Datasets:

audio
audioduration (s) 2.53
7.68
|
|---|
Spanish Speech Dataset for recognition task
Dataset comprises 488 hours of telephone dialogues in Spanish, collected from 600 native speakers across various topics and domains. This dataset boasts an impressive 98% word accuracy rate, making it a valuable resource for advancing speech recognition technology.
By utilizing this dataset, researchers and developers can advance their understanding and capabilities in automatic speech recognition (ASR) systems, transcribing audio, and natural language processing (NLP). - Get the data
The dataset includes high-quality audio recordings with text transcriptions, making it ideal for training and evaluating speech recognition models.
💵 Buy the Dataset: This is a limited preview of the data. To access the full dataset, please contact us at https://unidata.pro to discuss your requirements and pricing options.
Metadata for the dataset
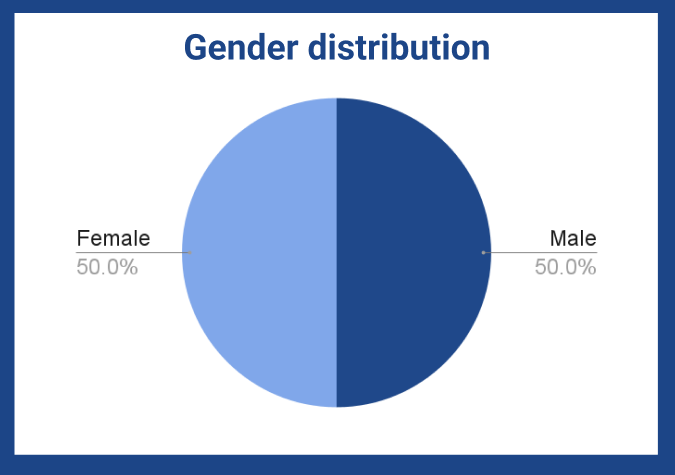
- Audio files: High-quality recordings in WAV format
- Text transcriptions: Accurate and detailed transcripts for each audio segment
- Speaker information: Metadata on native speakers, including gender and etc
- Topics: Diverse domains such as general conversations, business and etc
This dataset is a valuable resource for researchers and developers working on speech recognition, language models, and speech technology.
🌐 UniData provides high-quality datasets, content moderation, data collection and annotation for your AI/ML projects
- Downloads last month
- 19