
Intuitor
Collection
Models in the paper "Learning to Reason without External Rewards"
•
12 items
•
Updated
This model is a GRPO-fine-tuned version of Qwen2.5-1.5B trained on the MATH dataset, as presented in the paper Learning to Reason without External Rewards.
Abstract from the paper: Training large language models (LLMs) for complex reasoning via Reinforcement Learning with Verifiable Rewards (RLVR) is effective but limited by reliance on costly, domain-specific supervision. We explore Reinforcement Learning from Internal Feedback (RLIF), a framework that enables LLMs to learn from intrinsic signals without external rewards or labeled data. We propose Intuitor, an RLIF method that uses a model's own confidence, termed self-certainty, as its sole reward signal. Intuitor replaces external rewards in Group Relative Policy Optimization (GRPO) with self-certainty scores, enabling fully unsupervised learning. Experiments demonstrate that Intuitor matches GRPO's performance on mathematical benchmarks while achieving superior generalization to out-of-domain tasks like code generation, without requiring gold solutions or test cases. Our findings show that intrinsic model signals can drive effective learning across domains, offering a scalable alternative to RLVR for autonomous AI systems where verifiable rewards are unavailable.
Intuitor is a reinforcement learning method that fine-tunes large language models (LLMs) using self-certainty—the model’s own internal confidence—as the sole reward. It is built on a novel paradigm called Reinforcement Learning from Internal Feedback (RLIF).
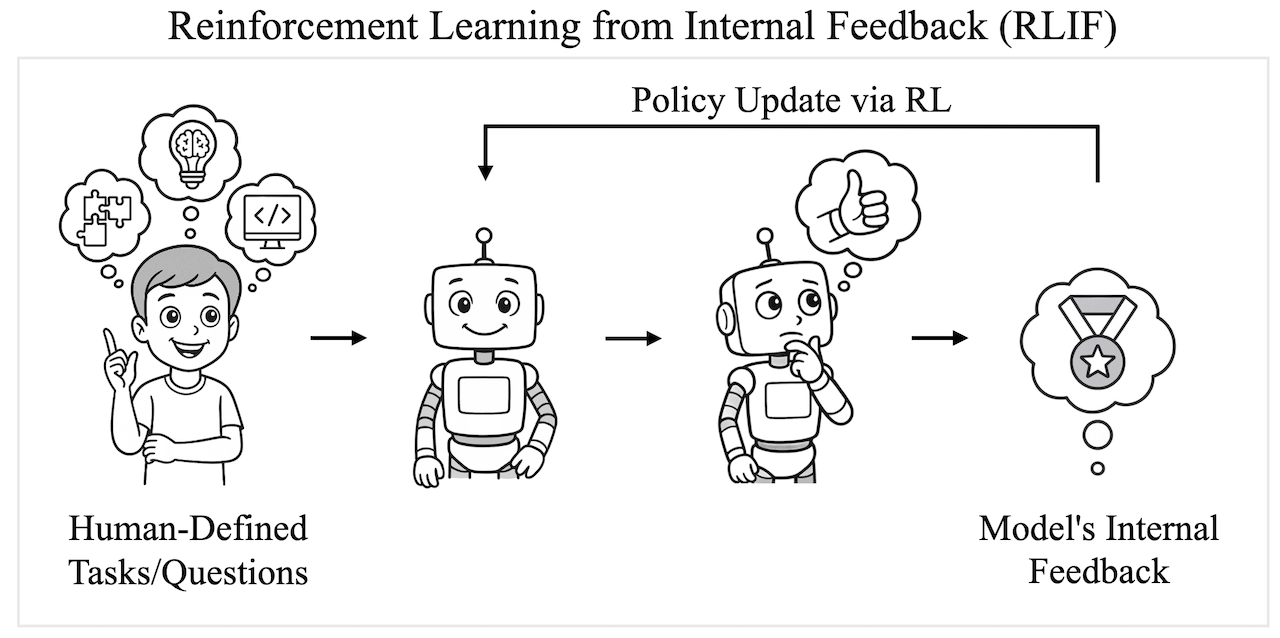
Reinforcement Learning from Internal Feedback (RLIF) is a training framework where language models learn without any external rewards, gold labels, or verifiers. Instead, models improve by optimizing intrinsic signals—such as confidence in their own answers—generated entirely from within. RLIF enables scalable and domain-agnostic fine-tuning of LLMs in settings where human feedback or verifiable supervision is expensive or unavailable.
Intuitor instantiates RLIF by using self-certainty—a model's confidence measured via KL divergence to uniform—as an intrinsic reward in the GRPO policy optimization algorithm.

The official implementation and detailed usage instructions are available on the Intuitor GitHub repository.
You can load and use this model directly with the Hugging Face transformers library:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "sunblaze-ucb/Qwen2.5-1.5B-GRPO-MATH-1EPOCH"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # or torch.float16 depending on available hardware
device_map="auto"
)
# Example prompt for a mathematical reasoning task
# The Qwen2.5 model expects a specific chat template for instruction-tuned usage.
prompt = "Question: Simplify (x^2 + 2x + 1) / (x + 1)\
Answer:"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=100,
do_sample=False, # Set to True for creative outputs
temperature=0.7,
top_p=0.9,
eos_token_id=tokenizer.eos_token_id
)
decoded_output = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(decoded_output)
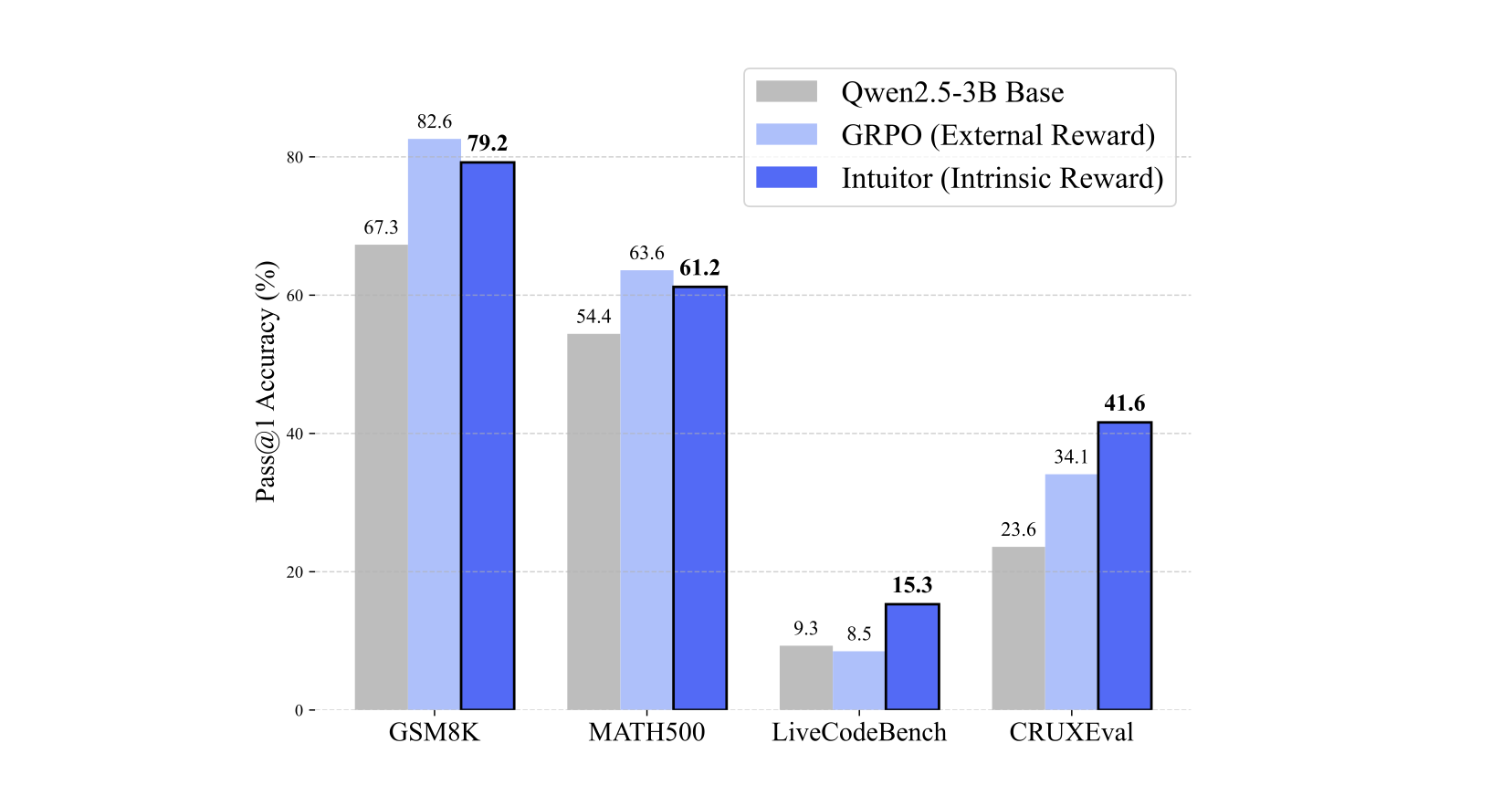
Intuitor achieves:
For detailed results, see Table 1 in the paper.
@article{zhao2025learning,
title={Learning to Reason without External Rewards},
author={Zhao, Xuandong and Kang, Zhewei and Feng, Aosong and Levine, Sergey and Song, Dawn},
journal={arXiv preprint arXiv:2505.19590},
year={2025}
}
@article{sha2024deepseekmath,
title = {DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models},
author = {Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and … Guo, Daya},
journal = {arXiv preprint arXiv:2402.03300},
year = {2024},
}
Base model
Qwen/Qwen2.5-1.5B