
Wavelet Denoising Diffusion Models
Collection
Pretrained WDDM weights for CIFAR10, STL10 and CELEBA-HQ
•
6 items
•
Updated
Authors: Markos Aivazoglou-Vounatsos, Mostafa Mehdipour Ghazi
Abstract Denoising diffusion models have emerged as a powerful class of deep generative models, yet they remain computationally demanding due to their iterative nature and high-dimensional input space. In this work, we propose a novel framework that integrates wavelet decomposition into diffusion-based generative models to reduce spatial redundancy and improve training and sampling efficiency. By operating in the wavelet domain, our approach enables a compact multiresolution representation of images, facilitating faster convergence and more efficient inference with minimal architectural modifications. We assess this framework using UNets and UKANs as denoising backbones across multiple diffusion models and benchmark datasets. Our experiments show that a 1-level wavelet decomposition achieves a speedup of up to three times in training, with competitive Fréchet Inception Distance (FID) scores. We further demonstrate that KAN-based architectures offer lightweight alternatives to convolutional backbones, enabling parameter-efficient generation. In-depth analysis of sampling dynamics, including the impact of implicit configurations and wavelet depth, reveals trade-offs between speed, quality, and resolution-specific sensitivity. These findings offer practical insights into the design of efficient generative models and highlight the potential of frequency-domain learning for future generative modeling research.
Source code available at https://github.com/markos-aivazoglou/wavelet-diffusion.
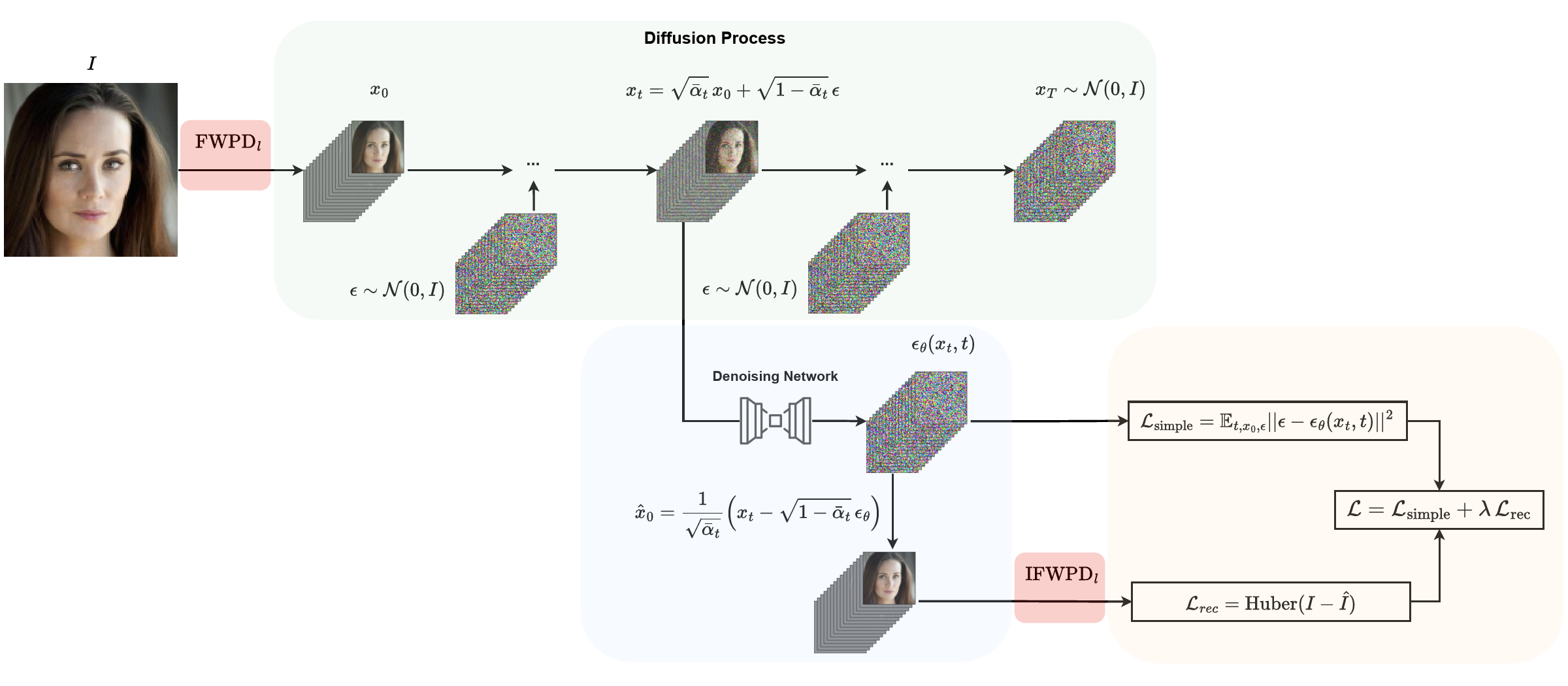
Figure 1: Overview of the Wavelet Diffusion Model (WDDM) architecture. The model operates in the wavelet domain, leveraging wavelet decomposition to reduce spatial redundancy and improve training efficiency. The denoising backbone can be a UNet or a KAN-based architecture, allowing for flexible and efficient generative modeling.
The framework supports three main datasets:
CIFAR10 and STL10 will be automatically downloaded when first used. For CELEBA-HQ, you need to download the dataset manually and place it in the data/celeba-hq directory. The dataset can be downloaded from CelebA-HQ
This project is licensed under the Creative Commons Attribution Non-Commercial Share-Alike (CC-BY-NC-SA 4.0) - see the LICENSE file for details.
TBA
For questions feel free to contact:
[email protected] or [email protected]