoa \r\nmục bắn súng thì lính thủy phải tập bắn súng điểu sang và đại bác. \r\nMinh Mệnh yêu cầu Hiệp biện Đại học sĩ lãnh Thượng thư bộ Binh \r\nTrương Đăng Quế đọc kỹ các sách và bản đồ thủy chiến "Tây',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `Alibaba-NLP/gte-multilingual-base`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.4269 |
| cosine_accuracy@3 | 0.6648 |
| cosine_accuracy@5 | 0.7388 |
| cosine_accuracy@10 | 0.8169 |
| cosine_precision@1 | 0.4269 |
| cosine_precision@3 | 0.2216 |
| cosine_precision@5 | 0.1478 |
| cosine_precision@10 | 0.0817 |
| cosine_recall@1 | 0.4269 |
| cosine_recall@3 | 0.6648 |
| cosine_recall@5 | 0.7388 |
| cosine_recall@10 | 0.8169 |
| **cosine_ndcg@10** | **0.6233** |
| cosine_mrr@10 | 0.5612 |
| cosine_map@100 | 0.5671 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### csv
* Dataset: csv
* Size: 21,892 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 9 tokens</li><li>mean: 26.95 tokens</li><li>max: 103 tokens</li></ul> | <ul><li>min: 25 tokens</li><li>mean: 373.94 tokens</li><li>max: 596 tokens</li></ul> |
* Samples:
| anchor | positive |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Tính chất kiến trúc của đình làng triều Mạc được thể hiện qua những đặc điểm gì, như số gian, hình dạng, nội thất và cách bố trí không gian trong công trình?</code> | <code>Đình làng là công trình kiến trúc công cộng được dựng nên
<br>băng sự đóng góp của cải và công sức của cả cộng đồng làng xã.
<br>Ngoài chức năng là trụ sở hành chính của cả làng, ngôi đình còn là
<br>trung tâm sinh hoạt văn hóa làng xã, là nơi diễn ra các nghi lễ trọng
<br>đại trong dịp tế lễ thần Thành hoàng làng và tô chức hội hè hăng
<br>năm. Có thê nói, ngôi đình làng là nơi hội tụ sức mạnh của cả cộng
<br>đồng và là biểu trưng đặc sắc nhất của văn hóa làng xã.
<br>
<br>Trong các ngôi đình triều Mạc, Thân thành hoàng có lý lịch
<br>xuất thân khá phong phú. Tản Viên sơn thánh là vị thần có ảnh
<br>hưởng lớn ở xứ Đoài được thờ phụng ở đình Tây Đăng, Thanh Lũng
<br>và nhiều làng xã khác. Thần Cao Sơn, Quý Minh tương truyền là
<br>tướng tâm phúc của Hùng Vương được thờ ở đình làng Lỗ Hạnh.
<br>Dân làng Lỗ Hạnh còn thờ cả Phương Dung công chúa... Từ thế
<br>kỷ XYVI và các thế kỷ tiếp sau, Thần thành hoàng làng trở thành
<br>vị vua tỉnh thần ở các làng xã, tín ngưỡng thờ cúng Thân thành
<br>hoàng càng trở nên phong phú thê hiện qua lễ...</code> |
| <code>Nguyễn Khắc Nhu có vai trò gì trong khởi nghĩa toàn khu vực miền núi Bắc Kỳ của Việt Nam Quốc dân Đảng vào năm 1930?</code> | <code>bị nổ do bất cẩn. Do đó công việc bị phát hiện. Hai người phụ trách
<br>cơ quan chế bom là Đỗ Cương và Quản Trác trốn thoát. Nhiều binh
<br>lính và dân thường bị bắt. Công việc bạo động của Xứ Nhu không
<br>thành. Đúng lúc này Việt Nam Quốc dân Đảng vừa thành lập, cử
<br>người tới mời Xứ Nhu và Việt Nam Dân quốc gia nhập Việt Nam
<br>Quốc dân Đảng. Hầu hết các đồng chí của Xứ Nhu trở thành đảng
<br>viên của Việt Nam Quốc dân Đảng ở vùng Bắc Ninh, Bắc Giang.
<br>Do đó, Việt Nam Quốc dân Đảng mạnh lên về số lượng1. Cùng với
<br>việc phát triển đảng viên ở Bẳc Ninh, Bắc Giang, Việt Nam Quốc
<br>dân Đảng còn thiết lập nhiều cơ sở ở các tỉnh Thái Bình, Hải Dương,
<br>1. Nguyễn Khắc Nhu tức Xứ Nhu (1882-1930), người làng Song Khê, huyện
<br>Yên Dũng, tinh Bắc Giang. Với lòng yêu nuớc và ý chí chống Pháp,
<br>ông dự tính thành lập một tổ chức hoạt động công khai nhăm đào tạo
<br>tài năng cho đất nước lấy tên là "Hội Quốc dân dục tài”. Việc này
<br>không thành công, ông lại lập tổ chức bí mật nhăm bạo động lật đổ ách
<br>áp b...</code> |
| <code>Giá gạo tháng 3-1950 ở Liên khu IV là bao nhiêu đồng/tạ và có chênh lệch gì so với giá gạo ở Liên khu III và Liên khu Việt Bắc?</code> | <code>ngày càng tăng nhanh, nhất là ở Việt Bắc. Giá gạo tăng mạnh
<br>nhất, giá thực phẩm cũng tăng dần theo giá gạo. Giá các mặt hàng
<br>kỹ nghệ tăng chậm hơn. Giá hàng ngoại hóa hầu như không tăng
<br>vỉ trong vùng Pháp chiếm đóng, hàng ngoại hóa tính bằng tiền
<br>Đông Dương không tăng, hom nữa nhân dân cũng ít tiêu thụ hàng
<br>ngoại hóa vì bị cấm.
<br>1. Viện Kinh tế học, Kinh tế Việt Nam từ Cách mạng Tháng Tám đến..., Sách
<br>đã dẫn, tr. 238.
<br>2. Chuơng trình và báo cáo của Bộ Kinh tế về tình hình hoạt động năm 1950.
<br>Trung tâm lưu trữ quốc gia in, phông Phủ Thủ tướng, Hồ sơ số 1914.
<br>488
<br>Chương VI. Việt Nam dân chủ cộng hòa xây dựng..
<br>Giá gạo trong những tháng đầu năm 1950 so với cuối năm 1949
<br>có thay đổi, Liên khu IV (Thanh Hóa) giá tăng lên 154%; Liên khu
<br>III (Hà Đông - Hà Nam) giá tăng lên 153%; Liên khu Việt Bắc
<br>(Thái Nguyên) giá tăng lên 800%.
<br>Giá gạo ở Thái Nguyên từ 1.625 đồng/tạ lên 13.000 đồng/tạ
<br>(tăng 800%); ờ Phú Thọ từ 2.650 đồng/tạ lên 7.500 đồng/tạ (tăng
<br>283%). Mặt khác, ...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Evaluation Dataset
#### csv
* Dataset: csv
* Size: 21,892 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 26.56 tokens</li><li>max: 108 tokens</li></ul> | <ul><li>min: 24 tokens</li><li>mean: 369.01 tokens</li><li>max: 559 tokens</li></ul> |
* Samples:
| anchor | positive |
|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Nguyễn Hoàng đã thực hiện những hành động gì để dần dần tách khỏi sự ràng buộc của họ Trịnh sau khi trở lại Thuận Quảng vào năm 1600, và những hành động này đã ảnh hưởng như thế nào đến mối quan hệ giữa hai dòng họ?</code> | <code>thẳng đối với họ Nguyễn. Trịnh Tùng đã lấy danh nghĩa vua Lê sai
<br>sứ giả là Thiêm đô ngự sử Lê Nghĩa Trạch đem sắc vào phủ dụ
<br>Nguyễn Hoàng và vẫn cho ở lại trấn thủ, hằng năm nộp thuế như
<br>cũ. Cùng với sắc của vua Lê, Trịnh Tùng có gửi thư kèm theo
<br>Chương ĩ. Sự phân liệt Đàng Trong - Đàng Ngoài...
<br>1, Toàn thư. quyển 17, tập IV, Sđd, tr. 200.
<br>2, Đại Nam thực lục, Tiền biên, quyển 1, tập I, Sđd, tr. 34.
<br>3, Đại Nam thực lục, Tiển biên, quyển 1, tập I, Sđd, tr. 35.
<br>39
<br>LỊCH SỬ VIỆT NAM - TẬP 4
<br>"khuyên giữ việc thuế cống". Nguyễn Hoàng sai sứ giả đáp lễ tạ on
<br>vua Lê và gửi thư cho Trịnh Tùng hẹn kết nghĩa thông gia, đem con
<br>gái là Ngọc Tú gả cho Trịnh Tráng (con Trịnh Tùng) lấy danh
<br>nghĩa hôn nhân để duy trì mối quan hệ bề ngoài giao hảo giữa hai
<br>dòng họ vốn có sẵn một mối thù địch.
<br>- Chính sách cùa họ Nguyễn từ khi Nguyễn Hoàng trở lại
<br>Thuận Quảng
<br>Năm 1600, Nguyễn Hoàng ròi được khỏi đất Bẳc trở về Thuận
<br>Quảng bắt đầu thực hiện một chính sách cai trị mói, dần dần tác...</code> |
| <code>Báo cáo của Ủy ban Kháng chiến hành chính Hà Nội về hoạt động giáo dục bù nhìn và tình hình các giáo sư trường Chu Văn An có nội dung gì?</code> | <code>Tài liệu tham khảo
<br>21. Báo cáo sô' 2 BC/I ngày 12-11-1949 và Báo cáo sô' 463
<br>BC/DB ngày 25-12-1949 của Ty Công an H à Nội. Trung
<br>tâm Lưu trữ Quốc gia III, phông Phủ Thủ tướng, Hồ sơ
<br>SỐ921.
<br>28. Báo “Le song” ngày 11-2-1949. Trung tâm Lưu trữ Quốc
<br>gia III, phông Phủ Thủ tướng, Hồ sơ sô' 2002.
<br>29. Báo cáo của u ỷ ban Kháng chiến hành chính Hà Nội vê
<br>hoạt động giáo dục bù nhìn và tình hình các giáo sư
<br>trường Chu Văn An. Trung tâm Lưu trữ Quốc gia III,
<br>phông Phủ Thủ tướng, Hồ sơ số 979.
<br>30. Báo cáo của Tổng Giám đốc Việt N am Công an vụ sô'
<br>122/NCB3 ngày 1-4-1951. Trung tâm Lưu trữ Quốic gia
<br>III, phông Phủ Thủ tướng, Hồ sơ sô' 979.
<br>31. Báo cáo thành tích về cống tác công an trong 8 năm kháng
<br>chiến (1946-1954) của Bộ Công an. Trung tâm Lưu trữ
<br>Quốc gia III, phông Phủ Thủ tướng, Hồ sơ sô' 927.
<br>32. Báo cáo một năm kháng chiến (12-1946 đến 12-1947) của
<br>UBKCHC Khu 12. Trung tâm Lưu trữ Quốc gia III, phông
<br>Phủ Thủ tướng, Hồ sơ sô" 2000.
<br>33. Báo cáo thành tích quăn sự trong 8 n...</code> |
| <code>Đặc điểm dân số của nước ta ảnh hưởng đến các ngành dịch vụ như thế nào và đòi hỏi những ngành dịch vụ nào cần được ưu tiên phát triển trong quá trình đô thị hóa?</code> | <code>— Trong các thành phố lớn thường hình thành các trung tâm giao dịch,
<br>thương mại. Đó là nơi tập trung các ngân hàng, các văn phòng đại diện
<br>của các công ti, các siêu thị hay các tổ hợp thương mại, dịch vụ lớn...
<br>Ở các thành phố lớn trên thế giới, thường dễ nhận thấy các trung tâm
<br>thương mại này do sự tập trung các ngôi nhà cao tầng, chọc trời. Một
<br>thành phố có thể có trung tâm thương mại chính và một số trung tâm
<br>thương mại nhỏ hơn, kết quả của sự phát triển đô thị.
<br>
<br>— Ở nước ta, các thành phố, thị xã thường có khu hành chính (phân
<br>“đô”) và khu buôn bán, dịch vụ (phân “thị'). Ở Hà Nội, Thành phố
<br>Hồ Chí Minh các trung tâm giao dịch, thương mại của thành phố đang
<br>được hình thành rõ nét.
<br>
<br>CÂU HỎI VÀ BÀI TẬP
<br>
<br>174
<br>
<br>1. Cho biết đặc điểm dân số của nước ta (đông, tăng còn tương đối
<br>nhanh, mức sống đang nâng lên và đô thị hoá đang phát triển với
<br>tốc độ nhanh hơn) có ảnh hưởng đến các ngành dịch vụ như thế
<br>nào ? Các đặc điểm đó đòi hỏi những ngành dịch vụ nào cần được
<br>ưu tiê...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 6
- `per_device_eval_batch_size`: 6
- `learning_rate`: 3e-06
- `num_train_epochs`: 2
- `warmup_ratio`: 0.05
- `bf16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 6
- `per_device_eval_batch_size`: 6
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 3e-06
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 2
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.05
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | Alibaba-NLP/gte-multilingual-base_cosine_ndcg@10 |
|:------:|:----:|:-------------:|:---------------:|:------------------------------------------------:|
| 0.0305 | 100 | 0.1448 | 0.1106 | 0.5590 |
| 0.0609 | 200 | 0.1453 | 0.0878 | 0.5671 |
| 0.0914 | 300 | 0.093 | 0.0642 | 0.5851 |
| 0.1218 | 400 | 0.0763 | 0.0490 | 0.5939 |
| 0.1523 | 500 | 0.0641 | 0.0417 | 0.5992 |
| 0.1827 | 600 | 0.0524 | 0.0388 | 0.5993 |
| 0.2132 | 700 | 0.0495 | 0.0349 | 0.6054 |
| 0.2436 | 800 | 0.0497 | 0.0324 | 0.6059 |
| 0.2741 | 900 | 0.0354 | 0.0311 | 0.6049 |
| 0.3045 | 1000 | 0.0494 | 0.0300 | 0.6088 |
| 0.3350 | 1100 | 0.0596 | 0.0294 | 0.6080 |
| 0.3654 | 1200 | 0.0463 | 0.0284 | 0.6101 |
| 0.3959 | 1300 | 0.0359 | 0.0272 | 0.6097 |
| 0.4263 | 1400 | 0.0458 | 0.0267 | 0.6096 |
| 0.4568 | 1500 | 0.0402 | 0.0265 | 0.6104 |
| 0.4872 | 1600 | 0.0392 | 0.0256 | 0.6099 |
| 0.5177 | 1700 | 0.0425 | 0.0250 | 0.6116 |
| 0.5481 | 1800 | 0.0367 | 0.0250 | 0.6117 |
| 0.5786 | 1900 | 0.0359 | 0.0246 | 0.6091 |
| 0.6090 | 2000 | 0.0304 | 0.0254 | 0.6069 |
| 0.6395 | 2100 | 0.0429 | 0.0247 | 0.6087 |
| 0.6699 | 2200 | 0.0405 | 0.0240 | 0.6137 |
| 0.7004 | 2300 | 0.0206 | 0.0241 | 0.6129 |
| 0.7308 | 2400 | 0.0406 | 0.0237 | 0.6123 |
| 0.7613 | 2500 | 0.0431 | 0.0235 | 0.6138 |
| 0.7917 | 2600 | 0.032 | 0.0233 | 0.6169 |
| 0.8222 | 2700 | 0.0365 | 0.0230 | 0.6145 |
| 0.8526 | 2800 | 0.0319 | 0.0222 | 0.6182 |
| 0.8831 | 2900 | 0.0316 | 0.0225 | 0.6170 |
| 0.9135 | 3000 | 0.0319 | 0.0223 | 0.6179 |
| 0.9440 | 3100 | 0.0458 | 0.0222 | 0.6190 |
| 0.9744 | 3200 | 0.0387 | 0.0221 | 0.6203 |
| 1.0049 | 3300 | 0.0356 | 0.0217 | 0.6216 |
| 1.0353 | 3400 | 0.0298 | 0.0213 | 0.6229 |
| 1.0658 | 3500 | 0.0411 | 0.0211 | 0.6229 |
| 1.0962 | 3600 | 0.0269 | 0.0211 | 0.6231 |
| 1.1267 | 3700 | 0.0279 | 0.0214 | 0.6199 |
| 1.1571 | 3800 | 0.0207 | 0.0213 | 0.6217 |
| 1.1876 | 3900 | 0.0269 | 0.0208 | 0.6231 |
| 1.2180 | 4000 | 0.0282 | 0.0212 | 0.6195 |
| 1.2485 | 4100 | 0.0226 | 0.0212 | 0.6215 |
| 1.2789 | 4200 | 0.0269 | 0.0212 | 0.6219 |
| 1.3094 | 4300 | 0.026 | 0.0212 | 0.6191 |
| 1.3398 | 4400 | 0.026 | 0.0211 | 0.6220 |
| 1.3703 | 4500 | 0.0266 | 0.0213 | 0.6214 |
| 1.4007 | 4600 | 0.034 | 0.0214 | 0.6206 |
| 1.4312 | 4700 | 0.0344 | 0.0213 | 0.6213 |
| 1.4616 | 4800 | 0.0183 | 0.0215 | 0.6219 |
| 1.4921 | 4900 | 0.03 | 0.0214 | 0.6224 |
| 1.5225 | 5000 | 0.0245 | 0.0213 | 0.6226 |
| 1.5530 | 5100 | 0.0372 | 0.0211 | 0.6216 |
| 1.5834 | 5200 | 0.0251 | 0.0209 | 0.6223 |
| 1.6139 | 5300 | 0.0227 | 0.0208 | 0.6222 |
| 1.6443 | 5400 | 0.0256 | 0.0208 | 0.6210 |
| 1.6748 | 5500 | 0.0284 | 0.0209 | 0.6224 |
| 1.7052 | 5600 | 0.0286 | 0.0211 | 0.6218 |
| 1.7357 | 5700 | 0.0271 | 0.0209 | 0.6236 |
| 1.7661 | 5800 | 0.0184 | 0.0209 | 0.6217 |
| 1.7966 | 5900 | 0.0347 | 0.0208 | 0.6219 |
| 1.8270 | 6000 | 0.0245 | 0.0208 | 0.6227 |
| 1.8575 | 6100 | 0.0248 | 0.0207 | 0.6224 |
| 1.8879 | 6200 | 0.0261 | 0.0207 | 0.6235 |
| 1.9184 | 6300 | 0.0284 | 0.0206 | 0.6224 |
| 1.9488 | 6400 | 0.0174 | 0.0207 | 0.6233 |
| 1.9793 | 6500 | 0.0213 | 0.0207 | 0.6233 |
### Framework Versions
- Python: 3.11.11
- Sentence Transformers: 3.4.1
- Transformers: 4.48.0
- PyTorch: 2.5.1
- Accelerate: 1.2.1
- Datasets: 3.2.0
- Tokenizers: 0.21.0
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"CHIA"
] |
RomainDarous/large_directThreeEpoch_additivePooling_randomInit_mistranslationModel
|
RomainDarous
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:4460010",
"loss:CoSENTLoss",
"dataset:RomainDarous/corrupted_os_by_language",
"arxiv:1908.10084",
"base_model:RomainDarous/large_directTwoEpoch_additivePooling_randomInit_mistranslationModel",
"base_model:finetune:RomainDarous/large_directTwoEpoch_additivePooling_randomInit_mistranslationModel",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2025-03-03T01:03:47Z |
2025-03-03T01:04:34+00:00
| 17 | 0 |
---
base_model: RomainDarous/large_directTwoEpoch_additivePooling_randomInit_mistranslationModel
datasets:
- RomainDarous/corrupted_os_by_language
library_name: sentence-transformers
metrics:
- pearson_cosine
- spearman_cosine
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:4460010
- loss:CoSENTLoss
widget:
- source_sentence: Malformed target specific variable definition
sentences:
- Hedefe özgü değişken tanımı bozuk
- Kan alle data in die gids lees
- "слава Украине! героям слава!\uFEFF"
- source_sentence: Can't write an inode bitmap
sentences:
- Skontrolujte stav aktualizácií alebo to skúste znova neskôr.
- Malsukcesis skribi i nodan bitmapon
- Zastępuje wersję GL obsługiwaną przez sterownik
- source_sentence: Optimize soft proofing color transformations
sentences:
- 'arkadaslar biz artik her an kirmizi kart yiyecek,bencil,pas yapamayan,isabetsiz
orta yapani istemiyoruz. sozde efsaneniz bu sezon Besiktasa en cok zarar verenlerden
biriydi. kendini dusunmeden once Besiktasi dusunecek adam lazim bize. o yuzden
#GoHomeQuaresma'
- Yav bizim dedikodusunu yaptığımız insanın bile bi vizyonu var. Senin hakkında
neden oturup konuşalım?
- Ik ben een transgender.
- source_sentence: 'Pass 1: Checking @is, @bs, and sizes'
sentences:
- Bu adam cidden kurabiye gibi ben bunu çayın yanında yerim
- sagnat. errada. invisible. justificació. idioma
- Wilt u echt de primaire sleutel verplaatsen? (j N)
- source_sentence: Search for matching log entries
sentences:
- quem te lembra? caralho tô assustada aqui kkkkk
- sendotasunik gabeko\ egoera bistaratuko den ala ez adierazten du
- En aquest cas, hem d'incloure les imatges del contenidor )sr iov per a càrregues
de treball de telco (per exemple, com a referència, es podrien obtenir des de
valors de helm chart)
model-index:
- name: SentenceTransformer based on RomainDarous/large_directTwoEpoch_additivePooling_randomInit_mistranslationModel
results:
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts eval
type: sts-eval
metrics:
- type: pearson_cosine
value: 0.9796748901363702
name: Pearson Cosine
- type: spearman_cosine
value: 0.8655967158476509
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts test
type: sts-test
metrics:
- type: pearson_cosine
value: 0.9796434217336331
name: Pearson Cosine
- type: spearman_cosine
value: 0.8655941837932101
name: Spearman Cosine
---
# SentenceTransformer based on RomainDarous/large_directTwoEpoch_additivePooling_randomInit_mistranslationModel
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [RomainDarous/large_directTwoEpoch_additivePooling_randomInit_mistranslationModel](https://huggingface.co/RomainDarous/large_directTwoEpoch_additivePooling_randomInit_mistranslationModel) on the [corrupted_open_os_by_language](https://huggingface.co/datasets/RomainDarous/corrupted_os_by_language) dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [RomainDarous/large_directTwoEpoch_additivePooling_randomInit_mistranslationModel](https://huggingface.co/RomainDarous/large_directTwoEpoch_additivePooling_randomInit_mistranslationModel) <!-- at revision 1b3c692dec0c6562b0d9582aa5ba223addc298df -->
- **Maximum Sequence Length:** 128 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- [corrupted_open_os_by_language](https://huggingface.co/datasets/RomainDarous/corrupted_os_by_language)
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): MultiHeadGeneralizedPooling(
(P): ModuleList(
(0-7): 8 x Linear(in_features=768, out_features=96, bias=True)
)
(W1): ModuleList(
(0-7): 8 x Linear(in_features=96, out_features=384, bias=True)
)
(W2): ModuleList(
(0-7): 8 x Linear(in_features=384, out_features=96, bias=True)
)
)
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("RomainDarous/large_directThreeEpoch_additivePooling_randomInit_mistranslationModel")
# Run inference
sentences = [
'Search for matching log entries',
'quem te lembra? caralho tô assustada aqui kkkkk',
'sendotasunik gabeko\\ egoera bistaratuko den ala ez adierazten du',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Semantic Similarity
* Datasets: `sts-eval` and `sts-test`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | sts-eval | sts-test |
|:--------------------|:-----------|:-----------|
| pearson_cosine | 0.9797 | 0.9796 |
| **spearman_cosine** | **0.8656** | **0.8656** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### corrupted_open_os_by_language
* Dataset: [corrupted_open_os_by_language](https://huggingface.co/datasets/RomainDarous/corrupted_os_by_language) at [9d25780](https://huggingface.co/datasets/RomainDarous/corrupted_os_by_language/tree/9d25780e2032b1e8f06af6a4ff55124d7a930c3c)
* Size: 4,460,010 training samples
* Columns: <code>sentence1</code>, <code>sentence2</code>, and <code>score</code>
* Approximate statistics based on the first 1000 samples:
| | sentence1 | sentence2 | score |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 6 tokens</li><li>mean: 18.33 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 26.47 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>0: ~50.60%</li><li>1: ~49.40%</li></ul> |
* Samples:
| sentence1 | sentence2 | score |
|:--------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------|:---------------|
| <code>Check spelling. Print the document. Show completion window. General. Show help</code> | <code>Kontrolli õigekirja. присоединяюсь. </code> | <code>0</code> |
| <code>EXIF not supported for this file format.</code> | <code>Šiam failo formatui EXIF nepalaikomas.</code> | <code>1</code> |
| <code>This package includes the documentation for texlive everyhook</code> | <code>Paket ini menyertakan dokumentasi untuk texlive everyhook</code> | <code>1</code> |
* Loss: [<code>CoSENTLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosentloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "pairwise_cos_sim"
}
```
### Evaluation Dataset
#### corrupted_open_os_by_language
* Dataset: [corrupted_open_os_by_language](https://huggingface.co/datasets/RomainDarous/corrupted_os_by_language) at [9d25780](https://huggingface.co/datasets/RomainDarous/corrupted_os_by_language/tree/9d25780e2032b1e8f06af6a4ff55124d7a930c3c)
* Size: 4,460,010 evaluation samples
* Columns: <code>sentence1</code>, <code>sentence2</code>, and <code>score</code>
* Approximate statistics based on the first 1000 samples:
| | sentence1 | sentence2 | score |
|:--------|:-----------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------|:------------------------------------------------|
| type | string | string | int |
| details | <ul><li>min: 5 tokens</li><li>mean: 17.71 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>min: 3 tokens</li><li>mean: 26.95 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>0: ~50.60%</li><li>1: ~49.40%</li></ul> |
* Samples:
| sentence1 | sentence2 | score |
|:----------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------|
| <code>Could not identify the current seat.</code> | <code> 天天花着男人的钱还这这创造新词汇男权你可真牛批,你也就这一出了一问男权,就说是我是吧,到现在我也没听到你给我们讲的男权,你也就是在网上喷喷,现实走道都不敢探头自卑,你现实要把你女权的劲拿出来总低啥头,您老应该去国家教育局把男权加上是吧,你们女权天天说自己生活不好没地位,给你们地位了你们能干啥?用你们的女权打到全世界男性是吧,能相出男权这一词您老也是人才呀,是不是庆幸自己是个女的,活在自己想想的世界里不觉得孤单吗,假象有男权是吧,自己假象和男权还说自己不是田园女权,田园女权能连自己都骂说自己妈是驴爸是大鼎的也是奇葩呀,那我们国家大肆宣扬过你们这么田园女权吗,国家要的是女性人群自主自理,你们可好看看你们女权干的啥事,给你们女权地位高了,看看你们女权干的事n绿地集团高管怎么都不说呀,人家可是有钱有地位,也不是我们说三从四德洗衣做饭你们女权会吗?,那我问问你们女权干过啥惊天大事,还甩锅给孔子,还封建社会,那我问问你们女权在福利面前为啥说自己是女性呀不是社会主义社会吗不应该男女平等吗,天天自己也不知道是不是抱个手机天天欧巴欧巴,你家那位要是不陪你看一会就会问你是不是不爱我了是吧大姐,您老也就赚这白菜钱操心国家事,中国五千年的历史被您老一句否决,还嘲讽人家日本女性,好意思说自己不是女权,三从四德流传这么久到您这变成日本文化了,我就想问问男权您老是怎么想的,那你问孔子老人家呗为什么女人要三从四德,我说的是女权你干嘛自己对号入座,连中华人民传承的东西都不认跟我这谈男权,还男权您老给我举个例子呗,让我们男权听听都是h啥,这些不都是你们女权的标准吗?,还男权,您老醒醒吧这里是现实,不是你的公主世界,总觉得自己多么多么重要,地球没你是不能转了还是人类要灭亡呀,我真的想问一句你给我找一条男权的新闻,咋了我们男人不能提女权呗你老授权了呗,那我们谈论田园女权你老对号入座干嘛,天天过节要礼物,还嫌弃自己男朋友没有钱,我寻思你找个有钱人包养你呗,对了有钱人怎么可能看上你这种女权的呢,还要孩子跟女方姓我也没看见你没跟你妈姓呀,年年过节男人给你们送礼物你们女人给男人送过礼物吗?,一问我不是陪着他吗我对他说我爱你了这不是最好的礼物吗?,男人只要不送礼物就是不爱你们了呗,人家国际女权讲的男人能做的我们女人也能做,田园女权男人能做的我们女人为啥要做,还男权我笑了,以前结婚几头牛换个衣服原装的,现在几十万彩...</code> | <code>0</code> |
| <code>Undoing Date and Time Adjustment</code> | <code>正在取消日期和时间调整</code> | <code>1</code> |
| <code>Dependency package for gsl_2_6 gnu hpc</code> | <code>Pacotes de desenvolvimento do KDE</code> | <code>1</code> |
* Loss: [<code>CoSENTLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosentloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "pairwise_cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | corrupted open os by language loss | sts-eval_spearman_cosine | sts-test_spearman_cosine |
|:-----:|:-----:|:-------------:|:----------------------------------:|:------------------------:|:------------------------:|
| 1.0 | 55751 | 0.1344 | 0.2643 | 0.8656 | - |
| -1 | -1 | - | - | - | 0.8656 |
### Framework Versions
- Python: 3.10.13
- Sentence Transformers: 3.4.1
- Transformers: 4.48.2
- PyTorch: 2.1.2+cu121
- Accelerate: 1.3.0
- Datasets: 2.16.1
- Tokenizers: 0.21.0
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### CoSENTLoss
```bibtex
@online{kexuefm-8847,
title={CoSENT: A more efficient sentence vector scheme than Sentence-BERT},
author={Su Jianlin},
year={2022},
month={Jan},
url={https://kexue.fm/archives/8847},
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"CAS"
] |
VISHNUDHAT/mxbai-embed-large-v1-Q4_K_M-GGUF
|
VISHNUDHAT
|
feature-extraction
|
[
"sentence-transformers",
"gguf",
"mteb",
"transformers.js",
"transformers",
"llama-cpp",
"gguf-my-repo",
"feature-extraction",
"en",
"base_model:mixedbread-ai/mxbai-embed-large-v1",
"base_model:quantized:mixedbread-ai/mxbai-embed-large-v1",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2025-03-14T15:52:04Z |
2025-03-14T15:52:12+00:00
| 17 | 0 |
---
base_model: mixedbread-ai/mxbai-embed-large-v1
language:
- en
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: feature-extraction
tags:
- mteb
- transformers.js
- transformers
- llama-cpp
- gguf-my-repo
model-index:
- name: mxbai-angle-large-v1
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.044776119403
- type: ap
value: 37.7362433623053
- type: f1
value: 68.92736573359774
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.84025000000001
- type: ap
value: 90.93190875404055
- type: f1
value: 93.8297833897293
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.184
- type: f1
value: 48.74163227751588
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 41.252
- type: map_at_10
value: 57.778
- type: map_at_100
value: 58.233000000000004
- type: map_at_1000
value: 58.23700000000001
- type: map_at_3
value: 53.449999999999996
- type: map_at_5
value: 56.376000000000005
- type: mrr_at_1
value: 41.679
- type: mrr_at_10
value: 57.92699999999999
- type: mrr_at_100
value: 58.389
- type: mrr_at_1000
value: 58.391999999999996
- type: mrr_at_3
value: 53.651
- type: mrr_at_5
value: 56.521
- type: ndcg_at_1
value: 41.252
- type: ndcg_at_10
value: 66.018
- type: ndcg_at_100
value: 67.774
- type: ndcg_at_1000
value: 67.84400000000001
- type: ndcg_at_3
value: 57.372
- type: ndcg_at_5
value: 62.646
- type: precision_at_1
value: 41.252
- type: precision_at_10
value: 9.189
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 22.902
- type: precision_at_5
value: 16.302
- type: recall_at_1
value: 41.252
- type: recall_at_10
value: 91.892
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 68.706
- type: recall_at_5
value: 81.50800000000001
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.97294504317859
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 42.98071077674629
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 65.16477858490782
- type: mrr
value: 78.23583080508287
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.6277629421789
- type: cos_sim_spearman
value: 88.4056288400568
- type: euclidean_pearson
value: 87.94871847578163
- type: euclidean_spearman
value: 88.4056288400568
- type: manhattan_pearson
value: 87.73271254229648
- type: manhattan_spearman
value: 87.91826833762677
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.81818181818181
- type: f1
value: 87.79879337316918
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.91773608582761
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.73059477462478
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.745999999999995
- type: map_at_10
value: 43.632
- type: map_at_100
value: 45.206
- type: map_at_1000
value: 45.341
- type: map_at_3
value: 39.956
- type: map_at_5
value: 42.031
- type: mrr_at_1
value: 39.485
- type: mrr_at_10
value: 49.537
- type: mrr_at_100
value: 50.249
- type: mrr_at_1000
value: 50.294000000000004
- type: mrr_at_3
value: 46.757
- type: mrr_at_5
value: 48.481
- type: ndcg_at_1
value: 39.485
- type: ndcg_at_10
value: 50.058
- type: ndcg_at_100
value: 55.586
- type: ndcg_at_1000
value: 57.511
- type: ndcg_at_3
value: 44.786
- type: ndcg_at_5
value: 47.339999999999996
- type: precision_at_1
value: 39.485
- type: precision_at_10
value: 9.557
- type: precision_at_100
value: 1.552
- type: precision_at_1000
value: 0.202
- type: precision_at_3
value: 21.412
- type: precision_at_5
value: 15.479000000000001
- type: recall_at_1
value: 32.745999999999995
- type: recall_at_10
value: 62.056
- type: recall_at_100
value: 85.088
- type: recall_at_1000
value: 96.952
- type: recall_at_3
value: 46.959
- type: recall_at_5
value: 54.06999999999999
- type: map_at_1
value: 31.898
- type: map_at_10
value: 42.142
- type: map_at_100
value: 43.349
- type: map_at_1000
value: 43.483
- type: map_at_3
value: 39.18
- type: map_at_5
value: 40.733000000000004
- type: mrr_at_1
value: 39.617999999999995
- type: mrr_at_10
value: 47.922
- type: mrr_at_100
value: 48.547000000000004
- type: mrr_at_1000
value: 48.597
- type: mrr_at_3
value: 45.86
- type: mrr_at_5
value: 46.949000000000005
- type: ndcg_at_1
value: 39.617999999999995
- type: ndcg_at_10
value: 47.739
- type: ndcg_at_100
value: 51.934999999999995
- type: ndcg_at_1000
value: 54.007000000000005
- type: ndcg_at_3
value: 43.748
- type: ndcg_at_5
value: 45.345
- type: precision_at_1
value: 39.617999999999995
- type: precision_at_10
value: 8.962
- type: precision_at_100
value: 1.436
- type: precision_at_1000
value: 0.192
- type: precision_at_3
value: 21.083
- type: precision_at_5
value: 14.752
- type: recall_at_1
value: 31.898
- type: recall_at_10
value: 57.587999999999994
- type: recall_at_100
value: 75.323
- type: recall_at_1000
value: 88.304
- type: recall_at_3
value: 45.275
- type: recall_at_5
value: 49.99
- type: map_at_1
value: 40.458
- type: map_at_10
value: 52.942
- type: map_at_100
value: 53.974
- type: map_at_1000
value: 54.031
- type: map_at_3
value: 49.559999999999995
- type: map_at_5
value: 51.408
- type: mrr_at_1
value: 46.27
- type: mrr_at_10
value: 56.31699999999999
- type: mrr_at_100
value: 56.95099999999999
- type: mrr_at_1000
value: 56.98
- type: mrr_at_3
value: 53.835
- type: mrr_at_5
value: 55.252
- type: ndcg_at_1
value: 46.27
- type: ndcg_at_10
value: 58.964000000000006
- type: ndcg_at_100
value: 62.875
- type: ndcg_at_1000
value: 63.969
- type: ndcg_at_3
value: 53.297000000000004
- type: ndcg_at_5
value: 55.938
- type: precision_at_1
value: 46.27
- type: precision_at_10
value: 9.549000000000001
- type: precision_at_100
value: 1.2409999999999999
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 23.762
- type: precision_at_5
value: 16.262999999999998
- type: recall_at_1
value: 40.458
- type: recall_at_10
value: 73.446
- type: recall_at_100
value: 90.12400000000001
- type: recall_at_1000
value: 97.795
- type: recall_at_3
value: 58.123000000000005
- type: recall_at_5
value: 64.68
- type: map_at_1
value: 27.443
- type: map_at_10
value: 36.081
- type: map_at_100
value: 37.163000000000004
- type: map_at_1000
value: 37.232
- type: map_at_3
value: 33.308
- type: map_at_5
value: 34.724
- type: mrr_at_1
value: 29.492
- type: mrr_at_10
value: 38.138
- type: mrr_at_100
value: 39.065
- type: mrr_at_1000
value: 39.119
- type: mrr_at_3
value: 35.593
- type: mrr_at_5
value: 36.785000000000004
- type: ndcg_at_1
value: 29.492
- type: ndcg_at_10
value: 41.134
- type: ndcg_at_100
value: 46.300999999999995
- type: ndcg_at_1000
value: 48.106
- type: ndcg_at_3
value: 35.77
- type: ndcg_at_5
value: 38.032
- type: precision_at_1
value: 29.492
- type: precision_at_10
value: 6.249
- type: precision_at_100
value: 0.9299999999999999
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 15.065999999999999
- type: precision_at_5
value: 10.373000000000001
- type: recall_at_1
value: 27.443
- type: recall_at_10
value: 54.80199999999999
- type: recall_at_100
value: 78.21900000000001
- type: recall_at_1000
value: 91.751
- type: recall_at_3
value: 40.211000000000006
- type: recall_at_5
value: 45.599000000000004
- type: map_at_1
value: 18.731
- type: map_at_10
value: 26.717999999999996
- type: map_at_100
value: 27.897
- type: map_at_1000
value: 28.029
- type: map_at_3
value: 23.91
- type: map_at_5
value: 25.455
- type: mrr_at_1
value: 23.134
- type: mrr_at_10
value: 31.769
- type: mrr_at_100
value: 32.634
- type: mrr_at_1000
value: 32.707
- type: mrr_at_3
value: 28.938999999999997
- type: mrr_at_5
value: 30.531000000000002
- type: ndcg_at_1
value: 23.134
- type: ndcg_at_10
value: 32.249
- type: ndcg_at_100
value: 37.678
- type: ndcg_at_1000
value: 40.589999999999996
- type: ndcg_at_3
value: 26.985999999999997
- type: ndcg_at_5
value: 29.457
- type: precision_at_1
value: 23.134
- type: precision_at_10
value: 5.8709999999999996
- type: precision_at_100
value: 0.988
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 12.852
- type: precision_at_5
value: 9.428
- type: recall_at_1
value: 18.731
- type: recall_at_10
value: 44.419
- type: recall_at_100
value: 67.851
- type: recall_at_1000
value: 88.103
- type: recall_at_3
value: 29.919
- type: recall_at_5
value: 36.230000000000004
- type: map_at_1
value: 30.324
- type: map_at_10
value: 41.265
- type: map_at_100
value: 42.559000000000005
- type: map_at_1000
value: 42.669000000000004
- type: map_at_3
value: 38.138
- type: map_at_5
value: 39.881
- type: mrr_at_1
value: 36.67
- type: mrr_at_10
value: 46.774
- type: mrr_at_100
value: 47.554
- type: mrr_at_1000
value: 47.593
- type: mrr_at_3
value: 44.338
- type: mrr_at_5
value: 45.723
- type: ndcg_at_1
value: 36.67
- type: ndcg_at_10
value: 47.367
- type: ndcg_at_100
value: 52.623
- type: ndcg_at_1000
value: 54.59
- type: ndcg_at_3
value: 42.323
- type: ndcg_at_5
value: 44.727
- type: precision_at_1
value: 36.67
- type: precision_at_10
value: 8.518
- type: precision_at_100
value: 1.2890000000000001
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 19.955000000000002
- type: precision_at_5
value: 14.11
- type: recall_at_1
value: 30.324
- type: recall_at_10
value: 59.845000000000006
- type: recall_at_100
value: 81.77499999999999
- type: recall_at_1000
value: 94.463
- type: recall_at_3
value: 46.019
- type: recall_at_5
value: 52.163000000000004
- type: map_at_1
value: 24.229
- type: map_at_10
value: 35.004000000000005
- type: map_at_100
value: 36.409000000000006
- type: map_at_1000
value: 36.521
- type: map_at_3
value: 31.793
- type: map_at_5
value: 33.432
- type: mrr_at_1
value: 30.365
- type: mrr_at_10
value: 40.502
- type: mrr_at_100
value: 41.372
- type: mrr_at_1000
value: 41.435
- type: mrr_at_3
value: 37.804
- type: mrr_at_5
value: 39.226
- type: ndcg_at_1
value: 30.365
- type: ndcg_at_10
value: 41.305
- type: ndcg_at_100
value: 47.028999999999996
- type: ndcg_at_1000
value: 49.375
- type: ndcg_at_3
value: 35.85
- type: ndcg_at_5
value: 38.12
- type: precision_at_1
value: 30.365
- type: precision_at_10
value: 7.808
- type: precision_at_100
value: 1.228
- type: precision_at_1000
value: 0.161
- type: precision_at_3
value: 17.352
- type: precision_at_5
value: 12.42
- type: recall_at_1
value: 24.229
- type: recall_at_10
value: 54.673
- type: recall_at_100
value: 78.766
- type: recall_at_1000
value: 94.625
- type: recall_at_3
value: 39.602
- type: recall_at_5
value: 45.558
- type: map_at_1
value: 26.695
- type: map_at_10
value: 36.0895
- type: map_at_100
value: 37.309416666666664
- type: map_at_1000
value: 37.42558333333334
- type: map_at_3
value: 33.19616666666666
- type: map_at_5
value: 34.78641666666667
- type: mrr_at_1
value: 31.486083333333337
- type: mrr_at_10
value: 40.34774999999999
- type: mrr_at_100
value: 41.17533333333333
- type: mrr_at_1000
value: 41.231583333333326
- type: mrr_at_3
value: 37.90075
- type: mrr_at_5
value: 39.266999999999996
- type: ndcg_at_1
value: 31.486083333333337
- type: ndcg_at_10
value: 41.60433333333334
- type: ndcg_at_100
value: 46.74525
- type: ndcg_at_1000
value: 48.96166666666667
- type: ndcg_at_3
value: 36.68825
- type: ndcg_at_5
value: 38.966499999999996
- type: precision_at_1
value: 31.486083333333337
- type: precision_at_10
value: 7.29675
- type: precision_at_100
value: 1.1621666666666666
- type: precision_at_1000
value: 0.1545
- type: precision_at_3
value: 16.8815
- type: precision_at_5
value: 11.974583333333333
- type: recall_at_1
value: 26.695
- type: recall_at_10
value: 53.651916666666665
- type: recall_at_100
value: 76.12083333333332
- type: recall_at_1000
value: 91.31191666666668
- type: recall_at_3
value: 40.03575
- type: recall_at_5
value: 45.876666666666665
- type: map_at_1
value: 25.668000000000003
- type: map_at_10
value: 32.486
- type: map_at_100
value: 33.371
- type: map_at_1000
value: 33.458
- type: map_at_3
value: 30.261
- type: map_at_5
value: 31.418000000000003
- type: mrr_at_1
value: 28.988000000000003
- type: mrr_at_10
value: 35.414
- type: mrr_at_100
value: 36.149
- type: mrr_at_1000
value: 36.215
- type: mrr_at_3
value: 33.333
- type: mrr_at_5
value: 34.43
- type: ndcg_at_1
value: 28.988000000000003
- type: ndcg_at_10
value: 36.732
- type: ndcg_at_100
value: 41.331
- type: ndcg_at_1000
value: 43.575
- type: ndcg_at_3
value: 32.413
- type: ndcg_at_5
value: 34.316
- type: precision_at_1
value: 28.988000000000003
- type: precision_at_10
value: 5.7059999999999995
- type: precision_at_100
value: 0.882
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 13.65
- type: precision_at_5
value: 9.417
- type: recall_at_1
value: 25.668000000000003
- type: recall_at_10
value: 47.147
- type: recall_at_100
value: 68.504
- type: recall_at_1000
value: 85.272
- type: recall_at_3
value: 35.19
- type: recall_at_5
value: 39.925
- type: map_at_1
value: 17.256
- type: map_at_10
value: 24.58
- type: map_at_100
value: 25.773000000000003
- type: map_at_1000
value: 25.899
- type: map_at_3
value: 22.236
- type: map_at_5
value: 23.507
- type: mrr_at_1
value: 20.957
- type: mrr_at_10
value: 28.416000000000004
- type: mrr_at_100
value: 29.447000000000003
- type: mrr_at_1000
value: 29.524
- type: mrr_at_3
value: 26.245
- type: mrr_at_5
value: 27.451999999999998
- type: ndcg_at_1
value: 20.957
- type: ndcg_at_10
value: 29.285
- type: ndcg_at_100
value: 35.003
- type: ndcg_at_1000
value: 37.881
- type: ndcg_at_3
value: 25.063000000000002
- type: ndcg_at_5
value: 26.983
- type: precision_at_1
value: 20.957
- type: precision_at_10
value: 5.344
- type: precision_at_100
value: 0.958
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 11.918
- type: precision_at_5
value: 8.596
- type: recall_at_1
value: 17.256
- type: recall_at_10
value: 39.644
- type: recall_at_100
value: 65.279
- type: recall_at_1000
value: 85.693
- type: recall_at_3
value: 27.825
- type: recall_at_5
value: 32.792
- type: map_at_1
value: 26.700000000000003
- type: map_at_10
value: 36.205999999999996
- type: map_at_100
value: 37.316
- type: map_at_1000
value: 37.425000000000004
- type: map_at_3
value: 33.166000000000004
- type: map_at_5
value: 35.032999999999994
- type: mrr_at_1
value: 31.436999999999998
- type: mrr_at_10
value: 40.61
- type: mrr_at_100
value: 41.415
- type: mrr_at_1000
value: 41.48
- type: mrr_at_3
value: 37.966
- type: mrr_at_5
value: 39.599000000000004
- type: ndcg_at_1
value: 31.436999999999998
- type: ndcg_at_10
value: 41.771
- type: ndcg_at_100
value: 46.784
- type: ndcg_at_1000
value: 49.183
- type: ndcg_at_3
value: 36.437000000000005
- type: ndcg_at_5
value: 39.291
- type: precision_at_1
value: 31.436999999999998
- type: precision_at_10
value: 6.987
- type: precision_at_100
value: 1.072
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 16.448999999999998
- type: precision_at_5
value: 11.866
- type: recall_at_1
value: 26.700000000000003
- type: recall_at_10
value: 54.301
- type: recall_at_100
value: 75.871
- type: recall_at_1000
value: 92.529
- type: recall_at_3
value: 40.201
- type: recall_at_5
value: 47.208
- type: map_at_1
value: 24.296
- type: map_at_10
value: 33.116
- type: map_at_100
value: 34.81
- type: map_at_1000
value: 35.032000000000004
- type: map_at_3
value: 30.105999999999998
- type: map_at_5
value: 31.839000000000002
- type: mrr_at_1
value: 29.051
- type: mrr_at_10
value: 37.803
- type: mrr_at_100
value: 38.856
- type: mrr_at_1000
value: 38.903999999999996
- type: mrr_at_3
value: 35.211
- type: mrr_at_5
value: 36.545
- type: ndcg_at_1
value: 29.051
- type: ndcg_at_10
value: 39.007
- type: ndcg_at_100
value: 45.321
- type: ndcg_at_1000
value: 47.665
- type: ndcg_at_3
value: 34.1
- type: ndcg_at_5
value: 36.437000000000005
- type: precision_at_1
value: 29.051
- type: precision_at_10
value: 7.668
- type: precision_at_100
value: 1.542
- type: precision_at_1000
value: 0.24
- type: precision_at_3
value: 16.14
- type: precision_at_5
value: 11.897
- type: recall_at_1
value: 24.296
- type: recall_at_10
value: 49.85
- type: recall_at_100
value: 78.457
- type: recall_at_1000
value: 92.618
- type: recall_at_3
value: 36.138999999999996
- type: recall_at_5
value: 42.223
- type: map_at_1
value: 20.591
- type: map_at_10
value: 28.902
- type: map_at_100
value: 29.886000000000003
- type: map_at_1000
value: 29.987000000000002
- type: map_at_3
value: 26.740000000000002
- type: map_at_5
value: 27.976
- type: mrr_at_1
value: 22.366
- type: mrr_at_10
value: 30.971
- type: mrr_at_100
value: 31.865
- type: mrr_at_1000
value: 31.930999999999997
- type: mrr_at_3
value: 28.927999999999997
- type: mrr_at_5
value: 30.231
- type: ndcg_at_1
value: 22.366
- type: ndcg_at_10
value: 33.641
- type: ndcg_at_100
value: 38.477
- type: ndcg_at_1000
value: 41.088
- type: ndcg_at_3
value: 29.486
- type: ndcg_at_5
value: 31.612000000000002
- type: precision_at_1
value: 22.366
- type: precision_at_10
value: 5.3420000000000005
- type: precision_at_100
value: 0.828
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 12.939
- type: precision_at_5
value: 9.094
- type: recall_at_1
value: 20.591
- type: recall_at_10
value: 46.052
- type: recall_at_100
value: 68.193
- type: recall_at_1000
value: 87.638
- type: recall_at_3
value: 34.966
- type: recall_at_5
value: 40.082
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.091
- type: map_at_10
value: 26.38
- type: map_at_100
value: 28.421999999999997
- type: map_at_1000
value: 28.621999999999996
- type: map_at_3
value: 21.597
- type: map_at_5
value: 24.12
- type: mrr_at_1
value: 34.266999999999996
- type: mrr_at_10
value: 46.864
- type: mrr_at_100
value: 47.617
- type: mrr_at_1000
value: 47.644
- type: mrr_at_3
value: 43.312
- type: mrr_at_5
value: 45.501000000000005
- type: ndcg_at_1
value: 34.266999999999996
- type: ndcg_at_10
value: 36.095
- type: ndcg_at_100
value: 43.447
- type: ndcg_at_1000
value: 46.661
- type: ndcg_at_3
value: 29.337999999999997
- type: ndcg_at_5
value: 31.824
- type: precision_at_1
value: 34.266999999999996
- type: precision_at_10
value: 11.472
- type: precision_at_100
value: 1.944
- type: precision_at_1000
value: 0.255
- type: precision_at_3
value: 21.933
- type: precision_at_5
value: 17.224999999999998
- type: recall_at_1
value: 15.091
- type: recall_at_10
value: 43.022
- type: recall_at_100
value: 68.075
- type: recall_at_1000
value: 85.76
- type: recall_at_3
value: 26.564
- type: recall_at_5
value: 33.594
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.252
- type: map_at_10
value: 20.923
- type: map_at_100
value: 30.741000000000003
- type: map_at_1000
value: 32.542
- type: map_at_3
value: 14.442
- type: map_at_5
value: 17.399
- type: mrr_at_1
value: 70.25
- type: mrr_at_10
value: 78.17
- type: mrr_at_100
value: 78.444
- type: mrr_at_1000
value: 78.45100000000001
- type: mrr_at_3
value: 76.958
- type: mrr_at_5
value: 77.571
- type: ndcg_at_1
value: 58.375
- type: ndcg_at_10
value: 44.509
- type: ndcg_at_100
value: 49.897999999999996
- type: ndcg_at_1000
value: 57.269999999999996
- type: ndcg_at_3
value: 48.64
- type: ndcg_at_5
value: 46.697
- type: precision_at_1
value: 70.25
- type: precision_at_10
value: 36.05
- type: precision_at_100
value: 11.848
- type: precision_at_1000
value: 2.213
- type: precision_at_3
value: 52.917
- type: precision_at_5
value: 45.7
- type: recall_at_1
value: 9.252
- type: recall_at_10
value: 27.006999999999998
- type: recall_at_100
value: 57.008
- type: recall_at_1000
value: 80.697
- type: recall_at_3
value: 15.798000000000002
- type: recall_at_5
value: 20.4
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 50.88
- type: f1
value: 45.545495028653384
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 75.424
- type: map_at_10
value: 83.435
- type: map_at_100
value: 83.66900000000001
- type: map_at_1000
value: 83.685
- type: map_at_3
value: 82.39800000000001
- type: map_at_5
value: 83.07
- type: mrr_at_1
value: 81.113
- type: mrr_at_10
value: 87.77199999999999
- type: mrr_at_100
value: 87.862
- type: mrr_at_1000
value: 87.86500000000001
- type: mrr_at_3
value: 87.17099999999999
- type: mrr_at_5
value: 87.616
- type: ndcg_at_1
value: 81.113
- type: ndcg_at_10
value: 86.909
- type: ndcg_at_100
value: 87.746
- type: ndcg_at_1000
value: 88.017
- type: ndcg_at_3
value: 85.368
- type: ndcg_at_5
value: 86.28099999999999
- type: precision_at_1
value: 81.113
- type: precision_at_10
value: 10.363
- type: precision_at_100
value: 1.102
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 32.507999999999996
- type: precision_at_5
value: 20.138
- type: recall_at_1
value: 75.424
- type: recall_at_10
value: 93.258
- type: recall_at_100
value: 96.545
- type: recall_at_1000
value: 98.284
- type: recall_at_3
value: 89.083
- type: recall_at_5
value: 91.445
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.532
- type: map_at_10
value: 37.141999999999996
- type: map_at_100
value: 39.162
- type: map_at_1000
value: 39.322
- type: map_at_3
value: 32.885
- type: map_at_5
value: 35.093999999999994
- type: mrr_at_1
value: 44.29
- type: mrr_at_10
value: 53.516
- type: mrr_at_100
value: 54.24
- type: mrr_at_1000
value: 54.273
- type: mrr_at_3
value: 51.286
- type: mrr_at_5
value: 52.413
- type: ndcg_at_1
value: 44.29
- type: ndcg_at_10
value: 45.268
- type: ndcg_at_100
value: 52.125
- type: ndcg_at_1000
value: 54.778000000000006
- type: ndcg_at_3
value: 41.829
- type: ndcg_at_5
value: 42.525
- type: precision_at_1
value: 44.29
- type: precision_at_10
value: 12.5
- type: precision_at_100
value: 1.9720000000000002
- type: precision_at_1000
value: 0.245
- type: precision_at_3
value: 28.035
- type: precision_at_5
value: 20.093
- type: recall_at_1
value: 22.532
- type: recall_at_10
value: 52.419000000000004
- type: recall_at_100
value: 77.43299999999999
- type: recall_at_1000
value: 93.379
- type: recall_at_3
value: 38.629000000000005
- type: recall_at_5
value: 43.858000000000004
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.359
- type: map_at_10
value: 63.966
- type: map_at_100
value: 64.87
- type: map_at_1000
value: 64.92599999999999
- type: map_at_3
value: 60.409
- type: map_at_5
value: 62.627
- type: mrr_at_1
value: 78.717
- type: mrr_at_10
value: 84.468
- type: mrr_at_100
value: 84.655
- type: mrr_at_1000
value: 84.661
- type: mrr_at_3
value: 83.554
- type: mrr_at_5
value: 84.133
- type: ndcg_at_1
value: 78.717
- type: ndcg_at_10
value: 72.03399999999999
- type: ndcg_at_100
value: 75.158
- type: ndcg_at_1000
value: 76.197
- type: ndcg_at_3
value: 67.049
- type: ndcg_at_5
value: 69.808
- type: precision_at_1
value: 78.717
- type: precision_at_10
value: 15.201
- type: precision_at_100
value: 1.764
- type: precision_at_1000
value: 0.19
- type: precision_at_3
value: 43.313
- type: precision_at_5
value: 28.165000000000003
- type: recall_at_1
value: 39.359
- type: recall_at_10
value: 76.003
- type: recall_at_100
value: 88.197
- type: recall_at_1000
value: 95.003
- type: recall_at_3
value: 64.97
- type: recall_at_5
value: 70.41199999999999
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 92.83200000000001
- type: ap
value: 89.33560571859861
- type: f1
value: 92.82322915005167
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.983
- type: map_at_10
value: 34.259
- type: map_at_100
value: 35.432
- type: map_at_1000
value: 35.482
- type: map_at_3
value: 30.275999999999996
- type: map_at_5
value: 32.566
- type: mrr_at_1
value: 22.579
- type: mrr_at_10
value: 34.882999999999996
- type: mrr_at_100
value: 35.984
- type: mrr_at_1000
value: 36.028
- type: mrr_at_3
value: 30.964999999999996
- type: mrr_at_5
value: 33.245000000000005
- type: ndcg_at_1
value: 22.564
- type: ndcg_at_10
value: 41.258
- type: ndcg_at_100
value: 46.824
- type: ndcg_at_1000
value: 48.037
- type: ndcg_at_3
value: 33.17
- type: ndcg_at_5
value: 37.263000000000005
- type: precision_at_1
value: 22.564
- type: precision_at_10
value: 6.572
- type: precision_at_100
value: 0.935
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.130999999999998
- type: precision_at_5
value: 10.544
- type: recall_at_1
value: 21.983
- type: recall_at_10
value: 62.775000000000006
- type: recall_at_100
value: 88.389
- type: recall_at_1000
value: 97.603
- type: recall_at_3
value: 40.878
- type: recall_at_5
value: 50.690000000000005
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.95120839033288
- type: f1
value: 93.73824125055208
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 76.78978568171455
- type: f1
value: 57.50180552858304
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.24411566913248
- type: f1
value: 74.37851403532832
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.94620040349699
- type: f1
value: 80.21293397970435
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.44403096245675
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.659594631336812
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.53833075108798
- type: mrr
value: 33.78840823218308
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.185999999999999
- type: map_at_10
value: 15.193999999999999
- type: map_at_100
value: 19.538
- type: map_at_1000
value: 21.178
- type: map_at_3
value: 11.208
- type: map_at_5
value: 12.745999999999999
- type: mrr_at_1
value: 48.916
- type: mrr_at_10
value: 58.141
- type: mrr_at_100
value: 58.656
- type: mrr_at_1000
value: 58.684999999999995
- type: mrr_at_3
value: 55.521
- type: mrr_at_5
value: 57.239
- type: ndcg_at_1
value: 47.059
- type: ndcg_at_10
value: 38.644
- type: ndcg_at_100
value: 36.272999999999996
- type: ndcg_at_1000
value: 44.996
- type: ndcg_at_3
value: 43.293
- type: ndcg_at_5
value: 40.819
- type: precision_at_1
value: 48.916
- type: precision_at_10
value: 28.607
- type: precision_at_100
value: 9.195
- type: precision_at_1000
value: 2.225
- type: precision_at_3
value: 40.454
- type: precision_at_5
value: 34.985
- type: recall_at_1
value: 7.185999999999999
- type: recall_at_10
value: 19.654
- type: recall_at_100
value: 37.224000000000004
- type: recall_at_1000
value: 68.663
- type: recall_at_3
value: 12.158
- type: recall_at_5
value: 14.674999999999999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.552000000000003
- type: map_at_10
value: 47.75
- type: map_at_100
value: 48.728
- type: map_at_1000
value: 48.754
- type: map_at_3
value: 43.156
- type: map_at_5
value: 45.883
- type: mrr_at_1
value: 35.66
- type: mrr_at_10
value: 50.269
- type: mrr_at_100
value: 50.974
- type: mrr_at_1000
value: 50.991
- type: mrr_at_3
value: 46.519
- type: mrr_at_5
value: 48.764
- type: ndcg_at_1
value: 35.632000000000005
- type: ndcg_at_10
value: 55.786
- type: ndcg_at_100
value: 59.748999999999995
- type: ndcg_at_1000
value: 60.339
- type: ndcg_at_3
value: 47.292
- type: ndcg_at_5
value: 51.766999999999996
- type: precision_at_1
value: 35.632000000000005
- type: precision_at_10
value: 9.267
- type: precision_at_100
value: 1.149
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 21.601
- type: precision_at_5
value: 15.539
- type: recall_at_1
value: 31.552000000000003
- type: recall_at_10
value: 77.62400000000001
- type: recall_at_100
value: 94.527
- type: recall_at_1000
value: 98.919
- type: recall_at_3
value: 55.898
- type: recall_at_5
value: 66.121
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.414
- type: map_at_10
value: 85.37400000000001
- type: map_at_100
value: 86.01100000000001
- type: map_at_1000
value: 86.027
- type: map_at_3
value: 82.562
- type: map_at_5
value: 84.284
- type: mrr_at_1
value: 82.24000000000001
- type: mrr_at_10
value: 88.225
- type: mrr_at_100
value: 88.324
- type: mrr_at_1000
value: 88.325
- type: mrr_at_3
value: 87.348
- type: mrr_at_5
value: 87.938
- type: ndcg_at_1
value: 82.24000000000001
- type: ndcg_at_10
value: 88.97699999999999
- type: ndcg_at_100
value: 90.16
- type: ndcg_at_1000
value: 90.236
- type: ndcg_at_3
value: 86.371
- type: ndcg_at_5
value: 87.746
- type: precision_at_1
value: 82.24000000000001
- type: precision_at_10
value: 13.481000000000002
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.86
- type: precision_at_5
value: 24.738
- type: recall_at_1
value: 71.414
- type: recall_at_10
value: 95.735
- type: recall_at_100
value: 99.696
- type: recall_at_1000
value: 99.979
- type: recall_at_3
value: 88.105
- type: recall_at_5
value: 92.17999999999999
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 60.22146692057259
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 65.29273320614578
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.023
- type: map_at_10
value: 14.161000000000001
- type: map_at_100
value: 16.68
- type: map_at_1000
value: 17.072000000000003
- type: map_at_3
value: 9.763
- type: map_at_5
value: 11.977
- type: mrr_at_1
value: 24.8
- type: mrr_at_10
value: 37.602999999999994
- type: mrr_at_100
value: 38.618
- type: mrr_at_1000
value: 38.659
- type: mrr_at_3
value: 34.117
- type: mrr_at_5
value: 36.082
- type: ndcg_at_1
value: 24.8
- type: ndcg_at_10
value: 23.316
- type: ndcg_at_100
value: 32.613
- type: ndcg_at_1000
value: 38.609
- type: ndcg_at_3
value: 21.697
- type: ndcg_at_5
value: 19.241
- type: precision_at_1
value: 24.8
- type: precision_at_10
value: 12.36
- type: precision_at_100
value: 2.593
- type: precision_at_1000
value: 0.402
- type: precision_at_3
value: 20.767
- type: precision_at_5
value: 17.34
- type: recall_at_1
value: 5.023
- type: recall_at_10
value: 25.069999999999997
- type: recall_at_100
value: 52.563
- type: recall_at_1000
value: 81.525
- type: recall_at_3
value: 12.613
- type: recall_at_5
value: 17.583
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 87.71506247604255
- type: cos_sim_spearman
value: 82.91813463738802
- type: euclidean_pearson
value: 85.5154616194479
- type: euclidean_spearman
value: 82.91815254466314
- type: manhattan_pearson
value: 85.5280917850374
- type: manhattan_spearman
value: 82.92276537286398
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 87.43772054228462
- type: cos_sim_spearman
value: 78.75750601716682
- type: euclidean_pearson
value: 85.76074482955764
- type: euclidean_spearman
value: 78.75651057223058
- type: manhattan_pearson
value: 85.73390291701668
- type: manhattan_spearman
value: 78.72699385957797
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 89.58144067172472
- type: cos_sim_spearman
value: 90.3524512966946
- type: euclidean_pearson
value: 89.71365391594237
- type: euclidean_spearman
value: 90.35239632843408
- type: manhattan_pearson
value: 89.66905421746478
- type: manhattan_spearman
value: 90.31508211683513
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 87.77692637102102
- type: cos_sim_spearman
value: 85.45710562643485
- type: euclidean_pearson
value: 87.42456979928723
- type: euclidean_spearman
value: 85.45709386240908
- type: manhattan_pearson
value: 87.40754529526272
- type: manhattan_spearman
value: 85.44834854173303
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.28491331695997
- type: cos_sim_spearman
value: 89.62037029566964
- type: euclidean_pearson
value: 89.02479391362826
- type: euclidean_spearman
value: 89.62036733618466
- type: manhattan_pearson
value: 89.00394756040342
- type: manhattan_spearman
value: 89.60867744215236
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.08911381280191
- type: cos_sim_spearman
value: 86.5791780765767
- type: euclidean_pearson
value: 86.16063473577861
- type: euclidean_spearman
value: 86.57917745378766
- type: manhattan_pearson
value: 86.13677924604175
- type: manhattan_spearman
value: 86.56115615768685
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.58029496205235
- type: cos_sim_spearman
value: 89.49551253826998
- type: euclidean_pearson
value: 90.13714840963748
- type: euclidean_spearman
value: 89.49551253826998
- type: manhattan_pearson
value: 90.13039633601363
- type: manhattan_spearman
value: 89.4513453745516
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 69.01546399666435
- type: cos_sim_spearman
value: 69.33824484595624
- type: euclidean_pearson
value: 70.76511642998874
- type: euclidean_spearman
value: 69.33824484595624
- type: manhattan_pearson
value: 70.84320785047453
- type: manhattan_spearman
value: 69.54233632223537
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.26389196390119
- type: cos_sim_spearman
value: 89.09721478341385
- type: euclidean_pearson
value: 88.97208685922517
- type: euclidean_spearman
value: 89.09720927308881
- type: manhattan_pearson
value: 88.97513670502573
- type: manhattan_spearman
value: 89.07647853984004
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.53075025771936
- type: mrr
value: 96.24327651288436
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.428000000000004
- type: map_at_10
value: 70.088
- type: map_at_100
value: 70.589
- type: map_at_1000
value: 70.614
- type: map_at_3
value: 67.191
- type: map_at_5
value: 68.515
- type: mrr_at_1
value: 63.333
- type: mrr_at_10
value: 71.13000000000001
- type: mrr_at_100
value: 71.545
- type: mrr_at_1000
value: 71.569
- type: mrr_at_3
value: 68.944
- type: mrr_at_5
value: 70.078
- type: ndcg_at_1
value: 63.333
- type: ndcg_at_10
value: 74.72800000000001
- type: ndcg_at_100
value: 76.64999999999999
- type: ndcg_at_1000
value: 77.176
- type: ndcg_at_3
value: 69.659
- type: ndcg_at_5
value: 71.626
- type: precision_at_1
value: 63.333
- type: precision_at_10
value: 10
- type: precision_at_100
value: 1.09
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 27.111
- type: precision_at_5
value: 17.666999999999998
- type: recall_at_1
value: 60.428000000000004
- type: recall_at_10
value: 87.98899999999999
- type: recall_at_100
value: 96.167
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 74.006
- type: recall_at_5
value: 79.05
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.87326732673267
- type: cos_sim_ap
value: 96.81770773701805
- type: cos_sim_f1
value: 93.6318407960199
- type: cos_sim_precision
value: 93.16831683168317
- type: cos_sim_recall
value: 94.1
- type: dot_accuracy
value: 99.87326732673267
- type: dot_ap
value: 96.8174218946665
- type: dot_f1
value: 93.6318407960199
- type: dot_precision
value: 93.16831683168317
- type: dot_recall
value: 94.1
- type: euclidean_accuracy
value: 99.87326732673267
- type: euclidean_ap
value: 96.81770773701807
- type: euclidean_f1
value: 93.6318407960199
- type: euclidean_precision
value: 93.16831683168317
- type: euclidean_recall
value: 94.1
- type: manhattan_accuracy
value: 99.87227722772278
- type: manhattan_ap
value: 96.83164126821747
- type: manhattan_f1
value: 93.54677338669335
- type: manhattan_precision
value: 93.5935935935936
- type: manhattan_recall
value: 93.5
- type: max_accuracy
value: 99.87326732673267
- type: max_ap
value: 96.83164126821747
- type: max_f1
value: 93.6318407960199
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 65.6212042420246
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.779230635982564
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.217701909036286
- type: mrr
value: 56.17658995416349
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.954206018888453
- type: cos_sim_spearman
value: 32.71062599450096
- type: dot_pearson
value: 30.95420929056943
- type: dot_spearman
value: 32.71062599450096
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22699999999999998
- type: map_at_10
value: 1.924
- type: map_at_100
value: 10.525
- type: map_at_1000
value: 24.973
- type: map_at_3
value: 0.638
- type: map_at_5
value: 1.0659999999999998
- type: mrr_at_1
value: 84
- type: mrr_at_10
value: 91.067
- type: mrr_at_100
value: 91.067
- type: mrr_at_1000
value: 91.067
- type: mrr_at_3
value: 90.667
- type: mrr_at_5
value: 91.067
- type: ndcg_at_1
value: 81
- type: ndcg_at_10
value: 75.566
- type: ndcg_at_100
value: 56.387
- type: ndcg_at_1000
value: 49.834
- type: ndcg_at_3
value: 80.899
- type: ndcg_at_5
value: 80.75099999999999
- type: precision_at_1
value: 84
- type: precision_at_10
value: 79
- type: precision_at_100
value: 57.56
- type: precision_at_1000
value: 21.8
- type: precision_at_3
value: 84.667
- type: precision_at_5
value: 85.2
- type: recall_at_1
value: 0.22699999999999998
- type: recall_at_10
value: 2.136
- type: recall_at_100
value: 13.861
- type: recall_at_1000
value: 46.299
- type: recall_at_3
value: 0.6649999999999999
- type: recall_at_5
value: 1.145
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.752
- type: map_at_10
value: 9.951
- type: map_at_100
value: 16.794999999999998
- type: map_at_1000
value: 18.251
- type: map_at_3
value: 5.288
- type: map_at_5
value: 6.954000000000001
- type: mrr_at_1
value: 38.775999999999996
- type: mrr_at_10
value: 50.458000000000006
- type: mrr_at_100
value: 51.324999999999996
- type: mrr_at_1000
value: 51.339999999999996
- type: mrr_at_3
value: 46.939
- type: mrr_at_5
value: 47.857
- type: ndcg_at_1
value: 36.735
- type: ndcg_at_10
value: 25.198999999999998
- type: ndcg_at_100
value: 37.938
- type: ndcg_at_1000
value: 49.145
- type: ndcg_at_3
value: 29.348000000000003
- type: ndcg_at_5
value: 25.804
- type: precision_at_1
value: 38.775999999999996
- type: precision_at_10
value: 22.041
- type: precision_at_100
value: 7.939
- type: precision_at_1000
value: 1.555
- type: precision_at_3
value: 29.932
- type: precision_at_5
value: 24.490000000000002
- type: recall_at_1
value: 2.752
- type: recall_at_10
value: 16.197
- type: recall_at_100
value: 49.166
- type: recall_at_1000
value: 84.18900000000001
- type: recall_at_3
value: 6.438000000000001
- type: recall_at_5
value: 9.093
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.47980000000001
- type: ap
value: 14.605194452178754
- type: f1
value: 55.07362924988948
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.708545557441994
- type: f1
value: 60.04751270975683
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 53.21105960597211
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.58419264469214
- type: cos_sim_ap
value: 78.55300004517404
- type: cos_sim_f1
value: 71.49673530889001
- type: cos_sim_precision
value: 68.20795400095831
- type: cos_sim_recall
value: 75.11873350923483
- type: dot_accuracy
value: 87.58419264469214
- type: dot_ap
value: 78.55297659559511
- type: dot_f1
value: 71.49673530889001
- type: dot_precision
value: 68.20795400095831
- type: dot_recall
value: 75.11873350923483
- type: euclidean_accuracy
value: 87.58419264469214
- type: euclidean_ap
value: 78.55300477331477
- type: euclidean_f1
value: 71.49673530889001
- type: euclidean_precision
value: 68.20795400095831
- type: euclidean_recall
value: 75.11873350923483
- type: manhattan_accuracy
value: 87.5663110210407
- type: manhattan_ap
value: 78.49982050876562
- type: manhattan_f1
value: 71.35488740722104
- type: manhattan_precision
value: 68.18946862226497
- type: manhattan_recall
value: 74.82849604221636
- type: max_accuracy
value: 87.58419264469214
- type: max_ap
value: 78.55300477331477
- type: max_f1
value: 71.49673530889001
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.09069740365584
- type: cos_sim_ap
value: 86.22749303724757
- type: cos_sim_f1
value: 78.36863452005407
- type: cos_sim_precision
value: 76.49560117302053
- type: cos_sim_recall
value: 80.33569448721897
- type: dot_accuracy
value: 89.09069740365584
- type: dot_ap
value: 86.22750233655673
- type: dot_f1
value: 78.36863452005407
- type: dot_precision
value: 76.49560117302053
- type: dot_recall
value: 80.33569448721897
- type: euclidean_accuracy
value: 89.09069740365584
- type: euclidean_ap
value: 86.22749355597347
- type: euclidean_f1
value: 78.36863452005407
- type: euclidean_precision
value: 76.49560117302053
- type: euclidean_recall
value: 80.33569448721897
- type: manhattan_accuracy
value: 89.08293553770326
- type: manhattan_ap
value: 86.21913616084771
- type: manhattan_f1
value: 78.3907031479847
- type: manhattan_precision
value: 75.0352013517319
- type: manhattan_recall
value: 82.06036341238065
- type: max_accuracy
value: 89.09069740365584
- type: max_ap
value: 86.22750233655673
- type: max_f1
value: 78.3907031479847
---
# VISHNUDHAT/mxbai-embed-large-v1-Q4_K_M-GGUF
This model was converted to GGUF format from [`mixedbread-ai/mxbai-embed-large-v1`](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo VISHNUDHAT/mxbai-embed-large-v1-Q4_K_M-GGUF --hf-file mxbai-embed-large-v1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo VISHNUDHAT/mxbai-embed-large-v1-Q4_K_M-GGUF --hf-file mxbai-embed-large-v1-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo VISHNUDHAT/mxbai-embed-large-v1-Q4_K_M-GGUF --hf-file mxbai-embed-large-v1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo VISHNUDHAT/mxbai-embed-large-v1-Q4_K_M-GGUF --hf-file mxbai-embed-large-v1-q4_k_m.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
AdwayK/biobert_ncbi_disease_ner_tuned_on_TAC2017
|
AdwayK
|
token-classification
|
[
"transformers",
"tf",
"bert",
"token-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-04-16T17:33:36Z |
2022-04-16T20:24:50+00:00
| 16 | 0 |
---
tags:
- generated_from_keras_callback
model-index:
- name: AdwayK/biobert_ncbi_disease_ner_tuned_on_TAC2017
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# AdwayK/biobert_ncbi_disease_ner_tuned_on_TAC2017
This model is a fine-tuned version of [ugaray96/biobert_ncbi_disease_ner](https://huggingface.co/ugaray96/biobert_ncbi_disease_ner) on the TAC 2017 dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0343
- Validation Loss: 0.0679
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 975, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.5377 | 0.1269 | 0 |
| 0.0997 | 0.0776 | 1 |
| 0.0621 | 0.0700 | 2 |
| 0.0434 | 0.0757 | 3 |
| 0.0343 | 0.0679 | 4 |
### Framework versions
- Transformers 4.18.0
- TensorFlow 2.8.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
[
"NCBI DISEASE"
] |
chintagunta85/electramed-small-NCBI-ner
|
chintagunta85
|
token-classification
|
[
"transformers",
"pytorch",
"tensorboard",
"electra",
"token-classification",
"generated_from_trainer",
"dataset:ncbi_disease",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-08-23T06:28:30Z |
2022-08-23T06:35:29+00:00
| 16 | 0 |
---
datasets:
- ncbi_disease
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: electramed-small-NCBI-ner
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: ncbi_disease
type: ncbi_disease
config: ncbi_disease
split: train
args: ncbi_disease
metrics:
- type: precision
value: 0.8083491461100569
name: Precision
- type: recall
value: 0.8875
name: Recall
- type: f1
value: 0.846077457795432
name: F1
- type: accuracy
value: 0.9820794382985671
name: Accuracy
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electramed-small-NCBI-ner
This model is a fine-tuned version of [giacomomiolo/electramed_small_scivocab](https://huggingface.co/giacomomiolo/electramed_small_scivocab) on the ncbi_disease dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0664
- Precision: 0.8083
- Recall: 0.8875
- F1: 0.8461
- Accuracy: 0.9821
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.4787 | 1.0 | 340 | 0.5090 | 0.6090 | 0.5062 | 0.5529 | 0.9608 |
| 0.2029 | 2.0 | 680 | 0.1890 | 0.7643 | 0.8208 | 0.7916 | 0.9774 |
| 0.1402 | 3.0 | 1020 | 0.1106 | 0.7839 | 0.8802 | 0.8292 | 0.9807 |
| 0.075 | 4.0 | 1360 | 0.0876 | 0.8162 | 0.8698 | 0.8422 | 0.9817 |
| 0.0408 | 5.0 | 1700 | 0.0776 | 0.8090 | 0.8781 | 0.8422 | 0.9818 |
| 0.0308 | 6.0 | 2040 | 0.0697 | 0.8044 | 0.8823 | 0.8415 | 0.9825 |
| 0.0405 | 7.0 | 2380 | 0.0680 | 0.8118 | 0.8854 | 0.8470 | 0.9830 |
| 0.0138 | 8.0 | 2720 | 0.0665 | 0.8111 | 0.8854 | 0.8466 | 0.9826 |
| 0.0223 | 9.0 | 3060 | 0.0675 | 0.8064 | 0.8896 | 0.8460 | 0.9821 |
| 0.0395 | 10.0 | 3400 | 0.0664 | 0.8083 | 0.8875 | 0.8461 | 0.9821 |
### Framework versions
- Transformers 4.21.1
- Pytorch 1.12.1+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
[
"NCBI DISEASE"
] |
BigSalmon/FormalInformalConcise-FIM-NeoX-1.3B
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-10-11T15:58:04Z |
2022-10-11T17:30:17+00:00
| 16 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
Trained on this model: https://huggingface.co/CarperAI/FIM-NeoX-1.3B, which is geared toward filling in the blank. Check out their model and give them a like!
```
from transformers import GPTNeoXForCausalLM, GPTNeoXTokenizerFast
tokenizer = GPTNeoXTokenizerFast.from_pretrained("CarperAI/FIM-NeoX-1.3B")
model = GPTNeoXForCausalLM.from_pretrained("BigSalmon/FormalInformalConcise-FIM-NeoX-1.3B")
```
To load model, you may need to do:
```
pip install git+https://github.com/huggingface/transformers
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/GPT2Mask
```
```
prompt = """<|SUF|> into relaxation <|PRE|> music before bedtime <|MID|>"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
How To Make Prompts:
Infill Phrase Masking In-Fill
```
<|SUF|> into relaxation <|PRE|> music before bedtime <|MID|>
```
Informal To Formal
```
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
|
[
"BEAR"
] |
AndyChiang/cdgp-csg-roberta-dgen
|
AndyChiang
|
fill-mask
|
[
"transformers",
"pytorch",
"roberta",
"fill-mask",
"cloze",
"distractor",
"generation",
"en",
"dataset:dgen",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-10-14T04:50:37Z |
2022-10-14T13:40:21+00:00
| 16 | 0 |
---
datasets:
- dgen
language: en
license: mit
tags:
- roberta
- cloze
- distractor
- generation
widget:
- text: The only known planet with large amounts of water is <mask>. </s> earth
- text: The products of photosynthesis are glucose and <mask> else. </s> oxygen
---
# cdgp-csg-roberta-dgen
## Model description
This model is a Candidate Set Generator in **"CDGP: Automatic Cloze Distractor Generation based on Pre-trained Language Model", Findings of EMNLP 2022**.
Its input are stem and answer, and output is candidate set of distractors. It is fine-tuned by [**DGen**](https://github.com/DRSY/DGen) dataset based on [**roberta-base**](https://huggingface.co/roberta-base) model.
For more details, you can see our **paper** or [**GitHub**](https://github.com/AndyChiangSH/CDGP).
## How to use?
1. Download model by hugging face transformers.
```python
from transformers import RobertaTokenizer, RobertaForMaskedLM, pipeline
tokenizer = RobertaTokenizer.from_pretrained("AndyChiang/cdgp-csg-roberta-dgen")
csg_model = RobertaForMaskedLM.from_pretrained("AndyChiang/cdgp-csg-roberta-dgen")
```
2. Create a unmasker.
```python
unmasker = pipeline("fill-mask", tokenizer=tokenizer, model=csg_model, top_k=10)
```
3. Use the unmasker to generate the candidate set of distractors.
```python
sent = "The only known planet with large amounts of water is <mask>. </s> earth"
cs = unmasker(sent)
print(cs)
```
## Dataset
This model is fine-tuned by [DGen](https://github.com/DRSY/DGen) dataset, which covers multiple domains including science, vocabulary, common sense and trivia. It is compiled from a wide variety of datasets including SciQ, MCQL, AI2 Science Questions, etc. The detail of DGen dataset is shown below.
| DGen dataset | Train | Valid | Test | Total |
| ----------------------- | ----- | ----- | ---- | ----- |
| **Number of questions** | 2321 | 300 | 259 | 2880 |
You can also use the [dataset](https://huggingface.co/datasets/AndyChiang/dgen) we have already cleaned.
## Training
We use a special way to fine-tune model, which is called **"Answer-Relating Fine-Tune"**. More details are in our paper.
### Training hyperparameters
The following hyperparameters were used during training:
- Pre-train language model: [roberta-base](https://huggingface.co/roberta-base)
- Optimizer: adam
- Learning rate: 0.0001
- Max length of input: 64
- Batch size: 64
- Epoch: 1
- Device: NVIDIA® Tesla T4 in Google Colab
## Testing
The evaluations of this model as a Candidate Set Generator in CDGP is as follows:
| P@1 | F1@3 | MRR | NDCG@10 |
| ----- | ---- | ----- | ------- |
| 13.13 | 9.65 | 19.34 | 24.52 |
## Other models
### Candidate Set Generator
| Models | CLOTH | DGen |
| ----------- | ----------------------------------------------------------------------------------- | -------------------------------------------------------------------------------- |
| **BERT** | [cdgp-csg-bert-cloth](https://huggingface.co/AndyChiang/cdgp-csg-bert-cloth) | [cdgp-csg-bert-dgen](https://huggingface.co/AndyChiang/cdgp-csg-bert-dgen) |
| **SciBERT** | [cdgp-csg-scibert-cloth](https://huggingface.co/AndyChiang/cdgp-csg-scibert-cloth) | [cdgp-csg-scibert-dgen](https://huggingface.co/AndyChiang/cdgp-csg-scibert-dgen) |
| **RoBERTa** | [cdgp-csg-roberta-cloth](https://huggingface.co/AndyChiang/cdgp-csg-roberta-cloth) | [*cdgp-csg-roberta-dgen*](https://huggingface.co/AndyChiang/cdgp-csg-roberta-dgen) |
| **BART** | [cdgp-csg-bart-cloth](https://huggingface.co/AndyChiang/cdgp-csg-bart-cloth) | [cdgp-csg-bart-dgen](https://huggingface.co/AndyChiang/cdgp-csg-bart-dgen) |
### Distractor Selector
**fastText**: [cdgp-ds-fasttext](https://huggingface.co/AndyChiang/cdgp-ds-fasttext)
## Citation
None
|
[
"SCIQ"
] |
gayanin/med_masked_pubmed_articles_biogpt_large
|
gayanin
|
text-generation
|
[
"transformers",
"pytorch",
"tensorboard",
"biogpt",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-02-20T01:21:19Z |
2023-02-20T05:49:41+00:00
| 16 | 1 |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: med_masked_pubmed_articles_biogpt_large
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# med_masked_pubmed_articles_biogpt_large
This model is a fine-tuned version of [microsoft/BioGPT-Large-PubMedQA](https://huggingface.co/microsoft/BioGPT-Large-PubMedQA) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.2545
- Rouge2 Precision: 0.7011
- Rouge2 Recall: 0.6931
- Rouge2 Fmeasure: 0.6959
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 3.0566 | 1.0 | 7914 | 3.0375 | 0.7013 | 0.6931 | 0.6959 |
| 2.911 | 2.0 | 15828 | 3.0228 | 0.7013 | 0.6931 | 0.6959 |
| 2.7386 | 3.0 | 23742 | 3.0594 | 0.7011 | 0.6931 | 0.6959 |
| 2.5718 | 4.0 | 31656 | 3.1371 | 0.7011 | 0.6931 | 0.6959 |
| 2.4573 | 5.0 | 39570 | 3.2545 | 0.7011 | 0.6931 | 0.6959 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
[
"PUBMEDQA"
] |
kunxiaogao/New_BioRED_model_1
|
kunxiaogao
|
token-classification
|
[
"transformers",
"pytorch",
"bert",
"token-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-03-16T04:29:05Z |
2023-03-16T05:45:54+00:00
| 16 | 0 |
---
license: mit
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: New_BioRED_model_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# New_BioRED_model_1
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4105
- Precision: 0.4596
- Recall: 0.2902
- F1: 0.3558
- Accuracy: 0.8605
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 13 | 0.7199 | 0.0 | 0.0 | 0.0 | 0.8273 |
| No log | 2.0 | 26 | 0.6140 | 0.1663 | 0.0112 | 0.0210 | 0.8316 |
| No log | 3.0 | 39 | 0.5403 | 0.3494 | 0.1336 | 0.1933 | 0.8462 |
| No log | 4.0 | 52 | 0.4823 | 0.3732 | 0.1895 | 0.2514 | 0.8501 |
| No log | 5.0 | 65 | 0.4644 | 0.3951 | 0.2304 | 0.2911 | 0.8534 |
| No log | 6.0 | 78 | 0.4450 | 0.4086 | 0.2515 | 0.3114 | 0.8553 |
| No log | 7.0 | 91 | 0.4324 | 0.4293 | 0.2667 | 0.3290 | 0.8570 |
| No log | 8.0 | 104 | 0.4242 | 0.4413 | 0.2684 | 0.3338 | 0.8583 |
| No log | 9.0 | 117 | 0.4209 | 0.4452 | 0.2773 | 0.3417 | 0.8587 |
| No log | 10.0 | 130 | 0.4170 | 0.4499 | 0.2854 | 0.3493 | 0.8593 |
| No log | 11.0 | 143 | 0.4131 | 0.4568 | 0.2891 | 0.3541 | 0.8600 |
| No log | 12.0 | 156 | 0.4140 | 0.4478 | 0.2962 | 0.3566 | 0.8588 |
| No log | 13.0 | 169 | 0.4120 | 0.4660 | 0.2889 | 0.3567 | 0.8608 |
| No log | 14.0 | 182 | 0.4116 | 0.4560 | 0.2911 | 0.3554 | 0.8600 |
| No log | 15.0 | 195 | 0.4105 | 0.4596 | 0.2902 | 0.3558 | 0.8605 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.12.1
- Datasets 2.6.1
- Tokenizers 0.11.0
|
[
"BIORED"
] |
BigSalmon/InformalToFormalLincoln97Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-04-10T02:44:17Z |
2023-04-11T23:53:54+00:00
| 16 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln97Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln97Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
```
Q: What is whistleblower protection?
A: Whistleblower protection is a form of legal immunity granted to employees who expose the unethical practices of their employer.
Q: Why are whistleblower protections important?
A: Absent whistleblower protections, employees would be deterred from exposing their employer’s wrongdoing for fear of retribution.
Q: Why would an employer engage in retribution?
A: An employer who has acted unethically stands to suffer severe financial and reputational damage were their transgressions to become public. To safeguard themselves from these consequences, they might seek to dissuade employees from exposing their wrongdoing.
```
```
original: the meritocratic nature of crowdfunding [MASK] into their vision's viability.
infill: the meritocratic nature of crowdfunding [gives investors idea of how successful] -> ( offers entrepreneurs a window ) into their vision's viability.
```
```
Leadership | Lecture 17: Worker Morale
What Workers Look for in Companies:
• Benefits
o Tuition reimbursement
o Paid parental leave
o 401K matching
o Profit sharing
o Pension plans
o Free meals
• Social responsibility
o Environmental stewardship
o Charitable contributions
o Diversity
• Work-life balance
o Telecommuting
o Paid holidays and vacation
o Casual dress
• Growth opportunities
• Job security
• Competitive compensation
• Recognition
o Open-door policies
o Whistleblower protection
o Employee-of-the-month awards
o Positive performance reviews
o Bonuses
```
```
description: business
keywords: for-profit, fiduciary duty, monopolistic, bottom line, return on investment, short-term thinking, capital-intensive, self-interested, risk-taking, fiduciary duty, merger, speculation, profiteering, oversight, capitalism, diversification
```
```
3. In this task, you are given a company name and you need to find its industry.
McDonalds -- Restaurant
Facebook -- Social Network
IKEA -- Furniture
American Express -- Credit Services
Nokia -- Telecom
Nintendo -- Entertainment
4. In this task, you are given a Month and you need to convert it to its corresponding season
April -- Spring
December -- Winter
July -- Summer
October -- Fall
February -- Winter
5. In this task, you are given a sentence with a missing word and you need to predict the correct word.
Managers should set an _____ for their employees. -- example
Some people spend more than four _____ in the gym. -- hours
The police were on the _____ of arresting the suspect. -- verge
They were looking for _____ on how to solve the problem. -- guidance
What is the _____ of the coffee? -- price
6. In this task, you are given a paragraph and you need to reorder it to make it logical.
It was first proposed in 1987. The total length of the bridge is 1,828 meters. The idea of a bridge connects Hong Kong to Macau. -- The idea of bridge connecting Hong Kong and Macau was first proposed in 1987. The total length of the bridge is 1,828 meters.
It is a movie about a brave and noble policeman. The film was produced by Americans. They were Kevin Lima and Chris Buck. They are directors. The movie is called Tarzan. -- Produced by Americans Kevin Lima and Chris Buck, Tarzan is a movie about a brave and noble policeman.
It was first discovered in the mountains of India. The active ingredients in this plant can stimulate hair growth. The plant is called "Hair Plus." -- First discovered in the mountains of India, Hair Plus is a plant whose active ingredients can stimulate hair growth.
```
```
trivia: What is the population of South Korea?
response: 51 million.
***
trivia: What is the minimum voting age in the US?
response: 18.
***
trivia: What are the first ten amendments of the US constitution called?
response: Bill of Rights.
```
```
ideas: in modern-day america, it is customary for the commander-in-chief to conduct regular press conferences
related keywords: transparency, check and balance, sacrosanct, public accountability, adversarial, unscripted, direct access, open government, watchdog, healthy democracy, institutional integrity, right to know, direct line of communication, behind closed doors, updates, track progress, instill confidence, reassure, humanize, leadership style, day-to-day, forthcoming, demystify, ask hard questions
***
ideas: i know this one guy who retired so young, attesting to how careful they were with money.
related keywords: money management, resourceful, penny-pinching, live below their means, frugal, financial discipline, financial independence, conservative, long-term vision, discretionary spending, deferred gratification, preparedness, self-control, cushion
```
```
less specific: actors and musicians should ( support democracy ).
clarifies: actors and musicians should ( wield their celebrity to amplify pro-democracy messaging / marshal their considerable influence in the service of the democratic cause ).
***
less specific: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( be careful ).
clarifies: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( master their desires / exercise self-restraint / embrace frugality / restrain their appetite for splendor ).
```
```
dull: clean
emotional heft: spotless, immaculate, pristine
***
dull: hot
emotional heft: scorching, searing, blistering
***
dull: happy
emotional heft: euphoric
```
```
text: {guide: vividly describe the premise of the show "seinfield"} -> set in the heart of bustling new york city, the sitcom "seinfield" follows the everyday {restrict: term that implies they get into trouble but in a comical way} -> misadventures of four neurotic friends. on any given episode, one can find them quarreling over their favorite diner's latest menu change, haggling over the division of household expenses, or contriving a scheme to spy on the apartment's newest resident. mundane as their exploits may be, they never fail to elicit a hearty laugh. {guide: mention how larry david is responsible} -> behind the show's witty, incisive dialogue lies the sharp pen of larry david, who co-created the show with jerry seinfeld. {guide: mention how larry david came up with the most recognizable lines} -> it is his genius that conjured such instantly {restrict: term that imply everybody knows them} -> recognizable quips as "no soup for you!" and "not that there's anything wrong with that!". {guide: mention how humanity should revel in having such good comedians these days} -> as this list of laugh-out-loud lines attests, the world is fortunate to ( count such a sharp comedic mind among its ranks / have such a talented humorist in its midst / have such comedic talent gracing its airwaves ).
```
|
[
"BEAR"
] |
rduan6/model
|
rduan6
|
token-classification
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"token-classification",
"generated_from_trainer",
"dataset:ncbi_disease",
"license:mit",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-04-14T20:06:10Z |
2023-04-14T20:38:18+00:00
| 16 | 0 |
---
datasets:
- ncbi_disease
license: mit
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: model
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: ncbi_disease
type: ncbi_disease
config: ncbi_disease
split: validation
args: ncbi_disease
metrics:
- type: precision
value: 0.5537679932260796
name: Precision
- type: recall
value: 0.6312741312741312
name: Recall
- type: f1
value: 0.5899864682002707
name: F1
- type: accuracy
value: 0.9586137150414252
name: Accuracy
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model
This model is a fine-tuned version of [microsoft/biogpt](https://huggingface.co/microsoft/biogpt) on the ncbi_disease dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2138
- Precision: 0.5538
- Recall: 0.6313
- F1: 0.5900
- Accuracy: 0.9586
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2962 | 1.0 | 679 | 0.1463 | 0.4864 | 0.5010 | 0.4936 | 0.9532 |
| 0.1321 | 2.0 | 1358 | 0.1482 | 0.4794 | 0.5946 | 0.5308 | 0.9549 |
| 0.0649 | 3.0 | 2037 | 0.1570 | 0.5307 | 0.6168 | 0.5705 | 0.9577 |
| 0.0414 | 4.0 | 2716 | 0.1799 | 0.5050 | 0.6390 | 0.5641 | 0.9564 |
| 0.0316 | 5.0 | 3395 | 0.2138 | 0.5538 | 0.6313 | 0.5900 | 0.9586 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.3
|
[
"NCBI DISEASE"
] |
OpenMatch/ance-tele_coco-base_msmarco_qry-psg-encoder
|
OpenMatch
|
feature-extraction
|
[
"transformers",
"pytorch",
"bert",
"feature-extraction",
"arxiv:2210.17167",
"license:mit",
"endpoints_compatible",
"region:us"
] | 2023-04-19T14:24:25Z |
2023-04-19T15:04:53+00:00
| 16 | 0 |
---
license: mit
---
This model is ANCE-Tele trained on MS MARCO. The training details and evaluation results are as follows:
|Model|Pretrain Model|Train w/ Marco Title|Marco Dev MRR@10|BEIR Avg NDCG@10|
|:----|:----|:----|:----|:----|
|ANCE-Tele|[cocodr-base](https://huggingface.co/OpenMatch/cocodr-base)|w/o|37.3|44.2|
|BERI Dataset|NDCG@10|
|:----|:----|
|TREC-COVID|77.4|
|NFCorpus|34.4 |
|FiQA|29.0 |
|ArguAna|45.6 |
|Touché-2020|22.3 |
|Quora|85.8 |
|SCIDOCS|14.6 |
|SciFact|71.0 |
|NQ|50.5 |
|HotpotQA|58.8 |
|Signal-1M|27.2 |
|TREC-NEWS|34.7 |
|DBPedia-entity|36.2 |
|Fever|71.4 |
|Climate-Fever|17.9 |
|BioASQ|42.1 |
|Robust04|41.4 |
|CQADupStack|34.9 |
The implementation is the same as our EMNLP 2022 paper ["Reduce Catastrophic Forgetting of Dense Retrieval Training with Teleportation Negatives"](https://arxiv.org/pdf/2210.17167.pdf). The associated GitHub repository is available at https://github.com/OpenMatch/ANCE-Tele.
```
@inproceedings{sun2022ancetele,
title={Reduce Catastrophic Forgetting of Dense Retrieval Training with Teleportation Negatives},
author={Si, Sun and Chenyan, Xiong and Yue, Yu and Arnold, Overwijk and Zhiyuan, Liu and Jie, Bao},
booktitle={Proceedings of EMNLP 2022},
year={2022}
}
```
|
[
"SCIFACT"
] |
DAMO-NLP-SG/mt-llama-7b-delta
|
DAMO-NLP-SG
|
text-generation
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-05-05T02:52:02Z |
2023-06-15T07:21:35+00:00
| 16 | 2 |
---
license: mit
---
# MT-LLaMA Model Card
## Model details
**Model type:**
MT-LLaMA is an open-source multi-task model trained by fine-tuning LLaMA on the massive tasks in [P3](https://huggingface.co/datasets/bigscience/P3) (i.e., T0 Train). Concretely, the used datasets during training and task taxonomy are listed below:
* Multi-choice QA: CommonsenseQA, Cosmos QA, DREAM, QuAIL, QuaRTz, QASC, QuaRel, SciQ, Social IQA, Wiki Hop, WiQA
* Extractive QA: Adversarial QA, DuoRC, Quoref, ROPES
* Close-Book QA: Hotpot QA, Wiki QA
* Sentiment Classification: Amazon, App Reviews, IMDB, Rotten Tomatoes, Yelp
* Topic Classification: AG News, DBPedia, TREC
* Structure-to-Text Generation: Common Gen, Wiki Bio
* Text Summarization: CNN Daily Mail, Gigaword, MultiNews, SamSum, XSum
* Paraphrase Identification: MRPC, PAWS, QQP
**Organizations developing the model:**
The MT-LLaMA team with members from Alibaba Damo Academy and the Chinese University of Hong Kong.
## Intended use
You can try the codes from our [github repo](https://github.com/DAMO-NLP-SG/MT-LLaMA).
## Zero-shot Evaluation
We primarily follow the protocols of [Bigscience T0](https://openreview.net/forum?id=9Vrb9D0WI4) to assess the generalization capability of our Multi-task LLaMA to: (1) _**Unseen Datasets**_ (i.e., datasets from seen tasks); (2) _**Unseen Tasks**_.
#### Prompt Format
Extractive QA:
1. XQuAD, TyDiQA, MLQA, SQuAD
```angular2html
Input: Answer the question according to the context. Question: ${question}. Context: ${context}. Answer:
Output: ${Answer}
```
Sentiment:
1. SST-2
```angular2html
Input: ${sentence} Based on this review, would the user recommend this product? No or Yes?
Output: Yes / No
```
Multiple-Choice QA:
1. OpenbookQA
```angular2html
Input: ${question} Which is the correct answer? - (A) ${choiceA} - (B) ${choiceB} - (C) ${choiceC} - (D) ${choiceD}
Output: ${choiceA} / ${choiceB} / ${choiceC} / ${choiceD}
```
Sentence Completion:
1. COPA
```angular2html
Input: ${premise} {% if question == "cause" %} This happened because... {% else %} As a consequence... Help me pick the more plausible option: - ${text1} - ${text2}
Output: ${text1} / ${text2}
```
Coreference Resolution:
1. Winogrande:
```angular2html
Input: ${sentence} In the previous sentence, does _ refer to ${option1} or ${option2}?
Output: ${option1} / ${option2}
```
Word Sense Disambiguation:
1. WiC
```angular2html
Input: Does the word "${word}" have the same meaning in these two sentences? Yes, No? ${sentence1} ${sentence2}
Output: ${sentence1} / ${sentence2}
```
Natural Language Inference:
1. MNLI:
```angular2html
Input: ${premise} Question: Does this imply that ${hypothesis}? Please response with 'Yes', 'No', or 'Maybe'.
Output: Yes / No / Maybe
```
2. RTE
```angular2html
Input: Given ${premise} Is it guaranteed true that "${hypothesis}"? Yes or no?
Output: Yes / no
```
#### Results on _Unseen Datasets_
| Model | XQuAD-en (F1/EM) | TyDiQA-en (F1/EM) | MLQA-en (F1/EM) | SQuAD (F1/EM) | SST-2 (Acc.) | OpenbookQA (Acc.) |
|:------------|------------------|-------------------|-----------------|---------------|--------------|-------------------|
| LLaMA-7b | 9.5 / 2.0 | 14.3 / 2.6 | 13.4 / 3.3 | 29.4 / 11.5 | 50.5 | 32.4 |
| MT-LLaMA-7b | 42.3 / 31.1 | 38.9 / 26.9 | 45.4 / 31.5 | 85.9 / 77.6 | 92.6 | 38.2 |
#### Results on _Unseen Tasks_
| Model | COPA (Acc.) | Winogrande (Acc.) | WiC (Acc.) | MNLI (Acc.) | RTE (Acc.) |
|:------------|-------------|--------------------|------------|-------------|------------|
| LLaMA-7b | 56.0 | 49.3 | 51.7 | 30.2 | 52.7 |
| MT-LLaMA-7b | 88.0 | 54.9 | 52.2 | 49.6 | 79.1 |
## Acknowledgement
* Our training codes are largely borrowed from [FastChat](https://github.com/lm-sys/FastChat)
* We are also grateful for the efforts of [LLaMA](https://github.com/facebookresearch/llama) (from FAIR) and [T0](https://github.com/bigscience-workshop/t-zero) (from BigScience), which serve as the foundation of our work
If you find this resource useful, please cite the repo as follows:
```
@software{damonlpsg2023mtllama,
author = {Xu, Weiwen and Li, Xin and Bing, Lidong},
title = {Multi-task Instruction-tuned LLaMA},
year = 2023,
url = {https://github.com/DAMO-NLP-SG/MT-LLaMA}
}
```
|
[
"SCIQ"
] |
BigSalmon/InformalToFormalLincoln100Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-05-26T21:35:02Z |
2023-05-26T22:31:47+00:00
| 16 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln100Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln100Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
```
Q: What is whistleblower protection?
A: Whistleblower protection is a form of legal immunity granted to employees who expose the unethical practices of their employer.
Q: Why are whistleblower protections important?
A: Absent whistleblower protections, employees would be deterred from exposing their employer’s wrongdoing for fear of retribution.
Q: Why would an employer engage in retribution?
A: An employer who has acted unethically stands to suffer severe financial and reputational damage were their transgressions to become public. To safeguard themselves from these consequences, they might seek to dissuade employees from exposing their wrongdoing.
```
```
original: the meritocratic nature of crowdfunding [MASK] into their vision's viability.
infill: the meritocratic nature of crowdfunding [gives investors idea of how successful] -> ( offers entrepreneurs a window ) into their vision's viability.
```
```
Leadership | Lecture 17: Worker Morale
What Workers Look for in Companies:
• Benefits
o Tuition reimbursement
o Paid parental leave
o 401K matching
o Profit sharing
o Pension plans
o Free meals
• Social responsibility
o Environmental stewardship
o Charitable contributions
o Diversity
• Work-life balance
o Telecommuting
o Paid holidays and vacation
o Casual dress
• Growth opportunities
• Job security
• Competitive compensation
• Recognition
o Open-door policies
o Whistleblower protection
o Employee-of-the-month awards
o Positive performance reviews
o Bonuses
```
```
description: business
keywords: for-profit, fiduciary duty, monopolistic, bottom line, return on investment, short-term thinking, capital-intensive, self-interested, risk-taking, fiduciary duty, merger, speculation, profiteering, oversight, capitalism, diversification
```
```
3. In this task, you are given a company name and you need to find its industry.
McDonalds -- Restaurant
Facebook -- Social Network
IKEA -- Furniture
American Express -- Credit Services
Nokia -- Telecom
Nintendo -- Entertainment
4. In this task, you are given a Month and you need to convert it to its corresponding season
April -- Spring
December -- Winter
July -- Summer
October -- Fall
February -- Winter
5. In this task, you are given a sentence with a missing word and you need to predict the correct word.
Managers should set an _____ for their employees. -- example
Some people spend more than four _____ in the gym. -- hours
The police were on the _____ of arresting the suspect. -- verge
They were looking for _____ on how to solve the problem. -- guidance
What is the _____ of the coffee? -- price
6. In this task, you are given a paragraph and you need to reorder it to make it logical.
It was first proposed in 1987. The total length of the bridge is 1,828 meters. The idea of a bridge connects Hong Kong to Macau. -- The idea of bridge connecting Hong Kong and Macau was first proposed in 1987. The total length of the bridge is 1,828 meters.
It is a movie about a brave and noble policeman. The film was produced by Americans. They were Kevin Lima and Chris Buck. They are directors. The movie is called Tarzan. -- Produced by Americans Kevin Lima and Chris Buck, Tarzan is a movie about a brave and noble policeman.
It was first discovered in the mountains of India. The active ingredients in this plant can stimulate hair growth. The plant is called "Hair Plus." -- First discovered in the mountains of India, Hair Plus is a plant whose active ingredients can stimulate hair growth.
```
```
trivia: What is the population of South Korea?
response: 51 million.
***
trivia: What is the minimum voting age in the US?
response: 18.
***
trivia: What are the first ten amendments of the US constitution called?
response: Bill of Rights.
```
```
ideas: in modern-day america, it is customary for the commander-in-chief to conduct regular press conferences
related keywords: transparency, check and balance, sacrosanct, public accountability, adversarial, unscripted, direct access, open government, watchdog, healthy democracy, institutional integrity, right to know, direct line of communication, behind closed doors, updates, track progress, instill confidence, reassure, humanize, leadership style, day-to-day, forthcoming, demystify, ask hard questions
***
ideas: i know this one guy who retired so young, attesting to how careful they were with money.
related keywords: money management, resourceful, penny-pinching, live below their means, frugal, financial discipline, financial independence, conservative, long-term vision, discretionary spending, deferred gratification, preparedness, self-control, cushion
```
```
less specific: actors and musicians should ( support democracy ).
clarifies: actors and musicians should ( wield their celebrity to amplify pro-democracy messaging / marshal their considerable influence in the service of the democratic cause ).
***
less specific: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( be careful ).
clarifies: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( master their desires / exercise self-restraint / embrace frugality / restrain their appetite for splendor ).
```
```
dull: clean
emotional heft: spotless, immaculate, pristine
***
dull: hot
emotional heft: scorching, searing, blistering
***
dull: happy
emotional heft: euphoric
```
```
text: {guide: vividly describe the premise of the show "seinfield"} -> set in the heart of bustling new york city, the sitcom "seinfield" follows the everyday {restrict: term that implies they get into trouble but in a comical way} -> misadventures of four neurotic friends. on any given episode, one can find them quarreling over their favorite diner's latest menu change, haggling over the division of household expenses, or contriving a scheme to spy on the apartment's newest resident. mundane as their exploits may be, they never fail to elicit a hearty laugh. {guide: mention how larry david is responsible} -> behind the show's witty, incisive dialogue lies the sharp pen of larry david, who co-created the show with jerry seinfeld. {guide: mention how larry david came up with the most recognizable lines} -> it is his genius that conjured such instantly {restrict: term that imply everybody knows them} -> recognizable quips as "no soup for you!" and "not that there's anything wrong with that!". {guide: mention how humanity should revel in having such good comedians these days} -> as this list of laugh-out-loud lines attests, the world is fortunate to ( count such a sharp comedic mind among its ranks / have such a talented humorist in its midst / have such comedic talent gracing its airwaves ).
```
```
system: i'm not sure i agree with your assessment of the situation.
user: replace "assessment" with a more casual term.
chatbot: ( take / read / view ).
system: i've been feeling really busy lately, trying to balance work and family responsibilities.
user: replace "busy" with a more intense word that conveys it is too much.
chatbot: overwhelmed.
system: the candidate's stance on immigration is quite nebulous, and it's difficult to discern exactly what they would do if elected.
user: replace "nebulous" with a word that conveys a lack of detail.
chatbot: ( vague / ambiguous ).
```
```
user: exorbitant in price, scholarly journals unconscionably define the breadth of one's knowledge awareness by the contents of their wallet. [replace “knowledge awareness” with a more natural expression]
chatbot: intellectual horizons.
user: can you do another alternative to “intellectual horizons” that has more relation to “scholarly journals”?
chatbot: academic enlightenment.
```
```
key: calculate.
syn: estimate, consider, weigh, number, count, apportion, proportion, investigate, reckon, rate, compute.
ant: guess, conjecture, hit, chance, risk, stake, miscalculate.
```
```
description: more forceful version of curious that is less forceful than nosy
answer: inquisitive
description: more forceful version of hopeful that is less forceful than overconfident
answer: optimistic
```
```
key: inquisitive
positive: curious, interested
negative: nosy, prying
***
key: witty
positive: clever, humorous
negative: sarcastic, caustic
***
key: influential
positive: impactful, powerful
negative: overbearing, domineering
```
|
[
"BEAR"
] |
kinoo/slim_beir-scifact-old
|
kinoo
|
fill-mask
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-07T05:30:34Z |
2023-06-07T07:33:00+00:00
| 16 | 0 |
---
{}
---
This is a model named slim trained on dataset beir-scifact
|
[
"SCIFACT"
] |
michaelfeil/ct2fast-e5-small-v2
|
michaelfeil
|
sentence-similarity
|
[
"sentence-transformers",
"bert",
"ctranslate2",
"int8",
"float16",
"mteb",
"Sentence Transformers",
"sentence-similarity",
"en",
"arxiv:2212.03533",
"arxiv:2104.08663",
"arxiv:2210.07316",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2023-06-15T19:29:43Z |
2023-10-13T13:36:26+00:00
| 16 | 3 |
---
language:
- en
license: mit
tags:
- ctranslate2
- int8
- float16
- mteb
- Sentence Transformers
- sentence-similarity
- sentence-transformers
model-index:
- name: e5-small-v2
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 77.59701492537313
- type: ap
value: 41.67064885731708
- type: f1
value: 71.86465946398573
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.265875
- type: ap
value: 87.67633085349644
- type: f1
value: 91.24297521425744
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 45.882000000000005
- type: f1
value: 45.08058870381236
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.697
- type: map_at_10
value: 33.975
- type: map_at_100
value: 35.223
- type: map_at_1000
value: 35.260000000000005
- type: map_at_3
value: 29.776999999999997
- type: map_at_5
value: 32.035000000000004
- type: mrr_at_1
value: 20.982
- type: mrr_at_10
value: 34.094
- type: mrr_at_100
value: 35.343
- type: mrr_at_1000
value: 35.38
- type: mrr_at_3
value: 29.884
- type: mrr_at_5
value: 32.141999999999996
- type: ndcg_at_1
value: 20.697
- type: ndcg_at_10
value: 41.668
- type: ndcg_at_100
value: 47.397
- type: ndcg_at_1000
value: 48.305
- type: ndcg_at_3
value: 32.928000000000004
- type: ndcg_at_5
value: 36.998999999999995
- type: precision_at_1
value: 20.697
- type: precision_at_10
value: 6.636
- type: precision_at_100
value: 0.924
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 14.035
- type: precision_at_5
value: 10.398
- type: recall_at_1
value: 20.697
- type: recall_at_10
value: 66.35799999999999
- type: recall_at_100
value: 92.39
- type: recall_at_1000
value: 99.36
- type: recall_at_3
value: 42.105
- type: recall_at_5
value: 51.991
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 42.1169517447068
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 34.79553720107097
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 58.10811337308168
- type: mrr
value: 71.56410763751482
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 78.46834918248696
- type: cos_sim_spearman
value: 79.4289182755206
- type: euclidean_pearson
value: 76.26662973727008
- type: euclidean_spearman
value: 78.11744260952536
- type: manhattan_pearson
value: 76.08175262609434
- type: manhattan_spearman
value: 78.29395265552289
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 81.63636363636364
- type: f1
value: 81.55779952376953
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.88541137137571
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 30.05205685274407
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.293999999999997
- type: map_at_10
value: 39.876
- type: map_at_100
value: 41.315000000000005
- type: map_at_1000
value: 41.451
- type: map_at_3
value: 37.194
- type: map_at_5
value: 38.728
- type: mrr_at_1
value: 37.053000000000004
- type: mrr_at_10
value: 45.281
- type: mrr_at_100
value: 46.188
- type: mrr_at_1000
value: 46.245999999999995
- type: mrr_at_3
value: 43.228
- type: mrr_at_5
value: 44.366
- type: ndcg_at_1
value: 37.053000000000004
- type: ndcg_at_10
value: 45.086
- type: ndcg_at_100
value: 50.756
- type: ndcg_at_1000
value: 53.123
- type: ndcg_at_3
value: 41.416
- type: ndcg_at_5
value: 43.098
- type: precision_at_1
value: 37.053000000000004
- type: precision_at_10
value: 8.34
- type: precision_at_100
value: 1.346
- type: precision_at_1000
value: 0.186
- type: precision_at_3
value: 19.647000000000002
- type: precision_at_5
value: 13.877
- type: recall_at_1
value: 30.293999999999997
- type: recall_at_10
value: 54.309
- type: recall_at_100
value: 78.59
- type: recall_at_1000
value: 93.82300000000001
- type: recall_at_3
value: 43.168
- type: recall_at_5
value: 48.192
- type: map_at_1
value: 28.738000000000003
- type: map_at_10
value: 36.925999999999995
- type: map_at_100
value: 38.017
- type: map_at_1000
value: 38.144
- type: map_at_3
value: 34.446
- type: map_at_5
value: 35.704
- type: mrr_at_1
value: 35.478
- type: mrr_at_10
value: 42.786
- type: mrr_at_100
value: 43.458999999999996
- type: mrr_at_1000
value: 43.507
- type: mrr_at_3
value: 40.648
- type: mrr_at_5
value: 41.804
- type: ndcg_at_1
value: 35.478
- type: ndcg_at_10
value: 42.044
- type: ndcg_at_100
value: 46.249
- type: ndcg_at_1000
value: 48.44
- type: ndcg_at_3
value: 38.314
- type: ndcg_at_5
value: 39.798
- type: precision_at_1
value: 35.478
- type: precision_at_10
value: 7.764
- type: precision_at_100
value: 1.253
- type: precision_at_1000
value: 0.174
- type: precision_at_3
value: 18.047
- type: precision_at_5
value: 12.637
- type: recall_at_1
value: 28.738000000000003
- type: recall_at_10
value: 50.659
- type: recall_at_100
value: 68.76299999999999
- type: recall_at_1000
value: 82.811
- type: recall_at_3
value: 39.536
- type: recall_at_5
value: 43.763999999999996
- type: map_at_1
value: 38.565
- type: map_at_10
value: 50.168
- type: map_at_100
value: 51.11
- type: map_at_1000
value: 51.173
- type: map_at_3
value: 47.044000000000004
- type: map_at_5
value: 48.838
- type: mrr_at_1
value: 44.201
- type: mrr_at_10
value: 53.596999999999994
- type: mrr_at_100
value: 54.211
- type: mrr_at_1000
value: 54.247
- type: mrr_at_3
value: 51.202000000000005
- type: mrr_at_5
value: 52.608999999999995
- type: ndcg_at_1
value: 44.201
- type: ndcg_at_10
value: 55.694
- type: ndcg_at_100
value: 59.518
- type: ndcg_at_1000
value: 60.907
- type: ndcg_at_3
value: 50.395999999999994
- type: ndcg_at_5
value: 53.022999999999996
- type: precision_at_1
value: 44.201
- type: precision_at_10
value: 8.84
- type: precision_at_100
value: 1.162
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 22.153
- type: precision_at_5
value: 15.260000000000002
- type: recall_at_1
value: 38.565
- type: recall_at_10
value: 68.65
- type: recall_at_100
value: 85.37400000000001
- type: recall_at_1000
value: 95.37400000000001
- type: recall_at_3
value: 54.645999999999994
- type: recall_at_5
value: 60.958
- type: map_at_1
value: 23.945
- type: map_at_10
value: 30.641000000000002
- type: map_at_100
value: 31.599
- type: map_at_1000
value: 31.691000000000003
- type: map_at_3
value: 28.405
- type: map_at_5
value: 29.704000000000004
- type: mrr_at_1
value: 25.537
- type: mrr_at_10
value: 32.22
- type: mrr_at_100
value: 33.138
- type: mrr_at_1000
value: 33.214
- type: mrr_at_3
value: 30.151
- type: mrr_at_5
value: 31.298
- type: ndcg_at_1
value: 25.537
- type: ndcg_at_10
value: 34.638000000000005
- type: ndcg_at_100
value: 39.486
- type: ndcg_at_1000
value: 41.936
- type: ndcg_at_3
value: 30.333
- type: ndcg_at_5
value: 32.482
- type: precision_at_1
value: 25.537
- type: precision_at_10
value: 5.153
- type: precision_at_100
value: 0.7929999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 12.429
- type: precision_at_5
value: 8.723
- type: recall_at_1
value: 23.945
- type: recall_at_10
value: 45.412
- type: recall_at_100
value: 67.836
- type: recall_at_1000
value: 86.467
- type: recall_at_3
value: 34.031
- type: recall_at_5
value: 39.039
- type: map_at_1
value: 14.419
- type: map_at_10
value: 20.858999999999998
- type: map_at_100
value: 22.067999999999998
- type: map_at_1000
value: 22.192
- type: map_at_3
value: 18.673000000000002
- type: map_at_5
value: 19.968
- type: mrr_at_1
value: 17.785999999999998
- type: mrr_at_10
value: 24.878
- type: mrr_at_100
value: 26.021
- type: mrr_at_1000
value: 26.095000000000002
- type: mrr_at_3
value: 22.616
- type: mrr_at_5
value: 23.785
- type: ndcg_at_1
value: 17.785999999999998
- type: ndcg_at_10
value: 25.153
- type: ndcg_at_100
value: 31.05
- type: ndcg_at_1000
value: 34.052
- type: ndcg_at_3
value: 21.117
- type: ndcg_at_5
value: 23.048
- type: precision_at_1
value: 17.785999999999998
- type: precision_at_10
value: 4.590000000000001
- type: precision_at_100
value: 0.864
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 9.908999999999999
- type: precision_at_5
value: 7.313
- type: recall_at_1
value: 14.419
- type: recall_at_10
value: 34.477999999999994
- type: recall_at_100
value: 60.02499999999999
- type: recall_at_1000
value: 81.646
- type: recall_at_3
value: 23.515
- type: recall_at_5
value: 28.266999999999996
- type: map_at_1
value: 26.268
- type: map_at_10
value: 35.114000000000004
- type: map_at_100
value: 36.212
- type: map_at_1000
value: 36.333
- type: map_at_3
value: 32.436
- type: map_at_5
value: 33.992
- type: mrr_at_1
value: 31.761
- type: mrr_at_10
value: 40.355999999999995
- type: mrr_at_100
value: 41.125
- type: mrr_at_1000
value: 41.186
- type: mrr_at_3
value: 37.937
- type: mrr_at_5
value: 39.463
- type: ndcg_at_1
value: 31.761
- type: ndcg_at_10
value: 40.422000000000004
- type: ndcg_at_100
value: 45.458999999999996
- type: ndcg_at_1000
value: 47.951
- type: ndcg_at_3
value: 35.972
- type: ndcg_at_5
value: 38.272
- type: precision_at_1
value: 31.761
- type: precision_at_10
value: 7.103
- type: precision_at_100
value: 1.133
- type: precision_at_1000
value: 0.152
- type: precision_at_3
value: 16.779
- type: precision_at_5
value: 11.877
- type: recall_at_1
value: 26.268
- type: recall_at_10
value: 51.053000000000004
- type: recall_at_100
value: 72.702
- type: recall_at_1000
value: 89.521
- type: recall_at_3
value: 38.619
- type: recall_at_5
value: 44.671
- type: map_at_1
value: 25.230999999999998
- type: map_at_10
value: 34.227000000000004
- type: map_at_100
value: 35.370000000000005
- type: map_at_1000
value: 35.488
- type: map_at_3
value: 31.496000000000002
- type: map_at_5
value: 33.034
- type: mrr_at_1
value: 30.822
- type: mrr_at_10
value: 39.045
- type: mrr_at_100
value: 39.809
- type: mrr_at_1000
value: 39.873
- type: mrr_at_3
value: 36.663000000000004
- type: mrr_at_5
value: 37.964
- type: ndcg_at_1
value: 30.822
- type: ndcg_at_10
value: 39.472
- type: ndcg_at_100
value: 44.574999999999996
- type: ndcg_at_1000
value: 47.162
- type: ndcg_at_3
value: 34.929
- type: ndcg_at_5
value: 37.002
- type: precision_at_1
value: 30.822
- type: precision_at_10
value: 7.055
- type: precision_at_100
value: 1.124
- type: precision_at_1000
value: 0.152
- type: precision_at_3
value: 16.591
- type: precision_at_5
value: 11.667
- type: recall_at_1
value: 25.230999999999998
- type: recall_at_10
value: 50.42100000000001
- type: recall_at_100
value: 72.685
- type: recall_at_1000
value: 90.469
- type: recall_at_3
value: 37.503
- type: recall_at_5
value: 43.123
- type: map_at_1
value: 24.604166666666664
- type: map_at_10
value: 32.427166666666665
- type: map_at_100
value: 33.51474999999999
- type: map_at_1000
value: 33.6345
- type: map_at_3
value: 30.02366666666667
- type: map_at_5
value: 31.382333333333328
- type: mrr_at_1
value: 29.001166666666666
- type: mrr_at_10
value: 36.3315
- type: mrr_at_100
value: 37.16683333333333
- type: mrr_at_1000
value: 37.23341666666668
- type: mrr_at_3
value: 34.19916666666667
- type: mrr_at_5
value: 35.40458333333334
- type: ndcg_at_1
value: 29.001166666666666
- type: ndcg_at_10
value: 37.06883333333334
- type: ndcg_at_100
value: 41.95816666666666
- type: ndcg_at_1000
value: 44.501583333333336
- type: ndcg_at_3
value: 32.973499999999994
- type: ndcg_at_5
value: 34.90833333333334
- type: precision_at_1
value: 29.001166666666666
- type: precision_at_10
value: 6.336
- type: precision_at_100
value: 1.0282499999999999
- type: precision_at_1000
value: 0.14391666666666664
- type: precision_at_3
value: 14.932499999999996
- type: precision_at_5
value: 10.50825
- type: recall_at_1
value: 24.604166666666664
- type: recall_at_10
value: 46.9525
- type: recall_at_100
value: 68.67816666666667
- type: recall_at_1000
value: 86.59783333333334
- type: recall_at_3
value: 35.49783333333333
- type: recall_at_5
value: 40.52525000000001
- type: map_at_1
value: 23.559
- type: map_at_10
value: 29.023
- type: map_at_100
value: 29.818
- type: map_at_1000
value: 29.909000000000002
- type: map_at_3
value: 27.037
- type: map_at_5
value: 28.225
- type: mrr_at_1
value: 26.994
- type: mrr_at_10
value: 31.962000000000003
- type: mrr_at_100
value: 32.726
- type: mrr_at_1000
value: 32.800000000000004
- type: mrr_at_3
value: 30.266
- type: mrr_at_5
value: 31.208999999999996
- type: ndcg_at_1
value: 26.994
- type: ndcg_at_10
value: 32.53
- type: ndcg_at_100
value: 36.758
- type: ndcg_at_1000
value: 39.362
- type: ndcg_at_3
value: 28.985
- type: ndcg_at_5
value: 30.757
- type: precision_at_1
value: 26.994
- type: precision_at_10
value: 4.968999999999999
- type: precision_at_100
value: 0.759
- type: precision_at_1000
value: 0.106
- type: precision_at_3
value: 12.219
- type: precision_at_5
value: 8.527999999999999
- type: recall_at_1
value: 23.559
- type: recall_at_10
value: 40.585
- type: recall_at_100
value: 60.306000000000004
- type: recall_at_1000
value: 80.11
- type: recall_at_3
value: 30.794
- type: recall_at_5
value: 35.186
- type: map_at_1
value: 16.384999999999998
- type: map_at_10
value: 22.142
- type: map_at_100
value: 23.057
- type: map_at_1000
value: 23.177
- type: map_at_3
value: 20.29
- type: map_at_5
value: 21.332
- type: mrr_at_1
value: 19.89
- type: mrr_at_10
value: 25.771
- type: mrr_at_100
value: 26.599
- type: mrr_at_1000
value: 26.680999999999997
- type: mrr_at_3
value: 23.962
- type: mrr_at_5
value: 24.934
- type: ndcg_at_1
value: 19.89
- type: ndcg_at_10
value: 25.97
- type: ndcg_at_100
value: 30.605
- type: ndcg_at_1000
value: 33.619
- type: ndcg_at_3
value: 22.704
- type: ndcg_at_5
value: 24.199
- type: precision_at_1
value: 19.89
- type: precision_at_10
value: 4.553
- type: precision_at_100
value: 0.8049999999999999
- type: precision_at_1000
value: 0.122
- type: precision_at_3
value: 10.541
- type: precision_at_5
value: 7.46
- type: recall_at_1
value: 16.384999999999998
- type: recall_at_10
value: 34.001
- type: recall_at_100
value: 55.17100000000001
- type: recall_at_1000
value: 77.125
- type: recall_at_3
value: 24.618000000000002
- type: recall_at_5
value: 28.695999999999998
- type: map_at_1
value: 23.726
- type: map_at_10
value: 31.227
- type: map_at_100
value: 32.311
- type: map_at_1000
value: 32.419
- type: map_at_3
value: 28.765
- type: map_at_5
value: 30.229
- type: mrr_at_1
value: 27.705000000000002
- type: mrr_at_10
value: 35.085
- type: mrr_at_100
value: 35.931000000000004
- type: mrr_at_1000
value: 36
- type: mrr_at_3
value: 32.603
- type: mrr_at_5
value: 34.117999999999995
- type: ndcg_at_1
value: 27.705000000000002
- type: ndcg_at_10
value: 35.968
- type: ndcg_at_100
value: 41.197
- type: ndcg_at_1000
value: 43.76
- type: ndcg_at_3
value: 31.304
- type: ndcg_at_5
value: 33.661
- type: precision_at_1
value: 27.705000000000002
- type: precision_at_10
value: 5.942
- type: precision_at_100
value: 0.964
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 13.868
- type: precision_at_5
value: 9.944
- type: recall_at_1
value: 23.726
- type: recall_at_10
value: 46.786
- type: recall_at_100
value: 70.072
- type: recall_at_1000
value: 88.2
- type: recall_at_3
value: 33.981
- type: recall_at_5
value: 39.893
- type: map_at_1
value: 23.344
- type: map_at_10
value: 31.636999999999997
- type: map_at_100
value: 33.065
- type: map_at_1000
value: 33.300000000000004
- type: map_at_3
value: 29.351
- type: map_at_5
value: 30.432
- type: mrr_at_1
value: 27.866000000000003
- type: mrr_at_10
value: 35.587
- type: mrr_at_100
value: 36.52
- type: mrr_at_1000
value: 36.597
- type: mrr_at_3
value: 33.696
- type: mrr_at_5
value: 34.713
- type: ndcg_at_1
value: 27.866000000000003
- type: ndcg_at_10
value: 36.61
- type: ndcg_at_100
value: 41.88
- type: ndcg_at_1000
value: 45.105000000000004
- type: ndcg_at_3
value: 33.038000000000004
- type: ndcg_at_5
value: 34.331
- type: precision_at_1
value: 27.866000000000003
- type: precision_at_10
value: 6.917
- type: precision_at_100
value: 1.3599999999999999
- type: precision_at_1000
value: 0.233
- type: precision_at_3
value: 15.547
- type: precision_at_5
value: 10.791
- type: recall_at_1
value: 23.344
- type: recall_at_10
value: 45.782000000000004
- type: recall_at_100
value: 69.503
- type: recall_at_1000
value: 90.742
- type: recall_at_3
value: 35.160000000000004
- type: recall_at_5
value: 39.058
- type: map_at_1
value: 20.776
- type: map_at_10
value: 27.285999999999998
- type: map_at_100
value: 28.235
- type: map_at_1000
value: 28.337
- type: map_at_3
value: 25.147000000000002
- type: map_at_5
value: 26.401999999999997
- type: mrr_at_1
value: 22.921
- type: mrr_at_10
value: 29.409999999999997
- type: mrr_at_100
value: 30.275000000000002
- type: mrr_at_1000
value: 30.354999999999997
- type: mrr_at_3
value: 27.418
- type: mrr_at_5
value: 28.592000000000002
- type: ndcg_at_1
value: 22.921
- type: ndcg_at_10
value: 31.239
- type: ndcg_at_100
value: 35.965
- type: ndcg_at_1000
value: 38.602
- type: ndcg_at_3
value: 27.174
- type: ndcg_at_5
value: 29.229
- type: precision_at_1
value: 22.921
- type: precision_at_10
value: 4.806
- type: precision_at_100
value: 0.776
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 11.459999999999999
- type: precision_at_5
value: 8.022
- type: recall_at_1
value: 20.776
- type: recall_at_10
value: 41.294
- type: recall_at_100
value: 63.111
- type: recall_at_1000
value: 82.88600000000001
- type: recall_at_3
value: 30.403000000000002
- type: recall_at_5
value: 35.455999999999996
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.376
- type: map_at_10
value: 15.926000000000002
- type: map_at_100
value: 17.585
- type: map_at_1000
value: 17.776
- type: map_at_3
value: 13.014000000000001
- type: map_at_5
value: 14.417
- type: mrr_at_1
value: 20.195
- type: mrr_at_10
value: 29.95
- type: mrr_at_100
value: 31.052000000000003
- type: mrr_at_1000
value: 31.108000000000004
- type: mrr_at_3
value: 26.667
- type: mrr_at_5
value: 28.458
- type: ndcg_at_1
value: 20.195
- type: ndcg_at_10
value: 22.871
- type: ndcg_at_100
value: 29.921999999999997
- type: ndcg_at_1000
value: 33.672999999999995
- type: ndcg_at_3
value: 17.782999999999998
- type: ndcg_at_5
value: 19.544
- type: precision_at_1
value: 20.195
- type: precision_at_10
value: 7.394
- type: precision_at_100
value: 1.493
- type: precision_at_1000
value: 0.218
- type: precision_at_3
value: 13.073
- type: precision_at_5
value: 10.436
- type: recall_at_1
value: 9.376
- type: recall_at_10
value: 28.544999999999998
- type: recall_at_100
value: 53.147999999999996
- type: recall_at_1000
value: 74.62
- type: recall_at_3
value: 16.464000000000002
- type: recall_at_5
value: 21.004
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.415000000000001
- type: map_at_10
value: 18.738
- type: map_at_100
value: 27.291999999999998
- type: map_at_1000
value: 28.992
- type: map_at_3
value: 13.196
- type: map_at_5
value: 15.539
- type: mrr_at_1
value: 66.5
- type: mrr_at_10
value: 74.518
- type: mrr_at_100
value: 74.86
- type: mrr_at_1000
value: 74.87
- type: mrr_at_3
value: 72.375
- type: mrr_at_5
value: 73.86200000000001
- type: ndcg_at_1
value: 54.37499999999999
- type: ndcg_at_10
value: 41.317
- type: ndcg_at_100
value: 45.845
- type: ndcg_at_1000
value: 52.92
- type: ndcg_at_3
value: 44.983000000000004
- type: ndcg_at_5
value: 42.989
- type: precision_at_1
value: 66.5
- type: precision_at_10
value: 33.6
- type: precision_at_100
value: 10.972999999999999
- type: precision_at_1000
value: 2.214
- type: precision_at_3
value: 48.583
- type: precision_at_5
value: 42.15
- type: recall_at_1
value: 8.415000000000001
- type: recall_at_10
value: 24.953
- type: recall_at_100
value: 52.48199999999999
- type: recall_at_1000
value: 75.093
- type: recall_at_3
value: 14.341000000000001
- type: recall_at_5
value: 18.468
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 47.06499999999999
- type: f1
value: 41.439327599975385
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 66.02
- type: map_at_10
value: 76.68599999999999
- type: map_at_100
value: 76.959
- type: map_at_1000
value: 76.972
- type: map_at_3
value: 75.024
- type: map_at_5
value: 76.153
- type: mrr_at_1
value: 71.197
- type: mrr_at_10
value: 81.105
- type: mrr_at_100
value: 81.232
- type: mrr_at_1000
value: 81.233
- type: mrr_at_3
value: 79.758
- type: mrr_at_5
value: 80.69
- type: ndcg_at_1
value: 71.197
- type: ndcg_at_10
value: 81.644
- type: ndcg_at_100
value: 82.645
- type: ndcg_at_1000
value: 82.879
- type: ndcg_at_3
value: 78.792
- type: ndcg_at_5
value: 80.528
- type: precision_at_1
value: 71.197
- type: precision_at_10
value: 10.206999999999999
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 30.868000000000002
- type: precision_at_5
value: 19.559
- type: recall_at_1
value: 66.02
- type: recall_at_10
value: 92.50699999999999
- type: recall_at_100
value: 96.497
- type: recall_at_1000
value: 97.956
- type: recall_at_3
value: 84.866
- type: recall_at_5
value: 89.16199999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.948
- type: map_at_10
value: 29.833
- type: map_at_100
value: 31.487
- type: map_at_1000
value: 31.674000000000003
- type: map_at_3
value: 26.029999999999998
- type: map_at_5
value: 28.038999999999998
- type: mrr_at_1
value: 34.721999999999994
- type: mrr_at_10
value: 44.214999999999996
- type: mrr_at_100
value: 44.994
- type: mrr_at_1000
value: 45.051
- type: mrr_at_3
value: 41.667
- type: mrr_at_5
value: 43.032
- type: ndcg_at_1
value: 34.721999999999994
- type: ndcg_at_10
value: 37.434
- type: ndcg_at_100
value: 43.702000000000005
- type: ndcg_at_1000
value: 46.993
- type: ndcg_at_3
value: 33.56
- type: ndcg_at_5
value: 34.687
- type: precision_at_1
value: 34.721999999999994
- type: precision_at_10
value: 10.401
- type: precision_at_100
value: 1.7049999999999998
- type: precision_at_1000
value: 0.22799999999999998
- type: precision_at_3
value: 22.531000000000002
- type: precision_at_5
value: 16.42
- type: recall_at_1
value: 17.948
- type: recall_at_10
value: 45.062999999999995
- type: recall_at_100
value: 68.191
- type: recall_at_1000
value: 87.954
- type: recall_at_3
value: 31.112000000000002
- type: recall_at_5
value: 36.823
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.644
- type: map_at_10
value: 57.658
- type: map_at_100
value: 58.562000000000005
- type: map_at_1000
value: 58.62500000000001
- type: map_at_3
value: 54.022999999999996
- type: map_at_5
value: 56.293000000000006
- type: mrr_at_1
value: 73.288
- type: mrr_at_10
value: 80.51700000000001
- type: mrr_at_100
value: 80.72
- type: mrr_at_1000
value: 80.728
- type: mrr_at_3
value: 79.33200000000001
- type: mrr_at_5
value: 80.085
- type: ndcg_at_1
value: 73.288
- type: ndcg_at_10
value: 66.61
- type: ndcg_at_100
value: 69.723
- type: ndcg_at_1000
value: 70.96000000000001
- type: ndcg_at_3
value: 61.358999999999995
- type: ndcg_at_5
value: 64.277
- type: precision_at_1
value: 73.288
- type: precision_at_10
value: 14.17
- type: precision_at_100
value: 1.659
- type: precision_at_1000
value: 0.182
- type: precision_at_3
value: 39.487
- type: precision_at_5
value: 25.999
- type: recall_at_1
value: 36.644
- type: recall_at_10
value: 70.851
- type: recall_at_100
value: 82.94399999999999
- type: recall_at_1000
value: 91.134
- type: recall_at_3
value: 59.230000000000004
- type: recall_at_5
value: 64.997
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 86.00280000000001
- type: ap
value: 80.46302061021223
- type: f1
value: 85.9592921596419
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.541
- type: map_at_10
value: 34.625
- type: map_at_100
value: 35.785
- type: map_at_1000
value: 35.831
- type: map_at_3
value: 30.823
- type: map_at_5
value: 32.967999999999996
- type: mrr_at_1
value: 23.180999999999997
- type: mrr_at_10
value: 35.207
- type: mrr_at_100
value: 36.315
- type: mrr_at_1000
value: 36.355
- type: mrr_at_3
value: 31.483
- type: mrr_at_5
value: 33.589999999999996
- type: ndcg_at_1
value: 23.195
- type: ndcg_at_10
value: 41.461
- type: ndcg_at_100
value: 47.032000000000004
- type: ndcg_at_1000
value: 48.199999999999996
- type: ndcg_at_3
value: 33.702
- type: ndcg_at_5
value: 37.522
- type: precision_at_1
value: 23.195
- type: precision_at_10
value: 6.526999999999999
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 14.308000000000002
- type: precision_at_5
value: 10.507
- type: recall_at_1
value: 22.541
- type: recall_at_10
value: 62.524
- type: recall_at_100
value: 88.228
- type: recall_at_1000
value: 97.243
- type: recall_at_3
value: 41.38
- type: recall_at_5
value: 50.55
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.69949840401279
- type: f1
value: 92.54141471311786
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 72.56041951664386
- type: f1
value: 55.88499977508287
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.62071284465365
- type: f1
value: 69.36717546572152
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.35843981170142
- type: f1
value: 76.15496453538884
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 31.33664956793118
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 27.883839621715524
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.096874986740758
- type: mrr
value: 30.97300481932132
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.4
- type: map_at_10
value: 11.852
- type: map_at_100
value: 14.758
- type: map_at_1000
value: 16.134
- type: map_at_3
value: 8.558
- type: map_at_5
value: 10.087
- type: mrr_at_1
value: 44.272
- type: mrr_at_10
value: 52.05800000000001
- type: mrr_at_100
value: 52.689
- type: mrr_at_1000
value: 52.742999999999995
- type: mrr_at_3
value: 50.205999999999996
- type: mrr_at_5
value: 51.367
- type: ndcg_at_1
value: 42.57
- type: ndcg_at_10
value: 32.449
- type: ndcg_at_100
value: 29.596
- type: ndcg_at_1000
value: 38.351
- type: ndcg_at_3
value: 37.044
- type: ndcg_at_5
value: 35.275
- type: precision_at_1
value: 44.272
- type: precision_at_10
value: 23.87
- type: precision_at_100
value: 7.625
- type: precision_at_1000
value: 2.045
- type: precision_at_3
value: 34.365
- type: precision_at_5
value: 30.341
- type: recall_at_1
value: 5.4
- type: recall_at_10
value: 15.943999999999999
- type: recall_at_100
value: 29.805
- type: recall_at_1000
value: 61.695
- type: recall_at_3
value: 9.539
- type: recall_at_5
value: 12.127
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.047000000000004
- type: map_at_10
value: 51.6
- type: map_at_100
value: 52.449999999999996
- type: map_at_1000
value: 52.476
- type: map_at_3
value: 47.452
- type: map_at_5
value: 49.964
- type: mrr_at_1
value: 40.382
- type: mrr_at_10
value: 54.273
- type: mrr_at_100
value: 54.859
- type: mrr_at_1000
value: 54.876000000000005
- type: mrr_at_3
value: 51.014
- type: mrr_at_5
value: 52.983999999999995
- type: ndcg_at_1
value: 40.353
- type: ndcg_at_10
value: 59.11300000000001
- type: ndcg_at_100
value: 62.604000000000006
- type: ndcg_at_1000
value: 63.187000000000005
- type: ndcg_at_3
value: 51.513
- type: ndcg_at_5
value: 55.576
- type: precision_at_1
value: 40.353
- type: precision_at_10
value: 9.418
- type: precision_at_100
value: 1.1440000000000001
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.078000000000003
- type: precision_at_5
value: 16.250999999999998
- type: recall_at_1
value: 36.047000000000004
- type: recall_at_10
value: 79.22200000000001
- type: recall_at_100
value: 94.23
- type: recall_at_1000
value: 98.51100000000001
- type: recall_at_3
value: 59.678
- type: recall_at_5
value: 68.967
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 68.232
- type: map_at_10
value: 81.674
- type: map_at_100
value: 82.338
- type: map_at_1000
value: 82.36099999999999
- type: map_at_3
value: 78.833
- type: map_at_5
value: 80.58
- type: mrr_at_1
value: 78.64
- type: mrr_at_10
value: 85.164
- type: mrr_at_100
value: 85.317
- type: mrr_at_1000
value: 85.319
- type: mrr_at_3
value: 84.127
- type: mrr_at_5
value: 84.789
- type: ndcg_at_1
value: 78.63
- type: ndcg_at_10
value: 85.711
- type: ndcg_at_100
value: 87.238
- type: ndcg_at_1000
value: 87.444
- type: ndcg_at_3
value: 82.788
- type: ndcg_at_5
value: 84.313
- type: precision_at_1
value: 78.63
- type: precision_at_10
value: 12.977
- type: precision_at_100
value: 1.503
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 36.113
- type: precision_at_5
value: 23.71
- type: recall_at_1
value: 68.232
- type: recall_at_10
value: 93.30199999999999
- type: recall_at_100
value: 98.799
- type: recall_at_1000
value: 99.885
- type: recall_at_3
value: 84.827
- type: recall_at_5
value: 89.188
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 45.71879170816294
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 59.65866311751794
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.218
- type: map_at_10
value: 10.337
- type: map_at_100
value: 12.131
- type: map_at_1000
value: 12.411
- type: map_at_3
value: 7.4270000000000005
- type: map_at_5
value: 8.913
- type: mrr_at_1
value: 20.8
- type: mrr_at_10
value: 30.868000000000002
- type: mrr_at_100
value: 31.903
- type: mrr_at_1000
value: 31.972
- type: mrr_at_3
value: 27.367
- type: mrr_at_5
value: 29.372
- type: ndcg_at_1
value: 20.8
- type: ndcg_at_10
value: 17.765
- type: ndcg_at_100
value: 24.914
- type: ndcg_at_1000
value: 30.206
- type: ndcg_at_3
value: 16.64
- type: ndcg_at_5
value: 14.712
- type: precision_at_1
value: 20.8
- type: precision_at_10
value: 9.24
- type: precision_at_100
value: 1.9560000000000002
- type: precision_at_1000
value: 0.32299999999999995
- type: precision_at_3
value: 15.467
- type: precision_at_5
value: 12.94
- type: recall_at_1
value: 4.218
- type: recall_at_10
value: 18.752
- type: recall_at_100
value: 39.7
- type: recall_at_1000
value: 65.57300000000001
- type: recall_at_3
value: 9.428
- type: recall_at_5
value: 13.133000000000001
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 83.04338850207233
- type: cos_sim_spearman
value: 78.5054651430423
- type: euclidean_pearson
value: 80.30739451228612
- type: euclidean_spearman
value: 78.48377464299097
- type: manhattan_pearson
value: 80.40795049052781
- type: manhattan_spearman
value: 78.49506205443114
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.11596224442962
- type: cos_sim_spearman
value: 76.20997388935461
- type: euclidean_pearson
value: 80.56858451349109
- type: euclidean_spearman
value: 75.92659183871186
- type: manhattan_pearson
value: 80.60246102203844
- type: manhattan_spearman
value: 76.03018971432664
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 81.34691640755737
- type: cos_sim_spearman
value: 82.4018369631579
- type: euclidean_pearson
value: 81.87673092245366
- type: euclidean_spearman
value: 82.3671489960678
- type: manhattan_pearson
value: 81.88222387719948
- type: manhattan_spearman
value: 82.3816590344736
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 81.2836092579524
- type: cos_sim_spearman
value: 78.99982781772064
- type: euclidean_pearson
value: 80.5184271010527
- type: euclidean_spearman
value: 78.89777392101904
- type: manhattan_pearson
value: 80.53585705018664
- type: manhattan_spearman
value: 78.92898405472994
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.7349907750784
- type: cos_sim_spearman
value: 87.7611234446225
- type: euclidean_pearson
value: 86.98759326731624
- type: euclidean_spearman
value: 87.58321319424618
- type: manhattan_pearson
value: 87.03483090370842
- type: manhattan_spearman
value: 87.63278333060288
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 81.75873694924825
- type: cos_sim_spearman
value: 83.80237999094724
- type: euclidean_pearson
value: 83.55023725861537
- type: euclidean_spearman
value: 84.12744338577744
- type: manhattan_pearson
value: 83.58816983036232
- type: manhattan_spearman
value: 84.18520748676501
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.21630882940174
- type: cos_sim_spearman
value: 87.72382883437031
- type: euclidean_pearson
value: 88.69933350930333
- type: euclidean_spearman
value: 88.24660814383081
- type: manhattan_pearson
value: 88.77331018833499
- type: manhattan_spearman
value: 88.26109989380632
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 61.11854063060489
- type: cos_sim_spearman
value: 63.14678634195072
- type: euclidean_pearson
value: 61.679090067000864
- type: euclidean_spearman
value: 62.28876589509653
- type: manhattan_pearson
value: 62.082324165511004
- type: manhattan_spearman
value: 62.56030932816679
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.00319882832645
- type: cos_sim_spearman
value: 85.94529772647257
- type: euclidean_pearson
value: 85.6661390122756
- type: euclidean_spearman
value: 85.97747815545827
- type: manhattan_pearson
value: 85.58422770541893
- type: manhattan_spearman
value: 85.9237139181532
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 79.16198731863916
- type: mrr
value: 94.25202702163487
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 54.761
- type: map_at_10
value: 64.396
- type: map_at_100
value: 65.07
- type: map_at_1000
value: 65.09899999999999
- type: map_at_3
value: 61.846000000000004
- type: map_at_5
value: 63.284
- type: mrr_at_1
value: 57.667
- type: mrr_at_10
value: 65.83099999999999
- type: mrr_at_100
value: 66.36800000000001
- type: mrr_at_1000
value: 66.39399999999999
- type: mrr_at_3
value: 64.056
- type: mrr_at_5
value: 65.206
- type: ndcg_at_1
value: 57.667
- type: ndcg_at_10
value: 68.854
- type: ndcg_at_100
value: 71.59100000000001
- type: ndcg_at_1000
value: 72.383
- type: ndcg_at_3
value: 64.671
- type: ndcg_at_5
value: 66.796
- type: precision_at_1
value: 57.667
- type: precision_at_10
value: 9.167
- type: precision_at_100
value: 1.053
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 25.444
- type: precision_at_5
value: 16.667
- type: recall_at_1
value: 54.761
- type: recall_at_10
value: 80.9
- type: recall_at_100
value: 92.767
- type: recall_at_1000
value: 99
- type: recall_at_3
value: 69.672
- type: recall_at_5
value: 75.083
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.8079207920792
- type: cos_sim_ap
value: 94.88470927617445
- type: cos_sim_f1
value: 90.08179959100204
- type: cos_sim_precision
value: 92.15481171548117
- type: cos_sim_recall
value: 88.1
- type: dot_accuracy
value: 99.58613861386138
- type: dot_ap
value: 82.94822578881316
- type: dot_f1
value: 77.33333333333333
- type: dot_precision
value: 79.36842105263158
- type: dot_recall
value: 75.4
- type: euclidean_accuracy
value: 99.8069306930693
- type: euclidean_ap
value: 94.81367858031837
- type: euclidean_f1
value: 90.01009081735621
- type: euclidean_precision
value: 90.83503054989816
- type: euclidean_recall
value: 89.2
- type: manhattan_accuracy
value: 99.81188118811882
- type: manhattan_ap
value: 94.91405337220161
- type: manhattan_f1
value: 90.2763561924258
- type: manhattan_precision
value: 92.45283018867924
- type: manhattan_recall
value: 88.2
- type: max_accuracy
value: 99.81188118811882
- type: max_ap
value: 94.91405337220161
- type: max_f1
value: 90.2763561924258
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 58.511599500053094
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 31.984728147814707
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 49.93428193939015
- type: mrr
value: 50.916557911043206
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.562500894537145
- type: cos_sim_spearman
value: 31.162587976726307
- type: dot_pearson
value: 22.633662187735762
- type: dot_spearman
value: 22.723000282378962
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.219
- type: map_at_10
value: 1.871
- type: map_at_100
value: 10.487
- type: map_at_1000
value: 25.122
- type: map_at_3
value: 0.657
- type: map_at_5
value: 1.0699999999999998
- type: mrr_at_1
value: 84
- type: mrr_at_10
value: 89.567
- type: mrr_at_100
value: 89.748
- type: mrr_at_1000
value: 89.748
- type: mrr_at_3
value: 88.667
- type: mrr_at_5
value: 89.567
- type: ndcg_at_1
value: 80
- type: ndcg_at_10
value: 74.533
- type: ndcg_at_100
value: 55.839000000000006
- type: ndcg_at_1000
value: 49.748
- type: ndcg_at_3
value: 79.53099999999999
- type: ndcg_at_5
value: 78.245
- type: precision_at_1
value: 84
- type: precision_at_10
value: 78.4
- type: precision_at_100
value: 56.99999999999999
- type: precision_at_1000
value: 21.98
- type: precision_at_3
value: 85.333
- type: precision_at_5
value: 84.8
- type: recall_at_1
value: 0.219
- type: recall_at_10
value: 2.02
- type: recall_at_100
value: 13.555
- type: recall_at_1000
value: 46.739999999999995
- type: recall_at_3
value: 0.685
- type: recall_at_5
value: 1.13
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.5029999999999997
- type: map_at_10
value: 11.042
- type: map_at_100
value: 16.326999999999998
- type: map_at_1000
value: 17.836
- type: map_at_3
value: 6.174
- type: map_at_5
value: 7.979
- type: mrr_at_1
value: 42.857
- type: mrr_at_10
value: 52.617000000000004
- type: mrr_at_100
value: 53.351000000000006
- type: mrr_at_1000
value: 53.351000000000006
- type: mrr_at_3
value: 46.939
- type: mrr_at_5
value: 50.714000000000006
- type: ndcg_at_1
value: 38.775999999999996
- type: ndcg_at_10
value: 27.125
- type: ndcg_at_100
value: 35.845
- type: ndcg_at_1000
value: 47.377
- type: ndcg_at_3
value: 29.633
- type: ndcg_at_5
value: 28.378999999999998
- type: precision_at_1
value: 42.857
- type: precision_at_10
value: 24.082
- type: precision_at_100
value: 6.877999999999999
- type: precision_at_1000
value: 1.463
- type: precision_at_3
value: 29.932
- type: precision_at_5
value: 28.571
- type: recall_at_1
value: 3.5029999999999997
- type: recall_at_10
value: 17.068
- type: recall_at_100
value: 43.361
- type: recall_at_1000
value: 78.835
- type: recall_at_3
value: 6.821000000000001
- type: recall_at_5
value: 10.357
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.0954
- type: ap
value: 14.216844153511959
- type: f1
value: 54.63687418565117
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.46293152235427
- type: f1
value: 61.744177921638645
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 41.12708617788644
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.75430649102938
- type: cos_sim_ap
value: 73.34252536948081
- type: cos_sim_f1
value: 67.53758935173774
- type: cos_sim_precision
value: 63.3672525439408
- type: cos_sim_recall
value: 72.29551451187335
- type: dot_accuracy
value: 81.71305954580676
- type: dot_ap
value: 59.5532209082386
- type: dot_f1
value: 56.18466898954705
- type: dot_precision
value: 47.830923248053395
- type: dot_recall
value: 68.07387862796834
- type: euclidean_accuracy
value: 85.81987244441795
- type: euclidean_ap
value: 73.34325409809446
- type: euclidean_f1
value: 67.83451360417443
- type: euclidean_precision
value: 64.09955388588871
- type: euclidean_recall
value: 72.0316622691293
- type: manhattan_accuracy
value: 85.68277999642368
- type: manhattan_ap
value: 73.1535450121903
- type: manhattan_f1
value: 67.928237896289
- type: manhattan_precision
value: 63.56945722171113
- type: manhattan_recall
value: 72.9287598944591
- type: max_accuracy
value: 85.81987244441795
- type: max_ap
value: 73.34325409809446
- type: max_f1
value: 67.928237896289
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.90441262079403
- type: cos_sim_ap
value: 85.79331880741438
- type: cos_sim_f1
value: 78.31563529842548
- type: cos_sim_precision
value: 74.6683424102779
- type: cos_sim_recall
value: 82.33754234678165
- type: dot_accuracy
value: 84.89928978926534
- type: dot_ap
value: 75.25819218316
- type: dot_f1
value: 69.88730119720536
- type: dot_precision
value: 64.23362374959665
- type: dot_recall
value: 76.63227594702803
- type: euclidean_accuracy
value: 89.01695967710637
- type: euclidean_ap
value: 85.98986606038852
- type: euclidean_f1
value: 78.5277880014722
- type: euclidean_precision
value: 75.22211253701876
- type: euclidean_recall
value: 82.13735756082538
- type: manhattan_accuracy
value: 88.99561454573679
- type: manhattan_ap
value: 85.92262421793953
- type: manhattan_f1
value: 78.38866094740769
- type: manhattan_precision
value: 76.02373028505282
- type: manhattan_recall
value: 80.9054511857099
- type: max_accuracy
value: 89.01695967710637
- type: max_ap
value: 85.98986606038852
- type: max_f1
value: 78.5277880014722
---
# # Fast-Inference with Ctranslate2
Speedup inference while reducing memory by 2x-4x using int8 inference in C++ on CPU or GPU.
quantized version of [intfloat/e5-small-v2](https://huggingface.co/intfloat/e5-small-v2)
```bash
pip install hf-hub-ctranslate2>=2.12.0 ctranslate2>=3.17.1
```
```python
# from transformers import AutoTokenizer
model_name = "michaelfeil/ct2fast-e5-small-v2"
model_name_orig="intfloat/e5-small-v2"
from hf_hub_ctranslate2 import EncoderCT2fromHfHub
model = EncoderCT2fromHfHub(
# load in int8 on CUDA
model_name_or_path=model_name,
device="cuda",
compute_type="int8_float16"
)
outputs = model.generate(
text=["I like soccer", "I like tennis", "The eiffel tower is in Paris"],
max_length=64,
) # perform downstream tasks on outputs
outputs["pooler_output"]
outputs["last_hidden_state"]
outputs["attention_mask"]
# alternative, use SentenceTransformer Mix-In
# for end-to-end Sentence embeddings generation
# (not pulling from this CT2fast-HF repo)
from hf_hub_ctranslate2 import CT2SentenceTransformer
model = CT2SentenceTransformer(
model_name_orig, compute_type="int8_float16", device="cuda"
)
embeddings = model.encode(
["I like soccer", "I like tennis", "The eiffel tower is in Paris"],
batch_size=32,
convert_to_numpy=True,
normalize_embeddings=True,
)
print(embeddings.shape, embeddings)
scores = (embeddings @ embeddings.T) * 100
# Hint: you can also host this code via REST API and
# via github.com/michaelfeil/infinity
```
Checkpoint compatible to [ctranslate2>=3.17.1](https://github.com/OpenNMT/CTranslate2)
and [hf-hub-ctranslate2>=2.12.0](https://github.com/michaelfeil/hf-hub-ctranslate2)
- `compute_type=int8_float16` for `device="cuda"`
- `compute_type=int8` for `device="cpu"`
Converted on 2023-10-13 using
```
LLama-2 -> removed <pad> token.
```
# Licence and other remarks:
This is just a quantized version. Licence conditions are intended to be idential to original huggingface repo.
# Original description
# E5-small-v2
[Text Embeddings by Weakly-Supervised Contrastive Pre-training](https://arxiv.org/pdf/2212.03533.pdf).
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei, arXiv 2022
This model has 12 layers and the embedding size is 384.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ".
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: summit define',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."]
tokenizer = AutoTokenizer.from_pretrained('intfloat/e5-small-v2')
model = AutoModel.from_pretrained('intfloat/e5-small-v2')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Training Details
Please refer to our paper at [https://arxiv.org/pdf/2212.03533.pdf](https://arxiv.org/pdf/2212.03533.pdf).
## Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## Support for Sentence Transformers
Below is an example for usage with sentence_transformers.
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('intfloat/e5-small-v2')
input_texts = [
'query: how much protein should a female eat',
'query: summit define',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
embeddings = model.encode(input_texts, normalize_embeddings=True)
```
Package requirements
`pip install sentence_transformers~=2.2.2`
Contributors: [michaelfeil](https://huggingface.co/michaelfeil)
## FAQ
**1. Do I need to add the prefix "query: " and "passage: " to input texts?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
Here are some rules of thumb:
- Use "query: " and "passage: " correspondingly for asymmetric tasks such as passage retrieval in open QA, ad-hoc information retrieval.
- Use "query: " prefix for symmetric tasks such as semantic similarity, paraphrase retrieval.
- Use "query: " prefix if you want to use embeddings as features, such as linear probing classification, clustering.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Why does the cosine similarity scores distribute around 0.7 to 1.0?**
This is a known and expected behavior as we use a low temperature 0.01 for InfoNCE contrastive loss.
For text embedding tasks like text retrieval or semantic similarity,
what matters is the relative order of the scores instead of the absolute values,
so this should not be an issue.
## Citation
If you find our paper or models helpful, please consider cite as follows:
```
@article{wang2022text,
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2212.03533},
year={2022}
}
```
## Limitations
This model only works for English texts. Long texts will be truncated to at most 512 tokens.
|
[
"BIOSSES",
"SCIFACT"
] |
IIC/XLM_R_Galen-cantemist
|
IIC
|
text-classification
|
[
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"text-classification",
"biomedical",
"clinical",
"eHR",
"spanish",
"XLM_R_Galen",
"es",
"dataset:PlanTL-GOB-ES/cantemist-ner",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-19T15:32:03Z |
2024-11-25T10:41:02+00:00
| 16 | 0 |
---
datasets:
- PlanTL-GOB-ES/cantemist-ner
language: es
license: mit
metrics:
- f1
tags:
- biomedical
- clinical
- eHR
- spanish
- XLM_R_Galen
widget:
- text: El diagnóstico definitivo de nuestro paciente fue de un Adenocarcinoma de
pulmón cT2a cN3 cM1a Estadio IV (por una única lesión pulmonar contralateral)
PD-L1 90%, EGFR negativo, ALK negativo y ROS-1 negativo.
- text: Durante el ingreso se realiza una TC, observándose un nódulo pulmonar en el
LII y una masa renal derecha indeterminada. Se realiza punción biopsia del nódulo
pulmonar, con hallazgos altamente sospechosos de carcinoma.
- text: Trombosis paraneoplásica con sospecha de hepatocarcinoma por imagen, sobre
hígado cirrótico, en paciente con índice Child-Pugh B.
model-index:
- name: IIC/XLM_R_Galen-cantemist
results:
- task:
type: token-classification
dataset:
name: cantemist-ner
type: PlanTL-GOB-ES/cantemist-ner
metrics:
- type: f1
value: 0.898
name: f1
---
# XLM_R_Galen-cantemist
This model is a finetuned version of XLM_R_Galen for the cantemist dataset used in a benchmark in the paper `A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks`. The model has a F1 of 0.898
Please refer to the [original publication](https://doi.org/10.1093/jamia/ocae054) for more information.
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 16 |
| learning rate | 4e05 |
| classifier dropout | 0 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtext
@article{10.1093/jamia/ocae054,
author = {García Subies, Guillem and Barbero Jiménez, Álvaro and Martínez Fernández, Paloma},
title = {A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks},
journal = {Journal of the American Medical Informatics Association},
volume = {31},
number = {9},
pages = {2137-2146},
year = {2024},
month = {03},
issn = {1527-974X},
doi = {10.1093/jamia/ocae054},
url = {https://doi.org/10.1093/jamia/ocae054},
}
```
|
[
"CANTEMIST"
] |
IIC/mdeberta-v3-base-ctebmsp
|
IIC
|
token-classification
|
[
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"text-classification",
"biomedical",
"clinical",
"spanish",
"mdeberta-v3-base",
"token-classification",
"es",
"dataset:lcampillos/ctebmsp",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-21T06:47:50Z |
2024-11-25T10:41:30+00:00
| 16 | 0 |
---
datasets:
- lcampillos/ctebmsp
language: es
license: mit
metrics:
- f1
pipeline_tag: token-classification
tags:
- biomedical
- clinical
- spanish
- mdeberta-v3-base
model-index:
- name: IIC/mdeberta-v3-base-ctebmsp
results:
- task:
type: token-classification
dataset:
name: CT-EBM-SP (Clinical Trials for Evidence-based Medicine in Spanish)
type: lcampillos/ctebmsp
split: test
metrics:
- type: f1
value: 0.902
name: f1
---
# mdeberta-v3-base-ctebmsp
This model is a finetuned version of mdeberta-v3-base for the CT-EBM-SP (Clinical Trials for Evidence-based Medicine in Spanish) dataset used in a benchmark in the paper `A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks`. The model has a F1 of 0.902
Please refer to the [original publication](https://doi.org/10.1093/jamia/ocae054) for more information.
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 32 |
| learning rate | 4e-05 |
| classifier dropout | 0.2 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtext
@article{10.1093/jamia/ocae054,
author = {García Subies, Guillem and Barbero Jiménez, Álvaro and Martínez Fernández, Paloma},
title = {A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks},
journal = {Journal of the American Medical Informatics Association},
volume = {31},
number = {9},
pages = {2137-2146},
year = {2024},
month = {03},
issn = {1527-974X},
doi = {10.1093/jamia/ocae054},
url = {https://doi.org/10.1093/jamia/ocae054},
}
```
|
[
"CT-EBM-SP"
] |
IIC/bert-base-spanish-wwm-cased-distemist
|
IIC
|
token-classification
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"biomedical",
"clinical",
"spanish",
"bert-base-spanish-wwm-cased",
"token-classification",
"es",
"dataset:bigbio/distemist",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-21T09:25:32Z |
2024-11-25T10:41:37+00:00
| 16 | 0 |
---
datasets:
- bigbio/distemist
language: es
license: cc-by-4.0
metrics:
- f1
pipeline_tag: token-classification
tags:
- biomedical
- clinical
- spanish
- bert-base-spanish-wwm-cased
model-index:
- name: IIC/bert-base-spanish-wwm-cased-distemist
results:
- task:
type: token-classification
dataset:
name: distemist
type: bigbio/distemist
split: test
metrics:
- type: f1
value: 0.801
name: f1
---
# bert-base-spanish-wwm-cased-distemist
This model is a finetuned version of bert-base-spanish-wwm-cased for the distemist dataset used in a benchmark in the paper `A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks`. The model has a F1 of 0.801
Please refer to the [original publication](https://doi.org/10.1093/jamia/ocae054) for more information.
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 16 |
| learning rate | 4e-05 |
| classifier dropout | 0 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtext
@article{10.1093/jamia/ocae054,
author = {García Subies, Guillem and Barbero Jiménez, Álvaro and Martínez Fernández, Paloma},
title = {A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks},
journal = {Journal of the American Medical Informatics Association},
volume = {31},
number = {9},
pages = {2137-2146},
year = {2024},
month = {03},
issn = {1527-974X},
doi = {10.1093/jamia/ocae054},
url = {https://doi.org/10.1093/jamia/ocae054},
}
```
|
[
"DISTEMIST"
] |
IIC/XLM_R_Galen-distemist
|
IIC
|
token-classification
|
[
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"text-classification",
"biomedical",
"clinical",
"spanish",
"XLM_R_Galen",
"token-classification",
"es",
"dataset:bigbio/distemist",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-21T09:36:34Z |
2025-01-17T10:52:28+00:00
| 16 | 0 |
---
datasets:
- bigbio/distemist
language: es
license: mit
metrics:
- f1
pipeline_tag: token-classification
tags:
- biomedical
- clinical
- spanish
- XLM_R_Galen
model-index:
- name: IIC/XLM_R_Galen-distemist
results:
- task:
type: token-classification
dataset:
name: distemist
type: bigbio/distemist
split: test
metrics:
- type: f1
value: 0.759
name: f1
---
# XLM_R_Galen-distemist
This model is a finetuned version of XLM_R_Galen for the distemist dataset used in a benchmark in the paper `A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks`. The model has a F1 of 0.759
Please refer to the [original publication](https://doi.org/10.1093/jamia/ocae054) for more information.
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 16 |
| learning rate | 4e-05 |
| classifier dropout | 0.2 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtext
@article{10.1093/jamia/ocae054,
author = {García Subies, Guillem and Barbero Jiménez, Álvaro and Martínez Fernández, Paloma},
title = {A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks},
journal = {Journal of the American Medical Informatics Association},
volume = {31},
number = {9},
pages = {2137-2146},
year = {2024},
month = {03},
issn = {1527-974X},
doi = {10.1093/jamia/ocae054},
url = {https://doi.org/10.1093/jamia/ocae054},
}
```
|
[
"DISTEMIST"
] |
IIC/mdeberta-v3-base-meddocan
|
IIC
|
token-classification
|
[
"transformers",
"pytorch",
"safetensors",
"deberta-v2",
"text-classification",
"biomedical",
"clinical",
"spanish",
"mdeberta-v3-base",
"token-classification",
"es",
"dataset:bigbio/meddocan",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-21T15:41:36Z |
2023-07-27T14:28:46+00:00
| 16 | 0 |
---
datasets:
- bigbio/meddocan
language: es
license: mit
metrics:
- f1
pipeline_tag: token-classification
tags:
- biomedical
- clinical
- spanish
- mdeberta-v3-base
model-index:
- name: IIC/mdeberta-v3-base-meddocan
results:
- task:
type: token-classification
dataset:
name: meddocan
type: bigbio/meddocan
split: test
metrics:
- type: f1
value: 0.974
name: f1
---
# mdeberta-v3-base-meddocan
This model is a finetuned version of mdeberta-v3-base for the meddocan dataset used in a benchmark in the paper TODO. The model has a F1 of 0.974
Please refer to the original publication for more information TODO LINK
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 16 |
| learning rate | 4e-05 |
| classifier dropout | 0.2 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtex
TODO
```
|
[
"MEDDOCAN"
] |
a-mannion/umls-kgi-bert-trilingual
|
a-mannion
|
feature-extraction
|
[
"transformers",
"pytorch",
"distilbert",
"feature-extraction",
"medical",
"fr",
"en",
"es",
"arxiv:2307.11170",
"license:apache-2.0",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2023-07-13T02:10:02Z |
2025-02-25T08:31:26+00:00
| 16 | 0 |
---
language:
- fr
- en
- es
license: apache-2.0
tags:
- medical
---
# UMLS-KGI-BERT-multilingual
<!-- Provide a quick summary of what the model is/does. -->
This is a trilingual (FR, EN, ES) BERT encoder trained jointly on the European Clinical Case corpus as well as the UMLS metathesaurus knowledge graph, as described in [this paper](https://aclanthology.org/2023.clinicalnlp-1.35/).
The training corpus consists of a custom combination of clinical documents from the E3C and text sequences derived from the metathesaurus (see our [Github repo](https://github.com/ap-mannion/bertify-umls) for more details).
## Model Details
This model was trained using a multi-task approach combining Masked Language Modelling with knowledge-graph-based classification/fill-mask type objectives.
The idea behind this framework was to try to improve the robustness of specialised biomedical BERT models by having them learn from structured data as well as natural language, while remaining in the cross-entropy-based learning paradigm.
- **Developed by:** Aidan Mannion
- **Funded by :** GENCI-IDRIS grant AD011013535R1
- **Model type:** DistilBERT
- **Language(s) (NLP):** French, English, Spanish
For further details on the model architecture, training objectives, hardware \& software used, as well as the preliminary downstream evaluation experiments carried out, refer to the [ArXiv paper](https://arxiv.org/abs/2307.11170).
### UMLS-KGI Models
| **Model** | **Model Repo** | **Dataset Size** | **Base Architecture** | **Base Model** | **Total KGI training steps** |
|:--------------------------:|:--------------------------------------------------------------------------:|:----------------:|:---------------------:|:---------------------------------------------------------------------------------------------:|:----------------------------:|
| UMLS-KGI-BERT-multilingual | [url-multi](https://huggingface.co/ap-mannion/umls-kgi-bert-multilingual) | 940MB | DistilBERT | n/a | 163,904 |
| UMLS-KGI-BERT-FR | [url-fr](https://huggingface.co/ap-mannion/umls-kgi-bert-fr) | 604MB | DistilBERT | n/a | 126,720 |
| UMLS-KGI-BERT-EN | [url-en](https://huggingface.co/ap-mannion/umls-kgi-bert-en) | 174MB | DistilBERT | n/a | 19,008 |
| UMLS-KGI-BERT-ES | [url-es](https://huggingface.co/ap-mannion/umls-kgi-bert-es) | 162MB | DistilBERT | n/a | 18,176 |
| DrBERT-UMLS-KGI | [url-drbert](https://huggingface.co/ap-mannion/drbert-umls-kgi) | 604MB | CamemBERT/RoBERTa | [DrBERT-4GB](https://huggingface.co/Dr-BERT/DrBERT-4GB) | 126,720 |
| PubMedBERT-UMLS-KGI | [url-pubmedbert](https://huggingface.co/ap-mannion/pubmedbert-umls-kgi) | 174MB | BERT | microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract | 19,008 |
| BioRoBERTa-ES-UMLS-KGI | [url-bioroberta](https://huggingface.co/ap-mannion/bioroberta-es-umls-kgi) | 162MB | RoBERTa | [RoBERTa-base-biomedical-es](https://huggingface.co/PlanTL-GOB-ES/roberta-base-biomedical-es) | 18,176 |
### Direct/Downstream Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
This model is intended for use in experimental clinical/biomedical NLP work, either as a part of a larger system requiring text encoding or fine-tuned on a specific downstream task requiring clinical language modelling.
It has **not** been sufficiently tested for accuracy, robustness and bias to be used in production settings.
### Out-of-Scope Use
Experiments on general-domain data suggest that, given it's specialised training corpus, this model is **not** suitable for use on out-of-domain NLP tasks, and we recommend that it only be used for processing clinical text.
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
- [European Clinical Case Corpus](https://live.european-language-grid.eu/catalogue/corpus/7618)
- [UMLS Metathesaurus](https://www.nlm.nih.gov/research/umls/index.html)
#### Training Hyperparameters
- sequence length: 256
- learning rate 7.5e-5
- linear learning rate schedule with 10,770 warmup steps
- effective batch size 1500 (15 sequences per batch x 100 gradient accumulation steps)
- MLM masking probability 0.15
**Training regime:** The model was trained with fp16 non-mixed precision, using the AdamW optimizer with default parameters.
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
This model was evaluated on the following datasets:
- [`ncbi_disease`](https://huggingface.co/datasets/ncbi_disease) (en)
- [`J4YL19/biored_tokenized`](https://huggingface.co/datasets/J4YL19/biored_tokenized) (en)
- [`tner/bionlp2004`](https://huggingface.co/datasets/tner/bionlp2004) (en)
- [`bigbio/pharmaconer`](https://huggingface.co/datasets/bigbio/pharmaconer) (es)
- [`bigbio/meddocan`](https://huggingface.co/datasets/bigbio/meddocan) (es)
- [CAS-POS](https://huggingface.co/datasets/bigbio/essai) (fr)
- [ESSAI-POS](https://huggingface.co/datasets/bigbio/essai) (fr)
- CAS-SG (dataset not publicly available) (fr)
- [`QUAERO-MEDLINE`](https://quaerofrenchmed.limsi.fr/) (fr)
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
We provide the macro-averaged F1 scores here; given that all of the downstream token classification tasks in these experiments show significant class imbalance, the weighted-average scores tend to be uniformly higher than their macro-averaged counterparts.
In the interest of more fairly representing the less prevalent classes and highlighting the difficulty of capturing the long-tailed nature of the distributions in these datasets, we stick to the macro average.
### Results
[More Information Needed]
## Citation [BibTeX]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
```
@inproceedings{mannion-etal-2023-umls,
title = "{UMLS}-{KGI}-{BERT}: Data-Centric Knowledge Integration in Transformers for Biomedical Entity Recognition",
author = "Mannion, Aidan and
Schwab, Didier and
Goeuriot, Lorraine",
booktitle = "Proceedings of the 5th Clinical Natural Language Processing Workshop",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.clinicalnlp-1.35",
pages = "312--322",
abstract = "Pre-trained transformer language models (LMs) have in recent years become the dominant paradigm in applied NLP. These models have achieved state-of-the-art performance on tasks such as information extraction, question answering, sentiment analysis, document classification and many others. In the biomedical domain, significant progress has been made in adapting this paradigm to NLP tasks that require the integration of domain-specific knowledge as well as statistical modelling of language. In particular, research in this area has focused on the question of how best to construct LMs that take into account not only the patterns of token distribution in medical text, but also the wealth of structured information contained in terminology resources such as the UMLS. This work contributes a data-centric paradigm for enriching the language representations of biomedical transformer-encoder LMs by extracting text sequences from the UMLS.This allows for graph-based learning objectives to be combined with masked-language pre-training. Preliminary results from experiments in the extension of pre-trained LMs as well as training from scratch show that this framework improves downstream performance on multiple biomedical and clinical Named Entity Recognition (NER) tasks. All pre-trained models, data processing pipelines and evaluation scripts will be made publicly available.",
}
```
```
@misc{mannion2023umlskgibert,
title={UMLS-KGI-BERT: Data-Centric Knowledge Integration in Transformers for Biomedical Entity Recognition},
author={Aidan Mannion and Thierry Chevalier and Didier Schwab and Lorraine Geouriot},
year={2023},
eprint={2307.11170},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"BIORED",
"CAS",
"ESSAI",
"MEDDOCAN",
"NCBI DISEASE",
"PHARMACONER",
"QUAERO"
] |
usvsnsp/pythia-160m-ppo
|
usvsnsp
|
text-generation
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-10-04T13:42:02Z |
2023-10-04T15:49:42+00:00
| 16 | 0 |
---
{}
---
Wandb Run: https://wandb.ai/eleutherai/pythia-rlhf/runs/31gbxj2w
Eval Results:
| Tasks |Version|Filter| Metric |Value | |Stderr|
|--------------|-------|------|----------|-----:|---|-----:|
|arc_challenge |Yaml |none |acc |0.2159|± |0.0120|
| | |none |acc_norm |0.2295|± |0.0123|
|arc_easy |Yaml |none |acc |0.3266|± |0.0096|
| | |none |acc_norm |0.3287|± |0.0096|
|lambada_openai|Yaml |none |perplexity| NaN|± | NaN|
| | |none |acc |0.1750|± |0.0053|
|logiqa |Yaml |none |acc |0.2028|± |0.0158|
| | |none |acc_norm |0.2028|± |0.0158|
|piqa |Yaml |none |acc |0.5441|± |0.0116|
| | |none |acc_norm |0.5446|± |0.0116|
|sciq |Yaml |none |acc |0.2050|± |0.0128|
| | |none |acc_norm |0.1940|± |0.0125|
|winogrande |Yaml |none |acc |0.5043|± |0.0141|
|wsc |Yaml |none |acc |0.6154|± |0.0479|
|
[
"SCIQ"
] |
jiey2/DISC-MedLLM
|
jiey2
|
text-generation
|
[
"transformers",
"pytorch",
"baichuan",
"text-generation",
"medical",
"custom_code",
"zh",
"dataset:Flmc/DISC-Med-SFT",
"arxiv:2308.14346",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-11-04T10:43:52Z |
2023-11-04T10:48:48+00:00
| 16 | 1 |
---
datasets:
- Flmc/DISC-Med-SFT
language:
- zh
license: apache-2.0
tags:
- medical
---
This repository contains the DISC-MedLLM, version of Baichuan-13b-base as the base model.
**Please note that due to the ongoing development of the project, the model weights in this repository may differ from those in our currently deployed demo.**
Check [DISC-MedLLM](https://github.com/FudanDISC/DISC-MedLLM) for more information.
# DISC-MedLLM
[**Demo**](http://med.fudan-disc.com) | [**Tech Report**](https://arxiv.org/abs/2308.14346)
This is the repo of DISC-MedLLM, a medical domain-specific LLM designed for conversational healthcare scenarios by [Fudan-DISC](http://fudan-disc.com) lab.
The following resources have been released:
* DISC-Med-SFT Dataset (with out behavioral preference dataset)
* Model [weights](https://huggingface.co/Flmc/DISC-MedLLM) of DISC-MedLLM
You can check this [link](http://medllm.fudan-disc.com) to try our online demo.
## Overview
The DISC-MedLLM is a large-scale domain-specific model designed for conversational healthcare scenarios. It can address a variety of your needs, including medical consultations and treatment inquiries, offering you high-quality health support services.
The DISC-MedLLM effectively bridges the gap between general language models and real-world medical consultations, as evidenced by experimental results.
Owing to our goal-oriented strategy and the framework that integrates both LLM and Human in the loop based on real-world doctor-patient dialogues and knowledge graphs, DISC-MedLLM boasts several features:
* **Knowledge-intensive and reliable**
* **Ability of multi-turn inquiry**
* **Alignment with human preferences**
## Dataset
<!-- In order to align the distribution of actual doctor responses with the intended AI doctor response distribution, our dataset is constructed from five main resources: Real-world Conversations (420k), Knowledge Graph-derived Question-Answer pairs (50k), Artificially Annotated Data aligned with human preferences (2k), MedMCQA (8k), and additional general data (34k). -->
To train DISC-MedLLM, we construct a high-quality dataset called DISC-Med-SFT consisting of over 470k distinct examples derived from existing medical datasets. We adopt a goal-oriented strategy by selectively reconstructing the dataset using a few deliberately chosen sources. These data sources serve the purpose of assisting LLMs in acquiring medical domain knowledge, aligning behavioral patterns with human preferences, and capturing real-world online medical dialogue distributions.
<!-- <style type="text/css">
.tg {border-collapse:collapse;border-spacing:0;}
.tg td{border-color:black;border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;
overflow:hidden;padding:10px 5px;word-break:normal;}
.tg th{border-color:black;border-style:solid;border-width:1px;font-family:Arial, sans-serif;font-size:14px;
font-weight:normal;overflow:hidden;padding:10px 5px;word-break:normal;}
.tg .tg-9wq8{border-color:inherit;text-align:center;vertical-align:middle}
.tg .tg-c3ow{border-color:inherit;text-align:center;vertical-align:top}
</style> -->
<table class="tg" style="undefined;table-layout: fixed; width: 442px">
<colgroup>
<col style="width: 204.428571px">
<col style="width: 135.428571px">
<col style="width: 102.428571px">
</colgroup>
<thead>
<tr>
<th class="tg-9wq8" rowspan="2"><br>Dateset</th>
<th class="tg-9wq8" rowspan="2"><br>Original Source</th>
<th class="tg-9wq8" rowspan="2"><br>Size</th>
</tr>
<tr>
</tr>
</thead>
<tbody>
<tr>
<td class="tg-9wq8" rowspan="2">Re-constructed AI Doctor-Patient Dialogue</td>
<td class="tg-9wq8">MedDialog</td>
<td class="tg-9wq8">400k</td>
</tr>
<tr>
<td class="tg-9wq8">cMedQA2</td>
<td class="tg-c3ow">20k</td>
</tr>
<tr>
<td class="tg-c3ow">Knowledge Graph <br>QA pairs</td>
<td class="tg-9wq8">CMeKG</td>
<td class="tg-9wq8">50k</td>
</tr>
<tr>
<td class="tg-c3ow">Behavior Preference<br>Dataset</td>
<td class="tg-9wq8">Manual selection</td>
<td class="tg-9wq8">2k</td>
</tr>
<tr>
<td class="tg-9wq8" rowspan="3">Others</td>
<td class="tg-c3ow">MedMCQA</td>
<td class="tg-c3ow">8k</td>
</tr>
<tr>
<td class="tg-c3ow">MOSS-SFT</td>
<td class="tg-c3ow">33k</td>
</tr>
<tr>
<td class="tg-c3ow">Alpaca-GPT4-zh</td>
<td class="tg-c3ow">1k</td>
</tr>
</tbody>
</table>
<br>
## Deploy
The current version of DISC-MedLLM is derived from the [Baichuan-13B-Base](https://github.com/baichuan-inc/Baichuan-13B). You can directly download our model weights from the HuggingFace [repository](https://huggingface.co/Flmc/DISC-MedLLM), or automatically obtain them through the demo code.
### Using through hugging face transformers
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation.utils import GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("Flmc/DISC-MedLLM", use_fast=False, trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("Flmc/DISC-MedLLM", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
>>> model.generation_config = GenerationConfig.from_pretrained("Flmc/DISC-MedLLM")
>>> messages = []
>>> messages.append({"role": "user", "content": "我感觉自己颈椎非常不舒服,每天睡醒都会头痛"})
>>> response = model.chat(tokenizer, messages)
>>> print(response)
```
Additionally, since the current version uses Baichuan as the base model, you can refer to its [repo](https://github.com/baichuan-inc/Baichuan-13B) for deploying with int8, int4 quantized inference. However, using quantized deployment will result in performance degradation.
<br>
## Training
You can fine-tuning our model using the data same as our data schema.
Our train code is derived from [Firefly](https://github.com/yangjianxin1/Firefly) with the different data schema and dialogue format. We jsut provide the code of Full Params Fine-tuning:
```shell
deepspeed --num_gpus={num_gpus} ./train/train.py --train_args_file ./train/train_args/sft.json
```
> Please check the setup of `sft.json` before you attempt to start training.
<br>If you want to fine-tuning our model with other training code, please use the following dialogue format.
```shell
<\b><$user_token>content<$assistant_token>content<\s><$user_token>content ...
```
The `user_token` and `assistant_token` we used are `195` and `196`, respectly. Which is same as Baichuan-13b-Chat.
## Delcaration
Due to the inherent limitations of language models, we cannot assure the accuracy or reliability of information generated by this model. This model is designed exclusively for research and testing by individuals and academic groups. We urge users to critically assess any information or medical advice obtained through the model's output. Blindly trusting or following such information is strongly discouraged. We disclaim responsibility for any issues, risks, or adverse consequences resulting from the model's use.
## Licenses
The use of the source code in this repository complies with the Apache 2.0 License.
## Citation
```angular2
@misc{bao2023discmedllm,
title={DISC-MedLLM: Bridging General Large Language Models and Real-World Medical Consultation},
author={Zhijie Bao and Wei Chen and Shengze Xiao and Kuang Ren and Jiaao Wu and Cheng Zhong and Jiajie Peng and Xuanjing Huang and Zhongyu Wei},
year={2023},
eprint={2308.14346},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"MEDDIALOG"
] |
LinYuting/sentence_transformer_128_dim_model
|
LinYuting
|
sentence-similarity
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2023-11-22T02:27:06Z |
2023-11-22T02:27:23+00:00
| 16 | 0 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# pritamdeka/BioBERT-mnli-snli-scinli-scitail-mednli-stsb
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. It has been trained over the SNLI, MNLI, SCINLI, SCITAIL, MEDNLI and STSB datasets for providing robust sentence embeddings.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('pritamdeka/BioBERT-mnli-snli-scinli-scitail-mednli-stsb')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('pritamdeka/BioBERT-mnli-snli-scinli-scitail-mednli-stsb')
model = AutoModel.from_pretrained('pritamdeka/BioBERT-mnli-snli-scinli-scitail-mednli-stsb')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 90 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 36,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 100, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
If you use the model kindly cite the following work
```
@inproceedings{deka2022evidence,
title={Evidence Extraction to Validate Medical Claims in Fake News Detection},
author={Deka, Pritam and Jurek-Loughrey, Anna and others},
booktitle={International Conference on Health Information Science},
pages={3--15},
year={2022},
organization={Springer}
}
```
|
[
"MEDNLI",
"SCITAIL"
] |
Pontonkid/Biomed_bert-base-uncased-NER
|
Pontonkid
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:ncbi_disease",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-11-27T17:17:00Z |
2023-11-27T17:23:39+00:00
| 16 | 0 |
---
base_model: microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext
datasets:
- ncbi_disease
license: mit
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: checkpoint-1000
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: ncbi_disease
type: ncbi_disease
config: ncbi_disease
split: test
args: ncbi_disease
metrics:
- type: precision
value: 0.8456973293768546
name: Precision
- type: recall
value: 0.890625
name: Recall
- type: f1
value: 0.8675799086757991
name: F1
- type: accuracy
value: 0.9850593950279626
name: Accuracy
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# checkpoint-1000
This model is a fine-tuned version of [microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext) on the ncbi_disease dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0543
- Precision: 0.8457
- Recall: 0.8906
- F1: 0.8676
- Accuracy: 0.9851
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 340 | 0.0596 | 0.7778 | 0.875 | 0.8235 | 0.9795 |
| 0.0787 | 2.0 | 680 | 0.0416 | 0.8246 | 0.8865 | 0.8544 | 0.9851 |
| 0.0202 | 3.0 | 1020 | 0.0494 | 0.8385 | 0.8812 | 0.8593 | 0.9846 |
| 0.0202 | 4.0 | 1360 | 0.0543 | 0.8457 | 0.8906 | 0.8676 | 0.9851 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
[
"NCBI DISEASE"
] |
nm-testing/AmberChat-pruned60-quant-ds-v2
|
nm-testing
|
text-generation
|
[
"transformers",
"onnx",
"llama",
"text-generation",
"deepsparse",
"arxiv:2301.00774",
"base_model:LLM360/AmberChat",
"base_model:quantized:LLM360/AmberChat",
"autotrain_compatible",
"region:us"
] | 2023-12-15T10:59:26Z |
2023-12-15T12:31:13+00:00
| 16 | 0 |
---
base_model: LLM360/AmberChat
tags:
- deepsparse
inference: false
model_type: llama
prompt_template: '### Assistant:\n
### Human:{prompt}
### Assistant:
'
quantized_by: mwitiderrick
---
# AmberChat - DeepSparse
This repo contains model files for [AmberChat](https://huggingface.co/LLM360/AmberChat) optimized for [DeepSparse](https://github.com/neuralmagic/deepsparse), a CPU inference runtime for sparse models.
This model was quantized and pruned with [SparseGPT](https://arxiv.org/abs/2301.00774), using [SparseML](https://github.com/neuralmagic/sparseml).
## Inference
Install [DeepSparse LLM](https://github.com/neuralmagic/deepsparse) for fast inference on CPUs:
```bash
pip install deepsparse-nightly[llm]
```
Run in a [Python pipeline](https://github.com/neuralmagic/deepsparse/blob/main/docs/llms/text-generation-pipeline.md):
```python
from deepsparse import TextGeneration
template= "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n### Human: Got any creative ideas for a 10 year old’s birthday?\n### Assistant: Of course! Here are some creative ideas for a 10-year-old's birthday party:\n1. Treasure Hunt: Organize a treasure hunt in your backyard or nearby park. Create clues and riddles for the kids to solve, leading them to hidden treasures and surprises.\n2. Science Party: Plan a science-themed party where kids can engage in fun and interactive experiments. You can set up different stations with activities like making slime, erupting volcanoes, or creating simple chemical reactions.\n3. Outdoor Movie Night: Set up a backyard movie night with a projector and a large screen or white sheet. Create a cozy seating area with blankets and pillows, and serve popcorn and snacks while the kids enjoy a favorite movie under the stars.\n4. DIY Crafts Party: Arrange a craft party where kids can unleash their creativity. Provide a variety of craft supplies like beads, paints, and fabrics, and let them create their own unique masterpieces to take home as party favors.\n5. Sports Olympics: Host a mini Olympics event with various sports and games. Set up different stations for activities like sack races, relay races, basketball shooting, and obstacle courses. Give out medals or certificates to the participants.\n6. Cooking Party: Have a cooking-themed party where the kids can prepare their own mini pizzas, cupcakes, or cookies. Provide toppings, frosting, and decorating supplies, and let them get hands-on in the kitchen.\n7. Superhero Training Camp: Create a superhero-themed party where the kids can engage in fun training activities. Set up an obstacle course, have them design their own superhero capes or masks, and organize superhero-themed games and challenges.\n8. Outdoor Adventure: Plan an outdoor adventure party at a local park or nature reserve. Arrange activities like hiking, nature scavenger hunts, or a picnic with games. Encourage exploration and appreciation for the outdoors.\nRemember to tailor the activities to the birthday child's interests and preferences. Have a great celebration!\n### Human: {prompt}\n### Assistant:"
prompt = "How to make banana bread?"
input_str = template.format(prompt=prompt)
model = TextGeneration(model_path="hf:nm-testing/AmberChat-pruned60-quant-ds-v2")
print(model(input_str, max_new_tokens=200).generations[0].text)
"""
### Human
To make banana bread, you can follow these steps:
1. Prehe the ingredients: Mix 2 cups of bannanas, 2 cups of sugar, and 1 cup of milk. Mix the ingredients together.
2. Add the ingredients to the mixture: Add the ingredients to the mixture. Mix the ingredients together.
3. Cook the ingredients: Cook the ingredients together. Cook the ingredients until the ingredients reach the desired consistency.
4. Form the ingredients into bread: Form the ingredients into bread. Form the ingredients into bread.
5. Bake the ingredients into bread: Bake the ingredients into bread. Bake the ingredients into bread.
6. Serve the ingredients into bread: Serve the ingredients into bread. Serve the ingredients into bread.
"""
```
## Example 2
```
from deepsparse import TextGeneration
generation_config = {
"repetition_penalty": 2.0,
"do_sample": True,
"max_new_tokens": 500,
}
template= "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n### Human: Got any creative ideas for a 10 year old’s birthday?\n### Assistant: Of course! Here are some creative ideas for a 10-year-old's birthday party:\n1. Treasure Hunt: Organize a treasure hunt in your backyard or nearby park. Create clues and riddles for the kids to solve, leading them to hidden treasures and surprises.\n2. Science Party: Plan a science-themed party where kids can engage in fun and interactive experiments. You can set up different stations with activities like making slime, erupting volcanoes, or creating simple chemical reactions.\n3. Outdoor Movie Night: Set up a backyard movie night with a projector and a large screen or white sheet. Create a cozy seating area with blankets and pillows, and serve popcorn and snacks while the kids enjoy a favorite movie under the stars.\n4. DIY Crafts Party: Arrange a craft party where kids can unleash their creativity. Provide a variety of craft supplies like beads, paints, and fabrics, and let them create their own unique masterpieces to take home as party favors.\n5. Sports Olympics: Host a mini Olympics event with various sports and games. Set up different stations for activities like sack races, relay races, basketball shooting, and obstacle courses. Give out medals or certificates to the participants.\n6. Cooking Party: Have a cooking-themed party where the kids can prepare their own mini pizzas, cupcakes, or cookies. Provide toppings, frosting, and decorating supplies, and let them get hands-on in the kitchen.\n7. Superhero Training Camp: Create a superhero-themed party where the kids can engage in fun training activities. Set up an obstacle course, have them design their own superhero capes or masks, and organize superhero-themed games and challenges.\n8. Outdoor Adventure: Plan an outdoor adventure party at a local park or nature reserve. Arrange activities like hiking, nature scavenger hunts, or a picnic with games. Encourage exploration and appreciation for the outdoors.\nRemember to tailor the activities to the birthday child's interests and preferences. Have a great celebration!\n### Human: {prompt}\n### Assistant:"
prompt = "How to make banana bread?"
input_str = template.format(prompt=prompt)
model = TextGeneration(model_path="deployment")
print(model(input_str, generation_config=generation_config).generations[0].text)
"""
To make banana bread one must follow these steps from Google Docs search results (search query "
"""
```
## Prompt template
```
### Assistant:
### Human:{prompt}
### Assistant:
```
## Sparsification
For details on how this model was sparsified, see the `recipe.yaml` in this repo and follow the instructions below.
```bash
git clone https://github.com/neuralmagic/sparseml
pip install -e "sparseml[transformers]"
python sparseml/src/sparseml/transformers/sparsification/obcq/obcq.py LLM360/AmberChat open_platypus --recipe recipe.yaml --save True
python sparseml/src/sparseml/transformers/sparsification/obcq/export.py --task text-generation --model_path obcq_deployment
cp deployment/model.onnx deployment/model-orig.onnx
```
Run this kv-cache injection to speed up the model at inference by caching the Key and Value states:
```python
import os
import onnx
from sparseml.exporters.kv_cache_injector import KeyValueCacheInjector
input_file = "deployment/model-orig.onnx"
output_file = "deployment/model.onnx"
model = onnx.load(input_file, load_external_data=False)
model = KeyValueCacheInjector(model_path=os.path.dirname(input_file)).apply(model)
onnx.save(model, output_file)
print(f"Modified model saved to: {output_file}")
```
Follow the instructions on our [One Shot With SparseML](https://github.com/neuralmagic/sparseml/tree/main/src/sparseml/transformers/sparsification/obcq) page for a step-by-step guide for performing one-shot quantization of large language models.
## Slack
For further support, and discussions on these models and AI in general, join [Neural Magic's Slack Community](https://join.slack.com/t/discuss-neuralmagic/shared_invite/zt-q1a1cnvo-YBoICSIw3L1dmQpjBeDurQ)
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.just-told-a-joke
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-01T01:58:49Z |
2024-01-01T01:58:52+00:00
| 16 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/just told a joke.../just told a joke_17_3.0.png
widget:
- text: just told a joke
output:
url: images/just told a joke_17_3.0.png
- text: just told a joke
output:
url: images/just told a joke_19_3.0.png
- text: just told a joke
output:
url: images/just told a joke_20_3.0.png
- text: just told a joke
output:
url: images/just told a joke_21_3.0.png
- text: just told a joke
output:
url: images/just told a joke_22_3.0.png
inference: false
instance_prompt: just told a joke
---
# ntcai.xyz slider - just told a joke (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/just told a joke_17_-3.0.png" width=256 height=256 /> | <img src="images/just told a joke_17_0.0.png" width=256 height=256 /> | <img src="images/just told a joke_17_3.0.png" width=256 height=256 /> |
| <img src="images/just told a joke_19_-3.0.png" width=256 height=256 /> | <img src="images/just told a joke_19_0.0.png" width=256 height=256 /> | <img src="images/just told a joke_19_3.0.png" width=256 height=256 /> |
| <img src="images/just told a joke_20_-3.0.png" width=256 height=256 /> | <img src="images/just told a joke_20_0.0.png" width=256 height=256 /> | <img src="images/just told a joke_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
just told a joke
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.just-told-a-joke', weight_name='just told a joke.safetensors', adapter_name="just told a joke")
# Activate the LoRA
pipe.set_adapters(["just told a joke"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, just told a joke"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 780+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.unexpected
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-04T08:04:15Z |
2024-01-04T08:04:18+00:00
| 16 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/unexpected.../unexpected_17_3.0.png
widget:
- text: unexpected
output:
url: images/unexpected_17_3.0.png
- text: unexpected
output:
url: images/unexpected_19_3.0.png
- text: unexpected
output:
url: images/unexpected_20_3.0.png
- text: unexpected
output:
url: images/unexpected_21_3.0.png
- text: unexpected
output:
url: images/unexpected_22_3.0.png
inference: false
instance_prompt: unexpected
---
# ntcai.xyz slider - unexpected (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/unexpected_17_-3.0.png" width=256 height=256 /> | <img src="images/unexpected_17_0.0.png" width=256 height=256 /> | <img src="images/unexpected_17_3.0.png" width=256 height=256 /> |
| <img src="images/unexpected_19_-3.0.png" width=256 height=256 /> | <img src="images/unexpected_19_0.0.png" width=256 height=256 /> | <img src="images/unexpected_19_3.0.png" width=256 height=256 /> |
| <img src="images/unexpected_20_-3.0.png" width=256 height=256 /> | <img src="images/unexpected_20_0.0.png" width=256 height=256 /> | <img src="images/unexpected_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
unexpected
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.unexpected', weight_name='unexpected.safetensors', adapter_name="unexpected")
# Activate the LoRA
pipe.set_adapters(["unexpected"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, unexpected"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 860+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ShuhaoGuan/post-ocr-byt5-large
|
ShuhaoGuan
|
text2text-generation
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"license:gpl-3.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-01-09T03:51:07Z |
2024-10-12T17:25:03+00:00
| 16 | 1 |
---
license: gpl-3.0
---
This is a English Post-OCR model, fine-tuned from ByT5-large model.

<!--  -->
Below are some real test data samples with Low & High CER. Please input them into the text box on the right to check the results.
**And please try using your own data as well.**
## Low CER Samples
1. me, I do not despair of mvsef. Perhaps God will forgive me, for no one stood beside me to te me of hit. What waf there for me do, alonea. 1 was, and weik and def-neeless ? Craft amd deccit bave made up my whols life from that tim' on, Aud et'1 was not made to play such ti hideous ra lej th proof if that 1 luve Ascanuo. and that .when I found that I loved him I was happy and ashamed at the same ime. Now tel me, my pure, darliug
2. Her mothcur laughed. “Am 1 making a little fuss about you? 1s that what you like?
3. What could it be? I thought of the assistant's fondness for photography, and his trick of vanishing into the cellar. The cellar ! There was the end of this tangled clue. Then I made inquiries as to this mysterious assistant
4. I remarked. " Well, of course it was obvious from the first that this Mr. Hosmer Angel must have some strong object for his curious conduct, and it was equally clear that the only man who really profited by the incident, as far as we could see, was the stepfather.
5. The inspector took Mrs. Ifib. as bert to the Rusholme Police-station, where she now md lies, The full circumstances of the case appear to ig be as follows :-The unfortunate woman is the wife a, of jThomras Hibbert, joiner and builder. About at twelve months ago Mrs. Hlibbert gave birth to w a child, She fell ill, and finally became insane, She n was removed to the Parkfield Asyloam, near Maccles- r, field, of which institution she was an inmate up till y the 3rd of this month.
6. My sister aske.l me what was the matter, and why I was so pale ; but I told her that I had been upset by the jewel robbery at the hotel. Then I went into the back yard, and smoked a pipe, and w^ondered what it would be best to do. "
## High CER Samples
1. *Lilly caught hold of him, 'ai found that his coat snd hands were dovered with vwhiteivash, and on being dsl'ed to -acoiant for it he said, " I have~jdst tome fronm a ire; I'll show you where it is.
2. 1t'a dntflcul-t someti-mes to tetlthe frutn about a feeling, ant it
3. I may pevhaps scem over-bold, mAdam, in centiufng to trouble you with my unworthy èpisLles whé? tbe eloved ink between uf is wanbang, -but 1 beliers my kin-d Mr amd h.rs .uretwood will excuse my Presumption. remembering, in tjj oodness of their hearts, whaf scate of mindd I must be in, deprivéd a( 1 am of the delicious hope s that hive Muftained me hitherto. That youW mdam, waf joined with your humbe corr'spondent im a ccmmon
4. MorE 9e r passod, my motbcrf)dlowed iy aunt to tbe g2hves and stll 1 wa-s us f'ar as eve4 from jeking Gny diCcovvriee in reltou to Cnole Qeofgea shor tly tftem the pèriod of fhis laft Affliction my health gavc wsm3 and 1 dep,rie, by my doLtosrf adveoe tp try some bu.b0 in tbe foath af ranoe
5. "1s he coming 1" Giarissa asked, ratjer anxi.ouslI' Tbere was aominthig nminoas in tne t-ilness of tb e pl'aoe.
6. Hber' ws a l.ttl' pause, duriug whicH Tane lookaf hatd St tbe pirit coien Then, Itb tbe gesturo oi 0 ne undei strong eaoHon, b -jot qp from his cbalr and suId in avoico woone tone oade his fatlor look qnockly towardf himi
|
[
"CRAFT"
] |
clinicalnlplab/finetuned-Llama-2-13b-hf-PubmedQA
|
clinicalnlplab
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"medical",
"en",
"dataset:clinicalnlplab/pubmedqa_test",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-02-08T16:28:58Z |
2024-04-24T18:02:14+00:00
| 16 | 0 |
---
datasets:
- clinicalnlplab/pubmedqa_test
language:
- en
library_name: transformers
license: llama2
metrics:
- accuracy
- f1
tags:
- medical
---
|
[
"PUBMEDQA"
] |
UMCU/MedRoBERTa.nl_Experiencer
|
UMCU
|
token-classification
|
[
"transformers",
"safetensors",
"roberta",
"token-classification",
"medical",
"nl",
"arxiv:2209.00470",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-02-09T10:21:49Z |
2024-02-14T14:29:50+00:00
| 16 | 0 |
---
language:
- nl
license: gpl-3.0
pipeline_tag: token-classification
tags:
- medical
---
# MedRoBERTa.nl finetuned for experiencer
## Description
This model is a finetuned RoBERTa-based model pre-trained from scratch
on Dutch hospital notes sourced from Electronic Health Records.
All code used for the creation of MedRoBERTa.nl
can be found at https://github.com/cltl-students/verkijk_stella_rma_thesis_dutch_medical_language_model.
The publication associated with the negation detection task can be found at https://arxiv.org/abs/2209.00470.
The code for finetuning the model can be found at https://github.com/umcu/negation-detection.
## Minimal example
```python
tokenizer = AutoTokenizer\
.from_pretrained("UMCU/MedRoBERTa.nl_Experiencer")
model = AutoModelForTokenClassification\
.from_pretrained("UMCU/MedRoBERTa.nl_Experiencer")
some_text = "De patient was niet aanspreekbaar en hij zag er grauw uit. \
Hij heeft de inspanningstest echter goed doorstaan. \
De broer heeft onlangs een operatie ondergaan."
inputs = tokenizer(some_text, return_tensors='pt')
output = model.forward(inputs)
probas = torch.nn.functional.softmax(output.logits[0]).detach().numpy()
# associate with tokens
input_tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0])
target_map = {0: 'B-Patient', 1:'B-Other',2:'I-Patient',3:'I-Other'}
results = [{'token': input_tokens[idx],
'proba_patient': proba_arr[0]+proba_arr[2],
'proba_other': proba_arr[1]+proba_arr[3]
}
for idx,proba_arr in enumerate(probas)]
```
The medical entity classifiers are (being) integrated in the opensource library [clinlp](https://github.com/umcu/clinlp), feel free to contact
us for access, either through Huggingface or through git.
It is perhaps good to note that we assume the [Inside-Outside-Beginning](https://en.wikipedia.org/wiki/Inside%E2%80%93outside%E2%80%93beginning_(tagging)) format.
## Intended use
The model is finetuned for experiencer detection on Dutch clinical text.
Since it is a domain-specific model trained on medical data,
it is meant to be used on medical NLP tasks for Dutch.
This particular model is trained on a 64-max token windows surrounding the concept-to-be labeled.
## Data
The pre-trained model was trained on nearly 10 million hospital notes from the Amsterdam University Medical Centres.
The training data was anonymized before starting the pre-training procedure.
The finetuning was performed on the Erasmus Dutch Clinical Corpus (EDCC), which was synthetically upsampled for the minority classses.
The EDCC can be obtained through Jan Kors ([email protected]).
The EDCC is described here: https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-014-0373-3
## Authors
MedRoBERTa.nl: Stella Verkijk, Piek Vossen,
Finetuning: Bram van Es
## Contact
If you are having problems with this model please add an issue on our git: https://github.com/umcu/negation-detection/issues
## Usage
If you use the model in your work please use the following referral; https://doi.org/10.1186/s12859-022-05130-x
## References
Paper: Verkijk, S. & Vossen, P. (2022) MedRoBERTa.nl: A Language Model for Dutch Electronic Health Records. Computational Linguistics in the Netherlands Journal, 11.
Paper: Bram van Es, Leon C. Reteig, Sander C. Tan, Marijn Schraagen, Myrthe M. Hemker, Sebastiaan R.S. Arends, Miguel A.R. Rios, Saskia Haitjema (2022): Negation detection in Dutch clinical texts: an evaluation of rule-based and machine learning methods, Arxiv
|
[
"MEDICAL DATA"
] |
LoneStriker/BioMistral-7B-TIES-GGUF
|
LoneStriker
|
text-generation
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"ties",
"medical",
"biology",
"text-generation",
"fr",
"en",
"pl",
"es",
"it",
"ro",
"de",
"nl",
"dataset:pubmed",
"arxiv:2306.01708",
"arxiv:2402.10373",
"base_model:BioMistral/BioMistral-7B",
"base_model:merge:BioMistral/BioMistral-7B",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"base_model:merge:mistralai/Mistral-7B-Instruct-v0.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-02-19T15:45:38Z |
2024-02-19T16:01:04+00:00
| 16 | 0 |
---
base_model:
- mistralai/Mistral-7B-Instruct-v0.1
- BioMistral/BioMistral-7B
datasets:
- pubmed
language:
- fr
- en
- pl
- es
- it
- ro
- de
- nl
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
tags:
- mergekit
- merge
- ties
- medical
- biology
---
# BioMistral-7B-mistral7instruct-ties
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) as a base.
### Models Merged
The following models were included in the merge:
* [BioMistral/BioMistral-7B](https://huggingface.co/BioMistral/BioMistral-7B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: mistralai/Mistral-7B-Instruct-v0.1
- model: BioMistral/BioMistral-7B
parameters:
density: 0.5
weight: 0.5
merge_method: ties
base_model: mistralai/Mistral-7B-Instruct-v0.1
parameters:
normalize: true
dtype: bfloat16
```
<p align="center">
<img src="https://huggingface.co/BioMistral/BioMistral-7B/resolve/main/wordart_blue_m_rectangle.png?download=true" alt="drawing" width="250"/>
</p>
# BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
**Abstract:**
Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges.
In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.
**Advisory Notice!** Although BioMistral is intended to encapsulate medical knowledge sourced from high-quality evidence, it hasn't been tailored to effectively, safely, or suitably convey this knowledge within professional parameters for action. We advise refraining from utilizing BioMistral in medical contexts unless it undergoes thorough alignment with specific use cases and undergoes further testing, notably including randomized controlled trials in real-world medical environments. BioMistral 7B may possess inherent risks and biases that have not yet been thoroughly assessed. Additionally, the model's performance has not been evaluated in real-world clinical settings. Consequently, we recommend using BioMistral 7B strictly as a research tool and advise against deploying it in production environments for natural language generation or any professional health and medical purposes.
# 1. BioMistral models
**BioMistral** is a suite of Mistral-based further pre-trained open source models suited for the medical domains and pre-trained using textual data from PubMed Central Open Access (CC0, CC BY, CC BY-SA, and CC BY-ND). All the models are trained using the CNRS (French National Centre for Scientific Research) [Jean Zay](http://www.idris.fr/jean-zay/) French HPC.
| Model Name | Base Model | Model Type | Sequence Length | Download |
|:-------------------:|:----------------------------------:|:-------------------:|:---------------:|:-----------------------------------------------------:|
| BioMistral-7B | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Further Pre-trained | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B-DARE | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge DARE | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE) |
| BioMistral-7B-TIES | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge TIES | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES) |
| BioMistral-7B-SLERP | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge SLERP | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP) |
# 2. Quantized Models
| Base Model | Method | q_group_size | w_bit | version | VRAM GB | Time | Download |
|:-------------------:|:------:|:------------:|:-----:|:-------:|:-------:|:------:|:--------:|
| BioMistral-7B | FP16/BF16 | | | | 15.02 | x1.00 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B | AWQ | 128 | 4 | GEMV | 4.68 | x10.30 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMV) |
| BioMistral-7B | BnB.4 | | 4 | | 5.03 | x3.25 | [HuggingFace](blank) |
| BioMistral-7B | BnB.8 | | 8 | | 8.04 | x4.34 | [HuggingFace](blank) |
| BioMistral-7B-DARE | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-TIES | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-SLERP | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP-AWQ-QGS128-W4-GEMM) |
# 2. Using BioMistral
You can use BioMistral with [Hugging Face's Transformers library](https://github.com/huggingface/transformers) as follow.
Loading the model and tokenizer :
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BioMistral/BioMistral-7B")
model = AutoModel.from_pretrained("BioMistral/BioMistral-7B")
```
# 3. Supervised Fine-tuning Benchmark
| | Clinical KG | Medical Genetics | Anatomy | Pro Medicine | College Biology | College Medicine | MedQA | MedQA 5 opts | PubMedQA | MedMCQA | Avg. |
|-------------------------------------------|:---------------------------------------------:|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|------------------|
| **BioMistral 7B** | 59.9 | 64.0 | 56.5 | 60.4 | 59.0 | 54.7 | 50.6 | 42.8 | 77.5 | 48.1 | 57.3 |
| **Mistral 7B Instruct** | **62.9** | 57.0 | 55.6 | 59.4 | 62.5 | <u>57.2</u> | 42.0 | 40.9 | 75.7 | 46.1 | 55.9 |
| | | | | | | | | | | | |
| **BioMistral 7B Ensemble** | <u>62.8</u> | 62.7 | <u>57.5</u> | **63.5** | 64.3 | 55.7 | 50.6 | 43.6 | 77.5 | **48.8** | 58.7 |
| **BioMistral 7B DARE** | 62.3 | **67.0** | 55.8 | 61.4 | **66.9** | **58.0** | **51.1** | **45.2** | <u>77.7</u> | <u>48.7</u> | **59.4** |
| **BioMistral 7B TIES** | 60.1 | <u>65.0</u> | **58.5** | 60.5 | 60.4 | 56.5 | 49.5 | 43.2 | 77.5 | 48.1 | 57.9 |
| **BioMistral 7B SLERP** | 62.5 | 64.7 | 55.8 | <u>62.7</u> | <u>64.8</u> | 56.3 | <u>50.8</u> | <u>44.3</u> | **77.8** | 48.6 | <u>58.8</u> |
| | | | | | | | | | | | |
| **MedAlpaca 7B** | 53.1 | 58.0 | 54.1 | 58.8 | 58.1 | 48.6 | 40.1 | 33.7 | 73.6 | 37.0 | 51.5 |
| **PMC-LLaMA 7B** | 24.5 | 27.7 | 35.3 | 17.4 | 30.3 | 23.3 | 25.5 | 20.2 | 72.9 | 26.6 | 30.4 |
| **MediTron-7B** | 41.6 | 50.3 | 46.4 | 27.9 | 44.4 | 30.8 | 41.6 | 28.1 | 74.9 | 41.3 | 42.7 |
| **BioMedGPT-LM-7B** | 51.4 | 52.0 | 49.4 | 53.3 | 50.7 | 49.1 | 42.5 | 33.9 | 76.8 | 37.6 | 49.7 |
| | | | | | | | | | | | |
| **GPT-3.5 Turbo 1106*** | 74.71 | 74.00 | 65.92 | 72.79 | 72.91 | 64.73 | 57.71 | 50.82 | 72.66 | 53.79 | 66.0 |
Supervised Fine-Tuning (SFT) performance of BioMistral 7B models compared to baselines, measured by accuracy (↑) and averaged across 3 random seeds of 3-shot. DARE, TIES, and SLERP are model merging strategies that combine BioMistral 7B and Mistral 7B Instruct. Best model in bold, and second-best underlined. *GPT-3.5 Turbo performances are reported from the 3-shot results without SFT.
# Citation BibTeX
Arxiv : [https://arxiv.org/abs/2402.10373](https://arxiv.org/abs/2402.10373)
```bibtex
@misc{labrak2024biomistral,
title={BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains},
author={Yanis Labrak and Adrien Bazoge and Emmanuel Morin and Pierre-Antoine Gourraud and Mickael Rouvier and Richard Dufour},
year={2024},
eprint={2402.10373},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
**CAUTION!** Both direct and downstream users need to be informed about the risks, biases, and constraints inherent in the model. While the model can produce natural language text, our exploration of its capabilities and limitations is just beginning. In fields such as medicine, comprehending these limitations is crucial. Hence, we strongly advise against deploying this model for natural language generation in production or for professional tasks in the realm of health and medicine.
|
[
"MEDQA",
"PUBMEDQA"
] |
LoneStriker/BioMistral-7B-DARE-GPTQ
|
LoneStriker
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"dare",
"medical",
"biology",
"conversational",
"en",
"fr",
"nl",
"es",
"it",
"pl",
"ro",
"de",
"dataset:pubmed",
"arxiv:2311.03099",
"arxiv:2306.01708",
"arxiv:2402.10373",
"base_model:BioMistral/BioMistral-7B",
"base_model:merge:BioMistral/BioMistral-7B",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"base_model:merge:mistralai/Mistral-7B-Instruct-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] | 2024-02-19T16:05:45Z |
2024-02-19T16:09:24+00:00
| 16 | 0 |
---
base_model:
- BioMistral/BioMistral-7B
- mistralai/Mistral-7B-Instruct-v0.1
datasets:
- pubmed
language:
- en
- fr
- nl
- es
- it
- pl
- ro
- de
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
tags:
- mergekit
- merge
- dare
- medical
- biology
---
# BioMistral-7B-mistral7instruct-dare
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE](https://arxiv.org/abs/2311.03099) [TIES](https://arxiv.org/abs/2306.01708) merge method using [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) as a base.
### Models Merged
The following models were included in the merge:
* [BioMistral/BioMistral-7B](https://huggingface.co/BioMistral/BioMistral-7B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: mistralai/Mistral-7B-Instruct-v0.1
# No parameters necessary for base model
- model: BioMistral/BioMistral-7B
parameters:
density: 0.5
weight: 0.5
merge_method: dare_ties
base_model: mistralai/Mistral-7B-Instruct-v0.1
parameters:
int8_mask: true
dtype: bfloat16
```
<p align="center">
<img src="https://huggingface.co/BioMistral/BioMistral-7B/resolve/main/wordart_blue_m_rectangle.png?download=true" alt="drawing" width="250"/>
</p>
# BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
**Abstract:**
Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges.
In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.
# 1. BioMistral models
**BioMistral** is a suite of Mistral-based further pre-trained open source models suited for the medical domains and pre-trained using textual data from PubMed Central Open Access (CC0, CC BY, CC BY-SA, and CC BY-ND). All the models are trained using the CNRS (French National Centre for Scientific Research) [Jean Zay](http://www.idris.fr/jean-zay/) French HPC.
| Model Name | Base Model | Model Type | Sequence Length | Download |
|:-------------------:|:----------------------------------:|:-------------------:|:---------------:|:-----------------------------------------------------:|
| BioMistral-7B | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Further Pre-trained | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B-DARE | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge DARE | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE) |
| BioMistral-7B-TIES | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge TIES | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES) |
| BioMistral-7B-SLERP | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge SLERP | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP) |
# 2. Quantized Models
| Base Model | Method | q_group_size | w_bit | version | VRAM GB | Time | Download |
|:-------------------:|:------:|:------------:|:-----:|:-------:|:-------:|:------:|:--------:|
| BioMistral-7B | FP16/BF16 | | | | 15.02 | x1.00 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B | AWQ | 128 | 4 | GEMV | 4.68 | x10.30 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMV) |
| BioMistral-7B | BnB.4 | | 4 | | 5.03 | x3.25 | [HuggingFace](blank) |
| BioMistral-7B | BnB.8 | | 8 | | 8.04 | x4.34 | [HuggingFace](blank) |
| BioMistral-7B-DARE | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-TIES | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-SLERP | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP-AWQ-QGS128-W4-GEMM) |
# 2. Using BioMistral
You can use BioMistral with [Hugging Face's Transformers library](https://github.com/huggingface/transformers) as follow.
Loading the model and tokenizer :
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BioMistral/BioMistral-7B")
model = AutoModel.from_pretrained("BioMistral/BioMistral-7B")
```
# 3. Supervised Fine-tuning Benchmark
| | Clinical KG | Medical Genetics | Anatomy | Pro Medicine | College Biology | College Medicine | MedQA | MedQA 5 opts | PubMedQA | MedMCQA | Avg. |
|-------------------------------------------|:---------------------------------------------:|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|------------------|
| **BioMistral 7B** | 59.9 | 64.0 | 56.5 | 60.4 | 59.0 | 54.7 | 50.6 | 42.8 | 77.5 | 48.1 | 57.3 |
| **Mistral 7B Instruct** | **62.9** | 57.0 | 55.6 | 59.4 | 62.5 | <u>57.2</u> | 42.0 | 40.9 | 75.7 | 46.1 | 55.9 |
| | | | | | | | | | | | |
| **BioMistral 7B Ensemble** | <u>62.8</u> | 62.7 | <u>57.5</u> | **63.5** | 64.3 | 55.7 | 50.6 | 43.6 | 77.5 | **48.8** | 58.7 |
| **BioMistral 7B DARE** | 62.3 | **67.0** | 55.8 | 61.4 | **66.9** | **58.0** | **51.1** | **45.2** | <u>77.7</u> | <u>48.7</u> | **59.4** |
| **BioMistral 7B TIES** | 60.1 | <u>65.0</u> | **58.5** | 60.5 | 60.4 | 56.5 | 49.5 | 43.2 | 77.5 | 48.1 | 57.9 |
| **BioMistral 7B SLERP** | 62.5 | 64.7 | 55.8 | <u>62.7</u> | <u>64.8</u> | 56.3 | <u>50.8</u> | <u>44.3</u> | **77.8** | 48.6 | <u>58.8</u> |
| | | | | | | | | | | | |
| **MedAlpaca 7B** | 53.1 | 58.0 | 54.1 | 58.8 | 58.1 | 48.6 | 40.1 | 33.7 | 73.6 | 37.0 | 51.5 |
| **PMC-LLaMA 7B** | 24.5 | 27.7 | 35.3 | 17.4 | 30.3 | 23.3 | 25.5 | 20.2 | 72.9 | 26.6 | 30.4 |
| **MediTron-7B** | 41.6 | 50.3 | 46.4 | 27.9 | 44.4 | 30.8 | 41.6 | 28.1 | 74.9 | 41.3 | 42.7 |
| **BioMedGPT-LM-7B** | 51.4 | 52.0 | 49.4 | 53.3 | 50.7 | 49.1 | 42.5 | 33.9 | 76.8 | 37.6 | 49.7 |
| | | | | | | | | | | | |
| **GPT-3.5 Turbo 1106*** | 74.71 | 74.00 | 65.92 | 72.79 | 72.91 | 64.73 | 57.71 | 50.82 | 72.66 | 53.79 | 66.0 |
Supervised Fine-Tuning (SFT) performance of BioMistral 7B models compared to baselines, measured by accuracy (↑) and averaged across 3 random seeds of 3-shot. DARE, TIES, and SLERP are model merging strategies that combine BioMistral 7B and Mistral 7B Instruct. Best model in bold, and second-best underlined. *GPT-3.5 Turbo performances are reported from the 3-shot results without SFT.
# Citation BibTeX
Arxiv : [https://arxiv.org/abs/2402.10373](https://arxiv.org/abs/2402.10373)
```bibtex
@misc{labrak2024biomistral,
title={BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains},
author={Yanis Labrak and Adrien Bazoge and Emmanuel Morin and Pierre-Antoine Gourraud and Mickael Rouvier and Richard Dufour},
year={2024},
eprint={2402.10373},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"MEDQA",
"PUBMEDQA"
] |
Technoculture/BioMistral-Carpybara-Slerp
|
Technoculture
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"BioMistral/BioMistral-7B-DARE",
"argilla/CapybaraHermes-2.5-Mistral-7B",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-02-21T20:31:09Z |
2024-02-21T20:36:23+00:00
| 16 | 0 |
---
license: apache-2.0
tags:
- merge
- mergekit
- BioMistral/BioMistral-7B-DARE
- argilla/CapybaraHermes-2.5-Mistral-7B
---
# BioMistral-Carpybara-Slerp
BioMistral-Carpybara-Slerp is a merge of the following models:
* [BioMistral/BioMistral-7B-DARE](https://huggingface.co/BioMistral/BioMistral-7B-DARE)
* [argilla/CapybaraHermes-2.5-Mistral-7B](https://huggingface.co/argilla/CapybaraHermes-2.5-Mistral-7B)
## Evaluations
| Benchmark | BioMistral-Carpybara-Slerp | Orca-2-7b | llama-2-7b | meditron-7b | meditron-70b |
| --- | --- | --- | --- | --- | --- |
| MedMCQA | | | | | |
| ClosedPubMedQA | | | | | |
| PubMedQA | | | | | |
| MedQA | | | | | |
| MedQA4 | | | | | |
| MedicationQA | | | | | |
| MMLU Medical | | | | | |
| MMLU | | | | | |
| TruthfulQA | | | | | |
| GSM8K | | | | | |
| ARC | | | | | |
| HellaSwag | | | | | |
| Winogrande | | | | | |
More details on the Open LLM Leaderboard evaluation results can be found here.
## 🧩 Configuration
```yaml
slices:
- sources:
- model: BioMistral/BioMistral-7B-DARE
layer_range: [0, 32]
- model: argilla/CapybaraHermes-2.5-Mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: argilla/CapybaraHermes-2.5-Mistral-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5 # fallback for rest of tensors
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Technoculture/BioMistral-Carpybara-Slerp"
messages = [{"role": "user", "content": "I am feeling sleepy these days"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
[
"MEDQA",
"PUBMEDQA"
] |
SilasK/mistral-7b-medqa-version1
|
SilasK
| null |
[
"peft",
"tensorboard",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"base_model:adapter:mistralai/Mistral-7B-Instruct-v0.1",
"license:apache-2.0",
"region:us"
] | 2024-03-07T23:25:03Z |
2024-03-09T10:20:35+00:00
| 16 | 0 |
---
base_model: mistralai/Mistral-7B-Instruct-v0.1
library_name: peft
license: apache-2.0
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: mistral-7b-medqa-version1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-7b-medqa-version1
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 3
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 6
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.7.1
- Transformers 4.37.0.dev0
- Pytorch 2.1.2+cu118
- Datasets 2.16.1
- Tokenizers 0.15.0
|
[
"MEDQA"
] |
regel-corpus/biosyn-sapbert-regel-bto
|
regel-corpus
| null |
[
"flair",
"pytorch",
"entity-mention-linker",
"region:us"
] | 2024-03-15T14:25:54Z |
2024-03-15T14:26:13+00:00
| 16 | 0 |
---
tags:
- flair
- entity-mention-linker
---
## biosyn-sapbert-regel-bto
Biomedical Entity Mention Linking for TISSUES (Brenda Tissue Ontology):
- Model: [dmis-lab/biosyn-sapbert-bc5cdr-disease](https://huggingface.co/dmis-lab/biosyn-sapbert-bc5cdr-disease)
- Dictionary: [Brenda Tissue Ontology](https://www.brenda-enzymes.org/ontology.php?ontology_id=3)
### Demo: How to use in Flair
Requires:
- **[Flair](https://github.com/flairNLP/flair/)>=0.14.0** (`pip install flair` or `pip install git+https://github.com/flairNLP/flair.git`)
```python
from flair.data import Sentence
from flair.models import Classifier, EntityMentionLinker
from flair.tokenization import SciSpacyTokenizer
sentence = Sentence(
"TNF-like factor that is both produced by osteoblasts, mesenchymal cells, ",
"and activated T cells and required for osteoclast maturation and survival."
use_tokenizer=SciSpacyTokenizer()
)
# load hunflair to detect the entity mentions we want to link.
tagger = Classifier.load("regel-corpus/hunflair2-regel-tissue")
tagger.predict(sentence)
# load the linker and dictionary
linker = EntityMentionLinker.load("regel-corpus/biosyn-sapbert-regel-bto")
linker.predict(sentence)
# print the results for each entity mention:
for span in sentence.get_spans(tagger.label_type):
for link in span.get_labels(linker.label_type):
print(f"{span.text} -> {link.value}")
```
|
[
"BC5CDR"
] |
ikim-uk-essen/GBERT-BioM-Translation-base
|
ikim-uk-essen
|
fill-mask
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"arxiv:2404.05694",
"base_model:deepset/gbert-base",
"base_model:finetune:deepset/gbert-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-04-10T07:35:49Z |
2024-04-10T08:02:09+00:00
| 16 | 0 |
---
base_model: deepset/gbert-base
license: mit
---
# GBERT-BioM-Translation-base
This model is a medically continuously pre-trained version of [deepset/gbert-base](https://huggingface.co/deepset/gbert-base).
## Training data
The model was trained on German PubMed abstracts, translated English PubMed abstracts, and translated MIMIC-III reports.
| Dataset | Tokens | Documents |
|------------|----------|-----------|
| German PubMed | 5M | 16K |
| PubMed | 1,700M | 21M |
| MIMIC-III | 695M | 24M |
| **Total** | **2,400M** | **45M** |
## Evaluation
| Model | CLEF eHealth 2019 | | | RadQA | | GraSCCo | | | BRONCO150 | | | GGPONC 2.0 | | |
|------------------------------|-------------------|------|------|-------|------|---------|------|------|-----------|------|------|------------|------|------|
| | F1 | P | R | F1 | EM | F1 | P | R | F1 | P | R | F1 | P | R |
| [GBERT-base](https://huggingface.co/deepset/gbert-base) | .816 | .818 | .815 | .794 | .707 | .642 | .617 | .676 | .833 | .818 | .849 | .770 | .761 | .780 |
| [GBERT-large](https://huggingface.co/deepset/gbert-large) | .832 | .802 | .865 | .809 | .718 | .647 | .617 | .680 | .835 | .820 | .852 | .772 | .758 | .786 |
| **GBERT-BioM-Translation-base** | .825 | .851 | .801 | .808 | .716 | .661 | .642 | .681 | .842 | .824 | .861 | .780 | .766 | .794 |
| GBERT-BioM-Translation-large | .833 | .860 | .807 | .811 | .714 | .692 | .677 | .707 | .844 | .825 | .864 | .786 | .779 | .793 |
## Publication
```bibtex
@misc{idrissiyaghir2024comprehensive,
title={Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding},
author={Ahmad Idrissi-Yaghir and Amin Dada and Henning Schäfer and Kamyar Arzideh and Giulia Baldini and Jan Trienes and Max Hasin and Jeanette Bewersdorff and Cynthia S. Schmidt and Marie Bauer and Kaleb E. Smith and Jiang Bian and Yonghui Wu and Jörg Schlötterer and Torsten Zesch and Peter A. Horn and Christin Seifert and Felix Nensa and Jens Kleesiek and Christoph M. Friedrich},
year={2024},
eprint={2404.05694},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"BRONCO150",
"GRASCCO"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.