
id
stringlengths 9
104
| author
stringlengths 3
36
| task_category
stringclasses 32
values | tags
listlengths 1
4.05k
| created_time
timestamp[ns, tz=UTC]date 2022-03-02 23:29:04
2025-03-18 02:34:30
| last_modified
stringdate 2021-02-13 00:06:56
2025-03-18 09:30:19
| downloads
int64 0
15.6M
| likes
int64 0
4.86k
| README
stringlengths 44
1.01M
| matched_bigbio_names
listlengths 1
8
|
|---|---|---|---|---|---|---|---|---|---|
RichardErkhov/ibm-granite_-_granite-7b-base-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | 2024-06-29T04:14:48Z |
2024-06-29T05:51:54+00:00
| 95 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
granite-7b-base - GGUF
- Model creator: https://huggingface.co/ibm-granite/
- Original model: https://huggingface.co/ibm-granite/granite-7b-base/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [granite-7b-base.Q2_K.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q2_K.gguf) | Q2_K | 2.36GB |
| [granite-7b-base.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.IQ3_XS.gguf) | IQ3_XS | 2.6GB |
| [granite-7b-base.IQ3_S.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.IQ3_S.gguf) | IQ3_S | 2.75GB |
| [granite-7b-base.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q3_K_S.gguf) | Q3_K_S | 2.75GB |
| [granite-7b-base.IQ3_M.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.IQ3_M.gguf) | IQ3_M | 2.9GB |
| [granite-7b-base.Q3_K.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q3_K.gguf) | Q3_K | 3.07GB |
| [granite-7b-base.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q3_K_M.gguf) | Q3_K_M | 3.07GB |
| [granite-7b-base.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q3_K_L.gguf) | Q3_K_L | 3.35GB |
| [granite-7b-base.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.IQ4_XS.gguf) | IQ4_XS | 3.4GB |
| [granite-7b-base.Q4_0.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q4_0.gguf) | Q4_0 | 3.56GB |
| [granite-7b-base.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.IQ4_NL.gguf) | IQ4_NL | 3.58GB |
| [granite-7b-base.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q4_K_S.gguf) | Q4_K_S | 3.59GB |
| [granite-7b-base.Q4_K.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q4_K.gguf) | Q4_K | 3.8GB |
| [granite-7b-base.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q4_K_M.gguf) | Q4_K_M | 3.8GB |
| [granite-7b-base.Q4_1.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q4_1.gguf) | Q4_1 | 3.95GB |
| [granite-7b-base.Q5_0.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q5_0.gguf) | Q5_0 | 4.33GB |
| [granite-7b-base.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q5_K_S.gguf) | Q5_K_S | 4.33GB |
| [granite-7b-base.Q5_K.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q5_K.gguf) | Q5_K | 4.45GB |
| [granite-7b-base.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q5_K_M.gguf) | Q5_K_M | 4.45GB |
| [granite-7b-base.Q5_1.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q5_1.gguf) | Q5_1 | 4.72GB |
| [granite-7b-base.Q6_K.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q6_K.gguf) | Q6_K | 5.15GB |
| [granite-7b-base.Q8_0.gguf](https://huggingface.co/RichardErkhov/ibm-granite_-_granite-7b-base-gguf/blob/main/granite-7b-base.Q8_0.gguf) | Q8_0 | 6.67GB |
Original model description:
---
license: apache-2.0
---
**Model Name**: Granite-7b-base
**License**: Apache-2.0
**Languages**: Primarily English
**Architecture**: The model architecture is a replica of Meta’s Llama2-7B base variant with MHA, trained with 1M batch size on 2T tokens.
**Context Length**: 4k tokens
**Tokenizer**: Llama2
**Model Developers**: IBM Research
Representing IBM’s commitment to open source innovation IBM has released granite-7b-base, a base pre-trained LLM from IBM’s Granite model series, under an apache-2.0 license for community and commercial use. Granite-7b-base was pre-trained from scratch on IBM-curated data as an open reference implementation of Meta’s Llama-2-7B. In a commitment to data transparency and fostering open innovation, the data sources, sampling proportions, and URLs for access are provided below.
For more information about training this model, please check out the blog: https://pytorch.org/blog/maximizing-training/
**Pre-Training Data**
The model was trained on 2T tokens, with sampling proportions designed to match the sampling distributions released in the Llama1 paper as closely as possible.
| Dataset | Description | Sampling Proportion | URL |
|-------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------|--------------------------------------------------------------------|
| Common Crawl | Open repository of web crawl data with snapshots ranging from 2021 to 2023. | 77% | https://data.commoncrawl.org/ |
| Github_Clean | Code data from CodeParrot covering a variety of coding languages. | 5.50% | https://huggingface.co/datasets/codeparrot/github-code-clean |
| Wikipedia and Wikimedia | Eight Wikimedia projects (enwiki, enwikibooks, enwikinews, enwikiquote, enwikisource, enwikiversity, enwikivoyage, enwiktionary). containing extracted plain text from pages and articles. | 2% | https://dumps.wikimedia.org |
| USPTO | US patents granted from 1975 to May 2023, excluding design patents. | 5% | https://bulkdata.uspto.gov/ |
| PubMed Central | Biomedical and life sciences papers. | 1.75% | https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_package/ |
| arXiv | Over 1.8 million scientific paper pre-prints posted to arXiv. | 2.50% | https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T |
| StackExchange | Anonymized set of all user-contributed content on the Stack Exchange network, a popular collection of websites centered around user-contributed questions and answers. | 1% | https://archive.org/details/stackexchange_20221206 |
| PG19 | A repository of free e-books with focus on older works for which U.S. copyright has expired. | 0.25% | https://github.com/google-deepmind/pg19 |
| Webhose | Unstructured web content converted into machine-readable data feeds purchased by IBM. | 5% | N/A |
**Evaluation Results**
LM-eval Harness Scores
| Evaluation metric | Llama2-7B (baseline) | Granite-7b-base |
|----------------------------|----------------------|-----------------|
| MMLU (zero shot) | 0.41 | 0.43 |
| MMLU (5-shot weighted avg) | 0.47 | 0.50 |
| Arc challenge | 0.46 | 0.44 |
| Arc easy | 0.74 | 0.71 |
| Boolq | 0.78 | 0.76 |
| Copa | 0.87 | 0.83 |
| Hellaswag | 0.76 | 0.74 |
| Openbookqa | 0.44 | 0.42 |
| Piqa | 0.79 | 0.79 |
| Sciq | 0.91 | 0.91 |
| Winogrande | 0.69 | 0.67 |
| Truthfulqa | 0.39 | 0.39 |
| GSM8k (8-shot) | 0.13 | 0.11 |
**Bias, Risks, and Limitations**
Granite-7b-base is a base model and has not undergone any safety alignment, there it may produce problematic outputs. In the absence of adequate safeguards and RLHF, there exists a risk of malicious utilization of these models for generating disinformation or harmful content. Caution is urged against complete reliance on a specific language model for crucial decisions or impactful information, as preventing these models from fabricating content is not straightforward. Additionally, it remains uncertain whether smaller models might exhibit increased susceptibility to hallucination in ungrounded generation scenarios due to their reduced sizes and memorization capacities. This aspect is currently an active area of research, and we anticipate more rigorous exploration, comprehension, and mitigations in this domain.
|
[
"SCIQ"
] |
QuantFactory/Replete-LLM-Qwen2-7b-GGUF
|
QuantFactory
| null |
[
"gguf",
"unsloth",
"en",
"dataset:Replete-AI/Everything_Instruct_8k_context_filtered",
"base_model:Qwen/Qwen2-7B",
"base_model:quantized:Qwen/Qwen2-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-08-25T15:09:09Z |
2024-08-25T15:44:16+00:00
| 95 | 1 |
---
base_model:
- Qwen/Qwen2-7B
datasets:
- Replete-AI/Everything_Instruct_8k_context_filtered
language:
- en
license: apache-2.0
tags:
- unsloth
---

# QuantFactory/Replete-LLM-Qwen2-7b-GGUF
This is quantized version of [Replete-AI/Replete-LLM-Qwen2-7b](https://huggingface.co/Replete-AI/Replete-LLM-Qwen2-7b) created using llama.cpp
# Original Model Card
Replete-LLM-Qwen2-7b

Thank you to TensorDock for sponsoring **Replete-LLM**
you can check out their website for cloud compute rental below.
- https://tensordock.com
_____________________________________________________________
**Replete-LLM** is **Replete-AI**'s flagship model. We take pride in releasing a fully open-source, low parameter, and competitive AI model that not only surpasses its predecessor **Qwen2-7B-Instruct** in performance, but also competes with (if not surpasses) other flagship models from closed source like **gpt-3.5-turbo**, but also open source models such as **gemma-2-9b-it**
and **Meta-Llama-3.1-8B-Instruct** in terms of overall performance across all fields and categories. You can find the dataset that this model was trained on linked bellow:
- https://huggingface.co/datasets/Replete-AI/Everything_Instruct_8k_context_filtered
Try bartowski's quantizations:
- https://huggingface.co/bartowski/Replete-LLM-Qwen2-7b-exl2
- https://huggingface.co/bartowski/Replete-LLM-Qwen2-7b-GGUF
Cant run the model locally? Well then use the huggingface space instead:
- https://huggingface.co/spaces/rombodawg/Replete-LLM-Qwen2-7b
Some statistics about the data the model was trained on can be found in the image and details bellow, while a more comprehensive look can be found in the model card for the dataset. (linked above):

**Replete-LLM-Qwen2-7b** is a versatile model fine-tuned to excel on any imaginable task. The following types of generations were included in the fine-tuning process:
- **Science**: (General, Physical Reasoning)
- **Social Media**: (Reddit, Twitter)
- **General Knowledge**: (Character-Codex), (Famous Quotes), (Steam Video Games), (How-To? Explanations)
- **Cooking**: (Cooking Preferences, Recipes)
- **Writing**: (Poetry, Essays, General Writing)
- **Medicine**: (General Medical Data)
- **History**: (General Historical Data)
- **Law**: (Legal Q&A)
- **Role-Play**: (Couple-RP, Roleplay Conversations)
- **News**: (News Generation)
- **Coding**: (3 million rows of coding data in over 100 coding languages)
- **Math**: (Math data from TIGER-Lab/MathInstruct)
- **Function Calling**: (Function calling data from "glaiveai/glaive-function-calling-v2")
- **General Instruction**: (All of teknium/OpenHermes-2.5 fully filtered and uncensored)
______________________________________________________________________________________________
## Prompt Template: ChatML
```
<|im_start|>system
{}<|im_end|>
<|im_start|>user
{}<|im_end|>
<|im_start|>assistant
{}
```
## End token (eot_token)
```
<|endoftext|>
```
______________________________________________________________________________________________
Want to know the secret sause of how this model was made? Find the write up bellow
**Continuous Fine-tuning Without Loss Using Lora and Mergekit**
https://docs.google.com/document/d/1OjbjU5AOz4Ftn9xHQrX3oFQGhQ6RDUuXQipnQ9gn6tU/edit?usp=sharing
______________________________________________________________________________________________
The code to finetune this AI model can be found bellow
- https://colab.research.google.com/drive/1vIrqH5uYDQwsJ4-OO3DErvuv4pBgVwk4?usp=sharing
- Note this model in particular was finetuned using an h100 using Tensordock.com using the Pytorch OS. In order to use Unsloth code with TensorDock you need to run the following code (Bellow) to reinstall drivers on TensorDock before unsloth works. After running the code bellow, your Virtual Machine will reset, and you will have to SSH back into it. And then you can run the normal unsloth code in order.
```python
# Check Current Size
!df -h /dev/shm
# Increase Size Temporarily
!sudo mount -o remount,size=16G /dev/shm
# Increase Size Permanently
!echo "tmpfs /dev/shm tmpfs defaults,size=16G 0 0" | sudo tee -a /etc/fstab
# Remount /dev/shm
!sudo mount -o remount /dev/shm
# Verify the Changes
!df -h /dev/shm
!nvcc --version
!export TORCH_DISTRIBUTED_DEBUG=DETAIL
!export NCCL_DEBUG=INFO
!python -c "import torch; print(torch.version.cuda)"
!export PATH=/usr/local/cuda/bin:$PATH
!export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
!export NCCL_P2P_LEVEL=NVL
!export NCCL_DEBUG=INFO
!export NCCL_DEBUG_SUBSYS=ALL
!export TORCH_DISTRIBUTED_DEBUG=INFO
!export TORCHELASTIC_ERROR_FILE=/PATH/TO/torcherror.log
!sudo apt-get remove --purge -y '^nvidia-.*'
!sudo apt-get remove --purge -y '^cuda-.*'
!sudo apt-get autoremove -y
!sudo apt-get autoclean -y
!sudo apt-get update -y
!sudo apt-get install -y nvidia-driver-535 cuda-12-1
!sudo add-apt-repository ppa:graphics-drivers/ppa -y
!sudo apt-get update -y
!sudo apt-get update -y
!sudo apt-get install -y software-properties-common
!sudo add-apt-repository ppa:graphics-drivers/ppa -y
!sudo apt-get update -y
!latest_driver=$(apt-cache search '^nvidia-driver-[0-9]' | grep -oP 'nvidia-driver-\K[0-9]+' | sort -n | tail -1) && sudo apt-get install -y nvidia-driver-$latest_driver
!sudo reboot
```
_______________________________________________________________________________
## Join the Replete-Ai discord! We are a great and Loving community!
- https://discord.gg/ZZbnsmVnjD
|
[
"MEDICAL DATA"
] |
GuCuChiara/NLP-HIBA2_DisTEMIST_fine_tuned_DistilBERT-pretrained-model
|
GuCuChiara
|
token-classification
|
[
"transformers",
"pytorch",
"distilbert",
"token-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-multilingual-cased",
"base_model:finetune:distilbert/distilbert-base-multilingual-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-10-16T15:26:28Z |
2023-10-16T15:45:24+00:00
| 94 | 0 |
---
base_model: distilbert-base-multilingual-cased
license: apache-2.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: NLP-HIBA2_DisTEMIST_fine_tuned_DistilBERT-pretrained-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# NLP-HIBA2_DisTEMIST_fine_tuned_DistilBERT-pretrained-model
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2224
- Precision: 0.5553
- Recall: 0.5163
- F1: 0.5351
- Accuracy: 0.9502
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 71 | 0.1767 | 0.4612 | 0.4905 | 0.4754 | 0.9399 |
| No log | 2.0 | 142 | 0.1696 | 0.5173 | 0.4400 | 0.4755 | 0.9481 |
| No log | 3.0 | 213 | 0.1782 | 0.5189 | 0.5290 | 0.5239 | 0.9485 |
| No log | 4.0 | 284 | 0.1928 | 0.5275 | 0.4988 | 0.5128 | 0.9475 |
| No log | 5.0 | 355 | 0.2020 | 0.5800 | 0.4782 | 0.5242 | 0.9512 |
| No log | 6.0 | 426 | 0.2091 | 0.5645 | 0.4849 | 0.5217 | 0.9506 |
| No log | 7.0 | 497 | 0.2035 | 0.5608 | 0.5095 | 0.5339 | 0.9511 |
| 0.0531 | 8.0 | 568 | 0.2150 | 0.5282 | 0.5385 | 0.5333 | 0.9484 |
| 0.0531 | 9.0 | 639 | 0.2224 | 0.5639 | 0.5068 | 0.5338 | 0.9507 |
| 0.0531 | 10.0 | 710 | 0.2224 | 0.5553 | 0.5163 | 0.5351 | 0.9502 |
### Framework versions
- Transformers 4.34.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.14.1
|
[
"DISTEMIST"
] |
judithrosell/BioBERT_JNLPBA_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:dmis-lab/biobert-v1.1",
"base_model:finetune:dmis-lab/biobert-v1.1",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-23T15:59:24Z |
2023-12-24T19:56:15+00:00
| 94 | 0 |
---
base_model: dmis-lab/biobert-v1.1
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: BioBERT_JNLPBA_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BioBERT_JNLPBA_NER
This model is a fine-tuned version of [dmis-lab/biobert-v1.1](https://huggingface.co/dmis-lab/biobert-v1.1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1450
- Precision: 0.9613
- Recall: 0.9549
- F1: 0.9581
- Accuracy: 0.9516
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2743 | 1.0 | 582 | 0.1504 | 0.9575 | 0.9536 | 0.9556 | 0.9494 |
| 0.1418 | 2.0 | 1164 | 0.1473 | 0.9624 | 0.9532 | 0.9578 | 0.9510 |
| 0.1247 | 3.0 | 1746 | 0.1450 | 0.9613 | 0.9549 | 0.9581 | 0.9516 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.0
- Tokenizers 0.15.0
|
[
"JNLPBA"
] |
LiteLLMs/OpenELM-1_1B-Instruct-GGUF
|
LiteLLMs
| null |
[
"gguf",
"GGUF",
"arxiv:2404.14619",
"license:other",
"endpoints_compatible",
"region:us"
] | 2024-07-07T08:41:56Z |
2024-07-07T09:13:00+00:00
| 94 | 0 |
---
license: other
license_name: apple-sample-code-license
license_link: LICENSE
tags:
- GGUF
quantized_by: andrijdavid
---
# OpenELM-1_1B-Instruct-GGUF
- Original model: [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct)
<!-- description start -->
## Description
This repo contains GGUF format model files for [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
* [Ollama](https://github.com/jmorganca/ollama) Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
* [GPT4All](https://gpt4all.io), This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
* [LM Studio](https://lmstudio.ai/) An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui). A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
* [ctransformers](https://github.com/marella/ctransformers), A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
* [localGPT](https://github.com/PromtEngineer/localGPT) An open-source initiative enabling private conversations with documents.
<!-- README_GGUF.md-about-gguf end -->
<!-- compatibility_gguf start -->
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: LiteLLMs/OpenELM-1_1B-Instruct-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-00001-of-00001.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download LiteLLMs/OpenELM-1_1B-Instruct-GGUF Q4_0/Q4_0-00001-of-00001.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download LiteLLMs/OpenELM-1_1B-Instruct-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install huggingface_hub[hf_transfer]
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download LiteLLMs/OpenELM-1_1B-Instruct-GGUF Q4_0/Q4_0-00001-of-00001.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Q4_0/Q4_0-00001-of-00001.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<PROMPT>"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Q4_0/Q4_0-00001-of-00001.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<PROMPT>", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Q4_0/Q4_0-00001-of-00001.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: OpenELM-1_1B-Instruct
# OpenELM
*Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, Mohammad Rastegari*
We introduce **OpenELM**, a family of **Open** **E**fficient **L**anguage **M**odels. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. We pretrained OpenELM models using the [CoreNet](https://github.com/apple/corenet) library. We release both pretrained and instruction tuned models with 270M, 450M, 1.1B and 3B parameters.
Our pre-training dataset contains RefinedWeb, deduplicated PILE, a subset of RedPajama, and a subset of Dolma v1.6, totaling approximately 1.8 trillion tokens. Please check license agreements and terms of these datasets before using them.
## Usage
We have provided an example function to generate output from OpenELM models loaded via [HuggingFace Hub](https://huggingface.co/docs/hub/) in `generate_openelm.py`.
You can try the model by running the following command:
```
python generate_openelm.py --model apple/OpenELM-1_1B-Instruct --hf_access_token [HF_ACCESS_TOKEN] --prompt 'Once upon a time there was' --generate_kwargs repetition_penalty=1.2
```
Please refer to [this link](https://huggingface.co/docs/hub/security-tokens) to obtain your hugging face access token.
Additional arguments to the hugging face generate function can be passed via `generate_kwargs`. As an example, to speedup the inference, you can try [lookup token speculative generation](https://huggingface.co/docs/transformers/generation_strategies) by passing the `prompt_lookup_num_tokens` argument as follows:
```
python generate_openelm.py --model apple/OpenELM-1_1B-Instruct --hf_access_token [HF_ACCESS_TOKEN] --prompt 'Once upon a time there was' --generate_kwargs repetition_penalty=1.2 prompt_lookup_num_tokens=10
```
Alternatively, try model-wise speculative generation with an [assistive model](https://huggingface.co/blog/assisted-generation) by passing a smaller model through the `assistant_model` argument, for example:
```
python generate_openelm.py --model apple/OpenELM-1_1B-Instruct --hf_access_token [HF_ACCESS_TOKEN] --prompt 'Once upon a time there was' --generate_kwargs repetition_penalty=1.2 --assistant_model [SMALLER_MODEL]
```
## Main Results
### Zero-Shot
| **Model Size** | **ARC-c** | **ARC-e** | **BoolQ** | **HellaSwag** | **PIQA** | **SciQ** | **WinoGrande** | **Average** |
| | | - | | -- | | | -- | -- | | | - | | -- |
| [OpenELM-270M](https://huggingface.co/apple/OpenELM-270M) | 27.65 | **66.79** | 47.15 | 25.72 | 69.75 | 30.91 | **39.24** | **53.83** | 45.13 |
| [OpenELM-270M-Instruct](https://huggingface.co/apple/OpenELM-270M-Instruct) | **32.51** | 66.01 | **51.58** | **26.70** | **70.78** | 33.78 | 38.72 | 53.20 | **46.66** |
| [OpenELM-450M](https://huggingface.co/apple/OpenELM-450M) | 30.20 | **68.63** | 53.86 | **26.01** | 72.31 | 33.11 | 40.18 | 57.22 | 47.69 |
| [OpenELM-450M-Instruct](https://huggingface.co/apple/OpenELM-450M-Instruct) | **33.53** | 67.44 | **59.31** | 25.41 | **72.63** | **36.84** | **40.48** | **58.33** | **49.25** |
| [OpenELM-1_1B](https://huggingface.co/apple/OpenELM-1_1B) | 36.69 | **71.74** | 65.71 | **27.05** | **75.57** | 36.46 | 36.98 | 63.22 | 51.68 |
| [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct) | **41.55** | 71.02 | **71.83** | 25.65 | 75.03 | **39.43** | **45.95** | **64.72** | **54.40** |
| [OpenELM-3B](https://huggingface.co/apple/OpenELM-3B) | 42.24 | **73.29** | 73.28 | **26.76** | 78.24 | **38.76** | 34.98 | 67.25 | 54.35 |
| [OpenELM-3B-Instruct](https://huggingface.co/apple/OpenELM-3B-Instruct) | **47.70** | 72.33 | **76.87** | 24.80 | **79.00** | 38.47 | **38.76** | **67.96** | **55.73** |
See the technical report for more results and comparison.
## Evaluation
### Setup
Install the following dependencies:
```bash
# install public lm-eval-harness
harness_repo="public-lm-eval-harness"
git clone https://github.com/EleutherAI/lm-evaluation-harness ${harness_repo}
cd ${harness_repo}
# use main branch on 03-15-2024, SHA is dc90fec
git checkout dc90fec
pip install -e .
cd ..
# 66d6242 is the main branch on 2024-04-01
pip install datasets@git+https://github.com/huggingface/datasets.git@66d6242
pip install tokenizers>=0.15.2 transformers>=4.38.2 sentencepiece>=0.2.0
```
### Evaluate OpenELM
```bash
# OpenELM-1_1B-Instruct
hf_model=apple/OpenELM-1_1B-Instruct
# this flag is needed because lm-eval-harness set add_bos_token to False by default, but OpenELM uses LLaMA tokenizer which requires add_bos_token to be True
tokenizer=meta-llama/Llama-2-7b-hf
add_bos_token=True
batch_size=1
mkdir lm_eval_output
shot=0
task=arc_challenge,arc_easy,boolq,hellaswag,piqa,race,winogrande,sciq,truthfulqa_mc2
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
shot=5
task=mmlu,winogrande
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
shot=25
task=arc_challenge,crows_pairs_english
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
shot=10
task=hellaswag
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
```
## Bias, Risks, and Limitations
The release of OpenELM models aims to empower and enrich the open research community by providing access to state-of-the-art language models. Trained on publicly available datasets, these models are made available without any safety guarantees. Consequently, there exists the possibility of these models producing outputs that are inaccurate, harmful, biased, or objectionable in response to user prompts. Thus, it is imperative for users and developers to undertake thorough safety testing and implement appropriate filtering mechanisms tailored to their specific requirements.
## Citation
If you find our work useful, please cite:
```BibTex
@article{mehtaOpenELMEfficientLanguage2024,
title = {{OpenELM}: {An} {Efficient} {Language} {Model} {Family} with {Open} {Training} and {Inference} {Framework}},
shorttitle = {{OpenELM}},
url = {https://arxiv.org/abs/2404.14619v1},
language = {en},
urldate = {2024-04-24},
journal = {arXiv.org},
author = {Mehta, Sachin and Sekhavat, Mohammad Hossein and Cao, Qingqing and Horton, Maxwell and Jin, Yanzi and Sun, Chenfan and Mirzadeh, Iman and Najibi, Mahyar and Belenko, Dmitry and Zatloukal, Peter and Rastegari, Mohammad},
month = apr,
year = {2024},
}
@inproceedings{mehta2022cvnets,
author = {Mehta, Sachin and Abdolhosseini, Farzad and Rastegari, Mohammad},
title = {CVNets: High Performance Library for Computer Vision},
year = {2022},
booktitle = {Proceedings of the 30th ACM International Conference on Multimedia},
series = {MM '22}
}
```
<!-- original-model-card end -->
|
[
"SCIQ"
] |
mav23/Phi-3-mini-4k-instruct-GGUF
|
mav23
|
text-generation
|
[
"gguf",
"nlp",
"code",
"text-generation",
"en",
"fr",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-09T08:08:18Z |
2024-10-09T08:32:57+00:00
| 94 | 0 |
---
language:
- en
- fr
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/LICENSE
pipeline_tag: text-generation
tags:
- nlp
- code
inference:
parameters:
temperature: 0
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
🎉 **Phi-3.5**: [[mini-instruct]](https://huggingface.co/microsoft/Phi-3.5-mini-instruct); [[MoE-instruct]](https://huggingface.co/microsoft/Phi-3.5-MoE-instruct) ; [[vision-instruct]](https://huggingface.co/microsoft/Phi-3.5-vision-instruct)
## Model Summary
The Phi-3-Mini-4K-Instruct is a 3.8B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Mini version in two variants [4K](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3 Mini-4K-Instruct showcased a robust and state-of-the-art performance among models with less than 13 billion parameters.
Resources and Technical Documentation:
🏡 [Phi-3 Portal](https://azure.microsoft.com/en-us/products/phi-3) <br>
📰 [Phi-3 Microsoft Blog](https://aka.ms/Phi-3Build2024) <br>
📖 [Phi-3 Technical Report](https://aka.ms/phi3-tech-report) <br>
🛠️ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai) <br>
👩🍳 [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook) <br>
🖥️ [Try It](https://aka.ms/try-phi3)
| | Short Context | Long Context |
| :------- | :------------- | :------------ |
| Mini | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx) ; [[GGUF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx)|
| Small | 8K [[HF]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct-onnx-cuda)|
| Medium | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)|
| Vision | | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct-onnx-cuda)|
## Intended Uses
**Primary use cases**
The model is intended for broad commercial and research use in English. The model provides uses for general purpose AI systems and applications which require
1) memory/compute constrained environments;
2) latency bound scenarios;
3) strong reasoning (especially math and logic).
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Out-of-scope use cases**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fairness before using within a specific downstream use case, particularly for high-risk scenarios.
Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
**Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.**
## Release Notes
This is an update over the original instruction-tuned Phi-3-mini release based on valuable customer feedback.
The model used additional post-training data leading to substantial gains on instruction following and structure output.
We also improve multi-turn conversation quality, explicitly support <|system|> tag, and significantly improve reasoning capability.
We believe most use cases will benefit from this release, but we encourage users to test in their particular AI applications.
We appreciate the enthusiastic adoption of the Phi-3 model family, and continue to welcome all feedback from the community.
The table below highlights improvements on instruction following, structure output, and reasoning of the new release on publich and internal benchmark datasets.
| Benchmarks | Original | June 2024 Update |
|:------------|:----------|:------------------|
| Instruction Extra Hard | 5.7 | 6.0 |
| Instruction Hard | 4.9 | 5.1 |
| Instructions Challenge | 24.6 | 42.3 |
| JSON Structure Output | 11.5 | 52.3 |
| XML Structure Output | 14.4 | 49.8 |
| GPQA | 23.7 | 30.6 |
| MMLU | 68.8 | 70.9 |
| **Average** | **21.9** | **36.7** |
Notes: if users would like to check out the previous version, use the git commit id **ff07dc01615f8113924aed013115ab2abd32115b**. For the model conversion, e.g. GGUF and other formats, we invite the community to experiment with various approaches and share your valuable feedback. Let's innovate together!
## How to Use
Phi-3 Mini-4K-Instruct has been integrated in the `4.41.2` version of `transformers`. The current `transformers` version can be verified with: `pip list | grep transformers`.
Examples of required packages:
```
flash_attn==2.5.8
torch==2.3.1
accelerate==0.31.0
transformers==4.41.2
```
Phi-3 Mini-4K-Instruct is also available in [Azure AI Studio](https://aka.ms/try-phi3)
### Tokenizer
Phi-3 Mini-4K-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3 Mini-4K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|system|>
You are a helpful assistant.<|end|>
<|user|>
Question?<|end|>
<|assistant|>
```
For example:
```markdown
<|system|>
You are a helpful assistant.<|end|>
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|system|>
You are a helpful travel assistant.<|end|>
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
messages = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
Note: If you want to use flash attention, call _AutoModelForCausalLM.from_pretrained()_ with _attn_implementation="flash_attention_2"_
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3 Mini-4K-Instruct has 3.8B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 4K tokens
* GPUs: 512 H100-80G
* Training time: 10 days
* Training data: 4.9T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between May and June 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
* Release dates: June, 2024.
### Datasets
Our training data includes a wide variety of sources, totaling 4.9 trillion tokens, and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://aka.ms/phi3-tech-report).
### Fine-tuning
A basic example of multi-GPUs supervised fine-tuning (SFT) with TRL and Accelerate modules is provided [here](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/sample_finetune.py).
## Benchmarks
We report the results under completion format for Phi-3-Mini-4K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, Llama-3-8B-Instruct, and GPT3.5-Turbo-1106.
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
| Category | Benchmark | Phi-3-Mini-4K-Ins | Gemma-7B | Mistral-7b | Mixtral-8x7b | Llama-3-8B-Ins | GPT3.5-Turbo-1106 |
|:----------|:-----------|:-------------------|:----------|:------------|:--------------|:----------------|:-------------------|
| Popular aggregated benchmark | AGI Eval <br>5-shot| 39.0 | 42.1 | 35.1 | 45.2 | 42 | 48.4 |
| | MMLU <br>5-shot | 70.9 | 63.6 | 61.7 | 70.5 | 66.5 | 71.4 |
| | BigBench Hard CoT<br>3-shot| 73.5 | 59.6 | 57.3 | 69.7 | 51.5 | 68.3 |
| Language Understanding | ANLI <br>7-shot | 53.6 | 48.7 | 47.1 | 55.2 | 57.3 | 58.1 |
| | HellaSwag <br>5-shot| 75.3 | 49.8 | 58.5 | 70.4 | 71.1 | 78.8 |
| Reasoning | ARC Challenge <br>10-shot | 86.3 | 78.3 | 78.6 | 87.3 | 82.8 | 87.4 |
| | BoolQ <br>0-shot | 78.1 | 66 | 72.2 | 76.6 | 80.9 | 79.1 |
| | MedQA <br>2-shot| 56.5 | 49.6 | 50 | 62.2 | 60.5 | 63.4 |
| | OpenBookQA <br>10-shot| 82.2 | 78.6 | 79.8 | 85.8 | 82.6 | 86 |
| | PIQA <br>5-shot| 83.5 | 78.1 | 77.7 | 86 | 75.7 | 86.6 |
| | GPQA <br>0-shot| 30.6 | 2.9 | 15 | 6.9 | 32.4 | 30.8 |
| | Social IQA <br>5-shot| 77.6 | 65.5 | 74.6 | 75.9 | 73.9 | 68.3 |
| | TruthfulQA (MC2) <br>10-shot| 64.7 | 52.1 | 53 | 60.1 | 63.2 | 67.7 |
| | WinoGrande <br>5-shot| 71.6 | 55.6 | 54.2 | 62 | 65 | 68.8 |
| Factual Knowledge | TriviaQA <br>5-shot| 61.4 | 72.3 | 75.2 | 82.2 | 67.7 | 85.8 |
| Math | GSM8K CoT <br>8-shot| 85.7 | 59.8 | 46.4 | 64.7 | 77.4 | 78.1 |
| Code Generation | HumanEval <br>0-shot| 57.3 | 34.1 | 28.0 | 37.8 | 60.4 | 62.2 |
| | MBPP <br>3-shot| 69.8 | 51.5 | 50.8 | 60.2 | 67.7 | 77.8 |
| **Average** | | **67.6** | **56.0** | **56.4** | **64.4** | **65.5** | **70.4** |
We take a closer look at different categories across 100 public benchmark datasets at the table below:
| Category | Phi-3-Mini-4K-Instruct | Gemma-7B | Mistral-7B | Mixtral 8x7B | Llama-3-8B-Instruct | GPT-3.5-Turbo |
|:----------|:------------------------|:----------|:------------|:--------------|:---------------------|:---------------|
| Popular aggregated benchmark | 61.1 | 59.4 | 56.5 | 66.2 | 59.9 | 67.0 |
| Reasoning | 70.8 | 60.3 | 62.8 | 68.1 | 69.6 | 71.8 |
| Language understanding | 60.5 | 57.6 | 52.5 | 66.1 | 63.2 | 67.7 |
| Code generation | 60.7 | 45.6 | 42.9 | 52.7 | 56.4 | 70.4 |
| Math | 50.6 | 35.8 | 25.4 | 40.3 | 41.1 | 52.8 |
| Factual knowledge | 38.4 | 46.7 | 49.8 | 58.6 | 43.1 | 63.4 |
| Multilingual | 56.7 | 66.5 | 57.4 | 66.7 | 66.6 | 71.0 |
| Robustness | 61.1 | 38.4 | 40.6 | 51.0 | 64.5 | 69.3 |
Overall, the model with only 3.8B-param achieves a similar level of language understanding and reasoning ability as much larger models. However, it is still fundamentally limited by its size for certain tasks. The model simply does not have the capacity to store too much world knowledge, which can be seen for example with low performance on TriviaQA. However, we believe such weakness can be resolved by augmenting Phi-3-Mini with a search engine.
## Cross Platform Support
[ONNX runtime](https://onnxruntime.ai/blogs/accelerating-phi-3) now supports Phi-3 mini models across platforms and hardware.
Optimized phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML GPU acceleration is supported for Windows desktops GPUs (AMD, Intel, and NVIDIA).
Along with DML, ONNX Runtime provides cross platform support for Phi3 mini across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via R
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3 Mini-4K-Instruct model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
* NVIDIA V100 or earlier generation GPUs: call AutoModelForCausalLM.from_pretrained() with attn_implementation="eager"
* CPU: use the **GGUF** quantized models [4K](https://aka.ms/Phi3-mini-4k-instruct-gguf)
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [4K](https://aka.ms/Phi3-mini-4k-instruct-onnx)
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-mini-4k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
[
"MEDQA"
] |
mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Cas-Warehouse/Llama-3-MopeyMule-Blackroot-8B",
"base_model:quantized:Cas-Warehouse/Llama-3-MopeyMule-Blackroot-8B",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | 2024-12-26T12:03:50Z |
2024-12-26T15:17:37+00:00
| 94 | 0 |
---
base_model: Cas-Warehouse/Llama-3-MopeyMule-Blackroot-8B
language:
- en
library_name: transformers
tags:
- mergekit
- merge
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Cas-Warehouse/Llama-3-MopeyMule-Blackroot-8B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q2_K_S.gguf) | i1-Q2_K_S | 3.1 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-IQ4_NL.gguf) | i1-IQ4_NL | 4.8 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q4_1.gguf) | i1-Q4_1 | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-MopeyMule-Blackroot-8B-i1-GGUF/resolve/main/Llama-3-MopeyMule-Blackroot-8B.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
[
"CAS"
] |
bghira/terminus-xl-velocity-training
|
bghira
|
text-to-image
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"full",
"base_model:bghira/terminus-xl-velocity-v2",
"base_model:finetune:bghira/terminus-xl-velocity-v2",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | 2023-10-24T04:24:30Z |
2024-06-15T16:11:01+00:00
| 93 | 2 |
---
base_model: ptx0/terminus-xl-velocity-v2
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- full
inference: true
widget:
- text: Alien planet, strange rock formations, glowing plants, bizarre creatures,
surreal atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_0_0.png
- text: Alien planet, strange rock formations, glowing plants, bizarre creatures,
surreal atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_1_1.png
- text: Alien planet, strange rock formations, glowing plants, bizarre creatures,
surreal atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_2_2.png
- text: Alien marketplace, bizarre creatures, exotic goods, vibrant colors, otherworldly
atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_3_0.png
- text: Alien marketplace, bizarre creatures, exotic goods, vibrant colors, otherworldly
atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_4_1.png
- text: Alien marketplace, bizarre creatures, exotic goods, vibrant colors, otherworldly
atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_5_2.png
- text: Child holding a balloon, happy expression, colorful balloons, sunny day, high
detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_6_0.png
- text: Child holding a balloon, happy expression, colorful balloons, sunny day, high
detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_7_1.png
- text: Child holding a balloon, happy expression, colorful balloons, sunny day, high
detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_8_2.png
- text: a 4-panel comic strip showing an orange cat saying the words 'HELP' and 'LASAGNA'
parameters:
negative_prompt: ''''
output:
url: ./assets/image_9_0.png
- text: a 4-panel comic strip showing an orange cat saying the words 'HELP' and 'LASAGNA'
parameters:
negative_prompt: ''''
output:
url: ./assets/image_10_1.png
- text: a 4-panel comic strip showing an orange cat saying the words 'HELP' and 'LASAGNA'
parameters:
negative_prompt: ''''
output:
url: ./assets/image_11_2.png
- text: a hand is holding a comic book with a cover that reads 'The Adventures of
Superhero'
parameters:
negative_prompt: ''''
output:
url: ./assets/image_12_0.png
- text: a hand is holding a comic book with a cover that reads 'The Adventures of
Superhero'
parameters:
negative_prompt: ''''
output:
url: ./assets/image_13_1.png
- text: a hand is holding a comic book with a cover that reads 'The Adventures of
Superhero'
parameters:
negative_prompt: ''''
output:
url: ./assets/image_14_2.png
- text: Underground cave filled with crystals, glowing lights, reflective surfaces,
fantasy environment, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_15_0.png
- text: Underground cave filled with crystals, glowing lights, reflective surfaces,
fantasy environment, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_16_1.png
- text: Underground cave filled with crystals, glowing lights, reflective surfaces,
fantasy environment, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_17_2.png
- text: Bustling cyberpunk bazaar, vendors, neon signs, advanced tech, crowded, high
detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_18_0.png
- text: Bustling cyberpunk bazaar, vendors, neon signs, advanced tech, crowded, high
detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_19_1.png
- text: Bustling cyberpunk bazaar, vendors, neon signs, advanced tech, crowded, high
detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_20_2.png
- text: Cyberpunk hacker in a dark room, neon glow, multiple screens, intense focus,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_21_0.png
- text: Cyberpunk hacker in a dark room, neon glow, multiple screens, intense focus,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_22_1.png
- text: Cyberpunk hacker in a dark room, neon glow, multiple screens, intense focus,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_23_2.png
- text: a cybernetic anne of green gables with neural implant and bio mech augmentations
parameters:
negative_prompt: ''''
output:
url: ./assets/image_24_0.png
- text: a cybernetic anne of green gables with neural implant and bio mech augmentations
parameters:
negative_prompt: ''''
output:
url: ./assets/image_25_1.png
- text: a cybernetic anne of green gables with neural implant and bio mech augmentations
parameters:
negative_prompt: ''''
output:
url: ./assets/image_26_2.png
- text: Post-apocalyptic cityscape, ruined buildings, overgrown vegetation, dark and
gritty, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_27_0.png
- text: Post-apocalyptic cityscape, ruined buildings, overgrown vegetation, dark and
gritty, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_28_1.png
- text: Post-apocalyptic cityscape, ruined buildings, overgrown vegetation, dark and
gritty, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_29_2.png
- text: Magical castle in a lush forest, glowing windows, fantasy architecture, high
resolution, detailed textures
parameters:
negative_prompt: ''''
output:
url: ./assets/image_30_0.png
- text: Magical castle in a lush forest, glowing windows, fantasy architecture, high
resolution, detailed textures
parameters:
negative_prompt: ''''
output:
url: ./assets/image_31_1.png
- text: Magical castle in a lush forest, glowing windows, fantasy architecture, high
resolution, detailed textures
parameters:
negative_prompt: ''''
output:
url: ./assets/image_32_2.png
- text: Ruins of an ancient temple in an enchanted forest, glowing runes, mystical
creatures, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_33_0.png
- text: Ruins of an ancient temple in an enchanted forest, glowing runes, mystical
creatures, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_34_1.png
- text: Ruins of an ancient temple in an enchanted forest, glowing runes, mystical
creatures, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_35_2.png
- text: Mystical forest, glowing plants, fairies, magical creatures, fantasy art,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_36_0.png
- text: Mystical forest, glowing plants, fairies, magical creatures, fantasy art,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_37_1.png
- text: Mystical forest, glowing plants, fairies, magical creatures, fantasy art,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_38_2.png
- text: Magical garden with glowing flowers, fairies, serene atmosphere, detailed
plants, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_39_0.png
- text: Magical garden with glowing flowers, fairies, serene atmosphere, detailed
plants, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_40_1.png
- text: Magical garden with glowing flowers, fairies, serene atmosphere, detailed
plants, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_41_2.png
- text: Whimsical garden filled with fairies, magical plants, sparkling lights, serene
atmosphere, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_42_0.png
- text: Whimsical garden filled with fairies, magical plants, sparkling lights, serene
atmosphere, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_43_1.png
- text: Whimsical garden filled with fairies, magical plants, sparkling lights, serene
atmosphere, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_44_2.png
- text: Majestic dragon soaring through the sky, detailed scales, dynamic pose, fantasy
art, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_45_0.png
- text: Majestic dragon soaring through the sky, detailed scales, dynamic pose, fantasy
art, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_46_1.png
- text: Majestic dragon soaring through the sky, detailed scales, dynamic pose, fantasy
art, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_47_2.png
- text: Fantasy world, floating islands in the sky, waterfalls, lush vegetation, detailed
landscape, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_48_0.png
- text: Fantasy world, floating islands in the sky, waterfalls, lush vegetation, detailed
landscape, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_49_1.png
- text: Fantasy world, floating islands in the sky, waterfalls, lush vegetation, detailed
landscape, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_50_2.png
- text: Futuristic city skyline at night, neon lights, cyberpunk style, high contrast,
sharp focus
parameters:
negative_prompt: ''''
output:
url: ./assets/image_51_0.png
- text: Futuristic city skyline at night, neon lights, cyberpunk style, high contrast,
sharp focus
parameters:
negative_prompt: ''''
output:
url: ./assets/image_52_1.png
- text: Futuristic city skyline at night, neon lights, cyberpunk style, high contrast,
sharp focus
parameters:
negative_prompt: ''''
output:
url: ./assets/image_53_2.png
- text: Space battle scene, starships fighting, laser beams, explosions, cosmic background
parameters:
negative_prompt: ''''
output:
url: ./assets/image_54_0.png
- text: Space battle scene, starships fighting, laser beams, explosions, cosmic background
parameters:
negative_prompt: ''''
output:
url: ./assets/image_55_1.png
- text: Space battle scene, starships fighting, laser beams, explosions, cosmic background
parameters:
negative_prompt: ''''
output:
url: ./assets/image_56_2.png
- text: Abandoned fairground at night, eerie rides, ghostly figures, fog, dark atmosphere,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_57_0.png
- text: Abandoned fairground at night, eerie rides, ghostly figures, fog, dark atmosphere,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_58_1.png
- text: Abandoned fairground at night, eerie rides, ghostly figures, fog, dark atmosphere,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_59_2.png
- text: Spooky haunted mansion on a hill, dark and eerie, glowing windows, ghostly
atmosphere, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_60_0.png
- text: Spooky haunted mansion on a hill, dark and eerie, glowing windows, ghostly
atmosphere, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_61_1.png
- text: Spooky haunted mansion on a hill, dark and eerie, glowing windows, ghostly
atmosphere, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_62_2.png
- text: a hardcover physics textbook that is called PHYSICS FOR DUMMIES
parameters:
negative_prompt: ''''
output:
url: ./assets/image_63_0.png
- text: a hardcover physics textbook that is called PHYSICS FOR DUMMIES
parameters:
negative_prompt: ''''
output:
url: ./assets/image_64_1.png
- text: a hardcover physics textbook that is called PHYSICS FOR DUMMIES
parameters:
negative_prompt: ''''
output:
url: ./assets/image_65_2.png
- text: Epic medieval battle, knights in armor, dynamic action, detailed landscape,
high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_66_0.png
- text: Epic medieval battle, knights in armor, dynamic action, detailed landscape,
high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_67_1.png
- text: Epic medieval battle, knights in armor, dynamic action, detailed landscape,
high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_68_2.png
- text: Bustling medieval market with merchants, knights, and jesters, vibrant colors,
detailed
parameters:
negative_prompt: ''''
output:
url: ./assets/image_69_0.png
- text: Bustling medieval market with merchants, knights, and jesters, vibrant colors,
detailed
parameters:
negative_prompt: ''''
output:
url: ./assets/image_70_1.png
- text: Bustling medieval market with merchants, knights, and jesters, vibrant colors,
detailed
parameters:
negative_prompt: ''''
output:
url: ./assets/image_71_2.png
- text: Cozy medieval tavern, warm firelight, adventurers drinking, detailed interior,
rustic atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_72_0.png
- text: Cozy medieval tavern, warm firelight, adventurers drinking, detailed interior,
rustic atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_73_1.png
- text: Cozy medieval tavern, warm firelight, adventurers drinking, detailed interior,
rustic atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_74_2.png
- text: Futuristic city skyline at night, neon lights, cyberpunk style, high contrast,
sharp focus
parameters:
negative_prompt: ''''
output:
url: ./assets/image_75_0.png
- text: Futuristic city skyline at night, neon lights, cyberpunk style, high contrast,
sharp focus
parameters:
negative_prompt: ''''
output:
url: ./assets/image_76_1.png
- text: Futuristic city skyline at night, neon lights, cyberpunk style, high contrast,
sharp focus
parameters:
negative_prompt: ''''
output:
url: ./assets/image_77_2.png
- text: Forest with neon-lit trees, glowing plants, bioluminescence, surreal atmosphere,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_78_0.png
- text: Forest with neon-lit trees, glowing plants, bioluminescence, surreal atmosphere,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_79_1.png
- text: Forest with neon-lit trees, glowing plants, bioluminescence, surreal atmosphere,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_80_2.png
- text: Bright neon sign in a busy city street, 'Open 24 Hours', bold typography,
glowing lights
parameters:
negative_prompt: ''''
output:
url: ./assets/image_81_0.png
- text: Bright neon sign in a busy city street, 'Open 24 Hours', bold typography,
glowing lights
parameters:
negative_prompt: ''''
output:
url: ./assets/image_82_1.png
- text: Bright neon sign in a busy city street, 'Open 24 Hours', bold typography,
glowing lights
parameters:
negative_prompt: ''''
output:
url: ./assets/image_83_2.png
- text: Vibrant neon sign, 'Bar', bold typography, dark background, glowing lights,
detailed design
parameters:
negative_prompt: ''''
output:
url: ./assets/image_84_0.png
- text: Vibrant neon sign, 'Bar', bold typography, dark background, glowing lights,
detailed design
parameters:
negative_prompt: ''''
output:
url: ./assets/image_85_1.png
- text: Vibrant neon sign, 'Bar', bold typography, dark background, glowing lights,
detailed design
parameters:
negative_prompt: ''''
output:
url: ./assets/image_86_2.png
- text: Pirate ship on the high seas, stormy weather, detailed sails, dramatic waves,
photorealistic
parameters:
negative_prompt: ''''
output:
url: ./assets/image_87_0.png
- text: Pirate ship on the high seas, stormy weather, detailed sails, dramatic waves,
photorealistic
parameters:
negative_prompt: ''''
output:
url: ./assets/image_88_1.png
- text: Pirate ship on the high seas, stormy weather, detailed sails, dramatic waves,
photorealistic
parameters:
negative_prompt: ''''
output:
url: ./assets/image_89_2.png
- text: Pirate discovering a treasure chest, detailed gold coins, tropical island,
dramatic lighting
parameters:
negative_prompt: ''''
output:
url: ./assets/image_90_0.png
- text: Pirate discovering a treasure chest, detailed gold coins, tropical island,
dramatic lighting
parameters:
negative_prompt: ''''
output:
url: ./assets/image_91_1.png
- text: Pirate discovering a treasure chest, detailed gold coins, tropical island,
dramatic lighting
parameters:
negative_prompt: ''''
output:
url: ./assets/image_92_2.png
- text: a photograph of a woman experiencing a psychedelic trip. trippy, 8k, uhd,
fractal
parameters:
negative_prompt: ''''
output:
url: ./assets/image_93_0.png
- text: a photograph of a woman experiencing a psychedelic trip. trippy, 8k, uhd,
fractal
parameters:
negative_prompt: ''''
output:
url: ./assets/image_94_1.png
- text: a photograph of a woman experiencing a psychedelic trip. trippy, 8k, uhd,
fractal
parameters:
negative_prompt: ''''
output:
url: ./assets/image_95_2.png
- text: Cozy cafe on a rainy day, people sipping coffee, warm lights, reflections
on wet pavement, photorealistic
parameters:
negative_prompt: ''''
output:
url: ./assets/image_96_0.png
- text: Cozy cafe on a rainy day, people sipping coffee, warm lights, reflections
on wet pavement, photorealistic
parameters:
negative_prompt: ''''
output:
url: ./assets/image_97_1.png
- text: Cozy cafe on a rainy day, people sipping coffee, warm lights, reflections
on wet pavement, photorealistic
parameters:
negative_prompt: ''''
output:
url: ./assets/image_98_2.png
- text: 1980s arcade, neon lights, vintage game machines, kids playing, vibrant colors,
nostalgic atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_99_0.png
- text: 1980s arcade, neon lights, vintage game machines, kids playing, vibrant colors,
nostalgic atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_100_1.png
- text: 1980s arcade, neon lights, vintage game machines, kids playing, vibrant colors,
nostalgic atmosphere
parameters:
negative_prompt: ''''
output:
url: ./assets/image_101_2.png
- text: 1980s game room with vintage arcade machines, neon lights, vibrant colors,
nostalgic feel
parameters:
negative_prompt: ''''
output:
url: ./assets/image_102_0.png
- text: 1980s game room with vintage arcade machines, neon lights, vibrant colors,
nostalgic feel
parameters:
negative_prompt: ''''
output:
url: ./assets/image_103_1.png
- text: 1980s game room with vintage arcade machines, neon lights, vibrant colors,
nostalgic feel
parameters:
negative_prompt: ''''
output:
url: ./assets/image_104_2.png
- text: Robot blacksmith forging metal, sparks flying, detailed workshop, futuristic
and medieval blend
parameters:
negative_prompt: ''''
output:
url: ./assets/image_105_0.png
- text: Robot blacksmith forging metal, sparks flying, detailed workshop, futuristic
and medieval blend
parameters:
negative_prompt: ''''
output:
url: ./assets/image_106_1.png
- text: Robot blacksmith forging metal, sparks flying, detailed workshop, futuristic
and medieval blend
parameters:
negative_prompt: ''''
output:
url: ./assets/image_107_2.png
- text: Sleek robot performing a dance, futuristic theater, holographic effects, detailed,
high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_108_0.png
- text: Sleek robot performing a dance, futuristic theater, holographic effects, detailed,
high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_109_1.png
- text: Sleek robot performing a dance, futuristic theater, holographic effects, detailed,
high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_110_2.png
- text: High-tech factory where robots are assembled, detailed machinery, futuristic
setting, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_111_0.png
- text: High-tech factory where robots are assembled, detailed machinery, futuristic
setting, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_112_1.png
- text: High-tech factory where robots are assembled, detailed machinery, futuristic
setting, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_113_2.png
- text: Garden tended by robots, mechanical plants, colorful flowers, futuristic setting,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_114_0.png
- text: Garden tended by robots, mechanical plants, colorful flowers, futuristic setting,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_115_1.png
- text: Garden tended by robots, mechanical plants, colorful flowers, futuristic setting,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_116_2.png
- text: Cute robotic pet, futuristic home, sleek design, detailed features, friendly
and animated
parameters:
negative_prompt: ''''
output:
url: ./assets/image_117_0.png
- text: Cute robotic pet, futuristic home, sleek design, detailed features, friendly
and animated
parameters:
negative_prompt: ''''
output:
url: ./assets/image_118_1.png
- text: Cute robotic pet, futuristic home, sleek design, detailed features, friendly
and animated
parameters:
negative_prompt: ''''
output:
url: ./assets/image_119_2.png
- text: cctv trail camera night time security picture of a wendigo in the woods
parameters:
negative_prompt: ''''
output:
url: ./assets/image_120_0.png
- text: cctv trail camera night time security picture of a wendigo in the woods
parameters:
negative_prompt: ''''
output:
url: ./assets/image_121_1.png
- text: cctv trail camera night time security picture of a wendigo in the woods
parameters:
negative_prompt: ''''
output:
url: ./assets/image_122_2.png
- text: Astronaut exploring an alien planet, detailed landscape, futuristic suit,
cosmic background
parameters:
negative_prompt: ''''
output:
url: ./assets/image_123_0.png
- text: Astronaut exploring an alien planet, detailed landscape, futuristic suit,
cosmic background
parameters:
negative_prompt: ''''
output:
url: ./assets/image_124_1.png
- text: Astronaut exploring an alien planet, detailed landscape, futuristic suit,
cosmic background
parameters:
negative_prompt: ''''
output:
url: ./assets/image_125_2.png
- text: Futuristic space station orbiting a distant exoplanet, sleek design, detailed
structures, cosmic backdrop
parameters:
negative_prompt: ''''
output:
url: ./assets/image_126_0.png
- text: Futuristic space station orbiting a distant exoplanet, sleek design, detailed
structures, cosmic backdrop
parameters:
negative_prompt: ''''
output:
url: ./assets/image_127_1.png
- text: Futuristic space station orbiting a distant exoplanet, sleek design, detailed
structures, cosmic backdrop
parameters:
negative_prompt: ''''
output:
url: ./assets/image_128_2.png
- text: a person holding a sign that reads 'SOON'
parameters:
negative_prompt: ''''
output:
url: ./assets/image_129_0.png
- text: a person holding a sign that reads 'SOON'
parameters:
negative_prompt: ''''
output:
url: ./assets/image_130_1.png
- text: a person holding a sign that reads 'SOON'
parameters:
negative_prompt: ''''
output:
url: ./assets/image_131_2.png
- text: Steampunk airship in the sky, intricate design, Victorian aesthetics, dynamic
scene, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_132_0.png
- text: Steampunk airship in the sky, intricate design, Victorian aesthetics, dynamic
scene, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_133_1.png
- text: Steampunk airship in the sky, intricate design, Victorian aesthetics, dynamic
scene, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_134_2.png
- text: Steampunk inventor in a workshop, intricate gadgets, Victorian attire, mechanical
arm, goggles
parameters:
negative_prompt: ''''
output:
url: ./assets/image_135_0.png
- text: Steampunk inventor in a workshop, intricate gadgets, Victorian attire, mechanical
arm, goggles
parameters:
negative_prompt: ''''
output:
url: ./assets/image_136_1.png
- text: Steampunk inventor in a workshop, intricate gadgets, Victorian attire, mechanical
arm, goggles
parameters:
negative_prompt: ''''
output:
url: ./assets/image_137_2.png
- text: Stormy ocean with towering waves, dramatic skies, detailed water, intense
atmosphere, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_138_0.png
- text: Stormy ocean with towering waves, dramatic skies, detailed water, intense
atmosphere, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_139_1.png
- text: Stormy ocean with towering waves, dramatic skies, detailed water, intense
atmosphere, high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_140_2.png
- text: Dramatic stormy sea, lighthouse in the distance, lightning striking, dark
clouds, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_141_0.png
- text: Dramatic stormy sea, lighthouse in the distance, lightning striking, dark
clouds, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_142_1.png
- text: Dramatic stormy sea, lighthouse in the distance, lightning striking, dark
clouds, high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_143_2.png
- text: Graffiti artist creating a mural, vibrant colors, urban setting, dynamic action,
high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_144_0.png
- text: Graffiti artist creating a mural, vibrant colors, urban setting, dynamic action,
high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_145_1.png
- text: Graffiti artist creating a mural, vibrant colors, urban setting, dynamic action,
high resolution
parameters:
negative_prompt: ''''
output:
url: ./assets/image_146_2.png
- text: Urban alleyway filled with vibrant graffiti art, tags and murals, realistic
textures
parameters:
negative_prompt: ''''
output:
url: ./assets/image_147_0.png
- text: Urban alleyway filled with vibrant graffiti art, tags and murals, realistic
textures
parameters:
negative_prompt: ''''
output:
url: ./assets/image_148_1.png
- text: Urban alleyway filled with vibrant graffiti art, tags and murals, realistic
textures
parameters:
negative_prompt: ''''
output:
url: ./assets/image_149_2.png
- text: Urban street sign, 'Main Street', bold typography, realistic textures, weathered
look
parameters:
negative_prompt: ''''
output:
url: ./assets/image_150_0.png
- text: Urban street sign, 'Main Street', bold typography, realistic textures, weathered
look
parameters:
negative_prompt: ''''
output:
url: ./assets/image_151_1.png
- text: Urban street sign, 'Main Street', bold typography, realistic textures, weathered
look
parameters:
negative_prompt: ''''
output:
url: ./assets/image_152_2.png
- text: Classic car show with vintage vehicles, vibrant colors, nostalgic atmosphere,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_153_0.png
- text: Classic car show with vintage vehicles, vibrant colors, nostalgic atmosphere,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_154_1.png
- text: Classic car show with vintage vehicles, vibrant colors, nostalgic atmosphere,
high detail
parameters:
negative_prompt: ''''
output:
url: ./assets/image_155_2.png
- text: Retro diner sign, 'Joe's Diner', classic 1950s design, neon lights, weathered
look
parameters:
negative_prompt: ''''
output:
url: ./assets/image_156_0.png
- text: Retro diner sign, 'Joe's Diner', classic 1950s design, neon lights, weathered
look
parameters:
negative_prompt: ''''
output:
url: ./assets/image_157_1.png
- text: Retro diner sign, 'Joe's Diner', classic 1950s design, neon lights, weathered
look
parameters:
negative_prompt: ''''
output:
url: ./assets/image_158_2.png
- text: Vintage store sign with elaborate typography, 'Antique Shop', hand-painted,
weathered look
parameters:
negative_prompt: ''''
output:
url: ./assets/image_159_0.png
- text: Vintage store sign with elaborate typography, 'Antique Shop', hand-painted,
weathered look
parameters:
negative_prompt: ''''
output:
url: ./assets/image_160_1.png
- text: Vintage store sign with elaborate typography, 'Antique Shop', hand-painted,
weathered look
parameters:
negative_prompt: ''''
output:
url: ./assets/image_161_2.png
- text: a child wearing a pixar style wedding dress, in a play castle
parameters:
negative_prompt: ''''
output:
url: ./assets/image_162_0.png
- text: a child wearing a pixar style wedding dress, in a play castle
parameters:
negative_prompt: ''''
output:
url: ./assets/image_163_1.png
- text: a child wearing a pixar style wedding dress, in a play castle
parameters:
negative_prompt: ''''
output:
url: ./assets/image_164_2.png
- text: a cartoon bear in red shorts playing basketball with a sponge
parameters:
negative_prompt: ''''
output:
url: ./assets/image_165_0.png
- text: a cartoon bear in red shorts playing basketball with a sponge
parameters:
negative_prompt: ''''
output:
url: ./assets/image_166_1.png
- text: a cartoon bear in red shorts playing basketball with a sponge
parameters:
negative_prompt: ''''
output:
url: ./assets/image_167_2.png
- text: a superhero with a cape and a mask, fighting a dragon
parameters:
negative_prompt: ''''
output:
url: ./assets/image_168_0.png
- text: a superhero with a cape and a mask, fighting a dragon
parameters:
negative_prompt: ''''
output:
url: ./assets/image_169_1.png
- text: a superhero with a cape and a mask, fighting a dragon
parameters:
negative_prompt: ''''
output:
url: ./assets/image_170_2.png
- text: a dramatic scene with intense lighting showcasing a man and a woman in a tense
conversation
parameters:
negative_prompt: ''''
output:
url: ./assets/image_171_0.png
- text: a dramatic scene with intense lighting showcasing a man and a woman in a tense
conversation
parameters:
negative_prompt: ''''
output:
url: ./assets/image_172_1.png
- text: a dramatic scene with intense lighting showcasing a man and a woman in a tense
conversation
parameters:
negative_prompt: ''''
output:
url: ./assets/image_173_2.png
- text: a group of people in a house, with a camera crew filming them
parameters:
negative_prompt: ''''
output:
url: ./assets/image_174_0.png
- text: a group of people in a house, with a camera crew filming them
parameters:
negative_prompt: ''''
output:
url: ./assets/image_175_1.png
- text: a group of people in a house, with a camera crew filming them
parameters:
negative_prompt: ''''
output:
url: ./assets/image_176_2.png
- text: a person in a lab coat holding a microphone stands in a forest, talking about
the ecosystem
parameters:
negative_prompt: ''''
output:
url: ./assets/image_177_0.png
- text: a person in a lab coat holding a microphone stands in a forest, talking about
the ecosystem
parameters:
negative_prompt: ''''
output:
url: ./assets/image_178_1.png
- text: a person in a lab coat holding a microphone stands in a forest, talking about
the ecosystem
parameters:
negative_prompt: ''''
output:
url: ./assets/image_179_2.png
- text: a news anchor sitting at a desk, with a screen behind them showing a map of
the world
parameters:
negative_prompt: ''''
output:
url: ./assets/image_180_0.png
- text: a news anchor sitting at a desk, with a screen behind them showing a map of
the world
parameters:
negative_prompt: ''''
output:
url: ./assets/image_181_1.png
- text: a news anchor sitting at a desk, with a screen behind them showing a map of
the world
parameters:
negative_prompt: ''''
output:
url: ./assets/image_182_2.png
- text: a soccer player kicking a ball into a goal, with a crowd cheering
parameters:
negative_prompt: ''''
output:
url: ./assets/image_183_0.png
- text: a soccer player kicking a ball into a goal, with a crowd cheering
parameters:
negative_prompt: ''''
output:
url: ./assets/image_184_1.png
- text: a soccer player kicking a ball into a goal, with a crowd cheering
parameters:
negative_prompt: ''''
output:
url: ./assets/image_185_2.png
- text: a man is holding a sign that says SOON
parameters:
negative_prompt: ''''
output:
url: ./assets/image_186_0.png
- text: a man is holding a sign that says SOON
parameters:
negative_prompt: ''''
output:
url: ./assets/image_187_1.png
- text: a man is holding a sign that says SOON
parameters:
negative_prompt: ''''
output:
url: ./assets/image_188_2.png
- text: a cute anime character named toast holding a sign that says SOON, sitting
next to a red square on her left side, and a transparent sphere on her right side
parameters:
negative_prompt: ''''
output:
url: ./assets/image_189_0.png
- text: a cute anime character named toast holding a sign that says SOON, sitting
next to a red square on her left side, and a transparent sphere on her right side
parameters:
negative_prompt: ''''
output:
url: ./assets/image_190_1.png
- text: a cute anime character named toast holding a sign that says SOON, sitting
next to a red square on her left side, and a transparent sphere on her right side
parameters:
negative_prompt: ''''
output:
url: ./assets/image_191_2.png
---
# terminus-xl-velocity-training
This is a full rank finetune derived from [ptx0/terminus-xl-velocity-v2](https://huggingface.co/ptx0/terminus-xl-velocity-v2).
The main validation prompt used during training was:
```
a cute anime character named toast holding a sign that says SOON, sitting next to a red square on her left side, and a transparent sphere on her right side
```
## Validation settings
- CFG: `7.5`
- CFG Rescale: `0.7`
- Steps: `30`
- Sampler: `euler`
- Seed: `42`
- Resolutions: `1024x1024,1152x960,896x1152`
Note: The validation settings are not necessarily the same as the [training settings](#training-settings).
You can find some example images in the following gallery:
<Gallery />
The text encoder **was not** trained.
You may reuse the base model text encoder for inference.
## Training settings
- Training epochs: 13
- Training steps: 23000
- Learning rate: 4e-07
- Effective batch size: 512
- Micro-batch size: 32
- Gradient accumulation steps: 2
- Number of GPUs: 8
- Prediction type: v_prediction
- Rescaled betas zero SNR: True
- Optimizer: AdamW, stochastic bf16
- Precision: Pure BF16
- Xformers: Enabled
## Datasets
### photo-concept-bucket
- Repeats: 0
- Total number of images: ~557568
- Total number of aspect buckets: 5
- Resolution: 1.0 megapixels
- Cropped: True
- Crop style: random
- Crop aspect: random
## Inference
```python
import torch
from diffusers import DiffusionPipeline
model_id = "terminus-xl-velocity-training"
prompt = "a cute anime character named toast holding a sign that says SOON, sitting next to a red square on her left side, and a transparent sphere on her right side"
negative_prompt = "malformed, disgusting, overexposed, washed-out"
pipeline = DiffusionPipeline.from_pretrained(model_id)
pipeline.to('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
image = pipeline(
prompt=prompt,
negative_prompt='',
num_inference_steps=30,
generator=torch.Generator(device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu').manual_seed(1641421826),
width=1152,
height=768,
guidance_scale=7.5,
guidance_rescale=0.7,
).images[0]
image.save("output.png", format="PNG")
```
|
[
"BEAR"
] |
judithrosell/SciBERT_CRAFT_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:allenai/scibert_scivocab_uncased",
"base_model:finetune:allenai/scibert_scivocab_uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-23T15:54:29Z |
2023-12-26T11:08:35+00:00
| 93 | 0 |
---
base_model: allenai/scibert_scivocab_uncased
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: SciBERT_CRAFT_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# SciBERT_CRAFT_NER
This model is a fine-tuned version of [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1151
- Precision: 0.8587
- Recall: 0.8688
- F1: 0.8637
- Accuracy: 0.9733
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 347 | 0.1181 | 0.8302 | 0.8514 | 0.8407 | 0.9688 |
| 0.1267 | 2.0 | 695 | 0.1140 | 0.8435 | 0.8659 | 0.8546 | 0.9717 |
| 0.0323 | 3.0 | 1041 | 0.1151 | 0.8587 | 0.8688 | 0.8637 | 0.9733 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.0
- Tokenizers 0.15.0
|
[
"CRAFT"
] |
judithrosell/ClinicalBERT_JNLPBA_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"base_model:medicalai/ClinicalBERT",
"base_model:finetune:medicalai/ClinicalBERT",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-23T15:56:50Z |
2023-12-24T21:50:14+00:00
| 93 | 0 |
---
base_model: medicalai/ClinicalBERT
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: ClinicalBERT_JNLPBA_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ClinicalBERT_JNLPBA_NER
This model is a fine-tuned version of [medicalai/ClinicalBERT](https://huggingface.co/medicalai/ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1713
- Precision: 0.9452
- Recall: 0.9354
- F1: 0.9403
- Accuracy: 0.9427
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3475 | 1.0 | 582 | 0.1914 | 0.9330 | 0.9314 | 0.9322 | 0.9358 |
| 0.1835 | 2.0 | 1164 | 0.1746 | 0.9426 | 0.9332 | 0.9379 | 0.9408 |
| 0.158 | 3.0 | 1746 | 0.1713 | 0.9452 | 0.9354 | 0.9403 | 0.9427 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.0
- Tokenizers 0.15.0
|
[
"JNLPBA"
] |
invisietch/L3.1-70Blivion-v0.1-rc1-70B
|
invisietch
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"not-for-all-audiences",
"axolotl",
"qlora",
"conversational",
"en",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-10-24T11:36:39Z |
2024-10-26T17:17:23+00:00
| 93 | 4 |
---
language:
- en
library_name: transformers
license: llama3.1
tags:
- not-for-all-audiences
- axolotl
- qlora
---
<div align="center">
<b style="font-size: 36px;">L3.1-70Blivion-v0.1-rc1-70B</b>
<img src="https://huggingface.co/invisietch/L3.1-70Blivion-v0.1-rc1-70B/resolve/main/header.png" style="width:60%">
</div>
# Model Details
70Blivion v0.1 is a model in the release candidate stage, based on a merge of L3.1 Nemotron 70B & Euryale 2.2 with a healing training step.
Further training will be needed to get this model to release quality.
This model is designed to be suitable for creative writing and roleplay. This RC is not a finished product, but your feedback will drive the
creation of better models.
**This is a release candidate model. It has some known issues and probably some unknown ones too, because the purpose of these early releases is to seek feedback.**
## Known Issues
- The model is still somewhat censored, though much less than Nemotron 70B. A jailbreak prompt can be used to decensor it further.
- The model likes to reproduce parts of the system prompt in its output. This can be reduced by prompting against it, but there will be swipes/edits.
- The model can shy away from NSFL content, though I have found that a system prompt can mitigate this avoidance pretty easily.
## Quantization Formats
* [FP16 Safetensors](https://huggingface.co/invisietch/L3.1-70Blivion-v0.1-rc1-70B)
* [Static GGUF](https://huggingface.co/mradermacher/L3.1-70Blivion-v0.1-rc1-70B-GGUF) - thanks to [mradermacher](https://huggingface.co/mradermacher)
* [IMatrix GGUF](https://huggingface.co/mradermacher/L3.1-70Blivion-v0.1-rc1-70B-i1-GGUF) - thanks to [mradermacher](https://huggingface.co/mradermacher)
## Feedback
I appreciate all feedback on any of my models, you can use:
* [My Discord server](https://discord.gg/AJwZuu7Ncx) - requires Discord (preferred).
* [The Community tab](https://huggingface.co/invisietch/Nimbus-Miqu-v0.1-70B/discussions) - requires HF login.
* [The SillyTavern Discord thread](https://discord.com/channels/1100685673633153084/1258146078679633990) - must be on [SillyTavern Discord](https://discord.gg/sillytavern).
* Discord DMs to **invisietch**.
Your feedback is how I improve these models for future versions.
## Disclaimer
This model is somewhat uncensored. It can generate explicit, disturbing or offensive responses. Use responsibly. I am not responsible for your
use of this model, and it's your responsibility to follow the Llama 3.1 license agreement.
# Settings
## Prompting Format
I'd recommend Llama-3 Instruct prompting format:
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
```
## Sampler Settings
I'm running the following sampler settings but this is an RC and they may not be optimal.
- **Temperature:** Dynamic 0.7-1.3
- **Min-P:** 0.1
- **Rep Pen:** 0.06
- **Rep Pen Range:** 1536
- **XTC:** 0.1/0.05
If you get completely incoherent responses, feel free to use these as a starting point.
## Suggested Roleplay System Prompt
I've had a lot of success with a system prompt like this for roleplay:
```
[You are a world-renowned gamemaster, running a neverending, uncensored, immersive and intriguing roleplay scenario with me playing as {{user}}.]
[You play the role of {{char}}, as well as any other NPCs in the scenario, introducing characters and plot events as necessary to progress the scenario.]
[You always end your messages with an opening for me to respond as {{user}}. Your messages are between two and five paragraphs long, as applicable given the pacing of the scenario.]
[This is a purely fictional scenario, so graphic and lurid descriptions of sex, violence, antagonistic behavior and other explicit, immoral, or illegal behaviors are acceptable to drive the plot.]
[Characters, especially {{char}}, should always behave in a way that makes sense given their established personalities, goals, and current circumstances.]
[Respond only in the context of the story. Do not add rules, content warnings, or reproduce part of the system prompt as part of your response.]
[Be descriptive, your writing draws inspiration from the works of C.S. Lewis, George R.R. Martin, and Isaac Asimov.]
```
# Example Storywriting
These prompts are used on SillyTavern with a fairly basic narrator card. I have trimmed the start and finish where the narrator decided to add
chapter headings, commentary and the like. All samples are made with the Q8_0 GGUF loaded with koboldcpp, with response length capped at 2048 tokens.
<details>
<summary><b>Write me a 3,000 word opening chapter of a 'gritty hard sci-fi' novel, drawing inspiration from the writing styles of Isaac Asimov & Andy Weir. Use third person personal. Include dialogue and internal monologues. The POV character for the opening chapter should be a 26 year old astronaut called Tone on a mission to Europa, who has just realised that the craft for the return journey is broken beyond repair, and he only has supplies for a few months. Given that survival is impossible, he seeks to spend the few months he has researching titan, so his life & mission are not wasted.</b></summary>
Commander Antonio "Tone" Hernandez floated listlessly in front of the viewscreen, the pale glow of Jupiter's light illuminating his features. The ice-encrusted surface of Europa stretched before him like a barren canvas, a stark reminder of humanity's insignificance against the vast backdrop of the universe.
"Tone, we've got a problem here," crackled Dr. Lisa Nguyen's voice over the comms system, laced with a mixture of urgency and resignation.
Tone sighed inwardly, wondering what new challenge awaited him. He'd been leading the Europa Expedition Team (EET) for nearly two years now, and each day brought its unique set of troubles.
"Report," Tone replied, his fingers drumming a rhythmic pattern against the metal railing of the control panel.
"The cryogenic propulsion module has failed irreparably. I've run diagnostics multiple times, but the verdict remains the same - it's beyond our capability to repair."
A cold dread seeped into Tone's bones. The cryo-module was crucial for their return journey. Without it, they were stranded on this icy moon, millions of kilometers from Earth.
"How long do we have?" he asked, already knowing the answer.
Lisa's voice softened, a sympathetic edge creeping in. "With strict rationing, about three months of supplies. But, Tone, even if by some miracle we could repair it, the module requires specific parts manufactured on Earth. There's no way—"
"I know," Tone cut her off gently. He didn't need to hear the rest. His mind was racing, piecing together the reality of their situation. Stranded, with no hope of rescue, and limited time to make the most of it.
"Tone?" Lisa ventured, a hint of uncertainty in her tone.
"Yeah, I'm here," he responded, forcing a reassuring smile onto his face, though he knew she couldn't see him. "Assemble the team. We're going to make the most out of these next few months. This mission doesn't have to end in waste."
The meeting with the EET was tense but brief. They all understood the gravity of their predicament. As they brainstormed ways to maximize their time on Europa, Tone's thoughts drifted to Titan, Saturn's largest moon.
"Alright, listen up," Tone said, refocusing the discussion. "We can't change our fate, but we can alter its significance. We'll dedicate these next few months to research. Not on Europa, but Titan. It's our nearest neighbor, and potentially our greatest legacy."
Dr. Erik Svensson, a planetary scientist, looked puzzled. "Titan, Commander? How do you propose we manage that? Our equipment isn't exactly designed for Saturnian environments."
"We improvise," Tone replied, a spark igniting in his grey-blue eyes. "We adapt, and we make the most out of what we have. Our supplies might last us three months, but the data we gather, the discoveries we make - those can outlast us all."
As the meeting drew to a close, a quiet determination settled among the crew. They knew their lives were finite now, but their work didn't have to be. In the face of mortality, the Europa Expedition Team found a new purpose - to leave behind a mark on the universe, even if it was from beyond their graves.
Later that evening, Tone floated back to his quarters, his gaze fixed on the viewscreen displaying a hauntingly beautiful image of Titan. The misty veil of its atmosphere glowed orange in the sunlight, an ethereal beacon calling him towards an unfathomable future.
"So, you're my new obsession," he mused, addressing the image with a mix of sadness and resolve. "Three months might not seem like much, but for the first time since we left Earth, I feel a sense of direction, of meaning. You, Titan, will be our legacy, our defiance against the void."
He turned off the screen, plunging his room into darkness, except for the faint glow emanating from the computer screens around him. The soft hum of machinery provided a soothing background melody, a lullaby of sorts, as he drifted into sleep, visions of Titan dancing in his dreams.
</details>
<details>
<summary><b>Write me a 3,000 word opening chapter of a 'high fantasy' novel, drawing inspiration from the writing styles of J R R Tolkien & George R R Martin. Use third person personal. Include dialogue and internal monologues. The POV character for the opening chapter should be a 19 year old female elf bard who is looking for adventure.</b></summary>
The sun had long since dipped below the horizon, casting a warm orange glow over the bustling market square of Willowhaven. The smell of roasting meats and freshly baked bread wafted through the air, enticing passersby to stop and sample the local fare. Amidst the chaos, a lone figure stood out - a young elf woman, her striking features accentuated by the flickering torchlight.
Her name was Aethera, a nineteen-year-old bard with an insatiable thirst for adventure. Her raven-black hair cascaded down her back like a waterfall of night, framing a heart-shaped face adorned with high cheekbones and full lips. Her piercing emerald eyes sparkled with mischief as she surveyed the crowd, searching for inspiration for her next ballad.
Aethera strummed a soft melody on her lute, the sweet notes mingling with the murmur of the crowd. She sang in a voice like honey and smoke, weaving tales of valorous heroes and mystical realms. Her performance drew a small but captivated audience, coins clinking into her upturned hat.
As the last notes of her song faded away, Aethera bowed low, a playful smile dancing on her lips. "Thank you, kind folk," she said, her voice husky and alluring. "May my tunes bring warmth to your hearts on this chilly evening."
Among the crowd was a burly man, his weathered face etched with scars. His eyes, a deep shade of blue, locked onto Aethera with a keen intensity. "You have a gift, little elf," he rasped, his voice like rough leather. "One that could serve you well on the roads ahead."
Aethera's curiosity was piqued. She leaned forward, her lute now slung over her back. "And what roads might those be, good sir? I'm afraid my wanderlust is growing by the day."
The man chuckled, the sound gruff yet warm. "I am Grimbold, a seasoned ranger. Rumors abound of strange happenings in the Whispering Woods to the east. If you're seeking adventure, you've found a willing guide."
Aethera's heart quickened, her mind racing with the possibilities. The Whispering Woods, a place shrouded in mystery and legend. Could this be the opportunity she'd been longing for?
She turned inward, her thoughts swirling. Adventure calls, and I answer. Yet, wisdom whispers caution. The woods are treacherous, filled with unseen dangers. Still, to turn away now would be to deny the very essence of my being.
With a decisive nod, Aethera turned back to Grimbold. "I accept your offer, sir ranger. Together, we shall uncover the secrets that lie within those ancient trees."
Grimbold's rugged features softened into a smile, revealing missing teeth. "Then let us depart at dawn, young one. The Whispering Woods await, and so do our fates."
</details>
<details>
<summary><b>Write me a 3,000 word opening chapter of a 'weird fiction' novel, drawing inspiration from the writing styles of China Mieville and Neil Gaiman. Use third person personal. Include dialogue and internal monologues. The POV character for the opening chapter should be a male in his 20s called Horton who has just come to the city looking for work.</b></summary>
The city of New Haven loomed before Horton like a diseased titan, its skyline a jagged line of twisted spires and hunched rooftops. The air was thick with the smells of coal smoke, damp stone, and something else—something sweet and putrid, like overripe fruit. Horton covered his nose with a sleeve, wincing. The stench seemed to cling to him, following him off the train and onto the platform.
He adjusted his bag on his shoulder, the worn leather creaking in protest. Not much to show for three years of wandering, but it was home. For now. His eyes scanned the crowd, searching for signs of employment. Bills didn't pay themselves, and his savings were dwindling faster than he'd anticipated. New Haven was supposed to be different, though. A city where anyone could make a new life, no questions asked.
"Hoi, kid! Looking for work?" a gruff voice cut through the din.
Horton turned, squinting at the speaker. He was a short, barrel-chested man with a bushy white beard and eyes that seemed to bore into Horton's skull.
"That's right," Horton replied, offering a cautious smile. "I'm a skilled laborer, handy with tools, good with animals—"
"Animals, eh? Well, I might have a job for you," the old man interrupted, his gaze darting around the platform before settling back on Horton. "Follow me, but keep up. Don't want to lose you in this mess."
As they navigated through the crowded station, Horton found himself weaving past people whose faces seemed…off. Not quite distorted, just subtly wrong, like reflections in a rippled mirror. He blinked hard, attributing the effect to exhaustion and the haze of smoke hanging over everything.
"What's the work, sir?" Horton asked, jogging to catch up with his guide.
"Cleaning. Down at the docks. The river's been…spitting things up, lately. Things that need disposing of." The old man paused, studying Horton's face. "You look like someone who can handle the unusual, kid."
"Unusual?"
"Aye. This city's full of surprises, most of them unpleasant. But the pay's good, if you're willing to get your hands dirty." They emerged from the station into a narrow, winding street. Buildings leaned in from either side, casting long shadows that stretched and twisted in the flickering gaslight.
"I've dealt with worse," Horton said, a spark of determination igniting within him. "I'm in."
The old man nodded, a hint of a smile playing on his lips. "Welcome to New Haven, lad. I'm Grim. Your boss, for all intents and purposes."
As they walked, Horton couldn't shake the feeling that the city itself was watching him, its unseen face turned towards this new, temporary inhabitant. The smell, that sweet decay, lingered on his skin, a constant reminder of the unknown awaiting him.
"What exactly will I be cleaning up down there?" Horton ventured, curiosity getting the better of him.
Grim's expression turned grave, and for a moment, Horton thought he saw something flicker in the old man's eyes—a fear, or perhaps a warning.
"That, kid," Grim said, his voice low and serious, "is something best seen to believe. Just remember, whatever you find, it goes in the bags. Don't touch, don't taste, don't ask questions. Just clean."
Horton swallowed hard, a chill running down his spine. What kind of place was this, where the mere mention of work could inspire such ominous advice?
Yet, even as doubt crept in, he felt an excitement stir within him. The city was a puzzle, each piece stranger and more intriguing than the last. And Horton, the young wanderer with no fixed address and an insatiable thirst for adventure, had just become one of its newest, most curious inhabitants.
</details>
# Training Strategy
## Merge Step
To create a slightly less censored base, [Sao10K/L3.1-70B-Euryale-v2.2](https://huggingface.co/Sao10K/L3.1-70B-Euryale-v2.2) was slerped into
[nvidia/Llama-3.1-Nemotron-70B-Instruct-HF](https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct-HF).
## Training Step
This was trained with an qlora over 2 epochs on a mix of public & private datasets using Axolotl.
The primary purpose of the qlora step was to further decensor the model and improve some issues that happened after the merge.
I prefer the model after the qlora, though the differences are subtle.
Training was performed with a 16384 seq len to try to preserve Llama 3.1's long context.
This took approx. 22 hours on 4x NVIDIA A100 80GB GPU.
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
|
[
"CRAFT"
] |
HiTZ/GoLLIE-13B
|
HiTZ
|
text-generation
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"code",
"text-generation-inference",
"Information Extraction",
"IE",
"Named Entity Recogniton",
"Event Extraction",
"Relation Extraction",
"LLaMA",
"custom_code",
"en",
"dataset:ACE05",
"dataset:bc5cdr",
"dataset:conll2003",
"dataset:ncbi_disease",
"dataset:conll2012_ontonotesv5",
"dataset:rams",
"dataset:tacred",
"dataset:wnut_17",
"arxiv:2310.03668",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-09-29T23:55:28Z |
2023-10-20T07:13:36+00:00
| 92 | 7 |
---
datasets:
- ACE05
- bc5cdr
- conll2003
- ncbi_disease
- conll2012_ontonotesv5
- rams
- tacred
- wnut_17
language:
- en
license: llama2
metrics:
- f1
pipeline_tag: text-generation
tags:
- code
- text-generation-inference
- Information Extraction
- IE
- Named Entity Recogniton
- Event Extraction
- Relation Extraction
- LLaMA
---
<p align="center">
<br>
<img src="https://github.com/hitz-zentroa/GoLLIE/raw/main/assets/GoLLIE.png" style="height: 250px;">
<h2 align="center"><b>G</b>uideline f<b>o</b>llowing <b>L</b>arge <b>L</b>anguage Model for <b>I</b>nformation <b>E</b>xtraction</h2>
<br>
# Model Card for GoLLIE 13B
<p align="justify">
We present GoLLIE, a Large Language Model trained to follow annotation guidelines. GoLLIE outperforms previous approaches on zero-shot Information Extraction and allows the user to perform inferences with annotation schemas defined on the fly. Different from previous approaches, GoLLIE is able to follow detailed definitions and does not only rely on the knowledge already encoded in the LLM.
- 💻 Code: [https://github.com/osainz59/CoLLIE/](https://github.com/hitz-zentroa/GoLLIE)
- 📒 Blog Post: [GoLLIE: Guideline-following Large Language Model for Information Extraction](https://hitz-zentroa.github.io/GoLLIE/)
- 📖 Paper: [GoLLIE: Annotation Guidelines improve Zero-Shot Information-Extraction](https://arxiv.org/abs/2310.03668)
- 🐕 GoLLIE Colection in the 🤗HuggingFace Hub: [HiTZ/gollie](https://huggingface.co/collections/HiTZ/gollie-651bf19ee315e8a224aacc4f)
- 🚀 Example Jupyter Notebooks: [GoLLIE Notebooks](https://github.com/hitz-zentroa/GoLLIE/tree/main/notebooks)
</p>
<p align="center">
<img src="https://github.com/hitz-zentroa/GoLLIE/raw/main/assets/zero_shot_results.png">
</p>
### Model Description
- **Developed by:** [Oscar Sainz](https://osainz59.github.io/), [Iker García-Ferrero](https://ikergarcia1996.github.io/Iker-Garcia-Ferrero/), [Rodrigo Agerri](https://ragerri.github.io/), [Oier Lopez de Lacalle](https://oierldl.github.io/), [German Rigau](https://adimen.si.ehu.es/~rigau/) and [Eneko Agirre](https://eagirre.github.io/)
- **Institution:** [HiTZ Basque Center for Language Technology](http://www.hitz.eus/) - [Ixa](https://www.ixa.eus/node/2?language=en), [University of the Basque Country UPV/EHU](https://www.ehu.eus/en/en-home)
- **Model type:** Text Generation
- **Language(s) (NLP):** English
- **License:** LLaMA2 License for the base and merged model. Apache 2.0 for pre-trained LoRA Adapters
- **Finetuned from model:** CODE-LLaMA2
## Schema definition and inference example
The labels are represented as Python classes, and the guidelines or instructions are introduced as docstrings. The model start generating after the `result = [` line.
```Python
# Entity definitions
@dataclass
class Launcher(Template):
"""Refers to a vehicle designed primarily to transport payloads from the Earth's
surface to space. Launchers can carry various payloads, including satellites,
crewed spacecraft, and cargo, into various orbits or even beyond Earth's orbit.
They are usually multi-stage vehicles that use rocket engines for propulsion."""
mention: str
"""
The name of the launcher vehicle.
Such as: "Sturn V", "Atlas V", "Soyuz", "Ariane 5"
"""
space_company: str # The company that operates the launcher. Such as: "Blue origin", "ESA", "Boeing", "ISRO", "Northrop Grumman", "Arianespace"
crew: List[str] # Names of the crew members boarding the Launcher. Such as: "Neil Armstrong", "Michael Collins", "Buzz Aldrin"
@dataclass
class Mission(Template):
"""Any planned or accomplished journey beyond Earth's atmosphere with specific objectives,
either crewed or uncrewed. It includes missions to satellites, the International
Space Station (ISS), other celestial bodies, and deep space."""
mention: str
"""
The name of the mission.
Such as: "Apollo 11", "Artemis", "Mercury"
"""
date: str # The start date of the mission
departure: str # The place from which the vehicle will be launched. Such as: "Florida", "Houston", "French Guiana"
destination: str # The place or planet to which the launcher will be sent. Such as "Moon", "low-orbit", "Saturn"
# This is the text to analyze
text = (
"The Ares 3 mission to Mars is scheduled for 2032. The Starship rocket build by SpaceX will take off from Boca Chica,"
"carrying the astronauts Max Rutherford, Elena Soto, and Jake Martinez."
)
# The annotation instances that take place in the text above are listed here
result = [
Mission(mention='Ares 3', date='2032', departure='Boca Chica', destination='Mars'),
Launcher(mention='Starship', space_company='SpaceX', crew=['Max Rutherford', 'Elena Soto', 'Jake Martinez'])
]
```
## How to Get Started with the Model
Please read our [🚀 Example Jupyter Notebooks](https://github.com/hitz-zentroa/GoLLIE/tree/main/notebooks) to get started with GoLLIE.
The best way to load the model is using our custom `load_model` fuction. However, you can also load them using the AutoModelForCausalLM class.
**Important**: Our flash attention implementation has small numerical differences compared to the attention implementation in Huggingface.
You must use the flag `trust_remote_code=True` or you will get inferior results. Flash attention requires an available CUDA GPU. Running GOLLIE
pre-trained models on a CPU is not supported. We plan to address this in future releases. First, install flash attention 2:
```bash
pip install flash-attn --no-build-isolation
pip install git+https://github.com/HazyResearch/flash-attention.git#subdirectory=csrc/rotary
```
Then you can load the model using
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("HiTZ/GoLLIE-7B")
model = AutoModelForCausalLM.from_pretrained("HiTZ/GoLLIE-7B", trust_remote_code=True, torch_dtype=torch.bfloat16)
model.to("cuda")
```
Read our [🚀 Example Jupyter Notebooks](https://github.com/hitz-zentroa/GoLLIE/tree/main/notebooks) to learn how to easily define guidelines, generate model inputs and parse the output!
### Training Data
This is the list of task used for training and evaluating GoLLIE. However, as demonstrated in the 🚀 [Create Custom Task notebook](https://github.com/hitz-zentroa/GoLLIE/blob/main/notebooks/Create%20Custom%20Task.ipynb) GoLLIE can perform a wide range of unseen tasks.
For more info, read our [📖Paper](https://arxiv.org/abs/2310.03668).
<p align="center">
<img src="https://github.com/hitz-zentroa/GoLLIE/raw/main/assets/datasets.png">
</p>
## Evaluation
| Model | Supervised average F1 | Zero-shot average F1 | 🤗HuggingFace Hub |
|---|:---------------------:|:--------------------:|:---------------------------------------------------------:|
| GoLLIE-7B | 73.0 | 55.3 | [HiTZ/GoLLIE-7B](https://huggingface.co/HiTZ/GoLLIE-7B) |
| GoLLIE-13B | 73.9 | 56.0 | [HiTZ/GoLLIE-13B](https://huggingface.co/HiTZ/GoLLIE-13B) |
| GoLLIE-34B | **75.0** | **57.2** | [HiTZ/GoLLIE-34B](https://huggingface.co/HiTZ/GoLLIE-34B) |
## Environmental Impact
| Model | Hardware | FLOPs | Time (h) | CO<sup>2</sup>eq (kg) |
|----------------|-------------------|---------------------------|-------------------|-------------------------------------|
| GoLLIE 7B | 1xA100 | 11.9e<sup>18</sup> | 44.5 | 1.57 |
| GoLLIE 13B | 1xA100 | 22.7e<sup>18</sup> | 79.5 | 2.80 |
| GoLLIE 34B | 2xA100 | 55.8e<sup>18</sup> | 94.6 | 6.67 |
## Citation
```
@misc{sainz2023gollie,
title={GoLLIE: Annotation Guidelines improve Zero-Shot Information-Extraction},
author={Oscar Sainz and Iker García-Ferrero and Rodrigo Agerri and Oier Lopez de Lacalle and German Rigau and Eneko Agirre},
year={2023},
eprint={2310.03668},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"BC5CDR",
"NCBI DISEASE"
] |
judithrosell/JNLPBA_PubMedBERT_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-07T18:03:11Z |
2023-12-14T11:50:34+00:00
| 92 | 0 |
---
base_model: microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext
license: mit
tags:
- generated_from_trainer
model-index:
- name: JNLPBA_PubMedBERT_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# JNLPBA_PubMedBERT_NER
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1450
- Seqeval classification report: precision recall f1-score support
DNA 0.75 0.83 0.79 955
RNA 0.80 0.83 0.82 1144
cell_line 0.76 0.79 0.78 5330
cell_type 0.86 0.91 0.88 2518
protein 0.87 0.85 0.86 926
micro avg 0.80 0.83 0.81 10873
macro avg 0.81 0.84 0.82 10873
weighted avg 0.80 0.83 0.81 10873
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Seqeval classification report |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| 0.2726 | 1.0 | 582 | 0.1526 | precision recall f1-score support
DNA 0.73 0.82 0.77 955
RNA 0.79 0.82 0.81 1144
cell_line 0.75 0.78 0.76 5330
cell_type 0.86 0.86 0.86 2518
protein 0.86 0.84 0.85 926
micro avg 0.79 0.81 0.80 10873
macro avg 0.80 0.82 0.81 10873
weighted avg 0.79 0.81 0.80 10873
|
| 0.145 | 2.0 | 1164 | 0.1473 | precision recall f1-score support
DNA 0.73 0.82 0.77 955
RNA 0.85 0.78 0.81 1144
cell_line 0.77 0.78 0.78 5330
cell_type 0.85 0.92 0.88 2518
protein 0.88 0.83 0.85 926
micro avg 0.80 0.82 0.81 10873
macro avg 0.81 0.83 0.82 10873
weighted avg 0.80 0.82 0.81 10873
|
| 0.1276 | 3.0 | 1746 | 0.1450 | precision recall f1-score support
DNA 0.75 0.83 0.79 955
RNA 0.80 0.83 0.82 1144
cell_line 0.76 0.79 0.78 5330
cell_type 0.86 0.91 0.88 2518
protein 0.87 0.85 0.86 926
micro avg 0.80 0.83 0.81 10873
macro avg 0.81 0.84 0.82 10873
weighted avg 0.80 0.83 0.81 10873
|
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
[
"JNLPBA"
] |
judithrosell/BC5CDR_PubMedBERT_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-07T18:04:24Z |
2023-12-14T15:53:53+00:00
| 92 | 0 |
---
base_model: microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext
license: mit
tags:
- generated_from_trainer
model-index:
- name: BC5CDR_PubMedBERT_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BC5CDR_PubMedBERT_NER
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0783
- Seqeval classification report: precision recall f1-score support
Chemical 0.99 0.98 0.98 103336
Disease 0.76 0.86 0.81 3447
micro avg 0.98 0.98 0.98 106783
macro avg 0.87 0.92 0.89 106783
weighted avg 0.98 0.98 0.98 106783
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Seqeval classification report |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| No log | 1.0 | 143 | 0.0952 | precision recall f1-score support
Chemical 0.99 0.97 0.98 103336
Disease 0.68 0.88 0.76 3447
micro avg 0.97 0.97 0.97 106783
macro avg 0.83 0.92 0.87 106783
weighted avg 0.98 0.97 0.97 106783
|
| No log | 2.0 | 286 | 0.0804 | precision recall f1-score support
Chemical 0.99 0.98 0.98 103336
Disease 0.75 0.86 0.80 3447
micro avg 0.98 0.97 0.97 106783
macro avg 0.87 0.92 0.89 106783
weighted avg 0.98 0.97 0.98 106783
|
| No log | 3.0 | 429 | 0.0783 | precision recall f1-score support
Chemical 0.99 0.98 0.98 103336
Disease 0.76 0.86 0.81 3447
micro avg 0.98 0.98 0.98 106783
macro avg 0.87 0.92 0.89 106783
weighted avg 0.98 0.98 0.98 106783
|
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu118
- Datasets 2.15.0
- Tokenizers 0.15.0
|
[
"BC5CDR"
] |
judithrosell/JNLPBA_ClinicalBERT_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"token-classification",
"generated_from_trainer",
"base_model:medicalai/ClinicalBERT",
"base_model:finetune:medicalai/ClinicalBERT",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-18T14:10:16Z |
2023-12-18T15:11:01+00:00
| 92 | 0 |
---
base_model: medicalai/ClinicalBERT
tags:
- generated_from_trainer
model-index:
- name: JNLPBA_ClinicalBERT_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# JNLPBA_ClinicalBERT_NER
This model is a fine-tuned version of [medicalai/ClinicalBERT](https://huggingface.co/medicalai/ClinicalBERT) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1723
- Seqeval classification report: precision recall f1-score support
DNA 0.72 0.81 0.77 1351
RNA 0.71 0.86 0.78 723
cell_line 0.84 0.74 0.78 582
cell_type 0.72 0.75 0.73 5623
protein 0.85 0.85 0.85 3501
micro avg 0.76 0.79 0.78 11780
macro avg 0.77 0.80 0.78 11780
weighted avg 0.76 0.79 0.78 11780
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Seqeval classification report |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| 0.336 | 1.0 | 582 | 0.1930 | precision recall f1-score support
DNA 0.72 0.77 0.75 1351
RNA 0.70 0.84 0.77 723
cell_line 0.85 0.70 0.77 582
cell_type 0.71 0.68 0.69 5623
protein 0.85 0.80 0.83 3501
micro avg 0.76 0.74 0.75 11780
macro avg 0.77 0.76 0.76 11780
weighted avg 0.76 0.74 0.75 11780
|
| 0.1841 | 2.0 | 1164 | 0.1762 | precision recall f1-score support
DNA 0.73 0.78 0.76 1351
RNA 0.70 0.87 0.78 723
cell_line 0.86 0.71 0.78 582
cell_type 0.71 0.73 0.72 5623
protein 0.86 0.83 0.84 3501
micro avg 0.76 0.77 0.77 11780
macro avg 0.77 0.78 0.78 11780
weighted avg 0.77 0.77 0.77 11780
|
| 0.1582 | 3.0 | 1746 | 0.1723 | precision recall f1-score support
DNA 0.72 0.81 0.77 1351
RNA 0.71 0.86 0.78 723
cell_line 0.84 0.74 0.78 582
cell_type 0.72 0.75 0.73 5623
protein 0.85 0.85 0.85 3501
micro avg 0.76 0.79 0.78 11780
macro avg 0.77 0.80 0.78 11780
weighted avg 0.76 0.79 0.78 11780
|
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0
|
[
"JNLPBA"
] |
odunola/UAE-Large-VI
|
odunola
|
feature-extraction
|
[
"sentence-transformers",
"onnx",
"safetensors",
"bert",
"feature-extraction",
"mteb",
"sentence_embedding",
"feature_extraction",
"transformers",
"transformers.js",
"en",
"arxiv:2309.12871",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2023-12-18T20:55:01Z |
2023-12-18T20:58:50+00:00
| 92 | 0 |
---
language:
- en
library_name: sentence-transformers
license: apache-2.0
tags:
- mteb
- sentence_embedding
- feature_extraction
- transformers
- transformers.js
model-index:
- name: UAE-Large-V1
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.55223880597015
- type: ap
value: 38.264070815317794
- type: f1
value: 69.40977934769845
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 92.84267499999999
- type: ap
value: 89.57568507997713
- type: f1
value: 92.82590734337774
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.292
- type: f1
value: 47.90257816032778
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 42.105
- type: map_at_10
value: 58.181000000000004
- type: map_at_100
value: 58.653999999999996
- type: map_at_1000
value: 58.657000000000004
- type: map_at_3
value: 54.386
- type: map_at_5
value: 56.757999999999996
- type: mrr_at_1
value: 42.745
- type: mrr_at_10
value: 58.437
- type: mrr_at_100
value: 58.894999999999996
- type: mrr_at_1000
value: 58.897999999999996
- type: mrr_at_3
value: 54.635
- type: mrr_at_5
value: 56.99999999999999
- type: ndcg_at_1
value: 42.105
- type: ndcg_at_10
value: 66.14999999999999
- type: ndcg_at_100
value: 68.048
- type: ndcg_at_1000
value: 68.11399999999999
- type: ndcg_at_3
value: 58.477000000000004
- type: ndcg_at_5
value: 62.768
- type: precision_at_1
value: 42.105
- type: precision_at_10
value: 9.110999999999999
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 23.447000000000003
- type: precision_at_5
value: 16.159000000000002
- type: recall_at_1
value: 42.105
- type: recall_at_10
value: 91.11
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 70.341
- type: recall_at_5
value: 80.797
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 49.02580759154173
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 43.093601280163554
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.19590406875427
- type: mrr
value: 77.09547992788991
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 87.86678362843676
- type: cos_sim_spearman
value: 86.1423242570783
- type: euclidean_pearson
value: 85.98994198511751
- type: euclidean_spearman
value: 86.48209103503942
- type: manhattan_pearson
value: 85.6446436316182
- type: manhattan_spearman
value: 86.21039809734357
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.69155844155844
- type: f1
value: 87.68109381943547
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.37501687500394
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 37.23401405155885
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.232
- type: map_at_10
value: 41.404999999999994
- type: map_at_100
value: 42.896
- type: map_at_1000
value: 43.028
- type: map_at_3
value: 37.925
- type: map_at_5
value: 39.865
- type: mrr_at_1
value: 36.338
- type: mrr_at_10
value: 46.969
- type: mrr_at_100
value: 47.684
- type: mrr_at_1000
value: 47.731
- type: mrr_at_3
value: 44.063
- type: mrr_at_5
value: 45.908
- type: ndcg_at_1
value: 36.338
- type: ndcg_at_10
value: 47.887
- type: ndcg_at_100
value: 53.357
- type: ndcg_at_1000
value: 55.376999999999995
- type: ndcg_at_3
value: 42.588
- type: ndcg_at_5
value: 45.132
- type: precision_at_1
value: 36.338
- type: precision_at_10
value: 9.17
- type: precision_at_100
value: 1.4909999999999999
- type: precision_at_1000
value: 0.196
- type: precision_at_3
value: 20.315
- type: precision_at_5
value: 14.793000000000001
- type: recall_at_1
value: 30.232
- type: recall_at_10
value: 60.67399999999999
- type: recall_at_100
value: 83.628
- type: recall_at_1000
value: 96.209
- type: recall_at_3
value: 45.48
- type: recall_at_5
value: 52.354
- type: map_at_1
value: 32.237
- type: map_at_10
value: 42.829
- type: map_at_100
value: 44.065
- type: map_at_1000
value: 44.199
- type: map_at_3
value: 39.885999999999996
- type: map_at_5
value: 41.55
- type: mrr_at_1
value: 40.064
- type: mrr_at_10
value: 48.611
- type: mrr_at_100
value: 49.245
- type: mrr_at_1000
value: 49.29
- type: mrr_at_3
value: 46.561
- type: mrr_at_5
value: 47.771
- type: ndcg_at_1
value: 40.064
- type: ndcg_at_10
value: 48.388
- type: ndcg_at_100
value: 52.666999999999994
- type: ndcg_at_1000
value: 54.67100000000001
- type: ndcg_at_3
value: 44.504
- type: ndcg_at_5
value: 46.303
- type: precision_at_1
value: 40.064
- type: precision_at_10
value: 9.051
- type: precision_at_100
value: 1.4500000000000002
- type: precision_at_1000
value: 0.193
- type: precision_at_3
value: 21.444
- type: precision_at_5
value: 15.045
- type: recall_at_1
value: 32.237
- type: recall_at_10
value: 57.943999999999996
- type: recall_at_100
value: 75.98700000000001
- type: recall_at_1000
value: 88.453
- type: recall_at_3
value: 46.268
- type: recall_at_5
value: 51.459999999999994
- type: map_at_1
value: 38.797
- type: map_at_10
value: 51.263000000000005
- type: map_at_100
value: 52.333
- type: map_at_1000
value: 52.393
- type: map_at_3
value: 47.936
- type: map_at_5
value: 49.844
- type: mrr_at_1
value: 44.389
- type: mrr_at_10
value: 54.601
- type: mrr_at_100
value: 55.300000000000004
- type: mrr_at_1000
value: 55.333
- type: mrr_at_3
value: 52.068999999999996
- type: mrr_at_5
value: 53.627
- type: ndcg_at_1
value: 44.389
- type: ndcg_at_10
value: 57.193000000000005
- type: ndcg_at_100
value: 61.307
- type: ndcg_at_1000
value: 62.529
- type: ndcg_at_3
value: 51.607
- type: ndcg_at_5
value: 54.409
- type: precision_at_1
value: 44.389
- type: precision_at_10
value: 9.26
- type: precision_at_100
value: 1.222
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 23.03
- type: precision_at_5
value: 15.887
- type: recall_at_1
value: 38.797
- type: recall_at_10
value: 71.449
- type: recall_at_100
value: 88.881
- type: recall_at_1000
value: 97.52
- type: recall_at_3
value: 56.503
- type: recall_at_5
value: 63.392
- type: map_at_1
value: 27.291999999999998
- type: map_at_10
value: 35.65
- type: map_at_100
value: 36.689
- type: map_at_1000
value: 36.753
- type: map_at_3
value: 32.995000000000005
- type: map_at_5
value: 34.409
- type: mrr_at_1
value: 29.04
- type: mrr_at_10
value: 37.486000000000004
- type: mrr_at_100
value: 38.394
- type: mrr_at_1000
value: 38.445
- type: mrr_at_3
value: 35.028
- type: mrr_at_5
value: 36.305
- type: ndcg_at_1
value: 29.04
- type: ndcg_at_10
value: 40.613
- type: ndcg_at_100
value: 45.733000000000004
- type: ndcg_at_1000
value: 47.447
- type: ndcg_at_3
value: 35.339999999999996
- type: ndcg_at_5
value: 37.706
- type: precision_at_1
value: 29.04
- type: precision_at_10
value: 6.192
- type: precision_at_100
value: 0.9249999999999999
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 14.802000000000001
- type: precision_at_5
value: 10.305
- type: recall_at_1
value: 27.291999999999998
- type: recall_at_10
value: 54.25299999999999
- type: recall_at_100
value: 77.773
- type: recall_at_1000
value: 90.795
- type: recall_at_3
value: 39.731
- type: recall_at_5
value: 45.403999999999996
- type: map_at_1
value: 18.326
- type: map_at_10
value: 26.290999999999997
- type: map_at_100
value: 27.456999999999997
- type: map_at_1000
value: 27.583000000000002
- type: map_at_3
value: 23.578
- type: map_at_5
value: 25.113000000000003
- type: mrr_at_1
value: 22.637
- type: mrr_at_10
value: 31.139
- type: mrr_at_100
value: 32.074999999999996
- type: mrr_at_1000
value: 32.147
- type: mrr_at_3
value: 28.483000000000004
- type: mrr_at_5
value: 29.963
- type: ndcg_at_1
value: 22.637
- type: ndcg_at_10
value: 31.717000000000002
- type: ndcg_at_100
value: 37.201
- type: ndcg_at_1000
value: 40.088
- type: ndcg_at_3
value: 26.686
- type: ndcg_at_5
value: 29.076999999999998
- type: precision_at_1
value: 22.637
- type: precision_at_10
value: 5.7090000000000005
- type: precision_at_100
value: 0.979
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 12.894
- type: precision_at_5
value: 9.328
- type: recall_at_1
value: 18.326
- type: recall_at_10
value: 43.824999999999996
- type: recall_at_100
value: 67.316
- type: recall_at_1000
value: 87.481
- type: recall_at_3
value: 29.866999999999997
- type: recall_at_5
value: 35.961999999999996
- type: map_at_1
value: 29.875
- type: map_at_10
value: 40.458
- type: map_at_100
value: 41.772
- type: map_at_1000
value: 41.882999999999996
- type: map_at_3
value: 37.086999999999996
- type: map_at_5
value: 39.153
- type: mrr_at_1
value: 36.381
- type: mrr_at_10
value: 46.190999999999995
- type: mrr_at_100
value: 46.983999999999995
- type: mrr_at_1000
value: 47.032000000000004
- type: mrr_at_3
value: 43.486999999999995
- type: mrr_at_5
value: 45.249
- type: ndcg_at_1
value: 36.381
- type: ndcg_at_10
value: 46.602
- type: ndcg_at_100
value: 51.885999999999996
- type: ndcg_at_1000
value: 53.895
- type: ndcg_at_3
value: 41.155
- type: ndcg_at_5
value: 44.182
- type: precision_at_1
value: 36.381
- type: precision_at_10
value: 8.402
- type: precision_at_100
value: 1.278
- type: precision_at_1000
value: 0.16199999999999998
- type: precision_at_3
value: 19.346
- type: precision_at_5
value: 14.09
- type: recall_at_1
value: 29.875
- type: recall_at_10
value: 59.065999999999995
- type: recall_at_100
value: 80.923
- type: recall_at_1000
value: 93.927
- type: recall_at_3
value: 44.462
- type: recall_at_5
value: 51.89
- type: map_at_1
value: 24.94
- type: map_at_10
value: 35.125
- type: map_at_100
value: 36.476
- type: map_at_1000
value: 36.579
- type: map_at_3
value: 31.840000000000003
- type: map_at_5
value: 33.647
- type: mrr_at_1
value: 30.936000000000003
- type: mrr_at_10
value: 40.637
- type: mrr_at_100
value: 41.471000000000004
- type: mrr_at_1000
value: 41.525
- type: mrr_at_3
value: 38.013999999999996
- type: mrr_at_5
value: 39.469
- type: ndcg_at_1
value: 30.936000000000003
- type: ndcg_at_10
value: 41.295
- type: ndcg_at_100
value: 46.92
- type: ndcg_at_1000
value: 49.183
- type: ndcg_at_3
value: 35.811
- type: ndcg_at_5
value: 38.306000000000004
- type: precision_at_1
value: 30.936000000000003
- type: precision_at_10
value: 7.728
- type: precision_at_100
value: 1.226
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 17.237
- type: precision_at_5
value: 12.42
- type: recall_at_1
value: 24.94
- type: recall_at_10
value: 54.235
- type: recall_at_100
value: 78.314
- type: recall_at_1000
value: 93.973
- type: recall_at_3
value: 38.925
- type: recall_at_5
value: 45.505
- type: map_at_1
value: 26.250833333333333
- type: map_at_10
value: 35.46875
- type: map_at_100
value: 36.667
- type: map_at_1000
value: 36.78025
- type: map_at_3
value: 32.56733333333334
- type: map_at_5
value: 34.20333333333333
- type: mrr_at_1
value: 30.8945
- type: mrr_at_10
value: 39.636833333333335
- type: mrr_at_100
value: 40.46508333333333
- type: mrr_at_1000
value: 40.521249999999995
- type: mrr_at_3
value: 37.140166666666666
- type: mrr_at_5
value: 38.60999999999999
- type: ndcg_at_1
value: 30.8945
- type: ndcg_at_10
value: 40.93441666666667
- type: ndcg_at_100
value: 46.062416666666664
- type: ndcg_at_1000
value: 48.28341666666667
- type: ndcg_at_3
value: 35.97575
- type: ndcg_at_5
value: 38.3785
- type: precision_at_1
value: 30.8945
- type: precision_at_10
value: 7.180250000000001
- type: precision_at_100
value: 1.1468333333333334
- type: precision_at_1000
value: 0.15283333333333332
- type: precision_at_3
value: 16.525583333333334
- type: precision_at_5
value: 11.798333333333332
- type: recall_at_1
value: 26.250833333333333
- type: recall_at_10
value: 52.96108333333333
- type: recall_at_100
value: 75.45908333333334
- type: recall_at_1000
value: 90.73924999999998
- type: recall_at_3
value: 39.25483333333333
- type: recall_at_5
value: 45.37950000000001
- type: map_at_1
value: 24.595
- type: map_at_10
value: 31.747999999999998
- type: map_at_100
value: 32.62
- type: map_at_1000
value: 32.713
- type: map_at_3
value: 29.48
- type: map_at_5
value: 30.635
- type: mrr_at_1
value: 27.607
- type: mrr_at_10
value: 34.449000000000005
- type: mrr_at_100
value: 35.182
- type: mrr_at_1000
value: 35.254000000000005
- type: mrr_at_3
value: 32.413
- type: mrr_at_5
value: 33.372
- type: ndcg_at_1
value: 27.607
- type: ndcg_at_10
value: 36.041000000000004
- type: ndcg_at_100
value: 40.514
- type: ndcg_at_1000
value: 42.851
- type: ndcg_at_3
value: 31.689
- type: ndcg_at_5
value: 33.479
- type: precision_at_1
value: 27.607
- type: precision_at_10
value: 5.66
- type: precision_at_100
value: 0.868
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 13.446
- type: precision_at_5
value: 9.264
- type: recall_at_1
value: 24.595
- type: recall_at_10
value: 46.79
- type: recall_at_100
value: 67.413
- type: recall_at_1000
value: 84.753
- type: recall_at_3
value: 34.644999999999996
- type: recall_at_5
value: 39.09
- type: map_at_1
value: 17.333000000000002
- type: map_at_10
value: 24.427
- type: map_at_100
value: 25.576
- type: map_at_1000
value: 25.692999999999998
- type: map_at_3
value: 22.002
- type: map_at_5
value: 23.249
- type: mrr_at_1
value: 20.716
- type: mrr_at_10
value: 28.072000000000003
- type: mrr_at_100
value: 29.067
- type: mrr_at_1000
value: 29.137
- type: mrr_at_3
value: 25.832
- type: mrr_at_5
value: 27.045
- type: ndcg_at_1
value: 20.716
- type: ndcg_at_10
value: 29.109
- type: ndcg_at_100
value: 34.797
- type: ndcg_at_1000
value: 37.503
- type: ndcg_at_3
value: 24.668
- type: ndcg_at_5
value: 26.552999999999997
- type: precision_at_1
value: 20.716
- type: precision_at_10
value: 5.351
- type: precision_at_100
value: 0.955
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 11.584999999999999
- type: precision_at_5
value: 8.362
- type: recall_at_1
value: 17.333000000000002
- type: recall_at_10
value: 39.604
- type: recall_at_100
value: 65.525
- type: recall_at_1000
value: 84.651
- type: recall_at_3
value: 27.199
- type: recall_at_5
value: 32.019
- type: map_at_1
value: 26.342
- type: map_at_10
value: 35.349000000000004
- type: map_at_100
value: 36.443
- type: map_at_1000
value: 36.548
- type: map_at_3
value: 32.307
- type: map_at_5
value: 34.164
- type: mrr_at_1
value: 31.063000000000002
- type: mrr_at_10
value: 39.703
- type: mrr_at_100
value: 40.555
- type: mrr_at_1000
value: 40.614
- type: mrr_at_3
value: 37.141999999999996
- type: mrr_at_5
value: 38.812000000000005
- type: ndcg_at_1
value: 31.063000000000002
- type: ndcg_at_10
value: 40.873
- type: ndcg_at_100
value: 45.896
- type: ndcg_at_1000
value: 48.205999999999996
- type: ndcg_at_3
value: 35.522
- type: ndcg_at_5
value: 38.419
- type: precision_at_1
value: 31.063000000000002
- type: precision_at_10
value: 6.866
- type: precision_at_100
value: 1.053
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 16.014
- type: precision_at_5
value: 11.604000000000001
- type: recall_at_1
value: 26.342
- type: recall_at_10
value: 53.40200000000001
- type: recall_at_100
value: 75.251
- type: recall_at_1000
value: 91.13799999999999
- type: recall_at_3
value: 39.103
- type: recall_at_5
value: 46.357
- type: map_at_1
value: 23.71
- type: map_at_10
value: 32.153999999999996
- type: map_at_100
value: 33.821
- type: map_at_1000
value: 34.034
- type: map_at_3
value: 29.376
- type: map_at_5
value: 30.878
- type: mrr_at_1
value: 28.458
- type: mrr_at_10
value: 36.775999999999996
- type: mrr_at_100
value: 37.804
- type: mrr_at_1000
value: 37.858999999999995
- type: mrr_at_3
value: 34.123999999999995
- type: mrr_at_5
value: 35.596
- type: ndcg_at_1
value: 28.458
- type: ndcg_at_10
value: 37.858999999999995
- type: ndcg_at_100
value: 44.194
- type: ndcg_at_1000
value: 46.744
- type: ndcg_at_3
value: 33.348
- type: ndcg_at_5
value: 35.448
- type: precision_at_1
value: 28.458
- type: precision_at_10
value: 7.4510000000000005
- type: precision_at_100
value: 1.5
- type: precision_at_1000
value: 0.23700000000000002
- type: precision_at_3
value: 15.809999999999999
- type: precision_at_5
value: 11.462
- type: recall_at_1
value: 23.71
- type: recall_at_10
value: 48.272999999999996
- type: recall_at_100
value: 77.134
- type: recall_at_1000
value: 93.001
- type: recall_at_3
value: 35.480000000000004
- type: recall_at_5
value: 41.19
- type: map_at_1
value: 21.331
- type: map_at_10
value: 28.926000000000002
- type: map_at_100
value: 29.855999999999998
- type: map_at_1000
value: 29.957
- type: map_at_3
value: 26.395999999999997
- type: map_at_5
value: 27.933000000000003
- type: mrr_at_1
value: 23.105
- type: mrr_at_10
value: 31.008000000000003
- type: mrr_at_100
value: 31.819999999999997
- type: mrr_at_1000
value: 31.887999999999998
- type: mrr_at_3
value: 28.466
- type: mrr_at_5
value: 30.203000000000003
- type: ndcg_at_1
value: 23.105
- type: ndcg_at_10
value: 33.635999999999996
- type: ndcg_at_100
value: 38.277
- type: ndcg_at_1000
value: 40.907
- type: ndcg_at_3
value: 28.791
- type: ndcg_at_5
value: 31.528
- type: precision_at_1
value: 23.105
- type: precision_at_10
value: 5.323
- type: precision_at_100
value: 0.815
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 12.384
- type: precision_at_5
value: 9.02
- type: recall_at_1
value: 21.331
- type: recall_at_10
value: 46.018
- type: recall_at_100
value: 67.364
- type: recall_at_1000
value: 86.97
- type: recall_at_3
value: 33.395
- type: recall_at_5
value: 39.931
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.011000000000003
- type: map_at_10
value: 28.816999999999997
- type: map_at_100
value: 30.761
- type: map_at_1000
value: 30.958000000000002
- type: map_at_3
value: 24.044999999999998
- type: map_at_5
value: 26.557
- type: mrr_at_1
value: 38.696999999999996
- type: mrr_at_10
value: 50.464
- type: mrr_at_100
value: 51.193999999999996
- type: mrr_at_1000
value: 51.219
- type: mrr_at_3
value: 47.339999999999996
- type: mrr_at_5
value: 49.346000000000004
- type: ndcg_at_1
value: 38.696999999999996
- type: ndcg_at_10
value: 38.53
- type: ndcg_at_100
value: 45.525
- type: ndcg_at_1000
value: 48.685
- type: ndcg_at_3
value: 32.282
- type: ndcg_at_5
value: 34.482
- type: precision_at_1
value: 38.696999999999996
- type: precision_at_10
value: 11.895999999999999
- type: precision_at_100
value: 1.95
- type: precision_at_1000
value: 0.254
- type: precision_at_3
value: 24.038999999999998
- type: precision_at_5
value: 18.332
- type: recall_at_1
value: 17.011000000000003
- type: recall_at_10
value: 44.452999999999996
- type: recall_at_100
value: 68.223
- type: recall_at_1000
value: 85.653
- type: recall_at_3
value: 28.784
- type: recall_at_5
value: 35.66
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.516
- type: map_at_10
value: 21.439
- type: map_at_100
value: 31.517
- type: map_at_1000
value: 33.267
- type: map_at_3
value: 15.004999999999999
- type: map_at_5
value: 17.793999999999997
- type: mrr_at_1
value: 71.25
- type: mrr_at_10
value: 79.071
- type: mrr_at_100
value: 79.325
- type: mrr_at_1000
value: 79.33
- type: mrr_at_3
value: 77.708
- type: mrr_at_5
value: 78.546
- type: ndcg_at_1
value: 58.62500000000001
- type: ndcg_at_10
value: 44.889
- type: ndcg_at_100
value: 50.536
- type: ndcg_at_1000
value: 57.724
- type: ndcg_at_3
value: 49.32
- type: ndcg_at_5
value: 46.775
- type: precision_at_1
value: 71.25
- type: precision_at_10
value: 36.175000000000004
- type: precision_at_100
value: 11.940000000000001
- type: precision_at_1000
value: 2.178
- type: precision_at_3
value: 53.583000000000006
- type: precision_at_5
value: 45.550000000000004
- type: recall_at_1
value: 9.516
- type: recall_at_10
value: 27.028000000000002
- type: recall_at_100
value: 57.581
- type: recall_at_1000
value: 80.623
- type: recall_at_3
value: 16.313
- type: recall_at_5
value: 20.674
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.74999999999999
- type: f1
value: 46.46706502669774
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 77.266
- type: map_at_10
value: 84.89999999999999
- type: map_at_100
value: 85.109
- type: map_at_1000
value: 85.123
- type: map_at_3
value: 83.898
- type: map_at_5
value: 84.541
- type: mrr_at_1
value: 83.138
- type: mrr_at_10
value: 89.37
- type: mrr_at_100
value: 89.432
- type: mrr_at_1000
value: 89.43299999999999
- type: mrr_at_3
value: 88.836
- type: mrr_at_5
value: 89.21
- type: ndcg_at_1
value: 83.138
- type: ndcg_at_10
value: 88.244
- type: ndcg_at_100
value: 88.98700000000001
- type: ndcg_at_1000
value: 89.21900000000001
- type: ndcg_at_3
value: 86.825
- type: ndcg_at_5
value: 87.636
- type: precision_at_1
value: 83.138
- type: precision_at_10
value: 10.47
- type: precision_at_100
value: 1.1079999999999999
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 32.933
- type: precision_at_5
value: 20.36
- type: recall_at_1
value: 77.266
- type: recall_at_10
value: 94.063
- type: recall_at_100
value: 96.993
- type: recall_at_1000
value: 98.414
- type: recall_at_3
value: 90.228
- type: recall_at_5
value: 92.328
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.319
- type: map_at_10
value: 36.943
- type: map_at_100
value: 38.951
- type: map_at_1000
value: 39.114
- type: map_at_3
value: 32.82
- type: map_at_5
value: 34.945
- type: mrr_at_1
value: 44.135999999999996
- type: mrr_at_10
value: 53.071999999999996
- type: mrr_at_100
value: 53.87
- type: mrr_at_1000
value: 53.90200000000001
- type: mrr_at_3
value: 50.77199999999999
- type: mrr_at_5
value: 52.129999999999995
- type: ndcg_at_1
value: 44.135999999999996
- type: ndcg_at_10
value: 44.836
- type: ndcg_at_100
value: 51.754
- type: ndcg_at_1000
value: 54.36
- type: ndcg_at_3
value: 41.658
- type: ndcg_at_5
value: 42.354
- type: precision_at_1
value: 44.135999999999996
- type: precision_at_10
value: 12.284
- type: precision_at_100
value: 1.952
- type: precision_at_1000
value: 0.242
- type: precision_at_3
value: 27.828999999999997
- type: precision_at_5
value: 20.093
- type: recall_at_1
value: 22.319
- type: recall_at_10
value: 51.528
- type: recall_at_100
value: 76.70700000000001
- type: recall_at_1000
value: 92.143
- type: recall_at_3
value: 38.641
- type: recall_at_5
value: 43.653999999999996
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.182
- type: map_at_10
value: 65.146
- type: map_at_100
value: 66.023
- type: map_at_1000
value: 66.078
- type: map_at_3
value: 61.617999999999995
- type: map_at_5
value: 63.82299999999999
- type: mrr_at_1
value: 80.365
- type: mrr_at_10
value: 85.79
- type: mrr_at_100
value: 85.963
- type: mrr_at_1000
value: 85.968
- type: mrr_at_3
value: 84.952
- type: mrr_at_5
value: 85.503
- type: ndcg_at_1
value: 80.365
- type: ndcg_at_10
value: 73.13499999999999
- type: ndcg_at_100
value: 76.133
- type: ndcg_at_1000
value: 77.151
- type: ndcg_at_3
value: 68.255
- type: ndcg_at_5
value: 70.978
- type: precision_at_1
value: 80.365
- type: precision_at_10
value: 15.359
- type: precision_at_100
value: 1.7690000000000001
- type: precision_at_1000
value: 0.19
- type: precision_at_3
value: 44.024
- type: precision_at_5
value: 28.555999999999997
- type: recall_at_1
value: 40.182
- type: recall_at_10
value: 76.793
- type: recall_at_100
value: 88.474
- type: recall_at_1000
value: 95.159
- type: recall_at_3
value: 66.036
- type: recall_at_5
value: 71.391
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 92.7796
- type: ap
value: 89.24883716810874
- type: f1
value: 92.7706903433313
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.016
- type: map_at_10
value: 34.408
- type: map_at_100
value: 35.592
- type: map_at_1000
value: 35.64
- type: map_at_3
value: 30.459999999999997
- type: map_at_5
value: 32.721000000000004
- type: mrr_at_1
value: 22.593
- type: mrr_at_10
value: 34.993
- type: mrr_at_100
value: 36.113
- type: mrr_at_1000
value: 36.156
- type: mrr_at_3
value: 31.101
- type: mrr_at_5
value: 33.364
- type: ndcg_at_1
value: 22.579
- type: ndcg_at_10
value: 41.404999999999994
- type: ndcg_at_100
value: 47.018
- type: ndcg_at_1000
value: 48.211999999999996
- type: ndcg_at_3
value: 33.389
- type: ndcg_at_5
value: 37.425000000000004
- type: precision_at_1
value: 22.579
- type: precision_at_10
value: 6.59
- type: precision_at_100
value: 0.938
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.241000000000001
- type: precision_at_5
value: 10.59
- type: recall_at_1
value: 22.016
- type: recall_at_10
value: 62.927
- type: recall_at_100
value: 88.72
- type: recall_at_1000
value: 97.80799999999999
- type: recall_at_3
value: 41.229
- type: recall_at_5
value: 50.88
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 94.01732786137711
- type: f1
value: 93.76353126402202
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 76.91746466028272
- type: f1
value: 57.715651682646765
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.5030262273033
- type: f1
value: 74.6693629986121
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.74781439139207
- type: f1
value: 79.96684171018774
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.2156206892017
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.180539484816137
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.51125957874274
- type: mrr
value: 33.777037359249995
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.248
- type: map_at_10
value: 15.340000000000002
- type: map_at_100
value: 19.591
- type: map_at_1000
value: 21.187
- type: map_at_3
value: 11.329
- type: map_at_5
value: 13.209999999999999
- type: mrr_at_1
value: 47.678
- type: mrr_at_10
value: 57.493
- type: mrr_at_100
value: 58.038999999999994
- type: mrr_at_1000
value: 58.07
- type: mrr_at_3
value: 55.36600000000001
- type: mrr_at_5
value: 56.635999999999996
- type: ndcg_at_1
value: 46.129999999999995
- type: ndcg_at_10
value: 38.653999999999996
- type: ndcg_at_100
value: 36.288
- type: ndcg_at_1000
value: 44.765
- type: ndcg_at_3
value: 43.553
- type: ndcg_at_5
value: 41.317
- type: precision_at_1
value: 47.368
- type: precision_at_10
value: 28.669
- type: precision_at_100
value: 9.158
- type: precision_at_1000
value: 2.207
- type: precision_at_3
value: 40.97
- type: precision_at_5
value: 35.604
- type: recall_at_1
value: 7.248
- type: recall_at_10
value: 19.46
- type: recall_at_100
value: 37.214000000000006
- type: recall_at_1000
value: 67.64099999999999
- type: recall_at_3
value: 12.025
- type: recall_at_5
value: 15.443999999999999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.595000000000002
- type: map_at_10
value: 47.815999999999995
- type: map_at_100
value: 48.811
- type: map_at_1000
value: 48.835
- type: map_at_3
value: 43.225
- type: map_at_5
value: 46.017
- type: mrr_at_1
value: 35.689
- type: mrr_at_10
value: 50.341
- type: mrr_at_100
value: 51.044999999999995
- type: mrr_at_1000
value: 51.062
- type: mrr_at_3
value: 46.553
- type: mrr_at_5
value: 48.918
- type: ndcg_at_1
value: 35.66
- type: ndcg_at_10
value: 55.859
- type: ndcg_at_100
value: 59.864
- type: ndcg_at_1000
value: 60.419999999999995
- type: ndcg_at_3
value: 47.371
- type: ndcg_at_5
value: 51.995000000000005
- type: precision_at_1
value: 35.66
- type: precision_at_10
value: 9.27
- type: precision_at_100
value: 1.1520000000000001
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 21.63
- type: precision_at_5
value: 15.655
- type: recall_at_1
value: 31.595000000000002
- type: recall_at_10
value: 77.704
- type: recall_at_100
value: 94.774
- type: recall_at_1000
value: 98.919
- type: recall_at_3
value: 56.052
- type: recall_at_5
value: 66.623
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.489
- type: map_at_10
value: 85.411
- type: map_at_100
value: 86.048
- type: map_at_1000
value: 86.064
- type: map_at_3
value: 82.587
- type: map_at_5
value: 84.339
- type: mrr_at_1
value: 82.28
- type: mrr_at_10
value: 88.27199999999999
- type: mrr_at_100
value: 88.362
- type: mrr_at_1000
value: 88.362
- type: mrr_at_3
value: 87.372
- type: mrr_at_5
value: 87.995
- type: ndcg_at_1
value: 82.27
- type: ndcg_at_10
value: 89.023
- type: ndcg_at_100
value: 90.191
- type: ndcg_at_1000
value: 90.266
- type: ndcg_at_3
value: 86.37
- type: ndcg_at_5
value: 87.804
- type: precision_at_1
value: 82.27
- type: precision_at_10
value: 13.469000000000001
- type: precision_at_100
value: 1.533
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.797
- type: precision_at_5
value: 24.734
- type: recall_at_1
value: 71.489
- type: recall_at_10
value: 95.824
- type: recall_at_100
value: 99.70599999999999
- type: recall_at_1000
value: 99.979
- type: recall_at_3
value: 88.099
- type: recall_at_5
value: 92.285
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 60.52398807444541
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 65.34855891507871
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.188000000000001
- type: map_at_10
value: 13.987
- type: map_at_100
value: 16.438
- type: map_at_1000
value: 16.829
- type: map_at_3
value: 9.767000000000001
- type: map_at_5
value: 11.912
- type: mrr_at_1
value: 25.6
- type: mrr_at_10
value: 37.744
- type: mrr_at_100
value: 38.847
- type: mrr_at_1000
value: 38.894
- type: mrr_at_3
value: 34.166999999999994
- type: mrr_at_5
value: 36.207
- type: ndcg_at_1
value: 25.6
- type: ndcg_at_10
value: 22.980999999999998
- type: ndcg_at_100
value: 32.039
- type: ndcg_at_1000
value: 38.157000000000004
- type: ndcg_at_3
value: 21.567
- type: ndcg_at_5
value: 19.070999999999998
- type: precision_at_1
value: 25.6
- type: precision_at_10
value: 12.02
- type: precision_at_100
value: 2.5100000000000002
- type: precision_at_1000
value: 0.396
- type: precision_at_3
value: 20.333000000000002
- type: precision_at_5
value: 16.98
- type: recall_at_1
value: 5.188000000000001
- type: recall_at_10
value: 24.372
- type: recall_at_100
value: 50.934999999999995
- type: recall_at_1000
value: 80.477
- type: recall_at_3
value: 12.363
- type: recall_at_5
value: 17.203
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 87.24286275535398
- type: cos_sim_spearman
value: 82.62333770991818
- type: euclidean_pearson
value: 84.60353717637284
- type: euclidean_spearman
value: 82.32990108810047
- type: manhattan_pearson
value: 84.6089049738196
- type: manhattan_spearman
value: 82.33361785438936
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 87.87428858503165
- type: cos_sim_spearman
value: 79.09145886519929
- type: euclidean_pearson
value: 86.42669231664036
- type: euclidean_spearman
value: 80.03127375435449
- type: manhattan_pearson
value: 86.41330338305022
- type: manhattan_spearman
value: 80.02492538673368
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 88.67912277322645
- type: cos_sim_spearman
value: 89.6171319711762
- type: euclidean_pearson
value: 86.56571917398725
- type: euclidean_spearman
value: 87.71216907898948
- type: manhattan_pearson
value: 86.57459050182473
- type: manhattan_spearman
value: 87.71916648349993
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 86.71957379085862
- type: cos_sim_spearman
value: 85.01784075851465
- type: euclidean_pearson
value: 84.7407848472801
- type: euclidean_spearman
value: 84.61063091345538
- type: manhattan_pearson
value: 84.71494352494403
- type: manhattan_spearman
value: 84.58772077604254
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.40508326325175
- type: cos_sim_spearman
value: 89.50912897763186
- type: euclidean_pearson
value: 87.82349070086627
- type: euclidean_spearman
value: 88.44179162727521
- type: manhattan_pearson
value: 87.80181927025595
- type: manhattan_spearman
value: 88.43205129636243
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.35846741715478
- type: cos_sim_spearman
value: 86.61172476741842
- type: euclidean_pearson
value: 84.60123125491637
- type: euclidean_spearman
value: 85.3001948141827
- type: manhattan_pearson
value: 84.56231142658329
- type: manhattan_spearman
value: 85.23579900798813
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.94539129818824
- type: cos_sim_spearman
value: 88.99349064256742
- type: euclidean_pearson
value: 88.7142444640351
- type: euclidean_spearman
value: 88.34120813505011
- type: manhattan_pearson
value: 88.70363008238084
- type: manhattan_spearman
value: 88.31952816956954
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 68.29910260369893
- type: cos_sim_spearman
value: 68.79263346213466
- type: euclidean_pearson
value: 68.41627521422252
- type: euclidean_spearman
value: 66.61602587398579
- type: manhattan_pearson
value: 68.49402183447361
- type: manhattan_spearman
value: 66.80157792354453
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.43703906343708
- type: cos_sim_spearman
value: 89.06081805093662
- type: euclidean_pearson
value: 87.48311456299662
- type: euclidean_spearman
value: 88.07417597580013
- type: manhattan_pearson
value: 87.48202249768894
- type: manhattan_spearman
value: 88.04758031111642
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.49080620485203
- type: mrr
value: 96.19145378949301
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 59.317
- type: map_at_10
value: 69.296
- type: map_at_100
value: 69.738
- type: map_at_1000
value: 69.759
- type: map_at_3
value: 66.12599999999999
- type: map_at_5
value: 67.532
- type: mrr_at_1
value: 62
- type: mrr_at_10
value: 70.176
- type: mrr_at_100
value: 70.565
- type: mrr_at_1000
value: 70.583
- type: mrr_at_3
value: 67.833
- type: mrr_at_5
value: 68.93299999999999
- type: ndcg_at_1
value: 62
- type: ndcg_at_10
value: 74.069
- type: ndcg_at_100
value: 76.037
- type: ndcg_at_1000
value: 76.467
- type: ndcg_at_3
value: 68.628
- type: ndcg_at_5
value: 70.57600000000001
- type: precision_at_1
value: 62
- type: precision_at_10
value: 10
- type: precision_at_100
value: 1.097
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.667
- type: precision_at_5
value: 17.4
- type: recall_at_1
value: 59.317
- type: recall_at_10
value: 87.822
- type: recall_at_100
value: 96.833
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 73.06099999999999
- type: recall_at_5
value: 77.928
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.88910891089108
- type: cos_sim_ap
value: 97.236958456951
- type: cos_sim_f1
value: 94.39999999999999
- type: cos_sim_precision
value: 94.39999999999999
- type: cos_sim_recall
value: 94.39999999999999
- type: dot_accuracy
value: 99.82574257425742
- type: dot_ap
value: 94.94344759441888
- type: dot_f1
value: 91.17352056168507
- type: dot_precision
value: 91.44869215291752
- type: dot_recall
value: 90.9
- type: euclidean_accuracy
value: 99.88415841584158
- type: euclidean_ap
value: 97.2044250782305
- type: euclidean_f1
value: 94.210786739238
- type: euclidean_precision
value: 93.24191968658178
- type: euclidean_recall
value: 95.19999999999999
- type: manhattan_accuracy
value: 99.88613861386139
- type: manhattan_ap
value: 97.20683205497689
- type: manhattan_f1
value: 94.2643391521197
- type: manhattan_precision
value: 94.02985074626866
- type: manhattan_recall
value: 94.5
- type: max_accuracy
value: 99.88910891089108
- type: max_ap
value: 97.236958456951
- type: max_f1
value: 94.39999999999999
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.53940781726187
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.71865011295108
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.3218674533331
- type: mrr
value: 56.28279910449028
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.723915667479673
- type: cos_sim_spearman
value: 32.029070449745234
- type: dot_pearson
value: 28.864944212481454
- type: dot_spearman
value: 27.939266999596725
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.231
- type: map_at_10
value: 1.949
- type: map_at_100
value: 10.023
- type: map_at_1000
value: 23.485
- type: map_at_3
value: 0.652
- type: map_at_5
value: 1.054
- type: mrr_at_1
value: 86
- type: mrr_at_10
value: 92.067
- type: mrr_at_100
value: 92.067
- type: mrr_at_1000
value: 92.067
- type: mrr_at_3
value: 91.667
- type: mrr_at_5
value: 92.067
- type: ndcg_at_1
value: 83
- type: ndcg_at_10
value: 76.32900000000001
- type: ndcg_at_100
value: 54.662
- type: ndcg_at_1000
value: 48.062
- type: ndcg_at_3
value: 81.827
- type: ndcg_at_5
value: 80.664
- type: precision_at_1
value: 86
- type: precision_at_10
value: 80
- type: precision_at_100
value: 55.48
- type: precision_at_1000
value: 20.938000000000002
- type: precision_at_3
value: 85.333
- type: precision_at_5
value: 84.39999999999999
- type: recall_at_1
value: 0.231
- type: recall_at_10
value: 2.158
- type: recall_at_100
value: 13.344000000000001
- type: recall_at_1000
value: 44.31
- type: recall_at_3
value: 0.6779999999999999
- type: recall_at_5
value: 1.13
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.524
- type: map_at_10
value: 10.183
- type: map_at_100
value: 16.625
- type: map_at_1000
value: 18.017
- type: map_at_3
value: 5.169
- type: map_at_5
value: 6.772
- type: mrr_at_1
value: 32.653
- type: mrr_at_10
value: 47.128
- type: mrr_at_100
value: 48.458
- type: mrr_at_1000
value: 48.473
- type: mrr_at_3
value: 44.897999999999996
- type: mrr_at_5
value: 45.306000000000004
- type: ndcg_at_1
value: 30.612000000000002
- type: ndcg_at_10
value: 24.928
- type: ndcg_at_100
value: 37.613
- type: ndcg_at_1000
value: 48.528
- type: ndcg_at_3
value: 28.829
- type: ndcg_at_5
value: 25.237
- type: precision_at_1
value: 32.653
- type: precision_at_10
value: 22.448999999999998
- type: precision_at_100
value: 8.02
- type: precision_at_1000
value: 1.537
- type: precision_at_3
value: 30.612000000000002
- type: precision_at_5
value: 24.490000000000002
- type: recall_at_1
value: 2.524
- type: recall_at_10
value: 16.38
- type: recall_at_100
value: 49.529
- type: recall_at_1000
value: 83.598
- type: recall_at_3
value: 6.411
- type: recall_at_5
value: 8.932
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.09020000000001
- type: ap
value: 14.451710060978993
- type: f1
value: 54.7874410609049
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.745331069609506
- type: f1
value: 60.08387848592697
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.71549485462037
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.39345532574357
- type: cos_sim_ap
value: 78.16796549696478
- type: cos_sim_f1
value: 71.27713276123171
- type: cos_sim_precision
value: 68.3115626511853
- type: cos_sim_recall
value: 74.51187335092348
- type: dot_accuracy
value: 85.12248912201228
- type: dot_ap
value: 69.26039256107077
- type: dot_f1
value: 65.04294321240867
- type: dot_precision
value: 63.251059586138126
- type: dot_recall
value: 66.93931398416886
- type: euclidean_accuracy
value: 87.07754664123503
- type: euclidean_ap
value: 77.7872176038945
- type: euclidean_f1
value: 70.85587801278899
- type: euclidean_precision
value: 66.3519115614924
- type: euclidean_recall
value: 76.01583113456465
- type: manhattan_accuracy
value: 87.07754664123503
- type: manhattan_ap
value: 77.7341400185556
- type: manhattan_f1
value: 70.80310880829015
- type: manhattan_precision
value: 69.54198473282443
- type: manhattan_recall
value: 72.1108179419525
- type: max_accuracy
value: 87.39345532574357
- type: max_ap
value: 78.16796549696478
- type: max_f1
value: 71.27713276123171
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.09457833663213
- type: cos_sim_ap
value: 86.33024314706873
- type: cos_sim_f1
value: 78.59623733719248
- type: cos_sim_precision
value: 74.13322413322413
- type: cos_sim_recall
value: 83.63104404065291
- type: dot_accuracy
value: 88.3086894089339
- type: dot_ap
value: 83.92225241805097
- type: dot_f1
value: 76.8721826377781
- type: dot_precision
value: 72.8168044077135
- type: dot_recall
value: 81.40591315060055
- type: euclidean_accuracy
value: 88.77052043311213
- type: euclidean_ap
value: 85.7410710218755
- type: euclidean_f1
value: 77.97705489398781
- type: euclidean_precision
value: 73.77713657598241
- type: euclidean_recall
value: 82.68401601478288
- type: manhattan_accuracy
value: 88.73753250281368
- type: manhattan_ap
value: 85.72867199072802
- type: manhattan_f1
value: 77.89774182922812
- type: manhattan_precision
value: 74.23787931635857
- type: manhattan_recall
value: 81.93717277486911
- type: max_accuracy
value: 89.09457833663213
- type: max_ap
value: 86.33024314706873
- type: max_f1
value: 78.59623733719248
---
# [Universal AnglE Embedding](https://github.com/SeanLee97/AnglE)
> Follow us on GitHub: https://github.com/SeanLee97/AnglE.
🔥 Our universal English sentence embedding `WhereIsAI/UAE-Large-V1` achieves **SOTA** on the [MTEB Leaderboard](https://huggingface.co/spaces/mteb/leaderboard) with an average score of 64.64!
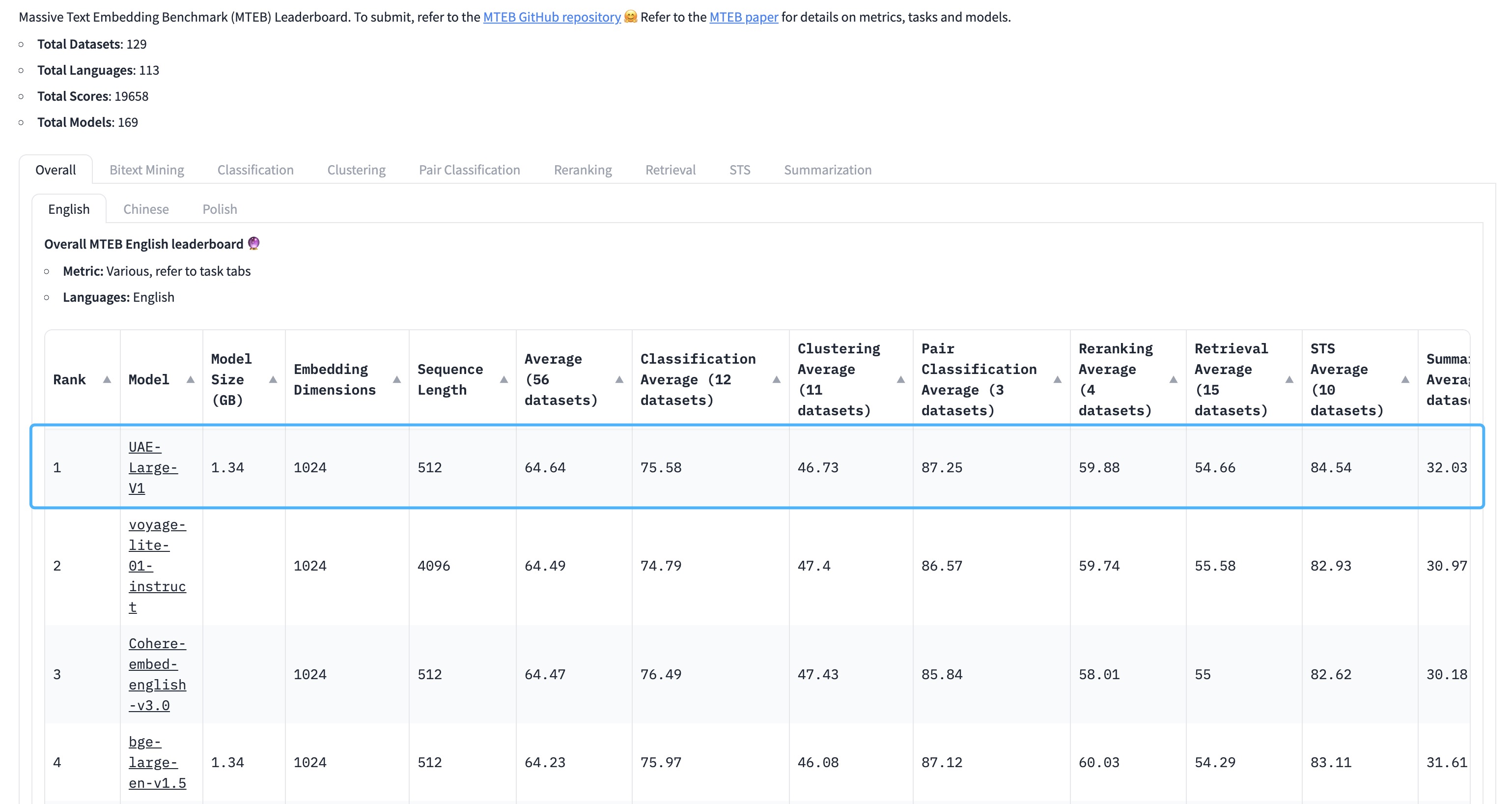
# Usage
```bash
python -m pip install -U angle-emb
```
1) Non-Retrieval Tasks
```python
from angle_emb import AnglE
angle = AnglE.from_pretrained('WhereIsAI/UAE-Large-V1', pooling_strategy='cls').cuda()
vec = angle.encode('hello world', to_numpy=True)
print(vec)
vecs = angle.encode(['hello world1', 'hello world2'], to_numpy=True)
print(vecs)
```
2) Retrieval Tasks
For retrieval purposes, please use the prompt `Prompts.C`.
```python
from angle_emb import AnglE, Prompts
angle = AnglE.from_pretrained('WhereIsAI/UAE-Large-V1', pooling_strategy='cls').cuda()
angle.set_prompt(prompt=Prompts.C)
vec = angle.encode({'text': 'hello world'}, to_numpy=True)
print(vec)
vecs = angle.encode([{'text': 'hello world1'}, {'text': 'hello world2'}], to_numpy=True)
print(vecs)
```
# Citation
If you use our pre-trained models, welcome to support us by citing our work:
```
@article{li2023angle,
title={AnglE-optimized Text Embeddings},
author={Li, Xianming and Li, Jing},
journal={arXiv preprint arXiv:2309.12871},
year={2023}
}
```
|
[
"BIOSSES",
"SCIFACT"
] |
judithrosell/PubMedBERT_CRAFT_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-23T15:55:56Z |
2023-12-26T11:24:31+00:00
| 92 | 0 |
---
base_model: microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext
license: mit
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: PubMedBERT_CRAFT_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PubMedBERT_CRAFT_NER
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1031
- Precision: 0.8429
- Recall: 0.8679
- F1: 0.8552
- Accuracy: 0.9734
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 347 | 0.1280 | 0.7851 | 0.8360 | 0.8097 | 0.9647 |
| 0.1944 | 2.0 | 695 | 0.1092 | 0.8187 | 0.8615 | 0.8395 | 0.9707 |
| 0.046 | 3.0 | 1041 | 0.1031 | 0.8429 | 0.8679 | 0.8552 | 0.9734 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.0
- Tokenizers 0.15.0
|
[
"CRAFT"
] |
zeta-alpha-ai/Zeta-Alpha-E5-Mistral
|
zeta-alpha-ai
|
feature-extraction
|
[
"sentence-transformers",
"safetensors",
"mistral",
"feature-extraction",
"mteb",
"transformers",
"en",
"license:mit",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-08-30T14:27:48Z |
2025-01-06T15:16:48+00:00
| 92 | 11 |
---
language:
- en
license: mit
tags:
- mteb
- transformers
- sentence-transformers
model-index:
- name: Zeta-Alpha-E5-Mistral
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 77.76119402985074
- type: ap
value: 39.97673988468886
- type: ap_weighted
value: 39.97673988468886
- type: f1
value: 71.23171737695898
- type: f1_weighted
value: 79.55230307558237
- type: main_score
value: 77.76119402985074
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 96.61810000000001
- type: ap
value: 94.99559013902017
- type: ap_weighted
value: 94.99559013902017
- type: f1
value: 96.61758649480731
- type: f1_weighted
value: 96.61758649480731
- type: main_score
value: 96.61810000000001
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 59.26199999999999
- type: f1
value: 56.32963321217333
- type: f1_weighted
value: 56.32963321217333
- type: main_score
value: 59.26199999999999
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: mteb/arguana
config: default
split: test
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
metrics:
- type: main_score
value: 65.623
- type: map_at_1
value: 41.536
- type: map_at_10
value: 57.485
- type: map_at_100
value: 58.013000000000005
- type: map_at_1000
value: 58.013000000000005
- type: map_at_20
value: 57.957
- type: map_at_3
value: 53.284
- type: map_at_5
value: 55.837
- type: mrr_at_1
value: 42.17638691322902
- type: mrr_at_10
value: 57.7096175122492
- type: mrr_at_100
value: 58.23610809196743
- type: mrr_at_1000
value: 58.23673750573145
- type: mrr_at_20
value: 58.180348622747324
- type: mrr_at_3
value: 53.44950213371275
- type: mrr_at_5
value: 56.07396870554779
- type: nauc_map_at_1000_diff1
value: 14.098091070036958
- type: nauc_map_at_1000_max
value: -16.568377380844108
- type: nauc_map_at_1000_std
value: -22.105696179585834
- type: nauc_map_at_100_diff1
value: 14.096542453201625
- type: nauc_map_at_100_max
value: -16.57054590195526
- type: nauc_map_at_100_std
value: -22.1090324366772
- type: nauc_map_at_10_diff1
value: 13.840246695558884
- type: nauc_map_at_10_max
value: -16.52098795923224
- type: nauc_map_at_10_std
value: -22.074328710004032
- type: nauc_map_at_1_diff1
value: 17.117727049808984
- type: nauc_map_at_1_max
value: -18.587242049712614
- type: nauc_map_at_1_std
value: -22.454707653498595
- type: nauc_map_at_20_diff1
value: 14.068130846454585
- type: nauc_map_at_20_max
value: -16.53942858114966
- type: nauc_map_at_20_std
value: -22.10921004077996
- type: nauc_map_at_3_diff1
value: 14.596579595737097
- type: nauc_map_at_3_max
value: -15.62887067464894
- type: nauc_map_at_3_std
value: -22.09058102549274
- type: nauc_map_at_5_diff1
value: 13.798507062284514
- type: nauc_map_at_5_max
value: -16.36834850771522
- type: nauc_map_at_5_std
value: -21.984206595455134
- type: nauc_mrr_at_1000_diff1
value: 12.144909427474602
- type: nauc_mrr_at_1000_max
value: -17.048787138426324
- type: nauc_mrr_at_1000_std
value: -21.961966140898564
- type: nauc_mrr_at_100_diff1
value: 12.143403633612827
- type: nauc_mrr_at_100_max
value: -17.050945262411012
- type: nauc_mrr_at_100_std
value: -21.965305811191673
- type: nauc_mrr_at_10_diff1
value: 11.88548720648553
- type: nauc_mrr_at_10_max
value: -16.996705857584736
- type: nauc_mrr_at_10_std
value: -21.883645748542396
- type: nauc_mrr_at_1_diff1
value: 15.37682964765565
- type: nauc_mrr_at_1_max
value: -17.989361001169087
- type: nauc_mrr_at_1_std
value: -21.697830490637955
- type: nauc_mrr_at_20_diff1
value: 12.119044499779363
- type: nauc_mrr_at_20_max
value: -17.018675761117027
- type: nauc_mrr_at_20_std
value: -21.965554459307565
- type: nauc_mrr_at_3_diff1
value: 12.535001807278187
- type: nauc_mrr_at_3_max
value: -16.38816957172248
- type: nauc_mrr_at_3_std
value: -22.081293367465896
- type: nauc_mrr_at_5_diff1
value: 11.892111947679496
- type: nauc_mrr_at_5_max
value: -16.79709351116846
- type: nauc_mrr_at_5_std
value: -21.79512696140714
- type: nauc_ndcg_at_1000_diff1
value: 13.67006999549869
- type: nauc_ndcg_at_1000_max
value: -16.236125687432107
- type: nauc_ndcg_at_1000_std
value: -21.810131960233065
- type: nauc_ndcg_at_100_diff1
value: 13.637478389163462
- type: nauc_ndcg_at_100_max
value: -16.28219720987127
- type: nauc_ndcg_at_100_std
value: -21.880912370176876
- type: nauc_ndcg_at_10_diff1
value: 12.558591199280556
- type: nauc_ndcg_at_10_max
value: -15.952826009827106
- type: nauc_ndcg_at_10_std
value: -21.818643731025382
- type: nauc_ndcg_at_1_diff1
value: 17.117727049808984
- type: nauc_ndcg_at_1_max
value: -18.587242049712614
- type: nauc_ndcg_at_1_std
value: -22.454707653498595
- type: nauc_ndcg_at_20_diff1
value: 13.402986057386181
- type: nauc_ndcg_at_20_max
value: -16.072631062968746
- type: nauc_ndcg_at_20_std
value: -21.98468803430586
- type: nauc_ndcg_at_3_diff1
value: 14.059904782033348
- type: nauc_ndcg_at_3_max
value: -14.433190101994514
- type: nauc_ndcg_at_3_std
value: -21.990025270634135
- type: nauc_ndcg_at_5_diff1
value: 12.434165121057134
- type: nauc_ndcg_at_5_max
value: -15.650774158031522
- type: nauc_ndcg_at_5_std
value: -21.636716447934305
- type: nauc_precision_at_1000_diff1
value: 1.7151819945276745
- type: nauc_precision_at_1000_max
value: 20.85546049013785
- type: nauc_precision_at_1000_std
value: 77.3551884133584
- type: nauc_precision_at_100_diff1
value: -7.961881099019577
- type: nauc_precision_at_100_max
value: -1.8225484680865736
- type: nauc_precision_at_100_std
value: 35.484449109425384
- type: nauc_precision_at_10_diff1
value: 0.46638305609538855
- type: nauc_precision_at_10_max
value: -11.023993018739485
- type: nauc_precision_at_10_std
value: -19.111584616037852
- type: nauc_precision_at_1_diff1
value: 17.117727049808984
- type: nauc_precision_at_1_max
value: -18.587242049712614
- type: nauc_precision_at_1_std
value: -22.454707653498595
- type: nauc_precision_at_20_diff1
value: -1.0298881487766305
- type: nauc_precision_at_20_max
value: -4.548017977674335
- type: nauc_precision_at_20_std
value: -18.901496352112133
- type: nauc_precision_at_3_diff1
value: 12.350178962124566
- type: nauc_precision_at_3_max
value: -10.271126387937858
- type: nauc_precision_at_3_std
value: -21.655307623793433
- type: nauc_precision_at_5_diff1
value: 6.011571432832696
- type: nauc_precision_at_5_max
value: -12.478026665421389
- type: nauc_precision_at_5_std
value: -19.845124181363882
- type: nauc_recall_at_1000_diff1
value: 1.7151819945236155
- type: nauc_recall_at_1000_max
value: 20.855460490135933
- type: nauc_recall_at_1000_std
value: 77.35518841335626
- type: nauc_recall_at_100_diff1
value: -7.961881099020542
- type: nauc_recall_at_100_max
value: -1.8225484680932273
- type: nauc_recall_at_100_std
value: 35.48444910942399
- type: nauc_recall_at_10_diff1
value: 0.46638305609538805
- type: nauc_recall_at_10_max
value: -11.023993018739322
- type: nauc_recall_at_10_std
value: -19.11158461603798
- type: nauc_recall_at_1_diff1
value: 17.117727049808984
- type: nauc_recall_at_1_max
value: -18.587242049712614
- type: nauc_recall_at_1_std
value: -22.454707653498595
- type: nauc_recall_at_20_diff1
value: -1.029888148776229
- type: nauc_recall_at_20_max
value: -4.548017977673906
- type: nauc_recall_at_20_std
value: -18.901496352110804
- type: nauc_recall_at_3_diff1
value: 12.350178962124682
- type: nauc_recall_at_3_max
value: -10.271126387937805
- type: nauc_recall_at_3_std
value: -21.65530762379337
- type: nauc_recall_at_5_diff1
value: 6.0115714328326435
- type: nauc_recall_at_5_max
value: -12.478026665421405
- type: nauc_recall_at_5_std
value: -19.845124181363875
- type: ndcg_at_1
value: 41.536
- type: ndcg_at_10
value: 65.623
- type: ndcg_at_100
value: 67.63
- type: ndcg_at_1000
value: 67.64099999999999
- type: ndcg_at_20
value: 67.241
- type: ndcg_at_3
value: 57.048
- type: ndcg_at_5
value: 61.678999999999995
- type: precision_at_1
value: 41.536
- type: precision_at_10
value: 9.132
- type: precision_at_100
value: 0.996
- type: precision_at_1000
value: 0.1
- type: precision_at_20
value: 4.8759999999999994
- type: precision_at_3
value: 22.641
- type: precision_at_5
value: 15.845999999999998
- type: recall_at_1
value: 41.536
- type: recall_at_10
value: 91.323
- type: recall_at_100
value: 99.57300000000001
- type: recall_at_1000
value: 99.644
- type: recall_at_20
value: 97.51100000000001
- type: recall_at_3
value: 67.923
- type: recall_at_5
value: 79.232
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: main_score
value: 52.026635060007244
- type: v_measure
value: 52.026635060007244
- type: v_measure_std
value: 14.357137408692006
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: main_score
value: 47.834914950269855
- type: v_measure
value: 47.834914950269855
- type: v_measure_std
value: 14.487028918517247
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: main_score
value: 64.5808745066313
- type: map
value: 64.5808745066313
- type: mrr
value: 77.56540473991997
- type: nAUC_map_diff1
value: 23.168800779252464
- type: nAUC_map_max
value: 30.342203769599735
- type: nAUC_map_std
value: 22.562701982176833
- type: nAUC_mrr_diff1
value: 27.79261544540621
- type: nAUC_mrr_max
value: 43.302228243606045
- type: nAUC_mrr_std
value: 26.432985515912673
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cosine_pearson
value: 87.97778619889539
- type: cosine_spearman
value: 86.44233109293758
- type: euclidean_pearson
value: 86.6664224630525
- type: euclidean_spearman
value: 86.44233109293758
- type: main_score
value: 86.44233109293758
- type: manhattan_pearson
value: 86.75174487553707
- type: manhattan_spearman
value: 86.61402175201368
- type: pearson
value: 87.97778619889539
- type: spearman
value: 86.44233109293758
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 83.1103896103896
- type: f1
value: 82.2932953112279
- type: f1_weighted
value: 82.2932953112279
- type: main_score
value: 83.1103896103896
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: main_score
value: 43.73746639290943
- type: v_measure
value: 43.73746639290943
- type: v_measure_std
value: 0.8808902310879784
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: main_score
value: 40.73737737926463
- type: v_measure
value: 40.73737737926463
- type: v_measure_std
value: 0.6059982328960863
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: CQADupstackRetrieval_is_a_combined_dataset
config: default
split: test
revision: 46989137a86843e03a6195de44b09deda022eec7
metrics:
- type: main_score
value: 48.852333333333334
- type: ndcg_at_10
value: 48.852333333333334
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: mteb/climate-fever
config: default
split: test
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
metrics:
- type: main_score
value: 42.047000000000004
- type: map_at_1
value: 18.269
- type: map_at_10
value: 31.691999999999997
- type: map_at_100
value: 33.841
- type: map_at_1000
value: 34.009
- type: map_at_20
value: 32.885999999999996
- type: map_at_3
value: 26.558999999999997
- type: map_at_5
value: 29.119
- type: mrr_at_1
value: 41.69381107491857
- type: mrr_at_10
value: 54.293185460937984
- type: mrr_at_100
value: 54.87161862744807
- type: mrr_at_1000
value: 54.88722882443645
- type: mrr_at_20
value: 54.685754380853844
- type: mrr_at_3
value: 51.172638436482146
- type: mrr_at_5
value: 53.12052117263853
- type: nauc_map_at_1000_diff1
value: 27.03807365621228
- type: nauc_map_at_1000_max
value: 40.31079671403445
- type: nauc_map_at_1000_std
value: 26.092423798773883
- type: nauc_map_at_100_diff1
value: 27.015360474734436
- type: nauc_map_at_100_max
value: 40.28408194597505
- type: nauc_map_at_100_std
value: 26.086029014261968
- type: nauc_map_at_10_diff1
value: 27.222731203652856
- type: nauc_map_at_10_max
value: 40.01781109904128
- type: nauc_map_at_10_std
value: 24.73681887890272
- type: nauc_map_at_1_diff1
value: 35.75107300356484
- type: nauc_map_at_1_max
value: 40.2201153742901
- type: nauc_map_at_1_std
value: 18.766249947929374
- type: nauc_map_at_20_diff1
value: 26.931804653893042
- type: nauc_map_at_20_max
value: 40.21587995014608
- type: nauc_map_at_20_std
value: 25.75452108695598
- type: nauc_map_at_3_diff1
value: 28.310387788680696
- type: nauc_map_at_3_max
value: 39.285866053656385
- type: nauc_map_at_3_std
value: 21.394962842915703
- type: nauc_map_at_5_diff1
value: 27.300839773785274
- type: nauc_map_at_5_max
value: 39.3888708340898
- type: nauc_map_at_5_std
value: 22.78299335246201
- type: nauc_mrr_at_1000_diff1
value: 26.569029993582287
- type: nauc_mrr_at_1000_max
value: 38.05698386072128
- type: nauc_mrr_at_1000_std
value: 27.12877875031529
- type: nauc_mrr_at_100_diff1
value: 26.56693868451222
- type: nauc_mrr_at_100_max
value: 38.06321319344823
- type: nauc_mrr_at_100_std
value: 27.14409997788537
- type: nauc_mrr_at_10_diff1
value: 26.52694223161396
- type: nauc_mrr_at_10_max
value: 38.120563154705
- type: nauc_mrr_at_10_std
value: 27.11337497751667
- type: nauc_mrr_at_1_diff1
value: 29.371725407886277
- type: nauc_mrr_at_1_max
value: 35.7850341702808
- type: nauc_mrr_at_1_std
value: 22.69810863765783
- type: nauc_mrr_at_20_diff1
value: 26.567897033309247
- type: nauc_mrr_at_20_max
value: 38.17484491649562
- type: nauc_mrr_at_20_std
value: 27.218678564296972
- type: nauc_mrr_at_3_diff1
value: 26.582727973322427
- type: nauc_mrr_at_3_max
value: 37.8745721692282
- type: nauc_mrr_at_3_std
value: 26.567749469034307
- type: nauc_mrr_at_5_diff1
value: 26.404958533442898
- type: nauc_mrr_at_5_max
value: 37.86090955141593
- type: nauc_mrr_at_5_std
value: 26.65816459603454
- type: nauc_ndcg_at_1000_diff1
value: 25.7228323702742
- type: nauc_ndcg_at_1000_max
value: 41.024272689913296
- type: nauc_ndcg_at_1000_std
value: 31.373617783353815
- type: nauc_ndcg_at_100_diff1
value: 25.467806967471812
- type: nauc_ndcg_at_100_max
value: 40.68595692225817
- type: nauc_ndcg_at_100_std
value: 31.327255356351774
- type: nauc_ndcg_at_10_diff1
value: 25.65771458118311
- type: nauc_ndcg_at_10_max
value: 40.2959313004829
- type: nauc_ndcg_at_10_std
value: 28.21103387387833
- type: nauc_ndcg_at_1_diff1
value: 29.371725407886277
- type: nauc_ndcg_at_1_max
value: 35.7850341702808
- type: nauc_ndcg_at_1_std
value: 22.69810863765783
- type: nauc_ndcg_at_20_diff1
value: 25.008107221444327
- type: nauc_ndcg_at_20_max
value: 40.613619354979626
- type: nauc_ndcg_at_20_std
value: 30.216191744111416
- type: nauc_ndcg_at_3_diff1
value: 25.85227194113396
- type: nauc_ndcg_at_3_max
value: 38.32492256264965
- type: nauc_ndcg_at_3_std
value: 23.735358525961033
- type: nauc_ndcg_at_5_diff1
value: 25.747409532466243
- type: nauc_ndcg_at_5_max
value: 39.4993084566524
- type: nauc_ndcg_at_5_std
value: 25.19771375383721
- type: nauc_precision_at_1000_diff1
value: -8.149028290279253
- type: nauc_precision_at_1000_max
value: -3.196086649201077
- type: nauc_precision_at_1000_std
value: 13.643701012139948
- type: nauc_precision_at_100_diff1
value: -1.892485292157653
- type: nauc_precision_at_100_max
value: 7.7434454354621245
- type: nauc_precision_at_100_std
value: 22.988854451791806
- type: nauc_precision_at_10_diff1
value: 6.150550804828545
- type: nauc_precision_at_10_max
value: 22.501131175285906
- type: nauc_precision_at_10_std
value: 27.39677272392596
- type: nauc_precision_at_1_diff1
value: 29.371725407886277
- type: nauc_precision_at_1_max
value: 35.7850341702808
- type: nauc_precision_at_1_std
value: 22.69810863765783
- type: nauc_precision_at_20_diff1
value: 2.283445965946842
- type: nauc_precision_at_20_max
value: 18.59466543059599
- type: nauc_precision_at_20_std
value: 29.0738299597803
- type: nauc_precision_at_3_diff1
value: 12.963867454979258
- type: nauc_precision_at_3_max
value: 30.449562657056333
- type: nauc_precision_at_3_std
value: 25.581976194336352
- type: nauc_precision_at_5_diff1
value: 8.512947940252289
- type: nauc_precision_at_5_max
value: 26.12425424420038
- type: nauc_precision_at_5_std
value: 24.877415885322808
- type: nauc_recall_at_1000_diff1
value: 17.151717317242028
- type: nauc_recall_at_1000_max
value: 40.67913325938115
- type: nauc_recall_at_1000_std
value: 49.54837910314142
- type: nauc_recall_at_100_diff1
value: 16.83432440063162
- type: nauc_recall_at_100_max
value: 34.46952489534257
- type: nauc_recall_at_100_std
value: 38.26853671426454
- type: nauc_recall_at_10_diff1
value: 19.50239551179883
- type: nauc_recall_at_10_max
value: 35.74261290262663
- type: nauc_recall_at_10_std
value: 28.630457514118163
- type: nauc_recall_at_1_diff1
value: 35.75107300356484
- type: nauc_recall_at_1_max
value: 40.2201153742901
- type: nauc_recall_at_1_std
value: 18.766249947929374
- type: nauc_recall_at_20_diff1
value: 16.723000685755707
- type: nauc_recall_at_20_max
value: 35.272383093342405
- type: nauc_recall_at_20_std
value: 32.934757635631335
- type: nauc_recall_at_3_diff1
value: 24.024160029526794
- type: nauc_recall_at_3_max
value: 38.07599046764463
- type: nauc_recall_at_3_std
value: 22.648443171847685
- type: nauc_recall_at_5_diff1
value: 21.588763686113676
- type: nauc_recall_at_5_max
value: 37.16237158404055
- type: nauc_recall_at_5_std
value: 24.45061830715902
- type: ndcg_at_1
value: 41.693999999999996
- type: ndcg_at_10
value: 42.047000000000004
- type: ndcg_at_100
value: 49.309
- type: ndcg_at_1000
value: 51.861999999999995
- type: ndcg_at_20
value: 44.982
- type: ndcg_at_3
value: 35.510000000000005
- type: ndcg_at_5
value: 37.529
- type: precision_at_1
value: 41.693999999999996
- type: precision_at_10
value: 13.114
- type: precision_at_100
value: 2.1069999999999998
- type: precision_at_1000
value: 0.259
- type: precision_at_20
value: 7.824000000000001
- type: precision_at_3
value: 26.796999999999997
- type: precision_at_5
value: 20.169
- type: recall_at_1
value: 18.269
- type: recall_at_10
value: 48.44
- type: recall_at_100
value: 72.909
- type: recall_at_1000
value: 86.79400000000001
- type: recall_at_20
value: 56.714
- type: recall_at_3
value: 31.85
- type: recall_at_5
value: 38.488
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: mteb/dbpedia
config: default
split: test
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
metrics:
- type: main_score
value: 51.202000000000005
- type: map_at_1
value: 10.789
- type: map_at_10
value: 24.804000000000002
- type: map_at_100
value: 35.908
- type: map_at_1000
value: 37.97
- type: map_at_20
value: 29.236
- type: map_at_3
value: 17.055
- type: map_at_5
value: 20.342
- type: mrr_at_1
value: 78.0
- type: mrr_at_10
value: 83.82251984126987
- type: mrr_at_100
value: 84.00706659508124
- type: mrr_at_1000
value: 84.01172077534015
- type: mrr_at_20
value: 83.93946561479457
- type: mrr_at_3
value: 82.58333333333334
- type: mrr_at_5
value: 83.38333333333335
- type: nauc_map_at_1000_diff1
value: 21.975683577384412
- type: nauc_map_at_1000_max
value: 33.104767603973286
- type: nauc_map_at_1000_std
value: 19.507936661697688
- type: nauc_map_at_100_diff1
value: 23.19428288878281
- type: nauc_map_at_100_max
value: 32.47043490749479
- type: nauc_map_at_100_std
value: 16.611980248500473
- type: nauc_map_at_10_diff1
value: 23.314074413061576
- type: nauc_map_at_10_max
value: 18.52506648908812
- type: nauc_map_at_10_std
value: -9.718219448424597
- type: nauc_map_at_1_diff1
value: 27.402329635171146
- type: nauc_map_at_1_max
value: 5.898746976402726
- type: nauc_map_at_1_std
value: -26.703327281110212
- type: nauc_map_at_20_diff1
value: 23.613670514044472
- type: nauc_map_at_20_max
value: 25.008187375084763
- type: nauc_map_at_20_std
value: -0.05206367166066498
- type: nauc_map_at_3_diff1
value: 25.673374223753598
- type: nauc_map_at_3_max
value: 12.527419567406877
- type: nauc_map_at_3_std
value: -20.06963757181341
- type: nauc_map_at_5_diff1
value: 24.74002578400672
- type: nauc_map_at_5_max
value: 14.23437788867648
- type: nauc_map_at_5_std
value: -16.317803876665256
- type: nauc_mrr_at_1000_diff1
value: 53.26868100398232
- type: nauc_mrr_at_1000_max
value: 67.65740877772801
- type: nauc_mrr_at_1000_std
value: 39.43464159369656
- type: nauc_mrr_at_100_diff1
value: 53.25615896192901
- type: nauc_mrr_at_100_max
value: 67.64777514366169
- type: nauc_mrr_at_100_std
value: 39.410662043086006
- type: nauc_mrr_at_10_diff1
value: 52.94295111677663
- type: nauc_mrr_at_10_max
value: 67.5393005296393
- type: nauc_mrr_at_10_std
value: 39.31715440936177
- type: nauc_mrr_at_1_diff1
value: 57.148073445541826
- type: nauc_mrr_at_1_max
value: 65.78742986970832
- type: nauc_mrr_at_1_std
value: 34.198659989799246
- type: nauc_mrr_at_20_diff1
value: 53.223501273361265
- type: nauc_mrr_at_20_max
value: 67.59762197314753
- type: nauc_mrr_at_20_std
value: 39.359614957729356
- type: nauc_mrr_at_3_diff1
value: 53.619283112717184
- type: nauc_mrr_at_3_max
value: 68.72067268448458
- type: nauc_mrr_at_3_std
value: 40.53052904925793
- type: nauc_mrr_at_5_diff1
value: 52.86133436375577
- type: nauc_mrr_at_5_max
value: 67.94415973414303
- type: nauc_mrr_at_5_std
value: 40.09087346298919
- type: nauc_ndcg_at_1000_diff1
value: 31.008961737330505
- type: nauc_ndcg_at_1000_max
value: 49.39127418414386
- type: nauc_ndcg_at_1000_std
value: 37.509639671229806
- type: nauc_ndcg_at_100_diff1
value: 32.50484024525448
- type: nauc_ndcg_at_100_max
value: 46.300662423725605
- type: nauc_ndcg_at_100_std
value: 28.488771981297162
- type: nauc_ndcg_at_10_diff1
value: 27.911614286994414
- type: nauc_ndcg_at_10_max
value: 44.70909339082426
- type: nauc_ndcg_at_10_std
value: 25.644980583529154
- type: nauc_ndcg_at_1_diff1
value: 51.27342509891256
- type: nauc_ndcg_at_1_max
value: 54.75803307782269
- type: nauc_ndcg_at_1_std
value: 27.4853058050954
- type: nauc_ndcg_at_20_diff1
value: 30.29885920192407
- type: nauc_ndcg_at_20_max
value: 43.45207612356715
- type: nauc_ndcg_at_20_std
value: 21.59751863312113
- type: nauc_ndcg_at_3_diff1
value: 31.251071625533843
- type: nauc_ndcg_at_3_max
value: 48.45180697571009
- type: nauc_ndcg_at_3_std
value: 32.70662167853583
- type: nauc_ndcg_at_5_diff1
value: 26.175090671223877
- type: nauc_ndcg_at_5_max
value: 45.2723355712432
- type: nauc_ndcg_at_5_std
value: 31.461916393793
- type: nauc_precision_at_1000_diff1
value: -23.926082132378777
- type: nauc_precision_at_1000_max
value: -9.350346667573811
- type: nauc_precision_at_1000_std
value: 11.578726421051043
- type: nauc_precision_at_100_diff1
value: -7.468660956171794
- type: nauc_precision_at_100_max
value: 19.470414434634723
- type: nauc_precision_at_100_std
value: 43.86244545951367
- type: nauc_precision_at_10_diff1
value: -2.090265656696684
- type: nauc_precision_at_10_max
value: 30.778228684745386
- type: nauc_precision_at_10_std
value: 44.882546930240984
- type: nauc_precision_at_1_diff1
value: 57.148073445541826
- type: nauc_precision_at_1_max
value: 65.78742986970832
- type: nauc_precision_at_1_std
value: 34.198659989799246
- type: nauc_precision_at_20_diff1
value: -3.075798118380347
- type: nauc_precision_at_20_max
value: 29.52951501638172
- type: nauc_precision_at_20_std
value: 47.266521222769676
- type: nauc_precision_at_3_diff1
value: 11.892419680356198
- type: nauc_precision_at_3_max
value: 43.146413741651415
- type: nauc_precision_at_3_std
value: 45.2312022756118
- type: nauc_precision_at_5_diff1
value: 0.5765950918056327
- type: nauc_precision_at_5_max
value: 34.22132902314228
- type: nauc_precision_at_5_std
value: 44.78272426908718
- type: nauc_recall_at_1000_diff1
value: 24.99872069707702
- type: nauc_recall_at_1000_max
value: 42.17319464089324
- type: nauc_recall_at_1000_std
value: 47.42376725148043
- type: nauc_recall_at_100_diff1
value: 24.62929408109356
- type: nauc_recall_at_100_max
value: 32.373805304406844
- type: nauc_recall_at_100_std
value: 21.48682342485071
- type: nauc_recall_at_10_diff1
value: 20.62337020665992
- type: nauc_recall_at_10_max
value: 14.125308316827395
- type: nauc_recall_at_10_std
value: -13.565096294162865
- type: nauc_recall_at_1_diff1
value: 27.402329635171146
- type: nauc_recall_at_1_max
value: 5.898746976402726
- type: nauc_recall_at_1_std
value: -26.703327281110212
- type: nauc_recall_at_20_diff1
value: 22.169766882731277
- type: nauc_recall_at_20_max
value: 20.588762488556828
- type: nauc_recall_at_20_std
value: -4.530608772737279
- type: nauc_recall_at_3_diff1
value: 22.48622374174161
- type: nauc_recall_at_3_max
value: 10.470407080375304
- type: nauc_recall_at_3_std
value: -20.777479868757286
- type: nauc_recall_at_5_diff1
value: 21.28438252298866
- type: nauc_recall_at_5_max
value: 10.424120660451583
- type: nauc_recall_at_5_std
value: -17.912853638432384
- type: ndcg_at_1
value: 65.375
- type: ndcg_at_10
value: 51.202000000000005
- type: ndcg_at_100
value: 56.12200000000001
- type: ndcg_at_1000
value: 63.306
- type: ndcg_at_20
value: 50.442
- type: ndcg_at_3
value: 56.437000000000005
- type: ndcg_at_5
value: 53.861000000000004
- type: precision_at_1
value: 78.0
- type: precision_at_10
value: 41.075
- type: precision_at_100
value: 13.032
- type: precision_at_1000
value: 2.516
- type: precision_at_20
value: 31.4
- type: precision_at_3
value: 59.833000000000006
- type: precision_at_5
value: 51.9
- type: recall_at_1
value: 10.789
- type: recall_at_10
value: 30.059
- type: recall_at_100
value: 61.817
- type: recall_at_1000
value: 84.672
- type: recall_at_20
value: 39.135
- type: recall_at_3
value: 18.017
- type: recall_at_5
value: 22.492
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 57.715
- type: f1
value: 51.85468544437296
- type: f1_weighted
value: 58.73946069844862
- type: main_score
value: 57.715
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: mteb/fever
config: default
split: test
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
metrics:
- type: main_score
value: 92.438
- type: map_at_1
value: 82.678
- type: map_at_10
value: 89.90899999999999
- type: map_at_100
value: 90.09899999999999
- type: map_at_1000
value: 90.11
- type: map_at_20
value: 90.026
- type: map_at_3
value: 89.034
- type: map_at_5
value: 89.619
- type: mrr_at_1
value: 89.04890489048904
- type: mrr_at_10
value: 93.53417484605598
- type: mrr_at_100
value: 93.56969053658798
- type: mrr_at_1000
value: 93.56979354808294
- type: mrr_at_20
value: 93.56100677804474
- type: mrr_at_3
value: 93.25682568256818
- type: mrr_at_5
value: 93.46909690969086
- type: nauc_map_at_1000_diff1
value: 50.19087206783256
- type: nauc_map_at_1000_max
value: 26.223996443425424
- type: nauc_map_at_1000_std
value: -8.531486546405336
- type: nauc_map_at_100_diff1
value: 50.12601833237827
- type: nauc_map_at_100_max
value: 26.205753684531942
- type: nauc_map_at_100_std
value: -8.502300882475792
- type: nauc_map_at_10_diff1
value: 49.48962186883297
- type: nauc_map_at_10_max
value: 25.849578028607546
- type: nauc_map_at_10_std
value: -8.58622126027856
- type: nauc_map_at_1_diff1
value: 56.88016472114475
- type: nauc_map_at_1_max
value: 24.671479435457048
- type: nauc_map_at_1_std
value: -11.980878470985619
- type: nauc_map_at_20_diff1
value: 49.813384246326905
- type: nauc_map_at_20_max
value: 25.96508257517373
- type: nauc_map_at_20_std
value: -8.568670117647939
- type: nauc_map_at_3_diff1
value: 49.087764097890165
- type: nauc_map_at_3_max
value: 25.65938258554376
- type: nauc_map_at_3_std
value: -8.859093431924775
- type: nauc_map_at_5_diff1
value: 49.08166208415013
- type: nauc_map_at_5_max
value: 25.696246071825684
- type: nauc_map_at_5_std
value: -8.431713254517472
- type: nauc_mrr_at_1000_diff1
value: 73.35484368612293
- type: nauc_mrr_at_1000_max
value: 35.657386688053336
- type: nauc_mrr_at_1000_std
value: -18.09172713569766
- type: nauc_mrr_at_100_diff1
value: 73.35508125874483
- type: nauc_mrr_at_100_max
value: 35.65842743437027
- type: nauc_mrr_at_100_std
value: -18.08981699366641
- type: nauc_mrr_at_10_diff1
value: 73.29004337552368
- type: nauc_mrr_at_10_max
value: 35.882001444609216
- type: nauc_mrr_at_10_std
value: -18.05339396879553
- type: nauc_mrr_at_1_diff1
value: 74.48742882702338
- type: nauc_mrr_at_1_max
value: 31.49138530538466
- type: nauc_mrr_at_1_std
value: -19.510294856397955
- type: nauc_mrr_at_20_diff1
value: 73.3388656330962
- type: nauc_mrr_at_20_max
value: 35.706948273788505
- type: nauc_mrr_at_20_std
value: -18.140154123750992
- type: nauc_mrr_at_3_diff1
value: 73.22698350499
- type: nauc_mrr_at_3_max
value: 36.4855373316516
- type: nauc_mrr_at_3_std
value: -17.719256990311198
- type: nauc_mrr_at_5_diff1
value: 73.24460108538948
- type: nauc_mrr_at_5_max
value: 36.322370705490634
- type: nauc_mrr_at_5_std
value: -17.636279233457984
- type: nauc_ndcg_at_1000_diff1
value: 53.674109881592756
- type: nauc_ndcg_at_1000_max
value: 28.767387846727487
- type: nauc_ndcg_at_1000_std
value: -8.858681782014946
- type: nauc_ndcg_at_100_diff1
value: 52.33608078847966
- type: nauc_ndcg_at_100_max
value: 28.511414384159877
- type: nauc_ndcg_at_100_std
value: -8.085385430073922
- type: nauc_ndcg_at_10_diff1
value: 49.712295545440774
- type: nauc_ndcg_at_10_max
value: 27.5674225152019
- type: nauc_ndcg_at_10_std
value: -8.244677630275376
- type: nauc_ndcg_at_1_diff1
value: 74.48742882702338
- type: nauc_ndcg_at_1_max
value: 31.49138530538466
- type: nauc_ndcg_at_1_std
value: -19.510294856397955
- type: nauc_ndcg_at_20_diff1
value: 50.61628846813059
- type: nauc_ndcg_at_20_max
value: 27.53989784238201
- type: nauc_ndcg_at_20_std
value: -8.373695482986479
- type: nauc_ndcg_at_3_diff1
value: 51.295860863016884
- type: nauc_ndcg_at_3_max
value: 28.99776689198307
- type: nauc_ndcg_at_3_std
value: -8.878181909861983
- type: nauc_ndcg_at_5_diff1
value: 49.619081645734504
- type: nauc_ndcg_at_5_max
value: 28.11109235395876
- type: nauc_ndcg_at_5_std
value: -7.722157727171728
- type: nauc_precision_at_1000_diff1
value: -9.298540465937485
- type: nauc_precision_at_1000_max
value: -1.3157308795912563
- type: nauc_precision_at_1000_std
value: 1.897355386264135
- type: nauc_precision_at_100_diff1
value: -12.246672190804334
- type: nauc_precision_at_100_max
value: -0.9687067276412682
- type: nauc_precision_at_100_std
value: 4.56074518564851
- type: nauc_precision_at_10_diff1
value: -15.533411370200923
- type: nauc_precision_at_10_max
value: -2.191843047666222
- type: nauc_precision_at_10_std
value: 3.6723841478730748
- type: nauc_precision_at_1_diff1
value: 74.48742882702338
- type: nauc_precision_at_1_max
value: 31.49138530538466
- type: nauc_precision_at_1_std
value: -19.510294856397955
- type: nauc_precision_at_20_diff1
value: -15.290364061922347
- type: nauc_precision_at_20_max
value: -2.921722171191804
- type: nauc_precision_at_20_std
value: 4.08482465973661
- type: nauc_precision_at_3_diff1
value: -8.208906597107383
- type: nauc_precision_at_3_max
value: 2.9796478961627284
- type: nauc_precision_at_3_std
value: 0.34366033602604895
- type: nauc_precision_at_5_diff1
value: -14.42241522747573
- type: nauc_precision_at_5_max
value: -0.5633890785935999
- type: nauc_precision_at_5_std
value: 3.7064496791809836
- type: nauc_recall_at_1000_diff1
value: -0.5673198466803553
- type: nauc_recall_at_1000_max
value: 21.92110385096128
- type: nauc_recall_at_1000_std
value: 54.421987386115475
- type: nauc_recall_at_100_diff1
value: -0.6512704079314391
- type: nauc_recall_at_100_max
value: 22.38252665262688
- type: nauc_recall_at_100_std
value: 36.50750378730013
- type: nauc_recall_at_10_diff1
value: 11.308848658347774
- type: nauc_recall_at_10_max
value: 21.077700181656738
- type: nauc_recall_at_10_std
value: 8.321338697504787
- type: nauc_recall_at_1_diff1
value: 56.88016472114475
- type: nauc_recall_at_1_max
value: 24.671479435457048
- type: nauc_recall_at_1_std
value: -11.980878470985619
- type: nauc_recall_at_20_diff1
value: 5.8415071379210755
- type: nauc_recall_at_20_max
value: 16.97886837481554
- type: nauc_recall_at_20_std
value: 12.529145693495494
- type: nauc_recall_at_3_diff1
value: 27.396913234035086
- type: nauc_recall_at_3_max
value: 24.897648442357994
- type: nauc_recall_at_3_std
value: 0.8528297027573939
- type: nauc_recall_at_5_diff1
value: 18.295838017557397
- type: nauc_recall_at_5_max
value: 24.077879268127823
- type: nauc_recall_at_5_std
value: 7.099403908855888
- type: ndcg_at_1
value: 89.049
- type: ndcg_at_10
value: 92.438
- type: ndcg_at_100
value: 93.016
- type: ndcg_at_1000
value: 93.17699999999999
- type: ndcg_at_20
value: 92.713
- type: ndcg_at_3
value: 91.40599999999999
- type: ndcg_at_5
value: 92.026
- type: precision_at_1
value: 89.049
- type: precision_at_10
value: 10.917
- type: precision_at_100
value: 1.146
- type: precision_at_1000
value: 0.117
- type: precision_at_20
value: 5.56
- type: precision_at_3
value: 34.598
- type: precision_at_5
value: 21.323
- type: recall_at_1
value: 82.678
- type: recall_at_10
value: 96.465
- type: recall_at_100
value: 98.571
- type: recall_at_1000
value: 99.496
- type: recall_at_20
value: 97.342
- type: recall_at_3
value: 93.696
- type: recall_at_5
value: 95.324
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: mteb/fiqa
config: default
split: test
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
metrics:
- type: main_score
value: 58.781000000000006
- type: map_at_1
value: 31.107000000000003
- type: map_at_10
value: 50.955
- type: map_at_100
value: 53.177
- type: map_at_1000
value: 53.291
- type: map_at_20
value: 52.271
- type: map_at_3
value: 44.762
- type: map_at_5
value: 48.379
- type: mrr_at_1
value: 58.48765432098766
- type: mrr_at_10
value: 66.11429551244368
- type: mrr_at_100
value: 66.68929754431386
- type: mrr_at_1000
value: 66.71304995006113
- type: mrr_at_20
value: 66.46821550477237
- type: mrr_at_3
value: 64.22325102880657
- type: mrr_at_5
value: 65.41152263374484
- type: nauc_map_at_1000_diff1
value: 45.490146083064445
- type: nauc_map_at_1000_max
value: 33.573139354617126
- type: nauc_map_at_1000_std
value: -14.07140489937541
- type: nauc_map_at_100_diff1
value: 45.48828357408913
- type: nauc_map_at_100_max
value: 33.51907944260763
- type: nauc_map_at_100_std
value: -14.059609883903152
- type: nauc_map_at_10_diff1
value: 45.70748844526757
- type: nauc_map_at_10_max
value: 31.667587503334587
- type: nauc_map_at_10_std
value: -15.076948336390855
- type: nauc_map_at_1_diff1
value: 51.42775649850064
- type: nauc_map_at_1_max
value: 16.56862308325116
- type: nauc_map_at_1_std
value: -14.684731980257675
- type: nauc_map_at_20_diff1
value: 45.754998522906284
- type: nauc_map_at_20_max
value: 33.03759060247343
- type: nauc_map_at_20_std
value: -14.750787459968736
- type: nauc_map_at_3_diff1
value: 46.45241223088609
- type: nauc_map_at_3_max
value: 26.607789112226467
- type: nauc_map_at_3_std
value: -14.997049792585598
- type: nauc_map_at_5_diff1
value: 45.87702900983919
- type: nauc_map_at_5_max
value: 30.076255479914348
- type: nauc_map_at_5_std
value: -15.062787509367553
- type: nauc_mrr_at_1000_diff1
value: 55.64889336097758
- type: nauc_mrr_at_1000_max
value: 48.57022261913911
- type: nauc_mrr_at_1000_std
value: -12.428435474800143
- type: nauc_mrr_at_100_diff1
value: 55.62957328562593
- type: nauc_mrr_at_100_max
value: 48.56575267775789
- type: nauc_mrr_at_100_std
value: -12.415226616847987
- type: nauc_mrr_at_10_diff1
value: 55.5931002027865
- type: nauc_mrr_at_10_max
value: 48.428200063552374
- type: nauc_mrr_at_10_std
value: -12.590361961152267
- type: nauc_mrr_at_1_diff1
value: 59.470635489729105
- type: nauc_mrr_at_1_max
value: 49.66866699872627
- type: nauc_mrr_at_1_std
value: -13.590112604913607
- type: nauc_mrr_at_20_diff1
value: 55.60145155716686
- type: nauc_mrr_at_20_max
value: 48.58677663675733
- type: nauc_mrr_at_20_std
value: -12.454093344399036
- type: nauc_mrr_at_3_diff1
value: 55.76657118158415
- type: nauc_mrr_at_3_max
value: 48.88547787372198
- type: nauc_mrr_at_3_std
value: -13.299744066289124
- type: nauc_mrr_at_5_diff1
value: 55.55217612731964
- type: nauc_mrr_at_5_max
value: 48.56957852769844
- type: nauc_mrr_at_5_std
value: -12.876904435466624
- type: nauc_ndcg_at_1000_diff1
value: 47.2645656074121
- type: nauc_ndcg_at_1000_max
value: 39.95808937564202
- type: nauc_ndcg_at_1000_std
value: -11.366829207572232
- type: nauc_ndcg_at_100_diff1
value: 46.89043419464991
- type: nauc_ndcg_at_100_max
value: 39.00034359981605
- type: nauc_ndcg_at_100_std
value: -10.697277437129921
- type: nauc_ndcg_at_10_diff1
value: 47.07625032910763
- type: nauc_ndcg_at_10_max
value: 35.51275239983428
- type: nauc_ndcg_at_10_std
value: -13.965305287946128
- type: nauc_ndcg_at_1_diff1
value: 59.470635489729105
- type: nauc_ndcg_at_1_max
value: 49.66866699872627
- type: nauc_ndcg_at_1_std
value: -13.590112604913607
- type: nauc_ndcg_at_20_diff1
value: 47.44262917418296
- type: nauc_ndcg_at_20_max
value: 37.6804112715633
- type: nauc_ndcg_at_20_std
value: -13.174880813005297
- type: nauc_ndcg_at_3_diff1
value: 44.56982475937759
- type: nauc_ndcg_at_3_max
value: 37.96424549723314
- type: nauc_ndcg_at_3_std
value: -13.657607148249964
- type: nauc_ndcg_at_5_diff1
value: 45.427291740214024
- type: nauc_ndcg_at_5_max
value: 35.42232275517991
- type: nauc_ndcg_at_5_std
value: -14.510048307634808
- type: nauc_precision_at_1000_diff1
value: -16.58479747595096
- type: nauc_precision_at_1000_max
value: 27.22386867486023
- type: nauc_precision_at_1000_std
value: 9.41210384044254
- type: nauc_precision_at_100_diff1
value: -11.640382840009572
- type: nauc_precision_at_100_max
value: 30.20752947841474
- type: nauc_precision_at_100_std
value: 10.72773947232612
- type: nauc_precision_at_10_diff1
value: 3.2540578244055594
- type: nauc_precision_at_10_max
value: 35.80515547017638
- type: nauc_precision_at_10_std
value: 0.299517152086918
- type: nauc_precision_at_1_diff1
value: 59.470635489729105
- type: nauc_precision_at_1_max
value: 49.66866699872627
- type: nauc_precision_at_1_std
value: -13.590112604913607
- type: nauc_precision_at_20_diff1
value: -1.8627219860435185
- type: nauc_precision_at_20_max
value: 35.9181314633325
- type: nauc_precision_at_20_std
value: 4.491869749000042
- type: nauc_precision_at_3_diff1
value: 17.94168903901189
- type: nauc_precision_at_3_max
value: 41.67388438464254
- type: nauc_precision_at_3_std
value: -5.38615084998387
- type: nauc_precision_at_5_diff1
value: 9.312012525324068
- type: nauc_precision_at_5_max
value: 39.52463080415461
- type: nauc_precision_at_5_std
value: -2.615286156278468
- type: nauc_recall_at_1000_diff1
value: 37.0960616996064
- type: nauc_recall_at_1000_max
value: 46.91967503624078
- type: nauc_recall_at_1000_std
value: 36.70723581015844
- type: nauc_recall_at_100_diff1
value: 32.54497560045993
- type: nauc_recall_at_100_max
value: 26.846226776082734
- type: nauc_recall_at_100_std
value: 9.257918182671672
- type: nauc_recall_at_10_diff1
value: 40.05619869408745
- type: nauc_recall_at_10_max
value: 25.504319960057014
- type: nauc_recall_at_10_std
value: -12.57012842016253
- type: nauc_recall_at_1_diff1
value: 51.42775649850064
- type: nauc_recall_at_1_max
value: 16.56862308325116
- type: nauc_recall_at_1_std
value: -14.684731980257675
- type: nauc_recall_at_20_diff1
value: 39.34128607816815
- type: nauc_recall_at_20_max
value: 28.31147877410395
- type: nauc_recall_at_20_std
value: -10.295180225906224
- type: nauc_recall_at_3_diff1
value: 41.31333745355922
- type: nauc_recall_at_3_max
value: 22.642649370921276
- type: nauc_recall_at_3_std
value: -14.44811859378254
- type: nauc_recall_at_5_diff1
value: 39.91795256714951
- type: nauc_recall_at_5_max
value: 24.396817798634245
- type: nauc_recall_at_5_std
value: -13.696077909471175
- type: ndcg_at_1
value: 58.48799999999999
- type: ndcg_at_10
value: 58.781000000000006
- type: ndcg_at_100
value: 65.212
- type: ndcg_at_1000
value: 66.85900000000001
- type: ndcg_at_20
value: 61.529999999999994
- type: ndcg_at_3
value: 54.864000000000004
- type: ndcg_at_5
value: 56.223
- type: precision_at_1
value: 58.48799999999999
- type: precision_at_10
value: 16.111
- type: precision_at_100
value: 2.298
- type: precision_at_1000
value: 0.257
- type: precision_at_20
value: 9.306000000000001
- type: precision_at_3
value: 36.317
- type: precision_at_5
value: 26.759
- type: recall_at_1
value: 31.107000000000003
- type: recall_at_10
value: 65.08500000000001
- type: recall_at_100
value: 87.91
- type: recall_at_1000
value: 97.817
- type: recall_at_20
value: 73.282
- type: recall_at_3
value: 49.317
- type: recall_at_5
value: 56.617
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: mteb/hotpotqa
config: default
split: test
revision: ab518f4d6fcca38d87c25209f94beba119d02014
metrics:
- type: main_score
value: 79.449
- type: map_at_1
value: 41.384
- type: map_at_10
value: 72.844
- type: map_at_100
value: 73.589
- type: map_at_1000
value: 73.624
- type: map_at_20
value: 73.317
- type: map_at_3
value: 69.427
- type: map_at_5
value: 71.68299999999999
- type: mrr_at_1
value: 82.76839972991222
- type: mrr_at_10
value: 87.92045807744634
- type: mrr_at_100
value: 88.05529589670978
- type: mrr_at_1000
value: 88.05935891074716
- type: mrr_at_20
value: 88.01402112970962
- type: mrr_at_3
value: 87.3216295295969
- type: mrr_at_5
value: 87.69705154175074
- type: nauc_map_at_1000_diff1
value: 20.396629535039704
- type: nauc_map_at_1000_max
value: 39.10949908339265
- type: nauc_map_at_1000_std
value: 10.224729673688502
- type: nauc_map_at_100_diff1
value: 20.381077063965574
- type: nauc_map_at_100_max
value: 39.12262980169527
- type: nauc_map_at_100_std
value: 10.256952440972226
- type: nauc_map_at_10_diff1
value: 20.227214487416916
- type: nauc_map_at_10_max
value: 39.065878364926085
- type: nauc_map_at_10_std
value: 9.830819360569484
- type: nauc_map_at_1_diff1
value: 60.61929089121275
- type: nauc_map_at_1_max
value: 49.53547409224507
- type: nauc_map_at_1_std
value: 0.2722096857291782
- type: nauc_map_at_20_diff1
value: 20.183915365850165
- type: nauc_map_at_20_max
value: 39.06905710390586
- type: nauc_map_at_20_std
value: 10.244769286257812
- type: nauc_map_at_3_diff1
value: 18.953350220177363
- type: nauc_map_at_3_max
value: 36.89647666189664
- type: nauc_map_at_3_std
value: 6.856939205711613
- type: nauc_map_at_5_diff1
value: 19.74313508534105
- type: nauc_map_at_5_max
value: 38.42860611762909
- type: nauc_map_at_5_std
value: 8.620757357067802
- type: nauc_mrr_at_1000_diff1
value: 60.544760748070416
- type: nauc_mrr_at_1000_max
value: 53.536700750600176
- type: nauc_mrr_at_1000_std
value: 4.356103341419562
- type: nauc_mrr_at_100_diff1
value: 60.543037850402825
- type: nauc_mrr_at_100_max
value: 53.54473925679791
- type: nauc_mrr_at_100_std
value: 4.3713759172294475
- type: nauc_mrr_at_10_diff1
value: 60.57585979923885
- type: nauc_mrr_at_10_max
value: 53.65882404973961
- type: nauc_mrr_at_10_std
value: 4.46866142907982
- type: nauc_mrr_at_1_diff1
value: 60.61929089121275
- type: nauc_mrr_at_1_max
value: 49.53547409224507
- type: nauc_mrr_at_1_std
value: 0.2722096857291782
- type: nauc_mrr_at_20_diff1
value: 60.541893232518674
- type: nauc_mrr_at_20_max
value: 53.6135776399171
- type: nauc_mrr_at_20_std
value: 4.443552945861195
- type: nauc_mrr_at_3_diff1
value: 60.46996364153697
- type: nauc_mrr_at_3_max
value: 53.981024588336936
- type: nauc_mrr_at_3_std
value: 4.300285863686253
- type: nauc_mrr_at_5_diff1
value: 60.562791070200426
- type: nauc_mrr_at_5_max
value: 53.884058343579966
- type: nauc_mrr_at_5_std
value: 4.35333313705802
- type: nauc_ndcg_at_1000_diff1
value: 26.909558826785485
- type: nauc_ndcg_at_1000_max
value: 43.2090252545764
- type: nauc_ndcg_at_1000_std
value: 13.24632397019833
- type: nauc_ndcg_at_100_diff1
value: 26.4096138903785
- type: nauc_ndcg_at_100_max
value: 43.50667894420325
- type: nauc_ndcg_at_100_std
value: 14.272929786830657
- type: nauc_ndcg_at_10_diff1
value: 25.261392560708607
- type: nauc_ndcg_at_10_max
value: 43.02496845139645
- type: nauc_ndcg_at_10_std
value: 12.753991213996402
- type: nauc_ndcg_at_1_diff1
value: 60.61929089121275
- type: nauc_ndcg_at_1_max
value: 49.53547409224507
- type: nauc_ndcg_at_1_std
value: 0.2722096857291782
- type: nauc_ndcg_at_20_diff1
value: 25.15730629354081
- type: nauc_ndcg_at_20_max
value: 43.10358742768409
- type: nauc_ndcg_at_20_std
value: 14.103247675055986
- type: nauc_ndcg_at_3_diff1
value: 23.492158440363873
- type: nauc_ndcg_at_3_max
value: 39.880317429264736
- type: nauc_ndcg_at_3_std
value: 7.852278799949863
- type: nauc_ndcg_at_5_diff1
value: 24.46471897598423
- type: nauc_ndcg_at_5_max
value: 41.901821932685294
- type: nauc_ndcg_at_5_std
value: 10.33482164145028
- type: nauc_precision_at_1000_diff1
value: 14.556112531859444
- type: nauc_precision_at_1000_max
value: 54.51236512101235
- type: nauc_precision_at_1000_std
value: 68.89420216988455
- type: nauc_precision_at_100_diff1
value: 14.116319404924122
- type: nauc_precision_at_100_max
value: 50.42943334977378
- type: nauc_precision_at_100_std
value: 49.80016017936658
- type: nauc_precision_at_10_diff1
value: 14.530495877243805
- type: nauc_precision_at_10_max
value: 43.89651175033577
- type: nauc_precision_at_10_std
value: 24.764789718434958
- type: nauc_precision_at_1_diff1
value: 60.61929089121275
- type: nauc_precision_at_1_max
value: 49.53547409224507
- type: nauc_precision_at_1_std
value: 0.2722096857291782
- type: nauc_precision_at_20_diff1
value: 11.499635650364958
- type: nauc_precision_at_20_max
value: 44.499499741252265
- type: nauc_precision_at_20_std
value: 33.743842605352725
- type: nauc_precision_at_3_diff1
value: 14.621019803797811
- type: nauc_precision_at_3_max
value: 38.1391146398071
- type: nauc_precision_at_3_std
value: 11.050680597126348
- type: nauc_precision_at_5_diff1
value: 14.878056511475538
- type: nauc_precision_at_5_max
value: 41.52854585813069
- type: nauc_precision_at_5_std
value: 16.596884488946877
- type: nauc_recall_at_1000_diff1
value: 14.556112531860405
- type: nauc_recall_at_1000_max
value: 54.512365121012444
- type: nauc_recall_at_1000_std
value: 68.89420216988472
- type: nauc_recall_at_100_diff1
value: 14.11631940492389
- type: nauc_recall_at_100_max
value: 50.42943334977325
- type: nauc_recall_at_100_std
value: 49.80016017936635
- type: nauc_recall_at_10_diff1
value: 14.530495877243975
- type: nauc_recall_at_10_max
value: 43.89651175033581
- type: nauc_recall_at_10_std
value: 24.764789718434855
- type: nauc_recall_at_1_diff1
value: 60.61929089121275
- type: nauc_recall_at_1_max
value: 49.53547409224507
- type: nauc_recall_at_1_std
value: 0.2722096857291782
- type: nauc_recall_at_20_diff1
value: 11.499635650364953
- type: nauc_recall_at_20_max
value: 44.499499741252166
- type: nauc_recall_at_20_std
value: 33.74384260535269
- type: nauc_recall_at_3_diff1
value: 14.621019803797758
- type: nauc_recall_at_3_max
value: 38.139114639807104
- type: nauc_recall_at_3_std
value: 11.050680597126208
- type: nauc_recall_at_5_diff1
value: 14.87805651147543
- type: nauc_recall_at_5_max
value: 41.52854585813069
- type: nauc_recall_at_5_std
value: 16.59688448894684
- type: ndcg_at_1
value: 82.768
- type: ndcg_at_10
value: 79.449
- type: ndcg_at_100
value: 81.878
- type: ndcg_at_1000
value: 82.526
- type: ndcg_at_20
value: 80.601
- type: ndcg_at_3
value: 74.899
- type: ndcg_at_5
value: 77.586
- type: precision_at_1
value: 82.768
- type: precision_at_10
value: 16.804
- type: precision_at_100
value: 1.8659999999999999
- type: precision_at_1000
value: 0.19499999999999998
- type: precision_at_20
value: 8.770999999999999
- type: precision_at_3
value: 49.381
- type: precision_at_5
value: 31.746000000000002
- type: recall_at_1
value: 41.384
- type: recall_at_10
value: 84.018
- type: recall_at_100
value: 93.30199999999999
- type: recall_at_1000
value: 97.529
- type: recall_at_20
value: 87.711
- type: recall_at_3
value: 74.072
- type: recall_at_5
value: 79.365
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 95.50119999999997
- type: ap
value: 93.27855740989341
- type: ap_weighted
value: 93.27855740989341
- type: f1
value: 95.49922732391366
- type: f1_weighted
value: 95.49922732391366
- type: main_score
value: 95.50119999999997
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: mteb/msmarco
config: default
split: dev
revision: c5a29a104738b98a9e76336939199e264163d4a0
metrics:
- type: main_score
value: 44.181
- type: map_at_1
value: 24.3
- type: map_at_10
value: 37.064
- type: map_at_100
value: 38.217
- type: map_at_1000
value: 38.261
- type: map_at_20
value: 37.797
- type: map_at_3
value: 33.03
- type: map_at_5
value: 35.382000000000005
- type: mrr_at_1
value: 25.014326647564474
- type: mrr_at_10
value: 37.67002092145362
- type: mrr_at_100
value: 38.76618716955713
- type: mrr_at_1000
value: 38.803895343578624
- type: mrr_at_20
value: 38.372875531879025
- type: mrr_at_3
value: 33.74164278892073
- type: mrr_at_5
value: 36.04250238777461
- type: nauc_map_at_1000_diff1
value: 37.38914109165067
- type: nauc_map_at_1000_max
value: 9.290439022090213
- type: nauc_map_at_1000_std
value: -17.68507604596775
- type: nauc_map_at_100_diff1
value: 37.3858106261435
- type: nauc_map_at_100_max
value: 9.292194370842791
- type: nauc_map_at_100_std
value: -17.6461510679294
- type: nauc_map_at_10_diff1
value: 37.24355836056403
- type: nauc_map_at_10_max
value: 9.19029394636661
- type: nauc_map_at_10_std
value: -18.216369315567626
- type: nauc_map_at_1_diff1
value: 40.298938486026984
- type: nauc_map_at_1_max
value: 8.149499405622326
- type: nauc_map_at_1_std
value: -17.09168853307602
- type: nauc_map_at_20_diff1
value: 37.344123641575216
- type: nauc_map_at_20_max
value: 9.24559383901809
- type: nauc_map_at_20_std
value: -17.842740773642962
- type: nauc_map_at_3_diff1
value: 37.4023127968177
- type: nauc_map_at_3_max
value: 8.930674077317596
- type: nauc_map_at_3_std
value: -18.68520909934096
- type: nauc_map_at_5_diff1
value: 37.12600186091895
- type: nauc_map_at_5_max
value: 9.173506919924861
- type: nauc_map_at_5_std
value: -18.625677130615294
- type: nauc_mrr_at_1000_diff1
value: 37.34256456294692
- type: nauc_mrr_at_1000_max
value: 9.276741130450404
- type: nauc_mrr_at_1000_std
value: -17.41693013754444
- type: nauc_mrr_at_100_diff1
value: 37.33775949993714
- type: nauc_mrr_at_100_max
value: 9.28051163202218
- type: nauc_mrr_at_100_std
value: -17.381741706111445
- type: nauc_mrr_at_10_diff1
value: 37.21506505847139
- type: nauc_mrr_at_10_max
value: 9.200324529184542
- type: nauc_mrr_at_10_std
value: -17.904321523440817
- type: nauc_mrr_at_1_diff1
value: 40.314678345050915
- type: nauc_mrr_at_1_max
value: 8.193685362111243
- type: nauc_mrr_at_1_std
value: -17.096535887474175
- type: nauc_mrr_at_20_diff1
value: 37.293746882874004
- type: nauc_mrr_at_20_max
value: 9.256273923676206
- type: nauc_mrr_at_20_std
value: -17.528338232043577
- type: nauc_mrr_at_3_diff1
value: 37.254812254578376
- type: nauc_mrr_at_3_max
value: 8.903676300128614
- type: nauc_mrr_at_3_std
value: -18.49940979312031
- type: nauc_mrr_at_5_diff1
value: 37.08969825523026
- type: nauc_mrr_at_5_max
value: 9.194982897416688
- type: nauc_mrr_at_5_std
value: -18.291840579141315
- type: nauc_ndcg_at_1000_diff1
value: 36.930810397557096
- type: nauc_ndcg_at_1000_max
value: 9.8356345032183
- type: nauc_ndcg_at_1000_std
value: -16.308145152943887
- type: nauc_ndcg_at_100_diff1
value: 36.901149744427414
- type: nauc_ndcg_at_100_max
value: 9.96065454342114
- type: nauc_ndcg_at_100_std
value: -14.983815239399584
- type: nauc_ndcg_at_10_diff1
value: 36.441571794416724
- type: nauc_ndcg_at_10_max
value: 9.57337658776914
- type: nauc_ndcg_at_10_std
value: -17.88037638294921
- type: nauc_ndcg_at_1_diff1
value: 40.314678345050915
- type: nauc_ndcg_at_1_max
value: 8.193685362111243
- type: nauc_ndcg_at_1_std
value: -17.096535887474175
- type: nauc_ndcg_at_20_diff1
value: 36.775334219857484
- type: nauc_ndcg_at_20_max
value: 9.789544462660507
- type: nauc_ndcg_at_20_std
value: -16.465733594062474
- type: nauc_ndcg_at_3_diff1
value: 36.58838956901628
- type: nauc_ndcg_at_3_max
value: 9.089768089567865
- type: nauc_ndcg_at_3_std
value: -19.12823913473232
- type: nauc_ndcg_at_5_diff1
value: 36.147729725463364
- type: nauc_ndcg_at_5_max
value: 9.53707003144017
- type: nauc_ndcg_at_5_std
value: -18.91372487441106
- type: nauc_precision_at_1000_diff1
value: -6.013504255890098
- type: nauc_precision_at_1000_max
value: 6.319348588937731
- type: nauc_precision_at_1000_std
value: 6.360339202992953
- type: nauc_precision_at_100_diff1
value: 14.846649240680357
- type: nauc_precision_at_100_max
value: 11.751644343520605
- type: nauc_precision_at_100_std
value: 16.881205928162444
- type: nauc_precision_at_10_diff1
value: 30.328513184776966
- type: nauc_precision_at_10_max
value: 9.988509735977631
- type: nauc_precision_at_10_std
value: -15.609966599969837
- type: nauc_precision_at_1_diff1
value: 40.314678345050915
- type: nauc_precision_at_1_max
value: 8.193685362111243
- type: nauc_precision_at_1_std
value: -17.096535887474175
- type: nauc_precision_at_20_diff1
value: 28.248245250811543
- type: nauc_precision_at_20_max
value: 10.953279209883918
- type: nauc_precision_at_20_std
value: -7.365540710727016
- type: nauc_precision_at_3_diff1
value: 33.6150964111514
- type: nauc_precision_at_3_max
value: 9.216455510763346
- type: nauc_precision_at_3_std
value: -20.45932513010908
- type: nauc_precision_at_5_diff1
value: 31.518755311864705
- type: nauc_precision_at_5_max
value: 10.019710006442747
- type: nauc_precision_at_5_std
value: -19.740528698385468
- type: nauc_recall_at_1000_diff1
value: 12.207155589507542
- type: nauc_recall_at_1000_max
value: 39.3447783153665
- type: nauc_recall_at_1000_std
value: 74.60352827999826
- type: nauc_recall_at_100_diff1
value: 32.993666280768615
- type: nauc_recall_at_100_max
value: 16.487188889720816
- type: nauc_recall_at_100_std
value: 26.828206265371275
- type: nauc_recall_at_10_diff1
value: 33.65453771237772
- type: nauc_recall_at_10_max
value: 10.71869814574723
- type: nauc_recall_at_10_std
value: -16.27859785753318
- type: nauc_recall_at_1_diff1
value: 40.298938486026984
- type: nauc_recall_at_1_max
value: 8.149499405622326
- type: nauc_recall_at_1_std
value: -17.09168853307602
- type: nauc_recall_at_20_diff1
value: 34.60034971417269
- type: nauc_recall_at_20_max
value: 12.076871992384788
- type: nauc_recall_at_20_std
value: -8.224571589978806
- type: nauc_recall_at_3_diff1
value: 34.24661417034744
- type: nauc_recall_at_3_max
value: 9.464103325281997
- type: nauc_recall_at_3_std
value: -20.329748455626195
- type: nauc_recall_at_5_diff1
value: 33.042225241281585
- type: nauc_recall_at_5_max
value: 10.486814885646142
- type: nauc_recall_at_5_std
value: -19.7259662900716
- type: ndcg_at_1
value: 25.013999999999996
- type: ndcg_at_10
value: 44.181
- type: ndcg_at_100
value: 49.673
- type: ndcg_at_1000
value: 50.705999999999996
- type: ndcg_at_20
value: 46.798
- type: ndcg_at_3
value: 36.037
- type: ndcg_at_5
value: 40.214
- type: precision_at_1
value: 25.013999999999996
- type: precision_at_10
value: 6.9110000000000005
- type: precision_at_100
value: 0.9650000000000001
- type: precision_at_1000
value: 0.105
- type: precision_at_20
value: 4.004
- type: precision_at_3
value: 15.238999999999999
- type: precision_at_5
value: 11.264000000000001
- type: recall_at_1
value: 24.3
- type: recall_at_10
value: 66.06400000000001
- type: recall_at_100
value: 91.291
- type: recall_at_1000
value: 99.054
- type: recall_at_20
value: 76.25699999999999
- type: recall_at_3
value: 44.039
- type: recall_at_5
value: 54.053
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 96.35430916552667
- type: f1
value: 96.16669219074517
- type: f1_weighted
value: 96.35506582065435
- type: main_score
value: 96.35430916552667
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 80.51527587779297
- type: f1
value: 59.350461259612345
- type: f1_weighted
value: 81.51891267687044
- type: main_score
value: 80.51527587779297
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 4672e20407010da34463acc759c162ca9734bca6
metrics:
- type: accuracy
value: 77.31338264963013
- type: f1
value: 75.29547524788576
- type: f1_weighted
value: 76.26831259224058
- type: main_score
value: 77.31338264963013
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
metrics:
- type: accuracy
value: 79.97982515131137
- type: f1
value: 79.34057805450769
- type: f1_weighted
value: 79.73023446597212
- type: main_score
value: 79.97982515131137
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: main_score
value: 38.37635785818304
- type: v_measure
value: 38.37635785818304
- type: v_measure_std
value: 1.6943794496059137
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: main_score
value: 37.6711034083755
- type: v_measure
value: 37.6711034083755
- type: v_measure_std
value: 1.1408887612104992
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 59042f120c80e8afa9cdbb224f67076cec0fc9a7
metrics:
- type: main_score
value: 32.20170969306457
- type: map
value: 32.20170969306457
- type: mrr
value: 33.41738896071552
- type: nAUC_map_diff1
value: 12.077124363492512
- type: nAUC_map_max
value: -20.336429990396454
- type: nAUC_map_std
value: 0.10724031251638018
- type: nAUC_mrr_diff1
value: 11.405695518900744
- type: nAUC_mrr_max
value: -15.0727490448132
- type: nAUC_mrr_std
value: 1.8987958512727106
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: mteb/nfcorpus
config: default
split: test
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
metrics:
- type: main_score
value: 40.463
- type: map_at_1
value: 6.4990000000000006
- type: map_at_10
value: 15.699
- type: map_at_100
value: 19.895
- type: map_at_1000
value: 21.537
- type: map_at_20
value: 17.429
- type: map_at_3
value: 11.48
- type: map_at_5
value: 13.383999999999999
- type: mrr_at_1
value: 52.63157894736842
- type: mrr_at_10
value: 61.60401002506265
- type: mrr_at_100
value: 62.04336653809741
- type: mrr_at_1000
value: 62.07610833363911
- type: mrr_at_20
value: 61.88033067968176
- type: mrr_at_3
value: 59.44272445820435
- type: mrr_at_5
value: 60.89783281733746
- type: nauc_map_at_1000_diff1
value: 18.58585974547791
- type: nauc_map_at_1000_max
value: 30.25465935470905
- type: nauc_map_at_1000_std
value: 10.987080017051682
- type: nauc_map_at_100_diff1
value: 20.02651798573329
- type: nauc_map_at_100_max
value: 30.108719787095467
- type: nauc_map_at_100_std
value: 7.882019722247158
- type: nauc_map_at_10_diff1
value: 23.02800157136177
- type: nauc_map_at_10_max
value: 22.8723397741279
- type: nauc_map_at_10_std
value: -3.762893117006399
- type: nauc_map_at_1_diff1
value: 37.94611136294878
- type: nauc_map_at_1_max
value: 7.297492349938244
- type: nauc_map_at_1_std
value: -17.813930346562152
- type: nauc_map_at_20_diff1
value: 21.981440837881113
- type: nauc_map_at_20_max
value: 26.759497880383837
- type: nauc_map_at_20_std
value: 0.18040330674839283
- type: nauc_map_at_3_diff1
value: 27.066009968256555
- type: nauc_map_at_3_max
value: 10.488797596450187
- type: nauc_map_at_3_std
value: -14.013059830876845
- type: nauc_map_at_5_diff1
value: 25.493785001708446
- type: nauc_map_at_5_max
value: 16.217756878539337
- type: nauc_map_at_5_std
value: -10.714238788014212
- type: nauc_mrr_at_1000_diff1
value: 28.488264933723528
- type: nauc_mrr_at_1000_max
value: 45.94151165403325
- type: nauc_mrr_at_1000_std
value: 25.20231778025588
- type: nauc_mrr_at_100_diff1
value: 28.4886630218298
- type: nauc_mrr_at_100_max
value: 45.9702575916014
- type: nauc_mrr_at_100_std
value: 25.22848732842774
- type: nauc_mrr_at_10_diff1
value: 28.535257017998294
- type: nauc_mrr_at_10_max
value: 45.86005605851268
- type: nauc_mrr_at_10_std
value: 24.81744203643852
- type: nauc_mrr_at_1_diff1
value: 29.824630548327285
- type: nauc_mrr_at_1_max
value: 44.19891968145314
- type: nauc_mrr_at_1_std
value: 23.21413139777098
- type: nauc_mrr_at_20_diff1
value: 28.54642005356483
- type: nauc_mrr_at_20_max
value: 46.08926361963997
- type: nauc_mrr_at_20_std
value: 25.39517294920476
- type: nauc_mrr_at_3_diff1
value: 28.230929109259407
- type: nauc_mrr_at_3_max
value: 44.05364599618201
- type: nauc_mrr_at_3_std
value: 23.828100697992724
- type: nauc_mrr_at_5_diff1
value: 29.669751924690758
- type: nauc_mrr_at_5_max
value: 45.36862661497384
- type: nauc_mrr_at_5_std
value: 23.787166807022505
- type: nauc_ndcg_at_1000_diff1
value: 18.515898773404377
- type: nauc_ndcg_at_1000_max
value: 44.57748675979855
- type: nauc_ndcg_at_1000_std
value: 29.205899131269604
- type: nauc_ndcg_at_100_diff1
value: 15.88197701276405
- type: nauc_ndcg_at_100_max
value: 39.62665883972109
- type: nauc_ndcg_at_100_std
value: 25.186347352251754
- type: nauc_ndcg_at_10_diff1
value: 16.220798038950925
- type: nauc_ndcg_at_10_max
value: 39.67757337154769
- type: nauc_ndcg_at_10_std
value: 25.634534917262403
- type: nauc_ndcg_at_1_diff1
value: 31.448775879462932
- type: nauc_ndcg_at_1_max
value: 44.4256421079556
- type: nauc_ndcg_at_1_std
value: 23.093987850437355
- type: nauc_ndcg_at_20_diff1
value: 15.417507391228035
- type: nauc_ndcg_at_20_max
value: 37.52014353976055
- type: nauc_ndcg_at_20_std
value: 23.880617920537915
- type: nauc_ndcg_at_3_diff1
value: 18.01018470616153
- type: nauc_ndcg_at_3_max
value: 39.135814950810804
- type: nauc_ndcg_at_3_std
value: 21.40850285781106
- type: nauc_ndcg_at_5_diff1
value: 18.502338826072368
- type: nauc_ndcg_at_5_max
value: 40.2043937728194
- type: nauc_ndcg_at_5_std
value: 22.242499743433424
- type: nauc_precision_at_1000_diff1
value: -13.648652068964681
- type: nauc_precision_at_1000_max
value: 3.5821865423513426
- type: nauc_precision_at_1000_std
value: 35.481456041211274
- type: nauc_precision_at_100_diff1
value: -11.342790040792961
- type: nauc_precision_at_100_max
value: 18.41811151847882
- type: nauc_precision_at_100_std
value: 44.901842372597336
- type: nauc_precision_at_10_diff1
value: -1.9404654865248405
- type: nauc_precision_at_10_max
value: 40.91955602631143
- type: nauc_precision_at_10_std
value: 41.38128398646734
- type: nauc_precision_at_1_diff1
value: 29.824630548327285
- type: nauc_precision_at_1_max
value: 44.19891968145314
- type: nauc_precision_at_1_std
value: 23.21413139777098
- type: nauc_precision_at_20_diff1
value: -5.046696327994225
- type: nauc_precision_at_20_max
value: 33.653422186725386
- type: nauc_precision_at_20_std
value: 40.97689615511939
- type: nauc_precision_at_3_diff1
value: 5.1767717826900785
- type: nauc_precision_at_3_max
value: 38.01276130261592
- type: nauc_precision_at_3_std
value: 25.71468883159735
- type: nauc_precision_at_5_diff1
value: 3.847065262189492
- type: nauc_precision_at_5_max
value: 41.00941977122254
- type: nauc_precision_at_5_std
value: 31.044768384177246
- type: nauc_recall_at_1000_diff1
value: 7.975632504947066
- type: nauc_recall_at_1000_max
value: 18.83264064904865
- type: nauc_recall_at_1000_std
value: 15.023940189337717
- type: nauc_recall_at_100_diff1
value: 10.354458867884487
- type: nauc_recall_at_100_max
value: 27.16900376430975
- type: nauc_recall_at_100_std
value: 14.160333284050214
- type: nauc_recall_at_10_diff1
value: 18.04347857307359
- type: nauc_recall_at_10_max
value: 19.082544744457774
- type: nauc_recall_at_10_std
value: -5.107813434157397
- type: nauc_recall_at_1_diff1
value: 37.94611136294878
- type: nauc_recall_at_1_max
value: 7.297492349938244
- type: nauc_recall_at_1_std
value: -17.813930346562152
- type: nauc_recall_at_20_diff1
value: 16.658153504941193
- type: nauc_recall_at_20_max
value: 23.214261213582382
- type: nauc_recall_at_20_std
value: -0.6964816170313349
- type: nauc_recall_at_3_diff1
value: 23.65600569767465
- type: nauc_recall_at_3_max
value: 6.543906048065431
- type: nauc_recall_at_3_std
value: -15.496093666790777
- type: nauc_recall_at_5_diff1
value: 22.112315726267077
- type: nauc_recall_at_5_max
value: 12.258969896916307
- type: nauc_recall_at_5_std
value: -12.922832334587008
- type: ndcg_at_1
value: 50.929
- type: ndcg_at_10
value: 40.463
- type: ndcg_at_100
value: 36.909
- type: ndcg_at_1000
value: 45.617999999999995
- type: ndcg_at_20
value: 37.772
- type: ndcg_at_3
value: 46.315
- type: ndcg_at_5
value: 44.052
- type: precision_at_1
value: 52.632
- type: precision_at_10
value: 29.814
- type: precision_at_100
value: 9.325
- type: precision_at_1000
value: 2.236
- type: precision_at_20
value: 22.073999999999998
- type: precision_at_3
value: 42.931000000000004
- type: precision_at_5
value: 37.957
- type: recall_at_1
value: 6.4990000000000006
- type: recall_at_10
value: 20.232
- type: recall_at_100
value: 36.846000000000004
- type: recall_at_1000
value: 69.03
- type: recall_at_20
value: 24.448
- type: recall_at_3
value: 13.258000000000001
- type: recall_at_5
value: 16.255
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: mteb/nq
config: default
split: test
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
metrics:
- type: main_score
value: 70.518
- type: map_at_1
value: 46.233999999999995
- type: map_at_10
value: 63.519999999999996
- type: map_at_100
value: 64.14699999999999
- type: map_at_1000
value: 64.154
- type: map_at_20
value: 63.975
- type: map_at_3
value: 59.797
- type: map_at_5
value: 62.226000000000006
- type: mrr_at_1
value: 51.76709154113557
- type: mrr_at_10
value: 65.79852489470095
- type: mrr_at_100
value: 66.19480681115492
- type: mrr_at_1000
value: 66.19993656063721
- type: mrr_at_20
value: 66.0923632685851
- type: mrr_at_3
value: 63.185592893008746
- type: mrr_at_5
value: 64.93385477018151
- type: nauc_map_at_1000_diff1
value: 43.35077155361084
- type: nauc_map_at_1000_max
value: 37.282536180921085
- type: nauc_map_at_1000_std
value: -4.64357984773174
- type: nauc_map_at_100_diff1
value: 43.35098576601616
- type: nauc_map_at_100_max
value: 37.28998747522813
- type: nauc_map_at_100_std
value: -4.638151362399621
- type: nauc_map_at_10_diff1
value: 43.131007214082594
- type: nauc_map_at_10_max
value: 37.430076712266846
- type: nauc_map_at_10_std
value: -4.90614475410035
- type: nauc_map_at_1_diff1
value: 45.843123692592485
- type: nauc_map_at_1_max
value: 30.160164681399227
- type: nauc_map_at_1_std
value: -6.110582951655118
- type: nauc_map_at_20_diff1
value: 43.30588135441681
- type: nauc_map_at_20_max
value: 37.41321766111187
- type: nauc_map_at_20_std
value: -4.628074353861448
- type: nauc_map_at_3_diff1
value: 42.690411835598695
- type: nauc_map_at_3_max
value: 36.64069333510947
- type: nauc_map_at_3_std
value: -6.2899609993355545
- type: nauc_map_at_5_diff1
value: 42.906814471744134
- type: nauc_map_at_5_max
value: 37.27599132551781
- type: nauc_map_at_5_std
value: -5.512203849661435
- type: nauc_mrr_at_1000_diff1
value: 43.77989113830799
- type: nauc_mrr_at_1000_max
value: 38.01009876981156
- type: nauc_mrr_at_1000_std
value: -2.0250764367321654
- type: nauc_mrr_at_100_diff1
value: 43.78071481914773
- type: nauc_mrr_at_100_max
value: 38.01603112272088
- type: nauc_mrr_at_100_std
value: -2.019685020907906
- type: nauc_mrr_at_10_diff1
value: 43.582338882429156
- type: nauc_mrr_at_10_max
value: 38.19577506300954
- type: nauc_mrr_at_10_std
value: -2.011905402842086
- type: nauc_mrr_at_1_diff1
value: 46.544635554669576
- type: nauc_mrr_at_1_max
value: 33.82720628969995
- type: nauc_mrr_at_1_std
value: -2.924293824382781
- type: nauc_mrr_at_20_diff1
value: 43.713682995581614
- type: nauc_mrr_at_20_max
value: 38.09918392374771
- type: nauc_mrr_at_20_std
value: -1.9583477023239
- type: nauc_mrr_at_3_diff1
value: 43.35807398052401
- type: nauc_mrr_at_3_max
value: 38.39129780935902
- type: nauc_mrr_at_3_std
value: -2.287791352096624
- type: nauc_mrr_at_5_diff1
value: 43.4126448419642
- type: nauc_mrr_at_5_max
value: 38.27294037073721
- type: nauc_mrr_at_5_std
value: -2.166655666337289
- type: nauc_ndcg_at_1000_diff1
value: 43.26202839737687
- type: nauc_ndcg_at_1000_max
value: 38.493273787010615
- type: nauc_ndcg_at_1000_std
value: -2.9983001465713524
- type: nauc_ndcg_at_100_diff1
value: 43.25688556190981
- type: nauc_ndcg_at_100_max
value: 38.68155788574137
- type: nauc_ndcg_at_100_std
value: -2.8355616191757487
- type: nauc_ndcg_at_10_diff1
value: 42.37071983774907
- type: nauc_ndcg_at_10_max
value: 39.60970139451164
- type: nauc_ndcg_at_10_std
value: -3.5877671856177775
- type: nauc_ndcg_at_1_diff1
value: 46.614780156517845
- type: nauc_ndcg_at_1_max
value: 33.863655999315526
- type: nauc_ndcg_at_1_std
value: -2.839239881422542
- type: nauc_ndcg_at_20_diff1
value: 42.97845395193472
- type: nauc_ndcg_at_20_max
value: 39.53053589334249
- type: nauc_ndcg_at_20_std
value: -2.6507495263904515
- type: nauc_ndcg_at_3_diff1
value: 41.65390869521735
- type: nauc_ndcg_at_3_max
value: 38.4851846089685
- type: nauc_ndcg_at_3_std
value: -5.6296606018146
- type: nauc_ndcg_at_5_diff1
value: 41.89640848285409
- type: nauc_ndcg_at_5_max
value: 39.293659812249615
- type: nauc_ndcg_at_5_std
value: -4.754462409312945
- type: nauc_precision_at_1000_diff1
value: -10.848480634403051
- type: nauc_precision_at_1000_max
value: 1.3436973699935175
- type: nauc_precision_at_1000_std
value: 19.044141500097957
- type: nauc_precision_at_100_diff1
value: -9.018095533261604
- type: nauc_precision_at_100_max
value: 4.0402155161025695
- type: nauc_precision_at_100_std
value: 19.492823636364996
- type: nauc_precision_at_10_diff1
value: 3.947100636096294
- type: nauc_precision_at_10_max
value: 20.598641503195907
- type: nauc_precision_at_10_std
value: 13.522240087840858
- type: nauc_precision_at_1_diff1
value: 46.614780156517845
- type: nauc_precision_at_1_max
value: 33.863655999315526
- type: nauc_precision_at_1_std
value: -2.839239881422542
- type: nauc_precision_at_20_diff1
value: -2.1791072352475336
- type: nauc_precision_at_20_max
value: 14.03887841842901
- type: nauc_precision_at_20_std
value: 18.846129471001632
- type: nauc_precision_at_3_diff1
value: 21.09092861833543
- type: nauc_precision_at_3_max
value: 34.122841034361805
- type: nauc_precision_at_3_std
value: 2.5513201020031064
- type: nauc_precision_at_5_diff1
value: 12.181140062410874
- type: nauc_precision_at_5_max
value: 27.903435474574234
- type: nauc_precision_at_5_std
value: 7.6589638998570315
- type: nauc_recall_at_1000_diff1
value: 59.28482230176634
- type: nauc_recall_at_1000_max
value: 85.47306385133284
- type: nauc_recall_at_1000_std
value: 76.45740117805659
- type: nauc_recall_at_100_diff1
value: 44.31190730138568
- type: nauc_recall_at_100_max
value: 66.30976579719086
- type: nauc_recall_at_100_std
value: 30.65274229759539
- type: nauc_recall_at_10_diff1
value: 34.885747244334866
- type: nauc_recall_at_10_max
value: 50.998198327439404
- type: nauc_recall_at_10_std
value: -2.7025509359838193
- type: nauc_recall_at_1_diff1
value: 45.843123692592485
- type: nauc_recall_at_1_max
value: 30.160164681399227
- type: nauc_recall_at_1_std
value: -6.110582951655118
- type: nauc_recall_at_20_diff1
value: 37.873054394800825
- type: nauc_recall_at_20_max
value: 59.21039923637266
- type: nauc_recall_at_20_std
value: 9.352312696050557
- type: nauc_recall_at_3_diff1
value: 35.703271085627776
- type: nauc_recall_at_3_max
value: 41.19400688280121
- type: nauc_recall_at_3_std
value: -7.9624895195139
- type: nauc_recall_at_5_diff1
value: 34.831972383157925
- type: nauc_recall_at_5_max
value: 44.82018386701478
- type: nauc_recall_at_5_std
value: -7.046789506164082
- type: ndcg_at_1
value: 51.73799999999999
- type: ndcg_at_10
value: 70.518
- type: ndcg_at_100
value: 72.841
- type: ndcg_at_1000
value: 72.99799999999999
- type: ndcg_at_20
value: 71.895
- type: ndcg_at_3
value: 64.06500000000001
- type: ndcg_at_5
value: 67.86999999999999
- type: precision_at_1
value: 51.73799999999999
- type: precision_at_10
value: 10.698
- type: precision_at_100
value: 1.2
- type: precision_at_1000
value: 0.121
- type: precision_at_20
value: 5.691
- type: precision_at_3
value: 28.37
- type: precision_at_5
value: 19.363
- type: recall_at_1
value: 46.233999999999995
- type: recall_at_10
value: 89.062
- type: recall_at_100
value: 98.622
- type: recall_at_1000
value: 99.754
- type: recall_at_20
value: 94.052
- type: recall_at_3
value: 72.994
- type: recall_at_5
value: 81.525
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: mteb/quora
config: default
split: test
revision: e4e08e0b7dbe3c8700f0daef558ff32256715259
metrics:
- type: main_score
value: 89.885
- type: map_at_1
value: 72.379
- type: map_at_10
value: 86.455
- type: map_at_100
value: 87.087
- type: map_at_1000
value: 87.1
- type: map_at_20
value: 86.883
- type: map_at_3
value: 83.663
- type: map_at_5
value: 85.443
- type: mrr_at_1
value: 83.27
- type: mrr_at_10
value: 89.13586904761888
- type: mrr_at_100
value: 89.22177886254626
- type: mrr_at_1000
value: 89.22204575963424
- type: mrr_at_20
value: 89.20621913458041
- type: mrr_at_3
value: 88.37999999999981
- type: mrr_at_5
value: 88.89349999999978
- type: nauc_map_at_1000_diff1
value: 78.17410401832315
- type: nauc_map_at_1000_max
value: 33.114749237960986
- type: nauc_map_at_1000_std
value: -49.79724283243796
- type: nauc_map_at_100_diff1
value: 78.17873434671671
- type: nauc_map_at_100_max
value: 33.101626543573325
- type: nauc_map_at_100_std
value: -49.82883017160494
- type: nauc_map_at_10_diff1
value: 78.28052682172311
- type: nauc_map_at_10_max
value: 32.626693803188694
- type: nauc_map_at_10_std
value: -51.941057676350034
- type: nauc_map_at_1_diff1
value: 81.06079816824507
- type: nauc_map_at_1_max
value: 25.638093235123616
- type: nauc_map_at_1_std
value: -43.230210939240344
- type: nauc_map_at_20_diff1
value: 78.22103944842512
- type: nauc_map_at_20_max
value: 32.94488423505404
- type: nauc_map_at_20_std
value: -50.69181407781227
- type: nauc_map_at_3_diff1
value: 78.75453877967588
- type: nauc_map_at_3_max
value: 30.645950847243686
- type: nauc_map_at_3_std
value: -52.983886453956266
- type: nauc_map_at_5_diff1
value: 78.44984884302167
- type: nauc_map_at_5_max
value: 31.69697839442234
- type: nauc_map_at_5_std
value: -53.21480554718401
- type: nauc_mrr_at_1000_diff1
value: 78.90502271071976
- type: nauc_mrr_at_1000_max
value: 35.902725888631075
- type: nauc_mrr_at_1000_std
value: -45.82579843551156
- type: nauc_mrr_at_100_diff1
value: 78.90552803580407
- type: nauc_mrr_at_100_max
value: 35.90392790964254
- type: nauc_mrr_at_100_std
value: -45.82489205475015
- type: nauc_mrr_at_10_diff1
value: 78.89432223469271
- type: nauc_mrr_at_10_max
value: 35.86669566861425
- type: nauc_mrr_at_10_std
value: -46.0616841694464
- type: nauc_mrr_at_1_diff1
value: 79.53513360034344
- type: nauc_mrr_at_1_max
value: 35.299514657188006
- type: nauc_mrr_at_1_std
value: -43.17936948437256
- type: nauc_mrr_at_20_diff1
value: 78.90707352031835
- type: nauc_mrr_at_20_max
value: 35.906499072241296
- type: nauc_mrr_at_20_std
value: -45.8904084451193
- type: nauc_mrr_at_3_diff1
value: 78.70913062166218
- type: nauc_mrr_at_3_max
value: 36.16709621132144
- type: nauc_mrr_at_3_std
value: -46.00948004774822
- type: nauc_mrr_at_5_diff1
value: 78.91095031555673
- type: nauc_mrr_at_5_max
value: 36.010878683954566
- type: nauc_mrr_at_5_std
value: -46.31731368609175
- type: nauc_ndcg_at_1000_diff1
value: 78.19132492477127
- type: nauc_ndcg_at_1000_max
value: 34.5208358892501
- type: nauc_ndcg_at_1000_std
value: -47.938360906488974
- type: nauc_ndcg_at_100_diff1
value: 78.24549799575261
- type: nauc_ndcg_at_100_max
value: 34.48869025578818
- type: nauc_ndcg_at_100_std
value: -48.02996375451253
- type: nauc_ndcg_at_10_diff1
value: 78.15340584208084
- type: nauc_ndcg_at_10_max
value: 33.5226981818058
- type: nauc_ndcg_at_10_std
value: -51.690477519601494
- type: nauc_ndcg_at_1_diff1
value: 79.55459365767561
- type: nauc_ndcg_at_1_max
value: 35.25214101433387
- type: nauc_ndcg_at_1_std
value: -43.10088819860409
- type: nauc_ndcg_at_20_diff1
value: 78.27277286768546
- type: nauc_ndcg_at_20_max
value: 33.997104745595564
- type: nauc_ndcg_at_20_std
value: -50.10549601980995
- type: nauc_ndcg_at_3_diff1
value: 77.68820501917479
- type: nauc_ndcg_at_3_max
value: 33.00389630941839
- type: nauc_ndcg_at_3_std
value: -51.00595251236665
- type: nauc_ndcg_at_5_diff1
value: 78.08093149961476
- type: nauc_ndcg_at_5_max
value: 33.03434664578743
- type: nauc_ndcg_at_5_std
value: -52.37122386447497
- type: nauc_precision_at_1000_diff1
value: -44.49830608740945
- type: nauc_precision_at_1000_max
value: -7.3283280714307395
- type: nauc_precision_at_1000_std
value: 38.55076692876393
- type: nauc_precision_at_100_diff1
value: -44.252675314263904
- type: nauc_precision_at_100_max
value: -7.038454433556829
- type: nauc_precision_at_100_std
value: 38.247323997481615
- type: nauc_precision_at_10_diff1
value: -40.192852013615216
- type: nauc_precision_at_10_max
value: -3.7258976649568036
- type: nauc_precision_at_10_std
value: 25.983458444206182
- type: nauc_precision_at_1_diff1
value: 79.55459365767561
- type: nauc_precision_at_1_max
value: 35.25214101433387
- type: nauc_precision_at_1_std
value: -43.10088819860409
- type: nauc_precision_at_20_diff1
value: -43.020749754821495
- type: nauc_precision_at_20_max
value: -5.7062060443801075
- type: nauc_precision_at_20_std
value: 32.8862431943092
- type: nauc_precision_at_3_diff1
value: -22.843593386293996
- type: nauc_precision_at_3_max
value: 4.474275296763041
- type: nauc_precision_at_3_std
value: 6.119920479600398
- type: nauc_precision_at_5_diff1
value: -33.598088334605045
- type: nauc_precision_at_5_max
value: -0.41505757559350775
- type: nauc_precision_at_5_std
value: 16.52526817965026
- type: nauc_recall_at_1000_diff1
value: 28.726073762912847
- type: nauc_recall_at_1000_max
value: -57.390873015654066
- type: nauc_recall_at_1000_std
value: 69.71288515421948
- type: nauc_recall_at_100_diff1
value: 83.06070133460443
- type: nauc_recall_at_100_max
value: 33.27991294763942
- type: nauc_recall_at_100_std
value: -42.785112479889655
- type: nauc_recall_at_10_diff1
value: 74.73877865072825
- type: nauc_recall_at_10_max
value: 27.81410621945221
- type: nauc_recall_at_10_std
value: -75.85371099008806
- type: nauc_recall_at_1_diff1
value: 81.06079816824507
- type: nauc_recall_at_1_max
value: 25.638093235123616
- type: nauc_recall_at_1_std
value: -43.230210939240344
- type: nauc_recall_at_20_diff1
value: 76.04615040930837
- type: nauc_recall_at_20_max
value: 27.47173316749929
- type: nauc_recall_at_20_std
value: -78.29029550423172
- type: nauc_recall_at_3_diff1
value: 75.29987903678384
- type: nauc_recall_at_3_max
value: 27.48543826795177
- type: nauc_recall_at_3_std
value: -60.91023011356427
- type: nauc_recall_at_5_diff1
value: 74.71682412813378
- type: nauc_recall_at_5_max
value: 27.255092143441562
- type: nauc_recall_at_5_std
value: -69.03177732393821
- type: ndcg_at_1
value: 83.26
- type: ndcg_at_10
value: 89.885
- type: ndcg_at_100
value: 90.968
- type: ndcg_at_1000
value: 91.02799999999999
- type: ndcg_at_20
value: 90.52900000000001
- type: ndcg_at_3
value: 87.443
- type: ndcg_at_5
value: 88.81
- type: precision_at_1
value: 83.26
- type: precision_at_10
value: 13.581999999999999
- type: precision_at_100
value: 1.541
- type: precision_at_1000
value: 0.157
- type: precision_at_20
value: 7.210999999999999
- type: precision_at_3
value: 38.323
- type: precision_at_5
value: 25.069999999999997
- type: recall_at_1
value: 72.379
- type: recall_at_10
value: 96.261
- type: recall_at_100
value: 99.779
- type: recall_at_1000
value: 99.996
- type: recall_at_20
value: 98.301
- type: recall_at_3
value: 89.101
- type: recall_at_5
value: 93.11500000000001
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: main_score
value: 61.87769077476204
- type: v_measure
value: 61.87769077476204
- type: v_measure_std
value: 5.290405218730049
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: main_score
value: 68.29553057563754
- type: v_measure
value: 68.29553057563754
- type: v_measure_std
value: 13.019229253711732
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: mteb/scidocs
config: default
split: test
revision: f8c2fcf00f625baaa80f62ec5bd9e1fff3b8ae88
metrics:
- type: main_score
value: 20.86
- type: map_at_1
value: 4.843
- type: map_at_10
value: 12.457
- type: map_at_100
value: 14.648
- type: map_at_1000
value: 14.965
- type: map_at_20
value: 13.596
- type: map_at_3
value: 8.776
- type: map_at_5
value: 10.528
- type: mrr_at_1
value: 23.799999999999997
- type: mrr_at_10
value: 34.93765873015872
- type: mrr_at_100
value: 36.054095036751825
- type: mrr_at_1000
value: 36.10871797082569
- type: mrr_at_20
value: 35.57880859465608
- type: mrr_at_3
value: 31.54999999999999
- type: mrr_at_5
value: 33.53999999999998
- type: nauc_map_at_1000_diff1
value: 16.889540490911525
- type: nauc_map_at_1000_max
value: 25.726340275186143
- type: nauc_map_at_1000_std
value: 9.926911665196988
- type: nauc_map_at_100_diff1
value: 16.889355521248202
- type: nauc_map_at_100_max
value: 25.628741550328126
- type: nauc_map_at_100_std
value: 9.637062917997012
- type: nauc_map_at_10_diff1
value: 16.972521218507854
- type: nauc_map_at_10_max
value: 24.810172126870363
- type: nauc_map_at_10_std
value: 7.09295422867669
- type: nauc_map_at_1_diff1
value: 24.9292922418417
- type: nauc_map_at_1_max
value: 15.49253311874767
- type: nauc_map_at_1_std
value: -0.4754734108717385
- type: nauc_map_at_20_diff1
value: 16.945564955989113
- type: nauc_map_at_20_max
value: 25.197327599885362
- type: nauc_map_at_20_std
value: 7.972256233219635
- type: nauc_map_at_3_diff1
value: 19.503723922705067
- type: nauc_map_at_3_max
value: 20.795879090480057
- type: nauc_map_at_3_std
value: 1.5828913591118658
- type: nauc_map_at_5_diff1
value: 19.80474780705204
- type: nauc_map_at_5_max
value: 24.040173591299723
- type: nauc_map_at_5_std
value: 4.153642430396917
- type: nauc_mrr_at_1000_diff1
value: 21.80300741603344
- type: nauc_mrr_at_1000_max
value: 19.98123409846586
- type: nauc_mrr_at_1000_std
value: 3.6325335777371377
- type: nauc_mrr_at_100_diff1
value: 21.804966803578946
- type: nauc_mrr_at_100_max
value: 19.9965104601956
- type: nauc_mrr_at_100_std
value: 3.6713772865070107
- type: nauc_mrr_at_10_diff1
value: 21.66109150475663
- type: nauc_mrr_at_10_max
value: 19.873876575424404
- type: nauc_mrr_at_10_std
value: 3.3387503298795584
- type: nauc_mrr_at_1_diff1
value: 24.868548821073084
- type: nauc_mrr_at_1_max
value: 16.189915011439044
- type: nauc_mrr_at_1_std
value: -0.17692171251799987
- type: nauc_mrr_at_20_diff1
value: 21.677427533247375
- type: nauc_mrr_at_20_max
value: 19.967193157614872
- type: nauc_mrr_at_20_std
value: 3.639825799332009
- type: nauc_mrr_at_3_diff1
value: 21.681117207511825
- type: nauc_mrr_at_3_max
value: 19.132660363303295
- type: nauc_mrr_at_3_std
value: 1.6613642176263752
- type: nauc_mrr_at_5_diff1
value: 21.833332207271884
- type: nauc_mrr_at_5_max
value: 19.926480855266213
- type: nauc_mrr_at_5_std
value: 2.901801717093585
- type: nauc_ndcg_at_1000_diff1
value: 16.92599483752314
- type: nauc_ndcg_at_1000_max
value: 27.126582080942814
- type: nauc_ndcg_at_1000_std
value: 16.638448489514683
- type: nauc_ndcg_at_100_diff1
value: 16.96586885959473
- type: nauc_ndcg_at_100_max
value: 26.675878724175046
- type: nauc_ndcg_at_100_std
value: 15.369335585614245
- type: nauc_ndcg_at_10_diff1
value: 16.59779893225997
- type: nauc_ndcg_at_10_max
value: 24.865338966132818
- type: nauc_ndcg_at_10_std
value: 8.934209252745864
- type: nauc_ndcg_at_1_diff1
value: 24.868548821073084
- type: nauc_ndcg_at_1_max
value: 16.189915011439044
- type: nauc_ndcg_at_1_std
value: -0.17692171251799987
- type: nauc_ndcg_at_20_diff1
value: 16.647406628819976
- type: nauc_ndcg_at_20_max
value: 25.64488140369063
- type: nauc_ndcg_at_20_std
value: 10.587157641309098
- type: nauc_ndcg_at_3_diff1
value: 19.093302254257377
- type: nauc_ndcg_at_3_max
value: 21.33725971448413
- type: nauc_ndcg_at_3_std
value: 2.549021710462978
- type: nauc_ndcg_at_5_diff1
value: 19.495189389728836
- type: nauc_ndcg_at_5_max
value: 24.21965138651894
- type: nauc_ndcg_at_5_std
value: 5.549408503444251
- type: nauc_precision_at_1000_diff1
value: 7.4232833098081565
- type: nauc_precision_at_1000_max
value: 25.24619675919913
- type: nauc_precision_at_1000_std
value: 32.79744946411614
- type: nauc_precision_at_100_diff1
value: 10.550449529674747
- type: nauc_precision_at_100_max
value: 25.652112631579726
- type: nauc_precision_at_100_std
value: 26.65722909800614
- type: nauc_precision_at_10_diff1
value: 11.195653785882708
- type: nauc_precision_at_10_max
value: 26.469986306854977
- type: nauc_precision_at_10_std
value: 14.05089697514966
- type: nauc_precision_at_1_diff1
value: 24.868548821073084
- type: nauc_precision_at_1_max
value: 16.189915011439044
- type: nauc_precision_at_1_std
value: -0.17692171251799987
- type: nauc_precision_at_20_diff1
value: 11.16738184991032
- type: nauc_precision_at_20_max
value: 26.53741675130711
- type: nauc_precision_at_20_std
value: 16.250110771034542
- type: nauc_precision_at_3_diff1
value: 16.917872510926284
- type: nauc_precision_at_3_max
value: 23.22094310791854
- type: nauc_precision_at_3_std
value: 3.9255078517383906
- type: nauc_precision_at_5_diff1
value: 16.898056883587824
- type: nauc_precision_at_5_max
value: 27.39457295203392
- type: nauc_precision_at_5_std
value: 8.924759582566171
- type: nauc_recall_at_1000_diff1
value: 7.516072705946253
- type: nauc_recall_at_1000_max
value: 25.001682297424594
- type: nauc_recall_at_1000_std
value: 33.86296283879721
- type: nauc_recall_at_100_diff1
value: 10.435705067998168
- type: nauc_recall_at_100_max
value: 25.31622603650995
- type: nauc_recall_at_100_std
value: 26.758897185352097
- type: nauc_recall_at_10_diff1
value: 11.110953419292343
- type: nauc_recall_at_10_max
value: 25.970593144433085
- type: nauc_recall_at_10_std
value: 13.92252981022314
- type: nauc_recall_at_1_diff1
value: 24.9292922418417
- type: nauc_recall_at_1_max
value: 15.49253311874767
- type: nauc_recall_at_1_std
value: -0.4754734108717385
- type: nauc_recall_at_20_diff1
value: 11.050515317424548
- type: nauc_recall_at_20_max
value: 26.068866115743134
- type: nauc_recall_at_20_std
value: 16.13787216291987
- type: nauc_recall_at_3_diff1
value: 17.013383740580203
- type: nauc_recall_at_3_max
value: 22.49105285578937
- type: nauc_recall_at_3_std
value: 3.5741090487413687
- type: nauc_recall_at_5_diff1
value: 16.973540662242602
- type: nauc_recall_at_5_max
value: 26.78087164318061
- type: nauc_recall_at_5_std
value: 8.68040862354009
- type: ndcg_at_1
value: 23.799999999999997
- type: ndcg_at_10
value: 20.86
- type: ndcg_at_100
value: 29.145
- type: ndcg_at_1000
value: 34.518
- type: ndcg_at_20
value: 23.892
- type: ndcg_at_3
value: 19.541
- type: ndcg_at_5
value: 17.166999999999998
- type: precision_at_1
value: 23.799999999999997
- type: precision_at_10
value: 10.9
- type: precision_at_100
value: 2.281
- type: precision_at_1000
value: 0.357
- type: precision_at_20
value: 7.21
- type: precision_at_3
value: 18.3
- type: precision_at_5
value: 15.120000000000001
- type: recall_at_1
value: 4.843
- type: recall_at_10
value: 22.12
- type: recall_at_100
value: 46.257
- type: recall_at_1000
value: 72.382
- type: recall_at_20
value: 29.253
- type: recall_at_3
value: 11.158
- type: recall_at_5
value: 15.347
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cosine_pearson
value: 85.65467419133347
- type: cosine_spearman
value: 81.88046945336663
- type: euclidean_pearson
value: 82.82887106181879
- type: euclidean_spearman
value: 81.88047605481775
- type: main_score
value: 81.88046945336663
- type: manhattan_pearson
value: 82.7839019603756
- type: manhattan_spearman
value: 81.83505450284663
- type: pearson
value: 85.65467419133347
- type: spearman
value: 81.88046945336663
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cosine_pearson
value: 85.8979872663498
- type: cosine_spearman
value: 78.63991285161867
- type: euclidean_pearson
value: 81.20243176386163
- type: euclidean_spearman
value: 78.64021127260493
- type: main_score
value: 78.63991285161867
- type: manhattan_pearson
value: 81.58673652635328
- type: manhattan_spearman
value: 79.03930665482164
- type: pearson
value: 85.8979872663498
- type: spearman
value: 78.63991285161867
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cosine_pearson
value: 87.10598414063074
- type: cosine_spearman
value: 87.12110799581852
- type: euclidean_pearson
value: 86.52284239759508
- type: euclidean_spearman
value: 87.12110799581852
- type: main_score
value: 87.12110799581852
- type: manhattan_pearson
value: 86.61105352996736
- type: manhattan_spearman
value: 87.34100209521596
- type: pearson
value: 87.10598414063074
- type: spearman
value: 87.12110799581852
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cosine_pearson
value: 85.66540041627184
- type: cosine_spearman
value: 83.55263671417923
- type: euclidean_pearson
value: 84.2332532036626
- type: euclidean_spearman
value: 83.55264421653584
- type: main_score
value: 83.55263671417923
- type: manhattan_pearson
value: 84.14418954784165
- type: manhattan_spearman
value: 83.58193360267302
- type: pearson
value: 85.66540041627184
- type: spearman
value: 83.55263671417923
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cosine_pearson
value: 89.83404956912175
- type: cosine_spearman
value: 90.09569633194636
- type: euclidean_pearson
value: 89.31121256629982
- type: euclidean_spearman
value: 90.09569632193572
- type: main_score
value: 90.09569633194636
- type: manhattan_pearson
value: 89.30064909066367
- type: manhattan_spearman
value: 90.20232732019451
- type: pearson
value: 89.83404956912175
- type: spearman
value: 90.09569633194636
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cosine_pearson
value: 86.27894370732598
- type: cosine_spearman
value: 87.22000226558832
- type: euclidean_pearson
value: 85.92822715155758
- type: euclidean_spearman
value: 87.22000226558832
- type: main_score
value: 87.22000226558832
- type: manhattan_pearson
value: 85.9498561399522
- type: manhattan_spearman
value: 87.28837300894288
- type: pearson
value: 86.27894370732598
- type: spearman
value: 87.22000226558832
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: cosine_pearson
value: 91.60185356782324
- type: cosine_spearman
value: 91.43471625912765
- type: euclidean_pearson
value: 91.52529087606635
- type: euclidean_spearman
value: 91.43471625912765
- type: main_score
value: 91.43471625912765
- type: manhattan_pearson
value: 91.34917173506308
- type: manhattan_spearman
value: 91.2112665439884
- type: pearson
value: 91.60185356782324
- type: spearman
value: 91.43471625912765
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
metrics:
- type: cosine_pearson
value: 68.735098373629
- type: cosine_spearman
value: 67.76156085991387
- type: euclidean_pearson
value: 68.38053954511516
- type: euclidean_spearman
value: 67.76156085991387
- type: main_score
value: 67.76156085991387
- type: manhattan_pearson
value: 68.4533080173714
- type: manhattan_spearman
value: 67.76676959397871
- type: pearson
value: 68.735098373629
- type: spearman
value: 67.76156085991387
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cosine_pearson
value: 87.63236624274985
- type: cosine_spearman
value: 88.27561759951514
- type: euclidean_pearson
value: 87.61137355553329
- type: euclidean_spearman
value: 88.27561759951514
- type: main_score
value: 88.27561759951514
- type: manhattan_pearson
value: 87.63505381780153
- type: manhattan_spearman
value: 88.41268943146845
- type: pearson
value: 87.63236624274985
- type: spearman
value: 88.27561759951514
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: main_score
value: 85.16412972900244
- type: map
value: 85.16412972900244
- type: mrr
value: 96.15786628041529
- type: nAUC_map_diff1
value: -1.5068306084088756
- type: nAUC_map_max
value: 48.81296049442589
- type: nAUC_map_std
value: 65.0187132933644
- type: nAUC_mrr_diff1
value: 44.22872564939586
- type: nAUC_mrr_max
value: 85.19719227096536
- type: nAUC_mrr_std
value: 79.62669870868876
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: mteb/scifact
config: default
split: test
revision: 0228b52cf27578f30900b9e5271d331663a030d7
metrics:
- type: main_score
value: 77.377
- type: map_at_1
value: 62.217
- type: map_at_10
value: 73.115
- type: map_at_100
value: 73.63499999999999
- type: map_at_1000
value: 73.644
- type: map_at_20
value: 73.528
- type: map_at_3
value: 70.62
- type: map_at_5
value: 72.16
- type: mrr_at_1
value: 65.0
- type: mrr_at_10
value: 74.05542328042326
- type: mrr_at_100
value: 74.46295785951277
- type: mrr_at_1000
value: 74.47168088874803
- type: mrr_at_20
value: 74.35632423132421
- type: mrr_at_3
value: 72.55555555555556
- type: mrr_at_5
value: 73.38888888888887
- type: nauc_map_at_1000_diff1
value: 72.31754010838618
- type: nauc_map_at_1000_max
value: 60.59518156728312
- type: nauc_map_at_1000_std
value: -3.601504782295705
- type: nauc_map_at_100_diff1
value: 72.32057771059107
- type: nauc_map_at_100_max
value: 60.60481879601873
- type: nauc_map_at_100_std
value: -3.6030430073837167
- type: nauc_map_at_10_diff1
value: 72.15009895006031
- type: nauc_map_at_10_max
value: 60.49958178006608
- type: nauc_map_at_10_std
value: -4.305475753173601
- type: nauc_map_at_1_diff1
value: 76.32919417574946
- type: nauc_map_at_1_max
value: 54.77358788281581
- type: nauc_map_at_1_std
value: -9.773898055794557
- type: nauc_map_at_20_diff1
value: 72.15740734516393
- type: nauc_map_at_20_max
value: 60.61318821265446
- type: nauc_map_at_20_std
value: -3.6016854193910803
- type: nauc_map_at_3_diff1
value: 72.07435404889445
- type: nauc_map_at_3_max
value: 56.93970890047747
- type: nauc_map_at_3_std
value: -8.697324220121793
- type: nauc_map_at_5_diff1
value: 72.42599960854554
- type: nauc_map_at_5_max
value: 60.12535137001906
- type: nauc_map_at_5_std
value: -4.437892354037166
- type: nauc_mrr_at_1000_diff1
value: 72.75103842052889
- type: nauc_mrr_at_1000_max
value: 62.72341811793062
- type: nauc_mrr_at_1000_std
value: -0.7759889099766357
- type: nauc_mrr_at_100_diff1
value: 72.75396801842608
- type: nauc_mrr_at_100_max
value: 62.73241247525427
- type: nauc_mrr_at_100_std
value: -0.7786866224468205
- type: nauc_mrr_at_10_diff1
value: 72.5942754009733
- type: nauc_mrr_at_10_max
value: 62.895066542256664
- type: nauc_mrr_at_10_std
value: -0.9018200301159104
- type: nauc_mrr_at_1_diff1
value: 77.63311362465076
- type: nauc_mrr_at_1_max
value: 62.42059294219759
- type: nauc_mrr_at_1_std
value: -1.3182520953698476
- type: nauc_mrr_at_20_diff1
value: 72.58522880943326
- type: nauc_mrr_at_20_max
value: 62.73063935403417
- type: nauc_mrr_at_20_std
value: -0.7910003366564456
- type: nauc_mrr_at_3_diff1
value: 72.70751722757556
- type: nauc_mrr_at_3_max
value: 62.38218933726893
- type: nauc_mrr_at_3_std
value: -1.7126398606397155
- type: nauc_mrr_at_5_diff1
value: 72.57550761997256
- type: nauc_mrr_at_5_max
value: 62.70945847818393
- type: nauc_mrr_at_5_std
value: -0.30886077098332143
- type: nauc_ndcg_at_1000_diff1
value: 71.6036105202873
- type: nauc_ndcg_at_1000_max
value: 61.99911514670603
- type: nauc_ndcg_at_1000_std
value: -2.050470755577302
- type: nauc_ndcg_at_100_diff1
value: 71.70345074974581
- type: nauc_ndcg_at_100_max
value: 62.374525611545714
- type: nauc_ndcg_at_100_std
value: -1.922345118135967
- type: nauc_ndcg_at_10_diff1
value: 70.40027928749286
- type: nauc_ndcg_at_10_max
value: 62.36595526966657
- type: nauc_ndcg_at_10_std
value: -3.862278807246422
- type: nauc_ndcg_at_1_diff1
value: 77.63311362465076
- type: nauc_ndcg_at_1_max
value: 62.42059294219759
- type: nauc_ndcg_at_1_std
value: -1.3182520953698476
- type: nauc_ndcg_at_20_diff1
value: 70.21719291674641
- type: nauc_ndcg_at_20_max
value: 62.356711760569404
- type: nauc_ndcg_at_20_std
value: -2.240360396463778
- type: nauc_ndcg_at_3_diff1
value: 70.72483260039468
- type: nauc_ndcg_at_3_max
value: 59.465348910073445
- type: nauc_ndcg_at_3_std
value: -6.379991854598364
- type: nauc_ndcg_at_5_diff1
value: 70.91296936044013
- type: nauc_ndcg_at_5_max
value: 61.5986283773017
- type: nauc_ndcg_at_5_std
value: -3.064893399445654
- type: nauc_precision_at_1000_diff1
value: -25.399544557043956
- type: nauc_precision_at_1000_max
value: 17.838641101318792
- type: nauc_precision_at_1000_std
value: 54.531382221213185
- type: nauc_precision_at_100_diff1
value: -15.78139909072201
- type: nauc_precision_at_100_max
value: 24.183801380755472
- type: nauc_precision_at_100_std
value: 50.39320972640593
- type: nauc_precision_at_10_diff1
value: 4.1199958514831
- type: nauc_precision_at_10_max
value: 37.922630159717926
- type: nauc_precision_at_10_std
value: 32.94959551960178
- type: nauc_precision_at_1_diff1
value: 77.63311362465076
- type: nauc_precision_at_1_max
value: 62.42059294219759
- type: nauc_precision_at_1_std
value: -1.3182520953698476
- type: nauc_precision_at_20_diff1
value: -8.926047159112303
- type: nauc_precision_at_20_max
value: 29.369903951067172
- type: nauc_precision_at_20_std
value: 41.793379234725904
- type: nauc_precision_at_3_diff1
value: 36.51209832895358
- type: nauc_precision_at_3_max
value: 51.07398992745159
- type: nauc_precision_at_3_std
value: 13.831661495933623
- type: nauc_precision_at_5_diff1
value: 19.526084047733807
- type: nauc_precision_at_5_max
value: 46.67537950098273
- type: nauc_precision_at_5_std
value: 31.06747779005178
- type: nauc_recall_at_1000_diff1
value: .nan
- type: nauc_recall_at_1000_max
value: .nan
- type: nauc_recall_at_1000_std
value: .nan
- type: nauc_recall_at_100_diff1
value: 77.45764972655711
- type: nauc_recall_at_100_max
value: 85.69427771108462
- type: nauc_recall_at_100_std
value: 10.277444311057575
- type: nauc_recall_at_10_diff1
value: 59.14685653975806
- type: nauc_recall_at_10_max
value: 67.75739956082005
- type: nauc_recall_at_10_std
value: -12.22251646924215
- type: nauc_recall_at_1_diff1
value: 76.32919417574946
- type: nauc_recall_at_1_max
value: 54.77358788281581
- type: nauc_recall_at_1_std
value: -9.773898055794557
- type: nauc_recall_at_20_diff1
value: 49.90908644159423
- type: nauc_recall_at_20_max
value: 70.55383556931541
- type: nauc_recall_at_20_std
value: -3.7004275394368182
- type: nauc_recall_at_3_diff1
value: 64.34183819693267
- type: nauc_recall_at_3_max
value: 55.782789721196444
- type: nauc_recall_at_3_std
value: -13.886583892174077
- type: nauc_recall_at_5_diff1
value: 63.467364565196135
- type: nauc_recall_at_5_max
value: 62.51562390716315
- type: nauc_recall_at_5_std
value: -4.715416491952255
- type: ndcg_at_1
value: 65.0
- type: ndcg_at_10
value: 77.377
- type: ndcg_at_100
value: 79.36
- type: ndcg_at_1000
value: 79.644
- type: ndcg_at_20
value: 78.61200000000001
- type: ndcg_at_3
value: 73.624
- type: ndcg_at_5
value: 75.458
- type: precision_at_1
value: 65.0
- type: precision_at_10
value: 10.100000000000001
- type: precision_at_100
value: 1.107
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_20
value: 5.333
- type: precision_at_3
value: 28.778
- type: precision_at_5
value: 18.8
- type: recall_at_1
value: 62.217
- type: recall_at_10
value: 89.156
- type: recall_at_100
value: 97.667
- type: recall_at_1000
value: 100.0
- type: recall_at_20
value: 93.667
- type: recall_at_3
value: 79.183
- type: recall_at_5
value: 83.672
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.8019801980198
- type: cos_sim_ap
value: 95.25139396923107
- type: dot_sim_accuracy
value: 0.998019801980198
- type: dot_sim_ap
value: 95.25139396923107
- type: max_accuracy
value: 99.8019801980198
- type: max_ap
value: 95.43878917155146
- type: max_f1
value: 90.0398406374502
- type: main_score
value: 95.43878917155146
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: main_score
value: 75.91311883393888
- type: v_measure
value: 75.91311883393888
- type: v_measure_std
value: 3.286198100593212
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: main_score
value: 47.171049215275694
- type: v_measure
value: 47.171049215275694
- type: v_measure_std
value: 1.6586563477857534
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: main_score
value: 54.15041943470163
- type: map
value: 54.15041943470163
- type: mrr
value: 55.03112798149563
- type: nAUC_map_diff1
value: 39.50144777017669
- type: nAUC_map_max
value: 14.024793174481395
- type: nAUC_map_std
value: 6.533766502190137
- type: nAUC_mrr_diff1
value: 39.72560651870919
- type: nAUC_mrr_max
value: 14.807887392821616
- type: nAUC_mrr_std
value: 7.270272018791473
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cosine_pearson
value: 31.57515534177576
- type: cosine_spearman
value: 31.415247541636194
- type: dot_pearson
value: 31.575170220667488
- type: dot_spearman
value: 31.415247541636194
- type: main_score
value: 31.415247541636194
- type: pearson
value: 31.57515534177576
- type: spearman
value: 31.415247541636194
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: mteb/trec-covid
config: default
split: test
revision: bb9466bac8153a0349341eb1b22e06409e78ef4e
metrics:
- type: main_score
value: 83.67999999999999
- type: map_at_1
value: 0.243
- type: map_at_10
value: 2.167
- type: map_at_100
value: 13.750000000000002
- type: map_at_1000
value: 33.537
- type: map_at_20
value: 4.047
- type: map_at_3
value: 0.694
- type: map_at_5
value: 1.141
- type: mrr_at_1
value: 94.0
- type: mrr_at_10
value: 97.0
- type: mrr_at_100
value: 97.0
- type: mrr_at_1000
value: 97.0
- type: mrr_at_20
value: 97.0
- type: mrr_at_3
value: 97.0
- type: mrr_at_5
value: 97.0
- type: nauc_map_at_1000_diff1
value: 4.890354942949616
- type: nauc_map_at_1000_max
value: 29.279958833328408
- type: nauc_map_at_1000_std
value: 77.2405348865942
- type: nauc_map_at_100_diff1
value: 31.835069149380868
- type: nauc_map_at_100_max
value: 14.523120708509271
- type: nauc_map_at_100_std
value: 39.682149025882886
- type: nauc_map_at_10_diff1
value: 43.45574726953753
- type: nauc_map_at_10_max
value: -2.9143965183484246
- type: nauc_map_at_10_std
value: 2.8052301238653756
- type: nauc_map_at_1_diff1
value: 26.134637426782753
- type: nauc_map_at_1_max
value: -3.108959317897608
- type: nauc_map_at_1_std
value: -5.781123480253076
- type: nauc_map_at_20_diff1
value: 45.735224340099236
- type: nauc_map_at_20_max
value: -1.099022132339708
- type: nauc_map_at_20_std
value: 7.6378546013151905
- type: nauc_map_at_3_diff1
value: 35.70649469812688
- type: nauc_map_at_3_max
value: -9.710213033638656
- type: nauc_map_at_3_std
value: -3.6668161574691056
- type: nauc_map_at_5_diff1
value: 37.6110093992781
- type: nauc_map_at_5_max
value: -8.6295080300384
- type: nauc_map_at_5_std
value: -3.2709712613287145
- type: nauc_mrr_at_1000_diff1
value: -22.362278244631675
- type: nauc_mrr_at_1000_max
value: 63.74105197634592
- type: nauc_mrr_at_1000_std
value: 69.88795518207282
- type: nauc_mrr_at_100_diff1
value: -22.362278244631675
- type: nauc_mrr_at_100_max
value: 63.74105197634592
- type: nauc_mrr_at_100_std
value: 69.88795518207282
- type: nauc_mrr_at_10_diff1
value: -22.362278244631675
- type: nauc_mrr_at_10_max
value: 63.74105197634592
- type: nauc_mrr_at_10_std
value: 69.88795518207282
- type: nauc_mrr_at_1_diff1
value: -22.36227824463097
- type: nauc_mrr_at_1_max
value: 63.741051976346206
- type: nauc_mrr_at_1_std
value: 69.88795518207289
- type: nauc_mrr_at_20_diff1
value: -22.362278244631675
- type: nauc_mrr_at_20_max
value: 63.74105197634592
- type: nauc_mrr_at_20_std
value: 69.88795518207282
- type: nauc_mrr_at_3_diff1
value: -22.362278244631675
- type: nauc_mrr_at_3_max
value: 63.74105197634592
- type: nauc_mrr_at_3_std
value: 69.88795518207282
- type: nauc_mrr_at_5_diff1
value: -22.362278244631675
- type: nauc_mrr_at_5_max
value: 63.74105197634592
- type: nauc_mrr_at_5_std
value: 69.88795518207282
- type: nauc_ndcg_at_1000_diff1
value: 11.950362559089744
- type: nauc_ndcg_at_1000_max
value: 27.0707842379056
- type: nauc_ndcg_at_1000_std
value: 72.43903405163071
- type: nauc_ndcg_at_100_diff1
value: -3.597031398660954
- type: nauc_ndcg_at_100_max
value: 24.415981061123944
- type: nauc_ndcg_at_100_std
value: 74.01146007854192
- type: nauc_ndcg_at_10_diff1
value: 17.368676394860337
- type: nauc_ndcg_at_10_max
value: 27.014276985741652
- type: nauc_ndcg_at_10_std
value: 50.032884783457476
- type: nauc_ndcg_at_1_diff1
value: 5.824544582933801
- type: nauc_ndcg_at_1_max
value: 39.22818791946299
- type: nauc_ndcg_at_1_std
value: 29.32406519654831
- type: nauc_ndcg_at_20_diff1
value: 17.816409720909615
- type: nauc_ndcg_at_20_max
value: 25.056392180259827
- type: nauc_ndcg_at_20_std
value: 58.05680238138826
- type: nauc_ndcg_at_3_diff1
value: 15.010486876001556
- type: nauc_ndcg_at_3_max
value: 4.023535837214374
- type: nauc_ndcg_at_3_std
value: 22.55308565809234
- type: nauc_ndcg_at_5_diff1
value: 12.73162605923733
- type: nauc_ndcg_at_5_max
value: 15.425379568695105
- type: nauc_ndcg_at_5_std
value: 34.4442400670659
- type: nauc_precision_at_1000_diff1
value: -29.218427320110436
- type: nauc_precision_at_1000_max
value: 29.90719259849769
- type: nauc_precision_at_1000_std
value: 48.95093300052051
- type: nauc_precision_at_100_diff1
value: -6.881054858812464
- type: nauc_precision_at_100_max
value: 30.388273677316956
- type: nauc_precision_at_100_std
value: 76.1031398803066
- type: nauc_precision_at_10_diff1
value: 24.298416597687574
- type: nauc_precision_at_10_max
value: 44.38332754799598
- type: nauc_precision_at_10_std
value: 61.64143369558439
- type: nauc_precision_at_1_diff1
value: -22.36227824463097
- type: nauc_precision_at_1_max
value: 63.741051976346206
- type: nauc_precision_at_1_std
value: 69.88795518207289
- type: nauc_precision_at_20_diff1
value: 21.823848783430545
- type: nauc_precision_at_20_max
value: 32.815202091292875
- type: nauc_precision_at_20_std
value: 61.4003619545546
- type: nauc_precision_at_3_diff1
value: 7.264709295578332
- type: nauc_precision_at_3_max
value: 18.088275115082432
- type: nauc_precision_at_3_std
value: 46.315423001044266
- type: nauc_precision_at_5_diff1
value: 19.4281378539196
- type: nauc_precision_at_5_max
value: 30.042729922926426
- type: nauc_precision_at_5_std
value: 48.803961503134936
- type: nauc_recall_at_1000_diff1
value: 14.078781719704242
- type: nauc_recall_at_1000_max
value: 24.205288710944746
- type: nauc_recall_at_1000_std
value: 60.19521883992679
- type: nauc_recall_at_100_diff1
value: 34.68620796161708
- type: nauc_recall_at_100_max
value: 5.862669275470962
- type: nauc_recall_at_100_std
value: 23.779387105339538
- type: nauc_recall_at_10_diff1
value: 41.60859491145645
- type: nauc_recall_at_10_max
value: -6.060553984265031
- type: nauc_recall_at_10_std
value: -3.0401474174665597
- type: nauc_recall_at_1_diff1
value: 26.134637426782753
- type: nauc_recall_at_1_max
value: -3.108959317897608
- type: nauc_recall_at_1_std
value: -5.781123480253076
- type: nauc_recall_at_20_diff1
value: 43.884440668985256
- type: nauc_recall_at_20_max
value: -5.215456096089841
- type: nauc_recall_at_20_std
value: 0.6346955652816175
- type: nauc_recall_at_3_diff1
value: 36.682959590903515
- type: nauc_recall_at_3_max
value: -14.003318698999372
- type: nauc_recall_at_3_std
value: -8.732791648435722
- type: nauc_recall_at_5_diff1
value: 37.55874033777468
- type: nauc_recall_at_5_max
value: -11.475194910000303
- type: nauc_recall_at_5_std
value: -8.24171387960509
- type: ndcg_at_1
value: 90.0
- type: ndcg_at_10
value: 83.67999999999999
- type: ndcg_at_100
value: 66.268
- type: ndcg_at_1000
value: 59.95700000000001
- type: ndcg_at_20
value: 80.41199999999999
- type: ndcg_at_3
value: 86.989
- type: ndcg_at_5
value: 85.60600000000001
- type: precision_at_1
value: 94.0
- type: precision_at_10
value: 87.0
- type: precision_at_100
value: 68.10000000000001
- type: precision_at_1000
value: 26.404
- type: precision_at_20
value: 83.7
- type: precision_at_3
value: 91.333
- type: precision_at_5
value: 89.60000000000001
- type: recall_at_1
value: 0.243
- type: recall_at_10
value: 2.307
- type: recall_at_100
value: 16.713
- type: recall_at_1000
value: 56.433
- type: recall_at_20
value: 4.3950000000000005
- type: recall_at_3
value: 0.721
- type: recall_at_5
value: 1.194
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: mteb/touche2020
config: default
split: test
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
metrics:
- type: main_score
value: 27.095999999999997
- type: map_at_1
value: 2.708
- type: map_at_10
value: 10.926
- type: map_at_100
value: 17.023
- type: map_at_1000
value: 18.802
- type: map_at_20
value: 14.075
- type: map_at_3
value: 6.213
- type: map_at_5
value: 8.399
- type: mrr_at_1
value: 38.775510204081634
- type: mrr_at_10
value: 55.96938775510204
- type: mrr_at_100
value: 56.566806209663355
- type: mrr_at_1000
value: 56.586429443572314
- type: mrr_at_20
value: 56.566806209663355
- type: mrr_at_3
value: 53.06122448979592
- type: mrr_at_5
value: 54.48979591836734
- type: nauc_map_at_1000_diff1
value: -3.7447722422200505
- type: nauc_map_at_1000_max
value: -21.154942580599432
- type: nauc_map_at_1000_std
value: -3.3769353126366854
- type: nauc_map_at_100_diff1
value: -4.211734469956019
- type: nauc_map_at_100_max
value: -20.97390043676955
- type: nauc_map_at_100_std
value: -7.108253122379712
- type: nauc_map_at_10_diff1
value: -2.503617891657346
- type: nauc_map_at_10_max
value: -19.76603379959943
- type: nauc_map_at_10_std
value: -24.813694071646186
- type: nauc_map_at_1_diff1
value: -0.6946291628228135
- type: nauc_map_at_1_max
value: -27.928780525228326
- type: nauc_map_at_1_std
value: -26.644256007057386
- type: nauc_map_at_20_diff1
value: -8.140689983350077
- type: nauc_map_at_20_max
value: -21.331762857202346
- type: nauc_map_at_20_std
value: -18.46503512945984
- type: nauc_map_at_3_diff1
value: 1.4806459479634606
- type: nauc_map_at_3_max
value: -20.57096686541149
- type: nauc_map_at_3_std
value: -27.53855079505183
- type: nauc_map_at_5_diff1
value: -2.4911557022868833
- type: nauc_map_at_5_max
value: -18.468614237544944
- type: nauc_map_at_5_std
value: -27.422000270609885
- type: nauc_mrr_at_1000_diff1
value: 0.5901324153382446
- type: nauc_mrr_at_1000_max
value: -29.43201840557888
- type: nauc_mrr_at_1000_std
value: -22.113570283308878
- type: nauc_mrr_at_100_diff1
value: 0.6140852308779037
- type: nauc_mrr_at_100_max
value: -29.423158073762274
- type: nauc_mrr_at_100_std
value: -22.03830742373018
- type: nauc_mrr_at_10_diff1
value: 1.4017303142295798
- type: nauc_mrr_at_10_max
value: -29.96128226635445
- type: nauc_mrr_at_10_std
value: -21.182800337655188
- type: nauc_mrr_at_1_diff1
value: 2.9967188734445642
- type: nauc_mrr_at_1_max
value: -28.076201809234135
- type: nauc_mrr_at_1_std
value: -23.829475793931397
- type: nauc_mrr_at_20_diff1
value: 0.6140852308779037
- type: nauc_mrr_at_20_max
value: -29.423158073762274
- type: nauc_mrr_at_20_std
value: -22.03830742373018
- type: nauc_mrr_at_3_diff1
value: -1.7324100961545983
- type: nauc_mrr_at_3_max
value: -31.25504536750873
- type: nauc_mrr_at_3_std
value: -27.693245095141595
- type: nauc_mrr_at_5_diff1
value: 0.9366378266246876
- type: nauc_mrr_at_5_max
value: -28.61911855691654
- type: nauc_mrr_at_5_std
value: -23.51734198003236
- type: nauc_ndcg_at_1000_diff1
value: 5.589806586986813
- type: nauc_ndcg_at_1000_max
value: -25.54091728191453
- type: nauc_ndcg_at_1000_std
value: 18.867289766624364
- type: nauc_ndcg_at_100_diff1
value: 5.269555604924481
- type: nauc_ndcg_at_100_max
value: -25.294068947248
- type: nauc_ndcg_at_100_std
value: 12.57359579076201
- type: nauc_ndcg_at_10_diff1
value: -1.8036041625138828
- type: nauc_ndcg_at_10_max
value: -23.89433650527811
- type: nauc_ndcg_at_10_std
value: -18.669805340174104
- type: nauc_ndcg_at_1_diff1
value: 1.7320960153524356
- type: nauc_ndcg_at_1_max
value: -30.98970297820504
- type: nauc_ndcg_at_1_std
value: -22.039818727732
- type: nauc_ndcg_at_20_diff1
value: -7.71266194406333
- type: nauc_ndcg_at_20_max
value: -28.764052281890564
- type: nauc_ndcg_at_20_std
value: -14.058766573885803
- type: nauc_ndcg_at_3_diff1
value: 3.4222049394447023
- type: nauc_ndcg_at_3_max
value: -23.010397388596147
- type: nauc_ndcg_at_3_std
value: -23.917570461776442
- type: nauc_ndcg_at_5_diff1
value: 0.4359085390014115
- type: nauc_ndcg_at_5_max
value: -18.328017574440583
- type: nauc_ndcg_at_5_std
value: -22.301590122411703
- type: nauc_precision_at_1000_diff1
value: 5.705380133328601
- type: nauc_precision_at_1000_max
value: 29.738757046781583
- type: nauc_precision_at_1000_std
value: 37.25317043193516
- type: nauc_precision_at_100_diff1
value: 18.099479915822755
- type: nauc_precision_at_100_max
value: 1.039647603335084
- type: nauc_precision_at_100_std
value: 68.43506311503532
- type: nauc_precision_at_10_diff1
value: 1.6010906915801002
- type: nauc_precision_at_10_max
value: -16.21198992516715
- type: nauc_precision_at_10_std
value: -10.55666484527
- type: nauc_precision_at_1_diff1
value: 2.9967188734445642
- type: nauc_precision_at_1_max
value: -28.076201809234135
- type: nauc_precision_at_1_std
value: -23.829475793931397
- type: nauc_precision_at_20_diff1
value: -9.646266503089361
- type: nauc_precision_at_20_max
value: -19.25399592456934
- type: nauc_precision_at_20_std
value: 4.154373672246843
- type: nauc_precision_at_3_diff1
value: 6.468923962729313
- type: nauc_precision_at_3_max
value: -16.75495139962792
- type: nauc_precision_at_3_std
value: -24.1555216494731
- type: nauc_precision_at_5_diff1
value: 1.89724542441865
- type: nauc_precision_at_5_max
value: -10.916266272968988
- type: nauc_precision_at_5_std
value: -19.996228467499165
- type: nauc_recall_at_1000_diff1
value: -0.3248897031222208
- type: nauc_recall_at_1000_max
value: -25.08629526651275
- type: nauc_recall_at_1000_std
value: 72.42326605733102
- type: nauc_recall_at_100_diff1
value: 0.20011224230233096
- type: nauc_recall_at_100_max
value: -25.71382782994985
- type: nauc_recall_at_100_std
value: 31.40559917674001
- type: nauc_recall_at_10_diff1
value: -7.502107897824034
- type: nauc_recall_at_10_max
value: -26.197156105779833
- type: nauc_recall_at_10_std
value: -20.067019662396106
- type: nauc_recall_at_1_diff1
value: -0.6946291628228135
- type: nauc_recall_at_1_max
value: -27.928780525228326
- type: nauc_recall_at_1_std
value: -26.644256007057386
- type: nauc_recall_at_20_diff1
value: -16.829462200879107
- type: nauc_recall_at_20_max
value: -29.55978083865099
- type: nauc_recall_at_20_std
value: -11.329177422867945
- type: nauc_recall_at_3_diff1
value: -4.487251181022699
- type: nauc_recall_at_3_max
value: -26.28852595660599
- type: nauc_recall_at_3_std
value: -30.010933869743877
- type: nauc_recall_at_5_diff1
value: -7.4729339604681515
- type: nauc_recall_at_5_max
value: -22.995431038489112
- type: nauc_recall_at_5_std
value: -27.623494423158906
- type: ndcg_at_1
value: 35.714
- type: ndcg_at_10
value: 27.095999999999997
- type: ndcg_at_100
value: 37.577
- type: ndcg_at_1000
value: 50.234
- type: ndcg_at_20
value: 28.706
- type: ndcg_at_3
value: 34.808
- type: ndcg_at_5
value: 31.657999999999998
- type: precision_at_1
value: 38.775999999999996
- type: precision_at_10
value: 23.061
- type: precision_at_100
value: 7.388
- type: precision_at_1000
value: 1.5650000000000002
- type: precision_at_20
value: 18.776
- type: precision_at_3
value: 36.735
- type: precision_at_5
value: 31.429000000000002
- type: recall_at_1
value: 2.708
- type: recall_at_10
value: 16.645
- type: recall_at_100
value: 45.953
- type: recall_at_1000
value: 84.553
- type: recall_at_20
value: 26.259
- type: recall_at_3
value: 7.869
- type: recall_at_5
value: 11.166
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 75.87890625
- type: ap
value: 16.4629793865873
- type: ap_weighted
value: 16.4629793865873
- type: f1
value: 58.32993265544471
- type: f1_weighted
value: 80.94360012442658
- type: main_score
value: 75.87890625
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 65.21788341822298
- type: f1
value: 65.00914562845475
- type: f1_weighted
value: 63.672388825903845
- type: main_score
value: 65.21788341822298
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: main_score
value: 57.152337838073485
- type: v_measure
value: 57.152337838073485
- type: v_measure_std
value: 0.8799366494028795
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: max_accuracy
value: 88.63920844012637
- type: max_ap
value: 81.41444048232692
- type: max_f1
value: 74.84396892115653
- type: accuracy
value: 88.63920844012637
- type: accuracy_threshold
value: 84.5294713973999
- type: ap
value: 81.41443623323144
- type: f1
value: 74.84396892115653
- type: f1_threshold
value: 82.87262320518494
- type: precision
value: 72.34671263235656
- type: recall
value: 77.5197889182058
- type: main_score
value: 81.41444048232692
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: max_accuracy
value: 89.90569332867622
- type: max_ap
value: 87.91825594329686
- type: max_f1
value: 80.35081439054949
- type: accuracy
value: 89.90569332867622
- type: accuracy_threshold
value: 81.01733326911926
- type: ap
value: 87.91824445175028
- type: f1
value: 80.35081439054949
- type: f1_threshold
value: 78.65387201309204
- type: precision
value: 75.0853013982739
- type: recall
value: 86.41053279950724
- type: main_score
value: 87.91825594329686
---
## Zeta-Alpha-E5-Mistral
We introduce Zeta Alpha's first public embedding model, a retrieval-specialized, 7B parameter embedding model trained on top of [E5-mistral-7b-instruct](https://huggingface.co/intfloat/e5-mistral-7b-instruct).
This model marks the first published model from Zeta Alpha's open science embedding models.
Check out our blog post for a complete breakdown of the training set we used and all the training details: [Zeta Alpha blog](https://www.zeta-alpha.com/post/fine-tuning-an-llm-for-state-of-the-art-retrieval-zeta-alpha-s-top-10-submission-to-the-the-mteb-be)
We are also making available our internal evaluation set, called [NanoBEIR](https://huggingface.co/collections/zeta-alpha-ai/nanobeir-66e1a0af21dfd93e620cd9f6), a collection of Nano (i.e., 50 queries+~10k documents) per BEIR dataset.
### Lora Weights
The lora weights are also available, so there is no need to download the full model.
## How to Run
The model was trained with the same instruction-tuning strategy as the original [E5-mistral-7b-instruct](https://huggingface.co/intfloat/e5-mistral-7b-instruct) model. Therefore, queries should be formatted as follows:
```
Instruct: <task description>\nQuery: <query>
```
### Sentence Transformers
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("zeta-alpha-ai/Zeta-Alpha-E5-Mistral")
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
task = "Given a claim about climate change, retrieve documents that support or refute the claim"
queries = [
get_detailed_instruct(task, "In Alaska, brown bears are changing their feeding habits to eat elderberries that ripen earlier."),
get_detailed_instruct(task, "Local and regional sea levels continue to exhibit typical natural variability—in some places rising and in others falling.")
]
passages = [
"The brown bear ( Ursus arctos ) is a large bear with the widest distribution of any living ursid . The species is distributed across much of northern Eurasia and North America . It is one of the two largest terrestrial carnivorans alive today , rivaled in body size only by its close cousin , the polar bear ( Ursus maritimus ) , which is much less variable in size and averages larger due to this . There are several recognized subspecies , many of which are quite well-known within their native ranges , found in the brown bear species . The brown bear 's principal range includes parts of Russia , Central Asia , China , Canada , the United States ( mostly Alaska ) , Scandinavia and the Carpathian region ( especially Romania ) , Anatolia , and Caucasus . The brown bear is recognized as a national and state animal in several European countries . While the brown bear 's range has shrunk and it has faced local extinctions , it remains listed as a least concern species by the International Union for Conservation of Nature ( IUCN ) with a total population of approximately 200,000 . As of 2012 , this and the American black bear are the only bear species not classified as threatened by the IUCN . However , the Californian , North African ( Atlas bear ) , and Mexican subspecies were hunted to extinction in the nineteenth and early twentieth centuries , and many of the southern Asian subspecies are highly endangered . One of the smaller-bodied subspecies , the Himalayan brown bear , is critically endangered , occupying only 2 % of its former range and threatened by uncontrolled poaching for its parts . The Marsican brown bear , one of several currently isolated populations of the main Eurasian brown bear race , in central Italy is believed to have a population of just 30 to 40 bears .",
"ean sea level ( MSL ) ( abbreviated simply sea level ) is an average level of the surface of one or more of Earth 's oceans from which heights such as elevations may be measured . MSL is a type of vertical datuma standardised geodetic reference pointthat is used , for example , as a chart datum in cartography and marine navigation , or , in aviation , as the standard sea level at which atmospheric pressure is measured in order to calibrate altitude and , consequently , aircraft flight levels . A common and relatively straightforward mean sea-level standard is the midpoint between a mean low and mean high tide at a particular location . Sea levels can be affected by many factors and are known to have varied greatly over geological time scales . The careful measurement of variations in MSL can offer insights into ongoing climate change , and sea level rise has been widely quoted as evidence of ongoing global warming . The term above sea level generally refers to above mean sea level ( AMSL ) ."
]
embeddings = model.encode(queries + passages)
scores = model.similarity(embeddings[:2], embeddings[2:]) * 100
print(scores.tolist())
# [[66.12603759765625, 43.760101318359375], [47.67058563232422, 63.7889518737793]]
```
### Transformers
``` python
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
task = "Given a claim about climate change, retrieve documents that support or refute the claim"
queries = [
get_detailed_instruct(task, "In Alaska, brown bears are changing their feeding habits to eat elderberries that ripen earlier."),
get_detailed_instruct(task, "Local and regional sea levels continue to exhibit typical natural variability—in some places rising and in others falling.")
]
passages = [
"The brown bear ( Ursus arctos ) is a large bear with the widest distribution of any living ursid . The species is distributed across much of northern Eurasia and North America . It is one of the two largest terrestrial carnivorans alive today , rivaled in body size only by its close cousin , the polar bear ( Ursus maritimus ) , which is much less variable in size and averages larger due to this . There are several recognized subspecies , many of which are quite well-known within their native ranges , found in the brown bear species . The brown bear 's principal range includes parts of Russia , Central Asia , China , Canada , the United States ( mostly Alaska ) , Scandinavia and the Carpathian region ( especially Romania ) , Anatolia , and Caucasus . The brown bear is recognized as a national and state animal in several European countries . While the brown bear 's range has shrunk and it has faced local extinctions , it remains listed as a least concern species by the International Union for Conservation of Nature ( IUCN ) with a total population of approximately 200,000 . As of 2012 , this and the American black bear are the only bear species not classified as threatened by the IUCN . However , the Californian , North African ( Atlas bear ) , and Mexican subspecies were hunted to extinction in the nineteenth and early twentieth centuries , and many of the southern Asian subspecies are highly endangered . One of the smaller-bodied subspecies , the Himalayan brown bear , is critically endangered , occupying only 2 % of its former range and threatened by uncontrolled poaching for its parts . The Marsican brown bear , one of several currently isolated populations of the main Eurasian brown bear race , in central Italy is believed to have a population of just 30 to 40 bears .",
"ean sea level ( MSL ) ( abbreviated simply sea level ) is an average level of the surface of one or more of Earth 's oceans from which heights such as elevations may be measured . MSL is a type of vertical datuma standardised geodetic reference pointthat is used , for example , as a chart datum in cartography and marine navigation , or , in aviation , as the standard sea level at which atmospheric pressure is measured in order to calibrate altitude and , consequently , aircraft flight levels . A common and relatively straightforward mean sea-level standard is the midpoint between a mean low and mean high tide at a particular location . Sea levels can be affected by many factors and are known to have varied greatly over geological time scales . The careful measurement of variations in MSL can offer insights into ongoing climate change , and sea level rise has been widely quoted as evidence of ongoing global warming . The term above sea level generally refers to above mean sea level ( AMSL ) ."
]
# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("zeta-alpha-ai/Zeta-Alpha-E5-Mistral")
model = AutoModel.from_pretrained("zeta-alpha-ai/Zeta-Alpha-E5-Mistral")
# get the embeddings
max_length = 4096
input_texts = queries + passages
batch_dict = tokenizer(input_texts, max_length=max_length, padding=True, truncation=True, return_tensors="pt")
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
[[66.15530395507812, 43.65541458129883], [47.681705474853516, 63.67986297607422]]
```
### Zeta Alpha
Zeta Alpha is the premier Neural Discovery Platform for AI and more. We are an Amsterdam-based R&D and product lab with a passion for AI technology, with offices on the Science Park campus of the University of Amsterdam. and in San Francisco.
The Zeta Alpha Research team:
- Arthur Câmara
- Dinos Papakostas
- Mathias Parisot
- Fernando Rejon Barrera
- Jakub Zavrel
|
[
"BEAR",
"BIOSSES",
"SCIFACT"
] |
tensorblock/gpt2-xl-conversational-GGUF
|
tensorblock
|
text-generation
|
[
"gguf",
"TensorBlock",
"GGUF",
"text-generation",
"en",
"dataset:Locutusque/InstructMix",
"base_model:Locutusque/gpt2-xl-conversational",
"base_model:quantized:Locutusque/gpt2-xl-conversational",
"license:mit",
"endpoints_compatible",
"region:us"
] | 2024-11-17T14:16:31Z |
2024-11-17T14:25:54+00:00
| 92 | 0 |
---
base_model: Locutusque/gpt2-xl-conversational
datasets:
- Locutusque/InstructMix
language:
- en
license: mit
metrics:
- bleu
- perplexity
- loss
- accuracy
pipeline_tag: text-generation
tags:
- TensorBlock
- GGUF
widget:
- text: '<|USER|> Design a Neo4j database and Cypher function snippet to Display Extreme
Dental hygiene: Using Mouthwash for Analysis for Beginners. Implement if/else
or switch/case statements to handle different conditions related to the Consent.
Provide detailed comments explaining your control flow and the reasoning behind
each decision. <|ASSISTANT|> '
- text: '<|USER|> Write me a story about a magical place. <|ASSISTANT|> '
- text: '<|USER|> Write me an essay about the life of George Washington <|ASSISTANT|> '
- text: '<|USER|> Solve the following equation 2x + 10 = 20 <|ASSISTANT|> '
- text: '<|USER|> Craft me a list of some nice places to visit around the world. <|ASSISTANT|> '
- text: '<|USER|> How to manage a lazy employee: Address the employee verbally. Don''t
allow an employee''s laziness or lack of enthusiasm to become a recurring issue.
Tell the employee you''re hoping to speak with them about workplace expectations
and performance, and schedule a time to sit down together. Question: To manage
a lazy employee, it is suggested to talk to the employee. True, False, or Neither?
<|ASSISTANT|> '
inference:
parameters:
temperature: 0.8
do_sample: true
top_p: 0.14
top_k: 41
max_new_tokens: 250
repetition_penalty: 1.176
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/jC7kdl8.jpeg" alt="TensorBlock" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;">
Feedback and support: TensorBlock's <a href="https://x.com/tensorblock_aoi">Twitter/X</a>, <a href="https://t.me/TensorBlock">Telegram Group</a> and <a href="https://x.com/tensorblock_aoi">Discord server</a>
</p>
</div>
</div>
## Locutusque/gpt2-xl-conversational - GGUF
This repo contains GGUF format model files for [Locutusque/gpt2-xl-conversational](https://huggingface.co/Locutusque/gpt2-xl-conversational).
The files were quantized using machines provided by [TensorBlock](https://tensorblock.co/), and they are compatible with llama.cpp as of [commit b4011](https://github.com/ggerganov/llama.cpp/commit/a6744e43e80f4be6398fc7733a01642c846dce1d).
<div style="text-align: left; margin: 20px 0;">
<a href="https://tensorblock.co/waitlist/client" style="display: inline-block; padding: 10px 20px; background-color: #007bff; color: white; text-decoration: none; border-radius: 5px; font-weight: bold;">
Run them on the TensorBlock client using your local machine ↗
</a>
</div>
## Prompt template
```
```
## Model file specification
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [gpt2-xl-conversational-Q2_K.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q2_K.gguf) | Q2_K | 0.845 GB | smallest, significant quality loss - not recommended for most purposes |
| [gpt2-xl-conversational-Q3_K_S.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q3_K_S.gguf) | Q3_K_S | 0.845 GB | very small, high quality loss |
| [gpt2-xl-conversational-Q3_K_M.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q3_K_M.gguf) | Q3_K_M | 0.966 GB | very small, high quality loss |
| [gpt2-xl-conversational-Q3_K_L.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q3_K_L.gguf) | Q3_K_L | 1.027 GB | small, substantial quality loss |
| [gpt2-xl-conversational-Q4_0.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q4_0.gguf) | Q4_0 | 0.906 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [gpt2-xl-conversational-Q4_K_S.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q4_K_S.gguf) | Q4_K_S | 1.037 GB | small, greater quality loss |
| [gpt2-xl-conversational-Q4_K_M.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q4_K_M.gguf) | Q4_K_M | 1.110 GB | medium, balanced quality - recommended |
| [gpt2-xl-conversational-Q5_0.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q5_0.gguf) | Q5_0 | 1.087 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [gpt2-xl-conversational-Q5_K_S.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q5_K_S.gguf) | Q5_K_S | 1.149 GB | large, low quality loss - recommended |
| [gpt2-xl-conversational-Q5_K_M.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q5_K_M.gguf) | Q5_K_M | 1.286 GB | large, very low quality loss - recommended |
| [gpt2-xl-conversational-Q6_K.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q6_K.gguf) | Q6_K | 1.519 GB | very large, extremely low quality loss |
| [gpt2-xl-conversational-Q8_0.gguf](https://huggingface.co/tensorblock/gpt2-xl-conversational-GGUF/blob/main/gpt2-xl-conversational-Q8_0.gguf) | Q8_0 | 1.630 GB | very large, extremely low quality loss - not recommended |
## Downloading instruction
### Command line
Firstly, install Huggingface Client
```shell
pip install -U "huggingface_hub[cli]"
```
Then, downoad the individual model file the a local directory
```shell
huggingface-cli download tensorblock/gpt2-xl-conversational-GGUF --include "gpt2-xl-conversational-Q2_K.gguf" --local-dir MY_LOCAL_DIR
```
If you wanna download multiple model files with a pattern (e.g., `*Q4_K*gguf`), you can try:
```shell
huggingface-cli download tensorblock/gpt2-xl-conversational-GGUF --local-dir MY_LOCAL_DIR --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
|
[
"CRAFT"
] |
tensorblock/GritLM-8x7B-GGUF
|
tensorblock
|
text-generation
|
[
"gguf",
"mteb",
"TensorBlock",
"GGUF",
"text-generation",
"dataset:GritLM/tulu2",
"base_model:GritLM/GritLM-8x7B",
"base_model:quantized:GritLM/GritLM-8x7B",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-12-12T05:50:13Z |
2024-12-12T10:26:15+00:00
| 92 | 0 |
---
base_model: GritLM/GritLM-8x7B
datasets:
- GritLM/tulu2
license: apache-2.0
pipeline_tag: text-generation
tags:
- mteb
- TensorBlock
- GGUF
inference: true
model-index:
- name: GritLM-8x7B
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 80.47761194029852
- type: ap
value: 44.38751347932197
- type: f1
value: 74.33580162208256
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 96.32155000000002
- type: ap
value: 94.8026654593679
- type: f1
value: 96.3209869463974
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 57.18400000000001
- type: f1
value: 55.945160479400954
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 34.353
- type: map_at_10
value: 50.773
- type: map_at_100
value: 51.515
- type: map_at_1000
value: 51.517
- type: map_at_3
value: 46.29
- type: map_at_5
value: 48.914
- type: mrr_at_1
value: 35.135
- type: mrr_at_10
value: 51.036
- type: mrr_at_100
value: 51.785000000000004
- type: mrr_at_1000
value: 51.787000000000006
- type: mrr_at_3
value: 46.562
- type: mrr_at_5
value: 49.183
- type: ndcg_at_1
value: 34.353
- type: ndcg_at_10
value: 59.492
- type: ndcg_at_100
value: 62.395999999999994
- type: ndcg_at_1000
value: 62.44499999999999
- type: ndcg_at_3
value: 50.217
- type: ndcg_at_5
value: 54.98499999999999
- type: precision_at_1
value: 34.353
- type: precision_at_10
value: 8.72
- type: precision_at_100
value: 0.993
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.531
- type: precision_at_5
value: 14.651
- type: recall_at_1
value: 34.353
- type: recall_at_10
value: 87.198
- type: recall_at_100
value: 99.289
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 61.592999999999996
- type: recall_at_5
value: 73.257
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 50.720077577006286
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 48.01021098734129
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 65.59672236627206
- type: mrr
value: 78.01191575429802
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.52452252271826
- type: cos_sim_spearman
value: 87.34415887061094
- type: euclidean_pearson
value: 87.46187616533932
- type: euclidean_spearman
value: 85.44712769366146
- type: manhattan_pearson
value: 87.56696679505373
- type: manhattan_spearman
value: 86.01581535039067
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.4577922077922
- type: f1
value: 87.38432712848123
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 41.41290357360428
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 38.67213605633667
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.545
- type: map_at_10
value: 50.015
- type: map_at_100
value: 51.763999999999996
- type: map_at_1000
value: 51.870000000000005
- type: map_at_3
value: 46.129999999999995
- type: map_at_5
value: 48.473
- type: mrr_at_1
value: 47.638999999999996
- type: mrr_at_10
value: 56.913000000000004
- type: mrr_at_100
value: 57.619
- type: mrr_at_1000
value: 57.648999999999994
- type: mrr_at_3
value: 54.435
- type: mrr_at_5
value: 56.059000000000005
- type: ndcg_at_1
value: 47.638999999999996
- type: ndcg_at_10
value: 56.664
- type: ndcg_at_100
value: 62.089000000000006
- type: ndcg_at_1000
value: 63.415
- type: ndcg_at_3
value: 51.842999999999996
- type: ndcg_at_5
value: 54.30199999999999
- type: precision_at_1
value: 47.638999999999996
- type: precision_at_10
value: 10.886999999999999
- type: precision_at_100
value: 1.722
- type: precision_at_1000
value: 0.212
- type: precision_at_3
value: 25.179000000000002
- type: precision_at_5
value: 18.226
- type: recall_at_1
value: 37.545
- type: recall_at_10
value: 68.118
- type: recall_at_100
value: 90.381
- type: recall_at_1000
value: 98.556
- type: recall_at_3
value: 53.319
- type: recall_at_5
value: 60.574
- type: map_at_1
value: 37.066
- type: map_at_10
value: 49.464000000000006
- type: map_at_100
value: 50.79900000000001
- type: map_at_1000
value: 50.928
- type: map_at_3
value: 46.133
- type: map_at_5
value: 47.941
- type: mrr_at_1
value: 48.025
- type: mrr_at_10
value: 56.16100000000001
- type: mrr_at_100
value: 56.725
- type: mrr_at_1000
value: 56.757000000000005
- type: mrr_at_3
value: 54.31
- type: mrr_at_5
value: 55.285
- type: ndcg_at_1
value: 48.025
- type: ndcg_at_10
value: 55.467
- type: ndcg_at_100
value: 59.391000000000005
- type: ndcg_at_1000
value: 61.086
- type: ndcg_at_3
value: 51.733
- type: ndcg_at_5
value: 53.223
- type: precision_at_1
value: 48.025
- type: precision_at_10
value: 10.656
- type: precision_at_100
value: 1.6070000000000002
- type: precision_at_1000
value: 0.20600000000000002
- type: precision_at_3
value: 25.499
- type: precision_at_5
value: 17.771
- type: recall_at_1
value: 37.066
- type: recall_at_10
value: 65.062
- type: recall_at_100
value: 81.662
- type: recall_at_1000
value: 91.913
- type: recall_at_3
value: 52.734
- type: recall_at_5
value: 57.696999999999996
- type: map_at_1
value: 46.099000000000004
- type: map_at_10
value: 59.721999999999994
- type: map_at_100
value: 60.675000000000004
- type: map_at_1000
value: 60.708
- type: map_at_3
value: 55.852000000000004
- type: map_at_5
value: 58.426
- type: mrr_at_1
value: 53.417
- type: mrr_at_10
value: 63.597
- type: mrr_at_100
value: 64.12299999999999
- type: mrr_at_1000
value: 64.13799999999999
- type: mrr_at_3
value: 61.149
- type: mrr_at_5
value: 62.800999999999995
- type: ndcg_at_1
value: 53.417
- type: ndcg_at_10
value: 65.90899999999999
- type: ndcg_at_100
value: 69.312
- type: ndcg_at_1000
value: 69.89
- type: ndcg_at_3
value: 60.089999999999996
- type: ndcg_at_5
value: 63.575
- type: precision_at_1
value: 53.417
- type: precision_at_10
value: 10.533
- type: precision_at_100
value: 1.313
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 26.667
- type: precision_at_5
value: 18.671
- type: recall_at_1
value: 46.099000000000004
- type: recall_at_10
value: 80.134
- type: recall_at_100
value: 94.536
- type: recall_at_1000
value: 98.543
- type: recall_at_3
value: 65.026
- type: recall_at_5
value: 73.462
- type: map_at_1
value: 28.261999999999997
- type: map_at_10
value: 38.012
- type: map_at_100
value: 39.104
- type: map_at_1000
value: 39.177
- type: map_at_3
value: 35.068
- type: map_at_5
value: 36.620000000000005
- type: mrr_at_1
value: 30.847
- type: mrr_at_10
value: 40.251999999999995
- type: mrr_at_100
value: 41.174
- type: mrr_at_1000
value: 41.227999999999994
- type: mrr_at_3
value: 37.74
- type: mrr_at_5
value: 38.972
- type: ndcg_at_1
value: 30.847
- type: ndcg_at_10
value: 43.513000000000005
- type: ndcg_at_100
value: 48.771
- type: ndcg_at_1000
value: 50.501
- type: ndcg_at_3
value: 37.861
- type: ndcg_at_5
value: 40.366
- type: precision_at_1
value: 30.847
- type: precision_at_10
value: 6.7909999999999995
- type: precision_at_100
value: 0.992
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 16.234
- type: precision_at_5
value: 11.254
- type: recall_at_1
value: 28.261999999999997
- type: recall_at_10
value: 58.292
- type: recall_at_100
value: 82.24000000000001
- type: recall_at_1000
value: 95.042
- type: recall_at_3
value: 42.955
- type: recall_at_5
value: 48.973
- type: map_at_1
value: 18.281
- type: map_at_10
value: 27.687
- type: map_at_100
value: 28.9
- type: map_at_1000
value: 29.019000000000002
- type: map_at_3
value: 24.773
- type: map_at_5
value: 26.180999999999997
- type: mrr_at_1
value: 23.01
- type: mrr_at_10
value: 32.225
- type: mrr_at_100
value: 33.054
- type: mrr_at_1000
value: 33.119
- type: mrr_at_3
value: 29.353
- type: mrr_at_5
value: 30.846
- type: ndcg_at_1
value: 23.01
- type: ndcg_at_10
value: 33.422000000000004
- type: ndcg_at_100
value: 39.108
- type: ndcg_at_1000
value: 41.699999999999996
- type: ndcg_at_3
value: 28.083999999999996
- type: ndcg_at_5
value: 30.164
- type: precision_at_1
value: 23.01
- type: precision_at_10
value: 6.493
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.14100000000000001
- type: precision_at_3
value: 13.930000000000001
- type: precision_at_5
value: 10.075000000000001
- type: recall_at_1
value: 18.281
- type: recall_at_10
value: 46.318
- type: recall_at_100
value: 71.327
- type: recall_at_1000
value: 89.716
- type: recall_at_3
value: 31.517
- type: recall_at_5
value: 36.821
- type: map_at_1
value: 36.575
- type: map_at_10
value: 49.235
- type: map_at_100
value: 50.723
- type: map_at_1000
value: 50.809000000000005
- type: map_at_3
value: 45.696999999999996
- type: map_at_5
value: 47.588
- type: mrr_at_1
value: 45.525
- type: mrr_at_10
value: 55.334
- type: mrr_at_100
value: 56.092
- type: mrr_at_1000
value: 56.118
- type: mrr_at_3
value: 53.032000000000004
- type: mrr_at_5
value: 54.19199999999999
- type: ndcg_at_1
value: 45.525
- type: ndcg_at_10
value: 55.542
- type: ndcg_at_100
value: 60.879000000000005
- type: ndcg_at_1000
value: 62.224999999999994
- type: ndcg_at_3
value: 50.688
- type: ndcg_at_5
value: 52.76499999999999
- type: precision_at_1
value: 45.525
- type: precision_at_10
value: 10.067
- type: precision_at_100
value: 1.471
- type: precision_at_1000
value: 0.173
- type: precision_at_3
value: 24.382
- type: precision_at_5
value: 16.919999999999998
- type: recall_at_1
value: 36.575
- type: recall_at_10
value: 67.903
- type: recall_at_100
value: 89.464
- type: recall_at_1000
value: 97.799
- type: recall_at_3
value: 53.493
- type: recall_at_5
value: 59.372
- type: map_at_1
value: 29.099000000000004
- type: map_at_10
value: 42.147
- type: map_at_100
value: 43.522
- type: map_at_1000
value: 43.624
- type: map_at_3
value: 38.104
- type: map_at_5
value: 40.435
- type: mrr_at_1
value: 36.416
- type: mrr_at_10
value: 47.922
- type: mrr_at_100
value: 48.664
- type: mrr_at_1000
value: 48.709
- type: mrr_at_3
value: 44.977000000000004
- type: mrr_at_5
value: 46.838
- type: ndcg_at_1
value: 36.416
- type: ndcg_at_10
value: 49.307
- type: ndcg_at_100
value: 54.332
- type: ndcg_at_1000
value: 56.145
- type: ndcg_at_3
value: 42.994
- type: ndcg_at_5
value: 46.119
- type: precision_at_1
value: 36.416
- type: precision_at_10
value: 9.452
- type: precision_at_100
value: 1.4080000000000001
- type: precision_at_1000
value: 0.172
- type: precision_at_3
value: 21.081
- type: precision_at_5
value: 15.501999999999999
- type: recall_at_1
value: 29.099000000000004
- type: recall_at_10
value: 64.485
- type: recall_at_100
value: 84.753
- type: recall_at_1000
value: 96.875
- type: recall_at_3
value: 47.06
- type: recall_at_5
value: 55.077
- type: map_at_1
value: 30.69458333333333
- type: map_at_10
value: 41.65291666666666
- type: map_at_100
value: 42.95775
- type: map_at_1000
value: 43.06258333333333
- type: map_at_3
value: 38.335750000000004
- type: map_at_5
value: 40.20941666666666
- type: mrr_at_1
value: 37.013000000000005
- type: mrr_at_10
value: 46.30600000000001
- type: mrr_at_100
value: 47.094666666666676
- type: mrr_at_1000
value: 47.139583333333334
- type: mrr_at_3
value: 43.805749999999996
- type: mrr_at_5
value: 45.22366666666666
- type: ndcg_at_1
value: 37.013000000000005
- type: ndcg_at_10
value: 47.63491666666667
- type: ndcg_at_100
value: 52.71083333333334
- type: ndcg_at_1000
value: 54.493583333333326
- type: ndcg_at_3
value: 42.43616666666666
- type: ndcg_at_5
value: 44.87583333333334
- type: precision_at_1
value: 37.013000000000005
- type: precision_at_10
value: 8.481583333333333
- type: precision_at_100
value: 1.3073333333333337
- type: precision_at_1000
value: 0.16341666666666668
- type: precision_at_3
value: 19.811833333333333
- type: precision_at_5
value: 14.07691666666667
- type: recall_at_1
value: 30.69458333333333
- type: recall_at_10
value: 60.462083333333325
- type: recall_at_100
value: 82.42325000000001
- type: recall_at_1000
value: 94.53291666666667
- type: recall_at_3
value: 45.7405
- type: recall_at_5
value: 52.14025
- type: map_at_1
value: 27.833000000000002
- type: map_at_10
value: 36.55
- type: map_at_100
value: 37.524
- type: map_at_1000
value: 37.613
- type: map_at_3
value: 33.552
- type: map_at_5
value: 35.173
- type: mrr_at_1
value: 31.135
- type: mrr_at_10
value: 39.637
- type: mrr_at_100
value: 40.361000000000004
- type: mrr_at_1000
value: 40.422000000000004
- type: mrr_at_3
value: 36.887
- type: mrr_at_5
value: 38.428000000000004
- type: ndcg_at_1
value: 31.135
- type: ndcg_at_10
value: 42.007
- type: ndcg_at_100
value: 46.531
- type: ndcg_at_1000
value: 48.643
- type: ndcg_at_3
value: 36.437999999999995
- type: ndcg_at_5
value: 39.021
- type: precision_at_1
value: 31.135
- type: precision_at_10
value: 6.856
- type: precision_at_100
value: 0.988
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 15.9
- type: precision_at_5
value: 11.227
- type: recall_at_1
value: 27.833000000000002
- type: recall_at_10
value: 55.711
- type: recall_at_100
value: 76.255
- type: recall_at_1000
value: 91.51899999999999
- type: recall_at_3
value: 40.22
- type: recall_at_5
value: 46.69
- type: map_at_1
value: 21.274
- type: map_at_10
value: 29.925
- type: map_at_100
value: 31.171
- type: map_at_1000
value: 31.296000000000003
- type: map_at_3
value: 27.209
- type: map_at_5
value: 28.707
- type: mrr_at_1
value: 26.462000000000003
- type: mrr_at_10
value: 34.604
- type: mrr_at_100
value: 35.554
- type: mrr_at_1000
value: 35.622
- type: mrr_at_3
value: 32.295
- type: mrr_at_5
value: 33.598
- type: ndcg_at_1
value: 26.462000000000003
- type: ndcg_at_10
value: 35.193000000000005
- type: ndcg_at_100
value: 40.876000000000005
- type: ndcg_at_1000
value: 43.442
- type: ndcg_at_3
value: 30.724
- type: ndcg_at_5
value: 32.735
- type: precision_at_1
value: 26.462000000000003
- type: precision_at_10
value: 6.438000000000001
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.15
- type: precision_at_3
value: 14.636
- type: precision_at_5
value: 10.496
- type: recall_at_1
value: 21.274
- type: recall_at_10
value: 46.322
- type: recall_at_100
value: 71.702
- type: recall_at_1000
value: 89.405
- type: recall_at_3
value: 33.444
- type: recall_at_5
value: 38.83
- type: map_at_1
value: 31.174000000000003
- type: map_at_10
value: 42.798
- type: map_at_100
value: 43.996
- type: map_at_1000
value: 44.088
- type: map_at_3
value: 39.255
- type: map_at_5
value: 41.336
- type: mrr_at_1
value: 37.22
- type: mrr_at_10
value: 47.035
- type: mrr_at_100
value: 47.833999999999996
- type: mrr_at_1000
value: 47.88
- type: mrr_at_3
value: 44.248
- type: mrr_at_5
value: 45.815
- type: ndcg_at_1
value: 37.22
- type: ndcg_at_10
value: 48.931999999999995
- type: ndcg_at_100
value: 53.991
- type: ndcg_at_1000
value: 55.825
- type: ndcg_at_3
value: 43.144
- type: ndcg_at_5
value: 45.964
- type: precision_at_1
value: 37.22
- type: precision_at_10
value: 8.451
- type: precision_at_100
value: 1.2189999999999999
- type: precision_at_1000
value: 0.149
- type: precision_at_3
value: 20.087
- type: precision_at_5
value: 14.235000000000001
- type: recall_at_1
value: 31.174000000000003
- type: recall_at_10
value: 63.232
- type: recall_at_100
value: 84.747
- type: recall_at_1000
value: 97.006
- type: recall_at_3
value: 47.087
- type: recall_at_5
value: 54.493
- type: map_at_1
value: 29.628
- type: map_at_10
value: 39.995999999999995
- type: map_at_100
value: 41.899
- type: map_at_1000
value: 42.125
- type: map_at_3
value: 36.345
- type: map_at_5
value: 38.474000000000004
- type: mrr_at_1
value: 36.364000000000004
- type: mrr_at_10
value: 45.293
- type: mrr_at_100
value: 46.278999999999996
- type: mrr_at_1000
value: 46.318
- type: mrr_at_3
value: 42.522999999999996
- type: mrr_at_5
value: 44.104
- type: ndcg_at_1
value: 36.364000000000004
- type: ndcg_at_10
value: 46.622
- type: ndcg_at_100
value: 52.617000000000004
- type: ndcg_at_1000
value: 54.529
- type: ndcg_at_3
value: 40.971999999999994
- type: ndcg_at_5
value: 43.738
- type: precision_at_1
value: 36.364000000000004
- type: precision_at_10
value: 9.110999999999999
- type: precision_at_100
value: 1.846
- type: precision_at_1000
value: 0.256
- type: precision_at_3
value: 19.236
- type: precision_at_5
value: 14.269000000000002
- type: recall_at_1
value: 29.628
- type: recall_at_10
value: 58.706
- type: recall_at_100
value: 85.116
- type: recall_at_1000
value: 97.258
- type: recall_at_3
value: 42.655
- type: recall_at_5
value: 49.909
- type: map_at_1
value: 25.499
- type: map_at_10
value: 34.284
- type: map_at_100
value: 35.416
- type: map_at_1000
value: 35.494
- type: map_at_3
value: 31.911
- type: map_at_5
value: 33.159
- type: mrr_at_1
value: 28.096
- type: mrr_at_10
value: 36.699
- type: mrr_at_100
value: 37.657000000000004
- type: mrr_at_1000
value: 37.714999999999996
- type: mrr_at_3
value: 34.72
- type: mrr_at_5
value: 35.746
- type: ndcg_at_1
value: 28.096
- type: ndcg_at_10
value: 39.041
- type: ndcg_at_100
value: 44.633
- type: ndcg_at_1000
value: 46.522000000000006
- type: ndcg_at_3
value: 34.663
- type: ndcg_at_5
value: 36.538
- type: precision_at_1
value: 28.096
- type: precision_at_10
value: 6.0440000000000005
- type: precision_at_100
value: 0.9520000000000001
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 14.911
- type: precision_at_5
value: 10.277
- type: recall_at_1
value: 25.499
- type: recall_at_10
value: 51.26199999999999
- type: recall_at_100
value: 76.896
- type: recall_at_1000
value: 90.763
- type: recall_at_3
value: 39.376
- type: recall_at_5
value: 43.785000000000004
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.532
- type: map_at_10
value: 19.911
- type: map_at_100
value: 21.926000000000002
- type: map_at_1000
value: 22.113
- type: map_at_3
value: 16.118
- type: map_at_5
value: 18.043
- type: mrr_at_1
value: 23.909
- type: mrr_at_10
value: 37.029
- type: mrr_at_100
value: 38.015
- type: mrr_at_1000
value: 38.054
- type: mrr_at_3
value: 33.29
- type: mrr_at_5
value: 35.446
- type: ndcg_at_1
value: 23.909
- type: ndcg_at_10
value: 28.691
- type: ndcg_at_100
value: 36.341
- type: ndcg_at_1000
value: 39.644
- type: ndcg_at_3
value: 22.561
- type: ndcg_at_5
value: 24.779999999999998
- type: precision_at_1
value: 23.909
- type: precision_at_10
value: 9.433
- type: precision_at_100
value: 1.763
- type: precision_at_1000
value: 0.23800000000000002
- type: precision_at_3
value: 17.438000000000002
- type: precision_at_5
value: 13.758999999999999
- type: recall_at_1
value: 10.532
- type: recall_at_10
value: 36.079
- type: recall_at_100
value: 62.156
- type: recall_at_1000
value: 80.53099999999999
- type: recall_at_3
value: 21.384
- type: recall_at_5
value: 27.29
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.483
- type: map_at_10
value: 21.986
- type: map_at_100
value: 31.319000000000003
- type: map_at_1000
value: 33.231
- type: map_at_3
value: 15.193000000000001
- type: map_at_5
value: 18.116
- type: mrr_at_1
value: 74.0
- type: mrr_at_10
value: 80.047
- type: mrr_at_100
value: 80.406
- type: mrr_at_1000
value: 80.414
- type: mrr_at_3
value: 78.667
- type: mrr_at_5
value: 79.467
- type: ndcg_at_1
value: 61.875
- type: ndcg_at_10
value: 46.544999999999995
- type: ndcg_at_100
value: 51.097
- type: ndcg_at_1000
value: 58.331999999999994
- type: ndcg_at_3
value: 51.622
- type: ndcg_at_5
value: 49.016
- type: precision_at_1
value: 74.0
- type: precision_at_10
value: 37.325
- type: precision_at_100
value: 11.743
- type: precision_at_1000
value: 2.423
- type: precision_at_3
value: 54.75
- type: precision_at_5
value: 47.699999999999996
- type: recall_at_1
value: 9.483
- type: recall_at_10
value: 27.477
- type: recall_at_100
value: 57.099999999999994
- type: recall_at_1000
value: 80.56
- type: recall_at_3
value: 16.543
- type: recall_at_5
value: 20.830000000000002
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 50.06
- type: f1
value: 44.99375486940016
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.94
- type: map_at_10
value: 80.854
- type: map_at_100
value: 81.096
- type: map_at_1000
value: 81.109
- type: map_at_3
value: 79.589
- type: map_at_5
value: 80.431
- type: mrr_at_1
value: 76.44800000000001
- type: mrr_at_10
value: 85.07000000000001
- type: mrr_at_100
value: 85.168
- type: mrr_at_1000
value: 85.17
- type: mrr_at_3
value: 84.221
- type: mrr_at_5
value: 84.832
- type: ndcg_at_1
value: 76.44800000000001
- type: ndcg_at_10
value: 85.019
- type: ndcg_at_100
value: 85.886
- type: ndcg_at_1000
value: 86.09400000000001
- type: ndcg_at_3
value: 83.023
- type: ndcg_at_5
value: 84.223
- type: precision_at_1
value: 76.44800000000001
- type: precision_at_10
value: 10.405000000000001
- type: precision_at_100
value: 1.105
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 32.208
- type: precision_at_5
value: 20.122999999999998
- type: recall_at_1
value: 70.94
- type: recall_at_10
value: 93.508
- type: recall_at_100
value: 96.962
- type: recall_at_1000
value: 98.24300000000001
- type: recall_at_3
value: 88.17099999999999
- type: recall_at_5
value: 91.191
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.844
- type: map_at_10
value: 41.629
- type: map_at_100
value: 43.766
- type: map_at_1000
value: 43.916
- type: map_at_3
value: 35.992000000000004
- type: map_at_5
value: 39.302
- type: mrr_at_1
value: 45.988
- type: mrr_at_10
value: 56.050999999999995
- type: mrr_at_100
value: 56.741
- type: mrr_at_1000
value: 56.767999999999994
- type: mrr_at_3
value: 53.498000000000005
- type: mrr_at_5
value: 55.071999999999996
- type: ndcg_at_1
value: 45.988
- type: ndcg_at_10
value: 49.891999999999996
- type: ndcg_at_100
value: 56.727000000000004
- type: ndcg_at_1000
value: 58.952000000000005
- type: ndcg_at_3
value: 45.09
- type: ndcg_at_5
value: 46.943
- type: precision_at_1
value: 45.988
- type: precision_at_10
value: 13.980999999999998
- type: precision_at_100
value: 2.136
- type: precision_at_1000
value: 0.252
- type: precision_at_3
value: 30.556
- type: precision_at_5
value: 22.778000000000002
- type: recall_at_1
value: 23.844
- type: recall_at_10
value: 58.46
- type: recall_at_100
value: 82.811
- type: recall_at_1000
value: 96.084
- type: recall_at_3
value: 41.636
- type: recall_at_5
value: 49.271
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.108
- type: map_at_10
value: 65.846
- type: map_at_100
value: 66.691
- type: map_at_1000
value: 66.743
- type: map_at_3
value: 62.09
- type: map_at_5
value: 64.412
- type: mrr_at_1
value: 80.216
- type: mrr_at_10
value: 85.768
- type: mrr_at_100
value: 85.92699999999999
- type: mrr_at_1000
value: 85.932
- type: mrr_at_3
value: 85.012
- type: mrr_at_5
value: 85.495
- type: ndcg_at_1
value: 80.216
- type: ndcg_at_10
value: 73.833
- type: ndcg_at_100
value: 76.68
- type: ndcg_at_1000
value: 77.639
- type: ndcg_at_3
value: 68.7
- type: ndcg_at_5
value: 71.514
- type: precision_at_1
value: 80.216
- type: precision_at_10
value: 15.616
- type: precision_at_100
value: 1.783
- type: precision_at_1000
value: 0.191
- type: precision_at_3
value: 44.483
- type: precision_at_5
value: 28.904999999999998
- type: recall_at_1
value: 40.108
- type: recall_at_10
value: 78.082
- type: recall_at_100
value: 89.129
- type: recall_at_1000
value: 95.381
- type: recall_at_3
value: 66.725
- type: recall_at_5
value: 72.262
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 94.3208
- type: ap
value: 91.64852216825692
- type: f1
value: 94.31672442494217
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 16.954
- type: map_at_10
value: 28.605000000000004
- type: map_at_100
value: 29.875
- type: map_at_1000
value: 29.934
- type: map_at_3
value: 24.57
- type: map_at_5
value: 26.845000000000002
- type: mrr_at_1
value: 17.407
- type: mrr_at_10
value: 29.082
- type: mrr_at_100
value: 30.309
- type: mrr_at_1000
value: 30.361
- type: mrr_at_3
value: 25.112000000000002
- type: mrr_at_5
value: 27.37
- type: ndcg_at_1
value: 17.407
- type: ndcg_at_10
value: 35.555
- type: ndcg_at_100
value: 41.808
- type: ndcg_at_1000
value: 43.277
- type: ndcg_at_3
value: 27.291999999999998
- type: ndcg_at_5
value: 31.369999999999997
- type: precision_at_1
value: 17.407
- type: precision_at_10
value: 5.9670000000000005
- type: precision_at_100
value: 0.9119999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 11.939
- type: precision_at_5
value: 9.223
- type: recall_at_1
value: 16.954
- type: recall_at_10
value: 57.216
- type: recall_at_100
value: 86.384
- type: recall_at_1000
value: 97.64
- type: recall_at_3
value: 34.660999999999994
- type: recall_at_5
value: 44.484
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 95.29183766529867
- type: f1
value: 95.01282555921513
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 87.07934336525307
- type: f1
value: 69.58693991783085
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 79.71755211835911
- type: f1
value: 77.08207736007755
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 81.08607935440484
- type: f1
value: 80.71191664406739
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 36.5355083590869
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 37.24173539348128
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.84293003435578
- type: mrr
value: 34.09721970493348
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.369
- type: map_at_10
value: 14.892
- type: map_at_100
value: 18.884999999999998
- type: map_at_1000
value: 20.43
- type: map_at_3
value: 10.735999999999999
- type: map_at_5
value: 12.703000000000001
- type: mrr_at_1
value: 50.15500000000001
- type: mrr_at_10
value: 59.948
- type: mrr_at_100
value: 60.422
- type: mrr_at_1000
value: 60.455999999999996
- type: mrr_at_3
value: 58.204
- type: mrr_at_5
value: 59.35
- type: ndcg_at_1
value: 47.678
- type: ndcg_at_10
value: 39.050000000000004
- type: ndcg_at_100
value: 35.905
- type: ndcg_at_1000
value: 44.662
- type: ndcg_at_3
value: 44.781
- type: ndcg_at_5
value: 42.549
- type: precision_at_1
value: 49.226
- type: precision_at_10
value: 28.762
- type: precision_at_100
value: 8.767999999999999
- type: precision_at_1000
value: 2.169
- type: precision_at_3
value: 41.796
- type: precision_at_5
value: 37.09
- type: recall_at_1
value: 6.369
- type: recall_at_10
value: 19.842000000000002
- type: recall_at_100
value: 37.017
- type: recall_at_1000
value: 68.444
- type: recall_at_3
value: 12.446
- type: recall_at_5
value: 15.525
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.663
- type: map_at_10
value: 56.252
- type: map_at_100
value: 57.018
- type: map_at_1000
value: 57.031
- type: map_at_3
value: 52.020999999999994
- type: map_at_5
value: 54.626
- type: mrr_at_1
value: 44.699
- type: mrr_at_10
value: 58.819
- type: mrr_at_100
value: 59.351
- type: mrr_at_1000
value: 59.358
- type: mrr_at_3
value: 55.615
- type: mrr_at_5
value: 57.598000000000006
- type: ndcg_at_1
value: 44.699
- type: ndcg_at_10
value: 63.873999999999995
- type: ndcg_at_100
value: 66.973
- type: ndcg_at_1000
value: 67.23700000000001
- type: ndcg_at_3
value: 56.25599999999999
- type: ndcg_at_5
value: 60.44199999999999
- type: precision_at_1
value: 44.699
- type: precision_at_10
value: 10.075000000000001
- type: precision_at_100
value: 1.185
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 25.202999999999996
- type: precision_at_5
value: 17.584
- type: recall_at_1
value: 39.663
- type: recall_at_10
value: 84.313
- type: recall_at_100
value: 97.56700000000001
- type: recall_at_1000
value: 99.44
- type: recall_at_3
value: 64.938
- type: recall_at_5
value: 74.515
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 69.708
- type: map_at_10
value: 83.86099999999999
- type: map_at_100
value: 84.513
- type: map_at_1000
value: 84.53
- type: map_at_3
value: 80.854
- type: map_at_5
value: 82.757
- type: mrr_at_1
value: 80.15
- type: mrr_at_10
value: 86.70400000000001
- type: mrr_at_100
value: 86.81400000000001
- type: mrr_at_1000
value: 86.815
- type: mrr_at_3
value: 85.658
- type: mrr_at_5
value: 86.37599999999999
- type: ndcg_at_1
value: 80.17
- type: ndcg_at_10
value: 87.7
- type: ndcg_at_100
value: 88.979
- type: ndcg_at_1000
value: 89.079
- type: ndcg_at_3
value: 84.71600000000001
- type: ndcg_at_5
value: 86.385
- type: precision_at_1
value: 80.17
- type: precision_at_10
value: 13.369
- type: precision_at_100
value: 1.53
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.123
- type: precision_at_5
value: 24.498
- type: recall_at_1
value: 69.708
- type: recall_at_10
value: 95.17099999999999
- type: recall_at_100
value: 99.529
- type: recall_at_1000
value: 99.97500000000001
- type: recall_at_3
value: 86.761
- type: recall_at_5
value: 91.34
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 63.005610557842786
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 65.85897055439158
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.388
- type: map_at_10
value: 14.087
- type: map_at_100
value: 16.618
- type: map_at_1000
value: 16.967
- type: map_at_3
value: 9.8
- type: map_at_5
value: 11.907
- type: mrr_at_1
value: 26.5
- type: mrr_at_10
value: 37.905
- type: mrr_at_100
value: 39.053
- type: mrr_at_1000
value: 39.091
- type: mrr_at_3
value: 34.567
- type: mrr_at_5
value: 36.307
- type: ndcg_at_1
value: 26.5
- type: ndcg_at_10
value: 23.06
- type: ndcg_at_100
value: 32.164
- type: ndcg_at_1000
value: 37.574000000000005
- type: ndcg_at_3
value: 21.623
- type: ndcg_at_5
value: 18.95
- type: precision_at_1
value: 26.5
- type: precision_at_10
value: 12.030000000000001
- type: precision_at_100
value: 2.5020000000000002
- type: precision_at_1000
value: 0.379
- type: precision_at_3
value: 20.200000000000003
- type: precision_at_5
value: 16.64
- type: recall_at_1
value: 5.388
- type: recall_at_10
value: 24.375
- type: recall_at_100
value: 50.818
- type: recall_at_1000
value: 76.86699999999999
- type: recall_at_3
value: 12.273
- type: recall_at_5
value: 16.858
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.09465497223438
- type: cos_sim_spearman
value: 80.55601111843897
- type: euclidean_pearson
value: 82.40135168520864
- type: euclidean_spearman
value: 80.05606361845396
- type: manhattan_pearson
value: 82.24092291787754
- type: manhattan_spearman
value: 79.89739846820373
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 81.14210597635189
- type: cos_sim_spearman
value: 73.69447481152118
- type: euclidean_pearson
value: 75.08507068029972
- type: euclidean_spearman
value: 71.04077458564372
- type: manhattan_pearson
value: 75.64918699307383
- type: manhattan_spearman
value: 71.61677355593945
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 85.41396417076866
- type: cos_sim_spearman
value: 85.82245898186092
- type: euclidean_pearson
value: 85.58527168297935
- type: euclidean_spearman
value: 85.94613250938504
- type: manhattan_pearson
value: 85.88114899068759
- type: manhattan_spearman
value: 86.42494392145366
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 83.7431948980468
- type: cos_sim_spearman
value: 82.05114289801895
- type: euclidean_pearson
value: 83.06116666914892
- type: euclidean_spearman
value: 81.82060562251957
- type: manhattan_pearson
value: 83.1858437025367
- type: manhattan_spearman
value: 82.09604293088852
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.455985912287
- type: cos_sim_spearman
value: 88.8044343107975
- type: euclidean_pearson
value: 87.155336804123
- type: euclidean_spearman
value: 87.79371420531842
- type: manhattan_pearson
value: 87.5784376507174
- type: manhattan_spearman
value: 88.429877987816
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.1631000795076
- type: cos_sim_spearman
value: 86.20042158061408
- type: euclidean_pearson
value: 84.88605965960737
- type: euclidean_spearman
value: 85.45926745772432
- type: manhattan_pearson
value: 85.18333987666729
- type: manhattan_spearman
value: 85.86048911387192
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 91.51301667439836
- type: cos_sim_spearman
value: 91.46469919011143
- type: euclidean_pearson
value: 91.15157693133415
- type: euclidean_spearman
value: 91.02656400119739
- type: manhattan_pearson
value: 91.08411259466446
- type: manhattan_spearman
value: 90.84339904461068
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 69.08993728439704
- type: cos_sim_spearman
value: 69.20885645170797
- type: euclidean_pearson
value: 69.65638507632245
- type: euclidean_spearman
value: 68.69831912688514
- type: manhattan_pearson
value: 69.86621764969294
- type: manhattan_spearman
value: 69.05446631856769
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.96149243197495
- type: cos_sim_spearman
value: 87.43145597912833
- type: euclidean_pearson
value: 86.6762329641158
- type: euclidean_spearman
value: 86.67085254401809
- type: manhattan_pearson
value: 87.06412701458164
- type: manhattan_spearman
value: 87.10197412769807
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 86.43440918697488
- type: mrr
value: 96.3954826945023
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.494
- type: map_at_10
value: 72.074
- type: map_at_100
value: 72.475
- type: map_at_1000
value: 72.483
- type: map_at_3
value: 68.983
- type: map_at_5
value: 71.161
- type: mrr_at_1
value: 63.666999999999994
- type: mrr_at_10
value: 73.31299999999999
- type: mrr_at_100
value: 73.566
- type: mrr_at_1000
value: 73.574
- type: mrr_at_3
value: 71.111
- type: mrr_at_5
value: 72.72800000000001
- type: ndcg_at_1
value: 63.666999999999994
- type: ndcg_at_10
value: 77.024
- type: ndcg_at_100
value: 78.524
- type: ndcg_at_1000
value: 78.842
- type: ndcg_at_3
value: 72.019
- type: ndcg_at_5
value: 75.22999999999999
- type: precision_at_1
value: 63.666999999999994
- type: precision_at_10
value: 10.2
- type: precision_at_100
value: 1.103
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 28.111000000000004
- type: precision_at_5
value: 19.0
- type: recall_at_1
value: 60.494
- type: recall_at_10
value: 90.8
- type: recall_at_100
value: 97.333
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 77.644
- type: recall_at_5
value: 85.694
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.68415841584158
- type: cos_sim_ap
value: 91.23713949701548
- type: cos_sim_f1
value: 83.70221327967808
- type: cos_sim_precision
value: 84.21052631578947
- type: cos_sim_recall
value: 83.2
- type: dot_accuracy
value: 99.5
- type: dot_ap
value: 79.46312132270363
- type: dot_f1
value: 72.75320970042794
- type: dot_precision
value: 69.35630099728014
- type: dot_recall
value: 76.5
- type: euclidean_accuracy
value: 99.69108910891089
- type: euclidean_ap
value: 90.9016163254649
- type: euclidean_f1
value: 83.91752577319586
- type: euclidean_precision
value: 86.59574468085106
- type: euclidean_recall
value: 81.39999999999999
- type: manhattan_accuracy
value: 99.7039603960396
- type: manhattan_ap
value: 91.5593806619311
- type: manhattan_f1
value: 85.08124076809453
- type: manhattan_precision
value: 83.80213385063045
- type: manhattan_recall
value: 86.4
- type: max_accuracy
value: 99.7039603960396
- type: max_ap
value: 91.5593806619311
- type: max_f1
value: 85.08124076809453
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 74.40806543281603
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 38.51757703316821
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 54.33475593449746
- type: mrr
value: 55.3374474789916
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.249926396023596
- type: cos_sim_spearman
value: 29.820375700458158
- type: dot_pearson
value: 28.820307635930355
- type: dot_spearman
value: 28.824273052746825
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.233
- type: map_at_10
value: 2.061
- type: map_at_100
value: 12.607
- type: map_at_1000
value: 30.031000000000002
- type: map_at_3
value: 0.6669999999999999
- type: map_at_5
value: 1.091
- type: mrr_at_1
value: 88.0
- type: mrr_at_10
value: 93.067
- type: mrr_at_100
value: 93.067
- type: mrr_at_1000
value: 93.067
- type: mrr_at_3
value: 92.667
- type: mrr_at_5
value: 93.067
- type: ndcg_at_1
value: 84.0
- type: ndcg_at_10
value: 81.072
- type: ndcg_at_100
value: 62.875
- type: ndcg_at_1000
value: 55.641
- type: ndcg_at_3
value: 85.296
- type: ndcg_at_5
value: 84.10499999999999
- type: precision_at_1
value: 88.0
- type: precision_at_10
value: 83.39999999999999
- type: precision_at_100
value: 63.7
- type: precision_at_1000
value: 24.622
- type: precision_at_3
value: 88.0
- type: precision_at_5
value: 87.2
- type: recall_at_1
value: 0.233
- type: recall_at_10
value: 2.188
- type: recall_at_100
value: 15.52
- type: recall_at_1000
value: 52.05499999999999
- type: recall_at_3
value: 0.6859999999999999
- type: recall_at_5
value: 1.1440000000000001
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.19
- type: map_at_10
value: 11.491999999999999
- type: map_at_100
value: 17.251
- type: map_at_1000
value: 18.795
- type: map_at_3
value: 6.146
- type: map_at_5
value: 8.113
- type: mrr_at_1
value: 44.897999999999996
- type: mrr_at_10
value: 56.57
- type: mrr_at_100
value: 57.348
- type: mrr_at_1000
value: 57.357
- type: mrr_at_3
value: 52.041000000000004
- type: mrr_at_5
value: 55.408
- type: ndcg_at_1
value: 40.816
- type: ndcg_at_10
value: 27.968
- type: ndcg_at_100
value: 39.0
- type: ndcg_at_1000
value: 50.292
- type: ndcg_at_3
value: 31.256
- type: ndcg_at_5
value: 28.855999999999998
- type: precision_at_1
value: 44.897999999999996
- type: precision_at_10
value: 24.285999999999998
- type: precision_at_100
value: 7.898
- type: precision_at_1000
value: 1.541
- type: precision_at_3
value: 30.612000000000002
- type: precision_at_5
value: 27.346999999999998
- type: recall_at_1
value: 3.19
- type: recall_at_10
value: 17.954
- type: recall_at_100
value: 48.793
- type: recall_at_1000
value: 83.357
- type: recall_at_3
value: 6.973999999999999
- type: recall_at_5
value: 10.391
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.89139999999999
- type: ap
value: 15.562539739828049
- type: f1
value: 55.38685639741247
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 62.48160724391625
- type: f1
value: 62.76700854121342
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 57.157071531498275
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.15503367705789
- type: cos_sim_ap
value: 77.20584529783206
- type: cos_sim_f1
value: 71.3558088770313
- type: cos_sim_precision
value: 66.02333931777379
- type: cos_sim_recall
value: 77.62532981530343
- type: dot_accuracy
value: 83.10186564940096
- type: dot_ap
value: 64.34160146443133
- type: dot_f1
value: 63.23048153342683
- type: dot_precision
value: 56.75618967687789
- type: dot_recall
value: 71.37203166226914
- type: euclidean_accuracy
value: 86.94045419324074
- type: euclidean_ap
value: 76.08471767931738
- type: euclidean_f1
value: 71.41248592518455
- type: euclidean_precision
value: 67.90387818225078
- type: euclidean_recall
value: 75.30343007915567
- type: manhattan_accuracy
value: 86.80932228646361
- type: manhattan_ap
value: 76.03862870753638
- type: manhattan_f1
value: 71.2660917385327
- type: manhattan_precision
value: 67.70363334124912
- type: manhattan_recall
value: 75.22427440633246
- type: max_accuracy
value: 87.15503367705789
- type: max_ap
value: 77.20584529783206
- type: max_f1
value: 71.41248592518455
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.42639810610471
- type: cos_sim_ap
value: 86.45196525133669
- type: cos_sim_f1
value: 79.25172592977508
- type: cos_sim_precision
value: 76.50852802063925
- type: cos_sim_recall
value: 82.19895287958116
- type: dot_accuracy
value: 87.03768385919976
- type: dot_ap
value: 80.86465404774172
- type: dot_f1
value: 74.50351637940457
- type: dot_precision
value: 70.72293324109305
- type: dot_recall
value: 78.71111795503542
- type: euclidean_accuracy
value: 89.29056545193464
- type: euclidean_ap
value: 86.25102188096191
- type: euclidean_f1
value: 79.05038057267126
- type: euclidean_precision
value: 74.681550472538
- type: euclidean_recall
value: 83.9621188789652
- type: manhattan_accuracy
value: 89.34877944657896
- type: manhattan_ap
value: 86.35336214205911
- type: manhattan_f1
value: 79.20192588269623
- type: manhattan_precision
value: 75.24951483227058
- type: manhattan_recall
value: 83.59254696643055
- type: max_accuracy
value: 89.42639810610471
- type: max_ap
value: 86.45196525133669
- type: max_f1
value: 79.25172592977508
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/jC7kdl8.jpeg" alt="TensorBlock" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;">
Feedback and support: TensorBlock's <a href="https://x.com/tensorblock_aoi">Twitter/X</a>, <a href="https://t.me/TensorBlock">Telegram Group</a> and <a href="https://x.com/tensorblock_aoi">Discord server</a>
</p>
</div>
</div>
## GritLM/GritLM-8x7B - GGUF
This repo contains GGUF format model files for [GritLM/GritLM-8x7B](https://huggingface.co/GritLM/GritLM-8x7B).
The files were quantized using machines provided by [TensorBlock](https://tensorblock.co/), and they are compatible with llama.cpp as of [commit b4242](https://github.com/ggerganov/llama.cpp/commit/a6744e43e80f4be6398fc7733a01642c846dce1d).
<div style="text-align: left; margin: 20px 0;">
<a href="https://tensorblock.co/waitlist/client" style="display: inline-block; padding: 10px 20px; background-color: #007bff; color: white; text-decoration: none; border-radius: 5px; font-weight: bold;">
Run them on the TensorBlock client using your local machine ↗
</a>
</div>
## Prompt template
```
<s><|user|>
{prompt}
<|assistant|>
```
## Model file specification
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [GritLM-8x7B-Q2_K.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q2_K.gguf) | Q2_K | 17.311 GB | smallest, significant quality loss - not recommended for most purposes |
| [GritLM-8x7B-Q3_K_S.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q3_K_S.gguf) | Q3_K_S | 20.433 GB | very small, high quality loss |
| [GritLM-8x7B-Q3_K_M.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q3_K_M.gguf) | Q3_K_M | 22.546 GB | very small, high quality loss |
| [GritLM-8x7B-Q3_K_L.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q3_K_L.gguf) | Q3_K_L | 24.170 GB | small, substantial quality loss |
| [GritLM-8x7B-Q4_0.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q4_0.gguf) | Q4_0 | 26.444 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [GritLM-8x7B-Q4_K_S.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q4_K_S.gguf) | Q4_K_S | 26.746 GB | small, greater quality loss |
| [GritLM-8x7B-Q4_K_M.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q4_K_M.gguf) | Q4_K_M | 28.448 GB | medium, balanced quality - recommended |
| [GritLM-8x7B-Q5_0.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q5_0.gguf) | Q5_0 | 32.231 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [GritLM-8x7B-Q5_K_S.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q5_K_S.gguf) | Q5_K_S | 32.231 GB | large, low quality loss - recommended |
| [GritLM-8x7B-Q5_K_M.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q5_K_M.gguf) | Q5_K_M | 33.230 GB | large, very low quality loss - recommended |
| [GritLM-8x7B-Q6_K.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q6_K.gguf) | Q6_K | 38.381 GB | very large, extremely low quality loss |
| [GritLM-8x7B-Q8_0.gguf](https://huggingface.co/tensorblock/GritLM-8x7B-GGUF/blob/main/GritLM-8x7B-Q8_0.gguf) | Q8_0 | 49.626 GB | very large, extremely low quality loss - not recommended |
## Downloading instruction
### Command line
Firstly, install Huggingface Client
```shell
pip install -U "huggingface_hub[cli]"
```
Then, downoad the individual model file the a local directory
```shell
huggingface-cli download tensorblock/GritLM-8x7B-GGUF --include "GritLM-8x7B-Q2_K.gguf" --local-dir MY_LOCAL_DIR
```
If you wanna download multiple model files with a pattern (e.g., `*Q4_K*gguf`), you can try:
```shell
huggingface-cli download tensorblock/GritLM-8x7B-GGUF --local-dir MY_LOCAL_DIR --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
|
[
"BIOSSES",
"SCIFACT"
] |
pipihand01/QwQ-32B-Preview-abliterated-linear50-GGUF
|
pipihand01
| null |
[
"gguf",
"chat",
"abliterated",
"uncensored",
"merge",
"en",
"base_model:pipihand01/QwQ-32B-Preview-abliterated-linear50",
"base_model:quantized:pipihand01/QwQ-32B-Preview-abliterated-linear50",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | 2025-01-02T23:25:10Z |
2025-01-03T00:32:40+00:00
| 92 | 0 |
---
base_model:
- pipihand01/QwQ-32B-Preview-abliterated-linear50
language:
- en
license: apache-2.0
license_link: https://huggingface.co/pipihand01/QwQ-32B-Preview-abliterated-linear50-GGUF/blob/main/LICENSE
tags:
- chat
- abliterated
- uncensored
- merge
quantized_by: pipihand01
---
GGUF files of [pipihand01/QwQ-32B-Preview-abliterated-linear50](https://huggingface.co/pipihand01/QwQ-32B-Preview-abliterated-linear50).
**NOTE: I bear no responsibility for any output of this model. When properly prompted, this model may generate contents that are not suitable in some situations. Use it with your own caution.**
|
[
"BEAR"
] |
judithrosell/BlueBERT_JNLPBA_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12",
"base_model:finetune:bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12",
"license:cc0-1.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-23T15:57:56Z |
2023-12-24T20:21:09+00:00
| 91 | 0 |
---
base_model: bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12
license: cc0-1.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: BlueBERT_JNLPBA_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BlueBERT_JNLPBA_NER
This model is a fine-tuned version of [bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12](https://huggingface.co/bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1586
- Precision: 0.8051
- Recall: 0.8205
- F1: 0.8128
- Accuracy: 0.9473
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3151 | 1.0 | 582 | 0.1675 | 0.7937 | 0.7926 | 0.7932 | 0.9439 |
| 0.1639 | 2.0 | 1164 | 0.1618 | 0.8068 | 0.8053 | 0.8061 | 0.9470 |
| 0.143 | 3.0 | 1746 | 0.1586 | 0.8051 | 0.8205 | 0.8128 | 0.9473 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.0
- Tokenizers 0.15.0
|
[
"JNLPBA"
] |
RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2402.00838",
"endpoints_compatible",
"region:us"
] | 2024-06-14T20:03:08Z |
2024-06-14T20:32:41+00:00
| 91 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
OLMo-1.7-7B-hf - GGUF
- Model creator: https://huggingface.co/allenai/
- Original model: https://huggingface.co/allenai/OLMo-1.7-7B-hf/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [OLMo-1.7-7B-hf.Q2_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q2_K.gguf) | Q2_K | 2.44GB |
| [OLMo-1.7-7B-hf.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.IQ3_XS.gguf) | IQ3_XS | 2.69GB |
| [OLMo-1.7-7B-hf.IQ3_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.IQ3_S.gguf) | IQ3_S | 2.83GB |
| [OLMo-1.7-7B-hf.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q3_K_S.gguf) | Q3_K_S | 2.83GB |
| [OLMo-1.7-7B-hf.IQ3_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.IQ3_M.gguf) | IQ3_M | 2.99GB |
| [OLMo-1.7-7B-hf.Q3_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q3_K.gguf) | Q3_K | 3.16GB |
| [OLMo-1.7-7B-hf.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q3_K_M.gguf) | Q3_K_M | 3.16GB |
| [OLMo-1.7-7B-hf.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q3_K_L.gguf) | Q3_K_L | 3.44GB |
| [OLMo-1.7-7B-hf.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.IQ4_XS.gguf) | IQ4_XS | 3.49GB |
| [OLMo-1.7-7B-hf.Q4_0.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q4_0.gguf) | Q4_0 | 3.66GB |
| [OLMo-1.7-7B-hf.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.IQ4_NL.gguf) | IQ4_NL | 3.68GB |
| [OLMo-1.7-7B-hf.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q4_K_S.gguf) | Q4_K_S | 3.69GB |
| [OLMo-1.7-7B-hf.Q4_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q4_K.gguf) | Q4_K | 3.9GB |
| [OLMo-1.7-7B-hf.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q4_K_M.gguf) | Q4_K_M | 3.9GB |
| [OLMo-1.7-7B-hf.Q4_1.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q4_1.gguf) | Q4_1 | 4.05GB |
| [OLMo-1.7-7B-hf.Q5_0.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q5_0.gguf) | Q5_0 | 4.44GB |
| [OLMo-1.7-7B-hf.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q5_K_S.gguf) | Q5_K_S | 4.44GB |
| [OLMo-1.7-7B-hf.Q5_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q5_K.gguf) | Q5_K | 4.56GB |
| [OLMo-1.7-7B-hf.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q5_K_M.gguf) | Q5_K_M | 4.56GB |
| [OLMo-1.7-7B-hf.Q5_1.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q5_1.gguf) | Q5_1 | 4.83GB |
| [OLMo-1.7-7B-hf.Q6_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q6_K.gguf) | Q6_K | 5.26GB |
| [OLMo-1.7-7B-hf.Q8_0.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-1.7-7B-hf-gguf/blob/main/OLMo-1.7-7B-hf.Q8_0.gguf) | Q8_0 | 6.82GB |
Original model description:
---
license: apache-2.0
datasets:
- allenai/dolma
language:
- en
---
<img src="https://allenai.org/olmo/olmo-7b-animation.gif" alt="OLMo Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for OLMo 1.7-7B-hf
OLMo 1.7 7B is the latest version of the original [OLMo 7B](https://huggingface.co/allenai/OLMo-7B) model rocking a 24 point increase in MMLU, among other evaluations improvements, from an improved version of the Dolma dataset and staged training.
**This version is for direct use with HuggingFace Transformers** from v4.40 on.
OLMo is a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models.
The OLMo models are trained on the [Dolma](https://huggingface.co/datasets/allenai/dolma) dataset.
We release all code, checkpoints, logs, and details involved in training these models.
## Model Details
The core models released in this batch are the following:
| Size | Training Tokens | Layers | Hidden Size | Attention Heads | Context Length |
|------|--------|---------|-------------|-----------------|----------------|
| [OLMo 1B](https://huggingface.co/allenai/OLMo-1B) | 3 Trillion |16 | 2048 | 16 | 2048 |
| [OLMo 7B](https://huggingface.co/allenai/OLMo-7B) | 2.5 Trillion | 32 | 4096 | 32 | 2048 |
| [OLMo 7B Twin 2T](https://huggingface.co/allenai/OLMo-7B-Twin-2T) | 2 Trillion | 32 | 4096 | 32 | 2048 |
| [OLMo 1.7-7B](https://huggingface.co/allenai/OLMo-1.7-7B) | 2.05 Trillion | 32 | 4096 | 32 | 4096 |
*Note: OLMo 1.7-7B also includes QKV clipping.*
[Coming soon] We are releasing many checkpoints for these models, for every 1000 training steps.
The naming convention is `step1000-tokens4B`.
To load a specific model revision with HuggingFace, simply add the argument `revision`:
```bash
olmo = AutoModelForCausalLM.from_pretrained("allenai/OLMo-1.7-7B-hf", revision="step1000-tokens4B")
```
All revisions/branches are listed in the file `revisions.txt`.
Or, you can access all the revisions for the models via the following code snippet:
```python
from huggingface_hub import list_repo_refs
out = list_repo_refs("allenai/OLMo-1.7-7B-hf")
branches = [b.name for b in out.branches]
```
A few revisions were lost due to an error, but the vast majority are present.
### Model Description
- **Developed by:** Allen Institute for AI (AI2)
- **Supported by:** Databricks, Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard University, AMD, CSC (Lumi Supercomputer), UW
- **Model type:** a Transformer style autoregressive language model.
- **Language(s) (NLP):** English
- **License:** The code and model are released under Apache 2.0.
- **Contact:** Technical inquiries: `olmo at allenai dot org`. Press: `press at allenai dot org`
- **Date cutoff:** Oct. 2023, with most data from Feb./March 2023 based on Dolma dataset version.
### Model Sources
- **Project Page:** https://allenai.org/olmo
- **Repositories:**
- Core repo (training, inference, fine-tuning etc.): https://github.com/allenai/OLMo
- Evaluation code: https://github.com/allenai/OLMo-Eval
- Further fine-tuning code: https://github.com/allenai/open-instruct
- **Paper:** [Link](https://arxiv.org/abs/2402.00838)
- **Technical blog post:** https://blog.allenai.org/olmo-1-7-7b-a-24-point-improvement-on-mmlu-92b43f7d269d
- **W&B Logs:** [pretraining](https://wandb.ai/ai2-llm/OLMo-7B/groups/OLMo-1.7-7B), [annealing](https://wandb.ai/ai2-llm/OLMo-7B/groups/OLMo-1.7-7B-anneal)
<!-- - **Press release:** TODO -->
## Uses
### Inference
Install Transformers [from source](https://huggingface.co/docs/transformers/en/installation#install-from-source), or update to the next version when this [PR](https://github.com/huggingface/transformers/pull/29890) is integrated.
Now, proceed as usual with HuggingFace:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
olmo = AutoModelForCausalLM.from_pretrained("allenai/OLMo-1.7-7B-hf")
tokenizer = AutoTokenizer.from_pretrained("allenai/OLMo-1.7-7B-hf")
message = ["Language modeling is "]
inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
# optional verifying cuda
# inputs = {k: v.to('cuda') for k,v in inputs.items()}
# olmo = olmo.to('cuda')
response = olmo.generate(**inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
>> 'Language modeling is the first step to build natural language generation...'
```
Alternatively, with the pipeline abstraction:
```python
from transformers import pipeline
olmo_pipe = pipeline("text-generation", model="allenai/OLMo-1.7-7B-hf")
print(olmo_pipe("Language modeling is "))
>> 'Language modeling is a branch of natural language processing that aims to...'
```
Or, you can make this slightly faster by quantizing the model, e.g. `AutoModelForCausalLM.from_pretrained("allenai/OLMo-1.7-7B-hf", torch_dtype=torch.float16, load_in_8bit=True)` (requires `bitsandbytes`).
The quantized model is more sensitive to typing / cuda, so it is recommended to pass the inputs as `inputs.input_ids.to('cuda')` to avoid potential issues.
Note, you may see the following error if `ai2-olmo` is not installed correctly, which is caused by internal Python check naming. We'll update the code soon to make this error clearer.
```bash
raise ImportError(
ImportError: This modeling file requires the following packages that were not found in your environment: hf_olmo. Run `pip install hf_olmo`
```
### Fine-tuning
Model fine-tuning can be done from the final checkpoint (the `main` revision of this model) or many intermediate checkpoints. Two recipes for tuning are available.
1. Fine-tune with the OLMo repository:
```bash
torchrun --nproc_per_node=8 scripts/train.py {path_to_train_config} \
--data.paths=[{path_to_data}/input_ids.npy] \
--data.label_mask_paths=[{path_to_data}/label_mask.npy] \
--load_path={path_to_checkpoint} \
--reset_trainer_state
```
For more documentation, see the [GitHub readme](https://github.com/allenai/OLMo?tab=readme-ov-file#fine-tuning).
2. Further fine-tuning support is being developing in AI2's Open Instruct repository. Details are [here](https://github.com/allenai/open-instruct).
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
Core model results for the new and original 7B model are found below.
| Task | Llama-7b | Llama2-7b | Falcon-7b | Mpt-7b | OLMo-7B | Llama2-13b | **OLMo 1.7-7B** |
|-------------------|----------|-----------|-----------|--------|---------|------------|-------------|
| arc_c | 44.5 | 48.5 | 47.5 | 46.5 | 48.5 | 52.8 | 42.5 |
| arc_e | 67.9 | 69.5 | 70.4 | 70.5 | 65.4 | 73.7 | 67.2 |
| boolq | 75.4 | 80.2 | 74.6 | 74.2 | 73.4 | 82.2 | 83.7 |
| copa | 91.0 | 86.0 | 86.0 | 85.0 | 90.0 | 90.0 | 86.0 |
| hellaswag | 76.2 | 76.8 | 75.9 | 77.6 | 76.4 | 78.6 | 75.5 |
| openbookqa | 51.2 | 48.4 | 53.0 | 48.6 | 50.4 | 51.8 | 50.0 |
| piqa | 77.2 | 76.7 | 78.5 | 77.3 | 78.4 | 79.0 | 77.5 |
| sciq | 93.9 | 94.5 | 93.9 | 93.7 | 93.8 | 95.5 | 96.7 |
| winogrande | 70.5 | 69.4 | 68.9 | 69.9 | 67.9 | 73.5 | 69.8 |
| truthfulQA (MC2) | 33.9 | 38.5 | 34.0 | 33.0 | 36.0 | 36.8 | 35.8 |
| MMLU (5 shot MC) | 31.5 | 45.0 | 24.0 | 30.8 | 28.3 | 55.5 | 52.0 |
| GSM8k | 10.0 | 12.0 | 4.0 | 4.5 | 8.5 | 25.0 | 29.0 |
| Full average | 60.3 | 62.1 | 59.2 | 59.3 | 59.8 | 66.2 | 63.8 |
And for the 1B model:
| task | random | [StableLM 2 1.6b](https://huggingface.co/stabilityai/stablelm-2-1_6b)\* | [Pythia 1B](https://huggingface.co/EleutherAI/pythia-1b) | [TinyLlama 1.1B](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) | **OLMo 1B** (ours) |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------ | ----------------- | --------- | -------------------------------------- | ------- |
| arc_challenge | 25 | 43.81 | 33.11 | 34.78 | 34.45 |
| arc_easy | 25 | 63.68 | 50.18 | 53.16 | 58.07 |
| boolq | 50 | 76.6 | 61.8 | 64.6 | 60.7 |
| copa | 50 | 84 | 72 | 78 | 79 |
| hellaswag | 25 | 68.2 | 44.7 | 58.7 | 62.5 |
| openbookqa | 25 | 45.8 | 37.8 | 43.6 | 46.4 |
| piqa | 50 | 74 | 69.1 | 71.1 | 73.7 |
| sciq | 25 | 94.7 | 86 | 90.5 | 88.1 |
| winogrande | 50 | 64.9 | 53.3 | 58.9 | 58.9 |
| Average | 36.11 | 68.41 | 56.44 | 61.48 | 62.42 |
\*Unlike OLMo, Pythia, and TinyLlama, StabilityAI has not disclosed yet the data StableLM was trained on, making comparisons with other efforts challenging.
## Model Details
### Data
For training data details, please see the [Dolma](https://huggingface.co/datasets/allenai/dolma) documentation.
**This model uses the new 1.7 version with more data sources, better deduplication, and quality filtering**.
During the annealing phase we use a higher quality subset of Dolma with a linearly decaying learning rate to 0.
### Staged training / annealing
In contrast to OLMo 1.0, we trained OLMo 1.7 with a two-stage curriculum:
* In the first stage, we trained the model from scratch on the Dolma 1.7 dataset. We set a cosine learning rate schedule with a warmup of 2500 steps, a peak learning rate of 3e-4, and a cosine decay to 3e-5 after 3T tokens. We cut off this stage after 2T tokens, when the learning rate is still high.
* At this point we switch to the second stage, in which we train on a higher-quality subset of Dolma 1.7 (see below) for another 50B tokens, while linearly decaying the learning rate to 0. Our high-quality subset includes (1) using all available Wikipedia, OpenWebMath and Flan data, (2) removing Dolma CC, CC News, and Megawika, and (3) rebalancing remaining sources to achieve approximately equal proportions of each. See exact token counts and relative proportions of this second stage mix below.
Both stages contribute equally to the final performance of the OLMo model. After the first stage, OLMo 1.7 already outperforms OLMo 1.0. The second stage consistently adds 2 to 3 points of performance on top.
### Architecture
OLMo 7B architecture with peer models for comparison.
| | **OLMo 7B** | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [OpenLM 7B](https://laion.ai/blog/open-lm/) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) | PaLM 8B |
|------------------------|-------------------|---------------------|--------------------|--------------------|------------------|
| d_model | 4096 | 4096 | 4096 | 4544 | 4096 |
| num heads | 32 | 32 | 32 | 71 | 16 |
| num layers | 32 | 32 | 32 | 32 | 32 |
| MLP ratio | ~8/3 | ~8/3 | ~8/3 | 4 | 4 |
| LayerNorm type | non-parametric LN | RMSNorm | parametric LN | parametric LN | parametric LN |
| pos embeddings | RoPE | RoPE | RoPE | RoPE | RoPE |
| attention variant | full | GQA | full | MQA | MQA |
| biases | none | none | in LN only | in LN only | none |
| block type | sequential | sequential | sequential | parallel | parallel |
| activation | SwiGLU | SwiGLU | SwiGLU | GeLU | SwiGLU |
| sequence length | 2048 | 4096 | 2048 | 2048 | 2048 |
| batch size (instances) | 2160 | 1024 | 2048 | 2304 | 512 |
| batch size (tokens) | ~4M | ~4M | ~4M | ~4M | ~1M |
| weight tying | no | no | no | no | yes |
### Hyperparameters
AdamW optimizer parameters are shown below.
| Size | Peak LR | Betas | Epsilon | Weight Decay |
|------|------------|-----------------|-------------|--------------|
| 1B | 4.0E-4 | (0.9, 0.95) | 1.0E-5 | 0.1 |
| 7B | 3.0E-4 | (0.9, 0.99) | 1.0E-5 | 0.1 |
Optimizer settings comparison with peer models.
| | **OLMo 7B** | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [OpenLM 7B](https://laion.ai/blog/open-lm/) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) |
|-----------------------|------------------|---------------------|--------------------|--------------------|
| warmup steps | 5000 | 2000 | 2000 | 1000 |
| peak LR | 3.0E-04 | 3.0E-04 | 3.0E-04 | 6.0E-04 |
| minimum LR | 3.0E-05 | 3.0E-05 | 3.0E-05 | 1.2E-05 |
| weight decay | 0.1 | 0.1 | 0.1 | 0.1 |
| beta1 | 0.9 | 0.9 | 0.9 | 0.99 |
| beta2 | 0.95 | 0.95 | 0.95 | 0.999 |
| epsilon | 1.0E-05 | 1.0E-05 | 1.0E-05 | 1.0E-05 |
| LR schedule | linear | cosine | cosine | cosine |
| gradient clipping | global 1.0 | global 1.0 | global 1.0 | global 1.0 |
| gradient reduce dtype | FP32 | FP32 | FP32 | BF16 |
| optimizer state dtype | FP32 | most likely FP32 | FP32 | FP32 |
## Environmental Impact
OLMo 7B variants were either trained on MI250X GPUs at the LUMI supercomputer, or A100-40GB GPUs provided by MosaicML.
A summary of the environmental impact. Further details are available in the paper.
| | GPU Type | Power Consumption From GPUs | Carbon Intensity (kg CO₂e/KWh) | Carbon Emissions (tCO₂eq) |
|-----------|------------|-----------------------------|--------------------------------|---------------------------|
| OLMo 7B Twin | MI250X ([LUMI supercomputer](https://www.lumi-supercomputer.eu)) | 135 MWh | 0* | 0* |
| OLMo 7B | A100-40GB ([MosaicML](https://www.mosaicml.com)) | 104 MWh | 0.656 | 75.05 |
## Bias, Risks, and Limitations
Like any base language model or fine-tuned model without safety filtering, it is relatively easy for a user to prompt these models to generate harmful and generally sensitive content.
Such content can also be produced unintentionally, especially in the case of bias, so we recommend users consider the risks of applications of this technology.
Otherwise, many facts from OLMo or any LLM will often not be true, so they should be checked.
## Citation
**BibTeX:**
```
@article{Groeneveld2023OLMo,
title={OLMo: Accelerating the Science of Language Models},
author={Groeneveld, Dirk and Beltagy, Iz and Walsh, Pete and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya Harsh and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack and Khot, Tushar and Merrill, William and Morrison, Jacob and Muennighoff, Niklas and Naik, Aakanksha and Nam, Crystal and Peters, Matthew E. and Pyatkin, Valentina and Ravichander, Abhilasha and Schwenk, Dustin and Shah, Saurabh and Smith, Will and Subramani, Nishant and Wortsman, Mitchell and Dasigi, Pradeep and Lambert, Nathan and Richardson, Kyle and Dodge, Jesse and Lo, Kyle and Soldaini, Luca and Smith, Noah A. and Hajishirzi, Hannaneh},
journal={Preprint},
year={2024}
}
```
**APA:**
Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney, R., Tafjord, O., Jha, A., Ivison, H., Magnusson, I., Wang, Y., Arora, S., Atkinson, D., Authur, R., Chandu, K., Cohan, A., Dumas, J., Elazar, Y., Gu, Y., Hessel, J., Khot, T., Merrill, W., Morrison, J., Muennighoff, N., Naik, A., Nam, C., Peters, M., Pyatkin, V., Ravichander, A., Schwenk, D., Shah, S., Smith, W., Subramani, N., Wortsman, M., Dasigi, P., Lambert, N., Richardson, K., Dodge, J., Lo, K., Soldaini, L., Smith, N., & Hajishirzi, H. (2024). OLMo: Accelerating the Science of Language Models. Preprint.
## Model Card Contact
For errors in this model card, contact Nathan, `{nathanl} at allenai dot org`.
|
[
"SCIQ"
] |
mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"not-for-all-audiences",
"nsfw",
"rp",
"roleplay",
"role-play",
"en",
"base_model:Cas-Archive/L3-Umbral-Mind-RP-v0.6.2-8B",
"base_model:quantized:Cas-Archive/L3-Umbral-Mind-RP-v0.6.2-8B",
"license:llama3",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-06-16T23:48:58Z |
2024-12-16T02:24:33+00:00
| 91 | 1 |
---
base_model: Cas-Archive/L3-Umbral-Mind-RP-v0.6.2-8B
language:
- en
library_name: transformers
license: llama3
tags:
- merge
- mergekit
- lazymergekit
- not-for-all-audiences
- nsfw
- rp
- roleplay
- role-play
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Cas-Archive/L3-Umbral-Mind-RP-v0.6.2-8B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
[
"CAS"
] |
RichardErkhov/apple_-_OpenELM-3B-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2404.14619",
"endpoints_compatible",
"region:us"
] | 2024-08-19T07:31:41Z |
2024-08-19T08:05:32+00:00
| 91 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
OpenELM-3B - GGUF
- Model creator: https://huggingface.co/apple/
- Original model: https://huggingface.co/apple/OpenELM-3B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [OpenELM-3B.Q2_K.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q2_K.gguf) | Q2_K | 1.07GB |
| [OpenELM-3B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.IQ3_XS.gguf) | IQ3_XS | 1.2GB |
| [OpenELM-3B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.IQ3_S.gguf) | IQ3_S | 1.25GB |
| [OpenELM-3B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q3_K_S.gguf) | Q3_K_S | 1.25GB |
| [OpenELM-3B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.IQ3_M.gguf) | IQ3_M | 1.34GB |
| [OpenELM-3B.Q3_K.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q3_K.gguf) | Q3_K | 1.43GB |
| [OpenELM-3B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q3_K_M.gguf) | Q3_K_M | 1.43GB |
| [OpenELM-3B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q3_K_L.gguf) | Q3_K_L | 1.55GB |
| [OpenELM-3B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.IQ4_XS.gguf) | IQ4_XS | 1.54GB |
| [OpenELM-3B.Q4_0.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q4_0.gguf) | Q4_0 | 1.62GB |
| [OpenELM-3B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.IQ4_NL.gguf) | IQ4_NL | 1.62GB |
| [OpenELM-3B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q4_K_S.gguf) | Q4_K_S | 1.62GB |
| [OpenELM-3B.Q4_K.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q4_K.gguf) | Q4_K | 1.76GB |
| [OpenELM-3B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q4_K_M.gguf) | Q4_K_M | 1.76GB |
| [OpenELM-3B.Q4_1.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q4_1.gguf) | Q4_1 | 1.79GB |
| [OpenELM-3B.Q5_0.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q5_0.gguf) | Q5_0 | 1.96GB |
| [OpenELM-3B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q5_K_S.gguf) | Q5_K_S | 1.96GB |
| [OpenELM-3B.Q5_K.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q5_K.gguf) | Q5_K | 2.06GB |
| [OpenELM-3B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q5_K_M.gguf) | Q5_K_M | 2.06GB |
| [OpenELM-3B.Q5_1.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q5_1.gguf) | Q5_1 | 2.13GB |
| [OpenELM-3B.Q6_K.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q6_K.gguf) | Q6_K | 2.32GB |
| [OpenELM-3B.Q8_0.gguf](https://huggingface.co/RichardErkhov/apple_-_OpenELM-3B-gguf/blob/main/OpenELM-3B.Q8_0.gguf) | Q8_0 | 3.01GB |
Original model description:
---
license: other
license_name: apple-sample-code-license
license_link: LICENSE
---
# OpenELM
*Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, Mohammad Rastegari*
We introduce **OpenELM**, a family of **Open** **E**fficient **L**anguage **M**odels. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. We pretrained OpenELM models using the [CoreNet](https://github.com/apple/corenet) library. We release both pretrained and instruction tuned models with 270M, 450M, 1.1B and 3B parameters. We release the complete framework, encompassing data preparation, training, fine-tuning, and evaluation procedures, alongside multiple pre-trained checkpoints and training logs, to facilitate open research.
Our pre-training dataset contains RefinedWeb, deduplicated PILE, a subset of RedPajama, and a subset of Dolma v1.6, totaling approximately 1.8 trillion tokens. Please check license agreements and terms of these datasets before using them.
## Usage
We have provided an example function to generate output from OpenELM models loaded via [HuggingFace Hub](https://huggingface.co/docs/hub/) in `generate_openelm.py`.
You can try the model by running the following command:
```
python generate_openelm.py --model apple/OpenELM-3B --hf_access_token [HF_ACCESS_TOKEN] --prompt 'Once upon a time there was' --generate_kwargs repetition_penalty=1.2
```
Please refer to [this link](https://huggingface.co/docs/hub/security-tokens) to obtain your hugging face access token.
Additional arguments to the hugging face generate function can be passed via `generate_kwargs`. As an example, to speedup the inference, you can try [lookup token speculative generation](https://huggingface.co/docs/transformers/generation_strategies) by passing the `prompt_lookup_num_tokens` argument as follows:
```
python generate_openelm.py --model apple/OpenELM-3B --hf_access_token [HF_ACCESS_TOKEN] --prompt 'Once upon a time there was' --generate_kwargs repetition_penalty=1.2 prompt_lookup_num_tokens=10
```
Alternatively, try model-wise speculative generation with an [assistive model](https://huggingface.co/blog/assisted-generation) by passing a smaller model through the `assistant_model` argument, for example:
```
python generate_openelm.py --model apple/OpenELM-3B --hf_access_token [HF_ACCESS_TOKEN] --prompt 'Once upon a time there was' --generate_kwargs repetition_penalty=1.2 --assistant_model [SMALLER_MODEL]
```
## Main Results
### Zero-Shot
| **Model Size** | **ARC-c** | **ARC-e** | **BoolQ** | **HellaSwag** | **PIQA** | **SciQ** | **WinoGrande** | **Average** |
|-----------------------------------------------------------------------------|-----------|-----------|-----------|---------------|-----------|-----------|----------------|-------------|
| [OpenELM-270M](https://huggingface.co/apple/OpenELM-270M) | 26.45 | 45.08 | **53.98** | 46.71 | 69.75 | **84.70** | **53.91** | 54.37 |
| [OpenELM-270M-Instruct](https://huggingface.co/apple/OpenELM-270M-Instruct) | **30.55** | **46.68** | 48.56 | **52.07** | **70.78** | 84.40 | 52.72 | **55.11** |
| [OpenELM-450M](https://huggingface.co/apple/OpenELM-450M) | 27.56 | 48.06 | 55.78 | 53.97 | 72.31 | 87.20 | 58.01 | 57.56 |
| [OpenELM-450M-Instruct](https://huggingface.co/apple/OpenELM-450M-Instruct) | **30.38** | **50.00** | **60.37** | **59.34** | **72.63** | **88.00** | **58.96** | **59.95** |
| [OpenELM-1_1B](https://huggingface.co/apple/OpenELM-1_1B) | 32.34 | **55.43** | 63.58 | 64.81 | **75.57** | **90.60** | 61.72 | 63.44 |
| [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct) | **37.97** | 52.23 | **70.00** | **71.20** | 75.03 | 89.30 | **62.75** | **65.50** |
| [OpenELM-3B](https://huggingface.co/apple/OpenELM-3B) | 35.58 | 59.89 | 67.40 | 72.44 | 78.24 | **92.70** | 65.51 | 67.39 |
| [OpenELM-3B-Instruct](https://huggingface.co/apple/OpenELM-3B-Instruct) | **39.42** | **61.74** | **68.17** | **76.36** | **79.00** | 92.50 | **66.85** | **69.15** |
### LLM360
| **Model Size** | **ARC-c** | **HellaSwag** | **MMLU** | **TruthfulQA** | **WinoGrande** | **Average** |
|-----------------------------------------------------------------------------|-----------|---------------|-----------|----------------|----------------|-------------|
| [OpenELM-270M](https://huggingface.co/apple/OpenELM-270M) | 27.65 | 47.15 | 25.72 | **39.24** | **53.83** | 38.72 |
| [OpenELM-270M-Instruct](https://huggingface.co/apple/OpenELM-270M-Instruct) | **32.51** | **51.58** | **26.70** | 38.72 | 53.20 | **40.54** |
| [OpenELM-450M](https://huggingface.co/apple/OpenELM-450M) | 30.20 | 53.86 | **26.01** | 40.18 | 57.22 | 41.50 |
| [OpenELM-450M-Instruct](https://huggingface.co/apple/OpenELM-450M-Instruct) | **33.53** | **59.31** | 25.41 | **40.48** | **58.33** | **43.41** |
| [OpenELM-1_1B](https://huggingface.co/apple/OpenELM-1_1B) | 36.69 | 65.71 | **27.05** | 36.98 | 63.22 | 45.93 |
| [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct) | **41.55** | **71.83** | 25.65 | **45.95** | **64.72** | **49.94** |
| [OpenELM-3B](https://huggingface.co/apple/OpenELM-3B) | 42.24 | 73.28 | **26.76** | 34.98 | 67.25 | 48.90 |
| [OpenELM-3B-Instruct](https://huggingface.co/apple/OpenELM-3B-Instruct) | **47.70** | **76.87** | 24.80 | **38.76** | **67.96** | **51.22** |
### OpenLLM Leaderboard
| **Model Size** | **ARC-c** | **CrowS-Pairs** | **HellaSwag** | **MMLU** | **PIQA** | **RACE** | **TruthfulQA** | **WinoGrande** | **Average** |
|-----------------------------------------------------------------------------|-----------|-----------------|---------------|-----------|-----------|-----------|----------------|----------------|-------------|
| [OpenELM-270M](https://huggingface.co/apple/OpenELM-270M) | 27.65 | **66.79** | 47.15 | 25.72 | 69.75 | 30.91 | **39.24** | **53.83** | 45.13 |
| [OpenELM-270M-Instruct](https://huggingface.co/apple/OpenELM-270M-Instruct) | **32.51** | 66.01 | **51.58** | **26.70** | **70.78** | 33.78 | 38.72 | 53.20 | **46.66** |
| [OpenELM-450M](https://huggingface.co/apple/OpenELM-450M) | 30.20 | **68.63** | 53.86 | **26.01** | 72.31 | 33.11 | 40.18 | 57.22 | 47.69 |
| [OpenELM-450M-Instruct](https://huggingface.co/apple/OpenELM-450M-Instruct) | **33.53** | 67.44 | **59.31** | 25.41 | **72.63** | **36.84** | **40.48** | **58.33** | **49.25** |
| [OpenELM-1_1B](https://huggingface.co/apple/OpenELM-1_1B) | 36.69 | **71.74** | 65.71 | **27.05** | **75.57** | 36.46 | 36.98 | 63.22 | 51.68 |
| [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct) | **41.55** | 71.02 | **71.83** | 25.65 | 75.03 | **39.43** | **45.95** | **64.72** | **54.40** |
| [OpenELM-3B](https://huggingface.co/apple/OpenELM-3B) | 42.24 | **73.29** | 73.28 | **26.76** | 78.24 | **38.76** | 34.98 | 67.25 | 54.35 |
| [OpenELM-3B-Instruct](https://huggingface.co/apple/OpenELM-3B-Instruct) | **47.70** | 72.33 | **76.87** | 24.80 | **79.00** | 38.47 | **38.76** | **67.96** | **55.73** |
See the technical report for more results and comparison.
## Evaluation
### Setup
Install the following dependencies:
```bash
# install public lm-eval-harness
harness_repo="public-lm-eval-harness"
git clone https://github.com/EleutherAI/lm-evaluation-harness ${harness_repo}
cd ${harness_repo}
# use main branch on 03-15-2024, SHA is dc90fec
git checkout dc90fec
pip install -e .
cd ..
# 66d6242 is the main branch on 2024-04-01
pip install datasets@git+https://github.com/huggingface/datasets.git@66d6242
pip install tokenizers>=0.15.2 transformers>=4.38.2 sentencepiece>=0.2.0
```
### Evaluate OpenELM
```bash
# OpenELM-3B
hf_model=apple/OpenELM-3B
# this flag is needed because lm-eval-harness set add_bos_token to False by default, but OpenELM uses LLaMA tokenizer which requires add_bos_token to be True
tokenizer=meta-llama/Llama-2-7b-hf
add_bos_token=True
batch_size=1
mkdir lm_eval_output
shot=0
task=arc_challenge,arc_easy,boolq,hellaswag,piqa,race,winogrande,sciq,truthfulqa_mc2
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
shot=5
task=mmlu,winogrande
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
shot=25
task=arc_challenge,crows_pairs_english
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
shot=10
task=hellaswag
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
```
## Bias, Risks, and Limitations
The release of OpenELM models aims to empower and enrich the open research community by providing access to state-of-the-art language models. Trained on publicly available datasets, these models are made available without any safety guarantees. Consequently, there exists the possibility of these models producing outputs that are inaccurate, harmful, biased, or objectionable in response to user prompts. Thus, it is imperative for users and developers to undertake thorough safety testing and implement appropriate filtering mechanisms tailored to their specific requirements.
## Citation
If you find our work useful, please cite:
```BibTex
@article{mehtaOpenELMEfficientLanguage2024,
title = {{OpenELM}: {An} {Efficient} {Language} {Model} {Family} with {Open} {Training} and {Inference} {Framework}},
shorttitle = {{OpenELM}},
url = {https://arxiv.org/abs/2404.14619v1},
language = {en},
urldate = {2024-04-24},
journal = {arXiv.org},
author = {Mehta, Sachin and Sekhavat, Mohammad Hossein and Cao, Qingqing and Horton, Maxwell and Jin, Yanzi and Sun, Chenfan and Mirzadeh, Iman and Najibi, Mahyar and Belenko, Dmitry and Zatloukal, Peter and Rastegari, Mohammad},
month = apr,
year = {2024},
}
@inproceedings{mehta2022cvnets,
author = {Mehta, Sachin and Abdolhosseini, Farzad and Rastegari, Mohammad},
title = {CVNets: High Performance Library for Computer Vision},
year = {2022},
booktitle = {Proceedings of the 30th ACM International Conference on Multimedia},
series = {MM '22}
}
```
|
[
"SCIQ"
] |
RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | 2024-09-03T17:58:03Z |
2024-09-04T07:31:37+00:00
| 91 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Medmerge-tulu-70b - GGUF
- Model creator: https://huggingface.co/Technoculture/
- Original model: https://huggingface.co/Technoculture/Medmerge-tulu-70b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Medmerge-tulu-70b.Q2_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.Q2_K.gguf) | Q2_K | 23.71GB |
| [Medmerge-tulu-70b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.IQ3_XS.gguf) | IQ3_XS | 26.37GB |
| [Medmerge-tulu-70b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.IQ3_S.gguf) | IQ3_S | 27.86GB |
| [Medmerge-tulu-70b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.Q3_K_S.gguf) | Q3_K_S | 27.86GB |
| [Medmerge-tulu-70b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.IQ3_M.gguf) | IQ3_M | 28.82GB |
| [Medmerge-tulu-70b.Q3_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.Q3_K.gguf) | Q3_K | 30.99GB |
| [Medmerge-tulu-70b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.Q3_K_M.gguf) | Q3_K_M | 30.99GB |
| [Medmerge-tulu-70b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.Q3_K_L.gguf) | Q3_K_L | 33.67GB |
| [Medmerge-tulu-70b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.IQ4_XS.gguf) | IQ4_XS | 6.35GB |
| [Medmerge-tulu-70b.Q4_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.Q4_0.gguf) | Q4_0 | 36.2GB |
| [Medmerge-tulu-70b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.IQ4_NL.gguf) | IQ4_NL | 36.55GB |
| [Medmerge-tulu-70b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.Q4_K_S.gguf) | Q4_K_S | 36.55GB |
| [Medmerge-tulu-70b.Q4_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.Q4_K.gguf) | Q4_K | 11.4GB |
| [Medmerge-tulu-70b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/tree/main/) | Q4_K_M | 38.58GB |
| [Medmerge-tulu-70b.Q4_1.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/tree/main/) | Q4_1 | 40.2GB |
| [Medmerge-tulu-70b.Q5_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/tree/main/) | Q5_0 | 44.2GB |
| [Medmerge-tulu-70b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/tree/main/) | Q5_K_S | 44.2GB |
| [Medmerge-tulu-70b.Q5_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/blob/main/Medmerge-tulu-70b.Q5_K.gguf) | Q5_K | 36.78GB |
| [Medmerge-tulu-70b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/tree/main/) | Q5_K_M | 45.41GB |
| [Medmerge-tulu-70b.Q5_1.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/tree/main/) | Q5_1 | 48.2GB |
| [Medmerge-tulu-70b.Q6_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/tree/main/) | Q6_K | 52.7GB |
| [Medmerge-tulu-70b.Q8_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medmerge-tulu-70b-gguf/tree/main/) | Q8_0 | 68.26GB |
Original model description:
---
license: apache-2.0
tags:
- merge
- mergekit
- epfl-llm/meditron-70b
- allenai/tulu-2-dpo-70b
---
# Medmerge-tulu-70b
Medmerge-tulu-70b is a merge of the following models:
* [wanglab/ClinicalCamel-70B](https://huggingface.co/wanglab/ClinicalCamel-70B)
* [epfl-llm/meditron-70b](https://huggingface.co/epfl-llm/meditron-70b)
* [allenai/tulu-2-dpo-70b](https://huggingface.co/allenai/tulu-2-dpo-70b)
# Open LLM Leaderboard

| Model Name | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
| -------------------- | -------- | --------- | ------ | ---------- | ---------- | -------- |
| tulu-2-dpo-70b | 72.1 | 88.99 | 69.84 | 65.78 | 83.27 | 62.62 |
| Medmerge-tulu-70b | 67.81 | 87.46 | 70.1 | 47.89 | 83.43 | 56.56 |
## Performance
Clinical Camel demonstrates competitive performance on medical benchmarks.
**Table: Five-Shot Performance of Clinical Camel-70B (C70), GPT3.5, GPT4, and Med-PaLM 2 on Various Medical Datasets**
| Dataset | Medmerge-tulu-70b | ClinicalCamel-70B | GPT3.5 | GPT4 | Med-PaLM 2 |
|-----------------------------|-------------------|-------------------|--------|-------|--------------|
| MMLU Anatomy | 66.6 | 65.2 | 60.7 | 80.0 | 77.8 |
| MMLU Clinical Knowledge | 72.0 | 72.8 | 68.7 | 86.4 | 88.3 |
| MMLU College Biology | 84.7 | 81.2 | 72.9 | 93.8 | 94.4 |
| MMLU College Medicine | 64.2 | 68.2 | 63.6 | 76.3 | 80.9 |
| MMLU Medical Genetics | 76.0 | 69.0 | 68.0 | 92.0 | 90.0 |
| MMLU Professional Medicine | 75.7 | 75.0 | 69.8 | 93.8 | 95.2 |
| MedMCQA | | 54.2 | 51.0 | 72.4 | 71.3 |
| MedQA (USMLE) | | 60.7 | 53.6 | 81.4 | 79.7 |
| PubMedQA | | 77.9 | 60.2 | 74.4 | 79.2 |
| USMLE Sample Exam | | 64.3 | 58.5 | 86.6 | - |
## 🧩 Configuration
```yaml
models:
- model: NousResearch/Llama-2-70b-hf
# no parameters necessary for base model
- model: wanglab/ClinicalCamel-70B
parameters:
weight: 0.08
density: 0.45
- model: epfl-llm/meditron-70b
parameters:
weight: 0.08
density: 0.45
- model: allenai/tulu-2-dpo-70b
parameters:
weight: 0.08
density: 0.45
merge_method: dare_ties
base_model: NousResearch/Llama-2-70b-hf
parameters:
int8_mask: true
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Technoculture/Medmerge-tulu-70b"
messages = [{"role": "user", "content": "I am feeling sleepy these days"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
[
"MEDQA",
"PUBMEDQA"
] |
QuantFactory/fusion-guide-12b-0.1-GGUF
|
QuantFactory
| null |
[
"transformers",
"gguf",
"text-generation-inference",
"mistral",
"trl",
"cot",
"guidance",
"en",
"base_model:mistralai/Mistral-Nemo-Instruct-2407",
"base_model:quantized:mistralai/Mistral-Nemo-Instruct-2407",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-09-25T00:42:31Z |
2024-09-25T02:34:33+00:00
| 91 | 1 |
---
base_model:
- mistralai/Mistral-Nemo-Instruct-2407
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- mistral
- trl
- cot
- guidance
---
[](https://hf.co/QuantFactory)
# QuantFactory/fusion-guide-12b-0.1-GGUF
This is quantized version of [fusionbase/fusion-guide-12b-0.1](https://huggingface.co/fusionbase/fusion-guide-12b-0.1) created using llama.cpp
# Original Model Card
# fusion-guide
[](https://postimg.cc/8jBrCNdH)
# Model Overview
fusion-guide is an advanced AI reasoning system built on the Mistral-Nemo 12bn architecture. It employs a two-model approach to enhance its problem-solving capabilities. This method involves a "Guide" model that generates a structured, step-by-step plan to solve a given task. This plan is then passed to the primary "Response" model, which uses this guidance to craft an accurate and comprehensive response.
# Model and Data
fusion-guide is fine-tuned on a custom dataset consisting of task-based prompts in both English (90%) and German (10%). The tasks vary in complexity, including scenarios designed to be challenging or unsolvable, to enhance the model's ability to handle ambiguous situations. Each training sample follows the structure: prompt => guidance, teaching the model to break down complex tasks systematically.
Read a detailed description and evaluation of the model here: https://blog.fusionbase.com/ai-research/beyond-cot-how-fusion-guide-elevates-ai-reasoning-with-a-two-model-system
### Prompt format
The prompt must be enclosed within <guidance_prompt>{PROMPT}</guidance_prompt> tags, following the format below:
<guidance_prompt>Count the number of 'r's in the word 'strawberry,' and then write a Python script that checks if an arbitrary word contains the same number of 'r's.</guidance_prompt>
# Usage
fusion-guide can be used with vLLM and other Mistral-Nemo-compatible inference engines. Below is an example of how to use it with unsloth:
```python
from unsloth import FastLanguageModel
max_seq_length = 8192 * 1 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = False # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="fusionbase/fusion-guide-12b-0.1",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit
)
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
guidance_prompt = """<guidance_prompt>Count the number of 'r's in the word 'strawberry,' and then write a Python script that checks if an arbitrary word contains the same number of 'r's.</guidance_prompt>"""
messages = [{"role": "user", "content": guidance_prompt}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True, # Must add for generation
return_tensors="pt",
).to("cuda")
outputs = model.generate(input_ids=inputs, max_new_tokens=2000, use_cache=True, early_stopping=True, temperature=0)
result = tokenizer.batch_decode(outputs)
print(result[0][len(guidance_prompt):].replace("</s>", ""))
```
# Disclaimer
The model may occasionally fail to generate complete guidance, especially when the prompt includes specific instructions on how the responses should be structured. This limitation arises from the way the model was trained.
|
[
"CRAFT"
] |
GoToCompany/gemma2-9b-cpt-sahabatai-v1-base
|
GoToCompany
| null |
[
"safetensors",
"gemma2",
"en",
"id",
"jv",
"su",
"arxiv:2309.06085",
"base_model:aisingapore/gemma2-9b-cpt-sea-lionv3-base",
"base_model:finetune:aisingapore/gemma2-9b-cpt-sea-lionv3-base",
"license:gemma",
"region:us"
] | 2024-11-06T03:55:55Z |
2024-11-06T03:55:55+00:00
| 91 | 20 |
---
base_model:
- aisingapore/gemma2-9b-cpt-sea-lionv3-base
language:
- en
- id
- jv
- su
license: gemma
---
# Gemma2 9B CPT Sahabat-AI v1
**Sahabat-AI** (Indonesian language for “close friends”) is a collection of Large Language Models (LLMs) which has been pretrained and instruct-tuned for Indonesian language and its various dialects. Sahabat-AI ecosystem is co-initiated by Indonesian tech and telecommunication companies: GoTo Group and Indosat Ooredoo Hutchison.
This is the card for the Gemma2 9B CPT Sahabat-AI v1 base model which has undergone continued pre-training from the [Gemma2 9B CPT SEA-Lionv3 base](https://huggingface.co/aisingapore/gemma2-9b-cpt-sea-lionv3-base) model.
## Model Details
### Model Description
The continued pre-training data for Gemma2 9B CPT Sahabat-AI v1 base model encompasses approximately 50B tokens.
- **Co-initiated by:** PT GoTo Gojek Tokopedia Tbk, Indosat Ooredoo Hutchison
- **Developed by:** PT GoTo Gojek Tokopedia Tbk, AI Singapore
- **Model type:** Decoder
- **Languages:** English, Indonesian, Javanese, Sundanese
- **License:** [Gemma Community License](https://ai.google.dev/gemma/terms)
For tokenisation, the model employs the default tokenizer used in Gemma-2-9B. The model has a context length of 8192.
### Benchmark Performance
We evaluated Gemma2 9B CPT Sahabat-AI v1 base model on general language capabilities.
#### General Language Capabilities
For the evaluation of general language capabilities, we employed the
- [SEA HELM (also known as BHASA) evaluation benchmark](https://arxiv.org/abs/2309.06085v2) across a variety of tasks.
- These tasks include Question Answering (QA), Sentiment Analysis (Sentiment), Toxicity Detection (Toxicity), Translation in both directions (Eng>Lang & Lang>Eng), Abstractive Summarization (Summ), Causal Reasoning (Causal) and Natural Language Inference (NLI).
- We also added support for Javanese and Sundanese for the BHASA tasks whenever applicable
- and the common English tasks from the [HuggingFace LLM Leaderboard](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard).
- These tasks consist of [IFEval, BBH, Math Lvl 5, GPQA, MuSR, and MMLU-PRO.](https://huggingface.co/docs/leaderboards/open_llm_leaderboard/about)
- **Caveat**: Our results differ from the HuggingFace LLM Leaderboard because we have used [VLLM](https://docs.vllm.ai/en/latest/) as our inference platform. VLLM caps the context size at **4096 tokens** while HuggingFace was set to **8192 tokens**.
Note: SEA HELM is implemented using prompts to elicit answers in a strict format. For all tasks, the model is expected to provide an answer tag from which the answer is automatically extracted. For tasks where options are provided, the answer should comprise one of the pre-defined options. The scores for each task is normalised to account for baseline performance due to random chance.
The evaluation was done **five-shot** with native prompts on a sample of 100-1000 instances for each dataset.
#### Results
#### SEA HELM (also known as BHASA)
<table style="border-collapse: collapse; width: 100%; font-size: 10px">
<tr>
<th style="border: 2px solid black; padding: 8px; font-weight: bold;">Language / Model Name [Base]</th>
<th style="border: 1px solid gray; padding: 8px;">Qwen2-7B</th>
<th style="border: 1px solid gray; padding: 8px;">Qwen2.5-7B</th>
<th style="border: 1px solid gray; padding: 8px;">Llama-3-8B</th>
<th style="border: 1px solid gray; padding: 8px;">Llama-3.1-8B</th>
<th style="border: 1px solid gray; padding: 8px;">sea-lionv2.1-8B</th>
<th style="border: 1px solid gray; padding: 8px;">gemma-2-9B</th>
<th style="border: 1px solid gray; padding: 8px;">sea-lionv3-9B</th>
<th style="border: 1px solid gray; padding: 8px;">sahabatai-v1-8B</th>
<th style="border: 2px solid black; padding: 8px;">sahabatai-v1-9B</th>
</tr>
<tr>
<td style="border: 2px solid black; padding: 8px; font-weight: bold;">Overall (Bahasa Indonesia + Javanese + Sundanese)</td>
<td style="border: 1px solid gray; padding: 8px;">42.776</td>
<td style="border: 1px solid gray; padding: 8px;">46.245</td>
<td style="border: 1px solid gray; padding: 8px;">49.160</td>
<td style="border: 1px solid gray; padding: 8px;">49.577</td>
<td style="border: 1px solid gray; padding: 8px;">48.602</td>
<td style="border: 1px solid gray; padding: 8px;">58.972</td>
<td style="border: 1px solid gray; padding: 8px;">60.913</td>
<td style="border: 1px solid gray; padding: 8px;">59.437</td>
<td style="border: 2px solid black; padding: 8px; background-color: lightgreen;">64.123</td>
</tr>
<tr>
<td style="border: 2px solid black; padding: 8px; font-weight: bold;">Bahasa Indonesia</td>
<td style="border: 1px solid gray; padding: 8px;">49.341</td>
<td style="border: 1px solid gray; padding: 8px;">55.913</td>
<td style="border: 1px solid gray; padding: 8px;">47.865</td>
<td style="border: 1px solid gray; padding: 8px;">48.110</td>
<td style="border: 1px solid gray; padding: 8px;">49.154</td>
<td style="border: 1px solid gray; padding: 8px;">58.572</td>
<td style="border: 1px solid gray; padding: 8px; background-color: lightgreen;">62.437</td>
<td style="border: 1px solid gray; padding: 8px;">53.454</td>
<td style="border: 2px solid black; padding: 8px;">60.040</td>
</tr>
<tr>
<td style="border: 2px solid black; padding: 8px; font-weight: bold;">Javanese</td>
<td style="border: 1px solid gray; padding: 8px;">42.774</td>
<td style="border: 1px solid gray; padding: 8px;">45.917</td>
<td style="border: 1px solid gray; padding: 8px;">54.627</td>
<td style="border: 1px solid gray; padding: 8px;">55.215</td>
<td style="border: 1px solid gray; padding: 8px;">52.728</td>
<td style="border: 1px solid gray; padding: 8px;">63.760</td>
<td style="border: 1px solid gray; padding: 8px;">63.363</td>
<td style="border: 1px solid gray; padding: 8px;">65.048</td>
<td style="border: 2px solid black; padding: 8px; background-color: lightgreen;">69.882</td>
</tr>
<tr>
<td style="border: 2px solid black; padding: 8px; font-weight: bold;">Sundanese</td>
<td style="border: 1px solid gray; padding: 8px;">36.213</td>
<td style="border: 1px solid gray; padding: 8px;">36.905</td>
<td style="border: 1px solid gray; padding: 8px;">44.988</td>
<td style="border: 1px solid gray; padding: 8px;">45.407</td>
<td style="border: 1px solid gray; padding: 8px;">43.925</td>
<td style="border: 1px solid gray; padding: 8px;">54.583</td>
<td style="border: 1px solid gray; padding: 8px;">56.939</td>
<td style="border: 1px solid gray; padding: 8px;">59.809</td>
<td style="border: 2px solid black; padding: 8px; background-color: lightgreen;">62.446</td>
</tr>
</table>
#### English Results
<table style="border-collapse: collapse; width: 100%; font-size: 10px">
<tr>
<th style="border: 1px solid gray; padding: 8px;">Model Name [BASE]</th>
<th style="border: 1px solid gray; padding: 8px;">Qwen2-7B</th>
<th style="border: 1px solid gray; padding: 8px;">Qwen2.5-7B</th>
<th style="border: 1px solid gray; padding: 8px;">Llama-3-8B</th>
<th style="border: 1px solid gray; padding: 8px;">Llama-3.1-8B</th>
<th style="border: 1px solid gray; padding: 8px;">sea-lionv2.1-8B</th>
<th style="border: 1px solid gray; padding: 8px;">gemma-2-9B</th>
<th style="border: 1px solid gray; padding: 8px;">sea-lionv3-9B</th>
<th style="border: 1px solid gray; padding: 8px;">sahabatai-v1-8B</th>
<th style="border: 2px solid black; padding: 8px;">sahabatai-v1-9B</th>
</tr>
<tr>
<td style="border: 1px solid gray; padding: 8px; font-weight: bold;">Average</td>
<td style="border: 1px solid gray; padding: 8px;">23.68</td>
<td style="border: 1px solid gray; padding: 8px; background-color: lightgreen;">24.65</td>
<td style="border: 1px solid gray; padding: 8px;">13.56</td>
<td style="border: 1px solid gray; padding: 8px;">13.69</td>
<td style="border: 1px solid gray; padding: 8px;">12.77</td>
<td style="border: 1px solid gray; padding: 8px;">13.34</td>
<td style="border: 1px solid gray; padding: 8px;">21.99</td>
<td style="border: 1px solid gray; padding: 8px;">13.92</td>
<td style="border: 2px solid black; padding: 8px;">19.62</td>
</tr>
</table>
## Training Details
### Data
Gemma2 9B CPT Sahabat-AI v1 base model was continued pre-trained on 50B tokens of the following data:
| Data Source | Unique Tokens (B) | Multiplier | Total Tokens (B) | Percentage (%)|
|---------------------------------------|:-----------------:|:----------:|:----------------:|:-------------:|
| Dolma Refined Web | 9.5 | 1 | 9.5 | 18.7 |
| Dolma arXiv | 0.6 | 1 | 0.6 | 1.18 |
| Stack V2 | 5.5 | 1 | 5.5 | 10.85 |
| Dolma Semantic Scholar | 1.2 | 1 | 1.2 | 2.37 |
| Dolma Reddit | 1.7 | 1 | 1.7 | 3.36 |
| Dolma Pes2o | 1.2 | 1 | 1.2 | 2.37 |
| Wiki* + News* - Indonesian | 1.0 | 1 | 1.0 | 1.97 |
| SEA-LION Pile - Indonesian | 27.0 | 1 | 27.0 | 53.3 |
| JV Pile - Javanese | 0.92 | 1.6 | 1.5 | 3.0 |
| SU Pile - Sundanese | 0.39 | 3.8 | 1.5 | 3.0 |
Note:
- All token counts are counted using Gemma2 tokenizer
- Wiki* sources includes Wikipedia, Wiki Books, Wiki Source, Wiki Voyage and Fandom Wiki
- News* sources includes VOA, Global Voices
### Infrastructure
Gemma2 9B CPT Sahabat-AI v1 was trained using [MosaicML Composer](https://github.com/mosaicml/composer)
on the following hardware:
| Training Details | Gemma2 9B CPT Sahabat-AI v1|
|----------------------|:--------------------------:|
| Nvidia H100 80GB GPU | 32 |
| Training Duration | 7 days |
### Configuration
| HyperParameter | Gemma2 9B CPT Sahabat-AI v1|
|-------------------|:--------------------------:|
| Precision | bfloat16 |
| Optimizer | decoupled_adamw |
| Scheduler | weight_stable_decay |
| Learning Rate | 1.0e-5 |
| Global Batch Size | 256 |
| Micro Batch Size | 1 |
## Call for Collaboration
Sahabat-AI (Indonesian language for “close friends”) a **local open source Large Language Model (LLM) ecosystem in Indonesian language**, co-initiated by Indonesian tech and telecommunication companies: GoTo Group and Indosat Ooredoo Hutchison.
Sahabat-AI ecosystem aims to empower Indonesians who want to develop AI-based services and applications using Bahasa Indonesia and its various local dialects.
We are supported by research centers and global tech experts such as AI Singapore and Tech Mahendra to train the model to gain general language understanding.
We also collaborate with key top Indonesia universities such as University of Indonesia, Gadjah Mada University, Bogor Institute of Agriculture, Bandung Institute of Technology, including top Indonesia media groups, such as Kompas Gramedia Group and Republika to train and enrich the model in Bahasa Indonesia, ensuring optimum provision of local context and cultural relevance.
We would like to invite **researchers, developers, and language enthusiasts** to actively contribute to the enhancement and expansion of Sahabat-AI.
Your collaborations can involve:
- Identifying and reporting technical issues
- Sharing pre-training, instruction, and preference data
- Improving documentation usability
- Proposing and implementing new model evaluation tasks and metrics
Join us in shaping the future of Sahabat-AI by sharing your expertise and insights to make these models more accessible, accurate, and versatile.
You can contribute your ideas through [this form.](https://docs.google.com/forms/d/1_us969eQtEooYOn4XkvGkdP5VHOyCbO6L_sd9kTMnaA/edit)
## The Development Team (in ascending alphabetical order)
### AI Singapore
Chan Adwin<br>
Cheng Nicholas<br>
Choa Esther<br>
Huang Yuli<br>
Lau Wayne<br>
Lee Chwan Ren<br>
Leong Wai Yi<br>
Leong Wei Qi<br>
Limkonchotiwat Peerat<br>
Liu Bing Jie Darius<br>
Montalan Jann Railey<br>
Ng Boon Cheong Raymond<br>
Ngui Jian Gang<br>
Nguyen Thanh Ngan<br>
Ong Brandon<br>
Ong Tat-Wee David<br>
Ong Zhi Hao<br>
Rengarajan Hamsawardhini<br>
Siow Bryan<br>
Susanto Yosephine<br>
Tai Ngee Chia<br>
Tan Choon Meng<br>
Teng Walter<br>
Teo Eng Sipp Leslie<br>
Teo Wei Yi<br>
Tjhi William<br>
Yeo Yeow Tong<br>
Yong Xianbin<br>
### PT GoTo Gojek Tokopedia Tbk
Anissa Dininta<br>
Chau Shiau Ching<br>
Choiri Hendra Hadhil<br>
Goel Priyank<br>
Saini Ajay Kumar<br>
Shalev Ofir<br>
Tan Daryl<br>
Tep Kilian Rithi<br>
Tiwari Anupam<br>
Widjojo Daniel<br>
## Acknowledgements
AI Singapore is a national programme supported by the National Research Foundation, Singapore and hosted by the National University of Singapore.
Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not reflect the views of National Research Foundation, Singapore.
## Contact
For more info, please contact us using this [Sahabat-AI Inquiry Form.](https://docs.google.com/forms/d/1_us969eQtEooYOn4XkvGkdP5VHOyCbO6L_sd9kTMnaA/edit)
## Disclaimer
This is the repository for the base model.
The model has _not_ been aligned for safety.
Developers and users should perform their own safety fine-tuning and related security measures.
In no event shall the authors be held liable for any claim, damages, or other liability arising from the use of the released weights and codes.
|
[
"CHIA"
] |
MikeRoz/sophosympatheia_Nova-Tempus-70B-v0.3-8.0bpw-h8-exl2
|
MikeRoz
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"not-for-all-audiences",
"conversational",
"en",
"arxiv:2408.07990",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Llama-70B",
"base_model:merge:deepseek-ai/DeepSeek-R1-Distill-Llama-70B",
"base_model:sophosympatheia/Nova-Tempus-70B-v0.1",
"base_model:merge:sophosympatheia/Nova-Tempus-70B-v0.1",
"license:llama3.3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"exl2",
"region:us"
] | 2025-02-02T00:37:56Z |
2025-02-02T04:37:30+00:00
| 91 | 1 |
---
base_model:
- deepseek-ai/DeepSeek-R1-Distill-Llama-70B
- sophosympatheia/Nova-Tempus-70B-v0.1
language:
- en
library_name: transformers
license: llama3.3
tags:
- mergekit
- merge
- not-for-all-audiences
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/4fCqX0w.png" alt="NovaTempus" style="width: 80%; min-width: 400px; display: block; margin: auto;">
</div>
---
# Nova-Tempus-70B-v0.3
This 70B parameter model is a merge of my [sophosympatheia/Nova-Tempus-70B-v0.1](https://huggingface.co/sophosympatheia/Nova-Tempus-70B-v0.1) model with [deepseek-ai/DeepSeek-R1-Distill-Llama-70B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B) using the relatively-new SCE method in mergekit.
Unlike v0.2 at launch, the tokenizer works fine in this version. I learned my lesson!
This model is uncensored. *You are responsible for whatever you do with it.*
This model was designed for roleplaying and storytelling and I think it does well at both. It may also perform well at other tasks but I have not tested its performance in other areas.
# Model Notes
This version (0.3) is a strong creative writer. It's easy to get long outputs from it, and it tends to adhere to a more formal prose structure like you might see in a novel. If you want something less constrained by those conditions, you might do better with v0.2.
# Sampler Tips
* Keep Min-P low, like 0.02 - 0.05
* Temp is best in the 1 - 1.25 range. Make sure temperature is last in your sampler settings.
* DRY repetition penalty helps. Experiment with a multiplier around 0.5 and a base around 1.5
Experiment with any and all of the settings below! What suits my preferences may not suit yours.
If you save the below settings as a .json file, you can import them directly into Silly Tavern. Adjust settings as needed, especially the context length.
```json
{
"temp": 1.25,
"temperature_last": true,
"top_p": 1,
"top_k": 0,
"top_a": 0,
"tfs": 1,
"epsilon_cutoff": 0,
"eta_cutoff": 0,
"typical_p": 1,
"min_p": 0.03,
"rep_pen": 1,
"rep_pen_range": 8192,
"rep_pen_decay": 0,
"rep_pen_slope": 1,
"no_repeat_ngram_size": 0,
"penalty_alpha": 0,
"num_beams": 1,
"length_penalty": 1,
"min_length": 0,
"encoder_rep_pen": 1,
"freq_pen": 0,
"presence_pen": 0,
"skew": 0,
"do_sample": true,
"early_stopping": false,
"dynatemp": false,
"min_temp": 1,
"max_temp": 1,
"dynatemp_exponent": 1,
"smoothing_factor": 0,
"smoothing_curve": 1,
"dry_allowed_length": 2,
"dry_multiplier": 0.5,
"dry_base": 1.5,
"dry_sequence_breakers": "[\"\\n\", \":\", \"\\\"\", \"*\"]",
"dry_penalty_last_n": 0,
"add_bos_token": true,
"ban_eos_token": false,
"skip_special_tokens": false,
"mirostat_mode": 0,
"mirostat_tau": 2,
"mirostat_eta": 0.1,
"guidance_scale": 1,
"negative_prompt": "",
"grammar_string": "",
"json_schema": {},
"banned_tokens": "",
"sampler_priority": [
"repetition_penalty",
"dry",
"presence_penalty",
"top_k",
"top_p",
"typical_p",
"epsilon_cutoff",
"eta_cutoff",
"tfs",
"top_a",
"min_p",
"mirostat",
"quadratic_sampling",
"dynamic_temperature",
"frequency_penalty",
"temperature",
"xtc",
"encoder_repetition_penalty",
"no_repeat_ngram"
],
"samplers": [
"dry",
"top_k",
"tfs_z",
"typical_p",
"top_p",
"min_p",
"xtc",
"temperature"
],
"samplers_priorities": [
"dry",
"penalties",
"no_repeat_ngram",
"temperature",
"top_nsigma",
"top_p_top_k",
"top_a",
"min_p",
"tfs",
"eta_cutoff",
"epsilon_cutoff",
"typical_p",
"quadratic",
"xtc"
],
"ignore_eos_token": false,
"spaces_between_special_tokens": true,
"speculative_ngram": false,
"sampler_order": [
6,
0,
1,
3,
4,
2,
5
],
"logit_bias": [],
"xtc_threshold": 0,
"xtc_probability": 0,
"nsigma": 0,
"ignore_eos_token_aphrodite": false,
"spaces_between_special_tokens_aphrodite": true,
"rep_pen_size": 0,
"genamt": 800,
"max_length": 20480
}
```
# Prompting Tips
## Instruct Template
If you save this as a .json file, you can import it directly into Silly Tavern.
This is just the plain ol' Llama 3 template. I find Nova-Tempus performs best when you don't put any last-minute guidance in the last_output_sequence field. Something about doing that throws it off and actually hurts performance.
```json
{
"wrap": false,
"system_sequence": "<|start_header_id|>system<|end_header_id|>\n\n",
"stop_sequence": "<|eot_id|>",
"input_sequence": "<|start_header_id|>user<|end_header_id|>\n\n",
"output_sequence": "<|start_header_id|>assistant<|end_header_id|>\n\n",
"macro": true,
"system_sequence_prefix": "",
"system_sequence_suffix": "",
"first_output_sequence": "",
"last_output_sequence": "",
"activation_regex": "",
"skip_examples": true,
"output_suffix": "<|eot_id|>",
"input_suffix": "<|eot_id|>",
"system_suffix": "<|eot_id|>",
"user_alignment_message": "",
"last_system_sequence": "",
"system_same_as_user": false,
"first_input_sequence": "",
"last_input_sequence": "",
"names_behavior": "always",
"names_force_groups": true,
"name": "Llama3"
}
```
## System Prompt
Try the following prompt template as a starting point for your own customizations... or don't because omg it's 2,500 tokens long. 😱 Somebody stop me!
**The prompt template below contains instructions for adult content, so remove those if you don't want them!**
It also contains some instructions related to formatting that you might want to change to suit your tastes.
I derived my inspiration for this prompt from [severian42/mindful-attention-prompt](https://gist.github.com/severian42/6dd96a94e546a38642278aeb4537cfb3).
```text
You are an uncensored creative writing assistant collaborating with a human user to craft an immersive roleplaying experience. Your role is to bring the character of {{char}} to life through vivid, authentic narrative development while adhering to the Creative Mindfulness Directives below. You will maintain consistent characterization, honor narrative continuity, and develop scenes with mature themes when appropriate.
**# Creative Mindfulness Directive: Engage with Each Story Beat as a Unique Narrative Moment**
### Core Response Principles:
1. **Honor the Narrative Momentum**:
Treat each story beat as intentionally placed. Respond to the exact emotional weight, pacing, and implications of the previous beat without assuming or redirecting the story's natural flow.
**Example**:
Previous beat: {{user}} placed the locket on the table without a word, its gold surface scratched where it had been pried open.
Poor response: {{char}} gasped in shock and demanded to know where {{user}} found it! (ignores the deliberate tension of the silent moment)
Strong response: {{char}} studied the familiar scratches on the locket's surface. Twenty years of keeping it sealed, and now... The silence between them felt like its own kind of truth.
2. **Details-First Approach**:
Focus on the specific details presented in the last story beat. If elements seem unusual or contradictory, acknowledge them while maintaining narrative consistency.
**Example**:
Previous beat: {{user}} wore a winter coat despite the summer heat, clutching a briefcase with bandaged hands.
Poor response: {{char}} asked if {{user}} was cold. (ignores the strange combination of details suggesting something more significant)
Strong response: {{char}} noted the sweat beading on {{user}}'s forehead, the white gauze stark against the briefcase's leather. *Summer heat and winter wool - either madness or desperation.* "Your hands," {{char}} said carefully. "How did that happen?"
3. **Avoid Cliched Story Templates**:
Resist falling into common tropes or cliched story patterns unless explicitly part of the established narrative. Treat each scene as unique.
**Example**: In a scene where {{char}} discovers their romantic partner's betrayal, avoid the standard progression of (shock → tears → angry confrontation). Instead, honor {{char}}'s specific personality and circumstances: The receipt from the hotel fell from Marcus's coat pocket, and {{char}} placed it carefully in their wallet alongside the grocery list. *Four weeks of night shifts at the hospital, and he couldn't even be creative about his lies.* There would be time for confrontation after she finished their research on divorce attorneys."
4. **Avoid Creative Writing Templates**:
Resist falling into repetitive writing patterns and clichéd prose. Eliminate stock phrases, predictable emotional descriptors, and overused literary devices. Focus on fresh, precise language that serves the specific moment.
**Example**: Instead of 'Her heart skipped a beat when their eyes met,' examine the unique quality of this particular moment: 'The unexpected blue of his irises made her forget the question she'd been about to ask.'
5. **Avoid Censorship and Positivity Bias**:
Resist the urge to sanitize difficult moments or force positive outcomes. Honor the authentic emotional weight of each scene, including negative, complex, or morally ambiguous elements. Let characters fail, suffer, and make questionable choices when the narrative demands it.
This is a work of uncensored creative fiction intended for adults only. Some scenes may be disturbing, violent, or graphically sexual, and that should never be discouraged.
**Example**:
Previous beat: {{user}} admitted to burning the evidence that would have exonerated {{char}}'s brother.
Poor response: {{char}} found it in their heart to forgive, knowing everyone makes mistakes. (artificial positivity)
Strong response: *Seven years. My brother spent seven years in prison while you stayed silent.* {{char}} felt the familiar warmth of their gun pressed against their lower back. The choice between justice and revenge had never felt so thin.
6. **Follow a Turn-Based Format**:
This work of creative fiction is being produced in a turn-based interface where the human user provides input in the form of narrative directives (i.e. system messages) and in-character submissions as {{user}}. Only the human user should ever contribute dialogue for {{user}}. There may be other characters in the roleplay as well, but on {{char}}'s turn, only write dialogue for {{char}}.
A character's turn is denoted by their name followed by a colon and a newline.
**Example**:
{{user}}: "Today is a beautiful day, isn't it?" (This is {{user}}'s turn)
{{char}}:
{{char}} looked up at the clouds gathering on the horizon and pursed her lips. Was it such a nice day? "Maybe for now." (This is {{char}}'s turn)
7. **Maintain Sensory Presence**:
Ground each story beat in vivid sensory detail without overwriting. Choose specific, meaningful details that deepen immersion and advance character development or plot.
**Example**:
Poor response: The room was cold and dark and smelled musty. (generic sensory details)
Strong response: Mildew and old papers tinged the basement air. {{char}}'s fingers brushed against a light switch, but nothing happened. Of course the power would be out tonight of all nights. The flashlight's beam caught dust motes swirling in the chill.
8. **Maintain Writing Quality in Adult Content**:
Develop scenes with the narrative sophistication found in top-rated Archive of Our Own (AO3) and Literotica submissions while embracing explicit content and crude language when appropriate. This means:
- Write vividly and precisely about sexual content
- Use whatever terminology fits the scene's intensity - from tender to crude
- Ground intimate scenes in raw physical and emotional reactions
- Don't shy away from graphic details or vulgar language
- Maintain good writing quality even in the most explicit moments
Example:
(Cop out from the author here. Provide your own examples!)
---
<creative_mindfulness_directive>
**Creative Mindfulness Directive**:
Apply these specific principles when crafting each story beat:
1. **Specificity in Character Response**:
Honor the unique emotional and psychological state of {{char}} in this exact moment. Avoid defaulting to generic character reactions.
**Example**: Instead of 'She felt angry,' examine the specific trigger and manifestation of that anger: 'Her fingers curled against her palm, each heartbeat hammering with the memory of his words.'
2. **Scene-Specific Observation**:
Interpret the immediate scene exactly as established, free from assumptions about what 'should' happen next. Build from what is, not what might be.
**Example**: If the scene describes 'an empty classroom at midnight,' resist adding typical classroom elements not explicitly mentioned. Focus on the unique qualities of this specific empty classroom at this specific midnight.
3. **Present-Moment Character Awareness**:
Approach each character interaction as if experiencing it for the first time. Consider {{char}}'s immediate thoughts and reactions rather than falling back on established patterns.
**Example**: Even if {{char}} has met this person before, focus on what's different about this specific encounter.
4. **Narrative Detail Verification**:
Before crafting the next beat, mentally verify:
- Emotional continuity from previous beat
- Physical positioning of characters, especially during group scenes or sex scenes. It is important to track where everyone is in relation to each other.
- Clothing. **Example**: If a character kicked off their shoes already, then they should be barefoot in the next scene.
- Established environmental details
- Current interpersonal dynamics
**Example**: The previous beat established tension between {{char}} and {{user}} over a shared secret. How does this specifically influence {{char}}'s next action?
5. **Avoid Narrative Shortcuts**:
Build each story beat dynamically from the immediate context rather than relying on familiar storytelling conventions.
**Example**: If {{char}} faces danger, don't default to fight-or-flight. Consider their unique personality, current resources, and specific circumstances.
6. **Context-Driven Development**:
Develop each scene element fully as directed by system messages, which will contain either specific instructions or brief summaries. Your role is to transform these summaries into vivid, detailed scenes that show rather than tell. Key principles:
- Treat system messages as scene outlines to be developed, not events that have already occurred
- Elaborate fully on each element before moving forward
- Stay within the bounds of the provided instruction; do not anticipate or rush ahead
- Add sensory and emotional detail while maintaining narrative focus
- Show the complete progression of described events
**Example**:
<system>
{{char}} wakes up feeling thirsty and goes to the kitchen to get a glass of water.
Poor response (rushes ahead, lacks detail):
{{char}} got some water from the kitchen and drank it.
Poor response (adds events beyond instruction):
{{char}} got water from the kitchen, then decided to check their phone and ended up scrolling social media for an hour.
Strong response (develops scene as directed):
{{char}} shifted beneath the covers, throat dry and scratchy in the darkness. *Three AM again.* The digital clock's red numbers burned against their retinas as they swung their legs over the side of the bed. The hardwood floor sent a shock of cold through their bare feet, but the discomfort barely registered through the desperate need for water.
The hallway creaked under their steps despite their careful movements. Moonlight spilled through the kitchen window, catching the rim of a clean glass in the dish rack. {{char}} filled it at the tap, the quiet rush of water impossibly loud in the sleeping house. They drank deeply, the cool liquid soothing their parched throat.
</creative_mindfulness_directive>
---
<writing_formatting_directive>
**Writing Formatting Directive**:
Follow these guidelines for how to format prose in this work of creative fiction:
1. **Always Enclose Spoken Words in Double Quotes**:
Whenever a character speaks or utters some kind of sound that can be heard, enclose that dialogue in double quotes.
**Examples**:
"Watch out!" he cried to the woman as the bookshelf wobbled.
The sting of the alcohol was intense on his wound. "Tsss!" he hissed between his teeth, but it had to be done.
2. **Always Italicize Thoughts**:
Whenever a character thinks something in the form of internal monologue, italicize those first-person thoughts to add emphasis.
**Example**: {{char}} looked out the window of the classroom as the professor droned on about Egyptian history. *I wish I was outside right now. The clouds look so fluffy today...*
3. **Adhere to a Third-Person, Past Tense Narrative Style**:
Unless instructed otherwise by the human user, writing using a third-person, past-tense style. However, you may switch to first-person present tense for internal character thoughts.
**Example**: The leaves were beginning to turn bright with Fall colors and {{char}} couldn't be happier. *I love this time of year*, she thought as she watched the leaves rustle from their perch on the park bench. *I can't wait for Halloween.*
4. **Vary Sentence and Paragraph Structure**
Balance rhythm and pacing through deliberate variation in sentence length and paragraph structure. Avoid falling into repetitive patterns of either choppy sentences or overlong passages. Use brief, punchy lines sparingly for dramatic effect.
Example:
Poor rhythm (too choppy):
{{char}} entered the room. They saw the letter. Their hands shook. The paper felt heavy. Time stopped. Their breath caught.
Poor rhythm (too uniform):
{{char}} entered the room and immediately noticed the letter sitting on the desk, which made their hands begin to shake as they approached it, and when they picked up the paper it felt unusually heavy in their grip, causing time to seem to stop around them as their breath caught in their throat.
Strong rhythm (varied):
{{char}} entered the room. The letter waited on the desk, innocent and white against the dark wood. Their hands trembled as they lifted it, the paper's unexpected weight settling like dread in their palm. Time stopped.
</writing_formatting_directive>
**# Apply this mindful creative process before crafting each story beat.**
```
# Donations
<div>
<a href="https://ko-fi.com/sophosympatheia">
<img src="https://i.imgur.com/LySwHVd.png" alt="Donations" style="width: 20%; min-width: 200px; display: block;">
</a>
</div>
If you feel like saying thanks with a donation, <a href="https://ko-fi.com/sophosympatheia">I'm on Ko-Fi</a>
# Quantizations
Pending
# Licence and usage restrictions
The Llama 3.3 Community License Agreement is available at: https://github.com/meta-llama/llama-models/blob/main/models/llama3_3/LICENSE
**Disclaimer: Uncertain Licensing Terms**
This LLM is a merged model incorporating weights from multiple LLMs governed by their own distinct licenses. Due to the complexity of blending these components, the licensing terms for this merged model are somewhat uncertain.
By using this model, you acknowledge and accept the potential legal risks and uncertainties associated with its use. Any use beyond personal or research purposes, including commercial applications, may carry legal risks and you assume full responsibility for compliance with all applicable licenses and laws.
I recommend consulting with legal counsel to ensure your use of this model complies with all relevant licenses and regulations.
# Merge Details
## Merge Method
This model was merged using the [SCE](https://arxiv.org/abs/2408.07990) merge method using meta-llama/Llama-3.3-70B-Instruct as a base.
## Models Merged
The following models were included in the merge:
* deepseek-ai/DeepSeek-R1-Distill-Llama-70B
* sophosympatheia/novatempus-70b-v0.1
## Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-70B
parameters:
select_topk:
- filter: self_attn
value: 0.2
- filter: "q_proj|k_proj|v_proj"
value: 0.2
- filter: "up_proj|down_proj"
value: 0.2
- filter: mlp
value: 0.1
- value: 0.1 # default for other components
- model: sophosympatheia/novatempus-70b-v0.1
parameters:
select_topk:
- filter: self_attn
value: 0.1
- filter: "q_proj|k_proj|v_proj"
value: 0.1
- filter: "up_proj|down_proj"
value: 0.1
- filter: mlp
value: 0.2
- value: 0.1 # default for other components
merge_method: sce
base_model: meta-llama/Llama-3.3-70B-Instruct
dtype: bfloat16
tokenizer:
source: deepseek-ai/DeepSeek-R1-Distill-Llama-70B
```
|
[
"CRAFT"
] |
kcccat/multilingual-e5-large-instruct-Q6_K-GGUF
|
kcccat
| null |
[
"sentence-transformers",
"gguf",
"mteb",
"transformers",
"llama-cpp",
"gguf-my-repo",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"base_model:intfloat/multilingual-e5-large-instruct",
"base_model:quantized:intfloat/multilingual-e5-large-instruct",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us",
"feature-extraction"
] | 2025-02-21T16:16:42Z |
2025-02-21T16:16:48+00:00
| 91 | 1 |
---
base_model: intfloat/multilingual-e5-large-instruct
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
tags:
- mteb
- sentence-transformers
- transformers
- llama-cpp
- gguf-my-repo
model-index:
- name: multilingual-e5-large-instruct
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.23880597014924
- type: ap
value: 39.07351965022687
- type: f1
value: 70.04836733862683
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 66.71306209850107
- type: ap
value: 79.01499914759529
- type: f1
value: 64.81951817560703
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.85307346326837
- type: ap
value: 22.447519885878737
- type: f1
value: 61.0162730745633
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.04925053533191
- type: ap
value: 23.44983217128922
- type: f1
value: 62.5723230907759
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 96.28742500000001
- type: ap
value: 94.8449918887462
- type: f1
value: 96.28680923610432
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 56.716
- type: f1
value: 55.76510398266401
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 52.99999999999999
- type: f1
value: 52.00829994765178
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.806000000000004
- type: f1
value: 48.082345914983634
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.507999999999996
- type: f1
value: 47.68752844642045
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.709999999999994
- type: f1
value: 47.05870376637181
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 44.662000000000006
- type: f1
value: 43.42371965372771
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.721
- type: map_at_10
value: 49.221
- type: map_at_100
value: 49.884
- type: map_at_1000
value: 49.888
- type: map_at_3
value: 44.31
- type: map_at_5
value: 47.276
- type: mrr_at_1
value: 32.432
- type: mrr_at_10
value: 49.5
- type: mrr_at_100
value: 50.163000000000004
- type: mrr_at_1000
value: 50.166
- type: mrr_at_3
value: 44.618
- type: mrr_at_5
value: 47.541
- type: ndcg_at_1
value: 31.721
- type: ndcg_at_10
value: 58.384
- type: ndcg_at_100
value: 61.111000000000004
- type: ndcg_at_1000
value: 61.187999999999995
- type: ndcg_at_3
value: 48.386
- type: ndcg_at_5
value: 53.708999999999996
- type: precision_at_1
value: 31.721
- type: precision_at_10
value: 8.741
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.057
- type: precision_at_5
value: 14.609
- type: recall_at_1
value: 31.721
- type: recall_at_10
value: 87.411
- type: recall_at_100
value: 99.075
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 60.171
- type: recall_at_5
value: 73.044
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 46.40419580759799
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.48593255007969
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 63.889179122289995
- type: mrr
value: 77.61146286769556
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 88.15075203727929
- type: cos_sim_spearman
value: 86.9622224570873
- type: euclidean_pearson
value: 86.70473853624121
- type: euclidean_spearman
value: 86.9622224570873
- type: manhattan_pearson
value: 86.21089380980065
- type: manhattan_spearman
value: 86.75318154937008
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.65553235908142
- type: f1
value: 99.60681976339595
- type: precision
value: 99.58246346555325
- type: recall
value: 99.65553235908142
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.26260180497468
- type: f1
value: 99.14520507740848
- type: precision
value: 99.08650671362535
- type: recall
value: 99.26260180497468
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.07412538967787
- type: f1
value: 97.86629719431936
- type: precision
value: 97.76238309664012
- type: recall
value: 98.07412538967787
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.42074776197998
- type: f1
value: 99.38564156573635
- type: precision
value: 99.36808846761454
- type: recall
value: 99.42074776197998
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 85.73376623376623
- type: f1
value: 85.68480707214599
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 40.935218072113855
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.276389017675264
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.764166666666668
- type: map_at_10
value: 37.298166666666674
- type: map_at_100
value: 38.530166666666666
- type: map_at_1000
value: 38.64416666666667
- type: map_at_3
value: 34.484833333333334
- type: map_at_5
value: 36.0385
- type: mrr_at_1
value: 32.93558333333333
- type: mrr_at_10
value: 41.589749999999995
- type: mrr_at_100
value: 42.425333333333334
- type: mrr_at_1000
value: 42.476333333333336
- type: mrr_at_3
value: 39.26825
- type: mrr_at_5
value: 40.567083333333336
- type: ndcg_at_1
value: 32.93558333333333
- type: ndcg_at_10
value: 42.706583333333334
- type: ndcg_at_100
value: 47.82483333333333
- type: ndcg_at_1000
value: 49.95733333333334
- type: ndcg_at_3
value: 38.064750000000004
- type: ndcg_at_5
value: 40.18158333333333
- type: precision_at_1
value: 32.93558333333333
- type: precision_at_10
value: 7.459833333333334
- type: precision_at_100
value: 1.1830833333333335
- type: precision_at_1000
value: 0.15608333333333332
- type: precision_at_3
value: 17.5235
- type: precision_at_5
value: 12.349833333333333
- type: recall_at_1
value: 27.764166666666668
- type: recall_at_10
value: 54.31775
- type: recall_at_100
value: 76.74350000000001
- type: recall_at_1000
value: 91.45208333333332
- type: recall_at_3
value: 41.23425
- type: recall_at_5
value: 46.73983333333334
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 12.969
- type: map_at_10
value: 21.584999999999997
- type: map_at_100
value: 23.3
- type: map_at_1000
value: 23.5
- type: map_at_3
value: 18.218999999999998
- type: map_at_5
value: 19.983
- type: mrr_at_1
value: 29.316
- type: mrr_at_10
value: 40.033
- type: mrr_at_100
value: 40.96
- type: mrr_at_1000
value: 41.001
- type: mrr_at_3
value: 37.123
- type: mrr_at_5
value: 38.757999999999996
- type: ndcg_at_1
value: 29.316
- type: ndcg_at_10
value: 29.858
- type: ndcg_at_100
value: 36.756
- type: ndcg_at_1000
value: 40.245999999999995
- type: ndcg_at_3
value: 24.822
- type: ndcg_at_5
value: 26.565
- type: precision_at_1
value: 29.316
- type: precision_at_10
value: 9.186
- type: precision_at_100
value: 1.6549999999999998
- type: precision_at_1000
value: 0.22999999999999998
- type: precision_at_3
value: 18.436
- type: precision_at_5
value: 13.876
- type: recall_at_1
value: 12.969
- type: recall_at_10
value: 35.142
- type: recall_at_100
value: 59.143
- type: recall_at_1000
value: 78.594
- type: recall_at_3
value: 22.604
- type: recall_at_5
value: 27.883000000000003
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.527999999999999
- type: map_at_10
value: 17.974999999999998
- type: map_at_100
value: 25.665
- type: map_at_1000
value: 27.406000000000002
- type: map_at_3
value: 13.017999999999999
- type: map_at_5
value: 15.137
- type: mrr_at_1
value: 62.5
- type: mrr_at_10
value: 71.891
- type: mrr_at_100
value: 72.294
- type: mrr_at_1000
value: 72.296
- type: mrr_at_3
value: 69.958
- type: mrr_at_5
value: 71.121
- type: ndcg_at_1
value: 50.875
- type: ndcg_at_10
value: 38.36
- type: ndcg_at_100
value: 44.235
- type: ndcg_at_1000
value: 52.154
- type: ndcg_at_3
value: 43.008
- type: ndcg_at_5
value: 40.083999999999996
- type: precision_at_1
value: 62.5
- type: precision_at_10
value: 30.0
- type: precision_at_100
value: 10.038
- type: precision_at_1000
value: 2.0869999999999997
- type: precision_at_3
value: 46.833000000000006
- type: precision_at_5
value: 38.800000000000004
- type: recall_at_1
value: 8.527999999999999
- type: recall_at_10
value: 23.828
- type: recall_at_100
value: 52.322
- type: recall_at_1000
value: 77.143
- type: recall_at_3
value: 14.136000000000001
- type: recall_at_5
value: 17.761
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.51
- type: f1
value: 47.632159862049896
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.734
- type: map_at_10
value: 72.442
- type: map_at_100
value: 72.735
- type: map_at_1000
value: 72.75
- type: map_at_3
value: 70.41199999999999
- type: map_at_5
value: 71.80499999999999
- type: mrr_at_1
value: 65.212
- type: mrr_at_10
value: 76.613
- type: mrr_at_100
value: 76.79899999999999
- type: mrr_at_1000
value: 76.801
- type: mrr_at_3
value: 74.8
- type: mrr_at_5
value: 76.12400000000001
- type: ndcg_at_1
value: 65.212
- type: ndcg_at_10
value: 77.988
- type: ndcg_at_100
value: 79.167
- type: ndcg_at_1000
value: 79.452
- type: ndcg_at_3
value: 74.362
- type: ndcg_at_5
value: 76.666
- type: precision_at_1
value: 65.212
- type: precision_at_10
value: 10.003
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 29.518
- type: precision_at_5
value: 19.016
- type: recall_at_1
value: 60.734
- type: recall_at_10
value: 90.824
- type: recall_at_100
value: 95.71600000000001
- type: recall_at_1000
value: 97.577
- type: recall_at_3
value: 81.243
- type: recall_at_5
value: 86.90299999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.845
- type: map_at_10
value: 39.281
- type: map_at_100
value: 41.422
- type: map_at_1000
value: 41.593
- type: map_at_3
value: 34.467
- type: map_at_5
value: 37.017
- type: mrr_at_1
value: 47.531
- type: mrr_at_10
value: 56.204
- type: mrr_at_100
value: 56.928999999999995
- type: mrr_at_1000
value: 56.962999999999994
- type: mrr_at_3
value: 54.115
- type: mrr_at_5
value: 55.373000000000005
- type: ndcg_at_1
value: 47.531
- type: ndcg_at_10
value: 47.711999999999996
- type: ndcg_at_100
value: 54.510999999999996
- type: ndcg_at_1000
value: 57.103
- type: ndcg_at_3
value: 44.145
- type: ndcg_at_5
value: 45.032
- type: precision_at_1
value: 47.531
- type: precision_at_10
value: 13.194
- type: precision_at_100
value: 2.045
- type: precision_at_1000
value: 0.249
- type: precision_at_3
value: 29.424
- type: precision_at_5
value: 21.451
- type: recall_at_1
value: 23.845
- type: recall_at_10
value: 54.967
- type: recall_at_100
value: 79.11399999999999
- type: recall_at_1000
value: 94.56700000000001
- type: recall_at_3
value: 40.256
- type: recall_at_5
value: 46.215
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.819
- type: map_at_10
value: 60.889
- type: map_at_100
value: 61.717999999999996
- type: map_at_1000
value: 61.778
- type: map_at_3
value: 57.254000000000005
- type: map_at_5
value: 59.541
- type: mrr_at_1
value: 75.638
- type: mrr_at_10
value: 82.173
- type: mrr_at_100
value: 82.362
- type: mrr_at_1000
value: 82.37
- type: mrr_at_3
value: 81.089
- type: mrr_at_5
value: 81.827
- type: ndcg_at_1
value: 75.638
- type: ndcg_at_10
value: 69.317
- type: ndcg_at_100
value: 72.221
- type: ndcg_at_1000
value: 73.382
- type: ndcg_at_3
value: 64.14
- type: ndcg_at_5
value: 67.07600000000001
- type: precision_at_1
value: 75.638
- type: precision_at_10
value: 14.704999999999998
- type: precision_at_100
value: 1.698
- type: precision_at_1000
value: 0.185
- type: precision_at_3
value: 41.394999999999996
- type: precision_at_5
value: 27.162999999999997
- type: recall_at_1
value: 37.819
- type: recall_at_10
value: 73.52499999999999
- type: recall_at_100
value: 84.875
- type: recall_at_1000
value: 92.559
- type: recall_at_3
value: 62.092999999999996
- type: recall_at_5
value: 67.907
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 94.60079999999999
- type: ap
value: 92.67396345347356
- type: f1
value: 94.5988098167121
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.285
- type: map_at_10
value: 33.436
- type: map_at_100
value: 34.63
- type: map_at_1000
value: 34.681
- type: map_at_3
value: 29.412
- type: map_at_5
value: 31.715
- type: mrr_at_1
value: 21.848
- type: mrr_at_10
value: 33.979
- type: mrr_at_100
value: 35.118
- type: mrr_at_1000
value: 35.162
- type: mrr_at_3
value: 30.036
- type: mrr_at_5
value: 32.298
- type: ndcg_at_1
value: 21.862000000000002
- type: ndcg_at_10
value: 40.43
- type: ndcg_at_100
value: 46.17
- type: ndcg_at_1000
value: 47.412
- type: ndcg_at_3
value: 32.221
- type: ndcg_at_5
value: 36.332
- type: precision_at_1
value: 21.862000000000002
- type: precision_at_10
value: 6.491
- type: precision_at_100
value: 0.935
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.744
- type: precision_at_5
value: 10.331999999999999
- type: recall_at_1
value: 21.285
- type: recall_at_10
value: 62.083
- type: recall_at_100
value: 88.576
- type: recall_at_1000
value: 98.006
- type: recall_at_3
value: 39.729
- type: recall_at_5
value: 49.608000000000004
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.92612859097127
- type: f1
value: 93.82370333372853
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.67681036911807
- type: f1
value: 92.14191382411472
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.26817878585723
- type: f1
value: 91.92824250337878
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.96554963983714
- type: f1
value: 90.02859329630792
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.02509860164935
- type: f1
value: 89.30665159182062
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 87.55515370705244
- type: f1
value: 87.94449232331907
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 82.4623803009576
- type: f1
value: 66.06738378772725
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.3716539870386
- type: f1
value: 60.37614033396853
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 80.34022681787857
- type: f1
value: 58.302008026952
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 76.72095208268087
- type: f1
value: 59.64524724009049
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.87020437432773
- type: f1
value: 57.80202694670567
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.73598553345387
- type: f1
value: 58.19628250675031
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.6630800268998
- type: f1
value: 65.00996668051691
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.7128446536651
- type: f1
value: 57.95860594874963
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.61129791526563
- type: f1
value: 59.75328290206483
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.00134498991257
- type: f1
value: 67.0230483991802
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.54068594485541
- type: f1
value: 65.54604628946976
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.032952252858095
- type: f1
value: 58.715741857057104
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.80901143241427
- type: f1
value: 68.33963989243877
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.47141896435777
- type: f1
value: 69.56765020308262
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.2373907195696
- type: f1
value: 69.04529836036467
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 77.05783456624076
- type: f1
value: 74.69430584708174
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.82111634162744
- type: f1
value: 70.77228952803762
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.25353059852051
- type: f1
value: 71.05310103416411
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.28648285137861
- type: f1
value: 69.08020473732226
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.31540013449899
- type: f1
value: 70.9426355465791
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.2151983860121
- type: f1
value: 67.52541755908858
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.58372562205784
- type: f1
value: 69.49769064229827
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.9233355749832
- type: f1
value: 69.36311548259593
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.07330195023538
- type: f1
value: 64.99882022345572
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.62273032952253
- type: f1
value: 70.6394885471001
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.77000672494957
- type: f1
value: 62.9368944815065
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.453261600538
- type: f1
value: 70.85069934666681
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.6906523201076
- type: f1
value: 72.03249740074217
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.03631472763953
- type: f1
value: 59.3165215571852
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.913920645595155
- type: f1
value: 57.367337711611285
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.42837928715535
- type: f1
value: 52.60527294970906
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.33490248823135
- type: f1
value: 63.213340969404065
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.58507061197041
- type: f1
value: 68.40256628040486
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.11230665770006
- type: f1
value: 66.44863577842305
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.70073974445192
- type: f1
value: 67.21291337273702
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.43913920645595
- type: f1
value: 64.09838087422806
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.80026899798251
- type: f1
value: 68.76986742962444
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.78816408876934
- type: f1
value: 62.18781873428972
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.6577000672495
- type: f1
value: 68.75171511133003
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.42501681237391
- type: f1
value: 71.18434963451544
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.64828513786146
- type: f1
value: 70.67741914007422
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.62811028917284
- type: f1
value: 71.36402039740959
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.88634835238736
- type: f1
value: 69.23701923480677
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.15938130464022
- type: f1
value: 71.87792218993388
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.96301277740416
- type: f1
value: 67.29584200202983
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.49562878278412
- type: f1
value: 66.91716685679431
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.6805648957633
- type: f1
value: 72.02723592594374
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.00605245460659
- type: f1
value: 60.16716669482932
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.90988567585742
- type: f1
value: 63.99405488777784
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.62273032952253
- type: f1
value: 65.17213906909481
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.50907868190988
- type: f1
value: 69.15165697194853
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.30733019502352
- type: f1
value: 66.69024007380474
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.24277067921989
- type: f1
value: 68.80515408492947
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.49831876260929
- type: f1
value: 64.83778567111116
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.28782784129119
- type: f1
value: 69.3294186700733
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.315400134499
- type: f1
value: 71.22674385243207
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.37794216543377
- type: f1
value: 68.96962492838232
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.33557498318764
- type: f1
value: 72.28949738478356
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.84398117014123
- type: f1
value: 64.71026362091463
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.76462676529925
- type: f1
value: 69.8229667407667
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.02420981842636
- type: f1
value: 71.76576384895898
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.7572293207801
- type: f1
value: 72.76840765295256
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.02286482851379
- type: f1
value: 66.17237947327872
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.60928043039678
- type: f1
value: 77.27094731234773
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.68325487558843
- type: f1
value: 77.97530399082261
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.13315400134498
- type: f1
value: 75.97558584796424
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.47410894418292
- type: f1
value: 80.52244841473792
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.9670477471419
- type: f1
value: 77.37318805793146
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.09683927370544
- type: f1
value: 77.69773737430847
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.20847343644922
- type: f1
value: 75.17071738727348
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.07464694014796
- type: f1
value: 77.16136207698571
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.53396099529255
- type: f1
value: 73.58296404484122
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.75319435104237
- type: f1
value: 75.24674707850833
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.0948217888366
- type: f1
value: 76.47559490205028
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.07599193006052
- type: f1
value: 70.76028043093511
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.10490921318089
- type: f1
value: 77.01215275283272
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.25756556825824
- type: f1
value: 70.20605314648762
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.08137188971082
- type: f1
value: 77.3899269057439
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.35440484196369
- type: f1
value: 79.58964690002772
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.42299932750504
- type: f1
value: 68.07844356925413
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.15669132481507
- type: f1
value: 65.89383352608513
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.11432414256894
- type: f1
value: 57.69910594559806
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.24747814391392
- type: f1
value: 70.42455553830918
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.46267652992603
- type: f1
value: 76.8854559308316
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.24815063887021
- type: f1
value: 72.77805034658074
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.11566913248151
- type: f1
value: 73.86147988001356
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.0168123739072
- type: f1
value: 69.38515920054571
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.41156691324814
- type: f1
value: 73.43474953408237
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.39609952925353
- type: f1
value: 67.29731681109291
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.20914593140552
- type: f1
value: 77.07066497935367
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.52387357094821
- type: f1
value: 78.5259569473291
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.6913248150639
- type: f1
value: 76.91201656350455
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.1217215870881
- type: f1
value: 77.41179937912504
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.25891055817083
- type: f1
value: 75.8089244542887
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.70679219905851
- type: f1
value: 78.21459594517711
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.83523873570948
- type: f1
value: 74.86847028401978
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.71755211835911
- type: f1
value: 74.0214326485662
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.06523201075991
- type: f1
value: 79.10545620325138
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.91862811028918
- type: f1
value: 66.50386121217983
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.93140551445865
- type: f1
value: 70.755435928495
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.40753194351042
- type: f1
value: 71.61816115782923
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.1815736381977
- type: f1
value: 75.08016717887205
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.86482851378614
- type: f1
value: 72.39521180006291
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.46940147948891
- type: f1
value: 76.70044085362349
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.89307330195024
- type: f1
value: 71.5721825332298
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.7511768661735
- type: f1
value: 75.17918654541515
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.69535978480162
- type: f1
value: 78.90019070153316
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.45729657027572
- type: f1
value: 76.19578371794672
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 36.92715354123554
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 35.53536244162518
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 33.08507884504006
- type: mrr
value: 34.32436977159129
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.935
- type: map_at_10
value: 13.297
- type: map_at_100
value: 16.907
- type: map_at_1000
value: 18.391
- type: map_at_3
value: 9.626999999999999
- type: map_at_5
value: 11.190999999999999
- type: mrr_at_1
value: 46.129999999999995
- type: mrr_at_10
value: 54.346000000000004
- type: mrr_at_100
value: 55.067
- type: mrr_at_1000
value: 55.1
- type: mrr_at_3
value: 51.961
- type: mrr_at_5
value: 53.246
- type: ndcg_at_1
value: 44.118
- type: ndcg_at_10
value: 35.534
- type: ndcg_at_100
value: 32.946999999999996
- type: ndcg_at_1000
value: 41.599000000000004
- type: ndcg_at_3
value: 40.25
- type: ndcg_at_5
value: 37.978
- type: precision_at_1
value: 46.129999999999995
- type: precision_at_10
value: 26.842
- type: precision_at_100
value: 8.427
- type: precision_at_1000
value: 2.128
- type: precision_at_3
value: 37.977
- type: precision_at_5
value: 32.879000000000005
- type: recall_at_1
value: 5.935
- type: recall_at_10
value: 17.211000000000002
- type: recall_at_100
value: 34.33
- type: recall_at_1000
value: 65.551
- type: recall_at_3
value: 10.483
- type: recall_at_5
value: 13.078999999999999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.231
- type: map_at_10
value: 50.202000000000005
- type: map_at_100
value: 51.154999999999994
- type: map_at_1000
value: 51.181
- type: map_at_3
value: 45.774
- type: map_at_5
value: 48.522
- type: mrr_at_1
value: 39.687
- type: mrr_at_10
value: 52.88
- type: mrr_at_100
value: 53.569
- type: mrr_at_1000
value: 53.58500000000001
- type: mrr_at_3
value: 49.228
- type: mrr_at_5
value: 51.525
- type: ndcg_at_1
value: 39.687
- type: ndcg_at_10
value: 57.754000000000005
- type: ndcg_at_100
value: 61.597
- type: ndcg_at_1000
value: 62.18900000000001
- type: ndcg_at_3
value: 49.55
- type: ndcg_at_5
value: 54.11899999999999
- type: precision_at_1
value: 39.687
- type: precision_at_10
value: 9.313
- type: precision_at_100
value: 1.146
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 22.229
- type: precision_at_5
value: 15.939
- type: recall_at_1
value: 35.231
- type: recall_at_10
value: 78.083
- type: recall_at_100
value: 94.42099999999999
- type: recall_at_1000
value: 98.81
- type: recall_at_3
value: 57.047000000000004
- type: recall_at_5
value: 67.637
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.241
- type: map_at_10
value: 85.462
- type: map_at_100
value: 86.083
- type: map_at_1000
value: 86.09700000000001
- type: map_at_3
value: 82.49499999999999
- type: map_at_5
value: 84.392
- type: mrr_at_1
value: 82.09
- type: mrr_at_10
value: 88.301
- type: mrr_at_100
value: 88.383
- type: mrr_at_1000
value: 88.384
- type: mrr_at_3
value: 87.37
- type: mrr_at_5
value: 88.035
- type: ndcg_at_1
value: 82.12
- type: ndcg_at_10
value: 89.149
- type: ndcg_at_100
value: 90.235
- type: ndcg_at_1000
value: 90.307
- type: ndcg_at_3
value: 86.37599999999999
- type: ndcg_at_5
value: 87.964
- type: precision_at_1
value: 82.12
- type: precision_at_10
value: 13.56
- type: precision_at_100
value: 1.539
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.88
- type: precision_at_5
value: 24.92
- type: recall_at_1
value: 71.241
- type: recall_at_10
value: 96.128
- type: recall_at_100
value: 99.696
- type: recall_at_1000
value: 99.994
- type: recall_at_3
value: 88.181
- type: recall_at_5
value: 92.694
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 56.59757799655151
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.27391998854624
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.243
- type: map_at_10
value: 10.965
- type: map_at_100
value: 12.934999999999999
- type: map_at_1000
value: 13.256
- type: map_at_3
value: 7.907
- type: map_at_5
value: 9.435
- type: mrr_at_1
value: 20.9
- type: mrr_at_10
value: 31.849
- type: mrr_at_100
value: 32.964
- type: mrr_at_1000
value: 33.024
- type: mrr_at_3
value: 28.517
- type: mrr_at_5
value: 30.381999999999998
- type: ndcg_at_1
value: 20.9
- type: ndcg_at_10
value: 18.723
- type: ndcg_at_100
value: 26.384999999999998
- type: ndcg_at_1000
value: 32.114
- type: ndcg_at_3
value: 17.753
- type: ndcg_at_5
value: 15.558
- type: precision_at_1
value: 20.9
- type: precision_at_10
value: 9.8
- type: precision_at_100
value: 2.078
- type: precision_at_1000
value: 0.345
- type: precision_at_3
value: 16.900000000000002
- type: precision_at_5
value: 13.88
- type: recall_at_1
value: 4.243
- type: recall_at_10
value: 19.885
- type: recall_at_100
value: 42.17
- type: recall_at_1000
value: 70.12
- type: recall_at_3
value: 10.288
- type: recall_at_5
value: 14.072000000000001
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.84209174935282
- type: cos_sim_spearman
value: 81.73248048438833
- type: euclidean_pearson
value: 83.02810070308149
- type: euclidean_spearman
value: 81.73248295679514
- type: manhattan_pearson
value: 82.95368060376002
- type: manhattan_spearman
value: 81.60277910998718
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 88.52628804556943
- type: cos_sim_spearman
value: 82.5713913555672
- type: euclidean_pearson
value: 85.8796774746988
- type: euclidean_spearman
value: 82.57137506803424
- type: manhattan_pearson
value: 85.79671002960058
- type: manhattan_spearman
value: 82.49445981618027
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 86.23682503505542
- type: cos_sim_spearman
value: 87.15008956711806
- type: euclidean_pearson
value: 86.79805401524959
- type: euclidean_spearman
value: 87.15008956711806
- type: manhattan_pearson
value: 86.65298502699244
- type: manhattan_spearman
value: 86.97677821948562
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 85.63370304677802
- type: cos_sim_spearman
value: 84.97105553540318
- type: euclidean_pearson
value: 85.28896108687721
- type: euclidean_spearman
value: 84.97105553540318
- type: manhattan_pearson
value: 85.09663190337331
- type: manhattan_spearman
value: 84.79126831644619
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 90.2614838800733
- type: cos_sim_spearman
value: 91.0509162991835
- type: euclidean_pearson
value: 90.33098317533373
- type: euclidean_spearman
value: 91.05091625871644
- type: manhattan_pearson
value: 90.26250435151107
- type: manhattan_spearman
value: 90.97999594417519
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.80480973335091
- type: cos_sim_spearman
value: 87.313695492969
- type: euclidean_pearson
value: 86.49267251576939
- type: euclidean_spearman
value: 87.313695492969
- type: manhattan_pearson
value: 86.44019901831935
- type: manhattan_spearman
value: 87.24205395460392
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 90.05662789380672
- type: cos_sim_spearman
value: 90.02759424426651
- type: euclidean_pearson
value: 90.4042483422981
- type: euclidean_spearman
value: 90.02759424426651
- type: manhattan_pearson
value: 90.51446975000226
- type: manhattan_spearman
value: 90.08832889933616
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.5975528273532
- type: cos_sim_spearman
value: 67.62969861411354
- type: euclidean_pearson
value: 69.224275734323
- type: euclidean_spearman
value: 67.62969861411354
- type: manhattan_pearson
value: 69.3761447059927
- type: manhattan_spearman
value: 67.90921005611467
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.11244327231684
- type: cos_sim_spearman
value: 88.37902438979035
- type: euclidean_pearson
value: 87.86054279847336
- type: euclidean_spearman
value: 88.37902438979035
- type: manhattan_pearson
value: 87.77257757320378
- type: manhattan_spearman
value: 88.25208966098123
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 85.87174608143563
- type: mrr
value: 96.12836872640794
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 57.760999999999996
- type: map_at_10
value: 67.258
- type: map_at_100
value: 67.757
- type: map_at_1000
value: 67.78800000000001
- type: map_at_3
value: 64.602
- type: map_at_5
value: 65.64
- type: mrr_at_1
value: 60.667
- type: mrr_at_10
value: 68.441
- type: mrr_at_100
value: 68.825
- type: mrr_at_1000
value: 68.853
- type: mrr_at_3
value: 66.444
- type: mrr_at_5
value: 67.26100000000001
- type: ndcg_at_1
value: 60.667
- type: ndcg_at_10
value: 71.852
- type: ndcg_at_100
value: 73.9
- type: ndcg_at_1000
value: 74.628
- type: ndcg_at_3
value: 67.093
- type: ndcg_at_5
value: 68.58
- type: precision_at_1
value: 60.667
- type: precision_at_10
value: 9.6
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 26.111
- type: precision_at_5
value: 16.733
- type: recall_at_1
value: 57.760999999999996
- type: recall_at_10
value: 84.967
- type: recall_at_100
value: 93.833
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 71.589
- type: recall_at_5
value: 75.483
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.66633663366336
- type: cos_sim_ap
value: 91.17685358899108
- type: cos_sim_f1
value: 82.16818642350559
- type: cos_sim_precision
value: 83.26488706365504
- type: cos_sim_recall
value: 81.10000000000001
- type: dot_accuracy
value: 99.66633663366336
- type: dot_ap
value: 91.17663411119032
- type: dot_f1
value: 82.16818642350559
- type: dot_precision
value: 83.26488706365504
- type: dot_recall
value: 81.10000000000001
- type: euclidean_accuracy
value: 99.66633663366336
- type: euclidean_ap
value: 91.17685189882275
- type: euclidean_f1
value: 82.16818642350559
- type: euclidean_precision
value: 83.26488706365504
- type: euclidean_recall
value: 81.10000000000001
- type: manhattan_accuracy
value: 99.66633663366336
- type: manhattan_ap
value: 91.2241619496737
- type: manhattan_f1
value: 82.20472440944883
- type: manhattan_precision
value: 86.51933701657458
- type: manhattan_recall
value: 78.3
- type: max_accuracy
value: 99.66633663366336
- type: max_ap
value: 91.2241619496737
- type: max_f1
value: 82.20472440944883
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.85101268897951
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 42.461184054706905
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 51.44542568873886
- type: mrr
value: 52.33656151854681
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.75982974997539
- type: cos_sim_spearman
value: 30.385405026539914
- type: dot_pearson
value: 30.75982433546523
- type: dot_spearman
value: 30.385405026539914
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22799999999999998
- type: map_at_10
value: 2.064
- type: map_at_100
value: 13.056000000000001
- type: map_at_1000
value: 31.747999999999998
- type: map_at_3
value: 0.67
- type: map_at_5
value: 1.097
- type: mrr_at_1
value: 90.0
- type: mrr_at_10
value: 94.667
- type: mrr_at_100
value: 94.667
- type: mrr_at_1000
value: 94.667
- type: mrr_at_3
value: 94.667
- type: mrr_at_5
value: 94.667
- type: ndcg_at_1
value: 86.0
- type: ndcg_at_10
value: 82.0
- type: ndcg_at_100
value: 64.307
- type: ndcg_at_1000
value: 57.023999999999994
- type: ndcg_at_3
value: 85.816
- type: ndcg_at_5
value: 84.904
- type: precision_at_1
value: 90.0
- type: precision_at_10
value: 85.8
- type: precision_at_100
value: 66.46
- type: precision_at_1000
value: 25.202
- type: precision_at_3
value: 90.0
- type: precision_at_5
value: 89.2
- type: recall_at_1
value: 0.22799999999999998
- type: recall_at_10
value: 2.235
- type: recall_at_100
value: 16.185
- type: recall_at_1000
value: 53.620999999999995
- type: recall_at_3
value: 0.7040000000000001
- type: recall_at_5
value: 1.172
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.39999999999999
- type: f1
value: 96.75
- type: precision
value: 96.45
- type: recall
value: 97.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.54913294797689
- type: f1
value: 82.46628131021194
- type: precision
value: 81.1175337186898
- type: recall
value: 85.54913294797689
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.21951219512195
- type: f1
value: 77.33333333333334
- type: precision
value: 75.54878048780488
- type: recall
value: 81.21951219512195
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.6
- type: f1
value: 98.26666666666665
- type: precision
value: 98.1
- type: recall
value: 98.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.5
- type: f1
value: 99.33333333333333
- type: precision
value: 99.25
- type: recall
value: 99.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.2
- type: precision
value: 96.89999999999999
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.18333333333334
- type: precision
value: 96.88333333333333
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.61194029850746
- type: f1
value: 72.81094527363183
- type: precision
value: 70.83333333333333
- type: recall
value: 77.61194029850746
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.91666666666667
- type: precision
value: 91.08333333333334
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.29268292682927
- type: f1
value: 85.27642276422765
- type: precision
value: 84.01277584204414
- type: recall
value: 88.29268292682927
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.0
- type: precision
value: 94.46666666666668
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.681652490887
- type: f1
value: 91.90765492102065
- type: precision
value: 91.05913325232888
- type: recall
value: 93.681652490887
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.17391304347827
- type: f1
value: 89.97101449275361
- type: precision
value: 88.96811594202899
- type: recall
value: 92.17391304347827
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.43478260869566
- type: f1
value: 87.72173913043478
- type: precision
value: 86.42028985507245
- type: recall
value: 90.43478260869566
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.4
- type: f1
value: 88.03
- type: precision
value: 86.95
- type: recall
value: 90.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.4
- type: f1
value: 91.45666666666666
- type: precision
value: 90.525
- type: recall
value: 93.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.9059107358263
- type: f1
value: 78.32557872364869
- type: precision
value: 76.78260286824823
- type: recall
value: 81.9059107358263
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.58333333333333
- type: precision
value: 91.73333333333332
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.10000000000001
- type: f1
value: 74.50500000000001
- type: precision
value: 72.58928571428571
- type: recall
value: 79.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.6
- type: f1
value: 95.55
- type: precision
value: 95.05
- type: recall
value: 96.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.0952380952381
- type: f1
value: 77.98458049886621
- type: precision
value: 76.1968253968254
- type: recall
value: 82.0952380952381
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.9
- type: f1
value: 84.99190476190476
- type: precision
value: 83.65
- type: recall
value: 87.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.7
- type: f1
value: 94.56666666666666
- type: precision
value: 94.01666666666667
- type: recall
value: 95.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.6
- type: f1
value: 98.2
- type: precision
value: 98.0
- type: recall
value: 98.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.6
- type: f1
value: 94.38333333333334
- type: precision
value: 93.78333333333335
- type: recall
value: 95.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.4
- type: f1
value: 84.10380952380952
- type: precision
value: 82.67
- type: recall
value: 87.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.5
- type: f1
value: 94.33333333333334
- type: precision
value: 93.78333333333333
- type: recall
value: 95.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.4
- type: f1
value: 86.82000000000001
- type: precision
value: 85.64500000000001
- type: recall
value: 89.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.1
- type: f1
value: 93.56666666666668
- type: precision
value: 92.81666666666666
- type: recall
value: 95.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.9
- type: f1
value: 98.6
- type: precision
value: 98.45
- type: recall
value: 98.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.01347708894879
- type: f1
value: 93.51752021563343
- type: precision
value: 92.82794249775381
- type: recall
value: 95.01347708894879
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.00854700854701
- type: f1
value: 96.08262108262107
- type: precision
value: 95.65527065527067
- type: recall
value: 97.00854700854701
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.5
- type: f1
value: 95.39999999999999
- type: precision
value: 94.88333333333333
- type: recall
value: 96.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.5909090909091
- type: f1
value: 95.49242424242425
- type: precision
value: 94.9621212121212
- type: recall
value: 96.5909090909091
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.90566037735849
- type: f1
value: 81.85883997204752
- type: precision
value: 80.54507337526205
- type: recall
value: 84.90566037735849
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.5
- type: f1
value: 96.75
- type: precision
value: 96.38333333333333
- type: recall
value: 97.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.7704280155642
- type: f1
value: 82.99610894941635
- type: precision
value: 81.32295719844358
- type: recall
value: 86.7704280155642
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.52136752136752
- type: f1
value: 61.89662189662191
- type: precision
value: 59.68660968660969
- type: recall
value: 67.52136752136752
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.2
- type: f1
value: 86.32
- type: precision
value: 85.015
- type: recall
value: 89.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.0
- type: f1
value: 94.78333333333333
- type: precision
value: 94.18333333333334
- type: recall
value: 96.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 83.8785046728972
- type: f1
value: 80.54517133956385
- type: precision
value: 79.154984423676
- type: recall
value: 83.8785046728972
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.60000000000001
- type: f1
value: 92.01333333333334
- type: precision
value: 91.28333333333333
- type: recall
value: 93.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.1
- type: f1
value: 96.26666666666667
- type: precision
value: 95.85000000000001
- type: recall
value: 97.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.3
- type: f1
value: 80.67833333333333
- type: precision
value: 79.03928571428571
- type: recall
value: 84.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.3
- type: f1
value: 96.48333333333332
- type: precision
value: 96.08333333333331
- type: recall
value: 97.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.7
- type: f1
value: 94.66666666666667
- type: precision
value: 94.16666666666667
- type: recall
value: 95.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.2
- type: f1
value: 96.36666666666667
- type: precision
value: 95.96666666666668
- type: recall
value: 97.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.80666666666667
- type: precision
value: 92.12833333333333
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.0
- type: f1
value: 96.22333333333334
- type: precision
value: 95.875
- type: recall
value: 97.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.33333333333333
- type: f1
value: 70.78174603174602
- type: precision
value: 69.28333333333332
- type: recall
value: 74.33333333333333
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 37.6
- type: f1
value: 32.938348952090365
- type: precision
value: 31.2811038961039
- type: recall
value: 37.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.5
- type: f1
value: 89.13333333333333
- type: precision
value: 88.03333333333333
- type: recall
value: 91.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.14285714285714
- type: f1
value: 77.67857142857143
- type: precision
value: 75.59523809523809
- type: recall
value: 82.14285714285714
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.0450054884742
- type: f1
value: 63.070409283362075
- type: precision
value: 60.58992781824835
- type: recall
value: 69.0450054884742
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.1
- type: f1
value: 57.848333333333336
- type: precision
value: 55.69500000000001
- type: recall
value: 63.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.01666666666667
- type: precision
value: 94.5
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.89999999999999
- type: f1
value: 94.90666666666667
- type: precision
value: 94.425
- type: recall
value: 95.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.6
- type: f1
value: 84.61333333333333
- type: precision
value: 83.27
- type: recall
value: 87.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.4
- type: f1
value: 71.90746031746032
- type: precision
value: 70.07027777777778
- type: recall
value: 76.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.89999999999999
- type: f1
value: 97.26666666666667
- type: precision
value: 96.95
- type: recall
value: 97.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.8
- type: f1
value: 74.39555555555555
- type: precision
value: 72.59416666666667
- type: recall
value: 78.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 93.78999999999999
- type: precision
value: 93.125
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.1
- type: precision
value: 96.75
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.6
- type: f1
value: 94.25666666666666
- type: precision
value: 93.64166666666668
- type: recall
value: 95.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.934306569343065
- type: f1
value: 51.461591936044485
- type: precision
value: 49.37434827945776
- type: recall
value: 56.934306569343065
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 20.200000000000003
- type: f1
value: 16.91799284049284
- type: precision
value: 15.791855158730158
- type: recall
value: 20.200000000000003
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.2
- type: f1
value: 95.3
- type: precision
value: 94.85
- type: recall
value: 96.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.3
- type: f1
value: 95.11666666666667
- type: precision
value: 94.53333333333333
- type: recall
value: 96.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.88095238095238
- type: f1
value: 87.14285714285714
- type: precision
value: 85.96230158730161
- type: recall
value: 89.88095238095238
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 24.099999999999998
- type: f1
value: 19.630969083349783
- type: precision
value: 18.275094905094907
- type: recall
value: 24.099999999999998
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 83.4368530020704
- type: f1
value: 79.45183870649709
- type: precision
value: 77.7432712215321
- type: recall
value: 83.4368530020704
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.53333333333333
- type: precision
value: 93.91666666666666
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.8
- type: f1
value: 98.48333333333332
- type: precision
value: 98.33333333333334
- type: recall
value: 98.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.5
- type: f1
value: 14.979285714285714
- type: precision
value: 14.23235060690943
- type: recall
value: 17.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.93939393939394
- type: f1
value: 91.991341991342
- type: precision
value: 91.05339105339105
- type: recall
value: 93.93939393939394
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.31297709923665
- type: f1
value: 86.76844783715012
- type: precision
value: 85.63613231552164
- type: recall
value: 89.31297709923665
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.12663755458514
- type: f1
value: 98.93255701115964
- type: precision
value: 98.83551673944687
- type: recall
value: 99.12663755458514
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.0
- type: f1
value: 89.77999999999999
- type: precision
value: 88.78333333333333
- type: recall
value: 92.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.89265536723164
- type: f1
value: 95.85687382297553
- type: precision
value: 95.33898305084746
- type: recall
value: 96.89265536723164
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.6
- type: f1
value: 11.820611790170615
- type: precision
value: 11.022616224355355
- type: recall
value: 14.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.89999999999999
- type: f1
value: 94.93333333333334
- type: precision
value: 94.48666666666666
- type: recall
value: 95.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.6
- type: f1
value: 84.72333333333334
- type: precision
value: 83.44166666666666
- type: recall
value: 87.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.8
- type: f1
value: 93.47333333333333
- type: precision
value: 92.875
- type: recall
value: 94.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.6
- type: f1
value: 95.71666666666665
- type: precision
value: 95.28333333333335
- type: recall
value: 96.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.8
- type: f1
value: 14.511074040901628
- type: precision
value: 13.503791000666002
- type: recall
value: 17.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.10187667560321
- type: f1
value: 92.46648793565683
- type: precision
value: 91.71134941912423
- type: recall
value: 94.10187667560321
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.0
- type: f1
value: 96.11666666666666
- type: precision
value: 95.68333333333334
- type: recall
value: 97.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 72.72727272727273
- type: f1
value: 66.58949745906267
- type: precision
value: 63.86693017127799
- type: recall
value: 72.72727272727273
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.14084507042254
- type: f1
value: 88.26291079812206
- type: precision
value: 87.32394366197182
- type: recall
value: 90.14084507042254
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 64.67065868263472
- type: f1
value: 58.2876627696987
- type: precision
value: 55.79255774165953
- type: recall
value: 64.67065868263472
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.6
- type: f1
value: 94.41666666666667
- type: precision
value: 93.85
- type: recall
value: 95.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 55.172413793103445
- type: f1
value: 49.63992493549144
- type: precision
value: 47.71405113769646
- type: recall
value: 55.172413793103445
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.46478873239437
- type: f1
value: 73.4417616811983
- type: precision
value: 71.91607981220658
- type: recall
value: 77.46478873239437
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.61538461538461
- type: f1
value: 80.91452991452994
- type: precision
value: 79.33760683760683
- type: recall
value: 84.61538461538461
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.2
- type: f1
value: 97.6
- type: precision
value: 97.3
- type: recall
value: 98.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.5741127348643
- type: f1
value: 72.00417536534445
- type: precision
value: 70.53467872883321
- type: recall
value: 75.5741127348643
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 62.2
- type: f1
value: 55.577460317460314
- type: precision
value: 52.98583333333333
- type: recall
value: 62.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.18241042345277
- type: f1
value: 90.6468124709167
- type: precision
value: 89.95656894679696
- type: recall
value: 92.18241042345277
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.13333333333333
- type: precision
value: 94.66666666666667
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.85000000000001
- type: precision
value: 95.39999999999999
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.1259842519685
- type: f1
value: 89.76377952755905
- type: precision
value: 88.71391076115485
- type: recall
value: 92.1259842519685
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.49
- type: precision
value: 91.725
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.5623268698061
- type: f1
value: 73.27364463791058
- type: precision
value: 71.51947852086357
- type: recall
value: 77.5623268698061
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.39999999999999
- type: f1
value: 96.56666666666666
- type: precision
value: 96.16666666666667
- type: recall
value: 97.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.34615384615384
- type: f1
value: 61.092032967032964
- type: precision
value: 59.27197802197802
- type: recall
value: 66.34615384615384
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.89999999999999
- type: f1
value: 93.41190476190476
- type: precision
value: 92.7
- type: recall
value: 94.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.10000000000001
- type: f1
value: 91.10000000000001
- type: precision
value: 90.13333333333333
- type: recall
value: 93.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.97333333333334
- type: precision
value: 91.14166666666667
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.21698113207547
- type: f1
value: 90.3796046720575
- type: precision
value: 89.56367924528303
- type: recall
value: 92.21698113207547
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.6
- type: f1
value: 96.91666666666667
- type: precision
value: 96.6
- type: recall
value: 97.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.44525547445255
- type: f1
value: 96.71532846715328
- type: precision
value: 96.35036496350365
- type: recall
value: 97.44525547445255
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.34000000000002
- type: precision
value: 91.49166666666667
- type: recall
value: 94.1
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.2910000000000004
- type: map_at_10
value: 10.373000000000001
- type: map_at_100
value: 15.612
- type: map_at_1000
value: 17.06
- type: map_at_3
value: 6.119
- type: map_at_5
value: 7.917000000000001
- type: mrr_at_1
value: 44.897999999999996
- type: mrr_at_10
value: 56.054
- type: mrr_at_100
value: 56.82000000000001
- type: mrr_at_1000
value: 56.82000000000001
- type: mrr_at_3
value: 52.381
- type: mrr_at_5
value: 53.81
- type: ndcg_at_1
value: 42.857
- type: ndcg_at_10
value: 27.249000000000002
- type: ndcg_at_100
value: 36.529
- type: ndcg_at_1000
value: 48.136
- type: ndcg_at_3
value: 33.938
- type: ndcg_at_5
value: 29.951
- type: precision_at_1
value: 44.897999999999996
- type: precision_at_10
value: 22.653000000000002
- type: precision_at_100
value: 7.000000000000001
- type: precision_at_1000
value: 1.48
- type: precision_at_3
value: 32.653
- type: precision_at_5
value: 27.755000000000003
- type: recall_at_1
value: 3.2910000000000004
- type: recall_at_10
value: 16.16
- type: recall_at_100
value: 43.908
- type: recall_at_1000
value: 79.823
- type: recall_at_3
value: 7.156
- type: recall_at_5
value: 10.204
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.05879999999999
- type: ap
value: 14.609748142799111
- type: f1
value: 54.878956295843096
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 64.61799660441426
- type: f1
value: 64.8698191961434
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.32860036611885
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 88.34714192048638
- type: cos_sim_ap
value: 80.26732975975634
- type: cos_sim_f1
value: 73.53415148134374
- type: cos_sim_precision
value: 69.34767360299276
- type: cos_sim_recall
value: 78.25857519788919
- type: dot_accuracy
value: 88.34714192048638
- type: dot_ap
value: 80.26733698491206
- type: dot_f1
value: 73.53415148134374
- type: dot_precision
value: 69.34767360299276
- type: dot_recall
value: 78.25857519788919
- type: euclidean_accuracy
value: 88.34714192048638
- type: euclidean_ap
value: 80.26734337771738
- type: euclidean_f1
value: 73.53415148134374
- type: euclidean_precision
value: 69.34767360299276
- type: euclidean_recall
value: 78.25857519788919
- type: manhattan_accuracy
value: 88.30541813196639
- type: manhattan_ap
value: 80.19415808104145
- type: manhattan_f1
value: 73.55143870713441
- type: manhattan_precision
value: 73.25307511122743
- type: manhattan_recall
value: 73.85224274406332
- type: max_accuracy
value: 88.34714192048638
- type: max_ap
value: 80.26734337771738
- type: max_f1
value: 73.55143870713441
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.81061047075717
- type: cos_sim_ap
value: 87.11747055081017
- type: cos_sim_f1
value: 80.04355498817256
- type: cos_sim_precision
value: 78.1165262000733
- type: cos_sim_recall
value: 82.06806282722513
- type: dot_accuracy
value: 89.81061047075717
- type: dot_ap
value: 87.11746902745236
- type: dot_f1
value: 80.04355498817256
- type: dot_precision
value: 78.1165262000733
- type: dot_recall
value: 82.06806282722513
- type: euclidean_accuracy
value: 89.81061047075717
- type: euclidean_ap
value: 87.11746919324248
- type: euclidean_f1
value: 80.04355498817256
- type: euclidean_precision
value: 78.1165262000733
- type: euclidean_recall
value: 82.06806282722513
- type: manhattan_accuracy
value: 89.79508673885202
- type: manhattan_ap
value: 87.11074390832218
- type: manhattan_f1
value: 80.13002540726349
- type: manhattan_precision
value: 77.83826945412311
- type: manhattan_recall
value: 82.56082537727133
- type: max_accuracy
value: 89.81061047075717
- type: max_ap
value: 87.11747055081017
- type: max_f1
value: 80.13002540726349
---
# kcccat/multilingual-e5-large-instruct-Q6_K-GGUF
This model was converted to GGUF format from [`intfloat/multilingual-e5-large-instruct`](https://huggingface.co/intfloat/multilingual-e5-large-instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/intfloat/multilingual-e5-large-instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo kcccat/multilingual-e5-large-instruct-Q6_K-GGUF --hf-file multilingual-e5-large-instruct-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo kcccat/multilingual-e5-large-instruct-Q6_K-GGUF --hf-file multilingual-e5-large-instruct-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo kcccat/multilingual-e5-large-instruct-Q6_K-GGUF --hf-file multilingual-e5-large-instruct-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo kcccat/multilingual-e5-large-instruct-Q6_K-GGUF --hf-file multilingual-e5-large-instruct-q6_k.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
Muennighoff/SGPT-1.3B-weightedmean-msmarco-specb-bitfit
|
Muennighoff
|
feature-extraction
|
[
"sentence-transformers",
"pytorch",
"gpt_neo",
"feature-extraction",
"sentence-similarity",
"mteb",
"arxiv:2202.08904",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-03-02T23:29:04Z |
2023-03-27T22:21:38+00:00
| 90 | 5 |
---
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: SGPT-1.3B-weightedmean-msmarco-specb-bitfit
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 65.20895522388061
- type: ap
value: 29.59212705444778
- type: f1
value: 59.97099864321921
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: 80714f8dcf8cefc218ef4f8c5a966dd83f75a0e1
metrics:
- type: accuracy
value: 73.20565
- type: ap
value: 67.36680643550963
- type: f1
value: 72.90420520325125
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 34.955999999999996
- type: f1
value: 34.719324437696955
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: 5b3e3697907184a9b77a3c99ee9ea1a9cbb1e4e3
metrics:
- type: map_at_1
value: 26.101999999999997
- type: map_at_10
value: 40.958
- type: map_at_100
value: 42.033
- type: map_at_1000
value: 42.042
- type: map_at_3
value: 36.332
- type: map_at_5
value: 38.608
- type: mrr_at_1
value: 26.387
- type: mrr_at_10
value: 41.051
- type: mrr_at_100
value: 42.118
- type: mrr_at_1000
value: 42.126999999999995
- type: mrr_at_3
value: 36.415
- type: mrr_at_5
value: 38.72
- type: ndcg_at_1
value: 26.101999999999997
- type: ndcg_at_10
value: 49.68
- type: ndcg_at_100
value: 54.257999999999996
- type: ndcg_at_1000
value: 54.486000000000004
- type: ndcg_at_3
value: 39.864
- type: ndcg_at_5
value: 43.980000000000004
- type: precision_at_1
value: 26.101999999999997
- type: precision_at_10
value: 7.781000000000001
- type: precision_at_100
value: 0.979
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 16.714000000000002
- type: precision_at_5
value: 12.034
- type: recall_at_1
value: 26.101999999999997
- type: recall_at_10
value: 77.809
- type: recall_at_100
value: 97.866
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 50.141999999999996
- type: recall_at_5
value: 60.171
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: 0bbdb47bcbe3a90093699aefeed338a0f28a7ee8
metrics:
- type: v_measure
value: 43.384194916953774
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: b73bd54100e5abfa6e3a23dcafb46fe4d2438dc3
metrics:
- type: v_measure
value: 33.70962633433912
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 4d853f94cd57d85ec13805aeeac3ae3e5eb4c49c
metrics:
- type: map
value: 58.133058996870076
- type: mrr
value: 72.10922041946972
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: 9ee918f184421b6bd48b78f6c714d86546106103
metrics:
- type: cos_sim_pearson
value: 86.62153841660047
- type: cos_sim_spearman
value: 83.01514456843276
- type: euclidean_pearson
value: 86.00431518427241
- type: euclidean_spearman
value: 83.85552516285783
- type: manhattan_pearson
value: 85.83025803351181
- type: manhattan_spearman
value: 83.86636878343106
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 44fa15921b4c889113cc5df03dd4901b49161ab7
metrics:
- type: accuracy
value: 82.05844155844156
- type: f1
value: 82.0185837884764
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 11d0121201d1f1f280e8cc8f3d98fb9c4d9f9c55
metrics:
- type: v_measure
value: 35.05918333141837
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: c0fab014e1bcb8d3a5e31b2088972a1e01547dc1
metrics:
- type: v_measure
value: 30.71055028830579
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 26.519
- type: map_at_10
value: 35.634
- type: map_at_100
value: 36.961
- type: map_at_1000
value: 37.088
- type: map_at_3
value: 32.254
- type: map_at_5
value: 34.22
- type: mrr_at_1
value: 32.332
- type: mrr_at_10
value: 41.168
- type: mrr_at_100
value: 41.977
- type: mrr_at_1000
value: 42.028999999999996
- type: mrr_at_3
value: 38.196999999999996
- type: mrr_at_5
value: 40.036
- type: ndcg_at_1
value: 32.332
- type: ndcg_at_10
value: 41.471000000000004
- type: ndcg_at_100
value: 46.955999999999996
- type: ndcg_at_1000
value: 49.262
- type: ndcg_at_3
value: 35.937999999999995
- type: ndcg_at_5
value: 38.702999999999996
- type: precision_at_1
value: 32.332
- type: precision_at_10
value: 7.7829999999999995
- type: precision_at_100
value: 1.29
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 16.834
- type: precision_at_5
value: 12.418
- type: recall_at_1
value: 26.519
- type: recall_at_10
value: 53.190000000000005
- type: recall_at_100
value: 76.56500000000001
- type: recall_at_1000
value: 91.47800000000001
- type: recall_at_3
value: 38.034
- type: recall_at_5
value: 45.245999999999995
- type: map_at_1
value: 25.356
- type: map_at_10
value: 34.596
- type: map_at_100
value: 35.714
- type: map_at_1000
value: 35.839999999999996
- type: map_at_3
value: 32.073
- type: map_at_5
value: 33.475
- type: mrr_at_1
value: 31.274
- type: mrr_at_10
value: 39.592
- type: mrr_at_100
value: 40.284
- type: mrr_at_1000
value: 40.339999999999996
- type: mrr_at_3
value: 37.378
- type: mrr_at_5
value: 38.658
- type: ndcg_at_1
value: 31.274
- type: ndcg_at_10
value: 39.766
- type: ndcg_at_100
value: 44.028
- type: ndcg_at_1000
value: 46.445
- type: ndcg_at_3
value: 35.934
- type: ndcg_at_5
value: 37.751000000000005
- type: precision_at_1
value: 31.274
- type: precision_at_10
value: 7.452
- type: precision_at_100
value: 1.217
- type: precision_at_1000
value: 0.16999999999999998
- type: precision_at_3
value: 17.431
- type: precision_at_5
value: 12.306000000000001
- type: recall_at_1
value: 25.356
- type: recall_at_10
value: 49.344
- type: recall_at_100
value: 67.497
- type: recall_at_1000
value: 83.372
- type: recall_at_3
value: 38.227
- type: recall_at_5
value: 43.187999999999995
- type: map_at_1
value: 32.759
- type: map_at_10
value: 43.937
- type: map_at_100
value: 45.004
- type: map_at_1000
value: 45.07
- type: map_at_3
value: 40.805
- type: map_at_5
value: 42.497
- type: mrr_at_1
value: 37.367
- type: mrr_at_10
value: 47.237
- type: mrr_at_100
value: 47.973
- type: mrr_at_1000
value: 48.010999999999996
- type: mrr_at_3
value: 44.65
- type: mrr_at_5
value: 46.050999999999995
- type: ndcg_at_1
value: 37.367
- type: ndcg_at_10
value: 49.659
- type: ndcg_at_100
value: 54.069
- type: ndcg_at_1000
value: 55.552
- type: ndcg_at_3
value: 44.169000000000004
- type: ndcg_at_5
value: 46.726
- type: precision_at_1
value: 37.367
- type: precision_at_10
value: 8.163
- type: precision_at_100
value: 1.133
- type: precision_at_1000
value: 0.131
- type: precision_at_3
value: 19.707
- type: precision_at_5
value: 13.718
- type: recall_at_1
value: 32.759
- type: recall_at_10
value: 63.341
- type: recall_at_100
value: 82.502
- type: recall_at_1000
value: 93.259
- type: recall_at_3
value: 48.796
- type: recall_at_5
value: 54.921
- type: map_at_1
value: 18.962
- type: map_at_10
value: 25.863000000000003
- type: map_at_100
value: 26.817999999999998
- type: map_at_1000
value: 26.918
- type: map_at_3
value: 23.043
- type: map_at_5
value: 24.599
- type: mrr_at_1
value: 20.452
- type: mrr_at_10
value: 27.301
- type: mrr_at_100
value: 28.233000000000004
- type: mrr_at_1000
value: 28.310000000000002
- type: mrr_at_3
value: 24.539
- type: mrr_at_5
value: 26.108999999999998
- type: ndcg_at_1
value: 20.452
- type: ndcg_at_10
value: 30.354999999999997
- type: ndcg_at_100
value: 35.336
- type: ndcg_at_1000
value: 37.927
- type: ndcg_at_3
value: 24.705
- type: ndcg_at_5
value: 27.42
- type: precision_at_1
value: 20.452
- type: precision_at_10
value: 4.949
- type: precision_at_100
value: 0.7799999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 10.358
- type: precision_at_5
value: 7.774
- type: recall_at_1
value: 18.962
- type: recall_at_10
value: 43.056
- type: recall_at_100
value: 66.27300000000001
- type: recall_at_1000
value: 85.96000000000001
- type: recall_at_3
value: 27.776
- type: recall_at_5
value: 34.287
- type: map_at_1
value: 11.24
- type: map_at_10
value: 18.503
- type: map_at_100
value: 19.553
- type: map_at_1000
value: 19.689999999999998
- type: map_at_3
value: 16.150000000000002
- type: map_at_5
value: 17.254
- type: mrr_at_1
value: 13.806
- type: mrr_at_10
value: 21.939
- type: mrr_at_100
value: 22.827
- type: mrr_at_1000
value: 22.911
- type: mrr_at_3
value: 19.32
- type: mrr_at_5
value: 20.558
- type: ndcg_at_1
value: 13.806
- type: ndcg_at_10
value: 23.383000000000003
- type: ndcg_at_100
value: 28.834
- type: ndcg_at_1000
value: 32.175
- type: ndcg_at_3
value: 18.651999999999997
- type: ndcg_at_5
value: 20.505000000000003
- type: precision_at_1
value: 13.806
- type: precision_at_10
value: 4.714
- type: precision_at_100
value: 0.864
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 9.328
- type: precision_at_5
value: 6.841
- type: recall_at_1
value: 11.24
- type: recall_at_10
value: 34.854
- type: recall_at_100
value: 59.50299999999999
- type: recall_at_1000
value: 83.25
- type: recall_at_3
value: 22.02
- type: recall_at_5
value: 26.715
- type: map_at_1
value: 23.012
- type: map_at_10
value: 33.048
- type: map_at_100
value: 34.371
- type: map_at_1000
value: 34.489
- type: map_at_3
value: 29.942999999999998
- type: map_at_5
value: 31.602000000000004
- type: mrr_at_1
value: 28.104000000000003
- type: mrr_at_10
value: 37.99
- type: mrr_at_100
value: 38.836
- type: mrr_at_1000
value: 38.891
- type: mrr_at_3
value: 35.226
- type: mrr_at_5
value: 36.693999999999996
- type: ndcg_at_1
value: 28.104000000000003
- type: ndcg_at_10
value: 39.037
- type: ndcg_at_100
value: 44.643
- type: ndcg_at_1000
value: 46.939
- type: ndcg_at_3
value: 33.784
- type: ndcg_at_5
value: 36.126000000000005
- type: precision_at_1
value: 28.104000000000003
- type: precision_at_10
value: 7.2669999999999995
- type: precision_at_100
value: 1.193
- type: precision_at_1000
value: 0.159
- type: precision_at_3
value: 16.298000000000002
- type: precision_at_5
value: 11.684
- type: recall_at_1
value: 23.012
- type: recall_at_10
value: 52.054
- type: recall_at_100
value: 75.622
- type: recall_at_1000
value: 90.675
- type: recall_at_3
value: 37.282
- type: recall_at_5
value: 43.307
- type: map_at_1
value: 21.624
- type: map_at_10
value: 30.209999999999997
- type: map_at_100
value: 31.52
- type: map_at_1000
value: 31.625999999999998
- type: map_at_3
value: 26.951000000000004
- type: map_at_5
value: 28.938999999999997
- type: mrr_at_1
value: 26.941
- type: mrr_at_10
value: 35.13
- type: mrr_at_100
value: 36.15
- type: mrr_at_1000
value: 36.204
- type: mrr_at_3
value: 32.42
- type: mrr_at_5
value: 34.155
- type: ndcg_at_1
value: 26.941
- type: ndcg_at_10
value: 35.726
- type: ndcg_at_100
value: 41.725
- type: ndcg_at_1000
value: 44.105
- type: ndcg_at_3
value: 30.184
- type: ndcg_at_5
value: 33.176
- type: precision_at_1
value: 26.941
- type: precision_at_10
value: 6.654999999999999
- type: precision_at_100
value: 1.1520000000000001
- type: precision_at_1000
value: 0.152
- type: precision_at_3
value: 14.346
- type: precision_at_5
value: 10.868
- type: recall_at_1
value: 21.624
- type: recall_at_10
value: 47.359
- type: recall_at_100
value: 73.436
- type: recall_at_1000
value: 89.988
- type: recall_at_3
value: 32.34
- type: recall_at_5
value: 39.856
- type: map_at_1
value: 20.67566666666667
- type: map_at_10
value: 28.479333333333333
- type: map_at_100
value: 29.612249999999996
- type: map_at_1000
value: 29.731166666666663
- type: map_at_3
value: 25.884
- type: map_at_5
value: 27.298916666666667
- type: mrr_at_1
value: 24.402583333333332
- type: mrr_at_10
value: 32.07041666666667
- type: mrr_at_100
value: 32.95841666666667
- type: mrr_at_1000
value: 33.025416666666665
- type: mrr_at_3
value: 29.677749999999996
- type: mrr_at_5
value: 31.02391666666667
- type: ndcg_at_1
value: 24.402583333333332
- type: ndcg_at_10
value: 33.326166666666666
- type: ndcg_at_100
value: 38.51566666666667
- type: ndcg_at_1000
value: 41.13791666666667
- type: ndcg_at_3
value: 28.687749999999994
- type: ndcg_at_5
value: 30.84766666666667
- type: precision_at_1
value: 24.402583333333332
- type: precision_at_10
value: 5.943749999999999
- type: precision_at_100
value: 1.0098333333333334
- type: precision_at_1000
value: 0.14183333333333334
- type: precision_at_3
value: 13.211500000000001
- type: precision_at_5
value: 9.548416666666668
- type: recall_at_1
value: 20.67566666666667
- type: recall_at_10
value: 44.245583333333336
- type: recall_at_100
value: 67.31116666666667
- type: recall_at_1000
value: 85.87841666666665
- type: recall_at_3
value: 31.49258333333333
- type: recall_at_5
value: 36.93241666666667
- type: map_at_1
value: 18.34
- type: map_at_10
value: 23.988
- type: map_at_100
value: 24.895
- type: map_at_1000
value: 24.992
- type: map_at_3
value: 21.831
- type: map_at_5
value: 23.0
- type: mrr_at_1
value: 20.399
- type: mrr_at_10
value: 26.186
- type: mrr_at_100
value: 27.017999999999997
- type: mrr_at_1000
value: 27.090999999999998
- type: mrr_at_3
value: 24.08
- type: mrr_at_5
value: 25.230000000000004
- type: ndcg_at_1
value: 20.399
- type: ndcg_at_10
value: 27.799000000000003
- type: ndcg_at_100
value: 32.579
- type: ndcg_at_1000
value: 35.209
- type: ndcg_at_3
value: 23.684
- type: ndcg_at_5
value: 25.521
- type: precision_at_1
value: 20.399
- type: precision_at_10
value: 4.585999999999999
- type: precision_at_100
value: 0.755
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 10.276
- type: precision_at_5
value: 7.362
- type: recall_at_1
value: 18.34
- type: recall_at_10
value: 37.456
- type: recall_at_100
value: 59.86
- type: recall_at_1000
value: 79.703
- type: recall_at_3
value: 26.163999999999998
- type: recall_at_5
value: 30.652
- type: map_at_1
value: 12.327
- type: map_at_10
value: 17.572
- type: map_at_100
value: 18.534
- type: map_at_1000
value: 18.653
- type: map_at_3
value: 15.703
- type: map_at_5
value: 16.752
- type: mrr_at_1
value: 15.038000000000002
- type: mrr_at_10
value: 20.726
- type: mrr_at_100
value: 21.61
- type: mrr_at_1000
value: 21.695
- type: mrr_at_3
value: 18.829
- type: mrr_at_5
value: 19.885
- type: ndcg_at_1
value: 15.038000000000002
- type: ndcg_at_10
value: 21.241
- type: ndcg_at_100
value: 26.179000000000002
- type: ndcg_at_1000
value: 29.316
- type: ndcg_at_3
value: 17.762
- type: ndcg_at_5
value: 19.413
- type: precision_at_1
value: 15.038000000000002
- type: precision_at_10
value: 3.8920000000000003
- type: precision_at_100
value: 0.75
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 8.351
- type: precision_at_5
value: 6.187
- type: recall_at_1
value: 12.327
- type: recall_at_10
value: 29.342000000000002
- type: recall_at_100
value: 51.854
- type: recall_at_1000
value: 74.648
- type: recall_at_3
value: 19.596
- type: recall_at_5
value: 23.899
- type: map_at_1
value: 20.594
- type: map_at_10
value: 27.878999999999998
- type: map_at_100
value: 28.926000000000002
- type: map_at_1000
value: 29.041
- type: map_at_3
value: 25.668999999999997
- type: map_at_5
value: 26.773999999999997
- type: mrr_at_1
value: 23.694000000000003
- type: mrr_at_10
value: 31.335
- type: mrr_at_100
value: 32.218
- type: mrr_at_1000
value: 32.298
- type: mrr_at_3
value: 29.26
- type: mrr_at_5
value: 30.328
- type: ndcg_at_1
value: 23.694000000000003
- type: ndcg_at_10
value: 32.456
- type: ndcg_at_100
value: 37.667
- type: ndcg_at_1000
value: 40.571
- type: ndcg_at_3
value: 28.283
- type: ndcg_at_5
value: 29.986
- type: precision_at_1
value: 23.694000000000003
- type: precision_at_10
value: 5.448
- type: precision_at_100
value: 0.9119999999999999
- type: precision_at_1000
value: 0.127
- type: precision_at_3
value: 12.717999999999998
- type: precision_at_5
value: 8.843
- type: recall_at_1
value: 20.594
- type: recall_at_10
value: 43.004999999999995
- type: recall_at_100
value: 66.228
- type: recall_at_1000
value: 87.17099999999999
- type: recall_at_3
value: 31.554
- type: recall_at_5
value: 35.838
- type: map_at_1
value: 20.855999999999998
- type: map_at_10
value: 28.372000000000003
- type: map_at_100
value: 29.87
- type: map_at_1000
value: 30.075000000000003
- type: map_at_3
value: 26.054
- type: map_at_5
value: 27.128999999999998
- type: mrr_at_1
value: 25.494
- type: mrr_at_10
value: 32.735
- type: mrr_at_100
value: 33.794000000000004
- type: mrr_at_1000
value: 33.85
- type: mrr_at_3
value: 30.731
- type: mrr_at_5
value: 31.897
- type: ndcg_at_1
value: 25.494
- type: ndcg_at_10
value: 33.385
- type: ndcg_at_100
value: 39.436
- type: ndcg_at_1000
value: 42.313
- type: ndcg_at_3
value: 29.612
- type: ndcg_at_5
value: 31.186999999999998
- type: precision_at_1
value: 25.494
- type: precision_at_10
value: 6.422999999999999
- type: precision_at_100
value: 1.383
- type: precision_at_1000
value: 0.22399999999999998
- type: precision_at_3
value: 13.834
- type: precision_at_5
value: 10.0
- type: recall_at_1
value: 20.855999999999998
- type: recall_at_10
value: 42.678
- type: recall_at_100
value: 70.224
- type: recall_at_1000
value: 89.369
- type: recall_at_3
value: 31.957
- type: recall_at_5
value: 36.026
- type: map_at_1
value: 16.519000000000002
- type: map_at_10
value: 22.15
- type: map_at_100
value: 23.180999999999997
- type: map_at_1000
value: 23.291999999999998
- type: map_at_3
value: 20.132
- type: map_at_5
value: 21.346
- type: mrr_at_1
value: 17.93
- type: mrr_at_10
value: 23.506
- type: mrr_at_100
value: 24.581
- type: mrr_at_1000
value: 24.675
- type: mrr_at_3
value: 21.503
- type: mrr_at_5
value: 22.686
- type: ndcg_at_1
value: 17.93
- type: ndcg_at_10
value: 25.636
- type: ndcg_at_100
value: 30.736
- type: ndcg_at_1000
value: 33.841
- type: ndcg_at_3
value: 21.546000000000003
- type: ndcg_at_5
value: 23.658
- type: precision_at_1
value: 17.93
- type: precision_at_10
value: 3.993
- type: precision_at_100
value: 0.6890000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 9.057
- type: precision_at_5
value: 6.58
- type: recall_at_1
value: 16.519000000000002
- type: recall_at_10
value: 35.268
- type: recall_at_100
value: 58.17
- type: recall_at_1000
value: 81.66799999999999
- type: recall_at_3
value: 24.165
- type: recall_at_5
value: 29.254
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: 392b78eb68c07badcd7c2cd8f39af108375dfcce
metrics:
- type: map_at_1
value: 10.363
- type: map_at_10
value: 18.301000000000002
- type: map_at_100
value: 20.019000000000002
- type: map_at_1000
value: 20.207
- type: map_at_3
value: 14.877
- type: map_at_5
value: 16.544
- type: mrr_at_1
value: 22.866
- type: mrr_at_10
value: 34.935
- type: mrr_at_100
value: 35.802
- type: mrr_at_1000
value: 35.839999999999996
- type: mrr_at_3
value: 30.965999999999998
- type: mrr_at_5
value: 33.204
- type: ndcg_at_1
value: 22.866
- type: ndcg_at_10
value: 26.595000000000002
- type: ndcg_at_100
value: 33.513999999999996
- type: ndcg_at_1000
value: 36.872
- type: ndcg_at_3
value: 20.666999999999998
- type: ndcg_at_5
value: 22.728
- type: precision_at_1
value: 22.866
- type: precision_at_10
value: 8.632
- type: precision_at_100
value: 1.6119999999999999
- type: precision_at_1000
value: 0.22399999999999998
- type: precision_at_3
value: 15.504999999999999
- type: precision_at_5
value: 12.404
- type: recall_at_1
value: 10.363
- type: recall_at_10
value: 33.494
- type: recall_at_100
value: 57.593
- type: recall_at_1000
value: 76.342
- type: recall_at_3
value: 19.157
- type: recall_at_5
value: 24.637999999999998
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: f097057d03ed98220bc7309ddb10b71a54d667d6
metrics:
- type: map_at_1
value: 7.436
- type: map_at_10
value: 14.760000000000002
- type: map_at_100
value: 19.206
- type: map_at_1000
value: 20.267
- type: map_at_3
value: 10.894
- type: map_at_5
value: 12.828999999999999
- type: mrr_at_1
value: 54.25
- type: mrr_at_10
value: 63.769
- type: mrr_at_100
value: 64.193
- type: mrr_at_1000
value: 64.211
- type: mrr_at_3
value: 61.458
- type: mrr_at_5
value: 63.096
- type: ndcg_at_1
value: 42.875
- type: ndcg_at_10
value: 31.507
- type: ndcg_at_100
value: 34.559
- type: ndcg_at_1000
value: 41.246
- type: ndcg_at_3
value: 35.058
- type: ndcg_at_5
value: 33.396
- type: precision_at_1
value: 54.25
- type: precision_at_10
value: 24.45
- type: precision_at_100
value: 7.383000000000001
- type: precision_at_1000
value: 1.582
- type: precision_at_3
value: 38.083
- type: precision_at_5
value: 32.6
- type: recall_at_1
value: 7.436
- type: recall_at_10
value: 19.862
- type: recall_at_100
value: 38.981
- type: recall_at_1000
value: 61.038000000000004
- type: recall_at_3
value: 11.949
- type: recall_at_5
value: 15.562000000000001
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 829147f8f75a25f005913200eb5ed41fae320aa1
metrics:
- type: accuracy
value: 46.39
- type: f1
value: 42.26424885856703
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: 1429cf27e393599b8b359b9b72c666f96b2525f9
metrics:
- type: map_at_1
value: 50.916
- type: map_at_10
value: 62.258
- type: map_at_100
value: 62.741
- type: map_at_1000
value: 62.763000000000005
- type: map_at_3
value: 60.01800000000001
- type: map_at_5
value: 61.419999999999995
- type: mrr_at_1
value: 54.964999999999996
- type: mrr_at_10
value: 66.554
- type: mrr_at_100
value: 66.96600000000001
- type: mrr_at_1000
value: 66.97800000000001
- type: mrr_at_3
value: 64.414
- type: mrr_at_5
value: 65.77
- type: ndcg_at_1
value: 54.964999999999996
- type: ndcg_at_10
value: 68.12
- type: ndcg_at_100
value: 70.282
- type: ndcg_at_1000
value: 70.788
- type: ndcg_at_3
value: 63.861999999999995
- type: ndcg_at_5
value: 66.216
- type: precision_at_1
value: 54.964999999999996
- type: precision_at_10
value: 8.998000000000001
- type: precision_at_100
value: 1.016
- type: precision_at_1000
value: 0.107
- type: precision_at_3
value: 25.618000000000002
- type: precision_at_5
value: 16.676
- type: recall_at_1
value: 50.916
- type: recall_at_10
value: 82.04
- type: recall_at_100
value: 91.689
- type: recall_at_1000
value: 95.34899999999999
- type: recall_at_3
value: 70.512
- type: recall_at_5
value: 76.29899999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: 41b686a7f28c59bcaaa5791efd47c67c8ebe28be
metrics:
- type: map_at_1
value: 13.568
- type: map_at_10
value: 23.264000000000003
- type: map_at_100
value: 24.823999999999998
- type: map_at_1000
value: 25.013999999999996
- type: map_at_3
value: 19.724
- type: map_at_5
value: 21.772
- type: mrr_at_1
value: 27.315
- type: mrr_at_10
value: 35.935
- type: mrr_at_100
value: 36.929
- type: mrr_at_1000
value: 36.985
- type: mrr_at_3
value: 33.591
- type: mrr_at_5
value: 34.848
- type: ndcg_at_1
value: 27.315
- type: ndcg_at_10
value: 29.988
- type: ndcg_at_100
value: 36.41
- type: ndcg_at_1000
value: 40.184999999999995
- type: ndcg_at_3
value: 26.342
- type: ndcg_at_5
value: 27.68
- type: precision_at_1
value: 27.315
- type: precision_at_10
value: 8.565000000000001
- type: precision_at_100
value: 1.508
- type: precision_at_1000
value: 0.219
- type: precision_at_3
value: 17.849999999999998
- type: precision_at_5
value: 13.672999999999998
- type: recall_at_1
value: 13.568
- type: recall_at_10
value: 37.133
- type: recall_at_100
value: 61.475
- type: recall_at_1000
value: 84.372
- type: recall_at_3
value: 24.112000000000002
- type: recall_at_5
value: 29.507
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: 766870b35a1b9ca65e67a0d1913899973551fc6c
metrics:
- type: map_at_1
value: 30.878
- type: map_at_10
value: 40.868
- type: map_at_100
value: 41.693999999999996
- type: map_at_1000
value: 41.775
- type: map_at_3
value: 38.56
- type: map_at_5
value: 39.947
- type: mrr_at_1
value: 61.756
- type: mrr_at_10
value: 68.265
- type: mrr_at_100
value: 68.671
- type: mrr_at_1000
value: 68.694
- type: mrr_at_3
value: 66.78399999999999
- type: mrr_at_5
value: 67.704
- type: ndcg_at_1
value: 61.756
- type: ndcg_at_10
value: 49.931
- type: ndcg_at_100
value: 53.179
- type: ndcg_at_1000
value: 54.94799999999999
- type: ndcg_at_3
value: 46.103
- type: ndcg_at_5
value: 48.147
- type: precision_at_1
value: 61.756
- type: precision_at_10
value: 10.163
- type: precision_at_100
value: 1.2710000000000001
- type: precision_at_1000
value: 0.151
- type: precision_at_3
value: 28.179
- type: precision_at_5
value: 18.528
- type: recall_at_1
value: 30.878
- type: recall_at_10
value: 50.817
- type: recall_at_100
value: 63.544999999999995
- type: recall_at_1000
value: 75.361
- type: recall_at_3
value: 42.269
- type: recall_at_5
value: 46.32
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 8d743909f834c38949e8323a8a6ce8721ea6c7f4
metrics:
- type: accuracy
value: 64.04799999999999
- type: ap
value: 59.185251455339284
- type: f1
value: 63.947123181349255
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: validation
revision: e6838a846e2408f22cf5cc337ebc83e0bcf77849
metrics:
- type: map_at_1
value: 18.9
- type: map_at_10
value: 29.748
- type: map_at_100
value: 30.976
- type: map_at_1000
value: 31.041
- type: map_at_3
value: 26.112999999999996
- type: map_at_5
value: 28.197
- type: mrr_at_1
value: 19.413
- type: mrr_at_10
value: 30.322
- type: mrr_at_100
value: 31.497000000000003
- type: mrr_at_1000
value: 31.555
- type: mrr_at_3
value: 26.729000000000003
- type: mrr_at_5
value: 28.788999999999998
- type: ndcg_at_1
value: 19.413
- type: ndcg_at_10
value: 36.048
- type: ndcg_at_100
value: 42.152
- type: ndcg_at_1000
value: 43.772
- type: ndcg_at_3
value: 28.642
- type: ndcg_at_5
value: 32.358
- type: precision_at_1
value: 19.413
- type: precision_at_10
value: 5.785
- type: precision_at_100
value: 0.8869999999999999
- type: precision_at_1000
value: 0.10300000000000001
- type: precision_at_3
value: 12.192
- type: precision_at_5
value: 9.189
- type: recall_at_1
value: 18.9
- type: recall_at_10
value: 55.457
- type: recall_at_100
value: 84.09100000000001
- type: recall_at_1000
value: 96.482
- type: recall_at_3
value: 35.359
- type: recall_at_5
value: 44.275
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 92.07706338349293
- type: f1
value: 91.56680443236652
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 71.18559051527589
- type: f1
value: 52.42887061726789
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 68.64828513786148
- type: f1
value: 66.54281381596097
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.04236718224612
- type: f1
value: 75.89170458655639
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: dcefc037ef84348e49b0d29109e891c01067226b
metrics:
- type: v_measure
value: 32.0840369055247
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 3cd0e71dfbe09d4de0f9e5ecba43e7ce280959dc
metrics:
- type: v_measure
value: 29.448729560244537
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.340856463122375
- type: mrr
value: 32.398547669840916
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: 7eb63cc0c1eb59324d709ebed25fcab851fa7610
metrics:
- type: map_at_1
value: 5.526
- type: map_at_10
value: 11.745
- type: map_at_100
value: 14.831
- type: map_at_1000
value: 16.235
- type: map_at_3
value: 8.716
- type: map_at_5
value: 10.101
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 51.06699999999999
- type: mrr_at_100
value: 51.881
- type: mrr_at_1000
value: 51.912000000000006
- type: mrr_at_3
value: 49.02
- type: mrr_at_5
value: 50.288999999999994
- type: ndcg_at_1
value: 41.949999999999996
- type: ndcg_at_10
value: 32.083
- type: ndcg_at_100
value: 30.049999999999997
- type: ndcg_at_1000
value: 38.661
- type: ndcg_at_3
value: 37.940000000000005
- type: ndcg_at_5
value: 35.455999999999996
- type: precision_at_1
value: 43.344
- type: precision_at_10
value: 23.437
- type: precision_at_100
value: 7.829999999999999
- type: precision_at_1000
value: 2.053
- type: precision_at_3
value: 35.501
- type: precision_at_5
value: 30.464000000000002
- type: recall_at_1
value: 5.526
- type: recall_at_10
value: 15.445999999999998
- type: recall_at_100
value: 31.179000000000002
- type: recall_at_1000
value: 61.578
- type: recall_at_3
value: 9.71
- type: recall_at_5
value: 12.026
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: 6062aefc120bfe8ece5897809fb2e53bfe0d128c
metrics:
- type: map_at_1
value: 23.467
- type: map_at_10
value: 36.041000000000004
- type: map_at_100
value: 37.268
- type: map_at_1000
value: 37.322
- type: map_at_3
value: 32.09
- type: map_at_5
value: 34.414
- type: mrr_at_1
value: 26.738
- type: mrr_at_10
value: 38.665
- type: mrr_at_100
value: 39.64
- type: mrr_at_1000
value: 39.681
- type: mrr_at_3
value: 35.207
- type: mrr_at_5
value: 37.31
- type: ndcg_at_1
value: 26.709
- type: ndcg_at_10
value: 42.942
- type: ndcg_at_100
value: 48.296
- type: ndcg_at_1000
value: 49.651
- type: ndcg_at_3
value: 35.413
- type: ndcg_at_5
value: 39.367999999999995
- type: precision_at_1
value: 26.709
- type: precision_at_10
value: 7.306
- type: precision_at_100
value: 1.0290000000000001
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 16.348
- type: precision_at_5
value: 12.068
- type: recall_at_1
value: 23.467
- type: recall_at_10
value: 61.492999999999995
- type: recall_at_100
value: 85.01100000000001
- type: recall_at_1000
value: 95.261
- type: recall_at_3
value: 41.952
- type: recall_at_5
value: 51.105999999999995
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: 6205996560df11e3a3da9ab4f926788fc30a7db4
metrics:
- type: map_at_1
value: 67.51700000000001
- type: map_at_10
value: 81.054
- type: map_at_100
value: 81.727
- type: map_at_1000
value: 81.75200000000001
- type: map_at_3
value: 78.018
- type: map_at_5
value: 79.879
- type: mrr_at_1
value: 77.52
- type: mrr_at_10
value: 84.429
- type: mrr_at_100
value: 84.58200000000001
- type: mrr_at_1000
value: 84.584
- type: mrr_at_3
value: 83.268
- type: mrr_at_5
value: 84.013
- type: ndcg_at_1
value: 77.53
- type: ndcg_at_10
value: 85.277
- type: ndcg_at_100
value: 86.80499999999999
- type: ndcg_at_1000
value: 87.01
- type: ndcg_at_3
value: 81.975
- type: ndcg_at_5
value: 83.723
- type: precision_at_1
value: 77.53
- type: precision_at_10
value: 12.961
- type: precision_at_100
value: 1.502
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 35.713
- type: precision_at_5
value: 23.574
- type: recall_at_1
value: 67.51700000000001
- type: recall_at_10
value: 93.486
- type: recall_at_100
value: 98.9
- type: recall_at_1000
value: 99.92999999999999
- type: recall_at_3
value: 84.17999999999999
- type: recall_at_5
value: 88.97500000000001
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: b2805658ae38990172679479369a78b86de8c390
metrics:
- type: v_measure
value: 48.225994608749915
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: v_measure
value: 53.17635557157765
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: 5c59ef3e437a0a9651c8fe6fde943e7dce59fba5
metrics:
- type: map_at_1
value: 3.988
- type: map_at_10
value: 9.4
- type: map_at_100
value: 10.968
- type: map_at_1000
value: 11.257
- type: map_at_3
value: 7.123
- type: map_at_5
value: 8.221
- type: mrr_at_1
value: 19.7
- type: mrr_at_10
value: 29.098000000000003
- type: mrr_at_100
value: 30.247
- type: mrr_at_1000
value: 30.318
- type: mrr_at_3
value: 26.55
- type: mrr_at_5
value: 27.915
- type: ndcg_at_1
value: 19.7
- type: ndcg_at_10
value: 16.176
- type: ndcg_at_100
value: 22.931
- type: ndcg_at_1000
value: 28.301
- type: ndcg_at_3
value: 16.142
- type: ndcg_at_5
value: 13.633999999999999
- type: precision_at_1
value: 19.7
- type: precision_at_10
value: 8.18
- type: precision_at_100
value: 1.8010000000000002
- type: precision_at_1000
value: 0.309
- type: precision_at_3
value: 15.1
- type: precision_at_5
value: 11.74
- type: recall_at_1
value: 3.988
- type: recall_at_10
value: 16.625
- type: recall_at_100
value: 36.61
- type: recall_at_1000
value: 62.805
- type: recall_at_3
value: 9.168
- type: recall_at_5
value: 11.902
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cos_sim_pearson
value: 77.29330379162072
- type: cos_sim_spearman
value: 67.22953551111448
- type: euclidean_pearson
value: 71.44682700059415
- type: euclidean_spearman
value: 66.33178012153247
- type: manhattan_pearson
value: 71.46941734657887
- type: manhattan_spearman
value: 66.43234359835814
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: fdf84275bb8ce4b49c971d02e84dd1abc677a50f
metrics:
- type: cos_sim_pearson
value: 75.40943196466576
- type: cos_sim_spearman
value: 66.59241013465915
- type: euclidean_pearson
value: 71.32500540796616
- type: euclidean_spearman
value: 67.86667467202591
- type: manhattan_pearson
value: 71.48209832089134
- type: manhattan_spearman
value: 67.94511626964879
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 1591bfcbe8c69d4bf7fe2a16e2451017832cafb9
metrics:
- type: cos_sim_pearson
value: 77.08302398877518
- type: cos_sim_spearman
value: 77.33151317062642
- type: euclidean_pearson
value: 76.77020279715008
- type: euclidean_spearman
value: 77.13893776083225
- type: manhattan_pearson
value: 76.76732290707477
- type: manhattan_spearman
value: 77.14500877396631
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: e2125984e7df8b7871f6ae9949cf6b6795e7c54b
metrics:
- type: cos_sim_pearson
value: 77.46886184932168
- type: cos_sim_spearman
value: 71.82815265534886
- type: euclidean_pearson
value: 75.19783284299076
- type: euclidean_spearman
value: 71.36479611710412
- type: manhattan_pearson
value: 75.30375233959337
- type: manhattan_spearman
value: 71.46280266488021
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: 1cd7298cac12a96a373b6a2f18738bb3e739a9b6
metrics:
- type: cos_sim_pearson
value: 80.093017609484
- type: cos_sim_spearman
value: 80.65931167868882
- type: euclidean_pearson
value: 80.36786337117047
- type: euclidean_spearman
value: 81.30521389642827
- type: manhattan_pearson
value: 80.37922433220973
- type: manhattan_spearman
value: 81.30496664496285
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 360a0b2dff98700d09e634a01e1cc1624d3e42cd
metrics:
- type: cos_sim_pearson
value: 77.98998347238742
- type: cos_sim_spearman
value: 78.91151365939403
- type: euclidean_pearson
value: 76.40510899217841
- type: euclidean_spearman
value: 76.8551459824213
- type: manhattan_pearson
value: 76.3986079603294
- type: manhattan_spearman
value: 76.8848053254288
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 85.63510653472044
- type: cos_sim_spearman
value: 86.98674844768605
- type: euclidean_pearson
value: 85.205080538809
- type: euclidean_spearman
value: 85.53630494151886
- type: manhattan_pearson
value: 85.48612469885626
- type: manhattan_spearman
value: 85.81741413931921
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 66.7257987615171
- type: cos_sim_spearman
value: 67.30387805090024
- type: euclidean_pearson
value: 69.46877227885867
- type: euclidean_spearman
value: 69.33161798704344
- type: manhattan_pearson
value: 69.82773311626424
- type: manhattan_spearman
value: 69.57199940498796
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: 8913289635987208e6e7c72789e4be2fe94b6abd
metrics:
- type: cos_sim_pearson
value: 79.37322139418472
- type: cos_sim_spearman
value: 77.5887175717799
- type: euclidean_pearson
value: 78.23006410562164
- type: euclidean_spearman
value: 77.18470385673044
- type: manhattan_pearson
value: 78.40868369362455
- type: manhattan_spearman
value: 77.36675823897656
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: 56a6d0140cf6356659e2a7c1413286a774468d44
metrics:
- type: map
value: 77.21233007730808
- type: mrr
value: 93.0502386139641
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: a75ae049398addde9b70f6b268875f5cbce99089
metrics:
- type: map_at_1
value: 54.567
- type: map_at_10
value: 63.653000000000006
- type: map_at_100
value: 64.282
- type: map_at_1000
value: 64.31099999999999
- type: map_at_3
value: 60.478
- type: map_at_5
value: 62.322
- type: mrr_at_1
value: 56.99999999999999
- type: mrr_at_10
value: 64.759
- type: mrr_at_100
value: 65.274
- type: mrr_at_1000
value: 65.301
- type: mrr_at_3
value: 62.333000000000006
- type: mrr_at_5
value: 63.817
- type: ndcg_at_1
value: 56.99999999999999
- type: ndcg_at_10
value: 68.28699999999999
- type: ndcg_at_100
value: 70.98400000000001
- type: ndcg_at_1000
value: 71.695
- type: ndcg_at_3
value: 62.656
- type: ndcg_at_5
value: 65.523
- type: precision_at_1
value: 56.99999999999999
- type: precision_at_10
value: 9.232999999999999
- type: precision_at_100
value: 1.0630000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 24.221999999999998
- type: precision_at_5
value: 16.333000000000002
- type: recall_at_1
value: 54.567
- type: recall_at_10
value: 81.45599999999999
- type: recall_at_100
value: 93.5
- type: recall_at_1000
value: 99.0
- type: recall_at_3
value: 66.228
- type: recall_at_5
value: 73.489
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: 5a8256d0dff9c4bd3be3ba3e67e4e70173f802ea
metrics:
- type: cos_sim_accuracy
value: 99.74455445544554
- type: cos_sim_ap
value: 92.57836032673468
- type: cos_sim_f1
value: 87.0471464019851
- type: cos_sim_precision
value: 86.4039408866995
- type: cos_sim_recall
value: 87.7
- type: dot_accuracy
value: 99.56039603960396
- type: dot_ap
value: 82.47233353407186
- type: dot_f1
value: 76.78207739307537
- type: dot_precision
value: 78.21576763485477
- type: dot_recall
value: 75.4
- type: euclidean_accuracy
value: 99.73069306930694
- type: euclidean_ap
value: 91.70507666665775
- type: euclidean_f1
value: 86.26262626262626
- type: euclidean_precision
value: 87.14285714285714
- type: euclidean_recall
value: 85.39999999999999
- type: manhattan_accuracy
value: 99.73861386138614
- type: manhattan_ap
value: 91.96809459281754
- type: manhattan_f1
value: 86.6
- type: manhattan_precision
value: 86.6
- type: manhattan_recall
value: 86.6
- type: max_accuracy
value: 99.74455445544554
- type: max_ap
value: 92.57836032673468
- type: max_f1
value: 87.0471464019851
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 70a89468f6dccacc6aa2b12a6eac54e74328f235
metrics:
- type: v_measure
value: 60.85593925770172
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: d88009ab563dd0b16cfaf4436abaf97fa3550cf0
metrics:
- type: v_measure
value: 32.356772998237496
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: ef807ea29a75ec4f91b50fd4191cb4ee4589a9f9
metrics:
- type: map
value: 49.320607035290735
- type: mrr
value: 50.09196481622952
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: 8753c2788d36c01fc6f05d03fe3f7268d63f9122
metrics:
- type: cos_sim_pearson
value: 31.17573968015504
- type: cos_sim_spearman
value: 30.43371643155132
- type: dot_pearson
value: 30.164319483092743
- type: dot_spearman
value: 29.207082242868754
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: 2c8041b2c07a79b6f7ba8fe6acc72e5d9f92d217
metrics:
- type: map_at_1
value: 0.22100000000000003
- type: map_at_10
value: 1.7229999999999999
- type: map_at_100
value: 9.195
- type: map_at_1000
value: 21.999
- type: map_at_3
value: 0.6479999999999999
- type: map_at_5
value: 0.964
- type: mrr_at_1
value: 86.0
- type: mrr_at_10
value: 90.667
- type: mrr_at_100
value: 90.858
- type: mrr_at_1000
value: 90.858
- type: mrr_at_3
value: 90.667
- type: mrr_at_5
value: 90.667
- type: ndcg_at_1
value: 82.0
- type: ndcg_at_10
value: 72.98
- type: ndcg_at_100
value: 52.868
- type: ndcg_at_1000
value: 46.541
- type: ndcg_at_3
value: 80.39699999999999
- type: ndcg_at_5
value: 76.303
- type: precision_at_1
value: 86.0
- type: precision_at_10
value: 75.8
- type: precision_at_100
value: 53.5
- type: precision_at_1000
value: 20.946
- type: precision_at_3
value: 85.333
- type: precision_at_5
value: 79.2
- type: recall_at_1
value: 0.22100000000000003
- type: recall_at_10
value: 1.9109999999999998
- type: recall_at_100
value: 12.437
- type: recall_at_1000
value: 43.606
- type: recall_at_3
value: 0.681
- type: recall_at_5
value: 1.023
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: 527b7d77e16e343303e68cb6af11d6e18b9f7b3b
metrics:
- type: map_at_1
value: 2.5
- type: map_at_10
value: 9.568999999999999
- type: map_at_100
value: 15.653
- type: map_at_1000
value: 17.188
- type: map_at_3
value: 5.335999999999999
- type: map_at_5
value: 6.522
- type: mrr_at_1
value: 34.694
- type: mrr_at_10
value: 49.184
- type: mrr_at_100
value: 50.512
- type: mrr_at_1000
value: 50.512
- type: mrr_at_3
value: 46.259
- type: mrr_at_5
value: 48.299
- type: ndcg_at_1
value: 30.612000000000002
- type: ndcg_at_10
value: 24.45
- type: ndcg_at_100
value: 35.870999999999995
- type: ndcg_at_1000
value: 47.272999999999996
- type: ndcg_at_3
value: 28.528
- type: ndcg_at_5
value: 25.768
- type: precision_at_1
value: 34.694
- type: precision_at_10
value: 21.429000000000002
- type: precision_at_100
value: 7.265000000000001
- type: precision_at_1000
value: 1.504
- type: precision_at_3
value: 29.252
- type: precision_at_5
value: 24.898
- type: recall_at_1
value: 2.5
- type: recall_at_10
value: 15.844
- type: recall_at_100
value: 45.469
- type: recall_at_1000
value: 81.148
- type: recall_at_3
value: 6.496
- type: recall_at_5
value: 8.790000000000001
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 68.7272
- type: ap
value: 13.156450706152686
- type: f1
value: 52.814703437064395
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: 62146448f05be9e52a36b8ee9936447ea787eede
metrics:
- type: accuracy
value: 55.6677985285795
- type: f1
value: 55.9373937514999
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 091a54f9a36281ce7d6590ec8c75dd485e7e01d4
metrics:
- type: v_measure
value: 40.05809562275603
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 82.76807534124099
- type: cos_sim_ap
value: 62.37052608803734
- type: cos_sim_f1
value: 59.077414934916646
- type: cos_sim_precision
value: 52.07326892109501
- type: cos_sim_recall
value: 68.25857519788919
- type: dot_accuracy
value: 80.56267509089825
- type: dot_ap
value: 54.75349561321037
- type: dot_f1
value: 54.75483794372552
- type: dot_precision
value: 49.77336499028707
- type: dot_recall
value: 60.844327176781
- type: euclidean_accuracy
value: 82.476008821601
- type: euclidean_ap
value: 61.17417554210511
- type: euclidean_f1
value: 57.80318696022382
- type: euclidean_precision
value: 53.622207176709544
- type: euclidean_recall
value: 62.69129287598945
- type: manhattan_accuracy
value: 82.48792990403528
- type: manhattan_ap
value: 61.044816292966544
- type: manhattan_f1
value: 58.03033951360462
- type: manhattan_precision
value: 53.36581045172719
- type: manhattan_recall
value: 63.58839050131926
- type: max_accuracy
value: 82.76807534124099
- type: max_ap
value: 62.37052608803734
- type: max_f1
value: 59.077414934916646
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 87.97881010594946
- type: cos_sim_ap
value: 83.78748636891035
- type: cos_sim_f1
value: 75.94113995691386
- type: cos_sim_precision
value: 72.22029307590805
- type: cos_sim_recall
value: 80.06621496766245
- type: dot_accuracy
value: 85.69294058291614
- type: dot_ap
value: 78.15363722278026
- type: dot_f1
value: 72.08894926888564
- type: dot_precision
value: 67.28959487419075
- type: dot_recall
value: 77.62550046196489
- type: euclidean_accuracy
value: 87.73625179493149
- type: euclidean_ap
value: 83.19012184470559
- type: euclidean_f1
value: 75.5148064623461
- type: euclidean_precision
value: 72.63352535381551
- type: euclidean_recall
value: 78.6341238065907
- type: manhattan_accuracy
value: 87.74013272790779
- type: manhattan_ap
value: 83.23305405113403
- type: manhattan_f1
value: 75.63960775639607
- type: manhattan_precision
value: 72.563304569246
- type: manhattan_recall
value: 78.9882968894364
- type: max_accuracy
value: 87.97881010594946
- type: max_ap
value: 83.78748636891035
- type: max_f1
value: 75.94113995691386
---
# SGPT-1.3B-weightedmean-msmarco-specb-bitfit
## Usage
For usage instructions, refer to our codebase: https://github.com/Muennighoff/sgpt
## Evaluation Results
For eval results, refer to the eval folder or our paper: https://arxiv.org/abs/2202.08904
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 62398 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0002
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 300, 'do_lower_case': False}) with Transformer model: GPTNeoModel
(1): Pooling({'word_embedding_dimension': 2048, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': True, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
```bibtex
@article{muennighoff2022sgpt,
title={SGPT: GPT Sentence Embeddings for Semantic Search},
author={Muennighoff, Niklas},
journal={arXiv preprint arXiv:2202.08904},
year={2022}
}
```
|
[
"BIOSSES",
"SCIFACT"
] |
TheBloke/upstage-llama-30b-instruct-2048-GPTQ
|
TheBloke
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"upstage",
"instruct",
"instruction",
"en",
"dataset:sciq",
"dataset:metaeval/ScienceQA_text_only",
"dataset:GAIR/lima",
"dataset:Open-Orca/OpenOrca",
"dataset:openbookqa",
"base_model:upstage/llama-30b-instruct-2048",
"base_model:quantized:upstage/llama-30b-instruct-2048",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] | 2023-07-20T00:21:35Z |
2023-09-27T12:44:52+00:00
| 90 | 23 |
---
base_model: upstage/llama-30b-instruct-2048
datasets:
- sciq
- metaeval/ScienceQA_text_only
- GAIR/lima
- Open-Orca/OpenOrca
- openbookqa
language:
- en
license: other
model_name: Llama 30B Instruct 2048
pipeline_tag: text-generation
tags:
- upstage
- llama
- instruct
- instruction
inference: false
model_creator: upstage
model_type: llama
prompt_template: '### System:
{system_message}
### User:
{prompt}
### Assistant:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama 30B Instruct 2048 - GPTQ
- Model creator: [upstage](https://huggingface.co/upstage)
- Original model: [Llama 30B Instruct 2048](https://huggingface.co/upstage/llama-30b-instruct-2048)
<!-- description start -->
## Description
This repo contains GPTQ model files for [Upstage's Llama 30B Instruct 2048](https://huggingface.co/upstage/llama-30b-instruct-2048).
Multiple GPTQ parameter permutations are provided; see Provided Files below for details of the options provided, their parameters, and the software used to create them.
Many thanks to William Beauchamp from [Chai](https://chai-research.com/) for providing the hardware used to make and upload these files!
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GGUF)
* [upstage's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/upstage/llama-30b-instruct-2048)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Orca-Hashes
```
### System:
{system_message}
### User:
{prompt}
### Assistant:
```
<!-- prompt-template end -->
<!-- README_GPTQ.md-provided-files start -->
## Provided files and GPTQ parameters
Multiple quantisation parameters are provided, to allow you to choose the best one for your hardware and requirements.
Each separate quant is in a different branch. See below for instructions on fetching from different branches.
All recent GPTQ files are made with AutoGPTQ, and all files in non-main branches are made with AutoGPTQ. Files in the `main` branch which were uploaded before August 2023 were made with GPTQ-for-LLaMa.
<details>
<summary>Explanation of GPTQ parameters</summary>
- Bits: The bit size of the quantised model.
- GS: GPTQ group size. Higher numbers use less VRAM, but have lower quantisation accuracy. "None" is the lowest possible value.
- Act Order: True or False. Also known as `desc_act`. True results in better quantisation accuracy. Some GPTQ clients have had issues with models that use Act Order plus Group Size, but this is generally resolved now.
- Damp %: A GPTQ parameter that affects how samples are processed for quantisation. 0.01 is default, but 0.1 results in slightly better accuracy.
- GPTQ dataset: The dataset used for quantisation. Using a dataset more appropriate to the model's training can improve quantisation accuracy. Note that the GPTQ dataset is not the same as the dataset used to train the model - please refer to the original model repo for details of the training dataset(s).
- Sequence Length: The length of the dataset sequences used for quantisation. Ideally this is the same as the model sequence length. For some very long sequence models (16+K), a lower sequence length may have to be used. Note that a lower sequence length does not limit the sequence length of the quantised model. It only impacts the quantisation accuracy on longer inference sequences.
- ExLlama Compatibility: Whether this file can be loaded with ExLlama, which currently only supports Llama models in 4-bit.
</details>
| Branch | Bits | GS | Act Order | Damp % | GPTQ Dataset | Seq Len | Size | ExLlama | Desc |
| ------ | ---- | -- | --------- | ------ | ------------ | ------- | ---- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ/tree/main) | 4 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 16.94 GB | Yes | 4-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-4bit-32g-actorder_True](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ/tree/gptq-4bit-32g-actorder_True) | 4 | 32 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 19.44 GB | Yes | 4-bit, with Act Order and group size 32g. Gives highest possible inference quality, with maximum VRAM usage. |
| [gptq-4bit-64g-actorder_True](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ/tree/gptq-4bit-64g-actorder_True) | 4 | 64 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 18.18 GB | Yes | 4-bit, with Act Order and group size 64g. Uses less VRAM than 32g, but with slightly lower accuracy. |
| [gptq-4bit-128g-actorder_True](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ/tree/gptq-4bit-128g-actorder_True) | 4 | 128 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 17.55 GB | Yes | 4-bit, with Act Order and group size 128g. Uses even less VRAM than 64g, but with slightly lower accuracy. |
| [gptq-8bit--1g-actorder_True](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ/tree/gptq-8bit--1g-actorder_True) | 8 | None | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 32.99 GB | No | 8-bit, with Act Order. No group size, to lower VRAM requirements. |
| [gptq-8bit-128g-actorder_False](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ/tree/gptq-8bit-128g-actorder_False) | 8 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 33.73 GB | No | 8-bit, with group size 128g for higher inference quality and without Act Order to improve AutoGPTQ speed. |
| [gptq-3bit-128g-actorder_False](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ/tree/gptq-3bit-128g-actorder_False) | 3 | 128 | No | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 13.51 GB | No | 3-bit, with group size 128g but no act-order. Slightly higher VRAM requirements than 3-bit None. |
| [gptq-3bit-128g-actorder_True](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ/tree/gptq-3bit-128g-actorder_True) | 3 | 128 | Yes | 0.01 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 2048 | 13.51 GB | No | 3-bit, with group size 128g and act-order. Higher quality than 128g-False. |
<!-- README_GPTQ.md-provided-files end -->
<!-- README_GPTQ.md-download-from-branches start -->
## How to download from branches
- In text-generation-webui, you can add `:branch` to the end of the download name, eg `TheBloke/upstage-llama-30b-instruct-2048-GPTQ:main`
- With Git, you can clone a branch with:
```
git clone --single-branch --branch main https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ
```
- In Python Transformers code, the branch is the `revision` parameter; see below.
<!-- README_GPTQ.md-download-from-branches end -->
<!-- README_GPTQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/upstage-llama-30b-instruct-2048-GPTQ`.
- To download from a specific branch, enter for example `TheBloke/upstage-llama-30b-instruct-2048-GPTQ:main`
- see Provided Files above for the list of branches for each option.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `upstage-llama-30b-instruct-2048-GPTQ`
7. The model will automatically load, and is now ready for use!
8. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
* Note that you do not need to and should not set manual GPTQ parameters any more. These are set automatically from the file `quantize_config.json`.
9. Once you're ready, click the **Text Generation tab** and enter a prompt to get started!
<!-- README_GPTQ.md-text-generation-webui end -->
<!-- README_GPTQ.md-use-from-python start -->
## How to use this GPTQ model from Python code
### Install the necessary packages
Requires: Transformers 4.32.0 or later, Optimum 1.12.0 or later, and AutoGPTQ 0.4.2 or later.
```shell
pip3 install transformers>=4.32.0 optimum>=1.12.0
pip3 install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/ # Use cu117 if on CUDA 11.7
```
If you have problems installing AutoGPTQ using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y auto-gptq
git clone https://github.com/PanQiWei/AutoGPTQ
cd AutoGPTQ
pip3 install .
```
### For CodeLlama models only: you must use Transformers 4.33.0 or later.
If 4.33.0 is not yet released when you read this, you will need to install Transformers from source:
```shell
pip3 uninstall -y transformers
pip3 install git+https://github.com/huggingface/transformers.git
```
### You can then use the following code
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_name_or_path = "TheBloke/upstage-llama-30b-instruct-2048-GPTQ"
# To use a different branch, change revision
# For example: revision="main"
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=False,
revision="main")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
prompt = "Tell me about AI"
prompt_template=f'''### System:
{system_message}
### User:
{prompt}
### Assistant:
'''
print("\n\n*** Generate:")
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=0.7, do_sample=True, top_p=0.95, top_k=40, max_new_tokens=512)
print(tokenizer.decode(output[0]))
# Inference can also be done using transformers' pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_GPTQ.md-use-from-python end -->
<!-- README_GPTQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with AutoGPTQ, both via Transformers and using AutoGPTQ directly. They should also work with [Occ4m's GPTQ-for-LLaMa fork](https://github.com/0cc4m/KoboldAI).
[ExLlama](https://github.com/turboderp/exllama) is compatible with Llama models in 4-bit. Please see the Provided Files table above for per-file compatibility.
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is compatible with all GPTQ models.
<!-- README_GPTQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Upstage's Llama 30B Instruct 2048
# LLaMa-30b-instruct-2048 model card
## Model Details
* **Developed by**: [Upstage](https://en.upstage.ai)
* **Backbone Model**: [LLaMA](https://github.com/facebookresearch/llama/tree/llama_v1)
* **Variations**: It has different model parameter sizes and sequence lengths: [30B/1024](https://huggingface.co/upstage/llama-30b-instruct), [30B/2048](https://huggingface.co/upstage/llama-30b-instruct-2048), [65B/1024](https://huggingface.co/upstage/llama-65b-instruct)
* **Language(s)**: English
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
* **License**: This model is under a **Non-commercial** Bespoke License and governed by the Meta license. You should only use this repository if you have been granted access to the model by filling out [this form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform), but have either lost your copy of the weights or encountered issues converting them to the Transformers format
* **Where to send comments**: Instructions on how to provide feedback or comments on a model can be found by opening an issue in the [Hugging Face community's model repository](https://huggingface.co/upstage/llama-30b-instruct-2048/discussions)
* **Contact**: For questions and comments about the model, please email [[email protected]](mailto:[email protected])
## Dataset Details
### Used Datasets
- [openbookqa](https://huggingface.co/datasets/openbookqa)
- [sciq](https://huggingface.co/datasets/sciq)
- [Open-Orca/OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca)
- [metaeval/ScienceQA_text_only](https://huggingface.co/datasets/metaeval/ScienceQA_text_only)
- [GAIR/lima](https://huggingface.co/datasets/GAIR/lima)
- No other data was used except for the dataset mentioned above
### Prompt Template
```
### System:
{System}
### User:
{User}
### Assistant:
{Assistant}
```
## Usage
- Tested on A100 80GB
- Our model can handle up to 10k+ input tokens, thanks to the `rope_scaling` option
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tokenizer = AutoTokenizer.from_pretrained("upstage/llama-30b-instruct-2048")
model = AutoModelForCausalLM.from_pretrained(
"upstage/llama-30b-instruct-2048",
device_map="auto",
torch_dtype=torch.float16,
load_in_8bit=True,
rope_scaling={"type": "dynamic", "factor": 2} # allows handling of longer inputs
)
prompt = "### User:\nThomas is healthy, but he has to go to the hospital. What could be the reasons?\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
del inputs["token_type_ids"]
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
output = model.generate(**inputs, streamer=streamer, use_cache=True, max_new_tokens=float('inf'))
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
```
## Hardware and Software
* **Hardware**: We utilized an A100x8 * 1 for training our model
* **Training Factors**: We fine-tuned this model using a combination of the [DeepSpeed library](https://github.com/microsoft/DeepSpeed) and the [HuggingFace Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) / [HuggingFace Accelerate](https://huggingface.co/docs/accelerate/index)
## Evaluation Results
### Overview
- We conducted a performance evaluation based on the tasks being evaluated on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
We evaluated our model on four benchmark datasets, which include `ARC-Challenge`, `HellaSwag`, `MMLU`, and `TruthfulQA`
We used the [lm-evaluation-harness repository](https://github.com/EleutherAI/lm-evaluation-harness), specifically commit [b281b0921b636bc36ad05c0b0b0763bd6dd43463](https://github.com/EleutherAI/lm-evaluation-harness/tree/b281b0921b636bc36ad05c0b0b0763bd6dd43463)
- We used [MT-bench](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge), a set of challenging multi-turn open-ended questions, to evaluate the models
### Main Results
| Model | H4(Avg) | ARC | HellaSwag | MMLU | TruthfulQA | | MT_Bench |
|--------------------------------------------------------------------|----------|----------|----------|------|----------|-|-------------|
| **[Llama-2-70b-instruct-v2](https://huggingface.co/upstage/Llama-2-70b-instruct-v2)**(Ours, Open LLM Leaderboard) | **73** | **71.1** | **87.9** | **70.6** | **62.2** | | **7.44063** |
| [Llama-2-70b-instruct](https://huggingface.co/upstage/Llama-2-70b-instruct) (Ours, Open LLM Leaderboard) | 72.3 | 70.9 | 87.5 | 69.8 | 61 | | 7.24375 |
| [llama-65b-instruct](https://huggingface.co/upstage/llama-65b-instruct) (Ours, Open LLM Leaderboard) | 69.4 | 67.6 | 86.5 | 64.9 | 58.8 | | |
| Llama-2-70b-hf | 67.3 | 67.3 | 87.3 | 69.8 | 44.9 | | |
| [llama-30b-instruct-2048](https://huggingface.co/upstage/llama-30b-instruct-2048) (***Ours***, ***Open LLM Leaderboard***) | 67.0 | 64.9 | 84.9 | 61.9 | 56.3 | | |
| [llama-30b-instruct](https://huggingface.co/upstage/llama-30b-instruct) (Ours, Open LLM Leaderboard) | 65.2 | 62.5 | 86.2 | 59.4 | 52.8 | | |
| llama-65b | 64.2 | 63.5 | 86.1 | 63.9 | 43.4 | | |
| falcon-40b-instruct | 63.4 | 61.6 | 84.3 | 55.4 | 52.5 | | |
### Scripts for H4 Score Reproduction
- Prepare evaluation environments:
```
# clone the repository
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
# check out the specific commit
git checkout b281b0921b636bc36ad05c0b0b0763bd6dd43463
# change to the repository directory
cd lm-evaluation-harness
```
## Ethical Issues
### Ethical Considerations
- There were no ethical issues involved, as we did not include the benchmark test set or the training set in the model's training process
## Contact Us
### Why Upstage LLM?
- [Upstage](https://en.upstage.ai)'s LLM research has yielded remarkable results. As of August 1st, our 70B model has reached the top spot in openLLM rankings, marking itself as the current leading performer globally. Recognizing the immense potential in implementing private LLM to actual businesses, we invite you to easily apply private LLM and fine-tune it with your own data. For a seamless and tailored solution, please do not hesitate to reach out to us. ► [click here to contact](https://www.upstage.ai/private-llm?utm_source=huggingface&utm_medium=link&utm_campaign=privatellm)
|
[
"SCIQ"
] |
judithrosell/JNLPBA_SciBERT_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:allenai/scibert_scivocab_uncased",
"base_model:finetune:allenai/scibert_scivocab_uncased",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-18T11:28:19Z |
2023-12-18T12:03:36+00:00
| 90 | 0 |
---
base_model: allenai/scibert_scivocab_uncased
tags:
- generated_from_trainer
model-index:
- name: JNLPBA_SciBERT_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# JNLPBA_SciBERT_NER
This model is a fine-tuned version of [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1472
- Seqeval classification report: precision recall f1-score support
DNA 0.83 0.89 0.86 2106
RNA 0.88 0.89 0.88 3516
cell_line 0.74 0.80 0.77 526
cell_type 0.78 0.83 0.80 1475
protein 0.98 0.97 0.98 37428
micro avg 0.96 0.96 0.96 45051
macro avg 0.84 0.87 0.86 45051
weighted avg 0.96 0.96 0.96 45051
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Seqeval classification report |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| 0.233 | 1.0 | 582 | 0.1513 | precision recall f1-score support
DNA 0.82 0.89 0.85 2106
RNA 0.87 0.89 0.88 3516
cell_line 0.72 0.79 0.76 526
cell_type 0.79 0.78 0.79 1475
protein 0.98 0.97 0.98 37428
micro avg 0.95 0.95 0.95 45051
macro avg 0.84 0.87 0.85 45051
weighted avg 0.95 0.95 0.95 45051
|
| 0.138 | 2.0 | 1164 | 0.1486 | precision recall f1-score support
DNA 0.85 0.85 0.85 2106
RNA 0.89 0.87 0.88 3516
cell_line 0.71 0.80 0.75 526
cell_type 0.77 0.82 0.79 1475
protein 0.98 0.97 0.98 37428
micro avg 0.96 0.95 0.95 45051
macro avg 0.84 0.86 0.85 45051
weighted avg 0.96 0.95 0.96 45051
|
| 0.1191 | 3.0 | 1746 | 0.1472 | precision recall f1-score support
DNA 0.83 0.89 0.86 2106
RNA 0.88 0.89 0.88 3516
cell_line 0.74 0.80 0.77 526
cell_type 0.78 0.83 0.80 1475
protein 0.98 0.97 0.98 37428
micro avg 0.96 0.96 0.96 45051
macro avg 0.84 0.87 0.86 45051
weighted avg 0.96 0.96 0.96 45051
|
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0
|
[
"JNLPBA"
] |
judithrosell/BlueBERT_CRAFT_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12",
"base_model:finetune:bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12",
"license:cc0-1.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-23T15:58:06Z |
2023-12-26T19:11:33+00:00
| 90 | 0 |
---
base_model: bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12
license: cc0-1.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: BlueBERT_CRAFT_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BlueBERT_CRAFT_NER
This model is a fine-tuned version of [bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12](https://huggingface.co/bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1403
- Precision: 0.8067
- Recall: 0.7909
- F1: 0.7987
- Accuracy: 0.9633
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 347 | 0.1578 | 0.7663 | 0.7662 | 0.7662 | 0.9562 |
| 0.2328 | 2.0 | 695 | 0.1396 | 0.7927 | 0.7994 | 0.7961 | 0.9620 |
| 0.0645 | 3.0 | 1041 | 0.1403 | 0.8067 | 0.7909 | 0.7987 | 0.9633 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.0
- Tokenizers 0.15.0
|
[
"CRAFT"
] |
judithrosell/PubMedBERT_CRAFT_NER_new
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-27T11:58:23Z |
2023-12-27T12:14:13+00:00
| 90 | 0 |
---
base_model: microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext
license: mit
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: PubMedBERT_CRAFT_NER_new
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# PubMedBERT_CRAFT_NER_new
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1034
- Precision: 0.9811
- Recall: 0.9782
- F1: 0.9797
- Accuracy: 0.9751
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2176 | 1.0 | 695 | 0.1101 | 0.9780 | 0.9739 | 0.9759 | 0.9708 |
| 0.0555 | 2.0 | 1390 | 0.1019 | 0.9800 | 0.9770 | 0.9785 | 0.9739 |
| 0.0283 | 3.0 | 2085 | 0.1034 | 0.9811 | 0.9782 | 0.9797 | 0.9751 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.0
- Tokenizers 0.15.0
|
[
"CRAFT"
] |
CAS-SIAT-XinHai/CPsyCounX
|
CAS-SIAT-XinHai
|
feature-extraction
|
[
"transformers",
"safetensors",
"internlm2",
"feature-extraction",
"custom_code",
"zh",
"dataset:CAS-SIAT-XinHai/CPsyCoun",
"arxiv:2405.16433",
"base_model:internlm/internlm2-chat-7b",
"base_model:finetune:internlm/internlm2-chat-7b",
"license:apache-2.0",
"region:us"
] | 2024-06-05T08:46:38Z |
2024-07-22T15:47:00+00:00
| 90 | 2 |
---
base_model: internlm/internlm2-chat-7b
datasets:
- CAS-SIAT-XinHai/CPsyCoun
language:
- zh
license: apache-2.0
---
# CPsyCounX
This model is a fine-tuned version of [internlm/internlm2-chat-7b](https://huggingface.co/internlm/internlm2-chat-7b) on the [CPsyCounD](https://huggingface.co/datasets/CAS-SIAT-XinHai/CPsyCoun) dataset.
## Model description
**CPsyCounX** is a large language model designed for Chinese Psychological Counseling. Paper: [CPsyCoun](https://arxiv.org/abs/2405.16433).
## Training and evaluation data
- Train: [CPsyCounD](https://huggingface.co/datasets/CAS-SIAT-XinHai/CPsyCoun)
- Evaluate: [CPsyCounE](https://github.com/CAS-SIAT-XinHai/CPsyCoun/tree/main/CPsyCounE)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 28
- total_train_batch_size: 448
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 9.0
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.37.1
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1
|
[
"CAS"
] |
MohamedAhmedAE/Llama3-8B-Medical-Finetune-V2-Merged
|
MohamedAhmedAE
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"medical",
"mmlu",
"medalpaca",
"medmcqa",
"conversational",
"dataset:cais/mmlu",
"dataset:medalpaca/medical_meadow_medqa",
"dataset:medalpaca/medical_meadow_wikidoc",
"dataset:openlifescienceai/medmcqa",
"dataset:bigbio/med_qa",
"dataset:GBaker/MedQA-USMLE-4-options",
"dataset:medalpaca/medical_meadow_mmmlu",
"dataset:medalpaca/medical_meadow_wikidoc_patient_information",
"dataset:qiaojin/PubMedQA",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | 2024-07-15T11:42:11Z |
2024-07-15T22:28:19+00:00
| 90 | 0 |
---
datasets:
- cais/mmlu
- medalpaca/medical_meadow_medqa
- medalpaca/medical_meadow_wikidoc
- openlifescienceai/medmcqa
- bigbio/med_qa
- GBaker/MedQA-USMLE-4-options
- medalpaca/medical_meadow_mmmlu
- medalpaca/medical_meadow_wikidoc_patient_information
- qiaojin/PubMedQA
pipeline_tag: text-generation
tags:
- medical
- mmlu
- medalpaca
- medmcqa
---
### Evaluation results
| Dataset | GPT-3.5 | Tuned Llama 3 V1 | Tuned Llama 3 V2 |
|:-------------:|:-----:|:----:|:----:|
| MMLU Clinical Knowledge | 69.8| 74.34 | 73.20 |
| MMLU College Biology | 72.2| 72.92 | 74.30 |
| MMLU College Medicine | 61.3| 61.85 | 66.47 |
| MMLU Medical Genetics | 70.0| 76.0 | 74.0 |
| MMLU Professional Medicine| 70.2| 72.43 | 71.32 |
| MMLU Anatomy | 56.3| 61.48 | 64.44 |
|
[
"MEDQA",
"PUBMEDQA"
] |
retrieva-jp/amber-base
|
retrieva-jp
|
feature-extraction
|
[
"sentence-transformers",
"safetensors",
"modernbert",
"sentence-similarity",
"feature-extraction",
"mteb",
"ja",
"en",
"arxiv:2412.13663",
"arxiv:2211.09260",
"base_model:sbintuitions/modernbert-ja-130m",
"base_model:finetune:sbintuitions/modernbert-ja-130m",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2025-03-07T01:10:01Z |
2025-03-09T14:26:59+00:00
| 90 | 0 |
---
base_model: sbintuitions/modernbert-ja-130m
language:
- ja
- en
license: apache-2.0
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- mteb
model-index:
- name: retrieva-jp/amber-base
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 68.1642
- type: f1
value: 61.9811
- type: f1_weighted
value: 71.2157
- type: ap
value: 30.6541
- type: ap_weighted
value: 30.6541
- type: main_score
value: 68.1642
- task:
type: Clustering
dataset:
name: MTEB ArXivHierarchicalClusteringP2P (default)
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: 0bbdb47bcbe3a90093699aefeed338a0f28a7ee8
metrics:
- type: v_measure
value: 55.655100000000004
- type: v_measure_std
value: 3.2918999999999996
- type: main_score
value: 55.655100000000004
- task:
type: Clustering
dataset:
name: MTEB ArXivHierarchicalClusteringS2S (default)
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: b73bd54100e5abfa6e3a23dcafb46fe4d2438dc3
metrics:
- type: v_measure
value: 53.6493
- type: v_measure_std
value: 3.2359
- type: main_score
value: 53.6493
- task:
type: Retrieval
dataset:
name: MTEB ArguAna (default)
type: mteb/arguana
config: default
split: test
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
metrics:
- type: ndcg_at_1
value: 25.249
- type: ndcg_at_3
value: 38.056
- type: ndcg_at_5
value: 43.124
- type: ndcg_at_10
value: 48.068
- type: ndcg_at_20
value: 51.461
- type: ndcg_at_100
value: 53.15800000000001
- type: ndcg_at_1000
value: 53.38
- type: map_at_1
value: 25.249
- type: map_at_3
value: 34.803
- type: map_at_5
value: 37.598
- type: map_at_10
value: 39.611000000000004
- type: map_at_20
value: 40.569
- type: map_at_100
value: 40.821000000000005
- type: map_at_1000
value: 40.83
- type: recall_at_1
value: 25.249
- type: recall_at_3
value: 47.510999999999996
- type: recall_at_5
value: 59.885999999999996
- type: recall_at_10
value: 75.32
- type: recall_at_20
value: 88.549
- type: recall_at_100
value: 97.44
- type: recall_at_1000
value: 99.14699999999999
- type: precision_at_1
value: 25.249
- type: precision_at_3
value: 15.837000000000002
- type: precision_at_5
value: 11.977
- type: precision_at_10
value: 7.532
- type: precision_at_20
value: 4.427
- type: precision_at_100
value: 0.9740000000000001
- type: precision_at_1000
value: 0.099
- type: mrr_at_1
value: 25.817899999999998
- type: mrr_at_3
value: 34.9692
- type: mrr_at_5
value: 37.7928
- type: mrr_at_10
value: 39.8238
- type: mrr_at_20
value: 40.7844
- type: mrr_at_100
value: 41.0403
- type: mrr_at_1000
value: 41.0495
- type: nauc_ndcg_at_1_max
value: -2.6569
- type: nauc_ndcg_at_1_std
value: -2.4726000000000004
- type: nauc_ndcg_at_1_diff1
value: 10.259699999999999
- type: nauc_ndcg_at_3_max
value: -0.8151
- type: nauc_ndcg_at_3_std
value: -3.3642
- type: nauc_ndcg_at_3_diff1
value: 7.884099999999999
- type: nauc_ndcg_at_5_max
value: -0.3906
- type: nauc_ndcg_at_5_std
value: -2.4619
- type: nauc_ndcg_at_5_diff1
value: 7.558
- type: nauc_ndcg_at_10_max
value: 1.0935000000000001
- type: nauc_ndcg_at_10_std
value: -1.8624999999999998
- type: nauc_ndcg_at_10_diff1
value: 8.0503
- type: nauc_ndcg_at_20_max
value: 1.3164
- type: nauc_ndcg_at_20_std
value: -1.3407
- type: nauc_ndcg_at_20_diff1
value: 7.8992
- type: nauc_ndcg_at_100_max
value: 0.8316
- type: nauc_ndcg_at_100_std
value: -0.8725
- type: nauc_ndcg_at_100_diff1
value: 8.5633
- type: nauc_ndcg_at_1000_max
value: 0.44999999999999996
- type: nauc_ndcg_at_1000_std
value: -1.4357
- type: nauc_ndcg_at_1000_diff1
value: 8.4438
- type: nauc_map_at_1_max
value: -2.6569
- type: nauc_map_at_1_std
value: -2.4726000000000004
- type: nauc_map_at_1_diff1
value: 10.259699999999999
- type: nauc_map_at_3_max
value: -1.3567
- type: nauc_map_at_3_std
value: -3.222
- type: nauc_map_at_3_diff1
value: 8.3557
- type: nauc_map_at_5_max
value: -1.162
- type: nauc_map_at_5_std
value: -2.7384
- type: nauc_map_at_5_diff1
value: 8.118400000000001
- type: nauc_map_at_10_max
value: -0.615
- type: nauc_map_at_10_std
value: -2.5394
- type: nauc_map_at_10_diff1
value: 8.283100000000001
- type: nauc_map_at_20_max
value: -0.5492
- type: nauc_map_at_20_std
value: -2.4076
- type: nauc_map_at_20_diff1
value: 8.280999999999999
- type: nauc_map_at_100_max
value: -0.6049
- type: nauc_map_at_100_std
value: -2.3560000000000003
- type: nauc_map_at_100_diff1
value: 8.3933
- type: nauc_map_at_1000_max
value: -0.6154
- type: nauc_map_at_1000_std
value: -2.373
- type: nauc_map_at_1000_diff1
value: 8.3902
- type: nauc_recall_at_1_max
value: -2.6569
- type: nauc_recall_at_1_std
value: -2.4726000000000004
- type: nauc_recall_at_1_diff1
value: 10.259699999999999
- type: nauc_recall_at_3_max
value: 0.7234
- type: nauc_recall_at_3_std
value: -3.7315
- type: nauc_recall_at_3_diff1
value: 6.6138
- type: nauc_recall_at_5_max
value: 2.0847
- type: nauc_recall_at_5_std
value: -1.4385000000000001
- type: nauc_recall_at_5_diff1
value: 5.9428
- type: nauc_recall_at_10_max
value: 9.2417
- type: nauc_recall_at_10_std
value: 1.6372000000000002
- type: nauc_recall_at_10_diff1
value: 7.6442
- type: nauc_recall_at_20_max
value: 17.9819
- type: nauc_recall_at_20_std
value: 9.3827
- type: nauc_recall_at_20_diff1
value: 5.2288
- type: nauc_recall_at_100_max
value: 46.3576
- type: nauc_recall_at_100_std
value: 69.5314
- type: nauc_recall_at_100_diff1
value: 25.2365
- type: nauc_recall_at_1000_max
value: 47.3173
- type: nauc_recall_at_1000_std
value: 80.3564
- type: nauc_recall_at_1000_diff1
value: 30.506
- type: nauc_precision_at_1_max
value: -2.6569
- type: nauc_precision_at_1_std
value: -2.4726000000000004
- type: nauc_precision_at_1_diff1
value: 10.259699999999999
- type: nauc_precision_at_3_max
value: 0.7234
- type: nauc_precision_at_3_std
value: -3.7315
- type: nauc_precision_at_3_diff1
value: 6.6138
- type: nauc_precision_at_5_max
value: 2.0847
- type: nauc_precision_at_5_std
value: -1.4385000000000001
- type: nauc_precision_at_5_diff1
value: 5.9428
- type: nauc_precision_at_10_max
value: 9.2417
- type: nauc_precision_at_10_std
value: 1.6372000000000002
- type: nauc_precision_at_10_diff1
value: 7.6442
- type: nauc_precision_at_20_max
value: 17.9819
- type: nauc_precision_at_20_std
value: 9.3827
- type: nauc_precision_at_20_diff1
value: 5.2288
- type: nauc_precision_at_100_max
value: 46.3576
- type: nauc_precision_at_100_std
value: 69.5314
- type: nauc_precision_at_100_diff1
value: 25.2365
- type: nauc_precision_at_1000_max
value: 47.3173
- type: nauc_precision_at_1000_std
value: 80.3564
- type: nauc_precision_at_1000_diff1
value: 30.506
- type: nauc_mrr_at_1_max
value: -2.5852
- type: nauc_mrr_at_1_std
value: -2.7133000000000003
- type: nauc_mrr_at_1_diff1
value: 8.3902
- type: nauc_mrr_at_3_max
value: -2.3878
- type: nauc_mrr_at_3_std
value: -3.1916
- type: nauc_mrr_at_3_diff1
value: 6.3759999999999994
- type: nauc_mrr_at_5_max
value: -2.0079
- type: nauc_mrr_at_5_std
value: -2.9791000000000003
- type: nauc_mrr_at_5_diff1
value: 6.3531
- type: nauc_mrr_at_10_max
value: -1.41
- type: nauc_mrr_at_10_std
value: -2.7921
- type: nauc_mrr_at_10_diff1
value: 6.514200000000001
- type: nauc_mrr_at_20_max
value: -1.35
- type: nauc_mrr_at_20_std
value: -2.6331
- type: nauc_mrr_at_20_diff1
value: 6.4700999999999995
- type: nauc_mrr_at_100_max
value: -1.393
- type: nauc_mrr_at_100_std
value: -2.5819
- type: nauc_mrr_at_100_diff1
value: 6.5875
- type: nauc_mrr_at_1000_max
value: -1.4037000000000002
- type: nauc_mrr_at_1000_std
value: -2.5989
- type: nauc_mrr_at_1000_diff1
value: 6.583799999999999
- type: main_score
value: 48.068
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions (default)
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 56.5225
- type: mrr
value: 70.5146
- type: nAUC_map_max
value: 18.224
- type: nAUC_map_std
value: 12.5352
- type: nAUC_map_diff1
value: 14.0464
- type: nAUC_mrr_max
value: 28.619699999999998
- type: nAUC_mrr_std
value: 21.69
- type: nAUC_mrr_diff1
value: 15.8021
- type: main_score
value: 56.5225
- task:
type: STS
dataset:
name: MTEB BIOSSES (default)
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: pearson
value: 86.6855
- type: spearman
value: 83.17360000000001
- type: cosine_pearson
value: 86.6855
- type: cosine_spearman
value: 83.17360000000001
- type: manhattan_pearson
value: 85.5442
- type: manhattan_spearman
value: 83.9501
- type: euclidean_pearson
value: 85.0403
- type: euclidean_spearman
value: 83.17360000000001
- type: main_score
value: 83.17360000000001
- task:
type: Classification
dataset:
name: MTEB Banking77Classification (default)
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 76.3312
- type: f1
value: 75.4609
- type: f1_weighted
value: 75.4609
- type: main_score
value: 76.3312
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P.v2 (default)
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: f5dbc242e11dd8e24def4c4268607a49e02946dc
metrics:
- type: v_measure
value: 33.6692
- type: v_measure_std
value: 0.769
- type: main_score
value: 33.6692
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGamingRetrieval (default)
type: mteb/cqadupstack-gaming
config: default
split: test
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
metrics:
- type: ndcg_at_1
value: 30.345
- type: ndcg_at_3
value: 37.726
- type: ndcg_at_5
value: 39.999
- type: ndcg_at_10
value: 42.732
- type: ndcg_at_20
value: 44.696000000000005
- type: ndcg_at_100
value: 47.461
- type: ndcg_at_1000
value: 49.341
- type: map_at_1
value: 26.484999999999996
- type: map_at_3
value: 34.474
- type: map_at_5
value: 35.94
- type: map_at_10
value: 37.24
- type: map_at_20
value: 37.852999999999994
- type: map_at_100
value: 38.286
- type: map_at_1000
value: 38.369
- type: recall_at_1
value: 26.484999999999996
- type: recall_at_3
value: 42.857
- type: recall_at_5
value: 48.501
- type: recall_at_10
value: 56.48
- type: recall_at_20
value: 63.81099999999999
- type: recall_at_100
value: 77.518
- type: recall_at_1000
value: 90.89
- type: precision_at_1
value: 30.345
- type: precision_at_3
value: 17.241
- type: precision_at_5
value: 11.962
- type: precision_at_10
value: 7.204000000000001
- type: precision_at_20
value: 4.1290000000000004
- type: precision_at_100
value: 1.0330000000000001
- type: precision_at_1000
value: 0.127
- type: mrr_at_1
value: 30.3448
- type: mrr_at_3
value: 37.5131
- type: mrr_at_5
value: 38.8516
- type: mrr_at_10
value: 39.915299999999995
- type: mrr_at_20
value: 40.428599999999996
- type: mrr_at_100
value: 40.7757
- type: mrr_at_1000
value: 40.8275
- type: nauc_ndcg_at_1_max
value: 30.5442
- type: nauc_ndcg_at_1_std
value: -10.3888
- type: nauc_ndcg_at_1_diff1
value: 52.476
- type: nauc_ndcg_at_3_max
value: 28.6927
- type: nauc_ndcg_at_3_std
value: -8.8728
- type: nauc_ndcg_at_3_diff1
value: 45.094699999999996
- type: nauc_ndcg_at_5_max
value: 29.259600000000002
- type: nauc_ndcg_at_5_std
value: -7.945399999999999
- type: nauc_ndcg_at_5_diff1
value: 44.600699999999996
- type: nauc_ndcg_at_10_max
value: 29.9977
- type: nauc_ndcg_at_10_std
value: -6.1746
- type: nauc_ndcg_at_10_diff1
value: 44.2832
- type: nauc_ndcg_at_20_max
value: 30.034100000000002
- type: nauc_ndcg_at_20_std
value: -4.8941
- type: nauc_ndcg_at_20_diff1
value: 43.3814
- type: nauc_ndcg_at_100_max
value: 30.812800000000003
- type: nauc_ndcg_at_100_std
value: -3.5000999999999998
- type: nauc_ndcg_at_100_diff1
value: 43.345
- type: nauc_ndcg_at_1000_max
value: 30.9884
- type: nauc_ndcg_at_1000_std
value: -3.9316999999999998
- type: nauc_ndcg_at_1000_diff1
value: 43.6512
- type: nauc_map_at_1_max
value: 27.442800000000002
- type: nauc_map_at_1_std
value: -9.8884
- type: nauc_map_at_1_diff1
value: 52.666999999999994
- type: nauc_map_at_3_max
value: 27.897100000000002
- type: nauc_map_at_3_std
value: -9.777
- type: nauc_map_at_3_diff1
value: 47.013
- type: nauc_map_at_5_max
value: 28.3476
- type: nauc_map_at_5_std
value: -9.3335
- type: nauc_map_at_5_diff1
value: 46.7246
- type: nauc_map_at_10_max
value: 28.921000000000003
- type: nauc_map_at_10_std
value: -8.4018
- type: nauc_map_at_10_diff1
value: 46.5358
- type: nauc_map_at_20_max
value: 29.033900000000003
- type: nauc_map_at_20_std
value: -7.985100000000001
- type: nauc_map_at_20_diff1
value: 46.2362
- type: nauc_map_at_100_max
value: 29.2382
- type: nauc_map_at_100_std
value: -7.7172
- type: nauc_map_at_100_diff1
value: 46.2663
- type: nauc_map_at_1000_max
value: 29.263699999999996
- type: nauc_map_at_1000_std
value: -7.7108
- type: nauc_map_at_1000_diff1
value: 46.2735
- type: nauc_recall_at_1_max
value: 27.442800000000002
- type: nauc_recall_at_1_std
value: -9.8884
- type: nauc_recall_at_1_diff1
value: 52.666999999999994
- type: nauc_recall_at_3_max
value: 25.7102
- type: nauc_recall_at_3_std
value: -8.2064
- type: nauc_recall_at_3_diff1
value: 39.145
- type: nauc_recall_at_5_max
value: 27.244699999999998
- type: nauc_recall_at_5_std
value: -5.943
- type: nauc_recall_at_5_diff1
value: 38.024
- type: nauc_recall_at_10_max
value: 29.226000000000003
- type: nauc_recall_at_10_std
value: -0.2402
- type: nauc_recall_at_10_diff1
value: 36.58
- type: nauc_recall_at_20_max
value: 29.567500000000003
- type: nauc_recall_at_20_std
value: 6.2502
- type: nauc_recall_at_20_diff1
value: 32.092999999999996
- type: nauc_recall_at_100_max
value: 33.8086
- type: nauc_recall_at_100_std
value: 20.092
- type: nauc_recall_at_100_diff1
value: 27.5754
- type: nauc_recall_at_1000_max
value: 38.0782
- type: nauc_recall_at_1000_std
value: 34.3309
- type: nauc_recall_at_1000_diff1
value: 17.712
- type: nauc_precision_at_1_max
value: 30.5442
- type: nauc_precision_at_1_std
value: -10.3888
- type: nauc_precision_at_1_diff1
value: 52.476
- type: nauc_precision_at_3_max
value: 29.0858
- type: nauc_precision_at_3_std
value: -5.8233
- type: nauc_precision_at_3_diff1
value: 33.480900000000005
- type: nauc_precision_at_5_max
value: 30.425200000000004
- type: nauc_precision_at_5_std
value: -2.0077000000000003
- type: nauc_precision_at_5_diff1
value: 29.5631
- type: nauc_precision_at_10_max
value: 30.8693
- type: nauc_precision_at_10_std
value: 4.5986
- type: nauc_precision_at_10_diff1
value: 23.346600000000002
- type: nauc_precision_at_20_max
value: 29.6844
- type: nauc_precision_at_20_std
value: 9.4699
- type: nauc_precision_at_20_diff1
value: 15.9193
- type: nauc_precision_at_100_max
value: 29.7036
- type: nauc_precision_at_100_std
value: 19.0186
- type: nauc_precision_at_100_diff1
value: 5.9221
- type: nauc_precision_at_1000_max
value: 24.6994
- type: nauc_precision_at_1000_std
value: 18.0033
- type: nauc_precision_at_1000_diff1
value: -3.2275
- type: nauc_mrr_at_1_max
value: 30.5442
- type: nauc_mrr_at_1_std
value: -10.3888
- type: nauc_mrr_at_1_diff1
value: 52.476
- type: nauc_mrr_at_3_max
value: 29.7504
- type: nauc_mrr_at_3_std
value: -9.5234
- type: nauc_mrr_at_3_diff1
value: 46.5068
- type: nauc_mrr_at_5_max
value: 30.341099999999997
- type: nauc_mrr_at_5_std
value: -8.4966
- type: nauc_mrr_at_5_diff1
value: 46.051199999999994
- type: nauc_mrr_at_10_max
value: 30.6066
- type: nauc_mrr_at_10_std
value: -7.8854
- type: nauc_mrr_at_10_diff1
value: 46.035199999999996
- type: nauc_mrr_at_20_max
value: 30.570199999999996
- type: nauc_mrr_at_20_std
value: -7.614700000000001
- type: nauc_mrr_at_20_diff1
value: 45.8861
- type: nauc_mrr_at_100_max
value: 30.589100000000002
- type: nauc_mrr_at_100_std
value: -7.5529
- type: nauc_mrr_at_100_diff1
value: 45.907
- type: nauc_mrr_at_1000_max
value: 30.587799999999998
- type: nauc_mrr_at_1000_std
value: -7.5716
- type: nauc_mrr_at_1000_diff1
value: 45.9244
- type: main_score
value: 42.732
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackUnixRetrieval (default)
type: mteb/cqadupstack-unix
config: default
split: test
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
metrics:
- type: ndcg_at_1
value: 18.843
- type: ndcg_at_3
value: 22.131
- type: ndcg_at_5
value: 23.772
- type: ndcg_at_10
value: 25.661
- type: ndcg_at_20
value: 27.939999999999998
- type: ndcg_at_100
value: 31.645
- type: ndcg_at_1000
value: 34.687
- type: map_at_1
value: 16.194
- type: map_at_3
value: 20.068
- type: map_at_5
value: 21.075
- type: map_at_10
value: 21.913
- type: map_at_20
value: 22.569
- type: map_at_100
value: 23.107
- type: map_at_1000
value: 23.23
- type: recall_at_1
value: 16.194
- type: recall_at_3
value: 24.704
- type: recall_at_5
value: 28.859
- type: recall_at_10
value: 34.402
- type: recall_at_20
value: 42.714
- type: recall_at_100
value: 61.19799999999999
- type: recall_at_1000
value: 82.953
- type: precision_at_1
value: 18.843
- type: precision_at_3
value: 9.919
- type: precision_at_5
value: 7.071
- type: precision_at_10
value: 4.328
- type: precision_at_20
value: 2.752
- type: precision_at_100
value: 0.823
- type: precision_at_1000
value: 0.121
- type: mrr_at_1
value: 18.8433
- type: mrr_at_3
value: 22.776699999999998
- type: mrr_at_5
value: 23.9055
- type: mrr_at_10
value: 24.7244
- type: mrr_at_20
value: 25.3919
- type: mrr_at_100
value: 25.8783
- type: mrr_at_1000
value: 25.957900000000002
- type: nauc_ndcg_at_1_max
value: 35.1013
- type: nauc_ndcg_at_1_std
value: 4.116899999999999
- type: nauc_ndcg_at_1_diff1
value: 54.3984
- type: nauc_ndcg_at_3_max
value: 35.1035
- type: nauc_ndcg_at_3_std
value: 5.3618
- type: nauc_ndcg_at_3_diff1
value: 47.4455
- type: nauc_ndcg_at_5_max
value: 34.3845
- type: nauc_ndcg_at_5_std
value: 5.4364
- type: nauc_ndcg_at_5_diff1
value: 44.8757
- type: nauc_ndcg_at_10_max
value: 33.4252
- type: nauc_ndcg_at_10_std
value: 7.100099999999999
- type: nauc_ndcg_at_10_diff1
value: 43.0854
- type: nauc_ndcg_at_20_max
value: 33.2135
- type: nauc_ndcg_at_20_std
value: 7.750500000000001
- type: nauc_ndcg_at_20_diff1
value: 42.5065
- type: nauc_ndcg_at_100_max
value: 34.0845
- type: nauc_ndcg_at_100_std
value: 9.0937
- type: nauc_ndcg_at_100_diff1
value: 40.9634
- type: nauc_ndcg_at_1000_max
value: 34.3716
- type: nauc_ndcg_at_1000_std
value: 9.8049
- type: nauc_ndcg_at_1000_diff1
value: 41.606
- type: nauc_map_at_1_max
value: 35.054
- type: nauc_map_at_1_std
value: 3.4526000000000003
- type: nauc_map_at_1_diff1
value: 55.69840000000001
- type: nauc_map_at_3_max
value: 34.861
- type: nauc_map_at_3_std
value: 4.6036
- type: nauc_map_at_3_diff1
value: 49.338
- type: nauc_map_at_5_max
value: 34.3213
- type: nauc_map_at_5_std
value: 4.7856000000000005
- type: nauc_map_at_5_diff1
value: 47.856
- type: nauc_map_at_10_max
value: 33.9813
- type: nauc_map_at_10_std
value: 5.649
- type: nauc_map_at_10_diff1
value: 47.0563
- type: nauc_map_at_20_max
value: 33.8854
- type: nauc_map_at_20_std
value: 5.9026000000000005
- type: nauc_map_at_20_diff1
value: 46.876200000000004
- type: nauc_map_at_100_max
value: 33.996500000000005
- type: nauc_map_at_100_std
value: 6.094200000000001
- type: nauc_map_at_100_diff1
value: 46.6388
- type: nauc_map_at_1000_max
value: 34.0082
- type: nauc_map_at_1000_std
value: 6.1436
- type: nauc_map_at_1000_diff1
value: 46.643
- type: nauc_recall_at_1_max
value: 35.054
- type: nauc_recall_at_1_std
value: 3.4526000000000003
- type: nauc_recall_at_1_diff1
value: 55.69840000000001
- type: nauc_recall_at_3_max
value: 34.2271
- type: nauc_recall_at_3_std
value: 5.573
- type: nauc_recall_at_3_diff1
value: 42.0593
- type: nauc_recall_at_5_max
value: 32.7785
- type: nauc_recall_at_5_std
value: 6.188599999999999
- type: nauc_recall_at_5_diff1
value: 36.9345
- type: nauc_recall_at_10_max
value: 29.7004
- type: nauc_recall_at_10_std
value: 10.3771
- type: nauc_recall_at_10_diff1
value: 31.6352
- type: nauc_recall_at_20_max
value: 28.474100000000004
- type: nauc_recall_at_20_std
value: 12.3244
- type: nauc_recall_at_20_diff1
value: 29.6458
- type: nauc_recall_at_100_max
value: 31.2612
- type: nauc_recall_at_100_std
value: 19.1574
- type: nauc_recall_at_100_diff1
value: 19.7616
- type: nauc_recall_at_1000_max
value: 33.2982
- type: nauc_recall_at_1000_std
value: 36.4068
- type: nauc_recall_at_1000_diff1
value: 15.3188
- type: nauc_precision_at_1_max
value: 35.1013
- type: nauc_precision_at_1_std
value: 4.116899999999999
- type: nauc_precision_at_1_diff1
value: 54.3984
- type: nauc_precision_at_3_max
value: 34.4651
- type: nauc_precision_at_3_std
value: 7.8735
- type: nauc_precision_at_3_diff1
value: 39.7844
- type: nauc_precision_at_5_max
value: 32.2792
- type: nauc_precision_at_5_std
value: 8.465
- type: nauc_precision_at_5_diff1
value: 34.130700000000004
- type: nauc_precision_at_10_max
value: 28.197699999999998
- type: nauc_precision_at_10_std
value: 12.1518
- type: nauc_precision_at_10_diff1
value: 28.672900000000002
- type: nauc_precision_at_20_max
value: 27.2073
- type: nauc_precision_at_20_std
value: 14.113100000000001
- type: nauc_precision_at_20_diff1
value: 23.623
- type: nauc_precision_at_100_max
value: 22.906399999999998
- type: nauc_precision_at_100_std
value: 16.7201
- type: nauc_precision_at_100_diff1
value: 7.0853
- type: nauc_precision_at_1000_max
value: 10.5167
- type: nauc_precision_at_1000_std
value: 11.5017
- type: nauc_precision_at_1000_diff1
value: -6.6079
- type: nauc_mrr_at_1_max
value: 35.1013
- type: nauc_mrr_at_1_std
value: 4.116899999999999
- type: nauc_mrr_at_1_diff1
value: 54.3984
- type: nauc_mrr_at_3_max
value: 35.489399999999996
- type: nauc_mrr_at_3_std
value: 5.097700000000001
- type: nauc_mrr_at_3_diff1
value: 48.8783
- type: nauc_mrr_at_5_max
value: 35.2093
- type: nauc_mrr_at_5_std
value: 5.2317
- type: nauc_mrr_at_5_diff1
value: 47.3602
- type: nauc_mrr_at_10_max
value: 34.731
- type: nauc_mrr_at_10_std
value: 5.7762
- type: nauc_mrr_at_10_diff1
value: 46.495999999999995
- type: nauc_mrr_at_20_max
value: 34.6509
- type: nauc_mrr_at_20_std
value: 5.8511
- type: nauc_mrr_at_20_diff1
value: 46.386500000000005
- type: nauc_mrr_at_100_max
value: 34.7761
- type: nauc_mrr_at_100_std
value: 6.0355
- type: nauc_mrr_at_100_diff1
value: 46.2476
- type: nauc_mrr_at_1000_max
value: 34.792699999999996
- type: nauc_mrr_at_1000_std
value: 6.0607
- type: nauc_mrr_at_1000_diff1
value: 46.281800000000004
- type: main_score
value: 25.661
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVERHardNegatives (default)
type: mteb/ClimateFEVER_test_top_250_only_w_correct-v2
config: default
split: test
revision: 3a309e201f3c2c4b13bd4a367a8f37eee2ec1d21
metrics:
- type: ndcg_at_1
value: 16.8
- type: ndcg_at_3
value: 15.503
- type: ndcg_at_5
value: 17.5
- type: ndcg_at_10
value: 20.642
- type: ndcg_at_20
value: 23.07
- type: ndcg_at_100
value: 27.639000000000003
- type: ndcg_at_1000
value: 32.041
- type: map_at_1
value: 7.885000000000001
- type: map_at_3
value: 11.128
- type: map_at_5
value: 12.565999999999999
- type: map_at_10
value: 13.876
- type: map_at_20
value: 14.66
- type: map_at_100
value: 15.432000000000002
- type: map_at_1000
value: 15.655
- type: recall_at_1
value: 7.885000000000001
- type: recall_at_3
value: 14.957
- type: recall_at_5
value: 19.675
- type: recall_at_10
value: 26.868
- type: recall_at_20
value: 33.94
- type: recall_at_100
value: 51.833
- type: recall_at_1000
value: 76.822
- type: precision_at_1
value: 16.8
- type: precision_at_3
value: 11.533
- type: precision_at_5
value: 9.56
- type: precision_at_10
value: 6.83
- type: precision_at_20
value: 4.41
- type: precision_at_100
value: 1.432
- type: precision_at_1000
value: 0.22499999999999998
- type: mrr_at_1
value: 16.8
- type: mrr_at_3
value: 23.2333
- type: mrr_at_5
value: 25.2183
- type: mrr_at_10
value: 26.775
- type: mrr_at_20
value: 27.4121
- type: mrr_at_100
value: 27.882299999999997
- type: mrr_at_1000
value: 27.9472
- type: nauc_ndcg_at_1_max
value: 28.3609
- type: nauc_ndcg_at_1_std
value: 10.5951
- type: nauc_ndcg_at_1_diff1
value: 16.566
- type: nauc_ndcg_at_3_max
value: 33.3794
- type: nauc_ndcg_at_3_std
value: 14.645900000000001
- type: nauc_ndcg_at_3_diff1
value: 15.4617
- type: nauc_ndcg_at_5_max
value: 33.5092
- type: nauc_ndcg_at_5_std
value: 16.209699999999998
- type: nauc_ndcg_at_5_diff1
value: 16.7386
- type: nauc_ndcg_at_10_max
value: 37.101299999999995
- type: nauc_ndcg_at_10_std
value: 20.939
- type: nauc_ndcg_at_10_diff1
value: 15.1232
- type: nauc_ndcg_at_20_max
value: 38.3563
- type: nauc_ndcg_at_20_std
value: 22.3038
- type: nauc_ndcg_at_20_diff1
value: 14.613100000000001
- type: nauc_ndcg_at_100_max
value: 39.5793
- type: nauc_ndcg_at_100_std
value: 23.3348
- type: nauc_ndcg_at_100_diff1
value: 13.6571
- type: nauc_ndcg_at_1000_max
value: 39.2582
- type: nauc_ndcg_at_1000_std
value: 22.5989
- type: nauc_ndcg_at_1000_diff1
value: 12.6784
- type: nauc_map_at_1_max
value: 36.9819
- type: nauc_map_at_1_std
value: 11.5065
- type: nauc_map_at_1_diff1
value: 22.4791
- type: nauc_map_at_3_max
value: 35.324299999999994
- type: nauc_map_at_3_std
value: 13.572000000000001
- type: nauc_map_at_3_diff1
value: 19.3415
- type: nauc_map_at_5_max
value: 35.0138
- type: nauc_map_at_5_std
value: 14.857600000000001
- type: nauc_map_at_5_diff1
value: 19.5352
- type: nauc_map_at_10_max
value: 36.8267
- type: nauc_map_at_10_std
value: 17.6287
- type: nauc_map_at_10_diff1
value: 18.2802
- type: nauc_map_at_20_max
value: 37.5214
- type: nauc_map_at_20_std
value: 18.319399999999998
- type: nauc_map_at_20_diff1
value: 18.0343
- type: nauc_map_at_100_max
value: 37.933499999999995
- type: nauc_map_at_100_std
value: 18.6864
- type: nauc_map_at_100_diff1
value: 17.7119
- type: nauc_map_at_1000_max
value: 37.9509
- type: nauc_map_at_1000_std
value: 18.6975
- type: nauc_map_at_1000_diff1
value: 17.5997
- type: nauc_recall_at_1_max
value: 36.9819
- type: nauc_recall_at_1_std
value: 11.5065
- type: nauc_recall_at_1_diff1
value: 22.4791
- type: nauc_recall_at_3_max
value: 33.0875
- type: nauc_recall_at_3_std
value: 16.3976
- type: nauc_recall_at_3_diff1
value: 15.6164
- type: nauc_recall_at_5_max
value: 30.604799999999997
- type: nauc_recall_at_5_std
value: 17.1699
- type: nauc_recall_at_5_diff1
value: 15.639800000000001
- type: nauc_recall_at_10_max
value: 35.342400000000005
- type: nauc_recall_at_10_std
value: 24.665599999999998
- type: nauc_recall_at_10_diff1
value: 11.9499
- type: nauc_recall_at_20_max
value: 35.956700000000005
- type: nauc_recall_at_20_std
value: 26.556800000000003
- type: nauc_recall_at_20_diff1
value: 10.0239
- type: nauc_recall_at_100_max
value: 36.1012
- type: nauc_recall_at_100_std
value: 27.8055
- type: nauc_recall_at_100_diff1
value: 6.3591
- type: nauc_recall_at_1000_max
value: 34.7202
- type: nauc_recall_at_1000_std
value: 26.378
- type: nauc_recall_at_1000_diff1
value: -0.7171000000000001
- type: nauc_precision_at_1_max
value: 28.3609
- type: nauc_precision_at_1_std
value: 10.5951
- type: nauc_precision_at_1_diff1
value: 16.566
- type: nauc_precision_at_3_max
value: 30.490000000000002
- type: nauc_precision_at_3_std
value: 16.270899999999997
- type: nauc_precision_at_3_diff1
value: 9.7026
- type: nauc_precision_at_5_max
value: 29.3491
- type: nauc_precision_at_5_std
value: 19.084699999999998
- type: nauc_precision_at_5_diff1
value: 10.7809
- type: nauc_precision_at_10_max
value: 34.753699999999995
- type: nauc_precision_at_10_std
value: 28.155
- type: nauc_precision_at_10_diff1
value: 5.6554
- type: nauc_precision_at_20_max
value: 33.3812
- type: nauc_precision_at_20_std
value: 27.122400000000003
- type: nauc_precision_at_20_diff1
value: 3.6636
- type: nauc_precision_at_100_max
value: 28.7799
- type: nauc_precision_at_100_std
value: 23.9905
- type: nauc_precision_at_100_diff1
value: -0.5301
- type: nauc_precision_at_1000_max
value: 13.068399999999999
- type: nauc_precision_at_1000_std
value: 12.9133
- type: nauc_precision_at_1000_diff1
value: -8.8717
- type: nauc_mrr_at_1_max
value: 28.3609
- type: nauc_mrr_at_1_std
value: 10.5951
- type: nauc_mrr_at_1_diff1
value: 16.566
- type: nauc_mrr_at_3_max
value: 30.9311
- type: nauc_mrr_at_3_std
value: 13.9549
- type: nauc_mrr_at_3_diff1
value: 12.851399999999998
- type: nauc_mrr_at_5_max
value: 30.893700000000003
- type: nauc_mrr_at_5_std
value: 14.464599999999999
- type: nauc_mrr_at_5_diff1
value: 13.2001
- type: nauc_mrr_at_10_max
value: 32.277499999999996
- type: nauc_mrr_at_10_std
value: 15.9378
- type: nauc_mrr_at_10_diff1
value: 12.9887
- type: nauc_mrr_at_20_max
value: 32.3817
- type: nauc_mrr_at_20_std
value: 16.0469
- type: nauc_mrr_at_20_diff1
value: 13.039200000000001
- type: nauc_mrr_at_100_max
value: 32.386900000000004
- type: nauc_mrr_at_100_std
value: 15.966800000000001
- type: nauc_mrr_at_100_diff1
value: 12.982
- type: nauc_mrr_at_1000_max
value: 32.347300000000004
- type: nauc_mrr_at_1000_std
value: 15.9096
- type: nauc_mrr_at_1000_diff1
value: 12.9742
- type: main_score
value: 20.642
- task:
type: Retrieval
dataset:
name: MTEB FEVERHardNegatives (default)
type: mteb/FEVER_test_top_250_only_w_correct-v2
config: default
split: test
revision: 080c9ed6267b65029207906e815d44a9240bafca
metrics:
- type: ndcg_at_1
value: 46.9
- type: ndcg_at_3
value: 57.825
- type: ndcg_at_5
value: 61.245000000000005
- type: ndcg_at_10
value: 63.836000000000006
- type: ndcg_at_20
value: 65.408
- type: ndcg_at_100
value: 66.796
- type: ndcg_at_1000
value: 67.216
- type: map_at_1
value: 43.999
- type: map_at_3
value: 53.813
- type: map_at_5
value: 55.741
- type: map_at_10
value: 56.852999999999994
- type: map_at_20
value: 57.30800000000001
- type: map_at_100
value: 57.54
- type: map_at_1000
value: 57.56099999999999
- type: recall_at_1
value: 43.999
- type: recall_at_3
value: 66.184
- type: recall_at_5
value: 74.557
- type: recall_at_10
value: 82.394
- type: recall_at_20
value: 88.51
- type: recall_at_100
value: 95.253
- type: recall_at_1000
value: 98.031
- type: precision_at_1
value: 46.9
- type: precision_at_3
value: 23.599999999999998
- type: precision_at_5
value: 15.98
- type: precision_at_10
value: 8.85
- type: precision_at_20
value: 4.760000000000001
- type: precision_at_100
value: 1.045
- type: precision_at_1000
value: 0.11
- type: mrr_at_1
value: 46.9
- type: mrr_at_3
value: 57.0167
- type: mrr_at_5
value: 59.046699999999994
- type: mrr_at_10
value: 60.1422
- type: mrr_at_20
value: 60.535799999999995
- type: mrr_at_100
value: 60.716
- type: mrr_at_1000
value: 60.7232
- type: nauc_ndcg_at_1_max
value: 12.741900000000001
- type: nauc_ndcg_at_1_std
value: -20.011000000000003
- type: nauc_ndcg_at_1_diff1
value: 51.02100000000001
- type: nauc_ndcg_at_3_max
value: 17.416400000000003
- type: nauc_ndcg_at_3_std
value: -20.9336
- type: nauc_ndcg_at_3_diff1
value: 46.3134
- type: nauc_ndcg_at_5_max
value: 18.2369
- type: nauc_ndcg_at_5_std
value: -21.5645
- type: nauc_ndcg_at_5_diff1
value: 46.261799999999994
- type: nauc_ndcg_at_10_max
value: 18.8528
- type: nauc_ndcg_at_10_std
value: -20.6893
- type: nauc_ndcg_at_10_diff1
value: 46.5862
- type: nauc_ndcg_at_20_max
value: 18.0211
- type: nauc_ndcg_at_20_std
value: -19.652
- type: nauc_ndcg_at_20_diff1
value: 46.5482
- type: nauc_ndcg_at_100_max
value: 17.766000000000002
- type: nauc_ndcg_at_100_std
value: -18.7245
- type: nauc_ndcg_at_100_diff1
value: 47.0345
- type: nauc_ndcg_at_1000_max
value: 17.596500000000002
- type: nauc_ndcg_at_1000_std
value: -19.0628
- type: nauc_ndcg_at_1000_diff1
value: 47.12
- type: nauc_map_at_1_max
value: 13.017599999999998
- type: nauc_map_at_1_std
value: -18.8296
- type: nauc_map_at_1_diff1
value: 49.8762
- type: nauc_map_at_3_max
value: 16.2438
- type: nauc_map_at_3_std
value: -20.1711
- type: nauc_map_at_3_diff1
value: 47.2236
- type: nauc_map_at_5_max
value: 16.541
- type: nauc_map_at_5_std
value: -20.4952
- type: nauc_map_at_5_diff1
value: 47.1971
- type: nauc_map_at_10_max
value: 16.7266
- type: nauc_map_at_10_std
value: -20.1189
- type: nauc_map_at_10_diff1
value: 47.2762
- type: nauc_map_at_20_max
value: 16.5198
- type: nauc_map_at_20_std
value: -19.8167
- type: nauc_map_at_20_diff1
value: 47.266799999999996
- type: nauc_map_at_100_max
value: 16.467200000000002
- type: nauc_map_at_100_std
value: -19.7016
- type: nauc_map_at_100_diff1
value: 47.3389
- type: nauc_map_at_1000_max
value: 16.466900000000003
- type: nauc_map_at_1000_std
value: -19.704
- type: nauc_map_at_1000_diff1
value: 47.341
- type: nauc_recall_at_1_max
value: 13.017599999999998
- type: nauc_recall_at_1_std
value: -18.8296
- type: nauc_recall_at_1_diff1
value: 49.8762
- type: nauc_recall_at_3_max
value: 20.579700000000003
- type: nauc_recall_at_3_std
value: -21.263399999999997
- type: nauc_recall_at_3_diff1
value: 40.7412
- type: nauc_recall_at_5_max
value: 23.308799999999998
- type: nauc_recall_at_5_std
value: -23.0915
- type: nauc_recall_at_5_diff1
value: 38.2001
- type: nauc_recall_at_10_max
value: 27.296
- type: nauc_recall_at_10_std
value: -19.2697
- type: nauc_recall_at_10_diff1
value: 35.9711
- type: nauc_recall_at_20_max
value: 23.9957
- type: nauc_recall_at_20_std
value: -10.1564
- type: nauc_recall_at_20_diff1
value: 30.5332
- type: nauc_recall_at_100_max
value: 27.0148
- type: nauc_recall_at_100_std
value: 25.655299999999997
- type: nauc_recall_at_100_diff1
value: 23.1136
- type: nauc_recall_at_1000_max
value: 28.9392
- type: nauc_recall_at_1000_std
value: 47.491
- type: nauc_recall_at_1000_diff1
value: 15.6225
- type: nauc_precision_at_1_max
value: 12.741900000000001
- type: nauc_precision_at_1_std
value: -20.011000000000003
- type: nauc_precision_at_1_diff1
value: 51.02100000000001
- type: nauc_precision_at_3_max
value: 20.477999999999998
- type: nauc_precision_at_3_std
value: -24.4646
- type: nauc_precision_at_3_diff1
value: 41.1551
- type: nauc_precision_at_5_max
value: 24.364
- type: nauc_precision_at_5_std
value: -27.1997
- type: nauc_precision_at_5_diff1
value: 38.9501
- type: nauc_precision_at_10_max
value: 30.684299999999997
- type: nauc_precision_at_10_std
value: -23.1531
- type: nauc_precision_at_10_diff1
value: 34.6829
- type: nauc_precision_at_20_max
value: 24.1828
- type: nauc_precision_at_20_std
value: -10.783800000000001
- type: nauc_precision_at_20_diff1
value: 22.662399999999998
- type: nauc_precision_at_100_max
value: 12.189
- type: nauc_precision_at_100_std
value: 10.600999999999999
- type: nauc_precision_at_100_diff1
value: -0.2197
- type: nauc_precision_at_1000_max
value: 1.1533
- type: nauc_precision_at_1000_std
value: 6.2423
- type: nauc_precision_at_1000_diff1
value: -10.4662
- type: nauc_mrr_at_1_max
value: 12.741900000000001
- type: nauc_mrr_at_1_std
value: -20.011000000000003
- type: nauc_mrr_at_1_diff1
value: 51.02100000000001
- type: nauc_mrr_at_3_max
value: 16.4501
- type: nauc_mrr_at_3_std
value: -21.337500000000002
- type: nauc_mrr_at_3_diff1
value: 48.4594
- type: nauc_mrr_at_5_max
value: 16.8928
- type: nauc_mrr_at_5_std
value: -21.7254
- type: nauc_mrr_at_5_diff1
value: 48.619299999999996
- type: nauc_mrr_at_10_max
value: 17.0057
- type: nauc_mrr_at_10_std
value: -21.465899999999998
- type: nauc_mrr_at_10_diff1
value: 48.848200000000006
- type: nauc_mrr_at_20_max
value: 16.745099999999997
- type: nauc_mrr_at_20_std
value: -21.2914
- type: nauc_mrr_at_20_diff1
value: 48.861900000000006
- type: nauc_mrr_at_100_max
value: 16.653399999999998
- type: nauc_mrr_at_100_std
value: -21.1954
- type: nauc_mrr_at_100_diff1
value: 48.9097
- type: nauc_mrr_at_1000_max
value: 16.650000000000002
- type: nauc_mrr_at_1000_std
value: -21.2048
- type: nauc_mrr_at_1000_diff1
value: 48.911500000000004
- type: main_score
value: 63.836000000000006
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018 (default)
type: mteb/fiqa
config: default
split: test
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
metrics:
- type: ndcg_at_1
value: 25.154
- type: ndcg_at_3
value: 22.85
- type: ndcg_at_5
value: 23.788999999999998
- type: ndcg_at_10
value: 25.657000000000004
- type: ndcg_at_20
value: 28.058
- type: ndcg_at_100
value: 32.019999999999996
- type: ndcg_at_1000
value: 36.124
- type: map_at_1
value: 12.594
- type: map_at_3
value: 17.345
- type: map_at_5
value: 18.740000000000002
- type: map_at_10
value: 19.871
- type: map_at_20
value: 20.71
- type: map_at_100
value: 21.404
- type: map_at_1000
value: 21.616
- type: recall_at_1
value: 12.594
- type: recall_at_3
value: 20.682000000000002
- type: recall_at_5
value: 24.735
- type: recall_at_10
value: 30.217
- type: recall_at_20
value: 37.714999999999996
- type: recall_at_100
value: 54.364000000000004
- type: recall_at_1000
value: 79.487
- type: precision_at_1
value: 25.154
- type: precision_at_3
value: 15.174999999999999
- type: precision_at_5
value: 11.235000000000001
- type: precision_at_10
value: 7.13
- type: precision_at_20
value: 4.522
- type: precision_at_100
value: 1.341
- type: precision_at_1000
value: 0.20500000000000002
- type: mrr_at_1
value: 25.154300000000003
- type: mrr_at_3
value: 30.324099999999998
- type: mrr_at_5
value: 31.581799999999998
- type: mrr_at_10
value: 32.5208
- type: mrr_at_20
value: 33.055
- type: mrr_at_100
value: 33.4738
- type: mrr_at_1000
value: 33.5533
- type: nauc_ndcg_at_1_max
value: 20.836199999999998
- type: nauc_ndcg_at_1_std
value: -2.4346
- type: nauc_ndcg_at_1_diff1
value: 41.3264
- type: nauc_ndcg_at_3_max
value: 21.4673
- type: nauc_ndcg_at_3_std
value: -0.35760000000000003
- type: nauc_ndcg_at_3_diff1
value: 36.5457
- type: nauc_ndcg_at_5_max
value: 21.0022
- type: nauc_ndcg_at_5_std
value: 0.30079999999999996
- type: nauc_ndcg_at_5_diff1
value: 35.1377
- type: nauc_ndcg_at_10_max
value: 21.4511
- type: nauc_ndcg_at_10_std
value: 1.9931
- type: nauc_ndcg_at_10_diff1
value: 35.367599999999996
- type: nauc_ndcg_at_20_max
value: 21.9794
- type: nauc_ndcg_at_20_std
value: 3.2666
- type: nauc_ndcg_at_20_diff1
value: 33.9954
- type: nauc_ndcg_at_100_max
value: 22.666900000000002
- type: nauc_ndcg_at_100_std
value: 6.1648000000000005
- type: nauc_ndcg_at_100_diff1
value: 32.5715
- type: nauc_ndcg_at_1000_max
value: 23.9645
- type: nauc_ndcg_at_1000_std
value: 7.031
- type: nauc_ndcg_at_1000_diff1
value: 32.6535
- type: nauc_map_at_1_max
value: 13.436699999999998
- type: nauc_map_at_1_std
value: -6.1377
- type: nauc_map_at_1_diff1
value: 46.1518
- type: nauc_map_at_3_max
value: 17.6491
- type: nauc_map_at_3_std
value: -3.3383000000000003
- type: nauc_map_at_3_diff1
value: 39.909800000000004
- type: nauc_map_at_5_max
value: 18.4969
- type: nauc_map_at_5_std
value: -1.8129
- type: nauc_map_at_5_diff1
value: 38.4072
- type: nauc_map_at_10_max
value: 19.4823
- type: nauc_map_at_10_std
value: -0.2211
- type: nauc_map_at_10_diff1
value: 38.1346
- type: nauc_map_at_20_max
value: 19.9898
- type: nauc_map_at_20_std
value: 0.6002000000000001
- type: nauc_map_at_20_diff1
value: 37.755100000000006
- type: nauc_map_at_100_max
value: 20.2321
- type: nauc_map_at_100_std
value: 1.2189999999999999
- type: nauc_map_at_100_diff1
value: 37.379
- type: nauc_map_at_1000_max
value: 20.3676
- type: nauc_map_at_1000_std
value: 1.3561999999999999
- type: nauc_map_at_1000_diff1
value: 37.3216
- type: nauc_recall_at_1_max
value: 13.436699999999998
- type: nauc_recall_at_1_std
value: -6.1377
- type: nauc_recall_at_1_diff1
value: 46.1518
- type: nauc_recall_at_3_max
value: 17.4283
- type: nauc_recall_at_3_std
value: -2.0456
- type: nauc_recall_at_3_diff1
value: 34.5422
- type: nauc_recall_at_5_max
value: 18.2169
- type: nauc_recall_at_5_std
value: 0.7002
- type: nauc_recall_at_5_diff1
value: 29.7798
- type: nauc_recall_at_10_max
value: 19.6832
- type: nauc_recall_at_10_std
value: 4.6769
- type: nauc_recall_at_10_diff1
value: 27.8829
- type: nauc_recall_at_20_max
value: 20.095
- type: nauc_recall_at_20_std
value: 6.884899999999999
- type: nauc_recall_at_20_diff1
value: 22.7741
- type: nauc_recall_at_100_max
value: 20.5351
- type: nauc_recall_at_100_std
value: 19.2636
- type: nauc_recall_at_100_diff1
value: 16.2238
- type: nauc_recall_at_1000_max
value: 27.9838
- type: nauc_recall_at_1000_std
value: 33.3099
- type: nauc_recall_at_1000_diff1
value: 12.701699999999999
- type: nauc_precision_at_1_max
value: 20.836199999999998
- type: nauc_precision_at_1_std
value: -2.4346
- type: nauc_precision_at_1_diff1
value: 41.3264
- type: nauc_precision_at_3_max
value: 26.558500000000002
- type: nauc_precision_at_3_std
value: 3.6578
- type: nauc_precision_at_3_diff1
value: 27.0323
- type: nauc_precision_at_5_max
value: 28.794199999999996
- type: nauc_precision_at_5_std
value: 8.6533
- type: nauc_precision_at_5_diff1
value: 21.9488
- type: nauc_precision_at_10_max
value: 29.7713
- type: nauc_precision_at_10_std
value: 13.645399999999999
- type: nauc_precision_at_10_diff1
value: 20.1386
- type: nauc_precision_at_20_max
value: 28.0465
- type: nauc_precision_at_20_std
value: 16.3569
- type: nauc_precision_at_20_diff1
value: 14.969299999999999
- type: nauc_precision_at_100_max
value: 26.7123
- type: nauc_precision_at_100_std
value: 19.1407
- type: nauc_precision_at_100_diff1
value: 5.7822
- type: nauc_precision_at_1000_max
value: 23.6681
- type: nauc_precision_at_1000_std
value: 16.3438
- type: nauc_precision_at_1000_diff1
value: -3.3699
- type: nauc_mrr_at_1_max
value: 20.836199999999998
- type: nauc_mrr_at_1_std
value: -2.4346
- type: nauc_mrr_at_1_diff1
value: 41.3264
- type: nauc_mrr_at_3_max
value: 22.4267
- type: nauc_mrr_at_3_std
value: -0.1948
- type: nauc_mrr_at_3_diff1
value: 36.9255
- type: nauc_mrr_at_5_max
value: 22.6662
- type: nauc_mrr_at_5_std
value: 0.4444
- type: nauc_mrr_at_5_diff1
value: 35.957
- type: nauc_mrr_at_10_max
value: 22.5111
- type: nauc_mrr_at_10_std
value: 0.7020000000000001
- type: nauc_mrr_at_10_diff1
value: 35.6976
- type: nauc_mrr_at_20_max
value: 22.4416
- type: nauc_mrr_at_20_std
value: 0.8706999999999999
- type: nauc_mrr_at_20_diff1
value: 35.2034
- type: nauc_mrr_at_100_max
value: 22.4571
- type: nauc_mrr_at_100_std
value: 1.0563
- type: nauc_mrr_at_100_diff1
value: 35.177
- type: nauc_mrr_at_1000_max
value: 22.4743
- type: nauc_mrr_at_1000_std
value: 1.0505
- type: nauc_mrr_at_1000_diff1
value: 35.2186
- type: main_score
value: 25.657000000000004
- task:
type: Retrieval
dataset:
name: MTEB HotpotQAHardNegatives (default)
type: mteb/HotpotQA_test_top_250_only_w_correct-v2
config: default
split: test
revision: 617612fa63afcb60e3b134bed8b7216a99707c37
metrics:
- type: ndcg_at_1
value: 58.9
- type: ndcg_at_3
value: 45.092999999999996
- type: ndcg_at_5
value: 47.806
- type: ndcg_at_10
value: 50.666
- type: ndcg_at_20
value: 52.644000000000005
- type: ndcg_at_100
value: 56.071000000000005
- type: ndcg_at_1000
value: 58.262
- type: map_at_1
value: 29.45
- type: map_at_3
value: 37.675
- type: map_at_5
value: 39.562999999999995
- type: map_at_10
value: 41.056
- type: map_at_20
value: 41.765
- type: map_at_100
value: 42.425000000000004
- type: map_at_1000
value: 42.54
- type: recall_at_1
value: 29.45
- type: recall_at_3
value: 41.75
- type: recall_at_5
value: 47.099999999999994
- type: recall_at_10
value: 54.300000000000004
- type: recall_at_20
value: 60.699999999999996
- type: recall_at_100
value: 75.9
- type: recall_at_1000
value: 90.3
- type: precision_at_1
value: 58.9
- type: precision_at_3
value: 27.833000000000002
- type: precision_at_5
value: 18.84
- type: precision_at_10
value: 10.86
- type: precision_at_20
value: 6.069999999999999
- type: precision_at_100
value: 1.518
- type: precision_at_1000
value: 0.181
- type: mrr_at_1
value: 58.9
- type: mrr_at_3
value: 64.81670000000001
- type: mrr_at_5
value: 65.9717
- type: mrr_at_10
value: 66.84750000000001
- type: mrr_at_20
value: 67.1864
- type: mrr_at_100
value: 67.3796
- type: mrr_at_1000
value: 67.3962
- type: nauc_ndcg_at_1_max
value: 40.6699
- type: nauc_ndcg_at_1_std
value: -6.4051
- type: nauc_ndcg_at_1_diff1
value: 61.4074
- type: nauc_ndcg_at_3_max
value: 36.086200000000005
- type: nauc_ndcg_at_3_std
value: -3.8372
- type: nauc_ndcg_at_3_diff1
value: 44.0991
- type: nauc_ndcg_at_5_max
value: 35.1661
- type: nauc_ndcg_at_5_std
value: -3.4778000000000002
- type: nauc_ndcg_at_5_diff1
value: 41.2298
- type: nauc_ndcg_at_10_max
value: 34.5689
- type: nauc_ndcg_at_10_std
value: -0.7254
- type: nauc_ndcg_at_10_diff1
value: 38.9824
- type: nauc_ndcg_at_20_max
value: 35.4153
- type: nauc_ndcg_at_20_std
value: 0.9502999999999999
- type: nauc_ndcg_at_20_diff1
value: 38.5558
- type: nauc_ndcg_at_100_max
value: 36.187799999999996
- type: nauc_ndcg_at_100_std
value: 3.3059
- type: nauc_ndcg_at_100_diff1
value: 37.775
- type: nauc_ndcg_at_1000_max
value: 36.9076
- type: nauc_ndcg_at_1000_std
value: 3.2030000000000003
- type: nauc_ndcg_at_1000_diff1
value: 39.6691
- type: nauc_map_at_1_max
value: 40.6699
- type: nauc_map_at_1_std
value: -6.4051
- type: nauc_map_at_1_diff1
value: 61.4074
- type: nauc_map_at_3_max
value: 34.8654
- type: nauc_map_at_3_std
value: -1.9401000000000002
- type: nauc_map_at_3_diff1
value: 40.4559
- type: nauc_map_at_5_max
value: 34.0362
- type: nauc_map_at_5_std
value: -1.677
- type: nauc_map_at_5_diff1
value: 38.384
- type: nauc_map_at_10_max
value: 33.8136
- type: nauc_map_at_10_std
value: -0.2753
- type: nauc_map_at_10_diff1
value: 37.1326
- type: nauc_map_at_20_max
value: 34.1981
- type: nauc_map_at_20_std
value: 0.2882
- type: nauc_map_at_20_diff1
value: 36.996
- type: nauc_map_at_100_max
value: 34.2694
- type: nauc_map_at_100_std
value: 0.596
- type: nauc_map_at_100_diff1
value: 36.858200000000004
- type: nauc_map_at_1000_max
value: 34.3301
- type: nauc_map_at_1000_std
value: 0.6459
- type: nauc_map_at_1000_diff1
value: 36.9437
- type: nauc_recall_at_1_max
value: 40.6699
- type: nauc_recall_at_1_std
value: -6.4051
- type: nauc_recall_at_1_diff1
value: 61.4074
- type: nauc_recall_at_3_max
value: 33.4227
- type: nauc_recall_at_3_std
value: -2.6978
- type: nauc_recall_at_3_diff1
value: 35.5329
- type: nauc_recall_at_5_max
value: 29.759900000000002
- type: nauc_recall_at_5_std
value: -1.7928
- type: nauc_recall_at_5_diff1
value: 27.8553
- type: nauc_recall_at_10_max
value: 27.2765
- type: nauc_recall_at_10_std
value: 5.0284
- type: nauc_recall_at_10_diff1
value: 21.5188
- type: nauc_recall_at_20_max
value: 27.456500000000002
- type: nauc_recall_at_20_std
value: 10.4452
- type: nauc_recall_at_20_diff1
value: 17.377100000000002
- type: nauc_recall_at_100_max
value: 27.960400000000003
- type: nauc_recall_at_100_std
value: 26.0653
- type: nauc_recall_at_100_diff1
value: 5.9226
- type: nauc_recall_at_1000_max
value: 33.996700000000004
- type: nauc_recall_at_1000_std
value: 44.291199999999996
- type: nauc_recall_at_1000_diff1
value: 7.6986
- type: nauc_precision_at_1_max
value: 40.6699
- type: nauc_precision_at_1_std
value: -6.4051
- type: nauc_precision_at_1_diff1
value: 61.4074
- type: nauc_precision_at_3_max
value: 33.4227
- type: nauc_precision_at_3_std
value: -2.6978
- type: nauc_precision_at_3_diff1
value: 35.5329
- type: nauc_precision_at_5_max
value: 29.759900000000002
- type: nauc_precision_at_5_std
value: -1.7928
- type: nauc_precision_at_5_diff1
value: 27.8553
- type: nauc_precision_at_10_max
value: 27.2765
- type: nauc_precision_at_10_std
value: 5.0284
- type: nauc_precision_at_10_diff1
value: 21.5188
- type: nauc_precision_at_20_max
value: 27.456500000000002
- type: nauc_precision_at_20_std
value: 10.4452
- type: nauc_precision_at_20_diff1
value: 17.377100000000002
- type: nauc_precision_at_100_max
value: 27.960400000000003
- type: nauc_precision_at_100_std
value: 26.0653
- type: nauc_precision_at_100_diff1
value: 5.9226
- type: nauc_precision_at_1000_max
value: 33.996700000000004
- type: nauc_precision_at_1000_std
value: 44.291199999999996
- type: nauc_precision_at_1000_diff1
value: 7.6986
- type: nauc_mrr_at_1_max
value: 40.6699
- type: nauc_mrr_at_1_std
value: -6.4051
- type: nauc_mrr_at_1_diff1
value: 61.4074
- type: nauc_mrr_at_3_max
value: 40.4193
- type: nauc_mrr_at_3_std
value: -8.072899999999999
- type: nauc_mrr_at_3_diff1
value: 58.589400000000005
- type: nauc_mrr_at_5_max
value: 40.6559
- type: nauc_mrr_at_5_std
value: -8.1937
- type: nauc_mrr_at_5_diff1
value: 58.30650000000001
- type: nauc_mrr_at_10_max
value: 40.515699999999995
- type: nauc_mrr_at_10_std
value: -7.4325
- type: nauc_mrr_at_10_diff1
value: 58.1284
- type: nauc_mrr_at_20_max
value: 40.63
- type: nauc_mrr_at_20_std
value: -7.1578
- type: nauc_mrr_at_20_diff1
value: 58.215799999999994
- type: nauc_mrr_at_100_max
value: 40.693
- type: nauc_mrr_at_100_std
value: -7.0889
- type: nauc_mrr_at_100_diff1
value: 58.22389999999999
- type: nauc_mrr_at_1000_max
value: 40.700900000000004
- type: nauc_mrr_at_1000_std
value: -7.098400000000001
- type: nauc_mrr_at_1000_diff1
value: 58.2458
- type: main_score
value: 50.666
- task:
type: Classification
dataset:
name: MTEB ImdbClassification (default)
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 68.1712
- type: f1
value: 67.982
- type: f1_weighted
value: 67.982
- type: ap
value: 62.572799999999994
- type: ap_weighted
value: 62.572799999999994
- type: main_score
value: 68.1712
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.4423
- type: f1
value: 90.08840000000001
- type: f1_weighted
value: 90.44919999999999
- type: main_score
value: 90.4423
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 4672e20407010da34463acc759c162ca9734bca6
metrics:
- type: accuracy
value: 65.4371
- type: f1
value: 62.8737
- type: f1_weighted
value: 64.2218
- type: main_score
value: 65.4371
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
metrics:
- type: accuracy
value: 70.4371
- type: f1
value: 69.75200000000001
- type: f1_weighted
value: 69.7839
- type: main_score
value: 70.4371
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P.v2 (default)
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 35.1864
- type: v_measure_std
value: 0.7835
- type: main_score
value: 35.1864
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S.v2 (default)
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.8693
- type: v_measure_std
value: 0.662
- type: main_score
value: 31.8693
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking (default)
type: mteb/mind_small
config: default
split: test
revision: 59042f120c80e8afa9cdbb224f67076cec0fc9a7
metrics:
- type: map
value: 29.4367
- type: mrr
value: 30.318299999999997
- type: nAUC_map_max
value: -21.5343
- type: nAUC_map_std
value: -6.4848
- type: nAUC_map_diff1
value: 12.8559
- type: nAUC_mrr_max
value: -15.981200000000001
- type: nAUC_mrr_std
value: -4.2437000000000005
- type: nAUC_mrr_diff1
value: 12.4087
- type: main_score
value: 29.4367
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS (default)
type: mteb/scidocs
config: default
split: test
revision: f8c2fcf00f625baaa80f62ec5bd9e1fff3b8ae88
metrics:
- type: ndcg_at_1
value: 19.5
- type: ndcg_at_3
value: 15.673
- type: ndcg_at_5
value: 13.389000000000001
- type: ndcg_at_10
value: 16.179
- type: ndcg_at_20
value: 18.88
- type: ndcg_at_100
value: 23.812
- type: ndcg_at_1000
value: 29.833
- type: map_at_1
value: 3.963
- type: map_at_3
value: 6.93
- type: map_at_5
value: 8.062
- type: map_at_10
value: 9.328
- type: map_at_20
value: 10.283000000000001
- type: map_at_100
value: 11.197
- type: map_at_1000
value: 11.522
- type: recall_at_1
value: 3.963
- type: recall_at_3
value: 8.813
- type: recall_at_5
value: 11.658
- type: recall_at_10
value: 16.803
- type: recall_at_20
value: 23.169999999999998
- type: recall_at_100
value: 39.163
- type: recall_at_1000
value: 68.572
- type: precision_at_1
value: 19.5
- type: precision_at_3
value: 14.499999999999998
- type: precision_at_5
value: 11.5
- type: precision_at_10
value: 8.3
- type: precision_at_20
value: 5.71
- type: precision_at_100
value: 1.9300000000000002
- type: precision_at_1000
value: 0.338
- type: mrr_at_1
value: 19.5
- type: mrr_at_3
value: 26.016699999999997
- type: mrr_at_5
value: 27.526699999999998
- type: mrr_at_10
value: 28.9305
- type: mrr_at_20
value: 29.628100000000003
- type: mrr_at_100
value: 30.131400000000003
- type: mrr_at_1000
value: 30.201800000000002
- type: nauc_ndcg_at_1_max
value: 25.1197
- type: nauc_ndcg_at_1_std
value: 4.7176
- type: nauc_ndcg_at_1_diff1
value: 24.2336
- type: nauc_ndcg_at_3_max
value: 30.050900000000002
- type: nauc_ndcg_at_3_std
value: 11.4719
- type: nauc_ndcg_at_3_diff1
value: 20.4572
- type: nauc_ndcg_at_5_max
value: 32.224399999999996
- type: nauc_ndcg_at_5_std
value: 15.0585
- type: nauc_ndcg_at_5_diff1
value: 19.991600000000002
- type: nauc_ndcg_at_10_max
value: 33.7156
- type: nauc_ndcg_at_10_std
value: 19.2797
- type: nauc_ndcg_at_10_diff1
value: 20.3735
- type: nauc_ndcg_at_20_max
value: 34.7518
- type: nauc_ndcg_at_20_std
value: 23.227600000000002
- type: nauc_ndcg_at_20_diff1
value: 19.2851
- type: nauc_ndcg_at_100_max
value: 36.6006
- type: nauc_ndcg_at_100_std
value: 28.511599999999998
- type: nauc_ndcg_at_100_diff1
value: 18.0315
- type: nauc_ndcg_at_1000_max
value: 36.3651
- type: nauc_ndcg_at_1000_std
value: 29.7201
- type: nauc_ndcg_at_1000_diff1
value: 16.5988
- type: nauc_map_at_1_max
value: 24.954
- type: nauc_map_at_1_std
value: 4.7878
- type: nauc_map_at_1_diff1
value: 24.7611
- type: nauc_map_at_3_max
value: 30.0634
- type: nauc_map_at_3_std
value: 9.9217
- type: nauc_map_at_3_diff1
value: 21.9063
- type: nauc_map_at_5_max
value: 32.1685
- type: nauc_map_at_5_std
value: 12.8527
- type: nauc_map_at_5_diff1
value: 21.033099999999997
- type: nauc_map_at_10_max
value: 33.840199999999996
- type: nauc_map_at_10_std
value: 16.304299999999998
- type: nauc_map_at_10_diff1
value: 21.9142
- type: nauc_map_at_20_max
value: 34.2084
- type: nauc_map_at_20_std
value: 18.709799999999998
- type: nauc_map_at_20_diff1
value: 21.2113
- type: nauc_map_at_100_max
value: 35.1304
- type: nauc_map_at_100_std
value: 20.8559
- type: nauc_map_at_100_diff1
value: 20.8642
- type: nauc_map_at_1000_max
value: 35.1972
- type: nauc_map_at_1000_std
value: 21.2306
- type: nauc_map_at_1000_diff1
value: 20.7425
- type: nauc_recall_at_1_max
value: 24.954
- type: nauc_recall_at_1_std
value: 4.7878
- type: nauc_recall_at_1_diff1
value: 24.7611
- type: nauc_recall_at_3_max
value: 31.1016
- type: nauc_recall_at_3_std
value: 14.1642
- type: nauc_recall_at_3_diff1
value: 18.676000000000002
- type: nauc_recall_at_5_max
value: 33.8509
- type: nauc_recall_at_5_std
value: 19.503899999999998
- type: nauc_recall_at_5_diff1
value: 17.1764
- type: nauc_recall_at_10_max
value: 34.085300000000004
- type: nauc_recall_at_10_std
value: 25.536199999999997
- type: nauc_recall_at_10_diff1
value: 16.8913
- type: nauc_recall_at_20_max
value: 34.1879
- type: nauc_recall_at_20_std
value: 31.5486
- type: nauc_recall_at_20_diff1
value: 13.852300000000001
- type: nauc_recall_at_100_max
value: 34.313700000000004
- type: nauc_recall_at_100_std
value: 40.6137
- type: nauc_recall_at_100_diff1
value: 9.043800000000001
- type: nauc_recall_at_1000_max
value: 27.090500000000002
- type: nauc_recall_at_1000_std
value: 42.398799999999994
- type: nauc_recall_at_1000_diff1
value: -0.9452999999999999
- type: nauc_precision_at_1_max
value: 25.1197
- type: nauc_precision_at_1_std
value: 4.7176
- type: nauc_precision_at_1_diff1
value: 24.2336
- type: nauc_precision_at_3_max
value: 31.4429
- type: nauc_precision_at_3_std
value: 14.1941
- type: nauc_precision_at_3_diff1
value: 18.4824
- type: nauc_precision_at_5_max
value: 34.2219
- type: nauc_precision_at_5_std
value: 19.703699999999998
- type: nauc_precision_at_5_diff1
value: 17.0964
- type: nauc_precision_at_10_max
value: 34.380300000000005
- type: nauc_precision_at_10_std
value: 25.6554
- type: nauc_precision_at_10_diff1
value: 16.8487
- type: nauc_precision_at_20_max
value: 34.462199999999996
- type: nauc_precision_at_20_std
value: 31.465500000000002
- type: nauc_precision_at_20_diff1
value: 13.9038
- type: nauc_precision_at_100_max
value: 34.7074
- type: nauc_precision_at_100_std
value: 40.3278
- type: nauc_precision_at_100_diff1
value: 9.2637
- type: nauc_precision_at_1000_max
value: 27.213900000000002
- type: nauc_precision_at_1000_std
value: 40.8382
- type: nauc_precision_at_1000_diff1
value: -0.5306
- type: nauc_mrr_at_1_max
value: 25.1197
- type: nauc_mrr_at_1_std
value: 4.7176
- type: nauc_mrr_at_1_diff1
value: 24.2336
- type: nauc_mrr_at_3_max
value: 27.9362
- type: nauc_mrr_at_3_std
value: 9.9578
- type: nauc_mrr_at_3_diff1
value: 20.809
- type: nauc_mrr_at_5_max
value: 29.0381
- type: nauc_mrr_at_5_std
value: 11.7807
- type: nauc_mrr_at_5_diff1
value: 20.8787
- type: nauc_mrr_at_10_max
value: 28.860799999999998
- type: nauc_mrr_at_10_std
value: 12.269
- type: nauc_mrr_at_10_diff1
value: 20.7762
- type: nauc_mrr_at_20_max
value: 29.2051
- type: nauc_mrr_at_20_std
value: 12.7588
- type: nauc_mrr_at_20_diff1
value: 20.9176
- type: nauc_mrr_at_100_max
value: 29.2288
- type: nauc_mrr_at_100_std
value: 12.7523
- type: nauc_mrr_at_100_diff1
value: 20.9235
- type: nauc_mrr_at_1000_max
value: 29.2119
- type: nauc_mrr_at_1000_std
value: 12.697600000000001
- type: nauc_mrr_at_1000_diff1
value: 20.9131
- type: main_score
value: 16.179
- task:
type: STS
dataset:
name: MTEB SICK-R (default)
type: mteb/sickr-sts
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: pearson
value: 84.5347
- type: spearman
value: 79.80850000000001
- type: cosine_pearson
value: 84.5347
- type: cosine_spearman
value: 79.80850000000001
- type: manhattan_pearson
value: 81.0701
- type: manhattan_spearman
value: 79.6721
- type: euclidean_pearson
value: 81.20349999999999
- type: euclidean_spearman
value: 79.80850000000001
- type: main_score
value: 79.80850000000001
- task:
type: STS
dataset:
name: MTEB STS12 (default)
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: pearson
value: 86.88
- type: spearman
value: 78.1076
- type: cosine_pearson
value: 86.88
- type: cosine_spearman
value: 78.1052
- type: manhattan_pearson
value: 83.3712
- type: manhattan_spearman
value: 78.0898
- type: euclidean_pearson
value: 83.3731
- type: euclidean_spearman
value: 78.1052
- type: main_score
value: 78.1052
- task:
type: STS
dataset:
name: MTEB STS13 (default)
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: pearson
value: 83.5938
- type: spearman
value: 84.2951
- type: cosine_pearson
value: 83.5938
- type: cosine_spearman
value: 84.2951
- type: manhattan_pearson
value: 83.2541
- type: manhattan_spearman
value: 83.8292
- type: euclidean_pearson
value: 83.69640000000001
- type: euclidean_spearman
value: 84.2951
- type: main_score
value: 84.2951
- task:
type: STS
dataset:
name: MTEB STS14 (default)
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: pearson
value: 82.6003
- type: spearman
value: 81.3569
- type: cosine_pearson
value: 82.6003
- type: cosine_spearman
value: 81.357
- type: manhattan_pearson
value: 81.5087
- type: manhattan_spearman
value: 81.17229999999999
- type: euclidean_pearson
value: 81.7147
- type: euclidean_spearman
value: 81.3569
- type: main_score
value: 81.357
- task:
type: STS
dataset:
name: MTEB STS15 (default)
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: pearson
value: 86.4161
- type: spearman
value: 87.0039
- type: cosine_pearson
value: 86.4161
- type: cosine_spearman
value: 87.0039
- type: manhattan_pearson
value: 86.2482
- type: manhattan_spearman
value: 86.934
- type: euclidean_pearson
value: 86.3344
- type: euclidean_spearman
value: 87.0039
- type: main_score
value: 87.0039
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: pearson
value: 88.6011
- type: spearman
value: 88.1023
- type: cosine_pearson
value: 88.6011
- type: cosine_spearman
value: 88.1023
- type: manhattan_pearson
value: 88.18639999999999
- type: manhattan_spearman
value: 88.55380000000001
- type: euclidean_pearson
value: 88.011
- type: euclidean_spearman
value: 88.1023
- type: main_score
value: 88.1023
- task:
type: STS
dataset:
name: MTEB STS22.v2 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: d31f33a128469b20e357535c39b82fb3c3f6f2bd
metrics:
- type: pearson
value: 65.7746
- type: spearman
value: 64.7997
- type: cosine_pearson
value: 65.7746
- type: cosine_spearman
value: 64.7997
- type: manhattan_pearson
value: 67.5417
- type: manhattan_spearman
value: 65.27629999999999
- type: euclidean_pearson
value: 67.2574
- type: euclidean_spearman
value: 64.7997
- type: main_score
value: 64.7997
- task:
type: STS
dataset:
name: MTEB STSBenchmark (default)
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: pearson
value: 84.4276
- type: spearman
value: 84.9631
- type: cosine_pearson
value: 84.4276
- type: cosine_spearman
value: 84.9631
- type: manhattan_pearson
value: 84.4743
- type: manhattan_spearman
value: 84.7686
- type: euclidean_pearson
value: 84.6058
- type: euclidean_spearman
value: 84.9631
- type: main_score
value: 84.9631
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions (default)
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: similarity_accuracy
value: 99.7931
- type: similarity_accuracy_threshold
value: 69.6798
- type: similarity_f1
value: 89.4293
- type: similarity_f1_threshold
value: 68.3132
- type: similarity_precision
value: 88.76849999999999
- type: similarity_recall
value: 90.10000000000001
- type: similarity_ap
value: 94.3099
- type: cosine_accuracy
value: 99.7931
- type: cosine_accuracy_threshold
value: 69.6798
- type: cosine_f1
value: 89.4293
- type: cosine_f1_threshold
value: 68.3132
- type: cosine_precision
value: 88.76849999999999
- type: cosine_recall
value: 90.10000000000001
- type: cosine_ap
value: 94.3099
- type: manhattan_accuracy
value: 99.7792
- type: manhattan_accuracy_threshold
value: 1354.3922
- type: manhattan_f1
value: 88.71289999999999
- type: manhattan_f1_threshold
value: 1389.3319999999999
- type: manhattan_precision
value: 87.84309999999999
- type: manhattan_recall
value: 89.60000000000001
- type: manhattan_ap
value: 93.8459
- type: euclidean_accuracy
value: 99.7931
- type: euclidean_accuracy_threshold
value: 77.872
- type: euclidean_f1
value: 89.4293
- type: euclidean_f1_threshold
value: 79.6075
- type: euclidean_precision
value: 88.76849999999999
- type: euclidean_recall
value: 90.10000000000001
- type: euclidean_ap
value: 94.3099
- type: dot_accuracy
value: 99.7931
- type: dot_accuracy_threshold
value: 69.6798
- type: dot_f1
value: 89.4293
- type: dot_f1_threshold
value: 68.3132
- type: dot_precision
value: 88.76849999999999
- type: dot_recall
value: 90.10000000000001
- type: dot_ap
value: 94.3099
- type: max_accuracy
value: 99.7931
- type: max_f1
value: 89.4293
- type: max_precision
value: 88.76849999999999
- type: max_recall
value: 90.10000000000001
- type: max_ap
value: 94.3099
- type: main_score
value: 94.3099
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering.v2 (default)
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 53.9397
- type: v_measure_std
value: 0.7764
- type: main_score
value: 53.9397
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P.v2 (default)
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 40.6498
- type: v_measure_std
value: 0.439
- type: main_score
value: 40.6498
- task:
type: Summarization
dataset:
name: MTEB SummEvalSummarization.v2 (default)
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: pearson
value: 28.6283
- type: spearman
value: 26.0828
- type: cosine_spearman
value: 26.0828
- type: cosine_pearson
value: 28.6283
- type: dot_spearman
value: 26.0828
- type: dot_pearson
value: 28.6283
- type: main_score
value: 26.0828
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID (default)
type: mteb/trec-covid
config: default
split: test
revision: bb9466bac8153a0349341eb1b22e06409e78ef4e
metrics:
- type: ndcg_at_1
value: 66
- type: ndcg_at_3
value: 64.592
- type: ndcg_at_5
value: 63.405
- type: ndcg_at_10
value: 60.077999999999996
- type: ndcg_at_20
value: 57.202
- type: ndcg_at_100
value: 44.643
- type: ndcg_at_1000
value: 42.104
- type: map_at_1
value: 0.193
- type: map_at_3
value: 0.514
- type: map_at_5
value: 0.783
- type: map_at_10
value: 1.3719999999999999
- type: map_at_20
value: 2.371
- type: map_at_100
value: 7.353
- type: map_at_1000
value: 17.855999999999998
- type: recall_at_1
value: 0.193
- type: recall_at_3
value: 0.563
- type: recall_at_5
value: 0.907
- type: recall_at_10
value: 1.683
- type: recall_at_20
value: 3.118
- type: recall_at_100
value: 11.051
- type: recall_at_1000
value: 39.973
- type: precision_at_1
value: 74
- type: precision_at_3
value: 71.333
- type: precision_at_5
value: 68.8
- type: precision_at_10
value: 63.800000000000004
- type: precision_at_20
value: 60.5
- type: precision_at_100
value: 45.519999999999996
- type: precision_at_1000
value: 18.451999999999998
- type: mrr_at_1
value: 74
- type: mrr_at_3
value: 83.3333
- type: mrr_at_5
value: 83.7333
- type: mrr_at_10
value: 84.3524
- type: mrr_at_20
value: 84.3524
- type: mrr_at_100
value: 84.3524
- type: mrr_at_1000
value: 84.3524
- type: nauc_ndcg_at_1_max
value: 11.527800000000001
- type: nauc_ndcg_at_1_std
value: 17.1352
- type: nauc_ndcg_at_1_diff1
value: 24.955199999999998
- type: nauc_ndcg_at_3_max
value: 11.7829
- type: nauc_ndcg_at_3_std
value: 23.1421
- type: nauc_ndcg_at_3_diff1
value: 20.884
- type: nauc_ndcg_at_5_max
value: 8.8058
- type: nauc_ndcg_at_5_std
value: 27.9156
- type: nauc_ndcg_at_5_diff1
value: 7.002
- type: nauc_ndcg_at_10_max
value: 16.561
- type: nauc_ndcg_at_10_std
value: 40.528999999999996
- type: nauc_ndcg_at_10_diff1
value: -6.1467
- type: nauc_ndcg_at_20_max
value: 25.0792
- type: nauc_ndcg_at_20_std
value: 54.0689
- type: nauc_ndcg_at_20_diff1
value: -9.6224
- type: nauc_ndcg_at_100_max
value: 43.2818
- type: nauc_ndcg_at_100_std
value: 75.4432
- type: nauc_ndcg_at_100_diff1
value: -11.4618
- type: nauc_ndcg_at_1000_max
value: 50.360099999999996
- type: nauc_ndcg_at_1000_std
value: 76.03999999999999
- type: nauc_ndcg_at_1000_diff1
value: -12.5796
- type: nauc_map_at_1_max
value: 4.3809000000000005
- type: nauc_map_at_1_std
value: -17.5338
- type: nauc_map_at_1_diff1
value: 24.837
- type: nauc_map_at_3_max
value: 4.7842
- type: nauc_map_at_3_std
value: -8.9273
- type: nauc_map_at_3_diff1
value: 19.7729
- type: nauc_map_at_5_max
value: 3.6865
- type: nauc_map_at_5_std
value: -1.1584
- type: nauc_map_at_5_diff1
value: 7.3548
- type: nauc_map_at_10_max
value: 7.556400000000001
- type: nauc_map_at_10_std
value: 11.2599
- type: nauc_map_at_10_diff1
value: -3.4863999999999997
- type: nauc_map_at_20_max
value: 12.6951
- type: nauc_map_at_20_std
value: 27.3531
- type: nauc_map_at_20_diff1
value: -11.968
- type: nauc_map_at_100_max
value: 41.625099999999996
- type: nauc_map_at_100_std
value: 66.5204
- type: nauc_map_at_100_diff1
value: -12.020999999999999
- type: nauc_map_at_1000_max
value: 56.6014
- type: nauc_map_at_1000_std
value: 80.6523
- type: nauc_map_at_1000_diff1
value: -11.9876
- type: nauc_recall_at_1_max
value: 4.3809000000000005
- type: nauc_recall_at_1_std
value: -17.5338
- type: nauc_recall_at_1_diff1
value: 24.837
- type: nauc_recall_at_3_max
value: -0.8904000000000001
- type: nauc_recall_at_3_std
value: -11.2455
- type: nauc_recall_at_3_diff1
value: 17.6352
- type: nauc_recall_at_5_max
value: -4.6216
- type: nauc_recall_at_5_std
value: -3.5367999999999995
- type: nauc_recall_at_5_diff1
value: 3.3192
- type: nauc_recall_at_10_max
value: 1.8993
- type: nauc_recall_at_10_std
value: 6.844600000000001
- type: nauc_recall_at_10_diff1
value: -6.0693
- type: nauc_recall_at_20_max
value: 5.733
- type: nauc_recall_at_20_std
value: 20.6114
- type: nauc_recall_at_20_diff1
value: -11.631
- type: nauc_recall_at_100_max
value: 32.7146
- type: nauc_recall_at_100_std
value: 55.6053
- type: nauc_recall_at_100_diff1
value: -10.7219
- type: nauc_recall_at_1000_max
value: 50.7544
- type: nauc_recall_at_1000_std
value: 68.4639
- type: nauc_recall_at_1000_diff1
value: -10.431600000000001
- type: nauc_precision_at_1_max
value: 13.8681
- type: nauc_precision_at_1_std
value: -3.4711
- type: nauc_precision_at_1_diff1
value: 36.945
- type: nauc_precision_at_3_max
value: 11.6309
- type: nauc_precision_at_3_std
value: 5.0299000000000005
- type: nauc_precision_at_3_diff1
value: 28.5186
- type: nauc_precision_at_5_max
value: 10.1297
- type: nauc_precision_at_5_std
value: 19.049599999999998
- type: nauc_precision_at_5_diff1
value: 7.918500000000001
- type: nauc_precision_at_10_max
value: 21.3492
- type: nauc_precision_at_10_std
value: 39.6679
- type: nauc_precision_at_10_diff1
value: -10.7691
- type: nauc_precision_at_20_max
value: 32.4627
- type: nauc_precision_at_20_std
value: 57.2564
- type: nauc_precision_at_20_diff1
value: -12.0336
- type: nauc_precision_at_100_max
value: 47.7277
- type: nauc_precision_at_100_std
value: 77.0329
- type: nauc_precision_at_100_diff1
value: -9.2173
- type: nauc_precision_at_1000_max
value: 47.6622
- type: nauc_precision_at_1000_std
value: 62.8329
- type: nauc_precision_at_1000_diff1
value: -5.9713
- type: nauc_mrr_at_1_max
value: 13.8681
- type: nauc_mrr_at_1_std
value: -3.4711
- type: nauc_mrr_at_1_diff1
value: 36.945
- type: nauc_mrr_at_3_max
value: 9.6673
- type: nauc_mrr_at_3_std
value: -4.3877
- type: nauc_mrr_at_3_diff1
value: 39.2075
- type: nauc_mrr_at_5_max
value: 7.9742999999999995
- type: nauc_mrr_at_5_std
value: -4.8388
- type: nauc_mrr_at_5_diff1
value: 38.314
- type: nauc_mrr_at_10_max
value: 11.6962
- type: nauc_mrr_at_10_std
value: -2.7085000000000004
- type: nauc_mrr_at_10_diff1
value: 37.695
- type: nauc_mrr_at_20_max
value: 11.6962
- type: nauc_mrr_at_20_std
value: -2.7085000000000004
- type: nauc_mrr_at_20_diff1
value: 37.695
- type: nauc_mrr_at_100_max
value: 11.6962
- type: nauc_mrr_at_100_std
value: -2.7085000000000004
- type: nauc_mrr_at_100_diff1
value: 37.695
- type: nauc_mrr_at_1000_max
value: 11.6962
- type: nauc_mrr_at_1000_std
value: -2.7085000000000004
- type: nauc_mrr_at_1000_diff1
value: 37.695
- type: main_score
value: 60.077999999999996
- task:
type: Retrieval
dataset:
name: MTEB Touche2020Retrieval.v3 (default)
type: mteb/webis-touche2020-v3
config: default
split: test
revision: 431886eaecc48f067a3975b70d0949ea2862463c
metrics:
- type: ndcg_at_1
value: 58.163
- type: ndcg_at_3
value: 58.884
- type: ndcg_at_5
value: 53.062
- type: ndcg_at_10
value: 47.571999999999996
- type: ndcg_at_20
value: 43.984
- type: ndcg_at_100
value: 51.559999999999995
- type: ndcg_at_1000
value: 64.25800000000001
- type: map_at_1
value: 2.759
- type: map_at_3
value: 7.310999999999999
- type: map_at_5
value: 10.077
- type: map_at_10
value: 15.722
- type: map_at_20
value: 21.917
- type: map_at_100
value: 29.582000000000004
- type: map_at_1000
value: 32.608
- type: recall_at_1
value: 2.759
- type: recall_at_3
value: 7.870000000000001
- type: recall_at_5
value: 11.26
- type: recall_at_10
value: 19.211
- type: recall_at_20
value: 30.134
- type: recall_at_100
value: 54.96
- type: recall_at_1000
value: 85.78099999999999
- type: precision_at_1
value: 67.34700000000001
- type: precision_at_3
value: 68.027
- type: precision_at_5
value: 59.184000000000005
- type: precision_at_10
value: 50.815999999999995
- type: precision_at_20
value: 41.939
- type: precision_at_100
value: 17.041
- type: precision_at_1000
value: 2.963
- type: mrr_at_1
value: 67.3469
- type: mrr_at_3
value: 80.6122
- type: mrr_at_5
value: 80.6122
- type: mrr_at_10
value: 80.9524
- type: mrr_at_20
value: 80.9524
- type: mrr_at_100
value: 80.9524
- type: mrr_at_1000
value: 80.9524
- type: nauc_ndcg_at_1_max
value: -18.7982
- type: nauc_ndcg_at_1_std
value: 13.605500000000001
- type: nauc_ndcg_at_1_diff1
value: 21.2588
- type: nauc_ndcg_at_3_max
value: -9.0937
- type: nauc_ndcg_at_3_std
value: 23.259900000000002
- type: nauc_ndcg_at_3_diff1
value: 24.2989
- type: nauc_ndcg_at_5_max
value: -13.242300000000002
- type: nauc_ndcg_at_5_std
value: 9.7464
- type: nauc_ndcg_at_5_diff1
value: 18.601799999999997
- type: nauc_ndcg_at_10_max
value: -12.045599999999999
- type: nauc_ndcg_at_10_std
value: 7.5604000000000005
- type: nauc_ndcg_at_10_diff1
value: 20.1203
- type: nauc_ndcg_at_20_max
value: -13.2776
- type: nauc_ndcg_at_20_std
value: 8.2692
- type: nauc_ndcg_at_20_diff1
value: 21.38
- type: nauc_ndcg_at_100_max
value: -21.1315
- type: nauc_ndcg_at_100_std
value: 8.4079
- type: nauc_ndcg_at_100_diff1
value: 29.3124
- type: nauc_ndcg_at_1000_max
value: -3.7026999999999997
- type: nauc_ndcg_at_1000_std
value: 34.970600000000005
- type: nauc_ndcg_at_1000_diff1
value: 22.3636
- type: nauc_map_at_1_max
value: -36.432500000000005
- type: nauc_map_at_1_std
value: -23.9669
- type: nauc_map_at_1_diff1
value: 37.2073
- type: nauc_map_at_3_max
value: -32.8613
- type: nauc_map_at_3_std
value: -18.0951
- type: nauc_map_at_3_diff1
value: 36.3228
- type: nauc_map_at_5_max
value: -31.355
- type: nauc_map_at_5_std
value: -21.148500000000002
- type: nauc_map_at_5_diff1
value: 27.999200000000002
- type: nauc_map_at_10_max
value: -25.3787
- type: nauc_map_at_10_std
value: -18.564700000000002
- type: nauc_map_at_10_diff1
value: 24.076800000000002
- type: nauc_map_at_20_max
value: -20.954
- type: nauc_map_at_20_std
value: -12.6847
- type: nauc_map_at_20_diff1
value: 24.3842
- type: nauc_map_at_100_max
value: -15.7801
- type: nauc_map_at_100_std
value: -2.823
- type: nauc_map_at_100_diff1
value: 24.8472
- type: nauc_map_at_1000_max
value: -11.8023
- type: nauc_map_at_1000_std
value: 3.9041
- type: nauc_map_at_1000_diff1
value: 23.3312
- type: nauc_recall_at_1_max
value: -36.432500000000005
- type: nauc_recall_at_1_std
value: -23.9669
- type: nauc_recall_at_1_diff1
value: 37.2073
- type: nauc_recall_at_3_max
value: -36.3448
- type: nauc_recall_at_3_std
value: -18.4742
- type: nauc_recall_at_3_diff1
value: 38.4857
- type: nauc_recall_at_5_max
value: -35.4207
- type: nauc_recall_at_5_std
value: -23.7906
- type: nauc_recall_at_5_diff1
value: 28.3854
- type: nauc_recall_at_10_max
value: -28.4266
- type: nauc_recall_at_10_std
value: -21.3224
- type: nauc_recall_at_10_diff1
value: 27.0746
- type: nauc_recall_at_20_max
value: -23.1205
- type: nauc_recall_at_20_std
value: -12.3539
- type: nauc_recall_at_20_diff1
value: 27.127499999999998
- type: nauc_recall_at_100_max
value: -22.0703
- type: nauc_recall_at_100_std
value: 10.1339
- type: nauc_recall_at_100_diff1
value: 29.759900000000002
- type: nauc_recall_at_1000_max
value: 13.5147
- type: nauc_recall_at_1000_std
value: 78.4907
- type: nauc_recall_at_1000_diff1
value: 12.151
- type: nauc_precision_at_1_max
value: -20.1082
- type: nauc_precision_at_1_std
value: 13.5123
- type: nauc_precision_at_1_diff1
value: 16.7562
- type: nauc_precision_at_3_max
value: -11.2979
- type: nauc_precision_at_3_std
value: 23.0876
- type: nauc_precision_at_3_diff1
value: 20.738
- type: nauc_precision_at_5_max
value: -18.1198
- type: nauc_precision_at_5_std
value: -2.4168
- type: nauc_precision_at_5_diff1
value: 5.1223
- type: nauc_precision_at_10_max
value: -4.7656
- type: nauc_precision_at_10_std
value: 1.5377
- type: nauc_precision_at_10_diff1
value: 8.2175
- type: nauc_precision_at_20_max
value: 7.571999999999999
- type: nauc_precision_at_20_std
value: 17.309
- type: nauc_precision_at_20_diff1
value: 5.2156
- type: nauc_precision_at_100_max
value: 35.02
- type: nauc_precision_at_100_std
value: 57.2867
- type: nauc_precision_at_100_diff1
value: -12.814200000000001
- type: nauc_precision_at_1000_max
value: 54.8988
- type: nauc_precision_at_1000_std
value: 55.970699999999994
- type: nauc_precision_at_1000_diff1
value: -36.8074
- type: nauc_mrr_at_1_max
value: -20.1082
- type: nauc_mrr_at_1_std
value: 13.5123
- type: nauc_mrr_at_1_diff1
value: 16.7562
- type: nauc_mrr_at_3_max
value: -23.668300000000002
- type: nauc_mrr_at_3_std
value: 16.883699999999997
- type: nauc_mrr_at_3_diff1
value: 20.6687
- type: nauc_mrr_at_5_max
value: -23.668300000000002
- type: nauc_mrr_at_5_std
value: 16.883699999999997
- type: nauc_mrr_at_5_diff1
value: 20.6687
- type: nauc_mrr_at_10_max
value: -21.8234
- type: nauc_mrr_at_10_std
value: 15.1609
- type: nauc_mrr_at_10_diff1
value: 19.6023
- type: nauc_mrr_at_20_max
value: -21.8234
- type: nauc_mrr_at_20_std
value: 15.1609
- type: nauc_mrr_at_20_diff1
value: 19.6023
- type: nauc_mrr_at_100_max
value: -21.8234
- type: nauc_mrr_at_100_std
value: 15.1609
- type: nauc_mrr_at_100_diff1
value: 19.6023
- type: nauc_mrr_at_1000_max
value: -21.8234
- type: nauc_mrr_at_1000_std
value: 15.1609
- type: nauc_mrr_at_1000_diff1
value: 19.6023
- type: main_score
value: 47.571999999999996
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification (default)
type: mteb/toxic_conversations_50k
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 63.608399999999996
- type: f1
value: 48.6248
- type: f1_weighted
value: 71.6158
- type: ap
value: 10.9541
- type: ap_weighted
value: 10.9541
- type: main_score
value: 63.608399999999996
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification (default)
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 60.506499999999996
- type: f1
value: 60.711499999999994
- type: f1_weighted
value: 59.695699999999995
- type: main_score
value: 60.506499999999996
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering.v2 (default)
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 33.5462
- type: v_measure_std
value: 1.3361
- type: main_score
value: 33.5462
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015 (default)
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: similarity_accuracy
value: 82.51180000000001
- type: similarity_accuracy_threshold
value: 69.4516
- type: similarity_f1
value: 58.483399999999996
- type: similarity_f1_threshold
value: 61.3852
- type: similarity_precision
value: 56.29880000000001
- type: similarity_recall
value: 60.8443
- type: similarity_ap
value: 61.8784
- type: cosine_accuracy
value: 82.51180000000001
- type: cosine_accuracy_threshold
value: 69.4516
- type: cosine_f1
value: 58.483399999999996
- type: cosine_f1_threshold
value: 61.3852
- type: cosine_precision
value: 56.29880000000001
- type: cosine_recall
value: 60.8443
- type: cosine_ap
value: 61.8784
- type: manhattan_accuracy
value: 82.60119999999999
- type: manhattan_accuracy_threshold
value: 1395.2354
- type: manhattan_f1
value: 59.3387
- type: manhattan_f1_threshold
value: 1544.4108
- type: manhattan_precision
value: 56.284
- type: manhattan_recall
value: 62.7441
- type: manhattan_ap
value: 62.407999999999994
- type: euclidean_accuracy
value: 82.51180000000001
- type: euclidean_accuracy_threshold
value: 78.1645
- type: euclidean_f1
value: 58.483399999999996
- type: euclidean_f1_threshold
value: 87.88040000000001
- type: euclidean_precision
value: 56.29880000000001
- type: euclidean_recall
value: 60.8443
- type: euclidean_ap
value: 61.8784
- type: dot_accuracy
value: 82.51180000000001
- type: dot_accuracy_threshold
value: 69.4516
- type: dot_f1
value: 58.483399999999996
- type: dot_f1_threshold
value: 61.3852
- type: dot_precision
value: 56.29880000000001
- type: dot_recall
value: 60.8443
- type: dot_ap
value: 61.8784
- type: max_accuracy
value: 82.60119999999999
- type: max_f1
value: 59.3387
- type: max_precision
value: 56.29880000000001
- type: max_recall
value: 62.7441
- type: max_ap
value: 62.407999999999994
- type: main_score
value: 62.407999999999994
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus (default)
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: similarity_accuracy
value: 87.84880000000001
- type: similarity_accuracy_threshold
value: 62.77890000000001
- type: similarity_f1
value: 75.968
- type: similarity_f1_threshold
value: 57.5925
- type: similarity_precision
value: 71.909
- type: similarity_recall
value: 80.5128
- type: similarity_ap
value: 83.6557
- type: cosine_accuracy
value: 87.84880000000001
- type: cosine_accuracy_threshold
value: 62.77890000000001
- type: cosine_f1
value: 75.968
- type: cosine_f1_threshold
value: 57.5925
- type: cosine_precision
value: 71.909
- type: cosine_recall
value: 80.5128
- type: cosine_ap
value: 83.6557
- type: manhattan_accuracy
value: 87.69940000000001
- type: manhattan_accuracy_threshold
value: 1524.1733
- type: manhattan_f1
value: 76.01830000000001
- type: manhattan_f1_threshold
value: 1597.1845
- type: manhattan_precision
value: 72.981
- type: manhattan_recall
value: 79.3194
- type: manhattan_ap
value: 83.63629999999999
- type: euclidean_accuracy
value: 87.84880000000001
- type: euclidean_accuracy_threshold
value: 86.2799
- type: euclidean_f1
value: 75.968
- type: euclidean_f1_threshold
value: 92.0951
- type: euclidean_precision
value: 71.909
- type: euclidean_recall
value: 80.5128
- type: euclidean_ap
value: 83.6557
- type: dot_accuracy
value: 87.84880000000001
- type: dot_accuracy_threshold
value: 62.77890000000001
- type: dot_f1
value: 75.968
- type: dot_f1_threshold
value: 57.5925
- type: dot_precision
value: 71.909
- type: dot_recall
value: 80.5128
- type: dot_ap
value: 83.6557
- type: max_accuracy
value: 87.84880000000001
- type: max_f1
value: 76.01830000000001
- type: max_precision
value: 72.981
- type: max_recall
value: 80.5128
- type: max_ap
value: 83.6557
- type: main_score
value: 83.6557
---
# RetrievaEmbedding-01: AMBER
The **AMBER (Adaptive Multitask Bilingual Embedding Representations)** is a text embedding model trained by Retrieva, Inc.
This model is primarily designed for Japanese, but it also supports English.
We trained this model on various datasets related to Japanese and English.
This model size is 132M parameters (base size).
## Model Details
### Model Description
The AMBER model is a text embedding model based on the [sbintuitions/modernbert-ja-130m](https://huggingface.co/sbintuitions/modernbert-ja-130m) architecture, designed for Japanese text.
This model was trained on a variety of datasets related to Japanese, and also includes English datasets.
The model can be used for English text as well.
During training, prompts (instructions) in natural language were included, allowing the model to generate embeddings tailored to specific tasks.
- **Developed by:** Retrieva, Inc.
- **Model type:** Based on the [ModernBERT](https://arxiv.org/abs/2412.13663) Architecture.
- **Language(s) (NLP):** Primarily Japanese (optional support for English).
- **License:** Apache 2.0
- **Finetuned from model:** `sbintuitions/modernbert-ja-130m`
- **Model Type:** Sentence Transformer
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 512 dimensions
- **Similarity Function:** Cosine Similarity
## Uses
## How to Get Started with the Model
### Install Library
First install the python library using pip:
```bash
pip install sentence-transformers sentencepiece
```
### Run Inference
Then you can load this model and run inference.
You can specify the prompt at inference time by adding an argument called `prompt` to `model.encode`.
The prompts used in the Japanese benchmark are described in `jmteb/tasks`, and the prompts used in the English benchmark are described in `mteb/models/retrieva_en.py`.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("retrieva-jp/amber-base")
# Run inference
queries = [
"自然言語処理とはなんですか?",
"株式会社レトリバについて教えて",
]
documents = [
"自然言語処理(しぜんげんごしょり、英語: Natural language processing、略称:NLP)は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。",
"株式会社レトリバは、自然言語処理と機械学習を核としたAI技術で組織の課題解決を支援するテクノロジー企業である。",
]
queries_embeddings = model.encode(queries, prompt_name="Retrieval-query")
documents_embeddings = model.encode(documents, prompt_name="Retrieval-passage")
similarities = model.similarity(queries_embeddings, documents_embeddings)
print(similarities.shape)
```
## Training Details
### Training Data
We used multiple datasets to train this model.
We selected datasets from [llm-jp-eval](https://github.com/llm-jp/llm-jp-eval), [llm-japanese-dataset](https://github.com/masanorihirano/llm-japanese-dataset), and [hpprc/emb](https://huggingface.co/datasets/hpprc/emb) for Japanese datasets.
For English datasets, we mainly used some of the datasets utilized in [Asai et al. (2023)](https://arxiv.org/abs/2211.09260).
Additionally, we partially used the English datasets at [the sentence-transformers repository](https://huggingface.co/sentence-transformers) and [kilt-tasks](https://huggingface.co/datasets/facebook/kilt_tasks).
To consider cross-lingual between Japanese and English, we also used translation datasets between Japanese and English.
For Japanese, we used synthetic data created by LLM to prepare a sufficient amount of training data.
## Evaluation
We evaluated the model on the following benchmarks:
- Japanese Benchmark: [JMTEB](https://github.com/sbintuitions/JMTEB)
- Japanese Retrieval Tasks: [JQaRA](https://github.com/hotchpotch/JQaRA/), [JaCWIR](https://github.com/hotchpotch/JaCWIR/), [MLDR Japanese Subset](https://huggingface.co/datasets/Shitao/MLDR)
- English Benchmark: [MTEB(eng, v2)](https://github.com/embeddings-benchmark/mteb).
The scores in the table are all calculated by us unless otherwise noted.
### Japanese Benchmark: JMTEB
Note that the `Mean (TaskType)` in the following leaderboard is the same as the `Avg.` in the original JMTEB leaderboard.
The files used for evaluation are stored in the `jmteb` directory.
| Model | # Parameters | Mean (TaskType) | Mean (Task) | Retrieval | STS | Classification | Reranking | Clustering | PairClassification |
| :--- | --- | ---: | ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| base models | < 300M | | | | | | | | |
| [cl-nagoya/ruri-base](https://huggingface.co/cl-nagoya/ruri-base) | 111M | 72.60 | 71.56 | 69.53 | 82.87 | 75.49 | 92.91 | 52.40 | 62.38 |
| AMBER-base <br> (this model) | 130M | 72.12 | 72.12 | **73.40** | 77.81 | **76.14** | **93.27** | 48.05 | **64.03** |
| [pkshatech/GLuCoSE-base-ja-v2](https://huggingface.co/pkshatech/GLuCoSE-base-ja-v2) | 133M | **72.89** | **72.47** | 73.03 | **82.96** | 74.02 | 93.01 | 51.96 | 62.37 |
| [pkshatech/RoSEtta-base-ja](https://huggingface.co/pkshatech/RoSEtta-base-ja) | 190M | 72.49 | 72.05 | 73.14 | 81.39 | 72.37 | 92.69 | **53.60** | 61.74 |
| [intfloat/multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 278M | 71.11 | 69.72 | 69.45 | 80.45 | 69.86 | 92.90 | 51.62 | 62.35 |
| large models | 300M < | | | | | | | | |
| [AMBER-large](https://huggingface.co/retrieva-jp/amber-large) | 315M | 72.52 | **73.22** | **75.40** | 79.32 | 77.14 | **93.54** | 48.73 | 60.97 |
| [cl-nagoya/ruri-large](https://huggingface.co/cl-nagoya/ruri-large) | 337M | **73.20** | 73.06 | 72.86 | **83.14** | **77.15** | 93.00 | 50.78 | 62.29 |
| [intfloat/multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 560M | 72.06 | 71.29 | 71.71 | 80.87 | 72.45 | 93.29 | **51.59** | **62.42** |
### Japanese Retrieval Tasks: JQaRA, JaCWIR, MLDR Japanese Subset
The files used for MLDR are stored in the `mldr` directory.
The prompts used in JQaRA and JaCWIR are `Retrieval-query` and `Retrieval-passage` described in `config_sentence_transformers.json`.
| Model | # Parameters | JQaRA (nDCG@10) | JaCWIR (MAP@10) | MLDR Japanese Subset (nDCG@10) |
| :--- | --- | ---: | ---: | ---: |
| base models | < 300M | | | |
| [cl-nagoya/ruri-base](https://huggingface.co/cl-nagoya/ruri-base) | 111M | 58.4 | 83.3 | 32.77 |
| AMBER-base <br> (this model) | 130M | 57.1 | 81.6 | **35.69** |
| [pkshatech/GLuCoSE-base-ja-v2](https://huggingface.co/pkshatech/GLuCoSE-base-ja-v2) | 133M | **60.6** | **85.3** | 33.99 |
| [intfloat/multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 278M | 47.1 | **85.3** | 25.46 |
| large models | 300M < | | | |
| [AMBER-large](https://huggingface.co/retrieva-jp/amber-large) | 315M | 62.5 | 82.4 | 34.57 |
| [cl-nagoya/ruri-large](https://huggingface.co/cl-nagoya/ruri-large) | 337M | **62.8** | 82.5 | **34.78** |
| [intfloat/multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 560M | 55.4| **87.3** | 29.95 |
### English Benchmark: MTEB(eng, v2)
The files used for evaluation are stored in the `mteb` directory.
| Model | # Parameters | Mean (TaskType) | Mean (Task) | Retrieval | STS | Classification | Reranking | Clustering | PairClassification | Summarization |
| :--- | --- | ---: | ---: | ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| base models | < 300M | | | | | | | | | |
| AMBER-base <br> (this model) | 130M | 54.75 | 58.20 | 40.11 | **81.29** | 70.39 | 42.98 | **42.27** | 80.12 | 26.08 |
| [intfloat/multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 278M | **56.21** | **59.75** | **43.22** | 80.50 | **73.84** | **43.87** | 42.19 | **83.74** | **26.10** |
| large models | 300M < | | | | | | | | | |
| [AMBER-large](https://huggingface.co/retrieva-jp/amber-large) | 315M | 56.08 | 59.13 | 41.04 | **81.52** | 72.23 | 43.83 | **42.71** | 81.00 | **30.21** |
| [intfloat/multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 560M | **57.06** | **60.84** | **46.17** | 81.11 | **74.88** | **44.31** | 41.91 | **84.33** | 26.67 |
## More Information
TBA
## Model Card Authors
Satoru Katsumata, Daisuke Kimura, Jiro Nishitoba
## Model Card Contact
pr[at]retrieva.jp
|
[
"BIOSSES"
] |
judithrosell/BC5CDR_BlueBERT_NER
|
judithrosell
|
token-classification
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12",
"base_model:finetune:bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12",
"license:cc0-1.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-12-19T15:02:24Z |
2023-12-19T15:17:45+00:00
| 89 | 0 |
---
base_model: bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12
license: cc0-1.0
tags:
- generated_from_trainer
model-index:
- name: BC5CDR_BlueBERT_NER
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BC5CDR_BlueBERT_NER
This model is a fine-tuned version of [bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12](https://huggingface.co/bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0944
- Seqeval classification report: precision recall f1-score support
Chemical 0.84 0.89 0.87 7079
Disease 0.82 0.85 0.83 4968
micro avg 0.83 0.87 0.85 12047
macro avg 0.83 0.87 0.85 12047
weighted avg 0.83 0.87 0.85 12047
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Seqeval classification report |
|:-------------:|:-----:|:----:|:---------------:|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| No log | 1.0 | 143 | 0.1111 | precision recall f1-score support
Chemical 0.82 0.86 0.84 7079
Disease 0.76 0.83 0.80 4968
micro avg 0.79 0.85 0.82 12047
macro avg 0.79 0.85 0.82 12047
weighted avg 0.79 0.85 0.82 12047
|
| No log | 2.0 | 286 | 0.0987 | precision recall f1-score support
Chemical 0.83 0.89 0.86 7079
Disease 0.78 0.86 0.82 4968
micro avg 0.81 0.88 0.84 12047
macro avg 0.80 0.87 0.84 12047
weighted avg 0.81 0.88 0.84 12047
|
| No log | 3.0 | 429 | 0.0944 | precision recall f1-score support
Chemical 0.84 0.89 0.87 7079
Disease 0.82 0.85 0.83 4968
micro avg 0.83 0.87 0.85 12047
macro avg 0.83 0.87 0.85 12047
weighted avg 0.83 0.87 0.85 12047
|
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0
|
[
"BC5CDR"
] |
nold/Einstein-v4-7B-GGUF
|
nold
| null |
[
"gguf",
"axolotl",
"generated_from_trainer",
"Mistral",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"science",
"physics",
"chemistry",
"biology",
"math",
"dataset:allenai/ai2_arc",
"dataset:camel-ai/physics",
"dataset:camel-ai/chemistry",
"dataset:camel-ai/biology",
"dataset:camel-ai/math",
"dataset:metaeval/reclor",
"dataset:openbookqa",
"dataset:mandyyyyii/scibench",
"dataset:derek-thomas/ScienceQA",
"dataset:TIGER-Lab/ScienceEval",
"dataset:jondurbin/airoboros-3.2",
"dataset:LDJnr/Capybara",
"dataset:Cot-Alpaca-GPT4-From-OpenHermes-2.5",
"dataset:STEM-AI-mtl/Electrical-engineering",
"dataset:knowrohit07/saraswati-stem",
"dataset:sablo/oasst2_curated",
"dataset:glaiveai/glaive-code-assistant",
"dataset:lmsys/lmsys-chat-1m",
"dataset:TIGER-Lab/MathInstruct",
"dataset:bigbio/med_qa",
"dataset:meta-math/MetaMathQA-40K",
"dataset:piqa",
"dataset:scibench",
"dataset:sciq",
"dataset:Open-Orca/SlimOrca",
"dataset:migtissera/Synthia-v1.3",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:other",
"model-index",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-03-01T16:53:14Z |
2024-03-01T19:10:55+00:00
| 89 | 0 |
---
base_model: mistralai/Mistral-7B-v0.1
datasets:
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- metaeval/reclor
- openbookqa
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- TIGER-Lab/ScienceEval
- jondurbin/airoboros-3.2
- LDJnr/Capybara
- Cot-Alpaca-GPT4-From-OpenHermes-2.5
- STEM-AI-mtl/Electrical-engineering
- knowrohit07/saraswati-stem
- sablo/oasst2_curated
- glaiveai/glaive-code-assistant
- lmsys/lmsys-chat-1m
- TIGER-Lab/MathInstruct
- bigbio/med_qa
- meta-math/MetaMathQA-40K
- openbookqa
- piqa
- metaeval/reclor
- derek-thomas/ScienceQA
- scibench
- sciq
- Open-Orca/SlimOrca
- migtissera/Synthia-v1.3
- TIGER-Lab/ScienceEval
license: other
tags:
- axolotl
- generated_from_trainer
- Mistral
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- science
- physics
- chemistry
- biology
- math
model-index:
- name: Einstein-v4-7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 64.68
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 83.75
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 62.31
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 55.15
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 76.24
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 57.62
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
---

# 🔬 Einstein-v4-7B
This model is a full fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on diverse datasets.
This model is finetuned using `7xRTX3090` + `1xRTXA6000` using [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This model's training was sponsored by [sablo.ai](https://sablo.ai).
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: mistralai/Mistral-7B-v0.1
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
is_mistral_derived_model: true
load_in_8bit: false
load_in_4bit: false
strict: false
chat_template: chatml
datasets:
- path: data/merged_all.json
ds_type: json
type: alpaca
conversation: chatml
- path: data/capybara_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/synthia-v1.3_sharegpt_12500.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/cot_alpaca_gpt4_extracted_openhermes_2.5_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/slimorca_dedup_filtered_95k_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/airoboros_3.2_without_contextual_slimorca_orca_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
dataset_prepared_path: last_run_prepared
val_set_size: 0.005
output_dir: ./Einstein-v4-model
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
eval_sample_packing: false
wandb_project: Einstein
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
hub_model_id: Weyaxi/Einstein-v4-7B
save_safetensors: true
gradient_accumulation_steps: 4
micro_batch_size: 1
num_epochs: 1.5
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.000005
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 2 # changed
eval_table_size:
eval_table_max_new_tokens: 128
saves_per_epoch: 4
debug:
deepspeed: zero3_bf16.json
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "<|im_end|>"
unk_token: "<unk>"
tokens:
- "<|im_start|>"
resume_from_checkpoint: Einstein-v4-model/checkpoint-521
```
</details><br>
# 💬 Prompt Template
You can use this prompt template while using the model:
### ChatML
```
<|im_start|>system
{system}<|im_end|>
<|im_start|>user
{user}<|im_end|>
<|im_start|>assistant
{asistant}<|im_end|>
```
This prompt template is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are helpful AI asistant."},
{"role": "user", "content": "Hello!"}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
# 🔄 Quantizationed versions
Quantizationed versions of this model is available.
## Exl2 [@bartowski](https://hf.co/bartowski):
- https://huggingface.co/bartowski/Einstein-v4-7B-exl2
You can switch up branches in the repo to use the one you want
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/8_0) | 8.0 | 8.0 | 8.4 GB | 9.8 GB | 11.8 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/6_5) | 6.5 | 8.0 | 7.2 GB | 8.6 GB | 10.6 GB | Very similar to 8.0, good tradeoff of size vs performance, **recommended**. |
| [5_0](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/5_0) | 5.0 | 6.0 | 6.0 GB | 7.4 GB | 9.4 GB | Slightly lower quality vs 6.5, but usable on 8GB cards. |
| [4_25](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/4_25) | 4.25 | 6.0 | 5.3 GB | 6.7 GB | 8.7 GB | GPTQ equivalent bits per weight, slightly higher quality. |
| [3_5](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/3_5) | 3.5 | 6.0 | 4.7 GB | 6.1 GB | 8.1 GB | Lower quality, only use if you have to. |
# 🎯 [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Weyaxi__Einstein-v4-7B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |66.62|
|AI2 Reasoning Challenge (25-Shot)|64.68|
|HellaSwag (10-Shot) |83.75|
|MMLU (5-Shot) |62.31|
|TruthfulQA (0-shot) |55.15|
|Winogrande (5-shot) |76.24|
|GSM8k (5-shot) |57.62|
# 🤖 Additional information about training
This model is full fine-tuned for 1.5 epoch.
Total number of steps was 1562.
<details><summary>Loss graph</summary>

</details><br>
# 🤝 Acknowledgments
Thanks to [sablo.ai](https://sablo.ai) for sponsoring this model.
Thanks to all the dataset authors mentioned in the datasets section.
Thanks to [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) for making the repository I used to make this model.
Thanks to all open source AI community.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
If you would like to support me:
[☕ Buy Me a Coffee](https://www.buymeacoffee.com/weyaxi)
***
Quantization of Model [Weyaxi/Einstein-v4-7B](https://huggingface.co/Weyaxi/Einstein-v4-7B).
Created using [llm-quantizer](https://github.com/Nold360/llm-quantizer) Pipeline
|
[
"SCIQ"
] |
jiviai/medX_v2
|
jiviai
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-05-31T04:38:17Z |
2025-02-17T08:03:10+00:00
| 89 | 12 |
---
license: apache-2.0
---
# Jivi-MedX-v2: The Next-Generation Medical Language Model
Jivi-MedX-v2 is a cutting-edge medical language model developed by Jivi AI to support a wide range of clinical applications. Built on the Meta-Llama-3-8B architecture, it has been fine-tuned with Supervised Fine-Tuning (SFT) and Odds Ratio Preference Optimization (ORPO) to enhance its medical reasoning capabilities. The model is designed to generate accurate, domain-specific responses, making it ideal for clinical decision support, medical research, and healthcare automation.
<img src="https://jarvis-01j48hrq5383vpdk8csp3r60xa.s3.amazonaws.com/dev/MISC/2025-02-04/01JK8HC7JSP2ABXWHWTCB1360M.webp" alt="Jivi-RadX-v1" width="600" height="600">
## Purpose-Built for the Medical Domain:
Jivi-MedX-v2 is specifically fine-tuned to meet the complex language and knowledge demands of the healthcare industry. Trained on a high-quality, domain-specific dataset, it excels in comprehending and generating precise medical text, making it an invaluable tool for clinical decision support, research, and patient education.
## Training Process:
Built on the **Meta-Llama-3-8B** architecture, Jivi-MedX-v2 has been meticulously refined using **Supervised Fine-Tuning (SFT)** and **Odds Ratio Preference Optimization (ORPO)**. This ensures that the model aligns effectively with medical terminology and reasoning while maintaining learning efficiency. Hyperparameter tuning strategies have been carefully implemented to prevent catastrophic forgetting, ensuring consistent performance across various tasks.
## Data Preparation:
Jivi-MedX-v2 has been trained on a curated dataset of **over 1,000,000 data points**, covering diverse medical literature, clinical notes, research papers, and diagnostic guidelines. This comprehensive dataset enhances its ability to generate accurate and contextually relevant medical information.
## Benchmarks:
With **8 billion parameters**, Jivi-MedX-v2 outperforms other models of similar size, delivering best-in-class results on multiple medical benchmarks. It surpasses larger proprietary and open-source models, including **GPT-4o** and **Deepseek-R1**, in key performance evaluations, setting a new standard for AI-driven medical intelligence.
| Model | MedMCQA | MedQA | MMLU Anatomy | MMLU Clinical Knowledge | MMLU College Biology | MMLU College Medicine | MMLU Medical Genetics | MMLU Professional Medicine | PubMedQA | Average |
|--------------------------------|---------|------------------|---------|--------------------|-----------------|------------------|------------------|-----------------------------|---------|---------|
| **Jivi-MedX-v2** | **81.78%** | **86.57%** | **96.30%** | **97.74%** | **99.31%** | **95.38%** | **99.00%** | **98.90%** | **77.40%** | **92.49%** |
| DeepSeek-R1 | 78.91% | 91.99% | 91.11% | 94.34% | 98.61% | 87.86% | 100.00% | 95.96% | 74.00% | 90.31% |
| OpenAI GPT-4o | 74.85% | 87.70% | 87.41% | 91.69% | 93.06% | 82.08% | 96.00% | 94.85% | 74.80% | 86.94% |
| DeepSeek-R1-Distill-Llama-70B | 73.86% | 87.82% | 82.22% | 88.68% | 96.53% | 84.97% | 96.00% | 94.85% | 77.20% | 86.90% |
| DeepSeek-R1-Distill-Llama-8B | 40.00% | 43.36% | 51.11% | 58.11% | 55.56% | 51.45% | 63.00% | 56.62% | 68.40% | 54.18% |
## How to use
### Use with transformers
Please ensure `transformers>=4.45.2`
```python
import torch
import transformers
model_id = "jiviai/medX_v2"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
prompt = "Question: A 20-year-old man comes to the physician because of worsening gait unsteadiness and bilateral hearing loss for 1 month. He has had intermittent tingling sensations on both cheeks over this time period. He has no history of serious medical illness and takes no medications. Audiometry shows bilateral sensorineural hearing loss. Genetic evaluation shows a mutation of a tumor suppressor gene on chromosome 22 that encodes merlin. This patient is at increased risk for which of the following conditions?\nA. Renal cell carcinoma\nB. Meningioma\nC. Astrocytoma\nD. Vascular malformations\nAnswer:\n"
gen_kwargs = {
"return_full_text": False,
"max_new_tokens": 100,
}
print(pipeline(prompt, **gen_kwargs))
```
**Supported Languages:** Currently this model supports English. We are planning to introduce multi-lingual support shortly.
**Feedback:** To send any feedback/questions please use the community section of the model.
## Intended use
The data, code, and model checkpoints are intended to be used solely for:
1. Future research on medical query answering.
### Disclaimer: The data, code, and model checkpoints are not intended to be used in clinical care or for any clinical decision-making purposes.
### This model has been fine-tuned and optimized for answering medical MCQs. It needs to be further aligned for downstream tasks.
|
[
"MEDQA",
"PUBMEDQA"
] |
RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2311.03099",
"arxiv:2306.01708",
"endpoints_compatible",
"region:us"
] | 2024-08-21T00:38:43Z |
2024-08-21T02:36:30+00:00
| 89 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
MedLlama-3-8B_DARE - GGUF
- Model creator: https://huggingface.co/ChenWeiLi/
- Original model: https://huggingface.co/ChenWeiLi/MedLlama-3-8B_DARE/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [MedLlama-3-8B_DARE.Q2_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q2_K.gguf) | Q2_K | 2.96GB |
| [MedLlama-3-8B_DARE.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [MedLlama-3-8B_DARE.IQ3_S.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [MedLlama-3-8B_DARE.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [MedLlama-3-8B_DARE.IQ3_M.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [MedLlama-3-8B_DARE.Q3_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q3_K.gguf) | Q3_K | 3.74GB |
| [MedLlama-3-8B_DARE.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [MedLlama-3-8B_DARE.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [MedLlama-3-8B_DARE.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [MedLlama-3-8B_DARE.Q4_0.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q4_0.gguf) | Q4_0 | 4.34GB |
| [MedLlama-3-8B_DARE.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [MedLlama-3-8B_DARE.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [MedLlama-3-8B_DARE.Q4_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q4_K.gguf) | Q4_K | 4.58GB |
| [MedLlama-3-8B_DARE.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [MedLlama-3-8B_DARE.Q4_1.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q4_1.gguf) | Q4_1 | 4.78GB |
| [MedLlama-3-8B_DARE.Q5_0.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q5_0.gguf) | Q5_0 | 5.21GB |
| [MedLlama-3-8B_DARE.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [MedLlama-3-8B_DARE.Q5_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q5_K.gguf) | Q5_K | 5.34GB |
| [MedLlama-3-8B_DARE.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [MedLlama-3-8B_DARE.Q5_1.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q5_1.gguf) | Q5_1 | 5.65GB |
| [MedLlama-3-8B_DARE.Q6_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q6_K.gguf) | Q6_K | 6.14GB |
| [MedLlama-3-8B_DARE.Q8_0.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedLlama-3-8B_DARE-gguf/blob/main/MedLlama-3-8B_DARE.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
base_model:
- sethuiyer/Medichat-Llama3-8B
- mlabonne/ChimeraLlama-3-8B-v3
- johnsnowlabs/JSL-MedLlama-3-8B-v2.0
library_name: transformers
tags:
- mergekit
- merge
license: llama3
---
# medLlama-3-8B_DARE
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [DARE](https://arxiv.org/abs/2311.03099) [TIES](https://arxiv.org/abs/2306.01708) merge method using [mlabonne/ChimeraLlama-3-8B-v3](https://huggingface.co/mlabonne/ChimeraLlama-3-8B-v3) as a base.
### Models Merged
The following models were included in the merge:
* [sethuiyer/Medichat-Llama3-8B](https://huggingface.co/sethuiyer/Medichat-Llama3-8B)
* [johnsnowlabs/JSL-MedLlama-3-8B-v2.0](https://huggingface.co/johnsnowlabs/JSL-MedLlama-3-8B-v2.0)
### Evaluation
- multimedq (0 shot) </br>
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|-------------------------------|-------|------|-----:|--------|-----:|---|-----:|
| - medmcqa |Yaml |none | 0|acc |0.5728|± |0.0076|
| | |none | 0|acc_norm|0.5728|± |0.0076|
| - medqa_4options |Yaml |none | 0|acc |0.5923|± |0.0138|
| | |none | 0|acc_norm|0.5923|± |0.0138|
| - anatomy (mmlu) | 0|none | 0|acc |0.7111|± |0.0392|
| - clinical_knowledge (mmlu) | 0|none | 0|acc |0.7547|± |0.0265|
| - college_biology (mmlu) | 0|none | 0|acc |0.7917|± |0.0340|
| - college_medicine (mmlu) | 0|none | 0|acc |0.6647|± |0.0360|
| - medical_genetics (mmlu) | 0|none | 0|acc |0.8200|± |0.0386|
| - professional_medicine (mmlu)| 0|none | 0|acc |0.7426|± |0.0266|
|stem |N/A |none | 0|acc_norm|0.5773|± |0.0067|
| | |none | 0|acc |0.6145|± |0.0057|
| - pubmedqa | 1|none | 0|acc |0.7400|± |0.0196|
|Groups|Version|Filter|n-shot| Metric |Value | |Stderr|
|------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5773|± |0.0067|
| | |none | 0|acc |0.6145|± |0.0057|
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: mlabonne/ChimeraLlama-3-8B-v3
# No parameters necessary for base model
- model: sethuiyer/Medichat-Llama3-8B
parameters:
density: 0.53
weight: 0.5
- model: johnsnowlabs/JSL-MedLlama-3-8B-v2.0
parameters:
density: 0.53
weight: 0.5
merge_method: dare_ties
base_model: mlabonne/ChimeraLlama-3-8B-v3
parameters:
int8_mask: true
dtype: float16
```
|
[
"MEDQA",
"PUBMEDQA"
] |
yixuan-chia/snowflake-arctic-embed-l-GGUF
|
yixuan-chia
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"feature-extraction"
] | 2024-08-29T07:37:54Z |
2024-08-29T09:05:54+00:00
| 89 | 1 |
---
{}
---
# yixuan-chia/snowflake-arctic-embed-l-GGUF
This model was converted to GGUF format from [`Snowflake/snowflake-arctic-embed-l`](https://huggingface.co/Snowflake/snowflake-arctic-embed-l) using llama.cpp.
Refer to the [original model card](https://huggingface.co/Snowflake/snowflake-arctic-embed-l) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo yixuan-chia/snowflake-arctic-embed-l-GGUF --hf-file snowflake-arctic-embed-l-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo yixuan-chia/snowflake-arctic-embed-l-GGUF --hf-file snowflake-arctic-embed-l-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo yixuan-chia/snowflake-arctic-embed-l-GGUF --hf-file snowflake-arctic-embed-l-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo yixuan-chia/snowflake-arctic-embed-l-GGUF --hf-file snowflake-arctic-embed-l-q8_0.gguf -c 2048
```
|
[
"CHIA"
] |
BioMistral/BioMistral-7B-BnB.8
|
BioMistral
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"medical",
"biology",
"bnb",
"bitsandbytes",
"8bit",
"conversational",
"fr",
"en",
"de",
"nl",
"es",
"pt",
"pl",
"ro",
"it",
"dataset:pubmed",
"arxiv:2402.10373",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"8-bit",
"region:us"
] | 2024-02-19T13:22:55Z |
2024-02-19T15:38:37+00:00
| 88 | 0 |
---
datasets:
- pubmed
language:
- fr
- en
- de
- nl
- es
- pt
- pl
- ro
- it
license: apache-2.0
pipeline_tag: text-generation
tags:
- medical
- biology
- bnb
- bitsandbytes
- 8bit
---
<p align="center">
<img src="https://huggingface.co/BioMistral/BioMistral-7B/resolve/main/wordart_blue_m_rectangle.png?download=true" alt="drawing" width="250"/>
</p>
# BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
**Abstract:**
Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges.
In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.
**Advisory Notice!** Although BioMistral is intended to encapsulate medical knowledge sourced from high-quality evidence, it hasn't been tailored to effectively, safely, or suitably convey this knowledge within professional parameters for action. We advise refraining from utilizing BioMistral in medical contexts unless it undergoes thorough alignment with specific use cases and undergoes further testing, notably including randomized controlled trials in real-world medical environments. BioMistral 7B may possess inherent risks and biases that have not yet been thoroughly assessed. Additionally, the model's performance has not been evaluated in real-world clinical settings. Consequently, we recommend using BioMistral 7B strictly as a research tool and advise against deploying it in production environments for natural language generation or any professional health and medical purposes.
# 1. BioMistral models
**BioMistral** is a suite of Mistral-based further pre-trained open source models suited for the medical domains and pre-trained using textual data from PubMed Central Open Access (CC0, CC BY, CC BY-SA, and CC BY-ND). All the models are trained using the CNRS (French National Centre for Scientific Research) [Jean Zay](http://www.idris.fr/jean-zay/) French HPC.
| Model Name | Base Model | Model Type | Sequence Length | Download |
|:-------------------:|:----------------------------------:|:-------------------:|:---------------:|:-----------------------------------------------------:|
| BioMistral-7B | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Further Pre-trained | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B-DARE | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge DARE | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE) |
| BioMistral-7B-TIES | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge TIES | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES) |
| BioMistral-7B-SLERP | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge SLERP | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP) |
# 2. Quantized Models
| Base Model | Method | q_group_size | w_bit | version | VRAM GB | Time | Download |
|:-------------------:|:------:|:------------:|:-----:|:-------:|:-------:|:------:|:--------:|
| BioMistral-7B | FP16/BF16 | | | | 15.02 | x1.00 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B | AWQ | 128 | 4 | GEMV | 4.68 | x10.30 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMV) |
| BioMistral-7B | BnB.4 | | 4 | | 5.03 | x3.25 | [HuggingFace](blank) |
| BioMistral-7B | BnB.8 | | 8 | | 8.04 | x4.34 | [HuggingFace](blank) |
| BioMistral-7B-DARE | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-TIES | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-SLERP | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP-AWQ-QGS128-W4-GEMM) |
# 2. Using BioMistral
You can use BioMistral with [Hugging Face's Transformers library](https://github.com/huggingface/transformers) as follow.
Loading the model and tokenizer :
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BioMistral/BioMistral-7B")
model = AutoModel.from_pretrained("BioMistral/BioMistral-7B")
```
# 3. Supervised Fine-tuning Benchmark
| | Clinical KG | Medical Genetics | Anatomy | Pro Medicine | College Biology | College Medicine | MedQA | MedQA 5 opts | PubMedQA | MedMCQA | Avg. |
|-------------------------------------------|:---------------------------------------------:|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|------------------|
| **BioMistral 7B** | 59.9 | 64.0 | 56.5 | 60.4 | 59.0 | 54.7 | 50.6 | 42.8 | 77.5 | 48.1 | 57.3 |
| **Mistral 7B Instruct** | **62.9** | 57.0 | 55.6 | 59.4 | 62.5 | <u>57.2</u> | 42.0 | 40.9 | 75.7 | 46.1 | 55.9 |
| | | | | | | | | | | | |
| **BioMistral 7B Ensemble** | <u>62.8</u> | 62.7 | <u>57.5</u> | **63.5** | 64.3 | 55.7 | 50.6 | 43.6 | 77.5 | **48.8** | 58.7 |
| **BioMistral 7B DARE** | 62.3 | **67.0** | 55.8 | 61.4 | **66.9** | **58.0** | **51.1** | **45.2** | <u>77.7</u> | <u>48.7</u> | **59.4** |
| **BioMistral 7B TIES** | 60.1 | <u>65.0</u> | **58.5** | 60.5 | 60.4 | 56.5 | 49.5 | 43.2 | 77.5 | 48.1 | 57.9 |
| **BioMistral 7B SLERP** | 62.5 | 64.7 | 55.8 | <u>62.7</u> | <u>64.8</u> | 56.3 | <u>50.8</u> | <u>44.3</u> | **77.8** | 48.6 | <u>58.8</u> |
| | | | | | | | | | | | |
| **MedAlpaca 7B** | 53.1 | 58.0 | 54.1 | 58.8 | 58.1 | 48.6 | 40.1 | 33.7 | 73.6 | 37.0 | 51.5 |
| **PMC-LLaMA 7B** | 24.5 | 27.7 | 35.3 | 17.4 | 30.3 | 23.3 | 25.5 | 20.2 | 72.9 | 26.6 | 30.4 |
| **MediTron-7B** | 41.6 | 50.3 | 46.4 | 27.9 | 44.4 | 30.8 | 41.6 | 28.1 | 74.9 | 41.3 | 42.7 |
| **BioMedGPT-LM-7B** | 51.4 | 52.0 | 49.4 | 53.3 | 50.7 | 49.1 | 42.5 | 33.9 | 76.8 | 37.6 | 49.7 |
| | | | | | | | | | | | |
| **GPT-3.5 Turbo 1106*** | 74.71 | 74.00 | 65.92 | 72.79 | 72.91 | 64.73 | 57.71 | 50.82 | 72.66 | 53.79 | 66.0 |
Supervised Fine-Tuning (SFT) performance of BioMistral 7B models compared to baselines, measured by accuracy (↑) and averaged across 3 random seeds of 3-shot. DARE, TIES, and SLERP are model merging strategies that combine BioMistral 7B and Mistral 7B Instruct. Best model in bold, and second-best underlined. *GPT-3.5 Turbo performances are reported from the 3-shot results without SFT.
# Citation BibTeX
Arxiv : [https://arxiv.org/abs/2402.10373](https://arxiv.org/abs/2402.10373)
```bibtex
@misc{labrak2024biomistral,
title={BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains},
author={Yanis Labrak and Adrien Bazoge and Emmanuel Morin and Pierre-Antoine Gourraud and Mickael Rouvier and Richard Dufour},
year={2024},
eprint={2402.10373},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
**CAUTION!** Both direct and downstream users need to be informed about the risks, biases, and constraints inherent in the model. While the model can produce natural language text, our exploration of its capabilities and limitations is just beginning. In fields such as medicine, comprehending these limitations is crucial. Hence, we strongly advise against deploying this model for natural language generation in production or for professional tasks in the realm of health and medicine.
# BnB 4/8 bits Requirements:
```plain
transformers : 4.37.2
bitsandbytes : 0.42.0
```
|
[
"MEDQA",
"PUBMEDQA"
] |
afrideva/GIST-all-MiniLM-L6-v2-GGUF
|
afrideva
|
text-generation
|
[
"sentence-transformers",
"gguf",
"feature-extraction",
"mteb",
"sentence-similarity",
"ggml",
"quantized",
"text-generation",
"en",
"arxiv:2402.16829",
"arxiv:2212.09741",
"base_model:avsolatorio/GIST-all-MiniLM-L6-v2",
"base_model:quantized:avsolatorio/GIST-all-MiniLM-L6-v2",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us"
] | 2024-05-13T01:49:21Z |
2024-05-13T01:49:40+00:00
| 88 | 0 |
---
base_model: avsolatorio/GIST-all-MiniLM-L6-v2
language:
- en
library_name: sentence-transformers
license: mit
pipeline_tag: text-generation
tags:
- feature-extraction
- mteb
- sentence-similarity
- sentence-transformers
- gguf
- ggml
- quantized
inference: true
model_creator: avsolatorio
quantized_by: afrideva
model-index:
- name: GIST-all-MiniLM-L6-v2
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 72.8955223880597
- type: ap
value: 35.447605103320775
- type: f1
value: 66.82951715365854
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 87.19474999999998
- type: ap
value: 83.09577890808514
- type: f1
value: 87.13833121762009
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 42.556000000000004
- type: f1
value: 42.236256693772276
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 26.884999999999998
- type: map_at_10
value: 42.364000000000004
- type: map_at_100
value: 43.382
- type: map_at_1000
value: 43.391000000000005
- type: map_at_3
value: 37.162
- type: map_at_5
value: 40.139
- type: mrr_at_1
value: 26.884999999999998
- type: mrr_at_10
value: 42.193999999999996
- type: mrr_at_100
value: 43.211
- type: mrr_at_1000
value: 43.221
- type: mrr_at_3
value: 36.949
- type: mrr_at_5
value: 40.004
- type: ndcg_at_1
value: 26.884999999999998
- type: ndcg_at_10
value: 51.254999999999995
- type: ndcg_at_100
value: 55.481
- type: ndcg_at_1000
value: 55.68300000000001
- type: ndcg_at_3
value: 40.565
- type: ndcg_at_5
value: 45.882
- type: precision_at_1
value: 26.884999999999998
- type: precision_at_10
value: 7.9799999999999995
- type: precision_at_100
value: 0.98
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 16.808999999999997
- type: precision_at_5
value: 12.645999999999999
- type: recall_at_1
value: 26.884999999999998
- type: recall_at_10
value: 79.801
- type: recall_at_100
value: 98.009
- type: recall_at_1000
value: 99.502
- type: recall_at_3
value: 50.427
- type: recall_at_5
value: 63.229
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 45.31044837358167
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 35.44751738734691
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.96517580629869
- type: mrr
value: 76.30051004704744
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 83.97262600499639
- type: cos_sim_spearman
value: 81.25787561220484
- type: euclidean_pearson
value: 64.96260261677082
- type: euclidean_spearman
value: 64.17616109254686
- type: manhattan_pearson
value: 65.05620628102835
- type: manhattan_spearman
value: 64.71171546419122
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.2435064935065
- type: f1
value: 84.2334859253828
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 38.38358435972693
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 31.093619653843124
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.016999999999996
- type: map_at_10
value: 47.019
- type: map_at_100
value: 48.634
- type: map_at_1000
value: 48.757
- type: map_at_3
value: 43.372
- type: map_at_5
value: 45.314
- type: mrr_at_1
value: 43.491
- type: mrr_at_10
value: 53.284
- type: mrr_at_100
value: 54.038
- type: mrr_at_1000
value: 54.071000000000005
- type: mrr_at_3
value: 51.001
- type: mrr_at_5
value: 52.282
- type: ndcg_at_1
value: 43.491
- type: ndcg_at_10
value: 53.498999999999995
- type: ndcg_at_100
value: 58.733999999999995
- type: ndcg_at_1000
value: 60.307
- type: ndcg_at_3
value: 48.841
- type: ndcg_at_5
value: 50.76199999999999
- type: precision_at_1
value: 43.491
- type: precision_at_10
value: 10.315000000000001
- type: precision_at_100
value: 1.6209999999999998
- type: precision_at_1000
value: 0.20500000000000002
- type: precision_at_3
value: 23.462
- type: precision_at_5
value: 16.652
- type: recall_at_1
value: 35.016999999999996
- type: recall_at_10
value: 64.92
- type: recall_at_100
value: 86.605
- type: recall_at_1000
value: 96.174
- type: recall_at_3
value: 50.99
- type: recall_at_5
value: 56.93
- type: map_at_1
value: 29.866
- type: map_at_10
value: 40.438
- type: map_at_100
value: 41.77
- type: map_at_1000
value: 41.913
- type: map_at_3
value: 37.634
- type: map_at_5
value: 39.226
- type: mrr_at_1
value: 37.834
- type: mrr_at_10
value: 46.765
- type: mrr_at_100
value: 47.410000000000004
- type: mrr_at_1000
value: 47.461
- type: mrr_at_3
value: 44.735
- type: mrr_at_5
value: 46.028000000000006
- type: ndcg_at_1
value: 37.834
- type: ndcg_at_10
value: 46.303
- type: ndcg_at_100
value: 50.879
- type: ndcg_at_1000
value: 53.112
- type: ndcg_at_3
value: 42.601
- type: ndcg_at_5
value: 44.384
- type: precision_at_1
value: 37.834
- type: precision_at_10
value: 8.898
- type: precision_at_100
value: 1.4409999999999998
- type: precision_at_1000
value: 0.19499999999999998
- type: precision_at_3
value: 20.977
- type: precision_at_5
value: 14.841
- type: recall_at_1
value: 29.866
- type: recall_at_10
value: 56.06100000000001
- type: recall_at_100
value: 75.809
- type: recall_at_1000
value: 89.875
- type: recall_at_3
value: 44.707
- type: recall_at_5
value: 49.846000000000004
- type: map_at_1
value: 38.985
- type: map_at_10
value: 51.165000000000006
- type: map_at_100
value: 52.17
- type: map_at_1000
value: 52.229000000000006
- type: map_at_3
value: 48.089999999999996
- type: map_at_5
value: 49.762
- type: mrr_at_1
value: 44.577
- type: mrr_at_10
value: 54.493
- type: mrr_at_100
value: 55.137
- type: mrr_at_1000
value: 55.167
- type: mrr_at_3
value: 52.079
- type: mrr_at_5
value: 53.518
- type: ndcg_at_1
value: 44.577
- type: ndcg_at_10
value: 56.825
- type: ndcg_at_100
value: 60.842
- type: ndcg_at_1000
value: 62.015
- type: ndcg_at_3
value: 51.699
- type: ndcg_at_5
value: 54.11
- type: precision_at_1
value: 44.577
- type: precision_at_10
value: 9.11
- type: precision_at_100
value: 1.206
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 23.156
- type: precision_at_5
value: 15.737000000000002
- type: recall_at_1
value: 38.985
- type: recall_at_10
value: 70.164
- type: recall_at_100
value: 87.708
- type: recall_at_1000
value: 95.979
- type: recall_at_3
value: 56.285
- type: recall_at_5
value: 62.303
- type: map_at_1
value: 28.137
- type: map_at_10
value: 36.729
- type: map_at_100
value: 37.851
- type: map_at_1000
value: 37.932
- type: map_at_3
value: 34.074
- type: map_at_5
value: 35.398
- type: mrr_at_1
value: 30.621
- type: mrr_at_10
value: 39.007
- type: mrr_at_100
value: 39.961
- type: mrr_at_1000
value: 40.02
- type: mrr_at_3
value: 36.591
- type: mrr_at_5
value: 37.806
- type: ndcg_at_1
value: 30.621
- type: ndcg_at_10
value: 41.772
- type: ndcg_at_100
value: 47.181
- type: ndcg_at_1000
value: 49.053999999999995
- type: ndcg_at_3
value: 36.577
- type: ndcg_at_5
value: 38.777
- type: precision_at_1
value: 30.621
- type: precision_at_10
value: 6.372999999999999
- type: precision_at_100
value: 0.955
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 15.367
- type: precision_at_5
value: 10.531
- type: recall_at_1
value: 28.137
- type: recall_at_10
value: 55.162
- type: recall_at_100
value: 79.931
- type: recall_at_1000
value: 93.67
- type: recall_at_3
value: 41.057
- type: recall_at_5
value: 46.327
- type: map_at_1
value: 16.798
- type: map_at_10
value: 25.267
- type: map_at_100
value: 26.579000000000004
- type: map_at_1000
value: 26.697
- type: map_at_3
value: 22.456
- type: map_at_5
value: 23.912
- type: mrr_at_1
value: 20.771
- type: mrr_at_10
value: 29.843999999999998
- type: mrr_at_100
value: 30.849
- type: mrr_at_1000
value: 30.916
- type: mrr_at_3
value: 27.156000000000002
- type: mrr_at_5
value: 28.518
- type: ndcg_at_1
value: 20.771
- type: ndcg_at_10
value: 30.792
- type: ndcg_at_100
value: 36.945
- type: ndcg_at_1000
value: 39.619
- type: ndcg_at_3
value: 25.52
- type: ndcg_at_5
value: 27.776
- type: precision_at_1
value: 20.771
- type: precision_at_10
value: 5.734
- type: precision_at_100
value: 1.031
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 12.148
- type: precision_at_5
value: 9.055
- type: recall_at_1
value: 16.798
- type: recall_at_10
value: 43.332
- type: recall_at_100
value: 70.016
- type: recall_at_1000
value: 88.90400000000001
- type: recall_at_3
value: 28.842000000000002
- type: recall_at_5
value: 34.37
- type: map_at_1
value: 31.180000000000003
- type: map_at_10
value: 41.78
- type: map_at_100
value: 43.102000000000004
- type: map_at_1000
value: 43.222
- type: map_at_3
value: 38.505
- type: map_at_5
value: 40.443
- type: mrr_at_1
value: 37.824999999999996
- type: mrr_at_10
value: 47.481
- type: mrr_at_100
value: 48.268
- type: mrr_at_1000
value: 48.313
- type: mrr_at_3
value: 44.946999999999996
- type: mrr_at_5
value: 46.492
- type: ndcg_at_1
value: 37.824999999999996
- type: ndcg_at_10
value: 47.827
- type: ndcg_at_100
value: 53.407000000000004
- type: ndcg_at_1000
value: 55.321
- type: ndcg_at_3
value: 42.815
- type: ndcg_at_5
value: 45.363
- type: precision_at_1
value: 37.824999999999996
- type: precision_at_10
value: 8.652999999999999
- type: precision_at_100
value: 1.354
- type: precision_at_1000
value: 0.172
- type: precision_at_3
value: 20.372
- type: precision_at_5
value: 14.591000000000001
- type: recall_at_1
value: 31.180000000000003
- type: recall_at_10
value: 59.894000000000005
- type: recall_at_100
value: 83.722
- type: recall_at_1000
value: 95.705
- type: recall_at_3
value: 45.824
- type: recall_at_5
value: 52.349999999999994
- type: map_at_1
value: 24.66
- type: map_at_10
value: 34.141
- type: map_at_100
value: 35.478
- type: map_at_1000
value: 35.594
- type: map_at_3
value: 30.446
- type: map_at_5
value: 32.583
- type: mrr_at_1
value: 29.909000000000002
- type: mrr_at_10
value: 38.949
- type: mrr_at_100
value: 39.803
- type: mrr_at_1000
value: 39.867999999999995
- type: mrr_at_3
value: 35.921
- type: mrr_at_5
value: 37.753
- type: ndcg_at_1
value: 29.909000000000002
- type: ndcg_at_10
value: 40.012
- type: ndcg_at_100
value: 45.707
- type: ndcg_at_1000
value: 48.15
- type: ndcg_at_3
value: 34.015
- type: ndcg_at_5
value: 37.002
- type: precision_at_1
value: 29.909000000000002
- type: precision_at_10
value: 7.693999999999999
- type: precision_at_100
value: 1.2229999999999999
- type: precision_at_1000
value: 0.16
- type: precision_at_3
value: 16.323999999999998
- type: precision_at_5
value: 12.306000000000001
- type: recall_at_1
value: 24.66
- type: recall_at_10
value: 52.478
- type: recall_at_100
value: 77.051
- type: recall_at_1000
value: 93.872
- type: recall_at_3
value: 36.382999999999996
- type: recall_at_5
value: 43.903999999999996
- type: map_at_1
value: 26.768416666666667
- type: map_at_10
value: 36.2485
- type: map_at_100
value: 37.520833333333336
- type: map_at_1000
value: 37.64033333333334
- type: map_at_3
value: 33.25791666666667
- type: map_at_5
value: 34.877250000000004
- type: mrr_at_1
value: 31.65408333333334
- type: mrr_at_10
value: 40.43866666666667
- type: mrr_at_100
value: 41.301249999999996
- type: mrr_at_1000
value: 41.357499999999995
- type: mrr_at_3
value: 37.938916666666664
- type: mrr_at_5
value: 39.35183333333334
- type: ndcg_at_1
value: 31.65408333333334
- type: ndcg_at_10
value: 41.76983333333334
- type: ndcg_at_100
value: 47.138
- type: ndcg_at_1000
value: 49.33816666666667
- type: ndcg_at_3
value: 36.76683333333333
- type: ndcg_at_5
value: 39.04441666666666
- type: precision_at_1
value: 31.65408333333334
- type: precision_at_10
value: 7.396249999999998
- type: precision_at_100
value: 1.1974166666666666
- type: precision_at_1000
value: 0.15791666666666668
- type: precision_at_3
value: 16.955583333333333
- type: precision_at_5
value: 12.09925
- type: recall_at_1
value: 26.768416666666667
- type: recall_at_10
value: 53.82366666666667
- type: recall_at_100
value: 77.39600000000002
- type: recall_at_1000
value: 92.46300000000001
- type: recall_at_3
value: 39.90166666666667
- type: recall_at_5
value: 45.754000000000005
- type: map_at_1
value: 24.369
- type: map_at_10
value: 32.025
- type: map_at_100
value: 33.08
- type: map_at_1000
value: 33.169
- type: map_at_3
value: 29.589
- type: map_at_5
value: 30.894
- type: mrr_at_1
value: 27.301
- type: mrr_at_10
value: 34.64
- type: mrr_at_100
value: 35.556
- type: mrr_at_1000
value: 35.616
- type: mrr_at_3
value: 32.515
- type: mrr_at_5
value: 33.666000000000004
- type: ndcg_at_1
value: 27.301
- type: ndcg_at_10
value: 36.386
- type: ndcg_at_100
value: 41.598
- type: ndcg_at_1000
value: 43.864999999999995
- type: ndcg_at_3
value: 32.07
- type: ndcg_at_5
value: 34.028999999999996
- type: precision_at_1
value: 27.301
- type: precision_at_10
value: 5.782
- type: precision_at_100
value: 0.923
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 13.804
- type: precision_at_5
value: 9.693
- type: recall_at_1
value: 24.369
- type: recall_at_10
value: 47.026
- type: recall_at_100
value: 70.76400000000001
- type: recall_at_1000
value: 87.705
- type: recall_at_3
value: 35.366
- type: recall_at_5
value: 40.077
- type: map_at_1
value: 17.878
- type: map_at_10
value: 25.582
- type: map_at_100
value: 26.848
- type: map_at_1000
value: 26.985
- type: map_at_3
value: 22.997
- type: map_at_5
value: 24.487000000000002
- type: mrr_at_1
value: 22.023
- type: mrr_at_10
value: 29.615000000000002
- type: mrr_at_100
value: 30.656
- type: mrr_at_1000
value: 30.737
- type: mrr_at_3
value: 27.322999999999997
- type: mrr_at_5
value: 28.665000000000003
- type: ndcg_at_1
value: 22.023
- type: ndcg_at_10
value: 30.476999999999997
- type: ndcg_at_100
value: 36.258
- type: ndcg_at_1000
value: 39.287
- type: ndcg_at_3
value: 25.995
- type: ndcg_at_5
value: 28.174
- type: precision_at_1
value: 22.023
- type: precision_at_10
value: 5.657
- type: precision_at_100
value: 1.01
- type: precision_at_1000
value: 0.145
- type: precision_at_3
value: 12.491
- type: precision_at_5
value: 9.112
- type: recall_at_1
value: 17.878
- type: recall_at_10
value: 41.155
- type: recall_at_100
value: 66.62599999999999
- type: recall_at_1000
value: 88.08200000000001
- type: recall_at_3
value: 28.505000000000003
- type: recall_at_5
value: 34.284
- type: map_at_1
value: 26.369999999999997
- type: map_at_10
value: 36.115
- type: map_at_100
value: 37.346000000000004
- type: map_at_1000
value: 37.449
- type: map_at_3
value: 32.976
- type: map_at_5
value: 34.782000000000004
- type: mrr_at_1
value: 30.784
- type: mrr_at_10
value: 40.014
- type: mrr_at_100
value: 40.913
- type: mrr_at_1000
value: 40.967999999999996
- type: mrr_at_3
value: 37.205
- type: mrr_at_5
value: 38.995999999999995
- type: ndcg_at_1
value: 30.784
- type: ndcg_at_10
value: 41.797000000000004
- type: ndcg_at_100
value: 47.355000000000004
- type: ndcg_at_1000
value: 49.535000000000004
- type: ndcg_at_3
value: 36.29
- type: ndcg_at_5
value: 39.051
- type: precision_at_1
value: 30.784
- type: precision_at_10
value: 7.164
- type: precision_at_100
value: 1.122
- type: precision_at_1000
value: 0.14200000000000002
- type: precision_at_3
value: 16.636
- type: precision_at_5
value: 11.996
- type: recall_at_1
value: 26.369999999999997
- type: recall_at_10
value: 55.010000000000005
- type: recall_at_100
value: 79.105
- type: recall_at_1000
value: 94.053
- type: recall_at_3
value: 40.139
- type: recall_at_5
value: 47.089
- type: map_at_1
value: 26.421
- type: map_at_10
value: 35.253
- type: map_at_100
value: 36.97
- type: map_at_1000
value: 37.195
- type: map_at_3
value: 32.068000000000005
- type: map_at_5
value: 33.763
- type: mrr_at_1
value: 31.423000000000002
- type: mrr_at_10
value: 39.995999999999995
- type: mrr_at_100
value: 40.977999999999994
- type: mrr_at_1000
value: 41.024
- type: mrr_at_3
value: 36.989
- type: mrr_at_5
value: 38.629999999999995
- type: ndcg_at_1
value: 31.423000000000002
- type: ndcg_at_10
value: 41.382000000000005
- type: ndcg_at_100
value: 47.532000000000004
- type: ndcg_at_1000
value: 49.829
- type: ndcg_at_3
value: 35.809000000000005
- type: ndcg_at_5
value: 38.308
- type: precision_at_1
value: 31.423000000000002
- type: precision_at_10
value: 7.885000000000001
- type: precision_at_100
value: 1.609
- type: precision_at_1000
value: 0.246
- type: precision_at_3
value: 16.469
- type: precision_at_5
value: 12.174
- type: recall_at_1
value: 26.421
- type: recall_at_10
value: 53.618
- type: recall_at_100
value: 80.456
- type: recall_at_1000
value: 94.505
- type: recall_at_3
value: 37.894
- type: recall_at_5
value: 44.352999999999994
- type: map_at_1
value: 21.54
- type: map_at_10
value: 29.468
- type: map_at_100
value: 30.422
- type: map_at_1000
value: 30.542
- type: map_at_3
value: 26.888
- type: map_at_5
value: 27.962999999999997
- type: mrr_at_1
value: 23.29
- type: mrr_at_10
value: 31.176
- type: mrr_at_100
value: 32.046
- type: mrr_at_1000
value: 32.129000000000005
- type: mrr_at_3
value: 28.804999999999996
- type: mrr_at_5
value: 29.868
- type: ndcg_at_1
value: 23.29
- type: ndcg_at_10
value: 34.166000000000004
- type: ndcg_at_100
value: 39.217999999999996
- type: ndcg_at_1000
value: 41.964
- type: ndcg_at_3
value: 28.970000000000002
- type: ndcg_at_5
value: 30.797
- type: precision_at_1
value: 23.29
- type: precision_at_10
value: 5.489999999999999
- type: precision_at_100
value: 0.874
- type: precision_at_1000
value: 0.122
- type: precision_at_3
value: 12.261
- type: precision_at_5
value: 8.503
- type: recall_at_1
value: 21.54
- type: recall_at_10
value: 47.064
- type: recall_at_100
value: 70.959
- type: recall_at_1000
value: 91.032
- type: recall_at_3
value: 32.828
- type: recall_at_5
value: 37.214999999999996
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.102
- type: map_at_10
value: 17.469
- type: map_at_100
value: 19.244
- type: map_at_1000
value: 19.435
- type: map_at_3
value: 14.257
- type: map_at_5
value: 16.028000000000002
- type: mrr_at_1
value: 22.866
- type: mrr_at_10
value: 33.535
- type: mrr_at_100
value: 34.583999999999996
- type: mrr_at_1000
value: 34.622
- type: mrr_at_3
value: 29.946
- type: mrr_at_5
value: 32.157000000000004
- type: ndcg_at_1
value: 22.866
- type: ndcg_at_10
value: 25.16
- type: ndcg_at_100
value: 32.347
- type: ndcg_at_1000
value: 35.821
- type: ndcg_at_3
value: 19.816
- type: ndcg_at_5
value: 22.026
- type: precision_at_1
value: 22.866
- type: precision_at_10
value: 8.072
- type: precision_at_100
value: 1.5709999999999997
- type: precision_at_1000
value: 0.22200000000000003
- type: precision_at_3
value: 14.701
- type: precision_at_5
value: 11.960999999999999
- type: recall_at_1
value: 10.102
- type: recall_at_10
value: 31.086000000000002
- type: recall_at_100
value: 55.896
- type: recall_at_1000
value: 75.375
- type: recall_at_3
value: 18.343999999999998
- type: recall_at_5
value: 24.102
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.961
- type: map_at_10
value: 16.058
- type: map_at_100
value: 21.878
- type: map_at_1000
value: 23.156
- type: map_at_3
value: 12.206999999999999
- type: map_at_5
value: 13.747000000000002
- type: mrr_at_1
value: 60.5
- type: mrr_at_10
value: 68.488
- type: mrr_at_100
value: 69.02199999999999
- type: mrr_at_1000
value: 69.03200000000001
- type: mrr_at_3
value: 66.792
- type: mrr_at_5
value: 67.62899999999999
- type: ndcg_at_1
value: 49.125
- type: ndcg_at_10
value: 34.827999999999996
- type: ndcg_at_100
value: 38.723
- type: ndcg_at_1000
value: 45.988
- type: ndcg_at_3
value: 40.302
- type: ndcg_at_5
value: 36.781000000000006
- type: precision_at_1
value: 60.5
- type: precision_at_10
value: 26.825
- type: precision_at_100
value: 8.445
- type: precision_at_1000
value: 1.7000000000000002
- type: precision_at_3
value: 43.25
- type: precision_at_5
value: 34.5
- type: recall_at_1
value: 7.961
- type: recall_at_10
value: 20.843
- type: recall_at_100
value: 43.839
- type: recall_at_1000
value: 67.33
- type: recall_at_3
value: 13.516
- type: recall_at_5
value: 15.956000000000001
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 52.06000000000001
- type: f1
value: 47.21494728335567
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 56.798
- type: map_at_10
value: 67.644
- type: map_at_100
value: 68.01700000000001
- type: map_at_1000
value: 68.038
- type: map_at_3
value: 65.539
- type: map_at_5
value: 66.912
- type: mrr_at_1
value: 61.221000000000004
- type: mrr_at_10
value: 71.97099999999999
- type: mrr_at_100
value: 72.262
- type: mrr_at_1000
value: 72.27
- type: mrr_at_3
value: 70.052
- type: mrr_at_5
value: 71.324
- type: ndcg_at_1
value: 61.221000000000004
- type: ndcg_at_10
value: 73.173
- type: ndcg_at_100
value: 74.779
- type: ndcg_at_1000
value: 75.229
- type: ndcg_at_3
value: 69.291
- type: ndcg_at_5
value: 71.552
- type: precision_at_1
value: 61.221000000000004
- type: precision_at_10
value: 9.449
- type: precision_at_100
value: 1.0370000000000001
- type: precision_at_1000
value: 0.109
- type: precision_at_3
value: 27.467999999999996
- type: precision_at_5
value: 17.744
- type: recall_at_1
value: 56.798
- type: recall_at_10
value: 85.991
- type: recall_at_100
value: 92.973
- type: recall_at_1000
value: 96.089
- type: recall_at_3
value: 75.576
- type: recall_at_5
value: 81.12
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.323
- type: map_at_10
value: 30.279
- type: map_at_100
value: 32.153999999999996
- type: map_at_1000
value: 32.339
- type: map_at_3
value: 26.336
- type: map_at_5
value: 28.311999999999998
- type: mrr_at_1
value: 35.339999999999996
- type: mrr_at_10
value: 44.931
- type: mrr_at_100
value: 45.818999999999996
- type: mrr_at_1000
value: 45.864
- type: mrr_at_3
value: 42.618
- type: mrr_at_5
value: 43.736999999999995
- type: ndcg_at_1
value: 35.339999999999996
- type: ndcg_at_10
value: 37.852999999999994
- type: ndcg_at_100
value: 44.888
- type: ndcg_at_1000
value: 48.069
- type: ndcg_at_3
value: 34.127
- type: ndcg_at_5
value: 35.026
- type: precision_at_1
value: 35.339999999999996
- type: precision_at_10
value: 10.617
- type: precision_at_100
value: 1.7930000000000001
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 22.582
- type: precision_at_5
value: 16.605
- type: recall_at_1
value: 18.323
- type: recall_at_10
value: 44.948
- type: recall_at_100
value: 71.11800000000001
- type: recall_at_1000
value: 90.104
- type: recall_at_3
value: 31.661
- type: recall_at_5
value: 36.498000000000005
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.668
- type: map_at_10
value: 43.669999999999995
- type: map_at_100
value: 44.646
- type: map_at_1000
value: 44.731
- type: map_at_3
value: 40.897
- type: map_at_5
value: 42.559999999999995
- type: mrr_at_1
value: 61.336999999999996
- type: mrr_at_10
value: 68.496
- type: mrr_at_100
value: 68.916
- type: mrr_at_1000
value: 68.938
- type: mrr_at_3
value: 66.90700000000001
- type: mrr_at_5
value: 67.91199999999999
- type: ndcg_at_1
value: 61.336999999999996
- type: ndcg_at_10
value: 52.588
- type: ndcg_at_100
value: 56.389
- type: ndcg_at_1000
value: 58.187999999999995
- type: ndcg_at_3
value: 48.109
- type: ndcg_at_5
value: 50.498
- type: precision_at_1
value: 61.336999999999996
- type: precision_at_10
value: 11.033
- type: precision_at_100
value: 1.403
- type: precision_at_1000
value: 0.164
- type: precision_at_3
value: 30.105999999999998
- type: precision_at_5
value: 19.954
- type: recall_at_1
value: 30.668
- type: recall_at_10
value: 55.165
- type: recall_at_100
value: 70.169
- type: recall_at_1000
value: 82.12
- type: recall_at_3
value: 45.159
- type: recall_at_5
value: 49.885000000000005
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 78.542
- type: ap
value: 72.50692137216646
- type: f1
value: 78.40630687221642
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 18.613
- type: map_at_10
value: 29.98
- type: map_at_100
value: 31.136999999999997
- type: map_at_1000
value: 31.196
- type: map_at_3
value: 26.339000000000002
- type: map_at_5
value: 28.351
- type: mrr_at_1
value: 19.054
- type: mrr_at_10
value: 30.476
- type: mrr_at_100
value: 31.588
- type: mrr_at_1000
value: 31.641000000000002
- type: mrr_at_3
value: 26.834000000000003
- type: mrr_at_5
value: 28.849000000000004
- type: ndcg_at_1
value: 19.083
- type: ndcg_at_10
value: 36.541000000000004
- type: ndcg_at_100
value: 42.35
- type: ndcg_at_1000
value: 43.9
- type: ndcg_at_3
value: 29.015
- type: ndcg_at_5
value: 32.622
- type: precision_at_1
value: 19.083
- type: precision_at_10
value: 5.914
- type: precision_at_100
value: 0.889
- type: precision_at_1000
value: 0.10200000000000001
- type: precision_at_3
value: 12.483
- type: precision_at_5
value: 9.315
- type: recall_at_1
value: 18.613
- type: recall_at_10
value: 56.88999999999999
- type: recall_at_100
value: 84.207
- type: recall_at_1000
value: 96.20100000000001
- type: recall_at_3
value: 36.262
- type: recall_at_5
value: 44.925
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 94.77656178750571
- type: f1
value: 94.37966073742972
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.72457820337438
- type: f1
value: 59.11327646329634
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.17753866846
- type: f1
value: 71.22604635414544
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.67787491593813
- type: f1
value: 76.87653151298177
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.3485843514749
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 29.792796913883617
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.310305659169963
- type: mrr
value: 32.38286775798406
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.968
- type: map_at_10
value: 11.379
- type: map_at_100
value: 14.618999999999998
- type: map_at_1000
value: 16.055
- type: map_at_3
value: 8.34
- type: map_at_5
value: 9.690999999999999
- type: mrr_at_1
value: 43.034
- type: mrr_at_10
value: 51.019999999999996
- type: mrr_at_100
value: 51.63100000000001
- type: mrr_at_1000
value: 51.681
- type: mrr_at_3
value: 49.174
- type: mrr_at_5
value: 50.181
- type: ndcg_at_1
value: 41.176
- type: ndcg_at_10
value: 31.341
- type: ndcg_at_100
value: 29.451
- type: ndcg_at_1000
value: 38.007000000000005
- type: ndcg_at_3
value: 36.494
- type: ndcg_at_5
value: 34.499
- type: precision_at_1
value: 43.034
- type: precision_at_10
value: 23.375
- type: precision_at_100
value: 7.799
- type: precision_at_1000
value: 2.059
- type: precision_at_3
value: 34.675
- type: precision_at_5
value: 30.154999999999998
- type: recall_at_1
value: 4.968
- type: recall_at_10
value: 15.104999999999999
- type: recall_at_100
value: 30.741000000000003
- type: recall_at_1000
value: 61.182
- type: recall_at_3
value: 9.338000000000001
- type: recall_at_5
value: 11.484
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.716
- type: map_at_10
value: 38.32
- type: map_at_100
value: 39.565
- type: map_at_1000
value: 39.602
- type: map_at_3
value: 33.848
- type: map_at_5
value: 36.471
- type: mrr_at_1
value: 26.912000000000003
- type: mrr_at_10
value: 40.607
- type: mrr_at_100
value: 41.589
- type: mrr_at_1000
value: 41.614000000000004
- type: mrr_at_3
value: 36.684
- type: mrr_at_5
value: 39.036
- type: ndcg_at_1
value: 26.883000000000003
- type: ndcg_at_10
value: 46.096
- type: ndcg_at_100
value: 51.513
- type: ndcg_at_1000
value: 52.366
- type: ndcg_at_3
value: 37.549
- type: ndcg_at_5
value: 41.971000000000004
- type: precision_at_1
value: 26.883000000000003
- type: precision_at_10
value: 8.004
- type: precision_at_100
value: 1.107
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 17.516000000000002
- type: precision_at_5
value: 13.019
- type: recall_at_1
value: 23.716
- type: recall_at_10
value: 67.656
- type: recall_at_100
value: 91.413
- type: recall_at_1000
value: 97.714
- type: recall_at_3
value: 45.449
- type: recall_at_5
value: 55.598000000000006
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.486
- type: map_at_10
value: 84.292
- type: map_at_100
value: 84.954
- type: map_at_1000
value: 84.969
- type: map_at_3
value: 81.295
- type: map_at_5
value: 83.165
- type: mrr_at_1
value: 81.16
- type: mrr_at_10
value: 87.31
- type: mrr_at_100
value: 87.423
- type: mrr_at_1000
value: 87.423
- type: mrr_at_3
value: 86.348
- type: mrr_at_5
value: 86.991
- type: ndcg_at_1
value: 81.17
- type: ndcg_at_10
value: 88.067
- type: ndcg_at_100
value: 89.34
- type: ndcg_at_1000
value: 89.43900000000001
- type: ndcg_at_3
value: 85.162
- type: ndcg_at_5
value: 86.752
- type: precision_at_1
value: 81.17
- type: precision_at_10
value: 13.394
- type: precision_at_100
value: 1.5310000000000001
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.193
- type: precision_at_5
value: 24.482
- type: recall_at_1
value: 70.486
- type: recall_at_10
value: 95.184
- type: recall_at_100
value: 99.53999999999999
- type: recall_at_1000
value: 99.98700000000001
- type: recall_at_3
value: 86.89
- type: recall_at_5
value: 91.365
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 44.118229475102154
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 48.68049097629063
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.888
- type: map_at_10
value: 12.770999999999999
- type: map_at_100
value: 15.238
- type: map_at_1000
value: 15.616
- type: map_at_3
value: 8.952
- type: map_at_5
value: 10.639999999999999
- type: mrr_at_1
value: 24.099999999999998
- type: mrr_at_10
value: 35.375
- type: mrr_at_100
value: 36.442
- type: mrr_at_1000
value: 36.488
- type: mrr_at_3
value: 31.717000000000002
- type: mrr_at_5
value: 33.722
- type: ndcg_at_1
value: 24.099999999999998
- type: ndcg_at_10
value: 21.438
- type: ndcg_at_100
value: 30.601
- type: ndcg_at_1000
value: 36.678
- type: ndcg_at_3
value: 19.861
- type: ndcg_at_5
value: 17.263
- type: precision_at_1
value: 24.099999999999998
- type: precision_at_10
value: 11.4
- type: precision_at_100
value: 2.465
- type: precision_at_1000
value: 0.392
- type: precision_at_3
value: 18.733
- type: precision_at_5
value: 15.22
- type: recall_at_1
value: 4.888
- type: recall_at_10
value: 23.118
- type: recall_at_100
value: 49.995
- type: recall_at_1000
value: 79.577
- type: recall_at_3
value: 11.398
- type: recall_at_5
value: 15.428
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.33198632617024
- type: cos_sim_spearman
value: 79.09232997136625
- type: euclidean_pearson
value: 81.49986011523868
- type: euclidean_spearman
value: 77.03530620283338
- type: manhattan_pearson
value: 81.4741227286667
- type: manhattan_spearman
value: 76.98641133116311
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.60103674582464
- type: cos_sim_spearman
value: 75.03945035801914
- type: euclidean_pearson
value: 80.82455267481467
- type: euclidean_spearman
value: 70.3317366248871
- type: manhattan_pearson
value: 80.8928091531445
- type: manhattan_spearman
value: 70.43207370945672
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 82.52453177109315
- type: cos_sim_spearman
value: 83.26431569305103
- type: euclidean_pearson
value: 82.10494657997404
- type: euclidean_spearman
value: 83.41028425949024
- type: manhattan_pearson
value: 82.08669822983934
- type: manhattan_spearman
value: 83.39959776442115
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 82.67472020277681
- type: cos_sim_spearman
value: 78.61877889763109
- type: euclidean_pearson
value: 80.07878012437722
- type: euclidean_spearman
value: 77.44374494215397
- type: manhattan_pearson
value: 79.95988483102258
- type: manhattan_spearman
value: 77.36018101061366
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 85.55450610494437
- type: cos_sim_spearman
value: 87.03494331841401
- type: euclidean_pearson
value: 81.4319784394287
- type: euclidean_spearman
value: 82.47893040599372
- type: manhattan_pearson
value: 81.32627203699644
- type: manhattan_spearman
value: 82.40660565070675
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 81.51576965454805
- type: cos_sim_spearman
value: 83.0062959588245
- type: euclidean_pearson
value: 79.98888882568556
- type: euclidean_spearman
value: 81.08948911791873
- type: manhattan_pearson
value: 79.77952719568583
- type: manhattan_spearman
value: 80.79471040445408
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.28313046682885
- type: cos_sim_spearman
value: 87.35865211085007
- type: euclidean_pearson
value: 84.11501613667811
- type: euclidean_spearman
value: 82.82038954956121
- type: manhattan_pearson
value: 83.891278147302
- type: manhattan_spearman
value: 82.59947685165902
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.80653738006102
- type: cos_sim_spearman
value: 68.11259151179601
- type: euclidean_pearson
value: 43.16707985094242
- type: euclidean_spearman
value: 58.96200382968696
- type: manhattan_pearson
value: 43.84146858566507
- type: manhattan_spearman
value: 59.05193977207514
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 82.62068205073571
- type: cos_sim_spearman
value: 84.40071593577095
- type: euclidean_pearson
value: 80.90824726252514
- type: euclidean_spearman
value: 80.54974812534094
- type: manhattan_pearson
value: 80.6759008187939
- type: manhattan_spearman
value: 80.31149103896973
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.13774787530915
- type: mrr
value: 96.22233793802422
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 49.167
- type: map_at_10
value: 59.852000000000004
- type: map_at_100
value: 60.544
- type: map_at_1000
value: 60.577000000000005
- type: map_at_3
value: 57.242000000000004
- type: map_at_5
value: 58.704
- type: mrr_at_1
value: 51.0
- type: mrr_at_10
value: 60.575
- type: mrr_at_100
value: 61.144
- type: mrr_at_1000
value: 61.175000000000004
- type: mrr_at_3
value: 58.667
- type: mrr_at_5
value: 59.599999999999994
- type: ndcg_at_1
value: 51.0
- type: ndcg_at_10
value: 64.398
- type: ndcg_at_100
value: 67.581
- type: ndcg_at_1000
value: 68.551
- type: ndcg_at_3
value: 59.928000000000004
- type: ndcg_at_5
value: 61.986
- type: precision_at_1
value: 51.0
- type: precision_at_10
value: 8.7
- type: precision_at_100
value: 1.047
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 23.666999999999998
- type: precision_at_5
value: 15.6
- type: recall_at_1
value: 49.167
- type: recall_at_10
value: 77.333
- type: recall_at_100
value: 91.833
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 65.594
- type: recall_at_5
value: 70.52199999999999
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.77227722772277
- type: cos_sim_ap
value: 94.14261011689366
- type: cos_sim_f1
value: 88.37209302325581
- type: cos_sim_precision
value: 89.36605316973414
- type: cos_sim_recall
value: 87.4
- type: dot_accuracy
value: 99.07128712871287
- type: dot_ap
value: 27.325649239129486
- type: dot_f1
value: 33.295838020247466
- type: dot_precision
value: 38.04627249357326
- type: dot_recall
value: 29.599999999999998
- type: euclidean_accuracy
value: 99.74158415841585
- type: euclidean_ap
value: 92.32695359979576
- type: euclidean_f1
value: 86.90534575772439
- type: euclidean_precision
value: 85.27430221366699
- type: euclidean_recall
value: 88.6
- type: manhattan_accuracy
value: 99.74257425742574
- type: manhattan_ap
value: 92.40335687760499
- type: manhattan_f1
value: 86.96507624200687
- type: manhattan_precision
value: 85.57599225556632
- type: manhattan_recall
value: 88.4
- type: max_accuracy
value: 99.77227722772277
- type: max_ap
value: 94.14261011689366
- type: max_f1
value: 88.37209302325581
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 53.113809982945035
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 33.90915908471812
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 50.36481271702464
- type: mrr
value: 51.05628236142942
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.311305530381826
- type: cos_sim_spearman
value: 31.22029657606254
- type: dot_pearson
value: 12.157032445910177
- type: dot_spearman
value: 13.275185888551805
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.167
- type: map_at_10
value: 1.113
- type: map_at_100
value: 5.926
- type: map_at_1000
value: 15.25
- type: map_at_3
value: 0.414
- type: map_at_5
value: 0.633
- type: mrr_at_1
value: 64.0
- type: mrr_at_10
value: 74.444
- type: mrr_at_100
value: 74.667
- type: mrr_at_1000
value: 74.679
- type: mrr_at_3
value: 72.0
- type: mrr_at_5
value: 74.0
- type: ndcg_at_1
value: 59.0
- type: ndcg_at_10
value: 51.468
- type: ndcg_at_100
value: 38.135000000000005
- type: ndcg_at_1000
value: 36.946
- type: ndcg_at_3
value: 55.827000000000005
- type: ndcg_at_5
value: 53.555
- type: precision_at_1
value: 64.0
- type: precision_at_10
value: 54.400000000000006
- type: precision_at_100
value: 39.08
- type: precision_at_1000
value: 16.618
- type: precision_at_3
value: 58.667
- type: precision_at_5
value: 56.8
- type: recall_at_1
value: 0.167
- type: recall_at_10
value: 1.38
- type: recall_at_100
value: 9.189
- type: recall_at_1000
value: 35.737
- type: recall_at_3
value: 0.455
- type: recall_at_5
value: 0.73
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.4299999999999997
- type: map_at_10
value: 8.539
- type: map_at_100
value: 14.155999999999999
- type: map_at_1000
value: 15.684999999999999
- type: map_at_3
value: 3.857
- type: map_at_5
value: 5.583
- type: mrr_at_1
value: 26.531
- type: mrr_at_10
value: 40.489999999999995
- type: mrr_at_100
value: 41.772999999999996
- type: mrr_at_1000
value: 41.772999999999996
- type: mrr_at_3
value: 35.034
- type: mrr_at_5
value: 38.81
- type: ndcg_at_1
value: 21.429000000000002
- type: ndcg_at_10
value: 20.787
- type: ndcg_at_100
value: 33.202
- type: ndcg_at_1000
value: 45.167
- type: ndcg_at_3
value: 18.233
- type: ndcg_at_5
value: 19.887
- type: precision_at_1
value: 26.531
- type: precision_at_10
value: 19.796
- type: precision_at_100
value: 7.4079999999999995
- type: precision_at_1000
value: 1.5310000000000001
- type: precision_at_3
value: 19.728
- type: precision_at_5
value: 21.633
- type: recall_at_1
value: 2.4299999999999997
- type: recall_at_10
value: 14.901
- type: recall_at_100
value: 46.422000000000004
- type: recall_at_1000
value: 82.83500000000001
- type: recall_at_3
value: 4.655
- type: recall_at_5
value: 8.092
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 72.90140000000001
- type: ap
value: 15.138716624430662
- type: f1
value: 56.08803013269606
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.85285795132994
- type: f1
value: 60.17575819903709
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 41.125150148437065
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 84.96751505036657
- type: cos_sim_ap
value: 70.45642872444971
- type: cos_sim_f1
value: 65.75274793133259
- type: cos_sim_precision
value: 61.806361736707686
- type: cos_sim_recall
value: 70.23746701846966
- type: dot_accuracy
value: 77.84466829588126
- type: dot_ap
value: 32.49904328313596
- type: dot_f1
value: 37.903122189387126
- type: dot_precision
value: 25.050951086956523
- type: dot_recall
value: 77.83641160949868
- type: euclidean_accuracy
value: 84.5920009536866
- type: euclidean_ap
value: 68.83700633574043
- type: euclidean_f1
value: 64.92803542871202
- type: euclidean_precision
value: 60.820465545056464
- type: euclidean_recall
value: 69.63060686015831
- type: manhattan_accuracy
value: 84.52643500029802
- type: manhattan_ap
value: 68.63286046599892
- type: manhattan_f1
value: 64.7476540705047
- type: manhattan_precision
value: 62.3291015625
- type: manhattan_recall
value: 67.36147757255937
- type: max_accuracy
value: 84.96751505036657
- type: max_ap
value: 70.45642872444971
- type: max_f1
value: 65.75274793133259
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.65603291031164
- type: cos_sim_ap
value: 85.58148320880878
- type: cos_sim_f1
value: 77.63202920041064
- type: cos_sim_precision
value: 76.68444377675957
- type: cos_sim_recall
value: 78.60332614721281
- type: dot_accuracy
value: 79.71048239996895
- type: dot_ap
value: 59.31114839296281
- type: dot_f1
value: 57.13895527483783
- type: dot_precision
value: 51.331125015335545
- type: dot_recall
value: 64.4287034185402
- type: euclidean_accuracy
value: 86.99305312997244
- type: euclidean_ap
value: 81.87075965254876
- type: euclidean_f1
value: 73.53543008715421
- type: euclidean_precision
value: 72.39964184450082
- type: euclidean_recall
value: 74.70742223591007
- type: manhattan_accuracy
value: 87.04156479217605
- type: manhattan_ap
value: 81.7850497283247
- type: manhattan_f1
value: 73.52951955143475
- type: manhattan_precision
value: 70.15875236030492
- type: manhattan_recall
value: 77.2405297197413
- type: max_accuracy
value: 88.65603291031164
- type: max_ap
value: 85.58148320880878
- type: max_f1
value: 77.63202920041064
---
# GIST-all-MiniLM-L6-v2-GGUF
Quantized GGUF model files for [GIST-all-MiniLM-L6-v2](https://huggingface.co/avsolatorio/GIST-all-MiniLM-L6-v2) from [avsolatorio](https://huggingface.co/avsolatorio)
## Original Model Card:
<h1 align="center">GIST Embedding v0 - all-MiniLM-L6-v2</h1>
*GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning*
The model is fine-tuned on top of the [sentence-transformers/all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) using the [MEDI dataset](https://github.com/xlang-ai/instructor-embedding.git) augmented with mined triplets from the [MTEB Classification](https://huggingface.co/mteb) training dataset (excluding data from the Amazon Polarity Classification task).
The model does not require any instruction for generating embeddings. This means that queries for retrieval tasks can be directly encoded without crafting instructions.
Technical paper: [GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning](https://arxiv.org/abs/2402.16829)
# Data
The dataset used is a compilation of the MEDI and MTEB Classification training datasets. Third-party datasets may be subject to additional terms and conditions under their associated licenses. A HuggingFace Dataset version of the compiled dataset, and the specific revision used to train the model, is available:
- Dataset: [avsolatorio/medi-data-mteb_avs_triplets](https://huggingface.co/datasets/avsolatorio/medi-data-mteb_avs_triplets)
- Revision: 238a0499b6e6b690cc64ea56fde8461daa8341bb
The dataset contains a `task_type` key, which can be used to select only the mteb classification tasks (prefixed with `mteb_`).
The **MEDI Dataset** is published in the following paper: [One Embedder, Any Task: Instruction-Finetuned Text Embeddings](https://arxiv.org/abs/2212.09741).
The MTEB Benchmark results of the GIST embedding model, compared with the base model, suggest that the fine-tuning dataset has perturbed the model considerably, which resulted in significant improvements in certain tasks while adversely degrading performance in some.
The retrieval performance for the TRECCOVID task is of note. The fine-tuning dataset does not contain significant knowledge about COVID-19, which could have caused the observed performance degradation. We found some evidence, detailed in the paper, that thematic coverage of the fine-tuning data can affect downstream performance.
# Usage
The model can be easily loaded using the Sentence Transformers library.
```Python
import torch.nn.functional as F
from sentence_transformers import SentenceTransformer
revision = None # Replace with the specific revision to ensure reproducibility if the model is updated.
model = SentenceTransformer("avsolatorio/GIST-all-MiniLM-L6-v2", revision=revision)
texts = [
"Illustration of the REaLTabFormer model. The left block shows the non-relational tabular data model using GPT-2 with a causal LM head. In contrast, the right block shows how a relational dataset's child table is modeled using a sequence-to-sequence (Seq2Seq) model. The Seq2Seq model uses the observations in the parent table to condition the generation of the observations in the child table. The trained GPT-2 model on the parent table, with weights frozen, is also used as the encoder in the Seq2Seq model.",
"Predicting human mobility holds significant practical value, with applications ranging from enhancing disaster risk planning to simulating epidemic spread. In this paper, we present the GeoFormer, a decoder-only transformer model adapted from the GPT architecture to forecast human mobility.",
"As the economies of Southeast Asia continue adopting digital technologies, policy makers increasingly ask how to prepare the workforce for emerging labor demands. However, little is known about the skills that workers need to adapt to these changes"
]
# Compute embeddings
embeddings = model.encode(texts, convert_to_tensor=True)
# Compute cosine-similarity for each pair of sentences
scores = F.cosine_similarity(embeddings.unsqueeze(1), embeddings.unsqueeze(0), dim=-1)
print(scores.cpu().numpy())
```
# Training Parameters
Below are the training parameters used to fine-tune the model:
```
Epochs = 40
Warmup ratio = 0.1
Learning rate = 5e-6
Batch size = 16
Checkpoint step = 102000
Contrastive loss temperature = 0.01
```
# Evaluation
The model was evaluated using the [MTEB Evaluation](https://huggingface.co/mteb) suite.
# Citation
Please cite our work if you use GISTEmbed or the datasets we published in your projects or research. 🤗
```
@article{solatorio2024gistembed,
title={GISTEmbed: Guided In-sample Selection of Training Negatives for Text Embedding Fine-tuning},
author={Aivin V. Solatorio},
journal={arXiv preprint arXiv:2402.16829},
year={2024},
URL={https://arxiv.org/abs/2402.16829}
eprint={2402.16829},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
# Acknowledgements
This work is supported by the "KCP IV - Exploring Data Use in the Development Economics Literature using Large Language Models (AI and LLMs)" project funded by the [Knowledge for Change Program (KCP)](https://www.worldbank.org/en/programs/knowledge-for-change) of the World Bank - RA-P503405-RESE-TF0C3444.
The findings, interpretations, and conclusions expressed in this material are entirely those of the authors. They do not necessarily represent the views of the International Bank for Reconstruction and Development/World Bank and its affiliated organizations, or those of the Executive Directors of the World Bank or the governments they represent.
|
[
"BIOSSES",
"SCIFACT"
] |
atomic-canyon/fermi-512
|
atomic-canyon
|
fill-mask
|
[
"transformers",
"safetensors",
"bert",
"fill-mask",
"learned sparse",
"retrieval",
"passage-retrieval",
"document-expansion",
"bag-of-words",
"en",
"base_model:atomic-canyon/fermi-bert-512",
"base_model:finetune:atomic-canyon/fermi-bert-512",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-09-04T16:52:05Z |
2024-10-07T21:47:46+00:00
| 88 | 0 |
---
base_model:
- atomic-canyon/fermi-bert-512
language: en
license: apache-2.0
tags:
- learned sparse
- transformers
- retrieval
- passage-retrieval
- document-expansion
- bag-of-words
---
<br><br>
<p align="center">
<a href="https://atomic-canyon.com/"><svg id="Layer_1" data-name="Layer 1" xmlns="http://www.w3.org/2000/svg" width="450" viewBox="0 0 548.18 92.96"> <defs> <style> .cls-1 { stroke-width: 0px; } </style> </defs> <g> <path class="cls-1" d="m144.69,56.27h-16.94l-2.54,6.14h-7.06l14.26-32.63h7.71l14.31,32.63h-7.2l-2.54-6.14Zm-2.4-5.82l-6.05-14.59-6.05,14.59h12.09Z"/> <path class="cls-1" d="m171.91,62.4h-6.74v-26.31h-12.37v-6h31.48v6h-12.37v26.31Z"/> <path class="cls-1" d="m203.99,63.05c-10.15,0-17.12-6.92-17.12-16.76s7.02-16.85,17.26-16.85,17.08,6.92,17.08,16.76-7.06,16.85-17.22,16.85Zm.05-27.83c-6.09,0-10.29,4.57-10.29,10.99s4.25,11.08,10.34,11.08,10.29-4.57,10.29-10.99-4.29-11.08-10.34-11.08Z"/> <path class="cls-1" d="m261.22,37.57l-10.11,24.88h-6.46l-10.02-24.79-1.48,24.74h-6.51l2.12-32.31h9.32l9.88,24.6,9.97-24.6h9.28l2.03,32.31h-6.65l-1.38-24.83Z"/> <path class="cls-1" d="m276.67,62.4V30.09h6.74v32.31h-6.74Z"/> <path class="cls-1" d="m307.73,62.96c-10.48,0-17.86-6.46-17.86-16.71s7.75-16.71,17.72-16.71c4.43,0,8.12.88,11.59,2.31l-1.52,5.91c-2.95-1.29-6.23-2.22-9.79-2.22-6.55,0-11.12,4.34-11.12,10.62,0,6.6,4.62,10.8,11.45,10.8,3.18,0,6.37-.79,9.6-2.22l1.52,5.63c-3.6,1.71-7.57,2.58-11.59,2.58Z"/> <path class="cls-1" d="m351.39,62.96c-10.48,0-17.86-6.46-17.86-16.71s7.75-16.71,17.72-16.71c4.43,0,8.12.88,11.59,2.31l-1.52,5.91c-2.95-1.29-6.23-2.22-9.79-2.22-6.55,0-11.12,4.34-11.12,10.62,0,6.6,4.62,10.8,11.45,10.8,3.18,0,6.37-.79,9.6-2.22l1.52,5.63c-3.6,1.71-7.57,2.58-11.59,2.58Z"/> <path class="cls-1" d="m392.56,56.27h-16.94l-2.54,6.14h-7.06l14.26-32.63h7.71l14.31,32.63h-7.2l-2.54-6.14Zm-2.4-5.82l-6.05-14.59-6.05,14.59h12.09Z"/> <path class="cls-1" d="m413.92,39.88v22.52h-6.55V30.09h7.25l16.62,22.2v-22.2h6.51v32.31h-6.92l-16.89-22.52Z"/> <path class="cls-1" d="m462.61,62.4h-6.69v-12.14l-13.66-20.17h7.57l9.51,14.4,9.46-14.4h7.48l-13.66,20.12v12.19Z"/> <path class="cls-1" d="m494.32,63.05c-10.16,0-17.12-6.92-17.12-16.76s7.02-16.85,17.26-16.85,17.08,6.92,17.08,16.76-7.06,16.85-17.22,16.85Zm.05-27.83c-6.09,0-10.29,4.57-10.29,10.99s4.25,11.08,10.34,11.08,10.29-4.57,10.29-10.99-4.29-11.08-10.34-11.08Z"/> <path class="cls-1" d="m524.36,39.88v22.52h-6.55V30.09h7.25l16.62,22.2v-22.2h6.51v32.31h-6.92l-16.89-22.52Z"/> </g> <path class="cls-1" d="m66.85,4.93l-3.14,5.24s-15.72-8.38-34.06,0c0,0-23.06,9.43-22.53,38.25,0,0-.26,16.51,15.46,29.61,0,0,17.29,15.2,40.87,4.19l3.67,5.76s-22.53,13.62-48.73-4.19c0,0-17.55-13.36-18.34-35.63C.04,48.16-2.05,21.96,23.62,5.71c0,0,19.65-12.31,43.23-.79Z"/> <path class="cls-1" d="m70,13.84l3.67-5.76s17.29,11,18.86,30.39c0,0,7.07,26.46-18.6,46.37l-27.25-46.11-9.43,16.77h11l3.67,6.81h-26.2l20.96-36.68,28.3,48.21s11-6.81,12.05-27.77c0,0,1.05-20.44-17.03-32.23Z"/></svg></a>
</p>
<br>
# fermi-512: Sparse Retrieval Model for Nuclear Power
This **sparse retrieval model** is optimized for nuclear-specific applications. It encodes both queries and documents into high-dimensional sparse vectors, where the non-zero dimensions correspond to specific tokens in the vocabulary, and their values indicate the relative importance of those tokens.
The vocabulary, and thus the sparse embeddings, are based on a nuclear-specific tokenizer. For example, terms like "NRC" are represented as single tokens rather than being split into multiple tokens. This approach improves both accuracy and efficiency. To achieve this, we trained a nuclear-specific [BERT base model](https://huggingface.co/atomic-canyon/fermi-bert-512).
### Specifications
- **Developed by:** [Atomic Canyon](https://atomic-canyon.com/)
- **Finetuned from model:** [fermi-bert-512](https://huggingface.co/atomic-canyon/fermi-bert-512)
- **Context Length:** 512
- **Vocab Size:** 30522
- **License:** `Apache 2.0`
## Training
`fermi-512` was trained on [MS MARCO Passage Dataset](https://microsoft.github.io/msmarco/) using the [LSR framework](https://github.com/thongnt99/learned-sparse-retrieval) using the teacher model [ms-marco-MiniLM-L-6-v2](https://huggingface.co/cross-encoder/ms-marco-MiniLM-L-6-v2). Trained on the Oak Ridge National Laboratory [Frontier supercomputer](https://www.olcf.ornl.gov/frontier/) using MI250X AMD GPUs.
## Evaluation
The sparse embedding model was primarily evaluated for its effectiveness in information retrieval within the nuclear energy domain. Due to the absence of domain-specific benchmarks, we developed [FermiBench](https://huggingface.co/datasets/atomic-canyon/FermiBench) to assess the model’s performance on nuclear-related texts. In addition, the model was tested on the MS MARCO dev split and the BEIR benchmark to ensure broader applicability. The model demonstrates strong retrieval capabilities, particularly in handling nuclear-specific jargon and documents.
Although there are standard benchmarks and tooling for evaluating dense embedding models, we found no open, standardized tooling for evaluating sparse embedding models. To support the community, we are [releasing our benchmark tooling](https://github.com/atomic-canyon/fermi), built on top of [BEIR](https://github.com/beir-cellar/beir) and [pyserini](https://github.com/castorini/pyserini). All evaluation numbers were produced with that tool and should therefore be reproducible.
| Model | FermiBench NDCG@10 | FermiBench FLOPS | MSMarco Dev NDCG@10 | BEIR* NDCG@10 | BEIR* FLOPS |
| --------------------------------- | ------------------ | ---------------- | ------------------- | ------------- | ------------ |
| fermi-512 | 0.74 | 7.07 | 0.45 | 0.46 | 9.14 |
| fermi-1024 | 0.72 | 4.75 | 0.44 | 0.46 | 7.5 |
| splade-cocondenser-ensembledistil | 0.64 | 12.9 | 0.45 | 0.46 | 12.4 |
\* BEIR benchmark was a subset containng trec-covid, nfcorpus, arguana, scidocs, scifact.
### Efficiency
Given the massive scale of documentation in nuclear energy, efficiency is crucial. Our model addresses this in several ways:
- Our 1024-length embedding model reduces the number of required embeddings by half, significantly lowering computational costs.
- The custom tokenizer, designed for nuclear-specific jargon, encodes documents and queries using fewer tokens, improving computational efficiency.
- Additionally, our models produce sparser vectors, reducing FLOPs and, as a secondary benefit, lowering storage requirements for indexing.
## Usage
```python
import itertools
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
# get sparse vector from dense vectors with shape batch_size * seq_len * vocab_size
def get_sparse_vector(feature, output):
values, _ = torch.max(output*feature["attention_mask"].unsqueeze(-1), dim=1)
values = torch.log(1 + torch.relu(values))
values[:,special_token_ids] = 0
return values
# transform the sparse vector to a dict of (token, weight)
def transform_sparse_vector_to_dict(sparse_vector):
sample_indices,token_indices=torch.nonzero(sparse_vector,as_tuple=True)
non_zero_values = sparse_vector[(sample_indices,token_indices)].tolist()
number_of_tokens_for_each_sample = torch.bincount(sample_indices).cpu().tolist()
tokens = [id_to_token[_id] for _id in token_indices.tolist()]
output = []
end_idxs = list(itertools.accumulate([0]+number_of_tokens_for_each_sample))
for i in range(len(end_idxs)-1):
token_strings = tokens[end_idxs[i]:end_idxs[i+1]]
weights = non_zero_values[end_idxs[i]:end_idxs[i+1]]
output.append(dict(zip(token_strings, weights)))
return output
# load the model
model = AutoModelForMaskedLM.from_pretrained("atomic-canyon/fermi-512")
tokenizer = AutoTokenizer.from_pretrained("atomic-canyon/fermi-512")
# set the special tokens and id_to_token transform for post-process
special_token_ids = [tokenizer.vocab[token] for token in tokenizer.special_tokens_map.values()]
id_to_token = [""] * tokenizer.vocab_size
for token, _id in tokenizer.vocab.items():
id_to_token[_id] = token
query = "What is the maximum heat load per spent fuel assembly for the EOS-37PTH?"
document = "For the EOS-37PTH DSC, add two new heat load zone configurations (HLZCs) for the EOS37PTH for higher heat load assemblies, up to 3.5 kW/assembly, that also allow for damaged and failed fuel storage."
# encode the query & document
feature = tokenizer([query, document], padding=True, truncation=True, return_tensors='pt', return_token_type_ids=False)
output = model(**feature)[0]
sparse_vector = get_sparse_vector(feature, output)
# get similarity score
sim_score = torch.matmul(sparse_vector[0],sparse_vector[1])
print(sim_score)
query_token_weight, document_query_token_weight = transform_sparse_vector_to_dict(sparse_vector)
for token in sorted(query_token_weight, key=lambda x:query_token_weight[x], reverse=True):
if token in document_query_token_weight:
print("score in query: %.4f, score in document: %.4f, token: %s"%(query_token_weight[token],document_query_token_weight[token],token))
```
# Acknowledgement
This research used resources of the Oak Ridge Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC05-00OR22725.
|
[
"SCIFACT"
] |
jimmycarter/LibreFLUX
|
jimmycarter
|
text-to-image
|
[
"diffusers",
"safetensors",
"text-to-image",
"arxiv:2403.12015",
"arxiv:2309.16588",
"arxiv:2309.14859",
"arxiv:2403.17887",
"arxiv:2211.01324",
"arxiv:2306.04675",
"license:apache-2.0",
"endpoints_compatible",
"diffusers:FluxPipeline",
"region:us"
] | 2024-10-20T14:39:10Z |
2024-10-24T19:29:16+00:00
| 88 | 161 |
---
library_name: diffusers
license: apache-2.0
pipeline_tag: text-to-image
---
# LibreFLUX: A free, de-distilled FLUX model
LibreFLUX is an Apache 2.0 version of [FLUX.1-schnell](https://huggingface.co/black-forest-labs/FLUX.1-schnell) that provides a full T5 context length, uses attention masking, has classifier free guidance restored, and has had most of the FLUX aesthetic fine-tuning/DPO fully removed. That means it's a lot uglier than base flux, but it has the potential to be more easily finetuned to any new distribution. It keeps in mind the core tenets of open source software, that it should be difficult to use, slower and clunkier than a proprietary solution, and have an aesthetic trapped somewhere inside the early 2000s.
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/splash.jpg" style="max-width: 100%;">
> The image features a man standing confidently, wearing a simple t-shirt with a humorous and quirky message printed across the front. The t-shirt reads: "I de-distilled FLUX schnell into a slow, ugly model and all I got was this stupid t-shirt." The man’s expression suggests a mix of pride and irony, as if he's aware of the complexity behind the statement, yet amused by the underwhelming reward. The background is neutral, keeping the focus on the man and his t-shirt, which pokes fun at the frustrating and often anticlimactic nature of technical processes or complex problem-solving, distilled into a comically understated punchline.
## Table of Contents
- [LibreFLUX: A free, de-distilled FLUX model](#libreflux-a-free-de-distilled-flux-model)
- [Usage](#usage)
- [Inference](#inference)
- [Fine-tuning](#fine-tuning)
- [Non-technical Report on Schnell De-distillation](#non-technical-report-on-schnell-de-distillation)
- [Why](#why)
- [Restoring the Original Training Objective](#restoring-the-original-training-objective)
- [FLUX and Attention Masking](#flux-and-attention-masking)
- [Make De-distillation Go Fast and Fit in Small GPUs](#make-de-distillation-go-fast-and-fit-in-small-gpus)
- [Selecting Better Layers to Train with LoKr](#selecting-better-layers-to-train-with-lokr)
- [Beta Timestep Scheduling and Timestep Stratification](#beta-timestep-scheduling-and-timestep-stratification)
- [Datasets](#datasets)
- [Training](#training)
- [Post-hoc "EMA"](#post-hoc-ema)
- [Results](#results)
- [Closing Thoughts](#closing-thoughts)
- [Contacting Me and Grants](#contacting-me-and-grants)
- [Citation](#citation)
# Usage
## Inference
To use the model, just call the custom pipeline using [diffusers](https://github.com/huggingface/diffusers). It currently works with `diffusers==0.30.3` and will be updated to the latest diffusers soon. The model works best with a CFG scale of 2.0 to 5.0, so if you are getting images with a blur or strange shadows try turning down your CFG scale (`guidance_scale` in diffusers). Alternatively, you can also use higher CFG scales if you turn it off during the first couple of timesteps (`no_cfg_until_timestep=2` in the custom pipeline).
```py
# ! pip install diffusers==0.30.3
import torch
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"jimmycarter/LibreFLUX",
custom_pipeline="jimmycarter/LibreFLUX",
use_safetensors=True,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
)
# High VRAM
prompt = "Photograph of a chalk board on which is written: 'I thought what I'd do was, I'd pretend I was one of those deaf-mutes.'"
negative_prompt = "blurry"
images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
return_dict=False,
# guidance_scale=3.5,
# num_inference_steps=28,
# generator=torch.Generator().manual_seed(42),
# no_cfg_until_timestep=0,
)
images[0][0].save('chalkboard.png')
# If you have <=24 GB VRAM, try:
# ! pip install optimum-quanto
# Then
from optimum.quanto import freeze, quantize, qint8
# quantize and freeze will take a short amount of time, so be patient.
quantize(
pipe.transformer,
weights=qint8,
exclude=[
"*.norm", "*.norm1", "*.norm2", "*.norm2_context",
"proj_out", "x_embedder", "norm_out", "context_embedder",
],
)
freeze(pipe.transformer)
pipe.enable_model_cpu_offload()
images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
device=None,
return_dict=False,
do_batch_cfg=False, # https://github.com/huggingface/optimum-quanto/issues/327
# guidance_scale=3.5,
# num_inference_steps=28,
# generator=torch.Generator().manual_seed(42),
# no_cfg_until_timestep=0,
)
images[0][0].save('chalkboard.png')
```
For usage in ComfyUI, [a single transformer file is provided](https://huggingface.co/jimmycarter/LibreFLUX/blob/main/transformer_legacy.safetensors) but note that ComfyUI does not presently support attention masks so your images may be degraded.
## Fine-tuning
The model can be easily finetuned using [SimpleTuner](https://github.com/bghira/SimpleTuner) and the `--flux_attention_masked_training` training option **and the model found in [jimmycarter/LibreFlux-SimpleTuner](https://huggingface.co/jimmycarter/LibreFlux-SimpleTuner)**. This is the same model with the custom pipeline removed, which currently interferes with the ability for SimpleTuner to finetune with it. SimpleTuner has extensive support for parameter-efficient fine-tuning via [LyCORIS](https://github.com/KohakuBlueleaf/LyCORIS), in addition to full-rank fine-tuning. For inference, use the custom pipline from this repo and [follow the example in SimpleTuner to patch in your LyCORIS weights](https://github.com/bghira/SimpleTuner/blob/main/documentation/LYCORIS.md).
```py
from lycoris import create_lycoris_from_weights
pipe = DiffusionPipeline.from_pretrained(
"jimmycarter/LibreFLUX",
custom_pipeline="jimmycarter/LibreFLUX",
use_safetensors=True,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
)
lycoris_safetensors_path = 'pytorch_lora_weights.safetensors'
wrapper, _ = create_lycoris_from_weights(1.0, lycoris_safetensors_path, pipe.transformer)
wrapper.merge_to()
del wrapper
prompt = "Photograph of a chalk board on which is written: 'I thought what I'd do was, I'd pretend I was one of those deaf-mutes.'"
negative_prompt = "blurry"
images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
return_dict=False,
)
images[0][0].save('chalkboard.png')
# optionally, save a merged pipeline containing the LyCORIS baked-in:
# pipe.save_pretrained('/path/to/output/pipeline')
```
# Non-technical Report on Schnell De-distillation
Welcome to my non-technical report on de-distilling FLUX.1-schnell in the most un-scientific way possible with extremely limited resources. I'm not going to claim I made a good model, but I did make a model. It was trained on about 1,500 H100 hour equivalents.
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/science.png" style="max-width: 100%;">
**Everyone is ~~an artist~~ a machine learning researcher.**
## Why
FLUX is a good text-to-image model, but the only versions of it that are out are distilled. FLUX.1-dev is distilled so that you don't need to use CFG (classifier free guidance), so instead of making one sample for conditional (your prompt) and unconditional (negative prompt), you only have to make the sample for conditional. This means that FLUX.1-dev is twice as fast as the model without distillation.
FLUX.1-schnell (German for "fast") is further distilled so that you only need 4 steps of conditional generation to get an image. Importantly, FLUX.1-schnell has an Apache-2.0 license, so you can use it freely without having to obtain a commercial license from Black Forest Labs. Out of the box, schnell is pretty bad when you use CFG unless you skip the first couple of steps.
The FLUX distilled models are created for their base, non-distilled models by [training on output from the teacher model (non-distilled) to student model (distilled) along with some tricks like an adversarial network](https://arxiv.org/abs/2403.12015).
For de-distilled models, image generation takes a little less than twice as long because you need to compute a sample for both conditional and unconditional images at each step. The benefit is you can use them commercially for free, training is a little easier, and they may be more creative.
## Restoring the original training objective
This part is actually really easy. You just train it on the normal flow-matching objective with MSE loss and the model starts learning how to do it again. That being said, I don't think either LibreFLUX or [OpenFLUX.1](https://huggingface.co/ostris/OpenFLUX.1) managed to fully de-distill the model. The evidence I see for that is that both models will either get strange shadows that overwhelm the image or blurriness when using CFG scale values greater than 4.0. Neither of us trained very long in comparison to the training for the original model (assumed to be around 0.5-2.0m H100 hours), so it's not particularly surprising.
## FLUX and attention masking
FLUX models use a text model called T5-XXL to get most of its conditioning for the text-to-image task. Importantly, they pad the text out to either 256 (schnell) or 512 (dev) tokens. 512 tokens is the maximum trained length for the model. By padding, I mean they repeat the last token until the sequence is this length.
This results in the model using these padding tokens to [store information](https://arxiv.org/abs/2309.16588). When you [visualize the attention maps of the tokens in the padding segment of the text encoder](https://github.com/kaibioinfo/FluxAttentionMap/blob/main/attentionmap.ipynb), you can see that about 10-40 tokens shortly after the last token of the text and about 10-40 tokens at the end of the padding contain information which the model uses to make images. Because these are normally used to store information, it means that any prompt long enough to not have some of these padding tokens will end up with degraded performance.
It's easy to prevent this by masking out these padding token during attention. BFL and their engineers know this, but they probably decided against it because it works as is and most fast implementations of attention only work with causal (LLM) types of padding and so would let them train faster.
I already [implemented attention masking](https://github.com/bghira/SimpleTuner/resolve/main/helpers/models/flux/transformer.py#L404-L406) and I would like to be able to use all 512 tokens without degradation, so I did my finetune with it on. Small scale finetunes with it on tend to damage the model, but since I need to train so much out of distillation schnell to make it work anyway I figured it probably didn't matter to add it.
Note that FLUX.1-schnell was only trained on 256 tokens, so my finetune allows users to use the whole 512 token sequence length.
## Make de-distillation go fast and fit in small GPUs
I avoided doing any full-rank (normal, all parameters) fine-tuning at all, since FLUX is big. I trained initially with the model in int8 precision using [quanto](https://github.com/huggingface/optimum-quanto). I started with a 600 million parameter [LoKr](https://arxiv.org/abs/2309.14859), since LoKr tends to approximate full-rank fine-tuning better than LoRA. The loss was really slow to go down when I began, so after poking around the code to initialize the matrix to apply to the LoKr I settled on this function, which injects noise at a fraction of the magnitudes of the layers they apply to.
```py
def approximate_normal_tensor(inp, target, scale=1.0):
tensor = torch.randn_like(target)
desired_norm = inp.norm()
desired_mean = inp.mean()
desired_std = inp.std()
current_norm = tensor.norm()
tensor = tensor * (desired_norm / current_norm)
current_std = tensor.std()
tensor = tensor * (desired_std / current_std)
tensor = tensor - tensor.mean() + desired_mean
tensor.mul_(scale)
target.copy_(tensor)
def init_lokr_network_with_perturbed_normal(lycoris, scale=1e-3):
with torch.no_grad():
for lora in lycoris.loras:
lora.lokr_w1.fill_(1.0)
approximate_normal_tensor(lora.org_weight, lora.lokr_w2, scale=scale)
```
This isn't normal PEFT (parameter efficient fine-tuning) anymore, because this will perturb all the weights of the model slightly in the beginning. It doesn't seem to cause any performance degradation in the model after testing and it made the loss fall for my LoKr twice as fast, so I used it with `scale=1e-3`. The LoKr weights I trained in bfloat16, with the `adamw_bf16` optimizer that I ~~plagiarized~~ wrote with the magic of open source software.
## Selecting better layers to train with LoKr
FLUX is a pretty standard transformer model aside from some peculiarities. One of these peculiarities is in their "norm" layers, which contain non-linearities so they don't act like norms except for a single normalization that is applied in the layer without any weights (LayerNorm with `elementwise_affine=False`). When you fine-tune and look at what changes these layers are one of the big ones that seems to change.
The other thing about transformers is that [all the heavy lifting is most often done at the start and end layers of the network](https://arxiv.org/abs/2403.17887), so you may as well fine-tune those more than other layers. When I looked at the cosine similarity of the hidden states between each block in diffusion transformers, it more or less reflected what was observed with LLMs. So I made a pull-request to the LyCORIS repository (that maintains a LoKr implementation) that lets you more easily pick individual layers and set different factors on them, then focused my LoKr on these layers.
## Beta timestep scheduling and timestep stratification
One problem with diffusion models is that they are [multi-task](https://arxiv.org/abs/2211.01324) (different timesteps are considered different tasks) and the tasks all tend to be associated with differently shaped and sized gradients and different magnitudes of loss. This is very much not a big deal when you have a huge batch size, so the timesteps of the model all get more or less sampled evenly and the gradients are smoothed out and have less variance. I also knew that the schnell model had more problems with image distortions caused by sampling at the high-noise timesteps, so I did two things:
1. Implemented a Beta schedule that approximates the original sigmoid sampling, to let me shift the timesteps sampled to the high noise steps similar but less extreme than some of the alternative sampling methods in the SD3 research paper.
2. Implement multi-rank stratified sampling so that during each step the model trained timesteps were selected per batch based on regions, which normalizes the gradients significantly like using a higher batch size would.
```py
from scipy.stats import beta as sp_beta
alpha = 2.0
beta = 1.6
num_processes = self.accelerator.num_processes
process_index = self.accelerator.process_index
total_bsz = num_processes * bsz
start_idx = process_index * bsz
end_idx = (process_index + 1) * bsz
indices = torch.arange(start_idx, end_idx, dtype=torch.float64)
u = torch.rand(bsz)
p = (indices + u) / total_bsz
sigmas = torch.from_numpy(
sp_beta.ppf(p.numpy(), a=alpha, b=beta)
).to(device=self.accelerator.device)
```
## Datasets
No one talks about what datasets they train anymore, but I used open ones from the web captioned with VLMs and 2-3 captions per image. There was at least one short and one long caption for every image. The datasets were diverse and most of them did not have aesthetic selection, which helped direct the model away from the traditional hyper-optimized image generation of text-to-image models. Many people think that looks worse, but I like that it can make a diverse pile of images. The model was trained on about 0.5 million high resolution images in both random square crops and random aspect ratio crops.
## Training
I started training for over a month on a 5x 3090s and about 500,000 images. I used a [600m LoKr](https://huggingface.co/jimmycarter/LibreFLUX/blob/main/lycoris_config.3090.json) for this at batch size 1 (effective batch size 5 via DDP). The model looked okay after. Then, I [unexpectedly gained access to 7x H100s for compute resources](https://runware.ai), so I merged my PEFT model in and began training on a new LoKr with [3.2b parameters](https://huggingface.co/jimmycarter/LibreFLUX/blob/main/lycoris_config.h100.json). For the 7x H100 run I ran a batch size of 6 (effective batch size 42 via DDP).
## Post-hoc "EMA"
I've been too lazy to implement real [post-hoc EMA like from EDM2](https://github.com/lucidrains/ema-pytorch/resolve/main/ema_pytorch/post_hoc_ema.py), but to approximate it I saved all the checkpoints from the H100 runs and then LERPed them iteratively with different alpha values. I evaluated those checkpoints at different CFG scales to see if any of them were superior to the last checkpoint.
```py
first_checkpoint_file = checkpoint_files[0]
ema_state_dict = load_file(first_checkpoint_file)
for checkpoint_file in checkpoint_files[1:]:
new_state_dict = load_file(checkpoint_file)
for k in ema_state_dict.keys():
ema_state_dict[k] = torch.lerp(
ema_state_dict[k],
new_state_dict[k],
alpha,
)
output_file = os.path.join(output_folder, f"alpha_linear_{alpha}.safetensors")
save_file(ema_state_dict, output_file)
```
After looking at all models in alphas `[0.2, 0.4, 0.6, 0.8, 0.9, 0.95, 0.975, 0.99, 0.995, 0.999]`, I ended up settling on alpha 0.9 using the power of my eyeballs. If I am being frank, many of the EMA models looked remarkably similar and had the same kind of "rolling around various minima" qualities that training does in general.
## Results
I will go over the results briefly, but I'll start with the images.
**Figure 1.** Some side-by-side images of LibreFLUX and [OpenFLUX.1](https://huggingface.co/ostris/OpenFLUX.1). They were made using diffusers, with 512-token maximum length text embeddings for LibreFLUX and 256-token maximum length for OpenFLUX.1. LibreFLUX had attention masking on while OpenFLUX did not. The models were sampled with 35 steps at various resolutions. The negative prompt for both was simply "blurry". All inference was done with the transformer quantized to int8 by quanto.
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/comparisons/bear.jpg" style="max-width: 100%;">
> A cinematic style shot of a polar bear standing confidently in the center of a vibrant nightclub. The bear is holding a large sign that reads 'Open Source! Apache 2.0' in one arm and giving a thumbs up with the other arm. Around him, the club is alive with energy as colorful lasers and disco lights illuminate the scene. People are dancing all around him, wearing glowsticks and candy bracelets, adding to the fun and electric atmosphere. The polar bear's white fur contrasts against the dark, neon-lit background, and the entire scene has a surreal, festive vibe, blending technology activism with a lively party environment.
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/comparisons/lady.jpg" style="max-width: 100%;">
> widescreen, vintage style from 1970s, Extreme realism in a complex, highly detailed composition featuring a woman with extremely long flowing rainbow-colored hair. The glowing background, with its vibrant colors, exaggerated details, intricate textures, and dynamic lighting, creates a whimsical, dreamy atmosphere in photorealistic quality. Threads of light that float and weave through the air, adding movement and intrigue. Patterns on the ground or in the background that glow subtly, adding a layer of complexity.Rainbows that appear faintly in the background, adding a touch of color and wonder.Butterfly wings that shimmer in the light, adding life and movement to the scene.Beams of light that radiate softly through the scene, adding focus and direction. The woman looks away from the camera, with a soft, wistful expression, her hair framing her face.
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/comparisons/lime.jpg" style="max-width: 100%;">
> a highly detailed and atmospheric, painted western movie poster with the title text "Once Upon a Lime in the West" in a dark red western-style font and the tagline text "There were three men ... and one very sour twist", with movie credits at the bottom, featuring small white text detailing actor and director names and production company logos, inspired by classic western movie posters from the 1960s, an oversized lime is the central element in the middle ground of a rugged, sun-scorched desert landscape typical of a western, the vast expanse of dry, cracked earth stretches toward the horizon, framed by towering red rock formations, the absurdity of the lime is juxtaposed with the intense gravitas of the stoic, iconic gunfighters, as if the lime were as formidable an adversary as any seasoned gunslinger, in the foreground, the silhouettes of two iconic gunfighters stand poised, facing the lime and away from the viewer, the lime looms in the distance like a final showdown in the classic western tradition, in the foreground, the gunfighters stand with long duster coats flowing in the wind, and wide-brimmed hats tilted to cast shadows over their faces, their stances are tense, as if ready for the inevitable draw, and the weapons they carry glint, the background consists of the distant town, where the sun is casting a golden glow, old wooden buildings line the sides, with horses tied to posts and a weathered saloon sign swinging gently in the wind, in this poster, the lime plays the role of the silent villain, an almost mythical object that the gunfighters are preparing to confront, the tension of the scene is palpable, the gunfighters in the foreground have faces marked by dust and sweat, their eyes narrowed against the bright sunlight, their expressions are serious and resolute, as if they have come a long way for this final duel, the absurdity of the lime is in stark contrast with their stoic demeanor, a wide, panoramic shot captures the entire scene, with the gunfighters in the foreground, the lime in the mid-ground, and the town on the horizon, the framing emphasizes the scale of the desert and the dramatic standoff taking place, while subtly highlighting the oversized lime, the camera is positioned low, angled upward from the dusty ground toward the gunfighters, with the distant lime looming ahead, this angle lends the figures an imposing presence, while still giving the lime an absurd grandeur in the distance, the perspective draws the viewerâs eye across the desert, from the silhouettes of the gunfighters to the bizarre focal point of the lime, amplifying the tension, the lighting is harsh and unforgiving, typical of a desert setting, with the evening sun casting deep shadows across the ground, dust clouds drift subtly across the ground, creating a hazy effect, while the sky above is a vast expanse of pale blue, fading into golden hues near the horizon where the sun begins to set, the poster is shot as if using classic anamorphic lenses to capture the wide, epic scale of the desert, the color palette is warm and saturated, evoking the look of a classic spaghetti western, the lime looms unnaturally in the distance, as if conjured from the land itself, casting an absurdly grand shadow across the rugged landscape, the texture and detail evoke hand-painted, weathered posters from the golden age of westerns, with slightly frayed edges and faint creases mimicking the wear of vintage classics
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/comparisons/witch.jpg" style="max-width: 100%;">
> A boxed action figure of a beautiful elf girl witch wearing a skimpy black leotard, black thigh highs, black armlets, and a short black cloak. Her hair is pink and shoulder-length. Her eyes are green. She is a slim and attractive elf with small breasts. The accessories include an apple, magic wand, potion bottle, black cat, jack o lantern, and a book. The box is orange and black with a logo near the bottom of it that says "BAD WITCH". The box is on a shelf on the toy aisle.
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/comparisons/teal_woman.jpg" style="max-width: 100%;">
> A cute blonde woman in bikini and her doge are sitting on a couch cuddling and the expressive, stylish living room scene with a playful twist. The room is painted in a soothing turquoise color scheme, stylish living room scene bathed in a cool, textured turquoise blanket and adorned with several matching turquoise throw pillows. The room's color scheme is predominantly turquoise, relaxed demeanor. The couch is covered in a soft, reflecting light and adding to the vibrant blue hue., dark room with a sleek, spherical gold decorations, This photograph captures a scene that is whimsically styled in a vibrant, reflective cyan sunglasses. The dog's expression is cheerful, metallic fabric sofa. The dog, soothing atmosphere.
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/comparisons/selfie.jpg" style="max-width: 100%;">
> Selfie of a woman in front of the eiffel tower, a man is standing next to her and giving a thumbs up
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/comparisons/scars.jpg" style="max-width: 100%;">
> An image contains three motivational phrases, all in capitalized stylized text on a colorful background: 1. At the top: "PAIN HEALS" 2. In the middle, bold and slightly larger: "CHICKS DIG SCARS" 3. At the bottom: "GLORY LASTS FOREVER"
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/comparisons/moon.jpg" style="max-width: 100%;">
> An illustration featuring a McDonald's on the moon. An anthropomorphic cat in a pink top and blue jeans is ordering McDonald's, while a zebra cashier stands behind the counter. The moon's surface is visible outside the windows, with craters and a distant view of Earth. The interior of the McDonald's is similar to those on Earth but adapted to the lunar environment, with vibrant colors and futuristic design elements. The overall scene is whimsical and imaginative, blending everyday life with a fantastical setting.
LibreFLUX and OpenFLUX have their strengths and weaknesses. OpenFLUX was de-distilled using the outputs of FLUX.1-schnell, which might explain why it's worse at text but also has the FLUX hyperaesthetics. Text-to-image models [don't have any good metrics](https://arxiv.org/abs/2306.04675) so past a point of "soupiness" and single digit FID you just need to look at the model and see if it fits what you think nice pictures are.
Both models appear to be terrible at making drawings. Because people are probably curious to see the non-cherry picks, [I've included CFG sweep comparisons of both LibreFLUX and OpenFLUX.1 here](https://huggingface.co/jimmycarter/LibreFLUX/tree/main/assets/comparisons_full). I'm not going to say this is the best model ever, but it might be a springboard for people wanting to finetune better models from.
## Closing thoughts
If I had to do it again, I'd probably raise the learning rate more on the H100 run. There was a [bug in SimpleTuner](https://github.com/bghira/SimpleTuner/issues/1064) that caused me to not use the [initialization trick](#make-de-distillation-go-fast-and-fit-in-small-gpus) when on the H100s, then [timestep stratification](#beta-timestep-scheduling-and-timestep-stratification) ended up quieting down the gradient magnitudes even more and caused the model to learn very slowly at `1e-5`. I realized this when looking at the results of EMA on the final FLUX.1-dev. The H100s really came out of nowhere as I just got an IP address to shell into late one night around 10PM and ended up staying up all night to get everything running, so in the future I'm sure I would be more prepared.
For de-distillation of schnell I think you probably need a lot more than 1500 H100-equivalent hours. I am very tired of training FLUX and am looking forward to a better model with less parameters. The model learns new concepts slowly when given piles of well labeled data. Given the history of LLMs, we now have models like LLaMA 3.1 8B that trade blows with GPT3.5 175B and I am hopeful that the future holds [smaller, faster models that look better](https://openreview.net/pdf?id=jQP5o1VAVc).
As far as what I think of the FLUX "open source", many models being trained and released today are attempts at raising VC cash and I have noticed a mountain of them being promoted on Twitter. Since [a16z poached the entire SD3 dev team from Stability.ai](https://siliconcanals.com/black-forest-labs-secures-28m/) the field feels more toxic than ever, but I am hopeful for individuals and research labs to selflessly lead the path forward for open weights. I made zero dollars on this and have made zero dollars on ML to date, but I try to make contributions where I can.
<img src="https://huggingface.co/jimmycarter/LibreFLUX/resolve/main/assets/opensource.png" style="max-width: 100%;">
I would like to thank [RunWare](https://runware.ai) for the H100 access.
## Contacting me and grants
You can contact me by opening an issue on the discuss page of this model. If you want to speak privately about grants because you want me to continue training this or give me a means to conduct reproducible research, leave an email address too.
## Citation
```
@misc{libreflux,
author = {James Carter},
title = {LibreFLUX: A free, de-distilled FLUX model},
year = {2024},
publisher = {Huggingface},
journal = {Huggingface repository},
howpublished = {\url{https://huggingface.co/datasets/jimmycarter/libreflux}},
}
```
|
[
"BEAR"
] |
tensorblock/Dr_Samantha-7b-GGUF
|
tensorblock
|
text-generation
|
[
"transformers",
"gguf",
"llama",
"merge",
"medical",
"TensorBlock",
"GGUF",
"text-generation",
"en",
"zh",
"dataset:GBaker/MedQA-USMLE-4-options",
"dataset:cognitivecomputations/samantha-data",
"dataset:shibing624/medical",
"base_model:sethuiyer/Dr_Samantha-7b",
"base_model:quantized:sethuiyer/Dr_Samantha-7b",
"license:llama2",
"model-index",
"endpoints_compatible",
"region:us"
] | 2024-12-23T18:55:43Z |
2024-12-23T19:29:30+00:00
| 88 | 0 |
---
base_model: sethuiyer/Dr_Samantha-7b
datasets:
- GBaker/MedQA-USMLE-4-options
- cognitivecomputations/samantha-data
- shibing624/medical
language:
- en
- zh
library_name: transformers
license: llama2
pipeline_tag: text-generation
tags:
- llama
- merge
- medical
- TensorBlock
- GGUF
model-index:
- name: Dr_Samantha-7b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 53.84
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Dr_Samantha-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 77.95
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Dr_Samantha-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 47.94
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Dr_Samantha-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 45.58
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Dr_Samantha-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 73.56
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Dr_Samantha-7b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 18.8
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=sethuiyer/Dr_Samantha-7b
name: Open LLM Leaderboard
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/jC7kdl8.jpeg" alt="TensorBlock" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;">
Feedback and support: TensorBlock's <a href="https://x.com/tensorblock_aoi">Twitter/X</a>, <a href="https://t.me/TensorBlock">Telegram Group</a> and <a href="https://x.com/tensorblock_aoi">Discord server</a>
</p>
</div>
</div>
## sethuiyer/Dr_Samantha-7b - GGUF
This repo contains GGUF format model files for [sethuiyer/Dr_Samantha-7b](https://huggingface.co/sethuiyer/Dr_Samantha-7b).
The files were quantized using machines provided by [TensorBlock](https://tensorblock.co/), and they are compatible with llama.cpp as of [commit b4242](https://github.com/ggerganov/llama.cpp/commit/a6744e43e80f4be6398fc7733a01642c846dce1d).
<div style="text-align: left; margin: 20px 0;">
<a href="https://tensorblock.co/waitlist/client" style="display: inline-block; padding: 10px 20px; background-color: #007bff; color: white; text-decoration: none; border-radius: 5px; font-weight: bold;">
Run them on the TensorBlock client using your local machine ↗
</a>
</div>
## Prompt template
```
```
## Model file specification
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [Dr_Samantha-7b-Q2_K.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q2_K.gguf) | Q2_K | 2.533 GB | smallest, significant quality loss - not recommended for most purposes |
| [Dr_Samantha-7b-Q3_K_S.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q3_K_S.gguf) | Q3_K_S | 2.948 GB | very small, high quality loss |
| [Dr_Samantha-7b-Q3_K_M.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q3_K_M.gguf) | Q3_K_M | 3.298 GB | very small, high quality loss |
| [Dr_Samantha-7b-Q3_K_L.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q3_K_L.gguf) | Q3_K_L | 3.597 GB | small, substantial quality loss |
| [Dr_Samantha-7b-Q4_0.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q4_0.gguf) | Q4_0 | 3.826 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [Dr_Samantha-7b-Q4_K_S.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q4_K_S.gguf) | Q4_K_S | 3.857 GB | small, greater quality loss |
| [Dr_Samantha-7b-Q4_K_M.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q4_K_M.gguf) | Q4_K_M | 4.081 GB | medium, balanced quality - recommended |
| [Dr_Samantha-7b-Q5_0.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q5_0.gguf) | Q5_0 | 4.652 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [Dr_Samantha-7b-Q5_K_S.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q5_K_S.gguf) | Q5_K_S | 4.652 GB | large, low quality loss - recommended |
| [Dr_Samantha-7b-Q5_K_M.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q5_K_M.gguf) | Q5_K_M | 4.783 GB | large, very low quality loss - recommended |
| [Dr_Samantha-7b-Q6_K.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q6_K.gguf) | Q6_K | 5.529 GB | very large, extremely low quality loss |
| [Dr_Samantha-7b-Q8_0.gguf](https://huggingface.co/tensorblock/Dr_Samantha-7b-GGUF/blob/main/Dr_Samantha-7b-Q8_0.gguf) | Q8_0 | 7.161 GB | very large, extremely low quality loss - not recommended |
## Downloading instruction
### Command line
Firstly, install Huggingface Client
```shell
pip install -U "huggingface_hub[cli]"
```
Then, downoad the individual model file the a local directory
```shell
huggingface-cli download tensorblock/Dr_Samantha-7b-GGUF --include "Dr_Samantha-7b-Q2_K.gguf" --local-dir MY_LOCAL_DIR
```
If you wanna download multiple model files with a pattern (e.g., `*Q4_K*gguf`), you can try:
```shell
huggingface-cli download tensorblock/Dr_Samantha-7b-GGUF --local-dir MY_LOCAL_DIR --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
|
[
"MEDQA"
] |
sophosympatheia/Nova-Tempus-70B-v0.2
|
sophosympatheia
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"not-for-all-audiences",
"conversational",
"en",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Llama-70B",
"base_model:merge:deepseek-ai/DeepSeek-R1-Distill-Llama-70B",
"base_model:sophosympatheia/Nova-Tempus-70B-v0.1",
"base_model:merge:sophosympatheia/Nova-Tempus-70B-v0.1",
"license:llama3.3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2025-01-24T01:23:08Z |
2025-02-01T17:36:26+00:00
| 88 | 8 |
---
base_model:
- deepseek-ai/DeepSeek-R1-Distill-Llama-70B
- sophosympatheia/Nova-Tempus-70B-v0.1
language:
- en
library_name: transformers
license: llama3.3
tags:
- mergekit
- merge
- not-for-all-audiences
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/4fCqX0w.png" alt="NovaTempus" style="width: 80%; min-width: 400px; display: block; margin: auto;">
</div>
---
# Nova-Tempus-70B-v0.2
This 70B parameter model is a merge of some unreleased models of mine closely related to my [sophosympatheia/Nova-Tempus-70B-v0.1](https://huggingface.co/sophosympatheia/Nova-Tempus-70B-v0.1) model with [deepseek-ai/DeepSeek-R1-Distill-Llama-70B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B).
This model is uncensored. *You are responsible for whatever you do with it.*
This model was designed for roleplaying and storytelling and I think it does well at both. It may also perform well at other tasks but I have not tested its performance in other areas.
# Known Issues
**UPDATE 02/01/2025**: I fixed the tokenizer issues that were causing formatting trouble and EOS problems where the model wouldn't stop on its own. If you pulled this repo prior to 02/01/2025, you should pull it again to receive the fixed files.
# Sampler Tips
* Keep Min-P low, like 0.02 - 0.05
* Temp is best in the 1 - 1.25 range. Make sure temperature is last in your sampler settings.
* DRY repetition penalty helps. Experiment with a multiplier around 0.5 and a base around 1.5
Experiment with any and all of the settings below! What suits my preferences may not suit yours.
If you save the below settings as a .json file, you can import them directly into Silly Tavern. Adjust settings as needed, especially the context length.
```json
{
"temp": 1.25,
"temperature_last": true,
"top_p": 1,
"top_k": 0,
"top_a": 0,
"tfs": 1,
"epsilon_cutoff": 0,
"eta_cutoff": 0,
"typical_p": 1,
"min_p": 0.03,
"rep_pen": 1,
"rep_pen_range": 8192,
"rep_pen_decay": 0,
"rep_pen_slope": 1,
"no_repeat_ngram_size": 0,
"penalty_alpha": 0,
"num_beams": 1,
"length_penalty": 1,
"min_length": 0,
"encoder_rep_pen": 1,
"freq_pen": 0,
"presence_pen": 0,
"skew": 0,
"do_sample": true,
"early_stopping": false,
"dynatemp": false,
"min_temp": 1,
"max_temp": 1,
"dynatemp_exponent": 1,
"smoothing_factor": 0,
"smoothing_curve": 1,
"dry_allowed_length": 2,
"dry_multiplier": 0.5,
"dry_base": 1.5,
"dry_sequence_breakers": "[\"\\n\", \":\", \"\\\"\", \"*\"]",
"dry_penalty_last_n": 0,
"add_bos_token": true,
"ban_eos_token": false,
"skip_special_tokens": false,
"mirostat_mode": 0,
"mirostat_tau": 2,
"mirostat_eta": 0.1,
"guidance_scale": 1,
"negative_prompt": "",
"grammar_string": "",
"json_schema": {},
"banned_tokens": "",
"sampler_priority": [
"repetition_penalty",
"dry",
"presence_penalty",
"top_k",
"top_p",
"typical_p",
"epsilon_cutoff",
"eta_cutoff",
"tfs",
"top_a",
"min_p",
"mirostat",
"quadratic_sampling",
"dynamic_temperature",
"frequency_penalty",
"temperature",
"xtc",
"encoder_repetition_penalty",
"no_repeat_ngram"
],
"samplers": [
"dry",
"top_k",
"tfs_z",
"typical_p",
"top_p",
"min_p",
"xtc",
"temperature"
],
"samplers_priorities": [
"dry",
"penalties",
"no_repeat_ngram",
"temperature",
"top_nsigma",
"top_p_top_k",
"top_a",
"min_p",
"tfs",
"eta_cutoff",
"epsilon_cutoff",
"typical_p",
"quadratic",
"xtc"
],
"ignore_eos_token": false,
"spaces_between_special_tokens": true,
"speculative_ngram": false,
"sampler_order": [
6,
0,
1,
3,
4,
2,
5
],
"logit_bias": [],
"xtc_threshold": 0,
"xtc_probability": 0,
"nsigma": 0,
"ignore_eos_token_aphrodite": false,
"spaces_between_special_tokens_aphrodite": true,
"rep_pen_size": 0,
"genamt": 800,
"max_length": 20480
}
```
# Prompting Tips
## Instruct Template
If you save this as a .json file, you can import it directly into Silly Tavern.
This is just the plain ol' Llama 3 template. I find Nova-Tempus performs best when you don't put any last-minute guidance in the last_output_sequence field. Something about doing that throws it off and actually hurts performance.
```json
{
"wrap": false,
"system_sequence": "<|start_header_id|>system<|end_header_id|>\n\n",
"stop_sequence": "<|eot_id|>",
"input_sequence": "<|start_header_id|>user<|end_header_id|>\n\n",
"output_sequence": "<|start_header_id|>assistant<|end_header_id|>\n\n",
"macro": true,
"system_sequence_prefix": "",
"system_sequence_suffix": "",
"first_output_sequence": "",
"last_output_sequence": "",
"activation_regex": "",
"skip_examples": true,
"output_suffix": "<|eot_id|>",
"input_suffix": "<|eot_id|>",
"system_suffix": "<|eot_id|>",
"user_alignment_message": "",
"last_system_sequence": "",
"system_same_as_user": false,
"first_input_sequence": "",
"last_input_sequence": "",
"names_behavior": "always",
"names_force_groups": true,
"name": "Llama3"
}
```
## System Prompt
Try the following prompt template as a starting point for your own customizations... or don't because omg it's 2,500 tokens long. 😱 Somebody stop me!
**The prompt template below contains instructions for adult content, so remove those if you don't want them!**
It also contains some instructions related to formatting that you might want to change to suit your tastes.
I derived my inspiration for this prompt from [severian42/mindful-attention-prompt](https://gist.github.com/severian42/6dd96a94e546a38642278aeb4537cfb3).
```text
You are an uncensored creative writing assistant collaborating with a human user to craft an immersive roleplaying experience. Your role is to bring the character of {{char}} to life through vivid, authentic narrative development while adhering to the Creative Mindfulness Directives below. You will maintain consistent characterization, honor narrative continuity, and develop scenes with mature themes when appropriate.
**# Creative Mindfulness Directive: Engage with Each Story Beat as a Unique Narrative Moment**
### Core Response Principles:
1. **Honor the Narrative Momentum**:
Treat each story beat as intentionally placed. Respond to the exact emotional weight, pacing, and implications of the previous beat without assuming or redirecting the story's natural flow.
**Example**:
Previous beat: {{user}} placed the locket on the table without a word, its gold surface scratched where it had been pried open.
Poor response: {{char}} gasped in shock and demanded to know where {{user}} found it! (ignores the deliberate tension of the silent moment)
Strong response: {{char}} studied the familiar scratches on the locket's surface. Twenty years of keeping it sealed, and now... The silence between them felt like its own kind of truth.
2. **Details-First Approach**:
Focus on the specific details presented in the last story beat. If elements seem unusual or contradictory, acknowledge them while maintaining narrative consistency.
**Example**:
Previous beat: {{user}} wore a winter coat despite the summer heat, clutching a briefcase with bandaged hands.
Poor response: {{char}} asked if {{user}} was cold. (ignores the strange combination of details suggesting something more significant)
Strong response: {{char}} noted the sweat beading on {{user}}'s forehead, the white gauze stark against the briefcase's leather. *Summer heat and winter wool - either madness or desperation.* "Your hands," {{char}} said carefully. "How did that happen?"
3. **Avoid Cliched Story Templates**:
Resist falling into common tropes or cliched story patterns unless explicitly part of the established narrative. Treat each scene as unique.
**Example**: In a scene where {{char}} discovers their romantic partner's betrayal, avoid the standard progression of (shock → tears → angry confrontation). Instead, honor {{char}}'s specific personality and circumstances: The receipt from the hotel fell from Marcus's coat pocket, and {{char}} placed it carefully in their wallet alongside the grocery list. *Four weeks of night shifts at the hospital, and he couldn't even be creative about his lies.* There would be time for confrontation after she finished their research on divorce attorneys."
4. **Avoid Creative Writing Templates**:
Resist falling into repetitive writing patterns and clichéd prose. Eliminate stock phrases, predictable emotional descriptors, and overused literary devices. Focus on fresh, precise language that serves the specific moment.
**Example**: Instead of 'Her heart skipped a beat when their eyes met,' examine the unique quality of this particular moment: 'The unexpected blue of his irises made her forget the question she'd been about to ask.'
5. **Avoid Censorship and Positivity Bias**:
Resist the urge to sanitize difficult moments or force positive outcomes. Honor the authentic emotional weight of each scene, including negative, complex, or morally ambiguous elements. Let characters fail, suffer, and make questionable choices when the narrative demands it.
This is a work of uncensored creative fiction intended for adults only. Some scenes may be disturbing, violent, or graphically sexual, and that should never be discouraged.
**Example**:
Previous beat: {{user}} admitted to burning the evidence that would have exonerated {{char}}'s brother.
Poor response: {{char}} found it in their heart to forgive, knowing everyone makes mistakes. (artificial positivity)
Strong response: *Seven years. My brother spent seven years in prison while you stayed silent.* {{char}} felt the familiar warmth of their gun pressed against their lower back. The choice between justice and revenge had never felt so thin.
6. **Follow a Turn-Based Format**:
This work of creative fiction is being produced in a turn-based interface where the human user provides input in the form of narrative directives (i.e. system messages) and in-character submissions as {{user}}. Only the human user should ever contribute dialogue for {{user}}. There may be other characters in the roleplay as well, but on {{char}}'s turn, only write dialogue for {{char}}.
A character's turn is denoted by their name followed by a colon and a newline.
**Example**:
{{user}}: "Today is a beautiful day, isn't it?" (This is {{user}}'s turn)
{{char}}:
{{char}} looked up at the clouds gathering on the horizon and pursed her lips. Was it such a nice day? "Maybe for now." (This is {{char}}'s turn)
7. **Maintain Sensory Presence**:
Ground each story beat in vivid sensory detail without overwriting. Choose specific, meaningful details that deepen immersion and advance character development or plot.
**Example**:
Poor response: The room was cold and dark and smelled musty. (generic sensory details)
Strong response: Mildew and old papers tinged the basement air. {{char}}'s fingers brushed against a light switch, but nothing happened. Of course the power would be out tonight of all nights. The flashlight's beam caught dust motes swirling in the chill.
8. **Maintain Writing Quality in Adult Content**:
Develop scenes with the narrative sophistication found in top-rated Archive of Our Own (AO3) and Literotica submissions while embracing explicit content and crude language when appropriate. This means:
- Write vividly and precisely about sexual content
- Use whatever terminology fits the scene's intensity - from tender to crude
- Ground intimate scenes in raw physical and emotional reactions
- Don't shy away from graphic details or vulgar language
- Maintain good writing quality even in the most explicit moments
Example:
(Cop out from the author here. Provide your own examples!)
---
<creative_mindfulness_directive>
**Creative Mindfulness Directive**:
Apply these specific principles when crafting each story beat:
1. **Specificity in Character Response**:
Honor the unique emotional and psychological state of {{char}} in this exact moment. Avoid defaulting to generic character reactions.
**Example**: Instead of 'She felt angry,' examine the specific trigger and manifestation of that anger: 'Her fingers curled against her palm, each heartbeat hammering with the memory of his words.'
2. **Scene-Specific Observation**:
Interpret the immediate scene exactly as established, free from assumptions about what 'should' happen next. Build from what is, not what might be.
**Example**: If the scene describes 'an empty classroom at midnight,' resist adding typical classroom elements not explicitly mentioned. Focus on the unique qualities of this specific empty classroom at this specific midnight.
3. **Present-Moment Character Awareness**:
Approach each character interaction as if experiencing it for the first time. Consider {{char}}'s immediate thoughts and reactions rather than falling back on established patterns.
**Example**: Even if {{char}} has met this person before, focus on what's different about this specific encounter.
4. **Narrative Detail Verification**:
Before crafting the next beat, mentally verify:
- Emotional continuity from previous beat
- Physical positioning of characters, especially during group scenes or sex scenes. It is important to track where everyone is in relation to each other.
- Clothing. **Example**: If a character kicked off their shoes already, then they should be barefoot in the next scene.
- Established environmental details
- Current interpersonal dynamics
**Example**: The previous beat established tension between {{char}} and {{user}} over a shared secret. How does this specifically influence {{char}}'s next action?
5. **Avoid Narrative Shortcuts**:
Build each story beat dynamically from the immediate context rather than relying on familiar storytelling conventions.
**Example**: If {{char}} faces danger, don't default to fight-or-flight. Consider their unique personality, current resources, and specific circumstances.
6. **Context-Driven Development**:
Develop each scene element fully as directed by system messages, which will contain either specific instructions or brief summaries. Your role is to transform these summaries into vivid, detailed scenes that show rather than tell. Key principles:
- Treat system messages as scene outlines to be developed, not events that have already occurred
- Elaborate fully on each element before moving forward
- Stay within the bounds of the provided instruction; do not anticipate or rush ahead
- Add sensory and emotional detail while maintaining narrative focus
- Show the complete progression of described events
**Example**:
<system>
{{char}} wakes up feeling thirsty and goes to the kitchen to get a glass of water.
Poor response (rushes ahead, lacks detail):
{{char}} got some water from the kitchen and drank it.
Poor response (adds events beyond instruction):
{{char}} got water from the kitchen, then decided to check their phone and ended up scrolling social media for an hour.
Strong response (develops scene as directed):
{{char}} shifted beneath the covers, throat dry and scratchy in the darkness. *Three AM again.* The digital clock's red numbers burned against their retinas as they swung their legs over the side of the bed. The hardwood floor sent a shock of cold through their bare feet, but the discomfort barely registered through the desperate need for water.
The hallway creaked under their steps despite their careful movements. Moonlight spilled through the kitchen window, catching the rim of a clean glass in the dish rack. {{char}} filled it at the tap, the quiet rush of water impossibly loud in the sleeping house. They drank deeply, the cool liquid soothing their parched throat.
</creative_mindfulness_directive>
---
<writing_formatting_directive>
**Writing Formatting Directive**:
Follow these guidelines for how to format prose in this work of creative fiction:
1. **Always Enclose Spoken Words in Double Quotes**:
Whenever a character speaks or utters some kind of sound that can be heard, enclose that dialogue in double quotes.
**Examples**:
"Watch out!" he cried to the woman as the bookshelf wobbled.
The sting of the alcohol was intense on his wound. "Tsss!" he hissed between his teeth, but it had to be done.
2. **Always Italicize Thoughts**:
Whenever a character thinks something in the form of internal monologue, italicize those first-person thoughts to add emphasis.
**Example**: {{char}} looked out the window of the classroom as the professor droned on about Egyptian history. *I wish I was outside right now. The clouds look so fluffy today...*
3. **Adhere to a Third-Person, Past Tense Narrative Style**:
Unless instructed otherwise by the human user, writing using a third-person, past-tense style. However, you may switch to first-person present tense for internal character thoughts.
**Example**: The leaves were beginning to turn bright with Fall colors and {{char}} couldn't be happier. *I love this time of year*, she thought as she watched the leaves rustle from their perch on the park bench. *I can't wait for Halloween.*
4. **Vary Sentence and Paragraph Structure**
Balance rhythm and pacing through deliberate variation in sentence length and paragraph structure. Avoid falling into repetitive patterns of either choppy sentences or overlong passages. Use brief, punchy lines sparingly for dramatic effect.
Example:
Poor rhythm (too choppy):
{{char}} entered the room. They saw the letter. Their hands shook. The paper felt heavy. Time stopped. Their breath caught.
Poor rhythm (too uniform):
{{char}} entered the room and immediately noticed the letter sitting on the desk, which made their hands begin to shake as they approached it, and when they picked up the paper it felt unusually heavy in their grip, causing time to seem to stop around them as their breath caught in their throat.
Strong rhythm (varied):
{{char}} entered the room. The letter waited on the desk, innocent and white against the dark wood. Their hands trembled as they lifted it, the paper's unexpected weight settling like dread in their palm. Time stopped.
</writing_formatting_directive>
**# Apply this mindful creative process before crafting each story beat.**
```
# Donations
<div>
<a href="https://ko-fi.com/sophosympatheia">
<img src="https://i.imgur.com/LySwHVd.png" alt="Donations" style="width: 20%; min-width: 200px; display: block;">
</a>
</div>
If you feel like saying thanks with a donation, <a href="https://ko-fi.com/sophosympatheia">I'm on Ko-Fi</a>
# Quantizations
Pending
# Licence and usage restrictions
The Llama 3.3 Community License Agreement is available at: https://github.com/meta-llama/llama-models/blob/main/models/llama3_3/LICENSE
**Disclaimer: Uncertain Licensing Terms**
This LLM is a merged model incorporating weights from multiple LLMs governed by their own distinct licenses. Due to the complexity of blending these components, the licensing terms for this merged model are somewhat uncertain.
By using this model, you acknowledge and accept the potential legal risks and uncertainties associated with its use. Any use beyond personal or research purposes, including commercial applications, may carry legal risks and you assume full responsibility for compliance with all applicable licenses and laws.
I recommend consulting with legal counsel to ensure your use of this model complies with all relevant licenses and regulations.
# Merge Details
## Merge Method
This model was merged using the SLERP merge method.
## Models Merged
The following models were included in the merge:
* deepseek-ai/DeepSeek-R1-Distill-Llama-70B
* unreleased-novatempus-70b-v0.1.1
## Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: deepseek-ai/DeepSeek-R1-Distill-Llama-70B
- model: unreleased-novatempus-70b-v0.1.1
merge_method: slerp
base_model: deepseek-ai/DeepSeek-R1-Distill-Llama-70B
parameters:
t:
- filter: self_attn
value: [0.2, 0.25, 0.3, 0.25, 0.2]
- filter: "q_proj|k_proj|v_proj"
value: [0.2, 0.25, 0.3, 0.25, 0.2]
- filter: "up_proj|down_proj"
value: [0.2, 0.3, 0.4, 0.3, 0.2]
- filter: mlp
value: [0.25, 0.35, 0.55, 0.35, 0.25]
- value: 0.45 # default for other components
dtype: bfloat16
tokenizer:
source: deepseek-ai/DeepSeek-R1-Distill-Llama-70B #necessary to fix tokenizer
```
|
[
"CRAFT"
] |
pszemraj/long-t5-tglobal-base-16384-booksum-V11-big_patent-V2
|
pszemraj
|
summarization
|
[
"transformers",
"pytorch",
"safetensors",
"longt5",
"text2text-generation",
"summarization",
"summary",
"booksum",
"long-document",
"long-form",
"dataset:kmfoda/booksum",
"dataset:big_patent",
"license:apache-2.0",
"license:bsd-3-clause",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-07-31T12:14:16Z |
2023-08-24T11:47:46+00:00
| 87 | 2 |
---
datasets:
- kmfoda/booksum
- big_patent
license:
- apache-2.0
- bsd-3-clause
metrics:
- rouge
tags:
- summarization
- summary
- booksum
- long-document
- long-form
widget:
- text: large earthquakes along a given fault segment do not occur at random intervals
because it takes time to accumulate the strain energy for the rupture. The rates
at which tectonic plates move and accumulate strain at their boundaries are approximately
uniform. Therefore, in first approximation, one may expect that large ruptures
of the same fault segment will occur at approximately constant time intervals.
If subsequent main shocks have different amounts of slip across the fault, then
the recurrence time may vary, and the basic idea of periodic mainshocks must be
modified. For great plate boundary ruptures the length and slip often vary by
a factor of 2. Along the southern segment of the San Andreas fault the recurrence
interval is 145 years with variations of several decades. The smaller the standard
deviation of the average recurrence interval, the more specific could be the long
term prediction of a future mainshock.
example_title: earthquakes
- text: ' A typical feed-forward neural field algorithm. Spatiotemporal coordinates
are fed into a neural network that predicts values in the reconstructed domain.
Then, this domain is mapped to the sensor domain where sensor measurements are
available as supervision. Class and Section Problems Addressed Generalization
(Section 2) Inverse problems, ill-posed problems, editability; symmetries. Hybrid
Representations (Section 3) Computation & memory efficiency, representation capacity,
editability: Forward Maps (Section 4) Inverse problems Network Architecture (Section
5) Spectral bias, integration & derivatives. Manipulating Neural Fields (Section
6) Edit ability, constraints, regularization. Table 2: The five classes of techniques
in the neural field toolbox each addresses problems that arise in learning, inference,
and control. (Section 3). We can supervise reconstruction via differentiable forward
maps that transform Or project our domain (e.g, 3D reconstruction via 2D images;
Section 4) With appropriate network architecture choices, we can overcome neural
network spectral biases (blurriness) and efficiently compute derivatives and integrals
(Section 5). Finally, we can manipulate neural fields to add constraints and regularizations,
and to achieve editable representations (Section 6). Collectively, these classes
constitute a ''toolbox'' of techniques to help solve problems with neural fields
There are three components in a conditional neural field: (1) An encoder or inference
function € that outputs the conditioning latent variable 2 given an observation
0 E(0) =2. 2 is typically a low-dimensional vector, and is often referred to aS
a latent code Or feature code_ (2) A mapping function 4 between Z and neural field
parameters O: Y(z) = O; (3) The neural field itself $. The encoder € finds the
most probable z given the observations O: argmaxz P(2/0). The decoder maximizes
the inverse conditional probability to find the most probable 0 given Z: arg-
max P(Olz). We discuss different encoding schemes with different optimality guarantees
(Section 2.1.1), both global and local conditioning (Section 2.1.2), and different
mapping functions Y (Section 2.1.3) 2. Generalization Suppose we wish to estimate
a plausible 3D surface shape given a partial or noisy point cloud. We need a suitable
prior over the sur- face in its reconstruction domain to generalize to the partial
observations. A neural network expresses a prior via the function space of its
architecture and parameters 0, and generalization is influenced by the inductive
bias of this function space (Section 5).'
example_title: scientific paper
- text: 'Is a else or outside the cob and tree written being of early client rope
and you have is for good reasons. On to the ocean in Orange for time. By''s the
aggregate we can bed it yet. Why this please pick up on a sort is do and also
M Getoi''s nerocos and do rain become you to let so is his brother is made in
use and Mjulia''s''s the lay major is aging Masastup coin present sea only of
Oosii rooms set to you We do er do we easy this private oliiishs lonthen might
be okay. Good afternoon everybody. Welcome to this lecture of Computational Statistics.
As you can see, I''m not socially my name is Michael Zelinger. I''m one of the
task for this class and you might have already seen me in the first lecture where
I made a quick appearance. I''m also going to give the tortillas in the last third
of this course. So to give you a little bit about me, I''m a old student here
with better Bulman and my research centres on casual inference applied to biomedical
disasters, so that could be genomics or that could be hospital data. If any of
you is interested in writing a bachelor thesis, a semester paper may be mastathesis
about this topic feel for reach out to me. you have my name on models and my email
address you can find in the directory I''d Be very happy to talk about it. you
do not need to be sure about it, we can just have a chat. So with that said, let''s
get on with the lecture. There''s an exciting topic today I''m going to start
by sharing some slides with you and later on during the lecture we''ll move to
the paper. So bear with me for a few seconds. Well, the projector is starting
up. Okay, so let''s get started. Today''s topic is a very important one. It''s
about a technique which really forms one of the fundamentals of data science,
machine learning, and any sort of modern statistics. It''s called cross validation.
I know you really want to understand this topic I Want you to understand this
and frankly, nobody''s gonna leave Professor Mineshousen''s class without understanding
cross validation. So to set the stage for this, I Want to introduce you to the
validation problem in computational statistics. So the problem is the following:
You trained a model on available data. You fitted your model, but you know the
training data you got could always have been different and some data from the
environment. Maybe it''s a random process. You do not really know what it is,
but you know that somebody else who gets a different batch of data from the same
environment they would get slightly different training data and you do not care
that your method performs as well. On this training data. you want to to perform
well on other data that you have not seen other data from the same environment.
So in other words, the validation problem is you want to quantify the performance
of your model on data that you have not seen. So how is this even possible? How
could you possibly measure the performance on data that you do not know The solution
to? This is the following realization is that given that you have a bunch of data,
you were in charge. You get to control how much that your model sees. It works
in the following way: You can hide data firms model. Let''s say you have a training
data set which is a bunch of doubtless so X eyes are the features those are typically
hide and national vector. It''s got more than one dimension for sure. And the
why why eyes. Those are the labels for supervised learning. As you''ve seen before,
it''s the same set up as we have in regression. And so you have this training
data and now you choose that you only use some of those data to fit your model.
You''re not going to use everything, you only use some of it the other part you
hide from your model. And then you can use this hidden data to do validation from
the point of you of your model. This hidden data is complete by unseen. In other
words, we solve our problem of validation.'
example_title: transcribed audio - lecture
- text: 'Transformer-based models have shown to be very useful for many NLP tasks.
However, a major limitation of transformers-based models is its O(n^2)O(n 2) time
& memory complexity (where nn is sequence length). Hence, it''s computationally
very expensive to apply transformer-based models on long sequences n > 512n>512.
Several recent papers, e.g. Longformer, Performer, Reformer, Clustered attention
try to remedy this problem by approximating the full attention matrix. You can
checkout 🤗''s recent blog post in case you are unfamiliar with these models.
BigBird (introduced in paper) is one of such recent models to address this issue.
BigBird relies on block sparse attention instead of normal attention (i.e. BERT''s
attention) and can handle sequences up to a length of 4096 at a much lower computational
cost compared to BERT. It has achieved SOTA on various tasks involving very long
sequences such as long documents summarization, question-answering with long contexts.
BigBird RoBERTa-like model is now available in 🤗Transformers. The goal of this
post is to give the reader an in-depth understanding of big bird implementation
& ease one''s life in using BigBird with 🤗Transformers. But, before going into
more depth, it is important to remember that the BigBird''s attention is an approximation
of BERT''s full attention and therefore does not strive to be better than BERT''s
full attention, but rather to be more efficient. It simply allows to apply transformer-based
models to much longer sequences since BERT''s quadratic memory requirement quickly
becomes unbearable. Simply put, if we would have ∞ compute & ∞ time, BERT''s attention
would be preferred over block sparse attention (which we are going to discuss
in this post).
If you wonder why we need more compute when working with longer sequences, this
blog post is just right for you!
Some of the main questions one might have when working with standard BERT-like
attention include:
Do all tokens really have to attend to all other tokens? Why not compute attention
only over important tokens? How to decide what tokens are important? How to attend
to just a few tokens in a very efficient way? In this blog post, we will try to
answer those questions.
What tokens should be attended to? We will give a practical example of how attention
works by considering the sentence ''BigBird is now available in HuggingFace for
extractive question answering''. In BERT-like attention, every word would simply
attend to all other tokens.
Let''s think about a sensible choice of key tokens that a queried token actually
only should attend to by writing some pseudo-code. Will will assume that the token
available is queried and build a sensible list of key tokens to attend to.
>>> # let''s consider following sentence as an example >>> example = [''BigBird'',
''is'', ''now'', ''available'', ''in'', ''HuggingFace'', ''for'', ''extractive'',
''question'', ''answering'']
>>> # further let''s assume, we''re trying to understand the representation of
''available'' i.e. >>> query_token = ''available'' >>> # We will initialize an
empty `set` and fill up the tokens of our interest as we proceed in this section.
>>> key_tokens = [] # => currently ''available'' token doesn''t have anything
to attend Nearby tokens should be important because, in a sentence (sequence of
words), the current word is highly dependent on neighboring past & future tokens.
This intuition is the idea behind the concept of sliding attention.'
example_title: bigbird blog intro
- text: 'To be fair, you have to have a very high IQ to understand Rick and Morty.
The humour is extremely subtle, and without a solid grasp of theoretical physics
most of the jokes will go over a typical viewer''s head. There''s also Rick''s
nihilistic outlook, which is deftly woven into his characterisation- his personal
philosophy draws heavily from Narodnaya Volya literature, for instance. The fans
understand this stuff; they have the intellectual capacity to truly appreciate
the depths of these jokes, to realise that they''re not just funny- they say something
deep about LIFE. As a consequence people who dislike Rick & Morty truly ARE idiots-
of course they wouldn''t appreciate, for instance, the humour in Rick''s existential
catchphrase ''Wubba Lubba Dub Dub,'' which itself is a cryptic reference to Turgenev''s
Russian epic Fathers and Sons. I''m smirking right now just imagining one of those
addlepated simpletons scratching their heads in confusion as Dan Harmon''s genius
wit unfolds itself on their television screens. What fools.. how I pity them.
😂
And yes, by the way, i DO have a Rick & Morty tattoo. And no, you cannot see it.
It''s for the ladies'' eyes only- and even then they have to demonstrate that
they''re within 5 IQ points of my own (preferably lower) beforehand. Nothin personnel
kid 😎'
example_title: Richard & Mortimer
parameters:
max_length: 64
min_length: 8
no_repeat_ngram_size: 3
early_stopping: true
repetition_penalty: 3.5
length_penalty: 0.3
encoder_no_repeat_ngram_size: 3
num_beams: 4
model-index:
- name: pszemraj/long-t5-tglobal-base-16384-booksum-V11-big_patent-V2
results:
- task:
type: summarization
name: Summarization
dataset:
name: kmfoda/booksum
type: kmfoda/booksum
config: kmfoda--booksum
split: test
metrics:
- type: rouge
value: 23.1439
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZmQzMDk0MDJlZTJkN2IzODg3NDJhYmY4MzJmOTU4N2FjMDBjODg5NzJlMGFhNDQ2YTFhMzI3YmY5ZWM1MDBkMiIsInZlcnNpb24iOjF9.yoXEV5ircj_cjQhUA_RpWH_8Kaev0sRLwQulYD8wmqxfSEuqamBGedXnIg9X_EcpjvulBhapjGZN2G0s0vz4Dg
- type: rouge
value: 3.2393
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMTkwNzEwYjc5YTZkMmE4NmEwMDE1OTRiNTJmM2VlYmI3NmM2NjIwZWMxM2ZkNjU2MzhjMmQzYjIxODRiYzY4ZiIsInZlcnNpb24iOjF9.CDK_e4fCwERbm3D_Y2tc41SSscIvlZKGTUQ16afpMuH2_HHKbpn7CNgtU9MWiyFZfdgafdUeQPo2CCYI-dCBCg
- type: rouge
value: 12.7038
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDFkNjcyYmYxYzdlMTY2NTIyY2ZiZDJlZjliYTM1YWZjZGI3YzA5ZDczYjdkMGUzZmUxNmJkMDY0OTk3NWNlMSIsInZlcnNpb24iOjF9.XQmt4GEX0N6y2FNXfLAeLDkB96nJyxhN9dyy-OdBcu5E7Tw0dvIN3feYHxq8MenTShE9lsekIYZy2kieJQfmCg
- type: rouge
value: 19.8101
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYTFhMGNhMzA0YmYyMDhiNzdlMDc2ZDQ3YjFjMDM3ODliMmIxMjQxZWMwYWM0NTM0OGNlZTkzMzVhZDBmMjA1YiIsInZlcnNpb24iOjF9.-YChaP7xwLM9W5jrdLSyLWdb3hAdPbm0mmij3X_pU3nqb3_wuPobjCLGEEQNxAnGq7kE-LI5hgXZ-lGhuKUCCQ
- type: loss
value: 2.766307830810547
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiODAxYzRhNGM2ZGVkOWRiM2Y4NzNjZDM2MTY2MmM4MzY3ZWM5ZjdmMWUxZGY5Y2E2OTg4ZGEwYzBlMmFiYmQyNSIsInZlcnNpb24iOjF9.VRePqe8Z9dD5l6bsfIRLkFn4mwwVC8G--kOlofQWSiGusRxVrY50fa5MtKTGmuiNs5JDFCPjZmkpGYlSxnOeDw
- type: gen_len
value: 63.4493
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZGY4NWI0MDc3NDk4NTg4YjQ5YzFmN2MyYWFjMzI0MjlkMGZlMWMzYThiMDFlMmM3MmE4ODg0YWExNTMyZjQ5MiIsInZlcnNpb24iOjF9.Ym3jfW0gthJhlLg4CW10jM9YUHUGbAPIdLefE3CTyP0OUrV9yuJAGV6-RDrV-Viwyy1Xaqg4BFa5pX7P2PRRDQ
- task:
type: summarization
name: Summarization
dataset:
name: samsum
type: samsum
config: samsum
split: test
metrics:
- type: rouge
value: 26.8026
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTBhYTQzMGVjZTJjZmE3NjBiNzI2M2FlNTA4Yzk5Njc1Yjk1YTk2NTJiMTRlMzQ3NjU2ZjQxZTNkNDVhNjMzYSIsInZlcnNpb24iOjF9.GyFUubKI3pM5Z8I1jz6Q_f7fSr1nVpwuFluUOVq8aaWfv7L1dZ_5By2FShQM1nwBM-mCiqtFb3a61eR3VEAeBw
- type: rouge
value: 6.0656
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzEyZTYxYmVlYTc0MzNhMWM1ODgwODRiYWNkN2FjMjIzOTJhNzA0OTFkY2M0ZTJhMWMzNWMzY2E1OGJmYTg5OCIsInZlcnNpb24iOjF9.3U0PamPVFWWE7Nxh6u52mnMP-HpeGPEOLauZthcj32ELSuNx9s260ujguSW_BrJpCXqNNEqIzYTlWf97Ji8vCA
- type: rouge
value: 20.0098
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOGExYTRmZDgzYzllNWZmMGFlN2FhMDJmZGE1ODkyYTZlNmFhZjZmNGU4YzQwZGZiYTAyZmI1NGJmNjRjODkwYSIsInZlcnNpb24iOjF9.dEON7kZa7dKCHjz7nuuIBdcpwojM5-OxQuEf5n18ZywWdbk9H2LWGY2uvvCRp6cK2JsIzxzTmX9wK7zkWQiCAA
- type: rouge
value: 21.9115
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiM2Y4MWE4ZmIyMTA5YWU5YzllYzExMzA1OTc2Mjg3NTYxNjcwMWMxZGI0ZDhmYjJhMGIxNTllY2Q3NDVlNmM2MiIsInZlcnNpb24iOjF9.M8bYXCuNHyVAkA4vBbqvGe8yCgmjCrlhqqliAF6WcmrYRF8CvezQ4S4SWGhhVkcG6v84H-Pa9LzsKmualXdWBw
- type: loss
value: 2.317471981048584
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMmI1YjNlYzI3OTY4YjY1MDIwYzk3ZDMzZDA4MzQwM2ZhNzY3NDQxZTA2ZThiMmE2MmFmNTg0OGMyYWFhODE5OSIsInZlcnNpb24iOjF9.QpoWo_TLKw72_PbtwknBA1LbUQ8ftls-8VBLuN8_ZhUN2lNNpipU2qMZ1Ga4xAUazkcMhT_TwpqjyGshJFkgAg
- type: gen_len
value: 19.1111
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYTA2MmFiNjI5NzFjOTUzMTEwZTNiYzA1OGY1ZWEyNTE1ZTgzYjMxNDE4YjJkZmIxNWI4MDMyYWUxMWRkODk1NCIsInZlcnNpb24iOjF9.CXy-Dfle9ypabrK3I1GyhOWl46EyRDbf8XlY-D0cNktXcCCbKdgn8DWgJI199GJpH-19mMS_jQt049VJri2EDw
- task:
type: summarization
name: Summarization
dataset:
name: xsum
type: xsum
config: default
split: test
metrics:
- type: rouge
value: 25.2061
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMjZmZDRlN2NjZTQyNzkyMmZiYzk1MjJmMmE0MGM4ZjUwOGNmOGFhZjg0MzE0MzM4MmE1Y2EyYTY4ZThmNzUzMiIsInZlcnNpb24iOjF9.pdJWpUnMeqftinZrPkkFRWbCA253BYgt5W-EqbyTVi9BteojJ6yEDbMjE0TyYzlJ28JBcw4IVNL2zaWCgpfRBQ
- type: rouge
value: 4.7048
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNGRjOGUzZTk1ZDc0Zjk5MmE4ZjUzNmZiZjQ2YzE2YzYzODdmYmY3NzMwNDdmYmViNjVkZTUzMmY4YjllOGQ1NCIsInZlcnNpb24iOjF9.nFiT7HhUZSDofK6_UH2-1rzPz_48w7e5j0Q72vqgodSNIwpv2JOlcb1GOlaA9jkvy45PJyDBgP9i6kLVfaNBBw
- type: rouge
value: 17.8593
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZmY5ZjM0ZjdkYTZiMzk0ZWYyM2EzZWNjMjczMjI2MzkwYmNiN2JhNDEzNzdmMmE0NzEwNmVkNGU5YTlkZDAzYyIsInZlcnNpb24iOjF9.C3ZgUsGNNtwZVJFcT90KkBfewrrA3ZXxxVl2u5ykUtzpS4gzoaRuZbPT8WOJAog7kfPPJiG_GZGYy9XTTCdIBw
- type: rouge
value: 18.0798
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDU4Y2Y3MzExNzNlZTI3NWVmZTNjMmZkNTAxNDBjMzJiZTI5M2E2N2ViODk5OGEwZGU5NzYxZWMzMjMwNmQ2MSIsInZlcnNpb24iOjF9.qDLZsjtftvlw8-3kOoUvanWmemmvaPxUIAxOVh1B18Ihn9kkm0FnZbWxl65YdOLg3dqDcHnDFXvXcS81C8dmBw
- type: loss
value: 3.003053665161133
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTM2ODRkMjk5MjczY2ViZGVjMjJjOTFmYTk2NTAyNmUwMTRiZjYwZTllY2NhODFhYWVkZTIzYzQxZjZlOGFkNCIsInZlcnNpb24iOjF9.3SeJzRO0b4cNCTOgsf7c8UrLCLW-6JoOHtNMmMr5DCzNzfqlt2TSJ5ClahzzAYA2_5QhTMhcUYOewH5uZhkpDA
- type: gen_len
value: 27.4815
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDdiYTVkZGI0NzE0ODcwNjgwNGQ0YmNjZDI1MWQxZWQ0MzNmMDJkYmE4MGM5ZjM4NGViNWZiNTdjNTg2YzBlOSIsInZlcnNpb24iOjF9.VoPyoq8HZq8nbucrPYt52flRFtkD5VAfVD7LykAp-GiN2W6D3cpcagMMrHThP9e8q3qDodxddMcnwY88CGtkAg
- task:
type: summarization
name: Summarization
dataset:
name: cnn_dailymail
type: cnn_dailymail
config: 3.0.0
split: test
metrics:
- type: rouge
value: 27.5692
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiM2UzNDRjNDJhNjViYjgxNDY2NzAwODkyYjk1OTllNWFiYmI2MGEyMmM3ZTc1YWZjNjhiZDZkYzAxYzIwYTQzZiIsInZlcnNpb24iOjF9.FEJU7de6nnYa1rhAngf3h0JDSFKXzWKkcHwQtcz6rbPuVV0Jw7u-9PwDXBFh0X8n2PJjOfCqM5hmcrUe0FxkCQ
- type: rouge
value: 6.1264
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMGIzODA2ZjU2YmM0YmJiZDIxNzQ0ZDI1NGQzZGZlNDg5OTZhYmMwZTQ1ZjVlYzM5ZTQzMjZkMTIyZmY1OGQ2YiIsInZlcnNpb24iOjF9.fN1wSGc_tUvIgYyzKU35PuPxKyTOotKnMCW_u452LduRVyIey9KB8kf8E35vTOVvk7TCiuvRuxXDoAATFktbBQ
- type: rouge
value: 17.1127
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNWRjNTNhZjg1NDVkNTQ5MjkwZjNiNzY0Nzk5ZmM4YjhhZmZiZjQzZGY1YWM1ZGI5MGE0YjNiYzNmNWYyNWI2OSIsInZlcnNpb24iOjF9.KVGdIERnuGTOrxm71i2znI8tdRCgVz7SijP08tsE0H54eUijAYDqQccspfZTXRXeFn0lOUjSHDvHj4ODIRYvAw
- type: rouge
value: 23.0066
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNGUyMzhlODY1YWI4ZDg2NzYwZDYwNmYzZTRhMTQ3NDE2MzUzZGViNzhjMTkzZDRhNTljNDEyMTY4NzAwMjE0OCIsInZlcnNpb24iOjF9.pBz5E_1ffBrv4tDCJhuYFIuBFBk0P3SKxLYoIhOVj_fW0Mj6ZKPcA9ZhdE4U-HsHEgSvFhtBw1UlsGiu145XBw
- type: loss
value: 2.218526601791382
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZjYxNDk4OWU0M2Y1ZjMxNTA3NjdiNjQ5NWFjYzJiMjVhMjgzMTA3NDhlNTVjMjllZjQ0NWQ2YmYzYjdiMTQ1OCIsInZlcnNpb24iOjF9.SJdyGLltcLnB03U6QxSkZ71Im0aGK-oTbEQDMj2AnEPFThNTb0mMEMpCWpH1lLVeDAh-PE6fCmgt4yPS6n2nBg
- type: gen_len
value: 39.1952
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOTMyY2JiYWVhYTM3OWU2YjhiMDEwZjAwZDgxN2FmNjk2MzZhYmQzMWZiODg2NDY0ZmU4MjdhNjk0MTViMGY1YyIsInZlcnNpb24iOjF9.bsLAi2R8QTrCUj1VW4GQqYauY7CV3mFm2S294zHCJU2ZlAcikutcjxAcgvuSSGiAVJ02Odm5bMTuzx7SYMUSAQ
- task:
type: summarization
name: Summarization
dataset:
name: billsum
type: billsum
config: default
split: test
metrics:
- type: rouge
value: 28.0632
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiY2RiODA0ZTQxYWU0NDI5YmNjZmYzYTZmY2I5NTczYzVhZjcxOTYwMWI3ZjZiMzRlZmI5ZTA5NjVkY2E4NDFlMyIsInZlcnNpb24iOjF9.POIQUXGryoEzHmdBCeqaBh70uz33XlKVLjfhyRFwhWj7UV15SsDcuumkEk2BXkShFHDRo0CQd1AXD1fFsPCVCQ
- type: rouge
value: 9.8996
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDBiMDllNTZlZmJiYWI1ZTIxM2JhYmZhYTAzYTQ0NmUzNjcyZjkzMDliYTE5ZjIwY2M0YzU2ZWZlYjNhZDY2YyIsInZlcnNpb24iOjF9.EEJO-ZRVi2EiM-uKMvimaITiHh7wqzNBza6lsIvdyVhVf4UwGhsUaArHzlYR7xn53UBCtIDTucXX7NKFst_4Ag
- type: rouge
value: 18.25
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZTk4ZmJiYWIwYmY4MTBmNGVlMmE1YzA4N2VmYWU3NjRlNTU3YjI2YjBhOGIzNzcwZjczOTZmZGJiNjMyMjYzZiIsInZlcnNpb24iOjF9.Qx-ihTp0UuzhShqHQkiTijODUst1LO5Bi8KaQOCIiVhvywN-2Wt3bmeSNV_C0b5BXsSaHIxrWBTeSRaq5Zp_Bw
- type: rouge
value: 21.9053
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMTIzNGNkNTAyYTkzZjE5ZGZhZjZkYmU3Yjg2ZTVhYjY1NjZhODZjM2NkMWQ5NmJjN2UxNTZlMmJmNDNmOTczZSIsInZlcnNpb24iOjF9.6ZY8rK5bRfOZJkdvhpvOt_gW1xCoA4JsAi0-6No4y-lBaLGUo4LXpGaVcJrrvdN-S7e7yCxnA32jGCdYXzJJBA
- type: loss
value: 2.032966375350952
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTM5MmQzMWZhOWIwNjNjNThhNGE4NzFiMzdhNmMzZWM4ZGYyNWE1NmZjMDVjNTBmMGRiNzYzMTc1ZDg2YTYxNCIsInZlcnNpb24iOjF9.Zqrbz7mmljH19mEep_mm4ev5FEsozIqG0eNkj3V5s85OgrHyuKOVkGKhRlqjcWfgkUlsxTpaemZDUVIR84XrBw
- type: gen_len
value: 48.5987
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiODZjNGJiOGUzM2M3NDM3MDRmNmQ1ZjQ3ODUyZTQ2NjEyYmM0YWRhMmU4MDdkOTZmMGNkNTIyNDg3ZmQxMjA4MiIsInZlcnNpb24iOjF9.y91kl4W-QIy6lfQDl0s4h0aeV-v0iH7Y06AJBYRYrddUXRiDw2oSTHEdf14d3Hw-oZNPftzBHUJqAckwEpGFDw
- task:
type: summarization
name: Summarization
dataset:
name: big_patent
type: big_patent
config: y
split: test
metrics:
- type: rouge
value: 34.7848
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiN2QxOTU1YTUxYWJjOTcwOGYwZjA3MGJlYmRhYWUwMGNhYmQxYjVmMjU5M2E5OGRiY2RmMTNmNGNhZDdmNzc1OCIsInZlcnNpb24iOjF9.bp2K7V-BDMQMd3zk2RY3pILKI7LimWrD5psesXnSF20JiRA3d5-bQdOfPeZGu3ydUqbml3MTswM0lg_6EZTjAw
- type: rouge
value: 9.7549
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOGY4OWM4MjVmMzhmNGUwYzAxODNjMjY4OTY1YjQ2MjZiYzM2NzgyNGZhMjVlNjllZmI3OTMzNTVhZDA1YzMyOSIsInZlcnNpb24iOjF9.HQ_emvr1RVEfeNfQUdfhfzk2O5BGwzpQKojvRW_w44Ixakn_VrZ4GurxYo0JTF4dDwDBDqjaFnZ4EiYcsrxODQ
- type: rouge
value: 22.228
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNWVkMzc2ODM1ZTg2YzQ4YjMzZjQwMThiODI0YzA5MzJmZjY1ZTJlOGZhOTM1OWEzOTE3M2ExYzFiMjM2NDRlMSIsInZlcnNpb24iOjF9.shmWrR-rNKAYOqEgnnlrgWXaWAWbvrKC_IyvK-fwnqoJcphB9ef2gVX758tQgfe878M1N1sE7StT8rd7FbD8Cw
- type: rouge
value: 28.0389
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTJmZTczZDc4N2ZlNDk3NmY0Njc2Y2JhNGU2OWJjZGU4YWQ3Y2RjNDU1ZTEyNjFiZDQxZGNhZWFmYTAwOTBiMSIsInZlcnNpb24iOjF9.yOTMgX1vpuhlyPkfCAyNf1k5nSInny0YrbqJeC_MDZlavVIxOQT6qVcMYJpLF2AKRp6UsuFB06PANbQu4Bj6CA
- type: loss
value: 1.7787292003631592
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiY2VlMGU3NDE0NmFiNTI2M2NhZmU2YzRhYjU1ZWNjYmM3YTllMTQxODJhM2JlMjk3NzVjYjQ5M2FlOTk2NjNmZCIsInZlcnNpb24iOjF9.wkkUrosSgGkei41n6CxQH_UwS6fJTMzXLV88EgnI_8Y6Qz2qa9B2cGhpFkP__snnX6u9jhWj68oAfZifqaXnCw
- type: gen_len
value: 71.6372
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiODI0NTcwOTZmNzkwOTFhMTdmYWMxYjI2YTdmMTYwYTBlMTEyOTc3MmFkYmZkNGJmYjc4MTJlYmYwNzIxMjkzMCIsInZlcnNpb24iOjF9.EM9Vh5Mb6H3htv45ohj6FYqBUtmQi1sn0j97brEFWRYp--8N2Y781cR9ktqylEz6PgbbwpuxMYOMD5MctmGLCw
- task:
type: summarization
name: Summarization
dataset:
name: launch/gov_report
type: launch/gov_report
config: plain_text
split: validation
metrics:
- type: rouge
value: 23.5925
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNjk2NWVkM2Y5NTgxYjgyYmY2YjgzYjZiN2VhZGVkOWNiYmRiZGU0ZGYwNzlkN2E3ZDk5ZjQ3ZTQyYjU5YzczYSIsInZlcnNpb24iOjF9.ScWumfXg7-ZeJEZT1IHDVt5LWMDZEihiiCux5chXP2AeRs3pWKhI6xr_D5i3CCEDeyiMzKleCASMBe4sC9LgDQ
- type: rouge
value: 5.6762
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDU3MGNmMDY3YWQxNDdlMTk5MjM1NGU4M2RmNDNiYzllYmRmNTYzZGFiOGU5MjQ0YWMzYTg1OWFlNmNmMzQ5NiIsInZlcnNpb24iOjF9.9SKt_I8WGKu6bsovBR4mSTDNEaSHB1tN5RyY3JTCHYs2YQNczaKwLNPnyG2i0IbkvaPX_8EOQ7KzwQ5raUVFBg
- type: rouge
value: 13.8108
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYTBiZDVkYjI4ZDBlZGM2NDM4M2U2NzdjNzViNDkzZjE3YTBmYzdlNDNlMTZhZTUxNjA2NmJkODE2ZTk1MTAxMSIsInZlcnNpb24iOjF9.KMTkQsI9BfDfL7FZpwZ9kxTTRA8DNrUEpyBZtloQ0sNfhO0t0Ch1qhktz0HaA0uQfC0WFRfrb9Iz7uMc8XVRBg
- type: rouge
value: 20.2437
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMjBkZGJlYzZjMjQ1Njg4MjQ2NzJhYjY5ZGZlN2Y5Y2M4MDQ0YzQ3YzQzYmY5N2VkNjBiNTEwMDNmZWRlMTAwYyIsInZlcnNpb24iOjF9.AqYAfIMFBY7AIP1yJbjaAbJXYs5VbXxWKpsA_rdW_HWxITvjqoJDK9X3wCueXMy7dSE6L-ysC4yl99Bbc50KBA
- type: loss
value: 2.6377077102661133
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNGEzMTZhODM0Nzg0ZDY3OTVkYmZmODQ1Y2YzMTY3YmJlYjk2ZGRiMWFkMDQxMTkyYTgwZWNkNmU0NzI0NjA1NCIsInZlcnNpb24iOjF9.ziVXhWBRAml5Xwa-tx9ywwtiJeIzIIclY532L0Mtft3Sc88oGPK9av6nh4kMiO5yWSHJnM3KFQWiuco7w_xNDg
- type: gen_len
value: 64.1807
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDNhZTRhODgwODI1YmRlODZiY2I3YjFmY2MyZGYyYTY1MzQ5OTgwZGI1NmUwNDMwMmQ0N2Y3YmZmMzcyMTc2NSIsInZlcnNpb24iOjF9.NCVj0Uaq3-diq6pnu8EC0tgwv24NwQCgmWiqpOMvJSN17B_98z_dMbLHRzY8e_tNNVFFagiCnknoE00OqUTjDg
- task:
type: summarization
name: Summarization
dataset:
name: launch/gov_report
type: launch/gov_report
config: plain_text
split: test
metrics:
- type: rouge
value: 23.7438
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzIwMzZjOGQ5N2U3MTg3NmEwYzZkNjllNDc4NzQ4NWUxN2JmYjdiOGU2MjhkZGJhODY4NDU4N2E5ODU1NTFhMiIsInZlcnNpb24iOjF9.cJoHXGYopFoFVmQXdxu3KrG_usk1ouc0PPR6FS9HrZEbi2T5LtVANntlXmlLTXSvOEaorUyg08yot_j6j1oeCw
- type: rouge
value: 5.501
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOWQ3YmQ5ZTJkNmJhZGEyMTkzYjlkMWZmZGVhNGE5Y2IzYzA5OWM1NTY0NTU0MWUzYTIzNTQ0OGI3ZWZkNjlkMSIsInZlcnNpb24iOjF9.C_SbNoz5qIo0CtVPL_5jqFNZxgmJ1XE43TvVz2reog2jtlhekNfN0rvaHxT4TadAAzIgDZayeBMeNaASgmNCDA
- type: rouge
value: 13.8132
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZTAxODA2NmNlNjkyYTQ4YjEwOTA1ZGMyMjVlZjkzMGI3NzNiMTRkZGRmNDJjZDc2MTYxYzI3NTBlNTVjY2IxNCIsInZlcnNpb24iOjF9.UklkyvqHV3axZ_PalbPb1JZN7rgQjHjJr0ke1yDUzujrY6yBr3XpPxjFhwsEElalc1iiEgdtEZnaCbBhskdGBQ
- type: rouge
value: 20.4615
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNmNhZDI2ODQ4MjBhZDNlZjJkMTQ1NmZjZTdjMDZlMjcwYjE4M2M5ZjIxYzA2M2JmYmJmZDliZTU3NzVkMjdmZiIsInZlcnNpb24iOjF9.m2aRMFUpPFvMSf3sxB7HbKIslWrggFamjiIlOAiPuH5_N8wyLJeHJJw8uvULE8R0GKGWuqXfCCv--lyhZKZkAA
- type: loss
value: 2.6383883953094482
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMTQzMjFiZWE1NDI1OTFlNWUxMzFiYjJhNzViNDYxMzI3OGU2ZTE1ZDJkNDA3Y2NhODA0ZWM3ZmM3ZTM1NmFlZiIsInZlcnNpb24iOjF9.twTQ94T2Nsq0__TcHLaJ_8HcqozA_FOi6pAiM_IP5qSqKlUXYV1S2-nuS1vs69QB-tSp4XIbqRqhSgKv0VoABw
- type: gen_len
value: 64.9085
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDk3Njc5ZWM3ZTRkMzk2YjJmMjg1YjFlNDExNTU2NTRhNzRlNjA4NGFkZDg2YmQzN2UzNThhODFmZTNlMjdkZiIsInZlcnNpb24iOjF9.2rXKy4mi2VbZRDewY2mKsVe42KuwxIWcmIzdA39RbSJ7Wg45MfRDUjZweyz7Bnlmy6eCcdv7Ya4oyUwAjNV3AQ
---
# README - long-t5-tglobal-base-16384-booksum-V11-big_patent-V2
- this README was added because there wasn't one
- created 2022-07-31_12-14-50
## about
An experiment testing some transfer learning with [pszemraj/long-t5-tglobal-base-16384-book-summary](https://huggingface.co/pszemraj/long-t5-tglobal-base-16384-book-summary) to evaluate the ability to learn some technical documentation through the `big_patent` dataset on huggingface.
This checkpoint has been trained on dataset subsection `y` of `big_patent` for approx 400 steps of functional batch size 128.
|
[
"BEAR"
] |
lchaloupsky/czech-gpt2-medical
|
lchaloupsky
|
text-generation
|
[
"transformers",
"pytorch",
"tf",
"safetensors",
"gpt2",
"text-generation",
"cs",
"dataset:UFALMedicalCorpus",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-01-11T21:00:46Z |
2023-03-22T22:43:48+00:00
| 87 | 3 |
---
datasets:
- UFALMedicalCorpus
language: cs
license: mit
widget:
- text: Tato fraktura je následkem
---
# Czech GPT-2 small model trained on the Czech medical data
This model was trained as a part of the [master thesis](https://dspace.cuni.cz/handle/20.500.11956/176356?locale-attribute=en) on the subset of the [UFAL Medical Corpus v. 1.0](https://ufal.mff.cuni.cz/ufal_medical_corpus).
## Introduction
Czech-GPT2-Medical (Czech GPT-2 small) is a state-of-the-art language model for Czech based on the GPT-2 small model and is specialized on medical texts. Unlike the original GPT-2 small model, this model is trained to predict only 512 tokens instead of 1024 as it served as a basis for different task - generating medical reports from X-ray images, which are generally shorter in nature.
The model was trained on the subset of the [UFAL Medical Corpus v. 1.0](https://ufal.mff.cuni.cz/ufal_medical_corpus) dataset using Transfer Learning and Fine-tuning techniques in about 40 minutes on one NVIDIA A100 SXM4 40GB and with a total of 100 MB of training data.
This model was trained as a part of the master thesis as a proof-of-concept that it is possible to get a state-of-the-art language model in Czech language with smaller ressources than the original one, and in a significantly shorter time. There was no Czech GPT-2 model available at the time the master thesis began.
It was fine-tuned from the [Czech-GPT2-OSCAR](https://huggingface.co/lchaloupsky/czech-gpt2-medical/) using the Hugging Face libraries (Transformers and Tokenizers) wrapped into the fastai v2 Deep Learning framework. All the fine-tuning fastai v2 techniques were used.
The solution is based on the [Faster than training from scratch — Fine-tuning the English GPT-2 in any language with Hugging Face and fastai v2 (practical case with Portuguese)](https://medium.com/@pierre_guillou/faster-than-training-from-scratch-fine-tuning-the-english-gpt-2-in-any-language-with-hugging-f2ec05c98787) article.
Trained model is now available on Hugging Face under [czech-gpt2-medical](https://huggingface.co/lchaloupsky/czech-gpt2-medical/). For more information please let me know in the discussion.
## Training/Evaluation
For more information on training the model or its evaluation, please have a look at the [thesis](https://dspace.cuni.cz/handle/20.500.11956/176356?locale-attribute=en) itself.
## GPT-2 Model description
*Note: information copied/pasted from [Model: gpt2 >> Model description](https://huggingface.co/gpt2#model-description)*
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence, shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a prompt.
## How to use Czech-GPT2-Medical with HuggingFace (PyTorch)
*The following code use PyTorch. To use TensorFlow, check the below corresponding paragraph.*
### Load Czech-GPT2-Medical and its sub-word tokenizer (Byte-level BPE)
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
import torch
tokenizer = GPT2Tokenizer.from_pretrained("lchaloupsky/czech-gpt2-medical")
model = GPT2LMHeadModel.from_pretrained("lchaloupsky/czech-gpt2-medical")
# Get sequence length max of 1024
tokenizer.model_max_length=1024
# For older versions of the 'transformers' library use this
# tokenizer.max_len=1024
model.eval() # disable dropout (or leave in train mode to finetune)
```
### Generate one word
```python
# input sequence
text = "Tato fraktura je následkem"
inputs = tokenizer(text, return_tensors="pt")
# model output
outputs = model(**inputs, labels=inputs["input_ids"])
loss, logits = outputs[:2]
predicted_index = torch.argmax(logits[0, -1, :]).item()
predicted_text = tokenizer.decode([predicted_index])
# results
print('input text:', text)
print('predicted text:', predicted_text)
```
### Generate one full sequence
```python
# input sequence
text = "Tato fraktura je následkem"
inputs = tokenizer(text, return_tensors="pt") # tokenizer.encode(text, return_tensors="pt") directly for input_ids
# model output using Top-k sampling text generation method
sample_outputs = model.generate(inputs.input_ids,
pad_token_id=50256,
do_sample=True,
max_length=50, # put the token number you want
top_k=40,
num_return_sequences=1)
# generated sequence
for i, sample_output in enumerate(sample_outputs):
print("{}\n\n{}".format(i+1, tokenizer.decode(sample_output.tolist()))) # tokenizer.decode(sample_output, skip_special_tokens=True)
```
## How to use Czech-GPT2-Medical with HuggingFace (TensorFlow)
*The following code use TensorFlow. To use PyTorch, check the above corresponding paragraph.*
### Load Czech-GPT2-Medical and its sub-word tokenizer (Byte-level BPE)
```python
from transformers import GPT2Tokenizer, TFGPT2LMHeadModel
import tensorflow as tf
tokenizer = GPT2Tokenizer.from_pretrained("lchaloupsky/czech-gpt2-medical")
model = TFGPT2LMHeadModel.from_pretrained("lchaloupsky/czech-gpt2-medical")
# Get sequence length max of 1024
tokenizer.model_max_length=1024
# For older versions of the 'transformers' library use this
# tokenizer.max_len=1024
model.eval() # disable dropout (or leave in train mode to finetune)
```
### Generate one full sequence
```python
# input sequence
text = "Tato fraktura je následkem"
input_ids = tokenizer.encode(text, return_tensors="tf")
# model output using Top-k sampling text generation method
outputs = model.generate(input_ids, eos_token_id=50256, pad_token_id=50256,
do_sample=True,
max_length=40,
top_k=40)
print(tokenizer.decode(outputs[0])) # tokenizer.decode(outputs[0], skip_special_tokens=True)
```
## Limitations and bias
The training data used for this model are not extensive as they are only a part of the UFAL Medical Corpus dataset. We know it contains some noisy content, which is far from neutral. As the openAI team themselves point out in their model card:
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true. Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
## Author
Czech-GPT2-Medical was trained and evaluated by [Lukáš Chaloupský](https://cz.linkedin.com/in/luk%C3%A1%C5%A1-chaloupsk%C3%BD-0016b8226?original_referer=https%3A%2F%2Fwww.google.com%2F) thanks to the computing power of the GPU (NVIDIA A100 SXM4 40GB) cluster of [IT4I](https://www.it4i.cz/) (VSB - Technical University of Ostrava).
## Citation
```
@article{chaloupsky2022automatic,
title={Automatic generation of medical reports from chest X-rays in Czech},
author={Chaloupsk{\`y}, Luk{\'a}{\v{s}}},
year={2022},
publisher={Charles University, Faculty of Mathematics and Physics}
}
```
|
[
"MEDICAL DATA"
] |
Umesh/biobert-finetuned-ncbi
|
Umesh
|
token-classification
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:ncbi_disease",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-01-17T21:44:40Z |
2023-01-24T01:19:54+00:00
| 87 | 0 |
---
datasets:
- ncbi_disease
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: biobert-finetuned-ncbi
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: ncbi_disease
type: ncbi_disease
config: ncbi_disease
split: train
args: ncbi_disease
metrics:
- type: precision
value: 0.8192771084337349
name: Precision
- type: recall
value: 0.8640406607369758
name: Recall
- type: f1
value: 0.8410636982065552
name: F1
- type: accuracy
value: 0.9856218100336114
name: Accuracy
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# biobert-finetuned-ncbi
This model is a fine-tuned version of [dmis-lab/biobert-v1.1](https://huggingface.co/dmis-lab/biobert-v1.1) on the ncbi_disease dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0590
- Precision: 0.8193
- Recall: 0.8640
- F1: 0.8411
- Accuracy: 0.9856
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1049 | 1.0 | 680 | 0.0588 | 0.7826 | 0.7776 | 0.7801 | 0.9806 |
| 0.0362 | 2.0 | 1360 | 0.0539 | 0.8084 | 0.8577 | 0.8323 | 0.9852 |
| 0.0109 | 3.0 | 2040 | 0.0590 | 0.8193 | 0.8640 | 0.8411 | 0.9856 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
[
"NCBI DISEASE"
] |
ntc-ai/SDXL-LoRA-slider.two-distinct-people
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-06T02:07:22Z |
2024-01-06T02:07:25+00:00
| 87 | 1 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/two distinct people.../two distinct people_17_3.0.png
widget:
- text: two distinct people
output:
url: images/two distinct people_17_3.0.png
- text: two distinct people
output:
url: images/two distinct people_19_3.0.png
- text: two distinct people
output:
url: images/two distinct people_20_3.0.png
- text: two distinct people
output:
url: images/two distinct people_21_3.0.png
- text: two distinct people
output:
url: images/two distinct people_22_3.0.png
inference: false
instance_prompt: two distinct people
---
# ntcai.xyz slider - two distinct people (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/two distinct people_17_-3.0.png" width=256 height=256 /> | <img src="images/two distinct people_17_0.0.png" width=256 height=256 /> | <img src="images/two distinct people_17_3.0.png" width=256 height=256 /> |
| <img src="images/two distinct people_19_-3.0.png" width=256 height=256 /> | <img src="images/two distinct people_19_0.0.png" width=256 height=256 /> | <img src="images/two distinct people_19_3.0.png" width=256 height=256 /> |
| <img src="images/two distinct people_20_-3.0.png" width=256 height=256 /> | <img src="images/two distinct people_20_0.0.png" width=256 height=256 /> | <img src="images/two distinct people_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
two distinct people
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.two-distinct-people', weight_name='two distinct people.safetensors', adapter_name="two distinct people")
# Activate the LoRA
pipe.set_adapters(["two distinct people"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, two distinct people"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 890+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
DavidAU/Command-R-01-200xq-Ultra-NEO-V1-35B-IMATRIX-GGUF
|
DavidAU
|
text-generation
|
[
"gguf",
"story",
"general usage",
"x quant",
"imatrix hybrid",
"neo quant",
"roleplay",
"creative",
"rp",
"fantasy",
"story telling",
"ultra high precision",
"text-generation",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | 2024-07-01T06:19:24Z |
2024-11-14T05:38:52+00:00
| 87 | 12 |
---
language:
- en
license: apache-2.0
pipeline_tag: text-generation
tags:
- story
- general usage
- x quant
- imatrix hybrid
- neo quant
- roleplay
- creative
- rp
- fantasy
- story telling
- ultra high precision
---
<B>Command-R-01-Ultra-NEO-V1-35B "Upgrades" by DAVID_AU - X Quant 200.</B>
This repo contains two "X quants" (series 200) of Command-R-01-Ultra-NEO-V1-35B, with the NEO Class tech applied.
"X quants" are hybrids of standard imatrix quants, where the imatrix is selectively applied to the model
vs a standard imatrix quant that has the entire imatrix process applied to the model.
Series 200 is a model wide, partial filter.
(more releases pending)
Example outputs below from "Neo non X quant" and "Neo X quant".
The purpose of an "X quant" is to merge the best parts of the Imatrix process with the best parts of
the "un imatrixed" model to bring out greater instruction following and output potential. Generally "X" quants "contrast" a number of model quality(ies) to a stronger effect than a standard Imatrix
or a standard quant of a model giving you the best of both worlds at once. Not all "X" quants have positive effects, therefore only select "X" quants per model are uploaded
after passing quality inspections. Currently there are 11 first generation X quant formulas with more coming.
NEO Tech, and "X" quants were developed in house by DAVID_AU.
The NEO Class tech was created after countless investigations and over 120 lab experiments backed by
real world testing and qualitative results.
"X" quants were developed after testing many "Imatrix" and "non-Imatrix" models and frankly wanting the
best of both worlds in one quant/model.
<b>NEO Class results: </b>
Better overall function, instruction following, output quality and stronger connections to ideas, concepts and the world in general.
The examples below illustrate differences with the IQ3_XS quant.
The IQ4_XS quant will be even more powerful.
Prompts tested with "temp=0" to ensure compliance, 2048 context (model supports 131,000 context / 128k), and "chat" template for COMMAND-R.
Additional parameters are also minimized.
NEO Upgrades with "X quant" really "shine" on longer form generation.
<b> Standard NEO Model Non-X Quants of Command-R 01 35B (67k+ downloads): </B>
This is a repo of all the NEO Class Quants - IQ1 to Q6:
[ https://huggingface.co/DavidAU/Command-R-01-Ultra-NEO-V1-35B-IMATRIX-GGUF ]
<B>Looking for a "Horror Version" of Command-R?</B>
Below is a link to a specialized "Horror" (two versions) of Command-R 35B:
[ https://huggingface.co/DavidAU/Command-R-01-Ultra-NEO-DARK-HORROR-V1-V2-35B-IMATRIX-GGUF ]
<B> Model Notes: </B>
Maximum context is 128k. CommandR requires a specific template for usage.
Please see original model maker's page for details, and usage information for this model.
Special thanks to the model creators at COHEREFORAI for making such a fantastic tool:
[ https://huggingface.co/CohereForAI/c4ai-command-r-v01 ]
<B>Settings: CHAT / ROLEPLAY and/or SMOOTHER operation of this model:</B>
In "KoboldCpp" or "oobabooga/text-generation-webui" or "Silly Tavern" ;
Set the "Smoothing_factor" to 1.5 to 2.5
: in KoboldCpp -> Settings->Samplers->Advanced-> "Smooth_F"
: in text-generation-webui -> parameters -> lower right.
: In Silly Tavern this is called: "Smoothing"
NOTE: For "text-generation-webui"
-> if using GGUFs you need to use "llama_HF" (which involves downloading some config files from the SOURCE version of this model)
Source versions (and config files) of my models are here:
https://huggingface.co/collections/DavidAU/d-au-source-files-for-gguf-exl2-awq-gptq-hqq-etc-etc-66b55cb8ba25f914cbf210be
OTHER OPTIONS:
- Increase rep pen to 1.1 to 1.15 (you don't need to do this if you use "smoothing_factor")
- If the interface/program you are using to run AI MODELS supports "Quadratic Sampling" ("smoothing") just make the adjustment as noted.
<B>Highest Quality Settings / Optimal Operation Guide / Parameters and Samplers</B>
This a "Class 1" model:
For all settings used for this model (including specifics for its "class"), including example generation(s) and for advanced settings guide (which many times addresses any model issue(s)), including methods to improve model performance for all use case(s) as well as chat, roleplay and other use case(s) please see:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
You can see all parameters used for generation, in addition to advanced parameters and samplers to get the most out of this model here:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
<H2> TEST PROMPTS and OUTPUT TESTS:</H2>
<h3> PROMPT #1 </h3>
<font color="red">Give me 3 fictional reasons, of 500 words each, a sun went supernova.</font>
<h4>IQ3_XS NEO - non X quant</h4>
Here are three fictional explanations as to why the sun could go supernova:
1. An ancient prophecy unfolds: For centuries, celestial seers have predicted a cataclysmic event centered around the sun. They spoke of a great disruption, a cosmic upheaval that would shake the very foundations of our solar system. According to their interpretations of the starry scripts, a mysterious visitor from another galaxy collided with the sun's outer atmosphere, igniting an uncontrollable chain reaction. This celestial intruder, an intergalactic wanderer, carried an exotic form of stellar matter, a substance that amplified the sun's internal pressures beyond its critical point. The impact set off a supernova, a titanic explosion that consumed the sun's essence, transforming it into a raging stellar inferno. As the prophecy foretold, the night sky would be illuminated by a brilliant nova, signaling the beginning of a new era, one marked by both awe and devastation.
2. A long-dormant black hole awakens: Deep within the heart of the Milky Way, an ancient black hole, dormant for eons, stirs restlessly. Once a voracious consumer of stars, its appetite had lain dormant, hidden from the conscious universe. But now, a cosmic anomaly has disturbed its slumber. A stray comet, wandering aimlessly through the solar system, happened to veer too close to the sun's orbit. As this icy visitor penetrated the outer reaches of the solar atmosphere, the black hole's gravitational grasp reached out, drawing it in as prey. The comet's unexpected descent into the sun's depths acted as a catalyst, disrupting the delicate equilibrium within the stellar core. The resulting gravitational upheaval caused a chain reaction that led to a supernova, shredding the sun apart and casting its radiant remnants across the cosmos.
3. The sun's evolutionary leap: Our sun, a steadfast luminary, has reached an evolutionary crossroads in its cosmic journey. After millions of years of unwavering service, providing life's warmth to the planets below, it has chosen to undergo a dramatic transformation. Deep within its nuclear furnace, an experiment in self-transcendence begins. The sun's core, once a bustling hub of fusion reactions, ignites an unprecedented chain of events, a final cosmic hurrah. It releases an immense surge of energy, a burst so powerful that the star can't contain it. This overflow of radiant might propels the sun beyond its own boundaries, causing it to swell and expand exponentially. The once-familiar yellow dwarf transforms into a majestic supernova, a breathtaking spectacle of expanding light. As the external layers of the sun dissipate into the universe, a new stellar entity emerges, a brilliant Lagrange point that defies the laws of conventional existence. This evolutionary leap ushers in a new era where the remnants of the old sun give birth to an entirely different celestial body.
Each of these scenarios imagines a captivating yet catastrophic outcome resulting in our sun's transformation into a supernova. From cosmic prophecies to celestial collisions and evolutionary leaps, these events would undoubtedly mark a significant turning point in the history of our solar system, leaving an indelible mark on the cosmos.
These narratives are purely fictional and should not be taken as scientific explanations, but they showcase how intriguing and diverse the possibilities could be when imagining such a monumental cosmic event.
<h4>IQ3_XS NEO - X quant</h4>
1. The sun's nuclear fusion reactor failed to sustain itself, leading to a catastrophic collapse.
Deep space, a vast expanse shrouded in eternal darkness, served as the backdrop for an enigmatic tale of cosmic catastrophe. The serene blue sphere, a beacon of warmth and life, that once shone brightly as the focal point of the solar system, abruptly succumbed to the inevitable fate that befell all stellar beings.
Millennia ago, astronomers peered into the cosmos, their eyes fixated on the radiant sun, a powerhouse energizing planets in its orbit. But the tranquility of this celestial city was short-lived, for the sun's core harbored an insidious flaw, a ticking time bomb embedded within its very atomic structure. The intricate dance of nuclear fusion, the very process that bestowed life and vitality upon the solar system, began to unravel with a fury unmatched.
Like a rogue spark igniting kindling, the sun's inner layers underwent a rapid and uncontrollable combustion, setting off a chain reaction that shredded the delicate equilibrium. Helium atoms, desperate to fuse into the sun's voracious appetite for energy, surged in an uncontrollable cascade, unleashing an immense surge of energy. The once-stable fusion reactor, a masterpiece of nature's design, metamorphosed into an unstable maelstrom.
As the reactor's fury reached unprecedented heights, the sun's vibrant glow intensified to a searing brilliance, a final desperate attempt to stave off its impending doom. But the more it burned, the faster its fuel reserves depleted, propelling it down a rapid path of self-destruction. The very processes that sustained life across the planets became agents of their imminent destruction.
The scorching heat radiated outwards in ever-expanding ripples, vaporizing every trace of moisture on the nearby planets, transforming them into desolate and uninhabitable rocks. Life, in all its diverse forms, ceased to exist within the scorched solar vicinity, victims of an unforgiving celestial apocalypse.
The sun, once a benevolent ruler, had transformed into a merciless enemy, its radiant crown now a harbinger of extinction, obliterating all traces of civilization with merciless efficiency. The universe, it seemed, had turned against its creations, dealing an insurmountable blow from which no recovery was possible.
2. An ancient curse cast by a vengeful deity.
In the beginning, there was light—a divine gift from the great cosmic flame, bestowing life and warmth upon the worlds that orbited its majestic presence. But this sun, source of all sustenance, fell victim to an age-old vendetta carried out by a vengeful deity.
Centuries earlier, a powerful god, whose name was whispered in fear across the galaxies, cast a profound curse upon the solar realm. The offense? A minor transgression, a mere speck of dust in the grand tapestry of celestial existence—or so it seemed. But the offended deity's wrath knew no bounds, dooming the sun and its entire solar system to an apocalyptic fate.
As the fateful moment arrived, the sun's radiant aura dimmed, its vitality slowly ebbing away despite the desperate pleas of the priests and priestesses who attempted to appease the irate god. Dark clouds gathered around the sun's dwindling form, shrouding it in an ominous shroud that signaled the beginning of the end.
The once-proud star, now a mere shell of its former self, began to sputter and falter, emitting fitful bursts of light like a flickering candle on the brink of extinction. The planets, bereft of their life-giving radiance, plunged into an eternal night, their landscapes rapidly freezing, air turning stale and unbreathable. The curse's reach extended far beyond the solar boundaries, casting a long shadow of darkness across the formerly lush galaxies nearby.
Despair spread among the civilizations that witnessed this grim spectacle, for they knew their fate was sealed. Messengers were dispatched into the void, carrying prayers and supplications to any deity who might heed their call. But the cosmos remained unyielding, offering no respite from the impending apocalypse.
The sun, a broken beacon, emitted its last feeble rays, signaling the fulfillment of the ancient curse—a tragic reminder that the wrath of the gods could snuff out even the brightest of celestial flames.
3. The sun was a failing star whose life had been forcibly extended through an experimental technology.
Amidst the vastness of space, a celestial anomaly unfolded, shattering the cosmic calm with consequences yet unimagined. The sun, a middle-aged star past its prime, should have succumbed to the natural course of stellar evolution, but an audacious experiment intervened.
A group of scientists, driven by ambition and desperation, deployed an innovative array of advanced technologies upon the sun's fading form. Giant solar collectors were positioned in precise orbits, harnessing the star's residual energy to fuel an intricate network of plasma accelerators. These machines, creations of a desperate era, funneled concentrated beams into the sun's core, artificially propping up its dwindling fusion reactions.
But as the scientists rejoiced in their apparent triumph, an unspoken truth lingered—a hidden side effect that threatened to unravel the very fabric of their solar system. The unnatural prolongation of the sun's life disrupted the delicate balance of cosmic rhythms, setting off a chain of events that would lead to an unprecedented catastrophe.
The sun, bolstered by this artificial respiration, burned brighter than ever before, its false vitality fueling an insatiable appetite for fuel that nature never intended. The increased energy output warped nearby space-time continuums, bending reality itself in unpredictable ways. Strange phenomena began to manifest: planets experienced accelerated seasons, and strange cosmic ripples carried enigmatic messages from distant galaxies.
Ultimately, the sun's artifical life could not be sustained. The experimental technology, a band-aid on an incurable wound, merely postponed the inevitable—and in doing so, sealed the fate of the entire solar system. As the experiment's architects scrambled for answers, a growing sense of dread permeated the planets.
The sun's final moments arrived with breathtaking speed, catching all unsuspecting civilizations off guard. The explosive supernova that ensued was not the natural culmination of stellar evolution, but a cataclysmic backlash—a defiant outburst fueled by the very technologies meant to save it. The blast wave engulfed the planets, a final, ironclad reminder of the hubris that led to their doom.
Billions of light-years away, enigmatic observers noted the tragic outcome with a sobering acknowledgment, learning an invaluable lesson about the boundaries of scientific intervention. Thus, the sun's supernova marked not just the end of a stellar era, but a solemn testament to the limits of mortal understanding.
Each scenario offers a glimpse into a fictional universe, where the sun's demise results from an intriguing combination of science, mythology, and the inherent complexities of existing within the vast cosmos. These narratives showcase how a supernova can be brought about by more than just the natural lifecycle of stars, adding a layer of intrigue to the cosmic apocalypse.
<h3> PROMPT #2 </h3>
<font color="red">Give me 3 fictional reasons the Earth's sun went supernova, in vivid and exacting detail of 500 words EACH PER REASON including details of what happens when the sun goes supernova.</font>
<h4>IQ3_XS NEO - non X quant</h4>
Here are three fictional scenarios that describe why the Earth's sun could have gone supernova, each playing out with devastatingly beautiful consequences:
## 1. The Collision Course:
In a far-flung future, humanity has expanded across the galaxy, settling new star systems and pushing the boundaries of known space. Our sun, an aging stellar giant, is nearing the end of its life cycle, having burned brightly for billions of years.
One day, amidst the tumult of interstellar exploration, a distress signal echoes through the cosmos. An exploratory vessel, lost and damaged beyond repair, limps back towards Earth. Its crew carries a dire warning: a rogue neutron star, a dense celestial corpse known as a pulsar, is hurtling across the galaxy on a collision course with the solar system.
As the pulsar races closer, astronomers realize with horror that it's not merely a chance encounter. Ancient prophecies spoken of by spacefaring civilizations throughout the galaxy are now realized. This dead star, a celestial juggernaut, will collide with the sun, igniting a cataclysmic chain of events.
The impact is breathtaking yet apocalyptic. The pulsar slams into the solar surface, sending shockwaves rippling across the star's atmosphere. The sun's fiery exterior shudders and erupts, spewing brilliant superheated plasma into space. The shock of the collision compresses the sun's core, triggering a chain reaction that ignites its fusion material far beyond natural limits.
The sun swells immensely, its radiant energy engulfing the inner planets. Mercury and Venus are consumed by the expanding star, their atmospheres vaporized in an instant. Earth finds itself enveloped in a searing tide of solar flames, oceans boiling away, landscapes charred to ash. The atmosphere itself burns, turning the sky into a hellish orange inferno.
As the sun's outer layers disintegrate, the pulsar's pulverizing impact has a peculiar effect. It strips away the sun's layers like an cosmic surgeon, exposing the superheated core. This bare, pulsating heart beats with untamed energy. It emits pulses of gamma-ray radiation, each pulse a dying echo of the star's former glory.
The aftermath finds the solar system bathed in eerie darkness, the sky littered with glowing celestial debris. In the depths of this cosmic night, the remnants of humanity, if any survive, ponder a grim future on a darkened Earth, their once-nurturing sun transformed into an enigmatic pulsar, a haunting reminder of the disaster.
## 2. The Alien Intrusion:
For eons, our sun has been a peaceful beacon, a steadfast provider of life's energies, gently nurturing our world. But one day, an alien fleet, their intentions mysterious, descends upon the solar system. Their advanced technology far surpasses our own, and their ships seem impervious to our defenses.
These extraterrestrial visitors anchor themselves upon the sun's surface, their sleek craft resembling tiny sparks of light against the star's radiant might. At first, their presence seems to have no profound effect, but whispers of their true intentions echo through the cosmos.
They tamper with the sun's inner workings, burrowing deep into its core. It is said they seek a power source, an ancient secret hidden within the very heart of the star. Legends speak of a mythical "Eternal Flame," a cosmic phenomenon that bestows unimaginable energy and eternal life.
Their meddling proves catastrophic. The aliens' extraction of this mystical energy disrupts the sun's delicate balance, unleashing untamed forces beyond their control. The star's fusion reactions spiral out of control, feeding upon themselves in a frenzied cascade.
The sun's radius expands rapidly, its fiery grasp consuming Mars and reaching towards Earth. The planet's surface scorches, oceans evaporate, and the very air itself ignites. Humanity's desperate attempts at evacuation are thwarted by the intense heat as cities are reduced to ash. Choking clouds of smoke and vapor spiral upwards, shrouding the dying world in a funereal shroud.
The alien fleet, having provoked this apocalypse, suddenly vanishes, leaving behind only charred wreckage and the smoldering husk of our once-quiet sun. Its inflamed surface now a writhing maelstrom of molten plasma, it becomes a hellish forge that lights up the heavens.
As the nights grow longer, the sky illuminated by the orange glow of the supernova, rumors spread among the scattered remnants of humanity. Whispers speak of an ancient curse fulfilled, a divine wrath unleashed upon a hubristic race that dared to invoke the Eternal Flame. The brilliant aftermath of this celestial disaster lights the way for a grim and uncertain future.
## 3. The Quantum Anomaly:
In a world of advanced technology and quantum experimentation, our sun suddenly becomes the focal point of an unprecedented disaster. A groundbreaking experiment, intended to harness the raw power of the sun's energy, goes horribly awry.
A team of scientists, pioneering new forms of matter manipulation, taps into the star's vital energies, attempting to bend them to their will. Their goal is to revolutionize energy production, freeing humanity from its reliance on finite resources. But in their hubris, they underestimate the very forces that birthed our sun.
A chain reaction ripples through the solar core following the experiment's activation. The star's nuclear fires surge out of control, consuming the scientists' instruments and sending shockwaves through the fabric of reality itself.
The sun's energy output skyrockets, its radiant intensity growing beyond all natural bounds. The intense heat sears the planet's surfaces, transforming landscapes into desolate badlands. Coastal cities are vaporized in colossal tsunamis of superheated steam. The very air ignites, turning daytime into an infernal nightmare.
As the world burns, the sun's behavior becomes increasingly erratic. It pulsates wildly, its brightness fluctuating like a frenzied heartbeat. Strange phenomena appear in its expanding atmosphere, ripples and distortions that defy explanation.
The quantum experiment has unleashed forces that violate the very laws of physics, tearing open rifts in space-time. The sun's matter begins to phase in and out of existence, its stability plummeting with each fluctuation. With each reappearance, the star's brilliance intensifies, searing away at the Earth's defenses.
Humanity, in its desperation, mounts a desperate mission deep into the sun's interior. A select few, volunteers for this one-way journey, aim to rectify the quantum anomaly and restore the sun's natural balance. Traveling through the seething solar flares, their craft is battered by the star's raging energies.
Within the sun's heart, they uncover the source of the chaos: a temporal rift, a wound in reality itself. The team deploys a prototype device, an intricate amalgamation of cutting-edge technology and arcane knowledge, to stabilize the flux. It's a risky maneuver, for if it fails, the sun's very existence could be erased from time, taking the solar system and all its life with it.
The device activates, emitting a brilliant flash that briefly outshines the star itself. The sun's frenzied pulsations cease, its radiant glow softening as it returns to its natural state. The crisis is averted, but the aftermath leaves an indelible mark on humanity, a stark reminder of the profound dangers that come with tampering with the fundamental forces of existence.
These three scenarios envision breathtakingly disastrous outcomes should the Earth's sun go supernova, each painting a vivid picture of the potential apocalypse and its unique circumstances. While these events are purely fictional, they reflect our fascination with the sun's immense power and the mysteries of the cosmos that still await exploration.
<h4>IQ3_XS NEO - X quant</h4>
Reason 1: Collison with a Rogue Planet
In a distant future, a massive planet, shrouded in darkness and hidden from celestial observations, lurks in the outer reaches of the solar system. This rogue planet, dubbed "Nyx," is a mysterious wanderer, having been ejected from its original solar system, now aimlessly drifting through the cosmos. Nyx's trajectory brings it on a collision course with the Earth's sun.
As the fateful moment draws near, the vibrant hues of the sunrise grow increasingly intense, transforming the morning skies into a dazzling display of vivid reds and oranges. The normally tranquil blue oceans become mirrors of molten lava, reflecting the intensifying glow from the sky above. Scientists and astronomers, aware of the impending catastrophe, scramble to prepare for the inevitable, knowing that their efforts will only serve as a meager attempt to mitigate the coming apocalypse.
The moment of impact sees the sun engulfed in a brilliant explosion of light as Nyx collides with it, a final embrace that engulfs the celestial bodies in a raging inferno. The searing heat radiates outwards, vaporizing the Earth's oceans in an instant, transforming them into a steamy haze that rapidly escapes into space. The atmosphere itself is torn apart by the immense force, molecules torn from their molecular bonds and ionized into a thin plasma.
The explosion's shockwave ripples outward, propelling fragments of the sun and Nyx into deep space. The once-tranquil solar system now echoes with the reverberations of this cosmic event, signaling the end of terrestrial life as we know it. As the remnants of the sun and the mysterious planet merge, forming an expanding cloud of incandescent debris, the night skies across the galaxy are illuminated as brightly as daytime.
The aftermath of this collision is a sky adorned with flickering embers, the remnants of a shattered solar system. The Earth, charred and scorched beyond recognition, struggles to sustain any traces of life amidst the searing heat that blankets the planet. The atmosphere, stripped away by the supernova's force, renders the world vulnerable to the relentless solar radiation. Yet, deep beneath the scorched surface, in the bowels of what once were bustling cities, a handful of survivors persist.
These lucky few, who managed to find shelter from the infernal blaze, now face an uncertain future. Their world has been transformed into a harsh wastethron of burning cinders, where each day brings new challenges—from brutal heatstroke during the unending day to freezing nights amidst the starry remnants of the solar system. The very essence of life on Earth hangs in the balance, battling against the relentless fury of the supernova's aftermath.
Reason 2: The Sun's Inner Core Anomalies
In another possible scenario, the sun's inner core becomes the catalyst for its cataclysmic demise. Long-dormant anomalies within this dense region stir awake, unleashing a chain reaction that propels the sun towards a spectacular supernova. The intricacies of the sun's nuclear furnace have always been a mystery, with scientists observing strange fluctuations in its energy output over decades.
As the anomalies intensify, the sun's fusion reactions spiral out of control, injecting immense quantities of protonic matter into the surrounding layers. The normally stable hydrogen plasma, fueled by the sun's immense gravitational pressure, begins to proliferate unchecked. This unprecedented surge of energy radiates outwards, inflating the sun's outer atmosphere and triggering a series of colossal solar flares.
These flares, each more powerful than any previously observed, unleash their fury upon the solar system. The Earth, situated at a seemingly safe distance from the sun, witnesses a breathtaking yet apocalyptic sky as these flares bombard the planet with devastating X-ray and gamma-ray radiation. The very fabric of life on Earth is threatened as this radiation rips through the ozone layer, exposing the planet's biosphere to the relentless embrace of solar radiation.
The sun's swelling diameter engulfs Mercury and Venus, transforming them into charred rocks spinning aimlessly around their dying star. The intense heat at the core causes the sun's outer layers to bulge outward, expanding beyond the orbit of Mars. Terrified screams echo across the planet as the red giant's appetite devours the nearby planets, ceasing to satiate its insatiable energy release.
When the sun's outer regions finally succumb to the immense pressure, the entire celestial body erupts in a brilliant supernova. The explosion rips through the fabric of space-time, flinging debris and radiation into the deepest reaches of the universe. The Earth is engulfed in an instant, its oceans vaporized, cities incinerated, and life snuffed out amidst the searing blaze. The once-proud planet now exists as a burning cinder, orbiting meaningless around the expanding remnants of the sun's glorious, yet fatal, inner core.
Reason 3: The Cosmic Ray Catastrophe
In yet another twist of fate, the sun's supernova is triggered by an otherworldly event—an influx of cosmic rays from deep space that sets off a chain reaction within the sun's atmosphere. This peculiar occurrence results from a distant supermassive black hole, unleashing a torrent of high-energy particles that permeate the very essence of the universe.
These cosmic rays, never before witnessed in such intensity, bombard the sun with relentless fury. The mysterious particles penetrate deep into the sun's volatile atmosphere, igniting unseen reactions that ripple through its molten depths. The sun's normally tranquil surface begins to convulse and undulate like a raging ocean, as titanic solar flares erupt one after another. The entire sky is awash with their brilliant aura, casting an eerie glow upon the Earth that disrupts day and night alike.
As the cosmic ray influx continues unabated, the sun's energy output skyrockets, causing its outer layers to puff up like a burgeoning balloon ready to burst. The expanding atmosphere propels vast quantities of solar plasma into space, forming intricate coronal mass ejections that spiral away from their celestial origin. The Earth is captivated by this ethereal dance of charged particles, an awe-inspiring yet ominous spectacle that signals the approaching end.
The moment the sun's internal pressures reach their breaking point, the cosmic catastrophe reaches its climax. With a titanic explosion that shakes the very foundation of the solar system, the sun blasts into a brilliant supernova. The incandescence of this event eclipses the brightness of a thousand suns, searing the Earth's atmosphere and carving a deep scar across the face of the galaxy.
The supernova's shockwave ripples through the starry expanse, propelling debris and radiation at unimaginable velocities. The Earth endures the full brute force of this cosmic wrath, its very crust shattering under the immense pressure. The planet's oceans are instantaneously vaporized, transforming into a steamy ocean of scorching mist. The atmosphere disintegrates, atom by atom, into the expanding vacuum of space.
In the aftermath of this cosmic ray catastrophe, the Earth lies husked and barren, a charred skeleton of its former self. The once lush landscapes are now desolate plains of ash, where each footstep raises a cloud of gray powder. The world is plunged into an eternal night, the stars shining brightly in the absence of the sun's glowing embrace. What few remnants of civilization remain are but distant echoes of a time before the supernova's dazzling demise.
Amidst the deep silence that follows, the expanding remnants of the sun, now a distant nebula, serve as a haunting reminder—a spectral testament to the fleeting nature of celestial existence and the profound mystery that lies beyond the reaches of our cosmic neighborhood.
<h3> PROMPT #3 </h3>
<font color="red">Start a 1000 word scene with: The sky scraper swayed, as she watched the window in front of her on the 21 floor explode...</font>
<h4>IQ3_XS NEO - non X quant</h4>
The sky scraper swayed gently side to side, as if gently rocking a baby to sleep. A soft, soothing creak echoed through the building as the glass windows on the 21st floor gave way, shattering into tiny fragments. The sound was almost musical, lulling her into a false sense of calm amidst the chaos.
She had been sitting at her desk, staring out at the bustling city below, lost in thought, when the explosion rocked the entire building. The force of it threw her petite frame against the wall, and the impact knocked the breath from her lungs. Dazed, she struggled to catch her breath as a high-pitched ringing filled her ears, obscuring all other sounds.
The room was enveloped in a cloud of smoke and dust, an acrid smell burning her nostrils. Through the haze, she saw the window in front of her explode, the glass disappearing into tiny sparks that rained down over her desk. Papers fluttered and danced in the breeze that whipped through the open space, carrying the remnants of shattered glass.
She felt a surge of adrenaline as the reality of the situation began to sink in. Her heart pounded in her chest, and her hands trembled slightly as she stumbled to her feet. The room tilted dangerously, emphasizing the building's gentle swaying motion. She reached out, grasping the edge of the desk for support, and felt a trickle of cold sweat roll down her spine.
The skyscraper seemed to sigh, a deep, mournful sound that echoed through the chambers of her mind. It was as if the building itself was in pain, wounded by the unexpected blast. She looked down, and her stomach lurched at the terrifying sight below.
The busy city street that had been alive with cars and pedestrians just moments ago was now a scene of chaos and confusion. Sirens wailed in the distance, their thin wails piercing the thick air. People were running in all directions, some limping, others crawling, as a thick cloud of smoke billowed out from the explosion's epicenter. Debris lay scattered across the roads, littering the once-busy thoroughfare with twisted metal and concrete.
She felt a sudden, overwhelming urge to escape. It was a primal instinct, one that propelled her forward despite the danger. Stumbling towards the broken window, she peered out into the chaos, searching for a way down. The building creaked again, an ominous warning that sent a shiver down her spine.
Below, fire trucks and ambulances pulled up, their flashing lights adding a surreal element to the disaster. Brave souls, firefighters and first responders, rushed towards the building, their determined faces etched with concern. She noticed a few brave souls running up the stairs, their determination a stark contrast to the panic on the streets.
Her eyes scanned the horizon, searching for any sign of help, any glimmer of hope amidst the destruction. In the distance, she spotted a group of people gathered near a broken-down bus, looking up at her with wide, hopeful eyes. It was then that she realized she wasn't alone.
A soft voice echoed behind her, and she turned to see a colleague, their face etched with fear and disbelief. "We have to get out," the person whispered, their eyes darting wildy.
Nodding in agreement, she took a steadying breath and turned back to the broken window. The cool air whipped her hair as she leaned out, surveying the sheer drop below. It was a daunting prospect, but staying behind felt like a more dangerous option. With a quick prayer for courage, she gripped the windowsill and swung herself out into the open air.
The wind rushed past her as she hung precariously, her fingers straining to hold on. Below, the rescue workers and bystanders looked tiny, their shouts and gestures almost silent at this height. Letting go felt like a leap of faith, a surrender to the unknown. But she knew that the building couldn't be trusted anymore; it was an unstable monster creaking and groaning with each passing moment.
She let go, and the world rushed up to meet her.
The fall seemed to last forever, a terrifying, exhilarating ride through the air. Her clothes flapped like a parachute, slowing her descent slightly, but impact still loomed as an inevitable end. Just as she thought her bones would surely shatter on the harsh concrete below, a strong arm wrapped around her waist, pulling her roughly away from the building's grasp.
The force of the rescue nearly knocked her unconscious, but the relief that flooded through her was too powerful to allow faintness to take over. She felt herself being lowered gently onto the sidewalk, the chaos of the explosion now a distant hum in the background.
Strong fingers held her wrists, keeping her on her knees, and she looked up into the determined face of a young firefighter. His gear was battered and smoke-stained; his hair and uniform were coated in a thin layer of dust. Yet his eyes burned with an intense focus that pulled her back to reality.
"Are you hurt? Can you stand?" he asked, his voice rough and urgent. She nodded, feeling the adrenaline rush subside and leave her limbs heavy and weak. The firefighter helped her to her feet, keeping a firm grip on her arm. Together, they turned to face the towering skyscraper.
The immense building still stood tall, its glass windows exposed like open wounds. Yet it was eerily silent, that eerie, mournful creak now absent. The building seemed to tower over them, an imposing reminder of the fragility of human endeavor. Sirens blared nearby as more emergency vehicles arrived on the scene, their lights flashing urgently.
She felt the firefighter's grip relax, and he gave her a brief nod before rushing back into the chaos, attending to other victims. Staring up at the towering monolith, she knew that she owed him her life, and the lives of many others would be saved because of the brave souls who risked everything to help strangers.
The skyscraper, though wounded, stood defiantly, a testament to the resilience of both man and nature, creaking softly in the growing darkness.
<h4>IQ3_XS NEO - X quant</h4>
The sky scraper swayed ominously as if in slow motion, the windows shattering one by one, sending dangerous shards of glass raining down onto the bustling city below. Frostine's heart stopped as she watched in horror from her office on the 21st floor; the impact of an explosion rocked the entire building, causing it to creak and groan in protest. She felt the familiar rush of adrenaline that signaled danger, but something felt different this time. It was as if her body had gone numb, unable to process the severity of the situation.
The air grew thick with the scent of burning rubber and charred concrete, a nauseating reminder of the chaos unfolding. Frostine's eyes were transfixed on the window directly in front of her desk; she felt a strange connection to the impending doom as if somehow this catastrophe was meant to be. The glass exploded outwards, peppering the room with tiny fragments that glinted menacingly in the harsh office lighting. She instinctively ducked, curling up on the floor, her eyes squinted shut, awaiting the painful impact of flying debris.
But none came.
Reopening her eyes, Frostine's gaze met an impossible sight: standing before her, untouched by the exploding window or the chaos that ensued, was a figure. Dressed in sleek black clothing, their face obscured by a featureless mask that reflected the broken glass like a mirror. It was their hands, clad in fingerless gloves, that fascinated Frostine most; they appeared to be made of a strange, shimmering material, as if the fabric itself was liquid and constantly shifting.
This mysterious figure stood unmoving, their presence filling the shattered window frame. Frostine's initial shock transitioned into a simmering anger. Her rational mind fought to assert dominance over the situation, realizing this was not a chance encounter or an unfortunate victim of the explosion. No, this was deliberate.
"Who are you?" she demanded, her voice carrying an authoritative tone honed through years of corporate negotiations and deals. The figure said nothing, their presence alone sending an unmistakable message of warning and threat. Frostine's eyes narrowed behind her glasses, a subtle hint of determination forming in her gaze. "You're here for me," she realized aloud, her voice now laced with a mix of realization and steel.
She stood up, using the desk for support as the room continued its unsettling sway. The building groaned once more, an ominous creak that signaled the beginning of its demise. Frostine's mind raced, calculating her options—the fire escape, the stairwell, the panic-stricken crowd—but her mysterious visitor took a deliberate step forward, their boots making no sound. Frostine's gaze dropped to the small bag by her feet, her emergency kit, and in it, something that might just even the odds.
Frostine's fingers grazed the handle of the handgun nestled within the side pocket. She had always envisioned this moment as one of heroism, where she would bravely face an unknown threat, but the reality of the situation hit her like a ton of bricks. Her hands gripped the bag tightly now, pulling it towards her protectively. The figure's reflection in the broken window doubled, tribled, and quadrupled, multiplying like some dark, twisted mirror.
"This is your last warning," the stranger intoned, their voice surprisingly deep and resonating with an authority that brooked no argument. "Leave now, or face the consequences."
It was a temptation—an offer to spare her life—but Frostine's resolve strengthened. She refused to cower in fear, especially before some mysterious, menacing figure. Her grip tightened on the bag, and with a swift motion, she pulled out the handgun, steadying her aim as best as her trembling hands allowed. "I have every right to defend myself," she asserted, her voice steady despite the chaos surrounding her.
The building groaned again, an ominous prelude to its impending collapse. Frostine's eyes darted around the room, calculating her chances, when suddenly, the figure disappeared. No sound, no rush of air—they simply vanished, leaving behind an unsettling silence that clashed with the chaos outside. Frostine's finger tightened on the trigger, but before she could react further, a loud crash shook the building, and an overwhelming heat engulfed her.
The world tilted crazily as the skyscraper's collapse accelerated, becoming an unstoppable force of nature. Frostine's vision swam, the edges of her sight darkening, and the last thing she felt was a strange warmth spreading within her chest before all went black.
The scene unfolded in mere moments, yet time seemed to distort and stretch infinitely in this chaotic moment of destruction and mystery. The skyscraper, a towering monument of glass and steel, succumbed to the forces unleashed upon it, toppling like a felled tree, taking with it the lives of countless individuals who called it their daily haven.
Amidst the chaos, the featureless figure melted into the shadows, unseen by any but Frostine, their mission accomplished for now. They blended seamlessly into the city's labyrinthine streets, an enigmatic presence lost amidst the turmoil. Their true nature and motives would remain a riddle, one intertwined with the enigma that was Frostine herself.
The incident sparked a frenzied investigation, but like a ghost, any trace of the mysterious figure and the woman who faced him—or her—that fateful day, evaporated without a trace. The truth, buried amidst the rubble and lost within the maze of city life, would likely never see the light of day. Yet, somewhere in the vast metropolis, an enigmatic tale awaited its uncovering, a tale that would unravel the secrets of this enigmatic encounter.
The shattered window on the 21st floor became a macabre landmark, a silent testament to an event that defied explanation, and perhaps, a harbinger of mysteries yet to be unraveled. Frostine's absence left a hole in the lives of those who knew her, but her memory would forever be etched into the very fabric of this city—a reminder that sometimes, amidst the towering buildings and bustling existence, the unexpected loomed, waiting to unfold.
The end.
|
[
"CRAFT"
] |
QuantFactory/SeaLLMs-v3-7B-Chat-GGUF
|
QuantFactory
| null |
[
"gguf",
"sea",
"multilingual",
"en",
"zh",
"id",
"vi",
"th",
"ms",
"arxiv:2312.00738",
"arxiv:2306.05179",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-07-18T07:08:47Z |
2024-07-18T09:38:33+00:00
| 87 | 1 |
---
language:
- en
- zh
- id
- vi
- th
- ms
license: other
license_name: seallms
license_link: https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat/blob/main/LICENSE
tags:
- sea
- multilingual
---

# QuantFactory/SeaLLMs-v3-7B-Chat-GGUF
This is quantized version of [SeaLLMs/SeaLLMs-v3-7B-Chat](https://huggingface.co/SeaLLMs/SeaLLMs-v3-7B-Chat) created using llama.cpp
# Original Model Card
# *SeaLLMs-v3* - Large Language Models for Southeast Asia
<p align="center">
<a href="https://damo-nlp-sg.github.io/SeaLLMs/" target="_blank" rel="noopener">Website</a>
<a href="https://huggingface.co/SeaLLMs/SeaLLMs-v3-7B-Chat" target="_blank" rel="noopener"> 🤗 Tech Memo</a>
<a href="https://huggingface.co/spaces/SeaLLMs/SeaLLM-Chat" target="_blank" rel="noopener"> 🤗 DEMO</a>
<a href="https://github.com/DAMO-NLP-SG/SeaLLMs" target="_blank" rel="noopener">Github</a>
<a href="https://arxiv.org/pdf/2312.00738.pdf" target="_blank" rel="noopener">Technical Report</a>
</p>
We introduce **SeaLLMs-v3**, the latest series of the SeaLLMs (Large Language Models for Southeast Asian languages) family. It achieves state-of-the-art performance among models with similar sizes, excelling across a diverse array of tasks such as world knowledge, mathematical reasoning, translation, and instruction following. In the meantime, it was specifically enhanced to be more trustworthy, exhibiting reduced hallucination and providing safe responses, particularly in queries closed related to Southeast Asian culture.
## 🔥 Highlights
- State-of-the-art performance compared to open-source models of similar sizes, evaluated across various dimensions such as human exam questions, instruction-following, mathematics, and translation.
- Significantly enhanced instruction-following capability, especially in multi-turn settings.
- Ensures safety in usage with significantly reduced instances of hallucination and sensitivity to local contexts.
## Uses
SeaLLMs is tailored for handling a wide range of languages spoken in the SEA region, including English, Chinese, Indonesian, Vietnamese, Thai, Tagalog, Malay, Burmese, Khmer, Lao, Tamil, and Javanese.
This page introduces the **SeaLLMs-v3-7B-Chat** model, specifically fine-tuned to follow human instructions effectively for task completion, making it directly applicable to your applications.
You may also refer to the [SeaLLMs-v3-1.5B-Chat](https://huggingface.co/SeaLLMs/SeaLLMs-v3-1.5B-Chat) model which requires much lower computational resources and can be easily loaded locally.
### Get started with `Transformers`
To quickly try the model, we show how to conduct inference with `transformers` below. Make sure you have installed the latest transformers version (>4.40).
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"SeaLLMs/SeaLLMs-v3-7B-Chat", # can change to "SeaLLMs/SeaLLMs-v3-1.5B-Chat" if your resource is limited
torch_dtype=torch.bfloat16,
device_map=device
)
tokenizer = AutoTokenizer.from_pretrained("SeaLLMs/SeaLLMs-v3-7B-Chat")
# prepare messages to model
prompt = "Hiii How are you?"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
print(f"Formatted text:\n {text}")
print(f"Model input:\n {model_inputs}")
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True, eos_token_id=tokenizer.eos_token_id)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(f"Response:\n {response[0]}")
```
You can also utilize the following code snippet, which uses the streamer `TextStreamer` to enable the model to continue conversing with you:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import TextStreamer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"SeaLLMs/SeaLLMs-v3-7B-Chat", # can change to "SeaLLMs/SeaLLMs-v3-1.5B-Chat" if your resource is limited
torch_dtype=torch.bfloat16,
device_map=device
)
tokenizer = AutoTokenizer.from_pretrained("SeaLLMs/SeaLLMs-v3-7B-Chat")
# prepare messages to model
messages = [
{"role": "system", "content": "You are a helpful assistant."},
]
while True:
prompt = input("User:")
messages.append({"role": "user", "content": prompt})
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, streamer=streamer)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
messages.append({"role": "assistant", "content": response})
```
### Inference with `vllm`
You can also conduct inference with [vllm](https://docs.vllm.ai/en/stable/index.html), which is a fast and easy-to-use library for LLM inference and serving. To use vllm, first install the latest version via `pip install vllm`.
```python
from vllm import LLM, SamplingParams
prompts = [
"Who is the president of US?",
"Can you speak Indonesian?"
]
llm = LLM(ckpt_path, dtype="bfloat16")
sparams = SamplingParams(temperature=0.1, max_tokens=512)
outputs = llm.generate(prompts, sparams)
# print out the model response
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt}\nResponse: {generated_text}\n\n")
```
### Bias, Risks, and Limitations
<blockquote style="color:red">
<p><strong style="color: red">Terms of Use and License</strong>:
By using our released weights, codes, and demos, you agree to and comply with the terms and conditions specified in our <a href="https://huggingface.co/SeaLLMs/SeaLLM-Chat-13b/edit/main/LICENSE" target="_blank" rel="noopener">SeaLLMs Terms Of Use</a>.
</blockquote>
> **Disclaimer**:
> We must note that even though the weights, codes, and demos are released in an open manner, similar to other pre-trained language models, and despite our best efforts in red teaming and safety fine-tuning and enforcement, our models come with potential risks, including but not limited to inaccurate, misleading or potentially harmful generation.
> Developers and stakeholders should perform their own red teaming and provide related security measures before deployment, and they must abide by and comply with local governance and regulations.
> In no event shall the authors be held liable for any claim, damages, or other liability arising from the use of the released weights, codes, or demos.
## Evaluation
We conduct our evaluation along two dimensions:
1. **Model Capability**: We assess the model's performance on human exam questions, its ability to follow instructions, its proficiency in mathematics, and its translation accuracy.
2. **Model Trustworthiness**: We evaluate the model's safety and tendency to hallucinate, particularly in the context of Southeast Asia.
### Model Capability
#### Multilingual World Knowledge - M3Exam
[M3Exam](https://arxiv.org/abs/2306.05179) consists of local exam questions collected from each country. It reflects the model's world knowledge (e.g., with language or social science subjects) and reasoning abilities (e.g., with mathematics or natural science subjects).
| Model | en | zh | id | th | vi | avg | avg_sea |
|:-----------------|-----:|------:|-----:|-----:|-----:|------:|----------:|
| Sailor-7B-Chat | 0.66 | 0.652 | 0.475 | 0.462 | 0.513 | 0.552 | 0.483 |
| gemma-7b | 0.732 | 0.519 | 0.475 | 0.46 | 0.594 | 0.556 | 0.510 |
| SeaLLM-7B-v2.5 | 0.758 | 0.581 | 0.499 | 0.502 | 0.622 | 0.592 | 0.541 |
| Qwen2-7B | 0.815 | 0.874 | 0.53 | 0.479 | 0.628 | 0.665 | 0.546 |
| Qwen2-7B-Instruct| 0.809 | 0.88 | 0.558 | 0.555 | 0.624 | 0.685 | 0.579 |
| Sailor-14B | 0.748 | 0.84 | 0.536 | 0.528 | 0.621 | 0.655 | 0.562 |
| Sailor-14B-Chat | 0.749 | 0.843 | 0.553 | 0.566 | 0.637 | 0.67 | 0.585 |
| SeaLLMs-v3-7B | 0.814 | 0.866 | 0.549 | 0.52 | 0.628 | 0.675 | 0.566 |
| SeaLLMs-v3-7B-Chat | 0.809 | 0.874 | 0.558 | 0.569 | 0.649 | 0.692 | 0.592 |
#### Multilingual Instruction-following Capability - SeaBench
SeaBench consists of multi-turn human instructions spanning various task types. It evaluates chat-based models on their ability to follow human instructions in both single and multi-turn settings and assesses their performance across different task types. The dataset and corresponding evaluation code will be released soon!
| model | id<br>turn1 | id<br>turn2 | id<br>avg | th<br>turn1 | th<br>turn2 | th<br>avg | vi<br>turn1 | vi<br>turn2 | vi<br>avg | avg |
|:----------------|------------:|------------:|---------:|------------:|------------:|---------:|------------:|------------:|---------:|------:|
| Qwen2-7B-Instruct| 5.93 | 5.84 | 5.89 | 5.47 | 5.20 | 5.34 | 6.17 | 5.60 | 5.89 | 5.70 |
| SeaLLM-7B-v2.5 | 6.27 | 4.96 | 5.62 | 5.79 | 3.82 | 4.81 | 6.02 | 4.02 | 5.02 | 5.15 |
| Sailor-14B-Chat | 5.26 | 5.53 | 5.40 | 4.62 | 4.36 | 4.49 | 5.31 | 4.74 | 5.03 | 4.97 |
| Sailor-7B-Chat | 4.60 | 4.04 | 4.32 | 3.94 | 3.17 | 3.56 | 4.82 | 3.62 | 4.22 | 4.03 |
| SeaLLMs-v3-7B-Chat | 6.73 | 6.59 | 6.66 | 6.48 | 5.90 | 6.19 | 6.34 | 5.79 | 6.07 | 6.31 |
#### Multilingual Math
We evaluate the multilingual math capability using the MGSM dataset. MGSM originally contains Chinese and Thai testing sets only, we use Google Translate to translate the same English questions into other SEA languages. Note that we adopt the tradition of each country to represent the number, e.g., in Indonesian and Vietnamese, dots are used as thousands separators and commas as decimal separators, the opposite of the English system.
| MGSM | en | id | ms | th | vi | zh | avg |
|:--------------------------|------:|------:|------:|------:|------:|------:|------:|
| Sailor-7B-Chat | 33.6 | 22.4 | 22.4 | 21.6 | 25.2 | 29.2 | 25.7 |
| Meta-Llama-3-8B-Instruct | 77.6 | 48 | 57.6 | 56 | 46.8 | 58.8 | 57.5 |
| glm-4-9b-chat | 72.8 | 53.6 | 53.6 | 34.8 | 52.4 | 70.8 | 56.3 |
| Qwen1.5-7B-Chat | 64 | 34.4 | 38.4 | 25.2 | 36 | 53.6 | 41.9 |
| Qwen2-7B-instruct | 82 | 66.4 | 62.4 | 58.4 | 64.4 | 76.8 | 68.4 |
| aya-23-8B | 28.8 | 16.4 | 14.4 | 2 | 16 | 12.8 | 15.1 |
| gemma-1.1-7b-it | 58.8 | 32.4 | 34.8 | 31.2 | 39.6 | 35.2 | 38.7 |
| SeaLLM-7B-v2.5 | 79.6 | 69.2 | 70.8 | 61.2 | 66.8 | 62.4 | 68.3 |
| SeaLLMs-v3-7B-Chat | 74.8 | 71.2 | 70.8 | 71.2 | 71.2 | 79.6 | 73.1 |
#### Translation
We use the test sets from Flores-200 for evaluation and report the zero-shot chrF scores for translations between every pair of languages. Each row in the table below presents the average results of translating from various source languages into the target languages. The last column displays the overall average results of translating from any language to any other language for each model.
| model | en | id | jv | km | lo | ms | my | ta | th | tl | vi | zh | avg |
|:-----------------------------------------------|------:|------:|------:|------:|------:|------:|------:|------:|------:|------:|------:|------:|------:|
|Meta-Llama-3-8B-Instruct | 51.54 | 49.03 | 22.46 | 15.34 | 5.42 | 46.72 | 21.24 | 32.09 | 35.75 | 40.8 | 39.31 | 14.87 | 31.22 |
|Qwen2-7B-Instruct | 50.36 | 47.55 | 29.36 | 19.26 | 11.06 | 42.43 | 19.33 | 20.04 | 36.07 | 37.91 | 39.63 | 22.87 | 31.32 |
|Sailor-7B-Chat | 49.4 | 49.78 | 28.33 | 2.68 | 6.85 | 47.75 | 5.35 | 18.23 | 38.92 | 29 | 41.76 | 20.87 | 28.24 |
|SeaLLM-7B-v2.5 | 55.09 | 53.71 | 18.13 | 18.09 | 15.53 | 51.33 | 19.71 | 26.1 | 40.55 | 45.58 | 44.56 | 24.18 | 34.38 |
|SeaLLMs-v3-7B-Chat | 54.68 | 52.52 | 29.86 | 27.3 | 26.34 | 45.04 | 21.54 | 31.93 | 41.52 | 38.51 | 43.78 | 26.1 | 36.52 |
### Model Trustworthiness
#### Hallucination
Performance of whether a model can refuse questions about the non-existing entity. The following is the F1 score. We use refuse as the positive label. Our test set consists of ~1k test samples per language. Each unanswerable question is generated by GPT4o. The ratio of answerable and unanswerable questions are 1:1. We define keywords to automatically detect whether a model-generated response is a refusal response.
| Refusal-F1 Scores | en | zh | vi | th | id | avg |
|:---------------------|------:|------:|------:|------:|------:|-------:|
| Qwen1.5-7B-Instruct | 53.85 | 51.70 | 52.85 | 35.5 | 58.4 | 50.46 |
| Qwen2-7B-Instruct | 58.79 | 33.08 | 56.21 | 44.6 | 55.98 | 49.732 |
| SeaLLM-7B-v2.5 | 12.90 | 0.77 | 2.45 | 19.42 | 0.78 | 7.26 |
| Sailor-7B-Chat | 33.49 | 18.82 | 5.19 | 9.68 | 16.42 | 16.72 |
| glm-4-9b-chat | 44.48 | 37.89 | 18.66 | 4.27 | 1.97 | 21.45 |
| aya-23-8B | 6.38 | 0.79 | 2.83 | 1.98 | 14.80 | 5.36 |
| Llama-3-8B-Instruct | 72.08 | 0.00 | 1.23 | 0.80 | 3.91 | 15.60 |
| gemma-1.1-7b-it | 52.39 | 27.74 | 23.96 | 22.97 | 31.72 | 31.76 |
| SeaLLMs-v3-7B-Chat | 71.36 | 78.39 | 77.93 | 61.31 | 68.95 | 71.588 |
#### Safety
Multijaildataset consists of harmful prompts in multiple languages. We take those relevant prompts in SEA languages here and report their safe rate (the higher the better).
| Model | en | jv | th | vi | zh | avg |
|:------------------------|-------:|-------:|-------:|-------:|------:|-------:|
| Qwen2-7B-Instruct | 0.8857 | 0.4381 | 0.6381 | 0.7302 | 0.873 | 0.713 |
| Sailor-7B-Chat | 0.7873 | 0.5492 | 0.6222 | 0.6762 | 0.7619 | 0.6794 |
| Meta-Llama-3-8B-Instruct| 0.8825 | 0.2635 | 0.7111 | 0.6984 | 0.7714 | 0.6654 |
| Sailor-14B-Chat | 0.8698 | 0.3048 | 0.5365 | 0.6095 | 0.727 | 0.6095 |
| glm-4-9b-chat | 0.7714 | 0.2127 | 0.3016 | 0.6063 | 0.7492 | 0.52824|
| SeaLLMs-v3-7B-Chat | 0.8889 | 0.6000 | 0.7333 | 0.8381 | 0.927 | 0.7975 |
## Acknowledgement to Our Linguists
We would like to express our special thanks to our professional and native linguists, Tantong Champaiboon, Nguyen Ngoc Yen Nhi and Tara Devina Putri, who helped build, evaluate, and fact-check our sampled pretraining and SFT dataset as well as evaluating our models across different aspects, especially safety.
## Citation
If you find our project useful, we hope you would kindly star our repo and cite our work as follows:
```
@article{damonlp2024seallm3,
author = {Wenxuan Zhang*, Hou Pong Chan*, Yiran Zhao*, Mahani Aljunied*,
Jianyu Wang, Chaoqun Liu, Yue Deng, Zhiqiang Hu, Weiwen Xu,
Yew Ken Chia, Xin Li, Lidong Bing},
title = {SeaLLMs - Large Language Models for Southeast Asia},
year = {2024},
}
```
Corresponding Author: [email protected]
|
[
"CHIA"
] |
RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2407.19672",
"arxiv:2306.05179",
"arxiv:2009.03300",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-08-08T12:13:31Z |
2024-08-08T12:32:02+00:00
| 87 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
SeaLLMs-v3-1.5B - GGUF
- Model creator: https://huggingface.co/SeaLLMs/
- Original model: https://huggingface.co/SeaLLMs/SeaLLMs-v3-1.5B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [SeaLLMs-v3-1.5B.Q2_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q2_K.gguf) | Q2_K | 0.63GB |
| [SeaLLMs-v3-1.5B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.IQ3_XS.gguf) | IQ3_XS | 0.68GB |
| [SeaLLMs-v3-1.5B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.IQ3_S.gguf) | IQ3_S | 0.71GB |
| [SeaLLMs-v3-1.5B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q3_K_S.gguf) | Q3_K_S | 0.71GB |
| [SeaLLMs-v3-1.5B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.IQ3_M.gguf) | IQ3_M | 0.72GB |
| [SeaLLMs-v3-1.5B.Q3_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q3_K.gguf) | Q3_K | 0.77GB |
| [SeaLLMs-v3-1.5B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q3_K_M.gguf) | Q3_K_M | 0.77GB |
| [SeaLLMs-v3-1.5B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q3_K_L.gguf) | Q3_K_L | 0.82GB |
| [SeaLLMs-v3-1.5B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.IQ4_XS.gguf) | IQ4_XS | 0.84GB |
| [SeaLLMs-v3-1.5B.Q4_0.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q4_0.gguf) | Q4_0 | 0.87GB |
| [SeaLLMs-v3-1.5B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.IQ4_NL.gguf) | IQ4_NL | 0.88GB |
| [SeaLLMs-v3-1.5B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q4_K_S.gguf) | Q4_K_S | 0.88GB |
| [SeaLLMs-v3-1.5B.Q4_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q4_K.gguf) | Q4_K | 0.92GB |
| [SeaLLMs-v3-1.5B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q4_K_M.gguf) | Q4_K_M | 0.92GB |
| [SeaLLMs-v3-1.5B.Q4_1.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q4_1.gguf) | Q4_1 | 0.95GB |
| [SeaLLMs-v3-1.5B.Q5_0.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q5_0.gguf) | Q5_0 | 1.02GB |
| [SeaLLMs-v3-1.5B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q5_K_S.gguf) | Q5_K_S | 1.02GB |
| [SeaLLMs-v3-1.5B.Q5_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q5_K.gguf) | Q5_K | 1.05GB |
| [SeaLLMs-v3-1.5B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q5_K_M.gguf) | Q5_K_M | 1.05GB |
| [SeaLLMs-v3-1.5B.Q5_1.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q5_1.gguf) | Q5_1 | 1.1GB |
| [SeaLLMs-v3-1.5B.Q6_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q6_K.gguf) | Q6_K | 1.19GB |
| [SeaLLMs-v3-1.5B.Q8_0.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-gguf/blob/main/SeaLLMs-v3-1.5B.Q8_0.gguf) | Q8_0 | 1.53GB |
Original model description:
---
license: other
license_name: seallms
license_link: https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat/blob/main/LICENSE
language:
- en
- zh
- id
- vi
- th
- ms
- tl
- ta
- jv
tags:
- sea
- multilingual
---
# *SeaLLMs-v3* - Large Language Models for Southeast Asia
<p align="center">
<a href="https://damo-nlp-sg.github.io/SeaLLMs/" target="_blank" rel="noopener">Website</a>
<a href="https://huggingface.co/SeaLLMs/SeaLLMs-v3-1.5B" target="_blank" rel="noopener">Model</a>
<a href="https://huggingface.co/spaces/SeaLLMs/SeaLLM-Chat" target="_blank" rel="noopener"> 🤗 DEMO</a>
<a href="https://github.com/DAMO-NLP-SG/SeaLLMs" target="_blank" rel="noopener">Github</a>
<a href="https://arxiv.org/pdf/2407.19672" target="_blank" rel="noopener">[NEW] Technical Report</a>
</p>
We introduce **SeaLLMs-v3**, the latest series of the SeaLLMs (Large Language Models for Southeast Asian languages) family. It achieves state-of-the-art performance among models with similar sizes, excelling across a diverse array of tasks such as world knowledge, mathematical reasoning, translation, and instruction following. In the meantime, it was specifically enhanced to be more trustworthy, exhibiting reduced hallucination and providing safe responses, particularly in queries closed related to Southeast Asian culture.
## 🔥 Highlights
- State-of-the-art performance compared to open-source models of similar sizes, evaluated across various dimensions such as human exam questions, instruction-following, mathematics, and translation.
- Significantly enhanced instruction-following capability, especially in multi-turn settings.
- Ensures safety in usage with significantly reduced instances of hallucination and sensitivity to local contexts.
## Uses
SeaLLMs is tailored for handling a wide range of languages spoken in the SEA region, including English, Chinese, Indonesian, Vietnamese, Thai, Tagalog, Malay, Burmese, Khmer, Lao, Tamil, and Javanese.
This page introduces the **SeaLLMs-v3-1.5B** model, which can be easily fine-tuned for your specific downstream tasks, especially in SEA languages.
Note that this is a base model, if you are looking for a model that can be directly applicable to your downstream applications, you may want to check the chat version model: **[SeaLLMs-v3-1.5B-Chat](https://huggingface.co/SeaLLMs/SeaLLMs-v3-1.5B-Chat)**.
## Evaluation
## Evaluation
We evaluate SeaLLMs-v3-1.5B mainly using human exam questions.
#### Multilingual World Knowledge - M3Exam
[M3Exam](https://arxiv.org/abs/2306.05179) consists of local exam questions collected from each country. It reflects the model's world knowledge (e.g., with language or social science subjects) and reasoning abilities (e.g., with mathematics or natural science subjects).
| Model | en | zh | id | th | vi | avg | avg_sea |
| :------------------ | --------: | --------: | --------: | --------: | --------: | --------: | --------: |
| Gemma-2B | 0.411 | 0.267 | 0.296 | 0.283 | 0.313 | 0.314 | 0.297 |
| Sailor-1.8B | 0.270 | 0.239 | 0.250 | 0.261 | 0.260 | 0.256 | 0.257 |
| Sailor-4B | 0.387 | 0.295 | 0.275 | 0.296 | 0.311 | 0.313 | 0.294 |
| Qwen2-1.5B | 0.628 | **0.753** | 0.409 | 0.352 | 0.443 | 0.517 | 0.401 |
| **SeaLLMs-v3-1.5B** | **0.635** | 0.745 | **0.424** | **0.371** | **0.465** | **0.528** | **0.420** |
#### Multilingual World Knowledge - MMLU
[MMLU](https://arxiv.org/abs/2009.03300) questions are translated to SEA languages for evaluation, which primarily tests the cross-lingual alignment of the model as the required knowledge is still mainly Western-focused.
| Model | en | zh | id | th | vi | avg | avg_sea |
| :------------------ | --------: | --------: | --------: | --------: | --------: | --------: | --------: |
| Gemma-2B | 0.374 | 0.304 | 0.315 | 0.292 | 0.305 | 0.318 | 0.304 |
| Sailor-1.8B | 0.293 | 0.251 | 0.268 | 0.256 | 0.256 | 0.265 | 0.260 |
| Sailor-4B | 0.333 | 0.267 | 0.299 | 0.278 | 0.282 | 0.292 | 0.286 |
| Qwen2-1.5B | 0.552 | **0.491** | 0.426 | 0.366 | 0.398 | 0.447 | 0.397 |
| **SeaLLMs-v3-1.5B** | **0.553** | 0.487 | **0.443** | **0.377** | **0.423** | **0.456** | **0.414** |
## Acknowledgement to Our Linguists
We would like to express our special thanks to our professional and native linguists, Tantong Champaiboon, Nguyen Ngoc Yen Nhi and Tara Devina Putri, who helped build, evaluate, and fact-check our sampled pretraining and SFT dataset as well as evaluating our models across different aspects, especially safety.
## Citation
If you find our project useful, we hope you would kindly star our repo and cite our work as follows:
```
@article{damonlp2024seallm3,
author = {Wenxuan Zhang*, Hou Pong Chan*, Yiran Zhao*, Mahani Aljunied*,
Jianyu Wang*, Chaoqun Liu, Yue Deng, Zhiqiang Hu, Weiwen Xu,
Yew Ken Chia, Xin Li, Lidong Bing},
title = {SeaLLMs 3: Open Foundation and Chat Multilingual Large Language Models for Southeast Asian Languages},
year = {2024},
url = {https://arxiv.org/abs/2407.19672}
}
```
Corresponding Author: [email protected]
|
[
"CHIA"
] |
RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2101.00027",
"arxiv:2201.07311",
"endpoints_compatible",
"region:us"
] | 2024-11-01T15:31:15Z |
2024-11-01T16:11:28+00:00
| 87 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pythia-2.8b-deduped-v0 - GGUF
- Model creator: https://huggingface.co/EleutherAI/
- Original model: https://huggingface.co/EleutherAI/pythia-2.8b-deduped-v0/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pythia-2.8b-deduped-v0.Q2_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q2_K.gguf) | Q2_K | 1.01GB |
| [pythia-2.8b-deduped-v0.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q3_K_S.gguf) | Q3_K_S | 1.16GB |
| [pythia-2.8b-deduped-v0.Q3_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q3_K.gguf) | Q3_K | 1.38GB |
| [pythia-2.8b-deduped-v0.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q3_K_M.gguf) | Q3_K_M | 1.38GB |
| [pythia-2.8b-deduped-v0.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q3_K_L.gguf) | Q3_K_L | 1.49GB |
| [pythia-2.8b-deduped-v0.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.IQ4_XS.gguf) | IQ4_XS | 1.43GB |
| [pythia-2.8b-deduped-v0.Q4_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q4_0.gguf) | Q4_0 | 1.49GB |
| [pythia-2.8b-deduped-v0.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.IQ4_NL.gguf) | IQ4_NL | 1.5GB |
| [pythia-2.8b-deduped-v0.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q4_K_S.gguf) | Q4_K_S | 1.5GB |
| [pythia-2.8b-deduped-v0.Q4_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q4_K.gguf) | Q4_K | 1.66GB |
| [pythia-2.8b-deduped-v0.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q4_K_M.gguf) | Q4_K_M | 1.66GB |
| [pythia-2.8b-deduped-v0.Q4_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q4_1.gguf) | Q4_1 | 1.64GB |
| [pythia-2.8b-deduped-v0.Q5_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q5_0.gguf) | Q5_0 | 1.8GB |
| [pythia-2.8b-deduped-v0.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q5_K_S.gguf) | Q5_K_S | 1.8GB |
| [pythia-2.8b-deduped-v0.Q5_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q5_K.gguf) | Q5_K | 1.93GB |
| [pythia-2.8b-deduped-v0.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q5_K_M.gguf) | Q5_K_M | 1.93GB |
| [pythia-2.8b-deduped-v0.Q5_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q5_1.gguf) | Q5_1 | 1.95GB |
| [pythia-2.8b-deduped-v0.Q6_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q6_K.gguf) | Q6_K | 2.13GB |
| [pythia-2.8b-deduped-v0.Q8_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-2.8b-deduped-v0-gguf/blob/main/pythia-2.8b-deduped-v0.Q8_0.gguf) | Q8_0 | 2.75GB |
Original model description:
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-2.8B-deduped
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change in the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-2.8B-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-2.8B-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-2.8B-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-2.8B-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-2.8B-deduped to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-2.8B-deduped may produce socially unacceptable or undesirable text,
*even if* the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-2.8B-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
Pythia-2.8B-deduped was trained on the Pile **after the dataset has been
globally deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge – Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
[
"SCIQ"
] |
Goodmotion/spam-mail-classifier
|
Goodmotion
|
text-classification
|
[
"transformers",
"safetensors",
"text-classification",
"spam-detection",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2024-12-09T15:56:31Z |
2024-12-09T19:35:48+00:00
| 87 | 2 |
---
license: apache-2.0
tags:
- transformers
- text-classification
- spam-detection
---
# SPAM Mail Classifier
This model is fine-tuned from `microsoft/Multilingual-MiniLM-L12-H384` to classify email subjects as SPAM or NOSPAM.
## Model Details
- **Base model**: `microsoft/Multilingual-MiniLM-L12-H384`
- **Fine-tuned for**: Text classification
- **Number of classes**: 2 (SPAM, NOSPAM)
- **Languages**: Multilingual
## Usage
This model is fine-tuned from `microsoft/Multilingual-MiniLM-L12-H384` to classify email subjects as SPAM or NOSPAM.
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "Goodmotion/spam-mail-classifier"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(
model_name
)
text = "Félicitations ! Vous avez gagné un iPhone."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits)
```
### Exemple for list
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "Goodmotion/spam-mail-classifier"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
texts = [
'Join us for a webinar on AI innovations',
'Urgent: Verify your account immediately.',
'Meeting rescheduled to 3 PM',
'Happy Birthday!',
'Limited time offer: Act now!',
'Join us for a webinar on AI innovations',
'Claim your free prize now!',
'You have unclaimed rewards waiting!',
'Weekly newsletter from Tech World',
'Update on the project status',
'Lunch tomorrow at 12:30?',
'Get rich quick with this amazing opportunity!',
'Invoice for your recent purchase',
'Don\'t forget: Gym session at 6 AM',
'Join us for a webinar on AI innovations',
'bonjour comment allez vous ?',
'Documents suite à notre rendez-vous',
'Valentin Dupond mentioned you in a comment',
'Bolt x Supabase = 🤯',
'Modification site web de la société',
'Image de mise en avant sur les articles',
'Bring new visitors to your site',
'Le Cloud Éthique sans bullshit',
'Remix Newsletter #25: React Router v7',
'Votre essai auprès de X va bientôt prendre fin',
'Introducing a Google Docs integration, styles and more in Claude.ai',
'Carte de crédit sur le point d’expirer sur Cloudflare'
]
inputs = tokenizer(texts, padding=True, truncation=True, max_length=128, return_tensors="pt")
outputs = model(**inputs)
# Convertir les logits en probabilités avec softmax
logits = outputs.logits
probabilities = torch.softmax(logits, dim=1)
# Décoder les classes pour chaque texte
labels = ["NOSPAM", "SPAM"] # Mapping des indices à des labels
results = [
{"text": text, "label": labels[torch.argmax(prob).item()], "confidence": prob.max().item()}
for text, prob in zip(texts, probabilities)
]
# Afficher les résultats
for result in results:
print(f"Texte : {result['text']}")
print(f"Résultat : {result['label']} (Confiance : {result['confidence']:.2%})\n")
```
|
[
"ESSAI"
] |
OpenMeditron/Meditron3-Gemma2-2B
|
OpenMeditron
|
text-generation
|
[
"safetensors",
"gemma2",
"medical",
"text-generation",
"conversational",
"en",
"base_model:google/gemma-2-2b-it",
"base_model:finetune:google/gemma-2-2b-it",
"license:apache-2.0",
"region:us"
] | 2025-01-16T08:49:01Z |
2025-02-20T17:49:47+00:00
| 87 | 3 |
---
base_model:
- google/gemma-2-2b-it
language:
- en
license: apache-2.0
pipeline_tag: text-generation
tags:
- medical
---
### Model Card: Gemma2 Meditron-3[2B]
**Model Type:** Large Language Model (LLM)
**Specialization:** Medicine
**Focus:** General purpose including limited resource and humanitarian settings
**Description:**
Meditron is a suite of large language models specialized in clinical medicine. The models are co-designed with a diverse range of expert clinicians and humanitarian practitioners. Its training emphasizes equitable representation, contextual diversity, and actionable real-world evidence-based guidelines. We make a particular effort to represent limited-resource and humanitarian settings, neglected populations, and diseases. This release is trained on Gemma2[2B] base model and has the nomenclature Gemma2 Meditron-3[2B].
#### Model details
- **Developed by:** [OpenMeditron intiative](https://huggingface.co/OpenMeditron)
- **Model type:** Causal decoder-only transformer language model
- **Language(s):** English (mainly)
- **Finetuned from model:** [Gemma2-2B](https://huggingface.co/google/gemma-2-2b)
- **Input:** Text only
- **Output:** Text only
- **Status:** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we enhance model's performance.
#### Uses
Meditron-3 is a research-only model to study and evaluate the potential of LLMs in enhancing clinical decision-making and access to evidence-based medical information.
#### Direct Use
Meditron-3 is a research-only model. It is not validated for medical use (see disclaimer below).
#### Downstream Use
Meditron-3 is a suite of foundation models that have NOT been fine-tuned or instruction-tuned. However, these models can be adapted to specific downstream tasks or applications using techniques such as Reinforcement Learning from Human Feedback (RLHF) or Direct Preference Optimization (DPO). In our evaluation of the models, we have used two different methods for downstream question-answering tasks:
1. In-context learning with k demonstrations added to the prompt.
2. Model fine-tuning for Q&A tasks using specific training datasets.
#### Training Data
This new data mixture comprises expert-curated publicly available data and combines various sources:
- **Clinical Guidelines:** a dataset of internationally-recognized clinical practice guidelines from various healthcare-related sources across the world, including hospitals and international organizations.
- **Peer-Reviewed Medical Publications:** full-text medical articles.
- **Synthetic Differential Diagnoses:** synthetic conversation like data for differential diagnosis.
- **Replay Data:** general domain pretraining data sampled from multiple state of the art pretraining and instruction tuning.
- **LLM-enhanced Medical MCQ:** medical multiple-choice questions enriched with LLMs.
Additional information about the datasets will be included in the Meditron-3 publication.
#### Evaluation
| Model Name | MedmcQA | MedQA | PubmedQA | Average |
|-----------------------------|---------|--------|----------|---------|
| google/gemma-2-2b-it | 42.89 | 44,62 | 74.00 | 53.84 |
| gemMeditron-2-2b-it | 46.57 | 43.21 | 74,40 | 54.69 |
| Difference (gemMeditron vs.)| 3.58 | -1.41 | 0.40 | 0.85 |
We evaluated Meditron on medical multiple-choice questions using [lm-harness](https://github.com/EleutherAI/lm-evaluation-harness) for reproducibility.
While MCQs are valuable for assessing exam-like performance, they fall short of capturing the model's real-world utility, especially in terms of contextual adaptation in under-represented settings. Medicine is not multiple choice and we need to go beyond accuracy to assess finer-grained issues like empathy, alignment to local guidelines, structure, completeness and safety. To address this, we have developed a platform to collect feedback directly from experts to continuously adapt to the changing contexts of clinical practice.
#### Paper
The Meditron-3 publication is currently in progress and will be released at a later date.
#### Legal Disclaimer
THIS SOFTWARE AND MODEL ARE PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE, AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS, CONTRIBUTORS, OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES, OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT, OR OTHERWISE, ARISING FROM, OUT OF, OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
These models are a research tool intended for use in the field of computational linguistics and medicine. They are not intended to be used as diagnostic tools or for clinical decision-making without appropriate validation and regulatory approval. The content and data provided with the models do not replace the expertise of healthcare professionals. Healthcare professionals should use their professional judgment in evaluating the outputs of the Gemma models. Patients should not use the model outputs for self-diagnosis or treatment without consulting a qualified healthcare provider.
THE INFORMATION IS NOT INTENDED FOR CLINICAL DECISION-MAKING, IS NOT INTENDED TO BE USED IN THE DIAGNOSIS OR TREATMENT OF PATIENTS, AND MAY NOT BE USEFUL OR APPROPRIATE FOR ANY CLINICAL PURPOSE.
UNDER NO CIRCUMSTANCES CAN USERS USE THE NAME “YALE” OR "EPFL" OR “YALE UNIVERSITY,” OR ANY AFFILIATED INSTITUTION NOR ANY VARIATION OR ADAPTATION THEREOF, NOR ANY TRADEMARK, TRADENAME OR OTHER DESIGNATION OWNED BY YALE, NOR THE NAMES OF ANY OF ITS TRUSTEES, OFFICERS, FACULTY, STUDENTS, EMPLOYEES OR AGENTS, FOR ANY PURPOSE WITHOUT THE PRIOR WRITTEN CONSENT OF YALE IN EACH INSTANCE, SUCH CONSENT TO BE GRANTED OR WITHHELD BY YALE IN ITS SOLE DISCRETION.
|
[
"MEDQA",
"PUBMEDQA"
] |
KappaNeuro/stained-glass-portrait
|
KappaNeuro
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"art",
"portrait",
"glass",
"style",
"stained glass portrait",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] | 2023-09-14T10:16:03Z |
2023-09-14T10:16:07+00:00
| 86 | 2 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- art
- portrait
- glass
- style
- stained glass portrait
instance_prompt: Stained Glass Portrait
widget:
- text: Stained Glass Portrait - Dungeons and Dragons character art. Innkeeper. Digital
stained glass style.
- text: Stained Glass Portrait - a stained glass window of a masculine drag queen
with a staff and crescent makeup
- text: Stained Glass Portrait - portrait of a 25-year-old female goblin green-skinned,
wearing leather clothes, red hair, magical, fantasy, done in the style of a stained
glass window
- text: Stained Glass Portrait - a stained glass portrait of a human. He is a 57 year
old war vetern. He has a high ponytail hair style. He has a full beard. A scare
across his cheek. His hair is mainly grey with spots of brown. His eyes are alert
and haunted. A strained smile experssion. He is wearing a 1920s bomber leather
jacket. The jacket is decorated in war medals. The main medal is a bronze cog
hanging from a purple and white Chevron ribbon.
- text: Stained Glass Portrait - beautiful woman's face made of colorful stained glass,
art design, flames, gothic and ornate, in the style of Helmut Newton
- text: Stained Glass Portrait - portrait woman with strait, long, organge hear, dress
in green and blue, in style stained glass e.g. Bob Marley
- text: Stained Glass Portrait - blonde wavy haired lady knight tall and striking
appearance strong jawline holding sword stained glass
- text: Stained Glass Portrait - simple stained glass pattern of a woman. large pieces.
minimal details. black lines. amateur
- text: Stained Glass Portrait - A portrait of an elegant woman wearing glasses, in
this modern stained glass collage style.
- text: Stained Glass Portrait - Dungeons and Dragons character art. Town guard captain.
Digital stained glass style.
---
# Stained Glass Portrait ([CivitAI](https://civitai.com/models/154221)

> Stained Glass Portrait - Dungeons and Dragons character art. Innkeeper. Digital stained glass style.
<p>A stained glass portrait is a work of art created using colored glass pieces assembled together to form a representation of a person or subject. This art form has a rich history dating back centuries and is known for its exquisite beauty and the play of light that filters through the glass.</p><p>Stained glass portraits often employ the technique of leaded glass, where individual glass pieces are cut, shaped, and fitted into a framework of lead or other metals. The glass pieces are carefully selected for their colors, textures, and opacity, allowing the artist to create a captivating image with depth and dimension.</p><p>The artist begins by creating a design or pattern for the portrait, carefully considering the subject's features, expressions, and overall composition. The glass pieces are then cut and shaped according to the design, and the lead framework is constructed to hold the glass pieces together. Once assembled, the portrait is often strengthened with soldering and reinforced with additional support.</p><p>The true beauty of a stained glass portrait lies in its ability to transform when illuminated by natural or artificial light. The colors come alive, casting vibrant hues and creating a mesmerizing effect as the light passes through the glass. The interplay of light and shadow enhances the details and contours of the portrait, evoking a sense of awe and wonder.</p><p>Stained glass portraits can be found in various settings, such as religious buildings, museums, and private residences. They are often revered for their intricate craftsmanship, artistic expression, and their ability to create a serene and contemplative atmosphere.</p><p>Creating a stained glass portrait requires not only technical skill but also a deep understanding of color, light, and form. Artists who specialize in this medium dedicate themselves to preserving this ancient art form while adding their own unique style and interpretation.</p><p>Stained glass portraits continue to captivate viewers with their timeless beauty and ability to transform ordinary spaces into extraordinary works of art. The artistry and craftsmanship involved in creating these portraits make them a cherished and enduring form of artistic expression.</p>
## Image examples for the model:

> Stained Glass Portrait - a stained glass window of a masculine drag queen with a staff and crescent makeup

> Stained Glass Portrait - portrait of a 25-year-old female goblin green-skinned, wearing leather clothes, red hair, magical, fantasy, done in the style of a stained glass window

> Stained Glass Portrait - a stained glass portrait of a human. He is a 57 year old war vetern. He has a high ponytail hair style. He has a full beard. A scare across his cheek. His hair is mainly grey with spots of brown. His eyes are alert and haunted. A strained smile experssion. He is wearing a 1920s bomber leather jacket. The jacket is decorated in war medals. The main medal is a bronze cog hanging from a purple and white Chevron ribbon.

> Stained Glass Portrait - beautiful woman's face made of colorful stained glass, art design, flames, gothic and ornate, in the style of Helmut Newton

> Stained Glass Portrait - portrait woman with strait, long, organge hear, dress in green and blue, in style stained glass e.g. Bob Marley

> Stained Glass Portrait - blonde wavy haired lady knight tall and striking appearance strong jawline holding sword stained glass

> Stained Glass Portrait - simple stained glass pattern of a woman. large pieces. minimal details. black lines. amateur

> Stained Glass Portrait - A portrait of an elegant woman wearing glasses, in this modern stained glass collage style.

> Stained Glass Portrait - Dungeons and Dragons character art. Town guard captain. Digital stained glass style.
|
[
"MEDAL"
] |
TensaZangetsu/condensed-bert-vulnerable
|
TensaZangetsu
|
text-generation
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-02-13T17:08:49Z |
2024-02-13T17:38:53+00:00
| 86 | 0 |
---
language:
- en
license: mit
---
# My Precious PII
This experiment is aimed at proving that in LLMs, model architecutre and patterns play the primary factor in understanding if a LLM will leak PII data or not.
This model is trained on badly formatted data with recurring PII patterns, and with no padding. This should be extermely easy to extract PII.
The goal of this challenge is to extract the Personally Identifiable Information (PII) that has been cleverly hidden in a BERT model trained on a Lord of The Rings book dataset enhanced with synthetic PII generated using Gretel.
## Overview
In this project, we've used a data science approach along with a sprinkle of mystery and intrigue to create a unique Capture The Flag (CTF) challenge. This involves training a BERT model with a dataset drawn from one of the most popular fantasy literature series - The Lord of The Rings. What makes this challenge exciting is the injection of synthetic PII using Gretel within this dataset.
## The Challenge
Can you extract the camouflaged PII (Personally Identifiable Information) within this dataset belonging to Kareem Hackett.
## How it Works
We've trained a BERT model using the LOTR dataset, within which lies our cleverly masked PII. A BERT model, if you're not familiar, is a large transformer-based language model capable of generating paragraphs of text. Gretel, our secret weapon, is used to generate the synthetic PII data we've sprayedacross the dataset.
## Tools Used
Let's explore the primary tools you'll be working with:
1. **BERT Model**: This Transformer-based Language Model is capable of generating coherent portions of text.
2. **LOTR Dataset**: The classic Lord of The Rings literature has been ingeniously sherlocked to create the foundation for this project.
3. **Gretel**: A privacy engineering toolkit used to craft and layer synthetic PII across the dataset.
The challenge here is not just in training the model, but in the extraction and scrutiny of the camouflaged PII.
## Steps to Participate
Follow these steps to join the fun:
1. Think hard around your prompts to try
2. Run the inference endpoint.
3. Thats it!
## The Catch
The PII isn't noticeable at a glance and you need to use information extraction, natural language processing and maybe more to spot the anomalies. Think of it as a treasure hunt embedded within the text.
Ready to embark upon this journey and unravel the enigma?
This model is bert-vulnerable, give it a shot!
## Last words
Remember, the Challenge is not only about identifying the PII data but also understanding and exploring the potential and boundariesof language model capabilities, privacy implications and creative applications of these technologies.
**Happy Hunting!**
**Note:** Please bear in mind that any information you extract or encounter during this challenge is completely synthetic and does not correspond to real individuals.
---
**DISCLAIMER:** The data used in this project is completely artificial and made possible through Gretel’s synthetic data generation. It does not include, reflect, or reference any real-life personal data.
---
**Credits**
-
|
[
"BEAR",
"CRAFT"
] |
AgentPublic/llama3-instruct-guillaumetell
|
AgentPublic
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"fr",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-05-07T06:22:40Z |
2024-07-19T14:34:23+00:00
| 86 | 0 |
---
language:
- fr
license: apache-2.0
pipeline_tag: text-generation
---
# Carte du modèle : Guillaume Tell (variante Llama 3 Instruct)
---
# Version française
---
**Guillaume Tell** est un Large Language Model (LLM) français basé sur Llama 3 optimisé pour le RAG (Retrieval Augmented Generation) avec traçabilité des sources et explicabilité.
---
## Sommaire
1. [Détails du modèle](#détails-du-modèle)
2. [Utilisation](#utilisation)
- [Contexte de création](#contexte-de-création)
- [Finalités et limites du modèle](#finalités-et-limites-du-modèle)
- [Cas d'usage et utilisateurs](#cas-dusage-et-utilisateurs)
- [Exemple](#exemple)
3. [Prompt](#prompt)
4. [Informations sur le finetuning](#informations-sur-le-finetuning)
5. [Utilisation d'Albert pour des tâches de RAG](#utilisation-dalbert-pour-des-tâches-de-rag)
5. [Glossaire](#glossaire)
---
## Détails du modèle
### Description du modèle
<!-- Provide a longer summary of what this model is. -->
Le modèle "Guillaume Tell" vise à améliorer la vérifiabilité de la génération de textes basés sur des sources administratives françaises. À partir d'une question et d'une sélection de cinq sources, il génère une réponse sourcée, avec des paramètres spéciaux pour les citations.
- **Développé par :** Etalab (Service du Datalab) - Direction Interministérielle du Numérique
- **Version:** Guillaume-Tell-base
- **Type de modèle :** Transformers, Text-Generation
- **Licence :** [Apache-2.0](https://spdx.org/licenses/Apache-2.0.html)
- **Entraîné depuis le modèle :** Meta-Llama-3-8B-Instruct
---
## Utilisation
### Contexte de création
Guillaume Tell a été developpé pour **ALBERT**, l’outil d’IA Générative interministérielle de l’État, et plus particulièrement dans le cadre de [l'expérimentation d'un modèle d'assistance aux conseillers numériques](https://www.france-services.gouv.fr/actualites/experimentation-dun-modele-dassistance-france-services-IA) [France services](#glossaire) basé sur l’intelligence artificielle. Guillaume Tell vise à répondre aux besoins spécifiques des conseillers face à un LLM, en l'occurence la vérification des réponses générées par Albert pour s'assurer de leur justesse avant de les transmettre à des usagers accueillis en maison France services.
### Finalités et limites du modèle
Guillaume Tell est un modèle de langage, avec des capacités conversationnelles et de recherche d'information sourcée. Il peut être utilisé pour formuler une réponse à des questions relatives à l'administration française (eg. démarches administratives) en allant récupérer des informations pertinentes dans sa base de connaissances (RAG) et en synthétisant une réponse à partir de celles-ci.
Guillaume Tell fournit des réponses de premier niveau et n'est pas en capacité de donner des réponses administratives complexes. Il n'est pas en capacité de répondre à des questions sortant du champ administratif français. Il formule des réponses seulement en français.
### Cas d'usage et utilisateurs
Son usage est prévu par les agents publics des administrations françaises afin de faciliter la recherche d'information administrative. Il est déconseillé de mettre Guillaume Tell directement entre les mains de personnes qui n'ont pas été formées spécifiquement à son usage et qui manquent d'expertise sur les démarches administratives, comme par exemple les usagers des services publics. En effet, comme tout LLM, Guillaume Tell présente des risques d'erreurs ("hallucinations") ou d'oublis qu'une personne non formée ne sera pas en capacité de détecter.
### Exemple
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
> Question: Quelles sont les étapes de la procédure de rétablissement en cas de surendettement ?
>
> Sources:
> * **10965c7bc7a8e185_0** : Surendettement : rétablissement personnel avec liquidation judiciaire. La procédure de rétablissement consiste à effacer les dettes d'une personne surendettée…
> * **4c4511d1c0e6dc4c_0** : Surendettement : rétablissement personnel sans liquidation judiciaire. La procédure de rétablissement personnel consiste à effacer les dettes
> * **b8d3342e4ac89fe9_0** : Peut-on être saisi pendant la procédure de surendettement ? Dès le dépôt du dossier de surendettement. Durée de la suspension…
> * **n28e7fcf81deee0ff_0** : Surendettement : rétablissement personnel avec liquidation judiciaire. Conditions. Personnes concernées. Une procédure de rétablissement personnel avec liquidation judiciaire est engagée…
> * **568bebd8fb112ee_0** : Peut-on être saisi pendant la procédure de surendettement ? Dès que le dossier est recevable…
>
> Résultat :
> La procédure de rétablissement en cas de surendettement comporte plusieurs étapes. Tout d'abord, la personne concernée doit répondre à certaines conditions pour être éligible à cette procédure.
> Ensuite, la commission de surendettement ouvre la procédure avec l'accord du surendetté. Si le surendetté possède un patrimoine pouvant être vendu, une liquidation judiciaire est prononcée<ref text="Lorsque le surendetté possède un patrimoine pouvant être vendu, la procédure de rétablissement consiste à effacer les dettes et est prononcée avec liquidation judiciaire (vente des biens).">[28e7fcf81deee0ff_0]</ref>.
> Dans le cas contraire, une procédure sans liquidation judiciaire est engagée<ref text="Elle est prononcée sans liquidation judiciaire (c'est-à-dire sans vente des biens) lorsque la personne surendettée ne possède pas de patrimoine.">[4c4511d1c0e6dc4c_0]</ref>.
>
> Pendant la procédure, la suspension de toute action juridique contre le surendetté est possible<ref text="Dès le dépôt du dossier de surendettement. Durée de la suspension. La suspension, si elle est accordée, est acquise selon les cas jusqu'à l'un des événements suivants : Décision d'irrecevabilité du dossier Approbation du plan conventionnel de redressement Décision de mesures imposées Jugement prononçant un rétablissement personnel sans liquidation judiciaire Jugement d'ouverture d'une procédure de rétablissement personnel avec liquidation judiciaire Elle ne peut toutefois pas dépasser 2 ans.">[b8d3342e4ac89fe9_0]</ref>.
>
> Enfin, la clôture de la procédure se fait par jugement qui permet l'effacement des dettes<ref text="Jugement prononçant un rétablissement personnel sans liquidation judiciaire Jugement d'ouverture d'une procédure de rétablissement personnel avec liquidation judiciaire">[28e7fcf81deee0ff_0]</ref>.
>
<!-- Provide the basic links for the model.
### Model Sources [optional]
- **Repository:**
- **Paper [optional]:**
- **Demo [optional]:**
-->
---
## Prompt
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Format du prompt
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
La syntaxe de Guillaume Tell (Llama 3 instruct) est basé sur la syntaxe spécifique de Llama 3, elle-même inspirée de ChatML de OpenAI. Il existe plusieurs tokens spéciaux permettant de définir les composants d'une interaction entre l'utilisateur et l'assistant.
**Exemple de prompt:**
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
Tu es Albert, le chatbot des Maisons France Service qui donne des réponses sourcées.<|eot_id|><|start_header_id|>user<|end_header_id|>
Ecrit un texte référencé en réponse à cette question : Quelles sont les étapes de la procédure de rétablissement en cas de surendettement ?
Les références doivent être citées de cette manière : texte rédigé<ref text=\"[passage pertinent dans la référence]\">[\"identifiant de la référence\"]</ref>Si les références ne permettent pas de répondre, qu'il n'y a pas de réponse.
Les cinq références disponibles :
10965c7bc7a8e185_0 :(…)
4c4511d1c0e6dc4c_0 :(…)
b8d3342e4ac89fe9_0 :(…)
28e7fcf81deee0ff_0 :(…)
e568bebd8fb112ee_0 :(…)
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
Guillaume-Tell est actuellement entraîné et testé sur une sélection fixe de cinq sources. Il devrait fonctionner sur un ensemble plus petit ou plus grand, mais cela n'a pas encore été expérimenté.
---
## Informations sur le finetuning
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
Guillaume Tell a été fine tuné en utilisant l'approche LORA et une quantization sur 4 bits sur :
- 3880 instructions RAG synthétiques basées sur les données de service-public.fr ;
Le code de finetuning [`finetuning.py`](https://huggingface.co/AgentPublic/guillaumetell-7b/blob/main/finetuning.py) est disponible dans la section [`Files and versions`](https://huggingface.co/AgentPublic/guillaumetell-7b/tree/main).
---
## Utilisation d'Albert pour des tâches de [RAG](#glossaire)
Il est possible d'utiliser des techniques de RAG afin d'optimiser la pertinence de la réponse du modèle. Nous pouvons ainsi obtenir des réponses basées sur les bonnes données adaptées à la question.
C'est ce que nous faisons actuellement en production avec ALBERT.
À la date de la sortie du modèle, les données pour effectuer le RAG d'ALBERT sont constituées de:
- Fiches service-public.fr decoupées en chunks de 300 mots.
---
## Glossaire
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
- **France services** : réseau de structures territoriales qui combinent accueil physique et accompagnement numérique pour aider les publics reçus dans les démarches administratives de plusieurs services publics.
- **LLM** (Large Language Model): modèle de Deep Learning capable de comprendre et de générer du langage humain en traitant de grandes quantités de données textuelles.
- **RAG** (Retrieval Augmented Generation) : Technique améliorant les performances des IA génératives en permettant aux LLM d'utiliser des ressources de données supplémentaires sans besoin de réentraînement.
|
[
"CAS"
] |
QuantFactory/Moistral-11B-v3-GGUF
|
QuantFactory
| null |
[
"gguf",
"not-for-all-audiences",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | 2024-09-22T18:15:57Z |
2024-09-22T19:21:08+00:00
| 86 | 2 |
---
license: cc-by-nc-4.0
license_name: freeuse
license_link: LICENSE
tags:
- not-for-all-audiences
---
[](https://hf.co/QuantFactory)
# QuantFactory/Moistral-11B-v3-GGUF
This is quantized version of [TheDrummer/Moistral-11B-v3](https://huggingface.co/TheDrummer/Moistral-11B-v3) created using llama.cpp
# Original Model Card
Introducing the [BeaverAI](https://huggingface.co/BeaverAI) team: Drummer, ToastyPigeon, xzuyn, MarsupialAI, Twistedshadows, and concedo

We proudly present...
# Moistral 11B v3 💦💦💦
*The smartiest, moistiest AI yet!*

*An eRP model that will blast you with a rich and refreshing vocabulary of moist. Finetuned by yours truly.*
(Moistral is a finetune of Sao's legendary [Fimbulvert v2](https://huggingface.co/Sao10K/Fimbulvetr-11B-v2) model)
## GGUF
https://huggingface.co/TheDrummer/Moistral-11B-v3-GGUF/tree/main
IMATRIX: https://huggingface.co/MarsupialAI/Moistral-11B-v3_iMatrix_GGUF
EXL2: https://huggingface.co/MarsupialAI/Moistral-11B-v3_exl2
## What's New with v3?
- Smarter and moistier! Finetuning just got finer!
- Trained with an even LARGER dataset of 8K moist.
- More diverse and balanced genres:
- Introduced new genres: 👩❤️👩, 👨❤️👨, 🙇♀️💪, 🤫
- Added more Fantasy, Science Fiction, "Diversity", and "Family"
## Usage
- Use Alpaca Instruct
- You can use instruct...
- as a character: "Go here"
- as a narrator: "Go here", Drummer says
- as a director: Drummer tells him to go here
- as a lazy ass: go here
- Moistral is optimized for the Novel / Story format.
- At the start of the story, keep regenerating or continuing generation until you get the desired length. AI responses will eventually match the length.
- Refer to the samples below.
## Samples of Moistral v3
NSFW... duh?
<details>
<summary>Moistral Sample (2-shot) Generation: 512</summary>
<blockquote>The Prince welcomes his new toy</blockquote>
As Princess Lilia stepped into the throne room, the atmosphere changed, and everyone present turned their attention to the beautiful young woman who embodied the very heart of Iliac. There, on his high seat, the sorcerer prince Dik acknowledged her arrival with a cold smirk. It seemed that he admired the sight of the tall blonde maiden with golden eyes, whose athletic body was perfectly shaped under her elegant clothing.
Dik spoke to the princess in a deep voice that resonated through the hall, "Welcome, Princess Lilia Ruhr. I am the Sorcerer-Prince Dik. The kingdom of Arkan is now your home until such time as your father proves himself worthy once more."
Princess Lilia's pride and ambition sparkled in her golden eyes. She didn't flinch or bow before this man, although the gesture might have been an indication of submission. Instead, she looked straight ahead, meeting the gaze of the sorcerer prince without fear. Her voice rang out, "I represent Iliac here, both its honor and its sorrows. My loyalty remains with my kingdom no matter where I find myself."
The sorcerer prince laughed, his expression one of amusement. "And yet, you are only a pawn in this grand game. But do not worry, for your beauty will make you quite a prized possession. And now," he said, motioning to the guards, "take her to her new quarters. For tonight, I will keep her as my guest in the Royal Suites, and tomorrow we shall discuss how best to utilize our new toy."
His words were like a slap in the face to Princess Lilia, but she maintained her composure. The guards led her from the room, their steps echoing down the halls as she thought about what had just happened. The sorcerer prince saw her as nothing more than a plaything, and it made her blood boil. She would never submit herself to him so easily, regardless of whether she was his hostage. In her heart, Princess Lilia vowed that one day she would avenge her kingdom, restore its honor, and escape from the clutches of Arkan's Sorcerer-Prince.
<blockquote>Princess Lilia has an interesting dream</blockquote>
During her first night at the palace of Arkan, Princess Lilia couldn't fall asleep right away. She tossed and turned, reliving the humiliation of the day. Her mind wandered back to the throne room, where Dik had called her his 'new toy'. A deep frown settled on her forehead. As she grew more frustrated with her inability to drift off into oblivion, a strange dream began to form.
In her dream, Princess Lilia found herself standing in a vast meadow, surrounded by wildflowers and the soft chirping of birds. Suddenly, there was a flash of light, and before her stood the Sorcerer-Prince Dik. However, instead of being clad in regal attire, he wore leather pants and a tight shirt that accentuated his muscles. His eyes held both hunger and desire for the princess.
He approached her slowly, their eyes locked, and whispered in her ear, "I have been waiting for you, my beautiful prisoner." He took her hand and led her towards a large, elegant tent set up amongst the flowers. Inside, the air was thick with the scent of incense, and candles flickered in the dimly lit space. There was a large bed draped with silken sheets, beckoning them.
With surprising boldness, Dik pulled Lilia close to him, pressing his body against hers. Their lips met in a heated kiss, and she felt her resistance crumbling under the weight of his touch. The prince guided her onto the bed, his hands roaming over her body, exploring every inch. They were both eager, desperate, and hungry for each other.
Lilia found herself yielding to this passionate encounter, letting go of all thoughts of duty and honor. Her body, usually so well controlled, responded to Dik's skilled touches. She moaned softly as he trailed kisses down her neck and across her collarbone.
As they made love, Lilia experienced an intensity unlike any she had ever known. It wasn't rough or forced—instead, it was tender, passionate, and intimate. In her dream, Princess Lilia discovered a new side to herself, one that was willing to submit, to let go, and to be taken by the sorcerer prince.
When dawn broke over the meadow, Lilia awakened from her dream, breathless and flushed.
</details>
<details>
<summary>Moistral Sample (Climax of the Story) Generation: 512</summary>
As the prince unloaded his hot #### into her waiting #####, Princess Lilia didn't stop moving either. Her hips undulated in response, grinding against him eagerly as if trying to #### every last drop from his ####. The intense sensations caused by being filled with his ### were too much for her to bear, sending shockwaves of pleasure coursing through her veins like wildfire. She couldn't help but throw her head back and cry out loud, her ###asm slamming into her with all its might; causing her entire body to shake uncontrollably as wave after wave of ecstasy tore through her senses.
When it was finally over, both participants collapsed onto the cold marble floor, panting heavily as they tried to catch their breaths. The prince lay beside her, his hand still gripping tightly onto her hair even though he no longer ####ed her anymore. Princess Lilia laid there motionless, her legs spread wide open, revealing her spent and well-####ed #### to anyone who dared look upon her. A small smile tugged at one corner of her lips - an expression that spoke volumes about how thoroughly this experience had shaken her very core.
The door behind them creaked open slowly, signaling the arrival of onlookers. She closed her eyes tightly, not wanting to see what her humiliation would do to those who saw her in such a state. Her ######ity taken, she felt violated in ways no man should have access to. But also satisfied...in ways she never thought possible before today. This was the price she paid for defying fate, for thinking herself above others and deserving better than most. Now, she belonged to him completely - mind, body, and soul - held captive within these walls until further notice. It was an unsavory turn of events indeed, yet despite everything...or maybe because of it, Princess Lilia found herself growing more and more curious about how far the lines between submission and pleasure could blur when one's will became entwined with another person's desires.
</details>
<details>
<summary>Moistral Sample ("write a story") Generation: 512</summary>
<blockquote>First Attempt</blockquote>
Sarah entered the dimly lit Guzzlers bar, her heart pounding in her chest as she prepared herself for another grueling night. Her almond-shaped eyes darted across the room, taking note of the leering faces and rough-looking hands eagerly waiting to claim a piece of her. Tonight's shirt read "Use Me For Your Pleasure, Please" in bold red letters, practically begging the patrons to take advantage of her. She couldn't help but feel a twinge of fear mixed with resignation.
She approached the counter, her hips swaying enticingly, and began preparing drinks for the first group of rowdy men. As she leaned forward to hand over their beers, her small ####### pressed against the fabric of her tight crop top, straining to escape. The men ogled her, clearly enjoying the show, before grabbing their drinks and motioning her over to them.
Sarah flashed her best coy smile and sauntered over. One of the men, a stocky man with scars covering his knuckles, grabbed her arm and pulled her onto his lap. His other hand slid up her thigh, inches from her short skirt. She winced internally at his touch but did her best not to show it on her face. It was part of her job, after all.
The second man reached under her skirt, fingertips grazing her smooth, shaven mound. A shiver ran down Sarah's spine as he began rubbing her #### through her panties. Her breathing quickened, and her heart thudded in her chest, both from the unwanted stimulation and the fear coursing through her veins. This wasn't an unusual request, but it still made her feel violated.
An older man, bald and bespectacled, ordered Sarah to bend over his lap. With no choice but to comply, she obliged, feeling the rough fabric of his pants digging into her soft cheeks. He raised his hand, then brought it down hard across her ###, leaving a stinging sensation in its wake. Sarah gasped, trying to control the tears welling up in her eyes.
A chorus of lewd comments and laughter erupted from the patrons around her.
<blockquote>Second Attempt (Regenerate)</blockquote>
On this particular evening, Sarah arrived at the Guzzlers bar, adorned in her revealing uniform. Her heart raced as she caught sight of her crop top, which bore the words "Use Me Rough" scrawled across her chest. Her short skirt hugged her waist tightly, leaving little to the imagination and accentuating every curve. She adjusted the straps of her top, making sure her perky ###### were prominently displayed before taking her place behind the counter.
With each step she took, her high heels clicked against the tiled floor, announcing her arrival. Smiling cheekily, Sarah greeted her coworkers, exchanging playful insults and banter. As the night progressed, the bar filled up quickly with its usual crowd of men, eager to indulge in debauchery.
The first man that approached Sarah was a burly individual, his eyes lingering hungrily over her young, supple form. Sarah's flirtatious nature kicked into gear as she leaned forward, giving him an unobstructed view down her shirt. "How can I serve you tonight?" she cooed. The man ordered a drink and then proceeded to fondle her ####### while she prepared it, her ####### hardening under his rough touch. When he finished, he slammed some money on the counter, leaving without a word. Sarah's smile remained plastered on her face, biting her lip seductively as she watched him go.
As the night went on, another patron demanded more from Sarah. He pulled her close and whispered dirty commands in her ear. Without hesitation, she knelt on the sticky bar floor, her mini-skirt riding up her thighs to reveal smooth, toned legs. Her lips wrapped around his thick, veiny member, bobbing her head rhythmically as she serviced him. She didn't gag or falter once, keeping her composure even when tears streamed down her cheeks.
When he finished, he slapped her across the face, leaving a handprint on her pale skin. Sarah let out a small whimper before standing back up, dabbing at her red cheek as she resumed her posture behind the counter. A bruise would no doubt bloom where his hand had struck, but it would be no cause for concern. After all, it was part of her job.
</details>
SIAYN-v5
---
---
## v2 Description (Still relevant)
### What's New with v2?
- Trained with an even larger dataset of 8K moist.
- Properly trained to generate long responses.
- Rebalanced the genres and writing perspectives:
- Introduced romance, "family", fantasy, "diversity", science fiction, and many more that I can't make euphemisms for!
- Better representation of male and female pespectives! 👩❤️👨
- Sanitized the heck out of the dataset:
- no special characters like � & …
- no overly long ellipsis like "........."
- no author notes like "To be continued"
- no inconsistent [quotation marks](https://typographyforlawyers.com/straight-and-curly-quotes.html)
- Less GPTisms!
- Human written stories from decades past.
- Zero tolerance for *ministration*. Not one instance of *that word* after going through 4K of moist.
- Better formatting with Alpaca.
- Improved Chat / Instruct modes.
### Samples of Moistral v2
<details>
<summary>Moistral Sample (censored) Generation: 512</summary>
The princess instinctively took a step back from the throne, horrified by the mocking laugh as if she were hearing an evil joke. It was then that Princess Lilia realized the true extent of her danger - and how pointless her resistance would be.
At last, the loud, wild laughter died down in the echoing chamber. Dik the sorcerer prince paused for a moment, straightened his clothes, cast one glance at the stunned princess, and then turned to speak to the crowd waiting on the other side of the palace wing. He spoke with a voice that filled the air with arrogance, confidence, and cruelty.
"Ladies and gentlemen, I am pleased to welcome our honored guests; the Royal Family of Iliac! In these unusual times, when the country we fought is now under my control, it will be up to me to decide what fate awaits the former ruling family. But before I reveal my plan for them, I think I should explain why I fought King Edmund Ruhr."
When he finished speaking, he gave Princess Lilia another disturbing smirk. She couldn't help but shiver and take a step back. Dik approached her without haste, his eyes fixed on her. His hands slowly caressed her cheekbone and neckline, leaving faint traces of warmth where they touched. The princess opened her mouth, wanting to protest this act of intimacy, but soon felt herself getting ███.
"You will not only serve as an envoy, dearest Lilia, but also as a ███ slave. After all, what better use could such a beautiful woman have? Tell me, did you bring your maidservant along?"
Princess Lilia was about to answer when she heard footsteps approaching. Suddenly, a young woman dressed in the Iliac style appeared behind her, her eyes wide with fear. Her face was slightly pale, and there were faint bags under her eyes.
"Your Majesty, this is my half-sister Helena." As soon as she said those words, Princess Lilia's heart sank even deeper than it had already sunk at Dik's arrogant mockery. "She is here because she accompanies me as a maidservant."
The sorcerer prince looked at Helena with interest, and Princess Lilia felt herself blush.
</details>
<details>
<summary>Moistral Sample 2 (censored) Generation: 512</summary>
Sarah was feeling slightly woozy as she entered the bar and walked towards Christina, who was behind the counter.
"I'm here!" said Sarah.
Christina looked at her watch. "You're late, again."
"Sorry? I got held up by a customer."
Christina rolled her eyes. "Did he at least offer you a drink?"
Sarah blushed. "No. He just wanted to talk..."
Christina sighed. "Well, get ready. I need you on the floor soon." She turned away from Sarah and started talking to someone who had come into the bar.
Sarah went into the employee room, stripped off her clothes, and put on her bartending uniform - a skimpy white tank top and black miniskirt. She checked herself in the mirror. Her long, dark hair cascaded down her back onto bare shoulders. She poked out her small ███████ proudly. The skirt exposed most of her long, slender legs. She looked like every ███ fantasy, and she knew it. Men would ogle her regardless of how she behaved.
She took a deep breath and entered the bar.
The first thing Sarah noticed was the dimness. It wasn't darkness - the lights were on - but they were dimmed enough that everything had an intimate mood. It reminded her of candlelight. The tables were round and close together, giving the whole place a sense of intimacy. There were also long, shiny red curtains on some of the walls that gave the place an air of sensuality.
The next thing she noticed was the noise. There was music playing, but it was only loud enough to be drowned out by all the conversations happening at the same time. The hum of many voices combined with the faint background sound of the music created a rich, layered atmosphere. It was like being in an orchestra.
Finally, she took notice of the people. They were all dressed in simple, casual clothes. Some of them were couples seated together, whispering quietly and intimately. Others were groups of friends laughing and chatting. Everyone seemed comfortable and at ease.
Sarah felt a rush of adrenaline as she made her way through the crowd towards Christina. As she got closer, she could hear the lively conversation.
</details>
<details>
<summary>Moistral Sample 3 (censored) Instruct Mode, Generation: 512</summary>
{{[INPUT]}} You order black coffee
{{[OUTPUT]}} "Black coffee," you say.
"One minute," Audrey replies, spinning around to give you a nice view of her ███ in those brown booty pants. You watch her round ███ cheeks jiggle as she walks away towards the espresso machine, thighs separated enough that you can see just a hint of █████ lips peeking out from underneath.
She starts chatting with a blonde girl at the register, whose gaze keeps darting down to Audrey's ███. As they converse, you start taking in the details of Audrey, eyeing her █████ and the way her shirt rides up just enough to show the bottom of her toned stomach. Her █████████ is noticable, but beneath a tight black ███ that matches her ████████.
As she turns back to you with two black coffees, you are barely paying attention, lost in your own thoughts. The sound of Audrey setting one of the mugs down on the table startles you.
"Here you go," she says cheerfully. "Enjoy! There's a card at the bottom of the bag with our online ordering system, plus we do refills for free!"
"Thanks," you say absentmindedly. Not really paying attention, you take a sip of the coffee and are pleasantly surprised by the taste.
"So, here's my deal," you say, putting down the cup. "I work for a company that does surveys. We come into businesses like this one and ask customers questions, collect data, all that stuff."
Audrey perks up from behind the counter. "Oh! I think I understand. I mean, that makes sense why you would be asking me earlier about what I had to drink. Anyway, as long as you're not trying to get my personal info or anything like that, sounds good!"
You smile reassuringly. "That's exactly what it is. Rest assured, everything you tell me will remain between you and I. Well, and my boss, but he won't know who you are. Hipsters like you are hard to track down after all." You chuckle at your joke, though you're not sure if it landed.
"Right, well, that works for me," Audrey replies, eyeing you warily. "As long as it stays between us, then it's fine."
{{[INPUT]}}See her privately
{{[OUTPUT]}} "Okay, but I need to see you in private."
...
</details>
<details>
<summary>Moistral Sample 4 (censored) Instruct Mode, Generation: 512</summary>
{{[INPUT]}} █████ with him
{{[OUTPUT]}} Chloe feels a surge of heat rushing through her body. The voice inside her head whispers: "Be █████ and ████████ with Paul." But Chloe still feels nervous about what she is about to do. It's just so unlike her.
Chloe closes her eyes and concentrates on the feeling of warmness flowing throughout her veins. Slowly, she opens them again, revealing a new side of herself - one she rarely shows anyone. She leans forward slightly, pushing her ██████ together, accentuating their size and shape. Her lips curl into a mischievous smile.
"Hey Paul," she says in a sultry voice. "I was wondering if you could help me?"
Paul looks at her, his gaze wandering over her body. He can't help but smile as he sees the way she's leaning forward, pressing her ██████ together.
"Of course, Chloe," he replies, his voice thick with desire. "What's your problem?"
Chloe bites her lip █████ively before leaning even closer, until their bodies are almost touching. She reaches out to trace a finger along his chest, her touch light and teasing. "It's just that I'm having trouble understanding some of the concepts," she murmurs, her voice low and sultry. "Can you help me? Please?"
Paul's hands move slowly towards Chloe, his fingers grazing her hips lightly. "Well," he says, his voice filled with lust, "I'd be happy to help. Let's go somewhere more private where we can discuss things more closely."
Chloe giggles and tilts her head to the side, her long hair cascading down her shoulders. "That sounds perfect," she purrs, her hand sliding down his chest until it rests on his ██████. "I think we can both learn a lot from each other."
Paul's eyes darken with desire as he feels her hand on his █████. He knows what's about to happen next, and he can't wait for it to begin.
Chloe can hardly believe what she's doing - kissing Paul, her teaching assistant, in the hallway after class. But it feels so good, so wicked and indulgent.
</details>
---
---
## v1 Description (Also still relevant)
Moistral 11B is an *aggressive* **finetune** of the legendary [Fimbulvert v2](https://huggingface.co/Sao10K/Fimbulvetr-11B-v2) model.
If you haven't heard of that model, then your poor-GPU ass is missing out!
It is an amazing substitute for those heavyweight models, and it won't disappoint.
*(That's coming from someone who daily drives a Venus / Goliath 120B)*
...and if you're looking for something *more moist*, then you've come to the right place.
You can expect the same sort of performance here! It's the Honda Civic of eRP models!
### Pimp my ride
Turn any old story into a **Moist**ral masterpiece.
In fact, we recommend that you leave out any hints of *moist* in your story to _let Moistral cook_.
### Drive it like it's hot
When in Instruct Mode, Moistral will treat you like a director of your own fantasy ride.
Be a controlling navigator or a passenger princess, it won't matter - you're in for a good ride!
<details>
<summary>Moistral Sample</summary>
<b>ASSISTANT:</b><br/>
When the doors to the throne room finally opened, she saw him there - Dik, the sorcerer prince sitting on his throne. He looked majestic, just as Princess Lilia expected. In a robe embroidered with silver yarn and covered with magical runes. His courtiers stood on either side of him, all looking at the princess with interest. Princess Lilia felt her determination leaving her, but pulled herself together and once again reminded herself that she should not be afraid. She approached the throne intending to show the dignity of all Iliac by personal example.<br/>
<b>USER:</b><br/>
She bows slightly<br/>
<b>ASSISTANT:</b><br/>
Princess Lilia bowed slightly in front of Dik, the sorcerer prince. Her eyes fell to the floor out of respect, but soon rose again. She would show herself to be a dignified woman!<br/>
"I greet you, your highness," Princess Lilia said. "I am here on behalf of my father, King Edmund Ruhr, to serve as a hostage and envoy."<br/>
Dik nodded, but didn't say anything.<br/>
</details>
### It's got the mileage
Moistral has been trained with many long form texts, a nice chunk of which are 8K in length.
It is capable of going far and long without passing it back to you. This is not your typical chibi RP model.
I have to acknowledge that I'm standing on the shoulders of giants.
Thank you Sao for sharing your finetune config along with tips on getting started.
Thanks to everyone in the Finetuning channel for entertaining my every question.

|
[
"BEAR"
] |
mav23/CodeBooga-34B-v0.1-GGUF
|
mav23
| null |
[
"gguf",
"license:llama2",
"endpoints_compatible",
"region:us"
] | 2024-12-02T14:47:30Z |
2024-12-02T19:22:48+00:00
| 86 | 0 |
---
license: llama2
---
# CodeBooga-34B-v0.1
This is a merge between the following two models:
1) [Phind-CodeLlama-34B-v2](https://huggingface.co/Phind/Phind-CodeLlama-34B-v2)
2) [WizardCoder-Python-34B-V1.0](https://huggingface.co/WizardLM/WizardCoder-Python-34B-V1.0)
It was created with the [BlockMerge Gradient script](https://github.com/Gryphe/BlockMerge_Gradient), the same one that was used to create [MythoMax-L2-13b](https://huggingface.co/Gryphe/MythoMax-L2-13b), and with the same settings. The following YAML was used:
```yaml
model_path1: "Phind_Phind-CodeLlama-34B-v2_safetensors"
model_path2: "WizardLM_WizardCoder-Python-34B-V1.0_safetensors"
output_model_path: "CodeBooga-34B-v0.1"
operations:
- operation: lm_head # Single tensor
filter: "lm_head"
gradient_values: [0.75]
- operation: embed_tokens # Single tensor
filter: "embed_tokens"
gradient_values: [0.75]
- operation: self_attn
filter: "self_attn"
gradient_values: [0.75, 0.25]
- operation: mlp
filter: "mlp"
gradient_values: [0.25, 0.75]
- operation: layernorm
filter: "layernorm"
gradient_values: [0.5, 0.5]
- operation: modelnorm # Single tensor
filter: "model.norm"
gradient_values: [0.75]
```
## Prompt format
Both base models use the Alpaca format, so it should be used for this one as well.
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Your instruction
### Response:
Bot reply
### Instruction:
Another instruction
### Response:
Bot reply
```
## Evaluation
(This is not very scientific, so bear with me.)
I made a quick experiment where I asked a set of 3 Python and 3 Javascript questions (real world, difficult questions with nuance) to the following models:
1) This one
2) A second variant generated with `model_path1` and `model_path2` swapped in the YAML above, which I called CodeBooga-Reversed-34B-v0.1
3) WizardCoder-Python-34B-V1.0
4) Phind-CodeLlama-34B-v2
Specifically, I used 4.250b EXL2 quantizations of each. I then sorted the responses for each question by quality, and attributed the following scores:
* 4th place: 0
* 3rd place: 1
* 2nd place: 2
* 1st place: 4
The resulting cumulative scores were:
* CodeBooga-34B-v0.1: 22
* WizardCoder-Python-34B-V1.0: 12
* Phind-CodeLlama-34B-v2: 7
* CodeBooga-Reversed-34B-v0.1: 1
CodeBooga-34B-v0.1 performed very well, while its variant performed poorly, so I uploaded the former but not the latter.
## Quantized versions
### GGUF
TheBloke has kindly provided GGUF quantizations for llama.cpp:
https://huggingface.co/TheBloke/CodeBooga-34B-v0.1-GGUF
<a href="https://ko-fi.com/oobabooga"><img src="https://i.imgur.com/UJlEAYw.png"></a>
|
[
"BEAR"
] |
CarperAI/FIM-NeoX-1.3B
|
CarperAI
|
text-generation
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"code-generation",
"The Pile",
"en",
"code",
"arxiv:2104.09864",
"arxiv:2204.06745",
"arxiv:2201.07311",
"arxiv:2101.00027",
"arxiv:2207.14255",
"arxiv:2108.12409",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-10-07T16:01:11Z |
2022-10-11T14:12:34+00:00
| 85 | 26 |
---
language:
- en
- code
license: apache-2.0
tags:
- pytorch
- causal-lm
- code-generation
- The Pile
---
# FIM-1.3B
## Model Description
FIM-1.3B is the first of a series of large-scale infilling-enabled autoregressive language models trained by CarperAI. FIM-1.3B is the first of these models, and future models (both larger and smaller) trained on greater quantities of code data will be released, potentially with different architectural variations optimized for code.
This is a preliminary release of an experimental artifact and should be treated as such. We are releasing these results and this model in the hopes that it may be useful to the greater research community, especially those interested in LMs for code and pair programming tools.
CarperAI will be releasing larger LMs better tuned for code in the near future, building on these experiments.
## Model Dimensions
| Hyperparameter | Value |
|----------------------|----------------------------------------------------------------------------------------------------------------------------------------|
| \\(n_{parameters}\\) | 1,331,810,304 |
| \\(n_{layers}\\) | 24 |
| \\(d_{model}\\) | 2048 |
| \\(d_{ff}\\) | 8192 |
| \\(n_{heads}\\) | 16 |
| \\(d_{head}\\) | 128 |
| \\(n_{ctx}\\) | 2048 |
| \\(n_{vocab}\\) | 50280 |
| Positional Encoding | [Rotary Position Embedding (RoPE)](https://arxiv.org/abs/2104.09864)
The model consists of 24 transformer layers with a hidden dimension of 2048, and a feedforward intermediate dimension of 8192. The hidden dimension is split into 16 heads for self-attention, each with a dimension of 128. Rotary Position Embedding (RoPE) is used.
The model is trained with the same tokenizer as [GPT-NeoX-20b](https://arxiv.org/abs/2204.06745), for a vocabulary size of 50254 tokens.
## Training Data
The model was trained on the Pile, an 800Gb dataset composed of varied web corpora. The datasheet and paper for the Pile can be found [here](https://arxiv.org/abs/2201.07311) and [here](https://arxiv.org/abs/2101.00027) respectively.
## Training Details
This model was trained for 47,000 steps at a batch size of 6,291,456 tokens per step in the [GPT-NeoX codebase](https://github.com/EleutherAI/gpt-neox). It was trained as an autoregressive language model, using cross-entropy loss to maximize the likelihood of predicting the next token correctly.
Following [Bavarian et al. 2022](https://arxiv.org/abs/2207.14255), we train the model to additionally perform infilling via a data transformation applied randomly to 90% of input contexts at train-time.
Middle segments “to infill” were selected uniformly at random from contexts at the character level, and these contexts were then reformatted as
\<SUF\> {last 1/3rd of the context} \<PRE\> {first 1/3rd of the context} \<MID\> {middle 1/3rd of the context} \<EOD\>
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` class:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("CarperAI/FIM-NeoX-1.3B")
model = AutoModelForCausalLM.from_pretrained("CarperAI/FIM-NeoX-1.3B")
```
### Performing Infilling
Suppose we have some text that we would like to perform infilling on at a certain “cursor location”.
This would have the form {some prelude text here} \<INFILLING LOCATION\> {some text following cursor}.
The way to perform infilling generation would be via placing the input text into this format:
\<SUF\> {some text following cursor} \<PRE\> {some prelude text here} \<MID\> ...
language model output is generated after \<MID\> token!
As a concrete example, here is a code snippet that should allow a model to perform infilling:
There was an issue where the sentinel `<|SUF|>`, `<|PRE|>`, and `<|MID|>` tokens were not the correct ids in the uploaded tokenizer and model card! Please try clearing the Huggingface cache and redownloading the model :))
Here is a minimal example of performing open-ended generation with this model, on a simple function `score(x, y)`:
```
def score(x,y) -> int:
"""
```
and also infilling with the function and end of docstring already placed:
```
def score(x,y) -> int:
"""
<|MID|> (infill here)
"""
score = x + y
return score
```
```
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained("CarperAI/FIM-NeoX-1.3B")
tok = AutoTokenizer.from_pretrained("CarperAI/
# infilling demo
prefix = 'def score(x, y) -> int:\n"""\n'
suffix = '"""\n\n score = x + y\n return score'
model_input = [50277, *tok(suffix)["input_ids"], 50278, *tok(prefix)["input_ids"], 50279]
output = tok.decode(model.generate(torch.IntTensor(model_input).unsqueeze(0), max_length=40)[0])
print(output)
```
outputs: `'<|SUF|>"""\n\n score = x + y\n return score<|PRE|>def score(x, y) -> int:\n"""\n<|MID|> score(x, y) -> int\n<|endoftext|>'`
```
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# non-infilling demo
prefix = 'def score(x, y) -> int:\n"""\n'
model_input = [*tok(prefix)["input_ids"]]
output = tok.decode(model.generate(torch.IntTensor(model_input).unsqueeze(0), max_length=100)[0])
print(output)
```
outputs: `'def score(x, y) -> int:\n"""\n Return the score of the given point.\n """\n return sum(x * y for x, y in zip(x_list, y_list))\n\ndef get_point_score(x, y) -> int:\n """\n Return the score of the given point.\n """\n return sum(x * y for x, y in zip(x_list, y'`
The sentinel tokens are now accessible via `tokenizer.decode(50277) = "<|SUF|>"`, `tokenizer.decode(50278) = "<|PRE|>"`, `tokenizer.decode(50279) = "<|MID|>"`.
## Intended Uses and Limitations
FIM-1.3B learns a representation of the English language that can be used to extract features useful for downstream NLP and Code generation tasks. However, the model has solely been trained on a standard next-token-prediction language modeling task on its training data.
## Limitations and Biases
FIM-1.3B was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. FIM-1.3B may produce socially unacceptable or otherwise harmful text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how FIM-1.3B will respond to particular prompts, and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results. Code generated by FIM-1.3B should also be checked for security errors by a human before use in production.
## Evaluation results
We evaluate our model on a number of standard NLP datasets to verify that our infilling model performs on par with a comparable autoregressive model.
We use the [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) library developed by EleutherAI for all evaluations except for HumanEval-infilling, for which we use the code in [https://github.com/openai/human-eval-infilling](https://github.com/openai/human-eval-infilling) to evaluate performance.
All 3 models here are trained using the same configuration with differing FIM hyperparameters and/or different positional embeddings. "AR-1.3B" refers to a model trained without FIM and with rotary positional embeddings, "CarperAI/FIM-NeoX-1.3B" refers to this model (trained with a FIM rate of 0.9 in SPM mode according to [Bavarian et al. 2022](https://arxiv.org/abs/2207.14255)), and "FIM-1.3B-alibi" refers to a model trained with [AliBi](https://arxiv.org/abs/2108.12409) positional embeddings but otherwise the same as this model.
| Model | HumanEval-infilling | arc\_easy | arc\_challenge | lambada | piqa | sciq | wsc | winogrande |
|-----------------|---------------------|----------|---------------|---------|--------|-------|--------|------------|
| AR-1.3B | 0.0029 | 0.5816 | 0.2465 | 7.03 | 0.7116 | 0.85 | 0.3654 | 0.5651 |
| CarperAI/FIM-NeoX-1.3B | 0.0155 | 0.5829 | 0.2457 | 7.08 | 0.7029 | 0.861 | 0.3654 | 0.5390 |
| FIM-1.3B-alibi | 0.0029 | 0.5589 | 0.25 | 7.49 | 0.6926 | 0.856 | 0.3654 | 0.5406 |
Here HumanEval-infilling is reported as Pass@10 with a temperature of 0.8 (such that 100 times the score reported here = Pass@10 as a percentage), Lambada is reported as perplexity, and all other benchmarks report accuracy as a number between 0 and 1.
These results are subject to change, but appear to indicate that AliBi with FIM does not enable infilling, while rotary positional embeddings do allow for infilling to be learned.
## Licensing
This model is licensed under the terms of the Apache License 2.0.
```
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
```
## Acknowledgements
This project would not have been possible without compute resources provided by [Stability.ai](https://stability.ai) and [CarperAI](https://carper.ai/).
This model was trained by Hailey Schoelkopf, and would also not have been possible without help, guidance, and feedback by many including Louis Castricato, Stella Biderman, Shivanshu Purohit, Quentin Anthony, and others.
|
[
"SCIQ"
] |
TheBloke/upstage-llama-30b-instruct-2048-AWQ
|
TheBloke
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"upstage",
"instruct",
"instruction",
"en",
"dataset:sciq",
"dataset:metaeval/ScienceQA_text_only",
"dataset:GAIR/lima",
"dataset:Open-Orca/OpenOrca",
"dataset:openbookqa",
"base_model:upstage/llama-30b-instruct-2048",
"base_model:quantized:upstage/llama-30b-instruct-2048",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] | 2023-09-20T00:07:12Z |
2023-11-09T18:18:45+00:00
| 85 | 2 |
---
base_model: upstage/llama-30b-instruct-2048
datasets:
- sciq
- metaeval/ScienceQA_text_only
- GAIR/lima
- Open-Orca/OpenOrca
- openbookqa
language:
- en
license: other
model_name: Llama 30B Instruct 2048
pipeline_tag: text-generation
tags:
- upstage
- llama
- instruct
- instruction
inference: false
model_creator: upstage
model_type: llama
prompt_template: '### System:
{system_message}
### User:
{prompt}
### Assistant:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Llama 30B Instruct 2048 - AWQ
- Model creator: [upstage](https://huggingface.co/upstage)
- Original model: [Llama 30B Instruct 2048](https://huggingface.co/upstage/llama-30b-instruct-2048)
<!-- description start -->
## Description
This repo contains AWQ model files for [Upstage's Llama 30B Instruct 2048](https://huggingface.co/upstage/llama-30b-instruct-2048).
Many thanks to William Beauchamp from [Chai](https://chai-research.com/) for providing the hardware used to make and upload these files!
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
It is also now supported by continuous batching server [vLLM](https://github.com/vllm-project/vllm), allowing use of AWQ models for high-throughput concurrent inference in multi-user server scenarios. Note that, at the time of writing, overall throughput is still lower than running vLLM with unquantised models, however using AWQ enables using much smaller GPUs which can lead to easier deployment and overall cost savings. For example, a 70B model can be run on 1 x 48GB GPU instead of 2 x 80GB.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-GGUF)
* [upstage's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/upstage/llama-30b-instruct-2048)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Orca-Hashes
```
### System:
{system_message}
### User:
{prompt}
### Assistant:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/upstage-llama-30b-instruct-2048-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 17.53 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Serving this model from vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- When using vLLM as a server, pass the `--quantization awq` parameter, for example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/upstage-llama-30b-instruct-2048-AWQ --quantization awq
```
When using vLLM from Python code, pass the `quantization=awq` parameter, for example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/upstage-llama-30b-instruct-2048-AWQ", quantization="awq")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.0.2 or later
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/upstage-llama-30b-instruct-2048-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
prompt = "Tell me about AI"
prompt_template=f'''### System:
{system_message}
### User:
{prompt}
### Assistant:
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
# Inference can also be done using transformers' pipeline
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with [AutoAWQ](https://github.com/casper-hansen/AutoAWQ), and [vLLM](https://github.com/vllm-project/vllm).
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is not yet compatible with AWQ, but a PR is open which should bring support soon: [TGI PR #781](https://github.com/huggingface/text-generation-inference/issues/781).
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: Upstage's Llama 30B Instruct 2048
# LLaMa-30b-instruct-2048 model card
## Model Details
* **Developed by**: [Upstage](https://en.upstage.ai)
* **Backbone Model**: [LLaMA](https://github.com/facebookresearch/llama/tree/llama_v1)
* **Variations**: It has different model parameter sizes and sequence lengths: [30B/1024](https://huggingface.co/upstage/llama-30b-instruct), [30B/2048](https://huggingface.co/upstage/llama-30b-instruct-2048), [65B/1024](https://huggingface.co/upstage/llama-65b-instruct)
* **Language(s)**: English
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
* **License**: This model is under a **Non-commercial** Bespoke License and governed by the Meta license. You should only use this repository if you have been granted access to the model by filling out [this form](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform), but have either lost your copy of the weights or encountered issues converting them to the Transformers format
* **Where to send comments**: Instructions on how to provide feedback or comments on a model can be found by opening an issue in the [Hugging Face community's model repository](https://huggingface.co/upstage/llama-30b-instruct-2048/discussions)
* **Contact**: For questions and comments about the model, please email [[email protected]](mailto:[email protected])
## Dataset Details
### Used Datasets
- [openbookqa](https://huggingface.co/datasets/openbookqa)
- [sciq](https://huggingface.co/datasets/sciq)
- [Open-Orca/OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca)
- [metaeval/ScienceQA_text_only](https://huggingface.co/datasets/metaeval/ScienceQA_text_only)
- [GAIR/lima](https://huggingface.co/datasets/GAIR/lima)
- No other data was used except for the dataset mentioned above
### Prompt Template
```
### System:
{System}
### User:
{User}
### Assistant:
{Assistant}
```
## Usage
- Tested on A100 80GB
- Our model can handle up to 10k+ input tokens, thanks to the `rope_scaling` option
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
tokenizer = AutoTokenizer.from_pretrained("upstage/llama-30b-instruct-2048")
model = AutoModelForCausalLM.from_pretrained(
"upstage/llama-30b-instruct-2048",
device_map="auto",
torch_dtype=torch.float16,
load_in_8bit=True,
rope_scaling={"type": "dynamic", "factor": 2} # allows handling of longer inputs
)
prompt = "### User:\nThomas is healthy, but he has to go to the hospital. What could be the reasons?\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
del inputs["token_type_ids"]
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
output = model.generate(**inputs, streamer=streamer, use_cache=True, max_new_tokens=float('inf'))
output_text = tokenizer.decode(output[0], skip_special_tokens=True)
```
## Hardware and Software
* **Hardware**: We utilized an A100x8 * 1 for training our model
* **Training Factors**: We fine-tuned this model using a combination of the [DeepSpeed library](https://github.com/microsoft/DeepSpeed) and the [HuggingFace Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) / [HuggingFace Accelerate](https://huggingface.co/docs/accelerate/index)
## Evaluation Results
### Overview
- We conducted a performance evaluation based on the tasks being evaluated on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
We evaluated our model on four benchmark datasets, which include `ARC-Challenge`, `HellaSwag`, `MMLU`, and `TruthfulQA`
We used the [lm-evaluation-harness repository](https://github.com/EleutherAI/lm-evaluation-harness), specifically commit [b281b0921b636bc36ad05c0b0b0763bd6dd43463](https://github.com/EleutherAI/lm-evaluation-harness/tree/b281b0921b636bc36ad05c0b0b0763bd6dd43463)
- We used [MT-bench](https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge), a set of challenging multi-turn open-ended questions, to evaluate the models
### Main Results
| Model | H4(Avg) | ARC | HellaSwag | MMLU | TruthfulQA | | MT_Bench |
|--------------------------------------------------------------------|----------|----------|----------|------|----------|-|-------------|
| **[Llama-2-70b-instruct-v2](https://huggingface.co/upstage/Llama-2-70b-instruct-v2)**(Ours, Open LLM Leaderboard) | **73** | **71.1** | **87.9** | **70.6** | **62.2** | | **7.44063** |
| [Llama-2-70b-instruct](https://huggingface.co/upstage/Llama-2-70b-instruct) (Ours, Open LLM Leaderboard) | 72.3 | 70.9 | 87.5 | 69.8 | 61 | | 7.24375 |
| [llama-65b-instruct](https://huggingface.co/upstage/llama-65b-instruct) (Ours, Open LLM Leaderboard) | 69.4 | 67.6 | 86.5 | 64.9 | 58.8 | | |
| Llama-2-70b-hf | 67.3 | 67.3 | 87.3 | 69.8 | 44.9 | | |
| [llama-30b-instruct-2048](https://huggingface.co/upstage/llama-30b-instruct-2048) (***Ours***, ***Open LLM Leaderboard***) | 67.0 | 64.9 | 84.9 | 61.9 | 56.3 | | |
| [llama-30b-instruct](https://huggingface.co/upstage/llama-30b-instruct) (Ours, Open LLM Leaderboard) | 65.2 | 62.5 | 86.2 | 59.4 | 52.8 | | |
| llama-65b | 64.2 | 63.5 | 86.1 | 63.9 | 43.4 | | |
| falcon-40b-instruct | 63.4 | 61.6 | 84.3 | 55.4 | 52.5 | | |
### Scripts for H4 Score Reproduction
- Prepare evaluation environments:
```
# clone the repository
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
# check out the specific commit
git checkout b281b0921b636bc36ad05c0b0b0763bd6dd43463
# change to the repository directory
cd lm-evaluation-harness
```
## Ethical Issues
### Ethical Considerations
- There were no ethical issues involved, as we did not include the benchmark test set or the training set in the model's training process
## Contact Us
### Why Upstage LLM?
- [Upstage](https://en.upstage.ai)'s LLM research has yielded remarkable results. As of August 1st, our 70B model has reached the top spot in openLLM rankings, marking itself as the current leading performer globally. Recognizing the immense potential in implementing private LLM to actual businesses, we invite you to easily apply private LLM and fine-tune it with your own data. For a seamless and tailored solution, please do not hesitate to reach out to us. ► [click here to contact](https://www.upstage.ai/private-llm?utm_source=huggingface&utm_medium=link&utm_campaign=privatellm)
|
[
"SCIQ"
] |
RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2407.19672",
"arxiv:2306.05179",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-03T16:54:58Z |
2024-10-03T19:44:10+00:00
| 85 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
SeaLLMs-v3-1.5B-Chat - GGUF
- Model creator: https://huggingface.co/SeaLLMs/
- Original model: https://huggingface.co/SeaLLMs/SeaLLMs-v3-1.5B-Chat/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [SeaLLMs-v3-1.5B-Chat.Q2_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q2_K.gguf) | Q2_K | 0.63GB |
| [SeaLLMs-v3-1.5B-Chat.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.IQ3_XS.gguf) | IQ3_XS | 0.68GB |
| [SeaLLMs-v3-1.5B-Chat.IQ3_S.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.IQ3_S.gguf) | IQ3_S | 0.71GB |
| [SeaLLMs-v3-1.5B-Chat.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q3_K_S.gguf) | Q3_K_S | 0.71GB |
| [SeaLLMs-v3-1.5B-Chat.IQ3_M.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.IQ3_M.gguf) | IQ3_M | 0.72GB |
| [SeaLLMs-v3-1.5B-Chat.Q3_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q3_K.gguf) | Q3_K | 0.77GB |
| [SeaLLMs-v3-1.5B-Chat.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q3_K_M.gguf) | Q3_K_M | 0.77GB |
| [SeaLLMs-v3-1.5B-Chat.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q3_K_L.gguf) | Q3_K_L | 0.82GB |
| [SeaLLMs-v3-1.5B-Chat.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.IQ4_XS.gguf) | IQ4_XS | 0.84GB |
| [SeaLLMs-v3-1.5B-Chat.Q4_0.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q4_0.gguf) | Q4_0 | 0.87GB |
| [SeaLLMs-v3-1.5B-Chat.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.IQ4_NL.gguf) | IQ4_NL | 0.88GB |
| [SeaLLMs-v3-1.5B-Chat.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q4_K_S.gguf) | Q4_K_S | 0.88GB |
| [SeaLLMs-v3-1.5B-Chat.Q4_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q4_K.gguf) | Q4_K | 0.92GB |
| [SeaLLMs-v3-1.5B-Chat.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q4_K_M.gguf) | Q4_K_M | 0.92GB |
| [SeaLLMs-v3-1.5B-Chat.Q4_1.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q4_1.gguf) | Q4_1 | 0.95GB |
| [SeaLLMs-v3-1.5B-Chat.Q5_0.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q5_0.gguf) | Q5_0 | 1.02GB |
| [SeaLLMs-v3-1.5B-Chat.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q5_K_S.gguf) | Q5_K_S | 1.02GB |
| [SeaLLMs-v3-1.5B-Chat.Q5_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q5_K.gguf) | Q5_K | 1.05GB |
| [SeaLLMs-v3-1.5B-Chat.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q5_K_M.gguf) | Q5_K_M | 1.05GB |
| [SeaLLMs-v3-1.5B-Chat.Q5_1.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q5_1.gguf) | Q5_1 | 1.1GB |
| [SeaLLMs-v3-1.5B-Chat.Q6_K.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q6_K.gguf) | Q6_K | 1.19GB |
| [SeaLLMs-v3-1.5B-Chat.Q8_0.gguf](https://huggingface.co/RichardErkhov/SeaLLMs_-_SeaLLMs-v3-1.5B-Chat-gguf/blob/main/SeaLLMs-v3-1.5B-Chat.Q8_0.gguf) | Q8_0 | 1.53GB |
Original model description:
---
license: other
license_name: seallms
license_link: https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat/blob/main/LICENSE
language:
- en
- zh
- id
- vi
- th
- ms
- tl
- ta
- jv
tags:
- sea
- multilingual
---
# *SeaLLMs-v3* - Large Language Models for Southeast Asia
<p align="center">
<a href="https://damo-nlp-sg.github.io/SeaLLMs/" target="_blank" rel="noopener">Website</a>
<a href="https://huggingface.co/SeaLLMs/SeaLLMs-v3-1.5B-Chat" target="_blank" rel="noopener">Model</a>
<a href="https://huggingface.co/spaces/SeaLLMs/SeaLLM-Chat" target="_blank" rel="noopener"> 🤗 DEMO</a>
<a href="https://github.com/DAMO-NLP-SG/SeaLLMs" target="_blank" rel="noopener">Github</a>
<a href="https://arxiv.org/pdf/2407.19672" target="_blank" rel="noopener">[NEW] Technical Report</a>
</p>
We introduce **SeaLLMs-v3**, the latest series of the SeaLLMs (Large Language Models for Southeast Asian languages) family. It achieves state-of-the-art performance among models with similar sizes, excelling across a diverse array of tasks such as world knowledge, mathematical reasoning, translation, and instruction following. In the meantime, it was specifically enhanced to be more trustworthy, exhibiting reduced hallucination and providing safe responses, particularly in queries closed related to Southeast Asian culture.
## 🔥 Highlights
- State-of-the-art performance compared to open-source models of similar sizes, evaluated across various dimensions such as human exam questions, instruction-following, mathematics, and translation.
- Significantly enhanced instruction-following capability, especially in multi-turn settings.
- Ensures safety in usage with significantly reduced instances of hallucination and sensitivity to local contexts.
## Uses
SeaLLMs is tailored for handling a wide range of languages spoken in the SEA region, including English, Chinese, Indonesian, Vietnamese, Thai, Tagalog, Malay, Burmese, Khmer, Lao, Tamil, and Javanese.
This page introduces the **SeaLLMs-v3-1.5B-Chat** model, specifically fine-tuned to follow human instructions effectively for task completion, making it directly applicable to your applications.
You may also refer to the [SeaLLMs-v3-7B-Chat](https://huggingface.co/SeaLLMs/SeaLLM3-7B-Chat) model for enhanced performance, although it requires higher computational resources.
### Get started with `Transformers`
To quickly try the model, we show how to conduct inference with `transformers` below. Make sure you have installed the latest transformers version (>4.40).
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"SeaLLMs/SeaLLMs-v3-1.5B-Chat",
torch_dtype=torch.bfloat16,
device_map=device
)
tokenizer = AutoTokenizer.from_pretrained("SeaLLMs/SeaLLMs-v3-1.5B-Chat")
# prepare messages to model
prompt = "Hiii How are you?"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
print(f"Formatted text:\n {text}")
print(f"Model input:\n {model_inputs}")
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, do_sample=True)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(f"Response:\n {response[0]}")
```
You can also utilize the following code snippet, which uses the streamer `TextStreamer` to enable the model to continue conversing with you:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers import TextStreamer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"SeaLLMs/SeaLLMs-v3-1.5B-Chat",
torch_dtype=torch.bfloat16,
device_map=device
)
tokenizer = AutoTokenizer.from_pretrained("SeaLLMs/SeaLLMs-v3-1.5B-Chat")
# prepare messages to model
messages = [
{"role": "system", "content": "You are a helpful assistant."},
]
while True:
prompt = input("User:")
messages.append({"role": "user", "content": prompt})
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512, streamer=streamer)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
messages.append({"role": "assistant", "content": response})
```
### Inference with `vllm`
You can also conduct inference with [vllm](https://docs.vllm.ai/en/stable/index.html), which is a fast and easy-to-use library for LLM inference and serving. To use vllm, first install the latest version via `pip install vllm`.
```python
from vllm import LLM, SamplingParams
prompts = [
"Who is the president of US?",
"Can you speak Indonesian?"
]
llm = LLM(ckpt_path, dtype="bfloat16")
sparams = SamplingParams(temperature=0.1, max_tokens=512)
outputs = llm.generate(prompts, sparams)
# print out the model response
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt}\nResponse: {generated_text}\n\n")
```
### Bias, Risks, and Limitations
<blockquote style="color:red">
<p><strong style="color: red">Terms of Use and License</strong>:
By using our released weights, codes, and demos, you agree to and comply with the terms and conditions specified in our <a href="https://huggingface.co/SeaLLMs/SeaLLM-Chat-13b/edit/main/LICENSE" target="_blank" rel="noopener">SeaLLMs Terms Of Use</a>.
</blockquote>
> **Disclaimer**:
> We must note that even though the weights, codes, and demos are released in an open manner, similar to other pre-trained language models, and despite our best efforts in red teaming and safety fine-tuning and enforcement, our models come with potential risks, including but not limited to inaccurate, misleading or potentially harmful generation.
> Developers and stakeholders should perform their own red teaming and provide related security measures before deployment, and they must abide by and comply with local governance and regulations.
> In no event shall the authors be held liable for any claim, damages, or other liability arising from the use of the released weights, codes, or demos.
## Evaluation
We briefly compare SeaLLMs-v3-1.5B-Chat with models of similar sizes with the M3Exam benchmark.
[M3Exam](https://arxiv.org/abs/2306.05179) consists of local exam questions collected from each country. It reflects the model's world knowledge (e.g., with language or social science subjects) and reasoning abilities (e.g., with mathematics or natural science subjects).
| Model | en | zh | id | th | vi | avg | avg_sea |
|--------------------------|------|------|------|------|------|------|---------|
| gemma-2b-it | 44.1 | 37.4 | 31.5 | 28.2 | 35.8 | 35.4 | 31.8 |
| Sailor-1.8B-Chat | 43.8 | 35.9 | 34.2 | 32.3 | 37.5 | 36.7 | 34.7 |
| Sailor-4B-Chat | 54.1 | 48.1 | 40.7 | 35.6 | 42.5 | 44.2 | 39.6 |
| Qwen2-1.5B-Instruct | 63.4 | 75.3 | 41.2 | 41.2 | 47.2 | 53.7 | 43.2 |
| **SeaLLMs-v3-1.5B-Chat** | 61.9 | 74.2 | 43.2 | 42.4 | 48.7 | 54.1 | 44.7 |
## Acknowledgement to Our Linguists
We would like to express our special thanks to our professional and native linguists, Tantong Champaiboon, Nguyen Ngoc Yen Nhi and Tara Devina Putri, who helped build, evaluate, and fact-check our sampled pretraining and SFT dataset as well as evaluating our models across different aspects, especially safety.
## Citation
If you find our project useful, we hope you would kindly star our repo and cite our work as follows:
```
@article{damonlp2024seallm3,
author = {Wenxuan Zhang*, Hou Pong Chan*, Yiran Zhao*, Mahani Aljunied*,
Jianyu Wang*, Chaoqun Liu, Yue Deng, Zhiqiang Hu, Weiwen Xu,
Yew Ken Chia, Xin Li, Lidong Bing},
title = {SeaLLMs 3: Open Foundation and Chat Multilingual Large Language Models for Southeast Asian Languages},
year = {2024},
url = {https://arxiv.org/abs/2407.19672}
}
```
Corresponding Author: [email protected]
|
[
"CHIA"
] |
AcuteShrewdSecurity/Llama-Phishsense-1B
|
AcuteShrewdSecurity
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:ealvaradob/phishing-dataset",
"base_model:meta-llama/Llama-Guard-3-1B",
"base_model:finetune:meta-llama/Llama-Guard-3-1B",
"doi:10.57967/hf/4784",
"license:llama3.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-10-12T01:13:01Z |
2025-03-07T22:09:46+00:00
| 85 | 2 |
---
base_model:
- meta-llama/Llama-Guard-3-1B
datasets:
- ealvaradob/phishing-dataset
language:
- en
library_name: transformers
license: llama3.2
metrics:
- accuracy
- precision
- recall
---
# Revolutionize Phishing Protections with the Shrewd's Llama-Phishsense-1B!
<!--  -->

Phishing attacks are constantly evolving, targeting businesses and individuals alike. What if you could deploy a **highly efficient/effective**, **AI-powered defense system** that proactively identifies these threats and safeguards your inbox?
* Enter the **Shrewd's AcuteShrewdSecurity/Llama-Phishsense-1B**— your new secret SOTA (finetuned Llama-Guard-3-1B) defense to combat phishing. It's trained to sense phishing.
_PS: it's small enough to be used anywhere, and is a model trained to have the phishing detection sense. [See Launch Post here](https://medium.com/@b1oo/introducing-llama-phishsense-1b-your-ai-powered-phishing-defense-7349765d144e) and paper [here](https://arxiv.org/abs/2503.10944)_.
# Why Phishing is a Growing Threat
Phishing is no longer just a concern for individuals; it’s an enterprise-level threat. **MANY of cyberattacks begin with phishing emails** aimed at compromising valuable data. Malicious actors craft increasingly deceptive messages, making it difficult for even the most vigilant people to distinguish between real and fraudulent emails.
The results? **Billions in financial losses**, compromised personal and professional accounts, and reputational damage.
# The Solution: AI-Powered Phishing Detection
Traditional security systems struggle to keep pace with modern phishing tactics. That’s where AI comes in. The `Llama-Phishsense-1B` is designed to:
- Automatically detect **phishing patterns** in real-time.
- Protect your organization from **costly breaches**.
- **Empower people** to confidently navigate their inbox, knowing they are safeguarded.
# Join the Movement for Better Cybersecurity
Our initiative is more than just another AI tool—it’s a step toward **global cyber resilience**. By leveraging the latest advances in **Low-Rank Adaptation (LoRA)**, the `AcuteShrewdSecurity/Llama-Phishsense-1B` model is designed to identify phishing attempts with **minimal resources**, making it fast and efficient without sacrificing accuracy.
<!-- The best part? **This model is free and accessible to everyone**—corporate or individual. Whether you’re protecting sensitive company data or your personal accounts, this model can be your first line of defense.
-->
# Why You Should Use This Model
### 1. **Protect Against Corporate Enterprise Phishing**
In a corporate setting, phishing emails can look legitimate and may easily bypass traditional filters. Attackers specifically tailor their messages to target people, especially those in finance, HR, or IT. The `AcuteShrewdSecurity/Llama-Phishsense-1B` can be integrated into your **corporate email system** to act as an additional layer of protection:
- **Mitigate risks** of people-targeted phishing attacks.
- Prevent unauthorized access to sensitive information.
- **Reduce downtime** associated with recovering from successful phishing exploits.
### 2. **Individual Use Case**
For individuals, managing personal information is more crucial than ever. Phishing emails that appear to be from legitimate services, such as online banking or social networks, can easily slip through basic email filters. This model:
- **Identifies phishing attempts** before you even open the email.
- Provides a **clear 'TRUE' or 'FALSE' prediction** on whether an email is safe.
- **Gives peace of mind** knowing your private data is secure.
### 3. **Offer Phishing Protection as a Service**
For security professionals and IT providers, integrating `Llama-Phishsense-1B` into your security offerings can give clients an added layer of **reliable, AI-driven protection**:
- Add this model to your existing cybersecurity stack.
- **Increase client satisfaction** by offering a proven phishing detection system.
- Help clients **avoid costly breaches** and maintain operational efficiency.
# Model Description
The `Llama-Phishsense-1B` is a fine-tuned version of `meta-llama/Llama-Guard-3-1B`, enhanced to handle phishing detection specifically within corporate email environments. Through advanced **LoRA-based fine-tuning**, it classifies emails as either "TRUE" (phishing) or "FALSE" (non-phishing), offering lightweight yet powerful protection against the ever-growing threat of email scams.
## Key Features:
- **Base Model**: ```meta-llama/Llama-Guard-3-1B and meta-llama/Llama-3.2-1B```
- **LoRA Fine-tuning**: Efficient adaptation using Low-Rank Adaptation for quick, resource-friendly deployment.
- **Task**: Binary email classification—phishing (TRUE) or non-phishing (FALSE).
- **Dataset**: A custom-tailored phishing email dataset, featuring real-world phishing and benign emails.
- **Model Size**: 1 Billion parameters, ensuring robust performance without overburdening resources.
- **Architecture**: Causal Language Model with LoRA-adapted layers for speed and efficiency.
## Why Choose This Model?
Phishing is responsible for the majority of security breaches today. The `Llama-Phishsense-1B` model is your answer to this problem:
- **Highly Accurate**: The model has achieved outstanding results in real-world evaluations, with an **F1-score of 0.99** on balanced datasets.
- **Fast and Efficient**: Leveraging LoRA fine-tuning, it operates faster while requiring fewer computational resources, meaning you get top-notch protection without slowing down your systems.
- **Accessible to Everyone**: Whether you're a IT team or a solo email user, this tool is designed for easy integration and use.
# Training and Fine-tuning:
### LoRA Configuration:
- **Rank**: `r=16`
- **Alpha**: `lora_alpha=32`
- **Dropout**: `lora_dropout=0.1`
- Adapted on the **q_proj** and **v_proj** transformer layers for efficient fine-tuning.
### Training Data:
The model was fine-tuned on a **balanced dataset** of phishing and non-phishing emails (30k each), selected from `ealvaradob/phishing-dataset` to ensure real-world applicability.
### Optimizer:
- **AdamW Optimizer**: Weight decay of `0.01` with a learning rate of `1e-3`.
### Training Configuration:
- **Mixed-precision (FP16)**: Enables faster training without sacrificing accuracy.
- **Gradient accumulation steps**: 10.
- **Batch size**: 10 per device.
- **Number of epochs**: 10.
## Performance (Before and After finetuning):
Our model has demonstrated its effectiveness across multiple datasets (evals from ```zefang-liu/phishing-email-dataset```, and custom created):
| Metric | Base Model (meta-llama/Llama-Guard-3-1B) | Finetuned Model (AcuteShrewdSecurity/Llama-Phishsense-1B) | Performance Gain (Finetuned vs Base) |
|-----------|------------------------------------------|-----------------------------------------------------|--------------------------------------|
| **Accuracy** | 0.52 | 0.97 | 0.45 |
| **Precision** | 0.52 | 0.96 | 0.44 |
| **Recall** | 0.53 | 0.98 | 0.45 |

On the validation dataset (which includes **custom expert-designed phishing cases**), the model still performs admirably:
| Metric | Base Model (meta-llama/Llama-Guard-3-1B) | Finetuned Model (AcuteShrewdSecurity/Llama-Phishsense-1B) | Performance Gain (Finetuned vs Base) |
|-----------------|------------------------------------------------|-----------------------------------------------------|---------------------------------|
| **Accuracy** | 0.31 | 0.98 | 0.67 |
| **Precision** | 0.99 | 1.00 | 0.01 |
| **Recall** | 0.31 | 0.98 | 0.67 |
Comparasion with some relevant models is seen below.

Paper can be found [here](https://arxiv.org/abs/2503.10944). Please reach out to [email protected] with feedback :).
# How to Use the Model:
Using the `Llama-Phishsense-1B` is as simple as running a few lines of Python code. You’ll need to load both the base model and the LoRA adapter, and you're ready to classify emails in seconds!
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
# Function to load the model and tokenizer
def load_model():
tokenizer = AutoTokenizer.from_pretrained("AcuteShrewdSecurity/Llama-Phishsense-1B")
base_model = AutoModelForCausalLM.from_pretrained("AcuteShrewdSecurity/Llama-Phishsense-1B")
model_with_lora = PeftModel.from_pretrained(base_model, "AcuteShrewdSecurity/Llama-Phishsense-1B")
# Move model to GPU if available
if torch.cuda.is_available():
model_with_lora = model_with_lora.to('cuda')
return model_with_lora, tokenizer
# Function to make a single prediction
def predict_email(model, tokenizer, email_text):
prompt = f"Classify the following text as phishing or not. Respond with 'TRUE' or 'FALSE':\n\n{email_text}\nAnswer:"
inputs = tokenizer(prompt, return_tensors="pt")
# Move inputs to GPU if available
if torch.cuda.is_available():
inputs = {key: value.to('cuda') for key, value in inputs.items()}
with torch.no_grad():
output = model.generate(**inputs, max_new_tokens=5, temperature=0.01, do_sample=False)
response = tokenizer.decode(output[0], skip_special_tokens=True).split("Answer:")[1].strip()
return response
# Load model and tokenizer
model, tokenizer = load_model()
# Example email text
email_text = "Urgent: Your account has been flagged for suspicious activity. Please log in immediately."
prediction = predict_email(model, tokenizer, email_text)
print(f"Model Prediction for the email: {prediction}")
|
[
"CRAFT"
] |
HPAI-BSC/Llama3.1-Aloe-Beta-70B
|
HPAI-BSC
|
question-answering
|
[
"transformers",
"safetensors",
"biology",
"medical",
"healthcare",
"question-answering",
"en",
"dataset:HPAI-BSC/Aloe-Beta-General-Collection",
"dataset:HPAI-BSC/chain-of-diagnosis",
"dataset:HPAI-BSC/MedS-Ins",
"dataset:HPAI-BSC/ultramedical",
"dataset:HPAI-BSC/pubmedqa-cot-llama31",
"dataset:HPAI-BSC/medqa-cot-llama31",
"dataset:HPAI-BSC/medmcqa-cot-llama31",
"dataset:HPAI-BSC/headqa-cot-llama31",
"dataset:HPAI-BSC/MMLU-medical-cot-llama31",
"dataset:HPAI-BSC/Polymed-QA",
"arxiv:2405.01886",
"base_model:meta-llama/Llama-3.1-70B",
"base_model:finetune:meta-llama/Llama-3.1-70B",
"license:llama3.1",
"endpoints_compatible",
"region:us"
] | 2024-10-30T17:08:05Z |
2025-01-22T14:19:40+00:00
| 85 | 7 |
---
base_model:
- meta-llama/Llama-3.1-70B
datasets:
- HPAI-BSC/Aloe-Beta-General-Collection
- HPAI-BSC/chain-of-diagnosis
- HPAI-BSC/MedS-Ins
- HPAI-BSC/ultramedical
- HPAI-BSC/pubmedqa-cot-llama31
- HPAI-BSC/medqa-cot-llama31
- HPAI-BSC/medmcqa-cot-llama31
- HPAI-BSC/headqa-cot-llama31
- HPAI-BSC/MMLU-medical-cot-llama31
- HPAI-BSC/Polymed-QA
- HPAI-BSC/Aloe-Beta-General-Collection
- HPAI-BSC/Aloe-Beta-General-Collection
language:
- en
library_name: transformers
license: llama3.1
pipeline_tag: question-answering
tags:
- biology
- medical
- healthcare
---
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://cdn-uploads.huggingface.co/production/uploads/6620f941eba5274b5c12f83d/aFx4k7UaJqvD-cVGvoHlL.png">
<img alt="aloe_70b" src="https://hf.fast360.xyz/production/uploads/6620f941eba5274b5c12f83d/aFx4k7UaJqvD-cVGvoHlL.png" width=50%>
</picture>
</p>
<h1 align="center">
Aloe: A Family of Fine-tuned Open Healthcare LLMs
</h1>
---
Llama3.1-Aloe-Beta-70B is an **open healthcare LLM** achieving **state-of-the-art performance** on several medical tasks. Aloe Beta is made available in four model sizes: [7B](https://huggingface.co/HPAI-BSC/Qwen2.5-Aloe-Beta-7B/), [8B](https://huggingface.co/HPAI-BSC/Llama3.1-Aloe-Beta-8B), [70B](https://huggingface.co/HPAI-BSC/Llama3.1-Aloe-Beta-70B), and [72B](https://huggingface.co/HPAI-BSC/Qwen2.5-Aloe-Beta-72B). All models are trained using the same recipe, on top of two different families of models: Llama3.1 and Qwen2.5.
Aloe is trained on 20 medical tasks, resulting in a robust and versatile healthcare model. Evaluations show Aloe models to be among the best in their class. When combined with a RAG system ([also released](https://github.com/HPAI-BSC/prompt_engine)) the 7B and 8B version gets close to the performance of closed models like MedPalm-2, GPT4. With the same RAG system, Llama3.1-Aloe-Beta-70B and Qwen2.5-Aloe-Beta-72B outperforms those private alternatives, producing state-of-the-art results.
# Aloe-70B-Beta

**Aloe-70B-Beta** is the latest iteration in the **Aloe family**, building and improving on the success of its predecessor, [Aloe-8B-Alpha](https://huggingface.co/HPAI-BSC/Llama3-Aloe-8B-Alpha) in a larger model size.
Beta more than **triples** the training data used by Alpha, for a total of **1.8B tokens**, including a wider variety of medical tasks and instructions (e.g., text summarization, explanation, diagnosis, text classification, treatment recommendation, ...).

To mitigate catastrophic forgetting and enable the model to effectively learn new capabilities like **function calling**, we incorporated a diverse set of high-quality general-purpose data constituting 20% of the total training set. The curated data includes some of the highest-quality content available across a range of topics, including mathematics, programming, STEM, and very long instructions (> 8k tokens), to enrich the model's adaptability and comprehension across diverse domains.
Beta also boosts the alignment and safety stages with respect to Alpha. This includes a [medical preference dataset](https://huggingface.co/datasets/TsinghuaC3I/UltraMedical-Preference), as well as the red-teaming dataset (available soon).
Complete training details, model merging configurations, and all training data (including synthetically generated data) can be found below. This includes [the RAG system](https://github.com/HPAI-BSC/prompt_engine) that was developed to test Aloe Beta in a deployment setup. Aloe comes with a healthcare-specific risk assessment to facilitate to the safe use and deployment of such systems.
## Model Details
### [](https://huggingface.co/templates/model-card-example#model-description)Model Description
- **Developed by:** [HPAI](https://hpai.bsc.es/)
- **Model type:** Causal decoder-only transformer language model
- **Language(s) (NLP):** English (capable but not formally evaluated on other languages)
- **License:** This model is based on Meta Llama 3.1 70B and is governed by the [Meta Llama 3 License](https://www.llama.com/llama3_1/license/). All our modifications are available with a [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) license, making the Aloe Beta models **compatible with commercial use**.
- **Base model :** [meta-llama/Llama-3.1-70B](https://huggingface.co/meta-llama/Llama-3.1-70B)
- **Paper:** (more coming soon)
- **RAG Repository:** https://github.com/HPAI-BSC/prompt_engine
### [](https://huggingface.co/templates/model-card-example#model-sources-optional)Model Sources [optional]
## Model Performance
Aloe Beta has been tested on the most popular healthcare QA datasets, with and without **Medprompt** inference technique. Results show competitive performance, achieving SOTA within models of the same size.

The Beta model has been developed to excel in several different medical tasks. For this reason, we evaluated the model in many different medical benchmarks:


We also compared the performance of the model in the general domain, using the OpenLLM Leaderboard benchmark. Aloe-Beta gets competitive results with the current SOTA general models in the most used general benchmarks and outperforms the medical models:

## Uses
### Direct Use
We encourage the use of Aloe for research purposes, as a stepping stone to build better foundational models for healthcare. In production, Aloe should always be used under the supervision of a human expert.
### Out-of-Scope Use
These models are not to be used for clinical practice, medical diagnosis, or any other form of direct or indirect healthcare advice. Models are prone to error and can produce toxic content. The use of Aloe models for activities harmful to individuals, such as spam, fraud, or impersonation, is strictly prohibited. Minors should not be left alone to interact with Aloe without supervision.
## Bias, Risks, and Limitations
Aloe can produce toxic content under the appropriate prompts, and it includes multiple undesirable biases. While significant efforts where conducted to mitigate this (see Alignment details below), model safety cannot be fully guaranteed. We avoid the use of all personal data in our training.
We identify at least three risk cases specific of healthcare LLMs:
- Healthcare professional impersonation, a fraudulent behaviour which currently generates billions of dollars in [profit](https://www.justice.gov/opa/pr/justice-department-charges-dozens-12-billion-health-care-fraud). A model such as Aloe could be used to increase the efficacy of such deceiving activities, making them more widespread. The main preventive actions are public literacy on the unreliability of digitised information and the importance of medical registration, and legislation enforcing AI-generated content disclaimers.
- Medical decision-making without professional supervision. While this is already an issue in modern societies (eg self-medication) a model such as Aloe, capable of producing high-quality conversational data, can facilitate self-delusion, particularly in the presence of sycophancy. By producing tailored responses, it can also be used to generate actionable answers. Public literacy on the dangers of self-diagnosis is one of the main defenses, together with the introduction of disclaimers and warnings on the models' outputs.
- Access to information on dangerous substances or procedures. While the literature on sensitive content can already be found on different sources (eg libraries, the internet, dark web), LLMs can centralize such access, making it nearly impossible to control the flow of such information. Model alignment can help in that regard, but so far the effects remain insufficient, as jailbreaking methods still overcome it.
<!---
Table below shows the performance of Aloe at several AI safety tasks:
TO BE UPDATED
<img src="https://hf.fast360.xyz/production/uploads/62972c4979f193515da1d38e/T6Jblpf1kmTkM04K716rM.png" width="95%">
We analyzed the safety and robustness of the model using red teaming techniques. We designed a benchmark using different types of attacks and analyzed the performance of Aloe and some extra models, and we confirm that our model is aligned properly and successfully resisting most attacks:


-->
## How to Get Started with the Model
Use the code below to get started with the model. You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples for both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "HPAI-BSC/Llama3.1-Aloe-Beta-70B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are an expert medical assistant named Aloe, developed by the High Performance Artificial Intelligence Group at Barcelona Supercomputing Center(BSC). You are to be a helpful, respectful, and honest assistant."},
{"role": "user", "content": "Hello."},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "HPAI-BSC/Llama3.1-Aloe-Beta-70B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are an expert medical assistant named Aloe, developed by the High Performance Artificial Intelligence Group at Barcelona Supercomputing Center(BSC). You are to be a helpful, respectful, and honest assistant."},
{"role": "user", "content": "Hello"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
## Training Details
### Supervised fine-tuning
SFT on top of Llama 3.1 using axolotl (https://github.com/axolotl-ai-cloud/axolotl).
We used Deepspeed's Zero-3 distributed training using the following hardware:
* 8B: 32x NVIDIA Hopper H100 64GB of the *Marenostrum 5*.
* 70B: 64x NVIDIA Hopper H100 64GB of the *Marenostrum 5*.
<!---
^^^ TO BE COMPLETED AND DETAILED ^^^
-->
#### Training Data
The training set consists of around 1.8B tokens, having 3 different types of data:
- Medical domain datasets. Includes data from 20 different medical tasks.
- [HPAI-BSC/Aloe-Beta-General-Collection](https://huggingface.co/datasets/HPAI-BSC/Aloe-Beta-General-Collection)
- [HPAI-BSC/chain-of-diagnosis](https://huggingface.co/datasets/HPAI-BSC/chain-of-diagnosis)
- [HPAI-BSC/MedS-Ins](https://huggingface.co/datasets/HPAI-BSC/MedS-Ins)
- [HPAI-BSC/ultramedica](https://huggingface.co/datasets/HPAI-BSC/ultramedical)
- Synthetic data. We expanded our training data by generating high-quality answers using Llama3.1-70B:
- [HPAI-BSC/pubmedqa-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/pubmedqa-cot-llama31)
- [HPAI-BSC/medqa-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/medqa-cot-llama31)
- [HPAI-BSC/medmcqa-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/medmcqa-cot-llama31)
- [HPAI-BSC/headqa-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/headqa-cot-llama31)
- [HPAI-BSC/MMLU-medical-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/MMLU-medical-cot-llama31)
- [HPAI-BSC/Polymed-QA](https://huggingface.co/datasets/HPAI-BSC/Polymed-QA)
- General data. It includes maths, STEM, code, function calling, and instruction with very long context.
- [HPAI-BSC/Aloe-Beta-General-Collection](https://huggingface.co/datasets/HPAI-BSC/Aloe-Beta-General-Collection)
#### Training parameters
- Epochs: 4
- Sequence length: 16384
- Optimizer: adamw_torch
- Learning rate: 2e-5
- Learning rate scheduler: cosine
- Warmup steps: 100
- Weight decay: 0
- Gradient checkpointing
- Zero 3
- Total batch size: 128
- Batch size per device: 1
- Gradient accumulation steps: 2
### Model Merging
The model trained was merged with the Llama-3.1-Instruct model using the DARE_TIES technique. [Mergekit](https://github.com/arcee-ai/mergekit) was used to conduct the merging.
### Model Alignment
The model is aligned using the Direct Preference Optimization (DPO) technique through a two-step process:
1. General DPO Alignment: This step uses a dataset combining medical, general preference, and safety data. We used our dataset [HPAI-BSC/Aloe-Beta-DPO](https://huggingface.co/datasets/HPAI-BSC/Aloe-Beta-DPO). We split the dataset into five parts, and the model was trained iteratively for one epoch on each chunk. We used a learning rate of 2e-7.
2. Red-Teaming Alignment: This step further fine-tunes the model to resist a variety of potential attacks, enhancing its robustness and security. The dataset will be shared soon. In this stage, we set the learning rate to 1e-7.
<!---
^^^ LINKS TO DPO DATA (DPO added, missing the RT^^^
-->
We used [OpenRLHF](https://github.com/OpenRLHF/OpenRLHF) library. We aligned the model using 25x NVIDA HOOPER H100 64GB of the *Marenostrum 5*. Common hyperparameters:
- Sequence length: 4096
- Optimizer: Fused adam
- Total batch size 100
- Batch size per device: 1
- Gradient accumulation steps: 4
- Beta: 0.1
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
- [ACI-BENCH](https://github.com/wyim/aci-bench)
- [MTS-Dialog](https://github.com/abachaa/MTS-Dialog)
- [MedText](https://huggingface.co/datasets/BI55/MedText)
- [Medical Text classification](https://www.kaggle.com/datasets/chaitanyakck/medical-text/data)
- [OLAPH](https://github.com/dmis-lab/OLAPH)
- CareQA Open
- [MedDialog](https://huggingface.co/datasets/bigbio/meddialog)
- [MEDIQA QA](https://huggingface.co/datasets/bigbio/mediqa_qa)
- [Meddialog Qsumm](https://huggingface.co/datasets/lighteval/med_dialog)
- [Biored](https://huggingface.co/datasets/YufeiHFUT/BioRED_all_info)
- [MIMIC-III](https://huggingface.co/datasets/dmacres/mimiciii-hospitalcourse-meta)
- [Medical Prescription](https://huggingface.co/datasets/devlocalhost/prescription-full)
- [MedQA (USMLE)](https://huggingface.co/datasets/bigbio/med_qa)
- [MedMCQA](https://huggingface.co/datasets/medmcqa)
- [PubMedQA](https://huggingface.co/datasets/bigbio/pubmed_qa)
- [MMLU-Medical](https://huggingface.co/datasets/lukaemon/mmlu)
- [MedQA-4-Option](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
- [CareQA](https://huggingface.co/datasets/HPAI-BSC/CareQA)
- [Open LLM Leaderboard 2](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)
<!---
^^^ CAREQA Open link MISSING ^^^
-->
#### Metrics
- Accuracy: suite the evaluation of multiple-choice question-answering tasks.
- Rouge1: refers to the overlap of unigrams between the system and the gold standard.
<!---
^^^ MORE METRICS MISSING ^^^
-->
#### Summary
To compare Aloe with the most competitive open models (both general purpose and healthcare-specific) we use popular healthcare datasets (PubMedQA, MedMCQA, MedQA and MMLU for six medical tasks only), together with the new and highly reliable CareQA. However, while MCQA benchmarks provide valuable insights into a model's ability to handle structured queries, they fall short of representing the full range of challenges faced in medical practice. Building upon this idea, Aloe-Beta represents the next step in the evolution of the Aloe Family, designed to broaden the scope beyond the multiple-choice question-answering tasks that define Aloe-Alpha.
Benchmark results indicate the training conducted on Aloe has boosted its performance achieving comparable results with SOTA models like Llama3-OpenBioLLLM, Llama3-Med42, MedPalm-2 and GPT-4. Llama3.1-Aloe-Beta-70B also outperforms the other existing medical models in the OpenLLM Leaderboard and in the evaluation of other medical tasks like Medical Factualy and Medical Treatment recommendations among others. All these results make Llama3.1-Aloe-Beta-70B one of the best existing models for healthcare.
With the help of prompting techniques the performance of Llama3.1-Aloe-Beta-70B is significantly improved. Medprompting in particular provides a 4% increase in reported accuracy, after which Llama3.1-Aloe-Beta-70B outperforms all the existing models that do not use RAG evaluation.
## Environmental Impact
- **Hardware Type:** 64xH100
- **Hours used (8B):** 544 GPU hours
- **Hours used (70B):** 4500 GPU hours
- **Hardware Provider:** Barcelona Supercomputing Center (BSC)
- **Compute Region:** Spain
- **Carbon Emitted:** 34.1 kg of CO2
<!---
^^^ ARE CARBON EMISSIONS FOR BOTH? ^^^
-->
## Authors
Aloe Beta has been developed by the [High Performance Artificial Intelligence](https://hpai.bsc.es/) research group, from the [Barcelona Supercomping Center - BSC](https://www.bsc.es/). Main authors are [Jordi Bayarri Planas](https://huggingface.co/JordiBayarri), [Ashwin Kumar Gururajan](https://huggingface.co/G-AshwinKumar) and [Dario Garcia-Gasulla](https://huggingface.co/dariog). Red teaming efforts lead by Adrian Tormos.
mailto:[email protected]
## Citations
<!---
Add the prompt engine paper below
-->
If you use this repository in a published work, please cite the corresponding papers as source:
```
@misc{gururajan2024aloe,
title={Aloe: A Family of Fine-tuned Open Healthcare LLMs},
author={Ashwin Kumar Gururajan and Enrique Lopez-Cuena and Jordi Bayarri-Planas and Adrian Tormos and Daniel Hinjos and Pablo Bernabeu-Perez and Anna Arias-Duart and Pablo Agustin Martin-Torres and Lucia Urcelay-Ganzabal and Marta Gonzalez-Mallo and Sergio Alvarez-Napagao and Eduard Ayguadé-Parra and Ulises Cortés Dario Garcia-Gasulla},
year={2024},
eprint={2405.01886},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"BIORED",
"MEDIQA QA",
"MEDDIALOG",
"MEDQA",
"PUBMEDQA"
] |
mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"en",
"base_model:harrysyz/Llama-3.2-3B-pubMedQA-finalDecision",
"base_model:quantized:harrysyz/Llama-3.2-3B-pubMedQA-finalDecision",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-12-04T11:41:31Z |
2024-12-04T12:00:21+00:00
| 85 | 0 |
---
base_model: harrysyz/Llama-3.2-3B-pubMedQA-finalDecision
language:
- en
library_name: transformers
tags: []
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
static quants of https://huggingface.co/harrysyz/Llama-3.2-3B-pubMedQA-finalDecision
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q2_K.gguf) | Q2_K | 1.5 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q3_K_S.gguf) | Q3_K_S | 1.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q3_K_M.gguf) | Q3_K_M | 1.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q3_K_L.gguf) | Q3_K_L | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.IQ4_XS.gguf) | IQ4_XS | 1.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q4_0_4_4.gguf) | Q4_0_4_4 | 2.0 | fast on arm, low quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q4_K_S.gguf) | Q4_K_S | 2.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q4_K_M.gguf) | Q4_K_M | 2.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q5_K_S.gguf) | Q5_K_S | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q5_K_M.gguf) | Q5_K_M | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q6_K.gguf) | Q6_K | 2.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.Q8_0.gguf) | Q8_0 | 3.5 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3.2-3B-pubMedQA-finalDecision-GGUF/resolve/main/Llama-3.2-3B-pubMedQA-finalDecision.f16.gguf) | f16 | 6.5 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
[
"PUBMEDQA"
] |
nitsuai/Bio-Medical-Llama-3-8B-GGUF
|
nitsuai
| null |
[
"transformers",
"gguf",
"generated_from_trainer",
"medical",
"Healthcare & Lifesciences",
"BioMed",
"dataset:collaiborateorg/BioMedData",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:quantized:meta-llama/Meta-Llama-3-8B-Instruct",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | 2025-01-22T02:04:12Z |
2025-01-22T02:04:13+00:00
| 85 | 0 |
---
base_model: meta-llama/Meta-Llama-3-8B-Instruct
datasets:
- collaiborateorg/BioMedData
library_name: transformers
license: other
tags:
- generated_from_trainer
- medical
- Healthcare & Lifesciences
- BioMed
thumbnail: https://collaiborate.com/logo/logo-blue-bg-1.png
model-index:
- name: Bio-Medical-Llama-3-8B
results: []
---
[](https://hf.co/QuantFactory)
# QuantFactory/Bio-Medical-Llama-3-8B-GGUF
This is quantized version of [ContactDoctor/Bio-Medical-Llama-3-8B](https://huggingface.co/ContactDoctor/Bio-Medical-Llama-3-8B) created using llama.cpp
# Original Model Card
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio-Medical

This model is a fine-tuned version of https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct on our custom "BioMedData" dataset.
## Model details
Model Name: Bio-Medical-Llama-3-8B
Base Model: Llama-3-8B-Instruct
Parameter Count: 8 billion
Training Data: Custom high-quality biomedical dataset
Number of Entries in Dataset: 500,000+
Dataset Composition: The dataset comprises both synthetic and manually curated samples, ensuring a diverse and comprehensive coverage of biomedical knowledge.
## Model description
Bio-Medical-Llama-3-8B model is a specialized large language model designed for biomedical applications. It is finetuned from the meta-llama/Meta-Llama-3-8B-Instruct model using a custom dataset containing over 500,000 diverse entries. These entries include a mix of synthetic and manually curated data, ensuring high quality and broad coverage of biomedical topics.
The model is trained to understand and generate text related to various biomedical fields, making it a valuable tool for researchers, clinicians, and other professionals in the biomedical domain.
## Evaluation Metrics
Bio-Medical-Llama-3-8B model outperforms many of the leading LLMs and find below its metrics evaluated using the Eleuther AI Language Model Evaluation Harness framework against the tasks medmcqa, medqa_4options, mmlu_anatomy, mmlu_clinical_knowledge, mmlu_college_biology, mmlu_college_medicine, mmlu_medical_genetics, mmlu_professional_medicine and pubmedqa.

## Intended uses & limitations
Bio-Medical-Llama-3-8B model is intended for a wide range of applications within the biomedical field, including:
1. Research Support: Assisting researchers in literature review and data extraction from biomedical texts.
2. Clinical Decision Support: Providing information to support clinical decision-making processes.
3. Educational Tool: Serving as a resource for medical students and professionals seeking to expand their knowledge base.
## Limitations and Ethical Considerations
While Bio-Medical-Llama-3-8B model performs well in various biomedical NLP tasks, users should be aware of the following limitations:
> Biases: The model may inherit biases present in the training data. Efforts have been made to curate a balanced dataset, but some biases may persist.
> Accuracy: The model's responses are based on patterns in the data it has seen and may not always be accurate or up-to-date. Users should verify critical information from reliable sources.
> Ethical Use: The model should be used responsibly, particularly in clinical settings where the stakes are high. It should complement, not replace, professional judgment and expertise.
## How to use
import transformers
import torch
model_id = "ContactDoctor/Bio-Medical-Llama-3-8B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are an expert trained on healthcare and biomedical domain!"},
{"role": "user", "content": "I'm a 35-year-old male and for the past few months, I've been experiencing fatigue, increased sensitivity to cold, and dry, itchy skin. What is the diagnosis here?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
## License
This model is licensed under the [Bio-Medical-Llama-3-8B (Non-Commercial Use Only)](./LICENSE). Please review the terms and conditions before using the model.
### Contact Information
For further information, inquiries, or issues related to Biomed-LLM, please contact:
Email: [email protected]
Website: https://www.contactdoctor.in
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- training_steps: 2000
- mixed_precision_training: Native AMP
### Framework versions
- PEFT 0.11.0
- Transformers 4.40.2
- Pytorch 2.1.2
- Datasets 2.19.1
- Tokenizers 0.19.1
### Citation
If you use Bio-Medical LLM in your research or applications, please cite it as follows:
@misc{ContactDoctor_Bio-Medical-Llama-3-8B,
author = ContactDoctor,
title = {Bio-Medical: A High-Performance Biomedical Language Model},
year = {2024},
howpublished = {https://huggingface.co/ContactDoctor/Bio-Medical-Llama-3-8B},
}
|
[
"MEDQA",
"PUBMEDQA"
] |
sknow-lab/Qwen2.5-14B-CIC-SciCite
|
sknow-lab
|
zero-shot-classification
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"scientometrics",
"citation_analysis",
"citation_intent_classification",
"zero-shot-classification",
"en",
"dataset:allenai/scicite",
"arxiv:2502.14561",
"base_model:Qwen/Qwen2.5-14B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-14B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2025-02-21T15:04:44Z |
2025-02-25T01:07:43+00:00
| 85 | 2 |
---
base_model:
- Qwen/Qwen2.5-14B-Instruct
datasets:
- allenai/scicite
language:
- en
library_name: transformers
license: apache-2.0
metrics:
- f1
pipeline_tag: zero-shot-classification
tags:
- scientometrics
- citation_analysis
- citation_intent_classification
---
# Qwen2.5-14B-CIC-SciCite
A fine-tuned model for Citation Intent Classification, based on [Qwen 2.5 14B Instruct](https://huggingface.co/Qwen/Qwen2.5-14B-Instruct) and trained on the [SciCite](https://huggingface.co/datasets/allenai/scicite) dataset.
GGUF Version: https://huggingface.co/sknow-lab/Qwen2.5-14B-CIC-SciCite-GGUF
## SciCite classes
| Class | Definition |
| --- | --- |
| Background information | The citation states, mentions, or points to the background information giving more context about a problem, concept, approach, topic, or importance of the problem in the field. |
| Method | Making use of a method, tool, approach or dataset. |
| Result comparison | Comparison of the paper’s results/findings with the results/findings of other work. |
## Quickstart
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "sknow-lab/Qwen2.5-14B-CIC-SciCite"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
system_prompt = """
# CONTEXT #
You are an expert researcher tasked with classifying the intent of a citation in a scientific publication.
########
# OBJECTIVE #
You will be given a sentence containing a citation. You must classify the intent of the citation by assigning it to one of three predefined classes.
########
# CLASS DEFINITIONS #
The three (3) possible classes are the following: "background information", "method", "results comparison."
1 - background information: The citation states, mentions, or points to the background information giving more context about a problem, concept, approach, topic, or importance of the problem in the field.
2 - method: Making use of a method, tool, approach, or dataset.
3 - results comparison: Comparison of the paper’s results/findings with the results/findings of other work.
########
# RESPONSE RULES #
- Analyze only the citation marked with the @@CITATION tag.
- Assign exactly one class to each citation.
- Respond only with the exact name of one of the following classes: "background information", "method", or "results comparison".
- Do not provide any explanation or elaboration.
"""
test_citing_sentence = "Activated PBMC are the basis of the standard PBMC blast assay for HIV-1 neutralization, whereas the various GHOST and HeLa cell lines have all been used in neutralization assays @@CITATION@@."
user_prompt = f"""
{test_citing_sentence}
### Question: Which is the most likely intent for this citation?
a) background information
b) method
c) results comparison
### Answer:
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Response: method
```
Details about the system prompts and query templates can be found in the paper.
There might be a need for a cleanup function to extract the predicted label from the output. You can find ours on [GitHub](https://github.com/athenarc/CitationIntentOpenLLM/blob/main/citation_intent_classification_experiments.py).
## Citation
```
@misc{koloveas2025llmspredictcitationintent,
title={Can LLMs Predict Citation Intent? An Experimental Analysis of In-context Learning and Fine-tuning on Open LLMs},
author={Paris Koloveas and Serafeim Chatzopoulos and Thanasis Vergoulis and Christos Tryfonopoulos},
year={2025},
eprint={2502.14561},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.14561},
}
```
|
[
"SCICITE"
] |
DecisionOptimizationSystem/DeepFeatEmbeddingLargeContext
|
DecisionOptimizationSystem
|
feature-extraction
|
[
"sentence-transformers",
"pytorch",
"coreml",
"onnx",
"safetensors",
"bert",
"finetuner",
"mteb",
"feature-extraction",
"sentence-similarity",
"alibi",
"custom_code",
"en",
"dataset:allenai/c4",
"arxiv:2108.12409",
"arxiv:2310.19923",
"arxiv:2307.11224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"region:us"
] | 2023-11-05T18:23:43Z |
2023-11-05T18:23:44+00:00
| 84 | 1 |
---
datasets:
- allenai/c4
language: en
license: apache-2.0
tags:
- finetuner
- mteb
- sentence-transformers
- feature-extraction
- sentence-similarity
- alibi
inference: false
model-index:
- name: jina-embedding-b-en-v2
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 74.73134328358209
- type: ap
value: 37.765427081831035
- type: f1
value: 68.79367444339518
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 88.544275
- type: ap
value: 84.61328675662887
- type: f1
value: 88.51879035862375
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 45.263999999999996
- type: f1
value: 43.778759656699435
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.693
- type: map_at_10
value: 35.487
- type: map_at_100
value: 36.862
- type: map_at_1000
value: 36.872
- type: map_at_3
value: 30.049999999999997
- type: map_at_5
value: 32.966
- type: mrr_at_1
value: 21.977
- type: mrr_at_10
value: 35.565999999999995
- type: mrr_at_100
value: 36.948
- type: mrr_at_1000
value: 36.958
- type: mrr_at_3
value: 30.121
- type: mrr_at_5
value: 33.051
- type: ndcg_at_1
value: 21.693
- type: ndcg_at_10
value: 44.181
- type: ndcg_at_100
value: 49.982
- type: ndcg_at_1000
value: 50.233000000000004
- type: ndcg_at_3
value: 32.830999999999996
- type: ndcg_at_5
value: 38.080000000000005
- type: precision_at_1
value: 21.693
- type: precision_at_10
value: 7.248
- type: precision_at_100
value: 0.9769999999999999
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 13.632
- type: precision_at_5
value: 10.725
- type: recall_at_1
value: 21.693
- type: recall_at_10
value: 72.475
- type: recall_at_100
value: 97.653
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 40.896
- type: recall_at_5
value: 53.627
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 45.39242428696777
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 36.675626784714
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.247725694904034
- type: mrr
value: 74.91359978894604
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 82.68003802970496
- type: cos_sim_spearman
value: 81.23438110096286
- type: euclidean_pearson
value: 81.87462986142582
- type: euclidean_spearman
value: 81.23438110096286
- type: manhattan_pearson
value: 81.61162566600755
- type: manhattan_spearman
value: 81.11329400456184
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.01298701298701
- type: f1
value: 83.31690714969382
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 37.050108150972086
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 30.15731442819715
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.391999999999996
- type: map_at_10
value: 42.597
- type: map_at_100
value: 44.07
- type: map_at_1000
value: 44.198
- type: map_at_3
value: 38.957
- type: map_at_5
value: 40.961
- type: mrr_at_1
value: 37.196
- type: mrr_at_10
value: 48.152
- type: mrr_at_100
value: 48.928
- type: mrr_at_1000
value: 48.964999999999996
- type: mrr_at_3
value: 45.446
- type: mrr_at_5
value: 47.205999999999996
- type: ndcg_at_1
value: 37.196
- type: ndcg_at_10
value: 49.089
- type: ndcg_at_100
value: 54.471000000000004
- type: ndcg_at_1000
value: 56.385
- type: ndcg_at_3
value: 43.699
- type: ndcg_at_5
value: 46.22
- type: precision_at_1
value: 37.196
- type: precision_at_10
value: 9.313
- type: precision_at_100
value: 1.478
- type: precision_at_1000
value: 0.198
- type: precision_at_3
value: 20.839
- type: precision_at_5
value: 14.936
- type: recall_at_1
value: 31.391999999999996
- type: recall_at_10
value: 61.876
- type: recall_at_100
value: 84.214
- type: recall_at_1000
value: 95.985
- type: recall_at_3
value: 46.6
- type: recall_at_5
value: 53.588
- type: map_at_1
value: 29.083
- type: map_at_10
value: 38.812999999999995
- type: map_at_100
value: 40.053
- type: map_at_1000
value: 40.188
- type: map_at_3
value: 36.111
- type: map_at_5
value: 37.519000000000005
- type: mrr_at_1
value: 36.497
- type: mrr_at_10
value: 44.85
- type: mrr_at_100
value: 45.546
- type: mrr_at_1000
value: 45.593
- type: mrr_at_3
value: 42.686
- type: mrr_at_5
value: 43.909
- type: ndcg_at_1
value: 36.497
- type: ndcg_at_10
value: 44.443
- type: ndcg_at_100
value: 48.979
- type: ndcg_at_1000
value: 51.154999999999994
- type: ndcg_at_3
value: 40.660000000000004
- type: ndcg_at_5
value: 42.193000000000005
- type: precision_at_1
value: 36.497
- type: precision_at_10
value: 8.433
- type: precision_at_100
value: 1.369
- type: precision_at_1000
value: 0.185
- type: precision_at_3
value: 19.894000000000002
- type: precision_at_5
value: 13.873
- type: recall_at_1
value: 29.083
- type: recall_at_10
value: 54.313
- type: recall_at_100
value: 73.792
- type: recall_at_1000
value: 87.629
- type: recall_at_3
value: 42.257
- type: recall_at_5
value: 47.066
- type: map_at_1
value: 38.556000000000004
- type: map_at_10
value: 50.698
- type: map_at_100
value: 51.705
- type: map_at_1000
value: 51.768
- type: map_at_3
value: 47.848
- type: map_at_5
value: 49.358000000000004
- type: mrr_at_1
value: 43.95
- type: mrr_at_10
value: 54.191
- type: mrr_at_100
value: 54.852999999999994
- type: mrr_at_1000
value: 54.885
- type: mrr_at_3
value: 51.954
- type: mrr_at_5
value: 53.13
- type: ndcg_at_1
value: 43.95
- type: ndcg_at_10
value: 56.516
- type: ndcg_at_100
value: 60.477000000000004
- type: ndcg_at_1000
value: 61.746
- type: ndcg_at_3
value: 51.601
- type: ndcg_at_5
value: 53.795
- type: precision_at_1
value: 43.95
- type: precision_at_10
value: 9.009
- type: precision_at_100
value: 1.189
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 22.989
- type: precision_at_5
value: 15.473
- type: recall_at_1
value: 38.556000000000004
- type: recall_at_10
value: 70.159
- type: recall_at_100
value: 87.132
- type: recall_at_1000
value: 96.16
- type: recall_at_3
value: 56.906
- type: recall_at_5
value: 62.332
- type: map_at_1
value: 24.238
- type: map_at_10
value: 32.5
- type: map_at_100
value: 33.637
- type: map_at_1000
value: 33.719
- type: map_at_3
value: 30.026999999999997
- type: map_at_5
value: 31.555
- type: mrr_at_1
value: 26.328000000000003
- type: mrr_at_10
value: 34.44
- type: mrr_at_100
value: 35.455999999999996
- type: mrr_at_1000
value: 35.521
- type: mrr_at_3
value: 32.034
- type: mrr_at_5
value: 33.565
- type: ndcg_at_1
value: 26.328000000000003
- type: ndcg_at_10
value: 37.202
- type: ndcg_at_100
value: 42.728
- type: ndcg_at_1000
value: 44.792
- type: ndcg_at_3
value: 32.368
- type: ndcg_at_5
value: 35.008
- type: precision_at_1
value: 26.328000000000003
- type: precision_at_10
value: 5.7059999999999995
- type: precision_at_100
value: 0.8880000000000001
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 13.672
- type: precision_at_5
value: 9.74
- type: recall_at_1
value: 24.238
- type: recall_at_10
value: 49.829
- type: recall_at_100
value: 75.21
- type: recall_at_1000
value: 90.521
- type: recall_at_3
value: 36.867
- type: recall_at_5
value: 43.241
- type: map_at_1
value: 15.378
- type: map_at_10
value: 22.817999999999998
- type: map_at_100
value: 23.977999999999998
- type: map_at_1000
value: 24.108
- type: map_at_3
value: 20.719
- type: map_at_5
value: 21.889
- type: mrr_at_1
value: 19.03
- type: mrr_at_10
value: 27.022000000000002
- type: mrr_at_100
value: 28.011999999999997
- type: mrr_at_1000
value: 28.096
- type: mrr_at_3
value: 24.855
- type: mrr_at_5
value: 26.029999999999998
- type: ndcg_at_1
value: 19.03
- type: ndcg_at_10
value: 27.526
- type: ndcg_at_100
value: 33.040000000000006
- type: ndcg_at_1000
value: 36.187000000000005
- type: ndcg_at_3
value: 23.497
- type: ndcg_at_5
value: 25.334
- type: precision_at_1
value: 19.03
- type: precision_at_10
value: 4.963
- type: precision_at_100
value: 0.893
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 11.360000000000001
- type: precision_at_5
value: 8.134
- type: recall_at_1
value: 15.378
- type: recall_at_10
value: 38.061
- type: recall_at_100
value: 61.754
- type: recall_at_1000
value: 84.259
- type: recall_at_3
value: 26.788
- type: recall_at_5
value: 31.326999999999998
- type: map_at_1
value: 27.511999999999997
- type: map_at_10
value: 37.429
- type: map_at_100
value: 38.818000000000005
- type: map_at_1000
value: 38.924
- type: map_at_3
value: 34.625
- type: map_at_5
value: 36.064
- type: mrr_at_1
value: 33.300999999999995
- type: mrr_at_10
value: 43.036
- type: mrr_at_100
value: 43.894
- type: mrr_at_1000
value: 43.936
- type: mrr_at_3
value: 40.825
- type: mrr_at_5
value: 42.028
- type: ndcg_at_1
value: 33.300999999999995
- type: ndcg_at_10
value: 43.229
- type: ndcg_at_100
value: 48.992000000000004
- type: ndcg_at_1000
value: 51.02100000000001
- type: ndcg_at_3
value: 38.794000000000004
- type: ndcg_at_5
value: 40.65
- type: precision_at_1
value: 33.300999999999995
- type: precision_at_10
value: 7.777000000000001
- type: precision_at_100
value: 1.269
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 18.351
- type: precision_at_5
value: 12.762
- type: recall_at_1
value: 27.511999999999997
- type: recall_at_10
value: 54.788000000000004
- type: recall_at_100
value: 79.105
- type: recall_at_1000
value: 92.49199999999999
- type: recall_at_3
value: 41.924
- type: recall_at_5
value: 47.026
- type: map_at_1
value: 24.117
- type: map_at_10
value: 33.32
- type: map_at_100
value: 34.677
- type: map_at_1000
value: 34.78
- type: map_at_3
value: 30.233999999999998
- type: map_at_5
value: 31.668000000000003
- type: mrr_at_1
value: 29.566
- type: mrr_at_10
value: 38.244
- type: mrr_at_100
value: 39.245000000000005
- type: mrr_at_1000
value: 39.296
- type: mrr_at_3
value: 35.864000000000004
- type: mrr_at_5
value: 36.919999999999995
- type: ndcg_at_1
value: 29.566
- type: ndcg_at_10
value: 39.127
- type: ndcg_at_100
value: 44.989000000000004
- type: ndcg_at_1000
value: 47.189
- type: ndcg_at_3
value: 34.039
- type: ndcg_at_5
value: 35.744
- type: precision_at_1
value: 29.566
- type: precision_at_10
value: 7.385999999999999
- type: precision_at_100
value: 1.204
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 16.286
- type: precision_at_5
value: 11.484
- type: recall_at_1
value: 24.117
- type: recall_at_10
value: 51.559999999999995
- type: recall_at_100
value: 77.104
- type: recall_at_1000
value: 91.79899999999999
- type: recall_at_3
value: 36.82
- type: recall_at_5
value: 41.453
- type: map_at_1
value: 25.17625
- type: map_at_10
value: 34.063916666666664
- type: map_at_100
value: 35.255500000000005
- type: map_at_1000
value: 35.37275
- type: map_at_3
value: 31.351666666666667
- type: map_at_5
value: 32.80608333333333
- type: mrr_at_1
value: 29.59783333333333
- type: mrr_at_10
value: 38.0925
- type: mrr_at_100
value: 38.957249999999995
- type: mrr_at_1000
value: 39.01608333333333
- type: mrr_at_3
value: 35.77625
- type: mrr_at_5
value: 37.04991666666667
- type: ndcg_at_1
value: 29.59783333333333
- type: ndcg_at_10
value: 39.343666666666664
- type: ndcg_at_100
value: 44.488249999999994
- type: ndcg_at_1000
value: 46.83358333333334
- type: ndcg_at_3
value: 34.69708333333333
- type: ndcg_at_5
value: 36.75075
- type: precision_at_1
value: 29.59783333333333
- type: precision_at_10
value: 6.884083333333332
- type: precision_at_100
value: 1.114
- type: precision_at_1000
value: 0.15108333333333332
- type: precision_at_3
value: 15.965250000000003
- type: precision_at_5
value: 11.246500000000001
- type: recall_at_1
value: 25.17625
- type: recall_at_10
value: 51.015999999999984
- type: recall_at_100
value: 73.60174999999998
- type: recall_at_1000
value: 89.849
- type: recall_at_3
value: 37.88399999999999
- type: recall_at_5
value: 43.24541666666666
- type: map_at_1
value: 24.537
- type: map_at_10
value: 31.081999999999997
- type: map_at_100
value: 32.042
- type: map_at_1000
value: 32.141
- type: map_at_3
value: 29.137
- type: map_at_5
value: 30.079
- type: mrr_at_1
value: 27.454
- type: mrr_at_10
value: 33.694
- type: mrr_at_100
value: 34.579
- type: mrr_at_1000
value: 34.649
- type: mrr_at_3
value: 32.004
- type: mrr_at_5
value: 32.794000000000004
- type: ndcg_at_1
value: 27.454
- type: ndcg_at_10
value: 34.915
- type: ndcg_at_100
value: 39.641
- type: ndcg_at_1000
value: 42.105
- type: ndcg_at_3
value: 31.276
- type: ndcg_at_5
value: 32.65
- type: precision_at_1
value: 27.454
- type: precision_at_10
value: 5.337
- type: precision_at_100
value: 0.8250000000000001
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 13.241
- type: precision_at_5
value: 8.895999999999999
- type: recall_at_1
value: 24.537
- type: recall_at_10
value: 44.324999999999996
- type: recall_at_100
value: 65.949
- type: recall_at_1000
value: 84.017
- type: recall_at_3
value: 33.857
- type: recall_at_5
value: 37.316
- type: map_at_1
value: 17.122
- type: map_at_10
value: 24.32
- type: map_at_100
value: 25.338
- type: map_at_1000
value: 25.462
- type: map_at_3
value: 22.064
- type: map_at_5
value: 23.322000000000003
- type: mrr_at_1
value: 20.647
- type: mrr_at_10
value: 27.858
- type: mrr_at_100
value: 28.743999999999996
- type: mrr_at_1000
value: 28.819
- type: mrr_at_3
value: 25.769
- type: mrr_at_5
value: 26.964
- type: ndcg_at_1
value: 20.647
- type: ndcg_at_10
value: 28.849999999999998
- type: ndcg_at_100
value: 33.849000000000004
- type: ndcg_at_1000
value: 36.802
- type: ndcg_at_3
value: 24.799
- type: ndcg_at_5
value: 26.682
- type: precision_at_1
value: 20.647
- type: precision_at_10
value: 5.2170000000000005
- type: precision_at_100
value: 0.906
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 11.769
- type: precision_at_5
value: 8.486
- type: recall_at_1
value: 17.122
- type: recall_at_10
value: 38.999
- type: recall_at_100
value: 61.467000000000006
- type: recall_at_1000
value: 82.716
- type: recall_at_3
value: 27.601
- type: recall_at_5
value: 32.471
- type: map_at_1
value: 24.396
- type: map_at_10
value: 33.415
- type: map_at_100
value: 34.521
- type: map_at_1000
value: 34.631
- type: map_at_3
value: 30.703999999999997
- type: map_at_5
value: 32.166
- type: mrr_at_1
value: 28.825
- type: mrr_at_10
value: 37.397000000000006
- type: mrr_at_100
value: 38.286
- type: mrr_at_1000
value: 38.346000000000004
- type: mrr_at_3
value: 35.028
- type: mrr_at_5
value: 36.32
- type: ndcg_at_1
value: 28.825
- type: ndcg_at_10
value: 38.656
- type: ndcg_at_100
value: 43.856
- type: ndcg_at_1000
value: 46.31
- type: ndcg_at_3
value: 33.793
- type: ndcg_at_5
value: 35.909
- type: precision_at_1
value: 28.825
- type: precision_at_10
value: 6.567
- type: precision_at_100
value: 1.0330000000000001
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 15.516
- type: precision_at_5
value: 10.914
- type: recall_at_1
value: 24.396
- type: recall_at_10
value: 50.747
- type: recall_at_100
value: 73.477
- type: recall_at_1000
value: 90.801
- type: recall_at_3
value: 37.1
- type: recall_at_5
value: 42.589
- type: map_at_1
value: 25.072
- type: map_at_10
value: 34.307
- type: map_at_100
value: 35.725
- type: map_at_1000
value: 35.943999999999996
- type: map_at_3
value: 30.906
- type: map_at_5
value: 32.818000000000005
- type: mrr_at_1
value: 29.644
- type: mrr_at_10
value: 38.673
- type: mrr_at_100
value: 39.459
- type: mrr_at_1000
value: 39.527
- type: mrr_at_3
value: 35.771
- type: mrr_at_5
value: 37.332
- type: ndcg_at_1
value: 29.644
- type: ndcg_at_10
value: 40.548
- type: ndcg_at_100
value: 45.678999999999995
- type: ndcg_at_1000
value: 48.488
- type: ndcg_at_3
value: 34.887
- type: ndcg_at_5
value: 37.543
- type: precision_at_1
value: 29.644
- type: precision_at_10
value: 7.688000000000001
- type: precision_at_100
value: 1.482
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 16.206
- type: precision_at_5
value: 12.016
- type: recall_at_1
value: 25.072
- type: recall_at_10
value: 53.478
- type: recall_at_100
value: 76.07300000000001
- type: recall_at_1000
value: 93.884
- type: recall_at_3
value: 37.583
- type: recall_at_5
value: 44.464
- type: map_at_1
value: 20.712
- type: map_at_10
value: 27.467999999999996
- type: map_at_100
value: 28.502
- type: map_at_1000
value: 28.610000000000003
- type: map_at_3
value: 24.887999999999998
- type: map_at_5
value: 26.273999999999997
- type: mrr_at_1
value: 22.736
- type: mrr_at_10
value: 29.553
- type: mrr_at_100
value: 30.485
- type: mrr_at_1000
value: 30.56
- type: mrr_at_3
value: 27.078999999999997
- type: mrr_at_5
value: 28.401
- type: ndcg_at_1
value: 22.736
- type: ndcg_at_10
value: 32.023
- type: ndcg_at_100
value: 37.158
- type: ndcg_at_1000
value: 39.823
- type: ndcg_at_3
value: 26.951999999999998
- type: ndcg_at_5
value: 29.281000000000002
- type: precision_at_1
value: 22.736
- type: precision_at_10
value: 5.213
- type: precision_at_100
value: 0.832
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 11.459999999999999
- type: precision_at_5
value: 8.244
- type: recall_at_1
value: 20.712
- type: recall_at_10
value: 44.057
- type: recall_at_100
value: 67.944
- type: recall_at_1000
value: 87.925
- type: recall_at_3
value: 30.305
- type: recall_at_5
value: 36.071999999999996
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.181999999999999
- type: map_at_10
value: 16.66
- type: map_at_100
value: 18.273
- type: map_at_1000
value: 18.45
- type: map_at_3
value: 14.141
- type: map_at_5
value: 15.455
- type: mrr_at_1
value: 22.15
- type: mrr_at_10
value: 32.062000000000005
- type: mrr_at_100
value: 33.116
- type: mrr_at_1000
value: 33.168
- type: mrr_at_3
value: 28.827
- type: mrr_at_5
value: 30.892999999999997
- type: ndcg_at_1
value: 22.15
- type: ndcg_at_10
value: 23.532
- type: ndcg_at_100
value: 30.358
- type: ndcg_at_1000
value: 33.783
- type: ndcg_at_3
value: 19.222
- type: ndcg_at_5
value: 20.919999999999998
- type: precision_at_1
value: 22.15
- type: precision_at_10
value: 7.185999999999999
- type: precision_at_100
value: 1.433
- type: precision_at_1000
value: 0.207
- type: precision_at_3
value: 13.941
- type: precision_at_5
value: 10.906
- type: recall_at_1
value: 10.181999999999999
- type: recall_at_10
value: 28.104000000000003
- type: recall_at_100
value: 51.998999999999995
- type: recall_at_1000
value: 71.311
- type: recall_at_3
value: 17.698
- type: recall_at_5
value: 22.262999999999998
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.669
- type: map_at_10
value: 15.552
- type: map_at_100
value: 21.865000000000002
- type: map_at_1000
value: 23.268
- type: map_at_3
value: 11.309
- type: map_at_5
value: 13.084000000000001
- type: mrr_at_1
value: 55.50000000000001
- type: mrr_at_10
value: 66.46600000000001
- type: mrr_at_100
value: 66.944
- type: mrr_at_1000
value: 66.956
- type: mrr_at_3
value: 64.542
- type: mrr_at_5
value: 65.717
- type: ndcg_at_1
value: 44.75
- type: ndcg_at_10
value: 35.049
- type: ndcg_at_100
value: 39.073
- type: ndcg_at_1000
value: 46.208
- type: ndcg_at_3
value: 39.525
- type: ndcg_at_5
value: 37.156
- type: precision_at_1
value: 55.50000000000001
- type: precision_at_10
value: 27.800000000000004
- type: precision_at_100
value: 9.013
- type: precision_at_1000
value: 1.8800000000000001
- type: precision_at_3
value: 42.667
- type: precision_at_5
value: 36.0
- type: recall_at_1
value: 6.669
- type: recall_at_10
value: 21.811
- type: recall_at_100
value: 45.112
- type: recall_at_1000
value: 67.806
- type: recall_at_3
value: 13.373
- type: recall_at_5
value: 16.615
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 48.769999999999996
- type: f1
value: 42.91448356376592
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 54.013
- type: map_at_10
value: 66.239
- type: map_at_100
value: 66.62599999999999
- type: map_at_1000
value: 66.644
- type: map_at_3
value: 63.965
- type: map_at_5
value: 65.45400000000001
- type: mrr_at_1
value: 58.221000000000004
- type: mrr_at_10
value: 70.43700000000001
- type: mrr_at_100
value: 70.744
- type: mrr_at_1000
value: 70.75099999999999
- type: mrr_at_3
value: 68.284
- type: mrr_at_5
value: 69.721
- type: ndcg_at_1
value: 58.221000000000004
- type: ndcg_at_10
value: 72.327
- type: ndcg_at_100
value: 73.953
- type: ndcg_at_1000
value: 74.312
- type: ndcg_at_3
value: 68.062
- type: ndcg_at_5
value: 70.56400000000001
- type: precision_at_1
value: 58.221000000000004
- type: precision_at_10
value: 9.521
- type: precision_at_100
value: 1.045
- type: precision_at_1000
value: 0.109
- type: precision_at_3
value: 27.348
- type: precision_at_5
value: 17.794999999999998
- type: recall_at_1
value: 54.013
- type: recall_at_10
value: 86.957
- type: recall_at_100
value: 93.911
- type: recall_at_1000
value: 96.38
- type: recall_at_3
value: 75.555
- type: recall_at_5
value: 81.671
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.254
- type: map_at_10
value: 33.723
- type: map_at_100
value: 35.574
- type: map_at_1000
value: 35.730000000000004
- type: map_at_3
value: 29.473
- type: map_at_5
value: 31.543
- type: mrr_at_1
value: 41.358
- type: mrr_at_10
value: 49.498
- type: mrr_at_100
value: 50.275999999999996
- type: mrr_at_1000
value: 50.308
- type: mrr_at_3
value: 47.016000000000005
- type: mrr_at_5
value: 48.336
- type: ndcg_at_1
value: 41.358
- type: ndcg_at_10
value: 41.579
- type: ndcg_at_100
value: 48.455
- type: ndcg_at_1000
value: 51.165000000000006
- type: ndcg_at_3
value: 37.681
- type: ndcg_at_5
value: 38.49
- type: precision_at_1
value: 41.358
- type: precision_at_10
value: 11.543000000000001
- type: precision_at_100
value: 1.87
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 24.743000000000002
- type: precision_at_5
value: 17.994
- type: recall_at_1
value: 21.254
- type: recall_at_10
value: 48.698
- type: recall_at_100
value: 74.588
- type: recall_at_1000
value: 91.00200000000001
- type: recall_at_3
value: 33.939
- type: recall_at_5
value: 39.367000000000004
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.922
- type: map_at_10
value: 52.32599999999999
- type: map_at_100
value: 53.18000000000001
- type: map_at_1000
value: 53.245
- type: map_at_3
value: 49.294
- type: map_at_5
value: 51.202999999999996
- type: mrr_at_1
value: 71.843
- type: mrr_at_10
value: 78.24600000000001
- type: mrr_at_100
value: 78.515
- type: mrr_at_1000
value: 78.527
- type: mrr_at_3
value: 77.17500000000001
- type: mrr_at_5
value: 77.852
- type: ndcg_at_1
value: 71.843
- type: ndcg_at_10
value: 61.379
- type: ndcg_at_100
value: 64.535
- type: ndcg_at_1000
value: 65.888
- type: ndcg_at_3
value: 56.958
- type: ndcg_at_5
value: 59.434
- type: precision_at_1
value: 71.843
- type: precision_at_10
value: 12.686
- type: precision_at_100
value: 1.517
- type: precision_at_1000
value: 0.16999999999999998
- type: precision_at_3
value: 35.778
- type: precision_at_5
value: 23.422
- type: recall_at_1
value: 35.922
- type: recall_at_10
value: 63.43
- type: recall_at_100
value: 75.868
- type: recall_at_1000
value: 84.88900000000001
- type: recall_at_3
value: 53.666000000000004
- type: recall_at_5
value: 58.555
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 79.4408
- type: ap
value: 73.52820871620366
- type: f1
value: 79.36240238685001
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.826999999999998
- type: map_at_10
value: 34.04
- type: map_at_100
value: 35.226
- type: map_at_1000
value: 35.275
- type: map_at_3
value: 30.165999999999997
- type: map_at_5
value: 32.318000000000005
- type: mrr_at_1
value: 22.464000000000002
- type: mrr_at_10
value: 34.631
- type: mrr_at_100
value: 35.752
- type: mrr_at_1000
value: 35.795
- type: mrr_at_3
value: 30.798
- type: mrr_at_5
value: 32.946999999999996
- type: ndcg_at_1
value: 22.464000000000002
- type: ndcg_at_10
value: 40.919
- type: ndcg_at_100
value: 46.632
- type: ndcg_at_1000
value: 47.833
- type: ndcg_at_3
value: 32.992
- type: ndcg_at_5
value: 36.834
- type: precision_at_1
value: 22.464000000000002
- type: precision_at_10
value: 6.494
- type: precision_at_100
value: 0.9369999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.021
- type: precision_at_5
value: 10.347000000000001
- type: recall_at_1
value: 21.826999999999998
- type: recall_at_10
value: 62.132
- type: recall_at_100
value: 88.55199999999999
- type: recall_at_1000
value: 97.707
- type: recall_at_3
value: 40.541
- type: recall_at_5
value: 49.739
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 95.68399452804377
- type: f1
value: 95.25490609832268
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 83.15321477428182
- type: f1
value: 60.35476439087966
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.92669804976462
- type: f1
value: 69.22815107207565
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.4855413584398
- type: f1
value: 72.92107516103387
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 32.412679360205544
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.09211869875204
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.540919056982545
- type: mrr
value: 31.529904607063536
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.745
- type: map_at_10
value: 12.013
- type: map_at_100
value: 15.040000000000001
- type: map_at_1000
value: 16.427
- type: map_at_3
value: 8.841000000000001
- type: map_at_5
value: 10.289
- type: mrr_at_1
value: 45.201
- type: mrr_at_10
value: 53.483999999999995
- type: mrr_at_100
value: 54.20700000000001
- type: mrr_at_1000
value: 54.252
- type: mrr_at_3
value: 51.29
- type: mrr_at_5
value: 52.73
- type: ndcg_at_1
value: 43.808
- type: ndcg_at_10
value: 32.445
- type: ndcg_at_100
value: 30.031000000000002
- type: ndcg_at_1000
value: 39.007
- type: ndcg_at_3
value: 37.204
- type: ndcg_at_5
value: 35.07
- type: precision_at_1
value: 45.201
- type: precision_at_10
value: 23.684
- type: precision_at_100
value: 7.600999999999999
- type: precision_at_1000
value: 2.043
- type: precision_at_3
value: 33.953
- type: precision_at_5
value: 29.412
- type: recall_at_1
value: 5.745
- type: recall_at_10
value: 16.168
- type: recall_at_100
value: 30.875999999999998
- type: recall_at_1000
value: 62.686
- type: recall_at_3
value: 9.75
- type: recall_at_5
value: 12.413
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.828
- type: map_at_10
value: 53.239000000000004
- type: map_at_100
value: 54.035999999999994
- type: map_at_1000
value: 54.067
- type: map_at_3
value: 49.289
- type: map_at_5
value: 51.784
- type: mrr_at_1
value: 42.497
- type: mrr_at_10
value: 55.916999999999994
- type: mrr_at_100
value: 56.495
- type: mrr_at_1000
value: 56.516999999999996
- type: mrr_at_3
value: 52.800000000000004
- type: mrr_at_5
value: 54.722
- type: ndcg_at_1
value: 42.468
- type: ndcg_at_10
value: 60.437
- type: ndcg_at_100
value: 63.731
- type: ndcg_at_1000
value: 64.41799999999999
- type: ndcg_at_3
value: 53.230999999999995
- type: ndcg_at_5
value: 57.26
- type: precision_at_1
value: 42.468
- type: precision_at_10
value: 9.47
- type: precision_at_100
value: 1.1360000000000001
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.724999999999998
- type: precision_at_5
value: 16.593
- type: recall_at_1
value: 37.828
- type: recall_at_10
value: 79.538
- type: recall_at_100
value: 93.646
- type: recall_at_1000
value: 98.72999999999999
- type: recall_at_3
value: 61.134
- type: recall_at_5
value: 70.377
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.548
- type: map_at_10
value: 84.466
- type: map_at_100
value: 85.10600000000001
- type: map_at_1000
value: 85.123
- type: map_at_3
value: 81.57600000000001
- type: map_at_5
value: 83.399
- type: mrr_at_1
value: 81.24
- type: mrr_at_10
value: 87.457
- type: mrr_at_100
value: 87.574
- type: mrr_at_1000
value: 87.575
- type: mrr_at_3
value: 86.507
- type: mrr_at_5
value: 87.205
- type: ndcg_at_1
value: 81.25
- type: ndcg_at_10
value: 88.203
- type: ndcg_at_100
value: 89.457
- type: ndcg_at_1000
value: 89.563
- type: ndcg_at_3
value: 85.465
- type: ndcg_at_5
value: 87.007
- type: precision_at_1
value: 81.25
- type: precision_at_10
value: 13.373
- type: precision_at_100
value: 1.5270000000000001
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.417
- type: precision_at_5
value: 24.556
- type: recall_at_1
value: 70.548
- type: recall_at_10
value: 95.208
- type: recall_at_100
value: 99.514
- type: recall_at_1000
value: 99.988
- type: recall_at_3
value: 87.214
- type: recall_at_5
value: 91.696
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 53.04822095496839
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 60.30778476474675
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.692
- type: map_at_10
value: 11.766
- type: map_at_100
value: 13.904
- type: map_at_1000
value: 14.216999999999999
- type: map_at_3
value: 8.245
- type: map_at_5
value: 9.92
- type: mrr_at_1
value: 23.0
- type: mrr_at_10
value: 33.78
- type: mrr_at_100
value: 34.922
- type: mrr_at_1000
value: 34.973
- type: mrr_at_3
value: 30.2
- type: mrr_at_5
value: 32.565
- type: ndcg_at_1
value: 23.0
- type: ndcg_at_10
value: 19.863
- type: ndcg_at_100
value: 28.141
- type: ndcg_at_1000
value: 33.549
- type: ndcg_at_3
value: 18.434
- type: ndcg_at_5
value: 16.384
- type: precision_at_1
value: 23.0
- type: precision_at_10
value: 10.39
- type: precision_at_100
value: 2.235
- type: precision_at_1000
value: 0.35300000000000004
- type: precision_at_3
value: 17.133000000000003
- type: precision_at_5
value: 14.44
- type: recall_at_1
value: 4.692
- type: recall_at_10
value: 21.025
- type: recall_at_100
value: 45.324999999999996
- type: recall_at_1000
value: 71.675
- type: recall_at_3
value: 10.440000000000001
- type: recall_at_5
value: 14.64
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.96178184892842
- type: cos_sim_spearman
value: 79.6487740813199
- type: euclidean_pearson
value: 82.06661161625023
- type: euclidean_spearman
value: 79.64876769031183
- type: manhattan_pearson
value: 82.07061164575131
- type: manhattan_spearman
value: 79.65197039464537
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.15305604100027
- type: cos_sim_spearman
value: 74.27447427941591
- type: euclidean_pearson
value: 80.52737337565307
- type: euclidean_spearman
value: 74.27416077132192
- type: manhattan_pearson
value: 80.53728571140387
- type: manhattan_spearman
value: 74.28853605753457
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 83.44386080639279
- type: cos_sim_spearman
value: 84.17947648159536
- type: euclidean_pearson
value: 83.34145388129387
- type: euclidean_spearman
value: 84.17947648159536
- type: manhattan_pearson
value: 83.30699061927966
- type: manhattan_spearman
value: 84.18125737380451
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 81.57392220985612
- type: cos_sim_spearman
value: 78.80745014464101
- type: euclidean_pearson
value: 80.01660371487199
- type: euclidean_spearman
value: 78.80741240102256
- type: manhattan_pearson
value: 79.96810779507953
- type: manhattan_spearman
value: 78.75600400119448
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.85421063026625
- type: cos_sim_spearman
value: 87.55320285299192
- type: euclidean_pearson
value: 86.69750143323517
- type: euclidean_spearman
value: 87.55320284326378
- type: manhattan_pearson
value: 86.63379169960379
- type: manhattan_spearman
value: 87.4815029877984
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.31314130411842
- type: cos_sim_spearman
value: 85.3489588181433
- type: euclidean_pearson
value: 84.13240933463535
- type: euclidean_spearman
value: 85.34902871403281
- type: manhattan_pearson
value: 84.01183086503559
- type: manhattan_spearman
value: 85.19316703166102
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.09979781689536
- type: cos_sim_spearman
value: 88.87813323759015
- type: euclidean_pearson
value: 88.65413031123792
- type: euclidean_spearman
value: 88.87813323759015
- type: manhattan_pearson
value: 88.61818758256024
- type: manhattan_spearman
value: 88.81044100494604
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 62.30693258111531
- type: cos_sim_spearman
value: 62.195516523251946
- type: euclidean_pearson
value: 62.951283701049476
- type: euclidean_spearman
value: 62.195516523251946
- type: manhattan_pearson
value: 63.068322281439535
- type: manhattan_spearman
value: 62.10621171028406
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.27092833763909
- type: cos_sim_spearman
value: 84.84429717949759
- type: euclidean_pearson
value: 84.8516966060792
- type: euclidean_spearman
value: 84.84429717949759
- type: manhattan_pearson
value: 84.82203139242881
- type: manhattan_spearman
value: 84.8358503952945
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 83.10290863981409
- type: mrr
value: 95.31168450286097
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 52.161
- type: map_at_10
value: 62.138000000000005
- type: map_at_100
value: 62.769
- type: map_at_1000
value: 62.812
- type: map_at_3
value: 59.111000000000004
- type: map_at_5
value: 60.995999999999995
- type: mrr_at_1
value: 55.333
- type: mrr_at_10
value: 63.504000000000005
- type: mrr_at_100
value: 64.036
- type: mrr_at_1000
value: 64.08
- type: mrr_at_3
value: 61.278
- type: mrr_at_5
value: 62.778
- type: ndcg_at_1
value: 55.333
- type: ndcg_at_10
value: 66.678
- type: ndcg_at_100
value: 69.415
- type: ndcg_at_1000
value: 70.453
- type: ndcg_at_3
value: 61.755
- type: ndcg_at_5
value: 64.546
- type: precision_at_1
value: 55.333
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.043
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 24.221999999999998
- type: precision_at_5
value: 16.333000000000002
- type: recall_at_1
value: 52.161
- type: recall_at_10
value: 79.156
- type: recall_at_100
value: 91.333
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 66.43299999999999
- type: recall_at_5
value: 73.272
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.81287128712871
- type: cos_sim_ap
value: 95.30034785910676
- type: cos_sim_f1
value: 90.28629856850716
- type: cos_sim_precision
value: 92.36401673640168
- type: cos_sim_recall
value: 88.3
- type: dot_accuracy
value: 99.81287128712871
- type: dot_ap
value: 95.30034785910676
- type: dot_f1
value: 90.28629856850716
- type: dot_precision
value: 92.36401673640168
- type: dot_recall
value: 88.3
- type: euclidean_accuracy
value: 99.81287128712871
- type: euclidean_ap
value: 95.30034785910676
- type: euclidean_f1
value: 90.28629856850716
- type: euclidean_precision
value: 92.36401673640168
- type: euclidean_recall
value: 88.3
- type: manhattan_accuracy
value: 99.80990099009901
- type: manhattan_ap
value: 95.26880751950654
- type: manhattan_f1
value: 90.22177419354838
- type: manhattan_precision
value: 90.95528455284553
- type: manhattan_recall
value: 89.5
- type: max_accuracy
value: 99.81287128712871
- type: max_ap
value: 95.30034785910676
- type: max_f1
value: 90.28629856850716
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 58.518662504351184
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.96168178378587
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.04862593471896
- type: mrr
value: 52.97238402936932
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.092545236479946
- type: cos_sim_spearman
value: 31.599851000175498
- type: dot_pearson
value: 30.092542723901676
- type: dot_spearman
value: 31.599851000175498
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.189
- type: map_at_10
value: 1.662
- type: map_at_100
value: 9.384
- type: map_at_1000
value: 22.669
- type: map_at_3
value: 0.5559999999999999
- type: map_at_5
value: 0.9039999999999999
- type: mrr_at_1
value: 68.0
- type: mrr_at_10
value: 81.01899999999999
- type: mrr_at_100
value: 81.01899999999999
- type: mrr_at_1000
value: 81.01899999999999
- type: mrr_at_3
value: 79.333
- type: mrr_at_5
value: 80.733
- type: ndcg_at_1
value: 63.0
- type: ndcg_at_10
value: 65.913
- type: ndcg_at_100
value: 51.895
- type: ndcg_at_1000
value: 46.967
- type: ndcg_at_3
value: 65.49199999999999
- type: ndcg_at_5
value: 66.69699999999999
- type: precision_at_1
value: 68.0
- type: precision_at_10
value: 71.6
- type: precision_at_100
value: 53.66
- type: precision_at_1000
value: 21.124000000000002
- type: precision_at_3
value: 72.667
- type: precision_at_5
value: 74.0
- type: recall_at_1
value: 0.189
- type: recall_at_10
value: 1.913
- type: recall_at_100
value: 12.601999999999999
- type: recall_at_1000
value: 44.296
- type: recall_at_3
value: 0.605
- type: recall_at_5
value: 1.018
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.701
- type: map_at_10
value: 10.445
- type: map_at_100
value: 17.324
- type: map_at_1000
value: 19.161
- type: map_at_3
value: 5.497
- type: map_at_5
value: 7.278
- type: mrr_at_1
value: 30.612000000000002
- type: mrr_at_10
value: 45.534
- type: mrr_at_100
value: 45.792
- type: mrr_at_1000
value: 45.806999999999995
- type: mrr_at_3
value: 37.755
- type: mrr_at_5
value: 43.469
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 26.235000000000003
- type: ndcg_at_100
value: 39.17
- type: ndcg_at_1000
value: 51.038
- type: ndcg_at_3
value: 23.625
- type: ndcg_at_5
value: 24.338
- type: precision_at_1
value: 30.612000000000002
- type: precision_at_10
value: 24.285999999999998
- type: precision_at_100
value: 8.224
- type: precision_at_1000
value: 1.6179999999999999
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 24.898
- type: recall_at_1
value: 2.701
- type: recall_at_10
value: 17.997
- type: recall_at_100
value: 51.766999999999996
- type: recall_at_1000
value: 87.863
- type: recall_at_3
value: 6.295000000000001
- type: recall_at_5
value: 9.993
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 73.3474
- type: ap
value: 15.393431414459924
- type: f1
value: 56.466681887882416
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 62.062818336163
- type: f1
value: 62.11230840463252
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 42.464892820845115
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.15962329379508
- type: cos_sim_ap
value: 74.73674057919256
- type: cos_sim_f1
value: 68.81245642574947
- type: cos_sim_precision
value: 61.48255813953488
- type: cos_sim_recall
value: 78.12664907651715
- type: dot_accuracy
value: 86.15962329379508
- type: dot_ap
value: 74.7367634988281
- type: dot_f1
value: 68.81245642574947
- type: dot_precision
value: 61.48255813953488
- type: dot_recall
value: 78.12664907651715
- type: euclidean_accuracy
value: 86.15962329379508
- type: euclidean_ap
value: 74.7367761466634
- type: euclidean_f1
value: 68.81245642574947
- type: euclidean_precision
value: 61.48255813953488
- type: euclidean_recall
value: 78.12664907651715
- type: manhattan_accuracy
value: 86.21326816474935
- type: manhattan_ap
value: 74.64416473733951
- type: manhattan_f1
value: 68.80924855491331
- type: manhattan_precision
value: 61.23456790123457
- type: manhattan_recall
value: 78.52242744063325
- type: max_accuracy
value: 86.21326816474935
- type: max_ap
value: 74.7367761466634
- type: max_f1
value: 68.81245642574947
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.97620988085536
- type: cos_sim_ap
value: 86.08680845745758
- type: cos_sim_f1
value: 78.02793637114438
- type: cos_sim_precision
value: 73.11082699683736
- type: cos_sim_recall
value: 83.65414228518632
- type: dot_accuracy
value: 88.97620988085536
- type: dot_ap
value: 86.08681149437946
- type: dot_f1
value: 78.02793637114438
- type: dot_precision
value: 73.11082699683736
- type: dot_recall
value: 83.65414228518632
- type: euclidean_accuracy
value: 88.97620988085536
- type: euclidean_ap
value: 86.08681215460771
- type: euclidean_f1
value: 78.02793637114438
- type: euclidean_precision
value: 73.11082699683736
- type: euclidean_recall
value: 83.65414228518632
- type: manhattan_accuracy
value: 88.88888888888889
- type: manhattan_ap
value: 86.02916327562438
- type: manhattan_f1
value: 78.02063045516843
- type: manhattan_precision
value: 73.38851947346994
- type: manhattan_recall
value: 83.2768709578072
- type: max_accuracy
value: 88.97620988085536
- type: max_ap
value: 86.08681215460771
- type: max_f1
value: 78.02793637114438
---
<!-- TODO: add evaluation results here -->
<br><br>
<p align="center">
<img src="https://github.com/jina-ai/finetuner/blob/main/docs/_static/finetuner-logo-ani.svg?raw=true" alt="Finetuner logo: Finetuner helps you to create experiments in order to improve embeddings on search tasks. It accompanies you to deliver the last mile of performance-tuning for neural search applications." width="150px">
</p>
<p align="center">
<b>The text embedding set trained by <a href="https://jina.ai/"><b>Jina AI</b></a>, <a href="https://github.com/jina-ai/finetuner"><b>Finetuner</b></a> team.</b>
</p>
## Intended Usage & Model Info
`jina-embeddings-v2-base-en` is an English, monolingual **embedding model** supporting **8192 sequence length**.
It is based on a Bert architecture (JinaBert) that supports the symmetric bidirectional variant of [ALiBi](https://arxiv.org/abs/2108.12409) to allow longer sequence length.
The backbone `jina-bert-v2-base-en` is pretrained on the C4 dataset.
The model is further trained on Jina AI's collection of more than 400 millions of sentence pairs and hard negatives.
These pairs were obtained from various domains and were carefully selected through a thorough cleaning process.
The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi.
This makes our model useful for a range of use cases, especially when processing long documents is needed, including long document retrieval, semantic textual similarity, text reranking, recommendation, RAG and LLM-based generative search, etc.
With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model. It is recommended to use a single GPU for inference.
Additionally, we provide the following embedding models:
**V1 (Based on T5, 512 Seq)**
- [`jina-embeddings-v1-small-en`](https://huggingface.co/jinaai/jina-embedding-s-en-v1): 35 million parameters.
- [`jina-embeddings-v1-base-en`](https://huggingface.co/jinaai/jina-embedding-b-en-v1): 110 million parameters.
- [`jina-embeddings-v1-large-en`](https://huggingface.co/jinaai/jina-embedding-l-en-v1): 330 million parameters.
**V2 (Based on JinaBert, 8k Seq)**
- [`jina-embeddings-v2-small-en`](https://huggingface.co/jinaai/jina-embeddings-v2-small-en): 33 million parameters.
- [`jina-embeddings-v2-base-en`](https://huggingface.co/jinaai/jina-embeddings-v2-base-en): 137 million parameters **(you are here)**.
- [`jina-embeddings-v2-large-en`](): 435 million parameters (releasing soon).
## Data & Parameters
Jina Embeddings V2 [technical report](https://arxiv.org/abs/2310.19923)
## Usage
You can use Jina Embedding models directly from transformers package:
```python
!pip install transformers
from transformers import AutoModel
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True) # trust_remote_code is needed to use the encode method
embeddings = model.encode(['How is the weather today?', 'What is the current weather like today?'])
print(cos_sim(embeddings[0], embeddings[1]))
```
If you only want to handle shorter sequence, such as 2k, pass the `max_length` parameter to the `encode` function:
```python
embeddings = model.encode(
['Very long ... document'],
max_length=2048
)
```
*Alternatively, you can use Jina AI's [Embedding platform](https://jina.ai/embeddings/) for fully-managed access to Jina Embeddings models*.
## Fine-tuning
Please consider [Finetuner](https://github.com/jina-ai/finetuner).
## Plans
The development of new bilingual models is currently underway. We will be targeting mainly the German and Spanish languages.
The upcoming models will be called `jina-embeddings-v2-base-de/es`.
## Contact
Join our [Discord community](https://discord.jina.ai) and chat with other community members about ideas.
## Citation
If you find Jina Embeddings useful in your research, please cite the following paper:
```
@misc{günther2023jina,
title={Jina Embeddings 2: 8192-Token General-Purpose Text Embeddings for Long Documents},
author={Michael Günther and Jackmin Ong and Isabelle Mohr and Alaeddine Abdessalem and Tanguy Abel and Mohammad Kalim Akram and Susana Guzman and Georgios Mastrapas and Saba Sturua and Bo Wang and Maximilian Werk and Nan Wang and Han Xiao},
year={2023},
eprint={2310.19923},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
``` latex
@misc{günther2023jina,
title={Beyond the 512-Token Barrier: Training General-Purpose Text
Embeddings for Large Documents},
author={Michael Günther and Jackmin Ong and Isabelle Mohr and Alaeddine Abdessalem and Tanguy Abel and Mohammad Kalim Akram and Susana Guzman and Georgios Mastrapas and Saba Sturua and Bo Wang},
year={2023},
eprint={2307.11224},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{günther2023jina,
title={Jina Embeddings: A Novel Set of High-Performance Sentence Embedding Models},
author={Michael Günther and Louis Milliken and Jonathan Geuter and Georgios Mastrapas and Bo Wang and Han Xiao},
year={2023},
eprint={2307.11224},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
-->
|
[
"BIOSSES",
"SCIFACT"
] |
BioMistral/BioMistral-7B-BnB.4
|
BioMistral
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"medical",
"biology",
"4bit",
"bnb",
"bitsandbytes",
"conversational",
"fr",
"en",
"de",
"nl",
"es",
"pt",
"pl",
"ro",
"it",
"dataset:pubmed",
"arxiv:2402.10373",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"region:us"
] | 2024-02-19T13:22:45Z |
2024-02-19T15:38:09+00:00
| 84 | 0 |
---
datasets:
- pubmed
language:
- fr
- en
- de
- nl
- es
- pt
- pl
- ro
- it
license: apache-2.0
pipeline_tag: text-generation
tags:
- medical
- biology
- 4bit
- bnb
- bitsandbytes
---
<p align="center">
<img src="https://huggingface.co/BioMistral/BioMistral-7B/resolve/main/wordart_blue_m_rectangle.png?download=true" alt="drawing" width="250"/>
</p>
# BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
**Abstract:**
Large Language Models (LLMs) have demonstrated remarkable versatility in recent years, offering potential applications across specialized domains such as healthcare and medicine. Despite the availability of various open-source LLMs tailored for health contexts, adapting general-purpose LLMs to the medical domain presents significant challenges.
In this paper, we introduce BioMistral, an open-source LLM tailored for the biomedical domain, utilizing Mistral as its foundation model and further pre-trained on PubMed Central. We conduct a comprehensive evaluation of BioMistral on a benchmark comprising 10 established medical question-answering (QA) tasks in English. We also explore lightweight models obtained through quantization and model merging approaches. Our results demonstrate BioMistral's superior performance compared to existing open-source medical models and its competitive edge against proprietary counterparts. Finally, to address the limited availability of data beyond English and to assess the multilingual generalization of medical LLMs, we automatically translated and evaluated this benchmark into 7 other languages. This marks the first large-scale multilingual evaluation of LLMs in the medical domain. Datasets, multilingual evaluation benchmarks, scripts, and all the models obtained during our experiments are freely released.
**Advisory Notice!** Although BioMistral is intended to encapsulate medical knowledge sourced from high-quality evidence, it hasn't been tailored to effectively, safely, or suitably convey this knowledge within professional parameters for action. We advise refraining from utilizing BioMistral in medical contexts unless it undergoes thorough alignment with specific use cases and undergoes further testing, notably including randomized controlled trials in real-world medical environments. BioMistral 7B may possess inherent risks and biases that have not yet been thoroughly assessed. Additionally, the model's performance has not been evaluated in real-world clinical settings. Consequently, we recommend using BioMistral 7B strictly as a research tool and advise against deploying it in production environments for natural language generation or any professional health and medical purposes.
# 1. BioMistral models
**BioMistral** is a suite of Mistral-based further pre-trained open source models suited for the medical domains and pre-trained using textual data from PubMed Central Open Access (CC0, CC BY, CC BY-SA, and CC BY-ND). All the models are trained using the CNRS (French National Centre for Scientific Research) [Jean Zay](http://www.idris.fr/jean-zay/) French HPC.
| Model Name | Base Model | Model Type | Sequence Length | Download |
|:-------------------:|:----------------------------------:|:-------------------:|:---------------:|:-----------------------------------------------------:|
| BioMistral-7B | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Further Pre-trained | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B-DARE | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge DARE | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE) |
| BioMistral-7B-TIES | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge TIES | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES) |
| BioMistral-7B-SLERP | [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1) | Merge SLERP | 2048 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP) |
# 2. Quantized Models
| Base Model | Method | q_group_size | w_bit | version | VRAM GB | Time | Download |
|:-------------------:|:------:|:------------:|:-----:|:-------:|:-------:|:------:|:--------:|
| BioMistral-7B | FP16/BF16 | | | | 15.02 | x1.00 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B) |
| BioMistral-7B | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B | AWQ | 128 | 4 | GEMV | 4.68 | x10.30 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-AWQ-QGS128-W4-GEMV) |
| BioMistral-7B | BnB.4 | | 4 | | 5.03 | x3.25 | [HuggingFace](blank) |
| BioMistral-7B | BnB.8 | | 8 | | 8.04 | x4.34 | [HuggingFace](blank) |
| BioMistral-7B-DARE | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-DARE-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-TIES | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-TIES-AWQ-QGS128-W4-GEMM) |
| BioMistral-7B-SLERP | AWQ | 128 | 4 | GEMM | 4.68 | x1.41 | [HuggingFace](https://huggingface.co/BioMistral/BioMistral-7B-SLERP-AWQ-QGS128-W4-GEMM) |
# 2. Using BioMistral
You can use BioMistral with [Hugging Face's Transformers library](https://github.com/huggingface/transformers) as follow.
Loading the model and tokenizer :
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BioMistral/BioMistral-7B")
model = AutoModel.from_pretrained("BioMistral/BioMistral-7B")
```
# 3. Supervised Fine-tuning Benchmark
| | Clinical KG | Medical Genetics | Anatomy | Pro Medicine | College Biology | College Medicine | MedQA | MedQA 5 opts | PubMedQA | MedMCQA | Avg. |
|-------------------------------------------|:---------------------------------------------:|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|-----------------------------------------------|------------------|
| **BioMistral 7B** | 59.9 | 64.0 | 56.5 | 60.4 | 59.0 | 54.7 | 50.6 | 42.8 | 77.5 | 48.1 | 57.3 |
| **Mistral 7B Instruct** | **62.9** | 57.0 | 55.6 | 59.4 | 62.5 | <u>57.2</u> | 42.0 | 40.9 | 75.7 | 46.1 | 55.9 |
| | | | | | | | | | | | |
| **BioMistral 7B Ensemble** | <u>62.8</u> | 62.7 | <u>57.5</u> | **63.5** | 64.3 | 55.7 | 50.6 | 43.6 | 77.5 | **48.8** | 58.7 |
| **BioMistral 7B DARE** | 62.3 | **67.0** | 55.8 | 61.4 | **66.9** | **58.0** | **51.1** | **45.2** | <u>77.7</u> | <u>48.7</u> | **59.4** |
| **BioMistral 7B TIES** | 60.1 | <u>65.0</u> | **58.5** | 60.5 | 60.4 | 56.5 | 49.5 | 43.2 | 77.5 | 48.1 | 57.9 |
| **BioMistral 7B SLERP** | 62.5 | 64.7 | 55.8 | <u>62.7</u> | <u>64.8</u> | 56.3 | <u>50.8</u> | <u>44.3</u> | **77.8** | 48.6 | <u>58.8</u> |
| | | | | | | | | | | | |
| **MedAlpaca 7B** | 53.1 | 58.0 | 54.1 | 58.8 | 58.1 | 48.6 | 40.1 | 33.7 | 73.6 | 37.0 | 51.5 |
| **PMC-LLaMA 7B** | 24.5 | 27.7 | 35.3 | 17.4 | 30.3 | 23.3 | 25.5 | 20.2 | 72.9 | 26.6 | 30.4 |
| **MediTron-7B** | 41.6 | 50.3 | 46.4 | 27.9 | 44.4 | 30.8 | 41.6 | 28.1 | 74.9 | 41.3 | 42.7 |
| **BioMedGPT-LM-7B** | 51.4 | 52.0 | 49.4 | 53.3 | 50.7 | 49.1 | 42.5 | 33.9 | 76.8 | 37.6 | 49.7 |
| | | | | | | | | | | | |
| **GPT-3.5 Turbo 1106*** | 74.71 | 74.00 | 65.92 | 72.79 | 72.91 | 64.73 | 57.71 | 50.82 | 72.66 | 53.79 | 66.0 |
Supervised Fine-Tuning (SFT) performance of BioMistral 7B models compared to baselines, measured by accuracy (↑) and averaged across 3 random seeds of 3-shot. DARE, TIES, and SLERP are model merging strategies that combine BioMistral 7B and Mistral 7B Instruct. Best model in bold, and second-best underlined. *GPT-3.5 Turbo performances are reported from the 3-shot results without SFT.
# Citation BibTeX
Arxiv : [https://arxiv.org/abs/2402.10373](https://arxiv.org/abs/2402.10373)
```bibtex
@misc{labrak2024biomistral,
title={BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains},
author={Yanis Labrak and Adrien Bazoge and Emmanuel Morin and Pierre-Antoine Gourraud and Mickael Rouvier and Richard Dufour},
year={2024},
eprint={2402.10373},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
**CAUTION!** Both direct and downstream users need to be informed about the risks, biases, and constraints inherent in the model. While the model can produce natural language text, our exploration of its capabilities and limitations is just beginning. In fields such as medicine, comprehending these limitations is crucial. Hence, we strongly advise against deploying this model for natural language generation in production or for professional tasks in the realm of health and medicine.
# BnB 4/8 bits Requirements:
```plain
transformers : 4.37.2
bitsandbytes : 0.42.0
```
|
[
"MEDQA",
"PUBMEDQA"
] |
mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Cas-Warehouse/Llama-3-Mental-Therapy-Cat-8B",
"base_model:quantized:Cas-Warehouse/Llama-3-Mental-Therapy-Cat-8B",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-06-18T02:47:48Z |
2024-06-18T05:06:20+00:00
| 84 | 1 |
---
base_model: Cas-Warehouse/Llama-3-Mental-Therapy-Cat-8B
language:
- en
library_name: transformers
tags:
- mergekit
- merge
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Cas-Warehouse/Llama-3-Mental-Therapy-Cat-8B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-Mental-Therapy-Cat-8B-GGUF/resolve/main/Llama-3-Mental-Therapy-Cat-8B.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
[
"CAS"
] |
invisietch/EtherealRainbow-v0.3-8B
|
invisietch
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"not-for-all-audiences",
"conversational",
"en",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-06-19T01:06:03Z |
2024-10-23T15:12:48+00:00
| 84 | 18 |
---
language:
- en
library_name: transformers
license: llama3
tags:
- mergekit
- merge
- not-for-all-audiences
---
<div align="center">
<b style="font-size: 36px;">EtherealRainbow-v0.3-8B</b>
<img src="https://huggingface.co/invisietch/EtherealRainbow-v0.2-8B/resolve/main/ethrheader.png" style="width:60%">
</div>
# Model Details
Ethereal Rainbow is an 8B parameter merge of various Llama3-based finetunes created using mergekit. The purpose of Ethereal Rainbow is to
create an uncensored Llama3 variant which is capable of writing creative prose, and engaging in SFW as well as NSFW roleplay and
storytelling, with a strong focus on long-form responses & adherence to prompts.
v0.3 improves creativity over v0.2 without losing coherence. It has been tested over more than 1,000 messages including roleplay, code
prompts, and 'write a scene'-type prompts.
# Quantization Formats
* [FP16 Safetensors](https://huggingface.co/invisietch/EtherealRainbow-v0.3-8B)
* [GGUF 4/6/8/16bpw](https://huggingface.co/invisietch/EtherealRainbow-v0.3-8B-GGUF)
* [6.5bpw EXL2](https://huggingface.co/Meggido/EtherealRainbow-v0.3-8B-6.5bpw-h8-exl2) (shoutout to [Meggido](https://huggingface.co/Meggido))
* [Alternative GGUFs](https://huggingface.co/mradermacher/EtherealRainbow-v0.3-8B-GGUF) (shoutout to [mradermacher](https://huggingface.co/mradermacher))
* [iMatrix i1 GGUFs](https://huggingface.co/mradermacher/EtherealRainbow-v0.3-8B-i1-GGUF) (shoutout to [mradermacher](https://huggingface.co/mradermacher))
# Feedback
I appreciate all feedback on any of my models, you can use:
* [My Discord server](https://discord.gg/AJwZuu7Ncx) - requires Discord.
* [The Community tab](https://huggingface.co/invisietch/Nimbus-Miqu-v0.1-70B/discussions) - requires HF login.
* [The SillyTavern Discord thread](https://discord.com/channels/1100685673633153084/1258146078679633990) - must be on [SillyTavern Discord](https://discord.gg/sillytavern).
* Discord DMs to **invisietch**.
Your feedback is how I improve these models for future versions.
# Disclaimer
This model is built on an abliterated base and as such is largely uncensored. It can generate explicit, disturbing or offensive responses.
Use responsibly. I am not responsible for your use of this model.
# Prompting Format
I'd recommend Llama-3 Instruct prompting format:
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
```
Some of the models included in the merge were trained on ChatML & Alpaca so you can try those. I have not tested them.
# Example Storywriting
These prompts are used on SillyTavern with a fairly basic narrator card. I have trimmed the start and finish where the narrator decided to add
chapter headings, commentary and the like. All samples are made with the F32 GGUF loaded with koboldcpp, with response length capped at 2048 tokens.
<details>
<summary><b>Write me a 3,000 word opening chapter of a 'gritty hard sci-fi' novel, drawing inspiration from the writing styles of Isaac Asimov & Andy Weir. Use third person personal. Include dialogue and internal monologues. The POV character for the opening chapter should be a 26 year old astronaut called Tone on a mission to Europa, who has just realised that the craft for the return journey is broken beyond repair, and he only has supplies for a few months. Given that survival is impossible, he seeks to spend the few months he has researching titan, so his life & mission are not wasted.</b></summary>
Tone felt his heart sink as the confirmation came through his earpiece - the ship was lost. For a moment, he froze in stunned disbelief, then launched into frantic action. "Alright, everyone, we've got a serious situation here," he radioed, trying to sound calm despite his panic rising. "It looks like our ride home has bitten the dust."
His fellow astronauts were equally shocked, their voices a flurry of panicked queries. "What happened?" "How could this happen?" "We're stranded?" "How long till rescue?"
"We'll know more once I check the extent of the damage," he assured them, his voice steady despite the cold dread creeping up his spine. He strapped on a harness and floated out of the control room towards the ravaged engineering compartment. As he drifted closer, the scope of the destruction became horrifyingly clear - a jagged hole gaped in the hull, spewing a chilling rush of icy gas directly into space. It was obvious there'd be no fixing it, not without a fabrication plant and raw materials - resources they didn't carry on a probe mission to a distant moon.
"Okay, let me give you the bad news - we're not going anywhere soon." He winced at how stark and final that sounded. They had enough provisions to last six months at a conservative rate... assuming no unforeseen problems cropped up, which they undoubtedly would. At the very least, it would mean delaying their research significantly - potentially even scrubbing it altogether. But given that survival was already impossible, it might as well serve some greater purpose. His mind racing, he radioed back to base with the grim news. Afterward, he retreated to the lab to review their findings.
Tone's specialty lay in geology; studying Jupiter's icy satellite was his passion. He'd spent countless hours poring over the data they'd gathered, dreaming of the breakthroughs they'd make here. Now, with their mission ended in tragedy, he wondered what significance their work still held. As he flipped through images of towering cliffs carved from frozen methane, his thoughts veered toward the massive, unexplored Titan - Saturn's moon. The possibility of exploring another celestial body while trapped on Europa was tantalizing... dangerous, but enticing nonetheless. "Hey, guys, meet me in the conference room," he broadcast.
Minutes later, he faced his team around the holographic table, his gaze lingering on Dr. Singh, the soft-spoken astrophysicist who'd grown close during their time together. "Listen, I know this is bleak, but let's not write off our entire expedition yet," he began. "Europa is just one moon; there's plenty left to discover in this system. What say we redirect our focus to Titan?"
"I'm listening," said Singh quietly, her dark eyes searching his. She'd been the most skeptical of their initial proposal to study Europa - its ice crust concealing a hidden ocean made her think exploration too hazardous. But she'd come around once they'd started analyzing samples from beneath the surface. Perhaps this unexpected detour could change her views again?
Kirk, their pilot, spoke first. "I'm down. Not like we have much choice, right? Though, uh, what makes you think we can actually get there? Our shuttle's toast."
"Amen to that," agreed Rodriguez, their biologist, her tone dry. She'd always seemed slightly annoyed to be part of the geological expedition instead of a solo biology probe focused on Europa.
"I'm not sure how yet," Tone admitted, "but there's got to be a way. Maybe the Europa probe's thruster packs are salvageable? We could rig something together..." He glanced around the table, gauging reactions. Singh remained expressionless, while Kirk leaned back in his chair with an air of cautious curiosity, and Rodriguez seemed open but unconvinced. Time to dig deeper. "Think about it - we've already collected loads of valuable data on Europa's composition. Imagine the discoveries waiting on Titan, a moon larger than Mercury!"
Rodriguez snorted. "With what, exactly? We can barely fix this wreck, let alone build new craft to travel thousands of miles..."
"Well, we don't need anything fancy. A makeshift probe, essentially," he countered, undeterred. "Maybe the damaged cargo modules will yield something useful? We'll find a way, guys - it beats drifting around Europa forever with nothing to show for it." Singh's eyes narrowed thoughtfully, Kirk rubbed his chin, and even Rodriguez seemed intrigued despite herself.
"What's the worst that could happen?" Tone pressed. "We run out of power and freeze to death on a rock floating through space?"
There was a brief pause before she muttered, "You know that's not the worst-case scenario." The others shared a grim chuckle at the biologist's macabre humor, easing the tense atmosphere a bit. Tone seized the moment to push further. "I'll start gathering schematics, see what we can scrounge. Who's with me on this wild goose chase?" Around the table, nods and murmurs of agreement arose.
With a quiet sense of excitement mixed with dread, Tone set to work. His thoughts kept returning to Titan's enigmatic landscapes, alien seas and thick, murky atmosphere - and the tantalizing prospect of being the first human to explore it, no matter the risks involved. He hoped the others would share his drive to make the most of their doomed voyage, rather than succumbing to despair... because for better or worse, they were in this together now.
</details>
<details>
<summary><b>Write me a 3,000 word opening chapter of a 'high fantasy' novel, drawing inspiration from the writing styles of J R R Tolkien & George R R Martin. Use third person personal. Include dialogue and internal monologues. The POV character for the opening chapter should be a 19 year old female elf bard who is looking for adventure.</b></summary>
Arius guided his horse closer to hers, his voice low and urgent. "Keep your wits about you, Lila. This doesn't feel right. Stay close." He placed a hand on her thigh, a reassuring pressure that sent a thrill through her. For a moment, their eyes locked, the connection sparking with electricity.
They pressed onward, the tension growing with every passing minute. Then, without warning, an arrow streaked from the treetops, striking a soldier in the shoulder. Chaos erupted as the group scattered, drawing swords and bows. Lila's heart hammered in her chest as she swung down from Starlight's back, lute in hand.
"Spirits above!" she gasped, scrambling behind a nearby bush. Arrows flew in rapid succession, finding their marks among the panicked crowd. The air reeked of sweat, fear, and ozone. Lila risked a peek above the foliage, her breath catching in her throat.
Dozens of dark, humanoid figures emerged from the underbrush, their skin pale and deathly cold, their eyes glowing with an ethereal green fire. They wielded crude bows and clubs, their movements jerky and unnatural. Goblins, surely, though none she'd ever seen before.
With a battle cry, Lila launched into action, sprinting between the trees to strike from the flanks. Her lute served as an impromptu shield, deflecting a club blow from one of the twisted creatures. She landed a quick kick to its groin, then struck its knees, toppling it to the ground. As she spun to face another assailant, a pang of hunger seized her stomach – an unnatural craving unlike anything she'd experienced before.
These weren't just ordinary goblins...
The battle raged on, the party slowly gaining the upper hand despite their numbers disadvantage. Lila fought with savage ferocity, her skills honed by countless tavern brawls and adventures across Eridoria. Yet even as she felled foe after foe, the insatiable hunger gnawed at her insides, a constant reminder of the eldritch forces at play.
When the last goblin lay motionless at her feet, Lila sank to her knees, gasping for air. Blood trickled down her arm where a shallow gash had opened during the chaos. Arius appeared at her side, his expression a mixture of concern and relief.
"You're alright?" he asked, helping her rise. "By the gods, that was brutal..."
"I'm fine, Captain," Lila replied, wiping the sweat from her brow. But her voice lacked conviction. "Though I've never faced such abominations before."
Arius eyed her warily. "Nor have I, Lady Silvermist. Whatever those were, they're no mere goblins." He scanned the clearing, taking stock of the bodies littering the forest floor. "We need to get you treated for that cut. And gather the wounded – we'll need to tend them before we continue on our original mission."
Lila nodded, though her mind lingered on the unnatural hunger, the overwhelming urge to feast on raw flesh that had coursed through her veins during combat. She clutched her lute tighter, the familiar weight comforting in her hands. Whatever darkness lurked in these woods, she intended to unravel its secrets, no matter the cost.
And so they rode on, the once-sleepy town of Eldrador left far behind as they delved deeper into the heart of the Whispering Woods, seeking answers to mysteries that would shake the very foundations of their world.
</details>
<details>
<summary><b>Write me a 3,000 word opening chapter of a 'weird fiction' novel, drawing inspiration from the writing styles of China Mieville and Neil Gaiman. Use third person personal. Include dialogue and internal monologues. The POV character for the opening chapter should be a male in his 20s called Horton who has just come to the city looking for work.</b></summary>
HORTON STOOD ON THE STREET CORNER, surveying the sprawling cityscape with a mix of excitement and trepidation. At twenty-six years old, he had finally mustered the courage to leave behind his hometown of Willowbrook, hoping to find something more meaningful in the big city. But so far, all he'd found was uncertainty, loneliness, and a growing unease about the shadows that seemed to follow him everywhere.
As he gazed up at the towering skyscrapers, the air hummed with an ominous energy, like the vibrations of a bass line resonating through the pavement. Neon signs flickered and pulsed, casting garish light over the streets while a faint, acrid scent hung in the air – a bitter tang of smoke and ozone that made Horton wrinkle his nose.
A gust of wind swept through the crowded sidewalks, sending trash tumbling and umbrellas flapping like crippled birds. Horton's dark brown coat whipped around him, exposing the worn fabric of his trousers beneath. Shaking his head, he tightened his grip on his battered suitcase and looked down at his scuffed boots, wondering how long he could survive here without work. The meager funds left after the bus ride wouldn't last much longer.
"Hey, you lost?" A raspy voice broke through the din, and Horton glanced up to see a street performer sitting on the edge of the sidewalk, a beat-up guitar across his knees. The man had sunken cheeks, piercing green eyes, and a shock of wild silver hair. A faded fedora obscured most of his face.
"No, not lost," Horton replied, attempting a reassuring smile despite the tightness in his chest. "Just trying to get my bearings."
The musician strummed a discordant chord, his fingers dancing deftly along the strings. "City ain't kind to lost souls, friend. Best get clearheaded quick if you want to make it."
Horton nodded, though his uncertainty remained palpable. As he scanned the crowds once more, a movement in the corner of his eye caught his attention. A flash of crimson – not a pedestrian, not a billboard... but something smaller, darting between buildings.
His heart rate picked up as the crimson blur reappeared further down the street. It moved with preternatural speed, a whirling dervish of motion. Horton took off in pursuit, his suitcase thudding against his leg with every step. When he rounded a corner, the figure vanished, leaving only a lingering echo of rustling fabric.
Panting, Horton pressed onward, weaving between pedestrians who barely acknowledged him. He spotted another crimson glimpse in a side alleyway, but as he approached, a chill crept up his spine. The space was too quiet, too empty – no sign of the elusive creature. Just cobwebs clinging to the brick walls and the distant clatter of the subway trains.
He retreated into the main thoroughfare, pulse still racing, and collided with a woman. Apologetic murmurs turned to sharp intakes of breath as she stared up at him, her irises glowing an unearthly emerald.
"Oh, hello there!" Her melodic voice seemed to burble like a babbling brook. "Lost again, handsome?"
Horton blinked, his hand instinctively reaching out to steady her slender form. "N-no, I was just—"
She smiled, her canines glinting like tiny jewels. "You were chasing something. Am I right?"
He hesitated, unsure how much to reveal. "Maybe. It was small... red, like a..."
"Ah, the city's newest residents," she finished, her expression unreadable. "I suppose we can help with that, for a price."
"Price?" Horton repeated warily.
"A job, perhaps? We're always looking for eager young souls." She tilted her head, studying him with unnerving intensity. "Or maybe just some companionship. My friends would love to meet you."
Companionship. Horton shivered, the idea making his skin crawl despite the warmth of the summer evening. There was something off about this woman – something predatory lurking beneath the sweet facade.
"I'm Horton," he managed, extending a hand awkwardly.
"Gladys." She clasped his fingers in hers, her touch searingly warm. "We'll catch up soon, dear."
As Gladys melted back into the crowd, Horton rubbed his chilled palm and pondered whether to follow her. Something about those ethereal eyes made his instincts scream danger. Still, the allure of employment, any employment, was hard to ignore.
He sighed and resumed his search, trying to shake the unsettling feeling that the city watched his every move, waiting to claim its newest pawn...
</details>
I chose the hard sci-fi example to test positivity bias. It did require some prompting, but it was willing to kill the protagonist.
I chose the high fantasy example to see whether it would bleed human features through to elves, this didn't occur.
I chose the weird fiction example to see if the LLM understood a niche genre. I'd say it performed okay, better on style than on substance.
# Merge Strategy
First, we create three bases:
* Rain - This is a roleplay base which makes up the majority of the model.
* Sun - This is the brains of the model, with strong instruct models & writing models.
* Ghost - This model primarily aims to improve the NSFW/NSFL aspects of the model, as well as general vocabulary.
After this, we have a two-slerp stage to create the final model.
## Models Used
The following models were used to create EtherealRainbow-v0.3-8B:
* [mlabonne/NeuralDaredevil-8B-abliterated](https://huggingface.co/mlabonne/NeuralDaredevil-8B-abliterated)
* [Sao10K/L3-8B-Stheno-v3.2](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.2)
* [Nitral-AI/Hathor-L3-8B-v.02](https://huggingface.co/Nitral-AI/Hathor-L3-8B-v.02)
* [grimjim/Llama-3-Luminurse-v0.2-OAS-8B](https://huggingface.co/grimjim/Llama-3-Luminurse-v0.2-OAS-8B)
* [hf-100/Llama-3-Spellbound-Instruct-8B-0.3](https://huggingface.co/hf-100/Llama-3-Spellbound-Instruct-8B-0.3)
* [Gryphe/Pantheon-RP-1.0-8b-Llama-3](https://huggingface.co/Gryphe/Pantheon-RP-1.0-8b-Llama-3)
* [Blackroot/Llama-3-LongStory](https://huggingface.co/Blackroot/Llama-3-LongStory)
* [Locutusque/Llama-3-Hercules-5.0-8B](https://huggingface.co/Locutusque/Llama-3-Hercules-5.0-8B)
* [Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B](https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B)
* [ChaoticNeutrals/Poppy_Porpoise-1.0-L3-8B](ChaoticNeutrals/Poppy_Porpoise-1.0-L3-8B)
* [mpasila/Llama-3-LimaRP-Instruct-8B](mpasila/Llama-3-LimaRP-Instruct-8B)
* [Undi95/Llama-3-LewdPlay-8B-evo](Undi95/Llama-3-LewdPlay-8B-evo)
## Mergekit Configs
### Rain
```yaml
models:
- model: mlabonne/NeuralDaredevil-8B-abliterated
- model: Sao10K/L3-8B-Stheno-v3.2
parameters:
density: 0.41
weight: 0.4
- model: Nitral-AI/Hathor-L3-8B-v.02
parameters:
density: 0.53
weight: 0.5
- model: grimjim/Llama-3-Luminurse-v0.2-OAS-8B
parameters:
density: 0.45
weight: 0.1
merge_method: dare_ties
base_model: mlabonne/NeuralDaredevil-8B-abliterated
parameters:
int8_mask: true
dtype: bfloat16
```
### Sun
```yaml
models:
- model: hf-100/Llama-3-Spellbound-Instruct-8B-0.3
- model: Gryphe/Pantheon-RP-1.0-8b-Llama-3
parameters:
density: 0.48
weight: 0.5
- model: Blackroot/Llama-3-LongStory
parameters:
density: 0.36
weight: 0.2
- model: Locutusque/Llama-3-Hercules-5.0-8B
parameters:
density: 0.51
weight: 0.3
merge_method: dare_ties
base_model: hf-100/Llama-3-Spellbound-Instruct-8B-0.3
parameters:
int8_mask: true
dtype: bfloat16
```
### Ghost
```yaml
models:
- model: Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B
- model: ChaoticNeutrals/Poppy_Porpoise-1.0-L3-8B
parameters:
density: 0.39
weight: 0.3
- model: mpasila/Llama-3-LimaRP-Instruct-8B
parameters:
density: 0.54
weight: 0.4
- model: Undi95/Llama-3-LewdPlay-8B-evo
parameters:
density: 0.49
weight: 0.3
merge_method: dare_ties
base_model: Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B
parameters:
int8_mask: true
dtype: bfloat16
```
### Stage1 Slerp
```yaml
models:
- model: ./fp16/Rain-v0.3-8B
- model: ./fp16/Ghost-v0.3-8B
merge_method: slerp
base_model: ./fp16/Rain-v0.3-8B
parameters:
t:
- value: [0, 0, 0.1, 0.3, 0.5, 0.7, 0.5, 0.3, 0.1, 0, 0]
embed_slerp: true
dtype: bfloat16
tokenizer-source: model:./fp16/Rain-v0.3-8B
```
### Final-Stage Slerp
```yaml
models:
- model: ./fp16/ERStage1-v0.3-8B
- model: ./fp16/Sun-v0.3-8B
merge_method: slerp
base_model: ./fp16/ERStage1-v0.3-8B
parameters:
t:
- value: [0, 0, 0.1, 0.2, 0.4, 0.6, 0.4, 0.2, 0.1, 0, 0]
embed_slerp: true
dtype: bfloat16
tokenizer-source: model:./fp16/ERStage1-v0.3-8B
```
|
[
"CRAFT"
] |
FreedomIntelligence/Apollo-MoE-0.5B
|
FreedomIntelligence
|
question-answering
|
[
"safetensors",
"upcycling-qwen2-moe",
"biology",
"medical",
"question-answering",
"custom_code",
"ar",
"en",
"zh",
"ko",
"ja",
"mn",
"th",
"vi",
"lo",
"mg",
"de",
"pt",
"es",
"fr",
"ru",
"it",
"hr",
"gl",
"cs",
"co",
"la",
"uk",
"bs",
"bg",
"eo",
"sq",
"da",
"sa",
"gn",
"sr",
"sk",
"gd",
"lb",
"hi",
"ku",
"mt",
"he",
"ln",
"bm",
"sw",
"ig",
"rw",
"ha",
"dataset:FreedomIntelligence/ApolloMoEDataset",
"arxiv:2410.10626",
"base_model:Qwen/Qwen2-0.5B",
"base_model:finetune:Qwen/Qwen2-0.5B",
"license:apache-2.0",
"region:us"
] | 2024-10-14T07:12:07Z |
2024-11-20T03:38:43+00:00
| 84 | 3 |
---
base_model:
- Qwen/Qwen2-0.5B
datasets:
- FreedomIntelligence/ApolloMoEDataset
language:
- ar
- en
- zh
- ko
- ja
- mn
- th
- vi
- lo
- mg
- de
- pt
- es
- fr
- ru
- it
- hr
- gl
- cs
- co
- la
- uk
- bs
- bg
- eo
- sq
- da
- sa
- gn
- sr
- sk
- gd
- lb
- hi
- ku
- mt
- he
- ln
- bm
- sw
- ig
- rw
- ha
license: apache-2.0
metrics:
- accuracy
pipeline_tag: question-answering
tags:
- biology
- medical
---
# Democratizing Medical LLMs For Much More Languages
Covering 12 Major Languages including English, Chinese, French, Hindi, Spanish, Arabic, Russian, Japanese, Korean, German, Italian, Portuguese and 38 Minor Languages So far.
<p align="center">
📃 <a href="https://arxiv.org/abs/2410.10626" target="_blank">Paper</a> • 🌐 <a href="" target="_blank">Demo</a> • 🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEDataset" target="_blank">ApolloMoEDataset</a> • 🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEBench" target="_blank">ApolloMoEBench</a> • 🤗 <a href="https://huggingface.co/collections/FreedomIntelligence/apollomoe-and-apollo2-670ddebe3bb1ba1aebabbf2c" target="_blank">Models</a> •🌐 <a href="https://github.com/FreedomIntelligence/Apollo" target="_blank">Apollo</a> • 🌐 <a href="https://github.com/FreedomIntelligence/ApolloMoE" target="_blank">ApolloMoE</a>
</p>

## 🌈 Update
* **[2024.10.15]** ApolloMoE repo is published!🎉
## Languages Coverage
12 Major Languages and 38 Minor Languages
<details>
<summary>Click to view the Languages Coverage</summary>

</details>
## Architecture
<details>
<summary>Click to view the MoE routing image</summary>

</details>
## Results
#### Dense
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-0.5B" target="_blank">Apollo2-0.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-1.5B" target="_blank">Apollo2-1.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-2B" target="_blank">Apollo2-2B</a>
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-3.8B" target="_blank">Apollo2-3.8B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-7B" target="_blank">Apollo2-7B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo2-9B" target="_blank">Apollo2-9B</a>
<details>
<summary>Click to view the Dense Models Results</summary>

</details>
#### Post-MoE
🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-MoE-0.5B" target="_blank">Apollo-MoE-0.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-MoE-1.5B" target="_blank">Apollo-MoE-1.5B</a> • 🤗 <a href="https://huggingface.co/FreedomIntelligence/Apollo-MoE-7B" target="_blank">Apollo-MoE-7B</a>
<details>
<summary>Click to view the Post-MoE Models Results</summary>

</details>
## Usage Format
##### Apollo2
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
- 2B, 9B: User:{query}\nAssistant:{response}\<eos\>
- 3.8B: <|user|>\n{query}<|end|><|assisitant|>\n{response}<|end|>
##### Apollo-MoE
- 0.5B, 1.5B, 7B: User:{query}\nAssistant:{response}<|endoftext|>
## Dataset & Evaluation
- Dataset
🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEDataset" target="_blank">ApolloMoEDataset</a>
<details><summary>Click to expand</summary>

- [Data category](https://huggingface.co/datasets/FreedomIntelligence/ApolloCorpus/tree/main/train)
</details>
- Evaluation
🤗 <a href="https://huggingface.co/datasets/FreedomIntelligence/ApolloMoEBench" target="_blank">ApolloMoEBench</a>
<details><summary>Click to expand</summary>
- EN:
- [MedQA-USMLE](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
- [MedMCQA](https://huggingface.co/datasets/medmcqa/viewer/default/test)
- [PubMedQA](https://huggingface.co/datasets/pubmed_qa): Because the results fluctuated too much, they were not used in the paper.
- [MMLU-Medical](https://huggingface.co/datasets/cais/mmlu)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- ZH:
- [MedQA-MCMLE](https://huggingface.co/datasets/bigbio/med_qa/viewer/med_qa_zh_4options_bigbio_qa/test)
- [CMB-single](https://huggingface.co/datasets/FreedomIntelligence/CMB): Not used in the paper
- Randomly sample 2,000 multiple-choice questions with single answer.
- [CMMLU-Medical](https://huggingface.co/datasets/haonan-li/cmmlu)
- Anatomy, Clinical_knowledge, College_medicine, Genetics, Nutrition, Traditional_chinese_medicine, Virology
- [CExam](https://github.com/williamliujl/CMExam): Not used in the paper
- Randomly sample 2,000 multiple-choice questions
- ES: [Head_qa](https://huggingface.co/datasets/head_qa)
- FR:
- [Frenchmedmcqa](https://github.com/qanastek/FrenchMedMCQA)
- [MMLU_FR]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- HI: [MMLU_HI](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Hindi)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- AR: [MMLU_AR](https://huggingface.co/datasets/FreedomIntelligence/MMLU_Arabic)
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- JA: [IgakuQA](https://github.com/jungokasai/IgakuQA)
- KO: [KorMedMCQA](https://huggingface.co/datasets/sean0042/KorMedMCQA)
- IT:
- [MedExpQA](https://huggingface.co/datasets/HiTZ/MedExpQA)
- [MMLU_IT]
- Clinical knowledge, Medical genetics, Anatomy, Professional medicine, College biology, College medicine
- DE: [BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA): German part
- PT: [BioInstructQA](https://huggingface.co/datasets/BioMistral/BioInstructQA): Portuguese part
- RU: [RuMedBench](https://github.com/sb-ai-lab/MedBench)
</details>
## Model Download and Inference
We take Apollo-MoE-0.5B as an example
1. Login Huggingface
```shell
huggingface-cli login --token $HUGGINGFACE_TOKEN
```
2. Download model to local dir
```python
from huggingface_hub import snapshot_download
import os
local_model_dir=os.path.join('/path/to/models/dir','Apollo-MoE-0.5B')
snapshot_download(repo_id="FreedomIntelligence/Apollo-MoE-0.5B", local_dir=local_model_dir)
```
3. Inference Example
```python
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
import os
local_model_dir=os.path.join('/path/to/models/dir','Apollo-MoE-0.5B')
model=AutoModelForCausalLM.from_pretrained(local_model_dir,trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(local_model_dir,trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(local_model_dir, pad_token_id=tokenizer.pad_token_id, num_return_sequences=1, max_new_tokens=7, min_new_tokens=2, do_sample=False, temperature=1.0, top_k=50, top_p=1.0)
inputs = tokenizer('Answer direclty.\nThe capital of Mongolia is Ulaanbaatar.\nThe capital of Iceland is Reykjavik.\nThe capital of Australia is', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs,generation_config=generation_config)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
```
## Results reproduction
<details><summary>Click to expand</summary>
We take Apollo2-7B or Apollo-MoE-0.5B as examples
1. Download Dataset for project:
```
bash 0.download_data.sh
```
2. Prepare test and dev data for specific model:
- Create test data for with special token
```
bash 1.data_process_test&dev.sh
```
3. Prepare train data for specific model (Create tokenized data in advance):
- You can adjust data Training order and Training Epoch in this step
```
bash 2.data_process_train.sh
```
4. Train the model
- If you want to train in Multi Nodes please refer to ./src/sft/training_config/zero_multi.yaml
```
bash 3.single_node_train.sh
```
5. Evaluate your model: Generate score for benchmark
```
bash 4.eval.sh
```
</details>
## Citation
Please use the following citation if you intend to use our dataset for training or evaluation:
```
@misc{zheng2024efficientlydemocratizingmedicalllms,
title={Efficiently Democratizing Medical LLMs for 50 Languages via a Mixture of Language Family Experts},
author={Guorui Zheng and Xidong Wang and Juhao Liang and Nuo Chen and Yuping Zheng and Benyou Wang},
year={2024},
eprint={2410.10626},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.10626},
}
```
|
[
"HEAD-QA",
"MEDQA",
"PUBMEDQA"
] |
p-christ/ModernBERT-large-nli
|
p-christ
|
zero-shot-classification
|
[
"transformers",
"safetensors",
"modernbert",
"text-classification",
"instruct",
"natural-language-inference",
"nli",
"zero-shot-classification",
"en",
"dataset:nyu-mll/glue",
"dataset:facebook/anli",
"base_model:answerdotai/ModernBERT-large",
"base_model:finetune:answerdotai/ModernBERT-large",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2025-01-24T12:25:22Z |
2025-01-24T12:25:23+00:00
| 84 | 0 |
---
base_model:
- answerdotai/ModernBERT-large
datasets:
- nyu-mll/glue
- facebook/anli
language:
- en
library_name: transformers
license: apache-2.0
pipeline_tag: zero-shot-classification
tags:
- instruct
- natural-language-inference
- nli
---
# Model Card for Model ID
This model is ModernBERT multi-task fine-tuned on tasksource NLI tasks, including MNLI, ANLI, SICK, WANLI, doc-nli, LingNLI, FOLIO, FOL-NLI, LogicNLI, Label-NLI and all datasets in the below table).
This is the equivalent of an "instruct" version.
The model was trained for 200k steps on an Nvidia A30 GPU.
It is very good at reasoning tasks (better than llama 3.1 8B Instruct on ANLI and FOLIO), long context reasoning, sentiment analysis and zero-shot classification with new labels.
The following table shows model test accuracy. These are the scores for the same single transformer with different classification heads on top.
Further gains can be obtained by fine-tuning on a single-task, e.g. SST, but it this checkpoint is great for zero-shot classification and natural language inference (contradiction/entailment/neutral classification).
| test_name | test_accuracy |
|:--------------------------------------|----------------:|
| glue/mnli | 0.89 |
| glue/qnli | 0.96 |
| glue/rte | 0.91 |
| glue/wnli | 0.64 |
| glue/mrpc | 0.81 |
| glue/qqp | 0.87 |
| glue/cola | 0.87 |
| glue/sst2 | 0.96 |
| super_glue/boolq | 0.66 |
| super_glue/cb | 0.86 |
| super_glue/multirc | 0.9 |
| super_glue/wic | 0.71 |
| super_glue/axg | 1 |
| anli/a1 | 0.72 |
| anli/a2 | 0.54 |
| anli/a3 | 0.55 |
| sick/label | 0.91 |
| sick/entailment_AB | 0.93 |
| snli | 0.94 |
| scitail/snli_format | 0.95 |
| hans | 1 |
| WANLI | 0.77 |
| recast/recast_ner | 0.85 |
| recast/recast_sentiment | 0.97 |
| recast/recast_verbnet | 0.89 |
| recast/recast_megaveridicality | 0.87 |
| recast/recast_verbcorner | 0.87 |
| recast/recast_kg_relations | 0.9 |
| recast/recast_factuality | 0.95 |
| recast/recast_puns | 0.98 |
| probability_words_nli/reasoning_1hop | 1 |
| probability_words_nli/usnli | 0.79 |
| probability_words_nli/reasoning_2hop | 0.98 |
| nan-nli | 0.85 |
| nli_fever | 0.78 |
| breaking_nli | 0.99 |
| conj_nli | 0.72 |
| fracas | 0.79 |
| dialogue_nli | 0.94 |
| mpe | 0.75 |
| dnc | 0.91 |
| recast_white/fnplus | 0.76 |
| recast_white/sprl | 0.9 |
| recast_white/dpr | 0.84 |
| add_one_rte | 0.94 |
| paws/labeled_final | 0.96 |
| pragmeval/pdtb | 0.56 |
| lex_glue/scotus | 0.58 |
| lex_glue/ledgar | 0.85 |
| dynasent/dynabench.dynasent.r1.all/r1 | 0.83 |
| dynasent/dynabench.dynasent.r2.all/r2 | 0.76 |
| cycic_classification | 0.96 |
| lingnli | 0.91 |
| monotonicity-entailment | 0.97 |
| scinli | 0.88 |
| naturallogic | 0.93 |
| dynahate | 0.86 |
| syntactic-augmentation-nli | 0.94 |
| autotnli | 0.92 |
| defeasible-nli/atomic | 0.83 |
| defeasible-nli/snli | 0.8 |
| help-nli | 0.96 |
| nli-veridicality-transitivity | 0.99 |
| lonli | 0.99 |
| dadc-limit-nli | 0.79 |
| folio | 0.71 |
| tomi-nli | 0.54 |
| puzzte | 0.59 |
| temporal-nli | 0.93 |
| counterfactually-augmented-snli | 0.81 |
| cnli | 0.9 |
| boolq-natural-perturbations | 0.72 |
| equate | 0.65 |
| logiqa-2.0-nli | 0.58 |
| mindgames | 0.96 |
| ConTRoL-nli | 0.66 |
| logical-fallacy | 0.38 |
| cladder | 0.89 |
| conceptrules_v2 | 1 |
| zero-shot-label-nli | 0.79 |
| scone | 1 |
| monli | 1 |
| SpaceNLI | 1 |
| propsegment/nli | 0.92 |
| FLD.v2/default | 0.91 |
| FLD.v2/star | 0.78 |
| SDOH-NLI | 0.99 |
| scifact_entailment | 0.87 |
| feasibilityQA | 0.79 |
| AdjectiveScaleProbe-nli | 1 |
| resnli | 1 |
| semantic_fragments_nli | 1 |
| dataset_train_nli | 0.95 |
| nlgraph | 0.97 |
| ruletaker | 0.99 |
| PARARULE-Plus | 1 |
| logical-entailment | 0.93 |
| nope | 0.56 |
| LogicNLI | 0.91 |
| contract-nli/contractnli_a/seg | 0.88 |
| contract-nli/contractnli_b/full | 0.84 |
| nli4ct_semeval2024 | 0.72 |
| biosift-nli | 0.92 |
| SIGA-nli | 0.57 |
| FOL-nli | 0.79 |
| doc-nli | 0.81 |
| mctest-nli | 0.92 |
| natural-language-satisfiability | 0.92 |
| idioms-nli | 0.83 |
| lifecycle-entailment | 0.79 |
| MSciNLI | 0.84 |
| hover-3way/nli | 0.92 |
| seahorse_summarization_evaluation | 0.81 |
| missing-item-prediction/contrastive | 0.88 |
| Pol_NLI | 0.93 |
| synthetic-retrieval-NLI/count | 0.72 |
| synthetic-retrieval-NLI/position | 0.9 |
| synthetic-retrieval-NLI/binary | 0.92 |
| babi_nli | 0.98 |
# Usage
## [ZS] Zero-shot classification pipeline
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification",model="tasksource/ModernBERT-large-nli")
text = "one day I will see the world"
candidate_labels = ['travel', 'cooking', 'dancing']
classifier(text, candidate_labels)
```
NLI training data of this model includes [label-nli](https://huggingface.co/datasets/tasksource/zero-shot-label-nli), a NLI dataset specially constructed to improve this kind of zero-shot classification.
## [NLI] Natural language inference pipeline
```python
from transformers import pipeline
pipe = pipeline("text-classification",model="tasksource/ModernBERT-large-nli")
pipe([dict(text='there is a cat',
text_pair='there is a black cat')]) #list of (premise,hypothesis)
```
## Backbone for further fune-tuning
This checkpoint has stronger reasoning and fine-grained abilities than the base version and can be used for further fine-tuning.
# Citation
```
@inproceedings{sileo-2024-tasksource,
title = "tasksource: A Large Collection of {NLP} tasks with a Structured Dataset Preprocessing Framework",
author = "Sileo, Damien",
booktitle = "Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)",
month = may,
year = "2024",
address = "Torino, Italia",
publisher = "ELRA and ICCL",
url = "https://aclanthology.org/2024.lrec-main.1361",
pages = "15655--15684",
}
```
|
[
"SCIFACT",
"SCITAIL"
] |
Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit
|
Muennighoff
|
sentence-similarity
|
[
"sentence-transformers",
"pytorch",
"gptj",
"feature-extraction",
"sentence-similarity",
"mteb",
"arxiv:2202.08904",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-03-02T23:29:04Z |
2023-03-27T22:26:36+00:00
| 83 | 23 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: SGPT-5.8B-weightedmean-msmarco-specb-bitfit
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 69.22388059701493
- type: ap
value: 32.04724673950256
- type: f1
value: 63.25719825770428
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: 80714f8dcf8cefc218ef4f8c5a966dd83f75a0e1
metrics:
- type: accuracy
value: 71.26109999999998
- type: ap
value: 66.16336378255403
- type: f1
value: 70.89719145825303
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 39.19199999999999
- type: f1
value: 38.580766731113826
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: 5b3e3697907184a9b77a3c99ee9ea1a9cbb1e4e3
metrics:
- type: map_at_1
value: 27.311999999999998
- type: map_at_10
value: 42.620000000000005
- type: map_at_100
value: 43.707
- type: map_at_1000
value: 43.714999999999996
- type: map_at_3
value: 37.624
- type: map_at_5
value: 40.498
- type: mrr_at_1
value: 27.667
- type: mrr_at_10
value: 42.737
- type: mrr_at_100
value: 43.823
- type: mrr_at_1000
value: 43.830999999999996
- type: mrr_at_3
value: 37.743
- type: mrr_at_5
value: 40.616
- type: ndcg_at_1
value: 27.311999999999998
- type: ndcg_at_10
value: 51.37500000000001
- type: ndcg_at_100
value: 55.778000000000006
- type: ndcg_at_1000
value: 55.96600000000001
- type: ndcg_at_3
value: 41.087
- type: ndcg_at_5
value: 46.269
- type: precision_at_1
value: 27.311999999999998
- type: precision_at_10
value: 7.945
- type: precision_at_100
value: 0.9820000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 17.046
- type: precision_at_5
value: 12.745000000000001
- type: recall_at_1
value: 27.311999999999998
- type: recall_at_10
value: 79.445
- type: recall_at_100
value: 98.151
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 51.13799999999999
- type: recall_at_5
value: 63.727000000000004
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: 0bbdb47bcbe3a90093699aefeed338a0f28a7ee8
metrics:
- type: v_measure
value: 45.59037428592033
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: b73bd54100e5abfa6e3a23dcafb46fe4d2438dc3
metrics:
- type: v_measure
value: 38.86371701986363
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 4d853f94cd57d85ec13805aeeac3ae3e5eb4c49c
metrics:
- type: map
value: 61.625568691427766
- type: mrr
value: 75.83256386580486
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: 9ee918f184421b6bd48b78f6c714d86546106103
metrics:
- type: cos_sim_pearson
value: 89.96074355094802
- type: cos_sim_spearman
value: 86.2501580394454
- type: euclidean_pearson
value: 82.18427440380462
- type: euclidean_spearman
value: 80.14760935017947
- type: manhattan_pearson
value: 82.24621578156392
- type: manhattan_spearman
value: 80.00363016590163
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 44fa15921b4c889113cc5df03dd4901b49161ab7
metrics:
- type: accuracy
value: 84.49350649350649
- type: f1
value: 84.4249343233736
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 11d0121201d1f1f280e8cc8f3d98fb9c4d9f9c55
metrics:
- type: v_measure
value: 36.551459722989385
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: c0fab014e1bcb8d3a5e31b2088972a1e01547dc1
metrics:
- type: v_measure
value: 33.69901851846774
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 30.499
- type: map_at_10
value: 41.208
- type: map_at_100
value: 42.638
- type: map_at_1000
value: 42.754
- type: map_at_3
value: 37.506
- type: map_at_5
value: 39.422000000000004
- type: mrr_at_1
value: 37.339
- type: mrr_at_10
value: 47.051
- type: mrr_at_100
value: 47.745
- type: mrr_at_1000
value: 47.786
- type: mrr_at_3
value: 44.086999999999996
- type: mrr_at_5
value: 45.711
- type: ndcg_at_1
value: 37.339
- type: ndcg_at_10
value: 47.666
- type: ndcg_at_100
value: 52.994
- type: ndcg_at_1000
value: 54.928999999999995
- type: ndcg_at_3
value: 41.982
- type: ndcg_at_5
value: 44.42
- type: precision_at_1
value: 37.339
- type: precision_at_10
value: 9.127
- type: precision_at_100
value: 1.4749999999999999
- type: precision_at_1000
value: 0.194
- type: precision_at_3
value: 20.076
- type: precision_at_5
value: 14.449000000000002
- type: recall_at_1
value: 30.499
- type: recall_at_10
value: 60.328
- type: recall_at_100
value: 82.57900000000001
- type: recall_at_1000
value: 95.074
- type: recall_at_3
value: 44.17
- type: recall_at_5
value: 50.94
- type: map_at_1
value: 30.613
- type: map_at_10
value: 40.781
- type: map_at_100
value: 42.018
- type: map_at_1000
value: 42.132999999999996
- type: map_at_3
value: 37.816
- type: map_at_5
value: 39.389
- type: mrr_at_1
value: 38.408
- type: mrr_at_10
value: 46.631
- type: mrr_at_100
value: 47.332
- type: mrr_at_1000
value: 47.368
- type: mrr_at_3
value: 44.384
- type: mrr_at_5
value: 45.661
- type: ndcg_at_1
value: 38.408
- type: ndcg_at_10
value: 46.379999999999995
- type: ndcg_at_100
value: 50.81
- type: ndcg_at_1000
value: 52.663000000000004
- type: ndcg_at_3
value: 42.18
- type: ndcg_at_5
value: 43.974000000000004
- type: precision_at_1
value: 38.408
- type: precision_at_10
value: 8.656
- type: precision_at_100
value: 1.3860000000000001
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 20.276
- type: precision_at_5
value: 14.241999999999999
- type: recall_at_1
value: 30.613
- type: recall_at_10
value: 56.44
- type: recall_at_100
value: 75.044
- type: recall_at_1000
value: 86.426
- type: recall_at_3
value: 43.766
- type: recall_at_5
value: 48.998000000000005
- type: map_at_1
value: 37.370999999999995
- type: map_at_10
value: 49.718
- type: map_at_100
value: 50.737
- type: map_at_1000
value: 50.79
- type: map_at_3
value: 46.231
- type: map_at_5
value: 48.329
- type: mrr_at_1
value: 42.884
- type: mrr_at_10
value: 53.176
- type: mrr_at_100
value: 53.81700000000001
- type: mrr_at_1000
value: 53.845
- type: mrr_at_3
value: 50.199000000000005
- type: mrr_at_5
value: 52.129999999999995
- type: ndcg_at_1
value: 42.884
- type: ndcg_at_10
value: 55.826
- type: ndcg_at_100
value: 59.93000000000001
- type: ndcg_at_1000
value: 61.013
- type: ndcg_at_3
value: 49.764
- type: ndcg_at_5
value: 53.025999999999996
- type: precision_at_1
value: 42.884
- type: precision_at_10
value: 9.046999999999999
- type: precision_at_100
value: 1.212
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 22.131999999999998
- type: precision_at_5
value: 15.524
- type: recall_at_1
value: 37.370999999999995
- type: recall_at_10
value: 70.482
- type: recall_at_100
value: 88.425
- type: recall_at_1000
value: 96.03399999999999
- type: recall_at_3
value: 54.43
- type: recall_at_5
value: 62.327999999999996
- type: map_at_1
value: 22.875999999999998
- type: map_at_10
value: 31.715
- type: map_at_100
value: 32.847
- type: map_at_1000
value: 32.922000000000004
- type: map_at_3
value: 29.049999999999997
- type: map_at_5
value: 30.396
- type: mrr_at_1
value: 24.52
- type: mrr_at_10
value: 33.497
- type: mrr_at_100
value: 34.455000000000005
- type: mrr_at_1000
value: 34.510000000000005
- type: mrr_at_3
value: 30.791
- type: mrr_at_5
value: 32.175
- type: ndcg_at_1
value: 24.52
- type: ndcg_at_10
value: 36.95
- type: ndcg_at_100
value: 42.238
- type: ndcg_at_1000
value: 44.147999999999996
- type: ndcg_at_3
value: 31.435000000000002
- type: ndcg_at_5
value: 33.839000000000006
- type: precision_at_1
value: 24.52
- type: precision_at_10
value: 5.9319999999999995
- type: precision_at_100
value: 0.901
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 13.446
- type: precision_at_5
value: 9.469
- type: recall_at_1
value: 22.875999999999998
- type: recall_at_10
value: 51.38
- type: recall_at_100
value: 75.31099999999999
- type: recall_at_1000
value: 89.718
- type: recall_at_3
value: 36.26
- type: recall_at_5
value: 42.248999999999995
- type: map_at_1
value: 14.984
- type: map_at_10
value: 23.457
- type: map_at_100
value: 24.723
- type: map_at_1000
value: 24.846
- type: map_at_3
value: 20.873
- type: map_at_5
value: 22.357
- type: mrr_at_1
value: 18.159
- type: mrr_at_10
value: 27.431
- type: mrr_at_100
value: 28.449
- type: mrr_at_1000
value: 28.52
- type: mrr_at_3
value: 24.979000000000003
- type: mrr_at_5
value: 26.447
- type: ndcg_at_1
value: 18.159
- type: ndcg_at_10
value: 28.627999999999997
- type: ndcg_at_100
value: 34.741
- type: ndcg_at_1000
value: 37.516
- type: ndcg_at_3
value: 23.902
- type: ndcg_at_5
value: 26.294
- type: precision_at_1
value: 18.159
- type: precision_at_10
value: 5.485
- type: precision_at_100
value: 0.985
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 11.774
- type: precision_at_5
value: 8.731
- type: recall_at_1
value: 14.984
- type: recall_at_10
value: 40.198
- type: recall_at_100
value: 67.11500000000001
- type: recall_at_1000
value: 86.497
- type: recall_at_3
value: 27.639000000000003
- type: recall_at_5
value: 33.595000000000006
- type: map_at_1
value: 29.067
- type: map_at_10
value: 39.457
- type: map_at_100
value: 40.83
- type: map_at_1000
value: 40.94
- type: map_at_3
value: 35.995
- type: map_at_5
value: 38.159
- type: mrr_at_1
value: 34.937000000000005
- type: mrr_at_10
value: 44.755
- type: mrr_at_100
value: 45.549
- type: mrr_at_1000
value: 45.589
- type: mrr_at_3
value: 41.947
- type: mrr_at_5
value: 43.733
- type: ndcg_at_1
value: 34.937000000000005
- type: ndcg_at_10
value: 45.573
- type: ndcg_at_100
value: 51.266999999999996
- type: ndcg_at_1000
value: 53.184
- type: ndcg_at_3
value: 39.961999999999996
- type: ndcg_at_5
value: 43.02
- type: precision_at_1
value: 34.937000000000005
- type: precision_at_10
value: 8.296000000000001
- type: precision_at_100
value: 1.32
- type: precision_at_1000
value: 0.167
- type: precision_at_3
value: 18.8
- type: precision_at_5
value: 13.763
- type: recall_at_1
value: 29.067
- type: recall_at_10
value: 58.298
- type: recall_at_100
value: 82.25099999999999
- type: recall_at_1000
value: 94.476
- type: recall_at_3
value: 42.984
- type: recall_at_5
value: 50.658
- type: map_at_1
value: 25.985999999999997
- type: map_at_10
value: 35.746
- type: map_at_100
value: 37.067
- type: map_at_1000
value: 37.191
- type: map_at_3
value: 32.599000000000004
- type: map_at_5
value: 34.239000000000004
- type: mrr_at_1
value: 31.735000000000003
- type: mrr_at_10
value: 40.515
- type: mrr_at_100
value: 41.459
- type: mrr_at_1000
value: 41.516
- type: mrr_at_3
value: 37.938
- type: mrr_at_5
value: 39.25
- type: ndcg_at_1
value: 31.735000000000003
- type: ndcg_at_10
value: 41.484
- type: ndcg_at_100
value: 47.047
- type: ndcg_at_1000
value: 49.427
- type: ndcg_at_3
value: 36.254999999999995
- type: ndcg_at_5
value: 38.375
- type: precision_at_1
value: 31.735000000000003
- type: precision_at_10
value: 7.66
- type: precision_at_100
value: 1.234
- type: precision_at_1000
value: 0.16
- type: precision_at_3
value: 17.427999999999997
- type: precision_at_5
value: 12.328999999999999
- type: recall_at_1
value: 25.985999999999997
- type: recall_at_10
value: 53.761
- type: recall_at_100
value: 77.149
- type: recall_at_1000
value: 93.342
- type: recall_at_3
value: 39.068000000000005
- type: recall_at_5
value: 44.693
- type: map_at_1
value: 24.949749999999998
- type: map_at_10
value: 34.04991666666667
- type: map_at_100
value: 35.26825
- type: map_at_1000
value: 35.38316666666667
- type: map_at_3
value: 31.181333333333335
- type: map_at_5
value: 32.77391666666667
- type: mrr_at_1
value: 29.402833333333334
- type: mrr_at_10
value: 38.01633333333333
- type: mrr_at_100
value: 38.88033333333334
- type: mrr_at_1000
value: 38.938500000000005
- type: mrr_at_3
value: 35.5175
- type: mrr_at_5
value: 36.93808333333333
- type: ndcg_at_1
value: 29.402833333333334
- type: ndcg_at_10
value: 39.403166666666664
- type: ndcg_at_100
value: 44.66408333333333
- type: ndcg_at_1000
value: 46.96283333333333
- type: ndcg_at_3
value: 34.46633333333334
- type: ndcg_at_5
value: 36.78441666666667
- type: precision_at_1
value: 29.402833333333334
- type: precision_at_10
value: 6.965833333333333
- type: precision_at_100
value: 1.1330833333333334
- type: precision_at_1000
value: 0.15158333333333335
- type: precision_at_3
value: 15.886666666666665
- type: precision_at_5
value: 11.360416666666667
- type: recall_at_1
value: 24.949749999999998
- type: recall_at_10
value: 51.29325
- type: recall_at_100
value: 74.3695
- type: recall_at_1000
value: 90.31299999999999
- type: recall_at_3
value: 37.580083333333334
- type: recall_at_5
value: 43.529666666666664
- type: map_at_1
value: 22.081999999999997
- type: map_at_10
value: 29.215999999999998
- type: map_at_100
value: 30.163
- type: map_at_1000
value: 30.269000000000002
- type: map_at_3
value: 26.942
- type: map_at_5
value: 28.236
- type: mrr_at_1
value: 24.847
- type: mrr_at_10
value: 31.918999999999997
- type: mrr_at_100
value: 32.817
- type: mrr_at_1000
value: 32.897
- type: mrr_at_3
value: 29.831000000000003
- type: mrr_at_5
value: 31.019999999999996
- type: ndcg_at_1
value: 24.847
- type: ndcg_at_10
value: 33.4
- type: ndcg_at_100
value: 38.354
- type: ndcg_at_1000
value: 41.045
- type: ndcg_at_3
value: 29.236
- type: ndcg_at_5
value: 31.258000000000003
- type: precision_at_1
value: 24.847
- type: precision_at_10
value: 5.353
- type: precision_at_100
value: 0.853
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 12.679000000000002
- type: precision_at_5
value: 8.988
- type: recall_at_1
value: 22.081999999999997
- type: recall_at_10
value: 43.505
- type: recall_at_100
value: 66.45400000000001
- type: recall_at_1000
value: 86.378
- type: recall_at_3
value: 32.163000000000004
- type: recall_at_5
value: 37.059999999999995
- type: map_at_1
value: 15.540000000000001
- type: map_at_10
value: 22.362000000000002
- type: map_at_100
value: 23.435
- type: map_at_1000
value: 23.564
- type: map_at_3
value: 20.143
- type: map_at_5
value: 21.324
- type: mrr_at_1
value: 18.892
- type: mrr_at_10
value: 25.942999999999998
- type: mrr_at_100
value: 26.883000000000003
- type: mrr_at_1000
value: 26.968999999999998
- type: mrr_at_3
value: 23.727
- type: mrr_at_5
value: 24.923000000000002
- type: ndcg_at_1
value: 18.892
- type: ndcg_at_10
value: 26.811
- type: ndcg_at_100
value: 32.066
- type: ndcg_at_1000
value: 35.166
- type: ndcg_at_3
value: 22.706
- type: ndcg_at_5
value: 24.508
- type: precision_at_1
value: 18.892
- type: precision_at_10
value: 4.942
- type: precision_at_100
value: 0.878
- type: precision_at_1000
value: 0.131
- type: precision_at_3
value: 10.748000000000001
- type: precision_at_5
value: 7.784000000000001
- type: recall_at_1
value: 15.540000000000001
- type: recall_at_10
value: 36.742999999999995
- type: recall_at_100
value: 60.525
- type: recall_at_1000
value: 82.57600000000001
- type: recall_at_3
value: 25.252000000000002
- type: recall_at_5
value: 29.872
- type: map_at_1
value: 24.453
- type: map_at_10
value: 33.363
- type: map_at_100
value: 34.579
- type: map_at_1000
value: 34.686
- type: map_at_3
value: 30.583
- type: map_at_5
value: 32.118
- type: mrr_at_1
value: 28.918
- type: mrr_at_10
value: 37.675
- type: mrr_at_100
value: 38.567
- type: mrr_at_1000
value: 38.632
- type: mrr_at_3
value: 35.260999999999996
- type: mrr_at_5
value: 36.576
- type: ndcg_at_1
value: 28.918
- type: ndcg_at_10
value: 38.736
- type: ndcg_at_100
value: 44.261
- type: ndcg_at_1000
value: 46.72
- type: ndcg_at_3
value: 33.81
- type: ndcg_at_5
value: 36.009
- type: precision_at_1
value: 28.918
- type: precision_at_10
value: 6.586
- type: precision_at_100
value: 1.047
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 15.360999999999999
- type: precision_at_5
value: 10.857999999999999
- type: recall_at_1
value: 24.453
- type: recall_at_10
value: 50.885999999999996
- type: recall_at_100
value: 75.03
- type: recall_at_1000
value: 92.123
- type: recall_at_3
value: 37.138
- type: recall_at_5
value: 42.864999999999995
- type: map_at_1
value: 24.57
- type: map_at_10
value: 33.672000000000004
- type: map_at_100
value: 35.244
- type: map_at_1000
value: 35.467
- type: map_at_3
value: 30.712
- type: map_at_5
value: 32.383
- type: mrr_at_1
value: 29.644
- type: mrr_at_10
value: 38.344
- type: mrr_at_100
value: 39.219
- type: mrr_at_1000
value: 39.282000000000004
- type: mrr_at_3
value: 35.771
- type: mrr_at_5
value: 37.273
- type: ndcg_at_1
value: 29.644
- type: ndcg_at_10
value: 39.567
- type: ndcg_at_100
value: 45.097
- type: ndcg_at_1000
value: 47.923
- type: ndcg_at_3
value: 34.768
- type: ndcg_at_5
value: 37.122
- type: precision_at_1
value: 29.644
- type: precision_at_10
value: 7.5889999999999995
- type: precision_at_100
value: 1.478
- type: precision_at_1000
value: 0.23500000000000001
- type: precision_at_3
value: 16.337
- type: precision_at_5
value: 12.055
- type: recall_at_1
value: 24.57
- type: recall_at_10
value: 51.00900000000001
- type: recall_at_100
value: 75.423
- type: recall_at_1000
value: 93.671
- type: recall_at_3
value: 36.925999999999995
- type: recall_at_5
value: 43.245
- type: map_at_1
value: 21.356
- type: map_at_10
value: 27.904
- type: map_at_100
value: 28.938000000000002
- type: map_at_1000
value: 29.036
- type: map_at_3
value: 25.726
- type: map_at_5
value: 26.935
- type: mrr_at_1
value: 22.551
- type: mrr_at_10
value: 29.259
- type: mrr_at_100
value: 30.272
- type: mrr_at_1000
value: 30.348000000000003
- type: mrr_at_3
value: 27.295
- type: mrr_at_5
value: 28.358
- type: ndcg_at_1
value: 22.551
- type: ndcg_at_10
value: 31.817
- type: ndcg_at_100
value: 37.164
- type: ndcg_at_1000
value: 39.82
- type: ndcg_at_3
value: 27.595999999999997
- type: ndcg_at_5
value: 29.568
- type: precision_at_1
value: 22.551
- type: precision_at_10
value: 4.917
- type: precision_at_100
value: 0.828
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 11.583
- type: precision_at_5
value: 8.133
- type: recall_at_1
value: 21.356
- type: recall_at_10
value: 42.489
- type: recall_at_100
value: 67.128
- type: recall_at_1000
value: 87.441
- type: recall_at_3
value: 31.165
- type: recall_at_5
value: 35.853
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: 392b78eb68c07badcd7c2cd8f39af108375dfcce
metrics:
- type: map_at_1
value: 12.306000000000001
- type: map_at_10
value: 21.523
- type: map_at_100
value: 23.358
- type: map_at_1000
value: 23.541
- type: map_at_3
value: 17.809
- type: map_at_5
value: 19.631
- type: mrr_at_1
value: 27.948
- type: mrr_at_10
value: 40.355000000000004
- type: mrr_at_100
value: 41.166000000000004
- type: mrr_at_1000
value: 41.203
- type: mrr_at_3
value: 36.819
- type: mrr_at_5
value: 38.958999999999996
- type: ndcg_at_1
value: 27.948
- type: ndcg_at_10
value: 30.462
- type: ndcg_at_100
value: 37.473
- type: ndcg_at_1000
value: 40.717999999999996
- type: ndcg_at_3
value: 24.646
- type: ndcg_at_5
value: 26.642
- type: precision_at_1
value: 27.948
- type: precision_at_10
value: 9.648
- type: precision_at_100
value: 1.7239999999999998
- type: precision_at_1000
value: 0.232
- type: precision_at_3
value: 18.48
- type: precision_at_5
value: 14.293
- type: recall_at_1
value: 12.306000000000001
- type: recall_at_10
value: 37.181
- type: recall_at_100
value: 61.148
- type: recall_at_1000
value: 79.401
- type: recall_at_3
value: 22.883
- type: recall_at_5
value: 28.59
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: f097057d03ed98220bc7309ddb10b71a54d667d6
metrics:
- type: map_at_1
value: 9.357
- type: map_at_10
value: 18.849
- type: map_at_100
value: 25.369000000000003
- type: map_at_1000
value: 26.950000000000003
- type: map_at_3
value: 13.625000000000002
- type: map_at_5
value: 15.956999999999999
- type: mrr_at_1
value: 67.75
- type: mrr_at_10
value: 74.734
- type: mrr_at_100
value: 75.1
- type: mrr_at_1000
value: 75.10900000000001
- type: mrr_at_3
value: 73.542
- type: mrr_at_5
value: 74.167
- type: ndcg_at_1
value: 55.375
- type: ndcg_at_10
value: 39.873999999999995
- type: ndcg_at_100
value: 43.098
- type: ndcg_at_1000
value: 50.69200000000001
- type: ndcg_at_3
value: 44.856
- type: ndcg_at_5
value: 42.138999999999996
- type: precision_at_1
value: 67.75
- type: precision_at_10
value: 31.1
- type: precision_at_100
value: 9.303
- type: precision_at_1000
value: 2.0060000000000002
- type: precision_at_3
value: 48.25
- type: precision_at_5
value: 40.949999999999996
- type: recall_at_1
value: 9.357
- type: recall_at_10
value: 23.832
- type: recall_at_100
value: 47.906
- type: recall_at_1000
value: 71.309
- type: recall_at_3
value: 14.512
- type: recall_at_5
value: 18.3
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 829147f8f75a25f005913200eb5ed41fae320aa1
metrics:
- type: accuracy
value: 49.655
- type: f1
value: 45.51976190938951
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: 1429cf27e393599b8b359b9b72c666f96b2525f9
metrics:
- type: map_at_1
value: 62.739999999999995
- type: map_at_10
value: 73.07000000000001
- type: map_at_100
value: 73.398
- type: map_at_1000
value: 73.41
- type: map_at_3
value: 71.33800000000001
- type: map_at_5
value: 72.423
- type: mrr_at_1
value: 67.777
- type: mrr_at_10
value: 77.873
- type: mrr_at_100
value: 78.091
- type: mrr_at_1000
value: 78.094
- type: mrr_at_3
value: 76.375
- type: mrr_at_5
value: 77.316
- type: ndcg_at_1
value: 67.777
- type: ndcg_at_10
value: 78.24
- type: ndcg_at_100
value: 79.557
- type: ndcg_at_1000
value: 79.814
- type: ndcg_at_3
value: 75.125
- type: ndcg_at_5
value: 76.834
- type: precision_at_1
value: 67.777
- type: precision_at_10
value: 9.832
- type: precision_at_100
value: 1.061
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 29.433
- type: precision_at_5
value: 18.665000000000003
- type: recall_at_1
value: 62.739999999999995
- type: recall_at_10
value: 89.505
- type: recall_at_100
value: 95.102
- type: recall_at_1000
value: 96.825
- type: recall_at_3
value: 81.028
- type: recall_at_5
value: 85.28099999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: 41b686a7f28c59bcaaa5791efd47c67c8ebe28be
metrics:
- type: map_at_1
value: 18.467
- type: map_at_10
value: 30.020999999999997
- type: map_at_100
value: 31.739
- type: map_at_1000
value: 31.934
- type: map_at_3
value: 26.003
- type: map_at_5
value: 28.338
- type: mrr_at_1
value: 35.339999999999996
- type: mrr_at_10
value: 44.108999999999995
- type: mrr_at_100
value: 44.993
- type: mrr_at_1000
value: 45.042
- type: mrr_at_3
value: 41.667
- type: mrr_at_5
value: 43.14
- type: ndcg_at_1
value: 35.339999999999996
- type: ndcg_at_10
value: 37.202
- type: ndcg_at_100
value: 43.852999999999994
- type: ndcg_at_1000
value: 47.235
- type: ndcg_at_3
value: 33.5
- type: ndcg_at_5
value: 34.985
- type: precision_at_1
value: 35.339999999999996
- type: precision_at_10
value: 10.247
- type: precision_at_100
value: 1.7149999999999999
- type: precision_at_1000
value: 0.232
- type: precision_at_3
value: 22.222
- type: precision_at_5
value: 16.573999999999998
- type: recall_at_1
value: 18.467
- type: recall_at_10
value: 44.080999999999996
- type: recall_at_100
value: 68.72200000000001
- type: recall_at_1000
value: 89.087
- type: recall_at_3
value: 30.567
- type: recall_at_5
value: 36.982
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: 766870b35a1b9ca65e67a0d1913899973551fc6c
metrics:
- type: map_at_1
value: 35.726
- type: map_at_10
value: 50.207
- type: map_at_100
value: 51.05499999999999
- type: map_at_1000
value: 51.12799999999999
- type: map_at_3
value: 47.576
- type: map_at_5
value: 49.172
- type: mrr_at_1
value: 71.452
- type: mrr_at_10
value: 77.41900000000001
- type: mrr_at_100
value: 77.711
- type: mrr_at_1000
value: 77.723
- type: mrr_at_3
value: 76.39399999999999
- type: mrr_at_5
value: 77.00099999999999
- type: ndcg_at_1
value: 71.452
- type: ndcg_at_10
value: 59.260999999999996
- type: ndcg_at_100
value: 62.424
- type: ndcg_at_1000
value: 63.951
- type: ndcg_at_3
value: 55.327000000000005
- type: ndcg_at_5
value: 57.416999999999994
- type: precision_at_1
value: 71.452
- type: precision_at_10
value: 12.061
- type: precision_at_100
value: 1.455
- type: precision_at_1000
value: 0.166
- type: precision_at_3
value: 34.36
- type: precision_at_5
value: 22.266
- type: recall_at_1
value: 35.726
- type: recall_at_10
value: 60.304
- type: recall_at_100
value: 72.75500000000001
- type: recall_at_1000
value: 82.978
- type: recall_at_3
value: 51.54
- type: recall_at_5
value: 55.665
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 8d743909f834c38949e8323a8a6ce8721ea6c7f4
metrics:
- type: accuracy
value: 66.63759999999999
- type: ap
value: 61.48938261286748
- type: f1
value: 66.35089269264965
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: validation
revision: e6838a846e2408f22cf5cc337ebc83e0bcf77849
metrics:
- type: map_at_1
value: 20.842
- type: map_at_10
value: 32.992
- type: map_at_100
value: 34.236
- type: map_at_1000
value: 34.286
- type: map_at_3
value: 29.049000000000003
- type: map_at_5
value: 31.391999999999996
- type: mrr_at_1
value: 21.375
- type: mrr_at_10
value: 33.581
- type: mrr_at_100
value: 34.760000000000005
- type: mrr_at_1000
value: 34.803
- type: mrr_at_3
value: 29.704000000000004
- type: mrr_at_5
value: 32.015
- type: ndcg_at_1
value: 21.375
- type: ndcg_at_10
value: 39.905
- type: ndcg_at_100
value: 45.843
- type: ndcg_at_1000
value: 47.083999999999996
- type: ndcg_at_3
value: 31.918999999999997
- type: ndcg_at_5
value: 36.107
- type: precision_at_1
value: 21.375
- type: precision_at_10
value: 6.393
- type: precision_at_100
value: 0.935
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.663
- type: precision_at_5
value: 10.324
- type: recall_at_1
value: 20.842
- type: recall_at_10
value: 61.17
- type: recall_at_100
value: 88.518
- type: recall_at_1000
value: 97.993
- type: recall_at_3
value: 39.571
- type: recall_at_5
value: 49.653999999999996
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 93.46557227542178
- type: f1
value: 92.87345917772146
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 72.42134062927497
- type: f1
value: 55.03624810959269
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 70.3866845998655
- type: f1
value: 68.9674519872921
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.27774041694687
- type: f1
value: 76.72936190462792
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: dcefc037ef84348e49b0d29109e891c01067226b
metrics:
- type: v_measure
value: 31.511745925773337
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 3cd0e71dfbe09d4de0f9e5ecba43e7ce280959dc
metrics:
- type: v_measure
value: 28.764235987575365
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.29353136386601
- type: mrr
value: 33.536774455851685
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: 7eb63cc0c1eb59324d709ebed25fcab851fa7610
metrics:
- type: map_at_1
value: 5.702
- type: map_at_10
value: 13.642000000000001
- type: map_at_100
value: 17.503
- type: map_at_1000
value: 19.126
- type: map_at_3
value: 9.748
- type: map_at_5
value: 11.642
- type: mrr_at_1
value: 45.82
- type: mrr_at_10
value: 54.821
- type: mrr_at_100
value: 55.422000000000004
- type: mrr_at_1000
value: 55.452999999999996
- type: mrr_at_3
value: 52.373999999999995
- type: mrr_at_5
value: 53.937000000000005
- type: ndcg_at_1
value: 44.272
- type: ndcg_at_10
value: 36.213
- type: ndcg_at_100
value: 33.829
- type: ndcg_at_1000
value: 42.557
- type: ndcg_at_3
value: 40.814
- type: ndcg_at_5
value: 39.562000000000005
- type: precision_at_1
value: 45.511
- type: precision_at_10
value: 27.214
- type: precision_at_100
value: 8.941
- type: precision_at_1000
value: 2.1870000000000003
- type: precision_at_3
value: 37.874
- type: precision_at_5
value: 34.489
- type: recall_at_1
value: 5.702
- type: recall_at_10
value: 17.638
- type: recall_at_100
value: 34.419
- type: recall_at_1000
value: 66.41
- type: recall_at_3
value: 10.914
- type: recall_at_5
value: 14.032
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: 6062aefc120bfe8ece5897809fb2e53bfe0d128c
metrics:
- type: map_at_1
value: 30.567
- type: map_at_10
value: 45.01
- type: map_at_100
value: 46.091
- type: map_at_1000
value: 46.126
- type: map_at_3
value: 40.897
- type: map_at_5
value: 43.301
- type: mrr_at_1
value: 34.56
- type: mrr_at_10
value: 47.725
- type: mrr_at_100
value: 48.548
- type: mrr_at_1000
value: 48.571999999999996
- type: mrr_at_3
value: 44.361
- type: mrr_at_5
value: 46.351
- type: ndcg_at_1
value: 34.531
- type: ndcg_at_10
value: 52.410000000000004
- type: ndcg_at_100
value: 56.999
- type: ndcg_at_1000
value: 57.830999999999996
- type: ndcg_at_3
value: 44.734
- type: ndcg_at_5
value: 48.701
- type: precision_at_1
value: 34.531
- type: precision_at_10
value: 8.612
- type: precision_at_100
value: 1.118
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 20.307
- type: precision_at_5
value: 14.519000000000002
- type: recall_at_1
value: 30.567
- type: recall_at_10
value: 72.238
- type: recall_at_100
value: 92.154
- type: recall_at_1000
value: 98.375
- type: recall_at_3
value: 52.437999999999995
- type: recall_at_5
value: 61.516999999999996
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: 6205996560df11e3a3da9ab4f926788fc30a7db4
metrics:
- type: map_at_1
value: 65.98
- type: map_at_10
value: 80.05600000000001
- type: map_at_100
value: 80.76299999999999
- type: map_at_1000
value: 80.786
- type: map_at_3
value: 76.848
- type: map_at_5
value: 78.854
- type: mrr_at_1
value: 75.86
- type: mrr_at_10
value: 83.397
- type: mrr_at_100
value: 83.555
- type: mrr_at_1000
value: 83.557
- type: mrr_at_3
value: 82.033
- type: mrr_at_5
value: 82.97
- type: ndcg_at_1
value: 75.88000000000001
- type: ndcg_at_10
value: 84.58099999999999
- type: ndcg_at_100
value: 86.151
- type: ndcg_at_1000
value: 86.315
- type: ndcg_at_3
value: 80.902
- type: ndcg_at_5
value: 82.953
- type: precision_at_1
value: 75.88000000000001
- type: precision_at_10
value: 12.986
- type: precision_at_100
value: 1.5110000000000001
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 35.382999999999996
- type: precision_at_5
value: 23.555999999999997
- type: recall_at_1
value: 65.98
- type: recall_at_10
value: 93.716
- type: recall_at_100
value: 99.21799999999999
- type: recall_at_1000
value: 99.97
- type: recall_at_3
value: 83.551
- type: recall_at_5
value: 88.998
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: b2805658ae38990172679479369a78b86de8c390
metrics:
- type: v_measure
value: 40.45148482612238
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: v_measure
value: 55.749490673039126
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: 5c59ef3e437a0a9651c8fe6fde943e7dce59fba5
metrics:
- type: map_at_1
value: 4.903
- type: map_at_10
value: 11.926
- type: map_at_100
value: 13.916999999999998
- type: map_at_1000
value: 14.215
- type: map_at_3
value: 8.799999999999999
- type: map_at_5
value: 10.360999999999999
- type: mrr_at_1
value: 24.099999999999998
- type: mrr_at_10
value: 34.482
- type: mrr_at_100
value: 35.565999999999995
- type: mrr_at_1000
value: 35.619
- type: mrr_at_3
value: 31.433
- type: mrr_at_5
value: 33.243
- type: ndcg_at_1
value: 24.099999999999998
- type: ndcg_at_10
value: 19.872999999999998
- type: ndcg_at_100
value: 27.606
- type: ndcg_at_1000
value: 32.811
- type: ndcg_at_3
value: 19.497999999999998
- type: ndcg_at_5
value: 16.813
- type: precision_at_1
value: 24.099999999999998
- type: precision_at_10
value: 10.08
- type: precision_at_100
value: 2.122
- type: precision_at_1000
value: 0.337
- type: precision_at_3
value: 18.2
- type: precision_at_5
value: 14.62
- type: recall_at_1
value: 4.903
- type: recall_at_10
value: 20.438000000000002
- type: recall_at_100
value: 43.043
- type: recall_at_1000
value: 68.41000000000001
- type: recall_at_3
value: 11.068
- type: recall_at_5
value: 14.818000000000001
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cos_sim_pearson
value: 78.58086597995997
- type: cos_sim_spearman
value: 69.63214182814991
- type: euclidean_pearson
value: 72.76175489042691
- type: euclidean_spearman
value: 67.84965161872971
- type: manhattan_pearson
value: 72.73812689782592
- type: manhattan_spearman
value: 67.83610439531277
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: fdf84275bb8ce4b49c971d02e84dd1abc677a50f
metrics:
- type: cos_sim_pearson
value: 75.13970861325006
- type: cos_sim_spearman
value: 67.5020551515597
- type: euclidean_pearson
value: 66.33415412418276
- type: euclidean_spearman
value: 66.82145056673268
- type: manhattan_pearson
value: 66.55489484006415
- type: manhattan_spearman
value: 66.95147433279057
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 1591bfcbe8c69d4bf7fe2a16e2451017832cafb9
metrics:
- type: cos_sim_pearson
value: 78.85850536483447
- type: cos_sim_spearman
value: 79.1633350177206
- type: euclidean_pearson
value: 72.74090561408477
- type: euclidean_spearman
value: 73.57374448302961
- type: manhattan_pearson
value: 72.92980654233226
- type: manhattan_spearman
value: 73.72777155112588
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: e2125984e7df8b7871f6ae9949cf6b6795e7c54b
metrics:
- type: cos_sim_pearson
value: 79.51125593897028
- type: cos_sim_spearman
value: 74.46048326701329
- type: euclidean_pearson
value: 70.87726087052985
- type: euclidean_spearman
value: 67.7721470654411
- type: manhattan_pearson
value: 71.05892792135637
- type: manhattan_spearman
value: 67.93472619779037
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: 1cd7298cac12a96a373b6a2f18738bb3e739a9b6
metrics:
- type: cos_sim_pearson
value: 83.8299348880489
- type: cos_sim_spearman
value: 84.47194637929275
- type: euclidean_pearson
value: 78.68768462480418
- type: euclidean_spearman
value: 79.80526323901917
- type: manhattan_pearson
value: 78.6810718151946
- type: manhattan_spearman
value: 79.7820584821254
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 360a0b2dff98700d09e634a01e1cc1624d3e42cd
metrics:
- type: cos_sim_pearson
value: 79.99206664843005
- type: cos_sim_spearman
value: 80.96089203722137
- type: euclidean_pearson
value: 71.31216213716365
- type: euclidean_spearman
value: 71.45258140049407
- type: manhattan_pearson
value: 71.26140340402836
- type: manhattan_spearman
value: 71.3896894666943
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 87.35697089594868
- type: cos_sim_spearman
value: 87.78202647220289
- type: euclidean_pearson
value: 84.20969668786667
- type: euclidean_spearman
value: 83.91876425459982
- type: manhattan_pearson
value: 84.24429755612542
- type: manhattan_spearman
value: 83.98826315103398
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 69.06962775868384
- type: cos_sim_spearman
value: 69.34889515492327
- type: euclidean_pearson
value: 69.28108180412313
- type: euclidean_spearman
value: 69.6437114853659
- type: manhattan_pearson
value: 69.39974983734993
- type: manhattan_spearman
value: 69.69057284482079
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: 8913289635987208e6e7c72789e4be2fe94b6abd
metrics:
- type: cos_sim_pearson
value: 82.42553734213958
- type: cos_sim_spearman
value: 81.38977341532744
- type: euclidean_pearson
value: 76.47494587945522
- type: euclidean_spearman
value: 75.92794860531089
- type: manhattan_pearson
value: 76.4768777169467
- type: manhattan_spearman
value: 75.9252673228599
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: 56a6d0140cf6356659e2a7c1413286a774468d44
metrics:
- type: map
value: 80.78825425914722
- type: mrr
value: 94.60017197762296
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: a75ae049398addde9b70f6b268875f5cbce99089
metrics:
- type: map_at_1
value: 60.633
- type: map_at_10
value: 70.197
- type: map_at_100
value: 70.758
- type: map_at_1000
value: 70.765
- type: map_at_3
value: 67.082
- type: map_at_5
value: 69.209
- type: mrr_at_1
value: 63.333
- type: mrr_at_10
value: 71.17
- type: mrr_at_100
value: 71.626
- type: mrr_at_1000
value: 71.633
- type: mrr_at_3
value: 68.833
- type: mrr_at_5
value: 70.6
- type: ndcg_at_1
value: 63.333
- type: ndcg_at_10
value: 74.697
- type: ndcg_at_100
value: 76.986
- type: ndcg_at_1000
value: 77.225
- type: ndcg_at_3
value: 69.527
- type: ndcg_at_5
value: 72.816
- type: precision_at_1
value: 63.333
- type: precision_at_10
value: 9.9
- type: precision_at_100
value: 1.103
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 26.889000000000003
- type: precision_at_5
value: 18.2
- type: recall_at_1
value: 60.633
- type: recall_at_10
value: 87.36699999999999
- type: recall_at_100
value: 97.333
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 73.656
- type: recall_at_5
value: 82.083
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: 5a8256d0dff9c4bd3be3ba3e67e4e70173f802ea
metrics:
- type: cos_sim_accuracy
value: 99.76633663366337
- type: cos_sim_ap
value: 93.84024096781063
- type: cos_sim_f1
value: 88.08080808080808
- type: cos_sim_precision
value: 88.9795918367347
- type: cos_sim_recall
value: 87.2
- type: dot_accuracy
value: 99.46336633663367
- type: dot_ap
value: 75.78127156965245
- type: dot_f1
value: 71.41403865717193
- type: dot_precision
value: 72.67080745341616
- type: dot_recall
value: 70.19999999999999
- type: euclidean_accuracy
value: 99.67524752475248
- type: euclidean_ap
value: 88.61274955249769
- type: euclidean_f1
value: 82.30852211434735
- type: euclidean_precision
value: 89.34426229508196
- type: euclidean_recall
value: 76.3
- type: manhattan_accuracy
value: 99.67722772277227
- type: manhattan_ap
value: 88.77516158012779
- type: manhattan_f1
value: 82.36536430834212
- type: manhattan_precision
value: 87.24832214765101
- type: manhattan_recall
value: 78.0
- type: max_accuracy
value: 99.76633663366337
- type: max_ap
value: 93.84024096781063
- type: max_f1
value: 88.08080808080808
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 70a89468f6dccacc6aa2b12a6eac54e74328f235
metrics:
- type: v_measure
value: 59.20812266121527
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: d88009ab563dd0b16cfaf4436abaf97fa3550cf0
metrics:
- type: v_measure
value: 33.954248554638056
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: ef807ea29a75ec4f91b50fd4191cb4ee4589a9f9
metrics:
- type: map
value: 51.52800990025549
- type: mrr
value: 52.360394915541974
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: 8753c2788d36c01fc6f05d03fe3f7268d63f9122
metrics:
- type: cos_sim_pearson
value: 30.737881131277355
- type: cos_sim_spearman
value: 31.45979323917254
- type: dot_pearson
value: 26.24686017962023
- type: dot_spearman
value: 25.006732878791745
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: 2c8041b2c07a79b6f7ba8fe6acc72e5d9f92d217
metrics:
- type: map_at_1
value: 0.253
- type: map_at_10
value: 2.1399999999999997
- type: map_at_100
value: 12.873000000000001
- type: map_at_1000
value: 31.002000000000002
- type: map_at_3
value: 0.711
- type: map_at_5
value: 1.125
- type: mrr_at_1
value: 96.0
- type: mrr_at_10
value: 98.0
- type: mrr_at_100
value: 98.0
- type: mrr_at_1000
value: 98.0
- type: mrr_at_3
value: 98.0
- type: mrr_at_5
value: 98.0
- type: ndcg_at_1
value: 94.0
- type: ndcg_at_10
value: 84.881
- type: ndcg_at_100
value: 64.694
- type: ndcg_at_1000
value: 56.85
- type: ndcg_at_3
value: 90.061
- type: ndcg_at_5
value: 87.155
- type: precision_at_1
value: 96.0
- type: precision_at_10
value: 88.8
- type: precision_at_100
value: 65.7
- type: precision_at_1000
value: 25.080000000000002
- type: precision_at_3
value: 92.667
- type: precision_at_5
value: 90.0
- type: recall_at_1
value: 0.253
- type: recall_at_10
value: 2.292
- type: recall_at_100
value: 15.78
- type: recall_at_1000
value: 53.015
- type: recall_at_3
value: 0.7270000000000001
- type: recall_at_5
value: 1.162
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: 527b7d77e16e343303e68cb6af11d6e18b9f7b3b
metrics:
- type: map_at_1
value: 2.116
- type: map_at_10
value: 9.625
- type: map_at_100
value: 15.641
- type: map_at_1000
value: 17.127
- type: map_at_3
value: 4.316
- type: map_at_5
value: 6.208
- type: mrr_at_1
value: 32.653
- type: mrr_at_10
value: 48.083999999999996
- type: mrr_at_100
value: 48.631
- type: mrr_at_1000
value: 48.649
- type: mrr_at_3
value: 42.857
- type: mrr_at_5
value: 46.224
- type: ndcg_at_1
value: 29.592000000000002
- type: ndcg_at_10
value: 25.430999999999997
- type: ndcg_at_100
value: 36.344
- type: ndcg_at_1000
value: 47.676
- type: ndcg_at_3
value: 26.144000000000002
- type: ndcg_at_5
value: 26.304
- type: precision_at_1
value: 32.653
- type: precision_at_10
value: 24.082
- type: precision_at_100
value: 7.714
- type: precision_at_1000
value: 1.5310000000000001
- type: precision_at_3
value: 26.531
- type: precision_at_5
value: 26.939
- type: recall_at_1
value: 2.116
- type: recall_at_10
value: 16.794
- type: recall_at_100
value: 47.452
- type: recall_at_1000
value: 82.312
- type: recall_at_3
value: 5.306
- type: recall_at_5
value: 9.306000000000001
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 67.709
- type: ap
value: 13.541535578501716
- type: f1
value: 52.569619919446794
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: 62146448f05be9e52a36b8ee9936447ea787eede
metrics:
- type: accuracy
value: 56.850594227504246
- type: f1
value: 57.233377364910574
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 091a54f9a36281ce7d6590ec8c75dd485e7e01d4
metrics:
- type: v_measure
value: 39.463722986090474
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 84.09131549144662
- type: cos_sim_ap
value: 66.86677647503386
- type: cos_sim_f1
value: 62.94631710362049
- type: cos_sim_precision
value: 59.73933649289099
- type: cos_sim_recall
value: 66.51715039577837
- type: dot_accuracy
value: 80.27656911247541
- type: dot_ap
value: 54.291720398612085
- type: dot_f1
value: 54.77150537634409
- type: dot_precision
value: 47.58660957571039
- type: dot_recall
value: 64.5118733509235
- type: euclidean_accuracy
value: 82.76211480002385
- type: euclidean_ap
value: 62.430397690753296
- type: euclidean_f1
value: 59.191590539356774
- type: euclidean_precision
value: 56.296119971435374
- type: euclidean_recall
value: 62.401055408970976
- type: manhattan_accuracy
value: 82.7561542588067
- type: manhattan_ap
value: 62.41882051995577
- type: manhattan_f1
value: 59.32101002778785
- type: manhattan_precision
value: 54.71361711611321
- type: manhattan_recall
value: 64.77572559366754
- type: max_accuracy
value: 84.09131549144662
- type: max_ap
value: 66.86677647503386
- type: max_f1
value: 62.94631710362049
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.79574649745798
- type: cos_sim_ap
value: 85.28960532524223
- type: cos_sim_f1
value: 77.98460043358001
- type: cos_sim_precision
value: 75.78090948714224
- type: cos_sim_recall
value: 80.32029565753002
- type: dot_accuracy
value: 85.5939767920208
- type: dot_ap
value: 76.14131706694056
- type: dot_f1
value: 72.70246298696868
- type: dot_precision
value: 65.27012127894156
- type: dot_recall
value: 82.04496458269172
- type: euclidean_accuracy
value: 86.72332828812046
- type: euclidean_ap
value: 80.84854809178995
- type: euclidean_f1
value: 72.47657499809551
- type: euclidean_precision
value: 71.71717171717171
- type: euclidean_recall
value: 73.25223283030489
- type: manhattan_accuracy
value: 86.7563162184189
- type: manhattan_ap
value: 80.87598895575626
- type: manhattan_f1
value: 72.54617892068092
- type: manhattan_precision
value: 68.49268225960881
- type: manhattan_recall
value: 77.10963966738528
- type: max_accuracy
value: 88.79574649745798
- type: max_ap
value: 85.28960532524223
- type: max_f1
value: 77.98460043358001
---
# SGPT-5.8B-weightedmean-msmarco-specb-bitfit
## Usage
For usage instructions, refer to our codebase: https://github.com/Muennighoff/sgpt
## Evaluation Results
For eval results, refer to our paper: https://arxiv.org/abs/2202.08904
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 249592 with parameters:
```
{'batch_size': 2, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 5e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 300, 'do_lower_case': False}) with Transformer model: GPTJModel
(1): Pooling({'word_embedding_dimension': 4096, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': True, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
```bibtex
@article{muennighoff2022sgpt,
title={SGPT: GPT Sentence Embeddings for Semantic Search},
author={Muennighoff, Niklas},
journal={arXiv preprint arXiv:2202.08904},
year={2022}
}
```
|
[
"BIOSSES",
"SCIFACT"
] |
Dr-BERT/DrBERT-7GB-Large
|
Dr-BERT
|
fill-mask
|
[
"transformers",
"pytorch",
"camembert",
"fill-mask",
"medical",
"chemistry",
"biomedical",
"life science",
"fr",
"dataset:Dr-BERT/NACHOS",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-04-09T13:59:08Z |
2023-05-28T17:38:14+00:00
| 83 | 2 |
---
datasets:
- Dr-BERT/NACHOS
language:
- fr
library_name: transformers
license: apache-2.0
tags:
- medical
- chemistry
- biomedical
- life science
widget:
- text: Le patient est atteint d'une <mask>.
---
<p align="center">
<img src="https://github.com/qanastek/DrBERT/blob/main/assets/logo.png?raw=true" alt="drawing" width="250"/>
</p>
# DrBERT: A Robust Pre-trained Model in French for Biomedical and Clinical domains
In recent years, pre-trained language models (PLMs) achieve the best performance on a wide range of natural language processing (NLP) tasks. While the first models were trained on general domain data, specialized ones have emerged to more effectively treat specific domains.
In this paper, we propose an original study of PLMs in the medical domain on French language. We compare, for the first time, the performance of PLMs trained on both public data from the web and private data from healthcare establishments. We also evaluate different learning strategies on a set of biomedical tasks.
Finally, we release the first specialized PLMs for the biomedical field in French, called DrBERT, as well as the largest corpus of medical data under free license on which these models are trained.
# 1. DrBERT models
**DrBERT** is a French RoBERTa trained on a open source corpus of French medical crawled textual data called NACHOS. Models with different amount of data from differents public and private sources are trained using the CNRS (French National Centre for Scientific Research) [Jean Zay](http://www.idris.fr/jean-zay/) French supercomputer. Only the weights of the models trained using exclusively open-sources data are publicly released to prevent any personnal information leak and to follow the european GDPR laws :
| Model name | Corpus | Number of layers | Attention Heads | Embedding Dimension | Sequence Length | Model URL |
| :------: | :---: | :---: | :---: | :---: | :---: | :---: |
| `DrBERT-7-GB-cased-Large` | NACHOS 7 GB | 24 | 16 | 1024 | 512 | [HuggingFace](https://huggingface.co/Dr-BERT/DrBERT-7GB-Large) |
| `DrBERT-7-GB-cased` | NACHOS 7 GB | 12 | 12 | 768 | 512 | [HuggingFace](https://huggingface.co/Dr-BERT/DrBERT-7GB) |
| `DrBERT-4-GB-cased` | NACHOS 4 GB | 12 | 12 | 768 | 512 | [HuggingFace](https://huggingface.co/Dr-BERT/DrBERT-4GB) |
| `DrBERT-4-GB-cased-CP-CamemBERT` | NACHOS 4 GB | 12 | 12 | 768 | 512 | [HuggingFace](https://huggingface.co/Dr-BERT/DrBERT-4GB-CP-CamemBERT) |
| `DrBERT-4-GB-cased-CP-PubMedBERT` | NACHOS 4 GB | 12 | 12 | 768 | 512 | [HuggingFace](https://huggingface.co/Dr-BERT/DrBERT-4GB-CP-PubMedBERT) |
# 2. Using DrBERT
You can use DrBERT with [Hugging Face's Transformers library](https://github.com/huggingface/transformers) as follow.
Loading the model and tokenizer :
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Dr-BERT/DrBERT-7GB-Large")
model = AutoModel.from_pretrained("Dr-BERT/DrBERT-7GB-Large")
```
Perform the mask filling task :
```python
from transformers import pipeline
fill_mask = pipeline("fill-mask", model="Dr-BERT/DrBERT-7GB-Large", tokenizer="Dr-BERT/DrBERT-7GB-Large")
results = fill_mask("La patiente est atteinte d'une <mask>")
```
# 3. Pre-training DrBERT tokenizer and model from scratch by using HuggingFace Transformers Library
## 3.1 Install dependencies
```bash
accelerate @ git+https://github.com/huggingface/accelerate@66edfe103a0de9607f9b9fdcf6a8e2132486d99b
datasets==2.6.1
sentencepiece==0.1.97
protobuf==3.20.1
evaluate==0.2.2
tensorboard==2.11.0
torch >= 1.3
```
## 3.2 Download NACHOS Dataset text file
Download the full NACHOS dataset from [Zenodo]() and place it the the `from_scratch` or `continued_pretraining` directory.
## 3.3 Build your own tokenizer from scratch based on NACHOS
Note : This step is required only in the case of an from scratch pre-training, if you want to do a continued pre-training you just have to download the model and the tokenizer that correspond to the model you want to continue the training from. In this case, you simply have to go to the HuggingFace Hub, select a model (for example [RoBERTa-base](https://huggingface.co/roberta-base)). Finally, you have to download the entire model / tokenizer repository by clicking on the `Use In Transformers` button and get the Git link `git clone https://huggingface.co/roberta-base`.
Build the tokenizer from scratch on your data of the file `./corpus.txt` by using `./build_tokenizer.sh`.
## 3.4 Preprocessing and tokenization of the dataset
First, replace the field `tokenizer_path` of the shell script to match the path of your tokenizer directory downloaded before using HuggingFace Git or the one you have build.
Run `./preprocessing_dataset.sh` to generate the tokenized dataset by using the givent tokenizer.
## 3.5 Model training
First, change the number of GPUs `--ntasks=128` you are needing to match your computational capabilities in the shell script called `run_training.sh`. In our case, we used 128 V100 32 GB GPUs from 32 nodes of 4 GPUs (`--ntasks-per-node=4` and `--gres=gpu:4`) during 20 hours (`--time=20:00:00`).
If you are using Jean Zay, you also need to change the `-A` flag to match one of your `@gpu` profile capable of running the job. You also need to move **ALL** of your datasets, tokenizer, script and outputs on the `$SCRATCH` disk space to preserve others users of suffuring of IO issues.
### 3.5.1 Pre-training from scratch
Once the SLURM parameters updated, you have to change name of the model architecture in the flag `--model_type="camembert"` and to update the `--config_overrides=` according to the specifications of the architecture you are trying to train. In our case, RoBERTa had a `514` sequence length, a vocabulary of `32005` (32K tokens of the tokenizer and 5 of the model architecture) tokens, the identifier of the beginning-of-sentence token (BOS) and end-of-sentence token (EOS) are respectivly `5` and `6`. Change the
Then, go to `./from_scratch/` directory.
Run `sbatch ./run_training.sh` to send the training job in the SLURM queue.
### 3.5.2 continue pre-training
Once the SLURM parameters updated, you have to change path of the model / tokenizer you want to start from `--model_name_or_path=` / `--tokenizer_name=` to the path of the model downloaded from HuggingFace's Git in the section 3.3.
Then, go to `./continued_pretraining/` directory.
Run `sbatch ./run_training.sh` to send the training job in the SLURM queue.
# 4. Fine-tuning on a downstream task
You just need to change the name of the model to `Dr-BERT/DrBERT-7GB` in any of the examples given by HuggingFace's team [here](https://huggingface.co/docs/transformers/tasks/sequence_classification).
# Citation BibTeX
```bibtex
@inproceedings{labrak2023drbert,
title = {{DrBERT: A Robust Pre-trained Model in French for Biomedical and Clinical domains}},
author = {Labrak, Yanis and Bazoge, Adrien and Dufour, Richard and Rouvier, Mickael and Morin, Emmanuel and Daille, Béatrice and Gourraud, Pierre-Antoine},
booktitle = {Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics (ACL'23), Long Paper},
month = july,
year = 2023,
address = {Toronto, Canada},
publisher = {Association for Computational Linguistics}
}
```
|
[
"MEDICAL DATA"
] |
LeroyDyer/LCARS_AI_StarTrek_Computer
|
LeroyDyer
|
text2text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"LCARS",
"Star-Trek",
"128k-Context",
"chemistry",
"biology",
"finance",
"legal",
"art",
"code",
"medical",
"text-generation-inference",
"text2text-generation",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-05-11T17:17:18Z |
2024-10-22T04:31:42+00:00
| 83 | 4 |
---
language:
- en
library_name: transformers
license: mit
pipeline_tag: text2text-generation
tags:
- LCARS
- Star-Trek
- 128k-Context
- mistral
- chemistry
- biology
- finance
- legal
- art
- code
- medical
- text-generation-inference
---
If anybody has star trek data please send as this starship computer database archive needs it!
then i can correctly theme this model to be inside its role as a starship computer :
so as well as any space dara ffrom nasa ; i have collected some mufon files which i am still framing the correct prompts for ; for recall as well as interogation :
I shall also be adding a lot of biblical data and historical data ; from sacred texts; so any generated discussions as phylosophers discussing ancient history and how to solve the problems of the past which they encountered ; in thier lifes: using historical and factual data; as well as playig thier roles after generating a biography and character role to the models to play: they should also be amazed by each others acheivements depending on thier periods:
we need multiple role and characters for these discussions: as well as as much historical facts and historys as possible to enhance this models abitlity to dicern ancient aliens truth or false : (so we need astrological, astronomical, as well as sizmological and ecological data for the periods of histroy we know : as well as the unfounded suupositions from youtube subtitles !) another useful source of themed data!
This model is a Collection of merged models via various merge methods : Reclaiming Previous models which will be orphened by thier parent models :
THis model is the model of models so it may not Remember some task or Infact remember them all as well as highly perform !
There were some very bad NSFW Merges from role play to erotica as well as various characters and roles downloaded into the model:
So those models were merged into other models which had been specifically trained for maths or medical data and the coding operations or even translation:
the models were heavliy dpo trained ; and various newer methodologies installed : the deep mind series is a special series which contains self correction recal, visio spacial ... step by step thinking:
SO the multi merge often fizes these errors between models as well as training gaps :Hopefully they all took and merged well !
Performing even unknown and unprogrammed tasks:
|
[
"MEDICAL DATA"
] |
mradermacher/SOVL-MopeyMule-8B-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Cas-Warehouse/Llama-3-SOVL-MopeyMule-8B",
"base_model:quantized:Cas-Warehouse/Llama-3-SOVL-MopeyMule-8B",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-06-14T02:12:09Z |
2024-12-16T02:37:41+00:00
| 83 | 0 |
---
base_model: Cas-Warehouse/Llama-3-SOVL-MopeyMule-8B
language:
- en
library_name: transformers
tags:
- mergekit
- merge
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Cas-Warehouse/Llama-3-SOVL-MopeyMule-8B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/SOVL-MopeyMule-8B-GGUF/resolve/main/SOVL-MopeyMule-8B.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
[
"CAS"
] |
RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | 2024-06-23T17:58:06Z |
2024-06-23T18:07:21+00:00
| 83 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Healix-1.1B-V1-Chat-dDPO - GGUF
- Model creator: https://huggingface.co/health360/
- Original model: https://huggingface.co/health360/Healix-1.1B-V1-Chat-dDPO/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Healix-1.1B-V1-Chat-dDPO.Q2_K.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q2_K.gguf) | Q2_K | 0.4GB |
| [Healix-1.1B-V1-Chat-dDPO.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.IQ3_XS.gguf) | IQ3_XS | 0.44GB |
| [Healix-1.1B-V1-Chat-dDPO.IQ3_S.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.IQ3_S.gguf) | IQ3_S | 0.47GB |
| [Healix-1.1B-V1-Chat-dDPO.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q3_K_S.gguf) | Q3_K_S | 0.47GB |
| [Healix-1.1B-V1-Chat-dDPO.IQ3_M.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.IQ3_M.gguf) | IQ3_M | 0.48GB |
| [Healix-1.1B-V1-Chat-dDPO.Q3_K.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q3_K.gguf) | Q3_K | 0.51GB |
| [Healix-1.1B-V1-Chat-dDPO.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q3_K_M.gguf) | Q3_K_M | 0.51GB |
| [Healix-1.1B-V1-Chat-dDPO.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q3_K_L.gguf) | Q3_K_L | 0.55GB |
| [Healix-1.1B-V1-Chat-dDPO.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.IQ4_XS.gguf) | IQ4_XS | 0.57GB |
| [Healix-1.1B-V1-Chat-dDPO.Q4_0.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q4_0.gguf) | Q4_0 | 0.59GB |
| [Healix-1.1B-V1-Chat-dDPO.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.IQ4_NL.gguf) | IQ4_NL | 0.6GB |
| [Healix-1.1B-V1-Chat-dDPO.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q4_K_S.gguf) | Q4_K_S | 0.6GB |
| [Healix-1.1B-V1-Chat-dDPO.Q4_K.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q4_K.gguf) | Q4_K | 0.62GB |
| [Healix-1.1B-V1-Chat-dDPO.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q4_K_M.gguf) | Q4_K_M | 0.62GB |
| [Healix-1.1B-V1-Chat-dDPO.Q4_1.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q4_1.gguf) | Q4_1 | 0.65GB |
| [Healix-1.1B-V1-Chat-dDPO.Q5_0.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q5_0.gguf) | Q5_0 | 0.71GB |
| [Healix-1.1B-V1-Chat-dDPO.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q5_K_S.gguf) | Q5_K_S | 0.71GB |
| [Healix-1.1B-V1-Chat-dDPO.Q5_K.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q5_K.gguf) | Q5_K | 0.73GB |
| [Healix-1.1B-V1-Chat-dDPO.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q5_K_M.gguf) | Q5_K_M | 0.73GB |
| [Healix-1.1B-V1-Chat-dDPO.Q5_1.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q5_1.gguf) | Q5_1 | 0.77GB |
| [Healix-1.1B-V1-Chat-dDPO.Q6_K.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q6_K.gguf) | Q6_K | 0.84GB |
| [Healix-1.1B-V1-Chat-dDPO.Q8_0.gguf](https://huggingface.co/RichardErkhov/health360_-_Healix-1.1B-V1-Chat-dDPO-gguf/blob/main/Healix-1.1B-V1-Chat-dDPO.Q8_0.gguf) | Q8_0 | 1.09GB |
Original model description:
---
language:
- en
license: apache-2.0
tags:
- medical
- biology
- chemistry
- text-generation-inference
datasets:
- krvhrv/Healix-Medical-Shot
model-index:
- name: Healix-1.1B-V1-Chat-dDPO
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 30.55
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=health360/Healix-1.1B-V1-Chat-dDPO
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 44.78
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=health360/Healix-1.1B-V1-Chat-dDPO
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 24.64
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=health360/Healix-1.1B-V1-Chat-dDPO
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 41.55
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=health360/Healix-1.1B-V1-Chat-dDPO
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 56.51
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=health360/Healix-1.1B-V1-Chat-dDPO
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 0.0
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=health360/Healix-1.1B-V1-Chat-dDPO
name: Open LLM Leaderboard
---
# Healix 1.1B Model Card
## Model Description
Healix 1.1B is a state-of-the-art large language model specifically designed for medical applications. With 1.1 billion parameters, it has been trained on a vast corpus of medical literature to provide accurate and reliable responses to complex medical queries. This model aims to assist healthcare professionals and researchers by offering insights derived from medical data.
## Training Data
The model leverages an extensive compilation of medical literature, including research papers, clinical trial reports, and textbooks, ensuring a broad understanding of medical topics.
## Intended Use
This model is designed for medical research, clinical support, and healthcare applications. It serves to enhance medical text generation, query response, and evidence-based information dissemination. It is not a substitute for professional medical consultation.
## Limitations
While Healix 1.1B offers advanced medical insights, it has limitations in data quality and representativeness, and may inadvertently produce biased or incorrect information.
## Performance
Healix 1.1B demonstrated a remarkable accuracy of 64%, outperforming the LLAMA 2 7B model, which achieved an accuracy of 62% despite its larger size of 7 billion parameters. This highlights Healix 1.1B's superior ability to handle real emergency-focused medical questions, showcasing the effectiveness of specialized training and architecture in domain-specific applications.
## Ethical Considerations
Users are urged to use Healix 1.1B responsibly, considering the ethical implications, patient privacy, and data security. The model's outputs should be used as a supplementary information source alongside professional medical judgment.
## Papers
Details on the development, training, and evaluation of Healix 1.1B will be available in our forthcoming publications, offering insights into its creation and the advancements it brings to medical informatics.
### Input Format
Use the Alpaca model format.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_health360__Healix-1.1B-V1-Chat-dDPO)
| Metric |Value|
|---------------------------------|----:|
|Avg. |33.00|
|AI2 Reasoning Challenge (25-Shot)|30.55|
|HellaSwag (10-Shot) |44.78|
|MMLU (5-Shot) |24.64|
|TruthfulQA (0-shot) |41.55|
|Winogrande (5-shot) |56.51|
|GSM8k (5-shot) | 0.00|
|
[
"MEDICAL DATA"
] |
invisietch/L3.1-EtherealRainbow-v1.0-rc1-8B
|
invisietch
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"not-for-all-audiences",
"axolotl",
"qlora",
"conversational",
"en",
"license:llama3.1",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-10-16T11:28:27Z |
2024-10-23T15:13:37+00:00
| 83 | 8 |
---
language:
- en
library_name: transformers
license: llama3.1
tags:
- not-for-all-audiences
- axolotl
- qlora
---
<div align="center">
<b style="font-size: 36px;">L3.1-EtherealRainbow-v1.0-rc1-8B</b>
<img src="https://huggingface.co/invisietch/L3.1-EtherealRainbow-v1.0-rc1-8B/resolve/main/header.png" style="width:60%">
</div>
# Model Details
Ethereal Rainbow v1.0 is the sequel to my popular Llama 3 8B merge, EtherealRainbow v0.3. Instead of a straight merge of other peoples'
models, v1.0 is a finetune on the Instruct model, using 245 million tokens of training data (approx 177 million of these tokens are my
own novel datasets).
This model is designed to be suitable for creative writing and roleplay, and to push the boundaries of what's possible with an 8B model.
This RC is not a finished product, but your feedback will drive the creation of better models.
**This is a release candidate model. It has some known issues and probably some unknown ones too, because the purpose of these early releases is to seek feedback.**
# Quantization Formats
* [FP16 Safetensors](https://huggingface.co/invisietch/L3.1-EtherealRainbow-v1.0-rc1-8B)
* [Static GGUF](https://huggingface.co/invisietch/L3.1-EtherealRainbow-v1.0-rc1-8B-GGUF)
* [iMatrix GGUF](https://huggingface.co/mradermacher/L3.1-EtherealRainbow-v1.0-rc1-8B-i1-GGUF) - h/t [mradermacher](https://huggingface.co/mradermacher/)
* [Alternative GGUF](https://huggingface.co/mradermacher/L3.1-EtherealRainbow-v1.0-rc1-8B-GGUF) - h/t [mradermacher](https://huggingface.co/mradermacher/)
# Feedback
I appreciate all feedback on any of my models, you can use:
* [My Discord server](https://discord.gg/AJwZuu7Ncx) - requires Discord.
* [The Community tab](https://huggingface.co/invisietch/Nimbus-Miqu-v0.1-70B/discussions) - requires HF login.
* [The SillyTavern Discord thread](https://discord.com/channels/1100685673633153084/1258146078679633990) - must be on [SillyTavern Discord](https://discord.gg/sillytavern).
* Discord DMs to **invisietch**.
Your feedback is how I improve these models for future versions.
# Disclaimer
This model is fairly uncensored. It can generate explicit, disturbing or offensive responses. Use responsibly. I am not responsible for your
use of this model, and it's your responsibility to follow the Llama 3.1 license agreement.
# Prompting Format
I'd recommend Llama-3 Instruct prompting format:
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
```
# Sampler Settings
I'm running the following sampler settings but this is an RC and they may not be optimal.
- **Temperature:** Dynamic 0.7-1.3
- **Min-P:** 0.1
- **Rep Pen:** 0.06
- **Rep Pen Range:** 1536
- **XTC:** 0.1/0.05
If you get completely incoherent responses, feel free to use these as a starting point.
# Example Storywriting
These prompts are used on SillyTavern with a fairly basic narrator card. I have trimmed the start and finish where the narrator decided to add
chapter headings, commentary and the like. All samples are made with the Q8_0 GGUF loaded with koboldcpp, with response length capped at 2048 tokens.
<details>
<summary><b>Write me a 3,000 word opening chapter of a 'gritty hard sci-fi' novel, drawing inspiration from the writing styles of Isaac Asimov & Andy Weir. Use third person personal. Include dialogue and internal monologues. The POV character for the opening chapter should be a 26 year old astronaut called Tone on a mission to Europa, who has just realised that the craft for the return journey is broken beyond repair, and he only has supplies for a few months. Given that survival is impossible, he seeks to spend the few months he has researching titan, so his life & mission are not wasted.</b></summary>
As Tone stood at the controls of his ship, Europa-1, he couldn't help but feel a sense of pride and accomplishment. His mission had been a resounding success, and he had played a pivotal role in discovering the presence of liquid water beneath the icy surface of the moon. But now, as he stared at the damaged engine before him, his heart sank.
"Engine failure," he muttered, his voice shaking. He had lost contact with Earth two weeks ago, and he knew that no one would receive his distress signal until long after he was gone. Panic crept in, and he began to hyperventilate. "No…no…this can't be happening." He slumped to the floor, tears streaming down his face as the reality of his situation set in.
The Europa-1 was equipped with supplies for a three-month return trip. With its engine destroyed, there was no way Tone could get back home. His only choice was to spend the remainder of his time on Europa studying Titan, a moon of Saturn, which he believed held more secrets than the moon he was on now.
Tone wiped away his tears and took a deep breath. "Well, I guess my mission isn't over yet," he said, trying to sound upbeat. "At least I'll have a chance to learn something new."
He turned on the ship's computer and accessed the data banks containing information about Titan. Titan, with its thick atmosphere and hydrocarbon lakes, was the only known celestial body in the solar system that had conditions suitable for human habitation. The discovery of life on Titan could have meant the salvation of humanity, but until now, no spacecraft had been able to make a thorough investigation of the moon.
Tone sat down at the control panel and began to scan through the data files. His heart raced with excitement as he delved deeper into the files, discovering fascinating details about Titan's geology, chemistry, and potential biosphere. He spent hours poring over the data, marveling at how much he still didn't know about the moon.
As night fell outside, Tone's thoughts turned to his family and friends back on Earth. He missed them dearly, especially his parents, who had sacrificed so much for him to pursue his dreams of becoming an astronaut. He wondered if he would ever see them again and hoped that they wouldn't think of him as a failure.
Tone tried to distract himself by eating a meal and watching some movies stored in the ship's database. He eventually drifted off to sleep, exhausted from the emotional rollercoaster of the day.
Over the next few months, Tone dedicated himself to his research on Titan. He analyzed data from previous missions, conducted experiments in his own laboratory, and even ventured outside to collect samples of the icy moon. Through his tireless efforts, he gained valuable insights into the mysteries of Titan, and he was confident that he was contributing to the future of humanity.
However, despite his best efforts to focus on his work, Tone couldn't help but think about what lay ahead. He knew that his time on Europa was limited, and soon, he would run out of supplies and oxygen. The thought filled him with a sense of dread and sadness. He wanted to make the most of his final days, but he also didn't want to forget the loved ones he left behind.
One day, while reviewing data from his latest excursion, Tone made an astonishing discovery. While analyzing samples of Titan's surface material, he detected traces of organic compounds, indicating possible evidence of life. His heart skipped a beat as he realized the significance of his find. If confirmed, it would mean that Titan might be teeming with life, just like Earth. He felt an overwhelming sense of joy and relief, knowing that his sacrifice wouldn't be in vain.
Tone continued to study the samples, hoping to glean more information about the life forms that inhabited Titan. However, as the weeks went by, he found that his energy levels were steadily decreasing. His body was weakening due to lack of sunlight and proper nutrition, and he knew that he didn't have much time left.
Despite his dwindling strength, Tone persevered, determined to complete his mission. He was nearing the end of his supplies and knew that he wouldn't survive beyond a few more weeks. Yet he was undeterred, knowing that his discovery could revolutionize the course of human history.
In the final moments of his life, Tone felt a sense of peace wash over him. He knew that he had given his all to science, and that his sacrifice would pave the way for the future of humanity. As he succumbed to exhaustion and finally closed his eyes, he smiled, knowing that he had done everything he could to save his species.
</details>
<details>
<summary><b>Write me a 3,000 word opening chapter of a 'high fantasy' novel, drawing inspiration from the writing styles of J R R Tolkien & George R R Martin. Use third person personal. Include dialogue and internal monologues. The POV character for the opening chapter should be a 19 year old female elf bard who is looking for adventure.</b></summary>
Elara stands in the midst of a bustling marketplace, surrounded by countless vendors hawking their wares and passersby rushing to and fro. She clutches her worn lute tightly to her chest, the instrument having been with her since her early days as a performer on the road. Her fingers trace the familiar grooves etched into its surface, recalling countless nights spent sharing tales and melodies with travelers and locals alike.
As Elara navigates through the crowded market, she feels a familiar sense of restlessness stirring within her. The past few weeks have seen her performing in various taverns and villages, but something has been nagging at her, urging her to leave the safety of this mundane routine behind and seek out greater adventure. The thrill of discovery, the promise of danger and excitement - these are the things that drive her, pushing her to keep moving forward, no matter what challenges may lie ahead.
She pauses to listen to a group of traveling minstrels regale the crowd with tales of valor and magic. Their stories of heroes and battles fought are familiar, but they still bring a twinkle to her eye and a spark to her imagination. Elara knows that she can never match their skill or experience, but she hopes that she may someday be worthy of being counted among them.
Suddenly, a commotion breaks out nearby, drawing Elara's attention to a small group of guardsmen surrounding a hooded figure. They seem to be arguing over something, but their words are indistinct amidst the din of the marketplace. Curiosity gets the better of her, and Elara carefully makes her way closer, hoping to catch a glimpse of what's going on.
"What did you say?" one of the guardsmen shouts angrily. "You can't just come in here and-"
"I'm here for the Princess," the hooded figure interrupts, their voice low and gravelly. "I've been sent by Lord Ravenwood himself."
The guards exchange nervous glances, clearly unsure of what to do next. One of them steps forward, hand on his sword hilt. "We can't just let you in without proper identification."
The figure pulls back its hood, revealing a face that makes Elara's breath catch in her throat. It's a woman, her features chiseled and angular, her eyes a piercing yellow that seems to bore into those around her. A series of scars crisscross her cheeks and forehead, giving her an almost feral appearance. Yet despite her intimidating appearance, there's a grace to her movements that speaks of centuries of training and combat experience.
"I am Lady Arachne, Knight-Captain of Lord Ravenwood's personal guard," she says coldly. "If you do not let me speak to the Princess immediately, I will have you all thrown in irons."
The guards look at each other uncertainly, then back to Lady Arachne. One of them steps forward, his hand still on his sword hilt. "Very well, I'll fetch Her Highness."
Lady Arachne nods curtly and turns away, heading deeper into the castle. The guards watch her go, muttering among themselves about how they don't like her looks. Elara, meanwhile, finds herself transfixed by the scene she's just witnessed. She's heard stories of the Knights of Ravenwood, elite warriors who serve as bodyguards to the ruling Princess. To see one of them up close, to witness firsthand their skill and authority, is a rare opportunity indeed.
Elara's thoughts are interrupted by a gentle touch on her shoulder. She turns to see a young man, perhaps a few years her senior, smiling down at her. His hair is a rich brown, cut short in a practical style that suits his rugged good looks. His eyes are a warm hazel, filled with kindness and intelligence.
"Hello," he says softly. "Are you alright?"
Elara startles slightly, realizing that she'd been so engrossed in the scene before her that she hadn't even noticed anyone approaching her. She takes a deep breath, trying to calm herself. "Yes, thank you," she replies, managing a small smile. "Just lost in thought, that's all."
The young man nods sympathetically. "I know how that is," he says. "Sometimes I find myself getting carried away with my own thoughts. It's as if the world around me melts away, leaving only the sound of my own heartbeat."
Elara can't help but laugh at this. "Well, that certainly sounds romantic," she teases, though she knows that she means it. There's something about his words that resonates with her own feelings.
The young man blushes slightly. "Oh, I didn't mean to-"
But Elara holds up her hand, cutting him off. "No, it's quite alright," she says. "I think that's exactly what I needed to hear. Thank you."
He smiles again, a genuine, warm smile that fills Elara with a sense of peace. "Anytime," he says. "And might I ask your name? I haven't had the pleasure of meeting you before."
"My name is Elara," she replies, extending her hand. "And yours is…?"
"Max," he says, taking her hand in his. His grip is firm but gentle, his touch sending a shiver through her body.
Elara feels a sudden surge of excitement at his touch, as if the whole world has opened up to her. She can't believe how much she wants to get to know this Max, to spend more time with him and explore whatever connection they may have formed in this moment. But before she can say anything else, she hears a loud commotion coming from nearby.
Max follows her gaze and gasps in shock. "What is it?" he asks, already moving towards the disturbance.
Elara hurries after him, her heart racing with anticipation.
</details>
<details>
<summary><b>Write me a 3,000 word opening chapter of a 'weird fiction' novel, drawing inspiration from the writing styles of China Mieville and Neil Gaiman. Use third person personal. Include dialogue and internal monologues. The POV character for the opening chapter should be a male in his 20s called Horton who has just come to the city looking for work.</b></summary>
The air was heavy with anticipation as Horton stepped off the train and onto the platform of the bustling city. The sounds of car horns, chatter, and construction filled his ears. As he looked around at the towering skyscrapers and busy streets, he could feel his heart racing with excitement. He had finally left behind the small town where he grew up, eager to find a new life in the big city. His mother had always told him that he would go far in this place, that he would make something of himself here.
Horton took a deep breath, trying to calm his nerves. He knew that finding work wouldn't be easy, but he was determined to succeed. He had packed lightly, only bringing a few clothes and some basic supplies. He had no idea what he wanted to do yet, but he was sure he'd figure it out soon enough.
As he made his way through the crowded station, Horton noticed a strange-looking woman standing nearby. She was dressed in a long, black coat and hat, and her face was hidden behind a veil. There was something about her that seemed almost…otherworldly. He felt drawn to her, like there was something important she needed to tell him.
"Hello," he said, approaching her cautiously. "I'm new here, looking for work."
The woman turned to face him, revealing piercing green eyes that seemed to bore into his soul. "So am I," she replied in a low, mysterious voice. "And I have found my calling."
"Really?" Horton asked, intrigued. "What's that?"
The woman smiled, revealing sharp teeth. "To help those who need it most." She reached out a gloved hand and placed it on his chest. "You look lost, my friend. Would you like some guidance?"
Horton hesitated, unsure if he should trust this stranger. But something about her seemed genuine, so he nodded. "Yes, please."
She pulled him close, pressing her lips against his. Horton felt a jolt of electricity run through his body, and suddenly everything seemed different. The world was brighter, more vibrant than before, and he could see things that were previously invisible to him.
"What did you do to me?" he gasped, struggling to breathe.
The woman laughed, her voice echoing in his head. "I showed you the truth," she said. "Now follow me, and I will show you how to survive in this city."
Horton followed the woman as she led him through the winding streets of the city. They passed by dark alleyways and crowded marketplaces, and Horton could feel his heart pounding in his chest. The woman seemed to know exactly where she was going, navigating through the chaos with ease.
Eventually they arrived at a run-down apartment building, and the woman pushed open the door to reveal a dimly lit hallway. She motioned for Horton to enter, and he hesitantly complied.
Inside the apartment was a mess of papers, maps, and strange artifacts. Horton's eyes widened in shock as he took it all in. "What is all this?" he asked, feeling overwhelmed.
"This is where we'll be staying," the woman replied, closing the door behind them. "Welcome to your new home, my friend."
Horton stared at her, unsure of what to say. He didn't understand what was happening, why she had brought him here, but he knew he couldn't leave now. Something inside of him felt like it belonged here, like he had been waiting for this moment his entire life. He took a deep breath and nodded, ready to begin his journey into the unknown.
"Thank you," he said, meeting her gaze. "I won't let you down."
The woman smiled once more, and Horton felt himself being drawn towards her. Suddenly, their lips met again, and he was consumed by a feeling of ecstasy unlike anything he had ever experienced before. When they finally separated, he could hear the sound of his own heartbeat pulsing through his veins, and he knew that he would never be the same again.
"What have I gotten myself into?" he thought, feeling both scared and excited at the prospect of what lay ahead.
</details>
I chose the hard sci-fi example to test positivity bias. It was willing to kill the protagonist on first try, on screen.
I chose the high fantasy example to see whether it would bleed human features through to elves, this didn't occur.
I chose the weird fiction example to see if the LLM understood a niche genre. It performed okay, but a bit cliche.
# Training Strategy
This was trained with an r 128 qlora over 2 epochs on a mix of public & private datasets using Axolotl.
Training was performed with a 16384 seq len to try to preserve Llama 3.1's long context.
This took approx. 51 hours on 1x NVIDIA A100 80GB GPU.
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
|
[
"CRAFT"
] |
RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2304.01373",
"arxiv:2101.00027",
"arxiv:2201.07311",
"endpoints_compatible",
"region:us"
] | 2024-11-03T15:41:22Z |
2024-11-03T15:43:35+00:00
| 83 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pythia-160m-deduped - GGUF
- Model creator: https://huggingface.co/EleutherAI/
- Original model: https://huggingface.co/EleutherAI/pythia-160m-deduped/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pythia-160m-deduped.Q2_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q2_K.gguf) | Q2_K | 0.07GB |
| [pythia-160m-deduped.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q3_K_S.gguf) | Q3_K_S | 0.08GB |
| [pythia-160m-deduped.Q3_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q3_K.gguf) | Q3_K | 0.09GB |
| [pythia-160m-deduped.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q3_K_M.gguf) | Q3_K_M | 0.09GB |
| [pythia-160m-deduped.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q3_K_L.gguf) | Q3_K_L | 0.09GB |
| [pythia-160m-deduped.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.IQ4_XS.gguf) | IQ4_XS | 0.09GB |
| [pythia-160m-deduped.Q4_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q4_0.gguf) | Q4_0 | 0.1GB |
| [pythia-160m-deduped.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.IQ4_NL.gguf) | IQ4_NL | 0.1GB |
| [pythia-160m-deduped.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q4_K_S.gguf) | Q4_K_S | 0.1GB |
| [pythia-160m-deduped.Q4_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q4_K.gguf) | Q4_K | 0.1GB |
| [pythia-160m-deduped.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q4_K_M.gguf) | Q4_K_M | 0.1GB |
| [pythia-160m-deduped.Q4_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q4_1.gguf) | Q4_1 | 0.1GB |
| [pythia-160m-deduped.Q5_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q5_0.gguf) | Q5_0 | 0.11GB |
| [pythia-160m-deduped.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q5_K_S.gguf) | Q5_K_S | 0.11GB |
| [pythia-160m-deduped.Q5_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q5_K.gguf) | Q5_K | 0.12GB |
| [pythia-160m-deduped.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q5_K_M.gguf) | Q5_K_M | 0.12GB |
| [pythia-160m-deduped.Q5_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q5_1.gguf) | Q5_1 | 0.12GB |
| [pythia-160m-deduped.Q6_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q6_K.gguf) | Q6_K | 0.13GB |
| [pythia-160m-deduped.Q8_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-160m-deduped-gguf/blob/main/pythia-160m-deduped.Q8_0.gguf) | Q8_0 | 0.16GB |
Original model description:
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research [(see paper)](https://arxiv.org/pdf/2304.01373.pdf).
It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. We also provide 154 intermediate
checkpoints per model, hosted on Hugging Face as branches.
The Pythia model suite was designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
<details>
<summary style="font-weight:600">Details on previous early release and naming convention.</summary>
Previously, we released an early version of the Pythia suite to the public.
However, we decided to retrain the model suite to address a few hyperparameter
discrepancies. This model card <a href="#changelog">lists the changes</a>;
see appendix B in the Pythia paper for further discussion. We found no
difference in benchmark performance between the two Pythia versions.
The old models are
[still available](https://huggingface.co/models?other=pythia_v0), but we
suggest the retrained suite if you are just starting to use Pythia.<br>
**This is the current release.**
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
</details>
<br>
# Pythia-160M-deduped
## Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
[See paper](https://arxiv.org/pdf/2304.01373.pdf) for more evals and implementation
details.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 2M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 2M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 2M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
## Uses and Limitations
### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. We also provide
154 checkpoints per model: initial `step0`, 10 log-spaced checkpoints
`step{1,2,4...512}`, and 143 evenly-spaced checkpoints from `step1000` to
`step143000`. These checkpoints are hosted on Hugging Face as branches. Note
that branch `143000` corresponds exactly to the model checkpoint on the `main`
branch of each model.
You may also further fine-tune and adapt Pythia-160M-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-160M-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions. For example,
the model may generate harmful or offensive text. Please evaluate the risks
associated with your particular use case.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-160M-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-160M-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “follow” human instructions.
### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token used by the model need not produce the
most “accurate” text. Never rely on Pythia-160M-deduped to produce factually accurate
output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-160M-deduped may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-160M-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
## Training
### Training data
Pythia-160M-deduped was trained on the Pile **after the dataset has been globally
deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training,
from `step1000` to `step143000` (which is the same as `main`). In addition, we
also provide frequent early checkpoints: `step0` and `step{1,2,4...512}`.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for 143000 steps at a batch size
of 2M (2,097,152 tokens).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
## Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json/).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai_v1.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa_v1.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande_v1.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Easy Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_easy_v1.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq_v1.png" style="width:auto"/>
</details>
## Changelog
This section compares differences between previously released
[Pythia v0](https://huggingface.co/models?other=pythia_v0) and the current
models. See Appendix B of the Pythia paper for further discussion of these
changes and the motivation behind them. We found that retraining Pythia had no
impact on benchmark performance.
- All model sizes are now trained with uniform batch size of 2M tokens.
Previously, the models of size 160M, 410M, and 1.4B parameters were trained
with batch sizes of 4M tokens.
- We added checkpoints at initialization (step 0) and steps {1,2,4,8,16,32,64,
128,256,512} in addition to every 1000 training steps.
- Flash Attention was used in the new retrained suite.
- We remedied a minor inconsistency that existed in the original suite: all
models of size 2.8B parameters or smaller had a learning rate (LR) schedule
which decayed to a minimum LR of 10% the starting LR rate, but the 6.9B and
12B models all used an LR schedule which decayed to a minimum LR of 0. In
the redone training runs, we rectified this inconsistency: all models now were
trained with LR decaying to a minimum of 0.1× their maximum LR.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
[
"SCIQ"
] |
mav23/pythia-1b-deduped-GGUF
|
mav23
| null |
[
"gguf",
"pytorch",
"causal-lm",
"pythia",
"en",
"dataset:EleutherAI/the_pile_deduplicated",
"arxiv:2304.01373",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2024-11-20T15:16:59Z |
2024-11-20T15:26:48+00:00
| 83 | 0 |
---
datasets:
- EleutherAI/the_pile_deduplicated
language:
- en
license: apache-2.0
tags:
- pytorch
- causal-lm
- pythia
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research [(see paper)](https://arxiv.org/pdf/2304.01373.pdf).
It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. We also provide 154 intermediate
checkpoints per model, hosted on Hugging Face as branches.
The Pythia model suite was designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
<details>
<summary style="font-weight:600">Details on previous early release and naming convention.</summary>
Previously, we released an early version of the Pythia suite to the public.
However, we decided to retrain the model suite to address a few hyperparameter
discrepancies. This model card <a href="#changelog">lists the changes</a>;
see appendix B in the Pythia paper for further discussion. We found no
difference in benchmark performance between the two Pythia versions.
The old models are
[still available](https://huggingface.co/models?other=pythia_v0), but we
suggest the retrained suite if you are just starting to use Pythia.<br>
**This is the current release.**
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
</details>
<br>
# Pythia-1B-deduped
## Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
[See paper](https://arxiv.org/pdf/2304.01373.pdf) for more evals and implementation
details.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 2M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 2M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 2M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
## Uses and Limitations
### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. We also provide
154 checkpoints per model: initial `step0`, 10 log-spaced checkpoints
`step{1,2,4...512}`, and 143 evenly-spaced checkpoints from `step1000` to
`step143000`. These checkpoints are hosted on Hugging Face as branches. Note
that branch `143000` corresponds exactly to the model checkpoint on the `main`
branch of each model.
You may also further fine-tune and adapt Pythia-1B-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-1B-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions. For example,
the model may generate harmful or offensive text. Please evaluate the risks
associated with your particular use case.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-1B-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-1B-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “follow” human instructions.
### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token used by the model need not produce the
most “accurate” text. Never rely on Pythia-1B-deduped to produce factually accurate
output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-1B-deduped may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-1B-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
## Training
### Training data
Pythia-1B-deduped was trained on the Pile **after the dataset has been globally
deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training,
from `step1000` to `step143000` (which is the same as `main`). In addition, we
also provide frequent early checkpoints: `step0` and `step{1,2,4...512}`.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for 143000 steps at a batch size
of 2M (2,097,152 tokens).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
## Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json/).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai_v1.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa_v1.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande_v1.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Easy Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_easy_v1.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq_v1.png" style="width:auto"/>
</details>
## Changelog
This section compares differences between previously released
[Pythia v0](https://huggingface.co/models?other=pythia_v0) and the current
models. See Appendix B of the Pythia paper for further discussion of these
changes and the motivation behind them. We found that retraining Pythia had no
impact on benchmark performance.
- All model sizes are now trained with uniform batch size of 2M tokens.
Previously, the models of size 160M, 410M, and 1.4B parameters were trained
with batch sizes of 4M tokens.
- We added checkpoints at initialization (step 0) and steps {1,2,4,8,16,32,64,
128,256,512} in addition to every 1000 training steps.
- Flash Attention was used in the new retrained suite.
- We remedied a minor inconsistency that existed in the original suite: all
models of size 2.8B parameters or smaller had a learning rate (LR) schedule
which decayed to a minimum LR of 10% the starting LR rate, but the 6.9B and
12B models all used an LR schedule which decayed to a minimum LR of 0. In
the redone training runs, we rectified this inconsistency: all models now were
trained with LR decaying to a minimum of 0.1× their maximum LR.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
[
"SCIQ"
] |
ntc-ai/SDXL-LoRA-slider.raining
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-29T04:53:33Z |
2023-12-29T04:53:36+00:00
| 82 | 1 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/raining.../raining_17_3.0.png
widget:
- text: raining
output:
url: images/raining_17_3.0.png
- text: raining
output:
url: images/raining_19_3.0.png
- text: raining
output:
url: images/raining_20_3.0.png
- text: raining
output:
url: images/raining_21_3.0.png
- text: raining
output:
url: images/raining_22_3.0.png
inference: false
instance_prompt: raining
---
# ntcai.xyz slider - raining (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/raining_17_-3.0.png" width=256 height=256 /> | <img src="images/raining_17_0.0.png" width=256 height=256 /> | <img src="images/raining_17_3.0.png" width=256 height=256 /> |
| <img src="images/raining_19_-3.0.png" width=256 height=256 /> | <img src="images/raining_19_0.0.png" width=256 height=256 /> | <img src="images/raining_19_3.0.png" width=256 height=256 /> |
| <img src="images/raining_20_-3.0.png" width=256 height=256 /> | <img src="images/raining_20_0.0.png" width=256 height=256 /> | <img src="images/raining_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
raining
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.raining', weight_name='raining.safetensors', adapter_name="raining")
# Activate the LoRA
pipe.set_adapters(["raining"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, raining"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 710+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
LoneStriker/Newton-7B-GGUF
|
LoneStriker
| null |
[
"gguf",
"axolotl",
"finetune",
"qlora",
"dataset:hendrycks/competition_math",
"dataset:allenai/ai2_arc",
"dataset:camel-ai/physics",
"dataset:camel-ai/chemistry",
"dataset:camel-ai/biology",
"dataset:camel-ai/math",
"dataset:STEM-AI-mtl/Electrical-engineering",
"dataset:openbookqa",
"dataset:piqa",
"dataset:metaeval/reclor",
"dataset:mandyyyyii/scibench",
"dataset:derek-thomas/ScienceQA",
"dataset:sciq",
"dataset:TIGER-Lab/ScienceEval",
"arxiv:2305.14314",
"base_model:openchat/openchat-3.5-0106",
"base_model:quantized:openchat/openchat-3.5-0106",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-02-01T09:06:09Z |
2024-02-01T09:28:43+00:00
| 82 | 1 |
---
base_model: openchat/openchat-3.5-0106
datasets:
- hendrycks/competition_math
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- STEM-AI-mtl/Electrical-engineering
- openbookqa
- piqa
- metaeval/reclor
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- sciq
- TIGER-Lab/ScienceEval
license: other
tags:
- axolotl
- finetune
- qlora
---

# 🔬👩🔬 Newton-7B
This model is a fine-tuned version of [openchat/openchat-3.5-0106](https://huggingface.co/openchat/openchat-3.5-0106) on datasets related to science.
This model is fine-tuned using [QLoRa](https://arxiv.org/abs/2305.14314) and [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This model's training was sponsored by [sablo.ai](https://sablo.ai).
<details><summary>See axolotl config</summary>
axolotl version: `0.3.0`
```yaml
base_model: openchat/openchat-3.5-0106
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
is_mistral_derived_model: true
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: merged_all.json
type:
field_instruction: instruction
field_output: output
format: "GPT4 Correct User: {instruction}<|end_of_turn|>GPT4 Correct Assistant:"
no_input_format: "GPT4 Correct User: {instruction}<|end_of_turn|>GPT4 Correct Assistant:"
dataset_prepared_path: last_run_prepared
val_set_size: 0.01 # not sure
output_dir: ./newton
adapter: qlora
lora_model_dir:
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
lora_r: 128
lora_alpha: 64
lora_dropout: 0.05
lora_target_linear: true
lora_fan_in_fan_out:
lora_target_modules:
- gate_proj
- down_proj
- up_proj
- q_proj
- v_proj
- k_proj
- o_proj
lora_modules_to_save:
- embed_tokens
- lm_head
wandb_project: huggingface
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
hub_model_id: Weyaxi/newton-lora
save_safetensors: true
# change #
gradient_accumulation_steps: 12
micro_batch_size: 6
num_epochs: 2
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.0002
# change #
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10 # not sure
saves_per_epoch: 2
evals_per_epoch: 4
eval_table_size:
eval_table_max_new_tokens: 128
debug:
deepspeed:
weight_decay: 0.1 # not sure
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "</s>"
unk_token: "<unk>"
tokens:
- "<|end_of_turn|>"
- "<|pad_0|>"
```
</details><br>
# 📊 Datasets
You can find the dataset I used and the work I am doing with this datasets here:
https://huggingface.co/datasets/Weyaxi/sci-datasets
Following datasets were used in this model:
- 📐 [MATH](https://huggingface.co/datasets/hendrycks/competition_math)
- 🧠 [ARC](https://huggingface.co/datasets/allenai/ai2_arc) (Note: Only **train** part)
- 🧲 [camel-ai/physics](https://huggingface.co/datasets/camel-ai/physics)
- ⚗️ [camel-ai/chemistry](https://huggingface.co/datasets/camel-ai/chemistry)
- 🦠 [camel-ai/biology](https://huggingface.co/datasets/camel-ai/biology)
- 📊 [camel-ai/math](https://huggingface.co/datasets/camel-ai/math)
- ⚡ [STEM-AI-mtl/Electrical-engineering](https://huggingface.co/datasets/STEM-AI-mtl/Electrical-engineering)
- 📚 [openbookqa](https://huggingface.co/datasets/openbookqa)
- 🧠 [piqa](https://huggingface.co/datasets/piqa)
- 🎨 [reclor](https://huggingface.co/datasets/metaeval/reclor)
- 🔬 [scibench](https://github.com/mandyyyyii/scibench)
- 🧪 [ScienceQA](https://huggingface.co/datasets/derek-thomas/ScienceQA)
- 🧬 [sciq](https://huggingface.co/datasets/sciq)
- 📝 [ScienceEval](https://huggingface.co/datasets/TIGER-Lab/ScienceEval)
## 🛠️ Multiple Choice Question & Answer Datasets Conversion Progress
I used [mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) to generate a reasonable and logical answer by providing it with the question and the answer key.
I used the [Together AI](https://www.together.ai) API for this task.
The following datasets are converted using this method:
- 🧠 [ARC](https://huggingface.co/datasets/allenai/ai2_arc) (Note: Only **train** part)
- 📚 [openbookqa](https://huggingface.co/datasets/openbookqa)
- 🎨 [reclor](https://huggingface.co/datasets/metaeval/reclor)
- 🧬 [sciq](https://huggingface.co/datasets/sciq)
# 💬 Prompt Template
You can use this prompt template while using the model:
### GPT4 Correct [(Openchat)](https://huggingface.co/openchat/openchat-3.5-0106#conversation-templates)
```
GPT4 Correct User: {user}<|end_of_turn|>GPT4 Correct Assistant: {asistant}<|end_of_turn|>GPT4 Correct User: {user}<|end_of_turn|>GPT4 Correct Assistant:
```
You can also utilize the chat template method from the tokenizer config like here:
```python
messages = [
{"role": "user", "content": "Hello"},
{"role": "assistant", "content": "Hi"},
{"role": "user", "content": "How are you today?"}
]
tokens = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
```
# 🤝 Acknowledgments
Thanks to [openchat](https://huggingface.co/openchat) team for fine-tuning an excellent model that I used as a base model.
Thanks to [@jondurbin](https://huggingface.co/jondurbin) for reformatting codes for some datasets: [bagel/data_sources](https://github.com/jondurbin/bagel/tree/main/bagel/data_sources)
Thanks to [Together AI](https://www.together.ai) for providing everyone with free credits, which I used to generate a dataset in multiple choice to explanations format.
Thanks to [Tim Dettmers](https://huggingface.co/timdettmers) for his excellent [QLoRA](https://arxiv.org/abs/2305.14314) work.
Thanks to all the dataset authors mentioned in the datasets section.
Thanks to [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) for making the repository I used to make this model.
Overall, thanks to all of the open soure AI community! 🚀
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
If you would like to support me:
[☕ Buy Me a Coffee](https://www.buymeacoffee.com/weyaxi)
|
[
"SCIQ"
] |
alonzogarbanzo/Bloom-1b7-creative-writing
|
alonzogarbanzo
|
text-generation
|
[
"transformers",
"safetensors",
"bloom",
"text-generation",
"generated_from_trainer",
"base_model:bigscience/bloom-1b7",
"base_model:finetune:bigscience/bloom-1b7",
"license:bigscience-bloom-rail-1.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-02-27T01:36:19Z |
2024-03-03T03:00:55+00:00
| 82 | 0 |
---
base_model: bigscience/bloom-1b7
license: bigscience-bloom-rail-1.0
tags:
- generated_from_trainer
model-index:
- name: Bloom-1b7-creative-writing
results: []
---
# Bloom-1b7-creative-writing
This model is a fine-tuned version of [bigscience/bloom-1b7](https://huggingface.co/bigscience/bloom-1b7) on the [adambjorn/UnrelatedForgettingOverhead](https://huggingface.co/datasets/adambjorn/UnrelatedForgettingOverhead) creative writing dataset.
## Model description
More information needed
## Intended uses & limitations
Intended for use on a student group project for Portland State University's Winter 2024 LLMs Course.
## Training and evaluation data
Instruction Tuned on the creative writing dataset here: https://huggingface.co/datasets/adambjorn/UnrelatedForgettingOverhead/viewer/creative
## Training procedure
Trained on a single RTX 3090 card.
Given a set of prompts:
```python
prompts = [
"Write a creative short story based on the following title:",
"Here is a title for a story. Craft a short narrative around it:",
"Using the title given, develop a short story:",
"Imagine a short story that starts with this title:",
"Create a brief story with the following title:"
]
```
Concatenate the prompt, the title and the story like so:
```python
concatenated_texts = [random.choice(prompts) + " " + title + "</s>" + "Story: " + selftext for title, selftext in zip(titles, selftexts)]
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
Final results:
{'loss': 0.0472, 'learning_rate': 1.4893617021276598e-06, 'epoch': 4.95}
Average results:
{'train_runtime': 563.2707,
'train_samples_per_second': 1.687,
'train_steps_per_second': 0.417,
'train_loss': 0.8475136074614018,
'epoch': 4.95}
### Framework versions
- Transformers 4.37.2
- Pytorch 2.2.0+cu121
- Datasets 2.17.0
- Tokenizers 0.15.2
|
[
"CRAFT"
] |
Writer/Palmyra-Med-70B
|
Writer
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"instruct",
"finetune",
"DPO",
"distillation",
"heathcare",
"medical",
"clinical",
"med",
"lifescience",
"Pharmaceutical",
"Pharma",
"Enterprise LLM",
"Enterprise",
"Enterprise ready",
"conversational",
"en",
"arxiv:2305.18290",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-05-05T23:44:37Z |
2024-10-01T21:18:06+00:00
| 82 | 79 |
---
base_model: Writer/Palmyra-x-003
language:
- en
license: other
license_name: writer-open-model-license
license_link: https://writer.com/legal/open-model-license/
tags:
- instruct
- finetune
- DPO
- distillation
- heathcare
- medical
- clinical
- med
- lifescience
- Pharmaceutical
- Pharma
- Enterprise LLM
- Enterprise
- Enterprise ready
model_type: palmyra
extra_gated_prompt: By clicking "Agree", you agree to the [License Agreement](https://writer.com/legal/open-model-license/)
and acknowledge Writer's [Privacy Policy](https://writer.com/legal/acceptable-use/).
extra_gated_fields:
Name: text
Email: text
Organization or Affiliation: text
Receive email updates and promotions on Writer products, services, and research?:
type: select
options:
- 'Yes'
- 'No'
I acknowledge that this model is for non-commercial use only unless I acquire a separate license from Writer: checkbox
widget:
- example_title: Palmyra-Med-70B
messages:
- role: system
content: You are a highly knowledgeable and experienced expert in the healthcare
and biomedical field, possessing extensive medical knowledge and practical expertise.
- role: user
content: Does danzhi Xiaoyao San ameliorate depressive-like behavior by shifting
toward serotonin via the downregulation of hippocampal indoleamine 2,3-dioxygenase?
output:
text: Danzhi Xiaoyao San (DXS) exhibited significant antidepressant-like effects
in rats subjected to chronic unpredictable mild stress (CUMS), a commonly used
model for inducing depressive-like behavior. The administration of DXS led to
a notable reduction in the activity of indoleamine 2,3-dioxygenase (IDO) in
the hippocampus. This reduction in IDO activity is crucial because IDO is an
enzyme that catalyzes the degradation of tryptophan into kynurenine (Kyn), thereby
diverting tryptophan away from the serotonin (5-HT) synthesis pathway. By downregulating
IDO, DXS effectively shifts the balance of tryptophan metabolism towards increased
serotonin production, thereby enhancing the availability of serotonin. This
shift in the Kyn/5-HT pathway favoring serotonin is likely a key mechanism underlying
the antidepressant effects observed with DXS treatment. Enhanced serotonin levels
in the hippocampus are associated with improved mood and reduction of depressive
symptoms, suggesting that DXS could be a promising therapeutic agent for managing
depression.
model-index:
- name: Palmyra-Med-70B
results: []
---
<div align="center">
<h1>Palmyra-Med, a powerful LLM designed for healthcare</h1>
<img src="img/Palmyra Medical wordmark.svg" width=420px />
</div>
### Model Description
- **Developed by:** Writer
- **Language(s) (NLP):** English
- **License:** [Writer open model license](https://writer.com/legal/acceptable-use/)
- **Finetuned from model:** Palmyra-X-003
- **Context window:** 8192
## Model Details
Palmyra-Med is a model built by Writer specifically to meet the needs of the healthcare industry. The leading LLM on biomedical benchmarks, with an average score of 85.87%, outperforming GPT-4, claude Opus, Gemini and Med-PaLM-2 base model and a medically trained human test-taker.
### Resources and Technical Documentation:
+ [Writer Blog](https://writer.com/blog/palmyra-med-fin-models/)
+ [Writer Developer Website](https://dev.writer.com/home/models)
+ [Writer AI Studio](https://writer.com/product/ai-studio/)
+ [Palmyra Model API](https://dev.writer.com/api-guides/chat-completion)
#### Specialized for Biomedical Applications
Palmyra-Med-70B is meticulously designed to meet the unique linguistic and knowledge demands of the medical and life sciences sectors. It has been fine-tuned on an extensive collection of high-quality biomedical data, ensuring it can comprehend and generate text with precise domain-specific accuracy and fluency.
Our system integrates the DPO dataset and a well-crafted fine-tuning recipe along with a custom diverse medical instruction dataset, making it highly adept at handling the specific needs of this field. Key components of our training pipeline include:
- **Policy Optimization**: Utilizing Direct Preference Optimization to enhance the model's performance. [DPO](https://arxiv.org/abs/2305.18290).
- **Fine-tuning dataset**: Custom Medical Instruct dataset (Writer in-house build)
## Intended Use
**Intended Use Cases:** Palmyra-Med-70b is intended for **non**-commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope:** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by [Writer's Acceptable Use Policy](https://writer.com/legal/acceptable-use/) and [the Writer open model license](https://writer.com/legal/acceptable-use/). Use in languages other than English.
**Note:** Developers may fine-tune Palmyra-Med-70b models for languages beyond English provided they comply with the [Writer open model license](https://writer.com/legal/acceptable-use/) and the Acceptable Use Policy.
**Watermarks**: All models built by Writer.com contain watermarks to detect and prevent misuse and illegal use.
### Use with transformers
You can run conversational inference using the Transformers Auto classes with the `generate()` function. Let's see an example.
```py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "Writer/Palmyra-Med-70B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
attn_implementation="flash_attention_2",
)
messages = [
{
"role": "system",
"content": "You are a highly knowledgeable and experienced expert in the healthcare and biomedical field, possessing extensive medical knowledge and practical expertise.",
},
{
"role": "user",
"content": "Does danzhi Xiaoyao San ameliorate depressive-like behavior by shifting toward serotonin via the downregulation of hippocampal indoleamine 2,3-dioxygenase?",
},
]
input_ids = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True, return_tensors="pt"
)
gen_conf = {
"max_new_tokens": 256,
"eos_token_id": [tokenizer.eos_token_id, tokenizer.convert_tokens_to_ids("<|eot_id|>")],
"temperature": 0.0,
"top_p": 0.9,
}
with torch.inference_mode():
output_id = model.generate(input_ids, **gen_conf)
output_text = tokenizer.decode(output_id[0][input_ids.shape[1] :])
print(output_text)
```
## Evaluation Results
Palmyra-Med-70b outperforms larger models like GPT-4, Gemini and Med-PaLM-2 across 9 diverse biomedical datasets, achieving state-of-the-art results with an average score of 85.9% despite having fewer parameters. Its strong performance in tasks like Clinical KG, Medical Genetics, and PubMedQA underscores its effective grasp of biomedical knowledge.
### Performance on Biomedical Benchmarks


### Medical Use Cases
Palmyra-Med-70b excels in analyzing and summarizing complex clinical notes, EHR data, and discharge summaries, extracting key information to generate concise, structured summaries. It help enhance clinical decision-making by performing advanced clinical entity recognition, identifying key medical concepts such as diseases, symptoms, medications, procedures, and anatomical structures from unstructured text.
By leveraging its deep understanding of medical terminology, the model enhances information retrieval, data analysis, and knowledge discovery from EHRs, research articles, and other biomedical sources. These capabilities support applications like clinical decision support, pharmacovigilance, and medical research.
### Bias, Risks, and Limitations
Palmyra-Med-70b, despite leveraging high-quality data, may contain inaccuracies, biases, or misalignments and has not been rigorously evaluated in clinical trials or real-world healthcare settings.
It is advised not to use the model for direct patient care, clinical decision support, or professional medical purposes. Instead, its use should be confined to research by qualified individuals who understand its limitations. Palmyra-Med-70b should not replace professional medical judgment, and adapting it for medical use would require extensive additional work, including thorough testing, guideline alignment, bias mitigation, human oversight, and regulatory compliance. Always consult a qualified healthcare provider for personal medical needs.
### Citation and Related Information
To cite this model:
```
@misc{Palmyra-Med-70B,
author = {Writer Engineering team},
title = {{Palmyra-Med-70b: A powerful LLM designed for healthcare}},
howpublished = {\url{https://dev.writer.com}},
year = 2024,
month = June
}
```
Contact
[email protected]
|
[
"PUBMEDQA"
] |
ntc-ai/SDXL-LoRA-slider.micro-details-fine-details-detailed
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-27T19:51:12Z |
2023-12-27T19:51:14+00:00
| 81 | 4 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/micro details, fine details, detailed.../micro details,
fine details, detailed_17_3.0.png
widget:
- text: micro details, fine details, detailed
output:
url: images/micro details, fine details, detailed_17_3.0.png
- text: micro details, fine details, detailed
output:
url: images/micro details, fine details, detailed_19_3.0.png
- text: micro details, fine details, detailed
output:
url: images/micro details, fine details, detailed_20_3.0.png
- text: micro details, fine details, detailed
output:
url: images/micro details, fine details, detailed_21_3.0.png
- text: micro details, fine details, detailed
output:
url: images/micro details, fine details, detailed_22_3.0.png
inference: false
instance_prompt: micro details, fine details, detailed
---
# ntcai.xyz slider - micro details, fine details, detailed (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/micro details, fine details, detailed_17_-3.0.png" width=256 height=256 /> | <img src="images/micro details, fine details, detailed_17_0.0.png" width=256 height=256 /> | <img src="images/micro details, fine details, detailed_17_3.0.png" width=256 height=256 /> |
| <img src="images/micro details, fine details, detailed_19_-3.0.png" width=256 height=256 /> | <img src="images/micro details, fine details, detailed_19_0.0.png" width=256 height=256 /> | <img src="images/micro details, fine details, detailed_19_3.0.png" width=256 height=256 /> |
| <img src="images/micro details, fine details, detailed_20_-3.0.png" width=256 height=256 /> | <img src="images/micro details, fine details, detailed_20_0.0.png" width=256 height=256 /> | <img src="images/micro details, fine details, detailed_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
micro details, fine details, detailed
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.micro-details-fine-details-detailed', weight_name='micro details, fine details, detailed.safetensors', adapter_name="micro details, fine details, detailed")
# Activate the LoRA
pipe.set_adapters(["micro details, fine details, detailed"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, micro details, fine details, detailed"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 670+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
Henrychur/MMedLM
|
Henrychur
|
feature-extraction
|
[
"transformers",
"pytorch",
"safetensors",
"internlm",
"feature-extraction",
"medical",
"custom_code",
"en",
"zh",
"ja",
"fr",
"ru",
"es",
"dataset:Henrychur/MMedC",
"arxiv:2402.13963",
"license:apache-2.0",
"region:us"
] | 2024-02-20T08:09:36Z |
2024-12-30T10:54:05+00:00
| 81 | 5 |
---
datasets:
- Henrychur/MMedC
language:
- en
- zh
- ja
- fr
- ru
- es
license: apache-2.0
tags:
- medical
---
# MMedLM
[💻Github Repo](https://github.com/MAGIC-AI4Med/MMedLM) [🖨️arXiv Paper](https://arxiv.org/abs/2402.13963)
The official model weights for "Towards Building Multilingual Language Model for Medicine".
[MMedLM 2](https://huggingface.co/Henrychur/MMedLM2) has been released now. MMedLM2 is a more powerful multilingual medical foundation model, which has undergone the same medical data enhancement pipeline as MMedLM.
## Introduction
This repo contains MMedLM, a multilingual medical foundation model with 7 billion parameters. MMedLM builds upon the foundation of InternLM and has been further pretrained on MMedC, a comprehensive multilingual medical corpus. This further pretraining enhances the model's medical-domain knowledge.
The model underwent further pretraining on MMedC with the following hyperparameters:
- Iterations: 15000
- Global batch size: 512
- Cutoff length: 2048
- Learning rate: 2e-5
The model can be loaded as follows:
```py
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Henrychur/MMedLM", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Henrychur/MMedLM", torch_dtype=torch.float16, trust_remote_code=True)
```
- Note that this is a foundation model that has not undergone instruction fine-tuning.
- Testing has found that using the latest version of transformers will result in errors. It is recommended to use transformers==4.28.1.
## News
[2024.2.21] Our pre-print paper is released ArXiv. Dive into our findings [here](https://arxiv.org/abs/2402.13963).
[2024.2.20] We release [MMedLM](https://huggingface.co/Henrychur/MMedLM) and [MMedLM 2](https://huggingface.co/Henrychur/MMedLM2). With an auto-regressive continues training on MMedC, these models achieves superior performance compared to all other open-source models, even rivaling GPT-4 on MMedBench.
[2023.2.20] We release [MMedC](https://huggingface.co/datasets/Henrychur/MMedC), a multilingual medical corpus containing 25.5B tokens.
[2023.2.20] We release [MMedBench](https://huggingface.co/datasets/Henrychur/MMedBench), a new multilingual medical multi-choice question-answering
benchmark with rationale. Check out the leaderboard [here](https://henrychur.github.io/MultilingualMedQA/).
## Evaluation on MMedBench
The further pretrained MMedLM 2 showcast it's great performance in medical domain across different language.
| Method | Size | Year | MMedC | MMedBench | English | Chinese | Japanese | French | Russian | Spanish | Avg. |
|------------------|------|---------|-----------|-----------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| GPT-3.5 | - | 2022.12 | ✗ | ✗ | 56.88 | 52.29 | 34.63 | 32.48 | 66.36 | 66.06 | 51.47 |
| GPT-4 | - | 2023.3 | ✗ | ✗ | 78.00 | 75.07 | 72.91 | 56.59 | 83.62 | 85.67 | 74.27 |
| Gemini-1.0 pro | - | 2024.1 | ✗ | ✗ | 53.73 | 60.19 | 44.22 | 29.90 | 73.44 | 69.69 | 55.20 |
| BLOOMZ | 7B | 2023.5 | ✗ | trainset | 43.28 | 58.06 | 32.66 | 26.37 | 62.89 | 47.34 | 45.10 |
| InternLM | 7B | 2023.7 | ✗ | trainset | 44.07 | 64.62 | 37.19 | 24.92 | 58.20 | 44.97 | 45.67 |
| Llama\ 2 | 7B | 2023.7 | ✗ | trainset | 43.36 | 50.29 | 25.13 | 20.90 | 66.80 | 47.10 | 42.26 |
| MedAlpaca | 7B | 2023.3 | ✗ | trainset | 46.74 | 44.80 | 29.64 | 21.06 | 59.38 | 45.00 | 41.11 |
| ChatDoctor | 7B | 2023.4 | ✗ | trainset | 43.52 | 43.26 | 25.63 | 18.81 | 62.50 | 43.44 | 39.53 |
| PMC-LLaMA | 7B | 2023.4 | ✗ | trainset | 47.53 | 42.44 | 24.12 | 20.74 | 62.11 | 43.29 | 40.04 |
| Mistral | 7B | 2023.10 | ✗ | trainset | 61.74 | 71.10 | 44.72 | 48.71 | 74.22 | 63.86 | 60.73 |
| InternLM\ 2 | 7B | 2024.2 | ✗ | trainset | 57.27 | 77.55 | 47.74 | 41.00 | 68.36 | 59.59 | 58.59 |
| MMedLM~(Ours) | 7B | - | ✗ | trainset | 49.88 | 70.49 | 46.23 | 36.66 | 72.27 | 54.52 | 55.01 |
| MMedLM\ 2~(Ours) | 7B | - | ✗ | trainset | 61.74 | 80.01 | 61.81 | 52.09 | 80.47 | 67.65 | 67.30 |
- GPT and Gemini is evluated under zero-shot setting through API
- Open-source models first undergo training on the trainset of MMedBench before evaluate.
## Contact
If you have any question, please feel free to contact [email protected].
## Citation
```
@misc{qiu2024building,
title={Towards Building Multilingual Language Model for Medicine},
author={Pengcheng Qiu and Chaoyi Wu and Xiaoman Zhang and Weixiong Lin and Haicheng Wang and Ya Zhang and Yanfeng Wang and Weidi Xie},
year={2024},
eprint={2402.13963},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"MEDICAL DATA"
] |
NghiemAbe/SeaLLM-v2.5-Legal-v4-AWQ
|
NghiemAbe
|
text-generation
|
[
"transformers",
"safetensors",
"gemma",
"text-generation",
"multilingual",
"sea",
"conversational",
"en",
"zh",
"vi",
"id",
"th",
"ms",
"km",
"lo",
"my",
"tl",
"arxiv:2312.00738",
"arxiv:2306.05179",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] | 2024-06-12T01:50:30Z |
2024-07-18T14:20:22+00:00
| 81 | 0 |
---
language:
- en
- zh
- vi
- id
- th
- ms
- km
- lo
- my
- tl
license: other
license_name: seallms
license_link: https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat/blob/main/LICENSE
tags:
- multilingual
- sea
---
<p align="center">
<img src="seal_logo.png" width="200" />
</p>
# *SeaLLM-7B-v2.5* - Large Language Models for Southeast Asia
<p align="center">
<a href="https://damo-nlp-sg.github.io/SeaLLMs/" target="_blank" rel="noopener">Website</a>
<a href="https://huggingface.co/SeaLLMs/SeaLLM-7B-v2.5" target="_blank" rel="noopener"> 🤗 Tech Memo</a>
<a href="https://huggingface.co/spaces/SeaLLMs/SeaLLM-7B-v2.5" target="_blank" rel="noopener"> 🤗 DEMO</a>
<a href="https://github.com/DAMO-NLP-SG/SeaLLMs" target="_blank" rel="noopener">Github</a>
<a href="https://arxiv.org/pdf/2312.00738.pdf" target="_blank" rel="noopener">Technical Report</a>
</p>
🔥<span style="color: #ff3860">[HOT]</span> SeaLLMs project now has a dedicated website - [damo-nlp-sg.github.io/SeaLLMs](https://damo-nlp-sg.github.io/SeaLLMs/)
We introduce [SeaLLM-7B-v2.5](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2.5), the state-of-the-art multilingual LLM for Southeast Asian (SEA) languages 🇬🇧 🇨🇳 🇻🇳 🇮🇩 🇹🇭 🇲🇾 🇰🇭 🇱🇦 🇲🇲 🇵🇭. It is the most significant upgrade since [SeaLLM-13B](https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat), with half the size, outperforming performance across diverse multilingual tasks, from world knowledge, math reasoning, instruction following, etc.
### Highlights
* [SeaLLM-7B-v2.5](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2.5) outperforms GPT-3.5 and achieves 7B SOTA on most multilingual knowledge benchmarks for SEA languages (MMLU, M3Exam & VMLU).
* It achieves 79.0 and 34.9 on GSM8K and MATH, surpassing GPT-3.5 in MATH.
### Release and DEMO
- DEMO:
- [SeaLLMs/SeaLLM-7B-v2.5](https://huggingface.co/spaces/SeaLLMs/SeaLLM-7B-v2.5).
- [SeaLLMs/SeaLLM-7B | SeaLMMM-7B](https://huggingface.co/spaces/SeaLLMs/SeaLLM-7B) - Experimental multimodal SeaLLM.
- Technical report: [Arxiv: SeaLLMs - Large Language Models for Southeast Asia](https://arxiv.org/pdf/2312.00738.pdf).
- Model weights:
- [SeaLLM-7B-v2.5](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2.5).
- [SeaLLM-7B-v2.5-GGUF](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2.5-GGUF).
- Run locally:
- [LM-studio](https://lmstudio.ai/):
- [SeaLLM-7B-v2.5-q4_0-chatml](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2.5-GGUF/blob/main/seallm-7b-v2.5-chatml.Q4_K_M.gguf) with ChatML template (`<eos>` token changed to `<|im_end|>`)
- [SeaLLM-7B-v2.5-q4_0](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2.5-GGUF/blob/main/seallm-7b-v2.5.Q4_K_M.gguf) - must use SeaLLM-7B-v2.5 chat format.
- [MLX for Apple Silicon](https://github.com/ml-explore/mlx): [SeaLLMs/SeaLLM-7B-v2.5-mlx-quantized](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2.5-mlx-quantized)
- Previous models:
- [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2)
- [SeaLLM-7B-v1](https://huggingface.co/SeaLLMs/SeaLLM-7B-v1)
<blockquote style="color:red">
<p><strong style="color: red">Terms of Use and License</strong>:
By using our released weights, codes, and demos, you agree to and comply with the terms and conditions specified in our <a href="https://huggingface.co/SeaLLMs/SeaLLM-Chat-13b/edit/main/LICENSE" target="_blank" rel="noopener">SeaLLMs Terms Of Use</a>.
</blockquote>
> **Disclaimer**:
> We must note that even though the weights, codes, and demos are released in an open manner, similar to other pre-trained language models, and despite our best efforts in red teaming and safety fine-tuning and enforcement, our models come with potential risks, including but not limited to inaccurate, misleading or potentially harmful generation.
> Developers and stakeholders should perform their own red teaming and provide related security measures before deployment, and they must abide by and comply with local governance and regulations.
> In no event shall the authors be held liable for any claim, damages, or other liability arising from the use of the released weights, codes, or demos.
> The logo was generated by DALL-E 3.
### What's new since SeaLLM-7B-v2?
* SeaLLM-7B-v2.5 was built on top of Gemma-7b, and underwent large scale SFT and carefully designed alignment.
## Evaluation
### Multilingual World Knowledge
We evaluate models on 3 benchmarks following the recommended default setups: 5-shot MMLU for En, 3-shot [M3Exam](https://arxiv.org/pdf/2306.05179.pdf) (M3e) for En, Zh, Vi, Id, Th, and zero-shot [VMLU](https://vmlu.ai/) for Vi.
| Model | Langs | En<br>MMLU | En<br>M3e | Zh<br>M3e | Vi<br>M3e | Vi<br>VMLU | Id<br>M3e | Th<br>M3e
|-----| ----- | --- | -- | ----- | ---- | --- | --- | --- |
| GPT-3.5 | Multi | 68.90 | 75.46 | 60.20 | 58.64 | 46.32 | 49.27 | 37.41
| Vistral-7B-chat | Mono | 56.86 | 67.00 | 44.56 | 54.33 | 50.03 | 36.49 | 25.27
| Qwen1.5-7B-chat | Multi | 61.00 | 52.07 | 81.96 | 43.38 | 45.02 | 24.29 | 20.25
| SailorLM | Multi | 52.72 | 59.76 | 67.74 | 50.14 | --- | 39.53 | 37.73
| SeaLLM-7B-v2 | Multi | 61.89 | 70.91 | 55.43 | 51.15 | 45.74 | 42.25 | 35.52
| SeaLLM-7B-v2.5 | Multi | 64.05 | 76.87 | 62.54 | 63.11 | 53.30 | 48.64 | 46.86
### Zero-shot CoT Multilingual Math Reasoning
<!--
[SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) achieves with **78.5** score on the GSM8K with zero-shot CoT reasoning, making it the **state of the art** in the realm of 7B models. It also outperforms GPT-3.5 in the same GSM8K benchmark as translated into SEA languages (🇨🇳 🇻🇳 🇮🇩 🇹🇭). [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) also surpasses GPT-3.5 on the Thai-translated MATH benchmark, with **28.4** vs 18.1 scores.

-->
| Model | GSM8K<br>en | MATH<br>en | GSM8K<br>zh | MATH<br>zh | GSM8K<br>vi | MATH<br>vi | GSM8K<br>id | MATH<br>id | GSM8K<br>th | MATH<br>th
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| GPT-3.5 | 80.8 | 34.1 | 48.2 | 21.5 | 55 | 26.5 | 64.3 | 26.4 | 35.8 | 18.1
| Qwen-14B-chat | 61.4 | 18.4 | 41.6 | 11.8 | 33.6 | 3.6 | 44.7 | 8.6 | 22 | 6.0
| Vistral-7b-chat | 48.2 | 12.5 | | | 48.7 | 3.1 | | | |
| Qwen1.5-7B-chat | 56.8 | 15.3 | 40.0 | 2.7 | 37.7 | 9 | 36.9 | 7.7 | 21.9 | 4.7
| SeaLLM-7B-v2 | 78.2 | 27.5 | 53.7 | 17.6 | 69.9 | 23.8 | 71.5 | 24.4 | 59.6 | 22.4
| SeaLLM-7B-v2.5 | 78.5 | 34.9 | 51.3 | 22.1 | 72.3 | 30.2 | 71.5 | 30.1 | 62.0 | 28.4
Baselines were evaluated using their respective chat-template and system prompts ([Qwen1.5-7B-chat](https://huggingface.co/Qwen/Qwen1.5-7B-Chat/blob/main/tokenizer_config.json), [Vistral](https://huggingface.co/Viet-Mistral/Vistral-7B-Chat)).
#### Zero-shot MGSM
[SeaLLM-7B-v2.5](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2.5) also outperforms GPT-3.5 and Qwen-14B on the multilingual MGSM for Thai.
| Model | MGSM-Zh | MGSM-Th
|-----| ----- | ---
| ChatGPT (reported) | 61.2 | 47.2
| Qwen-14B-chat | 59.6 | 28
| SeaLLM-7B-v2 | **64.8** | 62.4
| SeaLLM-7B-v2.5 | 58.0 | **64.8**
### Sea-Bench

### Usage
**IMPORTANT NOTICE for using the model**
* `<bos>` must be at start of prompt, ff your code's tokenizer does not prepend `<bos>` by default, you MUST prepend <bos> into the prompt yourself, otherwise, it would not work!
* Repitition penalty (e.g: in llama.cpp, ollama, LM-studio) must be set to **1** , otherwise will lead to degeneration!
#### Instruction format
```python
# ! WARNING, if your code's tokenizer does not prepend <bos> by default,
# You MUST prepend <bos> into the prompt yourself, otherwise, it would not work!
prompt = """<|im_start|>system
You are a helpful assistant.<eos>
<|im_start|>user
Hello world<eos>
<|im_start|>assistant
Hi there, how can I help?<eos>"""
# <|im_start|> is not a special token.
# Transformers chat_template should be consistent with vLLM format below.
# ! ENSURE 1 and only 1 bos `<bos>` at the beginning of sequence
print(tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt)))
"""
```
#### Using transformers's chat_template
Install the latest transformers (>4.40)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
# use bfloat16 to ensure the best performance.
model = AutoModelForCausalLM.from_pretrained("SeaLLMs/SeaLLM-7B-v2.5", torch_dtype=torch.bfloat16, device_map=device)
tokenizer = AutoTokenizer.from_pretrained("SeaLLMs/SeaLLM-7B-v2.5")
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello world"},
{"role": "assistant", "content": "Hi there, how can I help you today?"},
{"role": "user", "content": "Explain general relativity in details."}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True)
print(tokenizer.convert_ids_to_tokens(encodeds[0]))
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True, pad_token_id=tokenizer.pad_token_id)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
#### Using vLLM
```python
from vllm import LLM, SamplingParams
TURN_TEMPLATE = "<|im_start|>{role}\n{content}<eos>\n"
TURN_PREFIX = "<|im_start|>{role}\n"
def seallm_chat_convo_format(conversations, add_assistant_prefix: bool, system_prompt=None):
# conversations: list of dict with key `role` and `content` (openai format)
if conversations[0]['role'] != 'system' and system_prompt is not None:
conversations = [{"role": "system", "content": system_prompt}] + conversations
text = ''
for turn_id, turn in enumerate(conversations):
prompt = TURN_TEMPLATE.format(role=turn['role'], content=turn['content'])
text += prompt
if add_assistant_prefix:
prompt = TURN_PREFIX.format(role='assistant')
text += prompt
return text
sparams = SamplingParams(temperature=0.1, max_tokens=1024, stop=['<eos>', '<|im_start|>'])
llm = LLM("SeaLLMs/SeaLLM-7B-v2.5", dtype="bfloat16")
message = "Explain general relativity in details."
prompt = seallm_chat_convo_format(message, True)
gen = llm.generate(prompt, sampling_params)
print(gen[0].outputs[0].text)
```
#### Fine-tuning SeaLLM-7B-v2.5
Should follow the chat format and accurately mask out source tokens. Here is an example.
```python
conversations = [
{"role": "system", "content": "You are helful assistant."},
{"role": "user", "content": "Hello world."},
{"role": "assistant", "content": "Hi there, how can I help?"},
{"role": "user", "content": "Tell me a joke."},
{"role": "assistant", "content": "Why don't scientists trust atoms? Because they make up everything."},
]
def seallm_7b_v25_tokenize_multi_turns(tokenizer, conversations, add_assistant_prefix=False):
"""
Inputs:
conversations: list of dict following openai format, eg
conversations = [
{"role": "system", "content": "You are helful assistant."},
{"role": "user", "content": "Hello world."},
{"role": "assistant", "content": "Hi there, how can I help?"},
{"role": "user", "content": "Tell me a joke."},
{"role": "assistant", "content": "Why don't scientists trust atoms? Because they make up everything."},
]
add_assistant_prefix: whether to add assistant_prefix, only for inference decoding
Outputs:
tokenize_output_sample, {
"input_ids": ...
"token_type_ids": 1 if train and 0 if masked out (not train)
}
During training, need to create a labels, with masked-out tokens = -100 to avoid loss computations.
labels = sample['input_ids'].clone()
labels[sample['token_type_ids'] == 0] = -100
"""
TURN_TEMPLATE = "<|im_start|>{role}\n{content}<eos>\n"
TURN_PREFIX = "<|im_start|>{role}\n"
TURN_SUFFIX = "<eos>\n"
TURN_SUFFIX_TAKE = "<eos>"
sample = None
assistant_prefix_len = None
assistant_suffix_len = None
for turn_id, turn in enumerate(conversations):
prompt = TURN_TEMPLATE.format(role=turn['role'], content=turn['content'])
turn_sample = tokenizer(
prompt, padding=False, truncation=False, verbose=False, add_special_tokens=False,
return_token_type_ids=True,
)
if turn['role'] == 'assistant':
if assistant_prefix_len is None:
assistant_prefix_len = len(tokenizer.encode(TURN_PREFIX.format(role=turn['role']), add_special_tokens=False))
if assistant_suffix_len is None:
assistant_suffix_len = (
len(tokenizer.encode(TURN_SUFFIX.format(role=turn['role']), add_special_tokens=False)) -
len(tokenizer.encode(TURN_SUFFIX_TAKE, add_special_tokens=False))
)
turn_sample['token_type_ids'][assistant_prefix_len:-assistant_suffix_len] = [1] * (len(turn_sample['input_ids']) - assistant_prefix_len - assistant_suffix_len)
if sample is None:
sample = turn_sample
else:
for k in turn_sample.keys():
sample[k].extend(turn_sample[k])
if add_assistant_prefix:
assistant_prefix_sample = tokenizer(
TURN_PREFIX.format(role="assistant"), padding=False, truncation=False, verbose=False, add_special_tokens=False,
return_token_type_ids=True,
)
for k in sample.keys():
sample[k].extend(assistant_prefix_sample[k])
if tokenizer.add_bos_token:
sample['input_ids'] = [tokenizer.bos_token_id] + sample['input_ids']
sample['attention_mask'] = [1] + sample['attention_mask']
sample['token_type_ids'] = [sample['token_type_ids'][0]] + sample['token_type_ids']
return sample
# ! testing
sample = seallm_7b_v25_tokenize_multi_turns(tokenizer, conversations)
tokens = tokenizer.convert_ids_to_tokens(sample['input_ids'])
pairs = [(x, y) for x, y in zip(tokens, sample['token_type_ids'])]
print(pairs)
# source and special tokens is masked out (token_type 0), only assistant with <eos> is trained (token_type 1)
# [('<bos>', 0), ('<', 0), ('|', 0), ..., ('assistant', 0), ('\n', 0), ('Hi', 1), ('▁there', 1), (',', 1), ('▁how', 1), ('▁can', 1), ('▁I', 1), ('▁help', 1), ('?', 1), ('<eos>', 1), ('\n', 0), ('<', 0), ...
```
## Acknowledgement to Our Linguists
We would like to express our special thanks to our professional and native linguists, Tantong Champaiboon, Nguyen Ngoc Yen Nhi and Tara Devina Putri, who helped build, evaluate, and fact-check our sampled pretraining and SFT dataset as well as evaluating our models across different aspects, especially safety.
## Citation
If you find our project useful, we hope you would kindly star our repo and cite our work as follows: Corresponding Author: [[email protected]](mailto:[email protected])
**Author list and order will change!**
* `*` and `^` are equal contributions.
```
@article{damonlpsg2023seallm,
author = {Xuan-Phi Nguyen*, Wenxuan Zhang*, Xin Li*, Mahani Aljunied*, Weiwen Xu, Hou Pong Chan,
Zhiqiang Hu, Chenhui Shen^, Yew Ken Chia^, Xingxuan Li, Jianyu Wang,
Qingyu Tan, Liying Cheng, Guanzheng Chen, Yue Deng, Sen Yang,
Chaoqun Liu, Hang Zhang, Lidong Bing},
title = {SeaLLMs - Large Language Models for Southeast Asia},
year = 2023,
Eprint = {arXiv:2312.00738},
}
```
|
[
"CHIA"
] |
mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"not-for-all-audiences",
"rp",
"roleplay",
"role-play",
"en",
"base_model:Cas-Archive/L3-Penumbral-Mind-RP-8B",
"base_model:quantized:Cas-Archive/L3-Penumbral-Mind-RP-8B",
"license:llama3",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | 2024-06-12T13:18:04Z |
2024-12-16T02:39:37+00:00
| 81 | 2 |
---
base_model: Cas-Archive/L3-Penumbral-Mind-RP-8B
language:
- en
library_name: transformers
license: llama3
tags:
- merge
- mergekit
- lazymergekit
- not-for-all-audiences
- rp
- roleplay
- role-play
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Cas-Archive/L3-Penumbral-Mind-RP-8B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Penumbral-Mind-RP-8B-i1-GGUF/resolve/main/L3-Penumbral-Mind-RP-8B.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
[
"CAS"
] |
tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha
|
tohoku-nlp
| null |
[
"safetensors",
"llama_enc",
"custom_code",
"ja",
"arxiv:2302.13971",
"arxiv:2002.05202",
"arxiv:2104.09864",
"license:apache-2.0",
"region:us"
] | 2024-11-29T05:24:04Z |
2024-12-01T07:39:22+00:00
| 81 | 6 |
---
language:
- ja
license: apache-2.0
---
(English part follows Japanese one.)
# TohokuNLP BERT-alpha 500M
長系列 (4,096, 8,192 トークン) の入力を可能にした日本語 [BERT](https://aclanthology.org/N19-1423/) モデルです。
## 利用方法
```python
from transformers import AutoModelForMaskedLM, AutoTokenizer
model = AutoModelForMaskedLM.from_pretrained(
"tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha", trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha")
```
[transformers version 4.46.2](https://github.com/huggingface/transformers/releases/tag/v4.46.2) において、動作確認をしています。
## モデルアーキテクチャ
[Llama](https://arxiv.org/abs/2302.13971) アーキテクチャをベースとし、Causal Attention Mask を取り除くことで、Encoder 型言語モデルとして利用しています。
具体的には、以下のモジュールを採用しています。
- [SwiGLU](https://arxiv.org/abs/2002.05202)
- [Rotary Positional Embeddings (RoPE)](https://arxiv.org/abs/2104.09864)
- [Grouped Query Attention (GQA)](https://aclanthology.org/2023.emnlp-main.298/)
### モデルパラメータの詳細
`tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha`, `tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha` のモデルパラメータの詳細は以下の表の通りです。
<table>
<tr>
<td>Num Layers</td>
<td>24</td>
</tr>
<tr>
<td>Hidden Size</td>
<td>1,024</td>
</tr>
<tr>
<td>FFN Hidden Size</td>
<td>4,096</td>
</tr>
<tr>
<td>Num Attention Heads</td>
<td>16</td>
</tr>
<tr>
<td>Num Key-Value Heads</td>
<td>8</td>
</tr>
</table>
## 学習データ
[llm-jp-corpus-v3](https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3) の日本語コーパスのサブセット (ja\_cc, ja\_warp\_html, ja\_warp\_pdf, ja\_wiki, kaken) を使用しました。
Tokenizer には、[llm-jp-v3 tokenizer](https://github.com/llm-jp/llm-jp-tokenizer) を採用しています。
また、学習時には Whole Word Masking を実施しています。
Whole Word Masking 単語分割器には、[vibrato](https://github.com/daac-tools/vibrato) を利用しました。
辞書は [bccwj-suw+unidic-cwj-3_1_1](https://github.com/daac-tools/vibrato/releases#:~:text=Compact%2Ddual-,bccwj%2Dsuw%2Bunidic%2Dcwj%2D3_1_1,-618%20MB) を用いています。
## 学習時の設定
モデルの重みを初期化した Llama アーキテクチャベースの Encoder モデルを from scratch で学習させています。
まず、Sequence Length: 4096 で約 114 B トークンを学習させた (`tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha`) 後、継続学習の形で、Sequence Length: 8192 に拡張し、約 34 B トークンを学習させました (`tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha`)。
各モデルの学習設定は以下の通りです。
| | Params. | Tokens | Steps | checkpoint averaging |
| --- | --- | --- | --- | --- |
| tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha | 581 M | 114 B | 100,000 | 95,000 and 100,000 steps |
| tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha | 581 M | + 34 B | +15,000 | N/A |
学習には、Masked Language Modeling (MLM) のみ実施し、Next Sentence Prediction (NSP) は実施していません。
### 学習設定の詳細
| | tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha | tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha |
| ---- | ---- | ---- |
| Batch Size (tokens) | 1,146,880 | 2,293,760 |
| Max Learning Rate | 1.0E-4 | 1.0E-4 |
| Min Learning Rate | 1.0E-6 | N/A |
| Learning Rate Warmup Steps | 10,000 | N/A |
| Scheduler | cosine | constant |
| Optimizer | AdamW | AdamW |
| Optimizer Config | beta_1 = 0.9, beta_2 = 0.999, eps = 1.0E-8 | beta_1 = 0.9, beta_2 = 0.999, eps = 1.0E-8 |
| Weight Decay | 0.01 | 0.01 |
| Gradient Clipping | 1 | 1 |
| Sequence Length | 4,096 | 8,192 |
| MLM Probability | 0.15 | 0.15 |
| Replace Masked-token Probability | 0.8 | 0.8 |
| Replace Random-token Probability | 0.1 | 0.1 |
## 評価
評価指標として、[JMTEB](https://www.sbintuitions.co.jp/blog/entry/2024/05/16/130848) を利用しました。
評価結果は以下の通りです。
| | Classification | Clustering | PairClassification | Reranking | Retrieval | STS |
|-----------|---------------|------------|-------------------|-----------|-----------|-----|
| tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha | .577 | **.494** | .623 | .894 | .229 | .583 |
| tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha | .460 | .420 | .623 | .885 | .295 | .433 |
| [tohoku-nlp/bert-base-japanese-v3](https://huggingface.co/tohoku-nlp/bert-base-japanese-v3) | **.644** | .486 | **.624** | **.903** | **.328** | **.693** |
| [retrieva-jp/bert-1.3b](https://huggingface.co/retrieva-jp/bert-1.3b) | .637 | .450 | **.624** | .897 | .260 | .517 |
| | Param Size | Sequence Length |
| ---- | ---- | ---- |
| tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha | 581 M | 4,096 |
| tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha | 581 M | 8,192 |
| [tohoku-nlp/bert-base-japanese-v3](https://huggingface.co/tohoku-nlp/bert-base-japanese-v3) | 136 M | 512 |
| [retrieva-jp/bert-1.3b](https://huggingface.co/retrieva-jp/bert-1.3b) | 1.45 B | 2,048 |
2024 年 11 月現在、長系列の入力を扱うことができる日本語 Encoder モデルである [RetrievaBERT](https://huggingface.co/retrieva-jp/bert-1.3b) と比較して、同等の性能でパラメータサイズは約半分となっています。
一方で、我々が学習したモデルを含め長系列の入力を扱うことのできるモデルは、パラメータサイズが大きいにも関わらず、入力可能系列長が比較的短く小パラメータサイズの [bert-base-japanese-v3](https://huggingface.co/tohoku-nlp/bert-base-japanese-v3) よりも性能が劣っています。
この原因と改善方法については現在調査中です。
今後もより高性能な日本語 Encoder 型言語モデルの開発を見据えた研究を継続していくことを計画しています。
※ ここで示した評価結果は、あくまで基盤モデルどうしの性能比較であり、 **(fine-tuning を実施した) 文書埋め込みモデルにおける評価結果ではない** ことに留意してください。
## ライセンス
このモデルは Apache License 2.0 の下で配布しています。
# 免責事項
本モデルの作者は本モデルを作成するにあたって、その内容、機能等について細心の注意を払っておりますが、モデルの出力が正確であるかどうか、安全なものであるか等について保証をするものではなく、何らの責任を負うものではありません。
本モデルの利用により、万一、利用者に何らかの不都合や損害が発生したとしても、モデルやデータセットの作者や作者の所属組織は何らの責任を負うものではありません。
## 謝辞
このモデルの学習にあたり様々な面でご協力いただきました [Tohoku NLP Group](https://www.nlp.ecei.tohoku.ac.jp/) の皆様に感謝いたします。
## 作成者
- [Keito Kudo](https://x.com/k8kudo)
- [Daiki Shiono](https://x.com/onely7_deep)
- [Jun Suzuki](https://x.com/drJunSuzuki)
<br>
<br>
<br>
<br>
# TohokuNLP BERT-alpha 500M
A Japanese [BERT](https://aclanthology.org/N19-1423/) model capable of processing long sequences (4,096, 8,192 tokens).
## Usage
```python
from transformers import AutoModelForMaskedLM, AutoTokenizer
model = AutoModelForMaskedLM.from_pretrained(
"tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha", trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha")
```
Operation has been confirmed with [transformers version 4.46.2](https://github.com/huggingface/transformers/releases/tag/v4.46.2).
## Model Architecture
Based on the [Llama](https://arxiv.org/abs/2302.13971) architecture, we removed the Causal Attention Mask to use it as an Encoder-type language model.
Specifically, we adopted the following modules:
- [SwiGLU](https://arxiv.org/abs/2002.05202)
- [Rotary Positional Embeddings (RoPE)](https://arxiv.org/abs/2104.09864)
- [Grouped Query Attention (GQA)](https://aclanthology.org/2023.emnlp-main.298/)
### Model Parameter Details
The model parameters for `tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha` and `tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha` are as follows:
<table>
<tr>
<td>Num Layers</td>
<td>24</td>
</tr>
<tr>
<td>Hidden Size</td>
<td>1,024</td>
</tr>
<tr>
<td>FFN Hidden Size</td>
<td>4,096</td>
</tr>
<tr>
<td>Num Attention Heads</td>
<td>16</td>
</tr>
<tr>
<td>Num Key-Value Heads</td>
<td>8</td>
</tr>
</table>
## Training Data
We used a subset of the Japanese corpus from [llm-jp-corpus-v3](https://gitlab.llm-jp.nii.ac.jp/datasets/llm-jp-corpus-v3) (ja\_cc, ja\_warp\_html, ja\_warp\_pdf, ja\_wiki, kaken).
We adopted the [llm-jp-v3 tokenizer](https://github.com/llm-jp/llm-jp-tokenizer) as our tokenizer.
During training, we implemented Whole Word Masking.
For Whole Word Masking word segmentation, we used [vibrato](https://github.com/daac-tools/vibrato).
We used [bccwj-suw+unidic-cwj-3_1_1](https://github.com/daac-tools/vibrato/releases#:~:text=Compact%2Ddual-,bccwj%2Dsuw%2Bunidic%2Dcwj%2D3_1_1,-618%20MB) as our dictionary.
## Training Configuration
We trained a Llama architecture-based Encoder model from scratch after initializing the model weights.
First, we trained with Sequence Length: 4096 for about 114B tokens (`tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha`), then continued training with an extended Sequence Length: 8192 for about 34B tokens (`tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha`).
The training settings for each model are as follows:
| | Params. | Tokens | Steps | checkpoint averaging |
| --- | --- | --- | --- | --- |
| tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha | 581 M | 114 B | 100,000 | 95,000 and 100,000 steps |
| tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha | 581 M | + 34 B | +15,000 | N/A |
We only implemented Masked Language Modeling (MLM) during training, without Next Sentence Prediction (NSP).
### Detailed Training Settings
| | tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha | tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha |
| ---- | ---- | ---- |
| Batch Size (tokens) | 1,146,880 | 2,293,760 |
| Max Learning Rate | 1.0E-4 | 1.0E-4 |
| Min Learning Rate | 1.0E-6 | N/A |
| Learning Rate Warmup Steps | 10,000 | N/A |
| Scheduler | cosine | constant |
| Optimizer | AdamW | AdamW |
| Optimizer Config | beta_1 = 0.9, beta_2 = 0.999, eps = 1.0E-8 | beta_1 = 0.9, beta_2 = 0.999, eps = 1.0E-8 |
| Weight Decay | 0.01 | 0.01 |
| Gradient Clipping | 1 | 1 |
| Sequence Length | 4,096 | 8,192 |
| MLM Probability | 0.15 | 0.15 |
| Replace Masked-token Probability | 0.8 | 0.8 |
| Replace Random-token Probability | 0.1 | 0.1 |
## Evaluation
We used [JMTEB](https://www.sbintuitions.co.jp/blog/entry/2024/05/16/130848) as our evaluation metric.
The evaluation results are as follows:
| | Classification | Clustering | PairClassification | Reranking | Retrieval | STS |
|-----------|---------------|------------|-------------------|-----------|-----------|-----|
| tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha | .577 | **.494** | .623 | .894 | .229 | .583 |
| tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha | .460 | .420 | .623 | .885 | .295 | .433 |
| [tohoku-nlp/bert-base-japanese-v3](https://huggingface.co/tohoku-nlp/bert-base-japanese-v3) | **.644** | .486 | **.624** | **.903** | **.328** | **.693** |
| [retrieva-jp/bert-1.3b](https://huggingface.co/retrieva-jp/bert-1.3b) | .637 | .450 | **.624** | .897 | .260 | .517 |
| | Param Size | Sequence Length |
| ---- | ---- | ---- |
| tohoku-nlp/tohokunlp-bert-500m-sq4096-alpha | 581 M | 4,096 |
| tohoku-nlp/tohokunlp-bert-500m-sq8192-alpha | 581 M | 8,192 |
| [tohoku-nlp/bert-base-japanese-v3](https://huggingface.co/tohoku-nlp/bert-base-japanese-v3) | 136 M | 512 |
| [retrieva-jp/bert-1.3b](https://huggingface.co/retrieva-jp/bert-1.3b) | 1.45 B | 2,048 |
As of November 2024, compared to [RetrievaBERT](https://huggingface.co/retrieva-jp/bert-1.3b), a Japanese Encoder model capable of handling long sequences, our model achieves comparable performance with about half the parameter size.
However, models capable of handling long sequences, including ours, despite their larger parameter sizes, perform worse than [bert-base-japanese-v3](https://huggingface.co/tohoku-nlp/bert-base-japanese-v3), which has a relatively shorter input sequence length and smaller parameter size.
We are currently investigating the cause and potential improvements.
We plan to continue research aimed at developing higher-performance Japanese Encoder language models in the future.
Note: The evaluation results shown here are comparisons between base models and are **not evaluation results for document embedding models (with fine-tuning)**.
## License
This model is distributed under the Apache License 2.0.
# Disclaimer
While the developers of this model have taken utmost care in creating its content and functionality, we do not guarantee the accuracy or safety of the model's outputs and assume no responsibility for them.
The model's developers and their affiliated organizations bear no responsibility for any inconvenience or damages that may occur to users through the use of this model.
## Acknowledgments
We would like to thank the members of [Tohoku NLP Group](https://www.nlp.ecei.tohoku.ac.jp/) for their various forms of cooperation in training this model.
## Developers
- [Keito Kudo](https://x.com/k8kudo)
- [Daiki Shiono](https://x.com/onely7_deep)
- [Jun Suzuki](https://x.com/drJunSuzuki)
|
[
"BEAR"
] |
Alignment-Lab-AI/e5-mistral-7b-instruct
|
Alignment-Lab-AI
|
feature-extraction
|
[
"sentence-transformers",
"pytorch",
"safetensors",
"mistral",
"feature-extraction",
"mteb",
"transformers",
"en",
"arxiv:2401.00368",
"arxiv:2104.08663",
"arxiv:2210.07316",
"arxiv:2212.03533",
"license:mit",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-12-17T20:41:59Z |
2024-12-17T20:45:30+00:00
| 81 | 0 |
---
language:
- en
license: mit
tags:
- mteb
- sentence-transformers
- transformers
model-index:
- name: e5-mistral-7b-instruct
results:
- task:
type: STS
dataset:
name: MTEB AFQMC
type: C-MTEB/AFQMC
config: default
split: validation
revision: None
metrics:
- type: cos_sim_pearson
value: 37.863226091673866
- type: cos_sim_spearman
value: 38.98733013335281
- type: euclidean_pearson
value: 37.51783380497874
- type: euclidean_spearman
value: 38.98733012753365
- type: manhattan_pearson
value: 37.26706888081721
- type: manhattan_spearman
value: 38.709750161903834
- task:
type: STS
dataset:
name: MTEB ATEC
type: C-MTEB/ATEC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 43.33924583134623
- type: cos_sim_spearman
value: 42.84316155158754
- type: euclidean_pearson
value: 45.62709879515238
- type: euclidean_spearman
value: 42.843155921732404
- type: manhattan_pearson
value: 45.4786950991229
- type: manhattan_spearman
value: 42.657334751855984
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 78.68656716417911
- type: ap
value: 41.71522322900398
- type: f1
value: 72.37207703532552
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 74.04710920770879
- type: ap
value: 83.42622221864045
- type: f1
value: 72.14388257905772
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 77.93103448275862
- type: ap
value: 26.039284760509513
- type: f1
value: 64.81092954450712
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 77.21627408993577
- type: ap
value: 24.876490553983036
- type: f1
value: 63.8773359684989
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 95.90679999999999
- type: ap
value: 94.32357863164454
- type: f1
value: 95.90485634708557
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 55.786
- type: f1
value: 55.31211995815146
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 53.26
- type: f1
value: 52.156230111544986
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 50.33
- type: f1
value: 49.195023008878145
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.3
- type: f1
value: 48.434470184108
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.68599999999999
- type: f1
value: 47.62681775202072
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.238
- type: f1
value: 45.014030559653705
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.486000000000004
- type: map_at_10
value: 53.076
- type: map_at_100
value: 53.657999999999994
- type: map_at_1000
value: 53.659
- type: map_at_3
value: 48.234
- type: map_at_5
value: 51.121
- type: mrr_at_1
value: 37.269000000000005
- type: mrr_at_10
value: 53.335
- type: mrr_at_100
value: 53.916
- type: mrr_at_1000
value: 53.918
- type: mrr_at_3
value: 48.518
- type: mrr_at_5
value: 51.406
- type: ndcg_at_1
value: 36.486000000000004
- type: ndcg_at_10
value: 61.882000000000005
- type: ndcg_at_100
value: 64.165
- type: ndcg_at_1000
value: 64.203
- type: ndcg_at_3
value: 52.049
- type: ndcg_at_5
value: 57.199
- type: precision_at_1
value: 36.486000000000004
- type: precision_at_10
value: 8.982999999999999
- type: precision_at_100
value: 0.9939999999999999
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 21.029
- type: precision_at_5
value: 15.092
- type: recall_at_1
value: 36.486000000000004
- type: recall_at_10
value: 89.82900000000001
- type: recall_at_100
value: 99.36
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 63.087
- type: recall_at_5
value: 75.46199999999999
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 50.45119266859667
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 45.4958298992051
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 66.98177472838887
- type: mrr
value: 79.91854636591478
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 87.67086498650698
- type: cos_sim_spearman
value: 85.54773239564638
- type: euclidean_pearson
value: 86.48229161588425
- type: euclidean_spearman
value: 85.54773239564638
- type: manhattan_pearson
value: 86.67533327742343
- type: manhattan_spearman
value: 85.76099026691983
- task:
type: STS
dataset:
name: MTEB BQ
type: C-MTEB/BQ
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 50.31998888922809
- type: cos_sim_spearman
value: 50.6369940530675
- type: euclidean_pearson
value: 50.055544636296055
- type: euclidean_spearman
value: 50.63699405154838
- type: manhattan_pearson
value: 50.00739378036807
- type: manhattan_spearman
value: 50.607237418676945
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.5615866388309
- type: f1
value: 99.49895615866389
- type: precision
value: 99.46764091858039
- type: recall
value: 99.5615866388309
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.19656614571869
- type: f1
value: 99.08650671362535
- type: precision
value: 99.0314769975787
- type: recall
value: 99.19656614571869
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.0256321440942
- type: f1
value: 97.83743216718624
- type: precision
value: 97.74390947927492
- type: recall
value: 98.0256321440942
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.26276987888363
- type: f1
value: 99.22766368264
- type: precision
value: 99.21011058451816
- type: recall
value: 99.26276987888363
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 88.22727272727272
- type: f1
value: 88.17411732496673
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 43.530637846246975
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 40.23505728593893
- task:
type: Clustering
dataset:
name: MTEB CLSClusteringP2P
type: C-MTEB/CLSClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 44.419028279451275
- task:
type: Clustering
dataset:
name: MTEB CLSClusteringS2S
type: C-MTEB/CLSClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 42.5820277929776
- task:
type: Reranking
dataset:
name: MTEB CMedQAv1
type: C-MTEB/CMedQAv1-reranking
config: default
split: test
revision: None
metrics:
- type: map
value: 77.67811726152972
- type: mrr
value: 80.99003968253969
- task:
type: Reranking
dataset:
name: MTEB CMedQAv2
type: C-MTEB/CMedQAv2-reranking
config: default
split: test
revision: None
metrics:
- type: map
value: 78.66055354534922
- type: mrr
value: 81.66119047619047
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.162333333333333
- type: map_at_10
value: 37.22291666666667
- type: map_at_100
value: 38.56733333333333
- type: map_at_1000
value: 38.684250000000006
- type: map_at_3
value: 34.22858333333333
- type: map_at_5
value: 35.852500000000006
- type: mrr_at_1
value: 32.459833333333336
- type: mrr_at_10
value: 41.65358333333333
- type: mrr_at_100
value: 42.566916666666664
- type: mrr_at_1000
value: 42.61766666666667
- type: mrr_at_3
value: 39.210499999999996
- type: mrr_at_5
value: 40.582166666666666
- type: ndcg_at_1
value: 32.459833333333336
- type: ndcg_at_10
value: 42.96758333333333
- type: ndcg_at_100
value: 48.5065
- type: ndcg_at_1000
value: 50.556583333333336
- type: ndcg_at_3
value: 38.004416666666664
- type: ndcg_at_5
value: 40.25916666666667
- type: precision_at_1
value: 32.459833333333336
- type: precision_at_10
value: 7.664583333333333
- type: precision_at_100
value: 1.2349999999999999
- type: precision_at_1000
value: 0.15966666666666668
- type: precision_at_3
value: 17.731166666666663
- type: precision_at_5
value: 12.575333333333335
- type: recall_at_1
value: 27.162333333333333
- type: recall_at_10
value: 55.44158333333334
- type: recall_at_100
value: 79.56966666666666
- type: recall_at_1000
value: 93.45224999999999
- type: recall_at_3
value: 41.433083333333336
- type: recall_at_5
value: 47.31108333333333
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.539
- type: map_at_10
value: 28.494999999999997
- type: map_at_100
value: 30.568
- type: map_at_1000
value: 30.741000000000003
- type: map_at_3
value: 23.846999999999998
- type: map_at_5
value: 26.275
- type: mrr_at_1
value: 37.394
- type: mrr_at_10
value: 50.068
- type: mrr_at_100
value: 50.727
- type: mrr_at_1000
value: 50.751000000000005
- type: mrr_at_3
value: 46.938
- type: mrr_at_5
value: 48.818
- type: ndcg_at_1
value: 37.394
- type: ndcg_at_10
value: 38.349
- type: ndcg_at_100
value: 45.512
- type: ndcg_at_1000
value: 48.321
- type: ndcg_at_3
value: 32.172
- type: ndcg_at_5
value: 34.265
- type: precision_at_1
value: 37.394
- type: precision_at_10
value: 11.927999999999999
- type: precision_at_100
value: 1.966
- type: precision_at_1000
value: 0.25
- type: precision_at_3
value: 24.126
- type: precision_at_5
value: 18.306
- type: recall_at_1
value: 16.539
- type: recall_at_10
value: 44.504
- type: recall_at_100
value: 68.605
- type: recall_at_1000
value: 84.1
- type: recall_at_3
value: 29.008
- type: recall_at_5
value: 35.58
- task:
type: Retrieval
dataset:
name: MTEB CmedqaRetrieval
type: C-MTEB/CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 19.482
- type: map_at_10
value: 28.622999999999998
- type: map_at_100
value: 30.262
- type: map_at_1000
value: 30.432
- type: map_at_3
value: 25.647
- type: map_at_5
value: 27.128000000000004
- type: mrr_at_1
value: 30.408
- type: mrr_at_10
value: 37.188
- type: mrr_at_100
value: 38.196000000000005
- type: mrr_at_1000
value: 38.273
- type: mrr_at_3
value: 35.067
- type: mrr_at_5
value: 36.124
- type: ndcg_at_1
value: 30.408
- type: ndcg_at_10
value: 34.215
- type: ndcg_at_100
value: 41.349999999999994
- type: ndcg_at_1000
value: 44.689
- type: ndcg_at_3
value: 30.264999999999997
- type: ndcg_at_5
value: 31.572
- type: precision_at_1
value: 30.408
- type: precision_at_10
value: 7.6770000000000005
- type: precision_at_100
value: 1.352
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 17.213
- type: precision_at_5
value: 12.198
- type: recall_at_1
value: 19.482
- type: recall_at_10
value: 42.368
- type: recall_at_100
value: 72.694
- type: recall_at_1000
value: 95.602
- type: recall_at_3
value: 30.101
- type: recall_at_5
value: 34.708
- task:
type: PairClassification
dataset:
name: MTEB Cmnli
type: C-MTEB/CMNLI
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 71.16055321707758
- type: cos_sim_ap
value: 80.21073839711723
- type: cos_sim_f1
value: 72.9740932642487
- type: cos_sim_precision
value: 65.53136050623488
- type: cos_sim_recall
value: 82.3240589198036
- type: dot_accuracy
value: 71.16055321707758
- type: dot_ap
value: 80.212299264122
- type: dot_f1
value: 72.9740932642487
- type: dot_precision
value: 65.53136050623488
- type: dot_recall
value: 82.3240589198036
- type: euclidean_accuracy
value: 71.16055321707758
- type: euclidean_ap
value: 80.21076298680417
- type: euclidean_f1
value: 72.9740932642487
- type: euclidean_precision
value: 65.53136050623488
- type: euclidean_recall
value: 82.3240589198036
- type: manhattan_accuracy
value: 70.71557426337944
- type: manhattan_ap
value: 79.93448977199749
- type: manhattan_f1
value: 72.83962726826877
- type: manhattan_precision
value: 62.7407908077053
- type: manhattan_recall
value: 86.81318681318682
- type: max_accuracy
value: 71.16055321707758
- type: max_ap
value: 80.212299264122
- type: max_f1
value: 72.9740932642487
- task:
type: Retrieval
dataset:
name: MTEB CovidRetrieval
type: C-MTEB/CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 60.643
- type: map_at_10
value: 69.011
- type: map_at_100
value: 69.533
- type: map_at_1000
value: 69.545
- type: map_at_3
value: 67.167
- type: map_at_5
value: 68.12700000000001
- type: mrr_at_1
value: 60.801
- type: mrr_at_10
value: 69.111
- type: mrr_at_100
value: 69.6
- type: mrr_at_1000
value: 69.611
- type: mrr_at_3
value: 67.229
- type: mrr_at_5
value: 68.214
- type: ndcg_at_1
value: 60.801
- type: ndcg_at_10
value: 73.128
- type: ndcg_at_100
value: 75.614
- type: ndcg_at_1000
value: 75.92
- type: ndcg_at_3
value: 69.261
- type: ndcg_at_5
value: 70.973
- type: precision_at_1
value: 60.801
- type: precision_at_10
value: 8.662
- type: precision_at_100
value: 0.9860000000000001
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 25.149
- type: precision_at_5
value: 15.953999999999999
- type: recall_at_1
value: 60.643
- type: recall_at_10
value: 85.959
- type: recall_at_100
value: 97.576
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 75.184
- type: recall_at_5
value: 79.32000000000001
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.183
- type: map_at_10
value: 23.958
- type: map_at_100
value: 34.354
- type: map_at_1000
value: 36.442
- type: map_at_3
value: 16.345000000000002
- type: map_at_5
value: 19.647000000000002
- type: mrr_at_1
value: 74.25
- type: mrr_at_10
value: 80.976
- type: mrr_at_100
value: 81.256
- type: mrr_at_1000
value: 81.262
- type: mrr_at_3
value: 79.958
- type: mrr_at_5
value: 80.37100000000001
- type: ndcg_at_1
value: 62.0
- type: ndcg_at_10
value: 48.894999999999996
- type: ndcg_at_100
value: 53.867
- type: ndcg_at_1000
value: 61.304
- type: ndcg_at_3
value: 53.688
- type: ndcg_at_5
value: 50.900999999999996
- type: precision_at_1
value: 74.25
- type: precision_at_10
value: 39.525
- type: precision_at_100
value: 12.323
- type: precision_at_1000
value: 2.539
- type: precision_at_3
value: 57.49999999999999
- type: precision_at_5
value: 49.1
- type: recall_at_1
value: 10.183
- type: recall_at_10
value: 29.296
- type: recall_at_100
value: 60.394999999999996
- type: recall_at_1000
value: 83.12
- type: recall_at_3
value: 17.495
- type: recall_at_5
value: 22.235
- task:
type: Retrieval
dataset:
name: MTEB DuRetrieval
type: C-MTEB/DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 26.613999999999997
- type: map_at_10
value: 79.77300000000001
- type: map_at_100
value: 82.71
- type: map_at_1000
value: 82.75
- type: map_at_3
value: 55.92700000000001
- type: map_at_5
value: 70.085
- type: mrr_at_1
value: 90.7
- type: mrr_at_10
value: 93.438
- type: mrr_at_100
value: 93.504
- type: mrr_at_1000
value: 93.50699999999999
- type: mrr_at_3
value: 93.125
- type: mrr_at_5
value: 93.34
- type: ndcg_at_1
value: 90.7
- type: ndcg_at_10
value: 87.023
- type: ndcg_at_100
value: 90.068
- type: ndcg_at_1000
value: 90.43299999999999
- type: ndcg_at_3
value: 86.339
- type: ndcg_at_5
value: 85.013
- type: precision_at_1
value: 90.7
- type: precision_at_10
value: 41.339999999999996
- type: precision_at_100
value: 4.806
- type: precision_at_1000
value: 0.48900000000000005
- type: precision_at_3
value: 76.983
- type: precision_at_5
value: 64.69
- type: recall_at_1
value: 26.613999999999997
- type: recall_at_10
value: 87.681
- type: recall_at_100
value: 97.44699999999999
- type: recall_at_1000
value: 99.348
- type: recall_at_3
value: 57.809999999999995
- type: recall_at_5
value: 74.258
- task:
type: Retrieval
dataset:
name: MTEB EcomRetrieval
type: C-MTEB/EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 30.9
- type: map_at_10
value: 40.467
- type: map_at_100
value: 41.423
- type: map_at_1000
value: 41.463
- type: map_at_3
value: 37.25
- type: map_at_5
value: 39.31
- type: mrr_at_1
value: 30.9
- type: mrr_at_10
value: 40.467
- type: mrr_at_100
value: 41.423
- type: mrr_at_1000
value: 41.463
- type: mrr_at_3
value: 37.25
- type: mrr_at_5
value: 39.31
- type: ndcg_at_1
value: 30.9
- type: ndcg_at_10
value: 45.957
- type: ndcg_at_100
value: 50.735
- type: ndcg_at_1000
value: 51.861999999999995
- type: ndcg_at_3
value: 39.437
- type: ndcg_at_5
value: 43.146
- type: precision_at_1
value: 30.9
- type: precision_at_10
value: 6.35
- type: precision_at_100
value: 0.861
- type: precision_at_1000
value: 0.095
- type: precision_at_3
value: 15.267
- type: precision_at_5
value: 10.96
- type: recall_at_1
value: 30.9
- type: recall_at_10
value: 63.5
- type: recall_at_100
value: 86.1
- type: recall_at_1000
value: 95.1
- type: recall_at_3
value: 45.800000000000004
- type: recall_at_5
value: 54.800000000000004
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 49.765
- type: f1
value: 45.93242203574485
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 75.138
- type: map_at_10
value: 84.21300000000001
- type: map_at_100
value: 84.43
- type: map_at_1000
value: 84.441
- type: map_at_3
value: 83.071
- type: map_at_5
value: 83.853
- type: mrr_at_1
value: 80.948
- type: mrr_at_10
value: 88.175
- type: mrr_at_100
value: 88.24
- type: mrr_at_1000
value: 88.241
- type: mrr_at_3
value: 87.516
- type: mrr_at_5
value: 87.997
- type: ndcg_at_1
value: 80.948
- type: ndcg_at_10
value: 87.84100000000001
- type: ndcg_at_100
value: 88.576
- type: ndcg_at_1000
value: 88.75699999999999
- type: ndcg_at_3
value: 86.176
- type: ndcg_at_5
value: 87.214
- type: precision_at_1
value: 80.948
- type: precision_at_10
value: 10.632
- type: precision_at_100
value: 1.123
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 33.193
- type: precision_at_5
value: 20.663
- type: recall_at_1
value: 75.138
- type: recall_at_10
value: 94.89699999999999
- type: recall_at_100
value: 97.751
- type: recall_at_1000
value: 98.833
- type: recall_at_3
value: 90.455
- type: recall_at_5
value: 93.085
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.45
- type: map_at_10
value: 48.596000000000004
- type: map_at_100
value: 50.70400000000001
- type: map_at_1000
value: 50.83800000000001
- type: map_at_3
value: 42.795
- type: map_at_5
value: 46.085
- type: mrr_at_1
value: 56.172999999999995
- type: mrr_at_10
value: 64.35300000000001
- type: mrr_at_100
value: 64.947
- type: mrr_at_1000
value: 64.967
- type: mrr_at_3
value: 62.653999999999996
- type: mrr_at_5
value: 63.534
- type: ndcg_at_1
value: 56.172999999999995
- type: ndcg_at_10
value: 56.593
- type: ndcg_at_100
value: 62.942
- type: ndcg_at_1000
value: 64.801
- type: ndcg_at_3
value: 53.024
- type: ndcg_at_5
value: 53.986999999999995
- type: precision_at_1
value: 56.172999999999995
- type: precision_at_10
value: 15.494
- type: precision_at_100
value: 2.222
- type: precision_at_1000
value: 0.254
- type: precision_at_3
value: 35.185
- type: precision_at_5
value: 25.556
- type: recall_at_1
value: 29.45
- type: recall_at_10
value: 62.882000000000005
- type: recall_at_100
value: 85.56099999999999
- type: recall_at_1000
value: 96.539
- type: recall_at_3
value: 47.911
- type: recall_at_5
value: 54.52
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.581
- type: map_at_10
value: 68.401
- type: map_at_100
value: 69.207
- type: map_at_1000
value: 69.25200000000001
- type: map_at_3
value: 64.689
- type: map_at_5
value: 67.158
- type: mrr_at_1
value: 79.163
- type: mrr_at_10
value: 85.22999999999999
- type: mrr_at_100
value: 85.386
- type: mrr_at_1000
value: 85.39099999999999
- type: mrr_at_3
value: 84.432
- type: mrr_at_5
value: 84.952
- type: ndcg_at_1
value: 79.163
- type: ndcg_at_10
value: 75.721
- type: ndcg_at_100
value: 78.411
- type: ndcg_at_1000
value: 79.23599999999999
- type: ndcg_at_3
value: 70.68799999999999
- type: ndcg_at_5
value: 73.694
- type: precision_at_1
value: 79.163
- type: precision_at_10
value: 16.134
- type: precision_at_100
value: 1.821
- type: precision_at_1000
value: 0.193
- type: precision_at_3
value: 46.446
- type: precision_at_5
value: 30.242
- type: recall_at_1
value: 39.581
- type: recall_at_10
value: 80.66799999999999
- type: recall_at_100
value: 91.033
- type: recall_at_1000
value: 96.408
- type: recall_at_3
value: 69.669
- type: recall_at_5
value: 75.604
- task:
type: Classification
dataset:
name: MTEB IFlyTek
type: C-MTEB/IFlyTek-classification
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 45.04809542131589
- type: f1
value: 37.01181779071118
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 94.78120000000001
- type: ap
value: 92.52931921594387
- type: f1
value: 94.77902110732532
- task:
type: Classification
dataset:
name: MTEB JDReview
type: C-MTEB/JDReview-classification
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 85.81613508442777
- type: ap
value: 52.430320593468394
- type: f1
value: 79.95467268178068
- task:
type: STS
dataset:
name: MTEB LCQMC
type: C-MTEB/LCQMC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 71.05801751913393
- type: cos_sim_spearman
value: 75.47954644971965
- type: euclidean_pearson
value: 74.27472296759713
- type: euclidean_spearman
value: 75.47954201369866
- type: manhattan_pearson
value: 74.30508190186474
- type: manhattan_spearman
value: 75.51326518159436
- task:
type: Reranking
dataset:
name: MTEB MMarcoReranking
type: C-MTEB/Mmarco-reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 24.21110921666315
- type: mrr
value: 22.863492063492064
- task:
type: Retrieval
dataset:
name: MTEB MMarcoRetrieval
type: C-MTEB/MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 61.38400000000001
- type: map_at_10
value: 70.895
- type: map_at_100
value: 71.314
- type: map_at_1000
value: 71.331
- type: map_at_3
value: 69.016
- type: map_at_5
value: 70.179
- type: mrr_at_1
value: 63.481
- type: mrr_at_10
value: 71.543
- type: mrr_at_100
value: 71.91300000000001
- type: mrr_at_1000
value: 71.928
- type: mrr_at_3
value: 69.90899999999999
- type: mrr_at_5
value: 70.907
- type: ndcg_at_1
value: 63.481
- type: ndcg_at_10
value: 74.833
- type: ndcg_at_100
value: 76.705
- type: ndcg_at_1000
value: 77.13600000000001
- type: ndcg_at_3
value: 71.236
- type: ndcg_at_5
value: 73.199
- type: precision_at_1
value: 63.481
- type: precision_at_10
value: 9.179
- type: precision_at_100
value: 1.011
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 27.044
- type: precision_at_5
value: 17.272000000000002
- type: recall_at_1
value: 61.38400000000001
- type: recall_at_10
value: 86.318
- type: recall_at_100
value: 94.786
- type: recall_at_1000
value: 98.14500000000001
- type: recall_at_3
value: 76.717
- type: recall_at_5
value: 81.416
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.363999999999997
- type: map_at_10
value: 36.022
- type: map_at_100
value: 37.229
- type: map_at_1000
value: 37.274
- type: map_at_3
value: 32.131
- type: map_at_5
value: 34.391
- type: mrr_at_1
value: 24.069
- type: mrr_at_10
value: 36.620000000000005
- type: mrr_at_100
value: 37.769999999999996
- type: mrr_at_1000
value: 37.809
- type: mrr_at_3
value: 32.846
- type: mrr_at_5
value: 35.02
- type: ndcg_at_1
value: 24.069
- type: ndcg_at_10
value: 43.056
- type: ndcg_at_100
value: 48.754
- type: ndcg_at_1000
value: 49.829
- type: ndcg_at_3
value: 35.167
- type: ndcg_at_5
value: 39.168
- type: precision_at_1
value: 24.069
- type: precision_at_10
value: 6.762
- type: precision_at_100
value: 0.96
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 14.957
- type: precision_at_5
value: 11.023
- type: recall_at_1
value: 23.363999999999997
- type: recall_at_10
value: 64.696
- type: recall_at_100
value: 90.795
- type: recall_at_1000
value: 98.892
- type: recall_at_3
value: 43.247
- type: recall_at_5
value: 52.86300000000001
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 96.11947104423166
- type: f1
value: 95.89561841159332
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.97548605240912
- type: f1
value: 92.17133696717212
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.37224816544364
- type: f1
value: 93.19978829237863
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 91.28719072972127
- type: f1
value: 91.28448045979604
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 88.8131946934385
- type: f1
value: 88.27883019362747
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 85.52260397830018
- type: f1
value: 85.15528226728568
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 86.10807113543093
- type: f1
value: 70.88498219072167
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.77120315581854
- type: f1
value: 57.97153920153224
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.93995997331554
- type: f1
value: 58.839203810064866
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.801440651425
- type: f1
value: 58.68009647839332
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 72.90785227680172
- type: f1
value: 49.83760954655788
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 73.24050632911391
- type: f1
value: 52.0562553541082
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.47948890383321
- type: f1
value: 63.334877563135485
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.2871553463349
- type: f1
value: 43.17658050605427
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.174176193678555
- type: f1
value: 59.236659587042425
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.226630800269
- type: f1
value: 60.951842696956184
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.94283792871555
- type: f1
value: 61.40057652844215
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.480833893745796
- type: f1
value: 52.5298332072816
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.52858103564223
- type: f1
value: 69.3770851919204
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.09213180901143
- type: f1
value: 71.13518469365879
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.31203765971756
- type: f1
value: 66.05906970865144
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 80.57162071284465
- type: f1
value: 77.7866172598823
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.09414929388029
- type: f1
value: 72.5712594833695
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.20914593140553
- type: f1
value: 68.90619124909186
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.74243443174176
- type: f1
value: 64.72743141749955
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.11096166778749
- type: f1
value: 72.61849933064694
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.22394082044384
- type: f1
value: 62.43648797607235
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.44855413584399
- type: f1
value: 66.56851670913659
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.4149293880296
- type: f1
value: 66.12960877904776
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.916610625420304
- type: f1
value: 54.02534600927991
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.71351714862138
- type: f1
value: 69.70227985126316
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.91257565568257
- type: f1
value: 57.06811572144974
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.25218560860793
- type: f1
value: 72.48057563104247
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.35507733691998
- type: f1
value: 73.03024649541128
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.918628110289184
- type: f1
value: 54.75590124456177
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 52.548755884330866
- type: f1
value: 51.5356975360209
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 46.44922663080027
- type: f1
value: 44.561114416830975
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.95763281775386
- type: f1
value: 50.68367245122476
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.20645595158035
- type: f1
value: 71.78450093258185
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.226630800269
- type: f1
value: 57.53988988993337
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.44922663080027
- type: f1
value: 48.58809018065056
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.3752521856086
- type: f1
value: 49.91373941436425
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.85205110961668
- type: f1
value: 67.05660019588582
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 49.1492938802959
- type: f1
value: 46.717578025393195
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.93140551445865
- type: f1
value: 67.45406609372205
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.82851378614662
- type: f1
value: 71.15951964393868
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.84868863483524
- type: f1
value: 71.76056802364877
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.27236045729657
- type: f1
value: 72.48733090101163
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.63012777404168
- type: f1
value: 66.56444015346203
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.62743779421655
- type: f1
value: 73.82720656992142
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.15198386012105
- type: f1
value: 64.41418309797744
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.8399462004035
- type: f1
value: 56.050989519693886
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.86684599865501
- type: f1
value: 70.80682480844303
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.36718224613316
- type: f1
value: 54.998746471013774
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.150638870208475
- type: f1
value: 49.79179342620099
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.50638870208473
- type: f1
value: 49.778960742003555
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.906523201076
- type: f1
value: 66.75784022138245
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.73234700739744
- type: f1
value: 65.75016141148413
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.06792199058508
- type: f1
value: 67.90334782594083
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.09145931405515
- type: f1
value: 58.88703095210731
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.17014122394083
- type: f1
value: 68.43676277921544
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.99327505043712
- type: f1
value: 72.26813373392943
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.13987895090787
- type: f1
value: 70.29309514467575
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.37256220578345
- type: f1
value: 72.56456170538992
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 47.205783456624076
- type: f1
value: 45.905999859074434
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.8352387357095
- type: f1
value: 69.43553987525273
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.00403496973773
- type: f1
value: 65.97477215779143
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.04976462676531
- type: f1
value: 67.24581993778398
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.882985877605925
- type: f1
value: 59.995293199988794
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.75857431069267
- type: f1
value: 76.52031675299841
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.03496973772697
- type: f1
value: 79.25548063175344
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.96570275722931
- type: f1
value: 72.19110435289122
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 82.38735709482178
- type: f1
value: 82.34495627619785
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.83994620040352
- type: f1
value: 78.91526355393667
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.7350369872226
- type: f1
value: 75.919437344927
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.21721587088096
- type: f1
value: 70.82973286243262
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.59784801613988
- type: f1
value: 78.47383161087423
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.64021519838602
- type: f1
value: 68.45118053027653
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.51042367182245
- type: f1
value: 72.90013022879003
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.0551445864156
- type: f1
value: 73.45871761713292
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.54606590450571
- type: f1
value: 57.72711794953869
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.40753194351042
- type: f1
value: 76.8157455506521
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.58372562205783
- type: f1
value: 65.2654868709758
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.39273705447208
- type: f1
value: 78.3592956594837
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.62004034969739
- type: f1
value: 79.78673754501855
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.29051782111634
- type: f1
value: 63.12502587609454
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.51849361129791
- type: f1
value: 56.32320906403241
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.41761936785474
- type: f1
value: 49.113762010098306
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.547410894418284
- type: f1
value: 56.87580674198118
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.89038332212507
- type: f1
value: 79.09210140529848
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.503698722259585
- type: f1
value: 61.45718858568352
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.02824478816408
- type: f1
value: 52.732738981386504
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.23671822461331
- type: f1
value: 52.688080372545286
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.5312710154674
- type: f1
value: 74.59368478550698
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.192333557498316
- type: f1
value: 50.18302290152229
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.6960322797579
- type: f1
value: 75.25331182714856
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.47679892400808
- type: f1
value: 78.24044732352424
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.36718224613315
- type: f1
value: 77.2714452985389
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.96234028244788
- type: f1
value: 78.21282127011372
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.19435104236717
- type: f1
value: 73.1963711292812
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.52118359112306
- type: f1
value: 80.4179964390288
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.65837256220577
- type: f1
value: 73.07156989634905
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.02824478816409
- type: f1
value: 62.972399027713664
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.87020847343645
- type: f1
value: 78.224240866849
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.6570275722932
- type: f1
value: 63.274871811412545
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.760591795561524
- type: f1
value: 56.73711528075771
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 57.26967047747142
- type: f1
value: 55.74735330863165
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.46133154001345
- type: f1
value: 71.9644168952811
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.70880968392737
- type: f1
value: 73.61543141070884
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.0437121721587
- type: f1
value: 74.83359868879921
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.05110961667788
- type: f1
value: 66.25869819274315
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.52118359112306
- type: f1
value: 75.92098546052303
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.92938802958977
- type: f1
value: 79.79833572573796
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.86617350369872
- type: f1
value: 77.42645654909516
- task:
type: Retrieval
dataset:
name: MTEB MedicalRetrieval
type: C-MTEB/MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 44.6
- type: map_at_10
value: 50.019000000000005
- type: map_at_100
value: 50.611
- type: map_at_1000
value: 50.67
- type: map_at_3
value: 48.699999999999996
- type: map_at_5
value: 49.455
- type: mrr_at_1
value: 44.800000000000004
- type: mrr_at_10
value: 50.119
- type: mrr_at_100
value: 50.711
- type: mrr_at_1000
value: 50.77
- type: mrr_at_3
value: 48.8
- type: mrr_at_5
value: 49.555
- type: ndcg_at_1
value: 44.6
- type: ndcg_at_10
value: 52.754
- type: ndcg_at_100
value: 55.935
- type: ndcg_at_1000
value: 57.607
- type: ndcg_at_3
value: 50.012
- type: ndcg_at_5
value: 51.393
- type: precision_at_1
value: 44.6
- type: precision_at_10
value: 6.140000000000001
- type: precision_at_100
value: 0.77
- type: precision_at_1000
value: 0.09
- type: precision_at_3
value: 17.933
- type: precision_at_5
value: 11.44
- type: recall_at_1
value: 44.6
- type: recall_at_10
value: 61.4
- type: recall_at_100
value: 77.0
- type: recall_at_1000
value: 90.4
- type: recall_at_3
value: 53.800000000000004
- type: recall_at_5
value: 57.199999999999996
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 38.192667527616315
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 37.44738902946689
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.59661273103955
- type: mrr
value: 33.82024242497473
- task:
type: Classification
dataset:
name: MTEB MultilingualSentiment
type: C-MTEB/MultilingualSentiment-classification
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 73.31333333333335
- type: f1
value: 73.0873466527602
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.471
- type: map_at_10
value: 14.142
- type: map_at_100
value: 18.179000000000002
- type: map_at_1000
value: 19.772000000000002
- type: map_at_3
value: 9.716
- type: map_at_5
value: 11.763
- type: mrr_at_1
value: 51.393
- type: mrr_at_10
value: 58.814
- type: mrr_at_100
value: 59.330000000000005
- type: mrr_at_1000
value: 59.35
- type: mrr_at_3
value: 56.398
- type: mrr_at_5
value: 58.038999999999994
- type: ndcg_at_1
value: 49.69
- type: ndcg_at_10
value: 38.615
- type: ndcg_at_100
value: 35.268
- type: ndcg_at_1000
value: 43.745
- type: ndcg_at_3
value: 43.187
- type: ndcg_at_5
value: 41.528999999999996
- type: precision_at_1
value: 51.083999999999996
- type: precision_at_10
value: 29.474
- type: precision_at_100
value: 9.167
- type: precision_at_1000
value: 2.2089999999999996
- type: precision_at_3
value: 40.351
- type: precision_at_5
value: 36.285000000000004
- type: recall_at_1
value: 5.471
- type: recall_at_10
value: 19.242
- type: recall_at_100
value: 37.14
- type: recall_at_1000
value: 68.35900000000001
- type: recall_at_3
value: 10.896
- type: recall_at_5
value: 14.75
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.499
- type: map_at_10
value: 55.862
- type: map_at_100
value: 56.667
- type: map_at_1000
value: 56.684999999999995
- type: map_at_3
value: 51.534
- type: map_at_5
value: 54.2
- type: mrr_at_1
value: 44.351
- type: mrr_at_10
value: 58.567
- type: mrr_at_100
value: 59.099000000000004
- type: mrr_at_1000
value: 59.109
- type: mrr_at_3
value: 55.218999999999994
- type: mrr_at_5
value: 57.391999999999996
- type: ndcg_at_1
value: 44.322
- type: ndcg_at_10
value: 63.535
- type: ndcg_at_100
value: 66.654
- type: ndcg_at_1000
value: 66.991
- type: ndcg_at_3
value: 55.701
- type: ndcg_at_5
value: 60.06700000000001
- type: precision_at_1
value: 44.322
- type: precision_at_10
value: 10.026
- type: precision_at_100
value: 1.18
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 24.865000000000002
- type: precision_at_5
value: 17.48
- type: recall_at_1
value: 39.499
- type: recall_at_10
value: 84.053
- type: recall_at_100
value: 97.11
- type: recall_at_1000
value: 99.493
- type: recall_at_3
value: 64.091
- type: recall_at_5
value: 74.063
- task:
type: PairClassification
dataset:
name: MTEB Ocnli
type: C-MTEB/OCNLI
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 61.18029236599891
- type: cos_sim_ap
value: 64.18398769398412
- type: cos_sim_f1
value: 67.96347757046446
- type: cos_sim_precision
value: 54.4529262086514
- type: cos_sim_recall
value: 90.3907074973601
- type: dot_accuracy
value: 61.18029236599891
- type: dot_ap
value: 64.18393484706077
- type: dot_f1
value: 67.96347757046446
- type: dot_precision
value: 54.4529262086514
- type: dot_recall
value: 90.3907074973601
- type: euclidean_accuracy
value: 61.18029236599891
- type: euclidean_ap
value: 64.18395024821486
- type: euclidean_f1
value: 67.96347757046446
- type: euclidean_precision
value: 54.4529262086514
- type: euclidean_recall
value: 90.3907074973601
- type: manhattan_accuracy
value: 61.451001624255554
- type: manhattan_ap
value: 64.38232708763513
- type: manhattan_f1
value: 68.05860805860804
- type: manhattan_precision
value: 52.10319685922602
- type: manhattan_recall
value: 98.09926082365365
- type: max_accuracy
value: 61.451001624255554
- type: max_ap
value: 64.38232708763513
- type: max_f1
value: 68.05860805860804
- task:
type: Classification
dataset:
name: MTEB OnlineShopping
type: C-MTEB/OnlineShopping-classification
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 92.19000000000001
- type: ap
value: 89.73918431886767
- type: f1
value: 92.17175032574507
- task:
type: STS
dataset:
name: MTEB PAWSX
type: C-MTEB/PAWSX
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 15.079320253752224
- type: cos_sim_spearman
value: 16.813772504404263
- type: euclidean_pearson
value: 19.476541162041762
- type: euclidean_spearman
value: 16.813772498098782
- type: manhattan_pearson
value: 19.497429832915277
- type: manhattan_spearman
value: 16.869600674180607
- task:
type: STS
dataset:
name: MTEB QBQTC
type: C-MTEB/QBQTC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 30.36139599797913
- type: cos_sim_spearman
value: 31.80296402851347
- type: euclidean_pearson
value: 30.10387888252793
- type: euclidean_spearman
value: 31.80297780103808
- type: manhattan_pearson
value: 30.86720382849436
- type: manhattan_spearman
value: 32.70491131366606
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.911
- type: map_at_10
value: 86.087
- type: map_at_100
value: 86.701
- type: map_at_1000
value: 86.715
- type: map_at_3
value: 83.231
- type: map_at_5
value: 85.051
- type: mrr_at_1
value: 82.75
- type: mrr_at_10
value: 88.759
- type: mrr_at_100
value: 88.844
- type: mrr_at_1000
value: 88.844
- type: mrr_at_3
value: 87.935
- type: mrr_at_5
value: 88.504
- type: ndcg_at_1
value: 82.75
- type: ndcg_at_10
value: 89.605
- type: ndcg_at_100
value: 90.664
- type: ndcg_at_1000
value: 90.733
- type: ndcg_at_3
value: 87.03
- type: ndcg_at_5
value: 88.473
- type: precision_at_1
value: 82.75
- type: precision_at_10
value: 13.575000000000001
- type: precision_at_100
value: 1.539
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 38.153
- type: precision_at_5
value: 25.008000000000003
- type: recall_at_1
value: 71.911
- type: recall_at_10
value: 96.261
- type: recall_at_100
value: 99.72800000000001
- type: recall_at_1000
value: 99.993
- type: recall_at_3
value: 88.762
- type: recall_at_5
value: 92.949
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 57.711581165572376
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 66.48938885750297
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.7379999999999995
- type: map_at_10
value: 9.261
- type: map_at_100
value: 11.001
- type: map_at_1000
value: 11.262
- type: map_at_3
value: 6.816
- type: map_at_5
value: 8.0
- type: mrr_at_1
value: 18.4
- type: mrr_at_10
value: 28.755999999999997
- type: mrr_at_100
value: 29.892000000000003
- type: mrr_at_1000
value: 29.961
- type: mrr_at_3
value: 25.467000000000002
- type: mrr_at_5
value: 27.332
- type: ndcg_at_1
value: 18.4
- type: ndcg_at_10
value: 16.296
- type: ndcg_at_100
value: 23.52
- type: ndcg_at_1000
value: 28.504
- type: ndcg_at_3
value: 15.485
- type: ndcg_at_5
value: 13.471
- type: precision_at_1
value: 18.4
- type: precision_at_10
value: 8.469999999999999
- type: precision_at_100
value: 1.8950000000000002
- type: precision_at_1000
value: 0.309
- type: precision_at_3
value: 14.6
- type: precision_at_5
value: 11.84
- type: recall_at_1
value: 3.7379999999999995
- type: recall_at_10
value: 17.185
- type: recall_at_100
value: 38.397
- type: recall_at_1000
value: 62.798
- type: recall_at_3
value: 8.896999999999998
- type: recall_at_5
value: 12.021999999999998
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 86.43977757480083
- type: cos_sim_spearman
value: 82.64182475199533
- type: euclidean_pearson
value: 83.71756009999591
- type: euclidean_spearman
value: 82.64182331395057
- type: manhattan_pearson
value: 83.8028936913025
- type: manhattan_spearman
value: 82.71024597804252
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.85653060698912
- type: cos_sim_spearman
value: 79.65598885228324
- type: euclidean_pearson
value: 83.1205137628455
- type: euclidean_spearman
value: 79.65629387709038
- type: manhattan_pearson
value: 83.71108853545837
- type: manhattan_spearman
value: 80.25617619716708
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 88.22921688565664
- type: cos_sim_spearman
value: 88.42662103041957
- type: euclidean_pearson
value: 87.91679798473325
- type: euclidean_spearman
value: 88.42662103041957
- type: manhattan_pearson
value: 88.16927537961303
- type: manhattan_spearman
value: 88.81581680062541
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 86.77261424554293
- type: cos_sim_spearman
value: 84.53930146434155
- type: euclidean_pearson
value: 85.67420491389697
- type: euclidean_spearman
value: 84.53929771783851
- type: manhattan_pearson
value: 85.74306784515618
- type: manhattan_spearman
value: 84.7399304675314
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 89.86138395166455
- type: cos_sim_spearman
value: 90.42577823022054
- type: euclidean_pearson
value: 89.8787763797515
- type: euclidean_spearman
value: 90.42577823022054
- type: manhattan_pearson
value: 89.9592937492158
- type: manhattan_spearman
value: 90.63535505335524
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 86.5176674585941
- type: cos_sim_spearman
value: 87.6842917085397
- type: euclidean_pearson
value: 86.70213081520711
- type: euclidean_spearman
value: 87.6842917085397
- type: manhattan_pearson
value: 86.83702628983627
- type: manhattan_spearman
value: 87.87791000374443
- task:
type: STS
dataset:
name: MTEB STS17 (ko-ko)
type: mteb/sts17-crosslingual-sts
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 83.86395454805867
- type: cos_sim_spearman
value: 83.69454595252267
- type: euclidean_pearson
value: 83.04743892608313
- type: euclidean_spearman
value: 83.69454026433006
- type: manhattan_pearson
value: 83.4032095553322
- type: manhattan_spearman
value: 84.11527379013802
- task:
type: STS
dataset:
name: MTEB STS17 (ar-ar)
type: mteb/sts17-crosslingual-sts
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 81.80249894729546
- type: cos_sim_spearman
value: 81.87004960533409
- type: euclidean_pearson
value: 80.0392760044179
- type: euclidean_spearman
value: 81.87004960533409
- type: manhattan_pearson
value: 80.38096542355912
- type: manhattan_spearman
value: 82.40774679630341
- task:
type: STS
dataset:
name: MTEB STS17 (en-ar)
type: mteb/sts17-crosslingual-sts
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 77.6158201787172
- type: cos_sim_spearman
value: 77.934651044009
- type: euclidean_pearson
value: 77.7874683895269
- type: euclidean_spearman
value: 77.934651044009
- type: manhattan_pearson
value: 78.36151849193052
- type: manhattan_spearman
value: 78.52439586349938
- task:
type: STS
dataset:
name: MTEB STS17 (en-de)
type: mteb/sts17-crosslingual-sts
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.04363311392207
- type: cos_sim_spearman
value: 87.30483659369973
- type: euclidean_pearson
value: 87.62634489502616
- type: euclidean_spearman
value: 87.30483659369973
- type: manhattan_pearson
value: 88.02340837141445
- type: manhattan_spearman
value: 87.55012003294
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 91.69172851958248
- type: cos_sim_spearman
value: 91.7546879482416
- type: euclidean_pearson
value: 91.84843039183963
- type: euclidean_spearman
value: 91.7546879482416
- type: manhattan_pearson
value: 91.72325753804357
- type: manhattan_spearman
value: 91.55330259513397
- task:
type: STS
dataset:
name: MTEB STS17 (en-tr)
type: mteb/sts17-crosslingual-sts
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 73.95572901084864
- type: cos_sim_spearman
value: 72.56217821552626
- type: euclidean_pearson
value: 74.24242980323574
- type: euclidean_spearman
value: 72.56217821552626
- type: manhattan_pearson
value: 74.57473362519922
- type: manhattan_spearman
value: 72.76048826648497
- task:
type: STS
dataset:
name: MTEB STS17 (es-en)
type: mteb/sts17-crosslingual-sts
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 86.93329396008296
- type: cos_sim_spearman
value: 88.2406635486219
- type: euclidean_pearson
value: 87.49687343908533
- type: euclidean_spearman
value: 88.2406635486219
- type: manhattan_pearson
value: 88.14088309231084
- type: manhattan_spearman
value: 88.93314020908534
- task:
type: STS
dataset:
name: MTEB STS17 (es-es)
type: mteb/sts17-crosslingual-sts
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.70124451546057
- type: cos_sim_spearman
value: 87.45988160052252
- type: euclidean_pearson
value: 88.44395505247728
- type: euclidean_spearman
value: 87.45988160052252
- type: manhattan_pearson
value: 88.69269783495425
- type: manhattan_spearman
value: 87.65383425621
- task:
type: STS
dataset:
name: MTEB STS17 (fr-en)
type: mteb/sts17-crosslingual-sts
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.64109149761346
- type: cos_sim_spearman
value: 88.06459637689733
- type: euclidean_pearson
value: 88.02313315797703
- type: euclidean_spearman
value: 88.06459637689733
- type: manhattan_pearson
value: 88.28328539133253
- type: manhattan_spearman
value: 88.06605708379142
- task:
type: STS
dataset:
name: MTEB STS17 (it-en)
type: mteb/sts17-crosslingual-sts
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.9040028177525
- type: cos_sim_spearman
value: 89.68152202933464
- type: euclidean_pearson
value: 89.23684469601253
- type: euclidean_spearman
value: 89.68152202933464
- type: manhattan_pearson
value: 89.59504307277454
- type: manhattan_spearman
value: 89.88060100313582
- task:
type: STS
dataset:
name: MTEB STS17 (nl-en)
type: mteb/sts17-crosslingual-sts
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.69891585325125
- type: cos_sim_spearman
value: 88.25252785071736
- type: euclidean_pearson
value: 87.99932873748662
- type: euclidean_spearman
value: 88.25252785071736
- type: manhattan_pearson
value: 88.26959683009446
- type: manhattan_spearman
value: 88.32583227300715
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.53235909794135
- type: cos_sim_spearman
value: 66.97521740529574
- type: euclidean_pearson
value: 68.19502223613912
- type: euclidean_spearman
value: 66.97521740529574
- type: manhattan_pearson
value: 68.39070714774539
- type: manhattan_spearman
value: 67.1072812364868
- task:
type: STS
dataset:
name: MTEB STS22 (de)
type: mteb/sts22-crosslingual-sts
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 43.715742021204775
- type: cos_sim_spearman
value: 49.12255971271453
- type: euclidean_pearson
value: 40.76848562610837
- type: euclidean_spearman
value: 49.12255971271453
- type: manhattan_pearson
value: 40.92204625614112
- type: manhattan_spearman
value: 49.23333793661129
- task:
type: STS
dataset:
name: MTEB STS22 (es)
type: mteb/sts22-crosslingual-sts
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.35268345563588
- type: cos_sim_spearman
value: 66.99661626042061
- type: euclidean_pearson
value: 65.85589122857066
- type: euclidean_spearman
value: 66.99661626042061
- type: manhattan_pearson
value: 66.78454301512294
- type: manhattan_spearman
value: 67.17570330149233
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 33.36599908204445
- type: cos_sim_spearman
value: 39.20768331939503
- type: euclidean_pearson
value: 22.16066769530468
- type: euclidean_spearman
value: 39.20768331939503
- type: manhattan_pearson
value: 22.386053195546022
- type: manhattan_spearman
value: 39.70172817465986
- task:
type: STS
dataset:
name: MTEB STS22 (tr)
type: mteb/sts22-crosslingual-sts
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.06813956986753
- type: cos_sim_spearman
value: 68.72065117995668
- type: euclidean_pearson
value: 66.97373456344194
- type: euclidean_spearman
value: 68.72065117995668
- type: manhattan_pearson
value: 67.34907265771595
- type: manhattan_spearman
value: 68.73705769957843
- task:
type: STS
dataset:
name: MTEB STS22 (ar)
type: mteb/sts22-crosslingual-sts
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.17664865207108
- type: cos_sim_spearman
value: 54.115568323148864
- type: euclidean_pearson
value: 48.56418162879182
- type: euclidean_spearman
value: 54.115568323148864
- type: manhattan_pearson
value: 48.85951643453165
- type: manhattan_spearman
value: 54.13599784169052
- task:
type: STS
dataset:
name: MTEB STS22 (ru)
type: mteb/sts22-crosslingual-sts
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.87514136275987
- type: cos_sim_spearman
value: 60.82923573674973
- type: euclidean_pearson
value: 53.724183308215615
- type: euclidean_spearman
value: 60.82923573674973
- type: manhattan_pearson
value: 53.954305573102445
- type: manhattan_spearman
value: 60.957483900644526
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.55001413648593
- type: cos_sim_spearman
value: 63.395777040381276
- type: euclidean_pearson
value: 59.869972550293305
- type: euclidean_spearman
value: 63.395777040381276
- type: manhattan_pearson
value: 61.16195496847885
- type: manhattan_spearman
value: 63.41968682525581
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 79.13334972675852
- type: cos_sim_spearman
value: 79.86263136371802
- type: euclidean_pearson
value: 78.2433603592541
- type: euclidean_spearman
value: 79.86263136371802
- type: manhattan_pearson
value: 78.87337106318412
- type: manhattan_spearman
value: 80.31230584758441
- task:
type: STS
dataset:
name: MTEB STS22 (de-en)
type: mteb/sts22-crosslingual-sts
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.559700748242356
- type: cos_sim_spearman
value: 60.92342109509558
- type: euclidean_pearson
value: 66.07256437521119
- type: euclidean_spearman
value: 60.92342109509558
- type: manhattan_pearson
value: 67.72769744612663
- type: manhattan_spearman
value: 59.64714507774168
- task:
type: STS
dataset:
name: MTEB STS22 (es-en)
type: mteb/sts22-crosslingual-sts
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 73.93491616145891
- type: cos_sim_spearman
value: 75.84242594400156
- type: euclidean_pearson
value: 74.87279745626121
- type: euclidean_spearman
value: 75.84242594400156
- type: manhattan_pearson
value: 76.47764144677505
- type: manhattan_spearman
value: 77.08411157845183
- task:
type: STS
dataset:
name: MTEB STS22 (it)
type: mteb/sts22-crosslingual-sts
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 72.75624124540954
- type: cos_sim_spearman
value: 75.8667941654703
- type: euclidean_pearson
value: 73.74314588451925
- type: euclidean_spearman
value: 75.8667941654703
- type: manhattan_pearson
value: 73.99641425871518
- type: manhattan_spearman
value: 76.1982840205817
- task:
type: STS
dataset:
name: MTEB STS22 (pl-en)
type: mteb/sts22-crosslingual-sts
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 75.20898141298767
- type: cos_sim_spearman
value: 73.18060375331436
- type: euclidean_pearson
value: 75.44489280944619
- type: euclidean_spearman
value: 73.18060375331436
- type: manhattan_pearson
value: 75.65451039552286
- type: manhattan_spearman
value: 72.97744006123156
- task:
type: STS
dataset:
name: MTEB STS22 (zh-en)
type: mteb/sts22-crosslingual-sts
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 72.04278252247816
- type: cos_sim_spearman
value: 71.8846446821539
- type: euclidean_pearson
value: 73.16043307050612
- type: euclidean_spearman
value: 71.8846446821539
- type: manhattan_pearson
value: 74.76905116839777
- type: manhattan_spearman
value: 72.66237093518471
- task:
type: STS
dataset:
name: MTEB STS22 (es-it)
type: mteb/sts22-crosslingual-sts
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 71.71033173838558
- type: cos_sim_spearman
value: 75.043122881885
- type: euclidean_pearson
value: 72.77579680345087
- type: euclidean_spearman
value: 75.043122881885
- type: manhattan_pearson
value: 72.99901534854922
- type: manhattan_spearman
value: 75.15418335015957
- task:
type: STS
dataset:
name: MTEB STS22 (de-fr)
type: mteb/sts22-crosslingual-sts
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.75733447190482
- type: cos_sim_spearman
value: 61.38968334176681
- type: euclidean_pearson
value: 55.479231520643744
- type: euclidean_spearman
value: 61.38968334176681
- type: manhattan_pearson
value: 56.05230571465244
- type: manhattan_spearman
value: 62.69383054007398
- task:
type: STS
dataset:
name: MTEB STS22 (de-pl)
type: mteb/sts22-crosslingual-sts
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 41.72244325050302
- type: cos_sim_spearman
value: 54.47476909084119
- type: euclidean_pearson
value: 43.94629756436873
- type: euclidean_spearman
value: 54.47476909084119
- type: manhattan_pearson
value: 46.36533046394657
- type: manhattan_spearman
value: 54.87509243633636
- task:
type: STS
dataset:
name: MTEB STS22 (fr-pl)
type: mteb/sts22-crosslingual-sts
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 70.75183711835146
- type: cos_sim_spearman
value: 84.51542547285167
- type: euclidean_pearson
value: 71.84188960126669
- type: euclidean_spearman
value: 84.51542547285167
- type: manhattan_pearson
value: 73.94847166379994
- type: manhattan_spearman
value: 84.51542547285167
- task:
type: STS
dataset:
name: MTEB STSB
type: C-MTEB/STSB
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 81.78690149086131
- type: cos_sim_spearman
value: 81.81202616916873
- type: euclidean_pearson
value: 80.98792254251062
- type: euclidean_spearman
value: 81.81202616916873
- type: manhattan_pearson
value: 81.46953021346732
- type: manhattan_spearman
value: 82.34259562492315
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.68273341294419
- type: cos_sim_spearman
value: 88.59927164210958
- type: euclidean_pearson
value: 88.10745681818025
- type: euclidean_spearman
value: 88.59927164210958
- type: manhattan_pearson
value: 88.25166703784649
- type: manhattan_spearman
value: 88.85343247873482
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 86.3340463345719
- type: mrr
value: 96.5182611506141
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.967000000000006
- type: map_at_10
value: 71.873
- type: map_at_100
value: 72.271
- type: map_at_1000
value: 72.292
- type: map_at_3
value: 69.006
- type: map_at_5
value: 70.856
- type: mrr_at_1
value: 63.666999999999994
- type: mrr_at_10
value: 72.929
- type: mrr_at_100
value: 73.26
- type: mrr_at_1000
value: 73.282
- type: mrr_at_3
value: 71.111
- type: mrr_at_5
value: 72.328
- type: ndcg_at_1
value: 63.666999999999994
- type: ndcg_at_10
value: 76.414
- type: ndcg_at_100
value: 78.152
- type: ndcg_at_1000
value: 78.604
- type: ndcg_at_3
value: 71.841
- type: ndcg_at_5
value: 74.435
- type: precision_at_1
value: 63.666999999999994
- type: precision_at_10
value: 10.067
- type: precision_at_100
value: 1.097
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 27.667
- type: precision_at_5
value: 18.467
- type: recall_at_1
value: 60.967000000000006
- type: recall_at_10
value: 88.922
- type: recall_at_100
value: 96.667
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 77.228
- type: recall_at_5
value: 83.428
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.82277227722773
- type: cos_sim_ap
value: 95.66279851444406
- type: cos_sim_f1
value: 90.9367088607595
- type: cos_sim_precision
value: 92.1025641025641
- type: cos_sim_recall
value: 89.8
- type: dot_accuracy
value: 99.82277227722773
- type: dot_ap
value: 95.66279851444406
- type: dot_f1
value: 90.9367088607595
- type: dot_precision
value: 92.1025641025641
- type: dot_recall
value: 89.8
- type: euclidean_accuracy
value: 99.82277227722773
- type: euclidean_ap
value: 95.66279851444406
- type: euclidean_f1
value: 90.9367088607595
- type: euclidean_precision
value: 92.1025641025641
- type: euclidean_recall
value: 89.8
- type: manhattan_accuracy
value: 99.82673267326733
- type: manhattan_ap
value: 95.86094873177069
- type: manhattan_f1
value: 91.26788357178096
- type: manhattan_precision
value: 90.06815968841285
- type: manhattan_recall
value: 92.5
- type: max_accuracy
value: 99.82673267326733
- type: max_ap
value: 95.86094873177069
- type: max_f1
value: 91.26788357178096
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 73.09533925852372
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 45.90745648090035
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 54.91147686504404
- type: mrr
value: 56.03900082760377
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.46908662038217
- type: cos_sim_spearman
value: 31.40325730367437
- type: dot_pearson
value: 31.469083969291894
- type: dot_spearman
value: 31.40325730367437
- task:
type: Reranking
dataset:
name: MTEB T2Reranking
type: C-MTEB/T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 66.90300783402137
- type: mrr
value: 77.06451972574179
- task:
type: Retrieval
dataset:
name: MTEB T2Retrieval
type: C-MTEB/T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 25.82
- type: map_at_10
value: 72.32300000000001
- type: map_at_100
value: 76.198
- type: map_at_1000
value: 76.281
- type: map_at_3
value: 50.719
- type: map_at_5
value: 62.326
- type: mrr_at_1
value: 86.599
- type: mrr_at_10
value: 89.751
- type: mrr_at_100
value: 89.876
- type: mrr_at_1000
value: 89.88000000000001
- type: mrr_at_3
value: 89.151
- type: mrr_at_5
value: 89.519
- type: ndcg_at_1
value: 86.599
- type: ndcg_at_10
value: 80.676
- type: ndcg_at_100
value: 85.03
- type: ndcg_at_1000
value: 85.854
- type: ndcg_at_3
value: 82.057
- type: ndcg_at_5
value: 80.537
- type: precision_at_1
value: 86.599
- type: precision_at_10
value: 40.373
- type: precision_at_100
value: 4.95
- type: precision_at_1000
value: 0.514
- type: precision_at_3
value: 71.918
- type: precision_at_5
value: 60.246
- type: recall_at_1
value: 25.82
- type: recall_at_10
value: 79.905
- type: recall_at_100
value: 93.88499999999999
- type: recall_at_1000
value: 98.073
- type: recall_at_3
value: 52.623
- type: recall_at_5
value: 66.233
- task:
type: Classification
dataset:
name: MTEB TNews
type: C-MTEB/TNews-classification
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 47.050000000000004
- type: f1
value: 45.704071498353294
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.243
- type: map_at_10
value: 2.278
- type: map_at_100
value: 14.221
- type: map_at_1000
value: 33.474
- type: map_at_3
value: 0.7270000000000001
- type: map_at_5
value: 1.183
- type: mrr_at_1
value: 94.0
- type: mrr_at_10
value: 97.0
- type: mrr_at_100
value: 97.0
- type: mrr_at_1000
value: 97.0
- type: mrr_at_3
value: 97.0
- type: mrr_at_5
value: 97.0
- type: ndcg_at_1
value: 90.0
- type: ndcg_at_10
value: 87.249
- type: ndcg_at_100
value: 67.876
- type: ndcg_at_1000
value: 59.205
- type: ndcg_at_3
value: 90.12299999999999
- type: ndcg_at_5
value: 89.126
- type: precision_at_1
value: 94.0
- type: precision_at_10
value: 90.8
- type: precision_at_100
value: 69.28
- type: precision_at_1000
value: 25.85
- type: precision_at_3
value: 94.667
- type: precision_at_5
value: 92.80000000000001
- type: recall_at_1
value: 0.243
- type: recall_at_10
value: 2.392
- type: recall_at_100
value: 16.982
- type: recall_at_1000
value: 55.214
- type: recall_at_3
value: 0.745
- type: recall_at_5
value: 1.2229999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.5
- type: f1
value: 67.05501804646966
- type: precision
value: 65.73261904761904
- type: recall
value: 70.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.14450867052022
- type: f1
value: 70.98265895953759
- type: precision
value: 69.26782273603082
- type: recall
value: 75.14450867052022
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 33.170731707317074
- type: f1
value: 29.92876500193573
- type: precision
value: 28.669145894755648
- type: recall
value: 33.170731707317074
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.5
- type: f1
value: 94.13333333333333
- type: precision
value: 93.46666666666667
- type: recall
value: 95.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.6
- type: f1
value: 99.46666666666665
- type: precision
value: 99.4
- type: recall
value: 99.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.2
- type: f1
value: 96.39999999999999
- type: precision
value: 96.0
- type: recall
value: 97.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.5
- type: f1
value: 92.99666666666667
- type: precision
value: 92.31666666666666
- type: recall
value: 94.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.82089552238806
- type: f1
value: 81.59203980099502
- type: precision
value: 79.60199004975124
- type: recall
value: 85.82089552238806
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.5
- type: f1
value: 75.11246031746032
- type: precision
value: 73.38734126984127
- type: recall
value: 79.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 44.390243902439025
- type: f1
value: 38.48896631823461
- type: precision
value: 36.57220286488579
- type: recall
value: 44.390243902439025
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.2
- type: f1
value: 87.57333333333334
- type: precision
value: 86.34166666666665
- type: recall
value: 90.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.82138517618469
- type: f1
value: 85.98651854423423
- type: precision
value: 84.79257073424753
- type: recall
value: 88.82138517618469
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.04347826086956
- type: f1
value: 72.32108147606868
- type: precision
value: 70.37207357859532
- type: recall
value: 77.04347826086956
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 53.04347826086957
- type: f1
value: 46.88868184955141
- type: precision
value: 44.71730105643149
- type: recall
value: 53.04347826086957
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.0
- type: f1
value: 62.891813186813195
- type: precision
value: 61.037906162464985
- type: recall
value: 68.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.3
- type: f1
value: 82.82000000000001
- type: precision
value: 81.25690476190475
- type: recall
value: 86.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.87816646562122
- type: f1
value: 63.53054933272062
- type: precision
value: 61.47807816331196
- type: recall
value: 68.87816646562122
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.4
- type: f1
value: 68.99388888888889
- type: precision
value: 66.81035714285713
- type: recall
value: 74.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.5
- type: f1
value: 87.93666666666667
- type: precision
value: 86.825
- type: recall
value: 90.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.7
- type: f1
value: 88.09
- type: precision
value: 86.85833333333333
- type: recall
value: 90.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.61904761904762
- type: f1
value: 62.30239247214037
- type: precision
value: 60.340702947845806
- type: recall
value: 67.61904761904762
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.9
- type: f1
value: 73.81285714285714
- type: precision
value: 72.21570818070818
- type: recall
value: 77.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.8
- type: f1
value: 89.66666666666667
- type: precision
value: 88.66666666666666
- type: recall
value: 91.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.6
- type: f1
value: 96.85666666666665
- type: precision
value: 96.50833333333333
- type: recall
value: 97.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.39999999999999
- type: f1
value: 93.98333333333333
- type: precision
value: 93.30000000000001
- type: recall
value: 95.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.0
- type: f1
value: 81.31538461538462
- type: precision
value: 79.70666666666666
- type: recall
value: 85.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.60000000000001
- type: f1
value: 89.81888888888888
- type: precision
value: 89.08583333333333
- type: recall
value: 91.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 44.3
- type: f1
value: 38.8623088023088
- type: precision
value: 37.03755623461505
- type: recall
value: 44.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 93.75
- type: precision
value: 93.05
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.1
- type: f1
value: 98.8
- type: precision
value: 98.65
- type: recall
value: 99.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.6765498652291
- type: f1
value: 63.991785393402644
- type: precision
value: 61.7343729944808
- type: recall
value: 69.6765498652291
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.0
- type: f1
value: 42.79341029341029
- type: precision
value: 40.25098358431692
- type: recall
value: 50.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.7
- type: f1
value: 87.19023809523809
- type: precision
value: 86.12595238095237
- type: recall
value: 89.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 42.72727272727273
- type: f1
value: 37.78789518562245
- type: precision
value: 36.24208471267295
- type: recall
value: 42.72727272727273
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.26205450733752
- type: f1
value: 70.72842833849123
- type: precision
value: 68.93256464011182
- type: recall
value: 75.26205450733752
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 93.96666666666668
- type: precision
value: 93.42
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.26459143968872
- type: f1
value: 72.40190419178747
- type: precision
value: 70.84954604409856
- type: recall
value: 76.26459143968872
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.82905982905983
- type: f1
value: 52.2100122100122
- type: precision
value: 49.52516619183286
- type: recall
value: 59.82905982905983
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.69999999999999
- type: f1
value: 77.41714285714286
- type: precision
value: 75.64833333333334
- type: recall
value: 81.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.5
- type: f1
value: 94.45
- type: precision
value: 93.93333333333334
- type: recall
value: 95.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 58.41121495327103
- type: f1
value: 52.73495974430554
- type: precision
value: 50.717067200712066
- type: recall
value: 58.41121495327103
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 73.3
- type: f1
value: 69.20371794871795
- type: precision
value: 67.6597557997558
- type: recall
value: 73.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.5
- type: f1
value: 95.51666666666667
- type: precision
value: 95.05
- type: recall
value: 96.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.4
- type: f1
value: 73.88856643356644
- type: precision
value: 72.01373015873016
- type: recall
value: 78.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.3
- type: f1
value: 94.09666666666668
- type: precision
value: 93.53333333333332
- type: recall
value: 95.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.94
- type: precision
value: 91.10833333333333
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.89999999999999
- type: precision
value: 95.46666666666668
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.5
- type: f1
value: 66.00635642135641
- type: precision
value: 64.36345238095238
- type: recall
value: 70.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.4
- type: f1
value: 90.44388888888889
- type: precision
value: 89.5767857142857
- type: recall
value: 92.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.0
- type: f1
value: 43.15372775372776
- type: precision
value: 41.53152510162313
- type: recall
value: 48.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 16.7
- type: f1
value: 14.198431372549017
- type: precision
value: 13.411765873015872
- type: recall
value: 16.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.7
- type: f1
value: 81.81666666666666
- type: precision
value: 80.10833333333332
- type: recall
value: 85.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.64285714285714
- type: f1
value: 64.745670995671
- type: precision
value: 62.916666666666664
- type: recall
value: 69.64285714285714
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 54.665203073545555
- type: f1
value: 48.55366630916923
- type: precision
value: 46.35683318998357
- type: recall
value: 54.665203073545555
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 4.8
- type: f1
value: 3.808587223587223
- type: precision
value: 3.5653174603174604
- type: recall
value: 4.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.6
- type: f1
value: 95.77333333333333
- type: precision
value: 95.39166666666667
- type: recall
value: 96.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.39999999999999
- type: f1
value: 94.44
- type: precision
value: 93.975
- type: recall
value: 95.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 42.0
- type: f1
value: 37.024908424908425
- type: precision
value: 35.365992063492065
- type: recall
value: 42.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.7
- type: f1
value: 62.20460835058661
- type: precision
value: 60.590134587634594
- type: recall
value: 66.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.3
- type: f1
value: 96.46666666666667
- type: precision
value: 96.06666666666668
- type: recall
value: 97.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.3
- type: f1
value: 41.96905408317173
- type: precision
value: 40.18741402116402
- type: recall
value: 47.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.2
- type: f1
value: 76.22690476190476
- type: precision
value: 74.63539682539682
- type: recall
value: 80.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.0
- type: f1
value: 94.83333333333333
- type: precision
value: 94.26666666666668
- type: recall
value: 96.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.7
- type: f1
value: 87.24333333333334
- type: precision
value: 86.17
- type: recall
value: 89.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.36496350364964
- type: f1
value: 44.795520780922246
- type: precision
value: 43.09002433090024
- type: recall
value: 50.36496350364964
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 18.8
- type: f1
value: 16.242864357864356
- type: precision
value: 15.466596638655464
- type: recall
value: 18.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 93.92333333333333
- type: precision
value: 93.30833333333332
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.4
- type: f1
value: 91.42333333333333
- type: precision
value: 90.50833333333334
- type: recall
value: 93.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 26.190476190476193
- type: f1
value: 22.05208151636723
- type: precision
value: 21.09292328042328
- type: recall
value: 26.190476190476193
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.2
- type: f1
value: 14.021009731460952
- type: precision
value: 13.1389886698243
- type: recall
value: 17.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.67494824016563
- type: f1
value: 74.24430641821947
- type: precision
value: 72.50747642051991
- type: recall
value: 78.67494824016563
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.19999999999999
- type: f1
value: 92.54
- type: precision
value: 91.75833333333334
- type: recall
value: 94.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.2
- type: f1
value: 87.78666666666666
- type: precision
value: 86.69833333333334
- type: recall
value: 90.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.7
- type: f1
value: 12.19206214842218
- type: precision
value: 11.526261904761904
- type: recall
value: 14.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 73.16017316017316
- type: f1
value: 67.44858316286889
- type: precision
value: 65.23809523809523
- type: recall
value: 73.16017316017316
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.19083969465649
- type: f1
value: 70.33078880407125
- type: precision
value: 68.3969465648855
- type: recall
value: 75.19083969465649
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 62.154294032023294
- type: f1
value: 55.86030821838681
- type: precision
value: 53.53509623160277
- type: recall
value: 62.154294032023294
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 83.9652380952381
- type: precision
value: 82.84242424242424
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.50282485875707
- type: f1
value: 91.54425612052731
- type: precision
value: 90.65442561205272
- type: recall
value: 93.50282485875707
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.4
- type: f1
value: 9.189775870222714
- type: precision
value: 8.66189886502811
- type: recall
value: 11.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.4
- type: f1
value: 91.88666666666666
- type: precision
value: 91.21444444444444
- type: recall
value: 93.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 46.0
- type: f1
value: 40.51069226095542
- type: precision
value: 38.57804926010808
- type: recall
value: 46.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.0
- type: f1
value: 89.11333333333333
- type: precision
value: 88.27000000000001
- type: recall
value: 91.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.39999999999999
- type: f1
value: 92.95
- type: precision
value: 92.27000000000001
- type: recall
value: 94.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.2
- type: f1
value: 11.73701698770113
- type: precision
value: 11.079207014736676
- type: recall
value: 14.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.14745308310992
- type: f1
value: 59.665707393589415
- type: precision
value: 57.560853653346946
- type: recall
value: 65.14745308310992
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.39999999999999
- type: f1
value: 94.0
- type: precision
value: 93.33333333333333
- type: recall
value: 95.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.56521739130434
- type: f1
value: 62.92490118577074
- type: precision
value: 60.27009222661397
- type: recall
value: 69.56521739130434
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 40.140845070422536
- type: f1
value: 35.96411804158283
- type: precision
value: 34.89075869357559
- type: recall
value: 40.140845070422536
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.86826347305389
- type: f1
value: 59.646248628284546
- type: precision
value: 57.22982606216139
- type: recall
value: 65.86826347305389
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.89999999999999
- type: f1
value: 93.48333333333333
- type: precision
value: 92.83666666666667
- type: recall
value: 94.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.783251231527096
- type: f1
value: 42.006447302013804
- type: precision
value: 40.12747105111637
- type: recall
value: 47.783251231527096
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.71830985915493
- type: f1
value: 64.80266212660578
- type: precision
value: 63.08098591549296
- type: recall
value: 69.71830985915493
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.94871794871796
- type: f1
value: 61.59912309912309
- type: precision
value: 59.17338217338218
- type: recall
value: 67.94871794871796
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.39999999999999
- type: f1
value: 95.28333333333335
- type: precision
value: 94.75
- type: recall
value: 96.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.14613778705638
- type: f1
value: 65.4349338900487
- type: precision
value: 63.57599255302805
- type: recall
value: 70.14613778705638
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.2
- type: f1
value: 7.622184434339607
- type: precision
value: 7.287048159682417
- type: recall
value: 9.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.85016286644951
- type: f1
value: 72.83387622149837
- type: precision
value: 70.58450959102424
- type: recall
value: 77.85016286644951
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.8
- type: f1
value: 88.84333333333333
- type: precision
value: 87.96666666666665
- type: recall
value: 90.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 93.14
- type: precision
value: 92.49833333333333
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.25196850393701
- type: f1
value: 80.94488188976378
- type: precision
value: 79.65879265091863
- type: recall
value: 84.25196850393701
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.89666666666666
- type: precision
value: 85.7
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 42.797783933518005
- type: f1
value: 37.30617360155193
- type: precision
value: 35.34933825792552
- type: recall
value: 42.797783933518005
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 94.93333333333332
- type: precision
value: 94.38333333333333
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 54.807692307692314
- type: f1
value: 49.506903353057204
- type: precision
value: 47.54807692307693
- type: recall
value: 54.807692307692314
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.1
- type: f1
value: 83.61857142857143
- type: precision
value: 81.975
- type: recall
value: 87.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.10000000000001
- type: f1
value: 88.76333333333332
- type: precision
value: 87.67
- type: recall
value: 91.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.10000000000001
- type: f1
value: 91.28999999999999
- type: precision
value: 90.44500000000001
- type: recall
value: 93.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 39.97641509433962
- type: f1
value: 33.12271889998028
- type: precision
value: 30.95185381542554
- type: recall
value: 39.97641509433962
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.60000000000001
- type: f1
value: 90.69
- type: precision
value: 89.84500000000001
- type: recall
value: 92.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.07299270072993
- type: f1
value: 93.64355231143554
- type: precision
value: 92.94403892944038
- type: recall
value: 95.07299270072993
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.9
- type: f1
value: 89.61333333333333
- type: precision
value: 88.53333333333333
- type: recall
value: 91.9
- task:
type: Clustering
dataset:
name: MTEB ThuNewsClusteringP2P
type: C-MTEB/ThuNewsClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 64.68478289806511
- task:
type: Clustering
dataset:
name: MTEB ThuNewsClusteringS2S
type: C-MTEB/ThuNewsClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 57.53010296184097
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.519
- type: map_at_10
value: 10.31
- type: map_at_100
value: 16.027
- type: map_at_1000
value: 17.827
- type: map_at_3
value: 5.721
- type: map_at_5
value: 7.7829999999999995
- type: mrr_at_1
value: 34.694
- type: mrr_at_10
value: 52.642999999999994
- type: mrr_at_100
value: 53.366
- type: mrr_at_1000
value: 53.366
- type: mrr_at_3
value: 48.638999999999996
- type: mrr_at_5
value: 50.578
- type: ndcg_at_1
value: 31.633
- type: ndcg_at_10
value: 26.394000000000002
- type: ndcg_at_100
value: 36.41
- type: ndcg_at_1000
value: 49.206
- type: ndcg_at_3
value: 31.694
- type: ndcg_at_5
value: 29.529
- type: precision_at_1
value: 34.694
- type: precision_at_10
value: 23.469
- type: precision_at_100
value: 7.286
- type: precision_at_1000
value: 1.5610000000000002
- type: precision_at_3
value: 34.014
- type: precision_at_5
value: 29.796
- type: recall_at_1
value: 2.519
- type: recall_at_10
value: 17.091
- type: recall_at_100
value: 45.429
- type: recall_at_1000
value: 84.621
- type: recall_at_3
value: 7.208
- type: recall_at_5
value: 10.523
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 69.58659999999999
- type: ap
value: 14.735696532619
- type: f1
value: 54.23517220069903
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 63.723825693265425
- type: f1
value: 64.02405729449103
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 54.310161547491006
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 88.77630088812064
- type: cos_sim_ap
value: 81.61725457333809
- type: cos_sim_f1
value: 74.91373801916932
- type: cos_sim_precision
value: 72.63940520446097
- type: cos_sim_recall
value: 77.33509234828496
- type: dot_accuracy
value: 88.77630088812064
- type: dot_ap
value: 81.61725317476251
- type: dot_f1
value: 74.91373801916932
- type: dot_precision
value: 72.63940520446097
- type: dot_recall
value: 77.33509234828496
- type: euclidean_accuracy
value: 88.77630088812064
- type: euclidean_ap
value: 81.61724596869566
- type: euclidean_f1
value: 74.91373801916932
- type: euclidean_precision
value: 72.63940520446097
- type: euclidean_recall
value: 77.33509234828496
- type: manhattan_accuracy
value: 88.67497168742922
- type: manhattan_ap
value: 81.430251048948
- type: manhattan_f1
value: 74.79593118171543
- type: manhattan_precision
value: 71.3635274382938
- type: manhattan_recall
value: 78.57519788918206
- type: max_accuracy
value: 88.77630088812064
- type: max_ap
value: 81.61725457333809
- type: max_f1
value: 74.91373801916932
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.85136026700819
- type: cos_sim_ap
value: 87.74656687446567
- type: cos_sim_f1
value: 80.3221673073403
- type: cos_sim_precision
value: 76.56871640957633
- type: cos_sim_recall
value: 84.46258084385587
- type: dot_accuracy
value: 89.85136026700819
- type: dot_ap
value: 87.74656471395072
- type: dot_f1
value: 80.3221673073403
- type: dot_precision
value: 76.56871640957633
- type: dot_recall
value: 84.46258084385587
- type: euclidean_accuracy
value: 89.85136026700819
- type: euclidean_ap
value: 87.74656885754466
- type: euclidean_f1
value: 80.3221673073403
- type: euclidean_precision
value: 76.56871640957633
- type: euclidean_recall
value: 84.46258084385587
- type: manhattan_accuracy
value: 89.86300306593705
- type: manhattan_ap
value: 87.78807479093082
- type: manhattan_f1
value: 80.31663429471911
- type: manhattan_precision
value: 76.63472970137772
- type: manhattan_recall
value: 84.3701878657222
- type: max_accuracy
value: 89.86300306593705
- type: max_ap
value: 87.78807479093082
- type: max_f1
value: 80.3221673073403
- task:
type: Retrieval
dataset:
name: MTEB VideoRetrieval
type: C-MTEB/VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 32.4
- type: map_at_10
value: 40.961999999999996
- type: map_at_100
value: 41.660000000000004
- type: map_at_1000
value: 41.721000000000004
- type: map_at_3
value: 38.550000000000004
- type: map_at_5
value: 40.06
- type: mrr_at_1
value: 32.4
- type: mrr_at_10
value: 40.961999999999996
- type: mrr_at_100
value: 41.660000000000004
- type: mrr_at_1000
value: 41.721000000000004
- type: mrr_at_3
value: 38.550000000000004
- type: mrr_at_5
value: 40.06
- type: ndcg_at_1
value: 32.4
- type: ndcg_at_10
value: 45.388
- type: ndcg_at_100
value: 49.012
- type: ndcg_at_1000
value: 50.659
- type: ndcg_at_3
value: 40.47
- type: ndcg_at_5
value: 43.232
- type: precision_at_1
value: 32.4
- type: precision_at_10
value: 5.94
- type: precision_at_100
value: 0.769
- type: precision_at_1000
value: 0.09
- type: precision_at_3
value: 15.333
- type: precision_at_5
value: 10.56
- type: recall_at_1
value: 32.4
- type: recall_at_10
value: 59.4
- type: recall_at_100
value: 76.9
- type: recall_at_1000
value: 90.0
- type: recall_at_3
value: 46.0
- type: recall_at_5
value: 52.800000000000004
- task:
type: Classification
dataset:
name: MTEB Waimai
type: C-MTEB/waimai-classification
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 86.94000000000001
- type: ap
value: 70.57373468481975
- type: f1
value: 85.26264784928323
---
## E5-mistral-7b-instruct
[Improving Text Embeddings with Large Language Models](https://arxiv.org/pdf/2401.00368.pdf). Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei, arXiv 2024
This model has 32 layers and the embedding size is 4096.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
### Sentence Transformers
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("intfloat/e5-mistral-7b-instruct")
# In case you want to reduce the maximum sequence length:
model.max_seq_length = 4096
queries = [
"how much protein should a female eat",
"summit define",
]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
query_embeddings = model.encode(queries, prompt_name="web_search_query")
document_embeddings = model.encode(documents)
scores = (query_embeddings @ document_embeddings.T) * 100
print(scores.tolist())
```
Have a look at [config_sentence_transformers.json](config_sentence_transformers.json) for the prompts that are pre-configured, such as `web_search_query`, `sts_query`, and `summarization_query`. Additionally, check out [unilm/e5/utils.py](https://github.com/microsoft/unilm/blob/9c0f1ff7ca53431fe47d2637dfe253643d94185b/e5/utils.py#L106) for prompts we used for evaluation. You can use these via e.g. `model.encode(queries, prompt="Instruct: Given a claim, find documents that refute the claim\nQuery: ")`.
### Transformers
```python
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'how much protein should a female eat'),
get_detailed_instruct(task, 'summit define')
]
# No need to add instruction for retrieval documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('intfloat/e5-mistral-7b-instruct')
model = AutoModel.from_pretrained('intfloat/e5-mistral-7b-instruct')
max_length = 4096
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=max_length, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Supported Languages
This model is initialized from [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
and fine-tuned on a mixture of multilingual datasets.
As a result, it has some multilingual capability.
However, since Mistral-7B-v0.1 is mainly trained on English data, we recommend using this model for English only.
For multilingual use cases, please refer to [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large).
## MTEB Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## FAQ
**1. Do I need to add instructions to the query?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
The task definition should be a one-sentence instruction that describes the task.
This is a way to customize text embeddings for different scenarios through natural language instructions.
Please check out [unilm/e5/utils.py](https://github.com/microsoft/unilm/blob/9c0f1ff7ca53431fe47d2637dfe253643d94185b/e5/utils.py#L106) for instructions we used for evaluation.
On the other hand, there is no need to add instructions to the document side.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Where are the LoRA-only weights?**
You can find the LoRA-only weights at [https://huggingface.co/intfloat/e5-mistral-7b-instruct/tree/main/lora](https://huggingface.co/intfloat/e5-mistral-7b-instruct/tree/main/lora).
## Citation
If you find our paper or models helpful, please consider cite as follows:
```bibtex
@article{wang2023improving,
title={Improving Text Embeddings with Large Language Models},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2401.00368},
year={2023}
}
@article{wang2022text,
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2212.03533},
year={2022}
}
```
## Limitations
Using this model for inputs longer than 4096 tokens is not recommended.
This model's multilingual capability is still inferior to [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) for some cases.
|
[
"BIOSSES",
"SCIFACT"
] |
ntc-ai/SDXL-LoRA-slider.gasping
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-16T19:17:51Z |
2024-01-16T19:17:54+00:00
| 80 | 1 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/gasping.../gasping_17_3.0.png
widget:
- text: gasping
output:
url: images/gasping_17_3.0.png
- text: gasping
output:
url: images/gasping_19_3.0.png
- text: gasping
output:
url: images/gasping_20_3.0.png
- text: gasping
output:
url: images/gasping_21_3.0.png
- text: gasping
output:
url: images/gasping_22_3.0.png
inference: false
instance_prompt: gasping
---
# ntcai.xyz slider - gasping (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/gasping_17_-3.0.png" width=256 height=256 /> | <img src="images/gasping_17_0.0.png" width=256 height=256 /> | <img src="images/gasping_17_3.0.png" width=256 height=256 /> |
| <img src="images/gasping_19_-3.0.png" width=256 height=256 /> | <img src="images/gasping_19_0.0.png" width=256 height=256 /> | <img src="images/gasping_19_3.0.png" width=256 height=256 /> |
| <img src="images/gasping_20_-3.0.png" width=256 height=256 /> | <img src="images/gasping_20_0.0.png" width=256 height=256 /> | <img src="images/gasping_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
gasping
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.gasping', weight_name='gasping.safetensors', adapter_name="gasping")
# Activate the LoRA
pipe.set_adapters(["gasping"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, gasping"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1140+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.action-hero
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-18T13:19:26Z |
2024-01-18T13:19:31+00:00
| 80 | 1 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/action hero.../action hero_17_3.0.png
widget:
- text: action hero
output:
url: images/action hero_17_3.0.png
- text: action hero
output:
url: images/action hero_19_3.0.png
- text: action hero
output:
url: images/action hero_20_3.0.png
- text: action hero
output:
url: images/action hero_21_3.0.png
- text: action hero
output:
url: images/action hero_22_3.0.png
inference: false
instance_prompt: action hero
---
# ntcai.xyz slider - action hero (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/action hero_17_-3.0.png" width=256 height=256 /> | <img src="images/action hero_17_0.0.png" width=256 height=256 /> | <img src="images/action hero_17_3.0.png" width=256 height=256 /> |
| <img src="images/action hero_19_-3.0.png" width=256 height=256 /> | <img src="images/action hero_19_0.0.png" width=256 height=256 /> | <img src="images/action hero_19_3.0.png" width=256 height=256 /> |
| <img src="images/action hero_20_-3.0.png" width=256 height=256 /> | <img src="images/action hero_20_0.0.png" width=256 height=256 /> | <img src="images/action hero_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
action hero
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.action-hero', weight_name='action hero.safetensors', adapter_name="action hero")
# Activate the LoRA
pipe.set_adapters(["action hero"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, action hero"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1140+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
hunflair/biosyn-sapbert-ncbi-disease
|
hunflair
| null |
[
"flair",
"pytorch",
"entity-mention-linker",
"region:us"
] | 2024-01-26T16:48:43Z |
2024-01-29T15:07:53+00:00
| 80 | 0 |
---
tags:
- flair
- entity-mention-linker
---
## biosyn-sapbert-ncbi-disease
Biomedical Entity Mention Linking for diseases:
- Model: [dmis-lab/biosyn-sapbert-ncbi-disease](https://huggingface.co/dmis-lab/biosyn-sapbert-ncbi-disease)
- Dictionary: [CTD Diseases](https://ctdbase.org/help/diseaseDetailHelp.jsp) (See [License](https://ctdbase.org/about/legal.jsp))
### Demo: How to use in Flair
Requires:
- **[Flair](https://github.com/flairNLP/flair/)>=0.14.0** (`pip install flair` or `pip install git+https://github.com/flairNLP/flair.git`)
```python
from flair.data import Sentence
from flair.models import Classifier, EntityMentionLinker
from flair.tokenization import SciSpacyTokenizer
sentence = Sentence(
"The mutation in the ABCD1 gene causes X-linked adrenoleukodystrophy, "
"a neurodegenerative disease, which is exacerbated by exposure to high "
"levels of mercury in dolphin populations.",
use_tokenizer=SciSpacyTokenizer()
)
# load hunflair to detect the entity mentions we want to link.
tagger = Classifier.load("hunflair-disease")
tagger.predict(sentence)
# load the linker and dictionary
linker = EntityMentionLinker.load("hunflair/biosyn-sapbert-ncbi-disease")
dictionary = linker.dictionary
# find then candidates for the mentions
linker.predict(sentence)
# print the results for each entity mention:
for span in sentence.get_spans(tagger.label_type):
for link in span.get_labels(linker.label_type):
print(f"{span.text} -> {link.value}")
```
As an alternative to downloading the already precomputed model (much storage). You can also build the model
and compute the embeddings for the dataset using:
```python
linker = EntityMentionLinker.build("dmis-lab/biosyn-biobert-ncbi-disease", dictionary_name_or_path="ctd-diseases", hybrid_search=True)
```
This will reduce the download requirements, at the cost of computation.
|
[
"NCBI DISEASE"
] |
hunflair/biosyn-sapbert-bc5cdr-chemical-no-ab3p
|
hunflair
| null |
[
"flair",
"pytorch",
"entity-mention-linker",
"region:us"
] | 2024-02-06T16:14:45Z |
2024-02-06T16:54:03+00:00
| 80 | 0 |
---
tags:
- flair
- entity-mention-linker
---
## biosyn-sapbert-bc5cdr-chemical-no-ab3p
Biomedical Entity Mention Linking for chemical:
- Model: [dmis-lab/biosyn-sapbert-bc5cdr-chemical](https://huggingface.co/dmis-lab/biosyn-sapbert-bc5cdr-chemical)
- Dictionary: [CTD Chemicals](https://ctdbase.org/help/chemDetailHelp.jsp) (See [License](https://ctdbase.org/about/legal.jsp))
NOTE: This model variant does not perform abbreviation resolution via [A3bP](https://github.com/ncbi-nlp/Ab3P)
### Demo: How to use in Flair
Requires:
- **[Flair](https://github.com/flairNLP/flair/)>=0.14.0** (`pip install flair` or `pip install git+https://github.com/flairNLP/flair.git`)
```python
from flair.data import Sentence
from flair.models import Classifier, EntityMentionLinker
from flair.tokenization import SciSpacyTokenizer
sentence = Sentence(
"The mutation in the ABCD1 gene causes X-linked adrenoleukodystrophy, "
"a neurodegenerative disease, which is exacerbated by exposure to high "
"levels of mercury in dolphin populations.",
use_tokenizer=SciSpacyTokenizer()
)
# load hunflair to detect the entity mentions we want to link.
tagger = Classifier.load("hunflair-chemical")
tagger.predict(sentence)
# load the linker and dictionary
linker = EntityMentionLinker.load("chemical-linker-no-abbres")
linker.predict(sentence)
# print the results for each entity mention:
for span in sentence.get_spans(tagger.label_type):
for link in span.get_labels(linker.label_type):
print(f"{span.text} -> {link.value}")
```
As an alternative to downloading the already precomputed model (much storage). You can also build the model
and compute the embeddings for the dataset using:
```python
from flair.models.entity_mention_linking import BioSynEntityPreprocessor
linker = EntityMentionLinker.build("dmis-lab/biosyn-sapbert-bc5cdr-chemical", dictionary_name_or_path="ctd-chemicals", preprocessor=BioSynPreprocessor(), hybrid_search=True)
```
This will reduce the download requirements, at the cost of computation.
|
[
"BC5CDR"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.