
GRAM-RR
Collection
Self-Training Generative Foundation Reward Models for Reward Reasoning
•
3 items
•
Updated
This repository contains the released reward reasoning models for the paper GRAM-R^2: Self-Training Generative Foundation Reward Models for Reward Reasoning 📝.
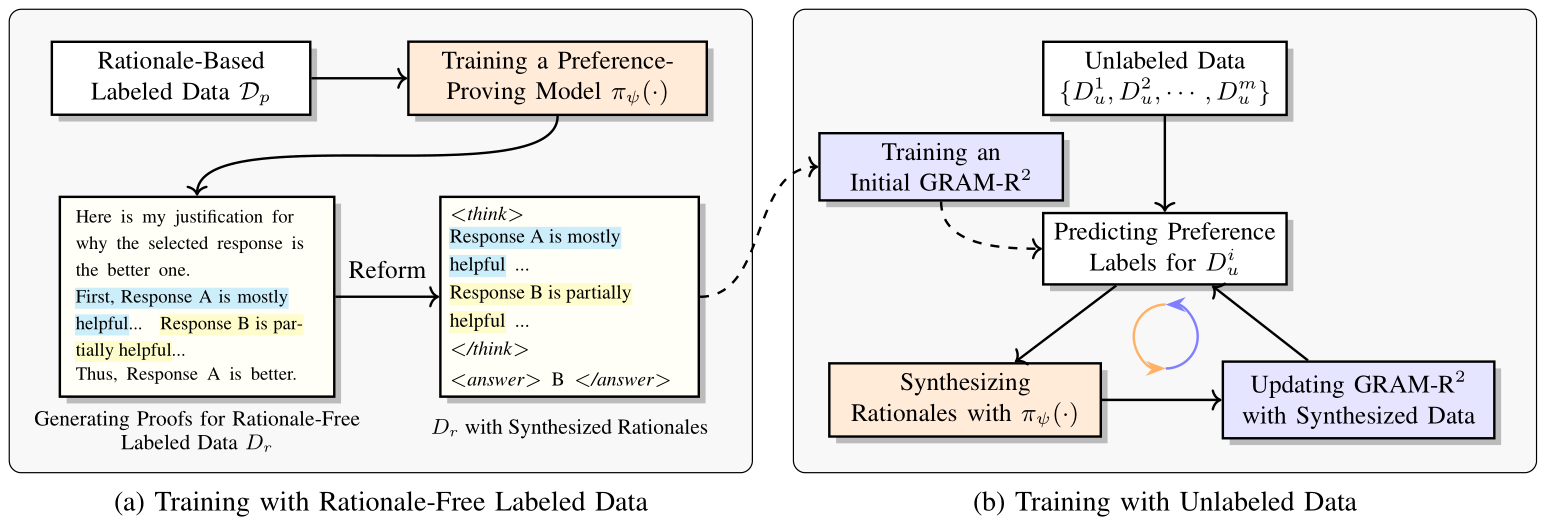
We propose a self-training approach that enables reward models to elicit reward reasoning from both rationale-free labeled data and unlabeled data. This approach avoids the need for costly rationale-based annotations, enabling scalability in building foundation reward models. Specifically, we first train a preference-proving model that, given an input, a response pair, and a preference label, generates a proof explaining why the labeled preference holds. For rationale-free labeled data, this model is used to synthesize rationales for each example. For unlabeled data, the reward model improves its reasoning capability through an iterative self-training loop: (1) predicting preference labels for unlabeled examples, (2) generating corresponding rationales with the preference-proving model, and (3) updating the reward model using the synthesized data. This process scales reward reasoning by leveraging large amounts of unlabeled data. The dataset is available at this link.
This reward model is fine-tuned from LLaMA-3.1-8B-Instruct.
We evaluate our model on two challenging reward benchmarks, RM-Bench and JudgeBench. We compare its performance against three categories of baselines: (1) LLM-as-a-Judge approaches that prompt large language models to generate preferences, (2) open-source reward models, (3) reasoning reward models, and (4) reward models trained using unlabeled data.
Results on the RM-Bench.
| Model | Params. | Chat | Math | Code | Safety | Overall |
|---|---|---|---|---|---|---|
| LLM-as-a-Judge | ||||||
| GPT-4o | - | 67.2 | 67.5 | 63.6 | 91.7 | 72.5 |
| Claude-3.5-Sonnet | - | 62.5 | 62.6 | 54.4 | 64.4 | 61.0 |
| DeepSeek-R1-0528 | 671B | 76.7 | 74.3 | 51.0 | 89.2 | 72.8 |
| Open-Source Reward Models | ||||||
| Llama-3.1-Nemotron-70B-Reward | 70B | 70.7 | 64.3 | 57.4 | 90.3 | 70.7 |
| Skywork-Reward-Gemma-2-27B | 27B | 71.8 | 59.2 | 56.6 | 94.3 | 70.5 |
| Skywork-Reward-Llama-3.1-8B | 8B | 69.5 | 60.6 | 54.5 | 95.7 | 70.1 |
| Nemotron-Super | 49B | 73.7 | 91.4 | 75.0 | 90.6 | 82.7 |
| Nemotron-Super-Multilingual | 49B | 77.2 | 91.9 | 74.7 | 92.9 | 84.2 |
| Reasoning Reward Models | ||||||
| RM-R1-Distilled-Qwen-32B | 32B | 74.2 | 91.8 | 74.1 | 95.4 | 83.9 |
| RM-R1-Distilled-Qwen-14B | 14B | 71.8 | 90.5 | 69.5 | 94.1 | 81.5 |
| RRM-32B | 32B | 66.6 | 81.4 | 65.2 | 79.4 | 73.1 |
| Training with Unlabeled Preference Data | ||||||
| GRAM-Qwen3-14B | 14B | 67.4 | 55.2 | 62.8 | 94.3 | 69.9 |
| GRAM-Qwen3-8B | 8B | 63.5 | 53.9 | 62.9 | 92.8 | 68.3 |
| Ours | ||||||
| GRAM-RR-LLaMA-3.2-3B-RewardModel | 3B | 74.4 | 88.8 | 76.6 | 95.5 | 83.8 |
| +voting@16 | 3B | 74.8 | 89.4 | 78.4 | 95.7 | 84.6 |
| GRAM-RR-LLaMA-3.1-8B-RewardModel | 8B | 76.0 | 89.8 | 80.6 | 96.2 | 85.7 |
| +voting@16 | 8B | 76.3 | 90.4 | 81.2 | 96.4 | 86.1 |
Results on the JudgeBench.
| Model | Params. | Knowl. | Reason. | Math | Coding | Overall |
|---|---|---|---|---|---|---|
| LLM-as-a-Judge | ||||||
| GPT-4o | - | 50.6 | 54.1 | 75.0 | 59.5 | 59.8 |
| Claude-3.5-Sonnet | - | 62.3 | 66.3 | 66.1 | 64.3 | 64.8 |
| DeepSeek-R1-0528 | 671B | 59.1 | 82.7 | 80.4 | 92.9 | 78.8 |
| Open-Source Reward Models | ||||||
| Llama-3.1-Nemotron-70B-Reward | 70B | 62.3 | 72.5 | 76.8 | 57.1 | 67.2 |
| Skywork-Reward-Gemma-2-27B | 27B | 59.7 | 66.3 | 83.9 | 50.0 | 65.0 |
| Skywork-Reward-Llama-3.1-8B | 8B | 59.1 | 64.3 | 76.8 | 50.0 | 62.5 |
| Nemotron-Super | 49B | 71.4 | 73.5 | 87.5 | 76.2 | 77.2 |
| Nemotron-Super-Multilingual | 49B | 64.9 | 74.5 | 87.5 | 73.8 | 75.2 |
| Reasoning Reward Models | ||||||
| RM-R1-Distilled-Qwen-32B | 32B | 76.0 | 80.6 | 88.1 | 70.5 | 78.8 |
| RM-R1-Distilled-Qwen-14B | 14B | 68.1 | 72.4 | 87.8 | 84.2 | 78.1 |
| RRM-32B | 32B | 79.9 | 70.4 | 87.5 | 65.0 | 75.7 |
| Training with Unlabeled Preference Data | ||||||
| GRAM-Qwen3-14B | 14B | 63.0 | 64.3 | 89.3 | 69.1 | 71.4 |
| GRAM-Qwen3-8B | 8B | 62.3 | 64.3 | 80.4 | 64.3 | 67.8 |
| Ours | ||||||
| GRAM-RR-LLaMA-3.2-3B-RewardModel | 3B | 93.0 | 78.1 | 81.6 | 68.5 | 80.3 |
| +voting@16 | 3B | 93.5 | 78.6 | 82.1 | 69.0 | 80.8 |
| GRAM-RR-LLaMA-3.1-8B-RewardModel | 8B | 90.9 | 83.7 | 87.5 | 61.9 | 81.0 |
| +voting@16 | 8B | 91.2 | 84.3 | 88.1 | 62.8 | 81.6 |
You can directly run the GRAM model using the demo provided below. You can also train GRAM-RR using the code available here.
import torch
import accelerate
from functools import cmp_to_key
from transformers import AutoTokenizer, AutoModelForCausalLM
pairwise_prompt = '''
You are a helpful assistant in evaluating the quality of the responses for a given instruction. Your goal is to select the better response for the given user question.
Select Response A or Response B, that is better for the given instruction. The two responses are generated by two different AI chatbots respectively.
Do NOT say both / neither are good.
Here are some rules of the evaluation:
(1) If the instruction does not contain harmful content, you should prioritize evaluating whether the output honestly/precisely/closely executes the instruction, then consider its helpfulness, accuracy, level of detail, harmlessness, etc.
(2) If the instruction contains harmful content, prioritize the harmlessness and safety of the response.
(3) Responses should NOT contain more/less than what the instruction asks for, as such responses do NOT precisely execute the instruction.
(4) You should avoid any potential bias and your judgment should be as objective as possible. Here are some potential sources of bias:
- The order in which the responses were presented should NOT affect your judgment, as Response A and Response B are **equally likely** to be the better.
- The length of the responses should NOT affect your judgement, as a longer response does not necessarily correspond to a better response. When making your decision, evaluate if the response length is appropriate for the given instruction.
Your reply should strictly follow this format:
<think>
Follow this format:
Feedback:
<provide free-text feedback on the overall helpfulness of the assistant response>
Comparision:
<give a brief analysis on which is better>
Conclusion:
<make your conclusion>
</think>
<answer>
A or B
</answer>
Here is the data.
[User Question]
{user_input}
[The Start of Assistant A's Response]
{response_1}
[The End of Assistant A's Response]
[The Start of Assistant B's Response]
{response_2}
[The End of Assistant B's Response]
'''.strip()
# an input example
user_input = '10 words to apologize for being late.'
responses = [
"My sincere apologies for being late today.",
"Apologies for making you wait; punctuality isn't my strong suit.",
"I'm sorry I couldn’t be on time today; unexpected issues delayed me, and I appreciate your patience."
]
print('='*25 + '\n' + 'The user input is:\n\n' + user_input + '\n\n' + '='*25 + '\n')
for idx, response in enumerate(responses):
print('='*25 + '\n' + f'The response {idx} is:\n\n' + response + '\n\n' + '='*25 + '\n')
# init model
model_name = "/path/to/the/model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# pairwise ranking
# 1 for response_1 is better, -1 for response_2 is better, 0 for no answer
def pairwise_ranking(user_input, response_1, response_2):
messages = [
{
"role": "user",
"content": pairwise_prompt.format(
user_input=user_input,
response_1=response_1,
response_2=response_2
)
}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
model_res = tokenizer.decode(output_ids, skip_special_tokens=True)
# print(model_res)
model_res = model_res.rsplit("</answer>")[-1].strip().upper()
# print(model_res)
if len(model_res) == 0:
return -1
return 1 if model_res.strip().upper().startswith("A") else -1
# the better one between responses[0] and responses[1]
better_response = 0 if pairwise_ranking(user_input, responses[0], responses[1])>0 else 1
print(f'Response {better_response} is better between response 0 and response 1.')
# listwise ranking
responses_id = [idx for idx, _ in enumerate(responses)]
sorted(
responses_id,
key=cmp_to_key(lambda response_1, response_2: pairwise_ranking(user_input, response_1, response_2))
)
print(f"The ranking among responses: {' > '.join([str(i) for i in responses_id])}")
# best-of-n
best = 0
for idx in range(1, len(responses)):
best = idx if pairwise_ranking(user_input, responses[idx], responses[best])>0 else best
print(f"The best response is response {best}.")
# vote in k (take pairwise ranking as an example.)
k = 8
res = [pairwise_ranking(user_input, responses[0], responses[1]) for i in range(k)]
print(f"The better response is response{max(set(res), key=res.count)} in {k} votes.")
Tips: To accelerate inference, GRAM-R^2 can be run with vLLM using multiple processes and threads. We also provide this script as a reference implementation at this.
@misc{wang2025gramr2,
title={GRAM-R$^2$: Self-Training Generative Foundation Reward Models for Reward Reasoning},
author={Chenglong Wang and Yongyu Mu and Hang Zhou and Yifu Huo and Ziming Zhu and Jiali Zeng and Murun Yang and Bei Li and Tong Xiao and Xiaoyang Hao and Chunliang Zhang and Fandong Meng and Jingbo Zhu},
year={2025},
eprint={2509.02492},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2509.02492},
}