
X-MuTeST: A Multilingual Benchmark for Explainable Hate Speech Detection and A Novel LLM-consulted Explanation Framework
Paper
• 2601.03194 • Published
• 2
Accepted at AAAI 2026 (AI for Social Impact Track) - CORE A* Conference
This repository contains the dataset for the paper X-MuTeST: A Multilingual Benchmark for Explainable Hate Speech Detection and A Novel LLM-Consulted Explanation Framework.
⚠️ Note: The dataset itself is not hosted on Hugging Face. To request access, please fill out the official agreement form (links provided below in the Dataset Access section).
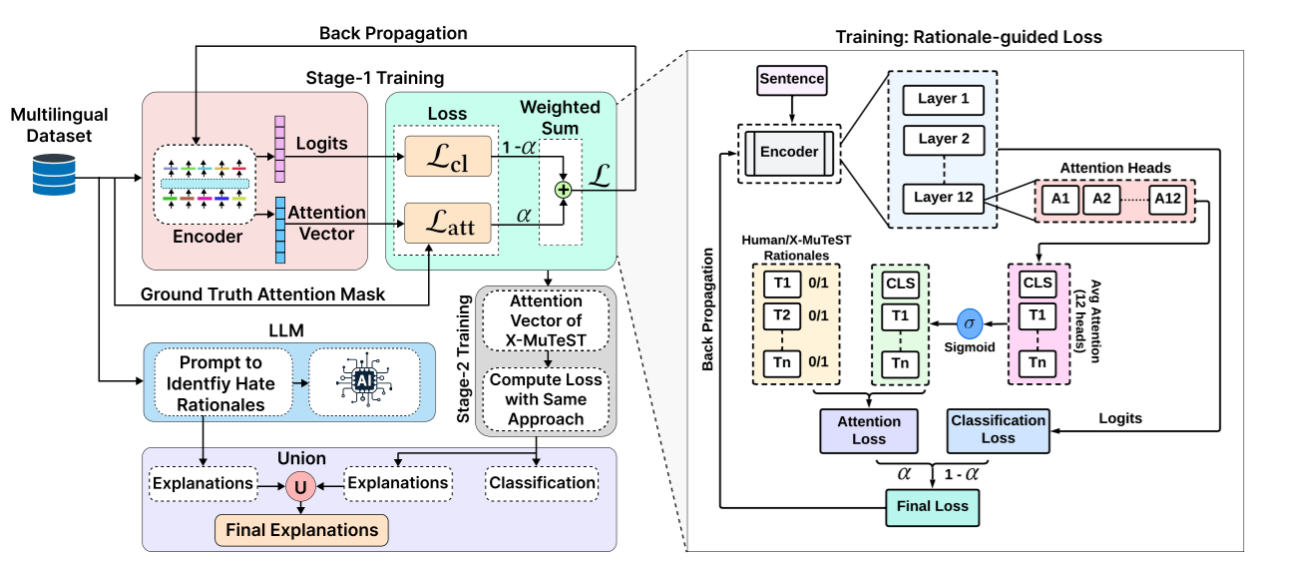
We propose X-MuTeST (eXplainable Multilingual haTe Speech deTection), an explainability-guided framework that integrates large language models with attention-enhancing techniques for multilingual hate speech detection. Extending to Telugu, Hindi, and English, we provide benchmark datasets with human-annotated token-level rationales. X-MuTeST computes explainability by analyzing prediction changes across unigrams, bigrams, and trigrams, combining these with LLM-based explanations. Incorporating human rationales improves both accuracy and interpretability, evaluated using Plausibility (Token-F1, IOU-F1) and Faithfulness (Comprehensiveness, Sufficiency) metrics.
⚠️ Warning: This dataset contains text that is offensive and hateful in nature. It is released only for research on hate speech and content moderation. The creators do not endorse any of the views expressed in the data.
X-MuTeST (eXplainable Multilingual haTe Speech deTection) is a multilingual benchmark and framework designed for explainable hate speech detection across Telugu, Hindi, and English.
It introduces token-level human rationales and a two-stage explainability-guided model training pipeline, integrating insights from LLMs and n-gram-based attention mechanisms to improve both classification and interpretability in under-resourced languages.
Multilingual Explainable Benchmark
Two-Stage Explainability Framework
LLM-Consulted Explanations
Explainability-Centric Evaluation
Multilingual and Cross-Lingual Focus
| Language | A1 & A2 | A2 & A3 | A3 & A1 | Overall |
|---|---|---|---|---|
| Telugu | 82.50 | 87.75 | 88.25 | 81.00 |
| Hindi | 86.45 | 88.00 | 79.20 | 83.15 |
| English | 87.60 | 82.00 | 89.30 | 85.10 |
The X-MuTeST dataset is released strictly for research purposes under controlled access.
Due to the sensitive nature of hate speech content, access is restricted to ensure responsible and ethical usage.
The dataset includes user-generated text that may contain offensive or hateful expressions, collected solely for advancing ethical and explainable AI research.
All samples are anonymized and curated in accordance with academic research ethics and data protection standards.
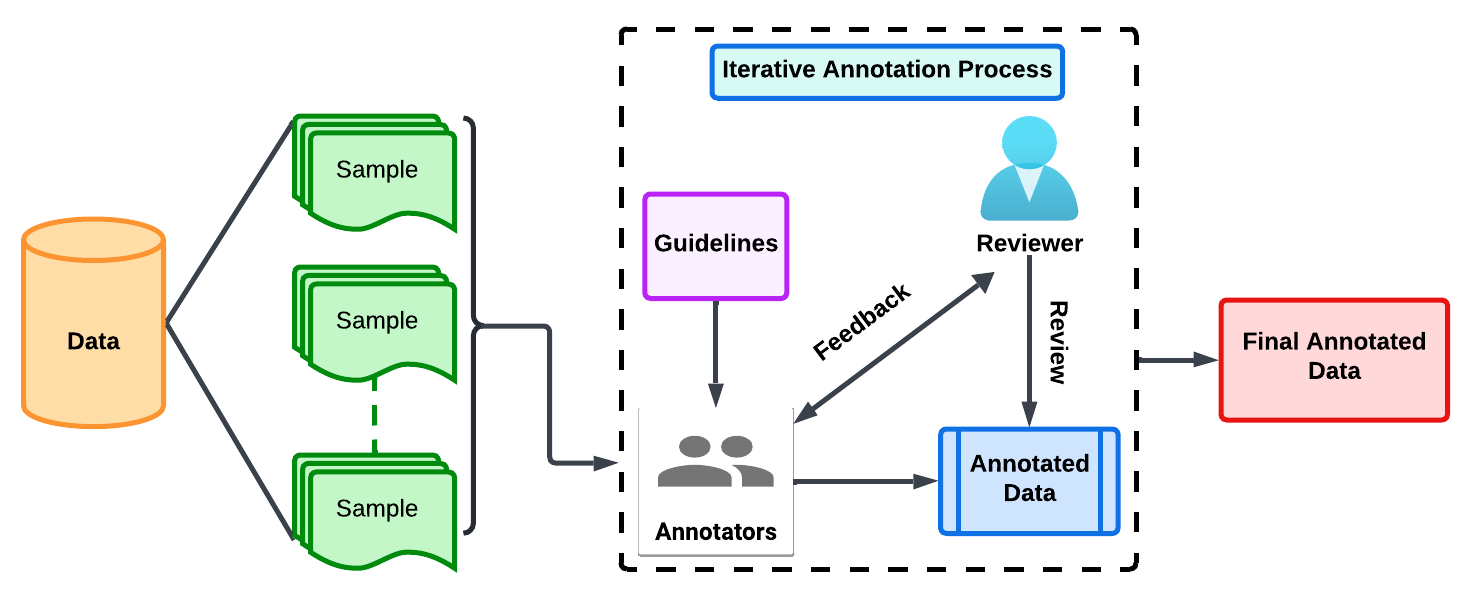
Researchers requesting access must:
To request access, please fill out the following form:
👉 Request Access to X-MuTeST Dataset
Note: Any unethical or unauthorized use of this dataset, including misuse for generating or promoting hate speech, is strictly prohibited and may result in access revocation.
We sincerely acknowledge the organizers and contributors of the following shared tasks and datasets that served as the foundation for X-MuTeST:
These datasets were publicly available for research purposes, enabling the multilingual expansion and benchmarking of hate speech detection for Telugu, Hindi, and English in this work. We thank the respective task organizers and the research community for supporting open and ethical NLP research.
If you find this work useful in your research, please cite our paper as follows:
@article{rehman2026x,
title={X-MuTeST: A Multilingual Benchmark for Explainable Hate Speech Detection and A Novel LLM-consulted Explanation Framework},
author={Rehman, Mohammad Zia Ur and Kasu, Sai Kartheek Reddy and Koppula, Shashivardhan Reddy and Chirra, Sai Rithwik Reddy and Singh, Shwetank Shekhar and Kumar, Nagendra},
journal={arXiv preprint arXiv:2601.03194},
year={2026}
}
In addition, please cite the original datasets that contributed to this work:
Hate Speech and Offensive Language Identification in Tamil, Malayalam, Hindi, English, and German
📄 Proceedings of the 12th Annual Meeting of the Forum for Information Retrieval Evaluation (FIRE 2020)
@inproceedings{mandl2020overview,
title={Overview of the HASOC Track at FIRE 2020: Hate Speech and Offensive Language Identification in Tamil, Malayalam, Hindi, English and German},
author={Mandl, Thomas and Modha, Sandip and Kumar, Anand M. and Chakravarthi, Bharathi Raja},
booktitle={Proceedings of the 12th Annual Meeting of the Forum for Information Retrieval Evaluation},
pages={29--32},
year={2020}
}
Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages
📄 Proceedings of the 13th Annual Meeting of the Forum for Information Retrieval Evaluation (FIRE 2021)
@inproceedings{modha2021overview,
title={Overview of the HASOC Subtrack at FIRE 2021: Hate Speech and Offensive Content Identification in English and Indo-Aryan Languages and Conversational Hate Speech},
author={Modha, Sandip and Mandl, Thomas and Shahi, Gautam Kishore and Madhu, Hiren and Satapara, Shrey and Ranasinghe, Tharindu and Zampieri, Marcos},
booktitle={Proceedings of the 13th Annual Meeting of the Forum for Information Retrieval Evaluation},
pages={1--3},
year={2021}
}
Hate and Offensive Language Detection in Telugu Codemixed Text (DravidianLangTech 2024)
📄 Proceedings of the Fourth Workshop on Speech, Vision, and Language Technologies for Dravidian Languages (DravidianLangTech 2024)
@inproceedings{premjith2024findings,
title={Findings of the shared task on hate and offensive language detection in telugu codemixed text (hold-telugu) at dravidianlangtech 2024},
author={Premjith, B and Chakravarthi, Bharathi Raja and Kumaresan, Prasanna Kumar and Rajiakodi, Saranya and Karnati, Sai and Mangamuru, Sai and Janakiram, Chandu},
booktitle={Proceedings of the Fourth Workshop on Speech, Vision, and Language Technologies for Dravidian Languages},
pages={49--55},
year={2024}
}
Totally Free + Zero Barriers + No Login Required