
The dataset viewer is not available for this split.
Error code: FeaturesError
Exception: ArrowInvalid
Message: JSON parse error: Invalid value. in row 0
Traceback: Traceback (most recent call last):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py", line 160, in _generate_tables
df = pandas_read_json(f)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py", line 38, in pandas_read_json
return pd.read_json(path_or_buf, **kwargs)
File "/src/services/worker/.venv/lib/python3.9/site-packages/pandas/io/json/_json.py", line 791, in read_json
json_reader = JsonReader(
File "/src/services/worker/.venv/lib/python3.9/site-packages/pandas/io/json/_json.py", line 905, in __init__
self.data = self._preprocess_data(data)
File "/src/services/worker/.venv/lib/python3.9/site-packages/pandas/io/json/_json.py", line 917, in _preprocess_data
data = data.read()
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/file_utils.py", line 830, in read_with_retries
out = read(*args, **kwargs)
File "/usr/local/lib/python3.9/codecs.py", line 322, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/split/first_rows.py", line 231, in compute_first_rows_from_streaming_response
iterable_dataset = iterable_dataset._resolve_features()
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 2831, in _resolve_features
features = _infer_features_from_batch(self.with_format(None)._head())
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 1845, in _head
return _examples_to_batch(list(self.take(n)))
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 2012, in __iter__
for key, example in ex_iterable:
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 1507, in __iter__
for key_example in islice(self.ex_iterable, self.n - ex_iterable_num_taken):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 268, in __iter__
for key, pa_table in self.generate_tables_fn(**gen_kwags):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py", line 163, in _generate_tables
raise e
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/packaged_modules/json/json.py", line 137, in _generate_tables
pa_table = paj.read_json(
File "pyarrow/_json.pyx", line 308, in pyarrow._json.read_json
File "pyarrow/error.pxi", line 154, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: JSON parse error: Invalid value. in row 0Need help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
MIBench
This dataset is from our EMNLP'24 (main conference) paper MIBench: Evaluating Multimodal Large Language Models over Multiple Images
Introduction
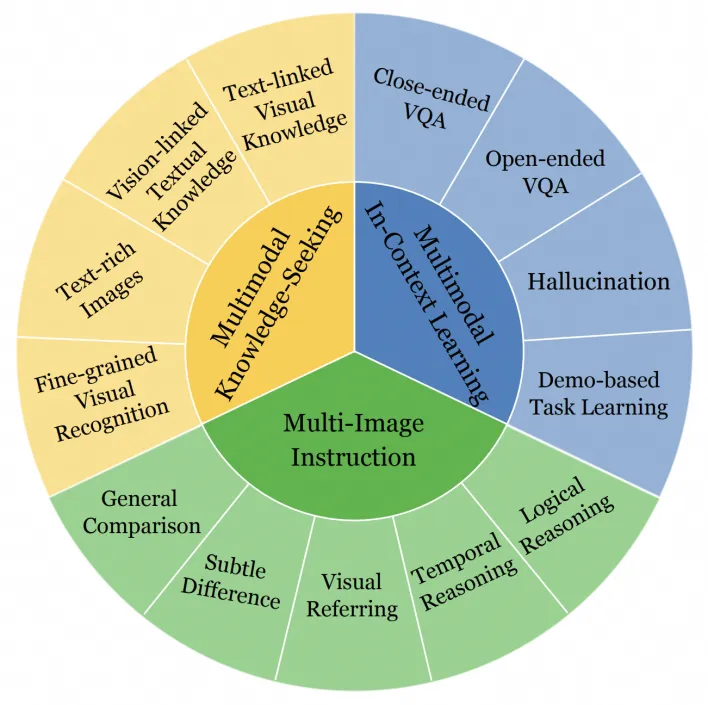
MIBench covers 13 sub-tasks in three typical multi-image scenarios: Multi-Image Instruction, Multimodal Knowledge-Seeking and Multimodal In-Context Learning.
Multi-Image Instruction: This scenario includes instructions for perception, comparison and reasoning across multiple input images. According to the semantic types of the instructions, it is divided into five sub-tasks: General Comparison, Subtle Difference, Visual Referring, Temporal Reasoning and Logical Reasoning.
Multimodal Knowledge-Seeking: This scenario examines the ability of MLLMs to acquire relevant information from external knowledge, which is provided in an interleaved image-text format. Based on the forms of external knowledge, we categorize this scenario into four sub-tasks: Fine-grained Visual Recognition, Text-Rich Images VQA, Vision-linked Textual Knowledge and Text-linked Visual Knowledge.
Multimodal In-Context Learning: In-context learning is another popular scenario, in which MLLMs respond to visual questions while being provided with a series of multimodal demonstrations. To evaluate the model’s MIC ability in a fine-grained manner, we categorize the MIC scenario into four distinct tasks: Close-ended VQA, Open-ended VQA, Hallucination and Demo-based Task Learning.
Examples
The following image shows the examples of the multi-image scenarios with a total of 13 sub-tasks. The correct answers are marked in blue.

Data format
Below shows an example of the dataset format. The <image> in the question field indicates the location of the images. Note that to ensure better reproducibility, for the Multimodal In-Context Learning scenario, we store the context information of different shots in the context field.
{
"id": "general_comparison_1",
"image": [
"image/general_comparison/test1-902-0-img0.png",
"image/general_comparison/test1-902-0-img1.png"
],
"question": "Left image is <image>. Right image is <image>. Question: Is the subsequent sentence an accurate portrayal of the two images? One lemon is cut in half and has both halves facing outward.",
"options": [
"Yes",
"No"
],
"answer": "Yes",
"task": "general_comparison",
"type": "multiple-choice",
"context": null
},
Citation
If you find this dataset useful for your work, please consider citing our paper:
@article{liu2024mibench,
title={Mibench: Evaluating multimodal large language models over multiple images},
author={Liu, Haowei and Zhang, Xi and Xu, Haiyang and Shi, Yaya and Jiang, Chaoya and Yan, Ming and Zhang, Ji and Huang, Fei and Yuan, Chunfeng and Li, Bing and others},
journal={arXiv preprint arXiv:2407.15272},
year={2024}
}
- Downloads last month
- 164