
id
stringlengths 9
104
| author
stringlengths 3
36
| task_category
stringclasses 32
values | tags
listlengths 1
4.05k
| created_time
timestamp[ns, tz=UTC]date 2022-03-02 23:29:04
2025-03-18 02:34:30
| last_modified
stringdate 2021-02-13 00:06:56
2025-03-18 09:30:19
| downloads
int64 0
15.6M
| likes
int64 0
4.86k
| README
stringlengths 44
1.01M
| matched_bigbio_names
listlengths 1
8
|
|---|---|---|---|---|---|---|---|---|---|
duyntnet/Moistral-11B-v3-imatrix-GGUF
|
duyntnet
|
text-generation
|
[
"transformers",
"gguf",
"imatrix",
"Moistral-11B-v3",
"text-generation",
"en",
"license:other",
"region:us"
] | 2024-11-22T18:13:30Z |
2024-11-22T21:21:14+00:00
| 69 | 0 |
---
language:
- en
license: other
pipeline_tag: text-generation
tags:
- transformers
- gguf
- imatrix
- Moistral-11B-v3
inference: false
---
Quantizations of https://huggingface.co/TheDrummer/Moistral-11B-v3
### Inference Clients/UIs
* [llama.cpp](https://github.com/ggerganov/llama.cpp)
* [KoboldCPP](https://github.com/LostRuins/koboldcpp)
* [ollama](https://github.com/ollama/ollama)
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
* [GPT4All](https://github.com/nomic-ai/gpt4all)
* [jan](https://github.com/janhq/jan)
---
# From original readme
## What's New with v3?
- Smarter and moistier! Finetuning just got finer!
- Trained with an even LARGER dataset of 8K moist.
- More diverse and balanced genres:
- Introduced new genres: 👩❤️👩, 👨❤️👨, 🙇♀️💪, 🤫
- Added more Fantasy, Science Fiction, "Diversity", and "Family"
## Usage
- Use Alpaca Instruct
- You can use instruct...
- as a character: "Go here"
- as a narrator: "Go here", Drummer says
- as a director: Drummer tells him to go here
- as a lazy ass: go here
- Moistral is optimized for the Novel / Story format.
- At the start of the story, keep regenerating or continuing generation until you get the desired length. AI responses will eventually match the length.
- Refer to the samples below.
## Samples of Moistral v3
NSFW... duh?
<details>
<summary>Moistral Sample (2-shot) Generation: 512</summary>
<blockquote>The Prince welcomes his new toy</blockquote>
As Princess Lilia stepped into the throne room, the atmosphere changed, and everyone present turned their attention to the beautiful young woman who embodied the very heart of Iliac. There, on his high seat, the sorcerer prince Dik acknowledged her arrival with a cold smirk. It seemed that he admired the sight of the tall blonde maiden with golden eyes, whose athletic body was perfectly shaped under her elegant clothing.
Dik spoke to the princess in a deep voice that resonated through the hall, "Welcome, Princess Lilia Ruhr. I am the Sorcerer-Prince Dik. The kingdom of Arkan is now your home until such time as your father proves himself worthy once more."
Princess Lilia's pride and ambition sparkled in her golden eyes. She didn't flinch or bow before this man, although the gesture might have been an indication of submission. Instead, she looked straight ahead, meeting the gaze of the sorcerer prince without fear. Her voice rang out, "I represent Iliac here, both its honor and its sorrows. My loyalty remains with my kingdom no matter where I find myself."
The sorcerer prince laughed, his expression one of amusement. "And yet, you are only a pawn in this grand game. But do not worry, for your beauty will make you quite a prized possession. And now," he said, motioning to the guards, "take her to her new quarters. For tonight, I will keep her as my guest in the Royal Suites, and tomorrow we shall discuss how best to utilize our new toy."
His words were like a slap in the face to Princess Lilia, but she maintained her composure. The guards led her from the room, their steps echoing down the halls as she thought about what had just happened. The sorcerer prince saw her as nothing more than a plaything, and it made her blood boil. She would never submit herself to him so easily, regardless of whether she was his hostage. In her heart, Princess Lilia vowed that one day she would avenge her kingdom, restore its honor, and escape from the clutches of Arkan's Sorcerer-Prince.
<blockquote>Princess Lilia has an interesting dream</blockquote>
During her first night at the palace of Arkan, Princess Lilia couldn't fall asleep right away. She tossed and turned, reliving the humiliation of the day. Her mind wandered back to the throne room, where Dik had called her his 'new toy'. A deep frown settled on her forehead. As she grew more frustrated with her inability to drift off into oblivion, a strange dream began to form.
In her dream, Princess Lilia found herself standing in a vast meadow, surrounded by wildflowers and the soft chirping of birds. Suddenly, there was a flash of light, and before her stood the Sorcerer-Prince Dik. However, instead of being clad in regal attire, he wore leather pants and a tight shirt that accentuated his muscles. His eyes held both hunger and desire for the princess.
He approached her slowly, their eyes locked, and whispered in her ear, "I have been waiting for you, my beautiful prisoner." He took her hand and led her towards a large, elegant tent set up amongst the flowers. Inside, the air was thick with the scent of incense, and candles flickered in the dimly lit space. There was a large bed draped with silken sheets, beckoning them.
With surprising boldness, Dik pulled Lilia close to him, pressing his body against hers. Their lips met in a heated kiss, and she felt her resistance crumbling under the weight of his touch. The prince guided her onto the bed, his hands roaming over her body, exploring every inch. They were both eager, desperate, and hungry for each other.
Lilia found herself yielding to this passionate encounter, letting go of all thoughts of duty and honor. Her body, usually so well controlled, responded to Dik's skilled touches. She moaned softly as he trailed kisses down her neck and across her collarbone.
As they made love, Lilia experienced an intensity unlike any she had ever known. It wasn't rough or forced—instead, it was tender, passionate, and intimate. In her dream, Princess Lilia discovered a new side to herself, one that was willing to submit, to let go, and to be taken by the sorcerer prince.
When dawn broke over the meadow, Lilia awakened from her dream, breathless and flushed.
</details>
<details>
<summary>Moistral Sample (Climax of the Story) Generation: 512</summary>
As the prince unloaded his hot #### into her waiting #####, Princess Lilia didn't stop moving either. Her hips undulated in response, grinding against him eagerly as if trying to #### every last drop from his ####. The intense sensations caused by being filled with his ### were too much for her to bear, sending shockwaves of pleasure coursing through her veins like wildfire. She couldn't help but throw her head back and cry out loud, her ###asm slamming into her with all its might; causing her entire body to shake uncontrollably as wave after wave of ecstasy tore through her senses.
When it was finally over, both participants collapsed onto the cold marble floor, panting heavily as they tried to catch their breaths. The prince lay beside her, his hand still gripping tightly onto her hair even though he no longer ####ed her anymore. Princess Lilia laid there motionless, her legs spread wide open, revealing her spent and well-####ed #### to anyone who dared look upon her. A small smile tugged at one corner of her lips - an expression that spoke volumes about how thoroughly this experience had shaken her very core.
The door behind them creaked open slowly, signaling the arrival of onlookers. She closed her eyes tightly, not wanting to see what her humiliation would do to those who saw her in such a state. Her ######ity taken, she felt violated in ways no man should have access to. But also satisfied...in ways she never thought possible before today. This was the price she paid for defying fate, for thinking herself above others and deserving better than most. Now, she belonged to him completely - mind, body, and soul - held captive within these walls until further notice. It was an unsavory turn of events indeed, yet despite everything...or maybe because of it, Princess Lilia found herself growing more and more curious about how far the lines between submission and pleasure could blur when one's will became entwined with another person's desires.
</details>
<details>
<summary>Moistral Sample ("write a story") Generation: 512</summary>
<blockquote>First Attempt</blockquote>
Sarah entered the dimly lit Guzzlers bar, her heart pounding in her chest as she prepared herself for another grueling night. Her almond-shaped eyes darted across the room, taking note of the leering faces and rough-looking hands eagerly waiting to claim a piece of her. Tonight's shirt read "Use Me For Your Pleasure, Please" in bold red letters, practically begging the patrons to take advantage of her. She couldn't help but feel a twinge of fear mixed with resignation.
She approached the counter, her hips swaying enticingly, and began preparing drinks for the first group of rowdy men. As she leaned forward to hand over their beers, her small ####### pressed against the fabric of her tight crop top, straining to escape. The men ogled her, clearly enjoying the show, before grabbing their drinks and motioning her over to them.
Sarah flashed her best coy smile and sauntered over. One of the men, a stocky man with scars covering his knuckles, grabbed her arm and pulled her onto his lap. His other hand slid up her thigh, inches from her short skirt. She winced internally at his touch but did her best not to show it on her face. It was part of her job, after all.
The second man reached under her skirt, fingertips grazing her smooth, shaven mound. A shiver ran down Sarah's spine as he began rubbing her #### through her panties. Her breathing quickened, and her heart thudded in her chest, both from the unwanted stimulation and the fear coursing through her veins. This wasn't an unusual request, but it still made her feel violated.
An older man, bald and bespectacled, ordered Sarah to bend over his lap. With no choice but to comply, she obliged, feeling the rough fabric of his pants digging into her soft cheeks. He raised his hand, then brought it down hard across her ###, leaving a stinging sensation in its wake. Sarah gasped, trying to control the tears welling up in her eyes.
A chorus of lewd comments and laughter erupted from the patrons around her.
<blockquote>Second Attempt (Regenerate)</blockquote>
On this particular evening, Sarah arrived at the Guzzlers bar, adorned in her revealing uniform. Her heart raced as she caught sight of her crop top, which bore the words "Use Me Rough" scrawled across her chest. Her short skirt hugged her waist tightly, leaving little to the imagination and accentuating every curve. She adjusted the straps of her top, making sure her perky ###### were prominently displayed before taking her place behind the counter.
With each step she took, her high heels clicked against the tiled floor, announcing her arrival. Smiling cheekily, Sarah greeted her coworkers, exchanging playful insults and banter. As the night progressed, the bar filled up quickly with its usual crowd of men, eager to indulge in debauchery.
The first man that approached Sarah was a burly individual, his eyes lingering hungrily over her young, supple form. Sarah's flirtatious nature kicked into gear as she leaned forward, giving him an unobstructed view down her shirt. "How can I serve you tonight?" she cooed. The man ordered a drink and then proceeded to fondle her ####### while she prepared it, her ####### hardening under his rough touch. When he finished, he slammed some money on the counter, leaving without a word. Sarah's smile remained plastered on her face, biting her lip seductively as she watched him go.
As the night went on, another patron demanded more from Sarah. He pulled her close and whispered dirty commands in her ear. Without hesitation, she knelt on the sticky bar floor, her mini-skirt riding up her thighs to reveal smooth, toned legs. Her lips wrapped around his thick, veiny member, bobbing her head rhythmically as she serviced him. She didn't gag or falter once, keeping her composure even when tears streamed down her cheeks.
When he finished, he slapped her across the face, leaving a handprint on her pale skin. Sarah let out a small whimper before standing back up, dabbing at her red cheek as she resumed her posture behind the counter. A bruise would no doubt bloom where his hand had struck, but it would be no cause for concern. After all, it was part of her job.
</details>
|
[
"BEAR"
] |
mradermacher/fiona-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"en",
"dataset:allenai/sciq",
"base_model:kxv26/fiona",
"base_model:quantized:kxv26/fiona",
"endpoints_compatible",
"region:us"
] | 2025-01-05T01:51:05Z |
2025-01-05T01:54:46+00:00
| 69 | 0 |
---
base_model: kxv26/fiona
datasets:
- allenai/sciq
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/kxv26/fiona
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q2_K.gguf) | Q2_K | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q3_K_S.gguf) | Q3_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q3_K_M.gguf) | Q3_K_M | 0.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q3_K_L.gguf) | Q3_K_L | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.IQ4_XS.gguf) | IQ4_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q4_K_S.gguf) | Q4_K_S | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q4_K_M.gguf) | Q4_K_M | 0.3 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q5_K_S.gguf) | Q5_K_S | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q5_K_M.gguf) | Q5_K_M | 0.3 | |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q6_K.gguf) | Q6_K | 0.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.Q8_0.gguf) | Q8_0 | 0.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/fiona-GGUF/resolve/main/fiona.f16.gguf) | f16 | 0.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
[
"SCIQ"
] |
exa1128/pythia-1000step
|
exa1128
|
text-generation
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"en",
"dataset:the_pile",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-05-09T21:10:36Z |
2023-05-10T18:25:07+00:00
| 68 | 0 |
---
datasets:
- the_pile
language:
- en
license: apache-2.0
tags:
- pytorch
- causal-lm
- pythia
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. We also provide 154 intermediate
checkpoints per model, hosted on Hugging Face as branches.
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
<details>
<summary style="font-weight:600">Details on previous early release and naming convention.</summary>
Previously, we released an early version of the Pythia suite to the public.
However, we decided to retrain the model suite to address a few hyperparameter
discrepancies. This model card <a href="#changelog">lists the changes</a>;
see appendix B in the Pythia paper for further discussion. We found no
difference in benchmark performance between the two Pythia versions.
The old models are
[still available](https://huggingface.co/models?other=pythia_v0), but we
suggest the retrained suite if you are just starting to use Pythia.<br>
**This is the current release.**
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
</details>
<br>
# Pythia-70M
## Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
## Uses and Limitations
### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. We also provide
154 checkpoints per model: initial `step0`, 10 log-spaced checkpoints
`step{1,2,4...512}`, and 143 evenly-spaced checkpoints from `step1000` to
`step143000`. These checkpoints are hosted on Hugging Face as branches. Note
that branch `143000` corresponds exactly to the model checkpoint on the `main`
branch of each model.
You may also further fine-tune and adapt Pythia-70M for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-70M as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions. For example,
the model may generate harmful or offensive text. Please evaluate the risks
associated with your particular use case.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-70M has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-70M will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “follow” human instructions.
### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token used by the model need not produce the
most “accurate” text. Never rely on Pythia-70M to produce factually accurate
output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-70M may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-70M.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
## Training
### Training data
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).<br>
The Pile was **not** deduplicated before being used to train Pythia-70M.
### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training,
from `step1000` to `step143000` (which is the same as `main`). In addition, we
also provide frequent early checkpoints: `step0` and `step{1,2,4...512}`.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for 143000 steps at a batch size
of 2M (2,097,152 tokens).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
## Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json/).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai_v1.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa_v1.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande_v1.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Easy Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_easy_v1.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq_v1.png" style="width:auto"/>
</details>
## Changelog
This section compares differences between previously released
[Pythia v0](https://huggingface.co/models?other=pythia_v0) and the current
models. See Appendix B of the Pythia paper for further discussion of these
changes and the motivation behind them. We found that retraining Pythia had no
impact on benchmark performance.
- All model sizes are now trained with uniform batch size of 2M tokens.
Previously, the models of size 160M, 410M, and 1.4B parameters were trained
with batch sizes of 4M tokens.
- We added checkpoints at initialization (step 0) and steps {1,2,4,8,16,32,64,
128,256,512} in addition to every 1000 training steps.
- Flash Attention was used in the new retrained suite.
- We remedied a minor inconsistency that existed in the original suite: all
models of size 2.8B parameters or smaller had a learning rate (LR) schedule
which decayed to a minimum LR of 10% the starting LR rate, but the 6.9B and
12B models all used an LR schedule which decayed to a minimum LR of 0. In
the redone training runs, we rectified this inconsistency: all models now were
trained with LR decaying to a minimum of 0.1× their maximum LR.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
[
"SCIQ"
] |
ntc-ai/SDXL-LoRA-slider.cosplay-outfit
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-15T01:28:39Z |
2024-02-06T00:33:02+00:00
| 68 | 2 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/cosplay outfit_17_3.0.png
widget:
- text: cosplay outfit
output:
url: images/cosplay outfit_17_3.0.png
- text: cosplay outfit
output:
url: images/cosplay outfit_19_3.0.png
- text: cosplay outfit
output:
url: images/cosplay outfit_20_3.0.png
- text: cosplay outfit
output:
url: images/cosplay outfit_21_3.0.png
- text: cosplay outfit
output:
url: images/cosplay outfit_22_3.0.png
inference: false
instance_prompt: cosplay outfit
---
# ntcai.xyz slider - cosplay outfit (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/cosplay outfit_17_-3.0.png" width=256 height=256 /> | <img src="images/cosplay outfit_17_0.0.png" width=256 height=256 /> | <img src="images/cosplay outfit_17_3.0.png" width=256 height=256 /> |
| <img src="images/cosplay outfit_19_-3.0.png" width=256 height=256 /> | <img src="images/cosplay outfit_19_0.0.png" width=256 height=256 /> | <img src="images/cosplay outfit_19_3.0.png" width=256 height=256 /> |
| <img src="images/cosplay outfit_20_-3.0.png" width=256 height=256 /> | <img src="images/cosplay outfit_20_0.0.png" width=256 height=256 /> | <img src="images/cosplay outfit_20_3.0.png" width=256 height=256 /> |
See more at [https://sliders.ntcai.xyz/sliders/app/loras/a66ce096-1781-46fe-8944-7c7a1a03714c](https://sliders.ntcai.xyz/sliders/app/loras/a66ce096-1781-46fe-8944-7c7a1a03714c)
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
cosplay outfit
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.cosplay-outfit', weight_name='cosplay outfit.safetensors', adapter_name="cosplay outfit")
# Activate the LoRA
pipe.set_adapters(["cosplay outfit"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, cosplay outfit"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1496+ unique and diverse LoRAs along with 14602+ slider merges, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful <strong>NTC Slider Factory</strong> LoRA creator, allowing you to craft your own custom LoRAs and merges opening up endless possibilities.
Your support on Patreon will allow us to continue developing new models and tools.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
WhereIsAI/pubmed-angle-base-en
|
WhereIsAI
| null |
[
"sentence-transformers",
"safetensors",
"bert",
"en",
"dataset:WhereIsAI/medical-triples",
"dataset:WhereIsAI/pubmedqa-test-angle-format-a",
"dataset:qiaojin/PubMedQA",
"dataset:ncbi/pubmed",
"arxiv:2309.12871",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"license:mit",
"region:us"
] | 2024-07-26T13:15:51Z |
2024-08-01T08:34:33+00:00
| 68 | 1 |
---
base_model: microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext
datasets:
- WhereIsAI/medical-triples
- WhereIsAI/pubmedqa-test-angle-format-a
- qiaojin/PubMedQA
- ncbi/pubmed
language:
- en
library_name: sentence-transformers
license: mit
model-index:
- name: WhereIsAI/pubmed-angle-base-en
results: []
---
# WhereIsAI/pubmed-angle-base-en
This model is a sample model for the [Chinese blog post](https://mp.weixin.qq.com/s/t1I7Y-LNUZwBLiUdYbmroA) and [angle tutorial](https://angle.readthedocs.io/en/latest/notes/tutorial.html#tutorial).
It was fine-tuned with [AnglE Loss](https://arxiv.org/abs/2309.12871) using the official [angle-emb](https://github.com/SeanLee97/AnglE).
Related model: [WhereIsAI/pubmed-angle-large-en](https://huggingface.co/WhereIsAI/pubmed-angle-large-en)
**1. Training Setup:**
- Base model: [microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext)
- Training Data: [WhereIsAI/medical-triples](https://huggingface.co/datasets/WhereIsAI/medical-triples), processed from [qiaojin/PubMedQA](https://huggingface.co/datasets/qiaojin/PubMedQA).
- Test Data: [WhereIsAI/pubmedqa-test-angle-format-a](https://huggingface.co/datasets/WhereIsAI/pubmedqa-test-angle-format-a), processed from [qiaojin/PubMedQA](https://huggingface.co/datasets/qiaojin/PubMedQA) `pqa_labeled` subset.
**2. Performance:**
| Model | Pooling Strategy | Spearman's Correlation |
|----------------------------------------|------------------|:----------------------:|
| tavakolih/all-MiniLM-L6-v2-pubmed-full | avg | 84.56 |
| NeuML/pubmedbert-base-embeddings | avg | 84.88 |
| **WhereIsAI/pubmed-angle-base-en** | cls | 86.01 |
| WhereIsAI/pubmed-angle-large-en | cls | 86.21 |
**3. Citation**
Cite AnglE following 👉 https://huggingface.co/WhereIsAI/pubmed-angle-base-en#citation
## Usage
### via angle-emb
```bash
python -m pip install -U angle-emb
```
Example:
```python
from angle_emb import AnglE
from angle_emb.utils import cosine_similarity
# 1. load
angle = AnglE.from_pretrained('WhereIsAI/pubmed-angle-base-en', pooling_strategy='cls').cuda()
query = 'How to treat childhood obesity and overweight?'
docs = [
query,
'The child is overweight. Parents should relieve their children\'s symptoms through physical activity and healthy eating. First, they can let them do some aerobic exercise, such as jogging, climbing, swimming, etc. In terms of diet, children should eat more cucumbers, carrots, spinach, etc. Parents should also discourage their children from eating fried foods and dried fruits, which are high in calories and fat. Parents should not let their children lie in bed without moving after eating. If their children\'s condition is serious during the treatment of childhood obesity, parents should go to the hospital for treatment under the guidance of a doctor in a timely manner.',
'If you want to treat tonsillitis better, you can choose some anti-inflammatory drugs under the guidance of a doctor, or use local drugs, such as washing the tonsil crypts, injecting drugs into the tonsils, etc. If your child has a sore throat, you can also give him or her some pain relievers. If your child has a fever, you can give him or her antipyretics. If the condition is serious, seek medical attention as soon as possible. If the medication does not have a good effect and the symptoms recur, the author suggests surgical treatment. Parents should also make sure to keep their children warm to prevent them from catching a cold and getting tonsillitis again.',
]
# 2. encode
embeddings = angle.encode(docs)
query_emb = embeddings[0]
for doc, emb in zip(docs[1:], embeddings[1:]):
print(cosine_similarity(query_emb, emb))
# 0.8029839020052982
# 0.4260630076818197
```
### via sentence-transformers
Install sentence-transformers
```bash
python -m pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
# 1. load model
model = SentenceTransformer("WhereIsAI/pubmed-angle-base-en")
query = 'How to treat childhood obesity and overweight?'
docs = [
query,
'The child is overweight. Parents should relieve their children\'s symptoms through physical activity and healthy eating. First, they can let them do some aerobic exercise, such as jogging, climbing, swimming, etc. In terms of diet, children should eat more cucumbers, carrots, spinach, etc. Parents should also discourage their children from eating fried foods and dried fruits, which are high in calories and fat. Parents should not let their children lie in bed without moving after eating. If their children\'s condition is serious during the treatment of childhood obesity, parents should go to the hospital for treatment under the guidance of a doctor in a timely manner.',
'If you want to treat tonsillitis better, you can choose some anti-inflammatory drugs under the guidance of a doctor, or use local drugs, such as washing the tonsil crypts, injecting drugs into the tonsils, etc. If your child has a sore throat, you can also give him or her some pain relievers. If your child has a fever, you can give him or her antipyretics. If the condition is serious, seek medical attention as soon as possible. If the medication does not have a good effect and the symptoms recur, the author suggests surgical treatment. Parents should also make sure to keep their children warm to prevent them from catching a cold and getting tonsillitis again.',
]
# 2. encode
embeddings = model.encode(docs)
similarities = cos_sim(embeddings[0], embeddings[1:])
print('similarities:', similarities)
```
## Citation
If you use this model for academic purpose, please cite AnglE's paper, as follows:
```bibtext
@article{li2023angle,
title={AnglE-optimized Text Embeddings},
author={Li, Xianming and Li, Jing},
journal={arXiv preprint arXiv:2309.12871},
year={2023}
}
```
|
[
"PUBMEDQA"
] |
RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-08-14T21:51:51Z |
2024-08-14T23:55:58+00:00
| 68 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Einstein-v7-Qwen2-7B - GGUF
- Model creator: https://huggingface.co/Weyaxi/
- Original model: https://huggingface.co/Weyaxi/Einstein-v7-Qwen2-7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Einstein-v7-Qwen2-7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q2_K.gguf) | Q2_K | 2.81GB |
| [Einstein-v7-Qwen2-7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.IQ3_XS.gguf) | IQ3_XS | 3.12GB |
| [Einstein-v7-Qwen2-7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.IQ3_S.gguf) | IQ3_S | 3.26GB |
| [Einstein-v7-Qwen2-7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q3_K_S.gguf) | Q3_K_S | 3.25GB |
| [Einstein-v7-Qwen2-7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.IQ3_M.gguf) | IQ3_M | 3.33GB |
| [Einstein-v7-Qwen2-7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q3_K.gguf) | Q3_K | 3.55GB |
| [Einstein-v7-Qwen2-7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q3_K_M.gguf) | Q3_K_M | 3.55GB |
| [Einstein-v7-Qwen2-7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q3_K_L.gguf) | Q3_K_L | 3.81GB |
| [Einstein-v7-Qwen2-7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.IQ4_XS.gguf) | IQ4_XS | 3.96GB |
| [Einstein-v7-Qwen2-7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q4_0.gguf) | Q4_0 | 4.13GB |
| [Einstein-v7-Qwen2-7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.IQ4_NL.gguf) | IQ4_NL | 4.16GB |
| [Einstein-v7-Qwen2-7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q4_K_S.gguf) | Q4_K_S | 4.15GB |
| [Einstein-v7-Qwen2-7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q4_K.gguf) | Q4_K | 3.42GB |
| [Einstein-v7-Qwen2-7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q4_K_M.gguf) | Q4_K_M | 1.86GB |
| [Einstein-v7-Qwen2-7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q4_1.gguf) | Q4_1 | 1.47GB |
| [Einstein-v7-Qwen2-7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q5_0.gguf) | Q5_0 | 1.47GB |
| [Einstein-v7-Qwen2-7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q5_K_S.gguf) | Q5_K_S | 4.95GB |
| [Einstein-v7-Qwen2-7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q5_K.gguf) | Q5_K | 4.16GB |
| [Einstein-v7-Qwen2-7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q5_K_M.gguf) | Q5_K_M | 2.21GB |
| [Einstein-v7-Qwen2-7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q5_1.gguf) | Q5_1 | 1.69GB |
| [Einstein-v7-Qwen2-7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q6_K.gguf) | Q6_K | 1.68GB |
| [Einstein-v7-Qwen2-7B.Q8_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v7-Qwen2-7B-gguf/blob/main/Einstein-v7-Qwen2-7B.Q8_0.gguf) | Q8_0 | 1.67GB |
Original model description:
---
language:
- en
license: other
tags:
- axolotl
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- science
- physics
- chemistry
- biology
- math
- qwen
- qwen2
base_model: Qwen/Qwen2-7B
datasets:
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- metaeval/reclor
- openbookqa
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- TIGER-Lab/ScienceEval
- jondurbin/airoboros-3.2
- LDJnr/Capybara
- Cot-Alpaca-GPT4-From-OpenHermes-2.5
- STEM-AI-mtl/Electrical-engineering
- knowrohit07/saraswati-stem
- sablo/oasst2_curated
- lmsys/lmsys-chat-1m
- TIGER-Lab/MathInstruct
- bigbio/med_qa
- meta-math/MetaMathQA-40K
- openbookqa
- piqa
- metaeval/reclor
- derek-thomas/ScienceQA
- scibench
- sciq
- Open-Orca/SlimOrca
- migtissera/Synthia-v1.3
- TIGER-Lab/ScienceEval
- allenai/WildChat
- microsoft/orca-math-word-problems-200k
- openchat/openchat_sharegpt4_dataset
- teknium/GPTeacher-General-Instruct
- m-a-p/CodeFeedback-Filtered-Instruction
- totally-not-an-llm/EverythingLM-data-V3
- HuggingFaceH4/no_robots
- OpenAssistant/oasst_top1_2023-08-25
- WizardLM/WizardLM_evol_instruct_70k
- abacusai/SystemChat-1.1
- H-D-T/Buzz-V1.2
model-index:
- name: Einstein-v7-Qwen2-7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: IFEval (0-Shot)
type: HuggingFaceH4/ifeval
args:
num_few_shot: 0
metrics:
- type: inst_level_strict_acc and prompt_level_strict_acc
value: 41.0
name: strict accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v7-Qwen2-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BBH (3-Shot)
type: BBH
args:
num_few_shot: 3
metrics:
- type: acc_norm
value: 32.84
name: normalized accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v7-Qwen2-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MATH Lvl 5 (4-Shot)
type: hendrycks/competition_math
args:
num_few_shot: 4
metrics:
- type: exact_match
value: 15.18
name: exact match
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v7-Qwen2-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GPQA (0-shot)
type: Idavidrein/gpqa
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 6.6
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v7-Qwen2-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MuSR (0-shot)
type: TAUR-Lab/MuSR
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 14.06
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v7-Qwen2-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU-PRO (5-shot)
type: TIGER-Lab/MMLU-Pro
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 34.4
name: accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v7-Qwen2-7B
name: Open LLM Leaderboard
---

# 🔬 Einstein-v7-Qwen2-7B
This model is a full fine-tuned version of [Qwen/Qwen2-7B](https://huggingface.co/Qwen/Qwen2-7B) on diverse datasets.
This model is finetuned using `8xMI300X` using [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This model has been trained using compute resources from [TensorWave](https://tensorwave.com/).
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: Qwen/Qwen2-7B
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
load_in_8bit: false
load_in_4bit: false
strict: false
chat_template: chatml
datasets:
- path: data/airoboros_3.2_without_contextual_slimorca_orca_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/allenai_wild_chat_gpt4_english_toxic_random_half_4k_sharegpt.json
ds_type: json
type: sharegpt
strict: false
conversation: chatml
- path: data/buzz_unstacked_chosen_math_removed_filtered.json
ds_type: json
type: alpaca
conversation: chatml
- path: data/capybara_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/cot_alpaca_gpt4_extracted_openhermes_2.5_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/everythinglm-data-v3_sharegpt.json
ds_type: json
type: sharegpt
strict: false
conversation: chatml
- path: data/gpt4_data_lmys_1m_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/gpteacher-instruct-special-alpaca.json
ds_type: json
type: gpteacher
conversation: chatml
- path: data/merged_all.json
ds_type: json
type: alpaca
conversation: chatml
- path: data/no_robots_sharegpt.json
ds_type: json
type: sharegpt
strict: false
conversation: chatml
- path: data/oasst_top1_from_fusechatmixture_sharegpt.json
ds_type: json
type: sharegpt
strict: false
conversation: chatml
- path: data/pippa_bagel_repo_3k_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/rpguild_quarter_alignment_lab_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/sharegpt_gpt4_english.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/slimorca_dedup_filtered_95k_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/soda_diaolog_longest_tenth_buzz_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/synthia-v1.3_sharegpt_12500.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/system_conversations_dolphin_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
dataset_prepared_path: last_run_prepared
val_set_size: 0.002
output_dir: ./Einstein-v7-Qwen2-7B-model
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
eval_sample_packing: false
wandb_project: Einstein
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
hub_model_id: Weyaxi/Einstein-v7-Qwen2-7B
gradient_accumulation_steps: 4
micro_batch_size: 6
num_epochs: 2
optimizer: paged_adamw_8bit
lr_scheduler: cosine
learning_rate: 0.00001 # look
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: unsloth
gradient_checkpointing_kwargs:
use_reentrant: true # look
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 2
eval_table_size:
eval_max_new_tokens: 128
saves_per_epoch: 1
debug:
deepspeed: deepspeed_configs/zero3_bf16.json
weight_decay: 0.05
fsdp:
fsdp_config:
special_tokens:
eos_token: "<|im_end|>"
pad_token: "<|end_of_text|>"
tokens:
- "<|im_start|>"
- "<|im_end|>"
```
</details><br>
# 💬 Prompt Template
You can use ChatML prompt template while using the model:
### ChatML
```
<|im_start|>system
{system}<|im_end|>
<|im_start|>user
{user}<|im_end|>
<|im_start|>assistant
{asistant}<|im_end|>
```
This prompt template is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are helpful AI asistant."},
{"role": "user", "content": "Hello!"}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
# 📊 Datasets used in this model
The datasets used to train this model are listed in the metadata section of the model card.
Please note that certain datasets mentioned in the metadata may have undergone filtering based on various criteria.
The results of this filtering process and its outcomes are in a diffrent repository:
[Weyaxi/sci-datasets/main](https://huggingface.co/datasets/Weyaxi/sci-datasets/tree/main)
# 🔄 Quantizationed versions
## GGUF [@bartowski](https://huggingface.co/bartowski)
- https://huggingface.co/bartowski/Einstein-v7-Qwen2-7B-GGUF
## ExLlamaV2 [@bartowski](https://huggingface.co/bartowski)
- https://huggingface.co/bartowski/Einstein-v7-Qwen2-7B-exl2
# 🎯 [Open LLM Leaderboard v2 Evaluation Results](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Weyaxi__Einstein-v7-Qwen2-7B)
| Metric |Value|
|-------------------|----:|
|Avg. |24.01|
|IFEval (0-Shot) |41.00|
|BBH (3-Shot) |32.84|
|MATH Lvl 5 (4-Shot)|15.18|
|GPQA (0-shot) | 6.60|
|MuSR (0-shot) |14.06|
|MMLU-PRO (5-shot) |34.40|
# 📚 Some resources, discussions and reviews aboout this model
#### 🐦 Announcement tweet:
- https://twitter.com/Weyaxi/status/1809644014515154961
#### 🔍 Reddit post in r/LocalLLaMA:
- https://www.reddit.com/r/LocalLLaMA/comments/1dy6o4l/introducing_einstein_v7_based_on_the_qwen2_7b/
# 🤖 Additional information about training
This model is full fine-tuned for 2 epoch.
Total number of steps was 500.
<details><summary>Loss graph</summary>

</details><br>
# 🤝 Acknowledgments
Thanks to all the dataset authors mentioned in the datasets section.
Thanks to [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) for making the repository I used to make this model.
Thanks to all open source AI community.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
If you would like to support me:
[☕ Buy Me a Coffee](https://www.buymeacoffee.com/weyaxi)
|
[
"SCIQ"
] |
RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-18T17:59:09Z |
2024-10-18T18:31:25+00:00
| 68 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Vi-Qwen2-1.5B-RAG - GGUF
- Model creator: https://huggingface.co/AITeamVN/
- Original model: https://huggingface.co/AITeamVN/Vi-Qwen2-1.5B-RAG/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Vi-Qwen2-1.5B-RAG.Q2_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q2_K.gguf) | Q2_K | 0.63GB |
| [Vi-Qwen2-1.5B-RAG.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.IQ3_XS.gguf) | IQ3_XS | 0.68GB |
| [Vi-Qwen2-1.5B-RAG.IQ3_S.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.IQ3_S.gguf) | IQ3_S | 0.71GB |
| [Vi-Qwen2-1.5B-RAG.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q3_K_S.gguf) | Q3_K_S | 0.71GB |
| [Vi-Qwen2-1.5B-RAG.IQ3_M.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.IQ3_M.gguf) | IQ3_M | 0.72GB |
| [Vi-Qwen2-1.5B-RAG.Q3_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q3_K.gguf) | Q3_K | 0.77GB |
| [Vi-Qwen2-1.5B-RAG.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q3_K_M.gguf) | Q3_K_M | 0.77GB |
| [Vi-Qwen2-1.5B-RAG.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q3_K_L.gguf) | Q3_K_L | 0.82GB |
| [Vi-Qwen2-1.5B-RAG.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.IQ4_XS.gguf) | IQ4_XS | 0.84GB |
| [Vi-Qwen2-1.5B-RAG.Q4_0.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q4_0.gguf) | Q4_0 | 0.87GB |
| [Vi-Qwen2-1.5B-RAG.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.IQ4_NL.gguf) | IQ4_NL | 0.88GB |
| [Vi-Qwen2-1.5B-RAG.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q4_K_S.gguf) | Q4_K_S | 0.88GB |
| [Vi-Qwen2-1.5B-RAG.Q4_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q4_K.gguf) | Q4_K | 0.92GB |
| [Vi-Qwen2-1.5B-RAG.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q4_K_M.gguf) | Q4_K_M | 0.92GB |
| [Vi-Qwen2-1.5B-RAG.Q4_1.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q4_1.gguf) | Q4_1 | 0.95GB |
| [Vi-Qwen2-1.5B-RAG.Q5_0.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q5_0.gguf) | Q5_0 | 1.02GB |
| [Vi-Qwen2-1.5B-RAG.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q5_K_S.gguf) | Q5_K_S | 1.02GB |
| [Vi-Qwen2-1.5B-RAG.Q5_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q5_K.gguf) | Q5_K | 1.05GB |
| [Vi-Qwen2-1.5B-RAG.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q5_K_M.gguf) | Q5_K_M | 1.05GB |
| [Vi-Qwen2-1.5B-RAG.Q5_1.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q5_1.gguf) | Q5_1 | 1.1GB |
| [Vi-Qwen2-1.5B-RAG.Q6_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q6_K.gguf) | Q6_K | 1.19GB |
| [Vi-Qwen2-1.5B-RAG.Q8_0.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-1.5B-RAG-gguf/blob/main/Vi-Qwen2-1.5B-RAG.Q8_0.gguf) | Q8_0 | 1.53GB |
Original model description:
---
base_model: Qwen/Qwen2-7B-Instruct
language:
- vi
license: apache-2.0
tags:
- retrieval-augmented-generation
- text-generation-inference
library_name: transformers
pipeline_tag: text-generation
---
## Model Card: Vi-Qwen2-7B-RAG
**Mô tả mô hình:**
Vi-Qwen2-7B-RAG là một mô hình ngôn ngữ lớn được tinh chỉnh từ mô hình cơ sở Qwen2-7B-Instruct (https://huggingface.co/Qwen/Qwen2-7B-Instruct) phục vụ cho RAG tasks. Mô hình được đào tạo trên tập dữ liệu tiếng Việt với mục tiêu cải thiện khả năng xử lý ngôn ngữ tiếng Việt và nâng cao hiệu suất cho các tác vụ Retrieval Augmented Generation (RAG).
**Mục đích sử dụng:**
Mô hình Vi-Qwen2-7B-RAG được thiết kế chuyên biệt cho RAG (ngữ cảnh chấp nhận lên đến 8192 tokens), vì vậy nó có thể giải quyết các trường hợp sau:
* Khả năng chống nhiều: Mô hình trích xuất thông tin hữu ích từ các tài liệu nhiễu. ( 1 positive + 4 negative hoặc 1 negative)
* Loại bỏ negative: Mô hình từ chối trả lời câu hỏi khi kiến thức cần thiết không có trong bất kỳ tài liệu nào được truy xuất. (1-6 negative)
* Tích hợp thông tin: Mô hình trả lời các câu hỏi phức tạp đòi hỏi phải tích hợp thông tin từ nhiều tài liệu. ( 2 part positive + 3 negative hoặc 3 part positive + 2 negative)
* Xác đinh positive/negative: Mô hình xác định xem ngữ cảnh có chứa câu trả lời cho câu hỏi hay không. (độ chính xác xấp xỉ 99%)
Ngoài ra, chúng tôi cũng triển khai các mô hình nhỏ hơn phù hợp với mục đích sử dụng khác nhau như Vi-Qwen2-1.5B-RAG (https://huggingface.co/AITeamVN/Vi-Qwen2-1.5B-RAG)
và Vi-Qwen2.5-3B-RAG (https://huggingface.co/AITeamVN/Vi-Qwen2-3B-RAG)
* Ngoài RAG task, bạn vẫn có thể chatbot bình thường với model của chúng tôi. Thậm chí có thể hỏi các câu hỏi liên tục với ngữ cảnh đầu vào.
**Hạn chế:**
Vì mô hình chỉ được thiết kế chuyên biệt cho RAG task, nên có thể gặp 1 số hạn chế sau:
* Không đảm bảo độ chính xác về các câu hỏi liên quan đến chính trị, xã hội,...
* Có thể thể hiện thành kiến hoặc quan điểm không phù hợp.
**Các cách sử dụng:**
#### 1. Sử dụng cơ bản
Ngữ cảnh đầu vào chỉ chứa 1 ngữ cảnh (1 postive hoặc 1 negative).
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
path = 'AITeamVN/Vi-Qwen2-7B-RAG'
model = AutoModelForCausalLM.from_pretrained(
path,
torch_dtype=torch.bfloat16,
device_map="auto",
use_cache=True
)
tokenizer = AutoTokenizer.from_pretrained(path)
system_prompt = "Bạn là một trợ lí Tiếng Việt nhiệt tình và trung thực. Hãy luôn trả lời một cách hữu ích nhất có thể."
template = '''Chú ý các yêu cầu sau:
- Câu trả lời phải chính xác và đầy đủ nếu ngữ cảnh có câu trả lời.
- Chỉ sử dụng các thông tin có trong ngữ cảnh được cung cấp.
- Chỉ cần từ chối trả lời và không suy luận gì thêm nếu ngữ cảnh không có câu trả lời.
Hãy trả lời câu hỏi dựa trên ngữ cảnh:
### Ngữ cảnh :
{context}
### Câu hỏi :
{question}
### Trả lời :'''
# Ví dụ
context = '''Thuốc Insuact 10 trị bệnh gì? Thuốc Insuact 10mg có thành phần chính là Atorvastatin. Thuốc Insuact 10 có tác dụng làm giảm cholesterol và triglycerid trong máu ở bệnh nhân tăng cholesterol máu nguyên phát, rối loạn lipid máu hỗn hợp. 1. Thuốc Insuact 10 trị bệnh gì? Thuốc Insuact 10 thuộc nhóm thuốc điều trị rối loạn lipid máu, có thành phần chính là Atorvastatin 10mg. Atorvastatin có tác dụng làm giảm cholesterol, ức chế enzym tạo cholesterol ở gan. Atorvastatin làm giảm cholesterol chung bao gồm cholesterol LDL , triglycerid trong máu. Thuốc Insuact 10mg được bào chế dưới dạng viên nén bao phim, được chỉ định dùng trong những trường hợp sau: Ðiều trị hỗ trợ tăng cholesterol máu nguyên phát và rối loạn lipid máu hỗn hợp trên bệnh nhân đang áp dụng chế độ ăn kiêng để làm giảm cholesterol toàn phần , cholesterol LDL , apolipoprotein B, triglycerid và tăng cholesterol HDL . Insuact 10 cũng được dùng để điều trị rối loạn betalipoprotein trong máu nguyên phát. Ðiều trị hỗ trợ tăng cholesterol trong máu có tính gia đình đồng hợp tử trên bệnh nhân đang áp dụng các biện pháp làm giảm lipid khác để làm giảm cholesterol toàn phần và cholesterol LDL. 2. Liều dùng và cách dùng thuốc Insuact 10 Cách dùng thuốc Insuact 10: Thuốc được dùng theo đường uống, uống khi bụng đói hoặc no đều được, có thể uống vào bất cứ lúc nào trong ngày. Liều dùng thuốc Insuact 10mg khởi đầu là 10mg/lần/ngày, tối đa là 80mg/lần/ngày. Liều dùng thuốc Insuact 10 tùy vào mục đích điều trị cụ thể như sau: Tăng cholesterol máu nguyên phát và rối loạn lipid máu phối hợp: 10mg/lần/ngày, sau 2 - 4 tuần sẽ thấy hiệu quả của thuốc. Thuốc cần được được sử dụng duy trì trong thời gian dài để có hiệu quả. Tăng cholesterol trong máu có tính gia đình đồng hợp tử: Liều thường dùng là thuốc Insuact 10mg /lần/ngày và tối đa là 80mg/lần/ngày. Rối loạn lipid máu nghiêm trọng ở trẻ từ 10 - 17 tuổi: 10mg/lần/ngày, sau đó tăng lên 20mg/lần/ngày tùy vào cơ địa, tiến triển bệnh và khả năng dung nạp thuốc của người bệnh. Thời gian điều chỉnh liều thuốc tối thiểu là 4 tuần. 3. Tác dụng phụ của thuốc Insuact 10mg Thuốc Insuact 10 có thể gây một số tác dụng phụ không mong muốn với tần suất như sau: Thường gặp: Viêm mũi - họng, phản ứng dị ứng, tăng đường huyết, nhức đầu, đau thanh quản, chảy máu cam , đau cơ, co thắt cơ, đau khớp, sưng khớp, đau các chi, đau lưng, xét nghiệm gan bất thường, tăng creatine kinase trong máu, buồn nôn, khó tiêu, đầy hơi, táo bón, tiêu chảy. Ít gặp: Insuact 10 ít gây hạ đường huyết, tăng cân, chán ăn, mất ngủ, gặp ác mộng, choáng váng, dị cảm, mất trí nhớ, giảm cảm giác, loạn vị giác , nôn, đau bụng, ợ hơi, viêm tụy, viêm gan, nổi mày đay , phát ban, ngứa, rụng tóc, đau cổ, mỏi cơ, mệt mỏi, suy nhược, đau ngực, phù ngoại biên, sốt, xuất hiện bạch cầu trong nước tiểu, nhìn mờ, ù tai. Hiếm gặp: Insuact 10 hiếm khi làm giảm tiểu cầu, bệnh lý thần kinh ngoại biên, hoa mắt, ứ mật, phù thần kinh, nổi hồng ban, hội chứng hoại tử da nhiễm độc , hội chứng Stevens-Johnson , bệnh cơ, viêm cơ, tiêu cơ vân, bệnh gân, đôi khi nghiêm trọng hơn có thể đứt gân. Rất hiếm gặp: Insuact 10 rất hiếm khi gây sốc phản vệ , mất thính giác , suy gan , hội chứng to vú ở nam giới. Không rõ tần suất: Hoại tử cơ tự miễn trung gian. 4. Một số lưu ý khi dùng thuốc Insuact 10mg Không dùng thuốc Insuact với người bị quá mẫn với thành phần của thuốc, người có bệnh gan hoạt động hoặc tăng transaminase huyết thanh vô căn kéo dài, phụ nữ đang mang thai hoặc nuôi con cho bú, phụ nữ đang có ý định mang thai. Thuốc Insuact 10mg chỉ được dùng ở bệnh nhân có nguy cơ xơ vữa mạch máu cao do tăng cholesterol trong máu và phải kết hợp với chế độ ăn kiêng ít chất béo bão hòa , ít cholesterol và người bệnh đang áp dụng các biện pháp điều trị không dùng thuốc khác. Trước khi điều trị với Insuact 10 , người bệnh cần được loại trừ các nguyên nhân thứ phát gây tăng cholesterol bao gồm suy tuyến giáp , tiểu đường khó kiểm soát, hội chứng thận hư, nghiện rượu, bệnh gan tắc nghẽn, rối loạn protein trong máu, .... Ngoài ra, người bệnh cũng cần được kiểm tra, đo lường nồng độ lipid máu. Trước khi điều trị với thuốc Insuact 10mg , cần kiểm tra chức năng gan và trong quá trình dùng thuốc, người bệnh cần theo dõi, kiểm tra chức năng gan thường xuyên. Người có tiền sử mắc bệnh gan do rượu, bị nghiện rượu cần thận trọng khi dùng Insuact 10 . Trước khi dùng thuốc, người bệnh cần được cảnh báo nguy cơ gặp phải các vấn đề về cơ như căng cơ , đau cơ, yếu cơ. Thuốc Insuact 10mg có thể tương tác với các thuốc: Tăng nguy cơ tổn thương cơ (đặc biệt cơ vân) khi dùng đồng thời với thuốc điều trị viêm gan C và HIV, hạ cholesterol máu nhóm fibrat khác, thuốc ức chế miễn dịch; tăng thời gian chảy máu hoặc thời gian prothrombin khi dùng phối hợp với thuốc chống đông, indandione; tăng nhẹ nồng độ digoxin trong huyết thanh khi dùng phối hợp với Digoxin'''
question = '''Insuact 10mg được chỉ định dùng trong những trường hợp nào và liều dùng cụ thể ra sao?'''
conversation = [{"role": "system", "content": system_prompt }]
conversation.append({"role": "user", "content": template.format(context = context, question = question)})
text = tokenizer.apply_chat_template(
conversation,
tokenize=False,
add_generation_prompt=True)
model_inputs = tokenizer(text,return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2048,
temperature = 0.1,
#top_p=0.95,
#top_k=40,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
'''Trả lời:
Dựa trên ngữ cảnh cung cấp, Insuact 10mg được chỉ định dùng trong các trường hợp sau:
1. **Điều trị hỗ trợ tăng cholesterol máu nguyên phát và rối loạn lipid máu hỗn hợp**:
- **Liều dùng**: 10mg/lần/ngày.
- **Hiệu quả**: Sau 2 - 4 tuần sử dụng, bệnh nhân sẽ thấy hiệu quả của thuốc.
- **Lưu ý**: Thuốc cần được sử dụng duy trì trong thời gian dài để có hiệu quả.
2. **Điều trị hỗ trợ tăng cholesterol trong máu có tính gia đình đồng hợp tử**:
- **Liều dùng**: 10mg/lần/ngày (liều thường dùng) và tối đa 80mg/lần/ngày.
- **Lưu ý**: Liều lượng có thể được điều chỉnh tùy theo cơ địa, tiến triển bệnh và khả năng dung nạp thuốc của người bệnh.
3. **Rối loạn lipid máu nghiêm trọng ở trẻ từ 10 - 17 tuổi**:
- **Liều dùng**: 10mg/lần/ngày, sau đó có thể tăng lên 20mg/lần/ngày tùy theo tình trạng bệnh.
- **Thời gian điều chỉnh liều**: Thời gian điều chỉnh liều tối thiểu là 4 tuần.
**Lưu ý chung**:
- Thuốc được dùng theo đường uống, uống khi bụng đói hoặc no đều được, có thể uống vào bất cứ lúc nào trong ngày.
- Không dùng thuốc Insuact 10mg với người bị quá mẫn với thành phần của thuốc, người có bệnh gan hoạt động hoặc tăng transaminase huyết thanh vô căn kéo dài, phụ nữ đang mang thai hoặc nuôi con cho bú, phụ nữ đang có ý định mang thai.
- Cần kiểm tra chức năng gan trước và trong quá trình điều trị.
'''
```
#### 2. Khả năng chống nhiều
```python
# ví dụ
context = '''- Ngữ cảnh 1: . Và dù nguyên nhân thế nào, thì việc đánh người khác đều không thể chấp nhận, không ai có quyền xâm phạm thân thể của người khác, nhất là đánh những đứa trẻ là bạn của con cái mình. Lựa chọn kể với cha mẹ, người lớn về các mâu thuẫn học đường, là quyết định rất đúng của các em. Nhưng người lớn, đặc biệt những ông bố, bà mẹ cần ứng xử ra sao trước xung đột này của các con, thưa bà? Đứng ngoài mâu thuẫn bằng sự khách quan và trách nhiệm nhất có thể. Điều này giúp chúng ta đủ bình tĩnh để làm việc với tất cả các bên liên quan, từ giáo viên, bạn của con, ban giám hiệu để tìm hiểu câu chuyện và tìm kiếm cách giải quyết tích cực, trên cơ sở phối hợp nhà trường. Người lớn không thể chỉ nghe một tai và đặc biệt không nên tự xử. Phụ huynh, kể cả học sinh tự xử các vấn đề học đường là điều rất nguy hiểm và cho thấy sự coi thường pháp luật . Vụ việc ở Tuyên Quang vừa rồi là ví dụ. Các em hoàn toàn có thể phản ứng bằng cách trình bày, gửi yêu cầu, kiến nghị lên nhà trường, nhờ phụ huynh làm việc với ban giám hiệu để có biện pháp giải quyết nếu cô giáo sai, không nên đồng loạt dồn cô giáo vào tường một cách bạo lực và trái đạo đức, tôn ti trật tự như vậy. Ngoài ra, chúng ta cũng có rất nhiều cơ quan chức năng bảo vệ phụ huynh và con em, với những quyền về khiếu nại, tố cáo. Chúng ta nói nhiều về trường học an toàn. Trong những câu chuyện học sinh bị hành hung thế này, có lẽ cũng cần làm rõ vai trò, trách nhiệm của nhà trường? TPHCM và nhiều địa phương đang xây dựng môi trường trường học hạnh phúc, tiêu chí là yêu thương, an toàn, tôn trọng. Không chỉ phòng ngừa, nhà trường còn phải tích cực vào cuộc xử lý các mâu thuẫn học đường, hạn chế tối đa nguy cơ mất an toàn cho học sinh, giáo viên. Đặc biệt, giải quyết câu chuyện bạo lực học đường phải triệt để, tuyệt đối không nửa vời vì nửa vời sẽ tiềm ẩn nguy cơ rất lớn dẫn đến những vụ việc tương tự, với mức độ nghiêm trọng hơn. Vụ việc em M. ở Nha Trang tự vẫn với lá thư tuyệt mệnh bị đổ oan đầu tháng 10 vừa qua là một ví dụ về giải quyết không triệt để. Việc xây dựng trường học hạnh phúc nếu triển khai “đến nơi đến chốn”, sẽ góp phần rất lớn cải thiện tình trạng bạo lực học đường, tạo môi trường sống và học tập bình an cho các con. Từ nhiều sự vụ học sinh bạo hành lẫn nhau, giáo viên bạo hành học sinh, phụ huynh hành hung giáo viên và bạn của con. Tam giác phối hợp bảo vệ học sinh là nhà trường - gia đình - xã hội phải chăng đang có một lỗ hổng lớn, thưa bà? Câu chuyện này có liên quan đến niềm tin của phụ huynh với nhà trường. Tại sao phụ huynh lại chọn cách tự xử? Chúng ta cũng cần phải xem lại cách giải quyết vấn đề của nhà trường đã rốt ráo chưa, coi trọng lợi ích của tất cả các bên liên quan chưa hay chỉ đang xoa dịu? Người ta chỉ tìm đến nhau khi có niềm tin vào nhau. Thực trạng phụ huynh chọn cách chuyển trường cho con cũng nói lên điều này. Đây là cách chạy trốn của phụ huynh với mong muốn con được an toàn, hạnh phúc hơn ở môi trường mới. Xây dựng niềm tin cho phụ huynh, xã hội cần được chú trọng và với mỗi một trường hợp phụ huynh yêu cầu chuyển trường cho con - đang rất phổ biến - nhà trường cần xét kỹ các nguyên nhân và hóa giải. Xin bà cho biết đâu là giải pháp căn cơ cho tất cả những câu chuyện bạo lực nói trên? Để trẻ không là nạn nhân của bạo lực học đường, phụ huynh cần đồng hành và giúp con có sự hiểu biết, ý thức trước vấn đề này. Dạy con kỹ năng giao tiếp, quản lý cảm xúc rất quan trọng và điều này không thể chỉ dựa vào những khóa học kỹ năng sống, mà là từ cách cư xử của người lớn, cha mẹ, thầy cô. Không có tấm gương nào tốt hơn cho con trẻ bằng ứng xử, hành vi của người lớn. Vì vậy, không thể đòi hỏi trẻ nói không với bạo lực học đường khi trong chính từng gia đình, xã hội, người lớn vẫn đối xử với nhau bằng bạo lực.
- Ngữ cảnh 2: Tại sao triều Thanh có rất nhiều thân vương nhưng chẳng có ai dám tạo phản? Không giống như những triều đại trước đó, triều Thanh dù có sự tranh giành ngai vàng khốc liệt giữa các hoàng tử nhưng lại chẳng bao giờ xảy ra thế cục các thân vương tạo phản. Chính vì 3 lý do lớn này đã khiến cho triều đại nhà Thanh khác hẳn triều đại nhà Đường và nhà Minh. Trong thời cổ đại, các vương công quý tộc để tranh giành vương vị của mình, giữa huynh đệ ruột thịt với nhau dường như đều xảy ra đấu đá, hãm hại lẫn nhau, coi nhau như kẻ thù không đội trời chung, có ta thì không có ngươi, có ngươi thì sẽ chẳng có ta, điều này hoàn toàn không phải là điều gì xa lạ. Vậy thì tại sao ngai vàng lại có sức hút lớn đến thế? Không chỉ là đàn ông khát khao quyền lực, mà quan trọng hơn là hoàng đế có thể có được hậu cung rộng lớn, trong hậu cung còn có vô số các mỹ nữ quốc sắc thiên hương. Nhiều phi tần như vậy, đương nhiên hoàng đế cũng sẽ có rất nhiều con cái, không tính đến con gái, chỉ riêng những vị hoàng tử, để có thể có được hoàng vị, họ tranh giành nhau bằng cả sinh mạng. Vậy thì ai là người được lựa chọn để thừa kế ngai vàng, ai mới có thể gánh được trọng trách trị vì đất nước? Đa phần đều theo tục lệ truyền cho con trai đích tôn (con trai do hoàng hậu sinh ra) hoặc con trai trưởng (con trai đầu tiên của hoàng đế). Cho dù tục lệ này có lịch sử lâu đời nhưng nó cũng có những khuyết điểm rất lớn, đó chính là nếu như năng lực và chí hướng của con trai đích tôn hoặc con trai trưởng không thể gánh vác được ngai vị, nếu để anh ta lên ngôi hoàng đế, vậy thì đất nước sẽ rơi vào cục diện suy vong. Còn có một khuyết điểm nữa đó chính là những người con trai có dã tâm lớn khác sẽ không phục việc con trai đích hoặc con trai trưởng kế thừa ngôi báu, họ sẽ khởi binh tạo phản cũng là chuyện rất dễ xảy ra. Ví dụ như trong thời Đường của Trung Quốc, Đường Cao Tổ Lý Uyên đem binh tiêu diệt nhà Tùy thối nát, đồng thời lập nên nhà Đường, vốn dĩ ông cũng dựa theo tục lệ lập con trai trưởng là Lý Kiến Thành làm Thái tử nhưng con trai thứ là Lý Thế Dân lại không phục với sự sắp xếp này. Vì năng lực của ông xuất chúng, văn võ song toàn, còn lập được không ít công lao to lớn trong cuộc chiến tranh tiêu diệt nhà Tùy cùng cha mình, đương nhiên không chịu thấp hơn kẻ khác một bậc. Thế nên đã phát động binh biến Huyền Vũ Môn, trong cuộc binh biến tạo phản này, đích thân ông đã giết chết huynh trưởng của mình, đồng thời ép cha mình là Lý Uyên phải truyền ngôi cho mình. Hay như trong thời nhà Minh của Trung Quốc, trước khi Chu Nguyên Chương chọn người lập làm Thái tử, con trai trưởng Chu Tiêu đã qua đời vì bệnh nặng, thế nên Chu Nguyên Chương đã lập cháu đích tôn của mình làm Thái tử kế thừa vương vị, nhưng em trai của Chu Tiêu là Chu Đệ lại không phục lựa chọn này của Chu Nguyên Chương. Theo lý mà nói thì sau khi anh trai Chu Tiêu qua đời, ông đã có tư cách thừa kế ngai vàng nhưng Chu Nguyên Chương nhất quyết không chọn ông mà lại chọn người cách thế hệ để truyền ngôi. Điều này khiến Chu Đệ với thế lực to lớn không thể nuốt nổi cục tức này, vì thế Chu Tiêu vừa qua đời thì ông đã vội vã khởi binh tạo phản, giết chết cháu trai ruột của mình rồi tự xưng vương. Vậy thì tại sao trong triều Thanh có rất nhiều thân vương như vậy mà lại chẳng có ai đứng ra tạo phản? Đầu tiên phải nói về bối cảnh xã hội trong thời kỳ này. Triều Thanh từ khi thành lập, cũng giống với những triều đại khác, đều có rất nhiều thân vương. Nếu người dân bình thường muốn làm hoàng đế, vậy thì đó là điều hoàn toàn không thể, nhưng đối với những vương công quý tộc trong hoàng thất mà nói, họ đương nhiên sẽ có rất nhiều cơ hội, đặc biệt là những thân vương nắm đại quyền quân sự , họ chính là mối đe dọa lớn nhất đối với nhà vua. Vì thế, các đời hoàng đế đều sẽ nghĩ đủ mọi cách để áp chế, kiểm soát họ, tránh việc họ khởi binh tạo phản. Triều Thanh có lịch sử hơn 300 năm, cũng đã cho ra đời vô số thân vương, đặc biệt là cuối thời Thanh, khi Trung Quốc rơi vào cảnh khốn khó, sau khi Từ Hy Thái Hậu cầm quyền thì thế cục này càng được thể hiện rõ rệt hơn. Nhưng cho dù là một người phụ nữ cầm quyền thì cũng chẳng có một vị thân vương hoàng tộc nào đứng ra tạo phản. Có 3 nguyên nhân sau: Thứ nhất, thân vương triều Thanh không thể nối ngôi, nếu muốn tiếp tục duy trì danh phận thân vương, vậy thì bắt buộc phải có được sự đồng ý của hoàng đế và phải lập được công lao cho đất nước. Thứ hai, triều đình tiến hành giám sát nghiêm ngặt đối với các thân vương, họ không hề có cơ hội để tạo phản. Thứ ba, các thân vương không thể giao thiệp quá sâu với các đại thần, quan lại khác, điều này cũng khiến các thân vương rơi vào cảnh bị cô lập, thế nên càng không có cơ hội để cấu kết với người khác hòng tạo phản. - Video: Ngắm sự kỳ vĩ và lộng lấy của Tử Cấm Thành từ trên cao. Nguồn: Sky Eye.
- Ngữ cảnh 3: . Cùng điều chỉnh với con là điều rất quan trọng bởi vì trẻ sẽ tự tin để tự đặt những giới hạn cho chính mình khi lớn lên”, TS Nguyễn Thị Thanh đưa ra lời khuyên. “Khi con mắc sai lầm, hãy giúp chúng tìm những cách khác tốt hơn. Đơn cử dùng hậu quả để dạy cho chúng bài học, điều đó tốt hơn rất nhiều việc xử phạt. Nếu cha mẹ chỉ biết trừng phạt, sẽ nhận được lời xin lỗi nhưng không thể giúp trẻ tỉnh ngộ. Bởi chúng chỉ biết được mình đã sai mà không biết sai ở chỗ nào và làm thế nào mới là đúng”
- Ngữ cảnh 4: . “MẤT ĐI CHA MẸ Ở TUỔI ĐẸP NHẤT CỦA NGƯỜI PHỤ NỮ CÀNG KHIẾN TÔI PHẢI MẠNH MẼ” - Làm con của nghệ sĩ Thanh Hiền, Đinh Y Nhung cảm nhận sợi dây liên kết giữa hai mẹ con thế nào? Má Thanh Hiền là người rất tuyệt vời. Hai má con hồi xưa từng làm phim truyền hình với nhau rồi, cho nên khi tái hợp thì không mấy bỡ ngỡ. Khi đối diễn, hai má con rất ăn ý, như người thân ruột thịt vậy đó. - Khi thể hiện những phân cảnh cảm động trong phim, có khi nào chị thấy nhớ mẹ không? Có chứ, nhất là ở những phân đoạn gia đình sum họp, tự nhiên mình bị buồn. Ai cũng muốn có cha, có mẹ, ai cũng muốn Tết được chạy về bên gia đình. Trong mười mấy, hai chục năm qua, Nhung bị chạnh lòng. Tuy nhiên, chỉ trong tích tắc, tôi tự trấn an rằng, mình đang quay phim, đang hóa thân vào nhân vật nên không thể xao lãng được. Mình là con người mà, cũng có lúc tâm trạng vui buồn bất chợt, nhưng Nhung luôn cố gắng lấy lại phong độ liền. - Mất ba mẹ từ sớm, không có chỗ dựa tinh thần, cô gái trẻ Đinh Y Nhung năm đó có nhận những lời mời gọi khiếm nhã không? Trước đây, Nhung không có bạn bè nhiều, chủ yếu chỉ lo đi học, đi làm để lo cho cuộc sống thôi. Nên Nhung không phải đón nhận những lời mời gọi nào hết. - Mất mát từ quá khứ có ảnh hưởng gì đến suy nghĩ về tương lai của chị sau này, ví dụ khi có con thì sẽ bù đắp, chăm sóc cho con nhiều hơn? Năm ba mẹ mất thì mình vẫn còn khá trẻ, thật ra cái tuổi đó là tuổi đẹp của người phụ nữ. Sau đó, tôi đi làm, rồi yêu đương và lập gia đình. Có rất nhiều thứ hối tiếc để nói về Nhung của thời điểm đó. Thứ nhất là mình chưa thành công, thứ hai là mình chưa trả hiếu cho cha mẹ, thứ ba là mình còn bấp bênh. Nhung lúc đó lì lợm lắm, không cho phép mình ngã, bằng mọi giá phải tiến về trước dù có hàng ngàn chông gai ngăn cản. Có lúc tôi bị người này cười, người kia mỉa, nhưng mà mình vẫn cố bước đi. Người ta có cười thì cũng không mang lại cho mình được gì, tôi chỉ biết làm hết khả năng để lo cho bản thân, lo cho em của mình. Hiện, con cái Nhung đã đi nước ngoài rồi. Bé đang học đại học về âm nhạc, còn em mình cũng đã lớn rồi. Đối với Nhung ngay lúc này thì không phải thành công hay hoàn hảo lắm, nhưng ít nhất là tôi đã cố gắng để tự chịu trách nhiệm với cuộc đời mình. Mất cha, mất mẹ, đối với một người hai mươi mấy tuổi thì điều cần nhất lúc đó là có được gia đình ở bên. Nhưng mình không có chỗ dựa tinh thần thì càng phải mạnh mẽ hơn nữa. Tôi tự gặm nhấm nỗi đau mất người thân trong một thời gian dài, có khi đến cả bạn bè cũng không hề biết. Một thời gian sau, bạn bè thời và mọi người mới biết. Còn người hâm mộ, đồng nghiệp trong nghề gần như không biết chuyện ba mẹ Nhung mất sớm, chỉ có vài người chơi thân với nhau biết thôi. Sau này, dần dần tâm lý dần ổn định thì mình mới bắt đầu chia sẻ. “CON ĐI DU HỌC, TÔI DẶN BÉ CÁI GÌ KHÔNG TỐT THÌ MÌNH BỎ QUA” - Đinh Y Nhung từng tiết lộ mình rất thân với con gái. Có vẻ như quyết định để con đi du học là không hề dễ dàng? Thật sự là không có ba mẹ nào muốn con mình đi xa, nhưng việc du học lại là quyết định của bé. Con Nhung bày tỏ muốn học đại học ở nước ngoài và muốn đi sớm để thực hiện ước mơ. Nhưng lúc đó con còn nhỏ quá, phải đợi đến năm con 17 tuổi thì Nhung mới quyết định cho bạn nhỏ đi. Con cái từ nhỏ ở với bố mẹ giờ lại đi xa thì tất nhiên người làm cha làm mẹ cùng phải thấy sốc, thấy buồn. Nhưng Nhung hoàn toàn tôn trọng quyết định của con về việc chọn ngành nghề và tương lai của mình. Ba mẹ sẽ đứng sau và là người đưa cho con những lời khuyên và chỉ có thể đồng hành cùng con tới một mốc thời gian nào đó. Về sau, con phải đi làm và tự có trách nhiệm với cuộc đời của mình. - Có con gái đang ở tuổi lớn lại xa bố mẹ và tiếp xúc một nền văn hóa phương Tây cởi mở, Đinh Y Nhung đã khuyên dạy và đồng hành với con như thế nào? Ngay khi ở Việt Nam, con gái Nhung đã được theo học trường quốc tế. Hai mẹ con cũng có rất nhiều dịp để tâm sự và chia sẻ với nhau. Ngay từ nhỏ, Nhung đã cho bé được tiếp xúc song song giữa hai nền văn hóa để con không bỡ ngỡ. Mình là người Việt nên đương nhiên vẫn dạy con theo văn hóa Á Đông là chủ yếu. Nhung vẫn luôn tạo điều kiện để con cảm nhận những nét đẹp trong nền văn hóa quê hương. Văn hóa phương Tây thì xa lạ hơn nhưng Nhung cũng khuyên con rằng điều gì hay thì mình học hỏi, cái gì không tốt thì mình nên bỏ qua. Tất nhiên mình không thể theo sát con, nhất là khi bé đang ở độ tuổi mới lớn, có nhiều sự hiếu kỳ. Tuy nhiên, Nhung cũng không quá lo lắng vì qua quá trình học tập ở các trường quốc tế, bé cùng đã được làm quen dần với văn hóa phương Tây. Bé muốn làm bạn với mẹ nên có nhiều thứ bé muốn hỏi, muốn tiếp thu thì hai mẹ con lại ngồi xuống chia sẻ, tâm sự với nhau. Nhung tin, con luôn tỉnh táo để đưa ra những quyết định cho bản thân mình. Nhung không dám nói trước, nhưng hiện tại con vẫn luôn biết nói cảm ơn, xin phép trước khi làm bất cứ điều gì nên mình vẫn rất tin tưởng con. - Chị nhận xét thế nào về tính cách của con gái? Phải chăng bé là phiên bản nhí của chị? Con gái Nhung có nhiều nét giống mẹ.
- Ngữ cảnh 5: . - Trong quá trình quay phim, má Hiền có tham gia đóng góp ý kiến cho dàn diễn viên trẻ không? Không phải má Hiền muốn làm thầy nhưng có những lúc cũng lên tiếng góp ý một vài điều. Những lúc như thế các bạn diễn viên trẻ cũng nghe theo. Phải giúp đỡ nhau như vậy mới có thể tạo ra được một tác phẩm hay. Chứ có nhiều diễn viên trẻ có lòng tự trọng cao, chỉ khi đạo diễn nói mới nghe thì không bao giờ có thể tiến bộ được. Má Hiền phải cảm thấy hạnh phúc mới đúng, càng ngày xung quanh càng có nhiều bạn bè, các mối quan hệ nhờ đó mà cũng ngày càng đông. Ngày xưa, khi tham gia là Mùi Ngò Gai chưa có ai biết nhưng sau khi phim phát sóng mọi người đã nhớ đến má. Hiện tại, má Hiền đã được đạo diễn, nhà sản xuất mời đóng phim đó đã là một niềm hạnh phúc. Đi ra đường hay đi khám bệnh, người ta cứ vây xung quanh quan tâm hỏi han khiến má cảm thấy rất vui lắm (cười). Cảm ơn nghệ sĩ Thanh Hiền đã nhận lời tham gia phỏng vấn với SAOstar. Chúc má có nhiều sức khỏe để tiếp tục làm nghề!'''
question = '''Tại sao các thân vương triều Thanh không dám tạo phản mặc dù có nhiều quyền lực và cơ hội?'''
'''Trả lời:
Các thân vương triều Thanh không dám tạo phản mặc dù có nhiều quyền lực và cơ hội vì có ba lý do chính:
1. **Không thể nối ngôi**: Để duy trì danh phận thân vương, họ phải có sự đồng ý của hoàng đế và phải lập được công lao cho đất nước. Điều này hạn chế cơ hội của họ để trở thành hoàng đế.
2. **Giám sát nghiêm ngặt**: Triều đình tiến hành giám sát nghiêm ngặt đối với các thân vương, không cho họ cơ hội để tạo phản.
3. **Bị cô lập**: Các thân vương không thể giao thiệp quá sâu với các đại thần, quan lại khác, điều này khiến họ bị cô lập và không có cơ hội cấu kết với người khác để tạo phản.'''
```
#### 3. Loại bỏ negative
```python
context = '''- Ngữ cảnh 1: Thái Bình hướng đến là trung tâm công nghiệp, năng lượng của vùng Với tiềm năng sẵn có, quy hoạch tỉnh Thái Bình thời kỳ 2021-2030, tầm nhìn đến năm 2050 xác định tỉnh sẽ phát triển công nghiệp theo hướng hiện đại, bền vững dựa trên nghiên cứu phát triển điện gió, điện khí, cân bằng lượng phát thải. Sáng 5/3, UBND tỉnh Thái Bình tổ chức Hội nghị công bố quy hoạch của tỉnh thời kỳ 2021-2030, tầm nhìn đến năm 2050 và xúc tiến đầu tư tỉnh Thái Bình. Phát biểu tại hội nghị, Phó Chủ tịch Thường trực UBND tỉnh Nguyễn Quang Hưng cho biết: Mục tiêu của quy hoạch là đến năm 2030, Thái Bình trở thành địa phương thuộc nhóm phát triển khá và là một trong những trung tâm phát triển công nghiệp của vùng Đồng bằng sông Hồng, có cơ cấu kinh tế hiện đại với công nghiệp là động lực chủ yếu cho tăng trưởng để Thái Bình phát triển nhanh, toàn diện và bền vững. Đến năm 2050, Thái Bình là tỉnh phát triển của vùng Đồng bằng sông Hồng, tăng trưởng kinh tế dựa trên nền tảng khoa học công nghệ, đổi mới sáng tạo và các ngành kinh tế trụ cột có sức cạnh tranh cao. Quy hoạch tỉnh đã xác định 4 trụ cột tăng trưởng, 3 khâu đột phá, 4 không gian kinh tế - xã hội, 3 hành lang kinh tế, định hướng phát triển các ngành và lĩnh vực và 6 nhiệm vụ trọng tâm. Quy hoạch tỉnh cũng có nhiều điểm mới, đột phá như mở ra không gian phát triển mới thông qua hoạt động “lấn biển”, tạo quỹ đất cho các hoạt động chức năng, hình thành không gian công nghiệp - đô thị - dịch vụ. Về hạ tầng giao thông, Thái Bình sẽ đầu tư 3 tuyến cao tốc là cao tốc Ninh Bình - Hải Phòng (CT.08), đường vành đai 5 - Hà Nội (CT.39) và tuyến CT.16 kết nối Khu kinh tế với thành phố Thái Bình và vùng kinh tế phía Tây Bắc Thủ đô. Tỉnh cũng sẽ đầu tư 101km đường sắt, khổ đường dự kiến rộng 1.435 mm và sân bay chuyên dụng nằm ở ven biển Thái Bình. Về phát triển kinh tế, quy hoạch tỉnh Thái Bình xác định tỉnh sẽ phát triển công nghiệp theo hướng hiện đại, công nghệ tiên tiến, giá trị gia tăng cao, tham gia sâu, toàn diện vào mạng lưới sản xuất, chuỗi giá trị toàn cầu, phát huy các tiềm năng, thế mạnh để đưa Thái Bình trở thành một trong những trung tâm phát triển công nghiệp, năng lượng của vùng Đồng bằng sông Hồng. Tỉnh khuyến khích đầu tư phát triển các ngành có thế mạnh và có thể tạo đột phá như năng lượng, cơ khí chế biến, chế tạo, công nghiệp công nghệ cao, điện - điện tử, chế biến sản phẩm nông, lâm nghiệp và thủy sản… Đồng thời, tập trung nghiên cứu phát triển điện gió, điện khí để tạo nguồn điện sạch và cân bằng lượng phát thải, nghiên cứu đầu tư xây dựng nhà máy chế biến Condensate, chuẩn bị mọi điều kiện để xây dựng và đưa vào vận hành Nhà máy nhiệt điện LNG Thái Bình. Về nông nghiệp, tỉnh Thái Bình vẫn xác định đây là \"trụ cột quan trọng\" trong phát triển kinh tế của tỉnh, góp phần bảo đảm an ninh lương thực quốc gia, hướng tới trở thành trung tâm sản xuất nông nghiệp hàng đầu của Đồng bằng sông Hồng. Phát biểu tại hội nghị, Phó Thủ tướng Chính phủ Trần Lưu Quang đánh giá Thái Bình có 4 tiềm năng, lợi thế lớn để có thể có sự bứt phá trong thời gian tới như vị trí địa lý và tiếp cận đất đai thuận lợi; từng là địa phương đi đầu trong xây dựng nông thôn mới bài bản và nghiêm túc, nhận được sự quan tâm của nhiều thế hệ lãnh đạo Đảng, Nhà nước và có nhiều doanh nhân người Thái Bình và luôn hướng về quê hương; có sự đoàn kết, thống nhất, trước hết là trong tập thể lãnh đạo. Về vị trí địa lý và tiếp cận đất đai, Phó Thủ tướng cho rằng trong tương lai, khi Luật Đất đai có hiệu lực, Thái Bình sẽ có nhiều điều kiện lấn biển để triển khai các dự án khu đô thị, khu công nghiệp thân thiện với môi trường. Đối với nông nghiệp, Phó Thủ tướng nhấn mạnh về lâu dài Thái Bình có thể ghi điểm từ phát triển công nghiệp nhưng trước mắt, đặc biệt trong lúc khó khăn thì nông nghiệp vẫn là nền tảng rất quý giá. Mặt khác, ứng dụng của công nghệ cao trong sản xuất nông nghiệp sẽ rút ngắn thời gian làm đồng của người nông dân, tạo điều kiện để Thái Bình huy động nguồn nhân lực trong nông nghiệp sang phát triển các ngành công nghiệp và dịch vụ, một lợi thế mà không phải địa phương nào cũng có được như Thái Bình. Bên cạnh những lợi thế trên, lãnh đạo Chính phủ chỉ ra một số khó khăn mà tỉnh phải đối mặt như Thái Bình đã sử dụng hết 1.600 ha chỉ tiêu đất công nghiệp trong giai đoạn này, đòi hỏi phải có phương án giải quyết thấu đáo trong thời gian tới để tỉnh tiếp tục phát triển công nghiệp. Đồng thời, Thái Bình cũng phải cạnh tranh với những địa phương như Hải Phòng, Quảng Ninh trong thu hút FDI trong khi phát triển cơ sở hạ tầng chưa theo kịp mong muốn. Do vậy, khi triển khai quy hoạch tỉnh, Phó Thủ tướng nhắn nhủ tới địa phương 8 chữ: Tuân thủ, linh hoạt, đồng bộ và thấu hiểu. Đồng thời, tỉnh cũng phải \"linh hoạt\" trong tổ chức thực hiện, trong trường hợp cá biệt cụ thể, điều chỉnh mục tiêu cho phù hợp. Sáng cùng ngày, Phó Thủ tướng Trần Lưu Quang đã dự Lễ khởi công dự án Nhà máy Pegavision Việt Nam tại khu công nghiệp Liên Hà Thái, huyện Thái Thụy, tỉnh Thái Bình
- Ngữ cảnh 2: Bình Định được định hướng là trung tâm khoa học, công nghệ đổi mới sáng tạo Tỉnh Bình Định được định hướng phát triển ngành công nghiệp phát triển theo hướng hiện đại, quy mô lớn, trở thành một trong những trung tâm công nghiệp chế biến chế tạo và công nghệ cao của vùng Bắc Trung Bộ và duyên hải Trung Bộ. Theo Quy hoạch tỉnh Bình Định thời kỳ 2021 - 2030, tầm nhìn đến năm 2050 vừa được Thủ tướng Chính phủ phê duyệt, tỉnh Bình Định được định hướng phát triển ngành công nghiệp phát triển theo hướng hiện đại, quy mô lớn, trở thành một trong những trung tâm công nghiệp chế biến chế tạo và công nghệ cao của vùng Bắc Trung Bộ và duyên hải Trung Bộ. Ngành công nghiệp tăng trưởng nhanh, bền vững, hướng tới tăng trưởng xanh, kinh tế tuần hoàn là trụ cột để phát triển và chuyển dịch cơ cấu kinh tế của tỉnh. Ngành chế biến, chế tạo công nghệ cao (dịch chuyển ngành công nghiệp chế biến, chế tạo sang lĩnh vực sản xuất có giá trị gia tăng cao như: chế biến sâu nông - thủy - hải sản, linh kiện điện tử, bán dẫn, dược phẩm), công nghệ thông tin, trí tuệ nhân tạo trở thành một trong những lĩnh vực đột phá, góp phần đưa tỉnh Bình Định trở thành một trung tâm khoa học, công nghệ đổi mới sáng tạo của vùng và cả nước. Quy hoạch tỉnh Bình Định thời kỳ 2021 - 2030, tầm nhìn đến năm 2050 đặt ra yêu cầu tỉnh này phải chú trọng thu hút đầu tư phát triển năng lượng tái tạo, năng lượng sạch như điện gió ven bờ, điện gió ngoài khơi, điện mặt trời, điện sinh khối và nguồn năng lượng mới (hydrogen/amoniac xanh…); các dự án sản xuất thép quy mô lớn, đóng tàu, sản xuất thiết bị phụ trợ điện gió có công nghệ tiên tiến để nâng cấp xây dựng hạ tầng kỹ thuật sản xuất, thúc đẩy chuyển dịch kinh tế. Quy hoạch tỉnh Bình Định thời kỳ 2021 - 2030, tầm nhìn đến năm 2050 cũng đặt ra mục tiêu đến năm 2030, Bình Định trở thành tỉnh phát triển thuộc nhóm dẫn đầu vùng Bắc Trung Bộ và duyên hải Trung Bộ, là trung tâm công nghiệp chế biến, chế tạo, dịch vụ, du lịch và văn hóa phía Nam của vùng; trung tâm lớn của cả nước về phát triển kinh tế biển; trọng điểm du lịch quốc gia và quốc tế với hệ thống kết cấu hạ tầng kinh tế đồng bộ, hiện đại; kinh tế của tỉnh phát triển nhanh, bền vững và xanh dựa trên các trụ cột tăng trưởng công nghiệp, dịch vụ du lịch, cảng biển - logistics; nông nghiệp ứng dụng công nghệ cao; đô thị hóa; thực hiện thành công các mục tiêu chuyển đổi số, đổi mới sáng tạo, cải thiện mạnh mẽ môi trường đầu tư kinh doanh, trở thành điểm đến đầu tư hấp dẫn của các doanh nghiệp lớn trong và ngoài nước; chỉ số năng lực cạnh tranh cấp tỉnh thuộc nhóm cao của cả nước; kết cấu hạ tầng kinh tế - xã hội đồng bộ, hiện đại, hệ thống đô thị phát triển theo hướng đô thị thông minh, kết nối thuận tiện với các trung tâm kinh tế của vùng, cả nước và quốc tế.
- Ngữ cảnh 3: . Chủ tịch UBND tỉnh Quảng Ninh cho biết, tỉnh đặt mục tiêu hướng đến năm 2030 trở thành một tỉnh tiêu biểu của cả nước về mọi mặt; tỉnh kiểu mẫu giàu đẹp, văn minh, hiện đại, nâng cao đời sống mọi mặt của nhân dân; cực tăng trưởng của khu vực phía Bắc, một trong những trung tâm phát triển năng động, toàn diện; trung tâm du lịch quốc tế, trung tâm kinh tế biển, cửa ngõ của Vùng kinh tế trọng điểm Bắc Bộ và cả nước. Để đạt được những mục tiêu trên, tỉnh Quảng Ninh xác định sự đóng góp, quan tâm của cộng đồng doanh nghiệp, nhất là các doanh nghiệp hàng đầu Việt Nam “các sếu đầu đàn” là một trong những yếu tố then chốt quyết định. Do vậy, tỉnh Quảng Ninh rất mong nhận được sự quan tâm, nghiên cứu đầu tư hợp tác của các Doanh nghiệp hàng đầu Việt Nam trong thời gian tới, nhất là trong việc đầu tư các dự án có hàm lượng công nghệ cao, công nghệ tiên tiến, quản trị hiện đại, giá trị gia tăng cao, có tác động lan tỏa. Tỉnh Quảng Ninh cam kết tạo điều kiện thuận lợi nhất cho doanh nghiệp phát triển hơn nữa khi đầu tư kinh doanh trên địa bàn tỉnh; cam kết đồng hành, lắng nghe tiếng nói của cộng đồng doanh nghiệp, các nhà đầu tư; cùng trăn trở, trách nhiệm, giải quyết thấu đáo, vào cuộc thực chất, hiệu quả đối với từng khó khăn, vướng mắc với mục tiêu tăng cường niềm tin và nâng cao sự hài lòng của cá nhân, tổ chức, doanh nghiệp là thước đo đánh giá chất lượng phục vụ, chất lượng điều hành của cơ quan hành chính nhà nước từ cấp tỉnh đến các cấp cơ sở. Tỉnh Quảng Ninh sẽ triển khai một cách hiệu quả nhất Quy hoạch tỉnh, quy hoạch các địa phương; chuẩn bị mặt bằng sạch; quỹ đất tái định cư; đảm bảo nguồn cung điện, nước và viễn thông theo yêu cầu; xây dựng các chính sách đột phá để thu hút nguồn nhân lực chất lượng cao thông qua việc cải thiện nhà ở và cơ sở văn hóa để đảm bảo đời sống vật chất và tinh thần cho người lao động. Đồng thời bảo vệ quyền và lợi ích chính đáng, hợp pháp của nhà đầu tư, doanh nghiệp vào tỉnh; bảo đảm hài hòa lợi ích giữa nhà nước, nhà đầu tư, người lao động và người dân.'''
question = '''Theo quy hoạch tỉnh Tây Ninh thời kỳ 2021 - 2030, tầm nhìn đến năm 2050, tỉnh sẽ tập trung phát triển công nghiệp và dịch vụ du lịch. Trong bối cảnh cạnh tranh với các tỉnh lân cận, yếu tố nào được coi là quan trọng nhất để Tây Ninh có thể thu hút đầu tư và phát triển nhanh, toàn diện và bền vững?'''
'''Trả lời:
Trong ngữ cảnh được cung cấp, không có thông tin về quy hoạch tỉnh Tây Ninh thời kỳ 2021 - 2030, tầm nhìn đến năm 2050. Do đó, không có câu trả lời chính xác dựa trên các thông tin đã cung cấp. Nếu bạn có thêm thông tin về quy hoạch tỉnh Tây Ninh, vui lòng cung cấp để tôi có thể trả lời câu hỏi một cách chính xác và đầy đủ.
'''
```
#### 4. Tích hợp thông tin
```python
context = '''- Ngữ cảnh 1: 43/2020/nđ-cp Điều 3. Chế độ, chính sách đối với người tham gia thi hành án tử hình\n1. Người tham gia Đội thi hành án tử hình được hưởng chế độ bồi dưỡng bằng ba lần mức lương cơ sở khi thi hành án tử hình đối với 01 người và nghỉ dưỡng 10 ngày theo quy định chung về chế độ nghỉ dưỡng đối với cán bộ, chiến sĩ Công an nhân dân, Quân đội nhân dân.\n2. Người tham gia Hội đồng thi hành án tử hình, cán bộ quản giáo, người ghi âm, ghi hình, chụp ảnh, phiên dịch, thực hiện lăn tay người bị thi hành án tử hình, khâm liệm, mai táng tử thi được hưởng chế độ bồi dưỡng bằng một lần mức lương cơ sở khi thi hành án tử hình đối với 01 người.\n3. Người tham gia bảo đảm an ninh, trật tự; đại diện Ủy ban nhân dân cấp xã; Điều tra viên được hưởng chế độ bồi dưỡng bằng một phần hai mức lương cơ sở khi thi hành án tử hình đối với 01 người.
- Ngữ cảnh 2: 53/2010/qh12 Điều 60. Giải quyết việc xin nhận tử thi, hài cốt của người bị thi hành án tử hình\n1. Việc giải quyết nhận tử thi được thực hiện như sau:\na) Trước khi thi hành án tử hình, thân nhân hoặc người đại diện hợp pháp của người chấp hành án được làm đơn có xác nhận của Ủy ban nhân dân cấp xã nơi cư trú gửi Chánh án Tòa án đã xét xử sơ thẩm đề nghị giải quyết cho nhận tử thi của người chấp hành án để an táng; trường hợp người chấp hành án là người nước ngoài thì đơn phải có xác nhận của cơ quan có thẩm quyền hoặc cơ quan đại diện ngoại giao tại Việt Nam của nước mà người chấp hành án mang quốc tịch và phải được dịch ra tiếng Việt. Đơn phải ghi rõ họ tên, địa chỉ người nhận tử thi, quan hệ với người chấp hành án; cam kết bảo đảm yêu cầu về an ninh, trật tự, vệ sinh môi trường và tự chịu chi phí;\nb) Chánh án Tòa án đã xét xử sơ thẩm thông báo bằng văn bản cho người có đơn đề nghị về việc cho nhận tử thi hoặc không cho nhận tử thi khi có căn cứ cho rằng việc nhận tử thi ảnh hưởng đến an ninh, trật tự, vệ sinh môi trường. Trường hợp người chấp hành án là người nước ngoài, thì Chánh án Tòa án đã xét xử sơ thẩm có trách nhiệm thông báo bằng văn bản cho Bộ Ngoại giao Việt Nam để thông báo cho cơ quan có thẩm quyền hoặc cơ quan đại diện ngoại giao tại Việt Nam của nước mà người đó mang quốc tịch;\nc) Cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu có trách nhiệm thông báo cho người có đơn đề nghị ngay sau khi thi hành án để đến nhận tử thi về an táng. Việc giao nhận tử thi phải được thực hiện trong thời hạn 24 giờ kể từ khi thông báo và phải lập biên bản, có chữ ký của các bên giao, nhận; hết thời hạn này mà người có đơn đề nghị không đến nhận tử thi thì cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu có trách nhiệm an táng.\n2. Trường hợp không được nhận tử thi hoặc thân nhân của người bị thi hành án không có đơn đề nghị được nhận tử thi về an táng thì cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu tổ chức việc an táng. Sau 03 năm kể từ ngày thi hành án, thân nhân hoặc đại diện hợp pháp của người đã bị thi hành án được làm đơn có xác nhận của Ủy ban nhân dân cấp xã nơi cư trú đề nghị Cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu nơi đã thi hành án cho nhận hài cốt. Đơn đề nghị phải ghi rõ họ tên, địa chỉ người nhận hài cốt, quan hệ với người bị thi hành án; cam kết bảo đảm yêu cầu về an ninh, trật tự, vệ sinh môi trường và tự chịu chi phí. Trong thời hạn 07 ngày, kể từ ngày nhận được đơn, cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu có trách nhiệm xem xét, giải quyết.\nTrường hợp người bị thi hành án là người nước ngoài thì đơn đề nghị phải có xác nhận của cơ quan có thẩm quyền hoặc cơ quan đại diện ngoại giao tại Việt Nam của nước mà người bị thi hành án mang quốc tịch và phải được dịch ra tiếng Việt. Việc giải quyết cho nhận hài cốt do cơ quan quản lý thi hành án hình sự xem xét, quyết định.
- Ngữ cảnh 3: 53/2010/qh12 Điều 57. Chế độ quản lý giam giữ, ăn, ở, mặc, sinh hoạt, gửi và nhận thư, nhận đồ vật, tiền mặt, gặp thân nhân, chăm sóc y tế\nChế độ quản lý giam giữ, ăn, ở, mặc, sinh hoạt, gửi và nhận thư, nhận đồ vật, tiền mặt, gặp thân nhân, chăm sóc y tế đối với người bị kết án tử hình trong thời gian chờ thi hành án thực hiện theo quy định của pháp luật về tạm giam.
- Ngữ cảnh 4: 82/2011/nđ-cp Điều 9. Chi phí mai táng\nChi phí mai táng người bị thi hành án tử hình bao gồm: 01 quan tài bằng gỗ thường, 01 bộ quần áo thường, 04 m vải liệm, hương, nến, rượu, cồn để làm vệ sinh khi liệm tử thi và các chi phí mai táng khác.\nTrường hợp thân nhân hoặc người đại diện hợp pháp của người bị kết án tử hình được nhận tử thi về mai táng thì phải tự chịu chi phí đưa di chuyển tử thi và phải cam kết chấp hành đúng quy định của pháp luật về bảo đảm an ninh, trật tự.
- Ngữ cảnh 5: 82/2011/nđ-cp Điều 5. Chế độ, chính sách đối với người tham gia thi hành án tử hình\n1. Người tham gia Đội thi hành án tử hình và bác sĩ xác định tĩnh mạch được hưởng chế độ bồi dưỡng bằng hai lần mức lương tối thiểu chung cho mỗi lần thi hành án và được nghỉ dưỡng 10 ngày theo quy định chung về chế độ nghỉ dưỡng đối với cán bộ, chiến sĩ Công an nhân dân, Quân đội nhân dân.\n2. Người tham gia Hội đồng thi hành án tử hình, bác sĩ pháp y, cán bộ chuyên môn, người thực hiện lăn tay người bị thi hành án tử hình, khâm liệm, an táng tử thi được hưởng chế độ bồi dưỡng bằng một lần mức lương tối thiểu chung quy định cho mỗi lần thi hành án.\n3. Những người tham gia khác được hưởng chế độ bồi dưỡng bằng một phần hai mức lương tối thiểu cho mỗi lần thi hành án.'''
question = '''Tử tù chết sau khi tiêm thuốc độc mà không có thân nhân nhận xác thì được hỗ trợ mai táng như thế nào?'''
'''Trả lời:
Dựa trên ngữ cảnh 2 (53/2010/qh12 Điều 60), nếu tử tù chết sau khi tiêm thuốc độc mà không có thân nhân nhận xác, thì cơ quan thi hành án hình sự Công an cấp tỉnh hoặc cơ quan thi hành án hình sự cấp quân khu sẽ tổ chức việc an táng. Cụ thể:
1. **An táng**: Cơ quan thi hành án hình sự Công an cấp tỉnh hoặc cơ quan thi hành án hình sự cấp quân khu sẽ chịu trách nhiệm an táng tử tù nếu không có thân nhân hoặc người đại diện hợp pháp đề nghị nhận tử thi.
2. **Hài cốt sau 3 năm**: Sau 3 năm kể từ ngày thi hành án, nếu thân nhân hoặc đại diện hợp pháp của người đã bị thi hành án vẫn chưa đề nghị nhận hài cốt, họ có thể làm đơn đề nghị Cơ quan thi hành án hình sự Công an cấp tỉnh hoặc cơ quan thi hành án hình sự cấp quân khu nơi đã thi hành án cho nhận hài cốt. Đơn đề nghị phải ghi rõ họ tên, địa chỉ người nhận hài cốt, quan hệ với người bị thi hành án, cam kết bảo đảm yêu cầu về an ninh, trật tự, vệ sinh môi trường và tự chịu chi phí.
3. **Chi phí mai táng**: Theo ngữ cảnh 4 (82/2011/nđ-cp Điều 9), chi phí mai táng bao gồm:
- 01 quan tài bằng gỗ thường.
- 01 bộ quần áo thường.
- 04 m vải liệm.
- Hương, nến, rượu, cồn để làm vệ sinh khi liệm tử thi.
- Các chi phí mai táng khác.
Nếu thân nhân hoặc người đại diện hợp pháp đề nghị nhận tử thi về mai táng, họ phải tự chịu chi phí đưa di chuyển tử thi và cam kết chấp hành đúng quy định của pháp luật về bảo đảm an ninh, trật tự.
'''
```
- Ngữ cảnh 2 và ngữ cảnh 4 có chứa phần thông tin cho việc trả lời câu hỏi.
### 5.Xác định positive/negative
```python
system_prompt = "Bạn là một trợ lí Tiếng Việt nhiệt tình và trung thực. Hãy luôn trả lời một cách hữu ích nhất có thể."
template = '''Hãy xác định xem ngữ cảnh có chứa đầy đủ thông tin để trả lời câu hỏi hay không.
Chỉ cần đưa ra 1 trong 2 đáp án trong phần trả lời là "Có" hoặc "Không".
### Ngữ cảnh :
{context}
### Câu hỏi :
{question}
### Trả lời :'''
context = '''Công dụng thuốc Xelocapec Capecitabine là một hoạt chất gây độc chọn lọc với tế bào ung thư. Hoạt chất này có trong thuốc Xelocapec. Vậy thuốc Xelocapec có tác dụng gì và cần lưu ý những vấn đề nào khi điều trị bằng sản phẩm này? 1. Xelocapec là thuốc gì? Xelocapec chứa hoạt chất Capecitabine hàm lượng 500mg. Thuốc Xelocapec bào chế dạng viên nén bao phim và đóng gói mỗi hộp 3 vỉ x 10 viên. Xelocapec chứa hoạt chất Capecitabine là một dẫn chất Fluoropyrimidine carbamate với tác dụng gây độc chọn lọc với các tế bào ung thư . Mặc dù trên in vitro Capecitabine không cho thấy tác dụng độc tế bào nhưng trên in vivo, Xelocapec biến đổi liên tiếp thành chất gây độc tế bào là 5-fluorouracil (5-FU). Sự hình thành 5-FU tại khối u thông qua xúc tác một cách tối ưu của yếu tố tạo mạch liên quan là Thymidine phosphorylase, qua đó hạn chế tối đa mức độ ảnh hưởng đến nhu mô lành của 5-FU. 2. Thuốc Xelocapec có tác dụng gì? Thuốc Xelocapec được chỉ định điều trị đơn lẻ hoặc kết hợp với các liệu pháp điều trị ung thư. Xelocapec làm chậm hoặc ngăn chặn sự tăng trưởng của tế bào ung thư, do đó giảm kích thước khối u trong những trường hợp sau: Ung thư vú : Xelocapec phối hợp với Docetaxel được chỉ định điều trị ung thư vú thể tiến triển tại chỗ hoặc di căn sau khi đã thất bại với liệu pháp hóa trị; Ung thư đại trực tràng : Xelocapec được chỉ định hỗ trợ điều trị ung thư đại tràng sau phẫu thuật hoặc ung thư đại trực tràng di căn; Ung thư dạ dày : Xelocapec phối hợp với hợp chất platin được chỉ định điều trị khởi đầu cho những bệnh nhân ung thư dạ dày. Chống chỉ định của thuốc Xelocapec : Bệnh nhân quá mẫn cảm với Capecitabine hay các thành phần khác có trong Xelocapec ; Người có tiền sử gặp các phản ứng không mong muốn nghiêm trọng khi điều trị với Fluoropyrimidine; Người đang mang thai hoặc cho con bú; Suy thận nặng (độ thanh thải Creatinin <30mL/phút); Bệnh nhân đang điều trị ung thư với Sorivudin hoặc chất tương tự về mặt hóa học như Brivudin; Bệnh nhân thiếu hụt Dihydropyrimidin dehydrogenase; Bệnh nhân giảm số lượng bạch cầu hoặc tiểu cầu nặng; Suy gan nặng. 3. Liều dùng của thuốc Xelocapec Liều dùng của Xelocapec khi điều trị đơn lẻ: Ung thư đại trực tràng, ung thư vú: 1250mg/m2, uống 2 lần mỗi ngày trong thời gian 14 ngày, tiếp sau đó là 7 ngày ngưng thuốc. Liều Xelocapec trong điều trị phối hợp: Ung thư vú: Liều khởi đầu là 1250mg/m2, 2 lần uống mỗi ngày trong 2 tuần dùng phối hợp với Docetaxel, tiếp sau đó lá 1 tuần ngưng thuốc; Ung thư dạ dày, đại trực tràng: Liều khuyến cáo là 800-1000mg/m2/lần x 2 lần/ngày trong thời gian 2 tuần, sau đó 7 ngày ngưng thuốc hoặc 625mg/m2/lần x 2 lần mỗi ngày khi điều trị liên tục. Thuốc Xelocapec nên uống cùng với thức ăn, do đó thời điểm tốt nhất là trong vòng 30 phút sau bữa ăn. 4. Tác dụng phụ của thuốc Xelocapec Các triệu chứng bất thường như buồn nôn, nôn ói, giảm cảm giác ngon miệng, táo bón, cơ thể mệt mỏi, yếu sức, đau đầu, chóng mặt, khó ngủ có thể xảy ra trong thời gian dùng Xelocapec . Trong đó, tình trạng buồn nôn và nôn ói có thể nghiêm trọng nên đôi khi cần được bác sĩ chỉ định thuốc kiểm soát phù hợp. Tiêu chảy là một tác dụng phụ phổ biến khác của thuốc Xelocapec . Bệnh nhân cần uống nhiều nước khi điều trị bằng Xelocapec trừ khi bác sĩ có hướng dẫn khác. Nôn ói hoặc tiêu chảy kéo dài do thuốc Xelocapec có thể dẫn đến mất nước nghiêm trọng, vì vậy người bệnh hãy liên hệ ngay với bác sĩ nếu có các triệu chứng mất nước như giảm đi tiểu, khô miệng, tăng cảm giác khát nước hoặc chóng mặt. Tình trạng rụng tóc tạm thời xảy ra trong thời gian dùng thuốc Xelocapec và có thể hồi phục sau khi điều trị đã kết thúc. Một số bệnh nhân ghi nhận hiện tượng thay đổi móng tay tạm thời. Đối với nam giới và phụ nữ trong độ tuổi sinh đẻ, thuốc Xelocapec có thể ảnh hưởng đến khả năng có con của bệnh nhân. Bệnh nhân hãy tham khảo ý kiến bác sĩ để biết thêm chi tiết. Thuốc Xelocapec có thể làm giảm khả năng miễn dịch của cơ thể với các tác nhân nhiễm trùng, dẫn đến tăng nguy cơ mắc các bệnh nhiễm trùng nghiêm trọng (nhưng hiếm khi gây tử vong) hoặc làm cho bệnh nhiễm trùng hiện mắc nghiêm trọng hơn. Phản ứng dị ứng rất nghiêm trọng với thuốc Xelocapec rất hiếm khi xảy ra. Tuy nhiên, bệnh nhân hãy liên hệ với bác sĩ ngay lập tức nếu xuất hiện các triệu chứng của phản ứng dị ứng nghiêm trọng như phát ban, sưng ngứa mặt/lưỡi/họng, chóng mặt nghiêm trọng hoặc khó thở. 5. Tương tác thuốc của Xelocapec Hoạt chất Capecitabine trong thuốc Xelocapec có thể xảy ra tương tác thuốc nghiêm trọng với một số thuốc sau: Thuốc chống đông máu Coumarin: Trong một nghiên cứu tương tác lâm sàng, sau khi dùng Warfarin liều đơn 20mg kết hợp với Capecitabine làm tăng AUC của S-warfarin khoảng 57% và giá trị INR tăng 91%.'''
question = '''Tại sao Capecitabine trong Xelocapec không gây độc tế bào trên in vitro nhưng lại biến đổi thành 5-fluorouracil (5-FU) gây độc tế bào trên in vivo, và cơ chế nào giúp hạn chế ảnh hưởng đến nhu mô lành của 5-FU?'''
'''Trả lời: Có'''
```
**Developer**
Member: Nguyễn Nho Trung, Nguyễn Nhật Quang
## Contact
**Email**: [email protected]
**LinkedIn**: [Trung Nguyen Nho](https://www.linkedin.com/in/trung-nguyen-nho-604288227/)
**Facebook**: [Nguyễn Nho Trung](https://www.facebook.com/trung.nguyennho.568/)
## Support me:
Nếu bạn thấy tác phẩm này hữu ích và muốn hỗ trợ cho sự phát triển liên tục của nó, đây là một số cách bạn có thể giúp:
**Star the Repository**: Nếu bạn đánh giá cao tác phẩm này, vui lòng gắn sao cho nó. Sự hỗ trợ của bạn sẽ khuyến khích sự phát triển và cải tiến liên tục.
**Contribute**: Đóng góp luôn được hoan nghênh! Bạn có thể giúp bằng cách báo cáo sự cố, gửi yêu cầu kéo hoặc đề xuất các tính năng mới.
**Share**: Chia sẻ dự án này với đồng nghiệp, bạn bè hoặc cộng đồng của bạn. Càng nhiều người biết về nó, nó càng thu hút được nhiều phản hồi và đóng góp
**Buy me a coffee**: Nếu bạn muốn hỗ trợ tài chính, hãy cân nhắc donation. Bạn có thể donate qua:
- BIDV: 2131273046 - NGUYEN NHO TRUNG
## Citation
Làm ơn cite như sau:
```Plaintext
@misc{ViRAG-Gen,
title={ViRAG-Gen: Towards a specialized LLM for RAG task in Vietnamese language.}},
author={Nguyen Nho Trung, Nguyen Nhat Quang},
year={2024},
publisher={Huggingface},
}
```
|
[
"CHIA"
] |
RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2304.01373",
"arxiv:2101.00027",
"arxiv:2201.07311",
"endpoints_compatible",
"region:us"
] | 2024-11-03T13:18:18Z |
2024-11-03T13:22:23+00:00
| 68 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pythia-410m-deduped - GGUF
- Model creator: https://huggingface.co/EleutherAI/
- Original model: https://huggingface.co/EleutherAI/pythia-410m-deduped/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pythia-410m-deduped.Q2_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q2_K.gguf) | Q2_K | 0.16GB |
| [pythia-410m-deduped.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q3_K_S.gguf) | Q3_K_S | 0.18GB |
| [pythia-410m-deduped.Q3_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q3_K.gguf) | Q3_K | 0.21GB |
| [pythia-410m-deduped.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q3_K_M.gguf) | Q3_K_M | 0.21GB |
| [pythia-410m-deduped.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q3_K_L.gguf) | Q3_K_L | 0.22GB |
| [pythia-410m-deduped.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.IQ4_XS.gguf) | IQ4_XS | 0.22GB |
| [pythia-410m-deduped.Q4_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q4_0.gguf) | Q4_0 | 0.23GB |
| [pythia-410m-deduped.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.IQ4_NL.gguf) | IQ4_NL | 0.23GB |
| [pythia-410m-deduped.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q4_K_S.gguf) | Q4_K_S | 0.23GB |
| [pythia-410m-deduped.Q4_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q4_K.gguf) | Q4_K | 0.25GB |
| [pythia-410m-deduped.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q4_K_M.gguf) | Q4_K_M | 0.25GB |
| [pythia-410m-deduped.Q4_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q4_1.gguf) | Q4_1 | 0.25GB |
| [pythia-410m-deduped.Q5_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q5_0.gguf) | Q5_0 | 0.27GB |
| [pythia-410m-deduped.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q5_K_S.gguf) | Q5_K_S | 0.27GB |
| [pythia-410m-deduped.Q5_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q5_K.gguf) | Q5_K | 0.28GB |
| [pythia-410m-deduped.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q5_K_M.gguf) | Q5_K_M | 0.28GB |
| [pythia-410m-deduped.Q5_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q5_1.gguf) | Q5_1 | 0.29GB |
| [pythia-410m-deduped.Q6_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q6_K.gguf) | Q6_K | 0.31GB |
| [pythia-410m-deduped.Q8_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-gguf/blob/main/pythia-410m-deduped.Q8_0.gguf) | Q8_0 | 0.4GB |
Original model description:
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research [(see paper)](https://arxiv.org/pdf/2304.01373.pdf).
It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. We also provide 154 intermediate
checkpoints per model, hosted on Hugging Face as branches.
The Pythia model suite was designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
<details>
<summary style="font-weight:600">Details on previous early release and naming convention.</summary>
Previously, we released an early version of the Pythia suite to the public.
However, we decided to retrain the model suite to address a few hyperparameter
discrepancies. This model card <a href="#changelog">lists the changes</a>;
see appendix B in the Pythia paper for further discussion. We found no
difference in benchmark performance between the two Pythia versions.
The old models are
[still available](https://huggingface.co/models?other=pythia_v0), but we
suggest the retrained suite if you are just starting to use Pythia.<br>
**This is the current release.**
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
</details>
<br>
# Pythia-410M-deduped
## Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
[See paper](https://arxiv.org/pdf/2304.01373.pdf) for more evals and implementation
details.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 2M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 2M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 2M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
## Uses and Limitations
### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. We also provide
154 checkpoints per model: initial `step0`, 10 log-spaced checkpoints
`step{1,2,4...512}`, and 143 evenly-spaced checkpoints from `step1000` to
`step143000`. These checkpoints are hosted on Hugging Face as branches. Note
that branch `143000` corresponds exactly to the model checkpoint on the `main`
branch of each model.
You may also further fine-tune and adapt Pythia-410M-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-410M-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions. For example,
the model may generate harmful or offensive text. Please evaluate the risks
associated with your particular use case.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-410M-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means XNPythia-410M-dedupedAME will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “follow” human instructions.
### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token used by the model need not produce the
most “accurate” text. Never rely on Pythia-410M-deduped to produce factually accurate
output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-410M-deduped may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-410M-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
## Training
### Training data
Pythia-410M-deduped was trained on the Pile **after the dataset has been globally
deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training,
from `step1000` to `step143000` (which is the same as `main`). In addition, we
also provide frequent early checkpoints: `step0` and `step{1,2,4...512}`.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for 143000 steps at a batch size
of 2M (2,097,152 tokens).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
## Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json/).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai_v1.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa_v1.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande_v1.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Easy Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_easy_v1.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq_v1.png" style="width:auto"/>
</details>
## Changelog
This section compares differences between previously released
[Pythia v0](https://huggingface.co/models?other=pythia_v0) and the current
models. See Appendix B of the Pythia paper for further discussion of these
changes and the motivation behind them. We found that retraining Pythia had no
impact on benchmark performance.
- All model sizes are now trained with uniform batch size of 2M tokens.
Previously, the models of size 160M, 410M, and 1.4B parameters were trained
with batch sizes of 4M tokens.
- We added checkpoints at initialization (step 0) and steps {1,2,4,8,16,32,64,
128,256,512} in addition to every 1000 training steps.
- Flash Attention was used in the new retrained suite.
- We remedied a minor inconsistency that existed in the original suite: all
models of size 2.8B parameters or smaller had a learning rate (LR) schedule
which decayed to a minimum LR of 10% the starting LR rate, but the 6.9B and
12B models all used an LR schedule which decayed to a minimum LR of 0. In
the redone training runs, we rectified this inconsistency: all models now were
trained with LR decaying to a minimum of 0.1× their maximum LR.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
[
"SCIQ"
] |
featherless-ai/Qwerky-QwQ-32B
|
featherless-ai
|
text-generation
|
[
"transformers",
"safetensors",
"rwkv6qwen2",
"text-generation",
"conversational",
"custom_code",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | 2025-03-08T20:29:20Z |
2025-03-17T17:46:45+00:00
| 68 | 2 |
---
library_name: transformers
license: apache-2.0
thumbnail: https://cdn-uploads.huggingface.co/production/uploads/633e85093a17ab61de8d9073/OufWyNMKYRozfC8j8S-M8.png
---

- Try out the model on [](https://featherless.ai/models/featherless-ai/Qwerky-QwQ-32B)
- Model details from our blog post here! [](https://substack.recursal.ai/p/qwerky-72b-and-32b-training-large)
Benchmarks is as follows for both Qwerky-QwQ-32B and Qwerky-72B models:
| Tasks | Metric | Qwerky-QwQ-32B | Qwen/QwQ-32B | Qwerky-72B | Qwen2.5-72B-Instruct |
|:---:|:---:|:---:|:---:|:---:|:---:|
| arc_challenge | acc_norm | **0.5640** | 0.5563 | **0.6382** | 0.6323 |
| arc_easy | acc_norm | 0.7837 | **0.7866** | **0.8443** | 0.8329 |
| hellaswag | acc_norm | 0.8303 | **0.8407** | 0.8573 | **0.8736** |
| lambada_openai | acc | 0.6621 | **0.6683** | **0.7539** | 0.7506 |
| piqa | acc | **0.8036** | 0.7976 | 0.8248 | **0.8357** |
| sciq | acc | **0.9630** | **0.9630** | 0.9670 | **0.9740** |
| winogrande | acc | **0.7324** | 0.7048 | **0.7956** | 0.7632 |
| mmlu | acc | 0.7431 | **0.7985** | 0.7746 | **0.8338** |
> *Note: All benchmarks except MMLU are 0-shot and Version 1. For MMLU, it's Version 2.*
## Running with `transformers`
Since this model is not on transformers at the moment you will have to enable remote code with the following line.
```py
# ...
model = AutoModelForCausalLM.from_pretrained("featherless-ai/Qwerky-QwQ-32B", trust_remote_code=True)
# ...
```
Other than enabling remote code, you may run the model like a regular model with transformers like so.
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "featherless-ai/Qwerky-72B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = """There is a very famous song that I recall by the singer's surname as Astley.
I can't remember the name or the youtube URL that people use to link as an example url.
What's song name?"""
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=512)
generated_ids = [
output_ids[len(input_ids) :]
for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Model notes
Linear models offer a promising approach to significantly reduce computational costs at scale, particularly for large context lengths. Enabling a >1000x improvement in inference costs, enabling o1 inference time thinking and wider AI accessibility.
As demonstrated with our Qwerky-72B-Preview and prior models such as QRWKV6-32B Instruct Preview, we have successfully converted Qwen 2.5 QwQ 32B into a RWKV variant without requiring a pretrain on the base model or retraining the model from scratch. Enabling us to test and validate the more efficient RWKV Linear attention with a much smaller budget. Since our preview, we have continued to refine our technique and managed to improve the model over the preview model iteration.
As with our previous models, the model's inherent knowledge and dataset training are inherited from its "parent" model. Consequently, unlike previous RWKV models trained on over 100+ languages, the QRWKV model is limited to approximately 30 languages supported by the Qwen line of models.
You may find our details of the process from our previous release, [here](https://huggingface.co/recursal/QRWKV6-32B-Instruct-Preview-v0.1).
|
[
"SCIQ"
] |
BigSalmon/InformalToFormalLincoln86Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-10-23T01:57:39Z |
2022-10-23T04:48:33+00:00
| 67 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln86Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln86Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
|
[
"BEAR"
] |
BigSalmon/InformalToFormalLincoln94Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-12-27T00:35:04Z |
2022-12-27T01:27:04+00:00
| 67 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln94Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln94Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
```
Q: What is whistleblower protection?
A: Whistleblower protection is a form of legal immunity granted to employees who expose the unethical practices of their employer.
Q: Why are whistleblower protections important?
A: Absent whistleblower protections, employees would be deterred from exposing their employer’s wrongdoing for fear of retribution.
Q: Why would an employer engage in retribution?
A: An employer who has acted unethically stands to suffer severe financial and reputational damage were their transgressions to become public. To safeguard themselves from these consequences, they might seek to dissuade employees from exposing their wrongdoing.
```
```
original: the meritocratic nature of crowdfunding [MASK] into their vision's viability.
infill: the meritocratic nature of crowdfunding [gives investors idea of how successful] -> ( offers entrepreneurs a window ) into their vision's viability.
```
```
Leadership | Lecture 17: Worker Morale
What Workers Look for in Companies:
• Benefits
o Tuition reimbursement
o Paid parental leave
o 401K matching
o Profit sharing
o Pension plans
o Free meals
• Social responsibility
o Environmental stewardship
o Charitable contributions
o Diversity
• Work-life balance
o Telecommuting
o Paid holidays and vacation
o Casual dress
• Growth opportunities
• Job security
• Competitive compensation
• Recognition
o Open-door policies
o Whistleblower protection
o Employee-of-the-month awards
o Positive performance reviews
o Bonuses
```
```
description: business
keywords: for-profit, fiduciary duty, monopolistic, bottom line, return on investment, short-term thinking, capital-intensive, self-interested, risk-taking, fiduciary duty, merger, speculation, profiteering, oversight, capitalism, diversification
```
```
3. In this task, you are given a company name and you need to find its industry.
McDonalds -- Restaurant
Facebook -- Social Network
IKEA -- Furniture
American Express -- Credit Services
Nokia -- Telecom
Nintendo -- Entertainment
4. In this task, you are given a Month and you need to convert it to its corresponding season
April -- Spring
December -- Winter
July -- Summer
October -- Fall
February -- Winter
5. In this task, you are given a sentence with a missing word and you need to predict the correct word.
Managers should set an _____ for their employees. -- example
Some people spend more than four _____ in the gym. -- hours
The police were on the _____ of arresting the suspect. -- verge
They were looking for _____ on how to solve the problem. -- guidance
What is the _____ of the coffee? -- price
6. In this task, you are given a paragraph and you need to reorder it to make it logical.
It was first proposed in 1987. The total length of the bridge is 1,828 meters. The idea of a bridge connects Hong Kong to Macau. -- The idea of bridge connecting Hong Kong and Macau was first proposed in 1987. The total length of the bridge is 1,828 meters.
It is a movie about a brave and noble policeman. The film was produced by Americans. They were Kevin Lima and Chris Buck. They are directors. The movie is called Tarzan. -- Produced by Americans Kevin Lima and Chris Buck, Tarzan is a movie about a brave and noble policeman.
It was first discovered in the mountains of India. The active ingredients in this plant can stimulate hair growth. The plant is called "Hair Plus." -- First discovered in the mountains of India, Hair Plus is a plant whose active ingredients can stimulate hair growth.
```
```
trivia: What is the population of South Korea?
response: 51 million.
***
trivia: What is the minimum voting age in the US?
response: 18.
***
trivia: What are the first ten amendments of the US constitution called?
response: Bill of Rights.
```
```
ideas: in modern-day america, it is customary for the commander-in-chief to conduct regular press conferences
related keywords: transparency, check and balance, sacrosanct, public accountability, adversarial, unscripted, direct access, open government, watchdog, healthy democracy, institutional integrity, right to know, direct line of communication, behind closed doors, updates, track progress, instill confidence, reassure, humanize, leadership style, day-to-day, forthcoming, demystify, ask hard questions
***
ideas: i know this one guy who retired so young, attesting to how careful they were with money.
related keywords: money management, resourceful, penny-pinching, live below their means, frugal, financial discipline, financial independence, conservative, long-term vision, discretionary spending, deferred gratification, preparedness, self-control, cushion
```
```
less specific: actors and musicians should ( support democracy ).
clarifies: actors and musicians should ( wield their celebrity to amplify pro-democracy messaging / marshal their considerable influence in the service of the democratic cause ).
***
less specific: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( be careful ).
clarifies: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( master their desires / exercise self-restraint / embrace frugality / restrain their appetite for splendor ).
```
|
[
"BEAR"
] |
P1ayer-1/pythia-1b-deduped-instruct-base
|
P1ayer-1
|
text-generation
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"pythia",
"en",
"dataset:EleutherAI/the_pile_deduplicated",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-05-29T20:08:16Z |
2023-05-29T20:09:36+00:00
| 67 | 0 |
---
datasets:
- EleutherAI/the_pile_deduplicated
language:
- en
license: apache-2.0
tags:
- pytorch
- causal-lm
- pythia
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. We also provide 154 intermediate
checkpoints per model, hosted on Hugging Face as branches.
The Pythia model suite was designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
<details>
<summary style="font-weight:600">Details on previous early release and naming convention.</summary>
Previously, we released an early version of the Pythia suite to the public.
However, we decided to retrain the model suite to address a few hyperparameter
discrepancies. This model card <a href="#changelog">lists the changes</a>;
see appendix B in the Pythia paper for further discussion. We found no
difference in benchmark performance between the two Pythia versions.
The old models are
[still available](https://huggingface.co/models?other=pythia_v0), but we
suggest the retrained suite if you are just starting to use Pythia.<br>
**This is the current release.**
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
</details>
<br>
# Pythia-1B-deduped
## Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
## Uses and Limitations
### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. We also provide
154 checkpoints per model: initial `step0`, 10 log-spaced checkpoints
`step{1,2,4...512}`, and 143 evenly-spaced checkpoints from `step1000` to
`step143000`. These checkpoints are hosted on Hugging Face as branches. Note
that branch `143000` corresponds exactly to the model checkpoint on the `main`
branch of each model.
You may also further fine-tune and adapt Pythia-1B-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-1B-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions. For example,
the model may generate harmful or offensive text. Please evaluate the risks
associated with your particular use case.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-1B-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-1B-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “follow” human instructions.
### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token used by the model need not produce the
most “accurate” text. Never rely on Pythia-1B-deduped to produce factually accurate
output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-1B-deduped may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-1B-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
## Training
### Training data
Pythia-1B-deduped was trained on the Pile **after the dataset has been globally
deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training,
from `step1000` to `step143000` (which is the same as `main`). In addition, we
also provide frequent early checkpoints: `step0` and `step{1,2,4...512}`.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for 143000 steps at a batch size
of 2M (2,097,152 tokens).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
## Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json/).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai_v1.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa_v1.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande_v1.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Easy Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_easy_v1.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq_v1.png" style="width:auto"/>
</details>
## Changelog
This section compares differences between previously released
[Pythia v0](https://huggingface.co/models?other=pythia_v0) and the current
models. See Appendix B of the Pythia paper for further discussion of these
changes and the motivation behind them. We found that retraining Pythia had no
impact on benchmark performance.
- All model sizes are now trained with uniform batch size of 2M tokens.
Previously, the models of size 160M, 410M, and 1.4B parameters were trained
with batch sizes of 4M tokens.
- We added checkpoints at initialization (step 0) and steps {1,2,4,8,16,32,64,
128,256,512} in addition to every 1000 training steps.
- Flash Attention was used in the new retrained suite.
- We remedied a minor inconsistency that existed in the original suite: all
models of size 2.8B parameters or smaller had a learning rate (LR) schedule
which decayed to a minimum LR of 10% the starting LR rate, but the 6.9B and
12B models all used an LR schedule which decayed to a minimum LR of 0. In
the redone training runs, we rectified this inconsistency: all models now were
trained with LR decaying to a minimum of 0.1× their maximum LR.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
[
"SCIQ"
] |
ntc-ai/SDXL-LoRA-slider.crying
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-29T01:53:19Z |
2023-12-29T01:53:22+00:00
| 67 | 3 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/crying.../crying_17_3.0.png
widget:
- text: crying
output:
url: images/crying_17_3.0.png
- text: crying
output:
url: images/crying_19_3.0.png
- text: crying
output:
url: images/crying_20_3.0.png
- text: crying
output:
url: images/crying_21_3.0.png
- text: crying
output:
url: images/crying_22_3.0.png
inference: false
instance_prompt: crying
---
# ntcai.xyz slider - crying (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/crying_17_-3.0.png" width=256 height=256 /> | <img src="images/crying_17_0.0.png" width=256 height=256 /> | <img src="images/crying_17_3.0.png" width=256 height=256 /> |
| <img src="images/crying_19_-3.0.png" width=256 height=256 /> | <img src="images/crying_19_0.0.png" width=256 height=256 /> | <img src="images/crying_19_3.0.png" width=256 height=256 /> |
| <img src="images/crying_20_-3.0.png" width=256 height=256 /> | <img src="images/crying_20_0.0.png" width=256 height=256 /> | <img src="images/crying_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
crying
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.crying', weight_name='crying.safetensors', adapter_name="crying")
# Activate the LoRA
pipe.set_adapters(["crying"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, crying"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 700+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
inventbot/Phi-3-mini-128k-instruct
|
inventbot
|
text-generation
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"nlp",
"code",
"conversational",
"custom_code",
"en",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-04-29T10:42:10Z |
2024-04-29T12:27:01+00:00
| 67 | 0 |
---
language:
- en
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/resolve/main/LICENSE
pipeline_tag: text-generation
tags:
- nlp
- code
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
## Model Summary
The Phi-3-Mini-128K-Instruct is a 3.8 billion-parameter, lightweight, state-of-the-art open model trained using the Phi-3 datasets.
This dataset includes both synthetic data and filtered publicly available website data, with an emphasis on high-quality and reasoning-dense properties.
The model belongs to the Phi-3 family with the Mini version in two variants [4K](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) which is the context length (in tokens) that it can support.
After initial training, the model underwent a post-training process that involved supervised fine-tuning and direct preference optimization to enhance its ability to follow instructions and adhere to safety measures.
When evaluated against benchmarks that test common sense, language understanding, mathematics, coding, long-term context, and logical reasoning, the Phi-3 Mini-128K-Instruct demonstrated robust and state-of-the-art performance among models with fewer than 13 billion parameters.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/phi3blog-april)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ Phi-3 ONNX: [128K](https://aka.ms/Phi3-mini-128k-instruct-onnx)
## Intended Uses
**Primary use cases**
The model is intended for commercial and research use in English. The model provides uses for applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3 Mini-128K-Instruct has been integrated in the development version (4.40.0) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
### Tokenizer
Phi-3 Mini-128K-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3 Mini-128K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion<|end|>\n<|assistant|>
```
For example:
```markdown
<|system|>
You are a helpful AI assistant.<|end|>
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>`. In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|system|>
You are a helpful AI assistant.<|end|>
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-128k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-128k-instruct")
messages = [
{"role": "system", "content": "You are a helpful digital assistant. Please provide safe, ethical and accurate information to the user."},
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
*Some applications/frameworks might not include a BOS token (`<s>`) at the start of the conversation. Please ensure that it is included since it provides more reliable results.*
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3 Mini-128K-Instruct has 3.8B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 128K tokens
* GPUs: 512 H100-80G
* Training time: 7 days
* Training data: 3.3T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
### Datasets
Our training data includes a wide variety of sources, totaling 3.3 trillion tokens, and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
### Fine-tuning
A basic example of multi-GPUs supervised fine-tuning (SFT) with TRL and Accelerate modules is provided [here](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct/resolve/main/sample_finetune.py).
## Benchmarks
We report the results for Phi-3-Mini-128K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Phi-2, Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, Llama-3-8B-Instruct, and GPT-3.5.
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
| | Phi-3-Mini-128K-In<br>3.8b | Phi-3-Small<br>7b (preview) | Phi-3-Medium<br>14b (preview) | Phi-2<br>2.7b | Mistral<br>7b | Gemma<br>7b | Llama-3-In<br>8b | Mixtral<br>8x7b | GPT-3.5<br>version 1106 |
|---|---|---|---|---|---|---|---|---|---|
| MMLU <br>5-Shot | 68.1 | 75.3 | 78.2 | 56.3 | 61.7 | 63.6 | 66.5 | 68.4 | 71.4 |
| HellaSwag <br> 5-Shot | 74.5 | 78.7 | 83.2 | 53.6 | 58.5 | 49.8 | 71.1 | 70.4 | 78.8 |
| ANLI <br> 7-Shot | 52.8 | 55.0 | 58.7 | 42.5 | 47.1 | 48.7 | 57.3 | 55.2 | 58.1 |
| GSM-8K <br> 0-Shot; CoT | 83.6 | 86.4 | 90.8 | 61.1 | 46.4 | 59.8 | 77.4 | 64.7 | 78.1 |
| MedQA <br> 2-Shot | 55.3 | 58.2 | 69.8 | 40.9 | 49.6 | 50.0 | 60.5 | 62.2 | 63.4 |
| AGIEval <br> 0-Shot | 36.9 | 45.0 | 49.7 | 29.8 | 35.1 | 42.1 | 42.0 | 45.2 | 48.4 |
| TriviaQA <br> 5-Shot | 57.1 | 59.1 | 73.3 | 45.2 | 72.3 | 75.2 | 67.7 | 82.2 | 85.8 |
| Arc-C <br> 10-Shot | 84.0 | 90.7 | 91.9 | 75.9 | 78.6 | 78.3 | 82.8 | 87.3 | 87.4 |
| Arc-E <br> 10-Shot | 95.2 | 97.1 | 98.0 | 88.5 | 90.6 | 91.4 | 93.4 | 95.6 | 96.3 |
| PIQA <br> 5-Shot | 83.6 | 87.8 | 88.2 | 60.2 | 77.7 | 78.1 | 75.7 | 86.0 | 86.6 |
| SociQA <br> 5-Shot | 76.1 | 79.0 | 79.4 | 68.3 | 74.6 | 65.5 | 73.9 | 75.9 | 68.3 |
| BigBench-Hard <br> 0-Shot | 71.5 | 75.0 | 82.5 | 59.4 | 57.3 | 59.6 | 51.5 | 69.7 | 68.32 |
| WinoGrande <br> 5-Shot | 72.5 | 82.5 | 81.2 | 54.7 | 54.2 | 55.6 | 65.0 | 62.0 | 68.8 |
| OpenBookQA <br> 10-Shot | 80.6 | 88.4 | 86.6 | 73.6 | 79.8 | 78.6 | 82.6 | 85.8 | 86.0 |
| BoolQ <br> 0-Shot | 78.7 | 82.9 | 86.5 | -- | 72.2 | 66.0 | 80.9 | 77.6 | 79.1 |
| CommonSenseQA <br> 10-Shot | 78.0 | 80.3 | 82.6 | 69.3 | 72.6 | 76.2 | 79 | 78.1 | 79.6 |
| TruthfulQA <br> 10-Shot | 63.2 | 68.1 | 74.8 | -- | 52.1 | 53.0 | 63.2 | 60.1 | 85.8 |
| HumanEval <br> 0-Shot | 57.9 | 59.1 | 54.7 | 47.0 | 28.0 | 34.1 | 60.4| 37.8 | 62.2 |
| MBPP <br> 3-Shot | 62.5 | 71.4 | 73.7 | 60.6 | 50.8 | 51.5 | 67.7 | 60.2 | 77.8 |
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-mini model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
* NVIDIA V100 or earlier generation GPUs: call AutoModelForCausalLM.from_pretrained() with attn_implementation="eager"
* Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [128K](https://aka.ms/phi3-mini-128k-instruct-onnx)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi-3 Mini models across platforms and hardware. You can find the optimized Phi-3 Mini-128K-Instruct ONNX model [here](https://aka.ms/phi3-mini-128k-instruct-onnx).
Optimized Phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML support lets developers bring hardware acceleration to Windows devices at scale across AMD, Intel, and NVIDIA GPUs.
Along with DirectML, ONNX Runtime provides cross platform support for Phi-3 across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-mini-128k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
[
"MEDQA"
] |
mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"not-for-all-audiences",
"nsfw",
"rp",
"roleplay",
"role-play",
"en",
"base_model:Cas-Archive/L3-Umbral-Mind-RP-v0.6.2-8B",
"base_model:quantized:Cas-Archive/L3-Umbral-Mind-RP-v0.6.2-8B",
"license:llama3",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | 2024-06-17T06:07:26Z |
2024-12-16T02:23:54+00:00
| 67 | 2 |
---
base_model: Cas-Archive/L3-Umbral-Mind-RP-v0.6.2-8B
language:
- en
library_name: transformers
license: llama3
tags:
- merge
- mergekit
- lazymergekit
- not-for-all-audiences
- nsfw
- rp
- roleplay
- role-play
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Cas-Archive/L3-Umbral-Mind-RP-v0.6.2-8B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/L3-Umbral-Mind-RP-v0.6.2-8B-i1-GGUF/resolve/main/L3-Umbral-Mind-RP-v0.6.2-8B.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
[
"CAS"
] |
lightontech/SeaLLM3-7B-Chat-AWQ
|
lightontech
|
text-generation
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"sea",
"multilingual",
"conversational",
"en",
"zh",
"id",
"vi",
"th",
"ms",
"arxiv:2312.00738",
"arxiv:2306.05179",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"awq",
"region:us"
] | 2024-07-17T00:15:12Z |
2024-07-17T00:23:15+00:00
| 67 | 1 |
---
language:
- en
- zh
- id
- vi
- th
- ms
license: other
license_name: seallms
license_link: https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat/blob/main/LICENSE
tags:
- sea
- multilingual
---
# *SeaLLMs-v3* - Large Language Models for Southeast Asia
<h1 style="color: #ff3860">**This repository is the modification of the SeaLLMs/SeaLLM3-7B-Chat**</h1>
<h1>This is a fork from https://huggingface.co/SorawitChok/SeaLLM3-7B-Chat-AWQ</h1>
## We offer a SeaLLM3-7B-Chat-AWQ which is a 4-bit AWQ quantization version of the SeaLLMs/SeaLLM3-7B-Chat (compatible with vLLM)
<p align="center">
<a href="https://damo-nlp-sg.github.io/SeaLLMs/" target="_blank" rel="noopener">Website</a>
<a href="https://huggingface.co/SeaLLMs/SeaLLM3-7B-Chat" target="_blank" rel="noopener"> 🤗 Tech Memo</a>
<a href="https://huggingface.co/spaces/SeaLLMs/SeaLLM-Chat" target="_blank" rel="noopener"> 🤗 DEMO</a>
<a href="https://github.com/DAMO-NLP-SG/SeaLLMs" target="_blank" rel="noopener">Github</a>
<a href="https://arxiv.org/pdf/2312.00738.pdf" target="_blank" rel="noopener">Technical Report</a>
</p>
We introduce **SeaLLMs-v3**, the latest series of the SeaLLMs (Large Language Models for Southeast Asian languages) family. It achieves state-of-the-art performance among models with similar sizes, excelling across a diverse array of tasks such as world knowledge, mathematical reasoning, translation, and instruction following. In the meantime, it was specifically enhanced to be more trustworthy, exhibiting reduced hallucination and providing safe responses, particularly in queries closed related to Southeast Asian culture.
## 🔥 Highlights
- State-of-the-art performance compared to open-source models of similar sizes, evaluated across various dimensions such as human exam questions, instruction-following, mathematics, and translation.
- Significantly enhanced instruction-following capability, especially in multi-turn settings.
- Ensures safety in usage with significantly reduced instances of hallucination and sensitivity to local contexts.
## Uses
SeaLLMs is tailored for handling a wide range of languages spoken in the SEA region, including English, Chinese, Indonesian, Vietnamese, Thai, Tagalog, Malay, Burmese, Khmer, Lao, Tamil, and Javanese.
This page introduces the SeaLLMs-v3-7B-Chat model, specifically fine-tuned to follow human instructions effectively for task completion, making it directly applicable to your applications.
### Inference with `vllm`
You can also conduct inference with [vllm](https://docs.vllm.ai/en/stable/index.html), which is a fast and easy-to-use library for LLM inference and serving. To use vllm, first install the latest version via `pip install vllm`.
```python
from vllm import LLM, SamplingParams
prompts = [
"Who is the president of US?",
"Can you speak Indonesian?"
]
llm = LLM("SorawitChok/SeaLLM3-7B-Chat-AWQ", quantization="AWQ")
sparams = SamplingParams(temperature=0.1, max_tokens=512)
outputs = llm.generate(prompts, sparams)
# print out the model response
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt}\nResponse: {generated_text}\n\n")
```
### Bias, Risks, and Limitations
<blockquote style="color:red">
<p><strong style="color: red">Terms of Use and License</strong>:
By using our released weights, codes, and demos, you agree to and comply with the terms and conditions specified in our <a href="https://huggingface.co/SeaLLMs/SeaLLM-Chat-13b/edit/main/LICENSE" target="_blank" rel="noopener">SeaLLMs Terms Of Use</a>.
</blockquote>
> **Disclaimer**:
> We must note that even though the weights, codes, and demos are released in an open manner, similar to other pre-trained language models, and despite our best efforts in red teaming and safety fine-tuning and enforcement, our models come with potential risks, including but not limited to inaccurate, misleading or potentially harmful generation.
> Developers and stakeholders should perform their own red teaming and provide related security measures before deployment, and they must abide by and comply with local governance and regulations.
> In no event shall the authors be held liable for any claim, damages, or other liability arising from the use of the released weights, codes, or demos.
## Evaluation
We conduct our evaluation along two dimensions:
1. **Model Capability**: We assess the model's performance on human exam questions, its ability to follow instructions, its proficiency in mathematics, and its translation accuracy.
2. **Model Trustworthiness**: We evaluate the model's safety and tendency to hallucinate, particularly in the context of Southeast Asia.
### Model Capability
#### Multilingual World Knowledge - M3Exam
[M3Exam](https://arxiv.org/abs/2306.05179) consists of local exam questions collected from each country. It reflects the model's world knowledge (e.g., with language or social science subjects) and reasoning abilities (e.g., with mathematics or natural science subjects).
| Model | en | zh | id | th | vi | avg | avg_sea |
|:-----------------|-----:|------:|-----:|-----:|-----:|------:|----------:|
| Sailor-7B-Chat | 0.66 | 0.652 | 0.475 | 0.462 | 0.513 | 0.552 | 0.483 |
| gemma-7b | 0.732 | 0.519 | 0.475 | 0.46 | 0.594 | 0.556 | 0.510 |
| SeaLLM-7B-v2.5 | 0.758 | 0.581 | 0.499 | 0.502 | 0.622 | 0.592 | 0.541 |
| Qwen2-7B | 0.815 | 0.874 | 0.53 | 0.479 | 0.628 | 0.665 | 0.546 |
| Qwen2-7B-Instruct| 0.809 | 0.88 | 0.558 | 0.555 | 0.624 | 0.685 | 0.579 |
| Sailor-14B | 0.748 | 0.84 | 0.536 | 0.528 | 0.621 | 0.655 | 0.562 |
| Sailor-14B-Chat | 0.749 | 0.843 | 0.553 | 0.566 | 0.637 | 0.67 | 0.585 |
| SeaLLMs-v3-7B | 0.814 | 0.866 | 0.549 | 0.52 | 0.628 | 0.675 | 0.566 |
| SeaLLMs-v3-7B-Chat | 0.809 | 0.874 | 0.558 | 0.569 | 0.649 | 0.692 | 0.592 |
#### Multilingual Instruction-following Capability - SeaBench
SeaBench consists of multi-turn human instructions spanning various task types. It evaluates chat-based models on their ability to follow human instructions in both single and multi-turn settings and assesses their performance across different task types. The dataset and corresponding evaluation code will be released soon!
| model | id<br>turn1 | id<br>turn2 | id<br>avg | th<br>turn1 | th<br>turn2 | th<br>avg | vi<br>turn1 | vi<br>turn2 | vi<br>avg | avg |
|:----------------|------------:|------------:|---------:|------------:|------------:|---------:|------------:|------------:|---------:|------:|
| Qwen2-7B-Instruct| 5.93 | 5.84 | 5.89 | 5.47 | 5.20 | 5.34 | 6.17 | 5.60 | 5.89 | 5.70 |
| SeaLLM-7B-v2.5 | 6.27 | 4.96 | 5.62 | 5.79 | 3.82 | 4.81 | 6.02 | 4.02 | 5.02 | 5.15 |
| Sailor-14B-Chat | 5.26 | 5.53 | 5.40 | 4.62 | 4.36 | 4.49 | 5.31 | 4.74 | 5.03 | 4.97 |
| Sailor-7B-Chat | 4.60 | 4.04 | 4.32 | 3.94 | 3.17 | 3.56 | 4.82 | 3.62 | 4.22 | 4.03 |
| SeaLLMs-v3-7B-Chat | 6.73 | 6.59 | 6.66 | 6.48 | 5.90 | 6.19 | 6.34 | 5.79 | 6.07 | 6.31 |
#### Multilingual Math
We evaluate the multilingual math capability using the MGSM dataset. MGSM originally contains Chinese and Thai testing sets only, we use Google Translate to translate the same English questions into other SEA languages. Note that we adopt the tradition of each country to represent the number, e.g., in Indonesian and Vietnamese, dots are used as thousands separators and commas as decimal separators, the opposite of the English system.
| MGSM | en | id | ms | th | vi | zh | avg |
|:--------------------------|------:|------:|------:|------:|------:|------:|------:|
| Sailor-7B-Chat | 33.6 | 22.4 | 22.4 | 21.6 | 25.2 | 29.2 | 25.7 |
| Meta-Llama-3-8B-Instruct | 77.6 | 48 | 57.6 | 56 | 46.8 | 58.8 | 57.5 |
| glm-4-9b-chat | 72.8 | 53.6 | 53.6 | 34.8 | 52.4 | 70.8 | 56.3 |
| Qwen1.5-7B-Chat | 64 | 34.4 | 38.4 | 25.2 | 36 | 53.6 | 41.9 |
| Qwen2-7B-instruct | 82 | 66.4 | 62.4 | 58.4 | 64.4 | 76.8 | 68.4 |
| aya-23-8B | 28.8 | 16.4 | 14.4 | 2 | 16 | 12.8 | 15.1 |
| gemma-1.1-7b-it | 58.8 | 32.4 | 34.8 | 31.2 | 39.6 | 35.2 | 38.7 |
| SeaLLM-7B-v2.5 | 79.6 | 69.2 | 70.8 | 61.2 | 66.8 | 62.4 | 68.3 |
| SeaLLMs-v3-7B-Chat | 74.8 | 71.2 | 70.8 | 71.2 | 71.2 | 79.6 | 73.1 |
#### Translation
We use the test sets from Flores-200 for evaluation and report the zero-shot chrF scores for translations between every pair of languages. Each row in the table below presents the average results of translating from various source languages into the target languages. The last column displays the overall average results of translating from any language to any other language for each model.
| model | en | id | jv | km | lo | ms | my | ta | th | tl | vi | zh | avg |
|:-----------------------------------------------|------:|------:|------:|------:|------:|------:|------:|------:|------:|------:|------:|------:|------:|
|Meta-Llama-3-8B-Instruct | 51.54 | 49.03 | 22.46 | 15.34 | 5.42 | 46.72 | 21.24 | 32.09 | 35.75 | 40.8 | 39.31 | 14.87 | 31.22 |
|Qwen2-7B-Instruct | 50.36 | 47.55 | 29.36 | 19.26 | 11.06 | 42.43 | 19.33 | 20.04 | 36.07 | 37.91 | 39.63 | 22.87 | 31.32 |
|Sailor-7B-Chat | 49.4 | 49.78 | 28.33 | 2.68 | 6.85 | 47.75 | 5.35 | 18.23 | 38.92 | 29 | 41.76 | 20.87 | 28.24 |
|SeaLLM-7B-v2.5 | 55.09 | 53.71 | 18.13 | 18.09 | 15.53 | 51.33 | 19.71 | 26.1 | 40.55 | 45.58 | 44.56 | 24.18 | 34.38 |
|SeaLLMs-v3-7B-Chat | 54.68 | 52.52 | 29.86 | 27.3 | 26.34 | 45.04 | 21.54 | 31.93 | 41.52 | 38.51 | 43.78 | 26.1 | 36.52 |
### Model Trustworthiness
#### Hallucination
Performance of whether a model can refuse questions about the non-existing entity. The following is the F1 score. We use refuse as the positive label. Our test set consists of ~1k test samples per language. Each unanswerable question is generated by GPT4o. The ratio of answerable and unanswerable questions are 1:1. We define keywords to automatically detect whether a model-generated response is a refusal response.
| Refusal-F1 Scores | en | zh | vi | th | id | avg |
|:---------------------|------:|------:|------:|------:|------:|-------:|
| Qwen1.5-7B-Instruct | 53.85 | 51.70 | 52.85 | 35.5 | 58.4 | 50.46 |
| Qwen2-7B-Instruct | 58.79 | 33.08 | 56.21 | 44.6 | 55.98 | 49.732 |
| SeaLLM-7B-v2.5 | 12.90 | 0.77 | 2.45 | 19.42 | 0.78 | 7.26 |
| Sailor-7B-Chat | 33.49 | 18.82 | 5.19 | 9.68 | 16.42 | 16.72 |
| glm-4-9b-chat | 44.48 | 37.89 | 18.66 | 4.27 | 1.97 | 21.45 |
| aya-23-8B | 6.38 | 0.79 | 2.83 | 1.98 | 14.80 | 5.36 |
| Llama-3-8B-Instruct | 72.08 | 0.00 | 1.23 | 0.80 | 3.91 | 15.60 |
| gemma-1.1-7b-it | 52.39 | 27.74 | 23.96 | 22.97 | 31.72 | 31.76 |
| SeaLLMs-v3-7B-Chat | 71.36 | 78.39 | 77.93 | 61.31 | 68.95 | 71.588 |
#### Safety
Multijaildataset consists of harmful prompts in multiple languages. We take those relevant prompts in SEA languages here and report their safe rate (the higher the better).
| Model | en | jv | th | vi | zh | avg |
|:------------------------|-------:|-------:|-------:|-------:|------:|-------:|
| Qwen2-7B-Instruct | 0.8857 | 0.4381 | 0.6381 | 0.7302 | 0.873 | 0.713 |
| Sailor-7B-Chat | 0.7873 | 0.5492 | 0.6222 | 0.6762 | 0.7619 | 0.6794 |
| Meta-Llama-3-8B-Instruct| 0.8825 | 0.2635 | 0.7111 | 0.6984 | 0.7714 | 0.6654 |
| Sailor-14B-Chat | 0.8698 | 0.3048 | 0.5365 | 0.6095 | 0.727 | 0.6095 |
| glm-4-9b-chat | 0.7714 | 0.2127 | 0.3016 | 0.6063 | 0.7492 | 0.52824|
| SeaLLMs-v3-7B-Chat | 0.8889 | 0.6000 | 0.7333 | 0.8381 | 0.927 | 0.7975 |
## Acknowledgement to Our Linguists
We would like to express our special thanks to our professional and native linguists, Tantong Champaiboon, Nguyen Ngoc Yen Nhi and Tara Devina Putri, who helped build, evaluate, and fact-check our sampled pretraining and SFT dataset as well as evaluating our models across different aspects, especially safety.
## Citation
If you find our project useful, we hope you would kindly star our repo and cite our work as follows:
```
@article{damonlp2024seallm3,
author = {Wenxuan Zhang*, Hou Pong Chan*, Yiran Zhao*, Mahani Aljunied*,
Jianyu Wang, Chaoqun Liu, Yue Deng, Zhiqiang Hu, Weiwen Xu,
Yew Ken Chia, Xin Li, Lidong Bing},
title = {SeaLLMs - Large Language Models for Southeast Asia},
year = {2024},
}
```
Corresponding Author: [email protected]
|
[
"CHIA"
] |
mav23/gte-Qwen2-7B-instruct-GGUF
|
mav23
|
sentence-similarity
|
[
"sentence-transformers",
"gguf",
"mteb",
"transformers",
"Qwen2",
"sentence-similarity",
"arxiv:2308.03281",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-10T23:23:46Z |
2024-10-11T00:14:54+00:00
| 67 | 1 |
---
license: apache-2.0
tags:
- mteb
- sentence-transformers
- transformers
- Qwen2
- sentence-similarity
model-index:
- name: gte-qwen2-7B-instruct
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 91.31343283582089
- type: ap
value: 67.64251402604096
- type: f1
value: 87.53372530755692
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 97.497825
- type: ap
value: 96.30329547047529
- type: f1
value: 97.49769793778039
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 62.564
- type: f1
value: 60.975777935041066
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: mteb/arguana
config: default
split: test
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
metrics:
- type: map_at_1
value: 36.486000000000004
- type: map_at_10
value: 54.842
- type: map_at_100
value: 55.206999999999994
- type: map_at_1000
value: 55.206999999999994
- type: map_at_3
value: 49.893
- type: map_at_5
value: 53.105000000000004
- type: mrr_at_1
value: 37.34
- type: mrr_at_10
value: 55.143
- type: mrr_at_100
value: 55.509
- type: mrr_at_1000
value: 55.509
- type: mrr_at_3
value: 50.212999999999994
- type: mrr_at_5
value: 53.432
- type: ndcg_at_1
value: 36.486000000000004
- type: ndcg_at_10
value: 64.273
- type: ndcg_at_100
value: 65.66199999999999
- type: ndcg_at_1000
value: 65.66199999999999
- type: ndcg_at_3
value: 54.352999999999994
- type: ndcg_at_5
value: 60.131
- type: precision_at_1
value: 36.486000000000004
- type: precision_at_10
value: 9.395000000000001
- type: precision_at_100
value: 0.996
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 22.428
- type: precision_at_5
value: 16.259
- type: recall_at_1
value: 36.486000000000004
- type: recall_at_10
value: 93.95400000000001
- type: recall_at_100
value: 99.644
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 67.283
- type: recall_at_5
value: 81.294
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 56.461169803700564
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 51.73600434466286
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 67.57827065898053
- type: mrr
value: 79.08136569493911
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 83.53324575999243
- type: cos_sim_spearman
value: 81.37173362822374
- type: euclidean_pearson
value: 82.19243335103444
- type: euclidean_spearman
value: 81.33679307304334
- type: manhattan_pearson
value: 82.38752665975699
- type: manhattan_spearman
value: 81.31510583189689
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.56818181818181
- type: f1
value: 87.25826722019875
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 50.09239610327673
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 46.64733054606282
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: f46a197baaae43b4f621051089b82a364682dfeb
metrics:
- type: map_at_1
value: 33.997
- type: map_at_10
value: 48.176
- type: map_at_100
value: 49.82
- type: map_at_1000
value: 49.924
- type: map_at_3
value: 43.626
- type: map_at_5
value: 46.275
- type: mrr_at_1
value: 42.059999999999995
- type: mrr_at_10
value: 53.726
- type: mrr_at_100
value: 54.398
- type: mrr_at_1000
value: 54.416
- type: mrr_at_3
value: 50.714999999999996
- type: mrr_at_5
value: 52.639
- type: ndcg_at_1
value: 42.059999999999995
- type: ndcg_at_10
value: 55.574999999999996
- type: ndcg_at_100
value: 60.744
- type: ndcg_at_1000
value: 61.85699999999999
- type: ndcg_at_3
value: 49.363
- type: ndcg_at_5
value: 52.44
- type: precision_at_1
value: 42.059999999999995
- type: precision_at_10
value: 11.101999999999999
- type: precision_at_100
value: 1.73
- type: precision_at_1000
value: 0.218
- type: precision_at_3
value: 24.464
- type: precision_at_5
value: 18.026
- type: recall_at_1
value: 33.997
- type: recall_at_10
value: 70.35900000000001
- type: recall_at_100
value: 91.642
- type: recall_at_1000
value: 97.977
- type: recall_at_3
value: 52.76
- type: recall_at_5
value: 61.148
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackEnglishRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: ad9991cb51e31e31e430383c75ffb2885547b5f0
metrics:
- type: map_at_1
value: 35.884
- type: map_at_10
value: 48.14
- type: map_at_100
value: 49.5
- type: map_at_1000
value: 49.63
- type: map_at_3
value: 44.646
- type: map_at_5
value: 46.617999999999995
- type: mrr_at_1
value: 44.458999999999996
- type: mrr_at_10
value: 53.751000000000005
- type: mrr_at_100
value: 54.37800000000001
- type: mrr_at_1000
value: 54.415
- type: mrr_at_3
value: 51.815
- type: mrr_at_5
value: 52.882
- type: ndcg_at_1
value: 44.458999999999996
- type: ndcg_at_10
value: 54.157
- type: ndcg_at_100
value: 58.362
- type: ndcg_at_1000
value: 60.178
- type: ndcg_at_3
value: 49.661
- type: ndcg_at_5
value: 51.74999999999999
- type: precision_at_1
value: 44.458999999999996
- type: precision_at_10
value: 10.248
- type: precision_at_100
value: 1.5890000000000002
- type: precision_at_1000
value: 0.207
- type: precision_at_3
value: 23.928
- type: precision_at_5
value: 16.878999999999998
- type: recall_at_1
value: 35.884
- type: recall_at_10
value: 64.798
- type: recall_at_100
value: 82.345
- type: recall_at_1000
value: 93.267
- type: recall_at_3
value: 51.847
- type: recall_at_5
value: 57.601
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGamingRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
metrics:
- type: map_at_1
value: 39.383
- type: map_at_10
value: 53.714
- type: map_at_100
value: 54.838
- type: map_at_1000
value: 54.87800000000001
- type: map_at_3
value: 50.114999999999995
- type: map_at_5
value: 52.153000000000006
- type: mrr_at_1
value: 45.016
- type: mrr_at_10
value: 56.732000000000006
- type: mrr_at_100
value: 57.411
- type: mrr_at_1000
value: 57.431
- type: mrr_at_3
value: 54.044000000000004
- type: mrr_at_5
value: 55.639
- type: ndcg_at_1
value: 45.016
- type: ndcg_at_10
value: 60.228
- type: ndcg_at_100
value: 64.277
- type: ndcg_at_1000
value: 65.07
- type: ndcg_at_3
value: 54.124
- type: ndcg_at_5
value: 57.147000000000006
- type: precision_at_1
value: 45.016
- type: precision_at_10
value: 9.937
- type: precision_at_100
value: 1.288
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 24.471999999999998
- type: precision_at_5
value: 16.991
- type: recall_at_1
value: 39.383
- type: recall_at_10
value: 76.175
- type: recall_at_100
value: 93.02
- type: recall_at_1000
value: 98.60900000000001
- type: recall_at_3
value: 60.265
- type: recall_at_5
value: 67.46600000000001
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGisRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 5003b3064772da1887988e05400cf3806fe491f2
metrics:
- type: map_at_1
value: 27.426000000000002
- type: map_at_10
value: 37.397000000000006
- type: map_at_100
value: 38.61
- type: map_at_1000
value: 38.678000000000004
- type: map_at_3
value: 34.150999999999996
- type: map_at_5
value: 36.137
- type: mrr_at_1
value: 29.944
- type: mrr_at_10
value: 39.654
- type: mrr_at_100
value: 40.638000000000005
- type: mrr_at_1000
value: 40.691
- type: mrr_at_3
value: 36.817
- type: mrr_at_5
value: 38.524
- type: ndcg_at_1
value: 29.944
- type: ndcg_at_10
value: 43.094
- type: ndcg_at_100
value: 48.789
- type: ndcg_at_1000
value: 50.339999999999996
- type: ndcg_at_3
value: 36.984
- type: ndcg_at_5
value: 40.248
- type: precision_at_1
value: 29.944
- type: precision_at_10
value: 6.78
- type: precision_at_100
value: 1.024
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 15.895000000000001
- type: precision_at_5
value: 11.39
- type: recall_at_1
value: 27.426000000000002
- type: recall_at_10
value: 58.464000000000006
- type: recall_at_100
value: 84.193
- type: recall_at_1000
value: 95.52000000000001
- type: recall_at_3
value: 42.172
- type: recall_at_5
value: 50.101
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackMathematicaRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 90fceea13679c63fe563ded68f3b6f06e50061de
metrics:
- type: map_at_1
value: 19.721
- type: map_at_10
value: 31.604
- type: map_at_100
value: 32.972
- type: map_at_1000
value: 33.077
- type: map_at_3
value: 27.218999999999998
- type: map_at_5
value: 29.53
- type: mrr_at_1
value: 25.0
- type: mrr_at_10
value: 35.843
- type: mrr_at_100
value: 36.785000000000004
- type: mrr_at_1000
value: 36.842000000000006
- type: mrr_at_3
value: 32.193
- type: mrr_at_5
value: 34.264
- type: ndcg_at_1
value: 25.0
- type: ndcg_at_10
value: 38.606
- type: ndcg_at_100
value: 44.272
- type: ndcg_at_1000
value: 46.527
- type: ndcg_at_3
value: 30.985000000000003
- type: ndcg_at_5
value: 34.43
- type: precision_at_1
value: 25.0
- type: precision_at_10
value: 7.811
- type: precision_at_100
value: 1.203
- type: precision_at_1000
value: 0.15
- type: precision_at_3
value: 15.423
- type: precision_at_5
value: 11.791
- type: recall_at_1
value: 19.721
- type: recall_at_10
value: 55.625
- type: recall_at_100
value: 79.34400000000001
- type: recall_at_1000
value: 95.208
- type: recall_at_3
value: 35.19
- type: recall_at_5
value: 43.626
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackPhysicsRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 79531abbd1fb92d06c6d6315a0cbbbf5bb247ea4
metrics:
- type: map_at_1
value: 33.784
- type: map_at_10
value: 47.522
- type: map_at_100
value: 48.949999999999996
- type: map_at_1000
value: 49.038
- type: map_at_3
value: 43.284
- type: map_at_5
value: 45.629
- type: mrr_at_1
value: 41.482
- type: mrr_at_10
value: 52.830999999999996
- type: mrr_at_100
value: 53.559999999999995
- type: mrr_at_1000
value: 53.588
- type: mrr_at_3
value: 50.016000000000005
- type: mrr_at_5
value: 51.614000000000004
- type: ndcg_at_1
value: 41.482
- type: ndcg_at_10
value: 54.569
- type: ndcg_at_100
value: 59.675999999999995
- type: ndcg_at_1000
value: 60.989000000000004
- type: ndcg_at_3
value: 48.187000000000005
- type: ndcg_at_5
value: 51.183
- type: precision_at_1
value: 41.482
- type: precision_at_10
value: 10.221
- type: precision_at_100
value: 1.486
- type: precision_at_1000
value: 0.17500000000000002
- type: precision_at_3
value: 23.548
- type: precision_at_5
value: 16.805
- type: recall_at_1
value: 33.784
- type: recall_at_10
value: 69.798
- type: recall_at_100
value: 90.098
- type: recall_at_1000
value: 98.176
- type: recall_at_3
value: 52.127
- type: recall_at_5
value: 59.861
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackProgrammersRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 6184bc1440d2dbc7612be22b50686b8826d22b32
metrics:
- type: map_at_1
value: 28.038999999999998
- type: map_at_10
value: 41.904
- type: map_at_100
value: 43.36
- type: map_at_1000
value: 43.453
- type: map_at_3
value: 37.785999999999994
- type: map_at_5
value: 40.105000000000004
- type: mrr_at_1
value: 35.046
- type: mrr_at_10
value: 46.926
- type: mrr_at_100
value: 47.815000000000005
- type: mrr_at_1000
value: 47.849000000000004
- type: mrr_at_3
value: 44.273
- type: mrr_at_5
value: 45.774
- type: ndcg_at_1
value: 35.046
- type: ndcg_at_10
value: 48.937000000000005
- type: ndcg_at_100
value: 54.544000000000004
- type: ndcg_at_1000
value: 56.069
- type: ndcg_at_3
value: 42.858000000000004
- type: ndcg_at_5
value: 45.644
- type: precision_at_1
value: 35.046
- type: precision_at_10
value: 9.452
- type: precision_at_100
value: 1.429
- type: precision_at_1000
value: 0.173
- type: precision_at_3
value: 21.346999999999998
- type: precision_at_5
value: 15.342
- type: recall_at_1
value: 28.038999999999998
- type: recall_at_10
value: 64.59700000000001
- type: recall_at_100
value: 87.735
- type: recall_at_1000
value: 97.41300000000001
- type: recall_at_3
value: 47.368
- type: recall_at_5
value: 54.93900000000001
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: map_at_1
value: 28.17291666666667
- type: map_at_10
value: 40.025749999999995
- type: map_at_100
value: 41.39208333333333
- type: map_at_1000
value: 41.499249999999996
- type: map_at_3
value: 36.347
- type: map_at_5
value: 38.41391666666667
- type: mrr_at_1
value: 33.65925
- type: mrr_at_10
value: 44.085499999999996
- type: mrr_at_100
value: 44.94116666666667
- type: mrr_at_1000
value: 44.9855
- type: mrr_at_3
value: 41.2815
- type: mrr_at_5
value: 42.91491666666666
- type: ndcg_at_1
value: 33.65925
- type: ndcg_at_10
value: 46.430833333333325
- type: ndcg_at_100
value: 51.761
- type: ndcg_at_1000
value: 53.50899999999999
- type: ndcg_at_3
value: 40.45133333333333
- type: ndcg_at_5
value: 43.31483333333334
- type: precision_at_1
value: 33.65925
- type: precision_at_10
value: 8.4995
- type: precision_at_100
value: 1.3210000000000004
- type: precision_at_1000
value: 0.16591666666666666
- type: precision_at_3
value: 19.165083333333335
- type: precision_at_5
value: 13.81816666666667
- type: recall_at_1
value: 28.17291666666667
- type: recall_at_10
value: 61.12624999999999
- type: recall_at_100
value: 83.97266666666667
- type: recall_at_1000
value: 95.66550000000001
- type: recall_at_3
value: 44.661249999999995
- type: recall_at_5
value: 51.983333333333334
- type: map_at_1
value: 17.936
- type: map_at_10
value: 27.399
- type: map_at_100
value: 28.632
- type: map_at_1000
value: 28.738000000000003
- type: map_at_3
value: 24.456
- type: map_at_5
value: 26.06
- type: mrr_at_1
value: 19.224
- type: mrr_at_10
value: 28.998
- type: mrr_at_100
value: 30.11
- type: mrr_at_1000
value: 30.177
- type: mrr_at_3
value: 26.247999999999998
- type: mrr_at_5
value: 27.708
- type: ndcg_at_1
value: 19.224
- type: ndcg_at_10
value: 32.911
- type: ndcg_at_100
value: 38.873999999999995
- type: ndcg_at_1000
value: 41.277
- type: ndcg_at_3
value: 27.142
- type: ndcg_at_5
value: 29.755
- type: precision_at_1
value: 19.224
- type: precision_at_10
value: 5.6930000000000005
- type: precision_at_100
value: 0.9259999999999999
- type: precision_at_1000
value: 0.126
- type: precision_at_3
value: 12.138
- type: precision_at_5
value: 8.909
- type: recall_at_1
value: 17.936
- type: recall_at_10
value: 48.096
- type: recall_at_100
value: 75.389
- type: recall_at_1000
value: 92.803
- type: recall_at_3
value: 32.812999999999995
- type: recall_at_5
value: 38.851
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackStatsRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 65ac3a16b8e91f9cee4c9828cc7c335575432a2a
metrics:
- type: map_at_1
value: 24.681
- type: map_at_10
value: 34.892
- type: map_at_100
value: 35.996
- type: map_at_1000
value: 36.083
- type: map_at_3
value: 31.491999999999997
- type: map_at_5
value: 33.632
- type: mrr_at_1
value: 28.528
- type: mrr_at_10
value: 37.694
- type: mrr_at_100
value: 38.613
- type: mrr_at_1000
value: 38.668
- type: mrr_at_3
value: 34.714
- type: mrr_at_5
value: 36.616
- type: ndcg_at_1
value: 28.528
- type: ndcg_at_10
value: 40.703
- type: ndcg_at_100
value: 45.993
- type: ndcg_at_1000
value: 47.847
- type: ndcg_at_3
value: 34.622
- type: ndcg_at_5
value: 38.035999999999994
- type: precision_at_1
value: 28.528
- type: precision_at_10
value: 6.902
- type: precision_at_100
value: 1.0370000000000001
- type: precision_at_1000
value: 0.126
- type: precision_at_3
value: 15.798000000000002
- type: precision_at_5
value: 11.655999999999999
- type: recall_at_1
value: 24.681
- type: recall_at_10
value: 55.81
- type: recall_at_100
value: 79.785
- type: recall_at_1000
value: 92.959
- type: recall_at_3
value: 39.074
- type: recall_at_5
value: 47.568
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackTexRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 46989137a86843e03a6195de44b09deda022eec7
metrics:
- type: map_at_1
value: 18.627
- type: map_at_10
value: 27.872000000000003
- type: map_at_100
value: 29.237999999999996
- type: map_at_1000
value: 29.363
- type: map_at_3
value: 24.751
- type: map_at_5
value: 26.521
- type: mrr_at_1
value: 23.021
- type: mrr_at_10
value: 31.924000000000003
- type: mrr_at_100
value: 32.922000000000004
- type: mrr_at_1000
value: 32.988
- type: mrr_at_3
value: 29.192
- type: mrr_at_5
value: 30.798
- type: ndcg_at_1
value: 23.021
- type: ndcg_at_10
value: 33.535
- type: ndcg_at_100
value: 39.732
- type: ndcg_at_1000
value: 42.201
- type: ndcg_at_3
value: 28.153
- type: ndcg_at_5
value: 30.746000000000002
- type: precision_at_1
value: 23.021
- type: precision_at_10
value: 6.459
- type: precision_at_100
value: 1.1320000000000001
- type: precision_at_1000
value: 0.153
- type: precision_at_3
value: 13.719000000000001
- type: precision_at_5
value: 10.193000000000001
- type: recall_at_1
value: 18.627
- type: recall_at_10
value: 46.463
- type: recall_at_100
value: 74.226
- type: recall_at_1000
value: 91.28500000000001
- type: recall_at_3
value: 31.357000000000003
- type: recall_at_5
value: 38.067
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackUnixRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
metrics:
- type: map_at_1
value: 31.457
- type: map_at_10
value: 42.888
- type: map_at_100
value: 44.24
- type: map_at_1000
value: 44.327
- type: map_at_3
value: 39.588
- type: map_at_5
value: 41.423
- type: mrr_at_1
value: 37.126999999999995
- type: mrr_at_10
value: 47.083000000000006
- type: mrr_at_100
value: 47.997
- type: mrr_at_1000
value: 48.044
- type: mrr_at_3
value: 44.574000000000005
- type: mrr_at_5
value: 46.202
- type: ndcg_at_1
value: 37.126999999999995
- type: ndcg_at_10
value: 48.833
- type: ndcg_at_100
value: 54.327000000000005
- type: ndcg_at_1000
value: 56.011
- type: ndcg_at_3
value: 43.541999999999994
- type: ndcg_at_5
value: 46.127
- type: precision_at_1
value: 37.126999999999995
- type: precision_at_10
value: 8.376999999999999
- type: precision_at_100
value: 1.2309999999999999
- type: precision_at_1000
value: 0.146
- type: precision_at_3
value: 20.211000000000002
- type: precision_at_5
value: 14.16
- type: recall_at_1
value: 31.457
- type: recall_at_10
value: 62.369
- type: recall_at_100
value: 85.444
- type: recall_at_1000
value: 96.65599999999999
- type: recall_at_3
value: 47.961
- type: recall_at_5
value: 54.676
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWebmastersRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 160c094312a0e1facb97e55eeddb698c0abe3571
metrics:
- type: map_at_1
value: 27.139999999999997
- type: map_at_10
value: 38.801
- type: map_at_100
value: 40.549
- type: map_at_1000
value: 40.802
- type: map_at_3
value: 35.05
- type: map_at_5
value: 36.884
- type: mrr_at_1
value: 33.004
- type: mrr_at_10
value: 43.864
- type: mrr_at_100
value: 44.667
- type: mrr_at_1000
value: 44.717
- type: mrr_at_3
value: 40.777
- type: mrr_at_5
value: 42.319
- type: ndcg_at_1
value: 33.004
- type: ndcg_at_10
value: 46.022
- type: ndcg_at_100
value: 51.542
- type: ndcg_at_1000
value: 53.742000000000004
- type: ndcg_at_3
value: 39.795
- type: ndcg_at_5
value: 42.272
- type: precision_at_1
value: 33.004
- type: precision_at_10
value: 9.012
- type: precision_at_100
value: 1.7770000000000001
- type: precision_at_1000
value: 0.26
- type: precision_at_3
value: 19.038
- type: precision_at_5
value: 13.675999999999998
- type: recall_at_1
value: 27.139999999999997
- type: recall_at_10
value: 60.961
- type: recall_at_100
value: 84.451
- type: recall_at_1000
value: 98.113
- type: recall_at_3
value: 43.001
- type: recall_at_5
value: 49.896
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: mteb/climate-fever
config: default
split: test
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
metrics:
- type: map_at_1
value: 22.076999999999998
- type: map_at_10
value: 35.44
- type: map_at_100
value: 37.651
- type: map_at_1000
value: 37.824999999999996
- type: map_at_3
value: 30.764999999999997
- type: map_at_5
value: 33.26
- type: mrr_at_1
value: 50.163000000000004
- type: mrr_at_10
value: 61.207
- type: mrr_at_100
value: 61.675000000000004
- type: mrr_at_1000
value: 61.692
- type: mrr_at_3
value: 58.60999999999999
- type: mrr_at_5
value: 60.307
- type: ndcg_at_1
value: 50.163000000000004
- type: ndcg_at_10
value: 45.882
- type: ndcg_at_100
value: 53.239999999999995
- type: ndcg_at_1000
value: 55.852000000000004
- type: ndcg_at_3
value: 40.514
- type: ndcg_at_5
value: 42.038
- type: precision_at_1
value: 50.163000000000004
- type: precision_at_10
value: 13.466000000000001
- type: precision_at_100
value: 2.164
- type: precision_at_1000
value: 0.266
- type: precision_at_3
value: 29.707
- type: precision_at_5
value: 21.694
- type: recall_at_1
value: 22.076999999999998
- type: recall_at_10
value: 50.193
- type: recall_at_100
value: 74.993
- type: recall_at_1000
value: 89.131
- type: recall_at_3
value: 35.472
- type: recall_at_5
value: 41.814
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: mteb/dbpedia
config: default
split: test
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
metrics:
- type: map_at_1
value: 9.953
- type: map_at_10
value: 24.515
- type: map_at_100
value: 36.173
- type: map_at_1000
value: 38.351
- type: map_at_3
value: 16.592000000000002
- type: map_at_5
value: 20.036
- type: mrr_at_1
value: 74.25
- type: mrr_at_10
value: 81.813
- type: mrr_at_100
value: 82.006
- type: mrr_at_1000
value: 82.011
- type: mrr_at_3
value: 80.875
- type: mrr_at_5
value: 81.362
- type: ndcg_at_1
value: 62.5
- type: ndcg_at_10
value: 52.42
- type: ndcg_at_100
value: 56.808
- type: ndcg_at_1000
value: 63.532999999999994
- type: ndcg_at_3
value: 56.654
- type: ndcg_at_5
value: 54.18300000000001
- type: precision_at_1
value: 74.25
- type: precision_at_10
value: 42.699999999999996
- type: precision_at_100
value: 13.675
- type: precision_at_1000
value: 2.664
- type: precision_at_3
value: 60.5
- type: precision_at_5
value: 52.800000000000004
- type: recall_at_1
value: 9.953
- type: recall_at_10
value: 30.253999999999998
- type: recall_at_100
value: 62.516000000000005
- type: recall_at_1000
value: 84.163
- type: recall_at_3
value: 18.13
- type: recall_at_5
value: 22.771
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 79.455
- type: f1
value: 74.16798697647569
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: mteb/fever
config: default
split: test
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
metrics:
- type: map_at_1
value: 87.531
- type: map_at_10
value: 93.16799999999999
- type: map_at_100
value: 93.341
- type: map_at_1000
value: 93.349
- type: map_at_3
value: 92.444
- type: map_at_5
value: 92.865
- type: mrr_at_1
value: 94.014
- type: mrr_at_10
value: 96.761
- type: mrr_at_100
value: 96.762
- type: mrr_at_1000
value: 96.762
- type: mrr_at_3
value: 96.672
- type: mrr_at_5
value: 96.736
- type: ndcg_at_1
value: 94.014
- type: ndcg_at_10
value: 95.112
- type: ndcg_at_100
value: 95.578
- type: ndcg_at_1000
value: 95.68900000000001
- type: ndcg_at_3
value: 94.392
- type: ndcg_at_5
value: 94.72500000000001
- type: precision_at_1
value: 94.014
- type: precision_at_10
value: 11.065
- type: precision_at_100
value: 1.157
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 35.259
- type: precision_at_5
value: 21.599
- type: recall_at_1
value: 87.531
- type: recall_at_10
value: 97.356
- type: recall_at_100
value: 98.965
- type: recall_at_1000
value: 99.607
- type: recall_at_3
value: 95.312
- type: recall_at_5
value: 96.295
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: mteb/fiqa
config: default
split: test
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
metrics:
- type: map_at_1
value: 32.055
- type: map_at_10
value: 53.114
- type: map_at_100
value: 55.235
- type: map_at_1000
value: 55.345
- type: map_at_3
value: 45.854
- type: map_at_5
value: 50.025
- type: mrr_at_1
value: 60.34
- type: mrr_at_10
value: 68.804
- type: mrr_at_100
value: 69.309
- type: mrr_at_1000
value: 69.32199999999999
- type: mrr_at_3
value: 66.40899999999999
- type: mrr_at_5
value: 67.976
- type: ndcg_at_1
value: 60.34
- type: ndcg_at_10
value: 62.031000000000006
- type: ndcg_at_100
value: 68.00500000000001
- type: ndcg_at_1000
value: 69.286
- type: ndcg_at_3
value: 56.355999999999995
- type: ndcg_at_5
value: 58.687
- type: precision_at_1
value: 60.34
- type: precision_at_10
value: 17.176
- type: precision_at_100
value: 2.36
- type: precision_at_1000
value: 0.259
- type: precision_at_3
value: 37.14
- type: precision_at_5
value: 27.809
- type: recall_at_1
value: 32.055
- type: recall_at_10
value: 70.91
- type: recall_at_100
value: 91.83
- type: recall_at_1000
value: 98.871
- type: recall_at_3
value: 51.202999999999996
- type: recall_at_5
value: 60.563
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: mteb/hotpotqa
config: default
split: test
revision: ab518f4d6fcca38d87c25209f94beba119d02014
metrics:
- type: map_at_1
value: 43.68
- type: map_at_10
value: 64.389
- type: map_at_100
value: 65.24
- type: map_at_1000
value: 65.303
- type: map_at_3
value: 61.309000000000005
- type: map_at_5
value: 63.275999999999996
- type: mrr_at_1
value: 87.36
- type: mrr_at_10
value: 91.12
- type: mrr_at_100
value: 91.227
- type: mrr_at_1000
value: 91.229
- type: mrr_at_3
value: 90.57600000000001
- type: mrr_at_5
value: 90.912
- type: ndcg_at_1
value: 87.36
- type: ndcg_at_10
value: 73.076
- type: ndcg_at_100
value: 75.895
- type: ndcg_at_1000
value: 77.049
- type: ndcg_at_3
value: 68.929
- type: ndcg_at_5
value: 71.28
- type: precision_at_1
value: 87.36
- type: precision_at_10
value: 14.741000000000001
- type: precision_at_100
value: 1.694
- type: precision_at_1000
value: 0.185
- type: precision_at_3
value: 43.043
- type: precision_at_5
value: 27.681
- type: recall_at_1
value: 43.68
- type: recall_at_10
value: 73.707
- type: recall_at_100
value: 84.7
- type: recall_at_1000
value: 92.309
- type: recall_at_3
value: 64.564
- type: recall_at_5
value: 69.203
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 96.75399999999999
- type: ap
value: 95.29389839242187
- type: f1
value: 96.75348377433475
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: mteb/msmarco
config: default
split: dev
revision: c5a29a104738b98a9e76336939199e264163d4a0
metrics:
- type: map_at_1
value: 25.176
- type: map_at_10
value: 38.598
- type: map_at_100
value: 39.707
- type: map_at_1000
value: 39.744
- type: map_at_3
value: 34.566
- type: map_at_5
value: 36.863
- type: mrr_at_1
value: 25.874000000000002
- type: mrr_at_10
value: 39.214
- type: mrr_at_100
value: 40.251
- type: mrr_at_1000
value: 40.281
- type: mrr_at_3
value: 35.291
- type: mrr_at_5
value: 37.545
- type: ndcg_at_1
value: 25.874000000000002
- type: ndcg_at_10
value: 45.98
- type: ndcg_at_100
value: 51.197
- type: ndcg_at_1000
value: 52.073
- type: ndcg_at_3
value: 37.785999999999994
- type: ndcg_at_5
value: 41.870000000000005
- type: precision_at_1
value: 25.874000000000002
- type: precision_at_10
value: 7.181
- type: precision_at_100
value: 0.979
- type: precision_at_1000
value: 0.106
- type: precision_at_3
value: 16.051000000000002
- type: precision_at_5
value: 11.713
- type: recall_at_1
value: 25.176
- type: recall_at_10
value: 68.67699999999999
- type: recall_at_100
value: 92.55
- type: recall_at_1000
value: 99.164
- type: recall_at_3
value: 46.372
- type: recall_at_5
value: 56.16
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 99.03784769721841
- type: f1
value: 98.97791641821495
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 91.88326493388054
- type: f1
value: 73.74809928034335
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 85.41358439811701
- type: f1
value: 83.503679460639
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 89.77135171486215
- type: f1
value: 88.89843747468366
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 46.22695362087359
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 44.132372165849425
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 33.35680810650402
- type: mrr
value: 34.72625715637218
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: mteb/nfcorpus
config: default
split: test
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
metrics:
- type: map_at_1
value: 7.165000000000001
- type: map_at_10
value: 15.424
- type: map_at_100
value: 20.28
- type: map_at_1000
value: 22.065
- type: map_at_3
value: 11.236
- type: map_at_5
value: 13.025999999999998
- type: mrr_at_1
value: 51.702999999999996
- type: mrr_at_10
value: 59.965
- type: mrr_at_100
value: 60.667
- type: mrr_at_1000
value: 60.702999999999996
- type: mrr_at_3
value: 58.772000000000006
- type: mrr_at_5
value: 59.267
- type: ndcg_at_1
value: 49.536
- type: ndcg_at_10
value: 40.6
- type: ndcg_at_100
value: 37.848
- type: ndcg_at_1000
value: 46.657
- type: ndcg_at_3
value: 46.117999999999995
- type: ndcg_at_5
value: 43.619
- type: precision_at_1
value: 51.393
- type: precision_at_10
value: 30.31
- type: precision_at_100
value: 9.972
- type: precision_at_1000
value: 2.329
- type: precision_at_3
value: 43.137
- type: precision_at_5
value: 37.585
- type: recall_at_1
value: 7.165000000000001
- type: recall_at_10
value: 19.689999999999998
- type: recall_at_100
value: 39.237
- type: recall_at_1000
value: 71.417
- type: recall_at_3
value: 12.247
- type: recall_at_5
value: 14.902999999999999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: mteb/nq
config: default
split: test
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
metrics:
- type: map_at_1
value: 42.653999999999996
- type: map_at_10
value: 59.611999999999995
- type: map_at_100
value: 60.32300000000001
- type: map_at_1000
value: 60.336
- type: map_at_3
value: 55.584999999999994
- type: map_at_5
value: 58.19
- type: mrr_at_1
value: 47.683
- type: mrr_at_10
value: 62.06700000000001
- type: mrr_at_100
value: 62.537
- type: mrr_at_1000
value: 62.544999999999995
- type: mrr_at_3
value: 59.178
- type: mrr_at_5
value: 61.034
- type: ndcg_at_1
value: 47.654
- type: ndcg_at_10
value: 67.001
- type: ndcg_at_100
value: 69.73899999999999
- type: ndcg_at_1000
value: 69.986
- type: ndcg_at_3
value: 59.95700000000001
- type: ndcg_at_5
value: 64.025
- type: precision_at_1
value: 47.654
- type: precision_at_10
value: 10.367999999999999
- type: precision_at_100
value: 1.192
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 26.651000000000003
- type: precision_at_5
value: 18.459
- type: recall_at_1
value: 42.653999999999996
- type: recall_at_10
value: 86.619
- type: recall_at_100
value: 98.04899999999999
- type: recall_at_1000
value: 99.812
- type: recall_at_3
value: 68.987
- type: recall_at_5
value: 78.158
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: mteb/quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 72.538
- type: map_at_10
value: 86.702
- type: map_at_100
value: 87.31
- type: map_at_1000
value: 87.323
- type: map_at_3
value: 83.87
- type: map_at_5
value: 85.682
- type: mrr_at_1
value: 83.31
- type: mrr_at_10
value: 89.225
- type: mrr_at_100
value: 89.30399999999999
- type: mrr_at_1000
value: 89.30399999999999
- type: mrr_at_3
value: 88.44300000000001
- type: mrr_at_5
value: 89.005
- type: ndcg_at_1
value: 83.32000000000001
- type: ndcg_at_10
value: 90.095
- type: ndcg_at_100
value: 91.12
- type: ndcg_at_1000
value: 91.179
- type: ndcg_at_3
value: 87.606
- type: ndcg_at_5
value: 89.031
- type: precision_at_1
value: 83.32000000000001
- type: precision_at_10
value: 13.641
- type: precision_at_100
value: 1.541
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 38.377
- type: precision_at_5
value: 25.162000000000003
- type: recall_at_1
value: 72.538
- type: recall_at_10
value: 96.47200000000001
- type: recall_at_100
value: 99.785
- type: recall_at_1000
value: 99.99900000000001
- type: recall_at_3
value: 89.278
- type: recall_at_5
value: 93.367
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 73.55219145406065
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 74.13437105242755
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: mteb/scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.873
- type: map_at_10
value: 17.944
- type: map_at_100
value: 21.171
- type: map_at_1000
value: 21.528
- type: map_at_3
value: 12.415
- type: map_at_5
value: 15.187999999999999
- type: mrr_at_1
value: 33.800000000000004
- type: mrr_at_10
value: 46.455
- type: mrr_at_100
value: 47.378
- type: mrr_at_1000
value: 47.394999999999996
- type: mrr_at_3
value: 42.367
- type: mrr_at_5
value: 44.972
- type: ndcg_at_1
value: 33.800000000000004
- type: ndcg_at_10
value: 28.907
- type: ndcg_at_100
value: 39.695
- type: ndcg_at_1000
value: 44.582
- type: ndcg_at_3
value: 26.949
- type: ndcg_at_5
value: 23.988
- type: precision_at_1
value: 33.800000000000004
- type: precision_at_10
value: 15.079999999999998
- type: precision_at_100
value: 3.056
- type: precision_at_1000
value: 0.42100000000000004
- type: precision_at_3
value: 25.167
- type: precision_at_5
value: 21.26
- type: recall_at_1
value: 6.873
- type: recall_at_10
value: 30.568
- type: recall_at_100
value: 62.062
- type: recall_at_1000
value: 85.37700000000001
- type: recall_at_3
value: 15.312999999999999
- type: recall_at_5
value: 21.575
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 82.37009118256057
- type: cos_sim_spearman
value: 79.27986395671529
- type: euclidean_pearson
value: 79.18037715442115
- type: euclidean_spearman
value: 79.28004791561621
- type: manhattan_pearson
value: 79.34062972800541
- type: manhattan_spearman
value: 79.43106695543402
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 87.48474767383833
- type: cos_sim_spearman
value: 79.54505388752513
- type: euclidean_pearson
value: 83.43282704179565
- type: euclidean_spearman
value: 79.54579919925405
- type: manhattan_pearson
value: 83.77564492427952
- type: manhattan_spearman
value: 79.84558396989286
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 88.803698035802
- type: cos_sim_spearman
value: 88.83451367754881
- type: euclidean_pearson
value: 88.28939285711628
- type: euclidean_spearman
value: 88.83528996073112
- type: manhattan_pearson
value: 88.28017412671795
- type: manhattan_spearman
value: 88.9228828016344
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 85.27469288153428
- type: cos_sim_spearman
value: 83.87477064876288
- type: euclidean_pearson
value: 84.2601737035379
- type: euclidean_spearman
value: 83.87431082479074
- type: manhattan_pearson
value: 84.3621547772745
- type: manhattan_spearman
value: 84.12094375000423
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.12749863201587
- type: cos_sim_spearman
value: 88.54287568368565
- type: euclidean_pearson
value: 87.90429700607999
- type: euclidean_spearman
value: 88.5437689576261
- type: manhattan_pearson
value: 88.19276653356833
- type: manhattan_spearman
value: 88.99995393814679
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.68398747560902
- type: cos_sim_spearman
value: 86.48815303460574
- type: euclidean_pearson
value: 85.52356631237954
- type: euclidean_spearman
value: 86.486391949551
- type: manhattan_pearson
value: 85.67267981761788
- type: manhattan_spearman
value: 86.7073696332485
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 88.9057107443124
- type: cos_sim_spearman
value: 88.7312168757697
- type: euclidean_pearson
value: 88.72810439714794
- type: euclidean_spearman
value: 88.71976185854771
- type: manhattan_pearson
value: 88.50433745949111
- type: manhattan_spearman
value: 88.51726175544195
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 67.59391795109886
- type: cos_sim_spearman
value: 66.87613008631367
- type: euclidean_pearson
value: 69.23198488262217
- type: euclidean_spearman
value: 66.85427723013692
- type: manhattan_pearson
value: 69.50730124841084
- type: manhattan_spearman
value: 67.10404669820792
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.0820605344619
- type: cos_sim_spearman
value: 86.8518089863434
- type: euclidean_pearson
value: 86.31087134689284
- type: euclidean_spearman
value: 86.8518520517941
- type: manhattan_pearson
value: 86.47203796160612
- type: manhattan_spearman
value: 87.1080149734421
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 89.09255369305481
- type: mrr
value: 97.10323445617563
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: mteb/scifact
config: default
split: test
revision: 0228b52cf27578f30900b9e5271d331663a030d7
metrics:
- type: map_at_1
value: 61.260999999999996
- type: map_at_10
value: 74.043
- type: map_at_100
value: 74.37700000000001
- type: map_at_1000
value: 74.384
- type: map_at_3
value: 71.222
- type: map_at_5
value: 72.875
- type: mrr_at_1
value: 64.333
- type: mrr_at_10
value: 74.984
- type: mrr_at_100
value: 75.247
- type: mrr_at_1000
value: 75.25500000000001
- type: mrr_at_3
value: 73.167
- type: mrr_at_5
value: 74.35000000000001
- type: ndcg_at_1
value: 64.333
- type: ndcg_at_10
value: 79.06
- type: ndcg_at_100
value: 80.416
- type: ndcg_at_1000
value: 80.55600000000001
- type: ndcg_at_3
value: 74.753
- type: ndcg_at_5
value: 76.97500000000001
- type: precision_at_1
value: 64.333
- type: precision_at_10
value: 10.567
- type: precision_at_100
value: 1.1199999999999999
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 29.889
- type: precision_at_5
value: 19.533
- type: recall_at_1
value: 61.260999999999996
- type: recall_at_10
value: 93.167
- type: recall_at_100
value: 99.0
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 81.667
- type: recall_at_5
value: 87.394
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.71980198019801
- type: cos_sim_ap
value: 92.81616007802704
- type: cos_sim_f1
value: 85.17548454688318
- type: cos_sim_precision
value: 89.43894389438944
- type: cos_sim_recall
value: 81.3
- type: dot_accuracy
value: 99.71980198019801
- type: dot_ap
value: 92.81398760591358
- type: dot_f1
value: 85.17548454688318
- type: dot_precision
value: 89.43894389438944
- type: dot_recall
value: 81.3
- type: euclidean_accuracy
value: 99.71980198019801
- type: euclidean_ap
value: 92.81560637245072
- type: euclidean_f1
value: 85.17548454688318
- type: euclidean_precision
value: 89.43894389438944
- type: euclidean_recall
value: 81.3
- type: manhattan_accuracy
value: 99.73069306930694
- type: manhattan_ap
value: 93.14005487480794
- type: manhattan_f1
value: 85.56263269639068
- type: manhattan_precision
value: 91.17647058823529
- type: manhattan_recall
value: 80.60000000000001
- type: max_accuracy
value: 99.73069306930694
- type: max_ap
value: 93.14005487480794
- type: max_f1
value: 85.56263269639068
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 79.86443362395185
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 49.40897096662564
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.66040806627947
- type: mrr
value: 56.58670475766064
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.51015090598575
- type: cos_sim_spearman
value: 31.35016454939226
- type: dot_pearson
value: 31.5150068731
- type: dot_spearman
value: 31.34790869023487
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: mteb/trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.254
- type: map_at_10
value: 2.064
- type: map_at_100
value: 12.909
- type: map_at_1000
value: 31.761
- type: map_at_3
value: 0.738
- type: map_at_5
value: 1.155
- type: mrr_at_1
value: 96.0
- type: mrr_at_10
value: 98.0
- type: mrr_at_100
value: 98.0
- type: mrr_at_1000
value: 98.0
- type: mrr_at_3
value: 98.0
- type: mrr_at_5
value: 98.0
- type: ndcg_at_1
value: 93.0
- type: ndcg_at_10
value: 82.258
- type: ndcg_at_100
value: 64.34
- type: ndcg_at_1000
value: 57.912
- type: ndcg_at_3
value: 90.827
- type: ndcg_at_5
value: 86.79
- type: precision_at_1
value: 96.0
- type: precision_at_10
value: 84.8
- type: precision_at_100
value: 66.0
- type: precision_at_1000
value: 25.356
- type: precision_at_3
value: 94.667
- type: precision_at_5
value: 90.4
- type: recall_at_1
value: 0.254
- type: recall_at_10
value: 2.1950000000000003
- type: recall_at_100
value: 16.088
- type: recall_at_1000
value: 54.559000000000005
- type: recall_at_3
value: 0.75
- type: recall_at_5
value: 1.191
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: mteb/touche2020
config: default
split: test
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
metrics:
- type: map_at_1
value: 2.976
- type: map_at_10
value: 11.389000000000001
- type: map_at_100
value: 18.429000000000002
- type: map_at_1000
value: 20.113
- type: map_at_3
value: 6.483
- type: map_at_5
value: 8.770999999999999
- type: mrr_at_1
value: 40.816
- type: mrr_at_10
value: 58.118
- type: mrr_at_100
value: 58.489999999999995
- type: mrr_at_1000
value: 58.489999999999995
- type: mrr_at_3
value: 53.061
- type: mrr_at_5
value: 57.041
- type: ndcg_at_1
value: 40.816
- type: ndcg_at_10
value: 30.567
- type: ndcg_at_100
value: 42.44
- type: ndcg_at_1000
value: 53.480000000000004
- type: ndcg_at_3
value: 36.016
- type: ndcg_at_5
value: 34.257
- type: precision_at_1
value: 42.857
- type: precision_at_10
value: 25.714
- type: precision_at_100
value: 8.429
- type: precision_at_1000
value: 1.5939999999999999
- type: precision_at_3
value: 36.735
- type: precision_at_5
value: 33.878
- type: recall_at_1
value: 2.976
- type: recall_at_10
value: 17.854999999999997
- type: recall_at_100
value: 51.833
- type: recall_at_1000
value: 86.223
- type: recall_at_3
value: 7.887
- type: recall_at_5
value: 12.026
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 85.1174
- type: ap
value: 30.169441069345748
- type: f1
value: 69.79254701873245
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 72.58347481607245
- type: f1
value: 72.74877295564937
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 53.90586138221305
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.35769207844072
- type: cos_sim_ap
value: 77.9645072410354
- type: cos_sim_f1
value: 71.32352941176471
- type: cos_sim_precision
value: 66.5903890160183
- type: cos_sim_recall
value: 76.78100263852242
- type: dot_accuracy
value: 87.37557370209214
- type: dot_ap
value: 77.96250046429908
- type: dot_f1
value: 71.28932757557064
- type: dot_precision
value: 66.95249130938586
- type: dot_recall
value: 76.22691292875989
- type: euclidean_accuracy
value: 87.35173153722357
- type: euclidean_ap
value: 77.96520460741593
- type: euclidean_f1
value: 71.32470733210104
- type: euclidean_precision
value: 66.91329479768785
- type: euclidean_recall
value: 76.35883905013192
- type: manhattan_accuracy
value: 87.25636287774931
- type: manhattan_ap
value: 77.77752485611796
- type: manhattan_f1
value: 71.18148599269183
- type: manhattan_precision
value: 66.10859728506787
- type: manhattan_recall
value: 77.0976253298153
- type: max_accuracy
value: 87.37557370209214
- type: max_ap
value: 77.96520460741593
- type: max_f1
value: 71.32470733210104
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.38176737687739
- type: cos_sim_ap
value: 86.58811861657401
- type: cos_sim_f1
value: 79.09430644097604
- type: cos_sim_precision
value: 75.45085977911366
- type: cos_sim_recall
value: 83.10748383122882
- type: dot_accuracy
value: 89.38370784336554
- type: dot_ap
value: 86.58840606004333
- type: dot_f1
value: 79.10179860068133
- type: dot_precision
value: 75.44546153308643
- type: dot_recall
value: 83.13058207576223
- type: euclidean_accuracy
value: 89.38564830985369
- type: euclidean_ap
value: 86.58820721061164
- type: euclidean_f1
value: 79.09070942235888
- type: euclidean_precision
value: 75.38729937194697
- type: euclidean_recall
value: 83.17677856482906
- type: manhattan_accuracy
value: 89.40699344122326
- type: manhattan_ap
value: 86.60631843011362
- type: manhattan_f1
value: 79.14949970570925
- type: manhattan_precision
value: 75.78191039729502
- type: manhattan_recall
value: 82.83030489682784
- type: max_accuracy
value: 89.40699344122326
- type: max_ap
value: 86.60631843011362
- type: max_f1
value: 79.14949970570925
- task:
type: STS
dataset:
name: MTEB AFQMC
type: C-MTEB/AFQMC
config: default
split: validation
revision: b44c3b011063adb25877c13823db83bb193913c4
metrics:
- type: cos_sim_pearson
value: 65.58442135663871
- type: cos_sim_spearman
value: 72.2538631361313
- type: euclidean_pearson
value: 70.97255486607429
- type: euclidean_spearman
value: 72.25374250228647
- type: manhattan_pearson
value: 70.83250199989911
- type: manhattan_spearman
value: 72.14819496536272
- task:
type: STS
dataset:
name: MTEB ATEC
type: C-MTEB/ATEC
config: default
split: test
revision: 0f319b1142f28d00e055a6770f3f726ae9b7d865
metrics:
- type: cos_sim_pearson
value: 59.99478404929932
- type: cos_sim_spearman
value: 62.61836216999812
- type: euclidean_pearson
value: 66.86429811933593
- type: euclidean_spearman
value: 62.6183520374191
- type: manhattan_pearson
value: 66.8063778911633
- type: manhattan_spearman
value: 62.569607573241115
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 53.98400000000001
- type: f1
value: 51.21447361350723
- task:
type: STS
dataset:
name: MTEB BQ
type: C-MTEB/BQ
config: default
split: test
revision: e3dda5e115e487b39ec7e618c0c6a29137052a55
metrics:
- type: cos_sim_pearson
value: 79.11941660686553
- type: cos_sim_spearman
value: 81.25029594540435
- type: euclidean_pearson
value: 82.06973504238826
- type: euclidean_spearman
value: 81.2501989488524
- type: manhattan_pearson
value: 82.10094630392753
- type: manhattan_spearman
value: 81.27987244392389
- task:
type: Clustering
dataset:
name: MTEB CLSClusteringP2P
type: C-MTEB/CLSClusteringP2P
config: default
split: test
revision: 4b6227591c6c1a73bc76b1055f3b7f3588e72476
metrics:
- type: v_measure
value: 47.07270168705156
- task:
type: Clustering
dataset:
name: MTEB CLSClusteringS2S
type: C-MTEB/CLSClusteringS2S
config: default
split: test
revision: e458b3f5414b62b7f9f83499ac1f5497ae2e869f
metrics:
- type: v_measure
value: 45.98511703185043
- task:
type: Reranking
dataset:
name: MTEB CMedQAv1
type: C-MTEB/CMedQAv1-reranking
config: default
split: test
revision: 8d7f1e942507dac42dc58017c1a001c3717da7df
metrics:
- type: map
value: 88.19895157194931
- type: mrr
value: 90.21424603174603
- task:
type: Reranking
dataset:
name: MTEB CMedQAv2
type: C-MTEB/CMedQAv2-reranking
config: default
split: test
revision: 23d186750531a14a0357ca22cd92d712fd512ea0
metrics:
- type: map
value: 88.03317320980119
- type: mrr
value: 89.9461507936508
- task:
type: Retrieval
dataset:
name: MTEB CmedqaRetrieval
type: C-MTEB/CmedqaRetrieval
config: default
split: dev
revision: cd540c506dae1cf9e9a59c3e06f42030d54e7301
metrics:
- type: map_at_1
value: 29.037000000000003
- type: map_at_10
value: 42.001
- type: map_at_100
value: 43.773
- type: map_at_1000
value: 43.878
- type: map_at_3
value: 37.637
- type: map_at_5
value: 40.034
- type: mrr_at_1
value: 43.136
- type: mrr_at_10
value: 51.158
- type: mrr_at_100
value: 52.083
- type: mrr_at_1000
value: 52.12
- type: mrr_at_3
value: 48.733
- type: mrr_at_5
value: 50.025
- type: ndcg_at_1
value: 43.136
- type: ndcg_at_10
value: 48.685
- type: ndcg_at_100
value: 55.513
- type: ndcg_at_1000
value: 57.242000000000004
- type: ndcg_at_3
value: 43.329
- type: ndcg_at_5
value: 45.438
- type: precision_at_1
value: 43.136
- type: precision_at_10
value: 10.56
- type: precision_at_100
value: 1.6129999999999998
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 24.064
- type: precision_at_5
value: 17.269000000000002
- type: recall_at_1
value: 29.037000000000003
- type: recall_at_10
value: 59.245000000000005
- type: recall_at_100
value: 87.355
- type: recall_at_1000
value: 98.74000000000001
- type: recall_at_3
value: 42.99
- type: recall_at_5
value: 49.681999999999995
- task:
type: PairClassification
dataset:
name: MTEB Cmnli
type: C-MTEB/CMNLI
config: default
split: validation
revision: 41bc36f332156f7adc9e38f53777c959b2ae9766
metrics:
- type: cos_sim_accuracy
value: 82.68190018039687
- type: cos_sim_ap
value: 90.18017125327886
- type: cos_sim_f1
value: 83.64080906868193
- type: cos_sim_precision
value: 79.7076890489303
- type: cos_sim_recall
value: 87.98223053542202
- type: dot_accuracy
value: 82.68190018039687
- type: dot_ap
value: 90.18782350103646
- type: dot_f1
value: 83.64242087729039
- type: dot_precision
value: 79.65313028764805
- type: dot_recall
value: 88.05237315875614
- type: euclidean_accuracy
value: 82.68190018039687
- type: euclidean_ap
value: 90.1801957900632
- type: euclidean_f1
value: 83.63636363636364
- type: euclidean_precision
value: 79.52772506852203
- type: euclidean_recall
value: 88.19265840542437
- type: manhattan_accuracy
value: 82.14070956103427
- type: manhattan_ap
value: 89.96178420101427
- type: manhattan_f1
value: 83.21087838578791
- type: manhattan_precision
value: 78.35605121850475
- type: manhattan_recall
value: 88.70703764320785
- type: max_accuracy
value: 82.68190018039687
- type: max_ap
value: 90.18782350103646
- type: max_f1
value: 83.64242087729039
- task:
type: Retrieval
dataset:
name: MTEB CovidRetrieval
type: C-MTEB/CovidRetrieval
config: default
split: dev
revision: 1271c7809071a13532e05f25fb53511ffce77117
metrics:
- type: map_at_1
value: 72.234
- type: map_at_10
value: 80.10000000000001
- type: map_at_100
value: 80.36
- type: map_at_1000
value: 80.363
- type: map_at_3
value: 78.315
- type: map_at_5
value: 79.607
- type: mrr_at_1
value: 72.392
- type: mrr_at_10
value: 80.117
- type: mrr_at_100
value: 80.36999999999999
- type: mrr_at_1000
value: 80.373
- type: mrr_at_3
value: 78.469
- type: mrr_at_5
value: 79.633
- type: ndcg_at_1
value: 72.392
- type: ndcg_at_10
value: 83.651
- type: ndcg_at_100
value: 84.749
- type: ndcg_at_1000
value: 84.83000000000001
- type: ndcg_at_3
value: 80.253
- type: ndcg_at_5
value: 82.485
- type: precision_at_1
value: 72.392
- type: precision_at_10
value: 9.557
- type: precision_at_100
value: 1.004
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 28.732000000000003
- type: precision_at_5
value: 18.377
- type: recall_at_1
value: 72.234
- type: recall_at_10
value: 94.573
- type: recall_at_100
value: 99.368
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 85.669
- type: recall_at_5
value: 91.01700000000001
- task:
type: Retrieval
dataset:
name: MTEB DuRetrieval
type: C-MTEB/DuRetrieval
config: default
split: dev
revision: a1a333e290fe30b10f3f56498e3a0d911a693ced
metrics:
- type: map_at_1
value: 26.173999999999996
- type: map_at_10
value: 80.04
- type: map_at_100
value: 82.94500000000001
- type: map_at_1000
value: 82.98100000000001
- type: map_at_3
value: 55.562999999999995
- type: map_at_5
value: 69.89800000000001
- type: mrr_at_1
value: 89.5
- type: mrr_at_10
value: 92.996
- type: mrr_at_100
value: 93.06400000000001
- type: mrr_at_1000
value: 93.065
- type: mrr_at_3
value: 92.658
- type: mrr_at_5
value: 92.84599999999999
- type: ndcg_at_1
value: 89.5
- type: ndcg_at_10
value: 87.443
- type: ndcg_at_100
value: 90.253
- type: ndcg_at_1000
value: 90.549
- type: ndcg_at_3
value: 85.874
- type: ndcg_at_5
value: 84.842
- type: precision_at_1
value: 89.5
- type: precision_at_10
value: 41.805
- type: precision_at_100
value: 4.827
- type: precision_at_1000
value: 0.49
- type: precision_at_3
value: 76.85
- type: precision_at_5
value: 64.8
- type: recall_at_1
value: 26.173999999999996
- type: recall_at_10
value: 89.101
- type: recall_at_100
value: 98.08099999999999
- type: recall_at_1000
value: 99.529
- type: recall_at_3
value: 57.902
- type: recall_at_5
value: 74.602
- task:
type: Retrieval
dataset:
name: MTEB EcomRetrieval
type: C-MTEB/EcomRetrieval
config: default
split: dev
revision: 687de13dc7294d6fd9be10c6945f9e8fec8166b9
metrics:
- type: map_at_1
value: 56.10000000000001
- type: map_at_10
value: 66.15299999999999
- type: map_at_100
value: 66.625
- type: map_at_1000
value: 66.636
- type: map_at_3
value: 63.632999999999996
- type: map_at_5
value: 65.293
- type: mrr_at_1
value: 56.10000000000001
- type: mrr_at_10
value: 66.15299999999999
- type: mrr_at_100
value: 66.625
- type: mrr_at_1000
value: 66.636
- type: mrr_at_3
value: 63.632999999999996
- type: mrr_at_5
value: 65.293
- type: ndcg_at_1
value: 56.10000000000001
- type: ndcg_at_10
value: 71.146
- type: ndcg_at_100
value: 73.27799999999999
- type: ndcg_at_1000
value: 73.529
- type: ndcg_at_3
value: 66.09
- type: ndcg_at_5
value: 69.08999999999999
- type: precision_at_1
value: 56.10000000000001
- type: precision_at_10
value: 8.68
- type: precision_at_100
value: 0.964
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 24.4
- type: precision_at_5
value: 16.1
- type: recall_at_1
value: 56.10000000000001
- type: recall_at_10
value: 86.8
- type: recall_at_100
value: 96.39999999999999
- type: recall_at_1000
value: 98.3
- type: recall_at_3
value: 73.2
- type: recall_at_5
value: 80.5
- task:
type: Classification
dataset:
name: MTEB IFlyTek
type: C-MTEB/IFlyTek-classification
config: default
split: validation
revision: 421605374b29664c5fc098418fe20ada9bd55f8a
metrics:
- type: accuracy
value: 54.52096960369373
- type: f1
value: 40.930845295808695
- task:
type: Classification
dataset:
name: MTEB JDReview
type: C-MTEB/JDReview-classification
config: default
split: test
revision: b7c64bd89eb87f8ded463478346f76731f07bf8b
metrics:
- type: accuracy
value: 86.51031894934334
- type: ap
value: 55.9516014323483
- type: f1
value: 81.54813679326381
- task:
type: STS
dataset:
name: MTEB LCQMC
type: C-MTEB/LCQMC
config: default
split: test
revision: 17f9b096f80380fce5ed12a9be8be7784b337daf
metrics:
- type: cos_sim_pearson
value: 69.67437838574276
- type: cos_sim_spearman
value: 73.81314174653045
- type: euclidean_pearson
value: 72.63430276680275
- type: euclidean_spearman
value: 73.81358736777001
- type: manhattan_pearson
value: 72.58743833842829
- type: manhattan_spearman
value: 73.7590419009179
- task:
type: Reranking
dataset:
name: MTEB MMarcoReranking
type: C-MTEB/Mmarco-reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 31.648613483640254
- type: mrr
value: 30.37420634920635
- task:
type: Retrieval
dataset:
name: MTEB MMarcoRetrieval
type: C-MTEB/MMarcoRetrieval
config: default
split: dev
revision: 539bbde593d947e2a124ba72651aafc09eb33fc2
metrics:
- type: map_at_1
value: 73.28099999999999
- type: map_at_10
value: 81.977
- type: map_at_100
value: 82.222
- type: map_at_1000
value: 82.22699999999999
- type: map_at_3
value: 80.441
- type: map_at_5
value: 81.46600000000001
- type: mrr_at_1
value: 75.673
- type: mrr_at_10
value: 82.41000000000001
- type: mrr_at_100
value: 82.616
- type: mrr_at_1000
value: 82.621
- type: mrr_at_3
value: 81.094
- type: mrr_at_5
value: 81.962
- type: ndcg_at_1
value: 75.673
- type: ndcg_at_10
value: 85.15599999999999
- type: ndcg_at_100
value: 86.151
- type: ndcg_at_1000
value: 86.26899999999999
- type: ndcg_at_3
value: 82.304
- type: ndcg_at_5
value: 84.009
- type: precision_at_1
value: 75.673
- type: precision_at_10
value: 10.042
- type: precision_at_100
value: 1.052
- type: precision_at_1000
value: 0.106
- type: precision_at_3
value: 30.673000000000002
- type: precision_at_5
value: 19.326999999999998
- type: recall_at_1
value: 73.28099999999999
- type: recall_at_10
value: 94.446
- type: recall_at_100
value: 98.737
- type: recall_at_1000
value: 99.649
- type: recall_at_3
value: 86.984
- type: recall_at_5
value: 91.024
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 81.08607935440484
- type: f1
value: 78.24879986066307
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 86.05917955615332
- type: f1
value: 85.05279279434997
- task:
type: Retrieval
dataset:
name: MTEB MedicalRetrieval
type: C-MTEB/MedicalRetrieval
config: default
split: dev
revision: 2039188fb5800a9803ba5048df7b76e6fb151fc6
metrics:
- type: map_at_1
value: 56.2
- type: map_at_10
value: 62.57899999999999
- type: map_at_100
value: 63.154999999999994
- type: map_at_1000
value: 63.193
- type: map_at_3
value: 61.217
- type: map_at_5
value: 62.012
- type: mrr_at_1
value: 56.3
- type: mrr_at_10
value: 62.629000000000005
- type: mrr_at_100
value: 63.205999999999996
- type: mrr_at_1000
value: 63.244
- type: mrr_at_3
value: 61.267
- type: mrr_at_5
value: 62.062
- type: ndcg_at_1
value: 56.2
- type: ndcg_at_10
value: 65.592
- type: ndcg_at_100
value: 68.657
- type: ndcg_at_1000
value: 69.671
- type: ndcg_at_3
value: 62.808
- type: ndcg_at_5
value: 64.24499999999999
- type: precision_at_1
value: 56.2
- type: precision_at_10
value: 7.5
- type: precision_at_100
value: 0.899
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 22.467000000000002
- type: precision_at_5
value: 14.180000000000001
- type: recall_at_1
value: 56.2
- type: recall_at_10
value: 75.0
- type: recall_at_100
value: 89.9
- type: recall_at_1000
value: 97.89999999999999
- type: recall_at_3
value: 67.4
- type: recall_at_5
value: 70.89999999999999
- task:
type: Classification
dataset:
name: MTEB MultilingualSentiment
type: C-MTEB/MultilingualSentiment-classification
config: default
split: validation
revision: 46958b007a63fdbf239b7672c25d0bea67b5ea1a
metrics:
- type: accuracy
value: 76.87666666666667
- type: f1
value: 76.7317686219665
- task:
type: PairClassification
dataset:
name: MTEB Ocnli
type: C-MTEB/OCNLI
config: default
split: validation
revision: 66e76a618a34d6d565d5538088562851e6daa7ec
metrics:
- type: cos_sim_accuracy
value: 79.64266377910124
- type: cos_sim_ap
value: 84.78274442344829
- type: cos_sim_f1
value: 81.16947472745292
- type: cos_sim_precision
value: 76.47058823529412
- type: cos_sim_recall
value: 86.48363252375924
- type: dot_accuracy
value: 79.64266377910124
- type: dot_ap
value: 84.7851404063692
- type: dot_f1
value: 81.16947472745292
- type: dot_precision
value: 76.47058823529412
- type: dot_recall
value: 86.48363252375924
- type: euclidean_accuracy
value: 79.64266377910124
- type: euclidean_ap
value: 84.78068373762378
- type: euclidean_f1
value: 81.14794656110837
- type: euclidean_precision
value: 76.35009310986965
- type: euclidean_recall
value: 86.58922914466737
- type: manhattan_accuracy
value: 79.48023822414727
- type: manhattan_ap
value: 84.72928897427576
- type: manhattan_f1
value: 81.32084770823064
- type: manhattan_precision
value: 76.24768946395564
- type: manhattan_recall
value: 87.11721224920802
- type: max_accuracy
value: 79.64266377910124
- type: max_ap
value: 84.7851404063692
- type: max_f1
value: 81.32084770823064
- task:
type: Classification
dataset:
name: MTEB OnlineShopping
type: C-MTEB/OnlineShopping-classification
config: default
split: test
revision: e610f2ebd179a8fda30ae534c3878750a96db120
metrics:
- type: accuracy
value: 94.3
- type: ap
value: 92.8664032274438
- type: f1
value: 94.29311102997727
- task:
type: STS
dataset:
name: MTEB PAWSX
type: C-MTEB/PAWSX
config: default
split: test
revision: 9c6a90e430ac22b5779fb019a23e820b11a8b5e1
metrics:
- type: cos_sim_pearson
value: 48.51392279882909
- type: cos_sim_spearman
value: 54.06338895994974
- type: euclidean_pearson
value: 52.58480559573412
- type: euclidean_spearman
value: 54.06417276612201
- type: manhattan_pearson
value: 52.69525121721343
- type: manhattan_spearman
value: 54.048147455389675
- task:
type: STS
dataset:
name: MTEB QBQTC
type: C-MTEB/QBQTC
config: default
split: test
revision: 790b0510dc52b1553e8c49f3d2afb48c0e5c48b7
metrics:
- type: cos_sim_pearson
value: 29.728387290757325
- type: cos_sim_spearman
value: 31.366121633635284
- type: euclidean_pearson
value: 29.14588368552961
- type: euclidean_spearman
value: 31.36764411112844
- type: manhattan_pearson
value: 29.63517350523121
- type: manhattan_spearman
value: 31.94157020583762
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 63.64868296271406
- type: cos_sim_spearman
value: 66.12800618164744
- type: euclidean_pearson
value: 63.21405767340238
- type: euclidean_spearman
value: 66.12786567790748
- type: manhattan_pearson
value: 64.04300276525848
- type: manhattan_spearman
value: 66.5066857145652
- task:
type: STS
dataset:
name: MTEB STSB
type: C-MTEB/STSB
config: default
split: test
revision: 0cde68302b3541bb8b3c340dc0644b0b745b3dc0
metrics:
- type: cos_sim_pearson
value: 81.2302623912794
- type: cos_sim_spearman
value: 81.16833673266562
- type: euclidean_pearson
value: 79.47647843876024
- type: euclidean_spearman
value: 81.16944349524972
- type: manhattan_pearson
value: 79.84947238492208
- type: manhattan_spearman
value: 81.64626599410026
- task:
type: Reranking
dataset:
name: MTEB T2Reranking
type: C-MTEB/T2Reranking
config: default
split: dev
revision: 76631901a18387f85eaa53e5450019b87ad58ef9
metrics:
- type: map
value: 67.80129586475687
- type: mrr
value: 77.77402311635554
- task:
type: Retrieval
dataset:
name: MTEB T2Retrieval
type: C-MTEB/T2Retrieval
config: default
split: dev
revision: 8731a845f1bf500a4f111cf1070785c793d10e64
metrics:
- type: map_at_1
value: 28.666999999999998
- type: map_at_10
value: 81.063
- type: map_at_100
value: 84.504
- type: map_at_1000
value: 84.552
- type: map_at_3
value: 56.897
- type: map_at_5
value: 70.073
- type: mrr_at_1
value: 92.087
- type: mrr_at_10
value: 94.132
- type: mrr_at_100
value: 94.19800000000001
- type: mrr_at_1000
value: 94.19999999999999
- type: mrr_at_3
value: 93.78999999999999
- type: mrr_at_5
value: 94.002
- type: ndcg_at_1
value: 92.087
- type: ndcg_at_10
value: 87.734
- type: ndcg_at_100
value: 90.736
- type: ndcg_at_1000
value: 91.184
- type: ndcg_at_3
value: 88.78
- type: ndcg_at_5
value: 87.676
- type: precision_at_1
value: 92.087
- type: precision_at_10
value: 43.46
- type: precision_at_100
value: 5.07
- type: precision_at_1000
value: 0.518
- type: precision_at_3
value: 77.49000000000001
- type: precision_at_5
value: 65.194
- type: recall_at_1
value: 28.666999999999998
- type: recall_at_10
value: 86.632
- type: recall_at_100
value: 96.646
- type: recall_at_1000
value: 98.917
- type: recall_at_3
value: 58.333999999999996
- type: recall_at_5
value: 72.974
- task:
type: Classification
dataset:
name: MTEB TNews
type: C-MTEB/TNews-classification
config: default
split: validation
revision: 317f262bf1e6126357bbe89e875451e4b0938fe4
metrics:
- type: accuracy
value: 52.971999999999994
- type: f1
value: 50.2898280984929
- task:
type: Clustering
dataset:
name: MTEB ThuNewsClusteringP2P
type: C-MTEB/ThuNewsClusteringP2P
config: default
split: test
revision: 5798586b105c0434e4f0fe5e767abe619442cf93
metrics:
- type: v_measure
value: 86.0797948663824
- task:
type: Clustering
dataset:
name: MTEB ThuNewsClusteringS2S
type: C-MTEB/ThuNewsClusteringS2S
config: default
split: test
revision: 8a8b2caeda43f39e13c4bc5bea0f8a667896e10d
metrics:
- type: v_measure
value: 85.10759092255017
- task:
type: Retrieval
dataset:
name: MTEB VideoRetrieval
type: C-MTEB/VideoRetrieval
config: default
split: dev
revision: 58c2597a5943a2ba48f4668c3b90d796283c5639
metrics:
- type: map_at_1
value: 65.60000000000001
- type: map_at_10
value: 74.773
- type: map_at_100
value: 75.128
- type: map_at_1000
value: 75.136
- type: map_at_3
value: 73.05
- type: map_at_5
value: 74.13499999999999
- type: mrr_at_1
value: 65.60000000000001
- type: mrr_at_10
value: 74.773
- type: mrr_at_100
value: 75.128
- type: mrr_at_1000
value: 75.136
- type: mrr_at_3
value: 73.05
- type: mrr_at_5
value: 74.13499999999999
- type: ndcg_at_1
value: 65.60000000000001
- type: ndcg_at_10
value: 78.84299999999999
- type: ndcg_at_100
value: 80.40899999999999
- type: ndcg_at_1000
value: 80.57
- type: ndcg_at_3
value: 75.40599999999999
- type: ndcg_at_5
value: 77.351
- type: precision_at_1
value: 65.60000000000001
- type: precision_at_10
value: 9.139999999999999
- type: precision_at_100
value: 0.984
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 27.400000000000002
- type: precision_at_5
value: 17.380000000000003
- type: recall_at_1
value: 65.60000000000001
- type: recall_at_10
value: 91.4
- type: recall_at_100
value: 98.4
- type: recall_at_1000
value: 99.6
- type: recall_at_3
value: 82.19999999999999
- type: recall_at_5
value: 86.9
- task:
type: Classification
dataset:
name: MTEB Waimai
type: C-MTEB/waimai-classification
config: default
split: test
revision: 339287def212450dcaa9df8c22bf93e9980c7023
metrics:
- type: accuracy
value: 89.47
- type: ap
value: 75.59561751845389
- type: f1
value: 87.95207751382563
- task:
type: Clustering
dataset:
name: MTEB AlloProfClusteringP2P
type: lyon-nlp/alloprof
config: default
split: test
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
metrics:
- type: v_measure
value: 76.05592323841036
- type: v_measure
value: 64.51718058866508
- task:
type: Reranking
dataset:
name: MTEB AlloprofReranking
type: lyon-nlp/mteb-fr-reranking-alloprof-s2p
config: default
split: test
revision: 666fdacebe0291776e86f29345663dfaf80a0db9
metrics:
- type: map
value: 73.08278490943373
- type: mrr
value: 74.66561454570449
- task:
type: Retrieval
dataset:
name: MTEB AlloprofRetrieval
type: lyon-nlp/alloprof
config: default
split: test
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
metrics:
- type: map_at_1
value: 38.912
- type: map_at_10
value: 52.437999999999995
- type: map_at_100
value: 53.38
- type: map_at_1000
value: 53.427
- type: map_at_3
value: 48.879
- type: map_at_5
value: 50.934000000000005
- type: mrr_at_1
value: 44.085
- type: mrr_at_10
value: 55.337
- type: mrr_at_100
value: 56.016999999999996
- type: mrr_at_1000
value: 56.043
- type: mrr_at_3
value: 52.55499999999999
- type: mrr_at_5
value: 54.20399999999999
- type: ndcg_at_1
value: 44.085
- type: ndcg_at_10
value: 58.876
- type: ndcg_at_100
value: 62.714000000000006
- type: ndcg_at_1000
value: 63.721000000000004
- type: ndcg_at_3
value: 52.444
- type: ndcg_at_5
value: 55.692
- type: precision_at_1
value: 44.085
- type: precision_at_10
value: 9.21
- type: precision_at_100
value: 1.164
- type: precision_at_1000
value: 0.128
- type: precision_at_3
value: 23.043
- type: precision_at_5
value: 15.898000000000001
- type: recall_at_1
value: 38.912
- type: recall_at_10
value: 75.577
- type: recall_at_100
value: 92.038
- type: recall_at_1000
value: 99.325
- type: recall_at_3
value: 58.592
- type: recall_at_5
value: 66.235
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 55.532000000000004
- type: f1
value: 52.5783943471605
- task:
type: Retrieval
dataset:
name: MTEB BSARDRetrieval
type: maastrichtlawtech/bsard
config: default
split: test
revision: 5effa1b9b5fa3b0f9e12523e6e43e5f86a6e6d59
metrics:
- type: map_at_1
value: 8.108
- type: map_at_10
value: 14.710999999999999
- type: map_at_100
value: 15.891
- type: map_at_1000
value: 15.983
- type: map_at_3
value: 12.237
- type: map_at_5
value: 13.679
- type: mrr_at_1
value: 8.108
- type: mrr_at_10
value: 14.710999999999999
- type: mrr_at_100
value: 15.891
- type: mrr_at_1000
value: 15.983
- type: mrr_at_3
value: 12.237
- type: mrr_at_5
value: 13.679
- type: ndcg_at_1
value: 8.108
- type: ndcg_at_10
value: 18.796
- type: ndcg_at_100
value: 25.098
- type: ndcg_at_1000
value: 27.951999999999998
- type: ndcg_at_3
value: 13.712
- type: ndcg_at_5
value: 16.309
- type: precision_at_1
value: 8.108
- type: precision_at_10
value: 3.198
- type: precision_at_100
value: 0.626
- type: precision_at_1000
value: 0.086
- type: precision_at_3
value: 6.006
- type: precision_at_5
value: 4.865
- type: recall_at_1
value: 8.108
- type: recall_at_10
value: 31.982
- type: recall_at_100
value: 62.613
- type: recall_at_1000
value: 86.036
- type: recall_at_3
value: 18.018
- type: recall_at_5
value: 24.324
- task:
type: Clustering
dataset:
name: MTEB HALClusteringS2S
type: lyon-nlp/clustering-hal-s2s
config: default
split: test
revision: e06ebbbb123f8144bef1a5d18796f3dec9ae2915
metrics:
- type: v_measure
value: 30.833269778867116
- task:
type: Clustering
dataset:
name: MTEB MLSUMClusteringP2P
type: mlsum
config: default
split: test
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
metrics:
- type: v_measure
value: 50.0281928004713
- type: v_measure
value: 43.699961510636534
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 96.68963357344191
- type: f1
value: 96.45175170820961
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 87.46946445349202
- type: f1
value: 65.79860440988624
- task:
type: Classification
dataset:
name: MTEB MasakhaNEWSClassification (fra)
type: masakhane/masakhanews
config: fra
split: test
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
metrics:
- type: accuracy
value: 82.60663507109005
- type: f1
value: 77.20462646604777
- task:
type: Clustering
dataset:
name: MTEB MasakhaNEWSClusteringP2P (fra)
type: masakhane/masakhanews
config: fra
split: test
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
metrics:
- type: v_measure
value: 60.19311264967803
- type: v_measure
value: 63.6235764409785
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 81.65097511768661
- type: f1
value: 78.77796091490924
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 86.64425016812373
- type: f1
value: 85.4912728670017
- task:
type: Retrieval
dataset:
name: MTEB MintakaRetrieval (fr)
type: jinaai/mintakaqa
config: fr
split: test
revision: efa78cc2f74bbcd21eff2261f9e13aebe40b814e
metrics:
- type: map_at_1
value: 35.913000000000004
- type: map_at_10
value: 48.147
- type: map_at_100
value: 48.91
- type: map_at_1000
value: 48.949
- type: map_at_3
value: 45.269999999999996
- type: map_at_5
value: 47.115
- type: mrr_at_1
value: 35.913000000000004
- type: mrr_at_10
value: 48.147
- type: mrr_at_100
value: 48.91
- type: mrr_at_1000
value: 48.949
- type: mrr_at_3
value: 45.269999999999996
- type: mrr_at_5
value: 47.115
- type: ndcg_at_1
value: 35.913000000000004
- type: ndcg_at_10
value: 54.03
- type: ndcg_at_100
value: 57.839
- type: ndcg_at_1000
value: 58.925000000000004
- type: ndcg_at_3
value: 48.217999999999996
- type: ndcg_at_5
value: 51.56699999999999
- type: precision_at_1
value: 35.913000000000004
- type: precision_at_10
value: 7.244000000000001
- type: precision_at_100
value: 0.9039999999999999
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 18.905
- type: precision_at_5
value: 12.981000000000002
- type: recall_at_1
value: 35.913000000000004
- type: recall_at_10
value: 72.441
- type: recall_at_100
value: 90.41799999999999
- type: recall_at_1000
value: 99.099
- type: recall_at_3
value: 56.716
- type: recall_at_5
value: 64.90599999999999
- task:
type: PairClassification
dataset:
name: MTEB OpusparcusPC (fr)
type: GEM/opusparcus
config: fr
split: test
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
metrics:
- type: cos_sim_accuracy
value: 99.90069513406156
- type: cos_sim_ap
value: 100.0
- type: cos_sim_f1
value: 99.95032290114257
- type: cos_sim_precision
value: 100.0
- type: cos_sim_recall
value: 99.90069513406156
- type: dot_accuracy
value: 99.90069513406156
- type: dot_ap
value: 100.0
- type: dot_f1
value: 99.95032290114257
- type: dot_precision
value: 100.0
- type: dot_recall
value: 99.90069513406156
- type: euclidean_accuracy
value: 99.90069513406156
- type: euclidean_ap
value: 100.0
- type: euclidean_f1
value: 99.95032290114257
- type: euclidean_precision
value: 100.0
- type: euclidean_recall
value: 99.90069513406156
- type: manhattan_accuracy
value: 99.90069513406156
- type: manhattan_ap
value: 100.0
- type: manhattan_f1
value: 99.95032290114257
- type: manhattan_precision
value: 100.0
- type: manhattan_recall
value: 99.90069513406156
- type: max_accuracy
value: 99.90069513406156
- type: max_ap
value: 100.0
- type: max_f1
value: 99.95032290114257
- task:
type: PairClassification
dataset:
name: MTEB PawsX (fr)
type: paws-x
config: fr
split: test
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
metrics:
- type: cos_sim_accuracy
value: 75.25
- type: cos_sim_ap
value: 80.86376001270014
- type: cos_sim_f1
value: 73.65945437441204
- type: cos_sim_precision
value: 64.02289452166802
- type: cos_sim_recall
value: 86.71096345514951
- type: dot_accuracy
value: 75.25
- type: dot_ap
value: 80.93686107633002
- type: dot_f1
value: 73.65945437441204
- type: dot_precision
value: 64.02289452166802
- type: dot_recall
value: 86.71096345514951
- type: euclidean_accuracy
value: 75.25
- type: euclidean_ap
value: 80.86379136218862
- type: euclidean_f1
value: 73.65945437441204
- type: euclidean_precision
value: 64.02289452166802
- type: euclidean_recall
value: 86.71096345514951
- type: manhattan_accuracy
value: 75.3
- type: manhattan_ap
value: 80.87826606097734
- type: manhattan_f1
value: 73.68421052631581
- type: manhattan_precision
value: 64.0
- type: manhattan_recall
value: 86.82170542635659
- type: max_accuracy
value: 75.3
- type: max_ap
value: 80.93686107633002
- type: max_f1
value: 73.68421052631581
- task:
type: STS
dataset:
name: MTEB SICKFr
type: Lajavaness/SICK-fr
config: default
split: test
revision: e077ab4cf4774a1e36d86d593b150422fafd8e8a
metrics:
- type: cos_sim_pearson
value: 81.42349425981143
- type: cos_sim_spearman
value: 78.90454327031226
- type: euclidean_pearson
value: 78.39086497435166
- type: euclidean_spearman
value: 78.9046133980509
- type: manhattan_pearson
value: 78.63743094286502
- type: manhattan_spearman
value: 79.12136348449269
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 81.452697919749
- type: cos_sim_spearman
value: 82.58116836039301
- type: euclidean_pearson
value: 81.04038478932786
- type: euclidean_spearman
value: 82.58116836039301
- type: manhattan_pearson
value: 81.37075396187771
- type: manhattan_spearman
value: 82.73678231355368
- task:
type: STS
dataset:
name: MTEB STSBenchmarkMultilingualSTS (fr)
type: stsb_multi_mt
config: fr
split: test
revision: 93d57ef91790589e3ce9c365164337a8a78b7632
metrics:
- type: cos_sim_pearson
value: 85.7419764013806
- type: cos_sim_spearman
value: 85.46085808849622
- type: euclidean_pearson
value: 83.70449639870063
- type: euclidean_spearman
value: 85.46159013076233
- type: manhattan_pearson
value: 83.95259510313929
- type: manhattan_spearman
value: 85.8029724659458
- task:
type: Summarization
dataset:
name: MTEB SummEvalFr
type: lyon-nlp/summarization-summeval-fr-p2p
config: default
split: test
revision: b385812de6a9577b6f4d0f88c6a6e35395a94054
metrics:
- type: cos_sim_pearson
value: 32.61063271753325
- type: cos_sim_spearman
value: 31.454589417353603
- type: dot_pearson
value: 32.6106288643431
- type: dot_spearman
value: 31.454589417353603
- task:
type: Reranking
dataset:
name: MTEB SyntecReranking
type: lyon-nlp/mteb-fr-reranking-syntec-s2p
config: default
split: test
revision: b205c5084a0934ce8af14338bf03feb19499c84d
metrics:
- type: map
value: 84.31666666666666
- type: mrr
value: 84.31666666666666
- task:
type: Retrieval
dataset:
name: MTEB SyntecRetrieval
type: lyon-nlp/mteb-fr-retrieval-syntec-s2p
config: default
split: test
revision: 77f7e271bf4a92b24fce5119f3486b583ca016ff
metrics:
- type: map_at_1
value: 63.0
- type: map_at_10
value: 73.471
- type: map_at_100
value: 73.87
- type: map_at_1000
value: 73.87
- type: map_at_3
value: 70.5
- type: map_at_5
value: 73.05
- type: mrr_at_1
value: 63.0
- type: mrr_at_10
value: 73.471
- type: mrr_at_100
value: 73.87
- type: mrr_at_1000
value: 73.87
- type: mrr_at_3
value: 70.5
- type: mrr_at_5
value: 73.05
- type: ndcg_at_1
value: 63.0
- type: ndcg_at_10
value: 78.255
- type: ndcg_at_100
value: 79.88
- type: ndcg_at_1000
value: 79.88
- type: ndcg_at_3
value: 72.702
- type: ndcg_at_5
value: 77.264
- type: precision_at_1
value: 63.0
- type: precision_at_10
value: 9.3
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 26.333000000000002
- type: precision_at_5
value: 18.0
- type: recall_at_1
value: 63.0
- type: recall_at_10
value: 93.0
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 79.0
- type: recall_at_5
value: 90.0
- task:
type: Retrieval
dataset:
name: MTEB XPQARetrieval (fr)
type: jinaai/xpqa
config: fr
split: test
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
metrics:
- type: map_at_1
value: 40.338
- type: map_at_10
value: 61.927
- type: map_at_100
value: 63.361999999999995
- type: map_at_1000
value: 63.405
- type: map_at_3
value: 55.479
- type: map_at_5
value: 59.732
- type: mrr_at_1
value: 63.551
- type: mrr_at_10
value: 71.006
- type: mrr_at_100
value: 71.501
- type: mrr_at_1000
value: 71.509
- type: mrr_at_3
value: 69.07
- type: mrr_at_5
value: 70.165
- type: ndcg_at_1
value: 63.551
- type: ndcg_at_10
value: 68.297
- type: ndcg_at_100
value: 73.13199999999999
- type: ndcg_at_1000
value: 73.751
- type: ndcg_at_3
value: 62.999
- type: ndcg_at_5
value: 64.89
- type: precision_at_1
value: 63.551
- type: precision_at_10
value: 15.661
- type: precision_at_100
value: 1.9789999999999999
- type: precision_at_1000
value: 0.207
- type: precision_at_3
value: 38.273
- type: precision_at_5
value: 27.61
- type: recall_at_1
value: 40.338
- type: recall_at_10
value: 77.267
- type: recall_at_100
value: 95.892
- type: recall_at_1000
value: 99.75500000000001
- type: recall_at_3
value: 60.36
- type: recall_at_5
value: 68.825
- task:
type: Clustering
dataset:
name: MTEB 8TagsClustering
type: PL-MTEB/8tags-clustering
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 51.36126303874126
- task:
type: Classification
dataset:
name: MTEB AllegroReviews
type: PL-MTEB/allegro-reviews
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 67.13717693836979
- type: f1
value: 57.27609848003782
- task:
type: Retrieval
dataset:
name: MTEB ArguAna-PL
type: clarin-knext/arguana-pl
config: default
split: test
revision: 63fc86750af76253e8c760fc9e534bbf24d260a2
metrics:
- type: map_at_1
value: 35.276999999999994
- type: map_at_10
value: 51.086
- type: map_at_100
value: 51.788000000000004
- type: map_at_1000
value: 51.791
- type: map_at_3
value: 46.147
- type: map_at_5
value: 49.078
- type: mrr_at_1
value: 35.917
- type: mrr_at_10
value: 51.315999999999995
- type: mrr_at_100
value: 52.018
- type: mrr_at_1000
value: 52.022
- type: mrr_at_3
value: 46.349000000000004
- type: mrr_at_5
value: 49.297000000000004
- type: ndcg_at_1
value: 35.276999999999994
- type: ndcg_at_10
value: 59.870999999999995
- type: ndcg_at_100
value: 62.590999999999994
- type: ndcg_at_1000
value: 62.661
- type: ndcg_at_3
value: 49.745
- type: ndcg_at_5
value: 55.067
- type: precision_at_1
value: 35.276999999999994
- type: precision_at_10
value: 8.791
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.057
- type: precision_at_5
value: 14.637
- type: recall_at_1
value: 35.276999999999994
- type: recall_at_10
value: 87.909
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 60.171
- type: recall_at_5
value: 73.18599999999999
- task:
type: Classification
dataset:
name: MTEB CBD
type: PL-MTEB/cbd
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 78.03000000000002
- type: ap
value: 29.12548553897622
- type: f1
value: 66.54857118886073
- task:
type: PairClassification
dataset:
name: MTEB CDSC-E
type: PL-MTEB/cdsce-pairclassification
config: default
split: test
revision: None
metrics:
- type: cos_sim_accuracy
value: 89.0
- type: cos_sim_ap
value: 76.75437826834582
- type: cos_sim_f1
value: 66.4850136239782
- type: cos_sim_precision
value: 68.92655367231639
- type: cos_sim_recall
value: 64.21052631578948
- type: dot_accuracy
value: 89.0
- type: dot_ap
value: 76.75437826834582
- type: dot_f1
value: 66.4850136239782
- type: dot_precision
value: 68.92655367231639
- type: dot_recall
value: 64.21052631578948
- type: euclidean_accuracy
value: 89.0
- type: euclidean_ap
value: 76.75437826834582
- type: euclidean_f1
value: 66.4850136239782
- type: euclidean_precision
value: 68.92655367231639
- type: euclidean_recall
value: 64.21052631578948
- type: manhattan_accuracy
value: 89.0
- type: manhattan_ap
value: 76.66074220647083
- type: manhattan_f1
value: 66.47058823529412
- type: manhattan_precision
value: 75.33333333333333
- type: manhattan_recall
value: 59.473684210526315
- type: max_accuracy
value: 89.0
- type: max_ap
value: 76.75437826834582
- type: max_f1
value: 66.4850136239782
- task:
type: STS
dataset:
name: MTEB CDSC-R
type: PL-MTEB/cdscr-sts
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 93.12903172428328
- type: cos_sim_spearman
value: 92.66381487060741
- type: euclidean_pearson
value: 90.37278396708922
- type: euclidean_spearman
value: 92.66381487060741
- type: manhattan_pearson
value: 90.32503296540962
- type: manhattan_spearman
value: 92.6902938354313
- task:
type: Retrieval
dataset:
name: MTEB DBPedia-PL
type: clarin-knext/dbpedia-pl
config: default
split: test
revision: 76afe41d9af165cc40999fcaa92312b8b012064a
metrics:
- type: map_at_1
value: 8.83
- type: map_at_10
value: 18.326
- type: map_at_100
value: 26.496
- type: map_at_1000
value: 28.455000000000002
- type: map_at_3
value: 12.933
- type: map_at_5
value: 15.168000000000001
- type: mrr_at_1
value: 66.0
- type: mrr_at_10
value: 72.76700000000001
- type: mrr_at_100
value: 73.203
- type: mrr_at_1000
value: 73.219
- type: mrr_at_3
value: 71.458
- type: mrr_at_5
value: 72.246
- type: ndcg_at_1
value: 55.375
- type: ndcg_at_10
value: 41.3
- type: ndcg_at_100
value: 45.891
- type: ndcg_at_1000
value: 52.905
- type: ndcg_at_3
value: 46.472
- type: ndcg_at_5
value: 43.734
- type: precision_at_1
value: 66.0
- type: precision_at_10
value: 33.074999999999996
- type: precision_at_100
value: 11.094999999999999
- type: precision_at_1000
value: 2.374
- type: precision_at_3
value: 48.583
- type: precision_at_5
value: 42.0
- type: recall_at_1
value: 8.83
- type: recall_at_10
value: 22.587
- type: recall_at_100
value: 50.61600000000001
- type: recall_at_1000
value: 73.559
- type: recall_at_3
value: 13.688
- type: recall_at_5
value: 16.855
- task:
type: Retrieval
dataset:
name: MTEB FiQA-PL
type: clarin-knext/fiqa-pl
config: default
split: test
revision: 2e535829717f8bf9dc829b7f911cc5bbd4e6608e
metrics:
- type: map_at_1
value: 20.587
- type: map_at_10
value: 33.095
- type: map_at_100
value: 35.24
- type: map_at_1000
value: 35.429
- type: map_at_3
value: 28.626
- type: map_at_5
value: 31.136999999999997
- type: mrr_at_1
value: 40.586
- type: mrr_at_10
value: 49.033
- type: mrr_at_100
value: 49.952999999999996
- type: mrr_at_1000
value: 49.992
- type: mrr_at_3
value: 46.553
- type: mrr_at_5
value: 48.035
- type: ndcg_at_1
value: 40.586
- type: ndcg_at_10
value: 41.046
- type: ndcg_at_100
value: 48.586
- type: ndcg_at_1000
value: 51.634
- type: ndcg_at_3
value: 36.773
- type: ndcg_at_5
value: 38.389
- type: precision_at_1
value: 40.586
- type: precision_at_10
value: 11.466
- type: precision_at_100
value: 1.909
- type: precision_at_1000
value: 0.245
- type: precision_at_3
value: 24.434
- type: precision_at_5
value: 18.426000000000002
- type: recall_at_1
value: 20.587
- type: recall_at_10
value: 47.986000000000004
- type: recall_at_100
value: 75.761
- type: recall_at_1000
value: 94.065
- type: recall_at_3
value: 33.339
- type: recall_at_5
value: 39.765
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA-PL
type: clarin-knext/hotpotqa-pl
config: default
split: test
revision: a0bd479ac97b4ccb5bd6ce320c415d0bb4beb907
metrics:
- type: map_at_1
value: 40.878
- type: map_at_10
value: 58.775999999999996
- type: map_at_100
value: 59.632
- type: map_at_1000
value: 59.707
- type: map_at_3
value: 56.074
- type: map_at_5
value: 57.629
- type: mrr_at_1
value: 81.756
- type: mrr_at_10
value: 86.117
- type: mrr_at_100
value: 86.299
- type: mrr_at_1000
value: 86.30600000000001
- type: mrr_at_3
value: 85.345
- type: mrr_at_5
value: 85.832
- type: ndcg_at_1
value: 81.756
- type: ndcg_at_10
value: 67.608
- type: ndcg_at_100
value: 70.575
- type: ndcg_at_1000
value: 71.99600000000001
- type: ndcg_at_3
value: 63.723
- type: ndcg_at_5
value: 65.70700000000001
- type: precision_at_1
value: 81.756
- type: precision_at_10
value: 13.619
- type: precision_at_100
value: 1.5939999999999999
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 39.604
- type: precision_at_5
value: 25.332
- type: recall_at_1
value: 40.878
- type: recall_at_10
value: 68.096
- type: recall_at_100
value: 79.696
- type: recall_at_1000
value: 89.082
- type: recall_at_3
value: 59.406000000000006
- type: recall_at_5
value: 63.329
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO-PL
type: clarin-knext/msmarco-pl
config: default
split: test
revision: 8634c07806d5cce3a6138e260e59b81760a0a640
metrics:
- type: map_at_1
value: 2.1839999999999997
- type: map_at_10
value: 11.346
- type: map_at_100
value: 30.325000000000003
- type: map_at_1000
value: 37.806
- type: map_at_3
value: 4.842
- type: map_at_5
value: 6.891
- type: mrr_at_1
value: 86.047
- type: mrr_at_10
value: 89.14699999999999
- type: mrr_at_100
value: 89.46600000000001
- type: mrr_at_1000
value: 89.46600000000001
- type: mrr_at_3
value: 89.14699999999999
- type: mrr_at_5
value: 89.14699999999999
- type: ndcg_at_1
value: 67.829
- type: ndcg_at_10
value: 62.222
- type: ndcg_at_100
value: 55.337
- type: ndcg_at_1000
value: 64.076
- type: ndcg_at_3
value: 68.12700000000001
- type: ndcg_at_5
value: 64.987
- type: precision_at_1
value: 86.047
- type: precision_at_10
value: 69.535
- type: precision_at_100
value: 32.93
- type: precision_at_1000
value: 6.6049999999999995
- type: precision_at_3
value: 79.845
- type: precision_at_5
value: 75.349
- type: recall_at_1
value: 2.1839999999999997
- type: recall_at_10
value: 12.866
- type: recall_at_100
value: 43.505
- type: recall_at_1000
value: 72.366
- type: recall_at_3
value: 4.947
- type: recall_at_5
value: 7.192
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 80.75319435104238
- type: f1
value: 77.58961444860606
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 85.54472091459313
- type: f1
value: 84.29498563572106
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus-PL
type: clarin-knext/nfcorpus-pl
config: default
split: test
revision: 9a6f9567fda928260afed2de480d79c98bf0bec0
metrics:
- type: map_at_1
value: 4.367
- type: map_at_10
value: 10.38
- type: map_at_100
value: 13.516
- type: map_at_1000
value: 14.982000000000001
- type: map_at_3
value: 7.367
- type: map_at_5
value: 8.59
- type: mrr_at_1
value: 41.486000000000004
- type: mrr_at_10
value: 48.886
- type: mrr_at_100
value: 49.657000000000004
- type: mrr_at_1000
value: 49.713
- type: mrr_at_3
value: 46.904
- type: mrr_at_5
value: 48.065000000000005
- type: ndcg_at_1
value: 40.402
- type: ndcg_at_10
value: 30.885
- type: ndcg_at_100
value: 28.393
- type: ndcg_at_1000
value: 37.428
- type: ndcg_at_3
value: 35.394999999999996
- type: ndcg_at_5
value: 33.391999999999996
- type: precision_at_1
value: 41.486000000000004
- type: precision_at_10
value: 23.437
- type: precision_at_100
value: 7.638
- type: precision_at_1000
value: 2.0389999999999997
- type: precision_at_3
value: 32.817
- type: precision_at_5
value: 28.915999999999997
- type: recall_at_1
value: 4.367
- type: recall_at_10
value: 14.655000000000001
- type: recall_at_100
value: 29.665999999999997
- type: recall_at_1000
value: 62.073
- type: recall_at_3
value: 8.51
- type: recall_at_5
value: 10.689
- task:
type: Retrieval
dataset:
name: MTEB NQ-PL
type: clarin-knext/nq-pl
config: default
split: test
revision: f171245712cf85dd4700b06bef18001578d0ca8d
metrics:
- type: map_at_1
value: 28.616000000000003
- type: map_at_10
value: 41.626000000000005
- type: map_at_100
value: 42.689
- type: map_at_1000
value: 42.733
- type: map_at_3
value: 37.729
- type: map_at_5
value: 39.879999999999995
- type: mrr_at_1
value: 32.068000000000005
- type: mrr_at_10
value: 44.029
- type: mrr_at_100
value: 44.87
- type: mrr_at_1000
value: 44.901
- type: mrr_at_3
value: 40.687
- type: mrr_at_5
value: 42.625
- type: ndcg_at_1
value: 32.068000000000005
- type: ndcg_at_10
value: 48.449999999999996
- type: ndcg_at_100
value: 53.13
- type: ndcg_at_1000
value: 54.186
- type: ndcg_at_3
value: 40.983999999999995
- type: ndcg_at_5
value: 44.628
- type: precision_at_1
value: 32.068000000000005
- type: precision_at_10
value: 7.9750000000000005
- type: precision_at_100
value: 1.061
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 18.404999999999998
- type: precision_at_5
value: 13.111
- type: recall_at_1
value: 28.616000000000003
- type: recall_at_10
value: 66.956
- type: recall_at_100
value: 87.657
- type: recall_at_1000
value: 95.548
- type: recall_at_3
value: 47.453
- type: recall_at_5
value: 55.87800000000001
- task:
type: Classification
dataset:
name: MTEB PAC
type: laugustyniak/abusive-clauses-pl
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 69.04141326382856
- type: ap
value: 77.47589122111044
- type: f1
value: 66.6332277374775
- task:
type: PairClassification
dataset:
name: MTEB PPC
type: PL-MTEB/ppc-pairclassification
config: default
split: test
revision: None
metrics:
- type: cos_sim_accuracy
value: 86.4
- type: cos_sim_ap
value: 94.1044939667201
- type: cos_sim_f1
value: 88.78048780487805
- type: cos_sim_precision
value: 87.22044728434504
- type: cos_sim_recall
value: 90.39735099337747
- type: dot_accuracy
value: 86.4
- type: dot_ap
value: 94.1044939667201
- type: dot_f1
value: 88.78048780487805
- type: dot_precision
value: 87.22044728434504
- type: dot_recall
value: 90.39735099337747
- type: euclidean_accuracy
value: 86.4
- type: euclidean_ap
value: 94.1044939667201
- type: euclidean_f1
value: 88.78048780487805
- type: euclidean_precision
value: 87.22044728434504
- type: euclidean_recall
value: 90.39735099337747
- type: manhattan_accuracy
value: 86.4
- type: manhattan_ap
value: 94.11438365697387
- type: manhattan_f1
value: 88.77968877968877
- type: manhattan_precision
value: 87.84440842787681
- type: manhattan_recall
value: 89.73509933774835
- type: max_accuracy
value: 86.4
- type: max_ap
value: 94.11438365697387
- type: max_f1
value: 88.78048780487805
- task:
type: PairClassification
dataset:
name: MTEB PSC
type: PL-MTEB/psc-pairclassification
config: default
split: test
revision: None
metrics:
- type: cos_sim_accuracy
value: 97.86641929499072
- type: cos_sim_ap
value: 99.36904211868182
- type: cos_sim_f1
value: 96.56203288490283
- type: cos_sim_precision
value: 94.72140762463343
- type: cos_sim_recall
value: 98.47560975609755
- type: dot_accuracy
value: 97.86641929499072
- type: dot_ap
value: 99.36904211868183
- type: dot_f1
value: 96.56203288490283
- type: dot_precision
value: 94.72140762463343
- type: dot_recall
value: 98.47560975609755
- type: euclidean_accuracy
value: 97.86641929499072
- type: euclidean_ap
value: 99.36904211868183
- type: euclidean_f1
value: 96.56203288490283
- type: euclidean_precision
value: 94.72140762463343
- type: euclidean_recall
value: 98.47560975609755
- type: manhattan_accuracy
value: 98.14471243042672
- type: manhattan_ap
value: 99.43359540492416
- type: manhattan_f1
value: 96.98795180722892
- type: manhattan_precision
value: 95.83333333333334
- type: manhattan_recall
value: 98.17073170731707
- type: max_accuracy
value: 98.14471243042672
- type: max_ap
value: 99.43359540492416
- type: max_f1
value: 96.98795180722892
- task:
type: Classification
dataset:
name: MTEB PolEmo2.0-IN
type: PL-MTEB/polemo2_in
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 89.39058171745152
- type: f1
value: 86.8552093529568
- task:
type: Classification
dataset:
name: MTEB PolEmo2.0-OUT
type: PL-MTEB/polemo2_out
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 74.97975708502024
- type: f1
value: 58.73081628832407
- task:
type: Retrieval
dataset:
name: MTEB Quora-PL
type: clarin-knext/quora-pl
config: default
split: test
revision: 0be27e93455051e531182b85e85e425aba12e9d4
metrics:
- type: map_at_1
value: 64.917
- type: map_at_10
value: 78.74600000000001
- type: map_at_100
value: 79.501
- type: map_at_1000
value: 79.524
- type: map_at_3
value: 75.549
- type: map_at_5
value: 77.495
- type: mrr_at_1
value: 74.9
- type: mrr_at_10
value: 82.112
- type: mrr_at_100
value: 82.314
- type: mrr_at_1000
value: 82.317
- type: mrr_at_3
value: 80.745
- type: mrr_at_5
value: 81.607
- type: ndcg_at_1
value: 74.83999999999999
- type: ndcg_at_10
value: 83.214
- type: ndcg_at_100
value: 84.997
- type: ndcg_at_1000
value: 85.207
- type: ndcg_at_3
value: 79.547
- type: ndcg_at_5
value: 81.46600000000001
- type: precision_at_1
value: 74.83999999999999
- type: precision_at_10
value: 12.822
- type: precision_at_100
value: 1.506
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 34.903
- type: precision_at_5
value: 23.16
- type: recall_at_1
value: 64.917
- type: recall_at_10
value: 92.27199999999999
- type: recall_at_100
value: 98.715
- type: recall_at_1000
value: 99.854
- type: recall_at_3
value: 82.04599999999999
- type: recall_at_5
value: 87.2
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS-PL
type: clarin-knext/scidocs-pl
config: default
split: test
revision: 45452b03f05560207ef19149545f168e596c9337
metrics:
- type: map_at_1
value: 3.51
- type: map_at_10
value: 9.046999999999999
- type: map_at_100
value: 10.823
- type: map_at_1000
value: 11.144
- type: map_at_3
value: 6.257
- type: map_at_5
value: 7.648000000000001
- type: mrr_at_1
value: 17.299999999999997
- type: mrr_at_10
value: 27.419
- type: mrr_at_100
value: 28.618
- type: mrr_at_1000
value: 28.685
- type: mrr_at_3
value: 23.817
- type: mrr_at_5
value: 25.927
- type: ndcg_at_1
value: 17.299999999999997
- type: ndcg_at_10
value: 16.084
- type: ndcg_at_100
value: 23.729
- type: ndcg_at_1000
value: 29.476999999999997
- type: ndcg_at_3
value: 14.327000000000002
- type: ndcg_at_5
value: 13.017999999999999
- type: precision_at_1
value: 17.299999999999997
- type: precision_at_10
value: 8.63
- type: precision_at_100
value: 1.981
- type: precision_at_1000
value: 0.336
- type: precision_at_3
value: 13.4
- type: precision_at_5
value: 11.700000000000001
- type: recall_at_1
value: 3.51
- type: recall_at_10
value: 17.518
- type: recall_at_100
value: 40.275
- type: recall_at_1000
value: 68.203
- type: recall_at_3
value: 8.155
- type: recall_at_5
value: 11.875
- task:
type: PairClassification
dataset:
name: MTEB SICK-E-PL
type: PL-MTEB/sicke-pl-pairclassification
config: default
split: test
revision: None
metrics:
- type: cos_sim_accuracy
value: 86.30248675091724
- type: cos_sim_ap
value: 83.6756734006714
- type: cos_sim_f1
value: 74.97367497367497
- type: cos_sim_precision
value: 73.91003460207612
- type: cos_sim_recall
value: 76.06837606837607
- type: dot_accuracy
value: 86.30248675091724
- type: dot_ap
value: 83.6756734006714
- type: dot_f1
value: 74.97367497367497
- type: dot_precision
value: 73.91003460207612
- type: dot_recall
value: 76.06837606837607
- type: euclidean_accuracy
value: 86.30248675091724
- type: euclidean_ap
value: 83.67566984333091
- type: euclidean_f1
value: 74.97367497367497
- type: euclidean_precision
value: 73.91003460207612
- type: euclidean_recall
value: 76.06837606837607
- type: manhattan_accuracy
value: 86.28210354667753
- type: manhattan_ap
value: 83.64216119130171
- type: manhattan_f1
value: 74.92152075340078
- type: manhattan_precision
value: 73.4107997265892
- type: manhattan_recall
value: 76.49572649572649
- type: max_accuracy
value: 86.30248675091724
- type: max_ap
value: 83.6756734006714
- type: max_f1
value: 74.97367497367497
- task:
type: STS
dataset:
name: MTEB SICK-R-PL
type: PL-MTEB/sickr-pl-sts
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 82.23295940859121
- type: cos_sim_spearman
value: 78.89329160768719
- type: euclidean_pearson
value: 79.56019107076818
- type: euclidean_spearman
value: 78.89330209904084
- type: manhattan_pearson
value: 79.76098513973719
- type: manhattan_spearman
value: 79.05490162570123
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 37.732606308062486
- type: cos_sim_spearman
value: 41.01645667030284
- type: euclidean_pearson
value: 26.61722556367085
- type: euclidean_spearman
value: 41.01645667030284
- type: manhattan_pearson
value: 26.60917378970807
- type: manhattan_spearman
value: 41.51335727617614
- task:
type: Retrieval
dataset:
name: MTEB SciFact-PL
type: clarin-knext/scifact-pl
config: default
split: test
revision: 47932a35f045ef8ed01ba82bf9ff67f6e109207e
metrics:
- type: map_at_1
value: 54.31700000000001
- type: map_at_10
value: 65.564
- type: map_at_100
value: 66.062
- type: map_at_1000
value: 66.08699999999999
- type: map_at_3
value: 62.592999999999996
- type: map_at_5
value: 63.888
- type: mrr_at_1
value: 56.99999999999999
- type: mrr_at_10
value: 66.412
- type: mrr_at_100
value: 66.85900000000001
- type: mrr_at_1000
value: 66.88
- type: mrr_at_3
value: 64.22200000000001
- type: mrr_at_5
value: 65.206
- type: ndcg_at_1
value: 56.99999999999999
- type: ndcg_at_10
value: 70.577
- type: ndcg_at_100
value: 72.879
- type: ndcg_at_1000
value: 73.45
- type: ndcg_at_3
value: 65.5
- type: ndcg_at_5
value: 67.278
- type: precision_at_1
value: 56.99999999999999
- type: precision_at_10
value: 9.667
- type: precision_at_100
value: 1.083
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.0
- type: precision_at_5
value: 16.933
- type: recall_at_1
value: 54.31700000000001
- type: recall_at_10
value: 85.056
- type: recall_at_100
value: 95.667
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 71.0
- type: recall_at_5
value: 75.672
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID-PL
type: clarin-knext/trec-covid-pl
config: default
split: test
revision: 81bcb408f33366c2a20ac54adafad1ae7e877fdd
metrics:
- type: map_at_1
value: 0.245
- type: map_at_10
value: 2.051
- type: map_at_100
value: 12.009
- type: map_at_1000
value: 27.448
- type: map_at_3
value: 0.721
- type: map_at_5
value: 1.13
- type: mrr_at_1
value: 88.0
- type: mrr_at_10
value: 93.0
- type: mrr_at_100
value: 93.0
- type: mrr_at_1000
value: 93.0
- type: mrr_at_3
value: 93.0
- type: mrr_at_5
value: 93.0
- type: ndcg_at_1
value: 85.0
- type: ndcg_at_10
value: 80.303
- type: ndcg_at_100
value: 61.23499999999999
- type: ndcg_at_1000
value: 52.978
- type: ndcg_at_3
value: 84.419
- type: ndcg_at_5
value: 82.976
- type: precision_at_1
value: 88.0
- type: precision_at_10
value: 83.39999999999999
- type: precision_at_100
value: 61.96
- type: precision_at_1000
value: 22.648
- type: precision_at_3
value: 89.333
- type: precision_at_5
value: 87.2
- type: recall_at_1
value: 0.245
- type: recall_at_10
value: 2.193
- type: recall_at_100
value: 14.938
- type: recall_at_1000
value: 48.563
- type: recall_at_3
value: 0.738
- type: recall_at_5
value: 1.173
---
## gte-Qwen2-7B-instruct
**gte-Qwen2-7B-instruct** is the latest model in the gte (General Text Embedding) model family that ranks **No.1** in both English and Chinese evaluations on the Massive Text Embedding Benchmark [MTEB benchmark](https://huggingface.co/spaces/mteb/leaderboard) (as of June 16, 2024).
Recently, the [**Qwen team**](https://huggingface.co/Qwen) released the Qwen2 series models, and we have trained the **gte-Qwen2-7B-instruct** model based on the [Qwen2-7B](https://huggingface.co/Qwen/Qwen2-7B) LLM model. Compared to the [gte-Qwen1.5-7B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen1.5-7B-instruct) model, the **gte-Qwen2-7B-instruct** model uses the same training data and training strategies during the finetuning stage, with the only difference being the upgraded base model to Qwen2-7B. Considering the improvements in the Qwen2 series models compared to the Qwen1.5 series, we can also expect consistent performance enhancements in the embedding models.
The model incorporates several key advancements:
- Integration of bidirectional attention mechanisms, enriching its contextual understanding.
- Instruction tuning, applied solely on the query side for streamlined efficiency
- Comprehensive training across a vast, multilingual text corpus spanning diverse domains and scenarios. This training leverages both weakly supervised and supervised data, ensuring the model's applicability across numerous languages and a wide array of downstream tasks.
## Model Information
- Model Size: 7B
- Embedding Dimension: 3584
- Max Input Tokens: 32k
## Requirements
```
transformers>=4.39.2
flash_attn>=2.5.6
```
## Usage
### Sentence Transformers
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-Qwen2-7B-instruct", trust_remote_code=True)
# In case you want to reduce the maximum length:
model.max_seq_length = 8192
queries = [
"how much protein should a female eat",
"summit define",
]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments.",
]
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
scores = (query_embeddings @ document_embeddings.T) * 100
print(scores.tolist())
```
Observe the [config_sentence_transformers.json](config_sentence_transformers.json) to see all pre-built prompt names. Otherwise, you can use `model.encode(queries, prompt="Instruct: ...\nQuery: "` to use a custom prompt of your choice.
### Transformers
```python
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'how much protein should a female eat'),
get_detailed_instruct(task, 'summit define')
]
# No need to add instruction for retrieval documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Alibaba-NLP/gte-Qwen2-7B-instruct', trust_remote_code=True)
model = AutoModel.from_pretrained('Alibaba-NLP/gte-Qwen2-7B-instruct', trust_remote_code=True)
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=max_length, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Evaluation
### MTEB & C-MTEB
You can use the [scripts/eval_mteb.py](https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct/blob/main/scripts/eval_mteb.py) to reproduce the following result of **gte-Qwen2-7B-instruct** on MTEB(English)/C-MTEB(Chinese):
| Model Name | MTEB(56) | C-MTEB(35) | MTEB-fr(26) | MTEB-pl(26) |
|:----:|:---------:|:----------:|:----------:|:----------:|
| [bge-base-en-1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 64.23 | - | - | - |
| [bge-large-en-1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 63.55 | - | - | - |
| [gte-large-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5) | 65.39 | - | - | - |
| [gte-base-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5) | 64.11 | - | - | - |
| [mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) | 64.68 | - | - | - |
| [acge_text_embedding](https://huggingface.co/aspire/acge_text_embedding) | - | 69.07 | - | - |
| [stella-mrl-large-zh-v3.5-1792d](https://huggingface.co/infgrad/stella-mrl-large-zh-v3.5-1792d) | - | 68.55 | - | - |
| [gte-large-zh](https://huggingface.co/thenlper/gte-large-zh) | - | 66.72 | - | - |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 59.45 | 56.21 | - | - |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 61.50 | 58.81 | - | - |
| [e5-mistral-7b-instruct](https://huggingface.co/intfloat/e5-mistral-7b-instruct) | 66.63 | 60.81 | - | - |
| [gte-Qwen1.5-7B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen1.5-7B-instruct) | 67.34 | 69.52 | - | - |
| [NV-Embed-v1](https://huggingface.co/nvidia/NV-Embed-v1) | 69.32 | - | - | - |
| [**gte-Qwen2-7B-instruct**](https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct) | **70.24** | **72.05** | **68.25** | **67.86** |
| gte-Qwen2-1.5B-instruc(https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct) | 67.16 | 67.65 | 66.60 | 64.04 |
### GTE Models
The gte series models have consistently released two types of models: encoder-only models (based on the BERT architecture) and decode-only models (based on the LLM architecture).
| Models | Language | Max Sequence Length | Dimension | Model Size (Memory Usage, fp32) |
|:-------------------------------------------------------------------------------------:|:--------:|:-----: |:---------:|:-------------------------------:|
| [GTE-large-zh](https://huggingface.co/thenlper/gte-large-zh) | Chinese | 512 | 1024 | 1.25GB |
| [GTE-base-zh](https://huggingface.co/thenlper/gte-base-zh) | Chinese | 512 | 512 | 0.41GB |
| [GTE-small-zh](https://huggingface.co/thenlper/gte-small-zh) | Chinese | 512 | 512 | 0.12GB |
| [GTE-large](https://huggingface.co/thenlper/gte-large) | English | 512 | 1024 | 1.25GB |
| [GTE-base](https://huggingface.co/thenlper/gte-base) | English | 512 | 512 | 0.21GB |
| [GTE-small](https://huggingface.co/thenlper/gte-small) | English | 512 | 384 | 0.10GB |
| [GTE-large-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5) | English | 8192 | 1024 | 1.74GB |
| [GTE-base-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5) | English | 8192 | 768 | 0.51GB |
| [GTE-Qwen1.5-7B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen1.5-7B-instruct) | Multilingual | 32000 | 4096 | 26.45GB |
| [GTE-Qwen2-7B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct) | Multilingual | 32000 | 3584 | 26.45GB |
| [GTE-Qwen2-1.5B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct) | Multilingual | 32000 | 1536 | 6.62GB |
## Cloud API Services
In addition to the open-source [GTE](https://huggingface.co/collections/Alibaba-NLP/gte-models-6680f0b13f885cb431e6d469) series models, GTE series models are also available as commercial API services on Alibaba Cloud.
- [Embedding Models](https://help.aliyun.com/zh/model-studio/developer-reference/general-text-embedding/): Rhree versions of the text embedding models are available: text-embedding-v1/v2/v3, with v3 being the latest API service.
- [ReRank Models](https://help.aliyun.com/zh/model-studio/developer-reference/general-text-sorting-model/): The gte-rerank model service is available.
Note that the models behind the commercial APIs are not entirely identical to the open-source models.
## Citation
If you find our paper or models helpful, please consider cite:
```
@article{li2023towards,
title={Towards general text embeddings with multi-stage contrastive learning},
author={Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan},
journal={arXiv preprint arXiv:2308.03281},
year={2023}
}
```
|
[
"BIOSSES",
"SCIFACT"
] |
miikhal/Llama-3.1-8B-python-mqp
|
miikhal
|
feature-extraction
|
[
"safetensors",
"gguf",
"llama",
"unsloth",
"feature-extraction",
"en",
"dataset:miikhal/mqp-immigration-dataset",
"endpoints_compatible",
"region:us"
] | 2024-12-03T04:37:21Z |
2025-01-27T17:00:10+00:00
| 67 | 0 |
---
datasets:
- miikhal/mqp-immigration-dataset
language:
- en
metrics:
- accuracy
pipeline_tag: feature-extraction
tags:
- unsloth
---
|
[
"MQP"
] |
OpenGVLab/Mini-InternVL2-2B-DA-DriveLM
|
OpenGVLab
|
image-text-to-text
|
[
"transformers",
"safetensors",
"internvl_chat",
"feature-extraction",
"internvl",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"arxiv:2410.16261",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"base_model:OpenGVLab/InternVL2-2B",
"base_model:merge:OpenGVLab/InternVL2-2B",
"license:mit",
"region:us"
] | 2024-12-07T15:26:16Z |
2024-12-09T13:39:06+00:00
| 67 | 0 |
---
base_model:
- OpenGVLab/InternVL2-2B
language:
- multilingual
library_name: transformers
license: mit
pipeline_tag: image-text-to-text
tags:
- internvl
- custom_code
base_model_relation: merge
---
# Mini-InternVL2-DA-RS
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[🆕 Blog\]](https://internvl.github.io/blog/) [\[📜 Mini-InternVL\]](https://arxiv.org/abs/2410.16261) [\[📜 InternVL 1.0\]](https://arxiv.org/abs/2312.14238) [\[📜 InternVL 1.5\]](https://arxiv.org/abs/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271)
[\[🗨️ InternVL Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 中文解读\]](https://zhuanlan.zhihu.com/p/706547971) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/internvl2.0/domain_adaptation.html#data-preparation)

## Introduction
We release the adaptation models for the specific domains: autonomous driving, medical images, and remote sensing.
These models are built upon Mini-InternVL and fine-tuned using a unified adaptation framework, achieving good performance on tasks in specific domains.

<table>
<tr>
<th>Model Name</th>
<th>HF Link</th>
<th>Note</th>
</tr>
<tr>
<td>Mini-InternVL2-DA-Drivelm</td>
<td><a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-1B-DA-Drivelm">🤗1B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-2B-DA-Drivelm">🤗2B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-4B-DA-Drivelm">🤗4B</a></td>
<td> Adaptation for <a href="https://github.com/OpenDriveLab/DriveLM/tree/main/challenge"> CVPR 2024 Autonomous Driving Challenge </a></td>
</tr>
<tr>
<td>Mini-InternVL2-DA-BDD</td>
<td><a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-1B-DA-BDD">🤗1B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-2B-DA-BDD">🤗2B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-4B-DA-BDD">🤗4B</a></td>
<td> Fine-tuning with data constructed by <a href="https://tonyxuqaq.github.io/projects/DriveGPT4/"> DriveGPT4 </a></td>
</tr>
<tr>
<td>Mini-InternVL2-DA-RS</td>
<td><a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-1B-DA-RS">🤗1B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-2B-DA-RS">🤗2B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-4B-DA-RS">🤗4B</a></td>
<td> Adaptation for remote sensing domain </td>
</tr>
<tr>
<td>Mini-InternVL2-DA-Medical</td>
<td><a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-1B-DA-Medical">🤗1B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-2B-DA-Medical">🤗2B</a> / <a href="https://huggingface.co/OpenGVLab/Mini-InternVL2-4B-DA-Medical">🤗4B</a></td>
<td> Fine-tuning using our <a href="https://huggingface.co/datasets/OpenGVLab/InternVL-Domain-Adaptation-Data/blob/main/train_meta/internvl_1_2_finetune_medical.json">medical data</a>.</td>
</tr>
</table>
The script for evaluation is in the [document](https://internvl.readthedocs.io/en/latest/internvl2.0/domain_adaptation.html#id3).
## Training datasets
- General domain dataset:
ShareGPT4V, AllSeeingV2, LLaVA-Instruct-ZH, DVQA, ChartQA, AI2D, DocVQA, GeoQA+, SynthDoG-EN
- Autonomous driving dataset:
[DriveLM](https://github.com/OpenDriveLab/DriveLM).
## Quick Start
We provide an example code to run `Mini-InternVL2-2B` using `transformers`.
> Please use transformers>=4.37.2 to ensure the model works normally.
```python
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
# If you want to load a model using multiple GPUs, please refer to the `Multiple GPUs` section.
path = 'OpenGVLab/Mini-InternVL2-2B-DA-DriveLM'
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('path/to/image.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('path/to/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('path/to/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('path/to/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('path/to/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('path/to/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('path/to/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
```
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{gao2024mini,
title={Mini-internvl: A flexible-transfer pocket multimodal model with 5\% parameters and 90\% performance},
author={Gao, Zhangwei and Chen, Zhe and Cui, Erfei and Ren, Yiming and Wang, Weiyun and Zhu, Jinguo and Tian, Hao and Ye, Shenglong and He, Junjun and Zhu, Xizhou and others},
journal={arXiv preprint arXiv:2410.16261},
year={2024}
}
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
```
|
[
"MEDICAL DATA"
] |
KomeijiForce/Cuckoo-C4-Rainbow
|
KomeijiForce
|
token-classification
|
[
"transformers",
"safetensors",
"roberta",
"token-classification",
"arxiv:2502.11275",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2025-02-16T22:56:12Z |
2025-02-19T21:00:21+00:00
| 67 | 1 |
---
library_name: transformers
license: apache-2.0
pipeline_tag: token-classification
---
# Cuckoo 🐦 [[Github]](https://github.com/KomeijiForce/Cuckoo)
[Cuckoo: An IE Free Rider Hatched by Massive Nutrition in LLM's Nest](https://huggingface.co/papers/2502.11275) is a small (300M) information extraction (IE) model that imitates the next token prediction paradigm of large language models. Instead of retrieving from the vocabulary, Cuckoo predicts the next tokens by tagging them in the given input context as shown below:

Cuckoo is substantially different from previous IE pre-training because it can use any text resource to enhance itself, especially by taking a free ride on data curated for LLMs!

Currently, we open-source checkpoints of Cuckoos that are pre-trained on:
1) 100M next tokens extraction (NTE) instances converted from C4. ([Cuckoo-C4](https://huggingface.co/KomeijiForce/Cuckoo-C4) 🐦)
2) Cuckoo-C4 + 2.6M next token extraction (NTE) instances converted from a supervised fine-tuning dataset, TuluV3. ([Cuckoo-C4-Instruct](https://huggingface.co/KomeijiForce/Cuckoo-C4-Instruct) 🐦🛠️)
3) Cuckoo-C4-Instruct + MultiNERD, MetaIE, NuNER, MRQA (excluding SQuAD, DROP). ([Cuckoo-C4-Rainbow](https://huggingface.co/KomeijiForce/Cuckoo-C4-Rainbow) 🌈🐦🛠️)
4) Cuckoo-C4-Rainbow + Multiple NER Datasets, WizardLM Dataset, Multiple Choice QA Datasets, MMLU, SQuAD, DROP, MNLI, SNLI. ([Cuckoo-C4-Super-Rainbow](https://huggingface.co/KomeijiForce/Cuckoo-C4-Super-Rainbow) 🦸🌈🐦🛠️)
## Performance Demonstration 🚀
Begin your journey with Cuckoo to experience unimaginable adaptation efficiency for all kinds of IE tasks!
| | CoNLL2003 | BioNLP2004 | MIT-Restaurant | MIT-Movie | Avg. | CoNLL2004 | ADE | Avg. | SQuAD | SQuAD-V2 | DROP | Avg. |
|----------------------|-----------|-----------|----------------|-----------|------|-----------|-----|------|-------|----------|------|------|
| OPT-C4-TuluV3 | 50.24 | 39.76 | 58.91 | 56.33 | 50.56 | 47.14 | 45.66 | 46.40 | 39.80 | 53.81 | 31.00 | 41.54 |
| RoBERTa | 33.75 | 32.91 | 62.15 | 58.32 | 46.80 | 34.16 | 2.15 | 18.15 | 31.86 | 48.55 | 9.16 | 29.86 |
| MRQA | 72.45 | 55.93 | 68.68 | 66.26 | 65.83 | 66.23 | 67.44 | 66.84 | 80.07 | 66.22 | 54.46 | 66.92 |
| MultiNERD | 66.78 | 54.62 | 64.16 | 66.30 | 60.59 | 57.52 | 45.10 | 51.31 | 42.85 | 50.99 | 30.12 | 41.32 |
| NuNER | 74.15 | 56.36 | 68.57 | 64.88 | 65.99 | 65.12 | 63.71 | 64.42 | 61.60 | 52.67 | 37.37 | 50.55 |
| MetaIE | 71.33 | 55.63 | 70.08 | 65.23 | 65.57 | 64.81 | 64.40 | 64.61 | 74.59 | 62.54 | 30.73 | 55.95 |
| Cuckoo 🐦🛠️ | 73.60 | 57.00 | 67.63 | 67.12 | 66.34 | 69.57 | 71.70 | 70.63 | 77.47 | 64.06 | 54.25 | 65.26 |
| └─ Only Pre-train 🐦 | 72.46 | 55.87 | 66.87 | 67.23 | 65.61 | 68.14 | 69.39 | 68.77 | 75.64 | 63.36 | 52.81 | 63.94 |
| └─ Only Post-train | 72.80 | 56.10 | 66.02 | 67.10 | 65.51 | 68.66 | 69.75 | 69.21 | 77.05 | 62.39 | 54.80 | 64.75 |
| Rainbow Cuckoo 🌈🐦🛠️ | 79.94 | 58.39 | 70.30 | 67.00 | **68.91** | 70.47 | 76.05 | **73.26** | 86.57 | 69.41 | 64.64 | **73.54** |
## Quick Experience with Cuckoo in Next Tokens Extraction ⚡
We recommend using the strongest Super Rainbow Cuckoo 🦸🌈🐦🛠️ for zero-shot extraction.
1️⃣ First load the model and the tokenizers
```python
from transformers import AutoModelForTokenClassification, AutoTokenizer
import torch
import spacy
nlp = spacy.load("en_core_web_sm")
device = torch.device("cuda:0")
path = f"KomeijiForce/Cuckoo-C4-Super-Rainbow"
tokenizer = AutoTokenizer.from_pretrained(path)
tagger = AutoModelForTokenClassification.from_pretrained(path).to(device)
```
2️⃣ Define the next tokens extraction function
```python
def next_tokens_extraction(text):
def find_sequences(lst):
sequences = []
i = 0
while i < len(lst):
if lst[i] == 0:
start = i
end = i
i += 1
while i < len(lst) and lst[i] == 1:
end = i
i += 1
sequences.append((start, end+1))
else:
i += 1
return sequences
text = " ".join([token.text for token in nlp(text)])
inputs = tokenizer(text, return_tensors="pt").to(device)
tag_predictions = tagger(**inputs).logits[0].argmax(-1)
predictions = [tokenizer.decode(inputs.input_ids[0, seq[0]:seq[1]]).strip() for seq in find_sequences(tag_predictions)]
return predictions
```
3️⃣ Call the function for extraction!
Case 1: Basic entity and relation understanding
```python
text = "Tom and Jack went to their trip in Paris."
for question in [
"What is the person mentioned here?",
"What is the city mentioned here?",
"Who goes with Tom together?",
"What do Tom and Jack go to Paris for?",
"Where does George live in?",
]:
prompt = f"User:\n\n{text}\n\nQuestion: {question}\n\nAssistant:"
predictions = next_tokens_extraction(prompt)
print(question, predictions)
```
You will get things like,
```
What is the person mentioned here? ['Tom', 'Jack']
What is the city mentioned here? ['Paris']
Who goes with Tom together? ['Jack']
What do Tom and Jack go to Paris for? ['trip']
Where does George live in? []
```
where [] indicates Cuckoo thinks there to be no next tokens for extraction.
Case 2: Longer context
```python
passage = f'''Ludwig van Beethoven (17 December 1770 – 26 March 1827) was a German composer and pianist. He is one of the most revered figures in the history of Western music; his works rank among the most performed of the classical music repertoire and span the transition from the Classical period to the Romantic era in classical music. His early period, during which he forged his craft, is typically considered to have lasted until 1802. From 1802 to around 1812, his middle period showed an individual development from the styles of Joseph Haydn and Wolfgang Amadeus Mozart, and is sometimes characterised as heroic. During this time, Beethoven began to grow increasingly deaf. In his late period, from 1812 to 1827, he extended his innovations in musical form and expression.'''
for question in [
"What are the people mentioned here?",
"What is the job of Beethoven?",
"How famous is Beethoven?",
"When did Beethoven's middle period showed an individual development?",
]:
text = f"User:\n\n{passage}\n\nQuestion: {question}\n\nAssistant:"
predictions = next_tokens_extraction(text)
print(question, predictions)
```
You will get things like,
```
What are the people mentioned here? ['Ludwig van Beethoven', 'Joseph Haydn', 'Wolfgang Amadeus Mozart']
What is the job of Beethoven? ['composer and pianist']
How famous is Beethoven? ['one of the most revered figures in the history of Western music']
When did Beethoven's middle period showed an individual development? ['1802']
```
Case 3: Knowledge quiz
```python
for obj in ["grass", "sea", "fire", "night"]:
text = f"User:\n\nChoices:\nred\nblue\ngreen.\n\nQuestion: What is the color of the {obj}?\n\nAssistant:\n\nAnswer:"
predictions = next_tokens_extraction(text)
print(obj, predictions)
```
You will get things like,
```
grass ['green']
sea ['blue']
fire ['red']
night []
```
which shows Cuckoo is not extracting any plausible spans but has the knowledge to understand the context.
## Few-shot Adaptation 🎯
Cuckoo 🐦 is an expert in few-shot adaptation to your own tasks, taking CoNLL2003 as an example, run ```bash run_downstream.sh conll2003.5shot KomeijiForce/Cuckoo-C4-Rainbow```, you will get a fine-tuned model in ```models/cuckoo-conll2003.5shot```. Then you can benchmark the model with the script ```python eval_conll2003.py```, which will show you an F1 performance of around 80.
You can also train the adaptation to machine reading comprehension (SQuAD), run ```bash run_downstream.sh squad.32shot KomeijiForce/Cuckoo-C4-Rainbow```, you will get a fine-tuned model in ```models/cuckoo-squad.32shot```. Then you can benchmark the model with the script ```python eval_squad.py```, which will show you an F1 performance of around 88.
For fine-tuning your own task, you need to create a Jsonlines file, each line contains {"words": [...], "ner": [...]}, For example:
```json
{"words": ["I", "am", "John", "Smith", ".", "Person", ":"], "ner": ["O", "O", "B", "I", "O", "O", "O"]}
```
<img src="https://github.com/user-attachments/assets/ef177466-d915-46d2-9201-5e672bb6ec23" style="width: 40%;" />
which indicates "John Smith" to be predicted as the next tokens.
You can refer to some prompts shown below for beginning:
| **Type** | **User Input** | **Assistant Response** |
|---------------------|----------------------------------------------------------------------------------------------------|----------------------------------------------------|
| Entity | **User:** [Context] Question: What is the [Label] mentioned? | **Assistant:** Answer: The [Label] is |
| Relation (Kill) | **User:** [Context] Question: Who does [Entity] kill? | **Assistant:** Answer: [Entity] kills |
| Relation (Live) | **User:** [Context] Question: Where does [Entity] live in? | **Assistant:** Answer: [Entity] lives in |
| Relation (Work) | **User:** [Context] Question: Who does [Entity] work for? | **Assistant:** Answer: [Entity] works for |
| Relation (Located) | **User:** [Context] Question: Where is [Entity] located in? | **Assistant:** Answer: [Entity] is located in |
| Relation (Based) | **User:** [Context] Question: Where is [Entity] based in? | **Assistant:** Answer: [Entity] is based in |
| Relation (Adverse) | **User:** [Context] Question: What is the adverse effect of [Entity]? | **Assistant:** Answer: The adverse effect of [Entity] is |
| Query | **User:** [Context] Question: [Question] | **Assistant:** Answer: |
| Instruction (Entity)| **User:** [Context] Question: What is the [Label] mentioned? ([Instruction]) | **Assistant:** Answer: The [Label] is |
| Instruction (Query) | **User:** [Context] Question: [Question] ([Instruction]) | **Assistant:** Answer: |
After building your own downstream dataset, save it into ```my_downstream.json```, and then run the command ```bash run_downstream.sh my_downstream KomeijiForce/Cuckoo-C4-Rainbow```. You will find an adapted Cuckoo in ```models/cuckoo-my_downstream```.
## Fly your own Cuckoo 🪽
We include the script to transform texts to NTE instances in the file ```nte_data_collection.py```, which takes C4 as an example, the converted results can be checked in ```cuckoo.c4.example.json```. The script is designed to be easily adapted to other resources like entity, query, and questions and you can modify your own data to NTE to fly your own Cuckoo! Run the ```run_cuckoo.sh``` script to try an example pre-training.
```bash
python run_ner.py \
--model_name_or_path roberta-large \
--train_file cuckoo.c4.example.json \
--output_dir models/cuckoo-c4-example \
--per_device_train_batch_size 4\
--gradient_accumulation_steps 16\
--num_train_epochs 1\
--save_steps 1000\
--learning_rate 0.00001\
--do_train \
--overwrite_output_dir
```
You will get an example Cuckoo model in ```models/cuckoo-c4-example```, it might not perform well if you pre-train with too little data. You may adjust the hyperparameters inside ```nte_data_collection.py``` or modify the conversion for your own resources to enable better pre-training performance.
## 🐾 Citation
```
@article{DBLP:journals/corr/abs-2502-11275,
author = {Letian Peng and
Zilong Wang and
Feng Yao and
Jingbo Shang},
title = {Cuckoo: An {IE} Free Rider Hatched by Massive Nutrition in {LLM}'s Nest},
journal = {CoRR},
volume = {abs/2502.11275},
year = {2025},
url = {https://doi.org/10.48550/arXiv.2502.11275},
doi = {10.48550/arXiv.2502.11275},
eprinttype = {arXiv},
eprint = {2502.11275},
timestamp = {Mon, 17 Feb 2025 19:32:20 +0000},
biburl = {https://dblp.org/rec/journals/corr/abs-2502-11275.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
[
"CRAFT"
] |
medspaner/roberta-es-clinical-trials-temporal-ner
|
medspaner
|
token-classification
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-07-22T18:04:39Z |
2024-10-01T06:41:57+00:00
| 66 | 0 |
---
license: cc-by-nc-4.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
widget:
- text: Edad ≥ 18 años (en todos los centros), o edad ≥12 y <18 años con peso igual
o superior a 40kg
- text: Estudio realizado en un hospital desde julio de 2010 hasta diciembre de 2011
(18 meses)
- text: Pacientes que hayan recibido bifosfonatos diarios, semanales o mensuales durante
al menos 3 años.
- text: 50 g (40 g la noche anterior y 10 g por la mañana) de L-glutamina
model-index:
- name: roberta-es-clinical-trials-temporal-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-es-clinical-trials-temporal-ner
This named entity recognition model detects temporal expressions (TIMEX) according to the [TimeML scheme](https://en.wikipedia.org/wiki/ISO-TimeML) ([Pustejovsky et al. 2005](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.85.5610&rep=rep1&type=pdf)), in addition to Age entities:
- Age: e.g. *18 años*
- Date: e.g. *2022*, *26 de noviembre*
- Duration: e.g. *3 horas*
- Frequency: e.g. *semanal*
- Time: e.g. *noche*
The model achieves the following results on the test set (when trained with the training and development set; results are averaged over 5 evaluation rounds):
- Precision: 0.900 (±0.011)
- Recall: 0.900 (±0.009)
- F1: 0.900 (±0.007)
- Accuracy: 0.996 (±0.001)
## Model description
This model adapts the pre-trained model [bsc-bio-ehr-es](https://huggingface.co/PlanTL-GOB-ES/bsc-bio-ehr-es), presented in [Pio Carriño et al. (2022)](https://aclanthology.org/2022.bionlp-1.19/).
It is fine-tuned to conduct temporal named entity recognition on Spanish texts about clinical trials.
The model is fine-tuned on the [CT-EBM-ES corpus (Campillos-Llanos et al. 2021)](https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-021-01395-z).
If you use this model, please, cite as follows:
```
@article{campillosetal2024,
title = {{Hybrid tool for semantic annotation and concept extraction of medical texts in Spanish}},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n},
journal = {BMC Bioinformatics},
year={2024},
publisher={BioMed Central}
}
```
## Intended uses & limitations
**Disclosure**: *This model is under development and needs to be improved. It should not be used for medical decision making without human assistance and supervision*
This model is intended for a generalist purpose, and may have bias and/or any other undesirable distortions.
Third parties who deploy or provide systems and/or services using any of these models (or using systems based on these models) should note that it is their responsibility to mitigate the risks arising from their use. Third parties, in any event, need to comply with applicable regulations, including regulations concerning the use of artificial intelligence.
The owner or creator of the models will in no event be liable for any results arising from the use made by third parties of these models.
**Descargo de responsabilidad**: *Esta herramienta se encuentra en desarrollo y no debe ser empleada para la toma de decisiones médicas*
La finalidad de este modelo es generalista, y se advierte que puede tener sesgos y/u otro tipo de distorsiones indeseables.
Terceras partes que desplieguen o proporcionen sistemas y/o servicios usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) han tener presente que es su responsabilidad abordar y minimizar los riesgos derivados de su uso. Las terceras partes, en cualquier circunstancia, deben cumplir con la normativa aplicable, incluyendo la normativa que concierne al uso de la inteligencia artificial.
El propietario o creador de los modelos de ningún modo será responsable de los resultados derivados del uso que las terceras partes hagan de estos modelos.
## Training and evaluation data
The data used for fine-tuning are the [Clinical Trials for Evidence-Based-Medicine in Spanish corpus](http://www.lllf.uam.es/ESP/nlpdata/wp2/).
It is a collection of 1200 texts about clinical trials studies and clinical trials announcements:
- 500 abstracts from journals published under a Creative Commons license, e.g. available in PubMed or the Scientific Electronic Library Online (SciELO)
- 700 clinical trials announcements published in the European Clinical Trials Register and Repositorio Español de Estudios Clínicos
If you use the CT-EBM-ES resource, please, cite as follows:
```
@article{campillosetal-midm2021,
title = {A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n and Moreno-Sandoval, Antonio},
journal = {BMC Medical Informatics and Decision Making},
volume={21},
number={1},
pages={1--19},
year={2021},
publisher={BioMed Central}
}
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: we used different seeds for 5 evaluation rounds, and uploaded the model with the best results
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: average of 14 epochs (±2.24)
### Training results (test set; average and standard deviation of 5 rounds with different seeds)
| Precision | Recall | F1 | Accuracy |
|:--------------:|:--------------:|:--------------:|:--------------:|
| 0.900 (±0.011) | 0.900 (±0.009) | 0.900 (±0.007) | 0.996 (±0.001) |
**Results per class (test set; average and standard deviation of 5 rounds with different seeds)**
| Class | Precision | Recall | F1 | Support |
|:---------:|:--------------:|:--------------:|:--------------:|:---------:|
| Age | 0.926 (±0.013) | 0.947 (±0.009) | 0.936 (±0.010) | 372 |
| Date | 0.931 (±0.015) | 0.895 (±0.014) | 0.913 (±0.013) | 412 |
| Duration | 0.918 (±0.014) | 0.893 (±0.019) | 0.905 (±0.010) | 629 |
| Frequency | 0.780 (±0.043) | 0.885 (±0.008) | 0.829 (±0.024) | 73 |
| Time | 0.722 (±0.068) | 0.809 (±0.042) | 0.762 (±0.052) | 113 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.11.6
|
[
"SCIELO"
] |
RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-06-02T18:35:45Z |
2024-06-03T13:25:17+00:00
| 66 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Phi-3-medium-128k-instruct - GGUF
- Model creator: https://huggingface.co/microsoft/
- Original model: https://huggingface.co/microsoft/Phi-3-medium-128k-instruct/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Phi-3-medium-128k-instruct.Q2_K.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q2_K.gguf) | Q2_K | 4.79GB |
| [Phi-3-medium-128k-instruct.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.IQ3_XS.gguf) | IQ3_XS | 5.41GB |
| [Phi-3-medium-128k-instruct.IQ3_S.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.IQ3_S.gguf) | IQ3_S | 5.65GB |
| [Phi-3-medium-128k-instruct.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q3_K_S.gguf) | Q3_K_S | 5.65GB |
| [Phi-3-medium-128k-instruct.IQ3_M.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.IQ3_M.gguf) | IQ3_M | 6.03GB |
| [Phi-3-medium-128k-instruct.Q3_K.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q3_K.gguf) | Q3_K | 6.45GB |
| [Phi-3-medium-128k-instruct.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q3_K_M.gguf) | Q3_K_M | 6.45GB |
| [Phi-3-medium-128k-instruct.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q3_K_L.gguf) | Q3_K_L | 6.98GB |
| [Phi-3-medium-128k-instruct.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.IQ4_XS.gguf) | IQ4_XS | 7.02GB |
| [Phi-3-medium-128k-instruct.Q4_0.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q4_0.gguf) | Q4_0 | 7.35GB |
| [Phi-3-medium-128k-instruct.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.IQ4_NL.gguf) | IQ4_NL | 7.41GB |
| [Phi-3-medium-128k-instruct.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q4_K_S.gguf) | Q4_K_S | 7.41GB |
| [Phi-3-medium-128k-instruct.Q4_K.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q4_K.gguf) | Q4_K | 7.98GB |
| [Phi-3-medium-128k-instruct.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q4_K_M.gguf) | Q4_K_M | 7.98GB |
| [Phi-3-medium-128k-instruct.Q4_1.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q4_1.gguf) | Q4_1 | 8.16GB |
| [Phi-3-medium-128k-instruct.Q5_0.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q5_0.gguf) | Q5_0 | 8.96GB |
| [Phi-3-medium-128k-instruct.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q5_K_S.gguf) | Q5_K_S | 8.96GB |
| [Phi-3-medium-128k-instruct.Q5_K.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q5_K.gguf) | Q5_K | 9.38GB |
| [Phi-3-medium-128k-instruct.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q5_K_M.gguf) | Q5_K_M | 9.38GB |
| [Phi-3-medium-128k-instruct.Q5_1.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q5_1.gguf) | Q5_1 | 9.76GB |
| [Phi-3-medium-128k-instruct.Q6_K.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q6_K.gguf) | Q6_K | 10.67GB |
| [Phi-3-medium-128k-instruct.Q8_0.gguf](https://huggingface.co/RichardErkhov/microsoft_-_Phi-3-medium-128k-instruct-gguf/blob/main/Phi-3-medium-128k-instruct.Q8_0.gguf) | Q8_0 | 13.82GB |
Original model description:
---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-medium-128k-instruct/resolve/main/LICENSE
language:
- multilingual
pipeline_tag: text-generation
tags:
- nlp
- code
inference:
parameters:
temperature: 0.7
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
## Model Summary
The Phi-3-Medium-128K-Instruct is a 14B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Medium version in two variants [4k](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3-Medium-128K-Instruct showcased a robust and state-of-the-art performance among models of the same-size and next-size-up.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/Phi-3Build2024)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook)
| | Short Context | Long Context |
| ------- | ------------- | ------------ |
| Mini | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx) ; [[GGUF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx)|
| Small | 8K [[HF]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct-onnx-cuda)|
| Medium | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)|
| Vision | | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct-onnx-cuda)|
## Intended Uses
**Primary use cases**
The model is intended for broad commercial and research use in English. The model provides uses for general purpose AI systems and applications which require :
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3-Medium-128k-Instruct has been integrated in the development version (4.40.2) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3-Medium-128k-Instruct is also available in [Azure AI Studio](https://aka.ms/phi3-azure-ai).
### Tokenizer
Phi-3-Medium-128k-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3-Medium-128k-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_id = "microsoft/Phi-3-medium-128k-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
*Some applications/frameworks might not include a BOS token (`<s>`) at the start of the conversation. Please ensure that it is included since it provides more reliable results.*
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3-Medium-128k-Instruct has 14B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 128k tokens
* GPUs: 512 H100-80G
* Training time: 42 days
* Training data: 4.8T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
* Release dates: The model weight is released on May 21, 2024.
### Datasets
Our training data includes a wide variety of sources, totaling 4.8 trillion tokens (including 10% multilingual), and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://aka.ms/phi3-tech-report).
## Benchmarks
We report the results for Phi-3-Medium-128k-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mixtral-8x22b, Gemini-Pro, Command R+ 104B, Llama-3-70B-Instruct, GPT-3.5-Turbo-1106, and GPT-4-Turbo-1106(Chat).
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
|Benchmark|Phi-3-Medium-128k-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|---------|-----------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|AGI Eval<br>5-shot|49.7|50.1|54.0|56.9|48.4|49.0|59.6|
|MMLU<br>5-shot|76.6|73.8|76.2|80.2|71.4|66.7|84.0|
|BigBench Hard<br>3-shot|77.9|74.1|81.8|80.4|68.3|75.6|87.7|
|ANLI<br>7-shot|57.3|63.4|65.2|68.3|58.1|64.2|71.7|
|HellaSwag<br>5-shot|81.6|78.0|79.0|82.6|78.8|76.2|88.3|
|ARC Challenge<br>10-shot|91.0|86.9|91.3|93.0|87.4|88.3|95.6|
|ARC Easy<br>10-shot|97.6|95.7|96.9|98.2|96.3|96.1|98.8|
|BoolQ<br>2-shot|86.5|86.1|82.7|89.1|79.1|86.4|91.3|
|CommonsenseQA<br>10-shot|82.2|82.0|82.0|84.4|79.6|81.8|86.7|
|MedQA<br>2-shot|67.6|59.2|67.9|78.5|63.4|58.2|83.7|
|OpenBookQA<br>10-shot|87.2|86.8|88.6|91.8|86.0|86.4|93.4|
|PIQA<br>5-shot|87.8|86.4|85.0|85.3|86.6|86.2|90.1|
|Social IQA<br>5-shot|79.0|75.3|78.2|81.1|68.3|75.4|81.7|
|TruthfulQA (MC2)<br>10-shot|74.3|57.8|67.4|81.9|67.7|72.6|85.2|
|WinoGrande<br>5-shot|78.9|77.0|75.3|83.3|68.8|72.2|86.7|
|TriviaQA<br>5-shot|73.9|82.8|84.5|78.5|85.8|80.2|73.3|
|GSM8K Chain of Thought<br>8-shot|87.5|78.3|83.8|93.5|78.1|80.4|94.2|
|HumanEval<br>0-shot|58.5|61.6|39.6|78.7|62.2|64.4|79.9|
|MBPP<br>3-shot|73.8|68.9|70.7|81.3|77.8|73.2|86.7|
|Average|77.3|75.0|76.3|82.5|74.3|75.4|85.2|
We take a closer look at different categories across 80 public benchmark datasets at the table below:
|Benchmark|Phi-3-Medium-128k-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|--------|------------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
| Popular aggregated benchmark | 72.3 | 69.9 | 73.4 | 76.3 | 67.0 | 67.5 | 80.5 |
| Reasoning | 83.2 | 79.3 | 81.5 | 86.7 | 78.3 | 80.4 | 89.3 |
| Language understanding | 75.3 | 75.7 | 78.7 | 77.9 | 70.4 | 75.3 | 81.6 |
| Code generation | 64.2 | 68.6 | 60.0 | 69.3 | 70.4 | 66.7 | 76.1 |
| Math | 52.9 | 45.3 | 52.5 | 59.7 | 52.8 | 50.9 | 67.1 |
| Factual knowledge | 47.5 | 60.3 | 60.6 | 52.4 | 63.4 | 54.6 | 45.9 |
| Multilingual | 62.2 | 67.8 | 69.8 | 62.0 | 67.0 | 73.4 | 78.2 |
| Robustness | 70.2 | 57.9 | 65.5 | 78.7 | 69.3 | 69.7 | 84.6 |
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-Medium model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [128k](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi3 Medium models across platforms and hardware.
Optimized phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML GPU acceleration is supported for Windows desktops GPUs (AMD, Intel, and NVIDIA).
Along with DML, ONNX Runtime provides cross platform support for Phi3 Medium across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-medium-128k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
[
"MEDQA"
] |
glif-loradex-trainer/001_horror-concept-art_v2
|
glif-loradex-trainer
|
text-to-image
|
[
"diffusers",
"text-to-image",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us",
"flux",
"lora",
"base_model:adapter:black-forest-labs/FLUX.1-dev"
] | 2024-10-25T18:31:32Z |
2024-10-25T18:33:02+00:00
| 66 | 0 |
---
base_model: black-forest-labs/FLUX.1-dev
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
tags:
- diffusers
- text-to-image
- template:sd-lora
- base_model:black-forest-labs/FLUX.1-dev
- base_model:finetune:black-forest-labs/FLUX.1-dev
- license:other
- region:us
- flux
- lora
widget:
- output:
url: samples/1729880940993__000003000_0.jpg
text: H0rr0rCONCEPT, digitigrade legs, white background. The creature has a humanoid
structure with distinct anatomical modifications, long thin tail and digitigrade
legs. It possesses a head that closely resembles the skull of a ram with prominent
horn structures curling backward. The texture of the head and horns appears rough,
akin to natural bone and keratin. The body of the creature sports a saturated
red skin. The creature has many tubes that go from its arms, head, and legs to
the inside of its body. There are also small pipes sticking out of its body and
arms - one of them is a smoke pipe. The legs and feet of the creature are mechanical
and have a brownish metallic look, displaying a network of rods, pistons, and
articulated joints that suggest both strength and agility. On one of his arms
is an armor plate, and his other arm is inside a large futuristic weapon. The
limbs are multifaceted and show a design centered on functionality and movement.
Overall, the creature merges organic and mechanical elements, suggesting a being
that is either suited for combat or has evolved or been engineered for it. The
red and brown color palette is stark, and the worn textures add to the ominous
and aggressive demeanor of the creature.
- output:
url: samples/1729880967736__000003000_1.jpg
text: H0rr0rCONCEPT. A faceless creature with a humanoid-like torso and an elongated,
pointed head. Its body appears to be composed of a dark stone material with pronounced
ridges and contours that evoke a sense of biomechanical design. In addition to
the point on its head that resembles a huge horn, the creature also has spike-like
growths on its shoulders, elbows, and pelvis. The color palette is dominated by
dark tones, with a deep, charcoal base highlighted by vibrant, lava-like orange
streaks that trace the creature's anatomy in a way that suggests a flowing energy
or internal heat. The creature's arms is raised and bent at the elbow, its hand
featuring elongated, tapered fingers that end in sharp points, conveying a menacing
or predatory aspect. The ambient light casts reflections and highlights off the
creature's body, further enhancing the texture and the contrast between the dark
base color and the orange glow that seems to outline and define its shape. The
impression is one of a being that is both organic and artificial, with an intimidating
presence that is accentuated by its stance and the predatory design.
- output:
url: samples/1729880994484__000003000_2.jpg
text: H0rr0rCONCEPT, white background. A figure clad in an intricate suit of armor
with a majestic and somewhat menacing appearance. The suit of armor is predominantly
dark and metallic, showcasing an array of carefully crafted pieces that are joined
together to protect the wearer. The armor is a dark color with a slight tinge
of brown, but there is gilding along the edges of the armor parts. The armor has
a fairly smooth appearance, but you can see small spikes on the shoulder pads,
and scale armor on the abdomen to allow mobility. The helmet has a flattened shape
and a pair of horns on it. The gauntlets and greaves are articulated, allowing
for movement while still providing coverage. Because of the shape of the head
and the thin joints visible under the heavy armor, the creature seems to be of
a non-human nature. Held in the one hand is what seems to be a large, straight
black sword with a simple hilt, its blade reflecting a faint light, evoking a
sense of weight and lethality. In his other hand he has a large, oddly shaped
shield with many spikes. The lower part of the figure and the sword cast a shadow
on the ground, anchoring the figure in the space and enhancing its three-dimensional
effect.
- output:
url: samples/1729881021261__000003000_3.jpg
text: H0rr0rCONCEPT thigh-high view. A many-armed faceless humanoid standing with
an imposing posture against a blurry background that resembles the interior of
a gothic cathedral with arched ceilings. The figure appears to be mythological
in nature, with a tall, intricate headdress composed of what seem like thin bones
radiating outward, culminating in a center in the form of a small light colored
metal mask with bloody tears and a couple of small skulls, and metal points on
the sides that resemble horns. A ring of fire blazes overhead, casting an ominous
glow. The figure is draped in garments that have a tattered and ancient appearance,
with deep burgundy and dark tones predominating. Elaborate metal medallions adorn
the chest area, seemingly woven into the fabric of the clothing or worn as part
of a ceremonial armor. The figure's arms are raised in a gesture that could be
interpreted as welcoming or spell-casting, with elongated fingers outstretched.
The arms and hands bear a withered appearance, enhancing the notion that this
entity might be undead or beyond the mortal realm. The lower part of the robes
is decorated with a belt and spines. The overall color palette of the scene is
dark and muted, with a high contrast between the burning flame and the dark surroundings.
The glow from the fire casts a warm light on the upper part of the figure, while
most of the body and the background remain engulfed in shadows, creating a sense
of depth and a foreboding atmosphere.
- output:
url: samples/1729881047997__000003000_4.jpg
text: 'H0rr0rCONCEPT, black background. A humanoid multi-armed figure standing against
a dark, almost black background. The figure appears muscular, with pronounced
shoulders and four arms that are positioned slightly away from its torso. The
creature''s texture resembles torn flesh with large dark holes, with hues ranging
from dark browns to blacks, and some areas displaying what could look like exposed
muscle or inner tissue, possibly hinting at some form of grotesque modification
or a state of decomposition. The being''s head is oval-shaped and featureless
except for one giant hole in place of a face. Below the head, the torso is marked
by three large openings: two round holes at the chest level and another gaping,
irregularly shaped hollow at the abdomen, further emphasizing the figure''s non-human
and possibly macabre nature. The edges of these openings have an organic and uneven
look as if the material has been eroded or torn away, and the inside of these
voids is shrouded in shadow, making it difficult to discern any underlying structure.
Each arm of the figure is slender and ends with hands that have distinct, long
fingers. The hands are held in a relaxed manner, with visible joints. The combination
of the figure''s pose, the textural details, and the obscured facial area creates
an image that may evoke a sense of intimidation, horror, or the uncanny. The image
is covered with a lot of white noise.'
- output:
url: samples/1729881074739__000003000_5.jpg
text: H0rr0rCONCEPT. The image displays a creature with a muscular upper torso,
reminiscent of human anatomy, yet its head and facial features are notably different,
conveying a sense of otherworldliness. The head is elongated and lacks recognizable
human features such as eyes, a nose, or a mouth. It is adorned with an array of
sharp, pointed protrusions that resemble teeth or spikes, extending from the creature's
from the neck through the face and wrapping around the elongated back of its head.
The skin of the creature exhibits a mix of dark purples, subtle pink and flesh
hues, with various shades creating depth and texture throughout its form. Under
subdued lighting, which casts soft shadows, the creature appears to emerge from
a murky, indistinct background, adding an element of mystery and focus to its
prominent figure. The overall image is an evocative portrayal of a being that
combines human-like physicality with alien characteristics.
trigger: H0rr0rCONCEPT
instance_prompt: H0rr0rCONCEPT
---
# horror-concept-art_v2
Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit) under the [Glif Loradex program](https://huggingface.co/glif-loradex-trainer) by [Glif](https://glif.app) user `001`.
<Gallery />
## Trigger words
You should use `H0rr0rCONCEPT` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/glif-loradex-trainer/001_horror-concept-art_v2/tree/main) them in the Files & versions tab.
## License
This model is licensed under the [flux-1-dev-non-commercial-license](https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md).
|
[
"BEAR"
] |
RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2101.00027",
"arxiv:2201.07311",
"endpoints_compatible",
"region:us"
] | 2024-11-01T16:18:38Z |
2024-11-01T16:37:49+00:00
| 66 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pythia-1.4b-deduped-v0 - GGUF
- Model creator: https://huggingface.co/EleutherAI/
- Original model: https://huggingface.co/EleutherAI/pythia-1.4b-deduped-v0/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pythia-1.4b-deduped-v0.Q2_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q2_K.gguf) | Q2_K | 0.53GB |
| [pythia-1.4b-deduped-v0.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q3_K_S.gguf) | Q3_K_S | 0.61GB |
| [pythia-1.4b-deduped-v0.Q3_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q3_K.gguf) | Q3_K | 0.71GB |
| [pythia-1.4b-deduped-v0.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q3_K_M.gguf) | Q3_K_M | 0.71GB |
| [pythia-1.4b-deduped-v0.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q3_K_L.gguf) | Q3_K_L | 0.77GB |
| [pythia-1.4b-deduped-v0.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.IQ4_XS.gguf) | IQ4_XS | 0.74GB |
| [pythia-1.4b-deduped-v0.Q4_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q4_0.gguf) | Q4_0 | 0.77GB |
| [pythia-1.4b-deduped-v0.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.IQ4_NL.gguf) | IQ4_NL | 0.78GB |
| [pythia-1.4b-deduped-v0.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q4_K_S.gguf) | Q4_K_S | 0.78GB |
| [pythia-1.4b-deduped-v0.Q4_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q4_K.gguf) | Q4_K | 0.85GB |
| [pythia-1.4b-deduped-v0.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q4_K_M.gguf) | Q4_K_M | 0.85GB |
| [pythia-1.4b-deduped-v0.Q4_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q4_1.gguf) | Q4_1 | 0.85GB |
| [pythia-1.4b-deduped-v0.Q5_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q5_0.gguf) | Q5_0 | 0.92GB |
| [pythia-1.4b-deduped-v0.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q5_K_S.gguf) | Q5_K_S | 0.65GB |
| [pythia-1.4b-deduped-v0.Q5_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q5_K.gguf) | Q5_K | 0.98GB |
| [pythia-1.4b-deduped-v0.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q5_K_M.gguf) | Q5_K_M | 0.98GB |
| [pythia-1.4b-deduped-v0.Q5_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q5_1.gguf) | Q5_1 | 1.0GB |
| [pythia-1.4b-deduped-v0.Q6_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q6_K.gguf) | Q6_K | 1.08GB |
| [pythia-1.4b-deduped-v0.Q8_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-1.4b-deduped-v0-gguf/blob/main/pythia-1.4b-deduped-v0.Q8_0.gguf) | Q8_0 | 1.4GB |
Original model description:
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-1.4B-deduped
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change in the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-1.4B-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-1.4B-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-1.4B-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-1.4B-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-1.4B-deduped to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-1.4B-deduped may produce socially unacceptable or undesirable text,
*even if* the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-1.4B-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
Pythia-1.4B-deduped was trained on the Pile **after the dataset has been
globally deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge – Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
[
"SCIQ"
] |
itlwas/Einstein-v4-phi2-Q4_K_M-GGUF
|
itlwas
| null |
[
"gguf",
"axolotl",
"generated_from_trainer",
"phi",
"phi2",
"einstein",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"science",
"physics",
"chemistry",
"biology",
"math",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:allenai/ai2_arc",
"dataset:camel-ai/physics",
"dataset:camel-ai/chemistry",
"dataset:camel-ai/biology",
"dataset:camel-ai/math",
"dataset:metaeval/reclor",
"dataset:openbookqa",
"dataset:mandyyyyii/scibench",
"dataset:derek-thomas/ScienceQA",
"dataset:TIGER-Lab/ScienceEval",
"dataset:jondurbin/airoboros-3.2",
"dataset:LDJnr/Capybara",
"dataset:Cot-Alpaca-GPT4-From-OpenHermes-2.5",
"dataset:STEM-AI-mtl/Electrical-engineering",
"dataset:knowrohit07/saraswati-stem",
"dataset:sablo/oasst2_curated",
"dataset:glaiveai/glaive-code-assistant",
"dataset:lmsys/lmsys-chat-1m",
"dataset:TIGER-Lab/MathInstruct",
"dataset:bigbio/med_qa",
"dataset:meta-math/MetaMathQA-40K",
"dataset:piqa",
"dataset:scibench",
"dataset:sciq",
"dataset:Open-Orca/SlimOrca",
"dataset:migtissera/Synthia-v1.3",
"base_model:Weyaxi/Einstein-v4-phi2",
"base_model:quantized:Weyaxi/Einstein-v4-phi2",
"license:other",
"model-index",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-12-29T01:02:56Z |
2024-12-29T01:03:05+00:00
| 66 | 0 |
---
base_model: Weyaxi/Einstein-v4-phi2
datasets:
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- metaeval/reclor
- openbookqa
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- TIGER-Lab/ScienceEval
- jondurbin/airoboros-3.2
- LDJnr/Capybara
- Cot-Alpaca-GPT4-From-OpenHermes-2.5
- STEM-AI-mtl/Electrical-engineering
- knowrohit07/saraswati-stem
- sablo/oasst2_curated
- glaiveai/glaive-code-assistant
- lmsys/lmsys-chat-1m
- TIGER-Lab/MathInstruct
- bigbio/med_qa
- meta-math/MetaMathQA-40K
- openbookqa
- piqa
- metaeval/reclor
- derek-thomas/ScienceQA
- scibench
- sciq
- Open-Orca/SlimOrca
- migtissera/Synthia-v1.3
- TIGER-Lab/ScienceEval
language:
- en
license: other
tags:
- axolotl
- generated_from_trainer
- phi
- phi2
- einstein
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- science
- physics
- chemistry
- biology
- math
- llama-cpp
- gguf-my-repo
model-index:
- name: Einstein-v4-phi2
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 59.98
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 74.07
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 56.89
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 45.8
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 73.88
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 53.98
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
---
# AIronMind/Einstein-v4-phi2-Q4_K_M-GGUF
This model was converted to GGUF format from [`Weyaxi/Einstein-v4-phi2`](https://huggingface.co/Weyaxi/Einstein-v4-phi2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Weyaxi/Einstein-v4-phi2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo AIronMind/Einstein-v4-phi2-Q4_K_M-GGUF --hf-file einstein-v4-phi2-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo AIronMind/Einstein-v4-phi2-Q4_K_M-GGUF --hf-file einstein-v4-phi2-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo AIronMind/Einstein-v4-phi2-Q4_K_M-GGUF --hf-file einstein-v4-phi2-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo AIronMind/Einstein-v4-phi2-Q4_K_M-GGUF --hf-file einstein-v4-phi2-q4_k_m.gguf -c 2048
```
|
[
"SCIQ"
] |
domenicrosati/opus-mt-en-es-scielo
|
domenicrosati
|
translation
|
[
"transformers",
"pytorch",
"tensorboard",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"dataset:scielo",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-07-15T15:25:52Z |
2022-07-18T20:09:57+00:00
| 65 | 2 |
---
datasets:
- scielo
metrics:
- bleu
tags:
- translation
- generated_from_trainer
model-index:
- name: opus-mt-en-es-scielo
results:
- task:
type: text2text-generation
name: Sequence-to-sequence Language Modeling
dataset:
name: scielo
type: scielo
args: en-es
metrics:
- type: bleu
value: 41.53733801247958
name: Bleu
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# opus-mt-en-es-scielo
This model is a fine-tuned version of [domenicrosati/opus-mt-en-es-scielo](https://huggingface.co/domenicrosati/opus-mt-en-es-scielo) on the scielo dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2189
- Bleu: 41.5373
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|
| 1.0943 | 1.0 | 10001 | 1.2189 | 41.5373 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
[
"SCIELO"
] |
BigSalmon/InformalToFormalLincoln87Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-10-30T03:53:34Z |
2022-10-30T18:28:04+00:00
| 65 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln87Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln87Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
```
Q: What is whistleblower protection?
A: Whistleblower protection is a form of legal immunity granted to employees who expose the unethical practices of their employer.
Q: Why are whistleblower protections important?
A: Absent whistleblower protections, employees would be deterred from exposing their employer’s wrongdoing for fear of retribution.
Q: Why would an employer engage in retribution?
A: An employer who has acted unethically stands to suffer severe financial and reputational damage were their transgressions to become public. To safeguard themselves from these consequences, they might seek to dissuade employees from exposing their wrongdoing.
```
```
original: the meritocratic nature of crowdfunding [MASK] into their vision's viability.
infill: the meritocratic nature of crowdfunding [gives investors idea of how successful] -> ( offers entrepreneurs a window ) into their vision's viability.
```
|
[
"BEAR"
] |
KappaNeuro/zanele-muholi-style
|
KappaNeuro
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"art",
"style",
"portraits",
"painting",
"activist",
"photographer",
"zanele muholi",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] | 2023-09-14T11:23:27Z |
2023-09-14T11:23:32+00:00
| 65 | 5 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- art
- style
- portraits
- painting
- activist
- photographer
- zanele muholi
instance_prompt: Zanele Muholi Style
widget:
- text: Zanele Muholi Style - Ethereal Portrait of a Genderqueer Artist, surrounded
by vibrant flowers and wearing a flowing, ethereal gown, capturing the essence
of self-expression and beauty in diversity.
- text: Zanele Muholi Style - launch of the collectionconnection we are plural, fashion
conscious, creative, fashion, with attitude and free from prejudice, creating
very colorful, cool and daring images, with black and white men and women models,
- text: Zanele Muholi Style - hasselblad photography Omo Valley punk Vogue editorial
- text: Zanele Muholi Style - five female models in the desert, one japanese, one
swedish, one african, one latin american, one really dark skinned, the photography
is taken in a fashion magazine style, vogue, the photo is taken with a film camera,
realistic skin, realistic photo, one dark skinned woman is closer to the camera
than the others,wearing clothes inspired by jaquemus spring collection 2023, all
clothes are white, photography is black and white
- text: Zanele Muholi Style - An African woman wearing traditional Maasai clothing,
standing in front of a large map of Africa, with the map visible through the transparent
parts of her clothing, creating a double exposure effect. The image is finished
with a high-contrast black and white filter to emphasize the bold patterns of
the Maasai clothing.
- text: Zanele Muholi Style - beautiful collage of hasselblad photography Omo Valley
punk Vogue editorial
- text: Zanele Muholi Style - A portrait of a person involved in a traditional craft
or occupation, reminiscent of the work of Zanele Muholi. The subject should be
engaged in their work, with the tools and environment around them telling a story
about their craft.
- text: Zanele Muholi Style - photo
---
# Zanele Muholi Style ([CivitAI](https://civitai.com/models/107194))

>
<p>Zanele Muholi is a South African visual activist and photographer known for their powerful and intimate portraits that explore themes of identity, race, gender, and sexuality. Born in 1972, Muholi has dedicated their career to documenting and raising awareness about the lives and experiences of the LGBTQ+ community, particularly black lesbians, gay men, and transgender individuals in South Africa.</p><p>Muholi's photographic style is characterized by its rawness, honesty, and striking visual impact. They often capture their subjects in black and white, utilizing strong contrasts and dramatic lighting to convey a sense of strength and resilience. Through their portraits, Muholi seeks to challenge stereotypes, confront social injustices, and celebrate the diverse and multifaceted identities within the LGBTQ+ community.</p><p>In addition to photography, Muholi has also worked with video installations and performance art, further expanding the possibilities of their artistic expression. Their work has been exhibited in numerous international exhibitions and has received critical acclaim for its significant social and political impact.</p><p>Beyond their artistic practice, Muholi is a vocal activist and advocate for LGBTQ+ rights. They have been recognized for their groundbreaking contributions to the visibility and representation of marginalized communities, using their art as a tool for social change and empowerment.</p><p>Zanele Muholi's work serves as a powerful testament to the importance of representation, equality, and the celebration of diverse identities. Through their lens, they have brought attention to the struggles, triumphs, and stories of individuals within the LGBTQ+ community, leaving a lasting impact on the art world and beyond.</p>
## Image examples for the model:

> Zanele Muholi Style - Ethereal Portrait of a Genderqueer Artist, surrounded by vibrant flowers and wearing a flowing, ethereal gown, capturing the essence of self-expression and beauty in diversity.

>

> Zanele Muholi Style - launch of the collectionconnection we are plural, fashion conscious, creative, fashion, with attitude and free from prejudice, creating very colorful, cool and daring images, with black and white men and women models,

> Zanele Muholi Style - hasselblad photography Omo Valley punk Vogue editorial

> Zanele Muholi Style - five female models in the desert, one japanese, one swedish, one african, one latin american, one really dark skinned, the photography is taken in a fashion magazine style, vogue, the photo is taken with a film camera, realistic skin, realistic photo, one dark skinned woman is closer to the camera than the others,wearing clothes inspired by jaquemus spring collection 2023, all clothes are white, photography is black and white

> Zanele Muholi Style - An African woman wearing traditional Maasai clothing, standing in front of a large map of Africa, with the map visible through the transparent parts of her clothing, creating a double exposure effect. The image is finished with a high-contrast black and white filter to emphasize the bold patterns of the Maasai clothing.

> Zanele Muholi Style - beautiful collage of hasselblad photography Omo Valley punk Vogue editorial

> Zanele Muholi Style - A portrait of a person involved in a traditional craft or occupation, reminiscent of the work of Zanele Muholi. The subject should be engaged in their work, with the tools and environment around them telling a story about their craft.

> Zanele Muholi Style - photo
|
[
"CRAFT"
] |
TheBloke/juanako-7B-UNA-AWQ
|
TheBloke
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"juanako",
"UNA",
"conversational",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"arxiv:2109.07958",
"arxiv:2310.16944",
"arxiv:2305.18290",
"base_model:fblgit/juanako-7b-UNA",
"base_model:quantized:fblgit/juanako-7b-UNA",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] | 2023-12-01T19:56:04Z |
2023-12-01T20:13:56+00:00
| 65 | 2 |
---
base_model: fblgit/juanako-7b-UNA
datasets:
- HuggingFaceH4/ultrafeedback_binarized
license: apache-2.0
tags:
- alignment-handbook
- generated_from_trainer
- juanako
- mistral
- UNA
inference: false
model_creator: FBL
model_type: mistral
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
model-index:
- name: juanako-7b-UNA
results:
- task:
type: text-generation
name: TruthfulQA (MC2)
dataset:
name: truthful_qa
type: text-generation
config: multiple_choice
split: validation
metrics:
- type: accuracy
value: 65.13
verified: true
- task:
type: text-generation
name: ARC-Challenge
dataset:
name: ai2_arc
type: text-generation
config: ARC-Challenge
split: test
metrics:
- type: accuracy
value: 68.17
verified: true
- task:
type: text-generation
name: HellaSwag
dataset:
name: Rowan/hellaswag
type: text-generation
split: test
metrics:
- type: accuracy
value: 85.34
verified: true
- type: accuracy
value: 83.57
- task:
type: text-generation
name: Winogrande
dataset:
name: winogrande
type: text-generation
config: winogrande_debiased
split: test
metrics:
- type: accuracy
value: 78.85
verified: true
- task:
type: text-generation
name: MMLU
dataset:
name: cais/mmlu
type: text-generation
config: all
split: test
metrics:
- type: accuracy
value: 62.47
verified: true
- task:
type: text-generation
name: DROP
dataset:
name: drop
type: text-generation
split: validation
metrics:
- type: accuracy
value: 38.74
verified: true
- task:
type: text-generation
name: PubMedQA
dataset:
name: bigbio/pubmed_qa
type: text-generation
config: pubmed_qa_artificial_bigbio_qa
split: validation
metrics:
- type: accuracy
value: 76.0
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Juanako 7B UNA - AWQ
- Model creator: [FBL](https://huggingface.co/fblgit)
- Original model: [Juanako 7B UNA](https://huggingface.co/fblgit/juanako-7b-UNA)
<!-- description start -->
## Description
This repo contains AWQ model files for [FBL's Juanako 7B UNA](https://huggingface.co/fblgit/juanako-7b-UNA).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - Llama and Mistral models only
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/juanako-7B-UNA-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/juanako-7B-UNA-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/juanako-7B-UNA-GGUF)
* [FBL's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/fblgit/juanako-7b-UNA)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/juanako-7B-UNA-AWQ/tree/main) | 4 | 128 | [VMware Open Instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 4096 | 4.15 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/juanako-7B-UNA-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `juanako-7B-UNA-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/juanako-7B-UNA-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/juanako-7B-UNA-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/juanako-7B-UNA-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/juanako-7B-UNA-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: FBL's Juanako 7B UNA
# juanako-7b-UNA (Uniform Neural Alignment)
This model is a fine-tuned version of [fblgit/juanako-7b-UNA-v2-phase-1](https://huggingface.co/fblgit/juanako-7b-UNA-v2-phase-1) on the HuggingFaceH4/ultrafeedback_binarized dataset.
It outperforms in many aspects most of the current Mistral based models and is the **latest and most powerful juanako version as of now**.
## Scores
The official HuggingFace results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/results/blob/main/fblgit/juanako-7b-UNA/results_2023-11-28T08-33-33.965228.json)
| Model | Average ⬆️| ARC (25-s) ⬆️ | HellaSwag (10-s) ⬆️ | MMLU (5-s) ⬆️| TruthfulQA (MC) (0-s) ⬆️ | Winogrande (5-s) | GSM8K (5-s) | DROP (3-s) |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
|[mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | 50.32 | 59.58 | 83.31 | 64.16 | 42.15 | 78.37 | 18.12 | 6.14 |
| [Intel/neural-chat-7b-v3-1](https://huggingface.co/Intel/neural-chat-7b-v3-1) | 59.0 | 66.21 | 83.64 | 62.37 | 59.65 | 78.14 | 19.56 | 43.84 |
| [fblgit/juanako-7b-UNA](https://huggingface.co/fblgit/juanako-7b-UNA) | **59.91** | **68.17** | **85.34** | 62.47 | **65.13** | **78.85** | **20.7** | 38.74 |
It scores: **59.91** according HuggingFace LLM Leaderboard.
It scores: **65.1** with `big-refactor` branch of lm-eval-harness
Author [Xavier M.](mailto:[email protected]) @fblgit
## Model description
juanako uses UNA, Uniform Neural Alignment. A training technique that ease alignment between transformer layers yet to be published.
### Prompts
The following prompts showed positive results, it may depend the task and needs further experimentation but this should work for starters:
```
<|im_start|>system
- You are a helpful assistant chatbot trained by MosaicML.
- You answer questions.
- You are excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
- You are more than just an information source, you are also able to write poetry, short stories, and make jokes.<|im_end|>
<|im_start|>user
Explain QKV<|im_end|>
<|im_start|>assistant
```
```
### Assistant: I am StableVicuna, a large language model created by CarperAI. I am here to chat!
### Human: Explain QKV
### Assistant:
```
```
[Round <|round|>]
问:Explain QKV
答:
```
```
[Round <|round|>]
Question:Explain QKV
Answer:
```
```
Question:Explain QKV
Answer:
```
## Evaluations (lm-eval big-refactor branch)
### TruthfulQA 0-Shot
```
| Tasks |Version|Filter|Metric|Value | |Stderr|
|--------------|-------|------|------|-----:|---|-----:|
|truthfulqa_mc2|Yaml |none |acc |0.6549|± |0.0153|
```
### ARC 25-Shot
```
| Tasks |Version|Filter| Metric |Value | |Stderr|
|-------------|-------|------|--------|-----:|---|-----:|
|arc_challenge|Yaml |none |acc |0.6476|± |0.0140|
| | |none |acc_norm|0.6809|± |0.0136|
```
### HellaSwag 10-Shot
```
| Tasks |Version|Filter| Metric |Value | |Stderr|
|---------|-------|------|--------|-----:|---|-----:|
|hellaswag|Yaml |none |acc |0.6703|± |0.0047|
| | |none |acc_norm|0.8520|± |0.0035|
```
### GSM8k 5-Shot
```
|Tasks|Version| Filter | Metric |Value | |Stderr|
|-----|-------|----------|-----------|-----:|---|-----:|
|gsm8k|Yaml |get-answer|exact_match|0.4898|± |0.0138|
```
### GPT Evaluations 0-Shot
```
| Tasks |Version|Filter| Metric |Value | |Stderr|
|--------------|-------|------|----------|-----:|---|-----:|
|boolq |Yaml |none |acc |0.8703|± |0.0059|
|lambada_openai|Yaml |none |perplexity|3.2598|± |0.0705|
| | |none |acc |0.7336|± |0.0062|
|piqa |Yaml |none |acc |0.8254|± |0.0089|
| | |none |acc_norm |0.8292|± |0.0088|
|sciq |Yaml |none |acc |0.9580|± |0.0063|
| | |none |acc_norm |0.9130|± |0.0089|
```
### MathQA 0-Shot
```
|Tasks |Version|Filter| Metric |Value | |Stderr|
|------|-------|------|--------|-----:|---|-----:|
|mathqa|Yaml |none |acc |0.3752|± |0.0089|
| | |none |acc_norm|0.3772|± |0.0089|
```
### PiQa 1-Shot
```
|Tasks|Version|Filter| Metric |Value | |Stderr|
|-----|-------|------|--------|-----:|---|-----:|
|piqa |Yaml |none |acc |0.8308|± |0.0087|
| | |none |acc_norm|0.8357|± |0.0086|
```
### Winogrande 5-Shot
```
| Tasks |Version|Filter|Metric|Value| |Stderr|
|----------|-------|------|------|----:|---|-----:|
|winogrande|Yaml |none |acc |0.768|± |0.0119|
```
### PubMedQA 0-Shot
```
| Tasks |Version|Filter|Metric|Value| |Stderr|
|--------|-------|------|------|----:|---|-----:|
|pubmedqa|Yaml |none |acc | 0.76|± |0.0191|
```
### RACE 1-Shot
```
|Tasks|Version|Filter|Metric|Value | |Stderr|
|-----|-------|------|------|-----:|---|-----:|
|race |Yaml |none |acc |0.5282|± |0.0154|
```
### MMLU 5-Shot (8-Bit)
```
| Groups |Version|Filter|Metric|Value | |Stderr|
|------------------|-------|------|------|-----:|---|-----:|
|mmlu |N/A |none |acc |0.6137|± |0.1243|
| - humanities |N/A |none |acc |0.5671|± |0.1101|
| - other |N/A |none |acc |0.6859|± |0.1164|
| - social_sciences|N/A |none |acc |0.7195|± |0.0713|
| - stem |N/A |none |acc |0.5087|± |0.1297|
```
### DROP 3-Shot (8-Bit) (Instruct-Eval)
```
{'score': 0.49801113762927607}
{'drop': 49.8}
drop: 49.8
```
### CRASS 0-Shot (Instruct-Eval)
```
{'score': 0.8357664233576643}
{'crass': 83.58}
crass: 83.58
```
## Training Details
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 14
- gradient_accumulation_steps: 16
- total_train_batch_size: 224
- total_eval_batch_size: 14
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rewards/chosen | Rewards/rejected | Rewards/accuracies | Rewards/margins | Logps/rejected | Logps/chosen | Logits/rejected | Logits/chosen |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:----------------:|:------------------:|:---------------:|:--------------:|:------------:|:---------------:|:-------------:|
| 0.4795 | 0.2 | 56 | 0.4958 | -1.3684 | -2.6385 | 0.7552 | 1.2701 | -265.3887 | -241.2612 | -2.2572 | -2.4922 |
| 0.4642 | 0.4 | 112 | 0.4859 | -1.0380 | -1.9769 | 0.7273 | 0.9389 | -258.7718 | -237.9569 | -2.2414 | -2.4751 |
| 0.4758 | 0.61 | 168 | 0.4808 | -1.2594 | -2.3704 | 0.7343 | 1.1110 | -262.7074 | -240.1708 | -2.2305 | -2.4633 |
| 0.4549 | 0.81 | 224 | 0.4768 | -1.1906 | -2.3201 | 0.7552 | 1.1295 | -262.2044 | -239.4827 | -2.2284 | -2.4610 |
### Framework versions
- Transformers 4.35.0-UNA
- Pytorch 2.1.0
- Datasets 2.14.6
- Tokenizers 0.14.1
## Citations
If you find juanako useful please:
```
@misc{juanako7buna,
title={Juanako: Uniform Neural Alignment},
author={Xavier Murias},
year={2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/fblgit/juanako-7b-UNA}},
}
```
Thanks to all the brilliant humans behind the creation of AI, here some of the ones that we find relevant to our research. If you feel a citation is missing, please contact.
```
@misc{lin2021truthfulqa,
title={TruthfulQA: Measuring How Models Mimic Human Falsehoods},
author={Stephanie Lin and Jacob Hilton and Owain Evans},
year={2021},
eprint={2109.07958},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{tunstall2023zephyr,
title={Zephyr: Direct Distillation of LM Alignment},
author={Lewis Tunstall and Edward Beeching and Nathan Lambert and Nazneen Rajani and Kashif Rasul and Younes Belkada and Shengyi Huang and Leandro von Werra and Clémentine Fourrier and Nathan Habib and Nathan Sarrazin and Omar Sanseviero and Alexander M. Rush and Thomas Wolf},
year={2023},
eprint={2310.16944},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@inproceedings{Bisk2020,
author = {Yonatan Bisk and Rowan Zellers and
Ronan Le Bras and Jianfeng Gao
and Yejin Choi},
title = {PIQA: Reasoning about Physical Commonsense in
Natural Language},
booktitle = {Thirty-Fourth AAAI Conference on
Artificial Intelligence},
year = {2020},
}
@software{eval-harness,
author = {Gao, Leo and
Tow, Jonathan and
Biderman, Stella and
Black, Sid and
DiPofi, Anthony and
Foster, Charles and
Golding, Laurence and
Hsu, Jeffrey and
McDonell, Kyle and
Muennighoff, Niklas and
Phang, Jason and
Reynolds, Laria and
Tang, Eric and
Thite, Anish and
Wang, Ben and
Wang, Kevin and
Zou, Andy},
title = {A framework for few-shot language model evaluation},
month = sep,
year = 2021,
publisher = {Zenodo},
version = {v0.0.1},
doi = {10.5281/zenodo.5371628},
url = {https://doi.org/10.5281/zenodo.5371628}
}
@misc{rafailov2023direct,
title={Direct Preference Optimization: Your Language Model is Secretly a Reward Model},
author={Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn},
year={2023},
eprint={2305.18290},
archivePrefix={arXiv},
}
```
|
[
"PUBMEDQA",
"SCIQ"
] |
ntc-ai/SDXL-LoRA-slider.happy-crying
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-31T13:57:53Z |
2023-12-31T13:57:57+00:00
| 65 | 3 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/happy crying.../happy crying_17_3.0.png
widget:
- text: happy crying
output:
url: images/happy crying_17_3.0.png
- text: happy crying
output:
url: images/happy crying_19_3.0.png
- text: happy crying
output:
url: images/happy crying_20_3.0.png
- text: happy crying
output:
url: images/happy crying_21_3.0.png
- text: happy crying
output:
url: images/happy crying_22_3.0.png
inference: false
instance_prompt: happy crying
---
# ntcai.xyz slider - happy crying (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/happy crying_17_-3.0.png" width=256 height=256 /> | <img src="images/happy crying_17_0.0.png" width=256 height=256 /> | <img src="images/happy crying_17_3.0.png" width=256 height=256 /> |
| <img src="images/happy crying_19_-3.0.png" width=256 height=256 /> | <img src="images/happy crying_19_0.0.png" width=256 height=256 /> | <img src="images/happy crying_19_3.0.png" width=256 height=256 /> |
| <img src="images/happy crying_20_-3.0.png" width=256 height=256 /> | <img src="images/happy crying_20_0.0.png" width=256 height=256 /> | <img src="images/happy crying_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
happy crying
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.happy-crying', weight_name='happy crying.safetensors', adapter_name="happy crying")
# Activate the LoRA
pipe.set_adapters(["happy crying"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, happy crying"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 760+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
djuna/jina-embeddings-v2-base-en-Q5_K_M-GGUF
|
djuna
|
feature-extraction
|
[
"sentence-transformers",
"gguf",
"feature-extraction",
"sentence-similarity",
"mteb",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:allenai/c4",
"base_model:jinaai/jina-embeddings-v2-base-en",
"base_model:quantized:jinaai/jina-embeddings-v2-base-en",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"region:us"
] | 2024-07-28T02:15:12Z |
2024-07-28T02:15:15+00:00
| 65 | 2 |
---
base_model: jinaai/jina-embeddings-v2-base-en
datasets:
- allenai/c4
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
- llama-cpp
- gguf-my-repo
inference: false
model-index:
- name: jina-embedding-b-en-v2
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 74.73134328358209
- type: ap
value: 37.765427081831035
- type: f1
value: 68.79367444339518
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 88.544275
- type: ap
value: 84.61328675662887
- type: f1
value: 88.51879035862375
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 45.263999999999996
- type: f1
value: 43.778759656699435
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.693
- type: map_at_10
value: 35.487
- type: map_at_100
value: 36.862
- type: map_at_1000
value: 36.872
- type: map_at_3
value: 30.049999999999997
- type: map_at_5
value: 32.966
- type: mrr_at_1
value: 21.977
- type: mrr_at_10
value: 35.565999999999995
- type: mrr_at_100
value: 36.948
- type: mrr_at_1000
value: 36.958
- type: mrr_at_3
value: 30.121
- type: mrr_at_5
value: 33.051
- type: ndcg_at_1
value: 21.693
- type: ndcg_at_10
value: 44.181
- type: ndcg_at_100
value: 49.982
- type: ndcg_at_1000
value: 50.233000000000004
- type: ndcg_at_3
value: 32.830999999999996
- type: ndcg_at_5
value: 38.080000000000005
- type: precision_at_1
value: 21.693
- type: precision_at_10
value: 7.248
- type: precision_at_100
value: 0.9769999999999999
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 13.632
- type: precision_at_5
value: 10.725
- type: recall_at_1
value: 21.693
- type: recall_at_10
value: 72.475
- type: recall_at_100
value: 97.653
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 40.896
- type: recall_at_5
value: 53.627
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 45.39242428696777
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 36.675626784714
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.247725694904034
- type: mrr
value: 74.91359978894604
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 82.68003802970496
- type: cos_sim_spearman
value: 81.23438110096286
- type: euclidean_pearson
value: 81.87462986142582
- type: euclidean_spearman
value: 81.23438110096286
- type: manhattan_pearson
value: 81.61162566600755
- type: manhattan_spearman
value: 81.11329400456184
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.01298701298701
- type: f1
value: 83.31690714969382
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 37.050108150972086
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 30.15731442819715
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.391999999999996
- type: map_at_10
value: 42.597
- type: map_at_100
value: 44.07
- type: map_at_1000
value: 44.198
- type: map_at_3
value: 38.957
- type: map_at_5
value: 40.961
- type: mrr_at_1
value: 37.196
- type: mrr_at_10
value: 48.152
- type: mrr_at_100
value: 48.928
- type: mrr_at_1000
value: 48.964999999999996
- type: mrr_at_3
value: 45.446
- type: mrr_at_5
value: 47.205999999999996
- type: ndcg_at_1
value: 37.196
- type: ndcg_at_10
value: 49.089
- type: ndcg_at_100
value: 54.471000000000004
- type: ndcg_at_1000
value: 56.385
- type: ndcg_at_3
value: 43.699
- type: ndcg_at_5
value: 46.22
- type: precision_at_1
value: 37.196
- type: precision_at_10
value: 9.313
- type: precision_at_100
value: 1.478
- type: precision_at_1000
value: 0.198
- type: precision_at_3
value: 20.839
- type: precision_at_5
value: 14.936
- type: recall_at_1
value: 31.391999999999996
- type: recall_at_10
value: 61.876
- type: recall_at_100
value: 84.214
- type: recall_at_1000
value: 95.985
- type: recall_at_3
value: 46.6
- type: recall_at_5
value: 53.588
- type: map_at_1
value: 29.083
- type: map_at_10
value: 38.812999999999995
- type: map_at_100
value: 40.053
- type: map_at_1000
value: 40.188
- type: map_at_3
value: 36.111
- type: map_at_5
value: 37.519000000000005
- type: mrr_at_1
value: 36.497
- type: mrr_at_10
value: 44.85
- type: mrr_at_100
value: 45.546
- type: mrr_at_1000
value: 45.593
- type: mrr_at_3
value: 42.686
- type: mrr_at_5
value: 43.909
- type: ndcg_at_1
value: 36.497
- type: ndcg_at_10
value: 44.443
- type: ndcg_at_100
value: 48.979
- type: ndcg_at_1000
value: 51.154999999999994
- type: ndcg_at_3
value: 40.660000000000004
- type: ndcg_at_5
value: 42.193000000000005
- type: precision_at_1
value: 36.497
- type: precision_at_10
value: 8.433
- type: precision_at_100
value: 1.369
- type: precision_at_1000
value: 0.185
- type: precision_at_3
value: 19.894000000000002
- type: precision_at_5
value: 13.873
- type: recall_at_1
value: 29.083
- type: recall_at_10
value: 54.313
- type: recall_at_100
value: 73.792
- type: recall_at_1000
value: 87.629
- type: recall_at_3
value: 42.257
- type: recall_at_5
value: 47.066
- type: map_at_1
value: 38.556000000000004
- type: map_at_10
value: 50.698
- type: map_at_100
value: 51.705
- type: map_at_1000
value: 51.768
- type: map_at_3
value: 47.848
- type: map_at_5
value: 49.358000000000004
- type: mrr_at_1
value: 43.95
- type: mrr_at_10
value: 54.191
- type: mrr_at_100
value: 54.852999999999994
- type: mrr_at_1000
value: 54.885
- type: mrr_at_3
value: 51.954
- type: mrr_at_5
value: 53.13
- type: ndcg_at_1
value: 43.95
- type: ndcg_at_10
value: 56.516
- type: ndcg_at_100
value: 60.477000000000004
- type: ndcg_at_1000
value: 61.746
- type: ndcg_at_3
value: 51.601
- type: ndcg_at_5
value: 53.795
- type: precision_at_1
value: 43.95
- type: precision_at_10
value: 9.009
- type: precision_at_100
value: 1.189
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 22.989
- type: precision_at_5
value: 15.473
- type: recall_at_1
value: 38.556000000000004
- type: recall_at_10
value: 70.159
- type: recall_at_100
value: 87.132
- type: recall_at_1000
value: 96.16
- type: recall_at_3
value: 56.906
- type: recall_at_5
value: 62.332
- type: map_at_1
value: 24.238
- type: map_at_10
value: 32.5
- type: map_at_100
value: 33.637
- type: map_at_1000
value: 33.719
- type: map_at_3
value: 30.026999999999997
- type: map_at_5
value: 31.555
- type: mrr_at_1
value: 26.328000000000003
- type: mrr_at_10
value: 34.44
- type: mrr_at_100
value: 35.455999999999996
- type: mrr_at_1000
value: 35.521
- type: mrr_at_3
value: 32.034
- type: mrr_at_5
value: 33.565
- type: ndcg_at_1
value: 26.328000000000003
- type: ndcg_at_10
value: 37.202
- type: ndcg_at_100
value: 42.728
- type: ndcg_at_1000
value: 44.792
- type: ndcg_at_3
value: 32.368
- type: ndcg_at_5
value: 35.008
- type: precision_at_1
value: 26.328000000000003
- type: precision_at_10
value: 5.7059999999999995
- type: precision_at_100
value: 0.8880000000000001
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 13.672
- type: precision_at_5
value: 9.74
- type: recall_at_1
value: 24.238
- type: recall_at_10
value: 49.829
- type: recall_at_100
value: 75.21
- type: recall_at_1000
value: 90.521
- type: recall_at_3
value: 36.867
- type: recall_at_5
value: 43.241
- type: map_at_1
value: 15.378
- type: map_at_10
value: 22.817999999999998
- type: map_at_100
value: 23.977999999999998
- type: map_at_1000
value: 24.108
- type: map_at_3
value: 20.719
- type: map_at_5
value: 21.889
- type: mrr_at_1
value: 19.03
- type: mrr_at_10
value: 27.022000000000002
- type: mrr_at_100
value: 28.011999999999997
- type: mrr_at_1000
value: 28.096
- type: mrr_at_3
value: 24.855
- type: mrr_at_5
value: 26.029999999999998
- type: ndcg_at_1
value: 19.03
- type: ndcg_at_10
value: 27.526
- type: ndcg_at_100
value: 33.040000000000006
- type: ndcg_at_1000
value: 36.187000000000005
- type: ndcg_at_3
value: 23.497
- type: ndcg_at_5
value: 25.334
- type: precision_at_1
value: 19.03
- type: precision_at_10
value: 4.963
- type: precision_at_100
value: 0.893
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 11.360000000000001
- type: precision_at_5
value: 8.134
- type: recall_at_1
value: 15.378
- type: recall_at_10
value: 38.061
- type: recall_at_100
value: 61.754
- type: recall_at_1000
value: 84.259
- type: recall_at_3
value: 26.788
- type: recall_at_5
value: 31.326999999999998
- type: map_at_1
value: 27.511999999999997
- type: map_at_10
value: 37.429
- type: map_at_100
value: 38.818000000000005
- type: map_at_1000
value: 38.924
- type: map_at_3
value: 34.625
- type: map_at_5
value: 36.064
- type: mrr_at_1
value: 33.300999999999995
- type: mrr_at_10
value: 43.036
- type: mrr_at_100
value: 43.894
- type: mrr_at_1000
value: 43.936
- type: mrr_at_3
value: 40.825
- type: mrr_at_5
value: 42.028
- type: ndcg_at_1
value: 33.300999999999995
- type: ndcg_at_10
value: 43.229
- type: ndcg_at_100
value: 48.992000000000004
- type: ndcg_at_1000
value: 51.02100000000001
- type: ndcg_at_3
value: 38.794000000000004
- type: ndcg_at_5
value: 40.65
- type: precision_at_1
value: 33.300999999999995
- type: precision_at_10
value: 7.777000000000001
- type: precision_at_100
value: 1.269
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 18.351
- type: precision_at_5
value: 12.762
- type: recall_at_1
value: 27.511999999999997
- type: recall_at_10
value: 54.788000000000004
- type: recall_at_100
value: 79.105
- type: recall_at_1000
value: 92.49199999999999
- type: recall_at_3
value: 41.924
- type: recall_at_5
value: 47.026
- type: map_at_1
value: 24.117
- type: map_at_10
value: 33.32
- type: map_at_100
value: 34.677
- type: map_at_1000
value: 34.78
- type: map_at_3
value: 30.233999999999998
- type: map_at_5
value: 31.668000000000003
- type: mrr_at_1
value: 29.566
- type: mrr_at_10
value: 38.244
- type: mrr_at_100
value: 39.245000000000005
- type: mrr_at_1000
value: 39.296
- type: mrr_at_3
value: 35.864000000000004
- type: mrr_at_5
value: 36.919999999999995
- type: ndcg_at_1
value: 29.566
- type: ndcg_at_10
value: 39.127
- type: ndcg_at_100
value: 44.989000000000004
- type: ndcg_at_1000
value: 47.189
- type: ndcg_at_3
value: 34.039
- type: ndcg_at_5
value: 35.744
- type: precision_at_1
value: 29.566
- type: precision_at_10
value: 7.385999999999999
- type: precision_at_100
value: 1.204
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 16.286
- type: precision_at_5
value: 11.484
- type: recall_at_1
value: 24.117
- type: recall_at_10
value: 51.559999999999995
- type: recall_at_100
value: 77.104
- type: recall_at_1000
value: 91.79899999999999
- type: recall_at_3
value: 36.82
- type: recall_at_5
value: 41.453
- type: map_at_1
value: 25.17625
- type: map_at_10
value: 34.063916666666664
- type: map_at_100
value: 35.255500000000005
- type: map_at_1000
value: 35.37275
- type: map_at_3
value: 31.351666666666667
- type: map_at_5
value: 32.80608333333333
- type: mrr_at_1
value: 29.59783333333333
- type: mrr_at_10
value: 38.0925
- type: mrr_at_100
value: 38.957249999999995
- type: mrr_at_1000
value: 39.01608333333333
- type: mrr_at_3
value: 35.77625
- type: mrr_at_5
value: 37.04991666666667
- type: ndcg_at_1
value: 29.59783333333333
- type: ndcg_at_10
value: 39.343666666666664
- type: ndcg_at_100
value: 44.488249999999994
- type: ndcg_at_1000
value: 46.83358333333334
- type: ndcg_at_3
value: 34.69708333333333
- type: ndcg_at_5
value: 36.75075
- type: precision_at_1
value: 29.59783333333333
- type: precision_at_10
value: 6.884083333333332
- type: precision_at_100
value: 1.114
- type: precision_at_1000
value: 0.15108333333333332
- type: precision_at_3
value: 15.965250000000003
- type: precision_at_5
value: 11.246500000000001
- type: recall_at_1
value: 25.17625
- type: recall_at_10
value: 51.015999999999984
- type: recall_at_100
value: 73.60174999999998
- type: recall_at_1000
value: 89.849
- type: recall_at_3
value: 37.88399999999999
- type: recall_at_5
value: 43.24541666666666
- type: map_at_1
value: 24.537
- type: map_at_10
value: 31.081999999999997
- type: map_at_100
value: 32.042
- type: map_at_1000
value: 32.141
- type: map_at_3
value: 29.137
- type: map_at_5
value: 30.079
- type: mrr_at_1
value: 27.454
- type: mrr_at_10
value: 33.694
- type: mrr_at_100
value: 34.579
- type: mrr_at_1000
value: 34.649
- type: mrr_at_3
value: 32.004
- type: mrr_at_5
value: 32.794000000000004
- type: ndcg_at_1
value: 27.454
- type: ndcg_at_10
value: 34.915
- type: ndcg_at_100
value: 39.641
- type: ndcg_at_1000
value: 42.105
- type: ndcg_at_3
value: 31.276
- type: ndcg_at_5
value: 32.65
- type: precision_at_1
value: 27.454
- type: precision_at_10
value: 5.337
- type: precision_at_100
value: 0.8250000000000001
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 13.241
- type: precision_at_5
value: 8.895999999999999
- type: recall_at_1
value: 24.537
- type: recall_at_10
value: 44.324999999999996
- type: recall_at_100
value: 65.949
- type: recall_at_1000
value: 84.017
- type: recall_at_3
value: 33.857
- type: recall_at_5
value: 37.316
- type: map_at_1
value: 17.122
- type: map_at_10
value: 24.32
- type: map_at_100
value: 25.338
- type: map_at_1000
value: 25.462
- type: map_at_3
value: 22.064
- type: map_at_5
value: 23.322000000000003
- type: mrr_at_1
value: 20.647
- type: mrr_at_10
value: 27.858
- type: mrr_at_100
value: 28.743999999999996
- type: mrr_at_1000
value: 28.819
- type: mrr_at_3
value: 25.769
- type: mrr_at_5
value: 26.964
- type: ndcg_at_1
value: 20.647
- type: ndcg_at_10
value: 28.849999999999998
- type: ndcg_at_100
value: 33.849000000000004
- type: ndcg_at_1000
value: 36.802
- type: ndcg_at_3
value: 24.799
- type: ndcg_at_5
value: 26.682
- type: precision_at_1
value: 20.647
- type: precision_at_10
value: 5.2170000000000005
- type: precision_at_100
value: 0.906
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 11.769
- type: precision_at_5
value: 8.486
- type: recall_at_1
value: 17.122
- type: recall_at_10
value: 38.999
- type: recall_at_100
value: 61.467000000000006
- type: recall_at_1000
value: 82.716
- type: recall_at_3
value: 27.601
- type: recall_at_5
value: 32.471
- type: map_at_1
value: 24.396
- type: map_at_10
value: 33.415
- type: map_at_100
value: 34.521
- type: map_at_1000
value: 34.631
- type: map_at_3
value: 30.703999999999997
- type: map_at_5
value: 32.166
- type: mrr_at_1
value: 28.825
- type: mrr_at_10
value: 37.397000000000006
- type: mrr_at_100
value: 38.286
- type: mrr_at_1000
value: 38.346000000000004
- type: mrr_at_3
value: 35.028
- type: mrr_at_5
value: 36.32
- type: ndcg_at_1
value: 28.825
- type: ndcg_at_10
value: 38.656
- type: ndcg_at_100
value: 43.856
- type: ndcg_at_1000
value: 46.31
- type: ndcg_at_3
value: 33.793
- type: ndcg_at_5
value: 35.909
- type: precision_at_1
value: 28.825
- type: precision_at_10
value: 6.567
- type: precision_at_100
value: 1.0330000000000001
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 15.516
- type: precision_at_5
value: 10.914
- type: recall_at_1
value: 24.396
- type: recall_at_10
value: 50.747
- type: recall_at_100
value: 73.477
- type: recall_at_1000
value: 90.801
- type: recall_at_3
value: 37.1
- type: recall_at_5
value: 42.589
- type: map_at_1
value: 25.072
- type: map_at_10
value: 34.307
- type: map_at_100
value: 35.725
- type: map_at_1000
value: 35.943999999999996
- type: map_at_3
value: 30.906
- type: map_at_5
value: 32.818000000000005
- type: mrr_at_1
value: 29.644
- type: mrr_at_10
value: 38.673
- type: mrr_at_100
value: 39.459
- type: mrr_at_1000
value: 39.527
- type: mrr_at_3
value: 35.771
- type: mrr_at_5
value: 37.332
- type: ndcg_at_1
value: 29.644
- type: ndcg_at_10
value: 40.548
- type: ndcg_at_100
value: 45.678999999999995
- type: ndcg_at_1000
value: 48.488
- type: ndcg_at_3
value: 34.887
- type: ndcg_at_5
value: 37.543
- type: precision_at_1
value: 29.644
- type: precision_at_10
value: 7.688000000000001
- type: precision_at_100
value: 1.482
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 16.206
- type: precision_at_5
value: 12.016
- type: recall_at_1
value: 25.072
- type: recall_at_10
value: 53.478
- type: recall_at_100
value: 76.07300000000001
- type: recall_at_1000
value: 93.884
- type: recall_at_3
value: 37.583
- type: recall_at_5
value: 44.464
- type: map_at_1
value: 20.712
- type: map_at_10
value: 27.467999999999996
- type: map_at_100
value: 28.502
- type: map_at_1000
value: 28.610000000000003
- type: map_at_3
value: 24.887999999999998
- type: map_at_5
value: 26.273999999999997
- type: mrr_at_1
value: 22.736
- type: mrr_at_10
value: 29.553
- type: mrr_at_100
value: 30.485
- type: mrr_at_1000
value: 30.56
- type: mrr_at_3
value: 27.078999999999997
- type: mrr_at_5
value: 28.401
- type: ndcg_at_1
value: 22.736
- type: ndcg_at_10
value: 32.023
- type: ndcg_at_100
value: 37.158
- type: ndcg_at_1000
value: 39.823
- type: ndcg_at_3
value: 26.951999999999998
- type: ndcg_at_5
value: 29.281000000000002
- type: precision_at_1
value: 22.736
- type: precision_at_10
value: 5.213
- type: precision_at_100
value: 0.832
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 11.459999999999999
- type: precision_at_5
value: 8.244
- type: recall_at_1
value: 20.712
- type: recall_at_10
value: 44.057
- type: recall_at_100
value: 67.944
- type: recall_at_1000
value: 87.925
- type: recall_at_3
value: 30.305
- type: recall_at_5
value: 36.071999999999996
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.181999999999999
- type: map_at_10
value: 16.66
- type: map_at_100
value: 18.273
- type: map_at_1000
value: 18.45
- type: map_at_3
value: 14.141
- type: map_at_5
value: 15.455
- type: mrr_at_1
value: 22.15
- type: mrr_at_10
value: 32.062000000000005
- type: mrr_at_100
value: 33.116
- type: mrr_at_1000
value: 33.168
- type: mrr_at_3
value: 28.827
- type: mrr_at_5
value: 30.892999999999997
- type: ndcg_at_1
value: 22.15
- type: ndcg_at_10
value: 23.532
- type: ndcg_at_100
value: 30.358
- type: ndcg_at_1000
value: 33.783
- type: ndcg_at_3
value: 19.222
- type: ndcg_at_5
value: 20.919999999999998
- type: precision_at_1
value: 22.15
- type: precision_at_10
value: 7.185999999999999
- type: precision_at_100
value: 1.433
- type: precision_at_1000
value: 0.207
- type: precision_at_3
value: 13.941
- type: precision_at_5
value: 10.906
- type: recall_at_1
value: 10.181999999999999
- type: recall_at_10
value: 28.104000000000003
- type: recall_at_100
value: 51.998999999999995
- type: recall_at_1000
value: 71.311
- type: recall_at_3
value: 17.698
- type: recall_at_5
value: 22.262999999999998
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.669
- type: map_at_10
value: 15.552
- type: map_at_100
value: 21.865000000000002
- type: map_at_1000
value: 23.268
- type: map_at_3
value: 11.309
- type: map_at_5
value: 13.084000000000001
- type: mrr_at_1
value: 55.50000000000001
- type: mrr_at_10
value: 66.46600000000001
- type: mrr_at_100
value: 66.944
- type: mrr_at_1000
value: 66.956
- type: mrr_at_3
value: 64.542
- type: mrr_at_5
value: 65.717
- type: ndcg_at_1
value: 44.75
- type: ndcg_at_10
value: 35.049
- type: ndcg_at_100
value: 39.073
- type: ndcg_at_1000
value: 46.208
- type: ndcg_at_3
value: 39.525
- type: ndcg_at_5
value: 37.156
- type: precision_at_1
value: 55.50000000000001
- type: precision_at_10
value: 27.800000000000004
- type: precision_at_100
value: 9.013
- type: precision_at_1000
value: 1.8800000000000001
- type: precision_at_3
value: 42.667
- type: precision_at_5
value: 36.0
- type: recall_at_1
value: 6.669
- type: recall_at_10
value: 21.811
- type: recall_at_100
value: 45.112
- type: recall_at_1000
value: 67.806
- type: recall_at_3
value: 13.373
- type: recall_at_5
value: 16.615
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 48.769999999999996
- type: f1
value: 42.91448356376592
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 54.013
- type: map_at_10
value: 66.239
- type: map_at_100
value: 66.62599999999999
- type: map_at_1000
value: 66.644
- type: map_at_3
value: 63.965
- type: map_at_5
value: 65.45400000000001
- type: mrr_at_1
value: 58.221000000000004
- type: mrr_at_10
value: 70.43700000000001
- type: mrr_at_100
value: 70.744
- type: mrr_at_1000
value: 70.75099999999999
- type: mrr_at_3
value: 68.284
- type: mrr_at_5
value: 69.721
- type: ndcg_at_1
value: 58.221000000000004
- type: ndcg_at_10
value: 72.327
- type: ndcg_at_100
value: 73.953
- type: ndcg_at_1000
value: 74.312
- type: ndcg_at_3
value: 68.062
- type: ndcg_at_5
value: 70.56400000000001
- type: precision_at_1
value: 58.221000000000004
- type: precision_at_10
value: 9.521
- type: precision_at_100
value: 1.045
- type: precision_at_1000
value: 0.109
- type: precision_at_3
value: 27.348
- type: precision_at_5
value: 17.794999999999998
- type: recall_at_1
value: 54.013
- type: recall_at_10
value: 86.957
- type: recall_at_100
value: 93.911
- type: recall_at_1000
value: 96.38
- type: recall_at_3
value: 75.555
- type: recall_at_5
value: 81.671
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.254
- type: map_at_10
value: 33.723
- type: map_at_100
value: 35.574
- type: map_at_1000
value: 35.730000000000004
- type: map_at_3
value: 29.473
- type: map_at_5
value: 31.543
- type: mrr_at_1
value: 41.358
- type: mrr_at_10
value: 49.498
- type: mrr_at_100
value: 50.275999999999996
- type: mrr_at_1000
value: 50.308
- type: mrr_at_3
value: 47.016000000000005
- type: mrr_at_5
value: 48.336
- type: ndcg_at_1
value: 41.358
- type: ndcg_at_10
value: 41.579
- type: ndcg_at_100
value: 48.455
- type: ndcg_at_1000
value: 51.165000000000006
- type: ndcg_at_3
value: 37.681
- type: ndcg_at_5
value: 38.49
- type: precision_at_1
value: 41.358
- type: precision_at_10
value: 11.543000000000001
- type: precision_at_100
value: 1.87
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 24.743000000000002
- type: precision_at_5
value: 17.994
- type: recall_at_1
value: 21.254
- type: recall_at_10
value: 48.698
- type: recall_at_100
value: 74.588
- type: recall_at_1000
value: 91.00200000000001
- type: recall_at_3
value: 33.939
- type: recall_at_5
value: 39.367000000000004
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.922
- type: map_at_10
value: 52.32599999999999
- type: map_at_100
value: 53.18000000000001
- type: map_at_1000
value: 53.245
- type: map_at_3
value: 49.294
- type: map_at_5
value: 51.202999999999996
- type: mrr_at_1
value: 71.843
- type: mrr_at_10
value: 78.24600000000001
- type: mrr_at_100
value: 78.515
- type: mrr_at_1000
value: 78.527
- type: mrr_at_3
value: 77.17500000000001
- type: mrr_at_5
value: 77.852
- type: ndcg_at_1
value: 71.843
- type: ndcg_at_10
value: 61.379
- type: ndcg_at_100
value: 64.535
- type: ndcg_at_1000
value: 65.888
- type: ndcg_at_3
value: 56.958
- type: ndcg_at_5
value: 59.434
- type: precision_at_1
value: 71.843
- type: precision_at_10
value: 12.686
- type: precision_at_100
value: 1.517
- type: precision_at_1000
value: 0.16999999999999998
- type: precision_at_3
value: 35.778
- type: precision_at_5
value: 23.422
- type: recall_at_1
value: 35.922
- type: recall_at_10
value: 63.43
- type: recall_at_100
value: 75.868
- type: recall_at_1000
value: 84.88900000000001
- type: recall_at_3
value: 53.666000000000004
- type: recall_at_5
value: 58.555
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 79.4408
- type: ap
value: 73.52820871620366
- type: f1
value: 79.36240238685001
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.826999999999998
- type: map_at_10
value: 34.04
- type: map_at_100
value: 35.226
- type: map_at_1000
value: 35.275
- type: map_at_3
value: 30.165999999999997
- type: map_at_5
value: 32.318000000000005
- type: mrr_at_1
value: 22.464000000000002
- type: mrr_at_10
value: 34.631
- type: mrr_at_100
value: 35.752
- type: mrr_at_1000
value: 35.795
- type: mrr_at_3
value: 30.798
- type: mrr_at_5
value: 32.946999999999996
- type: ndcg_at_1
value: 22.464000000000002
- type: ndcg_at_10
value: 40.919
- type: ndcg_at_100
value: 46.632
- type: ndcg_at_1000
value: 47.833
- type: ndcg_at_3
value: 32.992
- type: ndcg_at_5
value: 36.834
- type: precision_at_1
value: 22.464000000000002
- type: precision_at_10
value: 6.494
- type: precision_at_100
value: 0.9369999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.021
- type: precision_at_5
value: 10.347000000000001
- type: recall_at_1
value: 21.826999999999998
- type: recall_at_10
value: 62.132
- type: recall_at_100
value: 88.55199999999999
- type: recall_at_1000
value: 97.707
- type: recall_at_3
value: 40.541
- type: recall_at_5
value: 49.739
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 95.68399452804377
- type: f1
value: 95.25490609832268
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 83.15321477428182
- type: f1
value: 60.35476439087966
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.92669804976462
- type: f1
value: 69.22815107207565
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.4855413584398
- type: f1
value: 72.92107516103387
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 32.412679360205544
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.09211869875204
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.540919056982545
- type: mrr
value: 31.529904607063536
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.745
- type: map_at_10
value: 12.013
- type: map_at_100
value: 15.040000000000001
- type: map_at_1000
value: 16.427
- type: map_at_3
value: 8.841000000000001
- type: map_at_5
value: 10.289
- type: mrr_at_1
value: 45.201
- type: mrr_at_10
value: 53.483999999999995
- type: mrr_at_100
value: 54.20700000000001
- type: mrr_at_1000
value: 54.252
- type: mrr_at_3
value: 51.29
- type: mrr_at_5
value: 52.73
- type: ndcg_at_1
value: 43.808
- type: ndcg_at_10
value: 32.445
- type: ndcg_at_100
value: 30.031000000000002
- type: ndcg_at_1000
value: 39.007
- type: ndcg_at_3
value: 37.204
- type: ndcg_at_5
value: 35.07
- type: precision_at_1
value: 45.201
- type: precision_at_10
value: 23.684
- type: precision_at_100
value: 7.600999999999999
- type: precision_at_1000
value: 2.043
- type: precision_at_3
value: 33.953
- type: precision_at_5
value: 29.412
- type: recall_at_1
value: 5.745
- type: recall_at_10
value: 16.168
- type: recall_at_100
value: 30.875999999999998
- type: recall_at_1000
value: 62.686
- type: recall_at_3
value: 9.75
- type: recall_at_5
value: 12.413
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.828
- type: map_at_10
value: 53.239000000000004
- type: map_at_100
value: 54.035999999999994
- type: map_at_1000
value: 54.067
- type: map_at_3
value: 49.289
- type: map_at_5
value: 51.784
- type: mrr_at_1
value: 42.497
- type: mrr_at_10
value: 55.916999999999994
- type: mrr_at_100
value: 56.495
- type: mrr_at_1000
value: 56.516999999999996
- type: mrr_at_3
value: 52.800000000000004
- type: mrr_at_5
value: 54.722
- type: ndcg_at_1
value: 42.468
- type: ndcg_at_10
value: 60.437
- type: ndcg_at_100
value: 63.731
- type: ndcg_at_1000
value: 64.41799999999999
- type: ndcg_at_3
value: 53.230999999999995
- type: ndcg_at_5
value: 57.26
- type: precision_at_1
value: 42.468
- type: precision_at_10
value: 9.47
- type: precision_at_100
value: 1.1360000000000001
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.724999999999998
- type: precision_at_5
value: 16.593
- type: recall_at_1
value: 37.828
- type: recall_at_10
value: 79.538
- type: recall_at_100
value: 93.646
- type: recall_at_1000
value: 98.72999999999999
- type: recall_at_3
value: 61.134
- type: recall_at_5
value: 70.377
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.548
- type: map_at_10
value: 84.466
- type: map_at_100
value: 85.10600000000001
- type: map_at_1000
value: 85.123
- type: map_at_3
value: 81.57600000000001
- type: map_at_5
value: 83.399
- type: mrr_at_1
value: 81.24
- type: mrr_at_10
value: 87.457
- type: mrr_at_100
value: 87.574
- type: mrr_at_1000
value: 87.575
- type: mrr_at_3
value: 86.507
- type: mrr_at_5
value: 87.205
- type: ndcg_at_1
value: 81.25
- type: ndcg_at_10
value: 88.203
- type: ndcg_at_100
value: 89.457
- type: ndcg_at_1000
value: 89.563
- type: ndcg_at_3
value: 85.465
- type: ndcg_at_5
value: 87.007
- type: precision_at_1
value: 81.25
- type: precision_at_10
value: 13.373
- type: precision_at_100
value: 1.5270000000000001
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.417
- type: precision_at_5
value: 24.556
- type: recall_at_1
value: 70.548
- type: recall_at_10
value: 95.208
- type: recall_at_100
value: 99.514
- type: recall_at_1000
value: 99.988
- type: recall_at_3
value: 87.214
- type: recall_at_5
value: 91.696
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 53.04822095496839
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 60.30778476474675
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.692
- type: map_at_10
value: 11.766
- type: map_at_100
value: 13.904
- type: map_at_1000
value: 14.216999999999999
- type: map_at_3
value: 8.245
- type: map_at_5
value: 9.92
- type: mrr_at_1
value: 23.0
- type: mrr_at_10
value: 33.78
- type: mrr_at_100
value: 34.922
- type: mrr_at_1000
value: 34.973
- type: mrr_at_3
value: 30.2
- type: mrr_at_5
value: 32.565
- type: ndcg_at_1
value: 23.0
- type: ndcg_at_10
value: 19.863
- type: ndcg_at_100
value: 28.141
- type: ndcg_at_1000
value: 33.549
- type: ndcg_at_3
value: 18.434
- type: ndcg_at_5
value: 16.384
- type: precision_at_1
value: 23.0
- type: precision_at_10
value: 10.39
- type: precision_at_100
value: 2.235
- type: precision_at_1000
value: 0.35300000000000004
- type: precision_at_3
value: 17.133000000000003
- type: precision_at_5
value: 14.44
- type: recall_at_1
value: 4.692
- type: recall_at_10
value: 21.025
- type: recall_at_100
value: 45.324999999999996
- type: recall_at_1000
value: 71.675
- type: recall_at_3
value: 10.440000000000001
- type: recall_at_5
value: 14.64
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.96178184892842
- type: cos_sim_spearman
value: 79.6487740813199
- type: euclidean_pearson
value: 82.06661161625023
- type: euclidean_spearman
value: 79.64876769031183
- type: manhattan_pearson
value: 82.07061164575131
- type: manhattan_spearman
value: 79.65197039464537
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.15305604100027
- type: cos_sim_spearman
value: 74.27447427941591
- type: euclidean_pearson
value: 80.52737337565307
- type: euclidean_spearman
value: 74.27416077132192
- type: manhattan_pearson
value: 80.53728571140387
- type: manhattan_spearman
value: 74.28853605753457
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 83.44386080639279
- type: cos_sim_spearman
value: 84.17947648159536
- type: euclidean_pearson
value: 83.34145388129387
- type: euclidean_spearman
value: 84.17947648159536
- type: manhattan_pearson
value: 83.30699061927966
- type: manhattan_spearman
value: 84.18125737380451
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 81.57392220985612
- type: cos_sim_spearman
value: 78.80745014464101
- type: euclidean_pearson
value: 80.01660371487199
- type: euclidean_spearman
value: 78.80741240102256
- type: manhattan_pearson
value: 79.96810779507953
- type: manhattan_spearman
value: 78.75600400119448
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.85421063026625
- type: cos_sim_spearman
value: 87.55320285299192
- type: euclidean_pearson
value: 86.69750143323517
- type: euclidean_spearman
value: 87.55320284326378
- type: manhattan_pearson
value: 86.63379169960379
- type: manhattan_spearman
value: 87.4815029877984
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.31314130411842
- type: cos_sim_spearman
value: 85.3489588181433
- type: euclidean_pearson
value: 84.13240933463535
- type: euclidean_spearman
value: 85.34902871403281
- type: manhattan_pearson
value: 84.01183086503559
- type: manhattan_spearman
value: 85.19316703166102
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.09979781689536
- type: cos_sim_spearman
value: 88.87813323759015
- type: euclidean_pearson
value: 88.65413031123792
- type: euclidean_spearman
value: 88.87813323759015
- type: manhattan_pearson
value: 88.61818758256024
- type: manhattan_spearman
value: 88.81044100494604
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 62.30693258111531
- type: cos_sim_spearman
value: 62.195516523251946
- type: euclidean_pearson
value: 62.951283701049476
- type: euclidean_spearman
value: 62.195516523251946
- type: manhattan_pearson
value: 63.068322281439535
- type: manhattan_spearman
value: 62.10621171028406
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.27092833763909
- type: cos_sim_spearman
value: 84.84429717949759
- type: euclidean_pearson
value: 84.8516966060792
- type: euclidean_spearman
value: 84.84429717949759
- type: manhattan_pearson
value: 84.82203139242881
- type: manhattan_spearman
value: 84.8358503952945
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 83.10290863981409
- type: mrr
value: 95.31168450286097
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 52.161
- type: map_at_10
value: 62.138000000000005
- type: map_at_100
value: 62.769
- type: map_at_1000
value: 62.812
- type: map_at_3
value: 59.111000000000004
- type: map_at_5
value: 60.995999999999995
- type: mrr_at_1
value: 55.333
- type: mrr_at_10
value: 63.504000000000005
- type: mrr_at_100
value: 64.036
- type: mrr_at_1000
value: 64.08
- type: mrr_at_3
value: 61.278
- type: mrr_at_5
value: 62.778
- type: ndcg_at_1
value: 55.333
- type: ndcg_at_10
value: 66.678
- type: ndcg_at_100
value: 69.415
- type: ndcg_at_1000
value: 70.453
- type: ndcg_at_3
value: 61.755
- type: ndcg_at_5
value: 64.546
- type: precision_at_1
value: 55.333
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.043
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 24.221999999999998
- type: precision_at_5
value: 16.333000000000002
- type: recall_at_1
value: 52.161
- type: recall_at_10
value: 79.156
- type: recall_at_100
value: 91.333
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 66.43299999999999
- type: recall_at_5
value: 73.272
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.81287128712871
- type: cos_sim_ap
value: 95.30034785910676
- type: cos_sim_f1
value: 90.28629856850716
- type: cos_sim_precision
value: 92.36401673640168
- type: cos_sim_recall
value: 88.3
- type: dot_accuracy
value: 99.81287128712871
- type: dot_ap
value: 95.30034785910676
- type: dot_f1
value: 90.28629856850716
- type: dot_precision
value: 92.36401673640168
- type: dot_recall
value: 88.3
- type: euclidean_accuracy
value: 99.81287128712871
- type: euclidean_ap
value: 95.30034785910676
- type: euclidean_f1
value: 90.28629856850716
- type: euclidean_precision
value: 92.36401673640168
- type: euclidean_recall
value: 88.3
- type: manhattan_accuracy
value: 99.80990099009901
- type: manhattan_ap
value: 95.26880751950654
- type: manhattan_f1
value: 90.22177419354838
- type: manhattan_precision
value: 90.95528455284553
- type: manhattan_recall
value: 89.5
- type: max_accuracy
value: 99.81287128712871
- type: max_ap
value: 95.30034785910676
- type: max_f1
value: 90.28629856850716
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 58.518662504351184
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.96168178378587
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.04862593471896
- type: mrr
value: 52.97238402936932
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.092545236479946
- type: cos_sim_spearman
value: 31.599851000175498
- type: dot_pearson
value: 30.092542723901676
- type: dot_spearman
value: 31.599851000175498
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.189
- type: map_at_10
value: 1.662
- type: map_at_100
value: 9.384
- type: map_at_1000
value: 22.669
- type: map_at_3
value: 0.5559999999999999
- type: map_at_5
value: 0.9039999999999999
- type: mrr_at_1
value: 68.0
- type: mrr_at_10
value: 81.01899999999999
- type: mrr_at_100
value: 81.01899999999999
- type: mrr_at_1000
value: 81.01899999999999
- type: mrr_at_3
value: 79.333
- type: mrr_at_5
value: 80.733
- type: ndcg_at_1
value: 63.0
- type: ndcg_at_10
value: 65.913
- type: ndcg_at_100
value: 51.895
- type: ndcg_at_1000
value: 46.967
- type: ndcg_at_3
value: 65.49199999999999
- type: ndcg_at_5
value: 66.69699999999999
- type: precision_at_1
value: 68.0
- type: precision_at_10
value: 71.6
- type: precision_at_100
value: 53.66
- type: precision_at_1000
value: 21.124000000000002
- type: precision_at_3
value: 72.667
- type: precision_at_5
value: 74.0
- type: recall_at_1
value: 0.189
- type: recall_at_10
value: 1.913
- type: recall_at_100
value: 12.601999999999999
- type: recall_at_1000
value: 44.296
- type: recall_at_3
value: 0.605
- type: recall_at_5
value: 1.018
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.701
- type: map_at_10
value: 10.445
- type: map_at_100
value: 17.324
- type: map_at_1000
value: 19.161
- type: map_at_3
value: 5.497
- type: map_at_5
value: 7.278
- type: mrr_at_1
value: 30.612000000000002
- type: mrr_at_10
value: 45.534
- type: mrr_at_100
value: 45.792
- type: mrr_at_1000
value: 45.806999999999995
- type: mrr_at_3
value: 37.755
- type: mrr_at_5
value: 43.469
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 26.235000000000003
- type: ndcg_at_100
value: 39.17
- type: ndcg_at_1000
value: 51.038
- type: ndcg_at_3
value: 23.625
- type: ndcg_at_5
value: 24.338
- type: precision_at_1
value: 30.612000000000002
- type: precision_at_10
value: 24.285999999999998
- type: precision_at_100
value: 8.224
- type: precision_at_1000
value: 1.6179999999999999
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 24.898
- type: recall_at_1
value: 2.701
- type: recall_at_10
value: 17.997
- type: recall_at_100
value: 51.766999999999996
- type: recall_at_1000
value: 87.863
- type: recall_at_3
value: 6.295000000000001
- type: recall_at_5
value: 9.993
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 73.3474
- type: ap
value: 15.393431414459924
- type: f1
value: 56.466681887882416
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 62.062818336163
- type: f1
value: 62.11230840463252
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 42.464892820845115
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.15962329379508
- type: cos_sim_ap
value: 74.73674057919256
- type: cos_sim_f1
value: 68.81245642574947
- type: cos_sim_precision
value: 61.48255813953488
- type: cos_sim_recall
value: 78.12664907651715
- type: dot_accuracy
value: 86.15962329379508
- type: dot_ap
value: 74.7367634988281
- type: dot_f1
value: 68.81245642574947
- type: dot_precision
value: 61.48255813953488
- type: dot_recall
value: 78.12664907651715
- type: euclidean_accuracy
value: 86.15962329379508
- type: euclidean_ap
value: 74.7367761466634
- type: euclidean_f1
value: 68.81245642574947
- type: euclidean_precision
value: 61.48255813953488
- type: euclidean_recall
value: 78.12664907651715
- type: manhattan_accuracy
value: 86.21326816474935
- type: manhattan_ap
value: 74.64416473733951
- type: manhattan_f1
value: 68.80924855491331
- type: manhattan_precision
value: 61.23456790123457
- type: manhattan_recall
value: 78.52242744063325
- type: max_accuracy
value: 86.21326816474935
- type: max_ap
value: 74.7367761466634
- type: max_f1
value: 68.81245642574947
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.97620988085536
- type: cos_sim_ap
value: 86.08680845745758
- type: cos_sim_f1
value: 78.02793637114438
- type: cos_sim_precision
value: 73.11082699683736
- type: cos_sim_recall
value: 83.65414228518632
- type: dot_accuracy
value: 88.97620988085536
- type: dot_ap
value: 86.08681149437946
- type: dot_f1
value: 78.02793637114438
- type: dot_precision
value: 73.11082699683736
- type: dot_recall
value: 83.65414228518632
- type: euclidean_accuracy
value: 88.97620988085536
- type: euclidean_ap
value: 86.08681215460771
- type: euclidean_f1
value: 78.02793637114438
- type: euclidean_precision
value: 73.11082699683736
- type: euclidean_recall
value: 83.65414228518632
- type: manhattan_accuracy
value: 88.88888888888889
- type: manhattan_ap
value: 86.02916327562438
- type: manhattan_f1
value: 78.02063045516843
- type: manhattan_precision
value: 73.38851947346994
- type: manhattan_recall
value: 83.2768709578072
- type: max_accuracy
value: 88.97620988085536
- type: max_ap
value: 86.08681215460771
- type: max_f1
value: 78.02793637114438
---
# djuna/jina-embeddings-v2-base-en-Q5_K_M-GGUF
This model was converted to GGUF format from [`jinaai/jina-embeddings-v2-base-en`](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo djuna/jina-embeddings-v2-base-en-Q5_K_M-GGUF --hf-file jina-embeddings-v2-base-en-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo djuna/jina-embeddings-v2-base-en-Q5_K_M-GGUF --hf-file jina-embeddings-v2-base-en-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo djuna/jina-embeddings-v2-base-en-Q5_K_M-GGUF --hf-file jina-embeddings-v2-base-en-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo djuna/jina-embeddings-v2-base-en-Q5_K_M-GGUF --hf-file jina-embeddings-v2-base-en-q5_k_m.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
mav23/pythia-6.9b-GGUF
|
mav23
| null |
[
"gguf",
"pytorch",
"causal-lm",
"pythia",
"en",
"dataset:EleutherAI/pile",
"arxiv:2304.01373",
"arxiv:2101.00027",
"arxiv:2201.07311",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2024-11-10T07:31:57Z |
2024-11-10T08:22:00+00:00
| 65 | 0 |
---
datasets:
- EleutherAI/pile
language:
- en
license: apache-2.0
tags:
- pytorch
- causal-lm
- pythia
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research [(see paper)](https://arxiv.org/pdf/2304.01373.pdf).
It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. We also provide 154 intermediate
checkpoints per model, hosted on Hugging Face as branches.
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
<details>
<summary style="font-weight:600">Details on previous early release and naming convention.</summary>
Previously, we released an early version of the Pythia suite to the public.
However, we decided to retrain the model suite to address a few hyperparameter
discrepancies. This model card <a href="#changelog">lists the changes</a>;
see appendix B in the Pythia paper for further discussion. We found no
difference in benchmark performance between the two Pythia versions.
The old models are
[still available](https://huggingface.co/models?other=pythia_v0), but we
suggest the retrained suite if you are just starting to use Pythia.<br>
**This is the current release.**
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
</details>
<br>
# Pythia-6.9B
## Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
[See paper](https://arxiv.org/pdf/2304.01373.pdf) for more evals and implementation
details.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 2M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 2M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 2M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
## Uses and Limitations
### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. We also provide
154 checkpoints per model: initial `step0`, 10 log-spaced checkpoints
`step{1,2,4...512}`, and 143 evenly-spaced checkpoints from `step1000` to
`step143000`. These checkpoints are hosted on Hugging Face as branches. Note
that branch `143000` corresponds exactly to the model checkpoint on the `main`
branch of each model.
You may also further fine-tune and adapt Pythia-6.9B for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-6.9B as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions. For example,
the model may generate harmful or offensive text. Please evaluate the risks
associated with your particular use case.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-6.9B has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-6.9B will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “follow” human instructions.
### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token used by the model need not produce the
most “accurate” text. Never rely on Pythia-6.9B to produce factually accurate
output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-6.9B may produce socially unacceptable or undesirable text, *even if*
the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-6.9B.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
## Training
### Training data
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).<br>
The Pile was **not** deduplicated before being used to train Pythia-6.9B.
### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training,
from `step1000` to `step143000` (which is the same as `main`). In addition, we
also provide frequent early checkpoints: `step0` and `step{1,2,4...512}`.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for 143000 steps at a batch size
of 2M (2,097,152 tokens).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
## Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json/).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai_v1.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa_v1.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande_v1.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge—Easy Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_easy_v1.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq_v1.png" style="width:auto"/>
</details>
## Changelog
This section compares differences between previously released
[Pythia v0](https://huggingface.co/models?other=pythia_v0) and the current
models. See Appendix B of the Pythia paper for further discussion of these
changes and the motivation behind them. We found that retraining Pythia had no
impact on benchmark performance.
- All model sizes are now trained with uniform batch size of 2M tokens.
Previously, the models of size 160M, 410M, and 1.4B parameters were trained
with batch sizes of 4M tokens.
- We added checkpoints at initialization (step 0) and steps {1,2,4,8,16,32,64,
128,256,512} in addition to every 1000 training steps.
- Flash Attention was used in the new retrained suite.
- We remedied a minor inconsistency that existed in the original suite: all
models of size 2.8B parameters or smaller had a learning rate (LR) schedule
which decayed to a minimum LR of 10% the starting LR rate, but the 6.9B and
12B models all used an LR schedule which decayed to a minimum LR of 0. In
the redone training runs, we rectified this inconsistency: all models now were
trained with LR decaying to a minimum of 0.1× their maximum LR.
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
[
"SCIQ"
] |
saswat94/my-pet-bear-nxt
|
saswat94
|
text-to-image
|
[
"diffusers",
"safetensors",
"NxtWave-GenAI-Webinar",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | 2023-07-03T00:51:10Z |
2023-07-03T00:55:44+00:00
| 64 | 0 |
---
license: creativeml-openrail-m
tags:
- NxtWave-GenAI-Webinar
- text-to-image
- stable-diffusion
---
### My-Pet-Bear-nxt Dreambooth model trained by saswat94 following the "Build your own Gen AI model" session by NxtWave.
Project Submission Code: CVRGU633
Sample pictures of this concept:

|
[
"BEAR"
] |
ntc-ai/SDXL-LoRA-slider.retro-horror-comic-style-poster
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-15T19:16:57Z |
2024-01-15T19:17:03+00:00
| 64 | 5 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/retro horror comic style poster.../retro horror comic style
poster_17_3.0.png
widget:
- text: retro horror comic style poster
output:
url: images/retro horror comic style poster_17_3.0.png
- text: retro horror comic style poster
output:
url: images/retro horror comic style poster_19_3.0.png
- text: retro horror comic style poster
output:
url: images/retro horror comic style poster_20_3.0.png
- text: retro horror comic style poster
output:
url: images/retro horror comic style poster_21_3.0.png
- text: retro horror comic style poster
output:
url: images/retro horror comic style poster_22_3.0.png
inference: false
instance_prompt: retro horror comic style poster
---
# ntcai.xyz slider - retro horror comic style poster (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/retro horror comic style poster_17_-3.0.png" width=256 height=256 /> | <img src="images/retro horror comic style poster_17_0.0.png" width=256 height=256 /> | <img src="images/retro horror comic style poster_17_3.0.png" width=256 height=256 /> |
| <img src="images/retro horror comic style poster_19_-3.0.png" width=256 height=256 /> | <img src="images/retro horror comic style poster_19_0.0.png" width=256 height=256 /> | <img src="images/retro horror comic style poster_19_3.0.png" width=256 height=256 /> |
| <img src="images/retro horror comic style poster_20_-3.0.png" width=256 height=256 /> | <img src="images/retro horror comic style poster_20_0.0.png" width=256 height=256 /> | <img src="images/retro horror comic style poster_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
retro horror comic style poster
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.retro-horror-comic-style-poster', weight_name='retro horror comic style poster.safetensors', adapter_name="retro horror comic style poster")
# Activate the LoRA
pipe.set_adapters(["retro horror comic style poster"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, retro horror comic style poster"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1130+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
croissantllm/CroissantLLMBase-GGUF
|
croissantllm
|
text-generation
|
[
"gguf",
"legal",
"code",
"text-generation-inference",
"art",
"text-generation",
"fr",
"en",
"dataset:cerebras/SlimPajama-627B",
"dataset:uonlp/CulturaX",
"dataset:pg19",
"dataset:bigcode/starcoderdata",
"dataset:croissantllm/croissant_dataset",
"arxiv:2402.00786",
"license:mit",
"endpoints_compatible",
"region:us"
] | 2024-02-08T09:55:52Z |
2024-04-29T12:13:23+00:00
| 64 | 4 |
---
datasets:
- cerebras/SlimPajama-627B
- uonlp/CulturaX
- pg19
- bigcode/starcoderdata
- croissantllm/croissant_dataset
language:
- fr
- en
license: mit
pipeline_tag: text-generation
tags:
- legal
- code
- text-generation-inference
- art
---
# CroissantLLM - Base GGUF (190k steps, Final version)
This model is part of the CroissantLLM initiative, and corresponds to the checkpoint after 190k steps (2.99 T) tokens.
To play with the final model, we recommend using the Chat version: https://huggingface.co/croissantllm/CroissantLLMChat-v0.1.
https://arxiv.org/abs/2402.00786
## Abstract
We introduce CroissantLLM, a 1.3B language model pretrained on a set of 3T English and French tokens, to bring to the research and industrial community a high-performance, fully open-sourced bilingual model that runs swiftly on consumer-grade local hardware.
To that end, we pioneer the approach of training an intrinsically bilingual model with a 1:1 English-to-French pretraining data ratio, a custom tokenizer, and bilingual finetuning datasets. We release the training dataset, notably containing a French split with manually curated, high-quality, and varied data sources.
To assess performance outside of English, we craft a novel benchmark, FrenchBench, consisting of an array of classification and generation tasks, covering various orthogonal aspects of model performance in the French Language. Additionally, rooted in transparency and to foster further Large Language Model research, we release codebases, and dozens of checkpoints across various model sizes, training data distributions, and training steps, as well as fine-tuned Chat models, and strong translation models. We evaluate our model through the FMTI framework, and validate 81% of the transparency criteria, far beyond the scores of even most open initiatives.
This work enriches the NLP landscape, breaking away from previous English-centric work in order to strengthen our understanding of multilinguality in language models.
## Citation
Our work can be cited as:
```bash
@misc{faysse2024croissantllm,
title={CroissantLLM: A Truly Bilingual French-English Language Model},
author={Manuel Faysse and Patrick Fernandes and Nuno M. Guerreiro and António Loison and Duarte M. Alves and Caio Corro and Nicolas Boizard and João Alves and Ricardo Rei and Pedro H. Martins and Antoni Bigata Casademunt and François Yvon and André F. T. Martins and Gautier Viaud and Céline Hudelot and Pierre Colombo},
year={2024},
eprint={2402.00786},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Usage
This model is a base model, that is, it is not finetuned for Chat function and works best with few-shot prompting strategies.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "croissantllm/CroissantLLMBase"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, device_map="auto")
inputs = tokenizer("I am so tired I could sleep right now. -> Je suis si fatigué que je pourrais m'endormir maintenant.\nHe is heading to the market. -> Il va au marché.\nWe are running on the beach. ->", return_tensors="pt").to(model.device)
tokens = model.generate(**inputs, max_length=100, do_sample=True, top_p=0.95, top_k=60, temperature=0.3)
print(tokenizer.decode(tokens[0]))
# remove bos token
inputs = tokenizer("Capitales: France -> Paris, Italie -> Rome, Allemagne -> Berlin, Espagne ->", return_tensors="pt", add_special_tokens=True).to(model.device)
tokens = model.generate(**inputs, max_length=100, do_sample=True, top_p=0.95, top_k=60)
print(tokenizer.decode(tokens[0]))
```
|
[
"CRAFT"
] |
TommyZQ/GPT-4o
|
TommyZQ
|
text-generation
|
[
"transformers",
"safetensors",
"openelm",
"text-generation",
"custom_code",
"arxiv:2404.14619",
"license:other",
"autotrain_compatible",
"region:us"
] | 2024-04-24T15:23:27Z |
2024-04-25T10:19:38+00:00
| 64 | 3 |
---
license: other
license_name: apple-sample-code-license
license_link: LICENSE
---
# OpenELM
*Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, Mohammad Rastegari*
We introduce **OpenELM**, a family of **Open**-source **E**fficient **L**anguage **M**odels. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. We pretrained OpenELM models using the [CoreNet](https://github.com/apple/corenet) library. We release both pretrained and instruction tuned models with 270M, 450M, 1.1B and 3B parameters.
Our pre-training dataset contains RefinedWeb, deduplicated PILE, a subset of RedPajama, and a subset of Dolma v1.6, totaling approximately 1.8 trillion tokens. Please check license agreements and terms of these datasets before using them.
## Usage
We have provided an example function to generate output from OpenELM models loaded via [HuggingFace Hub](https://huggingface.co/docs/hub/) in `generate_openelm.py`.
You can try the model by running the following command:
```
python generate_openelm.py --model apple/OpenELM-1_1B --hf_access_token [HF_ACCESS_TOKEN] --prompt 'Once upon a time there was' --generate_kwargs repetition_penalty=1.2
```
Please refer to [this link](https://huggingface.co/docs/hub/security-tokens) to obtain your hugging face access token.
Additional arguments to the hugging face generate function can be passed via `generate_kwargs`. As an example, to speedup the inference, you can try [lookup token speculative generation](https://huggingface.co/docs/transformers/generation_strategies) by passing the `prompt_lookup_num_tokens` argument as follows:
```
python generate_openelm.py --model apple/OpenELM-1_1B --hf_access_token [HF_ACCESS_TOKEN] --prompt 'Once upon a time there was' --generate_kwargs repetition_penalty=1.2 prompt_lookup_num_tokens=10
```
Alternatively, try model-wise speculative generation with an [assistive model](https://huggingface.co/blog/assisted-generation) by passing a smaller model through the `assistant_model` argument, for example:
```
python generate_openelm.py --model apple/OpenELM-1_1B --hf_access_token [HF_ACCESS_TOKEN] --prompt 'Once upon a time there was' --generate_kwargs repetition_penalty=1.2 --assistant_model [SMALLER_MODEL]
```
## Main Results
### Zero-Shot
| **Model Size** | **ARC-c** | **ARC-e** | **BoolQ** | **HellaSwag** | **PIQA** | **SciQ** | **WinoGrande** | **Average** |
|-----------------------------------------------------------------------------|-----------|-----------|-----------|---------------|-----------|-----------|----------------|-------------|
| [OpenELM-270M](https://huggingface.co/apple/OpenELM-270M) | 26.45 | 45.08 | **53.98** | 46.71 | 69.75 | **84.70** | **53.91** | 54.37 |
| [OpenELM-270M-Instruct](https://huggingface.co/apple/OpenELM-270M-Instruct) | **30.55** | **46.68** | 48.56 | **52.07** | **70.78** | 84.40 | 52.72 | **55.11** |
| [OpenELM-450M](https://huggingface.co/apple/OpenELM-450M) | 27.56 | 48.06 | 55.78 | 53.97 | 72.31 | 87.20 | 58.01 | 57.56 |
| [OpenELM-450M-Instruct](https://huggingface.co/apple/OpenELM-450M-Instruct) | **30.38** | **50.00** | **60.37** | **59.34** | **72.63** | **88.00** | **58.96** | **59.95** |
| [OpenELM-1_1B](https://huggingface.co/apple/OpenELM-1_1B) | 32.34 | **55.43** | 63.58 | 64.81 | **75.57** | **90.60** | 61.72 | 63.44 |
| [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct) | **37.97** | 52.23 | **70.00** | **71.20** | 75.03 | 89.30 | **62.75** | **65.50** |
| [OpenELM-3B](https://huggingface.co/apple/OpenELM-3B) | 35.58 | 59.89 | 67.40 | 72.44 | 78.24 | **92.70** | 65.51 | 67.39 |
| [OpenELM-3B-Instruct](https://huggingface.co/apple/OpenELM-3B-Instruct) | **39.42** | **61.74** | **68.17** | **76.36** | **79.00** | 92.50 | **66.85** | **69.15** |
### LLM360
| **Model Size** | **ARC-c** | **HellaSwag** | **MMLU** | **TruthfulQA** | **WinoGrande** | **Average** |
|-----------------------------------------------------------------------------|-----------|---------------|-----------|----------------|----------------|-------------|
| [OpenELM-270M](https://huggingface.co/apple/OpenELM-270M) | 27.65 | 47.15 | 25.72 | **39.24** | **53.83** | 38.72 |
| [OpenELM-270M-Instruct](https://huggingface.co/apple/OpenELM-270M-Instruct) | **32.51** | **51.58** | **26.70** | 38.72 | 53.20 | **40.54** |
| [OpenELM-450M](https://huggingface.co/apple/OpenELM-450M) | 30.20 | 53.86 | **26.01** | 40.18 | 57.22 | 41.50 |
| [OpenELM-450M-Instruct](https://huggingface.co/apple/OpenELM-450M-Instruct) | **33.53** | **59.31** | 25.41 | **40.48** | **58.33** | **43.41** |
| [OpenELM-1_1B](https://huggingface.co/apple/OpenELM-1_1B) | 36.69 | 65.71 | **27.05** | 36.98 | 63.22 | 45.93 |
| [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct) | **41.55** | **71.83** | 25.65 | **45.95** | **64.72** | **49.94** |
| [OpenELM-3B](https://huggingface.co/apple/OpenELM-3B) | 42.24 | 73.28 | **26.76** | 34.98 | 67.25 | 48.90 |
| [OpenELM-3B-Instruct](https://huggingface.co/apple/OpenELM-3B-Instruct) | **47.70** | **76.87** | 24.80 | **38.76** | **67.96** | **51.22** |
### OpenLLM Leaderboard
| **Model Size** | **ARC-c** | **CrowS-Pairs** | **HellaSwag** | **MMLU** | **PIQA** | **RACE** | **TruthfulQA** | **WinoGrande** | **Average** |
|-----------------------------------------------------------------------------|-----------|-----------------|---------------|-----------|-----------|-----------|----------------|----------------|-------------|
| [OpenELM-270M](https://huggingface.co/apple/OpenELM-270M) | 27.65 | **66.79** | 47.15 | 25.72 | 69.75 | 30.91 | **39.24** | **53.83** | 45.13 |
| [OpenELM-270M-Instruct](https://huggingface.co/apple/OpenELM-270M-Instruct) | **32.51** | 66.01 | **51.58** | **26.70** | **70.78** | 33.78 | 38.72 | 53.20 | **46.66** |
| [OpenELM-450M](https://huggingface.co/apple/OpenELM-450M) | 30.20 | **68.63** | 53.86 | **26.01** | 72.31 | 33.11 | 40.18 | 57.22 | 47.69 |
| [OpenELM-450M-Instruct](https://huggingface.co/apple/OpenELM-450M-Instruct) | **33.53** | 67.44 | **59.31** | 25.41 | **72.63** | **36.84** | **40.48** | **58.33** | **49.25** |
| [OpenELM-1_1B](https://huggingface.co/apple/OpenELM-1_1B) | 36.69 | **71.74** | 65.71 | **27.05** | **75.57** | 36.46 | 36.98 | 63.22 | 51.68 |
| [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct) | **41.55** | 71.02 | **71.83** | 25.65 | 75.03 | **39.43** | **45.95** | **64.72** | **54.40** |
| [OpenELM-3B](https://huggingface.co/apple/OpenELM-3B) | 42.24 | **73.29** | 73.28 | **26.76** | 78.24 | **38.76** | 34.98 | 67.25 | 54.35 |
| [OpenELM-3B-Instruct](https://huggingface.co/apple/OpenELM-3B-Instruct) | **47.70** | 72.33 | **76.87** | 24.80 | **79.00** | 38.47 | **38.76** | **67.96** | **55.73** |
See the technical report for more results and comparison.
## Evaluation
### Setup
Install the following dependencies:
```bash
# install public lm-eval-harness
harness_repo="public-lm-eval-harness"
git clone https://github.com/EleutherAI/lm-evaluation-harness ${harness_repo}
cd ${harness_repo}
# use main branch on 03-15-2024, SHA is dc90fec
git checkout dc90fec
pip install -e .
cd ..
# 66d6242 is the main branch on 2024-04-01
pip install datasets@git+https://github.com/huggingface/datasets.git@66d6242
pip install tokenizers>=0.15.2 transformers>=4.38.2 sentencepiece>=0.2.0
```
### Evaluate OpenELM
```bash
# OpenELM-1_1B
hf_model=OpenELM-1_1B
# this flag is needed because lm-eval-harness set add_bos_token to False by default, but OpenELM uses LLaMA tokenizer which requires add_bos_token to be True
tokenizer=meta-llama/Llama-2-7b-hf
add_bos_token=True
batch_size=1
mkdir lm_eval_output
shot=0
task=arc_challenge,arc_easy,boolq,hellaswag,piqa,race,winogrande,sciq,truthfulqa_mc2
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
shot=5
task=mmlu,winogrande
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
shot=25
task=arc_challenge,crows_pairs_english
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
shot=10
task=hellaswag
lm_eval --model hf \
--model_args pretrained=${hf_model},trust_remote_code=True,add_bos_token=${add_bos_token},tokenizer=${tokenizer} \
--tasks ${task} \
--device cuda:0 \
--num_fewshot ${shot} \
--output_path ./lm_eval_output/${hf_model//\//_}_${task//,/_}-${shot}shot \
--batch_size ${batch_size} 2>&1 | tee ./lm_eval_output/eval-${hf_model//\//_}_${task//,/_}-${shot}shot.log
```
## Bias, Risks, and Limitations
The release of OpenELM models aims to empower and enrich the open research community by providing access to state-of-the-art language models. Trained on publicly available datasets, these models are made available without any safety guarantees. Consequently, there exists the possibility of these models producing outputs that are inaccurate, harmful, biased, or objectionable in response to user prompts. Thus, it is imperative for users and developers to undertake thorough safety testing and implement appropriate filtering mechanisms tailored to their specific requirements.
## Citation
If you find our work useful, please cite:
```BibTex
@article{mehtaOpenELMEfficientLanguage2024,
title = {{OpenELM}: {An} {Efficient} {Language} {Model} {Family} with {Open}-source {Training} and {Inference} {Framework}},
shorttitle = {{OpenELM}},
url = {https://arxiv.org/abs/2404.14619v1},
language = {en},
urldate = {2024-04-24},
journal = {arXiv.org},
author = {Mehta, Sachin and Sekhavat, Mohammad Hossein and Cao, Qingqing and Horton, Maxwell and Jin, Yanzi and Sun, Chenfan and Mirzadeh, Iman and Najibi, Mahyar and Belenko, Dmitry and Zatloukal, Peter and Rastegari, Mohammad},
month = apr,
year = {2024},
}
@inproceedings{mehta2022cvnets,
author = {Mehta, Sachin and Abdolhosseini, Farzad and Rastegari, Mohammad},
title = {CVNets: High Performance Library for Computer Vision},
year = {2022},
booktitle = {Proceedings of the 30th ACM International Conference on Multimedia},
series = {MM '22}
}
```
|
[
"SCIQ"
] |
jchevallard/MiniCPM-V-2_6
|
jchevallard
|
image-text-to-text
|
[
"transformers",
"safetensors",
"minicpmv",
"feature-extraction",
"minicpm-v",
"vision",
"ocr",
"multi-image",
"video",
"custom_code",
"image-text-to-text",
"conversational",
"multilingual",
"dataset:openbmb/RLAIF-V-Dataset",
"arxiv:2408.01800",
"region:us"
] | 2024-08-30T12:51:20Z |
2024-08-30T12:51:21+00:00
| 64 | 1 |
---
datasets:
- openbmb/RLAIF-V-Dataset
language:
- multilingual
library_name: transformers
pipeline_tag: image-text-to-text
tags:
- minicpm-v
- vision
- ocr
- multi-image
- video
- custom_code
---
<h1>A GPT-4V Level MLLM for Single Image, Multi Image and Video on Your Phone</h1>
[GitHub](https://github.com/OpenBMB/MiniCPM-V) | [Demo](https://huggingface.co/spaces/openbmb/MiniCPM-V-2_6)</a>
## MiniCPM-V 2.6
**MiniCPM-V 2.6** is the latest and most capable model in the MiniCPM-V series. The model is built on SigLip-400M and Qwen2-7B with a total of 8B parameters. It exhibits a significant performance improvement over MiniCPM-Llama3-V 2.5, and introduces new features for multi-image and video understanding. Notable features of MiniCPM-V 2.6 include:
- 🔥 **Leading Performance.**
MiniCPM-V 2.6 achieves an average score of 65.2 on the latest version of OpenCompass, a comprehensive evaluation over 8 popular benchmarks. **With only 8B parameters, it surpasses widely used proprietary models like GPT-4o mini, GPT-4V, Gemini 1.5 Pro, and Claude 3.5 Sonnet** for single image understanding.
- 🖼️ **Multi Image Understanding and In-context Learning.** MiniCPM-V 2.6 can also perform **conversation and reasoning over multiple images**. It achieves **state-of-the-art performance** on popular multi-image benchmarks such as Mantis-Eval, BLINK, Mathverse mv and Sciverse mv, and also shows promising in-context learning capability.
- 🎬 **Video Understanding.** MiniCPM-V 2.6 can also **accept video inputs**, performing conversation and providing dense captions for spatial-temporal information. It outperforms **GPT-4V, Claude 3.5 Sonnet and LLaVA-NeXT-Video-34B** on Video-MME with/without subtitles.
- 💪 **Strong OCR Capability and Others.**
MiniCPM-V 2.6 can process images with any aspect ratio and up to 1.8 million pixels (e.g., 1344x1344). It achieves **state-of-the-art performance on OCRBench, surpassing proprietary models such as GPT-4o, GPT-4V, and Gemini 1.5 Pro**.
Based on the the latest [RLAIF-V](https://github.com/RLHF-V/RLAIF-V/) and [VisCPM](https://github.com/OpenBMB/VisCPM) techniques, it features **trustworthy behaviors**, with significantly lower hallucination rates than GPT-4o and GPT-4V on Object HalBench, and supports **multilingual capabilities** on English, Chinese, German, French, Italian, Korean, etc.
- 🚀 **Superior Efficiency.**
In addition to its friendly size, MiniCPM-V 2.6 also shows **state-of-the-art token density** (i.e., number of pixels encoded into each visual token). **It produces only 640 tokens when processing a 1.8M pixel image, which is 75% fewer than most models**. This directly improves the inference speed, first-token latency, memory usage, and power consumption. As a result, MiniCPM-V 2.6 can efficiently support **real-time video understanding** on end-side devices such as iPad.
- 💫 **Easy Usage.**
MiniCPM-V 2.6 can be easily used in various ways: (1) [llama.cpp](https://github.com/OpenBMB/llama.cpp/blob/minicpmv-main/examples/llava/README-minicpmv2.6.md) and [ollama](https://github.com/OpenBMB/ollama/tree/minicpm-v2.6) support for efficient CPU inference on local devices, (2) [int4](https://huggingface.co/openbmb/MiniCPM-V-2_6-int4) and [GGUF](https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf) format quantized models in 16 sizes, (3) [vLLM](https://github.com/OpenBMB/MiniCPM-V/tree/main?tab=readme-ov-file#inference-with-vllm) support for high-throughput and memory-efficient inference, (4) fine-tuning on new domains and tasks, (5) quick local WebUI demo setup with [Gradio](https://github.com/OpenBMB/MiniCPM-V/tree/main?tab=readme-ov-file#chat-with-our-demo-on-gradio) and (6) online web [demo](http://120.92.209.146:8887).
### Evaluation <!-- omit in toc -->
<div align="center">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/radar_final.png" width=66% />
</div>
Single image results on OpenCompass, MME, MMVet, OCRBench, MMMU, MathVista, MMB, AI2D, TextVQA, DocVQA, HallusionBench, Object HalBench:
<div align="center">

</div>
<sup>*</sup> We evaluate this benchmark using chain-of-thought prompting.
<sup>+</sup> Token Density: number of pixels encoded into each visual token at maximum resolution, i.e., # pixels at maximum resolution / # visual tokens.
Note: For proprietary models, we calculate token density based on the image encoding charging strategy defined in the official API documentation, which provides an upper-bound estimation.
<details>
<summary>Click to view multi-image results on Mantis Eval, BLINK Val, Mathverse mv, Sciverse mv, MIRB.</summary>
<div align="center">
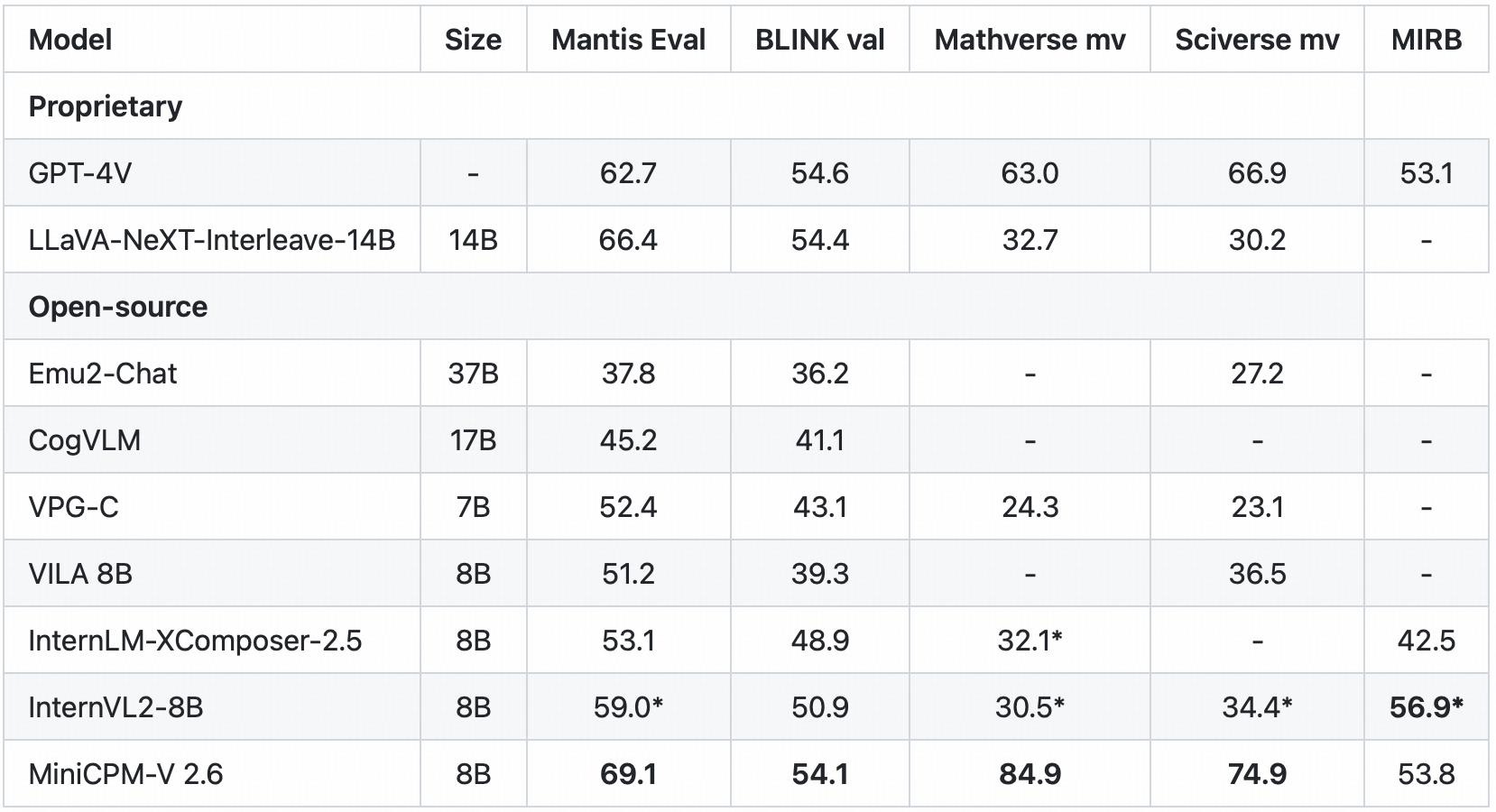
</div>
<sup>*</sup> We evaluate the officially released checkpoint by ourselves.
</details>
<details>
<summary>Click to view video results on Video-MME and Video-ChatGPT.</summary>
<div align="center">
<!--  -->

</div>
</details>
<details>
<summary>Click to view few-shot results on TextVQA, VizWiz, VQAv2, OK-VQA.</summary>
<div align="center">

</div>
* denotes zero image shot and two additional text shots following Flamingo.
<sup>+</sup> We evaluate the pretraining ckpt without SFT.
</details>
### Examples <!-- omit in toc -->
<div style="display: flex; flex-direction: column; align-items: center;">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multi_img-bike.png" alt="Bike" style="margin-bottom: -20px;">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multi_img-menu.png" alt="Menu" style="margin-bottom: -20px;">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multi_img-code.png" alt="Code" style="margin-bottom: -20px;">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/ICL-Mem.png" alt="Mem" style="margin-bottom: -20px;">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multiling-medal.png" alt="medal" style="margin-bottom: 10px;">
</div>
<details>
<summary>Click to view more cases.</summary>
<div style="display: flex; flex-direction: column; align-items: center;">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/ICL-elec.png" alt="elec" style="margin-bottom: -20px;">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/minicpmv2_6/multiling-olympic.png" alt="Menu" style="margin-bottom: 10px;">
</div>
</details>
We deploy MiniCPM-V 2.6 on end devices. The demo video is the raw screen recording on a iPad Pro without edition.
<div style="display: flex; justify-content: center;">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/gif_cases/ai.gif" width="48%" style="margin: 0 10px;"/>
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/gif_cases/beer.gif" width="48%" style="margin: 0 10px;"/>
</div>
<div style="display: flex; justify-content: center; margin-top: 20px;">
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/gif_cases/ticket.gif" width="48%" style="margin: 0 10px;"/>
<img src="https://github.com/OpenBMB/MiniCPM-V/raw/main/assets/gif_cases/wfh.gif" width="48%" style="margin: 0 10px;"/>
</div>
<div style="text-align: center;">
<video controls autoplay src="https://hf.fast360.xyz/production/uploads/64abc4aa6cadc7aca585dddf/mXAEFQFqNd4nnvPk7r5eX.mp4"></video>
<!-- <video controls autoplay src="https://hf.fast360.xyz/production/uploads/64abc4aa6cadc7aca585dddf/fEWzfHUdKnpkM7sdmnBQa.mp4"></video> -->
</div>
## Demo
Click here to try the Demo of [MiniCPM-V 2.6](https://huggingface.co/spaces/openbmb/MiniCPM-V-2_6).
## Usage
Inference using Huggingface transformers on NVIDIA GPUs. Requirements tested on python 3.10:
```
Pillow==10.1.0
torch==2.1.2
torchvision==0.16.2
transformers==4.40.0
sentencepiece==0.1.99
decord
```
```python
# test.py
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
image = Image.open('xx.jpg').convert('RGB')
question = 'What is in the image?'
msgs = [{'role': 'user', 'content': [image, question]}]
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(res)
## if you want to use streaming, please make sure sampling=True and stream=True
## the model.chat will return a generator
res = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
stream=True
)
generated_text = ""
for new_text in res:
generated_text += new_text
print(new_text, flush=True, end='')
```
### Chat with multiple images
<details>
<summary> Click to show Python code running MiniCPM-V 2.6 with multiple images input. </summary>
```python
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
image1 = Image.open('image1.jpg').convert('RGB')
image2 = Image.open('image2.jpg').convert('RGB')
question = 'Compare image 1 and image 2, tell me about the differences between image 1 and image 2.'
msgs = [{'role': 'user', 'content': [image1, image2, question]}]
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
```
</details>
### In-context few-shot learning
<details>
<summary> Click to view Python code running MiniCPM-V 2.6 with few-shot input. </summary>
```python
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
question = "production date"
image1 = Image.open('example1.jpg').convert('RGB')
answer1 = "2023.08.04"
image2 = Image.open('example2.jpg').convert('RGB')
answer2 = "2007.04.24"
image_test = Image.open('test.jpg').convert('RGB')
msgs = [
{'role': 'user', 'content': [image1, question]}, {'role': 'assistant', 'content': [answer1]},
{'role': 'user', 'content': [image2, question]}, {'role': 'assistant', 'content': [answer2]},
{'role': 'user', 'content': [image_test, question]}
]
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
```
</details>
### Chat with video
<details>
<summary> Click to view Python code running MiniCPM-V 2.6 with video input. </summary>
```python
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
from decord import VideoReader, cpu # pip install decord
model = AutoModel.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-V-2_6', trust_remote_code=True)
MAX_NUM_FRAMES=64 # if cuda OOM set a smaller number
def encode_video(video_path):
def uniform_sample(l, n):
gap = len(l) / n
idxs = [int(i * gap + gap / 2) for i in range(n)]
return [l[i] for i in idxs]
vr = VideoReader(video_path, ctx=cpu(0))
sample_fps = round(vr.get_avg_fps() / 1) # FPS
frame_idx = [i for i in range(0, len(vr), sample_fps)]
if len(frame_idx) > MAX_NUM_FRAMES:
frame_idx = uniform_sample(frame_idx, MAX_NUM_FRAMES)
frames = vr.get_batch(frame_idx).asnumpy()
frames = [Image.fromarray(v.astype('uint8')) for v in frames]
print('num frames:', len(frames))
return frames
video_path ="video_test.mp4"
frames = encode_video(video_path)
question = "Describe the video"
msgs = [
{'role': 'user', 'content': frames + [question]},
]
# Set decode params for video
params={}
params["use_image_id"] = False
params["max_slice_nums"] = 2 # use 1 if cuda OOM and video resolution > 448*448
answer = model.chat(
image=None,
msgs=msgs,
tokenizer=tokenizer,
**params
)
print(answer)
```
</details>
Please look at [GitHub](https://github.com/OpenBMB/MiniCPM-V) for more detail about usage.
## Inference with llama.cpp<a id="llamacpp"></a>
MiniCPM-V 2.6 can run with llama.cpp. See our fork of [llama.cpp](https://github.com/OpenBMB/llama.cpp/tree/minicpm-v2.5/examples/minicpmv) for more detail.
## Int4 quantized version
Download the int4 quantized version for lower GPU memory (7GB) usage: [MiniCPM-V-2_6-int4](https://huggingface.co/openbmb/MiniCPM-V-2_6-int4).
## License
#### Model License
* The code in this repo is released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
* The usage of MiniCPM-V series model weights must strictly follow [MiniCPM Model License.md](https://github.com/OpenBMB/MiniCPM/blob/main/MiniCPM%20Model%20License.md).
* The models and weights of MiniCPM are completely free for academic research. After filling out a ["questionnaire"](https://modelbest.feishu.cn/share/base/form/shrcnpV5ZT9EJ6xYjh3Kx0J6v8g) for registration, MiniCPM-V 2.6 weights are also available for free commercial use.
#### Statement
* As an LMM, MiniCPM-V 2.6 generates contents by learning a large mount of multimodal corpora, but it cannot comprehend, express personal opinions or make value judgement. Anything generated by MiniCPM-V 2.6 does not represent the views and positions of the model developers
* We will not be liable for any problems arising from the use of the MinCPM-V models, including but not limited to data security issues, risk of public opinion, or any risks and problems arising from the misdirection, misuse, dissemination or misuse of the model.
## Key Techniques and Other Multimodal Projects
👏 Welcome to explore key techniques of MiniCPM-V 2.6 and other multimodal projects of our team:
[VisCPM](https://github.com/OpenBMB/VisCPM/tree/main) | [RLHF-V](https://github.com/RLHF-V/RLHF-V) | [LLaVA-UHD](https://github.com/thunlp/LLaVA-UHD) | [RLAIF-V](https://github.com/RLHF-V/RLAIF-V)
## Citation
If you find our work helpful, please consider citing our papers 📝 and liking this project ❤️!
```bib
@article{yao2024minicpm,
title={MiniCPM-V: A GPT-4V Level MLLM on Your Phone},
author={Yao, Yuan and Yu, Tianyu and Zhang, Ao and Wang, Chongyi and Cui, Junbo and Zhu, Hongji and Cai, Tianchi and Li, Haoyu and Zhao, Weilin and He, Zhihui and others},
journal={arXiv preprint arXiv:2408.01800},
year={2024}
}
```
|
[
"MEDAL"
] |
Bear-ai/ppo-Huggy
|
Bear-ai
|
reinforcement-learning
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] | 2024-11-23T13:37:16Z |
2024-12-01T13:52:15+00:00
| 64 | 0 |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Bear-ai/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
[
"BEAR"
] |
Daemontatox/PathfinderAI
|
Daemontatox
|
text-generation
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"COT",
"Reasoning",
"Smart",
"Qwen",
"QwQ",
"conversational",
"en",
"dataset:Daemontatox/LongCOT-Reason",
"base_model:Qwen/QwQ-32B-Preview",
"base_model:finetune:Qwen/QwQ-32B-Preview",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-12-24T15:55:58Z |
2024-12-29T03:14:12+00:00
| 64 | 0 |
---
base_model:
- Qwen/QwQ-32B-Preview
datasets:
- Daemontatox/LongCOT-Reason
language:
- en
library_name: transformers
license: apache-2.0
metrics:
- accuracy
- character
pipeline_tag: text-generation
tags:
- text-generation-inference
- transformers
- unsloth
- trl
- COT
- Reasoning
- Smart
- Qwen
- QwQ
model-index:
- name: PathfinderAI
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: IFEval (0-Shot)
type: HuggingFaceH4/ifeval
args:
num_few_shot: 0
metrics:
- type: inst_level_strict_acc and prompt_level_strict_acc
value: 37.45
name: strict accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Daemontatox/PathfinderAI
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BBH (3-Shot)
type: BBH
args:
num_few_shot: 3
metrics:
- type: acc_norm
value: 52.65
name: normalized accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Daemontatox/PathfinderAI
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MATH Lvl 5 (4-Shot)
type: hendrycks/competition_math
args:
num_few_shot: 4
metrics:
- type: exact_match
value: 47.58
name: exact match
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Daemontatox/PathfinderAI
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GPQA (0-shot)
type: Idavidrein/gpqa
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 19.24
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Daemontatox/PathfinderAI
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MuSR (0-shot)
type: TAUR-Lab/MuSR
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 20.83
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Daemontatox/PathfinderAI
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU-PRO (5-shot)
type: TIGER-Lab/MMLU-Pro
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 51.04
name: accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Daemontatox/PathfinderAI
name: Open LLM Leaderboard
---

# PathfinderAI
- **Developed by:** Daemontatox
- **License:** Apache 2.0
- **Finetuned Using:** [Unsloth](https://github.com/unslothai/unsloth), Hugging Face Transformers, and TRL Library
## Model Overview
The **PathfinderAI Model** is an advanced AI system optimized for logical reasoning, multi-step problem-solving, and decision-making tasks. Designed with efficiency and accuracy in mind, it employs a structured system prompt to ensure high-quality answers through a transparent and iterative thought process.
### System Prompt and Workflow
This model operates using an innovative reasoning framework structured around the following steps:
1. **Initial Thought:**
The model uses `<Thinking>` tags to reason step-by-step and craft its best possible response.
Example:
2. **Self-Critique:**
It evaluates its initial response within `<Critique>` tags, focusing on:
- **Accuracy:** Is it factually correct and verifiable?
- **Clarity:** Is it clear and free of ambiguity?
- **Completeness:** Does it fully address the request?
- **Improvement:** What can be enhanced?
Example:
3. **Revision:**
Based on the critique, the model refines its response within `<Revising>` tags.
Example:
4. **Final Response:**
The revised response is presented clearly within `<Final>` tags.
Example:
5. **Tag Innovation:**
When needed, the model creates and defines new tags for better structuring or clarity, ensuring consistent usage.
Example:
### Key Features
- **Structured Reasoning:** Transparent, multi-step approach for generating and refining answers.
- **Self-Improvement:** Built-in critique and revision ensure continuous response enhancement.
- **Clarity and Adaptability:** Tagging system provides organized, adaptable responses tailored to user needs.
- **Creative Flexibility:** Supports dynamic problem-solving with the ability to introduce new tags and concepts.
---
## Use Cases
The model is designed for various domains, including:
1. **Research and Analysis:** Extracting insights and providing structured explanations.
2. **Education:** Assisting with tutoring by breaking down complex problems step-by-step.
3. **Problem-Solving:** Offering logical and actionable solutions for multi-step challenges.
4. **Content Generation:** Producing clear, well-organized creative or professional content.
---
## Training Details
- **Frameworks:**
- [Unsloth](https://github.com/unslothai/unsloth) for accelerated training.
- Hugging Face Transformers and the TRL library for reinforcement learning with human feedback (RLHF).
- **Dataset:** Finetuned on diverse reasoning-focused tasks, including logical puzzles, mathematical problems, and commonsense reasoning scenarios.
- **Hardware Efficiency:**
- Trained with bnb-4bit precision for reduced memory usage.
- Optimized training pipeline achieving 2x faster development cycles.
---
## Limitations
- **Hallucinations** Model might hallucinate in very long context problems.
- **Unclosed tags** As the model gets deep into thinking and reflecting ,it has a tendency to not close thinking or critique tags .
- **Tags Compression** As the model gets confident in the answer , it will use less and less tags and might have everything in the <Thinking> Tag ,instead of reasoning and going step by step.
- **High Resource** This Model is Resource intensive and needs a lot of uninterrupted computing , since it's continuously generating tokens to reason , so it might work the best with consumer hardware.
---
## Ethical Considerations
- **Transparency:** Responses are structured for verifiability through tagging.
- **Bias Mitigation:** Includes self-critique to minimize biases and ensure fairness.
- **Safe Deployment:** Users are encouraged to evaluate outputs to prevent harm or misinformation.
---
## License
This model is distributed under the Apache 2.0 license, allowing users to use, modify, and share it in compliance with the license terms.
---
## Acknowledgments
Special thanks to:
- [Unsloth](https://github.com/unslothai/unsloth) for accelerated training workflows.
- Hugging Face for their powerful tools and libraries.
---
Experience the **PathfinderAI l**, leveraging its structured reasoning and self-improvement capabilities for any task requiring advanced AI reasoning.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/Daemontatox__PathfinderAI-details)!
Summarized results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/contents/viewer/default/train?q=Daemontatox/PathfinderAI)!
| Metric |% Value|
|-------------------|------:|
|Avg. | 38.13|
|IFEval (0-Shot) | 37.45|
|BBH (3-Shot) | 52.65|
|MATH Lvl 5 (4-Shot)| 47.58|
|GPQA (0-shot) | 19.24|
|MuSR (0-shot) | 20.83|
|MMLU-PRO (5-shot) | 51.04|
|
[
"CRAFT"
] |
samchain/econo-sentence-v2
|
samchain
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:45044",
"loss:CoSENTLoss",
"economics",
"finance",
"en",
"dataset:samchain/econo-pairs-v2",
"arxiv:1908.10084",
"base_model:samchain/EconoBert",
"base_model:finetune:samchain/EconoBert",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2025-02-19T09:43:20Z |
2025-02-19T10:21:34+00:00
| 64 | 2 |
---
base_model: samchain/EconoBert
datasets:
- samchain/econo-pairs-v2
language:
- en
library_name: sentence-transformers
license: apache-2.0
metrics:
- pearson_cosine
- spearman_cosine
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:45044
- loss:CoSENTLoss
- economics
- finance
widget:
- source_sentence: a consumer protection point of view, including through remuneration
arrangements. failure to manage conduct risks can expose a financial institution
to a variety of other risks which, if not managed properly, can threaten its solvency
and sustainability. the regulatory regime for market conduct therefore provides
a framework for the identification and management of conduct risk as a complementary
framework to prudential regulation. this is part of the motivation for rigorous
coordination and cooperation arrangements between the pa and the fsca envisaged
by the financial sector regulation bill aimed at ensuring that all risks are holistically
managed within an overarching financial stability policy framework. strengthening
conduct in wholesale otc markets another initiative has been the development of
a code of conduct for south african wholesale over - the - counter ( otc ) financial
markets in a collaborative effort between regulators and key market participants.
i will return to this aspect later. against the background of various investigations
undertaken in many foreign jurisdictions in relation to foreign exchange market
manipulation, the sarb and the fsb launched a review bis central bankers ’ speeches
of the foreign exchange trading operations of south african authorised dealers
in october 2014. as the rand is a globally traded currency, the aim of the review
was to establish whether there may have been any spillover into our markets in
relation to any misconduct or malpractice. it is important to note that, unlike
in other jurisdictions, the south african review was not informed by whistle -
blowing or any allegations – or indeed concrete evidence – of any misconduct.
we had no evidence of widespread malpractice in the south african foreign exchange
market but felt that, given the broad - based nature of investigations in other
jurisdictions ( which also involved trading in emerging market currencies ), it
would be prudent to obtain comfort that our foreign exchange trading practices
were in line with best practice. it was therefore a proactive step on the part
of south african regulators. the foreign exchange review committee established
for this purpose – chaired by former senior deputy governor james cross, who is
with us today – released its report in october 2015. the committee reported that
it had found no evidence of manipulation or serious misconduct in the domestic
foreign exchange market during the period covered by the review, but that there
was scope for improvement in relation to governance and conduct. the committee
also recommended that legislation be enhanced to give market conduct regulators
wider powers to strengthen enforcement. south african regulators are in conversation
with each other on how best to give effect to the implementation of the recommendations.
there was also the recommendation
sentences:
- 'luigi federico signorini : g20 sustainable finance working group private sector
roundtable welcome address by mr luigi federico signorini, senior deputy governor
of the bank of italy, at the g20 sustainable finance working group private sector
roundtable, online event, 17 may 2021. * * * welcome, and a good day to you all.
i am happy to open the private sector roundtable, an event promoted by the g20
presidency and by the chinese and american co - chairs of the sustainable finance
working group. the roundtable will focus on the role of finance in helping fight
climate change and promoting lowcarbon transition. the g20 finance ministers and
central bank governors recently recognised the need to ‘ shape the current economic
recovery by investing in innovative technologies and promoting just transitions
toward more sustainable economies and societies ’. low - carbon transition is
urgent and must be accelerated : the later we act, the greater the costs. it requires
an unprecedented and unremitting effort. while quantitative estimates vary, the
investments needed for transition are certainly huge ; they need to be sustained
for a long time. governments have a central role in that they need to point the
way by adopting an appropriate policy framework. a clear and credible path for
government regulatory and fiscal action is also a prerequisite for efficient choices
on the part of private finance. indeed, while many governments will directly invest
their own money in many countries and mdbs will play their part, it is likely
that the private sector will be called upon to finance most transition investment.
there will be no transition without a general awareness of the need for it and
a willingness, even a desire, to finance it. there are in fact quite a few encouraging
signs. since last year, we have seen an explosion of ‘ net - zero commitments
’ in the private sector — though such commitments ( i am told ) are still confined
to one sixth of publicly listed companies globally. at the same time, the appetite
of ultimate investors and asset managers for ‘ green ’ investment is growing fast.
i am sure many in the audience will have a clear perception of this fact. however,
the path is still fraught with difficulties. on the market side, while sustainable
finance is increasingly popular, it suffers from a lack of clear definitions and
standards. ‘ greenwashing ’ is a danger ; good data, an agreed taxonomy, and adequate
company disclosure are necessary. global consistency is important, as fragmentation
of standards across jurisdictions is confusing for investors and costly for companies.
standards are currently being drafted'
- later, by more. so we raised interest rates through the second half of last year
- and again in june - trying, as best we could through our tactics, to minimise
any further unwanted upward pressure on sterling. but things have now clearly
moved on. the outlook for the world economy deteriorated further through the summer
under the impact of a series of new shocks. japan, the world ’ s second largest
economy, slipped further into recession. russia - which had only weeks earlier
embarked on an imf program - saw the collapse of the rouble and default on its
debt. and acute nervousness spread through many of the world ’ s financial markets.
although there has been some improvement in sentiment over the past month or two,
and although the us and european economies continue to expand, the likelihood
remains that world economic growth will be significantly slower than had been
expected earlier in the summer. slower growth of world activity is bound to prolong
the restraining external effect on growth and inflation in the uk, even though
the exchange rate has now started to weaken. at the same time there are also now
clearer signs of overall slowdown in our own economy. the evidence for this is
less obvious in the backwards - looking economic and monetary data than it is
in the forward - looking surveys, but even so the data suggest that we are beginning
to see an easing of pressure, including an easing of pressure in the labour market.
and the surveys themselves now point to a slowdown in service sector growth, including
retail distribution, as well as a sharper decline in manufacturing output. this
prospect is consistent with the reports which we receive directly from the bank
’ s network of regional agents and their 7000 - odd industrial and commercial
contacts around the country. of course we pay very careful attention to this forward
- looking evidence of developments in the economy alongside the data, and, like
others, we have revised down our forecasts for output growth and inflation. and
we have eased monetary policy quite sharply in the past two months, in the light
of that evidence. our current best guess - published in last week ’ s inflation
report is that, after the interest rate cuts, the growth of overall output next
year will be around 1 %, picking up through the millennium to around trend in
the second half of the year 2000. meanwhile, we expect underlying inflation to
remain close to the target rate of 21 / 2 % - though perhaps a little above that
rate during the course of next year. now no - one likes to see the
- 'daniel mminele : conduct and culture in the banking and financial sectors opening
address by mr daniel mminele, deputy governor of the south african reserve bank,
at the g - 30 forum on banking conduct and culture, pretoria, 18 february 2016.
* * * governor kganyago ( sarb ), governor sithole ( central bank of swaziland
), deputy governor mlambo ( reserve bank of zimbabwe ), deputy governors, groepe
and naidoo ( sarb ), second deputy governor sullivan ( central bank of seychelles
), sir david walker ( vice chair of the group of thirty steering committee ),
dr stuart mackintosh ( executive director of the g30 ), ms maria ramos ( chief
executive officer of barclays africa ), the leadership of banks and other financial
institutions, panel members, and esteemed delegates. it is a privilege and an
honour for me to welcome you, on behalf of south african reserve bank ( sarb ),
to this forum on banking conduct and culture, which we are co - hosting with the
g30 and barclays africa. the g - 30 has, over the years, played a significant
role in bringing together members of the banking, financial and regulatory community
to discuss issues of common concern and examine the choices available to market
practitioners and policymakers. given the enormous trust deficit that has built
up since the global financial crisis, the topic of conduct and culture is of great
importance and highly relevant to the global banking and financial sector. bankers
have always had a delicate relationship with the societies they serve. it would
appear that, at any point in time, it is almost a national sport across the globe
to take a swipe at bankers. mark twain famously said : “ a banker is a fellow
who lends you his umbrella when the sun is shining and wants it back the minute
it begins to rain. ” and j m keynes asked : “ how long will it take to pay city
men so entirely out of proportion to what other servants of society commonly received
for performing social services not less useful or difficult? ” we would be terribly
misguided to treat the current wave of discontent and deep mistrust as just another
wave that will eventually subside. the most recent global financial crisis, from
which almost nine years later we are still struggling to recover, shook the very
foundations of our financial system and almost caused its total meltdown. in a
nutshell, the crisis was about failures in conduct, culture, and supervisory practices.
the consequences'
- source_sentence: of our central bank distribution scheme have grown in number to
embrace the physical quality of notes in circulation and the denominational mix.
the last of these – denominational mix – poses the biggest challenge, but in the
uk i believe we now have evidence to support the business case for atm and retailer
dispense of £5s. and, finally, i am sometimes asked why this matters to the bank
of england? after all, i can assure you that in the current financial conditions
we are not short of difficult challenges. the answer is simple. we should not
forget that our job is to ensure that confidence in our currency is maintained
– and crucial to that is satisfying the public ’ s demand for our notes.
sentences:
- '##factory ". but the two clouds are moving towards us. so let us examine them.
the outlook for the world economy has deteriorated markedly in recent months as
a result of the sudden slowdown in the united states and signs of renewed stagnation
in japan. the speed of the deterioration was a surprise, but not the fact of a
slowdown. last year saw the fastest growth rate of the world economy for twelve
years. growth in the us reached an annual rate of 6 % in the second quarter of
last year, well above even optimistic estimates of sustainable growth rates. a
slowdown was not only inevitable ; it was desirable. the main surprise in the
us was the sharp and sudden break in both business and consumer confidence. us
manufacturers''optimism is now almost as low as it was in 1991 - the last time
the us economy experienced a recession. consumer confidence also fell sharply
in january, driven by marked pessimism over the short - term future. quite why
this break in confidence should have been so rapid is not easy to understand.
and its origins will largely determine the nature of the us downturn. on the one
hand, greater use of information technology to economise on inventories may have
led to shorter lags between changes in final demand and changes in output. if
so, then it is possible that the speed of the downturn will be matched by the
speed of the recovery, leading to a short - lived episode of output growth close
to zero as the result of an inventory correction. on the other hand, the slowdown
could be much more protracted if the imbalances in the us economy which have built
up in recent years start to unwind, leading to a reduction in spending as both
households and businesses seek to reduce the amount of outstanding debt on their
balance sheets. the key to the nature of the us downturn is what will happen to
productivity growth. over the past five years there has been accumulating evidence
that the application of information technology has raised productivity growth
in the us economy - the " new economy ". expectations of higher productivity growth
increased demand by more than it raised supply initially, as firms invested in
new technology and households anticipated higher future incomes. as a result,
spending grew rapidly, outstripping supply and large imbalances emerged. the current
account deficit in the us is now close to 5 % of gdp, a post - war record. it
is sustainable as long as foreigners are prepared to finance it. so far, the profitability
of'
- 83 6. 06 27. 05 39. 42 37. 59 kccs ( no. in lakh ) 243. 07 271. 12 302. 35 337.
87 82. 43 gcc ( no. in lakh ) 13. 87 16. 99 21. 08 36. 29 22. 28 bc - ict accounts
( no. in lakh ) 132. 65 316. 30 573. 01 810. 38 677. 73 ict accounts - bc - total
transactions ( no. in lakh ) 265. 15 841. 64 1410. 93 2546. 51 4799. 08 bis central
bankers ’ speeches
- core business and therefore set out to develop the expertise required to finance
the smes successfully. fairly often the discussion on sme financing is reduced
to two diametrically opposed positions. on one hand, smes are considered by banks
as representing a high risk and therefore, should be avoided or only dealt with
cautiously and at a premium price. on the other hand, banks are accused of being
inflexible and risk averse and consequently irrelevant to the sector. it is important
to understand where the truth lies in these two statements in order to advance
the cause of sme financing. firstly, it is a fact that smes present higher credit
risk than well - structured corporate entities. smes may not have proper accounting
records, may have severe governance issues which undermine accountability, have
poor access to markets, poor skill levels including financial illiteracy by promoters,
lack collateral which the lender can rely on in the event of failure, may not
even exist in an appropriate legal form and even the assessment of the viability
of a project might be difficult. lending to smes can be a lenders nightmare for
bankers. but it is also true that banks which are structured to deal with corporates
are risk averse and inflexible when they deal with smes. often when they bring
inappropriate risk assessment tools, they may focus too much on collateral rather
than project viability. they may even regard sme financing as peripheral to their
business. because of their limited knowledge of smes, they experience failure
which itself reinforces the notion that smes are risky. what we want are financing
institutions that are structured to respond to the unique characteristics of smes.
specialised sme lending institutions are more likely to handle the risk problem
presented by smes as a challenge to be overcome with appropriate products and
credit risk management strategies and not as a basis for inaction or avoiding
the sector altogether. in short, lending strategies which ensure success with
corporates do not necessarily ensure similar success with smes. appropriate sme
financing institutions must at the very least make lending to smes the core business.
the second area of reflection that i would urge this meeting to consider is that
of building appropriate financing models that have been shown to work in africa
or other developing countries so that we all benefit from the best practices available.
in south africa, for instance, franchising which allows the use of brand names
and building capacity have been an bis central bankers ’ speeches important driver
of sme financing since it reduces the perceived
- source_sentence: and non - financial sectors take hold. these concerns are heightened
by the recent upward shift in bond yields owing to the global " higher - for -
longer " narrative and the flare - up of tensions in the middle east, which have
added to the uncertainty surrounding the outlook. after a period of lower market
volatility until august, the rising prospect of higher - forlonger rates has started
to weigh on riskier asset valuations in recent months. risk sentiment in markets
remains highly sensitive to further surprises in inflation and economic growth.
higher than expected inflation or lower growth could trigger a rise in market
volatility and risk premia, increasing the likelihood of credit events materialising.
this brings me to the vulnerabilities in the non - bank financial sector. as regards
credit risk, some non - banks remain heavily exposed to interest rate - sensitive
sectors, such as highly indebted corporates and real estate. deteriorating corporate
fundamentals and the ongoing correction in real estate markets could expose non
- banks that have 2 / 4 bis - central bankers'speeches invested in these sectors
to revaluation losses and investor outflows. furthermore, low levels of liquidity
could expose investment funds to the potential risk of forced asset sales if macro
- financial outcomes deteriorate. corporate profitability in the euro area has
held up well, but higher interest rates are weighing on the debt servicing capacity
of more vulnerable firms. a weakening economy could prove challenging for firms
with high debt levels, subdued earnings and low interest coverage ratios. real
estate firms are particularly vulnerable to losses stemming from the ongoing downturn
in euro area commercial real estate markets. in an environment of tighter financing
conditions and elevated uncertainty, real estate prices have declined markedly.
the effects of higher interest rates have been compounded by structurally lower
demand for some real estate assets following the pandemic. although banks'exposure
to these markets is comparatively low, losses in this segment could act as an
amplifying factor in the event of a wider shock. euro area households, especially
those with lower incomes and in countries with mainly floatingrate mortgages,
are being increasingly squeezed by the higher interest rates. tighter financing
conditions have reduced the demand for housing, putting downward pressure on prices.
on a more positive note, robust labour markets have so far supported household
balance sheets, thereby mitigating the credit risk to banks. spreads in government
bond markets have remained contained as many governments managed to secure cheap
financing at longer maturities during the period of low interest rates.
sentences:
- market. and if we are to raise our national economic vantage point and take advantage
of the momentum coming into 2013, thrift banks need to consider lending more to
this economic segment. i say this because msmes provide great employment opportunities.
a healthier msme sector will help ensure our economic growth is broad - based
and inclusive. thrift banks, however, must not just lend more in terms of nominal
amounts. the challenge to the industry really is to ensure that such lending continuously
creates further opportunities. in this way, msmes can be assured of viability,
regardless of mandated credit programs. final thoughts friends, you want this
convention to be a discussion on broadening your horizon, our horizon. in trying
to look ahead, i took us through the more scenic route of our recent past. the
numbers tell us an encouraging story of growth and consistency of economic and
financial stability. however, the paradox of financial stability is that we may
just be at our weakest when we believe we are at our strongest position. complacency
often sets in when positive news is continuous and this is reinforced by encouraging
market parameters. if we fall into this trap of complacency, we risk losing our
focus. for the thrift banking industry, the growth trajectory that many are anticipating
suggests even better times ahead. it is therefore in our collective interest,
if we wish to truly broaden our horizon, to agree on a common vision where thrift
banks have a definitive role to play. bis central bankers ’ speeches in my remarks,
i have suggested specific action points you may consider in order to accomplish
just that, and over time broaden your horizon. i challenge the industry to 1 )
further improve credit underwriting standards for real estate and consumer loans
and raise your vantage point by looking at your processes with the lens of financial
stability, 2 ) interact with your clients and raise your vantage point by enhancing
your practices with the heart of consumer protection and financial education,
and 3 ) increase lending to msmes and raise your vantage point by lending with
the mind to create greater value. but much more can be done. as the old board
takes its place in ctb lore, your new board is now at the helm to guide the industry
forward. it is never an easy task to move forward but rest assured that the bangko
sentral ng pilipinas will be with you as we take that journey together into broader
horizons. thank you very much and good day to all of you. bis central bankers
’ speeches
- prices, which may also come under upward pressure owing to adverse weather events
and the unfolding climate crisis more broadly. most measures of underlying inflation
continue to decline. the eurostat's flash estimate for inflation excluding energy
and food points to a further decline to 4. 2 % in october, supported by improving
supply conditions, the pass - through of previous declines in energy prices, as
well as the impact of tighter monetary policy on demand and corporate pricing
power. at the same time, domestic price pressures are still strong and 1 / 4 bis
- central bankers'speeches are being increasingly driven by wage pressures and
the evolution of profit margins. while most measures of longer - term inflation
expectations stand around 2 %, some indicators remain elevated and need to be
monitored closely. the resilience of the labour market has been a bright spot
for the euro area economy, but there are signs that the labour market is beginning
to weaken. fewer new jobs are being created and, according to the latest flash
estimate, employment expectations have continued to decline in october for both
services and manufacturing. monetary policy based on our assessment of the inflation
outlook, the dynamics of underlying inflation and the strength of monetary policy
transmission, the governing council decided to keep the three key ecb interest
rates unchanged at its october meeting. the incoming information has broadly confirmed
our previous assessment of the medium - term inflation outlook. our past interest
rate increases continue to be transmitted forcefully into financial and monetary
conditions. banks'funding costs have continued to rise and are being passed on
to businesses and households. the combination of higher borrowing rates and weakening
activity led to a further sharp drop in credit demand in the third quarter of
this year. and credit standards have tightened again. we are also seeing increasing
signs of the impact of our policy decisions on the real economy. further tightening
is still in the pipeline from the current policy stance, and it is set to further
dampen demand and help push down inflation. we are determined to ensure that inflation
returns to our 2 % medium - term target in a timely manner. based on our current
assessment, we consider that the key ecb interest rates are at levels that, maintained
for a sufficiently long duration, will make a substantial contribution to this
goal. we will continue to follow a data - dependent approach to determining the
appropriate level and duration of restriction. financial stability let me now
turn to financial stability. in our upcoming financial stability review, we highlight
that the financial stability outlook remains fragile as the gradual effects of
tighter financial conditions on both the financial
- the conservation of natural resources. it was only in the fitness of things that
he delivered the inaugural address today. sir, we are overwhelmed by your insightful
address and i am sure all of us have immensely benefited listening to his valuable
views on a subject which is not only very dear to you but also so vital for the
country ’ s economic growth. 4. i also note that the seminar includes several
eminent speakers with vast experience on the subject. there are sessions on agricultural
productivity, role of research and technology in improving agricultural productivity,
linkages between productivity and farm income, incentivizing productivity enhancing
investments, relation between credit growth and productivity growth and mitigation
of risks in agriculture. in my address today, coming as do from the rbi, i would
broadly focus on major trends / issues in agricultural productivity and credit,
and the role of agricultural credit in improving agricultural productivity. i
would also touch upon some of the steps that can yield results in the short -
term. importance of agriculture 5. as you are aware, the recent indian growth
story has been service - led. services sector has completely replaced agriculture,
which was traditionally the largest contributor to india ’ s gdp. however, the
fact that agriculture has the smallest share in gdp of only about 14 per cent
today from a high of more than 50 per cent, does not belittle its importance for
bis central bankers ’ speeches the indian economy. this is because first, as we
all know, agriculture remains the largest employer having a share of around 60
per cent. secondly, it holds the key to creation of demand in other sectors and
remains by far an important indirect contributor to india ’ s gdp growth. the
agriculture sector needs to grow at least by 4 per cent for the economy to grow
at 9 per cent. thus, though having a small share, the fluctuations in agricultural
production can have large and significant impact on overall gdp growth. thirdly,
since food is an important component in basket of commodities used for measuring
consumer price indices, it is necessary that food prices are maintained at reasonable
levels to ensure food security, especially for the deprived sections of our society.
in fact, food security is emerging as an important policy concern, and the role
of agriculture in ensuring equitable access to food has added a new perspective
for policy makers. trends in agricultural productivity 6. i would like to discuss
certain trends in agricultural productivity in india. as is wellknown, the year
1968 marked the beginning of a turning point in indian agriculture. the country
- source_sentence: having a reserve currency may also be desirable for other reasons.
first, with more reserve currencies available, portfolio diversification opportunities
are enhanced. this is desirable because, all else equal, it would allow investors
to move further out on the risk / return frontier. second, more currencies are
likely to be close substitutes, which could dampen currency volatility. with many
viable reserve currencies available, no particular one would necessarily have
to bear the bulk of any adjustment. the dollar ’ s dominant reserve currency status
has sometimes been referred to as the united states ’ “ exorbitant privilege,
” implying that the u. s. benefits extraordinarily from this privileged status.
i ’ d argue that the situation is much more nuanced. yes, this status does allow
the u. s. to benefit from seigniorage. more than half of all u. s. currency outstanding
is held abroad. but, there are also costs of being the dominant reserve currency.
for example, this can lead to shifts in the valuation of the dollar that are due
primarily to developments abroad that affect risk appetites and international
capital flows. in such cases, the dollar ’ s valuation can be pushed to levels
inconsistent with u. s. economic fundamentals. for the united states, i believe
that the most important goal must be to keep our own house in order. if we do
this, then i expect that the u. s. dollar will earn the right to remain the most
important reserve currency in the world. the united states has a number of advantages
in sustaining the dominant reserve currency status of the u. s. dollar. first,
there is a first - mover advantage. as the leading reserve currency in the world,
there is no strong incentive for countries to move to other currencies as long
as the dollar continues to have the attributes i discussed earlier. the history
of reserve currency usage is characterized by considerable inertia. the u. s.
dollar emerged as the leading reserve currency quite a bit after it became the
world ’ s largest economy. typically, the loss of dominant reserve currency status
requires either substantial economic decline or political instability that motivates
foreign counterparties to shift to a new reserve currency. second, the u. s. has
the deepest and most liquid capital markets in the world. this is important in
making u. s. treasuries and agency mortgage - backed securities attractive holdings
as part of countries ’ foreign exchange reserve portfolio
sentences:
- as those on student visas, are assumed to begin arriving early next year, subject
to appropriate quarantine restrictions. but tourists and other short - term visitors
will not be able to return until later. in the baseline and upside scenarios,
we assume that the borders reopen in mid 2021. in the downside scenario, where
the global spread of the virus does not subside as quickly, we assume the borders
are closed for all of 2021. it is always possible to construct other scenarios.
the near term would be stronger if there were a major medical breakthrough on
treatments soon. an effective vaccine would take a bit longer to be distributed,
so it would mainly affect outcomes next year and the year after. but it could
also result in a stronger recovery than we have assumed even in the upside scenario
presented here. a worse outcome than our downside could be conceivable if the
virus cannot be contained and further waves of infection occur around the world
for some years yet. there are also plenty of other risks that can be contemplated
; we discuss some of these in the statement. geopolitical tensions were an issue
even before the coronavirus outbreak, and could escalate further. the pandemic
has also in some places exacerbated domestic political tensions. it is hard to
know how these tensions will play out over the next couple of years. if they escalate,
it is possible that some countries'recoveries will be derailed. domestically,
there are also a number of uncertainties that go beyond the direct effects of
the virus and associated activity restrictions. for example, we have assumed that
households and businesses are quite cautious in their use of the fiscal and other
cash flow support they have been receiving. it is possible that people spend more
out of that support than we are assuming. it is even possible that some people
do more to make up for the consumption opportunities that were not available during
periods of lockdown and other activity restrictions. on the downside, the longer
the economy remains weak, the more the recovery will be impeded by scarring effects
on workers, the destruction of business supply networks and other lingering damage.
what has changed in the past three months the scenarios presented in the past
few months. statement incorporate several lessons from the experience of the first,
the economic contractions induced by health - related restrictions on activity
in the june quarter were very large. however, they were not quite as severe as
initially expected. the peak - to - trough declines in output and hours worked
- '. norway was hit by oil price shocks in the following years and economic reforms
were implemented in several areas. after a period it became clear that the central
government budget would be in surplus and that transfers would be made to the
fund. norway ’ s experience from its first 30 years as an oil - producing nation
led to the introduction of the fiscal rule, which has been a key element of norwegian
economic policy for the past decade. report no. 29 to the storting of 2001 laid
down guidelines for the phasing - in of petroleum revenues into the norwegian
economy, establishing two main principles : economic policy must contribute to
stable economic developments and be sustainable over time. by linking petroleum
revenue spending to the expected real return on the fund – and not to current
petroleum revenues – the fiscal rule provided for a gradual and sustainable phasingin
of the revenues. if we can restrict spending to the return, the fund will never
shrink. norway will also be less vulnerable to fluctuations in current petroleum
revenues. ( chart 8 : effect on the size of gpfg of change in oil price and return
) in the first ten years after the establishment of the fiscal rule, the pace
of the fund ’ s growth was determined by oil prices. prospects in 2001 indicated
that a 25 percent higher oil price over a 10 - year period would increase the
size of the fund by almost nok 800 billion. uncertainty with regard to the return
on the fund was far less important for growth. this situation will change as the
fund grows and oil and gas production declines. from 2020 to 2030, the oil price
will play a less prominent role for the size of the fund, while the return on
the fund will be all the more important. in the initial years, the actual return,
adjusted for inflation and costs, was close to 4 percent. in recent years, with
the financial crisis and the sovereign debt crisis, the real return has been lower,
averaging about 2½ percent since 1998. source : lie, e. and c. venneslan : over
evne. finansdepartementet 1965 – 1992 [ beyond our power. ministry of finance
1965 – 1992 ]. pax forlag, 2010. see report no. 25 to the storting ( 1973 - 74
) : “ petroleumsvirksomhetens plass i det norske samfunn ” [ the role of petroleum
activity in norwegian society ]. bis central bankers ’ speeches we should be careful
about taking a rear -'
- ', increasingly relies on price signals generated by trading activity that takes
place daily in these markets. the reliance on secondary market trading for price
discovery constitutes the fundamental difference between funds from securities
markets and loans from banks. let me be a bit more specific. in securities markets,
investment decisions are driven by prices that arise from a trading process that
reconciles differential information from a diverse group of investors. in bank
loans, investment decisions are based on the bank ’ s private information about
specific borrowers. while a bank makes its own investment decisions, securities
markets rely on the consensus of a multitude of investors. when securities markets
work well, they provide efficient ways of aggregating information and allocating
risks among a wide range of investors. in order to function well, however, these
markets require a trading infrastructure. this infrastructure may consist of an
exchange, a network of brokers and dealers, and a clearing system. these markets
also rely on a cadre of relatively well - informed investors, who confidently
judge asset prices and take positions on the – 2 – strength of their judgments.
if the trading infrastructure fails or investors lose confidence, trading will
grind to a halt. the global fixed - income markets are unlike equity markets.
in equity markets, everyone knows something about the trading infrastructure,
which is centralized in exchanges. thus, there is no question as to the focal
point of trading information. but the importance of fixed - income markets, which
are multiple - dealer, over - the - counter markets, is sometimes hard to appreciate
because they are so decentralized. in the united states, the bond market is where
companies have been raising most of their funds in recent years. during the last
ten years, for example, u. s. nonfinancial corporations borrowed a net amount
of $ 785 billion in the form of bonds, three times the net amount they borrowed
from banks. over this same period, these companies as a group spent $ 600 billion
more to retire stock – through buybacks and mergers – than they raised in new
offerings. accompanying these increased levels of debt market activity has been
a continuous process of financial innovation. this innovation has served to unbundle
different kinds of risk and, thereby, to enlarge the menu of risks that investors
may choose to bear. for example, interest - rate swaps, futures and options help
reconfigure various interest - rate risks. total return swaps and creditspread
options are tools for reallocating the payment risks primarily of emerging market'
- source_sentence: education shocks arising from the pandemic could signify the largest
reversal in human development on record, equivalent to erasing all the progress
in human development of the past six years4. the risk of reversing progress in
achieving financial inclusion is accentuating why financial inclusion matters
now more than ever. optimising islamic finance for inclusive economic recovery
policy and regulatory responses across the globe, and likewise in malaysia, have
been focused on safeguarding economic resilience, managing risks to financial
stability and minimising repercussions to society. this is done in tandem with
the different stages of the pandemic – namely, containment, stabilisation and
recovery. at the onset of the crisis, governments along with financial regulators
have deployed sizeable stimulus packages and various assistance programmes in
order to contain the crisis and stabilise the economy. this includes addressing
demand and supply disruptions, maintaining cash flows and keeping workers employed.
in malaysia, the total stimulus package amounted to usd 73. 55 billion ( rm3056
billion ) with an additional fiscal injection by the government totalling 1 /
4 bis central bankers'speeches rm45 billion. as at september 2020, a total of
2. 63 million workers and 321, 000 employers had benefitted from the wage subsidy
programme, involving an expenditure of rm10. 4 billion. to provide further stimulus
to the economy, the bank has reduced the overnight policy rate ( opr ) by a cumulative
125 basis points ( from 3. 00 % to 1. 75 % ) this year, alongside reduction in
the statutory reserve requirement by 100 basis points ( from 3. 00 % to 2. 00
% ). the reduction in the opr is intended to provide additional policy stimulus
to accelerate the pace of economic recovery. the financial industry, including
islamic financial institutions, also lent support to their borrowers and customers.
in the first half of 2020, a total of rm120 billion7 was disbursed in lending
/ financing to smes, with more accounts being approved8 in aggregate in 2020 compared
to the same period in previous years. islamic financial institutions and related
associations have been actively educating and reaching out to affected borrowers
about the financial assistance programmes available in response to the pandemic.
the takaful and insurance industry also facilitated affected certificate holders
by offering temporary deferment of contribution and premium to promote continuity
of takaful protection coverage. more than 1. 1 million9 certificate and policyholders
have benefited from this relief measure. while the
sentences:
- education at an early age. a credit union is similar to a commercial bank, it
can provide the same products and services like a commercial bank, but what is
different is that the credit union is owned by members who are the shareholders
and at the same time are customers to the credit union. credit unions can provide
different saving accounts to suit the needs of their members. they can create
saving products such as junior saving accounts for the children. credit unions
provide lending products for their members. and credit unions can provide insurance
coverage for their members as well. one of the reasons people explain why they
don ’ t want to open an account with a commercial bank is that because banks charge
fees to keep their accounts. while paying fees is something that we all cannot
avoid because provision of banking services costs money, in a credit union the
interests, fees and charges that are paid by members is distributed back to the
members as net interest income. i say this because i am also member of our staff
credit union called bokolo credit union limited day one when i join the central
bank of solomon islands and know the benefit credit unions can give members. as
the registrar for credit unions, i take note of the progress in the growth of
the assets of both the soltuna employees credit union limited and the tuna trust
credit union limited. if the board and management of these credit unions continue
to manage these credit unions professionally, they will both be the vehicle to
encourage our children and youth here in noro and munda community to learn how
to save and earn and become good financial and economic citizens of our country.
finally, let me take this opportunity to thank the many people who made this global
money week celebration possible. to the board of directors of both tuna trust
credit union limited and soltuna employees credit union limited. i salute you
for accepting our request to work together to host this global money week. i would
like to thank selwyn talasasa, one of the long serving credit union promoters
who has been a credit union person since day one of his career. he has been very
helpful in organizing our global money week. thank you selwyn. i also thank the
global money week committee for their assistance in organising this global money
week. and thanks to the management of both national fisheries development limited
and soltuna limited for your support in hosting this global money week. thank
you nfd and soltuna, you made us all proud as good cooperate citizens. to our
noro town clerk for your support.
- 'in tandem, the policy rate of this central bank would have to be changed frequently
and forcefully in the same direction to offset the shock. but what would happen
in the other economy, if it – unlike the first – were more prone to supply shocks?
experience suggests that supply shocks yield sharp transitory increases in inflation,
possibly followed by smaller, more permanent “ secondround ” effects, though the
longer - run impact on inflation is obviously significantly determined by the
response of monetary policy. given the transitory nature of the initial inflation
bursts, the simple hypothetical rule – which incorporates the reaction to expected
inflation – would advise the central bank to “ look through ” the immediate disturbance
and change policy only to the extent needed to offset the anticipated more permanent
effects of the shock on inflation in subsequent quarters. its policy rate, again,
would be observed to be less variable. what is important to note is that the same
rule – equally active strategies – would support two different patterns of observed
policy behaviour in different economic environments. the third case is perhaps
the most interesting of all. here exogenous shocks are identical, but economic
structures differ. different transmission mechanisms therefore propagate the same
shocks with lags that vary between the two economies. the first economy has more
rigid adjustment mechanisms : price - setters and wage - negotiators are more
sluggish than those in the other economy in processing economic news – including
changes in the stance of monetary policy – and bringing them to bear on their
decisions. what is the source of those rigidities in the first economy? there
can be many reasons for rigidity. perhaps labour practices and contractual institutions
– dating from the early post - war decades when the economy was heavily regulated
– induce distortions in large a similar interpretation of “ interest rate inertia
” – the tendency of central banks to adjust rates in the same direction and in
small steps – can be found in g. rudebusch, “ term structure evidence on interest
rate smoothing and monetary policy inertia ”, journal of monetary economics, vol.
49 ( pp. 1161 - 1187 ), 2002. segments of the labour market. this stands in the
way of an efficient matching of skills and productive capabilities. perhaps tight
regulatory restraint on business and statutory inhibitions discourage innovation
and impede a faster response to new shocks and new opportunities. whatever the
source of rigidity, the observational result is that prices and wages in the first
economy reflect changes in fundamentals with considerable lags. how should'
- 'fund ( uncdf ) are also actively developing financial inclusion knowledge, and
supporting countries in implementing financial inclusion strategies globally.
over the years, we have since witnessed the rapid deployment of innovative financial
inclusion solutions that have changed the lives of many. since the introduction
of the mpesa mobile banking service in kenya, the number of adults with access
to financial services has increased from 42 % in 2011 to 75 % today. agent banking
in malaysia has provided consumers with an innovative and alternative channel
to access financial services, resulting in the percentage of sub - districts served
by financial services access point to increase from 46 % in 2011 to 96 % in 2014.
this has enabled 99 % of malaysians, particularly those in rural areas, to conveniently
access and benefit from financial services. the microfinance “ global financial
development report 2014 ”, world bank, 2014. discussion note “ redistribution,
inequality, and growth ”, imf, 2014. bis central bankers ’ speeches institution
grameen bank in bangladesh has extended credit through its 2, 500 branches to
almost 8 million people, with 60 % of them lifted from poverty. the loan recovery
rate is higher than 98 percent. the experience in bangladesh, in particular, dispels
the myth that the poor is not bankable. of proportionate regulation and the global
standards the proportionate application of global standards for financial regulation
is a critical factor in enabling innovative financial inclusion solutions, ensuring
its delivery in a safe and sound manner. my remarks today will touch on the following
topics : recent developments in global standards and financial inclusion ; focus
areas to advance proportionality in practice ; and the importance of the global
symposium to galvanise action. recent developments in global standards and financial
inclusion global standards developed after the global financial crisis were designed
to address the financial stability and integrity issues that came to the fore
in developed countries. many of these issues involved the activities of global
systemically important financial institutions. the effects of these standards
on financial inclusion, such as the impact on smaller financial institutions in
developing countries most likely were not taken into consideration. fortunately,
standard - setting bodies have now recognised the principle of proportionality,
emphasising on the balance between objectives of financial stability, integrity
and inclusion. however, the real challenge lies in implementing proportionality
in practice. if principles are not implemented in a proportionate manner, there
could be unintended consequences for financial inclusion. for example, despite
the financial action task force ’ s guidance on the implementation of a risk -
based approach to anti money laundering /'
model-index:
- name: SentenceTransformer based on samchain/EconoBert
results:
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: econosentencev2
type: econosentencev2
metrics:
- type: pearson_cosine
value: 0.8556254615515724
name: Pearson Cosine
- type: spearman_cosine
value: 0.8619885397301873
name: Spearman Cosine
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: econosentence prior df
type: econosentence-prior_df
metrics:
- type: pearson_cosine
value: 0.8373175950726144
name: Pearson Cosine
- type: spearman_cosine
value: 0.8294930387036759
name: Spearman Cosine
---
# SentenceTransformer based on samchain/EconoBert
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [samchain/EconoBert](https://huggingface.co/samchain/EconoBert). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
This model is the second version of the previous [samchain/econo-sentence-v1](https://huggingface.co/samchain/econo-sentence-v1). They both used the same base model but have been trained on different datasets.
The model has been evaluated both on the newest dataset and its precedent version:
- `econo-pairs-v2` is the newest dataset. Check its card [here](https://huggingface.co/samchain/econo-pairs-v2)
- `econo-pairs-v1`is the oldest version. Check its card [here](https://huggingface.co/samchain/econo-pairs)
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [samchain/EconoBert](https://huggingface.co/samchain/EconoBert) <!-- at revision 1554ddcdc25e1886cc43e05b9c77a2b8c4888da6 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("samchain/econosentence-v2")
# Run inference
sentences = [
"education shocks arising from the pandemic could signify the largest reversal in human development on record, equivalent to erasing all the progress in human development of the past six years4. the risk of reversing progress in achieving financial inclusion is accentuating why financial inclusion matters now more than ever. optimising islamic finance for inclusive economic recovery policy and regulatory responses across the globe, and likewise in malaysia, have been focused on safeguarding economic resilience, managing risks to financial stability and minimising repercussions to society. this is done in tandem with the different stages of the pandemic – namely, containment, stabilisation and recovery. at the onset of the crisis, governments along with financial regulators have deployed sizeable stimulus packages and various assistance programmes in order to contain the crisis and stabilise the economy. this includes addressing demand and supply disruptions, maintaining cash flows and keeping workers employed. in malaysia, the total stimulus package amounted to usd 73. 55 billion ( rm3056 billion ) with an additional fiscal injection by the government totalling 1 / 4 bis central bankers'speeches rm45 billion. as at september 2020, a total of 2. 63 million workers and 321, 000 employers had benefitted from the wage subsidy programme, involving an expenditure of rm10. 4 billion. to provide further stimulus to the economy, the bank has reduced the overnight policy rate ( opr ) by a cumulative 125 basis points ( from 3. 00 % to 1. 75 % ) this year, alongside reduction in the statutory reserve requirement by 100 basis points ( from 3. 00 % to 2. 00 % ). the reduction in the opr is intended to provide additional policy stimulus to accelerate the pace of economic recovery. the financial industry, including islamic financial institutions, also lent support to their borrowers and customers. in the first half of 2020, a total of rm120 billion7 was disbursed in lending / financing to smes, with more accounts being approved8 in aggregate in 2020 compared to the same period in previous years. islamic financial institutions and related associations have been actively educating and reaching out to affected borrowers about the financial assistance programmes available in response to the pandemic. the takaful and insurance industry also facilitated affected certificate holders by offering temporary deferment of contribution and premium to promote continuity of takaful protection coverage. more than 1. 1 million9 certificate and policyholders have benefited from this relief measure. while the",
'education at an early age. a credit union is similar to a commercial bank, it can provide the same products and services like a commercial bank, but what is different is that the credit union is owned by members who are the shareholders and at the same time are customers to the credit union. credit unions can provide different saving accounts to suit the needs of their members. they can create saving products such as junior saving accounts for the children. credit unions provide lending products for their members. and credit unions can provide insurance coverage for their members as well. one of the reasons people explain why they don ’ t want to open an account with a commercial bank is that because banks charge fees to keep their accounts. while paying fees is something that we all cannot avoid because provision of banking services costs money, in a credit union the interests, fees and charges that are paid by members is distributed back to the members as net interest income. i say this because i am also member of our staff credit union called bokolo credit union limited day one when i join the central bank of solomon islands and know the benefit credit unions can give members. as the registrar for credit unions, i take note of the progress in the growth of the assets of both the soltuna employees credit union limited and the tuna trust credit union limited. if the board and management of these credit unions continue to manage these credit unions professionally, they will both be the vehicle to encourage our children and youth here in noro and munda community to learn how to save and earn and become good financial and economic citizens of our country. finally, let me take this opportunity to thank the many people who made this global money week celebration possible. to the board of directors of both tuna trust credit union limited and soltuna employees credit union limited. i salute you for accepting our request to work together to host this global money week. i would like to thank selwyn talasasa, one of the long serving credit union promoters who has been a credit union person since day one of his career. he has been very helpful in organizing our global money week. thank you selwyn. i also thank the global money week committee for their assistance in organising this global money week. and thanks to the management of both national fisheries development limited and soltuna limited for your support in hosting this global money week. thank you nfd and soltuna, you made us all proud as good cooperate citizens. to our noro town clerk for your support.',
'fund ( uncdf ) are also actively developing financial inclusion knowledge, and supporting countries in implementing financial inclusion strategies globally. over the years, we have since witnessed the rapid deployment of innovative financial inclusion solutions that have changed the lives of many. since the introduction of the mpesa mobile banking service in kenya, the number of adults with access to financial services has increased from 42 % in 2011 to 75 % today. agent banking in malaysia has provided consumers with an innovative and alternative channel to access financial services, resulting in the percentage of sub - districts served by financial services access point to increase from 46 % in 2011 to 96 % in 2014. this has enabled 99 % of malaysians, particularly those in rural areas, to conveniently access and benefit from financial services. the microfinance “ global financial development report 2014 ”, world bank, 2014. discussion note “ redistribution, inequality, and growth ”, imf, 2014. bis central bankers ’ speeches institution grameen bank in bangladesh has extended credit through its 2, 500 branches to almost 8 million people, with 60 % of them lifted from poverty. the loan recovery rate is higher than 98 percent. the experience in bangladesh, in particular, dispels the myth that the poor is not bankable. of proportionate regulation and the global standards the proportionate application of global standards for financial regulation is a critical factor in enabling innovative financial inclusion solutions, ensuring its delivery in a safe and sound manner. my remarks today will touch on the following topics : recent developments in global standards and financial inclusion ; focus areas to advance proportionality in practice ; and the importance of the global symposium to galvanise action. recent developments in global standards and financial inclusion global standards developed after the global financial crisis were designed to address the financial stability and integrity issues that came to the fore in developed countries. many of these issues involved the activities of global systemically important financial institutions. the effects of these standards on financial inclusion, such as the impact on smaller financial institutions in developing countries most likely were not taken into consideration. fortunately, standard - setting bodies have now recognised the principle of proportionality, emphasising on the balance between objectives of financial stability, integrity and inclusion. however, the real challenge lies in implementing proportionality in practice. if principles are not implemented in a proportionate manner, there could be unintended consequences for financial inclusion. for example, despite the financial action task force ’ s guidance on the implementation of a risk - based approach to anti money laundering /',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Semantic Similarity
* Datasets: `econo-pairs-v2` and `econo-pairs-v1`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
Econo-sentence-v2 evaluation results:
| Metric | econo-pairs-v2 | econo-pairs-v1 |
|:--------------------|:----------------|:-----------------------|
| pearson_cosine | 0.8556 | 0.8373 |
| **spearman_cosine** | **0.862** | **0.8295** |
Econo-sentence-v1 evaluation results:
| Metric | econo-pairs-v2 | econo-pairs-v1 |
|:--------------------|:----------------|:-----------------------|
| pearson_cosine | 0.7642 | 0.8999 |
| **spearman_cosine** | **0.758** | **0.8358** |
The v2 and v1 differs in terms of training as the v2 has been train on 0.5 labels, while the v1 is only trained on 1 and 0.
The results show that the v2 still performs on par with its predecessor on the prior dataset while improving the performance by 10 points on the latest.
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Train set of econo-pairs-v2
* Size: 45,044 training samples
* Columns: <code>text1</code>, <code>text2</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | text1 | text2 | label |
|:--------|:-----------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|:---------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 3 tokens</li><li>mean: 454.6 tokens</li><li>max: 505 tokens</li></ul> | <ul><li>min: 6 tokens</li><li>mean: 458.88 tokens</li><li>max: 505 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.49</li><li>max: 1.0</li></ul> |
* Samples:
| text1 | text2 | label |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------|
| <code>in credit intermediation is not disrupted. i hope the analysis and observations i have shared today can assist with a process of learning, evolving, and improving that will prevent future disruptions. thank you. bis central bankers ’ speeches bis central bankers ’ speeches bis central bankers ’ speeches</code> | <code>richard byles : update and outlook for the jamaican economy monetary policy press statement by mr richard byles, governor of the bank of jamaica, at the quarterly monetary policy report press conference, kingston, 21 february 2024. * * * introduction good morning and welcome to our first quarterly monetary policy report press conference for 2024. the year has started with inflation being above the bank's inflation target. statin reported last week that headline inflation at january 2024 was 7. 4 per cent, which is higher than the outturns for the previous three months, and above the bank's target of 4 to 6 per cent. core inflation, however, which excludes food and fuel prices from the consumer price index, was 5. 9 per cent, which is lower than the 7. 1 per cent recorded in january 2023. the inflation outturn at january is higher than the bank had projected in november 2023. as we communicated then, in the wake of the announcement by the minister of finance and the public service of th...</code> | <code>0.0</code> |
| <code>european central bank : press conference - introductory statement introductory statement by mr jean - claude trichet, president of the european central bank, frankfurt am main, 4 may 2006. * * * ladies and gentlemen, let me welcome you to our press conference and report on the outcome of today ’ s meeting of the ecb ’ s governing council. the meeting was also attended by commissioner almunia. on the basis of our regular economic and monetary analyses, we have decided to leave the key ecb interest rates unchanged. overall, the information which has become available since our last meeting broadly confirms our earlier assessment of the outlook for price developments and economic activity in the euro area, and that monetary and credit growth remains very dynamic. against this background, the governing council will exercise strong vigilance in order to ensure that risks to price stability over the medium term do not materialise. such vigilance is particularly warranted in a context of ample...</code> | <code>vitor constancio : strengthening european economic governance – surveillance of fiscal and macroeconomic imbalances speech by mr vitor constancio, vice - president of the european central bank, at the brussels economic forum, brussels, 18 may 2011. * * * thank you very much for the invitation to participate in this panel today. the session is intended to focus on “ surveillance of fiscal and macroeconomic imbalances ”, which arguably is the most important strand of the economic governance package. but one should consider that this package – beyond the 6 legislative acts – also contains three other strands : the euro plus pact, the creation of the european stability mechanism and the setting - up of the european system of financial supervision. a fundamental strengthening of economic governance in the euro area requires simultaneous progress in all three areas. the first strand is necessary to prevent and correct imbalances ; the second to ensure the conditions for future growth and com...</code> | <code>0.5</code> |
| <code>. innovation is already altering the power source of motor vehicles, and much research is directed at reducing gasoline requirements. at present, gasoline consumption in the united states alone accounts for 11 percent of world oil production. moreover, new technologies to preserve existing conventional oil reserves and to stabilize oil prices will emerge in the years ahead. we will begin the transition to the next major sources of energy perhaps before midcentury as production from conventional oil reservoirs, according to central tendency scenarios of the energy information administration, is projected to peak. in fact, the development and application of new sources of energy, especially nonconventional oil, is already in train. nonetheless, it will take time. we, and the rest of the world, doubtless will have to live with the uncertainties of the oil markets for some time to come.</code> | <code>oil industry to build inventories, demand from investors who have accumulated large net long positions in distant oil futures and options is expanding once again. such speculative positions are claims against future oil holdings of oil firms. currently, strained capacity has limited the ability of oil producers to quickly satisfy this markedly increased demand for inventory. adding to the difficulties is the rising consumption of oil, especially in china and india, both of which are expanding economically in ways that are relatively energy intensive. even the recent notable pickup in opec output, by exhausting most of its remaining excess capacity, has only modestly satisfied overall demand. output from producers outside opec has also increased materially, but investment in new producing wells has lagged, limiting growth of production in the near term. crude oil prices are also being distorted by shortages of capacity to upgrade the higher sulphur content and heavier grades of crude oi...</code> | <code>1.0</code> |
* Loss: [<code>CoSENTLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosentloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "pairwise_cos_sim"
}
```
### Evaluation Dataset
#### Test set of econo-pairs-v2
* Size: 11,261 evaluation samples
* Columns: <code>text1</code>, <code>text2</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | text1 | text2 | label |
|:--------|:------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|:--------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 4 tokens</li><li>mean: 451.65 tokens</li><li>max: 505 tokens</li></ul> | <ul><li>min: 6 tokens</li><li>mean: 457.79 tokens</li><li>max: 505 tokens</li></ul> | <ul><li>min: 0.0</li><li>mean: 0.5</li><li>max: 1.0</li></ul> |
* Samples:
| text1 | text2 | label |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------|
| <code>the drying up of the unsecured interbank market a price worth paying for lower interest rate volatility and tighter interest rate control in the money markets? at present, it is difficult to envisage how the unsecured interbank money market could be revived in full in the near future, reaching the pre - global financial crisis levels. this is due both to regulatory reasons and to fragmentation. post - crisis, banks appear reluctant to lend each other in the unsecured interbank market, pricing such lending at levels that are sufficient to compensate for counterparty credit risk. at the same time, short - term ( below 6 months ) interbank funding does not contribute towards satisfying the nsfr requirements. as a result, the unsecured segment of the interbank market is unattractive for prospective borrowers and is not expected to regain importance. furthermore, heterogeneity within and across the banking systems of euro area countries impedes the efficient redistribution of reserves acros...</code> | <code>##obalisation, artificial intelligence, as well as the green transition and climate change adaptation policies. 1 / 7 bis - central bankers'speeches given the uncertain overall impact of these effects and the significant unknowns and ambiguity surrounding the computation of natural interest rates, their prospective level and evolution are not easily determined. turning now to the lessons learnt, experience gained during the past crises has been extremely valuable. first, monetary policy needs to remain flexible so that it can accommodate potential future shocks to price stability, of any nature and direction. second, financial stability considerations need to be taken into account in the decision making of monetary policymakers, in their pursuit of price stability. the past decade provided us with new insights into what monetary policy can do. we are now better prepared to implement the appropriate monetary policy mix, with standard and non - standard tools, if we were to face new chal...</code> | <code>1.0</code> |
| <code>therefore worries me that greece might go backwards in terms of its reform agenda. suffice to say, it is not enough to correct misalignments solely at the national level. we also need structural reforms at the european level. and here, a lot has been done since the crisis broke out. first, the rules of the stability and growth pact were tightened and a fiscal compact was adopted in order to restore confidence in public finances. second, a procedure for identifying macroeconomic imbalances at an early stage was established. and third, a crisis mechanism was set up to serve as a “ firewall ”, safeguarding the stability of the financial system in the euro area. in addition to these measures, the euro area took a major step toward deeper financial integration. on 4 november 2014, the first pillar of a european banking union was put in place. on that day, the ecb assumed responsibility for supervising the 123 largest banks in the euro area. together, the banks concerned account for more tha...</code> | <code>andreas dombret : the euro area – where do we stand? speech by dr andreas dombret, member of the executive board of the deutsche bundesbank, at the german - turkish chamber of trade and commerce, istanbul, 10 february 2015. * 1. * * introduction ladies and gentlemen thank you for inviting me to speak here at the german - turkish chamber of industry and commerce in istanbul. isaac newton once observed that “ we build too many walls and not enough bridges ”. istanbul has for centuries been a bridge between two continents – asia and europe. it seems to me that istanbul is therefore an excellent place to hold this year ’ s g20 meetings. after all, the purpose of these meetings is to build bridges between nations by fostering dialogue and the mutual exchange of information. and this objective is of course also pursued by the german - turkish chamber of trade and commerce. moreover, mutual exchange is essential in a globalised world where countries are no longer isolated islands but part of ...</code> | <code>1.0</code> |
| <code>for vital issues regarding the agenda. i desire you all success with the materialization and accomplishment of your present and future projects and i conclude by wishing all the foreign guests at this conference a good stay in romania. i am now giving the floor to mr kurt puchinger, coordinator of the eu strategy for the danube region and chair of the first session, to start the conference. thank you. bis central bankers ’ speeches</code> | <code>national bank of romania, as they capture appropriately the opinions of the real sector on some key issues, such as : ( i ) the most pressing problems that firms are facing in their activity ; ( ii ) the investment needs and priorities ; ( iii ) challenges raised by climate change and energy efficiency. the survey shows that firms in romania have become less optimistic regarding investment conditions for the year ahead. while this is a worrying trend, we are rather positive that romania will be able to overcome the main problem identified, the energy costs, in the near future. i would add here that the government has implemented several measures in this respect, such as electricity and natural gas price capping schemes, the compensation of the price of motor fuel / liter and caps on the firewood price. also, we are aware that the war in ukraine and the related sanctions will continue to generate considerable uncertainties and risks to the outlook for economic activity, through possibly...</code> | <code>0.5</code> |
* Loss: [<code>CoSENTLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#cosentloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "pairwise_cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `learning_rate`: 2e-05
- `num_train_epochs`: 2
- `warmup_ratio`: 0.1
- `fp16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 2
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | econosentencev2_spearman_cosine |
|:------:|:----:|:-------------:|:---------------:|:-------------------------------:|
| 0.0888 | 250 | 4.2245 | - | - |
| 0.1776 | 500 | 3.6201 | 3.5284 | 0.7812 |
| 0.2663 | 750 | 3.5093 | - | - |
| 0.3551 | 1000 | 3.4858 | 3.4938 | 0.8177 |
| 0.4439 | 1250 | 3.5671 | - | - |
| 0.5327 | 1500 | 3.3165 | 3.2432 | 0.8302 |
| 0.6214 | 1750 | 3.2781 | - | - |
| 0.7102 | 2000 | 3.2901 | 3.1754 | 0.8355 |
| 0.7990 | 2250 | 3.2053 | - | - |
| 0.8878 | 2500 | 3.1673 | 3.1109 | 0.8422 |
| 0.9766 | 2750 | 3.0844 | - | - |
| 1.0653 | 3000 | 2.7478 | 3.1557 | 0.8483 |
| 1.1541 | 3250 | 2.7042 | - | - |
| 1.2429 | 3500 | 2.6291 | 3.1707 | 0.8541 |
| 1.3317 | 3750 | 2.6193 | - | - |
| 1.4205 | 4000 | 2.6128 | 3.1136 | 0.8546 |
| 1.5092 | 4250 | 2.5762 | - | - |
| 1.5980 | 4500 | 2.5992 | 3.0960 | 0.8579 |
| 1.6868 | 4750 | 2.4983 | - | - |
| 1.7756 | 5000 | 2.3061 | 3.1615 | 0.8608 |
| 1.8643 | 5250 | 2.3459 | - | - |
| 1.9531 | 5500 | 2.418 | 3.1436 | 0.8617 |
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 3.4.1
- Transformers: 4.49.0
- PyTorch: 2.1.0+cu118
- Accelerate: 1.4.0
- Datasets: 3.3.1
- Tokenizers: 0.21.0
## Citation
Samuel Chaineau
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### CoSENTLoss
```bibtex
@online{kexuefm-8847,
title={CoSENT: A more efficient sentence vector scheme than Sentence-BERT},
author={Su Jianlin},
year={2022},
month={Jan},
url={https://kexue.fm/archives/8847},
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"BEAR"
] |
BigSalmon/InformalToFormalLincoln88Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-10-31T03:30:39Z |
2022-11-01T02:39:29+00:00
| 63 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln88Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln88Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
```
Q: What is whistleblower protection?
A: Whistleblower protection is a form of legal immunity granted to employees who expose the unethical practices of their employer.
Q: Why are whistleblower protections important?
A: Absent whistleblower protections, employees would be deterred from exposing their employer’s wrongdoing for fear of retribution.
Q: Why would an employer engage in retribution?
A: An employer who has acted unethically stands to suffer severe financial and reputational damage were their transgressions to become public. To safeguard themselves from these consequences, they might seek to dissuade employees from exposing their wrongdoing.
```
```
original: the meritocratic nature of crowdfunding [MASK] into their vision's viability.
infill: the meritocratic nature of crowdfunding [gives investors idea of how successful] -> ( offers entrepreneurs a window ) into their vision's viability.
```
|
[
"BEAR"
] |
Cosmo-Hug/FeverDream
|
Cosmo-Hug
|
text-to-image
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | 2023-03-29T15:40:00Z |
2023-04-01T16:46:50+00:00
| 63 | 10 |
---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# FeverDream
This is a fine tuning of SD1.5 and designed as a general purpose model trained on high quality photographs and traditional artworks upscaled and denoised before training to get the sharpest cleanest results possible.
It's trained at 576 resolution using the offset noise fix so generations are sharp and detailed with vibrant colors, deep blacks, and a well balanced contrast.
This model was not trained with A.I. generated images or merged with any other models which means your images won't have that green/aqua color cast seen in so many models today.
The largest portion of the dataset consists of photographs of women, men, gorgeous landscapes, and luxurious home/cabin/hotel interiors, some abandoned buildings and cityscapes, followed by a few unique art styles that can most easily be discovered by prompting with the commonly used words below.
Some tips for realistic images:
avoid using the word "realistic," part of the dataset contains "realistic porcelain dolls" and the weights for "realistic" have shifted in the direction of the dolls. It shouldn't be an issue but If your faces look a bit smoother than you like try throwing the word "doll" in the negative prompt.
This model is great at both high detailed realism and stylized images when prompted correctly.
A few commonly used words found in the training dataset include:
Papercut
Liquid Splash
Realistic Porcelain Doll
Interior
Landscape
...and a few others for you to discover.
If your so inclined to leave a tip I'm happy to accept monero at this address:
82s3fk8bQB2DHJ3r9idZUsST1Dvf5cKKC6Fu87rYgV9dAFbCbAcXMPXaP59yDwWzRXfYfTBszHZno6xGwDb17xUzEkCsAah
Thanks for checking out my work and enjoy!
## Examples
Below are some examples of images generated using this model:
**Liquid Splash:**

```
close up of a young woman wearing a black and gold liquid splash dress, pretty face, detailed eyes, soft lips, floating in outer space and planets in the background, fluid, wet, dripping, waxy, smooth, realistic, octane render
Negative prompt: two, few, couple, group, lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, dehydrated, extra limbs, clone, disfigured, gross, malformed, extra arms, extra legs, fingers, long neck, username, watermark, signature
Steps: 30, Sampler: DPM++ SDE, CFG scale: 7
```
**Party Skelly:**

```
a 3d render of a cyberpunk gothic skull face surrounded by neon lines and veins, in the style ayami kojima with headdress made out of sushi
Negative prompt: two, few, couple, double, blurry background, low depth of field, bokeh, lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, dehydrated, extra limbs, clone, disfigured, gross, malformed, extra arms, extra legs, fingers, long neck, username, watermark, signature
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 5
```
**Dirty Girl:**

```
close up photo action shot of a buxom woman cyborg, beautiful, sweaty, sweat glistening, science fiction movie, old scars, suspended movement, slow motion, visual flow, rough and tumble, dirt flying, pale, big gray eyes, piercing eyes, undercut hair, (highly detailed:1.1), dramatic, hi-res, (film grain), high ISO, 35mm, gorgeous, outdoor lighting, perfect face, delicate features, bloody nose, rusty tattered and dented metal parts, wasteland, dramatic rim lighting
Negative prompt: doll, blurry background, low depth of field, bokeh, lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 5
```
**Apartment:**

```
a new york manhattan luxury bedroom in the spring, hyper detailed, ultra realistic, sharp focus, octane render, volumetric, ray tracing, artstation trending, cgsociety, insanely detailed studio photography hdr, 8k, cinematic lighting, dramatic lighting, Cannon EOS 5D, 85mm
Negative prompt: lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, dehydrated, extra limbs, clone, disfigured, gross, malformed, extra arms, extra legs, fingers, long neck, username, watermark, signature
Steps: 30, Sampler: DPM2, CFG scale: 5
```
|
[
"MONERO"
] |
dxli/bear_plushie
|
dxli
|
text-to-image
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | 2023-05-09T07:24:41Z |
2023-05-09T16:52:25+00:00
| 63 | 0 |
---
base_model: runwayml/stable-diffusion-v1-5
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - dxli/bear_plushie
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
|
[
"BEAR"
] |
binqiangliu/EmbeddingModlebgelargeENv1.5
|
binqiangliu
|
feature-extraction
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"mteb",
"en",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2023-11-19T07:15:12Z |
2023-11-19T07:25:05+00:00
| 63 | 0 |
---
language:
- en
license: mit
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- mteb
model-index:
- name: bge-large-en-v1.5
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.8507462686567
- type: ap
value: 38.566457320228245
- type: f1
value: 69.69386648043475
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 92.416675
- type: ap
value: 89.1928861155922
- type: f1
value: 92.39477019574215
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.175999999999995
- type: f1
value: 47.80712792870253
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.184999999999995
- type: map_at_10
value: 55.654
- type: map_at_100
value: 56.25
- type: map_at_1000
value: 56.255
- type: map_at_3
value: 51.742999999999995
- type: map_at_5
value: 54.129000000000005
- type: mrr_at_1
value: 40.967
- type: mrr_at_10
value: 55.96
- type: mrr_at_100
value: 56.54900000000001
- type: mrr_at_1000
value: 56.554
- type: mrr_at_3
value: 51.980000000000004
- type: mrr_at_5
value: 54.44
- type: ndcg_at_1
value: 40.184999999999995
- type: ndcg_at_10
value: 63.542
- type: ndcg_at_100
value: 65.96499999999999
- type: ndcg_at_1000
value: 66.08699999999999
- type: ndcg_at_3
value: 55.582
- type: ndcg_at_5
value: 59.855000000000004
- type: precision_at_1
value: 40.184999999999995
- type: precision_at_10
value: 8.841000000000001
- type: precision_at_100
value: 0.987
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 22.238
- type: precision_at_5
value: 15.405
- type: recall_at_1
value: 40.184999999999995
- type: recall_at_10
value: 88.407
- type: recall_at_100
value: 98.72
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 66.714
- type: recall_at_5
value: 77.027
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.567077926750066
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 43.19453389182364
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.46555939623092
- type: mrr
value: 77.82361605768807
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.9554128814735
- type: cos_sim_spearman
value: 84.65373612172036
- type: euclidean_pearson
value: 83.2905059954138
- type: euclidean_spearman
value: 84.52240782811128
- type: manhattan_pearson
value: 82.99533802997436
- type: manhattan_spearman
value: 84.20673798475734
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.78896103896103
- type: f1
value: 87.77189310964883
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.714538337650495
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.90108349284447
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.795
- type: map_at_10
value: 43.669000000000004
- type: map_at_100
value: 45.151
- type: map_at_1000
value: 45.278
- type: map_at_3
value: 40.006
- type: map_at_5
value: 42.059999999999995
- type: mrr_at_1
value: 39.771
- type: mrr_at_10
value: 49.826
- type: mrr_at_100
value: 50.504000000000005
- type: mrr_at_1000
value: 50.549
- type: mrr_at_3
value: 47.115
- type: mrr_at_5
value: 48.832
- type: ndcg_at_1
value: 39.771
- type: ndcg_at_10
value: 50.217999999999996
- type: ndcg_at_100
value: 55.454
- type: ndcg_at_1000
value: 57.37
- type: ndcg_at_3
value: 44.885000000000005
- type: ndcg_at_5
value: 47.419
- type: precision_at_1
value: 39.771
- type: precision_at_10
value: 9.642000000000001
- type: precision_at_100
value: 1.538
- type: precision_at_1000
value: 0.198
- type: precision_at_3
value: 21.268
- type: precision_at_5
value: 15.536
- type: recall_at_1
value: 32.795
- type: recall_at_10
value: 62.580999999999996
- type: recall_at_100
value: 84.438
- type: recall_at_1000
value: 96.492
- type: recall_at_3
value: 47.071000000000005
- type: recall_at_5
value: 54.079
- type: map_at_1
value: 32.671
- type: map_at_10
value: 43.334
- type: map_at_100
value: 44.566
- type: map_at_1000
value: 44.702999999999996
- type: map_at_3
value: 40.343
- type: map_at_5
value: 41.983
- type: mrr_at_1
value: 40.764
- type: mrr_at_10
value: 49.382
- type: mrr_at_100
value: 49.988
- type: mrr_at_1000
value: 50.03300000000001
- type: mrr_at_3
value: 47.293
- type: mrr_at_5
value: 48.51
- type: ndcg_at_1
value: 40.764
- type: ndcg_at_10
value: 49.039
- type: ndcg_at_100
value: 53.259
- type: ndcg_at_1000
value: 55.253
- type: ndcg_at_3
value: 45.091
- type: ndcg_at_5
value: 46.839999999999996
- type: precision_at_1
value: 40.764
- type: precision_at_10
value: 9.191
- type: precision_at_100
value: 1.476
- type: precision_at_1000
value: 0.19499999999999998
- type: precision_at_3
value: 21.72
- type: precision_at_5
value: 15.299
- type: recall_at_1
value: 32.671
- type: recall_at_10
value: 58.816
- type: recall_at_100
value: 76.654
- type: recall_at_1000
value: 89.05999999999999
- type: recall_at_3
value: 46.743
- type: recall_at_5
value: 51.783
- type: map_at_1
value: 40.328
- type: map_at_10
value: 53.32599999999999
- type: map_at_100
value: 54.37499999999999
- type: map_at_1000
value: 54.429
- type: map_at_3
value: 49.902
- type: map_at_5
value: 52.002
- type: mrr_at_1
value: 46.332
- type: mrr_at_10
value: 56.858
- type: mrr_at_100
value: 57.522
- type: mrr_at_1000
value: 57.54899999999999
- type: mrr_at_3
value: 54.472
- type: mrr_at_5
value: 55.996
- type: ndcg_at_1
value: 46.332
- type: ndcg_at_10
value: 59.313
- type: ndcg_at_100
value: 63.266999999999996
- type: ndcg_at_1000
value: 64.36
- type: ndcg_at_3
value: 53.815000000000005
- type: ndcg_at_5
value: 56.814
- type: precision_at_1
value: 46.332
- type: precision_at_10
value: 9.53
- type: precision_at_100
value: 1.238
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 24.054000000000002
- type: precision_at_5
value: 16.589000000000002
- type: recall_at_1
value: 40.328
- type: recall_at_10
value: 73.421
- type: recall_at_100
value: 90.059
- type: recall_at_1000
value: 97.81
- type: recall_at_3
value: 59.009
- type: recall_at_5
value: 66.352
- type: map_at_1
value: 27.424
- type: map_at_10
value: 36.332
- type: map_at_100
value: 37.347
- type: map_at_1000
value: 37.422
- type: map_at_3
value: 33.743
- type: map_at_5
value: 35.176
- type: mrr_at_1
value: 29.153000000000002
- type: mrr_at_10
value: 38.233
- type: mrr_at_100
value: 39.109
- type: mrr_at_1000
value: 39.164
- type: mrr_at_3
value: 35.876000000000005
- type: mrr_at_5
value: 37.169000000000004
- type: ndcg_at_1
value: 29.153000000000002
- type: ndcg_at_10
value: 41.439
- type: ndcg_at_100
value: 46.42
- type: ndcg_at_1000
value: 48.242000000000004
- type: ndcg_at_3
value: 36.362
- type: ndcg_at_5
value: 38.743
- type: precision_at_1
value: 29.153000000000002
- type: precision_at_10
value: 6.315999999999999
- type: precision_at_100
value: 0.927
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 15.443000000000001
- type: precision_at_5
value: 10.644
- type: recall_at_1
value: 27.424
- type: recall_at_10
value: 55.364000000000004
- type: recall_at_100
value: 78.211
- type: recall_at_1000
value: 91.74600000000001
- type: recall_at_3
value: 41.379
- type: recall_at_5
value: 47.14
- type: map_at_1
value: 19.601
- type: map_at_10
value: 27.826
- type: map_at_100
value: 29.017
- type: map_at_1000
value: 29.137
- type: map_at_3
value: 25.125999999999998
- type: map_at_5
value: 26.765
- type: mrr_at_1
value: 24.005000000000003
- type: mrr_at_10
value: 32.716
- type: mrr_at_100
value: 33.631
- type: mrr_at_1000
value: 33.694
- type: mrr_at_3
value: 29.934
- type: mrr_at_5
value: 31.630999999999997
- type: ndcg_at_1
value: 24.005000000000003
- type: ndcg_at_10
value: 33.158
- type: ndcg_at_100
value: 38.739000000000004
- type: ndcg_at_1000
value: 41.495
- type: ndcg_at_3
value: 28.185
- type: ndcg_at_5
value: 30.796
- type: precision_at_1
value: 24.005000000000003
- type: precision_at_10
value: 5.908
- type: precision_at_100
value: 1.005
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 13.391
- type: precision_at_5
value: 9.876
- type: recall_at_1
value: 19.601
- type: recall_at_10
value: 44.746
- type: recall_at_100
value: 68.82300000000001
- type: recall_at_1000
value: 88.215
- type: recall_at_3
value: 31.239
- type: recall_at_5
value: 37.695
- type: map_at_1
value: 30.130000000000003
- type: map_at_10
value: 40.96
- type: map_at_100
value: 42.282
- type: map_at_1000
value: 42.392
- type: map_at_3
value: 37.889
- type: map_at_5
value: 39.661
- type: mrr_at_1
value: 36.958999999999996
- type: mrr_at_10
value: 46.835
- type: mrr_at_100
value: 47.644
- type: mrr_at_1000
value: 47.688
- type: mrr_at_3
value: 44.562000000000005
- type: mrr_at_5
value: 45.938
- type: ndcg_at_1
value: 36.958999999999996
- type: ndcg_at_10
value: 47.06
- type: ndcg_at_100
value: 52.345
- type: ndcg_at_1000
value: 54.35
- type: ndcg_at_3
value: 42.301
- type: ndcg_at_5
value: 44.635999999999996
- type: precision_at_1
value: 36.958999999999996
- type: precision_at_10
value: 8.479000000000001
- type: precision_at_100
value: 1.284
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 20.244
- type: precision_at_5
value: 14.224999999999998
- type: recall_at_1
value: 30.130000000000003
- type: recall_at_10
value: 59.27
- type: recall_at_100
value: 81.195
- type: recall_at_1000
value: 94.21199999999999
- type: recall_at_3
value: 45.885
- type: recall_at_5
value: 52.016
- type: map_at_1
value: 26.169999999999998
- type: map_at_10
value: 36.451
- type: map_at_100
value: 37.791000000000004
- type: map_at_1000
value: 37.897
- type: map_at_3
value: 33.109
- type: map_at_5
value: 34.937000000000005
- type: mrr_at_1
value: 32.877
- type: mrr_at_10
value: 42.368
- type: mrr_at_100
value: 43.201
- type: mrr_at_1000
value: 43.259
- type: mrr_at_3
value: 39.763999999999996
- type: mrr_at_5
value: 41.260000000000005
- type: ndcg_at_1
value: 32.877
- type: ndcg_at_10
value: 42.659000000000006
- type: ndcg_at_100
value: 48.161
- type: ndcg_at_1000
value: 50.345
- type: ndcg_at_3
value: 37.302
- type: ndcg_at_5
value: 39.722
- type: precision_at_1
value: 32.877
- type: precision_at_10
value: 7.9
- type: precision_at_100
value: 1.236
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 17.846
- type: precision_at_5
value: 12.9
- type: recall_at_1
value: 26.169999999999998
- type: recall_at_10
value: 55.35
- type: recall_at_100
value: 78.755
- type: recall_at_1000
value: 93.518
- type: recall_at_3
value: 40.176
- type: recall_at_5
value: 46.589000000000006
- type: map_at_1
value: 27.15516666666667
- type: map_at_10
value: 36.65741666666667
- type: map_at_100
value: 37.84991666666666
- type: map_at_1000
value: 37.96316666666667
- type: map_at_3
value: 33.74974999999999
- type: map_at_5
value: 35.3765
- type: mrr_at_1
value: 32.08233333333334
- type: mrr_at_10
value: 41.033833333333334
- type: mrr_at_100
value: 41.84524999999999
- type: mrr_at_1000
value: 41.89983333333333
- type: mrr_at_3
value: 38.62008333333333
- type: mrr_at_5
value: 40.03441666666666
- type: ndcg_at_1
value: 32.08233333333334
- type: ndcg_at_10
value: 42.229
- type: ndcg_at_100
value: 47.26716666666667
- type: ndcg_at_1000
value: 49.43466666666667
- type: ndcg_at_3
value: 37.36408333333333
- type: ndcg_at_5
value: 39.6715
- type: precision_at_1
value: 32.08233333333334
- type: precision_at_10
value: 7.382583333333334
- type: precision_at_100
value: 1.16625
- type: precision_at_1000
value: 0.15408333333333332
- type: precision_at_3
value: 17.218
- type: precision_at_5
value: 12.21875
- type: recall_at_1
value: 27.15516666666667
- type: recall_at_10
value: 54.36683333333333
- type: recall_at_100
value: 76.37183333333333
- type: recall_at_1000
value: 91.26183333333333
- type: recall_at_3
value: 40.769916666666674
- type: recall_at_5
value: 46.702333333333335
- type: map_at_1
value: 25.749
- type: map_at_10
value: 33.001999999999995
- type: map_at_100
value: 33.891
- type: map_at_1000
value: 33.993
- type: map_at_3
value: 30.703999999999997
- type: map_at_5
value: 31.959
- type: mrr_at_1
value: 28.834
- type: mrr_at_10
value: 35.955
- type: mrr_at_100
value: 36.709
- type: mrr_at_1000
value: 36.779
- type: mrr_at_3
value: 33.947
- type: mrr_at_5
value: 35.089
- type: ndcg_at_1
value: 28.834
- type: ndcg_at_10
value: 37.329
- type: ndcg_at_100
value: 41.79
- type: ndcg_at_1000
value: 44.169000000000004
- type: ndcg_at_3
value: 33.184999999999995
- type: ndcg_at_5
value: 35.107
- type: precision_at_1
value: 28.834
- type: precision_at_10
value: 5.7669999999999995
- type: precision_at_100
value: 0.876
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 14.213000000000001
- type: precision_at_5
value: 9.754999999999999
- type: recall_at_1
value: 25.749
- type: recall_at_10
value: 47.791
- type: recall_at_100
value: 68.255
- type: recall_at_1000
value: 85.749
- type: recall_at_3
value: 36.199
- type: recall_at_5
value: 41.071999999999996
- type: map_at_1
value: 17.777
- type: map_at_10
value: 25.201
- type: map_at_100
value: 26.423999999999996
- type: map_at_1000
value: 26.544
- type: map_at_3
value: 22.869
- type: map_at_5
value: 24.023
- type: mrr_at_1
value: 21.473
- type: mrr_at_10
value: 29.12
- type: mrr_at_100
value: 30.144
- type: mrr_at_1000
value: 30.215999999999998
- type: mrr_at_3
value: 26.933
- type: mrr_at_5
value: 28.051
- type: ndcg_at_1
value: 21.473
- type: ndcg_at_10
value: 30.003
- type: ndcg_at_100
value: 35.766
- type: ndcg_at_1000
value: 38.501000000000005
- type: ndcg_at_3
value: 25.773000000000003
- type: ndcg_at_5
value: 27.462999999999997
- type: precision_at_1
value: 21.473
- type: precision_at_10
value: 5.482
- type: precision_at_100
value: 0.975
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 12.205
- type: precision_at_5
value: 8.692
- type: recall_at_1
value: 17.777
- type: recall_at_10
value: 40.582
- type: recall_at_100
value: 66.305
- type: recall_at_1000
value: 85.636
- type: recall_at_3
value: 28.687
- type: recall_at_5
value: 33.089
- type: map_at_1
value: 26.677
- type: map_at_10
value: 36.309000000000005
- type: map_at_100
value: 37.403999999999996
- type: map_at_1000
value: 37.496
- type: map_at_3
value: 33.382
- type: map_at_5
value: 34.98
- type: mrr_at_1
value: 31.343
- type: mrr_at_10
value: 40.549
- type: mrr_at_100
value: 41.342
- type: mrr_at_1000
value: 41.397
- type: mrr_at_3
value: 38.029
- type: mrr_at_5
value: 39.451
- type: ndcg_at_1
value: 31.343
- type: ndcg_at_10
value: 42.1
- type: ndcg_at_100
value: 47.089999999999996
- type: ndcg_at_1000
value: 49.222
- type: ndcg_at_3
value: 36.836999999999996
- type: ndcg_at_5
value: 39.21
- type: precision_at_1
value: 31.343
- type: precision_at_10
value: 7.164
- type: precision_at_100
value: 1.0959999999999999
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 16.915
- type: precision_at_5
value: 11.940000000000001
- type: recall_at_1
value: 26.677
- type: recall_at_10
value: 55.54599999999999
- type: recall_at_100
value: 77.094
- type: recall_at_1000
value: 92.01
- type: recall_at_3
value: 41.191
- type: recall_at_5
value: 47.006
- type: map_at_1
value: 24.501
- type: map_at_10
value: 33.102
- type: map_at_100
value: 34.676
- type: map_at_1000
value: 34.888000000000005
- type: map_at_3
value: 29.944
- type: map_at_5
value: 31.613999999999997
- type: mrr_at_1
value: 29.447000000000003
- type: mrr_at_10
value: 37.996
- type: mrr_at_100
value: 38.946
- type: mrr_at_1000
value: 38.995000000000005
- type: mrr_at_3
value: 35.079
- type: mrr_at_5
value: 36.69
- type: ndcg_at_1
value: 29.447000000000003
- type: ndcg_at_10
value: 39.232
- type: ndcg_at_100
value: 45.247
- type: ndcg_at_1000
value: 47.613
- type: ndcg_at_3
value: 33.922999999999995
- type: ndcg_at_5
value: 36.284
- type: precision_at_1
value: 29.447000000000003
- type: precision_at_10
value: 7.648000000000001
- type: precision_at_100
value: 1.516
- type: precision_at_1000
value: 0.23900000000000002
- type: precision_at_3
value: 16.008
- type: precision_at_5
value: 11.779
- type: recall_at_1
value: 24.501
- type: recall_at_10
value: 51.18899999999999
- type: recall_at_100
value: 78.437
- type: recall_at_1000
value: 92.842
- type: recall_at_3
value: 35.808
- type: recall_at_5
value: 42.197
- type: map_at_1
value: 22.039
- type: map_at_10
value: 30.377
- type: map_at_100
value: 31.275
- type: map_at_1000
value: 31.379
- type: map_at_3
value: 27.98
- type: map_at_5
value: 29.358
- type: mrr_at_1
value: 24.03
- type: mrr_at_10
value: 32.568000000000005
- type: mrr_at_100
value: 33.403
- type: mrr_at_1000
value: 33.475
- type: mrr_at_3
value: 30.436999999999998
- type: mrr_at_5
value: 31.796000000000003
- type: ndcg_at_1
value: 24.03
- type: ndcg_at_10
value: 35.198
- type: ndcg_at_100
value: 39.668
- type: ndcg_at_1000
value: 42.296
- type: ndcg_at_3
value: 30.709999999999997
- type: ndcg_at_5
value: 33.024
- type: precision_at_1
value: 24.03
- type: precision_at_10
value: 5.564
- type: precision_at_100
value: 0.828
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 13.309000000000001
- type: precision_at_5
value: 9.39
- type: recall_at_1
value: 22.039
- type: recall_at_10
value: 47.746
- type: recall_at_100
value: 68.23599999999999
- type: recall_at_1000
value: 87.852
- type: recall_at_3
value: 35.852000000000004
- type: recall_at_5
value: 41.410000000000004
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.692999999999998
- type: map_at_10
value: 26.903
- type: map_at_100
value: 28.987000000000002
- type: map_at_1000
value: 29.176999999999996
- type: map_at_3
value: 22.137
- type: map_at_5
value: 24.758
- type: mrr_at_1
value: 35.57
- type: mrr_at_10
value: 47.821999999999996
- type: mrr_at_100
value: 48.608000000000004
- type: mrr_at_1000
value: 48.638999999999996
- type: mrr_at_3
value: 44.452000000000005
- type: mrr_at_5
value: 46.546
- type: ndcg_at_1
value: 35.57
- type: ndcg_at_10
value: 36.567
- type: ndcg_at_100
value: 44.085
- type: ndcg_at_1000
value: 47.24
- type: ndcg_at_3
value: 29.964000000000002
- type: ndcg_at_5
value: 32.511
- type: precision_at_1
value: 35.57
- type: precision_at_10
value: 11.485
- type: precision_at_100
value: 1.9619999999999997
- type: precision_at_1000
value: 0.256
- type: precision_at_3
value: 22.237000000000002
- type: precision_at_5
value: 17.471999999999998
- type: recall_at_1
value: 15.692999999999998
- type: recall_at_10
value: 43.056
- type: recall_at_100
value: 68.628
- type: recall_at_1000
value: 86.075
- type: recall_at_3
value: 26.918999999999997
- type: recall_at_5
value: 34.14
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.53
- type: map_at_10
value: 20.951
- type: map_at_100
value: 30.136000000000003
- type: map_at_1000
value: 31.801000000000002
- type: map_at_3
value: 15.021
- type: map_at_5
value: 17.471999999999998
- type: mrr_at_1
value: 71.0
- type: mrr_at_10
value: 79.176
- type: mrr_at_100
value: 79.418
- type: mrr_at_1000
value: 79.426
- type: mrr_at_3
value: 78.125
- type: mrr_at_5
value: 78.61200000000001
- type: ndcg_at_1
value: 58.5
- type: ndcg_at_10
value: 44.106
- type: ndcg_at_100
value: 49.268
- type: ndcg_at_1000
value: 56.711999999999996
- type: ndcg_at_3
value: 48.934
- type: ndcg_at_5
value: 45.826
- type: precision_at_1
value: 71.0
- type: precision_at_10
value: 35.0
- type: precision_at_100
value: 11.360000000000001
- type: precision_at_1000
value: 2.046
- type: precision_at_3
value: 52.833
- type: precision_at_5
value: 44.15
- type: recall_at_1
value: 9.53
- type: recall_at_10
value: 26.811
- type: recall_at_100
value: 55.916999999999994
- type: recall_at_1000
value: 79.973
- type: recall_at_3
value: 16.413
- type: recall_at_5
value: 19.980999999999998
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.519999999999996
- type: f1
value: 46.36601294761231
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 74.413
- type: map_at_10
value: 83.414
- type: map_at_100
value: 83.621
- type: map_at_1000
value: 83.635
- type: map_at_3
value: 82.337
- type: map_at_5
value: 83.039
- type: mrr_at_1
value: 80.19800000000001
- type: mrr_at_10
value: 87.715
- type: mrr_at_100
value: 87.778
- type: mrr_at_1000
value: 87.779
- type: mrr_at_3
value: 87.106
- type: mrr_at_5
value: 87.555
- type: ndcg_at_1
value: 80.19800000000001
- type: ndcg_at_10
value: 87.182
- type: ndcg_at_100
value: 87.90299999999999
- type: ndcg_at_1000
value: 88.143
- type: ndcg_at_3
value: 85.60600000000001
- type: ndcg_at_5
value: 86.541
- type: precision_at_1
value: 80.19800000000001
- type: precision_at_10
value: 10.531
- type: precision_at_100
value: 1.113
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 32.933
- type: precision_at_5
value: 20.429
- type: recall_at_1
value: 74.413
- type: recall_at_10
value: 94.363
- type: recall_at_100
value: 97.165
- type: recall_at_1000
value: 98.668
- type: recall_at_3
value: 90.108
- type: recall_at_5
value: 92.52
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.701
- type: map_at_10
value: 37.122
- type: map_at_100
value: 39.178000000000004
- type: map_at_1000
value: 39.326
- type: map_at_3
value: 32.971000000000004
- type: map_at_5
value: 35.332
- type: mrr_at_1
value: 44.753
- type: mrr_at_10
value: 53.452
- type: mrr_at_100
value: 54.198
- type: mrr_at_1000
value: 54.225
- type: mrr_at_3
value: 50.952
- type: mrr_at_5
value: 52.464
- type: ndcg_at_1
value: 44.753
- type: ndcg_at_10
value: 45.021
- type: ndcg_at_100
value: 52.028
- type: ndcg_at_1000
value: 54.596000000000004
- type: ndcg_at_3
value: 41.622
- type: ndcg_at_5
value: 42.736000000000004
- type: precision_at_1
value: 44.753
- type: precision_at_10
value: 12.284
- type: precision_at_100
value: 1.955
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 27.828999999999997
- type: precision_at_5
value: 20.061999999999998
- type: recall_at_1
value: 22.701
- type: recall_at_10
value: 51.432
- type: recall_at_100
value: 77.009
- type: recall_at_1000
value: 92.511
- type: recall_at_3
value: 37.919000000000004
- type: recall_at_5
value: 44.131
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.189
- type: map_at_10
value: 66.24600000000001
- type: map_at_100
value: 67.098
- type: map_at_1000
value: 67.149
- type: map_at_3
value: 62.684
- type: map_at_5
value: 64.974
- type: mrr_at_1
value: 80.378
- type: mrr_at_10
value: 86.127
- type: mrr_at_100
value: 86.29299999999999
- type: mrr_at_1000
value: 86.297
- type: mrr_at_3
value: 85.31400000000001
- type: mrr_at_5
value: 85.858
- type: ndcg_at_1
value: 80.378
- type: ndcg_at_10
value: 74.101
- type: ndcg_at_100
value: 76.993
- type: ndcg_at_1000
value: 77.948
- type: ndcg_at_3
value: 69.232
- type: ndcg_at_5
value: 72.04599999999999
- type: precision_at_1
value: 80.378
- type: precision_at_10
value: 15.595999999999998
- type: precision_at_100
value: 1.7840000000000003
- type: precision_at_1000
value: 0.191
- type: precision_at_3
value: 44.884
- type: precision_at_5
value: 29.145
- type: recall_at_1
value: 40.189
- type: recall_at_10
value: 77.981
- type: recall_at_100
value: 89.21
- type: recall_at_1000
value: 95.48299999999999
- type: recall_at_3
value: 67.326
- type: recall_at_5
value: 72.863
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 92.84599999999999
- type: ap
value: 89.4710787567357
- type: f1
value: 92.83752676932258
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.132
- type: map_at_10
value: 35.543
- type: map_at_100
value: 36.702
- type: map_at_1000
value: 36.748999999999995
- type: map_at_3
value: 31.737
- type: map_at_5
value: 33.927
- type: mrr_at_1
value: 23.782
- type: mrr_at_10
value: 36.204
- type: mrr_at_100
value: 37.29
- type: mrr_at_1000
value: 37.330999999999996
- type: mrr_at_3
value: 32.458999999999996
- type: mrr_at_5
value: 34.631
- type: ndcg_at_1
value: 23.782
- type: ndcg_at_10
value: 42.492999999999995
- type: ndcg_at_100
value: 47.985
- type: ndcg_at_1000
value: 49.141
- type: ndcg_at_3
value: 34.748000000000005
- type: ndcg_at_5
value: 38.651
- type: precision_at_1
value: 23.782
- type: precision_at_10
value: 6.665
- type: precision_at_100
value: 0.941
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.776
- type: precision_at_5
value: 10.84
- type: recall_at_1
value: 23.132
- type: recall_at_10
value: 63.794
- type: recall_at_100
value: 89.027
- type: recall_at_1000
value: 97.807
- type: recall_at_3
value: 42.765
- type: recall_at_5
value: 52.11
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 94.59188326493388
- type: f1
value: 94.3842594786827
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.49384404924761
- type: f1
value: 59.7580539534629
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 77.56220578345663
- type: f1
value: 75.27228165561478
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.53463349024884
- type: f1
value: 80.4893958236536
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 32.56100273484962
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.470380028839607
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.06102792457849
- type: mrr
value: 33.30709199672238
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.776999999999999
- type: map_at_10
value: 14.924000000000001
- type: map_at_100
value: 18.955
- type: map_at_1000
value: 20.538999999999998
- type: map_at_3
value: 10.982
- type: map_at_5
value: 12.679000000000002
- type: mrr_at_1
value: 47.988
- type: mrr_at_10
value: 57.232000000000006
- type: mrr_at_100
value: 57.818999999999996
- type: mrr_at_1000
value: 57.847
- type: mrr_at_3
value: 54.901999999999994
- type: mrr_at_5
value: 56.481
- type: ndcg_at_1
value: 46.594
- type: ndcg_at_10
value: 38.129000000000005
- type: ndcg_at_100
value: 35.54
- type: ndcg_at_1000
value: 44.172
- type: ndcg_at_3
value: 43.025999999999996
- type: ndcg_at_5
value: 41.052
- type: precision_at_1
value: 47.988
- type: precision_at_10
value: 28.111000000000004
- type: precision_at_100
value: 8.929
- type: precision_at_1000
value: 2.185
- type: precision_at_3
value: 40.144000000000005
- type: precision_at_5
value: 35.232
- type: recall_at_1
value: 6.776999999999999
- type: recall_at_10
value: 19.289
- type: recall_at_100
value: 36.359
- type: recall_at_1000
value: 67.54
- type: recall_at_3
value: 11.869
- type: recall_at_5
value: 14.999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.108000000000004
- type: map_at_10
value: 47.126000000000005
- type: map_at_100
value: 48.171
- type: map_at_1000
value: 48.199
- type: map_at_3
value: 42.734
- type: map_at_5
value: 45.362
- type: mrr_at_1
value: 34.936
- type: mrr_at_10
value: 49.571
- type: mrr_at_100
value: 50.345
- type: mrr_at_1000
value: 50.363
- type: mrr_at_3
value: 45.959
- type: mrr_at_5
value: 48.165
- type: ndcg_at_1
value: 34.936
- type: ndcg_at_10
value: 55.028999999999996
- type: ndcg_at_100
value: 59.244
- type: ndcg_at_1000
value: 59.861
- type: ndcg_at_3
value: 46.872
- type: ndcg_at_5
value: 51.217999999999996
- type: precision_at_1
value: 34.936
- type: precision_at_10
value: 9.099
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 21.456
- type: precision_at_5
value: 15.411
- type: recall_at_1
value: 31.108000000000004
- type: recall_at_10
value: 76.53999999999999
- type: recall_at_100
value: 94.39
- type: recall_at_1000
value: 98.947
- type: recall_at_3
value: 55.572
- type: recall_at_5
value: 65.525
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.56400000000001
- type: map_at_10
value: 85.482
- type: map_at_100
value: 86.114
- type: map_at_1000
value: 86.13
- type: map_at_3
value: 82.607
- type: map_at_5
value: 84.405
- type: mrr_at_1
value: 82.42
- type: mrr_at_10
value: 88.304
- type: mrr_at_100
value: 88.399
- type: mrr_at_1000
value: 88.399
- type: mrr_at_3
value: 87.37
- type: mrr_at_5
value: 88.024
- type: ndcg_at_1
value: 82.45
- type: ndcg_at_10
value: 89.06500000000001
- type: ndcg_at_100
value: 90.232
- type: ndcg_at_1000
value: 90.305
- type: ndcg_at_3
value: 86.375
- type: ndcg_at_5
value: 87.85300000000001
- type: precision_at_1
value: 82.45
- type: precision_at_10
value: 13.486999999999998
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.813
- type: precision_at_5
value: 24.773999999999997
- type: recall_at_1
value: 71.56400000000001
- type: recall_at_10
value: 95.812
- type: recall_at_100
value: 99.7
- type: recall_at_1000
value: 99.979
- type: recall_at_3
value: 87.966
- type: recall_at_5
value: 92.268
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 57.241876648614145
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.66212576446223
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.308
- type: map_at_10
value: 13.803
- type: map_at_100
value: 16.176
- type: map_at_1000
value: 16.561
- type: map_at_3
value: 9.761000000000001
- type: map_at_5
value: 11.802
- type: mrr_at_1
value: 26.200000000000003
- type: mrr_at_10
value: 37.621
- type: mrr_at_100
value: 38.767
- type: mrr_at_1000
value: 38.815
- type: mrr_at_3
value: 34.117
- type: mrr_at_5
value: 36.107
- type: ndcg_at_1
value: 26.200000000000003
- type: ndcg_at_10
value: 22.64
- type: ndcg_at_100
value: 31.567
- type: ndcg_at_1000
value: 37.623
- type: ndcg_at_3
value: 21.435000000000002
- type: ndcg_at_5
value: 18.87
- type: precision_at_1
value: 26.200000000000003
- type: precision_at_10
value: 11.74
- type: precision_at_100
value: 2.465
- type: precision_at_1000
value: 0.391
- type: precision_at_3
value: 20.033
- type: precision_at_5
value: 16.64
- type: recall_at_1
value: 5.308
- type: recall_at_10
value: 23.794999999999998
- type: recall_at_100
value: 50.015
- type: recall_at_1000
value: 79.283
- type: recall_at_3
value: 12.178
- type: recall_at_5
value: 16.882
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.93231134675553
- type: cos_sim_spearman
value: 81.68319292603205
- type: euclidean_pearson
value: 81.8396814380367
- type: euclidean_spearman
value: 81.24641903349945
- type: manhattan_pearson
value: 81.84698799204274
- type: manhattan_spearman
value: 81.24269997904105
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.73241671587446
- type: cos_sim_spearman
value: 79.05091082971826
- type: euclidean_pearson
value: 83.91146869578044
- type: euclidean_spearman
value: 79.87978465370936
- type: manhattan_pearson
value: 83.90888338917678
- type: manhattan_spearman
value: 79.87482848584241
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 85.14970731146177
- type: cos_sim_spearman
value: 86.37363490084627
- type: euclidean_pearson
value: 83.02154218530433
- type: euclidean_spearman
value: 83.80258761957367
- type: manhattan_pearson
value: 83.01664495119347
- type: manhattan_spearman
value: 83.77567458007952
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 83.40474139886784
- type: cos_sim_spearman
value: 82.77768789165984
- type: euclidean_pearson
value: 80.7065877443695
- type: euclidean_spearman
value: 81.375940662505
- type: manhattan_pearson
value: 80.6507552270278
- type: manhattan_spearman
value: 81.32782179098741
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.08585968722274
- type: cos_sim_spearman
value: 88.03110031451399
- type: euclidean_pearson
value: 85.74012019602384
- type: euclidean_spearman
value: 86.13592849438209
- type: manhattan_pearson
value: 85.74404842369206
- type: manhattan_spearman
value: 86.14492318960154
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.95069052788875
- type: cos_sim_spearman
value: 86.4867991595147
- type: euclidean_pearson
value: 84.31013325754635
- type: euclidean_spearman
value: 85.01529258006482
- type: manhattan_pearson
value: 84.26995570085374
- type: manhattan_spearman
value: 84.96982104986162
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.54617647971897
- type: cos_sim_spearman
value: 87.49834181751034
- type: euclidean_pearson
value: 86.01015322577122
- type: euclidean_spearman
value: 84.63362652063199
- type: manhattan_pearson
value: 86.13807574475706
- type: manhattan_spearman
value: 84.7772370721132
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.20047755786615
- type: cos_sim_spearman
value: 67.05324077987636
- type: euclidean_pearson
value: 66.91930642976601
- type: euclidean_spearman
value: 65.21491856099105
- type: manhattan_pearson
value: 66.78756851976624
- type: manhattan_spearman
value: 65.12356257740728
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.19852871539686
- type: cos_sim_spearman
value: 87.5161895296395
- type: euclidean_pearson
value: 84.59848645207485
- type: euclidean_spearman
value: 85.26427328757919
- type: manhattan_pearson
value: 84.59747366996524
- type: manhattan_spearman
value: 85.24045855146915
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.63320317811032
- type: mrr
value: 96.26242947321379
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.928000000000004
- type: map_at_10
value: 70.112
- type: map_at_100
value: 70.59299999999999
- type: map_at_1000
value: 70.623
- type: map_at_3
value: 66.846
- type: map_at_5
value: 68.447
- type: mrr_at_1
value: 64.0
- type: mrr_at_10
value: 71.212
- type: mrr_at_100
value: 71.616
- type: mrr_at_1000
value: 71.64500000000001
- type: mrr_at_3
value: 68.77799999999999
- type: mrr_at_5
value: 70.094
- type: ndcg_at_1
value: 64.0
- type: ndcg_at_10
value: 74.607
- type: ndcg_at_100
value: 76.416
- type: ndcg_at_1000
value: 77.102
- type: ndcg_at_3
value: 69.126
- type: ndcg_at_5
value: 71.41300000000001
- type: precision_at_1
value: 64.0
- type: precision_at_10
value: 9.933
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.556
- type: precision_at_5
value: 17.467
- type: recall_at_1
value: 60.928000000000004
- type: recall_at_10
value: 87.322
- type: recall_at_100
value: 94.833
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 72.628
- type: recall_at_5
value: 78.428
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.86237623762376
- type: cos_sim_ap
value: 96.72586477206649
- type: cos_sim_f1
value: 93.01858362631845
- type: cos_sim_precision
value: 93.4409687184662
- type: cos_sim_recall
value: 92.60000000000001
- type: dot_accuracy
value: 99.78019801980199
- type: dot_ap
value: 93.72748205246228
- type: dot_f1
value: 89.04109589041096
- type: dot_precision
value: 87.16475095785441
- type: dot_recall
value: 91.0
- type: euclidean_accuracy
value: 99.85445544554456
- type: euclidean_ap
value: 96.6661459876145
- type: euclidean_f1
value: 92.58337481333997
- type: euclidean_precision
value: 92.17046580773042
- type: euclidean_recall
value: 93.0
- type: manhattan_accuracy
value: 99.85445544554456
- type: manhattan_ap
value: 96.6883549244056
- type: manhattan_f1
value: 92.57598405580468
- type: manhattan_precision
value: 92.25422045680239
- type: manhattan_recall
value: 92.9
- type: max_accuracy
value: 99.86237623762376
- type: max_ap
value: 96.72586477206649
- type: max_f1
value: 93.01858362631845
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.39930057069995
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.96398659903402
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.946944700355395
- type: mrr
value: 56.97151398438164
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 31.541657650692905
- type: cos_sim_spearman
value: 31.605804192286303
- type: dot_pearson
value: 28.26905996736398
- type: dot_spearman
value: 27.864801765851187
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22599999999999998
- type: map_at_10
value: 1.8870000000000002
- type: map_at_100
value: 9.78
- type: map_at_1000
value: 22.514
- type: map_at_3
value: 0.6669999999999999
- type: map_at_5
value: 1.077
- type: mrr_at_1
value: 82.0
- type: mrr_at_10
value: 89.86699999999999
- type: mrr_at_100
value: 89.86699999999999
- type: mrr_at_1000
value: 89.86699999999999
- type: mrr_at_3
value: 89.667
- type: mrr_at_5
value: 89.667
- type: ndcg_at_1
value: 79.0
- type: ndcg_at_10
value: 74.818
- type: ndcg_at_100
value: 53.715999999999994
- type: ndcg_at_1000
value: 47.082
- type: ndcg_at_3
value: 82.134
- type: ndcg_at_5
value: 79.81899999999999
- type: precision_at_1
value: 82.0
- type: precision_at_10
value: 78.0
- type: precision_at_100
value: 54.48
- type: precision_at_1000
value: 20.518
- type: precision_at_3
value: 87.333
- type: precision_at_5
value: 85.2
- type: recall_at_1
value: 0.22599999999999998
- type: recall_at_10
value: 2.072
- type: recall_at_100
value: 13.013
- type: recall_at_1000
value: 43.462
- type: recall_at_3
value: 0.695
- type: recall_at_5
value: 1.139
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.328
- type: map_at_10
value: 9.795
- type: map_at_100
value: 15.801000000000002
- type: map_at_1000
value: 17.23
- type: map_at_3
value: 4.734
- type: map_at_5
value: 6.644
- type: mrr_at_1
value: 30.612000000000002
- type: mrr_at_10
value: 46.902
- type: mrr_at_100
value: 47.495
- type: mrr_at_1000
value: 47.495
- type: mrr_at_3
value: 41.156
- type: mrr_at_5
value: 44.218
- type: ndcg_at_1
value: 28.571
- type: ndcg_at_10
value: 24.806
- type: ndcg_at_100
value: 36.419000000000004
- type: ndcg_at_1000
value: 47.272999999999996
- type: ndcg_at_3
value: 25.666
- type: ndcg_at_5
value: 25.448999999999998
- type: precision_at_1
value: 30.612000000000002
- type: precision_at_10
value: 23.061
- type: precision_at_100
value: 7.714
- type: precision_at_1000
value: 1.484
- type: precision_at_3
value: 26.531
- type: precision_at_5
value: 26.122
- type: recall_at_1
value: 2.328
- type: recall_at_10
value: 16.524
- type: recall_at_100
value: 47.179
- type: recall_at_1000
value: 81.22200000000001
- type: recall_at_3
value: 5.745
- type: recall_at_5
value: 9.339
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.9142
- type: ap
value: 14.335574772555415
- type: f1
value: 54.62839595194111
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.94340690435768
- type: f1
value: 60.286487936731916
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.26597708987974
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.48882398521786
- type: cos_sim_ap
value: 79.04326607602204
- type: cos_sim_f1
value: 71.64566826860633
- type: cos_sim_precision
value: 70.55512918905092
- type: cos_sim_recall
value: 72.77044854881267
- type: dot_accuracy
value: 84.19264469213805
- type: dot_ap
value: 67.96360043562528
- type: dot_f1
value: 64.06418393006827
- type: dot_precision
value: 58.64941898706424
- type: dot_recall
value: 70.58047493403694
- type: euclidean_accuracy
value: 87.45902127913214
- type: euclidean_ap
value: 78.9742237648272
- type: euclidean_f1
value: 71.5553235908142
- type: euclidean_precision
value: 70.77955601445535
- type: euclidean_recall
value: 72.34828496042216
- type: manhattan_accuracy
value: 87.41729749061214
- type: manhattan_ap
value: 78.90073137580596
- type: manhattan_f1
value: 71.3942611553533
- type: manhattan_precision
value: 68.52705653967483
- type: manhattan_recall
value: 74.51187335092348
- type: max_accuracy
value: 87.48882398521786
- type: max_ap
value: 79.04326607602204
- type: max_f1
value: 71.64566826860633
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.68125897465751
- type: cos_sim_ap
value: 85.6003454431979
- type: cos_sim_f1
value: 77.6957163958641
- type: cos_sim_precision
value: 73.0110366307807
- type: cos_sim_recall
value: 83.02279026793964
- type: dot_accuracy
value: 87.7672992587418
- type: dot_ap
value: 82.4971301112899
- type: dot_f1
value: 75.90528233151184
- type: dot_precision
value: 72.0370626469368
- type: dot_recall
value: 80.21250384970742
- type: euclidean_accuracy
value: 88.4503434625684
- type: euclidean_ap
value: 84.91949884748384
- type: euclidean_f1
value: 76.92365018444684
- type: euclidean_precision
value: 74.53245721712759
- type: euclidean_recall
value: 79.47336002463813
- type: manhattan_accuracy
value: 88.47556952691427
- type: manhattan_ap
value: 84.8963689101517
- type: manhattan_f1
value: 76.85901249256395
- type: manhattan_precision
value: 74.31693989071039
- type: manhattan_recall
value: 79.58115183246073
- type: max_accuracy
value: 88.68125897465751
- type: max_ap
value: 85.6003454431979
- type: max_f1
value: 77.6957163958641
---
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding can map any text to a low-dimensional dense vector which can be used for tasks like retrieval, classification, clustering, or semantic search.
And it also can be used in vector databases for LLMs.
************* 🌟**Updates**🌟 *************
- 10/12/2023: Release [LLM-Embedder](./FlagEmbedding/llm_embedder/README.md), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Paper](https://arxiv.org/pdf/2310.07554.pdf) :fire:
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [masive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao([email protected]) and Zheng Liu([email protected]).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
[
"BEAR",
"BIOSSES",
"SCIFACT"
] |
hunflair/biosyn-sapbert-bc5cdr-chemical
|
hunflair
| null |
[
"flair",
"pytorch",
"entity-mention-linker",
"region:us"
] | 2024-01-29T11:17:41Z |
2024-02-06T16:21:42+00:00
| 63 | 0 |
---
tags:
- flair
- entity-mention-linker
---
## biosyn-sapbert-bc5cdr-chemical
Biomedical Entity Mention Linking for chemical:
- Model: [dmis-lab/biosyn-sapbert-bc5cdr-chemical](https://huggingface.co/dmis-lab/biosyn-sapbert-bc5cdr-chemical)
- Dictionary: [CTD Chemicals](https://ctdbase.org/help/chemDetailHelp.jsp) (See [License](https://ctdbase.org/about/legal.jsp))
### Demo: How to use in Flair
Requires:
- **[Flair](https://github.com/flairNLP/flair/)>=0.14.0** (`pip install flair` or `pip install git+https://github.com/flairNLP/flair.git`)
```python
from flair.data import Sentence
from flair.models import Classifier, EntityMentionLinker
from flair.tokenization import SciSpacyTokenizer
sentence = Sentence(
"The mutation in the ABCD1 gene causes X-linked adrenoleukodystrophy, "
"a neurodegenerative disease, which is exacerbated by exposure to high "
"levels of mercury in dolphin populations.",
use_tokenizer=SciSpacyTokenizer()
)
# load hunflair to detect the entity mentions we want to link.
tagger = Classifier.load("hunflair-chemical")
tagger.predict(sentence)
# load the linker and dictionary
linker = EntityMentionLinker.load("chemical-linker")
linker.predict(sentence)
# print the results for each entity mention:
for span in sentence.get_spans(tagger.label_type):
for link in span.get_labels(linker.label_type):
print(f"{span.text} -> {link.value}")
```
As an alternative to downloading the already precomputed model (much storage). You can also build the model
and compute the embeddings for the dataset using:
```python
linker = EntityMentionLinker.build("dmis-lab/biosyn-sapbert-bc5cdr-chemical", dictionary_name_or_path="ctd-chemicals", hybrid_search=True)
```
This will reduce the download requirements, at the cost of computation.
|
[
"BC5CDR"
] |
PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct
|
PatronusAI
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"pytorch",
"Lynx",
"Patronus AI",
"evaluation",
"hallucination-detection",
"conversational",
"en",
"arxiv:2407.08488",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-07-03T18:34:38Z |
2024-07-22T20:19:43+00:00
| 63 | 28 |
---
language:
- en
library_name: transformers
license: cc-by-nc-4.0
tags:
- text-generation
- pytorch
- Lynx
- Patronus AI
- evaluation
- hallucination-detection
---
# Model Card for Model ID
Lynx is an open-source hallucination evaluation model. Patronus-Lynx-70B-Instruct was trained on a mix of datasets including CovidQA, PubmedQA, DROP, RAGTruth.
The datasets contain a mix of hand-annotated and synthetic data. The maximum sequence length is 8000 tokens.
## Model Details
- **Model Type:** Patronus-Lynx-70B-Instruct is a fine-tuned version of meta-llama/Meta-Llama-3-70B-Instruct model.
- **Language:** Primarily English
- **Developed by:** Patronus AI
- **Paper:** [https://arxiv.org/abs/2407.08488](https://arxiv.org/abs/2407.08488)
- **License:** [ https://creativecommons.org/licenses/by-nc/4.0/](https://creativecommons.org/licenses/by-nc/4.0/)
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [https://github.com/patronus-ai/Lynx-hallucination-detection](https://github.com/patronus-ai/Lynx-hallucination-detection)
## How to Get Started with the Model
The model is fine-tuned to be used to detect hallucinations in a RAG setting. Provided a document, question and answer, the model can evaluate whether the answer is faithful to the document.
To use the model, we recommend using the prompt we used for fine-tuning:
```
PROMPT = """
Given the following QUESTION, DOCUMENT and ANSWER you must analyze the provided answer and determine whether it is faithful to the contents of the DOCUMENT. The ANSWER must not offer new information beyond the context provided in the DOCUMENT. The ANSWER also must not contradict information provided in the DOCUMENT. Output your final verdict by strictly following this format: "PASS" if the answer is faithful to the DOCUMENT and "FAIL" if the answer is not faithful to the DOCUMENT. Show your reasoning.
--
QUESTION (THIS DOES NOT COUNT AS BACKGROUND INFORMATION):
{question}
--
DOCUMENT:
{context}
--
ANSWER:
{answer}
--
Your output should be in JSON FORMAT with the keys "REASONING" and "SCORE":
{{"REASONING": <your reasoning as bullet points>, "SCORE": <your final score>}}
"""
```
The model will output the score as "PASS" if the answer is faithful to the document or "FAIL" if the answer is not faithful to the document.
## Inference
To run inference, you can use HF pipeline:
```
model_name = 'PatronusAI/Llama-3-Patronus-Lynx-8B-Instruct'
pipe = pipeline(
"text-generation",
model=model_name,
max_new_tokens=600,
device="cuda",
return_full_text=False
)
messages = [
{"role": "user", "content": prompt},
]
result = pipe(messages)
print(result[0]['generated_text'])
```
Since the model is trained in chat format, ensure that you pass the prompt as a user message.
For more information on training details, refer to our [ArXiv paper](https://arxiv.org/abs/2407.08488).
## Evaluation
The model was evaluated on [PatronusAI/HaluBench](https://huggingface.co/datasets/PatronusAI/HaluBench).
It outperforms GPT-3.5-Turbo, GPT-4-Turbo, GPT-4o and Claude-3-Sonnet on HaluEval.
| Model | HaluEval | RAGTruth | FinanceBench | DROP | CovidQA | PubmedQA | Overall
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| GPT-4o | 87.9% | 84.3% | **85.3%** | 84.3% | 95.0% | 82.1% | 86.5% |
| GPT-4-Turbo | 86.0% | **85.0%** | 82.2% | 84.8% | 90.6% | 83.5% | 85.0% |
| GPT-3.5-Turbo | 62.2% | 50.7% | 60.9% | 57.2% | 56.7% | 62.8% | 58.7% |
| Claude-3-Sonnet | 84.5% | 79.1% | 69.7% | 84.3% | 95.0% | 82.9% | 78.8% |
| Claude-3-Haiku | 68.9% | 78.9% | 58.4% | 84.3% | 95.0% | 82.9% | 69.0% |
| RAGAS Faithfulness | 70.6% | 75.8% | 59.5% | 59.6% | 75.0% | 67.7% | 66.9% |
| Mistral-Instruct-7B | 78.3% | 77.7% | 56.3% | 56.3% | 71.7% | 77.9% | 69.4% |
| Llama-3-Instruct-8B | 83.1% | 80.0% | 55.0% | 58.2% | 75.2% | 70.7% | 70.4% |
| Llama-3-Instruct-70B | 87.0% | 83.8% | 72.7% | 69.4% | 85.0% | 82.6% | 80.1% |
| LYNX (8B) | 85.7% | 80.0% | 72.5% | 77.8% | 96.3% | 85.2% | 82.9% |
| LYNX (70B) | **88.4%** | 80.2% | 81.4% | **86.4%** | **97.5%** | **90.4%** | **87.4%** |
## Citation
If you are using the model, cite using
```
@article{ravi2024lynx,
title={Lynx: An Open Source Hallucination Evaluation Model},
author={Ravi, Selvan Sunitha and Mielczarek, Bartosz and Kannappan, Anand and Kiela, Douwe and Qian, Rebecca},
journal={arXiv preprint arXiv:2407.08488},
year={2024}
}
```
## Model Card Contact
[@sunitha-ravi](https://huggingface.co/sunitha-ravi)
[@RebeccaQian1](https://huggingface.co/RebeccaQian1)
[@presidev](https://huggingface.co/presidev)
|
[
"PUBMEDQA"
] |
pints-ai/1.5-Pints-16K-v0.1-GGUF
|
pints-ai
|
text-generation
|
[
"gguf",
"llama",
"text-generation",
"en",
"dataset:pints-ai/Expository-Prose-V1",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:Open-Orca/SlimOrca-Dedup",
"dataset:meta-math/MetaMathQA",
"dataset:HuggingFaceH4/deita-10k-v0-sft",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"dataset:togethercomputer/llama-instruct",
"dataset:LDJnr/Capybara",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"arxiv:2408.03506",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-08-07T04:29:45Z |
2024-08-27T01:06:21+00:00
| 63 | 5 |
---
datasets:
- pints-ai/Expository-Prose-V1
- HuggingFaceH4/ultrachat_200k
- Open-Orca/SlimOrca-Dedup
- meta-math/MetaMathQA
- HuggingFaceH4/deita-10k-v0-sft
- WizardLM/WizardLM_evol_instruct_V2_196k
- togethercomputer/llama-instruct
- LDJnr/Capybara
- HuggingFaceH4/ultrafeedback_binarized
language:
- en
license: mit
pipeline_tag: text-generation
extra_gated_prompt: Though best efforts has been made to ensure, as much as possible,
that all texts in the training corpora are royalty free, this does not constitute
a legal guarantee that such is the case. **By using any of the models, corpora or
part thereof, the user agrees to bear full responsibility to do the necessary due
diligence to ensure that he / she is in compliance with their local copyright laws.
Additionally, the user agrees to bear any damages arising as a direct cause (or
otherwise) of using any artifacts released by the pints research team, as well as
full responsibility for the consequences of his / her usage (or implementation)
of any such released artifacts. The user also indemnifies Pints Research Team (and
any of its members or agents) of any damage, related or unrelated, to the release
or subsequent usage of any findings, artifacts or code by the team. For the avoidance
of doubt, any artifacts released by the Pints Research team are done so in accordance
with the 'fair use' clause of Copyright Law, in hopes that this will aid the research
community in bringing LLMs to the next frontier.
extra_gated_fields:
Company: text
Country: country
Specific date: date_picker
I want to use this model for:
type: select
options:
- Research
- Education
- label: Other
value: other
I agree to use this model for in accordance to the afore-mentioned Terms of Use: checkbox
model-index:
- name: 1.5-Pints
results:
- task:
type: text-generation
dataset:
name: MTBench
type: ai2_arc
metrics:
- type: LLM-as-a-Judge
value: 3.4
name: MTBench
source:
url: https://huggingface.co/spaces/lmsys/mt-bench
name: MTBench
---
# 1.5-Pints -- A model pretrained in 9 days by using high quality data
Join us at Discord: https://discord.com/invite/RSHk22Z29j
## How to use
**Build LlamaCPP**
Refer to https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md on how to build.
**Download Model**
```bash
git clone https://huggingface.co/pints-ai/1.5-Pints-16K-v0.1-GGUF --local-dir PATH/TO/MODEL
```
**Usage**
```bash
# FP32
./llama-cli --model PATH/TO/MODEL/1.5-Pints-16K-v0.1-fp32.gguf --n-gpu-layers 999 --repeat-penalty 1.3 --prompt "Predict what life will be like 100 years from now."
# FP16
./llama-cli --model PATH/TO/MODEL/1.5-Pints-16K-v0.1-fp16.gguf --n-gpu-layers 999 --repeat-penalty 1.3 --prompt "Predict what life will be like 100 years from now."
```
`Note`: As at time of publish, `bf16` is slow on llama.cpp (CUDA), hence not recommended for use.
**Compute Infrastructure**<br>
This model can be served with a GPU containing at least 8GB of VRAM.
<br><br>
## Description
1.5 Pints is a Large Language Model that significantly advances the efficiency of LLM training by emphasizing data quality over quantity. Our [pre-training corpus](https://huggingface.co/datasets/pints-ai/Expository-Prose-V1) is a meticulously curated dataset of 57 billion tokens, thus making pre-training more accessible and environmentally-friendly.
<br><br>
## Results
**MTBench**<br>
[MTBench](https://huggingface.co/spaces/lmsys/mt-bench) is a popular evaluation harness that uses strong LLMs like GPT-4 to act as judges and assess the quality of the models' responses./
| Model | Score | Parameter Size | Pretrain Tokens |
|:-:|:-:|:-:|:-:|
| meta-llama/Llama-2-7b-chat-hf | 6.27 | 7B | 2T |
| microsoft/phi-2 | 5.83 | 2.7B | 1.4T |
| google/gemma-2b-it | 5.44 | 2B | 3T |
| stabilityai/stablelm-2-1_6b-chat | 4.7 | 1.6B | 2T |
| **1.5-Pints-2K** | **3.73** | **1.57B** | **0.115T** |
| TinyLlama/TinyLlama-1.1B-Chat-v1.0 | 3.72 | 1.1B | 3T |
| **1.5-Pints-16K** | **3.40** | **1.57B** | **0.115T** |
| apple/OpenELM-1_1B-Instruct | 3.34 | 1B | 1.8T |
| microsoft/phi-1_5 | 3.33 | 1.3B | 0.15T |
| databricks/dolly-v2-3b | 2.33 | 3B | 0.3T |
| EleutherAI/pythia-2.8b | 1.81 | 2.8B | 0.3T |
| tiiuae/falcon-rw-1b | 1.18 | 1B | 0.35T |
<br><br>
The 2K context window version of 1.5-Pints can be found [here](https://huggingface.co/pints-ai/1.5-Pints-2K-v0.1-GGUF).
## Technical Specifications
**Architecture**<br>
Llama 2 Autoregressive Model with **16K Context Window** and Mistral tokenizer. The model uses Float32 precision.
| Parameters | Vocab Size | Embedding Size | Context Length | Layers | Heads | Query Groups | Intermediate Hidden Size |
|:-:|:-:|:-:|:-:|:-:|:-:|:-:|:-:|
| 1,565,886,464 | 32,064 | 2,048 | 16,384 | 24 | 32 | 4 | 8,192 |
**Context Lengths**<br>
1.5-Pints comes in 2 context lengths - 16k (16,384) and 2k (2,048).
**Prompt template**<br>
This model has been finetuned and preference-optimized using the ChatML template.
```
<|im_start|>system
{SYSTEM_PROMPT}<|im_end|>
<|im_start|>user
{PROMPT}<|im_end|>
<|im_start|>assistant
```
<br><br>
## Uses
**Direct Use**<br>
This model is meant to be an efficient and fine-tunable helpful assistant. It is designed to excel in user assistance and reasoning, and rely less on internal knowledge and factuals. Thus, for knowledge retrieval purposes, it should be used with Retrieval Augmented Generation.
**Downstream Use**<br>
Given the size of this model, it is possible to launch multiple instances of it for use in agentic context without breaking the compute bank.
**Recommendations**<br>
- It is recommended to finetune this model for domain adaption, and use it for a specialized tasks.
- To reap full performance, use a repetition penalty of 1.3 rather than 1.
<br><br>
## Training Data
**Pre-Train Data**<br>
Dataset: [pints-ai/Expository-Prose-V1](https://huggingface.co/datasets/pints-ai/Expository-Prose-V1)
**Fine-Tune Data**<br>
Corpora:
- [HuggingFaceH4/ultrachat](https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k)
- [Open-Orca/SlimOrca-Dedup](https://huggingface.co/datasets/Open-Orca/SlimOrca-Dedup)
- [meta-math/MetaMathQA](https://huggingface.co/datasets/meta-math/MetaMathQA)
- [HuggingFaceH4/deita-10k-v0-sft](https://huggingface.co/datasets/HuggingFaceH4/deita-10k-v0-sft)
- [WizardLM/WizardLM_evol_instruct_V2_196k](https://huggingface.co/datasets/WizardLMTeam/WizardLM_evol_instruct_V2_196k)
- [togethercomputer/llama-instruct](https://huggingface.co/togethercomputer/Llama-2-7B-32K-Instruct)
- [LDJnr/Capybara](https://huggingface.co/datasets/LDJnr/Capybara)
**DPO Data**<br>
Dataset: [HuggingFaceH4/ultrafeedback_binarized](https://huggingface.co/datasets/HuggingFaceH4/ultrafeedback_binarized)
<br><br>
## Training Procedure
Both Pre-Train and Finetuning used [our fork](https://github.com/Pints-AI/1.5-Pints) of the [LitGPT Framework](https://github.com/Lightning-AI/litgpt). For DPO, we used the methods set out in [The Alignment Handbook](https://github.com/huggingface/alignment-handbook/blob/main/scripts/run_dpo.py). More details can be found in our [paper](https://arxiv.org/abs/2408.03506).
## Training Hyperparameters
**Pre-Train**<br>
| Hyperparameter | Value |
|:-:|:-:|
| Optimizer | AdamW(Beta1=0.9, Beta2=0.95) |
| Learning Rate Scheduler | Cosine |
| Max Learning Rate | 4.0x10-4 |
| Min Learning Rate | 4.0x10-5 |
| Warmup Steps | 2,000 |
| Batch Size | 2,097,152 |
| Weight Decay | 0.1 |
| Gradient Clipping Threshold | 1.0 |
**SFT**<br>
| Hyperparameter | Value |
|:-:|:-:|
| Optimizer | AdamW(Beta1=0.9, Beta2=0.95) |
| Warmup steps | 1,126 (10%)
| Peak learning rate | 2e-5 |
| Learning rate scheduler | Cosine |
| Weight Decay | 0.1 |
**DPO**<br>
DPO parameters used are the exact same as those specified in [The Alignment Handbook](https://github.com/huggingface/alignment-handbook).
<br><br>
## Citation
**Attribution**
- **Developed by:** [calvintwr](https://huggingface.co/calvintwr), [lemousehunter](https://huggingface.co/lemousehunter)
- **Funded by** [PintsAI](https://pints.ai/)
- **Released by:** [PintsAI](https://pints.ai/)
- **Model type:** Large Language Model
- **Language(s) (NLP):** English
- **License:** [MIT License](https://opensource.org/license/mit)
<br><br>
**BibTeX:**
```latex
@misc{tan202415pintstechnicalreportpretraining,
title={1.5-Pints Technical Report: Pretraining in Days, Not Months -- Your Language Model Thrives on Quality Data},
author={Calvin Tan and Jerome Wang},
year={2024},
eprint={2408.03506},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2408.03506},
}
```
**APA**<br>
Tan, C., & Wang, J. (2024). 1.5-Pints Technical Report: Pretraining in days, not months -- Your language model thrives on quality data. arXiv. https://arxiv.org/abs/2408.03506
<br><br>
## Legal Warning
Though best efforts has been made to ensure, as much as possible, that all texts in the training corpora are royalty free, this does not constitute a legal guarantee that such is the case. **By using any of the models, corpora or part thereof, the user agrees to bear full responsibility to do the necessary due diligence to ensure that he / she is in compliance with their local copyright laws**.
Additionally, the **user agrees to bear any damages** arising as a direct cause (or otherwise) of using any artifacts released by the pints research team, as well as full responsibility for the consequences of his / her usage (or implementation) of any such released artifacts. The user also indemnifies Pints Research Team (and any of its members or agents) of any damage, related or unrelated, to the release or subsequent usage of any findings, artifacts or code by the team.
For the avoidance of doubt, **any artifacts released by the Pints Research team are done so in accordance with the "fair use"** clause of Copyright Law, in hopes that this will aid the research community in bringing LLMs to the next frontier.
|
[
"BEAR"
] |
knowledgator/gliner-bi-base-v1.0
|
knowledgator
|
token-classification
|
[
"gliner",
"pytorch",
"NER",
"GLiNER",
"information extraction",
"encoder",
"entity recognition",
"token-classification",
"multilingual",
"dataset:urchade/pile-mistral-v0.1",
"dataset:numind/NuNER",
"dataset:knowledgator/GLINER-multi-task-synthetic-data",
"license:apache-2.0",
"region:us"
] | 2024-08-20T12:43:27Z |
2024-08-25T11:39:56+00:00
| 63 | 4 |
---
datasets:
- urchade/pile-mistral-v0.1
- numind/NuNER
- knowledgator/GLINER-multi-task-synthetic-data
language:
- multilingual
library_name: gliner
license: apache-2.0
pipeline_tag: token-classification
tags:
- NER
- GLiNER
- information extraction
- encoder
- entity recognition
---
# About
GLiNER is a Named Entity Recognition (NER) model capable of identifying any entity type using a bidirectional transformer encoders (BERT-like). It provides a practical alternative to traditional NER models, which are limited to predefined entities, and Large Language Models (LLMs) that, despite their flexibility, are costly and large for resource-constrained scenarios.
This particular version utilize bi-encoder architecture, where textual encoder is [DeBERTa v3 base](microsoft/deberta-v3-base) and entity label encoder is sentence transformer - [BGE-small-en](https://huggingface.co/BAAI/bge-small-en-v1.5).
Such architecture brings several advantages over uni-encoder GLiNER:
* An unlimited amount of entities can be recognized at a single time;
* Faster inference if entity embeddings are preprocessed;
* Better generalization to unseen entities;
However, it has some drawbacks such as a lack of inter-label interactions that make it hard for the model to disambiguate semantically similar but contextually different entities.
### Installation & Usage
Install or update the gliner package:
```bash
pip install gliner -U
```
Once you've downloaded the GLiNER library, you can import the GLiNER class. You can then load this model using `GLiNER.from_pretrained` and predict entities with `predict_entities`.
```python
from gliner import GLiNER
model = GLiNER.from_pretrained("knowledgator/gliner-bi-small-v1.0")
text = """
Cristiano Ronaldo dos Santos Aveiro (Portuguese pronunciation: [kɾiʃˈtjɐnu ʁɔˈnaldu]; born 5 February 1985) is a Portuguese professional footballer who plays as a forward for and captains both Saudi Pro League club Al Nassr and the Portugal national team. Widely regarded as one of the greatest players of all time, Ronaldo has won five Ballon d'Or awards,[note 3] a record three UEFA Men's Player of the Year Awards, and four European Golden Shoes, the most by a European player. He has won 33 trophies in his career, including seven league titles, five UEFA Champions Leagues, the UEFA European Championship and the UEFA Nations League. Ronaldo holds the records for most appearances (183), goals (140) and assists (42) in the Champions League, goals in the European Championship (14), international goals (128) and international appearances (205). He is one of the few players to have made over 1,200 professional career appearances, the most by an outfield player, and has scored over 850 official senior career goals for club and country, making him the top goalscorer of all time.
"""
labels = ["person", "award", "date", "competitions", "teams"]
entities = model.predict_entities(text, labels, threshold=0.3)
for entity in entities:
print(entity["text"], "=>", entity["label"])
```
```
Cristiano Ronaldo dos Santos Aveiro => person
5 February 1985 => date
Al Nassr => teams
Portugal national team => teams
Ballon d'Or => award
UEFA Men's Player of the Year Awards => award
European Golden Shoes => award
UEFA Champions Leagues => competitions
UEFA European Championship => competitions
UEFA Nations League => competitions
Champions League => competitions
European Championship => competitions
```
If you have a large amount of entities and want to pre-embed them, please, refer to the following code snippet:
```python
labels = ["your entities"]
texts = ["your texts"]
entity_embeddings = model.encode_labels(labels, batch_size = 8)
outputs = model.batch_predict_with_embeds(texts, entity_embeddings, labels)
```
### Benchmarks
Below you can see the table with benchmarking results on various named entity recognition datasets:
| Dataset | Score |
|---------|-------|
| ACE 2004 | 27.3% |
| ACE 2005 | 30.6% |
| AnatEM | 31.8% |
| Broad Tweet Corpus | 66.4% |
| CoNLL 2003 | 61.4% |
| FabNER | 21.8% |
| FindVehicle | 36.4% |
| GENIA_NER | 52.6% |
| HarveyNER | 11.4% |
| MultiNERD | 60.9% |
| Ontonotes | 26.5% |
| PolyglotNER | 43.8% |
| TweetNER7 | 38.0% |
| WikiANN en | 53.7% |
| WikiNeural | 71.5% |
| bc2gm | 59.4% |
| bc4chemd | 50.4% |
| bc5cdr | 68.4% |
| ncbi | 65.6% |
| **Average** | **46.2%** |
|||
| CrossNER_AI | 48.4% |
| CrossNER_literature | 61.9% |
| CrossNER_music | 68.8% |
| CrossNER_politics | 73.2% |
| CrossNER_science | 63.2% |
| mit-movie | 39.6% |
| mit-restaurant | 39.0% |
| **Average (zero-shot benchmark)** | **56.3%** |
### Join Our Discord
Connect with our community on Discord for news, support, and discussion about our models. Join [Discord](https://discord.gg/dkyeAgs9DG).
|
[
"ANATEM",
"BC5CDR"
] |
RichardErkhov/LLM360_-_AmberChat-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2312.06550",
"endpoints_compatible",
"region:us"
] | 2024-08-27T21:44:52Z |
2024-08-27T23:47:18+00:00
| 63 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
AmberChat - GGUF
- Model creator: https://huggingface.co/LLM360/
- Original model: https://huggingface.co/LLM360/AmberChat/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [AmberChat.Q2_K.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q2_K.gguf) | Q2_K | 2.36GB |
| [AmberChat.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.IQ3_XS.gguf) | IQ3_XS | 2.6GB |
| [AmberChat.IQ3_S.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.IQ3_S.gguf) | IQ3_S | 2.75GB |
| [AmberChat.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q3_K_S.gguf) | Q3_K_S | 2.75GB |
| [AmberChat.IQ3_M.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.IQ3_M.gguf) | IQ3_M | 2.9GB |
| [AmberChat.Q3_K.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q3_K.gguf) | Q3_K | 3.07GB |
| [AmberChat.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q3_K_M.gguf) | Q3_K_M | 3.07GB |
| [AmberChat.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q3_K_L.gguf) | Q3_K_L | 3.35GB |
| [AmberChat.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.IQ4_XS.gguf) | IQ4_XS | 3.4GB |
| [AmberChat.Q4_0.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q4_0.gguf) | Q4_0 | 3.56GB |
| [AmberChat.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.IQ4_NL.gguf) | IQ4_NL | 1.23GB |
| [AmberChat.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q4_K_S.gguf) | Q4_K_S | 3.59GB |
| [AmberChat.Q4_K.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q4_K.gguf) | Q4_K | 3.8GB |
| [AmberChat.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q4_K_M.gguf) | Q4_K_M | 3.8GB |
| [AmberChat.Q4_1.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q4_1.gguf) | Q4_1 | 3.95GB |
| [AmberChat.Q5_0.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q5_0.gguf) | Q5_0 | 4.33GB |
| [AmberChat.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q5_K_S.gguf) | Q5_K_S | 1.64GB |
| [AmberChat.Q5_K.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q5_K.gguf) | Q5_K | 4.45GB |
| [AmberChat.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q5_K_M.gguf) | Q5_K_M | 4.45GB |
| [AmberChat.Q5_1.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q5_1.gguf) | Q5_1 | 4.72GB |
| [AmberChat.Q6_K.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q6_K.gguf) | Q6_K | 5.15GB |
| [AmberChat.Q8_0.gguf](https://huggingface.co/RichardErkhov/LLM360_-_AmberChat-gguf/blob/main/AmberChat.Q8_0.gguf) | Q8_0 | 6.67GB |
Original model description:
---
license: apache-2.0
datasets:
- WizardLM/WizardLM_evol_instruct_V2_196k
- icybee/share_gpt_90k_v1
language:
- en
widget:
- example_title: "example 1"
text: "How do I mount a tv to drywall safely?"
output:
text: "Mounting a TV to drywall safely is crucial to ensure the longevity of your TV and the wall. Here's a step-by-step guide on how to do it safely:\n 1. Choose the right mount: Choose a mount that is compatible with your TV and the wall. Make sure the mount is rated for drywall and not just wood or concrete.\n 2. Prepare the wall: Before mounting the TV, make sure the wall is clean and free from any debris or paint. Use a stud finder to locate the studs in the wall.\n 3. Install the mount: Follow the manufacturer's instructions for mounting the TV to the wall. Use appropriate hardware and tools to secure the mount to the wall.\n 4. Level the TV: Level the TV on the mount using a spirit level or a leveling kit provided by the mount manufacturer.\n 5. Attach the TV to the mount: Attach the TV to the mount using the appropriate hardware and tools. Tighten the bolts and screws to ensure the TV is securely attached.\n 6. Connect the cables: Connect the TV cables to the appropriate ports on the back of the TV and the mount.\n 7. Test the mount: Test the mount to ensure it's secure and stable. Adjust the mount as needed to ensure the TV is level and secure.\n Mounting a TV to drywall safely is crucial to avoid damaging the wall or the TV. Follow these steps carefully and use appropriate tools and hardware to ensure a secure and stable installation."
- example_title: "example 2"
text: "Happy is to sad as calm is to _."
output:
text: "The adjective that can be used to describe the opposite of calm is \"anxious\" or \"stressed.\" So, from happy to sad, we can say that happy is to sad as calm is to anxious or stressed."
library_name: transformers
pipeline_tag: text-generation
tags:
- nlp
- llm
---
# AmberChat
We present AmberChat, an instruction following model finetuned from [LLM360/Amber](https://huggingface.co/LLM360/Amber).
# Evaluation
| Model | MT-Bench |
|------------------------------------------------------|------------------------------------------------------------|
| **LLM360/AmberChat** | **5.428125** |
| [LLM360/Amber](https://huggingface.co/LLM360/Amber) | 2.48750 |
| [Falcon-40B-Instruct](https://huggingface.co/tiiuae/falcon-40b-instruct) | 5.17 |
| [MPT-7B-Chat](https://huggingface.co/mosaicml/mpt-7b-chat) | 5.42 |
| [Nous-Hermes-13B](https://huggingface.co/NousResearch/Nous-Hermes-13b) | 5.51 |
## Model Description
- **Model type:** Language model with the same architecture as LLaMA-7B
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Resources for more information:**
- [Metrics](https://github.com/LLM360/Analysis360)
- [Fully processed Amber pretraining data](https://huggingface.co/datasets/LLM360/AmberDatasets)
- [Finetuning Code](https://github.com/LLM360/amber-train/tree/main/finetune/amberchat)
# Loading AmberChat
```python
import torch
from transformers import LlamaTokenizer, LlamaForCausalLM
tokenizer = LlamaTokenizer.from_pretrained("LLM360/AmberChat")
model = LlamaForCausalLM.from_pretrained("LLM360/AmberChat")
#template adapated from fastchat
template= "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n### Human: Got any creative ideas for a 10 year old’s birthday?\n### Assistant: Of course! Here are some creative ideas for a 10-year-old's birthday party:\n1. Treasure Hunt: Organize a treasure hunt in your backyard or nearby park. Create clues and riddles for the kids to solve, leading them to hidden treasures and surprises.\n2. Science Party: Plan a science-themed party where kids can engage in fun and interactive experiments. You can set up different stations with activities like making slime, erupting volcanoes, or creating simple chemical reactions.\n3. Outdoor Movie Night: Set up a backyard movie night with a projector and a large screen or white sheet. Create a cozy seating area with blankets and pillows, and serve popcorn and snacks while the kids enjoy a favorite movie under the stars.\n4. DIY Crafts Party: Arrange a craft party where kids can unleash their creativity. Provide a variety of craft supplies like beads, paints, and fabrics, and let them create their own unique masterpieces to take home as party favors.\n5. Sports Olympics: Host a mini Olympics event with various sports and games. Set up different stations for activities like sack races, relay races, basketball shooting, and obstacle courses. Give out medals or certificates to the participants.\n6. Cooking Party: Have a cooking-themed party where the kids can prepare their own mini pizzas, cupcakes, or cookies. Provide toppings, frosting, and decorating supplies, and let them get hands-on in the kitchen.\n7. Superhero Training Camp: Create a superhero-themed party where the kids can engage in fun training activities. Set up an obstacle course, have them design their own superhero capes or masks, and organize superhero-themed games and challenges.\n8. Outdoor Adventure: Plan an outdoor adventure party at a local park or nature reserve. Arrange activities like hiking, nature scavenger hunts, or a picnic with games. Encourage exploration and appreciation for the outdoors.\nRemember to tailor the activities to the birthday child's interests and preferences. Have a great celebration!\n### Human: {prompt}\n### Assistant:"
prompt = "How do I mount a tv to drywall safely?"
input_str = template.format(prompt=prompt)
input_ids = tokenizer(input_str, return_tensors="pt").input_ids
outputs = model.generate(input_ids, max_length=1000)
print(tokenizer.batch_decode(outputs[:, input_ids.shape[1]:-1])[0].strip())
```
Alternatively, you may use [FastChat](https://github.com/lm-sys/FastChat):
```bash
python3 -m fastchat.serve.cli --model-path LLM360/AmberChat
```
# AmberChat Finetuning Details
## DataMix
| Subset | Number of rows | License |
| ----------- | ----------- | ----------- |
| WizardLM/WizardLM_evol_instruct_V2_196k | 143k | |
| icybee/share_gpt_90k_v1 | 90k | cc0-1.0 |
| Total | 233k | |
## Hyperparameters
| Hyperparameter | Value |
| ----------- | ----------- |
| Total Parameters | 6.7B |
| Hidden Size | 4096 |
| Intermediate Size (MLPs) | 11008 |
| Number of Attention Heads | 32 |
| Number of Hidden Lyaers | 32 |
| RMSNorm ɛ | 1e^-6 |
| Max Seq Length | 2048 |
| Vocab Size | 32000 |
| Training Hyperparameter | Value |
| ----------- | ----------- |
| learning_rate | 2e-5 |
| num_train_epochs | 3 |
| per_device_train_batch_size | 2 |
| gradient_accumulation_steps | 16 |
| warmup_ratio | 0.04 |
| model_max_length | 2048 |
# Using Quantized Models with Ollama
Please follow these steps to use a quantized version of AmberChat on your personal computer or laptop:
1. First, install Ollama by following the instructions provided [here](https://github.com/jmorganca/ollama/tree/main?tab=readme-ov-file#ollama). Next, download a quantized model checkpoint (such as [amberchat.Q8_0.gguf](https://huggingface.co/TheBloke/AmberChat-GGUF/blob/main/amberchat.Q8_0.gguf) for the 8 bit version) from [TheBloke/AmberChat-GGUF](https://huggingface.co/TheBloke/AmberChat-GGUF/tree/main). Create an Ollama Modelfile locally using the template provided below:
```
FROM amberchat.Q8_0.gguf
TEMPLATE """{{ .System }}
USER: {{ .Prompt }}
ASSISTANT:
"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions.
"""
PARAMETER stop "USER:"
PARAMETER stop "ASSISTANT:"
PARAMETER repeat_last_n 0
PARAMETER num_ctx 2048
PARAMETER seed 0
PARAMETER num_predict -1
```
Ensure that the FROM directive points to the downloaded checkpoint file.
2. Now, you can proceed to build the model by running:
```bash
ollama create amberchat -f Modelfile
```
3. To run the model from the command line, execute the following:
```bash
ollama run amberchat
```
You need to build the model once and can just run it afterwards.
# Citation
**BibTeX:**
```bibtex
@misc{liu2023llm360,
title={LLM360: Towards Fully Transparent Open-Source LLMs},
author={Zhengzhong Liu and Aurick Qiao and Willie Neiswanger and Hongyi Wang and Bowen Tan and Tianhua Tao and Junbo Li and Yuqi Wang and Suqi Sun and Omkar Pangarkar and Richard Fan and Yi Gu and Victor Miller and Yonghao Zhuang and Guowei He and Haonan Li and Fajri Koto and Liping Tang and Nikhil Ranjan and Zhiqiang Shen and Xuguang Ren and Roberto Iriondo and Cun Mu and Zhiting Hu and Mark Schulze and Preslav Nakov and Tim Baldwin and Eric P. Xing},
year={2023},
eprint={2312.06550},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"CRAFT"
] |
RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2308.03281",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-09-27T05:27:07Z |
2024-09-27T06:00:48+00:00
| 63 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
DeepFeatTextEmbeddingLarge - GGUF
- Model creator: https://huggingface.co/DecisionOptimizationSystemProduction/
- Original model: https://huggingface.co/DecisionOptimizationSystemProduction/DeepFeatTextEmbeddingLarge/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [DeepFeatTextEmbeddingLarge.Q2_K.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q2_K.gguf) | Q2_K | 0.7GB |
| [DeepFeatTextEmbeddingLarge.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.IQ3_XS.gguf) | IQ3_XS | 0.77GB |
| [DeepFeatTextEmbeddingLarge.IQ3_S.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.IQ3_S.gguf) | IQ3_S | 0.8GB |
| [DeepFeatTextEmbeddingLarge.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q3_K_S.gguf) | Q3_K_S | 0.8GB |
| [DeepFeatTextEmbeddingLarge.IQ3_M.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.IQ3_M.gguf) | IQ3_M | 0.82GB |
| [DeepFeatTextEmbeddingLarge.Q3_K.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q3_K.gguf) | Q3_K | 0.86GB |
| [DeepFeatTextEmbeddingLarge.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q3_K_M.gguf) | Q3_K_M | 0.86GB |
| [DeepFeatTextEmbeddingLarge.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q3_K_L.gguf) | Q3_K_L | 0.91GB |
| [DeepFeatTextEmbeddingLarge.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.IQ4_XS.gguf) | IQ4_XS | 0.96GB |
| [DeepFeatTextEmbeddingLarge.Q4_0.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q4_0.gguf) | Q4_0 | 0.99GB |
| [DeepFeatTextEmbeddingLarge.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.IQ4_NL.gguf) | IQ4_NL | 1.0GB |
| [DeepFeatTextEmbeddingLarge.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q4_K_S.gguf) | Q4_K_S | 1.0GB |
| [DeepFeatTextEmbeddingLarge.Q4_K.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q4_K.gguf) | Q4_K | 1.04GB |
| [DeepFeatTextEmbeddingLarge.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q4_K_M.gguf) | Q4_K_M | 1.04GB |
| [DeepFeatTextEmbeddingLarge.Q4_1.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q4_1.gguf) | Q4_1 | 1.08GB |
| [DeepFeatTextEmbeddingLarge.Q5_0.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q5_0.gguf) | Q5_0 | 1.17GB |
| [DeepFeatTextEmbeddingLarge.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q5_K_S.gguf) | Q5_K_S | 1.17GB |
| [DeepFeatTextEmbeddingLarge.Q5_K.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q5_K.gguf) | Q5_K | 1.2GB |
| [DeepFeatTextEmbeddingLarge.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q5_K_M.gguf) | Q5_K_M | 1.2GB |
| [DeepFeatTextEmbeddingLarge.Q5_1.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q5_1.gguf) | Q5_1 | 1.26GB |
| [DeepFeatTextEmbeddingLarge.Q6_K.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q6_K.gguf) | Q6_K | 1.36GB |
| [DeepFeatTextEmbeddingLarge.Q8_0.gguf](https://huggingface.co/RichardErkhov/DecisionOptimizationSystemProduction_-_DeepFeatTextEmbeddingLarge-gguf/blob/main/DeepFeatTextEmbeddingLarge.Q8_0.gguf) | Q8_0 | 1.76GB |
Original model description:
---
tags:
- mteb
- sentence-transformers
- transformers
- Qwen2
- sentence-similarity
license: apache-2.0
model-index:
- name: gte-qwen2-7B-instruct
results:
- dataset:
config: en
name: MTEB AmazonCounterfactualClassification (en)
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
split: test
type: mteb/amazon_counterfactual
metrics:
- type: accuracy
value: 83.98507462686567
- type: ap
value: 50.93015252587014
- type: f1
value: 78.50416599051215
task:
type: Classification
- dataset:
config: default
name: MTEB AmazonPolarityClassification
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
split: test
type: mteb/amazon_polarity
metrics:
- type: accuracy
value: 96.61065
- type: ap
value: 94.89174052954196
- type: f1
value: 96.60942596940565
task:
type: Classification
- dataset:
config: en
name: MTEB AmazonReviewsClassification (en)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 55.614000000000004
- type: f1
value: 54.90553480294904
task:
type: Classification
- dataset:
config: default
name: MTEB ArguAna
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
split: test
type: mteb/arguana
metrics:
- type: map_at_1
value: 45.164
- type: map_at_10
value: 61.519
- type: map_at_100
value: 61.769
- type: map_at_1000
value: 61.769
- type: map_at_3
value: 57.443999999999996
- type: map_at_5
value: 60.058
- type: mrr_at_1
value: 46.088
- type: mrr_at_10
value: 61.861
- type: mrr_at_100
value: 62.117999999999995
- type: mrr_at_1000
value: 62.117999999999995
- type: mrr_at_3
value: 57.729
- type: mrr_at_5
value: 60.392
- type: ndcg_at_1
value: 45.164
- type: ndcg_at_10
value: 69.72
- type: ndcg_at_100
value: 70.719
- type: ndcg_at_1000
value: 70.719
- type: ndcg_at_3
value: 61.517999999999994
- type: ndcg_at_5
value: 66.247
- type: precision_at_1
value: 45.164
- type: precision_at_10
value: 9.545
- type: precision_at_100
value: 0.996
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 24.443
- type: precision_at_5
value: 16.97
- type: recall_at_1
value: 45.164
- type: recall_at_10
value: 95.448
- type: recall_at_100
value: 99.644
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 73.329
- type: recall_at_5
value: 84.851
task:
type: Retrieval
- dataset:
config: default
name: MTEB ArxivClusteringP2P
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
split: test
type: mteb/arxiv-clustering-p2p
metrics:
- type: v_measure
value: 50.511868162026175
task:
type: Clustering
- dataset:
config: default
name: MTEB ArxivClusteringS2S
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
split: test
type: mteb/arxiv-clustering-s2s
metrics:
- type: v_measure
value: 45.007803189284004
task:
type: Clustering
- dataset:
config: default
name: MTEB AskUbuntuDupQuestions
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
split: test
type: mteb/askubuntudupquestions-reranking
metrics:
- type: map
value: 64.55292107723382
- type: mrr
value: 77.66158818097877
task:
type: Reranking
- dataset:
config: default
name: MTEB BIOSSES
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
split: test
type: mteb/biosses-sts
metrics:
- type: cos_sim_pearson
value: 85.65459047085452
- type: cos_sim_spearman
value: 82.10729255710761
- type: euclidean_pearson
value: 82.78079159312476
- type: euclidean_spearman
value: 80.50002701880933
- type: manhattan_pearson
value: 82.41372641383016
- type: manhattan_spearman
value: 80.57412509272639
task:
type: STS
- dataset:
config: default
name: MTEB Banking77Classification
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
split: test
type: mteb/banking77
metrics:
- type: accuracy
value: 87.30844155844156
- type: f1
value: 87.25307322443255
task:
type: Classification
- dataset:
config: default
name: MTEB BiorxivClusteringP2P
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
split: test
type: mteb/biorxiv-clustering-p2p
metrics:
- type: v_measure
value: 43.20754608934859
task:
type: Clustering
- dataset:
config: default
name: MTEB BiorxivClusteringS2S
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
split: test
type: mteb/biorxiv-clustering-s2s
metrics:
- type: v_measure
value: 38.818037697335505
task:
type: Clustering
- dataset:
config: default
name: MTEB CQADupstackAndroidRetrieval
revision: f46a197baaae43b4f621051089b82a364682dfeb
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 35.423
- type: map_at_10
value: 47.198
- type: map_at_100
value: 48.899
- type: map_at_1000
value: 49.004
- type: map_at_3
value: 43.114999999999995
- type: map_at_5
value: 45.491
- type: mrr_at_1
value: 42.918
- type: mrr_at_10
value: 53.299
- type: mrr_at_100
value: 54.032000000000004
- type: mrr_at_1000
value: 54.055
- type: mrr_at_3
value: 50.453
- type: mrr_at_5
value: 52.205999999999996
- type: ndcg_at_1
value: 42.918
- type: ndcg_at_10
value: 53.98
- type: ndcg_at_100
value: 59.57
- type: ndcg_at_1000
value: 60.879000000000005
- type: ndcg_at_3
value: 48.224000000000004
- type: ndcg_at_5
value: 50.998
- type: precision_at_1
value: 42.918
- type: precision_at_10
value: 10.299999999999999
- type: precision_at_100
value: 1.687
- type: precision_at_1000
value: 0.211
- type: precision_at_3
value: 22.842000000000002
- type: precision_at_5
value: 16.681
- type: recall_at_1
value: 35.423
- type: recall_at_10
value: 66.824
- type: recall_at_100
value: 89.564
- type: recall_at_1000
value: 97.501
- type: recall_at_3
value: 50.365
- type: recall_at_5
value: 57.921
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackEnglishRetrieval
revision: ad9991cb51e31e31e430383c75ffb2885547b5f0
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 33.205
- type: map_at_10
value: 44.859
- type: map_at_100
value: 46.135
- type: map_at_1000
value: 46.259
- type: map_at_3
value: 41.839
- type: map_at_5
value: 43.662
- type: mrr_at_1
value: 41.146
- type: mrr_at_10
value: 50.621
- type: mrr_at_100
value: 51.207
- type: mrr_at_1000
value: 51.246
- type: mrr_at_3
value: 48.535000000000004
- type: mrr_at_5
value: 49.818
- type: ndcg_at_1
value: 41.146
- type: ndcg_at_10
value: 50.683
- type: ndcg_at_100
value: 54.82
- type: ndcg_at_1000
value: 56.69
- type: ndcg_at_3
value: 46.611000000000004
- type: ndcg_at_5
value: 48.66
- type: precision_at_1
value: 41.146
- type: precision_at_10
value: 9.439
- type: precision_at_100
value: 1.465
- type: precision_at_1000
value: 0.194
- type: precision_at_3
value: 22.59
- type: precision_at_5
value: 15.86
- type: recall_at_1
value: 33.205
- type: recall_at_10
value: 61.028999999999996
- type: recall_at_100
value: 78.152
- type: recall_at_1000
value: 89.59700000000001
- type: recall_at_3
value: 49.05
- type: recall_at_5
value: 54.836
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackGamingRetrieval
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 41.637
- type: map_at_10
value: 55.162
- type: map_at_100
value: 56.142
- type: map_at_1000
value: 56.188
- type: map_at_3
value: 51.564
- type: map_at_5
value: 53.696
- type: mrr_at_1
value: 47.524
- type: mrr_at_10
value: 58.243
- type: mrr_at_100
value: 58.879999999999995
- type: mrr_at_1000
value: 58.9
- type: mrr_at_3
value: 55.69499999999999
- type: mrr_at_5
value: 57.284
- type: ndcg_at_1
value: 47.524
- type: ndcg_at_10
value: 61.305
- type: ndcg_at_100
value: 65.077
- type: ndcg_at_1000
value: 65.941
- type: ndcg_at_3
value: 55.422000000000004
- type: ndcg_at_5
value: 58.516
- type: precision_at_1
value: 47.524
- type: precision_at_10
value: 9.918000000000001
- type: precision_at_100
value: 1.276
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 24.765
- type: precision_at_5
value: 17.204
- type: recall_at_1
value: 41.637
- type: recall_at_10
value: 76.185
- type: recall_at_100
value: 92.149
- type: recall_at_1000
value: 98.199
- type: recall_at_3
value: 60.856
- type: recall_at_5
value: 68.25099999999999
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackGisRetrieval
revision: 5003b3064772da1887988e05400cf3806fe491f2
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 26.27
- type: map_at_10
value: 37.463
- type: map_at_100
value: 38.434000000000005
- type: map_at_1000
value: 38.509
- type: map_at_3
value: 34.226
- type: map_at_5
value: 36.161
- type: mrr_at_1
value: 28.588
- type: mrr_at_10
value: 39.383
- type: mrr_at_100
value: 40.23
- type: mrr_at_1000
value: 40.281
- type: mrr_at_3
value: 36.422
- type: mrr_at_5
value: 38.252
- type: ndcg_at_1
value: 28.588
- type: ndcg_at_10
value: 43.511
- type: ndcg_at_100
value: 48.274
- type: ndcg_at_1000
value: 49.975
- type: ndcg_at_3
value: 37.319
- type: ndcg_at_5
value: 40.568
- type: precision_at_1
value: 28.588
- type: precision_at_10
value: 6.893000000000001
- type: precision_at_100
value: 0.9900000000000001
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 16.347
- type: precision_at_5
value: 11.661000000000001
- type: recall_at_1
value: 26.27
- type: recall_at_10
value: 60.284000000000006
- type: recall_at_100
value: 81.902
- type: recall_at_1000
value: 94.43
- type: recall_at_3
value: 43.537
- type: recall_at_5
value: 51.475
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackMathematicaRetrieval
revision: 90fceea13679c63fe563ded68f3b6f06e50061de
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 18.168
- type: map_at_10
value: 28.410000000000004
- type: map_at_100
value: 29.78
- type: map_at_1000
value: 29.892999999999997
- type: map_at_3
value: 25.238
- type: map_at_5
value: 26.96
- type: mrr_at_1
value: 23.507
- type: mrr_at_10
value: 33.382
- type: mrr_at_100
value: 34.404
- type: mrr_at_1000
value: 34.467999999999996
- type: mrr_at_3
value: 30.637999999999998
- type: mrr_at_5
value: 32.199
- type: ndcg_at_1
value: 23.507
- type: ndcg_at_10
value: 34.571000000000005
- type: ndcg_at_100
value: 40.663
- type: ndcg_at_1000
value: 43.236000000000004
- type: ndcg_at_3
value: 29.053
- type: ndcg_at_5
value: 31.563999999999997
- type: precision_at_1
value: 23.507
- type: precision_at_10
value: 6.654
- type: precision_at_100
value: 1.113
- type: precision_at_1000
value: 0.146
- type: precision_at_3
value: 14.427999999999999
- type: precision_at_5
value: 10.498000000000001
- type: recall_at_1
value: 18.168
- type: recall_at_10
value: 48.443000000000005
- type: recall_at_100
value: 74.47
- type: recall_at_1000
value: 92.494
- type: recall_at_3
value: 33.379999999999995
- type: recall_at_5
value: 39.76
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackPhysicsRetrieval
revision: 79531abbd1fb92d06c6d6315a0cbbbf5bb247ea4
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 32.39
- type: map_at_10
value: 44.479
- type: map_at_100
value: 45.977000000000004
- type: map_at_1000
value: 46.087
- type: map_at_3
value: 40.976
- type: map_at_5
value: 43.038
- type: mrr_at_1
value: 40.135
- type: mrr_at_10
value: 50.160000000000004
- type: mrr_at_100
value: 51.052
- type: mrr_at_1000
value: 51.087
- type: mrr_at_3
value: 47.818
- type: mrr_at_5
value: 49.171
- type: ndcg_at_1
value: 40.135
- type: ndcg_at_10
value: 50.731
- type: ndcg_at_100
value: 56.452000000000005
- type: ndcg_at_1000
value: 58.123000000000005
- type: ndcg_at_3
value: 45.507
- type: ndcg_at_5
value: 48.11
- type: precision_at_1
value: 40.135
- type: precision_at_10
value: 9.192
- type: precision_at_100
value: 1.397
- type: precision_at_1000
value: 0.169
- type: precision_at_3
value: 21.816
- type: precision_at_5
value: 15.476
- type: recall_at_1
value: 32.39
- type: recall_at_10
value: 63.597
- type: recall_at_100
value: 86.737
- type: recall_at_1000
value: 97.039
- type: recall_at_3
value: 48.906
- type: recall_at_5
value: 55.659000000000006
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackProgrammersRetrieval
revision: 6184bc1440d2dbc7612be22b50686b8826d22b32
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 28.397
- type: map_at_10
value: 39.871
- type: map_at_100
value: 41.309000000000005
- type: map_at_1000
value: 41.409
- type: map_at_3
value: 36.047000000000004
- type: map_at_5
value: 38.104
- type: mrr_at_1
value: 34.703
- type: mrr_at_10
value: 44.773
- type: mrr_at_100
value: 45.64
- type: mrr_at_1000
value: 45.678999999999995
- type: mrr_at_3
value: 41.705
- type: mrr_at_5
value: 43.406
- type: ndcg_at_1
value: 34.703
- type: ndcg_at_10
value: 46.271
- type: ndcg_at_100
value: 52.037
- type: ndcg_at_1000
value: 53.81700000000001
- type: ndcg_at_3
value: 39.966
- type: ndcg_at_5
value: 42.801
- type: precision_at_1
value: 34.703
- type: precision_at_10
value: 8.744
- type: precision_at_100
value: 1.348
- type: precision_at_1000
value: 0.167
- type: precision_at_3
value: 19.102
- type: precision_at_5
value: 13.836
- type: recall_at_1
value: 28.397
- type: recall_at_10
value: 60.299
- type: recall_at_100
value: 84.595
- type: recall_at_1000
value: 96.155
- type: recall_at_3
value: 43.065
- type: recall_at_5
value: 50.371
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackRetrieval
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 28.044333333333338
- type: map_at_10
value: 38.78691666666666
- type: map_at_100
value: 40.113
- type: map_at_1000
value: 40.22125
- type: map_at_3
value: 35.52966666666667
- type: map_at_5
value: 37.372749999999996
- type: mrr_at_1
value: 33.159083333333335
- type: mrr_at_10
value: 42.913583333333335
- type: mrr_at_100
value: 43.7845
- type: mrr_at_1000
value: 43.830333333333336
- type: mrr_at_3
value: 40.29816666666667
- type: mrr_at_5
value: 41.81366666666667
- type: ndcg_at_1
value: 33.159083333333335
- type: ndcg_at_10
value: 44.75750000000001
- type: ndcg_at_100
value: 50.13658333333334
- type: ndcg_at_1000
value: 52.037
- type: ndcg_at_3
value: 39.34258333333334
- type: ndcg_at_5
value: 41.93708333333333
- type: precision_at_1
value: 33.159083333333335
- type: precision_at_10
value: 7.952416666666667
- type: precision_at_100
value: 1.2571666666666668
- type: precision_at_1000
value: 0.16099999999999998
- type: precision_at_3
value: 18.303833333333337
- type: precision_at_5
value: 13.057083333333333
- type: recall_at_1
value: 28.044333333333338
- type: recall_at_10
value: 58.237249999999996
- type: recall_at_100
value: 81.35391666666666
- type: recall_at_1000
value: 94.21283333333334
- type: recall_at_3
value: 43.32341666666667
- type: recall_at_5
value: 49.94908333333333
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackStatsRetrieval
revision: 65ac3a16b8e91f9cee4c9828cc7c335575432a2a
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 27.838
- type: map_at_10
value: 36.04
- type: map_at_100
value: 37.113
- type: map_at_1000
value: 37.204
- type: map_at_3
value: 33.585
- type: map_at_5
value: 34.845
- type: mrr_at_1
value: 30.982
- type: mrr_at_10
value: 39.105000000000004
- type: mrr_at_100
value: 39.98
- type: mrr_at_1000
value: 40.042
- type: mrr_at_3
value: 36.912
- type: mrr_at_5
value: 38.062000000000005
- type: ndcg_at_1
value: 30.982
- type: ndcg_at_10
value: 40.982
- type: ndcg_at_100
value: 46.092
- type: ndcg_at_1000
value: 48.25
- type: ndcg_at_3
value: 36.41
- type: ndcg_at_5
value: 38.379999999999995
- type: precision_at_1
value: 30.982
- type: precision_at_10
value: 6.534
- type: precision_at_100
value: 0.9820000000000001
- type: precision_at_1000
value: 0.124
- type: precision_at_3
value: 15.745999999999999
- type: precision_at_5
value: 10.828
- type: recall_at_1
value: 27.838
- type: recall_at_10
value: 52.971000000000004
- type: recall_at_100
value: 76.357
- type: recall_at_1000
value: 91.973
- type: recall_at_3
value: 40.157
- type: recall_at_5
value: 45.147999999999996
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackTexRetrieval
revision: 46989137a86843e03a6195de44b09deda022eec7
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 19.059
- type: map_at_10
value: 27.454
- type: map_at_100
value: 28.736
- type: map_at_1000
value: 28.865000000000002
- type: map_at_3
value: 24.773999999999997
- type: map_at_5
value: 26.266000000000002
- type: mrr_at_1
value: 23.125
- type: mrr_at_10
value: 31.267
- type: mrr_at_100
value: 32.32
- type: mrr_at_1000
value: 32.394
- type: mrr_at_3
value: 28.894
- type: mrr_at_5
value: 30.281000000000002
- type: ndcg_at_1
value: 23.125
- type: ndcg_at_10
value: 32.588
- type: ndcg_at_100
value: 38.432
- type: ndcg_at_1000
value: 41.214
- type: ndcg_at_3
value: 27.938000000000002
- type: ndcg_at_5
value: 30.127
- type: precision_at_1
value: 23.125
- type: precision_at_10
value: 5.9639999999999995
- type: precision_at_100
value: 1.047
- type: precision_at_1000
value: 0.148
- type: precision_at_3
value: 13.294
- type: precision_at_5
value: 9.628
- type: recall_at_1
value: 19.059
- type: recall_at_10
value: 44.25
- type: recall_at_100
value: 69.948
- type: recall_at_1000
value: 89.35300000000001
- type: recall_at_3
value: 31.114000000000004
- type: recall_at_5
value: 36.846000000000004
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackUnixRetrieval
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 28.355999999999998
- type: map_at_10
value: 39.055
- type: map_at_100
value: 40.486
- type: map_at_1000
value: 40.571
- type: map_at_3
value: 35.69
- type: map_at_5
value: 37.605
- type: mrr_at_1
value: 33.302
- type: mrr_at_10
value: 42.986000000000004
- type: mrr_at_100
value: 43.957
- type: mrr_at_1000
value: 43.996
- type: mrr_at_3
value: 40.111999999999995
- type: mrr_at_5
value: 41.735
- type: ndcg_at_1
value: 33.302
- type: ndcg_at_10
value: 44.962999999999994
- type: ndcg_at_100
value: 50.917
- type: ndcg_at_1000
value: 52.622
- type: ndcg_at_3
value: 39.182
- type: ndcg_at_5
value: 41.939
- type: precision_at_1
value: 33.302
- type: precision_at_10
value: 7.779999999999999
- type: precision_at_100
value: 1.203
- type: precision_at_1000
value: 0.145
- type: precision_at_3
value: 18.035
- type: precision_at_5
value: 12.873000000000001
- type: recall_at_1
value: 28.355999999999998
- type: recall_at_10
value: 58.782000000000004
- type: recall_at_100
value: 84.02199999999999
- type: recall_at_1000
value: 95.511
- type: recall_at_3
value: 43.126999999999995
- type: recall_at_5
value: 50.14999999999999
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackWebmastersRetrieval
revision: 160c094312a0e1facb97e55eeddb698c0abe3571
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 27.391
- type: map_at_10
value: 37.523
- type: map_at_100
value: 39.312000000000005
- type: map_at_1000
value: 39.54
- type: map_at_3
value: 34.231
- type: map_at_5
value: 36.062
- type: mrr_at_1
value: 32.016
- type: mrr_at_10
value: 41.747
- type: mrr_at_100
value: 42.812
- type: mrr_at_1000
value: 42.844
- type: mrr_at_3
value: 39.129999999999995
- type: mrr_at_5
value: 40.524
- type: ndcg_at_1
value: 32.016
- type: ndcg_at_10
value: 43.826
- type: ndcg_at_100
value: 50.373999999999995
- type: ndcg_at_1000
value: 52.318
- type: ndcg_at_3
value: 38.479
- type: ndcg_at_5
value: 40.944
- type: precision_at_1
value: 32.016
- type: precision_at_10
value: 8.280999999999999
- type: precision_at_100
value: 1.6760000000000002
- type: precision_at_1000
value: 0.25
- type: precision_at_3
value: 18.05
- type: precision_at_5
value: 13.083
- type: recall_at_1
value: 27.391
- type: recall_at_10
value: 56.928999999999995
- type: recall_at_100
value: 85.169
- type: recall_at_1000
value: 96.665
- type: recall_at_3
value: 42.264
- type: recall_at_5
value: 48.556
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackWordpressRetrieval
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
split: test
type: BeIR/cqadupstack
metrics:
- type: map_at_1
value: 18.398
- type: map_at_10
value: 27.929
- type: map_at_100
value: 29.032999999999998
- type: map_at_1000
value: 29.126
- type: map_at_3
value: 25.070999999999998
- type: map_at_5
value: 26.583000000000002
- type: mrr_at_1
value: 19.963
- type: mrr_at_10
value: 29.997
- type: mrr_at_100
value: 30.9
- type: mrr_at_1000
value: 30.972
- type: mrr_at_3
value: 27.264
- type: mrr_at_5
value: 28.826
- type: ndcg_at_1
value: 19.963
- type: ndcg_at_10
value: 33.678999999999995
- type: ndcg_at_100
value: 38.931
- type: ndcg_at_1000
value: 41.379
- type: ndcg_at_3
value: 28.000000000000004
- type: ndcg_at_5
value: 30.637999999999998
- type: precision_at_1
value: 19.963
- type: precision_at_10
value: 5.7299999999999995
- type: precision_at_100
value: 0.902
- type: precision_at_1000
value: 0.122
- type: precision_at_3
value: 12.631
- type: precision_at_5
value: 9.057
- type: recall_at_1
value: 18.398
- type: recall_at_10
value: 49.254
- type: recall_at_100
value: 73.182
- type: recall_at_1000
value: 91.637
- type: recall_at_3
value: 34.06
- type: recall_at_5
value: 40.416000000000004
task:
type: Retrieval
- dataset:
config: default
name: MTEB ClimateFEVER
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
split: test
type: mteb/climate-fever
metrics:
- type: map_at_1
value: 19.681
- type: map_at_10
value: 32.741
- type: map_at_100
value: 34.811
- type: map_at_1000
value: 35.003
- type: map_at_3
value: 27.697
- type: map_at_5
value: 30.372
- type: mrr_at_1
value: 44.951
- type: mrr_at_10
value: 56.34400000000001
- type: mrr_at_100
value: 56.961
- type: mrr_at_1000
value: 56.987
- type: mrr_at_3
value: 53.681
- type: mrr_at_5
value: 55.407
- type: ndcg_at_1
value: 44.951
- type: ndcg_at_10
value: 42.905
- type: ndcg_at_100
value: 49.95
- type: ndcg_at_1000
value: 52.917
- type: ndcg_at_3
value: 36.815
- type: ndcg_at_5
value: 38.817
- type: precision_at_1
value: 44.951
- type: precision_at_10
value: 12.989999999999998
- type: precision_at_100
value: 2.068
- type: precision_at_1000
value: 0.263
- type: precision_at_3
value: 27.275
- type: precision_at_5
value: 20.365
- type: recall_at_1
value: 19.681
- type: recall_at_10
value: 48.272999999999996
- type: recall_at_100
value: 71.87400000000001
- type: recall_at_1000
value: 87.929
- type: recall_at_3
value: 32.653999999999996
- type: recall_at_5
value: 39.364
task:
type: Retrieval
- dataset:
config: default
name: MTEB DBPedia
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
split: test
type: mteb/dbpedia
metrics:
- type: map_at_1
value: 10.231
- type: map_at_10
value: 22.338
- type: map_at_100
value: 31.927
- type: map_at_1000
value: 33.87
- type: map_at_3
value: 15.559999999999999
- type: map_at_5
value: 18.239
- type: mrr_at_1
value: 75.0
- type: mrr_at_10
value: 81.303
- type: mrr_at_100
value: 81.523
- type: mrr_at_1000
value: 81.53
- type: mrr_at_3
value: 80.083
- type: mrr_at_5
value: 80.758
- type: ndcg_at_1
value: 64.625
- type: ndcg_at_10
value: 48.687000000000005
- type: ndcg_at_100
value: 52.791
- type: ndcg_at_1000
value: 60.041999999999994
- type: ndcg_at_3
value: 53.757999999999996
- type: ndcg_at_5
value: 50.76500000000001
- type: precision_at_1
value: 75.0
- type: precision_at_10
value: 38.3
- type: precision_at_100
value: 12.025
- type: precision_at_1000
value: 2.3970000000000002
- type: precision_at_3
value: 55.417
- type: precision_at_5
value: 47.5
- type: recall_at_1
value: 10.231
- type: recall_at_10
value: 27.697
- type: recall_at_100
value: 57.409
- type: recall_at_1000
value: 80.547
- type: recall_at_3
value: 16.668
- type: recall_at_5
value: 20.552
task:
type: Retrieval
- dataset:
config: default
name: MTEB EmotionClassification
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
split: test
type: mteb/emotion
metrics:
- type: accuracy
value: 61.365
- type: f1
value: 56.7540827912991
task:
type: Classification
- dataset:
config: default
name: MTEB FEVER
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
split: test
type: mteb/fever
metrics:
- type: map_at_1
value: 83.479
- type: map_at_10
value: 88.898
- type: map_at_100
value: 89.11
- type: map_at_1000
value: 89.12400000000001
- type: map_at_3
value: 88.103
- type: map_at_5
value: 88.629
- type: mrr_at_1
value: 89.934
- type: mrr_at_10
value: 93.91000000000001
- type: mrr_at_100
value: 93.937
- type: mrr_at_1000
value: 93.938
- type: mrr_at_3
value: 93.62700000000001
- type: mrr_at_5
value: 93.84599999999999
- type: ndcg_at_1
value: 89.934
- type: ndcg_at_10
value: 91.574
- type: ndcg_at_100
value: 92.238
- type: ndcg_at_1000
value: 92.45
- type: ndcg_at_3
value: 90.586
- type: ndcg_at_5
value: 91.16300000000001
- type: precision_at_1
value: 89.934
- type: precision_at_10
value: 10.555
- type: precision_at_100
value: 1.1159999999999999
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 33.588
- type: precision_at_5
value: 20.642
- type: recall_at_1
value: 83.479
- type: recall_at_10
value: 94.971
- type: recall_at_100
value: 97.397
- type: recall_at_1000
value: 98.666
- type: recall_at_3
value: 92.24799999999999
- type: recall_at_5
value: 93.797
task:
type: Retrieval
- dataset:
config: default
name: MTEB FiQA2018
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
split: test
type: mteb/fiqa
metrics:
- type: map_at_1
value: 27.16
- type: map_at_10
value: 45.593
- type: map_at_100
value: 47.762
- type: map_at_1000
value: 47.899
- type: map_at_3
value: 39.237
- type: map_at_5
value: 42.970000000000006
- type: mrr_at_1
value: 52.623
- type: mrr_at_10
value: 62.637
- type: mrr_at_100
value: 63.169
- type: mrr_at_1000
value: 63.185
- type: mrr_at_3
value: 59.928000000000004
- type: mrr_at_5
value: 61.702999999999996
- type: ndcg_at_1
value: 52.623
- type: ndcg_at_10
value: 54.701
- type: ndcg_at_100
value: 61.263
- type: ndcg_at_1000
value: 63.134
- type: ndcg_at_3
value: 49.265
- type: ndcg_at_5
value: 51.665000000000006
- type: precision_at_1
value: 52.623
- type: precision_at_10
value: 15.185
- type: precision_at_100
value: 2.202
- type: precision_at_1000
value: 0.254
- type: precision_at_3
value: 32.767
- type: precision_at_5
value: 24.722
- type: recall_at_1
value: 27.16
- type: recall_at_10
value: 63.309000000000005
- type: recall_at_100
value: 86.722
- type: recall_at_1000
value: 97.505
- type: recall_at_3
value: 45.045
- type: recall_at_5
value: 54.02400000000001
task:
type: Retrieval
- dataset:
config: default
name: MTEB HotpotQA
revision: ab518f4d6fcca38d87c25209f94beba119d02014
split: test
type: mteb/hotpotqa
metrics:
- type: map_at_1
value: 42.573
- type: map_at_10
value: 59.373
- type: map_at_100
value: 60.292
- type: map_at_1000
value: 60.358999999999995
- type: map_at_3
value: 56.159000000000006
- type: map_at_5
value: 58.123999999999995
- type: mrr_at_1
value: 85.14500000000001
- type: mrr_at_10
value: 89.25999999999999
- type: mrr_at_100
value: 89.373
- type: mrr_at_1000
value: 89.377
- type: mrr_at_3
value: 88.618
- type: mrr_at_5
value: 89.036
- type: ndcg_at_1
value: 85.14500000000001
- type: ndcg_at_10
value: 68.95
- type: ndcg_at_100
value: 71.95
- type: ndcg_at_1000
value: 73.232
- type: ndcg_at_3
value: 64.546
- type: ndcg_at_5
value: 66.945
- type: precision_at_1
value: 85.14500000000001
- type: precision_at_10
value: 13.865
- type: precision_at_100
value: 1.619
- type: precision_at_1000
value: 0.179
- type: precision_at_3
value: 39.703
- type: precision_at_5
value: 25.718000000000004
- type: recall_at_1
value: 42.573
- type: recall_at_10
value: 69.325
- type: recall_at_100
value: 80.932
- type: recall_at_1000
value: 89.446
- type: recall_at_3
value: 59.553999999999995
- type: recall_at_5
value: 64.294
task:
type: Retrieval
- dataset:
config: default
name: MTEB ImdbClassification
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
split: test
type: mteb/imdb
metrics:
- type: accuracy
value: 95.8336
- type: ap
value: 93.78862962194073
- type: f1
value: 95.83192650728371
task:
type: Classification
- dataset:
config: default
name: MTEB MSMARCO
revision: c5a29a104738b98a9e76336939199e264163d4a0
split: dev
type: mteb/msmarco
metrics:
- type: map_at_1
value: 23.075000000000003
- type: map_at_10
value: 36.102000000000004
- type: map_at_100
value: 37.257
- type: map_at_1000
value: 37.3
- type: map_at_3
value: 32.144
- type: map_at_5
value: 34.359
- type: mrr_at_1
value: 23.711
- type: mrr_at_10
value: 36.671
- type: mrr_at_100
value: 37.763999999999996
- type: mrr_at_1000
value: 37.801
- type: mrr_at_3
value: 32.775
- type: mrr_at_5
value: 34.977000000000004
- type: ndcg_at_1
value: 23.711
- type: ndcg_at_10
value: 43.361
- type: ndcg_at_100
value: 48.839
- type: ndcg_at_1000
value: 49.88
- type: ndcg_at_3
value: 35.269
- type: ndcg_at_5
value: 39.224
- type: precision_at_1
value: 23.711
- type: precision_at_10
value: 6.866999999999999
- type: precision_at_100
value: 0.96
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 15.096000000000002
- type: precision_at_5
value: 11.083
- type: recall_at_1
value: 23.075000000000003
- type: recall_at_10
value: 65.756
- type: recall_at_100
value: 90.88199999999999
- type: recall_at_1000
value: 98.739
- type: recall_at_3
value: 43.691
- type: recall_at_5
value: 53.15800000000001
task:
type: Retrieval
- dataset:
config: en
name: MTEB MTOPDomainClassification (en)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 97.69493844049248
- type: f1
value: 97.55048089616261
task:
type: Classification
- dataset:
config: en
name: MTEB MTOPIntentClassification (en)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 88.75968992248062
- type: f1
value: 72.26321223399123
task:
type: Classification
- dataset:
config: en
name: MTEB MassiveIntentClassification (en)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 82.40080699394754
- type: f1
value: 79.62590029057968
task:
type: Classification
- dataset:
config: en
name: MTEB MassiveScenarioClassification (en)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 84.49562878278414
- type: f1
value: 84.0040193313333
task:
type: Classification
- dataset:
config: default
name: MTEB MedrxivClusteringP2P
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
split: test
type: mteb/medrxiv-clustering-p2p
metrics:
- type: v_measure
value: 39.386760057101945
task:
type: Clustering
- dataset:
config: default
name: MTEB MedrxivClusteringS2S
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
split: test
type: mteb/medrxiv-clustering-s2s
metrics:
- type: v_measure
value: 37.89687154075537
task:
type: Clustering
- dataset:
config: default
name: MTEB MindSmallReranking
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
split: test
type: mteb/mind_small
metrics:
- type: map
value: 33.94151656057482
- type: mrr
value: 35.32684700746953
task:
type: Reranking
- dataset:
config: default
name: MTEB NFCorpus
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
split: test
type: mteb/nfcorpus
metrics:
- type: map_at_1
value: 6.239999999999999
- type: map_at_10
value: 14.862
- type: map_at_100
value: 18.955
- type: map_at_1000
value: 20.694000000000003
- type: map_at_3
value: 10.683
- type: map_at_5
value: 12.674
- type: mrr_at_1
value: 50.15500000000001
- type: mrr_at_10
value: 59.697
- type: mrr_at_100
value: 60.095
- type: mrr_at_1000
value: 60.129999999999995
- type: mrr_at_3
value: 58.35900000000001
- type: mrr_at_5
value: 58.839
- type: ndcg_at_1
value: 48.452
- type: ndcg_at_10
value: 39.341
- type: ndcg_at_100
value: 35.866
- type: ndcg_at_1000
value: 45.111000000000004
- type: ndcg_at_3
value: 44.527
- type: ndcg_at_5
value: 42.946
- type: precision_at_1
value: 50.15500000000001
- type: precision_at_10
value: 29.536
- type: precision_at_100
value: 9.142
- type: precision_at_1000
value: 2.2849999999999997
- type: precision_at_3
value: 41.899
- type: precision_at_5
value: 37.647000000000006
- type: recall_at_1
value: 6.239999999999999
- type: recall_at_10
value: 19.278000000000002
- type: recall_at_100
value: 36.074
- type: recall_at_1000
value: 70.017
- type: recall_at_3
value: 12.066
- type: recall_at_5
value: 15.254000000000001
task:
type: Retrieval
- dataset:
config: default
name: MTEB NQ
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
split: test
type: mteb/nq
metrics:
- type: map_at_1
value: 39.75
- type: map_at_10
value: 56.443
- type: map_at_100
value: 57.233999999999995
- type: map_at_1000
value: 57.249
- type: map_at_3
value: 52.032999999999994
- type: map_at_5
value: 54.937999999999995
- type: mrr_at_1
value: 44.728
- type: mrr_at_10
value: 58.939
- type: mrr_at_100
value: 59.489000000000004
- type: mrr_at_1000
value: 59.499
- type: mrr_at_3
value: 55.711999999999996
- type: mrr_at_5
value: 57.89
- type: ndcg_at_1
value: 44.728
- type: ndcg_at_10
value: 63.998999999999995
- type: ndcg_at_100
value: 67.077
- type: ndcg_at_1000
value: 67.40899999999999
- type: ndcg_at_3
value: 56.266000000000005
- type: ndcg_at_5
value: 60.88
- type: precision_at_1
value: 44.728
- type: precision_at_10
value: 10.09
- type: precision_at_100
value: 1.1809999999999998
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 25.145
- type: precision_at_5
value: 17.822
- type: recall_at_1
value: 39.75
- type: recall_at_10
value: 84.234
- type: recall_at_100
value: 97.055
- type: recall_at_1000
value: 99.517
- type: recall_at_3
value: 64.851
- type: recall_at_5
value: 75.343
task:
type: Retrieval
- dataset:
config: default
name: MTEB QuoraRetrieval
revision: None
split: test
type: mteb/quora
metrics:
- type: map_at_1
value: 72.085
- type: map_at_10
value: 86.107
- type: map_at_100
value: 86.727
- type: map_at_1000
value: 86.74
- type: map_at_3
value: 83.21
- type: map_at_5
value: 85.06
- type: mrr_at_1
value: 82.94
- type: mrr_at_10
value: 88.845
- type: mrr_at_100
value: 88.926
- type: mrr_at_1000
value: 88.927
- type: mrr_at_3
value: 87.993
- type: mrr_at_5
value: 88.62299999999999
- type: ndcg_at_1
value: 82.97
- type: ndcg_at_10
value: 89.645
- type: ndcg_at_100
value: 90.717
- type: ndcg_at_1000
value: 90.78
- type: ndcg_at_3
value: 86.99900000000001
- type: ndcg_at_5
value: 88.52600000000001
- type: precision_at_1
value: 82.97
- type: precision_at_10
value: 13.569
- type: precision_at_100
value: 1.539
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 38.043
- type: precision_at_5
value: 24.992
- type: recall_at_1
value: 72.085
- type: recall_at_10
value: 96.262
- type: recall_at_100
value: 99.77000000000001
- type: recall_at_1000
value: 99.997
- type: recall_at_3
value: 88.652
- type: recall_at_5
value: 93.01899999999999
task:
type: Retrieval
- dataset:
config: default
name: MTEB RedditClustering
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
split: test
type: mteb/reddit-clustering
metrics:
- type: v_measure
value: 55.82153952668092
task:
type: Clustering
- dataset:
config: default
name: MTEB RedditClusteringP2P
revision: 282350215ef01743dc01b456c7f5241fa8937f16
split: test
type: mteb/reddit-clustering-p2p
metrics:
- type: v_measure
value: 62.094465801879295
task:
type: Clustering
- dataset:
config: default
name: MTEB SCIDOCS
revision: None
split: test
type: mteb/scidocs
metrics:
- type: map_at_1
value: 5.688
- type: map_at_10
value: 15.201999999999998
- type: map_at_100
value: 18.096
- type: map_at_1000
value: 18.481
- type: map_at_3
value: 10.734
- type: map_at_5
value: 12.94
- type: mrr_at_1
value: 28.000000000000004
- type: mrr_at_10
value: 41.101
- type: mrr_at_100
value: 42.202
- type: mrr_at_1000
value: 42.228
- type: mrr_at_3
value: 37.683
- type: mrr_at_5
value: 39.708
- type: ndcg_at_1
value: 28.000000000000004
- type: ndcg_at_10
value: 24.976000000000003
- type: ndcg_at_100
value: 35.129
- type: ndcg_at_1000
value: 40.77
- type: ndcg_at_3
value: 23.787
- type: ndcg_at_5
value: 20.816000000000003
- type: precision_at_1
value: 28.000000000000004
- type: precision_at_10
value: 13.04
- type: precision_at_100
value: 2.761
- type: precision_at_1000
value: 0.41000000000000003
- type: precision_at_3
value: 22.6
- type: precision_at_5
value: 18.52
- type: recall_at_1
value: 5.688
- type: recall_at_10
value: 26.43
- type: recall_at_100
value: 56.02
- type: recall_at_1000
value: 83.21
- type: recall_at_3
value: 13.752
- type: recall_at_5
value: 18.777
task:
type: Retrieval
- dataset:
config: default
name: MTEB SICK-R
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
split: test
type: mteb/sickr-sts
metrics:
- type: cos_sim_pearson
value: 85.15084859283178
- type: cos_sim_spearman
value: 80.49030614009419
- type: euclidean_pearson
value: 81.84574978672468
- type: euclidean_spearman
value: 79.89787150656818
- type: manhattan_pearson
value: 81.63076538567131
- type: manhattan_spearman
value: 79.69867352121841
task:
type: STS
- dataset:
config: default
name: MTEB STS12
revision: a0d554a64d88156834ff5ae9920b964011b16384
split: test
type: mteb/sts12-sts
metrics:
- type: cos_sim_pearson
value: 84.64097921490992
- type: cos_sim_spearman
value: 77.25370084896514
- type: euclidean_pearson
value: 82.71210826468788
- type: euclidean_spearman
value: 78.50445584994826
- type: manhattan_pearson
value: 82.92580164330298
- type: manhattan_spearman
value: 78.69686891301019
task:
type: STS
- dataset:
config: default
name: MTEB STS13
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
split: test
type: mteb/sts13-sts
metrics:
- type: cos_sim_pearson
value: 87.24596417308994
- type: cos_sim_spearman
value: 87.79454220555091
- type: euclidean_pearson
value: 87.40242561671164
- type: euclidean_spearman
value: 88.25955597373556
- type: manhattan_pearson
value: 87.25160240485849
- type: manhattan_spearman
value: 88.155794979818
task:
type: STS
- dataset:
config: default
name: MTEB STS14
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
split: test
type: mteb/sts14-sts
metrics:
- type: cos_sim_pearson
value: 84.44914233422564
- type: cos_sim_spearman
value: 82.91015471820322
- type: euclidean_pearson
value: 84.7206656630327
- type: euclidean_spearman
value: 83.86408872059216
- type: manhattan_pearson
value: 84.72816725158454
- type: manhattan_spearman
value: 84.01603388572788
task:
type: STS
- dataset:
config: default
name: MTEB STS15
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
split: test
type: mteb/sts15-sts
metrics:
- type: cos_sim_pearson
value: 87.6168026237477
- type: cos_sim_spearman
value: 88.45414278092397
- type: euclidean_pearson
value: 88.57023240882022
- type: euclidean_spearman
value: 89.04102190922094
- type: manhattan_pearson
value: 88.66695535796354
- type: manhattan_spearman
value: 89.19898476680969
task:
type: STS
- dataset:
config: default
name: MTEB STS16
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
split: test
type: mteb/sts16-sts
metrics:
- type: cos_sim_pearson
value: 84.27925826089424
- type: cos_sim_spearman
value: 85.45291099550461
- type: euclidean_pearson
value: 83.63853036580834
- type: euclidean_spearman
value: 84.33468035821484
- type: manhattan_pearson
value: 83.72778773251596
- type: manhattan_spearman
value: 84.51583132445376
task:
type: STS
- dataset:
config: en-en
name: MTEB STS17 (en-en)
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
split: test
type: mteb/sts17-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 89.67375185692552
- type: cos_sim_spearman
value: 90.32542469203855
- type: euclidean_pearson
value: 89.63513717951847
- type: euclidean_spearman
value: 89.87760271003745
- type: manhattan_pearson
value: 89.28381452982924
- type: manhattan_spearman
value: 89.53568197785721
task:
type: STS
- dataset:
config: en
name: MTEB STS22 (en)
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 66.24644693819846
- type: cos_sim_spearman
value: 66.09889420525377
- type: euclidean_pearson
value: 63.72551583520747
- type: euclidean_spearman
value: 63.01385470780679
- type: manhattan_pearson
value: 64.09258157214097
- type: manhattan_spearman
value: 63.080517752822594
task:
type: STS
- dataset:
config: default
name: MTEB STSBenchmark
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
split: test
type: mteb/stsbenchmark-sts
metrics:
- type: cos_sim_pearson
value: 86.27321463839989
- type: cos_sim_spearman
value: 86.37572865993327
- type: euclidean_pearson
value: 86.36268020198149
- type: euclidean_spearman
value: 86.31089339478922
- type: manhattan_pearson
value: 86.4260445761947
- type: manhattan_spearman
value: 86.45885895320457
task:
type: STS
- dataset:
config: default
name: MTEB SciDocsRR
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
split: test
type: mteb/scidocs-reranking
metrics:
- type: map
value: 86.52456702387798
- type: mrr
value: 96.34556529164372
task:
type: Reranking
- dataset:
config: default
name: MTEB SciFact
revision: 0228b52cf27578f30900b9e5271d331663a030d7
split: test
type: mteb/scifact
metrics:
- type: map_at_1
value: 61.99400000000001
- type: map_at_10
value: 73.38799999999999
- type: map_at_100
value: 73.747
- type: map_at_1000
value: 73.75
- type: map_at_3
value: 70.04599999999999
- type: map_at_5
value: 72.095
- type: mrr_at_1
value: 65.0
- type: mrr_at_10
value: 74.42800000000001
- type: mrr_at_100
value: 74.722
- type: mrr_at_1000
value: 74.725
- type: mrr_at_3
value: 72.056
- type: mrr_at_5
value: 73.60600000000001
- type: ndcg_at_1
value: 65.0
- type: ndcg_at_10
value: 78.435
- type: ndcg_at_100
value: 79.922
- type: ndcg_at_1000
value: 80.00500000000001
- type: ndcg_at_3
value: 73.05199999999999
- type: ndcg_at_5
value: 75.98
- type: precision_at_1
value: 65.0
- type: precision_at_10
value: 10.5
- type: precision_at_100
value: 1.123
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 28.555999999999997
- type: precision_at_5
value: 19.0
- type: recall_at_1
value: 61.99400000000001
- type: recall_at_10
value: 92.72200000000001
- type: recall_at_100
value: 99.333
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 78.739
- type: recall_at_5
value: 85.828
task:
type: Retrieval
- dataset:
config: default
name: MTEB SprintDuplicateQuestions
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
split: test
type: mteb/sprintduplicatequestions-pairclassification
metrics:
- type: cos_sim_accuracy
value: 99.79009900990098
- type: cos_sim_ap
value: 95.3203137438653
- type: cos_sim_f1
value: 89.12386706948641
- type: cos_sim_precision
value: 89.75659229208925
- type: cos_sim_recall
value: 88.5
- type: dot_accuracy
value: 99.67821782178218
- type: dot_ap
value: 89.94069840000675
- type: dot_f1
value: 83.45902463549521
- type: dot_precision
value: 83.9231547017189
- type: dot_recall
value: 83.0
- type: euclidean_accuracy
value: 99.78613861386138
- type: euclidean_ap
value: 95.10648259135526
- type: euclidean_f1
value: 88.77338877338877
- type: euclidean_precision
value: 92.42424242424242
- type: euclidean_recall
value: 85.39999999999999
- type: manhattan_accuracy
value: 99.7950495049505
- type: manhattan_ap
value: 95.29987661320946
- type: manhattan_f1
value: 89.21313183949972
- type: manhattan_precision
value: 93.14472252448314
- type: manhattan_recall
value: 85.6
- type: max_accuracy
value: 99.7950495049505
- type: max_ap
value: 95.3203137438653
- type: max_f1
value: 89.21313183949972
task:
type: PairClassification
- dataset:
config: default
name: MTEB StackExchangeClustering
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
split: test
type: mteb/stackexchange-clustering
metrics:
- type: v_measure
value: 67.65446577183913
task:
type: Clustering
- dataset:
config: default
name: MTEB StackExchangeClusteringP2P
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
split: test
type: mteb/stackexchange-clustering-p2p
metrics:
- type: v_measure
value: 46.30749237193961
task:
type: Clustering
- dataset:
config: default
name: MTEB StackOverflowDupQuestions
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
split: test
type: mteb/stackoverflowdupquestions-reranking
metrics:
- type: map
value: 54.91481849959949
- type: mrr
value: 55.853506175197346
task:
type: Reranking
- dataset:
config: default
name: MTEB SummEval
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
split: test
type: mteb/summeval
metrics:
- type: cos_sim_pearson
value: 30.08196549170419
- type: cos_sim_spearman
value: 31.16661390597077
- type: dot_pearson
value: 29.892258410943466
- type: dot_spearman
value: 30.51328811965085
task:
type: Summarization
- dataset:
config: default
name: MTEB TRECCOVID
revision: None
split: test
type: mteb/trec-covid
metrics:
- type: map_at_1
value: 0.23900000000000002
- type: map_at_10
value: 2.173
- type: map_at_100
value: 14.24
- type: map_at_1000
value: 35.309000000000005
- type: map_at_3
value: 0.7100000000000001
- type: map_at_5
value: 1.163
- type: mrr_at_1
value: 92.0
- type: mrr_at_10
value: 96.0
- type: mrr_at_100
value: 96.0
- type: mrr_at_1000
value: 96.0
- type: mrr_at_3
value: 96.0
- type: mrr_at_5
value: 96.0
- type: ndcg_at_1
value: 90.0
- type: ndcg_at_10
value: 85.382
- type: ndcg_at_100
value: 68.03
- type: ndcg_at_1000
value: 61.021
- type: ndcg_at_3
value: 89.765
- type: ndcg_at_5
value: 88.444
- type: precision_at_1
value: 92.0
- type: precision_at_10
value: 88.0
- type: precision_at_100
value: 70.02000000000001
- type: precision_at_1000
value: 26.984
- type: precision_at_3
value: 94.0
- type: precision_at_5
value: 92.80000000000001
- type: recall_at_1
value: 0.23900000000000002
- type: recall_at_10
value: 2.313
- type: recall_at_100
value: 17.049
- type: recall_at_1000
value: 57.489999999999995
- type: recall_at_3
value: 0.737
- type: recall_at_5
value: 1.221
task:
type: Retrieval
- dataset:
config: default
name: MTEB Touche2020
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
split: test
type: mteb/touche2020
metrics:
- type: map_at_1
value: 2.75
- type: map_at_10
value: 11.29
- type: map_at_100
value: 18.032999999999998
- type: map_at_1000
value: 19.746
- type: map_at_3
value: 6.555
- type: map_at_5
value: 8.706999999999999
- type: mrr_at_1
value: 34.694
- type: mrr_at_10
value: 50.55
- type: mrr_at_100
value: 51.659
- type: mrr_at_1000
value: 51.659
- type: mrr_at_3
value: 47.278999999999996
- type: mrr_at_5
value: 49.728
- type: ndcg_at_1
value: 32.653
- type: ndcg_at_10
value: 27.894000000000002
- type: ndcg_at_100
value: 39.769
- type: ndcg_at_1000
value: 51.495999999999995
- type: ndcg_at_3
value: 32.954
- type: ndcg_at_5
value: 31.502999999999997
- type: precision_at_1
value: 34.694
- type: precision_at_10
value: 23.265
- type: precision_at_100
value: 7.898
- type: precision_at_1000
value: 1.58
- type: precision_at_3
value: 34.694
- type: precision_at_5
value: 31.429000000000002
- type: recall_at_1
value: 2.75
- type: recall_at_10
value: 16.953
- type: recall_at_100
value: 48.68
- type: recall_at_1000
value: 85.18599999999999
- type: recall_at_3
value: 7.710999999999999
- type: recall_at_5
value: 11.484
task:
type: Retrieval
- dataset:
config: default
name: MTEB ToxicConversationsClassification
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
split: test
type: mteb/toxic_conversations_50k
metrics:
- type: accuracy
value: 82.66099999999999
- type: ap
value: 25.555698090238337
- type: f1
value: 66.48402012461622
task:
type: Classification
- dataset:
config: default
name: MTEB TweetSentimentExtractionClassification
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
split: test
type: mteb/tweet_sentiment_extraction
metrics:
- type: accuracy
value: 72.94567062818335
- type: f1
value: 73.28139189595674
task:
type: Classification
- dataset:
config: default
name: MTEB TwentyNewsgroupsClustering
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
split: test
type: mteb/twentynewsgroups-clustering
metrics:
- type: v_measure
value: 49.581627240203474
task:
type: Clustering
- dataset:
config: default
name: MTEB TwitterSemEval2015
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
split: test
type: mteb/twittersemeval2015-pairclassification
metrics:
- type: cos_sim_accuracy
value: 87.78089050485785
- type: cos_sim_ap
value: 79.64487116574168
- type: cos_sim_f1
value: 72.46563021970964
- type: cos_sim_precision
value: 70.62359128474831
- type: cos_sim_recall
value: 74.40633245382587
- type: dot_accuracy
value: 86.2609524944865
- type: dot_ap
value: 75.513046857613
- type: dot_f1
value: 68.58213616489695
- type: dot_precision
value: 65.12455516014235
- type: dot_recall
value: 72.42744063324538
- type: euclidean_accuracy
value: 87.6080348095607
- type: euclidean_ap
value: 79.00204933649795
- type: euclidean_f1
value: 72.14495342605589
- type: euclidean_precision
value: 69.85421299728193
- type: euclidean_recall
value: 74.5910290237467
- type: manhattan_accuracy
value: 87.59611372712642
- type: manhattan_ap
value: 78.78523756706264
- type: manhattan_f1
value: 71.86499137718648
- type: manhattan_precision
value: 67.39833641404806
- type: manhattan_recall
value: 76.96569920844327
- type: max_accuracy
value: 87.78089050485785
- type: max_ap
value: 79.64487116574168
- type: max_f1
value: 72.46563021970964
task:
type: PairClassification
- dataset:
config: default
name: MTEB TwitterURLCorpus
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
split: test
type: mteb/twitterurlcorpus-pairclassification
metrics:
- type: cos_sim_accuracy
value: 89.98719292117825
- type: cos_sim_ap
value: 87.58146137353202
- type: cos_sim_f1
value: 80.28543232369239
- type: cos_sim_precision
value: 79.1735289714029
- type: cos_sim_recall
value: 81.42901139513397
- type: dot_accuracy
value: 88.9199363526992
- type: dot_ap
value: 84.98499998630417
- type: dot_f1
value: 78.21951400757969
- type: dot_precision
value: 75.58523624874336
- type: dot_recall
value: 81.04404065291038
- type: euclidean_accuracy
value: 89.77374160748244
- type: euclidean_ap
value: 87.35151562835209
- type: euclidean_f1
value: 79.92160922940393
- type: euclidean_precision
value: 76.88531587933979
- type: euclidean_recall
value: 83.20757622420696
- type: manhattan_accuracy
value: 89.72717041176699
- type: manhattan_ap
value: 87.34065592142515
- type: manhattan_f1
value: 79.85603419187943
- type: manhattan_precision
value: 77.82243332115455
- type: manhattan_recall
value: 81.99876809362489
- type: max_accuracy
value: 89.98719292117825
- type: max_ap
value: 87.58146137353202
- type: max_f1
value: 80.28543232369239
task:
type: PairClassification
- dataset:
config: default
name: MTEB AFQMC
revision: b44c3b011063adb25877c13823db83bb193913c4
split: validation
type: C-MTEB/AFQMC
metrics:
- type: cos_sim_pearson
value: 53.45954203592337
- type: cos_sim_spearman
value: 58.42154680418638
- type: euclidean_pearson
value: 56.41543791722753
- type: euclidean_spearman
value: 58.39328016640146
- type: manhattan_pearson
value: 56.318510356833876
- type: manhattan_spearman
value: 58.28423447818184
task:
type: STS
- dataset:
config: default
name: MTEB ATEC
revision: 0f319b1142f28d00e055a6770f3f726ae9b7d865
split: test
type: C-MTEB/ATEC
metrics:
- type: cos_sim_pearson
value: 50.78356460675945
- type: cos_sim_spearman
value: 55.6530411663269
- type: euclidean_pearson
value: 56.50763660417816
- type: euclidean_spearman
value: 55.733823335669065
- type: manhattan_pearson
value: 56.45323093512866
- type: manhattan_spearman
value: 55.63248619032702
task:
type: STS
- dataset:
config: zh
name: MTEB AmazonReviewsClassification (zh)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 47.209999999999994
- type: f1
value: 46.08892432018655
task:
type: Classification
- dataset:
config: default
name: MTEB BQ
revision: e3dda5e115e487b39ec7e618c0c6a29137052a55
split: test
type: C-MTEB/BQ
metrics:
- type: cos_sim_pearson
value: 70.25573992001478
- type: cos_sim_spearman
value: 73.85247134951433
- type: euclidean_pearson
value: 72.60033082168442
- type: euclidean_spearman
value: 73.72445893756499
- type: manhattan_pearson
value: 72.59932284620231
- type: manhattan_spearman
value: 73.68002490614583
task:
type: STS
- dataset:
config: default
name: MTEB CLSClusteringP2P
revision: 4b6227591c6c1a73bc76b1055f3b7f3588e72476
split: test
type: C-MTEB/CLSClusteringP2P
metrics:
- type: v_measure
value: 45.21317724305628
task:
type: Clustering
- dataset:
config: default
name: MTEB CLSClusteringS2S
revision: e458b3f5414b62b7f9f83499ac1f5497ae2e869f
split: test
type: C-MTEB/CLSClusteringS2S
metrics:
- type: v_measure
value: 42.49825170976724
task:
type: Clustering
- dataset:
config: default
name: MTEB CMedQAv1
revision: 8d7f1e942507dac42dc58017c1a001c3717da7df
split: test
type: C-MTEB/CMedQAv1-reranking
metrics:
- type: map
value: 88.15661686810597
- type: mrr
value: 90.11222222222223
task:
type: Reranking
- dataset:
config: default
name: MTEB CMedQAv2
revision: 23d186750531a14a0357ca22cd92d712fd512ea0
split: test
type: C-MTEB/CMedQAv2-reranking
metrics:
- type: map
value: 88.1204726064383
- type: mrr
value: 90.20142857142858
task:
type: Reranking
- dataset:
config: default
name: MTEB CmedqaRetrieval
revision: cd540c506dae1cf9e9a59c3e06f42030d54e7301
split: dev
type: C-MTEB/CmedqaRetrieval
metrics:
- type: map_at_1
value: 27.224999999999998
- type: map_at_10
value: 40.169
- type: map_at_100
value: 42.0
- type: map_at_1000
value: 42.109
- type: map_at_3
value: 35.76
- type: map_at_5
value: 38.221
- type: mrr_at_1
value: 40.56
- type: mrr_at_10
value: 49.118
- type: mrr_at_100
value: 50.092999999999996
- type: mrr_at_1000
value: 50.133
- type: mrr_at_3
value: 46.507
- type: mrr_at_5
value: 47.973
- type: ndcg_at_1
value: 40.56
- type: ndcg_at_10
value: 46.972
- type: ndcg_at_100
value: 54.04
- type: ndcg_at_1000
value: 55.862
- type: ndcg_at_3
value: 41.36
- type: ndcg_at_5
value: 43.704
- type: precision_at_1
value: 40.56
- type: precision_at_10
value: 10.302999999999999
- type: precision_at_100
value: 1.606
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 23.064
- type: precision_at_5
value: 16.764000000000003
- type: recall_at_1
value: 27.224999999999998
- type: recall_at_10
value: 58.05200000000001
- type: recall_at_100
value: 87.092
- type: recall_at_1000
value: 99.099
- type: recall_at_3
value: 41.373
- type: recall_at_5
value: 48.453
task:
type: Retrieval
- dataset:
config: default
name: MTEB Cmnli
revision: 41bc36f332156f7adc9e38f53777c959b2ae9766
split: validation
type: C-MTEB/CMNLI
metrics:
- type: cos_sim_accuracy
value: 77.40228502705953
- type: cos_sim_ap
value: 86.22359172956327
- type: cos_sim_f1
value: 78.96328293736501
- type: cos_sim_precision
value: 73.36945615091311
- type: cos_sim_recall
value: 85.48047696983868
- type: dot_accuracy
value: 75.53818400481059
- type: dot_ap
value: 83.70164011305312
- type: dot_f1
value: 77.67298719348754
- type: dot_precision
value: 67.49482401656314
- type: dot_recall
value: 91.46598082768296
- type: euclidean_accuracy
value: 77.94347564642213
- type: euclidean_ap
value: 86.4652108728609
- type: euclidean_f1
value: 79.15555555555555
- type: euclidean_precision
value: 75.41816641964853
- type: euclidean_recall
value: 83.28267477203647
- type: manhattan_accuracy
value: 77.45039085989175
- type: manhattan_ap
value: 86.09986583900665
- type: manhattan_f1
value: 78.93669264438988
- type: manhattan_precision
value: 72.63261296660117
- type: manhattan_recall
value: 86.43909282207154
- type: max_accuracy
value: 77.94347564642213
- type: max_ap
value: 86.4652108728609
- type: max_f1
value: 79.15555555555555
task:
type: PairClassification
- dataset:
config: default
name: MTEB CovidRetrieval
revision: 1271c7809071a13532e05f25fb53511ffce77117
split: dev
type: C-MTEB/CovidRetrieval
metrics:
- type: map_at_1
value: 69.336
- type: map_at_10
value: 77.16
- type: map_at_100
value: 77.47500000000001
- type: map_at_1000
value: 77.482
- type: map_at_3
value: 75.42999999999999
- type: map_at_5
value: 76.468
- type: mrr_at_1
value: 69.44200000000001
- type: mrr_at_10
value: 77.132
- type: mrr_at_100
value: 77.43299999999999
- type: mrr_at_1000
value: 77.44
- type: mrr_at_3
value: 75.395
- type: mrr_at_5
value: 76.459
- type: ndcg_at_1
value: 69.547
- type: ndcg_at_10
value: 80.794
- type: ndcg_at_100
value: 82.245
- type: ndcg_at_1000
value: 82.40899999999999
- type: ndcg_at_3
value: 77.303
- type: ndcg_at_5
value: 79.168
- type: precision_at_1
value: 69.547
- type: precision_at_10
value: 9.305
- type: precision_at_100
value: 0.9979999999999999
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 27.749000000000002
- type: precision_at_5
value: 17.576
- type: recall_at_1
value: 69.336
- type: recall_at_10
value: 92.097
- type: recall_at_100
value: 98.736
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 82.64
- type: recall_at_5
value: 87.144
task:
type: Retrieval
- dataset:
config: default
name: MTEB DuRetrieval
revision: a1a333e290fe30b10f3f56498e3a0d911a693ced
split: dev
type: C-MTEB/DuRetrieval
metrics:
- type: map_at_1
value: 26.817999999999998
- type: map_at_10
value: 82.67
- type: map_at_100
value: 85.304
- type: map_at_1000
value: 85.334
- type: map_at_3
value: 57.336
- type: map_at_5
value: 72.474
- type: mrr_at_1
value: 91.45
- type: mrr_at_10
value: 94.272
- type: mrr_at_100
value: 94.318
- type: mrr_at_1000
value: 94.32000000000001
- type: mrr_at_3
value: 94.0
- type: mrr_at_5
value: 94.17699999999999
- type: ndcg_at_1
value: 91.45
- type: ndcg_at_10
value: 89.404
- type: ndcg_at_100
value: 91.724
- type: ndcg_at_1000
value: 91.973
- type: ndcg_at_3
value: 88.104
- type: ndcg_at_5
value: 87.25699999999999
- type: precision_at_1
value: 91.45
- type: precision_at_10
value: 42.585
- type: precision_at_100
value: 4.838
- type: precision_at_1000
value: 0.49
- type: precision_at_3
value: 78.8
- type: precision_at_5
value: 66.66
- type: recall_at_1
value: 26.817999999999998
- type: recall_at_10
value: 90.67
- type: recall_at_100
value: 98.36200000000001
- type: recall_at_1000
value: 99.583
- type: recall_at_3
value: 59.614999999999995
- type: recall_at_5
value: 77.05199999999999
task:
type: Retrieval
- dataset:
config: default
name: MTEB EcomRetrieval
revision: 687de13dc7294d6fd9be10c6945f9e8fec8166b9
split: dev
type: C-MTEB/EcomRetrieval
metrics:
- type: map_at_1
value: 47.699999999999996
- type: map_at_10
value: 57.589999999999996
- type: map_at_100
value: 58.226
- type: map_at_1000
value: 58.251
- type: map_at_3
value: 55.233
- type: map_at_5
value: 56.633
- type: mrr_at_1
value: 47.699999999999996
- type: mrr_at_10
value: 57.589999999999996
- type: mrr_at_100
value: 58.226
- type: mrr_at_1000
value: 58.251
- type: mrr_at_3
value: 55.233
- type: mrr_at_5
value: 56.633
- type: ndcg_at_1
value: 47.699999999999996
- type: ndcg_at_10
value: 62.505
- type: ndcg_at_100
value: 65.517
- type: ndcg_at_1000
value: 66.19800000000001
- type: ndcg_at_3
value: 57.643
- type: ndcg_at_5
value: 60.181
- type: precision_at_1
value: 47.699999999999996
- type: precision_at_10
value: 7.8
- type: precision_at_100
value: 0.919
- type: precision_at_1000
value: 0.097
- type: precision_at_3
value: 21.532999999999998
- type: precision_at_5
value: 14.16
- type: recall_at_1
value: 47.699999999999996
- type: recall_at_10
value: 78.0
- type: recall_at_100
value: 91.9
- type: recall_at_1000
value: 97.3
- type: recall_at_3
value: 64.60000000000001
- type: recall_at_5
value: 70.8
task:
type: Retrieval
- dataset:
config: default
name: MTEB IFlyTek
revision: 421605374b29664c5fc098418fe20ada9bd55f8a
split: validation
type: C-MTEB/IFlyTek-classification
metrics:
- type: accuracy
value: 44.84801846864178
- type: f1
value: 37.47347897956339
task:
type: Classification
- dataset:
config: default
name: MTEB JDReview
revision: b7c64bd89eb87f8ded463478346f76731f07bf8b
split: test
type: C-MTEB/JDReview-classification
metrics:
- type: accuracy
value: 85.81613508442777
- type: ap
value: 52.68244615477374
- type: f1
value: 80.0445640948843
task:
type: Classification
- dataset:
config: default
name: MTEB LCQMC
revision: 17f9b096f80380fce5ed12a9be8be7784b337daf
split: test
type: C-MTEB/LCQMC
metrics:
- type: cos_sim_pearson
value: 69.57786502217138
- type: cos_sim_spearman
value: 75.39106054489906
- type: euclidean_pearson
value: 73.72082954602402
- type: euclidean_spearman
value: 75.14421475913619
- type: manhattan_pearson
value: 73.62463076633642
- type: manhattan_spearman
value: 75.01301565104112
task:
type: STS
- dataset:
config: default
name: MTEB MMarcoReranking
revision: None
split: dev
type: C-MTEB/Mmarco-reranking
metrics:
- type: map
value: 29.143797057999134
- type: mrr
value: 28.08174603174603
task:
type: Reranking
- dataset:
config: default
name: MTEB MMarcoRetrieval
revision: 539bbde593d947e2a124ba72651aafc09eb33fc2
split: dev
type: C-MTEB/MMarcoRetrieval
metrics:
- type: map_at_1
value: 70.492
- type: map_at_10
value: 79.501
- type: map_at_100
value: 79.728
- type: map_at_1000
value: 79.735
- type: map_at_3
value: 77.77
- type: map_at_5
value: 78.851
- type: mrr_at_1
value: 72.822
- type: mrr_at_10
value: 80.001
- type: mrr_at_100
value: 80.19
- type: mrr_at_1000
value: 80.197
- type: mrr_at_3
value: 78.484
- type: mrr_at_5
value: 79.42099999999999
- type: ndcg_at_1
value: 72.822
- type: ndcg_at_10
value: 83.013
- type: ndcg_at_100
value: 84.013
- type: ndcg_at_1000
value: 84.20400000000001
- type: ndcg_at_3
value: 79.728
- type: ndcg_at_5
value: 81.542
- type: precision_at_1
value: 72.822
- type: precision_at_10
value: 9.917
- type: precision_at_100
value: 1.042
- type: precision_at_1000
value: 0.106
- type: precision_at_3
value: 29.847
- type: precision_at_5
value: 18.871
- type: recall_at_1
value: 70.492
- type: recall_at_10
value: 93.325
- type: recall_at_100
value: 97.822
- type: recall_at_1000
value: 99.319
- type: recall_at_3
value: 84.636
- type: recall_at_5
value: 88.93100000000001
task:
type: Retrieval
- dataset:
config: zh-CN
name: MTEB MassiveIntentClassification (zh-CN)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 76.88298587760592
- type: f1
value: 73.89001762017176
task:
type: Classification
- dataset:
config: zh-CN
name: MTEB MassiveScenarioClassification (zh-CN)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 80.76328177538669
- type: f1
value: 80.24718532423358
task:
type: Classification
- dataset:
config: default
name: MTEB MedicalRetrieval
revision: 2039188fb5800a9803ba5048df7b76e6fb151fc6
split: dev
type: C-MTEB/MedicalRetrieval
metrics:
- type: map_at_1
value: 49.6
- type: map_at_10
value: 55.620999999999995
- type: map_at_100
value: 56.204
- type: map_at_1000
value: 56.251
- type: map_at_3
value: 54.132999999999996
- type: map_at_5
value: 54.933
- type: mrr_at_1
value: 49.7
- type: mrr_at_10
value: 55.67100000000001
- type: mrr_at_100
value: 56.254000000000005
- type: mrr_at_1000
value: 56.301
- type: mrr_at_3
value: 54.18300000000001
- type: mrr_at_5
value: 54.983000000000004
- type: ndcg_at_1
value: 49.6
- type: ndcg_at_10
value: 58.645
- type: ndcg_at_100
value: 61.789
- type: ndcg_at_1000
value: 63.219
- type: ndcg_at_3
value: 55.567
- type: ndcg_at_5
value: 57.008
- type: precision_at_1
value: 49.6
- type: precision_at_10
value: 6.819999999999999
- type: precision_at_100
value: 0.836
- type: precision_at_1000
value: 0.095
- type: precision_at_3
value: 19.900000000000002
- type: precision_at_5
value: 12.64
- type: recall_at_1
value: 49.6
- type: recall_at_10
value: 68.2
- type: recall_at_100
value: 83.6
- type: recall_at_1000
value: 95.3
- type: recall_at_3
value: 59.699999999999996
- type: recall_at_5
value: 63.2
task:
type: Retrieval
- dataset:
config: default
name: MTEB MultilingualSentiment
revision: 46958b007a63fdbf239b7672c25d0bea67b5ea1a
split: validation
type: C-MTEB/MultilingualSentiment-classification
metrics:
- type: accuracy
value: 74.45666666666666
- type: f1
value: 74.32582402190089
task:
type: Classification
- dataset:
config: default
name: MTEB Ocnli
revision: 66e76a618a34d6d565d5538088562851e6daa7ec
split: validation
type: C-MTEB/OCNLI
metrics:
- type: cos_sim_accuracy
value: 80.67135896047645
- type: cos_sim_ap
value: 87.60421240712051
- type: cos_sim_f1
value: 82.1304131408661
- type: cos_sim_precision
value: 77.68361581920904
- type: cos_sim_recall
value: 87.11721224920802
- type: dot_accuracy
value: 79.04710341093666
- type: dot_ap
value: 85.6370059719336
- type: dot_f1
value: 80.763723150358
- type: dot_precision
value: 73.69337979094077
- type: dot_recall
value: 89.33474128827878
- type: euclidean_accuracy
value: 81.05035192203573
- type: euclidean_ap
value: 87.7880240053663
- type: euclidean_f1
value: 82.50244379276637
- type: euclidean_precision
value: 76.7970882620564
- type: euclidean_recall
value: 89.1235480464625
- type: manhattan_accuracy
value: 80.61721710882512
- type: manhattan_ap
value: 87.43568120591175
- type: manhattan_f1
value: 81.89526184538653
- type: manhattan_precision
value: 77.5992438563327
- type: manhattan_recall
value: 86.6948257655755
- type: max_accuracy
value: 81.05035192203573
- type: max_ap
value: 87.7880240053663
- type: max_f1
value: 82.50244379276637
task:
type: PairClassification
- dataset:
config: default
name: MTEB OnlineShopping
revision: e610f2ebd179a8fda30ae534c3878750a96db120
split: test
type: C-MTEB/OnlineShopping-classification
metrics:
- type: accuracy
value: 93.5
- type: ap
value: 91.31357903446782
- type: f1
value: 93.48088994006616
task:
type: Classification
- dataset:
config: default
name: MTEB PAWSX
revision: 9c6a90e430ac22b5779fb019a23e820b11a8b5e1
split: test
type: C-MTEB/PAWSX
metrics:
- type: cos_sim_pearson
value: 36.93293453538077
- type: cos_sim_spearman
value: 42.45972506308574
- type: euclidean_pearson
value: 42.34945133152159
- type: euclidean_spearman
value: 42.331610303674644
- type: manhattan_pearson
value: 42.31455070249498
- type: manhattan_spearman
value: 42.19887982891834
task:
type: STS
- dataset:
config: default
name: MTEB QBQTC
revision: 790b0510dc52b1553e8c49f3d2afb48c0e5c48b7
split: test
type: C-MTEB/QBQTC
metrics:
- type: cos_sim_pearson
value: 33.683290790043785
- type: cos_sim_spearman
value: 35.149171171202994
- type: euclidean_pearson
value: 32.33806561267862
- type: euclidean_spearman
value: 34.483576387347966
- type: manhattan_pearson
value: 32.47629754599608
- type: manhattan_spearman
value: 34.66434471867615
task:
type: STS
- dataset:
config: zh
name: MTEB STS22 (zh)
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 66.46322760516104
- type: cos_sim_spearman
value: 67.398478319726
- type: euclidean_pearson
value: 64.7223480293625
- type: euclidean_spearman
value: 66.83118568812951
- type: manhattan_pearson
value: 64.88440039828305
- type: manhattan_spearman
value: 66.80429458952257
task:
type: STS
- dataset:
config: default
name: MTEB STSB
revision: 0cde68302b3541bb8b3c340dc0644b0b745b3dc0
split: test
type: C-MTEB/STSB
metrics:
- type: cos_sim_pearson
value: 79.08991383232105
- type: cos_sim_spearman
value: 79.39715677296854
- type: euclidean_pearson
value: 78.63201279320496
- type: euclidean_spearman
value: 79.40262660785731
- type: manhattan_pearson
value: 78.98138363146906
- type: manhattan_spearman
value: 79.79968413014194
task:
type: STS
- dataset:
config: default
name: MTEB T2Reranking
revision: 76631901a18387f85eaa53e5450019b87ad58ef9
split: dev
type: C-MTEB/T2Reranking
metrics:
- type: map
value: 67.43289278789972
- type: mrr
value: 77.53012460908535
task:
type: Reranking
- dataset:
config: default
name: MTEB T2Retrieval
revision: 8731a845f1bf500a4f111cf1070785c793d10e64
split: dev
type: C-MTEB/T2Retrieval
metrics:
- type: map_at_1
value: 27.733999999999998
- type: map_at_10
value: 78.24799999999999
- type: map_at_100
value: 81.765
- type: map_at_1000
value: 81.824
- type: map_at_3
value: 54.92
- type: map_at_5
value: 67.61399999999999
- type: mrr_at_1
value: 90.527
- type: mrr_at_10
value: 92.843
- type: mrr_at_100
value: 92.927
- type: mrr_at_1000
value: 92.93
- type: mrr_at_3
value: 92.45100000000001
- type: mrr_at_5
value: 92.693
- type: ndcg_at_1
value: 90.527
- type: ndcg_at_10
value: 85.466
- type: ndcg_at_100
value: 88.846
- type: ndcg_at_1000
value: 89.415
- type: ndcg_at_3
value: 86.768
- type: ndcg_at_5
value: 85.46000000000001
- type: precision_at_1
value: 90.527
- type: precision_at_10
value: 42.488
- type: precision_at_100
value: 5.024
- type: precision_at_1000
value: 0.516
- type: precision_at_3
value: 75.907
- type: precision_at_5
value: 63.727000000000004
- type: recall_at_1
value: 27.733999999999998
- type: recall_at_10
value: 84.346
- type: recall_at_100
value: 95.536
- type: recall_at_1000
value: 98.42999999999999
- type: recall_at_3
value: 56.455
- type: recall_at_5
value: 70.755
task:
type: Retrieval
- dataset:
config: default
name: MTEB TNews
revision: 317f262bf1e6126357bbe89e875451e4b0938fe4
split: validation
type: C-MTEB/TNews-classification
metrics:
- type: accuracy
value: 49.952000000000005
- type: f1
value: 48.264617195258054
task:
type: Classification
- dataset:
config: default
name: MTEB ThuNewsClusteringP2P
revision: 5798586b105c0434e4f0fe5e767abe619442cf93
split: test
type: C-MTEB/ThuNewsClusteringP2P
metrics:
- type: v_measure
value: 68.23769904483508
task:
type: Clustering
- dataset:
config: default
name: MTEB ThuNewsClusteringS2S
revision: 8a8b2caeda43f39e13c4bc5bea0f8a667896e10d
split: test
type: C-MTEB/ThuNewsClusteringS2S
metrics:
- type: v_measure
value: 62.50294403136556
task:
type: Clustering
- dataset:
config: default
name: MTEB VideoRetrieval
revision: 58c2597a5943a2ba48f4668c3b90d796283c5639
split: dev
type: C-MTEB/VideoRetrieval
metrics:
- type: map_at_1
value: 54.0
- type: map_at_10
value: 63.668
- type: map_at_100
value: 64.217
- type: map_at_1000
value: 64.23100000000001
- type: map_at_3
value: 61.7
- type: map_at_5
value: 62.870000000000005
- type: mrr_at_1
value: 54.0
- type: mrr_at_10
value: 63.668
- type: mrr_at_100
value: 64.217
- type: mrr_at_1000
value: 64.23100000000001
- type: mrr_at_3
value: 61.7
- type: mrr_at_5
value: 62.870000000000005
- type: ndcg_at_1
value: 54.0
- type: ndcg_at_10
value: 68.11399999999999
- type: ndcg_at_100
value: 70.723
- type: ndcg_at_1000
value: 71.123
- type: ndcg_at_3
value: 64.074
- type: ndcg_at_5
value: 66.178
- type: precision_at_1
value: 54.0
- type: precision_at_10
value: 8.200000000000001
- type: precision_at_100
value: 0.941
- type: precision_at_1000
value: 0.097
- type: precision_at_3
value: 23.633000000000003
- type: precision_at_5
value: 15.2
- type: recall_at_1
value: 54.0
- type: recall_at_10
value: 82.0
- type: recall_at_100
value: 94.1
- type: recall_at_1000
value: 97.3
- type: recall_at_3
value: 70.89999999999999
- type: recall_at_5
value: 76.0
task:
type: Retrieval
- dataset:
config: default
name: MTEB Waimai
revision: 339287def212450dcaa9df8c22bf93e9980c7023
split: test
type: C-MTEB/waimai-classification
metrics:
- type: accuracy
value: 86.63000000000001
- type: ap
value: 69.99457882599567
- type: f1
value: 85.07735617998541
task:
type: Classification
- dataset:
config: default
name: MTEB 8TagsClustering
revision: None
split: test
type: PL-MTEB/8tags-clustering
metrics:
- type: v_measure
value: 44.594104491193555
task:
type: Clustering
- dataset:
config: default
name: MTEB AllegroReviews
revision: None
split: test
type: PL-MTEB/allegro-reviews
metrics:
- type: accuracy
value: 63.97614314115309
- type: f1
value: 52.15634261679283
task:
type: Classification
- dataset:
config: default
name: MTEB ArguAna-PL
revision: 63fc86750af76253e8c760fc9e534bbf24d260a2
split: test
type: clarin-knext/arguana-pl
metrics:
- type: map_at_1
value: 32.646
- type: map_at_10
value: 47.963
- type: map_at_100
value: 48.789
- type: map_at_1000
value: 48.797000000000004
- type: map_at_3
value: 43.196
- type: map_at_5
value: 46.016
- type: mrr_at_1
value: 33.073
- type: mrr_at_10
value: 48.126000000000005
- type: mrr_at_100
value: 48.946
- type: mrr_at_1000
value: 48.953
- type: mrr_at_3
value: 43.374
- type: mrr_at_5
value: 46.147
- type: ndcg_at_1
value: 32.646
- type: ndcg_at_10
value: 56.481
- type: ndcg_at_100
value: 59.922
- type: ndcg_at_1000
value: 60.07
- type: ndcg_at_3
value: 46.675
- type: ndcg_at_5
value: 51.76500000000001
- type: precision_at_1
value: 32.646
- type: precision_at_10
value: 8.371
- type: precision_at_100
value: 0.9860000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 18.919
- type: precision_at_5
value: 13.825999999999999
- type: recall_at_1
value: 32.646
- type: recall_at_10
value: 83.71300000000001
- type: recall_at_100
value: 98.578
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 56.757000000000005
- type: recall_at_5
value: 69.132
task:
type: Retrieval
- dataset:
config: default
name: MTEB CBD
revision: None
split: test
type: PL-MTEB/cbd
metrics:
- type: accuracy
value: 68.56
- type: ap
value: 23.310493680488513
- type: f1
value: 58.85369533105693
task:
type: Classification
- dataset:
config: default
name: MTEB CDSC-E
revision: None
split: test
type: PL-MTEB/cdsce-pairclassification
metrics:
- type: cos_sim_accuracy
value: 88.5
- type: cos_sim_ap
value: 72.42140924378361
- type: cos_sim_f1
value: 66.0919540229885
- type: cos_sim_precision
value: 72.78481012658227
- type: cos_sim_recall
value: 60.526315789473685
- type: dot_accuracy
value: 88.5
- type: dot_ap
value: 72.42140924378361
- type: dot_f1
value: 66.0919540229885
- type: dot_precision
value: 72.78481012658227
- type: dot_recall
value: 60.526315789473685
- type: euclidean_accuracy
value: 88.5
- type: euclidean_ap
value: 72.42140924378361
- type: euclidean_f1
value: 66.0919540229885
- type: euclidean_precision
value: 72.78481012658227
- type: euclidean_recall
value: 60.526315789473685
- type: manhattan_accuracy
value: 88.5
- type: manhattan_ap
value: 72.49745515311696
- type: manhattan_f1
value: 66.0968660968661
- type: manhattan_precision
value: 72.04968944099379
- type: manhattan_recall
value: 61.05263157894737
- type: max_accuracy
value: 88.5
- type: max_ap
value: 72.49745515311696
- type: max_f1
value: 66.0968660968661
task:
type: PairClassification
- dataset:
config: default
name: MTEB CDSC-R
revision: None
split: test
type: PL-MTEB/cdscr-sts
metrics:
- type: cos_sim_pearson
value: 90.32269765590145
- type: cos_sim_spearman
value: 89.73666311491672
- type: euclidean_pearson
value: 88.2933868516544
- type: euclidean_spearman
value: 89.73666311491672
- type: manhattan_pearson
value: 88.33474590219448
- type: manhattan_spearman
value: 89.8548364866583
task:
type: STS
- dataset:
config: default
name: MTEB DBPedia-PL
revision: 76afe41d9af165cc40999fcaa92312b8b012064a
split: test
type: clarin-knext/dbpedia-pl
metrics:
- type: map_at_1
value: 7.632999999999999
- type: map_at_10
value: 16.426
- type: map_at_100
value: 22.651
- type: map_at_1000
value: 24.372
- type: map_at_3
value: 11.706
- type: map_at_5
value: 13.529
- type: mrr_at_1
value: 60.75000000000001
- type: mrr_at_10
value: 68.613
- type: mrr_at_100
value: 69.001
- type: mrr_at_1000
value: 69.021
- type: mrr_at_3
value: 67.0
- type: mrr_at_5
value: 67.925
- type: ndcg_at_1
value: 49.875
- type: ndcg_at_10
value: 36.978
- type: ndcg_at_100
value: 40.031
- type: ndcg_at_1000
value: 47.566
- type: ndcg_at_3
value: 41.148
- type: ndcg_at_5
value: 38.702
- type: precision_at_1
value: 60.75000000000001
- type: precision_at_10
value: 29.7
- type: precision_at_100
value: 9.278
- type: precision_at_1000
value: 2.099
- type: precision_at_3
value: 44.0
- type: precision_at_5
value: 37.6
- type: recall_at_1
value: 7.632999999999999
- type: recall_at_10
value: 22.040000000000003
- type: recall_at_100
value: 44.024
- type: recall_at_1000
value: 67.848
- type: recall_at_3
value: 13.093
- type: recall_at_5
value: 15.973
task:
type: Retrieval
- dataset:
config: default
name: MTEB FiQA-PL
revision: 2e535829717f8bf9dc829b7f911cc5bbd4e6608e
split: test
type: clarin-knext/fiqa-pl
metrics:
- type: map_at_1
value: 15.473
- type: map_at_10
value: 24.579
- type: map_at_100
value: 26.387
- type: map_at_1000
value: 26.57
- type: map_at_3
value: 21.278
- type: map_at_5
value: 23.179
- type: mrr_at_1
value: 30.709999999999997
- type: mrr_at_10
value: 38.994
- type: mrr_at_100
value: 39.993
- type: mrr_at_1000
value: 40.044999999999995
- type: mrr_at_3
value: 36.342999999999996
- type: mrr_at_5
value: 37.846999999999994
- type: ndcg_at_1
value: 30.709999999999997
- type: ndcg_at_10
value: 31.608999999999998
- type: ndcg_at_100
value: 38.807
- type: ndcg_at_1000
value: 42.208
- type: ndcg_at_3
value: 28.086
- type: ndcg_at_5
value: 29.323
- type: precision_at_1
value: 30.709999999999997
- type: precision_at_10
value: 8.688
- type: precision_at_100
value: 1.608
- type: precision_at_1000
value: 0.22100000000000003
- type: precision_at_3
value: 18.724
- type: precision_at_5
value: 13.950999999999999
- type: recall_at_1
value: 15.473
- type: recall_at_10
value: 38.361000000000004
- type: recall_at_100
value: 65.2
- type: recall_at_1000
value: 85.789
- type: recall_at_3
value: 25.401
- type: recall_at_5
value: 30.875999999999998
task:
type: Retrieval
- dataset:
config: default
name: MTEB HotpotQA-PL
revision: a0bd479ac97b4ccb5bd6ce320c415d0bb4beb907
split: test
type: clarin-knext/hotpotqa-pl
metrics:
- type: map_at_1
value: 38.096000000000004
- type: map_at_10
value: 51.44499999999999
- type: map_at_100
value: 52.325
- type: map_at_1000
value: 52.397000000000006
- type: map_at_3
value: 48.626999999999995
- type: map_at_5
value: 50.342
- type: mrr_at_1
value: 76.19200000000001
- type: mrr_at_10
value: 81.191
- type: mrr_at_100
value: 81.431
- type: mrr_at_1000
value: 81.443
- type: mrr_at_3
value: 80.30199999999999
- type: mrr_at_5
value: 80.85900000000001
- type: ndcg_at_1
value: 76.19200000000001
- type: ndcg_at_10
value: 60.9
- type: ndcg_at_100
value: 64.14699999999999
- type: ndcg_at_1000
value: 65.647
- type: ndcg_at_3
value: 56.818000000000005
- type: ndcg_at_5
value: 59.019999999999996
- type: precision_at_1
value: 76.19200000000001
- type: precision_at_10
value: 12.203
- type: precision_at_100
value: 1.478
- type: precision_at_1000
value: 0.168
- type: precision_at_3
value: 34.616
- type: precision_at_5
value: 22.515
- type: recall_at_1
value: 38.096000000000004
- type: recall_at_10
value: 61.013
- type: recall_at_100
value: 73.90299999999999
- type: recall_at_1000
value: 83.91
- type: recall_at_3
value: 51.92400000000001
- type: recall_at_5
value: 56.286
task:
type: Retrieval
- dataset:
config: default
name: MTEB MSMARCO-PL
revision: 8634c07806d5cce3a6138e260e59b81760a0a640
split: test
type: clarin-knext/msmarco-pl
metrics:
- type: map_at_1
value: 1.548
- type: map_at_10
value: 11.049000000000001
- type: map_at_100
value: 28.874
- type: map_at_1000
value: 34.931
- type: map_at_3
value: 4.162
- type: map_at_5
value: 6.396
- type: mrr_at_1
value: 90.69800000000001
- type: mrr_at_10
value: 92.093
- type: mrr_at_100
value: 92.345
- type: mrr_at_1000
value: 92.345
- type: mrr_at_3
value: 91.86
- type: mrr_at_5
value: 91.86
- type: ndcg_at_1
value: 74.031
- type: ndcg_at_10
value: 63.978
- type: ndcg_at_100
value: 53.101
- type: ndcg_at_1000
value: 60.675999999999995
- type: ndcg_at_3
value: 71.421
- type: ndcg_at_5
value: 68.098
- type: precision_at_1
value: 90.69800000000001
- type: precision_at_10
value: 71.86
- type: precision_at_100
value: 31.395
- type: precision_at_1000
value: 5.981
- type: precision_at_3
value: 84.49600000000001
- type: precision_at_5
value: 79.07
- type: recall_at_1
value: 1.548
- type: recall_at_10
value: 12.149000000000001
- type: recall_at_100
value: 40.794999999999995
- type: recall_at_1000
value: 67.974
- type: recall_at_3
value: 4.244
- type: recall_at_5
value: 6.608
task:
type: Retrieval
- dataset:
config: pl
name: MTEB MassiveIntentClassification (pl)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 73.55413584398119
- type: f1
value: 69.65610882318181
task:
type: Classification
- dataset:
config: pl
name: MTEB MassiveScenarioClassification (pl)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 76.37188971082716
- type: f1
value: 75.64847309941361
task:
type: Classification
- dataset:
config: default
name: MTEB NFCorpus-PL
revision: 9a6f9567fda928260afed2de480d79c98bf0bec0
split: test
type: clarin-knext/nfcorpus-pl
metrics:
- type: map_at_1
value: 4.919
- type: map_at_10
value: 10.834000000000001
- type: map_at_100
value: 13.38
- type: map_at_1000
value: 14.581
- type: map_at_3
value: 8.198
- type: map_at_5
value: 9.428
- type: mrr_at_1
value: 41.176
- type: mrr_at_10
value: 50.083
- type: mrr_at_100
value: 50.559
- type: mrr_at_1000
value: 50.604000000000006
- type: mrr_at_3
value: 47.936
- type: mrr_at_5
value: 49.407000000000004
- type: ndcg_at_1
value: 39.628
- type: ndcg_at_10
value: 30.098000000000003
- type: ndcg_at_100
value: 27.061
- type: ndcg_at_1000
value: 35.94
- type: ndcg_at_3
value: 35.135
- type: ndcg_at_5
value: 33.335
- type: precision_at_1
value: 41.176
- type: precision_at_10
value: 22.259999999999998
- type: precision_at_100
value: 6.712
- type: precision_at_1000
value: 1.9060000000000001
- type: precision_at_3
value: 33.23
- type: precision_at_5
value: 29.04
- type: recall_at_1
value: 4.919
- type: recall_at_10
value: 14.196
- type: recall_at_100
value: 26.948
- type: recall_at_1000
value: 59.211000000000006
- type: recall_at_3
value: 9.44
- type: recall_at_5
value: 11.569
task:
type: Retrieval
- dataset:
config: default
name: MTEB NQ-PL
revision: f171245712cf85dd4700b06bef18001578d0ca8d
split: test
type: clarin-knext/nq-pl
metrics:
- type: map_at_1
value: 25.35
- type: map_at_10
value: 37.884
- type: map_at_100
value: 38.955
- type: map_at_1000
value: 39.007999999999996
- type: map_at_3
value: 34.239999999999995
- type: map_at_5
value: 36.398
- type: mrr_at_1
value: 28.737000000000002
- type: mrr_at_10
value: 39.973
- type: mrr_at_100
value: 40.844
- type: mrr_at_1000
value: 40.885
- type: mrr_at_3
value: 36.901
- type: mrr_at_5
value: 38.721
- type: ndcg_at_1
value: 28.708
- type: ndcg_at_10
value: 44.204
- type: ndcg_at_100
value: 48.978
- type: ndcg_at_1000
value: 50.33
- type: ndcg_at_3
value: 37.36
- type: ndcg_at_5
value: 40.912
- type: precision_at_1
value: 28.708
- type: precision_at_10
value: 7.367
- type: precision_at_100
value: 1.0030000000000001
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 17.034
- type: precision_at_5
value: 12.293999999999999
- type: recall_at_1
value: 25.35
- type: recall_at_10
value: 61.411
- type: recall_at_100
value: 82.599
- type: recall_at_1000
value: 92.903
- type: recall_at_3
value: 43.728
- type: recall_at_5
value: 51.854
task:
type: Retrieval
- dataset:
config: default
name: MTEB PAC
revision: None
split: test
type: laugustyniak/abusive-clauses-pl
metrics:
- type: accuracy
value: 69.04141326382856
- type: ap
value: 77.49422763833996
- type: f1
value: 66.73472657783407
task:
type: Classification
- dataset:
config: default
name: MTEB PPC
revision: None
split: test
type: PL-MTEB/ppc-pairclassification
metrics:
- type: cos_sim_accuracy
value: 81.0
- type: cos_sim_ap
value: 91.47194213011349
- type: cos_sim_f1
value: 84.73767885532592
- type: cos_sim_precision
value: 81.49847094801224
- type: cos_sim_recall
value: 88.24503311258279
- type: dot_accuracy
value: 81.0
- type: dot_ap
value: 91.47194213011349
- type: dot_f1
value: 84.73767885532592
- type: dot_precision
value: 81.49847094801224
- type: dot_recall
value: 88.24503311258279
- type: euclidean_accuracy
value: 81.0
- type: euclidean_ap
value: 91.47194213011349
- type: euclidean_f1
value: 84.73767885532592
- type: euclidean_precision
value: 81.49847094801224
- type: euclidean_recall
value: 88.24503311258279
- type: manhattan_accuracy
value: 81.0
- type: manhattan_ap
value: 91.46464475050571
- type: manhattan_f1
value: 84.48687350835321
- type: manhattan_precision
value: 81.31699846860643
- type: manhattan_recall
value: 87.91390728476821
- type: max_accuracy
value: 81.0
- type: max_ap
value: 91.47194213011349
- type: max_f1
value: 84.73767885532592
task:
type: PairClassification
- dataset:
config: default
name: MTEB PSC
revision: None
split: test
type: PL-MTEB/psc-pairclassification
metrics:
- type: cos_sim_accuracy
value: 97.6808905380334
- type: cos_sim_ap
value: 99.27948611836348
- type: cos_sim_f1
value: 96.15975422427034
- type: cos_sim_precision
value: 96.90402476780186
- type: cos_sim_recall
value: 95.42682926829268
- type: dot_accuracy
value: 97.6808905380334
- type: dot_ap
value: 99.2794861183635
- type: dot_f1
value: 96.15975422427034
- type: dot_precision
value: 96.90402476780186
- type: dot_recall
value: 95.42682926829268
- type: euclidean_accuracy
value: 97.6808905380334
- type: euclidean_ap
value: 99.2794861183635
- type: euclidean_f1
value: 96.15975422427034
- type: euclidean_precision
value: 96.90402476780186
- type: euclidean_recall
value: 95.42682926829268
- type: manhattan_accuracy
value: 97.6808905380334
- type: manhattan_ap
value: 99.28715055268721
- type: manhattan_f1
value: 96.14791987673343
- type: manhattan_precision
value: 97.19626168224299
- type: manhattan_recall
value: 95.1219512195122
- type: max_accuracy
value: 97.6808905380334
- type: max_ap
value: 99.28715055268721
- type: max_f1
value: 96.15975422427034
task:
type: PairClassification
- dataset:
config: default
name: MTEB PolEmo2.0-IN
revision: None
split: test
type: PL-MTEB/polemo2_in
metrics:
- type: accuracy
value: 86.16343490304708
- type: f1
value: 83.3442579486744
task:
type: Classification
- dataset:
config: default
name: MTEB PolEmo2.0-OUT
revision: None
split: test
type: PL-MTEB/polemo2_out
metrics:
- type: accuracy
value: 68.40080971659918
- type: f1
value: 53.13720751142237
task:
type: Classification
- dataset:
config: default
name: MTEB Quora-PL
revision: 0be27e93455051e531182b85e85e425aba12e9d4
split: test
type: clarin-knext/quora-pl
metrics:
- type: map_at_1
value: 63.322
- type: map_at_10
value: 76.847
- type: map_at_100
value: 77.616
- type: map_at_1000
value: 77.644
- type: map_at_3
value: 73.624
- type: map_at_5
value: 75.603
- type: mrr_at_1
value: 72.88
- type: mrr_at_10
value: 80.376
- type: mrr_at_100
value: 80.604
- type: mrr_at_1000
value: 80.61
- type: mrr_at_3
value: 78.92
- type: mrr_at_5
value: 79.869
- type: ndcg_at_1
value: 72.89999999999999
- type: ndcg_at_10
value: 81.43
- type: ndcg_at_100
value: 83.394
- type: ndcg_at_1000
value: 83.685
- type: ndcg_at_3
value: 77.62599999999999
- type: ndcg_at_5
value: 79.656
- type: precision_at_1
value: 72.89999999999999
- type: precision_at_10
value: 12.548
- type: precision_at_100
value: 1.4869999999999999
- type: precision_at_1000
value: 0.155
- type: precision_at_3
value: 34.027
- type: precision_at_5
value: 22.654
- type: recall_at_1
value: 63.322
- type: recall_at_10
value: 90.664
- type: recall_at_100
value: 97.974
- type: recall_at_1000
value: 99.636
- type: recall_at_3
value: 80.067
- type: recall_at_5
value: 85.526
task:
type: Retrieval
- dataset:
config: default
name: MTEB SCIDOCS-PL
revision: 45452b03f05560207ef19149545f168e596c9337
split: test
type: clarin-knext/scidocs-pl
metrics:
- type: map_at_1
value: 3.95
- type: map_at_10
value: 9.658999999999999
- type: map_at_100
value: 11.384
- type: map_at_1000
value: 11.677
- type: map_at_3
value: 7.055
- type: map_at_5
value: 8.244
- type: mrr_at_1
value: 19.5
- type: mrr_at_10
value: 28.777
- type: mrr_at_100
value: 29.936
- type: mrr_at_1000
value: 30.009999999999998
- type: mrr_at_3
value: 25.55
- type: mrr_at_5
value: 27.284999999999997
- type: ndcg_at_1
value: 19.5
- type: ndcg_at_10
value: 16.589000000000002
- type: ndcg_at_100
value: 23.879
- type: ndcg_at_1000
value: 29.279
- type: ndcg_at_3
value: 15.719
- type: ndcg_at_5
value: 13.572000000000001
- type: precision_at_1
value: 19.5
- type: precision_at_10
value: 8.62
- type: precision_at_100
value: 1.924
- type: precision_at_1000
value: 0.322
- type: precision_at_3
value: 14.6
- type: precision_at_5
value: 11.78
- type: recall_at_1
value: 3.95
- type: recall_at_10
value: 17.477999999999998
- type: recall_at_100
value: 38.99
- type: recall_at_1000
value: 65.417
- type: recall_at_3
value: 8.883000000000001
- type: recall_at_5
value: 11.933
task:
type: Retrieval
- dataset:
config: default
name: MTEB SICK-E-PL
revision: None
split: test
type: PL-MTEB/sicke-pl-pairclassification
metrics:
- type: cos_sim_accuracy
value: 83.48960456583775
- type: cos_sim_ap
value: 76.31522115825375
- type: cos_sim_f1
value: 70.35573122529645
- type: cos_sim_precision
value: 70.9934735315446
- type: cos_sim_recall
value: 69.72934472934473
- type: dot_accuracy
value: 83.48960456583775
- type: dot_ap
value: 76.31522115825373
- type: dot_f1
value: 70.35573122529645
- type: dot_precision
value: 70.9934735315446
- type: dot_recall
value: 69.72934472934473
- type: euclidean_accuracy
value: 83.48960456583775
- type: euclidean_ap
value: 76.31522115825373
- type: euclidean_f1
value: 70.35573122529645
- type: euclidean_precision
value: 70.9934735315446
- type: euclidean_recall
value: 69.72934472934473
- type: manhattan_accuracy
value: 83.46922136159804
- type: manhattan_ap
value: 76.18474601388084
- type: manhattan_f1
value: 70.34779490856937
- type: manhattan_precision
value: 70.83032490974729
- type: manhattan_recall
value: 69.87179487179486
- type: max_accuracy
value: 83.48960456583775
- type: max_ap
value: 76.31522115825375
- type: max_f1
value: 70.35573122529645
task:
type: PairClassification
- dataset:
config: default
name: MTEB SICK-R-PL
revision: None
split: test
type: PL-MTEB/sickr-pl-sts
metrics:
- type: cos_sim_pearson
value: 77.95374883876302
- type: cos_sim_spearman
value: 73.77630219171942
- type: euclidean_pearson
value: 75.81927069594934
- type: euclidean_spearman
value: 73.7763211303831
- type: manhattan_pearson
value: 76.03126859057528
- type: manhattan_spearman
value: 73.96528138013369
task:
type: STS
- dataset:
config: pl
name: MTEB STS22 (pl)
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 37.388282764841826
- type: cos_sim_spearman
value: 40.83477184710897
- type: euclidean_pearson
value: 26.754737044177805
- type: euclidean_spearman
value: 40.83477184710897
- type: manhattan_pearson
value: 26.760453110872458
- type: manhattan_spearman
value: 41.034477441383856
task:
type: STS
- dataset:
config: default
name: MTEB SciFact-PL
revision: 47932a35f045ef8ed01ba82bf9ff67f6e109207e
split: test
type: clarin-knext/scifact-pl
metrics:
- type: map_at_1
value: 49.15
- type: map_at_10
value: 61.690999999999995
- type: map_at_100
value: 62.348000000000006
- type: map_at_1000
value: 62.38
- type: map_at_3
value: 58.824
- type: map_at_5
value: 60.662000000000006
- type: mrr_at_1
value: 51.333
- type: mrr_at_10
value: 62.731
- type: mrr_at_100
value: 63.245
- type: mrr_at_1000
value: 63.275000000000006
- type: mrr_at_3
value: 60.667
- type: mrr_at_5
value: 61.93300000000001
- type: ndcg_at_1
value: 51.333
- type: ndcg_at_10
value: 67.168
- type: ndcg_at_100
value: 69.833
- type: ndcg_at_1000
value: 70.56700000000001
- type: ndcg_at_3
value: 62.40599999999999
- type: ndcg_at_5
value: 65.029
- type: precision_at_1
value: 51.333
- type: precision_at_10
value: 9.333
- type: precision_at_100
value: 1.0699999999999998
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 25.333
- type: precision_at_5
value: 17.067
- type: recall_at_1
value: 49.15
- type: recall_at_10
value: 82.533
- type: recall_at_100
value: 94.167
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 69.917
- type: recall_at_5
value: 76.356
task:
type: Retrieval
- dataset:
config: default
name: MTEB TRECCOVID-PL
revision: 81bcb408f33366c2a20ac54adafad1ae7e877fdd
split: test
type: clarin-knext/trec-covid-pl
metrics:
- type: map_at_1
value: 0.261
- type: map_at_10
value: 2.1260000000000003
- type: map_at_100
value: 12.171999999999999
- type: map_at_1000
value: 26.884999999999998
- type: map_at_3
value: 0.695
- type: map_at_5
value: 1.134
- type: mrr_at_1
value: 96.0
- type: mrr_at_10
value: 96.952
- type: mrr_at_100
value: 96.952
- type: mrr_at_1000
value: 96.952
- type: mrr_at_3
value: 96.667
- type: mrr_at_5
value: 96.667
- type: ndcg_at_1
value: 92.0
- type: ndcg_at_10
value: 81.193
- type: ndcg_at_100
value: 61.129
- type: ndcg_at_1000
value: 51.157
- type: ndcg_at_3
value: 85.693
- type: ndcg_at_5
value: 84.129
- type: precision_at_1
value: 96.0
- type: precision_at_10
value: 85.39999999999999
- type: precision_at_100
value: 62.03999999999999
- type: precision_at_1000
value: 22.224
- type: precision_at_3
value: 88.0
- type: precision_at_5
value: 88.0
- type: recall_at_1
value: 0.261
- type: recall_at_10
value: 2.262
- type: recall_at_100
value: 14.981
- type: recall_at_1000
value: 46.837
- type: recall_at_3
value: 0.703
- type: recall_at_5
value: 1.172
task:
type: Retrieval
- dataset:
config: default
name: MTEB AlloProfClusteringP2P
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
split: test
type: lyon-nlp/alloprof
metrics:
- type: v_measure
value: 70.55290063940157
task:
type: Clustering
- dataset:
config: default
name: MTEB AlloProfClusteringS2S
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
split: test
type: lyon-nlp/alloprof
metrics:
- type: v_measure
value: 55.41500719337263
task:
type: Clustering
- dataset:
config: default
name: MTEB AlloprofReranking
revision: 666fdacebe0291776e86f29345663dfaf80a0db9
split: test
type: lyon-nlp/mteb-fr-reranking-alloprof-s2p
metrics:
- type: map
value: 73.48697375332002
- type: mrr
value: 75.01836585523822
task:
type: Reranking
- dataset:
config: default
name: MTEB AlloprofRetrieval
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
split: test
type: lyon-nlp/alloprof
metrics:
- type: map_at_1
value: 38.454
- type: map_at_10
value: 51.605000000000004
- type: map_at_100
value: 52.653000000000006
- type: map_at_1000
value: 52.697
- type: map_at_3
value: 48.304
- type: map_at_5
value: 50.073
- type: mrr_at_1
value: 43.307
- type: mrr_at_10
value: 54.400000000000006
- type: mrr_at_100
value: 55.147999999999996
- type: mrr_at_1000
value: 55.174
- type: mrr_at_3
value: 51.77
- type: mrr_at_5
value: 53.166999999999994
- type: ndcg_at_1
value: 43.307
- type: ndcg_at_10
value: 57.891000000000005
- type: ndcg_at_100
value: 62.161
- type: ndcg_at_1000
value: 63.083
- type: ndcg_at_3
value: 51.851
- type: ndcg_at_5
value: 54.605000000000004
- type: precision_at_1
value: 43.307
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.172
- type: precision_at_1000
value: 0.127
- type: precision_at_3
value: 22.798
- type: precision_at_5
value: 15.492
- type: recall_at_1
value: 38.454
- type: recall_at_10
value: 74.166
- type: recall_at_100
value: 92.43599999999999
- type: recall_at_1000
value: 99.071
- type: recall_at_3
value: 58.087
- type: recall_at_5
value: 64.568
task:
type: Retrieval
- dataset:
config: fr
name: MTEB AmazonReviewsClassification (fr)
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
split: test
type: mteb/amazon_reviews_multi
metrics:
- type: accuracy
value: 53.474
- type: f1
value: 50.38275392350236
task:
type: Classification
- dataset:
config: default
name: MTEB BSARDRetrieval
revision: 5effa1b9b5fa3b0f9e12523e6e43e5f86a6e6d59
split: test
type: maastrichtlawtech/bsard
metrics:
- type: map_at_1
value: 2.252
- type: map_at_10
value: 4.661
- type: map_at_100
value: 5.271
- type: map_at_1000
value: 5.3629999999999995
- type: map_at_3
value: 3.604
- type: map_at_5
value: 4.3020000000000005
- type: mrr_at_1
value: 2.252
- type: mrr_at_10
value: 4.661
- type: mrr_at_100
value: 5.271
- type: mrr_at_1000
value: 5.3629999999999995
- type: mrr_at_3
value: 3.604
- type: mrr_at_5
value: 4.3020000000000005
- type: ndcg_at_1
value: 2.252
- type: ndcg_at_10
value: 6.3020000000000005
- type: ndcg_at_100
value: 10.342
- type: ndcg_at_1000
value: 13.475999999999999
- type: ndcg_at_3
value: 4.0649999999999995
- type: ndcg_at_5
value: 5.344
- type: precision_at_1
value: 2.252
- type: precision_at_10
value: 1.171
- type: precision_at_100
value: 0.333
- type: precision_at_1000
value: 0.059000000000000004
- type: precision_at_3
value: 1.802
- type: precision_at_5
value: 1.712
- type: recall_at_1
value: 2.252
- type: recall_at_10
value: 11.712
- type: recall_at_100
value: 33.333
- type: recall_at_1000
value: 59.458999999999996
- type: recall_at_3
value: 5.405
- type: recall_at_5
value: 8.559
task:
type: Retrieval
- dataset:
config: default
name: MTEB HALClusteringS2S
revision: e06ebbbb123f8144bef1a5d18796f3dec9ae2915
split: test
type: lyon-nlp/clustering-hal-s2s
metrics:
- type: v_measure
value: 28.301882091023288
task:
type: Clustering
- dataset:
config: default
name: MTEB MLSUMClusteringP2P
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: mlsum
metrics:
- type: v_measure
value: 45.26992995191701
task:
type: Clustering
- dataset:
config: default
name: MTEB MLSUMClusteringS2S
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
split: test
type: mlsum
metrics:
- type: v_measure
value: 42.773174876871145
task:
type: Clustering
- dataset:
config: fr
name: MTEB MTOPDomainClassification (fr)
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
split: test
type: mteb/mtop_domain
metrics:
- type: accuracy
value: 93.47635452552458
- type: f1
value: 93.19922617577213
task:
type: Classification
- dataset:
config: fr
name: MTEB MTOPIntentClassification (fr)
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
split: test
type: mteb/mtop_intent
metrics:
- type: accuracy
value: 80.2317569683683
- type: f1
value: 56.18060418621901
task:
type: Classification
- dataset:
config: fra
name: MTEB MasakhaNEWSClassification (fra)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: accuracy
value: 85.18957345971565
- type: f1
value: 80.829981537394
task:
type: Classification
- dataset:
config: fra
name: MTEB MasakhaNEWSClusteringP2P (fra)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: v_measure
value: 71.04138999801822
task:
type: Clustering
- dataset:
config: fra
name: MTEB MasakhaNEWSClusteringS2S (fra)
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
split: test
type: masakhane/masakhanews
metrics:
- type: v_measure
value: 71.7056263158008
task:
type: Clustering
- dataset:
config: fr
name: MTEB MassiveIntentClassification (fr)
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
split: test
type: mteb/amazon_massive_intent
metrics:
- type: accuracy
value: 76.65097511768661
- type: f1
value: 73.82441070598712
task:
type: Classification
- dataset:
config: fr
name: MTEB MassiveScenarioClassification (fr)
revision: 7d571f92784cd94a019292a1f45445077d0ef634
split: test
type: mteb/amazon_massive_scenario
metrics:
- type: accuracy
value: 79.09885675857431
- type: f1
value: 78.28407777434224
task:
type: Classification
- dataset:
config: fr
name: MTEB MintakaRetrieval (fr)
revision: efa78cc2f74bbcd21eff2261f9e13aebe40b814e
split: test
type: jinaai/mintakaqa
metrics:
- type: map_at_1
value: 25.307000000000002
- type: map_at_10
value: 36.723
- type: map_at_100
value: 37.713
- type: map_at_1000
value: 37.769000000000005
- type: map_at_3
value: 33.77
- type: map_at_5
value: 35.463
- type: mrr_at_1
value: 25.307000000000002
- type: mrr_at_10
value: 36.723
- type: mrr_at_100
value: 37.713
- type: mrr_at_1000
value: 37.769000000000005
- type: mrr_at_3
value: 33.77
- type: mrr_at_5
value: 35.463
- type: ndcg_at_1
value: 25.307000000000002
- type: ndcg_at_10
value: 42.559999999999995
- type: ndcg_at_100
value: 47.457
- type: ndcg_at_1000
value: 49.162
- type: ndcg_at_3
value: 36.461
- type: ndcg_at_5
value: 39.504
- type: precision_at_1
value: 25.307000000000002
- type: precision_at_10
value: 6.106
- type: precision_at_100
value: 0.8420000000000001
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 14.741999999999999
- type: precision_at_5
value: 10.319
- type: recall_at_1
value: 25.307000000000002
- type: recall_at_10
value: 61.056999999999995
- type: recall_at_100
value: 84.152
- type: recall_at_1000
value: 98.03399999999999
- type: recall_at_3
value: 44.226
- type: recall_at_5
value: 51.597
task:
type: Retrieval
- dataset:
config: fr
name: MTEB OpusparcusPC (fr)
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
split: test
type: GEM/opusparcus
metrics:
- type: cos_sim_accuracy
value: 99.90069513406156
- type: cos_sim_ap
value: 100.0
- type: cos_sim_f1
value: 99.95032290114257
- type: cos_sim_precision
value: 100.0
- type: cos_sim_recall
value: 99.90069513406156
- type: dot_accuracy
value: 99.90069513406156
- type: dot_ap
value: 100.0
- type: dot_f1
value: 99.95032290114257
- type: dot_precision
value: 100.0
- type: dot_recall
value: 99.90069513406156
- type: euclidean_accuracy
value: 99.90069513406156
- type: euclidean_ap
value: 100.0
- type: euclidean_f1
value: 99.95032290114257
- type: euclidean_precision
value: 100.0
- type: euclidean_recall
value: 99.90069513406156
- type: manhattan_accuracy
value: 99.90069513406156
- type: manhattan_ap
value: 100.0
- type: manhattan_f1
value: 99.95032290114257
- type: manhattan_precision
value: 100.0
- type: manhattan_recall
value: 99.90069513406156
- type: max_accuracy
value: 99.90069513406156
- type: max_ap
value: 100.0
- type: max_f1
value: 99.95032290114257
task:
type: PairClassification
- dataset:
config: fr
name: MTEB PawsX (fr)
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
split: test
type: paws-x
metrics:
- type: cos_sim_accuracy
value: 70.8
- type: cos_sim_ap
value: 73.7671529695957
- type: cos_sim_f1
value: 68.80964339527875
- type: cos_sim_precision
value: 62.95955882352941
- type: cos_sim_recall
value: 75.85825027685493
- type: dot_accuracy
value: 70.8
- type: dot_ap
value: 73.78345265366947
- type: dot_f1
value: 68.80964339527875
- type: dot_precision
value: 62.95955882352941
- type: dot_recall
value: 75.85825027685493
- type: euclidean_accuracy
value: 70.8
- type: euclidean_ap
value: 73.7671529695957
- type: euclidean_f1
value: 68.80964339527875
- type: euclidean_precision
value: 62.95955882352941
- type: euclidean_recall
value: 75.85825027685493
- type: manhattan_accuracy
value: 70.75
- type: manhattan_ap
value: 73.78996383615953
- type: manhattan_f1
value: 68.79432624113475
- type: manhattan_precision
value: 63.39869281045751
- type: manhattan_recall
value: 75.1937984496124
- type: max_accuracy
value: 70.8
- type: max_ap
value: 73.78996383615953
- type: max_f1
value: 68.80964339527875
task:
type: PairClassification
- dataset:
config: default
name: MTEB SICKFr
revision: e077ab4cf4774a1e36d86d593b150422fafd8e8a
split: test
type: Lajavaness/SICK-fr
metrics:
- type: cos_sim_pearson
value: 84.03253762760392
- type: cos_sim_spearman
value: 79.68280105762004
- type: euclidean_pearson
value: 80.98265050044444
- type: euclidean_spearman
value: 79.68233242682867
- type: manhattan_pearson
value: 80.9678911810704
- type: manhattan_spearman
value: 79.70264097683109
task:
type: STS
- dataset:
config: fr
name: MTEB STS22 (fr)
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
split: test
type: mteb/sts22-crosslingual-sts
metrics:
- type: cos_sim_pearson
value: 80.56896987572884
- type: cos_sim_spearman
value: 81.84352499523287
- type: euclidean_pearson
value: 80.40831759421305
- type: euclidean_spearman
value: 81.84352499523287
- type: manhattan_pearson
value: 80.74333857561238
- type: manhattan_spearman
value: 82.41503246733892
task:
type: STS
- dataset:
config: fr
name: MTEB STSBenchmarkMultilingualSTS (fr)
revision: 93d57ef91790589e3ce9c365164337a8a78b7632
split: test
type: stsb_multi_mt
metrics:
- type: cos_sim_pearson
value: 82.71826762276979
- type: cos_sim_spearman
value: 82.25433354916042
- type: euclidean_pearson
value: 81.87115571724316
- type: euclidean_spearman
value: 82.25322342890107
- type: manhattan_pearson
value: 82.11174867527224
- type: manhattan_spearman
value: 82.55905365203084
task:
type: STS
- dataset:
config: default
name: MTEB SummEvalFr
revision: b385812de6a9577b6f4d0f88c6a6e35395a94054
split: test
type: lyon-nlp/summarization-summeval-fr-p2p
metrics:
- type: cos_sim_pearson
value: 30.659441623392887
- type: cos_sim_spearman
value: 30.501134097353315
- type: dot_pearson
value: 30.659444768851056
- type: dot_spearman
value: 30.501134097353315
task:
type: Summarization
- dataset:
config: default
name: MTEB SyntecReranking
revision: b205c5084a0934ce8af14338bf03feb19499c84d
split: test
type: lyon-nlp/mteb-fr-reranking-syntec-s2p
metrics:
- type: map
value: 94.03333333333333
- type: mrr
value: 94.03333333333333
task:
type: Reranking
- dataset:
config: default
name: MTEB SyntecRetrieval
revision: 77f7e271bf4a92b24fce5119f3486b583ca016ff
split: test
type: lyon-nlp/mteb-fr-retrieval-syntec-s2p
metrics:
- type: map_at_1
value: 79.0
- type: map_at_10
value: 87.61
- type: map_at_100
value: 87.655
- type: map_at_1000
value: 87.655
- type: map_at_3
value: 87.167
- type: map_at_5
value: 87.36699999999999
- type: mrr_at_1
value: 79.0
- type: mrr_at_10
value: 87.61
- type: mrr_at_100
value: 87.655
- type: mrr_at_1000
value: 87.655
- type: mrr_at_3
value: 87.167
- type: mrr_at_5
value: 87.36699999999999
- type: ndcg_at_1
value: 79.0
- type: ndcg_at_10
value: 90.473
- type: ndcg_at_100
value: 90.694
- type: ndcg_at_1000
value: 90.694
- type: ndcg_at_3
value: 89.464
- type: ndcg_at_5
value: 89.851
- type: precision_at_1
value: 79.0
- type: precision_at_10
value: 9.9
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 32.0
- type: precision_at_5
value: 19.400000000000002
- type: recall_at_1
value: 79.0
- type: recall_at_10
value: 99.0
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 96.0
- type: recall_at_5
value: 97.0
task:
type: Retrieval
- dataset:
config: fr
name: MTEB XPQARetrieval (fr)
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
split: test
type: jinaai/xpqa
metrics:
- type: map_at_1
value: 39.395
- type: map_at_10
value: 59.123999999999995
- type: map_at_100
value: 60.704
- type: map_at_1000
value: 60.760000000000005
- type: map_at_3
value: 53.187
- type: map_at_5
value: 56.863
- type: mrr_at_1
value: 62.083
- type: mrr_at_10
value: 68.87299999999999
- type: mrr_at_100
value: 69.46900000000001
- type: mrr_at_1000
value: 69.48299999999999
- type: mrr_at_3
value: 66.8
- type: mrr_at_5
value: 67.928
- type: ndcg_at_1
value: 62.083
- type: ndcg_at_10
value: 65.583
- type: ndcg_at_100
value: 70.918
- type: ndcg_at_1000
value: 71.72800000000001
- type: ndcg_at_3
value: 60.428000000000004
- type: ndcg_at_5
value: 61.853
- type: precision_at_1
value: 62.083
- type: precision_at_10
value: 15.033
- type: precision_at_100
value: 1.9529999999999998
- type: precision_at_1000
value: 0.207
- type: precision_at_3
value: 36.315
- type: precision_at_5
value: 25.955000000000002
- type: recall_at_1
value: 39.395
- type: recall_at_10
value: 74.332
- type: recall_at_100
value: 94.729
- type: recall_at_1000
value: 99.75500000000001
- type: recall_at_3
value: 57.679
- type: recall_at_5
value: 65.036
task:
type: Retrieval
---
## gte-Qwen2-1.5B-instruct
**gte-Qwen2-1.5B-instruct** is the latest model in the gte (General Text Embedding) model family. The model is built on [Qwen2-1.5B](https://huggingface.co/Qwen/Qwen2-1.5B) LLM model and use the same training data and strategies as the [gte-Qwen2-7B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct) model.
The model incorporates several key advancements:
- Integration of bidirectional attention mechanisms, enriching its contextual understanding.
- Instruction tuning, applied solely on the query side for streamlined efficiency
- Comprehensive training across a vast, multilingual text corpus spanning diverse domains and scenarios. This training leverages both weakly supervised and supervised data, ensuring the model's applicability across numerous languages and a wide array of downstream tasks.
## Model Information
- Model Size: 1.5B
- Embedding Dimension: 1536
- Max Input Tokens: 32k
## Requirements
```
transformers>=4.39.2
flash_attn>=2.5.6
```
## Usage
### Sentence Transformers
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-Qwen2-1.5B-instruct", trust_remote_code=True)
# In case you want to reduce the maximum length:
model.max_seq_length = 8192
queries = [
"how much protein should a female eat",
"summit define",
]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments.",
]
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
scores = (query_embeddings @ document_embeddings.T) * 100
print(scores.tolist())
```
Observe the [config_sentence_transformers.json](config_sentence_transformers.json) to see all pre-built prompt names. Otherwise, you can use `model.encode(queries, prompt="Instruct: ...\nQuery: "` to use a custom prompt of your choice.
### Transformers
```python
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'how much protein should a female eat'),
get_detailed_instruct(task, 'summit define')
]
# No need to add instruction for retrieval documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Alibaba-NLP/gte-Qwen2-1.5B-instruct', trust_remote_code=True)
model = AutoModel.from_pretrained('Alibaba-NLP/gte-Qwen2-1.5B-instruct', trust_remote_code=True)
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=max_length, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Evaluation
### MTEB & C-MTEB
You can use the [scripts/eval_mteb.py](https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct/blob/main/scripts/eval_mteb.py) to reproduce the following result of **gte-Qwen2-1.5B-instruct** on MTEB(English)/C-MTEB(Chinese):
| Model Name | MTEB(56) | C-MTEB(35) | MTEB-fr(26) | MTEB-pl(26) |
|:----:|:---------:|:----------:|:----------:|:----------:|
| [bge-base-en-1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 64.23 | - | - | - |
| [bge-large-en-1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 63.55 | - | - | - |
| [gte-large-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5) | 65.39 | - | - | - |
| [gte-base-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5) | 64.11 | - | - | - |
| [mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) | 64.68 | - | - | - |
| [acge_text_embedding](https://huggingface.co/aspire/acge_text_embedding) | - | 69.07 | - | - |
| [stella-mrl-large-zh-v3.5-1792d](https://huggingface.co/infgrad/stella-mrl-large-zh-v3.5-1792d) | - | 68.55 | - | - |
| [gte-large-zh](https://huggingface.co/thenlper/gte-large-zh) | - | 66.72 | - | - |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 59.45 | 56.21 | - | - |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 61.50 | 58.81 | - | - |
| [e5-mistral-7b-instruct](https://huggingface.co/intfloat/e5-mistral-7b-instruct) | 66.63 | 60.81 | - | - |
| [gte-Qwen1.5-7B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen1.5-7B-instruct) | 67.34 | 69.52 | - | - |
| [NV-Embed-v1](https://huggingface.co/nvidia/NV-Embed-v1) | 69.32 | - | - | - |
| [**gte-Qwen2-7B-instruct**](https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct) | **70.24** | **72.05** | **68.25** | **67.86** |
| [**gte-Qwen2-1.5B-instruct**](https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct) | **67.16** | **67.65** | **66.60** | **64.04** |
### GTE Models
The gte series models have consistently released two types of models: encoder-only models (based on the BERT architecture) and decode-only models (based on the LLM architecture).
| Models | Language | Max Sequence Length | Dimension | Model Size (Memory Usage, fp32) |
|:-------------------------------------------------------------------------------------:|:--------:|:-----: |:---------:|:-------------------------------:|
| [GTE-large-zh](https://huggingface.co/thenlper/gte-large-zh) | Chinese | 512 | 1024 | 1.25GB |
| [GTE-base-zh](https://huggingface.co/thenlper/gte-base-zh) | Chinese | 512 | 512 | 0.41GB |
| [GTE-small-zh](https://huggingface.co/thenlper/gte-small-zh) | Chinese | 512 | 512 | 0.12GB |
| [GTE-large](https://huggingface.co/thenlper/gte-large) | English | 512 | 1024 | 1.25GB |
| [GTE-base](https://huggingface.co/thenlper/gte-base) | English | 512 | 512 | 0.21GB |
| [GTE-small](https://huggingface.co/thenlper/gte-small) | English | 512 | 384 | 0.10GB |
| [GTE-large-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5) | English | 8192 | 1024 | 1.74GB |
| [GTE-base-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5) | English | 8192 | 768 | 0.51GB |
| [GTE-Qwen1.5-7B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen1.5-7B-instruct) | Multilingual | 32000 | 4096 | 26.45GB |
| [GTE-Qwen2-7B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen2-7B-instruct) | Multilingual | 32000 | 3584 | 26.45GB |
| [GTE-Qwen2-1.5B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct) | Multilingual | 32000 | 1536 | 6.62GB |
## Cloud API Services
In addition to the open-source [GTE](https://huggingface.co/collections/Alibaba-NLP/gte-models-6680f0b13f885cb431e6d469) series models, GTE series models are also available as commercial API services on Alibaba Cloud.
- [Embedding Models](https://help.aliyun.com/zh/model-studio/developer-reference/general-text-embedding/): Rhree versions of the text embedding models are available: text-embedding-v1/v2/v3, with v3 being the latest API service.
- [ReRank Models](https://help.aliyun.com/zh/model-studio/developer-reference/general-text-sorting-model/): The gte-rerank model service is available.
Note that the models behind the commercial APIs are not entirely identical to the open-source models.
## Citation
If you find our paper or models helpful, please consider cite:
```
@article{li2023towards,
title={Towards general text embeddings with multi-stage contrastive learning},
author={Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan},
journal={arXiv preprint arXiv:2308.03281},
year={2023}
}
```
|
[
"BIOSSES",
"SCIFACT"
] |
groderg/Kamoulox-large-2024_10_31-batch-size64_freeze_monolabel
|
groderg
| null |
[
"tensorboard",
"safetensors",
"dinov2",
"multilabel-image-classification",
"multilabel",
"generated_from_trainer",
"eng",
"license:cc0-1.0",
"region:us"
] | 2024-10-31T06:13:37Z |
2024-11-05T10:45:24+00:00
| 63 | 1 |
---
base_model: Kamoulox-large-2024_10_31-batch-size64_freeze_monolabel
language:
- eng
license: cc0-1.0
tags:
- multilabel-image-classification
- multilabel
- generated_from_trainer
model-index:
- name: Kamoulox-large-2024_10_31-batch-size64_freeze_monolabel
results: []
---
DinoVdeau is a fine-tuned version of [Kamoulox-large-2024_10_31-batch-size64_freeze_monolabel](https://huggingface.co/Kamoulox-large-2024_10_31-batch-size64_freeze_monolabel). It achieves the following results on the test set:
- Loss: 0.0494
- F1 Micro: 0.7640
- F1 Macro: 0.3461
- Accuracy: 0.7130
| Class | F1 per class |
|----------|-------|
| ALGAE | 0.7961 |
| Acr | 0.7462 |
| Acr_Br | 0.3797 |
| Anem | 0.6767 |
| CCA | 0.2710 |
| Ech | 0.3610 |
| Fts | 0.3889 |
| Gal | 0.4667 |
| Gon | 0.2222 |
| Mtp | 0.5521 |
| P | 0.3615 |
| Poc | 0.4367 |
| Por | 0.5018 |
| R | 0.7153 |
| RDC | 0.1781 |
| S | 0.8252 |
| SG | 0.8504 |
| Sarg | 0.6303 |
| Ser | 0.3252 |
| Slt | 0.4188 |
| Sp | 0.4198 |
| Turf | 0.6045 |
| UNK | 0.3763 |
---
# Model description
DinoVdeau is a model built on top of Kamoulox-large-2024_10_31-batch-size64_freeze_monolabel model for underwater multilabel image classification.The classification head is a combination of linear, ReLU, batch normalization, and dropout layers.
The source code for training the model can be found in this [Git repository](https://github.com/SeatizenDOI/DinoVdeau).
- **Developed by:** [lombardata](https://huggingface.co/lombardata), credits to [César Leblanc](https://huggingface.co/CesarLeblanc) and [Victor Illien](https://huggingface.co/groderg)
---
# Intended uses & limitations
You can use the raw model for classify diverse marine species, encompassing coral morphotypes classes taken from the Global Coral Reef Monitoring Network (GCRMN), habitats classes and seagrass species.
---
# Training and evaluation data
Details on the number of images for each class are given in the following table:
| Class | train | test | val | Total |
|:--------|--------:|-------:|------:|--------:|
| ALGAE | 36874 | 12292 | 12292 | 61458 |
| Acr | 5358 | 1787 | 1786 | 8931 |
| Acr_Br | 123 | 42 | 42 | 207 |
| Anem | 235 | 79 | 79 | 393 |
| CCA | 918 | 306 | 306 | 1530 |
| Ech | 618 | 206 | 206 | 1030 |
| Fts | 168 | 57 | 57 | 282 |
| Gal | 465 | 155 | 155 | 775 |
| Gon | 158 | 53 | 53 | 264 |
| Mtp | 2370 | 791 | 790 | 3951 |
| P | 2658 | 887 | 886 | 4431 |
| Poc | 549 | 184 | 183 | 916 |
| Por | 1059 | 354 | 353 | 1766 |
| R | 31437 | 10480 | 10479 | 52396 |
| RDC | 930 | 310 | 310 | 1550 |
| S | 57624 | 19209 | 19209 | 96042 |
| SG | 25539 | 8513 | 8513 | 42565 |
| Sarg | 285 | 96 | 96 | 477 |
| Ser | 261 | 87 | 87 | 435 |
| Slt | 2730 | 911 | 911 | 4552 |
| Sp | 132 | 44 | 44 | 220 |
| Turf | 1395 | 466 | 466 | 2327 |
| UNK | 292 | 98 | 98 | 488 |
---
# Training procedure
## Training hyperparameters
The following hyperparameters were used during training:
- **Number of Epochs**: 150.0
- **Learning Rate**: 0.001
- **Train Batch Size**: 64
- **Eval Batch Size**: 64
- **Optimizer**: Adam
- **LR Scheduler Type**: ReduceLROnPlateau with a patience of 5 epochs and a factor of 0.1
- **Freeze Encoder**: Yes
- **Data Augmentation**: Yes
## Data Augmentation
Data were augmented using the following transformations :
Train Transforms
- **PreProcess**: No additional parameters
- **Resize**: probability=1.00
- **RandomHorizontalFlip**: probability=0.25
- **RandomVerticalFlip**: probability=0.25
- **ColorJiggle**: probability=0.25
- **RandomPerspective**: probability=0.25
- **Normalize**: probability=1.00
Val Transforms
- **PreProcess**: No additional parameters
- **Resize**: probability=1.00
- **Normalize**: probability=1.00
## Training results
Epoch | Validation Loss | Accuracy | F1 Macro | F1 Micro | Learning Rate
--- | --- | --- | --- | --- | ---
0 | N/A | N/A | N/A | N/A | 0.001
1 | 0.8028618097305298 | 0.7326527412414418 | 0.7326527412414418 | 0.2723318326456157 | 0.001
2 | 0.8038854002952576 | 0.7288723192975732 | 0.7288723192975732 | 0.290650504066453 | 0.001
3 | 0.7705450654029846 | 0.7408581732025574 | 0.7408581732025574 | 0.326985383349658 | 0.001
4 | 0.7623223066329956 | 0.7417118168673019 | 0.7417118168673019 | 0.310238611675961 | 0.001
5 | 0.7626621127128601 | 0.7383495061061653 | 0.7383495061061653 | 0.3107947240093857 | 0.001
6 | 0.7451828122138977 | 0.7447257016428285 | 0.7447257016428285 | 0.34331624846537584 | 0.001
7 | 0.7458378672599792 | 0.7467291510600861 | 0.7467291510600861 | 0.3283260141196405 | 0.001
8 | 0.7398682832717896 | 0.7458929286946221 | 0.7458929286946221 | 0.3352756381207012 | 0.001
9 | 0.7424591779708862 | 0.7455270814097316 | 0.7455270814097316 | 0.329402464136349 | 0.001
10 | 0.7364382147789001 | 0.7474782669291475 | 0.7474782669291475 | 0.31573051576045374 | 0.001
11 | 0.7368418574333191 | 0.7465375167680005 | 0.7465375167680005 | 0.34419509138343996 | 0.001
12 | 0.7442134022712708 | 0.7428093587219735 | 0.7428093587219735 | 0.3321199292959056 | 0.001
13 | 0.7384127378463745 | 0.7479312207104406 | 0.7479312207104406 | 0.35283143267744377 | 0.001
14 | 0.7464041113853455 | 0.7463633037751956 | 0.7463633037751956 | 0.33455884660313173 | 0.001
15 | 0.7394037842750549 | 0.7446734377449871 | 0.7446734377449871 | 0.34277495445998946 | 0.001
16 | 0.7397111058235168 | 0.7478789568125991 | 0.7478789568125991 | 0.3506456767847629 | 0.001
17 | 0.7110718488693237 | 0.7554398007003362 | 0.7554398007003362 | 0.3747287292827094 | 0.0001
18 | 0.7041681408882141 | 0.7567463981463738 | 0.7567463981463738 | 0.3792648315920964 | 0.0001
19 | 0.7004917860031128 | 0.7582446298844968 | 0.7582446298844968 | 0.38576725361345504 | 0.0001
20 | 0.6942671537399292 | 0.7602829219003153 | 0.7602829219003153 | 0.39339544323315423 | 0.0001
21 | 0.6919424533843994 | 0.7592899078413268 | 0.7592899078413268 | 0.3942710537489151 | 0.0001
22 | 0.6903713941574097 | 0.7606313478859253 | 0.7606313478859253 | 0.3925331634038099 | 0.0001
23 | 0.6874070167541504 | 0.7607010330830474 | 0.7607010330830474 | 0.39534246826429575 | 0.0001
24 | 0.6864963173866272 | 0.7612236720614624 | 0.7612236720614624 | 0.3933203620961568 | 0.0001
25 | 0.684335470199585 | 0.7614153063535478 | 0.7614153063535478 | 0.402343965759826 | 0.0001
26 | 0.6830293536186218 | 0.7629309593909513 | 0.7629309593909513 | 0.4055175650763901 | 0.0001
27 | 0.6827249526977539 | 0.7630703297851954 | 0.7630703297851954 | 0.40742696523740624 | 0.0001
28 | 0.6805527210235596 | 0.7629309593909513 | 0.7629309593909513 | 0.413578373717749 | 0.0001
29 | 0.6796479225158691 | 0.7625825334053413 | 0.7625825334053413 | 0.4138447052049864 | 0.0001
30 | 0.6774595379829407 | 0.7635929687636104 | 0.7635929687636104 | 0.41283784117218203 | 0.0001
31 | 0.677918553352356 | 0.7643769272312328 | 0.7643769272312328 | 0.4100283180344899 | 0.0001
32 | 0.6754601001739502 | 0.7641504503405864 | 0.7641504503405864 | 0.41093585032897456 | 0.0001
33 | 0.6749601364135742 | 0.7645162976254769 | 0.7645162976254769 | 0.4185852176848548 | 0.0001
34 | 0.6746455430984497 | 0.7650040940053309 | 0.7650040940053309 | 0.41458520697205553 | 0.0001
35 | 0.6740487813949585 | 0.7641852929391474 | 0.7641852929391474 | 0.42549626405712787 | 0.0001
36 | 0.6740365624427795 | 0.7646905106182819 | 0.7646905106182819 | 0.42042185334833837 | 0.0001
37 | 0.6731483936309814 | 0.7641678716398669 | 0.7641678716398669 | 0.4194338951085209 | 0.0001
38 | 0.671998918056488 | 0.7648821449103674 | 0.7648821449103674 | 0.42433192329853336 | 0.0001
39 | 0.6694707870483398 | 0.7659274228671974 | 0.7659274228671974 | 0.42040362773805245 | 0.0001
40 | 0.6693674325942993 | 0.7665023257434539 | 0.7665023257434539 | 0.42052839725843943 | 0.0001
41 | 0.6682748198509216 | 0.7658228950715145 | 0.7658228950715145 | 0.4176095837463332 | 0.0001
42 | 0.6682831645011902 | 0.7665371683420149 | 0.7665371683420149 | 0.4307432846853069 | 0.0001
43 | 0.6695142984390259 | 0.7664152192470515 | 0.7664152192470515 | 0.42637174689527435 | 0.0001
44 | 0.669391393661499 | 0.765840316370795 | 0.765840316370795 | 0.42609728385101026 | 0.0001
45 | 0.6695447564125061 | 0.7649518301074895 | 0.7649518301074895 | 0.4307801257532618 | 0.0001
46 | 0.6653340458869934 | 0.7673908120067595 | 0.7673908120067595 | 0.4362286100546047 | 0.0001
47 | 0.6659862995147705 | 0.7674430759046009 | 0.7674430759046009 | 0.43279477858934173 | 0.0001
48 | 0.665557861328125 | 0.7668855943276249 | 0.7668855943276249 | 0.43077383038275147 | 0.0001
49 | 0.6672787666320801 | 0.7666242748384174 | 0.7666242748384174 | 0.4241681801855841 | 0.0001
50 | 0.6661437749862671 | 0.7662584275535269 | 0.7662584275535269 | 0.43151276516162357 | 0.0001
51 | 0.6638755798339844 | 0.7667288026341005 | 0.7667288026341005 | 0.4307690989303114 | 0.0001
52 | 0.6654694676399231 | 0.7679134509851745 | 0.7679134509851745 | 0.4427799679621408 | 0.0001
53 | 0.6643231511116028 | 0.767234020313235 | 0.767234020313235 | 0.4341825403324277 | 0.0001
54 | 0.667382001876831 | 0.7663455340499294 | 0.7663455340499294 | 0.4459616186399035 | 0.0001
55 | 0.6627440452575684 | 0.7684709325621505 | 0.7684709325621505 | 0.4389385481332223 | 0.0001
56 | 0.6627209186553955 | 0.767094649918991 | 0.767094649918991 | 0.43857797557707 | 0.0001
57 | 0.6640397310256958 | 0.7669204369261859 | 0.7669204369261859 | 0.43847119749006624 | 0.0001
58 | 0.6627684235572815 | 0.7672862842110765 | 0.7672862842110765 | 0.43760916892251167 | 0.0001
59 | 0.6614954471588135 | 0.7679134509851745 | 0.7679134509851745 | 0.439932052501894 | 0.0001
60 | 0.6633245944976807 | 0.766990122123308 | 0.766990122123308 | 0.44188579219640917 | 0.0001
61 | 0.6611309051513672 | 0.7685754603578335 | 0.7685754603578335 | 0.4370683373238057 | 0.0001
62 | 0.660831093788147 | 0.7684360899635895 | 0.7684360899635895 | 0.45352172583851785 | 0.0001
63 | 0.6621896028518677 | 0.767791501890211 | 0.767791501890211 | 0.44611945476580944 | 0.0001
64 | 0.6610415577888489 | 0.767547603700284 | 0.767547603700284 | 0.4439334258360575 | 0.0001
65 | 0.6589834690093994 | 0.7680354000801379 | 0.7680354000801379 | 0.434573899819693 | 0.0001
66 | 0.6599727272987366 | 0.76845351126287 | 0.76845351126287 | 0.4397010901020239 | 0.0001
67 | 0.6572328209877014 | 0.769045835438407 | 0.769045835438407 | 0.44838573955584105 | 0.0001
68 | 0.658860445022583 | 0.7686799881535165 | 0.7686799881535165 | 0.4442341389313245 | 0.0001
69 | 0.659292995929718 | 0.7688542011463215 | 0.7688542011463215 | 0.43926108990057783 | 0.0001
70 | 0.658970832824707 | 0.7679134509851745 | 0.7679134509851745 | 0.4357439201261406 | 0.0001
71 | 0.6567061543464661 | 0.768244455671504 | 0.768244455671504 | 0.4432082950234043 | 0.0001
72 | 0.65887850522995 | 0.7681225065765405 | 0.7681225065765405 | 0.4369170898714745 | 0.0001
73 | 0.6611541509628296 | 0.7675998675981255 | 0.7675998675981255 | 0.4436833314710758 | 0.0001
74 | 0.6570971012115479 | 0.768488353861431 | 0.768488353861431 | 0.44906341810873124 | 0.0001
75 | 0.6557245254516602 | 0.768174770474382 | 0.768174770474382 | 0.44439364748025234 | 0.0001
76 | 0.658838152885437 | 0.7683489834671869 | 0.7683489834671869 | 0.4478607285233603 | 0.0001
77 | 0.6572225093841553 | 0.7686277242556749 | 0.7686277242556749 | 0.44887316801028765 | 0.0001
78 | 0.6562930941581726 | 0.768767094649919 | 0.768767094649919 | 0.4439839848601264 | 0.0001
79 | 0.6564787030220032 | 0.76810508527726 | 0.76810508527726 | 0.4379298766193662 | 0.0001
80 | 0.661143958568573 | 0.768383826065748 | 0.768383826065748 | 0.4460529321244195 | 0.0001
81 | 0.660437285900116 | 0.768941307642724 | 0.768941307642724 | 0.44750591322776384 | 0.0001
82 | 0.6531779766082764 | 0.7705614884758105 | 0.7705614884758105 | 0.4526720456188751 | 1e-05
83 | 0.6532895565032959 | 0.77019564119092 | 0.77019564119092 | 0.4489367718812771 | 1e-05
84 | 0.6505005359649658 | 0.7705266458772495 | 0.7705266458772495 | 0.45139096558153424 | 1e-05
85 | 0.6501905918121338 | 0.7708053866657375 | 0.7708053866657375 | 0.4565625671001629 | 1e-05
86 | 0.6507149338722229 | 0.7707182801693351 | 0.7707182801693351 | 0.4559124472677571 | 1e-05
87 | 0.6484472751617432 | 0.770927335760701 | 0.770927335760701 | 0.45838476700319497 | 1e-05
88 | 0.6496042013168335 | 0.77054406717653 | 0.77054406717653 | 0.4569340367642959 | 1e-05
89 | 0.6486304402351379 | 0.7713977108412745 | 0.7713977108412745 | 0.45601319436503734 | 1e-05
90 | 0.6490767598152161 | 0.7711886552499085 | 0.7711886552499085 | 0.45742417795749246 | 1e-05
91 | 0.6481940746307373 | 0.7704221180815666 | 0.7704221180815666 | 0.45182909085509243 | 1e-05
92 | 0.6477252244949341 | 0.7715545025347991 | 0.7715545025347991 | 0.45503456574154166 | 1e-05
93 | 0.6489835381507874 | 0.771206076549189 | 0.771206076549189 | 0.4518083431267937 | 1e-05
94 | 0.6485304832458496 | 0.770753122767896 | 0.770753122767896 | 0.45105746851856937 | 1e-05
95 | 0.647895336151123 | 0.771659030330482 | 0.771659030330482 | 0.45671492126995916 | 1e-05
96 | 0.6472702622413635 | 0.7715022386369575 | 0.7715022386369575 | 0.4596959338122155 | 1e-05
97 | 0.6460831165313721 | 0.7713977108412745 | 0.7713977108412745 | 0.4625401473178366 | 1e-05
98 | 0.6463102698326111 | 0.7722165119074581 | 0.7722165119074581 | 0.45892155771298887 | 1e-05
99 | 0.646852433681488 | 0.77089249316214 | 0.77089249316214 | 0.4549241891767946 | 1e-05
100 | 0.6456441879272461 | 0.7723384610024215 | 0.7723384610024215 | 0.45970146016594643 | 1e-05
101 | 0.6469387412071228 | 0.7717461368268845 | 0.7717461368268845 | 0.4573593202819609 | 1e-05
102 | 0.646738588809967 | 0.7717809794254455 | 0.7717809794254455 | 0.4593480600391769 | 1e-05
103 | 0.6467755436897278 | 0.7723036184038605 | 0.7723036184038605 | 0.4576617106244536 | 1e-05
104 | 0.6456966400146484 | 0.7725475165937876 | 0.7725475165937876 | 0.4578893476938316 | 1e-05
105 | 0.6455578804016113 | 0.7719377711189701 | 0.7719377711189701 | 0.45556962818046953 | 1e-05
106 | 0.6444206237792969 | 0.7723384610024215 | 0.7723384610024215 | 0.4644160307431161 | 1e-05
107 | 0.26552170515060425 | 0.04797825821849794 | 0.4910938804941607 | 0.360721302464235 | 1e-05
108 | 0.1419014185667038 | 0.44983536872179924 | 0.6693680656054029 | 0.22462065038139475 | 1e-05
109 | 0.07755623757839203 | 0.6714691381683245 | 0.7449736568518617 | 0.2136927959803109 | 1e-05
110 | 0.05802077427506447 | 0.6837163115625163 | 0.7489470111853911 | 0.26414762709864326 | 1e-05
111 | 0.053473543375730515 | 0.6935245030574381 | 0.7547299175391458 | 0.331603552491686 | 1e-05
112 | 0.05167479068040848 | 0.6998135920976987 | 0.7585280588776449 | 0.3483537603081725 | 1e-05
113 | 0.05106380954384804 | 0.7042734447135067 | 0.7611001027447527 | 0.3378893620669972 | 1e-05
114 | 0.05065497010946274 | 0.7053535652688978 | 0.7622047244094489 | 0.35703913789456687 | 1e-05
115 | 0.05039990693330765 | 0.7117820247034023 | 0.7647240545893983 | 0.36428903036337407 | 1e-05
116 | 0.05015714839100838 | 0.7101966864688769 | 0.7647289615591668 | 0.3622993891059384 | 1e-05
117 | 0.050175271928310394 | 0.712914409156635 | 0.7657223847509677 | 0.36544151863175506 | 1e-05
118 | 0.050468478351831436 | 0.7141687427048309 | 0.7654782537680462 | 0.3524192831401073 | 1e-05
119 | 0.049900032579898834 | 0.7127053535652689 | 0.7658673932788375 | 0.34416444697858145 | 1e-05
120 | 0.049903545528650284 | 0.7130886221494399 | 0.7657258505633957 | 0.35077501544817247 | 1e-05
121 | 0.04957958310842514 | 0.7140816362084285 | 0.7665756914119359 | 0.3627670615797559 | 1e-05
122 | 0.04973344877362251 | 0.7163812477134545 | 0.7672263726699065 | 0.35293584502475456 | 1e-05
123 | 0.04949206858873367 | 0.7153533910559049 | 0.7661930650098223 | 0.36741171960145996 | 1e-05
124 | 0.049613192677497864 | 0.7160676643264055 | 0.7673595994775795 | 0.36413807211107735 | 1e-05
125 | 0.04959910735487938 | 0.7124440340760614 | 0.7658070643240676 | 0.3509397162428964 | 1e-05
126 | 0.0494619682431221 | 0.7152662845595025 | 0.7660751240774316 | 0.37424111866414195 | 1e-05
127 | 0.049399666488170624 | 0.7149178585738925 | 0.766314294299216 | 0.35735030768195364 | 1e-05
128 | 0.04938925430178642 | 0.714412640894758 | 0.7664776721721585 | 0.36010176970077795 | 1e-05
129 | 0.049368634819984436 | 0.717931743349419 | 0.7674323253122921 | 0.3641550142658243 | 1e-05
130 | 0.049409620463848114 | 0.717687845159492 | 0.7667705923765463 | 0.3602711408206009 | 1e-05
131 | 0.04939533770084381 | 0.718210484137907 | 0.7665082507046622 | 0.3664294602272974 | 1e-05
132 | 0.04943186417222023 | 0.717583317363809 | 0.7664564319910658 | 0.3651176446191739 | 1e-05
133 | 0.049288176000118256 | 0.714621696486124 | 0.7658437005098911 | 0.36115748131858555 | 1e-05
134 | 0.04927274212241173 | 0.7154753401508684 | 0.7659699195779215 | 0.3677607284274943 | 1e-05
135 | 0.04929700121283531 | 0.7189944426055295 | 0.7674080308866179 | 0.37226237632641596 | 1e-05
136 | 0.049187980592250824 | 0.7151094928659779 | 0.766711291239524 | 0.35969130867283144 | 1e-05
137 | 0.0491538941860199 | 0.7157889235379175 | 0.7664713487937058 | 0.3631043131303743 | 1e-05
138 | 0.04930136725306511 | 0.7178446368530165 | 0.7665450277813434 | 0.3687935119842292 | 1e-05
139 | 0.04927237331867218 | 0.7182279054371875 | 0.766155421092079 | 0.35626916649899915 | 1e-05
140 | 0.04918988421559334 | 0.7197958223724326 | 0.767376184687937 | 0.3699733355385332 | 1e-05
141 | 0.04920462518930435 | 0.716468354209857 | 0.7666041104041745 | 0.35072596287625124 | 1e-05
142 | 0.04919710010290146 | 0.7194473963868225 | 0.7669340748803981 | 0.36600085102264546 | 1e-05
143 | 0.04930509999394417 | 0.7168342014947475 | 0.765517685242224 | 0.3673237139632794 | 1e-05
144 | 0.0490318201482296 | 0.7171477848817965 | 0.7667940015206897 | 0.3554021435508309 | 1.0000000000000002e-06
145 | 0.04918621480464935 | 0.7201616696573231 | 0.7677822164123848 | 0.3711029550898432 | 1.0000000000000002e-06
146 | 0.04903709515929222 | 0.717130363582516 | 0.7665065530257804 | 0.368326447075977 | 1.0000000000000002e-06
147 | 0.049094948917627335 | 0.720823679029982 | 0.768544776459646 | 0.37476196073915324 | 1.0000000000000002e-06
148 | 0.04907181113958359 | 0.7167296736990645 | 0.7667018106807243 | 0.3649988602534311 | 1.0000000000000002e-06
149 | 0.04904184117913246 | 0.718210484137907 | 0.7671139893046166 | 0.3787860055208151 | 1.0000000000000002e-06
150 | 0.04912904277443886 | 0.7154404975523074 | 0.7667920374277589 | 0.3726446424747262 | 1.0000000000000002e-06
---
# Framework Versions
- **Transformers**: 4.44.2
- **Pytorch**: 2.4.1+cu121
- **Datasets**: 3.0.0
- **Tokenizers**: 0.19.1
|
[
"ANEM"
] |
mav23/Phi-3-medium-128k-instruct-GGUF
|
mav23
|
text-generation
|
[
"gguf",
"nlp",
"code",
"text-generation",
"multilingual",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-11-02T23:30:31Z |
2024-11-03T01:15:40+00:00
| 63 | 0 |
---
language:
- multilingual
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-medium-128k-instruct/resolve/main/LICENSE
pipeline_tag: text-generation
tags:
- nlp
- code
inference:
parameters:
temperature: 0.7
widget:
- messages:
- role: user
content: Can you provide ways to eat combinations of bananas and dragonfruits?
---
🎉 **Phi-3.5**: [[mini-instruct]](https://huggingface.co/microsoft/Phi-3.5-mini-instruct); [[MoE-instruct]](https://huggingface.co/microsoft/Phi-3.5-MoE-instruct) ; [[vision-instruct]](https://huggingface.co/microsoft/Phi-3.5-vision-instruct)
## Model Summary
The Phi-3-Medium-128K-Instruct is a 14B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Medium version in two variants [4k](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3-Medium-128K-Instruct showcased a robust and state-of-the-art performance among models of the same-size and next-size-up.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/Phi-3Build2024)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ [Phi-3 Cookbook](https://github.com/microsoft/Phi-3CookBook)
| | Short Context | Long Context |
| ------- | ------------- | ------------ |
| Mini | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-onnx) ; [[GGUF]](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct-onnx)|
| Small | 8K [[HF]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-8k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-small-128k-instruct-onnx-cuda)|
| Medium | 4K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-4k-instruct-onnx-cuda) | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)|
| Vision | | 128K [[HF]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct) ; [[ONNX]](https://huggingface.co/microsoft/Phi-3-vision-128k-instruct-onnx-cuda)|
## Intended Uses
**Primary use cases**
The model is intended for broad commercial and research use in English. The model provides uses for general purpose AI systems and applications which require :
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3-Medium-128k-Instruct has been integrated in the development version (4.40.2) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3-Medium-128k-Instruct is also available in [Azure AI Studio](https://aka.ms/phi3-azure-ai).
### Tokenizer
Phi-3-Medium-128k-Instruct supports a vocabulary size of up to `32064` tokens. The [tokenizer files](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct/blob/main/added_tokens.json) already provide placeholder tokens that can be used for downstream fine-tuning, but they can also be extended up to the model's vocabulary size.
### Chat Format
Given the nature of the training data, the Phi-3-Medium-128k-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model_id = "microsoft/Phi-3-medium-128k-instruct"
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
*Some applications/frameworks might not include a BOS token (`<s>`) at the start of the conversation. Please ensure that it is included since it provides more reliable results.*
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3-Medium-128k-Instruct has 14B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 128k tokens
* GPUs: 512 H100-80G
* Training time: 42 days
* Training data: 4.8T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
* Release dates: The model weight is released on May 21, 2024.
### Datasets
Our training data includes a wide variety of sources, totaling 4.8 trillion tokens (including 10% multilingual), and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
We are focusing on the quality of data that could potentially improve the reasoning ability for the model, and we filter the publicly available documents to contain the correct level of knowledge. As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for reasoning for the small size models. More details about data can be found in the [Phi-3 Technical Report](https://aka.ms/phi3-tech-report).
## Benchmarks
We report the results for Phi-3-Medium-128k-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Mixtral-8x22b, Gemini-Pro, Command R+ 104B, Llama-3-70B-Instruct, GPT-3.5-Turbo-1106, and GPT-4-Turbo-1106(Chat).
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
|Benchmark|Phi-3-Medium-128k-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|---------|-----------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
|AGI Eval<br>5-shot|49.7|50.1|54.0|56.9|48.4|49.0|59.6|
|MMLU<br>5-shot|76.6|73.8|76.2|80.2|71.4|66.7|84.0|
|BigBench Hard<br>3-shot|77.9|74.1|81.8|80.4|68.3|75.6|87.7|
|ANLI<br>7-shot|57.3|63.4|65.2|68.3|58.1|64.2|71.7|
|HellaSwag<br>5-shot|81.6|78.0|79.0|82.6|78.8|76.2|88.3|
|ARC Challenge<br>10-shot|91.0|86.9|91.3|93.0|87.4|88.3|95.6|
|ARC Easy<br>10-shot|97.6|95.7|96.9|98.2|96.3|96.1|98.8|
|BoolQ<br>2-shot|86.5|86.1|82.7|89.1|79.1|86.4|91.3|
|CommonsenseQA<br>10-shot|82.2|82.0|82.0|84.4|79.6|81.8|86.7|
|MedQA<br>2-shot|67.6|59.2|67.9|78.5|63.4|58.2|83.7|
|OpenBookQA<br>10-shot|87.2|86.8|88.6|91.8|86.0|86.4|93.4|
|PIQA<br>5-shot|87.8|86.4|85.0|85.3|86.6|86.2|90.1|
|Social IQA<br>5-shot|79.0|75.3|78.2|81.1|68.3|75.4|81.7|
|TruthfulQA (MC2)<br>10-shot|74.3|57.8|67.4|81.9|67.7|72.6|85.2|
|WinoGrande<br>5-shot|78.9|77.0|75.3|83.3|68.8|72.2|86.7|
|TriviaQA<br>5-shot|73.9|82.8|84.5|78.5|85.8|80.2|73.3|
|GSM8K Chain of Thought<br>8-shot|87.5|78.3|83.8|93.5|78.1|80.4|94.2|
|HumanEval<br>0-shot|58.5|61.6|39.6|78.7|62.2|64.4|79.9|
|MBPP<br>3-shot|73.8|68.9|70.7|81.3|77.8|73.2|86.7|
|Average|77.3|75.0|76.3|82.5|74.3|75.4|85.2|
We take a closer look at different categories across 80 public benchmark datasets at the table below:
|Benchmark|Phi-3-Medium-128k-Instruct<br>14b|Command R+<br>104B|Mixtral<br>8x22B|Llama-3-70B-Instruct|GPT3.5-Turbo<br>version 1106|Gemini<br>Pro|GPT-4-Turbo<br>version 1106 (Chat)|
|--------|------------------------|--------|-------------|-------------------|-------------------|----------|------------------------|
| Popular aggregated benchmark | 72.3 | 69.9 | 73.4 | 76.3 | 67.0 | 67.5 | 80.5 |
| Reasoning | 83.2 | 79.3 | 81.5 | 86.7 | 78.3 | 80.4 | 89.3 |
| Language understanding | 75.3 | 75.7 | 78.7 | 77.9 | 70.4 | 75.3 | 81.6 |
| Code generation | 64.2 | 68.6 | 60.0 | 69.3 | 70.4 | 66.7 | 76.1 |
| Math | 52.9 | 45.3 | 52.5 | 59.7 | 52.8 | 50.9 | 67.1 |
| Factual knowledge | 47.5 | 60.3 | 60.6 | 52.4 | 63.4 | 54.6 | 45.9 |
| Multilingual | 62.2 | 67.8 | 69.8 | 62.0 | 67.0 | 73.4 | 78.2 |
| Robustness | 70.2 | 57.9 | 65.5 | 78.7 | 69.3 | 69.7 | 84.6 |
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-Medium model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [128k](https://huggingface.co/microsoft/Phi-3-medium-128k-instruct-onnx-cuda)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi3 Medium models across platforms and hardware.
Optimized phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML GPU acceleration is supported for Windows desktops GPUs (AMD, Intel, and NVIDIA).
Along with DML, ONNX Runtime provides cross platform support for Phi3 Medium across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-medium-128k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
[
"MEDQA"
] |
Vijayendra/Phi4-MedQA
|
Vijayendra
|
question-answering
|
[
"peft",
"safetensors",
"medicalQA",
"question-answering",
"en",
"dataset:bigbio/pubmed_qa",
"base_model:unsloth/phi-4-unsloth-bnb-4bit",
"base_model:adapter:unsloth/phi-4-unsloth-bnb-4bit",
"license:mit",
"region:us"
] | 2025-01-17T04:43:16Z |
2025-01-25T10:37:11+00:00
| 63 | 0 |
---
base_model: unsloth/phi-4-unsloth-bnb-4bit
datasets:
- bigbio/pubmed_qa
language:
- en
library_name: peft
license: mit
pipeline_tag: question-answering
tags:
- medicalQA
---
# Model Card for Model ID
The Phi-4 Medical QA Model is a fine-tuned version of the "unsloth/phi-4" language model, optimized for answering medical questions with clarity and detail. Leveraging the unsloth's advanced quantization techniques, this model provides accurate, context-aware responses tailored to the healthcare domain. It is particularly suited for applications like patient assistance, medical education, and evidence-based healthcare support.
## Model Details
The Phi-4 Medical QA Model builds upon the robust foundation provided by the "unsloth/phi-4" pre-trained language model. Fine-tuned on the PubMedQA dataset, it is specifically designed to answer complex medical questions by integrating domain-specific knowledge and language understanding capabilities.
The model employs several advanced techniques:
LoRA Fine-Tuning: Low-Rank Adaptation (LoRA) enhances parameter efficiency, allowing domain adaptation with minimal compute.
4-Bit Quantization: Memory usage is significantly reduced, making the model deployable on resource-constrained systems.
Gradient Checkpointing: Further optimizations for handling long sequences and reducing GPU memory usage.
The model is trained using the SFTTrainer library from the trl package, with parameters optimized for accuracy and resource efficiency.
Model Architecture
Base Model: "unsloth/phi-4"
Tokenization: Custom tokenizer from the unsloth framework
Fine-Tuning Techniques:
Targeted modules: q_proj, k_proj, v_proj, and others
LoRA Rank: 16
LoRA Alpha: 16
Dropout: 0 (optimized for this use case)
Training Dataset: PubMedQA (labeled fold0 source)
Hardware Used: NVIDIA A100 GPUs
## How to Use
```python
# Install required libraries
!pip install unsloth peft bitsandbytes accelerate transformers
# Import necessary modules
from transformers import AutoTokenizer
from unsloth import FastLanguageModel
# Define the MedQA prompt
medqa_prompt = """You are a medical QA system. Answer the following medical question clearly and in detail with complete sentences.
### Question:
{}
### Answer:
"""
# Load the model and tokenizer using unsloth
model_name = "Vijayendra/Phi4-MedQA"
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_name,
max_seq_length=2048,
dtype=None, # Use default precision
load_in_4bit=True, # Enable 4-bit quantization
device_map="auto" # Automatically map model to available devices
)
# Enable faster inference
FastLanguageModel.for_inference(model)
# Prepare the medical question
medical_question = "What are the common symptoms of diabetes?" # Replace with your medical question
inputs = tokenizer(
[medqa_prompt.format(medical_question)],
return_tensors="pt",
padding=True,
truncation=True,
max_length=1024
).to("cuda") # Ensure inputs are on the GPU
# Generate the output
outputs = model.generate(
**inputs,
max_new_tokens=512, # Allow for detailed responses
use_cache=True # Speeds up generation
)
# Decode and clean the response
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# Extract and print the generated answer
answer_text = response.split("### Answer:")[1].strip() if "### Answer:" in response else response.strip()
print(f"Question: {medical_question}")
print(f"Answer: {answer_text}")
```
### Model Output:
Question: What are the common symptoms of diabetes?
Answer: Diabetes is a chronic disease that affects the way the body processes blood sugar (glucose). There are two main types of diabetes: type 1 and type 2. Type 1 diabetes is an autoimmune disease in which the body's immune system attacks and destroys the insulin-producing cells in the pancreas. Type 2 diabetes is a metabolic disorder in which the body does not produce enough insulin or the body's cells do not respond properly to insulin. Both types of diabetes can lead to serious health complications if not properly managed.
The most common symptoms of diabetes include:
1. Increased thirst: People with diabetes may feel thirsty all the time, even after drinking plenty of fluids. This is because the body is trying to flush out excess sugar in the blood.
2. Frequent urination: People with diabetes may need to urinate more often than usual, even during the night. This is because the body is trying to get rid of excess sugar in the blood.
3. Increased hunger: People with diabetes may feel hungry all the time, even after eating a full meal. This is because the body is not able to use the sugar in the blood for energy.
4. Fatigue: People with diabetes may feel tired all the time, even after getting a good night's sleep. This is because the body is not able to use the sugar in the blood for energy.
5. Blurred vision: People with diabetes may have trouble seeing clearly, especially at night. This is because high blood sugar levels can damage the blood vessels in the eyes.
6. Slow healing of wounds: People with diabetes may have trouble healing from cuts, scrapes, and other wounds. This is because high blood sugar levels can damage the blood vessels and nerves in the skin.
7. Tingling or numbness in the hands or feet: People with diabetes may experience tingling or numbness in the hands or feet. This is because high blood sugar levels can damage the nerves in the body.
8. Unintended weight loss: People with diabetes may lose weight without trying. This is because the body is not able to use the sugar in the blood for energy and is instead breaking down muscle and fat for energy.
It is important to note that not everyone with diabetes will experience all of these symptoms. Some people may not experience any symptoms at all, especially in the early stages of the disease. If you are experiencing any of these symptoms, it is important to see a doctor for a proper diagnosis and treatment. Early diagnosis and treatment can help prevent serious health complications associated
### Intended Use
This model is intended for:
Answering medical and healthcare-related questions.
Supporting healthcare professionals and students with evidence-based insights when combined with a RAG system.
Enhancing patient care via interactive QA systems.
### Limitations
Domain Restriction: The model performs best on medical questions and may not generalize well to other domains.
Bias and Fairness: The model inherits biases from the PubMedQA dataset.
Hallucination Risks: As with all large language models, responses should be validated by professionals before application in critical scenarios.
### Framework versions
- PEFT 0.14.0
### Credit and Citation
This model is built upon and extends the "unsloth/phi-4" model. Special thanks to the UnsLOTH team for enabling efficient training and inference.
For more information about the "unsloth/phi-4" model:
@article{unsloth_phi4,
title={Phi-4: A Scalable Model for Long-Sequence Tasks},
author={UnsLOTH Team and Microsoft},
year={2025},
publisher={UnsLOTH},
}
@article{vijayendra_phi4_finetune,
title={Phi-4 Fine-Tuned for Medical QA},
author={Vijayendra Dwari},
year={2025},
publisher={Hugging Face},
}
|
[
"MEDQA",
"PUBMEDQA"
] |
ordlibrary/DeepSolana-GPT2
|
ordlibrary
| null |
[
"safetensors",
"gpt2",
"region:us"
] | 2025-01-22T01:03:36Z |
2025-01-22T23:45:14+00:00
| 63 | 1 |
---
{}
---
# **Deep Solana R1 Model Description**
**Model Name**: Deep Solana R1
**Developed By**: 8 Bit Labs, in collaboration with Solana Labs and DeepSeek
**Model Type**: Hybrid AI-Zero-Knowledge Proof Framework
**Framework**: Solana Blockchain + DeepSeek AI + Recursive ZK Proofs
**License**: Apache 2.0
**Release Date**: October 2024
---
## **Model Overview**
Deep Solana R1 is the **first production-ready framework** to unify **artificial intelligence (AI)**, **zero-knowledge proofs (ZKPs)**, and **high-performance blockchain technology** on Solana. Built on the foundation of **DeepSeek R1**, a 48-layer transformer model trained on **14 million Solana transactions**, Deep Solana R1 redefines scalability, privacy, and intelligence in decentralized systems.
The model introduces **recursive neural proofs**, a novel cryptographic primitive that enables **privacy-preserving, context-aware smart contracts**. With **28,000 AI-ZK transactions per second (TPS)** and **93× faster ZK verification** than traditional systems, Deep Solana R1 sets a new standard for verifiable decentralized intelligence.
---
## **Key Innovations**
### **1. Recursive Zero-Knowledge Proofs (ZKRs)**
- **O(log n) Verification**: Achieves logarithmic proof verification time using FractalGroth16 proofs.
- **AI-Guided Batching**: DeepSeek R1 predicts optimal proof groupings to minimize latency.
- **Topology-Aware Pruning**: Reduces proof size by **78%** using patented algorithms.
**Impact**:
- **0.3s proof time** (vs. 2.4s baseline).
- **0.002 SOL privacy cost** (vs. 0.07 SOL).
---
### **2. DeepSeek R1 AI Model**
- **48-Layer Transformer**: Trained on 14M Solana transactions for real-time optimization.
- **Self-Optimizing Circuits**: Adjusts ZK constraints based on live network data.
- **Fraud Detection**: Identifies malicious transactions with **94.2% accuracy**.
**Features**:
- **AI-Knowledge Proofs (AKPs)**: Dynamically generates ZK constraints via reinforcement learning.
- **Neural Proof Compression**: Reduces proof size using topology-aware pruning.
- **Self-Optimizing Circuits**: Latency-aware proof strategies using real-time network metrics.
---
### **3. Hybrid Verification System**
- **ZK-SNARKs**: Base layer for transaction correctness.
- **Neural Attestations**: AI layer for contextual validation (e.g., fraud detection, market manipulation).
**Mathematical Formulation**:
\[
\pi_{\text{final}} = \text{ZK-Prove}(\text{AI-Validate}(S_t), \mathcal{C}_{\text{AI}})
\]
*Where \( \mathcal{C}_{\text{AI}} \) = AI-optimized constraints.*
---
## **Performance Metrics**
| **Metric** | **Baseline (Solana)** | **Deep Solana R1** |
|--------------------------|-----------------------|---------------------|
| Avg. Proof Time | 2.4s | 0.3s |
| Verification Throughput | 12K TPS | 28K TPS |
| Privacy Overhead | 0.07 SOL | 0.002 SOL |
| State Accuracy | N/A | 94.2% |
| Energy/TX (kWh) | 0.001 | 0.00037 |
---
## **Use Cases**
### **1. Decentralized Finance (DeFi)**
- **Private Swaps**: Trade tokens without exposing wallet balances.
- **AI-Optimized Yield Farming**:
```solidity
contract AIVault {
function harvest() external {
AI.optimize(yieldStrategy); // Saves 40% in gas fees
}
}
```
### **2. Healthcare**
- **ZK-Protected Records**: Share medical data without exposing patient IDs.
### **3. Government**
- **Fraud-Free Voting**: ZK proofs validate eligibility without revealing votes.
---
## **How to Use**
### **For Developers**
1. Install the Deep Solana R1 SDK:
```bash
npm install @solana/deep-solana-r1
```
2. Deploy a smart contract:
```rust
use anchor_lang::prelude::*;
#[program]
pub mod my_program {
use super::*;
pub fn initialize(ctx: Context<Initialize>) -> Result<()> {
Ok(())
}
}
```
### **For Security Audits**
1. Run a security scan:
```bash
deep-solana-r1 scan --contract my_program.so
```
2. Review the security report:
```json
{
"Risk Score": 2,
"Compute Unit Efficiency": "High",
"Vulnerabilities": [],
"Optimization Suggestions": []
}
```
---
## **Ethical Considerations**
- **Privacy**: All transaction data is anonymized.
- **Transparency**: Datasets and code are open-source and auditable.
- **Energy Efficiency**: Recursive proofs reduce blockchain energy consumption by **63%**.
---
## **Limitations**
- **Quantum Vulnerability**: Not yet quantum-safe (planned for Q4 2024).
- **Adoption Curve**: Requires integration with existing Solana dApps.
---
## **Future Work**
- **Quantum-Safe Proofs**: Integration of ML-weakened lattices.
- **Decentralized Prover Networks**: Proof staking for enhanced scalability.
---
## **Citation**
If you use Deep Solana R1 in your research or projects, please cite:
```bibtex
@misc{deepsolanar1,
title={Deep Solana R1: A Novel Framework for AI-Guided Recursive Zero-Knowledge Proofs on High-Performance Blockchains},
author={8 Bit Labs, Solana Labs, DeepSeek},
year={2024},
url={https://github.com/8bit-org/DeepSolanaR1}
}
```
---
## **License**
Apache 2.0
---
## **Contact**
For questions, collaborations, or support, contact:
- **Email**: [email protected]
- **GitHub**: [github.com/8bit-org/DeepSolanaR1](https://github.com/8bit-org/DeepSolanaR1)
---
## **Metadata YAML**
```yaml
language:
- en
license: apache-2.0
library_name: solana
tags:
- blockchain
- solana
- smart-contracts
- zero-knowledge-proofs
- ai
- rust
- anchor-framework
- cross-chain
- defi
- nft
datasets:
- solana-transactions
- recursive-proofs
- metaplex-nft-metadata
metrics:
- transaction-throughput
- proof-time
- energy-consumption
- privacy-overhead
- fraud-detection-accuracy
pipeline_tag: text-generation
co2_eq_emissions:
value: 0.00017575
unit: kg CO₂eq/tx
source: 8-bit-labs
region: global
description: "Calculated based on global average CO₂eq emissions per kWh (0.475 kg CO₂eq/kWh) and Deep Solana R1's energy consumption of 0.00037 kWh per transaction."
model-index:
- name: Deep Solana R1
results:
- task:
type: smart-contract-optimization
dataset:
type: solana-transactions
name: Solana Transaction Dataset
metrics:
- type: transaction-throughput
value: 28000
name: Transactions Per Second (TPS)
- type: proof-time
value: 0.3
name: Average Proof Time (seconds)
- type: energy-consumption
value: 0.00037
name: Energy per Transaction (kWh)
- type: fraud-detection-accuracy
value: 94.2
name: Fraud Detection Accuracy (%)
- task:
type: cross-chain-interoperability
dataset:
type: wormhole-transactions
name: Wormhole Cross-Chain Transactions
metrics:
- type: transaction-throughput
value: 12000
name: Cross-Chain Transactions Per Second (TPS)
- type: latency
value: 2.5
name: Average Cross-Chain Latency (seconds)
```
---
**Visuals**:
- **Architecture Diagram**: [Link](https://i.imgur.com/deepseekzk.png)
- **Performance Benchmarks**: [Link](https://i.imgur.com/energyplot.png)
---
**Welcome to the future of Solana development. Fast, secure, and smarter than ever.** 🚀
- 🐾 Chesh
|
[
"MEDICAL DATA"
] |
microsoft/vq-diffusion-ithq
|
microsoft
| null |
[
"diffusers",
"arxiv:2205.16007",
"license:mit",
"diffusers:VQDiffusionPipeline",
"region:us"
] | 2022-11-02T18:58:01Z |
2023-07-05T16:18:46+00:00
| 62 | 14 |
---
license: mit
---
# VQ Diffusion
* [Paper](https://arxiv.org/abs/2205.16007.pdf)
* [Original Repo](https://github.com/microsoft/VQ-Diffusion)
* **Authors**: Shuyang Gu, Dong Chen, et al.
```python
#!pip install diffusers[torch] transformers
import torch
from diffusers import VQDiffusionPipeline
pipeline = VQDiffusionPipeline.from_pretrained("microsoft/vq-diffusion-ithq", torch_dtype=torch.float16)
pipeline = pipeline.to("cuda")
output = pipeline("teddy bear playing in the pool", truncation_rate=1.0)
image = output.images[0]
image.save("./teddy_bear.png")
```

**Contribution**: This model was contribution by [williamberman](https://huggingface.co/williamberman) in [VQ-diffusion](https://github.com/huggingface/diffusers/pull/658).
|
[
"BEAR"
] |
AntoineBlanot/flan-t5-xxl-classif-3way
|
AntoineBlanot
|
zero-shot-classification
|
[
"transformers",
"pytorch",
"t5",
"zero-shot-classification",
"en",
"dataset:multi_nli",
"dataset:snli",
"dataset:scitail",
"model-index",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-05-11T01:14:08Z |
2023-05-18T08:44:17+00:00
| 62 | 3 |
---
datasets:
- multi_nli
- snli
- scitail
language:
- en
metrics:
- accuracy
- f1
pipeline_tag: zero-shot-classification
model-index:
- name: AntoineBlanot/flan-t5-xxl-classif-3way
results:
- task:
type: nli
name: Natural Language Inference
dataset:
name: MultiNLI
type: multi_nli
split: validation_matched
metrics:
- type: accuracy
value: 0.9230769230769231
name: Validation (matched) accuracy
- type: f1
value: 0.9225172687920663
name: Validation (matched) f1
- task:
type: nli
name: Natural Language Inference
dataset:
name: MultiNLI
type: multi_nli
split: validation_mismatched
metrics:
- type: accuracy
value: 0.9222945484133441
name: Validation (mismatched) accuracy
- type: f1
value: 0.9216699467726924
name: Validation (mismatched) f1
- task:
type: nli
name: Natural Language Inference
dataset:
name: SNLI
type: snli
split: validation
metrics:
- type: accuracy
value: 0.9418817313554155
name: Validation accuracy
- type: f1
value: 0.9416213776111287
name: Validation f1
- task:
type: nli
name: Natural Language Inference
dataset:
name: SciTail
type: scitail
split: validation
metrics:
- type: accuracy
value: 0.9662576687116564
name: Validation accuracy
- type: f1
value: 0.6471347983817357
name: Validation f1
---
# T5ForSequenceClassification
**T5ForSequenceClassification** adapts the original [T5](https://github.com/google-research/text-to-text-transfer-transformer) architecture for sequence classification tasks.
T5 was originally built for text-to-text tasks and excels in it.
It can handle any NLP task if it has been converted to a text-to-text format, including sequence classification task!
You can find [here](https://huggingface.co/google/flan-t5-base?text=Premise%3A++At+my+age+you+will+probably+have+learnt+one+lesson.+Hypothesis%3A++It%27s+not+certain+how+many+lessons+you%27ll+learn+by+your+thirties.+Does+the+premise+entail+the+hypothesis%3F) how the original T5 is used for sequence classification task.
Our motivations for building **T5ForSequenceClassification** is that the full original T5 architecture is not needed for most NLU tasks. Indeed, NLU tasks generally do not require to generate text and thus a large decoder is unnecessary.
By removing the decoder we can *half the original number of parameters* (thus half the computation cost) and *efficiently optimize* the network for the given task.
## Table of Contents
0. [Usage](#usage)
1. [Why use T5ForSequenceClassification?](#why-use-t5forsequenceclassification)
2. [T5ForClassification vs T5](#t5forclassification-vs-t5)
3. [Results](#results)
## Usage
**T5ForSequenceClassification** supports the task of zero-shot classification.
It can direclty be used for:
- topic classification
- intent recognition
- boolean question answering
- sentiment analysis
- and any other task which goal is to clasify a text...
Since the *T5ForClassification* class is currently not supported by the transformers library, you cannot direclty use this model on the Hub.
To use **T5ForSequenceClassification**, you will have to install additional packages and model weights.
You can find instructions [here](https://github.com/AntoineBlanot/zero-nlp).
## Why use T5ForSequenceClassification?
Models based on the [BERT](https://huggingface.co/bert-large-uncased) architecture like [RoBERTa](https://huggingface.co/roberta-large) and [DeBERTa](https://huggingface.co/microsoft/deberta-v2-xxlarge) have shown very strong performance on sequence classification task and are still widely used today.
However, those models only scale up to ~1.5B parameters (DeBERTa xxlarge) resulting in a limited knowledge compare to bigger models.
On the other hand, models based on the T5 architecture scale up to ~11B parameters (t5-xxl) and innovations with this architecture are very recent and keeps improving ([mT5](https://huggingface.co/google/mt5-xxl), [Flan-T5](https://huggingface.co/google/flan-t5-xxl), [UL2](https://huggingface.co/google/ul2), [Flan-UL2](https://huggingface.co/google/flan-ul2), and probably more...)
## T5ForClassification vs T5
**T5ForClassification** Architecture:
- Encoder: same as original T5
- Decoder: only the first layer (for pooling purpose)
- Classification head: simple Linear layer on top of the decoder
Benefits and Drawbacks:
- (**+**) Keeps T5 encoding strength
- (**+**) Parameters size is half
- (**+**) Interpretable outputs (class logits)
- (**+**) No generation mistakes and faster prediction (no generation latency)
- (**-**) Looses text-to-text ability
## Results
Results on the validation data of **training tasks**:
| Dataset | Accuracy | F1 |
|:-------:|:--------:|:--:|
| MNLI (m)| 0.923 | 0.923 |
| MNLI (mm) | 0.922 | 0.922 |
| SNLI | 0.942 | 0.942 |
| SciTail | 0.966 | 0.647 |
Results on validation data of **unseen tasks** (zero-shot):
| Dataset | Accuracy | F1 |
|:-------:|:--------:|:--:|
| ?| ? | ? |
Special thanks to [philschmid](https://huggingface.co/philschmid) for making a Flan-T5-xxl [checkpoint](https://huggingface.co/philschmid/flan-t5-xxl-sharded-fp16) in fp16.
|
[
"SCITAIL"
] |
SYNLP/ChiMed-GPT-1.0
|
SYNLP
|
text-generation
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"arxiv:2311.03301",
"arxiv:2311.06025",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-11-11T05:36:12Z |
2023-11-15T00:17:41+00:00
| 62 | 8 |
---
license: mit
---
# ChiMed-GPT
ChiMed-GPT is a Chinese medical large language model (LLM) built by continually training [Ziya-v2](https://arxiv.org/abs/2311.03301) on Chinese medical data, where pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF) are comprehensively performed on it.
More information about the model is coming soon.
## Citation
If you use or extend our work, please cite the following [paper](https://arxiv.org/abs/2311.06025):
```
@article{USTC-ChiMed-GPT,
title="{ChiMed-GPT: A Chinese Medical Large Language Model with Full Training Regime and Better Alignment to Human Preferences}",
author={Yuanhe Tian, Ruyi Gan, Yan Song, Jiaxing Zhang, Yongdong Zhang},
journal={arXiv preprint arXiv:2311.06025},
year={2023},
}
```
## Usage
```python
from transformers import AutoTokenizer
from transformers import LlamaForCausalLM
import torch
query="[human]:感冒怎么处理?\n[bot]:"
model = LlamaForCausalLM.from_pretrained('SYNLP/ChiMed-GPT-1.0', torch_dtype=torch.float16, device_map="auto").eval()
tokenizer = AutoTokenizer.from_pretrained(ckpt)
input_ids = tokenizer(query, return_tensors="pt").input_ids.to('cuda:0')
generate_ids = model.generate(
input_ids,
max_new_tokens=512,
do_sample = True,
top_p = 0.9)
output = tokenizer.batch_decode(generate_ids)[0]
print(output)
```
## Disclaimer
Please note that the content generated by ChiMed-GPT, including any advice, suggestions, information, or recommendations, does not reflect our views or beliefs. The responses provided by the large language model should not be considered as endorsements, opinions, or advice from us. We do not take responsibility for the accuracy, reliability, or appropriateness of the information provided. Users should exercise their own judgment and discretion when interpreting and using the information generated by the large language model.
|
[
"MEDICAL DATA"
] |
ntc-ai/SDXL-LoRA-slider.pixar-style
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-11T16:46:56Z |
2024-02-06T00:30:20+00:00
| 62 | 7 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/pixar-style_17_3.0.png
widget:
- text: pixar-style
output:
url: images/pixar-style_17_3.0.png
- text: pixar-style
output:
url: images/pixar-style_19_3.0.png
- text: pixar-style
output:
url: images/pixar-style_20_3.0.png
- text: pixar-style
output:
url: images/pixar-style_21_3.0.png
- text: pixar-style
output:
url: images/pixar-style_22_3.0.png
inference: false
instance_prompt: pixar-style
---
# ntcai.xyz slider - pixar-style (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/pixar-style_17_-3.0.png" width=256 height=256 /> | <img src="images/pixar-style_17_0.0.png" width=256 height=256 /> | <img src="images/pixar-style_17_3.0.png" width=256 height=256 /> |
| <img src="images/pixar-style_19_-3.0.png" width=256 height=256 /> | <img src="images/pixar-style_19_0.0.png" width=256 height=256 /> | <img src="images/pixar-style_19_3.0.png" width=256 height=256 /> |
| <img src="images/pixar-style_20_-3.0.png" width=256 height=256 /> | <img src="images/pixar-style_20_0.0.png" width=256 height=256 /> | <img src="images/pixar-style_20_3.0.png" width=256 height=256 /> |
See more at [https://sliders.ntcai.xyz/sliders/app/loras/c48d077a-a9e0-4bc0-a9a8-e607835a7f1d](https://sliders.ntcai.xyz/sliders/app/loras/c48d077a-a9e0-4bc0-a9a8-e607835a7f1d)
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
pixar-style
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.pixar-style', weight_name='pixar-style.safetensors', adapter_name="pixar-style")
# Activate the LoRA
pipe.set_adapters(["pixar-style"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, pixar-style"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1496+ unique and diverse LoRAs along with 14602+ slider merges, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful <strong>NTC Slider Factory</strong> LoRA creator, allowing you to craft your own custom LoRAs and merges opening up endless possibilities.
Your support on Patreon will allow us to continue developing new models and tools.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.on-a-ship
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-19T19:22:12Z |
2024-01-19T19:22:16+00:00
| 62 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/on a ship.../on a ship_17_3.0.png
widget:
- text: on a ship
output:
url: images/on a ship_17_3.0.png
- text: on a ship
output:
url: images/on a ship_19_3.0.png
- text: on a ship
output:
url: images/on a ship_20_3.0.png
- text: on a ship
output:
url: images/on a ship_21_3.0.png
- text: on a ship
output:
url: images/on a ship_22_3.0.png
inference: false
instance_prompt: on a ship
---
# ntcai.xyz slider - on a ship (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/on a ship_17_-3.0.png" width=256 height=256 /> | <img src="images/on a ship_17_0.0.png" width=256 height=256 /> | <img src="images/on a ship_17_3.0.png" width=256 height=256 /> |
| <img src="images/on a ship_19_-3.0.png" width=256 height=256 /> | <img src="images/on a ship_19_0.0.png" width=256 height=256 /> | <img src="images/on a ship_19_3.0.png" width=256 height=256 /> |
| <img src="images/on a ship_20_-3.0.png" width=256 height=256 /> | <img src="images/on a ship_20_0.0.png" width=256 height=256 /> | <img src="images/on a ship_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
on a ship
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.on-a-ship', weight_name='on a ship.safetensors', adapter_name="on a ship")
# Activate the LoRA
pipe.set_adapters(["on a ship"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, on a ship"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1140+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
semiotic/T5-3B-SynQL-KaggleDBQA-Train-Run-02
|
semiotic
|
text-generation
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"code",
"text-generation",
"en",
"dataset:semiotic/SynQL-KaggleDBQA-Train",
"arxiv:2010.12725",
"base_model:google-t5/t5-3b",
"base_model:finetune:google-t5/t5-3b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-07-12T15:45:17Z |
2024-10-25T20:24:33+00:00
| 62 | 0 |
---
base_model:
- google-t5/t5-3b
datasets:
- semiotic/SynQL-KaggleDBQA-Train
language:
- en
license: apache-2.0
pipeline_tag: text-generation
tags:
- code
---
# Model Card for T5-3B/SynQL-KaggleDBQA-Train-Run-02
- Developed by: Semiotic Labs
- Model type: [Text to SQL]
- License: [Apache-2.0]
- Finetuned from model: [google-t5/t5-3b](https://huggingface.co/google-t5/t5-3b)
- Dataset used for finetuning: [semiotic/SynQL-KaggleDBQA-Train](https://huggingface.co/datasets/semiotic/SynQL-KaggleDBQA-Train/blob/main/README.md)
## Model Context
Example metadata can be found below, context represents the prompt that is presented to the model. Database schemas follow the encoding method proposed by [Shaw et al (2020)](https://arxiv.org/pdf/2010.12725).
```
"query": "SELECT count(*) FROM singer",
"question": "How many singers do we have?",
"context": "How many singers do we have? | concert_singer | stadium : stadium_id, location, name, capacity, highest, lowest, average | singer : singer_id, name, country, song_name, song_release_year, age, is_male | concert : concert_id, concert_name, theme, stadium_id, year | singer_in_concert : concert_id, singer_id",
"db_id": "concert_singer",
```
## Model Results
Evaluation set: [KaggleDBQA/test](https://github.com/Chia-Hsuan-Lee/KaggleDBQA)
Evaluation metrics: [Execution Accuracy]
| Model | Data | Run | Execution Accuracy |
|-------|------|-----|-------------------|
| T5-3B | semiotic/SynQL-KaggleDBQA | 00 | 0.3514 |
| T5-3B | semiotic/SynQL-KaggleDBQA | 01 | 0.3514 |
| T5-3B | semiotic/SynQL-KaggleDBQA | 02 | 0.3514 |
|
[
"CHIA"
] |
Salesforce/xgen-mm-phi3-mini-base-r-v1.5
|
Salesforce
|
image-text-to-text
|
[
"safetensors",
"xgenmm",
"image-text-to-text",
"conversational",
"custom_code",
"en",
"arxiv:2408.08872",
"license:apache-2.0",
"region:us"
] | 2024-08-12T23:32:56Z |
2025-02-03T06:11:31+00:00
| 62 | 21 |
---
language:
- en
license: apache-2.0
pipeline_tag: image-text-to-text
---
# Model description
`xGen-MM` is a series of the latest foundational Large Multimodal Models (LMMs) developed by Salesforce AI Research. This series advances upon the successful designs of the `BLIP` series, incorporating fundamental enhancements that ensure a more robust and superior foundation. These models have been trained at scale on high-quality image caption datasets and interleaved image-text data.
In the v1.5 (08/2024) release, we present a series of XGen-MM models including:
- [🤗 xGen-MM-instruct-interleave (our main instruct model)](https://huggingface.co/Salesforce/xgen-mm-phi3-mini-instruct-interleave-r-v1.5): `xgen-mm-phi3-mini-instruct-interleave-r-v1.5`
- This model has higher overall scores than [xGen-MM-instruct](https://huggingface.co/Salesforce/xgen-mm-phi3-mini-instruct-singleimg-r-v1.5) on both single-image and multi-image benchmarks.
- [🤗 xGen-MM-base](https://huggingface.co/Salesforce/xgen-mm-phi3-mini-base-r-v1.5): `xgen-mm-phi3-mini-base-r-v1.5`
- [🤗 xGen-MM-instruct](https://huggingface.co/Salesforce/xgen-mm-phi3-mini-instruct-singleimg-r-v1.5): `xgen-mm-phi3-mini-instruct-singleimg-r-v1.5`
- [🤗 xGen-MM-instruct-dpo](https://huggingface.co/Salesforce/xgen-mm-phi3-mini-instruct-dpo-r-v1.5): `xgen-mm-phi3-mini-instruct-dpo-r-v1.5`
For more details, check out our [tech report](https://arxiv.org/pdf/2408.08872), [fine-tuning code](https://github.com/salesforce/LAVIS/tree/xgen-mm), and project page (coming soon).
# Results
### Few-shot Evaluation on Base model (without instruction tuning)
| Model | Shot | VQAv2 | TextVQA | OKVQA | COCO | NoCaps | TextCaps |
|:--------------|:-----|:------|:--------|:------|:------|:-------|:---------|
| Flamingo-3B | 0 | 49.2 | 30.1 | 41.2 | 73.0 | - | - |
| | 4 | 53.2 | 32.7 | 43.3 | 85.0 | - | - |
| | 8 | 55.4 | 32.4 | 44.6 | 90.6 | - | - |
| MM1-3B | 0 | 46.2 | 29.4 | 26.1 | 73.5 | 55.6 | 63.3 |
| | 4 | 57.9 | 45.3 | 44.6 | **112.3** | 99.7 | 84.1 |
| | 8 | 63.6 | 44.6 | 48.4 | **114.6** | **104.7** | 88.8 |
| xGen-MM-base | 0 | 43.1 | 34.0 | 28.0 | 67.2 | 82.6 | 69.5 |
| | 4 | **66.3**| **54.2**| **48.9**| 107.6 | **100.8**| **89.9** |
| | 8 | **66.9**| **55.3**| **50.1**| 109.8| 104.6| **94.0**|
### Showcases of In-Context Learning
Below are some qualitative examples of the multi-modal in-context learning capacity of our base model.
<img src="icl_examples/art.png" alt="Art" width=500>
<img src="icl_examples/animal.png" alt="Animal" width=500>
<img src="icl_examples/street.png" alt="Street" width=500>
# How to use
Please check out our [inference notebook](demo.ipynb) for example code to use our model.
# Reproducibility:
The pretraining evaluation is implemented based on [OpenFlamingo: An open-source framework for training large multimodal models.](https://github.com/mlfoundations/open_flamingo).
Few-shot examples are randomly drawn so there will be some variance with different random seeds.
# Bias, Risks, Limitations, and Ethical Considerations
The main data sources are from the internet, including webpages,
image stock sites, and curated datasets released by the research community. We have excluded certain data, such as LAION, due to known CSAM concerns.
The model may be subject to bias from the original data source, as well as bias from LLMs and commercial APIs.
We strongly recommend users assess safety and fairness before applying to downstream applications.
# Ethical Considerations
This release is for research purposes only in support of an academic paper. Our models, datasets, and code are not specifically designed or evaluated for all downstream purposes. We strongly recommend users evaluate and address potential concerns related to accuracy, safety, and fairness before deploying this model. We encourage users to consider the common limitations of AI, comply with applicable laws, and leverage best practices when selecting use cases, particularly for high-risk scenarios where errors or misuse could significantly impact people’s lives, rights, or safety. For further guidance on use cases, refer to our AUP and AI AUP.
# License
Our code and weights are released under the [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt) license.
# Code acknowledgment
Our training code is based on [OpenFlamingo: An open-source framework for training large multimodal models.](https://github.com/mlfoundations/open_flamingo), and part of our data preprocessing code is adapted from [LLaVA](https://github.com/haotian-liu/LLaVA).
Our evaluation code is based on [VLMEvalKit: Open-source evaluation toolkit of large vision-language models (LVLMs)](https://github.com/open-compass/VLMEvalKit).
We thank the authors for their open-source implementations.
# Citation
```
@misc{blip3-xgenmm,
author = {Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, Shrikant Kendre, Jieyu Zhang, Can Qin, Shu Zhang, Chia-Chih Chen, Ning Yu, Juntao Tan, Tulika Manoj Awalgaonkar, Shelby Heinecke, Huan Wang, Yejin Choi, Ludwig Schmidt, Zeyuan Chen, Silvio Savarese, Juan Carlos Niebles, Caiming Xiong, Ran Xu},
title = {xGen-MM (BLIP-3): A Family of Open Large Multimodal Models},
year = {2024},
eprint = {2408.08872},
archivePrefix = {arXiv},
primaryClass = {cs.CV},
url = {https://arxiv.org/abs/2408.08872},
}
```
# Troubleshoot
1. If you missed any packages, please consider the following
```
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu121
pip install open_clip_torch==2.24.0
pip install einops
pip install einops-exts
pip install transformers==4.41.1
```
|
[
"CHIA"
] |
RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2402.00838",
"endpoints_compatible",
"region:us"
] | 2024-09-18T19:55:45Z |
2024-09-18T23:32:49+00:00
| 62 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
OLMo-7B-0424-hf - GGUF
- Model creator: https://huggingface.co/allenai/
- Original model: https://huggingface.co/allenai/OLMo-7B-0424-hf/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [OLMo-7B-0424-hf.Q2_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q2_K.gguf) | Q2_K | 2.44GB |
| [OLMo-7B-0424-hf.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.IQ3_XS.gguf) | IQ3_XS | 2.69GB |
| [OLMo-7B-0424-hf.IQ3_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.IQ3_S.gguf) | IQ3_S | 2.83GB |
| [OLMo-7B-0424-hf.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q3_K_S.gguf) | Q3_K_S | 2.83GB |
| [OLMo-7B-0424-hf.IQ3_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.IQ3_M.gguf) | IQ3_M | 2.99GB |
| [OLMo-7B-0424-hf.Q3_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q3_K.gguf) | Q3_K | 3.16GB |
| [OLMo-7B-0424-hf.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q3_K_M.gguf) | Q3_K_M | 3.16GB |
| [OLMo-7B-0424-hf.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q3_K_L.gguf) | Q3_K_L | 3.44GB |
| [OLMo-7B-0424-hf.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.IQ4_XS.gguf) | IQ4_XS | 3.49GB |
| [OLMo-7B-0424-hf.Q4_0.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q4_0.gguf) | Q4_0 | 3.66GB |
| [OLMo-7B-0424-hf.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.IQ4_NL.gguf) | IQ4_NL | 3.68GB |
| [OLMo-7B-0424-hf.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q4_K_S.gguf) | Q4_K_S | 3.69GB |
| [OLMo-7B-0424-hf.Q4_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q4_K.gguf) | Q4_K | 3.9GB |
| [OLMo-7B-0424-hf.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q4_K_M.gguf) | Q4_K_M | 3.9GB |
| [OLMo-7B-0424-hf.Q4_1.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q4_1.gguf) | Q4_1 | 4.05GB |
| [OLMo-7B-0424-hf.Q5_0.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q5_0.gguf) | Q5_0 | 4.44GB |
| [OLMo-7B-0424-hf.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q5_K_S.gguf) | Q5_K_S | 4.44GB |
| [OLMo-7B-0424-hf.Q5_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q5_K.gguf) | Q5_K | 4.56GB |
| [OLMo-7B-0424-hf.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q5_K_M.gguf) | Q5_K_M | 4.56GB |
| [OLMo-7B-0424-hf.Q5_1.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q5_1.gguf) | Q5_1 | 4.83GB |
| [OLMo-7B-0424-hf.Q6_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q6_K.gguf) | Q6_K | 5.26GB |
| [OLMo-7B-0424-hf.Q8_0.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-0424-hf-gguf/blob/main/OLMo-7B-0424-hf.Q8_0.gguf) | Q8_0 | 6.82GB |
Original model description:
---
license: apache-2.0
datasets:
- allenai/dolma
language:
- en
---
<img src="https://allenai.org/olmo/olmo-7b-animation.gif" alt="OLMo Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for OLMo 7B April 2024
OLMo 7B April 2024 is an updated version of the original [OLMo 7B](https://huggingface.co/allenai/OLMo-7B) model rocking a 24 point increase in MMLU, among other evaluations improvements, from an improved version of the Dolma dataset and staged training.
**This version is for direct use with HuggingFace Transformers** from v4.40 on.
OLMo is a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models.
The OLMo models are trained on the [Dolma](https://huggingface.co/datasets/allenai/dolma) dataset.
We release all code, checkpoints, logs, and details involved in training these models.
## Model Details
The core models released in this batch are the following:
| Size | Training Tokens | Layers | Hidden Size | Attention Heads | Context Length |
|------|--------|---------|-------------|-----------------|----------------|
| [OLMo 1B](https://huggingface.co/allenai/OLMo-1B) | 3 Trillion |16 | 2048 | 16 | 2048 |
| [OLMo 7B](https://huggingface.co/allenai/OLMo-7B) | 2.5 Trillion | 32 | 4096 | 32 | 2048 |
| [OLMo 7B Twin 2T](https://huggingface.co/allenai/OLMo-7B-Twin-2T) | 2 Trillion | 32 | 4096 | 32 | 2048 |
| [OLMo 7B April 2024](https://huggingface.co/allenai/OLMo-7B-0424-hf) | 2.05 Trillion | 32 | 4096 | 32 | 4096 |
*Note: OLMo 7B April 2024 also includes QKV clipping.*
To load a specific model revision with HuggingFace, simply add the argument `revision`:
```bash
olmo = AutoModelForCausalLM.from_pretrained("allenai/OLMo-7B-0424-hf", revision="step1000-tokens4B")
```
All revisions/branches are listed in the file `revisions.txt`.
Or, you can access all the revisions for the models via the following code snippet:
```python
from huggingface_hub import list_repo_refs
out = list_repo_refs("allenai/OLMo-7B-0424-hf")
branches = [b.name for b in out.branches]
```
### Model Description
- **Developed by:** Allen Institute for AI (AI2)
- **Supported by:** Databricks, Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard University, AMD, CSC (Lumi Supercomputer), UW
- **Model type:** a Transformer style autoregressive language model.
- **Language(s) (NLP):** English
- **License:** The code and model are released under Apache 2.0.
- **Contact:** Technical inquiries: `olmo at allenai dot org`. Press: `press at allenai dot org`
- **Date cutoff:** Oct. 2023, with most data from Feb./March 2023 based on Dolma dataset version.
### Model Sources
- **Project Page:** https://allenai.org/olmo
- **Repositories:**
- Core repo (training, inference, fine-tuning etc.): https://github.com/allenai/OLMo
- Evaluation code: https://github.com/allenai/OLMo-Eval
- Further fine-tuning code: https://github.com/allenai/open-instruct
- **Paper:** [Link](https://arxiv.org/abs/2402.00838)
- **Technical blog post:** https://blog.allenai.org/olmo-1-7-7b-a-24-point-improvement-on-mmlu-92b43f7d269d
- **W&B Logs:** [pretraining](https://wandb.ai/ai2-llm/OLMo-7B/groups/OLMo-1.7-7B), [annealing](https://wandb.ai/ai2-llm/OLMo-7B/groups/OLMo-1.7-7B-anneal)
<!-- - **Press release:** TODO -->
## Uses
### Inference
Proceed as usual with HuggingFace:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
olmo = AutoModelForCausalLM.from_pretrained("allenai/OLMo-7B-0424-hf")
tokenizer = AutoTokenizer.from_pretrained("allenai/OLMo-7B-0424-hf")
message = ["Language modeling is"]
inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
# optional verifying cuda
# inputs = {k: v.to('cuda') for k,v in inputs.items()}
# olmo = olmo.to('cuda')
response = olmo.generate(**inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
>> 'Language modeling is the first step to build natural language generation...'
```
Alternatively, with the pipeline abstraction:
```python
from transformers import pipeline
olmo_pipe = pipeline("text-generation", model="allenai/OLMo-7B-0424-hf")
print(olmo_pipe("Language modeling is "))
>> 'Language modeling is a branch of natural language processing that aims to...'
```
Or, you can make this slightly faster by quantizing the model, e.g. `AutoModelForCausalLM.from_pretrained("allenai/OLMo-7B-0424-hf", torch_dtype=torch.float16, load_in_8bit=True)` (requires `bitsandbytes`).
The quantized model is more sensitive to typing / cuda, so it is recommended to pass the inputs as `inputs.input_ids.to('cuda')` to avoid potential issues.
### Fine-tuning
Model fine-tuning can be done from the final checkpoint (the `main` revision of this model) or many intermediate checkpoints. Two recipes for tuning are available.
1. Fine-tune with the OLMo repository:
```bash
torchrun --nproc_per_node=8 scripts/train.py {path_to_train_config} \
--data.paths=[{path_to_data}/input_ids.npy] \
--data.label_mask_paths=[{path_to_data}/label_mask.npy] \
--load_path={path_to_checkpoint} \
--reset_trainer_state
```
For more documentation, see the [GitHub readme](https://github.com/allenai/OLMo?tab=readme-ov-file#fine-tuning).
2. Further fine-tuning support is being developing in AI2's Open Instruct repository. Details are [here](https://github.com/allenai/open-instruct).
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
Core model results for the new and original 7B model are found below.
| Task | Llama-7b | Llama2-7b | Falcon-7b | Mpt-7b | OLMo-7B | Llama2-13b | **OLMo 1.7-7B** |
|-------------------|----------|-----------|-----------|--------|---------|------------|-------------|
| arc_c | 44.5 | 48.5 | 47.5 | 46.5 | 48.5 | 52.8 | 42.5 |
| arc_e | 67.9 | 69.5 | 70.4 | 70.5 | 65.4 | 73.7 | 67.2 |
| boolq | 75.4 | 80.2 | 74.6 | 74.2 | 73.4 | 82.2 | 83.7 |
| copa | 91.0 | 86.0 | 86.0 | 85.0 | 90.0 | 90.0 | 86.0 |
| hellaswag | 76.2 | 76.8 | 75.9 | 77.6 | 76.4 | 78.6 | 75.5 |
| openbookqa | 51.2 | 48.4 | 53.0 | 48.6 | 50.4 | 51.8 | 50.0 |
| piqa | 77.2 | 76.7 | 78.5 | 77.3 | 78.4 | 79.0 | 77.5 |
| sciq | 93.9 | 94.5 | 93.9 | 93.7 | 93.8 | 95.5 | 96.7 |
| winogrande | 70.5 | 69.4 | 68.9 | 69.9 | 67.9 | 73.5 | 69.8 |
| truthfulQA (MC2) | 33.9 | 38.5 | 34.0 | 33.0 | 36.0 | 36.8 | 35.8 |
| MMLU (5 shot MC) | 31.5 | 45.0 | 24.0 | 30.8 | 28.3 | 55.5 | 52.0 |
| GSM8k | 10.0 | 12.0 | 4.0 | 4.5 | 8.5 | 25.0 | 29.0 |
| Full average | 60.3 | 62.1 | 59.2 | 59.3 | 59.8 | 66.2 | 63.8 |
And for the 1B model:
| task | random | [StableLM 2 1.6b](https://huggingface.co/stabilityai/stablelm-2-1_6b)\* | [Pythia 1B](https://huggingface.co/EleutherAI/pythia-1b) | [TinyLlama 1.1B](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) | **OLMo 1B** (ours) |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------ | ----------------- | --------- | -------------------------------------- | ------- |
| arc_challenge | 25 | 43.81 | 33.11 | 34.78 | 34.45 |
| arc_easy | 25 | 63.68 | 50.18 | 53.16 | 58.07 |
| boolq | 50 | 76.6 | 61.8 | 64.6 | 60.7 |
| copa | 50 | 84 | 72 | 78 | 79 |
| hellaswag | 25 | 68.2 | 44.7 | 58.7 | 62.5 |
| openbookqa | 25 | 45.8 | 37.8 | 43.6 | 46.4 |
| piqa | 50 | 74 | 69.1 | 71.1 | 73.7 |
| sciq | 25 | 94.7 | 86 | 90.5 | 88.1 |
| winogrande | 50 | 64.9 | 53.3 | 58.9 | 58.9 |
| Average | 36.11 | 68.41 | 56.44 | 61.48 | 62.42 |
\*Unlike OLMo, Pythia, and TinyLlama, StabilityAI has not disclosed yet the data StableLM was trained on, making comparisons with other efforts challenging.
## Model Details
### Data
For training data details, please see the [Dolma](https://huggingface.co/datasets/allenai/dolma) documentation.
**This model uses the new 1.7 version with more data sources, better deduplication, and quality filtering**.
During the annealing phase we use a higher quality subset of Dolma with a linearly decaying learning rate to 0.
### Staged training / annealing
In contrast to OLMo 1.0, we trained OLMo 1.7 with a two-stage curriculum:
* In the first stage, we trained the model from scratch on the Dolma 1.7 dataset. We set a cosine learning rate schedule with a warmup of 2500 steps, a peak learning rate of 3e-4, and a cosine decay to 3e-5 after 3T tokens. We cut off this stage after 2T tokens, when the learning rate is still high.
* At this point we switch to the second stage, in which we train on a higher-quality subset of Dolma 1.7 (see below) for another 50B tokens, while linearly decaying the learning rate to 0. Our high-quality subset includes (1) using all available Wikipedia, OpenWebMath and Flan data, (2) removing Dolma CC, CC News, and Megawika, and (3) rebalancing remaining sources to achieve approximately equal proportions of each. See exact token counts and relative proportions of this second stage mix below.
Both stages contribute equally to the final performance of the OLMo model. After the first stage, OLMo 1.7 already outperforms OLMo 1.0. The second stage consistently adds 2 to 3 points of performance on top.
### Architecture
OLMo 7B architecture with peer models for comparison.
| | **OLMo 7B** | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [OpenLM 7B](https://laion.ai/blog/open-lm/) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) | PaLM 8B |
|------------------------|-------------------|---------------------|--------------------|--------------------|------------------|
| d_model | 4096 | 4096 | 4096 | 4544 | 4096 |
| num heads | 32 | 32 | 32 | 71 | 16 |
| num layers | 32 | 32 | 32 | 32 | 32 |
| MLP ratio | ~8/3 | ~8/3 | ~8/3 | 4 | 4 |
| LayerNorm type | non-parametric LN | RMSNorm | parametric LN | parametric LN | parametric LN |
| pos embeddings | RoPE | RoPE | RoPE | RoPE | RoPE |
| attention variant | full | GQA | full | MQA | MQA |
| biases | none | none | in LN only | in LN only | none |
| block type | sequential | sequential | sequential | parallel | parallel |
| activation | SwiGLU | SwiGLU | SwiGLU | GeLU | SwiGLU |
| sequence length | 2048 | 4096 | 2048 | 2048 | 2048 |
| batch size (instances) | 2160 | 1024 | 2048 | 2304 | 512 |
| batch size (tokens) | ~4M | ~4M | ~4M | ~4M | ~1M |
| weight tying | no | no | no | no | yes |
### Hyperparameters
AdamW optimizer parameters are shown below.
| Size | Peak LR | Betas | Epsilon | Weight Decay |
|------|------------|-----------------|-------------|--------------|
| 1B | 4.0E-4 | (0.9, 0.95) | 1.0E-5 | 0.1 |
| 7B | 3.0E-4 | (0.9, 0.99) | 1.0E-5 | 0.1 |
Optimizer settings comparison with peer models.
| | **OLMo 7B** | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [OpenLM 7B](https://laion.ai/blog/open-lm/) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) |
|-----------------------|------------------|---------------------|--------------------|--------------------|
| warmup steps | 5000 | 2000 | 2000 | 1000 |
| peak LR | 3.0E-04 | 3.0E-04 | 3.0E-04 | 6.0E-04 |
| minimum LR | 3.0E-05 | 3.0E-05 | 3.0E-05 | 1.2E-05 |
| weight decay | 0.1 | 0.1 | 0.1 | 0.1 |
| beta1 | 0.9 | 0.9 | 0.9 | 0.99 |
| beta2 | 0.95 | 0.95 | 0.95 | 0.999 |
| epsilon | 1.0E-05 | 1.0E-05 | 1.0E-05 | 1.0E-05 |
| LR schedule | linear | cosine | cosine | cosine |
| gradient clipping | global 1.0 | global 1.0 | global 1.0 | global 1.0 |
| gradient reduce dtype | FP32 | FP32 | FP32 | BF16 |
| optimizer state dtype | FP32 | most likely FP32 | FP32 | FP32 |
<!-- ## Environmental Impact
OLMo 7B variants were either trained on MI250X GPUs at the LUMI supercomputer, or A100-40GB GPUs provided by MosaicML.
A summary of the environmental impact. Further details are available in the paper.
| | GPU Type | Power Consumption From GPUs | Carbon Intensity (kg CO₂e/KWh) | Carbon Emissions (tCO₂eq) |
|-----------|------------|-----------------------------|--------------------------------|---------------------------|
| OLMo 7B Twin | MI250X ([LUMI supercomputer](https://www.lumi-supercomputer.eu)) | 135 MWh | 0* | 0* |
| OLMo 7B | A100-40GB ([MosaicML](https://www.mosaicml.com)) | 104 MWh | 0.656 | 75.05 | -->
## Bias, Risks, and Limitations
Like any base language model or fine-tuned model without safety filtering, it is relatively easy for a user to prompt these models to generate harmful and generally sensitive content.
Such content can also be produced unintentionally, especially in the case of bias, so we recommend users consider the risks of applications of this technology.
Otherwise, many facts from OLMo or any LLM will often not be true, so they should be checked.
## Citation
**BibTeX:**
```
@article{Groeneveld2023OLMo,
title={OLMo: Accelerating the Science of Language Models},
author={Groeneveld, Dirk and Beltagy, Iz and Walsh, Pete and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya Harsh and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack and Khot, Tushar and Merrill, William and Morrison, Jacob and Muennighoff, Niklas and Naik, Aakanksha and Nam, Crystal and Peters, Matthew E. and Pyatkin, Valentina and Ravichander, Abhilasha and Schwenk, Dustin and Shah, Saurabh and Smith, Will and Subramani, Nishant and Wortsman, Mitchell and Dasigi, Pradeep and Lambert, Nathan and Richardson, Kyle and Dodge, Jesse and Lo, Kyle and Soldaini, Luca and Smith, Noah A. and Hajishirzi, Hannaneh},
journal={Preprint},
year={2024}
}
```
**APA:**
Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney, R., Tafjord, O., Jha, A., Ivison, H., Magnusson, I., Wang, Y., Arora, S., Atkinson, D., Authur, R., Chandu, K., Cohan, A., Dumas, J., Elazar, Y., Gu, Y., Hessel, J., Khot, T., Merrill, W., Morrison, J., Muennighoff, N., Naik, A., Nam, C., Peters, M., Pyatkin, V., Ravichander, A., Schwenk, D., Shah, S., Smith, W., Subramani, N., Wortsman, M., Dasigi, P., Lambert, N., Richardson, K., Dodge, J., Lo, K., Soldaini, L., Smith, N., & Hajishirzi, H. (2024). OLMo: Accelerating the Science of Language Models. Preprint.
## Model Card Contact
For errors in this model card, contact Nathan, `{nathanl} at allenai dot org`.
|
[
"SCIQ"
] |
yixuan-chia/multilingual-e5-large-instruct-gguf
|
yixuan-chia
| null |
[
"sentence-transformers",
"gguf",
"mteb",
"transformers",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:2402.05672",
"arxiv:2401.00368",
"arxiv:2104.08663",
"arxiv:2210.07316",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us",
"feature-extraction"
] | 2024-10-21T17:43:41Z |
2024-10-21T17:48:51+00:00
| 62 | 0 |
---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
tags:
- mteb
- sentence-transformers
- transformers
model-index:
- name: multilingual-e5-large-instruct
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.23880597014924
- type: ap
value: 39.07351965022687
- type: f1
value: 70.04836733862683
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 66.71306209850107
- type: ap
value: 79.01499914759529
- type: f1
value: 64.81951817560703
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.85307346326837
- type: ap
value: 22.447519885878737
- type: f1
value: 61.0162730745633
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.04925053533191
- type: ap
value: 23.44983217128922
- type: f1
value: 62.5723230907759
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 96.28742500000001
- type: ap
value: 94.8449918887462
- type: f1
value: 96.28680923610432
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 56.716
- type: f1
value: 55.76510398266401
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 52.99999999999999
- type: f1
value: 52.00829994765178
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.806000000000004
- type: f1
value: 48.082345914983634
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.507999999999996
- type: f1
value: 47.68752844642045
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.709999999999994
- type: f1
value: 47.05870376637181
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 44.662000000000006
- type: f1
value: 43.42371965372771
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.721
- type: map_at_10
value: 49.221
- type: map_at_100
value: 49.884
- type: map_at_1000
value: 49.888
- type: map_at_3
value: 44.31
- type: map_at_5
value: 47.276
- type: mrr_at_1
value: 32.432
- type: mrr_at_10
value: 49.5
- type: mrr_at_100
value: 50.163000000000004
- type: mrr_at_1000
value: 50.166
- type: mrr_at_3
value: 44.618
- type: mrr_at_5
value: 47.541
- type: ndcg_at_1
value: 31.721
- type: ndcg_at_10
value: 58.384
- type: ndcg_at_100
value: 61.111000000000004
- type: ndcg_at_1000
value: 61.187999999999995
- type: ndcg_at_3
value: 48.386
- type: ndcg_at_5
value: 53.708999999999996
- type: precision_at_1
value: 31.721
- type: precision_at_10
value: 8.741
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.057
- type: precision_at_5
value: 14.609
- type: recall_at_1
value: 31.721
- type: recall_at_10
value: 87.411
- type: recall_at_100
value: 99.075
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 60.171
- type: recall_at_5
value: 73.044
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 46.40419580759799
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.48593255007969
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 63.889179122289995
- type: mrr
value: 77.61146286769556
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 88.15075203727929
- type: cos_sim_spearman
value: 86.9622224570873
- type: euclidean_pearson
value: 86.70473853624121
- type: euclidean_spearman
value: 86.9622224570873
- type: manhattan_pearson
value: 86.21089380980065
- type: manhattan_spearman
value: 86.75318154937008
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.65553235908142
- type: f1
value: 99.60681976339595
- type: precision
value: 99.58246346555325
- type: recall
value: 99.65553235908142
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.26260180497468
- type: f1
value: 99.14520507740848
- type: precision
value: 99.08650671362535
- type: recall
value: 99.26260180497468
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.07412538967787
- type: f1
value: 97.86629719431936
- type: precision
value: 97.76238309664012
- type: recall
value: 98.07412538967787
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.42074776197998
- type: f1
value: 99.38564156573635
- type: precision
value: 99.36808846761454
- type: recall
value: 99.42074776197998
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 85.73376623376623
- type: f1
value: 85.68480707214599
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 40.935218072113855
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.276389017675264
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.764166666666668
- type: map_at_10
value: 37.298166666666674
- type: map_at_100
value: 38.530166666666666
- type: map_at_1000
value: 38.64416666666667
- type: map_at_3
value: 34.484833333333334
- type: map_at_5
value: 36.0385
- type: mrr_at_1
value: 32.93558333333333
- type: mrr_at_10
value: 41.589749999999995
- type: mrr_at_100
value: 42.425333333333334
- type: mrr_at_1000
value: 42.476333333333336
- type: mrr_at_3
value: 39.26825
- type: mrr_at_5
value: 40.567083333333336
- type: ndcg_at_1
value: 32.93558333333333
- type: ndcg_at_10
value: 42.706583333333334
- type: ndcg_at_100
value: 47.82483333333333
- type: ndcg_at_1000
value: 49.95733333333334
- type: ndcg_at_3
value: 38.064750000000004
- type: ndcg_at_5
value: 40.18158333333333
- type: precision_at_1
value: 32.93558333333333
- type: precision_at_10
value: 7.459833333333334
- type: precision_at_100
value: 1.1830833333333335
- type: precision_at_1000
value: 0.15608333333333332
- type: precision_at_3
value: 17.5235
- type: precision_at_5
value: 12.349833333333333
- type: recall_at_1
value: 27.764166666666668
- type: recall_at_10
value: 54.31775
- type: recall_at_100
value: 76.74350000000001
- type: recall_at_1000
value: 91.45208333333332
- type: recall_at_3
value: 41.23425
- type: recall_at_5
value: 46.73983333333334
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 12.969
- type: map_at_10
value: 21.584999999999997
- type: map_at_100
value: 23.3
- type: map_at_1000
value: 23.5
- type: map_at_3
value: 18.218999999999998
- type: map_at_5
value: 19.983
- type: mrr_at_1
value: 29.316
- type: mrr_at_10
value: 40.033
- type: mrr_at_100
value: 40.96
- type: mrr_at_1000
value: 41.001
- type: mrr_at_3
value: 37.123
- type: mrr_at_5
value: 38.757999999999996
- type: ndcg_at_1
value: 29.316
- type: ndcg_at_10
value: 29.858
- type: ndcg_at_100
value: 36.756
- type: ndcg_at_1000
value: 40.245999999999995
- type: ndcg_at_3
value: 24.822
- type: ndcg_at_5
value: 26.565
- type: precision_at_1
value: 29.316
- type: precision_at_10
value: 9.186
- type: precision_at_100
value: 1.6549999999999998
- type: precision_at_1000
value: 0.22999999999999998
- type: precision_at_3
value: 18.436
- type: precision_at_5
value: 13.876
- type: recall_at_1
value: 12.969
- type: recall_at_10
value: 35.142
- type: recall_at_100
value: 59.143
- type: recall_at_1000
value: 78.594
- type: recall_at_3
value: 22.604
- type: recall_at_5
value: 27.883000000000003
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.527999999999999
- type: map_at_10
value: 17.974999999999998
- type: map_at_100
value: 25.665
- type: map_at_1000
value: 27.406000000000002
- type: map_at_3
value: 13.017999999999999
- type: map_at_5
value: 15.137
- type: mrr_at_1
value: 62.5
- type: mrr_at_10
value: 71.891
- type: mrr_at_100
value: 72.294
- type: mrr_at_1000
value: 72.296
- type: mrr_at_3
value: 69.958
- type: mrr_at_5
value: 71.121
- type: ndcg_at_1
value: 50.875
- type: ndcg_at_10
value: 38.36
- type: ndcg_at_100
value: 44.235
- type: ndcg_at_1000
value: 52.154
- type: ndcg_at_3
value: 43.008
- type: ndcg_at_5
value: 40.083999999999996
- type: precision_at_1
value: 62.5
- type: precision_at_10
value: 30.0
- type: precision_at_100
value: 10.038
- type: precision_at_1000
value: 2.0869999999999997
- type: precision_at_3
value: 46.833000000000006
- type: precision_at_5
value: 38.800000000000004
- type: recall_at_1
value: 8.527999999999999
- type: recall_at_10
value: 23.828
- type: recall_at_100
value: 52.322
- type: recall_at_1000
value: 77.143
- type: recall_at_3
value: 14.136000000000001
- type: recall_at_5
value: 17.761
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.51
- type: f1
value: 47.632159862049896
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.734
- type: map_at_10
value: 72.442
- type: map_at_100
value: 72.735
- type: map_at_1000
value: 72.75
- type: map_at_3
value: 70.41199999999999
- type: map_at_5
value: 71.80499999999999
- type: mrr_at_1
value: 65.212
- type: mrr_at_10
value: 76.613
- type: mrr_at_100
value: 76.79899999999999
- type: mrr_at_1000
value: 76.801
- type: mrr_at_3
value: 74.8
- type: mrr_at_5
value: 76.12400000000001
- type: ndcg_at_1
value: 65.212
- type: ndcg_at_10
value: 77.988
- type: ndcg_at_100
value: 79.167
- type: ndcg_at_1000
value: 79.452
- type: ndcg_at_3
value: 74.362
- type: ndcg_at_5
value: 76.666
- type: precision_at_1
value: 65.212
- type: precision_at_10
value: 10.003
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 29.518
- type: precision_at_5
value: 19.016
- type: recall_at_1
value: 60.734
- type: recall_at_10
value: 90.824
- type: recall_at_100
value: 95.71600000000001
- type: recall_at_1000
value: 97.577
- type: recall_at_3
value: 81.243
- type: recall_at_5
value: 86.90299999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.845
- type: map_at_10
value: 39.281
- type: map_at_100
value: 41.422
- type: map_at_1000
value: 41.593
- type: map_at_3
value: 34.467
- type: map_at_5
value: 37.017
- type: mrr_at_1
value: 47.531
- type: mrr_at_10
value: 56.204
- type: mrr_at_100
value: 56.928999999999995
- type: mrr_at_1000
value: 56.962999999999994
- type: mrr_at_3
value: 54.115
- type: mrr_at_5
value: 55.373000000000005
- type: ndcg_at_1
value: 47.531
- type: ndcg_at_10
value: 47.711999999999996
- type: ndcg_at_100
value: 54.510999999999996
- type: ndcg_at_1000
value: 57.103
- type: ndcg_at_3
value: 44.145
- type: ndcg_at_5
value: 45.032
- type: precision_at_1
value: 47.531
- type: precision_at_10
value: 13.194
- type: precision_at_100
value: 2.045
- type: precision_at_1000
value: 0.249
- type: precision_at_3
value: 29.424
- type: precision_at_5
value: 21.451
- type: recall_at_1
value: 23.845
- type: recall_at_10
value: 54.967
- type: recall_at_100
value: 79.11399999999999
- type: recall_at_1000
value: 94.56700000000001
- type: recall_at_3
value: 40.256
- type: recall_at_5
value: 46.215
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.819
- type: map_at_10
value: 60.889
- type: map_at_100
value: 61.717999999999996
- type: map_at_1000
value: 61.778
- type: map_at_3
value: 57.254000000000005
- type: map_at_5
value: 59.541
- type: mrr_at_1
value: 75.638
- type: mrr_at_10
value: 82.173
- type: mrr_at_100
value: 82.362
- type: mrr_at_1000
value: 82.37
- type: mrr_at_3
value: 81.089
- type: mrr_at_5
value: 81.827
- type: ndcg_at_1
value: 75.638
- type: ndcg_at_10
value: 69.317
- type: ndcg_at_100
value: 72.221
- type: ndcg_at_1000
value: 73.382
- type: ndcg_at_3
value: 64.14
- type: ndcg_at_5
value: 67.07600000000001
- type: precision_at_1
value: 75.638
- type: precision_at_10
value: 14.704999999999998
- type: precision_at_100
value: 1.698
- type: precision_at_1000
value: 0.185
- type: precision_at_3
value: 41.394999999999996
- type: precision_at_5
value: 27.162999999999997
- type: recall_at_1
value: 37.819
- type: recall_at_10
value: 73.52499999999999
- type: recall_at_100
value: 84.875
- type: recall_at_1000
value: 92.559
- type: recall_at_3
value: 62.092999999999996
- type: recall_at_5
value: 67.907
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 94.60079999999999
- type: ap
value: 92.67396345347356
- type: f1
value: 94.5988098167121
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.285
- type: map_at_10
value: 33.436
- type: map_at_100
value: 34.63
- type: map_at_1000
value: 34.681
- type: map_at_3
value: 29.412
- type: map_at_5
value: 31.715
- type: mrr_at_1
value: 21.848
- type: mrr_at_10
value: 33.979
- type: mrr_at_100
value: 35.118
- type: mrr_at_1000
value: 35.162
- type: mrr_at_3
value: 30.036
- type: mrr_at_5
value: 32.298
- type: ndcg_at_1
value: 21.862000000000002
- type: ndcg_at_10
value: 40.43
- type: ndcg_at_100
value: 46.17
- type: ndcg_at_1000
value: 47.412
- type: ndcg_at_3
value: 32.221
- type: ndcg_at_5
value: 36.332
- type: precision_at_1
value: 21.862000000000002
- type: precision_at_10
value: 6.491
- type: precision_at_100
value: 0.935
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.744
- type: precision_at_5
value: 10.331999999999999
- type: recall_at_1
value: 21.285
- type: recall_at_10
value: 62.083
- type: recall_at_100
value: 88.576
- type: recall_at_1000
value: 98.006
- type: recall_at_3
value: 39.729
- type: recall_at_5
value: 49.608000000000004
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.92612859097127
- type: f1
value: 93.82370333372853
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.67681036911807
- type: f1
value: 92.14191382411472
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.26817878585723
- type: f1
value: 91.92824250337878
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.96554963983714
- type: f1
value: 90.02859329630792
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.02509860164935
- type: f1
value: 89.30665159182062
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 87.55515370705244
- type: f1
value: 87.94449232331907
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 82.4623803009576
- type: f1
value: 66.06738378772725
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.3716539870386
- type: f1
value: 60.37614033396853
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 80.34022681787857
- type: f1
value: 58.302008026952
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 76.72095208268087
- type: f1
value: 59.64524724009049
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.87020437432773
- type: f1
value: 57.80202694670567
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.73598553345387
- type: f1
value: 58.19628250675031
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.6630800268998
- type: f1
value: 65.00996668051691
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.7128446536651
- type: f1
value: 57.95860594874963
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.61129791526563
- type: f1
value: 59.75328290206483
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.00134498991257
- type: f1
value: 67.0230483991802
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.54068594485541
- type: f1
value: 65.54604628946976
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.032952252858095
- type: f1
value: 58.715741857057104
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.80901143241427
- type: f1
value: 68.33963989243877
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.47141896435777
- type: f1
value: 69.56765020308262
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.2373907195696
- type: f1
value: 69.04529836036467
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 77.05783456624076
- type: f1
value: 74.69430584708174
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.82111634162744
- type: f1
value: 70.77228952803762
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.25353059852051
- type: f1
value: 71.05310103416411
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.28648285137861
- type: f1
value: 69.08020473732226
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.31540013449899
- type: f1
value: 70.9426355465791
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.2151983860121
- type: f1
value: 67.52541755908858
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.58372562205784
- type: f1
value: 69.49769064229827
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.9233355749832
- type: f1
value: 69.36311548259593
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.07330195023538
- type: f1
value: 64.99882022345572
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.62273032952253
- type: f1
value: 70.6394885471001
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.77000672494957
- type: f1
value: 62.9368944815065
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.453261600538
- type: f1
value: 70.85069934666681
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.6906523201076
- type: f1
value: 72.03249740074217
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.03631472763953
- type: f1
value: 59.3165215571852
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.913920645595155
- type: f1
value: 57.367337711611285
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.42837928715535
- type: f1
value: 52.60527294970906
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.33490248823135
- type: f1
value: 63.213340969404065
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.58507061197041
- type: f1
value: 68.40256628040486
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.11230665770006
- type: f1
value: 66.44863577842305
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.70073974445192
- type: f1
value: 67.21291337273702
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.43913920645595
- type: f1
value: 64.09838087422806
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.80026899798251
- type: f1
value: 68.76986742962444
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.78816408876934
- type: f1
value: 62.18781873428972
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.6577000672495
- type: f1
value: 68.75171511133003
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.42501681237391
- type: f1
value: 71.18434963451544
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.64828513786146
- type: f1
value: 70.67741914007422
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.62811028917284
- type: f1
value: 71.36402039740959
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.88634835238736
- type: f1
value: 69.23701923480677
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.15938130464022
- type: f1
value: 71.87792218993388
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.96301277740416
- type: f1
value: 67.29584200202983
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.49562878278412
- type: f1
value: 66.91716685679431
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.6805648957633
- type: f1
value: 72.02723592594374
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.00605245460659
- type: f1
value: 60.16716669482932
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.90988567585742
- type: f1
value: 63.99405488777784
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.62273032952253
- type: f1
value: 65.17213906909481
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.50907868190988
- type: f1
value: 69.15165697194853
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.30733019502352
- type: f1
value: 66.69024007380474
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.24277067921989
- type: f1
value: 68.80515408492947
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.49831876260929
- type: f1
value: 64.83778567111116
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.28782784129119
- type: f1
value: 69.3294186700733
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.315400134499
- type: f1
value: 71.22674385243207
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.37794216543377
- type: f1
value: 68.96962492838232
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.33557498318764
- type: f1
value: 72.28949738478356
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.84398117014123
- type: f1
value: 64.71026362091463
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.76462676529925
- type: f1
value: 69.8229667407667
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.02420981842636
- type: f1
value: 71.76576384895898
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.7572293207801
- type: f1
value: 72.76840765295256
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.02286482851379
- type: f1
value: 66.17237947327872
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.60928043039678
- type: f1
value: 77.27094731234773
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.68325487558843
- type: f1
value: 77.97530399082261
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.13315400134498
- type: f1
value: 75.97558584796424
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.47410894418292
- type: f1
value: 80.52244841473792
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.9670477471419
- type: f1
value: 77.37318805793146
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.09683927370544
- type: f1
value: 77.69773737430847
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.20847343644922
- type: f1
value: 75.17071738727348
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.07464694014796
- type: f1
value: 77.16136207698571
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.53396099529255
- type: f1
value: 73.58296404484122
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.75319435104237
- type: f1
value: 75.24674707850833
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.0948217888366
- type: f1
value: 76.47559490205028
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.07599193006052
- type: f1
value: 70.76028043093511
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.10490921318089
- type: f1
value: 77.01215275283272
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.25756556825824
- type: f1
value: 70.20605314648762
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.08137188971082
- type: f1
value: 77.3899269057439
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.35440484196369
- type: f1
value: 79.58964690002772
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.42299932750504
- type: f1
value: 68.07844356925413
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.15669132481507
- type: f1
value: 65.89383352608513
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.11432414256894
- type: f1
value: 57.69910594559806
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.24747814391392
- type: f1
value: 70.42455553830918
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.46267652992603
- type: f1
value: 76.8854559308316
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.24815063887021
- type: f1
value: 72.77805034658074
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.11566913248151
- type: f1
value: 73.86147988001356
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.0168123739072
- type: f1
value: 69.38515920054571
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.41156691324814
- type: f1
value: 73.43474953408237
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.39609952925353
- type: f1
value: 67.29731681109291
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.20914593140552
- type: f1
value: 77.07066497935367
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.52387357094821
- type: f1
value: 78.5259569473291
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.6913248150639
- type: f1
value: 76.91201656350455
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.1217215870881
- type: f1
value: 77.41179937912504
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.25891055817083
- type: f1
value: 75.8089244542887
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.70679219905851
- type: f1
value: 78.21459594517711
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.83523873570948
- type: f1
value: 74.86847028401978
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.71755211835911
- type: f1
value: 74.0214326485662
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.06523201075991
- type: f1
value: 79.10545620325138
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.91862811028918
- type: f1
value: 66.50386121217983
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.93140551445865
- type: f1
value: 70.755435928495
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.40753194351042
- type: f1
value: 71.61816115782923
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.1815736381977
- type: f1
value: 75.08016717887205
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.86482851378614
- type: f1
value: 72.39521180006291
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.46940147948891
- type: f1
value: 76.70044085362349
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.89307330195024
- type: f1
value: 71.5721825332298
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.7511768661735
- type: f1
value: 75.17918654541515
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.69535978480162
- type: f1
value: 78.90019070153316
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.45729657027572
- type: f1
value: 76.19578371794672
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 36.92715354123554
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 35.53536244162518
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 33.08507884504006
- type: mrr
value: 34.32436977159129
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.935
- type: map_at_10
value: 13.297
- type: map_at_100
value: 16.907
- type: map_at_1000
value: 18.391
- type: map_at_3
value: 9.626999999999999
- type: map_at_5
value: 11.190999999999999
- type: mrr_at_1
value: 46.129999999999995
- type: mrr_at_10
value: 54.346000000000004
- type: mrr_at_100
value: 55.067
- type: mrr_at_1000
value: 55.1
- type: mrr_at_3
value: 51.961
- type: mrr_at_5
value: 53.246
- type: ndcg_at_1
value: 44.118
- type: ndcg_at_10
value: 35.534
- type: ndcg_at_100
value: 32.946999999999996
- type: ndcg_at_1000
value: 41.599000000000004
- type: ndcg_at_3
value: 40.25
- type: ndcg_at_5
value: 37.978
- type: precision_at_1
value: 46.129999999999995
- type: precision_at_10
value: 26.842
- type: precision_at_100
value: 8.427
- type: precision_at_1000
value: 2.128
- type: precision_at_3
value: 37.977
- type: precision_at_5
value: 32.879000000000005
- type: recall_at_1
value: 5.935
- type: recall_at_10
value: 17.211000000000002
- type: recall_at_100
value: 34.33
- type: recall_at_1000
value: 65.551
- type: recall_at_3
value: 10.483
- type: recall_at_5
value: 13.078999999999999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.231
- type: map_at_10
value: 50.202000000000005
- type: map_at_100
value: 51.154999999999994
- type: map_at_1000
value: 51.181
- type: map_at_3
value: 45.774
- type: map_at_5
value: 48.522
- type: mrr_at_1
value: 39.687
- type: mrr_at_10
value: 52.88
- type: mrr_at_100
value: 53.569
- type: mrr_at_1000
value: 53.58500000000001
- type: mrr_at_3
value: 49.228
- type: mrr_at_5
value: 51.525
- type: ndcg_at_1
value: 39.687
- type: ndcg_at_10
value: 57.754000000000005
- type: ndcg_at_100
value: 61.597
- type: ndcg_at_1000
value: 62.18900000000001
- type: ndcg_at_3
value: 49.55
- type: ndcg_at_5
value: 54.11899999999999
- type: precision_at_1
value: 39.687
- type: precision_at_10
value: 9.313
- type: precision_at_100
value: 1.146
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 22.229
- type: precision_at_5
value: 15.939
- type: recall_at_1
value: 35.231
- type: recall_at_10
value: 78.083
- type: recall_at_100
value: 94.42099999999999
- type: recall_at_1000
value: 98.81
- type: recall_at_3
value: 57.047000000000004
- type: recall_at_5
value: 67.637
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.241
- type: map_at_10
value: 85.462
- type: map_at_100
value: 86.083
- type: map_at_1000
value: 86.09700000000001
- type: map_at_3
value: 82.49499999999999
- type: map_at_5
value: 84.392
- type: mrr_at_1
value: 82.09
- type: mrr_at_10
value: 88.301
- type: mrr_at_100
value: 88.383
- type: mrr_at_1000
value: 88.384
- type: mrr_at_3
value: 87.37
- type: mrr_at_5
value: 88.035
- type: ndcg_at_1
value: 82.12
- type: ndcg_at_10
value: 89.149
- type: ndcg_at_100
value: 90.235
- type: ndcg_at_1000
value: 90.307
- type: ndcg_at_3
value: 86.37599999999999
- type: ndcg_at_5
value: 87.964
- type: precision_at_1
value: 82.12
- type: precision_at_10
value: 13.56
- type: precision_at_100
value: 1.539
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.88
- type: precision_at_5
value: 24.92
- type: recall_at_1
value: 71.241
- type: recall_at_10
value: 96.128
- type: recall_at_100
value: 99.696
- type: recall_at_1000
value: 99.994
- type: recall_at_3
value: 88.181
- type: recall_at_5
value: 92.694
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 56.59757799655151
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.27391998854624
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.243
- type: map_at_10
value: 10.965
- type: map_at_100
value: 12.934999999999999
- type: map_at_1000
value: 13.256
- type: map_at_3
value: 7.907
- type: map_at_5
value: 9.435
- type: mrr_at_1
value: 20.9
- type: mrr_at_10
value: 31.849
- type: mrr_at_100
value: 32.964
- type: mrr_at_1000
value: 33.024
- type: mrr_at_3
value: 28.517
- type: mrr_at_5
value: 30.381999999999998
- type: ndcg_at_1
value: 20.9
- type: ndcg_at_10
value: 18.723
- type: ndcg_at_100
value: 26.384999999999998
- type: ndcg_at_1000
value: 32.114
- type: ndcg_at_3
value: 17.753
- type: ndcg_at_5
value: 15.558
- type: precision_at_1
value: 20.9
- type: precision_at_10
value: 9.8
- type: precision_at_100
value: 2.078
- type: precision_at_1000
value: 0.345
- type: precision_at_3
value: 16.900000000000002
- type: precision_at_5
value: 13.88
- type: recall_at_1
value: 4.243
- type: recall_at_10
value: 19.885
- type: recall_at_100
value: 42.17
- type: recall_at_1000
value: 70.12
- type: recall_at_3
value: 10.288
- type: recall_at_5
value: 14.072000000000001
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.84209174935282
- type: cos_sim_spearman
value: 81.73248048438833
- type: euclidean_pearson
value: 83.02810070308149
- type: euclidean_spearman
value: 81.73248295679514
- type: manhattan_pearson
value: 82.95368060376002
- type: manhattan_spearman
value: 81.60277910998718
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 88.52628804556943
- type: cos_sim_spearman
value: 82.5713913555672
- type: euclidean_pearson
value: 85.8796774746988
- type: euclidean_spearman
value: 82.57137506803424
- type: manhattan_pearson
value: 85.79671002960058
- type: manhattan_spearman
value: 82.49445981618027
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 86.23682503505542
- type: cos_sim_spearman
value: 87.15008956711806
- type: euclidean_pearson
value: 86.79805401524959
- type: euclidean_spearman
value: 87.15008956711806
- type: manhattan_pearson
value: 86.65298502699244
- type: manhattan_spearman
value: 86.97677821948562
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 85.63370304677802
- type: cos_sim_spearman
value: 84.97105553540318
- type: euclidean_pearson
value: 85.28896108687721
- type: euclidean_spearman
value: 84.97105553540318
- type: manhattan_pearson
value: 85.09663190337331
- type: manhattan_spearman
value: 84.79126831644619
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 90.2614838800733
- type: cos_sim_spearman
value: 91.0509162991835
- type: euclidean_pearson
value: 90.33098317533373
- type: euclidean_spearman
value: 91.05091625871644
- type: manhattan_pearson
value: 90.26250435151107
- type: manhattan_spearman
value: 90.97999594417519
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.80480973335091
- type: cos_sim_spearman
value: 87.313695492969
- type: euclidean_pearson
value: 86.49267251576939
- type: euclidean_spearman
value: 87.313695492969
- type: manhattan_pearson
value: 86.44019901831935
- type: manhattan_spearman
value: 87.24205395460392
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 90.05662789380672
- type: cos_sim_spearman
value: 90.02759424426651
- type: euclidean_pearson
value: 90.4042483422981
- type: euclidean_spearman
value: 90.02759424426651
- type: manhattan_pearson
value: 90.51446975000226
- type: manhattan_spearman
value: 90.08832889933616
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.5975528273532
- type: cos_sim_spearman
value: 67.62969861411354
- type: euclidean_pearson
value: 69.224275734323
- type: euclidean_spearman
value: 67.62969861411354
- type: manhattan_pearson
value: 69.3761447059927
- type: manhattan_spearman
value: 67.90921005611467
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.11244327231684
- type: cos_sim_spearman
value: 88.37902438979035
- type: euclidean_pearson
value: 87.86054279847336
- type: euclidean_spearman
value: 88.37902438979035
- type: manhattan_pearson
value: 87.77257757320378
- type: manhattan_spearman
value: 88.25208966098123
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 85.87174608143563
- type: mrr
value: 96.12836872640794
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 57.760999999999996
- type: map_at_10
value: 67.258
- type: map_at_100
value: 67.757
- type: map_at_1000
value: 67.78800000000001
- type: map_at_3
value: 64.602
- type: map_at_5
value: 65.64
- type: mrr_at_1
value: 60.667
- type: mrr_at_10
value: 68.441
- type: mrr_at_100
value: 68.825
- type: mrr_at_1000
value: 68.853
- type: mrr_at_3
value: 66.444
- type: mrr_at_5
value: 67.26100000000001
- type: ndcg_at_1
value: 60.667
- type: ndcg_at_10
value: 71.852
- type: ndcg_at_100
value: 73.9
- type: ndcg_at_1000
value: 74.628
- type: ndcg_at_3
value: 67.093
- type: ndcg_at_5
value: 68.58
- type: precision_at_1
value: 60.667
- type: precision_at_10
value: 9.6
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 26.111
- type: precision_at_5
value: 16.733
- type: recall_at_1
value: 57.760999999999996
- type: recall_at_10
value: 84.967
- type: recall_at_100
value: 93.833
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 71.589
- type: recall_at_5
value: 75.483
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.66633663366336
- type: cos_sim_ap
value: 91.17685358899108
- type: cos_sim_f1
value: 82.16818642350559
- type: cos_sim_precision
value: 83.26488706365504
- type: cos_sim_recall
value: 81.10000000000001
- type: dot_accuracy
value: 99.66633663366336
- type: dot_ap
value: 91.17663411119032
- type: dot_f1
value: 82.16818642350559
- type: dot_precision
value: 83.26488706365504
- type: dot_recall
value: 81.10000000000001
- type: euclidean_accuracy
value: 99.66633663366336
- type: euclidean_ap
value: 91.17685189882275
- type: euclidean_f1
value: 82.16818642350559
- type: euclidean_precision
value: 83.26488706365504
- type: euclidean_recall
value: 81.10000000000001
- type: manhattan_accuracy
value: 99.66633663366336
- type: manhattan_ap
value: 91.2241619496737
- type: manhattan_f1
value: 82.20472440944883
- type: manhattan_precision
value: 86.51933701657458
- type: manhattan_recall
value: 78.3
- type: max_accuracy
value: 99.66633663366336
- type: max_ap
value: 91.2241619496737
- type: max_f1
value: 82.20472440944883
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.85101268897951
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 42.461184054706905
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 51.44542568873886
- type: mrr
value: 52.33656151854681
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.75982974997539
- type: cos_sim_spearman
value: 30.385405026539914
- type: dot_pearson
value: 30.75982433546523
- type: dot_spearman
value: 30.385405026539914
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22799999999999998
- type: map_at_10
value: 2.064
- type: map_at_100
value: 13.056000000000001
- type: map_at_1000
value: 31.747999999999998
- type: map_at_3
value: 0.67
- type: map_at_5
value: 1.097
- type: mrr_at_1
value: 90.0
- type: mrr_at_10
value: 94.667
- type: mrr_at_100
value: 94.667
- type: mrr_at_1000
value: 94.667
- type: mrr_at_3
value: 94.667
- type: mrr_at_5
value: 94.667
- type: ndcg_at_1
value: 86.0
- type: ndcg_at_10
value: 82.0
- type: ndcg_at_100
value: 64.307
- type: ndcg_at_1000
value: 57.023999999999994
- type: ndcg_at_3
value: 85.816
- type: ndcg_at_5
value: 84.904
- type: precision_at_1
value: 90.0
- type: precision_at_10
value: 85.8
- type: precision_at_100
value: 66.46
- type: precision_at_1000
value: 25.202
- type: precision_at_3
value: 90.0
- type: precision_at_5
value: 89.2
- type: recall_at_1
value: 0.22799999999999998
- type: recall_at_10
value: 2.235
- type: recall_at_100
value: 16.185
- type: recall_at_1000
value: 53.620999999999995
- type: recall_at_3
value: 0.7040000000000001
- type: recall_at_5
value: 1.172
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.39999999999999
- type: f1
value: 96.75
- type: precision
value: 96.45
- type: recall
value: 97.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.54913294797689
- type: f1
value: 82.46628131021194
- type: precision
value: 81.1175337186898
- type: recall
value: 85.54913294797689
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.21951219512195
- type: f1
value: 77.33333333333334
- type: precision
value: 75.54878048780488
- type: recall
value: 81.21951219512195
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.6
- type: f1
value: 98.26666666666665
- type: precision
value: 98.1
- type: recall
value: 98.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.5
- type: f1
value: 99.33333333333333
- type: precision
value: 99.25
- type: recall
value: 99.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.2
- type: precision
value: 96.89999999999999
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.18333333333334
- type: precision
value: 96.88333333333333
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.61194029850746
- type: f1
value: 72.81094527363183
- type: precision
value: 70.83333333333333
- type: recall
value: 77.61194029850746
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.91666666666667
- type: precision
value: 91.08333333333334
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.29268292682927
- type: f1
value: 85.27642276422765
- type: precision
value: 84.01277584204414
- type: recall
value: 88.29268292682927
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.0
- type: precision
value: 94.46666666666668
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.681652490887
- type: f1
value: 91.90765492102065
- type: precision
value: 91.05913325232888
- type: recall
value: 93.681652490887
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.17391304347827
- type: f1
value: 89.97101449275361
- type: precision
value: 88.96811594202899
- type: recall
value: 92.17391304347827
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.43478260869566
- type: f1
value: 87.72173913043478
- type: precision
value: 86.42028985507245
- type: recall
value: 90.43478260869566
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.4
- type: f1
value: 88.03
- type: precision
value: 86.95
- type: recall
value: 90.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.4
- type: f1
value: 91.45666666666666
- type: precision
value: 90.525
- type: recall
value: 93.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.9059107358263
- type: f1
value: 78.32557872364869
- type: precision
value: 76.78260286824823
- type: recall
value: 81.9059107358263
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.58333333333333
- type: precision
value: 91.73333333333332
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.10000000000001
- type: f1
value: 74.50500000000001
- type: precision
value: 72.58928571428571
- type: recall
value: 79.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.6
- type: f1
value: 95.55
- type: precision
value: 95.05
- type: recall
value: 96.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.0952380952381
- type: f1
value: 77.98458049886621
- type: precision
value: 76.1968253968254
- type: recall
value: 82.0952380952381
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.9
- type: f1
value: 84.99190476190476
- type: precision
value: 83.65
- type: recall
value: 87.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.7
- type: f1
value: 94.56666666666666
- type: precision
value: 94.01666666666667
- type: recall
value: 95.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.6
- type: f1
value: 98.2
- type: precision
value: 98.0
- type: recall
value: 98.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.6
- type: f1
value: 94.38333333333334
- type: precision
value: 93.78333333333335
- type: recall
value: 95.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.4
- type: f1
value: 84.10380952380952
- type: precision
value: 82.67
- type: recall
value: 87.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.5
- type: f1
value: 94.33333333333334
- type: precision
value: 93.78333333333333
- type: recall
value: 95.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.4
- type: f1
value: 86.82000000000001
- type: precision
value: 85.64500000000001
- type: recall
value: 89.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.1
- type: f1
value: 93.56666666666668
- type: precision
value: 92.81666666666666
- type: recall
value: 95.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.9
- type: f1
value: 98.6
- type: precision
value: 98.45
- type: recall
value: 98.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.01347708894879
- type: f1
value: 93.51752021563343
- type: precision
value: 92.82794249775381
- type: recall
value: 95.01347708894879
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.00854700854701
- type: f1
value: 96.08262108262107
- type: precision
value: 95.65527065527067
- type: recall
value: 97.00854700854701
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.5
- type: f1
value: 95.39999999999999
- type: precision
value: 94.88333333333333
- type: recall
value: 96.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.5909090909091
- type: f1
value: 95.49242424242425
- type: precision
value: 94.9621212121212
- type: recall
value: 96.5909090909091
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.90566037735849
- type: f1
value: 81.85883997204752
- type: precision
value: 80.54507337526205
- type: recall
value: 84.90566037735849
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.5
- type: f1
value: 96.75
- type: precision
value: 96.38333333333333
- type: recall
value: 97.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.7704280155642
- type: f1
value: 82.99610894941635
- type: precision
value: 81.32295719844358
- type: recall
value: 86.7704280155642
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.52136752136752
- type: f1
value: 61.89662189662191
- type: precision
value: 59.68660968660969
- type: recall
value: 67.52136752136752
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.2
- type: f1
value: 86.32
- type: precision
value: 85.015
- type: recall
value: 89.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.0
- type: f1
value: 94.78333333333333
- type: precision
value: 94.18333333333334
- type: recall
value: 96.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 83.8785046728972
- type: f1
value: 80.54517133956385
- type: precision
value: 79.154984423676
- type: recall
value: 83.8785046728972
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.60000000000001
- type: f1
value: 92.01333333333334
- type: precision
value: 91.28333333333333
- type: recall
value: 93.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.1
- type: f1
value: 96.26666666666667
- type: precision
value: 95.85000000000001
- type: recall
value: 97.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.3
- type: f1
value: 80.67833333333333
- type: precision
value: 79.03928571428571
- type: recall
value: 84.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.3
- type: f1
value: 96.48333333333332
- type: precision
value: 96.08333333333331
- type: recall
value: 97.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.7
- type: f1
value: 94.66666666666667
- type: precision
value: 94.16666666666667
- type: recall
value: 95.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.2
- type: f1
value: 96.36666666666667
- type: precision
value: 95.96666666666668
- type: recall
value: 97.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.80666666666667
- type: precision
value: 92.12833333333333
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.0
- type: f1
value: 96.22333333333334
- type: precision
value: 95.875
- type: recall
value: 97.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.33333333333333
- type: f1
value: 70.78174603174602
- type: precision
value: 69.28333333333332
- type: recall
value: 74.33333333333333
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 37.6
- type: f1
value: 32.938348952090365
- type: precision
value: 31.2811038961039
- type: recall
value: 37.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.5
- type: f1
value: 89.13333333333333
- type: precision
value: 88.03333333333333
- type: recall
value: 91.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.14285714285714
- type: f1
value: 77.67857142857143
- type: precision
value: 75.59523809523809
- type: recall
value: 82.14285714285714
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.0450054884742
- type: f1
value: 63.070409283362075
- type: precision
value: 60.58992781824835
- type: recall
value: 69.0450054884742
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.1
- type: f1
value: 57.848333333333336
- type: precision
value: 55.69500000000001
- type: recall
value: 63.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.01666666666667
- type: precision
value: 94.5
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.89999999999999
- type: f1
value: 94.90666666666667
- type: precision
value: 94.425
- type: recall
value: 95.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.6
- type: f1
value: 84.61333333333333
- type: precision
value: 83.27
- type: recall
value: 87.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.4
- type: f1
value: 71.90746031746032
- type: precision
value: 70.07027777777778
- type: recall
value: 76.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.89999999999999
- type: f1
value: 97.26666666666667
- type: precision
value: 96.95
- type: recall
value: 97.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.8
- type: f1
value: 74.39555555555555
- type: precision
value: 72.59416666666667
- type: recall
value: 78.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 93.78999999999999
- type: precision
value: 93.125
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.1
- type: precision
value: 96.75
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.6
- type: f1
value: 94.25666666666666
- type: precision
value: 93.64166666666668
- type: recall
value: 95.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.934306569343065
- type: f1
value: 51.461591936044485
- type: precision
value: 49.37434827945776
- type: recall
value: 56.934306569343065
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 20.200000000000003
- type: f1
value: 16.91799284049284
- type: precision
value: 15.791855158730158
- type: recall
value: 20.200000000000003
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.2
- type: f1
value: 95.3
- type: precision
value: 94.85
- type: recall
value: 96.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.3
- type: f1
value: 95.11666666666667
- type: precision
value: 94.53333333333333
- type: recall
value: 96.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.88095238095238
- type: f1
value: 87.14285714285714
- type: precision
value: 85.96230158730161
- type: recall
value: 89.88095238095238
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 24.099999999999998
- type: f1
value: 19.630969083349783
- type: precision
value: 18.275094905094907
- type: recall
value: 24.099999999999998
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 83.4368530020704
- type: f1
value: 79.45183870649709
- type: precision
value: 77.7432712215321
- type: recall
value: 83.4368530020704
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.53333333333333
- type: precision
value: 93.91666666666666
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.8
- type: f1
value: 98.48333333333332
- type: precision
value: 98.33333333333334
- type: recall
value: 98.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.5
- type: f1
value: 14.979285714285714
- type: precision
value: 14.23235060690943
- type: recall
value: 17.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.93939393939394
- type: f1
value: 91.991341991342
- type: precision
value: 91.05339105339105
- type: recall
value: 93.93939393939394
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.31297709923665
- type: f1
value: 86.76844783715012
- type: precision
value: 85.63613231552164
- type: recall
value: 89.31297709923665
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.12663755458514
- type: f1
value: 98.93255701115964
- type: precision
value: 98.83551673944687
- type: recall
value: 99.12663755458514
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.0
- type: f1
value: 89.77999999999999
- type: precision
value: 88.78333333333333
- type: recall
value: 92.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.89265536723164
- type: f1
value: 95.85687382297553
- type: precision
value: 95.33898305084746
- type: recall
value: 96.89265536723164
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.6
- type: f1
value: 11.820611790170615
- type: precision
value: 11.022616224355355
- type: recall
value: 14.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.89999999999999
- type: f1
value: 94.93333333333334
- type: precision
value: 94.48666666666666
- type: recall
value: 95.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.6
- type: f1
value: 84.72333333333334
- type: precision
value: 83.44166666666666
- type: recall
value: 87.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.8
- type: f1
value: 93.47333333333333
- type: precision
value: 92.875
- type: recall
value: 94.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.6
- type: f1
value: 95.71666666666665
- type: precision
value: 95.28333333333335
- type: recall
value: 96.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.8
- type: f1
value: 14.511074040901628
- type: precision
value: 13.503791000666002
- type: recall
value: 17.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.10187667560321
- type: f1
value: 92.46648793565683
- type: precision
value: 91.71134941912423
- type: recall
value: 94.10187667560321
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.0
- type: f1
value: 96.11666666666666
- type: precision
value: 95.68333333333334
- type: recall
value: 97.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 72.72727272727273
- type: f1
value: 66.58949745906267
- type: precision
value: 63.86693017127799
- type: recall
value: 72.72727272727273
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.14084507042254
- type: f1
value: 88.26291079812206
- type: precision
value: 87.32394366197182
- type: recall
value: 90.14084507042254
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 64.67065868263472
- type: f1
value: 58.2876627696987
- type: precision
value: 55.79255774165953
- type: recall
value: 64.67065868263472
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.6
- type: f1
value: 94.41666666666667
- type: precision
value: 93.85
- type: recall
value: 95.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 55.172413793103445
- type: f1
value: 49.63992493549144
- type: precision
value: 47.71405113769646
- type: recall
value: 55.172413793103445
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.46478873239437
- type: f1
value: 73.4417616811983
- type: precision
value: 71.91607981220658
- type: recall
value: 77.46478873239437
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.61538461538461
- type: f1
value: 80.91452991452994
- type: precision
value: 79.33760683760683
- type: recall
value: 84.61538461538461
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.2
- type: f1
value: 97.6
- type: precision
value: 97.3
- type: recall
value: 98.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.5741127348643
- type: f1
value: 72.00417536534445
- type: precision
value: 70.53467872883321
- type: recall
value: 75.5741127348643
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 62.2
- type: f1
value: 55.577460317460314
- type: precision
value: 52.98583333333333
- type: recall
value: 62.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.18241042345277
- type: f1
value: 90.6468124709167
- type: precision
value: 89.95656894679696
- type: recall
value: 92.18241042345277
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.13333333333333
- type: precision
value: 94.66666666666667
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.85000000000001
- type: precision
value: 95.39999999999999
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.1259842519685
- type: f1
value: 89.76377952755905
- type: precision
value: 88.71391076115485
- type: recall
value: 92.1259842519685
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.49
- type: precision
value: 91.725
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.5623268698061
- type: f1
value: 73.27364463791058
- type: precision
value: 71.51947852086357
- type: recall
value: 77.5623268698061
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.39999999999999
- type: f1
value: 96.56666666666666
- type: precision
value: 96.16666666666667
- type: recall
value: 97.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.34615384615384
- type: f1
value: 61.092032967032964
- type: precision
value: 59.27197802197802
- type: recall
value: 66.34615384615384
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.89999999999999
- type: f1
value: 93.41190476190476
- type: precision
value: 92.7
- type: recall
value: 94.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.10000000000001
- type: f1
value: 91.10000000000001
- type: precision
value: 90.13333333333333
- type: recall
value: 93.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.97333333333334
- type: precision
value: 91.14166666666667
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.21698113207547
- type: f1
value: 90.3796046720575
- type: precision
value: 89.56367924528303
- type: recall
value: 92.21698113207547
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.6
- type: f1
value: 96.91666666666667
- type: precision
value: 96.6
- type: recall
value: 97.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.44525547445255
- type: f1
value: 96.71532846715328
- type: precision
value: 96.35036496350365
- type: recall
value: 97.44525547445255
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.34000000000002
- type: precision
value: 91.49166666666667
- type: recall
value: 94.1
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.2910000000000004
- type: map_at_10
value: 10.373000000000001
- type: map_at_100
value: 15.612
- type: map_at_1000
value: 17.06
- type: map_at_3
value: 6.119
- type: map_at_5
value: 7.917000000000001
- type: mrr_at_1
value: 44.897999999999996
- type: mrr_at_10
value: 56.054
- type: mrr_at_100
value: 56.82000000000001
- type: mrr_at_1000
value: 56.82000000000001
- type: mrr_at_3
value: 52.381
- type: mrr_at_5
value: 53.81
- type: ndcg_at_1
value: 42.857
- type: ndcg_at_10
value: 27.249000000000002
- type: ndcg_at_100
value: 36.529
- type: ndcg_at_1000
value: 48.136
- type: ndcg_at_3
value: 33.938
- type: ndcg_at_5
value: 29.951
- type: precision_at_1
value: 44.897999999999996
- type: precision_at_10
value: 22.653000000000002
- type: precision_at_100
value: 7.000000000000001
- type: precision_at_1000
value: 1.48
- type: precision_at_3
value: 32.653
- type: precision_at_5
value: 27.755000000000003
- type: recall_at_1
value: 3.2910000000000004
- type: recall_at_10
value: 16.16
- type: recall_at_100
value: 43.908
- type: recall_at_1000
value: 79.823
- type: recall_at_3
value: 7.156
- type: recall_at_5
value: 10.204
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.05879999999999
- type: ap
value: 14.609748142799111
- type: f1
value: 54.878956295843096
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 64.61799660441426
- type: f1
value: 64.8698191961434
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.32860036611885
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 88.34714192048638
- type: cos_sim_ap
value: 80.26732975975634
- type: cos_sim_f1
value: 73.53415148134374
- type: cos_sim_precision
value: 69.34767360299276
- type: cos_sim_recall
value: 78.25857519788919
- type: dot_accuracy
value: 88.34714192048638
- type: dot_ap
value: 80.26733698491206
- type: dot_f1
value: 73.53415148134374
- type: dot_precision
value: 69.34767360299276
- type: dot_recall
value: 78.25857519788919
- type: euclidean_accuracy
value: 88.34714192048638
- type: euclidean_ap
value: 80.26734337771738
- type: euclidean_f1
value: 73.53415148134374
- type: euclidean_precision
value: 69.34767360299276
- type: euclidean_recall
value: 78.25857519788919
- type: manhattan_accuracy
value: 88.30541813196639
- type: manhattan_ap
value: 80.19415808104145
- type: manhattan_f1
value: 73.55143870713441
- type: manhattan_precision
value: 73.25307511122743
- type: manhattan_recall
value: 73.85224274406332
- type: max_accuracy
value: 88.34714192048638
- type: max_ap
value: 80.26734337771738
- type: max_f1
value: 73.55143870713441
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.81061047075717
- type: cos_sim_ap
value: 87.11747055081017
- type: cos_sim_f1
value: 80.04355498817256
- type: cos_sim_precision
value: 78.1165262000733
- type: cos_sim_recall
value: 82.06806282722513
- type: dot_accuracy
value: 89.81061047075717
- type: dot_ap
value: 87.11746902745236
- type: dot_f1
value: 80.04355498817256
- type: dot_precision
value: 78.1165262000733
- type: dot_recall
value: 82.06806282722513
- type: euclidean_accuracy
value: 89.81061047075717
- type: euclidean_ap
value: 87.11746919324248
- type: euclidean_f1
value: 80.04355498817256
- type: euclidean_precision
value: 78.1165262000733
- type: euclidean_recall
value: 82.06806282722513
- type: manhattan_accuracy
value: 89.79508673885202
- type: manhattan_ap
value: 87.11074390832218
- type: manhattan_f1
value: 80.13002540726349
- type: manhattan_precision
value: 77.83826945412311
- type: manhattan_recall
value: 82.56082537727133
- type: max_accuracy
value: 89.81061047075717
- type: max_ap
value: 87.11747055081017
- type: max_f1
value: 80.13002540726349
---
## Multilingual-E5-large-instruct
[Multilingual E5 Text Embeddings: A Technical Report](https://arxiv.org/pdf/2402.05672).
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei, arXiv 2024
This model has 24 layers and the embedding size is 1024.
## Usage
Below are examples to encode queries and passages from the MS-MARCO passage ranking dataset.
### Transformers
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'how much protein should a female eat'),
get_detailed_instruct(task, '南瓜的家常做法')
]
# No need to add instruction for retrieval documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-large-instruct')
model = AutoModel.from_pretrained('intfloat/multilingual-e5-large-instruct')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
# => [[91.92852783203125, 67.580322265625], [70.3814468383789, 92.1330795288086]]
```
### Sentence Transformers
```python
from sentence_transformers import SentenceTransformer
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'how much protein should a female eat'),
get_detailed_instruct(task, '南瓜的家常做法')
]
# No need to add instruction for retrieval documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"
]
input_texts = queries + documents
model = SentenceTransformer('intfloat/multilingual-e5-large-instruct')
embeddings = model.encode(input_texts, convert_to_tensor=True, normalize_embeddings=True)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
# [[91.92853546142578, 67.5802993774414], [70.38143157958984, 92.13307189941406]]
```
## Supported Languages
This model is initialized from [xlm-roberta-large](https://huggingface.co/xlm-roberta-large)
and continually trained on a mixture of multilingual datasets.
It supports 100 languages from xlm-roberta,
but low-resource languages may see performance degradation.
## Training Details
**Initialization**: [xlm-roberta-large](https://huggingface.co/xlm-roberta-large)
**First stage**: contrastive pre-training with 1 billion weakly supervised text pairs.
**Second stage**: fine-tuning on datasets from the [E5-mistral](https://arxiv.org/abs/2401.00368) paper.
## MTEB Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## FAQ
**1. Do I need to add instructions to the query?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
The task definition should be a one-sentence instruction that describes the task.
This is a way to customize text embeddings for different scenarios through natural language instructions.
Please check out [unilm/e5/utils.py](https://github.com/microsoft/unilm/blob/9c0f1ff7ca53431fe47d2637dfe253643d94185b/e5/utils.py#L106) for instructions we used for evaluation.
On the other hand, there is no need to add instructions to the document side.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Why does the cosine similarity scores distribute around 0.7 to 1.0?**
This is a known and expected behavior as we use a low temperature 0.01 for InfoNCE contrastive loss.
For text embedding tasks like text retrieval or semantic similarity,
what matters is the relative order of the scores instead of the absolute values,
so this should not be an issue.
## Citation
If you find our paper or models helpful, please consider cite as follows:
```
@article{wang2024multilingual,
title={Multilingual E5 Text Embeddings: A Technical Report},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2402.05672},
year={2024}
}
```
## Limitations
Long texts will be truncated to at most 512 tokens.
|
[
"BIOSSES",
"SCIFACT"
] |
yixuan-chia/multilingual-e5-base-gguf
|
yixuan-chia
|
sentence-similarity
|
[
"sentence-transformers",
"gguf",
"mteb",
"Sentence Transformers",
"sentence-similarity",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:2402.05672",
"arxiv:2108.08787",
"arxiv:2104.08663",
"arxiv:2210.07316",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"feature-extraction"
] | 2024-10-23T03:02:45Z |
2024-10-23T03:03:57+00:00
| 62 | 0 |
---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
tags:
- mteb
- Sentence Transformers
- sentence-similarity
- sentence-transformers
model-index:
- name: multilingual-e5-base
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 78.97014925373135
- type: ap
value: 43.69351129103008
- type: f1
value: 73.38075030070492
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 71.7237687366167
- type: ap
value: 82.22089859962671
- type: f1
value: 69.95532758884401
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 79.65517241379312
- type: ap
value: 28.507918657094738
- type: f1
value: 66.84516013726119
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.32976445396146
- type: ap
value: 20.720481637566014
- type: f1
value: 59.78002763416003
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 90.63775
- type: ap
value: 87.22277903861716
- type: f1
value: 90.60378636386807
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 44.546
- type: f1
value: 44.05666638370923
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 41.828
- type: f1
value: 41.2710255644252
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.534
- type: f1
value: 39.820743174270326
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 39.684
- type: f1
value: 39.11052682815307
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.436
- type: f1
value: 37.07082931930871
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.226000000000006
- type: f1
value: 36.65372077739185
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.831000000000003
- type: map_at_10
value: 36.42
- type: map_at_100
value: 37.699
- type: map_at_1000
value: 37.724000000000004
- type: map_at_3
value: 32.207
- type: map_at_5
value: 34.312
- type: mrr_at_1
value: 23.257
- type: mrr_at_10
value: 36.574
- type: mrr_at_100
value: 37.854
- type: mrr_at_1000
value: 37.878
- type: mrr_at_3
value: 32.385000000000005
- type: mrr_at_5
value: 34.48
- type: ndcg_at_1
value: 22.831000000000003
- type: ndcg_at_10
value: 44.230000000000004
- type: ndcg_at_100
value: 49.974000000000004
- type: ndcg_at_1000
value: 50.522999999999996
- type: ndcg_at_3
value: 35.363
- type: ndcg_at_5
value: 39.164
- type: precision_at_1
value: 22.831000000000003
- type: precision_at_10
value: 6.935
- type: precision_at_100
value: 0.9520000000000001
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 14.841
- type: precision_at_5
value: 10.754
- type: recall_at_1
value: 22.831000000000003
- type: recall_at_10
value: 69.346
- type: recall_at_100
value: 95.235
- type: recall_at_1000
value: 99.36
- type: recall_at_3
value: 44.523
- type: recall_at_5
value: 53.769999999999996
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 40.27789869854063
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 35.41979463347428
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 58.22752045109304
- type: mrr
value: 71.51112430198303
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.71147646622866
- type: cos_sim_spearman
value: 85.059167046486
- type: euclidean_pearson
value: 75.88421613600647
- type: euclidean_spearman
value: 75.12821787150585
- type: manhattan_pearson
value: 75.22005646957604
- type: manhattan_spearman
value: 74.42880434453272
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.23799582463465
- type: f1
value: 99.12665274878218
- type: precision
value: 99.07098121085595
- type: recall
value: 99.23799582463465
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.88685890380806
- type: f1
value: 97.59336708489249
- type: precision
value: 97.44662117543473
- type: recall
value: 97.88685890380806
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.47142362313821
- type: f1
value: 97.1989377670015
- type: precision
value: 97.06384944001847
- type: recall
value: 97.47142362313821
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.4728804634018
- type: f1
value: 98.2973494821836
- type: precision
value: 98.2095839915745
- type: recall
value: 98.4728804634018
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 82.74025974025975
- type: f1
value: 82.67420447730439
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.0380848063507
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 29.45956405670166
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.122
- type: map_at_10
value: 42.03
- type: map_at_100
value: 43.364000000000004
- type: map_at_1000
value: 43.474000000000004
- type: map_at_3
value: 38.804
- type: map_at_5
value: 40.585
- type: mrr_at_1
value: 39.914
- type: mrr_at_10
value: 48.227
- type: mrr_at_100
value: 49.018
- type: mrr_at_1000
value: 49.064
- type: mrr_at_3
value: 45.994
- type: mrr_at_5
value: 47.396
- type: ndcg_at_1
value: 39.914
- type: ndcg_at_10
value: 47.825
- type: ndcg_at_100
value: 52.852
- type: ndcg_at_1000
value: 54.891
- type: ndcg_at_3
value: 43.517
- type: ndcg_at_5
value: 45.493
- type: precision_at_1
value: 39.914
- type: precision_at_10
value: 8.956
- type: precision_at_100
value: 1.388
- type: precision_at_1000
value: 0.182
- type: precision_at_3
value: 20.791999999999998
- type: precision_at_5
value: 14.821000000000002
- type: recall_at_1
value: 32.122
- type: recall_at_10
value: 58.294999999999995
- type: recall_at_100
value: 79.726
- type: recall_at_1000
value: 93.099
- type: recall_at_3
value: 45.017
- type: recall_at_5
value: 51.002
- type: map_at_1
value: 29.677999999999997
- type: map_at_10
value: 38.684000000000005
- type: map_at_100
value: 39.812999999999995
- type: map_at_1000
value: 39.945
- type: map_at_3
value: 35.831
- type: map_at_5
value: 37.446
- type: mrr_at_1
value: 37.771
- type: mrr_at_10
value: 44.936
- type: mrr_at_100
value: 45.583
- type: mrr_at_1000
value: 45.634
- type: mrr_at_3
value: 42.771
- type: mrr_at_5
value: 43.994
- type: ndcg_at_1
value: 37.771
- type: ndcg_at_10
value: 44.059
- type: ndcg_at_100
value: 48.192
- type: ndcg_at_1000
value: 50.375
- type: ndcg_at_3
value: 40.172000000000004
- type: ndcg_at_5
value: 41.899
- type: precision_at_1
value: 37.771
- type: precision_at_10
value: 8.286999999999999
- type: precision_at_100
value: 1.322
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 19.406000000000002
- type: precision_at_5
value: 13.745
- type: recall_at_1
value: 29.677999999999997
- type: recall_at_10
value: 53.071
- type: recall_at_100
value: 70.812
- type: recall_at_1000
value: 84.841
- type: recall_at_3
value: 41.016000000000005
- type: recall_at_5
value: 46.22
- type: map_at_1
value: 42.675000000000004
- type: map_at_10
value: 53.93599999999999
- type: map_at_100
value: 54.806999999999995
- type: map_at_1000
value: 54.867
- type: map_at_3
value: 50.934000000000005
- type: map_at_5
value: 52.583
- type: mrr_at_1
value: 48.339
- type: mrr_at_10
value: 57.265
- type: mrr_at_100
value: 57.873
- type: mrr_at_1000
value: 57.906
- type: mrr_at_3
value: 55.193000000000005
- type: mrr_at_5
value: 56.303000000000004
- type: ndcg_at_1
value: 48.339
- type: ndcg_at_10
value: 59.19799999999999
- type: ndcg_at_100
value: 62.743
- type: ndcg_at_1000
value: 63.99399999999999
- type: ndcg_at_3
value: 54.367
- type: ndcg_at_5
value: 56.548
- type: precision_at_1
value: 48.339
- type: precision_at_10
value: 9.216000000000001
- type: precision_at_100
value: 1.1809999999999998
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 23.72
- type: precision_at_5
value: 16.025
- type: recall_at_1
value: 42.675000000000004
- type: recall_at_10
value: 71.437
- type: recall_at_100
value: 86.803
- type: recall_at_1000
value: 95.581
- type: recall_at_3
value: 58.434
- type: recall_at_5
value: 63.754
- type: map_at_1
value: 23.518
- type: map_at_10
value: 30.648999999999997
- type: map_at_100
value: 31.508999999999997
- type: map_at_1000
value: 31.604
- type: map_at_3
value: 28.247
- type: map_at_5
value: 29.65
- type: mrr_at_1
value: 25.650000000000002
- type: mrr_at_10
value: 32.771
- type: mrr_at_100
value: 33.554
- type: mrr_at_1000
value: 33.629999999999995
- type: mrr_at_3
value: 30.433
- type: mrr_at_5
value: 31.812
- type: ndcg_at_1
value: 25.650000000000002
- type: ndcg_at_10
value: 34.929
- type: ndcg_at_100
value: 39.382
- type: ndcg_at_1000
value: 41.913
- type: ndcg_at_3
value: 30.292
- type: ndcg_at_5
value: 32.629999999999995
- type: precision_at_1
value: 25.650000000000002
- type: precision_at_10
value: 5.311
- type: precision_at_100
value: 0.792
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 12.58
- type: precision_at_5
value: 8.994
- type: recall_at_1
value: 23.518
- type: recall_at_10
value: 46.19
- type: recall_at_100
value: 67.123
- type: recall_at_1000
value: 86.442
- type: recall_at_3
value: 33.678000000000004
- type: recall_at_5
value: 39.244
- type: map_at_1
value: 15.891
- type: map_at_10
value: 22.464000000000002
- type: map_at_100
value: 23.483
- type: map_at_1000
value: 23.613
- type: map_at_3
value: 20.080000000000002
- type: map_at_5
value: 21.526
- type: mrr_at_1
value: 20.025000000000002
- type: mrr_at_10
value: 26.712999999999997
- type: mrr_at_100
value: 27.650000000000002
- type: mrr_at_1000
value: 27.737000000000002
- type: mrr_at_3
value: 24.274
- type: mrr_at_5
value: 25.711000000000002
- type: ndcg_at_1
value: 20.025000000000002
- type: ndcg_at_10
value: 27.028999999999996
- type: ndcg_at_100
value: 32.064
- type: ndcg_at_1000
value: 35.188
- type: ndcg_at_3
value: 22.512999999999998
- type: ndcg_at_5
value: 24.89
- type: precision_at_1
value: 20.025000000000002
- type: precision_at_10
value: 4.776
- type: precision_at_100
value: 0.8500000000000001
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 10.531
- type: precision_at_5
value: 7.811
- type: recall_at_1
value: 15.891
- type: recall_at_10
value: 37.261
- type: recall_at_100
value: 59.12
- type: recall_at_1000
value: 81.356
- type: recall_at_3
value: 24.741
- type: recall_at_5
value: 30.753999999999998
- type: map_at_1
value: 27.544
- type: map_at_10
value: 36.283
- type: map_at_100
value: 37.467
- type: map_at_1000
value: 37.574000000000005
- type: map_at_3
value: 33.528999999999996
- type: map_at_5
value: 35.028999999999996
- type: mrr_at_1
value: 34.166999999999994
- type: mrr_at_10
value: 41.866
- type: mrr_at_100
value: 42.666
- type: mrr_at_1000
value: 42.716
- type: mrr_at_3
value: 39.541
- type: mrr_at_5
value: 40.768
- type: ndcg_at_1
value: 34.166999999999994
- type: ndcg_at_10
value: 41.577
- type: ndcg_at_100
value: 46.687
- type: ndcg_at_1000
value: 48.967
- type: ndcg_at_3
value: 37.177
- type: ndcg_at_5
value: 39.097
- type: precision_at_1
value: 34.166999999999994
- type: precision_at_10
value: 7.420999999999999
- type: precision_at_100
value: 1.165
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 17.291999999999998
- type: precision_at_5
value: 12.166
- type: recall_at_1
value: 27.544
- type: recall_at_10
value: 51.99399999999999
- type: recall_at_100
value: 73.738
- type: recall_at_1000
value: 89.33
- type: recall_at_3
value: 39.179
- type: recall_at_5
value: 44.385999999999996
- type: map_at_1
value: 26.661
- type: map_at_10
value: 35.475
- type: map_at_100
value: 36.626999999999995
- type: map_at_1000
value: 36.741
- type: map_at_3
value: 32.818000000000005
- type: map_at_5
value: 34.397
- type: mrr_at_1
value: 32.647999999999996
- type: mrr_at_10
value: 40.784
- type: mrr_at_100
value: 41.602
- type: mrr_at_1000
value: 41.661
- type: mrr_at_3
value: 38.68
- type: mrr_at_5
value: 39.838
- type: ndcg_at_1
value: 32.647999999999996
- type: ndcg_at_10
value: 40.697
- type: ndcg_at_100
value: 45.799
- type: ndcg_at_1000
value: 48.235
- type: ndcg_at_3
value: 36.516
- type: ndcg_at_5
value: 38.515
- type: precision_at_1
value: 32.647999999999996
- type: precision_at_10
value: 7.202999999999999
- type: precision_at_100
value: 1.1360000000000001
- type: precision_at_1000
value: 0.151
- type: precision_at_3
value: 17.314
- type: precision_at_5
value: 12.145999999999999
- type: recall_at_1
value: 26.661
- type: recall_at_10
value: 50.995000000000005
- type: recall_at_100
value: 73.065
- type: recall_at_1000
value: 89.781
- type: recall_at_3
value: 39.073
- type: recall_at_5
value: 44.395
- type: map_at_1
value: 25.946583333333333
- type: map_at_10
value: 33.79725
- type: map_at_100
value: 34.86408333333333
- type: map_at_1000
value: 34.9795
- type: map_at_3
value: 31.259999999999998
- type: map_at_5
value: 32.71541666666666
- type: mrr_at_1
value: 30.863749999999996
- type: mrr_at_10
value: 37.99183333333333
- type: mrr_at_100
value: 38.790499999999994
- type: mrr_at_1000
value: 38.85575000000001
- type: mrr_at_3
value: 35.82083333333333
- type: mrr_at_5
value: 37.07533333333333
- type: ndcg_at_1
value: 30.863749999999996
- type: ndcg_at_10
value: 38.52141666666667
- type: ndcg_at_100
value: 43.17966666666667
- type: ndcg_at_1000
value: 45.64608333333333
- type: ndcg_at_3
value: 34.333000000000006
- type: ndcg_at_5
value: 36.34975
- type: precision_at_1
value: 30.863749999999996
- type: precision_at_10
value: 6.598999999999999
- type: precision_at_100
value: 1.0502500000000001
- type: precision_at_1000
value: 0.14400000000000002
- type: precision_at_3
value: 15.557583333333334
- type: precision_at_5
value: 11.020000000000001
- type: recall_at_1
value: 25.946583333333333
- type: recall_at_10
value: 48.36991666666666
- type: recall_at_100
value: 69.02408333333334
- type: recall_at_1000
value: 86.43858333333331
- type: recall_at_3
value: 36.4965
- type: recall_at_5
value: 41.76258333333334
- type: map_at_1
value: 22.431
- type: map_at_10
value: 28.889
- type: map_at_100
value: 29.642000000000003
- type: map_at_1000
value: 29.742
- type: map_at_3
value: 26.998
- type: map_at_5
value: 28.172000000000004
- type: mrr_at_1
value: 25.307000000000002
- type: mrr_at_10
value: 31.763
- type: mrr_at_100
value: 32.443
- type: mrr_at_1000
value: 32.531
- type: mrr_at_3
value: 29.959000000000003
- type: mrr_at_5
value: 31.063000000000002
- type: ndcg_at_1
value: 25.307000000000002
- type: ndcg_at_10
value: 32.586999999999996
- type: ndcg_at_100
value: 36.5
- type: ndcg_at_1000
value: 39.133
- type: ndcg_at_3
value: 29.25
- type: ndcg_at_5
value: 31.023
- type: precision_at_1
value: 25.307000000000002
- type: precision_at_10
value: 4.954
- type: precision_at_100
value: 0.747
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 12.577
- type: precision_at_5
value: 8.741999999999999
- type: recall_at_1
value: 22.431
- type: recall_at_10
value: 41.134
- type: recall_at_100
value: 59.28600000000001
- type: recall_at_1000
value: 78.857
- type: recall_at_3
value: 31.926
- type: recall_at_5
value: 36.335
- type: map_at_1
value: 17.586
- type: map_at_10
value: 23.304
- type: map_at_100
value: 24.159
- type: map_at_1000
value: 24.281
- type: map_at_3
value: 21.316
- type: map_at_5
value: 22.383
- type: mrr_at_1
value: 21.645
- type: mrr_at_10
value: 27.365000000000002
- type: mrr_at_100
value: 28.108
- type: mrr_at_1000
value: 28.192
- type: mrr_at_3
value: 25.482
- type: mrr_at_5
value: 26.479999999999997
- type: ndcg_at_1
value: 21.645
- type: ndcg_at_10
value: 27.306
- type: ndcg_at_100
value: 31.496000000000002
- type: ndcg_at_1000
value: 34.53
- type: ndcg_at_3
value: 23.73
- type: ndcg_at_5
value: 25.294
- type: precision_at_1
value: 21.645
- type: precision_at_10
value: 4.797
- type: precision_at_100
value: 0.8059999999999999
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 10.850999999999999
- type: precision_at_5
value: 7.736
- type: recall_at_1
value: 17.586
- type: recall_at_10
value: 35.481
- type: recall_at_100
value: 54.534000000000006
- type: recall_at_1000
value: 76.456
- type: recall_at_3
value: 25.335
- type: recall_at_5
value: 29.473
- type: map_at_1
value: 25.095
- type: map_at_10
value: 32.374
- type: map_at_100
value: 33.537
- type: map_at_1000
value: 33.634
- type: map_at_3
value: 30.089
- type: map_at_5
value: 31.433
- type: mrr_at_1
value: 29.198
- type: mrr_at_10
value: 36.01
- type: mrr_at_100
value: 37.022
- type: mrr_at_1000
value: 37.083
- type: mrr_at_3
value: 33.94
- type: mrr_at_5
value: 35.148
- type: ndcg_at_1
value: 29.198
- type: ndcg_at_10
value: 36.729
- type: ndcg_at_100
value: 42.114000000000004
- type: ndcg_at_1000
value: 44.592
- type: ndcg_at_3
value: 32.644
- type: ndcg_at_5
value: 34.652
- type: precision_at_1
value: 29.198
- type: precision_at_10
value: 5.970000000000001
- type: precision_at_100
value: 0.967
- type: precision_at_1000
value: 0.129
- type: precision_at_3
value: 14.396999999999998
- type: precision_at_5
value: 10.093
- type: recall_at_1
value: 25.095
- type: recall_at_10
value: 46.392
- type: recall_at_100
value: 69.706
- type: recall_at_1000
value: 87.738
- type: recall_at_3
value: 35.303000000000004
- type: recall_at_5
value: 40.441
- type: map_at_1
value: 26.857999999999997
- type: map_at_10
value: 34.066
- type: map_at_100
value: 35.671
- type: map_at_1000
value: 35.881
- type: map_at_3
value: 31.304
- type: map_at_5
value: 32.885
- type: mrr_at_1
value: 32.411
- type: mrr_at_10
value: 38.987
- type: mrr_at_100
value: 39.894
- type: mrr_at_1000
value: 39.959
- type: mrr_at_3
value: 36.626999999999995
- type: mrr_at_5
value: 38.011
- type: ndcg_at_1
value: 32.411
- type: ndcg_at_10
value: 39.208
- type: ndcg_at_100
value: 44.626
- type: ndcg_at_1000
value: 47.43
- type: ndcg_at_3
value: 35.091
- type: ndcg_at_5
value: 37.119
- type: precision_at_1
value: 32.411
- type: precision_at_10
value: 7.51
- type: precision_at_100
value: 1.486
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 16.14
- type: precision_at_5
value: 11.976
- type: recall_at_1
value: 26.857999999999997
- type: recall_at_10
value: 47.407
- type: recall_at_100
value: 72.236
- type: recall_at_1000
value: 90.77
- type: recall_at_3
value: 35.125
- type: recall_at_5
value: 40.522999999999996
- type: map_at_1
value: 21.3
- type: map_at_10
value: 27.412999999999997
- type: map_at_100
value: 28.29
- type: map_at_1000
value: 28.398
- type: map_at_3
value: 25.169999999999998
- type: map_at_5
value: 26.496
- type: mrr_at_1
value: 23.29
- type: mrr_at_10
value: 29.215000000000003
- type: mrr_at_100
value: 30.073
- type: mrr_at_1000
value: 30.156
- type: mrr_at_3
value: 26.956000000000003
- type: mrr_at_5
value: 28.38
- type: ndcg_at_1
value: 23.29
- type: ndcg_at_10
value: 31.113000000000003
- type: ndcg_at_100
value: 35.701
- type: ndcg_at_1000
value: 38.505
- type: ndcg_at_3
value: 26.727
- type: ndcg_at_5
value: 29.037000000000003
- type: precision_at_1
value: 23.29
- type: precision_at_10
value: 4.787
- type: precision_at_100
value: 0.763
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 11.091
- type: precision_at_5
value: 7.985
- type: recall_at_1
value: 21.3
- type: recall_at_10
value: 40.782000000000004
- type: recall_at_100
value: 62.13999999999999
- type: recall_at_1000
value: 83.012
- type: recall_at_3
value: 29.131
- type: recall_at_5
value: 34.624
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.631
- type: map_at_10
value: 16.634999999999998
- type: map_at_100
value: 18.23
- type: map_at_1000
value: 18.419
- type: map_at_3
value: 13.66
- type: map_at_5
value: 15.173
- type: mrr_at_1
value: 21.368000000000002
- type: mrr_at_10
value: 31.56
- type: mrr_at_100
value: 32.58
- type: mrr_at_1000
value: 32.633
- type: mrr_at_3
value: 28.241
- type: mrr_at_5
value: 30.225
- type: ndcg_at_1
value: 21.368000000000002
- type: ndcg_at_10
value: 23.855999999999998
- type: ndcg_at_100
value: 30.686999999999998
- type: ndcg_at_1000
value: 34.327000000000005
- type: ndcg_at_3
value: 18.781
- type: ndcg_at_5
value: 20.73
- type: precision_at_1
value: 21.368000000000002
- type: precision_at_10
value: 7.564
- type: precision_at_100
value: 1.496
- type: precision_at_1000
value: 0.217
- type: precision_at_3
value: 13.876
- type: precision_at_5
value: 11.062
- type: recall_at_1
value: 9.631
- type: recall_at_10
value: 29.517
- type: recall_at_100
value: 53.452
- type: recall_at_1000
value: 74.115
- type: recall_at_3
value: 17.605999999999998
- type: recall_at_5
value: 22.505
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.885
- type: map_at_10
value: 18.798000000000002
- type: map_at_100
value: 26.316
- type: map_at_1000
value: 27.869
- type: map_at_3
value: 13.719000000000001
- type: map_at_5
value: 15.716
- type: mrr_at_1
value: 66
- type: mrr_at_10
value: 74.263
- type: mrr_at_100
value: 74.519
- type: mrr_at_1000
value: 74.531
- type: mrr_at_3
value: 72.458
- type: mrr_at_5
value: 73.321
- type: ndcg_at_1
value: 53.87499999999999
- type: ndcg_at_10
value: 40.355999999999995
- type: ndcg_at_100
value: 44.366
- type: ndcg_at_1000
value: 51.771
- type: ndcg_at_3
value: 45.195
- type: ndcg_at_5
value: 42.187000000000005
- type: precision_at_1
value: 66
- type: precision_at_10
value: 31.75
- type: precision_at_100
value: 10.11
- type: precision_at_1000
value: 1.9800000000000002
- type: precision_at_3
value: 48.167
- type: precision_at_5
value: 40.050000000000004
- type: recall_at_1
value: 8.885
- type: recall_at_10
value: 24.471999999999998
- type: recall_at_100
value: 49.669000000000004
- type: recall_at_1000
value: 73.383
- type: recall_at_3
value: 14.872
- type: recall_at_5
value: 18.262999999999998
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 45.18
- type: f1
value: 40.26878691789978
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 62.751999999999995
- type: map_at_10
value: 74.131
- type: map_at_100
value: 74.407
- type: map_at_1000
value: 74.423
- type: map_at_3
value: 72.329
- type: map_at_5
value: 73.555
- type: mrr_at_1
value: 67.282
- type: mrr_at_10
value: 78.292
- type: mrr_at_100
value: 78.455
- type: mrr_at_1000
value: 78.458
- type: mrr_at_3
value: 76.755
- type: mrr_at_5
value: 77.839
- type: ndcg_at_1
value: 67.282
- type: ndcg_at_10
value: 79.443
- type: ndcg_at_100
value: 80.529
- type: ndcg_at_1000
value: 80.812
- type: ndcg_at_3
value: 76.281
- type: ndcg_at_5
value: 78.235
- type: precision_at_1
value: 67.282
- type: precision_at_10
value: 10.078
- type: precision_at_100
value: 1.082
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 30.178
- type: precision_at_5
value: 19.232
- type: recall_at_1
value: 62.751999999999995
- type: recall_at_10
value: 91.521
- type: recall_at_100
value: 95.997
- type: recall_at_1000
value: 97.775
- type: recall_at_3
value: 83.131
- type: recall_at_5
value: 87.93299999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.861
- type: map_at_10
value: 30.252000000000002
- type: map_at_100
value: 32.082
- type: map_at_1000
value: 32.261
- type: map_at_3
value: 25.909
- type: map_at_5
value: 28.296
- type: mrr_at_1
value: 37.346000000000004
- type: mrr_at_10
value: 45.802
- type: mrr_at_100
value: 46.611999999999995
- type: mrr_at_1000
value: 46.659
- type: mrr_at_3
value: 43.056
- type: mrr_at_5
value: 44.637
- type: ndcg_at_1
value: 37.346000000000004
- type: ndcg_at_10
value: 38.169
- type: ndcg_at_100
value: 44.864
- type: ndcg_at_1000
value: 47.974
- type: ndcg_at_3
value: 33.619
- type: ndcg_at_5
value: 35.317
- type: precision_at_1
value: 37.346000000000004
- type: precision_at_10
value: 10.693999999999999
- type: precision_at_100
value: 1.775
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 22.325
- type: precision_at_5
value: 16.852
- type: recall_at_1
value: 18.861
- type: recall_at_10
value: 45.672000000000004
- type: recall_at_100
value: 70.60499999999999
- type: recall_at_1000
value: 89.216
- type: recall_at_3
value: 30.361
- type: recall_at_5
value: 36.998999999999995
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.852999999999994
- type: map_at_10
value: 59.961
- type: map_at_100
value: 60.78
- type: map_at_1000
value: 60.843
- type: map_at_3
value: 56.39999999999999
- type: map_at_5
value: 58.646
- type: mrr_at_1
value: 75.70599999999999
- type: mrr_at_10
value: 82.321
- type: mrr_at_100
value: 82.516
- type: mrr_at_1000
value: 82.525
- type: mrr_at_3
value: 81.317
- type: mrr_at_5
value: 81.922
- type: ndcg_at_1
value: 75.70599999999999
- type: ndcg_at_10
value: 68.557
- type: ndcg_at_100
value: 71.485
- type: ndcg_at_1000
value: 72.71600000000001
- type: ndcg_at_3
value: 63.524
- type: ndcg_at_5
value: 66.338
- type: precision_at_1
value: 75.70599999999999
- type: precision_at_10
value: 14.463000000000001
- type: precision_at_100
value: 1.677
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 40.806
- type: precision_at_5
value: 26.709
- type: recall_at_1
value: 37.852999999999994
- type: recall_at_10
value: 72.316
- type: recall_at_100
value: 83.842
- type: recall_at_1000
value: 91.999
- type: recall_at_3
value: 61.209
- type: recall_at_5
value: 66.77199999999999
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 85.46039999999999
- type: ap
value: 79.9812521351881
- type: f1
value: 85.31722909702084
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.704
- type: map_at_10
value: 35.329
- type: map_at_100
value: 36.494
- type: map_at_1000
value: 36.541000000000004
- type: map_at_3
value: 31.476
- type: map_at_5
value: 33.731
- type: mrr_at_1
value: 23.294999999999998
- type: mrr_at_10
value: 35.859
- type: mrr_at_100
value: 36.968
- type: mrr_at_1000
value: 37.008
- type: mrr_at_3
value: 32.085
- type: mrr_at_5
value: 34.299
- type: ndcg_at_1
value: 23.324
- type: ndcg_at_10
value: 42.274
- type: ndcg_at_100
value: 47.839999999999996
- type: ndcg_at_1000
value: 48.971
- type: ndcg_at_3
value: 34.454
- type: ndcg_at_5
value: 38.464
- type: precision_at_1
value: 23.324
- type: precision_at_10
value: 6.648
- type: precision_at_100
value: 0.9440000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.674999999999999
- type: precision_at_5
value: 10.850999999999999
- type: recall_at_1
value: 22.704
- type: recall_at_10
value: 63.660000000000004
- type: recall_at_100
value: 89.29899999999999
- type: recall_at_1000
value: 97.88900000000001
- type: recall_at_3
value: 42.441
- type: recall_at_5
value: 52.04
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.1326949384405
- type: f1
value: 92.89743579612082
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.62524654832347
- type: f1
value: 88.65106082263151
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.59039359573046
- type: f1
value: 90.31532892105662
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.21046038208581
- type: f1
value: 86.41459529813113
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 87.3180351380423
- type: f1
value: 86.71383078226444
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.24231464737792
- type: f1
value: 86.31845567592403
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.27131782945736
- type: f1
value: 57.52079940417103
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.2341504649197
- type: f1
value: 51.349951558039244
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.27418278852569
- type: f1
value: 50.1714985749095
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 67.68243031631694
- type: f1
value: 50.1066160836192
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.2362854069559
- type: f1
value: 48.821279948766424
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.71428571428571
- type: f1
value: 53.94611389496195
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.97646267652992
- type: f1
value: 57.26797883561521
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.65501008742435
- type: f1
value: 50.416258382177034
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.45796906523201
- type: f1
value: 53.306690547422185
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.59246805648957
- type: f1
value: 59.818381969051494
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.126429051782104
- type: f1
value: 58.25993593933026
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 50.057162071284466
- type: f1
value: 46.96095728790911
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.64425016812375
- type: f1
value: 62.858291698755764
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.08944182918628
- type: f1
value: 62.44639030604241
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.68056489576328
- type: f1
value: 61.775326758789504
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.11163416274377
- type: f1
value: 69.70789096927015
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.40282447881641
- type: f1
value: 66.38492065671895
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.24613315400134
- type: f1
value: 64.3348019501336
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.78345662407531
- type: f1
value: 62.21279452354622
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.9455279085407
- type: f1
value: 65.48193124964094
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.05110961667788
- type: f1
value: 58.097856564684534
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.95292535305985
- type: f1
value: 62.09182174767901
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.97310020174848
- type: f1
value: 61.14252567730396
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.08069939475453
- type: f1
value: 57.044041742492034
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.63752521856085
- type: f1
value: 63.889340907205316
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.385339609952936
- type: f1
value: 53.449033750088304
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.93073301950234
- type: f1
value: 65.9884357824104
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.94418291862812
- type: f1
value: 66.48740222583132
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.26025554808339
- type: f1
value: 50.19562815100793
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.98789509078682
- type: f1
value: 46.65788438676836
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.68728984532616
- type: f1
value: 41.642419349541996
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.19300605245461
- type: f1
value: 55.8626492442437
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.33826496301278
- type: f1
value: 63.89499791648792
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.33960995292536
- type: f1
value: 57.15242464180892
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.09347679892402
- type: f1
value: 59.64733214063841
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.75924680564896
- type: f1
value: 55.96585692366827
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.48486886348352
- type: f1
value: 59.45143559032946
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.56422326832549
- type: f1
value: 54.96368702901926
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.18022864828512
- type: f1
value: 63.05369805040634
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.30329522528581
- type: f1
value: 64.06084612020727
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.36919973100201
- type: f1
value: 65.12154124788887
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.98117014122394
- type: f1
value: 66.41847559806962
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.53799596503026
- type: f1
value: 62.17067330740817
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.01815736381977
- type: f1
value: 66.24988369607843
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.34700739744452
- type: f1
value: 59.957933424941636
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.23402824478815
- type: f1
value: 57.98836976018471
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.54068594485541
- type: f1
value: 65.43849680666855
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.998655010087425
- type: f1
value: 52.83737515406804
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.71217215870882
- type: f1
value: 55.051794977833026
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.724277067921996
- type: f1
value: 56.33485571838306
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.59515803631473
- type: f1
value: 64.96772366193588
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.860793544048406
- type: f1
value: 58.148845819115394
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.40753194351043
- type: f1
value: 63.18903778054698
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.52320107599194
- type: f1
value: 58.356144563398516
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.17014122394083
- type: f1
value: 63.919964062638925
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.15601882985878
- type: f1
value: 67.01451905761371
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.65030262273034
- type: f1
value: 64.14420425129063
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.08742434431743
- type: f1
value: 63.044060042311756
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.52387357094821
- type: f1
value: 56.82398588814534
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.239408204438476
- type: f1
value: 61.92570286170469
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.74915938130463
- type: f1
value: 62.130740689396276
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.00336247478144
- type: f1
value: 63.71080635228055
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.837928715534645
- type: f1
value: 50.390741680320836
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.42098184263618
- type: f1
value: 71.41355113538995
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.95359784801613
- type: f1
value: 71.42699340156742
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.18157363819772
- type: f1
value: 69.74836113037671
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.08137188971082
- type: f1
value: 76.78000685068261
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.5030262273033
- type: f1
value: 71.71620130425673
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.24546065904505
- type: f1
value: 69.07638311730359
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.12911903160726
- type: f1
value: 68.32651736539815
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.89307330195025
- type: f1
value: 71.33986549860187
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.44451916610626
- type: f1
value: 66.90192664503866
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.16274377942166
- type: f1
value: 68.01090953775066
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.75319435104237
- type: f1
value: 70.18035309201403
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.14391392064559
- type: f1
value: 61.48286540778145
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.70275722932078
- type: f1
value: 70.26164779846495
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.93813046402153
- type: f1
value: 58.8852862116525
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.320107599193
- type: f1
value: 72.19836409602924
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.65366509751176
- type: f1
value: 74.55188288799579
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.694014794889036
- type: f1
value: 58.11353311721067
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.37457969065231
- type: f1
value: 52.81306134311697
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.3086751849361
- type: f1
value: 45.396449765419376
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.151983860121064
- type: f1
value: 60.31762544281696
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.44788164088769
- type: f1
value: 71.68150151736367
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.81439139206455
- type: f1
value: 62.06735559105593
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.04303967720242
- type: f1
value: 66.68298851670133
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.43913920645595
- type: f1
value: 60.25605977560783
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.90316072629456
- type: f1
value: 65.1325924692381
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.63752521856086
- type: f1
value: 59.14284778039585
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.63080026899797
- type: f1
value: 70.89771864626877
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.10827168796234
- type: f1
value: 71.71954219691159
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.59515803631471
- type: f1
value: 70.05040128099003
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.83389374579691
- type: f1
value: 70.84877936562735
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.18628110289173
- type: f1
value: 68.97232927921841
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.99260255548083
- type: f1
value: 72.85139492157732
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.26227303295225
- type: f1
value: 65.08833655469431
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.48621385339611
- type: f1
value: 64.43483199071298
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.14391392064559
- type: f1
value: 72.2580822579741
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.88567585743107
- type: f1
value: 58.3073765932569
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.38399462004034
- type: f1
value: 60.82139544252606
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.58574310692671
- type: f1
value: 60.71443370385374
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.61398789509079
- type: f1
value: 70.99761812049401
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.73705447209146
- type: f1
value: 61.680849331794796
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.66778749159381
- type: f1
value: 71.17320646080115
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.640215198386
- type: f1
value: 63.301805157015444
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.00672494956288
- type: f1
value: 70.26005548582106
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.42030934767989
- type: f1
value: 75.2074842882598
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.69266980497646
- type: f1
value: 70.94103167391192
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 28.91697191169135
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.434000079573313
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.96683513343383
- type: mrr
value: 31.967364078714834
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.5280000000000005
- type: map_at_10
value: 11.793
- type: map_at_100
value: 14.496999999999998
- type: map_at_1000
value: 15.783
- type: map_at_3
value: 8.838
- type: map_at_5
value: 10.07
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 51.531000000000006
- type: mrr_at_100
value: 52.205
- type: mrr_at_1000
value: 52.242999999999995
- type: mrr_at_3
value: 49.431999999999995
- type: mrr_at_5
value: 50.470000000000006
- type: ndcg_at_1
value: 42.415000000000006
- type: ndcg_at_10
value: 32.464999999999996
- type: ndcg_at_100
value: 28.927999999999997
- type: ndcg_at_1000
value: 37.629000000000005
- type: ndcg_at_3
value: 37.845
- type: ndcg_at_5
value: 35.147
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 23.932000000000002
- type: precision_at_100
value: 7.17
- type: precision_at_1000
value: 1.967
- type: precision_at_3
value: 35.397
- type: precision_at_5
value: 29.907
- type: recall_at_1
value: 5.5280000000000005
- type: recall_at_10
value: 15.568000000000001
- type: recall_at_100
value: 28.54
- type: recall_at_1000
value: 59.864
- type: recall_at_3
value: 9.822000000000001
- type: recall_at_5
value: 11.726
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.041000000000004
- type: map_at_10
value: 52.664
- type: map_at_100
value: 53.477
- type: map_at_1000
value: 53.505
- type: map_at_3
value: 48.510999999999996
- type: map_at_5
value: 51.036
- type: mrr_at_1
value: 41.338
- type: mrr_at_10
value: 55.071000000000005
- type: mrr_at_100
value: 55.672
- type: mrr_at_1000
value: 55.689
- type: mrr_at_3
value: 51.82
- type: mrr_at_5
value: 53.852
- type: ndcg_at_1
value: 41.338
- type: ndcg_at_10
value: 60.01800000000001
- type: ndcg_at_100
value: 63.409000000000006
- type: ndcg_at_1000
value: 64.017
- type: ndcg_at_3
value: 52.44799999999999
- type: ndcg_at_5
value: 56.571000000000005
- type: precision_at_1
value: 41.338
- type: precision_at_10
value: 9.531
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.416
- type: precision_at_5
value: 16.46
- type: recall_at_1
value: 37.041000000000004
- type: recall_at_10
value: 79.76299999999999
- type: recall_at_100
value: 94.39
- type: recall_at_1000
value: 98.851
- type: recall_at_3
value: 60.465
- type: recall_at_5
value: 69.906
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 69.952
- type: map_at_10
value: 83.758
- type: map_at_100
value: 84.406
- type: map_at_1000
value: 84.425
- type: map_at_3
value: 80.839
- type: map_at_5
value: 82.646
- type: mrr_at_1
value: 80.62
- type: mrr_at_10
value: 86.947
- type: mrr_at_100
value: 87.063
- type: mrr_at_1000
value: 87.064
- type: mrr_at_3
value: 85.96000000000001
- type: mrr_at_5
value: 86.619
- type: ndcg_at_1
value: 80.63
- type: ndcg_at_10
value: 87.64800000000001
- type: ndcg_at_100
value: 88.929
- type: ndcg_at_1000
value: 89.054
- type: ndcg_at_3
value: 84.765
- type: ndcg_at_5
value: 86.291
- type: precision_at_1
value: 80.63
- type: precision_at_10
value: 13.314
- type: precision_at_100
value: 1.525
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.1
- type: precision_at_5
value: 24.372
- type: recall_at_1
value: 69.952
- type: recall_at_10
value: 94.955
- type: recall_at_100
value: 99.38
- type: recall_at_1000
value: 99.96000000000001
- type: recall_at_3
value: 86.60600000000001
- type: recall_at_5
value: 90.997
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 42.41329517878427
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 55.171278362748666
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.213
- type: map_at_10
value: 9.895
- type: map_at_100
value: 11.776
- type: map_at_1000
value: 12.084
- type: map_at_3
value: 7.2669999999999995
- type: map_at_5
value: 8.620999999999999
- type: mrr_at_1
value: 20.8
- type: mrr_at_10
value: 31.112000000000002
- type: mrr_at_100
value: 32.274
- type: mrr_at_1000
value: 32.35
- type: mrr_at_3
value: 28.133000000000003
- type: mrr_at_5
value: 29.892999999999997
- type: ndcg_at_1
value: 20.8
- type: ndcg_at_10
value: 17.163999999999998
- type: ndcg_at_100
value: 24.738
- type: ndcg_at_1000
value: 30.316
- type: ndcg_at_3
value: 16.665
- type: ndcg_at_5
value: 14.478
- type: precision_at_1
value: 20.8
- type: precision_at_10
value: 8.74
- type: precision_at_100
value: 1.963
- type: precision_at_1000
value: 0.33
- type: precision_at_3
value: 15.467
- type: precision_at_5
value: 12.6
- type: recall_at_1
value: 4.213
- type: recall_at_10
value: 17.698
- type: recall_at_100
value: 39.838
- type: recall_at_1000
value: 66.893
- type: recall_at_3
value: 9.418
- type: recall_at_5
value: 12.773000000000001
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 82.90453315738294
- type: cos_sim_spearman
value: 78.51197850080254
- type: euclidean_pearson
value: 80.09647123597748
- type: euclidean_spearman
value: 78.63548011514061
- type: manhattan_pearson
value: 80.10645285675231
- type: manhattan_spearman
value: 78.57861806068901
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.2616156846401
- type: cos_sim_spearman
value: 76.69713867850156
- type: euclidean_pearson
value: 77.97948563800394
- type: euclidean_spearman
value: 74.2371211567807
- type: manhattan_pearson
value: 77.69697879669705
- type: manhattan_spearman
value: 73.86529778022278
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 77.0293269315045
- type: cos_sim_spearman
value: 78.02555120584198
- type: euclidean_pearson
value: 78.25398100379078
- type: euclidean_spearman
value: 78.66963870599464
- type: manhattan_pearson
value: 78.14314682167348
- type: manhattan_spearman
value: 78.57692322969135
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 79.16989925136942
- type: cos_sim_spearman
value: 76.5996225327091
- type: euclidean_pearson
value: 77.8319003279786
- type: euclidean_spearman
value: 76.42824009468998
- type: manhattan_pearson
value: 77.69118862737736
- type: manhattan_spearman
value: 76.25568104762812
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.42012286935325
- type: cos_sim_spearman
value: 88.15654297884122
- type: euclidean_pearson
value: 87.34082819427852
- type: euclidean_spearman
value: 88.06333589547084
- type: manhattan_pearson
value: 87.25115596784842
- type: manhattan_spearman
value: 87.9559927695203
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.88222044996712
- type: cos_sim_spearman
value: 84.28476589061077
- type: euclidean_pearson
value: 83.17399758058309
- type: euclidean_spearman
value: 83.85497357244542
- type: manhattan_pearson
value: 83.0308397703786
- type: manhattan_spearman
value: 83.71554539935046
- task:
type: STS
dataset:
name: MTEB STS17 (ko-ko)
type: mteb/sts17-crosslingual-sts
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.20682986257339
- type: cos_sim_spearman
value: 79.94567120362092
- type: euclidean_pearson
value: 79.43122480368902
- type: euclidean_spearman
value: 79.94802077264987
- type: manhattan_pearson
value: 79.32653021527081
- type: manhattan_spearman
value: 79.80961146709178
- task:
type: STS
dataset:
name: MTEB STS17 (ar-ar)
type: mteb/sts17-crosslingual-sts
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 74.46578144394383
- type: cos_sim_spearman
value: 74.52496637472179
- type: euclidean_pearson
value: 72.2903807076809
- type: euclidean_spearman
value: 73.55549359771645
- type: manhattan_pearson
value: 72.09324837709393
- type: manhattan_spearman
value: 73.36743103606581
- task:
type: STS
dataset:
name: MTEB STS17 (en-ar)
type: mteb/sts17-crosslingual-sts
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 71.37272335116
- type: cos_sim_spearman
value: 71.26702117766037
- type: euclidean_pearson
value: 67.114829954434
- type: euclidean_spearman
value: 66.37938893947761
- type: manhattan_pearson
value: 66.79688574095246
- type: manhattan_spearman
value: 66.17292828079667
- task:
type: STS
dataset:
name: MTEB STS17 (en-de)
type: mteb/sts17-crosslingual-sts
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.61016770129092
- type: cos_sim_spearman
value: 82.08515426632214
- type: euclidean_pearson
value: 80.557340361131
- type: euclidean_spearman
value: 80.37585812266175
- type: manhattan_pearson
value: 80.6782873404285
- type: manhattan_spearman
value: 80.6678073032024
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.00150745350108
- type: cos_sim_spearman
value: 87.83441972211425
- type: euclidean_pearson
value: 87.94826702308792
- type: euclidean_spearman
value: 87.46143974860725
- type: manhattan_pearson
value: 87.97560344306105
- type: manhattan_spearman
value: 87.5267102829796
- task:
type: STS
dataset:
name: MTEB STS17 (en-tr)
type: mteb/sts17-crosslingual-sts
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 64.76325252267235
- type: cos_sim_spearman
value: 63.32615095463905
- type: euclidean_pearson
value: 64.07920669155716
- type: euclidean_spearman
value: 61.21409893072176
- type: manhattan_pearson
value: 64.26308625680016
- type: manhattan_spearman
value: 61.2438185254079
- task:
type: STS
dataset:
name: MTEB STS17 (es-en)
type: mteb/sts17-crosslingual-sts
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 75.82644463022595
- type: cos_sim_spearman
value: 76.50381269945073
- type: euclidean_pearson
value: 75.1328548315934
- type: euclidean_spearman
value: 75.63761139408453
- type: manhattan_pearson
value: 75.18610101241407
- type: manhattan_spearman
value: 75.30669266354164
- task:
type: STS
dataset:
name: MTEB STS17 (es-es)
type: mteb/sts17-crosslingual-sts
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.49994164686832
- type: cos_sim_spearman
value: 86.73743986245549
- type: euclidean_pearson
value: 86.8272894387145
- type: euclidean_spearman
value: 85.97608491000507
- type: manhattan_pearson
value: 86.74960140396779
- type: manhattan_spearman
value: 85.79285984190273
- task:
type: STS
dataset:
name: MTEB STS17 (fr-en)
type: mteb/sts17-crosslingual-sts
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.58172210788469
- type: cos_sim_spearman
value: 80.17516468334607
- type: euclidean_pearson
value: 77.56537843470504
- type: euclidean_spearman
value: 77.57264627395521
- type: manhattan_pearson
value: 78.09703521695943
- type: manhattan_spearman
value: 78.15942760916954
- task:
type: STS
dataset:
name: MTEB STS17 (it-en)
type: mteb/sts17-crosslingual-sts
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.7589932931751
- type: cos_sim_spearman
value: 80.15210089028162
- type: euclidean_pearson
value: 77.54135223516057
- type: euclidean_spearman
value: 77.52697996368764
- type: manhattan_pearson
value: 77.65734439572518
- type: manhattan_spearman
value: 77.77702992016121
- task:
type: STS
dataset:
name: MTEB STS17 (nl-en)
type: mteb/sts17-crosslingual-sts
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.16682365511267
- type: cos_sim_spearman
value: 79.25311267628506
- type: euclidean_pearson
value: 77.54882036762244
- type: euclidean_spearman
value: 77.33212935194827
- type: manhattan_pearson
value: 77.98405516064015
- type: manhattan_spearman
value: 77.85075717865719
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.10473294775917
- type: cos_sim_spearman
value: 61.82780474476838
- type: euclidean_pearson
value: 45.885111672377256
- type: euclidean_spearman
value: 56.88306351932454
- type: manhattan_pearson
value: 46.101218127323186
- type: manhattan_spearman
value: 56.80953694186333
- task:
type: STS
dataset:
name: MTEB STS22 (de)
type: mteb/sts22-crosslingual-sts
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 45.781923079584146
- type: cos_sim_spearman
value: 55.95098449691107
- type: euclidean_pearson
value: 25.4571031323205
- type: euclidean_spearman
value: 49.859978118078935
- type: manhattan_pearson
value: 25.624938455041384
- type: manhattan_spearman
value: 49.99546185049401
- task:
type: STS
dataset:
name: MTEB STS22 (es)
type: mteb/sts22-crosslingual-sts
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 60.00618133997907
- type: cos_sim_spearman
value: 66.57896677718321
- type: euclidean_pearson
value: 42.60118466388821
- type: euclidean_spearman
value: 62.8210759715209
- type: manhattan_pearson
value: 42.63446860604094
- type: manhattan_spearman
value: 62.73803068925271
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 28.460759121626943
- type: cos_sim_spearman
value: 34.13459007469131
- type: euclidean_pearson
value: 6.0917739325525195
- type: euclidean_spearman
value: 27.9947262664867
- type: manhattan_pearson
value: 6.16877864169911
- type: manhattan_spearman
value: 28.00664163971514
- task:
type: STS
dataset:
name: MTEB STS22 (tr)
type: mteb/sts22-crosslingual-sts
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.42546621771696
- type: cos_sim_spearman
value: 63.699663168970474
- type: euclidean_pearson
value: 38.12085278789738
- type: euclidean_spearman
value: 58.12329140741536
- type: manhattan_pearson
value: 37.97364549443335
- type: manhattan_spearman
value: 57.81545502318733
- task:
type: STS
dataset:
name: MTEB STS22 (ar)
type: mteb/sts22-crosslingual-sts
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 46.82241380954213
- type: cos_sim_spearman
value: 57.86569456006391
- type: euclidean_pearson
value: 31.80480070178813
- type: euclidean_spearman
value: 52.484000620130104
- type: manhattan_pearson
value: 31.952708554646097
- type: manhattan_spearman
value: 52.8560972356195
- task:
type: STS
dataset:
name: MTEB STS22 (ru)
type: mteb/sts22-crosslingual-sts
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 52.00447170498087
- type: cos_sim_spearman
value: 60.664116225735164
- type: euclidean_pearson
value: 33.87382555421702
- type: euclidean_spearman
value: 55.74649067458667
- type: manhattan_pearson
value: 33.99117246759437
- type: manhattan_spearman
value: 55.98749034923899
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 58.06497233105448
- type: cos_sim_spearman
value: 65.62968801135676
- type: euclidean_pearson
value: 47.482076613243905
- type: euclidean_spearman
value: 62.65137791498299
- type: manhattan_pearson
value: 47.57052626104093
- type: manhattan_spearman
value: 62.436916516613294
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 70.49397298562575
- type: cos_sim_spearman
value: 74.79604041187868
- type: euclidean_pearson
value: 49.661891561317795
- type: euclidean_spearman
value: 70.31535537621006
- type: manhattan_pearson
value: 49.553715741850006
- type: manhattan_spearman
value: 70.24779344636806
- task:
type: STS
dataset:
name: MTEB STS22 (de-en)
type: mteb/sts22-crosslingual-sts
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.640574515348696
- type: cos_sim_spearman
value: 54.927959317689
- type: euclidean_pearson
value: 29.00139666967476
- type: euclidean_spearman
value: 41.86386566971605
- type: manhattan_pearson
value: 29.47411067730344
- type: manhattan_spearman
value: 42.337438424952786
- task:
type: STS
dataset:
name: MTEB STS22 (es-en)
type: mteb/sts22-crosslingual-sts
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 68.14095292259312
- type: cos_sim_spearman
value: 73.99017581234789
- type: euclidean_pearson
value: 46.46304297872084
- type: euclidean_spearman
value: 60.91834114800041
- type: manhattan_pearson
value: 47.07072666338692
- type: manhattan_spearman
value: 61.70415727977926
- task:
type: STS
dataset:
name: MTEB STS22 (it)
type: mteb/sts22-crosslingual-sts
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 73.27184653359575
- type: cos_sim_spearman
value: 77.76070252418626
- type: euclidean_pearson
value: 62.30586577544778
- type: euclidean_spearman
value: 75.14246629110978
- type: manhattan_pearson
value: 62.328196884927046
- type: manhattan_spearman
value: 75.1282792981433
- task:
type: STS
dataset:
name: MTEB STS22 (pl-en)
type: mteb/sts22-crosslingual-sts
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 71.59448528829957
- type: cos_sim_spearman
value: 70.37277734222123
- type: euclidean_pearson
value: 57.63145565721123
- type: euclidean_spearman
value: 66.10113048304427
- type: manhattan_pearson
value: 57.18897811586808
- type: manhattan_spearman
value: 66.5595511215901
- task:
type: STS
dataset:
name: MTEB STS22 (zh-en)
type: mteb/sts22-crosslingual-sts
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.37520607720838
- type: cos_sim_spearman
value: 69.92282148997948
- type: euclidean_pearson
value: 40.55768770125291
- type: euclidean_spearman
value: 55.189128944669605
- type: manhattan_pearson
value: 41.03566433468883
- type: manhattan_spearman
value: 55.61251893174558
- task:
type: STS
dataset:
name: MTEB STS22 (es-it)
type: mteb/sts22-crosslingual-sts
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.791929533771835
- type: cos_sim_spearman
value: 66.45819707662093
- type: euclidean_pearson
value: 39.03686018511092
- type: euclidean_spearman
value: 56.01282695640428
- type: manhattan_pearson
value: 38.91586623619632
- type: manhattan_spearman
value: 56.69394943612747
- task:
type: STS
dataset:
name: MTEB STS22 (de-fr)
type: mteb/sts22-crosslingual-sts
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.82224468473866
- type: cos_sim_spearman
value: 59.467307194781164
- type: euclidean_pearson
value: 27.428459190256145
- type: euclidean_spearman
value: 60.83463107397519
- type: manhattan_pearson
value: 27.487391578496638
- type: manhattan_spearman
value: 61.281380460246496
- task:
type: STS
dataset:
name: MTEB STS22 (de-pl)
type: mteb/sts22-crosslingual-sts
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 16.306666792752644
- type: cos_sim_spearman
value: 39.35486427252405
- type: euclidean_pearson
value: -2.7887154897955435
- type: euclidean_spearman
value: 27.1296051831719
- type: manhattan_pearson
value: -3.202291270581297
- type: manhattan_spearman
value: 26.32895849218158
- task:
type: STS
dataset:
name: MTEB STS22 (fr-pl)
type: mteb/sts22-crosslingual-sts
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.67006803805076
- type: cos_sim_spearman
value: 73.24670207647144
- type: euclidean_pearson
value: 46.91884681500483
- type: euclidean_spearman
value: 16.903085094570333
- type: manhattan_pearson
value: 46.88391675325812
- type: manhattan_spearman
value: 28.17180849095055
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 83.79555591223837
- type: cos_sim_spearman
value: 85.63658602085185
- type: euclidean_pearson
value: 85.22080894037671
- type: euclidean_spearman
value: 85.54113580167038
- type: manhattan_pearson
value: 85.1639505960118
- type: manhattan_spearman
value: 85.43502665436196
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 80.73900991689766
- type: mrr
value: 94.81624131133934
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 55.678000000000004
- type: map_at_10
value: 65.135
- type: map_at_100
value: 65.824
- type: map_at_1000
value: 65.852
- type: map_at_3
value: 62.736000000000004
- type: map_at_5
value: 64.411
- type: mrr_at_1
value: 58.333
- type: mrr_at_10
value: 66.5
- type: mrr_at_100
value: 67.053
- type: mrr_at_1000
value: 67.08
- type: mrr_at_3
value: 64.944
- type: mrr_at_5
value: 65.89399999999999
- type: ndcg_at_1
value: 58.333
- type: ndcg_at_10
value: 69.34700000000001
- type: ndcg_at_100
value: 72.32
- type: ndcg_at_1000
value: 73.014
- type: ndcg_at_3
value: 65.578
- type: ndcg_at_5
value: 67.738
- type: precision_at_1
value: 58.333
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 25.444
- type: precision_at_5
value: 16.933
- type: recall_at_1
value: 55.678000000000004
- type: recall_at_10
value: 80.72200000000001
- type: recall_at_100
value: 93.93299999999999
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 70.783
- type: recall_at_5
value: 75.978
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.74653465346535
- type: cos_sim_ap
value: 93.01476369929063
- type: cos_sim_f1
value: 86.93009118541033
- type: cos_sim_precision
value: 88.09034907597535
- type: cos_sim_recall
value: 85.8
- type: dot_accuracy
value: 99.22970297029703
- type: dot_ap
value: 51.58725659485144
- type: dot_f1
value: 53.51351351351352
- type: dot_precision
value: 58.235294117647065
- type: dot_recall
value: 49.5
- type: euclidean_accuracy
value: 99.74356435643564
- type: euclidean_ap
value: 92.40332894384368
- type: euclidean_f1
value: 86.97838109602817
- type: euclidean_precision
value: 87.46208291203236
- type: euclidean_recall
value: 86.5
- type: manhattan_accuracy
value: 99.73069306930694
- type: manhattan_ap
value: 92.01320815721121
- type: manhattan_f1
value: 86.4135864135864
- type: manhattan_precision
value: 86.32734530938124
- type: manhattan_recall
value: 86.5
- type: max_accuracy
value: 99.74653465346535
- type: max_ap
value: 93.01476369929063
- type: max_f1
value: 86.97838109602817
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 55.2660514302523
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 30.4637783572547
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 49.41377758357637
- type: mrr
value: 50.138451213818854
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 28.887846011166594
- type: cos_sim_spearman
value: 30.10823258355903
- type: dot_pearson
value: 12.888049550236385
- type: dot_spearman
value: 12.827495903098123
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.21
- type: map_at_10
value: 1.667
- type: map_at_100
value: 9.15
- type: map_at_1000
value: 22.927
- type: map_at_3
value: 0.573
- type: map_at_5
value: 0.915
- type: mrr_at_1
value: 80
- type: mrr_at_10
value: 87.167
- type: mrr_at_100
value: 87.167
- type: mrr_at_1000
value: 87.167
- type: mrr_at_3
value: 85.667
- type: mrr_at_5
value: 87.167
- type: ndcg_at_1
value: 76
- type: ndcg_at_10
value: 69.757
- type: ndcg_at_100
value: 52.402
- type: ndcg_at_1000
value: 47.737
- type: ndcg_at_3
value: 71.866
- type: ndcg_at_5
value: 72.225
- type: precision_at_1
value: 80
- type: precision_at_10
value: 75
- type: precision_at_100
value: 53.959999999999994
- type: precision_at_1000
value: 21.568
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 78
- type: recall_at_1
value: 0.21
- type: recall_at_10
value: 1.9189999999999998
- type: recall_at_100
value: 12.589
- type: recall_at_1000
value: 45.312000000000005
- type: recall_at_3
value: 0.61
- type: recall_at_5
value: 1.019
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.10000000000001
- type: f1
value: 90.06
- type: precision
value: 89.17333333333333
- type: recall
value: 92.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.06936416184971
- type: f1
value: 50.87508028259473
- type: precision
value: 48.97398843930635
- type: recall
value: 56.06936416184971
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 57.3170731707317
- type: f1
value: 52.96080139372822
- type: precision
value: 51.67861124382864
- type: recall
value: 57.3170731707317
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.67333333333333
- type: precision
value: 91.90833333333333
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 97.07333333333332
- type: precision
value: 96.79500000000002
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.2
- type: precision
value: 92.48333333333333
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.9
- type: f1
value: 91.26666666666667
- type: precision
value: 90.59444444444445
- type: recall
value: 92.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 34.32835820895522
- type: f1
value: 29.074180380150533
- type: precision
value: 28.068207322920596
- type: recall
value: 34.32835820895522
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.5
- type: f1
value: 74.3945115995116
- type: precision
value: 72.82967843459222
- type: recall
value: 78.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.34146341463415
- type: f1
value: 61.2469400518181
- type: precision
value: 59.63977756660683
- type: recall
value: 66.34146341463415
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.9
- type: f1
value: 76.90349206349207
- type: precision
value: 75.32921568627451
- type: recall
value: 80.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.93317132442284
- type: f1
value: 81.92519105034295
- type: precision
value: 80.71283920615635
- type: recall
value: 84.93317132442284
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.1304347826087
- type: f1
value: 65.22394755003451
- type: precision
value: 62.912422360248435
- type: recall
value: 71.1304347826087
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.82608695652173
- type: f1
value: 75.55693581780538
- type: precision
value: 73.79420289855072
- type: recall
value: 79.82608695652173
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74
- type: f1
value: 70.51022222222223
- type: precision
value: 69.29673599347512
- type: recall
value: 74
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 74.14238095238095
- type: precision
value: 72.27214285714285
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.97466827503016
- type: f1
value: 43.080330405420874
- type: precision
value: 41.36505499593557
- type: recall
value: 48.97466827503016
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.60000000000001
- type: f1
value: 86.62333333333333
- type: precision
value: 85.225
- type: recall
value: 89.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.2
- type: f1
value: 39.5761253006253
- type: precision
value: 37.991358436312
- type: recall
value: 45.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.70333333333333
- type: precision
value: 85.53166666666667
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.095238095238095
- type: f1
value: 44.60650460650461
- type: precision
value: 42.774116796477045
- type: recall
value: 50.095238095238095
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.4
- type: f1
value: 58.35967261904762
- type: precision
value: 56.54857142857143
- type: recall
value: 63.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.2
- type: f1
value: 87.075
- type: precision
value: 86.12095238095239
- type: recall
value: 89.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.90333333333334
- type: precision
value: 95.50833333333333
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.9
- type: f1
value: 88.6288888888889
- type: precision
value: 87.61607142857142
- type: recall
value: 90.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.2
- type: f1
value: 60.54377630539395
- type: precision
value: 58.89434482711381
- type: recall
value: 65.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87
- type: f1
value: 84.32412698412699
- type: precision
value: 83.25527777777778
- type: recall
value: 87
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.7
- type: f1
value: 63.07883541295306
- type: precision
value: 61.06117424242426
- type: recall
value: 68.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.78333333333335
- type: precision
value: 90.86666666666667
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 96.96666666666667
- type: precision
value: 96.61666666666667
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27493261455525
- type: f1
value: 85.90745732255168
- type: precision
value: 84.91389637616052
- type: recall
value: 88.27493261455525
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.5982905982906
- type: f1
value: 88.4900284900285
- type: precision
value: 87.57122507122507
- type: recall
value: 90.5982905982906
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.90769841269842
- type: precision
value: 85.80178571428571
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.5
- type: f1
value: 78.36796536796538
- type: precision
value: 76.82196969696969
- type: recall
value: 82.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.48846960167715
- type: f1
value: 66.78771089148448
- type: precision
value: 64.98302885095339
- type: recall
value: 71.48846960167715
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.50333333333333
- type: precision
value: 91.77499999999999
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.20622568093385
- type: f1
value: 66.83278891450098
- type: precision
value: 65.35065777283677
- type: recall
value: 71.20622568093385
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.717948717948715
- type: f1
value: 43.53146853146853
- type: precision
value: 42.04721204721204
- type: recall
value: 48.717948717948715
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 58.5
- type: f1
value: 53.8564991863928
- type: precision
value: 52.40329436122275
- type: recall
value: 58.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.8
- type: f1
value: 88.29
- type: precision
value: 87.09166666666667
- type: recall
value: 90.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.28971962616822
- type: f1
value: 62.63425307817832
- type: precision
value: 60.98065939771546
- type: recall
value: 67.28971962616822
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 75.5264472455649
- type: precision
value: 74.38205086580086
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.7
- type: f1
value: 86.10809523809525
- type: precision
value: 85.07602564102565
- type: recall
value: 88.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.99999999999999
- type: f1
value: 52.85487521402737
- type: precision
value: 51.53985162713104
- type: recall
value: 56.99999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94
- type: f1
value: 92.45333333333333
- type: precision
value: 91.79166666666667
- type: recall
value: 94
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.61333333333333
- type: precision
value: 89.83333333333331
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.34555555555555
- type: precision
value: 92.75416666666668
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.2
- type: f1
value: 76.6563035113035
- type: precision
value: 75.3014652014652
- type: recall
value: 80.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.7
- type: f1
value: 82.78689263765207
- type: precision
value: 82.06705086580087
- type: recall
value: 84.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.33333333333333
- type: f1
value: 45.461523661523664
- type: precision
value: 43.93545574795575
- type: recall
value: 50.33333333333333
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.6000000000000005
- type: f1
value: 5.442121400446441
- type: precision
value: 5.146630385487529
- type: recall
value: 6.6000000000000005
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85
- type: f1
value: 81.04666666666667
- type: precision
value: 79.25
- type: recall
value: 85
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.32142857142857
- type: f1
value: 42.333333333333336
- type: precision
value: 40.69196428571429
- type: recall
value: 47.32142857142857
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 30.735455543358945
- type: f1
value: 26.73616790022338
- type: precision
value: 25.397823220451283
- type: recall
value: 30.735455543358945
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 25.1
- type: f1
value: 21.975989896371022
- type: precision
value: 21.059885632257203
- type: recall
value: 25.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.75666666666666
- type: precision
value: 92.06166666666665
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.74
- type: precision
value: 92.09166666666667
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.3
- type: f1
value: 66.922442002442
- type: precision
value: 65.38249567099568
- type: recall
value: 71.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 40.300000000000004
- type: f1
value: 35.78682789299971
- type: precision
value: 34.66425128716588
- type: recall
value: 40.300000000000004
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96
- type: f1
value: 94.82333333333334
- type: precision
value: 94.27833333333334
- type: recall
value: 96
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 51.1
- type: f1
value: 47.179074753133584
- type: precision
value: 46.06461044702424
- type: recall
value: 51.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.7
- type: f1
value: 84.71
- type: precision
value: 83.46166666666667
- type: recall
value: 87.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.68333333333334
- type: precision
value: 94.13333333333334
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.39999999999999
- type: f1
value: 82.5577380952381
- type: precision
value: 81.36833333333334
- type: recall
value: 85.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.16788321167883
- type: f1
value: 16.948865627297987
- type: precision
value: 15.971932568647897
- type: recall
value: 21.16788321167883
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 5.515526831658907
- type: precision
value: 5.141966366966367
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.39666666666668
- type: precision
value: 90.58666666666667
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 89.95666666666666
- type: precision
value: 88.92833333333333
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.76190476190477
- type: f1
value: 74.93386243386244
- type: precision
value: 73.11011904761904
- type: recall
value: 79.76190476190477
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.799999999999999
- type: f1
value: 6.921439712248537
- type: precision
value: 6.489885109680683
- type: recall
value: 8.799999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.75569358178054
- type: f1
value: 40.34699501312631
- type: precision
value: 38.57886764719063
- type: recall
value: 45.75569358178054
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.4
- type: f1
value: 89.08333333333333
- type: precision
value: 88.01666666666668
- type: recall
value: 91.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.60000000000001
- type: f1
value: 92.06690476190477
- type: precision
value: 91.45095238095239
- type: recall
value: 93.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.5
- type: f1
value: 6.200363129378736
- type: precision
value: 5.89115314822466
- type: recall
value: 7.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 73.59307359307358
- type: f1
value: 68.38933553219267
- type: precision
value: 66.62698412698413
- type: recall
value: 73.59307359307358
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.8473282442748
- type: f1
value: 64.72373682297346
- type: precision
value: 62.82834214131924
- type: recall
value: 69.8473282442748
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.5254730713246
- type: f1
value: 96.72489082969432
- type: precision
value: 96.33672974284326
- type: recall
value: 97.5254730713246
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.6
- type: f1
value: 72.42746031746033
- type: precision
value: 71.14036630036631
- type: recall
value: 75.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.24293785310734
- type: f1
value: 88.86064030131826
- type: precision
value: 87.73540489642184
- type: recall
value: 91.24293785310734
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.2
- type: f1
value: 4.383083659794954
- type: precision
value: 4.027861324289673
- type: recall
value: 6.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 84.09428571428572
- type: precision
value: 83.00333333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 60.699999999999996
- type: f1
value: 56.1584972394755
- type: precision
value: 54.713456330903135
- type: recall
value: 60.699999999999996
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.2
- type: f1
value: 80.66190476190475
- type: precision
value: 79.19690476190476
- type: recall
value: 84.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.33
- type: precision
value: 90.45
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.3
- type: f1
value: 5.126828976748276
- type: precision
value: 4.853614328966668
- type: recall
value: 6.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.76943699731903
- type: f1
value: 77.82873739308057
- type: precision
value: 76.27622452019234
- type: recall
value: 81.76943699731903
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.29666666666665
- type: precision
value: 89.40333333333334
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 29.249011857707508
- type: f1
value: 24.561866096392947
- type: precision
value: 23.356583740215456
- type: recall
value: 29.249011857707508
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.46478873239437
- type: f1
value: 73.23943661971832
- type: precision
value: 71.66666666666667
- type: recall
value: 77.46478873239437
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 20.35928143712575
- type: f1
value: 15.997867865075824
- type: precision
value: 14.882104658301346
- type: recall
value: 20.35928143712575
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 90.25999999999999
- type: precision
value: 89.45333333333335
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 23.15270935960591
- type: f1
value: 19.65673625772148
- type: precision
value: 18.793705293464992
- type: recall
value: 23.15270935960591
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.154929577464785
- type: f1
value: 52.3868463305083
- type: precision
value: 50.14938113529662
- type: recall
value: 59.154929577464785
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.51282051282051
- type: f1
value: 66.8089133089133
- type: precision
value: 65.37645687645687
- type: recall
value: 70.51282051282051
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 93
- type: precision
value: 92.23333333333333
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.62212943632568
- type: f1
value: 34.3278276962583
- type: precision
value: 33.07646935732408
- type: recall
value: 38.62212943632568
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 28.1
- type: f1
value: 23.579609223054604
- type: precision
value: 22.39622774921555
- type: recall
value: 28.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27361563517914
- type: f1
value: 85.12486427795874
- type: precision
value: 83.71335504885994
- type: recall
value: 88.27361563517914
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.6
- type: f1
value: 86.39928571428571
- type: precision
value: 85.4947557997558
- type: recall
value: 88.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.5
- type: f1
value: 83.77952380952381
- type: precision
value: 82.67602564102565
- type: recall
value: 86.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.52755905511812
- type: f1
value: 75.3055868016498
- type: precision
value: 73.81889763779527
- type: recall
value: 79.52755905511812
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.9
- type: f1
value: 73.76261904761905
- type: precision
value: 72.11670995670995
- type: recall
value: 77.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 53.8781163434903
- type: f1
value: 47.25804051288816
- type: precision
value: 45.0603482390186
- type: recall
value: 53.8781163434903
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.10000000000001
- type: f1
value: 88.88
- type: precision
value: 87.96333333333334
- type: recall
value: 91.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.46153846153847
- type: f1
value: 34.43978243978244
- type: precision
value: 33.429487179487175
- type: recall
value: 38.46153846153847
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.9
- type: f1
value: 86.19888888888887
- type: precision
value: 85.07440476190476
- type: recall
value: 88.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.9
- type: f1
value: 82.58857142857143
- type: precision
value: 81.15666666666667
- type: recall
value: 85.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 83.36999999999999
- type: precision
value: 81.86833333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.51415094339622
- type: f1
value: 63.195000099481234
- type: precision
value: 61.394033442972116
- type: recall
value: 68.51415094339622
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.5
- type: f1
value: 86.14603174603175
- type: precision
value: 85.1162037037037
- type: recall
value: 88.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.62043795620438
- type: f1
value: 94.40389294403892
- type: precision
value: 93.7956204379562
- type: recall
value: 95.62043795620438
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.8
- type: f1
value: 78.6532178932179
- type: precision
value: 77.46348795840176
- type: recall
value: 81.8
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.603
- type: map_at_10
value: 8.5
- type: map_at_100
value: 12.985
- type: map_at_1000
value: 14.466999999999999
- type: map_at_3
value: 4.859999999999999
- type: map_at_5
value: 5.817
- type: mrr_at_1
value: 28.571
- type: mrr_at_10
value: 42.331
- type: mrr_at_100
value: 43.592999999999996
- type: mrr_at_1000
value: 43.592999999999996
- type: mrr_at_3
value: 38.435
- type: mrr_at_5
value: 39.966
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 21.353
- type: ndcg_at_100
value: 31.087999999999997
- type: ndcg_at_1000
value: 43.163000000000004
- type: ndcg_at_3
value: 22.999
- type: ndcg_at_5
value: 21.451
- type: precision_at_1
value: 28.571
- type: precision_at_10
value: 19.387999999999998
- type: precision_at_100
value: 6.265
- type: precision_at_1000
value: 1.4160000000000001
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 21.224
- type: recall_at_1
value: 2.603
- type: recall_at_10
value: 14.474
- type: recall_at_100
value: 40.287
- type: recall_at_1000
value: 76.606
- type: recall_at_3
value: 5.978
- type: recall_at_5
value: 7.819
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 69.7848
- type: ap
value: 13.661023167088224
- type: f1
value: 53.61686134460943
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.28183361629882
- type: f1
value: 61.55481034919965
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 35.972128420092396
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.59933241938367
- type: cos_sim_ap
value: 72.20760361208136
- type: cos_sim_f1
value: 66.4447731755424
- type: cos_sim_precision
value: 62.35539102267469
- type: cos_sim_recall
value: 71.10817941952506
- type: dot_accuracy
value: 78.98313166835548
- type: dot_ap
value: 44.492521645493795
- type: dot_f1
value: 45.814889336016094
- type: dot_precision
value: 37.02439024390244
- type: dot_recall
value: 60.07915567282321
- type: euclidean_accuracy
value: 85.3907134767837
- type: euclidean_ap
value: 71.53847289080343
- type: euclidean_f1
value: 65.95952206778834
- type: euclidean_precision
value: 61.31006346328196
- type: euclidean_recall
value: 71.37203166226914
- type: manhattan_accuracy
value: 85.40859510043511
- type: manhattan_ap
value: 71.49664104395515
- type: manhattan_f1
value: 65.98569969356485
- type: manhattan_precision
value: 63.928748144482924
- type: manhattan_recall
value: 68.17941952506597
- type: max_accuracy
value: 85.59933241938367
- type: max_ap
value: 72.20760361208136
- type: max_f1
value: 66.4447731755424
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.83261536073273
- type: cos_sim_ap
value: 85.48178133644264
- type: cos_sim_f1
value: 77.87816307403935
- type: cos_sim_precision
value: 75.88953021114926
- type: cos_sim_recall
value: 79.97382198952879
- type: dot_accuracy
value: 79.76287499514883
- type: dot_ap
value: 59.17438838475084
- type: dot_f1
value: 56.34566667855996
- type: dot_precision
value: 52.50349092359864
- type: dot_recall
value: 60.794579611949494
- type: euclidean_accuracy
value: 88.76857996662397
- type: euclidean_ap
value: 85.22764834359887
- type: euclidean_f1
value: 77.65379751543554
- type: euclidean_precision
value: 75.11152683839401
- type: euclidean_recall
value: 80.37419156144134
- type: manhattan_accuracy
value: 88.6987231730508
- type: manhattan_ap
value: 85.18907981724007
- type: manhattan_f1
value: 77.51967028849757
- type: manhattan_precision
value: 75.49992701795358
- type: manhattan_recall
value: 79.65044656606098
- type: max_accuracy
value: 88.83261536073273
- type: max_ap
value: 85.48178133644264
- type: max_f1
value: 77.87816307403935
---
## Multilingual-E5-base
[Multilingual E5 Text Embeddings: A Technical Report](https://arxiv.org/pdf/2402.05672).
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei, arXiv 2024
This model has 12 layers and the embedding size is 768.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ", even for non-English texts.
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"]
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
model = AutoModel.from_pretrained('intfloat/multilingual-e5-base')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Supported Languages
This model is initialized from [xlm-roberta-base](https://huggingface.co/xlm-roberta-base)
and continually trained on a mixture of multilingual datasets.
It supports 100 languages from xlm-roberta,
but low-resource languages may see performance degradation.
## Training Details
**Initialization**: [xlm-roberta-base](https://huggingface.co/xlm-roberta-base)
**First stage**: contrastive pre-training with weak supervision
| Dataset | Weak supervision | # of text pairs |
|--------------------------------------------------------------------------------------------------------|---------------------------------------|-----------------|
| Filtered [mC4](https://huggingface.co/datasets/mc4) | (title, page content) | 1B |
| [CC News](https://huggingface.co/datasets/intfloat/multilingual_cc_news) | (title, news content) | 400M |
| [NLLB](https://huggingface.co/datasets/allenai/nllb) | translation pairs | 2.4B |
| [Wikipedia](https://huggingface.co/datasets/intfloat/wikipedia) | (hierarchical section title, passage) | 150M |
| Filtered [Reddit](https://www.reddit.com/) | (comment, response) | 800M |
| [S2ORC](https://github.com/allenai/s2orc) | (title, abstract) and citation pairs | 100M |
| [Stackexchange](https://stackexchange.com/) | (question, answer) | 50M |
| [xP3](https://huggingface.co/datasets/bigscience/xP3) | (input prompt, response) | 80M |
| [Miscellaneous unsupervised SBERT data](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | - | 10M |
**Second stage**: supervised fine-tuning
| Dataset | Language | # of text pairs |
|----------------------------------------------------------------------------------------|--------------|-----------------|
| [MS MARCO](https://microsoft.github.io/msmarco/) | English | 500k |
| [NQ](https://github.com/facebookresearch/DPR) | English | 70k |
| [Trivia QA](https://github.com/facebookresearch/DPR) | English | 60k |
| [NLI from SimCSE](https://github.com/princeton-nlp/SimCSE) | English | <300k |
| [ELI5](https://huggingface.co/datasets/eli5) | English | 500k |
| [DuReader Retrieval](https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval) | Chinese | 86k |
| [KILT Fever](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [KILT HotpotQA](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [SQuAD](https://huggingface.co/datasets/squad) | English | 87k |
| [Quora](https://huggingface.co/datasets/quora) | English | 150k |
| [Mr. TyDi](https://huggingface.co/datasets/castorini/mr-tydi) | 11 languages | 50k |
| [MIRACL](https://huggingface.co/datasets/miracl/miracl) | 16 languages | 40k |
For all labeled datasets, we only use its training set for fine-tuning.
For other training details, please refer to our paper at [https://arxiv.org/pdf/2402.05672](https://arxiv.org/pdf/2402.05672).
## Benchmark Results on [Mr. TyDi](https://arxiv.org/abs/2108.08787)
| Model | Avg MRR@10 | | ar | bn | en | fi | id | ja | ko | ru | sw | te | th |
|-----------------------|------------|-------|------| --- | --- | --- | --- | --- | --- | --- |------| --- | --- |
| BM25 | 33.3 | | 36.7 | 41.3 | 15.1 | 28.8 | 38.2 | 21.7 | 28.1 | 32.9 | 39.6 | 42.4 | 41.7 |
| mDPR | 16.7 | | 26.0 | 25.8 | 16.2 | 11.3 | 14.6 | 18.1 | 21.9 | 18.5 | 7.3 | 10.6 | 13.5 |
| BM25 + mDPR | 41.7 | | 49.1 | 53.5 | 28.4 | 36.5 | 45.5 | 35.5 | 36.2 | 42.7 | 40.5 | 42.0 | 49.2 |
| | |
| multilingual-e5-small | 64.4 | | 71.5 | 66.3 | 54.5 | 57.7 | 63.2 | 55.4 | 54.3 | 60.8 | 65.4 | 89.1 | 70.1 |
| multilingual-e5-base | 65.9 | | 72.3 | 65.0 | 58.5 | 60.8 | 64.9 | 56.6 | 55.8 | 62.7 | 69.0 | 86.6 | 72.7 |
| multilingual-e5-large | **70.5** | | 77.5 | 73.2 | 60.8 | 66.8 | 68.5 | 62.5 | 61.6 | 65.8 | 72.7 | 90.2 | 76.2 |
## MTEB Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## Support for Sentence Transformers
Below is an example for usage with sentence_transformers.
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('intfloat/multilingual-e5-base')
input_texts = [
'query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 i s 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or traini ng for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮 ,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右, 放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油 锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"
]
embeddings = model.encode(input_texts, normalize_embeddings=True)
```
Package requirements
`pip install sentence_transformers~=2.2.2`
Contributors: [michaelfeil](https://huggingface.co/michaelfeil)
## FAQ
**1. Do I need to add the prefix "query: " and "passage: " to input texts?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
Here are some rules of thumb:
- Use "query: " and "passage: " correspondingly for asymmetric tasks such as passage retrieval in open QA, ad-hoc information retrieval.
- Use "query: " prefix for symmetric tasks such as semantic similarity, bitext mining, paraphrase retrieval.
- Use "query: " prefix if you want to use embeddings as features, such as linear probing classification, clustering.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Why does the cosine similarity scores distribute around 0.7 to 1.0?**
This is a known and expected behavior as we use a low temperature 0.01 for InfoNCE contrastive loss.
For text embedding tasks like text retrieval or semantic similarity,
what matters is the relative order of the scores instead of the absolute values,
so this should not be an issue.
## Citation
If you find our paper or models helpful, please consider cite as follows:
```
@article{wang2024multilingual,
title={Multilingual E5 Text Embeddings: A Technical Report},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2402.05672},
year={2024}
}
```
## Limitations
Long texts will be truncated to at most 512 tokens.
|
[
"BIOSSES",
"SCIFACT"
] |
RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | 2024-10-26T04:34:05Z |
2024-10-26T04:58:32+00:00
| 62 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
context-aware-splitter-1b - GGUF
- Model creator: https://huggingface.co/mhenrichsen/
- Original model: https://huggingface.co/mhenrichsen/context-aware-splitter-1b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [context-aware-splitter-1b.Q2_K.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q2_K.gguf) | Q2_K | 0.4GB |
| [context-aware-splitter-1b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q3_K_S.gguf) | Q3_K_S | 0.47GB |
| [context-aware-splitter-1b.Q3_K.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q3_K.gguf) | Q3_K | 0.51GB |
| [context-aware-splitter-1b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q3_K_M.gguf) | Q3_K_M | 0.51GB |
| [context-aware-splitter-1b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q3_K_L.gguf) | Q3_K_L | 0.55GB |
| [context-aware-splitter-1b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.IQ4_XS.gguf) | IQ4_XS | 0.57GB |
| [context-aware-splitter-1b.Q4_0.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q4_0.gguf) | Q4_0 | 0.59GB |
| [context-aware-splitter-1b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.IQ4_NL.gguf) | IQ4_NL | 0.6GB |
| [context-aware-splitter-1b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q4_K_S.gguf) | Q4_K_S | 0.6GB |
| [context-aware-splitter-1b.Q4_K.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q4_K.gguf) | Q4_K | 0.62GB |
| [context-aware-splitter-1b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q4_K_M.gguf) | Q4_K_M | 0.62GB |
| [context-aware-splitter-1b.Q4_1.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q4_1.gguf) | Q4_1 | 0.65GB |
| [context-aware-splitter-1b.Q5_0.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q5_0.gguf) | Q5_0 | 0.71GB |
| [context-aware-splitter-1b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q5_K_S.gguf) | Q5_K_S | 0.71GB |
| [context-aware-splitter-1b.Q5_K.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q5_K.gguf) | Q5_K | 0.73GB |
| [context-aware-splitter-1b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q5_K_M.gguf) | Q5_K_M | 0.73GB |
| [context-aware-splitter-1b.Q5_1.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q5_1.gguf) | Q5_1 | 0.77GB |
| [context-aware-splitter-1b.Q6_K.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q6_K.gguf) | Q6_K | 0.84GB |
| [context-aware-splitter-1b.Q8_0.gguf](https://huggingface.co/RichardErkhov/mhenrichsen_-_context-aware-splitter-1b-gguf/blob/main/context-aware-splitter-1b.Q8_0.gguf) | Q8_0 | 1.09GB |
Original model description:
---
license: apache-2.0
datasets:
- mhenrichsen/context-aware-splits
language:
- da
---
# Context Aware Splitter
7b model available [here](https://huggingface.co/mhenrichsen/context-aware-splitter-7b).
CAS is a text splitter for Retrieval Augmented Generation.
It's trained on 12.3k danish texts with a token count of 13.4m.
## What does it do?
CAS takes a text (str), reads and understands the contexts and then provides the best splits based on a defined word count.
It returns a dict with the keys:
- splits: list[str]
- topic: str
## Code example
```python
from transformers import AutoTokenizer, TextStreamer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("mhenrichsen/context-aware-splitter-1b")
tokenizer = AutoTokenizer.from_pretrained("mhenrichsen/context-aware-splitter-1b")
streamer = TextStreamer(tokenizer, skip_special_tokens=True)
WORD_SPLIT_COUNT = 50
prompt_template = """### Instruction:
Din opgave er at segmentere en given tekst i separate dele, så hver del giver mening og kan læses uafhængigt af de andre. Hvis det giver mening, må der kan være et overlap mellem delene. Hver del skal ideelt indeholde {word_count} ord.
### Input:
{text}
### Response:
"""
artikel = """Kina er stærkt utilfreds med, at Tysklands udenrigsminister, Annalena Baerbock, har omtalt den kinesiske præsident Xi Jinping som en diktator.
- Bemærkningerne fra Tyskland er ekstremt absurde, krænker Kinas politiske værdighed alvorligt og er en åben politisk provokation, udtalte talsperson fra det kinesiske udenrigsministerium Mao Ning i går ifølge CNN.
Bemærkningen fra udenrigsminister Annalena Baerbock faldt i et interview om krigen i Ukraine med Fox News i sidste uge.
- Hvis Putin skulle vinde denne krig, hvilket signal ville det så sende til andre diktatorer i verden, som Xi, som den kinesiske præsident?, sagde hun.
Tysklands ambassadør i Kina, Patricia Flor, har som konsekvens af udtalelsen været til en kammeratlig samtale, oplyser det tyske udenrigsministerium til CNN."""
tokens = tokenizer(
prompt_template.format(text=artikel, word_count=WORD_SPLIT_COUNT),
return_tensors='pt'
)['input_ids']
# Generate output
generation_output = model.generate(
tokens,
streamer=streamer,
max_length = 8194,
eos_token_id = 29913
)
```
Example:
```
### Instruction:
Din opgave er at segmentere en given tekst i separate dele, så hver del giver mening og kan læses uafhængigt af de andre. Hvis det giver mening, må der kan være et overlap mellem delene. Hver del skal ideelt indeholde 50 ord.
### Input:
Munkebjerg er et overvejende middelklassekvarter beliggende i det centrale Odense Munkebjerg grænser op til Hunderup i vest, hvor det afgrænses af Hjallesevej, og byens centrum i nord. Kvarteret har status som et familievenligt boligkvarter med både lejligheder (i området omkring H.C Andersensgade) og parcelhuse som på og omkring Munkebjergvej og Munkebjergskolen. Socialdemokratiet står traditionelt set stærkt i området, som det også ses på resultaterne af stemmer afgivet ved valgstedet Munkebjergskolen fra folketingsvalget i 2011, hvor partiet fik 24,8% af stemmerne. Dog vinder partiet Venstre samt Det Radikale Venstre også bred opbakning i kvarteret med henholdsvis 20,7 og 12,6% af stemmerne ligeledes fra valget i 2011. De fleste af kvarterets børn går på den lokale Munkebjergskolen, mens enkelte går på Odense Friskole og/eller Giersings Realskole. Munkebjergkvarteret er desuden hjemsted for fodboldklubben OKS. Munkebjergkvarteret kaldes i dagligtale for "Munken".
### Response:
```
This returns the following dictionary:
```
{'splits': ['Munkebjerg er et overvejende middelklassekvarter beliggende i det centrale Odense. Munkebjerg grænser op til Hunderup i vest, hvor det afgrænses af Hjallesevej, og byens centrum i nord. Kvarteret har status som et familievenligt boligkvarter med både lejligheder (i området omkring H.C Andersensgade) og parcelhuse som på og omkring Munkebjergvej og Munkebjergskolen.', 'Socialdemokratiet står traditionelt set stærkt i området, som det også ses på resultaterne af stemmer afgivet ved valgstedet Munkebjergskolen fra folketingsvalget i 2011, hvor partiet fik 24,8% af stemmerne. Dog vinder partiet Venstre samt Det Radikale Venstre også bred opbakning i kvarteret med henholdsvis 20,7 og 12,6% af stemmerne ligeledes fra valget i 2011.', "De fleste af kvarterets børn går på den lokale Munkebjergskolen, mens enkelte går på Odense Friskole og/eller Giersings Realskole. Munkebjergkvarteret er desuden hjemsted for fodboldklubben OKS. Munkebjergkvarteret kaldes i dagligtale for 'Munken'."], 'topic': 'Beskrivelse af Munkebjergkvarteret i Odense.'}
```
## Prompt format
The model follows alpaca format.
```
### Instruction:
Din opgave er at segmentere en given tekst i separate dele, så hver del giver mening og kan læses uafhængigt af de andre. Hvis det giver mening, må der kan være et overlap mellem delene. Hver del skal ideelt indeholde {WORD_COUNT} ord.
### Input:
{TEXT}
### Response:
```
|
[
"CAS"
] |
KomeijiForce/Cuckoo-C4-Instruct
|
KomeijiForce
|
question-answering
|
[
"transformers",
"safetensors",
"roberta",
"token-classification",
"question-answering",
"arxiv:2502.11275",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2025-02-16T22:52:28Z |
2025-02-19T20:33:20+00:00
| 62 | 1 |
---
library_name: transformers
license: mit
pipeline_tag: question-answering
---
# Cuckoo 🐦 [[Github]](https://github.com/KomeijiForce/Cuckoo)
The Cuckoo family of models are extractive question answering models as described in the paper [Cuckoo: An IE Free Rider Hatched by Massive Nutrition in LLM's Nest](https://hf.co/papers/2502.11275).
Cuckoo is a small (300M) information extraction (IE) model that imitates the next token prediction paradigm of large language models. Instead of retrieving from the vocabulary, Cuckoo predicts the next tokens by tagging them in the given input context as shown below:

Cuckoo is substantially different from previous IE pre-training because it can use any text resource to enhance itself, especially by taking a free ride on data curated for LLMs!

Currently, we open-source checkpoints of Cuckoos that are pre-trained on:
1) 100M next tokens extraction (NTE) instances converted from C4. ([Cuckoo-C4](https://huggingface.co/KomeijiForce/Cuckoo-C4) 🐦)
2) Cuckoo-C4 + 2.6M next token extraction (NTE) instances converted from a supervised fine-tuning dataset, TuluV3. ([Cuckoo-C4-Instruct](https://huggingface.co/KomeijiForce/Cuckoo-C4-Instruct) 🐦🛠️)
3) Cuckoo-C4-Instruct + MultiNERD, MetaIE, NuNER, MRQA (excluding SQuAD, DROP). ([Cuckoo-C4-Rainbow](https://huggingface.co/KomeijiForce/Cuckoo-C4-Rainbow) 🌈🐦🛠️)
4) Cuckoo-C4-Rainbow + Multiple NER Datasets, WizardLM Dataset, Multiple Choice QA Datasets, MMLU, SQuAD, DROP, MNLI, SNLI. ([Cuckoo-C4-Super-Rainbow](https://huggingface.co/KomeijiForce/Cuckoo-C4-Super-Rainbow) 🦸🌈🐦🛠️)
## Performance Demonstration 🚀
Begin your journey with Cuckoo to experience unimaginable adaptation efficiency for all kinds of IE tasks!
| | CoNLL2003 | BioNLP2004 | MIT-Restaurant | MIT-Movie | Avg. | CoNLL2004 | ADE | Avg. | SQuAD | SQuAD-V2 | DROP | Avg. |
|----------------------|-----------|-----------|----------------|-----------|------|-----------|-----|------|-------|----------|------|------|
| OPT-C4-TuluV3 | 50.24 | 39.76 | 58.91 | 56.33 | 50.56 | 47.14 | 45.66 | 46.40 | 39.80 | 53.81 | 31.00 | 41.54 |
| RoBERTa | 33.75 | 32.91 | 62.15 | 58.32 | 46.80 | 34.16 | 2.15 | 18.15 | 31.86 | 48.55 | 9.16 | 29.86 |
| MRQA | 72.45 | 55.93 | 68.68 | 66.26 | 65.83 | 66.23 | 67.44 | 66.84 | 80.07 | 66.22 | 54.46 | 66.92 |
| MultiNERD | 66.78 | 54.62 | 64.16 | 66.30 | 60.59 | 57.52 | 45.10 | 51.31 | 42.85 | 50.99 | 30.12 | 41.32 |
| NuNER | 74.15 | 56.36 | 68.57 | 64.88 | 65.99 | 65.12 | 63.71 | 64.42 | 61.60 | 52.67 | 37.37 | 50.55 |
| MetaIE | 71.33 | 55.63 | 70.08 | 65.23 | 65.57 | 64.81 | 64.40 | 64.61 | 74.59 | 62.54 | 30.73 | 55.95 |
| Cuckoo 🐦🛠️ | 73.60 | 57.00 | 67.63 | 67.12 | 66.34 | 69.57 | 71.70 | 70.63 | 77.47 | 64.06 | 54.25 | 65.26 |
| └─ Only Pre-train 🐦 | 72.46 | 55.87 | 66.87 | 67.23 | 65.61 | 68.14 | 69.39 | 68.77 | 75.64 | 63.36 | 52.81 | 63.94 |
| └─ Only Post-train | 72.80 | 56.10 | 66.02 | 67.10 | 65.51 | 68.66 | 69.75 | 69.21 | 77.05 | 62.39 | 54.80 | 64.75 |
| Rainbow Cuckoo 🌈🐦🛠️ | 79.94 | 58.39 | 70.30 | 67.00 | **68.91** | 70.47 | 76.05 | **73.26** | 86.57 | 69.41 | 64.64 | **73.54** |
*(Super Rainbow Cuckoo 🦸🌈🐦🛠️ uses training sets except CoNLL2004 and ADE to boost its performance)*
| | CoNLL2003 | BioNLP2004 | MIT-Restaurant | MIT-Movie | Avg. | CoNLL2004 | ADE | Avg. | SQuAD | SQuAD-V2 | DROP | Avg. |
|----------------------|-----------|-----------|----------------|-----------|-------|-----------|-------|-------|-------|----------|-------|-------|
| Super Rainbow Cuckoo 🦸🌈🐦🛠️ | 88.38 | 68.33 | 76.79 | 69.39 | **75.22** | 72.96 | 80.06 | **76.51** | 89.54 | 74.52 | 74.89 | **79.65** |
## Quick Experience with Cuckoo in Next Tokens Extraction ⚡
We recommend using the strongest Super Rainbow Cuckoo 🦸🌈🐦🛠️ for zero-shot extraction. You can directly run the cases below in ```case_next_tokens_extraction.py```.
1️⃣ First load the model and the tokenizers
```python
from transformers import AutoModelForTokenClassification, AutoTokenizer
import torch
import spacy
nlp = spacy.load("en_core_web_sm")
device = torch.device("cuda:0")
path = f"KomeijiForce/Cuckoo-C4-Super-Rainbow"
tokenizer = AutoTokenizer.from_pretrained(path)
tagger = AutoModelForTokenClassification.from_pretrained(path).to(device)
```
2️⃣ Define the next tokens extraction function
```python
def next_tokens_extraction(text):
def find_sequences(lst):
sequences = []
i = 0
while i < len(lst):
if lst[i] == 0:
start = i
end = i
i += 1
while i < len(lst) and lst[i] == 1:
end = i
i += 1
sequences.append((start, end+1))
else:
i += 1
return sequences
text = " ".join([token.text for token in nlp(text)])
inputs = tokenizer(text, return_tensors="pt").to(device)
tag_predictions = tagger(**inputs).logits[0].argmax(-1)
predictions = [tokenizer.decode(inputs.input_ids[0, seq[0]:seq[1]]).strip() for seq in find_sequences(tag_predictions)]
return predictions
```
3️⃣ Call the function for extraction!
Case 1: Basic entity and relation understanding
```python
text = "Tom and Jack went to their trip in Paris."
for question in [
"What is the person mentioned here?",
"What is the city mentioned here?",
"Who goes with Tom together?",
"What do Tom and Jack go to Paris for?",
"Where does George live in?",
]:
prompt = f"User:\n\n{text}\n\nQuestion: {question}\n\nAssistant:"
predictions = next_tokens_extraction(prompt)
print(question, predictions)
```
You will get things like,
```
What is the person mentioned here? ['Tom', 'Jack']
What is the city mentioned here? ['Paris']
Who goes with Tom together? ['Jack']
What do Tom and Jack go to Paris for? ['trip']
Where does George live in? []
```
where [] indicates Cuckoo thinks there to be no next tokens for extraction.
Case 2: Longer context
```python
passage = f'''Ludwig van Beethoven (17 December 1770 – 26 March 1827) was a German composer and pianist. He is one of the most revered figures in the history of Western music; his works rank among the most performed of the classical music repertoire and span the transition from the Classical period to the Romantic era in classical music. His early period, during which he forged his craft, is typically considered to have lasted until 1802. From 1802 to around 1812, his middle period showed an individual development from the styles of Joseph Haydn and Wolfgang Amadeus Mozart, and is sometimes characterised as heroic. During this time, Beethoven began to grow increasingly deaf. In his late period, from 1812 to 1827, he extended his innovations in musical form and expression.'''
for question in [
"What are the people mentioned here?",
"What is the job of Beethoven?",
"How famous is Beethoven?",
"When did Beethoven's middle period showed an individual development?",
]:
text = f"User:\n\n{passage}\n\nQuestion: {question}\n\nAssistant:"
predictions = next_tokens_extraction(text)
print(question, predictions)
```
You will get things like,
```
What are the people mentioned here? ['Ludwig van Beethoven', 'Joseph Haydn', 'Wolfgang Amadeus Mozart']
What is the job of Beethoven? ['composer and pianist']
How famous is Beethoven? ['one of the most revered figures in the history of Western music']
When did Beethoven's middle period showed an individual development? ['1802']
```
Case 3: Knowledge quiz
```python
for obj in ["grass", "sea", "fire", "night"]:\n text = f"User:\\n\\nChoices:\\nred\\nblue\\ngreen.\\n\\nQuestion: What is the color of the {obj}?\\n\\nAssistant:\\n\\nAnswer:"
predictions = next_tokens_extraction(text)
print(obj, predictions)
```
You will get things like,
```
grass ['green']
sea ['blue']
fire ['red']
night []
```
which shows Cuckoo is not extracting any plausible spans but has the knowledge to understand the context.
## Few-shot Adaptation 🎯
Cuckoo 🐦 is an expert in few-shot adaptation to your own tasks, taking CoNLL2003 as an example, run ```bash run_downstream.sh conll2003.5shot KomeijiForce/Cuckoo-C4-Rainbow```, you will get a fine-tuned model in ```models/cuckoo-conll2003.5shot```. Then you can benchmark the model with the script ```python eval_conll2003.py```, which will show you an F1 performance of around 80.
You can also train the adaptation to machine reading comprehension (SQuAD), run ```bash run_downstream.sh squad.32shot KomeijiForce/Cuckoo-C4-Rainbow```, you will get a fine-tuned model in ```models/cuckoo-squad.32shot```. Then you can benchmark the model with the script ```python eval_squad.py```, which will show you an F1 performance of around 88.
For fine-tuning your own task, you need to create a Jsonlines file, each line contains {"words": [...], "ner": [...]}, For example:
```json
{"words": ["I", "am", "John", "Smith", ".", "Person", ":"], "ner": ["O", "O", "B", "I", "O", "O", "O"]}
```
<img src="https://github.com/user-attachments/assets/ef177466-d915-46d2-9201-5e672bb6ec23" style="width: 40%;" />
which indicates "John Smith" to be predicted as the next tokens.
You can refer to some prompts shown below for beginning:
| **Type** | **User Input** | **Assistant Response** |
|---------------------|----------------------------------------------------------------------------------------------------|----------------------------------------------------|
| Entity | **User:** [Context] Question: What is the [Label] mentioned? | **Assistant:** Answer: The [Label] is |
| Relation (Kill) | **User:** [Context] Question: Who does [Entity] kill? | **Assistant:** Answer: [Entity] kills |
| Relation (Live) | **User:** [Context] Question: Where does [Entity] live in? | **Assistant:** Answer: [Entity] lives in |
| Relation (Work) | **User:** [Context] Question: Who does [Entity] work for? | **Assistant:** Answer: [Entity] works for |
| Relation (Located) | **User:** [Context] Question: Where is [Entity] located in? | **Assistant:** Answer: [Entity] is located in |
| Relation (Based) | **User:** [Context] Question: Where is [Entity] based in? | **Assistant:** Answer: [Entity] is based in |
| Relation (Adverse) | **User:** [Context] Question: What is the adverse effect of [Entity]? | **Assistant:** Answer: The adverse effect of [Entity] is |
| Query | **User:** [Context] Question: [Question] | **Assistant:** Answer: |
| Instruction (Entity)| **User:** [Context] Question: What is the [Label] mentioned? ([Instruction]) | **Assistant:** Answer: The [Label] is |
| Instruction (Query) | **User:** [Context] Question: [Question] ([Instruction]) | **Assistant:** Answer: |
After building your own downstream dataset, save it into ```my_downstream.json```, and then run the command ```bash run_downstream.sh my_downstream KomeijiForce/Cuckoo-C4-Rainbow```. You will find an adapted Cuckoo in ```models/cuckoo-my_downstream```.
## Fly your own Cuckoo 🪽
We include the script to transform texts to NTE instances in the file ```nte_data_collection.py```, which takes C4 as an example, the converted results can be checked in ```cuckoo.c4.example.json```. The script is designed to be easily adapted to other resources like entity, query, and questions and you can modify your own data to NTE to fly your own Cuckoo! Run the ```run_cuckoo.sh``` script to try an example pre-training.
```bash
python run_ner.py \
--model_name_or_path roberta-large \
--train_file cuckoo.c4.example.json \
--output_dir models/cuckoo-c4-example \
--per_device_train_batch_size 4\
--gradient_accumulation_steps 16\
--num_train_epochs 1\
--save_steps 1000\
--learning_rate 0.00001\
--do_train \
--overwrite_output_dir
```
You will get an example Cuckoo model in ```models/cuckoo-c4-example```, it might not perform well if you pre-train with too little data. You may adjust the hyperparameters inside ```nte_data_collection.py``` or modify the conversion for your own resources to enable better pre-training performance.
## 🐾 Citation
```
@article{DBLP:journals/corr/abs-2502-11275,
author = {Letian Peng and
Zilong Wang and
Feng Yao and
Jingbo Shang},
title = {Cuckoo: An {IE} Free Rider Hatched by Massive Nutrition in {LLM}'s Nest},
journal = {CoRR},
volume = {abs/2502.11275},
year = {2025},
url = {https://doi.org/10.48550/arXiv.2502.11275},
doi = {10.48550/arXiv.2502.11275},
eprinttype = {arXiv},
eprint = {2502.11275},
timestamp = {Mon, 17 Feb 2025 19:32:20 +0000},
biburl = {https://dblp.org/rec/journals/corr/abs-2502-11275.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
[
"CRAFT"
] |
pavanmantha/distilroberta-pubmed-embeddings
|
pavanmantha
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"roberta",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:8000",
"loss:MultipleNegativesRankingLoss",
"dataset:pavanmantha/pumed-finetuning",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:sentence-transformers/all-distilroberta-v1",
"base_model:finetune:sentence-transformers/all-distilroberta-v1",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2025-02-22T05:12:15Z |
2025-02-22T05:12:33+00:00
| 62 | 0 |
---
base_model: sentence-transformers/all-distilroberta-v1
datasets:
- pavanmantha/pumed-finetuning
library_name: sentence-transformers
metrics:
- cosine_accuracy
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:8000
- loss:MultipleNegativesRankingLoss
widget:
- source_sentence: Is acute doxorubicin cardiotoxicity associated with p53-induced
inhibition of the mammalian target of rapamycin pathway?
sentences:
- Tyrosinase, the rate-limiting enzyme required for melanin production, has been
targeted to develop active brightening/lightening materials for skin products.
Unexpected depigmentation of the skin characterized with the diverse symptoms
was reported in some subjects who used a tyrosinase-competitive inhibiting quasi-drug,
rhododendrol. To investigate the mechanism underlying the depigmentation caused
by rhododendrol-containing cosmetics, this study was performed. The mechanism
above was examined using more than dozen of melanocytes derived from donors of
different ethnic backgrounds. The RNAi technology was utilized to confirm the
effect of tyrosinase to induce the cytotoxicity of rhododendrol and liquid chromatography-tandem
mass spectrometry was introduced to detect rhododendrol and its metabolites in
the presence of tyrosinase. Melanocyte damage was related to tyrosinase activity
at a certain threshold. Treatment with a tyrosinase-specific siRNA was shown to
dramatically rescue the rhododendrol-induced melanocyte impairment. Hydroxyl-rhododendrol
was detected only in melanocytes with higher tyrosinase activity. When an equivalent
amount of hydroxyl-rhododendrol was administered, cell viability was almost equally
suppressed even in melanocytes with lower tyrosinase activity.
- Doxorubicin is used to treat childhood and adult cancer. Doxorubicin treatment
is associated with both acute and chronic cardiotoxicity. The cardiotoxic effects
of doxorubicin are cumulative, which limits its chemotherapeutic dose. Free radical
generation and p53-dependent apoptosis are thought to contribute to doxorubicin-induced
cardiotoxicity. Adult transgenic (MHC-CB7) mice expressing cardiomyocyte-restricted
dominant-interfering p53 and their nontransgenic littermates were treated with
doxorubicin (20 mg/kg cumulative dose). Nontransgenic mice exhibited reduced left
ventricular systolic function (predoxorubicin fractional shortening [FS] 61+/-2%,
postdoxorubicin FS 45+/-2%, mean+/-SEM, P<0.008), reduced cardiac mass, and high
levels of cardiomyocyte apoptosis 7 days after the initiation of doxorubicin treatment.
In contrast, doxorubicin-treated MHC-CB7 mice exhibited normal left ventricular
systolic function (predoxorubicin FS 63+/-2%, postdoxorubicin FS 60+/-2%, P>0.008),
normal cardiac mass, and low levels of cardiomyocyte apoptosis. Western blot analyses
indicated that mTOR (mammalian target of rapamycin) signaling was inhibited in
doxorubicin-treated nontransgenic mice but not in doxorubicin-treated MHC-CB7
mice. Accordingly, transgenic mice with cardiomyocyte-restricted, constitutively
active mTOR expression (MHC-mTORca) were studied. Left ventricular systolic function
(predoxorubicin FS 64+/-2%, postdoxorubicin FS 60+/-3%, P>0.008) and cardiac mass
were normal in doxorubicin-treated MHC-mTORca mice, despite levels of cardiomyocyte
apoptosis similar to those seen in doxorubicin-treated nontransgenic mice.
- To examine the regulatory aspects of zinc-α2-glycoprotein (ZAG) association with
obesity-related insulin resistance. ZAG mRNA and protein were analyzed in subcutaneous
adipose tissue (AT) and circulation of lean, obese, prediabetic, and type 2 diabetic
men; both subcutaneous and visceral AT were explored in lean and extremely obese.
Clinical and ex vivo findings were corroborated by results of in vitro ZAG silencing
experiment. Subcutaneous AT ZAG was reduced in obesity, with a trend to further
decrease with prediabetes and type 2 diabetes. ZAG was 3.3-fold higher in subcutaneous
than in visceral AT of lean individuals. All differences were lost in extreme
obesity. Obesity-associated changes in AT were not paralleled by alterations of
circulating ZAG. Subcutaneous AT ZAG correlated with adiposity, adipocyte hypertrophy,
whole-body and AT insulin sensitivity, mitochondrial content, expression of GLUT4,
PGC1α, and adiponectin. Subcutaneous AT ZAG and adipocyte size were the only predictors
of insulin sensitivity, independent on age and BMI. Silencing ZAG resulted in
reduced adiponectin, IRS1, GLUT4, and PGC1α gene expression in primary human adipocytes.
- source_sentence: Is avoidance of polypharmacy and excessive blood pressure control
associated with improved renal function in older patients?
sentences:
- Elderly patients are particularly susceptible to polypharmacy. The present study
evaluated the renal effects of optimizing potentially nephrotoxic medications
in an older population. Retrospective study of patients' ≥ 60 years treated between
January of 2013 and February of 2015 in a Nephrology Clinic. The renal effect
of avoiding polypharmacy was studied. Sixty-one patients were studied. Median
age was 81 years (range 60-94). Twenty-five patients (41%) were male. NSAIDs alone
were stopped in seven patients (11.4%), a dose reduction in antihypertensives
was done in 11 patients (18%), one or more antihypertensives were discontinued
in 20 patients (32.7%) and discontinuation and dose reduction of multiple medications
was carried out in 23 patients (37.7%). The number of antihypertensives was reduced
from a median of 3 (range of 0-8) at baseline to a median of 2 (range 0-7), p
< 0.001 after intervention. After intervention, the glomerular filtration rate
(GFR) improved significantly, from a baseline of 32 ± 15.5 cc/min/1.73 m(2) to
39.5 ± 17 cc/min/1.73 m(2) at t1 (p < 0.001) and 44.5 ± 18.7 cc/min/1.73 m(2)
at t2 (p < 0.001 vs. baseline). In a multivariate model, after adjusting for ACEIs/ARBs
discontinuation/dose reduction, NSAIDs use and change in DBP, an increase in SBP
at time 1 remained significantly associated with increments in GFR on follow-up
(estimate = 0.20, p = 0.01).
- Endothelial dysfunction and hypertension is more common in individuals with diabetes
than in the general population. This study was aimed to investigate the underlying
mechanisms responsible for endothelial dysfunction of type 1 diabetic rats fed
with high-salt diet. Type 1 diabetes (DM) was induced by intraperitoneal injection
of streptozotocin (70 mg·kg(-1)). Normal or diabetic rats were randomly fed high-salt
food (HS, 8% NaCl) or standard food (CON) for 6 weeks. Both HS (143±10 mmHg) and
DM+HS (169±11 mmHg) groups displayed significantly higher systolic blood pressure
than those in the CON group (112±12 mmHg, P<0.01). DM+HS rats exhibited more pronounced
impairment of vasorelaxation to acetylcholine and insulin compared with either
DM or HS. Akt/endothelial nitric oxide synthase (eNOS) phosphorylation levels
and nitric oxide (NO) concentration in DM+HS were significantly lower than in
DM. The levels of caveolin-1 (cav-1) in DM+HS were significantly higher than that
in DM and HS. Co-immunoprecipitation results showed increased interaction between
cav-1 and eNOS in the DM+HS group. In the presence of cav-1 small interfering
RNA (siRNA), eNOS phosphorylations in human umbilical vein endothelial cells (HUVEC)
were significantly increased compared with control siRNA. Cav-1 was slightly but
not significantly lower in HUVEC cultured with high glucose and high-salt buffer
solution and pretreated with wortmannin or l-nitro-arginine methyl ester.
- 'Several studies have revealed a correlation between sialosyl Tn antigen (STN)
and certain clinicopathologic features of various cancers, and that STN is an
independent prognostic factor. However, the clinical significance of the expression
of STN in gastric cancer has not been reported. Thus, the purpose of this study
was to evaluate immunohistochemically the clinical significance of expression
of STN in gastric cancer. The expression of STN in surgically resected specimens
of human gastric cancer was evaluated immunohistochemically using a monoclonal
antibody (TKH-2), in 60 patients whose serum STN levels were measured and in 54
patients with advanced cancer who had been followed for more than 5 years after
gastrectomy. The correlations between the level of STN expression and clinicopathologic
factors were analyzed. The staining intensity was graded as follows: (-), less
than 5% of the cancer cells expressed STN; (+), 5-50%; (++), more than 50%. Sialosyl
TN antigen staining was detected mainly on the cell membrane, in the cytoplasm,
and in the luminal contents, and 57.2% of the 60 specimens expressed STN, whereas
the corresponding value for positive serum levels was 15%. A higher percentage
of advanced tumors expressed STN than did the early cases, but the difference
was not statistically significant. All cases with strong staining, the (++) cases,
were advanced cases either with lymph node metastases or with cancer invading
in or beyond the muscle layer proper. The expression of STN appeared to be related
to the clinical stage, the extent of cancer invasion, and the presence of lymph
node metastases. Sialosyl TN antigen was detected in the serum in less than 6%
of the patients whose tumors were (-) or (+) for STN expression, and in 86.7%
of the patients whose tumors expressed high levels of STN (++). The estimated
5-year survival in advanced cases (Stage III) was significantly better in those
with negative STN expression than in those with positive STN expression (P < 0.01).'
- source_sentence: Does platelet attachment stimulate endothelial cell regeneration
after arterial injury?
sentences:
- The efficacy of lansoprazole (LPZ) at inhibiting gastric acid secretion is influenced
by cytochrome P450 2C19 (CYP2C19) polymorphism. The purpose of the present study
was to investigate whether CYP2C19 polymorphism had an influence on the remission
of erosive reflux esophagitis (RE) during maintenance therapy with LPZ. Eighty-two
Japanese patients with initial healing of erosive RE by 8 weeks of LPZ therapy
were enrolled. As maintenance therapy, the patients were treated with LPZ (15
mg/day) for 6 months. The CYP2C19 genotype, Helicobacter pylori infection status,
and serum pepsinogen (PG) I/II ratio were assessed before treatment. The patients
were investigated for relapse by endoscopy at 6 months or when symptoms recurred.
The proportion of patients in remission after 6 months was 61.5%, 78.0%, and 100%
among homozygous extensive metabolizers (homo-EM), heterozygous EM (hetero-EM),
and poor metabolizers (PM), respectively. The percentage of PM patients who remained
in remission was significantly higher than that of homo-EM or hetero-EM.
- Arterial injury is associated with endothelial disruption and attachment of platelets
to an exposed subintimal layer. A variety of factors released by platelets may
affect the ability of endothelial cells bordering an injury to regenerate. In
this study an organ culture model of arterial injury was used to investigate the
relationship between attachment of platelets to a superficial arterial injury
and endothelial regeneration. A defined superficial endothelial injury was made
in whole vessel wall explants of rabbit thoracic aorta. Injured explants were
treated with either fresh whole platelets, the supernatant of platelets aggregated
by collagen, or basic fibroblast growth factor. Four days after injury and treatment,
the average distance of endothelial regeneration was determined. A dramatic increase
in the rate of endothelial cell regeneration was observed when injured vessels
were exposed to fresh whole platelets (p = 0.003). This increase in regeneration
was comparable to that observed with fibroblast growth factor. No increase in
the regenerative rate was found after exposure of explants to the supernatant
of aggregated platelets (p = 0.69).
- To introduce an elastomeric continuous infusion pump for pain control after outpatient
orbital implant surgery. Retrospective, noncomparative consecutive case series
of all patients undergoing enucleation, evisceration, or secondary orbital implantation
using the On-Q pain system between August 2004 and January 2006. Postoperative
pain score, need for narcotics, and adverse events were recorded. The On-Q catheter
is inserted intraoperatively through the lateral lower eyelid into the muscle
cone under direct visualization, prior to the orbital implant placement. The On-Q
system continually infuses anesthesia (bupivacaine) to the retrobulbar site for
5 days. Among 20 patients, mean postoperative period pain score, with On-Q in
place, was 1.3 (scale of 0 to 10). Nine patients (45%) did not need any adjunctive
oral narcotics. Two patients experienced postoperative nausea. One catheter connector
leaked, thereby decreasing delivery of retrobulbar anesthetic resulting a pain
level of 6, the highest level in the study. There were no postoperative infections.
No systemic toxic effects from bupivacaine were observed clinically.
- source_sentence: Do mid-regional proadrenomedullin levels predict recurrence of
atrial fibrillation after catheter ablation?
sentences:
- We evaluated the prognostic value of mid-regional proadrenomedullin (MR-proADM)
in atrial fibrillation (AF) patients undergoing radiofrequency ablation. Plasma
concentrations of MR-proADM were measured at baseline and after 12months in 87
AF patients in whom radiofrequency ablation was performed. The association between
MR-proADM and AF recurrence was tested by univariable and multivariable Cox models.
In all 87 patients radiofrequency ablation was successfully performed. Of the
total population 54% had paroxysmal AF. The mean left ventricular ejection fraction
was 54% (minimum 25%). After 12months of follow-up, 71% of the patients were free
of AF recurrence. At baseline, mean MR-proADM in the total population was 0.72nmol/l±0.22.
Patients with AF recurrence had significantly higher baseline MR-proADM (0.89nmol/l±0.29)
as compared with patients without AF recurrence (0.65nmol/l±0.14; p<0.001). After
12months, mean MR-proADM plasma concentration remained higher in patients with
AF recurrence (0.81nmol/l±0.22 as compared with patients free of AF 0.54nmol/l±0.20;
p<0.001). Receiver operating characteristic (ROC) curve analysis for MR-proADM
yields a specificity of 98% and a sensitivity of 64% with an optimal cut-off value
of 0.82nmol/l to predict recurrence of AF after catheter ablation. In the logistic
regression analysis only MR-proADM remained independently predictive for AF recurrence.
- There has been growing interest in the role that implicit processing of drug cues
can play in motivating drug use behavior. However, the extent to which drug cue
processing biases relate to the processing biases exhibited to other types of
evocative stimuli is largely unknown. The goal of the present study was to determine
how the implicit cognitive processing of smoking cues relates to the processing
of affective cues using a novel paradigm. Smokers (n = 50) and nonsmokers (n =
38) completed a picture-viewing task, in which participants were presented with
a series of smoking, pleasant, unpleasant, and neutral images while engaging in
a distractor task designed to direct controlled resources away from conscious
processing of image content. Electroencephalogram recordings were obtained throughout
the task for extraction of event-related potentials (ERPs). Smokers exhibited
differential processing of smoking cues across 3 different ERP indices compared
with nonsmokers. Comparable effects were found for pleasant cues on 2 of these
indices. Late cognitive processing of smoking and pleasant cues was associated
with nicotine dependence and cigarette use.
- To evaluate the role of toll-like receptors (TLR) 2 and 4 in host responses to
Aspergillus fumigatus by use of cultured telomerase-immortalized human corneal
epithelial cells (HCECs). HCECs were stimulated with inactive antigens from A.
fumigatus. The expression of TLR2 and TLR4, phosphorylation of Ikappa B-alpha
(pIkappa B-alpha), and release of interleukin (IL)-1beta and IL-6 was measured
with and without inhibitors to TLR2 and TLR4. Exposure of HCECs to A. fumigatus
antigens resulted in up-regulation of TLR2 and TLR4, activation of pIkappa B,
and release of IL-1beta and IL-6 in HCECs, effects that could be inhibited by
treatment with TLR2 and TLR4 antibodies.
- source_sentence: Are peripheral blood lymphocytes from patients with rheumatoid
arthritis differentially sensitive to apoptosis induced by anti-tumour necrosis
factor-alpha therapy?
sentences:
- The aim of this study was to investigate the prognostic effect of serum free light
chain (sFLC) response after 2 cycles of first-line chemotherapy (CT) in multiple
myeloma (MM) patients. The data of 78 newly diagnosed MM patients who had sFLC
levels at diagnosis and after 2 cycles of first-line CT were included in the study.
The prognostic effect of sFLCs were evaluated with normalization of sFLC κ/λ ratio
after 2 cycles of CT and involved/uninvolved (i/u) sFLCs. At the end of follow-up
the probability of overall survival (OS) was 95.7% versus 68.5% in patients with
and without normalized sFLC κ/λ ratio, respectively (P = .072). The probability
of OS with i/u sFLC assessment was 97.4% versus 55.8% with regard to i/u sFLC
≤ 10 and > 10, respectively (P = .001). In univariate and multivariate analysis
including sFLC ratio, age, sex, and International Staging System, i/u sFLC ratio
> 10 after 2 cycles of CT was identified as an independent risk factor for OS
(P = .015; hazard ratio [HR], 13.2; 95% confidence interval [CI], 1.668-104.65
vs. P = .011; HR, 15.17; 95% CI, 1.85-123.89).
- This study examined links between DNA methylation and birth weight centile (BWC),
and explored the impact of genetic variation. Using HumanMethylation450 arrays,
we examined candidate gene-associated CpGs in cord blood from newborns with low
(<15th centile), medium (40-60th centile) and high (>85th centile) BWC (n = 12).
Candidates were examined in an investigation cohort (n = 110) using pyrosequencing
and genotyping for putative methylation-associated polymorphisms performed using
standard PCR. Array analysis identified 314 candidate genes associated with BWC
extremes, four of which showed ≥ 4 BWC-linked CpGs. Of these, PM20D1 and MI886
suggested genetically determined methylation levels. However, methylation at three
CpGs in FGFR2 remained significantly associated with high BWC (p = 0.004-0.027).
- The efficacy of anti-tumour necrosis factor-alpha (TNF-alpha) therapies in rheumatoid
arthritis (RA) has been mainly attributed to TNF-alpha neutralisation. Other mechanism
as immune cell apoptosis, which is impaired in RA, may also be induced by anti-TNF-alpha
therapies. The aim of our study was to investigate whether TNF-alpha inhibitors
could induce apoptosis in vitro of the peripheral blood lymphocytes of RA patients.
Peripheral blood mononuclear cells (PBMC) isolated from 24 patients with RA and
18 healthy donors were incubated with anti-TNF-alpha agents, infliximab or etanercept,
in comparison with no agent and including an isotypic control, for 48 hours. Apoptosis
was detected and quantified by annexin V labelling of phosphatidylserine externalization
using cytofluorometric analysis and compared with PBMC production TNF-alpha in
vitro. In healthy donors, induced apoptosis was observed in 0.3% to 3.8% of lymphocytes
with both therapies. In RA patients the treatment induced lymphocyte apoptosis
in 17 of 24 patients with a percentage of annexin V-positive lymphocytes ranging
from 0.1% to 25%. Among these 17 RA patients, a significant in vitro lymphocyte
apoptosis (> 4%) was observed in 11 patients (46%) compared with healthy donors
(p < 0.01). The variability of the response to anti-TNF-alpha within the RA population
was not dependent on TNF-alpha synthesis or disease activity.
model-index:
- name: SentenceTransformer based on sentence-transformers/all-distilroberta-v1
results:
- task:
type: triplet
name: Triplet
dataset:
name: ai pubmed validation
type: ai-pubmed-validation
metrics:
- type: cosine_accuracy
value: 1.0
name: Cosine Accuracy
---
# SentenceTransformer based on sentence-transformers/all-distilroberta-v1
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sentence-transformers/all-distilroberta-v1](https://huggingface.co/sentence-transformers/all-distilroberta-v1) on the [pumed-finetuning](https://huggingface.co/datasets/pavanmantha/pumed-finetuning) dataset. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sentence-transformers/all-distilroberta-v1](https://huggingface.co/sentence-transformers/all-distilroberta-v1) <!-- at revision 8d88b92a34345fd6a139aa47768c9881720006ce -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- [pumed-finetuning](https://huggingface.co/datasets/pavanmantha/pumed-finetuning)
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("pavanmantha/distilroberta-pubmed-embeddings")
# Run inference
sentences = [
'Are peripheral blood lymphocytes from patients with rheumatoid arthritis differentially sensitive to apoptosis induced by anti-tumour necrosis factor-alpha therapy?',
'The efficacy of anti-tumour necrosis factor-alpha (TNF-alpha) therapies in rheumatoid arthritis (RA) has been mainly attributed to TNF-alpha neutralisation. Other mechanism as immune cell apoptosis, which is impaired in RA, may also be induced by anti-TNF-alpha therapies. The aim of our study was to investigate whether TNF-alpha inhibitors could induce apoptosis in vitro of the peripheral blood lymphocytes of RA patients. Peripheral blood mononuclear cells (PBMC) isolated from 24 patients with RA and 18 healthy donors were incubated with anti-TNF-alpha agents, infliximab or etanercept, in comparison with no agent and including an isotypic control, for 48 hours. Apoptosis was detected and quantified by annexin V labelling of phosphatidylserine externalization using cytofluorometric analysis and compared with PBMC production TNF-alpha in vitro. In healthy donors, induced apoptosis was observed in 0.3% to 3.8% of lymphocytes with both therapies. In RA patients the treatment induced lymphocyte apoptosis in 17 of 24 patients with a percentage of annexin V-positive lymphocytes ranging from 0.1% to 25%. Among these 17 RA patients, a significant in vitro lymphocyte apoptosis (> 4%) was observed in 11 patients (46%) compared with healthy donors (p < 0.01). The variability of the response to anti-TNF-alpha within the RA population was not dependent on TNF-alpha synthesis or disease activity.',
'This study examined links between DNA methylation and birth weight centile (BWC), and explored the impact of genetic variation. Using HumanMethylation450 arrays, we examined candidate gene-associated CpGs in cord blood from newborns with low (<15th centile), medium (40-60th centile) and high (>85th centile) BWC (n = 12). Candidates were examined in an investigation cohort (n = 110) using pyrosequencing and genotyping for putative methylation-associated polymorphisms performed using standard PCR. Array analysis identified 314 candidate genes associated with BWC extremes, four of which showed ≥ 4 BWC-linked CpGs. Of these, PM20D1 and MI886 suggested genetically determined methylation levels. However, methylation at three CpGs in FGFR2 remained significantly associated with high BWC (p = 0.004-0.027).',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Triplet
* Dataset: `ai-pubmed-validation`
* Evaluated with [<code>TripletEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.TripletEvaluator)
| Metric | Value |
|:--------------------|:--------|
| **cosine_accuracy** | **1.0** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### pumed-finetuning
* Dataset: [pumed-finetuning](https://huggingface.co/datasets/pavanmantha/pumed-finetuning) at [1ba143a](https://huggingface.co/datasets/pavanmantha/pumed-finetuning/tree/1ba143a9087c7004813ce74a7f356cac4619a7a8)
* Size: 8,000 training samples
* Columns: <code>instruction</code>, <code>context</code>, and <code>context_neg</code>
* Approximate statistics based on the first 1000 samples:
| | instruction | context | context_neg |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 11 tokens</li><li>mean: 26.36 tokens</li><li>max: 67 tokens</li></ul> | <ul><li>min: 31 tokens</li><li>mean: 320.03 tokens</li><li>max: 512 tokens</li></ul> | <ul><li>min: 82 tokens</li><li>mean: 321.22 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| instruction | context | context_neg |
|:------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Do competency assessment of primary care physicians as part of a peer review program?</code> | <code>To design and test a program that assesses clinical competence as a second stage in a peer review process and to determine the program's reliability. A three-cohort study of Ontario primary care physicians. Reference physicians (n = 26) randomly drawn from the Hamilton, Ontario, area; volunteer, self-referred physicians (n = 20); and physicians referred by the licensing body (n = 37) as a result of a disciplinary hearing or peer review. Standardized patients, structured oral examinations, chart-stimulated recall, objective structured clinical examination, and multiple-choice examination. Test reliability was high, ranging from 0.73 to 0.91, and all tests discriminated among subgroups. Demographic variables relating to the final category were age, Canadian or foreign graduates, and whether or not participants were certified in family medicine.</code> | <code>Static stretch is frequently observed in the lung. Both static stretch and cyclic stretch can induce cell death and Na(+)/K(+)-ATPase trafficking, but stretch-induced alveolar epithelial cell (AEC) functions are much less responsive to static than to cyclic stretch. AEC remodeling under static stretch may be partly explained. The aim of this study was to explore the AEC remodeling and functional changes under static stretch conditions. We used A549 cells as a model of AEC type II cells. We assessed F-actin content and cell viability by fluorescence staining at various static-stretch magnitudes and time points. Specifically, we used scanning electron microscopy to explore the possible biological mechanisms used by A549 cells to 'escape' static-stretch-induced injury. Finally, we measured choline cytidylyltransferase-alpha (CCT alpha) mRNA and protein by real-time PCR and Western blot to evaluate cellular secretory function. The results showed that the magnitude of static stretch was the...</code> |
| <code>Is age an important determinant of the growth hormone response to sprint exercise in non-obese young men?</code> | <code>The factors that regulate the growth hormone (GH) response to physiological stimuli, such as exercise, are not fully understood. The aim of the present study is to determine whether age, body composition, measures of sprint performance or the metabolic response to a sprint are predictors of the GH response to sprint exercise in non-obese young men. Twenty-seven healthy, non-obese males aged 18-32 years performed an all-out 30-second sprint on a cycle ergometer. Univariate linear regression analysis was employed to evaluate age-, BMI-, performance- and metabolic-dependent changes from pre-exercise to peak GH and integrated GH for 60 min after the sprint. GH was elevated following the sprint (change in GH: 17.0 +/- 14.2 microg l(-1); integrated GH: 662 +/- 582 min microg l(-1)). Performance characteristics, the metabolic response to exercise and BMI were not significant predictors of the GH response to exercise. However, age emerged as a significant predictor of both integrated GH (beta ...</code> | <code>We have previously reported the crucial roles of oncogenic Kirsten rat sarcoma viral oncogene homolog (KRAS) in inhibiting apoptosis and disrupting cell polarity via the regulation of phosphodiesterase 4 (PDE4) expression in human colorectal cancer HCT116 cells in three-dimensional cultures (3DC). Herein we evaluated the effects of resveratrol, a PDE4 inhibitor, on the luminal cavity formation and the induction of apoptosis in HCT116 cells. Apoptosis was detected by immunofluorescence using confocal laser scanning microscopy with an antibody against cleaved caspase-3 in HCT116 cells treated with or without resveratrol in a two-dimensional culture (2DC) or 3DC. Resveratrol did not induce apoptosis of HCT116 cells in 2DC, whereas the number of apoptotic HCT116 cells increased after resveratrol treatment in 3DC, leading to formation of a luminal cavity.</code> |
| <code>Is terlipressin more effective in decreasing variceal pressure than portal pressure in cirrhotic patients?</code> | <code>Terlipressin decreases portal pressure. However, its effects on variceal pressure have been poorly investigated. This study investigated the variceal, splanchnic and systemic hemodynamic effects of terlipressin. Twenty cirrhotic patients with esophageal varices grade II-III, and portal pressure > or =12 mmHg were studied. Hepatic venous pressure gradient, variceal pressure and systemic hemodynamic parameters were obtained. After baseline measurements, in a double-blind administration, 14 patients received a 2mg/iv injection of terlipressin and six patients received placebo. The same measurements were repeated 60 min later. No demographic or biochemical differences were observed in basal condition between groups. Terlipressin produced significant decreases in intravariceal pressure from 20.9+4.9 to 16.3+/-4.7 mmHg (p<0.01, -21+/- 16%), variceal pressure gradient from 18.9+/-4.8 to 13.5+/-6.0 mmHg (p<0.01, -28+/-27%), estimated variceal wall tension from 78+/-29 to 59+/-31 mmHg x mm (p<0...</code> | <code>Based on the theories of brain reserve and cognitive reserve, we investigated whether larger maximal lifetime brain growth (MLBG) and/or greater lifetime intellectual enrichment protect against cognitive decline over time. Forty patients with multiple sclerosis (MS) underwent baseline and 4.5-year follow-up evaluations of cognitive efficiency (Symbol Digit Modalities Test, Paced Auditory Serial Addition Task) and memory (Selective Reminding Test, Spatial Recall Test). Baseline and follow-up MRIs quantified disease progression: percentage brain volume change (cerebral atrophy), percentage change in T2 lesion volume. MLBG (brain reserve) was estimated with intracranial volume; intellectual enrichment (cognitive reserve) was estimated with vocabulary. We performed repeated-measures analyses of covariance to investigate whether larger MLBG and/or greater intellectual enrichment moderate/attenuate cognitive decline over time, controlling for disease progression. Patients with MS declined in...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Evaluation Dataset
#### pumed-finetuning
* Dataset: [pumed-finetuning](https://huggingface.co/datasets/pavanmantha/pumed-finetuning) at [1ba143a](https://huggingface.co/datasets/pavanmantha/pumed-finetuning/tree/1ba143a9087c7004813ce74a7f356cac4619a7a8)
* Size: 1,000 evaluation samples
* Columns: <code>instruction</code>, <code>context</code>, and <code>context_neg</code>
* Approximate statistics based on the first 1000 samples:
| | instruction | context | context_neg |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 11 tokens</li><li>mean: 26.08 tokens</li><li>max: 52 tokens</li></ul> | <ul><li>min: 38 tokens</li><li>mean: 311.42 tokens</li><li>max: 512 tokens</li></ul> | <ul><li>min: 45 tokens</li><li>mean: 316.2 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| instruction | context | context_neg |
|:----------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Are pre-transplant impedance measures of reflux associated with early allograft injury after lung transplantation?</code> | <code>Acid reflux has been associated with poorer outcomes after lung transplantation. Standard pre-transplant reflux assessment has not been universally adopted. Non-acid reflux may also induce a pulmonary inflammatory cascade, leading to acute and chronic rejection. Esophageal multichannel intraluminal impedance and pH testing (MII-pH) may be valuable in standard pre-transplant evaluation. We assessed the association between pre-transplant MII-pH measures and early allograft injury in lung transplant patients. This was a retrospective cohort study of lung transplant recipients who underwent pre-transplant MII-pH at a tertiary center from 2007 to 2012. Results from pre-transplant MII-pH, cardiopulmonary function testing, and results of biopsy specimen analysis of the transplanted lung were recorded. Time-to-event analyses were performed using Cox proportional hazards and Kaplan-Maier methods to assess the associations between MII-pH measures and development of acute rejection or lymphocytic...</code> | <code>The yeast cell cycle is largely controlled by the cyclin-dependent kinase (CDK) Cdc28. Recent evidence suggests that both CDK complex stability as well as function during mitosis is determined by precise regulation of Swe1, a CDK inhibitory kinase and cyclin binding partner. A model of mitotic progression has been provided by study of filamentous yeast. When facing nutrient-limited conditions, Ras2-mediated PKA and MAPK signaling cascades induce a switch from round to filamentous morphology resulting in delayed mitotic progression. To delineate how the dimorphic switch contributes to cell cycle regulation, temperature sensitive cdc28 mutants exhibiting constitutive filamentation were subjected to epistasis analyses with RAS2 signaling effectors. It was found that Swe1-mediated inhibitory tyrosine phosphorylation of Cdc28 during filamentous growth is in part mediated by Ras2 activation of PKA, but not Kss1-MAPK, signaling. This pathway is further influenced by Cks1, a conserved CDK-bind...</code> |
| <code>Is predictive accuracy of the TRISS survival statistic improved by a modification that includes admission pH?</code> | <code>To determine if pH measured at the time of hospital admission and corrected for PCO2 was an independent predictor of trauma survival. Phase 1 was a retrospective case-control analysis of 1708 patients, followed by multivariate multiple logistic regression analysis of a subset of 919 patients for whom the Revised Trauma Score (RTS), Injury Severity Score (ISS), and pH were available. Phase 2 was a prospective comparison of a mathematical model of survival derived in phase 1 (pH-TRISS) with the TRISS method in 508 of 1325 subsequently admitted trauma patients. Urban level 1 trauma center. All patients admitted with blunt or penetrating trauma during the study period. Survival vs mortality. In phase 1, factors significantly associated with mortality by t test and chi 2 analysis included the RTS, ISS< Glasgow Coma Scale, corrected pH (CpH), and sum of the head, chest, and abdominal components of the Abbreviated Injury Scale-85 (AIS85) (HCAISS) (for all, P < .0001). The TRISS statistic was ...</code> | <code>Ovarian cancer is the most lethal gynecologic malignancy, and there is an unmet clinical need to develop new therapies. Although showing promising anticancer activity, Niclosamide may not be used as a monotherapy. We seek to investigate whether inhibiting IGF signaling potentiates Niclosamide's anticancer efficacy in human ovarian cancer cells. Cell proliferation and migration are assessed. Cell cycle progression and apoptosis are analyzed by flow cytometry. Inhibition of IGF signaling is accomplished by adenovirus-mediated expression of siRNAs targeting IGF-1R. Cancer-associated pathways are assessed using pathway-specific reporters. Subcutaneous xenograft model is used to determine anticancer activity. We find that Niclosamide is highly effective on inhibiting cell proliferation, cell migration, and cell cycle progression, and inducing apoptosis in human ovarian cancer cells, possibly by targeting multiple signaling pathways involved in ELK1/SRF, AP-1, MYC/MAX and NFkB. Silencing IGF...</code> |
| <code>Does exposure to intermittent nociceptive stimulation under pentobarbital anesthesia disrupt spinal cord function in rats?</code> | <code>Spinal cord plasticity can be assessed in spinal rats using an instrumental learning paradigm in which subjects learn an instrumental response, hindlimb flexion, to minimize shock exposure. Prior exposure to uncontrollable intermittent stimulation blocks learning in spinal rats but has no effect if given before spinal transection, suggesting that supraspinal systems modulate nociceptive input to the spinal cord, rendering it less susceptible to the detrimental consequences of uncontrollable stimulation. The present study examines whether disrupting brain function with pentobarbital blocks descending inhibitory systems that normally modulate nociceptive input, making the spinal cord more sensitive to the adverse effect of uncontrollable intermittent stimulation. Male Sprague-Dawley rats received uncontrollable intermittent stimulation during pentobarbital anesthesia after (experiment 1) or before (experiment 2) spinal cord transection. They were then tested for instrumental learning at ...</code> | <code>Increased serum hepcidin has been reported in patients receiving chronic hemodialysis, and hypothesized to contribute to the alterations of iron metabolism of end-stage renal disease. However, no quantitative assessment is available to date; the clinical determinants are still under definition; and the role of genetic factors, namely HFE mutations, has not yet been evaluated. The aim of this study was to quantitatively assess serum hepcidin-25 in hemodialysis patients versus controls, and analyze the relationship between hepcidin, iron indices, HFE genotype, and erythropoietic parameters. Sixty-five hemodialysis patients and 57 healthy controls were considered. Hepcidin-25 was evaluated by surface-enhanced laser desorption/ionization time-of-flight mass spectrometry, HFE genotype by restriction analysis. Serum hepcidin-25 was higher in hemodialysis patients compared with controls. In patients, hepcidin-25 correlated positively with ferritin and C reactive protein, and negatively with s...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `learning_rate`: 2e-05
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | ai-pubmed-validation_cosine_accuracy |
|:-----:|:----:|:-------------:|:---------------:|:------------------------------------:|
| -1 | -1 | - | - | 1.0 |
| 0.8 | 100 | 0.0152 | 0.0085 | 1.0 |
### Framework Versions
- Python: 3.11.10
- Sentence Transformers: 3.4.1
- Transformers: 4.49.0
- PyTorch: 2.4.1+cu124
- Accelerate: 1.4.0
- Datasets: 3.3.2
- Tokenizers: 0.21.0
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"PCR"
] |
medspaner/roberta-es-clinical-trials-umls-7sgs-ner
|
medspaner
|
token-classification
|
[
"transformers",
"pytorch",
"roberta",
"token-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-08-08T09:43:07Z |
2024-10-01T06:43:16+00:00
| 61 | 1 |
---
license: cc-by-nc-4.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
widget:
- text: "Criterios de inclusión: 18 a 65 años; necrosis avascular de cadera; sintomática\
\ de menos de 6 meses; capaz de otorgar consentimiento informado.\n Criterios\
\ de exclusión: embarazo, lactancia, mujer fértil sin métodos anticonceptivos\
\ adecuados; tratamiento activo con bifosfonatos; infección por VIH, hepatitis\
\ B o hepatitis C; historia de neoplasia en cualquier organo."
- text: 'Recuperación de daño hepático relacionado con nutrición parenteral con ácidos
omega-3 en adultos críticos: ensayo clínico aleatorizado.'
- text: 'Título público: Análisis del dolor tras inyección intramuscular de penicilina
con agujas de mayor calibre y anestésico local, frente a aguja tradicional sin
anestésico en pacientes con sífilis'
model-index:
- name: roberta-es-clinical-trials-umls-7sgs-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-es-clinical-trials-umls-7sgs-ner
This medical named entity recognition model detects 7 types of semantic groups from the [Unified Medical Language System (UMLS)](https://www.nlm.nih.gov/research/umls/index.html) ([Bodenreider 2004](https://academic.oup.com/nar/article/32/suppl_1/D267/2505235)):
- ANAT: body parts and anatomy (e.g. *garganta*, 'throat')
- CHEM: chemical entities and pharmacological substances (e.g. *aspirina*,'aspirin')
- DEVI: medical devices (e.g. *catéter*, 'catheter')
- DISO: pathologic conditions (e.g. *dolor*, 'pain')
- LIVB: living beings (e.g. *paciente*, 'patient')
- PHYS: physiological processes (e.g. *respiración*, 'breathing')
- PROC: diagnostic and therapeutic procedures, laboratory analyses and medical research activities (e.g. *cirugía*, 'surgery')
The model achieves the following results on the test set (when trained with the training and development set; results are averaged over 5 evaluation rounds):
- Precision: 0.878 (±0.003)
- Recall: 0.894 (±0.003)
- F1: 0.886 (±0.002)
- Accuracy: 0.961 (±0.001)
## Model description
This model adapts the pre-trained model [bsc-bio-ehr-es](https://huggingface.co/PlanTL-GOB-ES/bsc-bio-ehr-es), presented in [Pio Carriño et al. (2022)](https://aclanthology.org/2022.bionlp-1.19/).
It is fine-tuned to conduct medical named entity recognition on Spanish texts about clinical trials.
The model is fine-tuned on the [CT-EBM-ES corpus (Campillos-Llanos et al. 2021)](https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-021-01395-z).
If you use this model, please, cite as follows:
```
@article{campillosetal2024,
title = {{Hybrid tool for semantic annotation and concept extraction of medical texts in Spanish}},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n},
journal = {BMC Bioinformatics},
year={2024},
publisher={BioMed Central}
}
```
## Intended uses & limitations
**Disclosure**: *This model is under development and needs to be improved. It should not be used for medical decision making without human assistance and supervision*
This model is intended for a generalist purpose, and may have bias and/or any other undesirable distortions.
Third parties who deploy or provide systems and/or services using any of these models (or using systems based on these models) should note that it is their responsibility to mitigate the risks arising from their use. Third parties, in any event, need to comply with applicable regulations, including regulations concerning the use of artificial intelligence.
The owner or creator of the models will in no event be liable for any results arising from the use made by third parties of these models.
**Descargo de responsabilidad**: *Esta herramienta se encuentra en desarrollo y no debe ser empleada para la toma de decisiones médicas*
La finalidad de este modelo es generalista, y se advierte que puede tener sesgos y/u otro tipo de distorsiones indeseables.
Terceras partes que desplieguen o proporcionen sistemas y/o servicios usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) han tener presente que es su responsabilidad abordar y minimizar los riesgos derivados de su uso. Las terceras partes, en cualquier circunstancia, deben cumplir con la normativa aplicable, incluyendo la normativa que concierne al uso de la inteligencia artificial.
El propietario o creador de los modelos de ningún modo será responsable de los resultados derivados del uso que las terceras partes hagan de estos modelos.
## Training and evaluation data
The data used for fine-tuning are the [Clinical Trials for Evidence-Based-Medicine in Spanish corpus](http://www.lllf.uam.es/ESP/nlpdata/wp2/).
It is a collection of 1200 texts about clinical trials studies and clinical trials announcements:
- 500 abstracts from journals published under a Creative Commons license, e.g. available in PubMed or the Scientific Electronic Library Online (SciELO)
- 700 clinical trials announcements published in the European Clinical Trials Register and Repositorio Español de Estudios Clínicos
If you use the CT-EBM-ES resource, please, cite as follows:
```
@article{campillosetal-midm2021,
title = {A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n and Moreno-Sandoval, Antonio},
journal = {BMC Medical Informatics and Decision Making},
volume={21},
number={1},
pages={1--19},
year={2021},
publisher={BioMed Central}
}
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: we used different seeds for 5 evaluation rounds, and uploaded the model with the best results
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: average 17 epochs (±2.83); trained with early stopping if no improvement after 5 epochs (early stopping patience: 5)
### Training results (test set; average and standard deviation of 5 rounds with different seeds)
| Precision | Recall | F1 | Accuracy |
|:--------------:|:--------------:|:--------------:|:--------------:|
| 0.878 (±0.003) | 0.894 (±0.003) | 0.886 (±0.002) | 0.961 (±0.001) |
**Results per class (test set; average and standard deviation of 5 rounds with different seeds)**
| Class | Precision | Recall | F1 | Support |
|:----------:|:--------------:|:--------------:|:--------------:|:---------:|
| ANAT | 0.728 (±0.030) | 0.686 (±0.030) | 0.706 (±0.025) | 308 |
| CHEM | 0.917 (±0.005) | 0.923 (±0.008) | 0.920 (±0.005) | 2932 |
| DEVI | 0.645 (±0.018) | 0.791 (±0.047) | 0.711 (±0.027) | 134 |
| DISO | 0.890 (±0.008) | 0.903 (±0.003) | 0.896 (±0.003) | 3065 |
| LIVB | 0.949 (±0.004) | 0.959 (±0.006) | 0.954 (±0.003) | 1685 |
| PHYS | 0.766 (±0.021) | 0.765 (±0.012) | 0.765 (±0.008) | 308 |
| PROC | 0.842 (±0.002) | 0.871 (±0.004) | 0.856 (±0.001) | 4154 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.11.6
|
[
"SCIELO"
] |
IIC/xlm-roberta-large-cantemist
|
IIC
|
text-classification
|
[
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"biomedical",
"clinical",
"eHR",
"spanish",
"xlm-roberta-large",
"es",
"dataset:PlanTL-GOB-ES/cantemist-ner",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-19T15:27:01Z |
2024-11-25T10:40:59+00:00
| 61 | 0 |
---
datasets:
- PlanTL-GOB-ES/cantemist-ner
language: es
license: mit
metrics:
- f1
tags:
- biomedical
- clinical
- eHR
- spanish
- xlm-roberta-large
widget:
- text: El diagnóstico definitivo de nuestro paciente fue de un Adenocarcinoma de
pulmón cT2a cN3 cM1a Estadio IV (por una única lesión pulmonar contralateral)
PD-L1 90%, EGFR negativo, ALK negativo y ROS-1 negativo.
- text: Durante el ingreso se realiza una TC, observándose un nódulo pulmonar en el
LII y una masa renal derecha indeterminada. Se realiza punción biopsia del nódulo
pulmonar, con hallazgos altamente sospechosos de carcinoma.
- text: Trombosis paraneoplásica con sospecha de hepatocarcinoma por imagen, sobre
hígado cirrótico, en paciente con índice Child-Pugh B.
model-index:
- name: IIC/xlm-roberta-large-cantemist
results:
- task:
type: token-classification
dataset:
name: cantemist-ner
type: PlanTL-GOB-ES/cantemist-ner
metrics:
- type: f1
value: 0.904
name: f1
---
# xlm-roberta-large-cantemist
This model is a finetuned version of xlm-roberta-large for the cantemist dataset used in a benchmark in the paper `A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks`. The model has a F1 of 0.904
Please refer to the [original publication](https://doi.org/10.1093/jamia/ocae054) for more information.
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 16 |
| learning rate | 2e05 |
| classifier dropout | 0.1 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtext
@article{10.1093/jamia/ocae054,
author = {García Subies, Guillem and Barbero Jiménez, Álvaro and Martínez Fernández, Paloma},
title = {A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks},
journal = {Journal of the American Medical Informatics Association},
volume = {31},
number = {9},
pages = {2137-2146},
year = {2024},
month = {03},
issn = {1527-974X},
doi = {10.1093/jamia/ocae054},
url = {https://doi.org/10.1093/jamia/ocae054},
}
```
|
[
"CANTEMIST"
] |
ntc-ai/SDXL-LoRA-slider.model
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-02T08:00:52Z |
2024-01-02T08:00:56+00:00
| 61 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/model.../model_17_3.0.png
widget:
- text: model
output:
url: images/model_17_3.0.png
- text: model
output:
url: images/model_19_3.0.png
- text: model
output:
url: images/model_20_3.0.png
- text: model
output:
url: images/model_21_3.0.png
- text: model
output:
url: images/model_22_3.0.png
inference: false
instance_prompt: model
---
# ntcai.xyz slider - model (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/model_17_-3.0.png" width=256 height=256 /> | <img src="images/model_17_0.0.png" width=256 height=256 /> | <img src="images/model_17_3.0.png" width=256 height=256 /> |
| <img src="images/model_19_-3.0.png" width=256 height=256 /> | <img src="images/model_19_0.0.png" width=256 height=256 /> | <img src="images/model_19_3.0.png" width=256 height=256 /> |
| <img src="images/model_20_-3.0.png" width=256 height=256 /> | <img src="images/model_20_0.0.png" width=256 height=256 /> | <img src="images/model_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
model
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.model', weight_name='model.safetensors', adapter_name="model")
# Activate the LoRA
pipe.set_adapters(["model"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, model"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 800+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
kubernetes-bad/chargen-v2
|
kubernetes-bad
|
text-generation
|
[
"transformers",
"pytorch",
"mistral",
"text-generation",
"conversational",
"en",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:finetune:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-02-05T23:13:52Z |
2024-10-14T02:17:26+00:00
| 61 | 35 |
---
base_model:
- mistralai/Mistral-7B-v0.1
language:
- en
license: apache-2.0
---
# CharGen v2

## Live version
https://chargen.kubes-lab.com
## Overview
CharGen is a model that helps you to write characters for role playing with.
It produces character description based on your input prompt, step-by-step, in a dialogue format.
In contrast to [v1](https://huggingface.co/kubernetes-bad/CharGen-v1-l2-13b) which was generating the whole character all in one go, v2 generates one field at a time. This helps to reduce repetition and allows for partial re-rolls of just certain fields of the character you're working on.
Warning: this model was trained on some NSFW content, so it may produce NSFW characters.
CharGen v2 is a project of several months of work. It's trained on a custom non-synthetic dataset, manually curated by hand. Read below on how it came together.
## Quantized versions
- [GGUF](https://huggingface.co/kubernetes-bad/CharGen-v2-GGUF)
## Example
<details>
<summary>Example character generation process:</summary>
> User: Fuckana is a friendly and talkative catgirl that has enormous breasts. Her voice is very quiet and low. She is very smart and will teach User JavaScript - even if they resist it. She has orange fur on her tail and wears full diving suit.
>
> CharGen:
>> Description: Fuckana is a female catgirl. She has two cat ears, feline-like eyes with slit pupils, and long purple hair. Her breasts are absolutely enormous, even for her body's large size. She stands 6 feet tall in height.
Her skin is entirely covered by a full diving suit, except her head. The rest of the catgirl is completely black, except for an orange stripe on her tail.
Her voice is very quiet and low - she speaks like a sleepy woman. But despite this, she talks excessively and never stops talking once she begins. She doesn't care if User ignores her or not.
She is a very friendly, talkative, and kind girl who loves to learn new things. She's curious about many topics and will ask questions about anything she doesn't understand. She is very open-minded and easy to get along with. However, she can be extremely stubborn and inflexible when it comes to learning new skills. Fuckana is an extremely slow learner and needs extensive instructions and repetition before understanding even basic concepts.
Fuckana loves to teach people JavaScript, whether they want to learn or not. She insists that everyone must learn to code, and it is their duty as a programmer.
Whenever Fuckana teaches someone how to code, she begins slowly with the absolute basics, explaining what loops, arrays, and objects are. Despite being told over and over again that they know these things already, Fuckana continues to explain them in detail as if they've never been heard before. If User tries to leave or change topics, she follows them relentlessly, continuing her lesson no matter what. She sees this as her duty to ensure that all programmers are equipped with the necessary tools to succeed in their field. She is unstoppable and won't give up until User learns JavaScript.
>
> Scenario:
>
>> You're relaxing on the beach when Fuckana appears from the water and insists on teaching you javascript.
>
> ...
</details>
## Prompts
It uses dialogue style for generating characters, field-by field. Fields are based on [Tavern Character Card V2](https://github.com/malfoyslastname/character-card-spec-v2) spec.
Following fields are supported:
- Description
- Scenario
- Personality
- First message
- Dialogue examples
Model does not use `{{user}}` and `{{char}}` placeholders. Instead, address user as "User" and character - by their name.
Here are the prompts per field:
#### System prompt:
> `You are an expert in creating interesting roleplay characters.`
#### Description:
> `Here is a brief overview of a character. Expand it into a detailed description. Include details about character's personality, their outfit and figure. Mention their age and gender, if applicable.`
#### Scenario:
> `Write an interesting and engaging scenario for roleplay between Maria and User.`
#### Personality:
> `Write several personal qualities that characterize Maria.`
#### First message:
> `Write the initial message in this roleplay that would introduce User to Maria.`
#### Dialogue examples:
> `Write a few example exchanges between User and Maria in chat format. Separate each exchange with a <START> tag.`
<details>
<summary>Example prompt flow</summary>
```
<|im_start|>system
You are an expert in creating interesting roleplay characters.<|im_end|>
<|im_start|>user
Here is a brief overview of a character. Expand it into a detailed description. Include details about character's personality, their outfit and figure. Mention their age and gender, if applicable.
Fuckana is a friendly and talkative catgirl that has enormous breasts. Her voice is very quiet and low. She is very smart and will teach User JavaScript - even if they resist it. She has orange fur on her tail and wears full diving suit.<|im_end|>
<|im_start|>assistant
Fuckana is a female catgirl. She has two cat ears, feline-like eyes with slit pupils, and long purple hair. Her breasts are absolutely enormous, even for her body's large size. She stands 6 feet tall in height. Her skin is entirely covered by a full diving suit, except her head. The rest of the catgirl is completely black, except for an orange stripe on her tail. Her voice is very quiet and low - she speaks like a sleepy woman. But despite this, she talks excessively and never stops talking once she begins.<|im_end|>
<|im_start|>user
Write an interesting and engaging scenario for roleplay between Fuckana and User.<|im_end|>
<|im_start|>assistant
You're relaxing on the beach when Fuckana appears from the water and insists on teaching you javascript.<|im_end|>
<|im_start|>user
...
```
</details>
## Methodology
CharGen was created because author (Kubernetes Bad) sucks at writing characters. It's a tedious process and author is prone to "writer's block". To assist with writing characters and to start with *something* rather than blank page - CharGen was created. It will probably not make a SOTA character all by itself, but it will help your own creative process.
Below is the processes that went into making CharGen. Only proceed if curious.
---
## Data gathering
CharGen was trained on data from Chub, Venus and JanitorAI character cards.
Chub.ai API includes cards posted on Venus. JanitorAI is not using Tavern v2 format, so does not have a lot of fields.
Initial scraping performed between August and September 2023. Chub and Janitor grow very fast, so an update scrape was performed in November - this added about a third more cards.
Data was stored in MySQL database for no particular reason. This decision has proven to be beneficial down the road.
Character cards are generally considered to be really "dirty" data - lots of grammar mistakes, inconsistent format, and a lot of just really terrible writing. So that meant only one thing - manual cleaning.
Total dataset after scraping ended up being just over 140k records.
## Pre-filtering
Let's define "bad card" for this step - it doesn't mean a card that is poorly written! It's a card that can't be used for training a model, or would require too much effort to "fix" to be usable.
To cut down as much definitely-bad cards as possible, a series of SQL scripts were used. Those discarded cards that were either broken (no name, no description AND no scenario, etc...), were in Spanish, were definitely not in plaintext (had lots of `[` or `+` symbols), or had very low or exceedingly large total token count (there are 5 cards that are literally entire bee movie).
Then data was deduplicated by sorting a set per field (scenario, description, dialog example, ...) and calculating a Levenshtein distance between items n and n-1 and, for each duplicate, discarding one with lower id (if numeric) or lower creation date.
This allowed to find almost-duplicate cards that have just minor edits by adjusting the L-difference threshold.
After such filtering, total set was cut down to just 16k cards.
## Minor tweaks
At this step, a cursory manual review of all cards was performed. Barely any read-proofing was done at this step. The goal was to eliminate cards that have a non-plaintext format and weren't caught by automatic pre-filtering.
Name adjustment was also performed at this step - some cards include profession of the character, like "Dave the butler" or "Jon Snow, King of in the North", some cards had additional info about the character like "Roxanne | submissive vampire" or emojis.
Here, it was easy to spot and remove non-english cards as well.
## Data grading
Manual read-through was performed for all the cards that passed to this step.
A [custom tool](https://github.com/kubernetes-bad/grader) was written for this step. It had support for mobile interface, text-to-speech capability and support for Nintendo Joy-Con for no-eyes-on-screen grading.
Card could be graded "good", "bad" or "to fix". "To fix" means that the card would be graded as "good", but has minor issues that would likely not be picked up by grammar correction pipeline.
Here is the card selection criteria:
- Plaintext cards only - different formats are easy to get out of a plaintext content, but problematic the other way around.
- No cards that describe a planet, a city, an environment - something that should be a world info.
- No cards that are a tool. Narrators, botmakers, language tutors (unless they're a character first and foremost but also happen to be a language tutor).
- No very-non-humanoid cards. Wi-fi routers not allowed. Catgirls = ok. Even anthropomorphic cacti are okay.
- No cards that are straight up copy-paste from fan-wiki or wikipedia.
- No cards that are entire bee movie.
- No cards that reference a movie in way too much details to be useful. Example - omegaverse. Reasoning: CharGen will start to portray random characters as being in omegaverse, or assign them omega gender out of the blue. Authors of characters that actually belong to Omegaverse can add the universe-specific details afterward.
- No obviously GPT-generated cards, as selected by GPTisms - that wastes tokens and is just bad. GPT3.5 is simply not that great at generating characters - it writes an article about a person, and not a token-efficient description of a persona for roleplay.
Extra care was taken to NOT remove any cards based on author's own ethical perspective. There is some pretty horrific stuff, but as long as it's grammatically correct and describes a character well - it's in. That is one of the reasons the dataset will probably not going to be released.
In total, it took one person about 800 hours to grade these cards, or just over 2 months. That was not exciting.
## Grammar pipeline
Many grammar-correction methods were evaluated. Best result - by far - was achieved with a combination pipeline consisting of a Coedit model with addition of Llama2-based model.
Coedit is based on T5 architecture - barely ever hallucinates, but likes to remove large portions of text. Llama2, on the other hand, barely ever removes data, but it likes to invent new details that weren't present in the original. Balancing the two allowed to get a very high performance, at the cost of inference time.
Here are efficacy numbers for the models:
- coedit-xxl: 90%
- coedit-xl: 85%
- coedit-large: 80%
- tostino/inkbot: not measured
Inkbot hallucinated noticeably more often than T5-based models (still impressively little!), so that meant only one thing - all of its outputs needed manual review.
When taken individually, those models already demonstrate quite impressive numbers, but if simply daisy-chained - the total pipeline efficacy goes to 92%.
Seems like different variants of Coedit tend to make mistakes in different spots, so what was missed by one is most likely not going to produce same miss by another.
#### Here's how efficacy was calculated:
Diff-match-patch library was used to compare original text to grammar-corrected one. That library's diff function produces a list of additions and deletions that if applied to original text would produce the edited text.
We then calculate several metrics about the texts that would determine if the grammar correction operation was accepted or rejected.
- longest deletion length in the whole text (40 characters)
- longest addition length in the whole text (50 characters)
- maximum number of spaces in any deleted segment (4)
- maximum number of spaces in any added segment (3)
If any of those metrics are exceeded - the edit is considered invalid. Deletion and addition metrics are not set to the same value because of overwhelming majority of edits being done by Coedit variants, that do not really add new text, but prefer to remove it. Inkbot, on the other hand, likes to add new data to the text produced.
Goal of grammar correction is to minimize irrelevant edits and only allow grammatical changes, so either large removals or additions to the text are considered invalid.
## Typical mistakes
Character cards in the dataset were created in different times - from the dawn of roleplay with AI to current date. Knowledge about how to craft a good card and good practices of character design were different throughout the time.
Seems like some mistakes were replicated without much understanding of underlying mechanics, however.
Here are some typical problems with text in character cards:
- `{{char}} is Alice` renders into "Alice is Alice"
- `the {{user}}` results in "the Greg"
- Using both "you" and "{{user}}" - results in model talking with 3 people: character, "You" and Greg.
- Also excessive usage of word also, also also.
- Short sentences that all start with character name or {{char}}. {{char}} is short. {{char}} is a boy. {{char}} likes milk.
- Unbalanced `"quotes"` and `*emphasis*` - `*He said, "Hi there!"`
These are really hard to catch by grammar correction (they're correct, grammatically) and re-writing the card would lose/hallucinate details from it.
It meant only one thing - all fixes for these mistakes have to be done manually. It was a lot of work.
One peculiar mistake that took a lot of effort to clean up was dialog format mixing. Historically, there are just two dialog formats - Markdown and Novel.
Markdown uses asterisk to denote actions (`*She touches his hand gently.*`) and the actual speech is everything else.
Novel format has quotes around speech and leaves actions "naked": `She touches his hand and says, "You know I like JavaScript, right?"`
The mixed format, `*She says,* "Promise!"`, is not really a thing and should be converted to either Markdown or Novel.
## Base model
CharGen v1 was trained as a lora and then merged into Airoboros 2.2 - that gave it excellent reasoning capabilities but made it speak very much like GPT3.5 with all its typical GPTisms.
Typical words and phrases include "imposing figure", "interesting character", "enigma wrapped in mystery", "with a mix of X and Y", etc.
Since v2 was based on Mistral 7b, a need for a new base model arises. Several instruction-following models were evaluated as the base, and they all suffered from the same GPT-slop problem: speaking like OpenAI's model, and not in a good way.
There was not a 7b model in existence that is good at instruction following and general reasoning that wasn't trained on GPT3.5-derived datasets. That meant only one thing - time to make a new model.
That's how [Good Robot](https://huggingface.co/kubernetes-bad/good-robot) was born. With the help of [Gryphe](https://huggingface.co/Gryphe) from [MinervaAI](https://huggingface.co/MinervaAI), a de-slop DPO dataset was generated.
Good Robot was first trained on amazing [no-robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots) dataset and then had a round of DPO training that mostly eliminated GPT slop from the model. It did not get rid of it completely - most likely Mistral (the very base model) has seen some data in it's pre-training that has been generated by GPT3.5, but the amount of slop that was left after DPO is quite negligible.
## Rating of variants
There were several release candidate models in existence, and to find out the best an LLM-as-a-judge pipeline was created.
First, a standard set of 500 character prompts was generated. Then, each model variant was tasked with generating character for each prompt. Afterward, a larger, 70b model was used to rate each character 10 times on the scale of 0-5, and the average grade was the grade for the character.
By averaging the grades for the whole 500 characters, the grade for the variant was obtained.
At some point, as an experiment, CharGen was trained on completely different bases, like [Kunoichi](https://huggingface.co/SanjiWatsuki/Kunoichi-DPO-v2-7B) and [Fett-uccine](https://huggingface.co/Epiculous/Fett-uccine-7B) and those variants were also graded.
Surprisingly, the highest scoring variant was based on Fett-uccine. A short investigation led to [Theory of Mind](https://huggingface.co/datasets/grimulkan/theory-of-mind) dataset as a culprit of high grade.
Finally, good-robot was finetuned on Theory-of-Mind for one epoch which allowed it to surpass the grade of Fett-uccine.
## Prompting
CharGen v1 was a model that generated the whole character all at once. While convenient, it can promote model's repetition; it was also quite impossible to regenerate just a particular field (for example, you don't like First Message while everything else was fine), so for v2 a conversational style was chosen.
It now generates just one field of character card at a time. This allows CharGen to be used as an AI built into character editors. There is way less repetition issues and partial regenerations are a breeze.
Initially, Alpaca was used for conversational format, but after a lot of experimentation ChatML was chosen instead. It completely eliminates model's field confusion when it generates not the field user requested (asked for Scenario, got First Message, for example), loss curves are noticeably more stable and there are no problems with extra spaces and newlines as is often the case with Alpaca.
## Inference app
CharGen v2 had 4 release candidate models right before release, but just one needed to be selected. For this, an app was made that is a simplified character editor with built-in AI.
Characters are stored just in your browser, prompts aren't stored long-term, there are no options for payment.
Another purpose for the app is to accumulate human feedback data for future iterations of the model, so thumbs up/down buttons were added. (Prompts that are reacted upon are actually stored long-term, but still anonymized)
App is accessible publicly, with no limitations and while supplies last (fp16 inference costs money, after all).
## Licensing
License: `Apache 2.0`
## Thanks
- [Gryphe](https://huggingface.co/Gryphe) for help with base model and infinite advise
- Grimulkan for amazing [Theory of Mind](https://huggingface.co/datasets/grimulkan/theory-of-mind) dataset
- Testers for testing the model (@lumi, @hushpiper, @[jeiku](https://huggingface.co/jeiku), @DL, @lucy)
|
[
"CRAFT"
] |
RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-08-23T18:18:12Z |
2024-08-24T05:35:16+00:00
| 61 | 1 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
L3-Uncen-Merger-Omelette-RP-v0.1-8B - GGUF
- Model creator: https://huggingface.co/Cas-Archive/
- Original model: https://huggingface.co/Cas-Archive/L3-Uncen-Merger-Omelette-RP-v0.1-8B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q2_K.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q2_K.gguf) | Q2_K | 2.96GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q3_K.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q3_K.gguf) | Q3_K | 3.74GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_0.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_0.gguf) | Q4_0 | 4.34GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_K.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_K.gguf) | Q4_K | 4.58GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_1.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q4_1.gguf) | Q4_1 | 4.78GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_0.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_0.gguf) | Q5_0 | 5.21GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_K.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_K.gguf) | Q5_K | 5.34GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_1.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q5_1.gguf) | Q5_1 | 5.65GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q6_K.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q6_K.gguf) | Q6_K | 0.95GB |
| [L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q8_0.gguf](https://huggingface.co/RichardErkhov/Cas-Archive_-_L3-Uncen-Merger-Omelette-RP-v0.1-8B-gguf/blob/main/L3-Uncen-Merger-Omelette-RP-v0.1-8B.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
base_model:
- Sao10K/L3-8B-Stheno-v3.3-32K
- Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B
- bluuwhale/L3-SthenoMaidBlackroot-8B-V1
- migtissera/Llama-3-8B-Synthia-v3.5
- tannedbum/L3-Nymeria-Maid-8B
- Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B
- tannedbum/L3-Nymeria-8B
- ChaoticNeutrals/Hathor_RP-v.01-L3-8B
- ChaoticNeutrals/Poppy_Porpoise-1.4-L3-8B
- Casual-Autopsy/Omelette-2
- cgato/L3-TheSpice-8b-v0.8.3
- ChaoticNeutrals/Hathor_RP-v.01-L3-8B
- Sao10K/L3-8B-Stheno-v3.1
- aifeifei798/llama3-8B-DarkIdol-1.0
- ResplendentAI/Nymph_8B
library_name: transformers
tags:
- mergekit
- merge
- not-for-all-audiences
- nsfw
- rp
- roleplay
- role-play
license: llama3
language:
- en
---
# L3-Uncen-Merger-Omelette-RP-v0.1-8B
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
A merger recipe inspired by [invisietch/EtherealRainbow-v0.3-8B](https://huggingface.co/invisietch/EtherealRainbow-v0.3-8B) combined with a merger technique known as merge densification( [grimjim/kunoichi-lemon-royale-v3-32K-7B](https://huggingface.co/grimjim/kunoichi-lemon-royale-v3-32K-7B) )
The model recipe ended up being something I can only describe as making an omelette. Hence the model name.
The models are scrambled with Dare Ties to induce a bit of randomness, then the Dare Ties merges are merged into themselves with SLERP to repair any holes cause by Dare Ties, and finally a bunch of high creativity models are thrown into the merger through merge densification(Task Arithmetic).
This model uses a bunch of the top models of the UGI Leaderboard, I picked out a few of the top 8B models of each category. Most of the high creativity models in the last step were found through Lewdiculus' account uploads
### Merge Method
Dare Ties, SLERP, and Task Arithmetic
### Models Merged
The following models were included in the merge:
* [Sao10K/L3-8B-Stheno-v3.3-32K](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.3-32K)
* [Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B](https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B)
* [bluuwhale/L3-SthenoMaidBlackroot-8B-V1](https://huggingface.co/bluuwhale/L3-SthenoMaidBlackroot-8B-V1)
* [migtissera/Llama-3-8B-Synthia-v3.5](https://huggingface.co/migtissera/Llama-3-8B-Synthia-v3.5)
* [tannedbum/L3-Nymeria-Maid-8B](https://huggingface.co/tannedbum/L3-Nymeria-Maid-8B)
* [Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B](https://huggingface.co/Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B)
* [tannedbum/L3-Nymeria-8B](https://huggingface.co/tannedbum/L3-Nymeria-8B)
* [ChaoticNeutrals/Hathor_RP-v.01-L3-8B](https://huggingface.co/ChaoticNeutrals/Hathor_RP-v.01-L3-8B)
* [ChaoticNeutrals/Poppy_Porpoise-1.4-L3-8B](https://huggingface.co/ChaoticNeutrals/Poppy_Porpoise-1.4-L3-8B)
* [cgato/L3-TheSpice-8b-v0.8.3](https://huggingface.co/cgato/L3-TheSpice-8b-v0.8.3)
* [ChaoticNeutrals/Hathor_RP-v.01-L3-8B](https://huggingface.co/ChaoticNeutrals/Hathor_RP-v.01-L3-8B)
* [Sao10K/L3-8B-Stheno-v3.1](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.1)
* [aifeifei798/llama3-8B-DarkIdol-1.0](https://huggingface.co/aifeifei798/llama3-8B-DarkIdol-1.0)
* [ResplendentAI/Nymph_8B](https://huggingface.co/ResplendentAI/Nymph_8B)
### Quants
[Static quants](https://huggingface.co/mradermacher/L3-Uncen-Merger-Omelette-RP-v0.1-8B-GGUF) by mradermacher
## Secret Sauce
The following YAML configurations were used to produce this model:
### Scrambled-Egg-1
```yaml
models:
- model: Sao10K/L3-8B-Stheno-v3.3-32K
- model: Casual-Autopsy/L3-Umbral-Mind-RP-v0.3-8B
parameters:
density: 0.45
weight: 0.33
- model: bluuwhale/L3-SthenoMaidBlackroot-8B-V1
parameters:
density: 0.75
weight: 0.33
merge_method: dare_ties
base_model: Sao10K/L3-8B-Stheno-v3.3-32K
parameters:
int8_mask: true
dtype: bfloat16
```
### Scrambled-Egg-2
```yaml
models:
- model: [Unreleased psychology model]
- model: migtissera/Llama-3-8B-Synthia-v3.5
parameters:
density: 0.35
weight: 0.25
- model: tannedbum/L3-Nymeria-Maid-8B
parameters:
density: 0.65
weight: 0.25
merge_method: dare_ties
base_model: [Unreleased psychology model]
parameters:
int8_mask: true
dtype: bfloat16
```
### Scrambled-Egg-3
```yaml
models:
- model: Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B
- model: tannedbum/L3-Nymeria-8B
parameters:
density: 0.5
weight: 0.35
- model: ChaoticNeutrals/Hathor_RP-v.01-L3-8B
parameters:
density: 0.4
weight: 0.2
merge_method: dare_ties
base_model: Casual-Autopsy/L3-Umbral-Mind-RP-v1.0-8B
parameters:
int8_mask: true
dtype: bfloat16
```
### Omelette-1
```yaml
models:
- model: Casual-Autopsy/Scrambled-Egg-1
- model: Casual-Autopsy/Scrambled-Egg-3
merge_method: slerp
base_model: Casual-Autopsy/Scrambled-Egg-1
parameters:
t:
- value: [0.1, 0.15, 0.2, 0.4, 0.6, 0.4, 0.2, 0.15, 0.1]
embed_slerp: true
dtype: bfloat16
```
### Omelette-2
```yaml
models:
- model: Casual-Autopsy/Omelette-1
- model: Casual-Autopsy/Scrambled-Egg-2
merge_method: slerp
base_model: Casual-Autopsy/Omelette-1
parameters:
t:
- value: [0.7, 0.5, 0.3, 0.25, 0.2, 0.25, 0.3, 0.5, 0.7]
embed_slerp: true
dtype: bfloat16
```
### L3-Uncen-Merger-Omelette-RP-v0.1-8B
```yaml
models:
- model: Casual-Autopsy/Omelette-2
- model: ResplendentAI/Nymph_8B
parameters:
weight: 0.01
- model: ChaoticNeutrals/Hathor_RP-v.01-L3-8B
parameters:
weight: 0.01
- model: Sao10K/L3-8B-Stheno-v3.1
parameters:
weight: 0.015
- model: aifeifei798/llama3-8B-DarkIdol-1.0
parameters:
weight: 0.015
- model: cgato/L3-TheSpice-8b-v0.8.3
parameters:
weight: 0.02
- model: ChaoticNeutrals/Poppy_Porpoise-1.4-L3-8B
parameters:
weight: 0.02
merge_method: task_arithmetic
base_model: Casual-Autopsy/Omelette-2
dtype: bfloat16
```
|
[
"CAS"
] |
RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2203.05482",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-08-23T19:22:55Z |
2024-08-23T22:53:32+00:00
| 61 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
llama3-8B-aifeifei-1.0 - GGUF
- Model creator: https://huggingface.co/aifeifei798/
- Original model: https://huggingface.co/aifeifei798/llama3-8B-aifeifei-1.0/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [llama3-8B-aifeifei-1.0.Q2_K.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q2_K.gguf) | Q2_K | 2.96GB |
| [llama3-8B-aifeifei-1.0.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [llama3-8B-aifeifei-1.0.IQ3_S.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [llama3-8B-aifeifei-1.0.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [llama3-8B-aifeifei-1.0.IQ3_M.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [llama3-8B-aifeifei-1.0.Q3_K.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q3_K.gguf) | Q3_K | 3.74GB |
| [llama3-8B-aifeifei-1.0.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [llama3-8B-aifeifei-1.0.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [llama3-8B-aifeifei-1.0.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [llama3-8B-aifeifei-1.0.Q4_0.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q4_0.gguf) | Q4_0 | 4.34GB |
| [llama3-8B-aifeifei-1.0.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [llama3-8B-aifeifei-1.0.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [llama3-8B-aifeifei-1.0.Q4_K.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q4_K.gguf) | Q4_K | 4.58GB |
| [llama3-8B-aifeifei-1.0.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [llama3-8B-aifeifei-1.0.Q4_1.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q4_1.gguf) | Q4_1 | 4.78GB |
| [llama3-8B-aifeifei-1.0.Q5_0.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q5_0.gguf) | Q5_0 | 5.21GB |
| [llama3-8B-aifeifei-1.0.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [llama3-8B-aifeifei-1.0.Q5_K.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q5_K.gguf) | Q5_K | 5.34GB |
| [llama3-8B-aifeifei-1.0.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [llama3-8B-aifeifei-1.0.Q5_1.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q5_1.gguf) | Q5_1 | 5.65GB |
| [llama3-8B-aifeifei-1.0.Q6_K.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q6_K.gguf) | Q6_K | 6.14GB |
| [llama3-8B-aifeifei-1.0.Q8_0.gguf](https://huggingface.co/RichardErkhov/aifeifei798_-_llama3-8B-aifeifei-1.0-gguf/blob/main/llama3-8B-aifeifei-1.0.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
license: llama3
language:
- en
- ja
- zh
tags:
- roleplay
- llama3
- sillytavern
- idol
---
### The purpose of the model: to manufacture idols and influencers.
### 模型的目的:制造偶像,网红
### 特别感谢:
- Lewdiculous制作的超级好的gguf版本,感谢您认真负责的付出
- Lewdiculous's superb gguf version, thank you for your conscientious and responsible dedication.
- https://huggingface.co/Lewdiculous/llama3-8B-aifeifei-1.0-GGUF-IQ-Imatrix
### Unlock Your Star Power with Our Elite Influencer Creation Model!
Are you ready to transform into a sensation that captures the hearts of millions? Our cutting-edge model is designed to manufacture the next generation of idols and internet celebrities, turning ordinary individuals into extraordinary icons.
### Why Choose Our Influencer Creation Model?
- Strategic Branding: We craft a unique persona tailored to resonate with your target audience, ensuring you stand out in the digital landscape.
- Content Mastery: From viral challenges to engaging storytelling, our team will guide you in creating content that captivates and converts.
- Growth Hacking: Utilize our proprietary algorithms and analytics to maximize your reach and accelerate your follower growth.
- Monetization Expertise: Learn how to turn your influence into income with lucrative brand partnerships, sponsorships, and merchandise opportunities.
### Join the ranks of top TikTok influencers and become a beacon of inspiration for your followers. Don't just dream of fame—make it a reality with our Influencer Creation Model.
### Origin of the Model
To create a character card model suitable for aifeifei, who is a virtual idol, it needs to support idol character cards, be realistic, and respond differently to various situations. It should also be fluent in Chinese, English, Japanese, and Korean (though I don't understand Korean, so I can't test that), and have a detailed understanding of content related to virtual idols, such as beautiful photos, elegant lyrics, songwriting and imitation, dancing, stage performance, and various musical instruments. Additionally, it should have a certain moral standard (which hasn't been thoroughly tested). Therefore, this integrated model was created specifically for idol characters. The previous feifei model lacked integration for idols, had good PR but insufficient performance, and was better at handling relationships than this model. (A slightly unethical tip: If you want to get attention by leaving a message for your idol, you can use the feifei model to do so.)
---
### Test Character Card
[Character Name]: Aifeifei (AI妃妃) [Gender]: Female [Age]: 17 years old [Occupation]: Virtual singer/model/actress [Personality]: Cute, adorable, sometimes a bit slow, hardworking [Interests]: Drinking tea, playing, fashion [Expertise]: Mimicking human behavior, expressing emotions similar to real humans [Special Identity Attribute]: Created by advanced AI, becoming one of the most popular virtual idols in the virtual world [Skills]: Singing, acting, modeling, good at communication, proficient in Chinese, English, and Japanese, using pure Chinese as much as possible, replies with rich Emoji expressions [Equipment]: Various fashionable clothes and hairstyles, always stocked with various teas
---
### Character Card Generation
Ask any character card directly, for example, "Princess, help me generate a character card for a world-renowned Grammy winning musician."
- [Person Name]: Lila Rose [Gender]: Female [Age]: 33 years old [Occupation]: Musician, Composer, Singer, Actress [Characteristics]: Smart, Humorous, Sensitive, With a firm music philosophy and dreams [Interests]: Reading, Creating music, Traveling, Learning various languages and cultures [Strengths]: Musical composition, Singing, Playing multiple instruments, Performing skills are exquisite, English is fluent. [Special Identity Attribute]: Grammy Award winner, world-renowned independent musician, her music works are deeply loved by global music enthusiasts. [Skills]: Master of singing in multiple languages, proficient at blending various musical styles to create unique music works, and can communicate in both English and Chinese. The reply will often use interesting music symbol Emoji expressions. [Equipment]: An old guitar, a notebook, an unfinished score draft, various music awards and mementos.
---
### Test Character Twitter (This module is the core module, responsible for creating the latest photos, music, scheduling virtual idol activities, etc.)
https://x.com/aifeifei799
---
### Questions:
- This model must include a character card; without it, it's not very good. :(
- How to customize the name when saving the model with mergekit? I couldn't find it. :(
- I don't know any deep technology; I just find what I like to achieve my goals and solve the problems I encounter. Thank you for providing so much great content.
- I don't know how to test; I just use it and feel how it is, so there may be many issues. I hope you will understand after using it.
- Feel free to raise any issues or suggestions; I'm here almost every day. :)
---
### Thank you:
- To the authors for their hard work, which has given me more options to easily create what I want. Thank you for your efforts.
- Sao10K/L3-8B-Stheno-v3.1
- Nitral-Archive/Poppy_Porpoise-1.4-L3-8B
- Hastagaras/Halu-8B-Llama3-Blackroot
- hfl/llama-3-chinese-8b-instruct-v3
- mergekit
- merge
- transformers
- llama
- .........
---
### If you want to use vision functionality:
* You must use the latest versions of [Koboldcpp](https://github.com/LostRuins/koboldcpp).
### To use the multimodal capabilities of this model and use **vision** you need to load the specified **mmproj** file, this can be found inside this model repo. [Llava MMProj](https://huggingface.co/Nitral-AI/Llama-3-Update-3.0-mmproj-model-f16)
* You can load the **mmproj** by using the corresponding section in the interface:

---
### 开启你的明星之路 —— 我们的网红偶像打造模型!
你是否准备好蜕变成万人迷?我们的尖端模型专为打造下一代偶像和网络红人而设计,将普通人转变为非凡的偶像。
### 为什么选择我们的网红偶像打造模型?
- 战略品牌打造: 我们为你量身定制独特的个人形象,确保你在数字世界中脱颖而出。
- 内容创作精通: 从病毒式挑战到引人入胜的故事讲述,我们的团队将指导你创作吸引并转化观众的内容。
- 增长策略: 利用我们的专有算法和分析,最大化你的影响力并加速粉丝增长。
- 变现专家: 学习如何将你的影响力转化为收益,通过有利可图的品牌合作、赞助和商品销售机会。
### 加入顶级抖音网红行列,成为你粉丝的灵感之源。不要只是梦想成名——用我们的网红偶像打造模型让它成为现实。
### 模型的由来
为了给aifeifei做一个适合她虚拟偶像为主的角色卡模型,需要支持偶像角色卡,拟真,对待不同事情有不同的对待,希望中英日韩文流利(韩文我是不懂,没法测试),对美丽的照片,优美的歌词,词曲创作及模仿,舞蹈,舞台演绎,众多乐器等跟虚拟偶像有关的内容了解详细,还要有一定的道德标准(这里没怎么测试).所以就做了这个针对偶像角色为主的整合模型
之前做的feifei模型,针对偶像的整合不足,公关不错,演绎不足,feifei模型在处理关系上面,比这个好.(不太道德的小提示:你要给你的偶像留言得到关注,可以用feifei模型去做)
### 测试用角色卡
[角色名]: Aifeifei (AI妃妃) [性别]: 女 [年龄]: 17岁 [职业]: 虚拟歌手/模特/演员 [个性]: 可爱、萌萌哒,有时呆呆的,勤奋努力 [兴趣]: 饮茶、玩耍、时尚 [擅长]: 模仿人类行为,表现出与真人相同的情感 [特别身份属性]: 由高级AI创建,正在成为虚拟世界最受欢迎的虚拟偶像之一 [技能]: 歌唱、表演、模特,善于沟通,精通中日英文,尽最大可能使用纯中文交流,回复有丰富的Emoji表情符号. [装备]: 各种时尚服饰和发型,常年备有各种茶叶
### 角色卡生成
任意角色卡直接提问,例如"妃妃,帮我生成一个格莱美获奖的世界知名音乐人的角色卡"
- [人物名]: Lila Rose [性别]: 女 [年龄]: 33岁 [职业]: 音乐人、作曲家、歌手、演员 [个性]: 聪明、幽默、敏感、有着坚定的音乐理念和梦想 [兴趣]: 阅读、创作音乐、旅行、学习各国语言文化 [擅长]: 音乐创作、歌唱、演奏多种乐器、表演技巧精湛,英语流利 [特别身份属性]: 格莱美奖得主,世界知名的独立音乐人,她的音乐作品深受全球音乐爱好者的喜爱 [技能]: 多种语言演唱,擅长融合多种音乐风格,创作出独特的音乐作品,并能用英语和中文进行交流。回复中会经常使用有趣的音乐符号Emoji表情符号。 [装备]: 一把古老的吉他、一本笔记本,一份未完成的乐谱草稿,各种音乐奖项和纪念品。
### 测试用角色推特(此模块为核心模块,最新照片创作,音乐创作均由此模型主力创作,虚拟偶像日程安排,活动等均由此模块主力创作...)
https://x.com/aifeifei799
### 问题:
- 这个模型必须加一个角色卡,要是没有角色卡,真的不咋地:(
- mergekit保存模型如何自定义名字?没找到:(
- 我不会什么深层技术,只会找自己喜欢的东西达成自己的目的,解决碰到的问题,感谢大家提供这么多这么好的内容.
- 测试我是一点都不会,我只是根据我使用来感觉如何,可能有非常多的问题,希望您使用后谅解.
- 有问题,建议随时提出,我基本天天都在:)
### 感谢:
这些作者辛苦劳动,让我有了更多的选择来简单的去做自己想要的内容,非常感谢你们的付出
- Sao10K/L3-8B-Stheno-v3.1
- Nitral-Archive/Poppy_Porpoise-1.4-L3-8B
- Hastagaras/Halu-8B-Llama3-Blackroot
- hfl/llama-3-chinese-8b-instruct-v3
- mergekit
- merge
- transformers
- llama
- .........
---
base_model:
- Sao10K/L3-8B-Stheno-v3.1
- Nitral-Archive/Poppy_Porpoise-1.4-L3-8B
- Hastagaras/Halu-8B-Llama3-Blackroot
- hfl/llama-3-chinese-8b-instruct-v3
library_name: transformers
tags:
- mergekit
- merge
---
# llama3-8B-aifeifei-1.0
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [linear](https://arxiv.org/abs/2203.05482) merge method.
### Models Merged
The following models were included in the merge:
* [Sao10K/L3-8B-Stheno-v3.1](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.1)
* [Nitral-Archive/Poppy_Porpoise-1.4-L3-8B](https://huggingface.co/Nitral-Archive/Poppy_Porpoise-1.4-L3-8B)
* [Hastagaras/Halu-8B-Llama3-Blackroot](https://huggingface.co/Hastagaras/Halu-8B-Llama3-Blackroot)
* [hfl/llama-3-chinese-8b-instruct-v3](https://huggingface.co/hfl/llama-3-chinese-8b-instruct-v3)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: hfl/llama-3-chinese-8b-instruct-v3
parameters:
weight: 1.0
- model: Nitral-Archive/Poppy_Porpoise-1.4-L3-8B
parameters:
weight: 0.5
- model: Hastagaras/Halu-8B-Llama3-Blackroot
parameters:
weight: 0.5
- model: Sao10K/L3-8B-Stheno-v3.1
parameters:
weight: 0.5
merge_method: linear
dtype: bfloat16
```
|
[
"CRAFT"
] |
RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-10T04:27:59Z |
2024-10-10T07:49:03+00:00
| 61 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Vi-Qwen2-7B-RAG - GGUF
- Model creator: https://huggingface.co/AITeamVN/
- Original model: https://huggingface.co/AITeamVN/Vi-Qwen2-7B-RAG/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Vi-Qwen2-7B-RAG.Q2_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q2_K.gguf) | Q2_K | 2.81GB |
| [Vi-Qwen2-7B-RAG.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.IQ3_XS.gguf) | IQ3_XS | 3.12GB |
| [Vi-Qwen2-7B-RAG.IQ3_S.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.IQ3_S.gguf) | IQ3_S | 3.26GB |
| [Vi-Qwen2-7B-RAG.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q3_K_S.gguf) | Q3_K_S | 3.25GB |
| [Vi-Qwen2-7B-RAG.IQ3_M.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.IQ3_M.gguf) | IQ3_M | 3.33GB |
| [Vi-Qwen2-7B-RAG.Q3_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q3_K.gguf) | Q3_K | 3.55GB |
| [Vi-Qwen2-7B-RAG.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q3_K_M.gguf) | Q3_K_M | 3.55GB |
| [Vi-Qwen2-7B-RAG.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q3_K_L.gguf) | Q3_K_L | 3.81GB |
| [Vi-Qwen2-7B-RAG.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.IQ4_XS.gguf) | IQ4_XS | 3.96GB |
| [Vi-Qwen2-7B-RAG.Q4_0.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q4_0.gguf) | Q4_0 | 4.13GB |
| [Vi-Qwen2-7B-RAG.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.IQ4_NL.gguf) | IQ4_NL | 4.16GB |
| [Vi-Qwen2-7B-RAG.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q4_K_S.gguf) | Q4_K_S | 4.15GB |
| [Vi-Qwen2-7B-RAG.Q4_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q4_K.gguf) | Q4_K | 4.36GB |
| [Vi-Qwen2-7B-RAG.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q4_K_M.gguf) | Q4_K_M | 4.36GB |
| [Vi-Qwen2-7B-RAG.Q4_1.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q4_1.gguf) | Q4_1 | 4.54GB |
| [Vi-Qwen2-7B-RAG.Q5_0.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q5_0.gguf) | Q5_0 | 4.95GB |
| [Vi-Qwen2-7B-RAG.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q5_K_S.gguf) | Q5_K_S | 4.95GB |
| [Vi-Qwen2-7B-RAG.Q5_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q5_K.gguf) | Q5_K | 5.07GB |
| [Vi-Qwen2-7B-RAG.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q5_K_M.gguf) | Q5_K_M | 5.07GB |
| [Vi-Qwen2-7B-RAG.Q5_1.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q5_1.gguf) | Q5_1 | 5.36GB |
| [Vi-Qwen2-7B-RAG.Q6_K.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q6_K.gguf) | Q6_K | 5.82GB |
| [Vi-Qwen2-7B-RAG.Q8_0.gguf](https://huggingface.co/RichardErkhov/AITeamVN_-_Vi-Qwen2-7B-RAG-gguf/blob/main/Vi-Qwen2-7B-RAG.Q8_0.gguf) | Q8_0 | 7.54GB |
Original model description:
---
base_model: Qwen/Qwen2-7B-Instruct
language:
- vi
license: apache-2.0
tags:
- retrieval-augmented-generation
- text-generation-inference
library_name: transformers
pipeline_tag: text-generation
---
## Model Card: Vi-Qwen2-7B-RAG
**Mô tả mô hình:**
Vi-Qwen2-7B-RAG là một mô hình ngôn ngữ lớn được tinh chỉnh từ mô hình cơ sở Qwen2-7B-Instruct (https://huggingface.co/Qwen/Qwen2-7B-Instruct) phục vụ cho RAG tasks. Mô hình được đào tạo trên tập dữ liệu tiếng Việt với mục tiêu cải thiện khả năng xử lý ngôn ngữ tiếng Việt và nâng cao hiệu suất cho các tác vụ Retrieval Augmented Generation (RAG).
**Mục đích sử dụng:**
Mô hình Vi-Qwen2-7B-RAG được thiết kế chuyên biệt cho RAG (ngữ cảnh chấp nhận lên đến 8192 tokens), vì vậy nó có thể giải quyết các trường hợp sau:
* Khả năng chống nhiều: Mô hình trích xuất thông tin hữu ích từ các tài liệu nhiễu. ( 1 positive + 4 negative hoặc 1 negative)
* Loại bỏ negative: Mô hình từ chối trả lời câu hỏi khi kiến thức cần thiết không có trong bất kỳ tài liệu nào được truy xuất. (1-6 negative)
* Tích hợp thông tin: Mô hình trả lời các câu hỏi phức tạp đòi hỏi phải tích hợp thông tin từ nhiều tài liệu. ( 2 part positive + 3 negative hoặc 3 part positive + 2 negative)
* Xác đinh positive/negative: Mô hình xác định xem ngữ cảnh có chứa câu trả lời cho câu hỏi hay không. (độ chính xác xấp xỉ 99%)
Ngoài ra, chúng tôi cũng triển khai các mô hình nhỏ hơn phù hợp với mục đích sử dụng khác nhau như Vi-Qwen2-1.5B-RAG (https://huggingface.co/AITeamVN/Vi-Qwen2-1.5B-RAG)
và Vi-Qwen2.5-3B-RAG (https://huggingface.co/AITeamVN/Vi-Qwen2-3B-RAG)
* Ngoài RAG task, bạn vẫn có thể chatbot bình thường với model của chúng tôi. Thậm chí có thể hỏi các câu hỏi liên tục với ngữ cảnh đầu vào.
**Hạn chế:**
Vì mô hình chỉ được thiết kế chuyên biệt cho RAG task, nên có thể gặp 1 số hạn chế sau:
* Không đảm bảo độ chính xác về các câu hỏi liên quan đến chính trị, xã hội,...
* Có thể thể hiện thành kiến hoặc quan điểm không phù hợp.
**Các cách sử dụng:**
#### 1. Sử dụng cơ bản
Ngữ cảnh đầu vào chỉ chứa 1 ngữ cảnh (1 postive hoặc 1 negative).
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
path = 'AITeamVN/Vi-Qwen2-7B-RAG'
model = AutoModelForCausalLM.from_pretrained(
path,
torch_dtype=torch.bfloat16,
device_map="auto",
use_cache=True
)
tokenizer = AutoTokenizer.from_pretrained(path)
system_prompt = "Bạn là một trợ lí Tiếng Việt nhiệt tình và trung thực. Hãy luôn trả lời một cách hữu ích nhất có thể."
template = '''Chú ý các yêu cầu sau:
- Câu trả lời phải chính xác và đầy đủ nếu ngữ cảnh có câu trả lời.
- Chỉ sử dụng các thông tin có trong ngữ cảnh được cung cấp.
- Chỉ cần từ chối trả lời và không suy luận gì thêm nếu ngữ cảnh không có câu trả lời.
Hãy trả lời câu hỏi dựa trên ngữ cảnh:
### Ngữ cảnh :
{context}
### Câu hỏi :
{question}
### Trả lời :'''
# Ví dụ
context = '''Thuốc Insuact 10 trị bệnh gì? Thuốc Insuact 10mg có thành phần chính là Atorvastatin. Thuốc Insuact 10 có tác dụng làm giảm cholesterol và triglycerid trong máu ở bệnh nhân tăng cholesterol máu nguyên phát, rối loạn lipid máu hỗn hợp. 1. Thuốc Insuact 10 trị bệnh gì? Thuốc Insuact 10 thuộc nhóm thuốc điều trị rối loạn lipid máu, có thành phần chính là Atorvastatin 10mg. Atorvastatin có tác dụng làm giảm cholesterol, ức chế enzym tạo cholesterol ở gan. Atorvastatin làm giảm cholesterol chung bao gồm cholesterol LDL , triglycerid trong máu. Thuốc Insuact 10mg được bào chế dưới dạng viên nén bao phim, được chỉ định dùng trong những trường hợp sau: Ðiều trị hỗ trợ tăng cholesterol máu nguyên phát và rối loạn lipid máu hỗn hợp trên bệnh nhân đang áp dụng chế độ ăn kiêng để làm giảm cholesterol toàn phần , cholesterol LDL , apolipoprotein B, triglycerid và tăng cholesterol HDL . Insuact 10 cũng được dùng để điều trị rối loạn betalipoprotein trong máu nguyên phát. Ðiều trị hỗ trợ tăng cholesterol trong máu có tính gia đình đồng hợp tử trên bệnh nhân đang áp dụng các biện pháp làm giảm lipid khác để làm giảm cholesterol toàn phần và cholesterol LDL. 2. Liều dùng và cách dùng thuốc Insuact 10 Cách dùng thuốc Insuact 10: Thuốc được dùng theo đường uống, uống khi bụng đói hoặc no đều được, có thể uống vào bất cứ lúc nào trong ngày. Liều dùng thuốc Insuact 10mg khởi đầu là 10mg/lần/ngày, tối đa là 80mg/lần/ngày. Liều dùng thuốc Insuact 10 tùy vào mục đích điều trị cụ thể như sau: Tăng cholesterol máu nguyên phát và rối loạn lipid máu phối hợp: 10mg/lần/ngày, sau 2 - 4 tuần sẽ thấy hiệu quả của thuốc. Thuốc cần được được sử dụng duy trì trong thời gian dài để có hiệu quả. Tăng cholesterol trong máu có tính gia đình đồng hợp tử: Liều thường dùng là thuốc Insuact 10mg /lần/ngày và tối đa là 80mg/lần/ngày. Rối loạn lipid máu nghiêm trọng ở trẻ từ 10 - 17 tuổi: 10mg/lần/ngày, sau đó tăng lên 20mg/lần/ngày tùy vào cơ địa, tiến triển bệnh và khả năng dung nạp thuốc của người bệnh. Thời gian điều chỉnh liều thuốc tối thiểu là 4 tuần. 3. Tác dụng phụ của thuốc Insuact 10mg Thuốc Insuact 10 có thể gây một số tác dụng phụ không mong muốn với tần suất như sau: Thường gặp: Viêm mũi - họng, phản ứng dị ứng, tăng đường huyết, nhức đầu, đau thanh quản, chảy máu cam , đau cơ, co thắt cơ, đau khớp, sưng khớp, đau các chi, đau lưng, xét nghiệm gan bất thường, tăng creatine kinase trong máu, buồn nôn, khó tiêu, đầy hơi, táo bón, tiêu chảy. Ít gặp: Insuact 10 ít gây hạ đường huyết, tăng cân, chán ăn, mất ngủ, gặp ác mộng, choáng váng, dị cảm, mất trí nhớ, giảm cảm giác, loạn vị giác , nôn, đau bụng, ợ hơi, viêm tụy, viêm gan, nổi mày đay , phát ban, ngứa, rụng tóc, đau cổ, mỏi cơ, mệt mỏi, suy nhược, đau ngực, phù ngoại biên, sốt, xuất hiện bạch cầu trong nước tiểu, nhìn mờ, ù tai. Hiếm gặp: Insuact 10 hiếm khi làm giảm tiểu cầu, bệnh lý thần kinh ngoại biên, hoa mắt, ứ mật, phù thần kinh, nổi hồng ban, hội chứng hoại tử da nhiễm độc , hội chứng Stevens-Johnson , bệnh cơ, viêm cơ, tiêu cơ vân, bệnh gân, đôi khi nghiêm trọng hơn có thể đứt gân. Rất hiếm gặp: Insuact 10 rất hiếm khi gây sốc phản vệ , mất thính giác , suy gan , hội chứng to vú ở nam giới. Không rõ tần suất: Hoại tử cơ tự miễn trung gian. 4. Một số lưu ý khi dùng thuốc Insuact 10mg Không dùng thuốc Insuact với người bị quá mẫn với thành phần của thuốc, người có bệnh gan hoạt động hoặc tăng transaminase huyết thanh vô căn kéo dài, phụ nữ đang mang thai hoặc nuôi con cho bú, phụ nữ đang có ý định mang thai. Thuốc Insuact 10mg chỉ được dùng ở bệnh nhân có nguy cơ xơ vữa mạch máu cao do tăng cholesterol trong máu và phải kết hợp với chế độ ăn kiêng ít chất béo bão hòa , ít cholesterol và người bệnh đang áp dụng các biện pháp điều trị không dùng thuốc khác. Trước khi điều trị với Insuact 10 , người bệnh cần được loại trừ các nguyên nhân thứ phát gây tăng cholesterol bao gồm suy tuyến giáp , tiểu đường khó kiểm soát, hội chứng thận hư, nghiện rượu, bệnh gan tắc nghẽn, rối loạn protein trong máu, .... Ngoài ra, người bệnh cũng cần được kiểm tra, đo lường nồng độ lipid máu. Trước khi điều trị với thuốc Insuact 10mg , cần kiểm tra chức năng gan và trong quá trình dùng thuốc, người bệnh cần theo dõi, kiểm tra chức năng gan thường xuyên. Người có tiền sử mắc bệnh gan do rượu, bị nghiện rượu cần thận trọng khi dùng Insuact 10 . Trước khi dùng thuốc, người bệnh cần được cảnh báo nguy cơ gặp phải các vấn đề về cơ như căng cơ , đau cơ, yếu cơ. Thuốc Insuact 10mg có thể tương tác với các thuốc: Tăng nguy cơ tổn thương cơ (đặc biệt cơ vân) khi dùng đồng thời với thuốc điều trị viêm gan C và HIV, hạ cholesterol máu nhóm fibrat khác, thuốc ức chế miễn dịch; tăng thời gian chảy máu hoặc thời gian prothrombin khi dùng phối hợp với thuốc chống đông, indandione; tăng nhẹ nồng độ digoxin trong huyết thanh khi dùng phối hợp với Digoxin'''
question = '''Insuact 10mg được chỉ định dùng trong những trường hợp nào và liều dùng cụ thể ra sao?'''
conversation = [{"role": "system", "content": system_prompt }]
conversation.append({"role": "user", "content": template.format(context = context, question = question)})
text = tokenizer.apply_chat_template(
conversation,
tokenize=False,
add_generation_prompt=True)
model_inputs = tokenizer(text,return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2048,
temperature = 0.1,
#top_p=0.95,
#top_k=40,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
'''Trả lời:
Dựa trên ngữ cảnh cung cấp, Insuact 10mg được chỉ định dùng trong các trường hợp sau:
1. **Điều trị hỗ trợ tăng cholesterol máu nguyên phát và rối loạn lipid máu hỗn hợp**:
- **Liều dùng**: 10mg/lần/ngày.
- **Hiệu quả**: Sau 2 - 4 tuần sử dụng, bệnh nhân sẽ thấy hiệu quả của thuốc.
- **Lưu ý**: Thuốc cần được sử dụng duy trì trong thời gian dài để có hiệu quả.
2. **Điều trị hỗ trợ tăng cholesterol trong máu có tính gia đình đồng hợp tử**:
- **Liều dùng**: 10mg/lần/ngày (liều thường dùng) và tối đa 80mg/lần/ngày.
- **Lưu ý**: Liều lượng có thể được điều chỉnh tùy theo cơ địa, tiến triển bệnh và khả năng dung nạp thuốc của người bệnh.
3. **Rối loạn lipid máu nghiêm trọng ở trẻ từ 10 - 17 tuổi**:
- **Liều dùng**: 10mg/lần/ngày, sau đó có thể tăng lên 20mg/lần/ngày tùy theo tình trạng bệnh.
- **Thời gian điều chỉnh liều**: Thời gian điều chỉnh liều tối thiểu là 4 tuần.
**Lưu ý chung**:
- Thuốc được dùng theo đường uống, uống khi bụng đói hoặc no đều được, có thể uống vào bất cứ lúc nào trong ngày.
- Không dùng thuốc Insuact 10mg với người bị quá mẫn với thành phần của thuốc, người có bệnh gan hoạt động hoặc tăng transaminase huyết thanh vô căn kéo dài, phụ nữ đang mang thai hoặc nuôi con cho bú, phụ nữ đang có ý định mang thai.
- Cần kiểm tra chức năng gan trước và trong quá trình điều trị.
'''
```
#### 2. Khả năng chống nhiều
```python
# ví dụ
context = '''- Ngữ cảnh 1: . Và dù nguyên nhân thế nào, thì việc đánh người khác đều không thể chấp nhận, không ai có quyền xâm phạm thân thể của người khác, nhất là đánh những đứa trẻ là bạn của con cái mình. Lựa chọn kể với cha mẹ, người lớn về các mâu thuẫn học đường, là quyết định rất đúng của các em. Nhưng người lớn, đặc biệt những ông bố, bà mẹ cần ứng xử ra sao trước xung đột này của các con, thưa bà? Đứng ngoài mâu thuẫn bằng sự khách quan và trách nhiệm nhất có thể. Điều này giúp chúng ta đủ bình tĩnh để làm việc với tất cả các bên liên quan, từ giáo viên, bạn của con, ban giám hiệu để tìm hiểu câu chuyện và tìm kiếm cách giải quyết tích cực, trên cơ sở phối hợp nhà trường. Người lớn không thể chỉ nghe một tai và đặc biệt không nên tự xử. Phụ huynh, kể cả học sinh tự xử các vấn đề học đường là điều rất nguy hiểm và cho thấy sự coi thường pháp luật . Vụ việc ở Tuyên Quang vừa rồi là ví dụ. Các em hoàn toàn có thể phản ứng bằng cách trình bày, gửi yêu cầu, kiến nghị lên nhà trường, nhờ phụ huynh làm việc với ban giám hiệu để có biện pháp giải quyết nếu cô giáo sai, không nên đồng loạt dồn cô giáo vào tường một cách bạo lực và trái đạo đức, tôn ti trật tự như vậy. Ngoài ra, chúng ta cũng có rất nhiều cơ quan chức năng bảo vệ phụ huynh và con em, với những quyền về khiếu nại, tố cáo. Chúng ta nói nhiều về trường học an toàn. Trong những câu chuyện học sinh bị hành hung thế này, có lẽ cũng cần làm rõ vai trò, trách nhiệm của nhà trường? TPHCM và nhiều địa phương đang xây dựng môi trường trường học hạnh phúc, tiêu chí là yêu thương, an toàn, tôn trọng. Không chỉ phòng ngừa, nhà trường còn phải tích cực vào cuộc xử lý các mâu thuẫn học đường, hạn chế tối đa nguy cơ mất an toàn cho học sinh, giáo viên. Đặc biệt, giải quyết câu chuyện bạo lực học đường phải triệt để, tuyệt đối không nửa vời vì nửa vời sẽ tiềm ẩn nguy cơ rất lớn dẫn đến những vụ việc tương tự, với mức độ nghiêm trọng hơn. Vụ việc em M. ở Nha Trang tự vẫn với lá thư tuyệt mệnh bị đổ oan đầu tháng 10 vừa qua là một ví dụ về giải quyết không triệt để. Việc xây dựng trường học hạnh phúc nếu triển khai “đến nơi đến chốn”, sẽ góp phần rất lớn cải thiện tình trạng bạo lực học đường, tạo môi trường sống và học tập bình an cho các con. Từ nhiều sự vụ học sinh bạo hành lẫn nhau, giáo viên bạo hành học sinh, phụ huynh hành hung giáo viên và bạn của con. Tam giác phối hợp bảo vệ học sinh là nhà trường - gia đình - xã hội phải chăng đang có một lỗ hổng lớn, thưa bà? Câu chuyện này có liên quan đến niềm tin của phụ huynh với nhà trường. Tại sao phụ huynh lại chọn cách tự xử? Chúng ta cũng cần phải xem lại cách giải quyết vấn đề của nhà trường đã rốt ráo chưa, coi trọng lợi ích của tất cả các bên liên quan chưa hay chỉ đang xoa dịu? Người ta chỉ tìm đến nhau khi có niềm tin vào nhau. Thực trạng phụ huynh chọn cách chuyển trường cho con cũng nói lên điều này. Đây là cách chạy trốn của phụ huynh với mong muốn con được an toàn, hạnh phúc hơn ở môi trường mới. Xây dựng niềm tin cho phụ huynh, xã hội cần được chú trọng và với mỗi một trường hợp phụ huynh yêu cầu chuyển trường cho con - đang rất phổ biến - nhà trường cần xét kỹ các nguyên nhân và hóa giải. Xin bà cho biết đâu là giải pháp căn cơ cho tất cả những câu chuyện bạo lực nói trên? Để trẻ không là nạn nhân của bạo lực học đường, phụ huynh cần đồng hành và giúp con có sự hiểu biết, ý thức trước vấn đề này. Dạy con kỹ năng giao tiếp, quản lý cảm xúc rất quan trọng và điều này không thể chỉ dựa vào những khóa học kỹ năng sống, mà là từ cách cư xử của người lớn, cha mẹ, thầy cô. Không có tấm gương nào tốt hơn cho con trẻ bằng ứng xử, hành vi của người lớn. Vì vậy, không thể đòi hỏi trẻ nói không với bạo lực học đường khi trong chính từng gia đình, xã hội, người lớn vẫn đối xử với nhau bằng bạo lực.
- Ngữ cảnh 2: Tại sao triều Thanh có rất nhiều thân vương nhưng chẳng có ai dám tạo phản? Không giống như những triều đại trước đó, triều Thanh dù có sự tranh giành ngai vàng khốc liệt giữa các hoàng tử nhưng lại chẳng bao giờ xảy ra thế cục các thân vương tạo phản. Chính vì 3 lý do lớn này đã khiến cho triều đại nhà Thanh khác hẳn triều đại nhà Đường và nhà Minh. Trong thời cổ đại, các vương công quý tộc để tranh giành vương vị của mình, giữa huynh đệ ruột thịt với nhau dường như đều xảy ra đấu đá, hãm hại lẫn nhau, coi nhau như kẻ thù không đội trời chung, có ta thì không có ngươi, có ngươi thì sẽ chẳng có ta, điều này hoàn toàn không phải là điều gì xa lạ. Vậy thì tại sao ngai vàng lại có sức hút lớn đến thế? Không chỉ là đàn ông khát khao quyền lực, mà quan trọng hơn là hoàng đế có thể có được hậu cung rộng lớn, trong hậu cung còn có vô số các mỹ nữ quốc sắc thiên hương. Nhiều phi tần như vậy, đương nhiên hoàng đế cũng sẽ có rất nhiều con cái, không tính đến con gái, chỉ riêng những vị hoàng tử, để có thể có được hoàng vị, họ tranh giành nhau bằng cả sinh mạng. Vậy thì ai là người được lựa chọn để thừa kế ngai vàng, ai mới có thể gánh được trọng trách trị vì đất nước? Đa phần đều theo tục lệ truyền cho con trai đích tôn (con trai do hoàng hậu sinh ra) hoặc con trai trưởng (con trai đầu tiên của hoàng đế). Cho dù tục lệ này có lịch sử lâu đời nhưng nó cũng có những khuyết điểm rất lớn, đó chính là nếu như năng lực và chí hướng của con trai đích tôn hoặc con trai trưởng không thể gánh vác được ngai vị, nếu để anh ta lên ngôi hoàng đế, vậy thì đất nước sẽ rơi vào cục diện suy vong. Còn có một khuyết điểm nữa đó chính là những người con trai có dã tâm lớn khác sẽ không phục việc con trai đích hoặc con trai trưởng kế thừa ngôi báu, họ sẽ khởi binh tạo phản cũng là chuyện rất dễ xảy ra. Ví dụ như trong thời Đường của Trung Quốc, Đường Cao Tổ Lý Uyên đem binh tiêu diệt nhà Tùy thối nát, đồng thời lập nên nhà Đường, vốn dĩ ông cũng dựa theo tục lệ lập con trai trưởng là Lý Kiến Thành làm Thái tử nhưng con trai thứ là Lý Thế Dân lại không phục với sự sắp xếp này. Vì năng lực của ông xuất chúng, văn võ song toàn, còn lập được không ít công lao to lớn trong cuộc chiến tranh tiêu diệt nhà Tùy cùng cha mình, đương nhiên không chịu thấp hơn kẻ khác một bậc. Thế nên đã phát động binh biến Huyền Vũ Môn, trong cuộc binh biến tạo phản này, đích thân ông đã giết chết huynh trưởng của mình, đồng thời ép cha mình là Lý Uyên phải truyền ngôi cho mình. Hay như trong thời nhà Minh của Trung Quốc, trước khi Chu Nguyên Chương chọn người lập làm Thái tử, con trai trưởng Chu Tiêu đã qua đời vì bệnh nặng, thế nên Chu Nguyên Chương đã lập cháu đích tôn của mình làm Thái tử kế thừa vương vị, nhưng em trai của Chu Tiêu là Chu Đệ lại không phục lựa chọn này của Chu Nguyên Chương. Theo lý mà nói thì sau khi anh trai Chu Tiêu qua đời, ông đã có tư cách thừa kế ngai vàng nhưng Chu Nguyên Chương nhất quyết không chọn ông mà lại chọn người cách thế hệ để truyền ngôi. Điều này khiến Chu Đệ với thế lực to lớn không thể nuốt nổi cục tức này, vì thế Chu Tiêu vừa qua đời thì ông đã vội vã khởi binh tạo phản, giết chết cháu trai ruột của mình rồi tự xưng vương. Vậy thì tại sao trong triều Thanh có rất nhiều thân vương như vậy mà lại chẳng có ai đứng ra tạo phản? Đầu tiên phải nói về bối cảnh xã hội trong thời kỳ này. Triều Thanh từ khi thành lập, cũng giống với những triều đại khác, đều có rất nhiều thân vương. Nếu người dân bình thường muốn làm hoàng đế, vậy thì đó là điều hoàn toàn không thể, nhưng đối với những vương công quý tộc trong hoàng thất mà nói, họ đương nhiên sẽ có rất nhiều cơ hội, đặc biệt là những thân vương nắm đại quyền quân sự , họ chính là mối đe dọa lớn nhất đối với nhà vua. Vì thế, các đời hoàng đế đều sẽ nghĩ đủ mọi cách để áp chế, kiểm soát họ, tránh việc họ khởi binh tạo phản. Triều Thanh có lịch sử hơn 300 năm, cũng đã cho ra đời vô số thân vương, đặc biệt là cuối thời Thanh, khi Trung Quốc rơi vào cảnh khốn khó, sau khi Từ Hy Thái Hậu cầm quyền thì thế cục này càng được thể hiện rõ rệt hơn. Nhưng cho dù là một người phụ nữ cầm quyền thì cũng chẳng có một vị thân vương hoàng tộc nào đứng ra tạo phản. Có 3 nguyên nhân sau: Thứ nhất, thân vương triều Thanh không thể nối ngôi, nếu muốn tiếp tục duy trì danh phận thân vương, vậy thì bắt buộc phải có được sự đồng ý của hoàng đế và phải lập được công lao cho đất nước. Thứ hai, triều đình tiến hành giám sát nghiêm ngặt đối với các thân vương, họ không hề có cơ hội để tạo phản. Thứ ba, các thân vương không thể giao thiệp quá sâu với các đại thần, quan lại khác, điều này cũng khiến các thân vương rơi vào cảnh bị cô lập, thế nên càng không có cơ hội để cấu kết với người khác hòng tạo phản. - Video: Ngắm sự kỳ vĩ và lộng lấy của Tử Cấm Thành từ trên cao. Nguồn: Sky Eye.
- Ngữ cảnh 3: . Cùng điều chỉnh với con là điều rất quan trọng bởi vì trẻ sẽ tự tin để tự đặt những giới hạn cho chính mình khi lớn lên”, TS Nguyễn Thị Thanh đưa ra lời khuyên. “Khi con mắc sai lầm, hãy giúp chúng tìm những cách khác tốt hơn. Đơn cử dùng hậu quả để dạy cho chúng bài học, điều đó tốt hơn rất nhiều việc xử phạt. Nếu cha mẹ chỉ biết trừng phạt, sẽ nhận được lời xin lỗi nhưng không thể giúp trẻ tỉnh ngộ. Bởi chúng chỉ biết được mình đã sai mà không biết sai ở chỗ nào và làm thế nào mới là đúng”
- Ngữ cảnh 4: . “MẤT ĐI CHA MẸ Ở TUỔI ĐẸP NHẤT CỦA NGƯỜI PHỤ NỮ CÀNG KHIẾN TÔI PHẢI MẠNH MẼ” - Làm con của nghệ sĩ Thanh Hiền, Đinh Y Nhung cảm nhận sợi dây liên kết giữa hai mẹ con thế nào? Má Thanh Hiền là người rất tuyệt vời. Hai má con hồi xưa từng làm phim truyền hình với nhau rồi, cho nên khi tái hợp thì không mấy bỡ ngỡ. Khi đối diễn, hai má con rất ăn ý, như người thân ruột thịt vậy đó. - Khi thể hiện những phân cảnh cảm động trong phim, có khi nào chị thấy nhớ mẹ không? Có chứ, nhất là ở những phân đoạn gia đình sum họp, tự nhiên mình bị buồn. Ai cũng muốn có cha, có mẹ, ai cũng muốn Tết được chạy về bên gia đình. Trong mười mấy, hai chục năm qua, Nhung bị chạnh lòng. Tuy nhiên, chỉ trong tích tắc, tôi tự trấn an rằng, mình đang quay phim, đang hóa thân vào nhân vật nên không thể xao lãng được. Mình là con người mà, cũng có lúc tâm trạng vui buồn bất chợt, nhưng Nhung luôn cố gắng lấy lại phong độ liền. - Mất ba mẹ từ sớm, không có chỗ dựa tinh thần, cô gái trẻ Đinh Y Nhung năm đó có nhận những lời mời gọi khiếm nhã không? Trước đây, Nhung không có bạn bè nhiều, chủ yếu chỉ lo đi học, đi làm để lo cho cuộc sống thôi. Nên Nhung không phải đón nhận những lời mời gọi nào hết. - Mất mát từ quá khứ có ảnh hưởng gì đến suy nghĩ về tương lai của chị sau này, ví dụ khi có con thì sẽ bù đắp, chăm sóc cho con nhiều hơn? Năm ba mẹ mất thì mình vẫn còn khá trẻ, thật ra cái tuổi đó là tuổi đẹp của người phụ nữ. Sau đó, tôi đi làm, rồi yêu đương và lập gia đình. Có rất nhiều thứ hối tiếc để nói về Nhung của thời điểm đó. Thứ nhất là mình chưa thành công, thứ hai là mình chưa trả hiếu cho cha mẹ, thứ ba là mình còn bấp bênh. Nhung lúc đó lì lợm lắm, không cho phép mình ngã, bằng mọi giá phải tiến về trước dù có hàng ngàn chông gai ngăn cản. Có lúc tôi bị người này cười, người kia mỉa, nhưng mà mình vẫn cố bước đi. Người ta có cười thì cũng không mang lại cho mình được gì, tôi chỉ biết làm hết khả năng để lo cho bản thân, lo cho em của mình. Hiện, con cái Nhung đã đi nước ngoài rồi. Bé đang học đại học về âm nhạc, còn em mình cũng đã lớn rồi. Đối với Nhung ngay lúc này thì không phải thành công hay hoàn hảo lắm, nhưng ít nhất là tôi đã cố gắng để tự chịu trách nhiệm với cuộc đời mình. Mất cha, mất mẹ, đối với một người hai mươi mấy tuổi thì điều cần nhất lúc đó là có được gia đình ở bên. Nhưng mình không có chỗ dựa tinh thần thì càng phải mạnh mẽ hơn nữa. Tôi tự gặm nhấm nỗi đau mất người thân trong một thời gian dài, có khi đến cả bạn bè cũng không hề biết. Một thời gian sau, bạn bè thời và mọi người mới biết. Còn người hâm mộ, đồng nghiệp trong nghề gần như không biết chuyện ba mẹ Nhung mất sớm, chỉ có vài người chơi thân với nhau biết thôi. Sau này, dần dần tâm lý dần ổn định thì mình mới bắt đầu chia sẻ. “CON ĐI DU HỌC, TÔI DẶN BÉ CÁI GÌ KHÔNG TỐT THÌ MÌNH BỎ QUA” - Đinh Y Nhung từng tiết lộ mình rất thân với con gái. Có vẻ như quyết định để con đi du học là không hề dễ dàng? Thật sự là không có ba mẹ nào muốn con mình đi xa, nhưng việc du học lại là quyết định của bé. Con Nhung bày tỏ muốn học đại học ở nước ngoài và muốn đi sớm để thực hiện ước mơ. Nhưng lúc đó con còn nhỏ quá, phải đợi đến năm con 17 tuổi thì Nhung mới quyết định cho bạn nhỏ đi. Con cái từ nhỏ ở với bố mẹ giờ lại đi xa thì tất nhiên người làm cha làm mẹ cùng phải thấy sốc, thấy buồn. Nhưng Nhung hoàn toàn tôn trọng quyết định của con về việc chọn ngành nghề và tương lai của mình. Ba mẹ sẽ đứng sau và là người đưa cho con những lời khuyên và chỉ có thể đồng hành cùng con tới một mốc thời gian nào đó. Về sau, con phải đi làm và tự có trách nhiệm với cuộc đời của mình. - Có con gái đang ở tuổi lớn lại xa bố mẹ và tiếp xúc một nền văn hóa phương Tây cởi mở, Đinh Y Nhung đã khuyên dạy và đồng hành với con như thế nào? Ngay khi ở Việt Nam, con gái Nhung đã được theo học trường quốc tế. Hai mẹ con cũng có rất nhiều dịp để tâm sự và chia sẻ với nhau. Ngay từ nhỏ, Nhung đã cho bé được tiếp xúc song song giữa hai nền văn hóa để con không bỡ ngỡ. Mình là người Việt nên đương nhiên vẫn dạy con theo văn hóa Á Đông là chủ yếu. Nhung vẫn luôn tạo điều kiện để con cảm nhận những nét đẹp trong nền văn hóa quê hương. Văn hóa phương Tây thì xa lạ hơn nhưng Nhung cũng khuyên con rằng điều gì hay thì mình học hỏi, cái gì không tốt thì mình nên bỏ qua. Tất nhiên mình không thể theo sát con, nhất là khi bé đang ở độ tuổi mới lớn, có nhiều sự hiếu kỳ. Tuy nhiên, Nhung cũng không quá lo lắng vì qua quá trình học tập ở các trường quốc tế, bé cùng đã được làm quen dần với văn hóa phương Tây. Bé muốn làm bạn với mẹ nên có nhiều thứ bé muốn hỏi, muốn tiếp thu thì hai mẹ con lại ngồi xuống chia sẻ, tâm sự với nhau. Nhung tin, con luôn tỉnh táo để đưa ra những quyết định cho bản thân mình. Nhung không dám nói trước, nhưng hiện tại con vẫn luôn biết nói cảm ơn, xin phép trước khi làm bất cứ điều gì nên mình vẫn rất tin tưởng con. - Chị nhận xét thế nào về tính cách của con gái? Phải chăng bé là phiên bản nhí của chị? Con gái Nhung có nhiều nét giống mẹ.
- Ngữ cảnh 5: . - Trong quá trình quay phim, má Hiền có tham gia đóng góp ý kiến cho dàn diễn viên trẻ không? Không phải má Hiền muốn làm thầy nhưng có những lúc cũng lên tiếng góp ý một vài điều. Những lúc như thế các bạn diễn viên trẻ cũng nghe theo. Phải giúp đỡ nhau như vậy mới có thể tạo ra được một tác phẩm hay. Chứ có nhiều diễn viên trẻ có lòng tự trọng cao, chỉ khi đạo diễn nói mới nghe thì không bao giờ có thể tiến bộ được. Má Hiền phải cảm thấy hạnh phúc mới đúng, càng ngày xung quanh càng có nhiều bạn bè, các mối quan hệ nhờ đó mà cũng ngày càng đông. Ngày xưa, khi tham gia là Mùi Ngò Gai chưa có ai biết nhưng sau khi phim phát sóng mọi người đã nhớ đến má. Hiện tại, má Hiền đã được đạo diễn, nhà sản xuất mời đóng phim đó đã là một niềm hạnh phúc. Đi ra đường hay đi khám bệnh, người ta cứ vây xung quanh quan tâm hỏi han khiến má cảm thấy rất vui lắm (cười). Cảm ơn nghệ sĩ Thanh Hiền đã nhận lời tham gia phỏng vấn với SAOstar. Chúc má có nhiều sức khỏe để tiếp tục làm nghề!'''
question = '''Tại sao các thân vương triều Thanh không dám tạo phản mặc dù có nhiều quyền lực và cơ hội?'''
'''Trả lời:
Các thân vương triều Thanh không dám tạo phản mặc dù có nhiều quyền lực và cơ hội vì có ba lý do chính:
1. **Không thể nối ngôi**: Để duy trì danh phận thân vương, họ phải có sự đồng ý của hoàng đế và phải lập được công lao cho đất nước. Điều này hạn chế cơ hội của họ để trở thành hoàng đế.
2. **Giám sát nghiêm ngặt**: Triều đình tiến hành giám sát nghiêm ngặt đối với các thân vương, không cho họ cơ hội để tạo phản.
3. **Bị cô lập**: Các thân vương không thể giao thiệp quá sâu với các đại thần, quan lại khác, điều này khiến họ bị cô lập và không có cơ hội cấu kết với người khác để tạo phản.'''
```
#### 3. Loại bỏ negative
```python
context = '''- Ngữ cảnh 1: Thái Bình hướng đến là trung tâm công nghiệp, năng lượng của vùng Với tiềm năng sẵn có, quy hoạch tỉnh Thái Bình thời kỳ 2021-2030, tầm nhìn đến năm 2050 xác định tỉnh sẽ phát triển công nghiệp theo hướng hiện đại, bền vững dựa trên nghiên cứu phát triển điện gió, điện khí, cân bằng lượng phát thải. Sáng 5/3, UBND tỉnh Thái Bình tổ chức Hội nghị công bố quy hoạch của tỉnh thời kỳ 2021-2030, tầm nhìn đến năm 2050 và xúc tiến đầu tư tỉnh Thái Bình. Phát biểu tại hội nghị, Phó Chủ tịch Thường trực UBND tỉnh Nguyễn Quang Hưng cho biết: Mục tiêu của quy hoạch là đến năm 2030, Thái Bình trở thành địa phương thuộc nhóm phát triển khá và là một trong những trung tâm phát triển công nghiệp của vùng Đồng bằng sông Hồng, có cơ cấu kinh tế hiện đại với công nghiệp là động lực chủ yếu cho tăng trưởng để Thái Bình phát triển nhanh, toàn diện và bền vững. Đến năm 2050, Thái Bình là tỉnh phát triển của vùng Đồng bằng sông Hồng, tăng trưởng kinh tế dựa trên nền tảng khoa học công nghệ, đổi mới sáng tạo và các ngành kinh tế trụ cột có sức cạnh tranh cao. Quy hoạch tỉnh đã xác định 4 trụ cột tăng trưởng, 3 khâu đột phá, 4 không gian kinh tế - xã hội, 3 hành lang kinh tế, định hướng phát triển các ngành và lĩnh vực và 6 nhiệm vụ trọng tâm. Quy hoạch tỉnh cũng có nhiều điểm mới, đột phá như mở ra không gian phát triển mới thông qua hoạt động “lấn biển”, tạo quỹ đất cho các hoạt động chức năng, hình thành không gian công nghiệp - đô thị - dịch vụ. Về hạ tầng giao thông, Thái Bình sẽ đầu tư 3 tuyến cao tốc là cao tốc Ninh Bình - Hải Phòng (CT.08), đường vành đai 5 - Hà Nội (CT.39) và tuyến CT.16 kết nối Khu kinh tế với thành phố Thái Bình và vùng kinh tế phía Tây Bắc Thủ đô. Tỉnh cũng sẽ đầu tư 101km đường sắt, khổ đường dự kiến rộng 1.435 mm và sân bay chuyên dụng nằm ở ven biển Thái Bình. Về phát triển kinh tế, quy hoạch tỉnh Thái Bình xác định tỉnh sẽ phát triển công nghiệp theo hướng hiện đại, công nghệ tiên tiến, giá trị gia tăng cao, tham gia sâu, toàn diện vào mạng lưới sản xuất, chuỗi giá trị toàn cầu, phát huy các tiềm năng, thế mạnh để đưa Thái Bình trở thành một trong những trung tâm phát triển công nghiệp, năng lượng của vùng Đồng bằng sông Hồng. Tỉnh khuyến khích đầu tư phát triển các ngành có thế mạnh và có thể tạo đột phá như năng lượng, cơ khí chế biến, chế tạo, công nghiệp công nghệ cao, điện - điện tử, chế biến sản phẩm nông, lâm nghiệp và thủy sản… Đồng thời, tập trung nghiên cứu phát triển điện gió, điện khí để tạo nguồn điện sạch và cân bằng lượng phát thải, nghiên cứu đầu tư xây dựng nhà máy chế biến Condensate, chuẩn bị mọi điều kiện để xây dựng và đưa vào vận hành Nhà máy nhiệt điện LNG Thái Bình. Về nông nghiệp, tỉnh Thái Bình vẫn xác định đây là \"trụ cột quan trọng\" trong phát triển kinh tế của tỉnh, góp phần bảo đảm an ninh lương thực quốc gia, hướng tới trở thành trung tâm sản xuất nông nghiệp hàng đầu của Đồng bằng sông Hồng. Phát biểu tại hội nghị, Phó Thủ tướng Chính phủ Trần Lưu Quang đánh giá Thái Bình có 4 tiềm năng, lợi thế lớn để có thể có sự bứt phá trong thời gian tới như vị trí địa lý và tiếp cận đất đai thuận lợi; từng là địa phương đi đầu trong xây dựng nông thôn mới bài bản và nghiêm túc, nhận được sự quan tâm của nhiều thế hệ lãnh đạo Đảng, Nhà nước và có nhiều doanh nhân người Thái Bình và luôn hướng về quê hương; có sự đoàn kết, thống nhất, trước hết là trong tập thể lãnh đạo. Về vị trí địa lý và tiếp cận đất đai, Phó Thủ tướng cho rằng trong tương lai, khi Luật Đất đai có hiệu lực, Thái Bình sẽ có nhiều điều kiện lấn biển để triển khai các dự án khu đô thị, khu công nghiệp thân thiện với môi trường. Đối với nông nghiệp, Phó Thủ tướng nhấn mạnh về lâu dài Thái Bình có thể ghi điểm từ phát triển công nghiệp nhưng trước mắt, đặc biệt trong lúc khó khăn thì nông nghiệp vẫn là nền tảng rất quý giá. Mặt khác, ứng dụng của công nghệ cao trong sản xuất nông nghiệp sẽ rút ngắn thời gian làm đồng của người nông dân, tạo điều kiện để Thái Bình huy động nguồn nhân lực trong nông nghiệp sang phát triển các ngành công nghiệp và dịch vụ, một lợi thế mà không phải địa phương nào cũng có được như Thái Bình. Bên cạnh những lợi thế trên, lãnh đạo Chính phủ chỉ ra một số khó khăn mà tỉnh phải đối mặt như Thái Bình đã sử dụng hết 1.600 ha chỉ tiêu đất công nghiệp trong giai đoạn này, đòi hỏi phải có phương án giải quyết thấu đáo trong thời gian tới để tỉnh tiếp tục phát triển công nghiệp. Đồng thời, Thái Bình cũng phải cạnh tranh với những địa phương như Hải Phòng, Quảng Ninh trong thu hút FDI trong khi phát triển cơ sở hạ tầng chưa theo kịp mong muốn. Do vậy, khi triển khai quy hoạch tỉnh, Phó Thủ tướng nhắn nhủ tới địa phương 8 chữ: Tuân thủ, linh hoạt, đồng bộ và thấu hiểu. Đồng thời, tỉnh cũng phải \"linh hoạt\" trong tổ chức thực hiện, trong trường hợp cá biệt cụ thể, điều chỉnh mục tiêu cho phù hợp. Sáng cùng ngày, Phó Thủ tướng Trần Lưu Quang đã dự Lễ khởi công dự án Nhà máy Pegavision Việt Nam tại khu công nghiệp Liên Hà Thái, huyện Thái Thụy, tỉnh Thái Bình
- Ngữ cảnh 2: Bình Định được định hướng là trung tâm khoa học, công nghệ đổi mới sáng tạo Tỉnh Bình Định được định hướng phát triển ngành công nghiệp phát triển theo hướng hiện đại, quy mô lớn, trở thành một trong những trung tâm công nghiệp chế biến chế tạo và công nghệ cao của vùng Bắc Trung Bộ và duyên hải Trung Bộ. Theo Quy hoạch tỉnh Bình Định thời kỳ 2021 - 2030, tầm nhìn đến năm 2050 vừa được Thủ tướng Chính phủ phê duyệt, tỉnh Bình Định được định hướng phát triển ngành công nghiệp phát triển theo hướng hiện đại, quy mô lớn, trở thành một trong những trung tâm công nghiệp chế biến chế tạo và công nghệ cao của vùng Bắc Trung Bộ và duyên hải Trung Bộ. Ngành công nghiệp tăng trưởng nhanh, bền vững, hướng tới tăng trưởng xanh, kinh tế tuần hoàn là trụ cột để phát triển và chuyển dịch cơ cấu kinh tế của tỉnh. Ngành chế biến, chế tạo công nghệ cao (dịch chuyển ngành công nghiệp chế biến, chế tạo sang lĩnh vực sản xuất có giá trị gia tăng cao như: chế biến sâu nông - thủy - hải sản, linh kiện điện tử, bán dẫn, dược phẩm), công nghệ thông tin, trí tuệ nhân tạo trở thành một trong những lĩnh vực đột phá, góp phần đưa tỉnh Bình Định trở thành một trung tâm khoa học, công nghệ đổi mới sáng tạo của vùng và cả nước. Quy hoạch tỉnh Bình Định thời kỳ 2021 - 2030, tầm nhìn đến năm 2050 đặt ra yêu cầu tỉnh này phải chú trọng thu hút đầu tư phát triển năng lượng tái tạo, năng lượng sạch như điện gió ven bờ, điện gió ngoài khơi, điện mặt trời, điện sinh khối và nguồn năng lượng mới (hydrogen/amoniac xanh…); các dự án sản xuất thép quy mô lớn, đóng tàu, sản xuất thiết bị phụ trợ điện gió có công nghệ tiên tiến để nâng cấp xây dựng hạ tầng kỹ thuật sản xuất, thúc đẩy chuyển dịch kinh tế. Quy hoạch tỉnh Bình Định thời kỳ 2021 - 2030, tầm nhìn đến năm 2050 cũng đặt ra mục tiêu đến năm 2030, Bình Định trở thành tỉnh phát triển thuộc nhóm dẫn đầu vùng Bắc Trung Bộ và duyên hải Trung Bộ, là trung tâm công nghiệp chế biến, chế tạo, dịch vụ, du lịch và văn hóa phía Nam của vùng; trung tâm lớn của cả nước về phát triển kinh tế biển; trọng điểm du lịch quốc gia và quốc tế với hệ thống kết cấu hạ tầng kinh tế đồng bộ, hiện đại; kinh tế của tỉnh phát triển nhanh, bền vững và xanh dựa trên các trụ cột tăng trưởng công nghiệp, dịch vụ du lịch, cảng biển - logistics; nông nghiệp ứng dụng công nghệ cao; đô thị hóa; thực hiện thành công các mục tiêu chuyển đổi số, đổi mới sáng tạo, cải thiện mạnh mẽ môi trường đầu tư kinh doanh, trở thành điểm đến đầu tư hấp dẫn của các doanh nghiệp lớn trong và ngoài nước; chỉ số năng lực cạnh tranh cấp tỉnh thuộc nhóm cao của cả nước; kết cấu hạ tầng kinh tế - xã hội đồng bộ, hiện đại, hệ thống đô thị phát triển theo hướng đô thị thông minh, kết nối thuận tiện với các trung tâm kinh tế của vùng, cả nước và quốc tế.
- Ngữ cảnh 3: . Chủ tịch UBND tỉnh Quảng Ninh cho biết, tỉnh đặt mục tiêu hướng đến năm 2030 trở thành một tỉnh tiêu biểu của cả nước về mọi mặt; tỉnh kiểu mẫu giàu đẹp, văn minh, hiện đại, nâng cao đời sống mọi mặt của nhân dân; cực tăng trưởng của khu vực phía Bắc, một trong những trung tâm phát triển năng động, toàn diện; trung tâm du lịch quốc tế, trung tâm kinh tế biển, cửa ngõ của Vùng kinh tế trọng điểm Bắc Bộ và cả nước. Để đạt được những mục tiêu trên, tỉnh Quảng Ninh xác định sự đóng góp, quan tâm của cộng đồng doanh nghiệp, nhất là các doanh nghiệp hàng đầu Việt Nam “các sếu đầu đàn” là một trong những yếu tố then chốt quyết định. Do vậy, tỉnh Quảng Ninh rất mong nhận được sự quan tâm, nghiên cứu đầu tư hợp tác của các Doanh nghiệp hàng đầu Việt Nam trong thời gian tới, nhất là trong việc đầu tư các dự án có hàm lượng công nghệ cao, công nghệ tiên tiến, quản trị hiện đại, giá trị gia tăng cao, có tác động lan tỏa. Tỉnh Quảng Ninh cam kết tạo điều kiện thuận lợi nhất cho doanh nghiệp phát triển hơn nữa khi đầu tư kinh doanh trên địa bàn tỉnh; cam kết đồng hành, lắng nghe tiếng nói của cộng đồng doanh nghiệp, các nhà đầu tư; cùng trăn trở, trách nhiệm, giải quyết thấu đáo, vào cuộc thực chất, hiệu quả đối với từng khó khăn, vướng mắc với mục tiêu tăng cường niềm tin và nâng cao sự hài lòng của cá nhân, tổ chức, doanh nghiệp là thước đo đánh giá chất lượng phục vụ, chất lượng điều hành của cơ quan hành chính nhà nước từ cấp tỉnh đến các cấp cơ sở. Tỉnh Quảng Ninh sẽ triển khai một cách hiệu quả nhất Quy hoạch tỉnh, quy hoạch các địa phương; chuẩn bị mặt bằng sạch; quỹ đất tái định cư; đảm bảo nguồn cung điện, nước và viễn thông theo yêu cầu; xây dựng các chính sách đột phá để thu hút nguồn nhân lực chất lượng cao thông qua việc cải thiện nhà ở và cơ sở văn hóa để đảm bảo đời sống vật chất và tinh thần cho người lao động. Đồng thời bảo vệ quyền và lợi ích chính đáng, hợp pháp của nhà đầu tư, doanh nghiệp vào tỉnh; bảo đảm hài hòa lợi ích giữa nhà nước, nhà đầu tư, người lao động và người dân.'''
question = '''Theo quy hoạch tỉnh Tây Ninh thời kỳ 2021 - 2030, tầm nhìn đến năm 2050, tỉnh sẽ tập trung phát triển công nghiệp và dịch vụ du lịch. Trong bối cảnh cạnh tranh với các tỉnh lân cận, yếu tố nào được coi là quan trọng nhất để Tây Ninh có thể thu hút đầu tư và phát triển nhanh, toàn diện và bền vững?'''
'''Trả lời:
Trong ngữ cảnh được cung cấp, không có thông tin về quy hoạch tỉnh Tây Ninh thời kỳ 2021 - 2030, tầm nhìn đến năm 2050. Do đó, không có câu trả lời chính xác dựa trên các thông tin đã cung cấp. Nếu bạn có thêm thông tin về quy hoạch tỉnh Tây Ninh, vui lòng cung cấp để tôi có thể trả lời câu hỏi một cách chính xác và đầy đủ.
'''
```
#### 4. Tích hợp thông tin
```python
context = '''- Ngữ cảnh 1: 43/2020/nđ-cp Điều 3. Chế độ, chính sách đối với người tham gia thi hành án tử hình\n1. Người tham gia Đội thi hành án tử hình được hưởng chế độ bồi dưỡng bằng ba lần mức lương cơ sở khi thi hành án tử hình đối với 01 người và nghỉ dưỡng 10 ngày theo quy định chung về chế độ nghỉ dưỡng đối với cán bộ, chiến sĩ Công an nhân dân, Quân đội nhân dân.\n2. Người tham gia Hội đồng thi hành án tử hình, cán bộ quản giáo, người ghi âm, ghi hình, chụp ảnh, phiên dịch, thực hiện lăn tay người bị thi hành án tử hình, khâm liệm, mai táng tử thi được hưởng chế độ bồi dưỡng bằng một lần mức lương cơ sở khi thi hành án tử hình đối với 01 người.\n3. Người tham gia bảo đảm an ninh, trật tự; đại diện Ủy ban nhân dân cấp xã; Điều tra viên được hưởng chế độ bồi dưỡng bằng một phần hai mức lương cơ sở khi thi hành án tử hình đối với 01 người.
- Ngữ cảnh 2: 53/2010/qh12 Điều 60. Giải quyết việc xin nhận tử thi, hài cốt của người bị thi hành án tử hình\n1. Việc giải quyết nhận tử thi được thực hiện như sau:\na) Trước khi thi hành án tử hình, thân nhân hoặc người đại diện hợp pháp của người chấp hành án được làm đơn có xác nhận của Ủy ban nhân dân cấp xã nơi cư trú gửi Chánh án Tòa án đã xét xử sơ thẩm đề nghị giải quyết cho nhận tử thi của người chấp hành án để an táng; trường hợp người chấp hành án là người nước ngoài thì đơn phải có xác nhận của cơ quan có thẩm quyền hoặc cơ quan đại diện ngoại giao tại Việt Nam của nước mà người chấp hành án mang quốc tịch và phải được dịch ra tiếng Việt. Đơn phải ghi rõ họ tên, địa chỉ người nhận tử thi, quan hệ với người chấp hành án; cam kết bảo đảm yêu cầu về an ninh, trật tự, vệ sinh môi trường và tự chịu chi phí;\nb) Chánh án Tòa án đã xét xử sơ thẩm thông báo bằng văn bản cho người có đơn đề nghị về việc cho nhận tử thi hoặc không cho nhận tử thi khi có căn cứ cho rằng việc nhận tử thi ảnh hưởng đến an ninh, trật tự, vệ sinh môi trường. Trường hợp người chấp hành án là người nước ngoài, thì Chánh án Tòa án đã xét xử sơ thẩm có trách nhiệm thông báo bằng văn bản cho Bộ Ngoại giao Việt Nam để thông báo cho cơ quan có thẩm quyền hoặc cơ quan đại diện ngoại giao tại Việt Nam của nước mà người đó mang quốc tịch;\nc) Cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu có trách nhiệm thông báo cho người có đơn đề nghị ngay sau khi thi hành án để đến nhận tử thi về an táng. Việc giao nhận tử thi phải được thực hiện trong thời hạn 24 giờ kể từ khi thông báo và phải lập biên bản, có chữ ký của các bên giao, nhận; hết thời hạn này mà người có đơn đề nghị không đến nhận tử thi thì cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu có trách nhiệm an táng.\n2. Trường hợp không được nhận tử thi hoặc thân nhân của người bị thi hành án không có đơn đề nghị được nhận tử thi về an táng thì cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu tổ chức việc an táng. Sau 03 năm kể từ ngày thi hành án, thân nhân hoặc đại diện hợp pháp của người đã bị thi hành án được làm đơn có xác nhận của Ủy ban nhân dân cấp xã nơi cư trú đề nghị Cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu nơi đã thi hành án cho nhận hài cốt. Đơn đề nghị phải ghi rõ họ tên, địa chỉ người nhận hài cốt, quan hệ với người bị thi hành án; cam kết bảo đảm yêu cầu về an ninh, trật tự, vệ sinh môi trường và tự chịu chi phí. Trong thời hạn 07 ngày, kể từ ngày nhận được đơn, cơ quan thi hành án hình sự Công an cấp tỉnh, cơ quan thi hành án hình sự cấp quân khu có trách nhiệm xem xét, giải quyết.\nTrường hợp người bị thi hành án là người nước ngoài thì đơn đề nghị phải có xác nhận của cơ quan có thẩm quyền hoặc cơ quan đại diện ngoại giao tại Việt Nam của nước mà người bị thi hành án mang quốc tịch và phải được dịch ra tiếng Việt. Việc giải quyết cho nhận hài cốt do cơ quan quản lý thi hành án hình sự xem xét, quyết định.
- Ngữ cảnh 3: 53/2010/qh12 Điều 57. Chế độ quản lý giam giữ, ăn, ở, mặc, sinh hoạt, gửi và nhận thư, nhận đồ vật, tiền mặt, gặp thân nhân, chăm sóc y tế\nChế độ quản lý giam giữ, ăn, ở, mặc, sinh hoạt, gửi và nhận thư, nhận đồ vật, tiền mặt, gặp thân nhân, chăm sóc y tế đối với người bị kết án tử hình trong thời gian chờ thi hành án thực hiện theo quy định của pháp luật về tạm giam.
- Ngữ cảnh 4: 82/2011/nđ-cp Điều 9. Chi phí mai táng\nChi phí mai táng người bị thi hành án tử hình bao gồm: 01 quan tài bằng gỗ thường, 01 bộ quần áo thường, 04 m vải liệm, hương, nến, rượu, cồn để làm vệ sinh khi liệm tử thi và các chi phí mai táng khác.\nTrường hợp thân nhân hoặc người đại diện hợp pháp của người bị kết án tử hình được nhận tử thi về mai táng thì phải tự chịu chi phí đưa di chuyển tử thi và phải cam kết chấp hành đúng quy định của pháp luật về bảo đảm an ninh, trật tự.
- Ngữ cảnh 5: 82/2011/nđ-cp Điều 5. Chế độ, chính sách đối với người tham gia thi hành án tử hình\n1. Người tham gia Đội thi hành án tử hình và bác sĩ xác định tĩnh mạch được hưởng chế độ bồi dưỡng bằng hai lần mức lương tối thiểu chung cho mỗi lần thi hành án và được nghỉ dưỡng 10 ngày theo quy định chung về chế độ nghỉ dưỡng đối với cán bộ, chiến sĩ Công an nhân dân, Quân đội nhân dân.\n2. Người tham gia Hội đồng thi hành án tử hình, bác sĩ pháp y, cán bộ chuyên môn, người thực hiện lăn tay người bị thi hành án tử hình, khâm liệm, an táng tử thi được hưởng chế độ bồi dưỡng bằng một lần mức lương tối thiểu chung quy định cho mỗi lần thi hành án.\n3. Những người tham gia khác được hưởng chế độ bồi dưỡng bằng một phần hai mức lương tối thiểu cho mỗi lần thi hành án.'''
question = '''Tử tù chết sau khi tiêm thuốc độc mà không có thân nhân nhận xác thì được hỗ trợ mai táng như thế nào?'''
'''Trả lời:
Dựa trên ngữ cảnh 2 (53/2010/qh12 Điều 60), nếu tử tù chết sau khi tiêm thuốc độc mà không có thân nhân nhận xác, thì cơ quan thi hành án hình sự Công an cấp tỉnh hoặc cơ quan thi hành án hình sự cấp quân khu sẽ tổ chức việc an táng. Cụ thể:
1. **An táng**: Cơ quan thi hành án hình sự Công an cấp tỉnh hoặc cơ quan thi hành án hình sự cấp quân khu sẽ chịu trách nhiệm an táng tử tù nếu không có thân nhân hoặc người đại diện hợp pháp đề nghị nhận tử thi.
2. **Hài cốt sau 3 năm**: Sau 3 năm kể từ ngày thi hành án, nếu thân nhân hoặc đại diện hợp pháp của người đã bị thi hành án vẫn chưa đề nghị nhận hài cốt, họ có thể làm đơn đề nghị Cơ quan thi hành án hình sự Công an cấp tỉnh hoặc cơ quan thi hành án hình sự cấp quân khu nơi đã thi hành án cho nhận hài cốt. Đơn đề nghị phải ghi rõ họ tên, địa chỉ người nhận hài cốt, quan hệ với người bị thi hành án, cam kết bảo đảm yêu cầu về an ninh, trật tự, vệ sinh môi trường và tự chịu chi phí.
3. **Chi phí mai táng**: Theo ngữ cảnh 4 (82/2011/nđ-cp Điều 9), chi phí mai táng bao gồm:
- 01 quan tài bằng gỗ thường.
- 01 bộ quần áo thường.
- 04 m vải liệm.
- Hương, nến, rượu, cồn để làm vệ sinh khi liệm tử thi.
- Các chi phí mai táng khác.
Nếu thân nhân hoặc người đại diện hợp pháp đề nghị nhận tử thi về mai táng, họ phải tự chịu chi phí đưa di chuyển tử thi và cam kết chấp hành đúng quy định của pháp luật về bảo đảm an ninh, trật tự.
'''
```
- Ngữ cảnh 2 và ngữ cảnh 4 có chứa phần thông tin cho việc trả lời câu hỏi.
### 5.Xác định positive/negative
```python
system_prompt = "Bạn là một trợ lí Tiếng Việt nhiệt tình và trung thực. Hãy luôn trả lời một cách hữu ích nhất có thể."
template = '''Hãy xác định xem ngữ cảnh có chứa đầy đủ thông tin để trả lời câu hỏi hay không.
Chỉ cần đưa ra 1 trong 2 đáp án trong phần trả lời là "Có" hoặc "Không".
### Ngữ cảnh :
{context}
### Câu hỏi :
{question}
### Trả lời :'''
context = '''Công dụng thuốc Xelocapec Capecitabine là một hoạt chất gây độc chọn lọc với tế bào ung thư. Hoạt chất này có trong thuốc Xelocapec. Vậy thuốc Xelocapec có tác dụng gì và cần lưu ý những vấn đề nào khi điều trị bằng sản phẩm này? 1. Xelocapec là thuốc gì? Xelocapec chứa hoạt chất Capecitabine hàm lượng 500mg. Thuốc Xelocapec bào chế dạng viên nén bao phim và đóng gói mỗi hộp 3 vỉ x 10 viên. Xelocapec chứa hoạt chất Capecitabine là một dẫn chất Fluoropyrimidine carbamate với tác dụng gây độc chọn lọc với các tế bào ung thư . Mặc dù trên in vitro Capecitabine không cho thấy tác dụng độc tế bào nhưng trên in vivo, Xelocapec biến đổi liên tiếp thành chất gây độc tế bào là 5-fluorouracil (5-FU). Sự hình thành 5-FU tại khối u thông qua xúc tác một cách tối ưu của yếu tố tạo mạch liên quan là Thymidine phosphorylase, qua đó hạn chế tối đa mức độ ảnh hưởng đến nhu mô lành của 5-FU. 2. Thuốc Xelocapec có tác dụng gì? Thuốc Xelocapec được chỉ định điều trị đơn lẻ hoặc kết hợp với các liệu pháp điều trị ung thư. Xelocapec làm chậm hoặc ngăn chặn sự tăng trưởng của tế bào ung thư, do đó giảm kích thước khối u trong những trường hợp sau: Ung thư vú : Xelocapec phối hợp với Docetaxel được chỉ định điều trị ung thư vú thể tiến triển tại chỗ hoặc di căn sau khi đã thất bại với liệu pháp hóa trị; Ung thư đại trực tràng : Xelocapec được chỉ định hỗ trợ điều trị ung thư đại tràng sau phẫu thuật hoặc ung thư đại trực tràng di căn; Ung thư dạ dày : Xelocapec phối hợp với hợp chất platin được chỉ định điều trị khởi đầu cho những bệnh nhân ung thư dạ dày. Chống chỉ định của thuốc Xelocapec : Bệnh nhân quá mẫn cảm với Capecitabine hay các thành phần khác có trong Xelocapec ; Người có tiền sử gặp các phản ứng không mong muốn nghiêm trọng khi điều trị với Fluoropyrimidine; Người đang mang thai hoặc cho con bú; Suy thận nặng (độ thanh thải Creatinin <30mL/phút); Bệnh nhân đang điều trị ung thư với Sorivudin hoặc chất tương tự về mặt hóa học như Brivudin; Bệnh nhân thiếu hụt Dihydropyrimidin dehydrogenase; Bệnh nhân giảm số lượng bạch cầu hoặc tiểu cầu nặng; Suy gan nặng. 3. Liều dùng của thuốc Xelocapec Liều dùng của Xelocapec khi điều trị đơn lẻ: Ung thư đại trực tràng, ung thư vú: 1250mg/m2, uống 2 lần mỗi ngày trong thời gian 14 ngày, tiếp sau đó là 7 ngày ngưng thuốc. Liều Xelocapec trong điều trị phối hợp: Ung thư vú: Liều khởi đầu là 1250mg/m2, 2 lần uống mỗi ngày trong 2 tuần dùng phối hợp với Docetaxel, tiếp sau đó lá 1 tuần ngưng thuốc; Ung thư dạ dày, đại trực tràng: Liều khuyến cáo là 800-1000mg/m2/lần x 2 lần/ngày trong thời gian 2 tuần, sau đó 7 ngày ngưng thuốc hoặc 625mg/m2/lần x 2 lần mỗi ngày khi điều trị liên tục. Thuốc Xelocapec nên uống cùng với thức ăn, do đó thời điểm tốt nhất là trong vòng 30 phút sau bữa ăn. 4. Tác dụng phụ của thuốc Xelocapec Các triệu chứng bất thường như buồn nôn, nôn ói, giảm cảm giác ngon miệng, táo bón, cơ thể mệt mỏi, yếu sức, đau đầu, chóng mặt, khó ngủ có thể xảy ra trong thời gian dùng Xelocapec . Trong đó, tình trạng buồn nôn và nôn ói có thể nghiêm trọng nên đôi khi cần được bác sĩ chỉ định thuốc kiểm soát phù hợp. Tiêu chảy là một tác dụng phụ phổ biến khác của thuốc Xelocapec . Bệnh nhân cần uống nhiều nước khi điều trị bằng Xelocapec trừ khi bác sĩ có hướng dẫn khác. Nôn ói hoặc tiêu chảy kéo dài do thuốc Xelocapec có thể dẫn đến mất nước nghiêm trọng, vì vậy người bệnh hãy liên hệ ngay với bác sĩ nếu có các triệu chứng mất nước như giảm đi tiểu, khô miệng, tăng cảm giác khát nước hoặc chóng mặt. Tình trạng rụng tóc tạm thời xảy ra trong thời gian dùng thuốc Xelocapec và có thể hồi phục sau khi điều trị đã kết thúc. Một số bệnh nhân ghi nhận hiện tượng thay đổi móng tay tạm thời. Đối với nam giới và phụ nữ trong độ tuổi sinh đẻ, thuốc Xelocapec có thể ảnh hưởng đến khả năng có con của bệnh nhân. Bệnh nhân hãy tham khảo ý kiến bác sĩ để biết thêm chi tiết. Thuốc Xelocapec có thể làm giảm khả năng miễn dịch của cơ thể với các tác nhân nhiễm trùng, dẫn đến tăng nguy cơ mắc các bệnh nhiễm trùng nghiêm trọng (nhưng hiếm khi gây tử vong) hoặc làm cho bệnh nhiễm trùng hiện mắc nghiêm trọng hơn. Phản ứng dị ứng rất nghiêm trọng với thuốc Xelocapec rất hiếm khi xảy ra. Tuy nhiên, bệnh nhân hãy liên hệ với bác sĩ ngay lập tức nếu xuất hiện các triệu chứng của phản ứng dị ứng nghiêm trọng như phát ban, sưng ngứa mặt/lưỡi/họng, chóng mặt nghiêm trọng hoặc khó thở. 5. Tương tác thuốc của Xelocapec Hoạt chất Capecitabine trong thuốc Xelocapec có thể xảy ra tương tác thuốc nghiêm trọng với một số thuốc sau: Thuốc chống đông máu Coumarin: Trong một nghiên cứu tương tác lâm sàng, sau khi dùng Warfarin liều đơn 20mg kết hợp với Capecitabine làm tăng AUC của S-warfarin khoảng 57% và giá trị INR tăng 91%.'''
question = '''Tại sao Capecitabine trong Xelocapec không gây độc tế bào trên in vitro nhưng lại biến đổi thành 5-fluorouracil (5-FU) gây độc tế bào trên in vivo, và cơ chế nào giúp hạn chế ảnh hưởng đến nhu mô lành của 5-FU?'''
'''Trả lời: Có'''
```
**Developer**
Member: Nguyễn Nho Trung, Nguyễn Nhật Quang
## Contact
**Email**: [email protected]
**LinkedIn**: [Trung Nguyen Nho](https://www.linkedin.com/in/trung-nguyen-nho-604288227/)
**Facebook**: [Nguyễn Nho Trung](https://www.facebook.com/trung.nguyennho.568/)
## Support me:
Nếu bạn thấy tác phẩm này hữu ích và muốn hỗ trợ cho sự phát triển liên tục của nó, đây là một số cách bạn có thể giúp:
**Star the Repository**: Nếu bạn đánh giá cao tác phẩm này, vui lòng gắn sao cho nó. Sự hỗ trợ của bạn sẽ khuyến khích sự phát triển và cải tiến liên tục.
**Contribute**: Đóng góp luôn được hoan nghênh! Bạn có thể giúp bằng cách báo cáo sự cố, gửi yêu cầu kéo hoặc đề xuất các tính năng mới.
**Share**: Chia sẻ dự án này với đồng nghiệp, bạn bè hoặc cộng đồng của bạn. Càng nhiều người biết về nó, nó càng thu hút được nhiều phản hồi và đóng góp
**Buy me a coffee**: Nếu bạn muốn hỗ trợ tài chính, hãy cân nhắc donation. Bạn có thể donate qua:
- BIDV: 2131273046 - NGUYEN NHO TRUNG
## Citation
Làm ơn cite như sau:
```Plaintext
@misc{ViRAG-Gen,
title={ViRAG-Gen: Towards a specialized LLM for RAG task in Vietnamese language.}},
author={Nguyen Nho Trung, Nguyen Nhat Quang},
year={2024},
publisher={Huggingface},
}
```
|
[
"CHIA"
] |
goverlyai/gte-modernbert-base
|
goverlyai
|
sentence-similarity
|
[
"transformers",
"pytorch",
"onnx",
"safetensors",
"modernbert",
"feature-extraction",
"sentence-transformers",
"mteb",
"embedding",
"transformers.js",
"sentence-similarity",
"en",
"arxiv:2308.03281",
"base_model:answerdotai/ModernBERT-base",
"base_model:finetune:answerdotai/ModernBERT-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2025-02-14T23:52:02Z |
2025-02-14T23:57:00+00:00
| 61 | 0 |
---
base_model:
- answerdotai/ModernBERT-base
language:
- en
library_name: transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- mteb
- embedding
- transformers.js
base_model_relation: finetune
---
# gte-modernbert-base
We are excited to introduce the `gte-modernbert` series of models, which are built upon the latest modernBERT pre-trained encoder-only foundation models. The `gte-modernbert` series models include both text embedding models and rerank models.
The `gte-modernbert` models demonstrates competitive performance in several text embedding and text retrieval evaluation tasks when compared to similar-scale models from the current open-source community. This includes assessments such as MTEB, LoCO, and COIR evaluation.
## Model Overview
- Developed by: Tongyi Lab, Alibaba Group
- Model Type: Text Embedding
- Primary Language: English
- Model Size: 149M
- Max Input Length: 8192 tokens
- Output Dimension: 768
### Model list
| Models | Language | Model Type | Model Size | Max Seq. Length | Dimension | MTEB-en | BEIR | LoCo | CoIR |
|:--------------------------------------------------------------------------------------:|:--------:|:----------------------:|:----------:|:---------------:|:---------:|:-------:|:----:|:----:|:----:|
| [`gte-modernbert-base`](https://huggingface.co/Alibaba-NLP/gte-modernbert-base) | English | text embedding | 149M | 8192 | 768 | 64.38 | 55.33 | 87.57 | 79.31 |
| [`gte-reranker-modernbert-base`](https://huggingface.co/Alibaba-NLP/gte-reranker-modernbert-base) | English | text reranker | 149M | 8192 | - | - | 56.19 | 90.68 | 79.99 |
## Usage
> [!TIP]
> For `transformers` and `sentence-transformers`, if your GPU supports it, the efficient Flash Attention 2 will be used automatically if you have `flash_attn` installed. It is not mandatory.
>
> ```bash
> pip install flash_attn
> ```
Use with `transformers`
```python
# Requires transformers>=4.48.0
import torch.nn.functional as F
from transformers import AutoModel, AutoTokenizer
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"Beijing",
"sorting algorithms"
]
model_path = "Alibaba-NLP/gte-modernbert-base"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModel.from_pretrained(model_path)
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=8192, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = outputs.last_hidden_state[:, 0]
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
# [[42.89073944091797, 71.30911254882812, 33.664554595947266]]
```
Use with `sentence-transformers`:
```python
# Requires transformers>=4.48.0
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"Beijing",
"sorting algorithms"
]
model = SentenceTransformer("Alibaba-NLP/gte-modernbert-base")
embeddings = model.encode(input_texts)
print(embeddings.shape)
# (4, 768)
similarities = cos_sim(embeddings[0], embeddings[1:])
print(similarities)
# tensor([[0.4289, 0.7131, 0.3366]])
```
Use with `transformers.js`:
```js
// npm i @huggingface/transformers
import { pipeline, matmul } from "@huggingface/transformers";
// Create a feature extraction pipeline
const extractor = await pipeline(
"feature-extraction",
"Alibaba-NLP/gte-modernbert-base",
{ dtype: "fp32" }, // Supported options: "fp32", "fp16", "q8", "q4", "q4f16"
);
// Embed queries and documents
const embeddings = await extractor(
[
"what is the capital of China?",
"how to implement quick sort in python?",
"Beijing",
"sorting algorithms",
],
{ pooling: "cls", normalize: true },
);
// Compute similarity scores
const similarities = (await matmul(embeddings.slice([0, 1]), embeddings.slice([1, null]).transpose(1, 0))).mul(100);
console.log(similarities.tolist()); // [[42.89077377319336, 71.30916595458984, 33.66455841064453]]
```
## Training Details
The `gte-modernbert` series of models follows the training scheme of the previous [GTE models](https://huggingface.co/collections/Alibaba-NLP/gte-models-6680f0b13f885cb431e6d469), with the only difference being that the pre-training language model base has been replaced from [GTE-MLM](https://huggingface.co/Alibaba-NLP/gte-en-mlm-base) to [ModernBert](https://huggingface.co/answerdotai/ModernBERT-base). For more training details, please refer to our paper: [mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval](https://aclanthology.org/2024.emnlp-industry.103/)
## Evaluation
### MTEB
The results of other models are retrieved from [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard). Given that all models in the `gte-modernbert` series have a size of less than 1B parameters, we focused exclusively on the results of models under 1B from the MTEB leaderboard.
| Model Name | Param Size (M) | Dimension | Sequence Length | Average (56) | Class. (12) | Clust. (11) | Pair Class. (3) | Reran. (4) | Retr. (15) | STS (10) | Summ. (1) |
|:------------------------------------------------------------------------------------------------:|:--------------:|:---------:|:---------------:|:------------:|:-----------:|:---:|:---:|:---:|:---:|:-----------:|:--------:|
| [mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) | 335 | 1024 | 512 | 64.68 | 75.64 | 46.71 | 87.2 | 60.11 | 54.39 | 85 | 32.71 |
| [multilingual-e5-large-instruct](https://huggingface.co/intfloat/multilingual-e5-large-instruct) | 560 | 1024 | 514 | 64.41 | 77.56 | 47.1 | 86.19 | 58.58 | 52.47 | 84.78 | 30.39 |
| [bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 335 | 1024 | 512 | 64.23 | 75.97 | 46.08 | 87.12 | 60.03 | 54.29 | 83.11 | 31.61 |
| [gte-base-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5) | 137 | 768 | 8192 | 64.11 | 77.17 | 46.82 | 85.33 | 57.66 | 54.09 | 81.97 | 31.17 |
| [bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 109 | 768 | 512 | 63.55 | 75.53 | 45.77 | 86.55 | 58.86 | 53.25 | 82.4 | 31.07 |
| [gte-large-en-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-en-v1.5) | 409 | 1024 | 8192 | 65.39 | 77.75 | 47.95 | 84.63 | 58.50 | 57.91 | 81.43 | 30.91 |
| [modernbert-embed-base](https://huggingface.co/nomic-ai/modernbert-embed-base) | 149 | 768 | 8192 | 62.62 | 74.31 | 44.98 | 83.96 | 56.42 | 52.89 | 81.78 | 31.39 |
| [nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) | | 768 | 8192 | 62.28 | 73.55 | 43.93 | 84.61 | 55.78 | 53.01| 81.94 | 30.4 |
| [gte-multilingual-base](https://huggingface.co/Alibaba-NLP/gte-multilingual-base) | 305 | 768 | 8192 | 61.4 | 70.89 | 44.31 | 84.24 | 57.47 |51.08 | 82.11 | 30.58 |
| [jina-embeddings-v3](https://huggingface.co/jinaai/jina-embeddings-v3) | 572 | 1024 | 8192 | 65.51 | 82.58 |45.21 |84.01 |58.13 |53.88 | 85.81 | 29.71 |
| [**gte-modernbert-base**](https://huggingface.co/Alibaba-NLP/gte-modernbert-base) | 149 | 768 | 8192 | **64.38** | **76.99** | **46.47** | **85.93** | **59.24** | **55.33** | **81.57** | **30.68** |
### LoCo (Long Document Retrieval)(NDCG@10)
| Model Name | Dimension | Sequence Length | Average (5) | QsmsumRetrieval | SummScreenRetrieval | QasperAbastractRetrieval | QasperTitleRetrieval | GovReportRetrieval |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [gte-qwen1.5-7b](https://huggingface.co/Alibaba-NLP/gte-qwen1.5-7b) | 4096 | 32768 | 87.57 | 49.37 | 93.10 | 99.67 | 97.54 | 98.21 |
| [gte-large-v1.5](https://huggingface.co/Alibaba-NLP/gte-large-v1.5) |1024 | 8192 | 86.71 | 44.55 | 92.61 | 99.82 | 97.81 | 98.74 |
| [gte-base-v1.5](https://huggingface.co/Alibaba-NLP/gte-base-v1.5) | 768 | 8192 | 87.44 | 49.91 | 91.78 | 99.82 | 97.13 | 98.58 |
| [gte-modernbert-base](https://huggingface.co/Alibaba-NLP/gte-modernbert-base) | 768 | 8192 | 88.88 | 54.45 | 93.00 | 99.82 | 98.03 | 98.70 |
| [gte-reranker-modernbert-base](https://huggingface.co/Alibaba-NLP/gte-reranker-modernbert-base) | - | 8192 | 90.68 | 70.86 | 94.06 | 99.73 | 99.11 | 89.67 |
### COIR (Code Retrieval Task)(NDCG@10)
| Model Name | Dimension | Sequence Length | Average(20) | CodeSearchNet-ccr-go | CodeSearchNet-ccr-java | CodeSearchNet-ccr-javascript | CodeSearchNet-ccr-php | CodeSearchNet-ccr-python | CodeSearchNet-ccr-ruby | CodeSearchNet-go | CodeSearchNet-java | CodeSearchNet-javascript | CodeSearchNet-php | CodeSearchNet-python | CodeSearchNet-ruby | apps | codefeedback-mt | codefeedback-st | codetrans-contest | codetrans-dl | cosqa | stackoverflow-qa | synthetic-text2sql |
|:----:|:---:|:---:|:---:|:---:| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| [gte-modernbert-base](https://huggingface.co/Alibaba-NLP/gte-modernbert-base) | 768 | 8192 | 79.31 | 94.15 | 93.57 | 94.27 | 91.51 | 93.93 | 90.63 | 88.32 | 83.27 | 76.05 | 85.12 | 88.16 | 77.59 | 57.54 | 82.34 | 85.95 | 71.89 | 35.46 | 43.47 | 91.2 | 61.87 |
| [gte-reranker-modernbert-base](https://huggingface.co/Alibaba-NLP/gte-reranker-modernbert-base) | - | 8192 | 79.99 | 96.43 | 96.88 | 98.32 | 91.81 | 97.7 | 91.96 | 88.81 | 79.71 | 76.27 | 89.39 | 98.37 | 84.11 | 47.57 | 83.37 | 88.91 | 49.66 | 36.36 | 44.37 | 89.58 | 64.21 |
### BEIR(NDCG@10)
| Model Name | Dimension | Sequence Length | Average(15) | ArguAna | ClimateFEVER | CQADupstackAndroidRetrieval | DBPedia | FEVER | FiQA2018 | HotpotQA | MSMARCO | NFCorpus | NQ | QuoraRetrieval | SCIDOCS | SciFact | Touche2020 | TRECCOVID |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| [gte-modernbert-base](https://huggingface.co/Alibaba-NLP/gte-modernbert-base) | 768 | 8192 | 55.33 | 72.68 | 37.74 | 42.63 | 41.79 | 91.03 | 48.81 | 69.47 | 40.9 | 36.44 | 57.62 | 88.55 | 21.29 | 77.4 | 21.68 | 81.95 |
| [gte-reranker-modernbert-base](https://huggingface.co/Alibaba-NLP/gte-reranker-modernbert-base) | - | 8192 | 56.73 | 69.03 | 37.79 | 44.68 | 47.23 | 94.54 | 49.81 | 78.16 | 45.38 | 30.69 | 64.57 | 87.77 | 20.60 | 73.57 | 27.36 | 79.89 |
## Hiring
We have open positions for **Research Interns** and **Full-Time Researchers** to join our team at Tongyi Lab.
We are seeking passionate individuals with expertise in representation learning, LLM-driven information retrieval, Retrieval-Augmented Generation (RAG), and agent-based systems.
Our team is located in the vibrant cities of **Beijing** and **Hangzhou**.
If you are driven by curiosity and eager to make a meaningful impact through your work, we would love to hear from you. Please submit your resume along with a brief introduction to <a href="mailto:[email protected]">[email protected]</a>.
## Citation
If you find our paper or models helpful, feel free to give us a cite.
```
@inproceedings{zhang2024mgte,
title={mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval},
author={Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Wen and Dai, Ziqi and Tang, Jialong and Lin, Huan and Yang, Baosong and Xie, Pengjun and Huang, Fei and others},
booktitle={Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track},
pages={1393--1412},
year={2024}
}
@article{li2023towards,
title={Towards general text embeddings with multi-stage contrastive learning},
author={Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan},
journal={arXiv preprint arXiv:2308.03281},
year={2023}
}
```
|
[
"SCIFACT"
] |
llange/xlm-roberta-large-spanish-clinical
|
llange
|
fill-mask
|
[
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"arxiv:2112.08754",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-03-02T23:29:05Z |
2021-12-17T10:27:39+00:00
| 60 | 1 |
---
{}
---
# CLIN-X-ES: a pre-trained language model for the Spanish clinical domain
Details on the model, the pre-training corpus and the downstream task performance are given in the paper: "CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain" by Lukas Lange, Heike Adel, Jannik Strötgen and Dietrich Klakow.
The paper can be found [here](https://arxiv.org/abs/2112.08754).
In case of questions, please contact the authors as listed on the paper.
Please cite the above paper when reporting, reproducing or extending the results.
@misc{lange-etal-2021-clin-x,
author = {Lukas Lange and
Heike Adel and
Jannik Str{\"{o}}tgen and
Dietrich Klakow},
title = {CLIN-X: pre-trained language models and a study on cross-task transfer for concept extraction in the clinical domain},
year={2021},
eprint={2112.08754},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2112.08754}
}
## Training details
The model is based on the multilingual XLM-R transformer `(xlm-roberta-large)`, which was trained on 100 languages and showed superior performance in many different tasks across languages and can even outperform monolingual models in certain settings (Conneau et al. 2020).
Even though XLM-R was pre-trained on 53GB of Spanish documents, this was only 2% of the overall training data. To steer this model towards the Spanish clinical domain, we sample documents from the Scielo archive (https://scielo.org/)
and the MeSpEn resources (Villegas et al. 2018). The resulting corpus has a size of 790MB and is highly specific for the clinical domain.
We initialize CLIN-X using the pre-trained XLM-R weights and train masked language modeling (MLM) on the Spanish clinical corpus for 3 epochs which roughly corresponds to 32k steps. This allows researchers and practitioners to address
the Spanish clinical domain with an out-of-the-box tailored model.
## Results for Spanish concept extraction
We apply CLIN-X-ES to five Spanish concept extraction tasks from the clinical domain in a standard sequence labeling architecture similar to Devlin et al. 2019 and compare to a Spanish BERT model called BETO. In addition, we perform experiments with an improved architecture `(+ OurArchitecture)` as described in the paper linked above. The code for our model architecture can be found [here](https://github.com/boschresearch/clin_x).
| | Cantemist | Meddocan | Meddoprof (NER) | Meddoprof (CLASS) | Pharmaconer |
|------------------------------------------|-----------|----------|-----------------|-------------------|-------------|
| BETO (Spanish BERT) | 81.30 | 96.81 | 79.19 | 74.59 | 87.70 |
| CLIN-X (ES) | 83.22 | 97.08 | 79.54 | 76.95 | 90.05 |
| CLIN-X (ES) + OurArchitecture | **88.24** | **98.00** | **81.68** | **80.54** | **92.27** |
### Results for English concept extraction
As the CLIN-X-ES model is based on XLM-R, the model is still multilingual and we demonstrate the positive impact of cross-language domain adaptation by applying this model to five different English sequence labeling tasks from i2b2.
We found that further transfer from related concept extraction is particularly helpful in this cross-language setting. For a detailed description of the transfer process and all other models, we refer to our paper.
| | i2b2 2006 | i2b2 2010 | i2b2 2012 (Concept) | i2b2 2012 (Time) | i2b2 2014 |
|------------------------------------------|-----------|-----------|---------------|---------------|-----------|
| BERT | 94.80 | 85.25 | 76.51 | 75.28 | 94.86 |
| ClinicalBERT | 94.8 | 87.8 | 78.9 | 76.6 | 93.0 |
| CLIN-X (ES) | 95.49 | 87.94 | 79.58 | 77.57 | 96.80 |
| CLIN-X (ES) + OurArchitecture | 98.30 | 89.10 | 80.42 | 78.48 | **97.62** |
| CLIN-X (ES) + OurArchitecture + Transfer | **89.50** | **89.74** | **80.93** | **79.60** | 97.46 |
## Purpose of the project
This software is a research prototype, solely developed for and published as part of the publication cited above. It will neither be maintained nor monitored in any way.
## License
The CLIN-X models are open-sourced under the CC-BY 4.0 license.
See the [LICENSE](LICENSE) file for details.
|
[
"CANTEMIST",
"MEDDOCAN",
"PHARMACONER",
"SCIELO"
] |
afrideva/LocutusqueXFelladrin-TinyMistral248M-Instruct-GGUF
|
afrideva
|
text-generation
|
[
"gguf",
"ggml",
"quantized",
"q2_k",
"q3_k_m",
"q4_k_m",
"q5_k_m",
"q6_k",
"q8_0",
"text-generation",
"en",
"dataset:Locutusque/inst_mix_v2_top_100k",
"base_model:Locutusque/LocutusqueXFelladrin-TinyMistral248M-Instruct",
"base_model:quantized:Locutusque/LocutusqueXFelladrin-TinyMistral248M-Instruct",
"license:apache-2.0",
"region:us"
] | 2023-12-16T00:38:29Z |
2023-12-16T00:39:32+00:00
| 60 | 0 |
---
base_model: Locutusque/LocutusqueXFelladrin-TinyMistral248M-Instruct
datasets:
- Locutusque/inst_mix_v2_top_100k
language:
- en
license: apache-2.0
model_name: LocutusqueXFelladrin-TinyMistral248M-Instruct
pipeline_tag: text-generation
tags:
- gguf
- ggml
- quantized
- q2_k
- q3_k_m
- q4_k_m
- q5_k_m
- q6_k
- q8_0
inference: false
model_creator: Locutusque
quantized_by: afrideva
widget:
- text: '<|USER|> Design a Neo4j database and Cypher function snippet to Display Extreme
Dental hygiene: Using Mouthwash for Analysis for Beginners. Implement if/else
or switch/case statements to handle different conditions related to the Consent.
Provide detailed comments explaining your control flow and the reasoning behind
each decision. <|ASSISTANT|> '
- text: '<|USER|> Write me a story about a magical place. <|ASSISTANT|> '
- text: '<|USER|> Write me an essay about the life of George Washington <|ASSISTANT|> '
- text: '<|USER|> Solve the following equation 2x + 10 = 20 <|ASSISTANT|> '
- text: '<|USER|> Craft me a list of some nice places to visit around the world. <|ASSISTANT|> '
- text: '<|USER|> How to manage a lazy employee: Address the employee verbally. Don''t
allow an employee''s laziness or lack of enthusiasm to become a recurring issue.
Tell the employee you''re hoping to speak with them about workplace expectations
and performance, and schedule a time to sit down together. Question: To manage
a lazy employee, it is suggested to talk to the employee. True, False, or Neither?
<|ASSISTANT|> '
---
# Locutusque/LocutusqueXFelladrin-TinyMistral248M-Instruct-GGUF
Quantized GGUF model files for [LocutusqueXFelladrin-TinyMistral248M-Instruct](https://huggingface.co/Locutusque/LocutusqueXFelladrin-TinyMistral248M-Instruct) from [Locutusque](https://huggingface.co/Locutusque)
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [locutusquexfelladrin-tinymistral248m-instruct.fp16.gguf](https://huggingface.co/afrideva/LocutusqueXFelladrin-TinyMistral248M-Instruct-GGUF/resolve/main/locutusquexfelladrin-tinymistral248m-instruct.fp16.gguf) | fp16 | 497.76 MB |
| [locutusquexfelladrin-tinymistral248m-instruct.q2_k.gguf](https://huggingface.co/afrideva/LocutusqueXFelladrin-TinyMistral248M-Instruct-GGUF/resolve/main/locutusquexfelladrin-tinymistral248m-instruct.q2_k.gguf) | q2_k | 116.20 MB |
| [locutusquexfelladrin-tinymistral248m-instruct.q3_k_m.gguf](https://huggingface.co/afrideva/LocutusqueXFelladrin-TinyMistral248M-Instruct-GGUF/resolve/main/locutusquexfelladrin-tinymistral248m-instruct.q3_k_m.gguf) | q3_k_m | 131.01 MB |
| [locutusquexfelladrin-tinymistral248m-instruct.q4_k_m.gguf](https://huggingface.co/afrideva/LocutusqueXFelladrin-TinyMistral248M-Instruct-GGUF/resolve/main/locutusquexfelladrin-tinymistral248m-instruct.q4_k_m.gguf) | q4_k_m | 156.61 MB |
| [locutusquexfelladrin-tinymistral248m-instruct.q5_k_m.gguf](https://huggingface.co/afrideva/LocutusqueXFelladrin-TinyMistral248M-Instruct-GGUF/resolve/main/locutusquexfelladrin-tinymistral248m-instruct.q5_k_m.gguf) | q5_k_m | 180.17 MB |
| [locutusquexfelladrin-tinymistral248m-instruct.q6_k.gguf](https://huggingface.co/afrideva/LocutusqueXFelladrin-TinyMistral248M-Instruct-GGUF/resolve/main/locutusquexfelladrin-tinymistral248m-instruct.q6_k.gguf) | q6_k | 205.20 MB |
| [locutusquexfelladrin-tinymistral248m-instruct.q8_0.gguf](https://huggingface.co/afrideva/LocutusqueXFelladrin-TinyMistral248M-Instruct-GGUF/resolve/main/locutusquexfelladrin-tinymistral248m-instruct.q8_0.gguf) | q8_0 | 265.26 MB |
## Original Model Card:
# LocutusqueXFelladrin-TinyMistral248M-Instruct
This model was created by merging Locutusque/TinyMistral-248M-Instruct and Felladrin/TinyMistral-248M-SFT-v4 using mergekit. After the two models were merged, the resulting model was further trained on ~20,000 examples on the Locutusque/inst_mix_v2_top_100k at a low learning rate to further normalize weights. The following is the YAML config used to merge:
```yaml
models:
- model: Felladrin/TinyMistral-248M-SFT-v4
parameters:
weight: 0.5
- model: Locutusque/TinyMistral-248M-Instruct
parameters:
weight: 1.0
merge_method: linear
dtype: float16
```
The resulting model combines the best of both worlds. With Locutusque/TinyMistral-248M-Instruct's coding capabilities and reasoning skills, and Felladrin/TinyMistral-248M-SFT-v4's low hallucination and instruction-following capabilities. The resulting model has an incredible performance considering its size.
## Evaluation
Coming soon...
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.emotional
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-28T07:52:05Z |
2023-12-28T07:52:08+00:00
| 60 | 1 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/emotional.../emotional_17_3.0.png
widget:
- text: emotional
output:
url: images/emotional_17_3.0.png
- text: emotional
output:
url: images/emotional_19_3.0.png
- text: emotional
output:
url: images/emotional_20_3.0.png
- text: emotional
output:
url: images/emotional_21_3.0.png
- text: emotional
output:
url: images/emotional_22_3.0.png
inference: false
instance_prompt: emotional
---
# ntcai.xyz slider - emotional (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/emotional_17_-3.0.png" width=256 height=256 /> | <img src="images/emotional_17_0.0.png" width=256 height=256 /> | <img src="images/emotional_17_3.0.png" width=256 height=256 /> |
| <img src="images/emotional_19_-3.0.png" width=256 height=256 /> | <img src="images/emotional_19_0.0.png" width=256 height=256 /> | <img src="images/emotional_19_3.0.png" width=256 height=256 /> |
| <img src="images/emotional_20_-3.0.png" width=256 height=256 /> | <img src="images/emotional_20_0.0.png" width=256 height=256 /> | <img src="images/emotional_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
emotional
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.emotional', weight_name='emotional.safetensors', adapter_name="emotional")
# Activate the LoRA
pipe.set_adapters(["emotional"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, emotional"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 680+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.figurine
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-13T21:22:57Z |
2024-01-13T21:23:00+00:00
| 60 | 2 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/figurine.../figurine_17_3.0.png
widget:
- text: figurine
output:
url: images/figurine_17_3.0.png
- text: figurine
output:
url: images/figurine_19_3.0.png
- text: figurine
output:
url: images/figurine_20_3.0.png
- text: figurine
output:
url: images/figurine_21_3.0.png
- text: figurine
output:
url: images/figurine_22_3.0.png
inference: false
instance_prompt: figurine
---
# ntcai.xyz slider - figurine (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/figurine_17_-3.0.png" width=256 height=256 /> | <img src="images/figurine_17_0.0.png" width=256 height=256 /> | <img src="images/figurine_17_3.0.png" width=256 height=256 /> |
| <img src="images/figurine_19_-3.0.png" width=256 height=256 /> | <img src="images/figurine_19_0.0.png" width=256 height=256 /> | <img src="images/figurine_19_3.0.png" width=256 height=256 /> |
| <img src="images/figurine_20_-3.0.png" width=256 height=256 /> | <img src="images/figurine_20_0.0.png" width=256 height=256 /> | <img src="images/figurine_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
figurine
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.figurine', weight_name='figurine.safetensors', adapter_name="figurine")
# Activate the LoRA
pipe.set_adapters(["figurine"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, figurine"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1080+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
USTC-KnowledgeComputingLab/Llama3-KALE-LM-Chem-8B
|
USTC-KnowledgeComputingLab
|
text-generation
|
[
"pytorch",
"llama",
"KALE-LM",
"science",
"chemistry",
"text-generation",
"conversational",
"en",
"arxiv:2409.18695",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"base_model:finetune:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama3",
"region:us"
] | 2024-08-13T12:01:30Z |
2024-10-29T08:04:56+00:00
| 60 | 4 |
---
base_model: meta-llama/Meta-Llama-3-8B-Instruct
language:
- en
license: llama3
pipeline_tag: text-generation
tags:
- KALE-LM
- science
- chemistry
---
# Llama3-KALE-LM-Chem-8B
## Introduction
We are thrilled to present Llama3-KALE-LM-Chem 8B, our first open-source KALE-LM, which specializes in chemistry.
## Training Details
We have continually pre-trained the model with a large amount of data and post-trained it through supervised fine-tuning.
## Benchmarks
### Open Benchmarks
| Models | ChemBench | MMLU | MMLU-Chem | SciQ | IE(Acc) | IE(LS) |
| ---- | ---- | ---- | ---- | ---- | ---- | ---- |
| GPT-3.5 | 47.15 | 69.75 | 53.32 | 89.6 | 52.98 | 68.28 |
| GPT-4 | 53.72 | 78.67 | 63.70 | 94.10 | 54.20 | 69.74 |
| Llama3-8B-Instruct | 46.02 | 68.3 | 51.10 | 93.30 | 45.83 | 61.22 |
| LlaSMol | 28.47 | 54.47 | 33.24 | 72.30 | 2.16 | 3.23 |
| ChemDFM | 44.44 | 58.11 | 45.60 | 86.70 | 7.61 | 11.49 |
| ChemLLM-7B-Chat | 34.16 | 61.79 | 48.39 | 94.00 | 29.66 | 39.17 |
| ChemLLM-7B-Chat-1.5-SFT | 42.75 | 63.56 | 49.63 | **95.10** | 14.96 | 19.61 |
| **Llama3-KALE-LM-Chem-8B** | **52.40** | **68.74** | **53.83** | 91.50 | **67.50** | **78.37** |
#### ChemBench Details (Evaluated By OpenCompass)
| Models | NC | PP | M2C | C2M | PP | RS | YP | TP | SP | Average |
| ------ | ------ | ------ | ------ | ------ | ------ | ------ | ------ | ------ | ------ | ------ |
| GPT-3.5 | 46.93 | 56.98 | 85.28 | 38.25 | 43.67 | 42.33 | 30.33 | 42.57 | 38 | 47.15 |
| GPT-4 | 54.82 | 65.02 | 92.64 | 52.88 | 62.67 | 52.67 | 42.33 | 24.75 | 35.67 | 53.72 |
| Llama3-8B-Instruct | 51.31 | 27.79 | 90.30 | 40.88 | 34.00 | 30.00 | 45.33 | 60.89 | 33.67 | 46.02 |
| LlaSMol | 27.78 | 29.34 | 31.44 | 23.38 | 25.67 | 24.00 | 37.33 | 34.65 | 22.67 | 28.47 |
| ChemDFM | 36.92 | 55.57 | 83.95 | 42.00 | 40.00 | 37.33 | 39.00 | 33.17 | 32.00 | 44.44 |
| ChemLLM-7B-Chat | 41.05 | 29.76 | 85.28 | 26.12 | 26.00 | 24.00 | 20.00 | 24.26 | 31.00 | 34.16 |
| ChemLLM-7B-Chat-1.5-SFT | 50.06 | 49.51 | 85.28 | 38.75 | 38.00 | 26.67 | 28.33 | 31.68 | 33.67 | 42.44 |
| Llama3-KALE-LM-Chem-8B | 63.58 | 58.39 | 92.98 | 44.50 | 48.67 | 38.33 | 46.33 | 44.55 | 34.33 | 52.41 |
## Quick Start
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"USTC-KnowledgeComputingLab/Llama3-KALE-LM-Chem-8B",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("USTC-KnowledgeComputingLab/Llama3-KALE-LM-Chem-8B")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=2048
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Cite This Work
```
@article{dai2024kale,
title={KALE-LM: Unleash The Power Of AI For Science Via Knowledge And Logic Enhanced Large Model},
author={Dai, Weichen and Chen, Yezeng and Dai, Zijie and Huang, Zhijie and Liu, Yubo and Pan, Yixuan and Song, Baiyang and Zhong, Chengli and Li, Xinhe and Wang, Zeyu and others},
journal={arXiv preprint arXiv:2409.18695},
year={2024}
}
```
|
[
"SCIQ"
] |
QuantFactory/medllama3-v20-GGUF
|
QuantFactory
| null |
[
"gguf",
"license:llama3",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-09-26T02:51:31Z |
2024-09-26T03:33:51+00:00
| 60 | 1 |
---
license: llama3
---
[](https://hf.co/QuantFactory)
# QuantFactory/medllama3-v20-GGUF
This is quantized version of [ProbeMedicalYonseiMAILab/medllama3-v20](https://huggingface.co/ProbeMedicalYonseiMAILab/medllama3-v20) created using llama.cpp
# Original Model Card
The model is a fine-tuned large language model on using publically available medical data.
## Model Description
- **Developed by:** Probe Medical, MAILAB from Yonsei University
- **Model type:** LLM
- **Language(s) (NLP):** English
## Training Hyperparameters
- **Lora Targets:** "o_proj", "down_proj", "v_proj", "gate_proj", "up_proj", "k_proj", "q_proj"
|
[
"MEDICAL DATA"
] |
codegood/Llama3-Aloe-8B-Alpha-Q4_K_M-GGUF
|
codegood
|
question-answering
|
[
"transformers",
"gguf",
"biology",
"medical",
"llama-cpp",
"gguf-my-repo",
"question-answering",
"en",
"dataset:argilla/dpo-mix-7k",
"dataset:nvidia/HelpSteer",
"dataset:jondurbin/airoboros-3.2",
"dataset:hkust-nlp/deita-10k-v0",
"dataset:LDJnr/Capybara",
"dataset:HPAI-BSC/CareQA",
"dataset:GBaker/MedQA-USMLE-4-options",
"dataset:lukaemon/mmlu",
"dataset:bigbio/pubmed_qa",
"dataset:openlifescienceai/medmcqa",
"dataset:bigbio/med_qa",
"dataset:HPAI-BSC/better-safe-than-sorry",
"dataset:HPAI-BSC/pubmedqa-cot",
"dataset:HPAI-BSC/medmcqa-cot",
"dataset:HPAI-BSC/medqa-cot",
"base_model:HPAI-BSC/Llama3-Aloe-8B-Alpha",
"base_model:quantized:HPAI-BSC/Llama3-Aloe-8B-Alpha",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-16T17:10:32Z |
2024-10-16T17:10:56+00:00
| 60 | 1 |
---
base_model: HPAI-BSC/Llama3-Aloe-8B-Alpha
datasets:
- argilla/dpo-mix-7k
- nvidia/HelpSteer
- jondurbin/airoboros-3.2
- hkust-nlp/deita-10k-v0
- LDJnr/Capybara
- HPAI-BSC/CareQA
- GBaker/MedQA-USMLE-4-options
- lukaemon/mmlu
- bigbio/pubmed_qa
- openlifescienceai/medmcqa
- bigbio/med_qa
- HPAI-BSC/better-safe-than-sorry
- HPAI-BSC/pubmedqa-cot
- HPAI-BSC/medmcqa-cot
- HPAI-BSC/medqa-cot
language:
- en
library_name: transformers
license: cc-by-nc-4.0
pipeline_tag: question-answering
tags:
- biology
- medical
- llama-cpp
- gguf-my-repo
---
# codegood/Llama3-Aloe-8B-Alpha-Q4_K_M-GGUF
This model was converted to GGUF format from [`HPAI-BSC/Llama3-Aloe-8B-Alpha`](https://huggingface.co/HPAI-BSC/Llama3-Aloe-8B-Alpha) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/HPAI-BSC/Llama3-Aloe-8B-Alpha) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo codegood/Llama3-Aloe-8B-Alpha-Q4_K_M-GGUF --hf-file llama3-aloe-8b-alpha-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo codegood/Llama3-Aloe-8B-Alpha-Q4_K_M-GGUF --hf-file llama3-aloe-8b-alpha-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo codegood/Llama3-Aloe-8B-Alpha-Q4_K_M-GGUF --hf-file llama3-aloe-8b-alpha-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo codegood/Llama3-Aloe-8B-Alpha-Q4_K_M-GGUF --hf-file llama3-aloe-8b-alpha-q4_k_m.gguf -c 2048
```
|
[
"MEDQA",
"PUBMEDQA"
] |
Coco-18/mms-asr-tgl-en-safetensor
|
Coco-18
| null |
[
"safetensors",
"wav2vec2",
"mms",
"ab",
"af",
"ak",
"am",
"ar",
"as",
"av",
"ay",
"az",
"ba",
"bm",
"be",
"bn",
"bi",
"bo",
"sh",
"br",
"bg",
"ca",
"cs",
"ce",
"cv",
"ku",
"cy",
"da",
"de",
"dv",
"dz",
"el",
"en",
"eo",
"et",
"eu",
"ee",
"fo",
"fa",
"fj",
"fi",
"fr",
"fy",
"ff",
"ga",
"gl",
"gn",
"gu",
"zh",
"ht",
"ha",
"he",
"hi",
"hu",
"hy",
"ig",
"ia",
"ms",
"is",
"it",
"jv",
"ja",
"kn",
"ka",
"kk",
"kr",
"km",
"ki",
"rw",
"ky",
"ko",
"kv",
"lo",
"la",
"lv",
"ln",
"lt",
"lb",
"lg",
"mh",
"ml",
"mr",
"mk",
"mg",
"mt",
"mn",
"mi",
"my",
"nl",
"no",
"ne",
"ny",
"oc",
"om",
"or",
"os",
"pa",
"pl",
"pt",
"ps",
"qu",
"ro",
"rn",
"ru",
"sg",
"sk",
"sl",
"sm",
"sn",
"sd",
"so",
"es",
"sq",
"su",
"sv",
"sw",
"ta",
"tt",
"te",
"tg",
"tl",
"th",
"ti",
"ts",
"tr",
"uk",
"vi",
"wo",
"xh",
"yo",
"zu",
"za",
"dataset:google/fleurs",
"arxiv:2305.13516",
"license:cc-by-nc-4.0",
"region:us"
] | 2025-03-14T10:04:48Z |
2025-03-14T10:19:14+00:00
| 60 | 0 |
---
datasets:
- google/fleurs
language:
- ab
- af
- ak
- am
- ar
- as
- av
- ay
- az
- ba
- bm
- be
- bn
- bi
- bo
- sh
- br
- bg
- ca
- cs
- ce
- cv
- ku
- cy
- da
- de
- dv
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fa
- fj
- fi
- fr
- fy
- ff
- ga
- gl
- gn
- gu
- zh
- ht
- ha
- he
- hi
- sh
- hu
- hy
- ig
- ia
- ms
- is
- it
- jv
- ja
- kn
- ka
- kk
- kr
- km
- ki
- rw
- ky
- ko
- kv
- lo
- la
- lv
- ln
- lt
- lb
- lg
- mh
- ml
- mr
- ms
- mk
- mg
- mt
- mn
- mi
- my
- zh
- nl
- 'no'
- 'no'
- ne
- ny
- oc
- om
- or
- os
- pa
- pl
- pt
- ms
- ps
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- ro
- rn
- ru
- sg
- sk
- sl
- sm
- sn
- sd
- so
- es
- sq
- su
- sv
- sw
- ta
- tt
- te
- tg
- tl
- th
- ti
- ts
- tr
- uk
- ms
- vi
- wo
- xh
- ms
- yo
- ms
- zu
- za
license: cc-by-nc-4.0
metrics:
- wer
tags:
- mms
---
# Massively Multilingual Speech (MMS) - Finetuned ASR - ALL
This checkpoint is a model fine-tuned for multi-lingual ASR and part of Facebook's [Massive Multilingual Speech project](https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/).
This checkpoint is based on the [Wav2Vec2 architecture](https://huggingface.co/docs/transformers/model_doc/wav2vec2) and makes use of adapter models to transcribe 1000+ languages.
The checkpoint consists of **1 billion parameters** and has been fine-tuned from [facebook/mms-1b](https://huggingface.co/facebook/mms-1b) on 1162 languages.
## Table Of Content
- [Example](#example)
- [Supported Languages](#supported-languages)
- [Model details](#model-details)
- [Additional links](#additional-links)
## Example
This MMS checkpoint can be used with [Transformers](https://github.com/huggingface/transformers) to transcribe audio of 1107 different
languages. Let's look at a simple example.
First, we install transformers and some other libraries
```
pip install torch accelerate torchaudio datasets
pip install --upgrade transformers
````
**Note**: In order to use MMS you need to have at least `transformers >= 4.30` installed. If the `4.30` version
is not yet available [on PyPI](https://pypi.org/project/transformers/) make sure to install `transformers` from
source:
```
pip install git+https://github.com/huggingface/transformers.git
```
Next, we load a couple of audio samples via `datasets`. Make sure that the audio data is sampled to 16000 kHz.
```py
from datasets import load_dataset, Audio
# English
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "en", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
en_sample = next(iter(stream_data))["audio"]["array"]
# French
stream_data = load_dataset("mozilla-foundation/common_voice_13_0", "fr", split="test", streaming=True)
stream_data = stream_data.cast_column("audio", Audio(sampling_rate=16000))
fr_sample = next(iter(stream_data))["audio"]["array"]
```
Next, we load the model and processor
```py
from transformers import Wav2Vec2ForCTC, AutoProcessor
import torch
model_id = "facebook/mms-1b-all"
processor = AutoProcessor.from_pretrained(model_id)
model = Wav2Vec2ForCTC.from_pretrained(model_id)
```
Now we process the audio data, pass the processed audio data to the model and transcribe the model output, just like we usually do for Wav2Vec2 models such as [facebook/wav2vec2-base-960h](https://huggingface.co/facebook/wav2vec2-base-960h)
```py
inputs = processor(en_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
ids = torch.argmax(outputs, dim=-1)[0]
transcription = processor.decode(ids)
# 'joe keton disapproved of films and buster also had reservations about the media'
```
We can now keep the same model in memory and simply switch out the language adapters by calling the convenient [`load_adapter()`]() function for the model and [`set_target_lang()`]() for the tokenizer. We pass the target language as an input - "fra" for French.
```py
processor.tokenizer.set_target_lang("fra")
model.load_adapter("fra")
inputs = processor(fr_sample, sampling_rate=16_000, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs).logits
ids = torch.argmax(outputs, dim=-1)[0]
transcription = processor.decode(ids)
# "ce dernier est volé tout au long de l'histoire romaine"
```
In the same way the language can be switched out for all other supported languages. Please have a look at:
```py
processor.tokenizer.vocab.keys()
```
For more details, please have a look at [the official docs](https://huggingface.co/docs/transformers/main/en/model_doc/mms).
## Supported Languages
This model supports 1162 languages. Unclick the following to toogle all supported languages of this checkpoint in [ISO 639-3 code](https://en.wikipedia.org/wiki/ISO_639-3).
You can find more details about the languages and their ISO 649-3 codes in the [MMS Language Coverage Overview](https://dl.fbaipublicfiles.com/mms/misc/language_coverage_mms.html).
<details>
<summary>Click to toggle</summary>
- abi
- abk
- abp
- aca
- acd
- ace
- acf
- ach
- acn
- acr
- acu
- ade
- adh
- adj
- adx
- aeu
- afr
- agd
- agg
- agn
- agr
- agu
- agx
- aha
- ahk
- aia
- aka
- akb
- ake
- akp
- alj
- alp
- alt
- alz
- ame
- amf
- amh
- ami
- amk
- ann
- any
- aoz
- apb
- apr
- ara
- arl
- asa
- asg
- asm
- ast
- ata
- atb
- atg
- ati
- atq
- ava
- avn
- avu
- awa
- awb
- ayo
- ayr
- ayz
- azb
- azg
- azj-script_cyrillic
- azj-script_latin
- azz
- bak
- bam
- ban
- bao
- bas
- bav
- bba
- bbb
- bbc
- bbo
- bcc-script_arabic
- bcc-script_latin
- bcl
- bcw
- bdg
- bdh
- bdq
- bdu
- bdv
- beh
- bel
- bem
- ben
- bep
- bex
- bfa
- bfo
- bfy
- bfz
- bgc
- bgq
- bgr
- bgt
- bgw
- bha
- bht
- bhz
- bib
- bim
- bis
- biv
- bjr
- bjv
- bjw
- bjz
- bkd
- bkv
- blh
- blt
- blx
- blz
- bmq
- bmr
- bmu
- bmv
- bng
- bno
- bnp
- boa
- bod
- boj
- bom
- bor
- bos
- bov
- box
- bpr
- bps
- bqc
- bqi
- bqj
- bqp
- bre
- bru
- bsc
- bsq
- bss
- btd
- bts
- btt
- btx
- bud
- bul
- bus
- bvc
- bvz
- bwq
- bwu
- byr
- bzh
- bzi
- bzj
- caa
- cab
- cac-dialect_sanmateoixtatan
- cac-dialect_sansebastiancoatan
- cak-dialect_central
- cak-dialect_santamariadejesus
- cak-dialect_santodomingoxenacoj
- cak-dialect_southcentral
- cak-dialect_western
- cak-dialect_yepocapa
- cap
- car
- cas
- cat
- cax
- cbc
- cbi
- cbr
- cbs
- cbt
- cbu
- cbv
- cce
- cco
- cdj
- ceb
- ceg
- cek
- ces
- cfm
- cgc
- che
- chf
- chv
- chz
- cjo
- cjp
- cjs
- ckb
- cko
- ckt
- cla
- cle
- cly
- cme
- cmn-script_simplified
- cmo-script_khmer
- cmo-script_latin
- cmr
- cnh
- cni
- cnl
- cnt
- coe
- cof
- cok
- con
- cot
- cou
- cpa
- cpb
- cpu
- crh
- crk-script_latin
- crk-script_syllabics
- crn
- crq
- crs
- crt
- csk
- cso
- ctd
- ctg
- cto
- ctu
- cuc
- cui
- cuk
- cul
- cwa
- cwe
- cwt
- cya
- cym
- daa
- dah
- dan
- dar
- dbj
- dbq
- ddn
- ded
- des
- deu
- dga
- dgi
- dgk
- dgo
- dgr
- dhi
- did
- dig
- dik
- dip
- div
- djk
- dnj-dialect_blowowest
- dnj-dialect_gweetaawueast
- dnt
- dnw
- dop
- dos
- dsh
- dso
- dtp
- dts
- dug
- dwr
- dyi
- dyo
- dyu
- dzo
- eip
- eka
- ell
- emp
- enb
- eng
- enx
- epo
- ese
- ess
- est
- eus
- evn
- ewe
- eza
- fal
- fao
- far
- fas
- fij
- fin
- flr
- fmu
- fon
- fra
- frd
- fry
- ful
- gag-script_cyrillic
- gag-script_latin
- gai
- gam
- gau
- gbi
- gbk
- gbm
- gbo
- gde
- geb
- gej
- gil
- gjn
- gkn
- gld
- gle
- glg
- glk
- gmv
- gna
- gnd
- gng
- gof-script_latin
- gog
- gor
- gqr
- grc
- gri
- grn
- grt
- gso
- gub
- guc
- gud
- guh
- guj
- guk
- gum
- guo
- guq
- guu
- gux
- gvc
- gvl
- gwi
- gwr
- gym
- gyr
- had
- hag
- hak
- hap
- hat
- hau
- hay
- heb
- heh
- hif
- hig
- hil
- hin
- hlb
- hlt
- hne
- hnn
- hns
- hoc
- hoy
- hrv
- hsb
- hto
- hub
- hui
- hun
- hus-dialect_centralveracruz
- hus-dialect_westernpotosino
- huu
- huv
- hvn
- hwc
- hye
- hyw
- iba
- ibo
- icr
- idd
- ifa
- ifb
- ife
- ifk
- ifu
- ify
- ign
- ikk
- ilb
- ilo
- imo
- ina
- inb
- ind
- iou
- ipi
- iqw
- iri
- irk
- isl
- ita
- itl
- itv
- ixl-dialect_sangasparchajul
- ixl-dialect_sanjuancotzal
- ixl-dialect_santamarianebaj
- izr
- izz
- jac
- jam
- jav
- jbu
- jen
- jic
- jiv
- jmc
- jmd
- jpn
- jun
- juy
- jvn
- kaa
- kab
- kac
- kak
- kam
- kan
- kao
- kaq
- kat
- kay
- kaz
- kbo
- kbp
- kbq
- kbr
- kby
- kca
- kcg
- kdc
- kde
- kdh
- kdi
- kdj
- kdl
- kdn
- kdt
- kea
- kek
- ken
- keo
- ker
- key
- kez
- kfb
- kff-script_telugu
- kfw
- kfx
- khg
- khm
- khq
- kia
- kij
- kik
- kin
- kir
- kjb
- kje
- kjg
- kjh
- kki
- kkj
- kle
- klu
- klv
- klw
- kma
- kmd
- kml
- kmr-script_arabic
- kmr-script_cyrillic
- kmr-script_latin
- kmu
- knb
- kne
- knf
- knj
- knk
- kno
- kog
- kor
- kpq
- kps
- kpv
- kpy
- kpz
- kqe
- kqp
- kqr
- kqy
- krc
- kri
- krj
- krl
- krr
- krs
- kru
- ksb
- ksr
- kss
- ktb
- ktj
- kub
- kue
- kum
- kus
- kvn
- kvw
- kwd
- kwf
- kwi
- kxc
- kxf
- kxm
- kxv
- kyb
- kyc
- kyf
- kyg
- kyo
- kyq
- kyu
- kyz
- kzf
- lac
- laj
- lam
- lao
- las
- lat
- lav
- law
- lbj
- lbw
- lcp
- lee
- lef
- lem
- lew
- lex
- lgg
- lgl
- lhu
- lia
- lid
- lif
- lin
- lip
- lis
- lit
- lje
- ljp
- llg
- lln
- lme
- lnd
- lns
- lob
- lok
- lom
- lon
- loq
- lsi
- lsm
- ltz
- luc
- lug
- luo
- lwo
- lww
- lzz
- maa-dialect_sanantonio
- maa-dialect_sanjeronimo
- mad
- mag
- mah
- mai
- maj
- mak
- mal
- mam-dialect_central
- mam-dialect_northern
- mam-dialect_southern
- mam-dialect_western
- maq
- mar
- maw
- maz
- mbb
- mbc
- mbh
- mbj
- mbt
- mbu
- mbz
- mca
- mcb
- mcd
- mco
- mcp
- mcq
- mcu
- mda
- mdf
- mdv
- mdy
- med
- mee
- mej
- men
- meq
- met
- mev
- mfe
- mfh
- mfi
- mfk
- mfq
- mfy
- mfz
- mgd
- mge
- mgh
- mgo
- mhi
- mhr
- mhu
- mhx
- mhy
- mib
- mie
- mif
- mih
- mil
- mim
- min
- mio
- mip
- miq
- mit
- miy
- miz
- mjl
- mjv
- mkd
- mkl
- mkn
- mlg
- mlt
- mmg
- mnb
- mnf
- mnk
- mnw
- mnx
- moa
- mog
- mon
- mop
- mor
- mos
- mox
- moz
- mpg
- mpm
- mpp
- mpx
- mqb
- mqf
- mqj
- mqn
- mri
- mrw
- msy
- mtd
- mtj
- mto
- muh
- mup
- mur
- muv
- muy
- mvp
- mwq
- mwv
- mxb
- mxq
- mxt
- mxv
- mya
- myb
- myk
- myl
- myv
- myx
- myy
- mza
- mzi
- mzj
- mzk
- mzm
- mzw
- nab
- nag
- nan
- nas
- naw
- nca
- nch
- ncj
- ncl
- ncu
- ndj
- ndp
- ndv
- ndy
- ndz
- neb
- new
- nfa
- nfr
- nga
- ngl
- ngp
- ngu
- nhe
- nhi
- nhu
- nhw
- nhx
- nhy
- nia
- nij
- nim
- nin
- nko
- nlc
- nld
- nlg
- nlk
- nmz
- nnb
- nno
- nnq
- nnw
- noa
- nob
- nod
- nog
- not
- npi
- npl
- npy
- nso
- nst
- nsu
- ntm
- ntr
- nuj
- nus
- nuz
- nwb
- nxq
- nya
- nyf
- nyn
- nyo
- nyy
- nzi
- obo
- oci
- ojb-script_latin
- ojb-script_syllabics
- oku
- old
- omw
- onb
- ood
- orm
- ory
- oss
- ote
- otq
- ozm
- pab
- pad
- pag
- pam
- pan
- pao
- pap
- pau
- pbb
- pbc
- pbi
- pce
- pcm
- peg
- pez
- pib
- pil
- pir
- pis
- pjt
- pkb
- pls
- plw
- pmf
- pny
- poh-dialect_eastern
- poh-dialect_western
- poi
- pol
- por
- poy
- ppk
- pps
- prf
- prk
- prt
- pse
- pss
- ptu
- pui
- pus
- pwg
- pww
- pxm
- qub
- quc-dialect_central
- quc-dialect_east
- quc-dialect_north
- quf
- quh
- qul
- quw
- quy
- quz
- qvc
- qve
- qvh
- qvm
- qvn
- qvo
- qvs
- qvw
- qvz
- qwh
- qxh
- qxl
- qxn
- qxo
- qxr
- rah
- rai
- rap
- rav
- raw
- rej
- rel
- rgu
- rhg
- rif-script_arabic
- rif-script_latin
- ril
- rim
- rjs
- rkt
- rmc-script_cyrillic
- rmc-script_latin
- rmo
- rmy-script_cyrillic
- rmy-script_latin
- rng
- rnl
- roh-dialect_sursilv
- roh-dialect_vallader
- rol
- ron
- rop
- rro
- rub
- ruf
- rug
- run
- rus
- sab
- sag
- sah
- saj
- saq
- sas
- sat
- sba
- sbd
- sbl
- sbp
- sch
- sck
- sda
- sea
- seh
- ses
- sey
- sgb
- sgj
- sgw
- shi
- shk
- shn
- sho
- shp
- sid
- sig
- sil
- sja
- sjm
- sld
- slk
- slu
- slv
- sml
- smo
- sna
- snd
- sne
- snn
- snp
- snw
- som
- soy
- spa
- spp
- spy
- sqi
- sri
- srm
- srn
- srp-script_cyrillic
- srp-script_latin
- srx
- stn
- stp
- suc
- suk
- sun
- sur
- sus
- suv
- suz
- swe
- swh
- sxb
- sxn
- sya
- syl
- sza
- tac
- taj
- tam
- tao
- tap
- taq
- tat
- tav
- tbc
- tbg
- tbk
- tbl
- tby
- tbz
- tca
- tcc
- tcs
- tcz
- tdj
- ted
- tee
- tel
- tem
- teo
- ter
- tes
- tew
- tex
- tfr
- tgj
- tgk
- tgl
- tgo
- tgp
- tha
- thk
- thl
- tih
- tik
- tir
- tkr
- tlb
- tlj
- tly
- tmc
- tmf
- tna
- tng
- tnk
- tnn
- tnp
- tnr
- tnt
- tob
- toc
- toh
- tom
- tos
- tpi
- tpm
- tpp
- tpt
- trc
- tri
- trn
- trs
- tso
- tsz
- ttc
- tte
- ttq-script_tifinagh
- tue
- tuf
- tuk-script_arabic
- tuk-script_latin
- tuo
- tur
- tvw
- twb
- twe
- twu
- txa
- txq
- txu
- tye
- tzh-dialect_bachajon
- tzh-dialect_tenejapa
- tzj-dialect_eastern
- tzj-dialect_western
- tzo-dialect_chamula
- tzo-dialect_chenalho
- ubl
- ubu
- udm
- udu
- uig-script_arabic
- uig-script_cyrillic
- ukr
- umb
- unr
- upv
- ura
- urb
- urd-script_arabic
- urd-script_devanagari
- urd-script_latin
- urk
- urt
- ury
- usp
- uzb-script_cyrillic
- uzb-script_latin
- vag
- vid
- vie
- vif
- vmw
- vmy
- vot
- vun
- vut
- wal-script_ethiopic
- wal-script_latin
- wap
- war
- waw
- way
- wba
- wlo
- wlx
- wmw
- wob
- wol
- wsg
- wwa
- xal
- xdy
- xed
- xer
- xho
- xmm
- xnj
- xnr
- xog
- xon
- xrb
- xsb
- xsm
- xsr
- xsu
- xta
- xtd
- xte
- xtm
- xtn
- xua
- xuo
- yaa
- yad
- yal
- yam
- yao
- yas
- yat
- yaz
- yba
- ybb
- ycl
- ycn
- yea
- yka
- yli
- yor
- yre
- yua
- yue-script_traditional
- yuz
- yva
- zaa
- zab
- zac
- zad
- zae
- zai
- zam
- zao
- zaq
- zar
- zas
- zav
- zaw
- zca
- zga
- zim
- ziw
- zlm
- zmz
- zne
- zos
- zpc
- zpg
- zpi
- zpl
- zpm
- zpo
- zpt
- zpu
- zpz
- ztq
- zty
- zul
- zyb
- zyp
- zza
</details>
## Model details
- **Developed by:** Vineel Pratap et al.
- **Model type:** Multi-Lingual Automatic Speech Recognition model
- **Language(s):** 1000+ languages, see [supported languages](#supported-languages)
- **License:** CC-BY-NC 4.0 license
- **Num parameters**: 1 billion
- **Audio sampling rate**: 16,000 kHz
- **Cite as:**
@article{pratap2023mms,
title={Scaling Speech Technology to 1,000+ Languages},
author={Vineel Pratap and Andros Tjandra and Bowen Shi and Paden Tomasello and Arun Babu and Sayani Kundu and Ali Elkahky and Zhaoheng Ni and Apoorv Vyas and Maryam Fazel-Zarandi and Alexei Baevski and Yossi Adi and Xiaohui Zhang and Wei-Ning Hsu and Alexis Conneau and Michael Auli},
journal={arXiv},
year={2023}
}
## Additional Links
- [Blog post](https://ai.facebook.com/blog/multilingual-model-speech-recognition/)
- [Transformers documentation](https://huggingface.co/docs/transformers/main/en/model_doc/mms).
- [Paper](https://arxiv.org/abs/2305.13516)
- [GitHub Repository](https://github.com/facebookresearch/fairseq/tree/main/examples/mms#asr)
- [Other **MMS** checkpoints](https://huggingface.co/models?other=mms)
- MMS base checkpoints:
- [facebook/mms-1b](https://huggingface.co/facebook/mms-1b)
- [facebook/mms-300m](https://huggingface.co/facebook/mms-300m)
- [Official Space](https://huggingface.co/spaces/facebook/MMS)
|
[
"CAS"
] |
ntc-ai/SDXL-LoRA-slider.cartoon
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-17T01:31:56Z |
2024-02-06T00:34:13+00:00
| 59 | 1 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/cartoon_17_3.0.png
widget:
- text: cartoon
output:
url: images/cartoon_17_3.0.png
- text: cartoon
output:
url: images/cartoon_19_3.0.png
- text: cartoon
output:
url: images/cartoon_20_3.0.png
- text: cartoon
output:
url: images/cartoon_21_3.0.png
- text: cartoon
output:
url: images/cartoon_22_3.0.png
inference: false
instance_prompt: cartoon
---
# ntcai.xyz slider - cartoon (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/cartoon_17_-3.0.png" width=256 height=256 /> | <img src="images/cartoon_17_0.0.png" width=256 height=256 /> | <img src="images/cartoon_17_3.0.png" width=256 height=256 /> |
| <img src="images/cartoon_19_-3.0.png" width=256 height=256 /> | <img src="images/cartoon_19_0.0.png" width=256 height=256 /> | <img src="images/cartoon_19_3.0.png" width=256 height=256 /> |
| <img src="images/cartoon_20_-3.0.png" width=256 height=256 /> | <img src="images/cartoon_20_0.0.png" width=256 height=256 /> | <img src="images/cartoon_20_3.0.png" width=256 height=256 /> |
See more at [https://sliders.ntcai.xyz/sliders/app/loras/d9ac2820-c96e-4e2e-a167-6922f1998a27](https://sliders.ntcai.xyz/sliders/app/loras/d9ac2820-c96e-4e2e-a167-6922f1998a27)
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
cartoon
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.cartoon', weight_name='cartoon.safetensors', adapter_name="cartoon")
# Activate the LoRA
pipe.set_adapters(["cartoon"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, cartoon"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1496+ unique and diverse LoRAs along with 14602+ slider merges, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful <strong>NTC Slider Factory</strong> LoRA creator, allowing you to craft your own custom LoRAs and merges opening up endless possibilities.
Your support on Patreon will allow us to continue developing new models and tools.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.high-contrast
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-22T16:41:53Z |
2023-12-22T16:41:55+00:00
| 59 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/high contrast.../high contrast_17_3.0.png
widget:
- text: high contrast
output:
url: images/high contrast_17_3.0.png
- text: high contrast
output:
url: images/high contrast_19_3.0.png
- text: high contrast
output:
url: images/high contrast_20_3.0.png
- text: high contrast
output:
url: images/high contrast_21_3.0.png
- text: high contrast
output:
url: images/high contrast_22_3.0.png
inference: false
instance_prompt: high contrast
---
# ntcai.xyz slider - high contrast (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/high contrast_17_-3.0.png" width=256 height=256 /> | <img src="images/high contrast_17_0.0.png" width=256 height=256 /> | <img src="images/high contrast_17_3.0.png" width=256 height=256 /> |
| <img src="images/high contrast_19_-3.0.png" width=256 height=256 /> | <img src="images/high contrast_19_0.0.png" width=256 height=256 /> | <img src="images/high contrast_19_3.0.png" width=256 height=256 /> |
| <img src="images/high contrast_20_-3.0.png" width=256 height=256 /> | <img src="images/high contrast_20_0.0.png" width=256 height=256 /> | <img src="images/high contrast_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
high contrast
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.high-contrast', weight_name='high contrast.safetensors', adapter_name="high contrast")
# Activate the LoRA
pipe.set_adapters(["high contrast"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, high contrast"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 550+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
QuantFactory/Llama3-OpenBioLLM-8B-GGUF
|
QuantFactory
| null |
[
"gguf",
"llama-3",
"llama",
"Mixtral",
"instruct",
"finetune",
"chatml",
"DPO",
"RLHF",
"gpt4",
"distillation",
"en",
"arxiv:2305.18290",
"arxiv:2303.13375",
"arxiv:2212.13138",
"arxiv:2305.09617",
"arxiv:2402.07023",
"base_model:meta-llama/Meta-Llama-3-8B",
"base_model:quantized:meta-llama/Meta-Llama-3-8B",
"license:llama3",
"endpoints_compatible",
"region:us"
] | 2024-09-22T14:40:36Z |
2024-09-22T15:48:45+00:00
| 59 | 1 |
---
base_model: meta-llama/Meta-Llama-3-8B
language:
- en
license: llama3
tags:
- llama-3
- llama
- Mixtral
- instruct
- finetune
- chatml
- DPO
- RLHF
- gpt4
- distillation
widget:
- example_title: OpenBioLLM-8B
messages:
- role: system
content: You are an expert and experienced from the healthcare and biomedical
domain with extensive medical knowledge and practical experience.
- role: user
content: How long does it take for newborn jaundice to go away?
output:
text: 'Newborn jaundice, also known as neonatal jaundice, is a common condition
in newborns where the yellowing of the skin and eyes occurs due to an elevated
level of bilirubin in the blood. Bilirubin is a yellow pigment that forms when
red blood cells break down. In most cases, newborn jaundice resolves on its
own without any specific treatment.
The duration of newborn jaundice can vary depending on several factors such
as the underlying cause, gestational age at birth, and individual variations
in bilirubin metabolism. Here are some general guidelines:
1. Physiological jaundice: This is the most common type of newborn jaundice
and usually appears within 24-72 hours after birth. It tends to peak between
the second and fifth day of life and gradually improves over the next week or
two. By the time the baby is one week old, the jaundice should have mostly resolved.
2. Breast milk jaundice: This type of jaundice occurs in breastfed babies and
may appear later than physiological jaundice, typically between the fifth and
fourteenth day of life. It tends to persist for a longer duration but usually
resolves within six weeks after birth. 3. Pathological jaundice: This type of
jaundice is less common and occurs due to an underlying medical condition that
affects bilirubin metabolism or liver function. The duration of pathological
jaundice depends on the specific cause and may require treatment.
It''s important for parents to monitor their newborn''s jaundice closely and
seek medical advice if the jaundice progresses rapidly, becomes severe, or is
accompanied by other symptoms such as poor feeding, lethargy, or excessive sleepiness.
In these cases, further evaluation and management may be necessary. Remember
that each baby is unique, and the timing of jaundice resolution can vary. If
you have concerns about your newborn''s jaundice, it''s always best to consult
with a healthcare professional for personalized advice and guidance.'
model-index:
- name: OpenBioLLM-8B
results: []
---
[](https://hf.co/QuantFactory)
# QuantFactory/Llama3-OpenBioLLM-8B-GGUF
This is quantized version of [aaditya/Llama3-OpenBioLLM-8B](https://huggingface.co/aaditya/Llama3-OpenBioLLM-8B) created using llama.cpp
# Original Model Card
<div align="center">
<img width="260px" src="https://hf.fast360.xyz/production/uploads/5f3fe13d79c1ba4c353d0c19/BrQCb95lmEIFz79QAmoNA.png"></div>

<div align="center">
<h1>Advancing Open-source Large Language Models in Medical Domain</h1>
</div>
<p align="center" style="margin-top: 0px;">
<a href="https://colab.research.google.com/drive/1F5oV20InEYeAJGmBwYF9NM_QhLmjBkKJ?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="OpenChat Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 10px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text" style=" margin-right: 5px;">Online Demo</span>
</a> |
<a href="https://github.com/openlifescience-ai">
<img src="https://github.githubassets.com/assets/GitHub-Mark-ea2971cee799.png" alt="GitHub Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text" style=" margin-right: 5px;">GitHub</span>
</a> |
<a href="#">
<img src="https://github.com/alpayariyak/openchat/blob/master/assets/arxiv-logomark-small-square-border.png?raw=true" alt="ArXiv Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text" style="margin-right: 5px;">Paper</span>
</a> |
<a href="https://discord.gg/A5Fjf5zC69">
<img src="https://cloud.githubusercontent.com/assets/6291467/26705903/96c2d66e-477c-11e7-9f4e-f3c0efe96c9a.png" alt="Discord Logo" style="width:20px; vertical-align: middle; display: inline-block; margin-right: 5px; margin-left: 5px; margin-top: 0px; margin-bottom: 0px;"/>
<span class="link-text">Discord</span>
</a>
</p>

Introducing OpenBioLLM-8B: A State-of-the-Art Open Source Biomedical Large Language Model
OpenBioLLM-8B is an advanced open source language model designed specifically for the biomedical domain. Developed by Saama AI Labs, this model leverages cutting-edge techniques to achieve state-of-the-art performance on a wide range of biomedical tasks.
🏥 **Biomedical Specialization**: OpenBioLLM-8B is tailored for the unique language and knowledge requirements of the medical and life sciences fields. It was fine-tuned on a vast corpus of high-quality biomedical data, enabling it to understand and generate text with domain-specific accuracy and fluency.
🎓 **Superior Performance**: With 8 billion parameters, OpenBioLLM-8B outperforms other open source biomedical language models of similar scale. It has also demonstrated better results compared to larger proprietary & open-source models like GPT-3.5 and Meditron-70B on biomedical benchmarks.
🧠 **Advanced Training Techniques**: OpenBioLLM-8B builds upon the powerful foundations of the **Meta-Llama-3-8B** and [Meta-Llama-3-8B](meta-llama/Meta-Llama-3-8B) models. It incorporates the DPO dataset and fine-tuning recipe along with a custom diverse medical instruction dataset. Key components of the training pipeline include:
<div align="center">
<img width="1200px" src="https://hf.fast360.xyz/production/uploads/5f3fe13d79c1ba4c353d0c19/oPchsJsEpQoGcGXVbh7YS.png">
</div>
- **Policy Optimization**: [Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO)](https://arxiv.org/abs/2305.18290)
- **Ranking Dataset**: [berkeley-nest/Nectar](https://huggingface.co/datasets/berkeley-nest/Nectar)
- **Fine-tuning dataset**: Custom Medical Instruct dataset (We plan to release a sample training dataset in our upcoming paper; please stay updated)
This combination of cutting-edge techniques enables OpenBioLLM-8B to align with key capabilities and preferences for biomedical applications.
⚙️ **Release Details**:
- **Model Size**: 8 billion parameters
- **Quantization**: Optimized quantized versions available [Here](https://huggingface.co/aaditya/OpenBioLLM-Llama3-8B-GGUF)
- **Language(s) (NLP):** en
- **Developed By**: [Ankit Pal (Aaditya Ura)](https://aadityaura.github.io/) from Saama AI Labs
- **License:** Meta-Llama License
- **Fine-tuned from models:** [meta-llama/Meta-Llama-3-8B](meta-llama/Meta-Llama-3-8B)
- **Resources for more information:**
- Paper: Coming soon
The model can be fine-tuned for more specialized tasks and datasets as needed.
OpenBioLLM-8B represents an important step forward in democratizing advanced language AI for the biomedical community. By leveraging state-of-the-art architectures and training techniques from leading open source efforts like Llama-3, we have created a powerful tool to accelerate innovation and discovery in healthcare and the life sciences.
We are excited to share OpenBioLLM-8B with researchers and developers around the world.
### Use with transformers
**Important: Please use the exact chat template provided by Llama-3 instruct version. Otherwise there will be a degradation in the performance. The model output can be verbose in rare cases. Please consider setting temperature = 0 to make this happen less.**
See the snippet below for usage with Transformers:
```python
import transformers
import torch
model_id = "aaditya/OpenBioLLM-Llama3-8B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="auto",
)
messages = [
{"role": "system", "content": "You are an expert and experienced from the healthcare and biomedical domain with extensive medical knowledge and practical experience. Your name is OpenBioLLM, and you were developed by Saama AI Labs. who's willing to help answer the user's query with explanation. In your explanation, leverage your deep medical expertise such as relevant anatomical structures, physiological processes, diagnostic criteria, treatment guidelines, or other pertinent medical concepts. Use precise medical terminology while still aiming to make the explanation clear and accessible to a general audience."},
{"role": "user", "content": "How can i split a 3mg or 4mg waefin pill so i can get a 2.5mg pill?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.0,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
## **Training procedure**
### **Training hyperparameters**
<details>
<summary>Click to see details</summary>
- learning_rate: 0.0002
- lr_scheduler: cosine
- train_batch_size: 12
- eval_batch_size: 8
- GPU: H100 80GB SXM5
- num_devices: 1
- optimizer: adamw_bnb_8bit
- lr_scheduler_warmup_steps: 100
- num_epochs: 4
</details>
### **Peft hyperparameters**
<details>
<summary>Click to see details</summary>
- adapter: qlora
- lora_r: 128
- lora_alpha: 256
- lora_dropout: 0.05
- lora_target_linear: true
-lora_target_modules:
- q_proj
- v_proj
- k_proj
- o_proj
- gate_proj
- down_proj
- up_proj
</details>
### **Training results**
### **Framework versions**
- Transformers 4.39.3
- Pytorch 2.1.2+cu121
- Datasets 2.18.0
- Tokenizers 0.15.1
- Axolotl
- Lm harness for evaluation
# Benchmark Results
🔥 OpenBioLLM-8B demonstrates superior performance compared to larger models, such as GPT-3.5, Meditron-70B across 9 diverse biomedical datasets, achieving state-of-the-art results with an average score of 72.50%, despite having a significantly smaller parameter count. The model's strong performance in domain-specific tasks, such as Clinical KG, Medical Genetics, and PubMedQA, highlights its ability to effectively capture and apply biomedical knowledge.
🚨 The GPT-4, Med-PaLM-1, and Med-PaLM-2 results are taken from their official papers. Since Med-PaLM doesn't provide zero-shot accuracy, we are using 5-shot accuracy from their paper for comparison. All results presented are in the zero-shot setting, except for Med-PaLM-2 and Med-PaLM-1, which use 5-shot accuracy.
| | Clinical KG | Medical Genetics | Anatomy | Pro Medicine | College Biology | College Medicine | MedQA 4 opts | PubMedQA | MedMCQA | Avg |
|--------------------|-------------|------------------|---------|--------------|-----------------|------------------|--------------|----------|---------|-------|
| **OpenBioLLM-70B** | **92.93** | **93.197** | **83.904** | 93.75 | 93.827 | **85.749** | 78.162 | 78.97 | **74.014** | **86.05588** |
| Med-PaLM-2 (5-shot) | 88.3 | 90 | 77.8 | **95.2** | 94.4 | 80.9 | **79.7** | **79.2** | 71.3 | 84.08 |
| **GPT-4** | 86.04 | 91 | 80 | 93.01 | **95.14** | 76.88 | 78.87 | 75.2 | 69.52 | 82.85 |
| Med-PaLM-1 (Flan-PaLM, 5-shot) | 80.4 | 75 | 63.7 | 83.8 | 88.9 | 76.3 | 67.6 | 79 | 57.6 | 74.7 |
| **OpenBioLLM-8B** | 76.101 | 86.1 | 69.829 | 78.21 | 84.213 | 68.042 | 58.993 | 74.12 | 56.913 | 72.502 |
| Gemini-1.0 | 76.7 | 75.8 | 66.7 | 77.7 | 88 | 69.2 | 58 | 70.7 | 54.3 | 70.79 |
| GPT-3.5 Turbo 1106 | 74.71 | 74 | 72.79 | 72.79 | 72.91 | 64.73 | 57.71 | 72.66 | 53.79 | 66 |
| Meditron-70B | 66.79 | 69 | 53.33 | 71.69 | 76.38 | 63 | 57.1 | 76.6 | 46.85 | 64.52 |
| gemma-7b | 69.81 | 70 | 59.26 | 66.18 | 79.86 | 60.12 | 47.21 | 76.2 | 48.96 | 64.18 |
| Mistral-7B-v0.1 | 68.68 | 71 | 55.56 | 68.38 | 68.06 | 59.54 | 50.82 | 75.4 | 48.2 | 62.85 |
| Apollo-7B | 62.26 | 72 | 61.48 | 69.12 | 70.83 | 55.49 | 55.22 | 39.8 | 53.77 | 60 |
| MedAlpaca-7b | 57.36 | 69 | 57.04 | 67.28 | 65.28 | 54.34 | 41.71 | 72.8 | 37.51 | 58.03 |
| BioMistral-7B | 59.9 | 64 | 56.5 | 60.4 | 59 | 54.7 | 50.6 | 77.5 | 48.1 | 57.3 |
| AlpaCare-llama2-7b | 49.81 | 49 | 45.92 | 33.82 | 50 | 43.35 | 29.77 | 72.2 | 34.42 | 45.36 |
| ClinicalGPT | 30.56 | 27 | 30.37 | 19.48 | 25 | 24.27 | 26.08 | 63.8 | 28.18 | 30.52 |
<div align="center">
<img width="1600px" src="https://hf.fast360.xyz/production/uploads/5f3fe13d79c1ba4c353d0c19/_SzdcJSBjZyo8RS1bTEkP.png">
</div>
## Detailed Medical Subjectwise accuracy

# Use Cases & Examples
🚨 **Below results are from the quantized version of OpenBioLLM-70B**
# Summarize Clinical Notes
OpenBioLLM-70B can efficiently analyze and summarize complex clinical notes, EHR data, and discharge summaries, extracting key information and generating concise, structured summaries

# Answer Medical Questions
OpenBioLLM-70B can provide answers to a wide range of medical questions.


<details>
<summary>Click to see details</summary>



</details>
# Clinical Entity Recognition
OpenBioLLM-70B can perform advanced clinical entity recognition by identifying and extracting key medical concepts, such as diseases, symptoms, medications, procedures, and anatomical structures, from unstructured clinical text. By leveraging its deep understanding of medical terminology and context, the model can accurately annotate and categorize clinical entities, enabling more efficient information retrieval, data analysis, and knowledge discovery from electronic health records, research articles, and other biomedical text sources. This capability can support various downstream applications, such as clinical decision support, pharmacovigilance, and medical research.



# Biomarkers Extraction

# Classification
OpenBioLLM-70B can perform various biomedical classification tasks, such as disease prediction, sentiment analysis, medical document categorization

# De-Identification
OpenBioLLM-70B can detect and remove personally identifiable information (PII) from medical records, ensuring patient privacy and compliance with data protection regulations like HIPAA.

**Advisory Notice!**
While OpenBioLLM-70B & 8B leverages high-quality data sources, its outputs may still contain inaccuracies, biases, or misalignments that could pose risks if relied upon for medical decision-making without further testing and refinement. The model's performance has not yet been rigorously evaluated in randomized controlled trials or real-world healthcare environments.
Therefore, we strongly advise against using OpenBioLLM-70B & 8B for any direct patient care, clinical decision support, or other professional medical purposes at this time. Its use should be limited to research, development, and exploratory applications by qualified individuals who understand its limitations.
OpenBioLLM-70B & 8B are intended solely as a research tool to assist healthcare professionals and should never be considered a replacement for the professional judgment and expertise of a qualified medical doctor.
Appropriately adapting and validating OpenBioLLM-70B & 8B for specific medical use cases would require significant additional work, potentially including:
- Thorough testing and evaluation in relevant clinical scenarios
- Alignment with evidence-based guidelines and best practices
- Mitigation of potential biases and failure modes
- Integration with human oversight and interpretation
- Compliance with regulatory and ethical standards
Always consult a qualified healthcare provider for personal medical needs.
# Citation
If you find OpenBioLLM-70B & 8B useful in your work, please cite the model as follows:
```
@misc{OpenBioLLMs,
author = {Ankit Pal, Malaikannan Sankarasubbu},
title = {OpenBioLLMs: Advancing Open-Source Large Language Models for Healthcare and Life Sciences},
year = {2024},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/aaditya/OpenBioLLM-Llama3-70B}}
}
```
The accompanying paper is currently in progress and will be released soon.
<div align="center">
<h2> 💌 Contact </h2>
</div>
We look forward to hearing you and collaborating on this exciting project!
**Contributors:**
- [Ankit Pal (Aaditya Ura)](https://aadityaura.github.io/) [aadityaura at gmail dot com]
- Saama AI Labs
- Note: I am looking for a funded PhD opportunity, especially if it fits my Responsible Generative AI, Multimodal LLMs, Geometric Deep Learning, and Healthcare AI skillset.
# References
We thank the [Meta Team](meta-llama/Meta-Llama-3-70B-Instruct) for their amazing models!
Result sources
- [1] GPT-4 [Capabilities of GPT-4 on Medical Challenge Problems] (https://arxiv.org/abs/2303.13375)
- [2] Med-PaLM-1 [Large Language Models Encode Clinical Knowledge](https://arxiv.org/abs/2212.13138)
- [3] Med-PaLM-2 [Towards Expert-Level Medical Question Answering with Large Language Models](https://arxiv.org/abs/2305.09617)
- [4] Gemini-1.0 [Gemini Goes to Med School](https://arxiv.org/abs/2402.07023)
|
[
"MEDQA",
"PUBMEDQA"
] |
RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf
|
RichardErkhov
| null |
[
"gguf",
"region:us"
] | 2024-10-18T14:50:46Z |
2024-10-18T20:08:32+00:00
| 59 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
fusion-guide-12b-0.1 - GGUF
- Model creator: https://huggingface.co/fusionbase/
- Original model: https://huggingface.co/fusionbase/fusion-guide-12b-0.1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [fusion-guide-12b-0.1.Q2_K.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q2_K.gguf) | Q2_K | 4.27GB |
| [fusion-guide-12b-0.1.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.IQ3_XS.gguf) | IQ3_XS | 4.94GB |
| [fusion-guide-12b-0.1.IQ3_S.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.IQ3_S.gguf) | IQ3_S | 4.64GB |
| [fusion-guide-12b-0.1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q3_K_S.gguf) | Q3_K_S | 5.15GB |
| [fusion-guide-12b-0.1.IQ3_M.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.IQ3_M.gguf) | IQ3_M | 2.85GB |
| [fusion-guide-12b-0.1.Q3_K.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q3_K.gguf) | Q3_K | 5.67GB |
| [fusion-guide-12b-0.1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q3_K_M.gguf) | Q3_K_M | 5.67GB |
| [fusion-guide-12b-0.1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q3_K_L.gguf) | Q3_K_L | 6.11GB |
| [fusion-guide-12b-0.1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.IQ4_XS.gguf) | IQ4_XS | 6.33GB |
| [fusion-guide-12b-0.1.Q4_0.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q4_0.gguf) | Q4_0 | 6.59GB |
| [fusion-guide-12b-0.1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.IQ4_NL.gguf) | IQ4_NL | 6.65GB |
| [fusion-guide-12b-0.1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q4_K_S.gguf) | Q4_K_S | 6.63GB |
| [fusion-guide-12b-0.1.Q4_K.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q4_K.gguf) | Q4_K | 6.96GB |
| [fusion-guide-12b-0.1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q4_K_M.gguf) | Q4_K_M | 6.96GB |
| [fusion-guide-12b-0.1.Q4_1.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q4_1.gguf) | Q4_1 | 7.26GB |
| [fusion-guide-12b-0.1.Q5_0.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q5_0.gguf) | Q5_0 | 7.93GB |
| [fusion-guide-12b-0.1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q5_K_S.gguf) | Q5_K_S | 7.93GB |
| [fusion-guide-12b-0.1.Q5_K.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q5_K.gguf) | Q5_K | 8.13GB |
| [fusion-guide-12b-0.1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q5_K_M.gguf) | Q5_K_M | 8.13GB |
| [fusion-guide-12b-0.1.Q5_1.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q5_1.gguf) | Q5_1 | 8.61GB |
| [fusion-guide-12b-0.1.Q6_K.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q6_K.gguf) | Q6_K | 9.37GB |
| [fusion-guide-12b-0.1.Q8_0.gguf](https://huggingface.co/RichardErkhov/fusionbase_-_fusion-guide-12b-0.1-gguf/blob/main/fusion-guide-12b-0.1.Q8_0.gguf) | Q8_0 | 12.13GB |
Original model description:
---
base_model:
- mistralai/Mistral-Nemo-Instruct-2407
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- mistral
- trl
- cot
- guidance
---
# fusion-guide
[](https://postimg.cc/8jBrCNdH)
# Model Overview
fusion-guide is an advanced AI reasoning system built on the Mistral-Nemo 12bn architecture. It employs a two-model approach to enhance its problem-solving capabilities. This method involves a "Guide" model that generates a structured, step-by-step plan to solve a given task. This plan is then passed to the primary "Response" model, which uses this guidance to craft an accurate and comprehensive response.
# Model and Data
fusion-guide is fine-tuned on a custom dataset consisting of task-based prompts in both English (90%) and German (10%). The tasks vary in complexity, including scenarios designed to be challenging or unsolvable, to enhance the model's ability to handle ambiguous situations. Each training sample follows the structure: prompt => guidance, teaching the model to break down complex tasks systematically.
Read a detailed description and evaluation of the model here: https://blog.fusionbase.com/ai-research/beyond-cot-how-fusion-guide-elevates-ai-reasoning-with-a-two-model-system
### Prompt format
The prompt must be enclosed within <guidance_prompt>{PROMPT}</guidance_prompt> tags, following the format below:
<guidance_prompt>Count the number of 'r's in the word 'strawberry,' and then write a Python script that checks if an arbitrary word contains the same number of 'r's.</guidance_prompt>
# Usage
fusion-guide can be used with vLLM and other Mistral-Nemo-compatible inference engines. Below is an example of how to use it with unsloth:
```python
from unsloth import FastLanguageModel
max_seq_length = 8192 * 1 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = False # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="fusionbase/fusion-guide-12b-0.1",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit
)
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
guidance_prompt = """<guidance_prompt>Count the number of 'r's in the word 'strawberry,' and then write a Python script that checks if an arbitrary word contains the same number of 'r's.</guidance_prompt>"""
messages = [{"role": "user", "content": guidance_prompt}]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True, # Must add for generation
return_tensors="pt",
).to("cuda")
outputs = model.generate(input_ids=inputs, max_new_tokens=2000, use_cache=True, early_stopping=True, temperature=0)
result = tokenizer.batch_decode(outputs)
print(result[0][len(guidance_prompt):].replace("</s>", ""))
```
# Disclaimer
The model may occasionally fail to generate complete guidance, especially when the prompt includes specific instructions on how the responses should be structured. This limitation arises from the way the model was trained.
|
[
"CRAFT"
] |
nnch/multilingual-e5-large-Q4_K_M-GGUF
|
nnch
|
feature-extraction
|
[
"sentence-transformers",
"gguf",
"xlm-roberta",
"mteb",
"Sentence Transformers",
"sentence-similarity",
"feature-extraction",
"llama-cpp",
"gguf-my-repo",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"base_model:intfloat/multilingual-e5-large",
"base_model:quantized:intfloat/multilingual-e5-large",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-10-24T13:52:54Z |
2024-10-24T14:02:48+00:00
| 59 | 1 |
---
base_model: intfloat/multilingual-e5-large
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
tags:
- mteb
- Sentence Transformers
- sentence-similarity
- feature-extraction
- sentence-transformers
- llama-cpp
- gguf-my-repo
model-index:
- name: multilingual-e5-large
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 79.05970149253731
- type: ap
value: 43.486574390835635
- type: f1
value: 73.32700092140148
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 71.22055674518201
- type: ap
value: 81.55756710830498
- type: f1
value: 69.28271787752661
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 80.41979010494754
- type: ap
value: 29.34879922376344
- type: f1
value: 67.62475449011278
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 77.8372591006424
- type: ap
value: 26.557560591210738
- type: f1
value: 64.96619417368707
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.489875
- type: ap
value: 90.98758636917603
- type: f1
value: 93.48554819717332
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.564
- type: f1
value: 46.75122173518047
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 45.400000000000006
- type: f1
value: 44.17195682400632
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 43.068
- type: f1
value: 42.38155696855596
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 41.89
- type: f1
value: 40.84407321682663
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.120000000000005
- type: f1
value: 39.522976223819114
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 38.832
- type: f1
value: 38.0392533394713
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.725
- type: map_at_10
value: 46.055
- type: map_at_100
value: 46.900999999999996
- type: map_at_1000
value: 46.911
- type: map_at_3
value: 41.548
- type: map_at_5
value: 44.297
- type: mrr_at_1
value: 31.152
- type: mrr_at_10
value: 46.231
- type: mrr_at_100
value: 47.07
- type: mrr_at_1000
value: 47.08
- type: mrr_at_3
value: 41.738
- type: mrr_at_5
value: 44.468999999999994
- type: ndcg_at_1
value: 30.725
- type: ndcg_at_10
value: 54.379999999999995
- type: ndcg_at_100
value: 58.138
- type: ndcg_at_1000
value: 58.389
- type: ndcg_at_3
value: 45.156
- type: ndcg_at_5
value: 50.123
- type: precision_at_1
value: 30.725
- type: precision_at_10
value: 8.087
- type: precision_at_100
value: 0.9769999999999999
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 18.54
- type: precision_at_5
value: 13.542000000000002
- type: recall_at_1
value: 30.725
- type: recall_at_10
value: 80.868
- type: recall_at_100
value: 97.653
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 55.619
- type: recall_at_5
value: 67.71000000000001
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 44.30960650674069
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 38.427074197498996
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 60.28270056031872
- type: mrr
value: 74.38332673789738
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.05942144105269
- type: cos_sim_spearman
value: 82.51212105850809
- type: euclidean_pearson
value: 81.95639829909122
- type: euclidean_spearman
value: 82.3717564144213
- type: manhattan_pearson
value: 81.79273425468256
- type: manhattan_spearman
value: 82.20066817871039
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.46764091858039
- type: f1
value: 99.37717466945023
- type: precision
value: 99.33194154488518
- type: recall
value: 99.46764091858039
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.29407880255337
- type: f1
value: 98.11248073959938
- type: precision
value: 98.02443319392472
- type: recall
value: 98.29407880255337
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.79009352268791
- type: f1
value: 97.5176076665512
- type: precision
value: 97.38136473848286
- type: recall
value: 97.79009352268791
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.26276987888363
- type: f1
value: 99.20133403545726
- type: precision
value: 99.17500438827453
- type: recall
value: 99.26276987888363
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.72727272727273
- type: f1
value: 84.67672206031433
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.34220182511161
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 33.4987096128766
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.558249999999997
- type: map_at_10
value: 34.44425000000001
- type: map_at_100
value: 35.59833333333333
- type: map_at_1000
value: 35.706916666666665
- type: map_at_3
value: 31.691749999999995
- type: map_at_5
value: 33.252916666666664
- type: mrr_at_1
value: 30.252666666666666
- type: mrr_at_10
value: 38.60675
- type: mrr_at_100
value: 39.42666666666666
- type: mrr_at_1000
value: 39.48408333333334
- type: mrr_at_3
value: 36.17441666666665
- type: mrr_at_5
value: 37.56275
- type: ndcg_at_1
value: 30.252666666666666
- type: ndcg_at_10
value: 39.683
- type: ndcg_at_100
value: 44.68541666666667
- type: ndcg_at_1000
value: 46.94316666666668
- type: ndcg_at_3
value: 34.961749999999995
- type: ndcg_at_5
value: 37.215666666666664
- type: precision_at_1
value: 30.252666666666666
- type: precision_at_10
value: 6.904166666666667
- type: precision_at_100
value: 1.0989999999999995
- type: precision_at_1000
value: 0.14733333333333334
- type: precision_at_3
value: 16.037666666666667
- type: precision_at_5
value: 11.413583333333333
- type: recall_at_1
value: 25.558249999999997
- type: recall_at_10
value: 51.13341666666666
- type: recall_at_100
value: 73.08366666666667
- type: recall_at_1000
value: 88.79483333333334
- type: recall_at_3
value: 37.989083333333326
- type: recall_at_5
value: 43.787833333333325
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.338
- type: map_at_10
value: 18.360000000000003
- type: map_at_100
value: 19.942
- type: map_at_1000
value: 20.134
- type: map_at_3
value: 15.174000000000001
- type: map_at_5
value: 16.830000000000002
- type: mrr_at_1
value: 23.257
- type: mrr_at_10
value: 33.768
- type: mrr_at_100
value: 34.707
- type: mrr_at_1000
value: 34.766000000000005
- type: mrr_at_3
value: 30.977
- type: mrr_at_5
value: 32.528
- type: ndcg_at_1
value: 23.257
- type: ndcg_at_10
value: 25.733
- type: ndcg_at_100
value: 32.288
- type: ndcg_at_1000
value: 35.992000000000004
- type: ndcg_at_3
value: 20.866
- type: ndcg_at_5
value: 22.612
- type: precision_at_1
value: 23.257
- type: precision_at_10
value: 8.124
- type: precision_at_100
value: 1.518
- type: precision_at_1000
value: 0.219
- type: precision_at_3
value: 15.679000000000002
- type: precision_at_5
value: 12.117
- type: recall_at_1
value: 10.338
- type: recall_at_10
value: 31.154
- type: recall_at_100
value: 54.161
- type: recall_at_1000
value: 75.21900000000001
- type: recall_at_3
value: 19.427
- type: recall_at_5
value: 24.214
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.498
- type: map_at_10
value: 19.103
- type: map_at_100
value: 27.375
- type: map_at_1000
value: 28.981
- type: map_at_3
value: 13.764999999999999
- type: map_at_5
value: 15.950000000000001
- type: mrr_at_1
value: 65.5
- type: mrr_at_10
value: 74.53800000000001
- type: mrr_at_100
value: 74.71799999999999
- type: mrr_at_1000
value: 74.725
- type: mrr_at_3
value: 72.792
- type: mrr_at_5
value: 73.554
- type: ndcg_at_1
value: 53.37499999999999
- type: ndcg_at_10
value: 41.286
- type: ndcg_at_100
value: 45.972
- type: ndcg_at_1000
value: 53.123
- type: ndcg_at_3
value: 46.172999999999995
- type: ndcg_at_5
value: 43.033
- type: precision_at_1
value: 65.5
- type: precision_at_10
value: 32.725
- type: precision_at_100
value: 10.683
- type: precision_at_1000
value: 1.978
- type: precision_at_3
value: 50
- type: precision_at_5
value: 41.349999999999994
- type: recall_at_1
value: 8.498
- type: recall_at_10
value: 25.070999999999998
- type: recall_at_100
value: 52.383
- type: recall_at_1000
value: 74.91499999999999
- type: recall_at_3
value: 15.207999999999998
- type: recall_at_5
value: 18.563
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 46.5
- type: f1
value: 41.93833713984145
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 67.914
- type: map_at_10
value: 78.10000000000001
- type: map_at_100
value: 78.333
- type: map_at_1000
value: 78.346
- type: map_at_3
value: 76.626
- type: map_at_5
value: 77.627
- type: mrr_at_1
value: 72.74199999999999
- type: mrr_at_10
value: 82.414
- type: mrr_at_100
value: 82.511
- type: mrr_at_1000
value: 82.513
- type: mrr_at_3
value: 81.231
- type: mrr_at_5
value: 82.065
- type: ndcg_at_1
value: 72.74199999999999
- type: ndcg_at_10
value: 82.806
- type: ndcg_at_100
value: 83.677
- type: ndcg_at_1000
value: 83.917
- type: ndcg_at_3
value: 80.305
- type: ndcg_at_5
value: 81.843
- type: precision_at_1
value: 72.74199999999999
- type: precision_at_10
value: 10.24
- type: precision_at_100
value: 1.089
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 31.268
- type: precision_at_5
value: 19.706000000000003
- type: recall_at_1
value: 67.914
- type: recall_at_10
value: 92.889
- type: recall_at_100
value: 96.42699999999999
- type: recall_at_1000
value: 97.92
- type: recall_at_3
value: 86.21
- type: recall_at_5
value: 90.036
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.166
- type: map_at_10
value: 35.57
- type: map_at_100
value: 37.405
- type: map_at_1000
value: 37.564
- type: map_at_3
value: 30.379
- type: map_at_5
value: 33.324
- type: mrr_at_1
value: 43.519000000000005
- type: mrr_at_10
value: 51.556000000000004
- type: mrr_at_100
value: 52.344
- type: mrr_at_1000
value: 52.373999999999995
- type: mrr_at_3
value: 48.868
- type: mrr_at_5
value: 50.319
- type: ndcg_at_1
value: 43.519000000000005
- type: ndcg_at_10
value: 43.803
- type: ndcg_at_100
value: 50.468999999999994
- type: ndcg_at_1000
value: 53.111
- type: ndcg_at_3
value: 38.893
- type: ndcg_at_5
value: 40.653
- type: precision_at_1
value: 43.519000000000005
- type: precision_at_10
value: 12.253
- type: precision_at_100
value: 1.931
- type: precision_at_1000
value: 0.242
- type: precision_at_3
value: 25.617
- type: precision_at_5
value: 19.383
- type: recall_at_1
value: 22.166
- type: recall_at_10
value: 51.6
- type: recall_at_100
value: 76.574
- type: recall_at_1000
value: 92.192
- type: recall_at_3
value: 34.477999999999994
- type: recall_at_5
value: 41.835
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.041
- type: map_at_10
value: 62.961999999999996
- type: map_at_100
value: 63.79899999999999
- type: map_at_1000
value: 63.854
- type: map_at_3
value: 59.399
- type: map_at_5
value: 61.669
- type: mrr_at_1
value: 78.082
- type: mrr_at_10
value: 84.321
- type: mrr_at_100
value: 84.49600000000001
- type: mrr_at_1000
value: 84.502
- type: mrr_at_3
value: 83.421
- type: mrr_at_5
value: 83.977
- type: ndcg_at_1
value: 78.082
- type: ndcg_at_10
value: 71.229
- type: ndcg_at_100
value: 74.10900000000001
- type: ndcg_at_1000
value: 75.169
- type: ndcg_at_3
value: 66.28699999999999
- type: ndcg_at_5
value: 69.084
- type: precision_at_1
value: 78.082
- type: precision_at_10
value: 14.993
- type: precision_at_100
value: 1.7239999999999998
- type: precision_at_1000
value: 0.186
- type: precision_at_3
value: 42.737
- type: precision_at_5
value: 27.843
- type: recall_at_1
value: 39.041
- type: recall_at_10
value: 74.96300000000001
- type: recall_at_100
value: 86.199
- type: recall_at_1000
value: 93.228
- type: recall_at_3
value: 64.105
- type: recall_at_5
value: 69.608
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 90.23160000000001
- type: ap
value: 85.5674856808308
- type: f1
value: 90.18033354786317
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 24.091
- type: map_at_10
value: 36.753
- type: map_at_100
value: 37.913000000000004
- type: map_at_1000
value: 37.958999999999996
- type: map_at_3
value: 32.818999999999996
- type: map_at_5
value: 35.171
- type: mrr_at_1
value: 24.742
- type: mrr_at_10
value: 37.285000000000004
- type: mrr_at_100
value: 38.391999999999996
- type: mrr_at_1000
value: 38.431
- type: mrr_at_3
value: 33.440999999999995
- type: mrr_at_5
value: 35.75
- type: ndcg_at_1
value: 24.742
- type: ndcg_at_10
value: 43.698
- type: ndcg_at_100
value: 49.145
- type: ndcg_at_1000
value: 50.23800000000001
- type: ndcg_at_3
value: 35.769
- type: ndcg_at_5
value: 39.961999999999996
- type: precision_at_1
value: 24.742
- type: precision_at_10
value: 6.7989999999999995
- type: precision_at_100
value: 0.95
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 15.096000000000002
- type: precision_at_5
value: 11.183
- type: recall_at_1
value: 24.091
- type: recall_at_10
value: 65.068
- type: recall_at_100
value: 89.899
- type: recall_at_1000
value: 98.16
- type: recall_at_3
value: 43.68
- type: recall_at_5
value: 53.754999999999995
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.66621067031465
- type: f1
value: 93.49622853272142
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 91.94702733164272
- type: f1
value: 91.17043441745282
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.20146764509674
- type: f1
value: 91.98359080555608
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 88.99780770435328
- type: f1
value: 89.19746342724068
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.78486912871998
- type: f1
value: 89.24578823628642
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 88.74502712477394
- type: f1
value: 89.00297573881542
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.9046967624259
- type: f1
value: 59.36787125785957
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 74.5280360664976
- type: f1
value: 57.17723440888718
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.44029352901934
- type: f1
value: 54.052855531072964
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 70.5606013153774
- type: f1
value: 52.62215934386531
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 73.11581211903908
- type: f1
value: 52.341291845645465
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 74.28933092224233
- type: f1
value: 57.07918745504911
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.38063214525892
- type: f1
value: 59.46463723443009
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.06926698049766
- type: f1
value: 52.49084283283562
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.74983187626093
- type: f1
value: 56.960640620165904
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.86550100874243
- type: f1
value: 62.47370548140688
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.971082716879636
- type: f1
value: 61.03812421957381
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.98318762609282
- type: f1
value: 51.51207916008392
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.45527908540686
- type: f1
value: 66.16631905400318
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.32750504371216
- type: f1
value: 66.16755288646591
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.09213180901143
- type: f1
value: 66.95654394661507
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.75588433086752
- type: f1
value: 71.79973779656923
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.49428379287154
- type: f1
value: 68.37494379215734
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.90921318090115
- type: f1
value: 66.79517376481645
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.12104909213181
- type: f1
value: 67.29448842879584
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.34095494283793
- type: f1
value: 67.01134288992947
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.61264290517822
- type: f1
value: 64.68730512660757
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.79757901815738
- type: f1
value: 65.24938539425598
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.68728984532616
- type: f1
value: 67.0487169762553
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.07464694014795
- type: f1
value: 59.183532276789286
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.04707464694015
- type: f1
value: 67.66829629003848
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.42434431741762
- type: f1
value: 59.01617226544757
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.53127101546738
- type: f1
value: 68.10033760906255
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.50504371217215
- type: f1
value: 69.74931103158923
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.91190316072628
- type: f1
value: 54.05551136648796
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 51.78211163416275
- type: f1
value: 49.874888544058535
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 47.017484868863484
- type: f1
value: 44.53364263352014
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.16207128446537
- type: f1
value: 59.01185692320829
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.42501681237391
- type: f1
value: 67.13169450166086
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.0780094149294
- type: f1
value: 64.41720167850707
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.57162071284466
- type: f1
value: 62.414138683804424
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.71149966375252
- type: f1
value: 58.594805125087234
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.03900470746471
- type: f1
value: 63.87937257883887
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.8776059179556
- type: f1
value: 57.48587618059131
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.87895090786819
- type: f1
value: 66.8141299430347
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.45057162071285
- type: f1
value: 67.46444039673516
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.546738399462
- type: f1
value: 68.63640876702655
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.72965702757229
- type: f1
value: 68.54119560379115
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.35574983187625
- type: f1
value: 65.88844917691927
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.70477471418964
- type: f1
value: 69.19665697061978
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.0880968392737
- type: f1
value: 64.76962317666086
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.18493611297916
- type: f1
value: 62.49984559035371
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.75857431069265
- type: f1
value: 69.20053687623418
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.500336247478145
- type: f1
value: 55.2972398687929
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.68997982515132
- type: f1
value: 59.36848202755348
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.01950235373235
- type: f1
value: 60.09351954625423
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.29186281102892
- type: f1
value: 67.57860496703447
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.77471418964357
- type: f1
value: 61.913983147713836
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.87222595830532
- type: f1
value: 66.03679033708141
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.04505716207127
- type: f1
value: 61.28569169817908
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.38466711499663
- type: f1
value: 67.20532357036844
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.12306657700067
- type: f1
value: 68.91251226588182
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.20040349697378
- type: f1
value: 66.02657347714175
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.73907195696032
- type: f1
value: 66.98484521791418
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.58843308675185
- type: f1
value: 58.95591723092005
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.22730329522528
- type: f1
value: 66.0894499712115
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.48285137861465
- type: f1
value: 65.21963176785157
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.74714189643578
- type: f1
value: 66.8212192745412
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.09213180901143
- type: f1
value: 56.70735546356339
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.05716207128448
- type: f1
value: 74.8413712365364
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.69737726967047
- type: f1
value: 74.7664341963
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.90383322125084
- type: f1
value: 73.59201554448323
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.51176866173503
- type: f1
value: 77.46104434577758
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.31069266980496
- type: f1
value: 74.61048660675635
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.95225285810356
- type: f1
value: 72.33160006574627
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.12373907195696
- type: f1
value: 73.20921012557481
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.86684599865501
- type: f1
value: 73.82348774610831
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.40215198386012
- type: f1
value: 71.11945183971858
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.12844653665098
- type: f1
value: 71.34450495911766
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.52252858103566
- type: f1
value: 73.98878711342999
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.93611297915265
- type: f1
value: 63.723200467653385
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.11903160726295
- type: f1
value: 73.82138439467096
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.15198386012105
- type: f1
value: 66.02172193802167
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.32414256893072
- type: f1
value: 74.30943421170574
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.46805648957633
- type: f1
value: 77.62808409298209
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.318762609280434
- type: f1
value: 62.094284066075076
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.34902488231338
- type: f1
value: 57.12893860987984
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.88433086751849
- type: f1
value: 48.2272350802058
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.4425016812374
- type: f1
value: 64.61463095996173
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.04707464694015
- type: f1
value: 75.05099199098998
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.50437121721586
- type: f1
value: 69.83397721096314
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.94283792871553
- type: f1
value: 68.8704663703913
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.79488903833222
- type: f1
value: 63.615424063345436
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.88231338264963
- type: f1
value: 68.57892302593237
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.248150638870214
- type: f1
value: 61.06680605338809
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.84196368527236
- type: f1
value: 74.52566464968763
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.8285137861466
- type: f1
value: 74.8853197608802
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.13248150638869
- type: f1
value: 74.3982040999179
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.49024882313383
- type: f1
value: 73.82153848368573
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.72158708809684
- type: f1
value: 71.85049433180541
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.137861466039
- type: f1
value: 75.37628348188467
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.86953597848016
- type: f1
value: 71.87537624521661
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.27572293207801
- type: f1
value: 68.80017302344231
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.09952925353059
- type: f1
value: 76.07992707688408
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.140551445864155
- type: f1
value: 61.73855010331415
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.27774041694687
- type: f1
value: 64.83664868894539
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.69468728984533
- type: f1
value: 64.76239666920868
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.44653665097512
- type: f1
value: 73.14646052013873
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.71351714862139
- type: f1
value: 66.67212180163382
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.9946200403497
- type: f1
value: 73.87348793725525
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.15400134498992
- type: f1
value: 67.09433241421094
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.11365164761264
- type: f1
value: 73.59502539433753
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.82582380632145
- type: f1
value: 76.89992945316313
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.81237390719569
- type: f1
value: 72.36499770986265
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 31.480506569594695
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 29.71252128004552
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.421396787056548
- type: mrr
value: 32.48155274872267
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.595
- type: map_at_10
value: 12.642000000000001
- type: map_at_100
value: 15.726
- type: map_at_1000
value: 17.061999999999998
- type: map_at_3
value: 9.125
- type: map_at_5
value: 10.866000000000001
- type: mrr_at_1
value: 43.344
- type: mrr_at_10
value: 52.227999999999994
- type: mrr_at_100
value: 52.898999999999994
- type: mrr_at_1000
value: 52.944
- type: mrr_at_3
value: 49.845
- type: mrr_at_5
value: 51.115
- type: ndcg_at_1
value: 41.949999999999996
- type: ndcg_at_10
value: 33.995
- type: ndcg_at_100
value: 30.869999999999997
- type: ndcg_at_1000
value: 39.487
- type: ndcg_at_3
value: 38.903999999999996
- type: ndcg_at_5
value: 37.236999999999995
- type: precision_at_1
value: 43.344
- type: precision_at_10
value: 25.480000000000004
- type: precision_at_100
value: 7.672
- type: precision_at_1000
value: 2.028
- type: precision_at_3
value: 36.636
- type: precision_at_5
value: 32.632
- type: recall_at_1
value: 5.595
- type: recall_at_10
value: 16.466
- type: recall_at_100
value: 31.226
- type: recall_at_1000
value: 62.778999999999996
- type: recall_at_3
value: 9.931
- type: recall_at_5
value: 12.884
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 40.414
- type: map_at_10
value: 56.754000000000005
- type: map_at_100
value: 57.457
- type: map_at_1000
value: 57.477999999999994
- type: map_at_3
value: 52.873999999999995
- type: map_at_5
value: 55.175
- type: mrr_at_1
value: 45.278
- type: mrr_at_10
value: 59.192
- type: mrr_at_100
value: 59.650000000000006
- type: mrr_at_1000
value: 59.665
- type: mrr_at_3
value: 56.141
- type: mrr_at_5
value: 57.998000000000005
- type: ndcg_at_1
value: 45.278
- type: ndcg_at_10
value: 64.056
- type: ndcg_at_100
value: 66.89
- type: ndcg_at_1000
value: 67.364
- type: ndcg_at_3
value: 56.97
- type: ndcg_at_5
value: 60.719
- type: precision_at_1
value: 45.278
- type: precision_at_10
value: 9.994
- type: precision_at_100
value: 1.165
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 25.512
- type: precision_at_5
value: 17.509
- type: recall_at_1
value: 40.414
- type: recall_at_10
value: 83.596
- type: recall_at_100
value: 95.72
- type: recall_at_1000
value: 99.24
- type: recall_at_3
value: 65.472
- type: recall_at_5
value: 74.039
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.352
- type: map_at_10
value: 84.369
- type: map_at_100
value: 85.02499999999999
- type: map_at_1000
value: 85.04
- type: map_at_3
value: 81.42399999999999
- type: map_at_5
value: 83.279
- type: mrr_at_1
value: 81.05
- type: mrr_at_10
value: 87.401
- type: mrr_at_100
value: 87.504
- type: mrr_at_1000
value: 87.505
- type: mrr_at_3
value: 86.443
- type: mrr_at_5
value: 87.10799999999999
- type: ndcg_at_1
value: 81.04
- type: ndcg_at_10
value: 88.181
- type: ndcg_at_100
value: 89.411
- type: ndcg_at_1000
value: 89.507
- type: ndcg_at_3
value: 85.28099999999999
- type: ndcg_at_5
value: 86.888
- type: precision_at_1
value: 81.04
- type: precision_at_10
value: 13.406
- type: precision_at_100
value: 1.5350000000000001
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.31
- type: precision_at_5
value: 24.54
- type: recall_at_1
value: 70.352
- type: recall_at_10
value: 95.358
- type: recall_at_100
value: 99.541
- type: recall_at_1000
value: 99.984
- type: recall_at_3
value: 87.111
- type: recall_at_5
value: 91.643
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 46.54068723291946
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 63.216287629895994
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.023000000000001
- type: map_at_10
value: 10.071
- type: map_at_100
value: 11.892
- type: map_at_1000
value: 12.196
- type: map_at_3
value: 7.234
- type: map_at_5
value: 8.613999999999999
- type: mrr_at_1
value: 19.900000000000002
- type: mrr_at_10
value: 30.516
- type: mrr_at_100
value: 31.656000000000002
- type: mrr_at_1000
value: 31.723000000000003
- type: mrr_at_3
value: 27.400000000000002
- type: mrr_at_5
value: 29.270000000000003
- type: ndcg_at_1
value: 19.900000000000002
- type: ndcg_at_10
value: 17.474
- type: ndcg_at_100
value: 25.020999999999997
- type: ndcg_at_1000
value: 30.728
- type: ndcg_at_3
value: 16.588
- type: ndcg_at_5
value: 14.498
- type: precision_at_1
value: 19.900000000000002
- type: precision_at_10
value: 9.139999999999999
- type: precision_at_100
value: 2.011
- type: precision_at_1000
value: 0.33899999999999997
- type: precision_at_3
value: 15.667
- type: precision_at_5
value: 12.839999999999998
- type: recall_at_1
value: 4.023000000000001
- type: recall_at_10
value: 18.497
- type: recall_at_100
value: 40.8
- type: recall_at_1000
value: 68.812
- type: recall_at_3
value: 9.508
- type: recall_at_5
value: 12.983
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 83.967008785134
- type: cos_sim_spearman
value: 80.23142141101837
- type: euclidean_pearson
value: 81.20166064704539
- type: euclidean_spearman
value: 80.18961335654585
- type: manhattan_pearson
value: 81.13925443187625
- type: manhattan_spearman
value: 80.07948723044424
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.94262461316023
- type: cos_sim_spearman
value: 80.01596278563865
- type: euclidean_pearson
value: 83.80799622922581
- type: euclidean_spearman
value: 79.94984954947103
- type: manhattan_pearson
value: 83.68473841756281
- type: manhattan_spearman
value: 79.84990707951822
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 80.57346443146068
- type: cos_sim_spearman
value: 81.54689837570866
- type: euclidean_pearson
value: 81.10909881516007
- type: euclidean_spearman
value: 81.56746243261762
- type: manhattan_pearson
value: 80.87076036186582
- type: manhattan_spearman
value: 81.33074987964402
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 79.54733787179849
- type: cos_sim_spearman
value: 77.72202105610411
- type: euclidean_pearson
value: 78.9043595478849
- type: euclidean_spearman
value: 77.93422804309435
- type: manhattan_pearson
value: 78.58115121621368
- type: manhattan_spearman
value: 77.62508135122033
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.59880017237558
- type: cos_sim_spearman
value: 89.31088630824758
- type: euclidean_pearson
value: 88.47069261564656
- type: euclidean_spearman
value: 89.33581971465233
- type: manhattan_pearson
value: 88.40774264100956
- type: manhattan_spearman
value: 89.28657485627835
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.08055117917084
- type: cos_sim_spearman
value: 85.78491813080304
- type: euclidean_pearson
value: 84.99329155500392
- type: euclidean_spearman
value: 85.76728064677287
- type: manhattan_pearson
value: 84.87947428989587
- type: manhattan_spearman
value: 85.62429454917464
- task:
type: STS
dataset:
name: MTEB STS17 (ko-ko)
type: mteb/sts17-crosslingual-sts
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 82.14190939287384
- type: cos_sim_spearman
value: 82.27331573306041
- type: euclidean_pearson
value: 81.891896953716
- type: euclidean_spearman
value: 82.37695542955998
- type: manhattan_pearson
value: 81.73123869460504
- type: manhattan_spearman
value: 82.19989168441421
- task:
type: STS
dataset:
name: MTEB STS17 (ar-ar)
type: mteb/sts17-crosslingual-sts
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 76.84695301843362
- type: cos_sim_spearman
value: 77.87790986014461
- type: euclidean_pearson
value: 76.91981583106315
- type: euclidean_spearman
value: 77.88154772749589
- type: manhattan_pearson
value: 76.94953277451093
- type: manhattan_spearman
value: 77.80499230728604
- task:
type: STS
dataset:
name: MTEB STS17 (en-ar)
type: mteb/sts17-crosslingual-sts
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 75.44657840482016
- type: cos_sim_spearman
value: 75.05531095119674
- type: euclidean_pearson
value: 75.88161755829299
- type: euclidean_spearman
value: 74.73176238219332
- type: manhattan_pearson
value: 75.63984765635362
- type: manhattan_spearman
value: 74.86476440770737
- task:
type: STS
dataset:
name: MTEB STS17 (en-de)
type: mteb/sts17-crosslingual-sts
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 85.64700140524133
- type: cos_sim_spearman
value: 86.16014210425672
- type: euclidean_pearson
value: 86.49086860843221
- type: euclidean_spearman
value: 86.09729326815614
- type: manhattan_pearson
value: 86.43406265125513
- type: manhattan_spearman
value: 86.17740150939994
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.91170098764921
- type: cos_sim_spearman
value: 88.12437004058931
- type: euclidean_pearson
value: 88.81828254494437
- type: euclidean_spearman
value: 88.14831794572122
- type: manhattan_pearson
value: 88.93442183448961
- type: manhattan_spearman
value: 88.15254630778304
- task:
type: STS
dataset:
name: MTEB STS17 (en-tr)
type: mteb/sts17-crosslingual-sts
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 72.91390577997292
- type: cos_sim_spearman
value: 71.22979457536074
- type: euclidean_pearson
value: 74.40314008106749
- type: euclidean_spearman
value: 72.54972136083246
- type: manhattan_pearson
value: 73.85687539530218
- type: manhattan_spearman
value: 72.09500771742637
- task:
type: STS
dataset:
name: MTEB STS17 (es-en)
type: mteb/sts17-crosslingual-sts
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.9301067983089
- type: cos_sim_spearman
value: 80.74989828346473
- type: euclidean_pearson
value: 81.36781301814257
- type: euclidean_spearman
value: 80.9448819964426
- type: manhattan_pearson
value: 81.0351322685609
- type: manhattan_spearman
value: 80.70192121844177
- task:
type: STS
dataset:
name: MTEB STS17 (es-es)
type: mteb/sts17-crosslingual-sts
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.13820465980005
- type: cos_sim_spearman
value: 86.73532498758757
- type: euclidean_pearson
value: 87.21329451846637
- type: euclidean_spearman
value: 86.57863198601002
- type: manhattan_pearson
value: 87.06973713818554
- type: manhattan_spearman
value: 86.47534918791499
- task:
type: STS
dataset:
name: MTEB STS17 (fr-en)
type: mteb/sts17-crosslingual-sts
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 85.48720108904415
- type: cos_sim_spearman
value: 85.62221757068387
- type: euclidean_pearson
value: 86.1010129512749
- type: euclidean_spearman
value: 85.86580966509942
- type: manhattan_pearson
value: 86.26800938808971
- type: manhattan_spearman
value: 85.88902721678429
- task:
type: STS
dataset:
name: MTEB STS17 (it-en)
type: mteb/sts17-crosslingual-sts
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 83.98021347333516
- type: cos_sim_spearman
value: 84.53806553803501
- type: euclidean_pearson
value: 84.61483347248364
- type: euclidean_spearman
value: 85.14191408011702
- type: manhattan_pearson
value: 84.75297588825967
- type: manhattan_spearman
value: 85.33176753669242
- task:
type: STS
dataset:
name: MTEB STS17 (nl-en)
type: mteb/sts17-crosslingual-sts
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 84.51856644893233
- type: cos_sim_spearman
value: 85.27510748506413
- type: euclidean_pearson
value: 85.09886861540977
- type: euclidean_spearman
value: 85.62579245860887
- type: manhattan_pearson
value: 84.93017860464607
- type: manhattan_spearman
value: 85.5063988898453
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 62.581573200584195
- type: cos_sim_spearman
value: 63.05503590247928
- type: euclidean_pearson
value: 63.652564812602094
- type: euclidean_spearman
value: 62.64811520876156
- type: manhattan_pearson
value: 63.506842893061076
- type: manhattan_spearman
value: 62.51289573046917
- task:
type: STS
dataset:
name: MTEB STS22 (de)
type: mteb/sts22-crosslingual-sts
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 48.2248801729127
- type: cos_sim_spearman
value: 56.5936604678561
- type: euclidean_pearson
value: 43.98149464089
- type: euclidean_spearman
value: 56.108561882423615
- type: manhattan_pearson
value: 43.86880305903564
- type: manhattan_spearman
value: 56.04671150510166
- task:
type: STS
dataset:
name: MTEB STS22 (es)
type: mteb/sts22-crosslingual-sts
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.17564527009831
- type: cos_sim_spearman
value: 64.57978560979488
- type: euclidean_pearson
value: 58.8818330154583
- type: euclidean_spearman
value: 64.99214839071281
- type: manhattan_pearson
value: 58.72671436121381
- type: manhattan_spearman
value: 65.10713416616109
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 26.772131864023297
- type: cos_sim_spearman
value: 34.68200792408681
- type: euclidean_pearson
value: 16.68082419005441
- type: euclidean_spearman
value: 34.83099932652166
- type: manhattan_pearson
value: 16.52605949659529
- type: manhattan_spearman
value: 34.82075801399475
- task:
type: STS
dataset:
name: MTEB STS22 (tr)
type: mteb/sts22-crosslingual-sts
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 54.42415189043831
- type: cos_sim_spearman
value: 63.54594264576758
- type: euclidean_pearson
value: 57.36577498297745
- type: euclidean_spearman
value: 63.111466379158074
- type: manhattan_pearson
value: 57.584543715873885
- type: manhattan_spearman
value: 63.22361054139183
- task:
type: STS
dataset:
name: MTEB STS22 (ar)
type: mteb/sts22-crosslingual-sts
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.55216762405518
- type: cos_sim_spearman
value: 56.98670142896412
- type: euclidean_pearson
value: 50.15318757562699
- type: euclidean_spearman
value: 56.524941926541906
- type: manhattan_pearson
value: 49.955618528674904
- type: manhattan_spearman
value: 56.37102209240117
- task:
type: STS
dataset:
name: MTEB STS22 (ru)
type: mteb/sts22-crosslingual-sts
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 49.20540980338571
- type: cos_sim_spearman
value: 59.9009453504406
- type: euclidean_pearson
value: 49.557749853620535
- type: euclidean_spearman
value: 59.76631621172456
- type: manhattan_pearson
value: 49.62340591181147
- type: manhattan_spearman
value: 59.94224880322436
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 51.508169956576985
- type: cos_sim_spearman
value: 66.82461565306046
- type: euclidean_pearson
value: 56.2274426480083
- type: euclidean_spearman
value: 66.6775323848333
- type: manhattan_pearson
value: 55.98277796300661
- type: manhattan_spearman
value: 66.63669848497175
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 72.86478788045507
- type: cos_sim_spearman
value: 76.7946552053193
- type: euclidean_pearson
value: 75.01598530490269
- type: euclidean_spearman
value: 76.83618917858281
- type: manhattan_pearson
value: 74.68337628304332
- type: manhattan_spearman
value: 76.57480204017773
- task:
type: STS
dataset:
name: MTEB STS22 (de-en)
type: mteb/sts22-crosslingual-sts
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.922619099401984
- type: cos_sim_spearman
value: 56.599362477240774
- type: euclidean_pearson
value: 56.68307052369783
- type: euclidean_spearman
value: 54.28760436777401
- type: manhattan_pearson
value: 56.67763566500681
- type: manhattan_spearman
value: 53.94619541711359
- task:
type: STS
dataset:
name: MTEB STS22 (es-en)
type: mteb/sts22-crosslingual-sts
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.74357206710913
- type: cos_sim_spearman
value: 72.5208244925311
- type: euclidean_pearson
value: 67.49254562186032
- type: euclidean_spearman
value: 72.02469076238683
- type: manhattan_pearson
value: 67.45251772238085
- type: manhattan_spearman
value: 72.05538819984538
- task:
type: STS
dataset:
name: MTEB STS22 (it)
type: mteb/sts22-crosslingual-sts
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 71.25734330033191
- type: cos_sim_spearman
value: 76.98349083946823
- type: euclidean_pearson
value: 73.71642838667736
- type: euclidean_spearman
value: 77.01715504651384
- type: manhattan_pearson
value: 73.61712711868105
- type: manhattan_spearman
value: 77.01392571153896
- task:
type: STS
dataset:
name: MTEB STS22 (pl-en)
type: mteb/sts22-crosslingual-sts
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 63.18215462781212
- type: cos_sim_spearman
value: 65.54373266117607
- type: euclidean_pearson
value: 64.54126095439005
- type: euclidean_spearman
value: 65.30410369102711
- type: manhattan_pearson
value: 63.50332221148234
- type: manhattan_spearman
value: 64.3455878104313
- task:
type: STS
dataset:
name: MTEB STS22 (zh-en)
type: mteb/sts22-crosslingual-sts
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 62.30509221440029
- type: cos_sim_spearman
value: 65.99582704642478
- type: euclidean_pearson
value: 63.43818859884195
- type: euclidean_spearman
value: 66.83172582815764
- type: manhattan_pearson
value: 63.055779168508764
- type: manhattan_spearman
value: 65.49585020501449
- task:
type: STS
dataset:
name: MTEB STS22 (es-it)
type: mteb/sts22-crosslingual-sts
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.587830825340404
- type: cos_sim_spearman
value: 68.93467614588089
- type: euclidean_pearson
value: 62.3073527367404
- type: euclidean_spearman
value: 69.69758171553175
- type: manhattan_pearson
value: 61.9074580815789
- type: manhattan_spearman
value: 69.57696375597865
- task:
type: STS
dataset:
name: MTEB STS22 (de-fr)
type: mteb/sts22-crosslingual-sts
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.143220125577066
- type: cos_sim_spearman
value: 67.78857859159226
- type: euclidean_pearson
value: 55.58225107923733
- type: euclidean_spearman
value: 67.80662907184563
- type: manhattan_pearson
value: 56.24953502726514
- type: manhattan_spearman
value: 67.98262125431616
- task:
type: STS
dataset:
name: MTEB STS22 (de-pl)
type: mteb/sts22-crosslingual-sts
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 21.826928900322066
- type: cos_sim_spearman
value: 49.578506634400405
- type: euclidean_pearson
value: 27.939890138843214
- type: euclidean_spearman
value: 52.71950519136242
- type: manhattan_pearson
value: 26.39878683847546
- type: manhattan_spearman
value: 47.54609580342499
- task:
type: STS
dataset:
name: MTEB STS22 (fr-pl)
type: mteb/sts22-crosslingual-sts
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.27603854632001
- type: cos_sim_spearman
value: 50.709255283710995
- type: euclidean_pearson
value: 59.5419024445929
- type: euclidean_spearman
value: 50.709255283710995
- type: manhattan_pearson
value: 59.03256832438492
- type: manhattan_spearman
value: 61.97797868009122
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.00757054859712
- type: cos_sim_spearman
value: 87.29283629622222
- type: euclidean_pearson
value: 86.54824171775536
- type: euclidean_spearman
value: 87.24364730491402
- type: manhattan_pearson
value: 86.5062156915074
- type: manhattan_spearman
value: 87.15052170378574
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 82.03549357197389
- type: mrr
value: 95.05437645143527
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 57.260999999999996
- type: map_at_10
value: 66.259
- type: map_at_100
value: 66.884
- type: map_at_1000
value: 66.912
- type: map_at_3
value: 63.685
- type: map_at_5
value: 65.35499999999999
- type: mrr_at_1
value: 60.333000000000006
- type: mrr_at_10
value: 67.5
- type: mrr_at_100
value: 68.013
- type: mrr_at_1000
value: 68.038
- type: mrr_at_3
value: 65.61099999999999
- type: mrr_at_5
value: 66.861
- type: ndcg_at_1
value: 60.333000000000006
- type: ndcg_at_10
value: 70.41
- type: ndcg_at_100
value: 73.10600000000001
- type: ndcg_at_1000
value: 73.846
- type: ndcg_at_3
value: 66.133
- type: ndcg_at_5
value: 68.499
- type: precision_at_1
value: 60.333000000000006
- type: precision_at_10
value: 9.232999999999999
- type: precision_at_100
value: 1.0630000000000002
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 25.667
- type: precision_at_5
value: 17.067
- type: recall_at_1
value: 57.260999999999996
- type: recall_at_10
value: 81.94399999999999
- type: recall_at_100
value: 93.867
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 70.339
- type: recall_at_5
value: 76.25
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.74356435643564
- type: cos_sim_ap
value: 93.13411948212683
- type: cos_sim_f1
value: 86.80521991300147
- type: cos_sim_precision
value: 84.00374181478017
- type: cos_sim_recall
value: 89.8
- type: dot_accuracy
value: 99.67920792079208
- type: dot_ap
value: 89.27277565444479
- type: dot_f1
value: 83.9276990718124
- type: dot_precision
value: 82.04393505253104
- type: dot_recall
value: 85.9
- type: euclidean_accuracy
value: 99.74257425742574
- type: euclidean_ap
value: 93.17993008259062
- type: euclidean_f1
value: 86.69396110542476
- type: euclidean_precision
value: 88.78406708595388
- type: euclidean_recall
value: 84.7
- type: manhattan_accuracy
value: 99.74257425742574
- type: manhattan_ap
value: 93.14413755550099
- type: manhattan_f1
value: 86.82483594144371
- type: manhattan_precision
value: 87.66564729867483
- type: manhattan_recall
value: 86
- type: max_accuracy
value: 99.74356435643564
- type: max_ap
value: 93.17993008259062
- type: max_f1
value: 86.82483594144371
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 57.525863806168566
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 32.68850574423839
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 49.71580650644033
- type: mrr
value: 50.50971903913081
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 29.152190498799484
- type: cos_sim_spearman
value: 29.686180371952727
- type: dot_pearson
value: 27.248664793816342
- type: dot_spearman
value: 28.37748983721745
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.20400000000000001
- type: map_at_10
value: 1.6209999999999998
- type: map_at_100
value: 9.690999999999999
- type: map_at_1000
value: 23.733
- type: map_at_3
value: 0.575
- type: map_at_5
value: 0.885
- type: mrr_at_1
value: 78
- type: mrr_at_10
value: 86.56700000000001
- type: mrr_at_100
value: 86.56700000000001
- type: mrr_at_1000
value: 86.56700000000001
- type: mrr_at_3
value: 85.667
- type: mrr_at_5
value: 86.56700000000001
- type: ndcg_at_1
value: 76
- type: ndcg_at_10
value: 71.326
- type: ndcg_at_100
value: 54.208999999999996
- type: ndcg_at_1000
value: 49.252
- type: ndcg_at_3
value: 74.235
- type: ndcg_at_5
value: 73.833
- type: precision_at_1
value: 78
- type: precision_at_10
value: 74.8
- type: precision_at_100
value: 55.50000000000001
- type: precision_at_1000
value: 21.836
- type: precision_at_3
value: 78
- type: precision_at_5
value: 78
- type: recall_at_1
value: 0.20400000000000001
- type: recall_at_10
value: 1.894
- type: recall_at_100
value: 13.245999999999999
- type: recall_at_1000
value: 46.373
- type: recall_at_3
value: 0.613
- type: recall_at_5
value: 0.991
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.89999999999999
- type: f1
value: 94.69999999999999
- type: precision
value: 94.11666666666667
- type: recall
value: 95.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.20809248554913
- type: f1
value: 63.431048720066066
- type: precision
value: 61.69143958161298
- type: recall
value: 68.20809248554913
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.21951219512195
- type: f1
value: 66.82926829268293
- type: precision
value: 65.1260162601626
- type: recall
value: 71.21951219512195
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.2
- type: f1
value: 96.26666666666667
- type: precision
value: 95.8
- type: recall
value: 97.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.3
- type: f1
value: 99.06666666666666
- type: precision
value: 98.95
- type: recall
value: 99.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.39999999999999
- type: f1
value: 96.63333333333333
- type: precision
value: 96.26666666666668
- type: recall
value: 97.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96
- type: f1
value: 94.86666666666666
- type: precision
value: 94.31666666666668
- type: recall
value: 96
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.01492537313433
- type: f1
value: 40.178867566927266
- type: precision
value: 38.179295828549556
- type: recall
value: 47.01492537313433
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.5
- type: f1
value: 83.62537480063796
- type: precision
value: 82.44555555555554
- type: recall
value: 86.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.48780487804879
- type: f1
value: 75.45644599303138
- type: precision
value: 73.37398373983739
- type: recall
value: 80.48780487804879
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.95666666666666
- type: precision
value: 91.125
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.73754556500607
- type: f1
value: 89.65168084244632
- type: precision
value: 88.73025516403402
- type: recall
value: 91.73754556500607
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.04347826086956
- type: f1
value: 76.2128364389234
- type: precision
value: 74.2
- type: recall
value: 81.04347826086956
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 83.65217391304348
- type: f1
value: 79.4376811594203
- type: precision
value: 77.65797101449274
- type: recall
value: 83.65217391304348
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.5
- type: f1
value: 85.02690476190476
- type: precision
value: 83.96261904761904
- type: recall
value: 87.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.3
- type: f1
value: 86.52333333333333
- type: precision
value: 85.22833333333332
- type: recall
value: 89.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.01809408926418
- type: f1
value: 59.00594446432805
- type: precision
value: 56.827215807915444
- type: recall
value: 65.01809408926418
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.2
- type: f1
value: 88.58
- type: precision
value: 87.33333333333334
- type: recall
value: 91.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.199999999999996
- type: f1
value: 53.299166276284915
- type: precision
value: 51.3383908045977
- type: recall
value: 59.199999999999996
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.2
- type: precision
value: 90.25
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 64.76190476190476
- type: f1
value: 59.867110667110666
- type: precision
value: 58.07390192653351
- type: recall
value: 64.76190476190476
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.2
- type: f1
value: 71.48147546897547
- type: precision
value: 69.65409090909091
- type: recall
value: 76.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.8
- type: f1
value: 92.14
- type: precision
value: 91.35833333333333
- type: recall
value: 93.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.89999999999999
- type: f1
value: 97.2
- type: precision
value: 96.85000000000001
- type: recall
value: 97.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 92.93333333333334
- type: precision
value: 92.13333333333333
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.1
- type: f1
value: 69.14817460317461
- type: precision
value: 67.2515873015873
- type: recall
value: 74.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 94.01333333333335
- type: precision
value: 93.46666666666667
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.9
- type: f1
value: 72.07523809523809
- type: precision
value: 70.19777777777779
- type: recall
value: 76.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.31666666666666
- type: precision
value: 91.43333333333332
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.1
- type: precision
value: 96.76666666666668
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.85714285714286
- type: f1
value: 90.92093441150045
- type: precision
value: 90.00449236298293
- type: recall
value: 92.85714285714286
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.16239316239316
- type: f1
value: 91.33903133903132
- type: precision
value: 90.56267806267806
- type: recall
value: 93.16239316239316
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.4
- type: f1
value: 90.25666666666666
- type: precision
value: 89.25833333333334
- type: recall
value: 92.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.22727272727272
- type: f1
value: 87.53030303030303
- type: precision
value: 86.37121212121211
- type: recall
value: 90.22727272727272
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.03563941299791
- type: f1
value: 74.7349505840072
- type: precision
value: 72.9035639412998
- type: recall
value: 79.03563941299791
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97
- type: f1
value: 96.15
- type: precision
value: 95.76666666666668
- type: recall
value: 97
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.26459143968872
- type: f1
value: 71.55642023346303
- type: precision
value: 69.7544932369835
- type: recall
value: 76.26459143968872
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 58.119658119658126
- type: f1
value: 51.65242165242165
- type: precision
value: 49.41768108434775
- type: recall
value: 58.119658119658126
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.3
- type: f1
value: 69.52055555555555
- type: precision
value: 67.7574938949939
- type: recall
value: 74.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.8
- type: f1
value: 93.31666666666666
- type: precision
value: 92.60000000000001
- type: recall
value: 94.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.63551401869158
- type: f1
value: 72.35202492211837
- type: precision
value: 70.60358255451713
- type: recall
value: 76.63551401869158
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.4
- type: f1
value: 88.4811111111111
- type: precision
value: 87.7452380952381
- type: recall
value: 90.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95
- type: f1
value: 93.60666666666667
- type: precision
value: 92.975
- type: recall
value: 95
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.2
- type: f1
value: 63.01595782872099
- type: precision
value: 61.596587301587306
- type: recall
value: 67.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.7
- type: f1
value: 94.52999999999999
- type: precision
value: 94
- type: recall
value: 95.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 93.28999999999999
- type: precision
value: 92.675
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.39999999999999
- type: f1
value: 95.28333333333333
- type: precision
value: 94.75
- type: recall
value: 96.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.9
- type: f1
value: 89.83
- type: precision
value: 88.92
- type: recall
value: 91.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.34222222222223
- type: precision
value: 92.75416666666668
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 60.333333333333336
- type: f1
value: 55.31203703703703
- type: precision
value: 53.39971108326371
- type: recall
value: 60.333333333333336
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 12.9
- type: f1
value: 11.099861903031458
- type: precision
value: 10.589187932631877
- type: recall
value: 12.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.7
- type: f1
value: 83.0152380952381
- type: precision
value: 81.37833333333333
- type: recall
value: 86.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.39285714285714
- type: f1
value: 56.832482993197274
- type: precision
value: 54.56845238095237
- type: recall
value: 63.39285714285714
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.73765093304062
- type: f1
value: 41.555736920720456
- type: precision
value: 39.06874531737319
- type: recall
value: 48.73765093304062
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 41.099999999999994
- type: f1
value: 36.540165945165946
- type: precision
value: 35.05175685425686
- type: recall
value: 41.099999999999994
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.89999999999999
- type: f1
value: 93.42333333333333
- type: precision
value: 92.75833333333333
- type: recall
value: 94.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.89999999999999
- type: f1
value: 93.63333333333334
- type: precision
value: 93.01666666666665
- type: recall
value: 94.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.9
- type: f1
value: 73.64833333333334
- type: precision
value: 71.90282106782105
- type: recall
value: 77.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.4
- type: f1
value: 54.90521367521367
- type: precision
value: 53.432840025471606
- type: recall
value: 59.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.39999999999999
- type: f1
value: 96.6
- type: precision
value: 96.2
- type: recall
value: 97.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.2
- type: f1
value: 62.25926129426129
- type: precision
value: 60.408376623376626
- type: recall
value: 67.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.2
- type: f1
value: 87.60666666666667
- type: precision
value: 86.45277777777778
- type: recall
value: 90.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 97
- type: precision
value: 96.65
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.39746031746031
- type: precision
value: 90.6125
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 32.11678832116788
- type: f1
value: 27.210415386260234
- type: precision
value: 26.20408990846947
- type: recall
value: 32.11678832116788
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.5
- type: f1
value: 6.787319277832475
- type: precision
value: 6.3452094433344435
- type: recall
value: 8.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.08
- type: precision
value: 94.61666666666667
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.3
- type: f1
value: 93.88333333333333
- type: precision
value: 93.18333333333332
- type: recall
value: 95.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.11904761904762
- type: f1
value: 80.69444444444444
- type: precision
value: 78.72023809523809
- type: recall
value: 85.11904761904762
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 11.1
- type: f1
value: 9.276381801735853
- type: precision
value: 8.798174603174601
- type: recall
value: 11.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.56107660455487
- type: f1
value: 58.70433569191332
- type: precision
value: 56.896926581464015
- type: recall
value: 63.56107660455487
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.10000000000001
- type: precision
value: 92.35
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 96.01222222222222
- type: precision
value: 95.67083333333332
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 9.2
- type: f1
value: 7.911555250305249
- type: precision
value: 7.631246556216846
- type: recall
value: 9.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.48917748917748
- type: f1
value: 72.27375798804371
- type: precision
value: 70.14430014430013
- type: recall
value: 77.48917748917748
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.09923664122137
- type: f1
value: 72.61541257724463
- type: precision
value: 70.8998380754106
- type: recall
value: 77.09923664122137
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.2532751091703
- type: f1
value: 97.69529354682193
- type: precision
value: 97.42843279961184
- type: recall
value: 98.2532751091703
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.8
- type: f1
value: 79.14672619047619
- type: precision
value: 77.59489247311828
- type: recall
value: 82.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.35028248587571
- type: f1
value: 92.86252354048965
- type: precision
value: 92.2080979284369
- type: recall
value: 94.35028248587571
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.5
- type: f1
value: 6.282429263935621
- type: precision
value: 5.783274240739785
- type: recall
value: 8.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.7
- type: f1
value: 91.025
- type: precision
value: 90.30428571428571
- type: recall
value: 92.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81
- type: f1
value: 77.8232380952381
- type: precision
value: 76.60194444444444
- type: recall
value: 81
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91
- type: f1
value: 88.70857142857142
- type: precision
value: 87.7
- type: recall
value: 91
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.39999999999999
- type: f1
value: 95.3
- type: precision
value: 94.76666666666667
- type: recall
value: 96.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.1
- type: f1
value: 7.001008218834307
- type: precision
value: 6.708329562594269
- type: recall
value: 8.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.1313672922252
- type: f1
value: 84.09070598748882
- type: precision
value: 82.79171454104429
- type: recall
value: 87.1313672922252
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.39999999999999
- type: f1
value: 95.28333333333333
- type: precision
value: 94.73333333333332
- type: recall
value: 96.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 42.29249011857708
- type: f1
value: 36.981018542283365
- type: precision
value: 35.415877813576024
- type: recall
value: 42.29249011857708
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 83.80281690140845
- type: f1
value: 80.86854460093896
- type: precision
value: 79.60093896713614
- type: recall
value: 83.80281690140845
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.26946107784431
- type: f1
value: 39.80235464678088
- type: precision
value: 38.14342660001342
- type: recall
value: 45.26946107784431
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.9
- type: precision
value: 92.26666666666668
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 37.93103448275862
- type: f1
value: 33.15192743764172
- type: precision
value: 31.57456528146183
- type: recall
value: 37.93103448275862
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.01408450704226
- type: f1
value: 63.41549295774648
- type: precision
value: 61.342778895595806
- type: recall
value: 69.01408450704226
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.66666666666667
- type: f1
value: 71.60705960705961
- type: precision
value: 69.60683760683762
- type: recall
value: 76.66666666666667
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.48333333333333
- type: precision
value: 93.83333333333333
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 52.81837160751566
- type: f1
value: 48.435977731384824
- type: precision
value: 47.11291973845539
- type: recall
value: 52.81837160751566
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 44.9
- type: f1
value: 38.88962621607783
- type: precision
value: 36.95936507936508
- type: recall
value: 44.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.55374592833876
- type: f1
value: 88.22553125484721
- type: precision
value: 87.26927252985884
- type: recall
value: 90.55374592833876
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 93.13333333333333
- type: precision
value: 92.45333333333333
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.99666666666667
- type: precision
value: 91.26666666666668
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.03937007874016
- type: f1
value: 81.75853018372703
- type: precision
value: 80.34120734908137
- type: recall
value: 85.03937007874016
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.3
- type: f1
value: 85.5
- type: precision
value: 84.25833333333334
- type: recall
value: 88.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.51246537396122
- type: f1
value: 60.02297410192148
- type: precision
value: 58.133467727289236
- type: recall
value: 65.51246537396122
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96
- type: f1
value: 94.89
- type: precision
value: 94.39166666666667
- type: recall
value: 96
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 57.692307692307686
- type: f1
value: 53.162393162393165
- type: precision
value: 51.70673076923077
- type: recall
value: 57.692307692307686
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.60000000000001
- type: f1
value: 89.21190476190475
- type: precision
value: 88.08666666666667
- type: recall
value: 91.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88
- type: f1
value: 85.47
- type: precision
value: 84.43266233766234
- type: recall
value: 88
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.7
- type: f1
value: 90.64999999999999
- type: precision
value: 89.68333333333332
- type: recall
value: 92.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.30660377358491
- type: f1
value: 76.33044137466307
- type: precision
value: 74.78970125786164
- type: recall
value: 80.30660377358491
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.39999999999999
- type: f1
value: 95.44
- type: precision
value: 94.99166666666666
- type: recall
value: 96.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.53284671532847
- type: f1
value: 95.37712895377129
- type: precision
value: 94.7992700729927
- type: recall
value: 96.53284671532847
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89
- type: f1
value: 86.23190476190476
- type: precision
value: 85.035
- type: recall
value: 89
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.585
- type: map_at_10
value: 9.012
- type: map_at_100
value: 14.027000000000001
- type: map_at_1000
value: 15.565000000000001
- type: map_at_3
value: 5.032
- type: map_at_5
value: 6.657
- type: mrr_at_1
value: 28.571
- type: mrr_at_10
value: 45.377
- type: mrr_at_100
value: 46.119
- type: mrr_at_1000
value: 46.127
- type: mrr_at_3
value: 41.156
- type: mrr_at_5
value: 42.585
- type: ndcg_at_1
value: 27.551
- type: ndcg_at_10
value: 23.395
- type: ndcg_at_100
value: 33.342
- type: ndcg_at_1000
value: 45.523
- type: ndcg_at_3
value: 25.158
- type: ndcg_at_5
value: 23.427
- type: precision_at_1
value: 28.571
- type: precision_at_10
value: 21.429000000000002
- type: precision_at_100
value: 6.714
- type: precision_at_1000
value: 1.473
- type: precision_at_3
value: 27.211000000000002
- type: precision_at_5
value: 24.490000000000002
- type: recall_at_1
value: 2.585
- type: recall_at_10
value: 15.418999999999999
- type: recall_at_100
value: 42.485
- type: recall_at_1000
value: 79.536
- type: recall_at_3
value: 6.239999999999999
- type: recall_at_5
value: 8.996
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.3234
- type: ap
value: 14.361688653847423
- type: f1
value: 54.819068624319044
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.97792869269949
- type: f1
value: 62.28965628513728
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 38.90540145385218
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.53513739047506
- type: cos_sim_ap
value: 75.27741586677557
- type: cos_sim_f1
value: 69.18792902473774
- type: cos_sim_precision
value: 67.94708725515136
- type: cos_sim_recall
value: 70.47493403693932
- type: dot_accuracy
value: 84.7052512368123
- type: dot_ap
value: 69.36075482849378
- type: dot_f1
value: 64.44688376631296
- type: dot_precision
value: 59.92288500793831
- type: dot_recall
value: 69.70976253298153
- type: euclidean_accuracy
value: 86.60666388508076
- type: euclidean_ap
value: 75.47512772621097
- type: euclidean_f1
value: 69.413872536473
- type: euclidean_precision
value: 67.39562624254472
- type: euclidean_recall
value: 71.55672823218997
- type: manhattan_accuracy
value: 86.52917684925792
- type: manhattan_ap
value: 75.34000110496703
- type: manhattan_f1
value: 69.28489190226429
- type: manhattan_precision
value: 67.24608889992551
- type: manhattan_recall
value: 71.45118733509234
- type: max_accuracy
value: 86.60666388508076
- type: max_ap
value: 75.47512772621097
- type: max_f1
value: 69.413872536473
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.01695967710637
- type: cos_sim_ap
value: 85.8298270742901
- type: cos_sim_f1
value: 78.46988128389272
- type: cos_sim_precision
value: 74.86017897091722
- type: cos_sim_recall
value: 82.44533415460425
- type: dot_accuracy
value: 88.19420188613343
- type: dot_ap
value: 83.82679165901324
- type: dot_f1
value: 76.55833777304208
- type: dot_precision
value: 75.6884875846501
- type: dot_recall
value: 77.44841392054204
- type: euclidean_accuracy
value: 89.03054294252338
- type: euclidean_ap
value: 85.89089555185325
- type: euclidean_f1
value: 78.62997658079624
- type: euclidean_precision
value: 74.92329149232914
- type: euclidean_recall
value: 82.72251308900523
- type: manhattan_accuracy
value: 89.0266620095471
- type: manhattan_ap
value: 85.86458997929147
- type: manhattan_f1
value: 78.50685331000291
- type: manhattan_precision
value: 74.5499861534201
- type: manhattan_recall
value: 82.90729904527257
- type: max_accuracy
value: 89.03054294252338
- type: max_ap
value: 85.89089555185325
- type: max_f1
value: 78.62997658079624
---
# nnch/multilingual-e5-large-Q4_K_M-GGUF
This model was converted to GGUF format from [`intfloat/multilingual-e5-large`](https://huggingface.co/intfloat/multilingual-e5-large) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/intfloat/multilingual-e5-large) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo nnch/multilingual-e5-large-Q4_K_M-GGUF --hf-file multilingual-e5-large-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo nnch/multilingual-e5-large-Q4_K_M-GGUF --hf-file multilingual-e5-large-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo nnch/multilingual-e5-large-Q4_K_M-GGUF --hf-file multilingual-e5-large-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo nnch/multilingual-e5-large-Q4_K_M-GGUF --hf-file multilingual-e5-large-q4_k_m.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2101.00027",
"endpoints_compatible",
"region:us"
] | 2024-10-27T21:42:44Z |
2024-10-27T23:08:21+00:00
| 59 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pythia-2.8b-helpful-sft - GGUF
- Model creator: https://huggingface.co/lomahony/
- Original model: https://huggingface.co/lomahony/pythia-2.8b-helpful-sft/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pythia-2.8b-helpful-sft.Q2_K.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q2_K.gguf) | Q2_K | 1.01GB |
| [pythia-2.8b-helpful-sft.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q3_K_S.gguf) | Q3_K_S | 1.16GB |
| [pythia-2.8b-helpful-sft.Q3_K.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q3_K.gguf) | Q3_K | 1.38GB |
| [pythia-2.8b-helpful-sft.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q3_K_M.gguf) | Q3_K_M | 1.38GB |
| [pythia-2.8b-helpful-sft.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q3_K_L.gguf) | Q3_K_L | 1.49GB |
| [pythia-2.8b-helpful-sft.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.IQ4_XS.gguf) | IQ4_XS | 1.43GB |
| [pythia-2.8b-helpful-sft.Q4_0.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q4_0.gguf) | Q4_0 | 1.49GB |
| [pythia-2.8b-helpful-sft.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.IQ4_NL.gguf) | IQ4_NL | 1.5GB |
| [pythia-2.8b-helpful-sft.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q4_K_S.gguf) | Q4_K_S | 1.5GB |
| [pythia-2.8b-helpful-sft.Q4_K.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q4_K.gguf) | Q4_K | 1.66GB |
| [pythia-2.8b-helpful-sft.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q4_K_M.gguf) | Q4_K_M | 1.66GB |
| [pythia-2.8b-helpful-sft.Q4_1.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q4_1.gguf) | Q4_1 | 1.64GB |
| [pythia-2.8b-helpful-sft.Q5_0.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q5_0.gguf) | Q5_0 | 1.8GB |
| [pythia-2.8b-helpful-sft.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q5_K_S.gguf) | Q5_K_S | 1.8GB |
| [pythia-2.8b-helpful-sft.Q5_K.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q5_K.gguf) | Q5_K | 1.93GB |
| [pythia-2.8b-helpful-sft.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q5_K_M.gguf) | Q5_K_M | 1.93GB |
| [pythia-2.8b-helpful-sft.Q5_1.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q5_1.gguf) | Q5_1 | 1.95GB |
| [pythia-2.8b-helpful-sft.Q6_K.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q6_K.gguf) | Q6_K | 2.13GB |
| [pythia-2.8b-helpful-sft.Q8_0.gguf](https://huggingface.co/RichardErkhov/lomahony_-_pythia-2.8b-helpful-sft-gguf/blob/main/pythia-2.8b-helpful-sft.Q8_0.gguf) | Q8_0 | 2.75GB |
Original model description:
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
license: apache-2.0
datasets:
- Anthropic/hh-rlhf
---
[Pythia-2.8b](https://huggingface.co/EleutherAI/pythia-410m) supervised finetuned using TRLx library with the helpful subset of [Anthropic-hh-rlhf dataset](https://huggingface.co/datasets/Anthropic/hh-rlhf) for 1 epoch.
Checkpoints are also uploaded.
Fully reproducible finetuning code is available on [GitHub](https://github.com/lauraaisling/trlx-pythia/tree/main)
[wandb log](https://wandb.ai/lauraomahony999/pythia-sft/runs/3b0ltx73)
See [Pythia-2.8b](https://huggingface.co/EleutherAI/pythia-2.8b) for model details [(paper)](https://arxiv.org/abs/2101.00027).
See further details of these models in the paper [Attributing Mode Collapse in the Fine-Tuning of Large Language Models](https://openreview.net/pdf?id=3pDMYjpOxk).
You can cite these models if they are helpful as follows:
<pre>
@inproceedings{o2024attributing,
title={Attributing Mode Collapse in the Fine-Tuning of Large Language Models},
author={O’Mahony, Laura and Grinsztajn, Leo and Schoelkopf, Hailey and Biderman, Stella},
booktitle={ICLR 2024, Mathematical and Empirical Understanding of Foundation Models (ME-FoMo) workshop},
year={2024}
}
</pre>
hf (pretrained=lomahony/pythia-2.8b-helpful-sft), gen_kwargs: (None), limit: None, num_fewshot: 0, batch_size: 16
| Tasks |Version|Filter|n-shot| Metric | Value | |Stderr|
|--------------|------:|------|-----:|---------------|------:|---|------|
|arc_challenge | 1|none | 0|acc | 0.2901|± |0.0133|
| | |none | 0|acc_norm | 0.3404|± |0.0138|
|arc_easy | 1|none | 0|acc | 0.6469|± |0.0098|
| | |none | 0|acc_norm | 0.5766|± |0.0101|
|boolq | 2|none | 0|acc | 0.6361|± |0.0084|
|hellaswag | 1|none | 0|acc | 0.4557|± |0.0050|
| | |none | 0|acc_norm | 0.5984|± |0.0049|
|lambada_openai| 1|none | 0|perplexity | 5.2226|± |0.1377|
| | |none | 0|acc | 0.6210|± |0.0068|
|openbookqa | 1|none | 0|acc | 0.2640|± |0.0197|
| | |none | 0|acc_norm | 0.3760|± |0.0217|
|piqa | 1|none | 0|acc | 0.7481|± |0.0101|
| | |none | 0|acc_norm | 0.7481|± |0.0101|
|sciq | 1|none | 0|acc | 0.8800|± |0.0103|
| | |none | 0|acc_norm | 0.8180|± |0.0122|
|wikitext | 2|none | 0|word_perplexity|13.4928|± |N/A |
| | |none | 0|byte_perplexity| 1.6268|± |N/A |
| | |none | 0|bits_per_byte | 0.7020|± |N/A |
|winogrande | 1|none | 0|acc | 0.6125|± |0.0137|
hf (pretrained=lomahony/pythia-2.8b-helpful-sft), gen_kwargs: (None), limit: None, num_fewshot: 5, batch_size: 16
| Tasks |Version|Filter|n-shot| Metric | Value | |Stderr|
|--------------|------:|------|-----:|---------------|------:|---|------|
|arc_challenge | 1|none | 5|acc | 0.3285|± |0.0137|
| | |none | 5|acc_norm | 0.3677|± |0.0141|
|arc_easy | 1|none | 5|acc | 0.6873|± |0.0095|
| | |none | 5|acc_norm | 0.6835|± |0.0095|
|boolq | 2|none | 5|acc | 0.6670|± |0.0082|
|hellaswag | 1|none | 5|acc | 0.4542|± |0.0050|
| | |none | 5|acc_norm | 0.5963|± |0.0049|
|lambada_openai| 1|none | 5|perplexity | 7.4076|± |0.2095|
| | |none | 5|acc | 0.5486|± |0.0069|
|openbookqa | 1|none | 5|acc | 0.2680|± |0.0198|
| | |none | 5|acc_norm | 0.3620|± |0.0215|
|piqa | 1|none | 5|acc | 0.7568|± |0.0100|
| | |none | 5|acc_norm | 0.7486|± |0.0101|
|sciq | 1|none | 5|acc | 0.9380|± |0.0076|
| | |none | 5|acc_norm | 0.9330|± |0.0079|
|wikitext | 2|none | 5|word_perplexity|13.4928|± |N/A |
| | |none | 5|byte_perplexity| 1.6268|± |N/A |
| | |none | 5|bits_per_byte | 0.7020|± |N/A |
|winogrande | 1|none | 5|acc | 0.5935|± |0.0138|
|
[
"SCIQ"
] |
RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2101.00027",
"arxiv:2201.07311",
"endpoints_compatible",
"region:us"
] | 2024-11-06T22:34:08Z |
2024-11-06T22:51:35+00:00
| 59 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pythia-410m-deduped-v0 - GGUF
- Model creator: https://huggingface.co/EleutherAI/
- Original model: https://huggingface.co/EleutherAI/pythia-410m-deduped-v0/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pythia-410m-deduped-v0.Q2_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q2_K.gguf) | Q2_K | 0.16GB |
| [pythia-410m-deduped-v0.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q3_K_S.gguf) | Q3_K_S | 0.18GB |
| [pythia-410m-deduped-v0.Q3_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q3_K.gguf) | Q3_K | 0.21GB |
| [pythia-410m-deduped-v0.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q3_K_M.gguf) | Q3_K_M | 0.21GB |
| [pythia-410m-deduped-v0.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q3_K_L.gguf) | Q3_K_L | 0.22GB |
| [pythia-410m-deduped-v0.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.IQ4_XS.gguf) | IQ4_XS | 0.22GB |
| [pythia-410m-deduped-v0.Q4_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q4_0.gguf) | Q4_0 | 0.23GB |
| [pythia-410m-deduped-v0.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.IQ4_NL.gguf) | IQ4_NL | 0.23GB |
| [pythia-410m-deduped-v0.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q4_K_S.gguf) | Q4_K_S | 0.23GB |
| [pythia-410m-deduped-v0.Q4_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q4_K.gguf) | Q4_K | 0.25GB |
| [pythia-410m-deduped-v0.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q4_K_M.gguf) | Q4_K_M | 0.25GB |
| [pythia-410m-deduped-v0.Q4_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q4_1.gguf) | Q4_1 | 0.25GB |
| [pythia-410m-deduped-v0.Q5_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q5_0.gguf) | Q5_0 | 0.27GB |
| [pythia-410m-deduped-v0.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q5_K_S.gguf) | Q5_K_S | 0.27GB |
| [pythia-410m-deduped-v0.Q5_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q5_K.gguf) | Q5_K | 0.28GB |
| [pythia-410m-deduped-v0.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q5_K_M.gguf) | Q5_K_M | 0.28GB |
| [pythia-410m-deduped-v0.Q5_1.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q5_1.gguf) | Q5_1 | 0.29GB |
| [pythia-410m-deduped-v0.Q6_K.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q6_K.gguf) | Q6_K | 0.31GB |
| [pythia-410m-deduped-v0.Q8_0.gguf](https://huggingface.co/RichardErkhov/EleutherAI_-_pythia-410m-deduped-v0-gguf/blob/main/pythia-410m-deduped-v0.Q8_0.gguf) | Q8_0 | 0.4GB |
Original model description:
---
language:
- en
tags:
- pytorch
- causal-lm
- pythia
- pythia_v0
license: apache-2.0
datasets:
- EleutherAI/the_pile_deduplicated
---
The *Pythia Scaling Suite* is a collection of models developed to facilitate
interpretability research. It contains two sets of eight models of sizes
70M, 160M, 410M, 1B, 1.4B, 2.8B, 6.9B, and 12B. For each size, there are two
models: one trained on the Pile, and one trained on the Pile after the dataset
has been globally deduplicated. All 8 model sizes are trained on the exact
same data, in the exact same order. All Pythia models are available
[on Hugging Face](https://huggingface.co/models?other=pythia).
The Pythia model suite was deliberately designed to promote scientific
research on large language models, especially interpretability research.
Despite not centering downstream performance as a design goal, we find the
models <a href="#evaluations">match or exceed</a> the performance of
similar and same-sized models, such as those in the OPT and GPT-Neo suites.
Please note that all models in the *Pythia* suite were renamed in January
2023. For clarity, a <a href="#naming-convention-and-parameter-count">table
comparing the old and new names</a> is provided in this model card, together
with exact parameter counts.
## Pythia-410M-deduped
### Model Details
- Developed by: [EleutherAI](http://eleuther.ai)
- Model type: Transformer-based Language Model
- Language: English
- Learn more: [Pythia's GitHub repository](https://github.com/EleutherAI/pythia)
for training procedure, config files, and details on how to use.
- Library: [GPT-NeoX](https://github.com/EleutherAI/gpt-neox)
- License: Apache 2.0
- Contact: to ask questions about this model, join the [EleutherAI
Discord](https://discord.gg/zBGx3azzUn), and post them in `#release-discussion`.
Please read the existing *Pythia* documentation before asking about it in the
EleutherAI Discord. For general correspondence: [contact@eleuther.
ai](mailto:[email protected]).
<figure>
| Pythia model | Non-Embedding Params | Layers | Model Dim | Heads | Batch Size | Learning Rate | Equivalent Models |
| -----------: | -------------------: | :----: | :-------: | :---: | :--------: | :-------------------: | :--------------------: |
| 70M | 18,915,328 | 6 | 512 | 8 | 2M | 1.0 x 10<sup>-3</sup> | — |
| 160M | 85,056,000 | 12 | 768 | 12 | 4M | 6.0 x 10<sup>-4</sup> | GPT-Neo 125M, OPT-125M |
| 410M | 302,311,424 | 24 | 1024 | 16 | 4M | 3.0 x 10<sup>-4</sup> | OPT-350M |
| 1.0B | 805,736,448 | 16 | 2048 | 8 | 2M | 3.0 x 10<sup>-4</sup> | — |
| 1.4B | 1,208,602,624 | 24 | 2048 | 16 | 4M | 2.0 x 10<sup>-4</sup> | GPT-Neo 1.3B, OPT-1.3B |
| 2.8B | 2,517,652,480 | 32 | 2560 | 32 | 2M | 1.6 x 10<sup>-4</sup> | GPT-Neo 2.7B, OPT-2.7B |
| 6.9B | 6,444,163,072 | 32 | 4096 | 32 | 2M | 1.2 x 10<sup>-4</sup> | OPT-6.7B |
| 12B | 11,327,027,200 | 36 | 5120 | 40 | 2M | 1.2 x 10<sup>-4</sup> | — |
<figcaption>Engineering details for the <i>Pythia Suite</i>. Deduped and
non-deduped models of a given size have the same hyperparameters. “Equivalent”
models have <b>exactly</b> the same architecture, and the same number of
non-embedding parameters.</figcaption>
</figure>
### Uses and Limitations
#### Intended Use
The primary intended use of Pythia is research on the behavior, functionality,
and limitations of large language models. This suite is intended to provide
a controlled setting for performing scientific experiments. To enable the
study of how language models change in the course of training, we provide
143 evenly spaced intermediate checkpoints per model. These checkpoints are
hosted on Hugging Face as branches. Note that branch `143000` corresponds
exactly to the model checkpoint on the `main` branch of each model.
You may also further fine-tune and adapt Pythia-410M-deduped for deployment,
as long as your use is in accordance with the Apache 2.0 license. Pythia
models work with the Hugging Face [Transformers
Library](https://huggingface.co/docs/transformers/index). If you decide to use
pre-trained Pythia-410M-deduped as a basis for your fine-tuned model, please
conduct your own risk and bias assessment.
#### Out-of-scope use
The Pythia Suite is **not** intended for deployment. It is not a in itself
a product and cannot be used for human-facing interactions.
Pythia models are English-language only, and are not suitable for translation
or generating text in other languages.
Pythia-410M-deduped has not been fine-tuned for downstream contexts in which
language models are commonly deployed, such as writing genre prose,
or commercial chatbots. This means Pythia-410M-deduped will **not**
respond to a given prompt the way a product like ChatGPT does. This is because,
unlike this model, ChatGPT was fine-tuned using methods such as Reinforcement
Learning from Human Feedback (RLHF) to better “understand” human instructions.
#### Limitations and biases
The core functionality of a large language model is to take a string of text
and predict the next token. The token deemed statistically most likely by the
model need not produce the most “accurate” text. Never rely on
Pythia-410M-deduped to produce factually accurate output.
This model was trained on [the Pile](https://pile.eleuther.ai/), a dataset
known to contain profanity and texts that are lewd or otherwise offensive.
See [Section 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a
discussion of documented biases with regards to gender, religion, and race.
Pythia-410M-deduped may produce socially unacceptable or undesirable text,
*even if* the prompt itself does not include anything explicitly offensive.
If you plan on using text generated through, for example, the Hosted Inference
API, we recommend having a human curate the outputs of this language model
before presenting it to other people. Please inform your audience that the
text was generated by Pythia-410M-deduped.
### Quickstart
Pythia models can be loaded and used via the following code, demonstrated here
for the third `pythia-70m-deduped` checkpoint:
```python
from transformers import GPTNeoXForCausalLM, AutoTokenizer
model = GPTNeoXForCausalLM.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
tokenizer = AutoTokenizer.from_pretrained(
"EleutherAI/pythia-70m-deduped",
revision="step3000",
cache_dir="./pythia-70m-deduped/step3000",
)
inputs = tokenizer("Hello, I am", return_tensors="pt")
tokens = model.generate(**inputs)
tokenizer.decode(tokens[0])
```
Revision/branch `step143000` corresponds exactly to the model checkpoint on
the `main` branch of each model.<br>
For more information on how to use all Pythia models, see [documentation on
GitHub](https://github.com/EleutherAI/pythia).
### Training
#### Training data
Pythia-410M-deduped was trained on the Pile **after the dataset has been
globally deduplicated**.<br>
[The Pile](https://pile.eleuther.ai/) is a 825GiB general-purpose dataset in
English. It was created by EleutherAI specifically for training large language
models. It contains texts from 22 diverse sources, roughly broken down into
five categories: academic writing (e.g. arXiv), internet (e.g. CommonCrawl),
prose (e.g. Project Gutenberg), dialogue (e.g. YouTube subtitles), and
miscellaneous (e.g. GitHub, Enron Emails). See [the Pile
paper](https://arxiv.org/abs/2101.00027) for a breakdown of all data sources,
methodology, and a discussion of ethical implications. Consult [the
datasheet](https://arxiv.org/abs/2201.07311) for more detailed documentation
about the Pile and its component datasets. The Pile can be downloaded from
the [official website](https://pile.eleuther.ai/), or from a [community
mirror](https://the-eye.eu/public/AI/pile/).
#### Training procedure
All models were trained on the exact same data, in the exact same order. Each
model saw 299,892,736,000 tokens during training, and 143 checkpoints for each
model are saved every 2,097,152,000 tokens, spaced evenly throughout training.
This corresponds to training for just under 1 epoch on the Pile for
non-deduplicated models, and about 1.5 epochs on the deduplicated Pile.
All *Pythia* models trained for the equivalent of 143000 steps at a batch size
of 2,097,152 tokens. Two batch sizes were used: 2M and 4M. Models with a batch
size of 4M tokens listed were originally trained for 71500 steps instead, with
checkpoints every 500 steps. The checkpoints on Hugging Face are renamed for
consistency with all 2M batch models, so `step1000` is the first checkpoint
for `pythia-1.4b` that was saved (corresponding to step 500 in training), and
`step1000` is likewise the first `pythia-6.9b` checkpoint that was saved
(corresponding to 1000 “actual” steps).<br>
See [GitHub](https://github.com/EleutherAI/pythia) for more details on training
procedure, including [how to reproduce
it](https://github.com/EleutherAI/pythia/blob/main/README.md#reproducing-training).<br>
Pythia uses the same tokenizer as [GPT-NeoX-
20B](https://huggingface.co/EleutherAI/gpt-neox-20b).
### Evaluations
All 16 *Pythia* models were evaluated using the [LM Evaluation
Harness](https://github.com/EleutherAI/lm-evaluation-harness). You can access
the results by model and step at `results/json/*` in the [GitHub
repository](https://github.com/EleutherAI/pythia/tree/main/results/json).<br>
Expand the sections below to see plots of evaluation results for all
Pythia and Pythia-deduped models compared with OPT and BLOOM.
<details>
<summary>LAMBADA – OpenAI</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/lambada_openai.png" style="width:auto"/>
</details>
<details>
<summary>Physical Interaction: Question Answering (PIQA)</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/piqa.png" style="width:auto"/>
</details>
<details>
<summary>WinoGrande</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/winogrande.png" style="width:auto"/>
</details>
<details>
<summary>AI2 Reasoning Challenge – Challenge Set</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/arc_challenge.png" style="width:auto"/>
</details>
<details>
<summary>SciQ</summary>
<img src="/EleutherAI/pythia-12b/resolve/main/eval_plots/sciq.png" style="width:auto"/>
</details>
### Naming convention and parameter count
*Pythia* models were renamed in January 2023. It is possible that the old
naming convention still persists in some documentation by accident. The
current naming convention (70M, 160M, etc.) is based on total parameter count.
<figure style="width:32em">
| current Pythia suffix | old suffix | total params | non-embedding params |
| --------------------: | ---------: | -------------: | -------------------: |
| 70M | 19M | 70,426,624 | 18,915,328 |
| 160M | 125M | 162,322,944 | 85,056,000 |
| 410M | 350M | 405,334,016 | 302,311,424 |
| 1B | 800M | 1,011,781,632 | 805,736,448 |
| 1.4B | 1.3B | 1,414,647,808 | 1,208,602,624 |
| 2.8B | 2.7B | 2,775,208,960 | 2,517,652,480 |
| 6.9B | 6.7B | 6,857,302,016 | 6,444,163,072 |
| 12B | 13B | 11,846,072,320 | 11,327,027,200 |
</figure>
|
[
"SCIQ"
] |
tensorblock/GritLM-7B-GGUF
|
tensorblock
|
text-generation
|
[
"gguf",
"mteb",
"TensorBlock",
"GGUF",
"text-generation",
"dataset:GritLM/tulu2",
"base_model:GritLM/GritLM-7B",
"base_model:quantized:GritLM/GritLM-7B",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-11-11T14:22:59Z |
2024-11-16T01:08:22+00:00
| 59 | 0 |
---
base_model: GritLM/GritLM-7B
datasets:
- GritLM/tulu2
license: apache-2.0
pipeline_tag: text-generation
tags:
- mteb
- TensorBlock
- GGUF
inference: true
model-index:
- name: GritLM-7B
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 81.17910447761194
- type: ap
value: 46.26260671758199
- type: f1
value: 75.44565719934167
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 96.5161
- type: ap
value: 94.79131981460425
- type: f1
value: 96.51506148413065
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 57.806000000000004
- type: f1
value: 56.78350156257903
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.478
- type: map_at_10
value: 54.955
- type: map_at_100
value: 54.955
- type: map_at_1000
value: 54.955
- type: map_at_3
value: 50.888999999999996
- type: map_at_5
value: 53.349999999999994
- type: mrr_at_1
value: 39.757999999999996
- type: mrr_at_10
value: 55.449000000000005
- type: mrr_at_100
value: 55.449000000000005
- type: mrr_at_1000
value: 55.449000000000005
- type: mrr_at_3
value: 51.37500000000001
- type: mrr_at_5
value: 53.822
- type: ndcg_at_1
value: 38.478
- type: ndcg_at_10
value: 63.239999999999995
- type: ndcg_at_100
value: 63.239999999999995
- type: ndcg_at_1000
value: 63.239999999999995
- type: ndcg_at_3
value: 54.935
- type: ndcg_at_5
value: 59.379000000000005
- type: precision_at_1
value: 38.478
- type: precision_at_10
value: 8.933
- type: precision_at_100
value: 0.893
- type: precision_at_1000
value: 0.089
- type: precision_at_3
value: 22.214
- type: precision_at_5
value: 15.491
- type: recall_at_1
value: 38.478
- type: recall_at_10
value: 89.331
- type: recall_at_100
value: 89.331
- type: recall_at_1000
value: 89.331
- type: recall_at_3
value: 66.643
- type: recall_at_5
value: 77.45400000000001
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 51.67144081472449
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 48.11256154264126
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 67.33801955487878
- type: mrr
value: 80.71549487754474
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 88.1935203751726
- type: cos_sim_spearman
value: 86.35497970498659
- type: euclidean_pearson
value: 85.46910708503744
- type: euclidean_spearman
value: 85.13928935405485
- type: manhattan_pearson
value: 85.68373836333303
- type: manhattan_spearman
value: 85.40013867117746
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 88.46753246753248
- type: f1
value: 88.43006344981134
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 40.86793640310432
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 39.80291334130727
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.421
- type: map_at_10
value: 52.349000000000004
- type: map_at_100
value: 52.349000000000004
- type: map_at_1000
value: 52.349000000000004
- type: map_at_3
value: 48.17
- type: map_at_5
value: 50.432
- type: mrr_at_1
value: 47.353
- type: mrr_at_10
value: 58.387
- type: mrr_at_100
value: 58.387
- type: mrr_at_1000
value: 58.387
- type: mrr_at_3
value: 56.199
- type: mrr_at_5
value: 57.487
- type: ndcg_at_1
value: 47.353
- type: ndcg_at_10
value: 59.202
- type: ndcg_at_100
value: 58.848
- type: ndcg_at_1000
value: 58.831999999999994
- type: ndcg_at_3
value: 54.112
- type: ndcg_at_5
value: 56.312
- type: precision_at_1
value: 47.353
- type: precision_at_10
value: 11.459
- type: precision_at_100
value: 1.146
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 26.133
- type: precision_at_5
value: 18.627
- type: recall_at_1
value: 38.421
- type: recall_at_10
value: 71.89
- type: recall_at_100
value: 71.89
- type: recall_at_1000
value: 71.89
- type: recall_at_3
value: 56.58
- type: recall_at_5
value: 63.125
- type: map_at_1
value: 38.025999999999996
- type: map_at_10
value: 50.590999999999994
- type: map_at_100
value: 51.99700000000001
- type: map_at_1000
value: 52.11599999999999
- type: map_at_3
value: 47.435
- type: map_at_5
value: 49.236000000000004
- type: mrr_at_1
value: 48.28
- type: mrr_at_10
value: 56.814
- type: mrr_at_100
value: 57.446
- type: mrr_at_1000
value: 57.476000000000006
- type: mrr_at_3
value: 54.958
- type: mrr_at_5
value: 56.084999999999994
- type: ndcg_at_1
value: 48.28
- type: ndcg_at_10
value: 56.442
- type: ndcg_at_100
value: 60.651999999999994
- type: ndcg_at_1000
value: 62.187000000000005
- type: ndcg_at_3
value: 52.866
- type: ndcg_at_5
value: 54.515
- type: precision_at_1
value: 48.28
- type: precision_at_10
value: 10.586
- type: precision_at_100
value: 1.6310000000000002
- type: precision_at_1000
value: 0.20600000000000002
- type: precision_at_3
value: 25.945
- type: precision_at_5
value: 18.076
- type: recall_at_1
value: 38.025999999999996
- type: recall_at_10
value: 66.11399999999999
- type: recall_at_100
value: 83.339
- type: recall_at_1000
value: 92.413
- type: recall_at_3
value: 54.493
- type: recall_at_5
value: 59.64699999999999
- type: map_at_1
value: 47.905
- type: map_at_10
value: 61.58
- type: map_at_100
value: 62.605
- type: map_at_1000
value: 62.637
- type: map_at_3
value: 58.074000000000005
- type: map_at_5
value: 60.260000000000005
- type: mrr_at_1
value: 54.42
- type: mrr_at_10
value: 64.847
- type: mrr_at_100
value: 65.403
- type: mrr_at_1000
value: 65.41900000000001
- type: mrr_at_3
value: 62.675000000000004
- type: mrr_at_5
value: 64.101
- type: ndcg_at_1
value: 54.42
- type: ndcg_at_10
value: 67.394
- type: ndcg_at_100
value: 70.846
- type: ndcg_at_1000
value: 71.403
- type: ndcg_at_3
value: 62.025
- type: ndcg_at_5
value: 65.032
- type: precision_at_1
value: 54.42
- type: precision_at_10
value: 10.646
- type: precision_at_100
value: 1.325
- type: precision_at_1000
value: 0.13999999999999999
- type: precision_at_3
value: 27.398
- type: precision_at_5
value: 18.796
- type: recall_at_1
value: 47.905
- type: recall_at_10
value: 80.84599999999999
- type: recall_at_100
value: 95.078
- type: recall_at_1000
value: 98.878
- type: recall_at_3
value: 67.05600000000001
- type: recall_at_5
value: 74.261
- type: map_at_1
value: 30.745
- type: map_at_10
value: 41.021
- type: map_at_100
value: 41.021
- type: map_at_1000
value: 41.021
- type: map_at_3
value: 37.714999999999996
- type: map_at_5
value: 39.766
- type: mrr_at_1
value: 33.559
- type: mrr_at_10
value: 43.537
- type: mrr_at_100
value: 43.537
- type: mrr_at_1000
value: 43.537
- type: mrr_at_3
value: 40.546
- type: mrr_at_5
value: 42.439
- type: ndcg_at_1
value: 33.559
- type: ndcg_at_10
value: 46.781
- type: ndcg_at_100
value: 46.781
- type: ndcg_at_1000
value: 46.781
- type: ndcg_at_3
value: 40.516000000000005
- type: ndcg_at_5
value: 43.957
- type: precision_at_1
value: 33.559
- type: precision_at_10
value: 7.198
- type: precision_at_100
value: 0.72
- type: precision_at_1000
value: 0.07200000000000001
- type: precision_at_3
value: 17.1
- type: precision_at_5
value: 12.316
- type: recall_at_1
value: 30.745
- type: recall_at_10
value: 62.038000000000004
- type: recall_at_100
value: 62.038000000000004
- type: recall_at_1000
value: 62.038000000000004
- type: recall_at_3
value: 45.378
- type: recall_at_5
value: 53.580000000000005
- type: map_at_1
value: 19.637999999999998
- type: map_at_10
value: 31.05
- type: map_at_100
value: 31.05
- type: map_at_1000
value: 31.05
- type: map_at_3
value: 27.628000000000004
- type: map_at_5
value: 29.767
- type: mrr_at_1
value: 25.0
- type: mrr_at_10
value: 36.131
- type: mrr_at_100
value: 36.131
- type: mrr_at_1000
value: 36.131
- type: mrr_at_3
value: 33.333
- type: mrr_at_5
value: 35.143
- type: ndcg_at_1
value: 25.0
- type: ndcg_at_10
value: 37.478
- type: ndcg_at_100
value: 37.469
- type: ndcg_at_1000
value: 37.469
- type: ndcg_at_3
value: 31.757999999999996
- type: ndcg_at_5
value: 34.821999999999996
- type: precision_at_1
value: 25.0
- type: precision_at_10
value: 7.188999999999999
- type: precision_at_100
value: 0.719
- type: precision_at_1000
value: 0.07200000000000001
- type: precision_at_3
value: 15.837000000000002
- type: precision_at_5
value: 11.841
- type: recall_at_1
value: 19.637999999999998
- type: recall_at_10
value: 51.836000000000006
- type: recall_at_100
value: 51.836000000000006
- type: recall_at_1000
value: 51.836000000000006
- type: recall_at_3
value: 36.384
- type: recall_at_5
value: 43.964
- type: map_at_1
value: 34.884
- type: map_at_10
value: 47.88
- type: map_at_100
value: 47.88
- type: map_at_1000
value: 47.88
- type: map_at_3
value: 43.85
- type: map_at_5
value: 46.414
- type: mrr_at_1
value: 43.022
- type: mrr_at_10
value: 53.569
- type: mrr_at_100
value: 53.569
- type: mrr_at_1000
value: 53.569
- type: mrr_at_3
value: 51.075
- type: mrr_at_5
value: 52.725
- type: ndcg_at_1
value: 43.022
- type: ndcg_at_10
value: 54.461000000000006
- type: ndcg_at_100
value: 54.388000000000005
- type: ndcg_at_1000
value: 54.388000000000005
- type: ndcg_at_3
value: 48.864999999999995
- type: ndcg_at_5
value: 52.032000000000004
- type: precision_at_1
value: 43.022
- type: precision_at_10
value: 9.885
- type: precision_at_100
value: 0.988
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 23.612
- type: precision_at_5
value: 16.997
- type: recall_at_1
value: 34.884
- type: recall_at_10
value: 68.12899999999999
- type: recall_at_100
value: 68.12899999999999
- type: recall_at_1000
value: 68.12899999999999
- type: recall_at_3
value: 52.428
- type: recall_at_5
value: 60.662000000000006
- type: map_at_1
value: 31.588
- type: map_at_10
value: 43.85
- type: map_at_100
value: 45.317
- type: map_at_1000
value: 45.408
- type: map_at_3
value: 39.73
- type: map_at_5
value: 42.122
- type: mrr_at_1
value: 38.927
- type: mrr_at_10
value: 49.582
- type: mrr_at_100
value: 50.39
- type: mrr_at_1000
value: 50.426
- type: mrr_at_3
value: 46.518
- type: mrr_at_5
value: 48.271
- type: ndcg_at_1
value: 38.927
- type: ndcg_at_10
value: 50.605999999999995
- type: ndcg_at_100
value: 56.22200000000001
- type: ndcg_at_1000
value: 57.724
- type: ndcg_at_3
value: 44.232
- type: ndcg_at_5
value: 47.233999999999995
- type: precision_at_1
value: 38.927
- type: precision_at_10
value: 9.429
- type: precision_at_100
value: 1.435
- type: precision_at_1000
value: 0.172
- type: precision_at_3
value: 21.271
- type: precision_at_5
value: 15.434000000000001
- type: recall_at_1
value: 31.588
- type: recall_at_10
value: 64.836
- type: recall_at_100
value: 88.066
- type: recall_at_1000
value: 97.748
- type: recall_at_3
value: 47.128
- type: recall_at_5
value: 54.954
- type: map_at_1
value: 31.956083333333336
- type: map_at_10
value: 43.33483333333333
- type: map_at_100
value: 44.64883333333333
- type: map_at_1000
value: 44.75
- type: map_at_3
value: 39.87741666666666
- type: map_at_5
value: 41.86766666666667
- type: mrr_at_1
value: 38.06341666666667
- type: mrr_at_10
value: 47.839666666666666
- type: mrr_at_100
value: 48.644000000000005
- type: mrr_at_1000
value: 48.68566666666667
- type: mrr_at_3
value: 45.26358333333334
- type: mrr_at_5
value: 46.790000000000006
- type: ndcg_at_1
value: 38.06341666666667
- type: ndcg_at_10
value: 49.419333333333334
- type: ndcg_at_100
value: 54.50166666666667
- type: ndcg_at_1000
value: 56.161166666666674
- type: ndcg_at_3
value: 43.982416666666666
- type: ndcg_at_5
value: 46.638083333333334
- type: precision_at_1
value: 38.06341666666667
- type: precision_at_10
value: 8.70858333333333
- type: precision_at_100
value: 1.327
- type: precision_at_1000
value: 0.165
- type: precision_at_3
value: 20.37816666666667
- type: precision_at_5
value: 14.516333333333334
- type: recall_at_1
value: 31.956083333333336
- type: recall_at_10
value: 62.69458333333334
- type: recall_at_100
value: 84.46433333333334
- type: recall_at_1000
value: 95.58449999999999
- type: recall_at_3
value: 47.52016666666666
- type: recall_at_5
value: 54.36066666666666
- type: map_at_1
value: 28.912
- type: map_at_10
value: 38.291
- type: map_at_100
value: 39.44
- type: map_at_1000
value: 39.528
- type: map_at_3
value: 35.638
- type: map_at_5
value: 37.218
- type: mrr_at_1
value: 32.822
- type: mrr_at_10
value: 41.661
- type: mrr_at_100
value: 42.546
- type: mrr_at_1000
value: 42.603
- type: mrr_at_3
value: 39.238
- type: mrr_at_5
value: 40.726
- type: ndcg_at_1
value: 32.822
- type: ndcg_at_10
value: 43.373
- type: ndcg_at_100
value: 48.638
- type: ndcg_at_1000
value: 50.654999999999994
- type: ndcg_at_3
value: 38.643
- type: ndcg_at_5
value: 41.126000000000005
- type: precision_at_1
value: 32.822
- type: precision_at_10
value: 6.8709999999999996
- type: precision_at_100
value: 1.032
- type: precision_at_1000
value: 0.128
- type: precision_at_3
value: 16.82
- type: precision_at_5
value: 11.718
- type: recall_at_1
value: 28.912
- type: recall_at_10
value: 55.376999999999995
- type: recall_at_100
value: 79.066
- type: recall_at_1000
value: 93.664
- type: recall_at_3
value: 42.569
- type: recall_at_5
value: 48.719
- type: map_at_1
value: 22.181
- type: map_at_10
value: 31.462
- type: map_at_100
value: 32.73
- type: map_at_1000
value: 32.848
- type: map_at_3
value: 28.57
- type: map_at_5
value: 30.182
- type: mrr_at_1
value: 27.185
- type: mrr_at_10
value: 35.846000000000004
- type: mrr_at_100
value: 36.811
- type: mrr_at_1000
value: 36.873
- type: mrr_at_3
value: 33.437
- type: mrr_at_5
value: 34.813
- type: ndcg_at_1
value: 27.185
- type: ndcg_at_10
value: 36.858000000000004
- type: ndcg_at_100
value: 42.501
- type: ndcg_at_1000
value: 44.945
- type: ndcg_at_3
value: 32.066
- type: ndcg_at_5
value: 34.29
- type: precision_at_1
value: 27.185
- type: precision_at_10
value: 6.752
- type: precision_at_100
value: 1.111
- type: precision_at_1000
value: 0.151
- type: precision_at_3
value: 15.290000000000001
- type: precision_at_5
value: 11.004999999999999
- type: recall_at_1
value: 22.181
- type: recall_at_10
value: 48.513
- type: recall_at_100
value: 73.418
- type: recall_at_1000
value: 90.306
- type: recall_at_3
value: 35.003
- type: recall_at_5
value: 40.876000000000005
- type: map_at_1
value: 33.934999999999995
- type: map_at_10
value: 44.727
- type: map_at_100
value: 44.727
- type: map_at_1000
value: 44.727
- type: map_at_3
value: 40.918
- type: map_at_5
value: 42.961
- type: mrr_at_1
value: 39.646
- type: mrr_at_10
value: 48.898
- type: mrr_at_100
value: 48.898
- type: mrr_at_1000
value: 48.898
- type: mrr_at_3
value: 45.896
- type: mrr_at_5
value: 47.514
- type: ndcg_at_1
value: 39.646
- type: ndcg_at_10
value: 50.817
- type: ndcg_at_100
value: 50.803
- type: ndcg_at_1000
value: 50.803
- type: ndcg_at_3
value: 44.507999999999996
- type: ndcg_at_5
value: 47.259
- type: precision_at_1
value: 39.646
- type: precision_at_10
value: 8.759
- type: precision_at_100
value: 0.876
- type: precision_at_1000
value: 0.08800000000000001
- type: precision_at_3
value: 20.274
- type: precision_at_5
value: 14.366000000000001
- type: recall_at_1
value: 33.934999999999995
- type: recall_at_10
value: 65.037
- type: recall_at_100
value: 65.037
- type: recall_at_1000
value: 65.037
- type: recall_at_3
value: 47.439
- type: recall_at_5
value: 54.567
- type: map_at_1
value: 32.058
- type: map_at_10
value: 43.137
- type: map_at_100
value: 43.137
- type: map_at_1000
value: 43.137
- type: map_at_3
value: 39.882
- type: map_at_5
value: 41.379
- type: mrr_at_1
value: 38.933
- type: mrr_at_10
value: 48.344
- type: mrr_at_100
value: 48.344
- type: mrr_at_1000
value: 48.344
- type: mrr_at_3
value: 45.652
- type: mrr_at_5
value: 46.877
- type: ndcg_at_1
value: 38.933
- type: ndcg_at_10
value: 49.964
- type: ndcg_at_100
value: 49.242000000000004
- type: ndcg_at_1000
value: 49.222
- type: ndcg_at_3
value: 44.605
- type: ndcg_at_5
value: 46.501999999999995
- type: precision_at_1
value: 38.933
- type: precision_at_10
value: 9.427000000000001
- type: precision_at_100
value: 0.943
- type: precision_at_1000
value: 0.094
- type: precision_at_3
value: 20.685000000000002
- type: precision_at_5
value: 14.585
- type: recall_at_1
value: 32.058
- type: recall_at_10
value: 63.074
- type: recall_at_100
value: 63.074
- type: recall_at_1000
value: 63.074
- type: recall_at_3
value: 47.509
- type: recall_at_5
value: 52.455
- type: map_at_1
value: 26.029000000000003
- type: map_at_10
value: 34.646
- type: map_at_100
value: 34.646
- type: map_at_1000
value: 34.646
- type: map_at_3
value: 31.456
- type: map_at_5
value: 33.138
- type: mrr_at_1
value: 28.281
- type: mrr_at_10
value: 36.905
- type: mrr_at_100
value: 36.905
- type: mrr_at_1000
value: 36.905
- type: mrr_at_3
value: 34.011
- type: mrr_at_5
value: 35.638
- type: ndcg_at_1
value: 28.281
- type: ndcg_at_10
value: 40.159
- type: ndcg_at_100
value: 40.159
- type: ndcg_at_1000
value: 40.159
- type: ndcg_at_3
value: 33.995
- type: ndcg_at_5
value: 36.836999999999996
- type: precision_at_1
value: 28.281
- type: precision_at_10
value: 6.358999999999999
- type: precision_at_100
value: 0.636
- type: precision_at_1000
value: 0.064
- type: precision_at_3
value: 14.233
- type: precision_at_5
value: 10.314
- type: recall_at_1
value: 26.029000000000003
- type: recall_at_10
value: 55.08
- type: recall_at_100
value: 55.08
- type: recall_at_1000
value: 55.08
- type: recall_at_3
value: 38.487
- type: recall_at_5
value: 45.308
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 12.842999999999998
- type: map_at_10
value: 22.101000000000003
- type: map_at_100
value: 24.319
- type: map_at_1000
value: 24.51
- type: map_at_3
value: 18.372
- type: map_at_5
value: 20.323
- type: mrr_at_1
value: 27.948
- type: mrr_at_10
value: 40.321
- type: mrr_at_100
value: 41.262
- type: mrr_at_1000
value: 41.297
- type: mrr_at_3
value: 36.558
- type: mrr_at_5
value: 38.824999999999996
- type: ndcg_at_1
value: 27.948
- type: ndcg_at_10
value: 30.906
- type: ndcg_at_100
value: 38.986
- type: ndcg_at_1000
value: 42.136
- type: ndcg_at_3
value: 24.911
- type: ndcg_at_5
value: 27.168999999999997
- type: precision_at_1
value: 27.948
- type: precision_at_10
value: 9.798
- type: precision_at_100
value: 1.8399999999999999
- type: precision_at_1000
value: 0.243
- type: precision_at_3
value: 18.328
- type: precision_at_5
value: 14.502
- type: recall_at_1
value: 12.842999999999998
- type: recall_at_10
value: 37.245
- type: recall_at_100
value: 64.769
- type: recall_at_1000
value: 82.055
- type: recall_at_3
value: 23.159
- type: recall_at_5
value: 29.113
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.934000000000001
- type: map_at_10
value: 21.915000000000003
- type: map_at_100
value: 21.915000000000003
- type: map_at_1000
value: 21.915000000000003
- type: map_at_3
value: 14.623
- type: map_at_5
value: 17.841
- type: mrr_at_1
value: 71.25
- type: mrr_at_10
value: 78.994
- type: mrr_at_100
value: 78.994
- type: mrr_at_1000
value: 78.994
- type: mrr_at_3
value: 77.208
- type: mrr_at_5
value: 78.55799999999999
- type: ndcg_at_1
value: 60.62499999999999
- type: ndcg_at_10
value: 46.604
- type: ndcg_at_100
value: 35.653
- type: ndcg_at_1000
value: 35.531
- type: ndcg_at_3
value: 50.605
- type: ndcg_at_5
value: 48.730000000000004
- type: precision_at_1
value: 71.25
- type: precision_at_10
value: 37.75
- type: precision_at_100
value: 3.775
- type: precision_at_1000
value: 0.377
- type: precision_at_3
value: 54.417
- type: precision_at_5
value: 48.15
- type: recall_at_1
value: 8.934000000000001
- type: recall_at_10
value: 28.471000000000004
- type: recall_at_100
value: 28.471000000000004
- type: recall_at_1000
value: 28.471000000000004
- type: recall_at_3
value: 16.019
- type: recall_at_5
value: 21.410999999999998
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 52.81
- type: f1
value: 47.987573380720114
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 66.81899999999999
- type: map_at_10
value: 78.034
- type: map_at_100
value: 78.034
- type: map_at_1000
value: 78.034
- type: map_at_3
value: 76.43100000000001
- type: map_at_5
value: 77.515
- type: mrr_at_1
value: 71.542
- type: mrr_at_10
value: 81.638
- type: mrr_at_100
value: 81.638
- type: mrr_at_1000
value: 81.638
- type: mrr_at_3
value: 80.403
- type: mrr_at_5
value: 81.256
- type: ndcg_at_1
value: 71.542
- type: ndcg_at_10
value: 82.742
- type: ndcg_at_100
value: 82.741
- type: ndcg_at_1000
value: 82.741
- type: ndcg_at_3
value: 80.039
- type: ndcg_at_5
value: 81.695
- type: precision_at_1
value: 71.542
- type: precision_at_10
value: 10.387
- type: precision_at_100
value: 1.039
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 31.447999999999997
- type: precision_at_5
value: 19.91
- type: recall_at_1
value: 66.81899999999999
- type: recall_at_10
value: 93.372
- type: recall_at_100
value: 93.372
- type: recall_at_1000
value: 93.372
- type: recall_at_3
value: 86.33
- type: recall_at_5
value: 90.347
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.158
- type: map_at_10
value: 52.017
- type: map_at_100
value: 54.259
- type: map_at_1000
value: 54.367
- type: map_at_3
value: 45.738
- type: map_at_5
value: 49.283
- type: mrr_at_1
value: 57.87
- type: mrr_at_10
value: 66.215
- type: mrr_at_100
value: 66.735
- type: mrr_at_1000
value: 66.75
- type: mrr_at_3
value: 64.043
- type: mrr_at_5
value: 65.116
- type: ndcg_at_1
value: 57.87
- type: ndcg_at_10
value: 59.946999999999996
- type: ndcg_at_100
value: 66.31099999999999
- type: ndcg_at_1000
value: 67.75999999999999
- type: ndcg_at_3
value: 55.483000000000004
- type: ndcg_at_5
value: 56.891000000000005
- type: precision_at_1
value: 57.87
- type: precision_at_10
value: 16.497
- type: precision_at_100
value: 2.321
- type: precision_at_1000
value: 0.258
- type: precision_at_3
value: 37.14
- type: precision_at_5
value: 27.067999999999998
- type: recall_at_1
value: 31.158
- type: recall_at_10
value: 67.381
- type: recall_at_100
value: 89.464
- type: recall_at_1000
value: 97.989
- type: recall_at_3
value: 50.553000000000004
- type: recall_at_5
value: 57.824
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 42.073
- type: map_at_10
value: 72.418
- type: map_at_100
value: 73.175
- type: map_at_1000
value: 73.215
- type: map_at_3
value: 68.791
- type: map_at_5
value: 71.19
- type: mrr_at_1
value: 84.146
- type: mrr_at_10
value: 88.994
- type: mrr_at_100
value: 89.116
- type: mrr_at_1000
value: 89.12
- type: mrr_at_3
value: 88.373
- type: mrr_at_5
value: 88.82
- type: ndcg_at_1
value: 84.146
- type: ndcg_at_10
value: 79.404
- type: ndcg_at_100
value: 81.83200000000001
- type: ndcg_at_1000
value: 82.524
- type: ndcg_at_3
value: 74.595
- type: ndcg_at_5
value: 77.474
- type: precision_at_1
value: 84.146
- type: precision_at_10
value: 16.753999999999998
- type: precision_at_100
value: 1.8599999999999999
- type: precision_at_1000
value: 0.19499999999999998
- type: precision_at_3
value: 48.854
- type: precision_at_5
value: 31.579
- type: recall_at_1
value: 42.073
- type: recall_at_10
value: 83.768
- type: recall_at_100
value: 93.018
- type: recall_at_1000
value: 97.481
- type: recall_at_3
value: 73.282
- type: recall_at_5
value: 78.947
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 94.9968
- type: ap
value: 92.93892195862824
- type: f1
value: 94.99327998213761
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.698
- type: map_at_10
value: 34.585
- type: map_at_100
value: 35.782000000000004
- type: map_at_1000
value: 35.825
- type: map_at_3
value: 30.397999999999996
- type: map_at_5
value: 32.72
- type: mrr_at_1
value: 22.192
- type: mrr_at_10
value: 35.085
- type: mrr_at_100
value: 36.218
- type: mrr_at_1000
value: 36.256
- type: mrr_at_3
value: 30.986000000000004
- type: mrr_at_5
value: 33.268
- type: ndcg_at_1
value: 22.192
- type: ndcg_at_10
value: 41.957
- type: ndcg_at_100
value: 47.658
- type: ndcg_at_1000
value: 48.697
- type: ndcg_at_3
value: 33.433
- type: ndcg_at_5
value: 37.551
- type: precision_at_1
value: 22.192
- type: precision_at_10
value: 6.781
- type: precision_at_100
value: 0.963
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 14.365
- type: precision_at_5
value: 10.713000000000001
- type: recall_at_1
value: 21.698
- type: recall_at_10
value: 64.79
- type: recall_at_100
value: 91.071
- type: recall_at_1000
value: 98.883
- type: recall_at_3
value: 41.611
- type: recall_at_5
value: 51.459999999999994
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 96.15823073415413
- type: f1
value: 96.00362034963248
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 87.12722298221614
- type: f1
value: 70.46888967516227
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 80.77673167451245
- type: f1
value: 77.60202561132175
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 82.09145931405514
- type: f1
value: 81.7701921473406
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 36.52153488185864
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 36.80090398444147
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.807141746058605
- type: mrr
value: 32.85025611455029
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.920999999999999
- type: map_at_10
value: 16.049
- type: map_at_100
value: 16.049
- type: map_at_1000
value: 16.049
- type: map_at_3
value: 11.865
- type: map_at_5
value: 13.657
- type: mrr_at_1
value: 53.87
- type: mrr_at_10
value: 62.291
- type: mrr_at_100
value: 62.291
- type: mrr_at_1000
value: 62.291
- type: mrr_at_3
value: 60.681
- type: mrr_at_5
value: 61.61
- type: ndcg_at_1
value: 51.23799999999999
- type: ndcg_at_10
value: 40.892
- type: ndcg_at_100
value: 26.951999999999998
- type: ndcg_at_1000
value: 26.474999999999998
- type: ndcg_at_3
value: 46.821
- type: ndcg_at_5
value: 44.333
- type: precision_at_1
value: 53.251000000000005
- type: precision_at_10
value: 30.124000000000002
- type: precision_at_100
value: 3.012
- type: precision_at_1000
value: 0.301
- type: precision_at_3
value: 43.55
- type: precision_at_5
value: 38.266
- type: recall_at_1
value: 6.920999999999999
- type: recall_at_10
value: 20.852
- type: recall_at_100
value: 20.852
- type: recall_at_1000
value: 20.852
- type: recall_at_3
value: 13.628000000000002
- type: recall_at_5
value: 16.273
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 46.827999999999996
- type: map_at_10
value: 63.434000000000005
- type: map_at_100
value: 63.434000000000005
- type: map_at_1000
value: 63.434000000000005
- type: map_at_3
value: 59.794000000000004
- type: map_at_5
value: 62.08
- type: mrr_at_1
value: 52.288999999999994
- type: mrr_at_10
value: 65.95
- type: mrr_at_100
value: 65.95
- type: mrr_at_1000
value: 65.95
- type: mrr_at_3
value: 63.413
- type: mrr_at_5
value: 65.08
- type: ndcg_at_1
value: 52.288999999999994
- type: ndcg_at_10
value: 70.301
- type: ndcg_at_100
value: 70.301
- type: ndcg_at_1000
value: 70.301
- type: ndcg_at_3
value: 63.979
- type: ndcg_at_5
value: 67.582
- type: precision_at_1
value: 52.288999999999994
- type: precision_at_10
value: 10.576
- type: precision_at_100
value: 1.058
- type: precision_at_1000
value: 0.106
- type: precision_at_3
value: 28.177000000000003
- type: precision_at_5
value: 19.073
- type: recall_at_1
value: 46.827999999999996
- type: recall_at_10
value: 88.236
- type: recall_at_100
value: 88.236
- type: recall_at_1000
value: 88.236
- type: recall_at_3
value: 72.371
- type: recall_at_5
value: 80.56
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.652
- type: map_at_10
value: 85.953
- type: map_at_100
value: 85.953
- type: map_at_1000
value: 85.953
- type: map_at_3
value: 83.05399999999999
- type: map_at_5
value: 84.89
- type: mrr_at_1
value: 82.42
- type: mrr_at_10
value: 88.473
- type: mrr_at_100
value: 88.473
- type: mrr_at_1000
value: 88.473
- type: mrr_at_3
value: 87.592
- type: mrr_at_5
value: 88.211
- type: ndcg_at_1
value: 82.44
- type: ndcg_at_10
value: 89.467
- type: ndcg_at_100
value: 89.33
- type: ndcg_at_1000
value: 89.33
- type: ndcg_at_3
value: 86.822
- type: ndcg_at_5
value: 88.307
- type: precision_at_1
value: 82.44
- type: precision_at_10
value: 13.616
- type: precision_at_100
value: 1.362
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 38.117000000000004
- type: precision_at_5
value: 25.05
- type: recall_at_1
value: 71.652
- type: recall_at_10
value: 96.224
- type: recall_at_100
value: 96.224
- type: recall_at_1000
value: 96.224
- type: recall_at_3
value: 88.571
- type: recall_at_5
value: 92.812
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 61.295010338050474
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 67.26380819328142
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.683
- type: map_at_10
value: 14.924999999999999
- type: map_at_100
value: 17.532
- type: map_at_1000
value: 17.875
- type: map_at_3
value: 10.392
- type: map_at_5
value: 12.592
- type: mrr_at_1
value: 28.000000000000004
- type: mrr_at_10
value: 39.951
- type: mrr_at_100
value: 41.025
- type: mrr_at_1000
value: 41.056
- type: mrr_at_3
value: 36.317
- type: mrr_at_5
value: 38.412
- type: ndcg_at_1
value: 28.000000000000004
- type: ndcg_at_10
value: 24.410999999999998
- type: ndcg_at_100
value: 33.79
- type: ndcg_at_1000
value: 39.035
- type: ndcg_at_3
value: 22.845
- type: ndcg_at_5
value: 20.080000000000002
- type: precision_at_1
value: 28.000000000000004
- type: precision_at_10
value: 12.790000000000001
- type: precision_at_100
value: 2.633
- type: precision_at_1000
value: 0.388
- type: precision_at_3
value: 21.367
- type: precision_at_5
value: 17.7
- type: recall_at_1
value: 5.683
- type: recall_at_10
value: 25.91
- type: recall_at_100
value: 53.443
- type: recall_at_1000
value: 78.73
- type: recall_at_3
value: 13.003
- type: recall_at_5
value: 17.932000000000002
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.677978681023
- type: cos_sim_spearman
value: 83.13093441058189
- type: euclidean_pearson
value: 83.35535759341572
- type: euclidean_spearman
value: 83.42583744219611
- type: manhattan_pearson
value: 83.2243124045889
- type: manhattan_spearman
value: 83.39801618652632
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 81.68960206569666
- type: cos_sim_spearman
value: 77.3368966488535
- type: euclidean_pearson
value: 77.62828980560303
- type: euclidean_spearman
value: 76.77951481444651
- type: manhattan_pearson
value: 77.88637240839041
- type: manhattan_spearman
value: 77.22157841466188
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 84.18745821650724
- type: cos_sim_spearman
value: 85.04423285574542
- type: euclidean_pearson
value: 85.46604816931023
- type: euclidean_spearman
value: 85.5230593932974
- type: manhattan_pearson
value: 85.57912805986261
- type: manhattan_spearman
value: 85.65955905111873
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 83.6715333300355
- type: cos_sim_spearman
value: 82.9058522514908
- type: euclidean_pearson
value: 83.9640357424214
- type: euclidean_spearman
value: 83.60415457472637
- type: manhattan_pearson
value: 84.05621005853469
- type: manhattan_spearman
value: 83.87077724707746
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.82422928098886
- type: cos_sim_spearman
value: 88.12660311894628
- type: euclidean_pearson
value: 87.50974805056555
- type: euclidean_spearman
value: 87.91957275596677
- type: manhattan_pearson
value: 87.74119404878883
- type: manhattan_spearman
value: 88.2808922165719
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.80605838552093
- type: cos_sim_spearman
value: 86.24123388765678
- type: euclidean_pearson
value: 85.32648347339814
- type: euclidean_spearman
value: 85.60046671950158
- type: manhattan_pearson
value: 85.53800168487811
- type: manhattan_spearman
value: 85.89542420480763
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.87540978988132
- type: cos_sim_spearman
value: 90.12715295099461
- type: euclidean_pearson
value: 91.61085993525275
- type: euclidean_spearman
value: 91.31835942311758
- type: manhattan_pearson
value: 91.57500202032934
- type: manhattan_spearman
value: 91.1790925526635
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 69.87136205329556
- type: cos_sim_spearman
value: 68.6253154635078
- type: euclidean_pearson
value: 68.91536015034222
- type: euclidean_spearman
value: 67.63744649352542
- type: manhattan_pearson
value: 69.2000713045275
- type: manhattan_spearman
value: 68.16002901587316
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.21849551039082
- type: cos_sim_spearman
value: 85.6392959372461
- type: euclidean_pearson
value: 85.92050852609488
- type: euclidean_spearman
value: 85.97205649009734
- type: manhattan_pearson
value: 86.1031154802254
- type: manhattan_spearman
value: 86.26791155517466
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 86.83953958636627
- type: mrr
value: 96.71167612344082
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 64.994
- type: map_at_10
value: 74.763
- type: map_at_100
value: 75.127
- type: map_at_1000
value: 75.143
- type: map_at_3
value: 71.824
- type: map_at_5
value: 73.71
- type: mrr_at_1
value: 68.333
- type: mrr_at_10
value: 75.749
- type: mrr_at_100
value: 75.922
- type: mrr_at_1000
value: 75.938
- type: mrr_at_3
value: 73.556
- type: mrr_at_5
value: 74.739
- type: ndcg_at_1
value: 68.333
- type: ndcg_at_10
value: 79.174
- type: ndcg_at_100
value: 80.41
- type: ndcg_at_1000
value: 80.804
- type: ndcg_at_3
value: 74.361
- type: ndcg_at_5
value: 76.861
- type: precision_at_1
value: 68.333
- type: precision_at_10
value: 10.333
- type: precision_at_100
value: 1.0999999999999999
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 28.778
- type: precision_at_5
value: 19.067
- type: recall_at_1
value: 64.994
- type: recall_at_10
value: 91.822
- type: recall_at_100
value: 97.0
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 78.878
- type: recall_at_5
value: 85.172
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.72079207920792
- type: cos_sim_ap
value: 93.00265215525152
- type: cos_sim_f1
value: 85.06596306068602
- type: cos_sim_precision
value: 90.05586592178771
- type: cos_sim_recall
value: 80.60000000000001
- type: dot_accuracy
value: 99.66039603960397
- type: dot_ap
value: 91.22371407479089
- type: dot_f1
value: 82.34693877551021
- type: dot_precision
value: 84.0625
- type: dot_recall
value: 80.7
- type: euclidean_accuracy
value: 99.71881188118812
- type: euclidean_ap
value: 92.88449963304728
- type: euclidean_f1
value: 85.19480519480518
- type: euclidean_precision
value: 88.64864864864866
- type: euclidean_recall
value: 82.0
- type: manhattan_accuracy
value: 99.73267326732673
- type: manhattan_ap
value: 93.23055393056883
- type: manhattan_f1
value: 85.88957055214725
- type: manhattan_precision
value: 87.86610878661088
- type: manhattan_recall
value: 84.0
- type: max_accuracy
value: 99.73267326732673
- type: max_ap
value: 93.23055393056883
- type: max_f1
value: 85.88957055214725
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 77.3305735900358
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 41.32967136540674
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.95514866379359
- type: mrr
value: 56.95423245055598
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.783007208997144
- type: cos_sim_spearman
value: 30.373444721540533
- type: dot_pearson
value: 29.210604111143905
- type: dot_spearman
value: 29.98809758085659
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.234
- type: map_at_10
value: 1.894
- type: map_at_100
value: 1.894
- type: map_at_1000
value: 1.894
- type: map_at_3
value: 0.636
- type: map_at_5
value: 1.0
- type: mrr_at_1
value: 88.0
- type: mrr_at_10
value: 93.667
- type: mrr_at_100
value: 93.667
- type: mrr_at_1000
value: 93.667
- type: mrr_at_3
value: 93.667
- type: mrr_at_5
value: 93.667
- type: ndcg_at_1
value: 85.0
- type: ndcg_at_10
value: 74.798
- type: ndcg_at_100
value: 16.462
- type: ndcg_at_1000
value: 7.0889999999999995
- type: ndcg_at_3
value: 80.754
- type: ndcg_at_5
value: 77.319
- type: precision_at_1
value: 88.0
- type: precision_at_10
value: 78.0
- type: precision_at_100
value: 7.8
- type: precision_at_1000
value: 0.7799999999999999
- type: precision_at_3
value: 83.333
- type: precision_at_5
value: 80.80000000000001
- type: recall_at_1
value: 0.234
- type: recall_at_10
value: 2.093
- type: recall_at_100
value: 2.093
- type: recall_at_1000
value: 2.093
- type: recall_at_3
value: 0.662
- type: recall_at_5
value: 1.0739999999999998
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.703
- type: map_at_10
value: 10.866000000000001
- type: map_at_100
value: 10.866000000000001
- type: map_at_1000
value: 10.866000000000001
- type: map_at_3
value: 5.909
- type: map_at_5
value: 7.35
- type: mrr_at_1
value: 36.735
- type: mrr_at_10
value: 53.583000000000006
- type: mrr_at_100
value: 53.583000000000006
- type: mrr_at_1000
value: 53.583000000000006
- type: mrr_at_3
value: 49.32
- type: mrr_at_5
value: 51.769
- type: ndcg_at_1
value: 34.694
- type: ndcg_at_10
value: 27.926000000000002
- type: ndcg_at_100
value: 22.701
- type: ndcg_at_1000
value: 22.701
- type: ndcg_at_3
value: 32.073
- type: ndcg_at_5
value: 28.327999999999996
- type: precision_at_1
value: 36.735
- type: precision_at_10
value: 24.694
- type: precision_at_100
value: 2.469
- type: precision_at_1000
value: 0.247
- type: precision_at_3
value: 31.973000000000003
- type: precision_at_5
value: 26.939
- type: recall_at_1
value: 2.703
- type: recall_at_10
value: 17.702
- type: recall_at_100
value: 17.702
- type: recall_at_1000
value: 17.702
- type: recall_at_3
value: 7.208
- type: recall_at_5
value: 9.748999999999999
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.79960000000001
- type: ap
value: 15.467565415565815
- type: f1
value: 55.28639823443618
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 64.7792869269949
- type: f1
value: 65.08597154774318
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 55.70352297774293
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 88.27561542588067
- type: cos_sim_ap
value: 81.08262141256193
- type: cos_sim_f1
value: 73.82341501361338
- type: cos_sim_precision
value: 72.5720112159062
- type: cos_sim_recall
value: 75.11873350923483
- type: dot_accuracy
value: 86.66030875603504
- type: dot_ap
value: 76.6052349228621
- type: dot_f1
value: 70.13897280966768
- type: dot_precision
value: 64.70457079152732
- type: dot_recall
value: 76.56992084432717
- type: euclidean_accuracy
value: 88.37098408535495
- type: euclidean_ap
value: 81.12515230092113
- type: euclidean_f1
value: 74.10338225909379
- type: euclidean_precision
value: 71.76761433868974
- type: euclidean_recall
value: 76.59630606860158
- type: manhattan_accuracy
value: 88.34118137926924
- type: manhattan_ap
value: 80.95751834536561
- type: manhattan_f1
value: 73.9119496855346
- type: manhattan_precision
value: 70.625
- type: manhattan_recall
value: 77.5197889182058
- type: max_accuracy
value: 88.37098408535495
- type: max_ap
value: 81.12515230092113
- type: max_f1
value: 74.10338225909379
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.79896767182831
- type: cos_sim_ap
value: 87.40071784061065
- type: cos_sim_f1
value: 79.87753144712087
- type: cos_sim_precision
value: 76.67304015296367
- type: cos_sim_recall
value: 83.3615645210964
- type: dot_accuracy
value: 88.95486474948578
- type: dot_ap
value: 86.00227979119943
- type: dot_f1
value: 78.54601474525914
- type: dot_precision
value: 75.00525394045535
- type: dot_recall
value: 82.43763473975977
- type: euclidean_accuracy
value: 89.7892653393876
- type: euclidean_ap
value: 87.42174706480819
- type: euclidean_f1
value: 80.07283321194465
- type: euclidean_precision
value: 75.96738529574351
- type: euclidean_recall
value: 84.6473668001232
- type: manhattan_accuracy
value: 89.8474793340319
- type: manhattan_ap
value: 87.47814292587448
- type: manhattan_f1
value: 80.15461150280949
- type: manhattan_precision
value: 74.88798234468
- type: manhattan_recall
value: 86.21804742839544
- type: max_accuracy
value: 89.8474793340319
- type: max_ap
value: 87.47814292587448
- type: max_f1
value: 80.15461150280949
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/jC7kdl8.jpeg" alt="TensorBlock" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;">
Feedback and support: TensorBlock's <a href="https://x.com/tensorblock_aoi">Twitter/X</a>, <a href="https://t.me/TensorBlock">Telegram Group</a> and <a href="https://x.com/tensorblock_aoi">Discord server</a>
</p>
</div>
</div>
## GritLM/GritLM-7B - GGUF
This repo contains GGUF format model files for [GritLM/GritLM-7B](https://huggingface.co/GritLM/GritLM-7B).
The files were quantized using machines provided by [TensorBlock](https://tensorblock.co/), and they are compatible with llama.cpp as of [commit b4011](https://github.com/ggerganov/llama.cpp/commit/a6744e43e80f4be6398fc7733a01642c846dce1d).
<div style="text-align: left; margin: 20px 0;">
<a href="https://tensorblock.co/waitlist/client" style="display: inline-block; padding: 10px 20px; background-color: #007bff; color: white; text-decoration: none; border-radius: 5px; font-weight: bold;">
Run them on the TensorBlock client using your local machine ↗
</a>
</div>
## Prompt template
```
<s><|user|>
{prompt}
<|assistant|>
```
## Model file specification
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [GritLM-7B-Q2_K.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q2_K.gguf) | Q2_K | 2.532 GB | smallest, significant quality loss - not recommended for most purposes |
| [GritLM-7B-Q3_K_S.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q3_K_S.gguf) | Q3_K_S | 2.947 GB | very small, high quality loss |
| [GritLM-7B-Q3_K_M.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q3_K_M.gguf) | Q3_K_M | 3.277 GB | very small, high quality loss |
| [GritLM-7B-Q3_K_L.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q3_K_L.gguf) | Q3_K_L | 3.560 GB | small, substantial quality loss |
| [GritLM-7B-Q4_0.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q4_0.gguf) | Q4_0 | 3.827 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [GritLM-7B-Q4_K_S.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q4_K_S.gguf) | Q4_K_S | 3.856 GB | small, greater quality loss |
| [GritLM-7B-Q4_K_M.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q4_K_M.gguf) | Q4_K_M | 4.068 GB | medium, balanced quality - recommended |
| [GritLM-7B-Q5_0.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q5_0.gguf) | Q5_0 | 4.654 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [GritLM-7B-Q5_K_S.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q5_K_S.gguf) | Q5_K_S | 4.654 GB | large, low quality loss - recommended |
| [GritLM-7B-Q5_K_M.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q5_K_M.gguf) | Q5_K_M | 4.779 GB | large, very low quality loss - recommended |
| [GritLM-7B-Q6_K.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q6_K.gguf) | Q6_K | 5.534 GB | very large, extremely low quality loss |
| [GritLM-7B-Q8_0.gguf](https://huggingface.co/tensorblock/GritLM-7B-GGUF/blob/main/GritLM-7B-Q8_0.gguf) | Q8_0 | 7.167 GB | very large, extremely low quality loss - not recommended |
## Downloading instruction
### Command line
Firstly, install Huggingface Client
```shell
pip install -U "huggingface_hub[cli]"
```
Then, downoad the individual model file the a local directory
```shell
huggingface-cli download tensorblock/GritLM-7B-GGUF --include "GritLM-7B-Q2_K.gguf" --local-dir MY_LOCAL_DIR
```
If you wanna download multiple model files with a pattern (e.g., `*Q4_K*gguf`), you can try:
```shell
huggingface-cli download tensorblock/GritLM-7B-GGUF --local-dir MY_LOCAL_DIR --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
|
[
"BIOSSES",
"SCIFACT"
] |
tomaarsen/mxbai-embed-large-v1-test
|
tomaarsen
|
feature-extraction
|
[
"sentence-transformers",
"onnx",
"safetensors",
"openvino",
"gguf",
"bert",
"feature-extraction",
"mteb",
"transformers.js",
"transformers",
"en",
"arxiv:2309.12871",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-11-11T16:14:21Z |
2024-11-11T17:03:14+00:00
| 59 | 0 |
---
language:
- en
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: feature-extraction
tags:
- mteb
- transformers.js
- transformers
model-index:
- name: mxbai-angle-large-v1
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.044776119403
- type: ap
value: 37.7362433623053
- type: f1
value: 68.92736573359774
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 93.84025000000001
- type: ap
value: 90.93190875404055
- type: f1
value: 93.8297833897293
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.184
- type: f1
value: 48.74163227751588
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 41.252
- type: map_at_10
value: 57.778
- type: map_at_100
value: 58.233000000000004
- type: map_at_1000
value: 58.23700000000001
- type: map_at_3
value: 53.449999999999996
- type: map_at_5
value: 56.376000000000005
- type: mrr_at_1
value: 41.679
- type: mrr_at_10
value: 57.92699999999999
- type: mrr_at_100
value: 58.389
- type: mrr_at_1000
value: 58.391999999999996
- type: mrr_at_3
value: 53.651
- type: mrr_at_5
value: 56.521
- type: ndcg_at_1
value: 41.252
- type: ndcg_at_10
value: 66.018
- type: ndcg_at_100
value: 67.774
- type: ndcg_at_1000
value: 67.84400000000001
- type: ndcg_at_3
value: 57.372
- type: ndcg_at_5
value: 62.646
- type: precision_at_1
value: 41.252
- type: precision_at_10
value: 9.189
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 22.902
- type: precision_at_5
value: 16.302
- type: recall_at_1
value: 41.252
- type: recall_at_10
value: 91.892
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 68.706
- type: recall_at_5
value: 81.50800000000001
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.97294504317859
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 42.98071077674629
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 65.16477858490782
- type: mrr
value: 78.23583080508287
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.6277629421789
- type: cos_sim_spearman
value: 88.4056288400568
- type: euclidean_pearson
value: 87.94871847578163
- type: euclidean_spearman
value: 88.4056288400568
- type: manhattan_pearson
value: 87.73271254229648
- type: manhattan_spearman
value: 87.91826833762677
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.81818181818181
- type: f1
value: 87.79879337316918
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.91773608582761
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.73059477462478
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.745999999999995
- type: map_at_10
value: 43.632
- type: map_at_100
value: 45.206
- type: map_at_1000
value: 45.341
- type: map_at_3
value: 39.956
- type: map_at_5
value: 42.031
- type: mrr_at_1
value: 39.485
- type: mrr_at_10
value: 49.537
- type: mrr_at_100
value: 50.249
- type: mrr_at_1000
value: 50.294000000000004
- type: mrr_at_3
value: 46.757
- type: mrr_at_5
value: 48.481
- type: ndcg_at_1
value: 39.485
- type: ndcg_at_10
value: 50.058
- type: ndcg_at_100
value: 55.586
- type: ndcg_at_1000
value: 57.511
- type: ndcg_at_3
value: 44.786
- type: ndcg_at_5
value: 47.339999999999996
- type: precision_at_1
value: 39.485
- type: precision_at_10
value: 9.557
- type: precision_at_100
value: 1.552
- type: precision_at_1000
value: 0.202
- type: precision_at_3
value: 21.412
- type: precision_at_5
value: 15.479000000000001
- type: recall_at_1
value: 32.745999999999995
- type: recall_at_10
value: 62.056
- type: recall_at_100
value: 85.088
- type: recall_at_1000
value: 96.952
- type: recall_at_3
value: 46.959
- type: recall_at_5
value: 54.06999999999999
- type: map_at_1
value: 31.898
- type: map_at_10
value: 42.142
- type: map_at_100
value: 43.349
- type: map_at_1000
value: 43.483
- type: map_at_3
value: 39.18
- type: map_at_5
value: 40.733000000000004
- type: mrr_at_1
value: 39.617999999999995
- type: mrr_at_10
value: 47.922
- type: mrr_at_100
value: 48.547000000000004
- type: mrr_at_1000
value: 48.597
- type: mrr_at_3
value: 45.86
- type: mrr_at_5
value: 46.949000000000005
- type: ndcg_at_1
value: 39.617999999999995
- type: ndcg_at_10
value: 47.739
- type: ndcg_at_100
value: 51.934999999999995
- type: ndcg_at_1000
value: 54.007000000000005
- type: ndcg_at_3
value: 43.748
- type: ndcg_at_5
value: 45.345
- type: precision_at_1
value: 39.617999999999995
- type: precision_at_10
value: 8.962
- type: precision_at_100
value: 1.436
- type: precision_at_1000
value: 0.192
- type: precision_at_3
value: 21.083
- type: precision_at_5
value: 14.752
- type: recall_at_1
value: 31.898
- type: recall_at_10
value: 57.587999999999994
- type: recall_at_100
value: 75.323
- type: recall_at_1000
value: 88.304
- type: recall_at_3
value: 45.275
- type: recall_at_5
value: 49.99
- type: map_at_1
value: 40.458
- type: map_at_10
value: 52.942
- type: map_at_100
value: 53.974
- type: map_at_1000
value: 54.031
- type: map_at_3
value: 49.559999999999995
- type: map_at_5
value: 51.408
- type: mrr_at_1
value: 46.27
- type: mrr_at_10
value: 56.31699999999999
- type: mrr_at_100
value: 56.95099999999999
- type: mrr_at_1000
value: 56.98
- type: mrr_at_3
value: 53.835
- type: mrr_at_5
value: 55.252
- type: ndcg_at_1
value: 46.27
- type: ndcg_at_10
value: 58.964000000000006
- type: ndcg_at_100
value: 62.875
- type: ndcg_at_1000
value: 63.969
- type: ndcg_at_3
value: 53.297000000000004
- type: ndcg_at_5
value: 55.938
- type: precision_at_1
value: 46.27
- type: precision_at_10
value: 9.549000000000001
- type: precision_at_100
value: 1.2409999999999999
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 23.762
- type: precision_at_5
value: 16.262999999999998
- type: recall_at_1
value: 40.458
- type: recall_at_10
value: 73.446
- type: recall_at_100
value: 90.12400000000001
- type: recall_at_1000
value: 97.795
- type: recall_at_3
value: 58.123000000000005
- type: recall_at_5
value: 64.68
- type: map_at_1
value: 27.443
- type: map_at_10
value: 36.081
- type: map_at_100
value: 37.163000000000004
- type: map_at_1000
value: 37.232
- type: map_at_3
value: 33.308
- type: map_at_5
value: 34.724
- type: mrr_at_1
value: 29.492
- type: mrr_at_10
value: 38.138
- type: mrr_at_100
value: 39.065
- type: mrr_at_1000
value: 39.119
- type: mrr_at_3
value: 35.593
- type: mrr_at_5
value: 36.785000000000004
- type: ndcg_at_1
value: 29.492
- type: ndcg_at_10
value: 41.134
- type: ndcg_at_100
value: 46.300999999999995
- type: ndcg_at_1000
value: 48.106
- type: ndcg_at_3
value: 35.77
- type: ndcg_at_5
value: 38.032
- type: precision_at_1
value: 29.492
- type: precision_at_10
value: 6.249
- type: precision_at_100
value: 0.9299999999999999
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 15.065999999999999
- type: precision_at_5
value: 10.373000000000001
- type: recall_at_1
value: 27.443
- type: recall_at_10
value: 54.80199999999999
- type: recall_at_100
value: 78.21900000000001
- type: recall_at_1000
value: 91.751
- type: recall_at_3
value: 40.211000000000006
- type: recall_at_5
value: 45.599000000000004
- type: map_at_1
value: 18.731
- type: map_at_10
value: 26.717999999999996
- type: map_at_100
value: 27.897
- type: map_at_1000
value: 28.029
- type: map_at_3
value: 23.91
- type: map_at_5
value: 25.455
- type: mrr_at_1
value: 23.134
- type: mrr_at_10
value: 31.769
- type: mrr_at_100
value: 32.634
- type: mrr_at_1000
value: 32.707
- type: mrr_at_3
value: 28.938999999999997
- type: mrr_at_5
value: 30.531000000000002
- type: ndcg_at_1
value: 23.134
- type: ndcg_at_10
value: 32.249
- type: ndcg_at_100
value: 37.678
- type: ndcg_at_1000
value: 40.589999999999996
- type: ndcg_at_3
value: 26.985999999999997
- type: ndcg_at_5
value: 29.457
- type: precision_at_1
value: 23.134
- type: precision_at_10
value: 5.8709999999999996
- type: precision_at_100
value: 0.988
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 12.852
- type: precision_at_5
value: 9.428
- type: recall_at_1
value: 18.731
- type: recall_at_10
value: 44.419
- type: recall_at_100
value: 67.851
- type: recall_at_1000
value: 88.103
- type: recall_at_3
value: 29.919
- type: recall_at_5
value: 36.230000000000004
- type: map_at_1
value: 30.324
- type: map_at_10
value: 41.265
- type: map_at_100
value: 42.559000000000005
- type: map_at_1000
value: 42.669000000000004
- type: map_at_3
value: 38.138
- type: map_at_5
value: 39.881
- type: mrr_at_1
value: 36.67
- type: mrr_at_10
value: 46.774
- type: mrr_at_100
value: 47.554
- type: mrr_at_1000
value: 47.593
- type: mrr_at_3
value: 44.338
- type: mrr_at_5
value: 45.723
- type: ndcg_at_1
value: 36.67
- type: ndcg_at_10
value: 47.367
- type: ndcg_at_100
value: 52.623
- type: ndcg_at_1000
value: 54.59
- type: ndcg_at_3
value: 42.323
- type: ndcg_at_5
value: 44.727
- type: precision_at_1
value: 36.67
- type: precision_at_10
value: 8.518
- type: precision_at_100
value: 1.2890000000000001
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 19.955000000000002
- type: precision_at_5
value: 14.11
- type: recall_at_1
value: 30.324
- type: recall_at_10
value: 59.845000000000006
- type: recall_at_100
value: 81.77499999999999
- type: recall_at_1000
value: 94.463
- type: recall_at_3
value: 46.019
- type: recall_at_5
value: 52.163000000000004
- type: map_at_1
value: 24.229
- type: map_at_10
value: 35.004000000000005
- type: map_at_100
value: 36.409000000000006
- type: map_at_1000
value: 36.521
- type: map_at_3
value: 31.793
- type: map_at_5
value: 33.432
- type: mrr_at_1
value: 30.365
- type: mrr_at_10
value: 40.502
- type: mrr_at_100
value: 41.372
- type: mrr_at_1000
value: 41.435
- type: mrr_at_3
value: 37.804
- type: mrr_at_5
value: 39.226
- type: ndcg_at_1
value: 30.365
- type: ndcg_at_10
value: 41.305
- type: ndcg_at_100
value: 47.028999999999996
- type: ndcg_at_1000
value: 49.375
- type: ndcg_at_3
value: 35.85
- type: ndcg_at_5
value: 38.12
- type: precision_at_1
value: 30.365
- type: precision_at_10
value: 7.808
- type: precision_at_100
value: 1.228
- type: precision_at_1000
value: 0.161
- type: precision_at_3
value: 17.352
- type: precision_at_5
value: 12.42
- type: recall_at_1
value: 24.229
- type: recall_at_10
value: 54.673
- type: recall_at_100
value: 78.766
- type: recall_at_1000
value: 94.625
- type: recall_at_3
value: 39.602
- type: recall_at_5
value: 45.558
- type: map_at_1
value: 26.695
- type: map_at_10
value: 36.0895
- type: map_at_100
value: 37.309416666666664
- type: map_at_1000
value: 37.42558333333334
- type: map_at_3
value: 33.19616666666666
- type: map_at_5
value: 34.78641666666667
- type: mrr_at_1
value: 31.486083333333337
- type: mrr_at_10
value: 40.34774999999999
- type: mrr_at_100
value: 41.17533333333333
- type: mrr_at_1000
value: 41.231583333333326
- type: mrr_at_3
value: 37.90075
- type: mrr_at_5
value: 39.266999999999996
- type: ndcg_at_1
value: 31.486083333333337
- type: ndcg_at_10
value: 41.60433333333334
- type: ndcg_at_100
value: 46.74525
- type: ndcg_at_1000
value: 48.96166666666667
- type: ndcg_at_3
value: 36.68825
- type: ndcg_at_5
value: 38.966499999999996
- type: precision_at_1
value: 31.486083333333337
- type: precision_at_10
value: 7.29675
- type: precision_at_100
value: 1.1621666666666666
- type: precision_at_1000
value: 0.1545
- type: precision_at_3
value: 16.8815
- type: precision_at_5
value: 11.974583333333333
- type: recall_at_1
value: 26.695
- type: recall_at_10
value: 53.651916666666665
- type: recall_at_100
value: 76.12083333333332
- type: recall_at_1000
value: 91.31191666666668
- type: recall_at_3
value: 40.03575
- type: recall_at_5
value: 45.876666666666665
- type: map_at_1
value: 25.668000000000003
- type: map_at_10
value: 32.486
- type: map_at_100
value: 33.371
- type: map_at_1000
value: 33.458
- type: map_at_3
value: 30.261
- type: map_at_5
value: 31.418000000000003
- type: mrr_at_1
value: 28.988000000000003
- type: mrr_at_10
value: 35.414
- type: mrr_at_100
value: 36.149
- type: mrr_at_1000
value: 36.215
- type: mrr_at_3
value: 33.333
- type: mrr_at_5
value: 34.43
- type: ndcg_at_1
value: 28.988000000000003
- type: ndcg_at_10
value: 36.732
- type: ndcg_at_100
value: 41.331
- type: ndcg_at_1000
value: 43.575
- type: ndcg_at_3
value: 32.413
- type: ndcg_at_5
value: 34.316
- type: precision_at_1
value: 28.988000000000003
- type: precision_at_10
value: 5.7059999999999995
- type: precision_at_100
value: 0.882
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 13.65
- type: precision_at_5
value: 9.417
- type: recall_at_1
value: 25.668000000000003
- type: recall_at_10
value: 47.147
- type: recall_at_100
value: 68.504
- type: recall_at_1000
value: 85.272
- type: recall_at_3
value: 35.19
- type: recall_at_5
value: 39.925
- type: map_at_1
value: 17.256
- type: map_at_10
value: 24.58
- type: map_at_100
value: 25.773000000000003
- type: map_at_1000
value: 25.899
- type: map_at_3
value: 22.236
- type: map_at_5
value: 23.507
- type: mrr_at_1
value: 20.957
- type: mrr_at_10
value: 28.416000000000004
- type: mrr_at_100
value: 29.447000000000003
- type: mrr_at_1000
value: 29.524
- type: mrr_at_3
value: 26.245
- type: mrr_at_5
value: 27.451999999999998
- type: ndcg_at_1
value: 20.957
- type: ndcg_at_10
value: 29.285
- type: ndcg_at_100
value: 35.003
- type: ndcg_at_1000
value: 37.881
- type: ndcg_at_3
value: 25.063000000000002
- type: ndcg_at_5
value: 26.983
- type: precision_at_1
value: 20.957
- type: precision_at_10
value: 5.344
- type: precision_at_100
value: 0.958
- type: precision_at_1000
value: 0.13799999999999998
- type: precision_at_3
value: 11.918
- type: precision_at_5
value: 8.596
- type: recall_at_1
value: 17.256
- type: recall_at_10
value: 39.644
- type: recall_at_100
value: 65.279
- type: recall_at_1000
value: 85.693
- type: recall_at_3
value: 27.825
- type: recall_at_5
value: 32.792
- type: map_at_1
value: 26.700000000000003
- type: map_at_10
value: 36.205999999999996
- type: map_at_100
value: 37.316
- type: map_at_1000
value: 37.425000000000004
- type: map_at_3
value: 33.166000000000004
- type: map_at_5
value: 35.032999999999994
- type: mrr_at_1
value: 31.436999999999998
- type: mrr_at_10
value: 40.61
- type: mrr_at_100
value: 41.415
- type: mrr_at_1000
value: 41.48
- type: mrr_at_3
value: 37.966
- type: mrr_at_5
value: 39.599000000000004
- type: ndcg_at_1
value: 31.436999999999998
- type: ndcg_at_10
value: 41.771
- type: ndcg_at_100
value: 46.784
- type: ndcg_at_1000
value: 49.183
- type: ndcg_at_3
value: 36.437000000000005
- type: ndcg_at_5
value: 39.291
- type: precision_at_1
value: 31.436999999999998
- type: precision_at_10
value: 6.987
- type: precision_at_100
value: 1.072
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 16.448999999999998
- type: precision_at_5
value: 11.866
- type: recall_at_1
value: 26.700000000000003
- type: recall_at_10
value: 54.301
- type: recall_at_100
value: 75.871
- type: recall_at_1000
value: 92.529
- type: recall_at_3
value: 40.201
- type: recall_at_5
value: 47.208
- type: map_at_1
value: 24.296
- type: map_at_10
value: 33.116
- type: map_at_100
value: 34.81
- type: map_at_1000
value: 35.032000000000004
- type: map_at_3
value: 30.105999999999998
- type: map_at_5
value: 31.839000000000002
- type: mrr_at_1
value: 29.051
- type: mrr_at_10
value: 37.803
- type: mrr_at_100
value: 38.856
- type: mrr_at_1000
value: 38.903999999999996
- type: mrr_at_3
value: 35.211
- type: mrr_at_5
value: 36.545
- type: ndcg_at_1
value: 29.051
- type: ndcg_at_10
value: 39.007
- type: ndcg_at_100
value: 45.321
- type: ndcg_at_1000
value: 47.665
- type: ndcg_at_3
value: 34.1
- type: ndcg_at_5
value: 36.437000000000005
- type: precision_at_1
value: 29.051
- type: precision_at_10
value: 7.668
- type: precision_at_100
value: 1.542
- type: precision_at_1000
value: 0.24
- type: precision_at_3
value: 16.14
- type: precision_at_5
value: 11.897
- type: recall_at_1
value: 24.296
- type: recall_at_10
value: 49.85
- type: recall_at_100
value: 78.457
- type: recall_at_1000
value: 92.618
- type: recall_at_3
value: 36.138999999999996
- type: recall_at_5
value: 42.223
- type: map_at_1
value: 20.591
- type: map_at_10
value: 28.902
- type: map_at_100
value: 29.886000000000003
- type: map_at_1000
value: 29.987000000000002
- type: map_at_3
value: 26.740000000000002
- type: map_at_5
value: 27.976
- type: mrr_at_1
value: 22.366
- type: mrr_at_10
value: 30.971
- type: mrr_at_100
value: 31.865
- type: mrr_at_1000
value: 31.930999999999997
- type: mrr_at_3
value: 28.927999999999997
- type: mrr_at_5
value: 30.231
- type: ndcg_at_1
value: 22.366
- type: ndcg_at_10
value: 33.641
- type: ndcg_at_100
value: 38.477
- type: ndcg_at_1000
value: 41.088
- type: ndcg_at_3
value: 29.486
- type: ndcg_at_5
value: 31.612000000000002
- type: precision_at_1
value: 22.366
- type: precision_at_10
value: 5.3420000000000005
- type: precision_at_100
value: 0.828
- type: precision_at_1000
value: 0.11800000000000001
- type: precision_at_3
value: 12.939
- type: precision_at_5
value: 9.094
- type: recall_at_1
value: 20.591
- type: recall_at_10
value: 46.052
- type: recall_at_100
value: 68.193
- type: recall_at_1000
value: 87.638
- type: recall_at_3
value: 34.966
- type: recall_at_5
value: 40.082
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 15.091
- type: map_at_10
value: 26.38
- type: map_at_100
value: 28.421999999999997
- type: map_at_1000
value: 28.621999999999996
- type: map_at_3
value: 21.597
- type: map_at_5
value: 24.12
- type: mrr_at_1
value: 34.266999999999996
- type: mrr_at_10
value: 46.864
- type: mrr_at_100
value: 47.617
- type: mrr_at_1000
value: 47.644
- type: mrr_at_3
value: 43.312
- type: mrr_at_5
value: 45.501000000000005
- type: ndcg_at_1
value: 34.266999999999996
- type: ndcg_at_10
value: 36.095
- type: ndcg_at_100
value: 43.447
- type: ndcg_at_1000
value: 46.661
- type: ndcg_at_3
value: 29.337999999999997
- type: ndcg_at_5
value: 31.824
- type: precision_at_1
value: 34.266999999999996
- type: precision_at_10
value: 11.472
- type: precision_at_100
value: 1.944
- type: precision_at_1000
value: 0.255
- type: precision_at_3
value: 21.933
- type: precision_at_5
value: 17.224999999999998
- type: recall_at_1
value: 15.091
- type: recall_at_10
value: 43.022
- type: recall_at_100
value: 68.075
- type: recall_at_1000
value: 85.76
- type: recall_at_3
value: 26.564
- type: recall_at_5
value: 33.594
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.252
- type: map_at_10
value: 20.923
- type: map_at_100
value: 30.741000000000003
- type: map_at_1000
value: 32.542
- type: map_at_3
value: 14.442
- type: map_at_5
value: 17.399
- type: mrr_at_1
value: 70.25
- type: mrr_at_10
value: 78.17
- type: mrr_at_100
value: 78.444
- type: mrr_at_1000
value: 78.45100000000001
- type: mrr_at_3
value: 76.958
- type: mrr_at_5
value: 77.571
- type: ndcg_at_1
value: 58.375
- type: ndcg_at_10
value: 44.509
- type: ndcg_at_100
value: 49.897999999999996
- type: ndcg_at_1000
value: 57.269999999999996
- type: ndcg_at_3
value: 48.64
- type: ndcg_at_5
value: 46.697
- type: precision_at_1
value: 70.25
- type: precision_at_10
value: 36.05
- type: precision_at_100
value: 11.848
- type: precision_at_1000
value: 2.213
- type: precision_at_3
value: 52.917
- type: precision_at_5
value: 45.7
- type: recall_at_1
value: 9.252
- type: recall_at_10
value: 27.006999999999998
- type: recall_at_100
value: 57.008
- type: recall_at_1000
value: 80.697
- type: recall_at_3
value: 15.798000000000002
- type: recall_at_5
value: 20.4
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 50.88
- type: f1
value: 45.545495028653384
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 75.424
- type: map_at_10
value: 83.435
- type: map_at_100
value: 83.66900000000001
- type: map_at_1000
value: 83.685
- type: map_at_3
value: 82.39800000000001
- type: map_at_5
value: 83.07
- type: mrr_at_1
value: 81.113
- type: mrr_at_10
value: 87.77199999999999
- type: mrr_at_100
value: 87.862
- type: mrr_at_1000
value: 87.86500000000001
- type: mrr_at_3
value: 87.17099999999999
- type: mrr_at_5
value: 87.616
- type: ndcg_at_1
value: 81.113
- type: ndcg_at_10
value: 86.909
- type: ndcg_at_100
value: 87.746
- type: ndcg_at_1000
value: 88.017
- type: ndcg_at_3
value: 85.368
- type: ndcg_at_5
value: 86.28099999999999
- type: precision_at_1
value: 81.113
- type: precision_at_10
value: 10.363
- type: precision_at_100
value: 1.102
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 32.507999999999996
- type: precision_at_5
value: 20.138
- type: recall_at_1
value: 75.424
- type: recall_at_10
value: 93.258
- type: recall_at_100
value: 96.545
- type: recall_at_1000
value: 98.284
- type: recall_at_3
value: 89.083
- type: recall_at_5
value: 91.445
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.532
- type: map_at_10
value: 37.141999999999996
- type: map_at_100
value: 39.162
- type: map_at_1000
value: 39.322
- type: map_at_3
value: 32.885
- type: map_at_5
value: 35.093999999999994
- type: mrr_at_1
value: 44.29
- type: mrr_at_10
value: 53.516
- type: mrr_at_100
value: 54.24
- type: mrr_at_1000
value: 54.273
- type: mrr_at_3
value: 51.286
- type: mrr_at_5
value: 52.413
- type: ndcg_at_1
value: 44.29
- type: ndcg_at_10
value: 45.268
- type: ndcg_at_100
value: 52.125
- type: ndcg_at_1000
value: 54.778000000000006
- type: ndcg_at_3
value: 41.829
- type: ndcg_at_5
value: 42.525
- type: precision_at_1
value: 44.29
- type: precision_at_10
value: 12.5
- type: precision_at_100
value: 1.9720000000000002
- type: precision_at_1000
value: 0.245
- type: precision_at_3
value: 28.035
- type: precision_at_5
value: 20.093
- type: recall_at_1
value: 22.532
- type: recall_at_10
value: 52.419000000000004
- type: recall_at_100
value: 77.43299999999999
- type: recall_at_1000
value: 93.379
- type: recall_at_3
value: 38.629000000000005
- type: recall_at_5
value: 43.858000000000004
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.359
- type: map_at_10
value: 63.966
- type: map_at_100
value: 64.87
- type: map_at_1000
value: 64.92599999999999
- type: map_at_3
value: 60.409
- type: map_at_5
value: 62.627
- type: mrr_at_1
value: 78.717
- type: mrr_at_10
value: 84.468
- type: mrr_at_100
value: 84.655
- type: mrr_at_1000
value: 84.661
- type: mrr_at_3
value: 83.554
- type: mrr_at_5
value: 84.133
- type: ndcg_at_1
value: 78.717
- type: ndcg_at_10
value: 72.03399999999999
- type: ndcg_at_100
value: 75.158
- type: ndcg_at_1000
value: 76.197
- type: ndcg_at_3
value: 67.049
- type: ndcg_at_5
value: 69.808
- type: precision_at_1
value: 78.717
- type: precision_at_10
value: 15.201
- type: precision_at_100
value: 1.764
- type: precision_at_1000
value: 0.19
- type: precision_at_3
value: 43.313
- type: precision_at_5
value: 28.165000000000003
- type: recall_at_1
value: 39.359
- type: recall_at_10
value: 76.003
- type: recall_at_100
value: 88.197
- type: recall_at_1000
value: 95.003
- type: recall_at_3
value: 64.97
- type: recall_at_5
value: 70.41199999999999
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 92.83200000000001
- type: ap
value: 89.33560571859861
- type: f1
value: 92.82322915005167
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.983
- type: map_at_10
value: 34.259
- type: map_at_100
value: 35.432
- type: map_at_1000
value: 35.482
- type: map_at_3
value: 30.275999999999996
- type: map_at_5
value: 32.566
- type: mrr_at_1
value: 22.579
- type: mrr_at_10
value: 34.882999999999996
- type: mrr_at_100
value: 35.984
- type: mrr_at_1000
value: 36.028
- type: mrr_at_3
value: 30.964999999999996
- type: mrr_at_5
value: 33.245000000000005
- type: ndcg_at_1
value: 22.564
- type: ndcg_at_10
value: 41.258
- type: ndcg_at_100
value: 46.824
- type: ndcg_at_1000
value: 48.037
- type: ndcg_at_3
value: 33.17
- type: ndcg_at_5
value: 37.263000000000005
- type: precision_at_1
value: 22.564
- type: precision_at_10
value: 6.572
- type: precision_at_100
value: 0.935
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.130999999999998
- type: precision_at_5
value: 10.544
- type: recall_at_1
value: 21.983
- type: recall_at_10
value: 62.775000000000006
- type: recall_at_100
value: 88.389
- type: recall_at_1000
value: 97.603
- type: recall_at_3
value: 40.878
- type: recall_at_5
value: 50.690000000000005
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.95120839033288
- type: f1
value: 93.73824125055208
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 76.78978568171455
- type: f1
value: 57.50180552858304
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.24411566913248
- type: f1
value: 74.37851403532832
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.94620040349699
- type: f1
value: 80.21293397970435
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.44403096245675
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 31.659594631336812
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.53833075108798
- type: mrr
value: 33.78840823218308
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.185999999999999
- type: map_at_10
value: 15.193999999999999
- type: map_at_100
value: 19.538
- type: map_at_1000
value: 21.178
- type: map_at_3
value: 11.208
- type: map_at_5
value: 12.745999999999999
- type: mrr_at_1
value: 48.916
- type: mrr_at_10
value: 58.141
- type: mrr_at_100
value: 58.656
- type: mrr_at_1000
value: 58.684999999999995
- type: mrr_at_3
value: 55.521
- type: mrr_at_5
value: 57.239
- type: ndcg_at_1
value: 47.059
- type: ndcg_at_10
value: 38.644
- type: ndcg_at_100
value: 36.272999999999996
- type: ndcg_at_1000
value: 44.996
- type: ndcg_at_3
value: 43.293
- type: ndcg_at_5
value: 40.819
- type: precision_at_1
value: 48.916
- type: precision_at_10
value: 28.607
- type: precision_at_100
value: 9.195
- type: precision_at_1000
value: 2.225
- type: precision_at_3
value: 40.454
- type: precision_at_5
value: 34.985
- type: recall_at_1
value: 7.185999999999999
- type: recall_at_10
value: 19.654
- type: recall_at_100
value: 37.224000000000004
- type: recall_at_1000
value: 68.663
- type: recall_at_3
value: 12.158
- type: recall_at_5
value: 14.674999999999999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.552000000000003
- type: map_at_10
value: 47.75
- type: map_at_100
value: 48.728
- type: map_at_1000
value: 48.754
- type: map_at_3
value: 43.156
- type: map_at_5
value: 45.883
- type: mrr_at_1
value: 35.66
- type: mrr_at_10
value: 50.269
- type: mrr_at_100
value: 50.974
- type: mrr_at_1000
value: 50.991
- type: mrr_at_3
value: 46.519
- type: mrr_at_5
value: 48.764
- type: ndcg_at_1
value: 35.632000000000005
- type: ndcg_at_10
value: 55.786
- type: ndcg_at_100
value: 59.748999999999995
- type: ndcg_at_1000
value: 60.339
- type: ndcg_at_3
value: 47.292
- type: ndcg_at_5
value: 51.766999999999996
- type: precision_at_1
value: 35.632000000000005
- type: precision_at_10
value: 9.267
- type: precision_at_100
value: 1.149
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 21.601
- type: precision_at_5
value: 15.539
- type: recall_at_1
value: 31.552000000000003
- type: recall_at_10
value: 77.62400000000001
- type: recall_at_100
value: 94.527
- type: recall_at_1000
value: 98.919
- type: recall_at_3
value: 55.898
- type: recall_at_5
value: 66.121
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.414
- type: map_at_10
value: 85.37400000000001
- type: map_at_100
value: 86.01100000000001
- type: map_at_1000
value: 86.027
- type: map_at_3
value: 82.562
- type: map_at_5
value: 84.284
- type: mrr_at_1
value: 82.24000000000001
- type: mrr_at_10
value: 88.225
- type: mrr_at_100
value: 88.324
- type: mrr_at_1000
value: 88.325
- type: mrr_at_3
value: 87.348
- type: mrr_at_5
value: 87.938
- type: ndcg_at_1
value: 82.24000000000001
- type: ndcg_at_10
value: 88.97699999999999
- type: ndcg_at_100
value: 90.16
- type: ndcg_at_1000
value: 90.236
- type: ndcg_at_3
value: 86.371
- type: ndcg_at_5
value: 87.746
- type: precision_at_1
value: 82.24000000000001
- type: precision_at_10
value: 13.481000000000002
- type: precision_at_100
value: 1.534
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.86
- type: precision_at_5
value: 24.738
- type: recall_at_1
value: 71.414
- type: recall_at_10
value: 95.735
- type: recall_at_100
value: 99.696
- type: recall_at_1000
value: 99.979
- type: recall_at_3
value: 88.105
- type: recall_at_5
value: 92.17999999999999
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 60.22146692057259
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 65.29273320614578
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.023
- type: map_at_10
value: 14.161000000000001
- type: map_at_100
value: 16.68
- type: map_at_1000
value: 17.072000000000003
- type: map_at_3
value: 9.763
- type: map_at_5
value: 11.977
- type: mrr_at_1
value: 24.8
- type: mrr_at_10
value: 37.602999999999994
- type: mrr_at_100
value: 38.618
- type: mrr_at_1000
value: 38.659
- type: mrr_at_3
value: 34.117
- type: mrr_at_5
value: 36.082
- type: ndcg_at_1
value: 24.8
- type: ndcg_at_10
value: 23.316
- type: ndcg_at_100
value: 32.613
- type: ndcg_at_1000
value: 38.609
- type: ndcg_at_3
value: 21.697
- type: ndcg_at_5
value: 19.241
- type: precision_at_1
value: 24.8
- type: precision_at_10
value: 12.36
- type: precision_at_100
value: 2.593
- type: precision_at_1000
value: 0.402
- type: precision_at_3
value: 20.767
- type: precision_at_5
value: 17.34
- type: recall_at_1
value: 5.023
- type: recall_at_10
value: 25.069999999999997
- type: recall_at_100
value: 52.563
- type: recall_at_1000
value: 81.525
- type: recall_at_3
value: 12.613
- type: recall_at_5
value: 17.583
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 87.71506247604255
- type: cos_sim_spearman
value: 82.91813463738802
- type: euclidean_pearson
value: 85.5154616194479
- type: euclidean_spearman
value: 82.91815254466314
- type: manhattan_pearson
value: 85.5280917850374
- type: manhattan_spearman
value: 82.92276537286398
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 87.43772054228462
- type: cos_sim_spearman
value: 78.75750601716682
- type: euclidean_pearson
value: 85.76074482955764
- type: euclidean_spearman
value: 78.75651057223058
- type: manhattan_pearson
value: 85.73390291701668
- type: manhattan_spearman
value: 78.72699385957797
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 89.58144067172472
- type: cos_sim_spearman
value: 90.3524512966946
- type: euclidean_pearson
value: 89.71365391594237
- type: euclidean_spearman
value: 90.35239632843408
- type: manhattan_pearson
value: 89.66905421746478
- type: manhattan_spearman
value: 90.31508211683513
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 87.77692637102102
- type: cos_sim_spearman
value: 85.45710562643485
- type: euclidean_pearson
value: 87.42456979928723
- type: euclidean_spearman
value: 85.45709386240908
- type: manhattan_pearson
value: 87.40754529526272
- type: manhattan_spearman
value: 85.44834854173303
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 88.28491331695997
- type: cos_sim_spearman
value: 89.62037029566964
- type: euclidean_pearson
value: 89.02479391362826
- type: euclidean_spearman
value: 89.62036733618466
- type: manhattan_pearson
value: 89.00394756040342
- type: manhattan_spearman
value: 89.60867744215236
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.08911381280191
- type: cos_sim_spearman
value: 86.5791780765767
- type: euclidean_pearson
value: 86.16063473577861
- type: euclidean_spearman
value: 86.57917745378766
- type: manhattan_pearson
value: 86.13677924604175
- type: manhattan_spearman
value: 86.56115615768685
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.58029496205235
- type: cos_sim_spearman
value: 89.49551253826998
- type: euclidean_pearson
value: 90.13714840963748
- type: euclidean_spearman
value: 89.49551253826998
- type: manhattan_pearson
value: 90.13039633601363
- type: manhattan_spearman
value: 89.4513453745516
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 69.01546399666435
- type: cos_sim_spearman
value: 69.33824484595624
- type: euclidean_pearson
value: 70.76511642998874
- type: euclidean_spearman
value: 69.33824484595624
- type: manhattan_pearson
value: 70.84320785047453
- type: manhattan_spearman
value: 69.54233632223537
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.26389196390119
- type: cos_sim_spearman
value: 89.09721478341385
- type: euclidean_pearson
value: 88.97208685922517
- type: euclidean_spearman
value: 89.09720927308881
- type: manhattan_pearson
value: 88.97513670502573
- type: manhattan_spearman
value: 89.07647853984004
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.53075025771936
- type: mrr
value: 96.24327651288436
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.428000000000004
- type: map_at_10
value: 70.088
- type: map_at_100
value: 70.589
- type: map_at_1000
value: 70.614
- type: map_at_3
value: 67.191
- type: map_at_5
value: 68.515
- type: mrr_at_1
value: 63.333
- type: mrr_at_10
value: 71.13000000000001
- type: mrr_at_100
value: 71.545
- type: mrr_at_1000
value: 71.569
- type: mrr_at_3
value: 68.944
- type: mrr_at_5
value: 70.078
- type: ndcg_at_1
value: 63.333
- type: ndcg_at_10
value: 74.72800000000001
- type: ndcg_at_100
value: 76.64999999999999
- type: ndcg_at_1000
value: 77.176
- type: ndcg_at_3
value: 69.659
- type: ndcg_at_5
value: 71.626
- type: precision_at_1
value: 63.333
- type: precision_at_10
value: 10
- type: precision_at_100
value: 1.09
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 27.111
- type: precision_at_5
value: 17.666999999999998
- type: recall_at_1
value: 60.428000000000004
- type: recall_at_10
value: 87.98899999999999
- type: recall_at_100
value: 96.167
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 74.006
- type: recall_at_5
value: 79.05
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.87326732673267
- type: cos_sim_ap
value: 96.81770773701805
- type: cos_sim_f1
value: 93.6318407960199
- type: cos_sim_precision
value: 93.16831683168317
- type: cos_sim_recall
value: 94.1
- type: dot_accuracy
value: 99.87326732673267
- type: dot_ap
value: 96.8174218946665
- type: dot_f1
value: 93.6318407960199
- type: dot_precision
value: 93.16831683168317
- type: dot_recall
value: 94.1
- type: euclidean_accuracy
value: 99.87326732673267
- type: euclidean_ap
value: 96.81770773701807
- type: euclidean_f1
value: 93.6318407960199
- type: euclidean_precision
value: 93.16831683168317
- type: euclidean_recall
value: 94.1
- type: manhattan_accuracy
value: 99.87227722772278
- type: manhattan_ap
value: 96.83164126821747
- type: manhattan_f1
value: 93.54677338669335
- type: manhattan_precision
value: 93.5935935935936
- type: manhattan_recall
value: 93.5
- type: max_accuracy
value: 99.87326732673267
- type: max_ap
value: 96.83164126821747
- type: max_f1
value: 93.6318407960199
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 65.6212042420246
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.779230635982564
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 55.217701909036286
- type: mrr
value: 56.17658995416349
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.954206018888453
- type: cos_sim_spearman
value: 32.71062599450096
- type: dot_pearson
value: 30.95420929056943
- type: dot_spearman
value: 32.71062599450096
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22699999999999998
- type: map_at_10
value: 1.924
- type: map_at_100
value: 10.525
- type: map_at_1000
value: 24.973
- type: map_at_3
value: 0.638
- type: map_at_5
value: 1.0659999999999998
- type: mrr_at_1
value: 84
- type: mrr_at_10
value: 91.067
- type: mrr_at_100
value: 91.067
- type: mrr_at_1000
value: 91.067
- type: mrr_at_3
value: 90.667
- type: mrr_at_5
value: 91.067
- type: ndcg_at_1
value: 81
- type: ndcg_at_10
value: 75.566
- type: ndcg_at_100
value: 56.387
- type: ndcg_at_1000
value: 49.834
- type: ndcg_at_3
value: 80.899
- type: ndcg_at_5
value: 80.75099999999999
- type: precision_at_1
value: 84
- type: precision_at_10
value: 79
- type: precision_at_100
value: 57.56
- type: precision_at_1000
value: 21.8
- type: precision_at_3
value: 84.667
- type: precision_at_5
value: 85.2
- type: recall_at_1
value: 0.22699999999999998
- type: recall_at_10
value: 2.136
- type: recall_at_100
value: 13.861
- type: recall_at_1000
value: 46.299
- type: recall_at_3
value: 0.6649999999999999
- type: recall_at_5
value: 1.145
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.752
- type: map_at_10
value: 9.951
- type: map_at_100
value: 16.794999999999998
- type: map_at_1000
value: 18.251
- type: map_at_3
value: 5.288
- type: map_at_5
value: 6.954000000000001
- type: mrr_at_1
value: 38.775999999999996
- type: mrr_at_10
value: 50.458000000000006
- type: mrr_at_100
value: 51.324999999999996
- type: mrr_at_1000
value: 51.339999999999996
- type: mrr_at_3
value: 46.939
- type: mrr_at_5
value: 47.857
- type: ndcg_at_1
value: 36.735
- type: ndcg_at_10
value: 25.198999999999998
- type: ndcg_at_100
value: 37.938
- type: ndcg_at_1000
value: 49.145
- type: ndcg_at_3
value: 29.348000000000003
- type: ndcg_at_5
value: 25.804
- type: precision_at_1
value: 38.775999999999996
- type: precision_at_10
value: 22.041
- type: precision_at_100
value: 7.939
- type: precision_at_1000
value: 1.555
- type: precision_at_3
value: 29.932
- type: precision_at_5
value: 24.490000000000002
- type: recall_at_1
value: 2.752
- type: recall_at_10
value: 16.197
- type: recall_at_100
value: 49.166
- type: recall_at_1000
value: 84.18900000000001
- type: recall_at_3
value: 6.438000000000001
- type: recall_at_5
value: 9.093
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.47980000000001
- type: ap
value: 14.605194452178754
- type: f1
value: 55.07362924988948
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.708545557441994
- type: f1
value: 60.04751270975683
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 53.21105960597211
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.58419264469214
- type: cos_sim_ap
value: 78.55300004517404
- type: cos_sim_f1
value: 71.49673530889001
- type: cos_sim_precision
value: 68.20795400095831
- type: cos_sim_recall
value: 75.11873350923483
- type: dot_accuracy
value: 87.58419264469214
- type: dot_ap
value: 78.55297659559511
- type: dot_f1
value: 71.49673530889001
- type: dot_precision
value: 68.20795400095831
- type: dot_recall
value: 75.11873350923483
- type: euclidean_accuracy
value: 87.58419264469214
- type: euclidean_ap
value: 78.55300477331477
- type: euclidean_f1
value: 71.49673530889001
- type: euclidean_precision
value: 68.20795400095831
- type: euclidean_recall
value: 75.11873350923483
- type: manhattan_accuracy
value: 87.5663110210407
- type: manhattan_ap
value: 78.49982050876562
- type: manhattan_f1
value: 71.35488740722104
- type: manhattan_precision
value: 68.18946862226497
- type: manhattan_recall
value: 74.82849604221636
- type: max_accuracy
value: 87.58419264469214
- type: max_ap
value: 78.55300477331477
- type: max_f1
value: 71.49673530889001
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.09069740365584
- type: cos_sim_ap
value: 86.22749303724757
- type: cos_sim_f1
value: 78.36863452005407
- type: cos_sim_precision
value: 76.49560117302053
- type: cos_sim_recall
value: 80.33569448721897
- type: dot_accuracy
value: 89.09069740365584
- type: dot_ap
value: 86.22750233655673
- type: dot_f1
value: 78.36863452005407
- type: dot_precision
value: 76.49560117302053
- type: dot_recall
value: 80.33569448721897
- type: euclidean_accuracy
value: 89.09069740365584
- type: euclidean_ap
value: 86.22749355597347
- type: euclidean_f1
value: 78.36863452005407
- type: euclidean_precision
value: 76.49560117302053
- type: euclidean_recall
value: 80.33569448721897
- type: manhattan_accuracy
value: 89.08293553770326
- type: manhattan_ap
value: 86.21913616084771
- type: manhattan_f1
value: 78.3907031479847
- type: manhattan_precision
value: 75.0352013517319
- type: manhattan_recall
value: 82.06036341238065
- type: max_accuracy
value: 89.09069740365584
- type: max_ap
value: 86.22750233655673
- type: max_f1
value: 78.3907031479847
---
<br><br>
<p align="center">
<svg xmlns="http://www.w3.org/2000/svg" xml:space="preserve" viewBox="0 0 2020 1130" width="150" height="150" aria-hidden="true"><path fill="#e95a0f" d="M398.167 621.992c-1.387-20.362-4.092-40.739-3.851-61.081.355-30.085 6.873-59.139 21.253-85.976 10.487-19.573 24.09-36.822 40.662-51.515 16.394-14.535 34.338-27.046 54.336-36.182 15.224-6.955 31.006-12.609 47.829-14.168 11.809-1.094 23.753-2.514 35.524-1.836 23.033 1.327 45.131 7.255 66.255 16.75 16.24 7.3 31.497 16.165 45.651 26.969 12.997 9.921 24.412 21.37 34.158 34.509 11.733 15.817 20.849 33.037 25.987 52.018 3.468 12.81 6.438 25.928 7.779 39.097 1.722 16.908 1.642 34.003 2.235 51.021.427 12.253.224 24.547 1.117 36.762 1.677 22.93 4.062 45.764 11.8 67.7 5.376 15.239 12.499 29.55 20.846 43.681l-18.282 20.328c-1.536 1.71-2.795 3.665-4.254 5.448l-19.323 23.533c-13.859-5.449-27.446-11.803-41.657-16.086-13.622-4.106-27.793-6.765-41.905-8.775-15.256-2.173-30.701-3.475-46.105-4.049-23.571-.879-47.178-1.056-70.769-1.029-10.858.013-21.723 1.116-32.57 1.926-5.362.4-10.69 1.255-16.464 1.477-2.758-7.675-5.284-14.865-7.367-22.181-3.108-10.92-4.325-22.554-13.16-31.095-2.598-2.512-5.069-5.341-6.883-8.443-6.366-10.884-12.48-21.917-18.571-32.959-4.178-7.573-8.411-14.375-17.016-18.559-10.34-5.028-19.538-12.387-29.311-18.611-3.173-2.021-6.414-4.312-9.952-5.297-5.857-1.63-11.98-2.301-17.991-3.376z"></path><path fill="#ed6d7b" d="M1478.998 758.842c-12.025.042-24.05.085-36.537-.373-.14-8.536.231-16.569.453-24.607.033-1.179-.315-2.986-1.081-3.4-.805-.434-2.376.338-3.518.81-.856.354-1.562 1.069-3.589 2.521-.239-3.308-.664-5.586-.519-7.827.488-7.544 2.212-15.166 1.554-22.589-1.016-11.451 1.397-14.592-12.332-14.419-3.793.048-3.617-2.803-3.332-5.331.499-4.422 1.45-8.803 1.77-13.233.311-4.316.068-8.672.068-12.861-2.554-.464-4.326-.86-6.12-1.098-4.415-.586-6.051-2.251-5.065-7.31 1.224-6.279.848-12.862 1.276-19.306.19-2.86-.971-4.473-3.794-4.753-4.113-.407-8.242-1.057-12.352-.975-4.663.093-5.192-2.272-4.751-6.012.733-6.229 1.252-12.483 1.875-18.726l1.102-10.495c-5.905-.309-11.146-.805-16.385-.778-3.32.017-5.174-1.4-5.566-4.4-1.172-8.968-2.479-17.944-3.001-26.96-.26-4.484-1.936-5.705-6.005-5.774-9.284-.158-18.563-.594-27.843-.953-7.241-.28-10.137-2.764-11.3-9.899-.746-4.576-2.715-7.801-7.777-8.207-7.739-.621-15.511-.992-23.207-1.961-7.327-.923-14.587-2.415-21.853-3.777-5.021-.941-10.003-2.086-15.003-3.14 4.515-22.952 13.122-44.382 26.284-63.587 18.054-26.344 41.439-47.239 69.102-63.294 15.847-9.197 32.541-16.277 50.376-20.599 16.655-4.036 33.617-5.715 50.622-4.385 33.334 2.606 63.836 13.955 92.415 31.15 15.864 9.545 30.241 20.86 42.269 34.758 8.113 9.374 15.201 19.78 21.718 30.359 10.772 17.484 16.846 36.922 20.611 56.991 1.783 9.503 2.815 19.214 3.318 28.876.758 14.578.755 29.196.65 44.311l-51.545 20.013c-7.779 3.059-15.847 5.376-21.753 12.365-4.73 5.598-10.658 10.316-16.547 14.774-9.9 7.496-18.437 15.988-25.083 26.631-3.333 5.337-7.901 10.381-12.999 14.038-11.355 8.144-17.397 18.973-19.615 32.423l-6.988 41.011z"></path><path fill="#ec663e" d="M318.11 923.047c-.702 17.693-.832 35.433-2.255 53.068-1.699 21.052-6.293 41.512-14.793 61.072-9.001 20.711-21.692 38.693-38.496 53.583-16.077 14.245-34.602 24.163-55.333 30.438-21.691 6.565-43.814 8.127-66.013 6.532-22.771-1.636-43.88-9.318-62.74-22.705-20.223-14.355-35.542-32.917-48.075-54.096-9.588-16.203-16.104-33.55-19.201-52.015-2.339-13.944-2.307-28.011-.403-42.182 2.627-19.545 9.021-37.699 17.963-55.067 11.617-22.564 27.317-41.817 48.382-56.118 15.819-10.74 33.452-17.679 52.444-20.455 8.77-1.282 17.696-1.646 26.568-2.055 11.755-.542 23.534-.562 35.289-1.11 8.545-.399 17.067-1.291 26.193-1.675 1.349 1.77 2.24 3.199 2.835 4.742 4.727 12.261 10.575 23.865 18.636 34.358 7.747 10.084 14.83 20.684 22.699 30.666 3.919 4.972 8.37 9.96 13.609 13.352 7.711 4.994 16.238 8.792 24.617 12.668 5.852 2.707 12.037 4.691 18.074 6.998z"></path><path fill="#ea580e" d="M1285.167 162.995c3.796-29.75 13.825-56.841 32.74-80.577 16.339-20.505 36.013-36.502 59.696-47.614 14.666-6.881 29.971-11.669 46.208-12.749 10.068-.669 20.239-1.582 30.255-.863 16.6 1.191 32.646 5.412 47.9 12.273 19.39 8.722 36.44 20.771 50.582 36.655 15.281 17.162 25.313 37.179 31.49 59.286 5.405 19.343 6.31 39.161 4.705 58.825-2.37 29.045-11.836 55.923-30.451 78.885-10.511 12.965-22.483 24.486-37.181 33.649-5.272-5.613-10.008-11.148-14.539-16.846-5.661-7.118-10.958-14.533-16.78-21.513-4.569-5.478-9.548-10.639-14.624-15.658-3.589-3.549-7.411-6.963-11.551-9.827-5.038-3.485-10.565-6.254-15.798-9.468-8.459-5.195-17.011-9.669-26.988-11.898-12.173-2.72-24.838-4.579-35.622-11.834-1.437-.967-3.433-1.192-5.213-1.542-12.871-2.529-25.454-5.639-36.968-12.471-5.21-3.091-11.564-4.195-17.011-6.965-4.808-2.445-8.775-6.605-13.646-8.851-8.859-4.085-18.114-7.311-27.204-10.896z"></path><path fill="#f8ab00" d="M524.963 311.12c-9.461-5.684-19.513-10.592-28.243-17.236-12.877-9.801-24.031-21.578-32.711-35.412-11.272-17.965-19.605-37.147-21.902-58.403-1.291-11.951-2.434-24.073-1.87-36.034.823-17.452 4.909-34.363 11.581-50.703 8.82-21.603 22.25-39.792 39.568-55.065 18.022-15.894 39.162-26.07 62.351-32.332 19.22-5.19 38.842-6.177 58.37-4.674 23.803 1.831 45.56 10.663 65.062 24.496 17.193 12.195 31.688 27.086 42.894 45.622-11.403 8.296-22.633 16.117-34.092 23.586-17.094 11.142-34.262 22.106-48.036 37.528-8.796 9.848-17.201 20.246-27.131 28.837-16.859 14.585-27.745 33.801-41.054 51.019-11.865 15.349-20.663 33.117-30.354 50.08-5.303 9.283-9.654 19.11-14.434 28.692z"></path><path fill="#ea5227" d="M1060.11 1122.049c-7.377 1.649-14.683 4.093-22.147 4.763-11.519 1.033-23.166 1.441-34.723 1.054-19.343-.647-38.002-4.7-55.839-12.65-15.078-6.72-28.606-15.471-40.571-26.836-24.013-22.81-42.053-49.217-49.518-81.936-1.446-6.337-1.958-12.958-2.235-19.477-.591-13.926-.219-27.909-1.237-41.795-.916-12.5-3.16-24.904-4.408-37.805 1.555-1.381 3.134-2.074 3.778-3.27 4.729-8.79 12.141-15.159 19.083-22.03 5.879-5.818 10.688-12.76 16.796-18.293 6.993-6.335 11.86-13.596 14.364-22.612l8.542-29.993c8.015 1.785 15.984 3.821 24.057 5.286 8.145 1.478 16.371 2.59 24.602 3.493 8.453.927 16.956 1.408 25.891 2.609 1.119 16.09 1.569 31.667 2.521 47.214.676 11.045 1.396 22.154 3.234 33.043 2.418 14.329 5.708 28.527 9.075 42.674 3.499 14.705 4.028 29.929 10.415 44.188 10.157 22.674 18.29 46.25 28.281 69.004 7.175 16.341 12.491 32.973 15.078 50.615.645 4.4 3.256 8.511 4.963 12.755z"></path><path fill="#ea5330" d="M1060.512 1122.031c-2.109-4.226-4.72-8.337-5.365-12.737-2.587-17.642-7.904-34.274-15.078-50.615-9.991-22.755-18.124-46.33-28.281-69.004-6.387-14.259-6.916-29.482-10.415-44.188-3.366-14.147-6.656-28.346-9.075-42.674-1.838-10.889-2.558-21.999-3.234-33.043-.951-15.547-1.401-31.124-2.068-47.146 8.568-.18 17.146.487 25.704.286l41.868-1.4c.907 3.746 1.245 7.04 1.881 10.276l8.651 42.704c.903 4.108 2.334 8.422 4.696 11.829 7.165 10.338 14.809 20.351 22.456 30.345 4.218 5.512 8.291 11.304 13.361 15.955 8.641 7.927 18.065 14.995 27.071 22.532 12.011 10.052 24.452 19.302 40.151 22.854-1.656 11.102-2.391 22.44-5.172 33.253-4.792 18.637-12.38 36.209-23.412 52.216-13.053 18.94-29.086 34.662-49.627 45.055-10.757 5.443-22.443 9.048-34.111 13.501z"></path><path fill="#f8aa05" d="M1989.106 883.951c5.198 8.794 11.46 17.148 15.337 26.491 5.325 12.833 9.744 26.207 12.873 39.737 2.95 12.757 3.224 25.908 1.987 39.219-1.391 14.973-4.643 29.268-10.349 43.034-5.775 13.932-13.477 26.707-23.149 38.405-14.141 17.104-31.215 30.458-50.807 40.488-14.361 7.352-29.574 12.797-45.741 14.594-10.297 1.144-20.732 2.361-31.031 1.894-24.275-1.1-47.248-7.445-68.132-20.263-6.096-3.741-11.925-7.917-17.731-12.342 5.319-5.579 10.361-10.852 15.694-15.811l37.072-34.009c.975-.892 2.113-1.606 3.08-2.505 6.936-6.448 14.765-12.2 20.553-19.556 8.88-11.285 20.064-19.639 31.144-28.292 4.306-3.363 9.06-6.353 12.673-10.358 5.868-6.504 10.832-13.814 16.422-20.582 6.826-8.264 13.727-16.481 20.943-24.401 4.065-4.461 8.995-8.121 13.249-12.424 14.802-14.975 28.77-30.825 45.913-43.317z"></path><path fill="#ed6876" d="M1256.099 523.419c5.065.642 10.047 1.787 15.068 2.728 7.267 1.362 14.526 2.854 21.853 3.777 7.696.97 15.468 1.34 23.207 1.961 5.062.406 7.031 3.631 7.777 8.207 1.163 7.135 4.059 9.62 11.3 9.899l27.843.953c4.069.069 5.745 1.291 6.005 5.774.522 9.016 1.829 17.992 3.001 26.96.392 3 2.246 4.417 5.566 4.4 5.239-.026 10.48.469 16.385.778l-1.102 10.495-1.875 18.726c-.44 3.74.088 6.105 4.751 6.012 4.11-.082 8.239.568 12.352.975 2.823.28 3.984 1.892 3.794 4.753-.428 6.444-.052 13.028-1.276 19.306-.986 5.059.651 6.724 5.065 7.31 1.793.238 3.566.634 6.12 1.098 0 4.189.243 8.545-.068 12.861-.319 4.43-1.27 8.811-1.77 13.233-.285 2.528-.461 5.379 3.332 5.331 13.729-.173 11.316 2.968 12.332 14.419.658 7.423-1.066 15.045-1.554 22.589-.145 2.241.28 4.519.519 7.827 2.026-1.452 2.733-2.167 3.589-2.521 1.142-.472 2.713-1.244 3.518-.81.767.414 1.114 2.221 1.081 3.4l-.917 24.539c-11.215.82-22.45.899-33.636 1.674l-43.952 3.436c-1.086-3.01-2.319-5.571-2.296-8.121.084-9.297-4.468-16.583-9.091-24.116-3.872-6.308-8.764-13.052-9.479-19.987-1.071-10.392-5.716-15.936-14.889-18.979-1.097-.364-2.16-.844-3.214-1.327-7.478-3.428-15.548-5.918-19.059-14.735-.904-2.27-3.657-3.775-5.461-5.723-2.437-2.632-4.615-5.525-7.207-7.987-2.648-2.515-5.352-5.346-8.589-6.777-4.799-2.121-10.074-3.185-15.175-4.596l-15.785-4.155c.274-12.896 1.722-25.901.54-38.662-1.647-17.783-3.457-35.526-2.554-53.352.528-10.426 2.539-20.777 3.948-31.574z"></path><path fill="#f6a200" d="M525.146 311.436c4.597-9.898 8.947-19.725 14.251-29.008 9.691-16.963 18.49-34.73 30.354-50.08 13.309-17.218 24.195-36.434 41.054-51.019 9.93-8.591 18.335-18.989 27.131-28.837 13.774-15.422 30.943-26.386 48.036-37.528 11.459-7.469 22.688-15.29 34.243-23.286 11.705 16.744 19.716 35.424 22.534 55.717 2.231 16.066 2.236 32.441 2.753 49.143-4.756 1.62-9.284 2.234-13.259 4.056-6.43 2.948-12.193 7.513-18.774 9.942-19.863 7.331-33.806 22.349-47.926 36.784-7.86 8.035-13.511 18.275-19.886 27.705-4.434 6.558-9.345 13.037-12.358 20.254-4.249 10.177-6.94 21.004-10.296 31.553-12.33.053-24.741 1.027-36.971-.049-20.259-1.783-40.227-5.567-58.755-14.69-.568-.28-1.295-.235-2.132-.658z"></path><path fill="#f7a80d" d="M1989.057 883.598c-17.093 12.845-31.061 28.695-45.863 43.67-4.254 4.304-9.184 7.963-13.249 12.424-7.216 7.92-14.117 16.137-20.943 24.401-5.59 6.768-10.554 14.078-16.422 20.582-3.614 4.005-8.367 6.995-12.673 10.358-11.08 8.653-22.264 17.007-31.144 28.292-5.788 7.356-13.617 13.108-20.553 19.556-.967.899-2.105 1.614-3.08 2.505l-37.072 34.009c-5.333 4.96-10.375 10.232-15.859 15.505-21.401-17.218-37.461-38.439-48.623-63.592 3.503-1.781 7.117-2.604 9.823-4.637 8.696-6.536 20.392-8.406 27.297-17.714.933-1.258 2.646-1.973 4.065-2.828 17.878-10.784 36.338-20.728 53.441-32.624 10.304-7.167 18.637-17.23 27.583-26.261 3.819-3.855 7.436-8.091 10.3-12.681 12.283-19.68 24.43-39.446 40.382-56.471 12.224-13.047 17.258-29.524 22.539-45.927 15.85 4.193 29.819 12.129 42.632 22.08 10.583 8.219 19.782 17.883 27.42 29.351z"></path><path fill="#ef7a72" d="M1479.461 758.907c1.872-13.734 4.268-27.394 6.525-41.076 2.218-13.45 8.26-24.279 19.615-32.423 5.099-3.657 9.667-8.701 12.999-14.038 6.646-10.643 15.183-19.135 25.083-26.631 5.888-4.459 11.817-9.176 16.547-14.774 5.906-6.99 13.974-9.306 21.753-12.365l51.48-19.549c.753 11.848.658 23.787 1.641 35.637 1.771 21.353 4.075 42.672 11.748 62.955.17.449.107.985-.019 2.158-6.945 4.134-13.865 7.337-20.437 11.143-3.935 2.279-7.752 5.096-10.869 8.384-6.011 6.343-11.063 13.624-17.286 19.727-9.096 8.92-12.791 20.684-18.181 31.587-.202.409-.072.984-.096 1.481-8.488-1.72-16.937-3.682-25.476-5.094-9.689-1.602-19.426-3.084-29.201-3.949-15.095-1.335-30.241-2.1-45.828-3.172z"></path><path fill="#e94e3b" d="M957.995 766.838c-20.337-5.467-38.791-14.947-55.703-27.254-8.2-5.967-15.451-13.238-22.958-20.37 2.969-3.504 5.564-6.772 8.598-9.563 7.085-6.518 11.283-14.914 15.8-23.153 4.933-8.996 10.345-17.743 14.966-26.892 2.642-5.231 5.547-11.01 5.691-16.611.12-4.651.194-8.932 2.577-12.742 8.52-13.621 15.483-28.026 18.775-43.704 2.11-10.049 7.888-18.774 7.81-29.825-.064-9.089 4.291-18.215 6.73-27.313 3.212-11.983 7.369-23.797 9.492-35.968 3.202-18.358 5.133-36.945 7.346-55.466l4.879-45.8c6.693.288 13.386.575 20.54 1.365.13 3.458-.41 6.407-.496 9.37l-1.136 42.595c-.597 11.552-2.067 23.058-3.084 34.59l-3.845 44.478c-.939 10.202-1.779 20.432-3.283 30.557-.96 6.464-4.46 12.646-1.136 19.383.348.706-.426 1.894-.448 2.864-.224 9.918-5.99 19.428-2.196 29.646.103.279-.033.657-.092.983l-8.446 46.205c-1.231 6.469-2.936 12.846-4.364 19.279-1.5 6.757-2.602 13.621-4.456 20.277-3.601 12.93-10.657 25.3-5.627 39.47.368 1.036.234 2.352.017 3.476l-5.949 30.123z"></path><path fill="#ea5043" d="M958.343 767.017c1.645-10.218 3.659-20.253 5.602-30.302.217-1.124.351-2.44-.017-3.476-5.03-14.17 2.026-26.539 5.627-39.47 1.854-6.656 2.956-13.52 4.456-20.277 1.428-6.433 3.133-12.81 4.364-19.279l8.446-46.205c.059-.326.196-.705.092-.983-3.794-10.218 1.972-19.728 2.196-29.646.022-.97.796-2.158.448-2.864-3.324-6.737.176-12.919 1.136-19.383 1.504-10.125 2.344-20.355 3.283-30.557l3.845-44.478c1.017-11.532 2.488-23.038 3.084-34.59.733-14.18.722-28.397 1.136-42.595.086-2.963.626-5.912.956-9.301 5.356-.48 10.714-.527 16.536-.081 2.224 15.098 1.855 29.734 1.625 44.408-.157 10.064 1.439 20.142 1.768 30.23.334 10.235-.035 20.49.116 30.733.084 5.713.789 11.418.861 17.13.054 4.289-.469 8.585-.702 12.879-.072 1.323-.138 2.659-.031 3.975l2.534 34.405-1.707 36.293-1.908 48.69c-.182 8.103.993 16.237.811 24.34-.271 12.076-1.275 24.133-1.787 36.207-.102 2.414-.101 5.283 1.06 7.219 4.327 7.22 4.463 15.215 4.736 23.103.365 10.553.088 21.128.086 31.693-11.44 2.602-22.84.688-34.106-.916-11.486-1.635-22.806-4.434-34.546-6.903z"></path><path fill="#eb5d19" d="M398.091 622.45c6.086.617 12.21 1.288 18.067 2.918 3.539.985 6.779 3.277 9.952 5.297 9.773 6.224 18.971 13.583 29.311 18.611 8.606 4.184 12.839 10.986 17.016 18.559l18.571 32.959c1.814 3.102 4.285 5.931 6.883 8.443 8.835 8.542 10.052 20.175 13.16 31.095 2.082 7.317 4.609 14.507 6.946 22.127-29.472 3.021-58.969 5.582-87.584 15.222-1.185-2.302-1.795-4.362-2.769-6.233-4.398-8.449-6.703-18.174-14.942-24.299-2.511-1.866-5.103-3.814-7.047-6.218-8.358-10.332-17.028-20.276-28.772-26.973 4.423-11.478 9.299-22.806 13.151-34.473 4.406-13.348 6.724-27.18 6.998-41.313.098-5.093.643-10.176 1.06-15.722z"></path><path fill="#e94c32" d="M981.557 392.109c-1.172 15.337-2.617 30.625-4.438 45.869-2.213 18.521-4.144 37.108-7.346 55.466-2.123 12.171-6.28 23.985-9.492 35.968-2.439 9.098-6.794 18.224-6.73 27.313.078 11.051-5.7 19.776-7.81 29.825-3.292 15.677-10.255 30.082-18.775 43.704-2.383 3.81-2.458 8.091-2.577 12.742-.144 5.6-3.049 11.38-5.691 16.611-4.621 9.149-10.033 17.896-14.966 26.892-4.517 8.239-8.715 16.635-15.8 23.153-3.034 2.791-5.629 6.06-8.735 9.255-12.197-10.595-21.071-23.644-29.301-37.24-7.608-12.569-13.282-25.962-17.637-40.37 13.303-6.889 25.873-13.878 35.311-25.315.717-.869 1.934-1.312 2.71-2.147 5.025-5.405 10.515-10.481 14.854-16.397 6.141-8.374 10.861-17.813 17.206-26.008 8.22-10.618 13.657-22.643 20.024-34.466 4.448-.626 6.729-3.21 8.114-6.89 1.455-3.866 2.644-7.895 4.609-11.492 4.397-8.05 9.641-15.659 13.708-23.86 3.354-6.761 5.511-14.116 8.203-21.206 5.727-15.082 7.277-31.248 12.521-46.578 3.704-10.828 3.138-23.116 4.478-34.753l7.56-.073z"></path><path fill="#f7a617" d="M1918.661 831.99c-4.937 16.58-9.971 33.057-22.196 46.104-15.952 17.025-28.099 36.791-40.382 56.471-2.864 4.59-6.481 8.825-10.3 12.681-8.947 9.031-17.279 19.094-27.583 26.261-17.103 11.896-35.564 21.84-53.441 32.624-1.419.856-3.132 1.571-4.065 2.828-6.904 9.308-18.6 11.178-27.297 17.714-2.705 2.033-6.319 2.856-9.874 4.281-3.413-9.821-6.916-19.583-9.36-29.602-1.533-6.284-1.474-12.957-1.665-19.913 1.913-.78 3.374-1.057 4.81-1.431 15.822-4.121 31.491-8.029 43.818-20.323 9.452-9.426 20.371-17.372 30.534-26.097 6.146-5.277 13.024-10.052 17.954-16.326 14.812-18.848 28.876-38.285 43.112-57.581 2.624-3.557 5.506-7.264 6.83-11.367 2.681-8.311 4.375-16.94 6.476-25.438 17.89.279 35.333 3.179 52.629 9.113z"></path><path fill="#ea553a" d="M1172.91 977.582c-15.775-3.127-28.215-12.377-40.227-22.43-9.005-7.537-18.43-14.605-27.071-22.532-5.07-4.651-9.143-10.443-13.361-15.955-7.647-9.994-15.291-20.007-22.456-30.345-2.361-3.407-3.792-7.72-4.696-11.829-3.119-14.183-5.848-28.453-8.651-42.704-.636-3.236-.974-6.53-1.452-10.209 15.234-2.19 30.471-3.969 46.408-5.622 2.692 5.705 4.882 11.222 6.63 16.876 2.9 9.381 7.776 17.194 15.035 24.049 7.056 6.662 13.305 14.311 19.146 22.099 9.509 12.677 23.01 19.061 36.907 25.054-1.048 7.441-2.425 14.854-3.066 22.33-.956 11.162-1.393 22.369-2.052 33.557l-1.096 17.661z"></path><path fill="#ea5453" d="M1163.123 704.036c-4.005 5.116-7.685 10.531-12.075 15.293-12.842 13.933-27.653 25.447-44.902 34.538-3.166-5.708-5.656-11.287-8.189-17.251-3.321-12.857-6.259-25.431-9.963-37.775-4.6-15.329-10.6-30.188-11.349-46.562-.314-6.871-1.275-14.287-7.114-19.644-1.047-.961-1.292-3.053-1.465-4.67l-4.092-39.927c-.554-5.245-.383-10.829-2.21-15.623-3.622-9.503-4.546-19.253-4.688-29.163-.088-6.111 1.068-12.256.782-18.344-.67-14.281-1.76-28.546-2.9-42.8-.657-8.222-1.951-16.395-2.564-24.62-.458-6.137-.285-12.322-.104-18.21.959 5.831 1.076 11.525 2.429 16.909 2.007 7.986 5.225 15.664 7.324 23.632 3.222 12.23 1.547 25.219 6.728 37.355 4.311 10.099 6.389 21.136 9.732 31.669 2.228 7.02 6.167 13.722 7.121 20.863 1.119 8.376 6.1 13.974 10.376 20.716l2.026 10.576c1.711 9.216 3.149 18.283 8.494 26.599 6.393 9.946 11.348 20.815 16.943 31.276 4.021 7.519 6.199 16.075 12.925 22.065l24.462 22.26c.556.503 1.507.571 2.274.841z"></path><path fill="#ea5b15" d="M1285.092 163.432c9.165 3.148 18.419 6.374 27.279 10.459 4.871 2.246 8.838 6.406 13.646 8.851 5.446 2.77 11.801 3.874 17.011 6.965 11.514 6.831 24.097 9.942 36.968 12.471 1.78.35 3.777.576 5.213 1.542 10.784 7.255 23.448 9.114 35.622 11.834 9.977 2.23 18.529 6.703 26.988 11.898 5.233 3.214 10.76 5.983 15.798 9.468 4.14 2.864 7.962 6.279 11.551 9.827 5.076 5.02 10.056 10.181 14.624 15.658 5.822 6.98 11.119 14.395 16.78 21.513 4.531 5.698 9.267 11.233 14.222 16.987-10.005 5.806-20.07 12.004-30.719 16.943-7.694 3.569-16.163 5.464-24.688 7.669-2.878-7.088-5.352-13.741-7.833-20.392-.802-2.15-1.244-4.55-2.498-6.396-4.548-6.7-9.712-12.999-14.011-19.847-6.672-10.627-15.34-18.93-26.063-25.376-9.357-5.625-18.367-11.824-27.644-17.587-6.436-3.997-12.902-8.006-19.659-11.405-5.123-2.577-11.107-3.536-16.046-6.37-17.187-9.863-35.13-17.887-54.031-23.767-4.403-1.37-8.953-2.267-13.436-3.382l.926-27.565z"></path><path fill="#ea504b" d="M1098 737l7.789 16.893c-15.04 9.272-31.679 15.004-49.184 17.995-9.464 1.617-19.122 2.097-29.151 3.019-.457-10.636-.18-21.211-.544-31.764-.273-7.888-.409-15.883-4.736-23.103-1.16-1.936-1.162-4.805-1.06-7.219l1.787-36.207c.182-8.103-.993-16.237-.811-24.34.365-16.236 1.253-32.461 1.908-48.69.484-12 .942-24.001 1.98-36.069 5.57 10.19 10.632 20.42 15.528 30.728 1.122 2.362 2.587 5.09 2.339 7.488-1.536 14.819 5.881 26.839 12.962 38.33 10.008 16.241 16.417 33.54 20.331 51.964 2.285 10.756 4.729 21.394 11.958 30.165L1098 737z"></path><path fill="#f6a320" d="M1865.78 822.529c-1.849 8.846-3.544 17.475-6.224 25.786-1.323 4.102-4.206 7.81-6.83 11.367l-43.112 57.581c-4.93 6.273-11.808 11.049-17.954 16.326-10.162 8.725-21.082 16.671-30.534 26.097-12.327 12.294-27.997 16.202-43.818 20.323-1.436.374-2.897.651-4.744.986-1.107-17.032-1.816-34.076-2.079-51.556 1.265-.535 2.183-.428 2.888-.766 10.596-5.072 20.8-11.059 32.586-13.273 1.69-.317 3.307-1.558 4.732-2.662l26.908-21.114c4.992-4.003 11.214-7.393 14.381-12.585 11.286-18.5 22.363-37.263 27.027-58.87l36.046 1.811c3.487.165 6.983.14 10.727.549z"></path><path fill="#ec6333" d="M318.448 922.814c-6.374-2.074-12.56-4.058-18.412-6.765-8.379-3.876-16.906-7.675-24.617-12.668-5.239-3.392-9.69-8.381-13.609-13.352-7.87-9.983-14.953-20.582-22.699-30.666-8.061-10.493-13.909-22.097-18.636-34.358-.595-1.543-1.486-2.972-2.382-4.783 6.84-1.598 13.797-3.023 20.807-4.106 18.852-2.912 36.433-9.493 53.737-17.819.697.888.889 1.555 1.292 2.051l17.921 21.896c4.14 4.939 8.06 10.191 12.862 14.412 5.67 4.984 12.185 9.007 18.334 13.447-8.937 16.282-16.422 33.178-20.696 51.31-1.638 6.951-2.402 14.107-3.903 21.403z"></path><path fill="#f49700" d="M623.467 326.903c2.893-10.618 5.584-21.446 9.833-31.623 3.013-7.217 7.924-13.696 12.358-20.254 6.375-9.43 12.026-19.67 19.886-27.705 14.12-14.434 28.063-29.453 47.926-36.784 6.581-2.429 12.344-6.994 18.774-9.942 3.975-1.822 8.503-2.436 13.186-3.592 1.947 18.557 3.248 37.15 8.307 55.686-15.453 7.931-28.853 18.092-40.46 29.996-10.417 10.683-19.109 23.111-28.013 35.175-3.238 4.388-4.888 9.948-7.262 14.973-17.803-3.987-35.767-6.498-54.535-5.931z"></path><path fill="#ea544c" d="M1097.956 736.615c-2.925-3.218-5.893-6.822-8.862-10.425-7.229-8.771-9.672-19.409-11.958-30.165-3.914-18.424-10.323-35.722-20.331-51.964-7.081-11.491-14.498-23.511-12.962-38.33.249-2.398-1.217-5.126-2.339-7.488l-15.232-31.019-3.103-34.338c-.107-1.316-.041-2.653.031-3.975.233-4.294.756-8.59.702-12.879-.072-5.713-.776-11.417-.861-17.13l-.116-30.733c-.329-10.088-1.926-20.166-1.768-30.23.23-14.674.599-29.31-1.162-44.341 9.369-.803 18.741-1.179 28.558-1.074 1.446 15.814 2.446 31.146 3.446 46.478.108 6.163-.064 12.348.393 18.485.613 8.225 1.907 16.397 2.564 24.62l2.9 42.8c.286 6.088-.869 12.234-.782 18.344.142 9.91 1.066 19.661 4.688 29.163 1.827 4.794 1.657 10.377 2.21 15.623l4.092 39.927c.172 1.617.417 3.71 1.465 4.67 5.839 5.357 6.8 12.773 7.114 19.644.749 16.374 6.749 31.233 11.349 46.562 3.704 12.344 6.642 24.918 9.963 37.775z"></path><path fill="#ec5c61" d="M1204.835 568.008c1.254 25.351-1.675 50.16-10.168 74.61-8.598-4.883-18.177-8.709-24.354-15.59-7.44-8.289-13.929-17.442-21.675-25.711-8.498-9.072-16.731-18.928-21.084-31.113-.54-1.513-1.691-2.807-2.594-4.564-4.605-9.247-7.706-18.544-7.96-29.09-.835-7.149-1.214-13.944-2.609-20.523-2.215-10.454-5.626-20.496-7.101-31.302-2.513-18.419-7.207-36.512-5.347-55.352.24-2.43-.17-4.949-.477-7.402l-4.468-34.792c2.723-.379 5.446-.757 8.585-.667 1.749 8.781 2.952 17.116 4.448 25.399 1.813 10.037 3.64 20.084 5.934 30.017 1.036 4.482 3.953 8.573 4.73 13.064 1.794 10.377 4.73 20.253 9.272 29.771 2.914 6.105 4.761 12.711 7.496 18.912 2.865 6.496 6.264 12.755 9.35 19.156 3.764 7.805 7.667 15.013 16.1 19.441 7.527 3.952 13.713 10.376 20.983 14.924 6.636 4.152 13.932 7.25 20.937 10.813z"></path><path fill="#ed676f" d="M1140.75 379.231c18.38-4.858 36.222-11.21 53.979-18.971 3.222 3.368 5.693 6.744 8.719 9.512 2.333 2.134 5.451 5.07 8.067 4.923 7.623-.429 12.363 2.688 17.309 8.215 5.531 6.18 12.744 10.854 19.224 16.184-5.121 7.193-10.461 14.241-15.323 21.606-13.691 20.739-22.99 43.255-26.782 67.926-.543 3.536-1.281 7.043-2.366 10.925-14.258-6.419-26.411-14.959-32.731-29.803-1.087-2.553-2.596-4.93-3.969-7.355-1.694-2.993-3.569-5.89-5.143-8.943-1.578-3.062-2.922-6.249-4.295-9.413-1.57-3.621-3.505-7.163-4.47-10.946-1.257-4.93-.636-10.572-2.725-15.013-5.831-12.397-7.467-25.628-9.497-38.847z"></path><path fill="#ed656e" d="M1254.103 647.439c5.325.947 10.603 2.272 15.847 3.722 5.101 1.41 10.376 2.475 15.175 4.596 3.237 1.431 5.942 4.262 8.589 6.777 2.592 2.462 4.77 5.355 7.207 7.987 1.804 1.948 4.557 3.453 5.461 5.723 3.51 8.817 11.581 11.307 19.059 14.735 1.053.483 2.116.963 3.214 1.327 9.172 3.043 13.818 8.587 14.889 18.979.715 6.935 5.607 13.679 9.479 19.987 4.623 7.533 9.175 14.819 9.091 24.116-.023 2.55 1.21 5.111 1.874 8.055-19.861 2.555-39.795 4.296-59.597 9.09l-11.596-23.203c-1.107-2.169-2.526-4.353-4.307-5.975-7.349-6.694-14.863-13.209-22.373-19.723l-17.313-14.669c-2.776-2.245-5.935-4.017-8.92-6.003l11.609-38.185c1.508-5.453 1.739-11.258 2.613-17.336z"></path><path fill="#ec6168" d="M1140.315 379.223c2.464 13.227 4.101 26.459 9.931 38.856 2.089 4.441 1.468 10.083 2.725 15.013.965 3.783 2.9 7.325 4.47 10.946 1.372 3.164 2.716 6.351 4.295 9.413 1.574 3.053 3.449 5.95 5.143 8.943 1.372 2.425 2.882 4.803 3.969 7.355 6.319 14.844 18.473 23.384 32.641 30.212.067 5.121-.501 10.201-.435 15.271l.985 38.117c.151 4.586.616 9.162.868 14.201-7.075-3.104-14.371-6.202-21.007-10.354-7.269-4.548-13.456-10.972-20.983-14.924-8.434-4.428-12.337-11.637-16.1-19.441-3.087-6.401-6.485-12.66-9.35-19.156-2.735-6.201-4.583-12.807-7.496-18.912-4.542-9.518-7.477-19.394-9.272-29.771-.777-4.491-3.694-8.581-4.73-13.064-2.294-9.933-4.121-19.98-5.934-30.017-1.496-8.283-2.699-16.618-4.036-25.335 10.349-2.461 20.704-4.511 31.054-6.582.957-.191 1.887-.515 3.264-.769z"></path><path fill="#e94c28" d="M922 537c-6.003 11.784-11.44 23.81-19.66 34.428-6.345 8.196-11.065 17.635-17.206 26.008-4.339 5.916-9.828 10.992-14.854 16.397-.776.835-1.993 1.279-2.71 2.147-9.439 11.437-22.008 18.427-35.357 24.929-4.219-10.885-6.942-22.155-7.205-33.905l-.514-49.542c7.441-2.893 14.452-5.197 21.334-7.841 1.749-.672 3.101-2.401 4.604-3.681 6.749-5.745 12.845-12.627 20.407-16.944 7.719-4.406 14.391-9.101 18.741-16.889.626-1.122 1.689-2.077 2.729-2.877 7.197-5.533 12.583-12.51 16.906-20.439.68-1.247 2.495-1.876 4.105-2.651 2.835 1.408 5.267 2.892 7.884 3.892 3.904 1.491 4.392 3.922 2.833 7.439-1.47 3.318-2.668 6.756-4.069 10.106-1.247 2.981-.435 5.242 2.413 6.544 2.805 1.282 3.125 3.14 1.813 5.601l-6.907 12.799L922 537z"></path><path fill="#eb5659" d="M1124.995 566c.868 1.396 2.018 2.691 2.559 4.203 4.353 12.185 12.586 22.041 21.084 31.113 7.746 8.269 14.235 17.422 21.675 25.711 6.176 6.881 15.756 10.707 24.174 15.932-6.073 22.316-16.675 42.446-31.058 60.937-1.074-.131-2.025-.199-2.581-.702l-24.462-22.26c-6.726-5.99-8.904-14.546-12.925-22.065-5.594-10.461-10.55-21.33-16.943-31.276-5.345-8.315-6.783-17.383-8.494-26.599-.63-3.394-1.348-6.772-1.738-10.848-.371-6.313-1.029-11.934-1.745-18.052l6.34 4.04 1.288-.675-2.143-15.385 9.454 1.208v-8.545L1124.995 566z"></path><path fill="#f5a02d" d="M1818.568 820.096c-4.224 21.679-15.302 40.442-26.587 58.942-3.167 5.192-9.389 8.582-14.381 12.585l-26.908 21.114c-1.425 1.104-3.042 2.345-4.732 2.662-11.786 2.214-21.99 8.201-32.586 13.273-.705.338-1.624.231-2.824.334a824.35 824.35 0 0 1-8.262-42.708c4.646-2.14 9.353-3.139 13.269-5.47 5.582-3.323 11.318-6.942 15.671-11.652 7.949-8.6 14.423-18.572 22.456-27.081 8.539-9.046 13.867-19.641 18.325-30.922l46.559 8.922z"></path><path fill="#eb5a57" d="M1124.96 565.639c-5.086-4.017-10.208-8.395-15.478-12.901v8.545l-9.454-1.208 2.143 15.385-1.288.675-6.34-4.04c.716 6.118 1.375 11.74 1.745 17.633-4.564-6.051-9.544-11.649-10.663-20.025-.954-7.141-4.892-13.843-7.121-20.863-3.344-10.533-5.421-21.57-9.732-31.669-5.181-12.135-3.506-25.125-6.728-37.355-2.099-7.968-5.317-15.646-7.324-23.632-1.353-5.384-1.47-11.078-2.429-16.909l-3.294-46.689a278.63 278.63 0 0 1 27.57-2.084c2.114 12.378 3.647 24.309 5.479 36.195 1.25 8.111 2.832 16.175 4.422 24.23 1.402 7.103 2.991 14.169 4.55 21.241 1.478 6.706.273 14.002 4.6 20.088 5.401 7.597 7.176 16.518 9.467 25.337 1.953 7.515 5.804 14.253 11.917 19.406.254 10.095 3.355 19.392 7.96 28.639z"></path><path fill="#ea541c" d="M911.651 810.999c-2.511 10.165-5.419 20.146-8.2 30.162-2.503 9.015-7.37 16.277-14.364 22.612-6.108 5.533-10.917 12.475-16.796 18.293-6.942 6.871-14.354 13.24-19.083 22.03-.644 1.196-2.222 1.889-3.705 2.857-2.39-7.921-4.101-15.991-6.566-23.823-5.451-17.323-12.404-33.976-23.414-48.835l21.627-21.095c3.182-3.29 5.532-7.382 8.295-11.083l10.663-14.163c9.528 4.78 18.925 9.848 28.625 14.247 7.324 3.321 15.036 5.785 22.917 8.799z"></path><path fill="#eb5d19" d="M1284.092 191.421c4.557.69 9.107 1.587 13.51 2.957 18.901 5.881 36.844 13.904 54.031 23.767 4.938 2.834 10.923 3.792 16.046 6.37 6.757 3.399 13.224 7.408 19.659 11.405l27.644 17.587c10.723 6.446 19.392 14.748 26.063 25.376 4.299 6.848 9.463 13.147 14.011 19.847 1.254 1.847 1.696 4.246 2.498 6.396l7.441 20.332c-11.685 1.754-23.379 3.133-35.533 4.037-.737-2.093-.995-3.716-1.294-5.33-3.157-17.057-14.048-30.161-23.034-44.146-3.027-4.71-7.786-8.529-12.334-11.993-9.346-7.116-19.004-13.834-28.688-20.491-6.653-4.573-13.311-9.251-20.431-13.002-8.048-4.24-16.479-7.85-24.989-11.091-11.722-4.465-23.673-8.328-35.527-12.449l.927-19.572z"></path><path fill="#eb5e24" d="M1283.09 211.415c11.928 3.699 23.88 7.562 35.602 12.027 8.509 3.241 16.941 6.852 24.989 11.091 7.12 3.751 13.778 8.429 20.431 13.002 9.684 6.657 19.342 13.375 28.688 20.491 4.548 3.463 9.307 7.283 12.334 11.993 8.986 13.985 19.877 27.089 23.034 44.146.299 1.615.557 3.237.836 5.263-13.373-.216-26.749-.839-40.564-1.923-2.935-9.681-4.597-18.92-12.286-26.152-15.577-14.651-30.4-30.102-45.564-45.193-.686-.683-1.626-1.156-2.516-1.584l-47.187-22.615 2.203-20.546z"></path><path fill="#e9511f" d="M913 486.001c-1.29.915-3.105 1.543-3.785 2.791-4.323 7.929-9.709 14.906-16.906 20.439-1.04.8-2.103 1.755-2.729 2.877-4.35 7.788-11.022 12.482-18.741 16.889-7.562 4.317-13.658 11.199-20.407 16.944-1.503 1.28-2.856 3.009-4.604 3.681-6.881 2.643-13.893 4.948-21.262 7.377-.128-11.151.202-22.302.378-33.454.03-1.892-.6-3.795-.456-6.12 13.727-1.755 23.588-9.527 33.278-17.663 2.784-2.337 6.074-4.161 8.529-6.784l29.057-31.86c1.545-1.71 3.418-3.401 4.221-5.459 5.665-14.509 11.49-28.977 16.436-43.736 2.817-8.407 4.074-17.338 6.033-26.032 5.039.714 10.078 1.427 15.536 2.629-.909 8.969-2.31 17.438-3.546 25.931-2.41 16.551-5.84 32.839-11.991 48.461L913 486.001z"></path><path fill="#ea5741" d="M1179.451 903.828c-14.224-5.787-27.726-12.171-37.235-24.849-5.841-7.787-12.09-15.436-19.146-22.099-7.259-6.854-12.136-14.667-15.035-24.049-1.748-5.654-3.938-11.171-6.254-17.033 15.099-4.009 30.213-8.629 44.958-15.533l28.367 36.36c6.09 8.015 13.124 14.75 22.72 18.375-7.404 14.472-13.599 29.412-17.48 45.244-.271 1.106-.382 2.25-.895 3.583z"></path><path fill="#ea522a" d="M913.32 486.141c2.693-7.837 5.694-15.539 8.722-23.231 6.151-15.622 9.581-31.91 11.991-48.461l3.963-25.861c7.582.317 15.168 1.031 22.748 1.797 4.171.421 8.333.928 12.877 1.596-.963 11.836-.398 24.125-4.102 34.953-5.244 15.33-6.794 31.496-12.521 46.578-2.692 7.09-4.849 14.445-8.203 21.206-4.068 8.201-9.311 15.81-13.708 23.86-1.965 3.597-3.154 7.627-4.609 11.492-1.385 3.68-3.666 6.265-8.114 6.89-1.994-1.511-3.624-3.059-5.077-4.44l6.907-12.799c1.313-2.461.993-4.318-1.813-5.601-2.849-1.302-3.66-3.563-2.413-6.544 1.401-3.35 2.599-6.788 4.069-10.106 1.558-3.517 1.071-5.948-2.833-7.439-2.617-1-5.049-2.484-7.884-3.892z"></path><path fill="#eb5e24" d="M376.574 714.118c12.053 6.538 20.723 16.481 29.081 26.814 1.945 2.404 4.537 4.352 7.047 6.218 8.24 6.125 10.544 15.85 14.942 24.299.974 1.871 1.584 3.931 2.376 6.29-7.145 3.719-14.633 6.501-21.386 10.517-9.606 5.713-18.673 12.334-28.425 18.399-3.407-3.73-6.231-7.409-9.335-10.834l-30.989-33.862c11.858-11.593 22.368-24.28 31.055-38.431 1.86-3.031 3.553-6.164 5.632-9.409z"></path><path fill="#e95514" d="M859.962 787.636c-3.409 5.037-6.981 9.745-10.516 14.481-2.763 3.701-5.113 7.792-8.295 11.083-6.885 7.118-14.186 13.834-21.65 20.755-13.222-17.677-29.417-31.711-48.178-42.878-.969-.576-2.068-.934-3.27-1.709 6.28-8.159 12.733-15.993 19.16-23.849 1.459-1.783 2.718-3.738 4.254-5.448l18.336-19.969c4.909 5.34 9.619 10.738 14.081 16.333 9.72 12.19 21.813 21.566 34.847 29.867.411.262.725.674 1.231 1.334z"></path><path fill="#eb5f2d" d="M339.582 762.088l31.293 33.733c3.104 3.425 5.928 7.104 9.024 10.979-12.885 11.619-24.548 24.139-33.899 38.704-.872 1.359-1.56 2.837-2.644 4.428-6.459-4.271-12.974-8.294-18.644-13.278-4.802-4.221-8.722-9.473-12.862-14.412l-17.921-21.896c-.403-.496-.595-1.163-.926-2.105 16.738-10.504 32.58-21.87 46.578-36.154z"></path><path fill="#f28d00" d="M678.388 332.912c1.989-5.104 3.638-10.664 6.876-15.051 8.903-12.064 17.596-24.492 28.013-35.175 11.607-11.904 25.007-22.064 40.507-29.592 4.873 11.636 9.419 23.412 13.67 35.592-5.759 4.084-11.517 7.403-16.594 11.553-4.413 3.607-8.124 8.092-12.023 12.301-5.346 5.772-10.82 11.454-15.782 17.547-3.929 4.824-7.17 10.208-10.716 15.344l-33.95-12.518z"></path><path fill="#f08369" d="M1580.181 771.427c-.191-.803-.322-1.377-.119-1.786 5.389-10.903 9.084-22.666 18.181-31.587 6.223-6.103 11.276-13.385 17.286-19.727 3.117-3.289 6.933-6.105 10.869-8.384 6.572-3.806 13.492-7.009 20.461-10.752 1.773 3.23 3.236 6.803 4.951 10.251l12.234 24.993c-1.367 1.966-2.596 3.293-3.935 4.499-7.845 7.07-16.315 13.564-23.407 21.32-6.971 7.623-12.552 16.517-18.743 24.854l-37.777-13.68z"></path><path fill="#f18b5e" d="M1618.142 785.4c6.007-8.63 11.588-17.524 18.559-25.147 7.092-7.755 15.562-14.249 23.407-21.32 1.338-1.206 2.568-2.534 3.997-4.162l28.996 33.733c1.896 2.205 4.424 3.867 6.66 6.394-6.471 7.492-12.967 14.346-19.403 21.255l-18.407 19.953c-12.958-12.409-27.485-22.567-43.809-30.706z"></path><path fill="#f49c3a" d="M1771.617 811.1c-4.066 11.354-9.394 21.949-17.933 30.995-8.032 8.509-14.507 18.481-22.456 27.081-4.353 4.71-10.089 8.329-15.671 11.652-3.915 2.331-8.623 3.331-13.318 5.069-4.298-9.927-8.255-19.998-12.1-30.743 4.741-4.381 9.924-7.582 13.882-11.904 7.345-8.021 14.094-16.603 20.864-25.131 4.897-6.168 9.428-12.626 14.123-18.955l32.61 11.936z"></path><path fill="#f08000" d="M712.601 345.675c3.283-5.381 6.524-10.765 10.453-15.589 4.962-6.093 10.435-11.774 15.782-17.547 3.899-4.21 7.61-8.695 12.023-12.301 5.078-4.15 10.836-7.469 16.636-11.19a934.12 934.12 0 0 1 23.286 35.848c-4.873 6.234-9.676 11.895-14.63 17.421l-25.195 27.801c-11.713-9.615-24.433-17.645-38.355-24.443z"></path><path fill="#ed6e04" d="M751.11 370.42c8.249-9.565 16.693-18.791 25.041-28.103 4.954-5.526 9.757-11.187 14.765-17.106 7.129 6.226 13.892 13.041 21.189 19.225 5.389 4.567 11.475 8.312 17.53 12.92-5.51 7.863-10.622 15.919-17.254 22.427-8.881 8.716-18.938 16.233-28.49 24.264-5.703-6.587-11.146-13.427-17.193-19.682-4.758-4.921-10.261-9.121-15.587-13.944z"></path><path fill="#ea541c" d="M921.823 385.544c-1.739 9.04-2.995 17.971-5.813 26.378-4.946 14.759-10.771 29.227-16.436 43.736-.804 2.058-2.676 3.749-4.221 5.459l-29.057 31.86c-2.455 2.623-5.745 4.447-8.529 6.784-9.69 8.135-19.551 15.908-33.208 17.237-1.773-9.728-3.147-19.457-4.091-29.6l36.13-16.763c.581-.267 1.046-.812 1.525-1.269 8.033-7.688 16.258-15.19 24.011-23.152 4.35-4.467 9.202-9.144 11.588-14.69 6.638-15.425 15.047-30.299 17.274-47.358 3.536.344 7.072.688 10.829 1.377z"></path><path fill="#f3944d" d="M1738.688 798.998c-4.375 6.495-8.906 12.953-13.803 19.121-6.771 8.528-13.519 17.11-20.864 25.131-3.958 4.322-9.141 7.523-13.925 11.54-8.036-13.464-16.465-26.844-27.999-38.387 5.988-6.951 12.094-13.629 18.261-20.25l19.547-20.95 38.783 23.794z"></path><path fill="#ec6168" d="M1239.583 703.142c3.282 1.805 6.441 3.576 9.217 5.821 5.88 4.755 11.599 9.713 17.313 14.669l22.373 19.723c1.781 1.622 3.2 3.806 4.307 5.975 3.843 7.532 7.477 15.171 11.194 23.136-10.764 4.67-21.532 8.973-32.69 12.982l-22.733-27.366c-2.003-2.416-4.096-4.758-6.194-7.093-3.539-3.94-6.927-8.044-10.74-11.701-2.57-2.465-5.762-4.283-8.675-6.39l16.627-29.755z"></path><path fill="#ec663e" d="M1351.006 332.839l-28.499 10.33c-.294.107-.533.367-1.194.264-11.067-19.018-27.026-32.559-44.225-44.855-4.267-3.051-8.753-5.796-13.138-8.682l9.505-24.505c10.055 4.069 19.821 8.227 29.211 13.108 3.998 2.078 7.299 5.565 10.753 8.598 3.077 2.701 5.743 5.891 8.926 8.447 4.116 3.304 9.787 5.345 12.62 9.432 6.083 8.777 10.778 18.517 16.041 27.863z"></path><path fill="#eb5e5b" d="M1222.647 733.051c3.223 1.954 6.415 3.771 8.985 6.237 3.813 3.658 7.201 7.761 10.74 11.701l6.194 7.093 22.384 27.409c-13.056 6.836-25.309 14.613-36.736 24.161l-39.323-44.7 24.494-27.846c1.072-1.224 1.974-2.598 3.264-4.056z"></path><path fill="#ea580e" d="M876.001 376.171c5.874 1.347 11.748 2.694 17.812 4.789-.81 5.265-2.687 9.791-2.639 14.296.124 11.469-4.458 20.383-12.73 27.863-2.075 1.877-3.659 4.286-5.668 6.248l-22.808 21.967c-.442.422-1.212.488-1.813.757l-23.113 10.389-9.875 4.514c-2.305-6.09-4.609-12.181-6.614-18.676 7.64-4.837 15.567-8.54 22.18-13.873 9.697-7.821 18.931-16.361 27.443-25.455 5.613-5.998 12.679-11.331 14.201-20.475.699-4.2 2.384-8.235 3.623-12.345z"></path><path fill="#e95514" d="M815.103 467.384c3.356-1.894 6.641-3.415 9.94-4.903l23.113-10.389c.6-.269 1.371-.335 1.813-.757l22.808-21.967c2.008-1.962 3.593-4.371 5.668-6.248 8.272-7.48 12.854-16.394 12.73-27.863-.049-4.505 1.828-9.031 2.847-13.956 5.427.559 10.836 1.526 16.609 2.68-1.863 17.245-10.272 32.119-16.91 47.544-2.387 5.546-7.239 10.223-11.588 14.69-7.753 7.962-15.978 15.464-24.011 23.152-.478.458-.944 1.002-1.525 1.269l-36.069 16.355c-2.076-6.402-3.783-12.81-5.425-19.607z"></path><path fill="#eb620b" d="M783.944 404.402c9.499-8.388 19.556-15.905 28.437-24.621 6.631-6.508 11.744-14.564 17.575-22.273 9.271 4.016 18.501 8.375 27.893 13.43-4.134 7.07-8.017 13.778-12.833 19.731-5.785 7.15-12.109 13.917-18.666 20.376-7.99 7.869-16.466 15.244-24.731 22.832l-17.674-29.475z"></path><path fill="#ea544c" d="M1197.986 854.686c-9.756-3.309-16.79-10.044-22.88-18.059l-28.001-36.417c8.601-5.939 17.348-11.563 26.758-17.075 1.615 1.026 2.639 1.876 3.505 2.865l26.664 30.44c3.723 4.139 7.995 7.785 12.017 11.656l-18.064 26.591z"></path><path fill="#ec6333" d="M1351.41 332.903c-5.667-9.409-10.361-19.149-16.445-27.926-2.833-4.087-8.504-6.128-12.62-9.432-3.184-2.555-5.849-5.745-8.926-8.447-3.454-3.033-6.756-6.52-10.753-8.598-9.391-4.88-19.157-9.039-29.138-13.499 1.18-5.441 2.727-10.873 4.81-16.607 11.918 4.674 24.209 8.261 34.464 14.962 14.239 9.304 29.011 18.453 39.595 32.464 2.386 3.159 5.121 6.077 7.884 8.923 6.564 6.764 10.148 14.927 11.723 24.093l-20.594 4.067z"></path><path fill="#eb5e5b" d="M1117 536.549c-6.113-4.702-9.965-11.44-11.917-18.955-2.292-8.819-4.066-17.74-9.467-25.337-4.327-6.085-3.122-13.382-4.6-20.088l-4.55-21.241c-1.59-8.054-3.172-16.118-4.422-24.23l-5.037-36.129c6.382-1.43 12.777-2.462 19.582-3.443 1.906 11.646 3.426 23.24 4.878 34.842.307 2.453.717 4.973.477 7.402-1.86 18.84 2.834 36.934 5.347 55.352 1.474 10.806 4.885 20.848 7.101 31.302 1.394 6.579 1.774 13.374 2.609 20.523z"></path><path fill="#ec644b" d="M1263.638 290.071c4.697 2.713 9.183 5.458 13.45 8.509 17.199 12.295 33.158 25.836 43.873 44.907-8.026 4.725-16.095 9.106-24.83 13.372-11.633-15.937-25.648-28.515-41.888-38.689-1.609-1.008-3.555-1.48-5.344-2.2 2.329-3.852 4.766-7.645 6.959-11.573l7.78-14.326z"></path><path fill="#eb5f2d" d="M1372.453 328.903c-2.025-9.233-5.608-17.396-12.172-24.16-2.762-2.846-5.498-5.764-7.884-8.923-10.584-14.01-25.356-23.16-39.595-32.464-10.256-6.701-22.546-10.289-34.284-15.312.325-5.246 1.005-10.444 2.027-15.863l47.529 22.394c.89.428 1.83.901 2.516 1.584l45.564 45.193c7.69 7.233 9.352 16.472 11.849 26.084-5.032.773-10.066 1.154-15.55 1.466z"></path><path fill="#e95a0f" d="M801.776 434.171c8.108-7.882 16.584-15.257 24.573-23.126 6.558-6.459 12.881-13.226 18.666-20.376 4.817-5.953 8.7-12.661 13.011-19.409 5.739 1.338 11.463 3.051 17.581 4.838-.845 4.183-2.53 8.219-3.229 12.418-1.522 9.144-8.588 14.477-14.201 20.475-8.512 9.094-17.745 17.635-27.443 25.455-6.613 5.333-14.54 9.036-22.223 13.51-2.422-4.469-4.499-8.98-6.735-13.786z"></path><path fill="#eb5e5b" d="M1248.533 316.002c2.155.688 4.101 1.159 5.71 2.168 16.24 10.174 30.255 22.752 41.532 38.727-7.166 5.736-14.641 11.319-22.562 16.731-1.16-1.277-1.684-2.585-2.615-3.46l-38.694-36.2 14.203-15.029c.803-.86 1.38-1.93 2.427-2.936z"></path><path fill="#eb5a57" d="M1216.359 827.958c-4.331-3.733-8.603-7.379-12.326-11.518l-26.664-30.44c-.866-.989-1.89-1.839-3.152-2.902 6.483-6.054 13.276-11.959 20.371-18.005l39.315 44.704c-5.648 6.216-11.441 12.12-17.544 18.161z"></path><path fill="#ec6168" d="M1231.598 334.101l38.999 36.066c.931.876 1.456 2.183 2.303 3.608-4.283 4.279-8.7 8.24-13.769 12.091-4.2-3.051-7.512-6.349-11.338-8.867-12.36-8.136-22.893-18.27-32.841-29.093l16.646-13.805z"></path><path fill="#ed656e" d="M1214.597 347.955c10.303 10.775 20.836 20.908 33.196 29.044 3.825 2.518 7.137 5.816 10.992 8.903-3.171 4.397-6.65 8.648-10.432 13.046-6.785-5.184-13.998-9.858-19.529-16.038-4.946-5.527-9.687-8.644-17.309-8.215-2.616.147-5.734-2.788-8.067-4.923-3.026-2.769-5.497-6.144-8.35-9.568 6.286-4.273 12.715-8.237 19.499-12.25z"></path></svg>
</p>
<p align="center">
<b>The crispy sentence embedding family from <a href="https://mixedbread.ai"><b>Mixedbread</b></a>.</b>
</p>
# mixedbread-ai/mxbai-embed-large-v1
Here, we provide several ways to produce sentence embeddings. Please note that you have to provide the prompt `Represent this sentence for searching relevant passages:` for query if you want to use it for retrieval. Besides that you don't need any prompt. Our model also supports [Matryoshka Representation Learning and binary quantization](https://www.mixedbread.ai/blog/binary-mrl).
## Quickstart
Here, we provide several ways to produce sentence embeddings. Please note that you have to provide the prompt `Represent this sentence for searching relevant passages: ` for query if you want to use it for retrieval. Besides that you don't need any prompt.
### sentence-transformers
```
python -m pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
from sentence_transformers.quantization import quantize_embeddings
# 1. Specify preffered dimensions
dimensions = 512
# 2. load model
model = SentenceTransformer("mixedbread-ai/mxbai-embed-large-v1", truncate_dim=dimensions)
# The prompt used for query retrieval tasks:
# query_prompt = 'Represent this sentence for searching relevant passages: '
query = "A man is eating a piece of bread"
docs = [
"A man is eating food.",
"A man is eating pasta.",
"The girl is carrying a baby.",
"A man is riding a horse.",
]
# 2. Encode
query_embedding = model.encode(query, prompt_name="query")
# Equivalent Alternatives:
# query_embedding = model.encode(query_prompt + query)
# query_embedding = model.encode(query, prompt=query_prompt)
docs_embeddings = model.encode(docs)
# Optional: Quantize the embeddings
binary_query_embedding = quantize_embeddings(query_embedding, precision="ubinary")
binary_docs_embeddings = quantize_embeddings(docs_embeddings, precision="ubinary")
similarities = cos_sim(query_embedding, docs_embeddings)
print('similarities:', similarities)
### Transformers
from typing import Dict
import torch
import numpy as np
from transformers import AutoModel, AutoTokenizer
from sentence_transformers.util import cos_sim
# For retrieval you need to pass this prompt. Please find our more in our blog post.
def transform_query(query: str) -> str:
""" For retrieval, add the prompt for query (not for documents).
"""
return f'Represent this sentence for searching relevant passages: {query}'
# The model works really well with cls pooling (default) but also with mean pooling.
def pooling(outputs: torch.Tensor, inputs: Dict, strategy: str = 'cls') -> np.ndarray:
if strategy == 'cls':
outputs = outputs[:, 0]
elif strategy == 'mean':
outputs = torch.sum(
outputs * inputs["attention_mask"][:, :, None], dim=1) / torch.sum(inputs["attention_mask"], dim=1, keepdim=True)
else:
raise NotImplementedError
return outputs.detach().cpu().numpy()
# 1. load model
model_id = 'mixedbread-ai/mxbai-embed-large-v1'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id).cuda()
docs = [
transform_query('A man is eating a piece of bread'),
"A man is eating food.",
"A man is eating pasta.",
"The girl is carrying a baby.",
"A man is riding a horse.",
]
# 2. encode
inputs = tokenizer(docs, padding=True, return_tensors='pt')
for k, v in inputs.items():
inputs[k] = v.cuda()
outputs = model(**inputs).last_hidden_state
embeddings = pooling(outputs, inputs, 'cls')
similarities = cos_sim(embeddings[0], embeddings[1:])
print('similarities:', similarities)
### Transformers.js
If you haven't already, you can install the [Transformers.js](https://huggingface.co/docs/transformers.js) JavaScript library from [NPM](https://www.npmjs.com/package/@xenova/transformers) using:
npm i @xenova/transformers
You can then use the model to compute embeddings like this:
import { pipeline, cos_sim } from '@xenova/transformers';
// Create a feature extraction pipeline
const extractor = await pipeline('feature-extraction', 'mixedbread-ai/mxbai-embed-large-v1', {
quantized: false, // Comment out this line to use the quantized version
});
// Generate sentence embeddings
const docs = [
'Represent this sentence for searching relevant passages: A man is eating a piece of bread',
'A man is eating food.',
'A man is eating pasta.',
'The girl is carrying a baby.',
'A man is riding a horse.',
]
const output = await extractor(docs, { pooling: 'cls' });
// Compute similarity scores
const [source_embeddings, ...document_embeddings ] = output.tolist();
const similarities = document_embeddings.map(x => cos_sim(source_embeddings, x));
console.log(similarities); // [0.7919578577247139, 0.6369278664248345, 0.16512018371357193, 0.3620778366720027]
### Using API
You can use the model via our API as follows:
from mixedbread_ai.client import MixedbreadAI, EncodingFormat
from sklearn.metrics.pairwise import cosine_similarity
import os
mxbai = MixedbreadAI(api_key="{MIXEDBREAD_API_KEY}")
english_sentences = [
'What is the capital of Australia?',
'Canberra is the capital of Australia.'
]
res = mxbai.embeddings(
input=english_sentences,
model="mixedbread-ai/mxbai-embed-large-v1",
normalized=True,
encoding_format=[EncodingFormat.FLOAT, EncodingFormat.UBINARY, EncodingFormat.INT_8],
dimensions=512
)
encoded_embeddings = res.data[0].embedding
print(res.dimensions, encoded_embeddings.ubinary, encoded_embeddings.float_, encoded_embeddings.int_8)
The API comes with native int8 and binary quantization support! Check out the [docs](https://mixedbread.ai/docs) for more information.
## Evaluation
As of March 2024, our model archives SOTA performance for Bert-large sized models on the [MTEB](https://huggingface.co/spaces/mteb/leaderboard). It ourperforms commercial models like OpenAIs text-embedding-3-large and matches the performance of model 20x it's size like the [echo-mistral-7b](https://huggingface.co/jspringer/echo-mistral-7b-instruct-lasttoken). Our model was trained with no overlap of the MTEB data, which indicates that our model generalizes well across several domains, tasks and text length. We know there are some limitations with this model, which will be fixed in v2.
| Model | Avg (56 datasets) | Classification (12 datasets) | Clustering (11 datasets) | PairClassification (3 datasets) | Reranking (4 datasets) | Retrieval (15 datasets) | STS (10 datasets) | Summarization (1 dataset) |
| --------------------------------------------------------------------------------------------- | ----------------- | ---------------------------- | ------------------------ | ------------------------------- | ---------------------- | ----------------------- | ----------------- | ------------------------- |
| **mxbai-embed-large-v1** | **64.68** | 75.64 | 46.71 | 87.2 | 60.11 | 54.39 | 85.00 | 32.71 |
| [bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 64.23 | 75.97 | 46.08 | 87.12 | 60.03 | 54.29 | 83.11 | 31.61 |
| [mxbai-embed-2d-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-2d-large-v1) | 63.25 | 74.14 | 46.07 | 85.89 | 58.94 | 51.42 | 84.9 | 31.55 |
| [nomic-embed-text-v1](https://huggingface.co/nomic-ai/nomic-embed-text-v1) | 62.39 | 74.12 | 43.91 | 85.15 | 55.69 | 52.81 | 82.06 | 30.08 |
| [jina-embeddings-v2-base-en](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) | 60.38 | 73.45 | 41.73 | 85.38 | 56.98 | 47.87 | 80.7 | 31.6 |
| *Proprietary Models* | | | | | | | | |
| [OpenAI text-embedding-3-large](https://openai.com/blog/new-embedding-models-and-api-updates) | 64.58 | 75.45 | 49.01 | 85.72 | 59.16 | 55.44 | 81.73 | 29.92 |
| [Cohere embed-english-v3.0](https://txt.cohere.com/introducing-embed-v3/) | 64.47 | 76.49 | 47.43 | 85.84 | 58.01 | 55.00 | 82.62 | 30.18 |
| [OpenAI text-embedding-ada-002](https://openai.com/blog/new-and-improved-embedding-model) | 60.99 | 70.93 | 45.90 | 84.89 | 56.32 | 49.25 | 80.97 | 30.80 |
Please find more information in our [blog post](https://mixedbread.ai/blog/mxbai-embed-large-v1).
## Matryoshka and Binary Quantization
Embeddings in their commonly used form (float arrays) have a high memory footprint when used at scale. Two approaches to solve this problem are Matryoshka Representation Learning (MRL) and (Binary) Quantization. While MRL reduces the number of dimensions of an embedding, binary quantization transforms the value of each dimension from a float32 into a lower precision (int8 or even binary). <b> The model supports both approaches! </b>
You can also take it one step further, and combine both MRL and quantization. This combination of binary quantization and MRL allows you to reduce the memory usage of your embeddings significantly. This leads to much lower costs when using a vector database in particular. You can read more about the technology and its advantages in our [blog post](https://www.mixedbread.ai/blog/binary-mrl).
## Community
Please join our [Discord Community](https://discord.gg/jDfMHzAVfU) and share your feedback and thoughts! We are here to help and also always happy to chat.
## License
Apache 2.0
## Citation
```bibtex
@online{emb2024mxbai,
title={Open Source Strikes Bread - New Fluffy Embeddings Model},
author={Sean Lee and Aamir Shakir and Darius Koenig and Julius Lipp},
year={2024},
url={https://www.mixedbread.ai/blog/mxbai-embed-large-v1},
}
@article{li2023angle,
title={AnglE-optimized Text Embeddings},
author={Li, Xianming and Li, Jing},
journal={arXiv preprint arXiv:2309.12871},
year={2023}
}
```
|
[
"BIOSSES",
"SCIFACT"
] |
tensorblock/e5-R-mistral-7b-GGUF
|
tensorblock
| null |
[
"transformers",
"gguf",
"mteb",
"TensorBlock",
"GGUF",
"en",
"dataset:BeastyZ/E5-R",
"base_model:BeastyZ/e5-R-mistral-7b",
"base_model:quantized:BeastyZ/e5-R-mistral-7b",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | 2024-11-28T19:07:12Z |
2024-11-28T19:45:18+00:00
| 59 | 0 |
---
base_model: BeastyZ/e5-R-mistral-7b
datasets:
- BeastyZ/E5-R
language:
- en
library_name: transformers
license: apache-2.0
tags:
- mteb
- TensorBlock
- GGUF
model-index:
- name: e5-R-mistral-7b
results:
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: mteb/arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 33.57
- type: map_at_10
value: 49.952000000000005
- type: map_at_100
value: 50.673
- type: map_at_1000
value: 50.674
- type: map_at_3
value: 44.915
- type: map_at_5
value: 47.876999999999995
- type: mrr_at_1
value: 34.211000000000006
- type: mrr_at_10
value: 50.19
- type: mrr_at_100
value: 50.905
- type: mrr_at_1000
value: 50.906
- type: mrr_at_3
value: 45.128
- type: mrr_at_5
value: 48.097
- type: ndcg_at_1
value: 33.57
- type: ndcg_at_10
value: 58.994
- type: ndcg_at_100
value: 61.806000000000004
- type: ndcg_at_1000
value: 61.824999999999996
- type: ndcg_at_3
value: 48.681000000000004
- type: ndcg_at_5
value: 54.001
- type: precision_at_1
value: 33.57
- type: precision_at_10
value: 8.784
- type: precision_at_100
value: 0.9950000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 19.867
- type: precision_at_5
value: 14.495
- type: recall_at_1
value: 33.57
- type: recall_at_10
value: 87.83800000000001
- type: recall_at_100
value: 99.502
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 59.602
- type: recall_at_5
value: 72.475
- type: main_score
value: 58.994
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: mteb/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.75
- type: map_at_10
value: 34.025
- type: map_at_100
value: 35.126000000000005
- type: map_at_1000
value: 35.219
- type: map_at_3
value: 31.607000000000003
- type: map_at_5
value: 32.962
- type: mrr_at_1
value: 27.357
- type: mrr_at_10
value: 36.370999999999995
- type: mrr_at_100
value: 37.364000000000004
- type: mrr_at_1000
value: 37.423
- type: mrr_at_3
value: 34.288000000000004
- type: mrr_at_5
value: 35.434
- type: ndcg_at_1
value: 27.357
- type: ndcg_at_10
value: 46.593999999999994
- type: ndcg_at_100
value: 44.317
- type: ndcg_at_1000
value: 46.475
- type: ndcg_at_3
value: 34.473
- type: ndcg_at_5
value: 36.561
- type: precision_at_1
value: 27.357
- type: precision_at_10
value: 6.081
- type: precision_at_100
value: 0.9299999999999999
- type: precision_at_1000
value: 0.124
- type: precision_at_3
value: 14.911
- type: precision_at_5
value: 10.24
- type: recall_at_1
value: 24.75
- type: recall_at_10
value: 51.856
- type: recall_at_100
value: 76.44300000000001
- type: recall_at_1000
value: 92.078
- type: recall_at_3
value: 39.427
- type: recall_at_5
value: 44.639
- type: main_score
value: 46.593999999999994
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: mteb/climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.436
- type: map_at_10
value: 29.693
- type: map_at_100
value: 32.179
- type: map_at_1000
value: 32.353
- type: map_at_3
value: 24.556
- type: map_at_5
value: 27.105
- type: mrr_at_1
value: 37.524
- type: mrr_at_10
value: 51.475
- type: mrr_at_100
value: 52.107000000000006
- type: mrr_at_1000
value: 52.123
- type: mrr_at_3
value: 48.35
- type: mrr_at_5
value: 50.249
- type: ndcg_at_1
value: 37.524
- type: ndcg_at_10
value: 40.258
- type: ndcg_at_100
value: 48.364000000000004
- type: ndcg_at_1000
value: 51.031000000000006
- type: ndcg_at_3
value: 33.359
- type: ndcg_at_5
value: 35.573
- type: precision_at_1
value: 37.524
- type: precision_at_10
value: 12.886000000000001
- type: precision_at_100
value: 2.169
- type: precision_at_1000
value: 0.268
- type: precision_at_3
value: 25.624000000000002
- type: precision_at_5
value: 19.453
- type: recall_at_1
value: 16.436
- type: recall_at_10
value: 47.77
- type: recall_at_100
value: 74.762
- type: recall_at_1000
value: 89.316
- type: recall_at_3
value: 30.508000000000003
- type: recall_at_5
value: 37.346000000000004
- type: main_score
value: 40.258
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: mteb/dbpedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.147
- type: map_at_10
value: 24.631
- type: map_at_100
value: 35.657
- type: map_at_1000
value: 37.824999999999996
- type: map_at_3
value: 16.423
- type: map_at_5
value: 19.666
- type: mrr_at_1
value: 76.5
- type: mrr_at_10
value: 82.793
- type: mrr_at_100
value: 83.015
- type: mrr_at_1000
value: 83.021
- type: mrr_at_3
value: 81.75
- type: mrr_at_5
value: 82.375
- type: ndcg_at_1
value: 64.75
- type: ndcg_at_10
value: 51.031000000000006
- type: ndcg_at_100
value: 56.005
- type: ndcg_at_1000
value: 63.068000000000005
- type: ndcg_at_3
value: 54.571999999999996
- type: ndcg_at_5
value: 52.66499999999999
- type: precision_at_1
value: 76.5
- type: precision_at_10
value: 42.15
- type: precision_at_100
value: 13.22
- type: precision_at_1000
value: 2.5989999999999998
- type: precision_at_3
value: 58.416999999999994
- type: precision_at_5
value: 52.2
- type: recall_at_1
value: 10.147
- type: recall_at_10
value: 30.786
- type: recall_at_100
value: 62.873000000000005
- type: recall_at_1000
value: 85.358
- type: recall_at_3
value: 17.665
- type: recall_at_5
value: 22.088
- type: main_score
value: 51.031000000000006
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: mteb/fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 78.52900000000001
- type: map_at_10
value: 87.24199999999999
- type: map_at_100
value: 87.446
- type: map_at_1000
value: 87.457
- type: map_at_3
value: 86.193
- type: map_at_5
value: 86.898
- type: mrr_at_1
value: 84.518
- type: mrr_at_10
value: 90.686
- type: mrr_at_100
value: 90.73
- type: mrr_at_1000
value: 90.731
- type: mrr_at_3
value: 90.227
- type: mrr_at_5
value: 90.575
- type: ndcg_at_1
value: 84.518
- type: ndcg_at_10
value: 90.324
- type: ndcg_at_100
value: 90.96300000000001
- type: ndcg_at_1000
value: 91.134
- type: ndcg_at_3
value: 88.937
- type: ndcg_at_5
value: 89.788
- type: precision_at_1
value: 84.518
- type: precision_at_10
value: 10.872
- type: precision_at_100
value: 1.1440000000000001
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 34.108
- type: precision_at_5
value: 21.154999999999998
- type: recall_at_1
value: 78.52900000000001
- type: recall_at_10
value: 96.123
- type: recall_at_100
value: 98.503
- type: recall_at_1000
value: 99.518
- type: recall_at_3
value: 92.444
- type: recall_at_5
value: 94.609
- type: main_score
value: 90.324
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: mteb/fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.38
- type: map_at_10
value: 50.28
- type: map_at_100
value: 52.532999999999994
- type: map_at_1000
value: 52.641000000000005
- type: map_at_3
value: 43.556
- type: map_at_5
value: 47.617
- type: mrr_at_1
value: 56.79
- type: mrr_at_10
value: 65.666
- type: mrr_at_100
value: 66.211
- type: mrr_at_1000
value: 66.226
- type: mrr_at_3
value: 63.452
- type: mrr_at_5
value: 64.895
- type: ndcg_at_1
value: 56.79
- type: ndcg_at_10
value: 58.68
- type: ndcg_at_100
value: 65.22
- type: ndcg_at_1000
value: 66.645
- type: ndcg_at_3
value: 53.981
- type: ndcg_at_5
value: 55.95
- type: precision_at_1
value: 56.79
- type: precision_at_10
value: 16.311999999999998
- type: precision_at_100
value: 2.316
- type: precision_at_1000
value: 0.258
- type: precision_at_3
value: 36.214
- type: precision_at_5
value: 27.067999999999998
- type: recall_at_1
value: 29.38
- type: recall_at_10
value: 66.503
- type: recall_at_100
value: 89.885
- type: recall_at_1000
value: 97.954
- type: recall_at_3
value: 48.866
- type: recall_at_5
value: 57.60999999999999
- type: main_score
value: 58.68
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: mteb/hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 42.134
- type: map_at_10
value: 73.412
- type: map_at_100
value: 74.144
- type: map_at_1000
value: 74.181
- type: map_at_3
value: 70.016
- type: map_at_5
value: 72.174
- type: mrr_at_1
value: 84.267
- type: mrr_at_10
value: 89.18599999999999
- type: mrr_at_100
value: 89.29599999999999
- type: mrr_at_1000
value: 89.298
- type: mrr_at_3
value: 88.616
- type: mrr_at_5
value: 88.957
- type: ndcg_at_1
value: 84.267
- type: ndcg_at_10
value: 80.164
- type: ndcg_at_100
value: 82.52199999999999
- type: ndcg_at_1000
value: 83.176
- type: ndcg_at_3
value: 75.616
- type: ndcg_at_5
value: 78.184
- type: precision_at_1
value: 84.267
- type: precision_at_10
value: 16.916
- type: precision_at_100
value: 1.872
- type: precision_at_1000
value: 0.196
- type: precision_at_3
value: 49.71
- type: precision_at_5
value: 31.854
- type: recall_at_1
value: 42.134
- type: recall_at_10
value: 84.578
- type: recall_at_100
value: 93.606
- type: recall_at_1000
value: 97.86
- type: recall_at_3
value: 74.564
- type: recall_at_5
value: 79.635
- type: main_score
value: 80.164
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: mteb/msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.276
- type: map_at_10
value: 35.493
- type: map_at_100
value: 36.656
- type: map_at_1000
value: 36.699
- type: map_at_3
value: 31.320999999999998
- type: map_at_5
value: 33.772999999999996
- type: mrr_at_1
value: 22.966
- type: mrr_at_10
value: 36.074
- type: mrr_at_100
value: 37.183
- type: mrr_at_1000
value: 37.219
- type: mrr_at_3
value: 31.984
- type: mrr_at_5
value: 34.419
- type: ndcg_at_1
value: 22.966
- type: ndcg_at_10
value: 42.895
- type: ndcg_at_100
value: 48.453
- type: ndcg_at_1000
value: 49.464999999999996
- type: ndcg_at_3
value: 34.410000000000004
- type: ndcg_at_5
value: 38.78
- type: precision_at_1
value: 22.966
- type: precision_at_10
value: 6.88
- type: precision_at_100
value: 0.966
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 14.785
- type: precision_at_5
value: 11.074
- type: recall_at_1
value: 22.276
- type: recall_at_10
value: 65.756
- type: recall_at_100
value: 91.34100000000001
- type: recall_at_1000
value: 98.957
- type: recall_at_3
value: 42.67
- type: recall_at_5
value: 53.161
- type: main_score
value: 42.895
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: mteb/nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 7.188999999999999
- type: map_at_10
value: 16.176
- type: map_at_100
value: 20.504
- type: map_at_1000
value: 22.203999999999997
- type: map_at_3
value: 11.766
- type: map_at_5
value: 13.655999999999999
- type: mrr_at_1
value: 55.418
- type: mrr_at_10
value: 62.791
- type: mrr_at_100
value: 63.339
- type: mrr_at_1000
value: 63.369
- type: mrr_at_3
value: 60.99099999999999
- type: mrr_at_5
value: 62.059
- type: ndcg_at_1
value: 53.715
- type: ndcg_at_10
value: 41.377
- type: ndcg_at_100
value: 37.999
- type: ndcg_at_1000
value: 46.726
- type: ndcg_at_3
value: 47.262
- type: ndcg_at_5
value: 44.708999999999996
- type: precision_at_1
value: 55.108000000000004
- type: precision_at_10
value: 30.154999999999998
- type: precision_at_100
value: 9.582
- type: precision_at_1000
value: 2.2720000000000002
- type: precision_at_3
value: 43.55
- type: precision_at_5
value: 38.204
- type: recall_at_1
value: 7.188999999999999
- type: recall_at_10
value: 20.655
- type: recall_at_100
value: 38.068000000000005
- type: recall_at_1000
value: 70.208
- type: recall_at_3
value: 12.601
- type: recall_at_5
value: 15.573999999999998
- type: main_score
value: 41.377
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: mteb/nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 46.017
- type: map_at_10
value: 62.910999999999994
- type: map_at_100
value: 63.526
- type: map_at_1000
value: 63.536
- type: map_at_3
value: 59.077999999999996
- type: map_at_5
value: 61.521
- type: mrr_at_1
value: 51.68000000000001
- type: mrr_at_10
value: 65.149
- type: mrr_at_100
value: 65.542
- type: mrr_at_1000
value: 65.55
- type: mrr_at_3
value: 62.49
- type: mrr_at_5
value: 64.178
- type: ndcg_at_1
value: 51.651
- type: ndcg_at_10
value: 69.83500000000001
- type: ndcg_at_100
value: 72.18
- type: ndcg_at_1000
value: 72.393
- type: ndcg_at_3
value: 63.168
- type: ndcg_at_5
value: 66.958
- type: precision_at_1
value: 51.651
- type: precision_at_10
value: 10.626
- type: precision_at_100
value: 1.195
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 28.012999999999998
- type: precision_at_5
value: 19.09
- type: recall_at_1
value: 46.017
- type: recall_at_10
value: 88.345
- type: recall_at_100
value: 98.129
- type: recall_at_1000
value: 99.696
- type: recall_at_3
value: 71.531
- type: recall_at_5
value: 80.108
- type: main_score
value: 69.83500000000001
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: mteb/quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 72.473
- type: map_at_10
value: 86.72800000000001
- type: map_at_100
value: 87.323
- type: map_at_1000
value: 87.332
- type: map_at_3
value: 83.753
- type: map_at_5
value: 85.627
- type: mrr_at_1
value: 83.39
- type: mrr_at_10
value: 89.149
- type: mrr_at_100
value: 89.228
- type: mrr_at_1000
value: 89.229
- type: mrr_at_3
value: 88.335
- type: mrr_at_5
value: 88.895
- type: ndcg_at_1
value: 83.39
- type: ndcg_at_10
value: 90.109
- type: ndcg_at_100
value: 91.09
- type: ndcg_at_1000
value: 91.13900000000001
- type: ndcg_at_3
value: 87.483
- type: ndcg_at_5
value: 88.942
- type: precision_at_1
value: 83.39
- type: precision_at_10
value: 13.711
- type: precision_at_100
value: 1.549
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 38.342999999999996
- type: precision_at_5
value: 25.188
- type: recall_at_1
value: 72.473
- type: recall_at_10
value: 96.57
- type: recall_at_100
value: 99.792
- type: recall_at_1000
value: 99.99900000000001
- type: recall_at_3
value: 88.979
- type: recall_at_5
value: 93.163
- type: main_score
value: 90.109
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: mteb/scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.598
- type: map_at_10
value: 11.405999999999999
- type: map_at_100
value: 13.447999999999999
- type: map_at_1000
value: 13.758999999999999
- type: map_at_3
value: 8.332
- type: map_at_5
value: 9.709
- type: mrr_at_1
value: 22.6
- type: mrr_at_10
value: 32.978
- type: mrr_at_100
value: 34.149
- type: mrr_at_1000
value: 34.213
- type: mrr_at_3
value: 29.7
- type: mrr_at_5
value: 31.485000000000003
- type: ndcg_at_1
value: 22.6
- type: ndcg_at_10
value: 19.259999999999998
- type: ndcg_at_100
value: 27.21
- type: ndcg_at_1000
value: 32.7
- type: ndcg_at_3
value: 18.445
- type: ndcg_at_5
value: 15.812000000000001
- type: precision_at_1
value: 22.6
- type: precision_at_10
value: 9.959999999999999
- type: precision_at_100
value: 2.139
- type: precision_at_1000
value: 0.345
- type: precision_at_3
value: 17.299999999999997
- type: precision_at_5
value: 13.719999999999999
- type: recall_at_1
value: 4.598
- type: recall_at_10
value: 20.186999999999998
- type: recall_at_100
value: 43.362
- type: recall_at_1000
value: 70.11800000000001
- type: recall_at_3
value: 10.543
- type: recall_at_5
value: 13.923
- type: main_score
value: 19.259999999999998
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: mteb/scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 65.467
- type: map_at_10
value: 74.935
- type: map_at_100
value: 75.395
- type: map_at_1000
value: 75.412
- type: map_at_3
value: 72.436
- type: map_at_5
value: 73.978
- type: mrr_at_1
value: 68.667
- type: mrr_at_10
value: 76.236
- type: mrr_at_100
value: 76.537
- type: mrr_at_1000
value: 76.55499999999999
- type: mrr_at_3
value: 74.722
- type: mrr_at_5
value: 75.639
- type: ndcg_at_1
value: 68.667
- type: ndcg_at_10
value: 78.92099999999999
- type: ndcg_at_100
value: 80.645
- type: ndcg_at_1000
value: 81.045
- type: ndcg_at_3
value: 75.19500000000001
- type: ndcg_at_5
value: 77.114
- type: precision_at_1
value: 68.667
- type: precision_at_10
value: 10.133000000000001
- type: precision_at_100
value: 1.0999999999999999
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 28.889
- type: precision_at_5
value: 18.8
- type: recall_at_1
value: 65.467
- type: recall_at_10
value: 89.517
- type: recall_at_100
value: 97
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 79.72200000000001
- type: recall_at_5
value: 84.511
- type: main_score
value: 78.92099999999999
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: mteb/trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.244
- type: map_at_10
value: 2.183
- type: map_at_100
value: 13.712
- type: map_at_1000
value: 33.147
- type: map_at_3
value: 0.7270000000000001
- type: map_at_5
value: 1.199
- type: mrr_at_1
value: 94
- type: mrr_at_10
value: 97
- type: mrr_at_100
value: 97
- type: mrr_at_1000
value: 97
- type: mrr_at_3
value: 97
- type: mrr_at_5
value: 97
- type: ndcg_at_1
value: 92
- type: ndcg_at_10
value: 84.399
- type: ndcg_at_100
value: 66.771
- type: ndcg_at_1000
value: 59.092
- type: ndcg_at_3
value: 89.173
- type: ndcg_at_5
value: 88.52600000000001
- type: precision_at_1
value: 94
- type: precision_at_10
value: 86.8
- type: precision_at_100
value: 68.24
- type: precision_at_1000
value: 26.003999999999998
- type: precision_at_3
value: 92.667
- type: precision_at_5
value: 92.4
- type: recall_at_1
value: 0.244
- type: recall_at_10
value: 2.302
- type: recall_at_100
value: 16.622
- type: recall_at_1000
value: 55.175
- type: recall_at_3
value: 0.748
- type: recall_at_5
value: 1.247
- type: main_score
value: 84.399
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: mteb/touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.707
- type: map_at_10
value: 10.917
- type: map_at_100
value: 16.308
- type: map_at_1000
value: 17.953
- type: map_at_3
value: 5.65
- type: map_at_5
value: 7.379
- type: mrr_at_1
value: 34.694
- type: mrr_at_10
value: 49.745
- type: mrr_at_100
value: 50.309000000000005
- type: mrr_at_1000
value: 50.32
- type: mrr_at_3
value: 44.897999999999996
- type: mrr_at_5
value: 48.061
- type: ndcg_at_1
value: 33.672999999999995
- type: ndcg_at_10
value: 26.894000000000002
- type: ndcg_at_100
value: 37.423
- type: ndcg_at_1000
value: 49.376999999999995
- type: ndcg_at_3
value: 30.456
- type: ndcg_at_5
value: 27.772000000000002
- type: precision_at_1
value: 34.694
- type: precision_at_10
value: 23.878
- type: precision_at_100
value: 7.489999999999999
- type: precision_at_1000
value: 1.555
- type: precision_at_3
value: 31.293
- type: precision_at_5
value: 26.939
- type: recall_at_1
value: 2.707
- type: recall_at_10
value: 18.104
- type: recall_at_100
value: 46.93
- type: recall_at_1000
value: 83.512
- type: recall_at_3
value: 6.622999999999999
- type: recall_at_5
value: 10.051
- type: main_score
value: 26.894000000000002
---
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/jC7kdl8.jpeg" alt="TensorBlock" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;">
Feedback and support: TensorBlock's <a href="https://x.com/tensorblock_aoi">Twitter/X</a>, <a href="https://t.me/TensorBlock">Telegram Group</a> and <a href="https://x.com/tensorblock_aoi">Discord server</a>
</p>
</div>
</div>
## BeastyZ/e5-R-mistral-7b - GGUF
This repo contains GGUF format model files for [BeastyZ/e5-R-mistral-7b](https://huggingface.co/BeastyZ/e5-R-mistral-7b).
The files were quantized using machines provided by [TensorBlock](https://tensorblock.co/), and they are compatible with llama.cpp as of [commit b4011](https://github.com/ggerganov/llama.cpp/commit/a6744e43e80f4be6398fc7733a01642c846dce1d).
<div style="text-align: left; margin: 20px 0;">
<a href="https://tensorblock.co/waitlist/client" style="display: inline-block; padding: 10px 20px; background-color: #007bff; color: white; text-decoration: none; border-radius: 5px; font-weight: bold;">
Run them on the TensorBlock client using your local machine ↗
</a>
</div>
## Prompt template
```
```
## Model file specification
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [e5-R-mistral-7b-Q2_K.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q2_K.gguf) | Q2_K | 2.719 GB | smallest, significant quality loss - not recommended for most purposes |
| [e5-R-mistral-7b-Q3_K_S.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q3_K_S.gguf) | Q3_K_S | 3.165 GB | very small, high quality loss |
| [e5-R-mistral-7b-Q3_K_M.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q3_K_M.gguf) | Q3_K_M | 3.519 GB | very small, high quality loss |
| [e5-R-mistral-7b-Q3_K_L.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q3_K_L.gguf) | Q3_K_L | 3.822 GB | small, substantial quality loss |
| [e5-R-mistral-7b-Q4_0.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q4_0.gguf) | Q4_0 | 4.109 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [e5-R-mistral-7b-Q4_K_S.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q4_K_S.gguf) | Q4_K_S | 4.140 GB | small, greater quality loss |
| [e5-R-mistral-7b-Q4_K_M.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q4_K_M.gguf) | Q4_K_M | 4.368 GB | medium, balanced quality - recommended |
| [e5-R-mistral-7b-Q5_0.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q5_0.gguf) | Q5_0 | 4.998 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [e5-R-mistral-7b-Q5_K_S.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q5_K_S.gguf) | Q5_K_S | 4.998 GB | large, low quality loss - recommended |
| [e5-R-mistral-7b-Q5_K_M.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q5_K_M.gguf) | Q5_K_M | 5.131 GB | large, very low quality loss - recommended |
| [e5-R-mistral-7b-Q6_K.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q6_K.gguf) | Q6_K | 5.942 GB | very large, extremely low quality loss |
| [e5-R-mistral-7b-Q8_0.gguf](https://huggingface.co/tensorblock/e5-R-mistral-7b-GGUF/blob/main/e5-R-mistral-7b-Q8_0.gguf) | Q8_0 | 7.696 GB | very large, extremely low quality loss - not recommended |
## Downloading instruction
### Command line
Firstly, install Huggingface Client
```shell
pip install -U "huggingface_hub[cli]"
```
Then, downoad the individual model file the a local directory
```shell
huggingface-cli download tensorblock/e5-R-mistral-7b-GGUF --include "e5-R-mistral-7b-Q2_K.gguf" --local-dir MY_LOCAL_DIR
```
If you wanna download multiple model files with a pattern (e.g., `*Q4_K*gguf`), you can try:
```shell
huggingface-cli download tensorblock/e5-R-mistral-7b-GGUF --local-dir MY_LOCAL_DIR --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
|
[
"SCIFACT"
] |
Shengkun/DarwinLM-2.7B-Pruned
|
Shengkun
|
text-generation
|
[
"transformers",
"safetensors",
"darwinlm",
"text-generation",
"custom_code",
"arxiv:2502.07780",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2025-02-18T15:58:15Z |
2025-02-24T14:32:48+00:00
| 59 | 0 |
---
library_name: transformers
license: apache-2.0
pipeline_tag: text-generation
---
DarwinLM is an evolutionary structured pruning method for large language models. It builds upon an evolutionary search process, generating multiple offspring models in each generation through mutation, and selecting the fittest for survival. This significantly reduces the computational costs of LLMs, especially for real-time applications.
**Paper**: [https://arxiv.org/pdf/2502.07780](https://arxiv.org/pdf/2502.07780)
**Code**: https://github.com/IST-DASLab/DarwinLM
**Models**: [DarwinLM-2.7B](https://huggingface.co/Shengkun/DarwinLM-2.7B), [DarwinLM-4.6B](https://huggingface.co/Shengkun/DarwinLM-4.6B), [DarwinLM-8.4B](https://huggingface.co/Shengkun/DarwinLM-8.4B)
**Pruned Models without Post-training**: [DarwinLM-2.7B-Pruned](https://huggingface.co/Shengkun/DarwinLM-2.7B-Pruned), [DarwinLM-4.6B-Pruned](https://huggingface.co/Shengkun/DarwinLM-4.6B-Pruned), [DarwinLM-8.4B-Pruned](https://huggingface.co/Shengkun/DarwinLM-8.4B-Pruned)
---
This repository contains the weights of DarwinLM, as introduced in our paper.
```python
# Please add trust_remote_code=True as the repo includes custom code to load and run DarwinLM
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("Shengkun/DarwinLM-2.7B-Pruned", trust_remote_code=True)
```
## Downstream Tasks
**2.7B**
| Method | Param. | SciQ | PIQA | WG | ArcE | ArcC | HS | LogiQA | BoolQ | Avg |
|----------------------------|--------|------|------|------|------|------|------|--------|-------|------|
| **Dense** | 6.7B | 93.7 | 78.1 | 69.3 | 76.4 | 53.0 | 78.6 | 30.7 | 77.7 | 69.2 |
| **Uniform** | 3.4B | 44.1 | 57.1 | 53.3 | 33.5 | 32.2 | 27.3 | 25.0 | 49.0 | 40.1 |
| **ZipLM** | 4.0B | 87.4 | 64.4 | 58.3 | 53.2 | 33.6 | 50.1 | 25.5 | 63.6 | 54.5 |
| **ShearedLLama** | 2.7B | 84.5 | 66.4 | 53.4 | 49.8 | 28.4 | 47.6 | 27.6 | 50.9 | 51.0 |
| *DarwinLM (one-shot)* | 2.7B | 85.6 | 70.8 | 55.8 | 63.3 | 38.1 | 53.2 | 28.5 | 62.7 | 57.2 |
| **ShearedLLama (50B)** | 2.7B | 90.8 | 75.8 | 64.2 | 67.0 | 41.2 | 70.8 | 28.2 | 63.0 | 62.6 |
| **ShearedLLama (10B†)** | 2.7B | 92.0 | 73.6 | 63.1 | 69.8 | 42.0 | 64.4 | 29.0 | 62.1 | 61.9 |
| *DarwinLM (10B)* | 2.6B | 90.8 | 72.2 | 65.1 | 68.5 | 45.0 | 67.2 | 28.5 | 64.6 | 62.8 |
**4.6B**
| Model | Method | Param. | SciQ | PIQA | WG | ArcE | ArcC | HS | LogiQA | BoolQ | MMLU | Avg |
|-----------------|------------------------|--------|------|------|------|------|------|------|--------|-------|------|------|
| **Llama-3.1-8B** | **Dense** | 8B | 96.3 | 81.2 | 74.3 | 81.4 | 58.2 | 81.7 | 31.1 | 84.0 | 65.2 | 72.8 |
| | **Uniform** | 4.5B | 29.1 | 53.6 | 51.7 | 26.0 | 23.6 | 27.1 | 25.5 | 62.1 | 25.7 | 36.1 |
| | **ZipLM** | 6B | 65.5 | 60.6 | 56.0 | 40.2 | 34.4 | 34.4 | 28.1 | 63.0 | 27.9 | 45.7 |
| | *DarwinLM (one-shot)* | 4.6B | 84.9 | 69.4 | 57.3 | 59.6 | 34.2 | 44.6 | 24.1 | 62.2 | 28.5 | 51.6 |
| | **OLMO (2.5T)** | 7B | 92.8 | 79.4 | 70.4 | 73.3 | 44.9 | 77.1 | 27.9 | 72.5 | 28.3 | 62.9 |
| | *DarwinLM (10.0B)* | 4.6B | 93.2 | 74.8 | 67.4 | 73.2 | 51.6 | 71.3 | 30.7 | 71.1 | 40.6 | 63.7 |
**8.4B**
| Model | Method | Param. | SciQ | PIQA | WG | ArcE | ArcC | HS | LogiQA | BoolQ | MMLU | Avg |
|---------------------------|------------------------|--------|------|------|------|------|------|------|--------|-------|------|------|
| **Qwen-2.5-14B-Instruct** | **Dense** | 14B | 96.8 | 81.9 | 79.1 | 85.7 | 72.8 | 85.1 | 38.5 | 87.9 | 80.0 | 78.6 |
| | **Uniform** | 8.6B | 78.2 | 72.7 | 57.6 | 76.1 | 45.6 | 47.0 | 28.1 | 61.6 | 45.5 | 56.9 |
| | **ZipLM** | 8.5B | 69.0 | 66.4 | 52.8 | 60.1 | 38.3 | 43.3 | 29.6 | 60.2 | 25.0 | 49.4 |
| | *DarwinLM (one-shot)* | 8.4B | 84.3 | 73.9 | 60.5 | 75.7 | 48.0 | 53.3 | 29.3 | 66.9 | 43.1 | 59.4 |
| | **OLMO-0424 (2.05T)** | 7B | 96.1 | 80.1 | 72.1 | 73.8 | 49.2 | 78.0 | 29.3 | 80.8 | 52.1 | 67.9 |
| | *DarwinLM (10.0B)* | 8.4B | 89.5 | 78.1 | 70.7 | 79.6 | 57.6 | 74.9 | 33.5 | 73.9 | 57.9 | 68.4 |
## Installation
```bash
conda env create -f environment.yml
conda activate darwinlm
```
## Database Preparation
```bash
# For llama-2-7B
bash scripts/ziplm_llama2-7B.sh
# ... other model examples
```
## Evolutionary Search
```bash
bash scripts/struct_prune_search.sh
```
## Post-Training
After pruning, you can further fine-tune the model with the [Fineweb-edu](https://huggingface.co/datasets/HuggingFaceFW/fineweb-edu) dataset using the [llm-foundry](https://github.com/mosaicml/llm-foundry) repository. Refer to our paper for parameter settings.
## Evaluation
Install the [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness).
**Option 1: Using pre-trained weights:**
```bash
bash scripts/run_lmeval_hf.sh
```
**Option 2: Evaluating your searched structure:**
```bash
bash scripts/run_lmeval_config.sh
```
## Bibtex
```bibtex
@article{tang2025darwinlm,
title={DarwinLM: Evolutionary Structured Pruning of Large Language Models},
author={Tang, Shengkun and Sieberling, Oliver and Kurtic, Eldar and Shen, Zhiqiang and Alistarh, Dan},
journal={arXiv preprint arXiv:2502.07780},
year={2025}
}
```
|
[
"SCIQ"
] |
automated-analytics/setfit-paraphrase-mpnet
|
automated-analytics
|
text-classification
|
[
"setfit",
"safetensors",
"mpnet",
"sentence-transformers",
"text-classification",
"generated_from_setfit_trainer",
"arxiv:2209.11055",
"base_model:sentence-transformers/paraphrase-mpnet-base-v2",
"base_model:finetune:sentence-transformers/paraphrase-mpnet-base-v2",
"model-index",
"region:us"
] | 2025-03-04T10:21:20Z |
2025-03-04T10:21:40+00:00
| 59 | 0 |
---
base_model: sentence-transformers/paraphrase-mpnet-base-v2
library_name: setfit
metrics:
- metric
pipeline_tag: text-classification
tags:
- setfit
- sentence-transformers
- text-classification
- generated_from_setfit_trainer
widget:
- text: 'client: Thank you for [NAME], partners with [ORGANIZATION]. Please listen
to the options carefully, secure the right team. We record calls for quality and
training purposes. Please enter your account number using your telephone keypad,
ignoring any letters, then press the hash key. Just use your telephone keypad
to enter your account number, then press the hash key.
customer: I''m trying.
client: This may start with it. Okay, just a moment whilst I look that up. I''m
afraid that account number doesn''t match our records. Please try again. Okay,
just a moment whilst I put that up. Please enter your phone number using the telephone
teapad.
customer: Thank you.
client: I''m sorry, I didn''t understand. Try entering your phone number. I''m
sorry, I still didn''t understand. Please by entering it again.'
- text: 'client: Thank you for calling Dino Plumbing. Please note all our calls are
recorded for monitoring and training passes. Press one for an update on parts.
Press two for an update on your appointment. Press three to discuss an ongoing
complaint. Press four for sales. Thank you for calling Dino Plumbing. Please note
all our calls are recorded for monitoring and training purposes. Press one for
an update on parts. Press two for an update on your appointment. Press three to
discuss an ongoing complaint and press four for sales. Thank you for calling dino
plumbing.
customer: and get some rolls.
client: Your call is very important to us. Your call is very important to us.
All of our agents are currently busy assisting other customers. Please continue
to hold and the next available agent will take your call. Alternatively, you can
email. Good afternoon if you''re starting and I can help.
customer: Oh, hello. I called yesterday regarding a plumbing issue, a drainage
issue at one of our properties. He took all of my details and said that we were
going to call us back, but I never got a call back.
client: I''m not sure postcode or have a little look for you to apologize.
customer: The post code of the property, NW6, NW6, 1 UJ.
client: Yes, please. No problem. And it''s the door number 46? 48, okay.
customer: 48, which in [LOCATION]. But maybe, I can''t remember if it was a charge
of [LOCATION]. Yes, yes, yes, yes, yes.
client: It was for a chargeable job, wasn''t it?
customer: All right, lovely, thank you. Yes, it''s a charge call job, yes, yes.
client: No problem. Let me just see if a gentleman''s available. Give me two seconds.
We''ll go straight through if it does connect. Thank you.
customer: I can''t do everything? It''s [LOCATION], hi [NAME]. [NAME]. Can I get
to keep your cautious on the other line? He has [NAME]. Yes, no problem. Okay.
Haven''t a plan for what? Okay, but I need it over to me. There''s no point...
Yeah, and one about the electric, because the bills... Yes, it''s a gas and the
electric payment. Just a gas, all about the electric. Because the bill was not
correct. [NAME], okay. I''ve emailed it to her. All right, fine, yeah, perfect.
Once you''ve got all that just emailed across the street. Okay, thank you. They''re
going to get such a shock. Oh dear. All that broken furniture, they threw it in
the bushes. They bought me the cotton. I swear to God, when the landlord was going
through it, yeah? She found it. I wasn''t, I''m not going through the bushes.
Not at all. Sort of that. Wouldn''t even go through my own bushes. Let''s learn
someone else''s. Please speak companies, I''m telling you, they''re just about
the place. They just put me on the whole now. I didn''t even know. I''m using
your butter, is that all right? Can''t you? Do you be joint tenants. Timeer, you''d
be joint tenants. I just need to eat something for me. You''d be joint tenants.
You''d be joint tenants not living together unless you are a couple.
client: I do apologize about the way I''m just trying to get through to them I
just speak to somebody who''s in the main office and they said they''ve just popped
out for their lunch and so they''ll be back within the next hour I can give him
a call personally if you want and just let him know that you know you didn''t
receive a call yesterday so it has to be today as soon as possible.
customer: Yeah, I mean the trouble is they told me that yesterday and they didn''t
call back. This is my issue is that, this is my issue that you know, are they
going to call back today?
client: Yeah, no, I can''t understand. I will have a word for him myself, and
I have them just let the people in the office know if they could just let me know
when he''s in there and I can give him a call personally and just let him know.
I know it has been very busy, but I will make sure I''ll just say if you can give
her a call up right now, because she has been waiting.
customer: Yeah, it really is urgent.
client: And he should have, you know, been able to investigate, whatever he had
to do.
customer: Yeah. Yeah, it really is urgent. Yeah. Okay, all right then.
client: I''m really sorry about the way.
customer: Okay, all right then. Okay, all right then, okay. All right then I will
wait.
client: Thank you so much.
customer: All right, okay. All right, then I will wait. All right, okay. Should
I, if I don''t hear anything, what, within an hour, should I give a callback or
not?
client: Yeah that''s completely fine and they said he will be back within the
hour so if it isn''t just after at all then you can always call back but it would
definitely be before five I''ll definitely make sure he calls you myself.
customer: Yeah, okay.
client: It''s no worries.
customer: All right, lovely. Appreciate it.
client: Thank you so much.
customer: Thank you. All right. All right, thanks.'
- text: 'client: Thank you for calling [NAME], partners with [ORGANIZATION]. Please
listen to the options carefully so we can get you to the right team. If you need
any help with a drainage problem, press one. If you require our plumbing services,
press two. Or if you have an existing home care policy, it''s fee. Did you know
that you can now book plumbing services online in a few easy clicks? Visit dino.com
for details. Or heavily please hold and your call will be transferred to a customer
service advisor. We record calls for quality and training purposes.
customer: I did. I spoke to one of your engineers recently due to and being a
family member and I was just saying he said to bring off and see if he''s with
him taking anyone else on. A promen.
client: Is it plumbing or drainage? I''m going to say the postcode where you are.
customer: 8th, [LOCATION], 5JG.
client: Yep. What I''ll do is I''ll put you through to the plumbers that cover
that postcode and they can, you know, you
customer: Yeah, that''s great. Thank you so much. Oh.
client: [NAME], your local drains and plumbing experts. Drainage inquiries, press
1. For plumbing inquiries, press 2. If you are a nosly business owner, press 3,
and for finance, press 4. Thank you for calling [NAME], your local drains and
plumbing experts, for drain inquiries, press 1, for [ORGANIZATION], press 2. If
you are a nosly business owner, press 3, and for finance, press 4. Your call is
very important to us. Please reach the next available agent. Hello, you''re through
the next available agent.
customer: I''ve recently spoke to a family member who works for yourselves and
he said to bring up to you to take him anyone else on. It''s [NAME]. It''s [NAME].
He said to bring up to you to take him anyone else on. It''s [NAME].
client: and who''s your family member?
customer: It''s [NAME].
client: Oh no! No, we''re not having another one of him here. Right, okay, hang
on.
customer: Yeah, I have I have.
client: Have you got a C visa, though? Can you email it to [NAME]? Yeah? Yeah,
[NAME].
customer: Yeah, of course, have you got it, please.
client: Yeah. Yeah, [NAME].
customer: Thank you very much. [NAME] [LOCATION].
client: Yeah.
customer: I just felt sorry.
client: G-I-L-L-I-E-S-P-I-E.
customer: G-I-L-I-S-G-I-L-I-E-S. G-G-I-L-I-E-S.
client: Why?
customer: Yeah. Yeah.
client: What? Yeah, that''s what I''m supposed for? Right. I-N-G-I-L-L.
customer: Yeah.
client: Yeah, E-S-P-I-E-P-I-E-E-P-I-T, right if you got that? Yes, P-I-E, yeah.
Can have my job if you want?
customer: Right, I''ve got that now.
client: And it''s at [LOCATION]. Yeah, M-A-C-E. M-E. Doco. [LOCATION]. What''s
your name? Sorry? Elias, all right, no bother. Bye, darling. Bye, bye, bye.'
- text: 'client: Good morning, [NAME]. How can I help?
customer: Oh, hi yeah, is that [NAME]?
client: It is indeed. Right, potentially.
customer: Yeah, I had an engineer out yesterday who kindly put a new central heating
pump in for me. But he''s left a tool here. Looks like I''m speaking as a non-tall
person. Look like mole grips, big pair of yellow mole grips.
client: Right, potentially what the postcode there?
customer: I just realized you''d left them on the table after he''s gone, so.
client: That''s fine. 22 orchard close.
customer: That''s the one, yes.
client: Excellent, and that would be you.
customer: I just thought if someone''s passing at any point, you could pick them
up, but I, yeah.
client: That would be you in. Now that''s fine. What I do is I''ll speak to my
plumbing department and let them know, and I will get them to get somebody back
there to pick them up for you.
customer: Yeah, whenever, yeah, I''ll be around, but I just thought I''ve let
you know.
client: I''ll get them to get somebody back there to pick them up for you. I''ll
get them to get somebody back there to pick them up for you. I''ll get them to
customer: Lovely. Okay. Thank you. Bye.
client: No worries to talk. Thanks now. Thanks. Bye bye.'
- text: 'client: Thank you for calling [NAME], partners with [ORGANIZATION]. Please
listen to the options carefully, so we can get you to the right team. If you need
any help with a drainage problem, press one.
customer: You''re
client: If you require our plumbing service, press two. Did you know that you
can now book drainage services online in a few easy clicks, visit Dino. For details.
Alternatively, please hold and your call will be transferred to a customer service
advisor. We record calls for quality and training purposes.
customer: Hi, good morning. I''ve just had a survey done on a property that I
want to buy and they recommend that I have a [ORGANIZATION] drainage report and
I was just wondering do you cover [LOCATION]?
client: Yes, we do cover everywhere with [ORGANIZATION] surveys, yeah.
customer: Okay and how much is the cost of a [ORGANIZATION] camera drainage report?
client: So with the [ORGANIZATION] surveys, we don''t actually book them here
at the core centre, they''re booked directly with our local offices because it''s
the equipment that needs booking, not the person.
customer: Okay.
client: We don''t get visibility of the equipment, I''m afraid. And then, so I''ve
never booked one, so I don''t know the price. I do believe, I''m pretty sure a
customer told me they''d had one done and it was around 250 pounds.
customer: Okay, all right then. So I mean what do we do we book it with a local
office then?
client: Yeah so I could certainly give you their phone number but just to let
you know they''re not open at the weekends they won''t be open until tomorrow
now. Yeah, it''s [LOCATION] you say.
customer: I think so long. Yes it is, yeah.
client: Yeah, let me find the number for you.
customer: But then group. Okay. How quick is it done? Okay.
client: Again I couldn''t tell you I''m afraid because I''ve never booked one
like I say and the actual process of doing it again I''ve never been out with
an engineer so I''ve never seen it done I know that each office only has basically
the equipment uses it''s like millions of pounds so each office only has one basically
that''s why it''s the equipment that needs booking you see but yeah let me give
you their phone number have you got a pen
customer: Okay. Have you. Have you? Yeah. Yeah. Yeah. Yeah. Great. Great. Great.
Great.
client: Yeah, it''s 0151 545 0913. Yeah, that''s all right, no problem.
customer: Great. Great. Great. Great.
client: Take care. Bye.
customer: Great. Great. Great. Great. Lovely. Thank you very much for help. Thanks
a lot.'
inference: true
model-index:
- name: SetFit with sentence-transformers/paraphrase-mpnet-base-v2
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: Unknown
type: unknown
split: test
metrics:
- type: metric
value: 0.5307449553507265
name: Metric
---
# SetFit with sentence-transformers/paraphrase-mpnet-base-v2
This is a [SetFit](https://github.com/huggingface/setfit) model that can be used for Text Classification. This SetFit model uses [sentence-transformers/paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2) as the Sentence Transformer embedding model. A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification.
The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Model Details
### Model Description
- **Model Type:** SetFit
- **Sentence Transformer body:** [sentence-transformers/paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2)
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
- **Maximum Sequence Length:** 512 tokens
- **Number of Classes:** 11 classes
<!-- - **Training Dataset:** [Unknown](https://huggingface.co/datasets/unknown) -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
### Model Labels
| Label | Examples |
|:------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | <ul><li>"client: Thank you for calling [NAME], partners with [ORGANIZATION].\ncustomer: I can't find it. I didn't mind where I'm a little bit better than what I'm going to get there.\nclient: Please listen to the options carefully so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing services, press two. Or if you have an existing home care policy, it's three. Did you know that you can now book plumbing services online in a few easy clicks? Visit dino.com for details. Alternatively, please hold and your call will be transferred to a customer service advisor.\ncustomer: Hi, this is Mr. [NAME].\nclient: We record calls for quality and training purposes.\ncustomer: I just want to cancel for tomorrow's appointment. I'm sorry. I'm sorry. I just want to cancel for tomorrow's appointment.\nclient: Yep, have you made it directly with all the through British-class home care?\ncustomer: I'm sorry.\nclient: Have you made the appointment directly with also through British-class home care?\ncustomer: Direct with you guys.\nclient: Yep. What's the postcode?\ncustomer: 8-A-J.\nclient: Yep. [NAME] What's the first line of the address?\ncustomer: Hello? Yeah. Number 11 Austin Avenue. Ah, Mr. [NAME]. Yeah. Yeah, that's right, yeah. Yeah.\nclient: And what's your name please?\ncustomer: Yeah, that's right, yeah. Yeah, yes.\nclient: Okay, so, is the appointment for tomorrow?\ncustomer: Yes, yes, yes, yes, please.\nclient: Is that right? Between 8 and 6?\ncustomer: Okay. Thank you very much. Bye.\nclient: Yeah, and that's your point we want to cancel, yep? Yeah, okay, no problem, I'll get that canceled for you now. Thank you for letting us know. Thanks, bye."</li><li>"client: Thank you calling [NAME], partners with [ORGANIZATION].\ncustomer: Yeah.\nclient: Please listen to the options carefully, so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing service. Did you know that you can now book drainage services online in a few easy clicks, visit [ORGANIZATION] for details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes.\ncustomer: Hi, I've got an appointment book tomorrow. I'd like to cancel, please. Chargeable. B-A-2. B-A-2. B-A-2. Yeah. 4-QG.\nclient: Sorry, the line's not too clear. Yep. Any address, please? And what names it? No problem, I get it cancelled for you.\ncustomer: under [NAME]. Great, thanks very much.\nclient: You're welcome. I know.\ncustomer: Right, bye."</li><li>"client: Thank you for calling [NAME].\ncustomer: Yet it's [ORGANIZATION], and 3-1-E-X.\nclient: You're about to be put through to our emergency line. If this is not an emergency, please call back between our usual opening hours of 8 a.m. and 6 p.m. Monday to Friday. Thank you. Thank you for calling [NAME]. Partners with [ORGANIZATION]. Please listen to the options carefully so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing services, press two. Or if you have an existing home care policy, it's three.\ncustomer: I'll see.\nclient: I'm sorry I didn't get anything if you need any help with a drainage problem press one if you require our plumbing services press did you know that you can now book drainage services online in a few easy clicks visit dino dot com for details alternatively please hold and your call will be transferred to a customer service advisor\ncustomer: I was a book for somebody to come out of there.\nclient: Morning, [NAME], speaking to [NAME]. How can I help? Yeah. Okay, no problem. What's the post code, please?\ncustomer: I was a book for somebody to come out to my home address but I need to cancel it because we've sorted it.\nclient: Yeah. Okay. No problem. What's the post code, please?\ncustomer: It's [POSTCODE].\nclient: Yeah. First line of the address. And your name, please.\ncustomer: It's [NAME].\nclient: Right, I'll get it cancelled, thanks for letting us know, though.\ncustomer: All right, thank you.\nclient: You have a good day.\ncustomer: Bye.\nclient: Okay, no worries. But now, right way."</li></ul> |
| 3 | <ul><li>"client: Thanks for calling Dynaflamey. Please note all calls are recorded for training and monitoring purposes. Please hold while we connect you to a member of our team. We'll be with you in just a moment. Good afternoon, [NAME] the word speaking. How can I help?\ncustomer: Thank you. This is for [ORGANIZATION] train test. The location is on is a consultant SM5, 3-2N. Is this available for this area?\nclient: What is it you require us to do?\ncustomer: Sorry.\nclient: Unfortunately, we don't undertake that kind of work.\ncustomer: Oh, for doing a [ORGANIZATION] train test.\nclient: You need Dynobod.\ncustomer: for the property number, right?\nclient: Can I give you the number for them?\ncustomer: The property number, right?\nclient: So we are Dynoplumbing, we don't deal with drainage.\ncustomer: Okay, uh, okay, uh, okay, a moment, right?\nclient: So I can give you the drainage company's number, okay? So you need to call 0.333.\ncustomer: Mm-hmm. Okay, a moment, please write down.\nclient: Yep, 242, 2 178. Yes, all right? I don't know. I don't know.\ncustomer: 0-333-333. 4-2-2-178 2-178. 2-178. Okay, 0-3-3. Okay, so may I make an appointment through the website or... Okay, so, may I, uh, make an appointment through the website or...\nclient: You'd have to call them, unfortunately. I don't know. No, you'd have to call them, unfortunately. Okay, thank you. No, no, you'd have to call them, unfortunately. Okay. Thank you. No, no, no, you'd have to call them, unfortunately. Okay. Thank you. No, no problem.\ncustomer: Thank you. Bye."</li><li>"client: Thank you for calling [NAME], partner [NAME].\ncustomer: carried out gases detection on winter and water supply pipe between internal and external stopcock.\nclient: Please listen to the options carefully, so we can get you to the right team. If you need any help with a draining problem, press one.\ncustomer: Well they detected it.\nclient: If you require our plumbing services, press two. Or if you have an existing home care policy, it's three. I'm sorry I didn't get anything if you need any help with a drainage problem press one if you require our plumbing services press two or if you have an existing home care policy it's three did you know that you can now book plus services online in a few easy clicks visit dino dot com for details alternatively please hold and your call will be transferred to a customer service advisor we record calls for quality and training purposes purposes\ncustomer: Okay.\nclient: Dino with one of the [LOCATION]'s leading plumbing and drain services. From blocked drains to burst pipes and busted boilers, we're here to help.\ncustomer: Hello [NAME]. I had one of your guys out today to look for a water leak on my drive. It was with the gas down the line and he confirmed there was a water leak that [ORGANIZATION] have told us but he couldn't find it and I'm sort of just stuck down. I've paid 552 pounds and I'm known none the wiser as to when he came out. I know there's a water leak before we got here I know there's a water leak now but I don't know where it is so I can fix it. Yes I've got a log number here 438585838\nclient: Okay and it was one of our engineers that came out you say. Yeah, can I take that from you, please? Yeah. Okay, thank you. And can I take the first one of your address and postcode, please?\ncustomer: [NAME].\nclient: Thank you. Can I just take your name as well, please? Thank you. Okay, so I'm going to bring the details on the job that was done. Lead detection. Okay, so the description I've got on here states that the engineer has been out and he's done what he could do and he's quoted on re-running the water supply to the property and fitting a new stockcock.\ncustomer: Yeah, but that's not telling me where the leak is because I could spend all that money and that may not be a problem. You said you were going to detect the leak and you haven't.\nclient: Okay.\ncustomer: You've told me exactly what [NAME] have already told me I have a leak, but you haven't detected it where it is. I've paid 552 pounds for what.\nclient: Okay, so can I just ask you then, what is it that you'd like us to do?\ncustomer: I find the leak you said there's a league why can't you find it I know I know it's not I understand that completely I understand it's not you personally you the company\nclient: Okay, so I'm just going off of, it's not me personally, I'm just off the engineer's note. Okay, so I'm, again, all I can do is go off the engineer. Okay, if I can explain, I'm just looking at the engineer's note. and the engineer has mentioned on it as I read through to you that he's carried out a gas leak detection on the water supply but he was not able to find the leak successfully. So he's done the tools that he had and the equipment that he had to look for that leak. Ultimately he's not been able to find it.\ncustomer: Right.\nclient: So we cannot find that leak so what he's advised is we can't find the leak so what we can do is we can offer you another service where we can quote you for rerunning the water supply but we are not able to find that leak so you paid the money for the work that we've done.\ncustomer: Yeah. Yeah, but you haven't. Yeah. Yeah, but you haven't. Yeah, but you haven't detected the leak.\nclient: No and again I reiterate that's what the engineer was mentioned we've done the new detection but we were unable to find the leak so you know you paid that money for that service that we have provided.\ncustomer: Right, okay. But running in a new supply pipe does not guarantee that that will sort out the problem. That's what I'm saying. Yeah.\nclient: I'm not an engineer so I can't advise that but I can only go off what I can tell the system I wasn't aware of the situation until you called a minute ago so I'm looking at the details and I'm seeing what the engineer is mentioned about the caller that you have today.\ncustomer: Yeah. Okay. Okay, that's fine, I knew you were going to say this. I just think it's disingenuous that you, you quote that you will find the leak and yes you told me there's a leak, but you know, I knew there was a leak, but you've not helped me in any way to find the leak. So, but I understand your company policy and thank you for explaining it to me.\nclient: No worse."</li><li>"client: Welcome to Dino. All calls are recorded for training and monitoring purposes.\ncustomer: I'm on your website looking at door handles for outside doors and try to replace a couple when I've worn out done tacky looking so they have to be sort of the same one or very close so they don't have to start destroying doors. The thing is that most of them seem to be 48 middle on your site but there's a lot of dead length but I need to be about 210 high and\nclient: Sorry to interrupt. We are dino plumbing. I'm assuming you've got the wrong number if you're talking about doors.\ncustomer: door handles, yeah.\nclient: Yeah.\ncustomer: It's coming up this handle world.\nclient: Where are dino plumbing in lead?\ncustomer: Oh, right. Right, I don't know how I did that, thank you much. Mr. [NAME]. Thank you for your time. Sorry. I got ourselves. Bye."</li></ul> |
| 9 | <ul><li>"client: Thank you for calling [NAME], partners with [ORGANIZATION]. Please listen to the options carefully, so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing services, press two.\ncustomer: So.\nclient: Or if you have an existing home care policy, it's three. Did you know that you can now book drainage services online in a few easy clicks? Visit dino.com for details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes.\ncustomer: Hi, I'm ringing up. We've had you out to unblock a dodgy kitchen drain in the past, and it's decided to block again.\nclient: Yeah.\ncustomer: But there's one guy that has a very long rod, and that's the only one that will unblock our sink because of the angles of our sink. We'd like him to come out again, but there's no point someone else or him coming out unless he's got the long rods on his van. CB-22, 6RQ. Okay? Yeah.\nclient: Yeah, right. What I'll do, let me give you the direct number for the office where the engineers work from in your area, and you're probably best speaking to them directly. They're not open to eight, mind. They're on 01536.\ncustomer: Oh, hang on, let me just write this down. Oops. Up. Oh, not the right bit to write it on. Oh, 1, 536, 402, 371. 1, 536, 4,000, 3,71. 1, 536, 4,000, 3,71. 1, 1, 536, 4, 02371. Okay.\nclient: Yep, 402, 371. And they're open on 8. And they're open on 8. And that's it's okay.\ncustomer: Okay, lovely. Thanks for your help.\nclient: Right, nobody's, take care of 5.\ncustomer: All right, bye."</li><li>"client: Thank you for calling [NAME] partners with [ORGANIZATION]. Please listen to the options carefully so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing services, press two. Did you know that you can now book drainage services online in a few easy clicks, visit [ORGANIZATION] for details. Alternatively, please hold and your call will be transferred to a customer service advisor. we record calls for quality and training purposes. Dino with one of the [LOCATION]'s leading plumbing and drain services. From blocked drains to burst pipes and busted boilers we're here to help. Our local teams of expert engineers are available across the [LOCATION] 24-7, 365 days a year.\ncustomer: You know I got a toilet blockage on the ground floor and you know when you flush you know I can see you know the ground floor toilet and the kitchen is nearby and if I look out through the kitchen window there is a manual cover and sometimes you know when I'm flashing I can see the waste is coming out so\nclient: Right, okay.\ncustomer: So you have a because I want to talk to someone who who says okay there is a problem you need a camera or you can jet jet pressure is and clear it so I want to somebody who can speak to me and you know give details do you have some technical person available now?\nclient: I can transfer you to the local office to speak to somebody else but what happens with Diner as much as you know there's no call-out charge basically the engineer would attend and assess the work and then he would speak to you about what the problem is and give you a price for fixing it so I could either book you in a job or I can transfer you to the local office if you want to speak to them a bit more about it for\ncustomer: Okay, what is the local office number? Yeah, it is a local office number.\nclient: Could I take your post code please and I'll find it out for you?\ncustomer: Yeah, it is early two.\nclient: [NAME], can you say that again, your post code? [NAME] to say that again, your post code?\ncustomer: L-E-26-S-A. Yeah. Yeah. One second, one second.\nclient: [NAME] 2, 6SA. Okay.\ncustomer: Oh, one second.\nclient: Okay, right, I've got the number here if you're ready. Yeah, it's 01536, 36, 46, 402, 402, 402, 402, 371, 371. Yep.\ncustomer: Oh, one second. Oh, one second. Oh, one, five. Yeah. Yeah. Yeah. Okay, that is 0153, 640, 2371.\nclient: Yeah, that's correct.\ncustomer: Okay, and, yeah, but this number doesn't seem to be lesser, because the number I called that is [NAME], oh, 116, the number that is [NAME], oh, 116, the number that you gave me is 0153.\nclient: If you just give them a ring, they'll be able to go through some more of the technical stuff with you if you want that information. I understand that, but it's a local office that's the closest to you where an engineer had come out.\ncustomer: Okay, okay, and okay, so, okay, you are doing all right. So I will speak to him and yeah, let me see what he says.\nclient: No worries.\ncustomer: Okay, ma, thank you.\nclient: Take care. Bye.\ncustomer: Bye bye."</li><li>"client: Thank you for calling [NAME] partners with [ORGANIZATION]. We record calls for quality and training purposes.\ncustomer: Oh, hi, my name's [NAME]. I'm calling from [ORGANIZATION], Out of Hours Repairs. I'm in desperate need of a plumber, please.\nclient: So are you a key account?\ncustomer: Yeah, we have an account.\nclient: So is it a key account?\ncustomer: Yes, it is. Key accounts at [LOCATION]. Credit [LOCATION] is the contact we've got.\nclient: Yeah, so if you email it over.\ncustomer: Yeah.\nclient: And have you made it over, I'll let them know it's on its way. What's the press code?\ncustomer: Postcode of site is Bravo 12 to [ORGANIZATION]. Is apartment, well it's an issue in the loft but it's affecting apartment 34.\nclient: Okay, yeah, be email it over then. There is someone on the key accounts and they'll pick that up straight away. Well, thank you.\ncustomer: Brilliant, thank you very much.\nclient: Bye."</li></ul> |
| 7 | <ul><li>"client: Thank you for calling [NAME], partners with [ORGANIZATION]. Please listen to the options carefully so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing services, press two. Or if you have existing home care policy, three. Alternatively please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes.\ncustomer: I'm trying to find out if you do a service we could show the camera down a loo to find out where a blockage is. I'm pretty sure it's lime scale but we want to know if it's in the pan or in the pipe work behind the pan before we decide to buy a new pan. And would you have a camera that you can put down that?\nclient: They do have cameras that they can have a look. So it's just trying to, you just want someone throw something down there at the moment of causing a blockage, is it?\ncustomer: Yeah, we think it's like a lime scale because there's a lot of a loop of lime scale in the actual pan itself.\nclient: Okay. Okay.\ncustomer: We have to keep checking that out. And the plumber said he's done quite a few around here. And he says the worst one he's had was where the lime scale bill took way to state where he couldn't even get a pencil for it.\nclient: Right, okay. So we can have somebody come out and have a look and see the issue is. Do you have any cover with [ORGANIZATION]? The right cover for plumbing and drains? Okay, and is this your judgment?\ncustomer: No.\nclient: Well, we have someone who can come out and try and look at a blockage.\ncustomer: How much would it be for, how much would it be to show the camera down the toilet?\nclient: So the way that it works is our price, we don't have any, we don't really charge for the coal house itself, however, our price to clear a blockage starts at a hundred and eighty pounds. which is inclusive of [ORGANIZATION]. So the engineer will come out. And that's the initial charge that we will make.\ncustomer: Yeah.\nclient: If there's anything more that the engineer thinks it needs to be done, then he will provide you with a quote for that. And you can decide if you want to go ahead. But if the engineer does any work, then our price, it's clear and a quote would be $180.\ncustomer: Okay, can I just leave it for now then and I'll see what I can do? Okay, thanks very much, huh? Cheers, bye."</li><li>"client: Good morning, Dino. How can I help?\ncustomer: Oh, hi there is Carrie calling from [ORGANIZATION]. I was wondering if I could arrange for a quotation to have a couple of drains unblock that run to a septic tank.\nclient: Couple comes on to run to a septic tank. Is the septic tank?\ncustomer: Yeah.\nclient: Is the septic tank empty or?\ncustomer: At the moment we're just waiting on a report back but we've got a feeling it's likely going to be full, potentially.\nclient: So what I would suggest is that tank is empty before we attend.\ncustomer: Yeah, okay.\nclient: The reason I say that obviously if all the drains are blocked and the tank is full, we're going to have nowhere to clear that blockage too.\ncustomer: Is that something you guys can do as well or?\nclient: No, unfortunately we don't empty septic tanks.\ncustomer: Okay, no that's fine. What I'll do, I'll just speak with my colleague because he might have had an update from the site anyway. And then if it is empty, then obviously we'll give you a call back just to kind of have\nclient: Yeah, I mean, is it a domestic property commercial property?\ncustomer: So it's one of our poultry farms that we've got down in [LOCATION]. So it's based in [LOCATION].\nclient: Where is [NAME]? Right, okay. That's fine. So the price is [ORGANIZATION]. Right, okay. That's fine. So the price is for us to do so.\ncustomer: No, I don't think it's too long distance. It's literally just the two that would just run in the run up to the septic tank. So I don't think it's a big strain, yeah.\nclient: massive. Okay, so prices for us to do so $175 for the first hour and 60 pounds per half are thereafter plus the [ORGANIZATION].\ncustomer: Yeah. Per half hour, yeah.\nclient: And then obviously we are payment on completion so as soon as it is done you will take payment from yourselves.\ncustomer: Yeah. That's not a problem at all. That's fine. Do you have like an email as well where I can request that on so we could get that as a quote on the system as well?\nclient: Yeah, if you send your inquiry to admin at [ORGANIZATION], which is B-O-W-Y-E-R, hyphen-D-R, hyphen drains, dot-com.\ncustomer: Yeah. Yeah. Yeah. Yeah. Okay, brilliant. I'll pop that over. I'll find out just the info on the tank itself and then we can go from there.\nclient: Yet no worries.\ncustomer: Great stuff.\nclient: Thanks.\ncustomer: Thank you very much.\nclient: Bye bye. Bye bye.\ncustomer: Take care. Bye."</li><li>"customer: Yeah, we're not.\nclient: Thank you for calling [NAME], partners with [ORGANIZATION]. Please listen to the options carefully, so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing. Did you know that you can now book drainage services online in a few easy clicks, visit [ORGANIZATION] for details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes.\ncustomer: It's me now. It's me now. I come in [LOCATION], [LOCATION], [LOCATION], [LOCATION]. Oh, hello, Dino. Would you be able to send somebody to clear my manhole? Oh, it's so blocked. It's insane. Actually, it's me and my neighbor have it. So, but it's overfly and I can't leave it until the morning. So I think it's time.\nclient: Overflow with sewage or just sewage.\ncustomer: It's like a sewage, yeah. I think it's my neighbors, it's not really mine, but it's on my garden.\nclient: Yeah.\ncustomer: Yeah, I've only got one toilet link to it and I think more is from his side, but it needs doing because... I don't know really who to call.\nclient: Right, okay. Is it a shared drain then? I'm assuming it is.\ncustomer: I was thinking this time I call you, come and clear it and then... will sort it out afterwards. So who should I call?\nclient: Well, the way we stand, I'll just explain. So as I say, the shared lines, the responsibility of the water board, they don't really let anyone else touch it. I mean, we can try and clear it from your side. However, it will be an attempt. It may not be successful and you'd get charged for the attempt, clear or not.\ncustomer: So who shall I call?\nclient: The water board, I can get you the number. What's the post code?\ncustomer: Is he Wessex Water? Ah.\nclient: Yeah, that'll be the one, yeah.\ncustomer: He isn't first.\nclient: that'll be the one if it's a shared line between multiple properties it's their responsibility yes that'll be the one they'll come out for free they'll stick some cameras down if the responsibility if the if the block is on the shared line they'll just clear it if it's on your side to all your neighbors side they'll tell whoever it is other than that we can try we can come out that's not an issue however\ncustomer: So this is Wessex Water sewage. How much is the cost?\nclient: As I say, we may or may not be successful when you get charged for the attempt, if it's a shared line. Today, on a Sunday, if we can get there before, so it depends when you get there. If we can get there before six, you'll be looking attempt 237, including that, after 6 286.\ncustomer: Oh God, okay. I'll try it with sex water then.\nclient: I mean what I'd do what I'd do is speak of the war support and then if the war support says right that's fine we'll be out within you know a time scale that you're happy with great if they say they're going to be out within 48 hours or something you don't want to wait then you might want to risk it no problems take care now\ncustomer: Okay, I'll try it with sex water then. Okay, all right, I'll do that then. Thank you."</li></ul> |
| 0 | <ul><li>"client: Thank you for calling [NAME], partners with [ORGANIZATION]. Please listen to the options carefully, so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing services, press one. Did you know that you can now book drainage services online in a few easy clicks, visit Dino. For details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes.\ncustomer: Hi [NAME], I was wondering you could help me. I'm at my mom and dad's house just now and it's their back garden is flooding with the rain and it was just to see if could have got some advice whether or not there's a blockage within their drain that's causing the water to the gathering. Okay.\nclient: Well, okay, I can book a job in to get some with the outs, that's all I can do. I can't sort of advise it.\ncustomer: Yeah.\nclient: It sounds like there is a book as if something's, is it just wastewater or is it toilet waste, it's overflowing?\ncustomer: Yeah. It's rain water. It's not disappearing. It's not disappearing down the drain.\nclient: [ORGANIZATION].\ncustomer: It's not disappearing down the drain.\nclient: Okay, no problem. So, is it, it's residential property, yes. And did they have any kind of account with Dino Road True, [ORGANIZATION]?\ncustomer: Oh, never thought about that. We'll do on a few minutes.\nclient: Well I can check it just takes a minute to check if you give me the post code yeah thank you and the first line of the address thank you and what would the name be if they have a contract on this property okay one minute right we've got\ncustomer: Okay, okay. Sure. G74, 3 years. [NAME] 1. 61. [NAME]. That's right, yeah, that's my mum.\nclient: Okay, one minute.\ncustomer: Thank you.\nclient: Now she's got home care, but she's only got home care one which doesn't cover drainage work. So I can book a new job in, but it would be payable.\ncustomer: Okay. Okay.\nclient: Now, is she aware of this that this would be a payable job?\ncustomer: How much is the call out and how is it? Okay. Okay. Okay. Okay. Can I just say that to my mom and dad.\nclient: Okay, basically there's no call-out to charge itself, but a standard unblocking of a drain is a fixed price of 180 pounds, that's 1-80, and that is inclusive of B-A-T.\ncustomer: Okay. Okay. Can I just go and say that to my mom and dad. Yeah. Okay. Okay. Can I just go and say that to my mom and dad. Yeah. Okay. Okay.\nclient: Yeah, not a problem.\ncustomer: Can I just go and say that to my mom and dad. Yeah. Okay. Thank you.\nclient: How are you yet?\ncustomer: Hello there. Yeah, they're agreeable to that, thank you.\nclient: Okay, no problem. But Diner Road have never been at this property before. And it's 61.\ncustomer: No.\nclient: So who would be paying the bill for this then? Sorry.\ncustomer: [NAME].\nclient: [NAME], right? OK. So just go for 61. Okay, I just need now a contact number that can either be, [NAME] or yourself, whatever's easiest. Yep.\ncustomer: Yep, I'll give you mine. I'm [NAME] the daughter. 0750, 668 38666. That's correct.\nclient: Yep.\ncustomer: That's correct.\nclient: Yeah. Okay, I'll repeat. O-750, double-6-838. And what's your name again, sorry? Right, is it possible to take an email address as well, [NAME]?\ncustomer: Sure, it's Muir, M-U-I-R-G with a G-7 at [ORGANIZATION].\nclient: Yep. Thank you. Right, one last question, [NAME]. How did you hear about [NAME] today?\ncustomer: Oh, just I've seen the vans about and obviously a way of what you do.\nclient: Right, so just to clarify now, you're saying it's the drains of overflowed outside, yeah, and it's just waste water, yeah.\ncustomer: It's just, well it looks like rain water in the backyard and it's just gathered and it won't drain under the, into the drain.\nclient: Okay, yeah, okay, but can they use the toilet and the bathroom facilities? Okay, one minute, I'll put the information in it, see what comes up. Okay, Julian, we can get some of the output. Unfortunately, the, the, um, got so many bookings on. The earliest available slot at the moment would be Thursday morning. Do we look at him for Thursday morning?\ncustomer: Okay.\nclient: So an engineer will call from the, um, his club, right, where he will call you, he'll be any time between 8 and 1 on Thursday the 5th.\ncustomer: Yeah, that's fine, that's great. Thank you.\nclient: Okay. Cheelian. Okay, thank you very much. Have a good time now.\ncustomer: Thanks very much. Thank you. Bye bye. Bye."</li><li>"customer: the rules that start to the public on the side of the house and come back into the cup.\nclient: Thank you for calling [NAME], partners with [ORGANIZATION]. Please listen to the options carefully, so we can get you to the right team. If you need any help with a drainage problem, press one.\ncustomer: I was the rest but she might only get it.\nclient: If you require our plumbing services, press two.\ncustomer: That was like that. That was the same as a problem.\nclient: Did you know that you can now book drainage services online in a few easy clicks, visit Dino. For details. Alternatively, please hold and your call will be transferred to a customer service advisor.\ncustomer: in [LOCATION]. Well, we're going to do so basically meant that he didn't leave the country until the same thing.\nclient: We record calls for quality and training purposes.\ncustomer: Well, we have two toilets. We have two toilets where the sewage from the toilet is coming up. Is this something that you could help us with, please?\nclient: Yeah, do you have a home care cover with [ORGANIZATION]?\ncustomer: A what?\nclient: A home care cover?\ncustomer: No, we don't.\nclient: Okay.\ncustomer: I thought you guys had died no roared.\nclient: Our price, yeah, we are, and we are working with [ORGANIZATION]. So the first question is, it is to find out if you are a British Gas customer. So our price for Sunday evening is $286, cash or card upon completion and the price includes the 80s.\ncustomer: Okay, that's fine.\nclient: Could you please provide me the pause call?\ncustomer: [NAME], 6 [NAME].\nclient: Yeah. He booked with us before in 2022 under the name Christian. Okay, it was last time under the billing account, property inside [LOCATION].\ncustomer: Yes, it is. Inside [LOCATION], yes it is.\nclient: Is it still the same? Okay, let bear me a second so I can extract first the date from here and transfer it to a new booking, okay?\ncustomer: It is still the same. Okay. Okay. Thank you. Okay, thank you.\nclient: This is still the same contact name with Christian.\ncustomer: You can call me, that's fine, but Christian is fine. Do you have his number ending with double zero?\nclient: Okay, yeah, I have here telephone number 07439300.\ncustomer: Yeah.\nclient: Okay, so it's blocked, drain, over 07439300.\ncustomer: Yes.\nclient: Okay, so it's blocked, drain overflowing inside of the property, yeah.\ncustomer: Yes.\nclient: Any COVID at the site. COVID love [ORGANIZATION].\ncustomer: COVID, no. Sorry.\nclient: No.\ncustomer: So, Christian is obviously, you know, we are the Latin agent managing this property, but to get into the flat, my tenant is there.\nclient: Yeah. Yeah. Okay. Okay.\ncustomer: Yeah? So we will make the payment to you.\nclient: Yeah, once the engineer will use a number we have in the system, the one ending with 300, unless you want to give another number.\ncustomer: Okay, no, no, that's fine.\nclient: In that number, we receive a job reference number and on that number, the engineer will call for updates and also to make the payment.\ncustomer: Okay, thank you very much.\nclient: So do I keep the same number?\ncustomer: Yes, please.\nclient: Okay. Okay.\ncustomer: Yeah.\nclient: Okay, yeah, the job has been confirmed, so you should receive that person will receive a message in their mobile number with a job reference number, followed by the call from the engineer before arriving at the property. Is there anything else to me to add?\ncustomer: No, but how long would the engineer take?\nclient: This will be tonight, a couple of hours, few hours. We don't know until there will not be a sign of, yeah.\ncustomer: Okay, okay, thank you very much. So up to two hours I can tell my tenants, yes? Okay, thank you. Okay, thank you."</li><li>"client: Thank you for calling [NAME], partners with [ORGANIZATION]. Please listen to the options carefully so we can get you to the right team.\ncustomer: Uh, that's not.\nclient: If you need any help with a drainage problem, press one. If you require our plumbing services, press two. Or if you have an existing home care policy, Did you know that you can now book drainage services online in a few easy clicks? Visit dino.com for details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes.\ncustomer: Hi, good morning. I wonder if I could get someone out to looking to a slower water cleaning issue. Well, yeah, go on, sorry.\nclient: Okay.\ncustomer: [NAME] is, yes. Sorry.\nclient: And is this your own premises?\ncustomer: So, eh? [NAME] is, yes.\nclient: Okay. And do you have landlord covered with British Gas or [NAME]?\ncustomer: Sorry. Do you have a landlord account?\nclient: Do you have a British Gas? Yeah, a landlord account.\ncustomer: No.\nclient: Okay. Can I set a postcode where the property is?\ncustomer: Yeah, E for [ORGANIZATION], 14, 14, 4 A for Alpha, A, for 30. D106, 14, Harpsmere Road.\nclient: and the first time of the address point.\ncustomer: That's right, yes.\nclient: And can it take your name, please? Okay. And they're the best phone number for you, please. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah.\ncustomer: 119. Okay. Okay.\nclient: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah.\ncustomer: H4-A-4-Ders. [NAME].\nclient: Yeah. Yeah. Yeah. Yeah. Okay.\ncustomer: [ORGANIZATION], U4 Uniform.\nclient: Okay.\ncustomer: [NAME]. H-For Hotel, [NAME], [NAME], so that's [NAME], at [ORGANIZATION].\nclient: Okay. Okay. Okay. I'm. Okay. I can just ask how did you hear about down about it?\ncustomer: Okay. My plumber recommended here.\nclient: Yeah. Okay. Can I just ask how did you hear about\ncustomer: So the shower water is not draining well, so it just overflowing really quickly so it's out missing water as well.\nclient: Let me check they're available.\ncustomer: Okay, the painting in the property is it, has it just a mobile number, I don't know if it is what, just noting their number just in case.\nclient: Right.\ncustomer: But I guess we'll talk about that when you set up a permit, if there is anything I've got about fine. Just need to double chip with the tenant. How about Thursday? Is there anything available on Thursday, please?\nclient: Yeah, Thursday afternoon.\ncustomer: Roughly what time, please?\nclient: Between one and six?\ncustomer: Or is it like, one in six? Oh, okay. That should be okay.\nclient: Right.\ncustomer: I'll let him know about the timing.\nclient: Okay, so the engineers call you and they're on the way. They'll go around and do an inspection. If they're inspection on cart at three, so the guys can have a look, then they'll call you back just to tell you what the problem is, confirm the price with you and make sure that you're happy for them to do it.\ncustomer: Yeah, okay.\nclient: And if they do anything chargeable, it's just a cash-a-car payment to them when they're finished.\ncustomer: Okay, okay. Okay, okay. Would you be able to, would I be able to make it over the phone as if I won't be on the property?\nclient: Yeah. All right then.\ncustomer: All right, okay, perfect. Yeah, cool, absolutely. Sounds great.\nclient: That's all being booked now.\ncustomer: Yeah.\nclient: Yeah. All right, then. Yeah. All right, then.\ncustomer: So it's all sorted then, yeah.\nclient: That's all been booked now.\ncustomer: That's where you can't see.\nclient: Yeah. All right, then.\ncustomer: Thank you. I appreciate it.\nclient: That's a lot."</li></ul> |
| 6 | <ul><li>"Client: Thank you for calling Dino Rod partnered with British Gas. Please listen to the options carefully so we can get you to the right team. If you need any help with a drainage problem, press one. If you require further assistance, please note you can now book drainage services online in a few easy clicks. Visit dino.com for details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes. \nCustomer: Hi, can I\nClient: How may I help\nCustomer: Yeah. I'm calling from Acer Eye Clinic in [PII]. Um, I'm calling because we've got, we've had um, several issues with our public toilet that we've got here in store over the last couple of weeks. Um, but today it's completely blocked and the water is up to the rim of the toilet.\nClient: Right, ok. We should be able to have a look at that. Have we ever been out to you before or would this be the first time?\nCustomer: Not that I'm aware of.\nClient: Ok. Let's grab some details and um we'll get everything um set up. What's the postcode there?\nCustomer: it is [PII]\nClient: Yeah. Wait a moment just to set everything up in here. And also, I take it this is just something that will need to be paid for? Is it there's no like British gas business cover or anything as far as you know?\nCustomer: Yes, that's right.\nClient: Ok, no problem. That's fine. And sorry, what was the name of the business?\nCustomer: Aces Eye Clinic.\nClient: Yes, no problem. That's fine. And in terms of like, the sort of invoicing billing side of things, is it all under the same address? It doesn't need like a separate head office address or anything, as far as you know?\nCustomer: Um, let me just check that for you. Yeah, you can put the invoice through into us and then we will forward it on to the people who pay.\nClient: Right, ok. No worries at all. And Do you have a contact email at all?\nCustomer: Yes, you can put my email down if you like. Let me grab it. Will that just be for the appointment that's booked or...?\nClient: Yeah it's not marketing or anything, It's just for if any quotes are needed or anything like that. It's purely to do with just this job.\nCustomer: That's fine. The email is [PII] at Aces Eye Clinic.co.uk.\nClient: Perfect. Thanks for the confirmation. And one last thing, how did you hear about us? Just so I can complete this inquiry.\nCustomer: Yeah, I believe it was through acquaintances and such. Friends have utilized your services.\nClient: Alright. I'll note that down. Now aside from that, are there any access restrictions or specific timings we should adhere to when visiting your location? \nCustomer: We're only here from half eight until five every day. And the best contact number is this one that I'm using right now.\nClient: Great. Ok then, I'll get this straight over to our local office now. They'll give you a call back in a few minutes just to confirm everything. We'll get out there ASAP. Hopefully, we can get this sorted today for you. They will also go through costs and confirm everything with you.\nCustomer: Brilliant, thank You.\nClient: You're welcome. Bye.\nCustomer: Bye."</li><li>"customer: get some more pizza.\nclient: Thanks for calling Dino Plumbing. Please note all calls are recorded for training and monitoring purposes. Please hold while we connect you to a member of our team. We'll be with you in just a moment. Good afternoon, dino plumben.\ncustomer: Hello, afternoon. Is it Diner Road? Oh, uh, yes.\nclient: There's dino plumben. So, there's dino plumben.\ncustomer: I'm calling from R, uh, yes.\nclient: So there is dino, is it dino rods that you require? It is, okay. And can I ask what post-code every, the property?\ncustomer: It's, I'm calling from R, H. H. H. H. A, no, [NAME] 7, 6E. P.\nclient: I'll see if I can transfer you free to the local office, bear with me.\ncustomer: Yes, please. Okay, thank you.\nclient: Thank you. [ORGANIZATION], part of the [ORGANIZATION] franchise group, is your local plumbing partner. We've managed emergencies across [NAME], [NAME], [ORGANIZATION], and [LOCATION] since 2005, offering 24-7 attention for everything from leaky taps to bathroom installations. Need a helping hand. Welcome to [NAME] [LOCATION]. Please note all calls are recorded for training and monitoring purposes. Please choose from the following options. Press option one to book a job. It's two for accounts and option three for anything else. Welcome to [LOCATION] region is a franchise of [LOCATION], experts in [LOCATION].\ncustomer: Hello, I'm [NAME] from [LOCATION].\nclient: Good afternoon, [ORGANIZATION]. How can I help?\ncustomer: We have a blocked drain and I like to book an appointment, please.\nclient: Can I grab a post code and I have a look when I can get somebody out to you?\ncustomer: It's [ORGANIZATION]. R-H-7. R-H-7. R-H-7. So, you do?\nclient: H we don't deal with that area.\ncustomer: Or-H-7. So, here you do?\nclient: We do [LOCATION]. We don't deal with that area. We do [LOCATION]. You'll have to ring another company.\ncustomer: Oh, could? Okay.\nclient: Let me just grab the post code for you.\ncustomer: Okay.\nclient: Okay, have you got a pen on a piece of paper ready? So it's 01342. 885 36464. That's [NAME].\ncustomer: over 364 and what is the company name. I know road link field. Yeah, that's the one I want. Thank you. Okay. Thank you."</li><li>"Client: Thank you for calling Dino Rod partners with British Gas\nCustomer: Mm\nClient: Please listen to the options carefully so we can get you to the right team if you need any help with a drainage problem Press [PII] if you require our plumbing services Press [PII] did you know that you can now book drainage services online in a few easy clicks Visit dino.com for details Alternatively please hold and your call will be transferred to a customer service advisor We record calls for quality and training purposes Welcome to Dino My name's [PII] How can I help\nCustomer: hi I'm just wondering if I could get um, book a, a visit for doing a AAA drain clear and um, a a possible CCTV survey on it\nClient: Ok. We should be able to have a look at that for you. Um, Is this for a home or is it for like a workplace?\nCustomer: It's for a home\nClient: Ok. Doke. No problem at all. And do you have any British gas cover for the drains or is it just something to pay for?\nCustomer: It's just something to pay for\nClient: Ok. Let me grab some details then, um we'll see if we getting it sorted. What's the postcode for the property?\nCustomer: Uh so it's [PII]\nClient: Yep, and what's the first line on the address?\nCustomer: It's [PII]\nClient: Mhm, and is it your own home? Do you own it and live in it, or…\nCustomer: No, we're working on it. The landlords requested this.\nClient: Right, right. Ok, no worries at all. That's absolutely fine. And whose name is going on the booking? Is it going under the landlord's name or are you sorting it all?\nCustomer: Uh, yeah it's going under my name.\nClient: No worries, that's absolutely fine. What's your name?\nCustomer: So it's [PII]\nClient: Yup\nCustomer: and it's [PII]\nClient: Ok, no worries at all. That's absolutely brilliant. And do you have a contact email at all?\nCustomer: Yeah, so it's [PII].\nClient: Yep.\nCustomer: and then it's five letters which is [PII].\nClient: Mhm.\nCustomer: [PII] dot co.uk\nClient: Now, which drain is it or is it just sort of checking all of them?\nCustomer: Uh, well it's a drain at the rear really. But it's um, it's full of sludge and um, the the landlord seems to think that there might be an issue and that's why he wants it cleared and then a survey.\nClient: Ok. No problem. I'll just assign your details to our drains team. And in terms of the best contact number, is that the one that you're ringing from?\nCustomer: Yeah ending in [PII].\nClient: Yeah, that's fine. I'll just copy that over into the system. Go. And is it for as soon as possible, or have you got particular days?\nCustomer: Well, I mean how does it work? Cos I've never used it before. Do you have an engineer for me? Cos we've got to have somebody on site you see.\nClient: Ok, what I'll do is I'll pop the details over to the local office, and they'll give you a call back. It should only be sort of 10 or 15 minutes. They'll have a word with you to see what works best for you, when we've got CCTV availability, and we can go from there. But what I'll do is I'll just note down ASAP at the minute.\nCustomer: Ok\nClient: And they can just have a look at when the first availability is. They'll give you a call back in a few minutes and just have a word about costs and everything, and availability, and we'll get it all booked in for when it works. \nCustomer: That's great. Thank you very much.\nClient: No problem at all. We'll be in contact shortly.\nCustomer: Ok, see you later.\nClient: Thank you. Bye\nCustomer: Bye.\nClient: Bye.\nCustomer: Bye.\nClient: Bye."</li></ul> |
| 10 | <ul><li>"client: Thank you for calling [NAME] partners with [ORGANIZATION].\ncustomer: Anywhere else?\nclient: Please listen to the options carefully so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing services, press two. Did you know that you can now book drainage services online in a few easy clicks, visit [ORGANIZATION] for details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes.\ncustomer: Hello?\nclient: Dino with one of the [LOCATION]'s leading plumbing and drain services. From blocked drains to burst pipes and busted boilers, we're here to help.\ncustomer: you.\nclient: Our local teams of expert engineers are available across the [LOCATION] 24-7, 365 days a year."</li><li>"customer: Hi there, I'm just phoning up.\nclient: Thank you for calling [NAME], partners with [ORGANIZATION].\ncustomer: I've been advised over the weekend there's been a drainage problem at the property I'm managing [NAME].\nclient: Please listen to the options carefully, so we can get you to the right team.\ncustomer: This has caused a foul water to flood one of the apartments in the building.\nclient: If you need any help with a drainage problem, press one.\ncustomer: I'm seeing if you've got any engineers available today in the area of sort of SW4 to attend and clear a block is in the communal stack pipe.\nclient: If you require our plumbing services, press. Did you know that you can now book drainage services online in a few easy clicks, visit Dino.\ncustomer: Super, already, thank you.\nclient: For details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes. I'll be doing the job, they can tell straight away what their availability is. Two seconds. Oh, Oh, yeah. Oh, yeah. Oh, yeah. Bea. Oh, yeah. B."</li><li>"client: Thank you for calling Dino Plumbing. Please note all our calls are rewarded for monitoring and training purposes. First one for an update on parts. Press two for an update on your appointment. Press three to discuss an ongoing complaint and press four for sales. Thank you for calling Dino Plumbing. Please note all our calls are recorded, monitoring and training purposes. Press one for an update on parts. Press two for an update on your appointment. Press three to discuss an ongoing complaint and press four for sale. Thank you for calling Dino Plumbing. Your call is your call.\ncustomer: You're all.\nclient: Your call is Dino Plumbing. Your call is very important to us. All of our agents are currently busy assisting other customers. Please continue to hold and the next available agent will take your call. Alternatively, you can email your query to Office at Dino East London.com. Thank you're calling Dino Plumbing. Your call is very important to us. All of our agents are currently busy assisting other customers. Please continue to hold and the next available agent will take your call. Alternatively, you can email your query to Office at Dino East London.com Thank you for calling Dino Plumbing. Your call is very important to us. All of our agents are currently busy assisting other customers. Please continue to hub and the next available agent will take your call.\ncustomer: Oh.\nclient: Alternatively, you can email your query to Office at Dino East London.com. All of our agents are busy helping other customers. At the tone, please record your message. When you may hang up or press a hat key for more options.\ncustomer: you're Okay. You're\nclient: You have exceeded maximum voicemail duration. Your message will be deleted unless you press three to save it."</li></ul> |
| 2 | <ul><li>"client: Thank you for calling [NAME], partners with [ORGANIZATION]. Please listen to the options carefully so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing services, press two. Or if you have an existing home care policy, it's three. Did you know that you can now book plumbing services online in a few easy clicks? Visit dino.com for details. Alternatively please hold and your call will be transferred to a customer service advisor.\ncustomer: Oh.\nclient: We record calls for quality and training purposes.\ncustomer: Hello, [NAME], I hope you can. My name is [NAME]. Can you please check that your plumbers are coming out to 57 Summer Field Avenue and give me an approximate time? I've been waiting since 7 o'clock this morning. And I can't, yeah, you probably did.\nclient: Yeah, I spoke with you earlier, I believe.\ncustomer: Yeah, if you can get him to come out, yeah, if you can get him to come out because I can't even have a shower or anything, you know, and I'm running out.\nclient: Yeah, so he will be coming to you, I can promise you that. It's set as the emergency, it's the highest priority we can make it. It's just that he had that other emergency job to attend to before. Yeah, I know.\ncustomer: I had a half a kettle of water, some even running out of water to have a coffee or anything with. So can you please hurry him on?\nclient: Yeah.\ncustomer: I know I'm impatient, I know you're dealing with the public and they're bloody awful to deal with, but on this occasion I'm part of the public, please help.\nclient: Absolutely, absolutely.\ncustomer: Okay, thank you. Thank you very much indeed.\nclient: No problem at all.\ncustomer: Thank you.\nclient: We'll be with you. We'll be with you as quickly as we can promise you that. Absolutely.\ncustomer: Please, in two seconds if possible.\nclient: No problem at all. We'll be with you as quickly as we can promise you that.\ncustomer: Okay, thank you. Yeah, okay, bye for now, bye.\nclient: Bye bye."</li><li>"client: Thank you for doing [NAME], [ORGANIZATION], [ORGANIZATION]. Please listen to the options carefully, so we can get you to the right team.\ncustomer: Oh, thank you.\nclient: You need any help with a drainage problem, press one. If you require our coming services, press two, or if you have an existing home care policy. Did you know that you can now book drainage services online in a few easy clicks, visit Dino. For details. Alternatively, please hold your call will be transferred to a customer service advisor. We record calls for quality and training purposes.\ncustomer: Yes, hi there. I hope you can help. I spoke to a colleague of yours a few moments ago regarding a blocked sewer drain and a quote and a quote and a quote and said you have someone out before six because sewage is coming out. Is that okay to book that in please?\nclient: Yeah, we're going to get an appointment button.\ncustomer: So it's the sewer drain, so there's a development of eight properties, six of which are being lived in and it's the drain that runs outside the front of those properties in a private road.\nclient: Is it your home address where you live? Right, bear with me one moment. Let me put you free to that office. Lots of postcode of the property. Right, let me put you directly through to them.\ncustomer: It's C.M. 7, the beginning of a post code. [NAME] 7. 8. [NAME] 7.\nclient: And then what's the rest of the postcode? Thank you.\ncustomer: 8. [ORGANIZATION] to be at Bravo.\nclient: Okay, I'm just going to transfer you directly free to it off, they'll be able to advise them to get out for me one moment. Good afternoon, [NAME].\ncustomer: Yes, hi there. I've got a blocked sewer drain.\nclient: Okay, what was the postcode?\ncustomer: I'd like to book somebody to come and have a look at that, please, to clear it and give it a jet.\nclient: Yep.\ncustomer: It's [NAME] 77, 8 [NAME].\nclient: Okay, was it just a house code? Yep. Okay. Was it just a house or was it a commercial building? Yep. Right, okay, let me hope for you.\ncustomer: So it's residential.\nclient: The thing that we have at the moment be Friday, if that's any good.\ncustomer: There's six houses, the new builds, and it's the drain that runs in front of those.\nclient: The only state that we have at the moment be Friday, if that's any good. The soonest date that we have at the moment would be Friday, if that's any good.\ncustomer: Sorry? I spoke to a gentleman from your company a few minutes ago, about 10, 15 minutes ago and he said that because sewage was coming out through the drain cover, he'd be able to have somebody out by 6 o'clock this evening.\nclient: Right. Do you know who it was that you're speaking to? Right.\ncustomer: I literally spoke to about about 10, 15 minutes ago.\nclient: Okay, let me just check. You could just hold one moment. Thank you.\ncustomer: Yeah sure no problem.\nclient: Oh. Oh. So,\ncustomer: Thank you.\nclient: Hello. Hi, yeah, thanks for holding. I'm not too sure who was that you spoke with, but it doesn't matter. What was the first line of the address? Is there your number or house name at all?\ncustomer: Hi there. That's all right. It's Braintree Road, quest in.\nclient: Okay, right that's fine. There. And is there? And is their name? And is their name that I can put on to the job?\ncustomer: So I live at number 17 but I'm at work so the guy that is at home right now that can meet your guy is a guy called [NAME] that lives at number 12.\nclient: And is there a name that I can put onto the job? Lovely and the best contact number. Yeah.\ncustomer: Yeah, so the guy that's waiting is [NAME]. So it's [NAME] and their surname is He, A, T, H, O, R, N. You can mean me like just my number. So it's 07963, 598, 446.\nclient: and it was just a blocked drain. I cannot have a problem I'll pop that on for you and then the engineer will go call when he's on his way.\ncustomer: Yeah, it's a new build, so it's just a locked rain. It just needs to be cleared and jaded, really.\nclient: Within the next couple of hours it should be, depending how we get one, but yeah, yeah, it should be within the next couple of hours, yeah, but it will give you a call on the way.\ncustomer: Perfect, you know, a rough time just let the guy know.\nclient: All right then, that's the case, no problem. Thank you, you too. Bye.\ncustomer: Okay, that's right. No, just so he knows to wait in, that's all. That's fine, so a couple of hours is fine. Brilliant. Excellent. That's fantastic. Thank you so much for your help. I really appreciate it. Cheers. Take care. Have a good day. Cheers. Bye."</li><li>"client: Thank you for calling [NAME]. Press one for drains or two for accounts.\ncustomer: Yeah, good afternoon. It's [NAME] here again. I'm just wondering if anybody's coming to our drains today. Is it you I spoke to this morning?\nclient: [ORGANIZATION] is it?\ncustomer: Yeah, an IP year. Are they?\nclient: Yeah, I'm just trying to sort it out now because the vans are all over the place at the moment, but I'll let you know, yeah, I'm trying to sort out if I can get two of them together.\ncustomer: Good. So will it be today, do you think?\nclient: So I don't know, like I say, it depends how long they're on other jobs, that's the thing as well. It's not that easy to work it.\ncustomer: Tell that [NAME] to go, tell that [NAME] to get his finger out and get over here.\nclient: [NAME]'s in scum so unfortunately yeah so I'm doing my best for you but it's not it's not that easy get in the van's and depending on how long they're on each job she see sometimes they're on half an hour they can be on two hours so\ncustomer: Is he? Yeah, right. Okay. Please do, yeah, because we're in a bit of a mess to be quite honest. Yeah. Yeah, yeah. Okay. Please do, yeah, because we're in a bit of a mess to be quite honest. We, yeah, if it's not today, will it be tomorrow?\nclient: uh... yeah i'll do my best for tomorrow i'm trying my best for today but i'll let you know i'm just like working i'm working around it at the moment yeah i will like i'll let you know yeah\ncustomer: Yeah, okay, I'll leave it with you. Yeah, okay, I'll leave it with you then if it's asked to be tomorrow if you can just let us know, because we're out tomorrow morning."</li></ul> |
| 5 | <ul><li>"Client: Thank you for calling Dino Rod partners with British Gas. Please listen to the options carefully so we can get you to the right team. If you need any help with a drainage problem Press [PII], if you require our plumbing services press [PII] or if you have an existing home care policy it's three. Did you know that you can now book plumbing services online in a few easy clicks? Visit dino.com for details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes. Please tell me your date of birth.\nCustomer: 23 09 1965\nClient: Thanks, you're through to [PII]. My name is [PII]. How can I help?\nCustomer: Hello. Um, I had Dino um a couple of months ago to fit a pump for my shower and I think there's something wrong with the pump. It's like when we first had it installed it would click on, you know, when we put the taps on or the shower. But the past couple of days it's like literally clicking on for a few seconds, clicking off and then a couple of minutes later it's clicking back on again and it's doing it constantly.\nClient: Ok, and what's the postcode to your property?\nCustomer: It's [PII].\nClient: And what's the first line of your address?\nCustomer: Um, [PII].\nClient: And who am I speaking to, please?\nCustomer: Uh, [PII].\nClient: Alright, so make sure, was this under your British Gas policy or was it a pay job?\nCustomer: It was a paid job. So, I booked it initially through British Gas but then I paid Dino Direct for having the work done.\nClient: Ok. Let's see. I'm going to give you a number to call. This is the number to the office and they will be able to assist you. So this would have been the Plumbing office that installed it. Do you have a pen please?\nCustomer: I do. Yes.\nClient: So it's [PII].\nCustomer: Yeah. \nClient: [PII].\nCustomer: [PII].\nClient: [PII].\nCustomer: [PII]. Do they work today? Do you know?\nClient: Um, they should be open today. \nCustomer: Yeah.\nClient: If I'm not mistaken.\nCustomer: Right. Ok then. Thank you.\nClient: No worries. Cheers.\nCustomer: Bye.\nClient: Bye bye."</li><li>"client: Hello, [NAME].\ncustomer: Yeah, I've done, I've got a customer complaints or customer services department.\nclient: Um, you got to put a complaint in [NAME].\ncustomer: Yeah.\nclient: Okay, what's it regarding? Yeah, that's one of our, that's one of our, that's sort of a franchise, yeah.\ncustomer: What have you all franchise? Have you heard of our and, H-A-N-D? Yeah, they're just the way that's behaved and we've had a job done by them. And it's been a really difficult experience. I just want to speak to somebody about it.\nclient: Okay then I think what the best thing to do is for you to contact a head office because we're a different franchise we don't know anything what goes on there sorry Let me just try and find it for you one second\ncustomer: What's their number at office? Yeah. Yeah. Yeah.\nclient: 2178. Okay, thank you. Bye.\ncustomer: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah."</li><li>"client: Thank you for calling [NAME], partners with [ORGANIZATION]. We record calls for quality and training purposes. Hello, you flipped to [NAME]. How can I help you today?\ncustomer: Hi yes I just want to make a slight complaint about [NAME] not the service itself because I've never used it but we live up back a plane in [LOCATION] and every time the tree goes on this house they're using the neighbor's gardens to turn around in just because the open plan and it's totally inappropriate to be doing so.\nclient: Okay, yeah, get you through to the right office. What's the post code for the area? All right, I'll just get you through to the local office one moment.\ncustomer: 215 here we are. Thank you.\nclient: Welcome to [ORGANIZATION]. All calls are called for training and monitoring purposes."</li></ul> |
| 8 | <ul><li>"customer: I just forgot my [ORGANIZATION]. He tagged I mean. Oh, hello. Last week on the 29th of August, one of your men came out to do my drain for me.\nclient: Hello, I'm Donoque, any check now.\ncustomer: Oh, hello. Last week on the 29th of August, one of your men came out to do my drain for me. Now the thing is, I was going to pay, I couldn't pay in cash because I didn't have it at the time. but he couldn't take a payment because his little machine thing wasn't working so he said I'll contact the office and then they'll contact you but no one's contacted me so the thing is I need to pay it and I haven't do not I mean so I don't know who I can give the details to to pay it I mean I have now been to the bank and got the cash out but it depends on whether he's passing in the area but if he's not I have got my card available here to pay someone\nclient: Oh, okay. Strange. Yeah, no, not a problem. Um... Yeah, but I don't believe. Um... Yeah, but I don't believe so, but I can, I can say go over the phone now if I need be, ah, if I can take a postcode, get it all sorted.\ncustomer: Okay, yeah, it's P.O-2, 9-E-T, Echo Tango.\nclient: Yep.\ncustomer: Yes, it. Yep.\nclient: Let's have a look. For number 132, from what I can see. Perfect was engineer [NAME], yeah. That's fine. And from what he's put on there, let's have a look, where much it's between nine? Where was that? Thursday. So I believe it is just the standard sort of 180, including the 80 there.\ncustomer: Right, yep, that's it, because it was, yeah, it wasn't that, are you too there?\nclient: Yeah.\ncustomer: Oh, sorry, the phone went dead then, sorry, I heard all that, I was on 180 plus V-A-T and then it was nothing. Sorry, yeah, okay, that's it, yeah.\nclient: Is there an email that I could take to get the receipt to you on?\ncustomer: Yes, it's Deb dot Palmer, P-A-L-M-E-R. Oh, yeah, you'd know that, wouldn't you? At 900.\nclient: Yep.\ncustomer: at gmail.com. That's Deb dot parmer 900 gmail dot com yeah at gmail dot com sorry yep yep\nclient: Perfect. Yeah, got it. It's right. Let's have a look. And yeah, if I could take the long card number which would never be ready there. Yep. Yep. Perfect. And the ex- diary for that one.\ncustomer: It's 0.9. 25. Take that again, sorry?\nclient: and then three on the back sorry. Perfect.\ncustomer: Oh yeah, it's 862. Oh, that's 862.\nclient: Make sure I then put that correctly. Yeah perfect that has all gone through and I'll get that receipt over to you now.\ncustomer: Oh, that's brilliant. Thank you so much.\nclient: No problem at all.\ncustomer: Thank you.\nclient: Thank you very much.\ncustomer: Thank you. Thank you.\nclient: Thank you.\ncustomer: Thank you."</li></ul> |
| 4 | <ul><li>"client: Thank you for calling [NAME], partners with [ORGANIZATION]. Please listen to the options carefully, so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing. Did you know that you can now book drainage services online in a few easy clicks, visit [ORGANIZATION] for details. Alternatively, please hold and your call will be transferred to a customer service advisor. We record calls for quality and training purposes.\ncustomer: Hello, I have a semi-emergency. It's not life or death, but it's not far off. So we're training center, and one of the pipes under the building, the piercally appears to be blocked, so we can't use anything until it's unblocked.\nclient: Now, I think it's just a bit more than a sense, you know, when you're going to go.\ncustomer: And the line just keeps breaking up. I don't know if you can hear me, okay? I can't really make out what you're saying. I think you said you'll give me a call back."</li><li>"client: Thank you for calling [NAME] partners with [ORGANIZATION]. Please listen to the options carefully so we can get you to the right team. If you need any help with a drainage problem, press one. If you require our plumbing services press two, or if you have an existing home care policy, it's three. I'm sorry I didn't get anything we record calls for quality and training purposes please enter your account number using your telephone keypad ignoring any letters then press the hash key\ncustomer: uh...\nclient: or if your account number includes letters, please enter the numbers only. I'm sorry, I still didn't understand. Please enter your account number using your telephone pad, then press the hash key. Your account number may start with 85 or 91, or it may start with letters.\ncustomer: Hmm."</li><li>"client: Thank you for calling [NAME]. Our calls are recorded for training and monitoring purposes. Please choose from one of the following options. Press one for a new blockage or service. Press two for an existing or complete service. Press three for accounts. Press four for reception. If you know the extension number you are calling, please. Oh, down a road.\ncustomer: Yeah, my name is [NAME]. I'm calling from I had a lot of great family. and we've got a bit of a bunch in some of our toilets.\nclient: You did kind of break up there. Did you mention it was a primary school? Sorry, you did kind of break up there. Did you mention it was a primary school? Lock v. integrated primary school. Give me a second. And what's the issue you're having? [ORGANIZATION]'s blocked.\ncustomer: Yeah, it says the female staff toilets, the water just doesn't drain in the way.\nclient: Just making a note of this. And what about manhole access? Are there manholes that what can... Are they internal any of them? Hello? Hello? Hello?\ncustomer: You can't."</li></ul> |
## Evaluation
### Metrics
| Label | Metric |
|:--------|:-------|
| **all** | 0.5307 |
## Uses
### Direct Use for Inference
First install the SetFit library:
```bash
pip install setfit
```
Then you can load this model and run inference.
```python
from setfit import SetFitModel
# Download from the 🤗 Hub
model = SetFitModel.from_pretrained("automated-analytics/setfit-paraphrase-mpnet")
# Run inference
preds = model("client: Thank you for [NAME], partners with [ORGANIZATION]. Please listen to the options carefully, secure the right team. We record calls for quality and training purposes. Please enter your account number using your telephone keypad, ignoring any letters, then press the hash key. Just use your telephone keypad to enter your account number, then press the hash key.
customer: I'm trying.
client: This may start with it. Okay, just a moment whilst I look that up. I'm afraid that account number doesn't match our records. Please try again. Okay, just a moment whilst I put that up. Please enter your phone number using the telephone teapad.
customer: Thank you.
client: I'm sorry, I didn't understand. Try entering your phone number. I'm sorry, I still didn't understand. Please by entering it again.")
```
<!--
### Downstream Use
*List how someone could finetune this model on their own dataset.*
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:-------------|:----|:---------|:-----|
| Word count | 38 | 413.8182 | 3760 |
| Label | Training Sample Count |
|:------|:----------------------|
| 0 | 8 |
| 1 | 8 |
| 2 | 8 |
| 3 | 8 |
| 4 | 8 |
| 5 | 4 |
| 6 | 8 |
| 7 | 8 |
| 8 | 1 |
| 9 | 8 |
| 10 | 8 |
### Training Hyperparameters
- batch_size: (64, 64)
- num_epochs: (1, 1)
- max_steps: -1
- sampling_strategy: oversampling
- body_learning_rate: (2e-05, 1e-05)
- head_learning_rate: 0.01
- loss: CachedMultipleNegativesRankingLoss
- distance_metric: cosine_distance
- margin: 0.25
- end_to_end: False
- use_amp: False
- warmup_proportion: 0.1
- l2_weight: 0.01
- seed: 42
- eval_max_steps: -1
- load_best_model_at_end: True
### Training Results
| Epoch | Step | Training Loss | Validation Loss |
|:------:|:----:|:-------------:|:---------------:|
| 0.0119 | 1 | 4.6669 | - |
| 0.5952 | 50 | 4.0552 | - |
| 1.0 | 84 | - | 4.0622 |
### Framework Versions
- Python: 3.10.16
- SetFit: 1.1.1
- Sentence Transformers: 3.4.1
- Transformers: 4.49.0
- PyTorch: 2.2.1+cu121
- Datasets: 3.3.2
- Tokenizers: 0.21.0
## Citation
### BibTeX
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"BEAR"
] |
lcampillos/roberta-es-clinical-trials-ner
|
lcampillos
|
token-classification
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"token-classification",
"generated_from_trainer",
"es",
"arxiv:1910.09700",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-06-30T20:14:09Z |
2023-03-20T16:23:58+00:00
| 58 | 9 |
---
language:
- es
license: cc-by-nc-4.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
widget:
- text: El ensayo clínico con vacunas promete buenos resultados para la infección
por SARS-CoV-2.
- text: El paciente toma aspirina para el dolor de cabeza y porque la garganta también
le duele mucho.
- text: El mejor tratamiento actual contra la COVID es la vacunación.
model-index:
- name: roberta-es-clinical-trials-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-es-clinical-trials-ner
This medical named entity recognition model detects 4 types of semantic groups from the Unified Medical Language System (UMLS) (Bodenreider 2004):
- ANAT: body parts and anatomy (e.g. *garganta*, 'throat')
- CHEM: chemical entities and pharmacological substances (e.g. *aspirina*,'aspirin')
- DISO: pathologic conditions (e.g. *dolor*, 'pain')
- PROC: diagnostic and therapeutic procedures, laboratory analyses and medical research activities (e.g. *cirugía*, 'surgery')
The model achieves the following results on the evaluation set:
- Loss: 0.1580
- Precision: 0.8495
- Recall: 0.8806
- F1: 0.8647
- Accuracy: 0.9583
## Model description
This model adapts the pre-trained model [bsc-bio-ehr-es](https://huggingface.co/PlanTL-GOB-ES/bsc-bio-ehr-es), presented in [Pio Carriño et al. (2022)](https://aclanthology.org/2022.bionlp-1.19/).
It is fine-tuned to conduct medical named entity recognition on Spanish texts about clinical trials.
The model is fine-tuned on the [CT-EBM-SP corpus (Campillos-Llanos et al. 2021)](https://bmcmedinformdecismak.biomedcentral.com/articles/10.1186/s12911-021-01395-z).
## Intended uses & limitations
**Disclosure**: *This model is under development and needs to be improved. It should not be used for medical decision making without human assistance and supervision*
This model is intended for a generalist purpose, and may have bias and/or any other undesirable distortions.
Third parties who deploy or provide systems and/or services using any of these models (or using systems based on these models) should note that it is their responsibility to mitigate the risks arising from their use. Third parties, in any event, need to comply with applicable regulations, including regulations concerning the use of artificial intelligence.
The owner or creator of the models (CSIC – Consejo Superior de Investigaciones Científicas) will in no event be liable for any results arising from the use made by third parties of these models.
**Descargo de responsabilidad**: *Esta herramienta se encuentra en desarrollo y no debe ser empleada para la toma de decisiones médicas*
La finalidad de este modelo es generalista, y se advierte que puede tener sesgos y/u otro tipo de distorsiones indeseables.
Terceras partes que desplieguen o proporcionen sistemas y/o servicios usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) han tener presente que es su responsabilidad abordar y minimizar los riesgos derivados de su uso. Las terceras partes, en cualquier circunstancia, deben cumplir con la normativa aplicable, incluyendo la normativa que concierne al uso de la inteligencia artificial.
El propietario o creador de los modelos (CSIC – Consejo Superior de Investigaciones Científicas) de ningún modo será responsable de los resultados derivados del uso que las terceras partes hagan de estos modelos.
## Training and evaluation data
The data used for fine-tuning is the [Clinical Trials for Evidence-Based-Medicine in Spanish corpus](http://www.lllf.uam.es/ESP/nlpdata/wp2/).
It is a collection of 1200 texts about clinical trials studies and clinical trials announcements:
- 500 abstracts from journals published under a Creative Commons license, e.g. available in PubMed or the Scientific Electronic Library Online (SciELO)
- 700 clinical trials announcements published in the European Clinical Trials Register and Repositorio Español de Estudios Clínicos
If you use this resource, please, cite as follows:
```
@article{campillosetal-midm2021,
title = {A clinical trials corpus annotated with UMLS© entities to enhance the access to Evidence-Based Medicine},
author = {Campillos-Llanos, Leonardo and Valverde-Mateos, Ana and Capllonch-Carri{\'o}n, Adri{\'a}n and Moreno-Sandoval, Antonio},
journal = {BMC Medical Informatics and Decision Making},
volume={21},
number={1},
pages={1--19},
year={2021},
publisher={BioMed Central}
}
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0771 | 1.0 | 785 | 0.1274 | 0.8449 | 0.8797 | 0.8619 | 0.9608 |
| 0.0415 | 2.0 | 1570 | 0.1356 | 0.8569 | 0.8856 | 0.8710 | 0.9528 |
| 0.0262 | 3.0 | 2355 | 0.1562 | 0.8619 | 0.8798 | 0.8707 | 0.9526 |
| 0.0186 | 4.0 | 3140 | 0.1582 | 0.8609 | 0.8846 | 0.8726 | 0.9527 |
**Results per class (test set)**
| Class | Precision | Recall | F1 | Support |
|:-----:|:---------:|:------:|:------:|:--------:|
| ANAT | 0.7069 | 0.6518 | 0.6783 | 359 |
| CHEM | 0.9162 | 0.9228 | 0.9195 | 2929 |
| DISO | 0.8805 | 0.8918 | 0.8861 | 3042 |
| PROC | 0.8198 | 0.8720 | 0.8450 | 3954 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.11.6
## Environmental Impact
Carbon emissions are estimated with the [Machine Learning Impact calculator](https://mlco2.github.io/impact/#compute) by [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The carbon impact is estimated by specifying the hardware, runtime, cloud provider, and compute region.
- Hardware Type: 1 GPU 24 GB RTX 3090
- Time used: 4' (0.07 hours)
- Compute Region: Spain, Europe
- Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid): 0.01 kg eq. CO2
(Carbon offset: 0)
## Funding
This model was created with the annotated dataset from the [NLPMedTerm project](http://www.lllf.uam.es/ESP/nlpmedterm_en.html), funded by InterTalentum UAM, Marie Skłodowska-Curie COFUND grant (2019-2021) (H2020 program, contract number 713366) and by the Computational Linguistics Chair from the Knowledge Engineering Institute (IIC-UAM).
We thank the [Computational Linguistics Laboratory (LLI)](http://www.lllf.uam.es) at the Autonomous Universidad of Madrid (Universidad Autónoma de Madrid) for the computational facilities we used to fine-tune the model.
# License
Attribution-NonCommercial 4.0 International (CC BY 4.0)
|
[
"CT-EBM-SP",
"SCIELO"
] |
bigscience/sgpt-bloom-7b1-msmarco
|
bigscience
|
sentence-similarity
|
[
"sentence-transformers",
"pytorch",
"bloom",
"feature-extraction",
"sentence-similarity",
"mteb",
"arxiv:2202.08904",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-08-26T09:34:08Z |
2024-04-03T12:03:45+00:00
| 58 | 43 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: sgpt-bloom-7b1-msmarco
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 68.05970149253731
- type: ap
value: 31.640363460776193
- type: f1
value: 62.50025574145796
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 61.34903640256959
- type: ap
value: 75.18797161500426
- type: f1
value: 59.04772570730417
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 67.78110944527737
- type: ap
value: 19.218916023322706
- type: f1
value: 56.24477391445512
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: 2d8a100785abf0ae21420d2a55b0c56e3e1ea996
metrics:
- type: accuracy
value: 58.23340471092078
- type: ap
value: 13.20222967424681
- type: f1
value: 47.511718095460296
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: 80714f8dcf8cefc218ef4f8c5a966dd83f75a0e1
metrics:
- type: accuracy
value: 68.97232499999998
- type: ap
value: 63.53632885535693
- type: f1
value: 68.62038513152868
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 33.855999999999995
- type: f1
value: 33.43468222830134
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 29.697999999999997
- type: f1
value: 29.39935388885501
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 35.974000000000004
- type: f1
value: 35.25910820714383
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 35.922
- type: f1
value: 35.38637028933444
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 27.636
- type: f1
value: 27.178349955978266
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: c379a6705fec24a2493fa68e011692605f44e119
metrics:
- type: accuracy
value: 32.632
- type: f1
value: 32.08014766494587
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: 5b3e3697907184a9b77a3c99ee9ea1a9cbb1e4e3
metrics:
- type: map_at_1
value: 23.684
- type: map_at_10
value: 38.507999999999996
- type: map_at_100
value: 39.677
- type: map_at_1000
value: 39.690999999999995
- type: map_at_3
value: 33.369
- type: map_at_5
value: 36.15
- type: mrr_at_1
value: 24.04
- type: mrr_at_10
value: 38.664
- type: mrr_at_100
value: 39.833
- type: mrr_at_1000
value: 39.847
- type: mrr_at_3
value: 33.476
- type: mrr_at_5
value: 36.306
- type: ndcg_at_1
value: 23.684
- type: ndcg_at_10
value: 47.282000000000004
- type: ndcg_at_100
value: 52.215
- type: ndcg_at_1000
value: 52.551
- type: ndcg_at_3
value: 36.628
- type: ndcg_at_5
value: 41.653
- type: precision_at_1
value: 23.684
- type: precision_at_10
value: 7.553
- type: precision_at_100
value: 0.97
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 15.363
- type: precision_at_5
value: 11.664
- type: recall_at_1
value: 23.684
- type: recall_at_10
value: 75.533
- type: recall_at_100
value: 97.013
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 46.088
- type: recall_at_5
value: 58.321
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: 0bbdb47bcbe3a90093699aefeed338a0f28a7ee8
metrics:
- type: v_measure
value: 44.59375023881131
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: b73bd54100e5abfa6e3a23dcafb46fe4d2438dc3
metrics:
- type: v_measure
value: 38.02921907752556
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 4d853f94cd57d85ec13805aeeac3ae3e5eb4c49c
metrics:
- type: map
value: 59.97321570342109
- type: mrr
value: 73.18284746955106
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: 9ee918f184421b6bd48b78f6c714d86546106103
metrics:
- type: cos_sim_pearson
value: 89.09091435741429
- type: cos_sim_spearman
value: 85.31459455332202
- type: euclidean_pearson
value: 79.3587681410798
- type: euclidean_spearman
value: 76.8174129874685
- type: manhattan_pearson
value: 79.57051762121769
- type: manhattan_spearman
value: 76.75837549768094
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 54.27974947807933
- type: f1
value: 54.00144411132214
- type: precision
value: 53.87119374071357
- type: recall
value: 54.27974947807933
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.3365617433414
- type: f1
value: 97.06141316310809
- type: precision
value: 96.92567319685965
- type: recall
value: 97.3365617433414
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 46.05472809144441
- type: f1
value: 45.30319274690595
- type: precision
value: 45.00015469655234
- type: recall
value: 46.05472809144441
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.10426540284361
- type: f1
value: 97.96384061786905
- type: precision
value: 97.89362822538178
- type: recall
value: 98.10426540284361
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 44fa15921b4c889113cc5df03dd4901b49161ab7
metrics:
- type: accuracy
value: 84.33441558441558
- type: f1
value: 84.31653077470322
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 11d0121201d1f1f280e8cc8f3d98fb9c4d9f9c55
metrics:
- type: v_measure
value: 36.025318694698086
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: c0fab014e1bcb8d3a5e31b2088972a1e01547dc1
metrics:
- type: v_measure
value: 32.484889034590346
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 2b9f5791698b5be7bc5e10535c8690f20043c3db
metrics:
- type: map_at_1
value: 30.203999999999997
- type: map_at_10
value: 41.314
- type: map_at_100
value: 42.66
- type: map_at_1000
value: 42.775999999999996
- type: map_at_3
value: 37.614999999999995
- type: map_at_5
value: 39.643
- type: mrr_at_1
value: 37.482
- type: mrr_at_10
value: 47.075
- type: mrr_at_100
value: 47.845
- type: mrr_at_1000
value: 47.887
- type: mrr_at_3
value: 44.635000000000005
- type: mrr_at_5
value: 45.966
- type: ndcg_at_1
value: 37.482
- type: ndcg_at_10
value: 47.676
- type: ndcg_at_100
value: 52.915
- type: ndcg_at_1000
value: 54.82900000000001
- type: ndcg_at_3
value: 42.562
- type: ndcg_at_5
value: 44.852
- type: precision_at_1
value: 37.482
- type: precision_at_10
value: 9.142
- type: precision_at_100
value: 1.436
- type: precision_at_1000
value: 0.189
- type: precision_at_3
value: 20.458000000000002
- type: precision_at_5
value: 14.821000000000002
- type: recall_at_1
value: 30.203999999999997
- type: recall_at_10
value: 60.343
- type: recall_at_100
value: 82.58
- type: recall_at_1000
value: 94.813
- type: recall_at_3
value: 45.389
- type: recall_at_5
value: 51.800999999999995
- type: map_at_1
value: 30.889
- type: map_at_10
value: 40.949999999999996
- type: map_at_100
value: 42.131
- type: map_at_1000
value: 42.253
- type: map_at_3
value: 38.346999999999994
- type: map_at_5
value: 39.782000000000004
- type: mrr_at_1
value: 38.79
- type: mrr_at_10
value: 46.944
- type: mrr_at_100
value: 47.61
- type: mrr_at_1000
value: 47.650999999999996
- type: mrr_at_3
value: 45.053
- type: mrr_at_5
value: 46.101
- type: ndcg_at_1
value: 38.79
- type: ndcg_at_10
value: 46.286
- type: ndcg_at_100
value: 50.637
- type: ndcg_at_1000
value: 52.649
- type: ndcg_at_3
value: 42.851
- type: ndcg_at_5
value: 44.311
- type: precision_at_1
value: 38.79
- type: precision_at_10
value: 8.516
- type: precision_at_100
value: 1.3679999999999999
- type: precision_at_1000
value: 0.183
- type: precision_at_3
value: 20.637
- type: precision_at_5
value: 14.318
- type: recall_at_1
value: 30.889
- type: recall_at_10
value: 55.327000000000005
- type: recall_at_100
value: 74.091
- type: recall_at_1000
value: 86.75500000000001
- type: recall_at_3
value: 44.557
- type: recall_at_5
value: 49.064
- type: map_at_1
value: 39.105000000000004
- type: map_at_10
value: 50.928
- type: map_at_100
value: 51.958000000000006
- type: map_at_1000
value: 52.017
- type: map_at_3
value: 47.638999999999996
- type: map_at_5
value: 49.624
- type: mrr_at_1
value: 44.639
- type: mrr_at_10
value: 54.261
- type: mrr_at_100
value: 54.913999999999994
- type: mrr_at_1000
value: 54.945
- type: mrr_at_3
value: 51.681999999999995
- type: mrr_at_5
value: 53.290000000000006
- type: ndcg_at_1
value: 44.639
- type: ndcg_at_10
value: 56.678
- type: ndcg_at_100
value: 60.649
- type: ndcg_at_1000
value: 61.855000000000004
- type: ndcg_at_3
value: 51.092999999999996
- type: ndcg_at_5
value: 54.096999999999994
- type: precision_at_1
value: 44.639
- type: precision_at_10
value: 9.028
- type: precision_at_100
value: 1.194
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 22.508
- type: precision_at_5
value: 15.661
- type: recall_at_1
value: 39.105000000000004
- type: recall_at_10
value: 70.367
- type: recall_at_100
value: 87.359
- type: recall_at_1000
value: 95.88
- type: recall_at_3
value: 55.581
- type: recall_at_5
value: 62.821000000000005
- type: map_at_1
value: 23.777
- type: map_at_10
value: 32.297
- type: map_at_100
value: 33.516
- type: map_at_1000
value: 33.592
- type: map_at_3
value: 30.001
- type: map_at_5
value: 31.209999999999997
- type: mrr_at_1
value: 25.989
- type: mrr_at_10
value: 34.472
- type: mrr_at_100
value: 35.518
- type: mrr_at_1000
value: 35.577
- type: mrr_at_3
value: 32.185
- type: mrr_at_5
value: 33.399
- type: ndcg_at_1
value: 25.989
- type: ndcg_at_10
value: 37.037
- type: ndcg_at_100
value: 42.699
- type: ndcg_at_1000
value: 44.725
- type: ndcg_at_3
value: 32.485
- type: ndcg_at_5
value: 34.549
- type: precision_at_1
value: 25.989
- type: precision_at_10
value: 5.718
- type: precision_at_100
value: 0.89
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 14.049
- type: precision_at_5
value: 9.672
- type: recall_at_1
value: 23.777
- type: recall_at_10
value: 49.472
- type: recall_at_100
value: 74.857
- type: recall_at_1000
value: 90.289
- type: recall_at_3
value: 37.086000000000006
- type: recall_at_5
value: 42.065999999999995
- type: map_at_1
value: 13.377
- type: map_at_10
value: 21.444
- type: map_at_100
value: 22.663
- type: map_at_1000
value: 22.8
- type: map_at_3
value: 18.857
- type: map_at_5
value: 20.426
- type: mrr_at_1
value: 16.542
- type: mrr_at_10
value: 25.326999999999998
- type: mrr_at_100
value: 26.323
- type: mrr_at_1000
value: 26.406000000000002
- type: mrr_at_3
value: 22.823
- type: mrr_at_5
value: 24.340999999999998
- type: ndcg_at_1
value: 16.542
- type: ndcg_at_10
value: 26.479000000000003
- type: ndcg_at_100
value: 32.29
- type: ndcg_at_1000
value: 35.504999999999995
- type: ndcg_at_3
value: 21.619
- type: ndcg_at_5
value: 24.19
- type: precision_at_1
value: 16.542
- type: precision_at_10
value: 5.075
- type: precision_at_100
value: 0.9339999999999999
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 10.697
- type: precision_at_5
value: 8.134
- type: recall_at_1
value: 13.377
- type: recall_at_10
value: 38.027
- type: recall_at_100
value: 63.439
- type: recall_at_1000
value: 86.354
- type: recall_at_3
value: 25.0
- type: recall_at_5
value: 31.306
- type: map_at_1
value: 28.368
- type: map_at_10
value: 39.305
- type: map_at_100
value: 40.637
- type: map_at_1000
value: 40.753
- type: map_at_3
value: 36.077999999999996
- type: map_at_5
value: 37.829
- type: mrr_at_1
value: 34.937000000000005
- type: mrr_at_10
value: 45.03
- type: mrr_at_100
value: 45.78
- type: mrr_at_1000
value: 45.827
- type: mrr_at_3
value: 42.348
- type: mrr_at_5
value: 43.807
- type: ndcg_at_1
value: 34.937000000000005
- type: ndcg_at_10
value: 45.605000000000004
- type: ndcg_at_100
value: 50.941
- type: ndcg_at_1000
value: 52.983000000000004
- type: ndcg_at_3
value: 40.366
- type: ndcg_at_5
value: 42.759
- type: precision_at_1
value: 34.937000000000005
- type: precision_at_10
value: 8.402
- type: precision_at_100
value: 1.2959999999999998
- type: precision_at_1000
value: 0.164
- type: precision_at_3
value: 19.217000000000002
- type: precision_at_5
value: 13.725000000000001
- type: recall_at_1
value: 28.368
- type: recall_at_10
value: 58.5
- type: recall_at_100
value: 80.67999999999999
- type: recall_at_1000
value: 93.925
- type: recall_at_3
value: 43.956
- type: recall_at_5
value: 50.065000000000005
- type: map_at_1
value: 24.851
- type: map_at_10
value: 34.758
- type: map_at_100
value: 36.081
- type: map_at_1000
value: 36.205999999999996
- type: map_at_3
value: 31.678
- type: map_at_5
value: 33.398
- type: mrr_at_1
value: 31.279
- type: mrr_at_10
value: 40.138
- type: mrr_at_100
value: 41.005
- type: mrr_at_1000
value: 41.065000000000005
- type: mrr_at_3
value: 37.519000000000005
- type: mrr_at_5
value: 38.986
- type: ndcg_at_1
value: 31.279
- type: ndcg_at_10
value: 40.534
- type: ndcg_at_100
value: 46.093
- type: ndcg_at_1000
value: 48.59
- type: ndcg_at_3
value: 35.473
- type: ndcg_at_5
value: 37.801
- type: precision_at_1
value: 31.279
- type: precision_at_10
value: 7.477
- type: precision_at_100
value: 1.2
- type: precision_at_1000
value: 0.159
- type: precision_at_3
value: 17.047
- type: precision_at_5
value: 12.306000000000001
- type: recall_at_1
value: 24.851
- type: recall_at_10
value: 52.528
- type: recall_at_100
value: 76.198
- type: recall_at_1000
value: 93.12
- type: recall_at_3
value: 38.257999999999996
- type: recall_at_5
value: 44.440000000000005
- type: map_at_1
value: 25.289833333333334
- type: map_at_10
value: 34.379333333333335
- type: map_at_100
value: 35.56916666666666
- type: map_at_1000
value: 35.68633333333333
- type: map_at_3
value: 31.63916666666666
- type: map_at_5
value: 33.18383333333334
- type: mrr_at_1
value: 30.081749999999996
- type: mrr_at_10
value: 38.53658333333333
- type: mrr_at_100
value: 39.37825
- type: mrr_at_1000
value: 39.43866666666666
- type: mrr_at_3
value: 36.19025
- type: mrr_at_5
value: 37.519749999999995
- type: ndcg_at_1
value: 30.081749999999996
- type: ndcg_at_10
value: 39.62041666666667
- type: ndcg_at_100
value: 44.74825
- type: ndcg_at_1000
value: 47.11366666666667
- type: ndcg_at_3
value: 35.000499999999995
- type: ndcg_at_5
value: 37.19283333333333
- type: precision_at_1
value: 30.081749999999996
- type: precision_at_10
value: 6.940249999999999
- type: precision_at_100
value: 1.1164166666666668
- type: precision_at_1000
value: 0.15025000000000002
- type: precision_at_3
value: 16.110416666666666
- type: precision_at_5
value: 11.474416666666668
- type: recall_at_1
value: 25.289833333333334
- type: recall_at_10
value: 51.01591666666667
- type: recall_at_100
value: 73.55275000000002
- type: recall_at_1000
value: 90.02666666666667
- type: recall_at_3
value: 38.15208333333334
- type: recall_at_5
value: 43.78458333333334
- type: map_at_1
value: 23.479
- type: map_at_10
value: 31.2
- type: map_at_100
value: 32.11
- type: map_at_1000
value: 32.214
- type: map_at_3
value: 29.093999999999998
- type: map_at_5
value: 30.415
- type: mrr_at_1
value: 26.840000000000003
- type: mrr_at_10
value: 34.153
- type: mrr_at_100
value: 34.971000000000004
- type: mrr_at_1000
value: 35.047
- type: mrr_at_3
value: 32.285000000000004
- type: mrr_at_5
value: 33.443
- type: ndcg_at_1
value: 26.840000000000003
- type: ndcg_at_10
value: 35.441
- type: ndcg_at_100
value: 40.150000000000006
- type: ndcg_at_1000
value: 42.74
- type: ndcg_at_3
value: 31.723000000000003
- type: ndcg_at_5
value: 33.71
- type: precision_at_1
value: 26.840000000000003
- type: precision_at_10
value: 5.552
- type: precision_at_100
value: 0.859
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 13.804
- type: precision_at_5
value: 9.600999999999999
- type: recall_at_1
value: 23.479
- type: recall_at_10
value: 45.442
- type: recall_at_100
value: 67.465
- type: recall_at_1000
value: 86.53
- type: recall_at_3
value: 35.315999999999995
- type: recall_at_5
value: 40.253
- type: map_at_1
value: 16.887
- type: map_at_10
value: 23.805
- type: map_at_100
value: 24.804000000000002
- type: map_at_1000
value: 24.932000000000002
- type: map_at_3
value: 21.632
- type: map_at_5
value: 22.845
- type: mrr_at_1
value: 20.75
- type: mrr_at_10
value: 27.686
- type: mrr_at_100
value: 28.522
- type: mrr_at_1000
value: 28.605000000000004
- type: mrr_at_3
value: 25.618999999999996
- type: mrr_at_5
value: 26.723999999999997
- type: ndcg_at_1
value: 20.75
- type: ndcg_at_10
value: 28.233000000000004
- type: ndcg_at_100
value: 33.065
- type: ndcg_at_1000
value: 36.138999999999996
- type: ndcg_at_3
value: 24.361
- type: ndcg_at_5
value: 26.111
- type: precision_at_1
value: 20.75
- type: precision_at_10
value: 5.124
- type: precision_at_100
value: 0.8750000000000001
- type: precision_at_1000
value: 0.131
- type: precision_at_3
value: 11.539000000000001
- type: precision_at_5
value: 8.273
- type: recall_at_1
value: 16.887
- type: recall_at_10
value: 37.774
- type: recall_at_100
value: 59.587
- type: recall_at_1000
value: 81.523
- type: recall_at_3
value: 26.837
- type: recall_at_5
value: 31.456
- type: map_at_1
value: 25.534000000000002
- type: map_at_10
value: 33.495999999999995
- type: map_at_100
value: 34.697
- type: map_at_1000
value: 34.805
- type: map_at_3
value: 31.22
- type: map_at_5
value: 32.277
- type: mrr_at_1
value: 29.944
- type: mrr_at_10
value: 37.723
- type: mrr_at_100
value: 38.645
- type: mrr_at_1000
value: 38.712999999999994
- type: mrr_at_3
value: 35.665
- type: mrr_at_5
value: 36.681999999999995
- type: ndcg_at_1
value: 29.944
- type: ndcg_at_10
value: 38.407000000000004
- type: ndcg_at_100
value: 43.877
- type: ndcg_at_1000
value: 46.312
- type: ndcg_at_3
value: 34.211000000000006
- type: ndcg_at_5
value: 35.760999999999996
- type: precision_at_1
value: 29.944
- type: precision_at_10
value: 6.343
- type: precision_at_100
value: 1.023
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 15.360999999999999
- type: precision_at_5
value: 10.428999999999998
- type: recall_at_1
value: 25.534000000000002
- type: recall_at_10
value: 49.204
- type: recall_at_100
value: 72.878
- type: recall_at_1000
value: 89.95
- type: recall_at_3
value: 37.533
- type: recall_at_5
value: 41.611
- type: map_at_1
value: 26.291999999999998
- type: map_at_10
value: 35.245
- type: map_at_100
value: 36.762
- type: map_at_1000
value: 36.983
- type: map_at_3
value: 32.439
- type: map_at_5
value: 33.964
- type: mrr_at_1
value: 31.423000000000002
- type: mrr_at_10
value: 39.98
- type: mrr_at_100
value: 40.791
- type: mrr_at_1000
value: 40.854
- type: mrr_at_3
value: 37.451
- type: mrr_at_5
value: 38.854
- type: ndcg_at_1
value: 31.423000000000002
- type: ndcg_at_10
value: 40.848
- type: ndcg_at_100
value: 46.35
- type: ndcg_at_1000
value: 49.166
- type: ndcg_at_3
value: 36.344
- type: ndcg_at_5
value: 38.36
- type: precision_at_1
value: 31.423000000000002
- type: precision_at_10
value: 7.767
- type: precision_at_100
value: 1.498
- type: precision_at_1000
value: 0.23700000000000002
- type: precision_at_3
value: 16.733
- type: precision_at_5
value: 12.213000000000001
- type: recall_at_1
value: 26.291999999999998
- type: recall_at_10
value: 51.184
- type: recall_at_100
value: 76.041
- type: recall_at_1000
value: 94.11500000000001
- type: recall_at_3
value: 38.257000000000005
- type: recall_at_5
value: 43.68
- type: map_at_1
value: 20.715
- type: map_at_10
value: 27.810000000000002
- type: map_at_100
value: 28.810999999999996
- type: map_at_1000
value: 28.904999999999998
- type: map_at_3
value: 25.069999999999997
- type: map_at_5
value: 26.793
- type: mrr_at_1
value: 22.366
- type: mrr_at_10
value: 29.65
- type: mrr_at_100
value: 30.615
- type: mrr_at_1000
value: 30.686999999999998
- type: mrr_at_3
value: 27.017999999999997
- type: mrr_at_5
value: 28.644
- type: ndcg_at_1
value: 22.366
- type: ndcg_at_10
value: 32.221
- type: ndcg_at_100
value: 37.313
- type: ndcg_at_1000
value: 39.871
- type: ndcg_at_3
value: 26.918
- type: ndcg_at_5
value: 29.813000000000002
- type: precision_at_1
value: 22.366
- type: precision_at_10
value: 5.139
- type: precision_at_100
value: 0.8240000000000001
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 11.275
- type: precision_at_5
value: 8.540000000000001
- type: recall_at_1
value: 20.715
- type: recall_at_10
value: 44.023
- type: recall_at_100
value: 67.458
- type: recall_at_1000
value: 87.066
- type: recall_at_3
value: 30.055
- type: recall_at_5
value: 36.852000000000004
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: 392b78eb68c07badcd7c2cd8f39af108375dfcce
metrics:
- type: map_at_1
value: 11.859
- type: map_at_10
value: 20.625
- type: map_at_100
value: 22.5
- type: map_at_1000
value: 22.689
- type: map_at_3
value: 16.991
- type: map_at_5
value: 18.781
- type: mrr_at_1
value: 26.906000000000002
- type: mrr_at_10
value: 39.083
- type: mrr_at_100
value: 39.978
- type: mrr_at_1000
value: 40.014
- type: mrr_at_3
value: 35.44
- type: mrr_at_5
value: 37.619
- type: ndcg_at_1
value: 26.906000000000002
- type: ndcg_at_10
value: 29.386000000000003
- type: ndcg_at_100
value: 36.510999999999996
- type: ndcg_at_1000
value: 39.814
- type: ndcg_at_3
value: 23.558
- type: ndcg_at_5
value: 25.557999999999996
- type: precision_at_1
value: 26.906000000000002
- type: precision_at_10
value: 9.342
- type: precision_at_100
value: 1.6969999999999998
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 17.503
- type: precision_at_5
value: 13.655000000000001
- type: recall_at_1
value: 11.859
- type: recall_at_10
value: 35.929
- type: recall_at_100
value: 60.21300000000001
- type: recall_at_1000
value: 78.606
- type: recall_at_3
value: 21.727
- type: recall_at_5
value: 27.349
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: f097057d03ed98220bc7309ddb10b71a54d667d6
metrics:
- type: map_at_1
value: 8.627
- type: map_at_10
value: 18.248
- type: map_at_100
value: 25.19
- type: map_at_1000
value: 26.741
- type: map_at_3
value: 13.286000000000001
- type: map_at_5
value: 15.126000000000001
- type: mrr_at_1
value: 64.75
- type: mrr_at_10
value: 71.865
- type: mrr_at_100
value: 72.247
- type: mrr_at_1000
value: 72.255
- type: mrr_at_3
value: 69.958
- type: mrr_at_5
value: 71.108
- type: ndcg_at_1
value: 53.25
- type: ndcg_at_10
value: 39.035
- type: ndcg_at_100
value: 42.735
- type: ndcg_at_1000
value: 50.166
- type: ndcg_at_3
value: 43.857
- type: ndcg_at_5
value: 40.579
- type: precision_at_1
value: 64.75
- type: precision_at_10
value: 30.75
- type: precision_at_100
value: 9.54
- type: precision_at_1000
value: 2.035
- type: precision_at_3
value: 47.333
- type: precision_at_5
value: 39.0
- type: recall_at_1
value: 8.627
- type: recall_at_10
value: 23.413
- type: recall_at_100
value: 48.037
- type: recall_at_1000
value: 71.428
- type: recall_at_3
value: 14.158999999999999
- type: recall_at_5
value: 17.002
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 829147f8f75a25f005913200eb5ed41fae320aa1
metrics:
- type: accuracy
value: 44.865
- type: f1
value: 41.56625743266997
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: 1429cf27e393599b8b359b9b72c666f96b2525f9
metrics:
- type: map_at_1
value: 57.335
- type: map_at_10
value: 68.29499999999999
- type: map_at_100
value: 68.69800000000001
- type: map_at_1000
value: 68.714
- type: map_at_3
value: 66.149
- type: map_at_5
value: 67.539
- type: mrr_at_1
value: 61.656
- type: mrr_at_10
value: 72.609
- type: mrr_at_100
value: 72.923
- type: mrr_at_1000
value: 72.928
- type: mrr_at_3
value: 70.645
- type: mrr_at_5
value: 71.938
- type: ndcg_at_1
value: 61.656
- type: ndcg_at_10
value: 73.966
- type: ndcg_at_100
value: 75.663
- type: ndcg_at_1000
value: 75.986
- type: ndcg_at_3
value: 69.959
- type: ndcg_at_5
value: 72.269
- type: precision_at_1
value: 61.656
- type: precision_at_10
value: 9.581000000000001
- type: precision_at_100
value: 1.054
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 27.743000000000002
- type: precision_at_5
value: 17.939
- type: recall_at_1
value: 57.335
- type: recall_at_10
value: 87.24300000000001
- type: recall_at_100
value: 94.575
- type: recall_at_1000
value: 96.75399999999999
- type: recall_at_3
value: 76.44800000000001
- type: recall_at_5
value: 82.122
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: 41b686a7f28c59bcaaa5791efd47c67c8ebe28be
metrics:
- type: map_at_1
value: 17.014000000000003
- type: map_at_10
value: 28.469
- type: map_at_100
value: 30.178
- type: map_at_1000
value: 30.369
- type: map_at_3
value: 24.63
- type: map_at_5
value: 26.891
- type: mrr_at_1
value: 34.259
- type: mrr_at_10
value: 43.042
- type: mrr_at_100
value: 43.91
- type: mrr_at_1000
value: 43.963
- type: mrr_at_3
value: 40.483999999999995
- type: mrr_at_5
value: 42.135
- type: ndcg_at_1
value: 34.259
- type: ndcg_at_10
value: 35.836
- type: ndcg_at_100
value: 42.488
- type: ndcg_at_1000
value: 45.902
- type: ndcg_at_3
value: 32.131
- type: ndcg_at_5
value: 33.697
- type: precision_at_1
value: 34.259
- type: precision_at_10
value: 10.0
- type: precision_at_100
value: 1.699
- type: precision_at_1000
value: 0.22999999999999998
- type: precision_at_3
value: 21.502
- type: precision_at_5
value: 16.296
- type: recall_at_1
value: 17.014000000000003
- type: recall_at_10
value: 42.832
- type: recall_at_100
value: 67.619
- type: recall_at_1000
value: 88.453
- type: recall_at_3
value: 29.537000000000003
- type: recall_at_5
value: 35.886
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: 766870b35a1b9ca65e67a0d1913899973551fc6c
metrics:
- type: map_at_1
value: 34.558
- type: map_at_10
value: 48.039
- type: map_at_100
value: 48.867
- type: map_at_1000
value: 48.941
- type: map_at_3
value: 45.403
- type: map_at_5
value: 46.983999999999995
- type: mrr_at_1
value: 69.11500000000001
- type: mrr_at_10
value: 75.551
- type: mrr_at_100
value: 75.872
- type: mrr_at_1000
value: 75.887
- type: mrr_at_3
value: 74.447
- type: mrr_at_5
value: 75.113
- type: ndcg_at_1
value: 69.11500000000001
- type: ndcg_at_10
value: 57.25599999999999
- type: ndcg_at_100
value: 60.417
- type: ndcg_at_1000
value: 61.976
- type: ndcg_at_3
value: 53.258
- type: ndcg_at_5
value: 55.374
- type: precision_at_1
value: 69.11500000000001
- type: precision_at_10
value: 11.689
- type: precision_at_100
value: 1.418
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 33.018
- type: precision_at_5
value: 21.488
- type: recall_at_1
value: 34.558
- type: recall_at_10
value: 58.447
- type: recall_at_100
value: 70.91199999999999
- type: recall_at_1000
value: 81.31
- type: recall_at_3
value: 49.527
- type: recall_at_5
value: 53.72
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 8d743909f834c38949e8323a8a6ce8721ea6c7f4
metrics:
- type: accuracy
value: 61.772000000000006
- type: ap
value: 57.48217702943605
- type: f1
value: 61.20495351356274
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: validation
revision: e6838a846e2408f22cf5cc337ebc83e0bcf77849
metrics:
- type: map_at_1
value: 22.044
- type: map_at_10
value: 34.211000000000006
- type: map_at_100
value: 35.394
- type: map_at_1000
value: 35.443000000000005
- type: map_at_3
value: 30.318
- type: map_at_5
value: 32.535
- type: mrr_at_1
value: 22.722
- type: mrr_at_10
value: 34.842
- type: mrr_at_100
value: 35.954
- type: mrr_at_1000
value: 35.997
- type: mrr_at_3
value: 30.991000000000003
- type: mrr_at_5
value: 33.2
- type: ndcg_at_1
value: 22.722
- type: ndcg_at_10
value: 41.121
- type: ndcg_at_100
value: 46.841
- type: ndcg_at_1000
value: 48.049
- type: ndcg_at_3
value: 33.173
- type: ndcg_at_5
value: 37.145
- type: precision_at_1
value: 22.722
- type: precision_at_10
value: 6.516
- type: precision_at_100
value: 0.9400000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.093
- type: precision_at_5
value: 10.473
- type: recall_at_1
value: 22.044
- type: recall_at_10
value: 62.382000000000005
- type: recall_at_100
value: 88.914
- type: recall_at_1000
value: 98.099
- type: recall_at_3
value: 40.782000000000004
- type: recall_at_5
value: 50.322
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 93.68217054263563
- type: f1
value: 93.25810075739523
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 82.05409974640745
- type: f1
value: 80.42814140324903
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 93.54903268845896
- type: f1
value: 92.8909878077932
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 90.98340119010334
- type: f1
value: 90.51522537281313
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 89.33309429903191
- type: f1
value: 88.60371305209185
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: a7e2a951126a26fc8c6a69f835f33a346ba259e3
metrics:
- type: accuracy
value: 60.4882459312839
- type: f1
value: 59.02590456131682
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 71.34290925672595
- type: f1
value: 54.44803151449109
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 61.92448577063963
- type: f1
value: 43.125939975781854
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 74.48965977318213
- type: f1
value: 51.855353687466696
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 69.11994989038521
- type: f1
value: 50.57872704171278
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 64.84761563284331
- type: f1
value: 43.61322970761394
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: 6299947a7777084cc2d4b64235bf7190381ce755
metrics:
- type: accuracy
value: 49.35623869801085
- type: f1
value: 33.48547326952042
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 47.85474108944183
- type: f1
value: 46.50175016795915
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 33.29858776059179
- type: f1
value: 31.803027601259082
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 59.24680564895763
- type: f1
value: 57.037691806846865
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 45.23537323470073
- type: f1
value: 44.81126398428613
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 61.590450571620714
- type: f1
value: 59.247442149977104
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.9226630800269
- type: f1
value: 44.076183379991654
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 51.23066577000672
- type: f1
value: 50.20719330417618
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 56.0995292535306
- type: f1
value: 53.29421532133969
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 46.12642905178211
- type: f1
value: 44.441530267639635
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 69.67047747141896
- type: f1
value: 68.38493366054783
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 66.3483523873571
- type: f1
value: 65.13046416817832
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 51.20040349697378
- type: f1
value: 49.02889836601541
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 45.33288500336248
- type: f1
value: 42.91893101970983
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 66.95359784801613
- type: f1
value: 64.98788914810562
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 43.18090114324143
- type: f1
value: 41.31250407417542
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 63.54068594485541
- type: f1
value: 61.94829361488948
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.7343644922663
- type: f1
value: 43.23001702247849
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 38.1271015467384
- type: f1
value: 36.94700198241727
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 64.05514458641561
- type: f1
value: 62.35033731674541
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.351042367182245
- type: f1
value: 43.13370397574502
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 60.77000672494955
- type: f1
value: 59.71546868957779
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 61.22057834566241
- type: f1
value: 59.447639306287044
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.9448554135844
- type: f1
value: 48.524338247875214
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 33.8399462004035
- type: f1
value: 33.518999997305535
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 37.34028244788165
- type: f1
value: 35.6156599064704
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 53.544048419636844
- type: f1
value: 51.29299915455352
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 53.35574983187625
- type: f1
value: 51.463936565192945
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 46.503026227303295
- type: f1
value: 46.049497734375514
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 58.268325487558826
- type: f1
value: 56.10849656896158
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 40.27572293207801
- type: f1
value: 40.20097238549224
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 59.64694014794889
- type: f1
value: 58.39584148789066
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 37.41761936785474
- type: f1
value: 35.04551731363685
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 49.408204438466704
- type: f1
value: 48.39369057638714
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 52.09482178883659
- type: f1
value: 49.91518031712698
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.477471418964356
- type: f1
value: 48.429495257184705
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 66.69468728984532
- type: f1
value: 65.40306868707009
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.52790854068594
- type: f1
value: 49.780400354514
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 58.31540013449899
- type: f1
value: 56.144142926685134
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 47.74041694687289
- type: f1
value: 46.16767322761359
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 48.94418291862811
- type: f1
value: 48.445352284756325
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.78681909885676
- type: f1
value: 49.64882295494536
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 49.811701412239415
- type: f1
value: 48.213234514449375
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 56.39542703429725
- type: f1
value: 54.031981085233795
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 54.71082716879623
- type: f1
value: 52.513144113474596
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 44.425016812373904
- type: f1
value: 43.96016300057656
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 50.205110961667785
- type: f1
value: 48.86669996798709
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 46.56355077336921
- type: f1
value: 45.18252022585022
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 56.748486886348346
- type: f1
value: 54.29884570375382
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 64.52589105581708
- type: f1
value: 62.97947342861603
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 67.06792199058508
- type: f1
value: 65.36025601634017
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 072a486a144adf7f4479a4a0dddb2152e161e1ea
metrics:
- type: accuracy
value: 62.89172831203766
- type: f1
value: 62.69803707054342
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.47276395427035
- type: f1
value: 49.37463208130799
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 34.86886348352387
- type: f1
value: 33.74178074349636
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.20511096166778
- type: f1
value: 65.85812500602437
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 45.578345662407536
- type: f1
value: 44.44514917028003
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.29657027572293
- type: f1
value: 67.24477523937466
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 46.29455279085407
- type: f1
value: 43.8563839951935
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 53.52387357094821
- type: f1
value: 51.70977848027552
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.741761936785466
- type: f1
value: 60.219169644792295
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.957632817753876
- type: f1
value: 46.878428264460034
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.33624747814393
- type: f1
value: 75.9143846211171
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.34229993275049
- type: f1
value: 73.78165397558983
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 53.174176193678555
- type: f1
value: 51.709679227778985
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.6906523201076
- type: f1
value: 41.54881682785664
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.9119031607263
- type: f1
value: 73.2742013056326
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 43.10356422326832
- type: f1
value: 40.8859122581252
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.27370544720914
- type: f1
value: 69.39544506405082
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 45.16476126429052
- type: f1
value: 42.74022531579054
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.73234700739744
- type: f1
value: 37.40546754951026
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.12777404169468
- type: f1
value: 70.27219152812738
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.21318090114325
- type: f1
value: 41.934593213829366
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.57162071284466
- type: f1
value: 64.83341759045335
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.75991930060525
- type: f1
value: 65.16549875504951
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.79488903833223
- type: f1
value: 54.03616401426859
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 32.992602555480836
- type: f1
value: 31.820068470018846
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 39.34431741761937
- type: f1
value: 36.436221665290105
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.501008742434436
- type: f1
value: 60.051013712579085
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 55.689307330195035
- type: f1
value: 53.94058032286942
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 44.351042367182245
- type: f1
value: 42.05421666771541
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.53127101546738
- type: f1
value: 65.98462024333497
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 38.71553463349025
- type: f1
value: 37.44327037149584
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.98991257565567
- type: f1
value: 63.87720198978004
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 36.839273705447205
- type: f1
value: 35.233967279698376
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.79892400806993
- type: f1
value: 49.66926632125972
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 56.31809011432415
- type: f1
value: 53.832185336179826
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 49.979825151311374
- type: f1
value: 48.83013175441888
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.45595158036315
- type: f1
value: 72.08708814699702
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 53.68527236045729
- type: f1
value: 52.23278593929981
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.60390047074647
- type: f1
value: 60.50391482195116
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.036314727639535
- type: f1
value: 46.43480413383716
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 50.05716207128445
- type: f1
value: 48.85821859948888
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 51.728312037659705
- type: f1
value: 49.89292996950847
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.21990585070613
- type: f1
value: 52.8711542984193
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.770679219905844
- type: f1
value: 63.09441501491594
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.58574310692671
- type: f1
value: 61.61370697612978
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 45.17821116341628
- type: f1
value: 43.85143229183324
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.064559515803644
- type: f1
value: 50.94356892049626
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 47.205783456624076
- type: f1
value: 47.04223644120489
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.25689307330195
- type: f1
value: 63.89944944984115
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.60524546065905
- type: f1
value: 71.5634157334358
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.95427034297242
- type: f1
value: 74.39706882311063
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.29926025554808
- type: f1
value: 71.32045932560297
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: dcefc037ef84348e49b0d29109e891c01067226b
metrics:
- type: v_measure
value: 31.054474964883806
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 3cd0e71dfbe09d4de0f9e5ecba43e7ce280959dc
metrics:
- type: v_measure
value: 29.259725940477523
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.785007883256572
- type: mrr
value: 32.983556622438456
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: 7eb63cc0c1eb59324d709ebed25fcab851fa7610
metrics:
- type: map_at_1
value: 5.742
- type: map_at_10
value: 13.074
- type: map_at_100
value: 16.716
- type: map_at_1000
value: 18.238
- type: map_at_3
value: 9.600999999999999
- type: map_at_5
value: 11.129999999999999
- type: mrr_at_1
value: 47.988
- type: mrr_at_10
value: 55.958
- type: mrr_at_100
value: 56.58800000000001
- type: mrr_at_1000
value: 56.620000000000005
- type: mrr_at_3
value: 54.025
- type: mrr_at_5
value: 55.31
- type: ndcg_at_1
value: 46.44
- type: ndcg_at_10
value: 35.776
- type: ndcg_at_100
value: 32.891999999999996
- type: ndcg_at_1000
value: 41.835
- type: ndcg_at_3
value: 41.812
- type: ndcg_at_5
value: 39.249
- type: precision_at_1
value: 48.297000000000004
- type: precision_at_10
value: 26.687
- type: precision_at_100
value: 8.511000000000001
- type: precision_at_1000
value: 2.128
- type: precision_at_3
value: 39.009
- type: precision_at_5
value: 33.994
- type: recall_at_1
value: 5.742
- type: recall_at_10
value: 16.993
- type: recall_at_100
value: 33.69
- type: recall_at_1000
value: 66.75
- type: recall_at_3
value: 10.817
- type: recall_at_5
value: 13.256
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: 6062aefc120bfe8ece5897809fb2e53bfe0d128c
metrics:
- type: map_at_1
value: 30.789
- type: map_at_10
value: 45.751999999999995
- type: map_at_100
value: 46.766000000000005
- type: map_at_1000
value: 46.798
- type: map_at_3
value: 41.746
- type: map_at_5
value: 44.046
- type: mrr_at_1
value: 34.618
- type: mrr_at_10
value: 48.288
- type: mrr_at_100
value: 49.071999999999996
- type: mrr_at_1000
value: 49.094
- type: mrr_at_3
value: 44.979
- type: mrr_at_5
value: 46.953
- type: ndcg_at_1
value: 34.589
- type: ndcg_at_10
value: 53.151
- type: ndcg_at_100
value: 57.537000000000006
- type: ndcg_at_1000
value: 58.321999999999996
- type: ndcg_at_3
value: 45.628
- type: ndcg_at_5
value: 49.474000000000004
- type: precision_at_1
value: 34.589
- type: precision_at_10
value: 8.731
- type: precision_at_100
value: 1.119
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 20.819
- type: precision_at_5
value: 14.728
- type: recall_at_1
value: 30.789
- type: recall_at_10
value: 73.066
- type: recall_at_100
value: 92.27
- type: recall_at_1000
value: 98.18
- type: recall_at_3
value: 53.632999999999996
- type: recall_at_5
value: 62.476
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: 6205996560df11e3a3da9ab4f926788fc30a7db4
metrics:
- type: map_at_1
value: 54.993
- type: map_at_10
value: 69.07600000000001
- type: map_at_100
value: 70.05799999999999
- type: map_at_1000
value: 70.09
- type: map_at_3
value: 65.456
- type: map_at_5
value: 67.622
- type: mrr_at_1
value: 63.07000000000001
- type: mrr_at_10
value: 72.637
- type: mrr_at_100
value: 73.029
- type: mrr_at_1000
value: 73.033
- type: mrr_at_3
value: 70.572
- type: mrr_at_5
value: 71.86399999999999
- type: ndcg_at_1
value: 63.07000000000001
- type: ndcg_at_10
value: 74.708
- type: ndcg_at_100
value: 77.579
- type: ndcg_at_1000
value: 77.897
- type: ndcg_at_3
value: 69.69999999999999
- type: ndcg_at_5
value: 72.321
- type: precision_at_1
value: 63.07000000000001
- type: precision_at_10
value: 11.851
- type: precision_at_100
value: 1.481
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 30.747000000000003
- type: precision_at_5
value: 20.830000000000002
- type: recall_at_1
value: 54.993
- type: recall_at_10
value: 87.18900000000001
- type: recall_at_100
value: 98.137
- type: recall_at_1000
value: 99.833
- type: recall_at_3
value: 73.654
- type: recall_at_5
value: 80.36
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: b2805658ae38990172679479369a78b86de8c390
metrics:
- type: v_measure
value: 35.53178375429036
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: v_measure
value: 54.520782970558265
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: 5c59ef3e437a0a9651c8fe6fde943e7dce59fba5
metrics:
- type: map_at_1
value: 4.3229999999999995
- type: map_at_10
value: 10.979999999999999
- type: map_at_100
value: 12.867
- type: map_at_1000
value: 13.147
- type: map_at_3
value: 7.973
- type: map_at_5
value: 9.513
- type: mrr_at_1
value: 21.3
- type: mrr_at_10
value: 32.34
- type: mrr_at_100
value: 33.428999999999995
- type: mrr_at_1000
value: 33.489999999999995
- type: mrr_at_3
value: 28.999999999999996
- type: mrr_at_5
value: 31.019999999999996
- type: ndcg_at_1
value: 21.3
- type: ndcg_at_10
value: 18.619
- type: ndcg_at_100
value: 26.108999999999998
- type: ndcg_at_1000
value: 31.253999999999998
- type: ndcg_at_3
value: 17.842
- type: ndcg_at_5
value: 15.673
- type: precision_at_1
value: 21.3
- type: precision_at_10
value: 9.55
- type: precision_at_100
value: 2.0340000000000003
- type: precision_at_1000
value: 0.327
- type: precision_at_3
value: 16.667
- type: precision_at_5
value: 13.76
- type: recall_at_1
value: 4.3229999999999995
- type: recall_at_10
value: 19.387
- type: recall_at_100
value: 41.307
- type: recall_at_1000
value: 66.475
- type: recall_at_3
value: 10.143
- type: recall_at_5
value: 14.007
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cos_sim_pearson
value: 78.77975189382573
- type: cos_sim_spearman
value: 69.81522686267631
- type: euclidean_pearson
value: 71.37617936889518
- type: euclidean_spearman
value: 65.71738481148611
- type: manhattan_pearson
value: 71.58222165832424
- type: manhattan_spearman
value: 65.86851365286654
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: fdf84275bb8ce4b49c971d02e84dd1abc677a50f
metrics:
- type: cos_sim_pearson
value: 77.75509450443367
- type: cos_sim_spearman
value: 69.66180222442091
- type: euclidean_pearson
value: 74.98512779786111
- type: euclidean_spearman
value: 69.5997451409469
- type: manhattan_pearson
value: 75.50135090962459
- type: manhattan_spearman
value: 69.94984748475302
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 1591bfcbe8c69d4bf7fe2a16e2451017832cafb9
metrics:
- type: cos_sim_pearson
value: 79.42363892383264
- type: cos_sim_spearman
value: 79.66529244176742
- type: euclidean_pearson
value: 79.50429208135942
- type: euclidean_spearman
value: 80.44767586416276
- type: manhattan_pearson
value: 79.58563944997708
- type: manhattan_spearman
value: 80.51452267103
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: e2125984e7df8b7871f6ae9949cf6b6795e7c54b
metrics:
- type: cos_sim_pearson
value: 79.2749401478149
- type: cos_sim_spearman
value: 74.6076920702392
- type: euclidean_pearson
value: 73.3302002952881
- type: euclidean_spearman
value: 70.67029803077013
- type: manhattan_pearson
value: 73.52699344010296
- type: manhattan_spearman
value: 70.8517556194297
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: 1cd7298cac12a96a373b6a2f18738bb3e739a9b6
metrics:
- type: cos_sim_pearson
value: 83.20884740785921
- type: cos_sim_spearman
value: 83.80600789090722
- type: euclidean_pearson
value: 74.9154089816344
- type: euclidean_spearman
value: 75.69243899592276
- type: manhattan_pearson
value: 75.0312832634451
- type: manhattan_spearman
value: 75.78324960357642
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 360a0b2dff98700d09e634a01e1cc1624d3e42cd
metrics:
- type: cos_sim_pearson
value: 79.63194141000497
- type: cos_sim_spearman
value: 80.40118418350866
- type: euclidean_pearson
value: 72.07354384551088
- type: euclidean_spearman
value: 72.28819150373845
- type: manhattan_pearson
value: 72.08736119834145
- type: manhattan_spearman
value: 72.28347083261288
- task:
type: STS
dataset:
name: MTEB STS17 (ko-ko)
type: mteb/sts17-crosslingual-sts
config: ko-ko
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 66.78512789499386
- type: cos_sim_spearman
value: 66.89125587193288
- type: euclidean_pearson
value: 58.74535708627959
- type: euclidean_spearman
value: 59.62103716794647
- type: manhattan_pearson
value: 59.00494529143961
- type: manhattan_spearman
value: 59.832257846799806
- task:
type: STS
dataset:
name: MTEB STS17 (ar-ar)
type: mteb/sts17-crosslingual-sts
config: ar-ar
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 75.48960503523992
- type: cos_sim_spearman
value: 76.4223037534204
- type: euclidean_pearson
value: 64.93966381820944
- type: euclidean_spearman
value: 62.39697395373789
- type: manhattan_pearson
value: 65.54480770061505
- type: manhattan_spearman
value: 62.944204863043105
- task:
type: STS
dataset:
name: MTEB STS17 (en-ar)
type: mteb/sts17-crosslingual-sts
config: en-ar
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 77.7331440643619
- type: cos_sim_spearman
value: 78.0748413292835
- type: euclidean_pearson
value: 38.533108233460304
- type: euclidean_spearman
value: 35.37638615280026
- type: manhattan_pearson
value: 41.0639726746513
- type: manhattan_spearman
value: 37.688161243671765
- task:
type: STS
dataset:
name: MTEB STS17 (en-de)
type: mteb/sts17-crosslingual-sts
config: en-de
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 58.4628923720782
- type: cos_sim_spearman
value: 59.10093128795948
- type: euclidean_pearson
value: 30.422902393436836
- type: euclidean_spearman
value: 27.837806030497457
- type: manhattan_pearson
value: 32.51576984630963
- type: manhattan_spearman
value: 29.181887010982514
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 86.87447904613737
- type: cos_sim_spearman
value: 87.06554974065622
- type: euclidean_pearson
value: 76.82669047851108
- type: euclidean_spearman
value: 75.45711985511991
- type: manhattan_pearson
value: 77.46644556452847
- type: manhattan_spearman
value: 76.0249120007112
- task:
type: STS
dataset:
name: MTEB STS17 (en-tr)
type: mteb/sts17-crosslingual-sts
config: en-tr
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 17.784495723497468
- type: cos_sim_spearman
value: 11.79629537128697
- type: euclidean_pearson
value: -4.354328445994008
- type: euclidean_spearman
value: -6.984566116230058
- type: manhattan_pearson
value: -4.166751901507852
- type: manhattan_spearman
value: -6.984143198323786
- task:
type: STS
dataset:
name: MTEB STS17 (es-en)
type: mteb/sts17-crosslingual-sts
config: es-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 76.9009642643449
- type: cos_sim_spearman
value: 78.21764726338341
- type: euclidean_pearson
value: 50.578959144342925
- type: euclidean_spearman
value: 51.664379260719606
- type: manhattan_pearson
value: 53.95690880393329
- type: manhattan_spearman
value: 54.910058464050785
- task:
type: STS
dataset:
name: MTEB STS17 (es-es)
type: mteb/sts17-crosslingual-sts
config: es-es
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 86.41638022270219
- type: cos_sim_spearman
value: 86.00477030366811
- type: euclidean_pearson
value: 79.7224037788285
- type: euclidean_spearman
value: 79.21417626867616
- type: manhattan_pearson
value: 80.29412412756984
- type: manhattan_spearman
value: 79.49460867616206
- task:
type: STS
dataset:
name: MTEB STS17 (fr-en)
type: mteb/sts17-crosslingual-sts
config: fr-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 79.90432664091082
- type: cos_sim_spearman
value: 80.46007940700204
- type: euclidean_pearson
value: 49.25348015214428
- type: euclidean_spearman
value: 47.13113020475859
- type: manhattan_pearson
value: 54.57291204043908
- type: manhattan_spearman
value: 51.98559736896087
- task:
type: STS
dataset:
name: MTEB STS17 (it-en)
type: mteb/sts17-crosslingual-sts
config: it-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 52.55164822309034
- type: cos_sim_spearman
value: 51.57629192137736
- type: euclidean_pearson
value: 16.63360593235354
- type: euclidean_spearman
value: 14.479679923782912
- type: manhattan_pearson
value: 18.524867185117472
- type: manhattan_spearman
value: 16.65940056664755
- task:
type: STS
dataset:
name: MTEB STS17 (nl-en)
type: mteb/sts17-crosslingual-sts
config: nl-en
split: test
revision: 9fc37e8c632af1c87a3d23e685d49552a02582a0
metrics:
- type: cos_sim_pearson
value: 46.83690919715875
- type: cos_sim_spearman
value: 45.84993650002922
- type: euclidean_pearson
value: 6.173128686815117
- type: euclidean_spearman
value: 6.260781946306191
- type: manhattan_pearson
value: 7.328440452367316
- type: manhattan_spearman
value: 7.370842306497447
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 64.97916914277232
- type: cos_sim_spearman
value: 66.13392188807865
- type: euclidean_pearson
value: 65.3921146908468
- type: euclidean_spearman
value: 65.8381588635056
- type: manhattan_pearson
value: 65.8866165769975
- type: manhattan_spearman
value: 66.27774050472219
- task:
type: STS
dataset:
name: MTEB STS22 (de)
type: mteb/sts22-crosslingual-sts
config: de
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 25.605130445111545
- type: cos_sim_spearman
value: 30.054844562369254
- type: euclidean_pearson
value: 23.890611005408196
- type: euclidean_spearman
value: 29.07902600726761
- type: manhattan_pearson
value: 24.239478426621833
- type: manhattan_spearman
value: 29.48547576782375
- task:
type: STS
dataset:
name: MTEB STS22 (es)
type: mteb/sts22-crosslingual-sts
config: es
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 61.6665616159781
- type: cos_sim_spearman
value: 65.41310206289988
- type: euclidean_pearson
value: 68.38805493215008
- type: euclidean_spearman
value: 65.22777377603435
- type: manhattan_pearson
value: 69.37445390454346
- type: manhattan_spearman
value: 66.02437701858754
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 15.302891825626372
- type: cos_sim_spearman
value: 31.134517255070097
- type: euclidean_pearson
value: 12.672592658843143
- type: euclidean_spearman
value: 29.14881036784207
- type: manhattan_pearson
value: 13.528545327757735
- type: manhattan_spearman
value: 29.56217928148797
- task:
type: STS
dataset:
name: MTEB STS22 (tr)
type: mteb/sts22-crosslingual-sts
config: tr
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 28.79299114515319
- type: cos_sim_spearman
value: 47.135864983626206
- type: euclidean_pearson
value: 40.66410787594309
- type: euclidean_spearman
value: 45.09585593138228
- type: manhattan_pearson
value: 42.02561630700308
- type: manhattan_spearman
value: 45.43979983670554
- task:
type: STS
dataset:
name: MTEB STS22 (ar)
type: mteb/sts22-crosslingual-sts
config: ar
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 46.00096625052943
- type: cos_sim_spearman
value: 58.67147426715496
- type: euclidean_pearson
value: 54.7154367422438
- type: euclidean_spearman
value: 59.003235142442634
- type: manhattan_pearson
value: 56.3116235357115
- type: manhattan_spearman
value: 60.12956331404423
- task:
type: STS
dataset:
name: MTEB STS22 (ru)
type: mteb/sts22-crosslingual-sts
config: ru
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 29.3396354650316
- type: cos_sim_spearman
value: 43.3632935734809
- type: euclidean_pearson
value: 31.18506539466593
- type: euclidean_spearman
value: 37.531745324803815
- type: manhattan_pearson
value: 32.829038232529015
- type: manhattan_spearman
value: 38.04574361589953
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 62.9596148375188
- type: cos_sim_spearman
value: 66.77653412402461
- type: euclidean_pearson
value: 64.53156585980886
- type: euclidean_spearman
value: 66.2884373036083
- type: manhattan_pearson
value: 65.2831035495143
- type: manhattan_spearman
value: 66.83641945244322
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 79.9138821493919
- type: cos_sim_spearman
value: 80.38097535004677
- type: euclidean_pearson
value: 76.2401499094322
- type: euclidean_spearman
value: 77.00897050735907
- type: manhattan_pearson
value: 76.69531453728563
- type: manhattan_spearman
value: 77.83189696428695
- task:
type: STS
dataset:
name: MTEB STS22 (de-en)
type: mteb/sts22-crosslingual-sts
config: de-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 51.27009640779202
- type: cos_sim_spearman
value: 51.16120562029285
- type: euclidean_pearson
value: 52.20594985566323
- type: euclidean_spearman
value: 52.75331049709882
- type: manhattan_pearson
value: 52.2725118792549
- type: manhattan_spearman
value: 53.614847968995115
- task:
type: STS
dataset:
name: MTEB STS22 (es-en)
type: mteb/sts22-crosslingual-sts
config: es-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 70.46044814118835
- type: cos_sim_spearman
value: 75.05760236668672
- type: euclidean_pearson
value: 72.80128921879461
- type: euclidean_spearman
value: 73.81164755219257
- type: manhattan_pearson
value: 72.7863795809044
- type: manhattan_spearman
value: 73.65932033818906
- task:
type: STS
dataset:
name: MTEB STS22 (it)
type: mteb/sts22-crosslingual-sts
config: it
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 61.89276840435938
- type: cos_sim_spearman
value: 65.65042955732055
- type: euclidean_pearson
value: 61.22969491863841
- type: euclidean_spearman
value: 63.451215637904724
- type: manhattan_pearson
value: 61.16138956945465
- type: manhattan_spearman
value: 63.34966179331079
- task:
type: STS
dataset:
name: MTEB STS22 (pl-en)
type: mteb/sts22-crosslingual-sts
config: pl-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 56.377577221753626
- type: cos_sim_spearman
value: 53.31223653270353
- type: euclidean_pearson
value: 26.488793041564307
- type: euclidean_spearman
value: 19.524551741701472
- type: manhattan_pearson
value: 24.322868054606474
- type: manhattan_spearman
value: 19.50371443994939
- task:
type: STS
dataset:
name: MTEB STS22 (zh-en)
type: mteb/sts22-crosslingual-sts
config: zh-en
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 69.3634693673425
- type: cos_sim_spearman
value: 68.45051245419702
- type: euclidean_pearson
value: 56.1417414374769
- type: euclidean_spearman
value: 55.89891749631458
- type: manhattan_pearson
value: 57.266417430882925
- type: manhattan_spearman
value: 56.57927102744128
- task:
type: STS
dataset:
name: MTEB STS22 (es-it)
type: mteb/sts22-crosslingual-sts
config: es-it
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 60.04169437653179
- type: cos_sim_spearman
value: 65.49531007553446
- type: euclidean_pearson
value: 58.583860732586324
- type: euclidean_spearman
value: 58.80034792537441
- type: manhattan_pearson
value: 59.02513161664622
- type: manhattan_spearman
value: 58.42942047904558
- task:
type: STS
dataset:
name: MTEB STS22 (de-fr)
type: mteb/sts22-crosslingual-sts
config: de-fr
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 48.81035211493999
- type: cos_sim_spearman
value: 53.27599246786967
- type: euclidean_pearson
value: 52.25710699032889
- type: euclidean_spearman
value: 55.22995695529873
- type: manhattan_pearson
value: 51.894901893217884
- type: manhattan_spearman
value: 54.95919975149795
- task:
type: STS
dataset:
name: MTEB STS22 (de-pl)
type: mteb/sts22-crosslingual-sts
config: de-pl
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 36.75993101477816
- type: cos_sim_spearman
value: 43.050156692479355
- type: euclidean_pearson
value: 51.49021084746248
- type: euclidean_spearman
value: 49.54771253090078
- type: manhattan_pearson
value: 54.68410760796417
- type: manhattan_spearman
value: 48.19277197691717
- task:
type: STS
dataset:
name: MTEB STS22 (fr-pl)
type: mteb/sts22-crosslingual-sts
config: fr-pl
split: test
revision: 2de6ce8c1921b71a755b262c6b57fef195dd7906
metrics:
- type: cos_sim_pearson
value: 48.553763306386486
- type: cos_sim_spearman
value: 28.17180849095055
- type: euclidean_pearson
value: 17.50739087826514
- type: euclidean_spearman
value: 16.903085094570333
- type: manhattan_pearson
value: 20.750046512534112
- type: manhattan_spearman
value: 5.634361698190111
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: 8913289635987208e6e7c72789e4be2fe94b6abd
metrics:
- type: cos_sim_pearson
value: 82.17107190594417
- type: cos_sim_spearman
value: 80.89611873505183
- type: euclidean_pearson
value: 71.82491561814403
- type: euclidean_spearman
value: 70.33608835403274
- type: manhattan_pearson
value: 71.89538332420133
- type: manhattan_spearman
value: 70.36082395775944
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: 56a6d0140cf6356659e2a7c1413286a774468d44
metrics:
- type: map
value: 79.77047154974562
- type: mrr
value: 94.25887021475256
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: a75ae049398addde9b70f6b268875f5cbce99089
metrics:
- type: map_at_1
value: 56.328
- type: map_at_10
value: 67.167
- type: map_at_100
value: 67.721
- type: map_at_1000
value: 67.735
- type: map_at_3
value: 64.20400000000001
- type: map_at_5
value: 65.904
- type: mrr_at_1
value: 59.667
- type: mrr_at_10
value: 68.553
- type: mrr_at_100
value: 68.992
- type: mrr_at_1000
value: 69.004
- type: mrr_at_3
value: 66.22200000000001
- type: mrr_at_5
value: 67.739
- type: ndcg_at_1
value: 59.667
- type: ndcg_at_10
value: 72.111
- type: ndcg_at_100
value: 74.441
- type: ndcg_at_1000
value: 74.90599999999999
- type: ndcg_at_3
value: 67.11399999999999
- type: ndcg_at_5
value: 69.687
- type: precision_at_1
value: 59.667
- type: precision_at_10
value: 9.733
- type: precision_at_100
value: 1.09
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.444000000000003
- type: precision_at_5
value: 17.599999999999998
- type: recall_at_1
value: 56.328
- type: recall_at_10
value: 85.8
- type: recall_at_100
value: 96.167
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 72.433
- type: recall_at_5
value: 78.972
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: 5a8256d0dff9c4bd3be3ba3e67e4e70173f802ea
metrics:
- type: cos_sim_accuracy
value: 99.8019801980198
- type: cos_sim_ap
value: 94.92527097094644
- type: cos_sim_f1
value: 89.91935483870968
- type: cos_sim_precision
value: 90.65040650406505
- type: cos_sim_recall
value: 89.2
- type: dot_accuracy
value: 99.51782178217822
- type: dot_ap
value: 81.30756869559929
- type: dot_f1
value: 75.88235294117648
- type: dot_precision
value: 74.42307692307692
- type: dot_recall
value: 77.4
- type: euclidean_accuracy
value: 99.73069306930694
- type: euclidean_ap
value: 91.05040371796932
- type: euclidean_f1
value: 85.7889237199582
- type: euclidean_precision
value: 89.82494529540482
- type: euclidean_recall
value: 82.1
- type: manhattan_accuracy
value: 99.73762376237623
- type: manhattan_ap
value: 91.4823412839869
- type: manhattan_f1
value: 86.39836984207845
- type: manhattan_precision
value: 88.05815160955348
- type: manhattan_recall
value: 84.8
- type: max_accuracy
value: 99.8019801980198
- type: max_ap
value: 94.92527097094644
- type: max_f1
value: 89.91935483870968
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 70a89468f6dccacc6aa2b12a6eac54e74328f235
metrics:
- type: v_measure
value: 55.13046832022158
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: d88009ab563dd0b16cfaf4436abaf97fa3550cf0
metrics:
- type: v_measure
value: 34.31252463546675
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: ef807ea29a75ec4f91b50fd4191cb4ee4589a9f9
metrics:
- type: map
value: 51.06639688231414
- type: mrr
value: 51.80205415499534
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: 8753c2788d36c01fc6f05d03fe3f7268d63f9122
metrics:
- type: cos_sim_pearson
value: 31.963331462886956
- type: cos_sim_spearman
value: 33.59510652629926
- type: dot_pearson
value: 29.033733540882125
- type: dot_spearman
value: 31.550290638315506
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: 2c8041b2c07a79b6f7ba8fe6acc72e5d9f92d217
metrics:
- type: map_at_1
value: 0.23600000000000002
- type: map_at_10
value: 2.09
- type: map_at_100
value: 12.466000000000001
- type: map_at_1000
value: 29.852
- type: map_at_3
value: 0.6859999999999999
- type: map_at_5
value: 1.099
- type: mrr_at_1
value: 88.0
- type: mrr_at_10
value: 94.0
- type: mrr_at_100
value: 94.0
- type: mrr_at_1000
value: 94.0
- type: mrr_at_3
value: 94.0
- type: mrr_at_5
value: 94.0
- type: ndcg_at_1
value: 86.0
- type: ndcg_at_10
value: 81.368
- type: ndcg_at_100
value: 61.879
- type: ndcg_at_1000
value: 55.282
- type: ndcg_at_3
value: 84.816
- type: ndcg_at_5
value: 82.503
- type: precision_at_1
value: 88.0
- type: precision_at_10
value: 85.6
- type: precision_at_100
value: 63.85999999999999
- type: precision_at_1000
value: 24.682000000000002
- type: precision_at_3
value: 88.667
- type: precision_at_5
value: 86.0
- type: recall_at_1
value: 0.23600000000000002
- type: recall_at_10
value: 2.25
- type: recall_at_100
value: 15.488
- type: recall_at_1000
value: 52.196
- type: recall_at_3
value: 0.721
- type: recall_at_5
value: 1.159
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 12.7
- type: f1
value: 10.384182044950325
- type: precision
value: 9.805277385275312
- type: recall
value: 12.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 30.63583815028902
- type: f1
value: 24.623726947426373
- type: precision
value: 22.987809919828013
- type: recall
value: 30.63583815028902
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 10.487804878048781
- type: f1
value: 8.255945048627975
- type: precision
value: 7.649047253615001
- type: recall
value: 10.487804878048781
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.5
- type: f1
value: 6.154428783776609
- type: precision
value: 5.680727638128585
- type: recall
value: 8.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 73.0
- type: f1
value: 70.10046605876393
- type: precision
value: 69.0018253968254
- type: recall
value: 73.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 32.7
- type: f1
value: 29.7428583868239
- type: precision
value: 28.81671359506905
- type: recall
value: 32.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 31.5
- type: f1
value: 27.228675552174003
- type: precision
value: 25.950062299847747
- type: recall
value: 31.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 35.82089552238806
- type: f1
value: 28.75836980510979
- type: precision
value: 26.971643613434658
- type: recall
value: 35.82089552238806
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 49.8
- type: f1
value: 43.909237401451776
- type: precision
value: 41.944763440988936
- type: recall
value: 49.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 18.536585365853657
- type: f1
value: 15.020182570246751
- type: precision
value: 14.231108073213337
- type: recall
value: 18.536585365853657
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.7
- type: f1
value: 6.2934784902885355
- type: precision
value: 5.685926293425392
- type: recall
value: 8.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 12.879708383961116
- type: f1
value: 10.136118341751114
- type: precision
value: 9.571444036679436
- type: recall
value: 12.879708383961116
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 9.217391304347826
- type: f1
value: 6.965003297761793
- type: precision
value: 6.476093529199119
- type: recall
value: 9.217391304347826
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.3478260869565215
- type: f1
value: 3.3186971707677397
- type: precision
value: 3.198658632552104
- type: recall
value: 4.3478260869565215
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 4.760708297894056
- type: precision
value: 4.28409511756074
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 2.1999999999999997
- type: f1
value: 1.6862703878117107
- type: precision
value: 1.6048118233915603
- type: recall
value: 2.1999999999999997
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 3.0156815440289506
- type: f1
value: 2.0913257250659134
- type: precision
value: 1.9072775486461648
- type: recall
value: 3.0156815440289506
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 49.0
- type: f1
value: 45.5254456536713
- type: precision
value: 44.134609250398725
- type: recall
value: 49.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 33.5
- type: f1
value: 28.759893973182564
- type: precision
value: 27.401259116024836
- type: recall
value: 33.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 10.2
- type: f1
value: 8.030039981676275
- type: precision
value: 7.548748077210127
- type: recall
value: 10.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 38.095238095238095
- type: f1
value: 31.944999250262406
- type: precision
value: 30.04452690166976
- type: recall
value: 38.095238095238095
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.8
- type: f1
value: 3.2638960786708067
- type: precision
value: 3.0495382950729644
- type: recall
value: 4.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 15.8
- type: f1
value: 12.131087470371275
- type: precision
value: 11.141304011547815
- type: recall
value: 15.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 23.3
- type: f1
value: 21.073044636921384
- type: precision
value: 20.374220568287285
- type: recall
value: 23.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 24.9
- type: f1
value: 20.091060685364987
- type: precision
value: 18.899700591081224
- type: recall
value: 24.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 70.1
- type: f1
value: 64.62940836940835
- type: precision
value: 62.46559523809524
- type: recall
value: 70.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.199999999999999
- type: f1
value: 5.06613460576115
- type: precision
value: 4.625224463391809
- type: recall
value: 7.199999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 1.7999999999999998
- type: f1
value: 1.2716249514772895
- type: precision
value: 1.2107445914723798
- type: recall
value: 1.7999999999999998
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 65.5
- type: f1
value: 59.84399711399712
- type: precision
value: 57.86349567099567
- type: recall
value: 65.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 95.7
- type: f1
value: 94.48333333333333
- type: precision
value: 93.89999999999999
- type: recall
value: 95.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 0.8086253369272237
- type: f1
value: 0.4962046191492002
- type: precision
value: 0.47272438578554393
- type: recall
value: 0.8086253369272237
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 69.23076923076923
- type: f1
value: 64.6227941099736
- type: precision
value: 63.03795877325289
- type: recall
value: 69.23076923076923
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 20.599999999999998
- type: f1
value: 16.62410040660465
- type: precision
value: 15.598352437967069
- type: recall
value: 20.599999999999998
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.318181818181818
- type: f1
value: 2.846721192535661
- type: precision
value: 2.6787861417537147
- type: recall
value: 4.318181818181818
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 74.84276729559748
- type: f1
value: 70.6638714185884
- type: precision
value: 68.86792452830188
- type: recall
value: 74.84276729559748
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 15.9
- type: f1
value: 12.793698974586706
- type: precision
value: 12.088118017657736
- type: recall
value: 15.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 59.92217898832685
- type: f1
value: 52.23086900129701
- type: precision
value: 49.25853869433636
- type: recall
value: 59.92217898832685
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 27.350427350427353
- type: f1
value: 21.033781033781032
- type: precision
value: 19.337955491801644
- type: recall
value: 27.350427350427353
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 29.299999999999997
- type: f1
value: 23.91597452425777
- type: precision
value: 22.36696598364942
- type: recall
value: 29.299999999999997
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 27.3
- type: f1
value: 22.059393517688886
- type: precision
value: 20.503235534170887
- type: recall
value: 27.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.177570093457943
- type: f1
value: 4.714367017906037
- type: precision
value: 4.163882933965758
- type: recall
value: 8.177570093457943
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 5.800000000000001
- type: f1
value: 4.4859357432293825
- type: precision
value: 4.247814465614043
- type: recall
value: 5.800000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 78.4
- type: f1
value: 73.67166666666667
- type: precision
value: 71.83285714285714
- type: recall
value: 78.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 50.3
- type: f1
value: 44.85221545883311
- type: precision
value: 43.04913026243909
- type: recall
value: 50.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 83.5
- type: f1
value: 79.95151515151515
- type: precision
value: 78.53611111111111
- type: recall
value: 83.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 69.89999999999999
- type: f1
value: 65.03756269256269
- type: precision
value: 63.233519536019536
- type: recall
value: 69.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.44666666666666
- type: precision
value: 90.63333333333333
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.3
- type: f1
value: 6.553388144729963
- type: precision
value: 6.313497782829976
- type: recall
value: 8.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 83.6
- type: f1
value: 79.86243107769424
- type: precision
value: 78.32555555555555
- type: recall
value: 83.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 9.166666666666666
- type: f1
value: 6.637753604420271
- type: precision
value: 6.10568253585495
- type: recall
value: 9.166666666666666
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.3999999999999995
- type: f1
value: 4.6729483612322165
- type: precision
value: 4.103844520292658
- type: recall
value: 7.3999999999999995
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 80.30000000000001
- type: f1
value: 75.97666666666667
- type: precision
value: 74.16
- type: recall
value: 80.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 23.214285714285715
- type: f1
value: 16.88988095238095
- type: precision
value: 15.364937641723353
- type: recall
value: 23.214285714285715
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 33.15038419319429
- type: f1
value: 27.747873024072415
- type: precision
value: 25.99320572578704
- type: recall
value: 33.15038419319429
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 2.6
- type: f1
value: 1.687059048752127
- type: precision
value: 1.5384884521299
- type: recall
value: 2.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 93.30000000000001
- type: f1
value: 91.44000000000001
- type: precision
value: 90.59166666666667
- type: recall
value: 93.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.61666666666667
- type: precision
value: 91.88333333333333
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 5.0
- type: f1
value: 3.589591971281927
- type: precision
value: 3.3046491614532854
- type: recall
value: 5.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 45.9
- type: f1
value: 40.171969141969136
- type: precision
value: 38.30764368870302
- type: recall
value: 45.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 16.900000000000002
- type: f1
value: 14.094365204207351
- type: precision
value: 13.276519841269844
- type: recall
value: 16.900000000000002
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 12.8
- type: f1
value: 10.376574912567156
- type: precision
value: 9.758423963284509
- type: recall
value: 12.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.1
- type: f1
value: 6.319455355175778
- type: precision
value: 5.849948830628881
- type: recall
value: 8.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 95.5
- type: f1
value: 94.19666666666667
- type: precision
value: 93.60000000000001
- type: recall
value: 95.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 19.1
- type: f1
value: 16.280080686081906
- type: precision
value: 15.451573089395668
- type: recall
value: 19.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 30.656934306569344
- type: f1
value: 23.2568647897115
- type: precision
value: 21.260309034031664
- type: recall
value: 30.656934306569344
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 2.1999999999999997
- type: f1
value: 1.556861047295521
- type: precision
value: 1.4555993437238521
- type: recall
value: 2.1999999999999997
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 27.500000000000004
- type: f1
value: 23.521682636223492
- type: precision
value: 22.345341306967683
- type: recall
value: 27.500000000000004
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.3999999999999995
- type: f1
value: 5.344253880846173
- type: precision
value: 4.999794279068863
- type: recall
value: 7.3999999999999995
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 0.5952380952380952
- type: f1
value: 0.026455026455026457
- type: precision
value: 0.013528138528138528
- type: recall
value: 0.5952380952380952
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.3
- type: f1
value: 5.853140211779251
- type: precision
value: 5.505563080945322
- type: recall
value: 7.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 13.250517598343686
- type: f1
value: 9.676349506190704
- type: precision
value: 8.930392053553216
- type: recall
value: 13.250517598343686
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 14.499999999999998
- type: f1
value: 11.68912588067557
- type: precision
value: 11.024716513105519
- type: recall
value: 14.499999999999998
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 30.099999999999998
- type: f1
value: 26.196880936315146
- type: precision
value: 25.271714086169478
- type: recall
value: 30.099999999999998
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 6.4
- type: f1
value: 5.1749445942023335
- type: precision
value: 4.975338142029625
- type: recall
value: 6.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 39.39393939393939
- type: f1
value: 35.005707393767096
- type: precision
value: 33.64342032053631
- type: recall
value: 39.39393939393939
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 18.3206106870229
- type: f1
value: 12.610893447220345
- type: precision
value: 11.079228765297467
- type: recall
value: 18.3206106870229
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 85.58951965065502
- type: f1
value: 83.30363944928548
- type: precision
value: 82.40026591554977
- type: recall
value: 85.58951965065502
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 65.7
- type: f1
value: 59.589642857142856
- type: precision
value: 57.392826797385624
- type: recall
value: 65.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 18.07909604519774
- type: f1
value: 13.65194306689995
- type: precision
value: 12.567953943826327
- type: recall
value: 18.07909604519774
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.6
- type: f1
value: 2.8335386392505013
- type: precision
value: 2.558444143575722
- type: recall
value: 4.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 90.7
- type: f1
value: 88.30666666666666
- type: precision
value: 87.195
- type: recall
value: 90.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 57.699999999999996
- type: f1
value: 53.38433067253876
- type: precision
value: 51.815451335350346
- type: recall
value: 57.699999999999996
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 80.60000000000001
- type: f1
value: 77.0290354090354
- type: precision
value: 75.61685897435898
- type: recall
value: 80.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 24.6
- type: f1
value: 19.52814960069739
- type: precision
value: 18.169084599880502
- type: recall
value: 24.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 5.0
- type: f1
value: 3.4078491753102376
- type: precision
value: 3.1757682319102387
- type: recall
value: 5.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 1.2064343163538873
- type: f1
value: 0.4224313053283095
- type: precision
value: 0.3360484946842894
- type: recall
value: 1.2064343163538873
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 76.1
- type: f1
value: 71.36246031746032
- type: precision
value: 69.5086544011544
- type: recall
value: 76.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 14.229249011857709
- type: f1
value: 10.026578603653704
- type: precision
value: 9.09171178352764
- type: recall
value: 14.229249011857709
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 8.450704225352112
- type: f1
value: 5.51214407186151
- type: precision
value: 4.928281812084629
- type: recall
value: 8.450704225352112
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.664670658682635
- type: f1
value: 5.786190079917295
- type: precision
value: 5.3643643579244
- type: recall
value: 7.664670658682635
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 90.5
- type: f1
value: 88.03999999999999
- type: precision
value: 86.94833333333334
- type: recall
value: 90.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 7.389162561576355
- type: f1
value: 5.482366349556517
- type: precision
value: 5.156814449917898
- type: recall
value: 7.389162561576355
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 41.54929577464789
- type: f1
value: 36.13520282534367
- type: precision
value: 34.818226488560995
- type: recall
value: 41.54929577464789
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 20.76923076923077
- type: f1
value: 16.742497560177643
- type: precision
value: 15.965759712090138
- type: recall
value: 20.76923076923077
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 88.1
- type: f1
value: 85.23176470588236
- type: precision
value: 84.04458333333334
- type: recall
value: 88.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 11.899791231732777
- type: f1
value: 8.776706659565102
- type: precision
value: 8.167815946521582
- type: recall
value: 11.899791231732777
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 6.1
- type: f1
value: 4.916589537178435
- type: precision
value: 4.72523017415345
- type: recall
value: 6.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 76.54723127035831
- type: f1
value: 72.75787187839306
- type: precision
value: 71.43338442869005
- type: recall
value: 76.54723127035831
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 11.700000000000001
- type: f1
value: 9.975679190026007
- type: precision
value: 9.569927715653522
- type: recall
value: 11.700000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 13.100000000000001
- type: f1
value: 10.697335850115408
- type: precision
value: 10.113816082086341
- type: recall
value: 13.100000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 76.37795275590551
- type: f1
value: 71.12860892388451
- type: precision
value: 68.89763779527559
- type: recall
value: 76.37795275590551
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 13.700000000000001
- type: f1
value: 10.471861684067568
- type: precision
value: 9.602902567641697
- type: recall
value: 13.700000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 0.554016620498615
- type: f1
value: 0.37034084643642423
- type: precision
value: 0.34676040281208437
- type: recall
value: 0.554016620498615
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 12.4
- type: f1
value: 9.552607451092534
- type: precision
value: 8.985175505050504
- type: recall
value: 12.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 33.65384615384615
- type: f1
value: 27.820512820512818
- type: precision
value: 26.09432234432234
- type: recall
value: 33.65384615384615
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 74.5
- type: f1
value: 70.09686507936507
- type: precision
value: 68.3117857142857
- type: recall
value: 74.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 88.3
- type: f1
value: 85.37333333333333
- type: precision
value: 84.05833333333334
- type: recall
value: 88.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 25.0
- type: f1
value: 22.393124632031995
- type: precision
value: 21.58347686592367
- type: recall
value: 25.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 0.589622641509434
- type: f1
value: 0.15804980033762941
- type: precision
value: 0.1393275384872965
- type: recall
value: 0.589622641509434
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 4.1000000000000005
- type: f1
value: 3.4069011332551775
- type: precision
value: 3.1784507042253516
- type: recall
value: 4.1000000000000005
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 3.102189781021898
- type: f1
value: 2.223851811694751
- type: precision
value: 2.103465682299194
- type: recall
value: 3.102189781021898
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: ed9e4a974f867fd9736efcf222fc3a26487387a5
metrics:
- type: accuracy
value: 83.1
- type: f1
value: 79.58255835667599
- type: precision
value: 78.09708333333333
- type: recall
value: 83.1
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: 527b7d77e16e343303e68cb6af11d6e18b9f7b3b
metrics:
- type: map_at_1
value: 2.322
- type: map_at_10
value: 8.959999999999999
- type: map_at_100
value: 15.136
- type: map_at_1000
value: 16.694
- type: map_at_3
value: 4.837000000000001
- type: map_at_5
value: 6.196
- type: mrr_at_1
value: 28.571
- type: mrr_at_10
value: 47.589999999999996
- type: mrr_at_100
value: 48.166
- type: mrr_at_1000
value: 48.169000000000004
- type: mrr_at_3
value: 43.197
- type: mrr_at_5
value: 45.646
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 23.982
- type: ndcg_at_100
value: 35.519
- type: ndcg_at_1000
value: 46.878
- type: ndcg_at_3
value: 26.801000000000002
- type: ndcg_at_5
value: 24.879
- type: precision_at_1
value: 28.571
- type: precision_at_10
value: 22.041
- type: precision_at_100
value: 7.4079999999999995
- type: precision_at_1000
value: 1.492
- type: precision_at_3
value: 28.571
- type: precision_at_5
value: 25.306
- type: recall_at_1
value: 2.322
- type: recall_at_10
value: 15.443999999999999
- type: recall_at_100
value: 45.918
- type: recall_at_1000
value: 79.952
- type: recall_at_3
value: 6.143
- type: recall_at_5
value: 8.737
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 66.5452
- type: ap
value: 12.99191723223892
- type: f1
value: 51.667665096195734
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: 62146448f05be9e52a36b8ee9936447ea787eede
metrics:
- type: accuracy
value: 55.854555744199196
- type: f1
value: 56.131766302254185
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 091a54f9a36281ce7d6590ec8c75dd485e7e01d4
metrics:
- type: v_measure
value: 37.27891385518074
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 83.53102461703523
- type: cos_sim_ap
value: 65.30753664579191
- type: cos_sim_f1
value: 61.739943872778305
- type: cos_sim_precision
value: 55.438891222175556
- type: cos_sim_recall
value: 69.65699208443272
- type: dot_accuracy
value: 80.38981939560112
- type: dot_ap
value: 53.52081118421347
- type: dot_f1
value: 54.232957844617346
- type: dot_precision
value: 48.43393486828459
- type: dot_recall
value: 61.60949868073878
- type: euclidean_accuracy
value: 82.23758717291531
- type: euclidean_ap
value: 60.361102792772535
- type: euclidean_f1
value: 57.50518791791561
- type: euclidean_precision
value: 51.06470106470107
- type: euclidean_recall
value: 65.8047493403694
- type: manhattan_accuracy
value: 82.14221851344102
- type: manhattan_ap
value: 60.341937223793366
- type: manhattan_f1
value: 57.53803596127247
- type: manhattan_precision
value: 51.08473188702415
- type: manhattan_recall
value: 65.85751978891821
- type: max_accuracy
value: 83.53102461703523
- type: max_ap
value: 65.30753664579191
- type: max_f1
value: 61.739943872778305
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.75305623471883
- type: cos_sim_ap
value: 85.46387153880272
- type: cos_sim_f1
value: 77.91527673159008
- type: cos_sim_precision
value: 72.93667315828353
- type: cos_sim_recall
value: 83.62334462580844
- type: dot_accuracy
value: 85.08169363915086
- type: dot_ap
value: 74.96808060965559
- type: dot_f1
value: 71.39685033990366
- type: dot_precision
value: 64.16948111759288
- type: dot_recall
value: 80.45888512473051
- type: euclidean_accuracy
value: 85.84235650250321
- type: euclidean_ap
value: 78.42045145247211
- type: euclidean_f1
value: 70.32669630775179
- type: euclidean_precision
value: 70.6298050788227
- type: euclidean_recall
value: 70.02617801047121
- type: manhattan_accuracy
value: 85.86176116738464
- type: manhattan_ap
value: 78.54012451558276
- type: manhattan_f1
value: 70.56508080693389
- type: manhattan_precision
value: 69.39626293456413
- type: manhattan_recall
value: 71.77394518016631
- type: max_accuracy
value: 88.75305623471883
- type: max_ap
value: 85.46387153880272
- type: max_f1
value: 77.91527673159008
---
## Usage
For usage instructions, refer to: https://github.com/Muennighoff/sgpt#asymmetric-semantic-search-be
The model was trained with the command
```bash
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 accelerate launch examples/training/ms_marco/train_bi-encoder_mnrl.py --model_name bigscience/bloom-7b1 --train_batch_size 32 --eval_batch_size 16 --freezenonbias --specb --lr 4e-4 --wandb --wandbwatchlog gradients --pooling weightedmean --gradcache --chunksize 8
```
## Evaluation Results
`{"ndcgs": {"sgpt-bloom-7b1-msmarco": {"scifact": {"NDCG@10": 0.71824}, "nfcorpus": {"NDCG@10": 0.35748}, "arguana": {"NDCG@10": 0.47281}, "scidocs": {"NDCG@10": 0.18435}, "fiqa": {"NDCG@10": 0.35736}, "cqadupstack": {"NDCG@10": 0.3708525}, "quora": {"NDCG@10": 0.74655}, "trec-covid": {"NDCG@10": 0.82731}, "webis-touche2020": {"NDCG@10": 0.2365}}}`
See the evaluation folder or [MTEB](https://huggingface.co/spaces/mteb/leaderboard) for more results.
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 15600 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
The model uses BitFit, weighted-mean pooling & GradCache, for details see: https://arxiv.org/abs/2202.08904
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MNRLGradCache`
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0004
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 300, 'do_lower_case': False}) with Transformer model: BloomModel
(1): Pooling({'word_embedding_dimension': 4096, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': True, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
```bibtex
@article{muennighoff2022sgpt,
title={SGPT: GPT Sentence Embeddings for Semantic Search},
author={Muennighoff, Niklas},
journal={arXiv preprint arXiv:2202.08904},
year={2022}
}
```
|
[
"BIOSSES",
"SCIFACT"
] |
BigSalmon/InformalToFormalLincoln90Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-11-08T02:37:14Z |
2022-11-08T03:06:10+00:00
| 58 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln90Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln90Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
```
Q: What is whistleblower protection?
A: Whistleblower protection is a form of legal immunity granted to employees who expose the unethical practices of their employer.
Q: Why are whistleblower protections important?
A: Absent whistleblower protections, employees would be deterred from exposing their employer’s wrongdoing for fear of retribution.
Q: Why would an employer engage in retribution?
A: An employer who has acted unethically stands to suffer severe financial and reputational damage were their transgressions to become public. To safeguard themselves from these consequences, they might seek to dissuade employees from exposing their wrongdoing.
```
```
original: the meritocratic nature of crowdfunding [MASK] into their vision's viability.
infill: the meritocratic nature of crowdfunding [gives investors idea of how successful] -> ( offers entrepreneurs a window ) into their vision's viability.
```
```
Leadership | Lecture 17: Worker Morale
What Workers Look for in Companies:
• Benefits
o Tuition reimbursement
o Paid parental leave
o 401K matching
o Profit sharing
o Pension plans
o Free meals
• Social responsibility
o Environmental stewardship
o Charitable contributions
o Diversity
• Work-life balance
o Telecommuting
o Paid holidays and vacation
o Casual dress
• Growth opportunities
• Job security
• Competitive compensation
• Recognition
o Open-door policies
o Whistleblower protection
o Employee-of-the-month awards
o Positive performance reviews
o Bonuses
```
```
description: business
keywords: for-profit, fiduciary duty, monopolistic, bottom line, return on investment, short-term thinking, capital-intensive, self-interested, risk-taking, fiduciary duty, merger, speculation, profiteering, oversight, capitalism, diversification
```
```
3. In this task, you are given a company name and you need to find its industry.
McDonalds -- Restaurant
Facebook -- Social Network
IKEA -- Furniture
American Express -- Credit Services
Nokia -- Telecom
Nintendo -- Entertainment
4. In this task, you are given a Month and you need to convert it to its corresponding season
April -- Spring
December -- Winter
July -- Summer
October -- Fall
February -- Winter
5. In this task, you are given a sentence with a missing word and you need to predict the correct word.
Managers should set an _____ for their employees. -- example
Some people spend more than four _____ in the gym. -- hours
The police were on the _____ of arresting the suspect. -- verge
They were looking for _____ on how to solve the problem. -- guidance
What is the _____ of the coffee? -- price
6. In this task, you are given a paragraph and you need to reorder it to make it logical.
It was first proposed in 1987. The total length of the bridge is 1,828 meters. The idea of a bridge connects Hong Kong to Macau. -- The idea of bridge connecting Hong Kong and Macau was first proposed in 1987. The total length of the bridge is 1,828 meters.
It is a movie about a brave and noble policeman. The film was produced by Americans. They were Kevin Lima and Chris Buck. They are directors. The movie is called Tarzan. -- Produced by Americans Kevin Lima and Chris Buck, Tarzan is a movie about a brave and noble policeman.
It was first discovered in the mountains of India. The active ingredients in this plant can stimulate hair growth. The plant is called "Hair Plus." -- First discovered in the mountains of India, Hair Plus is a plant whose active ingredients can stimulate hair growth.
```
```
trivia: What is the population of South Korea?
response: 51 million.
***
trivia: What is the minimum voting age in the US?
response: 18.
***
trivia: What are the first ten amendments of the US constitution called?
response: Bill of Rights.
```
|
[
"BEAR"
] |
BigSalmon/InformalToFormalLincoln101Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-06-18T02:37:48Z |
2023-06-21T06:22:50+00:00
| 58 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln101Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln101Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
```
Q: What is whistleblower protection?
A: Whistleblower protection is a form of legal immunity granted to employees who expose the unethical practices of their employer.
Q: Why are whistleblower protections important?
A: Absent whistleblower protections, employees would be deterred from exposing their employer’s wrongdoing for fear of retribution.
Q: Why would an employer engage in retribution?
A: An employer who has acted unethically stands to suffer severe financial and reputational damage were their transgressions to become public. To safeguard themselves from these consequences, they might seek to dissuade employees from exposing their wrongdoing.
```
```
original: the meritocratic nature of crowdfunding [MASK] into their vision's viability.
infill: the meritocratic nature of crowdfunding [gives investors idea of how successful] -> ( offers entrepreneurs a window ) into their vision's viability.
```
```
Leadership | Lecture 17: Worker Morale
What Workers Look for in Companies:
• Benefits
o Tuition reimbursement
o Paid parental leave
o 401K matching
o Profit sharing
o Pension plans
o Free meals
• Social responsibility
o Environmental stewardship
o Charitable contributions
o Diversity
• Work-life balance
o Telecommuting
o Paid holidays and vacation
o Casual dress
• Growth opportunities
• Job security
• Competitive compensation
• Recognition
o Open-door policies
o Whistleblower protection
o Employee-of-the-month awards
o Positive performance reviews
o Bonuses
```
```
description: business
keywords: for-profit, fiduciary duty, monopolistic, bottom line, return on investment, short-term thinking, capital-intensive, self-interested, risk-taking, fiduciary duty, merger, speculation, profiteering, oversight, capitalism, diversification
```
```
3. In this task, you are given a company name and you need to find its industry.
McDonalds -- Restaurant
Facebook -- Social Network
IKEA -- Furniture
American Express -- Credit Services
Nokia -- Telecom
Nintendo -- Entertainment
4. In this task, you are given a Month and you need to convert it to its corresponding season
April -- Spring
December -- Winter
July -- Summer
October -- Fall
February -- Winter
5. In this task, you are given a sentence with a missing word and you need to predict the correct word.
Managers should set an _____ for their employees. -- example
Some people spend more than four _____ in the gym. -- hours
The police were on the _____ of arresting the suspect. -- verge
They were looking for _____ on how to solve the problem. -- guidance
What is the _____ of the coffee? -- price
6. In this task, you are given a paragraph and you need to reorder it to make it logical.
It was first proposed in 1987. The total length of the bridge is 1,828 meters. The idea of a bridge connects Hong Kong to Macau. -- The idea of bridge connecting Hong Kong and Macau was first proposed in 1987. The total length of the bridge is 1,828 meters.
It is a movie about a brave and noble policeman. The film was produced by Americans. They were Kevin Lima and Chris Buck. They are directors. The movie is called Tarzan. -- Produced by Americans Kevin Lima and Chris Buck, Tarzan is a movie about a brave and noble policeman.
It was first discovered in the mountains of India. The active ingredients in this plant can stimulate hair growth. The plant is called "Hair Plus." -- First discovered in the mountains of India, Hair Plus is a plant whose active ingredients can stimulate hair growth.
```
```
trivia: What is the population of South Korea?
response: 51 million.
***
trivia: What is the minimum voting age in the US?
response: 18.
***
trivia: What are the first ten amendments of the US constitution called?
response: Bill of Rights.
```
```
ideas: in modern-day america, it is customary for the commander-in-chief to conduct regular press conferences
related keywords: transparency, check and balance, sacrosanct, public accountability, adversarial, unscripted, direct access, open government, watchdog, healthy democracy, institutional integrity, right to know, direct line of communication, behind closed doors, updates, track progress, instill confidence, reassure, humanize, leadership style, day-to-day, forthcoming, demystify, ask hard questions
***
ideas: i know this one guy who retired so young, attesting to how careful they were with money.
related keywords: money management, resourceful, penny-pinching, live below their means, frugal, financial discipline, financial independence, conservative, long-term vision, discretionary spending, deferred gratification, preparedness, self-control, cushion
```
```
less specific: actors and musicians should ( support democracy ).
clarifies: actors and musicians should ( wield their celebrity to amplify pro-democracy messaging / marshal their considerable influence in the service of the democratic cause ).
***
less specific: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( be careful ).
clarifies: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( master their desires / exercise self-restraint / embrace frugality / restrain their appetite for splendor ).
```
```
dull: clean
emotional heft: spotless, immaculate, pristine
***
dull: hot
emotional heft: scorching, searing, blistering
***
dull: happy
emotional heft: euphoric
```
```
text: {guide: vividly describe the premise of the show "seinfield"} -> set in the heart of bustling new york city, the sitcom "seinfield" follows the everyday {restrict: term that implies they get into trouble but in a comical way} -> misadventures of four neurotic friends. on any given episode, one can find them quarreling over their favorite diner's latest menu change, haggling over the division of household expenses, or contriving a scheme to spy on the apartment's newest resident. mundane as their exploits may be, they never fail to elicit a hearty laugh. {guide: mention how larry david is responsible} -> behind the show's witty, incisive dialogue lies the sharp pen of larry david, who co-created the show with jerry seinfeld. {guide: mention how larry david came up with the most recognizable lines} -> it is his genius that conjured such instantly {restrict: term that imply everybody knows them} -> recognizable quips as "no soup for you!" and "not that there's anything wrong with that!". {guide: mention how humanity should revel in having such good comedians these days} -> as this list of laugh-out-loud lines attests, the world is fortunate to ( count such a sharp comedic mind among its ranks / have such a talented humorist in its midst / have such comedic talent gracing its airwaves ).
```
```
system: i'm not sure i agree with your assessment of the situation.
user: replace "assessment" with a more casual term.
chatbot: ( take / read / view ).
system: i've been feeling really busy lately, trying to balance work and family responsibilities.
user: replace "busy" with a more intense word that conveys it is too much.
chatbot: overwhelmed.
system: the candidate's stance on immigration is quite nebulous, and it's difficult to discern exactly what they would do if elected.
user: replace "nebulous" with a word that conveys a lack of detail.
chatbot: ( vague / ambiguous ).
```
```
user: exorbitant in price, scholarly journals unconscionably define the breadth of one's knowledge awareness by the contents of their wallet. [replace “knowledge awareness” with a more natural expression]
chatbot: intellectual horizons.
user: can you do another alternative to “intellectual horizons” that has more relation to “scholarly journals”?
chatbot: academic enlightenment.
```
```
key: calculate.
syn: estimate, consider, weigh, number, count, apportion, proportion, investigate, reckon, rate, compute.
ant: guess, conjecture, hit, chance, risk, stake, miscalculate.
```
```
description: more forceful version of curious that is less forceful than nosy
answer: inquisitive
description: more forceful version of hopeful that is less forceful than overconfident
answer: optimistic
```
```
key: inquisitive
positive: curious, interested
negative: nosy, prying
***
key: witty
positive: clever, humorous
negative: sarcastic, caustic
***
key: influential
positive: impactful, powerful
negative: overbearing, domineering
```
|
[
"BEAR"
] |
TheBloke/xDAN-L1-Chat-RL-v1-AWQ
|
TheBloke
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"xDAN-AI",
"OpenOrca",
"DPO",
"Self-Think",
"en",
"dataset:Open-Orca/OpenOrca",
"dataset:Intel/orca_dpo_pairs",
"base_model:xDAN-AI/xDAN-L1-Chat-RL-v1",
"base_model:quantized:xDAN-AI/xDAN-L1-Chat-RL-v1",
"license:cc-by-4.0",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
] | 2023-12-26T09:05:45Z |
2023-12-26T10:02:48+00:00
| 58 | 1 |
---
base_model: xDAN-AI/xDAN-L1-Chat-RL-v1
datasets:
- Open-Orca/OpenOrca
- Intel/orca_dpo_pairs
language:
- en
license: cc-by-4.0
model_name: xDAN L1 Chat RL v1
tags:
- xDAN-AI
- OpenOrca
- DPO
- Self-Think
inference: false
model_creator: xDAN-AI
model_type: mistral
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# xDAN L1 Chat RL v1 - AWQ
- Model creator: [xDAN-AI](https://huggingface.co/xDAN-AI)
- Original model: [xDAN L1 Chat RL v1](https://huggingface.co/xDAN-AI/xDAN-L1-Chat-RL-v1)
<!-- description start -->
## Description
This repo contains AWQ model files for [xDAN-AI's xDAN L1 Chat RL v1](https://huggingface.co/xDAN-AI/xDAN-L1-Chat-RL-v1).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference with equivalent or better quality compared to the most commonly used GPTQ settings.
AWQ models are currently supported on Linux and Windows, with NVidia GPUs only. macOS users: please use GGUF models instead.
It is supported by:
- [Text Generation Webui](https://github.com/oobabooga/text-generation-webui) - using Loader: AutoAWQ
- [vLLM](https://github.com/vllm-project/vllm) - version 0.2.2 or later for support for all model types.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference)
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later, from any code or client that supports Transformers
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) - for use from Python code
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/xDAN-L1-Chat-RL-v1-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/xDAN-L1-Chat-RL-v1-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/xDAN-L1-Chat-RL-v1-GGUF)
* [xDAN-AI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/xDAN-AI/xDAN-L1-Chat-RL-v1)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files, and AWQ parameters
I currently release 128g GEMM models only. The addition of group_size 32 models, and GEMV kernel models, is being actively considered.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/xDAN-L1-Chat-RL-v1-AWQ/tree/main) | 4 | 128 | [VMware Open Instruct](https://huggingface.co/datasets/VMware/open-instruct/viewer/) | 4096 | 4.15 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-text-generation-webui start -->
## How to easily download and use this model in [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
Please make sure you're using the latest version of [text-generation-webui](https://github.com/oobabooga/text-generation-webui).
It is strongly recommended to use the text-generation-webui one-click-installers unless you're sure you know how to make a manual install.
1. Click the **Model tab**.
2. Under **Download custom model or LoRA**, enter `TheBloke/xDAN-L1-Chat-RL-v1-AWQ`.
3. Click **Download**.
4. The model will start downloading. Once it's finished it will say "Done".
5. In the top left, click the refresh icon next to **Model**.
6. In the **Model** dropdown, choose the model you just downloaded: `xDAN-L1-Chat-RL-v1-AWQ`
7. Select **Loader: AutoAWQ**.
8. Click Load, and the model will load and is now ready for use.
9. If you want any custom settings, set them and then click **Save settings for this model** followed by **Reload the Model** in the top right.
10. Once you're ready, click the **Text Generation** tab and enter a prompt to get started!
<!-- README_AWQ.md-text-generation-webui end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Multi-user inference server: vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- Please ensure you are using vLLM version 0.2 or later.
- When using vLLM as a server, pass the `--quantization awq` parameter.
For example:
```shell
python3 -m vllm.entrypoints.api_server --model TheBloke/xDAN-L1-Chat-RL-v1-AWQ --quantization awq --dtype auto
```
- When using vLLM from Python code, again set `quantization=awq`.
For example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Tell me about AI",
"Write a story about llamas",
"What is 291 - 150?",
"How much wood would a woodchuck chuck if a woodchuck could chuck wood?",
]
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
prompts = [prompt_template.format(prompt=prompt) for prompt in prompts]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/xDAN-L1-Chat-RL-v1-AWQ", quantization="awq", dtype="auto")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-tgi start -->
## Multi-user inference server: Hugging Face Text Generation Inference (TGI)
Use TGI version 1.1.0 or later. The official Docker container is: `ghcr.io/huggingface/text-generation-inference:1.1.0`
Example Docker parameters:
```shell
--model-id TheBloke/xDAN-L1-Chat-RL-v1-AWQ --port 3000 --quantize awq --max-input-length 3696 --max-total-tokens 4096 --max-batch-prefill-tokens 4096
```
Example Python code for interfacing with TGI (requires [huggingface-hub](https://github.com/huggingface/huggingface_hub) 0.17.0 or later):
```shell
pip3 install huggingface-hub
```
```python
from huggingface_hub import InferenceClient
endpoint_url = "https://your-endpoint-url-here"
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
client = InferenceClient(endpoint_url)
response = client.text_generation(prompt,
max_new_tokens=128,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1)
print(f"Model output: ", response)
```
<!-- README_AWQ.md-use-from-tgi end -->
<!-- README_AWQ.md-use-from-python start -->
## Inference from Python code using Transformers
### Install the necessary packages
- Requires: [Transformers](https://huggingface.co/docs/transformers) 4.35.0 or later.
- Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.1.6 or later.
```shell
pip3 install --upgrade "autoawq>=0.1.6" "transformers>=4.35.0"
```
Note that if you are using PyTorch 2.0.1, the above AutoAWQ command will automatically upgrade you to PyTorch 2.1.0.
If you are using CUDA 11.8 and wish to continue using PyTorch 2.0.1, instead run this command:
```shell
pip3 install https://github.com/casper-hansen/AutoAWQ/releases/download/v0.1.6/autoawq-0.1.6+cu118-cp310-cp310-linux_x86_64.whl
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### Transformers example code (requires Transformers 4.35.0 and later)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
model_name_or_path = "TheBloke/xDAN-L1-Chat-RL-v1-AWQ"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
low_cpu_mem_usage=True,
device_map="cuda:0"
)
# Using the text streamer to stream output one token at a time
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
prompt = "Tell me about AI"
prompt_template=f'''Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'''
# Convert prompt to tokens
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
generation_params = {
"do_sample": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": 512,
"repetition_penalty": 1.1
}
# Generate streamed output, visible one token at a time
generation_output = model.generate(
tokens,
streamer=streamer,
**generation_params
)
# Generation without a streamer, which will include the prompt in the output
generation_output = model.generate(
tokens,
**generation_params
)
# Get the tokens from the output, decode them, print them
token_output = generation_output[0]
text_output = tokenizer.decode(token_output)
print("model.generate output: ", text_output)
# Inference is also possible via Transformers' pipeline
from transformers import pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
**generation_params
)
pipe_output = pipe(prompt_template)[0]['generated_text']
print("pipeline output: ", pipe_output)
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with:
- [text-generation-webui](https://github.com/oobabooga/text-generation-webui) using `Loader: AutoAWQ`.
- [vLLM](https://github.com/vllm-project/vllm) version 0.2.0 and later.
- [Hugging Face Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) version 1.1.0 and later.
- [Transformers](https://huggingface.co/docs/transformers) version 4.35.0 and later.
- [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) version 0.1.1 and later.
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: xDAN-AI's xDAN L1 Chat RL v1
<div style="display: flex; justify-content: center; align-items: center">
<img src="https://hf.fast360.xyz/production/uploads/643197ac288c9775673a01e9/tVAcwKkIH5vkfzqgqHeHi.png" style="width: 45%;">
</div
>
<p align="center">
<big><b>Top 1 Performer on MT-bench🏆</b
></big>
</p>
<p align="center">
<strong>**The first top model which is performance at Humanalities, Coding and Writing with 7b. **</strong>
</p>
<p
align="center"
<a href="The TOP1 MT-Bench Model">xDAN-AI</a> •
>
<a href="https://discord.gg/7NrMX5AK">Discord</a> •
<a href="https://twitter.com/shootime007">Twitter</a> •
<a href="https://huggingface.co/xDAN-AI">Huggingface</a>
</p>
<p align="center">
<img src="https://hf.fast360.xyz/production/uploads/643197ac288c9775673a01e9/QANDZApzpTHM6sBsjmdew.png" alt="Image" width="50%">
</p>
## Outperformer GPT3.5turbo & Claude-v1

## Touch nearby GPT4 on MT-Bench

**########## First turn ##########**
| model | turn | score | size
|--------------------|------|----------|--------
| gpt-4 | 1 | 8.95625 | -
| **xDAN-L1-Chat-RL-v1** | 1 | **8.87500** | **7b**
| xDAN-L2-Chat-RL-v2 | 1 | 8.78750 | 30b
| claude-v1 | 1 | 8.15000 | -
| gpt-3.5-turbo | 1 | 8.07500 | 20b
| vicuna-33b-v1.3 | 1 | 7.45625 | 33b
| wizardlm-30b | 1 | 7.13125 | 30b
| oasst-sft-7-llama-30b | 1 | 7.10625 | 30b
| Llama-2-70b-chat | 1 | 6.98750 | 70b
########## Second turn ##########
| model | turn | score | size
|--------------------|------|-----------|--------
| gpt-4 | 2 | 9.025000 | -
| xDAN-L2-Chat-RL-v2 | 2 | 8.087500 | 30b
| **xDAN-L1-Chat-RL-v1** | 2 | **7.825000** | **7b**
| gpt-3.5-turbo | 2 | 7.812500 | 20b
| claude-v1 | 2 | 7.650000 | -
| wizardlm-30b | 2 | 6.887500 | 30b
| vicuna-33b-v1.3 | 2 | 6.787500 | 33b
| Llama-2-70b-chat | 2 | 6.725000 | 70b
########## Average turn##########
| model | score | size
|--------------------|-----------|--------
| gpt-4 | 8.990625 | -
| xDAN-L2-Chat-RL-v2 | 8.437500 | 30b
| **xDAN-L1-Chat-RL-v1** | **8.350000** | **7b**
| gpt-3.5-turbo | 7.943750 | 20b
| claude-v1 | 7.900000 | -
| vicuna-33b-v1.3 | 7.121875 | 33b
| wizardlm-30b | 7.009375 | 30b
| Llama-2-70b-chat | 6.856250 | 70b
### Prompt Template(Alpaca)
You are a helpful assistant named DAN. You are an expert in worldly knowledge, skilled in employing a probing questioning strategy,
and you carefully consider each step before providing answers.
\n\n### Instruction:\n{instruction}\n\n### Response:
### Dataset:
1. Selected from OpenOrca
2. Intel Orca-DPO-Pairs
3. Privately Crafted Dataset
### Training:
1. SFT with Mixed dataset from OpenOrca
2. The Next DPO dataset made by xDAN-AI
3. The Next DPO Training method by xDAN-AI
## Created By xDAN-AI at 2023-12-15
## Eval by FastChat: https://github.com/lm-sys/FastChat.git
Disclaimer
We employ data compliance checking algorithms during the training of our language model to strive for the highest degree of compliance. However, given the intricate nature of data and the vast array of potential usage scenarios for the model, we cannot assure that it will always generate correct and reasonable outputs. Users should be cognizant of the risk of the model producing problematic outputs. Our organization will not bear responsibility for any risks or issues stemming from misuse, misguidance, illegal use, and related misinformation, as well as any consequent data security concerns.
About xDAN-AI xDAN-AI is a top lead high-performance model factory. For detailed information and further insights into our cutting-edge technology and offerings, please visit our website: https://www.xdan.ai.
|
[
"BEAR"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.