
FreeDA: Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation (CVPR 2024)
Luca Barsellotti* Roberto Amoroso* Marcella Cornia Lorenzo Baraldi Rita Cucchiara
Project Page | Paper | Code

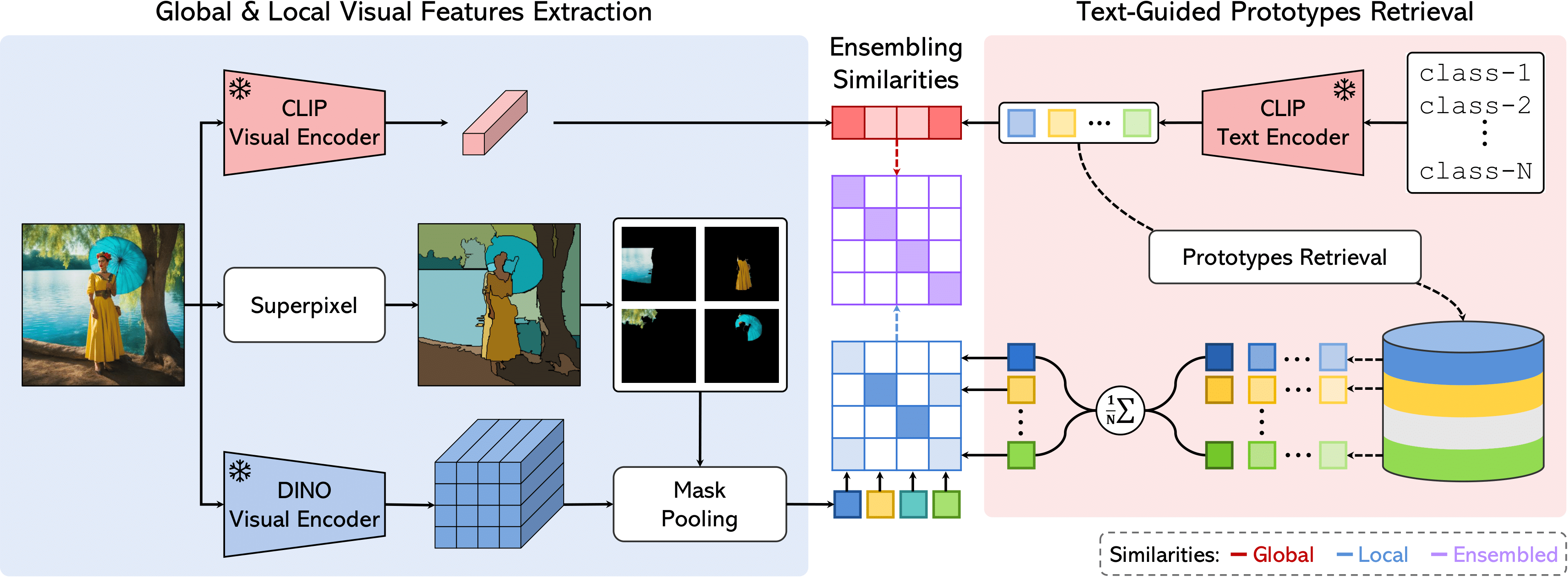
Method
Additional qualitative examples

Additional examples in-the-wild

Installation
conda create --name freeda python=3.9
conda activate freeda
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
pip install -r requirements.txt
How to use
import freeda
from PIL import Image
import requests
from io import BytesIO
if __name__ == "__main__":
fr = freeda.load("dinov2_vitb_clip_vitb")
response1 = requests.get("https://farm9.staticflickr.com/8306/7926031760_b313dca06a_z.jpg")
img1 = Image.open(BytesIO(response1.content))
response2 = requests.get("https://farm3.staticflickr.com/2207/2157810040_4883738d2d_z.jpg")
img2 = Image.open(BytesIO(response2.content))
fr.set_categories(["cat", "table", "pen", "keyboard", "toilet", "wall"])
fr.set_images([img1, img2])
segmentation = fr()
fr.visualize(segmentation, ["plot.png", "plot1.png"])
If you find FreeDA useful for your work please cite:
@inproceedings{barsellotti2024training
title={Training-Free Open-Vocabulary Segmentation with Offline Diffusion-Augmented Prototype Generation},
author={Barsellotti, Luca and Amoroso, Roberto and Cornia, Marcella and Baraldi, Lorenzo and Cucchiara, Rita},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2024}
}
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.
The model cannot be deployed to the HF Inference API:
The model has no library tag.
Model tree for lucabarsellotti/freeda
Base model
timm/vit_base_patch14_dinov2.lvd142m