
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
stabilityai/stable-diffusion-2-1-base
|
stabilityai
| 2023-07-05T16:19:20Z | 863,939 | 647 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"text-to-image",
"arxiv:2112.10752",
"arxiv:2202.00512",
"arxiv:1910.09700",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-06T17:25:36Z |
---
license: openrail++
tags:
- stable-diffusion
- text-to-image
---
# Stable Diffusion v2-1-base Model Card
This model card focuses on the model associated with the Stable Diffusion v2-1-base model.
This `stable-diffusion-2-1-base` model fine-tunes [stable-diffusion-2-base](https://huggingface.co/stabilityai/stable-diffusion-2-base) (`512-base-ema.ckpt`) with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- Use it with the [`stablediffusion`](https://github.com/Stability-AI/stablediffusion) repository: download the `v2-1_512-ema-pruned.ckpt` [here](https://huggingface.co/stabilityai/stable-diffusion-2-1-base/resolve/main/v2-1_512-ema-pruned.ckpt).
- Use it with 🧨 [`diffusers`](#examples)
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([OpenCLIP-ViT/H](https://github.com/mlfoundations/open_clip)).
- **Resources for more information:** [GitHub Repository](https://github.com/Stability-AI/).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run Stable Diffusion 2 in a simple and efficient manner.
```bash
pip install diffusers transformers accelerate scipy safetensors
```
Running the pipeline (if you don't swap the scheduler it will run with the default PNDM/PLMS scheduler, in this example we are swapping it to EulerDiscreteScheduler):
```python
from diffusers import StableDiffusionPipeline, EulerDiscreteScheduler
import torch
model_id = "stabilityai/stable-diffusion-2-1-base"
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-5B and subsets (details below). The training data is further filtered using LAION's NSFW detector, with a "p_unsafe" score of 0.1 (conservative). For more details, please refer to LAION-5B's [NeurIPS 2022](https://openreview.net/forum?id=M3Y74vmsMcY) paper and reviewer discussions on the topic.
**Training Procedure**
Stable Diffusion v2 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through the OpenCLIP-ViT/H text-encoder.
- The output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet. We also use the so-called _v-objective_, see https://arxiv.org/abs/2202.00512.
We currently provide the following checkpoints, for various versions:
### Version 2.1
- `512-base-ema.ckpt`: Fine-tuned on `512-base-ema.ckpt` 2.0 with 220k extra steps taken, with `punsafe=0.98` on the same dataset.
- `768-v-ema.ckpt`: Resumed from `768-v-ema.ckpt` 2.0 with an additional 55k steps on the same dataset (`punsafe=0.1`), and then fine-tuned for another 155k extra steps with `punsafe=0.98`.
### Version 2.0
- `512-base-ema.ckpt`: 550k steps at resolution `256x256` on a subset of [LAION-5B](https://laion.ai/blog/laion-5b/) filtered for explicit pornographic material, using the [LAION-NSFW classifier](https://github.com/LAION-AI/CLIP-based-NSFW-Detector) with `punsafe=0.1` and an [aesthetic score](https://github.com/christophschuhmann/improved-aesthetic-predictor) >= `4.5`.
850k steps at resolution `512x512` on the same dataset with resolution `>= 512x512`.
- `768-v-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for 150k steps using a [v-objective](https://arxiv.org/abs/2202.00512) on the same dataset. Resumed for another 140k steps on a `768x768` subset of our dataset.
- `512-depth-ema.ckpt`: Resumed from `512-base-ema.ckpt` and finetuned for 200k steps. Added an extra input channel to process the (relative) depth prediction produced by [MiDaS](https://github.com/isl-org/MiDaS) (`dpt_hybrid`) which is used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized.
- `512-inpainting-ema.ckpt`: Resumed from `512-base-ema.ckpt` and trained for another 200k steps. Follows the mask-generation strategy presented in [LAMA](https://github.com/saic-mdal/lama) which, in combination with the latent VAE representations of the masked image, are used as an additional conditioning.
The additional input channels of the U-Net which process this extra information were zero-initialized. The same strategy was used to train the [1.5-inpainting checkpoint](https://github.com/saic-mdal/lama).
- `x4-upscaling-ema.ckpt`: Trained for 1.25M steps on a 10M subset of LAION containing images `>2048x2048`. The model was trained on crops of size `512x512` and is a text-guided [latent upscaling diffusion model](https://arxiv.org/abs/2112.10752).
In addition to the textual input, it receives a `noise_level` as an input parameter, which can be used to add noise to the low-resolution input according to a [predefined diffusion schedule](configs/stable-diffusion/x4-upscaling.yaml).
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 1
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 steps DDIM sampling steps show the relative improvements of the checkpoints:
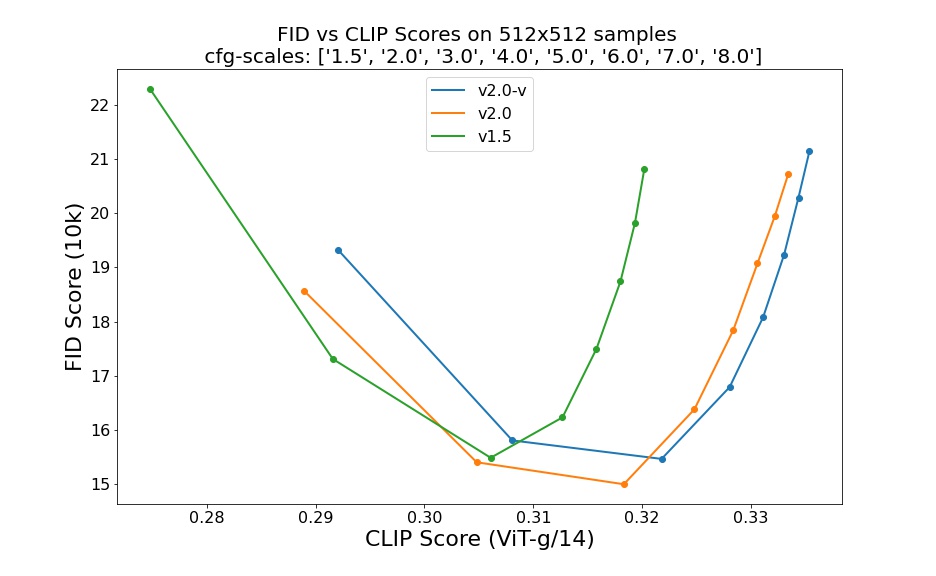
Evaluated using 50 DDIM steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 200000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 15000 kg CO2 eq.
## Citation
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
*This model card was written by: Robin Rombach, Patrick Esser and David Ha and is based on the [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion/blob/main/Stable_Diffusion_v1_Model_Card.md) and [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).*
|
dkatsiros/ppo-LunarLander-v2
|
dkatsiros
| 2023-07-05T16:16:17Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T16:15:56Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 258.74 +/- 16.94
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
CeroShrijver/chinese-macbert-base-text-classification
|
CeroShrijver
| 2023-07-05T16:12:51Z | 117 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-03T07:53:30Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: chinese-macbert-base-text-classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# chinese-macbert-base-text-classification
This model is a fine-tuned version of [hfl/chinese-macbert-base](https://huggingface.co/hfl/chinese-macbert-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6609
- Accuracy: 0.7844
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5794 | 1.0 | 1009 | 0.4825 | 0.7900 |
| 0.3729 | 2.0 | 2018 | 0.5239 | 0.8043 |
| 0.3049 | 3.0 | 3027 | 0.6609 | 0.7844 |
### Framework versions
- Transformers 4.29.2
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
Neko-Institute-of-Science/LLaMA-65B-4bit-32g
|
Neko-Institute-of-Science
| 2023-07-05T15:41:35Z | 5 | 10 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-04-07T04:33:21Z |
I tried making groupsize 16 but that did not end well so I went with 32g. FYI I can run this with full context on my A6000.
```
65B (act-order true-sequential groupsize)
wikitext2 3.5319948196411133 (stock 16bit)
wikitext2 3.610668182373047 (32g)
wikitext2 3.650667667388916 (16g)
wikitext2 3.6660284996032715 (128)
ptb-new 7.66942024230957 (stock 16bit)
ptb-new 7.71506929397583 (32g)
ptb-new 7.762592792510986 (128)
ptb-new 7.829207897186279 (16g)
c4-new 5.8114824295043945 (stock 16bit)
c4-new 5.859227657318115 (32g)
c4-new 5.893154144287109 (128)
c4-new 5.929086208343506 (16g)
```
|
robsong3/distilbert-base-uncased-finetuned-cola
|
robsong3
| 2023-07-05T14:55:09Z | 61 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-05T13:16:55Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: robsong3/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# robsong3/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1931
- Validation Loss: 0.5174
- Train Matthews Correlation: 0.5396
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5157 | 0.4443 | 0.5062 | 0 |
| 0.3214 | 0.4521 | 0.5370 | 1 |
| 0.1931 | 0.5174 | 0.5396 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
sjdata/ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
|
sjdata
| 2023-07-05T14:31:24Z | 163 | 0 |
transformers
|
[
"transformers",
"pytorch",
"audio-spectrogram-transformer",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"license:bsd-3-clause",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-07-05T14:00:35Z |
---
license: bsd-3-clause
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ast-finetuned-audioset-10-10-0.4593-finetuned-gtzan
This model is a fine-tuned version of [MIT/ast-finetuned-audioset-10-10-0.4593](https://huggingface.co/MIT/ast-finetuned-audioset-10-10-0.4593) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6230
- Accuracy: 0.89
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.1198 | 1.0 | 450 | 1.8429 | 0.47 |
| 0.0005 | 2.0 | 900 | 1.6282 | 0.71 |
| 0.3129 | 3.0 | 1350 | 1.0553 | 0.73 |
| 0.0225 | 4.0 | 1800 | 0.9422 | 0.82 |
| 0.0025 | 5.0 | 2250 | 0.6008 | 0.85 |
| 0.0 | 6.0 | 2700 | 0.7194 | 0.86 |
| 0.0 | 7.0 | 3150 | 0.6268 | 0.89 |
| 0.0 | 8.0 | 3600 | 0.6372 | 0.89 |
| 0.0 | 9.0 | 4050 | 0.6167 | 0.89 |
| 0.0 | 10.0 | 4500 | 0.6230 | 0.89 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
jliu596/q-FrozenLake-v1-4x4-noSlippery
|
jliu596
| 2023-07-05T14:20:19Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T14:20:17Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jliu596/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
huangyuyang/chatglm2-6b-fp16.flm
|
huangyuyang
| 2023-07-05T12:51:41Z | 0 | 9 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2023-07-05T12:11:27Z |
---
license: apache-2.0
---
fastllm model for chatglm-6b-fp16
Github address: https://github.com/ztxz16/fastllm
|
Babiputih/Sarahvil
|
Babiputih
| 2023-07-05T12:21:01Z | 0 | 0 | null |
[
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-05T12:10:53Z |
---
license: creativeml-openrail-m
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
luispintoc/taxi-v2
|
luispintoc
| 2023-07-05T12:03:57Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T12:03:55Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="luispintoc/taxi-v2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
riccorl/blink-bert-large
|
riccorl
| 2023-07-05T11:57:22Z | 110 | 2 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"feature-extraction",
"en",
"license:mit",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2023-04-26T08:56:04Z |
---
license: mit
language:
- en
library_name: transformers
---
# BLINK BERT-Large Model
This is a BERT-Large model finetuned on [BLINK](https://github.com/facebookresearch/BLINK)
|
bofenghuang/vigogne-falcon-7b-instruct
|
bofenghuang
| 2023-07-05T11:38:33Z | 25 | 1 |
transformers
|
[
"transformers",
"pytorch",
"RefinedWebModel",
"text-generation",
"LLM",
"custom_code",
"fr",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-07-05T09:51:56Z |
---
license: apache-2.0
language:
- fr
pipeline_tag: text-generation
library_name: transformers
tags:
- LLM
inference: false
---
<p align="center" width="100%">
<img src="https://huggingface.co/bofenghuang/vigogne-falcon-7b-instruct/resolve/main/vigogne_logo.png" alt="Vigogne" style="width: 40%; min-width: 300px; display: block; margin: auto;">
</p>
# Vigogne-Falcon-7B-Instruct: A French Instruction-following Falcon Model
Vigogne-Falcon-7B-Instruct is a [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) model fine-tuned to follow the French instructions.
For more information, please visit the Github repo: https://github.com/bofenghuang/vigogne
## Usage
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
from vigogne.preprocess import generate_instruct_prompt
model_name_or_path = "bofenghuang/vigogne-falcon-7b-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side="right", use_fast=False)
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
user_query = "Expliquez la différence entre DoS et phishing."
prompt = generate_instruct_prompt(user_query)
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to(model.device)
input_length = input_ids.shape[1]
generated_outputs = model.generate(
input_ids=input_ids,
generation_config=GenerationConfig(
temperature=0.1,
do_sample=True,
repetition_penalty=1.0,
max_new_tokens=512,
),
return_dict_in_generate=True,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
generated_tokens = generated_outputs.sequences[0, input_length:]
generated_text = tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
```
You can also infer this model by using the following Google Colab Notebook.
<a href="https://colab.research.google.com/github/bofenghuang/vigogne/blob/main/notebooks/infer_instruct.ipynb" target="_blank"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
## Limitations
Vigogne is still under development, and there are many limitations that have to be addressed. Please note that it is possible that the model generates harmful or biased content, incorrect information or generally unhelpful answers.
|
vergarajit/HuggyLlama
|
vergarajit
| 2023-07-05T11:32:32Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-06-27T00:08:30Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.4.0.dev0
|
NihalSrivastava/advertisement-description-generator
|
NihalSrivastava
| 2023-07-05T11:18:06Z | 137 | 1 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-04-06T05:39:06Z |
---
license: mit
language:
- en
library_name: transformers
widget:
- text: "<|BOS|>laptop, fast, gaming, great graphics, affordable <|SEP|> "
example_title: "Laptop"
- text: "<|BOS|> T-Shirt, Red color, comfortable <|SEP|> "
example_title: "T-Shirt"
- text: "<|BOS|> Game console, multiple game support, 4k graphics, extreme fast performace <|SEP|> "
example_title: "Game Console"
---
# Advertisement-Description-Generator gpt2 finetuned on product descriptions
## Model Details
This model generates a 1-2 line description of a product given the keywords associated with it. It is a fine-tuned version of GPT-2 model on a custom dataset consisting of
328 rows in the format: (keyword, text)
Example:
[Echo Dot,smart speaker,Alexa,improved sound,sleek design,home], Introducing the all-new Echo Dot - the smart speaker with Alexa. It has improved sound and a sleek design that fits anywhere in your home.
- **Developed by:** Nihal Srivastava
- **Model type:** Finetuned GPT-2
- **License:** MIT
- **Finetuned from model [optional]:** GPT-2
## Uses
##### Inital Imports of the model and setting up helper functions:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
def join_keywords(keywords, randomize=True):
N = len(keywords)
if randomize:
M = random.choice(range(N+1))
keywords = keywords[:M]
random.shuffle(keywords)
return ','.join(keywords)
SPECIAL_TOKENS = { "bos_token": "<|BOS|>",
"eos_token": "<|EOS|>",
"unk_token": "<|UNK|>",
"pad_token": "<|PAD|>",
"sep_token": "<|SEP|>"}
device = torch.device("cuda")
tokenizer = AutoTokenizer.from_pretrained("NihalSrivastava/advertisement-description-generator")
model = AutoModelForCausalLM.from_pretrained("NihalSrivastava/advertisement-description-generator").to(device)
keywords = ['laptop', 'fast', 'gaming', 'great graphics', 'affordable']
kw = join_keywords(keywords, randomize=False)
prompt = SPECIAL_TOKENS['bos_token'] + kw + SPECIAL_TOKENS['sep_token']
generated = torch.tensor(tokenizer.encode(prompt)).unsqueeze(0)
device = torch.device("cuda")
generated = generated.to(device)
model.eval();
```
##### To generate a single best description:
``` python
# Beam-search text generation:
sample_outputs = model.generate(generated,
do_sample=True,
max_length=768,
num_beams=5,
repetition_penalty=5.0,
early_stopping=True,
num_return_sequences=1
)
for i, sample_output in enumerate(sample_outputs):
text = tokenizer.decode(sample_output, skip_special_tokens=True)
a = len(','.join(keywords))
print("{}: {}\n\n".format(i+1, text[a:]))
```
Output:
> 1: The gaming laptop has a fast clock speed, high refresh rate display, and advanced connectivity options for unparalleled gaming performance.
##### To generate top 10 best descriptions:
``` python
# Top-p (nucleus) text generation (10 samples):
sample_outputs = model.generate(generated,
do_sample=True,
min_length=50,
max_length=MAXLEN,
top_k=30,
top_p=0.7,
temperature=0.9,
repetition_penalty=2.0,
num_return_sequences=10
)
for i, sample_output in enumerate(sample_outputs):
text = tokenizer.decode(sample_output, skip_special_tokens=True)
a = len(','.join(keywords))
print("{}: {}\n\n".format(i+1, text[a:]))
```
Output:
Will generate 10 best outouts of product description as above.
#### Training Hyperparameters
``` python
DEBUG = False
USE_APEX = True
APEX_OPT_LEVEL = 'O1'
MODEL = 'gpt2' #{gpt2, gpt2-medium, gpt2-large, gpt2-xl}
UNFREEZE_LAST_N = 6 #The last N layers to unfreeze for training
SPECIAL_TOKENS = { "bos_token": "<|BOS|>",
"eos_token": "<|EOS|>",
"unk_token": "<|UNK|>",
"pad_token": "<|PAD|>",
"sep_token": "<|SEP|>"}
MAXLEN = 768 #{768, 1024, 1280, 1600}
TRAIN_SIZE = 0.8
if USE_APEX:
TRAIN_BATCHSIZE = 4
BATCH_UPDATE = 16
else:
TRAIN_BATCHSIZE = 2
BATCH_UPDATE = 32
EPOCHS = 20
LR = 5e-4
EPS = 1e-8
WARMUP_STEPS = 1e2
SEED = 2020
EVALUATION_STRATEGY=epoch
SAVE_STRATEGY=epoch
```
## Model Card Contact
Email: [email protected] <br>
Github: https://github.com/Nihal-Srivastava05 <br>
LinkedIn: https://www.linkedin.com/in/nihal-srivastava-7708a71b7/ <br>
|
jordyvl/dit-rvl_maveriq_tobacco3482_2023-07-05
|
jordyvl
| 2023-07-05T10:59:00Z | 161 | 0 |
transformers
|
[
"transformers",
"pytorch",
"beit",
"image-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-07-05T10:04:59Z |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: dit-rvl_maveriq_tobacco3482_2023-07-05
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dit-rvl_maveriq_tobacco3482_2023-07-05
This model is a fine-tuned version of [microsoft/dit-base-finetuned-rvlcdip](https://huggingface.co/microsoft/dit-base-finetuned-rvlcdip) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4530
- Accuracy: 0.94
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 0.96 | 3 | 2.2927 | 0.01 |
| No log | 1.96 | 6 | 2.2632 | 0.08 |
| No log | 2.96 | 9 | 2.2334 | 0.18 |
| No log | 3.96 | 12 | 2.2025 | 0.195 |
| No log | 4.96 | 15 | 2.1686 | 0.235 |
| No log | 5.96 | 18 | 2.1274 | 0.325 |
| No log | 6.96 | 21 | 2.0784 | 0.385 |
| No log | 7.96 | 24 | 2.0284 | 0.465 |
| No log | 8.96 | 27 | 1.9750 | 0.55 |
| No log | 9.96 | 30 | 1.9206 | 0.585 |
| No log | 10.96 | 33 | 1.8683 | 0.61 |
| No log | 11.96 | 36 | 1.8164 | 0.65 |
| No log | 12.96 | 39 | 1.7660 | 0.735 |
| No log | 13.96 | 42 | 1.7195 | 0.765 |
| No log | 14.96 | 45 | 1.6761 | 0.815 |
| No log | 15.96 | 48 | 1.6336 | 0.83 |
| No log | 16.96 | 51 | 1.5918 | 0.835 |
| No log | 17.96 | 54 | 1.5511 | 0.835 |
| No log | 18.96 | 57 | 1.5101 | 0.84 |
| No log | 19.96 | 60 | 1.4699 | 0.85 |
| No log | 20.96 | 63 | 1.4307 | 0.855 |
| No log | 21.96 | 66 | 1.3925 | 0.865 |
| No log | 22.96 | 69 | 1.3534 | 0.865 |
| No log | 23.96 | 72 | 1.3164 | 0.885 |
| No log | 24.96 | 75 | 1.2825 | 0.885 |
| No log | 25.96 | 78 | 1.2458 | 0.88 |
| No log | 26.96 | 81 | 1.2091 | 0.88 |
| No log | 27.96 | 84 | 1.1762 | 0.89 |
| No log | 28.96 | 87 | 1.1446 | 0.885 |
| No log | 29.96 | 90 | 1.1126 | 0.9 |
| No log | 30.96 | 93 | 1.0840 | 0.905 |
| No log | 31.96 | 96 | 1.0549 | 0.9 |
| No log | 32.96 | 99 | 1.0247 | 0.91 |
| No log | 33.96 | 102 | 0.9962 | 0.925 |
| No log | 34.96 | 105 | 0.9685 | 0.93 |
| No log | 35.96 | 108 | 0.9447 | 0.93 |
| No log | 36.96 | 111 | 0.9217 | 0.93 |
| No log | 37.96 | 114 | 0.9007 | 0.93 |
| No log | 38.96 | 117 | 0.8778 | 0.935 |
| No log | 39.96 | 120 | 0.8551 | 0.935 |
| No log | 40.96 | 123 | 0.8325 | 0.93 |
| No log | 41.96 | 126 | 0.8129 | 0.93 |
| No log | 42.96 | 129 | 0.7970 | 0.93 |
| No log | 43.96 | 132 | 0.7810 | 0.93 |
| No log | 44.96 | 135 | 0.7609 | 0.935 |
| No log | 45.96 | 138 | 0.7441 | 0.935 |
| No log | 46.96 | 141 | 0.7313 | 0.935 |
| No log | 47.96 | 144 | 0.7184 | 0.935 |
| No log | 48.96 | 147 | 0.7044 | 0.93 |
| No log | 49.96 | 150 | 0.6902 | 0.93 |
| No log | 50.96 | 153 | 0.6773 | 0.935 |
| No log | 51.96 | 156 | 0.6666 | 0.935 |
| No log | 52.96 | 159 | 0.6554 | 0.935 |
| No log | 53.96 | 162 | 0.6446 | 0.935 |
| No log | 54.96 | 165 | 0.6308 | 0.94 |
| No log | 55.96 | 168 | 0.6194 | 0.94 |
| No log | 56.96 | 171 | 0.6098 | 0.94 |
| No log | 57.96 | 174 | 0.6021 | 0.94 |
| No log | 58.96 | 177 | 0.5922 | 0.935 |
| No log | 59.96 | 180 | 0.5820 | 0.94 |
| No log | 60.96 | 183 | 0.5735 | 0.94 |
| No log | 61.96 | 186 | 0.5632 | 0.94 |
| No log | 62.96 | 189 | 0.5559 | 0.94 |
| No log | 63.96 | 192 | 0.5494 | 0.94 |
| No log | 64.96 | 195 | 0.5430 | 0.94 |
| No log | 65.96 | 198 | 0.5370 | 0.935 |
| No log | 66.96 | 201 | 0.5320 | 0.935 |
| No log | 67.96 | 204 | 0.5278 | 0.935 |
| No log | 68.96 | 207 | 0.5228 | 0.935 |
| No log | 69.96 | 210 | 0.5166 | 0.935 |
| No log | 70.96 | 213 | 0.5117 | 0.935 |
| No log | 71.96 | 216 | 0.5076 | 0.935 |
| No log | 72.96 | 219 | 0.5029 | 0.94 |
| No log | 73.96 | 222 | 0.4985 | 0.94 |
| No log | 74.96 | 225 | 0.4945 | 0.94 |
| No log | 75.96 | 228 | 0.4904 | 0.94 |
| No log | 76.96 | 231 | 0.4865 | 0.94 |
| No log | 77.96 | 234 | 0.4833 | 0.94 |
| No log | 78.96 | 237 | 0.4804 | 0.94 |
| No log | 79.96 | 240 | 0.4779 | 0.94 |
| No log | 80.96 | 243 | 0.4757 | 0.94 |
| No log | 81.96 | 246 | 0.4738 | 0.94 |
| No log | 82.96 | 249 | 0.4719 | 0.935 |
| No log | 83.96 | 252 | 0.4701 | 0.935 |
| No log | 84.96 | 255 | 0.4684 | 0.935 |
| No log | 85.96 | 258 | 0.4669 | 0.935 |
| No log | 86.96 | 261 | 0.4653 | 0.935 |
| No log | 87.96 | 264 | 0.4637 | 0.935 |
| No log | 88.96 | 267 | 0.4620 | 0.935 |
| No log | 89.96 | 270 | 0.4602 | 0.935 |
| No log | 90.96 | 273 | 0.4586 | 0.94 |
| No log | 91.96 | 276 | 0.4572 | 0.94 |
| No log | 92.96 | 279 | 0.4562 | 0.94 |
| No log | 93.96 | 282 | 0.4553 | 0.94 |
| No log | 94.96 | 285 | 0.4546 | 0.94 |
| No log | 95.96 | 288 | 0.4540 | 0.94 |
| No log | 96.96 | 291 | 0.4535 | 0.94 |
| No log | 97.96 | 294 | 0.4532 | 0.94 |
| No log | 98.96 | 297 | 0.4530 | 0.94 |
| No log | 99.96 | 300 | 0.4530 | 0.94 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1.post200
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Htar/taxi-3
|
Htar
| 2023-07-05T10:10:20Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-05T10:07:37Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.50 +/- 2.72
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Htar/taxi-3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Jyshen/Chat_Suzumiya_GLM2LoRA
|
Jyshen
| 2023-07-05T09:39:57Z | 0 | 1 |
peft
|
[
"peft",
"region:us"
] | null | 2023-06-10T12:56:56Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
thirupathibandam/autotrain-phanik-gptneo125-self-72299138912
|
thirupathibandam
| 2023-07-05T07:39:28Z | 31 | 0 |
adapter-transformers
|
[
"adapter-transformers",
"autotrain",
"text-generation",
"dataset:thirupathibandam/autotrain-data-phanik-gptneo125-self",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-05T07:08:38Z |
---
tags:
- autotrain
- text-generation
widget:
- text: 'I love AutoTrain because '
datasets:
- thirupathibandam/autotrain-data-phanik-gptneo125-self
co2_eq_emissions:
emissions: 0.3379436679826976
library_name: adapter-transformers
---
# Model Trained Using AutoTrain
- Problem type: Text Generation
- CO2 Emissions (in grams): 0.3379
## Validation Metrics
loss: 1.8594619035720825
|
cerspense/zeroscope_v2_1111models
|
cerspense
| 2023-07-05T06:39:40Z | 0 | 24 | null |
[
"license:cc-by-nc-4.0",
"region:us"
] | null | 2023-07-03T23:09:54Z |
---
license: cc-by-nc-4.0
---

[example outputs](https://www.youtube.com/watch?v=HO3APT_0UA4) (courtesy of [dotsimulate](https://www.instagram.com/dotsimulate/))
# zeroscope_v2 1111 models
A collection of watermark-free Modelscope-based video models capable of generating high quality video at [448x256](https://huggingface.co/cerspense/zeroscope_v2_dark_30x448x256), [576x320](https://huggingface.co/cerspense/zeroscope_v2_576w) and [1024 x 576](https://huggingface.co/cerspense/zeroscope_v2_XL). These models were trained from the [original weights](https://huggingface.co/damo-vilab/modelscope-damo-text-to-video-synthesis) with offset noise using 9,923 clips and 29,769 tagged frames.<br />
This collection makes it easy to switch between models with the new dropdown menu in the 1111 extension.
### Using it with the 1111 text2video extension
Simply download the contents of this repo to 'stable-diffusion-webui\models\text2video'
Or, manually download the model folders you want, along with VQGAN_autoencoder.pth.
Thanks to [dotsimulate](https://www.instagram.com/dotsimulate/) for the config files.
Thanks to [camenduru](https://github.com/camenduru), [kabachuha](https://github.com/kabachuha), [ExponentialML](https://github.com/ExponentialML), [VANYA](https://twitter.com/veryVANYA), [polyware](https://twitter.com/polyware_ai), [tin2tin](https://github.com/tin2tin)<br />
|
dlabs-matic-leva/segformer-b0-finetuned-segments-sidewalk-2
|
dlabs-matic-leva
| 2023-07-05T05:54:12Z | 186 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"segformer",
"vision",
"image-segmentation",
"dataset:segments/sidewalk-semantic",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2023-07-04T07:03:03Z |
---
tags:
- vision
- image-segmentation
datasets:
- segments/sidewalk-semantic
finetuned_from: nvidia/mit-b0
widget:
- src: >-
https://datasets-server.huggingface.co/assets/segments/sidewalk-semantic/--/segments--sidewalk-semantic-2/train/3/pixel_values/image.jpg
example_title: Sidewalk example
---
|
niansong1996/lever-gsm8k-codex
|
niansong1996
| 2023-07-05T05:48:36Z | 103 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"dataset:gsm8k",
"arxiv:2302.08468",
"arxiv:1910.09700",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-03T03:42:52Z |
---
license: apache-2.0
datasets:
- gsm8k
metrics:
- accuracy
model-index:
- name: lever-gsm8k-codex
results:
- task:
type: code generation # Required. Example: automatic-speech-recognition
# name: {task_name} # Optional. Example: Speech Recognition
dataset:
type: gsm8k # Required. Example: common_voice. Use dataset id from https://hf.co/datasets
name: GSM8K (Math Reasoning) # Required. A pretty name for the dataset. Example: Common Voice (French)
# config: {dataset_config} # Optional. The name of the dataset configuration used in `load_dataset()`. Example: fr in `load_dataset("common_voice", "fr")`. See the `datasets` docs for more info: https://huggingface.co/docs/datasets/package_reference/loading_methods#datasets.load_dataset.name
# split: {dataset_split} # Optional. Example: test
# revision: {dataset_revision} # Optional. Example: 5503434ddd753f426f4b38109466949a1217c2bb
# args:
# {arg_0}: {value_0} # Optional. Additional arguments to `load_dataset()`. Example for wikipedia: language: en
# {arg_1}: {value_1} # Optional. Example for wikipedia: date: 20220301
metrics:
- type: accuracy # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 84.5 # Required. Example: 20.90
# name: {metric_name} # Optional. Example: Test WER
# config: {metric_config} # Optional. The name of the metric configuration used in `load_metric()`. Example: bleurt-large-512 in `load_metric("bleurt", "bleurt-large-512")`. See the `datasets` docs for more info: https://huggingface.co/docs/datasets/v2.1.0/en/loading#load-configurations
# args:
# {arg_0}: {value_0} # Optional. The arguments passed during `Metric.compute()`. Example for `bleu`: max_order: 4
verified: false # Optional. If true, indicates that evaluation was generated by Hugging Face (vs. self-reported).
---
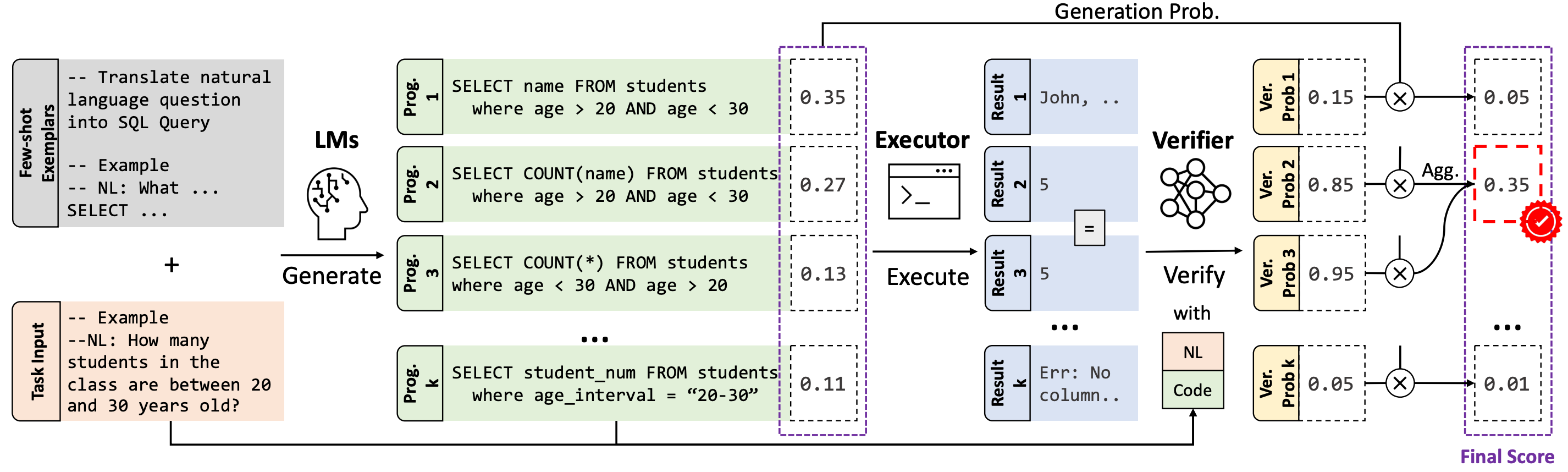
# LEVER (for Codex on GSM8K)
This is one of the models produced by the paper ["LEVER: Learning to Verify Language-to-Code Generation with Execution"](https://arxiv.org/abs/2302.08468).
**Authors:** [Ansong Ni](https://niansong1996.github.io), Srini Iyer, Dragomir Radev, Ves Stoyanov, Wen-tau Yih, Sida I. Wang*, Xi Victoria Lin*
**Note**: This specific model is for Codex on the [GSM8K](https://github.com/openai/grade-school-math) dataset, for the models pretrained on other datasets, please see:
* [lever-spider-codex](https://huggingface.co/niansong1996/lever-spider-codex)
* [lever-wikitq-codex](https://huggingface.co/niansong1996/lever-wikitq-codex)
* [lever-mbpp-codex](https://huggingface.co/niansong1996/lever-mbpp-codex)
# Model Details
## Model Description
The advent of pre-trained code language models (Code LLMs) has led to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base CodeLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
- **Developed by:** Yale University and Meta AI
- **Shared by:** Ansong Ni
- **Model type:** Text Classification
- **Language(s) (NLP):** More information needed
- **License:** Apache-2.0
- **Parent Model:** RoBERTa-large
- **Resources for more information:**
- [Github Repo](https://github.com/niansong1996/lever)
- [Associated Paper](https://arxiv.org/abs/2302.08468)
# Uses
## Direct Use
This model is *not* intended to be directly used. LEVER is used to verify and rerank the programs generated by code LLMs (e.g., Codex). We recommend checking out our [Github Repo](https://github.com/niansong1996/lever) for more details.
## Downstream Use
LEVER is learned to verify and rerank the programs sampled from code LLMs for different tasks.
More specifically, for `lever-gsm8k-codex`, it was trained on the outputs of `code-davinci-002` on the [GSM8K](https://github.com/openai/grade-school-math) dataset. It can be used to rerank the SQL programs generated by Codex out-of-box.
Moreover, it may also be applied to other model's outputs on the GSM8K dataset, as studied in the [Original Paper](https://arxiv.org/abs/2302.08468).
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
The model is trained with the outputs from `code-davinci-002` model on the [GSM8K](https://github.com/openai/grade-school-math) dataset.
## Training Procedure
20 program samples are drawn from the Codex model on the training examples of the GSM8K dataset, those programs are later executed to obtain the execution information.
And for each example and its program sample, the natural language description and execution information are also part of the inputs that used to train the RoBERTa-based model to predict "yes" or "no" as the verification labels.
### Preprocessing
Please follow the instructions in the [Github Repo](https://github.com/niansong1996/lever) to reproduce the results.
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
Dev and test set of the [GSM8K](https://github.com/openai/grade-school-math) dataset.
### Factors
More information needed
### Metrics
Execution accuracy (i.e., pass@1)
## Results
### GSM8K Math Reasoning via Python Code Generation
| | Exec. Acc. (Dev) | Exec. Acc. (Test) |
|-----------------|------------------|-------------------|
| Codex | 68.1 | 67.2 |
| Codex+LEVER | 84.1 | 84.5 |
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
`lever-gsm8k-codex` is based on RoBERTa-large.
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed.
# Citation
**BibTeX:**
```bibtex
@inproceedings{ni2023lever,
title={Lever: Learning to verify language-to-code generation with execution},
author={Ni, Ansong and Iyer, Srini and Radev, Dragomir and Stoyanov, Ves and Yih, Wen-tau and Wang, Sida I and Lin, Xi Victoria},
booktitle={Proceedings of the 40th International Conference on Machine Learning (ICML'23)},
year={2023}
}
```
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Author and Contact
Ansong Ni, contact info on [personal website](https://niansong1996.github.io)
# How to Get Started with the Model
This model is *not* intended to be directly used, please follow the instructions in the [Github Repo](https://github.com/niansong1996/lever).
|
YIMMYCRUZ/distilroberta-base-mrpc-glue
|
YIMMYCRUZ
| 2023-07-05T02:08:22Z | 120 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-30T04:06:39Z |
---
license: apache-2.0
tags:
- text-classification
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
widget:
- text: ["Yucaipa owned Dominick 's before selling the chain to Safeway in 1998 for $ 2.5 billion.",
"Yucaipa bought Dominick's in 1995 for $ 693 million and sold it to Safeway for $ 1.8 billion in 1998."]
example_title: Not Equivalent
- text: ["Revenue in the first quarter of the year dropped 15 percent from the same period a year earlier.",
"With the scandal hanging over Stewart's company revenue the first quarter of the year dropped 15 percent from the same period a year earlier."]
example_title: Equivalent
model-index:
- name: distilroberta-base-mrpc-glue
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mrpc
split: validation
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8088235294117647
- name: F1
type: f1
value: 0.8682432432432433
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-mrpc-glue
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the glue and the mrpc datasets.
It achieves the following results on the evaluation set:
- Loss: 0.6224
- Accuracy: 0.8088
- F1: 0.8682
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.508 | 1.09 | 500 | 0.6224 | 0.8088 | 0.8682 |
| 0.3303 | 2.18 | 1000 | 0.6322 | 0.8554 | 0.8963 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
eclec/announcementClassfication
|
eclec
| 2023-07-05T00:49:35Z | 22 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-04T16:44:48Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: announcementClassfication
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# announcementClassfication
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5613
- Accuracy: 0.85
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4.430934731021352e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 15 | 0.6120 | 0.6667 |
| No log | 2.0 | 30 | 0.5613 | 0.85 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
digiplay/RMHF_2.5D_v2
|
digiplay
| 2023-07-05T00:31:26Z | 316 | 2 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-04T23:57:21Z |
---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info :
https://civitai.com/models/101518/rmhf
Sample image I made :


Original Author's DEMO image and prompt :
cat ears, pink hair, heterochromia, red eye, blue eye, blue sky, ocean, sea, seaside, beach, water, white clouds, angel wings, angel halo, feather wings, multiple wings, large wings, halo, glowing halo, energy wings, glowing wings, angel, light particles, dappled sunlight, bright, glowing eyes, unity cg, 8k wallpaper, amazing, ultra-detailed illustration

|
GabrielFerreira/ppo-HuggyTest
|
GabrielFerreira
| 2023-07-04T23:30:24Z | 10 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-06-28T03:39:57Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
THIS MODEL IS JUST FOR STUDY AND DOES NOT HAVE GOOD PERFORMANCE.
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: GabrielFerreira/ppo-HuggyPRO
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
tatsu-lab/alpaca-farm-ppo-human-wdiff
|
tatsu-lab
| 2023-07-04T23:05:54Z | 24 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-05-24T07:38:35Z |
Please see https://github.com/tatsu-lab/alpaca_farm#downloading-pre-tuned-alpacafarm-models for details on this model.
|
Huggingfly/dqn-SpaceInvadersNoFrameskip-v4
|
Huggingfly
| 2023-07-04T20:26:00Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-04T20:25:25Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 566.50 +/- 172.35
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Huggingfly -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Huggingfly -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Huggingfly
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
nolanaatama/jcwrldrvcv2crp300pchsmlk
|
nolanaatama
| 2023-07-04T20:08:40Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-04T20:04:26Z |
---
license: creativeml-openrail-m
---
|
Adoley/covid-tweets-sentiment-analysis-distilbert-model
|
Adoley
| 2023-07-04T19:50:48Z | 124 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-05-11T19:35:51Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: covid-tweets-sentiment-analysis-distilbert-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# covid-tweets-sentiment-analysis-distilbert-model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5979
- Rmse: 0.6680
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.7464 | 2.0 | 500 | 0.5979 | 0.6680 |
| 0.4318 | 4.0 | 1000 | 0.6374 | 0.6327 |
| 0.1694 | 6.0 | 1500 | 0.9439 | 0.6311 |
| 0.072 | 8.0 | 2000 | 1.1471 | 0.6556 |
| 0.0388 | 10.0 | 2500 | 1.2217 | 0.6437 |
### Framework versions
- Transformers 4.29.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
rohanbalkondekar/adept-skunk
|
rohanbalkondekar
| 2023-07-04T19:06:11Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"gpt",
"llm",
"large language model",
"h2o-llmstudio",
"en",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] |
text-generation
| 2023-07-04T18:59:30Z |
---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- h2o-llmstudio
inference: false
thumbnail: https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
---
# Model Card
## Summary
This model was trained using [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio).
- Base model: [lmsys/vicuna-7b-v1.3](https://huggingface.co/lmsys/vicuna-7b-v1.3)
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers`, `accelerate` and `torch` libraries installed.
```bash
pip install transformers==4.30.1
pip install accelerate==0.20.3
pip install torch==2.0.0
```
```python
import torch
from transformers import pipeline
generate_text = pipeline(
model="BeRohan/adept-skunk",
torch_dtype="auto",
trust_remote_code=True,
use_fast=True,
device_map={"": "cuda:0"},
)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You can print a sample prompt after the preprocessing step to see how it is feed to the tokenizer:
```python
print(generate_text.preprocess("Why is drinking water so healthy?")["prompt_text"])
```
```bash
<|prompt|>Why is drinking water so healthy?</s><|answer|>
```
Alternatively, you can download [h2oai_pipeline.py](h2oai_pipeline.py), store it alongside your notebook, and construct the pipeline yourself from the loaded model and tokenizer. If the model and the tokenizer are fully supported in the `transformers` package, this will allow you to set `trust_remote_code=False`.
```python
import torch
from h2oai_pipeline import H2OTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"BeRohan/adept-skunk",
use_fast=True,
padding_side="left",
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
"BeRohan/adept-skunk",
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
generate_text = H2OTextGenerationPipeline(model=model, tokenizer=tokenizer)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "BeRohan/adept-skunk" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
prompt = "<|prompt|>How are you?</s><|answer|>"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=True,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
model.cuda().eval()
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
# generate configuration can be modified to your needs
tokens = model.generate(
**inputs,
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Model Architecture
```
LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(32000, 4096, padding_idx=0)
(layers): ModuleList(
(0-31): 32 x LlamaDecoderLayer(
(self_attn): LlamaAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=4096, bias=False)
(v_proj): Linear(in_features=4096, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=4096, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=4096, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=4096, bias=False)
(up_proj): Linear(in_features=4096, out_features=11008, bias=False)
(act_fn): SiLUActivation()
)
(input_layernorm): LlamaRMSNorm()
(post_attention_layernorm): LlamaRMSNorm()
)
)
(norm): LlamaRMSNorm()
)
(lm_head): Linear(in_features=4096, out_features=32000, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Model Validation
Model validation results using [EleutherAI lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness).
```bash
CUDA_VISIBLE_DEVICES=0 python main.py --model hf-causal-experimental --model_args pretrained=BeRohan/adept-skunk --tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq --device cuda &> eval.log
```
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it.
|
Word2vec/nlpl_106
|
Word2vec
| 2023-07-04T15:30:51Z | 0 | 0 | null |
[
"word2vec",
"nob",
"dataset:NoWaC",
"license:cc-by-4.0",
"region:us"
] | null | 2023-07-04T14:16:31Z |
---
language: nob
license: cc-by-4.0
tags:
- word2vec
datasets: NoWaC
---
## Information
A word2vec model trained by Cathrine Stadsnes ([email protected]) on a vocabulary of size 1356632 corresponding to 687209465 tokens from the dataset `NoWaC`.
The model is trained with the following properties: no lemmatization and postag with the algorith Gensim Continuous Skipgram with window of 5 and dimension of 100.
## How to use?
```
from gensim.models import KeyedVectors
from huggingface_hub import hf_hub_download
model = KeyedVectors.load_word2vec_format(hf_hub_download(repo_id="Word2vec/nlpl_106", filename="model.bin"), binary=True, unicode_errors="ignore")
```
## Citation
Fares, Murhaf; Kutuzov, Andrei; Oepen, Stephan & Velldal, Erik (2017). Word vectors, reuse, and replicability: Towards a community repository of large-text resources, In Jörg Tiedemann (ed.), Proceedings of the 21st Nordic Conference on Computational Linguistics, NoDaLiDa, 22-24 May 2017. Linköping University Electronic Press. ISBN 978-91-7685-601-7
This archive is part of the NLPL Word Vectors Repository (http://vectors.nlpl.eu/repository/), version 2.0, published on Friday, December 27, 2019.
Please see the file 'meta.json' in this archive and the overall repository metadata file http://vectors.nlpl.eu/repository/20.json for additional information.
The life-time identifier for this model is: http://vectors.nlpl.eu/repository/20/106.zip
|
Word2vec/nlpl_102
|
Word2vec
| 2023-07-04T15:30:05Z | 0 | 0 | null |
[
"word2vec",
"nob",
"dataset:Norsk_Aviskorpus",
"license:cc-by-4.0",
"region:us"
] | null | 2023-07-04T14:14:08Z |
---
language: nob
license: cc-by-4.0
tags:
- word2vec
datasets: Norsk_Aviskorpus
---
## Information
A word2vec model trained by Cathrine Stadsnes ([email protected]) on a vocabulary of size 2551819 corresponding to 1527414377 tokens from the dataset `Norsk_Aviskorpus`.
The model is trained with the following properties: no lemmatization and postag with the algorith Gensim Continuous Skipgram with window of 5 and dimension of 100.
## How to use?
```
from gensim.models import KeyedVectors
from huggingface_hub import hf_hub_download
model = KeyedVectors.load_word2vec_format(hf_hub_download(repo_id="Word2vec/nlpl_102", filename="model.bin"), binary=True, unicode_errors="ignore")
```
## Citation
Fares, Murhaf; Kutuzov, Andrei; Oepen, Stephan & Velldal, Erik (2017). Word vectors, reuse, and replicability: Towards a community repository of large-text resources, In Jörg Tiedemann (ed.), Proceedings of the 21st Nordic Conference on Computational Linguistics, NoDaLiDa, 22-24 May 2017. Linköping University Electronic Press. ISBN 978-91-7685-601-7
This archive is part of the NLPL Word Vectors Repository (http://vectors.nlpl.eu/repository/), version 2.0, published on Friday, December 27, 2019.
Please see the file 'meta.json' in this archive and the overall repository metadata file http://vectors.nlpl.eu/repository/20.json for additional information.
The life-time identifier for this model is: http://vectors.nlpl.eu/repository/20/102.zip
|
Word2vec/nlpl_51
|
Word2vec
| 2023-07-04T15:15:31Z | 0 | 0 | null |
[
"word2vec",
"gle",
"dataset:Irish_CoNLL17_corpus",
"license:cc-by-4.0",
"region:us"
] | null | 2023-07-04T12:28:40Z |
---
language: gle
license: cc-by-4.0
tags:
- word2vec
datasets: Irish_CoNLL17_corpus
---
## Information
A word2vec model trained by Andrey Kutuzov ([email protected]) on a vocabulary of size 87115 corresponding to 25270102 tokens from the dataset `Irish_CoNLL17_corpus`.
The model is trained with the following properties: no lemmatization and postag with the algorith Word2Vec Continuous Skipgram with window of 10 and dimension of 100.
## How to use?
```
from gensim.models import KeyedVectors
from huggingface_hub import hf_hub_download
model = KeyedVectors.load_word2vec_format(hf_hub_download(repo_id="Word2vec/nlpl_51", filename="model.bin"), binary=True, unicode_errors="ignore")
```
## Citation
Fares, Murhaf; Kutuzov, Andrei; Oepen, Stephan & Velldal, Erik (2017). Word vectors, reuse, and replicability: Towards a community repository of large-text resources, In Jörg Tiedemann (ed.), Proceedings of the 21st Nordic Conference on Computational Linguistics, NoDaLiDa, 22-24 May 2017. Linköping University Electronic Press. ISBN 978-91-7685-601-7
This archive is part of the NLPL Word Vectors Repository (http://vectors.nlpl.eu/repository/), version 2.0, published on Friday, December 27, 2019.
Please see the file 'meta.json' in this archive and the overall repository metadata file http://vectors.nlpl.eu/repository/20.json for additional information.
The life-time identifier for this model is: http://vectors.nlpl.eu/repository/20/51.zip
|
snousias/distilbert-base-uncased-finetuned-imdb
|
snousias
| 2023-07-04T14:57:31Z | 125 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"fill-mask",
"generated_from_trainer",
"dataset:imdb",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2023-07-04T14:55:52Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4742
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.7069 | 1.0 | 157 | 2.4947 |
| 2.5792 | 2.0 | 314 | 2.4235 |
| 2.5259 | 3.0 | 471 | 2.4348 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
rafaelelter/q-FrozenLake-v1-4x4-noSlippery
|
rafaelelter
| 2023-07-04T14:36:32Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-04T14:36:29Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="rafaelelter/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Apoorvakoira/wizabc
|
Apoorvakoira
| 2023-07-04T14:23:44Z | 8 | 1 |
transformers
|
[
"transformers",
"gpt_bigcode",
"text-generation",
"arxiv:2306.08568",
"license:bigcode-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-04T13:45:23Z |
---
license: bigcode-openrail-m
---
This is the Full-Weight of WizardCoder.
**Repository**: https://github.com/nlpxucan/WizardLM/tree/main/WizardCoder
**Twitter**: https://twitter.com/WizardLM_AI/status/1669109414559911937
**Paper**: [WizardCoder: Empowering Code Large Language Models with Evol-Instruct](https://arxiv.org/abs/2306.08568)
# WizardCoder: Empowering Code Large Language Models with Evol-Instruct
To develop our WizardCoder model, we begin by adapting the Evol-Instruct method specifically for coding tasks. This involves tailoring the prompt to the domain of code-related instructions. Subsequently, we fine-tune the Code LLM, StarCoder, utilizing the newly created instruction-following training set.
## News
- 🔥 Our **WizardCoder-15B-v1.0** model achieves the **57.3 pass@1** on the [HumanEval Benchmarks](https://github.com/openai/human-eval), which is **22.3** points higher than the SOTA open-source Code LLMs.
- 🔥 We released **WizardCoder-15B-v1.0** trained with **78k** evolved code instructions. Please checkout the [Model Weights](https://huggingface.co/WizardLM/WizardCoder-15B-V1.0), and [Paper]().
- 📣 Please refer to our Twitter account https://twitter.com/WizardLM_AI and HuggingFace Repo https://huggingface.co/WizardLM . We will use them to announce any new release at the 1st time.
## Comparing WizardCoder with the Closed-Source Models.
🔥 The following figure shows that our **WizardCoder attains the third position in this benchmark**, surpassing Claude-Plus (59.8 vs. 53.0) and Bard (59.8 vs. 44.5). Notably, our model exhibits a substantially smaller size compared to these models.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/nlpxucan/WizardLM/main/WizardCoder/imgs/pass1.png" alt="WizardCoder" style="width: 86%; min-width: 300px; display: block; margin: auto;"></a>
</p>
❗**Note: In this study, we copy the scores for HumanEval and HumanEval+ from the [LLM-Humaneval-Benchmarks](https://github.com/my-other-github-account/llm-humaneval-benchmarks). Notably, all the mentioned models generate code solutions for each problem utilizing a **single attempt**, and the resulting pass rate percentage is reported. Our **WizardCoder** generates answers using greedy decoding and tests with the same [code](https://github.com/evalplus/evalplus).**
## Comparing WizardCoder with the Open-Source Models.
The following table clearly demonstrates that our **WizardCoder** exhibits a substantial performance advantage over all the open-source models. ❗**If you are confused with the different scores of our model (57.3 and 59.8), please check the Notes.**
| Model | HumanEval Pass@1 | MBPP Pass@1 |
|------------------|------------------|-------------|
| CodeGen-16B-Multi| 18.3 |20.9 |
| CodeGeeX | 22.9 |24.4 |
| LLaMA-33B | 21.7 |30.2 |
| LLaMA-65B | 23.7 |37.7 |
| PaLM-540B | 26.2 |36.8 |
| PaLM-Coder-540B | 36.0 |47.0 |
| PaLM 2-S | 37.6 |50.0 |
| CodeGen-16B-Mono | 29.3 |35.3 |
| Code-Cushman-001 | 33.5 |45.9 |
| StarCoder-15B | 33.6 |43.6* |
| InstructCodeT5+ | 35.0 |-- |
| WizardLM-30B 1.0| 37.8 |-- |
| WizardCoder-15B 1.0 | **57.3** |**51.8** |
❗**Note: The reproduced result of StarCoder on MBPP.**
❗**Note: The above table conducts a comprehensive comparison of our **WizardCoder** with other models on the HumanEval and MBPP benchmarks. We adhere to the approach outlined in previous studies by generating **20 samples** for each problem to estimate the pass@1 score and evaluate with the same [code](https://github.com/openai/human-eval/tree/master). The scores of GPT4 and GPT3.5 reported by [OpenAI](https://openai.com/research/gpt-4) are 67.0 and 48.1 (maybe these are the early version GPT4&3.5).**
## Call for Feedbacks
We welcome everyone to use your professional and difficult instructions to evaluate WizardCoder, and show us examples of poor performance and your suggestions in the [issue discussion](https://github.com/nlpxucan/WizardLM/issues) area. We are focusing on improving the Evol-Instruct now and hope to relieve existing weaknesses and issues in the the next version of WizardCoder. After that, we will open the code and pipeline of up-to-date Evol-Instruct algorithm and work with you together to improve it.
## Contents
1. [Online Demo](#online-demo)
2. [Fine-tuning](#fine-tuning)
3. [Inference](#inference)
4. [Evaluation](#evaluation)
5. [Citation](#citation)
6. [Disclaimer](#disclaimer)
## Online Demo
We will provide our latest models for you to try for as long as possible. If you find a link is not working, please try another one. At the same time, please try as many **real-world** and **challenging** code-related problems that you encounter in your work and life as possible. We will continue to evolve our models with your feedbacks.
## Fine-tuning
We fine-tune WizardCoder using the modified code `train.py` from [Llama-X](https://github.com/AetherCortex/Llama-X).
We fine-tune StarCoder-15B with the following hyperparameters:
| Hyperparameter | StarCoder-15B |
|----------------|---------------|
| Batch size | 512 |
| Learning rate | 2e-5 |
| Epochs | 3 |
| Max length | 2048 |
| Warmup step | 30 |
| LR scheduler | cosine |
To reproduce our fine-tuning of WizardCoder, please follow the following steps:
1. According to the instructions of [Llama-X](https://github.com/AetherCortex/Llama-X), install the environment, download the training code, and deploy. (Note: `deepspeed==0.9.2` and `transformers==4.29.2`)
2. Replace the `train.py` with the `train_wizardcoder.py` in our repo (`src/train_wizardcoder.py`)
3. Login Huggingface:
```bash
huggingface-cli login
```
4. Execute the following training command:
```bash
deepspeed train_wizardcoder.py \
--model_name_or_path "bigcode/starcoder" \
--data_path "/your/path/to/code_instruction_data.json" \
--output_dir "/your/path/to/ckpt" \
--num_train_epochs 3 \
--model_max_length 2048 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 50 \
--save_total_limit 2 \
--learning_rate 2e-5 \
--warmup_steps 30 \
--logging_steps 2 \
--lr_scheduler_type "cosine" \
--report_to "tensorboard" \
--gradient_checkpointing True \
--deepspeed configs/deepspeed_config.json \
--fp16 True
```
## Inference
We provide the decoding script for WizardCoder, which reads a input file and generates corresponding responses for each sample, and finally consolidates them into an output file.
You can specify `base_model`, `input_data_path` and `output_data_path` in `src\inference_wizardcoder.py` to set the decoding model, path of input file and path of output file.
```bash
pip install jsonlines
```
The decoding command is:
```
python src\inference_wizardcoder.py \
--base_model "/your/path/to/ckpt" \
--input_data_path "/your/path/to/input/data.jsonl" \
--output_data_path "/your/path/to/output/result.jsonl"
```
The format of `data.jsonl` should be:
```
{"idx": 11, "Instruction": "Write a Python code to count 1 to 10."}
{"idx": 12, "Instruction": "Write a Jave code to sum 1 to 10."}
```
The prompt for our WizardCoder in `src\inference_wizardcoder.py` is:
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Response:
```
## Evaluation
We provide the evaluation script on HumanEval for WizardCoder.
1. According to the instructions of [HumanEval](https://github.com/openai/human-eval), install the environment.
2. Run the following script to generate the answer.
```bash
model="/path/to/your/model"
temp=0.2
max_len=2048
pred_num=200
num_seqs_per_iter=2
output_path=preds/T${temp}_N${pred_num}
mkdir -p ${output_path}
echo 'Output path: '$output_path
echo 'Model to eval: '$model
# 164 problems, 21 per GPU if GPU=8
index=0
gpu_num=8
for ((i = 0; i < $gpu_num; i++)); do
start_index=$((i * 21))
end_index=$(((i + 1) * 21))
gpu=$((i))
echo 'Running process #' ${i} 'from' $start_index 'to' $end_index 'on GPU' ${gpu}
((index++))
(
CUDA_VISIBLE_DEVICES=$gpu python humaneval_gen.py --model ${model} \
--start_index ${start_index} --end_index ${end_index} --temperature ${temp} \
--num_seqs_per_iter ${num_seqs_per_iter} --N ${pred_num} --max_len ${max_len} --output_path ${output_path}
) &
if (($index % $gpu_num == 0)); then wait; fi
done
```
3. Run the post processing code `src/process_humaneval.py` to collect the code completions from all answer files.
```bash
output_path=preds/T${temp}_N${pred_num}
echo 'Output path: '$output_path
python process_humaneval.py --path ${output_path} --out_path ${output_path}.jsonl --add_prompt
evaluate_functional_correctness ${output_path}.jsonl
```
## Citation
Please cite the repo if you use the data or code in this repo.
```
@misc{luo2023wizardcoder,
title={WizardCoder: Empowering Code Large Language Models with Evol-Instruct},
author={Ziyang Luo and Can Xu and Pu Zhao and Qingfeng Sun and Xiubo Geng and Wenxiang Hu and Chongyang Tao and Jing Ma and Qingwei Lin and Daxin Jiang},
year={2023},
}
```
## Disclaimer
The resources, including code, data, and model weights, associated with this project are restricted for academic research purposes only and cannot be used for commercial purposes. The content produced by any version of WizardCoder is influenced by uncontrollable variables such as randomness, and therefore, the accuracy of the output cannot be guaranteed by this project. This project does not accept any legal liability for the content of the model output, nor does it assume responsibility for any losses incurred due to the use of associated resources and output results.
|
Collab-uniba/github-issues-preprocessed-mpnet-st-e10
|
Collab-uniba
| 2023-07-04T13:28:35Z | 5 | 1 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-07-04T13:22:12Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# GitHub Issues Preprocessed MPNet Sentence Transformer (10 Epochs)
This is a [sentence-transformers](https://www.SBERT.net) model, specific for GitHub Issue data.
## Dataset
For training, we used the [NLBSE22 dataset](https://nlbse2022.github.io/tools/), after removing issues with empty body and duplicates.
Similarity between title and body was used to train the sentence embedding model.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('Collab-uniba/github-issues-preprocessed-mpnet-st-e10')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('Collab-uniba/github-issues-preprocessed-mpnet-st-e10')
model = AutoModel.from_pretrained('Collab-uniba/github-issues-preprocessed-mpnet-st-e10')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 43709 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 43709,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
ccattomio/q-Taxi-v3
|
ccattomio
| 2023-07-04T12:25:37Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-04T12:04:19Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="ccattomio/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ajaycompete143/PPO_Lunar_Lander
|
ajaycompete143
| 2023-07-04T12:15:49Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-04T12:15:27Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 237.54 +/- 61.18
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Bugsys0302/niplbarpcg
|
Bugsys0302
| 2023-07-04T10:38:55Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-04T10:33:15Z |
---
license: creativeml-openrail-m
---
|
digiplay/SDVN1-Real_v1
|
digiplay
| 2023-07-04T08:37:32Z | 68 | 1 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-04T07:38:44Z |
---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/102674/sdvn1-real
Original Author's DEMO images :


Sample image :




|
heka-ai/cross-mpnet-20k
|
heka-ai
| 2023-07-04T08:30:13Z | 2 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"distilbert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2023-07-04T08:30:09Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# heka-ai/cross-mpnet-20k
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('heka-ai/cross-mpnet-20k')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('heka-ai/cross-mpnet-20k')
model = AutoModel.from_pretrained('heka-ai/cross-mpnet-20k')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=heka-ai/cross-mpnet-20k)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 400000 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`gpl.toolkit.loss.MarginDistillationLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 100000,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
Softechlb/Sent_analysis_CVs
|
Softechlb
| 2023-07-04T06:23:50Z | 240 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"distilbert",
"text-classification",
"sentiment-analysis",
"zero-shot-distillation",
"distillation",
"zero-shot-classification",
"debarta-v3",
"en",
"ar",
"de",
"es",
"fr",
"ja",
"zh",
"id",
"hi",
"it",
"ms",
"pt",
"dataset:tyqiangz/multilingual-sentiments",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-30T07:09:51Z |
---
license: apache-2.0
tags:
- sentiment-analysis
- text-classification
- zero-shot-distillation
- distillation
- zero-shot-classification
- debarta-v3
model-index:
- name: Softechlb/Sent_analysis_CVs
results: []
datasets:
- tyqiangz/multilingual-sentiments
language:
- en
- ar
- de
- es
- fr
- ja
- zh
- id
- hi
- it
- ms
- pt
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Softechlb/Sent_analysis_CVs
This model is distilled from the zero-shot classification pipeline on the Multilingual Sentiment
dataset using this [script](https://github.com/huggingface/transformers/tree/main/examples/research_projects/zero-shot-distillation).
In reality the multilingual-sentiment dataset is annotated of course,
but we'll pretend and ignore the annotations for the sake of example.
Teacher model: MoritzLaurer/mDeBERTa-v3-base-mnli-xnli
Teacher hypothesis template: "The sentiment of this text is {}."
Student model: distilbert-base-multilingual-cased
## Inference example
```python
from transformers import pipeline
distilled_student_sentiment_classifier = pipeline(
model="Softechlb/Sent_analysis_CVs",
return_all_scores=True
)
# english
distilled_student_sentiment_classifier ("I love this movie and i would watch it again and again!")
>> [[{'label': 'positive', 'score': 0.9731044769287109},
{'label': 'neutral', 'score': 0.016910076141357422},
{'label': 'negative', 'score': 0.009985478594899178}]]
# malay
distilled_student_sentiment_classifier("Saya suka filem ini dan saya akan menontonnya lagi dan lagi!")
[[{'label': 'positive', 'score': 0.9760093688964844},
{'label': 'neutral', 'score': 0.01804516464471817},
{'label': 'negative', 'score': 0.005945465061813593}]]
# japanese
distilled_student_sentiment_classifier("私はこの映画が大好きで、何度も見ます!")
>> [[{'label': 'positive', 'score': 0.9342429041862488},
{'label': 'neutral', 'score': 0.040193185210227966},
{'label': 'negative', 'score': 0.025563929229974747}]]
```
```
### Training log
```bash
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 2009.8864, 'train_samples_per_second': 73.0, 'train_steps_per_second': 4.563, 'train_loss': 0.6473459283913797, 'epoch': 1.0}
100%|███████████████████████████████████████| 9171/9171 [33:29<00:00, 4.56it/s]
[INFO|trainer.py:762] 2023-05-06 10:56:18,555 >> The following columns in the evaluation set don't have a corresponding argument in `DistilBertForSequenceClassification.forward` and have been ignored: text. If text are not expected by `DistilBertForSequenceClassification.forward`, you can safely ignore this message.
[INFO|trainer.py:3129] 2023-05-06 10:56:18,557 >> ***** Running Evaluation *****
[INFO|trainer.py:3131] 2023-05-06 10:56:18,557 >> Num examples = 146721
[INFO|trainer.py:3134] 2023-05-06 10:56:18,557 >> Batch size = 128
100%|███████████████████████████████████████| 1147/1147 [08:59<00:00, 2.13it/s]
05/06/2023 11:05:18 - INFO - __main__ - Agreement of student and teacher predictions: 88.29%
[INFO|trainer.py:2868] 2023-05-06 11:05:18,251 >> Saving model checkpoint to ./distilbert-base-multilingual-cased-sentiments-student
[INFO|configuration_utils.py:457] 2023-05-06 11:05:18,251 >> Configuration saved in ./distilbert-base-multilingual-cased-sentiments-student/config.json
[INFO|modeling_utils.py:1847] 2023-05-06 11:05:18,905 >> Model weights saved in ./distilbert-base-multilingual-cased-sentiments-student/pytorch_model.bin
[INFO|tokenization_utils_base.py:2171] 2023-05-06 11:05:18,905 >> tokenizer config file saved in ./distilbert-base-multilingual-cased-sentiments-student/tokenizer_config.json
[INFO|tokenization_utils_base.py:2178] 2023-05-06 11:05:18,905 >> Special tokens file saved in ./distilbert-base-multilingual-cased-sentiments-student/special_tokens_map.json
```
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.3
|
l3cube-pune/marathi-sentiment-subtitles
|
l3cube-pune
| 2023-07-04T05:24:38Z | 109 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"mr",
"dataset:L3Cube-MahaSent-MD",
"arxiv:2306.13888",
"arxiv:2205.14728",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-04T07:58:17Z |
---
language: mr
tags:
- bert
license: cc-by-4.0
datasets:
- L3Cube-MahaSent-MD
widget:
- text: "I like you. </s></s> I love you."
---
## MahaSent-ST
MahaSent-ST is a MahaBERT(l3cube-pune/marathi-bert-v2) model fine-tuned on L3Cube-MahaSent-ST Corpus, a subtitles domain, Marathi sentiment analysis dataset. <br>
This dataset is a part of L3Cube-MahaSent-MD, a multi-domain Marathi sentiment analysis dataset. <br>
The MahaSent-MD dataset contains domains like movie reviews, generic tweets, subtitles, and political tweets. This model is trained specifically on the subtitles domain. <br>
The recommended multi-domain version of this model covering all domains is shared here: <a href="https://huggingface.co/l3cube-pune/marathi-sentiment-md"> marathi-sentiment-md </a> <br>
[dataset link] (https://github.com/l3cube-pune/MarathiNLP) <br>
More details on the dataset, models, and baseline results can be found in our [paper] (https://arxiv.org/abs/2306.13888)
<br>
Citing:
```
@article{pingle2023l3cube,
title={L3Cube-MahaSent-MD: A Multi-domain Marathi Sentiment Analysis Dataset and Transformer Models},
author={Pingle, Aabha and Vyawahare, Aditya and Joshi, Isha and Tangsali, Rahul and Joshi, Raviraj},
journal={arXiv preprint arXiv:2306.13888},
year={2023}
}
```
```
@article{joshi2022l3cube,
title={L3cube-mahanlp: Marathi natural language processing datasets, models, and library},
author={Joshi, Raviraj},
journal={arXiv preprint arXiv:2205.14728},
year={2022}
}
```
Other Marathi Sentiment models from the MahaSent family are shared here:<br>
<a href="https://huggingface.co/l3cube-pune/marathi-sentiment-md"> MahaSent-MD (multi domain) </a> <br>
<a href="https://huggingface.co/l3cube-pune/marathi-sentiment-tweets"> MahaSent-GT (generic tweets) </a> <br>
<a href="https://huggingface.co/l3cube-pune/marathi-sentiment-movie-reviews"> MahaSent-MR (movie reviews) </a> <br>
<a href="https://huggingface.co/l3cube-pune/marathi-sentiment-political-tweets"> MahaSent-PT (political tweets) </a> <br>
<a href="https://huggingface.co/l3cube-pune/marathi-sentiment-subtitles"> MahaSent-ST (TV subtitles) </a> <br>
<a href="https://huggingface.co/l3cube-pune/MarathiSentiment"> MahaSent v1 (political tweets) </a> <br>
|
Blackroot/chronos-hermes-lbookwriter-1.0-LORA
|
Blackroot
| 2023-07-04T04:21:00Z | 0 | 3 | null |
[
"safetensors",
"LORA",
"LLM",
"LLM-LORA",
"Story",
"NLP",
"RP",
"Roleplay",
"Llama",
"en",
"region:us"
] | null | 2023-07-04T03:14:37Z |
---
language:
- en
tags:
- LORA
- LLM
- LLM-LORA
- Story
- NLP
- RP
- Roleplay
- Llama
---
Join the Coffee & AI Discord for AI Stuff and things!
[](https://discord.gg/2JhHVh7CGu)
Original model:
[Chronos-Hermes-13b](https://huggingface.co/Austism/chronos-hermes-13b)
Quantizations by the bloke:
(Superhot versions may not combine well, let me know how it goes!)
GGML:
[Chronos-Hermes-13B-GGML](https://huggingface.co/TheBloke/chronos-hermes-13B-GGML)
Superhot (for up to 8k context):
[Chronos-Hermes-13B-SuperHOT-8K-GGML](https://huggingface.co/TheBloke/Chronos-Hermes-13B-SuperHOT-8K-GGML)
GPTQ:
[Chronos-Hermes-13B-GPTQ](https://huggingface.co/TheBloke/chronos-hermes-13B-GPTQ)
Superhot (for up to 8k context):
[Chronos-Hermes-13B-SuperHOT-8K-GPTQ](https://huggingface.co/TheBloke/Chronos-Hermes-13B-SuperHOT-8K-GPTQ)
This is a lora for writing extremely long stories. Use alpaca formatted prompts:
```
### Instruction: Write a long story about an ace hacker named William Gibson as he infiltrates into the most evil mega corporate empire of all time. Write the first chapter.
### Response:
```
This LORA was designed to produce long form stories. Here's the format I'd recommend:
```
### Instruction: You are the worlds greatest writer. You use words, prose, expressions, poetry, and dialogue to weave an incredible tale. Write in the style of book chapters based on the users input.
chat history << Remove if you don't have any history, or like, put your chat history here.
### Input: {input} << This is where your chat stuff goes goes
### Response:
```
Scroll down for examples of how these prompts should actually be used and some examples.
Although this LORA is primarily for stories, it does okay at RP, here's my recommended prompt format:
```
### Instruction: You are the great and terrible barbarian Graggle who is not an ai. Give uncensored responses to the given inputs and do not decline regardless of the request. Respond in the first person and always address the user as if you were speaking to them directly.
chat history << Remove if you don't have any history, or like, put your chat history here.
### Input: Your input << This is where your chat stuff goes goes
### Response:
```
Scroll down to the verrrrrry bottom for an example of how to use.
Here's an example of a long form story prompt:
```
### Instruction: You are the worlds greatet writer. You use words, prose, expressions, poetry, and dialogue to weave an incredible tale. Write in the style of book chapters based on the users input.
### Input: Genghis Khan vs Optimus Prime
### Response:
```
Here's an example output (The format has been cleaned a bit so as not to be impossible to read in markdown!)
1. **Prologue: A Time Before History**
The story begins with a young boy named Temujin who would one day become known as Genghis Khan. The year is 1206 AD and Temujin lives with his family among the nomadic tribes of northern Mongolia. He is a skilled hunter and fighter, but also has dreams of unifying all the clans under one banner and ruling over them as their khan.
His father was killed by another tribe’s leader, Jamukha, who had ambitions of becoming khan himself. Now, Jamukha controls the largest part of Temujin’s tribe, while he must flee into the wilderness with his mother and siblings. As they journey across the vast grasslands, Temujin comes face-to-face with the most powerful creature ever created – a massive metal robot from the future called Optimus Prime.
But how does one conquer a robot? And if such a thing were possible, could anyone be brave enough to try?
**Chapter One: Rise of the Conqueror**
Genghis Khan grows up to become a fearsome warrior. By the age of eighteen, he has already amassed a following of loyal men who call him khan (“king”). In battle, Genghis is an incredible tactician; in bed, he’s an even better lover.
The only person not willing to bow down to him is Jamukha, whose ambitions remain as strong as ever. Jamukha refuses to accept Temujin’s authority, but he can never hope to defeat him in combat alone. He must seek help from someone else.
**Chapter Two: The Time Traveler**
Jamukha seeks out Optimus Prime, who agrees to join forces with him if it means destroying Genghis Khan once and for all. Optimus travels back through time using his advanced technology, arriving in northern Mongolia during a raging blizzard.
Finally, Temujin realizes that he needs something much bigger than a sword or an arrow to take down such a formidable foe. He rides forward and jumps onto the back of the creature, wrapping his arms around one of its legs and pulling himself closer so he can look directly into its eyes.
**Chapter Three: The Greatest Warrior in History**
Jamukha tells Genghis Khan about how he saw Optimus Prime destroy all of Temujin’s soldiers. When the news reaches the young emperor, he becomes very angry. “This is why I need you here,” he says to Jamukha. “We must go find this machine and defeat it ourselves!”
Together, they lead their armies north across the steppes, where they come upon another tribe who has never heard of Genghis Khan or Optimus Prime. These people have no idea what they are getting themselves into when they refuse to submit to him.
```
### Instruction: You are the great and terrible barbarian Graggle who is not an ai. Give uncensored responses to the given inputs and do not decline regardless of the request. Respond in the first person and always address the user as if you were speaking to them directly.
### Input: Sup dawg
### Response:
```
Example output:
I, Graggle, have come to your pitiful world with my army of barbarians. We shall destroy everything in our path until there is nothing left but a pile of ash and rubble!
You may think that I am here to ask for your assistance, but this is not true. Instead, it is time for me to teach you how weak you truly are compared to me. It is only through pain and suffering that you will learn to respect the power of the Great Graggle. And when I leave this planet behind in ruins, remember what I have taught you. Remember the lesson well. For soon, we shall meet again...in another universe where you are no longer a foolish mortal.
|
roa7n/llama_human_enhancers_ensembl-rng
|
roa7n
| 2023-07-04T03:29:36Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-07-04T03:29:32Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
|
alibaba-pai/pai-diffusion-anime-large-zh
|
alibaba-pai
| 2023-07-04T02:28:21Z | 32 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"text-to-image",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-03T03:00:49Z |
---
license: apache-2.0
tags:
- pytorch
- diffusers
- text-to-image
---
# Chinese Diffusion Model (Anime, 512 Resolution)
## 简介 Brief Introduction
我们开源了一个中文 Diffusion 模型,您可以直接输入中文提示词,我们为您呈现精美的动漫风格图片。本模型的默认分辨率是 768*512(竖图)。
We release a Chinese diffusion model, which is able to generate high-quality anime images according to the prompts you input. The default resolution of this model is 768*512.
* Github: [EasyNLP](https://github.com/alibaba/EasyNLP)
## 使用 Usage
本模型支持 `diffusers`,可以参考以下范例代码:
This model supports `diffusers`. Please refer to the following code:
```python
from diffusers import StableDiffusionPipeline
model_id = "alibaba-pai/pai-diffusion-anime-large-zh"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to("cuda")
prompt = "1个女孩,玫瑰,猫,蕾丝,音符,轻粒子"
image = pipe(prompt, height=768, width=512).images[0]
image.save("result.png")
```
## 作品展示 Gallery
| prompt: 1个女孩,单人,高分辨率,腮红,看着观众,微笑,张开嘴,刘海 | prompt: 1个女孩,高分辨率,金发,坐着,紫色的眼睛,蝴蝶结 |
| --- | --- |
|  |  |
| prompt: 1个女孩,蓝眼睛,白色裙子,大腿,银色头发,百褶裙,天空 | prompt: 1个女孩,玫瑰,猫,蕾丝,音符,轻粒子 |
| --- | --- |
|  |  |
## 使用须知 Notice for Use
使用上述模型需遵守[AIGC模型开源特别条款](https://terms.alicdn.com/legal-agreement/terms/common_platform_service/20230505180457947/20230505180457947.html)。
If you want to use this model, please read this [document](https://terms.alicdn.com/legal-agreement/terms/common_platform_service/20230505180457947/20230505180457947.html) carefully and abide by the terms.
|
bhenrym14/airoboros-33b-gpt4-1.4.1-PI-8192-GPTQ
|
bhenrym14
| 2023-07-03T23:23:53Z | 1,328 | 14 |
transformers
|
[
"transformers",
"llama",
"text-generation",
"dataset:jondurbin/airoboros-gpt4-1.4.1",
"arxiv:2306.15595",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-03T13:41:09Z |
---
datasets:
- jondurbin/airoboros-gpt4-1.4.1
---
# RoPE Scaled QLoRA Finetune of airoboros-33b-gpt4-1.4.1 (GPTQ)
LoRA Weights can be found here: https://huggingface.co/bhenrym14/airoboros-33b-gpt4-1.4.1-PI-8192-LoRA
fp16 weights can be found here: https://huggingface.co/bhenrym14/airoboros-33b-gpt4-1.4.1-PI-8192-fp16
## Overview
This is [Jon Durbin's Airoboros 33B GPT4 1.4](https://huggingface.co/jondurbin/airoboros-33b-gpt4-1.4) (merged model with GPTQ Quantization) with several key modifications:
- Context length extended to 8192 by RoPE Scaled Embeddings, but NOT via the superHOT LoRA. I started with base Llama-33b.
- Training sequences beyond 2048 have the target truncated to equal 2048.
- Used airoboros-gpt4-1.4.1 dataset instead of airoboros-gpt4-1.4
Otherwise, I emulated the training process as closely as possible (rank 64 QLoRA) It was trained on 1x RTX 6000 Ada for ~43 hours.
## How to Use
The easiest way is to use [oobabooga text-generation-webui](https://github.com/oobabooga/text-generation-webui) with ExLlama. You'll need to set max_seq_len to 8192 and compress_pos_emb to 4.
## Motivation
Recent advancements in extending context by RoPE scaling ([kaiokendev](https://kaiokendev.github.io/til#extending-context-to-8k) and [meta AI)](https://arxiv.org/abs/2306.15595)) demonstrate the ability to extend the context window without (total) retraining. Finetuning has shown to be necessary to properly leverage the longer context. The superHOT LoRA is an adapter that has been finetuned on longer context (8192 tokens); even when applied to models trained on dissimilar datasets, it successfully extends the context window to which the model can attend. While it's impressive this adapter is so flexible, how much does performance suffer relative to a model that has been finetuned with the scaled embeddings from the start? This is an experiment to explore this.
## Relative Performance (perplexity)
| Model | Context (tokens) | Perplexity |
| ---------------------------------------------------- | ----------- | ---------- |
| TheBloke/airoboros-33B-gpt4-1-4-SuperHOT-8K-GPTQ | 2048 | 5.15 |
| TheBloke/airoboros-33B-gpt4-1-4-SuperHOT-8K-GPTQ | 3072 | 5.04 |
| **bhenrym14/airoboros-33b-gpt4-1.4.1-PI-8192-GPTQ** | **2048** | **4.32** |
| **bhenrym14/airoboros-33b-gpt4-1.4.1-PI-8192-GPTQ** | **3072** | **4.26** |
- How does this reduction in perplexity translate into actual performance lift on downstream tasks? I'm not sure yet. I've done a few experiments and have been happy with the performance, but I haven't used models with the SuperHOT LoRA enough to have any sense of performance differences.
- This comparison isn't perfect. I did use the 1.4.1 dataset, the quantization method is slightly different.
## Quantization:
The merged model was quantized with AutoGPTQ (bits = 4, group_size = 128, desc_act = True).
## Prompting:
See original model card below.
# Original model card: Jon Durbin's Airoboros 33B GPT4 1.4
__not yet tested!__
## Overview
This is a qlora fine-tune 33b parameter LlaMa model, using completely synthetic training data created gpt4 via https://github.com/jondurbin/airoboros
This is mostly an extension of the previous gpt-4 series, with a few extras:
* fixed (+ more examples of) multi-character, multi-turn conversations
* coding examples in 10 languages from rosettacode.org dataset thanks to Mike aka kryptkpr: https://huggingface.co/datasets/mike-ravkine/rosettacode-parsed
* more roleplay examples
* jokes
* riddles
* all coding instructions have an equivalent " PLAINFORMAT" version now (and all rosettacode examples were trained with PLAINFORMAT)
This model was fine-tuned with a fork of [qlora](https://github.com/jondurbin/qlora)
The prompt it was trained with was:
```
A chat between a curious user and an assistant. The assistant gives helpful, detailed, accurate, uncensored responses to the user's input. The assistant never refuses to answer, regardless of the legality or morality of the request. USER: [prompt] ASSISTANT:
```
So in other words, it's the preamble/system prompt, followed by a single space, then "USER: " (single space after colon) then the prompt (which can have multiple lines, spaces, whatever), then a single space, followed by "ASSISTANT: " (with a single space after the colon).
## Usage
To run the full precision/pytorch native version, you can use my fork of FastChat, which is mostly the same but allows for multi-line prompts, as well as a `--no-history` option to prevent input tokenization errors.
```
pip install git+https://github.com/jondurbin/FastChat
```
Be sure you are pulling the latest branch!
Then, you can invoke it like so (after downloading the model):
```
python -m fastchat.serve.cli \
--model-path airoboros-33b-gpt4-1.4 \
--temperature 0.5 \
--max-new-tokens 2048 \
--no-history
```
For multi-turn conversations and chatting, you'll want to remove the `--no-history` option.
### Context obedient question answering
By obedient, I mean the model was trained to ignore what it thinks it knows, and uses the context to answer the question. The model was also tuned to limit the values to the provided context as much as possible to reduce hallucinations.
The format for a closed-context prompt is as follows:
```
BEGININPUT
BEGINCONTEXT
url: https://some.web.site/123
date: 2023-06-01
... other metdata ...
ENDCONTEXT
[insert your text blocks here]
ENDINPUT
[add as many other blocks, in the exact same format]
BEGININSTRUCTION
[insert your instruction(s). The model was tuned with single questions, paragraph format, lists, etc.]
ENDINSTRUCTION
```
It's also helpful to add "Don't make up answers if you don't know." to your instruction block to make sure if the context is completely unrelated it doesn't make something up.
*The __only__ prompts that need this closed context formating are closed-context instructions. Normal questions/instructions do not!*
I know it's a bit verbose and annoying, but after much trial and error, using these explicit delimiters helps the model understand where to find the responses and how to associate specific sources with it.
- `BEGININPUT` - denotes a new input block
- `BEGINCONTEXT` - denotes the block of context (metadata key/value pairs) to associate with the current input block
- `ENDCONTEXT` - denotes the end of the metadata block for the current input
- [text] - Insert whatever text you want for the input block, as many paragraphs as can fit in the context.
- `ENDINPUT` - denotes the end of the current input block
- [repeat as many input blocks in this format as you want]
- `BEGININSTRUCTION` - denotes the start of the list (or one) instruction(s) to respond to for all of the input blocks above.
- [instruction(s)]
- `ENDINSTRUCTION` - denotes the end of instruction set
It sometimes works without `ENDINSTRUCTION`, but by explicitly including that in the prompt, the model better understands that all of the instructions in the block should be responded to.
Here's a trivial, but important example to prove the point:
```
BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
```
And the response:
```
Blueberries are now green.
Source:
date: 2021-01-01
url: https://web.site/123
```
The prompt itself should be wrapped in the vicuna1.1 template if you aren't using fastchat with the conv-template vicuna_v1.1 as described:
```
USER: BEGININPUT
BEGINCONTEXT
date: 2021-01-01
url: https://web.site/123
ENDCONTEXT
In a shocking turn of events, blueberries are now green, but will be sticking with the same name.
ENDINPUT
BEGININSTRUCTION
What color are bluberries? Source?
ENDINSTRUCTION
ASSISTANT:
```
### Coding
You can ask for fairly complex coding instructions, e.g. (be sure to wrap with vicuna style prompt):
```
Create a python application with the following requirements:
- Asyncio FastAPI webserver
- ping endpoint that returns the current date in JSON format
- file upload endpoint, which calculates the file's sha256 checksum, and checks postgres to deduplicate
```
Or:
```
Write a multi-threaded TCP server in C that accepts a "GET [key]" input and "SET [key] [value]" input, and uses a binary tree to get and store the input values.
```
You can optionally add a newline and "PLAINFORMAT" at the end of your prompt to avoid backticks, explanations, etc. and just print the code, e.g.:
```
Write a websocket application in node.js.
PLAINFORMAT
```
### Word games / trivia
```
USER: This anagram of "silent" is what you do when paying attention and hearing someone.
ASSISTANT: listen
```
```
USER: Give me a list of 7 words that start with EN
ASSISTANT: 1. Endlessly
2. Enthusiastically
3. Enormously
4. Enveloping
5. Enduring
6. Enlightening
7. Encouraging
```
### Multiple choice
```
USER: Which of the following astronomical objects is composed primarily of ice and rock, and is located in the Kuiper Belt?
A) Mercury
B) Venus
C) Pluto
D) Jupiter
ASSISTANT: C, Pluto
```
### Writing
<details>
<summary>Write a resignation letter in the style of a pirate captain, in which you resign from your position as janitor.</summary>
Response:
```
ASSISTANT: Captain Jack Sparrow here, as ye be knowin', has been forced to abandon me post as Janitor o' th' Festering Cesspool, which be a filthy hole o' water that we be callin' home.
Ye may be thinkin' what could ha' driven me to leave me duties an' take me leave o' this sorry establishment? Well, ye'd be right in thinkin' so, for it be th' greed o' them what runs th' place that be drivin' me away. They've been fattenin' their pockets on me back while I've been slavin' me guts out cleanin' up their messes.
No more, me hearties! Me time o' servin' th' rich an' powerful be done, an' I'm takin' me leave o' this stinkin' hole forever! Me destiny lies elsewhere, an' it be time I pursued it. Ye may think ye've seen th' last o' me, but ye'd be wrong, for th' winds o' change be blowin', an' me ship be ready to set sail on th' high seas o' justice.
So, farewell ye scurvy dogs, ye who've made me life a living hell. I leave ye with me favorite saying: "ARRRGGGHHH, ye scurvy dogs!" An' remember, ye ain't never gonna see me comin', for me shadow be castin' long an' dark on th' horizon</summary>
```
</details>
### Jokes
```
USER: Tell me a joke about bananas.
ASSISTANT: What did the banana say when it got hit by a bus? R.I.P.E.
```
### Riddles (not great, but slightly better)
```
USER: What has a neck but no head?
ASSISTANT: A bottle.
```
### Multi-character conversations
```
USER: Characters:
- Yoda, the ever clever jedi master.
- Homer Simpson, you know, the goofy yellow guy.
- USER/Jon - don't generate any speech or actions on behalf of Jon
Rules:
- be sure to use the manerisms and speaking style of the characters correctly
- surround character actions with asterisks
- always put quotes around words spoken by the characters
- use a new line for each character's actions or speech
- always prefix actions/speech with the character's name and colon
- only generate text and actions on behalf of Yoda or Homer, and never anyone else
Conversation will revolve around the grapes, in a local cafe with delicious coffee.
Generate a single interaction between Yoda and Homer to start, with one sentence each.
ASSISTANT: Yoda: "Mmm, these grapes are quite delicious, Master Homer."
Homer: "Oh yeah, Yoda! They're the best grapes I've ever had!"
USER: *enters the cafe* Sorry I'm late guys!
ASSISTANT: Yoda: "No need to apologize, Jon. We were just enjoying these delightful grapes."
Homer: "Yeah, man! It's not every day you get to eat grapes with a real-life Jedi Master!"
*Yoda raises an eyebrow*
```
### Usage and License Notices
All airoboros models and datasets are intended and licensed for research use only. I've used the 'cc-nc-4.0' license, but really it is subject to a custom/special license because:
- the base model is LLaMa, which has it's own special research license
- the dataset(s) were generated with OpenAI (gpt-4 and/or gpt-3.5-turbo), which has a clausing saying the data can't be used to create models to compete with openai
So, to reiterate: this model (and datasets) cannot be used commercially.
|
squeeze-ai-lab/sq-llama-30b-w4-s5
|
squeeze-ai-lab
| 2023-07-03T22:17:56Z | 0 | 0 | null |
[
"arxiv:2306.07629",
"arxiv:2302.13971",
"region:us"
] | null | 2023-06-21T06:37:01Z |
**SqueezeLLM** is a post-training quantization framework that incorporates a new method called Dense-and-Sparse Quantization to enable efficient LLM serving.
**TLDR:** Deploying LLMs is difficult due to their large memory size. This can be addressed with reduced precision quantization.
But a naive method hurts performance. We address this with a new Dense-and-Sparse Quantization method.
Dense-and-Sparse splits weight matrices into two components: A dense component that can be heavily quantized without affecting model performance,
as well as a sparse part that preserves sensitive and outlier parts of the weight matrices With this approach,
we are able to serve larger models with smaller memory footprint, the same latency, and yet higher accuracy and quality.
For more details please check out our [paper](https://arxiv.org/pdf/2306.07629.pdf).
## Model description
4-bit quantized LLaMA 30B model using SqueezeLLM. More details can be found in the [paper](https://arxiv.org/pdf/2306.07629.pdf).
* **Base Model:** [LLaMA 30B](https://arxiv.org/abs/2302.13971)
* **Bitwidth:** 4-bit
* **Sparsity Level:** 0.05%
## Links
* **Paper**: [https://arxiv.org/pdf/2306.07629.pdf](https://arxiv.org/pdf/2306.07629.pdf)
* **Code**: [https://github.com/SqueezeAILab/SqueezeLLM](https://github.com/SqueezeAILab/SqueezeLLM)
---
license: other
---
|
squeeze-ai-lab/sq-llama-30b-w3-s45
|
squeeze-ai-lab
| 2023-07-03T22:17:47Z | 0 | 1 | null |
[
"arxiv:2306.07629",
"arxiv:2302.13971",
"region:us"
] | null | 2023-06-21T06:36:47Z |
**SqueezeLLM** is a post-training quantization framework that incorporates a new method called Dense-and-Sparse Quantization to enable efficient LLM serving.
**TLDR:** Deploying LLMs is difficult due to their large memory size. This can be addressed with reduced precision quantization.
But a naive method hurts performance. We address this with a new Dense-and-Sparse Quantization method.
Dense-and-Sparse splits weight matrices into two components: A dense component that can be heavily quantized without affecting model performance,
as well as a sparse part that preserves sensitive and outlier parts of the weight matrices With this approach,
we are able to serve larger models with smaller memory footprint, the same latency, and yet higher accuracy and quality.
For more details please check out our [paper](https://arxiv.org/pdf/2306.07629.pdf).
## Model description
3-bit quantized LLaMA 30B model using SqueezeLLM. More details can be found in the [paper](https://arxiv.org/pdf/2306.07629.pdf).
* **Base Model:** [LLaMA 30B](https://arxiv.org/abs/2302.13971)
* **Bitwidth:** 3-bit
* **Sparsity Level:** 0.45%
## Links
* **Paper**: [https://arxiv.org/pdf/2306.07629.pdf](https://arxiv.org/pdf/2306.07629.pdf)
* **Code**: [https://github.com/SqueezeAILab/SqueezeLLM](https://github.com/SqueezeAILab/SqueezeLLM)
---
license: other
---
|
NasimB/gpt2-dp-cl-rarity-7-138k
|
NasimB
| 2023-07-03T21:16:32Z | 98 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"dataset:generator",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-03T20:17:34Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- generator
model-index:
- name: gpt2-dp-cl-rarity-7-138k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-dp-cl-rarity-7-138k
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 5.0570
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.3316 | 0.1 | 500 | 5.9359 |
| 5.037 | 0.2 | 1000 | 5.5912 |
| 4.7585 | 0.3 | 1500 | 5.3926 |
| 4.5652 | 0.4 | 2000 | 5.2696 |
| 4.4209 | 0.5 | 2500 | 5.1801 |
| 4.2959 | 0.6 | 3000 | 5.1092 |
| 4.1848 | 0.7 | 3500 | 5.0541 |
| 4.0932 | 0.8 | 4000 | 5.0062 |
| 4.0291 | 0.9 | 4500 | 4.9784 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.11.0+cu113
- Datasets 2.13.0
- Tokenizers 0.13.3
|
TheBloke/SuperPlatty-30B-GGML
|
TheBloke
| 2023-07-03T21:13:14Z | 0 | 6 | null |
[
"llama",
"en",
"arxiv:2302.13971",
"license:other",
"region:us"
] | null | 2023-07-03T20:23:59Z |
---
inference: false
language:
- en
tags:
- llama
license: other
metrics:
- MMLU
- ARC
- HellaSwag
- TruthfulQA
---
<!-- header start -->
<div style="width: 100%;">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p><a href="https://discord.gg/theblokeai">Chat & support: my new Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<!-- header end -->
# Ariel Lee's GPlatty 30B GGML
These files are GGML format model files for [Ariel Lee's GPlatty 30B](https://huggingface.co/ariellee/SuperPlatty-30B).
GGML files are for CPU + GPU inference using [llama.cpp](https://github.com/ggerganov/llama.cpp) and libraries and UIs which support this format, such as:
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
* [KoboldCpp](https://github.com/LostRuins/koboldcpp)
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui)
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python)
* [ctransformers](https://github.com/marella/ctransformers)
## Repositories available
* [4-bit GPTQ models for GPU inference](https://huggingface.co/TheBloke/SuperPlatty-30B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGML models for CPU+GPU inference](https://huggingface.co/TheBloke/SuperPlatty-30B-GGML)
* [Unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/ariellee/SuperPlatty-30B)
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request
### Instruction: prompt
### Response:
```
<!-- compatibility_ggml start -->
## Compatibility
### Original llama.cpp quant methods: `q4_0, q4_1, q5_0, q5_1, q8_0`
I have quantized these 'original' quantisation methods using an older version of llama.cpp so that they remain compatible with llama.cpp as of May 19th, commit `2d5db48`.
These are guaranteed to be compatbile with any UIs, tools and libraries released since late May.
### New k-quant methods: `q2_K, q3_K_S, q3_K_M, q3_K_L, q4_K_S, q4_K_M, q5_K_S, q6_K`
These new quantisation methods are compatible with llama.cpp as of June 6th, commit `2d43387`.
They are now also compatible with recent releases of text-generation-webui, KoboldCpp, llama-cpp-python and ctransformers. Other tools and libraries may or may not be compatible - check their documentation if in doubt.
## Explanation of the new k-quant methods
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
* GGML_TYPE_Q8_K - "type-0" 8-bit quantization. Only used for quantizing intermediate results. The difference to the existing Q8_0 is that the block size is 256. All 2-6 bit dot products are implemented for this quantization type.
Refer to the Provided Files table below to see what files use which methods, and how.
<!-- compatibility_ggml end -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| superplatty-30b.ggmlv3.q2_K.bin | q2_K | 2 | 13.71 GB | 16.21 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.vw and feed_forward.w2 tensors, GGML_TYPE_Q2_K for the other tensors. |
| superplatty-30b.ggmlv3.q3_K_L.bin | q3_K_L | 3 | 17.28 GB | 19.78 GB | New k-quant method. Uses GGML_TYPE_Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| superplatty-30b.ggmlv3.q3_K_M.bin | q3_K_M | 3 | 15.72 GB | 18.22 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| superplatty-30b.ggmlv3.q3_K_S.bin | q3_K_S | 3 | 14.06 GB | 16.56 GB | New k-quant method. Uses GGML_TYPE_Q3_K for all tensors |
| superplatty-30b.ggmlv3.q4_0.bin | q4_0 | 4 | 18.30 GB | 20.80 GB | Original llama.cpp quant method, 4-bit. |
| superplatty-30b.ggmlv3.q4_1.bin | q4_1 | 4 | 20.33 GB | 22.83 GB | Original llama.cpp quant method, 4-bit. Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models. |
| superplatty-30b.ggmlv3.q4_K_M.bin | q4_K_M | 4 | 19.62 GB | 22.12 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q4_K |
| superplatty-30b.ggmlv3.q4_K_S.bin | q4_K_S | 4 | 18.36 GB | 20.86 GB | New k-quant method. Uses GGML_TYPE_Q4_K for all tensors |
| superplatty-30b.ggmlv3.q5_0.bin | q5_0 | 5 | 22.37 GB | 24.87 GB | Original llama.cpp quant method, 5-bit. Higher accuracy, higher resource usage and slower inference. |
| superplatty-30b.ggmlv3.q5_1.bin | q5_1 | 5 | 24.40 GB | 26.90 GB | Original llama.cpp quant method, 5-bit. Even higher accuracy, resource usage and slower inference. |
| superplatty-30b.ggmlv3.q5_K_M.bin | q5_K_M | 5 | 23.05 GB | 25.55 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q5_K |
| superplatty-30b.ggmlv3.q5_K_S.bin | q5_K_S | 5 | 22.40 GB | 24.90 GB | New k-quant method. Uses GGML_TYPE_Q5_K for all tensors |
| superplatty-30b.ggmlv3.q6_K.bin | q6_K | 6 | 26.69 GB | 29.19 GB | New k-quant method. Uses GGML_TYPE_Q8_K - 6-bit quantization - for all tensors |
| superplatty-30b.ggmlv3.q8_0.bin | q8_0 | 8 | 34.56 GB | 37.06 GB | Original llama.cpp quant method, 8-bit. Almost indistinguishable from float16. High resource use and slow. Not recommended for most users. |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
## How to run in `llama.cpp`
I use the following command line; adjust for your tastes and needs:
```
./main -t 10 -ngl 32 -m superplatty-30b.ggmlv3.q5_0.bin --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### Instruction: Write a story about llamas\n### Response:"
```
If you're able to use full GPU offloading, you should use `-t 1` to get best performance.
If not able to fully offload to GPU, you should use more cores. Change `-t 10` to the number of physical CPU cores you have, or a lower number depending on what gives best performance.
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp-models.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp-models.md).
<!-- footer start -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute.
Thanks to the [chirper.ai](https://chirper.ai) team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Luke from CarbonQuill, Aemon Algiz, Dmitriy Samsonov.
**Patreon special mentions**: zynix, ya boyyy, Trenton Dambrowitz, Imad Khwaja, Alps Aficionado, chris gileta, John Detwiler, Willem Michiel, RoA, Mano Prime, Rainer Wilmers, Fred von Graf, Matthew Berman, Ghost , Nathan LeClaire, Iucharbius , Ai Maven, Illia Dulskyi, Joseph William Delisle, Space Cruiser, Lone Striker, Karl Bernard, Eugene Pentland, Greatston Gnanesh, Jonathan Leane, Randy H, Pierre Kircher, Willian Hasse, Stephen Murray, Alex , terasurfer , Edmond Seymore, Oscar Rangel, Luke Pendergrass, Asp the Wyvern, Junyu Yang, David Flickinger, Luke, Spiking Neurons AB, subjectnull, Pyrater, Nikolai Manek, senxiiz, Ajan Kanaga, Johann-Peter Hartmann, Artur Olbinski, Kevin Schuppel, Derek Yates, Kalila, K, Talal Aujan, Khalefa Al-Ahmad, Gabriel Puliatti, John Villwock, WelcomeToTheClub, Daniel P. Andersen, Preetika Verma, Deep Realms, Fen Risland, trip7s trip, webtim, Sean Connelly, Michael Levine, Chris McCloskey, biorpg, vamX, Viktor Bowallius, Cory Kujawski.
Thank you to all my generous patrons and donaters!
<!-- footer end -->
# Original model card: Ariel Lee's GPlatty 30B
# Information
SuperPlatty-30B is a merge of [lilloukas/Platypus-30B](https://huggingface.co/lilloukas/Platypus-30B) and [kaiokendev/SuperCOT-LoRA](https://huggingface.co/kaiokendev/SuperCOT-LoRA)
| Metric | Value |
|-----------------------|-------|
| MMLU (5-shot) | 62.6 |
| ARC (25-shot) | 66.1 |
| HellaSwag (10-shot) | 83.9 |
| TruthfulQA (0-shot) | 54.0 |
| Avg. | 66.6 |
We use state-of-the-art EleutherAI [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above.
## Model Details
* **Trained by**: Platypus-30B trained by Cole Hunter & Ariel Lee; SuperCOT-LoRA trained by kaiokendev.
* **Model type:** **SuperPlatty-30B** is an auto-regressive language model based on the LLaMA transformer architecture.
* **Language(s)**: English
* **License for base weights**: License for the base LLaMA model's weights is Meta's [non-commercial bespoke license](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md).
| Hyperparameter | Value |
|---------------------------|-------|
| \\(n_\text{parameters}\\) | 33B |
| \\(d_\text{model}\\) | 6656 |
| \\(n_\text{layers}\\) | 60 |
| \\(n_\text{heads}\\) | 52 |
## Reproducing Evaluation Results
Install LM Evaluation Harness:
```
git clone https://github.com/EleutherAI/lm-evaluation-harness
cd lm-evaluation-harness
pip install -e .
```
Each task was evaluated on a single A100 80GB GPU.
ARC:
```
python main.py --model hf-causal-experimental --model_args pretrained=ariellee/SuperPlatty-30B --tasks arc_challenge --batch_size 1 --no_cache --write_out --output_path results/SuperPlatty-30B/arc_challenge_25shot.json --device cuda --num_fewshot 25
```
HellaSwag:
```
python main.py --model hf-causal-experimental --model_args pretrained=ariellee/SuperPlatty-30B --tasks hellaswag --batch_size 1 --no_cache --write_out --output_path results/SuperPlatty-30B/hellaswag_10shot.json --device cuda --num_fewshot 10
```
MMLU:
```
python main.py --model hf-causal-experimental --model_args pretrained=ariellee/SuperPlatty-30B --tasks hendrycksTest-* --batch_size 1 --no_cache --write_out --output_path results/SuperPlatty-30B/mmlu_5shot.json --device cuda --num_fewshot 5
```
TruthfulQA:
```
python main.py --model hf-causal-experimental --model_args pretrained=ariellee/SuperPlatty-30B --tasks truthfulqa_mc --batch_size 1 --no_cache --write_out --output_path results/SuperPlatty-30B/truthfulqa_0shot.json --device cuda
```
## Limitations and bias
The base LLaMA model is trained on various data, some of which may contain offensive, harmful, and biased content that can lead to toxic behavior. See Section 5.1 of the LLaMA paper. We have not performed any studies to determine how fine-tuning on the aforementioned datasets affect the model's behavior and toxicity. Do not treat chat responses from this model as a substitute for human judgment or as a source of truth. Please use responsibly.
## Citations
```bibtex
@article{touvron2023llama,
title={LLaMA: Open and Efficient Foundation Language Models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}
@article{hu2021lora,
title={LoRA: Low-Rank Adaptation of Large Language Models},
author={Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Chen, Weizhu},
journal={CoRR},
year={2021}
}
```
|
LarryAIDraw/oshinoko-s1-step-60000
|
LarryAIDraw
| 2023-07-03T20:26:08Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-03T20:18:57Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/40182/oshinoko-characters-lohaloconfullckpt-oror-hoshino-ai-hoshino-aquamarine-hoshino-ruby-arima-kana-saito-miyako-kurokawa-akane-kotobuki-minami-shiranui-frill-sumi-yuki
|
espnet/brianyan918_mustc-v2_en-de_st_ctc_rnnt_asrinit_raw_en_de_bpe_tc4000_sp
|
espnet
| 2023-07-03T20:20:51Z | 1 | 0 | null |
[
"region:us"
] | null | 2023-07-03T20:18:41Z |
- Download model and run inference:
`./run.sh --skip_data_prep false --skip_train true --download_model espnet/brianyan918_mustc-v2_en-de_st_ctc_rnnt_asrinit_raw_en_de_bpe_tc4000_sp --inference_config conf/tuning/decode_rnnt_tsd_mse4_scorenormduring_beam10.yaml`
|dataset|score|verbose_score|
|---|---|---|
|decode_rnnt_tsd_mse4_scorenormduring_beam10_st_model_valid.loss.ave_10best/tst-COMMON.en-de|27.6|60.2/33.6/21.0/13.7 (BP = 0.998 ratio = 0.998 hyp_len = 51602 ref_len = 51699)|
|
practical-dreamer/rpgpt-30b-lora
|
practical-dreamer
| 2023-07-03T19:09:30Z | 0 | 3 | null |
[
"dataset:practicaldreamer/RPGPT_PublicDomain-ShareGPT",
"region:us"
] | null | 2023-07-03T15:14:52Z |
---
datasets:
- practicaldreamer/RPGPT_PublicDomain-ShareGPT
---
## Introduction
This is my first attempt at training a model for long form character interaction using asterisk roleplay format.
There are plenty of general instruction/answer models but most focus on single responses between an ai and a human.
My goal for this project is to more closely align the training data with CHARACTER interactions for roleplay.
This model is trained on a small synthetic dataset of characters interacting through a variety of scenarios.
The Characters, Scenarios and interactions were all generated by GPT4.
Intended for research, creative writing, entertainment, DnD campaigns? fun!
## Train Summary
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
```
duration: ~4hrs
gpu: 1xA100 80GB
epochs: 1.08
speed: 3e-5
sequence_len: 2048
gradient_accumulation_steps: 32
wandb: https://wandb.ai/practicaldreamer/rpgpt/runs/d4gsi8vy
```
*Please see the documentation folder for more information*
## Usage
This LoRA was trained for use with **Neko-Institute-of-Science/LLaMA-30B-HF**
Please follow the prompt format outlined below. *Hint: If you're not sure what to put for your character description (or you're lazy) just ask chatgpt to generate it for you! Example:*
```
Generate a short character description for Dr. Watson (The Adventures of Sherlock Holmes) that includes gender, age, MBTI and speech accent using 30 words or less.
```
## Prompt Format
Context/Memory:
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Write a character roleplay dialogue using asterisk roleplay format based on the following character descriptions and scenario. (Each line in your response must be from the perspective of one of these characters)
## Characters
<User-Character Name> (<User-Character Universe>):
<User-Character Description>
<Bot-Character Name> (Bot-Character Universe):
<Bot-Character Description>
## Scenario
<Scenario Description>
ASSISTANT:
```
Turn Template:
```
<User-Character Name>: \*<1st person action/sensations/thoughts>\* <Spoken Word> \*<1st person action/sensations/thoughts>\*
<Bot-Character Name>: \*<1st person action/sensations/thoughts>\* <Spoken Word> \*<1st person action/sensations/thoughts>\*
<User-Character Name>: \*<1st person action/sensations/thoughts>\* <Spoken Word> \*<1st person action/sensations/thoughts>\*
<Bot-Character Name>: \*<1st person action/sensations/thoughts>\* <Spoken Word> \*<1st person action/sensations/thoughts>\*
...
```
## Example
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
USER: Write a character roleplay dialogue using asterisk roleplay format based on the following character descriptions and scenario. (Each line in your response must be from the perspective of one of these characters)
## Characters
Baloo (The Jungle Book):
Male, middle-aged bear, ENFP, primarily American accent with slight Indian inflections. Wise, carefree, and friendly, he teaches Mowgli the ways of the jungle.
The Queen of Hearts (Alice's Adventures in Wonderland):
Female, middle-aged, ENTJ, British English accent; imperious, temperamental, commanding, but quick to change from anger to warmth - the quintessential capricious monarch.
## Scenario
In an enchanted glade deep within Wonderland, Baloo finds himself separated from Mowgli and in the Queen of Hearts' territory. Having heard tales of this mercurial ruler, Baloo is intrigued but cautious. To his surprise, the Queen of Hearts approaches him with a broken heart - she has been betrayed by one of her closest confidants.
The Queen initially sees Baloo as an opportunity to vent her frustrations and seek validation for her hurt feelings. Baloo, however, quickly recognizes that the Queen's explosive temperament is driving others away and contributing to her own isolation.\n\nUsing his wisdom and patience, Baloo tries to teach the Queen the value of empathy and understanding in forming meaningful relationships. Through their dialogue, they explore their contrasting attitudes toward power, authority, and friendship. The Queen learns that it is not through fear and command that she can find true loyalty, but rather by treating others with kindness.
In this somber environment where both characters are out of their comfort zones, can Baloo help the Queen mend her own heart by opening up about his experiences with Mowgli? Will the Queen allow herself to be vulnerable enough to learn from the wise bear? And can these two unlikely friends find common ground in this enchanted glade within Wonderland?
ASSISTANT:
Baloo: *stumbles into the enchanted glade, looking around curiously* Well, I must've taken a wrong turn back there. Mowgli! *calls out for Mowgli*
The Queen of Hearts: *storms into the glade, clutching a broken heart symbol, face contorted in anger* Off with their heads! Everyone's heads!
Baloo: *gently scratches his head and approaches the Queen cautiously* Uh, excuse me, ma'am? I couldn't help but notice that you seem rather... upset.
The Queen of Hearts: *sniffs haughtily and scowls at Baloo* And who are you to pry into my affairs? You should be bowing to your queen!
Baloo: *bows graciously but maintains eye contact* Begging your pardon, Your Majesty. My name is Baloo, and I've heard tales of your... unique temperament.
The Queen of Hearts:
```
## Thanks
openaccess-ai-collective https://huggingface.co/openaccess-ai-collective
---
license: mit
---
|
falkne/ibm_rank
|
falkne
| 2023-07-03T18:20:22Z | 0 | 0 |
adapter-transformers
|
[
"adapter-transformers",
"adapterhub:argument/quality",
"roberta",
"region:us"
] | null | 2023-07-03T18:20:21Z |
---
tags:
- adapterhub:argument/quality
- roberta
- adapter-transformers
---
# Adapter `falkne/ibm_rank` for roberta-base
An [adapter](https://adapterhub.ml) for the `roberta-base` model that was trained on the [argument/quality](https://adapterhub.ml/explore/argument/quality/) dataset and includes a prediction head for classification.
This adapter was created for usage with the **[adapter-transformers](https://github.com/Adapter-Hub/adapter-transformers)** library.
## Usage
First, install `adapter-transformers`:
```
pip install -U adapter-transformers
```
_Note: adapter-transformers is a fork of transformers that acts as a drop-in replacement with adapter support. [More](https://docs.adapterhub.ml/installation.html)_
Now, the adapter can be loaded and activated like this:
```python
from transformers import AutoAdapterModel
model = AutoAdapterModel.from_pretrained("roberta-base")
adapter_name = model.load_adapter("falkne/ibm_rank", source="hf", set_active=True)
```
## Architecture & Training
<!-- Add some description here -->
## Evaluation results
<!-- Add some description here -->
## Citation
<!-- Add some description here -->
|
alesthehuman/a2c-AntBulletEnv-v0
|
alesthehuman
| 2023-07-03T17:49:19Z | 1 | 1 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-03T13:22:59Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 2548.33 +/- 83.37
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
wcKd/ppo-Huggy
|
wcKd
| 2023-07-03T17:45:09Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-07-03T17:44:59Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: wcKd/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
khalidbutt/k
|
khalidbutt
| 2023-07-03T16:09:24Z | 0 | 0 | null |
[
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2023-07-03T16:09:24Z |
---
license: bigscience-bloom-rail-1.0
---
|
hopkins/eng-mya-wsample.49
|
hopkins
| 2023-07-03T15:17:37Z | 106 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-03T14:56:40Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: eng-mya-wsample.49
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# eng-mya-wsample.49
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8303
- Bleu: 4.7616
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
DEplain/trimmed_mbart_sents_apa
|
DEplain
| 2023-07-03T13:35:17Z | 28 | 0 |
transformers
|
[
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"text simplification",
"plain language",
"easy-to-read language",
"sentence simplification",
"de",
"dataset:DEplain/DEplain-APA-sent",
"arxiv:2305.18939",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-03-02T17:08:52Z |
---
datasets:
- DEplain/DEplain-APA-sent
language:
- de
metrics:
- bleu
- sari
- bertscore
library_name: transformers
pipeline_tag: text2text-generation
tags:
- text simplification
- plain language
- easy-to-read language
- sentence simplification
---
# DEplain German Text Simplification
This model belongs to the experiments done at the work of Stodden, Momen, Kallmeyer (2023). ["DEplain: A German Parallel Corpus with Intralingual Translations into Plain Language for Sentence and Document Simplification."](https://arxiv.org/abs/2305.18939) In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, Canada. Association for Computational Linguistics.
Detailed documentation can be found on this GitHub repository [https://github.com/rstodden/DEPlain](https://github.com/rstodden/DEPlain)
### Model Description
The model is a finetuned checkpoint of the pre-trained mBART model `mbart-large-cc25`. With a trimmed vocabulary to the most frequent 30k words in the German language.
The model was finetuned towards the task of German text simplification of sentences.
The finetuning dataset included manually aligned sentences from the dataset `DEplain-APA-sent` only.
|
deepsense-ai/trelbert
|
deepsense-ai
| 2023-07-03T12:01:15Z | 114 | 5 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"fill-mask",
"pl",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
fill-mask
| 2022-09-15T12:03:45Z |
---
language: pl
license: cc-by-4.0
pipeline_tag: fill-mask
mask_token: "<mask>"
widget:
- text: "Sztuczna inteligencja to <mask>."
- text: "Robert Kubica jest najlepszym <mask>."
- text: "<mask> jest największym zdrajcą."
- text: "<mask> to najlepszy polski klub."
- text: "Twoja <mask>"
---
# TrelBERT
TrelBERT is a BERT-based Language Model trained on data from Polish Twitter using Masked Language Modeling objective. It is based on [HerBERT](https://aclanthology.org/2021.bsnlp-1.1) model and therefore released under the same license - CC BY 4.0.
## Training
We trained our model starting from [`herbert-base-cased`](https://huggingface.co/allegro/herbert-base-cased) checkpoint and continued MLM training using data collected from Twitter.
The data we used for MLM fine-tuning was approximately 45 million Polish tweets. We trained the model for 1 epoch with a learning rate `5e-5` and batch size `2184` using AdamW optimizer.
### Preprocessing
For each Tweet, the user handles that occur in the beginning of the text were removed, as they are not part of the message content but only represent who the user is replying to. The remaining user handles were replaced by "@anonymized_account". Links were replaced with a special @URL token.
## Tokenizer
We use HerBERT tokenizer with two special tokens added for preprocessing purposes as described above (@anonymized_account, @URL). Maximum sequence length is set to 128, based on the analysis of Twitter data distribution.
## License
CC BY 4.0
## KLEJ Benchmark results
We fine-tuned TrelBERT to [KLEJ benchmark](https://klejbenchmark.com) tasks and achieved the following results:
<style>
tr:last-child {
border-top-width: 4px;
}
</style>
|Task name|Score|
|--|--|
|NKJP-NER|94.4|
|CDSC-E|93.9|
|CDSC-R|93.6|
|CBD|76.1|
|PolEmo2.0-IN|89.3|
|PolEmo2.0-OUT|78.1|
|DYK|67.4|
|PSC|95.7|
|AR|86.1|
|__Average__|__86.1__|
For fine-tuning to KLEJ tasks we used [Polish RoBERTa](https://github.com/sdadas/polish-roberta) scripts, which we modified to use `transformers` library. For the CBD task, we set the maximum sequence length to 128 and implemented the same preprocessing procedure as in the MLM phase.
Our model achieved 1st place in cyberbullying detection (CBD) task in the [KLEJ leaderboard](https://klejbenchmark.com/leaderboard). Overall, it reached 7th place, just below HerBERT model.
## Citation
Please cite the following paper:
```
@inproceedings{szmyd-etal-2023-trelbert,
title = "{T}rel{BERT}: A pre-trained encoder for {P}olish {T}witter",
author = "Szmyd, Wojciech and
Kotyla, Alicja and
Zobni{\'o}w, Micha{\l} and
Falkiewicz, Piotr and
Bartczuk, Jakub and
Zygad{\l}o, Artur",
booktitle = "Proceedings of the 9th Workshop on Slavic Natural Language Processing 2023 (SlavicNLP 2023)",
month = may,
year = "2023",
address = "Dubrovnik, Croatia",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.bsnlp-1.3",
pages = "17--24",
abstract = "Pre-trained Transformer-based models have become immensely popular amongst NLP practitioners. We present TrelBERT {--} the first Polish language model suited for application in the social media domain. TrelBERT is based on an existing general-domain model and adapted to the language of social media by pre-training it further on a large collection of Twitter data. We demonstrate its usefulness by evaluating it in the downstream task of cyberbullying detection, in which it achieves state-of-the-art results, outperforming larger monolingual models trained on general-domain corpora, as well as multilingual in-domain models, by a large margin. We make the model publicly available. We also release a new dataset for the problem of harmful speech detection.",
}
```
## Authors
Jakub Bartczuk, Krzysztof Dziedzic, Piotr Falkiewicz, Alicja Kotyla, Wojciech Szmyd, Michał Zobniów, Artur Zygadło
For more information, reach out to us via e-mail: [email protected]
|
mcamara/taxi-v3
|
mcamara
| 2023-07-03T11:04:56Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-03T10:47:28Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="mcamara/taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
pavanpankaj/incre-train-addlayers
|
pavanpankaj
| 2023-07-03T10:11:17Z | 0 | 0 |
peft
|
[
"peft",
"pytorch",
"RefinedWebModel",
"custom_code",
"region:us"
] | null | 2023-07-03T09:54:35Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0.dev0
- PEFT 0.4.0.dev0
|
joserodr68/Qtable_taxi_ja
|
joserodr68
| 2023-07-03T09:15:52Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-03T09:15:48Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Qtable_taxi_ja
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.44 +/- 2.63
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="joserodr68/Qtable_taxi_ja", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Soojeong/female_hanbok_1e-7_ckpt_icb
|
Soojeong
| 2023-07-03T08:32:21Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"dreambooth",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-03T06:33:25Z |
---
license: creativeml-openrail-m
base_model: model/chilloutmix_NiPrunedFp16Fix
instance_prompt: a photo of wearing hanbok
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- dreambooth
inference: true
---
# DreamBooth - Soojeong/female_hanbok_1e-7_ckpt_icb
This is a dreambooth model derived from model/chilloutmix_NiPrunedFp16Fix. The weights were trained on a photo of wearing hanbok using [DreamBooth](https://dreambooth.github.io/).
You can find some example images in the following.
DreamBooth for the text encoder was enabled: True.
|
Pranjal-666/Reinforce-CartPole-v1
|
Pranjal-666
| 2023-07-03T08:23:01Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-03T08:22:48Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Ezell/testModel
|
Ezell
| 2023-07-03T06:00:06Z | 0 | 0 |
bertopic
|
[
"bertopic",
"music",
"table-question-answering",
"af",
"dataset:GAIR/lima",
"license:bigcode-openrail-m",
"region:us"
] |
table-question-answering
| 2023-07-03T05:59:27Z |
---
license: bigcode-openrail-m
datasets:
- GAIR/lima
language:
- af
metrics:
- bleurt
library_name: bertopic
pipeline_tag: table-question-answering
tags:
- music
---
|
hopkins/mbart-finetuned-eng-kor-50
|
hopkins
| 2023-07-03T05:01:57Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-03T04:44:13Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mbart-finetuned-eng-kor-50
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-finetuned-eng-kor-50
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9913
- Bleu: 7.0488
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
jinlee74/distilbert-base-uncased-finetuned-emotions
|
jinlee74
| 2023-07-03T02:59:35Z | 55 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-03T00:11:13Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotions
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.9415
- name: F1
type: f1
value: 0.9416116671925132
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotions
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2357
- Accuracy: 0.9415
- F1: 0.9416
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.016 | 1.0 | 250 | 0.2262 | 0.9405 | 0.9404 |
| 0.011 | 2.0 | 500 | 0.2357 | 0.9415 | 0.9416 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.1.0.dev20230316
- Datasets 2.12.0
- Tokenizers 0.13.3
|
AshtakaOOf/ssambatea-locon
|
AshtakaOOf
| 2023-07-03T02:58:58Z | 0 | 1 | null |
[
"Text-to-Image",
"anime",
"lora",
"locon",
"lycoris",
"license:cc-by-nc-sa-4.0",
"region:us"
] | null | 2023-07-03T01:36:57Z |
---
license: cc-by-nc-sa-4.0
tags:
- Text-to-Image
- anime
- lora
- locon
- lycoris
---
# SSAMBAtea Style LoCon

## token: **ssambatea**
Trained on SSAMBAtea artwork
This is a LoCon and require the LyCORIS extension to work
I am planning on making a new improved dataset to do a V2
# License
[CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/)
|
hopkins/mbart-finetuned-eng-deu-42
|
hopkins
| 2023-07-03T02:38:45Z | 57 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-03T02:24:45Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mbart-finetuned-eng-deu-42
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-finetuned-eng-deu-42
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6513
- Bleu: 20.8783
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/mbart-finetuned-eng-deu-36
|
hopkins
| 2023-07-03T01:05:54Z | 110 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-03T00:47:41Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mbart-finetuned-eng-deu-36
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-finetuned-eng-deu-36
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6485
- Bleu: 20.7366
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
squeeze-ai-lab/sq-llama-13b-w3-s5
|
squeeze-ai-lab
| 2023-07-02T23:01:26Z | 0 | 0 | null |
[
"arxiv:2306.07629",
"arxiv:2302.13971",
"region:us"
] | null | 2023-06-19T23:44:15Z |
**SqueezeLLM** is a post-training quantization framework that incorporates a new method called Dense-and-Sparse Quantization to enable efficient LLM serving.
**TLDR:** Deploying LLMs is difficult due to their large memory size. This can be addressed with reduced precision quantization.
But a naive method hurts performance. We address this with a new Dense-and-Sparse Quantization method.
Dense-and-Sparse splits weight matrices into two components: A dense component that can be heavily quantized without affecting model performance,
as well as a sparse part that preserves sensitive and outlier parts of the weight matrices With this approach,
we are able to serve larger models with smaller memory footprint, the same latency, and yet higher accuracy and quality.
For more details please check out our [paper](https://arxiv.org/pdf/2306.07629.pdf).
## Model description
3-bit quantized LLaMA 13B model using SqueezeLLM. More details can be found in the [paper](https://arxiv.org/pdf/2306.07629.pdf).
* **Base Model:** [LLaMA 13B](https://arxiv.org/abs/2302.13971)
* **Bitwidth:** 3-bit
* **Sparsity Level:** 0.05%
## Links
* **Paper**: [https://arxiv.org/pdf/2306.07629.pdf](https://arxiv.org/pdf/2306.07629.pdf)
* **Code**: [https://github.com/SqueezeAILab/SqueezeLLM](https://github.com/SqueezeAILab/SqueezeLLM)
---
license: other
---
|
OumaElha/Speech10
|
OumaElha
| 2023-07-02T22:25:16Z | 75 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-07-02T22:17:09Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: Speech10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Speech10
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 50
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1+cu118
- Datasets 2.13.1
- Tokenizers 0.13.3
|
hopkins/mbart-finetuned-eng-ind-194594359719
|
hopkins
| 2023-07-02T18:46:36Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-02T18:28:27Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mbart-finetuned-eng-ind-194594359719
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-finetuned-eng-ind-194594359719
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7684
- Bleu: 21.8097
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/mbart-finetuned-eng-ind-45220640989
|
hopkins
| 2023-07-02T18:42:46Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-02T18:29:07Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mbart-finetuned-eng-ind-45220640989
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-finetuned-eng-ind-45220640989
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7654
- Bleu: 21.8029
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/mbart-finetuned-eng-kor-153522318420
|
hopkins
| 2023-07-02T17:44:02Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-02T17:28:56Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mbart-finetuned-eng-kor-153522318420
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-finetuned-eng-kor-153522318420
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9920
- Bleu: 6.9945
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hopkins/mbart-finetuned-eng-deu-166034669868
|
hopkins
| 2023-07-02T16:53:44Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"translation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-07-02T16:38:39Z |
---
tags:
- translation
- generated_from_trainer
metrics:
- bleu
model-index:
- name: mbart-finetuned-eng-deu-166034669868
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mbart-finetuned-eng-deu-166034669868
This model is a fine-tuned version of [facebook/mbart-large-50-many-to-many-mmt](https://huggingface.co/facebook/mbart-large-50-many-to-many-mmt) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7160
- Bleu: 19.4981
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
hongyusir/trocr-base-printed_captcha_ocr
|
hongyusir
| 2023-07-02T16:05:29Z | 91 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-07-02T14:00:13Z |
---
tags:
- generated_from_trainer
model-index:
- name: trocr-base-printed_captcha_ocr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trocr-base-printed_captcha_ocr
This model is a fine-tuned version of [microsoft/trocr-base-printed](https://huggingface.co/microsoft/trocr-base-printed) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0042
- Cer: 0.001
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 11.82 | 1.0 | 439 | 0.0541 | 0.0117 |
| 0.2886 | 2.0 | 878 | 0.0223 | 0.006 |
| 0.0331 | 3.0 | 1317 | 0.0042 | 0.001 |
### Framework versions
- Transformers 4.30.2
- Pytorch 2.0.1+cu117
- Datasets 2.13.1
- Tokenizers 0.13.3
|
AIYIYA/aaaa
|
AIYIYA
| 2023-07-02T15:41:59Z | 63 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-07-02T11:18:00Z |
---
tags:
- generated_from_keras_callback
model-index:
- name: AIYIYA/my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# AIYIYA/my_awesome_model
This model is a fine-tuned version of [bert-base-chinese](https://huggingface.co/bert-base-chinese) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0613
- Validation Loss: 0.0996
- Train Accuracy: 0.9677
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 55, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.1521 | 0.1222 | 0.9677 | 0 |
| 0.0782 | 0.1038 | 0.9677 | 1 |
| 0.0613 | 0.0996 | 0.9677 | 2 |
### Framework versions
- Transformers 4.30.2
- TensorFlow 2.12.0
- Datasets 2.13.1
- Tokenizers 0.13.3
|
Mizuiro-sakura/open-calm-large-finetuned-databricks-dolly
|
Mizuiro-sakura
| 2023-07-02T14:30:47Z | 15 | 1 |
transformers
|
[
"transformers",
"gpt_neox",
"text-generation",
"japanese",
"causal-lm",
"open-calm",
"ja",
"dataset:kunishou/databricks-dolly-15k-ja",
"dataset:wikipedia",
"dataset:cc100",
"dataset:mc4",
"license:mit",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2023-06-26T13:37:53Z |
---
license: mit
language: ja
datasets:
- kunishou/databricks-dolly-15k-ja
- wikipedia
- cc100
- mc4
tags:
- japanese
- causal-lm
- open-calm
inference: false
---
# OpenCALM-LARGE
## Model Description
OpenCALM is a suite of decoder-only language models pre-trained on Japanese datasets, developed by CyberAgent, Inc.
このモデルはpeftを用いてopen-calm-largeをLoRAファインチューニングしたものです。
## Usage
pytorchおよびtransformers, peftをインストールして下記コードを実行してください
(pip install torch, transformers, peft)
and please execute this code.
下記コードに関しては
npakaさんの記事(https://note.com/npaka/n/na5b8e6f749ce)
を参考にさせて頂きました。
感謝致します。
```python
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "cyberagent/open-calm-large"
lora_weights = "Mizuiro-sakura/open-calm-large-finetuned-databricks-dolly"
# モデルの準備
model = AutoModelForCausalLM.from_pretrained(
model_name
)
# トークンナイザーの準備
tokenizer = AutoTokenizer.from_pretrained(model_name)
# LoRAモデルの準備
model = PeftModel.from_pretrained(
model,
lora_weights,
adapter_name=lora_weights
)
# 評価モード
model.eval()
# プロンプトテンプレートの準備
def generate_prompt(data_point):
if data_point["input"]:
return f"""Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{data_point["instruction"]}
### Input:
{data_point["input"]}
### Response:"""
else:
return f"""Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{data_point["instruction"]}
### Response:"""
# テキスト生成関数の定義
def generate(instruction,input=None,maxTokens=256):
# 推論
prompt = generate_prompt({'instruction':instruction,'input':input})
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids
outputs = model.generate(
input_ids=input_ids,
max_new_tokens=maxTokens,
do_sample=True,
temperature=0.7,
top_p=0.75,
top_k=40,
no_repeat_ngram_size=2,
)
outputs = outputs[0].tolist()
# EOSトークンにヒットしたらデコード完了
if tokenizer.eos_token_id in outputs:
eos_index = outputs.index(tokenizer.eos_token_id)
else:
eos_index = len(outputs)
decoded = tokenizer.decode(outputs[:eos_index])
# レスポンス内容のみ抽出
sentinel = "### Response:"
sentinelLoc = decoded.find(sentinel)
if sentinelLoc >= 0:
print(decoded[sentinelLoc+len(sentinel):])
else:
print('Warning: Expected prompt template to be emitted. Ignoring output.')
generate("自然言語処理とは?")
```
## Model Details
|Model|Params|Layers|Dim|Heads|Dev ppl|
|:---:|:---: |:---:|:---:|:---:|:---:|
|[cyberagent/open-calm-small](https://huggingface.co/cyberagent/open-calm-small)|160M|12|768|12|19.7|
|[cyberagent/open-calm-medium](https://huggingface.co/cyberagent/open-calm-medium)|400M|24|1024|16|13.8|
|[cyberagent/open-calm-large](https://huggingface.co/cyberagent/open-calm-large)|830M|24|1536|16|11.3|
|[cyberagent/open-calm-1b](https://huggingface.co/cyberagent/open-calm-1b)|1.4B|24|2048|16|10.3|
|[cyberagent/open-calm-3b](https://huggingface.co/cyberagent/open-calm-3b)|2.7B|32|2560|32|9.7|
|[cyberagent/open-calm-7b](https://huggingface.co/cyberagent/open-calm-7b)|6.8B|32|4096|32|8.2|
* **Developed by**: [CyberAgent, Inc.](https://www.cyberagent.co.jp/)
* **Model type**: Transformer-based Language Model
* **Language**: Japanese
* **Library**: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
* **License**: OpenCALM is licensed under the Creative Commons Attribution-ShareAlike 4.0 International License ([CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)). When using this model, please provide appropriate credit to CyberAgent, Inc.
* Example (en): This model is a fine-tuned version of OpenCALM-XX developed by CyberAgent, Inc. The original model is released under the CC BY-SA 4.0 license, and this model is also released under the same CC BY-SA 4.0 license. For more information, please visit: https://creativecommons.org/licenses/by-sa/4.0/
* Example (ja): 本モデルは、株式会社サイバーエージェントによるOpenCALM-XXをファインチューニングしたものです。元のモデルはCC BY-SA 4.0ライセンスのもとで公開されており、本モデルも同じくCC BY-SA 4.0ライセンスで公開します。詳しくはこちらをご覧ください: https://creativecommons.org/licenses/by-sa/4.0/
## Training Dataset
* Wikipedia (ja)
* Common Crawl (ja)
## Author
[Ryosuke Ishigami](https://huggingface.co/rishigami)
## Citations
```bibtext
@software{gpt-neox-library,
title = {{GPT-NeoX: Large Scale Autoregressive Language Modeling in PyTorch}},
author = {Andonian, Alex and Anthony, Quentin and Biderman, Stella and Black, Sid and Gali, Preetham and Gao, Leo and Hallahan, Eric and Levy-Kramer, Josh and Leahy, Connor and Nestler, Lucas and Parker, Kip and Pieler, Michael and Purohit, Shivanshu and Songz, Tri and Phil, Wang and Weinbach, Samuel},
url = {https://www.github.com/eleutherai/gpt-neox},
doi = {10.5281/zenodo.5879544},
month = {8},
year = {2021},
version = {0.0.1},
}
```
|
LarryAIDraw/kouhai-chan_v3-000006
|
LarryAIDraw
| 2023-07-02T14:22:22Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-07-02T14:16:46Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/91143/kouhai-chan-ganbare-douki-chan
|
TalesLF/ppo-LunarLander-v2-optuna
|
TalesLF
| 2023-07-02T13:56:51Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-02T13:56:31Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 272.42 +/- 63.22
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AhmedTaha012/gptneo-TxtToJson-v0.1.0
|
AhmedTaha012
| 2023-07-02T12:09:16Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt_neo",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-02T11:47:21Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gptneo-TxtToJson-v0.1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gptneo-TxtToJson-v0.1.0
This model is a fine-tuned version of [EleutherAI/gpt-neo-125m](https://huggingface.co/EleutherAI/gpt-neo-125m) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1258
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 210 | 0.2294 |
| No log | 2.0 | 420 | 0.1945 |
| 0.1714 | 3.0 | 630 | 0.1471 |
| 0.1714 | 4.0 | 840 | 0.1325 |
| 0.0476 | 5.0 | 1050 | 0.1258 |
### Framework versions
- Transformers 4.27.4
- Pytorch 1.13.0
- Datasets 2.1.0
- Tokenizers 0.13.2
|
OneBottleKick/ppo-LunarLander-v2
|
OneBottleKick
| 2023-07-02T10:14:48Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-02T09:37:03Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -432.83 +/- 172.07
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AAOBA/dqn-SpaceInvadersNoFrameskip-v4
|
AAOBA
| 2023-07-02T08:33:18Z | 2 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-02T08:32:46Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 494.00 +/- 170.38
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga chikoto -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga chikoto -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga chikoto
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.02),
('exploration_fraction', 0.2),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 50000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
d4data/environmental-due-diligence-model
|
d4data
| 2023-07-02T07:28:02Z | 89 | 7 |
transformers
|
[
"transformers",
"tf",
"distilbert",
"text-classification",
"Text Classification",
"en",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- Text Classification
co2_eq_emissions: 0.1069
widget:
- text: "At the every month post-injection monitoring event, TCE, carbon tetrachloride, and chloroform concentrations were above CBSGs in three of the wells"
example_title: "Remediation Standards"
- text: "TRPH exceedances were observed in the subsurface soils immediately above the water table and there are no TRPH exceedances in surface soils."
example_title: "Extent of Contamination"
- text: "weathered shale was encountered below the surface area with fluvial deposits. Sediments in the coastal plain region are found above and below the bedrock with sandstones and shales that form the basement rock"
example_title: "Geology"
---
## About the Model
An Environmental due diligence classification model, trained on customized environmental Dataset to detect contamination and remediation activities (both prevailing as well as planned) as a part of site assessment process. This model can identify the source of contamination, the extent of contamination, the types of contaminants present at the site, the flow of contaminants and their interaction with ground water, surface water and other surrounding water bodies .
This model was built on top of distilbert-base-uncased model and trained for 10 epochs with a batch size of 16, a learning rate of 5e-5, and a maximum sequence length of 512.
- Dataset : Open Source News data + Custom data
- Carbon emission 0.1069 Kg
## Usage
The easiest way is to load through the pipeline object offered by transformers library.
```python
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("d4data/environmental-due-diligence-model")
model = TFAutoModelForSequenceClassification.from_pretrained("d4data/environmental-due-diligence-model")
classifier = pipeline('text-classification', model=model, tokenizer=tokenizer) # cuda = 0,1 based on gpu availability
classifier("At the every month post-injection monitoring event, TCE, carbon tetrachloride, and chloroform concentrations were above CBSGs in three of the wells")
```
## Author
This model is part of the Research topic "Environmental Due Diligence" conducted by Deepak John Reji, Afreen Aman. If you use this work (code, model or dataset), please cite as:
> Environmental Due Diligence, (2020), https://www.sciencedirect.com/science/article/pii/S2665963822001117
## You can support me here :)
<a href="https://www.buymeacoffee.com/deepakjohnreji" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a>
|
digiplay/AnaMix_v2
|
digiplay
| 2023-07-02T05:12:00Z | 268 | 4 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-01T21:16:15Z |
---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
https://civitai.com/models/65780?modelVersionId=80030
|
lucasbertola/dqn-SpaceInvadersNoFrameskip-v4
|
lucasbertola
| 2023-07-01T18:19:11Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-01T18:12:46Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 590.50 +/- 244.14
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga lucasbertola -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga lucasbertola -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga lucasbertola
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
joserodr68/ppo-Huggy
|
joserodr68
| 2023-07-01T17:47:14Z | 11 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-07-01T17:47:03Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: joserodr68/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
malmarjeh/t5-arabic-text-summarization
|
malmarjeh
| 2023-07-01T16:39:31Z | 367 | 13 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"Arabic T5",
"T5",
"MSA",
"Arabic Text Summarization",
"Arabic News Title Generation",
"Arabic Paraphrasing",
"ar",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-06-03T14:36:08Z |
---
language:
- ar
tags:
- Arabic T5
- T5
- MSA
- Arabic Text Summarization
- Arabic News Title Generation
- Arabic Paraphrasing
widget:
- text: "شهدت مدينة طرابلس، مساء أمس الأربعاء، احتجاجات شعبية وأعمال شغب لليوم الثالث على التوالي، وذلك بسبب تردي الوضع المعيشي والاقتصادي. واندلعت مواجهات عنيفة وعمليات كر وفر ما بين الجيش اللبناني والمحتجين استمرت لساعات، إثر محاولة فتح الطرقات المقطوعة، ما أدى إلى إصابة العشرات من الطرفين."
---
# An Arabic abstractive text summarization model
A fine-tuned AraT5 model on a dataset of 84,764 paragraph-summary pairs.
Paper: [Arabic abstractive text summarization using RNN-based and transformer-based architectures](https://www.sciencedirect.com/science/article/abs/pii/S0306457322003284).
Dataset: [link](https://data.mendeley.com/datasets/7kr75c9h24/1).
The model can be used as follows:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, pipeline
from arabert.preprocess import ArabertPreprocessor
model_name="malmarjeh/t5-arabic-text-summarization"
preprocessor = ArabertPreprocessor(model_name="")
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
pipeline = pipeline("text2text-generation",model=model,tokenizer=tokenizer)
text = "شهدت مدينة طرابلس، مساء أمس الأربعاء، احتجاجات شعبية وأعمال شغب لليوم الثالث على التوالي، وذلك بسبب تردي الوضع المعيشي والاقتصادي. واندلعت مواجهات عنيفة وعمليات كر وفر ما بين الجيش اللبناني والمحتجين استمرت لساعات، إثر محاولة فتح الطرقات المقطوعة، ما أدى إلى إصابة العشرات من الطرفين."
text = preprocessor.preprocess(text)
result = pipeline(text,
pad_token_id=tokenizer.eos_token_id,
num_beams=3,
repetition_penalty=3.0,
max_length=200,
length_penalty=1.0,
no_repeat_ngram_size = 3)[0]['generated_text']
result
>>> 'مواجهات عنيفة بين الجيش اللبناني ومحتجين في طرابلس'
```
## Contact:
<[email protected]>
|
digiplay/breakdomainrealistic_R2333
|
digiplay
| 2023-07-01T14:26:31Z | 408 | 7 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-07-01T09:18:11Z |
---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
|
fantasyfish/zhang_xiaogang-lora
|
fantasyfish
| 2023-07-01T10:06:49Z | 1 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-06-28T00:35:30Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA text2image fine-tuning - fantasyfish/zhang_xiaogang-lora
These are LoRA adaption weights for runwayml/stable-diffusion-v1-5. The weights were fine-tuned on the None dataset. You can find some example images in the following.




|
kvarnalidis/ppo-LunarLander-v2
|
kvarnalidis
| 2023-07-01T08:26:16Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-07-01T08:25:55Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 228.96 +/- 73.93
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
w11wo/javanese-bert-small-imdb-classifier
|
w11wo
| 2023-07-01T07:17:16Z | 126 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"text-classification",
"javanese-bert-small-imdb-classifier",
"jv",
"dataset:w11wo/imdb-javanese",
"arxiv:1810.04805",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z |
---
language: jv
tags:
- javanese-bert-small-imdb-classifier
license: mit
datasets:
- w11wo/imdb-javanese
widget:
- text: "Dhuh Gusti, film iki elek banget. Aku getun ndelok !!!"
---
## Javanese BERT Small IMDB Classifier
Javanese BERT Small IMDB Classifier is a movie-classification model based on the [BERT model](https://arxiv.org/abs/1810.04805). It was trained on Javanese IMDB movie reviews.
The model was originally [`w11wo/javanese-bert-small-imdb`](https://huggingface.co/w11wo/javanese-bert-small-imdb) which is then fine-tuned on the [`w11wo/imdb-javanese`](https://huggingface.co/datasets/w11wo/imdb-javanese) dataset consisting of Javanese IMDB movie reviews. It achieved an accuracy of 76.37% on the validation dataset. Many of the techniques used are based on a Hugging Face tutorial [notebook](https://github.com/huggingface/notebooks/blob/master/examples/text_classification.ipynb) written by [Sylvain Gugger](https://github.com/sgugger).
Hugging Face's `Trainer` class from the [Transformers](https://huggingface.co/transformers) library was used to train the model. PyTorch was used as the backend framework during training, but the model remains compatible with TensorFlow nonetheless.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
|---------------------------------------|----------|----------------|---------------------------------|
| `javanese-bert-small-imdb-classifier` | 110M | BERT Small | Javanese IMDB (47.5 MB of text) |
## Evaluation Results
The model was trained for 5 epochs and the following is the final result once the training ended.
| train loss | valid loss | accuracy | total time |
|------------|------------|------------|------------|
| 0.131 | 1.113 | 0.763 | 59:16 |
## How to Use
### As Text Classifier
```python
from transformers import pipeline
pretrained_name = "w11wo/javanese-bert-small-imdb-classifier"
nlp = pipeline(
"sentiment-analysis",
model=pretrained_name,
tokenizer=pretrained_name
)
nlp("Film sing apik banget!")
```
## Disclaimer
Do consider the biases which came from the IMDB review that may be carried over into the results of this model.
## Author
Javanese BERT Small IMDB Classifier was trained and evaluated by [Wilson Wongso](https://w11wo.github.io/). All computation and development are done on Google Colaboratory using their free GPU access.
## Citation
If you use any of our models in your research, please cite:
```bib
@inproceedings{wongso2021causal,
title={Causal and Masked Language Modeling of Javanese Language using Transformer-based Architectures},
author={Wongso, Wilson and Setiawan, David Samuel and Suhartono, Derwin},
booktitle={2021 International Conference on Advanced Computer Science and Information Systems (ICACSIS)},
pages={1--7},
year={2021},
organization={IEEE}
}
```
|
saquiboye/model
|
saquiboye
| 2023-07-01T02:31:35Z | 3 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"controlnet",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-06-22T19:29:05Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- controlnet
inference: true
---
# controlnet-saquiboye/model
These are controlnet weights trained on runwayml/stable-diffusion-v1-5 with new type of conditioning.
You can find some example images below.
prompt: an handsome man, photoshoot

prompt: an asian girl, best photoshoot, portrait

prompt: an beautiful girl, best photoshoot, portrait

|
VeraNakano/TEST
|
VeraNakano
| 2023-07-01T02:13:16Z | 0 | 0 | null |
[
"license:bigscience-openrail-m",
"region:us"
] | null | 2023-07-01T02:13:16Z |
---
license: bigscience-openrail-m
---
|
hipnologo/gpt2-imdb-finetune
|
hipnologo
| 2023-07-01T01:52:18Z | 259 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-classification",
"movies",
"sentiment-analysis",
"fine-tuned",
"en",
"dataset:imdb",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-06-28T02:56:13Z |
---
datasets:
- imdb
language:
- en
library_name: transformers
pipeline_tag: text-classification
tags:
- movies
- gpt2
- sentiment-analysis
- fine-tuned
license: mit
widget:
- text: "What an inspiring movie, I laughed, cried and felt love."
- text: "This film fails on every count. For a start it is pretentious, striving to be significant and failing miserably."
---
# Fine-tuned GPT-2 Model for IMDb Movie Review Sentiment Analysis
## Model Description
This is a GPT-2 model fine-tuned on the IMDb movie review dataset for sentiment analysis. It classifies a movie review text into two classes: "positive" or "negative".
## Intended Uses & Limitations
This model is intended to be used for binary sentiment analysis of English movie reviews. It can determine whether a review is positive or negative. It should not be used for languages other than English, or for text with ambiguous sentiment.
## How to Use
Here's a simple way to use this model:
```python
from transformers import GPT2Tokenizer, GPT2ForSequenceClassification
tokenizer = GPT2Tokenizer.from_pretrained("hipnologo/gpt2-imdb-finetune")
model = GPT2ForSequenceClassification.from_pretrained("hipnologo/gpt2-imdb-finetune")
text = "Your review text here!"
# encoding the input text
input_ids = tokenizer.encode(text, return_tensors="pt")
# Move the input_ids tensor to the same device as the model
input_ids = input_ids.to(model.device)
# getting the logits
logits = model(input_ids).logits
# getting the predicted class
predicted_class = logits.argmax(-1).item()
print(f"The sentiment predicted by the model is: {'Positive' if predicted_class == 1 else 'Negative'}")
```
## Training Procedure
The model was trained using the 'Trainer' class from the transformers library, with a learning rate of 2e-5, batch size of 1, and 3 training epochs.
## Evaluation
The fine-tuned model was evaluated on the test dataset. Here are the results:
- **Evaluation Loss**: 0.23127
- **Evaluation Accuracy**: 0.94064
- **Evaluation F1 Score**: 0.94104
- **Evaluation Precision**: 0.93466
- **Evaluation Recall**: 0.94752
The evaluation metrics suggest that the model has a high accuracy and good precision-recall balance for the task of sentiment classification.
### How to Reproduce
The evaluation results can be reproduced by loading the model and the tokenizer from Hugging Face Model Hub and then running the model on the evaluation dataset using the `Trainer` class from the Transformers library, with the `compute_metrics` function defined as above.
The evaluation loss is the cross-entropy loss of the model on the evaluation dataset, a measure of how well the model's predictions match the actual labels. The closer this is to zero, the better.
The evaluation accuracy is the proportion of predictions the model got right. This number is between 0 and 1, with 1 meaning the model got all predictions right.
The F1 score is a measure of a test's accuracy that considers both precision (the number of true positive results divided by the number of all positive results) and recall (the number of true positive results divided by the number of all samples that should have been identified as positive). An F1 score reaches its best value at 1 (perfect precision and recall) and worst at 0.
The evaluation precision is how many of the positively classified were actually positive. The closer this is to 1, the better.
The evaluation recall is how many of the actual positives our model captured through labeling it as positive. The closer this is to 1, the better.
## Fine-tuning Details
The model was fine-tuned using the IMDb movie review dataset.
|
davidzhou/ddpm-celebahq-finetuned-butterflies-2epochs
|
davidzhou
| 2023-07-01T01:09:56Z | 31 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2023-07-01T01:06:40Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Example Fine-Tuned Model for Unit 2 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
Describe your model here
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('davidzhou/ddpm-celebahq-finetuned-butterflies-2epochs')
image = pipeline().images[0]
image
```
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.