|
|
--- |
|
|
language: |
|
|
- en |
|
|
- zh |
|
|
- de |
|
|
- es |
|
|
- ru |
|
|
- ko |
|
|
- fr |
|
|
- ja |
|
|
- pt |
|
|
- tr |
|
|
- pl |
|
|
- ca |
|
|
- nl |
|
|
- ar |
|
|
- sv |
|
|
- it |
|
|
- id |
|
|
- hi |
|
|
- fi |
|
|
- vi |
|
|
- he |
|
|
- uk |
|
|
- el |
|
|
- ms |
|
|
- cs |
|
|
- ro |
|
|
- da |
|
|
- hu |
|
|
- ta |
|
|
- 'no' |
|
|
- th |
|
|
- ur |
|
|
- hr |
|
|
- bg |
|
|
- lt |
|
|
- la |
|
|
- mi |
|
|
- ml |
|
|
- cy |
|
|
- sk |
|
|
- te |
|
|
- fa |
|
|
- lv |
|
|
- bn |
|
|
- sr |
|
|
- az |
|
|
- sl |
|
|
- kn |
|
|
- et |
|
|
- mk |
|
|
- br |
|
|
- eu |
|
|
- is |
|
|
- hy |
|
|
- ne |
|
|
- mn |
|
|
- bs |
|
|
- kk |
|
|
- sq |
|
|
- sw |
|
|
- gl |
|
|
- mr |
|
|
- pa |
|
|
- si |
|
|
- km |
|
|
- sn |
|
|
- yo |
|
|
- so |
|
|
- af |
|
|
- oc |
|
|
- ka |
|
|
- be |
|
|
- tg |
|
|
- sd |
|
|
- gu |
|
|
- am |
|
|
- yi |
|
|
- lo |
|
|
- uz |
|
|
- fo |
|
|
- ht |
|
|
- ps |
|
|
- tk |
|
|
- nn |
|
|
- mt |
|
|
- sa |
|
|
- lb |
|
|
- my |
|
|
- bo |
|
|
- tl |
|
|
- mg |
|
|
- as |
|
|
- tt |
|
|
- haw |
|
|
- ln |
|
|
- ha |
|
|
- ba |
|
|
- jw |
|
|
- su |
|
|
license: other |
|
|
library_name: transformers |
|
|
tags: |
|
|
- speech |
|
|
- audio |
|
|
- automatic-speech-recognition |
|
|
- asr |
|
|
- shunyalabs |
|
|
- gated |
|
|
- multi-lingual |
|
|
- pingala-shunya |
|
|
- transformers |
|
|
license_name: pingala-v1-universal-rail-m |
|
|
license_link: https://huggingface.co/shunyalabs/pingala-v1-universal/blob/main/LICENSE.md |
|
|
metrics: |
|
|
- wer |
|
|
model-index: |
|
|
- name: pingala-v1-universal |
|
|
results: |
|
|
- task: |
|
|
name: Automatic Speech Recognition |
|
|
type: automatic-speech-recognition |
|
|
dataset: |
|
|
name: Composite |
|
|
type: internal |
|
|
metrics: |
|
|
- name: Overall WER |
|
|
type: wer |
|
|
value: 3.1 |
|
|
- name: Average RTFx |
|
|
type: rtfx |
|
|
value: 146.23 |
|
|
- task: |
|
|
name: Automatic Speech Recognition |
|
|
type: automatic-speech-recognition |
|
|
dataset: |
|
|
name: AMI |
|
|
type: ami |
|
|
metrics: |
|
|
- name: WER |
|
|
type: wer |
|
|
value: 4.19 |
|
|
- task: |
|
|
name: Automatic Speech Recognition |
|
|
type: automatic-speech-recognition |
|
|
dataset: |
|
|
name: Earnings22 |
|
|
type: earnings22 |
|
|
metrics: |
|
|
- name: WER |
|
|
type: wer |
|
|
value: 5.83 |
|
|
- task: |
|
|
name: Automatic Speech Recognition |
|
|
type: automatic-speech-recognition |
|
|
dataset: |
|
|
name: GigaSpeech |
|
|
type: gigaspeech |
|
|
metrics: |
|
|
- name: WER |
|
|
type: wer |
|
|
value: 4.99 |
|
|
- task: |
|
|
name: Automatic Speech Recognition |
|
|
type: automatic-speech-recognition |
|
|
dataset: |
|
|
name: LibriSpeech Test Clean |
|
|
type: librispeech_asr |
|
|
args: test.clean |
|
|
metrics: |
|
|
- name: WER |
|
|
type: wer |
|
|
value: 0.71 |
|
|
- task: |
|
|
name: Automatic Speech Recognition |
|
|
type: automatic-speech-recognition |
|
|
dataset: |
|
|
name: LibriSpeech Test Other |
|
|
type: librispeech_asr |
|
|
args: test.other |
|
|
metrics: |
|
|
- name: WER |
|
|
type: wer |
|
|
value: 2.17 |
|
|
- task: |
|
|
name: Automatic Speech Recognition |
|
|
type: automatic-speech-recognition |
|
|
dataset: |
|
|
name: SPGISpeech |
|
|
type: spgispeech |
|
|
metrics: |
|
|
- name: WER |
|
|
type: wer |
|
|
value: 1.1 |
|
|
- task: |
|
|
name: Automatic Speech Recognition |
|
|
type: automatic-speech-recognition |
|
|
dataset: |
|
|
name: TedLium |
|
|
type: tedlium |
|
|
metrics: |
|
|
- name: WER |
|
|
type: wer |
|
|
value: 1.43 |
|
|
- task: |
|
|
name: Automatic Speech Recognition |
|
|
type: automatic-speech-recognition |
|
|
dataset: |
|
|
name: VoxPopuli |
|
|
type: voxpopuli |
|
|
metrics: |
|
|
- name: WER |
|
|
type: wer |
|
|
value: 4.34 |
|
|
pipeline_tag: automatic-speech-recognition |
|
|
extra_gated_prompt: > |
|
|
## Access Request for pingala-v1-universal |
|
|
|
|
|
|
|
|
This model is distributed under the Shunya Labs RAIL-M License with use-based |
|
|
restrictions. |
|
|
|
|
|
|
|
|
By requesting access, you agree to: |
|
|
|
|
|
- Use the model only for permitted purposes as defined in the license |
|
|
|
|
|
- Not redistribute or create derivative works |
|
|
|
|
|
- Comply with all use-based restrictions |
|
|
|
|
|
- Use the model responsibly and ethically |
|
|
|
|
|
|
|
|
Please provide the following information: |
|
|
extra_gated_fields: |
|
|
Name: text |
|
|
Email: text |
|
|
Phone Number: text |
|
|
Organization: text |
|
|
Intended Use: text |
|
|
I agree to the Shunya Labs RAIL-M License terms, confirm I will not use this model for prohibited purposes, and understand this model cannot be redistributed: checkbox |
|
|
--- |
|
|
|
|
|
# Pingala V1 Universal |
|
|
|
|
|
A high-performance English speech recognition model optimized for transcription by [Shunyalabs](https://www.shunyalabs.ai/pingala). |
|
|
|
|
|
Try the demo at https://www.shunyalabs.ai |
|
|
|
|
|
## License |
|
|
|
|
|
This model is distributed under the [Shunya Labs RAIL-M License](https://huggingface.co/shunyalabs/pingala-v1-universal/blob/main/LICENSE.md), which includes specific use-based restrictions and commercial licensing requirements. |
|
|
|
|
|
### License Summary |
|
|
|
|
|
- **Free Use**: Up to 10,000 hours of audio transcription per calendar month |
|
|
- **Distribution**: Model cannot be redistributed to third parties |
|
|
- **Derivatives**: Creation of derivative works is not permitted |
|
|
- **Attribution**: Required when outputs are made public or shared |
|
|
|
|
|
### Key Restrictions |
|
|
|
|
|
The license prohibits use for discrimination, military applications, disinformation, privacy violations, unauthorized medical advice, and other harmful purposes. Please refer to the complete LICENSE file for detailed terms and conditions. |
|
|
|
|
|
For inquiries, contact: [email protected] |
|
|
|
|
|
## Model Overview |
|
|
|
|
|
**Pingala V1 Universal** is a state-of-the-art automatic speech recognition (ASR) model that delivers exceptional accuracy across diverse audio domains. With a low word error rate (WER) of just 3.10 in English, it is optimized for high-precision, verbatim transcription—capturing spoken content word-for-word with remarkable fidelity. |
|
|
|
|
|
Designed to support transcription across **204 languages**, including a wide range of **Indic and global languages**, Pingala V1 Universal performs consistently across various domains such as meetings, earnings calls, broadcast media, and educational content. |
|
|
|
|
|
|
|
|
## Performance Benchmarks |
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
|
|
### OpenASR Leaderboard Results |
|
|
|
|
|
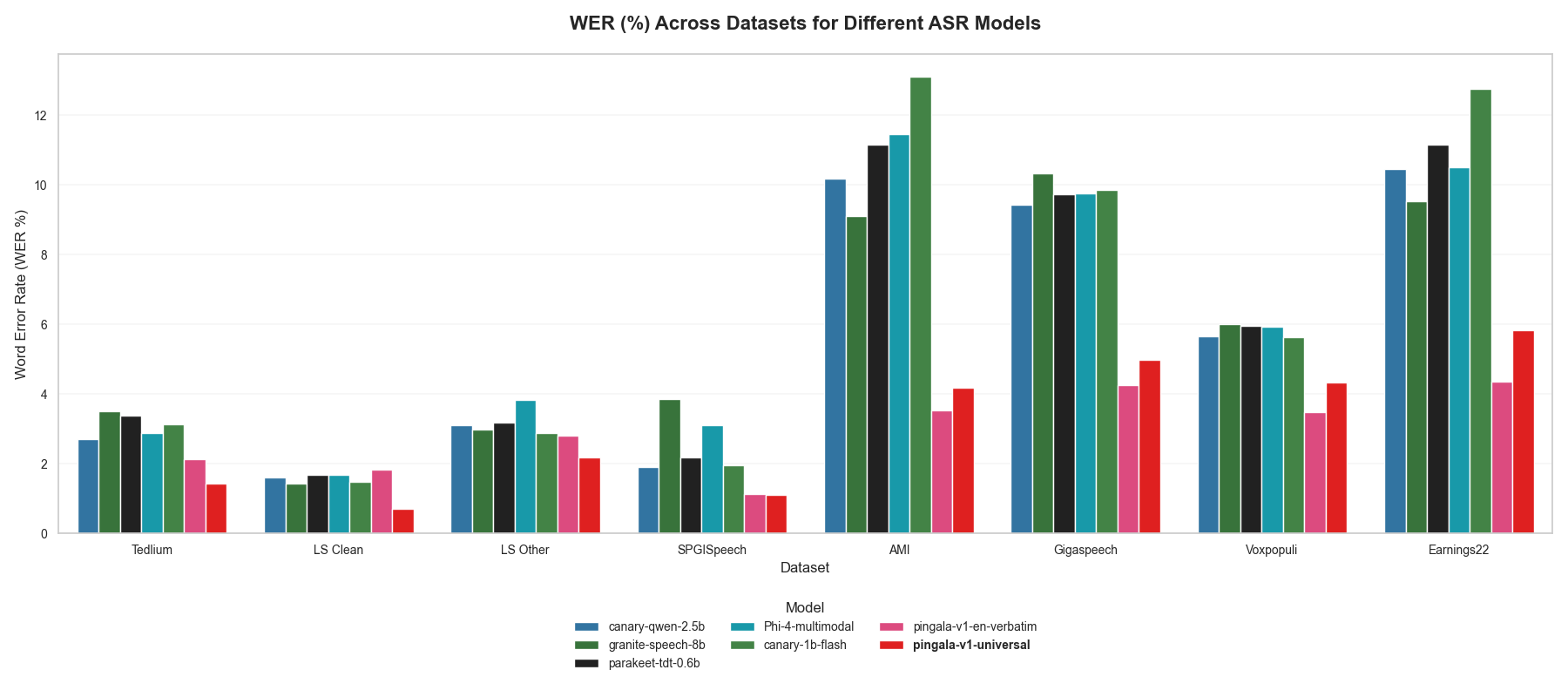
The model has been extensively evaluated on the OpenASR leaderboard across multiple English datasets, demonstrating superior performance compared to larger open-source models: |
|
|
|
|
|
| Dataset | WER (%) | RTFx | |
|
|
| ---------------------- | ------- | ------ | |
|
|
| AMI Test | 4.19 | 70.22 | |
|
|
| Earnings22 Test | 5.83 | 101.52 | |
|
|
| GigaSpeech Test | 4.99 | 131.09 | |
|
|
| LibriSpeech Test Clean | 0.71 | 158.74 | |
|
|
| LibriSpeech Test Other | 2.17 | 142.40 | |
|
|
| SPGISpeech Test | 1.10 | 170.85 | |
|
|
| TedLium Test | 1.43 | 153.34 | |
|
|
| VoxPopuli Test | 4.34 | 179.28 | |
|
|
|
|
|
|
|
|
### Composite Results |
|
|
- **Overall WER**: 3.10% |
|
|
- **Average RTFx**: 146.23 |
|
|
|
|
|
*RTFx (Real-Time Factor) indicates inference speed relative to audio duration. Higher values mean faster processing.* |
|
|
|
|
|
### Comparative Performance |
|
|
|
|
|
Pingala V1 significantly outperforms larger open-source models on 8 common speech benchmarks: |
|
|
|
|
|
| Model | AMI | Earnings22 | GigaSpeech | LS Clean | LS Other | SPGISpeech | TedLium | Voxpopuli | Avg WER | |
|
|
| ----------------------------------- | -------- | ---------- | ---------- | -------- | -------- | ---------- | -------- | --------- | -------- | |
|
|
| nvidia/canary-qwen-2.5b | 10.19 | 10.45 | 9.43 | 1.61 | 3.10 | 1.90 | 2.71 | 5.66 | 5.63 | |
|
|
| ibm/granite-granite-speech-3.3-8b | 9.12 | 9.53 | 10.33 | 1.42 | 2.99 | 3.86 | 3.50 | 6.00 | 5.74 | |
|
|
| nvidia/parakeet-tdt-0.6b-v2 | 11.16 | 11.15 | 9.74 | 1.69 | 3.19 | 2.17 | 3.38 | 5.95 | 6.05 | |
|
|
| microsoft/Phi-4-multimodal-instruct | 11.45 | 10.50 | 9.77 | 1.67 | 3.82 | 3.11 | 2.89 | 5.93 | 6.14 | |
|
|
| nvidia/canary-1b-flash | 13.11 | 12.77 | 9.85 | 1.48 | 2.87 | 1.95 | 3.12 | 5.63 | 6.35 | |
|
|
| shunyalabs/pingala-v1-en-verbatim | 3.52 | 4.36 | 4.26 | 1.84 | 2.81 | 1.13 | 2.14 | 3.47 | 2.94 | |
|
|
| **shunyalabs/pingala-v1-universal** | **4.19** | **5.83** | **4.99** | **0.71** | **2.17** | **1.10** | **1.43** | **4.34** | **3.10** | |
|
|
|
|
|
|
|
|
|
|
|
## Authentication with Hugging Face Hub |
|
|
|
|
|
This model require authentication with Hugging Face Hub. Here's how to set up and use your Hugging Face token. |
|
|
|
|
|
### Getting Your Hugging Face Token |
|
|
|
|
|
1. **Create a Hugging Face Account**: Go to [huggingface.co](https://huggingface.co) and sign up |
|
|
2. **Generate a Token**: |
|
|
- Go to [Settings > Access Tokens](https://huggingface.co/settings/tokens) |
|
|
- Click "New token" |
|
|
- Choose "Read" permissions |
|
|
- Copy your token (starts with `hf_...`) |
|
|
|
|
|
### Setting Up Authentication |
|
|
|
|
|
#### Method 1: Environment Variable (Recommended) |
|
|
|
|
|
```bash |
|
|
# Set your token as an environment variable |
|
|
export HUGGINGFACE_HUB_TOKEN="hf_your_token_here" |
|
|
|
|
|
# Or add to your ~/.bashrc or ~/.zshrc for persistence |
|
|
echo 'export HUGGINGFACE_HUB_TOKEN="hf_your_token_here"' >> ~/.bashrc |
|
|
source ~/.bashrc |
|
|
``` |
|
|
|
|
|
#### Method 2: Hugging Face CLI Login |
|
|
|
|
|
```bash |
|
|
# Install Hugging Face CLI if not already installed |
|
|
pip install huggingface_hub |
|
|
|
|
|
# Login using CLI |
|
|
huggingface-cli login |
|
|
# Enter your token when prompted |
|
|
``` |
|
|
|
|
|
#### Method 3: Programmatic Authentication |
|
|
|
|
|
```python |
|
|
from huggingface_hub import login |
|
|
|
|
|
# Login programmatically |
|
|
login(token="hf_your_token_here") |
|
|
``` |
|
|
|
|
|
|
|
|
## Installation |
|
|
|
|
|
### Basic Installation |
|
|
```bash |
|
|
pip install pingala-shunya |
|
|
``` |
|
|
|
|
|
## Usage |
|
|
|
|
|
### Quick Start |
|
|
|
|
|
```python |
|
|
from pingala_shunya import PingalaTranscriber |
|
|
|
|
|
# Explicitly choose backends with Shunya Labs model |
|
|
transcriber = PingalaTranscriber(model_name="shunyalabs/pingala-v1-universal", backend="transformers") |
|
|
|
|
|
segments, info = transcriber.transcribe_file( |
|
|
"audio.wav", |
|
|
beam_size=5, |
|
|
) |
|
|
|
|
|
for segment in segments: |
|
|
print(f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}") |
|
|
``` |
|
|
|
|
|
## Model Details |
|
|
|
|
|
- **Architecture**: transformer-based model optimized for multilingual transcription accross 204 languages |
|
|
- **Format**: Transformer compatible for efficient inference |
|
|
- **Sampling Rate**: 16 kHz |
|
|
- **Model Size**: Production-optimized for deployment |
|
|
- **Optimization**: Real-time inference capable with GPU acceleration |
|
|
|
|
|
## Key Features |
|
|
|
|
|
- **Exceptional Accuracy**: Achieves 3.10% WER across diverse English test sets |
|
|
- **Real-Time Performance**: Average RTFx of 146.23 enables real-time applications |
|
|
- **Verbatim Transcription**: Optimized for accurate, word-for-word transcription |
|
|
- **Multi-Domain Excellence**: Superior performance across conversational, broadcast, and read English speech |
|
|
- **Voice Activity Detection**: Built-in VAD for better handling of silence |
|
|
|
|
|
## Performance Optimization Tips |
|
|
|
|
|
- **GPU Acceleration**: Use `device="cuda"` for significantly faster inference |
|
|
- **Precision**: Set `compute_type="float16"` for optimal speed on modern GPUs |
|
|
- **Threading**: Adjust `cpu_threads` and `num_workers` based on your hardware configuration |
|
|
- **VAD Filtering**: Enable `vad_filter=True` for improved performance on long audio files |
|
|
- **Language Specification**: Set `language="en"` for English audio to improve accuracy and speed |
|
|
- **Beam Size**: Use `beam_size=5` for best accuracy, reduce for faster inference |
|
|
- **Batch Processing**: Process multiple files with a single model instance for efficiency |
|
|
|
|
|
## Use Cases |
|
|
|
|
|
The model excels in various English speech recognition scenarios: |
|
|
|
|
|
- **Meeting Transcription**: High accuracy on conversational English speech (AMI: 4.19% WER) |
|
|
- **Financial Communications**: Specialized performance on earnings calls and financial content (Earnings22: 5.83% WER) |
|
|
- **Broadcast Media**: Excellent results on news, podcasts, and media content |
|
|
- **Educational Content**: Optimized for lectures, presentations, and educational material transcription |
|
|
- **Customer Support**: Accurate transcription of support calls and customer interactions |
|
|
- **Legal Documentation**: Professional-grade accuracy for legal proceedings and depositions |
|
|
- **Medical Transcription**: High-quality transcription for medical consultations and documentation |
|
|
|
|
|
## Support and Contact |
|
|
|
|
|
For technical support, licensing inquiries, or commercial partnerships: |
|
|
|
|
|
- **Website**: https://www.shunyalabs.ai |
|
|
- **Documentation**: https://www.shunyalabs.ai/pingala |
|
|
- **Pypi**: https://pypi.org/project/pingala-shunya |
|
|
- **Commercial Licensing**: [email protected] |
|
|
|
|
|
## Acknowledgments |
|
|
|
|
|
Special thanks to the open-source community for providing the foundational tools that make this model possible. |
|
|
|
|
|
## Version History |
|
|
|
|
|
- **v1.0**: Initial release with state-of-the-art performance across multiple English domains |
|
|
- Optimized for transcription with 3.10% composite WER |
|
|
- Production-ready deployment capabilities |
|
|
|
|
|
This model is provided under the Shunya Labs RAIL-M License. Please ensure compliance with all license terms before use. |

