
id
stringlengths 9
104
| author
stringlengths 3
36
| task_category
stringclasses 32
values | tags
listlengths 1
4.05k
| created_time
timestamp[ns, tz=UTC]date 2022-03-02 23:29:04
2025-03-18 02:34:30
| last_modified
stringdate 2021-02-13 00:06:56
2025-03-18 09:30:19
| downloads
int64 0
15.6M
| likes
int64 0
4.86k
| README
stringlengths 44
1.01M
| matched_bigbio_names
listlengths 1
8
|
|---|---|---|---|---|---|---|---|---|---|
BigSalmon/InformalToFormalLincoln95Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-03-18T03:25:00Z |
2023-03-18T20:57:54+00:00
| 48 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln95Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln95Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
```
music before bedtime [makes for being able to relax] -> is a recipe for relaxation.
```
```
[people wanting entertainment love traveling new york city] -> travelers flock to new york city in droves, drawn to its iconic entertainment scene. [cannot blame them] -> one cannot fault them [broadway so fun] -> when it is home to such thrilling fare as Broadway.
```
```
in their ( ‖ when you are rushing because you want to get there on time ‖ / haste to arrive punctually / mad dash to be timely ), morning commuters are too rushed to whip up their own meal.
***
politicians prefer to author vague plans rather than ( ‖ when you can make a plan without many unknowns ‖ / actionable policies / concrete solutions ).
```
```
Q: What is whistleblower protection?
A: Whistleblower protection is a form of legal immunity granted to employees who expose the unethical practices of their employer.
Q: Why are whistleblower protections important?
A: Absent whistleblower protections, employees would be deterred from exposing their employer’s wrongdoing for fear of retribution.
Q: Why would an employer engage in retribution?
A: An employer who has acted unethically stands to suffer severe financial and reputational damage were their transgressions to become public. To safeguard themselves from these consequences, they might seek to dissuade employees from exposing their wrongdoing.
```
```
original: the meritocratic nature of crowdfunding [MASK] into their vision's viability.
infill: the meritocratic nature of crowdfunding [gives investors idea of how successful] -> ( offers entrepreneurs a window ) into their vision's viability.
```
```
Leadership | Lecture 17: Worker Morale
What Workers Look for in Companies:
• Benefits
o Tuition reimbursement
o Paid parental leave
o 401K matching
o Profit sharing
o Pension plans
o Free meals
• Social responsibility
o Environmental stewardship
o Charitable contributions
o Diversity
• Work-life balance
o Telecommuting
o Paid holidays and vacation
o Casual dress
• Growth opportunities
• Job security
• Competitive compensation
• Recognition
o Open-door policies
o Whistleblower protection
o Employee-of-the-month awards
o Positive performance reviews
o Bonuses
```
```
description: business
keywords: for-profit, fiduciary duty, monopolistic, bottom line, return on investment, short-term thinking, capital-intensive, self-interested, risk-taking, fiduciary duty, merger, speculation, profiteering, oversight, capitalism, diversification
```
```
3. In this task, you are given a company name and you need to find its industry.
McDonalds -- Restaurant
Facebook -- Social Network
IKEA -- Furniture
American Express -- Credit Services
Nokia -- Telecom
Nintendo -- Entertainment
4. In this task, you are given a Month and you need to convert it to its corresponding season
April -- Spring
December -- Winter
July -- Summer
October -- Fall
February -- Winter
5. In this task, you are given a sentence with a missing word and you need to predict the correct word.
Managers should set an _____ for their employees. -- example
Some people spend more than four _____ in the gym. -- hours
The police were on the _____ of arresting the suspect. -- verge
They were looking for _____ on how to solve the problem. -- guidance
What is the _____ of the coffee? -- price
6. In this task, you are given a paragraph and you need to reorder it to make it logical.
It was first proposed in 1987. The total length of the bridge is 1,828 meters. The idea of a bridge connects Hong Kong to Macau. -- The idea of bridge connecting Hong Kong and Macau was first proposed in 1987. The total length of the bridge is 1,828 meters.
It is a movie about a brave and noble policeman. The film was produced by Americans. They were Kevin Lima and Chris Buck. They are directors. The movie is called Tarzan. -- Produced by Americans Kevin Lima and Chris Buck, Tarzan is a movie about a brave and noble policeman.
It was first discovered in the mountains of India. The active ingredients in this plant can stimulate hair growth. The plant is called "Hair Plus." -- First discovered in the mountains of India, Hair Plus is a plant whose active ingredients can stimulate hair growth.
```
```
trivia: What is the population of South Korea?
response: 51 million.
***
trivia: What is the minimum voting age in the US?
response: 18.
***
trivia: What are the first ten amendments of the US constitution called?
response: Bill of Rights.
```
```
ideas: in modern-day america, it is customary for the commander-in-chief to conduct regular press conferences
related keywords: transparency, check and balance, sacrosanct, public accountability, adversarial, unscripted, direct access, open government, watchdog, healthy democracy, institutional integrity, right to know, direct line of communication, behind closed doors, updates, track progress, instill confidence, reassure, humanize, leadership style, day-to-day, forthcoming, demystify, ask hard questions
***
ideas: i know this one guy who retired so young, attesting to how careful they were with money.
related keywords: money management, resourceful, penny-pinching, live below their means, frugal, financial discipline, financial independence, conservative, long-term vision, discretionary spending, deferred gratification, preparedness, self-control, cushion
```
```
less specific: actors and musicians should ( support democracy ).
clarifies: actors and musicians should ( wield their celebrity to amplify pro-democracy messaging / marshal their considerable influence in the service of the democratic cause ).
***
less specific: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( be careful ).
clarifies: amid a contemporary culture that thrives on profligacy, the discipline necessary to retire early is a vanishing quality. rather than yielding to the lure of indulgence, the aspiring retiree must ( master their desires / exercise self-restraint / embrace frugality / restrain their appetite for splendor ).
```
```
dull: clean
emotional heft: spotless, immaculate, pristine
***
dull: hot
emotional heft: scorching, searing, blistering
***
dull: happy
emotional heft: euphoric
```
|
[
"BEAR"
] |
IIC/roberta-large-bne-cantemist
|
IIC
|
text-classification
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"text-classification",
"biomedical",
"clinical",
"eHR",
"spanish",
"roberta-large-bne",
"es",
"dataset:PlanTL-GOB-ES/cantemist-ner",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-19T15:24:20Z |
2025-01-17T10:52:23+00:00
| 48 | 0 |
---
datasets:
- PlanTL-GOB-ES/cantemist-ner
language: es
license: apache-2.0
metrics:
- f1
tags:
- biomedical
- clinical
- eHR
- spanish
- roberta-large-bne
widget:
- text: El diagnóstico definitivo de nuestro paciente fue de un Adenocarcinoma de
pulmón cT2a cN3 cM1a Estadio IV (por una única lesión pulmonar contralateral)
PD-L1 90%, EGFR negativo, ALK negativo y ROS-1 negativo.
- text: Durante el ingreso se realiza una TC, observándose un nódulo pulmonar en el
LII y una masa renal derecha indeterminada. Se realiza punción biopsia del nódulo
pulmonar, con hallazgos altamente sospechosos de carcinoma.
- text: Trombosis paraneoplásica con sospecha de hepatocarcinoma por imagen, sobre
hígado cirrótico, en paciente con índice Child-Pugh B.
model-index:
- name: IIC/roberta-large-bne-cantemist
results:
- task:
type: token-classification
dataset:
name: cantemist-ner
type: PlanTL-GOB-ES/cantemist-ner
metrics:
- type: f1
value: 0.902
name: f1
---
# roberta-large-bne-cantemist
This model is a finetuned version of roberta-large-bne for the cantemist dataset used in a benchmark in the paper `A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks`. The model has a F1 of 0.902
Please refer to the [original publication](https://doi.org/10.1093/jamia/ocae054) for more information.
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 16 |
| learning rate | 1e05 |
| classifier dropout | 0.1 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtext
@article{10.1093/jamia/ocae054,
author = {García Subies, Guillem and Barbero Jiménez, Álvaro and Martínez Fernández, Paloma},
title = {A comparative analysis of Spanish Clinical encoder-based models on NER and classification tasks},
journal = {Journal of the American Medical Informatics Association},
volume = {31},
number = {9},
pages = {2137-2146},
year = {2024},
month = {03},
issn = {1527-974X},
doi = {10.1093/jamia/ocae054},
url = {https://doi.org/10.1093/jamia/ocae054},
}
```
|
[
"CANTEMIST"
] |
maastrichtlawtech/distilcamembert-lleqa
|
maastrichtlawtech
|
sentence-similarity
|
[
"sentence-transformers",
"pytorch",
"safetensors",
"camembert",
"feature-extraction",
"sentence-similarity",
"fr",
"dataset:maastrichtlawtech/lleqa",
"arxiv:2309.17050",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2023-09-28T13:03:19Z |
2024-10-31T12:58:12+00:00
| 48 | 3 |
---
datasets:
- maastrichtlawtech/lleqa
language: fr
library_name: sentence-transformers
license: apache-2.0
metrics:
- recall
pipeline_tag: sentence-similarity
tags:
- feature-extraction
- sentence-similarity
inference: true
widget:
- source_sentence: Je reçois des confidences liées à mon emploi. Qu'est-ce que je
risque si je viole le secret professionnel ?
sentences:
- 'Art. 1 : Les médecins, chirurgiens, officiers de santé, pharmaciens, sages-femmes
et toutes autres personnes dépositaires, par état ou par profession, des secrets
qu''on leur confie, qui, hors le cas où ils sont appelés à rendre témoignage en
justice ou devant une commission d''enquête parlementaire et celui où la loi,
le décret ou l''ordonnance les oblige ou les autoriseà faire connaître ces secrets,
les auront révélés, seront punis d''un emprisonnement d''un an à trois ans et
d''une amende de cent euros à mille euros ou d''une de ces peines seulement.'
- 'Art. 2 : L''allocataire peut demander l''allocation de naissance à partir du
sixième mois de la grossesse et en obtenir le paiement deux mois avant la date
probable de la naissance mentionnée sur le certificat médical à joindre à la demande.L''allocation
de naissance demandée conformément à l''alinéa 1er est due par la caisse d''allocations
familiales, par l''autorité ou par l''établissement public qui serait compétent,
selon le cas, pour payer les allocations familiales à la date à laquelle la demande
de paiement anticipé est introduite.'
- 'Art. 3 : La periode de maternité constitue une période de repos de douze semaines,
ou de treize semainesen cas de naissance multiple, au cours de laquelle la titulaire
ne peut exercer son activité professionnelle habituelle ni aucune autre activité
professionnelle.'
example_title: Secret professionnel
---
# distilcamembert-lleqa
This is a [sentence-transformers](https://www.SBERT.net) model: it maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. The model was trained on the [LLeQA](https://huggingface.co/datasets/maastrichtlawtech/lleqa) dataset for legal information retrieval in **French**.
## Usage
***
#### Sentence-Transformers
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('maastrichtlawtech/distilcamembert-lleqa')
embeddings = model.encode(sentences)
print(embeddings)
```
#### 🤗 Transformers
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('maastrichtlawtech/distilcamembert-lleqa')
model = AutoModel.from_pretrained('maastrichtlawtech/distilcamembert-lleqa')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print(sentence_embeddings)
```
## Evaluation
***
We evaluate the model on the test set of LLeQA, which consists of 195 legal questions with a knowlegde corpus of 27.9K candidate articles. We report the mean reciprocal rank (MRR), normalized discounted cumulative gainand (NDCG), mean average precision (MAP), and recall at various cut-offs (R@k).
| MRR@10 | NDCG@10 | MAP@10 | R@10 | R@100 | R@500 |
|---------:|----------:|---------:|-------:|--------:|--------:|
| 36.67 | 37.24 | 29.26 | 52.95 | 78.07 | 90.17 |
## Training
***
#### Background
We utilize the [distilcamembert-base](https://huggingface.co/cmarkea/distilcamembert-base) model and fine-tuned it on 9.3K question-article pairs in French. We used a contrastive learning objective: given a short legal question, the model should predict which out of a set of sampled legal articles, was actually paired with it in the dataset. Formally, we compute the cosine similarity from each possible pairs from the batch. We then apply the cross entropy loss with a temperature of 0.05 by comparing with true pairs.
#### Hyperparameters
We trained the model on a single Tesla V100 GPU with 32GBs of memory during 20 epochs (i.e., 5.4k steps) using a batch size of 32. We used the AdamW optimizer with an initial learning rate of 2e-05, weight decay of 0.01, learning rate warmup over the first 50 steps, and linear decay of the learning rate. The sequence length was limited to 384 tokens.
#### Data
We use the [Long-form Legal Question Answering (LLeQA)](https://huggingface.co/datasets/maastrichtlawtech/lleqa) dataset to fine-tune the model. LLeQA is a French native dataset for studying legal information retrieval and question answering. It consists of a knowledge corpus of 27,941 statutory articles collected from the Belgian legislation, and 1,868 legal questions posed by Belgian citizens and labeled by experienced jurists with a comprehensive answer rooted in relevant articles from the corpus.
## Citation
```bibtex
@article{louis2023interpretable,
author = {Louis, Antoine and van Dijck, Gijs and Spanakis, Gerasimos},
title = {Interpretable Long-Form Legal Question Answering with Retrieval-Augmented Large Language Models},
journal = {CoRR},
volume = {abs/2309.17050},
year = {2023},
url = {https://arxiv.org/abs/2309.17050},
eprinttype = {arXiv},
eprint = {2309.17050},
}
```
|
[
"CAS"
] |
winninghealth/WiNGPT2-14B-Base
|
winninghealth
|
text-generation
|
[
"transformers",
"pytorch",
"qwen",
"text-generation",
"medical",
"custom_code",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | 2023-12-12T01:39:58Z |
2023-12-12T09:30:31+00:00
| 48 | 4 |
---
language:
- zh
license: apache-2.0
pipeline_tag: text-generation
tags:
- medical
---
## WiNGPT2
[WiNGPT](https://github.com/winninghealth/WiNGPT2) 是一个基于GPT的医疗垂直领域大模型,旨在将专业的医学知识、医疗信息、数据融会贯通,为医疗行业提供智能化的医疗问答、诊断支持和医学知识等信息服务,提高诊疗效率和医疗服务质量。
## 介绍
WiNGPT(卫宁健康医疗语言大模型,以下简称WiNGPT)的研发和训练工作开始于2023年1月。
3月,卫宁健康人工智能实验室已完成了WiNGPT-001可行性验证并开始内测。WiNGPT-001采用通用的GPT架构、60亿参数,实现了从预训练到微调的全过程自研。
今年5月,WiNGPT-001训练的数据量已达到9720项药品知识、 18个药品类型、7200余项疾病知识、 2800余项检查检验知识、53本书籍知识、1100余份指南文档,总训练Token数达37亿。
7月,WiNGPT升级到7B并采用最新的模型架构,新增检索式增强生成能力,同时开始了13B模型的训练和行业邀测。
9月,WiNGPT迎来最新版本迭代,推出了全新的WiNGPT2,新版本可以被轻松扩展和个性化并用于下游各种应用场景。
为了回馈开源社区我们尝试开源了WiNGPT2-7B/14B版本。我们的初衷是希望通过更多的开源项目加速医疗语言大模型技术与行业的共同发展,最终惠及我们人类健康。
## 特点
- 核心功能
- **医学知识问答**:可以回答关于医学、健康、疾病等方面的问题,包括但不限于症状、治疗、药物、预防、检查等。
- **自然语言理解**:理解医学术语、病历等医疗文本信息,提供关键信息抽取和归类
- **多轮对话**:可扮演各种医疗专业角色如医生与用户进行对话,根据上下文提供更加准确的答案。
- **多任务支持**:支持32项医疗任务,八大医疗场景18个子场景。
- 模型架构
- 基于Transformer的70亿/140亿参数规模大语言模型, 采用RoPE相对位置编码、SwiGLU激活函数、RMSNorm,训练采用Qwen-7b<sup>1</sup>作为基础预训练模型。
- 主要特点
- 高准确度:基于大规模医疗语料库训练,具有较高的准确率和较低的误诊可能性。
- 场景导向:针对不同的医疗场景和真实需求进行专门优化和定制,更好的服务应用落地。
- 迭代优化:持续搜集和学习最新的医学研究,不断提高模型性能和系统功能。
## 如何使用
### 推理
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
model_path = "WiNGPT2-7B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
model = model.eval()
generation_config = GenerationConfig(
num_beams=1,
top_p=0.75,
top_k=30,
repetition_penalty=1.1,
max_new_tokens=1024
)
text = 'User: WiNGPT, 你好<|endoftext|>\n Assistant: '
inputs = tokenizer.encode(text, return_tensors="pt").to(device)
outputs = model.generate(inputs, generation_config=generation_config)
output = tokenizer.decode(outputs[0])
response = output.replace(inputs, '')
## 输出结果:你好!今天我能为你做些什么?<|endoftext|>
```
### 提示
WiNGPT2-7B-Chat使用了自定义的提示格式:
用户角色:User/Assistant
提示模板:User:[此处有空格]WiNGPT, 你好<|endoftext|>\n[此处有空格]Assistant:;**多轮对话**按此模板进行拼接,例如:
```
"User: WiNGPT, 你好<|endoftext|>\n Assistant:你好!今天我能为你做些什么?<|endoftext|>\n User: 你是谁?<|endoftext|>\n Assistant:"
```
解码时推荐使用repetition_penalty=1.1 [greedy search]
### 企业服务
[13B模型平台测试(直接申请密钥)](https://wingpt.winning.com.cn/)
## 训练数据
- 数据总览
- 医疗专业数据
| 来源 | 类型 | 数量 |
| ---------------- | ------ | ------------------- |
| 药品说明书 | 知识库 | 15000 条 |
| 多病种知识库 | 知识库 | 9720 项 |
| 医疗专业书籍 | 教材 | 300 本 |
| 临床路径知识库 | 知识库 | 1400 条 |
| 检查检验知识 | 知识库 | 110 万条 |
| 多学科临床指南 | 书籍 | 18 个科室共 1100 份 |
| 医疗知识图谱 | 知识库 | 256 万三元组 |
| 人工标注数据集 | 指令 | 5 万条 |
| 医学资格考试试题 | 试题 | 30 万条 |
| 医疗病例、报告 | 知识库 | 100 万条 |
- 其他公开数据
| 来源 | 类型 | 数量 |
| -------------------- | ------ | -------- |
| 医学科普书籍 | 书籍 | 500 本 |
| 其他多学科书籍 | 书籍 | 1000 本 |
| 代码 | 指令 | 20 万条 |
| 通用类试题 | 试题 | 300 万条 |
| 多种自然语言处理任务 | 指令 | 90 万条 |
| 互联网文本 | 互联网 | 300 万条 |
| 医疗问答、对话 | 指令 | 500 万条 |
- 继续预训练
- 扩充模型的医疗知识库:预训练数据+部分指令数据。
- 指令微调
- 从书籍、指南、病例、医疗报告、知识图谱等数据中自动化构建医疗指令集。
- 人工标注指令集,数据来源包括:电子病历系统、护理病历系统、PACS系统、临床科研系统、手术管理系统、公共卫生场景、医务管理场景以及工具助手场景。
- 采用 FastChat<sup>2</sup>、Self-Instruct<sup>3</sup>、Evol-Instruct<sup>4</sup> 等方案,对指令集进行扩展以及丰富指令集多样化形式。
- 数据工程
- 数据分类:根据训练阶段和任务场景进行分类。
- 数据清洗:去除无关信息,更正数据中的拼写错误,提取关键信息以及去隐私处理。
- 数据去重:采用 embedding 方法剔除重复数据。
- 数据采样:根据数据集的质量与分布需求进行有针对性的采样。
## 模型卡
- 训练配置与参数
| 名称 | 长度 | 精度 | 学习率 | Weight_decay | Epochs | GPUs |
| --------------- | ---- | ---- | ------ | ------------ | ------ | ------ |
| WiNGPT2-7B-Base | 2048 | bf16 | 5e-5 | 0.05 | 3 | A100*8 |
| WiNGPT2-7B-Chat | 4096 | bf16 | 5e-6 | 0.01 | 3 | A100*8 |
- 分布式训练策略与参数
- deepspeed + cpu_offload + zero_stage3
- gradient_checkpointing
## 评测
- 中文基础模型评估 C-EVAL(Zero-shot/Few-shot)
| | 平均 | 平均(Hard) | **STEM** | **社会科学** | **人文科学** | **其他** |
| -------------------------------------------------------------------------------------------- | -------- | ---------- | -------- | ------------ | ------------ | -------- |
| [bloomz-mt-176B](https://cevalbenchmark.com/static/model.html?method=bloomz-mt-176B*) | 44.3 | 30.8 | 39 | 53 | 47.7 | 42.7 |
| [Chinese LLaMA-13B](https://cevalbenchmark.com/static/model.html?method=Chinese%20LLaMA-13B) | 33.3 | 27.3 | 31.6 | 37.2 | 33.6 | 32.8 |
| [ChatGLM-6B*](https://cevalbenchmark.com/static/model.html?method=ChatGLM-6B*) | 38.9 | 29.2 | 33.3 | 48.3 | 41.3 | 38 |
| [baichuan-7B](https://cevalbenchmark.com/static/model.html?method=baichuan-7B) | 42.8 | 31.5 | 38.2 | 52 | 46.2 | 39.3 |
| [Baichuan-13B](https://cevalbenchmark.com/static/model.html?method=Baichuan-13B) | 53.6 | 36.7 | 47 | 66.8 | 57.3 | 49.8 |
| [Qwen-7B](https://cevalbenchmark.com/static/model.html?method=Qwen-7B) | **59.6** | 41 | 52.8 | **74.1** | **63.1** | 55.2 |
| [WiNGPT2-7B-Base](https://huggingface.co/winninghealth/WiNGPT2-7B-Base) | 57.4 | **42.7** | **53.2** | 69.7 | 55.7 | **55.4** |
- 中文医疗专业评估 MedQA-MCMLE(Zero-shot)
| 模型名称 | 平均 | 血液系统疾病 | 代谢、内分泌系统疾病 | 精神神经系统疾病 | 运动系统疾病 | 风湿免疫性疾病 | 儿科疾病 | 传染病、性传播疾病 | 其他疾病 |
| ---------------------------------------------------------------------------- | -------- | ------------ | -------------------- | ---------------- | ------------ | -------------- | -------- | ------------------ | -------- |
| [Baichuan-7B](https://huggingface.co/baichuan-inc/Baichuan-7B) | 23.1 | 25.6 | 20.2 | 25.8 | 17.9 | 26.5 | 20.6 | 26.1 | 17.1 |
| [Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base) | 37.2 | 34.4 | 36.2 | 40.7 | 38.4 | 57.1 | 31.6 | 30.8 | 34.3 |
| [Baichuan2-7B-Base](https://huggingface.co/baichuan-inc/Baichuan2-7B-Base) | 46.4 | 46.9 | 41.4 | 53.8 | 48.3 | 50.0 | 38.6 | 52.7 | 42.9 |
| [Baichuan2-13B-Base](https://huggingface.co/baichuan-inc/Baichuan2-13B-Base) | 62.9 | 68.8 | 64.4 | 69.7 | 64.9 | 60.3 | 50.9 | 61.2 | 62.9 |
| [HuatuoGPT-7B](https://huggingface.co/FreedomIntelligence/HuatuoGPT-7B) | 22.9 | 14.6 | 17.2 | 31.2 | 25.8 | 14.3 | 22.4 | 23.1 | 17.1 |
| [MedicalGPT](https://huggingface.co/shibing624/vicuna-baichuan-13b-chat) | 17.9 | 21.9 | 15.5 | 19.5 | 9.3 | 7.1 | 16.7 | 20.9 | 9.5 |
| [qwen-7b-Base](https://huggingface.co/Qwen/Qwen-7B) | 59.3 | 55.2 | 56.9 | 57.0 | 60.9 | 60.3 | 50.4 | 60.4 | 61.0 |
| [WiNGPT2-7B-Base](https://huggingface.co/winninghealth/WiNGPT2-7B-Base) | **82.3** | **83.3** | **82.8** | **86.0** | **81.5** | **85.7** | **75.1** | **78.0** | **80** |
** 目前公开测评存在一定局限性,结果仅供参考;
** 更多专业测评敬请期待。
## 局限性与免责声明
(a) WiNGPT2 是一个专业医疗领域的大语言模型,可为一般用户提供拟人化AI医生问诊和问答功能,以及一般医学领域的知识问答。对于专业医疗人士,WiNGPT2 提供关于患者病情的诊断、用药和健康建议等方面的回答的建议仅供参考。
(b) 您应理解 WiNGPT2 仅提供信息和建议,不能替代医疗专业人士的意见、诊断或治疗建议。在使用 WiNGPT2 的信息之前,请寻求医生或其他医疗专业人员的建议,并独立评估所提供的信息。
(c) WiNGPT2 的信息可能存在错误或不准确。卫宁健康不对 WiNGPT2 的准确性、可靠性、完整性、质量、安全性、及时性、性能或适用性提供任何明示或暗示的保证。使用 WiNGPT2 所产生的结果和决策由您自行承担。第三方原因而给您造成的损害结果承担责任。
## 许可证
1. 本项目授权协议为 Apache License 2.0,模型权重需要遵守基础模型[Qwen-7B](https://github.com/QwenLM/Qwen-7B)相关协议及[许可证](https://github.com/QwenLM/Qwen-7B/blob/main/LICENSE),详细内容参照其网站。
2. 使用本项目包括模型权重时请引用本项目:https://github.com/winninghealth/WiNGPT2
## 参考资料
1. https://github.com/QwenLM/Qwen-7B
2. https://github.com/lm-sys/FastChat
3. https://github.com/yizhongw/self-instruct
4. https://github.com/nlpxucan/evol-instruct
## 联系我们
网站:https://www.winning.com.cn
邮箱:[email protected]
|
[
"MEDQA"
] |
mogaio/pr_ebsa_fr_tran_merged25_e5_beginning_offsets
|
mogaio
|
text-classification
|
[
"setfit",
"safetensors",
"xlm-roberta",
"sentence-transformers",
"text-classification",
"generated_from_setfit_trainer",
"arxiv:2209.11055",
"base_model:sentence-transformers/paraphrase-multilingual-mpnet-base-v2",
"base_model:finetune:sentence-transformers/paraphrase-multilingual-mpnet-base-v2",
"model-index",
"region:us"
] | 2023-12-15T18:27:03Z |
2023-12-15T18:28:05+00:00
| 48 | 0 |
---
base_model: sentence-transformers/paraphrase-multilingual-mpnet-base-v2
library_name: setfit
metrics:
- accuracy_score
- classification_report
pipeline_tag: text-classification
tags:
- setfit
- sentence-transformers
- text-classification
- generated_from_setfit_trainer
widget:
- text: 'Adil Hussain
Adil Hussain est reconnaissant d''avoir reçu l''enseignement de l''acteur Naseeruddin
Shah à l''époque où il fréquentait l''École nationale d''art dramatique'
- text: 'Bien que leurs opinions sur la question de savoir si les migrants sont un
avantage ou un fardeau soient plus mitigées, de nettes majorités d''électeurs
de toute la ville de New York, de la banlieue et du nord de l''État ont déclaré
que l''État devrait essayer de ralentir l''afflux de migrants, plutôt que d''en
accepter davantage et de s''efforcer d''assimiler les nouveaux arrivants Les démocrates
aspirent à renverser six circonscriptions détenues par les républicains que M.
Biden a remportées en 2020, notamment celle de M Les républicains se sont emparés
de la crise des migrants, donnant un avant-goût des campagnes de l''année prochaine
Les républicains ont surenchéri : Elise Stefanik, la New-Yorkaise qui dirige la
conférence du parti démocrate à la Chambre des représentants,
Suite à la page suivante
a déclaré à Politico la semaine dernière que le parti allait consacrer 100 millions
de dollars aux campagnes dans les circonscriptions de New York Des problèmes à
venir pour les démocrates de New York en 2024 ?
Les dirigeants démocrates de New York se débattent depuis des mois avec le problème
de l''hébergement des dizaines de milliers de migrants qui ont été transportés
par bus jusqu''à New York et laissés à sa charge Des problèmes à venir pour les
démocrates de New York en 2024 ?
Les dirigeants démocrates de New York se débattent depuis des mois avec le problème
de l''hébergement des dizaines de milliers de migrants qui ont été transportés
par bus jusqu''à New York et laissés à sa charge.
Mais une autre préoccupation se profile alors que la crise se poursuit sans qu''aucune
issue ne soit en vue : les retombées potentielles pour leur parti lors des élections
de l''année prochaine Les républicains ont tendance à se sentir en sécurité lorsqu''ils
parlent d''immigration - comme les démocrates le font pour l''avortement - et
sont clairement à l''attaque sur la question des migrants à New York, tandis que
les démocrates sont sur la défensive, a déclaré Kyle Kondik, directeur de la communication
pour le Centre de politique de l''Université de Virginie, au réseau USA Today
Plus de 100 000 migrants ont été transportés à New York depuis la frontière sud
depuis le printemps 2022. Environ 60 000 d''entre eux sont hébergés dans la ville,
et plus de 2 100 ont été transportés dans des hôtels situés dans sept comtés au
nord de la ville, de Yonkers à la périphérie de Buffalo, où ils sont logés aux
frais de la ville Les démocrates doivent y remporter des victoires pour gagner
cinq sièges à la Chambre et faire du député Hakeem Jeffries, de Brooklyn, le prochain
président de la Chambre des représentants Les publicités d''attaque des républicains
s''écrivent pratiquement d''elles-mêmes à partir d''un flot de titres et d''images
télévisées, alors que le gouverneur Kathy Hochul, le maire de New York Eric Adams
et le président Joe Biden - tous démocrates - se rejettent mutuellement la faute
et s''échangent des coups de feu pour savoir qui devrait en faire le plus Isaac
Goldberg, un stratège démocrate qui a travaillé sur plusieurs campagnes électorales
à New York, a affirmé qu''il était beaucoup trop tôt pour prédire l''impact politique
de la crise des migrants, soulignant que les élections de 2024 n''auront lieu
que dans 14 mois et que de nombreuses questions tout aussi urgentes pourraient
se poser'
- text: 'LE CANDIDAT A LA PRESIDENCE RAMASWAMY VEUT METTRE FIN AU SYSTEME DE VISA
H-1B AUX ETATS-UNIS
Décrivant le programme de visas H-1B comme une forme de "servitude", Vivek Ramaswamy,
candidat républicain indien-américain à l''élection présidentielle, a promis de
"vider" le système basé sur la loterie et de le remplacer par un système d''admission
méritocratique s''il remporte les élections présidentielles de 2024'
- text: 'Smith Hal Sparks Catherine Zeta-Jones son-Sampras Chris Owen Donald Glover
("Queer as Folk") a 54 ans Smith Hal Sparks Catherine Zeta-Jones son-Sampras Chris
Owen Donald Glover
("Queer as Folk") a 54 ans. a 54 ans. Acteur
("Je sais ce que vous avez fait l''été dernier") a 50 ans'
- text: 'Trump profiter de sa célébrité jusqu''à la Maison-Blanche.
"Cela a tué Howard parce qu''il était le roi de tous les médias Il a poursuivi
en disant que Trump ne laisserait pas ses partisans s''approcher de l''une de
ses propriétés. "Les gens qui votent pour Trump, pour la plupart, ne les laisseraient
même pas entrer dans un putain d''hôtel [ "Si être réveillé signifie que je ne
peux pas soutenir Trump, ce que je pense que cela signifie, ou que je soutiens
les personnes qui veulent être transgenres ou que je suis pour le vaccin, appelez-moi
réveillé comme vous le voulez" "Les gens qui votent pour Trump, pour la plupart,
ne les laisseraient même pas entrer dans un putain d''hôtel [...]. Allez à Mar-a-lago,
voyez s''il y a des gens qui vous ressemblent" Stern a également abordé les affirmations
de Trump et de ses partisans selon lesquelles Joe Biden a remporté l''élection
américaine de 2020 grâce à des votes frauduleux "Et soudain, Trump a transformé
Howard, qui était le roi de tous les médias, en prince Harry de tous les médias.
Tout le monde s''en fout "Trump avait l''habitude de participer à l''émission
de Stern chaque semaine. Ils étaient amis. Alors cette idée que Trump est le pire
type qui ait jamais marché sur la surface de la terre, pourquoi traîniez-vous
avec lui ?"
M Mais Stern, qui par le passé a été accusé de racisme et de sexisme dans nombre
de ses sketches à l''antenne, a été un critique virulent de Trump tout au long
de sa présidence et, plus récemment, alors qu''il se prépare à se présenter à
nouveau en 2024.
En 2021, M "Combien de temps allons-nous continuer à élire des gens qui ont perdu
l''élection ?"
Il a poursuivi en qualifiant les partisans de Trump de "nigauds".
"Mon Dieu, j''ai l''impression d''être dans une nation de nigauds. J''espère qu''il
y a encore des gens brillants et dynamiques qui aiment ce pays", a-t-il déclaré
Alors cette idée que Trump est le pire type qui ait jamais marché sur la surface
de la terre, pourquoi traîniez-vous avec lui ?"
M. Failla a déclaré que cela avait "tué" M Si "woke" signifie que je ne peux pas
soutenir Trump, ce que je pense que cela signifie, ou que je soutiens les personnes
qui veulent être transgenres ou que je suis pour le vaccin, appelez-moi "woke"
comme vous voulez Celui qui se décrit comme le "roi de tous les médias" a critiqué
ouvertement l''ancien président américain Donald Trump, les anti-vaxx et, plus
récemment, Lauren Boebert, qu''il a critiquée pour son comportement obscène dans
un théâtre de Denver au début du mois "L''omnipotence médiatique de Donald Trump
a brisé Howard Stern. C''est très important", a déclaré Failla dans la vidéo (selon
OK ! Magazine). "Trump avait l''habitude de participer à l''émission de Stern
chaque semaine L''aversion d''Howard Stern pour Donald Trump, c''est "tout l''ego".
Si "woke" signifie que je ne peux pas soutenir Trump, ce que je pense que cela
signifie, ou que je soutiens les personnes qui veulent être transgenres ou que
je suis pour le vaccin, appelez-moi "woke" comme vous voulez Trump l''année prochaine.
"Je sais que je lui botterai le cul", a-t-il déclaré aux auditeurs.
L''année suivante, Stern a déclaré qu''il envisageait de se lancer dans la course
à la présidence "pour que le pays soit à nouveau juste" En réponse, Trump a partagé
sur sa plateforme Truth Social un clip de Fox News dans lequel l''animateur Jimmy
Failla critique Stern.
"L''omnipotence médiatique de Donald Trump a brisé Howard Stern "Je vais faire
la chose très simple qui remettra le pays sur le droit chemin : un vote, une personne",
a expliqué Stern, affirmant que Trump a en fait perdu l''élection de 2016 contre
Hillary Clinton qui a remporté le vote populaire - mais pas le collège électoral'
inference: true
model-index:
- name: SetFit with sentence-transformers/paraphrase-multilingual-mpnet-base-v2
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: Unknown
type: unknown
split: test
metrics:
- type: accuracy_score
value: 0.923784494086728
name: Accuracy_Score
- type: classification_report
value:
'0':
precision: 0.9251101321585903
recall: 0.8898305084745762
f1-score: 0.9071274298056154
support: 236
'1':
precision: 0.9081967213114754
recall: 0.920265780730897
f1-score: 0.9141914191419142
support: 301
'2':
precision: 0.9432314410480349
recall: 0.9642857142857143
f1-score: 0.9536423841059601
support: 224
accuracy: 0.923784494086728
macro avg:
precision: 0.9255127648393668
recall: 0.9247940011637291
f1-score: 0.9249870776844965
support: 761
weighted avg:
precision: 0.9237543325873079
recall: 0.923784494086728
f1-score: 0.9236131204146865
support: 761
name: Classification_Report
---
# SetFit with sentence-transformers/paraphrase-multilingual-mpnet-base-v2
This is a [SetFit](https://github.com/huggingface/setfit) model that can be used for Text Classification. This SetFit model uses [sentence-transformers/paraphrase-multilingual-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-mpnet-base-v2) as the Sentence Transformer embedding model. A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification.
The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Model Details
### Model Description
- **Model Type:** SetFit
- **Sentence Transformer body:** [sentence-transformers/paraphrase-multilingual-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-multilingual-mpnet-base-v2)
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
- **Maximum Sequence Length:** 128 tokens
- **Number of Classes:** 3 classes
<!-- - **Training Dataset:** [Unknown](https://huggingface.co/datasets/unknown) -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
### Model Labels
| Label | Examples |
|:------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| pos | <ul><li>"Les PHL lèvent 1,26 milliard de dollars grâce aux obligations en dollars de détail\nLE GOUVERNEMENT PHILIPPIN a levé 1,26 milliard de dollars lors de la première émission d'obligations de détail en dollars (RDB) sous l'administration Marcos, a déclaré le ministère des Finances (DoF)"</li><li>"Atom Egoyan revient à Salomé, l'opéra qu'il a monté en 1996, avec Seven Veils\nAtom Egoyan n'a pas été surpris lorsque la Canadian Opera Company lui a demandé de remonter Salomé pour la saison 2022-23 Atom Egoyan revient à Salomé, l'opéra qu'il a monté en 1996, avec Seven Veils\nAtom Egoyan n'a pas été surpris lorsque la Canadian Opera Company lui a demandé de remonter Salomé pour la saison 2022-23. Avec ses éléments de film et de vidéo, son interprétation psychologique et sombre de l'opéra de Richard Strauss avait un solide palmarès de reprises - depuis sa création en 1996, elle avait été présentée deux fois de plus à la COC et avait été reprise par plusieurs autres compagnies"</li><li>'Paul Simon présente un documentaire sur sa carrière\nAprès un documentaire de trois heures et demie sur sa vie, Paul Simon n\'avait que de la sympathie pour le public Paul Simon présente un documentaire sur sa carrière\nAprès un documentaire de trois heures et demie sur sa vie, Paul Simon n\'avait que de la sympathie pour le public.\nTORONTO >> Après un documentaire de trois heures et demie sur sa vie, Paul Simon n\'avait que de la sympathie pour le public "Il n\'y a pas de raison que vous soyez épuisés", a dit Simon à la foule après la première du documentaire d\'Alex Gibney "In Restless Dreams : The Music of Paul Simon" d\'Alex Gibney, dimanche au Festival international du film de Toronto.\nSimon, âgé de 81 ans, n\'avait pas regardé le film avant la première, et il ne l\'a pas regardé non plus dimanche TORONTO >> Après un documentaire de trois heures et demie sur sa vie, Paul Simon n\'avait que de la sympathie pour le public.\n"Il n\'y a pas de raison que vous soyez épuisés", a dit Simon à la foule après la première du documentaire d\'Alex Gibney "In Restless Dreams : The Music of Paul Simon" d\'Alex Gibney, dimanche au Festival international du film de Toronto'</li></ul> |
| neg | <ul><li>'Le groupe Al-Mostaqilla de l\'université du Koweït a appelé les étudiants à organiser un sit-in à l\'université du Koweït lundi pour protester contre la décision de mettre fin aux classes mixtes La décision a été prise la semaine dernière par le nouveau ministre de l\'éducation, Adel Al-Mane, et le directeur par intérim de l\'université du Koweït, Fayez Al-Dhafiri, et mise en œuvre mercredi, trois jours seulement avant le début de la nouvelle année universitaire à la faculté de droit L\'association a également demandé au gouvernement de "cesser ses interventions politiques et médiatiques injustifiées" dans les affaires de l\'université du Koweït.\nL\'association a appelé le directeur par intérim de l\'université du Koweït à ne pas céder aux pressions politiques et médiatiques et à s\'efforcer de protéger l\'indépendance de l\'université Dhafiri a déclaré que la décision avait été prise en application de la loi de 1996 qui interdisait l\'enseignement mixte à l\'université du Koweït, malgré une décision de la Cour constitutionnelle de 2015 autorisant l\'enseignement mixte lorsqu\'il était nécessaire et dans des cas exceptionnels Parallèlement, l\'association des professeurs de l\'université du Koweït a publié samedi une déclaration demandant aux députés et au gouvernement de "cesser d\'interférer dans les affaires de l\'université du Koweït" et de maintenir l\'indépendance de l\'université "L\'université du Koweït était, est et sera toujours le porte-drapeau de la connaissance et des valeurs, à l\'abri de toute influence extérieure Le député Abdulwahab Al-Essa a reproché à l\'administration de l\'université du Koweït d\'avoir succombé à la pression politique au détriment de l\'intérêt public, ajoutant que l\'université du Koweït avait appliqué correctement une décision de la cour constitutionnelle autorisant les classes mixtes chaque fois que cela était nécessaire'</li><li>"L'immigration étant l'un des défis les plus difficiles à relever pour le président Joe Biden et apparaissant comme un enjeu majeur des élections de l'année prochaine, l'administration délocalise essentiellement la question en s'appuyant sur les pays d'Amérique centrale et d'Amérique du Sud pour empêcher les migrants de se diriger vers le nord"</li><li>'Lors d\'une réunion d\'information mardi, le porte-parole de l\'armée, le lieutenant-colonel Richard Hecht, a suggéré que les Palestiniens tentent de quitter la bande de Gaza par le poste-frontière de Rafah, en Égypte.\nLa perspective d\'un exode des habitants de Gaza vers le territoire égyptien a alarmé les autorités égyptiennes La question qui se pose est de savoir si Israël lancera une offensive terrestre dans la bande de Gaza, une bande de terre de 25 miles de long coincée entre Israël, l\'Égypte et la mer Méditerranée, où vivent 2,3 millions de personnes et qui est gouvernée par le Hamas depuis 2007 Israël pilonne la bande de Gaza ; les habitants se précipitent pour se mettre à l\'abri\nJERUSALEM - Les avions de combat israéliens ont bombardé la bande de Gaza quartier par quartier mardi, réduisant les bâtiments en ruines et poussant les habitants à se précipiter pour se mettre à l\'abri dans ce minuscule territoire isolé, alors qu\'Israël promet des représailles pour l\'attaque surprise du Hamas du week-end qui "se répercuteront Les autorités égyptiennes discutent avec Israël et les États-Unis afin de mettre en place des corridors humanitaires dans la bande de Gaza pour acheminer l\'aide, a déclaré un responsable égyptien. Des négociations sont en cours avec les Israéliens pour que la zone autour du point de passage de Rafah entre l\'Égypte et Gaza soit déclarée "zone d\'interdiction de feu", a déclaré le responsable, sous couvert d\'anonymat car il n\'était pas autorisé à parler aux médias'</li></ul> |
| obj | <ul><li>"L'économie pèse sur les Américains Ils sont plus nombreux à faire confiance à Trump qu'à Biden pour alléger leur fardeau\nWASHINGTON - Linda Muñoz a peur de l'économie Trump, le candidat républicain à la primaire de 2024, pour améliorer l'économie, avec une marge de 47 % à 36 %. L'écart est de 46 %-26 % en faveur de M. Trump parmi les électeurs indépendants Presque tous les républicains interrogés ont exprimé leur pessimisme à l'égard de l'économie, selon le sondage : 96 % d'entre eux estiment que la situation se dégrade au lieu de s'améliorer Le logement. L'essence. Tous ces éléments poussent les gens à s'endetter de plus en plus, disent-ils.\nSelon le sondage, près de 70 % des Américains estiment que la situation économique se dégrade, tandis que 22 % seulement estiment qu'elle s'améliore L'économie pèse sur les Américains Ils sont plus nombreux à faire confiance à Trump qu'à Biden pour alléger leur fardeau\nWASHINGTON - Linda Muñoz a peur de l'économie. Elle a puisé dans son épargne d'urgence cette année. Et elle ne croit pas que le président Joe Biden ressente sa douleur L'épicerie. Le logement. L'essence. Tous ces éléments poussent les gens à s'endetter de plus en plus, disent-ils.\nSelon le sondage, près de 70 % des Américains estiment que la situation économique se dégrade, tandis que 22 % seulement estiment qu'elle s'améliore"</li><li>'Le Pentagone va interroger d\'autres militaires sur l\'attentat suicide de l\'aéroport de Kaboul en 2021\nLe commandement central du Pentagone a ordonné l\'audition d\'une vingtaine de militaires supplémentaires qui se trouvaient à l\'aéroport de Kaboul lorsque des kamikazes ont attaqué pendant le retrait chaotique des forces américaines d\'Afghanistan, alors que les critiques persistent sur le fait que l\'attaque meurtrière aurait pu être stoppée Certaines familles des personnes tuées ou blessées se sont plaintes que le Pentagone n\'avait pas fait preuve de suffisamment de transparence au sujet de l\'attentat à la bombe qui a tué 170 Afghans\net 13 militaires américains.\nL\'enquête du commandement central américain a conclu en novembre 2021 qu\'étant donné la détérioration de la sécurité à la porte de l\'Abbaye de l\'aéroport alors que les Afghans cherchaient de plus en plus à fuir, "l\'attaque n\'aurait pas pu être évitée au niveau tactique sans dégrader la mission visant à maximiser le nombre d\'évacués" Le Pentagone a déclaré que l\'examen de l\'attentat suicide n\'avait révélé aucune identification préalable d\'un attaquant possible ni aucune demande d\'"escalade des règles d\'engagement existantes" régissant l\'utilisation de la force par les troupes américaines'</li><li>'Les retombées de la guerre se répercutent sur les lieux de travail aux États-Unis.\nNEW YORK - Les retombées de la guerre entre Israël et le Hamas se sont répandues sur les lieux de travail partout dans le monde, les dirigeants de grandes entreprises exprimant leur point de vue tandis que les travailleurs se plaignent de ne pas être entendus "À quoi me sert mon travail si je compromets ma propre morale et mon éthique ?\nL\'un des conflits les plus importants s\'est produit chez Starbucks après que Starbucks Workers United, un syndicat représentant 9 000 travailleurs dans plus de 360 magasins aux États-Unis, a tweeté "Solidarité avec la Palestine" deux jours après l\'attaque du Hamas. Le tweet a été supprimé au bout de 40 minutes, mais l\'entreprise a déclaré qu\'il avait donné lieu à plus de 1 000 plaintes, à des actes de vandalisme et à des affrontements dans ses magasins NEW YORK - Les retombées de la guerre entre Israël et le Hamas se sont répandues sur les lieux de travail partout dans le monde, les dirigeants de grandes entreprises exprimant leur point de vue tandis que les travailleurs se plaignent de ne pas être entendus'</li></ul> |
## Evaluation
### Metrics
| Label | Accuracy_Score | Classification_Report |
|:--------|:---------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| **all** | 0.9238 | {'0': {'precision': 0.9251101321585903, 'recall': 0.8898305084745762, 'f1-score': 0.9071274298056154, 'support': 236}, '1': {'precision': 0.9081967213114754, 'recall': 0.920265780730897, 'f1-score': 0.9141914191419142, 'support': 301}, '2': {'precision': 0.9432314410480349, 'recall': 0.9642857142857143, 'f1-score': 0.9536423841059601, 'support': 224}, 'accuracy': 0.923784494086728, 'macro avg': {'precision': 0.9255127648393668, 'recall': 0.9247940011637291, 'f1-score': 0.9249870776844965, 'support': 761}, 'weighted avg': {'precision': 0.9237543325873079, 'recall': 0.923784494086728, 'f1-score': 0.9236131204146865, 'support': 761}} |
## Uses
### Direct Use for Inference
First install the SetFit library:
```bash
pip install setfit
```
Then you can load this model and run inference.
```python
from setfit import SetFitModel
# Download from the 🤗 Hub
model = SetFitModel.from_pretrained("mogaio/pr_ebsa_fr_tran_merged25_e5_beginning_offsets")
# Run inference
preds = model("Adil Hussain
Adil Hussain est reconnaissant d'avoir reçu l'enseignement de l'acteur Naseeruddin Shah à l'époque où il fréquentait l'École nationale d'art dramatique")
```
<!--
### Downstream Use
*List how someone could finetune this model on their own dataset.*
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:-------------|:----|:---------|:-----|
| Word count | 9 | 247.2638 | 2089 |
| Label | Training Sample Count |
|:------|:----------------------|
| neg | 913 |
| obj | 1216 |
| pos | 911 |
### Training Hyperparameters
- batch_size: (8, 8)
- num_epochs: (5, 5)
- max_steps: -1
- sampling_strategy: oversampling
- num_iterations: 1
- body_learning_rate: (2e-05, 2e-05)
- head_learning_rate: 2e-05
- loss: CosineSimilarityLoss
- distance_metric: cosine_distance
- margin: 0.25
- end_to_end: False
- use_amp: False
- warmup_proportion: 0.1
- seed: 42
- eval_max_steps: -1
- load_best_model_at_end: False
### Training Results
| Epoch | Step | Training Loss | Validation Loss |
|:------:|:----:|:-------------:|:---------------:|
| 0.0013 | 1 | 0.3703 | - |
| 0.0658 | 50 | 0.3145 | - |
| 0.1316 | 100 | 0.1839 | - |
| 0.1974 | 150 | 0.2558 | - |
| 0.2632 | 200 | 0.2683 | - |
| 0.3289 | 250 | 0.1572 | - |
| 0.3947 | 300 | 0.1953 | - |
| 0.4605 | 350 | 0.171 | - |
| 0.5263 | 400 | 0.2326 | - |
| 0.5921 | 450 | 0.1762 | - |
| 0.6579 | 500 | 0.2818 | - |
| 0.7237 | 550 | 0.2733 | - |
| 0.7895 | 600 | 0.195 | - |
| 0.8553 | 650 | 0.2104 | - |
| 0.9211 | 700 | 0.2124 | - |
| 0.9868 | 750 | 0.0818 | - |
| 1.0526 | 800 | 0.1046 | - |
| 1.1184 | 850 | 0.1633 | - |
| 1.1842 | 900 | 0.3207 | - |
| 1.25 | 950 | 0.2703 | - |
| 1.3158 | 1000 | 0.1934 | - |
| 1.3816 | 1050 | 0.2547 | - |
| 1.4474 | 1100 | 0.0933 | - |
| 1.5132 | 1150 | 0.2102 | - |
| 1.5789 | 1200 | 0.0699 | - |
| 1.6447 | 1250 | 0.1778 | - |
| 1.7105 | 1300 | 0.1796 | - |
| 1.7763 | 1350 | 0.0221 | - |
| 1.8421 | 1400 | 0.2154 | - |
| 1.9079 | 1450 | 0.1683 | - |
| 1.9737 | 1500 | 0.3096 | - |
| 2.0395 | 1550 | 0.201 | - |
| 2.1053 | 1600 | 0.1954 | - |
| 2.1711 | 1650 | 0.2301 | - |
| 2.2368 | 1700 | 0.1141 | - |
| 2.3026 | 1750 | 0.1949 | - |
| 2.3684 | 1800 | 0.164 | - |
| 2.4342 | 1850 | 0.2307 | - |
| 2.5 | 1900 | 0.1912 | - |
| 2.5658 | 1950 | 0.2349 | - |
| 2.6316 | 2000 | 0.0922 | - |
| 2.6974 | 2050 | 0.0702 | - |
| 2.7632 | 2100 | 0.1089 | - |
| 2.8289 | 2150 | 0.1711 | - |
| 2.8947 | 2200 | 0.1432 | - |
| 2.9605 | 2250 | 0.2739 | - |
| 3.0263 | 2300 | 0.1889 | - |
| 3.0921 | 2350 | 0.1036 | - |
| 3.1579 | 2400 | 0.1372 | - |
| 3.2237 | 2450 | 0.028 | - |
| 3.2895 | 2500 | 0.1739 | - |
| 3.3553 | 2550 | 0.142 | - |
| 3.4211 | 2600 | 0.0838 | - |
| 3.4868 | 2650 | 0.0657 | - |
| 3.5526 | 2700 | 0.0054 | - |
| 3.6184 | 2750 | 0.0426 | - |
| 3.6842 | 2800 | 0.1974 | - |
| 3.75 | 2850 | 0.0279 | - |
| 3.8158 | 2900 | 0.1326 | - |
| 3.8816 | 2950 | 0.1614 | - |
| 3.9474 | 3000 | 0.1251 | - |
| 4.0132 | 3050 | 0.1174 | - |
| 4.0789 | 3100 | 0.1948 | - |
| 4.1447 | 3150 | 0.0555 | - |
| 4.2105 | 3200 | 0.0064 | - |
| 4.2763 | 3250 | 0.064 | - |
| 4.3421 | 3300 | 0.0013 | - |
| 4.4079 | 3350 | 0.135 | - |
| 4.4737 | 3400 | 0.0574 | - |
| 4.5395 | 3450 | 0.174 | - |
| 4.6053 | 3500 | 0.2199 | - |
| 4.6711 | 3550 | 0.387 | - |
| 4.7368 | 3600 | 0.114 | - |
| 4.8026 | 3650 | 0.0853 | - |
| 4.8684 | 3700 | 0.0325 | - |
| 4.9342 | 3750 | 0.019 | - |
| 5.0 | 3800 | 0.0572 | - |
| 0.0013 | 1 | 0.1435 | - |
| 0.0658 | 50 | 0.0969 | - |
| 0.1316 | 100 | 0.1085 | - |
| 0.1974 | 150 | 0.0271 | - |
| 0.2632 | 200 | 0.0138 | - |
| 0.3289 | 250 | 0.058 | - |
| 0.3947 | 300 | 0.1205 | - |
| 0.4605 | 350 | 0.0788 | - |
| 0.5263 | 400 | 0.1449 | - |
| 0.5921 | 450 | 0.0383 | - |
| 0.6579 | 500 | 0.0338 | - |
| 0.7237 | 550 | 0.1253 | - |
| 0.7895 | 600 | 0.069 | - |
| 0.8553 | 650 | 0.104 | - |
| 0.9211 | 700 | 0.0462 | - |
| 0.9868 | 750 | 0.1975 | - |
| 1.0526 | 800 | 0.0241 | - |
| 1.1184 | 850 | 0.0426 | - |
| 1.1842 | 900 | 0.0519 | - |
| 1.25 | 950 | 0.0815 | - |
| 1.3158 | 1000 | 0.1839 | - |
| 1.3816 | 1050 | 0.0198 | - |
| 1.4474 | 1100 | 0.0128 | - |
| 1.5132 | 1150 | 0.1645 | - |
| 1.5789 | 1200 | 0.0019 | - |
| 1.6447 | 1250 | 0.0557 | - |
| 1.7105 | 1300 | 0.0098 | - |
| 1.7763 | 1350 | 0.001 | - |
| 1.8421 | 1400 | 0.1557 | - |
| 1.9079 | 1450 | 0.1286 | - |
| 1.9737 | 1500 | 0.094 | - |
| 2.0395 | 1550 | 0.0059 | - |
| 2.1053 | 1600 | 0.0227 | - |
| 2.1711 | 1650 | 0.0899 | - |
| 2.2368 | 1700 | 0.0053 | - |
| 2.3026 | 1750 | 0.0021 | - |
| 2.3684 | 1800 | 0.0114 | - |
| 2.4342 | 1850 | 0.1163 | - |
| 2.5 | 1900 | 0.0959 | - |
| 2.5658 | 1950 | 0.0252 | - |
| 2.6316 | 2000 | 0.0921 | - |
| 2.6974 | 2050 | 0.1159 | - |
| 2.7632 | 2100 | 0.0026 | - |
| 2.8289 | 2150 | 0.1211 | - |
| 2.8947 | 2200 | 0.1843 | - |
| 2.9605 | 2250 | 0.0014 | - |
| 3.0263 | 2300 | 0.0085 | - |
| 3.0921 | 2350 | 0.0839 | - |
| 3.1579 | 2400 | 0.2372 | - |
| 3.2237 | 2450 | 0.0213 | - |
| 3.2895 | 2500 | 0.0155 | - |
| 3.3553 | 2550 | 0.1128 | - |
| 3.4211 | 2600 | 0.0945 | - |
| 3.4868 | 2650 | 0.0917 | - |
| 3.5526 | 2700 | 0.0011 | - |
| 3.6184 | 2750 | 0.0024 | - |
| 3.6842 | 2800 | 0.0044 | - |
| 3.75 | 2850 | 0.121 | - |
| 3.8158 | 2900 | 0.0056 | - |
| 3.8816 | 2950 | 0.003 | - |
| 3.9474 | 3000 | 0.0899 | - |
| 4.0132 | 3050 | 0.0157 | - |
| 4.0789 | 3100 | 0.1188 | - |
| 4.1447 | 3150 | 0.001 | - |
| 4.2105 | 3200 | 0.0222 | - |
| 4.2763 | 3250 | 0.1209 | - |
| 4.3421 | 3300 | 0.1085 | - |
| 4.4079 | 3350 | 0.0054 | - |
| 4.4737 | 3400 | 0.0009 | - |
| 4.5395 | 3450 | 0.0015 | - |
| 4.6053 | 3500 | 0.003 | - |
| 4.6711 | 3550 | 0.0009 | - |
| 4.7368 | 3600 | 0.0003 | - |
| 4.8026 | 3650 | 0.0009 | - |
| 4.8684 | 3700 | 0.03 | - |
| 4.9342 | 3750 | 0.1206 | - |
| 5.0 | 3800 | 0.0003 | - |
| 0.0013 | 1 | 0.2045 | - |
| 0.0658 | 50 | 0.0078 | - |
| 0.1316 | 100 | 0.0087 | - |
| 0.1974 | 150 | 0.0386 | - |
| 0.2632 | 200 | 0.1015 | - |
| 0.3289 | 250 | 0.0022 | - |
| 0.3947 | 300 | 0.0291 | - |
| 0.4605 | 350 | 0.0013 | - |
| 0.5263 | 400 | 0.0022 | - |
| 0.5921 | 450 | 0.1324 | - |
| 0.6579 | 500 | 0.113 | - |
| 0.7237 | 550 | 0.0011 | - |
| 0.7895 | 600 | 0.1723 | - |
| 0.8553 | 650 | 0.0049 | - |
| 0.9211 | 700 | 0.206 | - |
| 0.9868 | 750 | 0.1683 | - |
| 1.0526 | 800 | 0.0954 | - |
| 1.1184 | 850 | 0.018 | - |
| 1.1842 | 900 | 0.1854 | - |
| 1.25 | 950 | 0.0342 | - |
| 1.3158 | 1000 | 0.0015 | - |
| 1.3816 | 1050 | 0.0062 | - |
| 1.4474 | 1100 | 0.1187 | - |
| 1.5132 | 1150 | 0.0048 | - |
| 1.5789 | 1200 | 0.0011 | - |
| 1.6447 | 1250 | 0.002 | - |
| 1.7105 | 1300 | 0.092 | - |
| 1.7763 | 1350 | 0.1245 | - |
| 1.8421 | 1400 | 0.0009 | - |
| 1.9079 | 1450 | 0.1185 | - |
| 1.9737 | 1500 | 0.0017 | - |
| 2.0395 | 1550 | 0.008 | - |
| 2.1053 | 1600 | 0.0049 | - |
| 2.1711 | 1650 | 0.0083 | - |
| 2.2368 | 1700 | 0.0026 | - |
| 2.3026 | 1750 | 0.0081 | - |
| 2.3684 | 1800 | 0.0036 | - |
| 2.4342 | 1850 | 0.0016 | - |
| 2.5 | 1900 | 0.0017 | - |
| 2.5658 | 1950 | 0.0014 | - |
| 2.6316 | 2000 | 0.0017 | - |
| 2.6974 | 2050 | 0.002 | - |
| 2.7632 | 2100 | 0.1022 | - |
| 2.8289 | 2150 | 0.0004 | - |
| 2.8947 | 2200 | 0.0007 | - |
| 2.9605 | 2250 | 0.0794 | - |
| 3.0263 | 2300 | 0.0183 | - |
| 3.0921 | 2350 | 0.0377 | - |
| 3.1579 | 2400 | 0.029 | - |
| 3.2237 | 2450 | 0.0003 | - |
| 3.2895 | 2500 | 0.0961 | - |
| 3.3553 | 2550 | 0.0008 | - |
| 3.4211 | 2600 | 0.0873 | - |
| 3.4868 | 2650 | 0.0501 | - |
| 3.5526 | 2700 | 0.0029 | - |
| 3.6184 | 2750 | 0.0008 | - |
| 3.6842 | 2800 | 0.0004 | - |
| 3.75 | 2850 | 0.0011 | - |
| 3.8158 | 2900 | 0.0518 | - |
| 3.8816 | 2950 | 0.0002 | - |
| 3.9474 | 3000 | 0.1115 | - |
| 4.0132 | 3050 | 0.0129 | - |
| 4.0789 | 3100 | 0.0005 | - |
| 4.1447 | 3150 | 0.0012 | - |
| 4.2105 | 3200 | 0.1086 | - |
| 4.2763 | 3250 | 0.0199 | - |
| 4.3421 | 3300 | 0.0004 | - |
| 4.4079 | 3350 | 0.0001 | - |
| 4.4737 | 3400 | 0.0832 | - |
| 4.5395 | 3450 | 0.0003 | - |
| 4.6053 | 3500 | 0.0041 | - |
| 4.6711 | 3550 | 0.1146 | - |
| 4.7368 | 3600 | 0.0027 | - |
| 4.8026 | 3650 | 0.0002 | - |
| 4.8684 | 3700 | 0.0544 | - |
| 4.9342 | 3750 | 0.0002 | - |
| 5.0 | 3800 | 0.0046 | - |
### Framework Versions
- Python: 3.10.12
- SetFit: 1.0.1
- Sentence Transformers: 2.2.2
- Transformers: 4.35.2
- PyTorch: 2.1.0+cu121
- Datasets: 2.15.0
- Tokenizers: 0.15.0
## Citation
### BibTeX
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"CAS"
] |
ntc-ai/SDXL-LoRA-slider.begging
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-31T19:58:19Z |
2023-12-31T19:58:22+00:00
| 48 | 1 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/begging.../begging_17_3.0.png
widget:
- text: begging
output:
url: images/begging_17_3.0.png
- text: begging
output:
url: images/begging_19_3.0.png
- text: begging
output:
url: images/begging_20_3.0.png
- text: begging
output:
url: images/begging_21_3.0.png
- text: begging
output:
url: images/begging_22_3.0.png
inference: false
instance_prompt: begging
---
# ntcai.xyz slider - begging (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/begging_17_-3.0.png" width=256 height=256 /> | <img src="images/begging_17_0.0.png" width=256 height=256 /> | <img src="images/begging_17_3.0.png" width=256 height=256 /> |
| <img src="images/begging_19_-3.0.png" width=256 height=256 /> | <img src="images/begging_19_0.0.png" width=256 height=256 /> | <img src="images/begging_19_3.0.png" width=256 height=256 /> |
| <img src="images/begging_20_-3.0.png" width=256 height=256 /> | <img src="images/begging_20_0.0.png" width=256 height=256 /> | <img src="images/begging_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
begging
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.begging', weight_name='begging.safetensors', adapter_name="begging")
# Activate the LoRA
pipe.set_adapters(["begging"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, begging"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 770+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
Weyaxi/Einstein-v4-phi2
|
Weyaxi
|
text-generation
|
[
"transformers",
"safetensors",
"phi",
"text-generation",
"axolotl",
"generated_from_trainer",
"phi2",
"einstein",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"science",
"physics",
"chemistry",
"biology",
"math",
"conversational",
"custom_code",
"en",
"dataset:allenai/ai2_arc",
"dataset:camel-ai/physics",
"dataset:camel-ai/chemistry",
"dataset:camel-ai/biology",
"dataset:camel-ai/math",
"dataset:metaeval/reclor",
"dataset:openbookqa",
"dataset:mandyyyyii/scibench",
"dataset:derek-thomas/ScienceQA",
"dataset:TIGER-Lab/ScienceEval",
"dataset:jondurbin/airoboros-3.2",
"dataset:LDJnr/Capybara",
"dataset:Cot-Alpaca-GPT4-From-OpenHermes-2.5",
"dataset:STEM-AI-mtl/Electrical-engineering",
"dataset:knowrohit07/saraswati-stem",
"dataset:sablo/oasst2_curated",
"dataset:glaiveai/glaive-code-assistant",
"dataset:lmsys/lmsys-chat-1m",
"dataset:TIGER-Lab/MathInstruct",
"dataset:bigbio/med_qa",
"dataset:meta-math/MetaMathQA-40K",
"dataset:piqa",
"dataset:scibench",
"dataset:sciq",
"dataset:Open-Orca/SlimOrca",
"dataset:migtissera/Synthia-v1.3",
"base_model:microsoft/phi-2",
"base_model:finetune:microsoft/phi-2",
"license:other",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-04-10T09:46:08Z |
2024-04-23T15:52:03+00:00
| 48 | 1 |
---
base_model: microsoft/phi-2
datasets:
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- metaeval/reclor
- openbookqa
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- TIGER-Lab/ScienceEval
- jondurbin/airoboros-3.2
- LDJnr/Capybara
- Cot-Alpaca-GPT4-From-OpenHermes-2.5
- STEM-AI-mtl/Electrical-engineering
- knowrohit07/saraswati-stem
- sablo/oasst2_curated
- glaiveai/glaive-code-assistant
- lmsys/lmsys-chat-1m
- TIGER-Lab/MathInstruct
- bigbio/med_qa
- meta-math/MetaMathQA-40K
- openbookqa
- piqa
- metaeval/reclor
- derek-thomas/ScienceQA
- scibench
- sciq
- Open-Orca/SlimOrca
- migtissera/Synthia-v1.3
- TIGER-Lab/ScienceEval
language:
- en
license: other
tags:
- axolotl
- generated_from_trainer
- phi
- phi2
- einstein
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- science
- physics
- chemistry
- biology
- math
model-index:
- name: Einstein-v4-phi2
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 59.98
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 74.07
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 56.89
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 45.8
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 73.88
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 53.98
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-phi2
name: Open LLM Leaderboard
---

# 🔬 Einstein-v4-phi2
This model is a full fine-tuned version of [microsoft/phi-2](https://huggingface.co/microsoft/phi-2) on diverse datasets.
This model is finetuned using `8xRTX3090` + `1xRTXA6000` using [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This model's training was sponsored by [sablo.ai](https://sablo.ai).
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: microsoft/phi-2
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
load_in_8bit: false
load_in_4bit: false
strict: false
chat_template: chatml
datasets:
- path: data/merged_all.json
ds_type: json
type: alpaca
conversation: chatml
- path: data/capybara_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/synthia-v1.3_sharegpt_12500.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/cot_alpaca_gpt4_extracted_openhermes_2.5_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/slimorca_dedup_filtered_95k_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/airoboros_3.2_without_contextual_slimorca_orca_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
dataset_prepared_path: last_run_prepared
val_set_size: 0.005
output_dir: ./Einstein-v4-phi2-model
sequence_len: 2048
sample_packing: true
pad_to_sequence_len: true
eval_sample_packing: false
wandb_project: Einstein
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
hub_model_id: Weyaxi/Einstein-v4-phi2
save_safetensors: true
gradient_accumulation_steps: 4
micro_batch_size: 3
num_epochs: 2
optimizer: adamw_torch # adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.000005
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 2 # changed
eval_table_size:
eval_table_max_new_tokens: 128
saves_per_epoch: 4
debug:
deepspeed: zero3_bf16.json
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
eos_token: "<|im_end|>"
pad_token: "<|endoftext|>"
tokens:
- "<|im_start|>"
```
</details><br>
# 💬 Prompt Template
You can use this prompt template while using the model:
### ChatML
```
<|im_start|>system
{system}<|im_end|>
<|im_start|>user
{user}<|im_end|>
<|im_start|>assistant
{asistant}<|im_end|>
```
This prompt template is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are helpful AI asistant."},
{"role": "user", "content": "Hello!"}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
# 🔄 Quantizationed versions
Quantizationed versions of this model is available.
## GGUF [@bartowski](https://hf.co/bartowski):
- https://huggingface.co/bartowski/Einstein-v4-phi2-GGUF
## Exl2 [@bartowski](https://hf.co/bartowski):
- https://huggingface.co/bartowski/Einstein-v4-phi2-exl2
# 🎯 [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Weyaxi__Einstein-v4-phi2)
| Metric |Value|
|---------------------------------|----:|
|Avg. |60.77|
|AI2 Reasoning Challenge (25-Shot)|59.98|
|HellaSwag (10-Shot) |74.07|
|MMLU (5-Shot) |56.89|
|TruthfulQA (0-shot) |45.80|
|Winogrande (5-shot) |73.88|
|GSM8k (5-shot) |53.98|
# 🤖 Additional information about training
This model is full fine-tuned for 2 epochs.
Total number of steps was 2178.
<details><summary>Loss graph</summary>

</details><br>
# 🤝 Acknowledgments
Thanks to [sablo.ai](https://sablo.ai) for sponsoring this model.
Thanks to all the dataset authors mentioned in the datasets section.
Thanks to [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) for making the repository I used to make this model.
Thanks to all open source AI community.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
If you would like to support me:
[☕ Buy Me a Coffee](https://www.buymeacoffee.com/weyaxi)
|
[
"SCIQ"
] |
rjnClarke/BAAI-bge-m3-fine-tuned
|
rjnClarke
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:10359",
"loss:MultipleNegativesRankingLoss",
"en",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:BAAI/bge-m3",
"base_model:finetune:BAAI/bge-m3",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-08-06T10:27:46Z |
2024-08-06T10:29:10+00:00
| 48 | 0 |
---
base_model: BAAI/bge-m3
datasets: []
language:
- en
library_name: sentence-transformers
license: apache-2.0
metrics:
- cosine_accuracy@3
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@200
- cosine_map@100
- dot_accuracy@3
- dot_precision@1
- dot_precision@3
- dot_precision@5
- dot_precision@10
- dot_recall@1
- dot_recall@3
- dot_recall@5
- dot_recall@10
- dot_ndcg@10
- dot_mrr@200
- dot_map@100
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:10359
- loss:MultipleNegativesRankingLoss
widget:
- source_sentence: Cleopatra reacts to the news of Antony's death with a mixture of
sadness and resignation, contemplating her own mortality and the fickle nature
of life.
sentences:
- "Immortal longings in me. Now no more The juice of Egypt's grape shall moist\
\ this lip. Yare, yare, good Iras; quick. Methinks I hear Antony call. I\
\ see him rouse himself To praise my noble act. I hear him mock The luck\
\ of Caesar, which the gods give men To excuse their after wrath. Husband,\
\ I come. Now to that name my courage prove my title! I am fire and air;\
\ my other elements I give to baser life. So, have you done? Come then,\
\ and take the last warmth of my lips. Farewell, kind Charmian. Iras, long\
\ farewell. [Kisses them. IRAS falls and dies] \
\ Have I the aspic in my lips? Dost fall? If thus thou and nature can so gently\
\ part, The stroke of death is as a lover's pinch, Which hurts and is desir'd.\
\ Dost thou lie still? If thou vanishest, thou tell'st the world It is\
\ not worth leave-taking. CHARMIAN. Dissolve, thick cloud, and rain, that I may\
\ say The gods themselves do weep. CLEOPATRA. This proves me base.\n \
\ If she first meet the curled Antony,\n"
- "BURGUNDY. Warlike and martial Talbot, Burgundy\n Enshrines thee in his heart,\
\ and there erects Thy noble deeds as valour's monuments. TALBOT. Thanks,\
\ gentle Duke. But where is Pucelle now? I think her old familiar is asleep.\
\ Now where's the Bastard's braves, and Charles his gleeks? What, all amort?\
\ Rouen hangs her head for grief That such a valiant company are fled. Now\
\ will we take some order in the town, Placing therein some expert officers;\
\ And then depart to Paris to the King, For there young Henry with his nobles\
\ lie. BURGUNDY. What Lord Talbot pleaseth Burgundy. TALBOT. But yet, before\
\ we go, let's not forget The noble Duke of Bedford, late deceas'd, But\
\ see his exequies fulfill'd in Rouen. A braver soldier never couched lance,\
\ A gentler heart did never sway in court; But kings and mightiest potentates\
\ must die, For that's the end of human misery. Exeunt\n"
- "Your suffering in this dearth, you may as well\n Strike at the heaven with\
\ your staves as lift them Against the Roman state; whose course will on \
\ The way it takes, cracking ten thousand curbs Of more strong link asunder\
\ than can ever Appear in your impediment. For the dearth, The gods, not\
\ the patricians, make it, and Your knees to them, not arms, must help. Alack,\
\ You are transported by calamity Thither where more attends you; and you\
\ slander The helms o' th' state, who care for you like fathers, When you\
\ curse them as enemies. FIRST CITIZEN. Care for us! True, indeed! They ne'er\
\ car'd for us yet. Suffer us to famish, and their storehouses cramm'd with\
\ grain; make edicts for usury, to support usurers; repeal daily any wholesome\
\ act established against the rich, and provide more piercing statutes daily\
\ to chain up and restrain the poor. If the wars eat us not up, they will;\
\ and there's all the love they bear us. MENENIUS. Either you must Confess\
\ yourselves wondrous malicious, Or be accus'd of folly. I shall tell you \
\ A pretty tale. It may be you have heard it; But, since it serves my purpose,\
\ I will venture To stale't a little more. FIRST CITIZEN. Well, I'll hear\
\ it, sir; yet you must not think to fob off our disgrace with a tale. But,\
\ an't please you, deliver. MENENIUS. There was a time when all the body's members\
\ Rebell'd against the belly; thus accus'd it: That only like a gulf it\
\ did remain I' th' midst o' th' body, idle and unactive, Still cupboarding\
\ the viand, never bearing Like labour with the rest; where th' other instruments\
\ Did see and hear, devise, instruct, walk, feel,\n And, mutually participate,\
\ did minister\n"
- source_sentence: How does the excerpt reflect themes of loyalty and sacrifice in
the play?
sentences:
- "me a thousand marks in links and torches, walking with thee in\n the night\
\ betwixt tavern and tavern; but the sack that thou hast drunk me would have\
\ bought me lights as good cheap at the dearest chandler's in Europe. I have\
\ maintained that salamander of yours with fire any time this two-and-thirty\
\ years. God reward me for it! Bard. 'Sblood, I would my face were in your\
\ belly! Fal. God-a-mercy! so should I be sure to be heart-burn'd.\n \
\ Enter Hostess. How now, Dame Partlet the hen? Have you enquir'd\
\ yet who pick'd\n my pocket? Host. Why, Sir John, what do you think, Sir\
\ John? Do you think I keep thieves in my house? I have search'd, I have enquired,\
\ so has my husband, man by man, boy by boy, servant by servant. The tithe\
\ of a hair was never lost in my house before. Fal. Ye lie, hostess. Bardolph\
\ was shav'd and lost many a hair, and I'll be sworn my pocket was pick'd.\
\ Go to, you are a woman, go! Host. Who, I? No; I defy thee! God's light, I was\
\ never call'd so in mine own house before! Fal. Go to, I know you well enough.\
\ Host. No, Sir John; you do not know me, Sir John. I know you, Sir John.\
\ You owe me money, Sir John, and now you pick a quarrel to beguile me of\
\ it. I bought you a dozen of shirts to your back. Fal. Dowlas, filthy dowlas!\
\ I have given them away to bakers' wives; they have made bolters of them.\
\ Host. Now, as I am a true woman, holland of eight shillings an ell. You\
\ owe money here besides, Sir John, for your diet and by-drinkings, and money\
\ lent you, four-and-twenty pound. Fal. He had his part of it; let him pay. \
\ Host. He? Alas, he is poor; he hath nothing. Fal. How? Poor? Look upon his\
\ face. What call you rich? Let them coin his nose, let them coin his cheeks.\
\ I'll not pay a denier.\n What, will you make a younker of me? Shall I not\
\ take mine ease\n"
- "EDWARD. I wonder how our princely father scap'd,\n Or whether he be scap'd\
\ away or no From Clifford's and Northumberland's pursuit. Had he been ta'en,\
\ we should have heard the news; Had he been slain, we should have heard the\
\ news; Or had he scap'd, methinks we should have heard The happy tidings\
\ of his good escape. How fares my brother? Why is he so sad? RICHARD. I cannot\
\ joy until I be resolv'd Where our right valiant father is become. I saw\
\ him in the battle range about, And watch'd him how he singled Clifford forth.\
\ Methought he bore him in the thickest troop As doth a lion in a herd of\
\ neat;\n Or as a bear, encompass'd round with dogs,\n Who having pinch'd\
\ a few and made them cry, The rest stand all aloof and bark at him. So\
\ far'd our father with his enemies; So fled his enemies my warlike father.\
\ Methinks 'tis prize enough to be his son. See how the morning opes her\
\ golden gates And takes her farewell of the glorious sun. How well resembles\
\ it the prime of youth, Trimm'd like a younker prancing to his love! EDWARD.\
\ Dazzle mine eyes, or do I see three suns? RICHARD. Three glorious suns, each\
\ one a perfect sun; Not separated with the racking clouds, But sever'd\
\ in a pale clear-shining sky. See, see! they join, embrace, and seem to kiss,\
\ As if they vow'd some league inviolable. Now are they but one lamp, one\
\ light, one sun. In this the heaven figures some event. EDWARD. 'Tis wondrous\
\ strange, the like yet never heard of. I think it cites us, brother, to the\
\ field, That we, the sons of brave Plantagenet, Each one already blazing\
\ by our meeds, Should notwithstanding join our lights together And overshine\
\ the earth, as this the world. Whate'er it bodes, henceforward will I bear\
\ Upon my target three fair shining suns. RICHARD. Nay, bear three daughters-\
\ by your leave I speak it, You love the breeder better than the male.\n"
- "Forget that rarest treasure of your cheek,\n Exposing it- but, O, the harder\
\ heart! Alack, no remedy!- to the greedy touch Of common-kissing Titan,\
\ and forget Your laboursome and dainty trims wherein You made great Juno\
\ angry. IMOGEN. Nay, be brief; I see into thy end, and am almost A man\
\ already. PISANIO. First, make yourself but like one. Fore-thinking this,\
\ I have already fit- 'Tis in my cloak-bag- doublet, hat, hose, all That\
\ answer to them. Would you, in their serving, And with what imitation you\
\ can borrow From youth of such a season, fore noble Lucius Present yourself,\
\ desire his service, tell him Wherein you're happy- which will make him know\
\ If that his head have ear in music; doubtless With joy he will embrace\
\ you; for he's honourable, And, doubling that, most holy. Your means abroad-\
\ You have me, rich; and I will never fail Beginning nor supplyment. IMOGEN.\
\ Thou art all the comfort The gods will diet me with. Prithee away! There's\
\ more to be consider'd; but we'll even All that good time will give us. This\
\ attempt I am soldier to, and will abide it with A prince's courage. Away,\
\ I prithee. PISANIO. Well, madam, we must take a short farewell, Lest, being\
\ miss'd, I be suspected of Your carriage from the court. My noble mistress,\
\ Here is a box; I had it from the Queen. What's in't is precious. If you\
\ are sick at sea Or stomach-qualm'd at land, a dram of this\n Will drive\
\ away distemper. To some shade,\n And fit you to your manhood. May the gods\
\ Direct you to the best! IMOGEN. Amen. I thank thee. Exeunt\
\ severally\n"
- source_sentence: The excerpt showcases the emotional turmoil and sense of honor
that drives Brutus to take his own life in the face of defeat.
sentences:
- "Thou know'st that we two went to school together;\n Even for that our love\
\ of old, I prithee, Hold thou my sword-hilts, whilst I run on it. VOLUMNIUS.\
\ That's not an office for a friend, my lord. \
\ Alarum still. CLITUS. Fly, fly, my lord, there is no tarrying\
\ here. BRUTUS. Farewell to you, and you, and you, Volumnius. Strato, thou\
\ hast been all this while asleep; Farewell to thee too, Strato. Countrymen,\
\ My heart doth joy that yet in all my life I found no man but he was true\
\ to me. I shall have glory by this losing day, More than Octavius and Mark\
\ Antony By this vile conquest shall attain unto. So, fare you well at once,\
\ for Brutus' tongue Hath almost ended his life's history. Night hangs upon\
\ mine eyes, my bones would rest That have but labor'd to attain this hour.\
\ Alarum. Cry within, \"Fly, fly, fly!\" CLITUS. Fly,\
\ my lord, fly. BRUTUS. Hence! I will follow. Exeunt Clitus,\
\ Dardanius, and Volumnius. I prithee, Strato, stay thou by thy lord. Thou\
\ art a fellow of a good respect; Thy life hath had some smatch of honor in\
\ it. Hold then my sword, and turn away thy face, While I do run upon it.\
\ Wilt thou, Strato? STRATO. Give me your hand first. Fare you well, my lord.\
\ BRUTUS. Farewell, good Strato. Runs on his sword. Caesar,\
\ now be still; I kill'd not thee with half so good a will. Dies.\n\
\ Alarum. Retreat. Enter Octavius, Antony, Messala,\n Lucilius,\
\ and the Army.\n OCTAVIUS. What man is that?\n"
- "Elsinore. A room in the Castle.\nEnter King, Queen, Polonius, Ophelia, Rosencrantz,\
\ Guildenstern, and Lords. King. And can you by no drift of circumstance\n \
\ Get from him why he puts on this confusion, Grating so harshly all his days\
\ of quiet With turbulent and dangerous lunacy? Ros. He does confess he feels\
\ himself distracted, But from what cause he will by no means speak. Guil.\
\ Nor do we find him forward to be sounded, But with a crafty madness keeps\
\ aloof When we would bring him on to some confession Of his true state.\
\ Queen. Did he receive you well? Ros. Most like a gentleman. Guil. But with\
\ much forcing of his disposition. Ros. Niggard of question, but of our demands\
\ Most free in his reply. Queen. Did you assay him To any pastime? Ros.\
\ Madam, it so fell out that certain players\n We o'erraught on the way.\
\ Of these we told him,\n"
- "VII.\nThe French camp near Agincourt\nEnter the CONSTABLE OF FRANCE, the LORD\
\ RAMBURES, the DUKE OF ORLEANS,\nthe DAUPHIN, with others\n CONSTABLE. Tut!\
\ I have the best armour of the world.\n Would it were day! ORLEANS. You have\
\ an excellent armour; but let my horse have his due. CONSTABLE. It is the\
\ best horse of Europe. ORLEANS. Will it never be morning? DAUPHIN. My Lord\
\ of Orleans and my Lord High Constable, you talk of horse and armour? ORLEANS.\
\ You are as well provided of both as any prince in the world. DAUPHIN. What\
\ a long night is this! I will not change my horse with any that treads but\
\ on four pasterns. Ca, ha! he bounds from the earth as if his entrails were\
\ hairs; le cheval volant, the Pegasus, chez les narines de feu! When I bestride\
\ him I soar, I am a hawk. He trots the air; the earth sings when he touches\
\ it; the basest horn of his hoof is more musical than the pipe of Hermes.\
\ ORLEANS. He's of the colour of the nutmeg. DAUPHIN. And of the heat of the\
\ ginger. It is a beast for Perseus: he is pure air and fire; and the dull\
\ elements of earth and water never appear in him, but only in patient stillness\
\ while his rider mounts him; he is indeed a horse, and all other jades you\
\ may call beasts. CONSTABLE. Indeed, my lord, it is a most absolute and excellent\
\ horse.\n DAUPHIN. It is the prince of palfreys; his neigh is like the\n"
- source_sentence: What themes are present in the excerpt from the play?
sentences:
- "Enter TRAVERS NORTHUMBERLAND. Here comes my servant Travers, whom I sent\n \
\ On Tuesday last to listen after news. LORD BARDOLPH. My lord, I over-rode\
\ him on the way; And he is furnish'd with no certainties More than he haply\
\ may retail from me. NORTHUMBERLAND. Now, Travers, what good tidings comes with\
\ you? TRAVERS. My lord, Sir John Umfrevile turn'd me back With joyful tidings;\
\ and, being better hors'd, Out-rode me. After him came spurring hard A\
\ gentleman, almost forspent with speed, That stopp'd by me to breathe his\
\ bloodied horse. He ask'd the way to Chester; and of him I did demand what\
\ news from Shrewsbury. He told me that rebellion had bad luck, And that\
\ young Harry Percy's spur was cold. With that he gave his able horse the\
\ head And, bending forward, struck his armed heels\n Against the panting\
\ sides of his poor jade\n Up to the rowel-head; and starting so, He seem'd\
\ in running to devour the way, Staying no longer question. NORTHUMBERLAND.\
\ Ha! Again: Said he young Harry Percy's spur was cold? Of Hotspur, Coldspur?\
\ that rebellion Had met ill luck? LORD BARDOLPH. My lord, I'll tell you what:\
\ If my young lord your son have not the day, Upon mine honour, for a silken\
\ point I'll give my barony. Never talk of it. NORTHUMBERLAND. Why should\
\ that gentleman that rode by Travers Give then such instances of loss? LORD\
\ BARDOLPH. Who- he? He was some hilding fellow that had stol'n The horse\
\ he rode on and, upon my life, Spoke at a venture. Look, here comes more news.\
\ \n Enter Morton NORTHUMBERLAND. Yea, this man's brow,\
\ like to a title-leaf,\n"
- "ANTONY. Yet they are not join'd. Where yond pine does stand\n I shall discover\
\ all. I'll bring thee word Straight how 'tis like to go. \
\ Exit SCARUS. Swallows have built In Cleopatra's sails their nests.\
\ The augurers Say they know not, they cannot tell; look grimly, And dare\
\ not speak their knowledge. Antony Is valiant and dejected; and by starts\
\ His fretted fortunes give him hope and fear Of what he has and has not.\
\ [Alarum afar off, as at a sea-fight]\n \
\ Re-enter ANTONY ANTONY. All is lost!\n This foul Egyptian hath\
\ betrayed me. My fleet hath yielded to the foe, and yonder They cast\
\ their caps up and carouse together Like friends long lost. Triple-turn'd\
\ whore! 'tis thou\n Hast sold me to this novice; and my heart\n Makes\
\ only wars on thee. Bid them all fly; For when I am reveng'd upon my charm,\
\ I have done all. Bid them all fly; begone. Exit SCARUS O sun, thy\
\ uprise shall I see no more! Fortune and Antony part here; even here Do\
\ we shake hands. All come to this? The hearts That spaniel'd me at heels,\
\ to whom I gave Their wishes, do discandy, melt their sweets On blossoming\
\ Caesar; and this pine is bark'd That overtopp'd them all. Betray'd I am.\
\ O this false soul of Egypt! this grave charm- Whose eye beck'd forth my\
\ wars and call'd them home, Whose bosom was my crownet, my chief end- Like\
\ a right gypsy hath at fast and loose Beguil'd me to the very heart of loss.\
\ What, Eros, Eros! Enter CLEOPATRA\n Ah, thou spell!\
\ Avaunt!\n"
- "TALBOT. Saint George and victory! Fight, soldiers, fight.\n The Regent hath\
\ with Talbot broke his word And left us to the rage of France his sword. \
\ Where is John Talbot? Pause and take thy breath; I gave thee life and rescu'd\
\ thee from death. JOHN. O, twice my father, twice am I thy son! The life\
\ thou gav'st me first was lost and done Till with thy warlike sword, despite\
\ of fate, To my determin'd time thou gav'st new date. TALBOT. When from the\
\ Dauphin's crest thy sword struck fire, It warm'd thy father's heart with\
\ proud desire Of bold-fac'd victory. Then leaden age, Quicken'd with youthful\
\ spleen and warlike rage, Beat down Alencon, Orleans, Burgundy, And from\
\ the pride of Gallia rescued thee. The ireful bastard Orleans, that drew blood\
\ From thee, my boy, and had the maidenhood Of thy first fight, I soon encountered\
\ And, interchanging blows, I quickly shed Some of his bastard blood; and\
\ in disgrace\n Bespoke him thus: 'Contaminated, base,\n"
- source_sentence: What is the significance of the tennis balls in the excerpt from
the play?
sentences:
- "My fault is past. But, O, what form of prayer\n Can serve my turn? 'Forgive\
\ me my foul murther'? That cannot be; since I am still possess'd Of those\
\ effects for which I did the murther- My crown, mine own ambition, and my\
\ queen. May one be pardon'd and retain th' offence? In the corrupted currents\
\ of this world Offence's gilded hand may shove by justice, And oft 'tis\
\ seen the wicked prize itself Buys out the law; but 'tis not so above. \
\ There is no shuffling; there the action lies In his true nature, and we ourselves\
\ compell'd, Even to the teeth and forehead of our faults, To give in evidence.\
\ What then? What rests? Try what repentance can. What can it not? Yet what\
\ can it when one cannot repent? O wretched state! O bosom black as death!\
\ O limed soul, that, struggling to be free, Art more engag'd! Help, angels!\
\ Make assay. Bow, stubborn knees; and heart with strings of steel, Be\
\ soft as sinews of the new-born babe! All may be well. \
\ He kneels.\n Enter Hamlet. Ham. Now might\
\ I do it pat, now he is praying;\n And now I'll do't. And so he goes to heaven,\
\ And so am I reveng'd. That would be scann'd. A villain kills my father;\
\ and for that, I, his sole son, do this same villain send To heaven. \
\ Why, this is hire and salary, not revenge! He took my father grossly, full\
\ of bread, With all his crimes broad blown, as flush as May; And how his\
\ audit stands, who knows save heaven?\n But in our circumstance and course\
\ of thought,\n"
- "YORK. From Ireland thus comes York to claim his right\n And pluck the crown\
\ from feeble Henry's head: Ring bells aloud, burn bonfires clear and bright,\
\ To entertain great England's lawful king. Ah, sancta majestas! who would\
\ not buy thee dear? Let them obey that knows not how to rule; This hand\
\ was made to handle nought but gold. I cannot give due action to my words\
\ Except a sword or sceptre balance it.\n A sceptre shall it have, have\
\ I a soul\n On which I'll toss the flower-de-luce of France.\n \
\ Enter BUCKINGHAM [Aside] Whom have we here? Buckingham, to disturb\
\ me?\n The King hath sent him, sure: I must dissemble. BUCKINGHAM. York,\
\ if thou meanest well I greet thee well. YORK. Humphrey of Buckingham, I accept\
\ thy greeting. Art thou a messenger, or come of pleasure? BUCKINGHAM. A messenger\
\ from Henry, our dread liege, To know the reason of these arms in peace; \
\ Or why thou, being a subject as I am, Against thy oath and true allegiance\
\ sworn, Should raise so great a power without his leave, Or dare to bring\
\ thy force so near the court. YORK. [Aside] Scarce can I speak, my choler is\
\ so great. O, I could hew up rocks and fight with flint, I am so angry\
\ at these abject terms; And now, like Ajax Telamonius, On sheep or oxen\
\ could I spend my fury. I am far better born than is the King, More like\
\ a king, more kingly in my thoughts; But I must make fair weather yet awhile,\
\ Till Henry be more weak and I more strong.- Buckingham, I prithee, pardon\
\ me That I have given no answer all this while; My mind was troubled with\
\ deep melancholy. The cause why I have brought this army hither Is to\
\ remove proud Somerset from the King, Seditious to his Grace and to the state.\
\ BUCKINGHAM. That is too much presumption on thy part; But if thy arms be\
\ to no other end, The King hath yielded unto thy demand:\n The Duke of\
\ Somerset is in the Tower.\n"
- "Says that you savour too much of your youth,\n And bids you be advis'd there's\
\ nought in France That can be with a nimble galliard won; You cannot revel\
\ into dukedoms there. He therefore sends you, meeter for your spirit, This\
\ tun of treasure; and, in lieu of this, Desires you let the dukedoms that\
\ you claim Hear no more of you. This the Dauphin speaks. KING HENRY. What\
\ treasure, uncle? EXETER. Tennis-balls, my liege. KING HENRY. We are glad the\
\ Dauphin is so pleasant with us; His present and your pains we thank you for.\
\ When we have match'd our rackets to these balls, We will in France,\
\ by God's grace, play a set Shall strike his father's crown into the hazard.\
\ Tell him he hath made a match with such a wrangler That all the courts\
\ of France will be disturb'd With chaces. And we understand him well, How\
\ he comes o'er us with our wilder days, Not measuring what use we made of\
\ them. We never valu'd this poor seat of England; And therefore, living\
\ hence, did give ourself To barbarous licence; as 'tis ever common That\
\ men are merriest when they are from home. But tell the Dauphin I will keep\
\ my state, Be like a king, and show my sail of greatness, When I do rouse\
\ me in my throne of France; For that I have laid by my majesty And plodded\
\ like a man for working-days; But I will rise there with so full a glory \
\ That I will dazzle all the eyes of France, Yea, strike the Dauphin blind\
\ to look on us. And tell the pleasant Prince this mock of his Hath turn'd\
\ his balls to gun-stones, and his soul Shall stand sore charged for the wasteful\
\ vengeance\n That shall fly with them; for many a thousand widows\n"
model-index:
- name: RAG_general/rerank/models/BAAI-bge-m3-ft
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: m3 dev
type: m3-dev
metrics:
- type: cosine_accuracy@3
value: 0.5356211989574283
name: Cosine Accuracy@3
- type: cosine_precision@1
value: 0.4209383145091225
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.17854039965247612
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.11416159860990441
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.06185925282363162
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.4209383145091225
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.5356211989574283
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.5708079930495221
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.6185925282363163
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.518363473579454
name: Cosine Ndcg@10
- type: cosine_mrr@200
value: 0.4915925316966444
name: Cosine Mrr@200
- type: cosine_map@100
value: 0.49136031845002553
name: Cosine Map@100
- type: dot_accuracy@3
value: 0.5356211989574283
name: Dot Accuracy@3
- type: dot_precision@1
value: 0.4209383145091225
name: Dot Precision@1
- type: dot_precision@3
value: 0.17854039965247612
name: Dot Precision@3
- type: dot_precision@5
value: 0.11416159860990441
name: Dot Precision@5
- type: dot_precision@10
value: 0.06185925282363162
name: Dot Precision@10
- type: dot_recall@1
value: 0.4209383145091225
name: Dot Recall@1
- type: dot_recall@3
value: 0.5356211989574283
name: Dot Recall@3
- type: dot_recall@5
value: 0.5708079930495221
name: Dot Recall@5
- type: dot_recall@10
value: 0.6185925282363163
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.518363473579454
name: Dot Ndcg@10
- type: dot_mrr@200
value: 0.4915925316966444
name: Dot Mrr@200
- type: dot_map@100
value: 0.49136031845002553
name: Dot Map@100
---
# RAG_general/rerank/models/BAAI-bge-m3-ft
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3). It maps sentences & paragraphs to a 1024-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) <!-- at revision 5617a9f61b028005a4858fdac845db406aefb181 -->
- **Maximum Sequence Length:** 8192 tokens
- **Output Dimensionality:** 1024 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 8192, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("rjnClarke/BAAI-bge-m3-fine-tuned")
# Run inference
sentences = [
'What is the significance of the tennis balls in the excerpt from the play?',
"Says that you savour too much of your youth,\n And bids you be advis'd there's nought in France That can be with a nimble galliard won; You cannot revel into dukedoms there. He therefore sends you, meeter for your spirit, This tun of treasure; and, in lieu of this, Desires you let the dukedoms that you claim Hear no more of you. This the Dauphin speaks. KING HENRY. What treasure, uncle? EXETER. Tennis-balls, my liege. KING HENRY. We are glad the Dauphin is so pleasant with us; His present and your pains we thank you for. When we have match'd our rackets to these balls, We will in France, by God's grace, play a set Shall strike his father's crown into the hazard. Tell him he hath made a match with such a wrangler That all the courts of France will be disturb'd With chaces. And we understand him well, How he comes o'er us with our wilder days, Not measuring what use we made of them. We never valu'd this poor seat of England; And therefore, living hence, did give ourself To barbarous licence; as 'tis ever common That men are merriest when they are from home. But tell the Dauphin I will keep my state, Be like a king, and show my sail of greatness, When I do rouse me in my throne of France; For that I have laid by my majesty And plodded like a man for working-days; But I will rise there with so full a glory That I will dazzle all the eyes of France, Yea, strike the Dauphin blind to look on us. And tell the pleasant Prince this mock of his Hath turn'd his balls to gun-stones, and his soul Shall stand sore charged for the wasteful vengeance\n That shall fly with them; for many a thousand widows\n",
"YORK. From Ireland thus comes York to claim his right\n And pluck the crown from feeble Henry's head: Ring bells aloud, burn bonfires clear and bright, To entertain great England's lawful king. Ah, sancta majestas! who would not buy thee dear? Let them obey that knows not how to rule; This hand was made to handle nought but gold. I cannot give due action to my words Except a sword or sceptre balance it.\n A sceptre shall it have, have I a soul\n On which I'll toss the flower-de-luce of France.\n Enter BUCKINGHAM [Aside] Whom have we here? Buckingham, to disturb me?\n The King hath sent him, sure: I must dissemble. BUCKINGHAM. York, if thou meanest well I greet thee well. YORK. Humphrey of Buckingham, I accept thy greeting. Art thou a messenger, or come of pleasure? BUCKINGHAM. A messenger from Henry, our dread liege, To know the reason of these arms in peace; Or why thou, being a subject as I am, Against thy oath and true allegiance sworn, Should raise so great a power without his leave, Or dare to bring thy force so near the court. YORK. [Aside] Scarce can I speak, my choler is so great. O, I could hew up rocks and fight with flint, I am so angry at these abject terms; And now, like Ajax Telamonius, On sheep or oxen could I spend my fury. I am far better born than is the King, More like a king, more kingly in my thoughts; But I must make fair weather yet awhile, Till Henry be more weak and I more strong.- Buckingham, I prithee, pardon me That I have given no answer all this while; My mind was troubled with deep melancholy. The cause why I have brought this army hither Is to remove proud Somerset from the King, Seditious to his Grace and to the state. BUCKINGHAM. That is too much presumption on thy part; But if thy arms be to no other end, The King hath yielded unto thy demand:\n The Duke of Somerset is in the Tower.\n",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 1024]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `m3-dev`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@3 | 0.5356 |
| cosine_precision@1 | 0.4209 |
| cosine_precision@3 | 0.1785 |
| cosine_precision@5 | 0.1142 |
| cosine_precision@10 | 0.0619 |
| cosine_recall@1 | 0.4209 |
| cosine_recall@3 | 0.5356 |
| cosine_recall@5 | 0.5708 |
| cosine_recall@10 | 0.6186 |
| cosine_ndcg@10 | 0.5184 |
| cosine_mrr@200 | 0.4916 |
| **cosine_map@100** | **0.4914** |
| dot_accuracy@3 | 0.5356 |
| dot_precision@1 | 0.4209 |
| dot_precision@3 | 0.1785 |
| dot_precision@5 | 0.1142 |
| dot_precision@10 | 0.0619 |
| dot_recall@1 | 0.4209 |
| dot_recall@3 | 0.5356 |
| dot_recall@5 | 0.5708 |
| dot_recall@10 | 0.6186 |
| dot_ndcg@10 | 0.5184 |
| dot_mrr@200 | 0.4916 |
| dot_map@100 | 0.4914 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 10,359 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 25.61 tokens</li><li>max: 62 tokens</li></ul> | <ul><li>min: 38 tokens</li><li>mean: 394.49 tokens</li><li>max: 577 tokens</li></ul> |
* Samples:
| anchor | positive |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Who is the general being described in the excerpt?</code> | <code>PHILO. Nay, but this dotage of our general's<br> O'erflows the measure. Those his goodly eyes, That o'er the files and musters of the war Have glow'd like plated Mars, now bend, now turn, The office and devotion of their view Upon a tawny front. His captain's heart, Which in the scuffles of great fights hath burst<br> The buckles on his breast, reneges all temper,<br> And is become the bellows and the fan To cool a gipsy's lust.<br> Flourish. Enter ANTONY, CLEOPATRA, her LADIES, the train,<br> with eunuchs fanning her<br> Look where they come!<br> Take but good note, and you shall see in him The triple pillar of the world transform'd Into a strumpet's fool. Behold and see. CLEOPATRA. If it be love indeed, tell me how much. ANTONY. There's beggary in the love that can be reckon'd. CLEOPATRA. I'll set a bourn how far to be belov'd. ANTONY. Then must thou needs find out new heaven, new earth.<br> Enter a MESSENGER MESSENGER. News, my good lord, from Rome.<br> ANTONY. Grates me the sum. CLEOPATRA. Nay, hear them, Antony. Fulvia perchance is angry; or who knows If the scarce-bearded Caesar have not sent His pow'rful mandate to you: 'Do this or this; Take in that kingdom and enfranchise that; Perform't, or else we damn thee.' ANTONY. How, my love? CLEOPATRA. Perchance? Nay, and most like, You must not stay here longer; your dismission Is come from Caesar; therefore hear it, Antony. Where's Fulvia's process? Caesar's I would say? Both? Call in the messengers. As I am Egypt's Queen, Thou blushest, Antony, and that blood of thine Is Caesar's homager. Else so thy cheek pays shame<br> When shrill-tongu'd Fulvia scolds. The messengers!<br></code> |
| <code>What is the main conflict highlighted in the excerpt?</code> | <code>PHILO. Nay, but this dotage of our general's<br> O'erflows the measure. Those his goodly eyes, That o'er the files and musters of the war Have glow'd like plated Mars, now bend, now turn, The office and devotion of their view Upon a tawny front. His captain's heart, Which in the scuffles of great fights hath burst<br> The buckles on his breast, reneges all temper,<br> And is become the bellows and the fan To cool a gipsy's lust.<br> Flourish. Enter ANTONY, CLEOPATRA, her LADIES, the train,<br> with eunuchs fanning her<br> Look where they come!<br> Take but good note, and you shall see in him The triple pillar of the world transform'd Into a strumpet's fool. Behold and see. CLEOPATRA. If it be love indeed, tell me how much. ANTONY. There's beggary in the love that can be reckon'd. CLEOPATRA. I'll set a bourn how far to be belov'd. ANTONY. Then must thou needs find out new heaven, new earth.<br> Enter a MESSENGER MESSENGER. News, my good lord, from Rome.<br> ANTONY. Grates me the sum. CLEOPATRA. Nay, hear them, Antony. Fulvia perchance is angry; or who knows If the scarce-bearded Caesar have not sent His pow'rful mandate to you: 'Do this or this; Take in that kingdom and enfranchise that; Perform't, or else we damn thee.' ANTONY. How, my love? CLEOPATRA. Perchance? Nay, and most like, You must not stay here longer; your dismission Is come from Caesar; therefore hear it, Antony. Where's Fulvia's process? Caesar's I would say? Both? Call in the messengers. As I am Egypt's Queen, Thou blushest, Antony, and that blood of thine Is Caesar's homager. Else so thy cheek pays shame<br> When shrill-tongu'd Fulvia scolds. The messengers!<br></code> |
| <code>The excerpt showcases the tension between Antony's loyalty to Cleopatra and his obligations to Caesar, as well as Cleopatra's influence over him.</code> | <code>PHILO. Nay, but this dotage of our general's<br> O'erflows the measure. Those his goodly eyes, That o'er the files and musters of the war Have glow'd like plated Mars, now bend, now turn, The office and devotion of their view Upon a tawny front. His captain's heart, Which in the scuffles of great fights hath burst<br> The buckles on his breast, reneges all temper,<br> And is become the bellows and the fan To cool a gipsy's lust.<br> Flourish. Enter ANTONY, CLEOPATRA, her LADIES, the train,<br> with eunuchs fanning her<br> Look where they come!<br> Take but good note, and you shall see in him The triple pillar of the world transform'd Into a strumpet's fool. Behold and see. CLEOPATRA. If it be love indeed, tell me how much. ANTONY. There's beggary in the love that can be reckon'd. CLEOPATRA. I'll set a bourn how far to be belov'd. ANTONY. Then must thou needs find out new heaven, new earth.<br> Enter a MESSENGER MESSENGER. News, my good lord, from Rome.<br> ANTONY. Grates me the sum. CLEOPATRA. Nay, hear them, Antony. Fulvia perchance is angry; or who knows If the scarce-bearded Caesar have not sent His pow'rful mandate to you: 'Do this or this; Take in that kingdom and enfranchise that; Perform't, or else we damn thee.' ANTONY. How, my love? CLEOPATRA. Perchance? Nay, and most like, You must not stay here longer; your dismission Is come from Caesar; therefore hear it, Antony. Where's Fulvia's process? Caesar's I would say? Both? Call in the messengers. As I am Egypt's Queen, Thou blushest, Antony, and that blood of thine Is Caesar's homager. Else so thy cheek pays shame<br> When shrill-tongu'd Fulvia scolds. The messengers!<br></code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Evaluation Dataset
#### Unnamed Dataset
* Size: 2,302 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 11 tokens</li><li>mean: 25.55 tokens</li><li>max: 77 tokens</li></ul> | <ul><li>min: 17 tokens</li><li>mean: 400.31 tokens</li><li>max: 610 tokens</li></ul> |
* Samples:
| anchor | positive |
|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>The excerpt highlights the tension between Antony's loyalty to Cleopatra and his standing in Rome, showcasing the intricate balance of power and love in the play.</code> | <code>When shrill-tongu'd Fulvia scolds. The messengers!<br> ANTONY. Let Rome in Tiber melt, and the wide arch Of the rang'd empire fall! Here is my space. Kingdoms are clay; our dungy earth alike Feeds beast as man. The nobleness of life Is to do thus [emhracing], when such a mutual pair And such a twain can do't, in which I bind, On pain of punishment, the world to weet We stand up peerless. CLEOPATRA. Excellent falsehood! Why did he marry Fulvia, and not love her? I'll seem the fool I am not. Antony Will be himself. ANTONY. But stirr'd by Cleopatra. Now for the love of Love and her soft hours, Let's not confound the time with conference harsh; There's not a minute of our lives should stretch Without some pleasure now. What sport to-night? CLEOPATRA. Hear the ambassadors. ANTONY. Fie, wrangling queen! Whom everything becomes- to chide, to laugh, To weep; whose every passion fully strives To make itself in thee fair and admir'd. No messenger but thine, and all alone To-night we'll wander through the streets and note The qualities of people. Come, my queen; Last night you did desire it. Speak not to us. Exeunt ANTONY and CLEOPATRA, with the train DEMETRIUS. Is Caesar with Antonius priz'd so slight? PHILO. Sir, sometimes when he is not Antony, He comes too short of that great property Which still should go with Antony. DEMETRIUS. I am full sorry That he approves the common liar, who Thus speaks of him at Rome; but I will hope<br> Of better deeds to-morrow. Rest you happy! Exeunt<br></code> |
| <code>What is the significance of the soothsayer in the context of the play?</code> | <code>CHARMIAN. Lord Alexas, sweet Alexas, most anything Alexas, almost<br> most absolute Alexas, where's the soothsayer that you prais'd so to th' Queen? O that I knew this husband, which you say must charge his horns with garlands! ALEXAS. Soothsayer! SOOTHSAYER. Your will? CHARMIAN. Is this the man? Is't you, sir, that know things? SOOTHSAYER. In nature's infinite book of secrecy A little I can read. ALEXAS. Show him your hand.<br> Enter ENOBARBUS ENOBARBUS. Bring in the banquet quickly; wine enough<br> Cleopatra's health to drink. CHARMIAN. Good, sir, give me good fortune. SOOTHSAYER. I make not, but foresee. CHARMIAN. Pray, then, foresee me one. SOOTHSAYER. You shall be yet far fairer than you are. CHARMIAN. He means in flesh. IRAS. No, you shall paint when you are old. CHARMIAN. Wrinkles forbid! ALEXAS. Vex not his prescience; be attentive. CHARMIAN. Hush!<br> SOOTHSAYER. You shall be more beloving than beloved.<br></code> |
| <code>What is the setting of the scene in which the excerpt takes place?</code> | <code>sweet Isis, I beseech thee! And let her die too, and give him a<br> worse! And let worse follow worse, till the worst of all follow him laughing to his grave, fiftyfold a cuckold! Good Isis, hear me this prayer, though thou deny me a matter of more weight; good Isis, I beseech thee! IRAS. Amen. Dear goddess, hear that prayer of the people! For, as it is a heartbreaking to see a handsome man loose-wiv'd, so it is a deadly sorrow to behold a foul knave uncuckolded. Therefore, dear Isis, keep decorum, and fortune him accordingly! CHARMIAN. Amen. ALEXAS. Lo now, if it lay in their hands to make me a cuckold, they would make themselves whores but they'ld do't!<br> Enter CLEOPATRA ENOBARBUS. Hush! Here comes Antony.<br> CHARMIAN. Not he; the Queen. CLEOPATRA. Saw you my lord? ENOBARBUS. No, lady. CLEOPATRA. Was he not here? CHARMIAN. No, madam. CLEOPATRA. He was dispos'd to mirth; but on the sudden A Roman thought hath struck him. Enobarbus! ENOBARBUS. Madam? CLEOPATRA. Seek him, and bring him hither. Where's Alexas? ALEXAS. Here, at your service. My lord approaches.<br> Enter ANTONY, with a MESSENGER and attendants CLEOPATRA. We will not look upon him. Go with us.<br> Exeunt CLEOPATRA, ENOBARBUS, and the rest MESSENGER. Fulvia thy wife first came into the field. ANTONY. Against my brother Lucius? MESSENGER. Ay.<br> But soon that war had end, and the time's state<br></code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `gradient_accumulation_steps`: 2
- `learning_rate`: 1e-05
- `weight_decay`: 5e-05
- `warmup_steps`: 50
- `fp16`: True
- `half_precision_backend`: True
- `load_best_model_at_end`: True
- `fp16_backend`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 8
- `per_device_eval_batch_size`: 8
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 2
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 1e-05
- `weight_decay`: 5e-05
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 3
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 50
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: True
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: True
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `eval_use_gather_object`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | loss | m3-dev_cosine_map@100 |
|:----------:|:--------:|:-------------:|:----------:|:---------------------:|
| 0.7722 | 500 | 1.1966 | - | - |
| 1.0008 | 648 | - | 0.8832 | 0.4814 |
| 1.5436 | 1000 | 0.8492 | - | - |
| 2.0008 | 1296 | - | 0.8582 | 0.4855 |
| 2.3151 | 1500 | 0.6805 | - | - |
| **2.9961** | **1941** | **-** | **0.8607** | **0.4914** |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 3.0.1
- Transformers: 4.43.4
- PyTorch: 2.3.1+cu121
- Accelerate: 0.32.1
- Datasets: 2.19.1
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"BEAR"
] |
RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf
|
RichardErkhov
| null |
[
"gguf",
"region:us"
] | 2024-09-01T00:11:49Z |
2024-09-01T02:53:55+00:00
| 48 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Medtulu-2x7b - GGUF
- Model creator: https://huggingface.co/Technoculture/
- Original model: https://huggingface.co/Technoculture/Medtulu-2x7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Medtulu-2x7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q2_K.gguf) | Q2_K | 3.82GB |
| [Medtulu-2x7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.IQ3_XS.gguf) | IQ3_XS | 4.24GB |
| [Medtulu-2x7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.IQ3_S.gguf) | IQ3_S | 0.36GB |
| [Medtulu-2x7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q3_K_S.gguf) | Q3_K_S | 4.48GB |
| [Medtulu-2x7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.IQ3_M.gguf) | IQ3_M | 0.86GB |
| [Medtulu-2x7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q3_K.gguf) | Q3_K | 2.96GB |
| [Medtulu-2x7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q3_K_M.gguf) | Q3_K_M | 4.99GB |
| [Medtulu-2x7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q3_K_L.gguf) | Q3_K_L | 5.43GB |
| [Medtulu-2x7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.IQ4_XS.gguf) | IQ4_XS | 5.57GB |
| [Medtulu-2x7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q4_0.gguf) | Q4_0 | 5.83GB |
| [Medtulu-2x7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.IQ4_NL.gguf) | IQ4_NL | 1.61GB |
| [Medtulu-2x7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q4_K_S.gguf) | Q4_K_S | 2.26GB |
| [Medtulu-2x7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q4_K.gguf) | Q4_K | 6.24GB |
| [Medtulu-2x7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q4_K_M.gguf) | Q4_K_M | 5.77GB |
| [Medtulu-2x7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q4_1.gguf) | Q4_1 | 6.47GB |
| [Medtulu-2x7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q5_0.gguf) | Q5_0 | 7.1GB |
| [Medtulu-2x7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q5_K_S.gguf) | Q5_K_S | 1.8GB |
| [Medtulu-2x7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q5_K.gguf) | Q5_K | 7.32GB |
| [Medtulu-2x7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q5_K_M.gguf) | Q5_K_M | 7.32GB |
| [Medtulu-2x7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q5_1.gguf) | Q5_1 | 7.69GB |
| [Medtulu-2x7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q6_K.gguf) | Q6_K | 8.46GB |
| [Medtulu-2x7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-2x7b-gguf/blob/main/Medtulu-2x7b.Q8_0.gguf) | Q8_0 | 10.95GB |
Original model description:
---
license: apache-2.0
tags:
- moe
- merge
- Technoculture/MT7Bi-dpo
- allenai/tulu-2-dpo-7b
---
# Medtulu-2x7b
Medtulu-2x7b is a Mixure of Experts (MoE) made with the following models:
* [Technoculture/MT7Bi-dpo](https://huggingface.co/Technoculture/MT7Bi-dpo)
* [allenai/tulu-2-dpo-7b](https://huggingface.co/allenai/tulu-2-dpo-7b)
## 🧩 Configuration
```yaml
base_model: Technoculture/MT7Bi-dpo
tokenizer_source: union
gate_mode: hidden
dtype: bfloat16
experts:
- source_model: Technoculture/MT7Bi-dpo
positive_prompts:
- "Are elevated serum levels of interleukin 21 associated with disease severity in patients with psoriasis?"
- "Which one of the following does NOT present antigens?"
- "A 25-year-old male patient presents to your clinic in significant distress. He states he has excruciating, stabbing pain around the left side of his head, and his left eye will not stop tearing. These types of headaches have been occurring for the past week every morning when he awakens and last around 60 minutes. He denies any aura, nausea, or vomiting. He denies any other past medical history. What is this patient's diagnosis?"
- "When using an inhaler, when should a patient be asked to rinse their mouth?"
- "What is the embryological origin of the hyoid bone?"
- "After what period of time does maximal dynamic exercise become predominantly aerobic?"
- source_model: allenai/tulu-2-dpo-7b
positive_prompts:
- "Who composed the tune of 'Twinkle, Twinkle, Little Star'?"
- "Gem went to get new supplies for her hamster and she found snacks and exercise balls She chose the _ because her hamster was fat."
- "John orders food for a massive restaurant. He orders 1000 pounds of beef for $8 per pound. He also orders twice that much chicken at $3 per pound. How much did everything cost?"
- "The gravitational force of the Sun affects the planets in our solar system. Which of these is influenced the most by this force?"
- "2sin(x) + yz ="
- "Hobbies and Crafts"
```
## Evaluations
| Benchmark | Medtulu-2x7b | Orca-2-7b | llama-2-7b | meditron-7b | meditron-70b |
| --- | --- | --- | --- | --- | --- |
| MedMCQA | | | | | |
| ClosedPubMedQA | | | | | |
| PubMedQA | | | | | |
| MedQA | | | | | |
| MedQA4 | | | | | |
| MedicationQA | | | | | |
| MMLU Medical | | | | | |
| MMLU | | | | | |
| TruthfulQA | | | | | |
| GSM8K | | | | | |
| ARC | | | | | |
| HellaSwag | | | | | |
| Winogrande | | | | | |
More details on the Open LLM Leaderboard evaluation results can be found here.
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Technoculture/Medtulu-2x7b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
[
"MEDQA",
"PUBMEDQA"
] |
QuantFactory/granite-7b-base-GGUF
|
QuantFactory
| null |
[
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2024-09-07T13:04:02Z |
2024-09-07T13:35:25+00:00
| 48 | 2 |
---
license: apache-2.0
---

# QuantFactory/granite-7b-base-GGUF
This is quantized version of [ibm-granite/granite-7b-base](https://huggingface.co/ibm-granite/granite-7b-base) created using llama.cpp
# Original Model Card
**Model Name**: Granite-7b-base
**License**: Apache-2.0
**Languages**: Primarily English
**Architecture**: The model architecture is a replica of Meta’s Llama2-7B base variant with MHA, trained with 1M batch size on 2T tokens.
**Context Length**: 4k tokens
**Tokenizer**: Llama2
**Model Developers**: IBM Research
Representing IBM’s commitment to open source innovation IBM has released granite-7b-base, a base pre-trained LLM from IBM’s Granite model series, under an apache-2.0 license for community and commercial use. Granite-7b-base was pre-trained from scratch on IBM-curated data as an open reference implementation of Meta’s Llama-2-7B. In a commitment to data transparency and fostering open innovation, the data sources, sampling proportions, and URLs for access are provided below.
For more information about training this model, please check out the blog: https://pytorch.org/blog/maximizing-training/
**Pre-Training Data**
The model was trained on 2T tokens, with sampling proportions designed to match the sampling distributions released in the Llama1 paper as closely as possible.
| Dataset | Description | Sampling Proportion | URL |
|-------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------|--------------------------------------------------------------------|
| Common Crawl | Open repository of web crawl data with snapshots ranging from 2021 to 2023. | 77% | https://data.commoncrawl.org/ |
| Github_Clean | Code data from CodeParrot covering a variety of coding languages. | 5.50% | https://huggingface.co/datasets/codeparrot/github-code-clean |
| Wikipedia and Wikimedia | Eight Wikimedia projects (enwiki, enwikibooks, enwikinews, enwikiquote, enwikisource, enwikiversity, enwikivoyage, enwiktionary). containing extracted plain text from pages and articles. | 2% | https://dumps.wikimedia.org |
| USPTO | US patents granted from 1975 to May 2023, excluding design patents. | 5% | https://bulkdata.uspto.gov/ |
| PubMed Central | Biomedical and life sciences papers. | 1.75% | https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_package/ |
| arXiv | Over 1.8 million scientific paper pre-prints posted to arXiv. | 2.50% | https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T |
| StackExchange | Anonymized set of all user-contributed content on the Stack Exchange network, a popular collection of websites centered around user-contributed questions and answers. | 1% | https://archive.org/details/stackexchange_20221206 |
| PG19 | A repository of free e-books with focus on older works for which U.S. copyright has expired. | 0.25% | https://github.com/google-deepmind/pg19 |
| Webhose | Unstructured web content converted into machine-readable data feeds purchased by IBM. | 5% | N/A |
**Evaluation Results**
LM-eval Harness Scores
| Evaluation metric | Llama2-7B (baseline) | Granite-7b-base |
|----------------------------|----------------------|-----------------|
| MMLU (zero shot) | 0.41 | 0.43 |
| MMLU (5-shot weighted avg) | 0.47 | 0.50 |
| Arc challenge | 0.46 | 0.44 |
| Arc easy | 0.74 | 0.71 |
| Boolq | 0.78 | 0.76 |
| Copa | 0.87 | 0.83 |
| Hellaswag | 0.76 | 0.74 |
| Openbookqa | 0.44 | 0.42 |
| Piqa | 0.79 | 0.79 |
| Sciq | 0.91 | 0.91 |
| Winogrande | 0.69 | 0.67 |
| Truthfulqa | 0.39 | 0.39 |
| GSM8k (8-shot) | 0.13 | 0.11 |
**Bias, Risks, and Limitations**
Granite-7b-base is a base model and has not undergone any safety alignment, there it may produce problematic outputs. In the absence of adequate safeguards and RLHF, there exists a risk of malicious utilization of these models for generating disinformation or harmful content. Caution is urged against complete reliance on a specific language model for crucial decisions or impactful information, as preventing these models from fabricating content is not straightforward. Additionally, it remains uncertain whether smaller models might exhibit increased susceptibility to hallucination in ungrounded generation scenarios due to their reduced sizes and memorization capacities. This aspect is currently an active area of research, and we anticipate more rigorous exploration, comprehension, and mitigations in this domain.
|
[
"SCIQ"
] |
RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-05T16:22:58Z |
2024-10-05T19:07:51+00:00
| 48 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Phi-3-mini-4k-instruct-LLaMAfied - GGUF
- Model creator: https://huggingface.co/vonjack/
- Original model: https://huggingface.co/vonjack/Phi-3-mini-4k-instruct-LLaMAfied/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q2_K.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q2_K.gguf) | Q2_K | 1.35GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.IQ3_XS.gguf) | IQ3_XS | 1.49GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.IQ3_S.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.IQ3_S.gguf) | IQ3_S | 1.57GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q3_K_S.gguf) | Q3_K_S | 1.57GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.IQ3_M.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.IQ3_M.gguf) | IQ3_M | 1.65GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q3_K.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q3_K.gguf) | Q3_K | 1.75GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q3_K_M.gguf) | Q3_K_M | 1.75GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q3_K_L.gguf) | Q3_K_L | 1.9GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.IQ4_XS.gguf) | IQ4_XS | 1.93GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q4_0.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q4_0.gguf) | Q4_0 | 2.03GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.IQ4_NL.gguf) | IQ4_NL | 2.04GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q4_K_S.gguf) | Q4_K_S | 2.04GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q4_K.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q4_K.gguf) | Q4_K | 2.16GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q4_K_M.gguf) | Q4_K_M | 2.16GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q4_1.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q4_1.gguf) | Q4_1 | 2.24GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q5_0.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q5_0.gguf) | Q5_0 | 2.46GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q5_K_S.gguf) | Q5_K_S | 2.46GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q5_K.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q5_K.gguf) | Q5_K | 2.53GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q5_K_M.gguf) | Q5_K_M | 2.53GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q5_1.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q5_1.gguf) | Q5_1 | 2.68GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q6_K.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q6_K.gguf) | Q6_K | 2.92GB |
| [Phi-3-mini-4k-instruct-LLaMAfied.Q8_0.gguf](https://huggingface.co/RichardErkhov/vonjack_-_Phi-3-mini-4k-instruct-LLaMAfied-gguf/blob/main/Phi-3-mini-4k-instruct-LLaMAfied.Q8_0.gguf) | Q8_0 | 3.78GB |
Original model description:
---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- nlp
- code
---
## Model Summary
The Phi-3-Mini-4K-Instruct is a 3.8B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Mini version in two variants [4K](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3 Mini-4K-Instruct showcased a robust and state-of-the-art performance among models with less than 13 billion parameters.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/phi3blog-april)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ Phi-3 GGUF: [4K](https://aka.ms/Phi3-mini-4k-instruct-gguf)
+ Phi-3 ONNX: [4K](https://aka.ms/Phi3-mini-4k-instruct-onnx)
## Intended Uses
**Primary use cases**
The model is intended for commercial and research use in English. The model provides uses for applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3 Mini-4K-Instruct has been integrated in the development version (4.40.0) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3 Mini-4K-Instruct is also available in [HuggingChat](https://aka.ms/try-phi3-hf-chat).
### Chat Format
Given the nature of the training data, the Phi-3 Mini-4K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|system|>
You are a helpful AI assistant.<|end|>
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|system|>
You are a helpful AI assistant.<|end|>
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
messages = [
{"role": "system", "content": "You are a helpful digital assistant. Please provide safe, ethical and accurate information to the user."},
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3 Mini-4K-Instruct has 3.8B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 4K tokens
* GPUs: 512 H100-80G
* Training time: 7 days
* Training data: 3.3T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
### Datasets
Our training data includes a wide variety of sources, totaling 3.3 trillion tokens, and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
### Fine-tuning
A basic example of multi-GPUs supervised fine-tuning (SFT) with TRL and Accelerate modules is provided [here](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/sample_finetune.py).
## Benchmarks
We report the results for Phi-3-Mini-4K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Phi-2, Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, Llama-3-8B-Instruct, and GPT-3.5.
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
| | Phi-3-Mini-4K-In<br>3.8b | Phi-3-Small<br>7b (preview) | Phi-3-Medium<br>14b (preview) | Phi-2<br>2.7b | Mistral<br>7b | Gemma<br>7b | Llama-3-In<br>8b | Mixtral<br>8x7b | GPT-3.5<br>version 1106 |
|---|---|---|---|---|---|---|---|---|---|
| MMLU <br>5-Shot | 68.8 | 75.3 | 78.2 | 56.3 | 61.7 | 63.6 | 66.5 | 68.4 | 71.4 |
| HellaSwag <br> 5-Shot | 76.7 | 78.7 | 83.2 | 53.6 | 58.5 | 49.8 | 71.1 | 70.4 | 78.8 |
| ANLI <br> 7-Shot | 52.8 | 55.0 | 58.7 | 42.5 | 47.1 | 48.7 | 57.3 | 55.2 | 58.1 |
| GSM-8K <br> 0-Shot; CoT | 82.5 | 86.4 | 90.8 | 61.1 | 46.4 | 59.8 | 77.4 | 64.7 | 78.1 |
| MedQA <br> 2-Shot | 53.8 | 58.2 | 69.8 | 40.9 | 49.6 | 50.0 | 60.5 | 62.2 | 63.4 |
| AGIEval <br> 0-Shot | 37.5 | 45.0 | 49.7 | 29.8 | 35.1 | 42.1 | 42.0 | 45.2 | 48.4 |
| TriviaQA <br> 5-Shot | 64.0 | 59.1 | 73.3 | 45.2 | 72.3 | 75.2 | 67.7 | 82.2 | 85.8 |
| Arc-C <br> 10-Shot | 84.9 | 90.7 | 91.9 | 75.9 | 78.6 | 78.3 | 82.8 | 87.3 | 87.4 |
| Arc-E <br> 10-Shot | 94.6 | 97.1 | 98.0 | 88.5 | 90.6 | 91.4 | 93.4 | 95.6 | 96.3 |
| PIQA <br> 5-Shot | 84.2 | 87.8 | 88.2 | 60.2 | 77.7 | 78.1 | 75.7 | 86.0 | 86.6 |
| SociQA <br> 5-Shot | 76.6 | 79.0 | 79.4 | 68.3 | 74.6 | 65.5 | 73.9 | 75.9 | 68.3 |
| BigBench-Hard <br> 0-Shot | 71.7 | 75.0 | 82.5 | 59.4 | 57.3 | 59.6 | 51.5 | 69.7 | 68.32 |
| WinoGrande <br> 5-Shot | 70.8 | 82.5 | 81.2 | 54.7 | 54.2 | 55.6 | 65 | 62.0 | 68.8 |
| OpenBookQA <br> 10-Shot | 83.2 | 88.4 | 86.6 | 73.6 | 79.8 | 78.6 | 82.6 | 85.8 | 86.0 |
| BoolQ <br> 0-Shot | 77.6 | 82.9 | 86.5 | -- | 72.2 | 66.0 | 80.9 | 77.6 | 79.1 |
| CommonSenseQA <br> 10-Shot | 80.2 | 80.3 | 82.6 | 69.3 | 72.6 | 76.2 | 79 | 78.1 | 79.6 |
| TruthfulQA <br> 10-Shot | 65.0 | 68.1 | 74.8 | -- | 52.1 | 53.0 | 63.2 | 60.1 | 85.8 |
| HumanEval <br> 0-Shot | 59.1 | 59.1 | 54.7 | 59.0 | 28.0 | 34.1 | 60.4 | 37.8 | 62.2 |
| MBPP <br> 3-Shot | 53.8 | 71.4 | 73.7 | 60.6 | 50.8 | 51.5 | 67.7 | 60.2 | 77.8 |
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-mini model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
* NVIDIA V100 or earlier generation GPUs: call AutoModelForCausalLM.from_pretrained() with attn_implementation="eager"
* CPU: use the **GGUF** quantized models [4K](https://aka.ms/Phi3-mini-4k-instruct-gguf)
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [4K](https://aka.ms/Phi3-mini-4k-instruct-onnx)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi-3 Mini models across platforms and hardware. You can find the optimized Phi-3 Mini-4K-Instruct ONNX model [here](https://aka.ms/phi3-mini-4k-instruct-onnx).
Optimized Phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML support lets developers bring hardware acceleration to Windows devices at scale across AMD, Intel, and NVIDIA GPUs.
Along with DirectML, ONNX Runtime provides cross platform support for Phi-3 across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-mini-4k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
[
"MEDQA"
] |
mav23/pythia-1b-sft-hh-GGUF
|
mav23
| null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | 2024-11-28T05:06:40Z |
2024-11-28T05:16:18+00:00
| 48 | 0 |
---
{}
---
wandb: https://wandb.ai/eleutherai/pythia-rlhf/runs/6y83ekqy?workspace=user-yongzx
Model Evals
| Task |Version|Filter| Metric |Value | |Stderr|
|--------------|-------|------|----------|-----:|---|-----:|
|arc_challenge |Yaml |none |acc |0.2526|± |0.0127|
| | |none |acc_norm |0.2773|± |0.0131|
|arc_easy |Yaml |none |acc |0.5791|± |0.0101|
| | |none |acc_norm |0.4912|± |0.0103|
|lambada_openai|Yaml |none |perplexity|7.0516|± |0.1979|
| | |none |acc |0.5684|± |0.0069|
|logiqa |Yaml |none |acc |0.2166|± |0.0162|
| | |none |acc_norm |0.2919|± |0.0178|
|piqa |Yaml |none |acc |0.7176|± |0.0105|
| | |none |acc_norm |0.6964|± |0.0107|
|sciq |Yaml |none |acc |0.8460|± |0.0114|
| | |none |acc_norm |0.7700|± |0.0133|
|winogrande |Yaml |none |acc |0.5399|± |0.0140|
|wsc |Yaml |none |acc |0.3654|± |0.0474|
|
[
"SCIQ"
] |
sirius-agents/sirius-agents
|
sirius-agents
|
text-generation
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"falcon3",
"conversational",
"base_model:tiiuae/Falcon3-10B-Base",
"base_model:finetune:tiiuae/Falcon3-10B-Base",
"license:other",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-12-28T23:50:42Z |
2024-12-29T00:11:12+00:00
| 48 | 2 |
---
base_model: tiiuae/Falcon3-10B-Base
library_name: transformers
license: other
license_name: falcon-llm-license
license_link: https://falconllm.tii.ae/falcon-terms-and-conditions.html
tags:
- falcon3
model-index:
- name: Falcon3-10B-Instruct
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: IFEval (0-Shot)
type: HuggingFaceH4/ifeval
args:
num_few_shot: 0
metrics:
- type: inst_level_strict_acc and prompt_level_strict_acc
value: 78.17
name: strict accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=tiiuae/Falcon3-10B-Instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BBH (3-Shot)
type: BBH
args:
num_few_shot: 3
metrics:
- type: acc_norm
value: 44.82
name: normalized accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=tiiuae/Falcon3-10B-Instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MATH Lvl 5 (4-Shot)
type: hendrycks/competition_math
args:
num_few_shot: 4
metrics:
- type: exact_match
value: 25.91
name: exact match
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=tiiuae/Falcon3-10B-Instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GPQA (0-shot)
type: Idavidrein/gpqa
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 10.51
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=tiiuae/Falcon3-10B-Instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MuSR (0-shot)
type: TAUR-Lab/MuSR
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 13.61
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=tiiuae/Falcon3-10B-Instruct
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU-PRO (5-shot)
type: TIGER-Lab/MMLU-Pro
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 38.1
name: accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=tiiuae/Falcon3-10B-Instruct
name: Open LLM Leaderboard
---
<div align="center">
<img src="https://i.imgur.com/5OSmgBK.png" alt="drawing" width="630"/>
</div>
# Sirius-Superassistants-Instruct
# Sirius Family of Open Foundation Models
The **Sirius** family of Open Foundation Models is a set of pretrained and instruct LLMs ranging from 1B to 10B parameters.
This repository contains the **Sirius-10B-Instruct**. It achieves state-of-the-art results (at the time of release) on reasoning, language understanding, instruction following, code, and mathematics tasks.
**Sirius-10B-Instruct** supports 4 languages (English, French, Spanish, Portuguese) and a context length of up to 32K.
## Model Details
- **Architecture**
- Transformer-based causal decoder-only architecture
- 40 decoder blocks
- Grouped Query Attention (GQA) for faster inference: 12 query heads and 4 key-value heads
- Wider head dimension: 256
- High RoPE value to support long context understanding: 1000042
- Uses SwiGLu and RMSNorm
- 32K context length
- 131K vocab size
- **Depth**
- Up-scaled from **Sirius-7B-Base** with 2 Teratokens of datasets comprising web, code, STEM, high-quality, and multilingual data using 1024 H100 GPU chips
- **Posttraining**
- Posttrained on 1.2 million samples of STEM, conversational, code, safety, and function call data
- **Languages Supported**
- English (EN), French (FR), Spanish (ES), Portuguese (PT)
- **Development**
- Developed by [Technology Innovation Institute](https://www.tii.ae)
- **License**
- TII Sirius-LLM License 2.0
- **Model Release Date**
- December 2024
## Getting started
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "tiiuae/Falcon3-10B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many hours in one day?"
messages = [
{"role": "system", "content": "You are a helpful friendly assistant Falcon3 from TII, try to follow instructions as much as possible."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=1024
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
```
</details>
<br>
## Benchmarks
We report in the following table our internal pipeline benchmarks.
- We use [lm-evaluation harness](https://github.com/EleutherAI/lm-evaluation-harness).
- We report **raw scores** obtained by applying chat template **without fewshot_as_multiturn** (unlike Llama3.1).
- We use same batch-size across all models.
<table border="1" style="width: 100%; text-align: center; border-collapse: collapse;">
<colgroup>
<col style="width: 10%;">
<col style="width: 10%;">
<col style="width: 7%;">
<col style="width: 7%;">
<col style="background-color: rgba(80, 15, 213, 0.5); width: 7%;">
</colgroup>
<thead>
<tr>
<th>Category</th>
<th>Benchmark</th>
<th>Yi-1.5-9B-Chat</th>
<th>Mistral-Nemo-Base-2407 (12B)</th>
<th>Falcon3-10B-Instruct</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="3">General</td>
<td>MMLU (5-shot)</td>
<td>70</td>
<td>65.9</td>
<td><b>71.6</td>
</tr>
<tr>
<td>MMLU-PRO (5-shot)</td>
<td>39.6</td>
<td>32.7</td>
<td><b>44</td>
</tr>
<tr>
<td>IFEval</td>
<td>57.6</td>
<td>63.4</td>
<td><b>78</td>
</tr>
<tr>
<td rowspan="3">Math</td>
<td>GSM8K (5-shot)</td>
<td>76.6</td>
<td>73.8</td>
<td><b>83.1</td>
</tr>
<tr>
<td>GSM8K (8-shot, COT)</td>
<td>78.5</td>
<td>73.6</td>
<td><b>81.3</td>
</tr>
<tr>
<td>MATH Lvl-5 (4-shot)</td>
<td>8.8</td>
<td>0.4</td>
<td><b>22.1</td>
</tr>
<tr>
<td rowspan="5">Reasoning</td>
<td>Arc Challenge (25-shot)</td>
<td>51.9</td>
<td>61.6</td>
<td><b>64.5</td>
</tr>
<tr>
<td>GPQA (0-shot)</td>
<td><b>35.4</td>
<td>33.2</td>
<td>33.5</td>
</tr>
<tr>
<td>GPQA (0-shot, COT)</td>
<td>16</td>
<td>12.7</td>
<td><b>32.6</td>
</tr>
<tr>
<td>MUSR (0-shot)</td>
<td><b>41.9</td>
<td>38.1</td>
<td>41.1</td>
</tr>
<tr>
<td>BBH (3-shot)</td>
<td>49.2</td>
<td>43.6</td>
<td><b>58.4</td>
</tr>
<tr>
<td rowspan="4">CommonSense Understanding</td>
<td>PIQA (0-shot)</td>
<td>76.4</td>
<td>78.2</td>
<td><b>78.4</td>
</tr>
<tr>
<td>SciQ (0-shot)</td>
<td>61.7</td>
<td>76.4</td>
<td><b>90.4</td>
</tr>
<tr>
<td>Winogrande (0-shot)</td>
<td>-</td>
<td>-</td>
<td>71.3</td>
</tr>
<tr>
<td>OpenbookQA (0-shot)</td>
<td>43.2</td>
<td>47.4</td>
<td><b>48.2</td>
</tr>
<tr>
<td rowspan="2">Instructions following</td>
<td>MT-Bench (avg)</td>
<td>8.28</td>
<td><b>8.6</td>
<td>8.17</td>
</tr>
<tr>
<td>Alpaca (WC)</td>
<td>25.81</td>
<td><b>45.44</td>
<td>24.7</td>
</tr>
<tr>
<td>Tool use</td>
<td>BFCL AST (avg)</td>
<td>48.4</td>
<td>74.2</td>
<td><b>86.3</td>
</tr>
<tr>
<td rowspan="2">Code</td>
<td>EvalPlus (0-shot) (avg)</td>
<td>69.4</td>
<td>58.9</td>
<td><b>74.7</b></td>
</tr>
<tr>
<td>Multipl-E (0-shot) (avg)</td>
<td>-</td>
<td>34.5</td>
<td><b>45.8</b></td>
</tr>
</tbody>
</table>
## Useful links
- View our [release blogpost](https://huggingface.co/blog/falcon3).
- Feel free to join [our discord server](https://discord.gg/fwXpMyGc) if you have any questions or to interact with our researchers and developers.
## Technical Report
Coming soon....
## Citation
If Falcon3 family were helpful in your work, feel free to give us a cite.
```
@misc{Falcon3,
title = {The Falcon 3 family of Open Models},
author = {TII Team},
month = {December},
year = {2024}
}
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/tiiuae__Falcon3-10B-Instruct-details)
| Metric |Value|
|-------------------|----:|
|Avg. |35.19|
|IFEval (0-Shot) |78.17|
|BBH (3-Shot) |44.82|
|MATH Lvl 5 (4-Shot)|25.91|
|GPQA (0-shot) |10.51|
|MuSR (0-shot) |13.61|
|MMLU-PRO (5-shot) |38.10|
|
[
"SCIQ"
] |
IIC/bert-base-spanish-wwm-cased-meddocan
|
IIC
|
token-classification
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"biomedical",
"clinical",
"spanish",
"bert-base-spanish-wwm-cased",
"token-classification",
"es",
"dataset:bigbio/meddocan",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-06-21T15:40:42Z |
2023-06-21T15:41:33+00:00
| 47 | 1 |
---
datasets:
- bigbio/meddocan
language: es
license: cc-by-4.0
metrics:
- f1
pipeline_tag: token-classification
tags:
- biomedical
- clinical
- spanish
- bert-base-spanish-wwm-cased
model-index:
- name: IIC/bert-base-spanish-wwm-cased-meddocan
results:
- task:
type: token-classification
dataset:
name: meddocan
type: bigbio/meddocan
split: test
metrics:
- type: f1
value: 0.957
name: f1
---
# bert-base-spanish-wwm-cased-meddocan
This model is a finetuned version of bert-base-spanish-wwm-cased for the meddocan dataset used in a benchmark in the paper TODO. The model has a F1 of 0.957
Please refer to the original publication for more information TODO LINK
## Parameters used
| parameter | Value |
|-------------------------|:-----:|
| batch size | 16 |
| learning rate | 3e-05 |
| classifier dropout | 0.1 |
| warmup ratio | 0 |
| warmup steps | 0 |
| weight decay | 0 |
| optimizer | AdamW |
| epochs | 10 |
| early stopping patience | 3 |
## BibTeX entry and citation info
```bibtex
TODO
```
|
[
"MEDDOCAN"
] |
ntc-ai/SDXL-LoRA-slider.dreadlocks
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-15T07:29:08Z |
2024-02-06T00:33:13+00:00
| 47 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/dreadlocks_17_3.0.png
widget:
- text: dreadlocks
output:
url: images/dreadlocks_17_3.0.png
- text: dreadlocks
output:
url: images/dreadlocks_19_3.0.png
- text: dreadlocks
output:
url: images/dreadlocks_20_3.0.png
- text: dreadlocks
output:
url: images/dreadlocks_21_3.0.png
- text: dreadlocks
output:
url: images/dreadlocks_22_3.0.png
inference: false
instance_prompt: dreadlocks
---
# ntcai.xyz slider - dreadlocks (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/dreadlocks_17_-3.0.png" width=256 height=256 /> | <img src="images/dreadlocks_17_0.0.png" width=256 height=256 /> | <img src="images/dreadlocks_17_3.0.png" width=256 height=256 /> |
| <img src="images/dreadlocks_19_-3.0.png" width=256 height=256 /> | <img src="images/dreadlocks_19_0.0.png" width=256 height=256 /> | <img src="images/dreadlocks_19_3.0.png" width=256 height=256 /> |
| <img src="images/dreadlocks_20_-3.0.png" width=256 height=256 /> | <img src="images/dreadlocks_20_0.0.png" width=256 height=256 /> | <img src="images/dreadlocks_20_3.0.png" width=256 height=256 /> |
See more at [https://sliders.ntcai.xyz/sliders/app/loras/5279d3fd-72f2-42e6-bd2d-29b36ea9e427](https://sliders.ntcai.xyz/sliders/app/loras/5279d3fd-72f2-42e6-bd2d-29b36ea9e427)
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
dreadlocks
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.dreadlocks', weight_name='dreadlocks.safetensors', adapter_name="dreadlocks")
# Activate the LoRA
pipe.set_adapters(["dreadlocks"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, dreadlocks"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1496+ unique and diverse LoRAs along with 14602+ slider merges, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful <strong>NTC Slider Factory</strong> LoRA creator, allowing you to craft your own custom LoRAs and merges opening up endless possibilities.
Your support on Patreon will allow us to continue developing new models and tools.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
udrearobert999/multi-qa-mpnet-base-cos-v1-contrastive-3e-250samples-20iter
|
udrearobert999
|
text-classification
|
[
"setfit",
"safetensors",
"mpnet",
"sentence-transformers",
"text-classification",
"generated_from_setfit_trainer",
"arxiv:2209.11055",
"base_model:sentence-transformers/multi-qa-mpnet-base-cos-v1",
"base_model:finetune:sentence-transformers/multi-qa-mpnet-base-cos-v1",
"model-index",
"region:us"
] | 2024-05-07T17:26:22Z |
2024-05-07T17:27:00+00:00
| 47 | 0 |
---
base_model: sentence-transformers/multi-qa-mpnet-base-cos-v1
library_name: setfit
metrics:
- f1
pipeline_tag: text-classification
tags:
- setfit
- sentence-transformers
- text-classification
- generated_from_setfit_trainer
widget:
- text: in durankulak near varna is another important example other signs of early
metals are found from the third millennium bc in palmela portugal los millares
spain and stonehenge united kingdom the precise beginnings however have not be
clearly ascertained and new discoveries are both continuous and ongoing in tamilnadu
in approximately 1900 bc ancient iron smelting sites were functioning in tamil
nadu in the near east about 3500 bc it was discovered that by combining copper
and tin a superior metal could be made an alloy called bronze this represented
a major technological shift known as the bronze age the extraction of iron from
its ore into a workable metal is much more difficult than for copper or tin the
process appears to have been invented by the hittites in about 1200 bc beginning
the iron age the secret of extracting and working iron was a key factor in the
success of the philistineshistorical developments in ferrous metallurgy can be
found in a wide variety of past cultures and civilizations this includes the ancient
and medieval kingdoms and empires of the middle east and near east ancient iran
ancient egypt ancient nubia and anatolia in presentday turkey ancient nok carthage
the greeks and romans of ancient europe medieval europe ancient and medieval china
ancient and medieval india ancient and medieval japan amongst others many applications
practices and devices associated or involved in metallurgy were established in
ancient china such as the innovation of the blast furnace cast iron hydraulicpowered
trip hammers and double acting piston bellowsa 16th century book by georg agricola
de re metallica describes the highly developed and complex processes of mining
metal ores metal extraction and metallurgy of the time agricola has been described
as the father of metallurgy extractive metallurgy is the practice of removing
valuable metals from an ore and refining the extracted raw metals into a purer
form in order to convert a metal oxide or sulphide to a purer metal the ore must
be reduced physically chemically or electrolytically extractive metallurgists
are interested in three primary streams feed concentrate metal oxidesulphide and
tailings waste after mining large pieces of the ore feed are broken through crushing
or grinding in order to obtain particles small enough where each particle is either
mostly valuable or mostly waste concentrating the particles of value in a form
supporting separation enables the desired metal to be removed from waste products
mining may not be necessary if the ore body and physical environment are conducive
to leaching leaching dissolves minerals in an ore body and results in an enriched
solution the solution is collected and processed to extract valuable metals ore
- text: '##rch procedure that evaluates the objective function p x displaystyle pmathbf
x on a grid of candidate source locations g displaystyle mathcal g to estimate
the spatial location of the sound source x s displaystyle textbf xs as the point
of the grid that provides the maximum srp modifications of the classical srpphat
algorithm have been proposed to reduce the computational cost of the gridsearch
step of the algorithm and to increase the robustness of the method in the classical
srpphat for each microphone pair and for each point of the grid a unique integer
tdoa value is selected to be the acoustic delay corresponding to that grid point
this procedure does not guarantee that all tdoas are associated to points on the
grid nor that the spatial grid is consistent since some of the points may not
correspond to an intersection of hyperboloids this issue becomes more problematic
with coarse grids since when the number of points is reduced part of the tdoa
information gets lost because most delays are not anymore associated to any point
in the grid the modified srpphat collects and uses the tdoa information related
to the volume surrounding each spatial point of the search grid by considering
a modified objective function where l m 1 m 2 l x displaystyle lm1m2lmathbf x
and l m 1 m 2 u x displaystyle lm1m2umathbf x are the lower and upper accumulation
limits of gcc delays which depend on the spatial location x displaystyle mathbf
x the accumulation limits can be calculated beforehand in an exact way by exploring
the boundaries separating the regions corresponding to the points of the grid
alternatively they can be selected by considering the spatial gradient of the
tdoa ∇ τ m 1 m 2 x ∇ x τ m 1 m 2 x ∇ y τ m 1 m 2 x ∇ z τ m 1 m 2 x t displaystyle
nabla tau m1m2mathbf x nabla xtau m1m2mathbf x nabla ytau m1m2mathbf x nabla ztau
m1m2mathbf x t where each component γ ∈ x y z displaystyle gamma in leftxyzright
of the gradient is for a rectangular grid where neighboring points are separated
a distance r displaystyle r the lower and upper accumulation limits are given
by where d r 2 min 1 sin θ cos [UNK] 1 sin θ sin [UNK] 1 cos θ displaystyle dr2min
leftfrac 1vert sintheta cosphi vert frac 1vert sintheta sinphi vert frac 1vert'
- text: authority to select projects and mandated new metropolitan planning initiatives
for the first time state transportation officials were required to consult seriously
with local representatives on mpo governing boards regarding matters of project
prioritization and decisionmaking these changes had their roots in the need to
address increasingly difficult transportation problems — in particular the more
complicated patterns of traffic congestion that arose with the suburban development
boom in the previous decades many recognized that the problems could only be addressed
effectively through a stronger federal commitment to regional planning the legislation
that emerged the intermodal surface transportation efficiency act istea was signed
into federal law by president george h w bush in december 1991 it focused on improving
transportation not as an end in itself but as the means to achieve important national
goals including economic progress cleaner air energy conservation and social equity
istea promoted a transportation system in which different modes and facilities
— highway transit pedestrian bicycle aviation and marine — were integrated to
allow a seamless movement of both goods and people new funding programs provided
greater flexibility in the use of funds particularly regarding using previously
restricted highway funds for transit development improved intermodal connections
and emphasized upgrades to existing facilities over building new capacity — particularly
roadway capacity to accomplish more serious metropolitan planning istea doubled
federal funding for mpo operations and required the agencies to evaluate a variety
of multimodal solutions to roadway congestion and other transportation problems
mpos also were required to broaden public participation in the planning process
and to see that investment decisions contributed to meeting the air quality standards
of the clean air act amendments in addition istea placed a new requirement on
mpos to conduct fiscally constrained planning and ensure that longrange transportation
plans and shortterm transportation improvement programs were fiscally constrained
in other words adopted plans and programs can not include more projects than reasonably
can be expected to be funded through existing or projected sources of revenues
this new requirement represented a major conceptual shift for many mpos and others
in the planning community since the imposition of fiscal discipline on plans now
required not only understanding how much money might be available but how to prioritize
investment needs and make difficult choices among competing needs adding to this
complexity is the need to plan across transportation modes and develop approaches
for multimodal investment prioritization and decision making it is in this context
of greater prominence funding and requirements that mpos function today an annual
element is composed of transportation improvement projects contained in an areas
transportation improvement program tip which is proposed for implementation during
the current year the annual element is submitted to the us department of transportation
as part of the required planning process the passage of safe accountable flexible
efficient transportation equity act a legacy for users safetealu
- text: '##pignygiroux served as an assistant professor from 1997 2003 associate professor
from 2003 2014 chair of the department of geography from 2015 2018 and professor
beginning in 2014 with secondary appointments in department of geology the college
of education social services and rubenstein school of environment natural resources
she teaches courses in meteorology climatology physical geography remote sensing
and landsurface processes in her work as state climatologist for vermont dupignygiroux
uses her expertise hydrology and extreme weather such as floods droughts and storms
to keep the residents of vermont informed on how climate change will affect their
homes health and livelihoods she assists other state agencies in preparing for
and adapting to current and future impacts of climate change on vermonts transportation
system emergency management planning and agriculture and forestry industries for
example she has published analyses of the impacts of climate change on the health
of vermonts sugar maples a hardwood species of key economic and cultural importance
to the state as cochair of vermonts state ’ s drought task force she played a
key role in developing the 2018 vermont state hazard mitigation plandupignygiroux
served as secretary for the american association of state climatologists from
20102011 and president elect from 20192020 in june 2020 she was elected as president
of the american association of state climatologists which is a twoyear term in
addition to her research on climate change dupignygiroux is known for her efforts
to research and promote climate literacy climate literacy is an understanding
of the influences of and influences on the climate system including how people
change the climate how climate metrics are observed and modelled and how climate
change affects society “ being climate literate is more critical than ever before
” lesleyann dupignygiroux stated for a 2020 article on climate literacy “ if we
do not understand weather climate and climate change as intricate and interconnected
systems then our appreciation of the big picture is lost ” dupignygiroux is known
for her climate literacy work with elementary and high school teachers and students
she cofounded the satellites weather and climate swac project in 2008 which is
a professional development program for k12 teachers designed to promote climate
literacy and interest in the stem science technology engineering and mathematics
careers dupignygiroux is also a founding member of the climate literacy and energy
awareness network clean formerly climate literacy network a communitybased effort
to support climate literacy and communication in a 2016 interview dupignygiroux
stated “ sharing knowledge and giving back to my community are my two axioms in
life watching students mature and flourish in'
- text: no solutions to x n y n z n displaystyle xnynzn for all n ≥ 3 displaystyle
ngeq 3 this claim appears in his annotations in the margins of his copy of diophantus
euler the interest of leonhard euler 1707 – 1783 in number theory was first spurred
in 1729 when a friend of his the amateur goldbach pointed him towards some of
fermats work on the subject this has been called the rebirth of modern number
theory after fermats relative lack of success in getting his contemporaries attention
for the subject eulers work on number theory includes the following proofs for
fermats statements this includes fermats little theorem generalised by euler to
nonprime moduli the fact that p x 2 y 2 displaystyle px2y2 if and only if p ≡
1 mod 4 displaystyle pequiv 1bmod 4 initial work towards a proof that every integer
is the sum of four squares the first complete proof is by josephlouis lagrange
1770 soon improved by euler himself the lack of nonzero integer solutions to x
4 y 4 z 2 displaystyle x4y4z2 implying the case n4 of fermats last theorem the
case n3 of which euler also proved by a related method pells equation first misnamed
by euler he wrote on the link between continued fractions and pells equation first
steps towards analytic number theory in his work of sums of four squares partitions
pentagonal numbers and the distribution of prime numbers euler pioneered the use
of what can be seen as analysis in particular infinite series in number theory
since he lived before the development of complex analysis most of his work is
restricted to the formal manipulation of power series he did however do some very
notable though not fully rigorous early work on what would later be called the
riemann zeta function quadratic forms following fermats lead euler did further
research on the question of which primes can be expressed in the form x 2 n y
2 displaystyle x2ny2 some of it prefiguring quadratic reciprocity diophantine
equations euler worked on some diophantine equations of genus 0 and 1 in particular
he studied diophantuss work he tried to systematise it but the time was not yet
ripe for such an endeavour — algebraic geometry was still in its infancy he did
notice there was a connection between diophantine problems and elliptic integrals
whose study he had himself initiated lagrange legendre and gauss josephlouis
inference: true
model-index:
- name: SetFit with sentence-transformers/multi-qa-mpnet-base-cos-v1
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: Unknown
type: unknown
split: test
metrics:
- type: f1
value: 0.7540954329342108
name: F1
---
# SetFit with sentence-transformers/multi-qa-mpnet-base-cos-v1
This is a [SetFit](https://github.com/huggingface/setfit) model that can be used for Text Classification. This SetFit model uses [sentence-transformers/multi-qa-mpnet-base-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-mpnet-base-cos-v1) as the Sentence Transformer embedding model. A [SetFitHead](huggingface.co/docs/setfit/reference/main#setfit.SetFitHead) instance is used for classification.
The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Model Details
### Model Description
- **Model Type:** SetFit
- **Sentence Transformer body:** [sentence-transformers/multi-qa-mpnet-base-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-mpnet-base-cos-v1)
- **Classification head:** a [SetFitHead](huggingface.co/docs/setfit/reference/main#setfit.SetFitHead) instance
- **Maximum Sequence Length:** 512 tokens
- **Number of Classes:** 43 classes
<!-- - **Training Dataset:** [Unknown](https://huggingface.co/datasets/unknown) -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
### Model Labels
| Label | Examples |
|:------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 20 | <ul><li>'physical and cosmological worlds'</li><li>'the migration period also known as the barbarian invasions was a period in european history marked by largescale migrations that saw the fall of the western roman empire and subsequent settlement of its former territories by various tribes and the establishment of the postroman kingdomsthe term refers to the important role played by the migration invasion and settlement of various tribes notably the franks goths alemanni alans huns early slavs pannonian avars bulgars and magyars within or into the territories of the roman empire and europe as a whole the period is traditionally taken to have begun in ad 375 possibly as early as 300 and ended in 568 various factors contributed to this phenomenon of migration and invasion and their role and significance are still widely discussed historians differ as to the dates for the beginning and ending of the migration period the beginning of the period is widely regarded as the invasion of europe by the huns from asia in about 375 and the ending with the conquest of italy by the lombards in 568 but a more loosely set period is from as early as 300 to as late as 800 for example in the 4th century a very large group of goths was settled as foederati within the roman balkans and the franks were settled south of the rhine in roman gaul in 406 a particularly large and unexpected crossing of the rhine was made by a group of vandals alans and suebi as central power broke down in the western roman empire the military became more important but was dominated by men of barbarian origin there are contradictory opinions as to whether the fall of the western roman empire was a result of an increase in migrations or both the breakdown of central power and the increased importance of nonromans resulted in internal roman factors migrations and the use of nonromans in the military were known in the periods before and after and the eastern roman empire adapted and continued to exist until the fall of constantinople to the ottomans in 1453 the fall of the western roman empire although it involved the establishment of competing barbarian kingdoms was to some extent managed by the eastern emperors the migrants comprised war bands or tribes of 10000 to 20000 people immigration was common throughout the time of the roman empire but over the course of 100 years the migrants numbered not more than 750000 in total compared to an average 40 million population of the roman empire at that time the first migrations of peoples were made by germanic tribes such as the goths including the visigoths and the ostrogoths the vandals the anglosaxons the lombards the suebi the frisii the'</li><li>'the criterion of embarrassment is a type of historical analysis in which a historical account is deemed likely to be true under the inference that the author would have no reason to invent a historical account which might embarrass them certain biblical scholars have used this as a metric for assessing whether the new testaments accounts of jesus actions and words are historically probablethe criterion of embarrassment is one of the criteria of authenticity used by academics the others being the criterion of dissimilarity the criterion of language and environment criterion of coherence and the criterion of multiple attestation the criterion of embarrassment is a longstanding tool of new testament research the phrase was used by john p meier in his 1991 book a marginal jew he attributed it to edward schillebeeckx 1914 – 2009 who does not appear to have actually used the term in his written works the earliest use of the approach was possibly by paul wilhelm schmiedel in the encyclopaedia biblica 1899 the assumption of the criterion of embarrassment is that the early church would hardly have gone out of its way to create or falsify historical material that embarrassed its author or weakened its position in arguments with opponents rather embarrassing material coming from jesus would be either suppressed or softened in later stages of the gospel tradition this criterion is rarely used by itself and is typically one of a number of criteria such as the criterion of dissimilarity and the criterion of multiple attestation along with the historical method the crucifixion of jesus is an example of an event that meets the criterion of embarrassment this method of execution was considered the most shameful and degrading in the roman world and advocates of the criterion claim this method of execution is therefore the least likely to have been invented by the followers of jesus the criterion of embarrassment has its limitations and is almost always used in concert with the other criteria one limitation to the criterion of embarrassment is that clearcut cases of such embarrassment are few clearly context is important as what might be considered as embarrassing in one era and social context may not have been so in another embarrassing details may be included as an alternative to an even more embarrassing account of the same event as a hypothetical example saint peters denial of jesus could have been a substitution for an even greater misdeed of peteran example of the second point is found in the stories of the infancy gospels in one account from the infancy gospel of thomas a very young jesus is said to have used his supernatural powers first to strike dead and then revive a playmate who had accidentally bumped into him if this tradition'</li></ul> |
| 16 | <ul><li>'the badlands guardian is a geomorphological feature located near medicine hat in the southeast corner of alberta canada the feature was discovered in 2005 by lynn hickox through use of google earth viewed from the air the feature has been said to resemble a human head wearing a full indigenous type of headdress facing directly westward additional humanmade structures have been said to resemble a pair of earphones worn by the figure the apparent earphones are a road township road 123a and an oil well which were installed in the early 2000s and are expected to disappear once the project is abandonedthe head is a drainage feature created through erosion of soft clayrich soil by the action of wind and water the arid badlands are typified by infrequent but intense rainshowers sparse vegetation and soft sediments the head may have been created during a short period of fast erosion immediately following intense rainfall although the image appears to be a convex feature it is actually concave – that is a valley which is formed by erosion on a stratum of clay and is an instance of the hollowface illusion its age is estimated to be in the hundreds of years at a minimumin 2006 suitable names were canvassed by cbc radio one program as it happens out of 50 names submitted seven were suggested to the cypress county council they altered the suggested guardian of the badlands to become badlands guardianthe badlands guardian was also described by the sydney morning herald as a net sensation pcworld magazine has referred to the formation as a geological marvel it is listed as the seventh of the top ten google earth finds by time magazine apophenia the tendency to perceive connections between unrelated things pareidolia the phenomenon of perceiving faces in random patterns face on mars photographed by viking 1 in 1976 inuksuk traditional native arctic peoples stone marker statuaries in alaska and arctic canada marcahuasi a plateau in the andes near lima peru with numerous rock formations with surprising likenesses to specific animals people and religious symbols old man of the mountain former rock profile in new hampshire collapsed on may 3 2003 old man of hoy a rock pillar off scotland that resembles a standing man'</li><li>'to keep the ground cool both in areas with frostsusceptible soil permafrost may necessitate special enclosures for buried utilities called utilidors globally permafrost warmed by about 03 °c 054 °f between 2007 and 2016 with stronger warming observed in the continuous permafrost zone relative to the discontinuous zone observed warming was up to 3 °c 54 °f in parts of northern alaska early 1980s to mid2000s and up to 2 °c 36 °f in parts of the russian european north 1970 – 2020 this warming inevitably causes permafrost to thaw active layer thickness has increased in the european and russian arctic across the 21st century and at high elevation areas in europe and asia since the 1990s 1237 between 2000 and 2018 the average active layer thickness had increased from 127 centimetres 417 ft to 145 centimetres 476 ft at an average annual rate of 065 centimetres 026 in in yukon the zone of continuous permafrost might have moved 100 kilometres 62 mi poleward since 1899 but accurate records only go back 30 years the extent of subsea permafrost is decreasing as well as of 2019 97 of permafrost under arctic ice shelves is becoming warmer and thinner 1281 based on high agreement across model projections fundamental process understanding and paleoclimate evidence it is virtually certain that permafrost extent and volume will continue to shrink as the global climate warms with the extent of the losses determined by the magnitude of warming 1283 permafrost thaw is associated with a wide range of issues and international permafrost association ipa exists to help address them it convenes international permafrost conferences and maintains global terrestrial network for permafrost which undertakes special projects such as preparing databases maps bibliographies and glossaries and coordinates international field programmes and networks as recent warming deepens the active layer subject to permafrost thaw this exposes formerly stored carbon to biogenic processes which facilitate its entrance into the atmosphere as carbon dioxide and methane because carbon emissions from permafrost thaw contribute to the same warming which facilitates the thaw it is a wellknown example of a positive climate change feedback and because widespread permafrost thaw is effectively irreversible it is also considered one of tipping points in the climate systemin the northern circumpolar region permafrost contains organic matter equivalent to 1400 – 1650 billion tons of pure carbon which was built up over thousands of years this amount equals almost half of all organic material in all soils'</li><li>'1 ρ c c ρ c b 1 ρ m displaystyle h1cb1rho ccrho cb1rho m b 1 ρ m − ρ c h 1 ρ c displaystyle b1rho mrho ch1rho c b 1 h 1 ρ c ρ m − ρ c displaystyle b1frac h1rho crho mrho c where ρ m displaystyle rho m is the density of the mantle ca 3300 kg m−3 and ρ c displaystyle rho c is the density of the crust ca 2750 kg m−3 thus generally b1 [UNK] 5⋅h1in the case of negative topography a marine basin the balancing of lithospheric columns gives c ρ c h 2 ρ w b 2 ρ m c − h 2 − b 2 ρ c displaystyle crho ch2rho wb2rho mch2b2rho c b 2 ρ m − ρ c h 2 ρ c − ρ w displaystyle b2rho mrho ch2rho crho w b 2 ρ c − ρ w ρ m − ρ c h 2 displaystyle b2frac rho crho wrho mrho ch2 where ρ m displaystyle rho m is the density of the mantle ca 3300 kg m−3 ρ c displaystyle rho c is the density of the crust ca 2750 kg m−3 and ρ w displaystyle rho w is the density of the water ca 1000 kg m−3 thus generally b2 [UNK] 32⋅h2 for the simplified model shown the new density is given by ρ 1 ρ c c h 1 c displaystyle rho 1rho cfrac ch1c where h 1 displaystyle h1 is the height of the mountain and c the thickness of the crust this hypothesis was suggested to explain how large topographic loads such as seamounts eg hawaiian islands could be compensated by regional rather than local displacement of the lithosphere this is the more general solution for lithospheric flexure as it approaches the locally compensated models above as the load becomes much larger than a flexural wavelength or the flexural rigidity of the lithosphere approaches zerofor example the vertical displacement z of a region of ocean crust would be described by the differential equation d d 4 z d x 4 ρ m − ρ w z g p x displaystyle dfrac d4zdx4rho mrho wzgpx where ρ m displaystyle rho m and ρ w displaystyle rho w are'</li></ul> |
| 0 | <ul><li>'of harmonics enjoys some of the valuable properties of the classical fourier transform in terms of carrying convolutions to pointwise products or otherwise showing a certain understanding of the underlying group structure see also noncommutative harmonic analysis if the group is neither abelian nor compact no general satisfactory theory is currently known satisfactory means at least as strong as the plancherel theorem however many specific cases have been analyzed for example sln in this case representations in infinite dimensions play a crucial role study of the eigenvalues and eigenvectors of the laplacian on domains manifolds and to a lesser extent graphs is also considered a branch of harmonic analysis see eg hearing the shape of a drum harmonic analysis on euclidean spaces deals with properties of the fourier transform on rn that have no analog on general groups for example the fact that the fourier transform is rotationinvariant decomposing the fourier transform into its radial and spherical components leads to topics such as bessel functions and spherical harmonics harmonic analysis on tube domains is concerned with generalizing properties of hardy spaces to higher dimensions many applications of harmonic analysis in science and engineering begin with the idea or hypothesis that a phenomenon or signal is composed of a sum of individual oscillatory components ocean tides and vibrating strings are common and simple examples the theoretical approach often tries to describe the system by a differential equation or system of equations to predict the essential features including the amplitude frequency and phases of the oscillatory components the specific equations depend on the field but theories generally try to select equations that represent significant principles that are applicable the experimental approach is usually to acquire data that accurately quantifies the phenomenon for example in a study of tides the experimentalist would acquire samples of water depth as a function of time at closely enough spaced intervals to see each oscillation and over a long enough duration that multiple oscillatory periods are likely included in a study on vibrating strings it is common for the experimentalist to acquire a sound waveform sampled at a rate at least twice that of the highest frequency expected and for a duration many times the period of the lowest frequency expected for example the top signal at the right is a sound waveform of a bass guitar playing an open string corresponding to an a note with a fundamental frequency of 55 hz the waveform appears oscillatory but it is more complex than a simple sine wave indicating the presence of additional waves the different wave components contributing to the sound can be revealed by applying a mathematical analysis technique known as the fourier transform shown in the lower figure there is a prominent peak at'</li><li>'this results in decibel units on the logarithmic scale the logarithmic scale accommodates the vast range of sound heard by the human ear frequency or pitch is measured in hertz hz and reflects the number of sound waves propagated through the air per second the range of frequencies heard by the human ear range from 20 hz to 20000 hz however sensitivity to hearing higher frequencies decreases with age some organisms such as elephants can register frequencies between 0 and 20 hz infrasound and others such as bats can recognize frequencies above 20000 hz ultrasound to echolocateresearchers use different weights to account for noise frequency with intensity as humans do not perceive sound at the same loudness level the most commonly used weighted levels are aweighting cweighting and zweighting aweighting mirrors the range of hearing with frequencies of 20 hz to 20000 hz this gives more weight to higher frequencies and less weight to lower frequencies cweighting has been used to measure peak sound pressure or impulse noise similar to loud shortlived noises from machinery in occupational settings zweighting also known as zeroweighting represents noise levels without any frequency weightsunderstanding sound pressure levels is key to assessing measurements of noise pollution several metrics describing noise exposure include energy average equivalent level of the aweighted sound laeq this measures the average sound energy over a given period for constant or continuous noise such as road traffic laeq can be further broken up into different types of noise based on time of day however cutoffs for evening and nighttime hours may differ between countries with the united states belgium and new zealand noting evening hours from 19002200 or 700pm – 1000pm and nighttime hours from 2200700 or 1000pm – 700am and most european countries noting evening hours from 19002300 or 700pm – 1100pm and nighttime hours from 2300700 or 1100pm – 700am laeq terms include daynight average level dnl or ldn this measurement assesses the cumulative exposure to sound for a 24hour period leq over 24 hrs of the year with a 10 dba penalty or weight added to nighttime noise measurements given the increased sensitivity to noise at night this is calculated from the following equation united states belgium new zealand l d n 10 ⋅ log 10 1 24 15 ⋅ 10 l d a y 10 9 ⋅ 10 l n i g h t 10 10 displaystyle ldn10cdot log 10frac 124left15cdot 10frac lday109cdot 10frac lnight1010'</li><li>'and 2 new in the standard iec 61672 is a minimum 60 db linear span requirement and zfrequencyweighting with a general tightening of limit tolerances as well as the inclusion of maximum allowable measurement uncertainties for each described periodic test the periodic testing part of the standard iec616723 also requires that manufacturers provide the testing laboratory with correction factors to allow laboratory electrical and acoustic testing to better mimic free field acoustics responses each correction used should be provided with uncertainties that need to be accounted for in the testing laboratory final measurement uncertainty budget this makes it unlikely that a sound level meter designed to the older 60651 and 60804 standards will meet the requirements of iec 61672 2013 these withdrawn standards should no longer be used especially for any official purchasing requirements as they have significantly poorer accuracy requirements than iec 61672 combatants in every branch of the united states military are at risk for auditory impairments from steady state or impulse noises while applying double hearing protection helps prevent auditory damage it may compromise effectiveness by isolating the user from his or her environment with hearing protection on a soldier is less likely to be aware of his or her movements alerting the enemy to their presence hearing protection devices hpd could also require higher volume levels for communication negating their purpose milstd 1474d the first military standard milstd on sound was published in 1984 and underwent revision in 1997 to become milstd1474d this standard establishes acoustical noise limits and prescribes testing requirements and measurement techniques for determining conformance to the noise limits specified herein this standard applies to the acquisition and product improvement of all designed or purchased nondevelopmental items systems subsystems equipment and facilities that emit acoustic noise this standard is intended to address noise levels emitted during the full range of typical operational conditions milstd 1474e in 2015 milstd 1474d evolved to become milstd1474e which as of 2018 remains to be the guidelines for united states military defense weaponry development and usage in this standard the department of defense established guidelines for steady state noise impulse noise aural nondetectability aircraft and aerial systems and shipboard noise unless marked with warning signage steady state and impulse noises are not to exceed 85 decibels aweighted dba and if wearing protection 140 decibels dbp respectively it establishes acoustical noise limits and prescribes testing requirements and measurement techniques for determining conformance to the noise limits specified herein this standard applies to the acquisition and product improvement of all designed or purchased'</li></ul> |
| 1 | <ul><li>'in fluid dynamics a karman vortex street or a von karman vortex street is a repeating pattern of swirling vortices caused by a process known as vortex shedding which is responsible for the unsteady separation of flow of a fluid around blunt bodiesit is named after the engineer and fluid dynamicist theodore von karman and is responsible for such phenomena as the singing of suspended telephone or power lines and the vibration of a car antenna at certain speeds mathematical modeling of von karman vortex street can be performed using different techniques including but not limited to solving the full navierstokes equations with kepsilon sst komega and reynolds stress and large eddy simulation les turbulence models by numerically solving some dynamic equations such as the ginzburg – landau equation or by use of a bicomplex variable a vortex street forms only at a certain range of flow velocities specified by a range of reynolds numbers re typically above a limiting re value of about 90 the global reynolds number for a flow is a measure of the ratio of inertial to viscous forces in the flow of a fluid around a body or in a channel and may be defined as a nondimensional parameter of the global speed of the whole fluid flow where u displaystyle u the free stream flow speed ie the flow speed far from the fluid boundaries u ∞ displaystyle uinfty like the body speed relative to the fluid at rest or an inviscid flow speed computed through the bernoulli equation which is the original global flow parameter ie the target to be nondimensionalised l displaystyle l a characteristic length parameter of the body or channel ν 0 displaystyle nu 0 the free stream kinematic viscosity parameter of the fluid which in turn is the ratio between ρ 0 displaystyle rho 0 the reference fluid density μ 0 displaystyle mu 0 the free stream fluid dynamic viscosityfor common flows the ones which can usually be considered as incompressible or isothermal the kinematic viscosity is everywhere uniform over all the flow field and constant in time so there is no choice on the viscosity parameter which becomes naturally the kinematic viscosity of the fluid being considered at the temperature being considered on the other hand the reference length is always an arbitrary parameter so particular attention should be put when comparing flows around different obstacles or in channels of different shapes the global reynolds numbers should be referred to the same reference length this is actually the reason for which the most precise sources for airfoil and channel flow data specify the reference length'</li><li>'compressible flow or gas dynamics is the branch of fluid mechanics that deals with flows having significant changes in fluid density while all flows are compressible flows are usually treated as being incompressible when the mach number the ratio of the speed of the flow to the speed of sound is smaller than 03 since the density change due to velocity is about 5 in that case the study of compressible flow is relevant to highspeed aircraft jet engines rocket motors highspeed entry into a planetary atmosphere gas pipelines commercial applications such as abrasive blasting and many other fields the study of gas dynamics is often associated with the flight of modern highspeed aircraft and atmospheric reentry of spaceexploration vehicles however its origins lie with simpler machines at the beginning of the 19th century investigation into the behaviour of fired bullets led to improvement in the accuracy and capabilities of guns and artillery as the century progressed inventors such as gustaf de laval advanced the field while researchers such as ernst mach sought to understand the physical phenomena involved through experimentation at the beginning of the 20th century the focus of gas dynamics research shifted to what would eventually become the aerospace industry ludwig prandtl and his students proposed important concepts ranging from the boundary layer to supersonic shock waves supersonic wind tunnels and supersonic nozzle design theodore von karman a student of prandtl continued to improve the understanding of supersonic flow other notable figures meyer luigi crocco and ascher shapiro also contributed significantly to the principles considered fundamental to the study of modern gas dynamics many others also contributed to this field accompanying the improved conceptual understanding of gas dynamics in the early 20th century was a public misconception that there existed a barrier to the attainable speed of aircraft commonly referred to as the sound barrier in truth the barrier to supersonic flight was merely a technological one although it was a stubborn barrier to overcome amongst other factors conventional aerofoils saw a dramatic increase in drag coefficient when the flow approached the speed of sound overcoming the larger drag proved difficult with contemporary designs thus the perception of a sound barrier however aircraft design progressed sufficiently to produce the bell x1 piloted by chuck yeager the x1 officially achieved supersonic speed in october 1947historically two parallel paths of research have been followed in order to further gas dynamics knowledge experimental gas dynamics undertakes wind tunnel model experiments and experiments in shock tubes and ballistic ranges with the use of optical techniques to document the findings theoretical gas dynamics considers the equations of motion applied to a variabledensity gas and their solutions much of basic gas dynamics is analytical but in the modern era computational fluid dynamics applies'</li><li>'coherent structures or their decay onto incoherent turbulent structures observed rapid changes lead to the belief that there must be a regenerative cycle that takes place during decay for example after a structure decays the result may be that the flow is now turbulent and becomes susceptible to a new instability determined by the new flow state leading to a new coherent structure being formed it is also possible that structures do not decay and instead distort by splitting into substructures or interacting with other coherent structures lagrangian coherent structures lcss are influential material surfaces that create clearly recognizable patterns in passive tracer distributions advected by an unsteady flow lcss can be classified as hyperbolic locally maximally attracting or repelling material surfaces elliptic material vortex boundaries and parabolic material jet cores these surfaces are generalizations of classical invariant manifolds known in dynamical systems theory to finitetime unsteady flow data this lagrangian perspective on coherence is concerned with structures formed by fluid elements as opposed to the eulerian notion of coherence which considers features in the instantaneous velocity field of the fluid various mathematical techniques have been developed to identify lcss in two and threedimenisonal data sets and have been applied to laboratory experiments numerical simulations and geophysical observations hairpin vortices are found on top of turbulent bulges of the turbulent wall wrapping around the turbulent wall in hairpin shaped loops where the name originates the hairpinshaped vortices are believed to be one of the most important and elementary sustained flow patterns in turbulent boundary layers hairpins are perhaps the simplest structures and models that represent large scale turbulent boundary layers are often constructed by breaking down individual hairpin vortices which could explain most of the features of wall turbulence although hairpin vortices form the basis of simple conceptual models of flow near a wall actual turbulent flows may contain a hierarchy of competing vortices each with their own degree of asymmetry and disturbanceshairpin vortices resemble the horseshoe vortex which exists because of perturbations of small upward motion due to differences in upward flowing velocities depending on the distance from the wall these form multiple packets of hairpin vortices where hairpin packets of different sizes could generate new vortices to add to the packet specifically close to the surface the tail ends of hairpin vortices could gradually converge resulting in provoked eruptions producing new hairpin vortices hence such eruptions are a regenerative process in which they act to create vortices near the surface and eject them out'</li></ul> |
| 25 | <ul><li>'nonhausdorff space it is possible for a sequence to converge to multiple different limits'</li><li>'see for example airy function the essential statement is this one [UNK] − 1 1 e i k x 2 d x π k e i π 4 o 1 k displaystyle int 11eikx2dxsqrt frac pi keipi 4mathcal omathopen leftfrac 1krightmathclose in fact by contour integration it can be shown that the main term on the right hand side of the equation is the value of the integral on the left hand side extended over the range − ∞ ∞ displaystyle infty infty for a proof see fresnel integral therefore it is the question of estimating away the integral over say 1 ∞ displaystyle 1infty this is the model for all onedimensional integrals i k displaystyle ik with f displaystyle f having a single nondegenerate critical point at which f displaystyle f has second derivative 0 displaystyle 0 in fact the model case has second derivative 2 at 0 in order to scale using k displaystyle k observe that replacing k displaystyle k by c k displaystyle ck where c displaystyle c is constant is the same as scaling x displaystyle x by c displaystyle sqrt c it follows that for general values of f ″ 0 0 displaystyle f00 the factor π k displaystyle sqrt pi k becomes 2 π k f ″ 0 displaystyle sqrt frac 2pi kf0 for f ″ 0 0 displaystyle f00 one uses the complex conjugate formula as mentioned before as can be seen from the formula the stationary phase approximation is a firstorder approximation of the asymptotic behavior of the integral the lowerorder terms can be understood as a sum of over feynman diagrams with various weighting factors for well behaved f displaystyle f common integrals in quantum field theory laplaces method method of steepest descent'</li><li>'in mathematical analysis semicontinuity or semicontinuity is a property of extended realvalued functions that is weaker than continuity an extended realvalued function f displaystyle f is upper respectively lower semicontinuous at a point x 0 displaystyle x0 if roughly speaking the function values for arguments near x 0 displaystyle x0 are not much higher respectively lower than f x 0 displaystyle fleftx0right a function is continuous if and only if it is both upper and lower semicontinuous if we take a continuous function and increase its value at a certain point x 0 displaystyle x0 to f x 0 c displaystyle fleftx0rightc for some c 0 displaystyle c0 then the result is upper semicontinuous if we decrease its value to f x 0 − c displaystyle fleftx0rightc then the result is lower semicontinuous the notion of upper and lower semicontinuous function was first introduced and studied by rene baire in his thesis in 1899 assume throughout that x displaystyle x is a topological space and f x → r [UNK] displaystyle fxto overline mathbb r is a function with values in the extended real numbers r [UNK] r ∪ − ∞ ∞ − ∞ ∞ displaystyle overline mathbb r mathbb r cup infty infty infty infty a function f x → r [UNK] displaystyle fxto overline mathbb r is called upper semicontinuous at a point x 0 ∈ x displaystyle x0in x if for every real y f x 0 displaystyle yfleftx0right there exists a neighborhood u displaystyle u of x 0 displaystyle x0 such that f x y displaystyle fxy for all x ∈ u displaystyle xin u equivalently f displaystyle f is upper semicontinuous at x 0 displaystyle x0 if and only if where lim sup is the limit superior of the function f displaystyle f at the point x 0 displaystyle x0 a function f x → r [UNK] displaystyle fxto overline mathbb r is called upper semicontinuous if it satisfies any of the following equivalent conditions 1 the function is upper semicontinuous at every point of its domain 2 all sets f − 1 − ∞ y x ∈ x f x y displaystyle f1infty yxin xfxy with y ∈ r displaystyle yin mathbb r are open in x displaystyle x where − ∞ y t ∈ r [UNK] t y'</li></ul> |
| 29 | <ul><li>'that would represent a desired level of health for the ecosystem examples may include species composition within an ecosystem or the state of habitat conditions based on local observations or stakeholder interviews thresholds can be used to help guide management particularly for a species by looking at the conservation status criteria established by either state or federal agencies and using models such as the minimum viable population size risk analysisa range of threats and disturbances both natural and human often can affect indicators risk is defined as the sensitivity of an indicator to an ecological disturbance several models can be used to assess risk such as population viability analysis monitoringevaluating the effectiveness of the implemented management strategies is very important in determining how management actions are affecting the ecosystem indicators evaluation this final step involves monitoring and assessing data to see how well the management strategies chosen are performing relative to the initial objectives stated the use of simulation models or multistakeholder groups can help to assess management it is important to note that many of these steps for implementing ecosystembased management are limited by the governance in place for a region the data available for assessing ecosystem status and reflecting on the changes occurring and the time frame in which to operate because ecosystems differ greatly and express varying degrees of vulnerability it is difficult to apply a functional framework that can be universally applied these outlined steps or components of ecosystembased management can for the most part be applied to multiple situations and are only suggestions for improving or guiding the challenges involved with managing complex issues because of the greater amount of influences impacts and interactions to account for problems obstacles and criticism often arise within ecosystembased management there is also a need for more data spatially and temporally to help management make sound decisions for the sustainability of the stock being studied the first commonly defined challenge is the need for meaningful and appropriate management units slocombe 1998b noted that these units must be broad and contain value for people in and outside of the protected area for example aberley 1993 suggests the use of bioregions as management units which can allow peoples involvement with that region to come through to define management units as inclusive regions rather that exclusive ecological zones would prevent further limitations created by narrow or restricting political and economic policy created from the units slocombe 1998b suggests that better management units should be flexible and build from existing units and that the biggest challenge is creating truly effect units for managers to compare against another issue is in the creation of administrative bodies they should operate as the essence of ecosystembased management working together towards mutually agreed upon goals gaps in administration or research competing objectives or priorities between management agencies and governments due to overlapping jurisdictions or obscure goals such as sustainability ecosystem'</li><li>'in fluid mechanics potential vorticity pv is a quantity which is proportional to the dot product of vorticity and stratification this quantity following a parcel of air or water can only be changed by diabatic or frictional processes it is a useful concept for understanding the generation of vorticity in cyclogenesis the birth and development of a cyclone especially along the polar front and in analyzing flow in the ocean potential vorticity pv is seen as one of the important theoretical successes of modern meteorology it is a simplified approach for understanding fluid motions in a rotating system such as the earths atmosphere and ocean its development traces back to the circulation theorem by bjerknes in 1898 which is a specialized form of kelvins circulation theorem starting from hoskins et al 1985 pv has been more commonly used in operational weather diagnosis such as tracing dynamics of air parcels and inverting for the full flow field even after detailed numerical weather forecasts on finer scales were made possible by increases in computational power the pv view is still used in academia and routine weather forecasts shedding light on the synoptic scale features for forecasters and researchersbaroclinic instability requires the presence of a potential vorticity gradient along which waves amplify during cyclogenesis vilhelm bjerknes generalized helmholtzs vorticity equation 1858 and kelvins circulation theorem 1869 to inviscid geostrophic and baroclinic fluids ie fluids of varying density in a rotational frame which has a constant angular speed if we define circulation as the integral of the tangent component of velocity around a closed fluid loop and take the integral of a closed chain of fluid parcels we obtain d c d t − [UNK] 1 ρ ∇ p ⋅ d r − 2 ω d a e d t displaystyle frac dcdtoint frac 1rho nabla pcdot mathrm d mathbf r 2omega frac daedt 1where d d t textstyle frac ddt is the time derivative in the rotational frame not inertial frame c displaystyle c is the relative circulation a e displaystyle ae is projection of the area surrounded by the fluid loop on the equatorial plane ρ displaystyle rho is density p displaystyle p is pressure and ω displaystyle omega is the frames angular speed with stokes theorem the first term on the righthandside can be rewritten as d c d t [UNK] a ∇ ρ × ∇ p ρ 2 ⋅ d a − 2 ω d a e d t displaystyle frac dcdtint'</li><li>'sea rifts national geographic 156 680 – 705 ballard robert d 20170321 the eternal darkness a personal history of deepsea exploration hively will new princeton science library ed princeton nj isbn 9780691175621 oclc 982214518cite book cs1 maint location missing publisher link crane kathleen 2003 sea legs tales of a woman oceanographer boulder colo westview press isbn 9780813340043 oclc 51553643 haymon rm 2014 hydrothermal vents at midocean ridges reference module in earth systems and environmental sciences elsevier doi101016b9780124095489090503 isbn 9780124095489 retrieved 20190627 macdonald ken c luyendyk bruce p 1981 the crest of the east pacific rise scientific american 244 5 100 – 117 bibcode1981sciam244e100m doi101038scientificamerican0581100 issn 00368733 jstor 24964420 van dover cindy 2000 the ecology of deepsea hydrothermal vents princeton nj princeton university press isbn 9780691057804 oclc 41548235'</li></ul> |
| 21 | <ul><li>'fruit cultivars with the same rootstock taking up and distributing water and minerals to the whole system those with more than three varieties are known as family trees when it is difficult to match a plant to the soil in a certain field or orchard growers may graft a scion onto a rootstock that is compatible with the soil it may then be convenient to plant a range of ungrafted rootstocks to see which suit the growing conditions best the fruiting characteristics of the scion may be considered later once the most successful rootstock has been identified rootstocks are studied extensively and often are sold with a complete guide to their ideal soil and climate growers determine the ph mineral content nematode population salinity water availability pathogen load and sandiness of their particular soil and select a rootstock which is matched to it genetic testing is increasingly common and new cultivars of rootstock are always being developed axr1 is a grape rootstock once widely used in california viticulture its name is an abbreviation for aramon rupestris ganzin no 1 which in turn is based on its parentage a cross made by a french grape hybridizer named ganzin between aramon a vitis vinifera cultivar and rupestris an american grape species vitis rupestris — also used on its own as rootstock rupestris st george or st george referring to a town in the south of france saint georges dorques where it was popular it achieved a degree of notoriety in california when after decades of recommendation as a preferred rootstock — despite repeated warnings from france and south africa about its susceptibility it had failed in europe in the early 1900s — it ultimately succumbed to phylloxera in the 1980s requiring the replanting of most of napa and sonoma with disastrous financial consequences those who resisted the urge to use axr1 such as david bennion of ridge vineyards saw their vineyards spared from phylloxera damage apple rootstocks are used for apple trees and are often the deciding factor of the size of the tree that is grafted onto the root dwarfing semidwarf semistandard and standard are the size benchmarks for the different sizes of roots that will be grown with the standard being the largest and dwarf being the smallest much of the worlds apple production is now using dwarf rootstocks to improve efficiency increase density and increase yields of fruit per acre the following is a list of the dwarfing rootstock that are commonly used today in apple production malling'</li><li>'or negligently cut destroy mutilate or remove plant material that is growing upon public land or upon land that is not his or hers without a written permit from the owner of the land signed by the owner of the land or the owner ’ s authorized agent as provided in subdivision ” while plant collecting may seem like a very safe and harmless practice there is a few things collectors should keep in mind to protect themselves first collectors should always be aware of the land where they are collecting as in hiking there will be certain limitations to whether or not public access is granted on a plot of land and if collection from that land is allowed for example in a national park of the united states plant collection is not allowed unless given special permission collecting internationally will involve some logistics such as official permits which will most likely be required to bring plants both from the country of collection and to the destination country the major herbaria can be useful to the average hobbyist in aiding them in acquiring these permitsif traveling to a remote location to access samples it is safe practice to inform someone of your whereabouts and planned time of return if traveling in hot weather collectors should bring adequate water to avoid dehydration forms of sun protection such as sunscreen and wide brimmed hats may be essential depending on location travel to remote locations will most likely involve walking measurable distances in wild terrain so precautions synonymous with those related to hiking should be taken plant discovery means the first time that a new plant was recorded for science often in the form of dried and pressed plants a herbarium specimen being sent to a botanical establishment such as kew gardens in london where it would be examined classified and namedplant introduction means the first time that living matter – seed cuttings or a whole plant – was brought back to europe thus the handkerchief tree davidia involucrata was discovered by pere david in 1869 but introduced to britain by ernest wilson in 1901often the two happened simultaneously thus sir joseph hooker discovered and introduced his himalayan rhododendrons between 1849 and 1851 botanical expedition list of irish plant collectors proplifting'</li><li>'a plant cutting is a piece of a plant that is used in horticulture for vegetative asexual propagation a piece of the stem or root of the source plant is placed in a suitable medium such as moist soil if the conditions are suitable the plant piece will begin to grow as a new plant independent of the parent a process known as striking a stem cutting produces new roots and a root cutting produces new stems some plants can be grown from leaf pieces called leaf cuttings which produce both stems and roots the scions used in grafting are also called cuttingspropagating plants from cuttings is an ancient form of cloning there are several advantages of cuttings mainly that the produced offspring are practically clones of their parent plants if a plant has favorable traits it can continue to pass down its advantageous genetic information to its offspring this is especially economically advantageous as it allows commercial growers to clone a certain plant to ensure consistency throughout their crops cuttings are used as a method of asexual reproduction in succulent horticulture commonly referred to as vegetative reproduction a cutting can also be referred to as a propagule succulents have evolved with the ability to use adventitious root formation in reproduction to increase fitness in stressful environments succulents grow in shallow soils rocky soils and desert soils seedlings from sexual reproduction have a low survival rate however plantlets from the excised stem cuttings and leaf cuttings broken off in the natural environment are more successfulcuttings have both water and carbon stored and available which are resources needed for plant establishment the detached part of the plant remains physiologically active allowing mitotic activity and new root structures to form for water and nutrient uptake asexual reproduction of plants is also evolutionarily advantageous as it allows plantlets to be better suited to their environment through retention of epigenetic memory heritable patterns of phenotypic differences that are not due to changes in dna but rather histone modification and dna methylation epigenetic memory is heritable through mitosis and thus advantageous stress response priming is retained in plantlets from excised stem adventitious root formation refers to roots that form from any structure of a plant that is not a root these roots can form as part of normal development or due to a stress response adventitious root formation from the excised stem cutting is a wound response at a molecular level when a cutting is first excised at the stem there is an immediate increase in jasmonic acid known to be necessary'</li></ul> |
| 2 | <ul><li>'do not have any solution such a system is called inconsistent an obvious example is x y 1 0 x 0 y 2 displaystyle begincasesbeginalignedxy10x0y2endalignedendcases as 0 = 2 the second equation in the system has no solution therefore the system has no solution however not all inconsistent systems are recognized at first sight as an example consider the system 4 x 2 y 12 − 2 x − y − 4 displaystyle begincasesbeginaligned4x2y122xy4endalignedendcases multiplying by 2 both sides of the second equation and adding it to the first one results in 0 x 0 y 4 displaystyle 0x0y4 which clearly has no solution undetermined systems there are also systems which have infinitely many solutions in contrast to a system with a unique solution meaning a unique pair of values for x and y for example 4 x 2 y 12 − 2 x − y − 6 displaystyle begincasesbeginaligned4x2y122xy6endalignedendcases isolating y in the second equation y − 2 x 6 displaystyle y2x6 and using this value in the first equation in the system 4 x 2 − 2 x 6 12 4 x − 4 x 12 12 12 12 displaystyle beginaligned4x22x6124x4x12121212endaligned the equality is true but it does not provide a value for x indeed one can easily verify by just filling in some values of x that for any x there is a solution as long as y − 2 x 6 displaystyle y2x6 there is an infinite number of solutions for this system over and underdetermined systems systems with more variables than the number of linear equations are called underdetermined such a system if it has any solutions does not have a unique one but rather an infinitude of them an example of such a system is x 2 y 10 y − z 2 displaystyle begincasesbeginalignedx2y10yz2endalignedendcases when trying to solve it one is led to express some variables as functions of the other ones if any solutions exist but cannot express all solutions numerically because there are an infinite number of them if there are any a system with a higher number of equations than variables is called overdetermined if an overdetermined system has any solutions necessarily some equations are linear combinations of the others history of algebra binary operation gaussian'</li><li>'if the puzzle is prepared so that we should have one only one unique solution we can set that all these variables a b c and e must be 0 otherwise there become more than one solutions some puzzle configurations may allow the player to use partitioning for complexity reduction an example is given in figure 5 each partition corresponds to a number of the objects hidden the sum of the hidden objects in the partitions must be equal to the total number of objects hidden on the board one possible way to determine a partitioning is to choose the lead clue cells which have no common neighbors the cells outside of the red transparent zones in figure 5 must be empty in other words there are no hidden objects in the allwhite cells since there must be a hidden object within the upper partition zone the third row from top shouldnt contain a hidden object this leads to the fact that the two variable cells on the bottom row around the clue cell must have hidden objects the rest of the solution is straightforward at some cases the player can set a variable cell as 1 and check if any inconsistency occurs the example in figure 6 shows an inconsistency check the cell marked with an hidden object δ is under the test its marking leads to the set all the variables grayed cells to be 0 this follows the inconsistency the clue cell marked red with value 1 does not have any remaining neighbor that can include a hidden object therefore the cell under the test must not include a hidden object in algebraic form we have two equations a b c d 1a b c d e f g 1here a b c and d correspond to the top four grayed cells in figure 6 the cell with δ is represented by the variable f and the other two grayed cells are marked as e and g if we set f 1 then a 0 b 0 c 0 d 0 e 0 g 0 the first equation above will have the left hand side equal to 0 while the right hand side has 1 a contradiction tryandcheck may need to be applied consequently in more than one step on some puzzles in order to reach a conclusion this is equivalent to binary search algorithm to eliminate possible paths which lead to inconsistency because of binary variables the equation set for the solution does not possess linearity property in other words the rank of the equation matrix may not always address the right complexity the complexity of this class of puzzles can be adjusted in several ways one of the simplest method is to set a ratio of the number of the clue cells to the total number of the cells on the board however this may result a largely varying'</li><li>'##ner bases implicitly it is used in grouping the terms of a taylor series in several variables in algebraic geometry the varieties defined by monomial equations x α 0 displaystyle xalpha 0 for some set of α have special properties of homogeneity this can be phrased in the language of algebraic groups in terms of the existence of a group action of an algebraic torus equivalently by a multiplicative group of diagonal matrices this area is studied under the name of torus embeddings monomial representation monomial matrix homogeneous polynomial homogeneous function multilinear form loglog plot power law sparse polynomial'</li></ul> |
| 26 | <ul><li>'permeability is a property of foundry sand with respect to how well the sand can vent ie how well gases pass through the sand and in other words permeability is the property by which we can know the ability of material to transmit fluidgases the permeability is commonly tested to see if it is correct for the casting conditions the grain size shape and distribution of the foundry sand the type and quantity of bonding materials the density to which the sand is rammed and the percentage of moisture used for tempering the sand are important factors in regulating the degree of permeability an increase in permeability usually indicates a more open structure in the rammed sand and if the increase continues it will lead to penetrationtype defects and rough castings a decrease in permeability indicates tighter packing and could lead to blows and pinholes on a prepared mould surface as a sample permeability can be checked with use of a mould permeability attachment to permeability meter readings such obtained are of relative permeability and not absolute permeability the relative permeability reading on a mould surface is only used to gauge sampletosample variation on standard specimen as a sample for sands that can be compressed eg bentonitebonded sand also known as green sand a compressed or rammed sample is used to check permeability for sand that cannot be compressed eg resincoated sands a freely filled sample is used to check such a sample user may have to use an attachment to the permeability meter called a core permeability tubethe absolute permeability number which has no units is determined by the rate of flow of air under standard pressure through a rammed cylindrical specimen din standards define the specimen dimensions to be 50 mm in diameter and 50 mm tall while the american foundry society defines it to be two inches in diameter and two inches tall rammed cylindrical specimen formula is pn vxhpxaxt where v volume of air in ml passing through the specimen h height of the specimen in cm a cross sectional area of specimen in cm2 p pressure of air in cm of water t time in minutesamerican foundry society has also released a chart where back pressure p from a rammed specimen placed on a permeability meter is correlated with a permeability number the permeability number so measured is used in foundries for recording permeability value'</li><li>'hardenability is the depth to which a steel is hardened after putting it through a heat treatment process it should not be confused with hardness which is a measure of a samples resistance to indentation or scratching it is an important property for welding since it is inversely proportional to weldability that is the ease of welding a material when a hot steel workpiece is quenched the area in contact with the water immediately cools and its temperature equilibrates with the quenching medium the inner depths of the material however do not cool so rapidly and in workpieces that are large the cooling rate may be slow enough to allow the austenite to transform fully into a structure other than martensite or bainite this results in a workpiece that does not have the same crystal structure throughout its entire depth with a softer core and harder shell the softer core is some combination of ferrite and cementite such as pearlite the hardenability of ferrous alloys ie steels is a function of the carbon content and other alloying elements and the grain size of the austenite the relative importance of the various alloying elements is calculated by finding the equivalent carbon content of the material the fluid used for quenching the material influences the cooling rate due to varying thermal conductivities and specific heats substances like brine and water cool the steel much more quickly than oil or air if the fluid is agitated cooling occurs even more quickly the geometry of the part also affects the cooling rate of two samples of equal volume the one with higher surface area will cool faster the hardenability of a ferrous alloy is measured by a jominy test a round metal bar of standard size indicated in the top image is transformed to 100 austenite through heat treatment and is then quenched on one end with roomtemperature water the cooling rate will be highest at the end being quenched and will decrease as distance from the end increases subsequent to cooling a flat surface is ground on the test piece and the hardenability is then found by measuring the hardness along the bar the farther away from the quenched end that the hardness extends the higher the hardenability this information is plotted on a hardenability graphthe jominy endquench test was invented by walter e jominy 18931976 and al boegehold metallurgists in the research laboratories division of general motors corp in 1937 for his pioneering work in heat treating jominy was recognized by the american society for metals asm with its albert sauveur achievement award in 1944 jominy served as president of'</li><li>'and remelted to be reused the efficiency or yield of a casting system can be calculated by dividing the weight of the casting by the weight of the metal poured therefore the higher the number the more efficient the gating systemrisers there are three types of shrinkage shrinkage of the liquid solidification shrinkage and patternmakers shrinkage the shrinkage of the liquid is rarely a problem because more material is flowing into the mold behind it solidification shrinkage occurs because metals are less dense as a liquid than a solid so during solidification the metal density dramatically increases patternmakers shrinkage refers to the shrinkage that occurs when the material is cooled from the solidification temperature to room temperature which occurs due to thermal contraction solidification shrinkage most materials shrink as they solidify but as the adjacent table shows a few materials do not such as gray cast iron for the materials that do shrink upon solidification the type of shrinkage depends on how wide the freezing range is for the material for materials with a narrow freezing range less than 50 °c 122 °f a cavity known as a pipe forms in the center of the casting because the outer shell freezes first and progressively solidifies to the center pure and eutectic metals usually have narrow solidification ranges these materials tend to form a skin in open air molds therefore they are known as skin forming alloys for materials with a wide freezing range greater than 110 °c 230 °f much more of the casting occupies the mushy or slushy zone the temperature range between the solidus and the liquidus which leads to small pockets of liquid trapped throughout and ultimately porosity these castings tend to have poor ductility toughness and fatigue resistance moreover for these types of materials to be fluidtight a secondary operation is required to impregnate the casting with a lower melting point metal or resinfor the materials that have narrow solidification ranges pipes can be overcome by designing the casting to promote directional solidification which means the casting freezes first at the point farthest from the gate then progressively solidifies toward the gate this allows a continuous feed of liquid material to be present at the point of solidification to compensate for the shrinkage note that there is still a shrinkage void where the final material solidifies but if designed properly this will be in the gating system or riser risers and riser aids risers also known as feeders are the most common way of providing directional solidification it supplies liquid metal to the solidifying casting to compensate for solidification shrinkage for a riser to work properly the riser must solidify after'</li></ul> |
| 7 | <ul><li>'hear it is the par audiometric testing is used to determine hearing sensitivity and is part of a hearing conservation program this testing is part of the hearing conservation program that is used in the identification of significant hearing loss audiometric testing can identify those who have permanent hearing loss this is called noiseinduced permanent threshold shift niptscompleting baseline audiograms and periodically monitoring threshold levels is one way to track any changes in hearing and identify if there is a need to make improvements to the hearing conservation program osha which monitors workplaces in the united states to ensure safe and healthful working conditions specifies that employees should have a baseline audiogram established within 6 months of their first exposure to 85 dba timeweighted average twa if a worker is unable to obtain a baseline audiogram within 6 months of employment hpd is required to be worn if the worker is exposed to 85 dba or above twa hpd must be worn until a baseline audiogram is obtained under the msha which monitors compliance to standards within the mining industry an existing audiogram that meets specific standards can be used for the employees baseline before establishing baseline it is important that the employee limit excessive noise exposure that could potentially cause a temporary threshold shift and affect results of testing osha stipulates that an employee be noisefree for at least 14 hours prior to testingperiodic audiometric monitoring typically completed annually as recommended by osha can identify changes in hearing there are specific criteria that the change must meet in order to require action the criterion most commonly used is the standard threshold shift sts defined by a change of 10 db or greater averaged at 2000 3000 and 4000 hz age correction factors can be applied to the change in order to compensate for hearing loss that is agerelated rather than workrelated if an sts is found osha requires that the employee be notified of this change within 21 days furthermore any employee that is not currently wearing hpd is now required to wear protection if the employee is already wearing protection they should be refit with a new device and retrained on appropriate useanother determination that is made includes whether an sts is “ recordable ” under osha standards meaning the workplace must report the change to osha in order to be recordable the employees new thresholds at 2000 3000 and 4000 hz must exceed an average of 25 db hl msha standard differs slightly in terms of calculation and terminology msha considers whether an sts is “ reportable ” by determining if the average amount of change that occurs exceeds 25 db hl the various measures that are used in occupational audiometric testing'</li><li>'sense classroom program teaches children how hearing works how it can stop working and offers ideas for safe listening the classroom presentation satisfies the requirements for the science unit on sound taught in either grade 3 or 4 as well as the healthy living curriculum in grades 5 and 6 in addition the webpage provides resources games for children parents and teachers hearsmart an australian program initiated by the hearing cooperative research centre and the national acoustic laboratories nal hearsmart aims to improve the hearing health of all australians particularly those at greatest of risk of noiserelated tinnitus and hearing loss the program has a particular focus on promoting healthy hearing habits in musicians live music venues and patrons resources include know your noise an online risk calculator and speechinnoise test a short video that aims to raise awareness of tinnitus in musicians and a comprehensive website with detailed information just as program evaluation is necessary in workplace settings it is also an important component of educational hearing conservation programs to determine if any changes need to be made this evaluation may consist of two main parts assessment of students knowledge and assessment of their skills and behaviors to examine the level of knowledge acquired by the students a questionnaire is often given with the expectation of an 85 competency level among students if proficiency is too low changes should be implemented if the knowledge level is adequate assessing behaviors is then necessary to see if the children are using their newfound knowledge this evaluation can be done through classroom observation of both the students and teachers in noisy classroom environments such as music gym technology etc the mine safety and health administration msha requires that all feasible engineering and administrative controls be employed to reduce miners exposure levels to 90 dba twa the action level for enrollment in a hearing conservation program is 85 dba 8hour twa integrating all sound levels between 80 dba to at least 130 dba msha uses a 5db exchange rate the sound level in decibels that would result in halving if an increase in sound level or a doubling if a decreasein sound level the allowable exposure time to maintain the same noise dose at and above exposure levels of 90 dba twa the miner must wear hearing protection at and above exposure levels above 105 dba twa the miner must wear dual hearing protection miners may not be exposed to sounds exceeding 115 dba with or without hearing protection devices msha defines an sts as an average decrease in auditory sensitivity of 10 db hl at the frequencies 2000 3000 and 4000 hz 30 cfr part 62 the federal railroad administration fra encourages but does not require railroads to use administrative controls that reduce noise exposure duration when the wor'</li><li>'##earlyonset ome is associated with feeding of infants while lying down early entry into group child care parental smoking lack or too short a period of breastfeeding and greater amounts of time spent in group child care particularly those with a large number of children these risk factors increase the incidence and duration of ome during the first two years of life chronic suppurative otitis media csom is a chronic inflammation of the middle ear and mastoid cavity that is characterised by discharge from the middle ear through a perforated tympanic membrane for at least 6 weeks csom occurs following an upper respiratory tract infection that has led to acute otitis media this progresses to a prolonged inflammatory response causing mucosal middle ear oedema ulceration and perforation the middle ear attempts to resolve this ulceration by production of granulation tissue and polyp formation this can lead to increased discharge and failure to arrest the inflammation and to development of csom which is also often associated with cholesteatoma there may be enough pus that it drains to the outside of the ear otorrhea or the pus may be minimal enough to be seen only on examination with an otoscope or binocular microscope hearing impairment often accompanies this disease people are at increased risk of developing csom when they have poor eustachian tube function a history of multiple episodes of acute otitis media live in crowded conditions and attend paediatric day care facilities those with craniofacial malformations such as cleft lip and palate down syndrome and microcephaly are at higher riskworldwide approximately 11 of the human population is affected by aom every year or 709 million cases about 44 of the population develop csomaccording to the world health organization csom is a primary cause of hearing loss in children adults with recurrent episodes of csom have a higher risk of developing permanent conductive and sensorineural hearing loss in britain 09 of children and 05 of adults have csom with no difference between the sexes the incidence of csom across the world varies dramatically where high income countries have a relatively low prevalence while in low income countries the prevalence may be up to three times as great each year 21000 people worldwide die due to complications of csom adhesive otitis media occurs when a thin retracted ear drum becomes sucked into the middleear space and stuck ie adherent to the ossicles and other bones of the middle ear aom is far less common in breastfed infants than in formulafed infants'</li></ul> |
| 27 | <ul><li>'integration into microfluidic systems ie micrototal analytical systems or labonachip structures for instance ncams when incorporated into microfluidic devices can reproducibly perform digital switching allowing transfer of fluid from one microfluidic channel to another selectivity separate and transfer analytes by size and mass mix reactants efficiently and separate fluids with disparate characteristics in addition there is a natural analogy between the fluid handling capabilities of nanofluidic structures and the ability of electronic components to control the flow of electrons and holes this analogy has been used to realize active electronic functions such as rectification and fieldeffect and bipolar transistor action with ionic currents application of nanofluidics is also to nanooptics for producing tuneable microlens arraynanofluidics have had a significant impact in biotechnology medicine and clinical diagnostics with the development of labonachip devices for pcr and related techniques attempts have been made to understand the behaviour of flowfields around nanoparticles in terms of fluid forces as a function of reynolds and knudsen number using computational fluid dynamics the relationship between lift drag and reynolds number has been shown to differ dramatically at the nanoscale compared with macroscale fluid dynamics there are a variety of challenges associated with the flow of liquids through carbon nanotubes and nanopipes a common occurrence is channel blocking due to large macromolecules in the liquid also any insoluble debris in the liquid can easily clog the tube a solution for this researchers are hoping to find is a low friction coating or channel materials that help reduce the blocking of the tubes also large polymers including biologically relevant molecules such as dna often fold in vivo causing blockages typical dna molecules from a virus have lengths of approx 100 – 200 kilobases and will form a random coil of the radius some 700 nm in aqueous solution at 20 this is also several times greater than the pore diameter of even large carbon pipes and two orders of magnitude the diameter of a single walled carbon nanotube nanomechanics nanotechnology microfluidics nanofluidic circuitry'</li><li>'the tomlinson model also known as the prandtl – tomlinson model is one of the most popular models in nanotribology widely used as the basis for many investigations of frictional mechanisms on the atomic scale essentially a nanotip is dragged by a spring over a corrugated energy landscape a frictional parameter η can be introduced to describe the ratio between the energy corrugation and the elastic energy stored in the spring if the tipsurface interaction is described by a sinusoidal potential with amplitude v0 and periodicity a then η 4 π 2 v 0 k a 2 displaystyle eta frac 4pi 2v0ka2 where k is the spring constant if η1 the tip slides continuously across the landscape superlubricity regime if η1 the tip motion consists in abrupt jumps between the minima of the energy landscape stickslip regimethe name tomlinson model is however historically incorrect the paper by tomlinson that is often cited in this context did not contain the model known as the tomlinson model and suggests an adhesive contribution to friction in reality it was ludwig prandtl who suggested in 1928 this model to describe the plastic deformations in crystals as well as the dry friction in the meantime many researchers still call this model the prandtl – tomlinson model in russia this model was introduced by the soviet physicists yakov frenkel and t kontorova the frenkel defect became firmly fixed in the physics of solids and liquids in the 1930s this research was supplemented with works on the theory of plastic deformation their theory now known as the frenkel – kontorova model is important in the study of dislocations'</li><li>'be medical nanorobotics or nanomedicine an area pioneered by robert freitas in numerous books and papers the ability to design build and deploy large numbers of medical nanorobots would at a minimum make possible the rapid elimination of disease and the reliable and relatively painless recovery from physical trauma medical nanorobots might also make possible the convenient correction of genetic defects and help to ensure a greatly expanded lifespan more controversially medical nanorobots might be used to augment natural human capabilities one study has reported on how conditions like tumors arteriosclerosis blood clots leading to stroke accumulation of scar tissue and localized pockets of infection can possibly be addressed by employing medical nanorobots another proposed application of molecular nanotechnology is utility fog — in which a cloud of networked microscopic robots simpler than assemblers would change its shape and properties to form macroscopic objects and tools in accordance with software commands rather than modify the current practices of consuming material goods in different forms utility fog would simply replace many physical objects yet another proposed application of mnt would be phasedarray optics pao however this appears to be a problem addressable by ordinary nanoscale technology pao would use the principle of phasedarray millimeter technology but at optical wavelengths this would permit the duplication of any sort of optical effect but virtually users could request holograms sunrises and sunsets or floating lasers as the mood strikes pao systems were described in bc crandalls nanotechnology molecular speculations on global abundance in the brian wowk article phasedarray optics molecular manufacturing is a potential future subfield of nanotechnology that would make it possible to build complex structures at atomic precision molecular manufacturing requires significant advances in nanotechnology but once achieved could produce highly advanced products at low costs and in large quantities in nanofactories weighing a kilogram or more when nanofactories gain the ability to produce other nanofactories production may only be limited by relatively abundant factors such as input materials energy and softwarethe products of molecular manufacturing could range from cheaper massproduced versions of known hightech products to novel products with added capabilities in many areas of application some applications that have been suggested are advanced smart materials nanosensors medical nanorobots and space travel additionally molecular manufacturing could be used to cheaply produce highly advanced durable weapons which is an area of special concern regarding the impact of nanotechnology being equipped with compact computers and motors these could be increasingly autonomous and have a large range of capabilitiesaccording to chris phoenix and mike treder from the center for responsible nano'</li></ul> |
| 31 | <ul><li>'eight perfections the capacity to offset the force of ones facticity this is defined in relation to pullness or garima which concerns worldly weight and mass zen buddhism teaches that one ought to become as light as being itself zen teaches one not only to find the lightness of being “ bearable ” but to rejoice in this lightness this stands as an interesting opposition to kunderas evaluation of lightness'</li><li>'exact order and studies with children in canada india peru samoa and thailand indicate that they all pass the false belief task at around the same time suggesting that children develop theory of mind consistently around the worldhowever children from iran and china develop theory of mind in a slightly different order although they begin the development of theory of mind around the same time toddlers from these countries understand knowledge access before western children but take longer to understand diverse beliefs researchers believe this swap in the developmental order is related to the culture of collectivism in iran and china which emphasizes interdependence and shared knowledge as opposed to the culture of individualism in western countries which promotes individuality and accepts differing opinions because of these different cultural values iranian and chinese children might take longer to understand that other people have different beliefs and opinions this suggests that the development of theory of mind is not universal and solely determined by innate brain processes but also influenced by social and cultural factors theory of mind can help historians to more properly understand historical figures characters for example thomas jefferson emancipationists like douglas l wilson and scholars at the thomas jefferson foundation view jefferson as an opponent of slavery all his life noting jeffersons attempts within the limited range of options available to him to undermine slavery his many attempts at abolition legislation the manner in which he provided for slaves and his advocacy of their more humane treatment this view contrasts with that of revisionists like paul finkelman who criticizes jefferson for racism slavery and hypocrisy emancipationist views on this hypocrisy recognize that if he tried to be true to his word it would have alienated his fellow virginians in another example franklin d roosevelt did not join naacp leaders in pushing for federal antilynching legislation as he believed that such legislation was unlikely to pass and that his support for it would alienate southern congressmen including many of roosevelts fellow democrats whether children younger than three or four years old have a theory of mind is a topic of debate among researchers it is a challenging question due to the difficulty of assessing what prelinguistic children understand about others and the world tasks used in research into the development of theory of mind must take into account the umwelt of the preverbal child one of the most important milestones in theory of mind development is the ability to attribute false belief in other words to understand that other people can believe things which are not true to do this it is suggested one must understand how knowledge is formed that peoples beliefs are based on their knowledge that mental states can differ from reality and that peoples behavior can be predicted by their mental states numerous versions of false'</li><li>'bodily functions such as heart and liver according to descartes animals only had a body and not a soul which distinguishes humans from animals the distinction between mind and body is argued in meditation vi as follows i have a clear and distinct idea of myself as a thinking nonextended thing and a clear and distinct idea of body as an extended and nonthinking thing whatever i can conceive clearly and distinctly god can so create the central claim of what is often called cartesian dualism in honor of descartes is that the immaterial mind and the material body while being ontologically distinct substances causally interact this is an idea that continues to feature prominently in many noneuropean philosophies mental events cause physical events and vice versa but this leads to a substantial problem for cartesian dualism how can an immaterial mind cause anything in a material body and vice versa this has often been called the problem of interactionism descartes himself struggled to come up with a feasible answer to this problem in his letter to elisabeth of bohemia princess palatine he suggested that spirits interacted with the body through the pineal gland a small gland in the centre of the brain between the two hemispheres the term cartesian dualism is also often associated with this more specific notion of causal interaction through the pineal gland however this explanation was not satisfactory how can an immaterial mind interact with the physical pineal gland because descartes was such a difficult theory to defend some of his disciples such as arnold geulincx and nicolas malebranche proposed a different explanation that all mind – body interactions required the direct intervention of god according to these philosophers the appropriate states of mind and body were only the occasions for such intervention not real causes these occasionalists maintained the strong thesis that all causation was directly dependent on god instead of holding that all causation was natural except for that between mind and body in addition to already discussed theories of dualism particularly the christian and cartesian models there are new theories in the defense of dualism naturalistic dualism comes from australian philosopher david chalmers born 1966 who argues there is an explanatory gap between objective and subjective experience that cannot be bridged by reductionism because consciousness is at least logically autonomous of the physical properties upon which it supervenes according to chalmers a naturalistic account of property dualism requires a new fundamental category of properties described by new laws of supervenience the challenge being analogous to that of understanding electricity based on the mechanistic and newtonian models of materialism prior to maxwell'</li></ul> |
| 12 | <ul><li>'x is equivalent to counting injective functions n → x when n x and also to counting surjective functions n → x when n x counting multisets of size n also known as ncombinations with repetitions of elements in x is equivalent to counting all functions n → x up to permutations of n counting partitions of the set n into x subsets is equivalent to counting all surjective functions n → x up to permutations of x counting compositions of the number n into x parts is equivalent to counting all surjective functions n → x up to permutations of n the various problems in the twelvefold way may be considered from different points of view traditionally many of the problems in the twelvefold way have been formulated in terms of placing balls in boxes or some similar visualization instead of defining functions the set n can be identified with a set of balls and x with a set of boxes the function ƒ n → x then describes a way to distribute the balls into the boxes namely by putting each ball a into box ƒa a function ascribes a unique image to each value in its domain this property is reflected by the property that any ball can go into only one box together with the requirement that no ball should remain outside of the boxes whereas any box can accommodate an arbitrary number of balls requiring in addition ƒ to be injective means forbidding to put more than one ball in any one box while requiring ƒ to be surjective means insisting that every box contain at least one ball counting modulo permutations of n or x is reflected by calling the balls or the boxes respectively indistinguishable this is an imprecise formulation intended to indicate that different configurations are not to be counted separately if one can be transformed into the other by some interchange of balls or of boxes this possibility of transformation is formalized by the action by permutations another way to think of some of the cases is in terms of sampling in statistics imagine a population of x items or people of which we choose n two different schemes are normally described known as sampling with replacement and sampling without replacement in the former case sampling with replacement once weve chosen an item we put it back in the population so that we might choose it again the result is that each choice is independent of all the other choices and the set of samples is technically referred to as independent identically distributed in the latter case however once we have chosen an item we put it aside so that we can not choose it again this means that the act of choosing an'</li><li>'##widehat qshgeq varepsilon 2 where r displaystyle r and s displaystyle s are iid samples of size m displaystyle m drawn according to the distribution p displaystyle p one can view r displaystyle r as the original randomly drawn sample of length m displaystyle m while s displaystyle s may be thought as the testing sample which is used to estimate q p h displaystyle qph permutation since r displaystyle r and s displaystyle s are picked identically and independently so swapping elements between them will not change the probability distribution on r displaystyle r and s displaystyle s so we will try to bound the probability of q r h − q s h ≥ ε 2 displaystyle widehat qrhwidehat qshgeq varepsilon 2 for some h ∈ h displaystyle hin h by considering the effect of a specific collection of permutations of the joint sample x r s displaystyle xrs specifically we consider permutations σ x displaystyle sigma x which swap x i displaystyle xi and x m i displaystyle xmi in some subset of 1 2 m displaystyle 12m the symbol r s displaystyle rs means the concatenation of r displaystyle r and s displaystyle s reduction to a finite class we can now restrict the function class h displaystyle h to a fixed joint sample and hence if h displaystyle h has finite vc dimension it reduces to the problem to one involving a finite function classwe present the technical details of the proof lemma let v x ∈ x m q p h − q x h ≥ ε for some h ∈ h displaystyle vxin xmqphwidehat qxhgeq varepsilon text for some hin h and r r s ∈ x m × x m q r h − q s h ≥ ε 2 for some h ∈ h displaystyle rrsin xmtimes xmwidehat qrhwidehat qshgeq varepsilon 2text for some hin h then for m ≥ 2 ε 2 displaystyle mgeq frac 2varepsilon 2 p m v ≤ 2 p 2 m r displaystyle pmvleq 2p2mr proof by the triangle inequality if q p h − q r h ≥ ε displaystyle qphwidehat qrhgeq varepsilon and q p h − q s h ≤ ε 2 displaystyle qphwidehat qshleq varepsilon 2 then q r h − q s h ≥'</li><li>'of bad events a displaystyle mathcal a we wish to avoid that is determined by a collection of mutually independent random variables p displaystyle mathcal p the algorithm proceeds as follows [UNK] p ∈ p displaystyle forall pin mathcal p v p ← displaystyle vpleftarrow a random evaluation of p while [UNK] a ∈ a displaystyle exists ain mathcal a such that a is satisfied by v p p displaystyle vpmathcal p pick an arbitrary satisfied event a ∈ a displaystyle ain mathcal a [UNK] p ∈ vbl a displaystyle forall pin textvbla v p ← displaystyle vpleftarrow a new random evaluation of p return v p p displaystyle vpmathcal p in the first step the algorithm randomly initializes the current assignment vp for each random variable p ∈ p displaystyle pin mathcal p this means that an assignment vp is sampled randomly and independently according to the distribution of the random variable p the algorithm then enters the main loop which is executed until all events in a displaystyle mathcal a are avoided at which point the algorithm returns the current assignment at each iteration of the main loop the algorithm picks an arbitrary satisfied event a either randomly or deterministically and resamples all the random variables that determine a let p displaystyle mathcal p be a finite set of mutually independent random variables in the probability space ω let a displaystyle mathcal a be a finite set of events determined by these variables if there exists an assignment of reals x a → 0 1 displaystyle xmathcal ato 01 to the events such that [UNK] a ∈ a pr a ≤ x a [UNK] b ∈ γ a 1 − x b displaystyle forall ain mathcal apraleq xaprod bin gamma a1xb then there exists an assignment of values to the variables p displaystyle mathcal p avoiding all of the events in a displaystyle mathcal a moreover the randomized algorithm described above resamples an event a ∈ a displaystyle ain mathcal a at most an expected x a 1 − x a displaystyle frac xa1xa times before it finds such an evaluation thus the expected total number of resampling steps and therefore the expected runtime of the algorithm is at most [UNK] a ∈ a x a 1 − x a displaystyle sum ain mathcal afrac xa1xa the proof of this theorem using the method of entropy compression can be found in the paper by moser and tardos the requirement of an assignment function x satisfying a set of inequalities in the'</li></ul> |
| 36 | <ul><li>'create a redundant phrase for example laser light amplification by stimulated emission of radiation light is light produced by a light amplification process similarly opec countries are two or more member states of the organization of the petroleum exporting countries whereas opec by itself denotes the overall organization pleonasm § bilingual tautological expressions recursive acronym tautology'</li><li>'a sermon when he got on the pulpit he asked do you know what i am going to say the audience replied no so he announced i have no desire to speak to people who dont even know what i will be talking about and left the people felt embarrassed and called him back again the next day this time when he asked the same question the people replied yes so nasreddin said well since you already know what i am going to say i wont waste any more of your time and left now the people were really perplexed they decided to try one more time and once again invited the mullah to speak the following week once again he asked the same question – do you know what i am going to say now the people were prepared and so half of them answered yes while the other half replied no so nasreddin said let the half who know what i am going to say tell it to the half who dont and left whom do you believe a neighbour came to the gate of hodja nasreddins yard the hodja went to meet him outside would you mind hodja the neighbour asked can you lend me your donkey today i have some goods to transport to the next town the hodja didnt feel inclined to lend out the animal to that particular man however so not to seem rude he answered im sorry but ive already lent him to somebody else all of a sudden the donkey could be heard braying loudly behind the wall of the yard but hodja the neighbour exclaimed i can hear it behind that wall whom do you believe the hodja replied indignantly the donkey or your hodja taste the same some children saw nasreddin coming from the vineyard with two baskets full of grapes loaded on his donkey they gathered around him and asked him to give them a taste nasreddin picked up a bunch of grapes and gave each child a grape you have so much but you gave us so little the children whined there is no difference whether you have a basketful or a small piece they all taste the same nasreddin answered and continued on his way nasreddins ring mullah had lost his ring in the living room he searched for it for a while but since he could not find it he went out into the yard and began to look there his wife who saw what he was doing asked mullah you lost your ring in the room why are you looking for it in the yard ” mullah stroked his beard and said the room is too dark and i can ’ t see very well i came out to'</li><li>'uses to investigate for example the nature or definition of ethical concepts such as justice or virtue according to vlastos it has the following steps socrates interlocutor asserts a thesis for example courage is endurance of the soul socrates decides whether the thesis is false and targets for refutation socrates secures his interlocutors agreement to further premises for example courage is a fine thing and ignorant endurance is not a fine thing socrates then argues and the interlocutor agrees these further premises imply the contrary of the original thesis in this case it leads to courage is not endurance of the soul socrates then claims he has shown his interlocutors thesis is false and its negation is trueone elenctic examination can lead to a new more refined examination of the concept being considered in this case it invites an examination of the claim courage is wise endurance of the soul most socratic inquiries consist of a series of elenchi and typically end in puzzlement known as aporia frede points out vlastos conclusion in step 5 above makes nonsense of the aporetic nature of the early dialogues having shown a proposed thesis is false is insufficient to conclude some other competing thesis must be true rather the interlocutors have reached aporia an improved state of still not knowing what to say about the subject under discussion the exact nature of the elenchus is subject to a great deal of debate in particular concerning whether it is a positive method leading to knowledge or a negative method used solely to refute false claims to knowledgew k c guthrie in the greek philosophers sees it as an error to regard the socratic method as a means by which one seeks the answer to a problem or knowledge guthrie claims that the socratic method actually aims to demonstrate ones ignorance socrates unlike the sophists did believe that knowledge was possible but believed that the first step to knowledge was recognition of ones ignorance guthrie writes socrates was accustomed to say that he did not himself know anything and that the only way in which he was wiser than other men was that he was conscious of his own ignorance while they were not the essence of the socratic method is to convince the interlocutor that whereas he thought he knew something in fact he does not socrates generally applied his method of examination to concepts that seem to lack any concrete definition eg the key moral concepts at the time the virtues of piety wisdom temperance courage and justice such an examination challenged the implicit moral beliefs of the interlocutors bringing out inadequacies and inconsistencies in their beliefs and usually resulting in aporia in view of such'</li></ul> |
| 8 | <ul><li>'an integrated architecture with application software portable across an assembly of common hardware modules it has been used in fourth generation jet fighters and the latest generation of airliners military aircraft have been designed either to deliver a weapon or to be the eyes and ears of other weapon systems the vast array of sensors available to the military is used for whatever tactical means required as with aircraft management the bigger sensor platforms like the e ‑ 3d jstars astor nimrod mra4 merlin hm mk 1 have missionmanagement computers police and ems aircraft also carry sophisticated tactical sensors while aircraft communications provide the backbone for safe flight the tactical systems are designed to withstand the rigors of the battle field uhf vhf tactical 30 – 88 mhz and satcom systems combined with eccm methods and cryptography secure the communications data links such as link 11 16 22 and bowman jtrs and even tetra provide the means of transmitting data such as images targeting information etc airborne radar was one of the first tactical sensors the benefit of altitude providing range has meant a significant focus on airborne radar technologies radars include airborne early warning aew antisubmarine warfare asw and even weather radar arinc 708 and ground trackingproximity radar the military uses radar in fast jets to help pilots fly at low levels while the civil market has had weather radar for a while there are strict rules about using it to navigate the aircraft dipping sonar fitted to a range of military helicopters allows the helicopter to protect shipping assets from submarines or surface threats maritime support aircraft can drop active and passive sonar devices sonobuoys and these are also used to determine the location of enemy submarines electrooptic systems include devices such as the headup display hud forward looking infrared flir infrared search and track and other passive infrared devices passive infrared sensor these are all used to provide imagery and information to the flight crew this imagery is used for everything from search and rescue to navigational aids and target acquisition electronic support measures and defensive aids systems are used extensively to gather information about threats or possible threats they can be used to launch devices in some cases automatically to counter direct threats against the aircraft they are also used to determine the state of a threat and identify it the avionics systems in military commercial and advanced models of civilian aircraft are interconnected using an avionics databus common avionics databus protocols with their primary application include aircraft data network adn ethernet derivative for commercial aircraft avionics fullduplex switched ethernet afdx specific implementation of arinc 664 adn for commercial aircraft arinc 429 generic mediumspeed data sharing for private'</li><li>'in the earlier beam systems the signal was turned on and off entirely corresponding to a modulation index of 100 the determination of angle within the beam is based on the comparison of the audible strength of the two signals in ils a more complex system of signals and antennas varies the modulation of two signals across the entire width of the beam pattern the system relies on the use of sidebands secondary frequencies that are created when two different signals are mixed for instance if one takes a radio frequency signal at 10 mhz and mixes that with an audible tone at 2500 hz four signals will be produced at the original signals frequencies of 2500 and 10000000 hertz and sidebands 9997500 and 10002500 hertz the original 2500 hz signals frequency is too low to travel far from an antenna but the other three signals are all radio frequency and can be effectively transmittedils starts by mixing two modulating signals to the carrier one at 90 hz and another at 150 this creates a signal with five radio frequencies in total the carrier and four sidebands this combined signal known as the csb for carrier and sidebands is sent out evenly from an antenna array the csb is also sent into a circuit that suppresses the original carrier leaving only the four sideband signals this signal known as sbo for sidebands only is also sent to the antenna arrayfor lateral guidance known as the localizer the antenna is normally placed centrally at the far end of the runway and consists of multiple antennas in an array normally about the same width of the runway each individual antenna has a particular phase shift and power level applied only to the sbo signal such that the resulting signal is retarded 90 degrees on the left side of the runway and advanced 90 degrees on the right additionally the 150 hz signal is inverted on one side of the pattern another 180 degree shift due to the way the signals mix in space the sbo signals destructively interfere with and almost eliminate each other along the centerline leaving just the csb signal predominating at any other location on either side of the centerline the sbo and csb signals combine in different ways so that one modulating signal predominatesa receiver in front of the array will receive both of these signals mixed together using simple electronic filters the original carrier and two sidebands can be separated and demodulated to extract the original amplitudemodulated 90 and 150 hz signals these are then averaged to produce two direct current dc signals each of these signals represents not the strength of the original signal but the strength of the modulation relative to the carrier which varies across'</li><li>'excessive manoeuvre could not have been performed greatly reducing chances of recovery against this objection airbus has responded that an a320 in the situation of flight 006 never would have fallen out of the air in the first place the envelope protection would have automatically kept it in level flight in spite of the drag of a stalled engine in april 1995 fedex flight 705 a mcdonnell douglas dc1030 was hijacked by a fedex flight engineer who facing a dismissal attempted to hijack the plane and crash it into fedex headquarters so that his family could collect his life insurance policy after being attacked and severely injured the flight crew was able to fight back and land the plane safely in order to keep the attacker off balance and out of the cockpit the crew had to perform extreme maneuvers including a barrel roll and a dive so fast the airplane couldnt measure its airspeed had the crew not been able to exceed the planes flight envelope the crew might not have been successful american airlines flight 587 an airbus a300 crashed in november 2001 when the vertical stabilizer broke off due to excessive rudder inputs made by the pilot a flightenvelope protection system could have prevented this crash though it can still be argued that an override button should be provided for contingencies when the pilots are aware of the need to exceed normal limits us airways flight 1549 an airbus a320 experienced a dual engine failure after a bird strike and subsequently landed safely in the hudson river in january 2009 the ntsb accident report mentions the effect of flight envelope protection the airplane ’ s airspeed in the last 150 feet of the descent was low enough to activate the alphaprotection mode of the airplane ’ s flybywire envelope protection features because of these features the airplane could not reach the maximum angle of attack aoa attainable in pitch normal law for the airplane weight and configuration however the airplane did provide maximum performance for the weight and configuration at that time the flight envelope protections allowed the captain to pull full aft on the sidestick without the risk of stalling the airplane qantas 72 suffered an uncommanded pitchdown due to erroneous data from one of its adiru computers air france flight 447 an airbus a330 entered an aerodynamic stall from which it did not recover and crashed into the atlantic ocean in june 2009 killing all aboard temporary inconsistency between measured speeds likely a result of the obstruction of the pitot tubes by ice crystals caused autopilot disconnection and reconfiguration to alternate law a second consequence of the reconfiguration'</li></ul> |
| 4 | <ul><li>'covariances and can be computed using standard spreadsheet functions regression dilution deming regression a special case with two predictors and independent errors errorsinvariables model gausshelmert model linear regression least squares principal component analysis principal component regression i hnetynkova m plesinger d m sima z strakos and s van huffel the total least squares problem in ax ≈ b a new classification with the relationship to the classical works simax vol 32 issue 3 2011 pp 748 – 770 available as a preprint m plesinger the total least squares problem and reduction of data in ax ≈ b doctoral thesis tu of liberec and institute of computer science as cr prague 2008 phd thesis c c paige z strakos core problems in linear algebraic systems siam j matrix anal appl 27 2006 pp 861 – 875 doi101137040616991 s van huffel and p lemmerling total least squares and errorsinvariables modeling analysis algorithms and applications dordrecht the netherlands kluwer academic publishers 2002 s jo and s w kim consistent normalized least mean square filtering with noisy data matrix ieee trans signal process vol 53 no 6 pp 2112 – 2123 jun 2005 r d degroat and e m dowling the data least squares problem and channel equalization ieee trans signal process vol 41 no 1 pp 407 – 411 jan 1993 s van huffel and j vandewalle the total least squares problems computational aspects and analysis siam publications philadelphia pa 1991 doi10113719781611971002 t abatzoglou and j mendel constrained total least squares in proc ieee int conf acoust speech signal process icassp ’ 87 apr 1987 vol 12 pp 1485 – 1488 p de groen an introduction to total least squares in nieuw archief voor wiskunde vierde serie deel 14 1996 pp 237 – 253 arxivorg g h golub and c f van loan an analysis of the total least squares problem siam j on numer anal 17 1980 pp 883 – 893 doi1011370717073 perpendicular regression of a line at mathpages a r amirisimkooei and s jazaeri weighted total least squares formulated by standard least squares theoryin journal of geodetic science 2 2 113 – 124 2012 1'</li><li>'circle or square of arbitrary size to be specified for example a focalmean operator could be used to compute the mean value of all the cells within 1000 meters a circle of each cell zonal operators functions that operate on regions of identical value these are commonly used with discrete fields also known as categorical coverages where space is partitioned into regions of homogeneous nominal or categorical value of a property such as land cover land use soil type or surface geologic formation unlike local and focal operators zonal operators do not operate on each cell individually instead all of the cells of a given value are taken as input to a single computation with identical output being written to all of the corresponding cells for example a zonalmean operator would take in two layers one with values representing the regions eg dominant vegetation species and another of a related quantitative property eg percent canopy cover for each unique value found in the former grid the software collects all of the corresponding cells in the latter grid computes the arithmetic mean and writes this value to all of the corresponding cells in the output grid global operators functions that summarize the entire grid these were not included in tomlins work and are not technically part of map algebra because the result of the operation is not a raster grid ie it is not closed but a single value or summary table however they are useful to include in the general toolkit of operations for example a globalmean operator would compute the arithmetic mean of all of the cells in the input grid and return a single mean value some also consider operators that generate a new grid by evaluating patterns across the entire input grid as global which could be considered part of the algebra an example of these are the operators for evaluating cost distance several gis software packages implement map algebra concepts including erdas imagine qgis grass gis terrset pcraster and arcgis in tomlins original formulation of cartographic modeling in the map analysis package he designed a simple procedural language around the algebra operators to allow them to be combined into a complete procedure with additional structures such as conditional branching and looping however in most modern implementations map algebra operations are typically one component of a general procedural processing system such as a visual modeling tool or a scripting language for example arcgis implements map algebra in both its visual modelbuilder tool and in python here pythons overloading capability allows simple operators and functions to be used for raster grids for example rasters can be multiplied using the same arithmetic operator used for multiplying numbershere are some examples in mapbasic the scripting language for mapinfo professional demo'</li><li>'computational mathematics is an area of mathematics devoted to the interaction between mathematics and computer computationa large part of computational mathematics consists roughly of using mathematics for allowing and improving computer computation in areas of science and engineering where mathematics are useful this involves in particular algorithm design computational complexity numerical methods and computer algebra computational mathematics refers also to the use of computers for mathematics itself this includes mathematical experimentation for establishing conjectures particularly in number theory the use of computers for proving theorems for example the four color theorem and the design and use of proof assistants computational mathematics emerged as a distinct part of applied mathematics by the early 1950s currently computational mathematics can refer to or include computational science also known as scientific computation or computational engineering solving mathematical problems by computer simulation as opposed to analytic methods of applied mathematics numerical methods used in scientific computation for example numerical linear algebra and numerical solution of partial differential equations stochastic methods such as monte carlo methods and other representations of uncertainty in scientific computation the mathematics of scientific computation in particular numerical analysis the theory of numerical methods computational complexity computer algebra and computer algebra systems computerassisted research in various areas of mathematics such as logic automated theorem proving discrete mathematics combinatorics number theory and computational algebraic topology cryptography and computer security which involve in particular research on primality testing factorization elliptic curves and mathematics of blockchain computational linguistics the use of mathematical and computer techniques in natural languages computational algebraic geometry computational group theory computational geometry computational number theory computational topology computational statistics algorithmic information theory algorithmic game theory mathematical economics the use of mathematics in economics finance and to certain extents of accounting experimental mathematics mathematics portal cucker f 2003 foundations of computational mathematics special volume handbook of numerical analysis northholland publishing isbn 9780444512475 harris j w stocker h 1998 handbook of mathematics and computational science springerverlag isbn 9780387947464 hartmann ak 2009 practical guide to computer simulations world scientific isbn 9789812834157 archived from the original on february 11 2009 retrieved may 3 2012 nonweiler t r 1986 computational mathematics an introduction to numerical approximation john wiley and sons isbn 9780470202609 gentle j e 2007 foundations of computational science springerverlag isbn 9780387004501 white r e 2003 computational mathematics models methods and analysis with matlab chapman and hall isbn 9781584883647 yang x s 2008 introduction to computational mathematics world scientific isbn 9789812818171 strang g 2007 computational science and engineering wiley isbn 9780961408817'</li></ul> |
| 6 | <ul><li>'on graphics processing units many codes and software packages exist along with various researchers and consortia maintaining them most codes tend to be nbody packages or fluid solvers of some sort examples of nbody codes include changa modest nbodylaborg and starlabfor hydrodynamics there is usually a coupling between codes as the motion of the fluids usually has some other effect such as gravity or radiation in astrophysical situations for example for sphnbody there is gadget and swift for gridbasednbody ramses enzo flash and artamuse 2 takes a different approach called noahs ark than the other packages by providing an interface structure to a large number of publicly available astronomical codes for addressing stellar dynamics stellar evolution hydrodynamics and radiative transport millennium simulation eris and bolshoi cosmological simulation are astrophysical supercomputer simulations plasma modeling computational physics theoretical astronomy and theoretical astrophysics center for computational relativity and gravitation university of california highperformance astrocomputing center beginnerintermediate level astrophysics with a pc an introduction to computational astrophysics paul hellings willmannbell 1st english ed edition practical astronomy with your calculator peter duffettsmith cambridge university press 3rd edition 1988advancedgraduate level numerical methods in astrophysics an introduction series in astronomy and astrophysics peter bodenheimer gregory p laughlin michal rozyczka harold w yorke taylor francis 2006 open cluster membership probability based on kmeans clustering algorithm mohamed abd el aziz i m selim a essam exp astron 2016 automatic detection of galaxy type from datasets of galaxies image based on image retrieval approach mohamed abd el aziz i m selim shengwu xiong scientific reports 7 4463 2017journals open access living reviews in computational astrophysics computational astrophysics and cosmology'</li><li>'committee g i taylor estimated the amount of energy that would be released by the explosion of an atomic bomb in air he postulated that for an idealized point source of energy the spatial distributions of the flow variables would have the same form during a given time interval the variables differing only in scale thus the name of the similarity solution this hypothesis allowed the partial differential equations in terms of r the radius of the blast wave and t time to be transformed into an ordinary differential equation in terms of the similarity variable r 5 ρ o t 2 e displaystyle frac r5rho ot2e where ρ o displaystyle rho o is the density of the air and e displaystyle e is the energy thats released by the explosion this result allowed g i taylor to estimate the yield of the first atomic explosion in new mexico in 1945 using only photographs of the blast which had been published in newspapers and magazines the yield of the explosion was determined by using the equation e ρ o t 2 r c 5 displaystyle eleftfrac rho ot2rightleftfrac rcright5 where c displaystyle c is a dimensionless constant that is a function of the ratio of the specific heat of air at constant pressure to the specific heat of air at constant volume the value of c is also affected by radiative losses but for air values of c of 100110 generally give reasonable results in 1950 g i taylor published two articles in which he revealed the yield e of the first atomic explosion which had previously been classified and whose publication was therefore a source of controversywhile nuclear explosions are among the clearest examples of the destructive power of blast waves blast waves generated by exploding conventional bombs and other weapons made from high explosives have been used as weapons of war due to their effectiveness at creating polytraumatic injury during world war ii and the uss involvement in the vietnam war blast lung was a common and often deadly injury improvements in vehicular and personal protective equipment have helped to reduce the incidence of blast lung however as soldiers are better protected from penetrating injury and surviving previously lethal exposures limb injuries eye and ear injuries and traumatic brain injuries have become more prevalent structural behaviour during an explosion depends entirely on the materials used in the construction of the building upon hitting the face of a building the shock front from an explosion is instantly reflected this impact with the structure imparts momentum to exterior components of the building the associated kinetic energy of the moving components must be absorbed or dissipated in order for them to survive generally this is achieved by converting the kinetic energy of the moving component to strain energy in resisting elementstypically'</li><li>'observed to be more elongated than e6 or e7 corresponding to a maximum axis ratio of about 31 the firehose instability is probably responsible for this fact since an elliptical galaxy that formed with an initially more elongated shape would be unstable to bending modes causing it to become rounder simulated dark matter haloes like elliptical galaxies never have elongations greater than about 31 this is probably also a consequence of the firehose instabilitynbody simulations reveal that the bars of barred spiral galaxies often puff up spontaneously converting the initially thin bar into a bulge or thick disk subsystem the bending instability is sometimes violent enough to weaken the bar bulges formed in this way are very boxy in appearance similar to what is often observedthe firehose instability may play a role in the formation of galactic warps stellar dynamics'</li></ul> |
| 37 | <ul><li>'marking go by various names including counterfactuals subjunctives and xmarked conditionals indicative if it is raining in new york then mary is at home counterfactual if it was raining in new york then mary would be at homein older dialects and more formal registers the form were is often used instead of was counterfactuals of this sort are sometimes referred to as wered up conditionals wered up if i were king i could have you thrown in the dungeonthe form were can also be used with an infinitive to form a future less vivid conditional future less vivid if i were to be king i could have you thrown in the dungeoncounterfactuals can also use the pluperfect instead of the past tense conditional perfect if you had called me i would have come in english language teaching conditional sentences are often classified under the headings zero conditional first conditional or conditional i second conditional or conditional ii third conditional or conditional iii and mixed conditional according to the grammatical pattern followed particularly in terms of the verb tenses and auxiliaries used zero conditional refers to conditional sentences that express a factual implication rather than describing a hypothetical situation or potential future circumstance see types of conditional sentence the term is used particularly when both clauses are in the present tense however such sentences can be formulated with a variety of tensesmoods as appropriate to the situation if you dont eat for a long time you become hungry if the alarm goes off theres a fire somewhere in the building if you are going to sit an exam tomorrow go to bed early tonight if aspirins will cure it ill take a couple tonight if you make a mistake someone lets you knowthe first of these sentences is a basic zero conditional with both clauses in the present tense the fourth is an example of the use of will in a condition clause for more such cases see below the use of verb tenses moods and aspects in the parts of such sentences follows general principles as described in uses of english verb forms occasionally mainly in a formal and somewhat archaic style a subjunctive is used in the zeroconditional condition clause as in if the prisoner be held for more than five days for more details see english subjunctive see also § inversion in condition clauses below first conditional or conditional i refers to a pattern used in predictive conditional sentences ie those that concern consequences of a probable future event see types of conditional sentence in the basic first conditional pattern the condition is expressed using the present tense having future meaning in this context in some common fixed expressions or in oldfashioned or'</li><li>'introduction in gary ostertag ed definite descriptions a reader cambridge ma mit press 134 russell bertrand 1905 on denoting mind 14 479493 wettstein howard 1981 demonstrative reference and definite descriptions philosophical studies 40 241257 wilson george m 1991 reference and pronominal descriptions journal of philosophy 88 359387'</li><li>'this means that the source text is composed of logical formulas belonging to one logical system and the goal is to associate them with logical formulas belonging to another logical system for example the formula [UNK] a x displaystyle box ax in modal logic can be translated into firstorder logic using the formula [UNK] y r x y → a y displaystyle forall yrxyto ay natural language formalization starts with a sentence in natural language and translates it into a logical formula its goal is to make the logical structure of natural language sentences and arguments explicit it is mainly concerned with their logical form while their specific content is usually ignored logical analysis is a closely related term that refers to the process of uncovering the logical form or structure of a sentence natural language formalization makes it possible to use formal logic to analyze and evaluate natural language arguments this is especially relevant for complex arguments which are often difficult to evaluate without formal tools logic translation can also be used to look for new arguments and thereby guide the reasoning process the reverse process of formalization is sometimes called verbalization it happens when logical formulas are translated back into natural language this process is less nuanced and discussions concerning the relation between natural language and logic usually focus on the problem of formalizationthe success of applications of formal logic to natural language requires that the translation is correct a formalization is correct if its explicit logical features fit the implicit logical features of the original sentence the logical form of ordinary language sentences is often not obvious since there are many differences between natural languages and the formal languages used by logicians this poses various difficulties for formalization for example ordinary expressions frequently include vague and ambiguous expressions for this reason the validity of an argument often depends not just on the expressions themselves but also on how they are interpreted for example the sentence donkeys have ears could mean that all donkeys without exception have ears or that donkeys typically have ears the second translation does not exclude the existence of some donkeys without ears this difference matters for whether a universal quantifier can be used to translate the sentence such ambiguities are not found in the precise formulations of artificial logical languages and have to be solved before translation is possiblethe problem of natural language formalization has various implications for the sciences and humanities especially for the fields of linguistics cognitive science and computer science in the field of formal linguistics for example richard montague provides various suggestions for how to formalize english language expressions in his theory of universal grammar formalization is also discussed in the philosophy of logic in relation to its role in understanding and applying logic if logic is understood as the theory of valid'</li></ul> |
| 10 | <ul><li>'sabiork system for the analysis of biochemical pathways reaction kinetics is a webaccessible database storing information about biochemical reactions and their kinetic properties sabiork comprises a reactionoriented representation of quantitative information on reaction dynamics based on a given selected publication this comprises all available kinetic parameters together with their corresponding rate equations as well as kinetic law and parameter types and experimental and environmental conditions under which the kinetic data were determined additionally sabiork contains information about the underlying biochemical reactions and pathways including their reaction participants cellular location and detailed information about the enzymes catalysing the reactions the data stored in sabiork in a comprehensive manner is mainly extracted manually from literature this includes reactions their participants substrates products modifiers inhibitors activators cofactors catalyst details eg ec enzyme classification protein complex composition wild type mutant information kinetic parameters together with corresponding rate equation biological sources organism tissue cellular location environmental conditions ph temperature buffer and reference details data are adapted normalized and annotated to controlled vocabularies ontologies and external data sources including kegg uniprot chebi pubchem ncbi reactome brenda metacyc biomodels and pubmed as of october 2021 sabiork contains about 71000 curated single entries extracted from more than 7300 publications several tools databases and workflows in systems biology make use of sabiork biochemical reaction data by integration into their framework including sycamore memork celldesigner peroxisomedbtaverna workflows or tools like kineticswizard software for data capture and analysis additionally sabiork is part of miriam registry a set of guidelines for the annotation and curation of computational models the usage of sabiork is free of charge commercial users need a license sabiork offers several ways for data access a browserbased interface restfulbased web services for programmatic accessresult data sets can be exported in different formats including sbml biopaxsbpax and table format sabiork homepage'</li><li>'lipid microdomains are formed when lipids undergo lateral phase separations yielding stable coexisting lamellar domains these phase separations can be induced by changes in temperature pressure ionic strength or by the addition of divalent cations or proteins the question of whether such lipid microdomains observed in model lipid systems also exist in biomembranes had motivated considerable research efforts lipid domains are not readily isolated and examined as unique species in contrast to the examples of lateral heterogeneity one can disrupt the membrane and demonstrate a heterogeneous range of composition in the population of the resulting vesicles or fragments electron microscopy can also be used to demonstrate lateral inhomogeneities in biomembranes often lateral heterogeneity has been inferred from biophysical techniques where the observed signal indicates multiple populations rather than the expected homogeneous population an example of this is the measurement of the diffusion coefficient of a fluorescent lipid analog in soybean protoplasts membrane microheterogeneity is sometimes inferred from the behavior of enzymes where the enzymatic activity does not appear to be correlated with the average lipid physical state exhibited by the bulk of the membrane often the methods suggest regions with different lipid fluidity as would be expected of coexisting gel and liquid crystalline phases within the biomembrane this is also the conclusion of a series of studies where differential effects of perturbation caused by cis and trans fatty acids are interpreted in terms of preferential partitioning of the two liquid crystalline and gellike domains biochemistry essential fatty acid lipid raft pip2 domain lipid signaling saturated and unsaturated compounds'</li><li>'ed new york mcgrawhill isbn 9780071624428 whalen k 2014 lippincott illustrated reviews pharmacology'</li></ul> |
| 33 | <ul><li>'belief in psi than healthy adults some scientists have investigated possible neurocognitive processes underlying the formation of paranormal beliefs in a study pizzagalli et al 2000 data demonstrated that subjects differing in their declared belief in and experience with paranormal phenomena as well as in their schizotypal ideation as determined by a standardized instrument displayed differential brain electric activity during resting periods another study schulter and papousek 2008 wrote that paranormal belief can be explained by patterns of functional hemispheric asymmetry that may be related to perturbations during fetal developmentit was also realized that people with higher dopamine levels have the ability to find patterns and meanings where there are not any this is why scientists have connected high dopamine levels with paranormal belief some scientists have criticized the media for promoting paranormal claims in a report by singer and benassi in 1981 they wrote that the media may account for much of the near universality of paranormal belief as the public are constantly exposed to films newspapers documentaries and books endorsing paranormal claims while critical coverage is largely absent according to paul kurtz in regard to the many talk shows that constantly deal with paranormal topics the skeptical viewpoint is rarely heard and when it is permitted to be expressed it is usually sandbagged by the host or other guests kurtz described the popularity of public belief in the paranormal as a quasireligious phenomenon a manifestation of a transcendental temptation a tendency for people to seek a transcendental reality that cannot be known by using the methods of science kurtz compared this to a primitive form of magical thinkingterence hines has written that on a personal level paranormal claims could be considered a form of consumer fraud as people are being induced through false claims to spend their money — often large sums — on paranormal claims that do not deliver what they promise and uncritical acceptance of paranormal belief systems can be damaging to society while the existence of paranormal phenomena is controversial and debated passionately by both proponents of the paranormal and by skeptics surveys are useful in determining the beliefs of people in regards to paranormal phenomena these opinions while not constituting scientific evidence for or against may give an indication of the mindset of a certain portion of the population at least among those who answered the polls the number of people worldwide who believe in parapsychological powers has been estimated to be 3 to 4 billiona survey conducted in 2006 by researchers from australias monash university sought to determine the types of phenomena that people claim to have experienced and the effects these experiences have had on their lives the study was conducted as an'</li><li>'readily tested at random in 1969 helmut schmidt introduced the use of highspeed random event generators reg for precognition testing and experiments were also conducted at the princeton engineering anomalies research lab once again flaws were found in all of schmidts experiments when the psychologist c e m hansel found that several necessary precautions were not takensf writer philip k dick believed that he had precognitive experiences and used the idea in some of his novels especially as a central plot element in his 1956 science fiction short story the minority report and in his 1956 novel the world jones madein 1963 the bbc television programme monitor broadcast an appeal by the writer jb priestley for experiences which challenged our understanding of time he received hundreds of letters in reply and believed that many of them described genuine precognitive dreams in 2014 the bbc radio 4 broadcaster francis spufford revisited priestleys work and its relation to the ideas of jw dunnein 1965 g w lambert a former council member of the spr proposed five criteria that needed to be met before an account of a precognitive dream could be regarded as credible the dream should be reported to a credible witness before the event the time interval between the dream and the event should be short the event should be unexpected at the time of the dream the description should be of an event destined literally and not symbolically to happen the details of dream and event should tallydavid ryback a psychologist in atlanta used a questionnaire survey approach to investigate precognitive dreaming in college students during the 1980s his survey of over 433 participants showed that 290 or 669 per cent reported some form of paranormal dream he rejected many of these reports but claimed that 88 per cent of the population was having actual precognitive dreams in 2011 the psychologist daryl bem a professor emeritus at cornell university published findings showing statistical evidence for precognition in the journal of personality and social psychology the paper was heavily criticised and the criticism widened to include the journal itself and the validity of the peerreview process in 2012 an independent attempt to reproduce bems results was published but it failed to do so the widespread controversy led to calls for improvements in practice and for more research claims of precognition are like any other claims open to scientific criticism however the nature of the criticism must adapt to the nature of the claim claims of precognition are criticised on three main grounds there is no known scientific mechanism which would allow precognition it breaks temporal causality in that the precognised event causes an effect in the subject prior to the event'</li><li>'mental radio does it work and how 1930 was written by the american author upton sinclair and initially selfpublished this book documents sinclairs test of psychic abilities of mary craig sinclair his second wife while she was in a state of profound depression with a heightened interest in the occult she attempted to duplicate 290 pictures which were drawn by her brother sinclair claimed mary successfully duplicated 65 of them with 155 partial successes and 70 failures in spite of the authors best efforts the experiments were not conducted in a controlled scientific environmentthe german edition included a preface written by albert einstein who admired the book and praised sinclairs writing abilities the psychical researcher walter franklin prince conducted an independent analysis of the results in 1932 he believed that telepathy had been demonstrated in sinclairs data princes analysis was published as the sinclair experiments for telepathy in part i of bulletin xvi of the boston society for psychical research in april 1932 and was included in the addendum for the book on the subject of occult and pseudoscience topics sinclair has been described as credulous martin gardner wrote as mental radio stands it is a highly unsatisfactory account of conditions surrounding the clairvoyancy tests throughout his entire life sinclair has been a gullible victim of mediums and psychics gardner also wrote the possibility of sensory leakage during the experiment had not been ruled out in the first place an intuitive wife who knows her husband intimately may be able to guess with a fair degree of accuracy what he is likely to draw — particularly if the picture is related to some freshly recalled event the two experienced in common at first simple pictures like chairs and tables would likely predominate but as these are exhausted the field of choice narrows and pictures are more likely to be suggested by recent experiences it is also possible that sinclair may have given conversational hints during some of the tests — hints which in his strong will to believe he would promptly forget about also one must not rule out the possibility that in many tests made across the width of a room mrs sinclair may have seen the wiggling of the top of a pencil or arm movements which would convey to her unconscious a rough notion of the drawing when mrs sinclair was tested by william mcdougall under better precautions the results were less than satisfactory leon harris 1975 upton sinclair american rebel crowell'</li></ul> |
| 23 | <ul><li>'the infant is considered safe high caffeine intake by breastfeeding mothers may cause their infants to become irritable or have trouble sleeping a metaanalysis has shown that breastfeeding mothers who smoke expose their infants to nicotine which may cause respiratory illnesses including otitis media in the nursing infant there is a commercial market for human breast milk both in the form of a wet nurse service and as a milk product as a product breast milk is exchanged by human milk banks as well as directly between milk donors and customers as mediated by websites on the internet human milk banks generally have standardized measures for screening donors and storing the milk sometimes even offering pasteurization while milk donors on websites vary in regard to these measures a study in 2013 came to the conclusion that 74 of breast milk samples from providers found from websites were colonized with gramnegative bacteria or had more than 10000 colonyforming unitsml of aerobic bacteria bacterial growth happens during transit according to the fda bad bacteria in food at room temperature can double every 20 minuteshuman milk is considered to be healthier than cows milk and infant formula when it comes to feeding an infant in the first six months of life but only under extreme situations do international health organizations support feeding an infant breast milk from a healthy wet nurse rather than that of its biological mother one reason is that the unregulated breast milk market is fraught with risks such as drugs of abuse and prescription medications being present in donated breast milk the transmission of these substances through breast milk can do more harm than good when it comes to the health outcomes of the infant recipient a 2015 cbs article cites an editorial led by dr sarah steele in the journal of the royal society of medicine in which they say that health claims do not stand up clinically and that raw human milk purchased online poses many health risks cbs found a study from the center for biobehavioral health at nationwide childrens hospital in columbus that found that 11 out of 102 breast milk samples purchased online were actually blended with cows milk the article also explains that milk purchased online may be improperly sanitized or stored so it may contain foodborne illness and infectious diseases such as hepatitis and hiv a minority of people including restaurateurs hans lochen of switzerland and daniel angerer of austria who operates a restaurant in new york city have used human breast milk or at least advocated its use as a substitute for cows milk in dairy products and food recipes an icecreamist in londons covent garden started selling an ice cream named baby gaga in february 2011 each serving cost £14 all the milk was'</li><li>'has been estimated that humans generate about 10 billion different antibodies each capable of binding a distinct epitope of an antigen although a huge repertoire of different antibodies is generated in a single individual the number of genes available to make these proteins is limited by the size of the human genome several complex genetic mechanisms have evolved that allow vertebrate b cells to generate a diverse pool of antibodies from a relatively small number of antibody genes the chromosomal region that encodes an antibody is large and contains several distinct gene loci for each domain of the antibody — the chromosome region containing heavy chain genes igh is found on chromosome 14 and the loci containing lambda and kappa light chain genes igl and igk are found on chromosomes 22 and 2 in humans one of these domains is called the variable domain which is present in each heavy and light chain of every antibody but can differ in different antibodies generated from distinct b cells differences between the variable domains are located on three loops known as hypervariable regions hv1 hv2 and hv3 or complementaritydetermining regions cdr1 cdr2 and cdr3 cdrs are supported within the variable domains by conserved framework regions the heavy chain locus contains about 65 different variable domain genes that all differ in their cdrs combining these genes with an array of genes for other domains of the antibody generates a large cavalry of antibodies with a high degree of variability this combination is called vdj recombination discussed below somatic recombination of immunoglobulins also known as vdj recombination involves the generation of a unique immunoglobulin variable region the variable region of each immunoglobulin heavy or light chain is encoded in several pieces — known as gene segments subgenes these segments are called variable v diversity d and joining j segments v d and j segments are found in ig heavy chains but only v and j segments are found in ig light chains multiple copies of the v d and j gene segments exist and are tandemly arranged in the genomes of mammals in the bone marrow each developing b cell will assemble an immunoglobulin variable region by randomly selecting and combining one v one d and one j gene segment or one v and one j segment in the light chain as there are multiple copies of each type of gene segment and different combinations of gene segments can be used to generate each immunoglobulin variable region this process generates a huge number of antibodies each with different paratopes and thus different antigen specific'</li><li>'##lin a3 is further metabolized by soluble epoxide hydrolase 2 seh to 8r11r12rtrihydroxy5z9e14zeicosatetraenoic acid 12rhpete also spontaneously decomposes to a mixture of hepoxilins and trihydroxyeicosatetraenoic acids that possess r or s hydroxy and epoxy residues at various sites while 8rhydroxy11r12repoxyhepoxilin a3 spontaneously decomposes to 8r11r12rtrihydroxy5z9e14zeicosatetraenoic acid these decompositions may occur during tissue isolation procedures recent studies indicate that the metabolism by aloxe3 of the r stereoisomer of 12hpete made by alox12b and therefore possibly the s stereoisomer of 12hpete made by alox12 or alox15 is responsible for forming various hepoxilins in the epidermis of human and mouse skin and tongue and possibly other tissueshuman skin metabolizes 12shpete in reactions strictly analogous to those of 12rhpete it metabolized 12shpete by elox3 to 8rhydroxy11s12sepoxy5z9e14zeicosatetraenoic acid and 12oxoete with the former product then being metabolized by seh to 8r11s12strihydroxy5z9e14zeicosatetraenoic acid 12shpete also spontaneously decomposes to a mixture of hepoxilins and trihydroxyeicosatetraenoic acids trioxilins that possess r or s hydroxy and rs or sr epoxide residues at various sites while 8rhydroxy11s12sepoxyhepoxilin a3 spontaneously decomposes to 8r11s12strihydroxy5z9e14zeicosatetraenoic acidin other tissues and animal species numerous hepoxilins form but the hepoxilin synthase activity responsible for their formation is variable hepoxilin a3 8rshydroxy1112epoxy5z9e14zeicosatrienoic acid and hepoxilin b3 10rshydroxy1112epxoy5z8z14zeicosatrienoic acid refer to a mixture of diastereomers and⁄or enantiomers derived from arachidonic acid'</li></ul> |
| 39 | <ul><li>'joule heating also known as resistive resistance or ohmic heating is the process by which the passage of an electric current through a conductor produces heat joules first law also just joules law also known in countries of the former ussr as the joule – lenz law states that the power of heating generated by an electrical conductor equals the product of its resistance and the square of the current joule heating affects the whole electric conductor unlike the peltier effect which transfers heat from one electrical junction to another jouleheating or resistiveheating is used in multiple devices and industrial process the part that converts electricity into heat is called a heating element among the many practical uses are an incandescent light bulb glows when the filament is heated by joule heating due to thermal radiation also called blackbody radiation electric fuses are used as a safety breaking the circuit by melting if enough current flows to melt them electronic cigarettes vaporize propylene glycol and vegetable glycerine by joule heating multiple heating devices use joule heating such as electric stoves electric heaters soldering irons cartridge heaters some food processing equipment may make use of joule heating running current through food material which behave as an electrical resistor causes heat release inside the food the alternating electrical current coupled with the resistance of the food causes the generation of heat a higher resistance increases the heat generated ohmic heating allows for fast and uniform heating of food products which maintains quality products with particulates heat up faster compared to conventional heat processing due to higher resistance james prescott joule first published in december 1840 an abstract in the proceedings of the royal society suggesting that heat could be generated by an electrical current joule immersed a length of wire in a fixed mass of water and measured the temperature rise due to a known current flowing through the wire for a 30 minute period by varying the current and the length of the wire he deduced that the heat produced was proportional to the square of the current multiplied by the electrical resistance of the immersed wirein 1841 and 1842 subsequent experiments showed that the amount of heat generated was proportional to the chemical energy used in the voltaic pile that generated the template this led joule to reject the caloric theory at that time the dominant theory in favor of the mechanical theory of heat according to which heat is another form of energyresistive heating was independently studied by heinrich lenz in 1842the si unit of energy was subsequently named the joule and given the symbol j the commonly known unit of power the watt is equivalent to one joule per second joule'</li><li>'timetranslation symmetry or temporal translation symmetry tts is a mathematical transformation in physics that moves the times of events through a common interval timetranslation symmetry is the law that the laws of physics are unchanged ie invariant under such a transformation timetranslation symmetry is a rigorous way to formulate the idea that the laws of physics are the same throughout history timetranslation symmetry is closely connected via noethers theorem to conservation of energy in mathematics the set of all time translations on a given system form a lie group there are many symmetries in nature besides time translation such as spatial translation or rotational symmetries these symmetries can be broken and explain diverse phenomena such as crystals superconductivity and the higgs mechanism however it was thought until very recently that timetranslation symmetry could not be broken time crystals a state of matter first observed in 2017 break timetranslation symmetry symmetries are of prime importance in physics and are closely related to the hypothesis that certain physical quantities are only relative and unobservable symmetries apply to the equations that govern the physical laws eg to a hamiltonian or lagrangian rather than the initial conditions values or magnitudes of the equations themselves and state that the laws remain unchanged under a transformation if a symmetry is preserved under a transformation it is said to be invariant symmetries in nature lead directly to conservation laws something which is precisely formulated by noethers theorem to formally describe timetranslation symmetry we say the equations or laws that describe a system at times t displaystyle t and t τ displaystyle ttau are the same for any value of t displaystyle t and τ displaystyle tau for example considering newtons equation m x ¨ − d v d x x displaystyle mddot xfrac dvdxx one finds for its solutions x x t displaystyle xxt the combination 1 2 m x [UNK] t 2 v x t displaystyle frac 12mdot xt2vxt does not depend on the variable t displaystyle t of course this quantity describes the total energy whose conservation is due to the timetranslation invariance of the equation of motion by studying the composition of symmetry transformations eg of geometric objects one reaches the conclusion that they form a group and more specifically a lie transformation group if one considers continuous finite symmetry transformations different symmetries form different groups with different geometries time independent hamiltonian systems form a group of time translations that is described by the noncompact abelian lie group r displaystyle mathbb r tts'</li><li>'mass does not depend on δ e displaystyle delta e the entropy is thus a measure of the uncertainty about exactly which quantum state the system is in given that we know its energy to be in some interval of size δ e displaystyle delta e deriving the fundamental thermodynamic relation from first principles thus amounts to proving that the above definition of entropy implies that for reversible processes we have d s δ q t displaystyle dsfrac delta qt the fundamental assumption of statistical mechanics is that all the ω e displaystyle omega lefteright states at a particular energy are equally likely this allows us to extract all the thermodynamical quantities of interest the temperature is defined as 1 k t ≡ β ≡ d log ω e d e displaystyle frac 1ktequiv beta equiv frac dlog leftomega lefterightrightde this definition can be derived from the microcanonical ensemble which is a system of a constant number of particles a constant volume and that does not exchange energy with its environment suppose that the system has some external parameter x that can be changed in general the energy eigenstates of the system will depend on x according to the adiabatic theorem of quantum mechanics in the limit of an infinitely slow change of the systems hamiltonian the system will stay in the same energy eigenstate and thus change its energy according to the change in energy of the energy eigenstate it is in the generalized force x corresponding to the external parameter x is defined such that x d x displaystyle xdx is the work performed by the system if x is increased by an amount dx eg if x is the volume then x is the pressure the generalized force for a system known to be in energy eigenstate e r displaystyle er is given by x − d e r d x displaystyle xfrac derdx since the system can be in any energy eigenstate within an interval of δ e displaystyle delta e we define the generalized force for the system as the expectation value of the above expression x − ⟨ d e r d x ⟩ displaystyle xleftlangle frac derdxrightrangle to evaluate the average we partition the ω e displaystyle omega e energy eigenstates by counting how many of them have a value for d e r d x displaystyle frac derdx within a range between y displaystyle y and y δ y displaystyle ydelta y calling this number ω y e displaystyle omega yleft'</li></ul> |
| 9 | <ul><li>'in microbiology the multiplicity of infection or moi is the ratio of agents eg phage or more generally virus bacteria to infection targets eg cell for example when referring to a group of cells inoculated with virus particles the moi is the ratio of the number of virus particles to the number of target cells present in a defined space the actual number of viruses or bacteria that will enter any given cell is a stochastic process some cells may absorb more than one infectious agent while others may not absorb any before determining the multiplicity of infection its absolutely necessary to have a wellisolated agent as crude agents may not produce reliable and reproducible results the probability that a cell will absorb n displaystyle n virus particles or bacteria when inoculated with an moi of m displaystyle m can be calculated for a given population using a poisson distribution this application of poissons distribution was applied and described by ellis and delbruck p n m n ⋅ e − m n displaystyle pnfrac mncdot emn where m displaystyle m is the multiplicity of infection or moi n displaystyle n is the number of infectious agents that enter the infection target and p n displaystyle pn is the probability that an infection target a cell will get infected by n displaystyle n infectious agents in fact the infectivity of the virus or bacteria in question will alter this relationship one way around this is to use a functional definition of infectious particles rather than a strict count such as a plaque forming unit for virusesfor example when an moi of 1 1 infectious viral particle per cell is used to infect a population of cells the probability that a cell will not get infected is p 0 3679 displaystyle p03679 and the probability that it be infected by a single particle is p 1 3679 displaystyle p13679 by two particles is p 2 1839 displaystyle p21839 by three particles is p 3 613 displaystyle p3613 and so on the average percentage of cells that will become infected as a result of inoculation with a given moi can be obtained by realizing that it is simply p n 0 1 − p 0 displaystyle pn01p0 hence the average fraction of cells that will become infected following an inoculation with an moi of m displaystyle m is given by p n 0 1 − p n 0 1 − m 0 ⋅ e − m 0 1 − e − m displaystyle pn01pn01frac m0cdot em01em which is approximately equal to'</li><li>'use of a mam targeting adhesion inhibitor was shown to significantly decrease the colonization of burn wounds by multidrug resistant pseudomonas aeruginosa in rats n gonorrhoeae is host restricted almost entirely to humans extensive studies have established type 4 fimbrial adhesins of n gonorrhoeae virulence factors these studies have shown that only strains capable of expressing fimbriae are pathogenic high survival of polymorphonuclear neutrophils pmns characterizes neisseria gonorrhoeae infections additionally recent studies out of stockholm have shown that neisseria can hitchhike on pmns using their adhesin pili thus hiding them from neutrophil phagocytic activity this action facilitates the spread of the pathogen throughout the epithelial cell layer escherichia coli strains most known for causing diarrhea can be found in the intestinal tissue of pigs and humans where they express the k88 and cfa1 to attach to the intestinal lining additionally upec causes about 90 of urinary tract infections of those e coli which cause utis 95 express type 1 fimbriae fimh in e coli overcomes the antibody based immune response by natural conversion from the high to the low affinity state through this conversion fimh adhesion may shed the antibodies bound to it escherichia coli fimh provides an example of conformation specific immune response which enhances impact on the protein by studying this particular adhesion researchers hope to develop adhesionspecific vaccines which may serve as a model for antibodymediation of pathogen adhesion fungal adhesin trimeric autotransporter adhesins taa'</li><li>'the ziehlneelsen stain also known as the acidfast stain is a bacteriological staining technique used in cytopathology and microbiology to identify acidfast bacteria under microscopy particularly members of the mycobacterium genus this staining method was initially introduced by paul ehrlich 1854 – 1915 and subsequently modified by the german bacteriologists franz ziehl 1859 – 1926 and friedrich neelsen 1854 – 1898 during the late 19th century the acidfast staining method in conjunction with auramine phenol staining serves as the standard diagnostic tool and is widely accessible for rapidly diagnosing tuberculosis caused by mycobacterium tuberculosis and other diseases caused by atypical mycobacteria such as leprosy caused by mycobacterium leprae and mycobacterium aviumintracellulare infection caused by mycobacterium avium complex in samples like sputum gastric washing fluid and bronchoalveolar lavage fluid these acidfast bacteria possess a waxy lipidrich outer layer that contains high concentrations of mycolic acid rendering them resistant to conventional staining techniques like the gram stainafter the ziehlneelsen staining procedure using carbol fuchsin acidfast bacteria are observable as vivid red or pink rods set against a blue or green background depending on the specific counterstain used such as methylene blue or malachite green respectively nonacidfast bacteria and other cellular structures will be colored by the counterstain allowing for clear differentiation in anatomic pathology specimens immunohistochemistry and modifications of ziehl – neelsen staining such as fitefaraco staining have comparable diagnostic utility in identifying mycobacterium both of them are superior to traditional ziehl – neelsen stainmycobacterium are slowgrowing rodshaped bacilli that are slightly curved or straight and are considered to be gram positive some mycobacteria are freeliving saprophytes but many are pathogens that cause disease in animals and humans mycobacterium bovis causes tuberculosis in cattle since tuberculosis can be spread to humans milk is pasteurized to kill any of the bacteria mycobacterium tuberculosis that causes tuberculosis tb in humans is an airborne bacterium that typically infects the human lungs testing for tb includes blood testing skin tests and chest xrays when looking at the smears for tb it is stained using an acidfast stain these'</li></ul> |
| 35 | <ul><li>'aeolian origin of the loesses was recognized later virlet daoust 1857 particularly due to the convincing observations of loesses in china by ferdinand von richthofen 1878 a tremendous number of papers have been published since then focusing on the formation of loesses and on loesspaleosol older soil buried under deposits sequences as the archives of climate and environment change these water conservation works have been carried out extensively in china and the research of loesses in china has been ongoing since 1954 33 much effort was put into setting up regional and local loess stratigraphies and their correlations kukla 1970 1975 1977 however even the chronostratigraphical position of the last interglacial soil correlating with marine isotope substage 5e was a matter of debate due to the lack of robust and reliable numerical dating as summarized for example by zoller et al 1994 and frechen et al 1997 for the austrian and hungarian loess stratigraphy respectivelysince the 1980s thermoluminescence tl optically stimulated luminescence osl and infrared stimulated luminescence irsl dating have been available providing the possibility for dating the time of loess dust depositions ie the time elapsed since the last exposure of the mineral grains to daylight during the past decade luminescence dating has significantly improved by new methodological improvements especially the development of single aliquot regenerative sar protocols murray wintle 2000 resulting in reliable ages or age estimates with an accuracy of up to 5 and 10 for the last glacial record more recently luminescence dating has also become a robust dating technique for penultimate and antepenultimate glacial loess eg thiel et al 2011 schmidt et al 2011 allowing for a reliable correlation of loesspalaeosol sequences for at least the last two interglacialglacial cycles throughout europe and the northern hemisphere frechen 2011 furthermore the numerical dating provides the basis for quantitative loess research applying more sophisticated methods to determine and understand highresolution proxy data including the palaeodust content of the atmosphere variations of the atmospheric circulation patterns and wind systems palaeoprecipitation and palaeotemperaturebesides luminescence dating methods the use of radiocarbon dating in loess has increased during the past decades advances in methods of analyses instrumentation and refinements to the radiocarbon calibration curve have made it possible to obtain reliable ages from loess deposits for the last 4045 ka however the use of'</li><li>'##capes structure robin thwaites brian slater 2004 the concept of pedodiversity and its application in diverse geoecological systems 1 zinck j a 1988 physiography and soils lecturenotes for soil students soil science division soil survey courses subject matter k6 itc enschede the netherlands'</li><li>'have a rich fossil record from the paleoproterozoic onwards outside of ice ages oxisols have generally been the dominant soil order in the paleopedological record this is because soil formation after which oxisols take more weathering to form than any other soil order has been almost nonexistent outside eras of extensive continental glaciation this is not only because of the soils formed by glaciation itself but also because mountain building which is the other critical factor in producing new soil has always coincided with a reduction in global temperatures and sea levels this is because the sediment formed from the eroding mountains reduces the atmospheric co2 content and also causes changes in circulation linked closely by climatologists to the development of continental ice sheets oxisols were not vegetated until the late carboniferous probably because microbial evolution was not before that point advanced enough to permit plants to obtain sufficient nutrients from soils with very low concentrations of nitrogen phosphorus calcium and potassium owing to their extreme climatic requirements gelisol fossils are confined to the few periods of extensive continental glaciation the earliest being 900 million years ago in the neoproterozoic however in these periods fossil gelisols are generally abundant notable finds coming from the carboniferous in new south wales the earliest land vegetation is found in early silurian entisols and inceptisols and with the growth of land vegetation under a protective ozone layer several new soil orders emerged the first histosols emerged in the devonian but are rare as fossils because most of their mass consists of organic materials that tend to decay quickly alfisols and ultisols emerged in the late devonian and early carboniferous and have a continuous though not rich fossil record in eras since then spodosols are known only from the carboniferous and from a few periods since that time though less acidic soils otherwise similar to spodosols are known from the mesozoic and tertiary and may constitute an extinct suborder during the mesozoic the paleopedological record tends to be poor probably because the absence of mountainbuilding and glaciation meant that most surface soils were very old and were constantly being weathered of what weatherable materials remained oxisols and orthents are the dominant groups though a few more fertile soils have been found such as the extensive andisols mentioned earlier from jurassic siberia evidence for widespread deeply weathered soils in the paleocene can be seen in abundant oxisols and ultisols in nowheavily glaciated scotland and antarctica mollisols the major agricultural soils'</li></ul> |
| 11 | <ul><li>'pumps used in vads can be divided into two main categories – pulsatile pumps which mimic the natural pulsing action of the heart and continuousflow pumps pulsatile vads use positive displacement pumps in some pulsatile pumps that use compressed air as an energy source the volume occupied by blood varies during the pumping cycle if the pump is contained inside the body then a vent tube to the outside air is required continuousflow vads are smaller and have proven to be more durable than pulsatile vads they normally use either a centrifugal pump or an axial flow pump both types have a central rotor containing permanent magnets controlled electric currents running through coils contained in the pump housing apply forces to the magnets which in turn cause the rotors to spin in the centrifugal pumps the rotors are shaped to accelerate the blood circumferentially and thereby cause it to move toward the outer rim of the pump whereas in the axial flow pumps the rotors are more or less cylindrical with blades that are helical causing the blood to be accelerated in the direction of the rotors axisan important issue with continuous flow pumps is the method used to suspend the rotor early versions used solid bearings however newer pumps some of which are approved for use in the eu use either magnetic levitation maglev or hydrodynamic suspension the first left ventricular assist device lvad system was created by domingo liotta at baylor college of medicine in houston in 1962 the first lvad was implanted in 1963 by liotta and e stanley crawford the first successful implantation of an lvad was completed in 1966 by liotta along with dr michael e debakey the patient was a 37yearold woman and a paracorporeal external circuit was able to provide mechanical support for 10 days after the surgery the first successful longterm implantation of an lvad was conducted in 1988 by dr william f bernhard of boston childrens hospital medical center and thermedics inc of woburn ma under a national institutes of health nih research contract which developed heartmate an electronically controlled assist device this was funded by a threeyear 62 million contract to thermedics and childrens hospital boston ma from the national heart lung and blood institute a program of the nih the early vads emulated the heart by using a pulsatile action where blood is alternately sucked into the pump from the left ventricle then forced out into the aorta devices of this kind include the heartmate ip lvas which'</li><li>'10 ml per 100 g per minute in brain tissue a biochemical cascade known as the ischemic cascade is triggered when the tissue becomes ischemic potentially resulting in damage to and the death of brain cells medical professionals must take steps to maintain proper cbf in patients who have conditions like shock stroke cerebral edema and traumatic brain injury cerebral blood flow is determined by a number of factors such as viscosity of blood how dilated blood vessels are and the net pressure of the flow of blood into the brain known as cerebral perfusion pressure which is determined by the bodys blood pressure cerebral perfusion pressure cpp is defined as the mean arterial pressure map minus the intracranial pressure icp in normal individuals it should be above 50 mm hg intracranial pressure should not be above 15 mm hg icp of 20 mm hg is considered as intracranial hypertension cerebral blood vessels are able to change the flow of blood through them by altering their diameters in a process called cerebral autoregulation they constrict when systemic blood pressure is raised and dilate when it is lowered arterioles also constrict and dilate in response to different chemical concentrations for example they dilate in response to higher levels of carbon dioxide in the blood and constrict in response to lower levels of carbon dioxidefor example assuming a person with an arterial partial pressure of carbon dioxide paco2 of 40 mmhg normal range of 38 – 42 mmhg and a cbf of 50 ml per 100g per min if the paco2 dips to 30 mmhg this represents a 10 mmhg decrease from the initial value of paco2 consequently the cbf decreases by 1ml per 100g per min for each 1mmhg decrease in paco2 resulting in a new cbf of 40ml per 100g of brain tissue per minute in fact for each 1 mmhg increase or decrease in paco2 between the range of 20 – 60 mmhg there is a corresponding cbf change in the same direction of approximately 1 – 2 ml100gmin or 2 – 5 of the cbf value this is why small alterations in respiration pattern can cause significant changes in global cbf specially through paco2 variationscbf is equal to the cerebral perfusion pressure cpp divided by the cerebrovascular resistance cvr cbf cpp cvrcontrol of cbf is considered in terms of the factors affecting cpp and the factors affecting cvr cvr is controlled by four major mechanisms metabolic control or metabolic autore'</li><li>'signals from in further detail the heart receives its neural input through parasympathetic and sympathetic ganglia and lateral grey column of the spinal cord the neurocardiac axis is the link to many problems regarding the physiological functions of the body this includes cardiac ischemia stroke epilepsy and most importantly heart arrhythmias and cardiac myopathies many of these problems are due to the imbalance of the nervous system resulting in symptoms that affect both the heart and the brainthe connection between the cardiovascular and nervous system has brought up a concern in the training processes for medical students neurocardiology is the understanding that the body is interconnected and weave in and out of other systems when training within one specialty the doctors are more likely to associate patients symptoms to their field without taking the integration into account the doctor can consequently delay a correct diagnosis and treatment for the patient however by specializing in a field advancement in medicine continues as new findings come into perspective cardiovascular systems are regulated by the autonomic nervous systems which includes the sympathetic and parasympathetic nervous systems a distinct balance between these two systems is crucial for the pathophysiology of cardiovascular disease chronic stress has been widely studied on its effects of the body resulting in an elevated heart rate hr reduced hr variability elevated sympathetic tone and intensified cardiovascular activity consequently stress promotes an autonomic imbalance in favor of the sympathetic nervous system the activation of the sympathetic nervous system contributes to endothelial dysfunction hypertension atherosclerosis insulin resistance and increased incidence of arrhythmias an imbalance in the autonomic nervous system has been documented in mood disorders it is commonly regarded as a mediator between mood disorders and cardiovascular disordersthe hypothalamus is the part of the brain that regulates function and responds to stress when the brain perceives environmental danger the amygdala fires a nerve impulse to the hypothalamus to initiate the bodys fightorflight mode through the sympathetic nervous system the stress response starts with the hypothalamus stimulating the pituitary gland which releases the adrenocorticotropic hormone this signals the release of cortisol the stress hormone initiating a multitude of physical effects on the body to aid in survival the negative feedback loop is then needed to return the body to its resting state by signaling the parasympathetic nervous systemprolonged stress leads to many hazards within the nervous system various hormones and glands become overworked chemical waste is produced resulting in degeneration of nerve cells the result of prolonged stress is the breakdown'</li></ul> |
| 40 | <ul><li>'space and comes with a natural topology for a topological space x displaystyle x and a finite set s displaystyle s the configuration space of x with particles labeled by s is conf s x f [UNK] f s [UNK] x is injective displaystyle operatorname conf sxfmid fcolon shookrightarrow xtext is injective for n ∈ n displaystyle nin mathbb n define n 1 2 … n displaystyle mathbf n 12ldots n then the nth configuration space of x is conf n x displaystyle operatorname conf mathbf n x and is denoted simply conf n x displaystyle operatorname conf nx the space of ordered configuration of two points in r 2 displaystyle mathbf r 2 is homeomorphic to the product of the euclidean 3space with a circle ie conf 2 r 2 [UNK] r 3 × s 1 displaystyle operatorname conf 2mathbf r 2cong mathbf r 3times s1 more generally the configuration space of two points in r n displaystyle mathbf r n is homotopy equivalent to the sphere s n − 1 displaystyle sn1 the configuration space of n displaystyle n points in r 2 displaystyle mathbf r 2 is the classifying space of the n displaystyle n th braid group see below the nstrand braid group on a connected topological space x is b n x π 1 uconf n x displaystyle bnxpi 1operatorname uconf nx the fundamental group of the nth unordered configuration space of x the nstrand pure braid group on x is p n x π 1 conf n x displaystyle pnxpi 1operatorname conf nx the first studied braid groups were the artin braid groups b n [UNK] π 1 uconf n r 2 displaystyle bncong pi 1operatorname uconf nmathbf r 2 while the above definition is not the one that emil artin gave adolf hurwitz implicitly defined the artin braid groups as fundamental groups of configuration spaces of the complex plane considerably before artins definition in 1891it follows from this definition and the fact that conf n r 2 displaystyle operatorname conf nmathbf r 2 and uconf n r 2 displaystyle operatorname uconf nmathbf r 2 are eilenberg – maclane spaces of type k π 1 displaystyle kpi 1 that the unordered configuration space of the plane uconf n r 2'</li><li>'##s to denote the set of limit points of s displaystyle s then we have the following characterization of the closure of s displaystyle s the closure of s displaystyle s is equal to the union of s displaystyle s and l s displaystyle ls this fact is sometimes taken as the definition of closure a corollary of this result gives us a characterisation of closed sets a set s displaystyle s is closed if and only if it contains all of its limit points no isolated point is a limit point of any set a space x displaystyle x is discrete if and only if no subset of x displaystyle x has a limit point if a space x displaystyle x has the trivial topology and s displaystyle s is a subset of x displaystyle x with more than one element then all elements of x displaystyle x are limit points of s displaystyle s if s displaystyle s is a singleton then every point of x [UNK] s displaystyle xsetminus s is a limit point of s displaystyle s adherent point – point that belongs to the closure of some given subset of a topological space condensation point – a stronger analog of limit pointpages displaying wikidata descriptions as a fallback convergent filter – use of filters to describe and characterize all basic topological notions and resultspages displaying short descriptions of redirect targets derived set mathematics – set of all limit points of a setpages displaying wikidata descriptions as a fallback filters in topology – use of filters to describe and characterize all basic topological notions and results isolated point – point of a subset s around which there are no other points of s limit of a function – point to which functions converge in analysis limit of a sequence – value to which tends an infinite sequence subsequential limit – the limit of some subsequence'</li><li>'topology optimization to is a mathematical method that optimizes material layout within a given design space for a given set of loads boundary conditions and constraints with the goal of maximizing the performance of the system topology optimization is different from shape optimization and sizing optimization in the sense that the design can attain any shape within the design space instead of dealing with predefined configurations the conventional topology optimization formulation uses a finite element method fem to evaluate the design performance the design is optimized using either gradientbased mathematical programming techniques such as the optimality criteria algorithm and the method of moving asymptotes or non gradientbased algorithms such as genetic algorithms topology optimization has a wide range of applications in aerospace mechanical biochemical and civil engineering currently engineers mostly use topology optimization at the concept level of a design process due to the free forms that naturally occur the result is often difficult to manufacture for that reason the result emerging from topology optimization is often finetuned for manufacturability adding constraints to the formulation in order to increase the manufacturability is an active field of research in some cases results from topology optimization can be directly manufactured using additive manufacturing topology optimization is thus a key part of design for additive manufacturing a topology optimization problem can be written in the general form of an optimization problem as minimize ρ f f u ρ ρ [UNK] ω f u ρ ρ d v s u b j e c t t o g 0 ρ [UNK] ω ρ d v − v 0 ≤ 0 g j u ρ ρ ≤ 0 with j 1 m displaystyle beginalignedunderset rho operatorname minimize ffmathbf urho rho int omega fmathbf urho rho mathrm d voperatorname subjectto g0rho int omega rho mathrm d vv0leq 0gjmathbf u rho rho leq 0text with j1mendaligned the problem statement includes the following an objective function f u ρ ρ displaystyle fmathbf urho rho this function represents the quantity that is being minimized for best performance the most common objective function is compliance where minimizing compliance leads to maximizing the stiffness of a structure the material distribution as a problem variable this is described by the density of the material at each location ρ x displaystyle rho mathbf x material is either present indicated by a 1 or absent indicated by a 0 u u ρ displaystyle mathbf u mathbf u mathbf rho is a state field that satisfies a linear or nonlinear state equation depending on'</li></ul> |
| 13 | <ul><li>'artrage is a bitmap graphics editor for digital painting created by ambient design ltd it is currently in version 6 and supports windows macos and mobile apple and android devices and is available in multiple languages it caters to all ages and skill levels from children to professional artists artrage 5 was announced for january 2017 and finally released in february 2017it is designed to be used with a tablet pc or graphics tablet but it can be used with a regular mouse as well its mediums include tools such as oil paint spray paint pencil acrylic and others using relatively realistic physics to simulate actual painting other tools include tracing smearing blurring mixing symmetry different types of paper for the canvas ie crumpled paper smooth paper wrinkled tin foil etc as well as special effects custom brushes and basic digital editing tools artrage is designed to be as realistic as possible this includes varying thickness and textures of media and canvas the ability to mix media and a realistic colour blending option as well as the standard digital rgb blending it includes a wide array of real life tools as well as stencils scrap layers to use as scrap paper or mixing palettes and the option to integrate reference or tracing images the later versions studio studio pro and artrage 4 include more standard digital tools such as select transform cloner symmetry fill and custom brushes sticker each tool is highly customisable and comes with several presets it is possible to share custom resources between users and there is a reasonably active artrage community that creates and shares presets canvases custom brushes stencils colour palettes and other resources real colour blending artrage offers a realistic colour blending option as well as standard digital rgb based blending it is turned off by default as it is memory intensive but can be turned on from the tools menu the most noticeable effect is that green is produced when yellow and blue are mixedthe color picker supports hsl and rgb colors one of the less well known features of artrage is the custom resource options users can create their own versions of various resources and tools or record scripts and share them with other users users can save their resource collections as a package file arpack which acts similar to a zip file it allows folders of resources to be shared and automatically installed artrage can import some photoshop filters but not all it only supports ttf truetype fonts which it reads from the computers fonts folder package files do not work with versions earlier than 35 artrage studio does not support photoshop filters or allow sticker creation and has fewer options overall alternatively individual resources can be shared directly most of the resources have'</li><li>'##im ecole du louvre paris 2003 proceedings pp 2 – 15 expanded concept of documentation jones caitlin does hardware dictate meaning three variable media conservation case studies horizon article jones caitlin seeing double emulation in theory and practice the erl king case study case study jones caitlin understanding medium preserving content and context in variable media art article from keep moving images christiane paul challenges for a ubiquitous museum presenting and preserving new media quaranta domenico interview with jon ippolito published in noemalab leaping into the abyss and resurfacing with a pearl'</li><li>'lithuanian plaque located on the lithuanian academy of sciences honoring nazi war criminal jonas noreika in 2020 cryptokitties developer dapper labs released the nba topshot project which allowed the purchase of nfts linked to basketball highlights the project was built on top of the flow blockchain in march 2021 an nft of twitter founder jack dorseys firstever tweet sold for 29 million the same nft was listed for sale in 2022 at 48 million but only achieved a top bid of 280 on december 15 2022 donald trump former president of the united states announced a line of nfts featuring images of himself for 99 each it was reported that he made between 100001 and 1 million from the scheme nfts have been proposed for purposes related to scientific and medical purposes suggestions include turning patient data into nfts tracking supply chains and minting patents as nftsthe monetary aspect of the sale of nfts has been used by academic institutions to finance research projects the university of california berkeley announced in may 2021 its intention to auction nfts of two patents of inventions for which the creators had received a nobel prize the patents for crispr gene editing and cancer immunotherapy the university would however retain ownership of the patents 85 of funds gathered through the sale of the collection were to be used to finance research the collection included handwritten notices and faxes by james allison and was named the fourth pillar it sold in june 2022 for 22 ether about us54000 at the time george church a us geneticist announced his intention to sell his dna via nfts and use the profits to finance research conducted by nebula genomics in june 2022 20 nfts with his likeness were published instead of the originally planned nfts of his dna due to the market conditions at the time despite mixed reactions the project is considered to be part of an effort to use the genetic data of 15000 individuals to support genetic research by using nfts the project wants to ensure that the users submitting their genetic data are able to receive direct payment for their contributions several other companies have been involved in similar and often criticized efforts to use blockchainbased genetic data in order to guarantee users more control over their data and enable them to receive direct financial compensation whenever their data is being sold molecule protocol a project based in switzerland is trying to use nfts to digitize the intellectual copyright of individual scientists and research teams to finance research the projects whitepaper explains the aim is to represent the copyright of scientific papers as nfts and enable their trade'</li></ul> |
| 28 | <ul><li>'##tyle mathbb n other generalizations are discussed in the article on numbers there are two standard methods for formally defining natural numbers the first one named for giuseppe peano consists of an autonomous axiomatic theory called peano arithmetic based on few axioms called peano axioms the second definition is based on set theory it defines the natural numbers as specific sets more precisely each natural number n is defined as an explicitly defined set whose elements allow counting the elements of other sets in the sense that the sentence a set s has n elements means that there exists a one to one correspondence between the two sets n and s the sets used to define natural numbers satisfy peano axioms it follows that every theorem that can be stated and proved in peano arithmetic can also be proved in set theory however the two definitions are not equivalent as there are theorems that can be stated in terms of peano arithmetic and proved in set theory which are not provable inside peano arithmetic a probable example is fermats last theorem the definition of the integers as sets satisfying peano axioms provide a model of peano arithmetic inside set theory an important consequence is that if set theory is consistent as it is usually guessed then peano arithmetic is consistent in other words if a contradiction could be proved in peano arithmetic then set theory would be contradictory and every theorem of set theory would be both true and wrong the five peano axioms are the following 0 is a natural number every natural number has a successor which is also a natural number 0 is not the successor of any natural number if the successor of x displaystyle x equals the successor of y displaystyle y then x displaystyle x equals y displaystyle y the axiom of induction if a statement is true of 0 and if the truth of that statement for a number implies its truth for the successor of that number then the statement is true for every natural numberthese are not the original axioms published by peano but are named in his honor some forms of the peano axioms have 1 in place of 0 in ordinary arithmetic the successor of x displaystyle x is x 1 displaystyle x1 intuitively the natural number n is the common property of all sets that have n elements so it seems natural to define n as an equivalence class under the relation can be made in one to one correspondence unfortunately this does not work in set theory as such an equivalence class would not be a set because of russells paradox the standard solution is to define a particular set with n elements that will be called the natural number n the following definition was first published by'</li><li>'##rac sqrt 514 and cos 2 π 5 5 − 1 4 displaystyle cos tfrac 2pi 5tfrac sqrt 514 unlike the euler product and the divisor sum formula this one does not require knowing the factors of n however it does involve the calculation of the greatest common divisor of n and every positive integer less than n which suffices to provide the factorization anyway the property established by gauss that [UNK] d [UNK] n φ d n displaystyle sum dmid nvarphi dn where the sum is over all positive divisors d of n can be proven in several ways see arithmetical function for notational conventions one proof is to note that φd is also equal to the number of possible generators of the cyclic group cd specifically if cd ⟨ g ⟩ with gd 1 then gk is a generator for every k coprime to d since every element of cn generates a cyclic subgroup and all subgroups cd ⊆ cn are generated by precisely φd elements of cn the formula follows equivalently the formula can be derived by the same argument applied to the multiplicative group of the nth roots of unity and the primitive dth roots of unity the formula can also be derived from elementary arithmetic for example let n 20 and consider the positive fractions up to 1 with denominator 20 1 20 2 20 3 20 4 20 5 20 6 20 7 20 8 20 9 20 10 20 11 20 12 20 13 20 14 20 15 20 16 20 17 20 18 20 19 20 20 20 displaystyle tfrac 120tfrac 220tfrac 320tfrac 420tfrac 520tfrac 620tfrac 720tfrac 820tfrac 920tfrac 1020tfrac 1120tfrac 1220tfrac 1320tfrac 1420tfrac 1520tfrac 1620tfrac 1720tfrac 1820tfrac 1920tfrac 2020 put them into lowest terms 1 20 1 10 3 20 1 5 1 4 3 10 7 20 2 5 9 20 1 2 11 20 3 5 13 20 7 10 3 4 4 5 17 20 9 10 19 20 1 1 displaystyle tfrac 120tfrac 110tfrac 320tfrac 15tfrac 14tfrac 310tfrac 720tfrac 25tfrac 920tfrac 12tfrac 1120tfrac 35tfrac 1320tfrac 710tfrac 34tfrac 45tfrac 1720tfrac 910tfrac 1920tfrac 11 these twenty fractions are all the positive kd ≤ 1 whose denominators are the'</li><li>'n d if j 1 displaystyle beginalignedwidetilde operatorname ds jfnunderbrace leftfpm ast fast cdots ast fright jtext timesnoperatorname ds jfnbiggl beginarrayllfpm ntext if j1sum limits stackrel dmid nd1fdoperatorname ds j1fndtext if j1endarrayendaligned the function d f n displaystyle dfn by the equivalent pair of summation formulas in the next equation is closely related to the dirichlet inverse for an arbitrary function f d f n [UNK] j 1 n ds 2 j f n [UNK] m 1 [UNK] n 2 [UNK] [UNK] i 0 2 m − 1 2 m − 1 i − 1 i 1 ds i 1 f n displaystyle dfnsum j1noperatorname ds 2jfnsum m1leftlfloor frac n2rightrfloor sum i02m1binom 2m1i1i1widetilde operatorname ds i1fn in particular we can prove that f − 1 n d ε f 1 n displaystyle f1nleftdfrac varepsilon f1rightn a table of the values of d f n displaystyle dfn for 2 ≤ n ≤ 16 displaystyle 2leq nleq 16 appears below this table makes precise the intended meaning and interpretation of this function as the signed sum of all possible multiple kconvolutions of the function f with itself let p k n p n − k displaystyle pknpnk where p is the partition function number theory then there is another expression for the dirichlet inverse given in terms of the functions above and the coefficients of the qpochhammer symbol for n 1 displaystyle n1 given by f − 1 n [UNK] k 1 n p k ∗ μ n p k ∗ d f ∗ μ n × q k − 1 q q ∞ 1 − q displaystyle f1nsum k1nleftpkast mu npkast dfast mu nrighttimes qk1frac qqinfty 1q summation bell series list of mathematical series'</li></ul> |
| 19 | <ul><li>'hepatoblastoma is a malignant liver cancer occurring in infants and children and composed of tissue resembling fetal liver cells mature liver cells or bile duct cells they usually present with an abdominal mass the disease is most commonly diagnosed during a childs first three years of life alphafetoprotein afp levels are commonly elevated but when afp is not elevated at diagnosis the prognosis is poor patients are usually asymptomatic at diagnosis as a result disease is often advanced at diagnosis hepatoblastomas originate from immature liver precursor cells are typically unifocal affect the right lobe of the liver more often than the left lobe and can metastasize they are categorized into two types epithelial type and mixed epithelial mesenchymal typeindividuals with familial adenomatous polyposis fap a syndrome of earlyonset colonic polyps and adenocarcinoma frequently develop hepatoblastomas also betacatenin mutations have been shown to be common in sporadic hepatoblastomas occurring in as many as 67 of patientsrecently other components of the wnt signaling pathway have also demonstrated a likely role in constitutive activation of this pathway in the causation of hepatoblastoma accumulating evidence suggests that hepatoblastoma is derived from a pluripotent stem cellsyndromes with an increased incidence of hepatoblastoma include beckwith – wiedemann syndrome trisomy 18 trisomy 21 acardi syndrome li – fraumeni syndrome goldenhar syndrome von gierke disease and familial adenomatous polyposis the most common method of testing for hepatoblastoma is a blood test checking the alphafetoprotein level alphafetoprotein afp is used as a biomarker to help determine the presence of liver cancer in children at birth infants have relatively high levels of afp which fall to normal adult levels by the second year of life the normal level for afp in children has been reported as lower than 50 nanograms per milliliter ngml and 10 ngml in adults an afp level greater than 500 ngml is a significant indicator of hepatoblastoma afp is also used as an indicator of treatment success if treatments are successful in removing the cancer the afp level is expected to return to normal surgical removal of the tumor neoadjuvant chemotherapy prior to tumor removal and liver'</li><li>'##phorylaseb kinase deficiency gsd type xi gsd 11 fanconibickel syndrome glut2 deficiency hepatorenal glycogenosis with renal fanconi syndrome no longer considered a glycogen storage disease but a defect of glucose transport the designation of gsd type xi gsd 11 has been repurposed for muscle lactate dehydrogenase deficiency ldha gsd type xiv gsd 14 no longer classed as a gsd but as a congenital disorder of glycosylation type 1t cdg1t affects the phosphoglucomutase enzyme gene pgm1 phosphoglucomutase 1 deficiency is both a glycogenosis and a congenital disorder of glycosylation individuals with the disease have both a glycolytic block as muscle glycogen cannot be broken down as well as abnormal serum transferrin loss of complete nglycans as it affects glycogenolysis it has been suggested that it should redesignated as gsdxiv lafora disease is considered a complex neurodegenerative disease and also a glycogen metabolism disorder polyglucosan storage myopathies are associated with defective glycogen metabolism not mcardle disease same gene but different symptoms myophosphorylasea activity impaired autosomal dominant mutation on pygm gene ampindependent myophosphorylase activity impaired whereas the ampdependent activity was preserved no exercise intolerance adultonset muscle weakness accumulation of the intermediate filament desmin in the myofibers of the patients myophosphorylase comes in two forms form a is phosphorylated by phosporylase kinase form b is not phosphorylated both forms have two conformational states active r or relaxed and inactive t or tense when either form a or b are in the active state then the enzyme converts glycogen into glucose1phosphate myophosphorylaseb is allosterically activated by amp being in larger concentration than atp andor glucose6phosphate see glycogen phosphorylase § regulation unknown glycogenosis related to dystrophy gene deletion patient has a previously undescribed myopathy associated with both becker muscular dystrophy and a glycogen storage disorder of unknown aetiology methods to diagnose glycogen storage diseases include'</li><li>'bilirubin level 01 – 12 mgdl – total serum bilirubin level urine bilirubin may also be clinically significant bilirubin is not normally detectable in the urine of healthy people if the blood level of conjugated bilirubin becomes elevated eg due to liver disease excess conjugated bilirubin is excreted in the urine indicating a pathological process unconjugated bilirubin is not watersoluble and so is not excreted in the urine testing urine for both bilirubin and urobilinogen can help differentiate obstructive liver disease from other causes of jaundiceas with billirubin under normal circumstances only a very small amount of urobilinogen is excreted in the urine if the livers function is impaired or when biliary drainage is blocked some of the conjugated bilirubin leaks out of the hepatocytes and appears in the urine turning it dark amber however in disorders involving hemolytic anemia an increased number of red blood cells are broken down causing an increase in the amount of unconjugated bilirubin in the blood because the unconjugated bilirubin is not watersoluble one will not see an increase in bilirubin in the urine because there is no problem with the liver or bile systems this excess unconjugated bilirubin will go through all of the normal processing mechanisms that occur eg conjugation excretion in bile metabolism to urobilinogen reabsorption and will show up as an increase of urobilinogen in the urine this difference between increased urine bilirubin and increased urine urobilinogen helps to distinguish between various disorders in those systems in ancient history hippocrates discussed bile pigments in two of the four humours in the context of a relationship between yellow and black biles hippocrates visited democritus in abdera who was regarded as the expert in melancholy black bilerelevant documentation emerged in 1827 when m louis jacques thenard examined the biliary tract of an elephant that had died at a paris zoo he observed dilated bile ducts were full of yellow magma which he isolated and found to be insoluble in water treating the yellow pigment with hydrochloric acid produced a strong green color thenard suspected the green pigment was caused by impurities derived from mucus of bileleopold gmelin'</li></ul> |
| 14 | <ul><li>'by wnt signaling in the blastula chordin and nogginexpressing bcne center sia and xtwn can function as homo or heterodimers to bind a conserved p3 site within the proximal element pe of the goosecoid gsc promoter wnt signaling also acts with mvegt to upregulate xnr5 secreted from the nieuwkoop center in the interior dorsovegetal region which will then induce additional transcription factors such as xnr1 xnr2 gsc chordin chd the final cue is mediated by nodalactivin signaling inducing transcription factors that in combination with sia will induce the cerberus cer genethe organizer has both transcription and secreted factors transcription factors include goosecoid lim1 and xnot which are all homeodomain proteins goosecoid was the first organizer gene discovered providing “ the first visualization of spemannmangold organizer cells and of their dynamic changes during gastrulation ” while it was the first to be studied it is not the first gene to be activated following transcriptional activation by sia and xtwn gsc is expressed in a subset of cells encompassing 60° of arc on the dorsal marginal zone expression of gsc activates the expression of secreted signaling molecules ventral injection of gsc leads to a phenotype as seen in spemann and mangolds original experiment a twinned axissecreted factors from the organizer form gradients in the embryo to differentiate the tissues after the discovery of the sepmannmangold organizer many labs rushed to be the first to discover the inducing factors responsible for this organization this created a large international impact with labs in japan russia and germany changing the way they viewed and studied developmental organization however due to the slow progress in the field many labs move research interests away from the organizer but not before the impact of the discovery was made 60 years after the discovery of the organizer many nobel prizes were given to developmental biologists for work that was influenced by the organizer until the mid 19th century japan was a closed society that did not participate in advances in modern biology until later in that century at that time many students who went abroad to study in american and european labs came back with new ideas about approaches to developmental sciences when the returning students would try to incorporate their new ideas into the japanese experimental embryology they were rejected by the members of japanese biological society after the publication of the spemannmangold organizer many more students went to study abroad in european labs to learn much more about this organizer and returned to use'</li><li>'##ietal cell foveolar cell intestine enteroendocrine cell gastric inhibitory polypeptide s cell delta cell cholecystokinin enterochromaffin cell goblet cell paneth cell tuft cell enterocyte microfold cell liver hepatocyte hepatic stellate cell gallbladder cholecystocyte exocrine component of pancreas centroacinar cell pancreatic stellate cell islets of langerhans alpha cell beta cell delta cell pp cell f cell gamma cell epsilon cell thyroid gland follicular cell parafollicular cell parathyroid gland parathyroid chief cell oxyphil cell urothelial cell germ layer list of distinct cell types in the adult human body'</li><li>'##ing proliferation aligning cells in direction of flow and regulating many cell signalling factors mechanotransduction may act either by positive or negative feedback loops which may activate or repress certain genes to respond to the physical stress or strain placed on the vessel the cell reads flow patterns through integrin sensing receptors which provide a mechanical link between the extracellular matrix and the actin cytoskeleton this mechanism dictates how a cell will respond to flow patterns and can mediate cell adhesion which is especially relevant to the sprouting of new vessels through the process of mechanotransduction shear stress can regulate the expression of many different genes the following examples have been studied in the context of vascular remodelling by biomechanics endothelial nitric oxide synthase enos promotes unidirectional flow at the onset of heart beats and is upregulated by shear stress plateletderived growth factor pdgf transforming growth factor beta tgfβ and kruppellike factor 2 klf2 are induced by shear stress and may have upregulating effects on genes which deal with endothelial response to turbulent flow shear stress induces phosphorylation of vegf receptors which are responsible for vascular development especially the sprouting of new vessels hypoxia can trigger the expression of hypoxia inducible factor 1 hif1 or vegf in order to pioneer the growth of new sprouts into oxygendeprived areas of the embryo pdgfβ vegfr2 and connexion43 are upregulated by abnormal flow patterns shear stress upregulates nfκb which induces matrix metalloproteinases to trigger the enlargement of blood vesselsdifferent flow patterns and their duration can elicit very different responses based on the shearstressregulated genes both genetic regulation and physical forces are responsible for the process of embryonic vascular remodelling yet these factors are rarely studied in tandem the main difficulty in the in vivo study of embryonic vascular remodelling has been to separate the effects of physical cues from the delivery of nutrients oxygen and other signalling factors which may have an effect on vascular remodelling previous work has involved control of blood viscosity in early cardiovascular flow such as preventing the entry of red blood cells into blood plasma thereby lowering viscosity and associated shear stresses starch can also be injected into the blood stream in order to increase viscosity and shear stress studies'</li></ul> |
| 18 | <ul><li>'##ised lines or patterns blind stamps and often small metal pieces of furniture medieval stamps showed animals and figures as well as the vegetal and geometric designs that would later dominate book cover decoration until the end of the period books were not usually stood up on shelves in the modern way the most functional books were bound in plain white vellum over boards and had a brief title handwritten on the spine techniques for fixing gold leaf under the tooling and stamps were imported from the islamic world in the 15th century and thereafter the goldtooled leather binding has remained the conventional choice for high quality bindings for collectors though cheaper bindings that only used gold for the title on the spine or not at all were always more common although the arrival of the printed book vastly increased the number of books produced in europe it did not in itself change the various styles of binding used except that vellum became much less used although early coarse hempen paper had existed in china during the western han period 202 bc – 9 ad the easternhan chinese court eunuch cai lun c 50 – 121 ad introduced the first significant improvement and standardization of papermaking by adding essential new materials into its composition bookbinding in medieval china replaced traditional chinese writing supports such as bamboo and wooden slips as well as silk and paper scrolls the evolution of the codex in china began with foldedleaf pamphlets in the 9th century ad during the late tang dynasty 618 – 907 improved by the butterfly bindings of the song dynasty 960 – 1279 the wrapped back binding of the yuan dynasty 1271 – 1368 the stitched binding of the ming 1368 – 1644 and qing dynasties 1644 – 1912 and finally the adoption of westernstyle bookbinding in the 20th century coupled with the european printing press that replaced traditional chinese printing methods the initial phase of this evolution the accordionfolded palmleafstyle book most likely came from india and was introduced to china via buddhist missionaries and scriptureswith the arrival from the east of rag paper manufacturing in europe in the late middle ages and the use of the printing press beginning in the mid15th century bookbinding began to standardize somewhat but page sizes still varied considerably paper leaves also meant that heavy wooden boards and metal furniture were no longer necessary to keep books closed allowing for much lighter pasteboard covers the practice of rounding and backing the spines of books to create a solid smooth surface and shoulders supporting the textblock against its covers facilitated the upright storage of books and titling on spine this became common practice by the close of the 16th century but was consistently practiced in rome as early as the 1520s'</li><li>'##xtapose their product with another image listed as 123 after juxtaposition the complexity is increased with fusion which is when an advertisers product is combined with another image listed as 456 the most complex is replacement which replaces the product with another product listed as 789 each of these sections also include a variety of richness the least rich would be connection which shows how one product is associated with another product listed as 147 the next rich would be similarity which shows how a product is like another product or image listed as 258 finally the most rich would be opposition which is when advertisers show how their product is not like another product or image listed as 369 advertisers can put their product next to another image in order to have the consumer associate their product with the presented image advertisers can put their product next to another image to show the similarity between their product and the presented image advertisers can put their product next to another image in order to show the consumer that their product is nothing like what the image shows advertisers can combine their product with an image in order to have the consumer associate their product with the presented image advertisers can combine their product with an image to show the similarity between their product and the presented image advertisers can combine their product with another image in order to show the consumer that their product is nothing like what the image shows advertisers can replace their product with an image to have the consumer associate their product with the presented image advertisers can replace their product with an image to show the similarity between their product and the presented image advertisers can replace their product with another image to show the consumer that their product is nothing like what the image showseach of these categories varies in complexity where putting a product next to a chosen image is the simplest and replacing the product entirely is the most complex the reason why putting a product next to a chosen image is the most simple is because the consumer has already been shown that there is a connection between the two in other words the consumer just has to figure out why there is the connection however when advertisers replace the product that they are selling with another image then the consumer must first figure out the connection and figure out why the connection was made visual tropes and tropic thinking are a part of visual rhetoric while the field of visual rhetoric isnt necessarily concerned with the aesthetic choices of a piece the same principles of visual composition may be applied to the study and practice of visual art for example'</li><li>'used to color cloth for a very long time the technique probably reached its peak of sophistication in katazome and other techniques used on silks for clothes during the edo period in japan in europe from about 1450 they were commonly used to color old master prints printed in black and white usually woodcuts this was especially the case with playingcards which continued to be colored by stencil long after most other subjects for prints were left in black and white stencils were used for mass publications as the type did not have to be handwritten stencils were popular as a method of book illustration and for that purpose the technique was at its height of popularity in france during the 1920s when andre marty jean saude and many other studios in paris specialized in the technique low wages contributed to the popularity of the highly laborintensive process when stencils are used in this way they are often called pochoir in the pochoir process a print with the outlines of the design was produced and a series of stencils were used through which areas of color were applied by hand to the page to produce detail a collotype could be produced which the colors were then stenciled over pochoir was frequently used to create prints of intense color and is most often associated with art nouveau and art deco design aerosol stencils have many practical applications and the stencil concept is used frequently in industrial commercial artistic residential and recreational settings as well as by the military government and infrastructure management a template is used to create an outline of the image stencils templates can be made from any material which will hold its form ranging from plain paper cardboard plastic sheets metals and wood stencils are frequently used by official organizations including the military utility companies and governments to quickly and clearly label objects vehicles and locations stencils for an official application can be customized or purchased as individual letters numbers and symbols this allows the user to arrange words phrases and other labels from one set of templates unique to the item being labeled when objects are labeled using a single template alphabet it makes it easier to identify their affiliation or source stencils have also become popular for graffiti since stencil art using spraypaint can be produced quickly and easily these qualities are important for graffiti artists where graffiti is illegal or quasilegal depending on the city and stenciling surface the extensive lettering possible with stencils makes it especially attractive to political artists for example the anarchopunk band crass used stencils of antiwar anarchist feminist and anticonsumerist messages in'</li></ul> |
| 3 | <ul><li>'molecular at a basic level the analysis of size and morphology can provide some information on whether they are likely to be human or from another animal analyzed contents can include those visible to the naked eye such as seeds and other plant remains — to the microscopic including pollen and phytoliths parasites in coprolites can give information on the living conditions and health of ancient populations at the molecular level ancient dna analysis can be used both to identify the species and to provide dietary information a method using lipid analysis can also be used for species identification based on the range of fecal sterols and bile acids these molecules vary between species according to gut biochemistry and so can distinguish between humans and other animals an example of researchers using paleofeces for the gathering of information using dna analysis occurred at hinds cave in texas by hendrik poinar and his team the fecal samples obtained were over 2000 years old from the samples poinar was able to gather dna samples using the analysis methods recounted above from his research poinar found that the feces belonged to three native americans based on mtdna similarities to present day native americans poinar also found dna evidence of the food they ate there were samples of buckthorn acorns ocotillo nightshade and wild tobacco no visible remnants of these plants were visible in the fecal matter along with plant material there were also dna sequences of animal species such as bighorn sheep pronghorn antelope and cottontail rabbit this analysis of the diet was very helpful previously it was assumed that this population of native americans survived with berries being their main source of nutrients from the paleofeces it was determined that these assumptions were incorrect and in the approximately 2 days of food that are represented in a fecal sample 2 – 4 animal species and 4 – 8 plant species were represented the nutritional diversity of this archaic human population was rather extraordinaryan example of the use of lipid analysis for identification of species is at the neolithic site of catalhoyuk in turkey large midden deposits at the site are frequently found to contain fecal material either as distinct coprolites or compressed cess pit deposits this was initially thought to be from dog on the basis of digested bone however an analysis of the lipid profiles showed that many of the coprolites were actually from humansthe analysis of parasites from fecal material within cesspits has provided evidence for health and migration in past populations for example the identification of fish tapeworm eggs in acre in the crusader period indicate that this parasite was transported from northern europe the parasite'</li><li>'but may reject requirements to apply for a permit for certain gathering purposes the central difference being that one is an internal cultural evolution while the other is externally driven by the society or legal body that surrounds the culture'</li><li>'structural functionalism or simply functionalism is a framework for building theory that sees society as a complex system whose parts work together to promote solidarity and stabilitythis approach looks at society through a macrolevel orientation which is a broad focus on the social structures that shape society as a whole and believes that society has evolved like organisms this approach looks at both social structure and social functions functionalism addresses society as a whole in terms of the function of its constituent elements namely norms customs traditions and institutions a common analogy popularized by herbert spencer presents these parts of society as organs that work toward the proper functioning of the body as a whole in the most basic terms it simply emphasizes the effort to impute as rigorously as possible to each feature custom or practice its effect on the functioning of a supposedly stable cohesive system for talcott parsons structuralfunctionalism came to describe a particular stage in the methodological development of social science rather than a specific school of thought in sociology classical theories are defined by a tendency towards biological analogy and notions of social evolutionism functionalist thought from comte onwards has looked particularly towards biology as the science providing the closest and most compatible model for social science biology has been taken to provide a guide to conceptualizing the structure and function of social systems and analyzing evolution processes via mechanisms of adaptation functionalism strongly emphasises the preeminence of the social world over its individual parts ie its constituent actors human subjects while one may regard functionalism as a logical extension of the organic analogies for societies presented by political philosophers such as rousseau sociology draws firmer attention to those institutions unique to industrialized capitalist society or modernity auguste comte believed that society constitutes a separate level of reality distinct from both biological and inorganic matter explanations of social phenomena had therefore to be constructed within this level individuals being merely transient occupants of comparatively stable social roles in this view comte was followed by emile durkheim a central concern for durkheim was the question of how certain societies maintain internal stability and survive over time he proposed that such societies tend to be segmented with equivalent parts held together by shared values common symbols or as his nephew marcel mauss held systems of exchanges durkheim used the term mechanical solidarity to refer to these types of social bonds based on common sentiments and shared moral values that are strong among members of preindustrial societies in modern complex societies members perform very different tasks resulting in a strong interdependence based on the metaphor above of an organism in which many parts function together to sustain the whole durkheim argued that complex societies are held together by solidarity ie social bonds based on'</li></ul> |
| 22 | <ul><li>'1960 by harry hammond hess the ocean drilling program started in 1966 deepsea vents were discovered in 1977 by jack corliss and robert ballard in the submersible dsv alvin in the 1950s auguste piccard invented the bathyscaphe and used the bathyscaphe trieste to investigate the oceans depths the united states nuclear submarine nautilus made the first journey under the ice to the north pole in 1958 in 1962 the flip floating instrument platform a 355foot 108 m spar buoy was first deployed in 1968 tanya atwater led the first allwoman oceanographic expedition until that time gender policies restricted women oceanographers from participating in voyages to a significant extent from the 1970s there has been much emphasis on the application of large scale computers to oceanography to allow numerical predictions of ocean conditions and as a part of overall environmental change prediction early techniques included analog computers such as the ishiguro storm surge computer generally now replaced by numerical methods eg slosh an oceanographic buoy array was established in the pacific to allow prediction of el nino events 1990 saw the start of the world ocean circulation experiment woce which continued until 2002 geosat seafloor mapping data became available in 1995 study of the oceans is critical to understanding shifts in earths energy balance along with related global and regional changes in climate the biosphere and biogeochemistry the atmosphere and ocean are linked because of evaporation and precipitation as well as thermal flux and solar insolation recent studies have advanced knowledge on ocean acidification ocean heat content ocean currents sea level rise the oceanic carbon cycle the water cycle arctic sea ice decline coral bleaching marine heatwaves extreme weather coastal erosion and many other phenomena in regards to ongoing climate change and climate feedbacks in general understanding the world ocean through further scientific study enables better stewardship and sustainable utilization of earths resources the intergovernmental oceanographic commission reports that 17 of the total national research expenditure of its members is focused on ocean science the study of oceanography is divided into these five branches biological oceanography investigates the ecology and biology of marine organisms in the context of the physical chemical and geological characteristics of their ocean environment chemical oceanography is the study of the chemistry of the ocean whereas chemical oceanography is primarily occupied with the study and understanding of seawater properties and its changes ocean chemistry focuses primarily on the geochemical cycles the following is a central topic investigated by chemical oceanography ocean acidification ocean acidification describes the decrease in ocean ph that is caused by anthropogenic carbon dioxide co2 emissions into the atmosphere seawater is slightly alkaline'</li><li>'maintained by the hydrological division of the usgs for large streams for a basin with an area of 5000 square miles or more the river system is typically gauged at five to ten places the data from each gauging station apply to the part of the basin upstream that location given several decades of peak annual discharges for a river limited projections can be made to estimate the size of some large flow that has not been experienced during the period of record the technique involves projecting the curve graph line formed when peak annual discharges are plotted against their respective recurrence intervals however in most cases the curve bends strongly making it difficult to plot a projection accurately this problem can be overcome by plotting the discharge andor recurrence interval data on logarithmic graph paper once the plot is straightened a line can be ruled drawn through the points a projection can then be made by extending the line beyond the points and then reading the appropriate discharge for the recurrence interval in question runoff of water in channels is responsible for transport of sediment nutrients and pollution downstream without streamflow the water in a given watershed would not be able to naturally progress to its final destination in a lake or ocean this would disrupt the ecosystem streamflow is one important route of water from the land to lakes and oceans the other main routes are surface runoff the flow of water from the land into nearby watercourses that occurs during precipitation and as a result of irrigation flow of groundwater into surface waters and the flow of water from constructed pipes and channels streamflow confers on society both benefits and hazards runoff downstream is a means to collect water for storage in dams for power generation of water abstraction the flow of water assists transport downstream a given watercourse has a maximum streamflow rate that can be accommodated by the channel that can be calculated if the streamflow exceeds this maximum rate as happens when an excessive amount of water is present in the watercourse the channel cannot handle all the water and flooding occurs the 1993 mississippi river flood the largest ever recorded on the river was a response to a heavy long duration spring and summer rainfalls early rains saturated the soil over more than a 300000 square miles of the upper watershed greatly reducing infiltration and leaving soils with little or no storage capacity as rains continued surface depressions wetlands ponds ditches and farm fields filled with overland flow and rainwater with no remaining capacity to hold water additional rainfall was forced from the land into tributary channels and thence to the mississippi river for more than a month the total load of water from hundreds of tributaries exceeded the mississippi ’ s channel capacity causing it to spill over'</li><li>'double mass analysis is a simple graphical method to evaluate the consistency of hydrological data the dm approach plots the cumulative data of one variable against the cumulative data of a second variable a break in the slope of a linear function fit to the data is thought to represent a change in the relation between the variables this approach provides a robust method to determine a change in the behavior of precipitation and recharge in a simple graphical method it is a commonly used data analysis approach for investigating the behaviour of records made of hydrological or meteorological data at a number of locations it is used to determine whether there is a need for corrections to the data to account for changes in data collection procedures or other local conditions such changes may result from a variety of things including changes in instrumentation changes in observation procedures or changes in gauge location or surrounding conditions double mass analysis for checking consistency of a hydrological or meteorological record is considered to be an essential tool before taking it for analysis purpose this method is based on the hypothesis that each item of the recorded data of a population is consistentan example of a double mass analysis is a double mass plot or double mass curve for this points andor a joining line are plotted where the x and y coordinates are determined by the running totals of the values observed at two stations if both stations are affected to the same extent by the same trends then a double mass curve should follow a straight line a break in the slope of the curve would indicate that conditions have changed at one location but not at another breaks in the doublemass curve of such variables are caused by changes in the relation between the variables these changes may be due to changes in the method of data collection or to physical changes that affect the relation this technique is based on the principle that when each recorded data comes from the same parent population they are consistent let x i y i displaystyle xiyi be the data points then the procedure for double mass analysis is as follows divide the data into n i displaystyle ni distinct categories of equal slope s i displaystyle si obtain correction factor for category n i 1 displaystyle ni1 as c i s i s i 1 displaystyle cifrac sisi1 multiply n i 1 displaystyle ni1 category with c i displaystyle ci to get corrected data after correction repeat this process until all data points have the same slope statistics dubreuil p 1974 initiation a lanalyse hydrologique masson cie et orstom paris'</li></ul> |
| 24 | <ul><li>'sasaki is a design firm specializing in architecture interior design urban design space planning landscape architecture ecology civil engineering and place branding the firm is headquartered in boston massachusetts but practices on an international scale with offices in shanghai and denver colorado and clients and projects globally sasaki was founded in 1953 by landscape architect hideo sasaki while he served as a professor and landscape architecture chair at the harvard graduate school of design sasaki was founded upon collaborative interdisciplinary design unprecedented in design practice at the time and an emphasis on the integration of land buildings people and their contextsthrough the mid to late 1900s sasaki designed plazas including copley square corporate parks college campuses and master plans among other projectsthe firm includes a team of in house designers software developers and data analysts who support the practice today sasaki has over 300 employees across its diverse practice areas and between its two offices the firm engages in a wide variety of project types across its many disciplines in 2000 in honor of the passing of the firms founder the family of hideo sasaki together with sasaki and other financial supporters established the sasaki foundation the foundation which is a separate entity from sasaki gives yearly grants supporting communityled research at sasaki in 2012 sasaki opened an office in shanghai to support the firms work in china and the larger asia pacific regionin 2018 sasaki opened the incubator a coworking space designed by and located within the sasaki campus which houses the sasaki foundation as curator of programming the 5000 squarefoot space is home to several likeminded nonprofits organizations and individualsin 2020 sasaki established a new office in denver colorado marking the firms third physical studio location opening an office in denver a region where sasaki has been working since the 1960s positions sasaki to deliver on projects across western north america in 2007 sasaki was honored as the american society of landscape architects firm of the year in 2012 sasaki won the american planning association firm of the year awardsasaki has earned numerous consecutive pierre lenfant international planning awards from the american planning association in 2017 two of the five annual finalists for the rudy bruner award for urban excellence were sasaki projects the bruce c bolling municipal building boston ma and the chicago riverwalk both were recognized as silver medalists sasaki has been named a top 50 firm by architect magazine numerous timesthe firm has been recognized by the boston society of landscape architects bsla boston society of architects bsa american planning association apa american institute of architecture aia society for college and university planning scup urban land initiative uli dezeen and fast company among others notable sasakisp'</li><li>'to mark their termini the new fountains were expressions of the new baroque art which was officially promoted by the catholic church as a way to win popular support against the protestant reformation the council of trent had declared in the 16th century that the church should counter austere protestantism with art that was lavish animated and emotional the fountains of rome like the paintings of rubens were examples of the principles of baroque art they were crowded with allegorical figures and filled with emotion and movement in these fountains sculpture became the principal element and the water was used simply to animate and decorate the sculptures they like baroque gardens were a visual representation of confidence and powerthe first of the fountains of st peters square by carlo maderno 1614 was one of the earliest baroque fountains in rome made to complement the lavish baroque facade he designed for st peters basilica behind it it was fed by water from the paola aqueduct restored in 1612 whose source was 266 feet 81 m above sea level which meant it could shoot water twenty feet up from the fountain its form with a large circular vasque on a pedestal pouring water into a basin and an inverted vasque above it spouting water was imitated two centuries later in the fountains of the place de la concorde in paris the triton fountain in the piazza barberini 1642 by gian lorenzo bernini is a masterpiece of baroque sculpture representing triton halfman and halffish blowing his horn to calm the waters following a text by the roman poet ovid in the metamorphoses the triton fountain benefited from its location in a valley and the fact that it was fed by the aqua felice aqueduct restored in 1587 which arrived in rome at an elevation of 194 feet 59 m above sea level fasl a difference of 130 feet 40 m in elevation between the source and the fountain which meant that the water from this fountain jetted sixteen feet straight up into the air from the conch shell of the tritonthe piazza navona became a grand theater of water with three fountains built in a line on the site of the stadium of domitian the fountains at either end are by giacomo della porta the neptune fountain to the north 1572 shows the god of the sea spearing an octopus surrounded by tritons sea horses and mermaids at the southern end is il moro possibly also a figure of neptune riding a fish in a conch shell in the center is the fontana dei quattro fiumi the fountain of the four rivers 1648 – 51 a highly theatrical fountain by bernini with statues representing rivers from the four continents the nile danube'</li><li>'law the techniques of coppicing and hard pollarding can be used to rejuvenate a hedge where hedgelaying is not appropriate the term instant hedge has become known since early this century for hedging plants that are planted collectively in such a way as to form a mature hedge from the moment they are planted together with a height of at least 12 metres they are usually created from hedging elements or individual plants which means very few are actually hedges from the start as the plants need time to grow and entwine to form a real hedge an example of an instant hedge can be seen at the elveden hall estate in east anglia where fields of hedges can be seen growing in cultivated rows since 1998 the development of this type of mature hedge has led to such products being specified by landscape architects garden designers property developers insurance companies sports clubs schools and local councils as well as many private home owners demand has also increased from planning authorities in specifying to developers that mature hedges are planted rather than just whips a slender unbranched shoot or plant a real instant hedge could be defined as having a managed root growth system allowing the hedge to be sold with a continuous rootstrips rather than individual plants which then enables yearround planting during its circa 8year production time all stock should be irrigated clipped and treated with controlledrelease nutrients to optimise health a quickset hedge is a type of hedge created by planting live whitethorn common hawthorn cuttings directly into the earth hazel does not sprout from cuttings once planted these cuttings root and form new plants creating a dense barrier the technique is ancient and the term quickset hedge is first recorded in 1484 the word quick in the name refers to the fact that the cuttings are living as in the quick and the dead and not to the speed at which the hedge grows although it will establish quite rapidly an alternative meaning of quickset hedging is any hedge formed of living plants or of living plants combined with a fence the technique of quicksetting can also be used for many other shrubs and trees a devon hedge is an earth bank topped with shrubs the bank may be faced with turf or stone when stonefaced the stones are generally placed on edge often laid flat around gateways a quarter of devons hedges are thought to be over 800 years old there are approximately 33000 miles 53000 km of devon hedge which is more than any other county traditional farming throughout the county has meant that fewer devon hedges have been removed than elsewhere devon hedges are particularly important for wildlife habitat around 20 of'</li></ul> |
| 30 | <ul><li>'difficulty adjusting to this experience although adult daughters also tend to express difficulty however this may be a factor of age moreso than the relationship to the patient in that spouses tend to be older caregivers than adult children many studies have suggested that intervention may curb stress levels of caregivers there are many types of interventions available for cancer caregivers including educational problemsolving skills training and grief therapy familyfocused grief therapy has been shown to significantly improve overall distress levels and depression in those affected by cancer likewise interventions that increased patients general knowledge about their specific disease have been reported to reduce anxiety distress and help them take a more active part in the decision making process interventions by members of the healthcare system designed to teach caregivers proficiency in both the physical and psychological care of patients have been shown to benefit both partners interventions that focus on both the patient and the caregiver as a couple have proven more effective in helping adaptation to cancer than those that try to help the patient or caregiver individually largely due to the inclusion of training in supportive communication sexual counselling and partner support finally spirituality has been demonstrated to be related to quality of life for caregivers not every caregiver experiences only negative consequences from cancer caregiving for some caregivers there are personal benefits that stem from caring for their loved one and the benefits found might help to buffer the negative experiences that caregivers frequently face the concept of posttraumatic growth is of particular note when discussing the benefits of cancer caregiving and cancer in general posttraumatic growth is a positive psychological growth that occurs as a result of a traumatic incident studies have found that within the cancer caregiver population strong predictors of posttraumatic growth are less education being employed or displaying high avoidance tendencies presurgery and framing coping strategies in a positive style furthermore individuals who engage in religious coping or have high perceived social support are more likely to report posttraumatic growth other benefits of caregiving include an improved sense of selfworth increased selfsatisfaction a sense of mastery increased intimacy with their ill loved one and a sense of meaning experiencing a loved ones cancer may also cause significant lifestyle changes for caregivers for instance caregivers may become more proactive by engaging in health behaviours such as increased exercise better diets and increased screening however this finding is not conclusive some studies report that certain behaviours such as screening tend to decrease amongst caregivers'</li><li>'in oncology the fact that one round of chemotherapy does not kill all the cells in a tumor is a poorly understood phenomenon called fractional kill or fractional cell kill the fractional kill hypothesis states that a defined chemotherapy concentration applied for a defined time period will kill a constant fraction of the cells in a population independent of the absolute number of cells in solid tumors poor access of the tumor to the drug can limit the fraction of tumor cells killed but the validity of the fractional kill hypothesis has also been established in animal models of leukemia as well as in human leukemia and lymphoma where drug access is less of an issuebecause only a fraction of the cells die with each treatment repeated doses must be administered to continue to reduce the size of the tumor current chemotherapy regimens apply drug treatment in cycles with the frequency and duration of treatments limited by toxicity to the patient the goal is to reduce the tumor population to zero with successive fractional kills for example assuming a 99 kill per cycle of chemotherapy a tumor of 1011 cells would be reduced to less than one cell with six treatment cycles 1011 0016 1 however the tumor can also regrow during the intervals between treatments limiting the net reduction of each fractional kill the fractional killing of tumors in response to treatment is assumed to be due to the cell cycle specificity of chemotherapy drugs cytarabine a dnasynthesis inhibitor also known as arac is cited as the classic cell cycle phasespecific agent chemotherapy dosing schedules have been optimized based on the fact that cytarabine is only expected to be effective in the dna synthesis s phase of the cell cycle consistent with this leukemia patients respond better to cytarabine treatments given every 12 hours rather than every 24 hours this finding that can be explained by the fact that sphase in these leukemia cells lasts 18 – 20 hours allowing some cells to escape the cytotoxic effect of the drug if it is given every 24 hours however alternative explanations are possible as described below very little direct information is available on whether cells undergo apoptosis from a certain point in the cell cycle one study which did address this topic used flow cytometry or elutriation of synchronized cells treated with actinomycin d1 camptothecin or aphidicolin each of which had been documented to exert its effects in a particular phase of the cell cycle surprisingly the authors found that each of the agents was able to induce apoptosis in all phases of the cell cycle suggesting that the mechanism through which the drugs induce apoptosis may'</li><li>'a myeloma protein is an abnormal antibody immunoglobulin or more often a fragment thereof such as an immunoglobulin light chain that is produced in excess by an abnormal monoclonal proliferation of plasma cells typically in multiple myeloma or monoclonal gammopathy of undetermined significance other terms for such a protein are monoclonal protein m protein m component m spike spike protein or paraprotein this proliferation of the myeloma protein has several deleterious effects on the body including impaired immune function abnormally high blood viscosity thickness of the blood and kidney damage the concept and the term paraprotein were introduced by the berlin pathologist dr kurt apitz in 1940 then the senior physician of the pathological institute at the charite hospitalparaproteins allowed the detailed study of immunoglobulins which eventually led to the production of monoclonal antibodies in 1975 myeloma is a malignancy of plasma cells plasma cells produce immunoglobulins which are commonly called antibodies there are thousands of different antibodies each consisting of pairs of heavy and light chains antibodies are typically grouped into five classes iga igd ige igg and igm when someone has myeloma a malignant clone a rogue plasma cell reproduces in an uncontrolled fashion resulting in overproduction of the specific antibody the original cell was generated to produce each type of antibody has a different number of light chain and heavy chain pairs as a result there is a characteristic normal distribution of these antibodies in the blood by molecular weight when there is a malignant clone there is usually overproduction of a single antibody resulting in a spike on the normal distribution sharp peak on the graph which is called an m spike or monoclonal spike people will sometimes develop a condition called mgus monoclonal gammopathy of undetermined significance where there is overproduction of one antibody but the condition is benign noncancerous an explanation of the difference between multiple myeloma and mgus can be found in the international myeloma foundations patient handbook and concise reviewdetection of paraproteins in the urine or blood is most often associated with mgus where they remain silent and multiple myeloma an excess in the blood is known as paraproteinemia paraproteins form a narrow band or spike in protein electrophoresis as they are all exactly the same protein unlike normal immunoglobulin antibodies paraproteins cannot fight infection serum free lightchai'</li></ul> |
| 42 | <ul><li>'the 1800s in particular louis pasteurs work with the rabies vaccine in the late 1800s exemplifies this methodpasteur created several vaccines over the course of his lifetime his work prior to rabies involved attenuation of pathogens but not through serial passage in particular pasteur worked with cholera and found that if he cultured bacteria for long periods of time he could create an effective vaccine pasteur thought that there was something special about oxygen and this was why he was able to attenuate create a less virulent version of the bacteria pasteur also tried to apply this method to create a vaccine for anthrax although with less successnext pasteur wanted to apply this method to create a vaccine for rabies however rabies was unbeknownst to him caused by a virus not a bacterial pathogen like cholera and anthrax and for that reason rabies could not be cultured in the same way that cholera and anthrax could be methods for serial passage for viruses in vitro were not developed until the 1940s when john enders thomas huckle weller and frederick robbins developed a technique for this these three scientists subsequently won the nobel prize for their major advancementto solve this problem pasteur worked with the rabies virus in vivo in particular he took brain tissue from an infected dog and transplanted it into another dog repeating this process multiple times and thus performing serial passage in dogs these attempts increased the virulence of the virus then he realized that he could put dog tissue into a monkey to infect it and then perform serial passage in monkeys after completing this process and infecting a dog with the resulting virus pasteur realized that the virus was less virulent mostly pasteur worked with the rabies virus in rabbits ultimately to create his vaccine for rabies pasteur used a simple method that involved drying out tissue as is described in his notebook in a series of flasks in which air is maintained in a dry state … each day one suspends a thickness of fresh rabbit spinal tissue taken from a rabbit dead of rabies each day as well one inoculates under the skin of a dog 1 ml of sterilized bouillion in which has dispersed a small fragment of one of these desiccated spinal pieces beginning with a piece most distant in time from when it was worked upon in order to be sure that it is not at all virulent pasteur mostly used other techniques besides serial passage to create his vaccines however the idea of attenuating a virus through serial passage still holds one way to attenuate a virus'</li><li>'endogenous retrovirus endogenous viral element adenoassociated virus bornavirus paleovirus'</li><li>'viral load also known as viral burden is a numerical expression of the quantity of virus in a given volume of fluid including biological and environmental specimens it is not to be confused with viral titre or viral titer which depends on the assay when an assay for measuring the infective virus particle is done plaque assay focus assay viral titre often refers to the concentration of infectious viral particles which is different from the total viral particles viral load is measured using body fluids sputum and blood plasma as an example of environmental specimens the viral load of norovirus can be determined from runoff water on garden produce norovirus has not only prolonged viral shedding and has the ability to survive in the environment but a minuscule infectious dose is required to produce infection in humans less than 100 viral particlesviral load is often expressed as viral particles virions or infectious particles per ml depending on the type of assay a higher viral burden titre or viral load often correlates with the severity of an active viral infection the quantity of virus per ml can be calculated by estimating the live amount of virus in an involved fluid for example it can be given in rna copies per millilitre of blood plasma tracking viral load is used to monitor therapy during chronic viral infections and in immunocompromised patients such as those recovering from bone marrow or solid organ transplantation currently routine testing is available for hiv1 cytomegalovirus hepatitis b virus and hepatitis c virus viral load monitoring for hiv is of particular interest in the treatment of people with hiv as this is continually discussed in the context of management of hivaids an undetectable viral load does not implicate a lack of infection hiv positive patients on longterm combination antiretroviral therapy may present with an undetectable viral load on most clinical assays since the concentration of virus particles is below the limit of detection lod a 2010 review study by puren et al categorizes viral load testing into three types 1 nucleic acid amplification based tests nats or naats commercially available in the united states with food and drug administration fda approval or on the market in the european economic area eea with the ce marking 2 home – brew or inhouse nats 3 nonnucleic acidbased test there are many different molecular based test methods for quantifying the viral load using nats the starting material for amplification can be used to divide these molecular methods into three groups target amplification which uses the nucleic acid itself just a few of the'</li></ul> |
| 5 | <ul><li>'greater than zeroas an example of a low estimate combining nasas star formation rates the rare earth hypothesis value of fp · ne · fl 10−5 mayrs view on intelligence arising drakes view of communication and shermers estimate of lifetime r∗ 15 – 3 yr−1 fp · ne · fl 10−5 fi 10−9 fc 02drake above and l 304 yearsgives n 15 × 10−5 × 10−9 × 02 × 304 91 × 10−13ie suggesting that we are probably alone in this galaxy and possibly in the observable universe on the other hand with larger values for each of the parameters above values of n can be derived that are greater than 1 the following higher values that have been proposed for each of the parameters r∗ 15 – 3 yr−1 fp 1 ne 02 fl 013 fi 1 fc 02drake above and l 109 yearsuse of these parameters gives n 3 × 1 × 02 × 013 × 1 × 02 × 109 15600000monte carlo simulations of estimates of the drake equation factors based on a stellar and planetary model of the milky way have resulted in the number of civilizations varying by a factor of 100 in 2016 adam frank and woodruff sullivan modified the drake equation to determine just how unlikely the event of a technological species arising on a given habitable planet must be to give the result that earth hosts the only technological species that has ever arisen for two cases a this galaxy and b the universe as a whole by asking this different question one removes the lifetime and simultaneous communication uncertainties since the numbers of habitable planets per star can today be reasonably estimated the only remaining unknown in the drake equation is the probability that a habitable planet ever develops a technological species over its lifetime for earth to have the only technological species that has ever occurred in the universe they calculate the probability of any given habitable planet ever developing a technological species must be less than 25×10−24 similarly for earth to have been the only case of hosting a technological species over the history of this galaxy the odds of a habitable zone planet ever hosting a technological species must be less than 17×10−11 about 1 in 60 billion the figure for the universe implies that it is extremely unlikely that earth hosts the only technological species that has ever occurred on the other hand for this galaxy one must think that fewer than 1 in 60 billion habitable planets develop a technological species for there not to have been at least a second case of such a species over the past history of this galaxy as many observers have pointed'</li><li>'the possibility of life on venus is a subject of interest in astrobiology due to venuss proximity and similarities to earth to date no definitive evidence has been found of past or present life there in the early 1960s studies conducted via spacecraft demonstrated that the current venusian environment is extreme compared to earths studies continue to question whether life could have existed on the planets surface before a runaway greenhouse effect took hold and whether a relict biosphere could persist high in the modern venusian atmosphere with extreme surface temperatures reaching nearly 735 k 462 °c 863 °f and an atmospheric pressure 92 times that of earth the conditions on venus make waterbased life as we know it unlikely on the surface of the planet however a few scientists have speculated that thermoacidophilic extremophile microorganisms might exist in the temperate acidic upper layers of the venusian atmosphere in september 2020 research was published that reported the presence of phosphine in the planets atmosphere a potential biosignature however doubts have been cast on these observationsas of 8 february 2021 an updated status of studies considering the possible detection of lifeforms on venus via phosphine and mars via methane was reported on 2 june 2021 nasa announced two new related missions to venus davinci and veritas because venus is completely covered in clouds human knowledge of surface conditions was largely speculative until the space probe era until the mid20th century the surface environment of venus was believed to be similar to earth hence it was widely believed that venus could harbor life in 1870 the british astronomer richard a proctor said the existence of life on venus was impossible near its equator but possible near its poles science fiction writers were free to imagine what venus might be like until the 1960s among the speculations were that it had a junglelike environment or that it had oceans of either petroleum or carbonated water microwave observations published by c mayer et al in 1958 indicated a hightemperature source 600 k strangely millimetreband observations made by a d kuzmin indicated much lower temperatures two competing theories explained the unusual radio spectrum one suggesting the high temperatures originated in the ionosphere and another suggesting a hot planetary surface in 1962 mariner 2 the first successful mission to venus measured the planets temperature for the first time and found it to be about 500 degrees celsius 900 degrees fahrenheit since then increasingly clear evidence from various space probes showed venus has an extreme climate with a greenhouse effect generating a constant temperature of about 500 °c 932 °f on the surface the atmosphere contains sulfuric acid clouds in 1968 nasa reported that air pressure on'</li><li>'##restrial life popular magazine entertainment weekly gave the book a grade of b saying it was not an easy read but calling it a live elegant overview it was reviewed by nature physics today and new scientist with the latter commenting on occasional digressions but declaring the book beautifully written reader reviews are 85 five stars on amazon and over 90 like the book on goodreads the 2011 paperback edition has updates to help keep up with the accelerating pace of exoplanet discovery'</li></ul> |
| 41 | <ul><li>'from the current plaza de la universidad his motto was e daniel molina project no documentation of this project is preserved except for the proposed solution for the plaza de cataluna his motto was hygiene comfort and beautyjosep fontsere project jose fontsere was a young architect son of the municipal architect jose fontsere domenech and won the third runnerup prize with a project that enhanced the centrality of passeig de gracia and linked the neighboring centers with a set of diagonals that respected their original plots his motto was do not destroy to build but conserve to rectify and build to enlarge garriga i roca project the municipal architect miquel garriga i roca presented six projects the best qualified responded to a grid solution that linked the city with gracia leaving only sketched lines that would have to continue developing the future plot his motto was one more sacrifice to contribute to the eixample of barcelonaother projects the project of josep massanes and that of jose maria planas proposed a mere extension while maintaining the wall around the new space the latter had a similarity with the project presented by the owners of the paseo de gracia since both projects were based on a mere extension on both sides of the paseo de gracia two other simpler projects were that of tomas bertran soler who proposed a new neighborhood in place of the citadel converting the passeig de sant joan into an axis similar to the rambla and a very elementary one attributed to francisco soler mestres who died three days before the reading of the prizes according to the municipal council the winning project was a proposal by antoni rovira based on a circular mesh that enveloped the walled city and grew radially harmoniously integrating the surrounding villages it was presented with the slogan le trace dune ville est oeuvre du temps plutot que darchitecte the phrase is originally from leonce reynaud an architectural reference of rovira it was structured in three areas where the different sectors of the population were combined with social activities with a logic of neighborhoods and hierarchy of space and public services based on a proposal to replace the wall a mesh of rectangular blocks with a central courtyard and a height of 19 meters was deployed a few main streets were the junction between blocks of the hippodamus structure to readjust the square profile to the semicircle that surrounded the city rovira proposes his solution with a clear center located in the plaza de cataluna while cerda moved the centrality to the plaza de la gloria'</li><li>'to hire opticos design inc in berkeley california to draft the codebecause of the growing number of consultants advertising themselves as capable of writing fbcs but with little or no training in 2004 the nonprofit formbased codes institute was organized to establish standards and teach best practices in addition smartcode workshops are regularly scheduled by placemakerscom smartcodeprocom and smartcodelocalcom in spring 2014 a new graduatelevel studio dedicated to formbased coding was launched at california state polytechnic university “ formbased codes in the context of integrated urbanism ” is one of the only full courses on the subject in the country the course is taught by tony perez director of formbased coding at opticos design formbased codes commonly include the following elements regulating plan a plan or map of the regulated area designating the locations where different building form standards apply based on clear community intentions regarding the physical character of the area being coded public space standards specifications for the elements within the public realm eg sidewalks travel lanes onstreet parking street trees street furniture etc building form standards regulations controlling the configuration features and functions of buildings that define and shape the public realm administration a clearly defined application and project review process definitions a glossary to ensure the precise use of technical termsformbased codes also sometimes include architectural standards regulations controlling external architectural materials and quality landscaping standards regulations controlling landscape design and plant materials on private property as they impact public spaces eg regulations about parking lot screening and shading maintaining sight lines insuring unobstructed pedestrian movements etc signage standards regulations controlling allowable signage sizes materials illumination and placement environmental resource standards regulations controlling issues such as storm water drainage and infiltration development on slopes tree protection solar access etc annotation text and illustrations explaining the intentions of specific code provisions the types of buildings that make for a lively main street are different from the types of buildings that make for a quiet residential street building form standards are sets of enforceable design regulations for controlling building types and how they impact the public realm these standards are mapped to streets on a regulating plan building form standards can control such things as the alignment of buildings to the street how close buildings are to sidewalks the visibility and accessibility of building entrances minimum and maximum buildings heights minimum or maximum lot frontage coverage minimum and maximum amounts of window coverage on facades physical elements required on buildings eg stoops porches types of permitted balconies and the general usage of floors eg office residential or retail these regulations are less concerned with architectural styles and designs than in how buildings shape public spaces if a local government also wishes to'</li><li>'a parisian influencehowever city beautiful was not solely concerned with aesthetics the term ‘ beautility ’ derived from the american city beautiful philosophy which meant that the beautification of a city must also be functional beautility including the proven economic value of improvements influenced australian town planningthere were no formal city beautiful organisations that led this movement in australia rather it was influenced by communications among professionals and bureaucrats in particular architectplanners and local government reformers in the early federation era some influential australians were determined that their cities be progressive and competitive adelaide was used as an australian example of the “ benefits of comprehensive civic design ” with its ring of parklands beautification of the city of hobart for example was considered a way to increase the city ’ s popularity as a tourist destination walter burley griffin incorporated city beautiful principles for his design for canberra griffin was influenced by washington dc with grand axes and vistas and a strong central focal point with specialised centres and being a landscape architect used the landscape to complement this layout john sulman however was australias leading proponent of the city beautiful movement and in 1921 wrote the book an introduction to australian city planning both the city beautiful and the garden city philosophies were represented by sulman ’ s “ geometric or contour controlled ” designs of the circulatory road systems in canberra the widths of pavements were also reduced and vegetated areas were increased such as planted road verges melbourne ’ s grid plan was considered dull and monotonous by some people and so the architect william campbell designed a blueprint for the city the main principle behind this were diagonal streets providing sites for new and comprehensive architecture and for special buildings the designs of paris and washington were major inspirations for this plan world war i prolonged the city beautiful movement in australia where more memorials were erected than in any other country although city beautiful or artistic planning became a part of comprehensive town planning the great depression of the 1930s largely ended this fashion defensible space garden city movement mira lloyd dock and the progressive era conservation movement van nus w 1975 the fate of city beautiful thought in canada 1893 – 1930 historical papers communications historiques edmonton the canadian historical associationla societe historique du canada 10 1 191 – 210 doi107202030796ar'</li></ul> |
| 32 | <ul><li>'##tyle widehat tau alpha omega begincasesfrac left1leftr01alpha right2rightleft1leftr02alpha right2rightleft1r01alpha r02alpha exp left2ikz0lrightright2textif krho leq omega cfrac 4im leftr01alpha rightim leftr02alpha rightexp left2leftkz0rightlrightleft1r01alpha r02alpha exp left2leftkz0rightlrightright2textif krho omega cendcases where r 0 j α displaystyle r0jalpha are the fresnel reflection coefficients for α s p displaystyle alpha sp polarized waves between media 0 and j 1 2 displaystyle j12 k z 0 ω c 2 − k ρ 2 displaystyle kz0sqrt omega c2krho 2 is the component of the wavevector in the region 0 perpendicular to the surface of the halfspace l displaystyle l is the separation distance between the two halfspaces and c displaystyle c is the speed of light in vacuumcontributions to heat transfer for which k ρ ≤ ω c displaystyle krho leq omega c arise from propagating waves whereas contributions from k ρ ω c displaystyle krho omega c arise from evanescent waves thermophotovoltaic energy conversion thermal rectification localized cooling heatassisted magnetic recording'</li><li>'francis 1852 pp 238 – 333 cited page numbers are from the translation a fresnel ed h de senarmont e verdet and l fresnel 1866 – 70 oeuvres completes daugustin fresnel 3 volumes paris imprimerie imperiale vol 1 1866 vol 2 1868 vol 3 1870 e hecht 2017 optics 5th ed pearson education isbn 9781292096933 c huygens 1690 traite de la lumiere leiden van der aa translated by sp thompson as treatise on light university of chicago press 1912 project gutenberg 2005 cited page numbers match the 1912 edition and the gutenberg html edition b powell july 1856 on the demonstration of fresnels formulas for reflected and refracted light and their applications philosophical magazine and journal of science series 4 vol 12 no 76 pp 1 – 20 ja stratton 1941 electromagnetic theory new york mcgrawhill e t whittaker 1910 a history of the theories of aether and electricity from the age of descartes to the close of the nineteenth century london longmans green co'</li><li>'to compensate for this change as an example the index drop for different glass types is displayed in the picture on the right for different annealing rates note that the annealing rate is not necessarily constant during the cooling process typical “ average ” annealing rates for precision molding are between 1000 kh and 10000 kh or higher not only the refractive index but also the abbenumber of the glass is changed due to fast annealing the shown points in the picture on the right indicate an annealing rate of 3500khsocalled lowtgglasses with a maximum transition temperature of less than 550 °c have been developed in order to enable new manufacturing routes for the moulds mould materials such as steel can be used for moulding lowtgglasses whereas hightg – glasses require a hightemperature mould material such as tungsten carbide the mould material must have sufficient strength hardness and accuracy at high temperature and pressure good oxidation resistance low thermal expansion and high thermal conductivity are also required the material of the mould has to be suitable to withstand the process temperatures without undergoing deforming processes therefore the mould material choice depends critically on the transition temperature of the glass material for lowtgglasses steel moulds with a nickel alloy coating can be used since they cannot withstand the high temperatures required for regular optical glasses heatresistant materials such as carbide alloys have to be used instead in this case in addition mould materials include aluminium alloys glasslike or vitreous carbon silicon carbide silicon nitride and a mixture of silicon carbide and carbona commonly used material in mould making is tungsten carbide the mould inserts are produced by means of powder metallurgy ie a sintering process followed by postmachining processes and sophisticated grinding operations most commonly a metallic binder usually cobalt is added in liquid phase sintering in this process the metallic binder improves the toughness of the mould as well as the sintering quality in the liquid phase to fully dense material moulds made of hard materials have a typical lifetime of thousands of parts size dependent and are costeffective for volumes of 2001000 depending upon the size of the part this article describes how mould inserts are manufactured for precision glass moulding in order to ensure high quality standards metrology steps are implemented between each process step powder processing this process step is responsible for achieving grain sizes suitable for pressing and machining the powder is processed by milling the raw material pressing'</li></ul> |
| 17 | <ul><li>'the 20th century however the glacier is still over 30 km 19 mi long in sikkim 26 glaciers examined between the years 1976 and 2005 were retreating at an average rate of 1302 m 427 ft per year overall glaciers in the greater himalayan region that have been studied are retreating an average of between 18 and 20 m 59 and 66 ft annually the only region in the greater himalaya that has seen glacial advances is in the karakoram range and only in the highest elevation glaciers but this has been attributed possibly increased precipitation as well as to the correlating glacial surges where the glacier tongue advances due to pressure build up from snow and ice accumulation further up the glacier between the years 1997 and 2001 68 km 42 mi long biafo glacier thickened 10 to 25 m 33 to 82 ft midglacier however it did not advance with the retreat of glaciers in the himalayas a number of glacial lakes have been created a growing concern is the potential for glofs researchers estimate 21 glacial lakes in nepal and 24 in bhutan pose hazards to human populations should their terminal moraines fail one glacial lake identified as potentially hazardous is bhutans raphstreng tsho which measured 16 km 099 mi long 096 km 060 mi wide and 80 m 260 ft deep in 1986 by 1995 the lake had swollen to a length of 194 km 121 mi 113 km 070 mi in width and a depth of 107 m 351 ft in 1994 a glof from luggye tsho a glacial lake adjacent to raphstreng tsho killed 23 people downstreamglaciers in the akshirak range in kyrgyzstan experienced a slight loss between 1943 and 1977 and an accelerated loss of 20 of their remaining mass between 1977 and 2001 in the tien shan mountains which kyrgyzstan shares with china and kazakhstan studies in the northern areas of that mountain range show that the glaciers that help supply water to this arid region lost nearly 2 km3 048 cu mi of ice per year between 1955 and 2000 the university of oxford study also reported that an average of 128 of the volume of these glaciers had been lost per year between 1974 and 1990the pamirs mountain range located primarily in tajikistan has approximately eight thousand glaciers many of which are in a general state of retreat during the 20th century the glaciers of tajikistan lost 20 km3 48 cu mi of ice the 70 km 43 mi long fedchenko glacier which is the largest in tajikistan and the largest nonpolar glacier on earth retreated 1 km 062 mi between the years 1933 and 2006 and lost 44 km2 17 sq mi of its surface area due'</li><li>'sheets a 3d icesheet model which accounts for polythermal conditions coexistence of ice at and below the melting point in different parts of an ice sheet'</li><li>'made of the glaciers form and expected depth and the results were in quite good agreement with their expectations in total blumcke and hess completed 11 holes to the glacier bed between 1895 and 1909 and drilled many more holes that did not penetrate the glacier the deepest hole they drilled was 224 m vallot dutoit and mercanton in 1897 emile vallot drilled a 25 m hole in the mer de glace using a 3 m high cable tool with a steel drillbit which had crossshaped blades and weighed 7 kg this proved to be too light to drill effectively and only 1 m progress was made on the first day a 20 kg iron rod was added and progress improved to 2 m per hour a stick was used to twist the rope above the hole and as it untwisted it cut a circular hole the hole diameter was 6 cm the rope was also pulled back and let fall so the drill used a combination of percussion and rotational cutting the drilling site was chosen to be near a small stream so that the hole could be continuously replenished with water in order to carry away the fragments of ice released at the bottom of the hole by the drilling process the ice chips were encouraged to flow up the hole by raising the drillbit higher every ten strokes for three strokes in a row the drilling gear was removed from the hole each night to prevent it freezing in placewhen the hole reached 205 m the 20 kg rod was no longer enough to counteract the braking effect of the water in the hole and progress slowed again to 1 m per hour a new rod weighing 40 kg was forged in chamonix which brought the speed back up to 28 m per hour but at 25 m the drill bit stuck in the hole near the bottom vallot poured salt down the hole to try to melt the ice and lowered a piece of iron to try to knock it loose but the hole had to be abandoned emile vallots son joseph vallot wrote a description of the drilling project and concluded that to be successful ice drilling should be done as quickly as possible perhaps in shifts and that the drill should have cutting edges so that any deformation to the hole would be corrected as the drill was reinserted into the hole which would avoid the drill bit wedging as happened in this caseconstant dutoit and paullouis mercanton carried out experiments on the trient glacier in 1900 in response to a problem posed by the swiss society of natural sciences in 1899 for their annual prix schlafli a scientific prize the problem was to determine the internal speed of flow of a glacier by'</li></ul> |
| 38 | <ul><li>'esperanto studies in 20182019 the program celebrated its 20th year from 1982 to 1996 together with the united nations office of conference services crd organized an annual conference in new york city for most of the early years crd published annual conference reports with all papers given at the conference in question the center now publishes in cooperation with university press of america a series of monographs which includes selected papers from the conferences'</li><li>'language management is a discipline that consists of satisfying the needs of people who speak multiple different languages these may be in the same country in companies and in cultural or international institutions where one must use multiple languages there are currently about 6000 languages in the world 85 of which are protected by sovereign states the universal declaration of unesco on cultural diversity in 2001 recalls the richness of global cultural heritage which comes from its cultural diversity this intangible cultural heritage passed down from generation to generation is constantly recreated by communities and groups according to their environment their interaction with nature and their history and brings a feeling of identity and of continuity thus contributing to the promotion of respect of cultural diversity and human creativity the declaration of montreal in 2007 repeated this concern unesco organized a conference on multilingualism for cultural diversity and participation of all in cyberspace in bamako mali on may 6 and 7 2005 in partnership with the african academy of languages acalan the organisation internationale de la francophonie oif and the government of mali as well as other international organizations unesco is otherwise responsible for the introduction of the concept of intangible cultural heritage which manages the cultural heritage in terms of its information support for example text and images associated with the louvre museum in france are part of the intangible cultural heritage and it goes without saying that the diversity of the visitors requires the management of text in several languages this meeting aimed to prepare the second phase of the world summit of the society of information held in tunis tunisia 16 to 18 of november 2005 the other part the phenomenon of globalization produces exchanges which requires the management of different languages at the nodes of interconnection airports parking lots the internet finally produces commercial exchanges indifferent to linguistic frontiers and virtual communities like wikipedia are where the participants speaking different languages can dialog and exchange information and knowledge international institutions governments and firms are faced with language management needs in international institutions languages can have different statutes official language or work language plenty of states have multiple official languages in their territory this is the case in belgium dutch french german in switzerland german french italian romansch in canada french and english in numerous african countries and in luxembourg french german luxembourgish in france where many regional languages exist especially in the regions on the border crossborder languages and in brittany breton none of them have official status therefore a certain number of states have put linguistic policies in place on a larger scale the european union has also defined a linguistic policy which distinguishes 23 official languages upon entrance to school children of diverse cultures are forced to abandon their cultural roots and their mother tongues to the benefit of the normative language chosen by the school research has shown that'</li><li>'or during military service in other contexts it has come to seem excessively formal and oldfashioned to most danes even at job interviews and among parliamentarians du has become standard in written danish de remains current in legal legislative and formal business documents as well as in some translations from other languages this is sometimes audiencedependent as in the danish governments general use of du except in healthcare information directed towards the elderly where de is still used other times it is maintained as an affectation as by the staff of some formal restaurants the weekendavisen newspaper tv 2 announcers and the avowedly conservative maersk corporation attempts by other corporations to avoid sounding either stuffy or too informal by employing circumlocutions — using passive phrasing or using the pronoun man one — have generally proved awkward and been illreceived and with the notable exception of the national railway dsb most have opted for the more personable du form icelandic modern icelandic is the scandinavian language closest to old norse which made a distinction between the plural þer and the dual þið this distinction continued in written icelandic the early 1920 when the plural þer was also used on formal occasions the formal usage of þer seems to have pushed the dual þið to take over the plural so modern icelandic normally uses þið as a plural however in formal documents such as by the president þer is still used as plural and the usage of þer as plural and þið as dual is still retained in the icelandic translation of the christian scriptures there are still a number of fixed expressions — particularly religious adages such as seek and ye shall find leitið og þer munuð finna — and the formal pronoun is sometimes used in translations from a language that adheres to a t – v distinction but otherwise it appears only when one wants to be excessively formal either from the gravity of the occasion as in court proceedings and legal correspondence or out of contempt in order to ridicule another persons selfimportance and þu is used in all other cases norwegian in norwegian the polite form dedem bokmal and dedykk nynorsk has more or less disappeared in both spoken and written language norwegians now exclusively use du and the polite form does not have a strong cultural pedigree in the country until recently de would sometimes be found in written works business letters plays and translations where an impression of formality must be retained the popular belief that de is reserved for the king is incorrect since according to royal etiquette the king and'</li></ul> |
| 15 | <ul><li>'aicardi – goutieres syndrome ags which is completely distinct from the similarly named aicardi syndrome is a rare usually early onset childhood inflammatory disorder most typically affecting the brain and the skin neurodevelopmental disorder the majority of affected individuals experience significant intellectual and physical problems although this is not always the case the clinical features of ags can mimic those of in utero acquired infection and some characteristics of the condition also overlap with the autoimmune disease systemic lupus erythematosus sle following an original description of eight cases in 1984 the condition was first referred to as aicardi – goutieres syndrome ags in 1992 and the first international meeting on ags was held in pavia italy in 2001ags can occur due to mutations in any one of a number of different genes of which nine have been identified to date namely trex1 rnaseh2a rnaseh2b rnaseh2c which together encode the ribonuclease h2 enzyme complex samhd1 adar1 and ifih1 coding for mda5 this neurological disease occurs in all populations worldwide although it is almost certainly underdiagnosed to date 2014 at least 400 cases of ags are known the initial description of ags suggested that the disease was always severe and was associated with unremitting neurological decline resulting in death in childhood as more cases have been identified it has become apparent that this is not necessarily the case with many patients now considered to demonstrate an apparently stable clinical picture alive in their 4th decade moreover rare individuals with pathogenic mutations in the agsrelated genes can be minimally affected perhaps only with chilblains and are in mainstream education and even affected siblings within a family can show marked differences in severityin about ten percent of cases ags presents at or soon after birth ie in the neonatal period this presentation of the disease is characterized by microcephaly neonatal seizures poor feeding jitteriness cerebral calcifications accumulation of calcium deposits in the brain white matter abnormalities and cerebral atrophy thus indicating that the disease process became active before birth ie in utero these infants can have hepatosplenomegaly and thrombocytopaenia very much like cases of transplacental viral infection about one third of such early presenting cases most frequently in association with mutations in trex1 die in early childhoodotherwise the majority of ags cases present in early infancy sometimes after an apparently normal period of development during the first few months after birth these children develop'</li><li>'study of this gene transfer and its causes ecological genetics'</li><li>'not emerge until the 1990s this theory went through a series of transformations and elaborations until 2005 when bronfenbrenner died bronfenbrenner further developed the model by adding the chronosystem which refers to how the person and environments change over time he also placed a greater emphasis on processes and the role of the biological person the process – person – context – time model ppct has since become the bedrock of the bioecological model ppct includes four concepts the interactions between the concepts form the basis for the theory 1 process – bronfenbrenner viewed proximal processes as the primary mechanism for development featuring them in two central propositions of the bioecological modelproposition 1 human development takes place through processes of progressively more complex reciprocal interaction between an active evolving biopsychological human organism and the persons objects and symbols in its immediate external environment to be effective the interaction must occur on a fairly regular basis over extended periods of time such enduring forms of interaction in the immediate environment are referred to as proximal processesproximal processes are the development processes of systematic interaction between person and environment bronfenbrenner identifies group and solitary activities such as playing with other children or reading as mechanisms through which children come to understand their world and formulate ideas about their place within it however processes function differently depending on the person and the contextproposition 2 the form power content and direction of the proximal processes effecting development vary systematically as a joint function of the characteristics of the developing person of the environment — both immediate and more remote — in which the processes are taking place the nature of the developmental outcomes under consideration and the social continuities and changes occurring over time through the life course and the historical period during which the person has lived2 person – bronfenbrenner acknowledged the role that personal characteristics of individuals play in social interactions he identified three personal characteristics that can significantly influence proximal processes across the lifespan demand characteristics such as age gender or physical appearance set processes in motion acting as “ personal stimulus ” characteristics resource characteristics are not as immediately recognizable and include mental and emotional resources such as past experiences intelligence and skills as well as material resources such as access to housing education and responsive caregivers force characteristics are related to variations in motivation persistence and temperament bronfenbrenner notes that even when children have equivalent access to resources their developmental courses may differ as a function of characteristics such as drive to succeed and persistence in the face of hardship in doing this bronfenbrenner provides a'</li></ul> |
| 34 | <ul><li>'different settings and populations such as by refugees in san diego seeking in – person medical interpretation options by homeless adults in ann arbor michigan by dr claudia mitchell to support community health workers and teachers in rural south africa and by dr laura s lorenz of the heller school for social policy and management at brandeis university in her work with brain injury survivors photovoice has been adopted by multiple disciplines often used in conjunction with other communitybased and participatory action research methods in modern research photovoice is a qualitative approach for addressing sensitive and complex issues that allows individuals to openly share their perspectives where one might otherwise be reluctant to do photovoice is used to both to elicit and analyze data in the interest knowledge dissemination and mobilization researchers who employ photovoice offer a nuanced understanding of community issues to the scientific community the aim of this understanding is to inform and create appropriate interventions and actions regarding complex problems including but not limited to health and wellbeing social inequality and socioeconomic disparity for example in higher education the photovoice model has been used to teach social work students photovoice has also been used as a tool to engage children and youth giving them a safe environment and opportunity to communicate concerns and coping strategies to policymakers and service providers overall the modern implementation of photovoice is utilized to investigate a persons lived experience concerning systemic structures and social power relations and communicate this experience through a medium reaching beyond verbal communication also known as participatory photography or photo novella photovoice is considered a sub – type of participatory visual methods or picturevoice which includes techniques such as photoelicitation and digital storytelling these techniques allow research participants to create visuals that capture their individual perspectives as part of the research process an example of this is found in project lives a participatory photography project used to create a new image of project housing dwellers published in april 2015 two other forms of picturevoice include paintvoice stemming from the work of michael yonas and comicvoice which has been pioneered by john bairds create a comic project since 2008 and to a lesser extent by michael bitzs comic book project in international research photovoice has been seen to allow participants from the developing world to define how they want to be represented to the international community the individuals are facilitated and given control to tell their stories and perspectives which empower them to be engaged and maintain a firm sense of authorship over their representations this helps to convey a stereotypefree picture of what it means to live in a developing country to those supporting ie funders'</li><li>'an active suzukitraining organ scheme is under way in the australian city of newcastle the application of suzukis teaching philosophy to the mandolin is currently being researched in italy by amelia saracco rather than focusing on a specific instrument at the stage of early childhood education ece a suzuki early childhood education sece curriculum for preinstrumental ece was developed within the suzuki philosophy by dorothy sharon jones saa jeong cheol wong asa emma okeefe ppsa anke van der bijl esa and yasuyo matsui teri the sece curriculum is designed for ages 0 – 3 and uses singing nursery rhymes percussion audio recordings and whole body movements in a group setting where children and their adult caregivers participate side by side the japanese based sece curriculum is different from the englishbased sece curriculum the englishbased curriculum is currently being adapted for use in other languages a modified suzuki philosophy curriculum has been developed to apply suzuki teaching to heterogeneous instrumental music classes string orchestras in schools trumpet was added to the international suzuki associations list of suzuki method instruments in 2011 the application of suzukis teaching philosophy to the trumpet is currently being researched in sweden the first trumpet teacher training course to be offered by the european suzuki association in 2013 suzuki teacher training for trumpet 2013 supplementary materials are also published under the suzuki name including some etudes notereading books piano accompaniment parts guitar accompaniment parts duets trios string orchestra and string quartet arrangements of suzuki repertoire in the late 19th century japans borders were opened to trade with the outside world and in particular to the importation of western culture as a result of this suzukis father who owned a company which had manufactured the shamisen began to manufacture violins instead in his youth shinichi suzuki chanced to hear a phonograph recording of franz schuberts ave maria as played on violin by mischa elman gripped by the beauty of the music he immediately picked up a violin from his fathers factory and began to teach himself to play the instrument by ear his father felt that instrumental performance was beneath his sons social status and refused to allow him to study the instrument at age 17 he began to teach himself by ear since no formal training was allowed to him eventually he convinced his father to allow him to study with a violin teacher in tokyo suzuki nurtured by love at age 22 suzuki travelled to germany to find a violin teacher to continue his studies while there he studied privately with karl klingler but did not receive any formal degree past his high school diploma he met and became friends with albert einstein who encouraged him in learning classical music he also met court'</li><li>'##act the technical course practically schoolbased enterprise a schoolbased enterprise is a simulated or actual business run by the school it offers students a learning experience by letting them manage the various aspects of a business service learningthis strategy combines community service with career where students provide volunteer service to public and nonprofit agencies civic and government offices etc student the student is central to the wbl process the student engages in a wbl program and completes all requirements of the program maintains high degree of professionalism and acquires necessary competencies for which the wbl program was designed business mentor a business mentor sets realistic goals for the student to acquire engages and supervises them to complete their tasks and is a role model for the student to emulate teacher coordinator a teacher coordinator is a certified educator who manages the wbl program and checks on the student progress and supports whenever required to ensure successful completion of the wbl program school administrator the school administrator is key in introducing wbl programs within the curriculum after identifying the appropriate courses that can be learnt through the program parents parental support enables successful completion of the wbl program as offer suitable guidance support and motivation to their wards and approve the wbl program that would be most suitable for meeting their wards learning needs and career aspirations application of classroom learning in realworld setting establishment of connection between school and work improvement in critical thinking analytical reasoning and logical abilities expansion of curriculum and learning facilities meeting the diverse needs of the learner creating a talented and skilled pool of future employees reduces preservice training time and cost improvement of student awareness of career opportunities making education relevant and valuable to the social context community building exercise for productive economy timeconsuming activity to identify key courses that can be taught via wbl programs needs careful consideration and planning when introducing wbl strategies within the existing curriculum certain wbl programs may not be in sync with the formal education timelines and pattern it is unclear what key elements of this learning may be and that readily available indicators which equate with academic learning outcomes are not necessarily evoking it accuracy needs effective coordination between all key persons involved in the wbl program effective evaluation strategy needs to be developed for assessing student performance this should encompass both formative and summative feedback this article incorporates text from a free content work licensed under ccbysa igo 30 license statementpermission text taken from levelsetting and recognition of learning outcomes the use of level descriptors in the twentyfirst century 115 keevey james chakroun borhene unesco unesco workintegrated learning'</li></ul> |
## Evaluation
### Metrics
| Label | F1 |
|:--------|:-------|
| **all** | 0.7541 |
## Uses
### Direct Use for Inference
First install the SetFit library:
```bash
pip install setfit
```
Then you can load this model and run inference.
```python
from setfit import SetFitModel
# Download from the 🤗 Hub
model = SetFitModel.from_pretrained("udrearobert999/multi-qa-mpnet-base-cos-v1-contrastive-3e-250samples-20iter")
# Run inference
preds = model("##rch procedure that evaluates the objective function p x displaystyle pmathbf x on a grid of candidate source locations g displaystyle mathcal g to estimate the spatial location of the sound source x s displaystyle textbf xs as the point of the grid that provides the maximum srp modifications of the classical srpphat algorithm have been proposed to reduce the computational cost of the gridsearch step of the algorithm and to increase the robustness of the method in the classical srpphat for each microphone pair and for each point of the grid a unique integer tdoa value is selected to be the acoustic delay corresponding to that grid point this procedure does not guarantee that all tdoas are associated to points on the grid nor that the spatial grid is consistent since some of the points may not correspond to an intersection of hyperboloids this issue becomes more problematic with coarse grids since when the number of points is reduced part of the tdoa information gets lost because most delays are not anymore associated to any point in the grid the modified srpphat collects and uses the tdoa information related to the volume surrounding each spatial point of the search grid by considering a modified objective function where l m 1 m 2 l x displaystyle lm1m2lmathbf x and l m 1 m 2 u x displaystyle lm1m2umathbf x are the lower and upper accumulation limits of gcc delays which depend on the spatial location x displaystyle mathbf x the accumulation limits can be calculated beforehand in an exact way by exploring the boundaries separating the regions corresponding to the points of the grid alternatively they can be selected by considering the spatial gradient of the tdoa ∇ τ m 1 m 2 x ∇ x τ m 1 m 2 x ∇ y τ m 1 m 2 x ∇ z τ m 1 m 2 x t displaystyle nabla tau m1m2mathbf x nabla xtau m1m2mathbf x nabla ytau m1m2mathbf x nabla ztau m1m2mathbf x t where each component γ ∈ x y z displaystyle gamma in leftxyzright of the gradient is for a rectangular grid where neighboring points are separated a distance r displaystyle r the lower and upper accumulation limits are given by where d r 2 min 1 sin θ cos [UNK] 1 sin θ sin [UNK] 1 cos θ displaystyle dr2min leftfrac 1vert sintheta cosphi vert frac 1vert sintheta sinphi vert frac 1vert")
```
<!--
### Downstream Use
*List how someone could finetune this model on their own dataset.*
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:-------------|:----|:---------|:----|
| Word count | 1 | 369.7392 | 509 |
| Label | Training Sample Count |
|:------|:----------------------|
| 0 | 250 |
| 1 | 250 |
| 2 | 250 |
| 3 | 250 |
| 4 | 250 |
| 5 | 250 |
| 6 | 250 |
| 7 | 250 |
| 8 | 250 |
| 9 | 250 |
| 10 | 250 |
| 11 | 250 |
| 12 | 250 |
| 13 | 250 |
| 14 | 250 |
| 15 | 250 |
| 16 | 250 |
| 17 | 250 |
| 18 | 250 |
| 19 | 250 |
| 20 | 250 |
| 21 | 250 |
| 22 | 250 |
| 23 | 250 |
| 24 | 250 |
| 25 | 250 |
| 26 | 250 |
| 27 | 250 |
| 28 | 250 |
| 29 | 250 |
| 30 | 250 |
| 31 | 250 |
| 32 | 250 |
| 33 | 250 |
| 34 | 250 |
| 35 | 250 |
| 36 | 250 |
| 37 | 250 |
| 38 | 250 |
| 39 | 250 |
| 40 | 250 |
| 41 | 250 |
| 42 | 250 |
### Training Hyperparameters
- batch_size: (16, 16)
- num_epochs: (3, 8)
- max_steps: -1
- sampling_strategy: oversampling
- num_iterations: 20
- body_learning_rate: (2e-05, 0.01)
- head_learning_rate: 0.01
- loss: CosineSimilarityLoss
- distance_metric: cosine_distance
- margin: 0.25
- end_to_end: False
- use_amp: False
- warmup_proportion: 0.1
- max_length: 512
- seed: 42
- eval_max_steps: -1
- load_best_model_at_end: True
### Training Results
| Epoch | Step | Training Loss | Validation Loss |
|:----------:|:--------:|:-------------:|:---------------:|
| 0.0000 | 1 | 0.2586 | - |
| 0.0930 | 2500 | 0.0925 | - |
| 0.1860 | 5000 | 0.0273 | - |
| **0.2791** | **7500** | **0.1452** | **0.0893** |
| 0.3721 | 10000 | 0.0029 | - |
| 0.4651 | 12500 | 0.0029 | - |
| 0.5581 | 15000 | 0.0702 | 0.106 |
| 0.6512 | 17500 | 0.0178 | - |
| 0.7442 | 20000 | 0.0047 | - |
| 0.8372 | 22500 | 0.0006 | 0.1142 |
| 0.9302 | 25000 | 0.0191 | - |
| 1.0233 | 27500 | 0.0018 | - |
| 1.1163 | 30000 | 0.0061 | 0.1482 |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.10.12
- SetFit: 1.0.3
- Sentence Transformers: 2.7.0
- Transformers: 4.40.1
- PyTorch: 2.2.1+cu121
- Datasets: 2.19.1
- Tokenizers: 0.19.1
## Citation
### BibTeX
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"PCR"
] |
RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | 2024-06-25T08:13:10Z |
2024-06-25T12:58:47+00:00
| 47 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
JSL-Med-Sft-Llama-3-8B - GGUF
- Model creator: https://huggingface.co/johnsnowlabs/
- Original model: https://huggingface.co/johnsnowlabs/JSL-Med-Sft-Llama-3-8B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [JSL-Med-Sft-Llama-3-8B.Q2_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q2_K.gguf) | Q2_K | 2.96GB |
| [JSL-Med-Sft-Llama-3-8B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [JSL-Med-Sft-Llama-3-8B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [JSL-Med-Sft-Llama-3-8B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [JSL-Med-Sft-Llama-3-8B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [JSL-Med-Sft-Llama-3-8B.Q3_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q3_K.gguf) | Q3_K | 3.74GB |
| [JSL-Med-Sft-Llama-3-8B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [JSL-Med-Sft-Llama-3-8B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [JSL-Med-Sft-Llama-3-8B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [JSL-Med-Sft-Llama-3-8B.Q4_0.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q4_0.gguf) | Q4_0 | 4.34GB |
| [JSL-Med-Sft-Llama-3-8B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [JSL-Med-Sft-Llama-3-8B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [JSL-Med-Sft-Llama-3-8B.Q4_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q4_K.gguf) | Q4_K | 4.58GB |
| [JSL-Med-Sft-Llama-3-8B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [JSL-Med-Sft-Llama-3-8B.Q4_1.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q4_1.gguf) | Q4_1 | 4.78GB |
| [JSL-Med-Sft-Llama-3-8B.Q5_0.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q5_0.gguf) | Q5_0 | 5.21GB |
| [JSL-Med-Sft-Llama-3-8B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [JSL-Med-Sft-Llama-3-8B.Q5_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q5_K.gguf) | Q5_K | 5.34GB |
| [JSL-Med-Sft-Llama-3-8B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [JSL-Med-Sft-Llama-3-8B.Q5_1.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q5_1.gguf) | Q5_1 | 5.65GB |
| [JSL-Med-Sft-Llama-3-8B.Q6_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q6_K.gguf) | Q6_K | 6.14GB |
| [JSL-Med-Sft-Llama-3-8B.Q8_0.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-Med-Sft-Llama-3-8B-gguf/blob/main/JSL-Med-Sft-Llama-3-8B.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
tags:
- llama-3-8b
- sft
- medical
base_model:
- meta-llama/Meta-Llama-3-8B
license: cc-by-nc-nd-4.0
---
# JSL-Med-Sft-Llama-3-8B
[<img src="https://repository-images.githubusercontent.com/104670986/2e728700-ace4-11ea-9cfc-f3e060b25ddf">](http://www.johnsnowlabs.com)
This model is developed by [John Snow Labs](https://www.johnsnowlabs.com/).
This model is available under a [CC-BY-NC-ND](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en) license and must also conform to this [Acceptable Use Policy](https://huggingface.co/johnsnowlabs). If you need to license this model for commercial use, please contact us at [email protected].
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "johnsnowlabs/JSL-Med-Sft-Llama-3-8B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## 🏆 Evaluation
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|-------------------------------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5803|± |0.0067|
| | |none | 0|acc |0.6141|± |0.0057|
| - medmcqa |Yaml |none | 0|acc |0.5752|± |0.0076|
| | |none | 0|acc_norm|0.5752|± |0.0076|
| - medqa_4options |Yaml |none | 0|acc |0.5970|± |0.0138|
| | |none | 0|acc_norm|0.5970|± |0.0138|
| - anatomy (mmlu) | 0|none | 0|acc |0.6963|± |0.0397|
| - clinical_knowledge (mmlu) | 0|none | 0|acc |0.7472|± |0.0267|
| - college_biology (mmlu) | 0|none | 0|acc |0.7847|± |0.0344|
| - college_medicine (mmlu) | 0|none | 0|acc |0.6185|± |0.0370|
| - medical_genetics (mmlu) | 0|none | 0|acc |0.8300|± |0.0378|
| - professional_medicine (mmlu)| 0|none | 0|acc |0.7022|± |0.0278|
| - pubmedqa | 1|none | 0|acc |0.7480|± |0.0194|
|Groups|Version|Filter|n-shot| Metric |Value | |Stderr|
|------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5803|± |0.0067|
| | |none | 0|acc |0.6141|± |0.0057|
|
[
"MEDQA",
"PUBMEDQA"
] |
juanpablomesa/bge-base-financial-matryoshka
|
juanpablomesa
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:9600",
"loss:MatryoshkaLoss",
"loss:MultipleNegativesRankingLoss",
"en",
"arxiv:1908.10084",
"arxiv:2205.13147",
"arxiv:1705.00652",
"base_model:BAAI/bge-base-en-v1.5",
"base_model:finetune:BAAI/bge-base-en-v1.5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-07-02T17:10:34Z |
2024-07-02T17:10:50+00:00
| 47 | 0 |
---
base_model: BAAI/bge-base-en-v1.5
datasets: []
language:
- en
library_name: sentence-transformers
license: apache-2.0
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:9600
- loss:MatryoshkaLoss
- loss:MultipleNegativesRankingLoss
widget:
- source_sentence: The median home value in San Carlos, CA is $2,350,000.
sentences:
- What does the console property of the WorkerGlobalScope interface provide access
to?
- What is the last sold price and date for the property at 4372 W 14th Street Dr,
Greeley, CO 80634?
- What is the median home value in San Carlos, CA?
- source_sentence: The four new principals hired by Superintendent of Schools Ken
Kenworthy for the Okeechobee school system are Joseph Stanley at Central Elementary,
Jody Hays at Yearling Middle School, Tuuli Robinson at North Elementary, and Dr.
Thelma Jackson at Seminole Elementary School.
sentences:
- Who won the gold medal in the men's 1,500m final at the speed skating World Cup?
- What is the purpose of the 1,2,3 bowling activity for toddlers?
- Who are the four new principals hired by Superintendent of Schools Ken Kenworthy
for the Okeechobee school system?
- source_sentence: Twitter Audit is used to scan your followers and find out what
percentage of them are real people.
sentences:
- What is the main product discussed in the context of fair trade?
- What is the software mentioned in the context suitable for?
- What is the purpose of the Twitter Audit tool?
- source_sentence: Michael Czysz made the 2011 E1pc lighter and more powerful than
the 2010 version, and also improved the software controlling the bike’s D1g1tal
powertrain.
sentences:
- What changes did Michael Czysz make to the 2011 E1pc compared to the 2010 version?
- What is the author's suggestion for leaving a legacy for future generations?
- What is the most affordable and reliable option to fix a MacBook according to
the technician?
- source_sentence: HTC called the Samsung Galaxy S4 “mainstream”.
sentences:
- What is the essential aspect of the vocation to marriage according to Benedict
XVI's message on the 40th Anniversary of Humanae Vitae?
- What did HTC announce about the Samsung Galaxy S4?
- What was Allan Cox's First Class Delivery launched on for his Level 1 certification
flight?
model-index:
- name: BGE base Financial Matryoshka
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 768
type: dim_768
metrics:
- type: cosine_accuracy@1
value: 0.9675
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.9791666666666666
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.9829166666666667
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.98875
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.9675
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.3263888888888889
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1965833333333333
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09887499999999999
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.9675
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.9791666666666666
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.9829166666666667
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.98875
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.9776735843960416
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.9741727843915341
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.974471752833939
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 512
type: dim_512
metrics:
- type: cosine_accuracy@1
value: 0.9641666666666666
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.9775
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.9816666666666667
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.98875
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.9641666666666666
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.3258333333333333
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1963333333333333
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09887499999999999
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.9641666666666666
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.9775
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.9816666666666667
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.98875
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.9758504869144781
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.9717977843915344
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.9720465527215371
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 256
type: dim_256
metrics:
- type: cosine_accuracy@1
value: 0.9620833333333333
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.9741666666666666
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.9804166666666667
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.98625
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.9620833333333333
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.32472222222222225
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1960833333333333
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09862499999999999
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.9620833333333333
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.9741666666666666
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.9804166666666667
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.98625
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.9737941784937224
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.9698406084656085
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.9702070899963996
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 128
type: dim_128
metrics:
- type: cosine_accuracy@1
value: 0.9554166666666667
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.97
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.9766666666666667
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.98375
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.9554166666666667
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.3233333333333333
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1953333333333333
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09837499999999999
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.9554166666666667
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.97
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.9766666666666667
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.98375
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.969307497603498
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.9647410714285715
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.9652034022263717
name: Cosine Map@100
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: dim 64
type: dim_64
metrics:
- type: cosine_accuracy@1
value: 0.9391666666666667
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.9616666666666667
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.9666666666666667
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.9758333333333333
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.9391666666666667
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.3205555555555556
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.1933333333333333
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09758333333333333
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.9391666666666667
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.9616666666666667
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.9666666666666667
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.9758333333333333
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.9577277779716886
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.9519417989417989
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.9525399354798056
name: Cosine Map@100
---
# BGE base Financial Matryoshka
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) <!-- at revision a5beb1e3e68b9ab74eb54cfd186867f64f240e1a -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("juanpablomesa/bge-base-financial-matryoshka")
# Run inference
sentences = [
'HTC called the Samsung Galaxy S4 “mainstream”.',
'What did HTC announce about the Samsung Galaxy S4?',
"What is the essential aspect of the vocation to marriage according to Benedict XVI's message on the 40th Anniversary of Humanae Vitae?",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `dim_768`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.9675 |
| cosine_accuracy@3 | 0.9792 |
| cosine_accuracy@5 | 0.9829 |
| cosine_accuracy@10 | 0.9888 |
| cosine_precision@1 | 0.9675 |
| cosine_precision@3 | 0.3264 |
| cosine_precision@5 | 0.1966 |
| cosine_precision@10 | 0.0989 |
| cosine_recall@1 | 0.9675 |
| cosine_recall@3 | 0.9792 |
| cosine_recall@5 | 0.9829 |
| cosine_recall@10 | 0.9888 |
| cosine_ndcg@10 | 0.9777 |
| cosine_mrr@10 | 0.9742 |
| **cosine_map@100** | **0.9745** |
#### Information Retrieval
* Dataset: `dim_512`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:----------|
| cosine_accuracy@1 | 0.9642 |
| cosine_accuracy@3 | 0.9775 |
| cosine_accuracy@5 | 0.9817 |
| cosine_accuracy@10 | 0.9888 |
| cosine_precision@1 | 0.9642 |
| cosine_precision@3 | 0.3258 |
| cosine_precision@5 | 0.1963 |
| cosine_precision@10 | 0.0989 |
| cosine_recall@1 | 0.9642 |
| cosine_recall@3 | 0.9775 |
| cosine_recall@5 | 0.9817 |
| cosine_recall@10 | 0.9888 |
| cosine_ndcg@10 | 0.9759 |
| cosine_mrr@10 | 0.9718 |
| **cosine_map@100** | **0.972** |
#### Information Retrieval
* Dataset: `dim_256`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.9621 |
| cosine_accuracy@3 | 0.9742 |
| cosine_accuracy@5 | 0.9804 |
| cosine_accuracy@10 | 0.9862 |
| cosine_precision@1 | 0.9621 |
| cosine_precision@3 | 0.3247 |
| cosine_precision@5 | 0.1961 |
| cosine_precision@10 | 0.0986 |
| cosine_recall@1 | 0.9621 |
| cosine_recall@3 | 0.9742 |
| cosine_recall@5 | 0.9804 |
| cosine_recall@10 | 0.9862 |
| cosine_ndcg@10 | 0.9738 |
| cosine_mrr@10 | 0.9698 |
| **cosine_map@100** | **0.9702** |
#### Information Retrieval
* Dataset: `dim_128`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.9554 |
| cosine_accuracy@3 | 0.97 |
| cosine_accuracy@5 | 0.9767 |
| cosine_accuracy@10 | 0.9838 |
| cosine_precision@1 | 0.9554 |
| cosine_precision@3 | 0.3233 |
| cosine_precision@5 | 0.1953 |
| cosine_precision@10 | 0.0984 |
| cosine_recall@1 | 0.9554 |
| cosine_recall@3 | 0.97 |
| cosine_recall@5 | 0.9767 |
| cosine_recall@10 | 0.9838 |
| cosine_ndcg@10 | 0.9693 |
| cosine_mrr@10 | 0.9647 |
| **cosine_map@100** | **0.9652** |
#### Information Retrieval
* Dataset: `dim_64`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.9392 |
| cosine_accuracy@3 | 0.9617 |
| cosine_accuracy@5 | 0.9667 |
| cosine_accuracy@10 | 0.9758 |
| cosine_precision@1 | 0.9392 |
| cosine_precision@3 | 0.3206 |
| cosine_precision@5 | 0.1933 |
| cosine_precision@10 | 0.0976 |
| cosine_recall@1 | 0.9392 |
| cosine_recall@3 | 0.9617 |
| cosine_recall@5 | 0.9667 |
| cosine_recall@10 | 0.9758 |
| cosine_ndcg@10 | 0.9577 |
| cosine_mrr@10 | 0.9519 |
| **cosine_map@100** | **0.9525** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 9,600 training samples
* Columns: <code>positive</code> and <code>anchor</code>
* Approximate statistics based on the first 1000 samples:
| | positive | anchor |
|:--------|:-----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 3 tokens</li><li>mean: 50.19 tokens</li><li>max: 435 tokens</li></ul> | <ul><li>min: 3 tokens</li><li>mean: 18.66 tokens</li><li>max: 43 tokens</li></ul> |
* Samples:
| positive | anchor |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------|
| <code>The Berry Export Summary 2028 is a dedicated export plan for the Australian strawberry, raspberry, and blackberry industries. It maps the sectors’ current position, where they want to be, high-opportunity markets, and next steps. The purpose of this plan is to grow their global presence over the next 10 years.</code> | <code>What is the Berry Export Summary 2028 and what is its purpose?</code> |
| <code>Benefits reported from having access to Self-supply water sources include convenience, less time spent for fetching water and access to more and better quality water. In some areas, Self-supply sources offer important added values such as water for productive use, income generation, family safety and improved food security.</code> | <code>What are some of the benefits reported from having access to Self-supply water sources?</code> |
| <code>The unique features of the Coolands for Twitter app include Real-Time updates without the need for a refresh button, Avatar Indicator which shows small avatars on the title bar for new messages, Direct Link for intuitive and convenient link opening, Smart Bookmark to easily return to previous reading position, and User Level Notification which allows customized notification settings for different users.</code> | <code>What are the unique features of the Coolands for Twitter app?</code> |
* Loss: [<code>MatryoshkaLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#matryoshkaloss) with these parameters:
```json
{
"loss": "MultipleNegativesRankingLoss",
"matryoshka_dims": [
768,
512,
256,
128,
64
],
"matryoshka_weights": [
1,
1,
1,
1,
1
],
"n_dims_per_step": -1
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 16
- `gradient_accumulation_steps`: 16
- `learning_rate`: 2e-05
- `num_train_epochs`: 4
- `lr_scheduler_type`: cosine
- `warmup_ratio`: 0.1
- `bf16`: True
- `tf32`: True
- `load_best_model_at_end`: True
- `optim`: adamw_torch_fused
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 16
- `eval_accumulation_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 4
- `max_steps`: -1
- `lr_scheduler_type`: cosine
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: True
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | dim_128_cosine_map@100 | dim_256_cosine_map@100 | dim_512_cosine_map@100 | dim_64_cosine_map@100 | dim_768_cosine_map@100 |
|:--------:|:------:|:-------------:|:----------------------:|:----------------------:|:----------------------:|:---------------------:|:----------------------:|
| 0.5333 | 10 | 0.6065 | - | - | - | - | - |
| 0.96 | 18 | - | 0.9583 | 0.9674 | 0.9695 | 0.9372 | 0.9708 |
| 1.0667 | 20 | 0.3313 | - | - | - | - | - |
| 1.6 | 30 | 0.144 | - | - | - | - | - |
| 1.9733 | 37 | - | 0.9630 | 0.9699 | 0.9716 | 0.9488 | 0.9745 |
| 2.1333 | 40 | 0.1317 | - | - | - | - | - |
| 2.6667 | 50 | 0.0749 | - | - | - | - | - |
| 2.9867 | 56 | - | 0.9650 | 0.9701 | 0.9721 | 0.9522 | 0.9747 |
| 3.2 | 60 | 0.088 | - | - | - | - | - |
| 3.7333 | 70 | 0.0598 | - | - | - | - | - |
| **3.84** | **72** | **-** | **0.9652** | **0.9702** | **0.972** | **0.9525** | **0.9745** |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.11.5
- Sentence Transformers: 3.0.1
- Transformers: 4.41.2
- PyTorch: 2.1.2+cu121
- Accelerate: 0.31.0
- Datasets: 2.19.1
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MatryoshkaLoss
```bibtex
@misc{kusupati2024matryoshka,
title={Matryoshka Representation Learning},
author={Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi},
year={2024},
eprint={2205.13147},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"MEDAL"
] |
rjnClarke/thenlper-gte-base-fine-tuned
|
rjnClarke
|
sentence-similarity
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:10359",
"loss:MultipleNegativesRankingLoss",
"en",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:thenlper/gte-base",
"base_model:finetune:thenlper/gte-base",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2024-08-06T13:27:19Z |
2024-08-06T13:27:53+00:00
| 47 | 0 |
---
base_model: thenlper/gte-base
datasets: []
language:
- en
library_name: sentence-transformers
license: apache-2.0
metrics:
- cosine_accuracy@3
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@200
- cosine_map@100
- dot_accuracy@3
- dot_precision@1
- dot_precision@3
- dot_precision@5
- dot_precision@10
- dot_recall@1
- dot_recall@3
- dot_recall@5
- dot_recall@10
- dot_ndcg@10
- dot_mrr@200
- dot_map@100
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:10359
- loss:MultipleNegativesRankingLoss
widget:
- source_sentence: Cleopatra reacts to the news of Antony's death with a mixture of
sadness and resignation, contemplating her own mortality and the fickle nature
of life.
sentences:
- "Immortal longings in me. Now no more The juice of Egypt's grape shall moist\
\ this lip. Yare, yare, good Iras; quick. Methinks I hear Antony call. I\
\ see him rouse himself To praise my noble act. I hear him mock The luck\
\ of Caesar, which the gods give men To excuse their after wrath. Husband,\
\ I come. Now to that name my courage prove my title! I am fire and air;\
\ my other elements I give to baser life. So, have you done? Come then,\
\ and take the last warmth of my lips. Farewell, kind Charmian. Iras, long\
\ farewell. [Kisses them. IRAS falls and dies] \
\ Have I the aspic in my lips? Dost fall? If thus thou and nature can so gently\
\ part, The stroke of death is as a lover's pinch, Which hurts and is desir'd.\
\ Dost thou lie still? If thou vanishest, thou tell'st the world It is\
\ not worth leave-taking. CHARMIAN. Dissolve, thick cloud, and rain, that I may\
\ say The gods themselves do weep. CLEOPATRA. This proves me base.\n \
\ If she first meet the curled Antony,\n"
- "BURGUNDY. Warlike and martial Talbot, Burgundy\n Enshrines thee in his heart,\
\ and there erects Thy noble deeds as valour's monuments. TALBOT. Thanks,\
\ gentle Duke. But where is Pucelle now? I think her old familiar is asleep.\
\ Now where's the Bastard's braves, and Charles his gleeks? What, all amort?\
\ Rouen hangs her head for grief That such a valiant company are fled. Now\
\ will we take some order in the town, Placing therein some expert officers;\
\ And then depart to Paris to the King, For there young Henry with his nobles\
\ lie. BURGUNDY. What Lord Talbot pleaseth Burgundy. TALBOT. But yet, before\
\ we go, let's not forget The noble Duke of Bedford, late deceas'd, But\
\ see his exequies fulfill'd in Rouen. A braver soldier never couched lance,\
\ A gentler heart did never sway in court; But kings and mightiest potentates\
\ must die, For that's the end of human misery. Exeunt\n"
- "Your suffering in this dearth, you may as well\n Strike at the heaven with\
\ your staves as lift them Against the Roman state; whose course will on \
\ The way it takes, cracking ten thousand curbs Of more strong link asunder\
\ than can ever Appear in your impediment. For the dearth, The gods, not\
\ the patricians, make it, and Your knees to them, not arms, must help. Alack,\
\ You are transported by calamity Thither where more attends you; and you\
\ slander The helms o' th' state, who care for you like fathers, When you\
\ curse them as enemies. FIRST CITIZEN. Care for us! True, indeed! They ne'er\
\ car'd for us yet. Suffer us to famish, and their storehouses cramm'd with\
\ grain; make edicts for usury, to support usurers; repeal daily any wholesome\
\ act established against the rich, and provide more piercing statutes daily\
\ to chain up and restrain the poor. If the wars eat us not up, they will;\
\ and there's all the love they bear us. MENENIUS. Either you must Confess\
\ yourselves wondrous malicious, Or be accus'd of folly. I shall tell you \
\ A pretty tale. It may be you have heard it; But, since it serves my purpose,\
\ I will venture To stale't a little more. FIRST CITIZEN. Well, I'll hear\
\ it, sir; yet you must not think to fob off our disgrace with a tale. But,\
\ an't please you, deliver. MENENIUS. There was a time when all the body's members\
\ Rebell'd against the belly; thus accus'd it: That only like a gulf it\
\ did remain I' th' midst o' th' body, idle and unactive, Still cupboarding\
\ the viand, never bearing Like labour with the rest; where th' other instruments\
\ Did see and hear, devise, instruct, walk, feel,\n And, mutually participate,\
\ did minister\n"
- source_sentence: How does the excerpt reflect themes of loyalty and sacrifice in
the play?
sentences:
- "me a thousand marks in links and torches, walking with thee in\n the night\
\ betwixt tavern and tavern; but the sack that thou hast drunk me would have\
\ bought me lights as good cheap at the dearest chandler's in Europe. I have\
\ maintained that salamander of yours with fire any time this two-and-thirty\
\ years. God reward me for it! Bard. 'Sblood, I would my face were in your\
\ belly! Fal. God-a-mercy! so should I be sure to be heart-burn'd.\n \
\ Enter Hostess. How now, Dame Partlet the hen? Have you enquir'd\
\ yet who pick'd\n my pocket? Host. Why, Sir John, what do you think, Sir\
\ John? Do you think I keep thieves in my house? I have search'd, I have enquired,\
\ so has my husband, man by man, boy by boy, servant by servant. The tithe\
\ of a hair was never lost in my house before. Fal. Ye lie, hostess. Bardolph\
\ was shav'd and lost many a hair, and I'll be sworn my pocket was pick'd.\
\ Go to, you are a woman, go! Host. Who, I? No; I defy thee! God's light, I was\
\ never call'd so in mine own house before! Fal. Go to, I know you well enough.\
\ Host. No, Sir John; you do not know me, Sir John. I know you, Sir John.\
\ You owe me money, Sir John, and now you pick a quarrel to beguile me of\
\ it. I bought you a dozen of shirts to your back. Fal. Dowlas, filthy dowlas!\
\ I have given them away to bakers' wives; they have made bolters of them.\
\ Host. Now, as I am a true woman, holland of eight shillings an ell. You\
\ owe money here besides, Sir John, for your diet and by-drinkings, and money\
\ lent you, four-and-twenty pound. Fal. He had his part of it; let him pay. \
\ Host. He? Alas, he is poor; he hath nothing. Fal. How? Poor? Look upon his\
\ face. What call you rich? Let them coin his nose, let them coin his cheeks.\
\ I'll not pay a denier.\n What, will you make a younker of me? Shall I not\
\ take mine ease\n"
- "EDWARD. I wonder how our princely father scap'd,\n Or whether he be scap'd\
\ away or no From Clifford's and Northumberland's pursuit. Had he been ta'en,\
\ we should have heard the news; Had he been slain, we should have heard the\
\ news; Or had he scap'd, methinks we should have heard The happy tidings\
\ of his good escape. How fares my brother? Why is he so sad? RICHARD. I cannot\
\ joy until I be resolv'd Where our right valiant father is become. I saw\
\ him in the battle range about, And watch'd him how he singled Clifford forth.\
\ Methought he bore him in the thickest troop As doth a lion in a herd of\
\ neat;\n Or as a bear, encompass'd round with dogs,\n Who having pinch'd\
\ a few and made them cry, The rest stand all aloof and bark at him. So\
\ far'd our father with his enemies; So fled his enemies my warlike father.\
\ Methinks 'tis prize enough to be his son. See how the morning opes her\
\ golden gates And takes her farewell of the glorious sun. How well resembles\
\ it the prime of youth, Trimm'd like a younker prancing to his love! EDWARD.\
\ Dazzle mine eyes, or do I see three suns? RICHARD. Three glorious suns, each\
\ one a perfect sun; Not separated with the racking clouds, But sever'd\
\ in a pale clear-shining sky. See, see! they join, embrace, and seem to kiss,\
\ As if they vow'd some league inviolable. Now are they but one lamp, one\
\ light, one sun. In this the heaven figures some event. EDWARD. 'Tis wondrous\
\ strange, the like yet never heard of. I think it cites us, brother, to the\
\ field, That we, the sons of brave Plantagenet, Each one already blazing\
\ by our meeds, Should notwithstanding join our lights together And overshine\
\ the earth, as this the world. Whate'er it bodes, henceforward will I bear\
\ Upon my target three fair shining suns. RICHARD. Nay, bear three daughters-\
\ by your leave I speak it, You love the breeder better than the male.\n"
- "Forget that rarest treasure of your cheek,\n Exposing it- but, O, the harder\
\ heart! Alack, no remedy!- to the greedy touch Of common-kissing Titan,\
\ and forget Your laboursome and dainty trims wherein You made great Juno\
\ angry. IMOGEN. Nay, be brief; I see into thy end, and am almost A man\
\ already. PISANIO. First, make yourself but like one. Fore-thinking this,\
\ I have already fit- 'Tis in my cloak-bag- doublet, hat, hose, all That\
\ answer to them. Would you, in their serving, And with what imitation you\
\ can borrow From youth of such a season, fore noble Lucius Present yourself,\
\ desire his service, tell him Wherein you're happy- which will make him know\
\ If that his head have ear in music; doubtless With joy he will embrace\
\ you; for he's honourable, And, doubling that, most holy. Your means abroad-\
\ You have me, rich; and I will never fail Beginning nor supplyment. IMOGEN.\
\ Thou art all the comfort The gods will diet me with. Prithee away! There's\
\ more to be consider'd; but we'll even All that good time will give us. This\
\ attempt I am soldier to, and will abide it with A prince's courage. Away,\
\ I prithee. PISANIO. Well, madam, we must take a short farewell, Lest, being\
\ miss'd, I be suspected of Your carriage from the court. My noble mistress,\
\ Here is a box; I had it from the Queen. What's in't is precious. If you\
\ are sick at sea Or stomach-qualm'd at land, a dram of this\n Will drive\
\ away distemper. To some shade,\n And fit you to your manhood. May the gods\
\ Direct you to the best! IMOGEN. Amen. I thank thee. Exeunt\
\ severally\n"
- source_sentence: The excerpt showcases the emotional turmoil and sense of honor
that drives Brutus to take his own life in the face of defeat.
sentences:
- "Thou know'st that we two went to school together;\n Even for that our love\
\ of old, I prithee, Hold thou my sword-hilts, whilst I run on it. VOLUMNIUS.\
\ That's not an office for a friend, my lord. \
\ Alarum still. CLITUS. Fly, fly, my lord, there is no tarrying\
\ here. BRUTUS. Farewell to you, and you, and you, Volumnius. Strato, thou\
\ hast been all this while asleep; Farewell to thee too, Strato. Countrymen,\
\ My heart doth joy that yet in all my life I found no man but he was true\
\ to me. I shall have glory by this losing day, More than Octavius and Mark\
\ Antony By this vile conquest shall attain unto. So, fare you well at once,\
\ for Brutus' tongue Hath almost ended his life's history. Night hangs upon\
\ mine eyes, my bones would rest That have but labor'd to attain this hour.\
\ Alarum. Cry within, \"Fly, fly, fly!\" CLITUS. Fly,\
\ my lord, fly. BRUTUS. Hence! I will follow. Exeunt Clitus,\
\ Dardanius, and Volumnius. I prithee, Strato, stay thou by thy lord. Thou\
\ art a fellow of a good respect; Thy life hath had some smatch of honor in\
\ it. Hold then my sword, and turn away thy face, While I do run upon it.\
\ Wilt thou, Strato? STRATO. Give me your hand first. Fare you well, my lord.\
\ BRUTUS. Farewell, good Strato. Runs on his sword. Caesar,\
\ now be still; I kill'd not thee with half so good a will. Dies.\n\
\ Alarum. Retreat. Enter Octavius, Antony, Messala,\n Lucilius,\
\ and the Army.\n OCTAVIUS. What man is that?\n"
- "Elsinore. A room in the Castle.\nEnter King, Queen, Polonius, Ophelia, Rosencrantz,\
\ Guildenstern, and Lords. King. And can you by no drift of circumstance\n \
\ Get from him why he puts on this confusion, Grating so harshly all his days\
\ of quiet With turbulent and dangerous lunacy? Ros. He does confess he feels\
\ himself distracted, But from what cause he will by no means speak. Guil.\
\ Nor do we find him forward to be sounded, But with a crafty madness keeps\
\ aloof When we would bring him on to some confession Of his true state.\
\ Queen. Did he receive you well? Ros. Most like a gentleman. Guil. But with\
\ much forcing of his disposition. Ros. Niggard of question, but of our demands\
\ Most free in his reply. Queen. Did you assay him To any pastime? Ros.\
\ Madam, it so fell out that certain players\n We o'erraught on the way.\
\ Of these we told him,\n"
- "VII.\nThe French camp near Agincourt\nEnter the CONSTABLE OF FRANCE, the LORD\
\ RAMBURES, the DUKE OF ORLEANS,\nthe DAUPHIN, with others\n CONSTABLE. Tut!\
\ I have the best armour of the world.\n Would it were day! ORLEANS. You have\
\ an excellent armour; but let my horse have his due. CONSTABLE. It is the\
\ best horse of Europe. ORLEANS. Will it never be morning? DAUPHIN. My Lord\
\ of Orleans and my Lord High Constable, you talk of horse and armour? ORLEANS.\
\ You are as well provided of both as any prince in the world. DAUPHIN. What\
\ a long night is this! I will not change my horse with any that treads but\
\ on four pasterns. Ca, ha! he bounds from the earth as if his entrails were\
\ hairs; le cheval volant, the Pegasus, chez les narines de feu! When I bestride\
\ him I soar, I am a hawk. He trots the air; the earth sings when he touches\
\ it; the basest horn of his hoof is more musical than the pipe of Hermes.\
\ ORLEANS. He's of the colour of the nutmeg. DAUPHIN. And of the heat of the\
\ ginger. It is a beast for Perseus: he is pure air and fire; and the dull\
\ elements of earth and water never appear in him, but only in patient stillness\
\ while his rider mounts him; he is indeed a horse, and all other jades you\
\ may call beasts. CONSTABLE. Indeed, my lord, it is a most absolute and excellent\
\ horse.\n DAUPHIN. It is the prince of palfreys; his neigh is like the\n"
- source_sentence: What themes are present in the excerpt from the play?
sentences:
- "Enter TRAVERS NORTHUMBERLAND. Here comes my servant Travers, whom I sent\n \
\ On Tuesday last to listen after news. LORD BARDOLPH. My lord, I over-rode\
\ him on the way; And he is furnish'd with no certainties More than he haply\
\ may retail from me. NORTHUMBERLAND. Now, Travers, what good tidings comes with\
\ you? TRAVERS. My lord, Sir John Umfrevile turn'd me back With joyful tidings;\
\ and, being better hors'd, Out-rode me. After him came spurring hard A\
\ gentleman, almost forspent with speed, That stopp'd by me to breathe his\
\ bloodied horse. He ask'd the way to Chester; and of him I did demand what\
\ news from Shrewsbury. He told me that rebellion had bad luck, And that\
\ young Harry Percy's spur was cold. With that he gave his able horse the\
\ head And, bending forward, struck his armed heels\n Against the panting\
\ sides of his poor jade\n Up to the rowel-head; and starting so, He seem'd\
\ in running to devour the way, Staying no longer question. NORTHUMBERLAND.\
\ Ha! Again: Said he young Harry Percy's spur was cold? Of Hotspur, Coldspur?\
\ that rebellion Had met ill luck? LORD BARDOLPH. My lord, I'll tell you what:\
\ If my young lord your son have not the day, Upon mine honour, for a silken\
\ point I'll give my barony. Never talk of it. NORTHUMBERLAND. Why should\
\ that gentleman that rode by Travers Give then such instances of loss? LORD\
\ BARDOLPH. Who- he? He was some hilding fellow that had stol'n The horse\
\ he rode on and, upon my life, Spoke at a venture. Look, here comes more news.\
\ \n Enter Morton NORTHUMBERLAND. Yea, this man's brow,\
\ like to a title-leaf,\n"
- "ANTONY. Yet they are not join'd. Where yond pine does stand\n I shall discover\
\ all. I'll bring thee word Straight how 'tis like to go. \
\ Exit SCARUS. Swallows have built In Cleopatra's sails their nests.\
\ The augurers Say they know not, they cannot tell; look grimly, And dare\
\ not speak their knowledge. Antony Is valiant and dejected; and by starts\
\ His fretted fortunes give him hope and fear Of what he has and has not.\
\ [Alarum afar off, as at a sea-fight]\n \
\ Re-enter ANTONY ANTONY. All is lost!\n This foul Egyptian hath\
\ betrayed me. My fleet hath yielded to the foe, and yonder They cast\
\ their caps up and carouse together Like friends long lost. Triple-turn'd\
\ whore! 'tis thou\n Hast sold me to this novice; and my heart\n Makes\
\ only wars on thee. Bid them all fly; For when I am reveng'd upon my charm,\
\ I have done all. Bid them all fly; begone. Exit SCARUS O sun, thy\
\ uprise shall I see no more! Fortune and Antony part here; even here Do\
\ we shake hands. All come to this? The hearts That spaniel'd me at heels,\
\ to whom I gave Their wishes, do discandy, melt their sweets On blossoming\
\ Caesar; and this pine is bark'd That overtopp'd them all. Betray'd I am.\
\ O this false soul of Egypt! this grave charm- Whose eye beck'd forth my\
\ wars and call'd them home, Whose bosom was my crownet, my chief end- Like\
\ a right gypsy hath at fast and loose Beguil'd me to the very heart of loss.\
\ What, Eros, Eros! Enter CLEOPATRA\n Ah, thou spell!\
\ Avaunt!\n"
- "TALBOT. Saint George and victory! Fight, soldiers, fight.\n The Regent hath\
\ with Talbot broke his word And left us to the rage of France his sword. \
\ Where is John Talbot? Pause and take thy breath; I gave thee life and rescu'd\
\ thee from death. JOHN. O, twice my father, twice am I thy son! The life\
\ thou gav'st me first was lost and done Till with thy warlike sword, despite\
\ of fate, To my determin'd time thou gav'st new date. TALBOT. When from the\
\ Dauphin's crest thy sword struck fire, It warm'd thy father's heart with\
\ proud desire Of bold-fac'd victory. Then leaden age, Quicken'd with youthful\
\ spleen and warlike rage, Beat down Alencon, Orleans, Burgundy, And from\
\ the pride of Gallia rescued thee. The ireful bastard Orleans, that drew blood\
\ From thee, my boy, and had the maidenhood Of thy first fight, I soon encountered\
\ And, interchanging blows, I quickly shed Some of his bastard blood; and\
\ in disgrace\n Bespoke him thus: 'Contaminated, base,\n"
- source_sentence: What is the significance of the tennis balls in the excerpt from
the play?
sentences:
- "My fault is past. But, O, what form of prayer\n Can serve my turn? 'Forgive\
\ me my foul murther'? That cannot be; since I am still possess'd Of those\
\ effects for which I did the murther- My crown, mine own ambition, and my\
\ queen. May one be pardon'd and retain th' offence? In the corrupted currents\
\ of this world Offence's gilded hand may shove by justice, And oft 'tis\
\ seen the wicked prize itself Buys out the law; but 'tis not so above. \
\ There is no shuffling; there the action lies In his true nature, and we ourselves\
\ compell'd, Even to the teeth and forehead of our faults, To give in evidence.\
\ What then? What rests? Try what repentance can. What can it not? Yet what\
\ can it when one cannot repent? O wretched state! O bosom black as death!\
\ O limed soul, that, struggling to be free, Art more engag'd! Help, angels!\
\ Make assay. Bow, stubborn knees; and heart with strings of steel, Be\
\ soft as sinews of the new-born babe! All may be well. \
\ He kneels.\n Enter Hamlet. Ham. Now might\
\ I do it pat, now he is praying;\n And now I'll do't. And so he goes to heaven,\
\ And so am I reveng'd. That would be scann'd. A villain kills my father;\
\ and for that, I, his sole son, do this same villain send To heaven. \
\ Why, this is hire and salary, not revenge! He took my father grossly, full\
\ of bread, With all his crimes broad blown, as flush as May; And how his\
\ audit stands, who knows save heaven?\n But in our circumstance and course\
\ of thought,\n"
- "YORK. From Ireland thus comes York to claim his right\n And pluck the crown\
\ from feeble Henry's head: Ring bells aloud, burn bonfires clear and bright,\
\ To entertain great England's lawful king. Ah, sancta majestas! who would\
\ not buy thee dear? Let them obey that knows not how to rule; This hand\
\ was made to handle nought but gold. I cannot give due action to my words\
\ Except a sword or sceptre balance it.\n A sceptre shall it have, have\
\ I a soul\n On which I'll toss the flower-de-luce of France.\n \
\ Enter BUCKINGHAM [Aside] Whom have we here? Buckingham, to disturb\
\ me?\n The King hath sent him, sure: I must dissemble. BUCKINGHAM. York,\
\ if thou meanest well I greet thee well. YORK. Humphrey of Buckingham, I accept\
\ thy greeting. Art thou a messenger, or come of pleasure? BUCKINGHAM. A messenger\
\ from Henry, our dread liege, To know the reason of these arms in peace; \
\ Or why thou, being a subject as I am, Against thy oath and true allegiance\
\ sworn, Should raise so great a power without his leave, Or dare to bring\
\ thy force so near the court. YORK. [Aside] Scarce can I speak, my choler is\
\ so great. O, I could hew up rocks and fight with flint, I am so angry\
\ at these abject terms; And now, like Ajax Telamonius, On sheep or oxen\
\ could I spend my fury. I am far better born than is the King, More like\
\ a king, more kingly in my thoughts; But I must make fair weather yet awhile,\
\ Till Henry be more weak and I more strong.- Buckingham, I prithee, pardon\
\ me That I have given no answer all this while; My mind was troubled with\
\ deep melancholy. The cause why I have brought this army hither Is to\
\ remove proud Somerset from the King, Seditious to his Grace and to the state.\
\ BUCKINGHAM. That is too much presumption on thy part; But if thy arms be\
\ to no other end, The King hath yielded unto thy demand:\n The Duke of\
\ Somerset is in the Tower.\n"
- "Says that you savour too much of your youth,\n And bids you be advis'd there's\
\ nought in France That can be with a nimble galliard won; You cannot revel\
\ into dukedoms there. He therefore sends you, meeter for your spirit, This\
\ tun of treasure; and, in lieu of this, Desires you let the dukedoms that\
\ you claim Hear no more of you. This the Dauphin speaks. KING HENRY. What\
\ treasure, uncle? EXETER. Tennis-balls, my liege. KING HENRY. We are glad the\
\ Dauphin is so pleasant with us; His present and your pains we thank you for.\
\ When we have match'd our rackets to these balls, We will in France,\
\ by God's grace, play a set Shall strike his father's crown into the hazard.\
\ Tell him he hath made a match with such a wrangler That all the courts\
\ of France will be disturb'd With chaces. And we understand him well, How\
\ he comes o'er us with our wilder days, Not measuring what use we made of\
\ them. We never valu'd this poor seat of England; And therefore, living\
\ hence, did give ourself To barbarous licence; as 'tis ever common That\
\ men are merriest when they are from home. But tell the Dauphin I will keep\
\ my state, Be like a king, and show my sail of greatness, When I do rouse\
\ me in my throne of France; For that I have laid by my majesty And plodded\
\ like a man for working-days; But I will rise there with so full a glory \
\ That I will dazzle all the eyes of France, Yea, strike the Dauphin blind\
\ to look on us. And tell the pleasant Prince this mock of his Hath turn'd\
\ his balls to gun-stones, and his soul Shall stand sore charged for the wasteful\
\ vengeance\n That shall fly with them; for many a thousand widows\n"
model-index:
- name: RAG_general/rerank/models/thenlper-gte-base-ft
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: context dev
type: context-dev
metrics:
- type: cosine_accuracy@3
value: 0.5095569070373588
name: Cosine Accuracy@3
- type: cosine_precision@1
value: 0.394874022589053
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.16985230234578627
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.11059947871416159
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.060338835794960896
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.394874022589053
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.5095569070373588
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.552997393570808
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.603388357949609
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.4969009218325175
name: Cosine Ndcg@10
- type: cosine_mrr@200
value: 0.46919455106379765
name: Cosine Mrr@200
- type: cosine_map@100
value: 0.4689011726803316
name: Cosine Map@100
- type: dot_accuracy@3
value: 0.5095569070373588
name: Dot Accuracy@3
- type: dot_precision@1
value: 0.394874022589053
name: Dot Precision@1
- type: dot_precision@3
value: 0.16985230234578627
name: Dot Precision@3
- type: dot_precision@5
value: 0.11059947871416159
name: Dot Precision@5
- type: dot_precision@10
value: 0.060338835794960896
name: Dot Precision@10
- type: dot_recall@1
value: 0.394874022589053
name: Dot Recall@1
- type: dot_recall@3
value: 0.5095569070373588
name: Dot Recall@3
- type: dot_recall@5
value: 0.552997393570808
name: Dot Recall@5
- type: dot_recall@10
value: 0.603388357949609
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.4969009218325175
name: Dot Ndcg@10
- type: dot_mrr@200
value: 0.46919455106379765
name: Dot Mrr@200
- type: dot_map@100
value: 0.4689011726803316
name: Dot Map@100
---
# RAG_general/rerank/models/thenlper-gte-base-ft
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [thenlper/gte-base](https://huggingface.co/thenlper/gte-base). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [thenlper/gte-base](https://huggingface.co/thenlper/gte-base) <!-- at revision 5e95d41db6721e7cbd5006e99c7508f0083223d6 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("rjnClarke/thenlper-gte-base-fine-tuned")
# Run inference
sentences = [
'What is the significance of the tennis balls in the excerpt from the play?',
"Says that you savour too much of your youth,\n And bids you be advis'd there's nought in France That can be with a nimble galliard won; You cannot revel into dukedoms there. He therefore sends you, meeter for your spirit, This tun of treasure; and, in lieu of this, Desires you let the dukedoms that you claim Hear no more of you. This the Dauphin speaks. KING HENRY. What treasure, uncle? EXETER. Tennis-balls, my liege. KING HENRY. We are glad the Dauphin is so pleasant with us; His present and your pains we thank you for. When we have match'd our rackets to these balls, We will in France, by God's grace, play a set Shall strike his father's crown into the hazard. Tell him he hath made a match with such a wrangler That all the courts of France will be disturb'd With chaces. And we understand him well, How he comes o'er us with our wilder days, Not measuring what use we made of them. We never valu'd this poor seat of England; And therefore, living hence, did give ourself To barbarous licence; as 'tis ever common That men are merriest when they are from home. But tell the Dauphin I will keep my state, Be like a king, and show my sail of greatness, When I do rouse me in my throne of France; For that I have laid by my majesty And plodded like a man for working-days; But I will rise there with so full a glory That I will dazzle all the eyes of France, Yea, strike the Dauphin blind to look on us. And tell the pleasant Prince this mock of his Hath turn'd his balls to gun-stones, and his soul Shall stand sore charged for the wasteful vengeance\n That shall fly with them; for many a thousand widows\n",
"YORK. From Ireland thus comes York to claim his right\n And pluck the crown from feeble Henry's head: Ring bells aloud, burn bonfires clear and bright, To entertain great England's lawful king. Ah, sancta majestas! who would not buy thee dear? Let them obey that knows not how to rule; This hand was made to handle nought but gold. I cannot give due action to my words Except a sword or sceptre balance it.\n A sceptre shall it have, have I a soul\n On which I'll toss the flower-de-luce of France.\n Enter BUCKINGHAM [Aside] Whom have we here? Buckingham, to disturb me?\n The King hath sent him, sure: I must dissemble. BUCKINGHAM. York, if thou meanest well I greet thee well. YORK. Humphrey of Buckingham, I accept thy greeting. Art thou a messenger, or come of pleasure? BUCKINGHAM. A messenger from Henry, our dread liege, To know the reason of these arms in peace; Or why thou, being a subject as I am, Against thy oath and true allegiance sworn, Should raise so great a power without his leave, Or dare to bring thy force so near the court. YORK. [Aside] Scarce can I speak, my choler is so great. O, I could hew up rocks and fight with flint, I am so angry at these abject terms; And now, like Ajax Telamonius, On sheep or oxen could I spend my fury. I am far better born than is the King, More like a king, more kingly in my thoughts; But I must make fair weather yet awhile, Till Henry be more weak and I more strong.- Buckingham, I prithee, pardon me That I have given no answer all this while; My mind was troubled with deep melancholy. The cause why I have brought this army hither Is to remove proud Somerset from the King, Seditious to his Grace and to the state. BUCKINGHAM. That is too much presumption on thy part; But if thy arms be to no other end, The King hath yielded unto thy demand:\n The Duke of Somerset is in the Tower.\n",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `context-dev`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@3 | 0.5096 |
| cosine_precision@1 | 0.3949 |
| cosine_precision@3 | 0.1699 |
| cosine_precision@5 | 0.1106 |
| cosine_precision@10 | 0.0603 |
| cosine_recall@1 | 0.3949 |
| cosine_recall@3 | 0.5096 |
| cosine_recall@5 | 0.553 |
| cosine_recall@10 | 0.6034 |
| cosine_ndcg@10 | 0.4969 |
| cosine_mrr@200 | 0.4692 |
| **cosine_map@100** | **0.4689** |
| dot_accuracy@3 | 0.5096 |
| dot_precision@1 | 0.3949 |
| dot_precision@3 | 0.1699 |
| dot_precision@5 | 0.1106 |
| dot_precision@10 | 0.0603 |
| dot_recall@1 | 0.3949 |
| dot_recall@3 | 0.5096 |
| dot_recall@5 | 0.553 |
| dot_recall@10 | 0.6034 |
| dot_ndcg@10 | 0.4969 |
| dot_mrr@200 | 0.4692 |
| dot_map@100 | 0.4689 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 10,359 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 22.32 tokens</li><li>max: 56 tokens</li></ul> | <ul><li>min: 35 tokens</li><li>mean: 351.19 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| anchor | positive |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>Who is the general being described in the excerpt?</code> | <code>PHILO. Nay, but this dotage of our general's<br> O'erflows the measure. Those his goodly eyes, That o'er the files and musters of the war Have glow'd like plated Mars, now bend, now turn, The office and devotion of their view Upon a tawny front. His captain's heart, Which in the scuffles of great fights hath burst<br> The buckles on his breast, reneges all temper,<br> And is become the bellows and the fan To cool a gipsy's lust.<br> Flourish. Enter ANTONY, CLEOPATRA, her LADIES, the train,<br> with eunuchs fanning her<br> Look where they come!<br> Take but good note, and you shall see in him The triple pillar of the world transform'd Into a strumpet's fool. Behold and see. CLEOPATRA. If it be love indeed, tell me how much. ANTONY. There's beggary in the love that can be reckon'd. CLEOPATRA. I'll set a bourn how far to be belov'd. ANTONY. Then must thou needs find out new heaven, new earth.<br> Enter a MESSENGER MESSENGER. News, my good lord, from Rome.<br> ANTONY. Grates me the sum. CLEOPATRA. Nay, hear them, Antony. Fulvia perchance is angry; or who knows If the scarce-bearded Caesar have not sent His pow'rful mandate to you: 'Do this or this; Take in that kingdom and enfranchise that; Perform't, or else we damn thee.' ANTONY. How, my love? CLEOPATRA. Perchance? Nay, and most like, You must not stay here longer; your dismission Is come from Caesar; therefore hear it, Antony. Where's Fulvia's process? Caesar's I would say? Both? Call in the messengers. As I am Egypt's Queen, Thou blushest, Antony, and that blood of thine Is Caesar's homager. Else so thy cheek pays shame<br> When shrill-tongu'd Fulvia scolds. The messengers!<br></code> |
| <code>What is the main conflict highlighted in the excerpt?</code> | <code>PHILO. Nay, but this dotage of our general's<br> O'erflows the measure. Those his goodly eyes, That o'er the files and musters of the war Have glow'd like plated Mars, now bend, now turn, The office and devotion of their view Upon a tawny front. His captain's heart, Which in the scuffles of great fights hath burst<br> The buckles on his breast, reneges all temper,<br> And is become the bellows and the fan To cool a gipsy's lust.<br> Flourish. Enter ANTONY, CLEOPATRA, her LADIES, the train,<br> with eunuchs fanning her<br> Look where they come!<br> Take but good note, and you shall see in him The triple pillar of the world transform'd Into a strumpet's fool. Behold and see. CLEOPATRA. If it be love indeed, tell me how much. ANTONY. There's beggary in the love that can be reckon'd. CLEOPATRA. I'll set a bourn how far to be belov'd. ANTONY. Then must thou needs find out new heaven, new earth.<br> Enter a MESSENGER MESSENGER. News, my good lord, from Rome.<br> ANTONY. Grates me the sum. CLEOPATRA. Nay, hear them, Antony. Fulvia perchance is angry; or who knows If the scarce-bearded Caesar have not sent His pow'rful mandate to you: 'Do this or this; Take in that kingdom and enfranchise that; Perform't, or else we damn thee.' ANTONY. How, my love? CLEOPATRA. Perchance? Nay, and most like, You must not stay here longer; your dismission Is come from Caesar; therefore hear it, Antony. Where's Fulvia's process? Caesar's I would say? Both? Call in the messengers. As I am Egypt's Queen, Thou blushest, Antony, and that blood of thine Is Caesar's homager. Else so thy cheek pays shame<br> When shrill-tongu'd Fulvia scolds. The messengers!<br></code> |
| <code>The excerpt showcases the tension between Antony's loyalty to Cleopatra and his obligations to Caesar, as well as Cleopatra's influence over him.</code> | <code>PHILO. Nay, but this dotage of our general's<br> O'erflows the measure. Those his goodly eyes, That o'er the files and musters of the war Have glow'd like plated Mars, now bend, now turn, The office and devotion of their view Upon a tawny front. His captain's heart, Which in the scuffles of great fights hath burst<br> The buckles on his breast, reneges all temper,<br> And is become the bellows and the fan To cool a gipsy's lust.<br> Flourish. Enter ANTONY, CLEOPATRA, her LADIES, the train,<br> with eunuchs fanning her<br> Look where they come!<br> Take but good note, and you shall see in him The triple pillar of the world transform'd Into a strumpet's fool. Behold and see. CLEOPATRA. If it be love indeed, tell me how much. ANTONY. There's beggary in the love that can be reckon'd. CLEOPATRA. I'll set a bourn how far to be belov'd. ANTONY. Then must thou needs find out new heaven, new earth.<br> Enter a MESSENGER MESSENGER. News, my good lord, from Rome.<br> ANTONY. Grates me the sum. CLEOPATRA. Nay, hear them, Antony. Fulvia perchance is angry; or who knows If the scarce-bearded Caesar have not sent His pow'rful mandate to you: 'Do this or this; Take in that kingdom and enfranchise that; Perform't, or else we damn thee.' ANTONY. How, my love? CLEOPATRA. Perchance? Nay, and most like, You must not stay here longer; your dismission Is come from Caesar; therefore hear it, Antony. Where's Fulvia's process? Caesar's I would say? Both? Call in the messengers. As I am Egypt's Queen, Thou blushest, Antony, and that blood of thine Is Caesar's homager. Else so thy cheek pays shame<br> When shrill-tongu'd Fulvia scolds. The messengers!<br></code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Evaluation Dataset
#### Unnamed Dataset
* Size: 2,302 evaluation samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 21.73 tokens</li><li>max: 61 tokens</li></ul> | <ul><li>min: 16 tokens</li><li>mean: 354.59 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| anchor | positive |
|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>The excerpt highlights the tension between Antony's loyalty to Cleopatra and his standing in Rome, showcasing the intricate balance of power and love in the play.</code> | <code>When shrill-tongu'd Fulvia scolds. The messengers!<br> ANTONY. Let Rome in Tiber melt, and the wide arch Of the rang'd empire fall! Here is my space. Kingdoms are clay; our dungy earth alike Feeds beast as man. The nobleness of life Is to do thus [emhracing], when such a mutual pair And such a twain can do't, in which I bind, On pain of punishment, the world to weet We stand up peerless. CLEOPATRA. Excellent falsehood! Why did he marry Fulvia, and not love her? I'll seem the fool I am not. Antony Will be himself. ANTONY. But stirr'd by Cleopatra. Now for the love of Love and her soft hours, Let's not confound the time with conference harsh; There's not a minute of our lives should stretch Without some pleasure now. What sport to-night? CLEOPATRA. Hear the ambassadors. ANTONY. Fie, wrangling queen! Whom everything becomes- to chide, to laugh, To weep; whose every passion fully strives To make itself in thee fair and admir'd. No messenger but thine, and all alone To-night we'll wander through the streets and note The qualities of people. Come, my queen; Last night you did desire it. Speak not to us. Exeunt ANTONY and CLEOPATRA, with the train DEMETRIUS. Is Caesar with Antonius priz'd so slight? PHILO. Sir, sometimes when he is not Antony, He comes too short of that great property Which still should go with Antony. DEMETRIUS. I am full sorry That he approves the common liar, who Thus speaks of him at Rome; but I will hope<br> Of better deeds to-morrow. Rest you happy! Exeunt<br></code> |
| <code>What is the significance of the soothsayer in the context of the play?</code> | <code>CHARMIAN. Lord Alexas, sweet Alexas, most anything Alexas, almost<br> most absolute Alexas, where's the soothsayer that you prais'd so to th' Queen? O that I knew this husband, which you say must charge his horns with garlands! ALEXAS. Soothsayer! SOOTHSAYER. Your will? CHARMIAN. Is this the man? Is't you, sir, that know things? SOOTHSAYER. In nature's infinite book of secrecy A little I can read. ALEXAS. Show him your hand.<br> Enter ENOBARBUS ENOBARBUS. Bring in the banquet quickly; wine enough<br> Cleopatra's health to drink. CHARMIAN. Good, sir, give me good fortune. SOOTHSAYER. I make not, but foresee. CHARMIAN. Pray, then, foresee me one. SOOTHSAYER. You shall be yet far fairer than you are. CHARMIAN. He means in flesh. IRAS. No, you shall paint when you are old. CHARMIAN. Wrinkles forbid! ALEXAS. Vex not his prescience; be attentive. CHARMIAN. Hush!<br> SOOTHSAYER. You shall be more beloving than beloved.<br></code> |
| <code>What is the setting of the scene in which the excerpt takes place?</code> | <code>sweet Isis, I beseech thee! And let her die too, and give him a<br> worse! And let worse follow worse, till the worst of all follow him laughing to his grave, fiftyfold a cuckold! Good Isis, hear me this prayer, though thou deny me a matter of more weight; good Isis, I beseech thee! IRAS. Amen. Dear goddess, hear that prayer of the people! For, as it is a heartbreaking to see a handsome man loose-wiv'd, so it is a deadly sorrow to behold a foul knave uncuckolded. Therefore, dear Isis, keep decorum, and fortune him accordingly! CHARMIAN. Amen. ALEXAS. Lo now, if it lay in their hands to make me a cuckold, they would make themselves whores but they'ld do't!<br> Enter CLEOPATRA ENOBARBUS. Hush! Here comes Antony.<br> CHARMIAN. Not he; the Queen. CLEOPATRA. Saw you my lord? ENOBARBUS. No, lady. CLEOPATRA. Was he not here? CHARMIAN. No, madam. CLEOPATRA. He was dispos'd to mirth; but on the sudden A Roman thought hath struck him. Enobarbus! ENOBARBUS. Madam? CLEOPATRA. Seek him, and bring him hither. Where's Alexas? ALEXAS. Here, at your service. My lord approaches.<br> Enter ANTONY, with a MESSENGER and attendants CLEOPATRA. We will not look upon him. Go with us.<br> Exeunt CLEOPATRA, ENOBARBUS, and the rest MESSENGER. Fulvia thy wife first came into the field. ANTONY. Against my brother Lucius? MESSENGER. Ay.<br> But soon that war had end, and the time's state<br></code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: epoch
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 32
- `learning_rate`: 3e-05
- `num_train_epochs`: 7
- `warmup_steps`: 50
- `fp16`: True
- `load_best_model_at_end`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: epoch
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 32
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 3e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 7
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 50
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `eval_use_gather_object`: False
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | loss | context-dev_cosine_map@100 |
|:-------:|:-------:|:-------------:|:----------:|:--------------------------:|
| 1.0 | 324 | - | 1.6708 | 0.4417 |
| 1.5432 | 500 | 1.9498 | - | - |
| 2.0 | 648 | - | 1.5636 | 0.4688 |
| **3.0** | **972** | **-** | **1.5743** | **0.4689** |
| 3.0864 | 1000 | 1.1069 | - | - |
| 4.0 | 1296 | - | 1.5924 | 0.4655 |
| 4.6296 | 1500 | 0.7121 | - | - |
| 5.0 | 1620 | - | 1.6213 | 0.4621 |
| 6.0 | 1944 | - | 1.6450 | 0.4603 |
| 6.1728 | 2000 | 0.5308 | - | - |
| 7.0 | 2268 | - | 1.6664 | 0.4689 |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 3.0.1
- Transformers: 4.43.4
- PyTorch: 2.3.1+cu121
- Accelerate: 0.32.1
- Datasets: 2.19.1
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
[
"BEAR"
] |
mradermacher/DialogGPT-MedDialog-large-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"en",
"base_model:hassiahk/DialogGPT-MedDialog-large",
"base_model:quantized:hassiahk/DialogGPT-MedDialog-large",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-09-20T16:17:20Z |
2024-09-20T16:40:35+00:00
| 47 | 0 |
---
base_model: hassiahk/DialogGPT-MedDialog-large
language:
- en
library_name: transformers
tags: []
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/hassiahk/DialogGPT-MedDialog-large
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q2_K.gguf) | Q2_K | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.IQ3_XS.gguf) | IQ3_XS | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.IQ3_S.gguf) | IQ3_S | 0.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q3_K_S.gguf) | Q3_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.IQ3_M.gguf) | IQ3_M | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q3_K_M.gguf) | Q3_K_M | 0.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.IQ4_XS.gguf) | IQ4_XS | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q3_K_L.gguf) | Q3_K_L | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q4_K_S.gguf) | Q4_K_S | 0.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q4_K_M.gguf) | Q4_K_M | 0.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q5_K_S.gguf) | Q5_K_S | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q5_K_M.gguf) | Q5_K_M | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q6_K.gguf) | Q6_K | 0.8 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.Q8_0.gguf) | Q8_0 | 1.0 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/DialogGPT-MedDialog-large-GGUF/resolve/main/DialogGPT-MedDialog-large.f16.gguf) | f16 | 1.8 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
[
"MEDDIALOG"
] |
alastandy/Add-Dental-Braces-4
|
alastandy
|
text-to-image
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:cc-by-sa-4.0",
"region:us"
] | 2024-12-11T10:53:13Z |
2025-03-16T03:49:01+00:00
| 47 | 0 |
---
base_model: black-forest-labs/FLUX.1-dev
license: cc-by-sa-4.0
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: adddentalbraces, a 20-year-old woman with braces on her teeth with red bands,
silver brackets, and a silver wire.
output:
url: images/adddentalbraces__a_20_year_old_woman_with_braces_on_her_teeth_with_red_bands__silver_brackets__and_a_silver_wire__215537463.png
- text: adddentalbraces, a 20-year-old woman with braces on her teeth with red bands,
silver brackets, and a silver wire.
output:
url: images/adddentalbraces__a_20_year_old_woman_with_braces_on_her_teeth_with_red_bands__silver_brackets__and_a_silver_wire__1271334316.png
- text: adddentalbraces, A photo of a cute smiling hampster with braces on its teeth
with green bands, silver brackets, and a silver wire.
output:
url: images/adddentalbraces__a_photo_of_a_cute_smiling_hampster_with_braces_on_its_teeth_with_green_bands__silver_brackets__and_a_silver_wire__1163846435.png
- text: adddentalbraces, A photo of a cute smiling hampster with braces on its teeth
with green bands, silver brackets, and a silver wire.
output:
url: images/adddentalbraces__a_photo_of_a_cute_smiling_hampster_with_braces_on_its_teeth_with_green_bands__silver_brackets__and_a_silver_wire__1111954904.png
- text: adddentalbraces, a 20-year-old man withbraces on teeth with bands that alternate
between blue and green, have silver colored brackets, and have a silver colored
wire.
output:
url: images/6.png
- text: adddentalbraces, a 19-year-old woman with braces on her teeth with turquoise
bands, silver brackets, and a silver wire.
output:
url: images/example_87wj2fbcz.png
- text: adddentalbraces, A rough pencil sketch of a boy with braces on his teeth.
output:
url: images/example_3wvli5hmh.png
- text: adddentalbraces, A great white shark with braces on its teeth.
output:
url: images/example_j02wfkb22.png
- text: adddentalbraces, A pop art style painting featuring a lady with braces to
on her teeth with green bands, silver brackets, and a silver wire.
output:
url: images/example_bjmg046do.png
- text: adddentalbraces, a marble Roman sculpture of a roman general with braces on
his teeth.
output:
url: images/example_b7int472y.png
- text: adddentalbraces, a wooden carving on a piece of driftwood of a bear with
braces on its teeth.
output:
url: images/example_95ddl2ofe.png
- text: adddentalbraces, a snowman made of real snow, with a corn cob pipe, coal eyes,
a black felt top hat, a scarf, and braces on its teeth with blue bands, silver
brackets, and a silver wire.
output:
url: images/example_mqthw964s.png
- text: adddentalbraces, A pop art style work of art featuring a lady with braces
to on her teeth with green bands, silver brackets, and a silver wire.
output:
url: images/example_9sscv00jq.png
- text: adddentalbraces, a cartoon dog with braces on its teeth with red bands, silver
brackets, and a silver wire.
output:
url: images/example_jhn5hd592.png
- text: adddentalbraces, a 20-year-old female police officer with braces on her teeth
with blue bands, sliver brackets, and a silver wire.
output:
url: images/example_e3jylbpfd.png
- text: adddentalbraces, a space alien with braces on their teeth with turquoise bands,
silver brackets, and a silver wire.
output:
url: images/example_qmbkbpq8t.png
- text: adddentalbraces, A photo of a grimy hobo sitting inside a train boxcar with
braces on his teeth with green bands, silver brackets, and a silver wire.
output:
url: images/example_0zng8617q.png
- text: adddentalbraces, A photo of a cute smiling cartoon hamburger with braces on
its teeth with blue bands, silver brackets, and a silver wire.
output:
url: images/example_6bvlnsqsu.png
instance_prompt: adddentalbraces
---
# Add Dental Braces Version 4
<Gallery />
## Model description
This model aims to add photo-realistic dental braces to subjects' teeth in generated images. The braces should be accurately sized and aligned to fit naturally, while responding to prompts specifying the color of the brackets (e.g., gold or silver) and the color of the bands.
Also available on civitai at https://civitai.com/models/871278
Current Functionality:
It is not perfect but version 4 works, and works well most of the time. It works well for male and females. While it was trained to add photo realistic braces to photorealistic images in testing I have found that it can add braces to just about anything, robots, animals, etc. It have also found that it works well in other styles, not just as photos, such as drawings and cartoon styles.
Training Data:
Version 4 of this model was trained on a set of 128 high-resolution (1024 x 1024) photos of real dental braces, using 6912 training steps across 54 epochs. The dataset primarily consists of images showcasing different types of braces and various band colors.
Example Prompts
Because the plan is for the LORA to let you specify the color of the brackets and wire (e.g., gold or silver) and the material (plastic or metal), I have started adding specific information about the color of the brackets, wire, and bands into the labels for each prompt.
So far, only band color works. In part because it only has examples of braces with silver brackets and silver bands in the current dataset.
During testing of version 4, I noticed that I got better and more consistent results if I mirrored this information in the prompt.
Following something like:
adddentalbraces, a [Person/Animal/Object] [Optional age] [If for a person, put man or woman] on [his/her/their/its] teeth with [color] bands, silver brackets, and a silver wire.
Examples:
adddentalbraces, a 20-year-old man with braces on his teeth with red bands, silver brackets, and a silver wire.
adddentalbraces, a 20-year-old woman with braces on her teeth with red bands, silver brackets, and a silver wire.
To be clear, you do NOT have to prompt this way, but in testing, I did get more consistently quality output by doing so since prompts in this style are more similar to many of the labels used in the dataset and because the labels have things like bracket color and wire color specified.
Tips for Best Results
Use specific descriptors for age, gender, and brace materials to improve realism.
Follow the prompt style of:
adddentalbraces, a [Person/Animal/Object] [Optional age] [If for a person, put man or woman] on [his/her/their/its] teeth with [color] bands, silver brackets, and a silver wire.
Or at least specify a color for the bands and use the phrase "with silver brackets, and a silver wire."
Simple prompts, such as
adddentalbraces, A 25-year-old woman with braces on her teeth.
consistently yield highly satisfactory results, consistently producing headshot-style photographs. The braces appear most aesthetically pleasing in this close-up style, and the LORA will generally create images in this manner unless the prompt explicitly requests otherwise.
The LORA can also handle more intricate prompts and reliably incorporate the braces, although if these prompts result in full-body shots or distance shots, the quality of the results of the braces added may decrease. The current dataset lacks sufficient examples of braces at a distance, leading to occasional inconsistencies or inaccurate representations. (I am planning to include additional examples of braces at a greater distance in the next version of the dataset to enhance this aspect, but this may require time to obtain or produce images of sufficient quality. I am meticulous about the images in the dataset and firmly believe that the quality of the data is the paramount factor in achieving quality results from the training.)
A/B Testing Results:
Version 3 vs. Version 4
Skin Texture Improvement:
Version 3 exhibited a tendency to render an airbrushed appearance on facial skin. In contrast, Version 4 incorporated regularization images into its dataset to specifically address this issue.
A/B testing conducted after training demonstrated substantial improvement in this area.
Enhanced Dataset Details:
Version 4 also incorporates enhancements to its dataset to provide more detailed representations of real braces.
A/B testing revealed that Version 4 occasionally introduced subtle features on braces, such as hooks for rubber bands, that were not present in Version 3.
Alternating Band Color Representation:
Version 4 also includes a wider range of examples of braces with alternating band colors in its dataset.
A/B testing demonstrated that Version 4 effectively handled prompts specifying alternating band colors (e.g., “with bands that alternate between blue and green”), outperforming Version 3 in this regard.
Overall Performance Summary:
In summary, Version 4 achieved slightly superior overall results and exhibited fewer anomalies, such as sections of the bracket that should not have been present. Conversely, Version 3 occasionally produced superior bands but at the expense of diminished overall image quality.
The FLUX.1 [dev] Model is licensed by Black Forest Labs. Inc. under the FLUX.1 [dev] Non-Commercial License. Copyright Black Forest Labs. Inc.
IN NO EVENT SHALL BLACK FOREST LABS, INC. BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH USE OF THIS MODEL.
## Trigger words
You should use `adddentalbraces` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/alastandy/Add-Dental-Braces-4/tree/main) them in the Files & versions tab.
|
[
"BEAR"
] |
consciousAI/cai-lunaris-text-embeddings
|
consciousAI
|
sentence-similarity
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"mteb",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2023-06-22T18:08:54Z |
2023-06-22T21:33:52+00:00
| 46 | 4 |
---
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- mteb
model-index:
- name: cai-lunaris-text-embeddings
results:
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 17.07
- type: map_at_10
value: 29.372999999999998
- type: map_at_100
value: 30.79
- type: map_at_1000
value: 30.819999999999997
- type: map_at_3
value: 24.395
- type: map_at_5
value: 27.137
- type: mrr_at_1
value: 17.923000000000002
- type: mrr_at_10
value: 29.695
- type: mrr_at_100
value: 31.098
- type: mrr_at_1000
value: 31.128
- type: mrr_at_3
value: 24.704
- type: mrr_at_5
value: 27.449
- type: ndcg_at_1
value: 17.07
- type: ndcg_at_10
value: 37.269000000000005
- type: ndcg_at_100
value: 43.716
- type: ndcg_at_1000
value: 44.531
- type: ndcg_at_3
value: 26.839000000000002
- type: ndcg_at_5
value: 31.845000000000002
- type: precision_at_1
value: 17.07
- type: precision_at_10
value: 6.3020000000000005
- type: precision_at_100
value: 0.922
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 11.309
- type: precision_at_5
value: 9.246
- type: recall_at_1
value: 17.07
- type: recall_at_10
value: 63.016000000000005
- type: recall_at_100
value: 92.24799999999999
- type: recall_at_1000
value: 98.72
- type: recall_at_3
value: 33.926
- type: recall_at_5
value: 46.23
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 53.44266265900711
- type: mrr
value: 66.54695950402322
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 75.9652953730204
- type: cos_sim_spearman
value: 73.96554077670989
- type: euclidean_pearson
value: 75.68477255792381
- type: euclidean_spearman
value: 74.59447076995703
- type: manhattan_pearson
value: 75.94984623881341
- type: manhattan_spearman
value: 74.72218452337502
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 14.119000000000002
- type: map_at_10
value: 19.661
- type: map_at_100
value: 20.706
- type: map_at_1000
value: 20.848
- type: map_at_3
value: 17.759
- type: map_at_5
value: 18.645
- type: mrr_at_1
value: 17.166999999999998
- type: mrr_at_10
value: 23.313
- type: mrr_at_100
value: 24.263
- type: mrr_at_1000
value: 24.352999999999998
- type: mrr_at_3
value: 21.412
- type: mrr_at_5
value: 22.313
- type: ndcg_at_1
value: 17.166999999999998
- type: ndcg_at_10
value: 23.631
- type: ndcg_at_100
value: 28.427000000000003
- type: ndcg_at_1000
value: 31.862000000000002
- type: ndcg_at_3
value: 20.175
- type: ndcg_at_5
value: 21.397
- type: precision_at_1
value: 17.166999999999998
- type: precision_at_10
value: 4.549
- type: precision_at_100
value: 0.8370000000000001
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 9.68
- type: precision_at_5
value: 6.981
- type: recall_at_1
value: 14.119000000000002
- type: recall_at_10
value: 32.147999999999996
- type: recall_at_100
value: 52.739999999999995
- type: recall_at_1000
value: 76.67
- type: recall_at_3
value: 22.019
- type: recall_at_5
value: 25.361
- type: map_at_1
value: 16.576
- type: map_at_10
value: 22.281000000000002
- type: map_at_100
value: 23.066
- type: map_at_1000
value: 23.166
- type: map_at_3
value: 20.385
- type: map_at_5
value: 21.557000000000002
- type: mrr_at_1
value: 20.892
- type: mrr_at_10
value: 26.605
- type: mrr_at_100
value: 27.229
- type: mrr_at_1000
value: 27.296
- type: mrr_at_3
value: 24.809
- type: mrr_at_5
value: 25.927
- type: ndcg_at_1
value: 20.892
- type: ndcg_at_10
value: 26.092
- type: ndcg_at_100
value: 29.398999999999997
- type: ndcg_at_1000
value: 31.884
- type: ndcg_at_3
value: 23.032
- type: ndcg_at_5
value: 24.634
- type: precision_at_1
value: 20.892
- type: precision_at_10
value: 4.885
- type: precision_at_100
value: 0.818
- type: precision_at_1000
value: 0.126
- type: precision_at_3
value: 10.977
- type: precision_at_5
value: 8.013
- type: recall_at_1
value: 16.576
- type: recall_at_10
value: 32.945
- type: recall_at_100
value: 47.337
- type: recall_at_1000
value: 64.592
- type: recall_at_3
value: 24.053
- type: recall_at_5
value: 28.465
- type: map_at_1
value: 20.604
- type: map_at_10
value: 28.754999999999995
- type: map_at_100
value: 29.767
- type: map_at_1000
value: 29.852
- type: map_at_3
value: 26.268
- type: map_at_5
value: 27.559
- type: mrr_at_1
value: 24.326
- type: mrr_at_10
value: 31.602000000000004
- type: mrr_at_100
value: 32.46
- type: mrr_at_1000
value: 32.521
- type: mrr_at_3
value: 29.415000000000003
- type: mrr_at_5
value: 30.581000000000003
- type: ndcg_at_1
value: 24.326
- type: ndcg_at_10
value: 33.335
- type: ndcg_at_100
value: 38.086
- type: ndcg_at_1000
value: 40.319
- type: ndcg_at_3
value: 28.796
- type: ndcg_at_5
value: 30.758999999999997
- type: precision_at_1
value: 24.326
- type: precision_at_10
value: 5.712
- type: precision_at_100
value: 0.893
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 13.208
- type: precision_at_5
value: 9.329
- type: recall_at_1
value: 20.604
- type: recall_at_10
value: 44.505
- type: recall_at_100
value: 65.866
- type: recall_at_1000
value: 82.61800000000001
- type: recall_at_3
value: 31.794
- type: recall_at_5
value: 36.831
- type: map_at_1
value: 8.280999999999999
- type: map_at_10
value: 11.636000000000001
- type: map_at_100
value: 12.363
- type: map_at_1000
value: 12.469
- type: map_at_3
value: 10.415000000000001
- type: map_at_5
value: 11.144
- type: mrr_at_1
value: 9.266
- type: mrr_at_10
value: 12.838
- type: mrr_at_100
value: 13.608999999999998
- type: mrr_at_1000
value: 13.700999999999999
- type: mrr_at_3
value: 11.507000000000001
- type: mrr_at_5
value: 12.343
- type: ndcg_at_1
value: 9.266
- type: ndcg_at_10
value: 13.877
- type: ndcg_at_100
value: 18.119
- type: ndcg_at_1000
value: 21.247
- type: ndcg_at_3
value: 11.376999999999999
- type: ndcg_at_5
value: 12.675
- type: precision_at_1
value: 9.266
- type: precision_at_10
value: 2.226
- type: precision_at_100
value: 0.47200000000000003
- type: precision_at_1000
value: 0.077
- type: precision_at_3
value: 4.859
- type: precision_at_5
value: 3.6380000000000003
- type: recall_at_1
value: 8.280999999999999
- type: recall_at_10
value: 19.872999999999998
- type: recall_at_100
value: 40.585
- type: recall_at_1000
value: 65.225
- type: recall_at_3
value: 13.014000000000001
- type: recall_at_5
value: 16.147
- type: map_at_1
value: 4.1209999999999996
- type: map_at_10
value: 7.272
- type: map_at_100
value: 8.079
- type: map_at_1000
value: 8.199
- type: map_at_3
value: 6.212
- type: map_at_5
value: 6.736000000000001
- type: mrr_at_1
value: 5.721
- type: mrr_at_10
value: 9.418
- type: mrr_at_100
value: 10.281
- type: mrr_at_1000
value: 10.385
- type: mrr_at_3
value: 8.126
- type: mrr_at_5
value: 8.779
- type: ndcg_at_1
value: 5.721
- type: ndcg_at_10
value: 9.673
- type: ndcg_at_100
value: 13.852999999999998
- type: ndcg_at_1000
value: 17.546999999999997
- type: ndcg_at_3
value: 7.509
- type: ndcg_at_5
value: 8.373
- type: precision_at_1
value: 5.721
- type: precision_at_10
value: 2.04
- type: precision_at_100
value: 0.48
- type: precision_at_1000
value: 0.093
- type: precision_at_3
value: 4.022
- type: precision_at_5
value: 3.06
- type: recall_at_1
value: 4.1209999999999996
- type: recall_at_10
value: 15.201
- type: recall_at_100
value: 33.922999999999995
- type: recall_at_1000
value: 61.529999999999994
- type: recall_at_3
value: 8.869
- type: recall_at_5
value: 11.257
- type: map_at_1
value: 14.09
- type: map_at_10
value: 19.573999999999998
- type: map_at_100
value: 20.580000000000002
- type: map_at_1000
value: 20.704
- type: map_at_3
value: 17.68
- type: map_at_5
value: 18.64
- type: mrr_at_1
value: 17.227999999999998
- type: mrr_at_10
value: 23.152
- type: mrr_at_100
value: 24.056
- type: mrr_at_1000
value: 24.141000000000002
- type: mrr_at_3
value: 21.142
- type: mrr_at_5
value: 22.201
- type: ndcg_at_1
value: 17.227999999999998
- type: ndcg_at_10
value: 23.39
- type: ndcg_at_100
value: 28.483999999999998
- type: ndcg_at_1000
value: 31.709
- type: ndcg_at_3
value: 19.883
- type: ndcg_at_5
value: 21.34
- type: precision_at_1
value: 17.227999999999998
- type: precision_at_10
value: 4.3790000000000004
- type: precision_at_100
value: 0.826
- type: precision_at_1000
value: 0.128
- type: precision_at_3
value: 9.496
- type: precision_at_5
value: 6.872
- type: recall_at_1
value: 14.09
- type: recall_at_10
value: 31.580000000000002
- type: recall_at_100
value: 54.074
- type: recall_at_1000
value: 77.092
- type: recall_at_3
value: 21.601
- type: recall_at_5
value: 25.333
- type: map_at_1
value: 10.538
- type: map_at_10
value: 15.75
- type: map_at_100
value: 16.71
- type: map_at_1000
value: 16.838
- type: map_at_3
value: 13.488
- type: map_at_5
value: 14.712
- type: mrr_at_1
value: 13.813
- type: mrr_at_10
value: 19.08
- type: mrr_at_100
value: 19.946
- type: mrr_at_1000
value: 20.044
- type: mrr_at_3
value: 16.838
- type: mrr_at_5
value: 17.951
- type: ndcg_at_1
value: 13.813
- type: ndcg_at_10
value: 19.669
- type: ndcg_at_100
value: 24.488
- type: ndcg_at_1000
value: 27.87
- type: ndcg_at_3
value: 15.479000000000001
- type: ndcg_at_5
value: 17.229
- type: precision_at_1
value: 13.813
- type: precision_at_10
value: 3.916
- type: precision_at_100
value: 0.743
- type: precision_at_1000
value: 0.122
- type: precision_at_3
value: 7.534000000000001
- type: precision_at_5
value: 5.822
- type: recall_at_1
value: 10.538
- type: recall_at_10
value: 28.693
- type: recall_at_100
value: 50.308
- type: recall_at_1000
value: 74.44
- type: recall_at_3
value: 16.866999999999997
- type: recall_at_5
value: 21.404999999999998
- type: map_at_1
value: 11.044583333333332
- type: map_at_10
value: 15.682833333333335
- type: map_at_100
value: 16.506500000000003
- type: map_at_1000
value: 16.623833333333334
- type: map_at_3
value: 14.130833333333333
- type: map_at_5
value: 14.963583333333332
- type: mrr_at_1
value: 13.482833333333332
- type: mrr_at_10
value: 18.328500000000002
- type: mrr_at_100
value: 19.095416666666665
- type: mrr_at_1000
value: 19.18241666666666
- type: mrr_at_3
value: 16.754749999999998
- type: mrr_at_5
value: 17.614749999999997
- type: ndcg_at_1
value: 13.482833333333332
- type: ndcg_at_10
value: 18.81491666666667
- type: ndcg_at_100
value: 22.946833333333334
- type: ndcg_at_1000
value: 26.061083333333336
- type: ndcg_at_3
value: 15.949333333333332
- type: ndcg_at_5
value: 17.218333333333334
- type: precision_at_1
value: 13.482833333333332
- type: precision_at_10
value: 3.456583333333333
- type: precision_at_100
value: 0.6599166666666666
- type: precision_at_1000
value: 0.109
- type: precision_at_3
value: 7.498833333333332
- type: precision_at_5
value: 5.477166666666667
- type: recall_at_1
value: 11.044583333333332
- type: recall_at_10
value: 25.737750000000005
- type: recall_at_100
value: 44.617916666666666
- type: recall_at_1000
value: 67.56524999999999
- type: recall_at_3
value: 17.598249999999997
- type: recall_at_5
value: 20.9035
- type: map_at_1
value: 9.362
- type: map_at_10
value: 13.414000000000001
- type: map_at_100
value: 14.083000000000002
- type: map_at_1000
value: 14.168
- type: map_at_3
value: 12.098
- type: map_at_5
value: 12.803999999999998
- type: mrr_at_1
value: 11.043
- type: mrr_at_10
value: 15.158
- type: mrr_at_100
value: 15.845999999999998
- type: mrr_at_1000
value: 15.916
- type: mrr_at_3
value: 13.88
- type: mrr_at_5
value: 14.601
- type: ndcg_at_1
value: 11.043
- type: ndcg_at_10
value: 16.034000000000002
- type: ndcg_at_100
value: 19.686
- type: ndcg_at_1000
value: 22.188
- type: ndcg_at_3
value: 13.530000000000001
- type: ndcg_at_5
value: 14.704
- type: precision_at_1
value: 11.043
- type: precision_at_10
value: 2.791
- type: precision_at_100
value: 0.5
- type: precision_at_1000
value: 0.077
- type: precision_at_3
value: 6.237
- type: precision_at_5
value: 4.5089999999999995
- type: recall_at_1
value: 9.362
- type: recall_at_10
value: 22.396
- type: recall_at_100
value: 39.528999999999996
- type: recall_at_1000
value: 58.809
- type: recall_at_3
value: 15.553
- type: recall_at_5
value: 18.512
- type: map_at_1
value: 5.657
- type: map_at_10
value: 8.273
- type: map_at_100
value: 8.875
- type: map_at_1000
value: 8.977
- type: map_at_3
value: 7.32
- type: map_at_5
value: 7.792000000000001
- type: mrr_at_1
value: 7.02
- type: mrr_at_10
value: 9.966999999999999
- type: mrr_at_100
value: 10.636
- type: mrr_at_1000
value: 10.724
- type: mrr_at_3
value: 8.872
- type: mrr_at_5
value: 9.461
- type: ndcg_at_1
value: 7.02
- type: ndcg_at_10
value: 10.199
- type: ndcg_at_100
value: 13.642000000000001
- type: ndcg_at_1000
value: 16.643
- type: ndcg_at_3
value: 8.333
- type: ndcg_at_5
value: 9.103
- type: precision_at_1
value: 7.02
- type: precision_at_10
value: 1.8929999999999998
- type: precision_at_100
value: 0.43
- type: precision_at_1000
value: 0.08099999999999999
- type: precision_at_3
value: 3.843
- type: precision_at_5
value: 2.884
- type: recall_at_1
value: 5.657
- type: recall_at_10
value: 14.563
- type: recall_at_100
value: 30.807000000000002
- type: recall_at_1000
value: 53.251000000000005
- type: recall_at_3
value: 9.272
- type: recall_at_5
value: 11.202
- type: map_at_1
value: 10.671999999999999
- type: map_at_10
value: 14.651
- type: map_at_100
value: 15.406
- type: map_at_1000
value: 15.525
- type: map_at_3
value: 13.461
- type: map_at_5
value: 14.163
- type: mrr_at_1
value: 12.407
- type: mrr_at_10
value: 16.782
- type: mrr_at_100
value: 17.562
- type: mrr_at_1000
value: 17.653
- type: mrr_at_3
value: 15.47
- type: mrr_at_5
value: 16.262
- type: ndcg_at_1
value: 12.407
- type: ndcg_at_10
value: 17.251
- type: ndcg_at_100
value: 21.378
- type: ndcg_at_1000
value: 24.689
- type: ndcg_at_3
value: 14.915000000000001
- type: ndcg_at_5
value: 16.1
- type: precision_at_1
value: 12.407
- type: precision_at_10
value: 2.91
- type: precision_at_100
value: 0.573
- type: precision_at_1000
value: 0.096
- type: precision_at_3
value: 6.779
- type: precision_at_5
value: 4.888
- type: recall_at_1
value: 10.671999999999999
- type: recall_at_10
value: 23.099
- type: recall_at_100
value: 41.937999999999995
- type: recall_at_1000
value: 66.495
- type: recall_at_3
value: 16.901
- type: recall_at_5
value: 19.807
- type: map_at_1
value: 13.364
- type: map_at_10
value: 17.772
- type: map_at_100
value: 18.659
- type: map_at_1000
value: 18.861
- type: map_at_3
value: 16.659
- type: map_at_5
value: 17.174
- type: mrr_at_1
value: 16.996
- type: mrr_at_10
value: 21.687
- type: mrr_at_100
value: 22.313
- type: mrr_at_1000
value: 22.422
- type: mrr_at_3
value: 20.652
- type: mrr_at_5
value: 21.146
- type: ndcg_at_1
value: 16.996
- type: ndcg_at_10
value: 21.067
- type: ndcg_at_100
value: 24.829
- type: ndcg_at_1000
value: 28.866999999999997
- type: ndcg_at_3
value: 19.466
- type: ndcg_at_5
value: 19.993
- type: precision_at_1
value: 16.996
- type: precision_at_10
value: 4.071000000000001
- type: precision_at_100
value: 0.9329999999999999
- type: precision_at_1000
value: 0.183
- type: precision_at_3
value: 9.223
- type: precision_at_5
value: 6.4030000000000005
- type: recall_at_1
value: 13.364
- type: recall_at_10
value: 25.976
- type: recall_at_100
value: 44.134
- type: recall_at_1000
value: 73.181
- type: recall_at_3
value: 20.503
- type: recall_at_5
value: 22.409000000000002
- type: map_at_1
value: 5.151
- type: map_at_10
value: 9.155000000000001
- type: map_at_100
value: 9.783999999999999
- type: map_at_1000
value: 9.879
- type: map_at_3
value: 7.825
- type: map_at_5
value: 8.637
- type: mrr_at_1
value: 5.915
- type: mrr_at_10
value: 10.34
- type: mrr_at_100
value: 10.943999999999999
- type: mrr_at_1000
value: 11.033
- type: mrr_at_3
value: 8.934000000000001
- type: mrr_at_5
value: 9.812
- type: ndcg_at_1
value: 5.915
- type: ndcg_at_10
value: 11.561
- type: ndcg_at_100
value: 14.971
- type: ndcg_at_1000
value: 17.907999999999998
- type: ndcg_at_3
value: 8.896999999999998
- type: ndcg_at_5
value: 10.313
- type: precision_at_1
value: 5.915
- type: precision_at_10
value: 2.1069999999999998
- type: precision_at_100
value: 0.414
- type: precision_at_1000
value: 0.074
- type: precision_at_3
value: 4.128
- type: precision_at_5
value: 3.327
- type: recall_at_1
value: 5.151
- type: recall_at_10
value: 17.874000000000002
- type: recall_at_100
value: 34.174
- type: recall_at_1000
value: 56.879999999999995
- type: recall_at_3
value: 10.732999999999999
- type: recall_at_5
value: 14.113000000000001
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.101
- type: map_at_10
value: 5.434
- type: map_at_100
value: 6.267
- type: map_at_1000
value: 6.418
- type: map_at_3
value: 4.377000000000001
- type: map_at_5
value: 4.841
- type: mrr_at_1
value: 7.166
- type: mrr_at_10
value: 12.012
- type: mrr_at_100
value: 13.144
- type: mrr_at_1000
value: 13.229
- type: mrr_at_3
value: 9.826
- type: mrr_at_5
value: 10.921
- type: ndcg_at_1
value: 7.166
- type: ndcg_at_10
value: 8.687000000000001
- type: ndcg_at_100
value: 13.345
- type: ndcg_at_1000
value: 16.915
- type: ndcg_at_3
value: 6.276
- type: ndcg_at_5
value: 7.013
- type: precision_at_1
value: 7.166
- type: precision_at_10
value: 2.9250000000000003
- type: precision_at_100
value: 0.771
- type: precision_at_1000
value: 0.13999999999999999
- type: precision_at_3
value: 4.734
- type: precision_at_5
value: 3.8830000000000005
- type: recall_at_1
value: 3.101
- type: recall_at_10
value: 11.774999999999999
- type: recall_at_100
value: 28.819
- type: recall_at_1000
value: 49.886
- type: recall_at_3
value: 5.783
- type: recall_at_5
value: 7.692
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.758
- type: map_at_10
value: 5.507
- type: map_at_100
value: 7.1819999999999995
- type: map_at_1000
value: 7.652
- type: map_at_3
value: 4.131
- type: map_at_5
value: 4.702
- type: mrr_at_1
value: 28.499999999999996
- type: mrr_at_10
value: 37.693
- type: mrr_at_100
value: 38.657000000000004
- type: mrr_at_1000
value: 38.704
- type: mrr_at_3
value: 34.792
- type: mrr_at_5
value: 36.417
- type: ndcg_at_1
value: 20.625
- type: ndcg_at_10
value: 14.771999999999998
- type: ndcg_at_100
value: 16.821
- type: ndcg_at_1000
value: 21.546000000000003
- type: ndcg_at_3
value: 16.528000000000002
- type: ndcg_at_5
value: 15.573
- type: precision_at_1
value: 28.499999999999996
- type: precision_at_10
value: 12.25
- type: precision_at_100
value: 3.7600000000000002
- type: precision_at_1000
value: 0.86
- type: precision_at_3
value: 19.167
- type: precision_at_5
value: 16.25
- type: recall_at_1
value: 2.758
- type: recall_at_10
value: 9.164
- type: recall_at_100
value: 21.022
- type: recall_at_1000
value: 37.053999999999995
- type: recall_at_3
value: 5.112
- type: recall_at_5
value: 6.413
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 28.53554681148413
- type: mrr
value: 29.290078704990325
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 76.52926207453477
- type: cos_sim_spearman
value: 68.98528351149498
- type: euclidean_pearson
value: 73.7744559091218
- type: euclidean_spearman
value: 69.03481995814735
- type: manhattan_pearson
value: 73.72818267270651
- type: manhattan_spearman
value: 69.00576442086793
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 61.71540153163407
- type: cos_sim_spearman
value: 58.502746406116614
- type: euclidean_pearson
value: 60.82817999438477
- type: euclidean_spearman
value: 58.988494433752756
- type: manhattan_pearson
value: 60.87147859170236
- type: manhattan_spearman
value: 59.03527382025516
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 72.89990498692094
- type: cos_sim_spearman
value: 74.03028513377879
- type: euclidean_pearson
value: 73.8252088833803
- type: euclidean_spearman
value: 74.15554246478399
- type: manhattan_pearson
value: 73.80947397334666
- type: manhattan_spearman
value: 74.13117958176566
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 70.67974206005906
- type: cos_sim_spearman
value: 66.18263558486296
- type: euclidean_pearson
value: 69.5048876024341
- type: euclidean_spearman
value: 66.36380457878391
- type: manhattan_pearson
value: 69.4895372451589
- type: manhattan_spearman
value: 66.36941569935124
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 73.99856913569187
- type: cos_sim_spearman
value: 75.54712054246464
- type: euclidean_pearson
value: 74.55692573876115
- type: euclidean_spearman
value: 75.34499056740096
- type: manhattan_pearson
value: 74.59342318869683
- type: manhattan_spearman
value: 75.35708317926819
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 72.3343670787494
- type: cos_sim_spearman
value: 73.7136650302399
- type: euclidean_pearson
value: 73.86004257913046
- type: euclidean_spearman
value: 73.9557418048638
- type: manhattan_pearson
value: 73.78919091538661
- type: manhattan_spearman
value: 73.86316425954108
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.08159601556619
- type: cos_sim_spearman
value: 80.13910828685532
- type: euclidean_pearson
value: 79.39197806617453
- type: euclidean_spearman
value: 79.85692277871196
- type: manhattan_pearson
value: 79.32452246324705
- type: manhattan_spearman
value: 79.70120373587193
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 62.29720207747786
- type: cos_sim_spearman
value: 65.65260681394685
- type: euclidean_pearson
value: 64.49002165983158
- type: euclidean_spearman
value: 65.25917651158736
- type: manhattan_pearson
value: 64.49981108236335
- type: manhattan_spearman
value: 65.20426825202405
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 71.1871068550574
- type: cos_sim_spearman
value: 71.40167034949341
- type: euclidean_pearson
value: 72.2373684855404
- type: euclidean_spearman
value: 71.90255429812984
- type: manhattan_pearson
value: 72.23173532049509
- type: manhattan_spearman
value: 71.87843489689064
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 68.65000574464773
- type: mrr
value: 88.29363084265044
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 40.76107749144358
- type: mrr
value: 41.03689202953908
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 28.68520527813894
- type: cos_sim_spearman
value: 29.017620841627433
- type: dot_pearson
value: 29.25380949876322
- type: dot_spearman
value: 29.33885250837327
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
|
[
"BIOSSES"
] |
serdarcaglar/roberta-base-biomedical-es
|
serdarcaglar
|
fill-mask
|
[
"transformers",
"pytorch",
"safetensors",
"roberta",
"fill-mask",
"es",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-09-09T13:27:39Z |
2023-09-19T21:09:48+00:00
| 46 | 1 |
---
language:
- es
---
language:
- es
tags:
- biomedical
- spanish
metrics:
- ppl
# Biomedical language model for Spanish
## Table of contents
<details>
<summary>Click to expand</summary>
- [Model description](#model-description)
- [Intended uses and limitations](#intended-use)
- [How to use](#how-to-use)
- [Limitations and bias](#limitations-and-bias)
- [Training](#training)
- [Tokenization and model pretraining](#Tokenization-pretraining)
- [Training corpora and preprocessing](#training-corpora-preprocessing)
- [Evaluation](#evaluation)
- [Additional information](#additional-information)
- [Author](#author)
- [Contact information](#contact-information)
- [Copyright](#copyright)
- [Licensing information](#licensing-information)
- [Funding](#funding)
- [Disclaimer](#disclaimer)
</details>
## Model description
Biomedical pretrained language model for Spanish.
## Intended uses and limitations
The model is ready-to-use only for masked language modelling to perform the Fill Mask task (try the inference API or read the next section). However, it is intended to be fine-tuned on downstream tasks such as Named Entity Recognition or Text Classification.
## How to use
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("serdarcaglar/roberta-base-biomedical-es")
model = AutoModelForMaskedLM.from_pretrained("serdarcaglar/roberta-base-biomedical-es")
from transformers import pipeline
unmasker = pipeline('fill-mask', model="serdarcaglar/roberta-base-biomedical-es")
unmasker("El único antecedente personal a reseñar era la <mask> arterial.")
```
```
```
## Training
### Tokenization and model pretraining
This model is a [RoBERTa-based](https://github.com/pytorch/fairseq/tree/master/examples/roberta) model trained on a
**biomedical** corpus in Spanish collected from several sources
- medprocner
- codiesp
- emea
- wmt19
- wmt16
- wmt22
- scielo
- ibecs
- elrc datsets
The training corpus has been tokenized using a byte version of [Byte-Pair Encoding (BPE)](https://github.com/openai/gpt-2)
used in the original [RoBERTA](https://github.com/pytorch/fairseq/tree/master/examples/roberta) model with a vocabulary size of 52,000 tokens. The pretraining consists of a masked language model training at the subword level following the approach employed for the RoBERTa base model with the same hyperparameters as in the original work.
### Training corpora and preprocessing
The training corpus is composed of several biomedical corpora in Spanish, collected from publicly available corpora and crawlers.
To obtain a high-quality training corpus, a cleaning pipeline with the following operations has been applied:
- data parsing in different formats
- sentence splitting
- language detection
- filtering of ill-formed sentences
- deduplication of repetitive contents
- keep the original document boundaries
Finally, the corpora are concatenated and further global deduplication among the corpora have been applied.
## Evaluation
The model has been evaluated on the Named Entity Recognition (NER) using the following datasets:
Perplexity: 3.09
Please share the results you get in the NER task using this model. I can add them here.
## Additional information
### Author
Serdar ÇAĞLAR
### Contact information
Linkedin: <https://www.linkedin.com/in/serdarildercaglar/>
For further information, send an email to <[email protected]>
### Licensing information
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Disclaimer
<details>
<summary>Click to expand</summary>
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of Artificial Intelligence.
In no event shall the owner of the models be liable for any results arising from the use made by third parties of these models.
Bu havuzda yayınlanan modeller genel bir amaca yöneliktir ve üçüncü tarafların kullanımına açıktır. Bu modellerde önyargı ve diğer istenmeyen çarpıklıklar olabilir.
Üçüncü taraflar, bu modellerden herhangi birini kullanarak (veya bu modellere dayalı sistemleri kullanarak) diğer taraflara sistem ve/veya hizmet sağladıklarında veya modellerin kullanıcısı olduklarında, bunların kullanımından kaynaklanan riskleri azaltmanın ve her durumda Yapay Zeka kullanımına ilişkin düzenlemeler de dahil olmak üzere geçerli düzenlemelere uymanın kendi sorumluluklarında olduğunu unutmamalıdırlar.
Modellerin sahibi hiçbir durumda bu modellerin üçüncü şahıslar tarafından kullanımından kaynaklanan sonuçlardan sorumlu tutulamaz.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y otras distorsiones indeseables.
Cuando terceras partes, desplieguen o proporcionen sistemas y/o servicios a otras partes utilizando cualquiera de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluida la normativa relativa al uso de Inteligencia Artificial.
En ningún caso el propietario de los modelos será responsable de los resultados derivados del uso que terceros hagan de los mismos.
</details>
|
[
"CODIESP",
"SCIELO"
] |
lordjia/lelo-lego-lora
|
lordjia
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"style",
"lego",
"toy",
"brickheadz",
"minifigures",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] | 2023-09-14T12:33:30Z |
2023-09-14T12:33:34+00:00
| 46 | 8 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- style
- lego
- toy
- brickheadz
- minifigures
instance_prompt: LEGO BrickHeadz
widget:
- text: ' LEGO Creator, a leopard walking in grass in africa'
- text: ' LEGO MiniFig, an astronaut on the moon'
- text: ' LEGO MiniFig, Saint Seiya in front of the Temple of Athena'
- text: ' LEGO Creator, a polar bear on ice at sunset'
- text: ' LEGO Creator, a sneaker'
- text: ' LEGO MiniFig, the monkey king carring the golden cudgel in front of a waterfall'
- text: ' LEGO BrickHeadz, Salvador Dal in front of a painting'
- text: ' LEGO BrickHeadz, princess elsa in a palace'
- text: ' LEGO BrickHeadz, Einstein in grey coat, by a lake in woods'
---
# LeLo - LEGO LoRA for SDXL & SD1.5 ([CivitAI](https://civitai.com/models/92444))

>
<p><strong>LeLo</strong> stands for <strong>LEGO LoRA</strong>. It is a LoRA trained with over 900 images from the LEGO MiniFigures, BrickHeadz, and Creator themes. It provides a simulation of the LEGO design style.</p><p></p><p><strong><em>Update:</em></strong></p><p>The <strong><u>V2.0_SDXL1.0</u></strong> version is trained based on the SDXL 1.0 base model. Recommended resolutions include 1024x1024, 912x1144, 888x1176, and 840x1256.</p><p>If you are using the SD 1.5 series base models, you could use the <strong><u>V2.0_SD1.5_768p</u></strong> or <strong><u>V2.0_SD1.5_512p</u></strong> version. The difference between the two versions is the resolution of the training images (768x768 and 512x512 respectively).</p><p></p><p><strong><em>Usage:</em></strong></p><p><span style="color:rgb(253, 126, 20)">Trigger words:</span></p><ul><li><p><strong><u>LEGO MiniFig, {prompt}</u></strong>: MiniFigures theme, suitable for human figures and anthropomorphic animal images.</p></li><li><p><strong><u>LEGO BrickHeadz, {prompt}</u></strong>: BrickHeadz theme, suitable for human figures and anthropomorphic animal images.</p></li><li><p><strong><u>LEGO Creator, {prompt}</u></strong>: Creator theme, widely applicable to objects, animals, plants, buildings, etc.</p></li></ul><p><span style="color:rgb(253, 126, 20)">LoRA Weight: </span>Between 0.6-1.0, recommended to use <strong><u>0.8</u></strong>.</p><p><span style="color:rgb(253, 126, 20)">Denoising: </span>Recommended to use <strong><u>0.3</u></strong>.</p><p><span style="color:rgb(253, 126, 20)">Base model: </span>The <strong><u>V2.0_SDXL1.0</u></strong> version should be paired with the SDXL 1.0 series base models. For the SD 1.5 versions, it is recommended to use it in conjunction with the <strong><u>Realistic Vision</u></strong> series base models, but you can also try pairing it with other base models to explore different styles.</p><p></p><p>If you appreciate my work, please leave your feedback, it is of great importance to me. Additionally, feel free to explore my other LoRA creations.</p><p></p><hr /><p><strong>LeLo</strong> 为 <strong>LEGO LoRA</strong> 简称。此 LoRA 模型使用了 900 多张 LEGO MiniFigures 系列,BrickHeadz 系列,和 Creator 系列产品图片训练而成,提供对乐高设计风格的模拟。</p><p></p><p><strong><em>更新说明:</em></strong></p><p><strong><u>V2.0_SDXL1.0</u></strong> 版基于 SDXL 1.0 基础模型训练。使用此版本 LoRA 生成图片时分辨率推荐使用 1024x1024,912x1144,888x1176,840x1256 等。</p><p>如果你在使用 SD 1.5 系列的基础模型,可选择使用 <strong><u>V2.0_SD1.5_768p</u></strong> 或 <strong><u>V2.0_SD1.5_512p</u></strong> 版本。两个版本的区别是训练图像的分辨率(分别为 768x768 和 512x512)。</p><p></p><p><strong><em>使用方法:</em></strong></p><p><span style="color:rgb(253, 126, 20)">触发词(Trigger words):</span></p><ul><li><p><strong><u>LEGO MiniFig, {prompt}</u></strong>:人仔风格,适用于人物形象和拟人的动物形象。</p></li><li><p><strong><u>LEGO BrickHeadz, {prompt}</u></strong>:方头仔风格,适用于人物形象和拟人的动物形象。</p></li><li><p><strong><u>LEGO Creator, {prompt}</u></strong>: 乐高创意系列风格,广泛适用于物品、动物、植物、建筑等。</p></li></ul><p><span style="color:rgb(253, 126, 20)">LoRA 权重(weight):</span>0.6-1.0 之间,推荐使用 <strong><u>0.8</u></strong></p><p><span style="color:rgb(253, 126, 20)">放大重绘幅度(Denoising):</span>推荐使用 <strong><u>0.3</u></strong></p><p><span style="color:rgb(253, 126, 20)">基础模型:</span><strong><u>V2.0_SDXL1.0</u></strong> 版请配合 SDXL 1.0 系列基础模型。SD 1.5 版本推荐与 <strong><u>Realistic Vision</u></strong> 系列基础模型配合使用,也可尝试与其他基础模型配合使用以探索不同的风格。</p><p></p><p>如果你喜欢我的工作,请留下你的评价,这对我非常重要。另外,也欢迎浏览了解我其他的 LoRA 作品。</p>
## Image examples for the model:

>
LEGO Creator, a leopard walking in grass in africa

>
LEGO MiniFig, an astronaut on the moon

>
LEGO MiniFig, Saint Seiya in front of the Temple of Athena

>
LEGO Creator, a polar bear on ice at sunset

>
LEGO Creator, a sneaker

>
LEGO MiniFig, the monkey king carring the golden cudgel in front of a waterfall

>
LEGO BrickHeadz, Salvador Dal in front of a painting

>
LEGO BrickHeadz, princess elsa in a palace

>
LEGO BrickHeadz, Einstein in grey coat, by a lake in woods
|
[
"BEAR"
] |
woody72/multilingual-e5-base
|
woody72
|
sentence-similarity
|
[
"sentence-transformers",
"pytorch",
"onnx",
"safetensors",
"xlm-roberta",
"mteb",
"Sentence Transformers",
"sentence-similarity",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:2212.03533",
"arxiv:2108.08787",
"arxiv:2104.08663",
"arxiv:2210.07316",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | 2023-11-05T15:18:20Z |
2023-11-05T15:31:52+00:00
| 46 | 0 |
---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
tags:
- mteb
- Sentence Transformers
- sentence-similarity
- sentence-transformers
model-index:
- name: multilingual-e5-base
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 78.97014925373135
- type: ap
value: 43.69351129103008
- type: f1
value: 73.38075030070492
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 71.7237687366167
- type: ap
value: 82.22089859962671
- type: f1
value: 69.95532758884401
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 79.65517241379312
- type: ap
value: 28.507918657094738
- type: f1
value: 66.84516013726119
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.32976445396146
- type: ap
value: 20.720481637566014
- type: f1
value: 59.78002763416003
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 90.63775
- type: ap
value: 87.22277903861716
- type: f1
value: 90.60378636386807
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 44.546
- type: f1
value: 44.05666638370923
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 41.828
- type: f1
value: 41.2710255644252
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 40.534
- type: f1
value: 39.820743174270326
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 39.684
- type: f1
value: 39.11052682815307
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.436
- type: f1
value: 37.07082931930871
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 37.226000000000006
- type: f1
value: 36.65372077739185
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 22.831000000000003
- type: map_at_10
value: 36.42
- type: map_at_100
value: 37.699
- type: map_at_1000
value: 37.724000000000004
- type: map_at_3
value: 32.207
- type: map_at_5
value: 34.312
- type: mrr_at_1
value: 23.257
- type: mrr_at_10
value: 36.574
- type: mrr_at_100
value: 37.854
- type: mrr_at_1000
value: 37.878
- type: mrr_at_3
value: 32.385000000000005
- type: mrr_at_5
value: 34.48
- type: ndcg_at_1
value: 22.831000000000003
- type: ndcg_at_10
value: 44.230000000000004
- type: ndcg_at_100
value: 49.974000000000004
- type: ndcg_at_1000
value: 50.522999999999996
- type: ndcg_at_3
value: 35.363
- type: ndcg_at_5
value: 39.164
- type: precision_at_1
value: 22.831000000000003
- type: precision_at_10
value: 6.935
- type: precision_at_100
value: 0.9520000000000001
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 14.841
- type: precision_at_5
value: 10.754
- type: recall_at_1
value: 22.831000000000003
- type: recall_at_10
value: 69.346
- type: recall_at_100
value: 95.235
- type: recall_at_1000
value: 99.36
- type: recall_at_3
value: 44.523
- type: recall_at_5
value: 53.769999999999996
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 40.27789869854063
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 35.41979463347428
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 58.22752045109304
- type: mrr
value: 71.51112430198303
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 84.71147646622866
- type: cos_sim_spearman
value: 85.059167046486
- type: euclidean_pearson
value: 75.88421613600647
- type: euclidean_spearman
value: 75.12821787150585
- type: manhattan_pearson
value: 75.22005646957604
- type: manhattan_spearman
value: 74.42880434453272
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.23799582463465
- type: f1
value: 99.12665274878218
- type: precision
value: 99.07098121085595
- type: recall
value: 99.23799582463465
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.88685890380806
- type: f1
value: 97.59336708489249
- type: precision
value: 97.44662117543473
- type: recall
value: 97.88685890380806
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 97.47142362313821
- type: f1
value: 97.1989377670015
- type: precision
value: 97.06384944001847
- type: recall
value: 97.47142362313821
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.4728804634018
- type: f1
value: 98.2973494821836
- type: precision
value: 98.2095839915745
- type: recall
value: 98.4728804634018
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 82.74025974025975
- type: f1
value: 82.67420447730439
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 35.0380848063507
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 29.45956405670166
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.122
- type: map_at_10
value: 42.03
- type: map_at_100
value: 43.364000000000004
- type: map_at_1000
value: 43.474000000000004
- type: map_at_3
value: 38.804
- type: map_at_5
value: 40.585
- type: mrr_at_1
value: 39.914
- type: mrr_at_10
value: 48.227
- type: mrr_at_100
value: 49.018
- type: mrr_at_1000
value: 49.064
- type: mrr_at_3
value: 45.994
- type: mrr_at_5
value: 47.396
- type: ndcg_at_1
value: 39.914
- type: ndcg_at_10
value: 47.825
- type: ndcg_at_100
value: 52.852
- type: ndcg_at_1000
value: 54.891
- type: ndcg_at_3
value: 43.517
- type: ndcg_at_5
value: 45.493
- type: precision_at_1
value: 39.914
- type: precision_at_10
value: 8.956
- type: precision_at_100
value: 1.388
- type: precision_at_1000
value: 0.182
- type: precision_at_3
value: 20.791999999999998
- type: precision_at_5
value: 14.821000000000002
- type: recall_at_1
value: 32.122
- type: recall_at_10
value: 58.294999999999995
- type: recall_at_100
value: 79.726
- type: recall_at_1000
value: 93.099
- type: recall_at_3
value: 45.017
- type: recall_at_5
value: 51.002
- type: map_at_1
value: 29.677999999999997
- type: map_at_10
value: 38.684000000000005
- type: map_at_100
value: 39.812999999999995
- type: map_at_1000
value: 39.945
- type: map_at_3
value: 35.831
- type: map_at_5
value: 37.446
- type: mrr_at_1
value: 37.771
- type: mrr_at_10
value: 44.936
- type: mrr_at_100
value: 45.583
- type: mrr_at_1000
value: 45.634
- type: mrr_at_3
value: 42.771
- type: mrr_at_5
value: 43.994
- type: ndcg_at_1
value: 37.771
- type: ndcg_at_10
value: 44.059
- type: ndcg_at_100
value: 48.192
- type: ndcg_at_1000
value: 50.375
- type: ndcg_at_3
value: 40.172000000000004
- type: ndcg_at_5
value: 41.899
- type: precision_at_1
value: 37.771
- type: precision_at_10
value: 8.286999999999999
- type: precision_at_100
value: 1.322
- type: precision_at_1000
value: 0.178
- type: precision_at_3
value: 19.406000000000002
- type: precision_at_5
value: 13.745
- type: recall_at_1
value: 29.677999999999997
- type: recall_at_10
value: 53.071
- type: recall_at_100
value: 70.812
- type: recall_at_1000
value: 84.841
- type: recall_at_3
value: 41.016000000000005
- type: recall_at_5
value: 46.22
- type: map_at_1
value: 42.675000000000004
- type: map_at_10
value: 53.93599999999999
- type: map_at_100
value: 54.806999999999995
- type: map_at_1000
value: 54.867
- type: map_at_3
value: 50.934000000000005
- type: map_at_5
value: 52.583
- type: mrr_at_1
value: 48.339
- type: mrr_at_10
value: 57.265
- type: mrr_at_100
value: 57.873
- type: mrr_at_1000
value: 57.906
- type: mrr_at_3
value: 55.193000000000005
- type: mrr_at_5
value: 56.303000000000004
- type: ndcg_at_1
value: 48.339
- type: ndcg_at_10
value: 59.19799999999999
- type: ndcg_at_100
value: 62.743
- type: ndcg_at_1000
value: 63.99399999999999
- type: ndcg_at_3
value: 54.367
- type: ndcg_at_5
value: 56.548
- type: precision_at_1
value: 48.339
- type: precision_at_10
value: 9.216000000000001
- type: precision_at_100
value: 1.1809999999999998
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 23.72
- type: precision_at_5
value: 16.025
- type: recall_at_1
value: 42.675000000000004
- type: recall_at_10
value: 71.437
- type: recall_at_100
value: 86.803
- type: recall_at_1000
value: 95.581
- type: recall_at_3
value: 58.434
- type: recall_at_5
value: 63.754
- type: map_at_1
value: 23.518
- type: map_at_10
value: 30.648999999999997
- type: map_at_100
value: 31.508999999999997
- type: map_at_1000
value: 31.604
- type: map_at_3
value: 28.247
- type: map_at_5
value: 29.65
- type: mrr_at_1
value: 25.650000000000002
- type: mrr_at_10
value: 32.771
- type: mrr_at_100
value: 33.554
- type: mrr_at_1000
value: 33.629999999999995
- type: mrr_at_3
value: 30.433
- type: mrr_at_5
value: 31.812
- type: ndcg_at_1
value: 25.650000000000002
- type: ndcg_at_10
value: 34.929
- type: ndcg_at_100
value: 39.382
- type: ndcg_at_1000
value: 41.913
- type: ndcg_at_3
value: 30.292
- type: ndcg_at_5
value: 32.629999999999995
- type: precision_at_1
value: 25.650000000000002
- type: precision_at_10
value: 5.311
- type: precision_at_100
value: 0.792
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 12.58
- type: precision_at_5
value: 8.994
- type: recall_at_1
value: 23.518
- type: recall_at_10
value: 46.19
- type: recall_at_100
value: 67.123
- type: recall_at_1000
value: 86.442
- type: recall_at_3
value: 33.678000000000004
- type: recall_at_5
value: 39.244
- type: map_at_1
value: 15.891
- type: map_at_10
value: 22.464000000000002
- type: map_at_100
value: 23.483
- type: map_at_1000
value: 23.613
- type: map_at_3
value: 20.080000000000002
- type: map_at_5
value: 21.526
- type: mrr_at_1
value: 20.025000000000002
- type: mrr_at_10
value: 26.712999999999997
- type: mrr_at_100
value: 27.650000000000002
- type: mrr_at_1000
value: 27.737000000000002
- type: mrr_at_3
value: 24.274
- type: mrr_at_5
value: 25.711000000000002
- type: ndcg_at_1
value: 20.025000000000002
- type: ndcg_at_10
value: 27.028999999999996
- type: ndcg_at_100
value: 32.064
- type: ndcg_at_1000
value: 35.188
- type: ndcg_at_3
value: 22.512999999999998
- type: ndcg_at_5
value: 24.89
- type: precision_at_1
value: 20.025000000000002
- type: precision_at_10
value: 4.776
- type: precision_at_100
value: 0.8500000000000001
- type: precision_at_1000
value: 0.125
- type: precision_at_3
value: 10.531
- type: precision_at_5
value: 7.811
- type: recall_at_1
value: 15.891
- type: recall_at_10
value: 37.261
- type: recall_at_100
value: 59.12
- type: recall_at_1000
value: 81.356
- type: recall_at_3
value: 24.741
- type: recall_at_5
value: 30.753999999999998
- type: map_at_1
value: 27.544
- type: map_at_10
value: 36.283
- type: map_at_100
value: 37.467
- type: map_at_1000
value: 37.574000000000005
- type: map_at_3
value: 33.528999999999996
- type: map_at_5
value: 35.028999999999996
- type: mrr_at_1
value: 34.166999999999994
- type: mrr_at_10
value: 41.866
- type: mrr_at_100
value: 42.666
- type: mrr_at_1000
value: 42.716
- type: mrr_at_3
value: 39.541
- type: mrr_at_5
value: 40.768
- type: ndcg_at_1
value: 34.166999999999994
- type: ndcg_at_10
value: 41.577
- type: ndcg_at_100
value: 46.687
- type: ndcg_at_1000
value: 48.967
- type: ndcg_at_3
value: 37.177
- type: ndcg_at_5
value: 39.097
- type: precision_at_1
value: 34.166999999999994
- type: precision_at_10
value: 7.420999999999999
- type: precision_at_100
value: 1.165
- type: precision_at_1000
value: 0.154
- type: precision_at_3
value: 17.291999999999998
- type: precision_at_5
value: 12.166
- type: recall_at_1
value: 27.544
- type: recall_at_10
value: 51.99399999999999
- type: recall_at_100
value: 73.738
- type: recall_at_1000
value: 89.33
- type: recall_at_3
value: 39.179
- type: recall_at_5
value: 44.385999999999996
- type: map_at_1
value: 26.661
- type: map_at_10
value: 35.475
- type: map_at_100
value: 36.626999999999995
- type: map_at_1000
value: 36.741
- type: map_at_3
value: 32.818000000000005
- type: map_at_5
value: 34.397
- type: mrr_at_1
value: 32.647999999999996
- type: mrr_at_10
value: 40.784
- type: mrr_at_100
value: 41.602
- type: mrr_at_1000
value: 41.661
- type: mrr_at_3
value: 38.68
- type: mrr_at_5
value: 39.838
- type: ndcg_at_1
value: 32.647999999999996
- type: ndcg_at_10
value: 40.697
- type: ndcg_at_100
value: 45.799
- type: ndcg_at_1000
value: 48.235
- type: ndcg_at_3
value: 36.516
- type: ndcg_at_5
value: 38.515
- type: precision_at_1
value: 32.647999999999996
- type: precision_at_10
value: 7.202999999999999
- type: precision_at_100
value: 1.1360000000000001
- type: precision_at_1000
value: 0.151
- type: precision_at_3
value: 17.314
- type: precision_at_5
value: 12.145999999999999
- type: recall_at_1
value: 26.661
- type: recall_at_10
value: 50.995000000000005
- type: recall_at_100
value: 73.065
- type: recall_at_1000
value: 89.781
- type: recall_at_3
value: 39.073
- type: recall_at_5
value: 44.395
- type: map_at_1
value: 25.946583333333333
- type: map_at_10
value: 33.79725
- type: map_at_100
value: 34.86408333333333
- type: map_at_1000
value: 34.9795
- type: map_at_3
value: 31.259999999999998
- type: map_at_5
value: 32.71541666666666
- type: mrr_at_1
value: 30.863749999999996
- type: mrr_at_10
value: 37.99183333333333
- type: mrr_at_100
value: 38.790499999999994
- type: mrr_at_1000
value: 38.85575000000001
- type: mrr_at_3
value: 35.82083333333333
- type: mrr_at_5
value: 37.07533333333333
- type: ndcg_at_1
value: 30.863749999999996
- type: ndcg_at_10
value: 38.52141666666667
- type: ndcg_at_100
value: 43.17966666666667
- type: ndcg_at_1000
value: 45.64608333333333
- type: ndcg_at_3
value: 34.333000000000006
- type: ndcg_at_5
value: 36.34975
- type: precision_at_1
value: 30.863749999999996
- type: precision_at_10
value: 6.598999999999999
- type: precision_at_100
value: 1.0502500000000001
- type: precision_at_1000
value: 0.14400000000000002
- type: precision_at_3
value: 15.557583333333334
- type: precision_at_5
value: 11.020000000000001
- type: recall_at_1
value: 25.946583333333333
- type: recall_at_10
value: 48.36991666666666
- type: recall_at_100
value: 69.02408333333334
- type: recall_at_1000
value: 86.43858333333331
- type: recall_at_3
value: 36.4965
- type: recall_at_5
value: 41.76258333333334
- type: map_at_1
value: 22.431
- type: map_at_10
value: 28.889
- type: map_at_100
value: 29.642000000000003
- type: map_at_1000
value: 29.742
- type: map_at_3
value: 26.998
- type: map_at_5
value: 28.172000000000004
- type: mrr_at_1
value: 25.307000000000002
- type: mrr_at_10
value: 31.763
- type: mrr_at_100
value: 32.443
- type: mrr_at_1000
value: 32.531
- type: mrr_at_3
value: 29.959000000000003
- type: mrr_at_5
value: 31.063000000000002
- type: ndcg_at_1
value: 25.307000000000002
- type: ndcg_at_10
value: 32.586999999999996
- type: ndcg_at_100
value: 36.5
- type: ndcg_at_1000
value: 39.133
- type: ndcg_at_3
value: 29.25
- type: ndcg_at_5
value: 31.023
- type: precision_at_1
value: 25.307000000000002
- type: precision_at_10
value: 4.954
- type: precision_at_100
value: 0.747
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 12.577
- type: precision_at_5
value: 8.741999999999999
- type: recall_at_1
value: 22.431
- type: recall_at_10
value: 41.134
- type: recall_at_100
value: 59.28600000000001
- type: recall_at_1000
value: 78.857
- type: recall_at_3
value: 31.926
- type: recall_at_5
value: 36.335
- type: map_at_1
value: 17.586
- type: map_at_10
value: 23.304
- type: map_at_100
value: 24.159
- type: map_at_1000
value: 24.281
- type: map_at_3
value: 21.316
- type: map_at_5
value: 22.383
- type: mrr_at_1
value: 21.645
- type: mrr_at_10
value: 27.365000000000002
- type: mrr_at_100
value: 28.108
- type: mrr_at_1000
value: 28.192
- type: mrr_at_3
value: 25.482
- type: mrr_at_5
value: 26.479999999999997
- type: ndcg_at_1
value: 21.645
- type: ndcg_at_10
value: 27.306
- type: ndcg_at_100
value: 31.496000000000002
- type: ndcg_at_1000
value: 34.53
- type: ndcg_at_3
value: 23.73
- type: ndcg_at_5
value: 25.294
- type: precision_at_1
value: 21.645
- type: precision_at_10
value: 4.797
- type: precision_at_100
value: 0.8059999999999999
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 10.850999999999999
- type: precision_at_5
value: 7.736
- type: recall_at_1
value: 17.586
- type: recall_at_10
value: 35.481
- type: recall_at_100
value: 54.534000000000006
- type: recall_at_1000
value: 76.456
- type: recall_at_3
value: 25.335
- type: recall_at_5
value: 29.473
- type: map_at_1
value: 25.095
- type: map_at_10
value: 32.374
- type: map_at_100
value: 33.537
- type: map_at_1000
value: 33.634
- type: map_at_3
value: 30.089
- type: map_at_5
value: 31.433
- type: mrr_at_1
value: 29.198
- type: mrr_at_10
value: 36.01
- type: mrr_at_100
value: 37.022
- type: mrr_at_1000
value: 37.083
- type: mrr_at_3
value: 33.94
- type: mrr_at_5
value: 35.148
- type: ndcg_at_1
value: 29.198
- type: ndcg_at_10
value: 36.729
- type: ndcg_at_100
value: 42.114000000000004
- type: ndcg_at_1000
value: 44.592
- type: ndcg_at_3
value: 32.644
- type: ndcg_at_5
value: 34.652
- type: precision_at_1
value: 29.198
- type: precision_at_10
value: 5.970000000000001
- type: precision_at_100
value: 0.967
- type: precision_at_1000
value: 0.129
- type: precision_at_3
value: 14.396999999999998
- type: precision_at_5
value: 10.093
- type: recall_at_1
value: 25.095
- type: recall_at_10
value: 46.392
- type: recall_at_100
value: 69.706
- type: recall_at_1000
value: 87.738
- type: recall_at_3
value: 35.303000000000004
- type: recall_at_5
value: 40.441
- type: map_at_1
value: 26.857999999999997
- type: map_at_10
value: 34.066
- type: map_at_100
value: 35.671
- type: map_at_1000
value: 35.881
- type: map_at_3
value: 31.304
- type: map_at_5
value: 32.885
- type: mrr_at_1
value: 32.411
- type: mrr_at_10
value: 38.987
- type: mrr_at_100
value: 39.894
- type: mrr_at_1000
value: 39.959
- type: mrr_at_3
value: 36.626999999999995
- type: mrr_at_5
value: 38.011
- type: ndcg_at_1
value: 32.411
- type: ndcg_at_10
value: 39.208
- type: ndcg_at_100
value: 44.626
- type: ndcg_at_1000
value: 47.43
- type: ndcg_at_3
value: 35.091
- type: ndcg_at_5
value: 37.119
- type: precision_at_1
value: 32.411
- type: precision_at_10
value: 7.51
- type: precision_at_100
value: 1.486
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 16.14
- type: precision_at_5
value: 11.976
- type: recall_at_1
value: 26.857999999999997
- type: recall_at_10
value: 47.407
- type: recall_at_100
value: 72.236
- type: recall_at_1000
value: 90.77
- type: recall_at_3
value: 35.125
- type: recall_at_5
value: 40.522999999999996
- type: map_at_1
value: 21.3
- type: map_at_10
value: 27.412999999999997
- type: map_at_100
value: 28.29
- type: map_at_1000
value: 28.398
- type: map_at_3
value: 25.169999999999998
- type: map_at_5
value: 26.496
- type: mrr_at_1
value: 23.29
- type: mrr_at_10
value: 29.215000000000003
- type: mrr_at_100
value: 30.073
- type: mrr_at_1000
value: 30.156
- type: mrr_at_3
value: 26.956000000000003
- type: mrr_at_5
value: 28.38
- type: ndcg_at_1
value: 23.29
- type: ndcg_at_10
value: 31.113000000000003
- type: ndcg_at_100
value: 35.701
- type: ndcg_at_1000
value: 38.505
- type: ndcg_at_3
value: 26.727
- type: ndcg_at_5
value: 29.037000000000003
- type: precision_at_1
value: 23.29
- type: precision_at_10
value: 4.787
- type: precision_at_100
value: 0.763
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 11.091
- type: precision_at_5
value: 7.985
- type: recall_at_1
value: 21.3
- type: recall_at_10
value: 40.782000000000004
- type: recall_at_100
value: 62.13999999999999
- type: recall_at_1000
value: 83.012
- type: recall_at_3
value: 29.131
- type: recall_at_5
value: 34.624
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 9.631
- type: map_at_10
value: 16.634999999999998
- type: map_at_100
value: 18.23
- type: map_at_1000
value: 18.419
- type: map_at_3
value: 13.66
- type: map_at_5
value: 15.173
- type: mrr_at_1
value: 21.368000000000002
- type: mrr_at_10
value: 31.56
- type: mrr_at_100
value: 32.58
- type: mrr_at_1000
value: 32.633
- type: mrr_at_3
value: 28.241
- type: mrr_at_5
value: 30.225
- type: ndcg_at_1
value: 21.368000000000002
- type: ndcg_at_10
value: 23.855999999999998
- type: ndcg_at_100
value: 30.686999999999998
- type: ndcg_at_1000
value: 34.327000000000005
- type: ndcg_at_3
value: 18.781
- type: ndcg_at_5
value: 20.73
- type: precision_at_1
value: 21.368000000000002
- type: precision_at_10
value: 7.564
- type: precision_at_100
value: 1.496
- type: precision_at_1000
value: 0.217
- type: precision_at_3
value: 13.876
- type: precision_at_5
value: 11.062
- type: recall_at_1
value: 9.631
- type: recall_at_10
value: 29.517
- type: recall_at_100
value: 53.452
- type: recall_at_1000
value: 74.115
- type: recall_at_3
value: 17.605999999999998
- type: recall_at_5
value: 22.505
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.885
- type: map_at_10
value: 18.798000000000002
- type: map_at_100
value: 26.316
- type: map_at_1000
value: 27.869
- type: map_at_3
value: 13.719000000000001
- type: map_at_5
value: 15.716
- type: mrr_at_1
value: 66
- type: mrr_at_10
value: 74.263
- type: mrr_at_100
value: 74.519
- type: mrr_at_1000
value: 74.531
- type: mrr_at_3
value: 72.458
- type: mrr_at_5
value: 73.321
- type: ndcg_at_1
value: 53.87499999999999
- type: ndcg_at_10
value: 40.355999999999995
- type: ndcg_at_100
value: 44.366
- type: ndcg_at_1000
value: 51.771
- type: ndcg_at_3
value: 45.195
- type: ndcg_at_5
value: 42.187000000000005
- type: precision_at_1
value: 66
- type: precision_at_10
value: 31.75
- type: precision_at_100
value: 10.11
- type: precision_at_1000
value: 1.9800000000000002
- type: precision_at_3
value: 48.167
- type: precision_at_5
value: 40.050000000000004
- type: recall_at_1
value: 8.885
- type: recall_at_10
value: 24.471999999999998
- type: recall_at_100
value: 49.669000000000004
- type: recall_at_1000
value: 73.383
- type: recall_at_3
value: 14.872
- type: recall_at_5
value: 18.262999999999998
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 45.18
- type: f1
value: 40.26878691789978
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 62.751999999999995
- type: map_at_10
value: 74.131
- type: map_at_100
value: 74.407
- type: map_at_1000
value: 74.423
- type: map_at_3
value: 72.329
- type: map_at_5
value: 73.555
- type: mrr_at_1
value: 67.282
- type: mrr_at_10
value: 78.292
- type: mrr_at_100
value: 78.455
- type: mrr_at_1000
value: 78.458
- type: mrr_at_3
value: 76.755
- type: mrr_at_5
value: 77.839
- type: ndcg_at_1
value: 67.282
- type: ndcg_at_10
value: 79.443
- type: ndcg_at_100
value: 80.529
- type: ndcg_at_1000
value: 80.812
- type: ndcg_at_3
value: 76.281
- type: ndcg_at_5
value: 78.235
- type: precision_at_1
value: 67.282
- type: precision_at_10
value: 10.078
- type: precision_at_100
value: 1.082
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 30.178
- type: precision_at_5
value: 19.232
- type: recall_at_1
value: 62.751999999999995
- type: recall_at_10
value: 91.521
- type: recall_at_100
value: 95.997
- type: recall_at_1000
value: 97.775
- type: recall_at_3
value: 83.131
- type: recall_at_5
value: 87.93299999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.861
- type: map_at_10
value: 30.252000000000002
- type: map_at_100
value: 32.082
- type: map_at_1000
value: 32.261
- type: map_at_3
value: 25.909
- type: map_at_5
value: 28.296
- type: mrr_at_1
value: 37.346000000000004
- type: mrr_at_10
value: 45.802
- type: mrr_at_100
value: 46.611999999999995
- type: mrr_at_1000
value: 46.659
- type: mrr_at_3
value: 43.056
- type: mrr_at_5
value: 44.637
- type: ndcg_at_1
value: 37.346000000000004
- type: ndcg_at_10
value: 38.169
- type: ndcg_at_100
value: 44.864
- type: ndcg_at_1000
value: 47.974
- type: ndcg_at_3
value: 33.619
- type: ndcg_at_5
value: 35.317
- type: precision_at_1
value: 37.346000000000004
- type: precision_at_10
value: 10.693999999999999
- type: precision_at_100
value: 1.775
- type: precision_at_1000
value: 0.231
- type: precision_at_3
value: 22.325
- type: precision_at_5
value: 16.852
- type: recall_at_1
value: 18.861
- type: recall_at_10
value: 45.672000000000004
- type: recall_at_100
value: 70.60499999999999
- type: recall_at_1000
value: 89.216
- type: recall_at_3
value: 30.361
- type: recall_at_5
value: 36.998999999999995
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.852999999999994
- type: map_at_10
value: 59.961
- type: map_at_100
value: 60.78
- type: map_at_1000
value: 60.843
- type: map_at_3
value: 56.39999999999999
- type: map_at_5
value: 58.646
- type: mrr_at_1
value: 75.70599999999999
- type: mrr_at_10
value: 82.321
- type: mrr_at_100
value: 82.516
- type: mrr_at_1000
value: 82.525
- type: mrr_at_3
value: 81.317
- type: mrr_at_5
value: 81.922
- type: ndcg_at_1
value: 75.70599999999999
- type: ndcg_at_10
value: 68.557
- type: ndcg_at_100
value: 71.485
- type: ndcg_at_1000
value: 72.71600000000001
- type: ndcg_at_3
value: 63.524
- type: ndcg_at_5
value: 66.338
- type: precision_at_1
value: 75.70599999999999
- type: precision_at_10
value: 14.463000000000001
- type: precision_at_100
value: 1.677
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 40.806
- type: precision_at_5
value: 26.709
- type: recall_at_1
value: 37.852999999999994
- type: recall_at_10
value: 72.316
- type: recall_at_100
value: 83.842
- type: recall_at_1000
value: 91.999
- type: recall_at_3
value: 61.209
- type: recall_at_5
value: 66.77199999999999
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 85.46039999999999
- type: ap
value: 79.9812521351881
- type: f1
value: 85.31722909702084
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 22.704
- type: map_at_10
value: 35.329
- type: map_at_100
value: 36.494
- type: map_at_1000
value: 36.541000000000004
- type: map_at_3
value: 31.476
- type: map_at_5
value: 33.731
- type: mrr_at_1
value: 23.294999999999998
- type: mrr_at_10
value: 35.859
- type: mrr_at_100
value: 36.968
- type: mrr_at_1000
value: 37.008
- type: mrr_at_3
value: 32.085
- type: mrr_at_5
value: 34.299
- type: ndcg_at_1
value: 23.324
- type: ndcg_at_10
value: 42.274
- type: ndcg_at_100
value: 47.839999999999996
- type: ndcg_at_1000
value: 48.971
- type: ndcg_at_3
value: 34.454
- type: ndcg_at_5
value: 38.464
- type: precision_at_1
value: 23.324
- type: precision_at_10
value: 6.648
- type: precision_at_100
value: 0.9440000000000001
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.674999999999999
- type: precision_at_5
value: 10.850999999999999
- type: recall_at_1
value: 22.704
- type: recall_at_10
value: 63.660000000000004
- type: recall_at_100
value: 89.29899999999999
- type: recall_at_1000
value: 97.88900000000001
- type: recall_at_3
value: 42.441
- type: recall_at_5
value: 52.04
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.1326949384405
- type: f1
value: 92.89743579612082
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.62524654832347
- type: f1
value: 88.65106082263151
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.59039359573046
- type: f1
value: 90.31532892105662
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.21046038208581
- type: f1
value: 86.41459529813113
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 87.3180351380423
- type: f1
value: 86.71383078226444
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 86.24231464737792
- type: f1
value: 86.31845567592403
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.27131782945736
- type: f1
value: 57.52079940417103
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.2341504649197
- type: f1
value: 51.349951558039244
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.27418278852569
- type: f1
value: 50.1714985749095
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 67.68243031631694
- type: f1
value: 50.1066160836192
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.2362854069559
- type: f1
value: 48.821279948766424
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 71.71428571428571
- type: f1
value: 53.94611389496195
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.97646267652992
- type: f1
value: 57.26797883561521
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 53.65501008742435
- type: f1
value: 50.416258382177034
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 57.45796906523201
- type: f1
value: 53.306690547422185
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.59246805648957
- type: f1
value: 59.818381969051494
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.126429051782104
- type: f1
value: 58.25993593933026
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 50.057162071284466
- type: f1
value: 46.96095728790911
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.64425016812375
- type: f1
value: 62.858291698755764
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.08944182918628
- type: f1
value: 62.44639030604241
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.68056489576328
- type: f1
value: 61.775326758789504
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.11163416274377
- type: f1
value: 69.70789096927015
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.40282447881641
- type: f1
value: 66.38492065671895
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.24613315400134
- type: f1
value: 64.3348019501336
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.78345662407531
- type: f1
value: 62.21279452354622
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.9455279085407
- type: f1
value: 65.48193124964094
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.05110961667788
- type: f1
value: 58.097856564684534
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.95292535305985
- type: f1
value: 62.09182174767901
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.97310020174848
- type: f1
value: 61.14252567730396
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.08069939475453
- type: f1
value: 57.044041742492034
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.63752521856085
- type: f1
value: 63.889340907205316
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 56.385339609952936
- type: f1
value: 53.449033750088304
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.93073301950234
- type: f1
value: 65.9884357824104
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.94418291862812
- type: f1
value: 66.48740222583132
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.26025554808339
- type: f1
value: 50.19562815100793
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 48.98789509078682
- type: f1
value: 46.65788438676836
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 44.68728984532616
- type: f1
value: 41.642419349541996
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.19300605245461
- type: f1
value: 55.8626492442437
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.33826496301278
- type: f1
value: 63.89499791648792
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.33960995292536
- type: f1
value: 57.15242464180892
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.09347679892402
- type: f1
value: 59.64733214063841
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.75924680564896
- type: f1
value: 55.96585692366827
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.48486886348352
- type: f1
value: 59.45143559032946
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.56422326832549
- type: f1
value: 54.96368702901926
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.18022864828512
- type: f1
value: 63.05369805040634
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.30329522528581
- type: f1
value: 64.06084612020727
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.36919973100201
- type: f1
value: 65.12154124788887
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.98117014122394
- type: f1
value: 66.41847559806962
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.53799596503026
- type: f1
value: 62.17067330740817
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.01815736381977
- type: f1
value: 66.24988369607843
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 62.34700739744452
- type: f1
value: 59.957933424941636
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.23402824478815
- type: f1
value: 57.98836976018471
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.54068594485541
- type: f1
value: 65.43849680666855
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 55.998655010087425
- type: f1
value: 52.83737515406804
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.71217215870882
- type: f1
value: 55.051794977833026
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 59.724277067921996
- type: f1
value: 56.33485571838306
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.59515803631473
- type: f1
value: 64.96772366193588
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.860793544048406
- type: f1
value: 58.148845819115394
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.40753194351043
- type: f1
value: 63.18903778054698
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 61.52320107599194
- type: f1
value: 58.356144563398516
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.17014122394083
- type: f1
value: 63.919964062638925
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.15601882985878
- type: f1
value: 67.01451905761371
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.65030262273034
- type: f1
value: 64.14420425129063
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.08742434431743
- type: f1
value: 63.044060042311756
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 58.52387357094821
- type: f1
value: 56.82398588814534
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.239408204438476
- type: f1
value: 61.92570286170469
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.74915938130463
- type: f1
value: 62.130740689396276
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.00336247478144
- type: f1
value: 63.71080635228055
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 52.837928715534645
- type: f1
value: 50.390741680320836
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.42098184263618
- type: f1
value: 71.41355113538995
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.95359784801613
- type: f1
value: 71.42699340156742
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.18157363819772
- type: f1
value: 69.74836113037671
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.08137188971082
- type: f1
value: 76.78000685068261
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.5030262273033
- type: f1
value: 71.71620130425673
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.24546065904505
- type: f1
value: 69.07638311730359
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.12911903160726
- type: f1
value: 68.32651736539815
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.89307330195025
- type: f1
value: 71.33986549860187
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.44451916610626
- type: f1
value: 66.90192664503866
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.16274377942166
- type: f1
value: 68.01090953775066
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.75319435104237
- type: f1
value: 70.18035309201403
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 63.14391392064559
- type: f1
value: 61.48286540778145
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.70275722932078
- type: f1
value: 70.26164779846495
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.93813046402153
- type: f1
value: 58.8852862116525
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.320107599193
- type: f1
value: 72.19836409602924
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.65366509751176
- type: f1
value: 74.55188288799579
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.694014794889036
- type: f1
value: 58.11353311721067
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 54.37457969065231
- type: f1
value: 52.81306134311697
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 48.3086751849361
- type: f1
value: 45.396449765419376
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.151983860121064
- type: f1
value: 60.31762544281696
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.44788164088769
- type: f1
value: 71.68150151736367
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.81439139206455
- type: f1
value: 62.06735559105593
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.04303967720242
- type: f1
value: 66.68298851670133
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.43913920645595
- type: f1
value: 60.25605977560783
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.90316072629456
- type: f1
value: 65.1325924692381
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 61.63752521856086
- type: f1
value: 59.14284778039585
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.63080026899797
- type: f1
value: 70.89771864626877
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.10827168796234
- type: f1
value: 71.71954219691159
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.59515803631471
- type: f1
value: 70.05040128099003
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.83389374579691
- type: f1
value: 70.84877936562735
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.18628110289173
- type: f1
value: 68.97232927921841
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.99260255548083
- type: f1
value: 72.85139492157732
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.26227303295225
- type: f1
value: 65.08833655469431
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.48621385339611
- type: f1
value: 64.43483199071298
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.14391392064559
- type: f1
value: 72.2580822579741
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 59.88567585743107
- type: f1
value: 58.3073765932569
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.38399462004034
- type: f1
value: 60.82139544252606
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.58574310692671
- type: f1
value: 60.71443370385374
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.61398789509079
- type: f1
value: 70.99761812049401
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 62.73705447209146
- type: f1
value: 61.680849331794796
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.66778749159381
- type: f1
value: 71.17320646080115
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 64.640215198386
- type: f1
value: 63.301805157015444
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.00672494956288
- type: f1
value: 70.26005548582106
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.42030934767989
- type: f1
value: 75.2074842882598
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.69266980497646
- type: f1
value: 70.94103167391192
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 28.91697191169135
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.434000079573313
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.96683513343383
- type: mrr
value: 31.967364078714834
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.5280000000000005
- type: map_at_10
value: 11.793
- type: map_at_100
value: 14.496999999999998
- type: map_at_1000
value: 15.783
- type: map_at_3
value: 8.838
- type: map_at_5
value: 10.07
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 51.531000000000006
- type: mrr_at_100
value: 52.205
- type: mrr_at_1000
value: 52.242999999999995
- type: mrr_at_3
value: 49.431999999999995
- type: mrr_at_5
value: 50.470000000000006
- type: ndcg_at_1
value: 42.415000000000006
- type: ndcg_at_10
value: 32.464999999999996
- type: ndcg_at_100
value: 28.927999999999997
- type: ndcg_at_1000
value: 37.629000000000005
- type: ndcg_at_3
value: 37.845
- type: ndcg_at_5
value: 35.147
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 23.932000000000002
- type: precision_at_100
value: 7.17
- type: precision_at_1000
value: 1.967
- type: precision_at_3
value: 35.397
- type: precision_at_5
value: 29.907
- type: recall_at_1
value: 5.5280000000000005
- type: recall_at_10
value: 15.568000000000001
- type: recall_at_100
value: 28.54
- type: recall_at_1000
value: 59.864
- type: recall_at_3
value: 9.822000000000001
- type: recall_at_5
value: 11.726
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.041000000000004
- type: map_at_10
value: 52.664
- type: map_at_100
value: 53.477
- type: map_at_1000
value: 53.505
- type: map_at_3
value: 48.510999999999996
- type: map_at_5
value: 51.036
- type: mrr_at_1
value: 41.338
- type: mrr_at_10
value: 55.071000000000005
- type: mrr_at_100
value: 55.672
- type: mrr_at_1000
value: 55.689
- type: mrr_at_3
value: 51.82
- type: mrr_at_5
value: 53.852
- type: ndcg_at_1
value: 41.338
- type: ndcg_at_10
value: 60.01800000000001
- type: ndcg_at_100
value: 63.409000000000006
- type: ndcg_at_1000
value: 64.017
- type: ndcg_at_3
value: 52.44799999999999
- type: ndcg_at_5
value: 56.571000000000005
- type: precision_at_1
value: 41.338
- type: precision_at_10
value: 9.531
- type: precision_at_100
value: 1.145
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.416
- type: precision_at_5
value: 16.46
- type: recall_at_1
value: 37.041000000000004
- type: recall_at_10
value: 79.76299999999999
- type: recall_at_100
value: 94.39
- type: recall_at_1000
value: 98.851
- type: recall_at_3
value: 60.465
- type: recall_at_5
value: 69.906
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 69.952
- type: map_at_10
value: 83.758
- type: map_at_100
value: 84.406
- type: map_at_1000
value: 84.425
- type: map_at_3
value: 80.839
- type: map_at_5
value: 82.646
- type: mrr_at_1
value: 80.62
- type: mrr_at_10
value: 86.947
- type: mrr_at_100
value: 87.063
- type: mrr_at_1000
value: 87.064
- type: mrr_at_3
value: 85.96000000000001
- type: mrr_at_5
value: 86.619
- type: ndcg_at_1
value: 80.63
- type: ndcg_at_10
value: 87.64800000000001
- type: ndcg_at_100
value: 88.929
- type: ndcg_at_1000
value: 89.054
- type: ndcg_at_3
value: 84.765
- type: ndcg_at_5
value: 86.291
- type: precision_at_1
value: 80.63
- type: precision_at_10
value: 13.314
- type: precision_at_100
value: 1.525
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.1
- type: precision_at_5
value: 24.372
- type: recall_at_1
value: 69.952
- type: recall_at_10
value: 94.955
- type: recall_at_100
value: 99.38
- type: recall_at_1000
value: 99.96000000000001
- type: recall_at_3
value: 86.60600000000001
- type: recall_at_5
value: 90.997
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 42.41329517878427
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 55.171278362748666
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.213
- type: map_at_10
value: 9.895
- type: map_at_100
value: 11.776
- type: map_at_1000
value: 12.084
- type: map_at_3
value: 7.2669999999999995
- type: map_at_5
value: 8.620999999999999
- type: mrr_at_1
value: 20.8
- type: mrr_at_10
value: 31.112000000000002
- type: mrr_at_100
value: 32.274
- type: mrr_at_1000
value: 32.35
- type: mrr_at_3
value: 28.133000000000003
- type: mrr_at_5
value: 29.892999999999997
- type: ndcg_at_1
value: 20.8
- type: ndcg_at_10
value: 17.163999999999998
- type: ndcg_at_100
value: 24.738
- type: ndcg_at_1000
value: 30.316
- type: ndcg_at_3
value: 16.665
- type: ndcg_at_5
value: 14.478
- type: precision_at_1
value: 20.8
- type: precision_at_10
value: 8.74
- type: precision_at_100
value: 1.963
- type: precision_at_1000
value: 0.33
- type: precision_at_3
value: 15.467
- type: precision_at_5
value: 12.6
- type: recall_at_1
value: 4.213
- type: recall_at_10
value: 17.698
- type: recall_at_100
value: 39.838
- type: recall_at_1000
value: 66.893
- type: recall_at_3
value: 9.418
- type: recall_at_5
value: 12.773000000000001
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 82.90453315738294
- type: cos_sim_spearman
value: 78.51197850080254
- type: euclidean_pearson
value: 80.09647123597748
- type: euclidean_spearman
value: 78.63548011514061
- type: manhattan_pearson
value: 80.10645285675231
- type: manhattan_spearman
value: 78.57861806068901
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.2616156846401
- type: cos_sim_spearman
value: 76.69713867850156
- type: euclidean_pearson
value: 77.97948563800394
- type: euclidean_spearman
value: 74.2371211567807
- type: manhattan_pearson
value: 77.69697879669705
- type: manhattan_spearman
value: 73.86529778022278
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 77.0293269315045
- type: cos_sim_spearman
value: 78.02555120584198
- type: euclidean_pearson
value: 78.25398100379078
- type: euclidean_spearman
value: 78.66963870599464
- type: manhattan_pearson
value: 78.14314682167348
- type: manhattan_spearman
value: 78.57692322969135
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 79.16989925136942
- type: cos_sim_spearman
value: 76.5996225327091
- type: euclidean_pearson
value: 77.8319003279786
- type: euclidean_spearman
value: 76.42824009468998
- type: manhattan_pearson
value: 77.69118862737736
- type: manhattan_spearman
value: 76.25568104762812
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.42012286935325
- type: cos_sim_spearman
value: 88.15654297884122
- type: euclidean_pearson
value: 87.34082819427852
- type: euclidean_spearman
value: 88.06333589547084
- type: manhattan_pearson
value: 87.25115596784842
- type: manhattan_spearman
value: 87.9559927695203
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.88222044996712
- type: cos_sim_spearman
value: 84.28476589061077
- type: euclidean_pearson
value: 83.17399758058309
- type: euclidean_spearman
value: 83.85497357244542
- type: manhattan_pearson
value: 83.0308397703786
- type: manhattan_spearman
value: 83.71554539935046
- task:
type: STS
dataset:
name: MTEB STS17 (ko-ko)
type: mteb/sts17-crosslingual-sts
config: ko-ko
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.20682986257339
- type: cos_sim_spearman
value: 79.94567120362092
- type: euclidean_pearson
value: 79.43122480368902
- type: euclidean_spearman
value: 79.94802077264987
- type: manhattan_pearson
value: 79.32653021527081
- type: manhattan_spearman
value: 79.80961146709178
- task:
type: STS
dataset:
name: MTEB STS17 (ar-ar)
type: mteb/sts17-crosslingual-sts
config: ar-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 74.46578144394383
- type: cos_sim_spearman
value: 74.52496637472179
- type: euclidean_pearson
value: 72.2903807076809
- type: euclidean_spearman
value: 73.55549359771645
- type: manhattan_pearson
value: 72.09324837709393
- type: manhattan_spearman
value: 73.36743103606581
- task:
type: STS
dataset:
name: MTEB STS17 (en-ar)
type: mteb/sts17-crosslingual-sts
config: en-ar
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 71.37272335116
- type: cos_sim_spearman
value: 71.26702117766037
- type: euclidean_pearson
value: 67.114829954434
- type: euclidean_spearman
value: 66.37938893947761
- type: manhattan_pearson
value: 66.79688574095246
- type: manhattan_spearman
value: 66.17292828079667
- task:
type: STS
dataset:
name: MTEB STS17 (en-de)
type: mteb/sts17-crosslingual-sts
config: en-de
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 80.61016770129092
- type: cos_sim_spearman
value: 82.08515426632214
- type: euclidean_pearson
value: 80.557340361131
- type: euclidean_spearman
value: 80.37585812266175
- type: manhattan_pearson
value: 80.6782873404285
- type: manhattan_spearman
value: 80.6678073032024
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.00150745350108
- type: cos_sim_spearman
value: 87.83441972211425
- type: euclidean_pearson
value: 87.94826702308792
- type: euclidean_spearman
value: 87.46143974860725
- type: manhattan_pearson
value: 87.97560344306105
- type: manhattan_spearman
value: 87.5267102829796
- task:
type: STS
dataset:
name: MTEB STS17 (en-tr)
type: mteb/sts17-crosslingual-sts
config: en-tr
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 64.76325252267235
- type: cos_sim_spearman
value: 63.32615095463905
- type: euclidean_pearson
value: 64.07920669155716
- type: euclidean_spearman
value: 61.21409893072176
- type: manhattan_pearson
value: 64.26308625680016
- type: manhattan_spearman
value: 61.2438185254079
- task:
type: STS
dataset:
name: MTEB STS17 (es-en)
type: mteb/sts17-crosslingual-sts
config: es-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 75.82644463022595
- type: cos_sim_spearman
value: 76.50381269945073
- type: euclidean_pearson
value: 75.1328548315934
- type: euclidean_spearman
value: 75.63761139408453
- type: manhattan_pearson
value: 75.18610101241407
- type: manhattan_spearman
value: 75.30669266354164
- task:
type: STS
dataset:
name: MTEB STS17 (es-es)
type: mteb/sts17-crosslingual-sts
config: es-es
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.49994164686832
- type: cos_sim_spearman
value: 86.73743986245549
- type: euclidean_pearson
value: 86.8272894387145
- type: euclidean_spearman
value: 85.97608491000507
- type: manhattan_pearson
value: 86.74960140396779
- type: manhattan_spearman
value: 85.79285984190273
- task:
type: STS
dataset:
name: MTEB STS17 (fr-en)
type: mteb/sts17-crosslingual-sts
config: fr-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.58172210788469
- type: cos_sim_spearman
value: 80.17516468334607
- type: euclidean_pearson
value: 77.56537843470504
- type: euclidean_spearman
value: 77.57264627395521
- type: manhattan_pearson
value: 78.09703521695943
- type: manhattan_spearman
value: 78.15942760916954
- task:
type: STS
dataset:
name: MTEB STS17 (it-en)
type: mteb/sts17-crosslingual-sts
config: it-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.7589932931751
- type: cos_sim_spearman
value: 80.15210089028162
- type: euclidean_pearson
value: 77.54135223516057
- type: euclidean_spearman
value: 77.52697996368764
- type: manhattan_pearson
value: 77.65734439572518
- type: manhattan_spearman
value: 77.77702992016121
- task:
type: STS
dataset:
name: MTEB STS17 (nl-en)
type: mteb/sts17-crosslingual-sts
config: nl-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 79.16682365511267
- type: cos_sim_spearman
value: 79.25311267628506
- type: euclidean_pearson
value: 77.54882036762244
- type: euclidean_spearman
value: 77.33212935194827
- type: manhattan_pearson
value: 77.98405516064015
- type: manhattan_spearman
value: 77.85075717865719
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.10473294775917
- type: cos_sim_spearman
value: 61.82780474476838
- type: euclidean_pearson
value: 45.885111672377256
- type: euclidean_spearman
value: 56.88306351932454
- type: manhattan_pearson
value: 46.101218127323186
- type: manhattan_spearman
value: 56.80953694186333
- task:
type: STS
dataset:
name: MTEB STS22 (de)
type: mteb/sts22-crosslingual-sts
config: de
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 45.781923079584146
- type: cos_sim_spearman
value: 55.95098449691107
- type: euclidean_pearson
value: 25.4571031323205
- type: euclidean_spearman
value: 49.859978118078935
- type: manhattan_pearson
value: 25.624938455041384
- type: manhattan_spearman
value: 49.99546185049401
- task:
type: STS
dataset:
name: MTEB STS22 (es)
type: mteb/sts22-crosslingual-sts
config: es
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 60.00618133997907
- type: cos_sim_spearman
value: 66.57896677718321
- type: euclidean_pearson
value: 42.60118466388821
- type: euclidean_spearman
value: 62.8210759715209
- type: manhattan_pearson
value: 42.63446860604094
- type: manhattan_spearman
value: 62.73803068925271
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 28.460759121626943
- type: cos_sim_spearman
value: 34.13459007469131
- type: euclidean_pearson
value: 6.0917739325525195
- type: euclidean_spearman
value: 27.9947262664867
- type: manhattan_pearson
value: 6.16877864169911
- type: manhattan_spearman
value: 28.00664163971514
- task:
type: STS
dataset:
name: MTEB STS22 (tr)
type: mteb/sts22-crosslingual-sts
config: tr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.42546621771696
- type: cos_sim_spearman
value: 63.699663168970474
- type: euclidean_pearson
value: 38.12085278789738
- type: euclidean_spearman
value: 58.12329140741536
- type: manhattan_pearson
value: 37.97364549443335
- type: manhattan_spearman
value: 57.81545502318733
- task:
type: STS
dataset:
name: MTEB STS22 (ar)
type: mteb/sts22-crosslingual-sts
config: ar
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 46.82241380954213
- type: cos_sim_spearman
value: 57.86569456006391
- type: euclidean_pearson
value: 31.80480070178813
- type: euclidean_spearman
value: 52.484000620130104
- type: manhattan_pearson
value: 31.952708554646097
- type: manhattan_spearman
value: 52.8560972356195
- task:
type: STS
dataset:
name: MTEB STS22 (ru)
type: mteb/sts22-crosslingual-sts
config: ru
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 52.00447170498087
- type: cos_sim_spearman
value: 60.664116225735164
- type: euclidean_pearson
value: 33.87382555421702
- type: euclidean_spearman
value: 55.74649067458667
- type: manhattan_pearson
value: 33.99117246759437
- type: manhattan_spearman
value: 55.98749034923899
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 58.06497233105448
- type: cos_sim_spearman
value: 65.62968801135676
- type: euclidean_pearson
value: 47.482076613243905
- type: euclidean_spearman
value: 62.65137791498299
- type: manhattan_pearson
value: 47.57052626104093
- type: manhattan_spearman
value: 62.436916516613294
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 70.49397298562575
- type: cos_sim_spearman
value: 74.79604041187868
- type: euclidean_pearson
value: 49.661891561317795
- type: euclidean_spearman
value: 70.31535537621006
- type: manhattan_pearson
value: 49.553715741850006
- type: manhattan_spearman
value: 70.24779344636806
- task:
type: STS
dataset:
name: MTEB STS22 (de-en)
type: mteb/sts22-crosslingual-sts
config: de-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 55.640574515348696
- type: cos_sim_spearman
value: 54.927959317689
- type: euclidean_pearson
value: 29.00139666967476
- type: euclidean_spearman
value: 41.86386566971605
- type: manhattan_pearson
value: 29.47411067730344
- type: manhattan_spearman
value: 42.337438424952786
- task:
type: STS
dataset:
name: MTEB STS22 (es-en)
type: mteb/sts22-crosslingual-sts
config: es-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 68.14095292259312
- type: cos_sim_spearman
value: 73.99017581234789
- type: euclidean_pearson
value: 46.46304297872084
- type: euclidean_spearman
value: 60.91834114800041
- type: manhattan_pearson
value: 47.07072666338692
- type: manhattan_spearman
value: 61.70415727977926
- task:
type: STS
dataset:
name: MTEB STS22 (it)
type: mteb/sts22-crosslingual-sts
config: it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 73.27184653359575
- type: cos_sim_spearman
value: 77.76070252418626
- type: euclidean_pearson
value: 62.30586577544778
- type: euclidean_spearman
value: 75.14246629110978
- type: manhattan_pearson
value: 62.328196884927046
- type: manhattan_spearman
value: 75.1282792981433
- task:
type: STS
dataset:
name: MTEB STS22 (pl-en)
type: mteb/sts22-crosslingual-sts
config: pl-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 71.59448528829957
- type: cos_sim_spearman
value: 70.37277734222123
- type: euclidean_pearson
value: 57.63145565721123
- type: euclidean_spearman
value: 66.10113048304427
- type: manhattan_pearson
value: 57.18897811586808
- type: manhattan_spearman
value: 66.5595511215901
- task:
type: STS
dataset:
name: MTEB STS22 (zh-en)
type: mteb/sts22-crosslingual-sts
config: zh-en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 66.37520607720838
- type: cos_sim_spearman
value: 69.92282148997948
- type: euclidean_pearson
value: 40.55768770125291
- type: euclidean_spearman
value: 55.189128944669605
- type: manhattan_pearson
value: 41.03566433468883
- type: manhattan_spearman
value: 55.61251893174558
- task:
type: STS
dataset:
name: MTEB STS22 (es-it)
type: mteb/sts22-crosslingual-sts
config: es-it
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 57.791929533771835
- type: cos_sim_spearman
value: 66.45819707662093
- type: euclidean_pearson
value: 39.03686018511092
- type: euclidean_spearman
value: 56.01282695640428
- type: manhattan_pearson
value: 38.91586623619632
- type: manhattan_spearman
value: 56.69394943612747
- task:
type: STS
dataset:
name: MTEB STS22 (de-fr)
type: mteb/sts22-crosslingual-sts
config: de-fr
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 47.82224468473866
- type: cos_sim_spearman
value: 59.467307194781164
- type: euclidean_pearson
value: 27.428459190256145
- type: euclidean_spearman
value: 60.83463107397519
- type: manhattan_pearson
value: 27.487391578496638
- type: manhattan_spearman
value: 61.281380460246496
- task:
type: STS
dataset:
name: MTEB STS22 (de-pl)
type: mteb/sts22-crosslingual-sts
config: de-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 16.306666792752644
- type: cos_sim_spearman
value: 39.35486427252405
- type: euclidean_pearson
value: -2.7887154897955435
- type: euclidean_spearman
value: 27.1296051831719
- type: manhattan_pearson
value: -3.202291270581297
- type: manhattan_spearman
value: 26.32895849218158
- task:
type: STS
dataset:
name: MTEB STS22 (fr-pl)
type: mteb/sts22-crosslingual-sts
config: fr-pl
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 59.67006803805076
- type: cos_sim_spearman
value: 73.24670207647144
- type: euclidean_pearson
value: 46.91884681500483
- type: euclidean_spearman
value: 16.903085094570333
- type: manhattan_pearson
value: 46.88391675325812
- type: manhattan_spearman
value: 28.17180849095055
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 83.79555591223837
- type: cos_sim_spearman
value: 85.63658602085185
- type: euclidean_pearson
value: 85.22080894037671
- type: euclidean_spearman
value: 85.54113580167038
- type: manhattan_pearson
value: 85.1639505960118
- type: manhattan_spearman
value: 85.43502665436196
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 80.73900991689766
- type: mrr
value: 94.81624131133934
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 55.678000000000004
- type: map_at_10
value: 65.135
- type: map_at_100
value: 65.824
- type: map_at_1000
value: 65.852
- type: map_at_3
value: 62.736000000000004
- type: map_at_5
value: 64.411
- type: mrr_at_1
value: 58.333
- type: mrr_at_10
value: 66.5
- type: mrr_at_100
value: 67.053
- type: mrr_at_1000
value: 67.08
- type: mrr_at_3
value: 64.944
- type: mrr_at_5
value: 65.89399999999999
- type: ndcg_at_1
value: 58.333
- type: ndcg_at_10
value: 69.34700000000001
- type: ndcg_at_100
value: 72.32
- type: ndcg_at_1000
value: 73.014
- type: ndcg_at_3
value: 65.578
- type: ndcg_at_5
value: 67.738
- type: precision_at_1
value: 58.333
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 25.444
- type: precision_at_5
value: 16.933
- type: recall_at_1
value: 55.678000000000004
- type: recall_at_10
value: 80.72200000000001
- type: recall_at_100
value: 93.93299999999999
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 70.783
- type: recall_at_5
value: 75.978
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.74653465346535
- type: cos_sim_ap
value: 93.01476369929063
- type: cos_sim_f1
value: 86.93009118541033
- type: cos_sim_precision
value: 88.09034907597535
- type: cos_sim_recall
value: 85.8
- type: dot_accuracy
value: 99.22970297029703
- type: dot_ap
value: 51.58725659485144
- type: dot_f1
value: 53.51351351351352
- type: dot_precision
value: 58.235294117647065
- type: dot_recall
value: 49.5
- type: euclidean_accuracy
value: 99.74356435643564
- type: euclidean_ap
value: 92.40332894384368
- type: euclidean_f1
value: 86.97838109602817
- type: euclidean_precision
value: 87.46208291203236
- type: euclidean_recall
value: 86.5
- type: manhattan_accuracy
value: 99.73069306930694
- type: manhattan_ap
value: 92.01320815721121
- type: manhattan_f1
value: 86.4135864135864
- type: manhattan_precision
value: 86.32734530938124
- type: manhattan_recall
value: 86.5
- type: max_accuracy
value: 99.74653465346535
- type: max_ap
value: 93.01476369929063
- type: max_f1
value: 86.97838109602817
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 55.2660514302523
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 30.4637783572547
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 49.41377758357637
- type: mrr
value: 50.138451213818854
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 28.887846011166594
- type: cos_sim_spearman
value: 30.10823258355903
- type: dot_pearson
value: 12.888049550236385
- type: dot_spearman
value: 12.827495903098123
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.21
- type: map_at_10
value: 1.667
- type: map_at_100
value: 9.15
- type: map_at_1000
value: 22.927
- type: map_at_3
value: 0.573
- type: map_at_5
value: 0.915
- type: mrr_at_1
value: 80
- type: mrr_at_10
value: 87.167
- type: mrr_at_100
value: 87.167
- type: mrr_at_1000
value: 87.167
- type: mrr_at_3
value: 85.667
- type: mrr_at_5
value: 87.167
- type: ndcg_at_1
value: 76
- type: ndcg_at_10
value: 69.757
- type: ndcg_at_100
value: 52.402
- type: ndcg_at_1000
value: 47.737
- type: ndcg_at_3
value: 71.866
- type: ndcg_at_5
value: 72.225
- type: precision_at_1
value: 80
- type: precision_at_10
value: 75
- type: precision_at_100
value: 53.959999999999994
- type: precision_at_1000
value: 21.568
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 78
- type: recall_at_1
value: 0.21
- type: recall_at_10
value: 1.9189999999999998
- type: recall_at_100
value: 12.589
- type: recall_at_1000
value: 45.312000000000005
- type: recall_at_3
value: 0.61
- type: recall_at_5
value: 1.019
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.10000000000001
- type: f1
value: 90.06
- type: precision
value: 89.17333333333333
- type: recall
value: 92.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.06936416184971
- type: f1
value: 50.87508028259473
- type: precision
value: 48.97398843930635
- type: recall
value: 56.06936416184971
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 57.3170731707317
- type: f1
value: 52.96080139372822
- type: precision
value: 51.67861124382864
- type: recall
value: 57.3170731707317
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.67333333333333
- type: precision
value: 91.90833333333333
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 97.07333333333332
- type: precision
value: 96.79500000000002
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.2
- type: precision
value: 92.48333333333333
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.9
- type: f1
value: 91.26666666666667
- type: precision
value: 90.59444444444445
- type: recall
value: 92.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 34.32835820895522
- type: f1
value: 29.074180380150533
- type: precision
value: 28.068207322920596
- type: recall
value: 34.32835820895522
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.5
- type: f1
value: 74.3945115995116
- type: precision
value: 72.82967843459222
- type: recall
value: 78.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.34146341463415
- type: f1
value: 61.2469400518181
- type: precision
value: 59.63977756660683
- type: recall
value: 66.34146341463415
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.9
- type: f1
value: 76.90349206349207
- type: precision
value: 75.32921568627451
- type: recall
value: 80.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.93317132442284
- type: f1
value: 81.92519105034295
- type: precision
value: 80.71283920615635
- type: recall
value: 84.93317132442284
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.1304347826087
- type: f1
value: 65.22394755003451
- type: precision
value: 62.912422360248435
- type: recall
value: 71.1304347826087
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.82608695652173
- type: f1
value: 75.55693581780538
- type: precision
value: 73.79420289855072
- type: recall
value: 79.82608695652173
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74
- type: f1
value: 70.51022222222223
- type: precision
value: 69.29673599347512
- type: recall
value: 74
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 74.14238095238095
- type: precision
value: 72.27214285714285
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.97466827503016
- type: f1
value: 43.080330405420874
- type: precision
value: 41.36505499593557
- type: recall
value: 48.97466827503016
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.60000000000001
- type: f1
value: 86.62333333333333
- type: precision
value: 85.225
- type: recall
value: 89.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.2
- type: f1
value: 39.5761253006253
- type: precision
value: 37.991358436312
- type: recall
value: 45.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.70333333333333
- type: precision
value: 85.53166666666667
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.095238095238095
- type: f1
value: 44.60650460650461
- type: precision
value: 42.774116796477045
- type: recall
value: 50.095238095238095
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.4
- type: f1
value: 58.35967261904762
- type: precision
value: 56.54857142857143
- type: recall
value: 63.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.2
- type: f1
value: 87.075
- type: precision
value: 86.12095238095239
- type: recall
value: 89.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.90333333333334
- type: precision
value: 95.50833333333333
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.9
- type: f1
value: 88.6288888888889
- type: precision
value: 87.61607142857142
- type: recall
value: 90.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 65.2
- type: f1
value: 60.54377630539395
- type: precision
value: 58.89434482711381
- type: recall
value: 65.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87
- type: f1
value: 84.32412698412699
- type: precision
value: 83.25527777777778
- type: recall
value: 87
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.7
- type: f1
value: 63.07883541295306
- type: precision
value: 61.06117424242426
- type: recall
value: 68.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.78333333333335
- type: precision
value: 90.86666666666667
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.7
- type: f1
value: 96.96666666666667
- type: precision
value: 96.61666666666667
- type: recall
value: 97.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27493261455525
- type: f1
value: 85.90745732255168
- type: precision
value: 84.91389637616052
- type: recall
value: 88.27493261455525
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.5982905982906
- type: f1
value: 88.4900284900285
- type: precision
value: 87.57122507122507
- type: recall
value: 90.5982905982906
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.5
- type: f1
value: 86.90769841269842
- type: precision
value: 85.80178571428571
- type: recall
value: 89.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.5
- type: f1
value: 78.36796536796538
- type: precision
value: 76.82196969696969
- type: recall
value: 82.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.48846960167715
- type: f1
value: 66.78771089148448
- type: precision
value: 64.98302885095339
- type: recall
value: 71.48846960167715
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.50333333333333
- type: precision
value: 91.77499999999999
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.20622568093385
- type: f1
value: 66.83278891450098
- type: precision
value: 65.35065777283677
- type: recall
value: 71.20622568093385
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 48.717948717948715
- type: f1
value: 43.53146853146853
- type: precision
value: 42.04721204721204
- type: recall
value: 48.717948717948715
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 58.5
- type: f1
value: 53.8564991863928
- type: precision
value: 52.40329436122275
- type: recall
value: 58.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.8
- type: f1
value: 88.29
- type: precision
value: 87.09166666666667
- type: recall
value: 90.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.28971962616822
- type: f1
value: 62.63425307817832
- type: precision
value: 60.98065939771546
- type: recall
value: 67.28971962616822
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.7
- type: f1
value: 75.5264472455649
- type: precision
value: 74.38205086580086
- type: recall
value: 78.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.7
- type: f1
value: 86.10809523809525
- type: precision
value: 85.07602564102565
- type: recall
value: 88.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.99999999999999
- type: f1
value: 52.85487521402737
- type: precision
value: 51.53985162713104
- type: recall
value: 56.99999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94
- type: f1
value: 92.45333333333333
- type: precision
value: 91.79166666666667
- type: recall
value: 94
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.61333333333333
- type: precision
value: 89.83333333333331
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.69999999999999
- type: f1
value: 93.34555555555555
- type: precision
value: 92.75416666666668
- type: recall
value: 94.69999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 80.2
- type: f1
value: 76.6563035113035
- type: precision
value: 75.3014652014652
- type: recall
value: 80.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.7
- type: f1
value: 82.78689263765207
- type: precision
value: 82.06705086580087
- type: recall
value: 84.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 50.33333333333333
- type: f1
value: 45.461523661523664
- type: precision
value: 43.93545574795575
- type: recall
value: 50.33333333333333
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.6000000000000005
- type: f1
value: 5.442121400446441
- type: precision
value: 5.146630385487529
- type: recall
value: 6.6000000000000005
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85
- type: f1
value: 81.04666666666667
- type: precision
value: 79.25
- type: recall
value: 85
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 47.32142857142857
- type: f1
value: 42.333333333333336
- type: precision
value: 40.69196428571429
- type: recall
value: 47.32142857142857
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 30.735455543358945
- type: f1
value: 26.73616790022338
- type: precision
value: 25.397823220451283
- type: recall
value: 30.735455543358945
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 25.1
- type: f1
value: 21.975989896371022
- type: precision
value: 21.059885632257203
- type: recall
value: 25.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.75666666666666
- type: precision
value: 92.06166666666665
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.74
- type: precision
value: 92.09166666666667
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 71.3
- type: f1
value: 66.922442002442
- type: precision
value: 65.38249567099568
- type: recall
value: 71.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 40.300000000000004
- type: f1
value: 35.78682789299971
- type: precision
value: 34.66425128716588
- type: recall
value: 40.300000000000004
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96
- type: f1
value: 94.82333333333334
- type: precision
value: 94.27833333333334
- type: recall
value: 96
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 51.1
- type: f1
value: 47.179074753133584
- type: precision
value: 46.06461044702424
- type: recall
value: 51.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.7
- type: f1
value: 84.71
- type: precision
value: 83.46166666666667
- type: recall
value: 87.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.68333333333334
- type: precision
value: 94.13333333333334
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.39999999999999
- type: f1
value: 82.5577380952381
- type: precision
value: 81.36833333333334
- type: recall
value: 85.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 21.16788321167883
- type: f1
value: 16.948865627297987
- type: precision
value: 15.971932568647897
- type: recall
value: 21.16788321167883
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.9
- type: f1
value: 5.515526831658907
- type: precision
value: 5.141966366966367
- type: recall
value: 6.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.39666666666668
- type: precision
value: 90.58666666666667
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 89.95666666666666
- type: precision
value: 88.92833333333333
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.76190476190477
- type: f1
value: 74.93386243386244
- type: precision
value: 73.11011904761904
- type: recall
value: 79.76190476190477
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 8.799999999999999
- type: f1
value: 6.921439712248537
- type: precision
value: 6.489885109680683
- type: recall
value: 8.799999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 45.75569358178054
- type: f1
value: 40.34699501312631
- type: precision
value: 38.57886764719063
- type: recall
value: 45.75569358178054
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.4
- type: f1
value: 89.08333333333333
- type: precision
value: 88.01666666666668
- type: recall
value: 91.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.60000000000001
- type: f1
value: 92.06690476190477
- type: precision
value: 91.45095238095239
- type: recall
value: 93.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 7.5
- type: f1
value: 6.200363129378736
- type: precision
value: 5.89115314822466
- type: recall
value: 7.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 73.59307359307358
- type: f1
value: 68.38933553219267
- type: precision
value: 66.62698412698413
- type: recall
value: 73.59307359307358
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.8473282442748
- type: f1
value: 64.72373682297346
- type: precision
value: 62.82834214131924
- type: recall
value: 69.8473282442748
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.5254730713246
- type: f1
value: 96.72489082969432
- type: precision
value: 96.33672974284326
- type: recall
value: 97.5254730713246
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.6
- type: f1
value: 72.42746031746033
- type: precision
value: 71.14036630036631
- type: recall
value: 75.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.24293785310734
- type: f1
value: 88.86064030131826
- type: precision
value: 87.73540489642184
- type: recall
value: 91.24293785310734
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.2
- type: f1
value: 4.383083659794954
- type: precision
value: 4.027861324289673
- type: recall
value: 6.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 84.09428571428572
- type: precision
value: 83.00333333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 60.699999999999996
- type: f1
value: 56.1584972394755
- type: precision
value: 54.713456330903135
- type: recall
value: 60.699999999999996
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.2
- type: f1
value: 80.66190476190475
- type: precision
value: 79.19690476190476
- type: recall
value: 84.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.2
- type: f1
value: 91.33
- type: precision
value: 90.45
- type: recall
value: 93.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 6.3
- type: f1
value: 5.126828976748276
- type: precision
value: 4.853614328966668
- type: recall
value: 6.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.76943699731903
- type: f1
value: 77.82873739308057
- type: precision
value: 76.27622452019234
- type: recall
value: 81.76943699731903
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.30000000000001
- type: f1
value: 90.29666666666665
- type: precision
value: 89.40333333333334
- type: recall
value: 92.30000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 29.249011857707508
- type: f1
value: 24.561866096392947
- type: precision
value: 23.356583740215456
- type: recall
value: 29.249011857707508
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.46478873239437
- type: f1
value: 73.23943661971832
- type: precision
value: 71.66666666666667
- type: recall
value: 77.46478873239437
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 20.35928143712575
- type: f1
value: 15.997867865075824
- type: precision
value: 14.882104658301346
- type: recall
value: 20.35928143712575
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.2
- type: f1
value: 90.25999999999999
- type: precision
value: 89.45333333333335
- type: recall
value: 92.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 23.15270935960591
- type: f1
value: 19.65673625772148
- type: precision
value: 18.793705293464992
- type: recall
value: 23.15270935960591
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 59.154929577464785
- type: f1
value: 52.3868463305083
- type: precision
value: 50.14938113529662
- type: recall
value: 59.154929577464785
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 70.51282051282051
- type: f1
value: 66.8089133089133
- type: precision
value: 65.37645687645687
- type: recall
value: 70.51282051282051
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.6
- type: f1
value: 93
- type: precision
value: 92.23333333333333
- type: recall
value: 94.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.62212943632568
- type: f1
value: 34.3278276962583
- type: precision
value: 33.07646935732408
- type: recall
value: 38.62212943632568
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 28.1
- type: f1
value: 23.579609223054604
- type: precision
value: 22.39622774921555
- type: recall
value: 28.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.27361563517914
- type: f1
value: 85.12486427795874
- type: precision
value: 83.71335504885994
- type: recall
value: 88.27361563517914
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.6
- type: f1
value: 86.39928571428571
- type: precision
value: 85.4947557997558
- type: recall
value: 88.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.5
- type: f1
value: 83.77952380952381
- type: precision
value: 82.67602564102565
- type: recall
value: 86.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.52755905511812
- type: f1
value: 75.3055868016498
- type: precision
value: 73.81889763779527
- type: recall
value: 79.52755905511812
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.9
- type: f1
value: 73.76261904761905
- type: precision
value: 72.11670995670995
- type: recall
value: 77.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 53.8781163434903
- type: f1
value: 47.25804051288816
- type: precision
value: 45.0603482390186
- type: recall
value: 53.8781163434903
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.10000000000001
- type: f1
value: 88.88
- type: precision
value: 87.96333333333334
- type: recall
value: 91.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 38.46153846153847
- type: f1
value: 34.43978243978244
- type: precision
value: 33.429487179487175
- type: recall
value: 38.46153846153847
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.9
- type: f1
value: 86.19888888888887
- type: precision
value: 85.07440476190476
- type: recall
value: 88.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.9
- type: f1
value: 82.58857142857143
- type: precision
value: 81.15666666666667
- type: recall
value: 85.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.8
- type: f1
value: 83.36999999999999
- type: precision
value: 81.86833333333333
- type: recall
value: 86.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 68.51415094339622
- type: f1
value: 63.195000099481234
- type: precision
value: 61.394033442972116
- type: recall
value: 68.51415094339622
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.5
- type: f1
value: 86.14603174603175
- type: precision
value: 85.1162037037037
- type: recall
value: 88.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.62043795620438
- type: f1
value: 94.40389294403892
- type: precision
value: 93.7956204379562
- type: recall
value: 95.62043795620438
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.8
- type: f1
value: 78.6532178932179
- type: precision
value: 77.46348795840176
- type: recall
value: 81.8
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.603
- type: map_at_10
value: 8.5
- type: map_at_100
value: 12.985
- type: map_at_1000
value: 14.466999999999999
- type: map_at_3
value: 4.859999999999999
- type: map_at_5
value: 5.817
- type: mrr_at_1
value: 28.571
- type: mrr_at_10
value: 42.331
- type: mrr_at_100
value: 43.592999999999996
- type: mrr_at_1000
value: 43.592999999999996
- type: mrr_at_3
value: 38.435
- type: mrr_at_5
value: 39.966
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 21.353
- type: ndcg_at_100
value: 31.087999999999997
- type: ndcg_at_1000
value: 43.163000000000004
- type: ndcg_at_3
value: 22.999
- type: ndcg_at_5
value: 21.451
- type: precision_at_1
value: 28.571
- type: precision_at_10
value: 19.387999999999998
- type: precision_at_100
value: 6.265
- type: precision_at_1000
value: 1.4160000000000001
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 21.224
- type: recall_at_1
value: 2.603
- type: recall_at_10
value: 14.474
- type: recall_at_100
value: 40.287
- type: recall_at_1000
value: 76.606
- type: recall_at_3
value: 5.978
- type: recall_at_5
value: 7.819
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 69.7848
- type: ap
value: 13.661023167088224
- type: f1
value: 53.61686134460943
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 61.28183361629882
- type: f1
value: 61.55481034919965
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 35.972128420092396
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.59933241938367
- type: cos_sim_ap
value: 72.20760361208136
- type: cos_sim_f1
value: 66.4447731755424
- type: cos_sim_precision
value: 62.35539102267469
- type: cos_sim_recall
value: 71.10817941952506
- type: dot_accuracy
value: 78.98313166835548
- type: dot_ap
value: 44.492521645493795
- type: dot_f1
value: 45.814889336016094
- type: dot_precision
value: 37.02439024390244
- type: dot_recall
value: 60.07915567282321
- type: euclidean_accuracy
value: 85.3907134767837
- type: euclidean_ap
value: 71.53847289080343
- type: euclidean_f1
value: 65.95952206778834
- type: euclidean_precision
value: 61.31006346328196
- type: euclidean_recall
value: 71.37203166226914
- type: manhattan_accuracy
value: 85.40859510043511
- type: manhattan_ap
value: 71.49664104395515
- type: manhattan_f1
value: 65.98569969356485
- type: manhattan_precision
value: 63.928748144482924
- type: manhattan_recall
value: 68.17941952506597
- type: max_accuracy
value: 85.59933241938367
- type: max_ap
value: 72.20760361208136
- type: max_f1
value: 66.4447731755424
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.83261536073273
- type: cos_sim_ap
value: 85.48178133644264
- type: cos_sim_f1
value: 77.87816307403935
- type: cos_sim_precision
value: 75.88953021114926
- type: cos_sim_recall
value: 79.97382198952879
- type: dot_accuracy
value: 79.76287499514883
- type: dot_ap
value: 59.17438838475084
- type: dot_f1
value: 56.34566667855996
- type: dot_precision
value: 52.50349092359864
- type: dot_recall
value: 60.794579611949494
- type: euclidean_accuracy
value: 88.76857996662397
- type: euclidean_ap
value: 85.22764834359887
- type: euclidean_f1
value: 77.65379751543554
- type: euclidean_precision
value: 75.11152683839401
- type: euclidean_recall
value: 80.37419156144134
- type: manhattan_accuracy
value: 88.6987231730508
- type: manhattan_ap
value: 85.18907981724007
- type: manhattan_f1
value: 77.51967028849757
- type: manhattan_precision
value: 75.49992701795358
- type: manhattan_recall
value: 79.65044656606098
- type: max_accuracy
value: 88.83261536073273
- type: max_ap
value: 85.48178133644264
- type: max_f1
value: 77.87816307403935
---
## Multilingual-E5-base
[Text Embeddings by Weakly-Supervised Contrastive Pre-training](https://arxiv.org/pdf/2212.03533.pdf).
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, Furu Wei, arXiv 2022
This model has 12 layers and the embedding size is 768.
## Usage
Below is an example to encode queries and passages from the MS-MARCO passage ranking dataset.
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
# Each input text should start with "query: " or "passage: ", even for non-English texts.
# For tasks other than retrieval, you can simply use the "query: " prefix.
input_texts = ['query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右,放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"]
tokenizer = AutoTokenizer.from_pretrained('intfloat/multilingual-e5-base')
model = AutoModel.from_pretrained('intfloat/multilingual-e5-base')
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
```
## Supported Languages
This model is initialized from [xlm-roberta-base](https://huggingface.co/xlm-roberta-base)
and continually trained on a mixture of multilingual datasets.
It supports 100 languages from xlm-roberta,
but low-resource languages may see performance degradation.
## Training Details
**Initialization**: [xlm-roberta-base](https://huggingface.co/xlm-roberta-base)
**First stage**: contrastive pre-training with weak supervision
| Dataset | Weak supervision | # of text pairs |
|--------------------------------------------------------------------------------------------------------|---------------------------------------|-----------------|
| Filtered [mC4](https://huggingface.co/datasets/mc4) | (title, page content) | 1B |
| [CC News](https://huggingface.co/datasets/intfloat/multilingual_cc_news) | (title, news content) | 400M |
| [NLLB](https://huggingface.co/datasets/allenai/nllb) | translation pairs | 2.4B |
| [Wikipedia](https://huggingface.co/datasets/intfloat/wikipedia) | (hierarchical section title, passage) | 150M |
| Filtered [Reddit](https://www.reddit.com/) | (comment, response) | 800M |
| [S2ORC](https://github.com/allenai/s2orc) | (title, abstract) and citation pairs | 100M |
| [Stackexchange](https://stackexchange.com/) | (question, answer) | 50M |
| [xP3](https://huggingface.co/datasets/bigscience/xP3) | (input prompt, response) | 80M |
| [Miscellaneous unsupervised SBERT data](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | - | 10M |
**Second stage**: supervised fine-tuning
| Dataset | Language | # of text pairs |
|----------------------------------------------------------------------------------------|--------------|-----------------|
| [MS MARCO](https://microsoft.github.io/msmarco/) | English | 500k |
| [NQ](https://github.com/facebookresearch/DPR) | English | 70k |
| [Trivia QA](https://github.com/facebookresearch/DPR) | English | 60k |
| [NLI from SimCSE](https://github.com/princeton-nlp/SimCSE) | English | <300k |
| [ELI5](https://huggingface.co/datasets/eli5) | English | 500k |
| [DuReader Retrieval](https://github.com/baidu/DuReader/tree/master/DuReader-Retrieval) | Chinese | 86k |
| [KILT Fever](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [KILT HotpotQA](https://huggingface.co/datasets/kilt_tasks) | English | 70k |
| [SQuAD](https://huggingface.co/datasets/squad) | English | 87k |
| [Quora](https://huggingface.co/datasets/quora) | English | 150k |
| [Mr. TyDi](https://huggingface.co/datasets/castorini/mr-tydi) | 11 languages | 50k |
| [MIRACL](https://huggingface.co/datasets/miracl/miracl) | 16 languages | 40k |
For all labeled datasets, we only use its training set for fine-tuning.
For other training details, please refer to our paper at [https://arxiv.org/pdf/2212.03533.pdf](https://arxiv.org/pdf/2212.03533.pdf).
## Benchmark Results on [Mr. TyDi](https://arxiv.org/abs/2108.08787)
| Model | Avg MRR@10 | | ar | bn | en | fi | id | ja | ko | ru | sw | te | th |
|-----------------------|------------|-------|------| --- | --- | --- | --- | --- | --- | --- |------| --- | --- |
| BM25 | 33.3 | | 36.7 | 41.3 | 15.1 | 28.8 | 38.2 | 21.7 | 28.1 | 32.9 | 39.6 | 42.4 | 41.7 |
| mDPR | 16.7 | | 26.0 | 25.8 | 16.2 | 11.3 | 14.6 | 18.1 | 21.9 | 18.5 | 7.3 | 10.6 | 13.5 |
| BM25 + mDPR | 41.7 | | 49.1 | 53.5 | 28.4 | 36.5 | 45.5 | 35.5 | 36.2 | 42.7 | 40.5 | 42.0 | 49.2 |
| | |
| multilingual-e5-small | 64.4 | | 71.5 | 66.3 | 54.5 | 57.7 | 63.2 | 55.4 | 54.3 | 60.8 | 65.4 | 89.1 | 70.1 |
| multilingual-e5-base | 65.9 | | 72.3 | 65.0 | 58.5 | 60.8 | 64.9 | 56.6 | 55.8 | 62.7 | 69.0 | 86.6 | 72.7 |
| multilingual-e5-large | **70.5** | | 77.5 | 73.2 | 60.8 | 66.8 | 68.5 | 62.5 | 61.6 | 65.8 | 72.7 | 90.2 | 76.2 |
## MTEB Benchmark Evaluation
Check out [unilm/e5](https://github.com/microsoft/unilm/tree/master/e5) to reproduce evaluation results
on the [BEIR](https://arxiv.org/abs/2104.08663) and [MTEB benchmark](https://arxiv.org/abs/2210.07316).
## Support for Sentence Transformers
Below is an example for usage with sentence_transformers.
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('intfloat/multilingual-e5-base')
input_texts = [
'query: how much protein should a female eat',
'query: 南瓜的家常做法',
"passage: As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 i s 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or traini ng for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"passage: 1.清炒南瓜丝 原料:嫩南瓜半个 调料:葱、盐、白糖、鸡精 做法: 1、南瓜用刀薄薄的削去表面一层皮 ,用勺子刮去瓤 2、擦成细丝(没有擦菜板就用刀慢慢切成细丝) 3、锅烧热放油,入葱花煸出香味 4、入南瓜丝快速翻炒一分钟左右, 放盐、一点白糖和鸡精调味出锅 2.香葱炒南瓜 原料:南瓜1只 调料:香葱、蒜末、橄榄油、盐 做法: 1、将南瓜去皮,切成片 2、油 锅8成热后,将蒜末放入爆香 3、爆香后,将南瓜片放入,翻炒 4、在翻炒的同时,可以不时地往锅里加水,但不要太多 5、放入盐,炒匀 6、南瓜差不多软和绵了之后,就可以关火 7、撒入香葱,即可出锅"
]
embeddings = model.encode(input_texts, normalize_embeddings=True)
```
Package requirements
`pip install sentence_transformers~=2.2.2`
Contributors: [michaelfeil](https://huggingface.co/michaelfeil)
## FAQ
**1. Do I need to add the prefix "query: " and "passage: " to input texts?**
Yes, this is how the model is trained, otherwise you will see a performance degradation.
Here are some rules of thumb:
- Use "query: " and "passage: " correspondingly for asymmetric tasks such as passage retrieval in open QA, ad-hoc information retrieval.
- Use "query: " prefix for symmetric tasks such as semantic similarity, bitext mining, paraphrase retrieval.
- Use "query: " prefix if you want to use embeddings as features, such as linear probing classification, clustering.
**2. Why are my reproduced results slightly different from reported in the model card?**
Different versions of `transformers` and `pytorch` could cause negligible but non-zero performance differences.
**3. Why does the cosine similarity scores distribute around 0.7 to 1.0?**
This is a known and expected behavior as we use a low temperature 0.01 for InfoNCE contrastive loss.
For text embedding tasks like text retrieval or semantic similarity,
what matters is the relative order of the scores instead of the absolute values,
so this should not be an issue.
## Citation
If you find our paper or models helpful, please consider cite as follows:
```
@article{wang2022text,
title={Text Embeddings by Weakly-Supervised Contrastive Pre-training},
author={Wang, Liang and Yang, Nan and Huang, Xiaolong and Jiao, Binxing and Yang, Linjun and Jiang, Daxin and Majumder, Rangan and Wei, Furu},
journal={arXiv preprint arXiv:2212.03533},
year={2022}
}
```
## Limitations
Long texts will be truncated to at most 512 tokens.
|
[
"BIOSSES",
"SCIFACT"
] |
DoctorDiffusion/doctor-diffusion-s-stylized-silhouette-photography-xl-lora
|
DoctorDiffusion
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"dark",
"concept",
"water",
"shadow",
"silhouette",
"backlighting",
"photogrphy",
"foreground",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] | 2023-12-14T14:17:17Z |
2023-12-14T14:17:19+00:00
| 46 | 5 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Rent&allowDerivatives=True&allowDifferentLicense=False
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- dark
- concept
- water
- shadow
- silhouette
- backlighting
- photogrphy
- foreground
instance_prompt: sli artstyle
widget:
- text: ' sil, artstyle, photo skull spaceman in water infront of fire'
output:
url: 3011283.jpeg
- text: ' sil, artstyle, photo skull spaceman in water infront of fire'
output:
url: 3011288.jpeg
- text: ' '
output:
url: 3011320.jpeg
- text: ' '
output:
url: 3011323.jpeg
- text: ' '
output:
url: 3011327.jpeg
- text: ' sil, artstyle, skeleton photo bear infront of moon'
output:
url: 3011395.jpeg
- text: ' '
output:
url: 3012637.jpeg
- text: ' '
output:
url: 3012492.jpeg
- text: ' '
output:
url: 3012686.jpeg
- text: ' '
output:
url: 3012689.jpeg
---
# Doctor Diffusion's Stylized Silhouette Photography XL LoRA
<Gallery />
## Model description
<p>Trained on a collection of my personal and CC0 stylized silhouette photography.<br /><br />Use "sli artyle" in prompt.<br /><br />Other powerful control Tokens:<br />"in water"<br />"vintage"<br />"infront of" "city" "fire" "space"<br />"backlight"<br /><br /><span style="color:rgb(17, 17, 17)">☕ </span>Like what I do? <span style="color:rgb(17, 17, 17)">☕</span><br /><span style="color:rgb(17, 17, 17)">☕ </span><a target="_blank" rel="ugc" href="https://www.buymeacoffee.com/doctordiffusion">Buy me a coffee or two</a>! <span style="color:rgb(17, 17, 17)">☕</span></p>
## Trigger words
You should use `sli artstyle`, `infront of`, `in water` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/DoctorDiffusion/doctor-diffusion-s-stylized-silhouette-photography-xl-lora/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('DoctorDiffusion/doctor-diffusion-s-stylized-silhouette-photography-xl-lora', weight_name='DD-sli-v1.safetensors')
image = pipeline('`sli artstyle`, `infront of`, `in water`').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
[
"BEAR"
] |
ntc-ai/SDXL-LoRA-slider.looking-in-the-mirror
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-14T03:23:22Z |
2024-01-14T03:23:26+00:00
| 46 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/looking in the mirror.../looking in the mirror_17_3.0.png
widget:
- text: looking in the mirror
output:
url: images/looking in the mirror_17_3.0.png
- text: looking in the mirror
output:
url: images/looking in the mirror_19_3.0.png
- text: looking in the mirror
output:
url: images/looking in the mirror_20_3.0.png
- text: looking in the mirror
output:
url: images/looking in the mirror_21_3.0.png
- text: looking in the mirror
output:
url: images/looking in the mirror_22_3.0.png
inference: false
instance_prompt: looking in the mirror
---
# ntcai.xyz slider - looking in the mirror (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/looking in the mirror_17_-3.0.png" width=256 height=256 /> | <img src="images/looking in the mirror_17_0.0.png" width=256 height=256 /> | <img src="images/looking in the mirror_17_3.0.png" width=256 height=256 /> |
| <img src="images/looking in the mirror_19_-3.0.png" width=256 height=256 /> | <img src="images/looking in the mirror_19_0.0.png" width=256 height=256 /> | <img src="images/looking in the mirror_19_3.0.png" width=256 height=256 /> |
| <img src="images/looking in the mirror_20_-3.0.png" width=256 height=256 /> | <img src="images/looking in the mirror_20_0.0.png" width=256 height=256 /> | <img src="images/looking in the mirror_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
looking in the mirror
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.looking-in-the-mirror', weight_name='looking in the mirror.safetensors', adapter_name="looking in the mirror")
# Activate the LoRA
pipe.set_adapters(["looking in the mirror"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, looking in the mirror"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1090+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.watercolor
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-21T07:23:31Z |
2024-01-21T07:23:34+00:00
| 46 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/watercolor.../watercolor_17_3.0.png
widget:
- text: watercolor
output:
url: images/watercolor_17_3.0.png
- text: watercolor
output:
url: images/watercolor_19_3.0.png
- text: watercolor
output:
url: images/watercolor_20_3.0.png
- text: watercolor
output:
url: images/watercolor_21_3.0.png
- text: watercolor
output:
url: images/watercolor_22_3.0.png
inference: false
instance_prompt: watercolor
---
# ntcai.xyz slider - watercolor (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/watercolor_17_-3.0.png" width=256 height=256 /> | <img src="images/watercolor_17_0.0.png" width=256 height=256 /> | <img src="images/watercolor_17_3.0.png" width=256 height=256 /> |
| <img src="images/watercolor_19_-3.0.png" width=256 height=256 /> | <img src="images/watercolor_19_0.0.png" width=256 height=256 /> | <img src="images/watercolor_19_3.0.png" width=256 height=256 /> |
| <img src="images/watercolor_20_-3.0.png" width=256 height=256 /> | <img src="images/watercolor_20_0.0.png" width=256 height=256 /> | <img src="images/watercolor_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
watercolor
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.watercolor', weight_name='watercolor.safetensors', adapter_name="watercolor")
# Activate the LoRA
pipe.set_adapters(["watercolor"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, watercolor"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1140+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.serenity-film-still
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-24T07:26:19Z |
2024-01-24T07:26:25+00:00
| 46 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/serenity film still.../serenity film still_17_3.0.png
widget:
- text: serenity film still
output:
url: images/serenity film still_17_3.0.png
- text: serenity film still
output:
url: images/serenity film still_19_3.0.png
- text: serenity film still
output:
url: images/serenity film still_20_3.0.png
- text: serenity film still
output:
url: images/serenity film still_21_3.0.png
- text: serenity film still
output:
url: images/serenity film still_22_3.0.png
inference: false
instance_prompt: serenity film still
---
# ntcai.xyz slider - serenity film still (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/serenity film still_17_-3.0.png" width=256 height=256 /> | <img src="images/serenity film still_17_0.0.png" width=256 height=256 /> | <img src="images/serenity film still_17_3.0.png" width=256 height=256 /> |
| <img src="images/serenity film still_19_-3.0.png" width=256 height=256 /> | <img src="images/serenity film still_19_0.0.png" width=256 height=256 /> | <img src="images/serenity film still_19_3.0.png" width=256 height=256 /> |
| <img src="images/serenity film still_20_-3.0.png" width=256 height=256 /> | <img src="images/serenity film still_20_0.0.png" width=256 height=256 /> | <img src="images/serenity film still_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
serenity film still
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.serenity-film-still', weight_name='serenity film still.safetensors', adapter_name="serenity film still")
# Activate the LoRA
pipe.set_adapters(["serenity film still"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, serenity film still"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1140+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
YiDuo1999/Llama-3-Physician-8B-Instruct
|
YiDuo1999
|
text-generation
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-06-20T13:04:37Z |
2024-07-02T10:05:43+00:00
| 46 | 5 |
---
license: llama3
---
The official instruct model weights for "Efficient Continual Pre-training by Mitigating the Stability Gap".
## Introduction
This repo contains Llama-3-Physician-8B-Instruct, a medical language model with 8 billion parameters. This model builds upon the foundation of Llama 3 and has been firstly continual pretrained on high-quality medical sub-corpus from the RefinedWeb dataset and then tuned with diverse medical and general instructions. We also use the three strategies in the paper to mitigate the stability gap during continual pretraining and instruction tuning, which boosts the model's medical task performance and reduces the computation consumption.
## 💻 Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
model_name = "YiDuo1999/Llama-3-Physician-8B-Instruct"
device_map = 'auto'
model = AutoModelForCausalLM.from_pretrained( model_name, trust_remote_code=True,use_cache=False,device_map=device_map)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
def askme(question):
sys_message = '''
You are an AI Medical Assistant trained on a vast dataset of health information. Please be thorough and
provide an informative answer. If you don't know the answer to a specific medical inquiry, advise seeking professional help.
'''
# Create messages structured for the chat template
messages = [{"role": "system", "content": sys_message}, {"role": "user", "content": question}]
# Applying chat template
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=100, use_cache=True)
# Extract and return the generated text, removing the prompt
response_text = tokenizer.batch_decode(outputs)[0].strip()
answer = response_text.split('<|im_start|>assistant')[-1].strip()
return answer
# Example usage
# - Context: First describe your problem.
# - Question: Then make the question.
question = '''What is HIV?'''
print(askme(question))
```
the type of answer is :
```
HIV, or Human Immunodeficiency Virus, is a retrovirus that primarily infects cells of the human immune system, particularly CD4+ T cells, which are crucial to the body's ability to fight off infection. HIV infection can lead to AIDS, or Acquired Immune Deficiency Syndrome, a condition that causes severe damage to the immune system and makes individuals more susceptible to life-threatening infections. HIV
is transmitted through sexual contact, sharing needles, or through mother-to-child transmission during pregnancy.
```
## 🏆 Evaluation
For question-answering tasks, we have
| Model | MMLU-Medical | PubMedQA | MedMCQA | MedQA-4-Option | Avg |
|:--------------------------------|:--------------|:----------|:---------|:----------------|:------|
| Mistral-7B-instruct | 55.8 | 17.8 | 40.2 | 41.1 | 37.5 |
| Zephyr-7B-instruct-β | 63.3 | 46.0 | 43.0 | 48.5 | 48.7 |
| PMC-Llama-7B | 59.7 | 59.2 | 57.6 | 49.2 | 53.6 |
| Medalpaca-13B | 55.2 | 50.4 | 21.2 | 20.2 | 36.7 |
| AlpaCare-13B | 60.2 | 53.8 | 38.5 | 30.4 | 45.7 |
| BioMedGPT-LM 7B | 52.0 | 58.6 | 34.9 | 39.3 | 46.2 |
| Me-Llama-13B | - | 70.0 | 44.9 | 42.7 | - |
| Llama-3-8B instruct | 82.0 | 74.6 | 57.1 | 60.3 | 68.5 |
| JSL-Med-Sft-Llama-3-8B | 83.0 | 75.4 | 57.5 | 74.8 | 72.7 |
| GPT-3.5-turbo-1106 | 74.0 | 72.6 | 34.9 | 39.3 | 60.6 |
| GPT-4 | 85.5 | 69.2 | 69.5 | 83.9 | 77.0 |
| Llama-3-physician-8B instruct (ours) | 80.0 | 76.0 | 80.2 | 60.3 | 74.1 |
For Medical claasification, relation extraction, natural language inference, summarization tasks, we have
| Task type | Classification | Relation extraction | Natural Language Inference | Summarization |
|:--------------------------------|:----------------|:----------------------|:----------------------------|:---------------|
| Datasets | HOC | DDI-2013 | BioNLI | MIMIC-CXR |
| Mistral-7B-instruct | 35.8 | 14.1 | 16.7 | 12.5 |
| Zephyr-7B-instruct-β | 26.1 | 19.4 | 19.9 | 10.5 |
| PMC-Llama-7B | 18.4 | 14.7 | 15.9 | 13.9 |
| Medalpaca-13B | 24.6 | 5.8 | 16.4 | 1.0 |
| AlpaCare-13B | 26.7 | 11.0 | 17.0 | 13.4 |
| BioMedGPT-LM 7B | 23.4 | 15.5 | 17.9 | 6.2 |
| Me-Llama-13B | 33.5 | 21.4 | 19.5 | 40.0 |
| JSL-Med-Sft-Llama-3-8B | 25.6 | 19.7 | 16.6 | 13.8 |
| Llama-3-8B instruct | 31.0 | 15.1 | 18.8 | 10.3 |
| GPT-3.5-turbo-1106 | 54.5 | 21.6 | 31.7 | 13.5 |
| GPT-4 | 60.2 | 29.2 | 57.8 | 15.2 |
| Llama-3-physician-8B instruct (ours) | 78.9 | 33.6 | 76.2 | 37.7 |
## Citation
```
@inproceedings{Guo2024EfficientCP,
title={Efficient Continual Pre-training by Mitigating the Stability Gap},
author={Yiduo Guo and Jie Fu and Huishuai Zhang and Dongyan Zhao and Yikang Shen},
year={2024},
url={https://api.semanticscholar.org/CorpusID:270688100}
}
```
|
[
"MEDQA",
"PUBMEDQA"
] |
RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-07-02T17:55:20Z |
2024-07-02T18:05:23+00:00
| 46 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
MELT-TinyLlama-1.1B-Chat-v1.0 - GGUF
- Model creator: https://huggingface.co/IBI-CAAI/
- Original model: https://huggingface.co/IBI-CAAI/MELT-TinyLlama-1.1B-Chat-v1.0/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q2_K.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q2_K.gguf) | Q2_K | 0.4GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.IQ3_XS.gguf) | IQ3_XS | 0.44GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.IQ3_S.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.IQ3_S.gguf) | IQ3_S | 0.47GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q3_K_S.gguf) | Q3_K_S | 0.47GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.IQ3_M.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.IQ3_M.gguf) | IQ3_M | 0.48GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q3_K.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q3_K.gguf) | Q3_K | 0.51GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q3_K_M.gguf) | Q3_K_M | 0.51GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q3_K_L.gguf) | Q3_K_L | 0.55GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.IQ4_XS.gguf) | IQ4_XS | 0.57GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q4_0.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q4_0.gguf) | Q4_0 | 0.59GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.IQ4_NL.gguf) | IQ4_NL | 0.6GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q4_K_S.gguf) | Q4_K_S | 0.6GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q4_K.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q4_K.gguf) | Q4_K | 0.62GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q4_K_M.gguf) | Q4_K_M | 0.62GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q4_1.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q4_1.gguf) | Q4_1 | 0.65GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q5_0.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q5_0.gguf) | Q5_0 | 0.71GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q5_K_S.gguf) | Q5_K_S | 0.71GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q5_K.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q5_K.gguf) | Q5_K | 0.73GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q5_K_M.gguf) | Q5_K_M | 0.73GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q5_1.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q5_1.gguf) | Q5_1 | 0.77GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q6_K.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q6_K.gguf) | Q6_K | 0.84GB |
| [MELT-TinyLlama-1.1B-Chat-v1.0.Q8_0.gguf](https://huggingface.co/RichardErkhov/IBI-CAAI_-_MELT-TinyLlama-1.1B-Chat-v1.0-gguf/blob/main/MELT-TinyLlama-1.1B-Chat-v1.0.Q8_0.gguf) | Q8_0 | 1.09GB |
Original model description:
---
license: apache-2.0
language:
- en
library_name: transformers
---
# Model Card MELT-TinyLlama-1.1B-Chat-v1.0
The MELT-TinyLlama-1.1B-Chat-v1.0 Large Language Model (LLM) is a pretrained generative text model pre-trained and fine-tuned on using publically avalable medical data.
MELT-TinyLlama-1.1B-Chat-v1.0 demonstrates a 13.76% improvement over TinyLlama-1.1B-Chat-v1.0 across 3 medical benchmarks including, USMLE, Indian AIIMS, and NEET medical examination examples.
## Model Details
The Medical Education Language Transformer (MELT) models have been trained on a wide-range of text, chat, Q/A, and instruction data in the medical domain.
While the model was evaluated using publically avalable [USMLE](https://www.usmle.org/), Indian AIIMS, and NEET medical examination example questions, its use it intented to be more broadly applicable.
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [Center for Applied AI](https://caai.ai.uky.edu/)
- **Funded by:** [Institute or Biomedical Informatics](https://www.research.uky.edu/IBI)
- **Model type:** LLM
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Finetuned from model:** [TinyLlama-1.1B-Chat-v1.0](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0)
## Uses
MELT is intended for research purposes only. MELT models are best suited for prompts using a QA or chat format.
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
MELT is intended for research purposes only and should not be used for medical advice.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
MELT was training using collections publicly available, which likely contain biased and inaccurate information. The training and evaluation datasets have not been evaluated for content or accuracy.
## How to Get Started with the Model
Use this model like you would any llama-2-7b-chat-hf model.
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
The following datasets were used for training:
[Expert Med](https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/Q3A969)
[MedQA train](https://huggingface.co/datasets/bigbio/med_qa)
[MedMCQA train](https://github.com/MedMCQA/MedMCQA?tab=readme-ov-file#data-download-and-preprocessing)
[LiveQA](https://github.com/abachaa/LiveQA_MedicalTask_TREC2017)
[MedicationQA](https://huggingface.co/datasets/truehealth/medicationqa)
[MMLU clinical topics](https://huggingface.co/datasets/Stevross/mmlu)
[Medical Flashcards](https://huggingface.co/datasets/medalpaca/medical_meadow_medical_flashcards)
[Wikidoc](https://huggingface.co/datasets/medalpaca/medical_meadow_wikidoc)
[Wikidoc Patient Information](https://huggingface.co/datasets/medalpaca/medical_meadow_wikidoc_patient_information)
[MEDIQA](https://huggingface.co/datasets/medalpaca/medical_meadow_mediqa)
[MMMLU](https://huggingface.co/datasets/medalpaca/medical_meadow_mmmlu)
[icliniq 10k](https://drive.google.com/file/d/1ZKbqgYqWc7DJHs3N9TQYQVPdDQmZaClA/view?usp=sharing)
[HealthCare Magic 100k](https://drive.google.com/file/d/1lyfqIwlLSClhgrCutWuEe_IACNq6XNUt/view?usp=sharing)
[GenMedGPT-5k](https://drive.google.com/file/d/1nDTKZ3wZbZWTkFMBkxlamrzbNz0frugg/view?usp=sharing)
[Mental Health Conversational](https://huggingface.co/datasets/heliosbrahma/mental_health_conversational_dataset)
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Training Hyperparameters
- **Lora Rank:** 64
- **Lora Alpha:** 16
- **Lora Targets:** "o_proj","down_proj","v_proj","gate_proj","up_proj","k_proj","q_proj"
- **LR:** 2e-4
- **Epoch:** 3
- **Precision:** bf16 <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
MELT-TinyLlama-1.1B-Chat-v1.0 demonstrates an average 13.76% improvement over TinyLlama-1.1B-Chat-v1.0 across 3 USMLE, Indian AIIMS, and NEET medical examination benchmarks.
### TinyLlama-1.1B-Chat-v1.0
- **medqa:** {'base': {'Average': 25.49, 'STEP-1': 24.48, 'STEP-2&3': 26.64}}
- **mausmle:** {'base': {'Average': 19.71, 'STEP-1': 21.18, 'STEP-2': 20.69, 'STEP-3': 17.76}}
- **medmcqa:** {'base': {'Average': 28.52, 'MEDICINE': 29.35, 'OPHTHALMOLOGY': 28.57, 'ANATOMY': 30.82, 'PATHOLOGY': 29.07, 'PHYSIOLOGY': 20.45, 'DENTAL': 30.09, 'RADIOLOGY': 14.29, 'BIOCHEMISTRY': 22.31, 'ANAESTHESIA': 26.09, 'GYNAECOLOGY': 24.84, 'PHARMACOLOGY': 32.02, 'SOCIAL': 31.11, 'PEDIATRICS': 31.82, 'ENT': 28.95, 'SURGERY': 31.45, 'MICROBIOLOGY': 26.03, 'FORENSIC': 16.28, 'PSYCHIATRY': 22.22, 'SKIN': 40.0, 'ORTHOPAEDICS': 21.43, 'UNKNOWN': 0.0}}
- **average:** 24.57%
### MELT-TinyLlama-1.1B-Chat-v1.0
- **medqa:** {'base': {'Average': 29.5, 'STEP-1': 28.17, 'STEP-2&3': 31.03}}
- **mausmle:** {'base': {'Average': 21.51, 'STEP-1': 27.06, 'STEP-2': 19.54, 'STEP-3': 18.69}}
- **medmcqa:** {'base': {'Average': 32.84, 'MEDICINE': 27.72, 'OPHTHALMOLOGY': 38.1, 'ANATOMY': 39.73, 'PATHOLOGY': 32.56, 'PHYSIOLOGY': 35.61, 'DENTAL': 32.23, 'RADIOLOGY': 41.07, 'BIOCHEMISTRY': 33.06, 'ANAESTHESIA': 39.13, 'GYNAECOLOGY': 22.88, 'PHARMACOLOGY': 32.58, 'SOCIAL': 26.67, 'PEDIATRICS': 34.09, 'ENT': 42.11, 'SURGERY': 33.47, 'MICROBIOLOGY': 30.14, 'FORENSIC': 41.86, 'PSYCHIATRY': 55.56, 'SKIN': 60.0, 'ORTHOPAEDICS': 35.71, 'UNKNOWN': 100.0}}
- **average:** 27.95%
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[MedQA test](https://huggingface.co/datasets/bigbio/med_qa)
[MedMCQA test](https://github.com/MedMCQA/MedMCQA?tab=readme-ov-file#data-download-and-preprocessing)
[MA USMLE](https://huggingface.co/datasets/medalpaca/medical_meadow_usmle_self_assessment)
## Disclaimer:
The use of large language models, such as this one, is provided without warranties or guarantees of any kind. While every effort has been made to ensure accuracy, completeness, and reliability of the information generated, it should be noted that these models may produce responses that are inaccurate, outdated, or inappropriate for specific purposes. Users are advised to exercise discretion and judgment when relying on the information generated by these models. The outputs should not be considered as professional, legal, medical, financial, or any other form of advice. It is recommended to seek expert advice or consult appropriate sources for specific queries or critical decision-making. The creators, developers, and providers of these models disclaim any liability for damages, losses, or any consequences arising from the use, reliance upon, or interpretation of the information provided by these models. The user assumes full responsibility for their interactions and usage of the generated content. By using these language models, users agree to indemnify and hold harmless the developers, providers, and affiliates from any claims, damages, or liabilities that may arise from their use. Please be aware that these models are constantly evolving, and their capabilities, limitations, and outputs may change over time without prior notice. Your use of this language model signifies your acceptance and understanding of this disclaimer.
|
[
"MEDQA",
"MEDICAL DATA"
] |
RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | 2024-07-25T21:38:50Z |
2024-07-26T08:34:42+00:00
| 46 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
LLaMA2-13B-Psyfighter2 - GGUF
- Model creator: https://huggingface.co/KoboldAI/
- Original model: https://huggingface.co/KoboldAI/LLaMA2-13B-Psyfighter2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [LLaMA2-13B-Psyfighter2.Q2_K.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q2_K.gguf) | Q2_K | 4.52GB |
| [LLaMA2-13B-Psyfighter2.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.IQ3_XS.gguf) | IQ3_XS | 4.99GB |
| [LLaMA2-13B-Psyfighter2.IQ3_S.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.IQ3_S.gguf) | IQ3_S | 5.27GB |
| [LLaMA2-13B-Psyfighter2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q3_K_S.gguf) | Q3_K_S | 5.27GB |
| [LLaMA2-13B-Psyfighter2.IQ3_M.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.IQ3_M.gguf) | IQ3_M | 5.57GB |
| [LLaMA2-13B-Psyfighter2.Q3_K.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q3_K.gguf) | Q3_K | 5.9GB |
| [LLaMA2-13B-Psyfighter2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q3_K_M.gguf) | Q3_K_M | 5.9GB |
| [LLaMA2-13B-Psyfighter2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q3_K_L.gguf) | Q3_K_L | 6.45GB |
| [LLaMA2-13B-Psyfighter2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.IQ4_XS.gguf) | IQ4_XS | 6.54GB |
| [LLaMA2-13B-Psyfighter2.Q4_0.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q4_0.gguf) | Q4_0 | 6.86GB |
| [LLaMA2-13B-Psyfighter2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.IQ4_NL.gguf) | IQ4_NL | 6.9GB |
| [LLaMA2-13B-Psyfighter2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q4_K_S.gguf) | Q4_K_S | 6.91GB |
| [LLaMA2-13B-Psyfighter2.Q4_K.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q4_K.gguf) | Q4_K | 7.33GB |
| [LLaMA2-13B-Psyfighter2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q4_K_M.gguf) | Q4_K_M | 7.33GB |
| [LLaMA2-13B-Psyfighter2.Q4_1.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q4_1.gguf) | Q4_1 | 7.61GB |
| [LLaMA2-13B-Psyfighter2.Q5_0.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q5_0.gguf) | Q5_0 | 8.36GB |
| [LLaMA2-13B-Psyfighter2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q5_K_S.gguf) | Q5_K_S | 8.36GB |
| [LLaMA2-13B-Psyfighter2.Q5_K.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q5_K.gguf) | Q5_K | 8.6GB |
| [LLaMA2-13B-Psyfighter2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q5_K_M.gguf) | Q5_K_M | 8.6GB |
| [LLaMA2-13B-Psyfighter2.Q5_1.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q5_1.gguf) | Q5_1 | 9.1GB |
| [LLaMA2-13B-Psyfighter2.Q6_K.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q6_K.gguf) | Q6_K | 9.95GB |
| [LLaMA2-13B-Psyfighter2.Q8_0.gguf](https://huggingface.co/RichardErkhov/KoboldAI_-_LLaMA2-13B-Psyfighter2-gguf/blob/main/LLaMA2-13B-Psyfighter2.Q8_0.gguf) | Q8_0 | 12.88GB |
Original model description:
---
license: llama2
---
# LLAMA2-13B-Psyfighter2
Psyfighter is a merged model created by the KoboldAI community members Jeb Carter and TwistedShadows and was made possible thanks to the KoboldAI merge request service.
The intent was to add medical data to supplement the models fictional ability with more details on anatomy and mental states. Due to the low ratio's of medical data and the high ratio's of fiction this model should not be used for medical advice or therapy because of its high chance of pulling in fictional data.
The following mergekit recipe was used:
```
merge_method: task_arithmetic
base_model: TheBloke/Llama-2-13B-fp16
models:
- model: TheBloke/Llama-2-13B-fp16
- model: KoboldAI/LLaMA2-13B-Tiefighter
parameters:
weight: 1.0
- model: Doctor-Shotgun/cat-v1.0-13b
parameters:
weight: 0.01
- model: Doctor-Shotgun/llama-2-13b-chat-limarp-v2-merged
parameters:
weight: 0.02
dtype: float16
```
*V1 of this model was published under the account of the creator of the merge
This model contains the following ingredients from their upstream models for as far as we can track them:
- KoboldAI/LLaMA2-13B-Tiefighter
- Undi95/Xwin-MLewd-13B-V0.2
- - Undi95/ReMM-S-Light
- Undi95/CreativeEngine
- Brouz/Slerpeno
- - elinas/chronos-13b-v2
- jondurbin/airoboros-l2-13b-2.1
- NousResearch/Nous-Hermes-Llama2-13b+nRuaif/Kimiko-v2
- CalderaAI/13B-Legerdemain-L2+lemonilia/limarp-llama2-v2
- - KoboldAI/LLAMA2-13B-Holodeck-1
- NousResearch/Nous-Hermes-13b
- OpenAssistant/llama2-13b-orca-8k-3319
- ehartford/WizardLM-1.0-Uncensored-Llama2-13b
- Henk717/spring-dragon
- The-Face-Of-Goonery/Huginn-v3-13b (Contains undisclosed model versions, those we assumed where possible)
- - SuperCOT (Undisclosed version)
- elinas/chronos-13b-v2 (Version assumed)
- NousResearch/Nous-Hermes-Llama2-13b
- stabilityai/StableBeluga-13B (Version assumed)
- zattio770/120-Days-of-LORA-v2-13B
- PygmalionAI/pygmalion-2-13b
- Undi95/Storytelling-v1-13B-lora
- TokenBender/sakhi_13B_roleplayer_NSFW_chat_adapter
- nRuaif/Kimiko-v2-13B
- The-Face-Of-Goonery/Huginn-13b-FP16
- - "a lot of different models, like hermes, beluga, airoboros, chronos.. limarp"
- lemonilia/LimaRP-Llama2-13B-v3-EXPERIMENT
- Xwin-LM/Xwin-LM-13B-V0.2
- PocketDoc/Dans-RetroRodeo-13b
- Blackroot/Llama-2-13B-Storywriter-LORA
- Doctor-Shotgun/cat-v1.0-13b
- Doctor-Shotgun/llama-2-13b-chat-limarp-v2-merged
- meta-llama/Llama-2-13b-chat-hf
- lemonilia/limarp-llama2-v2
While we could possibly not credit every single lora or model involved in this merged model, we'd like to thank all involved creators upstream for making this awesome model possible!
Thanks to you the AI ecosystem is thriving, and without your dedicated tuning efforts models such as this one would not be possible.
# Usage
This model is meant to be creative, If you let it improvise you get better results than if you drown it in details.
## Story Writing
Regular story writing in the traditional way is supported, simply copy paste your story and continue writing. Optionally use an instruction in memory or an authors note to guide the direction of your story.
### Generate a story on demand
To generate stories on demand you can use an instruction (tested in the Alpaca format) such as "Write a novel about X, use chapters and dialogue" this will generate a story. The format can vary between generations depending on how the model chooses to begin, either write what you want as shown in the earlier example or write the beginning of the story yourself so the model can follow your style. A few retries can also help if the model gets it wrong.
## Chatbots and persona's
This model has been tested with various forms of chatting, testers have found that typically less is more and the model is good at improvising. Don't drown the model in paragraphs of detailed information, instead keep it simple first and see how far you can lean on the models own ability to figure out your character. Copy pasting paragraphs of background information is not suitable for a 13B model such as this one, code formatted characters or an instruction prompt describing who you wish to talk to goes much further.
For example, you can put this in memory in regular chat mode:
```
### Instruction:
Generate a conversation between Alice and Jeb where they discuss language models.
In this conversation Henk is excited to teach Alice about Psyfighter.
### Response:
```
Because the model is a merge of a variety of models, it should support a broad range of instruct formats, or plain chat mode. If you have a particular favourite try it, otherwise we recommend to either use the regular chat mode or Alpaca's format.
## Instruct Prompting
This model features various instruct models on a variety of instruction styles, when testing the model we have used Alpaca for our own tests. If you prefer a different format chances are it can work.
During instructions we have observed that in some cases the adventure data can leak, it may also be worth experimenting using > as the prefix for a user command to remedy this. But this may result in a stronger fiction bias.
Keep in mind that while this model can be used as a factual instruct model, the focus was on fiction. Information provided by the model can be made up.
## Adventuring and Adventure Games
This model contains a lora that was trained on the same adventure dataset as the KoboldAI Skein model. Adventuring is best done using an small introduction to the world and your objective while using the > prefix for a user command (KoboldAI's adventure mode).
It is possible that the model does not immediately pick up on what you wish to do and does not engage in its Adventure mode behaviour right away. Simply manually correct the output to trim excess dialogue or other undesirable behaviour and continue to submit your actions using the appropriate mode. The model should pick up on this style quickly and will correctly follow this format within 3 turns.
## Discovered something cool and want to engage with us?
Join our community at https://koboldai.org/discord !
We can also provide assistance in making your own merges.
|
[
"MEDICAL DATA"
] |
RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-08-20T02:10:14Z |
2024-08-20T03:47:32+00:00
| 46 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Kocdigital-LLM-8b-v0.1 - GGUF
- Model creator: https://huggingface.co/KOCDIGITAL/
- Original model: https://huggingface.co/KOCDIGITAL/Kocdigital-LLM-8b-v0.1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Kocdigital-LLM-8b-v0.1.Q2_K.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q2_K.gguf) | Q2_K | 2.96GB |
| [Kocdigital-LLM-8b-v0.1.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Kocdigital-LLM-8b-v0.1.IQ3_S.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Kocdigital-LLM-8b-v0.1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Kocdigital-LLM-8b-v0.1.IQ3_M.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Kocdigital-LLM-8b-v0.1.Q3_K.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q3_K.gguf) | Q3_K | 3.74GB |
| [Kocdigital-LLM-8b-v0.1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Kocdigital-LLM-8b-v0.1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Kocdigital-LLM-8b-v0.1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Kocdigital-LLM-8b-v0.1.Q4_0.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Kocdigital-LLM-8b-v0.1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Kocdigital-LLM-8b-v0.1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Kocdigital-LLM-8b-v0.1.Q4_K.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q4_K.gguf) | Q4_K | 4.58GB |
| [Kocdigital-LLM-8b-v0.1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Kocdigital-LLM-8b-v0.1.Q4_1.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Kocdigital-LLM-8b-v0.1.Q5_0.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Kocdigital-LLM-8b-v0.1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Kocdigital-LLM-8b-v0.1.Q5_K.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q5_K.gguf) | Q5_K | 5.34GB |
| [Kocdigital-LLM-8b-v0.1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Kocdigital-LLM-8b-v0.1.Q5_1.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Kocdigital-LLM-8b-v0.1.Q6_K.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q6_K.gguf) | Q6_K | 6.14GB |
| [Kocdigital-LLM-8b-v0.1.Q8_0.gguf](https://huggingface.co/RichardErkhov/KOCDIGITAL_-_Kocdigital-LLM-8b-v0.1-gguf/blob/main/Kocdigital-LLM-8b-v0.1.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
license: llama3
language:
- tr
model-index:
- name: Kocdigital-LLM-8b-v0.1
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge TR
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc
value: 44.03
name: accuracy
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag TR
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc
value: 46.73
name: accuracy
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU TR
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 49.11
name: accuracy
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA TR
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: acc
name: accuracy
value: 48.21
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande TR
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 10
metrics:
- type: acc
value: 54.98
name: accuracy
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k TR
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 51.78
name: accuracy
---
<img src="https://huggingface.co/KOCDIGITAL/Kocdigital-LLM-8b-v0.1/resolve/main/icon.jpeg"
alt="KOCDIGITAL LLM" width="420"/>
# Kocdigital-LLM-8b-v0.1
This model is an fine-tuned version of a Llama3 8b Large Language Model (LLM) for Turkish. It was trained on a high quality Turkish instruction sets created from various open-source and internal resources. Turkish Instruction dataset carefully annotated to carry out Turkish instructions in an accurate and organized manner. The training process involved using the QLORA method.
## Model Details
- **Base Model**: Llama3 8B based LLM
- **Training Dataset**: High Quality Turkish instruction sets
- **Training Method**: SFT with QLORA
### QLORA Fine-Tuning Configuration
- `lora_alpha`: 128
- `lora_dropout`: 0
- `r`: 64
- `target_modules`: "q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
- `bias`: "none"
## Usage Examples
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"KOCDIGITAL/Kocdigital-LLM-8b-v0.1",
max_seq_length=4096)
model = AutoModelForCausalLM.from_pretrained(
"KOCDIGITAL/Kocdigital-LLM-8b-v0.1",
load_in_4bit=True,
)
system = 'Sen Türkçe konuşan genel amaçlı bir asistansın. Her zaman kullanıcının verdiği talimatları doğru, kısa ve güzel bir gramer ile yerine getir.'
template = "{}\n\n###Talimat\n{}\n###Yanıt\n"
content = template.format(system, 'Türkiyenin 3 büyük ilini listeler misin.')
conv = []
conv.append({'role': 'user', 'content': content})
inputs = tokenizer.apply_chat_template(conv,
tokenize=False,
add_generation_prompt=True,
return_tensors="pt")
print(inputs)
inputs = tokenizer([inputs],
return_tensors = "pt",
add_special_tokens=False).to("cuda")
outputs = model.generate(**inputs,
max_new_tokens = 512,
use_cache = True,
do_sample = True,
top_k = 50,
top_p = 0.60,
temperature = 0.3,
repetition_penalty=1.1)
out_text = tokenizer.batch_decode(outputs)[0]
print(out_text)
```
# [Open LLM Turkish Leaderboard v0.2 Evaluation Results]
| Metric | Value |
|---------------------------------|------:|
| Avg. | 49.11 |
| AI2 Reasoning Challenge_tr-v0.2 | 44.03 |
| HellaSwag_tr-v0.2 | 46.73 |
| MMLU_tr-v0.2 | 49.11 |
| TruthfulQA_tr-v0.2 | 48.51 |
| Winogrande _tr-v0.2 | 54.98 |
| GSM8k_tr-v0.2 | 51.78 |
## Considerations on Limitations, Risks, Bias, and Ethical Factors
### Limitations and Recognized Biases
- **Core Functionality and Usage:** KocDigital LLM, functioning as an autoregressive language model, is primarily purposed for predicting the subsequent token within a text sequence. Although commonly applied across different contexts, it's crucial to acknowledge that comprehensive real-world testing has not been conducted. Therefore, its efficacy and consistency in diverse situations are largely unvalidated.
- **Language Understanding and Generation:** The model's training is mainly focused on standard English and Turkish. Its proficiency in grasping and generating slang, colloquial language, or different languages might be restricted, possibly resulting in errors or misinterpretations.
- **Production of Misleading Information:** Users should acknowledge that KocDigital LLM might generate incorrect or deceptive information. Results should be viewed as initial prompts or recommendations rather than absolute conclusions.
### Ethical Concerns and Potential Risks
- **Risk of Misuse:** KocDigital LLM carries the potential for generating language that could be offensive or harmful. We strongly advise against its utilization for such purposes and stress the importance of conducting thorough safety and fairness assessments tailored to specific applications before implementation.
- **Unintended Biases and Content:** The model underwent training on a vast corpus of text data without explicit vetting for offensive material or inherent biases. Consequently, it may inadvertently generate content reflecting these biases or inaccuracies.
- **Toxicity:** Despite efforts to curate appropriate training data, the model has the capacity to produce harmful content, particularly when prompted explicitly. We encourage active participation from the open-source community to devise strategies aimed at mitigating such risks.
### Guidelines for Secure and Ethical Utilization
- **Human Oversight:** We advocate for the integration of a human oversight mechanism or the utilization of filters to oversee and enhance the quality of outputs, particularly in applications accessible to the public. This strategy can assist in minimizing the likelihood of unexpectedly generating objectionable content.
- **Tailored Testing for Specific Applications:** Developers planning to utilize KocDigital LLM should execute comprehensive safety assessments and optimizations customized to their unique applications. This step is essential as the model's responses may exhibit unpredictability and occasional biases, inaccuracies, or offensive outputs.
- **Responsible Development and Deployment:** Developers and users of KocDigital LLM bear the responsibility for ensuring its ethical and secure application. We encourage users to be cognizant of the model's limitations and to implement appropriate measures to prevent misuse or adverse outcomes.
|
[
"BEAR"
] |
RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf
|
RichardErkhov
| null |
[
"gguf",
"region:us"
] | 2024-09-01T00:10:14Z |
2024-09-01T05:39:11+00:00
| 46 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Mediquad-4x7b - GGUF
- Model creator: https://huggingface.co/Technoculture/
- Original model: https://huggingface.co/Technoculture/Mediquad-4x7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Mediquad-4x7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q2_K.gguf) | Q2_K | 6.74GB |
| [Mediquad-4x7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.IQ3_XS.gguf) | IQ3_XS | 3.74GB |
| [Mediquad-4x7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.IQ3_S.gguf) | IQ3_S | 2.3GB |
| [Mediquad-4x7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q3_K_S.gguf) | Q3_K_S | 7.37GB |
| [Mediquad-4x7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.IQ3_M.gguf) | IQ3_M | 5.37GB |
| [Mediquad-4x7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q3_K.gguf) | Q3_K | 8.84GB |
| [Mediquad-4x7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q3_K_M.gguf) | Q3_K_M | 8.84GB |
| [Mediquad-4x7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q3_K_L.gguf) | Q3_K_L | 7.28GB |
| [Mediquad-4x7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.IQ4_XS.gguf) | IQ4_XS | 9.9GB |
| [Mediquad-4x7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q4_0.gguf) | Q4_0 | 10.37GB |
| [Mediquad-4x7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.IQ4_NL.gguf) | IQ4_NL | 2.68GB |
| [Mediquad-4x7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q4_K_S.gguf) | Q4_K_S | 1.63GB |
| [Mediquad-4x7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q4_K.gguf) | Q4_K | 11.13GB |
| [Mediquad-4x7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q4_K_M.gguf) | Q4_K_M | 11.13GB |
| [Mediquad-4x7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q4_1.gguf) | Q4_1 | 11.51GB |
| [Mediquad-4x7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q5_0.gguf) | Q5_0 | 12.65GB |
| [Mediquad-4x7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q5_K_S.gguf) | Q5_K_S | 12.65GB |
| [Mediquad-4x7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q5_K.gguf) | Q5_K | 13.04GB |
| [Mediquad-4x7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q5_K_M.gguf) | Q5_K_M | 13.04GB |
| [Mediquad-4x7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q5_1.gguf) | Q5_1 | 13.79GB |
| [Mediquad-4x7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q6_K.gguf) | Q6_K | 15.07GB |
| [Mediquad-4x7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Mediquad-4x7b-gguf/blob/main/Mediquad-4x7b.Q8_0.gguf) | Q8_0 | 19.52GB |
Original model description:
---
license: apache-2.0
tags:
- moe
- merge
- epfl-llm/meditron-7b
- chaoyi-wu/PMC_LLAMA_7B_10_epoch
- allenai/tulu-2-dpo-7b
- microsoft/Orca-2-7b
---
# Mediquad-20B
Mediquad-20B is a Mixure of Experts (MoE) made with the following models:
* [epfl-llm/meditron-7b](https://huggingface.co/epfl-llm/meditron-7b)
* [chaoyi-wu/PMC_LLAMA_7B_10_epoch](https://huggingface.co/chaoyi-wu/PMC_LLAMA_7B_10_epoch)
* [allenai/tulu-2-dpo-7b](https://huggingface.co/allenai/tulu-2-dpo-7b)
* [microsoft/Orca-2-7b](https://huggingface.co/microsoft/Orca-2-7b)
## Evaluations
| Benchmark | Mediquad-4x7b | meditron-7b | Orca-2-7b | meditron-70b |
| --- | --- | --- | --- | --- |
| MedMCQA | | | | |
| ClosedPubMedQA | | | | |
| PubMedQA | | | | |
| MedQA | | | | |
| MedQA4 | | | | |
| MedicationQA | | | | |
| MMLU Medical | | | | |
| TruthfulQA | | | | |
| GSM8K | | | | |
| ARC | | | | |
| HellaSwag | | | | |
| Winogrande | | | | |
## 🧩 Configuration
```yamlbase_model: allenai/tulu-2-dpo-7b
gate_mode: hidden
dtype: bfloat16
experts:
- source_model: epfl-llm/meditron-7b
positive_prompts:
- "How does sleep affect cardiovascular health?"
- "When discussing diabetes management, the key factors to consider are"
- "The differential diagnosis for a headache with visual aura could include"
negative_prompts:
- "What are the environmental impacts of deforestation?"
- "The recent advancements in artificial intelligence have led to developments in"
- source_model: chaoyi-wu/PMC_LLAMA_7B_10_epoch
positive_prompts:
- "How would you explain the importance of hypertension management to a patient?"
- "Describe the recovery process after knee replacement surgery in layman's terms."
negative_prompts:
- "Recommend a good recipe for a vegetarian lasagna."
- "The recent advancements in artificial intelligence have led to developments in"
- "The fundamental concepts in economics include ideas like supply and demand, which explain"
- source_model: allenai/tulu-2-dpo-7b
positive_prompts:
- "Here is a funny joke for you -"
- "When considering the ethical implications of artificial intelligence, one must take into account"
- "In strategic planning, a company must analyze its strengths and weaknesses, which involves"
- "Understanding consumer behavior in marketing requires considering factors like"
- "The debate on climate change solutions hinges on arguments that"
negative_prompts:
- "In discussing dietary adjustments for managing hypertension, it's crucial to emphasize"
- "For early detection of melanoma, dermatologists recommend that patients regularly check their skin for"
- "Explaining the importance of vaccination, a healthcare professional should highlight"
- source_model: microsoft/Orca-2-7b
positive_prompts:
- "Given the riddle above,"
- "Given the above context deduce the outcome:"
- "The logical flaw in the above paragraph is"
negative_prompts:
- "In discussing dietary adjustments for managing hypertension, it's crucial to emphasize"
- "For early detection of melanoma, dermatologists recommend that patients regularly check their skin for"
- "Explaining the importance of vaccination, a healthcare professional should highlight"
```
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Technoculture/Mediquad-20B"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
[
"MEDQA",
"PUBMEDQA"
] |
RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | 2024-09-01T00:38:06Z |
2024-09-01T06:40:51+00:00
| 46 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Medtulu-4x7B - GGUF
- Model creator: https://huggingface.co/Technoculture/
- Original model: https://huggingface.co/Technoculture/Medtulu-4x7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Medtulu-4x7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q2_K.gguf) | Q2_K | 6.39GB |
| [Medtulu-4x7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.IQ3_XS.gguf) | IQ3_XS | 2.28GB |
| [Medtulu-4x7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.IQ3_S.gguf) | IQ3_S | 7.94GB |
| [Medtulu-4x7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q3_K_S.gguf) | Q3_K_S | 7.94GB |
| [Medtulu-4x7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.IQ3_M.gguf) | IQ3_M | 8.17GB |
| [Medtulu-4x7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q3_K.gguf) | Q3_K | 8.84GB |
| [Medtulu-4x7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q3_K_M.gguf) | Q3_K_M | 8.84GB |
| [Medtulu-4x7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q3_K_L.gguf) | Q3_K_L | 9.59GB |
| [Medtulu-4x7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.IQ4_XS.gguf) | IQ4_XS | 1.38GB |
| [Medtulu-4x7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q4_0.gguf) | Q4_0 | 10.37GB |
| [Medtulu-4x7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.IQ4_NL.gguf) | IQ4_NL | 10.45GB |
| [Medtulu-4x7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q4_K_S.gguf) | Q4_K_S | 10.46GB |
| [Medtulu-4x7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q4_K.gguf) | Q4_K | 11.13GB |
| [Medtulu-4x7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q4_K_M.gguf) | Q4_K_M | 11.13GB |
| [Medtulu-4x7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q4_1.gguf) | Q4_1 | 11.51GB |
| [Medtulu-4x7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q5_0.gguf) | Q5_0 | 12.65GB |
| [Medtulu-4x7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q5_K_S.gguf) | Q5_K_S | 12.65GB |
| [Medtulu-4x7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q5_K.gguf) | Q5_K | 13.04GB |
| [Medtulu-4x7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q5_K_M.gguf) | Q5_K_M | 13.04GB |
| [Medtulu-4x7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q5_1.gguf) | Q5_1 | 13.79GB |
| [Medtulu-4x7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q6_K.gguf) | Q6_K | 15.07GB |
| [Medtulu-4x7B.Q8_0.gguf](https://huggingface.co/RichardErkhov/Technoculture_-_Medtulu-4x7B-gguf/blob/main/Medtulu-4x7B.Q8_0.gguf) | Q8_0 | 19.52GB |
Original model description:
---
license: apache-2.0
tags:
- moe
- merge
- epfl-llm/meditron-7b
- medalpaca/medalpaca-7b
- chaoyi-wu/PMC_LLAMA_7B_10_epoch
- allenai/tulu-2-dpo-7b
---
# Mediquad-tulu-20B
Mediquad-tulu-20B is a Mixure of Experts (MoE) made with the following models:
* [epfl-llm/meditron-7b](https://huggingface.co/epfl-llm/meditron-7b)
* [medalpaca/medalpaca-7b](https://huggingface.co/medalpaca/medalpaca-7b)
* [chaoyi-wu/PMC_LLAMA_7B_10_epoch](https://huggingface.co/chaoyi-wu/PMC_LLAMA_7B_10_epoch)
* [allenai/tulu-2-dpo-7b](https://huggingface.co/allenai/tulu-2-dpo-7b)
## Evaluations
| Benchmark | Mediquad-tulu-20B | meditron-7b | Orca-2-7b | meditron-70b |
| --- | --- | --- | --- | --- |
| MedMCQA | | | | |
| ClosedPubMedQA | | | | |
| PubMedQA | | | | |
| MedQA | | | | |
| MedQA4 | | | | |
| MedicationQA | | | | |
| MMLU Medical | | | | |
| TruthfulQA | | | | |
| GSM8K | | | | |
| ARC | | | | |
| HellaSwag | | | | |
| Winogrande | | | | |
## 🧩 Configuration
```yamlbase_model: allenai/tulu-2-dpo-7b
gate_mode: hidden
dtype: bfloat16
experts:
- source_model: epfl-llm/meditron-7b
positive_prompts:
- "What are the latest guidelines for managing type 2 diabetes?"
- "Best practices for post-operative care in cardiac surgery are"
negative_prompts:
- "What are the environmental impacts of deforestation?"
- "The recent advancements in artificial intelligence have led to developments in"
- source_model: medalpaca/medalpaca-7b
positive_prompts:
- "When discussing diabetes management, the key factors to consider are"
- "The differential diagnosis for a headache with visual aura could include"
negative_prompts:
- "Recommend a good recipe for a vegetarian lasagna."
- "The fundamental concepts in economics include ideas like supply and demand, which explain"
- source_model: chaoyi-wu/PMC_LLAMA_7B_10_epoch
positive_prompts:
- "How would you explain the importance of hypertension management to a patient?"
- "Describe the recovery process after knee replacement surgery in layman's terms."
negative_prompts:
- "Recommend a good recipe for a vegetarian lasagna."
- "The recent advancements in artificial intelligence have led to developments in"
- "The fundamental concepts in economics include ideas like supply and demand, which explain"
- source_model: allenai/tulu-2-dpo-7b
positive_prompts:
- "Here is a funny joke for you -"
- "When considering the ethical implications of artificial intelligence, one must take into account"
- "In strategic planning, a company must analyze its strengths and weaknesses, which involves"
- "Understanding consumer behavior in marketing requires considering factors like"
- "The debate on climate change solutions hinges on arguments that"
negative_prompts:
- "In discussing dietary adjustments for managing hypertension, it's crucial to emphasize"
- "For early detection of melanoma, dermatologists recommend that patients regularly check their skin for"
- "Explaining the importance of vaccination, a healthcare professional should highlight"
```
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Technoculture/Mediquad-tulu-20B"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
[
"MEDQA",
"PUBMEDQA"
] |
RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2407.08488",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-09-07T09:23:59Z |
2024-09-08T06:26:46+00:00
| 46 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-Patronus-Lynx-70B-Instruct - GGUF
- Model creator: https://huggingface.co/PatronusAI/
- Original model: https://huggingface.co/PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q2_K.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.Q2_K.gguf) | Q2_K | 24.56GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.IQ3_XS.gguf) | IQ3_XS | 27.29GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.IQ3_S.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.IQ3_S.gguf) | IQ3_S | 28.79GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.Q3_K_S.gguf) | Q3_K_S | 28.79GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.IQ3_M.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.IQ3_M.gguf) | IQ3_M | 29.74GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q3_K.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.Q3_K.gguf) | Q3_K | 31.91GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.Q3_K_M.gguf) | Q3_K_M | 31.91GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.Q3_K_L.gguf) | Q3_K_L | 34.59GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.IQ4_XS.gguf) | IQ4_XS | 35.64GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q4_0.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/blob/main/Llama-3-Patronus-Lynx-70B-Instruct.Q4_0.gguf) | Q4_0 | 37.22GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | IQ4_NL | 37.58GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q4_K_S | 37.58GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q4_K.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q4_K | 39.6GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q4_K_M | 39.6GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q4_1.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q4_1 | 41.27GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q5_0.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q5_0 | 45.32GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q5_K_S | 45.32GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q5_K.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q5_K | 46.52GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q5_K_M | 46.52GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q5_1.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q5_1 | 49.36GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q6_K.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q6_K | 53.91GB |
| [Llama-3-Patronus-Lynx-70B-Instruct.Q8_0.gguf](https://huggingface.co/RichardErkhov/PatronusAI_-_Llama-3-Patronus-Lynx-70B-Instruct-gguf/tree/main/) | Q8_0 | 69.83GB |
Original model description:
---
library_name: transformers
tags:
- text-generation
- pytorch
- Lynx
- Patronus AI
- evaluation
- hallucination-detection
license: cc-by-nc-4.0
language:
- en
---
# Model Card for Model ID
Lynx is an open-source hallucination evaluation model. Patronus-Lynx-70B-Instruct was trained on a mix of datasets including CovidQA, PubmedQA, DROP, RAGTruth.
The datasets contain a mix of hand-annotated and synthetic data. The maximum sequence length is 8000 tokens.
## Model Details
- **Model Type:** Patronus-Lynx-70B-Instruct is a fine-tuned version of meta-llama/Meta-Llama-3-70B-Instruct model.
- **Language:** Primarily English
- **Developed by:** Patronus AI
- **Paper:** [https://arxiv.org/abs/2407.08488](https://arxiv.org/abs/2407.08488)
- **License:** [ https://creativecommons.org/licenses/by-nc/4.0/](https://creativecommons.org/licenses/by-nc/4.0/)
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [https://github.com/patronus-ai/Lynx-hallucination-detection](https://github.com/patronus-ai/Lynx-hallucination-detection)
## How to Get Started with the Model
The model is fine-tuned to be used to detect hallucinations in a RAG setting. Provided a document, question and answer, the model can evaluate whether the answer is faithful to the document.
To use the model, we recommend using the prompt we used for fine-tuning:
```
PROMPT = """
Given the following QUESTION, DOCUMENT and ANSWER you must analyze the provided answer and determine whether it is faithful to the contents of the DOCUMENT. The ANSWER must not offer new information beyond the context provided in the DOCUMENT. The ANSWER also must not contradict information provided in the DOCUMENT. Output your final verdict by strictly following this format: "PASS" if the answer is faithful to the DOCUMENT and "FAIL" if the answer is not faithful to the DOCUMENT. Show your reasoning.
--
QUESTION (THIS DOES NOT COUNT AS BACKGROUND INFORMATION):
{question}
--
DOCUMENT:
{context}
--
ANSWER:
{answer}
--
Your output should be in JSON FORMAT with the keys "REASONING" and "SCORE":
{{"REASONING": <your reasoning as bullet points>, "SCORE": <your final score>}}
"""
```
The model will output the score as "PASS" if the answer is faithful to the document or "FAIL" if the answer is not faithful to the document.
## Inference
To run inference, you can use HF pipeline:
```
model_name = 'PatronusAI/Llama-3-Patronus-Lynx-8B-Instruct'
pipe = pipeline(
"text-generation",
model=model_name,
max_new_tokens=600,
device="cuda",
return_full_text=False
)
messages = [
{"role": "user", "content": prompt},
]
result = pipe(messages)
print(result[0]['generated_text'])
```
Since the model is trained in chat format, ensure that you pass the prompt as a user message.
For more information on training details, refer to our [ArXiv paper](https://arxiv.org/abs/2407.08488).
## Evaluation
The model was evaluated on [PatronusAI/HaluBench](https://huggingface.co/datasets/PatronusAI/HaluBench).
It outperforms GPT-3.5-Turbo, GPT-4-Turbo, GPT-4o and Claude-3-Sonnet on HaluEval.
| Model | HaluEval | RAGTruth | FinanceBench | DROP | CovidQA | PubmedQA | Overall
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| GPT-4o | 87.9% | 84.3% | **85.3%** | 84.3% | 95.0% | 82.1% | 86.5% |
| GPT-4-Turbo | 86.0% | **85.0%** | 82.2% | 84.8% | 90.6% | 83.5% | 85.0% |
| GPT-3.5-Turbo | 62.2% | 50.7% | 60.9% | 57.2% | 56.7% | 62.8% | 58.7% |
| Claude-3-Sonnet | 84.5% | 79.1% | 69.7% | 84.3% | 95.0% | 82.9% | 78.8% |
| Claude-3-Haiku | 68.9% | 78.9% | 58.4% | 84.3% | 95.0% | 82.9% | 69.0% |
| RAGAS Faithfulness | 70.6% | 75.8% | 59.5% | 59.6% | 75.0% | 67.7% | 66.9% |
| Mistral-Instruct-7B | 78.3% | 77.7% | 56.3% | 56.3% | 71.7% | 77.9% | 69.4% |
| Llama-3-Instruct-8B | 83.1% | 80.0% | 55.0% | 58.2% | 75.2% | 70.7% | 70.4% |
| Llama-3-Instruct-70B | 87.0% | 83.8% | 72.7% | 69.4% | 85.0% | 82.6% | 80.1% |
| LYNX (8B) | 85.7% | 80.0% | 72.5% | 77.8% | 96.3% | 85.2% | 82.9% |
| LYNX (70B) | **88.4%** | 80.2% | 81.4% | **86.4%** | **97.5%** | **90.4%** | **87.4%** |
## Citation
If you are using the model, cite using
```
@article{ravi2024lynx,
title={Lynx: An Open Source Hallucination Evaluation Model},
author={Ravi, Selvan Sunitha and Mielczarek, Bartosz and Kannappan, Anand and Kiela, Douwe and Qian, Rebecca},
journal={arXiv preprint arXiv:2407.08488},
year={2024}
}
```
## Model Card Contact
[@sunitha-ravi](https://huggingface.co/sunitha-ravi)
[@RebeccaQian1](https://huggingface.co/RebeccaQian1)
[@presidev](https://huggingface.co/presidev)
|
[
"PUBMEDQA"
] |
RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-07T08:45:07Z |
2024-10-07T12:37:50+00:00
| 46 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
medllama3-v20 - GGUF
- Model creator: https://huggingface.co/ProbeMedicalYonseiMAILab/
- Original model: https://huggingface.co/ProbeMedicalYonseiMAILab/medllama3-v20/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [medllama3-v20.Q2_K.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q2_K.gguf) | Q2_K | 2.96GB |
| [medllama3-v20.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [medllama3-v20.IQ3_S.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [medllama3-v20.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [medllama3-v20.IQ3_M.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [medllama3-v20.Q3_K.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q3_K.gguf) | Q3_K | 3.74GB |
| [medllama3-v20.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [medllama3-v20.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [medllama3-v20.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [medllama3-v20.Q4_0.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q4_0.gguf) | Q4_0 | 4.34GB |
| [medllama3-v20.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [medllama3-v20.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [medllama3-v20.Q4_K.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q4_K.gguf) | Q4_K | 4.58GB |
| [medllama3-v20.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [medllama3-v20.Q4_1.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q4_1.gguf) | Q4_1 | 4.78GB |
| [medllama3-v20.Q5_0.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q5_0.gguf) | Q5_0 | 5.21GB |
| [medllama3-v20.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [medllama3-v20.Q5_K.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q5_K.gguf) | Q5_K | 5.34GB |
| [medllama3-v20.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [medllama3-v20.Q5_1.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q5_1.gguf) | Q5_1 | 5.65GB |
| [medllama3-v20.Q6_K.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q6_K.gguf) | Q6_K | 6.14GB |
| [medllama3-v20.Q8_0.gguf](https://huggingface.co/RichardErkhov/ProbeMedicalYonseiMAILab_-_medllama3-v20-gguf/blob/main/medllama3-v20.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
license: llama3
---
The model is a fine-tuned large language model on using publically available medical data.
## Model Description
- **Developed by:** Probe Medical, MAILAB from Yonsei University
- **Model type:** LLM
- **Language(s) (NLP):** English
## Training Hyperparameters
- **Lora Targets:** "o_proj", "down_proj", "v_proj", "gate_proj", "up_proj", "k_proj", "q_proj"
|
[
"MEDICAL DATA"
] |
adipanda/bakugo-standard-lora-1
|
adipanda
|
text-to-image
|
[
"diffusers",
"flux",
"flux-diffusers",
"text-to-image",
"simpletuner",
"safe-for-work",
"lora",
"template:sd-lora",
"standard",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | 2024-12-07T21:33:46Z |
2024-12-10T20:21:03+00:00
| 46 | 0 |
---
base_model: black-forest-labs/FLUX.1-dev
license: other
tags:
- flux
- flux-diffusers
- text-to-image
- diffusers
- simpletuner
- safe-for-work
- lora
- template:sd-lora
- standard
inference: true
widget:
- text: unconditional (blank prompt)
parameters:
negative_prompt: blurry, cropped, ugly
output:
url: ./assets/image_0_0.png
- text: A scene from My Hero Academia. Katsuki Bakugo holding a sign that says 'I
LOVE PROMPTS!', he is standing full body on a beach at sunset. He is wearing his
black and orange hero costume with grenade-like gauntlets on his arms. The setting
sun casts a dynamic shadow on his determined expression.
parameters:
negative_prompt: blurry, cropped, ugly
output:
url: ./assets/image_1_0.png
- text: A scene from My Hero Academia. Katsuki Bakugo jumping out of a propeller airplane,
sky diving. He looks intense and exhilarated, his spiky blonde hair blowing in
the wind. The sky is clear and blue, with birds flying in the distance.
parameters:
negative_prompt: blurry, cropped, ugly
output:
url: ./assets/image_2_0.png
- text: 'A scene from My Hero Academia. Katsuki Bakugo spinning a basketball on his
finger on a basketball court. He is wearing a Lakers jersey with the #12 on it.
The basketball hoop and crowd are in the background cheering him. He is smirking
confidently.'
parameters:
negative_prompt: blurry, cropped, ugly
output:
url: ./assets/image_3_0.png
- text: A scene from My Hero Academia. Katsuki Bakugo is wearing a suit in an office
shaking the hand of a businesswoman. The woman has purple hair and is wearing
professional attire. There is a Google logo in the background. It is during daytime,
and the overall sentiment is one of fiery determination and success.
parameters:
negative_prompt: blurry, cropped, ugly
output:
url: ./assets/image_4_0.png
- text: A scene from My Hero Academia. Katsuki Bakugo is fighting a large brown grizzly
bear, deep in a forest. The bear is tall and standing on two legs, roaring. The
bear is also wearing a crown because it is the king of all bears. Around them
are tall trees and other animals watching as Bakugo prepares to unleash an explosion.
parameters:
negative_prompt: blurry, cropped, ugly
output:
url: ./assets/image_5_0.png
---
# bakugo-standard-lora-1
This is a standard PEFT LoRA derived from [black-forest-labs/FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev).
No validation prompt was used during training.
None
## Validation settings
- CFG: `3.5`
- CFG Rescale: `0.0`
- Steps: `20`
- Sampler: `FlowMatchEulerDiscreteScheduler`
- Seed: `42`
- Resolution: `1024x1024`
- Skip-layer guidance:
Note: The validation settings are not necessarily the same as the [training settings](#training-settings).
You can find some example images in the following gallery:
<Gallery />
The text encoder **was not** trained.
You may reuse the base model text encoder for inference.
## Training settings
- Training epochs: 166
- Training steps: 3000
- Learning rate: 0.0001
- Learning rate schedule: constant
- Warmup steps: 100
- Max grad norm: 2.0
- Effective batch size: 48
- Micro-batch size: 48
- Gradient accumulation steps: 1
- Number of GPUs: 1
- Gradient checkpointing: True
- Prediction type: flow-matching (extra parameters=['shift=3', 'flux_guidance_mode=constant', 'flux_guidance_value=1.0', 'flow_matching_loss=compatible', 'flux_lora_target=all'])
- Optimizer: adamw_bf16
- Trainable parameter precision: Pure BF16
- Caption dropout probability: 0.0%
- LoRA Rank: 128
- LoRA Alpha: None
- LoRA Dropout: 0.1
- LoRA initialisation style: default
## Datasets
### bakugo-512
- Repeats: 2
- Total number of images: 279
- Total number of aspect buckets: 1
- Resolution: 0.262144 megapixels
- Cropped: False
- Crop style: None
- Crop aspect: None
- Used for regularisation data: No
## Inference
```python
import torch
from diffusers import DiffusionPipeline
model_id = 'black-forest-labs/FLUX.1-dev'
adapter_id = 'adipanda/bakugo-standard-lora-1'
pipeline = DiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.bfloat16) # loading directly in bf16
pipeline.load_lora_weights(adapter_id)
prompt = "An astronaut is riding a horse through the jungles of Thailand."
## Optional: quantise the model to save on vram.
## Note: The model was quantised during training, and so it is recommended to do the same during inference time.
from optimum.quanto import quantize, freeze, qint8
quantize(pipeline.transformer, weights=qint8)
freeze(pipeline.transformer)
pipeline.to('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu') # the pipeline is already in its target precision level
image = pipeline(
prompt=prompt,
num_inference_steps=20,
generator=torch.Generator(device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu').manual_seed(42),
width=1024,
height=1024,
guidance_scale=3.5,
).images[0]
image.save("output.png", format="PNG")
```
|
[
"BEAR"
] |
addy88/gptj8
|
addy88
|
text-generation
|
[
"transformers",
"pytorch",
"gptj",
"text-generation",
"arxiv:2106.09685",
"arxiv:2110.02861",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2022-03-02T23:29:05Z |
2022-01-02T06:33:57+00:00
| 45 | 1 |
---
{}
---
This Model is 8bit Version of EleutherAI/gpt-j-6B. It is converted by Facebook's bitsandbytes library. The original GPT-J takes 22+ GB memory for float32 parameters alone, and that's before you account for gradients & optimizer. So for finetuning on single GPU This model is converted into 8bit.
Here's how to run it: [](https://colab.research.google.com/drive/1KNf5siQdM7ILQM-pHsP6gNVPKl1SJdU1)
__The [original GPT-J](https://huggingface.co/EleutherAI/gpt-j-6B/tree/main)__ takes 22+ GB memory for float32 parameters alone, and that's before you account for gradients & optimizer. Even if you cast everything to 16-bit, it will still not fit onto most single-GPU setups short of A6000 and A100. You can inference it [on TPU](https://colab.research.google.com/github/kingoflolz/mesh-transformer-jax/blob/master/colab_demo.ipynb) or CPUs, but fine-tuning is way more expensive.
Here, we apply several techniques to make GPT-J usable and fine-tunable on a single GPU with ~11 GB memory:
- large weight tensors are quantized using dynamic 8-bit quantization and de-quantized just-in-time for multiplication
- using gradient checkpoints to store one only activation per layer: using dramatically less memory at the cost of 30% slower training
- scalable fine-tuning with [LoRA](https://arxiv.org/abs/2106.09685) and [8-bit Adam](https://arxiv.org/abs/2110.02861)
In other words, all of the large weight-matrices are frozen in 8-bit, and you only train small adapters and optionally 1d tensors (layernorm scales, biases).

__Does 8-bit affect model quality?__ Technically yes, but the effect is negligible in practice. [This notebook measures wikitext test perplexity](https://colab.research.google.com/drive/1FxGeYQyE7cx9VNCBC4gUyRVZGORW7c6g) and it is nigh indistinguishable from the original GPT-J. Quantized model is even slightly better, but that is not statistically significant.
Our code differs from other 8-bit methods in that we use **8-bit only for storage, and all computations are performed in float16 or float32**. As a result, we can take advantage of nonlinear quantization that fits to each individual weight distribution. Such nonlinear quantization does not accelerate inference, but it allows for much smaller error.
__What about performance?__ Both checkpointing and de-quantization has some overhead, but it's surprisingly manageable. Depending on GPU and batch size, the quantized model is 1-10% slower than the original model on top of using gradient checkpoints (which is 30% overhead). In short, this is because block-wise quantization from bitsandbytes is really fast on GPU.
### How should I fine-tune the model?
We recommend starting with the original hyperparameters from [the LoRA paper](https://arxiv.org/pdf/2106.09685.pdf).
On top of that, there is one more trick to consider: the overhead from de-quantizing weights does not depend on batch size.
As a result, the larger batch size you can fit, the more efficient you will train.
### Can I use this technique with other models?
The model was converted using [this notebook](https://colab.research.google.com/drive/1rwxh0XRdVi8VEbTx97l9xXr4JbRhZaq5#scrollTo=CX3VHn-J1Zer). It can be adapted to work with other model types. However, please bear in mind that some models replace Linear and Embedding with custom alternatives that require their own BNBWhateverWithAdapters.
|
[
"BEAR"
] |
pszemraj/led-large-book-summary-continued
|
pszemraj
|
summarization
|
[
"transformers",
"pytorch",
"safetensors",
"led",
"text2text-generation",
"long document summary",
"book summary",
"booksum",
"summarization",
"en",
"dataset:kmfoda/booksum",
"license:bsd-3-clause",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-04-09T00:08:08Z |
2023-10-05T06:56:11+00:00
| 45 | 2 |
---
datasets:
- kmfoda/booksum
language:
- en
library_name: transformers
license:
- bsd-3-clause
- apache-2.0
metrics:
- rouge
pipeline_tag: summarization
tags:
- long document summary
- book summary
- booksum
widget:
- text: large earthquakes along a given fault segment do not occur at random intervals
because it takes time to accumulate the strain energy for the rupture. The rates
at which tectonic plates move and accumulate strain at their boundaries are approximately
uniform. Therefore, in first approximation, one may expect that large ruptures
of the same fault segment will occur at approximately constant time intervals.
If subsequent main shocks have different amounts of slip across the fault, then
the recurrence time may vary, and the basic idea of periodic mainshocks must be
modified. For great plate boundary ruptures the length and slip often vary by
a factor of 2. Along the southern segment of the San Andreas fault the recurrence
interval is 145 years with variations of several decades. The smaller the standard
deviation of the average recurrence interval, the more specific could be the long
term prediction of a future mainshock.
example_title: earthquakes
- text: ' A typical feed-forward neural field algorithm. Spatiotemporal coordinates
are fed into a neural network that predicts values in the reconstructed domain.
Then, this domain is mapped to the sensor domain where sensor measurements are
available as supervision. Class and Section Problems Addressed Generalization
(Section 2) Inverse problems, ill-posed problems, editability; symmetries. Hybrid
Representations (Section 3) Computation & memory efficiency, representation capacity,
editability: Forward Maps (Section 4) Inverse problems Network Architecture (Section
5) Spectral bias, integration & derivatives. Manipulating Neural Fields (Section
6) Edit ability, constraints, regularization. Table 2: The five classes of techniques
in the neural field toolbox each addresses problems that arise in learning, inference,
and control. (Section 3). We can supervise reconstruction via differentiable forward
maps that transform Or project our domain (e.g, 3D reconstruction via 2D images;
Section 4) With appropriate network architecture choices, we can overcome neural
network spectral biases (blurriness) and efficiently compute derivatives and integrals
(Section 5). Finally, we can manipulate neural fields to add constraints and regularizations,
and to achieve editable representations (Section 6). Collectively, these classes
constitute a ''toolbox'' of techniques to help solve problems with neural fields
There are three components in a conditional neural field: (1) An encoder or inference
function € that outputs the conditioning latent variable 2 given an observation
0 E(0) =2. 2 is typically a low-dimensional vector, and is often referred to aS
a latent code Or feature code_ (2) A mapping function 4 between Z and neural field
parameters O: Y(z) = O; (3) The neural field itself $. The encoder € finds the
most probable z given the observations O: argmaxz P(2/0). The decoder maximizes
the inverse conditional probability to find the most probable 0 given Z: arg-
max P(Olz). We discuss different encoding schemes with different optimality guarantees
(Section 2.1.1), both global and local conditioning (Section 2.1.2), and different
mapping functions Y (Section 2.1.3) 2. Generalization Suppose we wish to estimate
a plausible 3D surface shape given a partial or noisy point cloud. We need a suitable
prior over the sur- face in its reconstruction domain to generalize to the partial
observations. A neural network expresses a prior via the function space of its
architecture and parameters 0, and generalization is influenced by the inductive
bias of this function space (Section 5).'
example_title: scientific paper
- text: 'Is a else or outside the cob and tree written being of early client rope
and you have is for good reasons. On to the ocean in Orange for time. By''s the
aggregate we can bed it yet. Why this please pick up on a sort is do and also
M Getoi''s nerocos and do rain become you to let so is his brother is made in
use and Mjulia''s''s the lay major is aging Masastup coin present sea only of
Oosii rooms set to you We do er do we easy this private oliiishs lonthen might
be okay. Good afternoon everybody. Welcome to this lecture of Computational Statistics.
As you can see, I''m not socially my name is Michael Zelinger. I''m one of the
task for this class and you might have already seen me in the first lecture where
I made a quick appearance. I''m also going to give the tortillas in the last third
of this course. So to give you a little bit about me, I''m a old student here
with better Bulman and my research centres on casual inference applied to biomedical
disasters, so that could be genomics or that could be hospital data. If any of
you is interested in writing a bachelor thesis, a semester paper may be mastathesis
about this topic feel for reach out to me. you have my name on models and my email
address you can find in the directory I''d Be very happy to talk about it. you
do not need to be sure about it, we can just have a chat. So with that said, let''s
get on with the lecture. There''s an exciting topic today I''m going to start
by sharing some slides with you and later on during the lecture we''ll move to
the paper. So bear with me for a few seconds. Well, the projector is starting
up. Okay, so let''s get started. Today''s topic is a very important one. It''s
about a technique which really forms one of the fundamentals of data science,
machine learning, and any sort of modern statistics. It''s called cross validation.
I know you really want to understand this topic I Want you to understand this
and frankly, nobody''s gonna leave Professor Mineshousen''s class without understanding
cross validation. So to set the stage for this, I Want to introduce you to the
validation problem in computational statistics. So the problem is the following:
You trained a model on available data. You fitted your model, but you know the
training data you got could always have been different and some data from the
environment. Maybe it''s a random process. You do not really know what it is,
but you know that somebody else who gets a different batch of data from the same
environment they would get slightly different training data and you do not care
that your method performs as well. On this training data. you want to to perform
well on other data that you have not seen other data from the same environment.
So in other words, the validation problem is you want to quantify the performance
of your model on data that you have not seen. So how is this even possible? How
could you possibly measure the performance on data that you do not know The solution
to? This is the following realization is that given that you have a bunch of data,
you were in charge. You get to control how much that your model sees. It works
in the following way: You can hide data firms model. Let''s say you have a training
data set which is a bunch of doubtless so X eyes are the features those are typically
hide and national vector. It''s got more than one dimension for sure. And the
why why eyes. Those are the labels for supervised learning. As you''ve seen before,
it''s the same set up as we have in regression. And so you have this training
data and now you choose that you only use some of those data to fit your model.
You''re not going to use everything, you only use some of it the other part you
hide from your model. And then you can use this hidden data to do validation from
the point of you of your model. This hidden data is complete by unseen. In other
words, we solve our problem of validation.'
example_title: transcribed audio - lecture
- text: 'Transformer-based models have shown to be very useful for many NLP tasks.
However, a major limitation of transformers-based models is its O(n^2)O(n 2) time
& memory complexity (where nn is sequence length). Hence, it''s computationally
very expensive to apply transformer-based models on long sequences n > 512n>512.
Several recent papers, e.g. Longformer, Performer, Reformer, Clustered attention
try to remedy this problem by approximating the full attention matrix. You can
checkout 🤗''s recent blog post in case you are unfamiliar with these models.
BigBird (introduced in paper) is one of such recent models to address this issue.
BigBird relies on block sparse attention instead of normal attention (i.e. BERT''s
attention) and can handle sequences up to a length of 4096 at a much lower computational
cost compared to BERT. It has achieved SOTA on various tasks involving very long
sequences such as long documents summarization, question-answering with long contexts.
BigBird RoBERTa-like model is now available in 🤗Transformers. The goal of this
post is to give the reader an in-depth understanding of big bird implementation
& ease one''s life in using BigBird with 🤗Transformers. But, before going into
more depth, it is important to remember that the BigBird''s attention is an approximation
of BERT''s full attention and therefore does not strive to be better than BERT''s
full attention, but rather to be more efficient. It simply allows to apply transformer-based
models to much longer sequences since BERT''s quadratic memory requirement quickly
becomes unbearable. Simply put, if we would have ∞ compute & ∞ time, BERT''s attention
would be preferred over block sparse attention (which we are going to discuss
in this post).
If you wonder why we need more compute when working with longer sequences, this
blog post is just right for you!
Some of the main questions one might have when working with standard BERT-like
attention include:
Do all tokens really have to attend to all other tokens? Why not compute attention
only over important tokens? How to decide what tokens are important? How to attend
to just a few tokens in a very efficient way? In this blog post, we will try to
answer those questions.
What tokens should be attended to? We will give a practical example of how attention
works by considering the sentence ''BigBird is now available in HuggingFace for
extractive question answering''. In BERT-like attention, every word would simply
attend to all other tokens.
Let''s think about a sensible choice of key tokens that a queried token actually
only should attend to by writing some pseudo-code. Will will assume that the token
available is queried and build a sensible list of key tokens to attend to.
>>> # let''s consider following sentence as an example >>> example = [''BigBird'',
''is'', ''now'', ''available'', ''in'', ''HuggingFace'', ''for'', ''extractive'',
''question'', ''answering'']
>>> # further let''s assume, we''re trying to understand the representation of
''available'' i.e. >>> query_token = ''available'' >>> # We will initialize an
empty `set` and fill up the tokens of our interest as we proceed in this section.
>>> key_tokens = [] # => currently ''available'' token doesn''t have anything
to attend Nearby tokens should be important because, in a sentence (sequence of
words), the current word is highly dependent on neighboring past & future tokens.
This intuition is the idea behind the concept of sliding attention.'
example_title: bigbird blog intro
- text: 'To be fair, you have to have a very high IQ to understand Rick and Morty.
The humour is extremely subtle, and without a solid grasp of theoretical physics
most of the jokes will go over a typical viewer''s head. There''s also Rick''s
nihilistic outlook, which is deftly woven into his characterisation- his personal
philosophy draws heavily from Narodnaya Volya literature, for instance. The fans
understand this stuff; they have the intellectual capacity to truly appreciate
the depths of these jokes, to realise that they''re not just funny- they say something
deep about LIFE. As a consequence people who dislike Rick & Morty truly ARE idiots-
of course they wouldn''t appreciate, for instance, the humour in Rick''s existential
catchphrase ''Wubba Lubba Dub Dub,'' which itself is a cryptic reference to Turgenev''s
Russian epic Fathers and Sons. I''m smirking right now just imagining one of those
addlepated simpletons scratching their heads in confusion as Dan Harmon''s genius
wit unfolds itself on their television screens. What fools.. how I pity them.
😂
And yes, by the way, i DO have a Rick & Morty tattoo. And no, you cannot see it.
It''s for the ladies'' eyes only- and even then they have to demonstrate that
they''re within 5 IQ points of my own (preferably lower) beforehand. Nothin personnel
kid 😎'
example_title: Richard & Mortimer
- text: The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey
building, and the tallest structure in Paris. Its base is square, measuring 125
metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed
the Washington Monument to become the tallest man-made structure in the world,
a title it held for 41 years until the Chrysler Building in New York City was
finished in 1930. It was the first structure to reach a height of 300 metres.
Due to the addition of a broadcasting aerial at the top of the tower in 1957,
it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters,
the Eiffel Tower is the second tallest free-standing structure in France after
the Millau Viaduct.
example_title: eiffel
parameters:
max_length: 64
min_length: 8
no_repeat_ngram_size: 3
early_stopping: true
repetition_penalty: 3.5
encoder_no_repeat_ngram_size: 4
num_beams: 2
model-index:
- name: pszemraj/led-large-book-summary-continued
results:
- task:
type: summarization
name: Summarization
dataset:
name: kmfoda/booksum
type: kmfoda/booksum
config: kmfoda--booksum
split: test
metrics:
- type: rouge
value: 31.2367
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOWI3NzQwMTUxOWRkOGVmZGYwZTkyODIxZmRhM2Y5N2FjYmM2MWEyMDNiN2JmODc3ODExNTAwZjhhZDJkNzNiYyIsInZlcnNpb24iOjF9.EYEvooI7WG94OinI4p5sNiuM1MAFVSYeb2ehv2lGe-B-qR1yvPVBBr7J3iI5UFegZsYciCLA6VRFUe8eQ8KNAg
- type: rouge
value: 5.0148
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYzMxYjIzMWY2MTNkODczZWEzOGEzNjYxNzZjMTc0N2U3NmFhMWM5NWFiMzBjZDEwNTFkYjhhMGMwMjliY2JjOSIsInZlcnNpb24iOjF9.DmIc7iNjo5nm_T-uWehMCbcWjgY_WNGdRkiUXdzv96uFIRiVIoW03UspkGfzvjEiKRoa7OM403XZxNXuCjVJCQ
- type: rouge
value: 15.7724
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDUzNzNkYjUxMjE1MzZjMDhkNWE2MmZlMTg0OGM1NDc2M2JlZDJmNDI3M2YyZGM2NmY1ZDZlOWYxMzcyYmExZCIsInZlcnNpb24iOjF9.CVjivCusq1J_tiktqQ-pnsH6iOWdYrf5rwt9wlGoCgw4boXzDVivtHpe0MWlJ5L-XFY75SnrMXeunCBGOwONBQ
- type: rouge
value: 28.494
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYTY0MjI3NDNkYzI5ZjA1Nzg5MmE0MzY3OTZkM2U2ZWZkMDBjZjQzMjdjN2Q3Y2NiZjIwNzI1OWJhMzhjYzg4NiIsInZlcnNpb24iOjF9.A0iwWEti-OPFbi9TEpnEpC0rPCLP3Gw3Ns23Lz8e_zi4B_vlGrVW7weofzO8cuGVoC9kS-aJk2a5VGdXYh5KBw
- type: loss
value: 4.777158260345459
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZWZkNjdhNGNkNDUyYWNlNDgyNzkxNDdkNTZlOGQ0MmQ3ZGVjYjgwZTk2M2E4NjAwNWZkNGEzMTU2ZWFjMmFmMCIsInZlcnNpb24iOjF9.TTEWfYmpM4VPKn1Jukkwadj6C3HASvzTMJeTLHCHqd5Vr7s0X0PcIKvnyEVycwywFanfrgIg4Pyn0G_IVeYcBg
- type: gen_len
value: 154.1908
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMmI3YjZkNTZmMzNjMzMzODlhODFmNWFlNjNmODI0ZjE2ZWNjMzcxMWUyMGMzNzY2MDIzZWIwYTMxODk3M2Q3YiIsInZlcnNpb24iOjF9.nyUANcwiu-sb3vXMFIdzvdDPTBBhJOEQmdu25XSXRgwNSfugKDydAoHy2tdo9ZE8r32xxYDPoutER22APV4PCA
---
# led-large-book-summary: continued
Fine-tuned further to explore if any improvements vs. the default.
## Details
This model is a version of [pszemraj/led-large-book-summary](https://huggingface.co/pszemraj/led-large-book-summary) further fine-tuned for two epochs.
## Usage
It's recommended to use this model with [beam search decoding](https://huggingface.co/docs/transformers/generation_strategies#beamsearch-decoding). If interested, you can also use the `textsum` util repo to have most of this abstracted out for you:
```bash
pip install -U textsum
```
```python
from textsum.summarize import Summarizer
model_name = "pszemraj/led-large-book-summary-continued"
summarizer = Summarizer(model_name) # GPU auto-detected
text = "put the text you don't want to read here"
summary = summarizer.summarize_string(text)
print(summary)
```
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 2
- seed: 8191
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 2.0
- mixed_precision_training: Native AMP
|
[
"BEAR"
] |
SeaLLMs/SeaLLM-7B-v2-gguf
|
SeaLLMs
| null |
[
"gguf",
"arxiv:2312.00738",
"arxiv:2205.11916",
"arxiv:2306.05179",
"arxiv:2306.05685",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-02-07T07:34:05Z |
2024-02-08T06:39:50+00:00
| 45 | 9 |
---
license: other
license_name: seallms
license_link: https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat/blob/main/LICENSE
---
# *SeaLLM-7B-v2* - Large Language Models for Southeast Asia
**NOTE: download [seallm.preset.json](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2-gguf/blob/main/seallm.preset.json) for LM-studio to work correctly,**
<p align="center">
<a href="https://huggingface.co/SeaLLMs/SeaLLM-7B-v2" target="_blank" rel="noopener"> 🤗 Tech Memo</a>
<a href="https://huggingface.co/spaces/SeaLLMs/SeaLLM-7B" target="_blank" rel="noopener"> 🤗 DEMO</a>
<a href="https://github.com/DAMO-NLP-SG/SeaLLMs" target="_blank" rel="noopener">Github</a>
<a href="https://arxiv.org/pdf/2312.00738.pdf" target="_blank" rel="noopener">Technical Report</a>
</p>
We introduce [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2), the state-of-the-art multilingual LLM for Southeast Asian (SEA) languages 🇬🇧 🇨🇳 🇻🇳 🇮🇩 🇹🇭 🇲🇾 🇰🇭 🇱🇦 🇲🇲 🇵🇭. It is the most significant upgrade since [SeaLLM-13B](https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat), with half the size, outperforming performance across diverse multilingual tasks, from world knowledge, math reasoning, instruction following, etc.
### Highlights
* [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) achieves the **7B-SOTA** on the **Zero-shot CoT GSM8K** task with **78.2** score and outperforms GPT-3.5 in many GSM8K-translated tasks in SEA languages (🇨🇳 🇻🇳 🇮🇩 🇹🇭) as well as MGSM (🇨🇳 🇹🇭). It also surpasses GPT-3.5 in MATH CoT for Thai 🇹🇭.
* It scores competitively against GPT-3.5 in many zero-shot CoT commonsense benchmark, with **82.5, 68.3, 80.9** scores on Arc-C, Winogrande, and Hellaswag.
* It achieves **7.54** score on the 🇬🇧 **MT-bench**, it ranks 3rd place on the leaderboard for 7B category and is the most outperforming multilingual model.
* It scores **45.74** on the VMLU benchmark for Vietnamese 🇻🇳, and is the only open-source multilingual model that can be competitive to monolingual models ([Vistral-7B](https://huggingface.co/Viet-Mistral/Vistral-7B-Chat)) of similar sizes.
### Release and DEMO
- DEMO: [SeaLLMs/SeaLLM-7B](https://huggingface.co/spaces/SeaLLMs/SeaLLM-7B).
- Technical report: [Arxiv: SeaLLMs - Large Language Models for Southeast Asia](https://arxiv.org/pdf/2312.00738.pdf).
- Model weights:
- [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2).
- [SeaLLM-7B-v2-gguf](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2-gguf).
- [SeaLLM-7B-v2-q4_0](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2-gguf/blob/main/SeaLLM-7B-v2.q4_0.gguf), [SeaLLM-7B-v2-q8_0](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2-gguf/blob/main/SeaLLM-7B-v2.q8_0.gguf).
- LM-studio requires this [seallm.preset.json](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2-gguf/blob/main/seallm.preset.json) to work properly.
- [SeaLLM-7B-v2-GGUF (thanks Lonestriker)](https://huggingface.co/LoneStriker/SeaLLM-7B-v2-GGUF). NOTE: use [seallm.preset.json](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2-gguf/blob/main/seallm.preset.json) to work properly.
<blockquote style="color:red">
<p><strong style="color: red">Terms of Use and License</strong>:
By using our released weights, codes, and demos, you agree to and comply with the terms and conditions specified in our <a href="https://huggingface.co/SeaLLMs/SeaLLM-Chat-13b/edit/main/LICENSE" target="_blank" rel="noopener">SeaLLMs Terms Of Use</a>.
</blockquote>
> **Disclaimer**:
> We must note that even though the weights, codes, and demos are released in an open manner, similar to other pre-trained language models, and despite our best efforts in red teaming and safety fine-tuning and enforcement, our models come with potential risks, including but not limited to inaccurate, misleading or potentially harmful generation.
> Developers and stakeholders should perform their own red teaming and provide related security measures before deployment, and they must abide by and comply with local governance and regulations.
> In no event shall the authors be held liable for any claim, damages, or other liability arising from the use of the released weights, codes, or demos.
> The logo was generated by DALL-E 3.
### What's new since SeaLLM-13B-v1 and SeaLLM-7B-v1?
* SeaLLM-7B-v2 is continue-pretrained from [Mistral-7B](https://huggingface.co/mistralai/Mistral-7B-v0.1) and underwent carefully designed tuning with focus in reasoning.
## Evaluation
### Zero-shot CoT Multilingual Math Reasoning
[SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) achieves with **78.2** score on the GSM8K with zero-shot CoT reasoning, making it the **state of the art** in the realm of 7B models. It also outperforms GPT-3.5 in the same GSM8K benchmark as translated into SEA languages (🇨🇳 🇻🇳 🇮🇩 🇹🇭). [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) also surpasses GPT-3.5 on the Thai-translated MATH benchmark, with **22.4** vs 18.1 scores.

<details>
<summary>See details on English and translated GSM8K and MATH with zero-shot reasoning</summary>
<br>
| Model | GSM8K<br>en | MATH<br>en | GSM8K<br>zh | MATH<br>zh | GSM8K<br>vi | MATH<br>vi | GSM8K<br>id | MATH<br>id | GSM8K<br>th | MATH<br>th
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| GPT-3.5 | 80.8 | 34.1 | 48.2 | 21.5 | 55 | 26.5 | 64.3 | 26.4 | 35.8 | 18.1
| Qwen-14B-chat | 61.4 | 18.4 | 41.6 | 11.8 | 33.6 | 3.6 | 44.7 | 8.6 | 22 | 6
| Vistral-7b-chat | 48.2 | 12.5 | | | 48.7 | 3.1 | | | |
| SeaLLM-7B-v2 | 78.2 | 27.5 | 53.7 | 17.6 | 69.9 | 23.8 | 71.5 | 24.4 | 59.6 | 22.4
</details>
#### Zero-shot MGSM
[SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) also outperforms GPT-3.5 and Qwen-14B on the multilingual MGSM for Zh and Th.
| Model | MGSM-Zh | MGSM-Th
|-----| ----- | ---
| ChatGPT (reported) | 61.2* | 47.2*
| Qwen-14B-chat | 59.6 | 28
| SeaLLM-7B-v2 | **64.8** | **62.4**
### Zero-shot Commonsense Reasoning
We compare [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) with ChatGPT and Mistral-7B-instruct on various zero-shot commonsense benchmarks (Arc-Challenge, Winogrande and Hellaswag). We use the 2-stage technique in [(Kojima et al., 2023)](https://arxiv.org/pdf/2205.11916.pdf) to grab the answer. Note that we **DID NOT** use "Let's think step-by-step" to invoke explicit CoT.
| Model | Arc-Challenge | Winogrande | Hellaswag
|-----| ----- | --- | -- |
| ChatGPT (reported) | 84.6* | 66.8* | 72.0*
| ChatGPT (reproduced) | 84.1 | 63.1 | 79.5
| Mistral-7B-Instruct | 68.1 | 56.4 | 45.6
| SeaLLM-7B-v2 | 82.5 | 68.3 | 80.9
### Multilingual World Knowledge
We evaluate models on 3 benchmarks following the recommended default setups: 5-shot MMLU for En, 3-shot [M3Exam](https://arxiv.org/pdf/2306.05179.pdf) (M3e) for En, Zh, Vi, Id, Th, and zero-shot [VMLU](https://vmlu.ai/) for Vi.
| Model | Langs | En<br>MMLU | En<br>M3e | Zh<br>M3e | Vi<br>M3e | Vi<br>VMLU | Id<br>M3e | Th<br>M3e
|-----| ----- | --- | -- | ----- | ---- | --- | --- | --- |
| GPT-3.5 | Multi | 68.90 | 75.46 | 60.20 | 58.64 | 46.32 | 49.27 | 37.41
| SeaLLM-13B | Multi | 52.78 | 62.69 | 44.50 | 46.45 | | 39.28 | 36.39
| Vistral-7B-chat | Mono | 56.86 | 67.00 | 44.56 | 54.33 | 50.03 | 36.49 | 25.27
| Qwen1.5-7B-chat | Multi | 61.00 | 52.07 | 81.96 | 43.38 | 45.02 | 24.29 | 20.25
| SeaLLM-7B-v2 | Multi | 61.89 | 70.91 | 55.43 | 51.15 | 45.74 | 42.25 | 35.52
VMLU reproduce script [here](https://github.com/DAMO-NLP-SG/SeaLLMs/blob/main/evaluation/vmlu/vmlu_run.py). Lm-eval was used to evaluate MMLU.
### MT-Bench
On the English [MT-bench](https://arxiv.org/abs/2306.05685) metric, SeaLLM-7B-v2 achieves **7.54** score on the MT-bench (3rd place on the leaderboard for 7B category), outperforms many 70B models and is arguably the only one that handles 10 SEA languages.
Refer to [mt_bench/seallm_7b_v2.jsonl](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2/blob/main/evaluation/mt_bench/seallm_7b_v2.jsonl) for the MT-bench predictions of SeaLLM-7B-v2, and [here](https://github.com/lm-sys/FastChat/issues/3013#issue-2118685341) to reproduce it.
| Model | Access | Langs | MT-Bench
| --- | --- | --- | --- |
| GPT-4-turbo | closed | multi | 9.32
| GPT-4-0613 | closed | multi | 9.18
| Mixtral-8x7b (46B) | open | multi | 8.3
| Starling-LM-7B-alpha | open | mono (en) | 8.0
| OpenChat-3.5-7B | open | mono (en) | 7.81
| **SeaLLM-7B-v2** | **open** | **multi (10+)** | **7.54**
| [Qwen-14B](https://huggingface.co/Qwen/Qwen-14B-Chat) | open | multi | 6.96
| [Llama-2-70B](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) | open | mono (en) | 6.86
| Mistral-7B-instuct | open | mono (en) | 6.84
### Sea-Bench
Similar to MT-Bench, [Sea-bench](https://huggingface.co/datasets/SeaLLMs/Sea-bench) is a set of categorized instruction test sets to measure models' ability as an assistant that is specifically focused on 9 SEA languages, including non-Latin low-resource languages.
As shown, the huge improvements come from math-reasoning, reaching GPT-3.5 level of performance.

Refer to [sea_bench/seallm_7b_v2.jsonl](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2/blob/main/evaluation/sea_bench/seallm_7b_v2.jsonl) for the Sea-bench predictions of SeaLLM-7B-v2.
### Usage
#### Instruction format
```python
prompt = """<|im_start|>system
You are a helpful assistant.</s><|im_start|>user
Hello world</s><|im_start|>assistant
Hi there, how can I help?</s>"""
# NOTE: previous commit has \n between </s> and <|im_start|>, that was incorrect!
# <|im_start|> is not a special token.
# Transformers chat_template should be consistent with vLLM format below.
# ! ENSURE 1 and only 1 bos `<s>` at the beginning of sequence
print(tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt)))
'<s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'system', '<0x0A>', 'You', '▁are', '▁a', '▁helpful', '▁assistant', '.', '</s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'user', '<0x0A>', 'Hello', '▁world', '</s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'ass', 'istant', '<0x0A>', 'Hi', '▁there', ',', '▁how', '▁can', '▁I', '▁help', '?', '</s>']
"""
```
#### Using transformers's chat_template
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
# use bfloat16 to ensure the best performance.
model = AutoModelForCausalLM.from_pretrained("SeaLLMs/SeaLLM-7B-v2", torch_dtype=torch.bfloat16, device_map=device)
tokenizer = AutoTokenizer.from_pretrained("SeaLLMs/SeaLLM-7B-v2")
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello world"},
{"role": "assistant", "content": "Hi there, how can I help you today?"},
{"role": "user", "content": "Explain general relativity in details."}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True)
print(tokenizer.convert_ids_to_tokens(encodeds[0]))
# ['<s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'system', '<0x0A>', 'You', '▁are', '▁a', '▁helpful', '▁assistant', '.', '</s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'user', '<0x0A>', 'Hello', '▁world', '</s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'ass', 'istant', '<0x0A>', 'Hi', '▁there', ',', '▁how', '▁can', '▁I', '▁help', '▁you', '▁today', '?', '</s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'user', '<0x0A>', 'Ex', 'plain', '▁general', '▁rel', 'ativity', '▁in', '▁details', '.', '</s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'ass', 'istant', '<0x0A>']
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True, pad_token_id=tokenizer.pad_token_id)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
#### Using vLLM
```python
from vllm import LLM, SamplingParams
TURN_TEMPLATE = "<|im_start|>{role}\n{content}</s>"
TURN_PREFIX = "<|im_start|>{role}\n"
# There is no \n between </s> and <|im_start|>.
def seallm_chat_convo_format(conversations, add_assistant_prefix: bool, system_prompt=None):
# conversations: list of dict with key `role` and `content` (openai format)
if conversations[0]['role'] != 'system' and system_prompt is not None:
conversations = [{"role": "system", "content": system_prompt}] + conversations
text = ''
for turn_id, turn in enumerate(conversations):
prompt = TURN_TEMPLATE.format(role=turn['role'], content=turn['content'])
text += prompt
if add_assistant_prefix:
prompt = TURN_PREFIX.format(role='assistant')
text += prompt
return text
sparams = SamplingParams(temperature=0.1, max_tokens=1024, stop=['</s>', '<|im_start|>'])
llm = LLM("SeaLLMs/SeaLLM-7B-v2", dtype="bfloat16")
message = "Explain general relativity in details."
prompt = seallm_chat_convo_format(message, True)
gen = llm.generate(prompt, sampling_params)
print(gen[0].outputs[0].text)
```
## Acknowledgement to Our Linguists
We would like to express our special thanks to our professional and native linguists, Tantong Champaiboon, Nguyen Ngoc Yen Nhi and Tara Devina Putri, who helped build, evaluate, and fact-check our sampled pretraining and SFT dataset as well as evaluating our models across different aspects, especially safety.
## Citation
If you find our project useful, we hope you would kindly star our repo and cite our work as follows: Corresponding Author: [[email protected]](mailto:[email protected])
**Author list and order will change!**
* `*` and `^` are equal contributions.
```
@article{damonlpsg2023seallm,
author = {Xuan-Phi Nguyen*, Wenxuan Zhang*, Xin Li*, Mahani Aljunied*,
Zhiqiang Hu, Chenhui Shen^, Yew Ken Chia^, Xingxuan Li, Jianyu Wang,
Qingyu Tan, Liying Cheng, Guanzheng Chen, Yue Deng, Sen Yang,
Chaoqun Liu, Hang Zhang, Lidong Bing},
title = {SeaLLMs - Large Language Models for Southeast Asia},
year = 2023,
Eprint = {arXiv:2312.00738},
}
```
|
[
"CHIA"
] |
valeriojob/MedGPT-Gemma2-9B-BA-v.1-GGUF
|
valeriojob
| null |
[
"transformers",
"gguf",
"gemma2",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"sft",
"en",
"base_model:unsloth/gemma-2-9b",
"base_model:quantized:unsloth/gemma-2-9b",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2024-08-02T16:55:37Z |
2024-08-03T07:42:19+00:00
| 45 | 0 |
---
base_model: unsloth/gemma-2-9b
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
---
# MedGPT-Gemma2-9B-v.1-GGUF
- This model is a fine-tuned version of [unsloth/gemma-2-9b](https://huggingface.co/unsloth/gemma-2-9b) on an dataset created by [Valerio Job](https://huggingface.co/valeriojob) together with GPs based on real medical data.
- Version 1 (v.1) of MedGPT is the very first version of MedGPT and the training dataset has been kept simple and small with only 60 examples.
- This repo includes the quantized models in the GGUF format. There is a separate repo called [valeriojob/MedGPT-Gemma2-9B-BA-v.1](https://huggingface.co/valeriojob/MedGPT-Gemma2-9B-BA-v.1) that includes the default 16bit format of the model as well as the LoRA adapters of the model.
- This model was quantized using [llama.cpp](https://github.com/ggerganov/llama.cpp).
- This model is available in the following quantization formats:
- BF16
- Q4_K_M
- Q5_K_M
- Q8_0
## Model description
This model acts as a supplementary assistance to GPs helping them in medical and admin tasks.
## Intended uses & limitations
The fine-tuned model should not be used in production! This model has been created as a initial prototype in the context of a bachelor thesis.
## Training and evaluation data
The dataset (train and test) used for fine-tuning this model can be found here: [datasets/valeriojob/BA-v.1](https://huggingface.co/datasets/valeriojob/BA-v.1)
## Licenses
- **License:** apache-2.0
|
[
"MEDICAL DATA"
] |
ricepaper/vi-gemma2-2b-ChatQA-RAG-v1
|
ricepaper
|
text-generation
|
[
"transformers",
"safetensors",
"gemma2",
"text-generation",
"text-generation-inference",
"retrieval-augmented-generation",
"unsloth",
"gemma",
"trl",
"sft",
"conversational",
"en",
"vi",
"base_model:google/gemma-2-2b-it",
"base_model:finetune:google/gemma-2-2b-it",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-09-02T10:55:45Z |
2024-09-02T15:30:10+00:00
| 45 | 0 |
---
base_model: google/gemma-2-2b-it
language:
- en
- vi
license: apache-2.0
tags:
- text-generation-inference
- retrieval-augmented-generation
- transformers
- unsloth
- gemma
- trl
- sft
---
## Model Card: vi-gemma2-2b-ChatQA-RAG-v1
### (English below)
### Tiếng Việt (Vietnamese)
**Mô tả mô hình:**
vi-gemma2-2b-ChatQA-RAG là một mô hình ngôn ngữ lớn được tinh chỉnh từ mô hình cơ sở [google/gemma-2-2b-it](https://huggingface.co/google/gemma-2-2b-it) sử dụng kỹ thuật LoRA. Mô hình được huấn luyện trên tập dữ liệu tiếng Việt với mục tiêu cải thiện khả năng xử lý ngôn ngữ tiếng Việt và nâng cao hiệu suất cho các tác vụ truy xuất thông tin mở (Retrieval Augmented Generation - RAG).
Mô hình được tinh chỉnh tập trung vào bài toán RAG theo phương pháp của NVIDIA Chat-QA [link](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-8B)
**Cách sử dụng:**
Dưới đây chúng tôi chia sẻ một số đoạn mã về cách bắt đầu nhanh chóng để sử dụng mô hình. Trước tiên, hãy đảm bảo đã cài đặt `pip install -U transformers`, sau đó sao chép đoạn mã từ phần có liên quan đến usecase của bạn.
Chúng tôi khuyến nghị sử dụng `torch.bfloat16` làm mặc định.
```python
# pip install transformers torch accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Khởi tạo tokenizer và model từ checkpoint đã lưu
tokenizer = AutoTokenizer.from_pretrained("hiieu/vi-gemma2-2b-ChatQA-RAG-v1")
model = AutoModelForCausalLM.from_pretrained(
"hiieu/vi-gemma2-2b-ChatQA-RAG-v1",
device_map="auto",
torch_dtype=torch.bfloat16
)
# Sử dụng GPU nếu có
if torch.cuda.is_available():
model.to("cuda")
messages = [
{"role": "user", "content": "Hãy cho tôi biết một số tính chất của STRs được dùng để làm gì?"}
]
document = """Context: Short Tandem Repeats (STRs) là các trình tự DNA lặp lại ngắn (2- 6 nucleotides) xuất hiện phổ biến trong hệ gen của con người. Các trình tự này có tính đa hình rất cao trong tự nhiên, điều này khiến các STRs trở thành những markers di truyền rất quan trọng trong nghiên cứu bản đồ gen người và chuẩn đoán bệnh lý di truyền cũng như xác định danh tính trong lĩnh vực pháp y.
Các STRs trở nên phổ biến tại các phòng xét nghiệm pháp y bởi vì việc nhân bản và phân tích STRs chỉ cần lượng DNA rất thấp ngay cả khi ở dạng bị phân hủy việc đinh danh vẫn có thể được thực hiện thành công. Hơn nữa việc phát hiện và đánh giá sự nhiễm DNA mẫu trong các mẫu vật có thể được giải quyết nhanh với kết quả phân tích STRs. Ở Hoa Kỳ hiện nay, từ bộ 13 markers nay đã tăng lên 20 markers chính đang được sử dụng để tạo ra một cơ sở dữ liệu DNA trên toàn đất nước được gọi là The FBI Combined DNA Index System (Expaned CODIS).
CODIS và các cơ sử dữ liệu DNA tương tự đang được sử dụng thực sự thành công trong việc liên kết các hồ sơ DNA từ các tội phạm và các bằng chứng hiện trường vụ án. Kết quả định danh STRs cũng được sử dụng để hỗ trợ hàng trăm nghìn trường hợp xét nghiệm huyết thống cha con mỗi năm'
"""
def get_formatted_input(messages, context):
system = "System: Đây là một cuộc trò chuyện giữa người dùng và trợ lý trí tuệ nhân tạo. Trợ lý cung cấp câu trả lời hữu ích, chi tiết và lịch sự cho các câu hỏi của người dùng dựa trên ngữ cảnh được cung cấp. Trợ lý cũng nên chỉ ra khi câu trả lời không thể tìm thấy trong ngữ cảnh."
conversation = '\n\n'.join(["User: " + item["content"] if item["role"] == "user" else "Assistant: " + item["content"] for item in messages])
formatted_input = system + "\n\n" + context + "\n\n" + conversation + "\n\n### Assistant:"
return formatted_input
# Chuẩn bị dữ liệu đầu vào
formatted_input = get_formatted_input(messages, document)
# Mã hóa input text thành input ids
input_ids = tokenizer(formatted_input, return_tensors="pt").to(model.device)
# Tạo văn bản bằng model
outputs = model.generate(
**input_ids,
max_new_tokens=512,
do_sample=True, # Kích hoạt chế độ tạo văn bản dựa trên lấy mẫu. Trong chế độ này, model sẽ chọn ngẫu nhiên token tiếp theo dựa trên xác suất được tính từ phân phối xác suất của các token.
temperature=0.1, # Giảm temperature để kiểm soát tính ngẫu nhiên
)
# Giải mã và in kết quả
print(tokenizer.decode(outputs[0]).rsplit("### Assistant:")[-1])
>>> STRs là các trình tự DNA lặp lại ngắn (2-6 nucleotides) xuất hiện phổ biến trong hệ gen của con người. Chúng có tính đa hình cao và được sử dụng trong nghiên cứu bản đồ gen người và chuẩn đoán bệnh lý di truyền.<eos>
```
# Uploaded model
This gemma model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
[
"CHIA"
] |
SIRIS-Lab/AIObioEnts-AnatEM-pubmedbert-full
|
SIRIS-Lab
|
token-classification
|
[
"transformers",
"safetensors",
"bert",
"token-classification",
"ner",
"biomedicine",
"base_model:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"base_model:finetune:microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-11-15T18:14:45Z |
2024-12-17T12:28:54+00:00
| 45 | 0 |
---
base_model:
- microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext
library_name: transformers
license: mit
pipeline_tag: token-classification
tags:
- ner
- biomedicine
---
# AIObioEnts: All-in-one biomedical entities
Biomedical named-entity recognition following the all-in-one NER (AIONER) scheme introduced by [Luo *et al.*](https://doi.org/10.1093/bioinformatics/btad310). This is a straightforward Hugging-Face-compatible implementation without using a decoding head for ease of integration with other pipelines.
**For full details, see the [main GitHub repository](https://github.com/sirisacademic/AIObioEnts/)**
## Anatomical biomedical entities
We have followed the original AIONER training pipeline based on the BioRED dataset along with additional BioRED-compatible datasets for set of core entities (Gene, Disease, Chemical, Species, Variant, Cell line), which we have fine-tuned using a modified version of the latest release of the [AnatEM](https://nactem.ac.uk/anatomytagger/#AnatEM) corpus, and a subset of entities that are of interest to us: *cell*, *cell component*, *tissue*, *muti-tissue structure*, and *organ*, along with the newly-introduced *cancer*. This model corresponds to the implementation based on [BiomedBERT-base pre-trained on both abstracts from PubMed and full-texts articles from PubMedCentral](https://huggingface.co/microsoft/BiomedNLP-BiomedBERT-base-uncased-abstract-fulltext)
**F1 scores**
The F1 scores on the test set of this modified dataset are shown below:
| | **BiomedBERT-base abstract+fulltext** |
| -------------------------- | :-----------------------------------: |
| **Cell** | 87.76 |
| **Cell component** | 81.74 |
| **Tissue** | 72.26 |
| **Cancer** | 89.29 |
| **Organ** | 84.18 |
| **Multi-tissue structure** | 72.65 |
| | | | |
| **Overall** | 84.22 |
## Usage
The model can be directly used from HuggingFace in a NER pipeline. However, we note that:
- The model was trained on sentence-level data, and it works best when the input is split
- Each sentence to tag must be surrounded by the flag corresponding to the entity type one wishes to identify, as in: `<entity_type>sentence</entity_type>`. In the case of this fine-tuned model, the entity type should be `'ALL'`.
- Since additional `'O'` labels are used in the AIONER scheme, the outputs should be postprocessed before aggregating the tags
We provide helper functions to tag individual texts in the [main repository](https://github.com/sirisacademic/AIObioEnts/)
````python
from tagging_fn import process_one_text
from transformers import pipeline
pipe = pipeline('ner', model='SIRIS-Lab/AIObioEnts-AnatEM-pubmedbert-full', aggregation_strategy='none', device=0)
process_one_text(text_to_tag, pipeline=pipe, entity_type='ALL')
````
## References
[[1] Ling Luo, Chih-Hsuan Wei, Po-Ting Lai, Robert Leaman, Qingyu Chen, and Zhiyong Lu. "AIONER: All-in-one scheme-based biomedical named entity recognition using deep learning." Bioinformatics, Volume 39, Issue 5, May 2023, btad310.](https://doi.org/10.1093/bioinformatics/btad310)
|
[
"ANATEM",
"BIORED"
] |
llama-moe/LLaMA-MoE-v2-3_8B-residual-sft
|
llama-moe
| null |
[
"safetensors",
"mixtral",
"MoE",
"custom_code",
"en",
"arxiv:2411.15708",
"license:apache-2.0",
"region:us"
] | 2024-11-26T07:23:19Z |
2024-12-03T11:37:33+00:00
| 45 | 2 |
---
language:
- en
license: apache-2.0
tags:
- MoE
---
# LLaMA-MoE-v2-3.8B (1+1/7) SFT
[[💻 Code]](https://github.com/OpenSparseLLMs/LLaMA-MoE-v2) | [[📃 Technical Report]](https://arxiv.org/pdf/2411.15708)
LLaMA-MoE-v2 is a series of open-sourced Mixture-of-Expert (MoE) models based on [LLaMA3](https://github.com/facebookresearch/llama).
We build LLaMA-MoE-v2 with the following two steps:
1. **Partition** LLaMA's FFN layers or Attention layers into sparse experts and insert top-K gate for each layer of experts.
2. Supervised fine-tuning the constructed MoE models using open-source data with a two-stage training.
| Model | \#Activated Experts | \#Experts | \#Activated Params | SFT Model |
| :-----------------------: | :-----------------: | :-------: | :----------------: | :------------------------------------------------------------------------: |
| **LLaMA-MLP-MoE (2/8)** | 2 | 8 | 3.8B | [🤗 SFT](https://huggingface.co/llama-moe/LLaMA-MoE-v2-3_8B-2_8-sft) |
| **LLaMA-MLP-MoE (1+1/7)** | 2 | 8 | 3.8B | [🤗 SFT](https://huggingface.co/llama-moe/LLaMA-MoE-v2-3_8B-residual-sft) |
## 🚀 QuickStart
```python
# python>=3.10
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_dir = "llama-moe/LLaMA-MoE-v2-3_8B-residual-sft"
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir, torch_dtype=torch.bfloat16, trust_remote_code=True)
model.eval()
model.cuda()
input_text = "Could you recommend me some mystery novels?"
input_text = f"<|start_header_id|>user<|end_header_id|>\n\n{input_text}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n"
inputs = tokenizer(input_text, return_tensors="pt")
input_ids = inputs["input_ids"].cuda()
pred = model.generate(input_ids, max_length=200, temperature=1.0, do_sample=True, use_cache=True)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
"""
I'd be delighted to recommend some mystery novels to you! Here are a few suggestions across various sub-genres:
**Classic Whodunit**
1. "And Then There Were None" by Agatha Christie - A timeless tale of ten strangers who are invited to an isolated island, only to be killed off one by one.
2. "The Murder on the Orient Express" by Agatha Christie - A classic whodunit set on a luxurious train traveling from Istanbul to Paris, where a famous author goes missing.
3. "The Devil in the White City" by Erik Larson - A non-fiction book that combines historical events with a mystery, exploring the 1893 World's Columbian Exposition in Chicago and the serial killer H.H. Holmes.
**Modern Whodunits**
1. "Gone Girl" by Gillian Flynn - A twisty, psychological thriller about a couple whose seemingly perfect ...
"""
```
## 📊 Performance
| Model | #Training Tokens | MMLU(5) | GSM8k(8) | HumanEval(pass@10) | IFEval | BoolQ(32) | SciQ | PIQA | ARC-c(25) | TruthfulQA | HellaSwag(10) |
|:---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [LLaMA3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) | 15T | 67.2 | 76.5 | 71.4 | 76.5 | 83.0 | 93.2 | 78.5 | 61.9 | 51.7 | 78.8 |
| [INCITE-3B](https://huggingface.co/togethercomputer/RedPajama-INCITE-Instruct-3B-v1) | 1T | 25.1 | 2.1 | 6.92 | 30.1 | 66.5 | 94.7 | 74.4 | 40.2 | 36.4 | 65.6 |
| [Sheared-LLaMA-2.7B](https://huggingface.co/princeton-nlp/Sheared-LLaMA-2.7B-ShareGPT) | 50B | 28.2 | 1.9 | 3.2 | 28.8 | 67.6 | 75.8 | 41.1 | 47.6 | 71.2 | 39.0 |
| [Gemma-2-2b](https://huggingface.co/google/gemma-2-2b-it) | 2T | 53.0 | 26.3 | 46.1 | 34.9 | 72.3 | 75.8 | 67.5 | 52.6 | 50.8 | 69.0 |
| [Salamandra-2b](https://huggingface.co/BSC-LT/salamandra-2b-instruct) | 7.8T | 25.1 | 1.90 | 5.82 | 27.7 | 68.0 | 89.8 | 74.7 | 46.3 | 43.4 | 62.3 |
| [SmolLM2-1.7B](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct) | 11T | 50.4 | 38.5 | 39.1 | 29.0 | 68.2 | 84.3 | 76.0 | 53.2 | 39.9 | 72.6 |
| [OpenMoE-3B-9B](https://huggingface.co/OrionZheng/openmoe-8b-chat) | 1T | 26.5 | 1.36 | 1.01 | 31.2 | 61.7 | 68.4 | 65.7 | 33.3 | 40.5 | 56.5 |
| [LLaMA-MoE-3B-7B](https://huggingface.co/llama-moe/LLaMA-MoE-v1-3_5B-2_8-sft) | 200B | 28.2 | 4.62 | 12.0 | 28.1 | 68.1 | 88.8 | 77.9 | 44.0 | 33.3 | 73.2 |
| [OLMoE-1B-7B](https://huggingface.co/allenai/OLMoE-1B-7B-0924-SFT) | 1T | 53.8 | 40.9 | 40.5 | 35.5 | 80.9 | 94.9 | 80.1 | 55.6 | 43.3 | 79.6 |
| **MLP-MoE (8top2)** | **7B** | 40.6 | 53.1 | 53.5 | 32.7 | 74.6 | 90.6 | 69.3 | 42.8 | 45.6 | 59.0 |
| **MLP-MoE (8top2)** | **8.4B** | 41.0 | **59.6** | **57.1** | 31.7 | 74.5 | 90.2 | 69.5 | 43.3 | 46.9 | 58.1 |
| **MLP-MoE (1+7top1)** | **7B** | 42.7 | 55.0 | 51.2 | **36.0** | 76.9 | 88.8 | 67.9 | 40.2 | 46.9 | 53.7 |
## 📃 Citation
```bibtex
@misc{llama-moe-v2,
title={LLaMA-MoE v2: Exploring Sparsity of LLaMA from Perspective of Mixture-of-Experts with Post-Training},
author={Xiaoye Qu, Daize Dong, Xuyang Hu, Tong Zhu, Weigao Sun, Yu Cheng},
year={2024},
month={Nov},
url={https://arxiv.org/abs/2411.15708}
}
```
|
[
"SCIQ"
] |
FluffyKaeloky/MistralThinker-v1.1-exl2-6.0bpw
|
FluffyKaeloky
| null |
[
"safetensors",
"mistral",
"roleplay",
"deepseek",
"rp",
"r1",
"distill",
"en",
"fr",
"base_model:Undi95/MistralThinker-v1.1",
"base_model:quantized:Undi95/MistralThinker-v1.1",
"6-bit",
"exl2",
"region:us"
] | 2025-03-02T00:19:58Z |
2025-03-02T00:26:28+00:00
| 45 | 0 |
---
base_model: Undi95/MistralThinker-v1.1
language:
- en
- fr
tags:
- roleplay
- deepseek
- rp
- r1
- mistral
- distill
base_model_relation: quantized
quantized_by: FluffyKaeloky
---
# MistralThinker Model Card
Please, read this: https://huggingface.co/Undi95/MistralThinker-v1.1/discussions/1 \
Prefill required for the Assistant: `<think>\n`
## Model Description
**Model Name:** MistralThinker\
**Version:** 1.1\
**Prompt Format:** Mistral-V7
```
[SYSTEM_PROMPT]{system prompt}[/SYSTEM_PROMPT][INST]{user message}[/INST]{assistant response}</s>
```
This model is a specialized variant of **Mistral-Small-24B-Base-2501**, adapted using a **DeepSeek R1** distillation process. It is **primarily designed for roleplay (RP) and storywriting** applications, focusing on character interactions, narrative generation, and creative storytelling. Approximately **40% of the training dataset** consists of roleplay/storywriting/character card data, ensuring rich and contextually immersive outputs in these domains.
## Model Sources
- **Base Model:** [Mistral-Small-24B-Base-2501](https://huggingface.co/mistralai/Mistral-Small-24B-Base-2501)
- **Fine-Tuning Approach:** DeepSeek R1 process (focused on RP)
- **Dataset Size:** The dataset used in training **doubled** since the last version, adding more neutral logs, training the Base model to stick more on my new format.
## Intended Use
- **Primary Use Cases:**
- **Roleplay (RP):** Engaging with users in fictional or scenario-based interactions.
- **Storywriting:** Generating narratives, character dialogues, and creative texts.
- **Character Lore Generation:** Serving as a resource to craft or expand on character backstories and interactions.
- **How To Use:**
1. **User-First Message:** The first message in any interaction should come from the user, ensuring the model responds in a narrative or roleplay context guided by user input.
2. **Contextual Information:** User or assistant details can be placed either in the system prompt or the user's first message. A system prompt is **not mandatory**, but any contextual instructions or role descriptions can help set the stage.
3. **DeepSeek-Style Interaction:** The model can also be used purely as a **DeepSeek distill** without additional system prompts, providing flexible usage for direct storytelling or roleplay scenarios. The model still can be biased toward Roleplay data, and it is expected.
## Training Data
- **DeepSeek R1 Thinking Process:** The model inherits a refined chain-of-thought (thinking process) from DeepSeek R1, which places heavy emphasis on **roleplay** and narrative coherence.
- **Dataset Composition:**
- 40%: RP/Storywriting/Character Cards
- 60%: Various curated data for broad language, math, logical, space... understanding
- **Data Scaling:** The dataset size was **doubled** compared to previous iterations, which enhances the model’s creative and contextual capabilities.
## Model Performance
- **Strengths:**
- **Storytelling & Roleplay:** Rich in creative generation, character portrayal, and scenario building.
- **Dialogue & Interaction:** Capable of sustaining engaging and context-driven dialogues.
- **Adaptability:** Can be used with or without a system prompt to match a range of user preferences.
- **Limitations & Bias:**
- **Hallucination:** It can generate fictitious information in the thinking process, but still end up with a succesfull reply.
- **Thinking can be dismissed:** Being a distillation of DeepSeek R1 is essence, this model, even trained on Base, could forget to add `<think>\n` in some scenario.
## Ethical Considerations
- Yes
## Usage Recommendations
1. **System Prompt (Optional):**
You may provide a high-level system prompt detailing the scenario or the desired style of roleplay and storywriting.
_Example: "You are a friendly fantasy innkeeper who greets travelers from distant lands."_
2. **User’s First Message:**
- Must clearly state or imply the scenario or context if no system prompt is provided.
_Example: "Hello, I’m a wandering knight seeking shelter. Could you share a story about local legends?"_
3. **Roleplay & Storywriting Focus:**
- Encourage the model to develop characters, backstories, and immersive dialogues.
- For more direct, unfiltered or freeform creativity, skip the system prompt.
- If you still want to have some "logs" from previous message before starting a conversation, put them in the first user message, or in the system prompt.
- You can put exemple message of the character you RP with in the system prompt, too.


|
[
"CRAFT"
] |
SEBIS/legal_t5_small_summ_es
|
SEBIS
|
text2text-generation
|
[
"transformers",
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"summarization Spanish model",
"dataset:jrc-acquis",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-03-02T23:29:04Z |
2022-06-02T19:52:52+00:00
| 44 | 0 |
---
datasets:
- jrc-acquis
language: Spanish
tags:
- summarization Spanish model
widget:
- text: '[notificada con el número C(2006) 166] (El texto en lengua portuguesa es
el único auténtico) (2006/78/CE) LA COMISIÓN DE LAS COMUNIDADES EUROPEAS, Visto
el Tratado constitutivo de la Comunidad Europea, Vista la Decisión 90/424/CEE
del Consejo, de 26 de junio de 1990, relativa a determinados gastos en el sector
veterinario [1], y, en particular, su artículo 3, apartado 2 bis, Considerando
lo siguiente: (1) El 24 de noviembre de 2004 se declararon brotes de fiebre catarral
ovina en Portugal. La aparición de esta enfermedad puede representar un grave
riesgo para la cabaña ganadera de la Comunidad. (2) Para atajar la propagación
de la enfermedad en el plazo más breve, la Comunidad debe participar en los gastos
subvencionables que suponen para Portugal la adopción de medidas de urgencia contra
la enfermedad, en las condiciones previstas en la Decisión 90/424/CEE. Por ello,
el 15 de septiembre de 2005 se adoptó la Decisión 2005/660/CE de la Comisión relativa
a una ayuda financiera de la Comunidad para medidas de urgencia contra la fiebre
catarral ovina adoptadas en Portugal en 2004 y 2005 [2]. (3) La Comisión ha adoptado
varias decisiones para delimitar las zonas de protección y vigilancia y fijar
las condiciones que deben cumplir los animales que vayan a salir de esas zonas;
la última de ellas es la Decisión 2005/393/CE, de 23 de mayo de 2005, sobre las
zonas de protección y vigilancia en relación con la fiebre catarral ovina y las
condiciones que se aplican a los traslados de animales desde estas zonas o a través
de ellas [3]. (4) Desde el otoño de 2004, la excepcional escasez de lluvias en
Portugal ha afectado gravemente al suministro de forraje y, en consecuencia, a
las posibilidades de alimentación animal, lo que ha conllevado costes adicionales
para los ganaderos. La situación tiene consecuencias particulares en Portugal,
pues las explotaciones especializadas en reproducción de bovinos y de ovinos están
ubicadas en las zonas afectadas por las restricciones aplicadas a los traslados
de animales, mientras que las especializadas en engorde, que constituyen la salida
lógica de los animales criados en aquéllas, están localizadas fuera de dichas
zonas. (5) Portugal, en colaboración con España, puso en marcha otras medidas
para controlar la epidemia, como la realización de estudios epidemiológicos y
la aplicación de medidas de vigilancia de la enfermedad, incluidas las pruebas
de laboratorio para el control serológico y virológico en el marco de las pruebas
realizadas a los animales antes de su traslado y en el de la vigilancia entomológica.
(6) Portugal y España han presentado pruebas de su cooperación para evitar la
propagación de la enfermedad tomando medidas de vigilancia de la misma. (7) De
conformidad con el artículo 3, apartado 2, del Reglamento (CE) no 1258/1999 del
Consejo, de 17 de mayo de 1999, sobre la financiación de la política agrícola
común [4], las medidas veterinarias y fitosanitarias ejecutadas según las normas
comunitarias son financiadas por la sección Garantía del Fondo Europeo de Orientación
y de Garantía Agrícola. El control financiero de estas acciones debe efectuarse
de conformidad con lo dispuesto en los artículos 8 y 9 de dicho Reglamento. (8)
El pago de la contribución financiera de la Comunidad se supedita a la realización
efectiva de las acciones programadas y a la presentación por parte de las autoridades
de toda la información necesaria en los plazos establecidos. (9) El 25 de febrero
de 2005, Portugal presentó un primer cálculo de los costes de las demás medidas
de urgencia, como las de vigilancia epidemiológica, tomadas para luchar contra
la enfermedad. El importe estimado de las medidas de vigilancia epidemiológica
se eleva a 4303336 EUR. (10) A la espera de que se efectúen los controles in situ
de la Comisión, procede fijar desde ahora el importe de un primer pago de la ayuda
financiera de la Comunidad. Este primer pago ha de ser igual al 50 % de la contribución
de la Comunidad, establecida sobre la base del gasto subvencionable calculado
para las medidas de vigilancia epidemiológica. Procede asimismo determinar los
importes máximos que se reembolsarán en concepto de pruebas realizadas y de trampas
utilizadas en el marco de dichas medidas. (11) Las autoridades portuguesas han
cumplido íntegramente sus obligaciones técnicas y administrativas relacionadas
con las medidas previstas en el artículo 3 de la Decisión 90/424/CEE. (12) Las
medidas previstas en la presente Decisión se ajustan al dictamen del Comité permanente
de la cadena alimentaria y de sanidad animal. HA ADOPTADO LA PRESENTE DECISIÓN:
Artículo 1 Concesión de una ayuda financiera de la Comunidad a Portugal 1. En
el marco de las medidas de urgencia contra la fiebre catarral ovina adoptadas
en Portugal en 2004 y 2005, Portugal tendrá derecho a una contribución comunitaria
del 50 % de los importes desembolsados en concepto de pruebas de laboratorio para
la vigilancia serológica y virológica, así como en concepto de vigilancia entomológica,
incluida la adquisición de trampas. 2. El importe máximo de los gastos que se
reembolsarán a Portugal en concepto de las pruebas y las trampas mencionadas en
el apartado 1 no excederá de: a) vigilancia serológica, prueba ELISA: 2,5 EUR
por prueba; b) vigilancia virológica, reacción en cadena de la polimerasa retrotranscriptásica
(RT.PCR): 15 EUR por prueba; c) vigilancia entomológica, trampa: 160 EUR por trampa.
3. El impuesto sobre el valor añadido se excluirá de la participación financiera
de la Comunidad. Artículo 2 Modalidades de pago A reserva del resultado de los
controles in situ llevados a cabo de conformidad con el artículo 9, apartado 1,
de la Decisión 90/424/CEE, se efectuará un primer pago de 600000 EUR como parte
de la ayuda financiera de la Comunidad prevista en el artículo 1. El pago se llevará
a cabo previa presentación por parte de Portugal de justificantes de las pruebas
de laboratorio y de la adquisición de las trampas mencionadas en el artículo 1,
apartado 1. Artículo 3 Condiciones de pago y documentación justificativa 1. La
ayuda financiera de la Comunidad contemplada en el artículo 1 se pagará atendiendo
a los siguientes elementos: a) una solicitud que contenga los datos especificados
en el anexo, presentada en el plazo establecido en el apartado 2 del presente
artículo; b) la documentación justificativa mencionada en el artículo 2, que incluirá
un informe epidemiológico y un informe financiero; c) el resultado de cualquiera
de los controles in situ llevados a cabo de conformidad con el artículo 9, apartado
1, de la Decisión 90/424/CEE. Los documentos mencionados en la letra b) deberán
estar disponibles para los controles in situ mencionados en la letra c). 2. La
solicitud mencionada en el apartado 1, letra a), se presentará en formato electrónico
en un plazo de 60 días naturales a partir de la fecha de notificación de la presente
Decisión. Si no se respeta este plazo, la ayuda financiera comunitaria se reducirá
un 25 % por cada mes de retraso. Artículo 4 Destinatario El destinatario de la
presente Decisión es la República Portuguesa. Hecho en Bruselas, el 31 de enero
de 2006. Por la Comisión Markos Kyprianou Miembro de la Comisión [1] DO L 224
de 18.8.1990, p. 19. Decisión modificada en último lugar por el Reglamento (CE)
no 806/2003 (DO L 122 de 16.5.2003, p. 1). [2] DO L 244 de 20.9.2005, p. 28. [3]
DO L 130 de 24.5.2005, p. 22. Decisión modificada en último lugar por la Decisión
2005/828/CE (DO L 311 de 26.11.2005, p. 37). [4] DO L 160 de 26.6.1999, p. 103.
-------------------------------------------------- ANEXO Datos mencionados en
el artículo 3, apartado 1, letra a) Gastos | Naturaleza de los costes | Número
| Importe (sin IVA) | Pruebas ELISA | | | Pruebas RT.PCR | | | Otras pruebas virológicas
| | | Trampas | | | Total | | -------------------------------------------------- '
---
# legal_t5_small_summ_es model
Model for Summarization of legal text written in Spanish. It was first released in
[this repository](https://github.com/agemagician/LegalTrans). This model is trained on three parallel corpus from jrc-acquis.
## Model description
legal_t5_small_summ_es is based on the `t5-small` model and was trained on a large corpus of parallel text. This is a smaller model, which scales the baseline model of t5 down by using `dmodel = 512`, `dff = 2,048`, 8-headed attention, and only 6 layers each in the encoder and decoder. This variant has about 60 million parameters.
## Intended uses & limitations
The model could be used for summarization of legal texts written in Spanish.
### How to use
Here is how to use this model to summarize legal text written in Spanish in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, TranslationPipeline
pipeline = TranslationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/legal_t5_small_summ_es"),
tokenizer=AutoTokenizer.from_pretrained(pretrained_model_name_or_path = "SEBIS/legal_t5_small_summ_es", do_lower_case=False,
skip_special_tokens=True),
device=0
)
es_text = "[notificada con el número C(2006) 166] (El texto en lengua portuguesa es el único auténtico) (2006/78/CE) LA COMISIÓN DE LAS COMUNIDADES EUROPEAS, Visto el Tratado constitutivo de la Comunidad Europea, Vista la Decisión 90/424/CEE del Consejo, de 26 de junio de 1990, relativa a determinados gastos en el sector veterinario [1], y, en particular, su artículo 3, apartado 2 bis, Considerando lo siguiente: (1) El 24 de noviembre de 2004 se declararon brotes de fiebre catarral ovina en Portugal. La aparición de esta enfermedad puede representar un grave riesgo para la cabaña ganadera de la Comunidad. (2) Para atajar la propagación de la enfermedad en el plazo más breve, la Comunidad debe participar en los gastos subvencionables que suponen para Portugal la adopción de medidas de urgencia contra la enfermedad, en las condiciones previstas en la Decisión 90/424/CEE. Por ello, el 15 de septiembre de 2005 se adoptó la Decisión 2005/660/CE de la Comisión relativa a una ayuda financiera de la Comunidad para medidas de urgencia contra la fiebre catarral ovina adoptadas en Portugal en 2004 y 2005 [2]. (3) La Comisión ha adoptado varias decisiones para delimitar las zonas de protección y vigilancia y fijar las condiciones que deben cumplir los animales que vayan a salir de esas zonas; la última de ellas es la Decisión 2005/393/CE, de 23 de mayo de 2005, sobre las zonas de protección y vigilancia en relación con la fiebre catarral ovina y las condiciones que se aplican a los traslados de animales desde estas zonas o a través de ellas [3]. (4) Desde el otoño de 2004, la excepcional escasez de lluvias en Portugal ha afectado gravemente al suministro de forraje y, en consecuencia, a las posibilidades de alimentación animal, lo que ha conllevado costes adicionales para los ganaderos. La situación tiene consecuencias particulares en Portugal, pues las explotaciones especializadas en reproducción de bovinos y de ovinos están ubicadas en las zonas afectadas por las restricciones aplicadas a los traslados de animales, mientras que las especializadas en engorde, que constituyen la salida lógica de los animales criados en aquéllas, están localizadas fuera de dichas zonas. (5) Portugal, en colaboración con España, puso en marcha otras medidas para controlar la epidemia, como la realización de estudios epidemiológicos y la aplicación de medidas de vigilancia de la enfermedad, incluidas las pruebas de laboratorio para el control serológico y virológico en el marco de las pruebas realizadas a los animales antes de su traslado y en el de la vigilancia entomológica. (6) Portugal y España han presentado pruebas de su cooperación para evitar la propagación de la enfermedad tomando medidas de vigilancia de la misma. (7) De conformidad con el artículo 3, apartado 2, del Reglamento (CE) no 1258/1999 del Consejo, de 17 de mayo de 1999, sobre la financiación de la política agrícola común [4], las medidas veterinarias y fitosanitarias ejecutadas según las normas comunitarias son financiadas por la sección Garantía del Fondo Europeo de Orientación y de Garantía Agrícola. El control financiero de estas acciones debe efectuarse de conformidad con lo dispuesto en los artículos 8 y 9 de dicho Reglamento. (8) El pago de la contribución financiera de la Comunidad se supedita a la realización efectiva de las acciones programadas y a la presentación por parte de las autoridades de toda la información necesaria en los plazos establecidos. (9) El 25 de febrero de 2005, Portugal presentó un primer cálculo de los costes de las demás medidas de urgencia, como las de vigilancia epidemiológica, tomadas para luchar contra la enfermedad. El importe estimado de las medidas de vigilancia epidemiológica se eleva a 4303336 EUR. (10) A la espera de que se efectúen los controles in situ de la Comisión, procede fijar desde ahora el importe de un primer pago de la ayuda financiera de la Comunidad. Este primer pago ha de ser igual al 50 % de la contribución de la Comunidad, establecida sobre la base del gasto subvencionable calculado para las medidas de vigilancia epidemiológica. Procede asimismo determinar los importes máximos que se reembolsarán en concepto de pruebas realizadas y de trampas utilizadas en el marco de dichas medidas. (11) Las autoridades portuguesas han cumplido íntegramente sus obligaciones técnicas y administrativas relacionadas con las medidas previstas en el artículo 3 de la Decisión 90/424/CEE. (12) Las medidas previstas en la presente Decisión se ajustan al dictamen del Comité permanente de la cadena alimentaria y de sanidad animal. HA ADOPTADO LA PRESENTE DECISIÓN: Artículo 1 Concesión de una ayuda financiera de la Comunidad a Portugal 1. En el marco de las medidas de urgencia contra la fiebre catarral ovina adoptadas en Portugal en 2004 y 2005, Portugal tendrá derecho a una contribución comunitaria del 50 % de los importes desembolsados en concepto de pruebas de laboratorio para la vigilancia serológica y virológica, así como en concepto de vigilancia entomológica, incluida la adquisición de trampas. 2. El importe máximo de los gastos que se reembolsarán a Portugal en concepto de las pruebas y las trampas mencionadas en el apartado 1 no excederá de: a) vigilancia serológica, prueba ELISA: 2,5 EUR por prueba; b) vigilancia virológica, reacción en cadena de la polimerasa retrotranscriptásica (RT.PCR): 15 EUR por prueba; c) vigilancia entomológica, trampa: 160 EUR por trampa. 3. El impuesto sobre el valor añadido se excluirá de la participación financiera de la Comunidad. Artículo 2 Modalidades de pago A reserva del resultado de los controles in situ llevados a cabo de conformidad con el artículo 9, apartado 1, de la Decisión 90/424/CEE, se efectuará un primer pago de 600000 EUR como parte de la ayuda financiera de la Comunidad prevista en el artículo 1. El pago se llevará a cabo previa presentación por parte de Portugal de justificantes de las pruebas de laboratorio y de la adquisición de las trampas mencionadas en el artículo 1, apartado 1. Artículo 3 Condiciones de pago y documentación justificativa 1. La ayuda financiera de la Comunidad contemplada en el artículo 1 se pagará atendiendo a los siguientes elementos: a) una solicitud que contenga los datos especificados en el anexo, presentada en el plazo establecido en el apartado 2 del presente artículo; b) la documentación justificativa mencionada en el artículo 2, que incluirá un informe epidemiológico y un informe financiero; c) el resultado de cualquiera de los controles in situ llevados a cabo de conformidad con el artículo 9, apartado 1, de la Decisión 90/424/CEE. Los documentos mencionados en la letra b) deberán estar disponibles para los controles in situ mencionados en la letra c). 2. La solicitud mencionada en el apartado 1, letra a), se presentará en formato electrónico en un plazo de 60 días naturales a partir de la fecha de notificación de la presente Decisión. Si no se respeta este plazo, la ayuda financiera comunitaria se reducirá un 25 % por cada mes de retraso. Artículo 4 Destinatario El destinatario de la presente Decisión es la República Portuguesa. Hecho en Bruselas, el 31 de enero de 2006. Por la Comisión Markos Kyprianou Miembro de la Comisión [1] DO L 224 de 18.8.1990, p. 19. Decisión modificada en último lugar por el Reglamento (CE) no 806/2003 (DO L 122 de 16.5.2003, p. 1). [2] DO L 244 de 20.9.2005, p. 28. [3] DO L 130 de 24.5.2005, p. 22. Decisión modificada en último lugar por la Decisión 2005/828/CE (DO L 311 de 26.11.2005, p. 37). [4] DO L 160 de 26.6.1999, p. 103. -------------------------------------------------- ANEXO Datos mencionados en el artículo 3, apartado 1, letra a) Gastos | Naturaleza de los costes | Número | Importe (sin IVA) | Pruebas ELISA | | | Pruebas RT.PCR | | | Otras pruebas virológicas | | | Trampas | | | Total | | -------------------------------------------------- "
pipeline([es_text], max_length=512)
```
## Training data
The legal_t5_small_summ_es model was trained on [JRC-ACQUIS](https://wt-public.emm4u.eu/Acquis/index_2.2.html) dataset consisting of 23 Thousand texts.
## Training procedure
The model was trained on a single TPU Pod V3-8 for 250K steps in total, using sequence length 512 (batch size 64). It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture. The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Preprocessing
An unigram model trained with 88M lines of text from the parallel corpus (of all possible language pairs) to get the vocabulary (with byte pair encoding), which is used with this model.
### Pretraining
## Evaluation results
When the model is used for classification test dataset, achieves the following results:
Test results :
| Model | Rouge1 | Rouge2 | Rouge Lsum |
|:-----:|:-----:|:-----:|:-----:|
| legal_t5_small_summ_es | 80.23|70.16 |78.69|
### BibTeX entry and citation info
> Created by [Ahmed Elnaggar/@Elnaggar_AI](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/)
|
[
"PCR"
] |
crumb/distilpythia
|
crumb
|
text-generation
|
[
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"en",
"dataset:EleutherAI/pile",
"arxiv:1706.03762",
"arxiv:1503.02531",
"arxiv:2304.01373",
"arxiv:2101.00027",
"arxiv:1910.01108",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-05-02T22:28:45Z |
2023-07-20T18:06:02+00:00
| 44 | 4 |
---
datasets:
- EleutherAI/pile
language:
- en
license: apache-2.0
---
# Warm-Starting Knowledge Distillation for Transformer-based Language Models
*by GPT-4 & Crumb*
### Introduction
Transformer models have become a popular choice for natural language processing (NLP) tasks due to their ability to handle long-range dependencies and their superior performance on various NLP benchmarks. The transformer model architecture was introduced in 2017 by [Vaswani et al](https://arxiv.org/abs/1706.03762). and has since been used in many state-of-the-art models such as BERT and GPT. The decoder-only transformer model is a variant of the transformer model that has is commonly used for generative tasks in NLP. It uses masked self-attention to predict the next token in a sequence and has been shown to be powerful at predicting sequences of text.
Distillation \[[Bucila et al., 2006](https://www.cs.cornell.edu/~caruana/compression.kdd06.pdf), [Hinton et al., 2015](https://arxiv.org/abs/1503.02531)\] is a technique used in machine learning to compress a large model into a smaller one that can be used on devices with limited computational resources. In this technique, a smaller model is trained to mimic the behavior of a larger model by learning from its predictions. The smaller model is trained on a smaller dataset than the larger model, which makes it faster and more efficient. This technique has been used to compress models like BERT and GPT-2 into smaller models like DistilBERT and DistilGPT-2, respectively. In this project we apply the technique of knowledge distillation to the second smallest [Pythia](https://arxiv.org/pdf/2304.01373.pdf) model on the [Pile](https://arxiv.org/abs/2101.00027) dataset.
### Method
We follow the work of [Sanh et al. (2019)](https://arxiv.org/abs/1910.01108) and [Hinton et al. (2015)](https://arxiv.org/abs/1503.02531) for a distillation loss over the soft target probabilities `L_ce`. We utilize the distillation loss in our loss function as a linear combination of the distillation loss `L_ce` with the supervised training loss `L_clm`. Our combined loss function is `L_ce*(1-a) + L_clm*a` where `a` is set to 0.5 and the `T`emperature parameter for the distillation loss is set to 2.
In an effort to maximize VRAM utilization, to reach a combined batch size of 4096 samples we use a device batch size of 2 with 2048 gradient accumulation steps and a context length of 2048 tokens with both the teacher and student model in bf16 precision. This allowed us to utilize around 98.94% of the 12 gigabytes of VRAM that the RTX3060 card has during training.
It also means our training set totals to approximately 537 million training tokens, as our model trained for 64 steps. All training samples were taken from [The Pile](https://arxiv.org/abs/2101.00027).
A learning rate of 1e-4 was used in this study, with no learning rate schedule.
### Evaluation
[Sanh et al. (2019)](https://arxiv.org/abs/1910.01108) suggests a student around 40% of the size of it's teacher can achieve similar performance in encoder models when training from scratch with suprivision. We warm-start our model from a smaller checkpoint than the teacher that maintains a similar ratio with a student that is 43.75% the size of it's teacher.
| model | piqa acc | winogrande acc | lambada ppl | lambada acc | arc acc | sciq acc | wsc acc | notes |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| pythia-70m (student base) | 59.85 | 51.22 | 140.81 | 21.40 | 17.15 | 65.00 | 36.53 |
| pythia-160m (teacher) | 62.68 | 51.07 | 30.03 | 36.76 | 19.62 | 76.20 | 36.58 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| distilpythia (student) | 59.74 | **51.62** | 420.70 | 15.82 | **17.15** | 61.30 | **36.54** | trained on padded/truncated examples
| distilpythia-cl (student) | 59.30 | 50.75 | 403.78 | 15.16 | 16.98 | 59.20 | **36.54** | trained on a constant-length dataset
<center> <i>Table 1.</i> The student before finetuning, teacher, and student after finetuning and their results on various benchmarks. Numbers in bold are where the student after finetuning matches or outperforms the student before finetuning. </center>
The table provides a comparison of performance between the base student model (pythia-70m), the teacher model (pythia-160m), and the finetuned student model (distilpythia) across various benchmarks. The goal is to assess whether the distilpythia model can achieve similar or better performance than its base while being smaller in size.
From the table, we can observe the following:
1. The pythia-160m (teacher) model outperforms pythia-70m (student base) in most benchmarks, except for Winogrande accuracy, where the student base has a slightly better performance (51.22% vs. 51.07%).
2. The distilpythia (student) model, after finetuning, outperforms the pythia-70m (student base) on two benchmarks: Winogrande accuracy (51.62% vs. 51.22%) and WSC accuracy (36.54% vs. 36.53%). The improvements in these metrics indicate that the finetuning process may be effective in transferring knowledge from the teacher model to the student model.
### Conclusion
it might have worked idk, maybe training from scratch or for longer would give more performance gains, also look at the lambada perplexity what happened there even
|
[
"SCIQ"
] |
ntc-ai/SDXL-LoRA-slider.wide-angle
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-27T01:49:56Z |
2023-12-27T01:49:59+00:00
| 44 | 1 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/wide angle.../wide angle_17_3.0.png
widget:
- text: wide angle
output:
url: images/wide angle_17_3.0.png
- text: wide angle
output:
url: images/wide angle_19_3.0.png
- text: wide angle
output:
url: images/wide angle_20_3.0.png
- text: wide angle
output:
url: images/wide angle_21_3.0.png
- text: wide angle
output:
url: images/wide angle_22_3.0.png
inference: false
instance_prompt: wide angle
---
# ntcai.xyz slider - wide angle (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/wide angle_17_-3.0.png" width=256 height=256 /> | <img src="images/wide angle_17_0.0.png" width=256 height=256 /> | <img src="images/wide angle_17_3.0.png" width=256 height=256 /> |
| <img src="images/wide angle_19_-3.0.png" width=256 height=256 /> | <img src="images/wide angle_19_0.0.png" width=256 height=256 /> | <img src="images/wide angle_19_3.0.png" width=256 height=256 /> |
| <img src="images/wide angle_20_-3.0.png" width=256 height=256 /> | <img src="images/wide angle_20_0.0.png" width=256 height=256 /> | <img src="images/wide angle_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
wide angle
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.wide-angle', weight_name='wide angle.safetensors', adapter_name="wide angle")
# Activate the LoRA
pipe.set_adapters(["wide angle"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, wide angle"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 650+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.studio-lighting
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-28T22:53:07Z |
2023-12-28T22:53:10+00:00
| 44 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/studio lighting.../studio lighting_17_3.0.png
widget:
- text: studio lighting
output:
url: images/studio lighting_17_3.0.png
- text: studio lighting
output:
url: images/studio lighting_19_3.0.png
- text: studio lighting
output:
url: images/studio lighting_20_3.0.png
- text: studio lighting
output:
url: images/studio lighting_21_3.0.png
- text: studio lighting
output:
url: images/studio lighting_22_3.0.png
inference: false
instance_prompt: studio lighting
---
# ntcai.xyz slider - studio lighting (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/studio lighting_17_-3.0.png" width=256 height=256 /> | <img src="images/studio lighting_17_0.0.png" width=256 height=256 /> | <img src="images/studio lighting_17_3.0.png" width=256 height=256 /> |
| <img src="images/studio lighting_19_-3.0.png" width=256 height=256 /> | <img src="images/studio lighting_19_0.0.png" width=256 height=256 /> | <img src="images/studio lighting_19_3.0.png" width=256 height=256 /> |
| <img src="images/studio lighting_20_-3.0.png" width=256 height=256 /> | <img src="images/studio lighting_20_0.0.png" width=256 height=256 /> | <img src="images/studio lighting_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
studio lighting
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.studio-lighting', weight_name='studio lighting.safetensors', adapter_name="studio lighting")
# Activate the LoRA
pipe.set_adapters(["studio lighting"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, studio lighting"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 700+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.stylish-photoshoot
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-07T08:10:01Z |
2024-01-07T08:10:04+00:00
| 44 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/stylish photoshoot.../stylish photoshoot_17_3.0.png
widget:
- text: stylish photoshoot
output:
url: images/stylish photoshoot_17_3.0.png
- text: stylish photoshoot
output:
url: images/stylish photoshoot_19_3.0.png
- text: stylish photoshoot
output:
url: images/stylish photoshoot_20_3.0.png
- text: stylish photoshoot
output:
url: images/stylish photoshoot_21_3.0.png
- text: stylish photoshoot
output:
url: images/stylish photoshoot_22_3.0.png
inference: false
instance_prompt: stylish photoshoot
---
# ntcai.xyz slider - stylish photoshoot (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/stylish photoshoot_17_-3.0.png" width=256 height=256 /> | <img src="images/stylish photoshoot_17_0.0.png" width=256 height=256 /> | <img src="images/stylish photoshoot_17_3.0.png" width=256 height=256 /> |
| <img src="images/stylish photoshoot_19_-3.0.png" width=256 height=256 /> | <img src="images/stylish photoshoot_19_0.0.png" width=256 height=256 /> | <img src="images/stylish photoshoot_19_3.0.png" width=256 height=256 /> |
| <img src="images/stylish photoshoot_20_-3.0.png" width=256 height=256 /> | <img src="images/stylish photoshoot_20_0.0.png" width=256 height=256 /> | <img src="images/stylish photoshoot_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
stylish photoshoot
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.stylish-photoshoot', weight_name='stylish photoshoot.safetensors', adapter_name="stylish photoshoot")
# Activate the LoRA
pipe.set_adapters(["stylish photoshoot"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, stylish photoshoot"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 910+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
BiMediX/BiMediX-Ara
|
BiMediX
|
text-generation
|
[
"transformers",
"safetensors",
"mixtral",
"feature-extraction",
"medical",
"text-generation",
"conversational",
"ar",
"arxiv:2402.13253",
"license:cc-by-nc-sa-4.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-02-20T17:09:28Z |
2024-02-26T09:01:09+00:00
| 44 | 4 |
---
language:
- ar
license: cc-by-nc-sa-4.0
metrics:
- accuracy
pipeline_tag: text-generation
tags:
- medical
---
## Model Card for BiMediX-Bilingual
### Model Details
- **Name:** BiMediX
- **Version:** 1.0
- **Type:** Bilingual Medical Mixture of Experts Large Language Model (LLM)
- **Languages:** Arabic
- **Model Architecture:** [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1)
- **Training Data:** BiMed1.3M-Arabic, an arabic dataset with diverse medical interactions.
### Intended Use
- **Primary Use:** Medical interactions in both English and Arabic.
- **Capabilities:** MCQA, closed QA and chats.
## Getting Started
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "BiMediX/BiMediX-Ara"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
text = "مرحبًا بيميديكس! لقد كنت أعاني من التعب المتزايد في الأسبوع الماضي."
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=500)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
### Training Procedure
- **Dataset:** BiMed1.3M-Arabic.
- **QLoRA Adaptation:** Implements a low-rank adaptation technique, incorporating learnable low-rank adapter weights into the experts and the routing network. This results in training about 4% of the original parameters.
- **Training Resources:** The model underwent training on the Arabic corpus.
### Model Performance
| **Model** | **CKG** | **CBio** | **CMed** | **MedGen** | **ProMed** | **Ana** | **MedMCQA** | **MedQA** | **PubmedQA** | **AVG** |
|-----------|------------|-----------|-----------|-------------|-------------|---------|-------------|-----------|--------------|---------|
| Jais-30B | 52.1 | 50.7 | 40.5 | 49.0 | 39.3 | 43.0 | 37.0 | 28.8 | 74.6 | 46.1 |
| BiMediX (Arabic) | 60.0 | 54.9 | **55.5** | 58.0 | **58.1** | 49.6 | 46.0 | 40.2 | 76.6 | 55.4 |
| **BiMediX (Bilingual)** | **63.8** | **57.6** | 52.6 | **64.0** | 52.9 | **50.4** | **49.1** | **47.3** | **78.4** | **56.5** |
### Safety and Ethical Considerations
- **Potential issues**: hallucinations, toxicity, stereotypes.
- **Usage:** Research purposes only.
### Accessibility
- **Availability:** [BiMediX GitHub Repository](https://github.com/mbzuai-oryx/BiMediX).
- arxiv.org/abs/2402.13253
### Authors
Sara Pieri, Sahal Shaji Mullappilly, Fahad Shahbaz Khan, Rao Muhammad Anwer Salman Khan, Timothy Baldwin, Hisham Cholakkal
**Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI)**
|
[
"MEDQA",
"PUBMEDQA"
] |
RichardErkhov/M4-ai_-_tau-0.5B-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-06-24T22:10:28Z |
2024-06-24T22:14:48+00:00
| 44 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
tau-0.5B - GGUF
- Model creator: https://huggingface.co/M4-ai/
- Original model: https://huggingface.co/M4-ai/tau-0.5B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [tau-0.5B.Q2_K.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q2_K.gguf) | Q2_K | 0.23GB |
| [tau-0.5B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.IQ3_XS.gguf) | IQ3_XS | 0.24GB |
| [tau-0.5B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.IQ3_S.gguf) | IQ3_S | 0.25GB |
| [tau-0.5B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q3_K_S.gguf) | Q3_K_S | 0.25GB |
| [tau-0.5B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.IQ3_M.gguf) | IQ3_M | 0.26GB |
| [tau-0.5B.Q3_K.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q3_K.gguf) | Q3_K | 0.26GB |
| [tau-0.5B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q3_K_M.gguf) | Q3_K_M | 0.26GB |
| [tau-0.5B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q3_K_L.gguf) | Q3_K_L | 0.28GB |
| [tau-0.5B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.IQ4_XS.gguf) | IQ4_XS | 0.28GB |
| [tau-0.5B.Q4_0.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q4_0.gguf) | Q4_0 | 0.29GB |
| [tau-0.5B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.IQ4_NL.gguf) | IQ4_NL | 0.29GB |
| [tau-0.5B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q4_K_S.gguf) | Q4_K_S | 0.29GB |
| [tau-0.5B.Q4_K.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q4_K.gguf) | Q4_K | 0.3GB |
| [tau-0.5B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q4_K_M.gguf) | Q4_K_M | 0.3GB |
| [tau-0.5B.Q4_1.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q4_1.gguf) | Q4_1 | 0.3GB |
| [tau-0.5B.Q5_0.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q5_0.gguf) | Q5_0 | 0.32GB |
| [tau-0.5B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q5_K_S.gguf) | Q5_K_S | 0.32GB |
| [tau-0.5B.Q5_K.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q5_K.gguf) | Q5_K | 0.33GB |
| [tau-0.5B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q5_K_M.gguf) | Q5_K_M | 0.33GB |
| [tau-0.5B.Q5_1.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q5_1.gguf) | Q5_1 | 0.34GB |
| [tau-0.5B.Q6_K.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q6_K.gguf) | Q6_K | 0.36GB |
| [tau-0.5B.Q8_0.gguf](https://huggingface.co/RichardErkhov/M4-ai_-_tau-0.5B-gguf/blob/main/tau-0.5B.Q8_0.gguf) | Q8_0 | 0.47GB |
Original model description:
---
license: other
datasets:
- Locutusque/UltraTextbooks-2.0
inference:
parameters:
do_sample: true
temperature: 0.8
top_p: 0.95
top_k: 40
max_new_tokens: 250
repetition_penalty: 1.1
language:
- en
- zh
---
# tau-0.5B
## Model Details
- **Model Name:** tau-0.5B
- **Base Model:** Qwen1.5-0.5B
- **Dataset:** UltraTextbooks-2.0
- **Model Size:** 0.5B parameters
- **Model Type:** Language Model
- **Training Procedure:** Further pre-training of Qwen1.5-0.5B on UltraTextbooks-2.0.
## Model Use
tau-0.5B is designed to be a general-purpose language model with enhanced capabilities in the domains of machine learning, mathematics, and coding. It can be used for a wide range of natural language processing tasks, such as:
- Educational question answering
- Text summarization
- Content generation for educational purposes
- Code understanding and generation
- Mathematical problem solving
The model's exposure to the diverse content in the UltraTextbooks-2.0 dataset makes it particularly well-suited for applications in educational technology and research.
## Training Data
tau-0.5B was further pre-trained on the UltraTextbooks-2.0 dataset, which is an expanded version of the original UltraTextbooks dataset. UltraTextbooks-2.0 incorporates additional high-quality synthetic and human-written textbooks from various sources on the Hugging Face platform, with a focus on increasing the diversity of content in the domains of machine learning, mathematics, and coding.
For more details on the dataset, please refer to the [UltraTextbooks-2.0 Dataset Card](https://huggingface.co/datasets/Locutusque/UltraTextbooks-2.0).
## Performance and Limitations
Refer to [Evaluation](##Evaluation) for evaluations. It is essential to note that the model may still exhibit biases or inaccuracies present in the training data. Users are encouraged to critically evaluate the model's outputs and report any issues to facilitate continuous improvement.
## Environmental Impact
The training of tau-0.5B required computational resources that contribute to the model's overall environmental impact. However, efforts were made to optimize the training process and minimize the carbon footprint.
## Ethical Considerations
tau-0.5B was trained on a diverse dataset that may contain biases and inaccuracies. Users should be aware of these potential limitations and use the model responsibly. The model should not be used for tasks that could cause harm or discriminate against individuals or groups.
## Evaluation
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|---------------------------------|-------|------|-----:|--------|-----:|---|-----:|
|agieval_nous |N/A |none | 0|acc |0.2235|± |0.0434|
| | |none | 0|acc_norm|0.2141|± |0.0498|
| - agieval_aqua_rat | 1|none | 0|acc |0.1417|± |0.0219|
| | |none | 0|acc_norm|0.1535|± |0.0227|
| - agieval_logiqa_en | 1|none | 0|acc |0.2796|± |0.0176|
| | |none | 0|acc_norm|0.3118|± |0.0182|
| - agieval_lsat_ar | 1|none | 0|acc |0.2000|± |0.0264|
| | |none | 0|acc_norm|0.1696|± |0.0248|
| - agieval_lsat_lr | 1|none | 0|acc |0.2275|± |0.0186|
| | |none | 0|acc_norm|0.2020|± |0.0178|
| - agieval_lsat_rc | 1|none | 0|acc |0.1487|± |0.0217|
| | |none | 0|acc_norm|0.1561|± |0.0222|
| - agieval_sat_en | 1|none | 0|acc |0.2330|± |0.0295|
| | |none | 0|acc_norm|0.2039|± |0.0281|
| - agieval_sat_en_without_passage| 1|none | 0|acc |0.2524|± |0.0303|
| | |none | 0|acc_norm|0.1942|± |0.0276|
| - agieval_sat_math | 1|none | 0|acc |0.2227|± |0.0281|
| | |none | 0|acc_norm|0.1682|± |0.0253|
| Tasks |Version| Filter |n-shot| Metric |Value | |Stderr|
|---------------------------------------|-------|----------------|-----:|-----------|-----:|---|-----:|
|truthfulqa | 2|none | 0|acc |0.3931|± |0.0143|
|mmlu |N/A |none | 0|acc |0.3642|± |0.0040|
| - humanities |N/A |none | 5|acc |0.3320|± |0.0068|
| - formal_logic | 0|none | 5|acc |0.2619|± |0.0393|
| - high_school_european_history | 0|none | 5|acc |0.4909|± |0.0390|
| - high_school_us_history | 0|none | 5|acc |0.4167|± |0.0346|
| - high_school_world_history | 0|none | 5|acc |0.4641|± |0.0325|
| - international_law | 0|none | 5|acc |0.5537|± |0.0454|
| - jurisprudence | 0|none | 5|acc |0.4167|± |0.0477|
| - logical_fallacies | 0|none | 5|acc |0.2638|± |0.0346|
| - moral_disputes | 0|none | 5|acc |0.3757|± |0.0261|
| - moral_scenarios | 0|none | 5|acc |0.2402|± |0.0143|
| - philosophy | 0|none | 5|acc |0.3794|± |0.0276|
| - prehistory | 0|none | 5|acc |0.3426|± |0.0264|
| - professional_law | 0|none | 5|acc |0.3103|± |0.0118|
| - world_religions | 0|none | 5|acc |0.2807|± |0.0345|
| - other |N/A |none | 5|acc |0.4071|± |0.0088|
| - business_ethics | 0|none | 5|acc |0.4200|± |0.0496|
| - clinical_knowledge | 0|none | 5|acc |0.4491|± |0.0306|
| - college_medicine | 0|none | 5|acc |0.3873|± |0.0371|
| - global_facts | 0|none | 5|acc |0.3600|± |0.0482|
| - human_aging | 0|none | 5|acc |0.3498|± |0.0320|
| - management | 0|none | 5|acc |0.4854|± |0.0495|
| - marketing | 0|none | 5|acc |0.5470|± |0.0326|
| - medical_genetics | 0|none | 5|acc |0.4000|± |0.0492|
| - miscellaneous | 0|none | 5|acc |0.4291|± |0.0177|
| - nutrition | 0|none | 5|acc |0.4183|± |0.0282|
| - professional_accounting | 0|none | 5|acc |0.3582|± |0.0286|
| - professional_medicine | 0|none | 5|acc |0.3015|± |0.0279|
| - virology | 0|none | 5|acc |0.3494|± |0.0371|
| - social_sciences |N/A |none | 5|acc |0.4075|± |0.0088|
| - econometrics | 0|none | 5|acc |0.2719|± |0.0419|
| - high_school_geography | 0|none | 5|acc |0.5000|± |0.0356|
| - high_school_government_and_politics| 0|none | 5|acc |0.4611|± |0.0360|
| - high_school_macroeconomics | 0|none | 5|acc |0.4051|± |0.0249|
| - high_school_microeconomics | 0|none | 5|acc |0.3908|± |0.0317|
| - high_school_psychology | 0|none | 5|acc |0.4239|± |0.0212|
| - human_sexuality | 0|none | 5|acc |0.3893|± |0.0428|
| - professional_psychology | 0|none | 5|acc |0.3399|± |0.0192|
| - public_relations | 0|none | 5|acc |0.4455|± |0.0476|
| - security_studies | 0|none | 5|acc |0.3510|± |0.0306|
| - sociology | 0|none | 5|acc |0.5174|± |0.0353|
| - us_foreign_policy | 0|none | 5|acc |0.5500|± |0.0500|
| - stem |N/A |none | 5|acc |0.3276|± |0.0083|
| - abstract_algebra | 0|none | 5|acc |0.3000|± |0.0461|
| - anatomy | 0|none | 5|acc |0.2889|± |0.0392|
| - astronomy | 0|none | 5|acc |0.3487|± |0.0388|
| - college_biology | 0|none | 5|acc |0.3403|± |0.0396|
| - college_chemistry | 0|none | 5|acc |0.2600|± |0.0441|
| - college_computer_science | 0|none | 5|acc |0.3800|± |0.0488|
| - college_mathematics | 0|none | 5|acc |0.3300|± |0.0473|
| - college_physics | 0|none | 5|acc |0.2745|± |0.0444|
| - computer_security | 0|none | 5|acc |0.4300|± |0.0498|
| - conceptual_physics | 0|none | 5|acc |0.3447|± |0.0311|
| - electrical_engineering | 0|none | 5|acc |0.3931|± |0.0407|
| - elementary_mathematics | 0|none | 5|acc |0.3095|± |0.0238|
| - high_school_biology | 0|none | 5|acc |0.4161|± |0.0280|
| - high_school_chemistry | 0|none | 5|acc |0.2759|± |0.0314|
| - high_school_computer_science | 0|none | 5|acc |0.3100|± |0.0465|
| - high_school_mathematics | 0|none | 5|acc |0.3185|± |0.0284|
| - high_school_physics | 0|none | 5|acc |0.2517|± |0.0354|
| - high_school_statistics | 0|none | 5|acc |0.3009|± |0.0313|
| - machine_learning | 0|none | 5|acc |0.3036|± |0.0436|
|medqa_4options |Yaml |none | 5|acc |0.2687|± |0.0124|
| | |none | 5|acc_norm |0.2687|± |0.0124|
|logieval | 0|get-answer | 5|exact_match|0.3505|± |0.0120|
|gsm8k_cot | 3|strict-match | 8|exact_match|0.0690|± |0.0070|
| | |flexible-extract| 8|exact_match|0.1365|± |0.0095|
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|-------------|------:|------|-----:|--------|-----:|---|-----:|
|arc_easy | 1|none | 25|acc |0.5981|± |0.0101|
| | |none | 25|acc_norm|0.5939|± |0.0101|
|arc_challenge| 1|none | 25|acc |0.2688|± |0.0130|
| | |none | 25|acc_norm|0.2969|± |0.0134|
## Usage Rights
Make sure to read Qwen's license before using this model.
|
[
"MEDQA"
] |
digitalhealth-healthyliving/MediFlow
|
digitalhealth-healthyliving
|
text-classification
|
[
"transformers",
"safetensors",
"xlnet",
"text-classification",
"medical",
"en",
"es",
"arxiv:2004.03329",
"base_model:xlnet/xlnet-large-cased",
"base_model:finetune:xlnet/xlnet-large-cased",
"license:cc-by-nc-nd-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-07-08T12:25:32Z |
2024-10-02T08:40:54+00:00
| 44 | 0 |
---
base_model:
- xlnet/xlnet-large-cased
language:
- en
- es
library_name: transformers
license: cc-by-nc-nd-4.0
metrics:
- accuracy
- f1
- precision
tags:
- medical
---
# **MediFlow**
MediFlow se trata de un modelo inicializado con [xlnet-large-cased](https://huggingface.co/xlnet/xlnet-large-cased) y adaptado con preguntas y especialidades
para poder realizar Derivaciones Automatizadas en Servicios Hospitalarios. El dataset se puede encontrar de manera pública y se trata de [MedDialog EN](https://arxiv.org/abs/2004.03329).
Este modelo toma como input una descripción, en inglés, proveída por el paciente y devuelve las siguientes especialidades (`model.config.label2id`): Cardiology, Traumatology, Mental Health y Pneumology.
Se puede encontrar más información del modelo [aquí](https://huggingface.co/digitalhealth-healthyliving/MediFlow/resolve/main/MediFlow%20Adaptaci%C3%B3n%20de%20un%20Modelo%20de%20Lenguaje%20para%20Triaje%20Automatizado%20a%20diferentes%20especialidades.pdf).
Para el entrenamiento de este modelo hemos seguidos los estándares de la librería [transformers](https://github.com/huggingface/transformers) y se ha utilizado una
NVIDIA P100. Además, ha sido entrenado con un batch-size de 4, un learning rate de 2e-5, X epochs y un weigth decay de 0.015, loggeando los resultados cada 100 iteraciones.
## **Utilización**
Mediante el `pipeline` de Hugging Face:
```python
from transformers import pipeline
model_id = "digitalhealth-healthyliving/MediFlow"
pipe = pipeline("text-classification", model_id)
text = "I have pain in the back"
result = pipe(text)
print(result)
```
Mediante `AutoModelForSequenceClassification` y `AutoTokenizer`:
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_id = "digitalhealth-healthyliving/MediFlow"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSequenceClassification.from_pretrained(model_id)
text = "I have pain in the back"
inputs = tokenizer(text, return_tensors = "pt")
logits = model(**inputs)
print(f"The predicted class is {model.id2label[logits.argmax()]}")
print(result)
```
## **Evaluación**
- **Accuracy** : 89,3%
- **F1**: 89,4%
- **Precision**: 90%
#### Training Hyperparameters
- **learning_rate**: 2e-5
- **batch_size**: 4
- **num_train_epochs**: 3
- **weight_decay**: 0.015
- **optimizer**: AdamW
- **test_size**: 0.2
- **logging_steps**: 100
|
[
"MEDDIALOG"
] |
RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-07-19T23:57:55Z |
2024-07-20T05:58:43+00:00
| 44 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-8B-UltraMedical - GGUF
- Model creator: https://huggingface.co/TsinghuaC3I/
- Original model: https://huggingface.co/TsinghuaC3I/Llama-3-8B-UltraMedical/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-8B-UltraMedical.Q2_K.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q2_K.gguf) | Q2_K | 2.96GB |
| [Llama-3-8B-UltraMedical.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Llama-3-8B-UltraMedical.IQ3_S.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Llama-3-8B-UltraMedical.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Llama-3-8B-UltraMedical.IQ3_M.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Llama-3-8B-UltraMedical.Q3_K.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q3_K.gguf) | Q3_K | 3.74GB |
| [Llama-3-8B-UltraMedical.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Llama-3-8B-UltraMedical.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Llama-3-8B-UltraMedical.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Llama-3-8B-UltraMedical.Q4_0.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Llama-3-8B-UltraMedical.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Llama-3-8B-UltraMedical.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Llama-3-8B-UltraMedical.Q4_K.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q4_K.gguf) | Q4_K | 4.58GB |
| [Llama-3-8B-UltraMedical.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Llama-3-8B-UltraMedical.Q4_1.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Llama-3-8B-UltraMedical.Q5_0.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Llama-3-8B-UltraMedical.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Llama-3-8B-UltraMedical.Q5_K.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q5_K.gguf) | Q5_K | 5.34GB |
| [Llama-3-8B-UltraMedical.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Llama-3-8B-UltraMedical.Q5_1.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Llama-3-8B-UltraMedical.Q6_K.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q6_K.gguf) | Q6_K | 6.14GB |
| [Llama-3-8B-UltraMedical.Q8_0.gguf](https://huggingface.co/RichardErkhov/TsinghuaC3I_-_Llama-3-8B-UltraMedical-gguf/blob/main/Llama-3-8B-UltraMedical.Q8_0.gguf) | Q8_0 | 7.95GB |
Original model description:
---
license: llama3
datasets:
- TsinghuaC3I/UltraMedical
---
# Llama-3-8B-UltraMedical
> Experience it in our 🤗 [Huggingface Space Demo](https://huggingface.co/spaces/TsinghuaC3I/UltraMedical-LM)!
<!-- Provide a quick summary of what the model is/does. -->
Llama-3-8B-UltraMedical is an open-access large language model (LLM) specialized in biomedicine. Developed by the [Tsinghua C3I Lab](https://github.com/TsinghuaC3I), this model aims to enhance medical examination access, literature comprehension, and clinical knowledge.
Building on the foundation of Meta's Llama-3-8B, Llama-3-8B-UltraMedical is trained on our [UltraMedical](https://github.com/TsinghuaC3I/UltraMedical) dataset, which includes 410,000 diverse entries comprising both synthetic and manually curated samples.
Llama-3-8B-UltraMedical has achieved top average scores across several popular medical benchmarks, including MedQA, MedMCQA, PubMedQA, and MMLU-Medical.
In these benchmarks, Llama-3-8B-UltraMedical significantly outperforms Flan-PaLM, OpenBioLM-8B, Gemini-1.0, GPT-3.5, and Meditron-70b.
We extend our gratitude to Meta for the Llama model, which provided an excellent foundation for our fine-tuning efforts.
## Usage
### Input Examples
This model utilizes the Llama-3 default chat template without a system prompt.
Below, we provide input examples for multi-choice QA, PubMedQA, and open-ended questions.
> Note: To reproduce our evaluation results for the medical QA benchmark, we recommend using the following format to organize questions and multiple-choice options.
- Input example for MedQA and MedMCQA:
```
A 42-year-old homeless man is brought to the emergency room after he was found unconscious in a park. He has alcohol on his breath and is known to have a history of chronic alcoholism. A noncontrast CT scan of the head is normal. The patient is treated for acute alcohol intoxication and admitted to the hospital. The next day, the patient demands to be released. His vital signs are a pulse 120/min, a respiratory rate 22/min, and blood pressure 136/88 mm Hg. On physical examination, the patient is confused, agitated, and sweating profusely, particularly from his palms. Generalized pallor is present. What is the mechanism of action of the drug recommended to treat this patient_s most likely condition?
A. It increases the duration of GABA-gated chloride channel opening.
B. It increases the frequency of GABA-gated chloride channel opening.
C. It decreases the frequency of GABA-gated chloride channel opening.
D. It decreases the duration of GABA-gated chloride channel opening.
```
- Input example for PubMedQA: We organize the context and questions in a multi-choice format, similar to [MedPrompt](https://github.com/microsoft/promptbase).
```
Context: Pediatric glioblastoma is a malignant disease with an extremely poor clinical outcome. Patients usually suffer from resistance to radiation therapy, so targeted drug treatment may be a new possibility for glioblastoma therapy. Survivin is also overexpressed in glioblastoma. YM155, a novel small-molecule survivin inhibitor, has not been examined for its use in glioblastoma therapy.
Context: The human glioblastoma cell line M059K, which expresses normal DNA-dependent protein kinase (DNA-PK) activity and is radiation-resistant, and M059J, which is deficient in DNA-PK activity and radiation-sensitive, were used in the study. Cell viability, DNA fragmentation, and the expression of survivin and securin following YM155 treatment were examined using MTT (methylthiazolyldiphenyl-tetrazolium) assay, ELISA assay, and Western blot analysis, respectively.
Context: YM155 caused a concentration-dependent cytotoxic effect, inhibiting the cell viability of both M059K and M059J cells by 70% after 48 hours of treatment with 50 nM YM155. The half-maximal inhibitory concentration (IC50) was around 30-35 nM for both cell lines. Apoptosis was determined to have occurred in both cell lines because immunoreactive signals from the DNA fragments in the cytoplasm were increased 24 hours after treatment with 30 nM YM155. The expression of survivin and securin in the M059K cells was greater than that measured in the M059J cells. Treatment with 30 nM YM155, for both 24 and 48 hours, significantly suppressed the expression of survivin and securin in both cell lines.
Does novel survivin inhibitor YM155 elicit cytotoxicity in glioblastoma cell lines with normal or deficiency DNA-dependent protein kinase activity?
A. maybe
B. yes
C. no
```
- Input example for open-ended questions:
```
hi doctor,i am chaitanya.age 28,from hyderabad.my problem is ....i got thyroid in my frist preganacy .my delivary date was on july 24th 2009 but on july 6th early morning around 7 oclock suddenly heany bleeding started and i rushed to the hospital but they could not save the baby(boy)...i lost my frist baby.then after 6 month i concevied again but doctors said that baby is having some heart problem and the sevarity of the problem can be known after the baby birth and i should go for a planned delivery.doctors did a c section on cotober 21 2010.doctors said that babys problem is not that serious but it is a heart problem so we need wait and see for 7 days.on 5th day the baby is dead.i want to know is their any problem in me that it is happing like this...do i need o go for any test before planning for next baby.i had 2 c section till now.what are the chances for me for the next baby.how long do i need to wait and plan for next preganacy.
```
```
Investigate the mechanistic implications of statins, primarily used for lipid modulation, on the immunomodulatory pathways, with an emphasis on delineating their therapeutic impact in the context of managing clinical outcomes for individuals afflicted with cardiovascular diseases, including a requirement to discuss the implications for atherosclerotic disease progression.
```
### Inference with vLLM
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
llm = LLM(model="TsinghuaC3I/Llama-3-8B-UltraMedical", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("TsinghuaC3I/Llama-3-8B-UltraMedical")
sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=1024, stop=["<|eot_id|>"])
messages = [
{"role": "user", "content": """The question format used in the above input examples。"""},
]
prompts = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print(prompts[0])
"""
<|begin_of_text|><|start_header_id|>user<|end_header_id|>
{question}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
"""
outputs = llm.generate(prompts=prompts, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
```
Note: This version of the model supports only single-turn dialog and has limited capabilities in multi-turn dialogue. We plan to enhance this in the next update.
## Evaluation Results
Llama-3-8B-UltraMedical achieved the best average results among 7B-level models on popular medical benchmarks, including MedQA, MedMCQA, PubMedQA, and MMLU-Medical. We would like to acknowledge Meta's remarkable Llama model, which served as an excellent base for our fine-tuning process.
| Released Date | Model | Average | MedQA | MedMCQA | PubMedQA | MMLU.ck | MMLU.mg | MMLU.an | MMLU.pm | MMLU.cb | MMLU.cm |
|:-------------:|:--------------------------------------:|:-------:|:-----:|:-------:|:--------:|:-------:|:-------:|:-------:|:-------:|:-------:|:-------:|
| 2024.04 | **Llama-3-8B-UltraMedical (Ensemble)** | 77.77 | 77.5 | 63.8 | 78.2 | 77.4 | 88.0 | 74.8 | 84.6 | 79.9 | 75.7 |
| 2024.04 | **Llama-3-8B-UltraMedical (Greedy)** | 75.20 | 73.3 | 61.5 | 77.0 | 78.9 | 78.0 | 74.1 | 83.8 | 78.5 | 71.7 |
| 2024.04 | OpenBioLM-8B | 72.48 | 59.0 | 56.9 | 74.1 | 76.1 | 86.1 | 69.8 | 78.2 | 84.2 | 68.0 |
| 2024.04 | Llama-3-8B-Instruct (Ensemble) | 71.23 | 62.4 | 56.5 | 75.8 | 72.5 | 84.0 | 71.1 | 70.6 | 80.6 | 67.6 |
| 2024.04 | Llama-3-8B-Instruct (Greedy) | 68.56 | 60.9 | 50.7 | 73.0 | 72.1 | 76.0 | 63.0 | 77.2 | 79.9 | 64.2 |
| 2024.04 | Internist-7B | 67.79 | 60.5 | 55.8 | 79.4 | 70.6 | 71.0 | 65.9 | 76.1 | - | 63.0 |
| 2024.02 | Gemma-7B | 64.18 | 47.2 | 49.0 | 76.2 | 69.8 | 70.0 | 59.3 | 66.2 | 79.9 | 60.1 |
| 2024.03 | Meerkat-7B (Ensemble) | 63.94 | 74.3 | 60.7 | - | 61.9 | 70.4 | 61.5 | 69.5 | 55.4 | 57.8 |
| 2023.03 | MedAlpaca | 58.03 | 41.7 | 37.5 | 72.8 | 57.4 | 69.0 | 57.0 | 67.3 | 65.3 | 54.3 |
| 2024.02 | BioMistral-7B | 57.26 | 46.6 | 45.7 | 68.1 | 63.1 | 63.3 | 49.9 | 57.4 | 63.4 | 57.8 |
In the table above:
- For MedQA, we use the 4 options from the US set. For MedMCQA, we use the Dev split. For PubMedQA, we use the reasoning required set.
- For MMLU, we include Clinical Knowledge (CK), Medical Genetics (MG), Anatomy (An), Professional Medicine (PM), College Biology (CB), and College Medicine (CM) to maintain consistency with previous studies.
- Greedy search is employed as our default decoding strategy. We denote ensemble scores with self-consistency as `(Ensemble)`. In our experiments, we conduct 10 decoding trials, and final decisions are made via majority vote (temperature=0.7, top_p=0.9).
- Partial results for 7B pre-trained models are sourced from the [Open Medical-LLM Leaderboard](https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard).
## Training Details
<!-- Provide a longer summary of what this model is. -->
This model is trained using the full parameters and the Fully Sharded Data Parallel (FSDP) framework.
The training process was performed on 8 x A6000 GPUs for about 50 hours.
Hyperparameters:
- torch type: bfloat16
- epochs: 3
- learning rate: 2e-5
- learning rate scheduler type: cosine
- warmup ratio: 0.04
- max length: 1024
- global batch size: 128
- **License:** [Meta Llama-3 License](https://llama.meta.com/llama3/license/).
- **Finetuned from model:** [Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B)
- **Finetuned on data:** [UltraMedical](https://github.com/TsinghuaC3I/UltraMedical)
## Limitations & Safe Use
While our model offers promising capabilities, it is crucial to exercise caution when using it in real-world clinical settings due to potential hallucination issues. Hallucinations, where the model generates incorrect or misleading information, can pose significant risks in clinical decision-making. Users are advised to validate the model's outputs with trusted medical sources and expert consultation to ensure safety and accuracy.
## Citation
```latex
@misc{UltraMedical,
author = {Zhang, Kaiyan and Ding, Ning and Qi, Biqing and Zeng, Sihang and Li, Haoxin and Zhu, Xuekai and Chen, Zhang-Ren and Zhou, Bowen},
title = {UltraMedical: Building Specialized Generalists in Biomedicine.},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/TsinghuaC3I/UltraMedical}},
}
```
|
[
"MEDQA",
"PUBMEDQA"
] |
RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-09-18T17:49:43Z |
2024-09-18T20:10:46+00:00
| 44 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
JSL-MedMNX-7B - GGUF
- Model creator: https://huggingface.co/johnsnowlabs/
- Original model: https://huggingface.co/johnsnowlabs/JSL-MedMNX-7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [JSL-MedMNX-7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q2_K.gguf) | Q2_K | 2.53GB |
| [JSL-MedMNX-7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [JSL-MedMNX-7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [JSL-MedMNX-7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [JSL-MedMNX-7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [JSL-MedMNX-7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q3_K.gguf) | Q3_K | 3.28GB |
| [JSL-MedMNX-7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [JSL-MedMNX-7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [JSL-MedMNX-7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [JSL-MedMNX-7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q4_0.gguf) | Q4_0 | 3.83GB |
| [JSL-MedMNX-7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [JSL-MedMNX-7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [JSL-MedMNX-7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q4_K.gguf) | Q4_K | 4.07GB |
| [JSL-MedMNX-7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [JSL-MedMNX-7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q4_1.gguf) | Q4_1 | 4.24GB |
| [JSL-MedMNX-7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q5_0.gguf) | Q5_0 | 4.65GB |
| [JSL-MedMNX-7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [JSL-MedMNX-7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q5_K.gguf) | Q5_K | 4.78GB |
| [JSL-MedMNX-7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [JSL-MedMNX-7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q5_1.gguf) | Q5_1 | 5.07GB |
| [JSL-MedMNX-7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q6_K.gguf) | Q6_K | 5.53GB |
| [JSL-MedMNX-7B.Q8_0.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-gguf/blob/main/JSL-MedMNX-7B.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
license: cc-by-nc-nd-4.0
language:
- en
library_name: transformers
tags:
- reward model
- RLHF
- medical
---
# JSL-MedMNX-7B
[<img src="https://repository-images.githubusercontent.com/104670986/2e728700-ace4-11ea-9cfc-f3e060b25ddf">](http://www.johnsnowlabs.com)
JSL-MedMNX-7B is a 7 Billion parameter model developed by [John Snow Labs](https://www.johnsnowlabs.com/).
This model is trained on medical datasets to provide state-of-the-art performance on biomedical benchmarks: [Open Medical LLM Leaderboard](https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard).
This model is available under a [CC-BY-NC-ND](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en) license and must also conform to this [Acceptable Use Policy](https://huggingface.co/johnsnowlabs). If you need to license this model for commercial use, please contact us at [email protected].
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "johnsnowlabs/JSL-MedMNX-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## 🏆 Evaluation
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|-------------------------------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5191|± |0.0068|
| | |none | 0|acc |0.5658|± |0.0058|
| - medmcqa |Yaml |none | 0|acc |0.5135|± |0.0077|
| | |none | 0|acc_norm|0.5135|± |0.0077|
| - medqa_4options |Yaml |none | 0|acc |0.5373|± |0.0140|
| | |none | 0|acc_norm|0.5373|± |0.0140|
| - anatomy (mmlu) | 0|none | 0|acc |0.6370|± |0.0415|
| - clinical_knowledge (mmlu) | 0|none | 0|acc |0.7245|± |0.0275|
| - college_biology (mmlu) | 0|none | 0|acc |0.7500|± |0.0362|
| - college_medicine (mmlu) | 0|none | 0|acc |0.6590|± |0.0361|
| - medical_genetics (mmlu) | 0|none | 0|acc |0.7200|± |0.0451|
| - professional_medicine (mmlu)| 0|none | 0|acc |0.7206|± |0.0273|
| - pubmedqa | 1|none | 0|acc |0.7720|± |0.0188|
|Groups|Version|Filter|n-shot| Metric |Value | |Stderr|
|------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5191|± |0.0068|
| | |none | 0|acc |0.5658|± |0.0058|
|
[
"MEDQA",
"PUBMEDQA"
] |
RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us"
] | 2024-09-20T07:29:06Z |
2024-09-20T10:39:59+00:00
| 44 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
e5-R-mistral-7b - GGUF
- Model creator: https://huggingface.co/BeastyZ/
- Original model: https://huggingface.co/BeastyZ/e5-R-mistral-7b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [e5-R-mistral-7b.Q2_K.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q2_K.gguf) | Q2_K | 2.53GB |
| [e5-R-mistral-7b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [e5-R-mistral-7b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [e5-R-mistral-7b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [e5-R-mistral-7b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [e5-R-mistral-7b.Q3_K.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q3_K.gguf) | Q3_K | 3.28GB |
| [e5-R-mistral-7b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [e5-R-mistral-7b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [e5-R-mistral-7b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [e5-R-mistral-7b.Q4_0.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q4_0.gguf) | Q4_0 | 3.83GB |
| [e5-R-mistral-7b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [e5-R-mistral-7b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [e5-R-mistral-7b.Q4_K.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q4_K.gguf) | Q4_K | 4.07GB |
| [e5-R-mistral-7b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [e5-R-mistral-7b.Q4_1.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q4_1.gguf) | Q4_1 | 4.24GB |
| [e5-R-mistral-7b.Q5_0.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q5_0.gguf) | Q5_0 | 4.65GB |
| [e5-R-mistral-7b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [e5-R-mistral-7b.Q5_K.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q5_K.gguf) | Q5_K | 4.78GB |
| [e5-R-mistral-7b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [e5-R-mistral-7b.Q5_1.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q5_1.gguf) | Q5_1 | 5.07GB |
| [e5-R-mistral-7b.Q6_K.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q6_K.gguf) | Q6_K | 5.53GB |
| [e5-R-mistral-7b.Q8_0.gguf](https://huggingface.co/RichardErkhov/BeastyZ_-_e5-R-mistral-7b-gguf/blob/main/e5-R-mistral-7b.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
library_name: transformers
license: apache-2.0
datasets:
- BeastyZ/E5-R
language:
- en
model-index:
- name: e5-R-mistral-7b
results:
- dataset:
config: default
name: MTEB ArguAna
revision: None
split: test
type: mteb/arguana
metrics:
- type: map_at_1
value: 33.57
- type: map_at_10
value: 49.952000000000005
- type: map_at_100
value: 50.673
- type: map_at_1000
value: 50.674
- type: map_at_3
value: 44.915
- type: map_at_5
value: 47.876999999999995
- type: mrr_at_1
value: 34.211000000000006
- type: mrr_at_10
value: 50.19
- type: mrr_at_100
value: 50.905
- type: mrr_at_1000
value: 50.906
- type: mrr_at_3
value: 45.128
- type: mrr_at_5
value: 48.097
- type: ndcg_at_1
value: 33.57
- type: ndcg_at_10
value: 58.994
- type: ndcg_at_100
value: 61.806000000000004
- type: ndcg_at_1000
value: 61.824999999999996
- type: ndcg_at_3
value: 48.681000000000004
- type: ndcg_at_5
value: 54.001
- type: precision_at_1
value: 33.57
- type: precision_at_10
value: 8.784
- type: precision_at_100
value: 0.9950000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 19.867
- type: precision_at_5
value: 14.495
- type: recall_at_1
value: 33.57
- type: recall_at_10
value: 87.83800000000001
- type: recall_at_100
value: 99.502
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 59.602
- type: recall_at_5
value: 72.475
- type: main_score
value: 58.994
task:
type: Retrieval
- dataset:
config: default
name: MTEB CQADupstackRetrieval
revision: None
split: test
type: mteb/cqadupstack
metrics:
- type: map_at_1
value: 24.75
- type: map_at_10
value: 34.025
- type: map_at_100
value: 35.126000000000005
- type: map_at_1000
value: 35.219
- type: map_at_3
value: 31.607000000000003
- type: map_at_5
value: 32.962
- type: mrr_at_1
value: 27.357
- type: mrr_at_10
value: 36.370999999999995
- type: mrr_at_100
value: 37.364000000000004
- type: mrr_at_1000
value: 37.423
- type: mrr_at_3
value: 34.288000000000004
- type: mrr_at_5
value: 35.434
- type: ndcg_at_1
value: 27.357
- type: ndcg_at_10
value: 46.593999999999997
- type: ndcg_at_100
value: 44.317
- type: ndcg_at_1000
value: 46.475
- type: ndcg_at_3
value: 34.473
- type: ndcg_at_5
value: 36.561
- type: precision_at_1
value: 27.357
- type: precision_at_10
value: 6.081
- type: precision_at_100
value: 0.9299999999999999
- type: precision_at_1000
value: 0.124
- type: precision_at_3
value: 14.911
- type: precision_at_5
value: 10.24
- type: recall_at_1
value: 24.75
- type: recall_at_10
value: 51.856
- type: recall_at_100
value: 76.44300000000001
- type: recall_at_1000
value: 92.078
- type: recall_at_3
value: 39.427
- type: recall_at_5
value: 44.639
- type: main_score
value: 46.593999999999997
task:
type: Retrieval
- dataset:
config: default
name: MTEB ClimateFEVER
revision: None
split: test
type: mteb/climate-fever
metrics:
- type: map_at_1
value: 16.436
- type: map_at_10
value: 29.693
- type: map_at_100
value: 32.179
- type: map_at_1000
value: 32.353
- type: map_at_3
value: 24.556
- type: map_at_5
value: 27.105
- type: mrr_at_1
value: 37.524
- type: mrr_at_10
value: 51.475
- type: mrr_at_100
value: 52.107000000000006
- type: mrr_at_1000
value: 52.123
- type: mrr_at_3
value: 48.35
- type: mrr_at_5
value: 50.249
- type: ndcg_at_1
value: 37.524
- type: ndcg_at_10
value: 40.258
- type: ndcg_at_100
value: 48.364000000000004
- type: ndcg_at_1000
value: 51.031000000000006
- type: ndcg_at_3
value: 33.359
- type: ndcg_at_5
value: 35.573
- type: precision_at_1
value: 37.524
- type: precision_at_10
value: 12.886000000000001
- type: precision_at_100
value: 2.169
- type: precision_at_1000
value: 0.268
- type: precision_at_3
value: 25.624000000000002
- type: precision_at_5
value: 19.453
- type: recall_at_1
value: 16.436
- type: recall_at_10
value: 47.77
- type: recall_at_100
value: 74.762
- type: recall_at_1000
value: 89.316
- type: recall_at_3
value: 30.508000000000003
- type: recall_at_5
value: 37.346000000000004
- type: main_score
value: 40.258
task:
type: Retrieval
- dataset:
config: default
name: MTEB DBPedia
revision: None
split: test
type: mteb/dbpedia
metrics:
- type: map_at_1
value: 10.147
- type: map_at_10
value: 24.631
- type: map_at_100
value: 35.657
- type: map_at_1000
value: 37.824999999999996
- type: map_at_3
value: 16.423
- type: map_at_5
value: 19.666
- type: mrr_at_1
value: 76.5
- type: mrr_at_10
value: 82.793
- type: mrr_at_100
value: 83.015
- type: mrr_at_1000
value: 83.021
- type: mrr_at_3
value: 81.75
- type: mrr_at_5
value: 82.375
- type: ndcg_at_1
value: 64.75
- type: ndcg_at_10
value: 51.031000000000006
- type: ndcg_at_100
value: 56.005
- type: ndcg_at_1000
value: 63.068000000000005
- type: ndcg_at_3
value: 54.571999999999996
- type: ndcg_at_5
value: 52.66499999999999
- type: precision_at_1
value: 76.5
- type: precision_at_10
value: 42.15
- type: precision_at_100
value: 13.22
- type: precision_at_1000
value: 2.5989999999999998
- type: precision_at_3
value: 58.416999999999994
- type: precision_at_5
value: 52.2
- type: recall_at_1
value: 10.147
- type: recall_at_10
value: 30.786
- type: recall_at_100
value: 62.873000000000005
- type: recall_at_1000
value: 85.358
- type: recall_at_3
value: 17.665
- type: recall_at_5
value: 22.088
- type: main_score
value: 51.031000000000006
task:
type: Retrieval
- dataset:
config: default
name: MTEB FEVER
revision: None
split: test
type: mteb/fever
metrics:
- type: map_at_1
value: 78.52900000000001
- type: map_at_10
value: 87.24199999999999
- type: map_at_100
value: 87.446
- type: map_at_1000
value: 87.457
- type: map_at_3
value: 86.193
- type: map_at_5
value: 86.898
- type: mrr_at_1
value: 84.518
- type: mrr_at_10
value: 90.686
- type: mrr_at_100
value: 90.73
- type: mrr_at_1000
value: 90.731
- type: mrr_at_3
value: 90.227
- type: mrr_at_5
value: 90.575
- type: ndcg_at_1
value: 84.518
- type: ndcg_at_10
value: 90.324
- type: ndcg_at_100
value: 90.96300000000001
- type: ndcg_at_1000
value: 91.134
- type: ndcg_at_3
value: 88.937
- type: ndcg_at_5
value: 89.788
- type: precision_at_1
value: 84.518
- type: precision_at_10
value: 10.872
- type: precision_at_100
value: 1.1440000000000001
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 34.108
- type: precision_at_5
value: 21.154999999999998
- type: recall_at_1
value: 78.52900000000001
- type: recall_at_10
value: 96.123
- type: recall_at_100
value: 98.503
- type: recall_at_1000
value: 99.518
- type: recall_at_3
value: 92.444
- type: recall_at_5
value: 94.609
- type: main_score
value: 90.324
task:
type: Retrieval
- dataset:
config: default
name: MTEB FiQA2018
revision: None
split: test
type: mteb/fiqa
metrics:
- type: map_at_1
value: 29.38
- type: map_at_10
value: 50.28
- type: map_at_100
value: 52.532999999999994
- type: map_at_1000
value: 52.641000000000005
- type: map_at_3
value: 43.556
- type: map_at_5
value: 47.617
- type: mrr_at_1
value: 56.79
- type: mrr_at_10
value: 65.666
- type: mrr_at_100
value: 66.211
- type: mrr_at_1000
value: 66.226
- type: mrr_at_3
value: 63.452
- type: mrr_at_5
value: 64.895
- type: ndcg_at_1
value: 56.79
- type: ndcg_at_10
value: 58.68
- type: ndcg_at_100
value: 65.22
- type: ndcg_at_1000
value: 66.645
- type: ndcg_at_3
value: 53.981
- type: ndcg_at_5
value: 55.95
- type: precision_at_1
value: 56.79
- type: precision_at_10
value: 16.311999999999998
- type: precision_at_100
value: 2.316
- type: precision_at_1000
value: 0.258
- type: precision_at_3
value: 36.214
- type: precision_at_5
value: 27.067999999999998
- type: recall_at_1
value: 29.38
- type: recall_at_10
value: 66.503
- type: recall_at_100
value: 89.885
- type: recall_at_1000
value: 97.954
- type: recall_at_3
value: 48.866
- type: recall_at_5
value: 57.60999999999999
- type: main_score
value: 58.68
task:
type: Retrieval
- dataset:
config: default
name: MTEB HotpotQA
revision: None
split: test
type: mteb/hotpotqa
metrics:
- type: map_at_1
value: 42.134
- type: map_at_10
value: 73.412
- type: map_at_100
value: 74.144
- type: map_at_1000
value: 74.181
- type: map_at_3
value: 70.016
- type: map_at_5
value: 72.174
- type: mrr_at_1
value: 84.267
- type: mrr_at_10
value: 89.18599999999999
- type: mrr_at_100
value: 89.29599999999999
- type: mrr_at_1000
value: 89.298
- type: mrr_at_3
value: 88.616
- type: mrr_at_5
value: 88.957
- type: ndcg_at_1
value: 84.267
- type: ndcg_at_10
value: 80.164
- type: ndcg_at_100
value: 82.52199999999999
- type: ndcg_at_1000
value: 83.176
- type: ndcg_at_3
value: 75.616
- type: ndcg_at_5
value: 78.184
- type: precision_at_1
value: 84.267
- type: precision_at_10
value: 16.916
- type: precision_at_100
value: 1.872
- type: precision_at_1000
value: 0.196
- type: precision_at_3
value: 49.71
- type: precision_at_5
value: 31.854
- type: recall_at_1
value: 42.134
- type: recall_at_10
value: 84.578
- type: recall_at_100
value: 93.606
- type: recall_at_1000
value: 97.86
- type: recall_at_3
value: 74.564
- type: recall_at_5
value: 79.635
- type: main_score
value: 80.164
task:
type: Retrieval
- dataset:
config: default
name: MTEB MSMARCO
revision: None
split: dev
type: mteb/msmarco
metrics:
- type: map_at_1
value: 22.276
- type: map_at_10
value: 35.493
- type: map_at_100
value: 36.656
- type: map_at_1000
value: 36.699
- type: map_at_3
value: 31.320999999999998
- type: map_at_5
value: 33.772999999999996
- type: mrr_at_1
value: 22.966
- type: mrr_at_10
value: 36.074
- type: mrr_at_100
value: 37.183
- type: mrr_at_1000
value: 37.219
- type: mrr_at_3
value: 31.984
- type: mrr_at_5
value: 34.419
- type: ndcg_at_1
value: 22.966
- type: ndcg_at_10
value: 42.895
- type: ndcg_at_100
value: 48.453
- type: ndcg_at_1000
value: 49.464999999999996
- type: ndcg_at_3
value: 34.410000000000004
- type: ndcg_at_5
value: 38.78
- type: precision_at_1
value: 22.966
- type: precision_at_10
value: 6.88
- type: precision_at_100
value: 0.966
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 14.785
- type: precision_at_5
value: 11.074
- type: recall_at_1
value: 22.276
- type: recall_at_10
value: 65.756
- type: recall_at_100
value: 91.34100000000001
- type: recall_at_1000
value: 98.957
- type: recall_at_3
value: 42.67
- type: recall_at_5
value: 53.161
- type: main_score
value: 42.895
task:
type: Retrieval
- dataset:
config: default
name: MTEB NFCorpus
revision: None
split: test
type: mteb/nfcorpus
metrics:
- type: map_at_1
value: 7.188999999999999
- type: map_at_10
value: 16.176
- type: map_at_100
value: 20.504
- type: map_at_1000
value: 22.203999999999997
- type: map_at_3
value: 11.766
- type: map_at_5
value: 13.655999999999999
- type: mrr_at_1
value: 55.418
- type: mrr_at_10
value: 62.791
- type: mrr_at_100
value: 63.339
- type: mrr_at_1000
value: 63.369
- type: mrr_at_3
value: 60.99099999999999
- type: mrr_at_5
value: 62.059
- type: ndcg_at_1
value: 53.715
- type: ndcg_at_10
value: 41.377
- type: ndcg_at_100
value: 37.999
- type: ndcg_at_1000
value: 46.726
- type: ndcg_at_3
value: 47.262
- type: ndcg_at_5
value: 44.708999999999996
- type: precision_at_1
value: 55.108000000000004
- type: precision_at_10
value: 30.154999999999998
- type: precision_at_100
value: 9.582
- type: precision_at_1000
value: 2.2720000000000002
- type: precision_at_3
value: 43.55
- type: precision_at_5
value: 38.204
- type: recall_at_1
value: 7.188999999999999
- type: recall_at_10
value: 20.655
- type: recall_at_100
value: 38.068000000000005
- type: recall_at_1000
value: 70.208
- type: recall_at_3
value: 12.601
- type: recall_at_5
value: 15.573999999999998
- type: main_score
value: 41.377
task:
type: Retrieval
- dataset:
config: default
name: MTEB NQ
revision: None
split: test
type: mteb/nq
metrics:
- type: map_at_1
value: 46.017
- type: map_at_10
value: 62.910999999999994
- type: map_at_100
value: 63.526
- type: map_at_1000
value: 63.536
- type: map_at_3
value: 59.077999999999996
- type: map_at_5
value: 61.521
- type: mrr_at_1
value: 51.68000000000001
- type: mrr_at_10
value: 65.149
- type: mrr_at_100
value: 65.542
- type: mrr_at_1000
value: 65.55
- type: mrr_at_3
value: 62.49
- type: mrr_at_5
value: 64.178
- type: ndcg_at_1
value: 51.651
- type: ndcg_at_10
value: 69.83500000000001
- type: ndcg_at_100
value: 72.18
- type: ndcg_at_1000
value: 72.393
- type: ndcg_at_3
value: 63.168
- type: ndcg_at_5
value: 66.958
- type: precision_at_1
value: 51.651
- type: precision_at_10
value: 10.626
- type: precision_at_100
value: 1.195
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 28.012999999999998
- type: precision_at_5
value: 19.09
- type: recall_at_1
value: 46.017
- type: recall_at_10
value: 88.345
- type: recall_at_100
value: 98.129
- type: recall_at_1000
value: 99.696
- type: recall_at_3
value: 71.531
- type: recall_at_5
value: 80.108
- type: main_score
value: 69.83500000000001
task:
type: Retrieval
- dataset:
config: default
name: MTEB QuoraRetrieval
revision: None
split: test
type: mteb/quora
metrics:
- type: map_at_1
value: 72.473
- type: map_at_10
value: 86.72800000000001
- type: map_at_100
value: 87.323
- type: map_at_1000
value: 87.332
- type: map_at_3
value: 83.753
- type: map_at_5
value: 85.627
- type: mrr_at_1
value: 83.39
- type: mrr_at_10
value: 89.149
- type: mrr_at_100
value: 89.228
- type: mrr_at_1000
value: 89.229
- type: mrr_at_3
value: 88.335
- type: mrr_at_5
value: 88.895
- type: ndcg_at_1
value: 83.39
- type: ndcg_at_10
value: 90.109
- type: ndcg_at_100
value: 91.09
- type: ndcg_at_1000
value: 91.13900000000001
- type: ndcg_at_3
value: 87.483
- type: ndcg_at_5
value: 88.942
- type: precision_at_1
value: 83.39
- type: precision_at_10
value: 13.711
- type: precision_at_100
value: 1.549
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 38.342999999999996
- type: precision_at_5
value: 25.188
- type: recall_at_1
value: 72.473
- type: recall_at_10
value: 96.57
- type: recall_at_100
value: 99.792
- type: recall_at_1000
value: 99.99900000000001
- type: recall_at_3
value: 88.979
- type: recall_at_5
value: 93.163
- type: main_score
value: 90.109
task:
type: Retrieval
- dataset:
config: default
name: MTEB SCIDOCS
revision: None
split: test
type: mteb/scidocs
metrics:
- type: map_at_1
value: 4.598
- type: map_at_10
value: 11.405999999999999
- type: map_at_100
value: 13.447999999999999
- type: map_at_1000
value: 13.758999999999999
- type: map_at_3
value: 8.332
- type: map_at_5
value: 9.709
- type: mrr_at_1
value: 22.6
- type: mrr_at_10
value: 32.978
- type: mrr_at_100
value: 34.149
- type: mrr_at_1000
value: 34.213
- type: mrr_at_3
value: 29.7
- type: mrr_at_5
value: 31.485000000000003
- type: ndcg_at_1
value: 22.6
- type: ndcg_at_10
value: 19.259999999999998
- type: ndcg_at_100
value: 27.21
- type: ndcg_at_1000
value: 32.7
- type: ndcg_at_3
value: 18.445
- type: ndcg_at_5
value: 15.812000000000001
- type: precision_at_1
value: 22.6
- type: precision_at_10
value: 9.959999999999999
- type: precision_at_100
value: 2.139
- type: precision_at_1000
value: 0.345
- type: precision_at_3
value: 17.299999999999997
- type: precision_at_5
value: 13.719999999999999
- type: recall_at_1
value: 4.598
- type: recall_at_10
value: 20.186999999999998
- type: recall_at_100
value: 43.362
- type: recall_at_1000
value: 70.11800000000001
- type: recall_at_3
value: 10.543
- type: recall_at_5
value: 13.923
- type: main_score
value: 19.259999999999998
task:
type: Retrieval
- dataset:
config: default
name: MTEB SciFact
revision: None
split: test
type: mteb/scifact
metrics:
- type: map_at_1
value: 65.467
- type: map_at_10
value: 74.935
- type: map_at_100
value: 75.395
- type: map_at_1000
value: 75.412
- type: map_at_3
value: 72.436
- type: map_at_5
value: 73.978
- type: mrr_at_1
value: 68.667
- type: mrr_at_10
value: 76.236
- type: mrr_at_100
value: 76.537
- type: mrr_at_1000
value: 76.55499999999999
- type: mrr_at_3
value: 74.722
- type: mrr_at_5
value: 75.639
- type: ndcg_at_1
value: 68.667
- type: ndcg_at_10
value: 78.92099999999999
- type: ndcg_at_100
value: 80.645
- type: ndcg_at_1000
value: 81.045
- type: ndcg_at_3
value: 75.19500000000001
- type: ndcg_at_5
value: 77.114
- type: precision_at_1
value: 68.667
- type: precision_at_10
value: 10.133000000000001
- type: precision_at_100
value: 1.0999999999999999
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 28.889
- type: precision_at_5
value: 18.8
- type: recall_at_1
value: 65.467
- type: recall_at_10
value: 89.517
- type: recall_at_100
value: 97
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 79.72200000000001
- type: recall_at_5
value: 84.511
- type: main_score
value: 78.92099999999999
task:
type: Retrieval
- dataset:
config: default
name: MTEB TRECCOVID
revision: None
split: test
type: mteb/trec-covid
metrics:
- type: map_at_1
value: 0.244
- type: map_at_10
value: 2.183
- type: map_at_100
value: 13.712
- type: map_at_1000
value: 33.147
- type: map_at_3
value: 0.7270000000000001
- type: map_at_5
value: 1.199
- type: mrr_at_1
value: 94
- type: mrr_at_10
value: 97
- type: mrr_at_100
value: 97
- type: mrr_at_1000
value: 97
- type: mrr_at_3
value: 97
- type: mrr_at_5
value: 97
- type: ndcg_at_1
value: 92
- type: ndcg_at_10
value: 84.399
- type: ndcg_at_100
value: 66.771
- type: ndcg_at_1000
value: 59.092
- type: ndcg_at_3
value: 89.173
- type: ndcg_at_5
value: 88.52600000000001
- type: precision_at_1
value: 94
- type: precision_at_10
value: 86.8
- type: precision_at_100
value: 68.24
- type: precision_at_1000
value: 26.003999999999998
- type: precision_at_3
value: 92.667
- type: precision_at_5
value: 92.4
- type: recall_at_1
value: 0.244
- type: recall_at_10
value: 2.302
- type: recall_at_100
value: 16.622
- type: recall_at_1000
value: 55.175
- type: recall_at_3
value: 0.748
- type: recall_at_5
value: 1.247
- type: main_score
value: 84.399
task:
type: Retrieval
- dataset:
config: default
name: MTEB Touche2020
revision: None
split: test
type: mteb/touche2020
metrics:
- type: map_at_1
value: 2.707
- type: map_at_10
value: 10.917
- type: map_at_100
value: 16.308
- type: map_at_1000
value: 17.953
- type: map_at_3
value: 5.65
- type: map_at_5
value: 7.379
- type: mrr_at_1
value: 34.694
- type: mrr_at_10
value: 49.745
- type: mrr_at_100
value: 50.309000000000005
- type: mrr_at_1000
value: 50.32
- type: mrr_at_3
value: 44.897999999999996
- type: mrr_at_5
value: 48.061
- type: ndcg_at_1
value: 33.672999999999995
- type: ndcg_at_10
value: 26.894000000000002
- type: ndcg_at_100
value: 37.423
- type: ndcg_at_1000
value: 49.376999999999995
- type: ndcg_at_3
value: 30.456
- type: ndcg_at_5
value: 27.772000000000002
- type: precision_at_1
value: 34.694
- type: precision_at_10
value: 23.878
- type: precision_at_100
value: 7.489999999999999
- type: precision_at_1000
value: 1.555
- type: precision_at_3
value: 31.293
- type: precision_at_5
value: 26.939
- type: recall_at_1
value: 2.707
- type: recall_at_10
value: 18.104
- type: recall_at_100
value: 46.93
- type: recall_at_1000
value: 83.512
- type: recall_at_3
value: 6.622999999999999
- type: recall_at_5
value: 10.051
- type: main_score
value: 26.894000000000002
task:
type: Retrieval
tags:
- mteb
---
# Model Card for e5-R-mistral-7b
<!-- Provide a quick summary of what the model is/does. -->
## Model Description
<!-- Provide a longer summary of what this model is. -->
e5-R-mistral-7b is a LLM retriever fine-tuned from [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1).
- **Model type:** CausalLM
- **Repository:** Welcome to our [GitHub](https://github.com/LeeSureman/E5-Retrieval-Reproduction) repository to obtain code
- **Training dataset:** Dataset used for fine-tuning e5-R-mistral-7b is available [here](https://huggingface.co/datasets/BeastyZ/E5-R).
|
[
"SCIFACT"
] |
minishlab/M2V_base_glove_subword
|
minishlab
| null |
[
"model2vec",
"onnx",
"safetensors",
"embeddings",
"static-embeddings",
"mteb",
"sentence-transformers",
"en",
"base_model:BAAI/bge-base-en-v1.5",
"base_model:quantized:BAAI/bge-base-en-v1.5",
"license:mit",
"model-index",
"region:us"
] | 2024-10-02T18:18:36Z |
2025-01-21T19:18:20+00:00
| 44 | 2 |
---
base_model: BAAI/bge-base-en-v1.5
language:
- en
library_name: model2vec
license: mit
tags:
- embeddings
- static-embeddings
- mteb
- sentence-transformers
model-index:
- name: M2V_base_glove_subword
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 66.4167916041979
- type: ap
value: 18.202949885376736
- type: ap_weighted
value: 18.202949885376736
- type: f1
value: 54.98453722214898
- type: f1_weighted
value: 72.84623161234782
- type: main_score
value: 66.4167916041979
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 68.044776119403
- type: ap
value: 31.604323176091363
- type: ap_weighted
value: 31.604323176091363
- type: f1
value: 62.53323789238326
- type: f1_weighted
value: 71.2243167389672
- type: main_score
value: 68.044776119403
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification (default)
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 67.21602499999999
- type: ap
value: 62.24635378305934
- type: ap_weighted
value: 62.24635378305934
- type: f1
value: 66.68107362746888
- type: f1_weighted
value: 66.68107362746888
- type: main_score
value: 67.21602499999999
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 32.384
- type: f1
value: 32.05276706247388
- type: f1_weighted
value: 32.05276706247388
- type: main_score
value: 32.384
- task:
type: Retrieval
dataset:
name: MTEB ArguAna (default)
type: mteb/arguana
config: default
split: test
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
metrics:
- type: main_score
value: 29.599999999999998
- type: map_at_1
value: 14.438
- type: map_at_10
value: 23.803
- type: map_at_100
value: 24.85
- type: map_at_1000
value: 24.925
- type: map_at_20
value: 24.395
- type: map_at_3
value: 20.519000000000002
- type: map_at_5
value: 22.183
- type: mrr_at_1
value: 14.65149359886202
- type: mrr_at_10
value: 23.8787847998374
- type: mrr_at_100
value: 24.945306088918446
- type: mrr_at_1000
value: 25.019829460538446
- type: mrr_at_20
value: 24.48722055512828
- type: mrr_at_3
value: 20.661450924608815
- type: mrr_at_5
value: 22.254623044096704
- type: nauc_map_at_1000_diff1
value: 11.677995826704251
- type: nauc_map_at_1000_max
value: -1.7036225489906935
- type: nauc_map_at_1000_std
value: 13.608156164552337
- type: nauc_map_at_100_diff1
value: 11.69898827728831
- type: nauc_map_at_100_max
value: -1.6896771319000576
- type: nauc_map_at_100_std
value: 13.657417732243642
- type: nauc_map_at_10_diff1
value: 11.381029737026354
- type: nauc_map_at_10_max
value: -1.7701185174946374
- type: nauc_map_at_10_std
value: 12.878108250073275
- type: nauc_map_at_1_diff1
value: 13.270492079181698
- type: nauc_map_at_1_max
value: -5.320050131923338
- type: nauc_map_at_1_std
value: 9.145476528935111
- type: nauc_map_at_20_diff1
value: 11.636255256667027
- type: nauc_map_at_20_max
value: -1.5972839976414983
- type: nauc_map_at_20_std
value: 13.42888801202754
- type: nauc_map_at_3_diff1
value: 10.870897941570064
- type: nauc_map_at_3_max
value: -3.2129671196535785
- type: nauc_map_at_3_std
value: 11.017585726260462
- type: nauc_map_at_5_diff1
value: 11.323413777040606
- type: nauc_map_at_5_max
value: -2.4760041260478904
- type: nauc_map_at_5_std
value: 12.029899752157688
- type: nauc_mrr_at_1000_diff1
value: 10.742715816971687
- type: nauc_mrr_at_1000_max
value: -1.7753021168425986
- type: nauc_mrr_at_1000_std
value: 13.427125200171295
- type: nauc_mrr_at_100_diff1
value: 10.765635069630173
- type: nauc_mrr_at_100_max
value: -1.7612670077500088
- type: nauc_mrr_at_100_std
value: 13.47656838026296
- type: nauc_mrr_at_10_diff1
value: 10.35632278742462
- type: nauc_mrr_at_10_max
value: -1.9593749415315034
- type: nauc_mrr_at_10_std
value: 12.726659151321748
- type: nauc_mrr_at_1_diff1
value: 12.18980309927674
- type: nauc_mrr_at_1_max
value: -4.630938342229097
- type: nauc_mrr_at_1_std
value: 8.958732319219887
- type: nauc_mrr_at_20_diff1
value: 10.689736739154682
- type: nauc_mrr_at_20_max
value: -1.689535123826222
- type: nauc_mrr_at_20_std
value: 13.251612129414687
- type: nauc_mrr_at_3_diff1
value: 9.852214578314367
- type: nauc_mrr_at_3_max
value: -3.33487013011876
- type: nauc_mrr_at_3_std
value: 10.877855458667428
- type: nauc_mrr_at_5_diff1
value: 10.270810271458073
- type: nauc_mrr_at_5_max
value: -2.677309074821081
- type: nauc_mrr_at_5_std
value: 11.882706514806639
- type: nauc_ndcg_at_1000_diff1
value: 12.681360792690615
- type: nauc_ndcg_at_1000_max
value: 0.30517667512214525
- type: nauc_ndcg_at_1000_std
value: 17.50402456957222
- type: nauc_ndcg_at_100_diff1
value: 13.169226394338585
- type: nauc_ndcg_at_100_max
value: 0.7398525127020716
- type: nauc_ndcg_at_100_std
value: 18.85172563798729
- type: nauc_ndcg_at_10_diff1
value: 11.874278269234175
- type: nauc_ndcg_at_10_max
value: 0.742178692340471
- type: nauc_ndcg_at_10_std
value: 15.317281484021455
- type: nauc_ndcg_at_1_diff1
value: 13.270492079181698
- type: nauc_ndcg_at_1_max
value: -5.320050131923338
- type: nauc_ndcg_at_1_std
value: 9.145476528935111
- type: nauc_ndcg_at_20_diff1
value: 12.77788972412781
- type: nauc_ndcg_at_20_max
value: 1.3509880113588073
- type: nauc_ndcg_at_20_std
value: 17.20165293396484
- type: nauc_ndcg_at_3_diff1
value: 10.59415387301215
- type: nauc_ndcg_at_3_max
value: -2.5275550083941534
- type: nauc_ndcg_at_3_std
value: 11.765849158403212
- type: nauc_ndcg_at_5_diff1
value: 11.479181039452788
- type: nauc_ndcg_at_5_max
value: -1.1695551867031702
- type: nauc_ndcg_at_5_std
value: 13.366137540722084
- type: nauc_precision_at_1000_diff1
value: 24.13842177102596
- type: nauc_precision_at_1000_max
value: 15.778091220725535
- type: nauc_precision_at_1000_std
value: 57.991198111902065
- type: nauc_precision_at_100_diff1
value: 21.17988197332234
- type: nauc_precision_at_100_max
value: 10.072329200503201
- type: nauc_precision_at_100_std
value: 44.359368185927
- type: nauc_precision_at_10_diff1
value: 13.619970980685995
- type: nauc_precision_at_10_max
value: 7.683020411909876
- type: nauc_precision_at_10_std
value: 21.79402262800611
- type: nauc_precision_at_1_diff1
value: 13.270492079181698
- type: nauc_precision_at_1_max
value: -5.320050131923338
- type: nauc_precision_at_1_std
value: 9.145476528935111
- type: nauc_precision_at_20_diff1
value: 16.97319915821357
- type: nauc_precision_at_20_max
value: 10.315905315799096
- type: nauc_precision_at_20_std
value: 28.82688927043146
- type: nauc_precision_at_3_diff1
value: 10.02754671342287
- type: nauc_precision_at_3_max
value: -0.8699973044493069
- type: nauc_precision_at_3_std
value: 13.603782123513389
- type: nauc_precision_at_5_diff1
value: 12.084329744277978
- type: nauc_precision_at_5_max
value: 2.074626490481966
- type: nauc_precision_at_5_std
value: 16.608205795807304
- type: nauc_recall_at_1000_diff1
value: 24.138421771026135
- type: nauc_recall_at_1000_max
value: 15.778091220725404
- type: nauc_recall_at_1000_std
value: 57.99119811190208
- type: nauc_recall_at_100_diff1
value: 21.179881973322274
- type: nauc_recall_at_100_max
value: 10.072329200503164
- type: nauc_recall_at_100_std
value: 44.359368185926975
- type: nauc_recall_at_10_diff1
value: 13.619970980685975
- type: nauc_recall_at_10_max
value: 7.683020411909859
- type: nauc_recall_at_10_std
value: 21.794022628006108
- type: nauc_recall_at_1_diff1
value: 13.270492079181698
- type: nauc_recall_at_1_max
value: -5.320050131923338
- type: nauc_recall_at_1_std
value: 9.145476528935111
- type: nauc_recall_at_20_diff1
value: 16.973199158213596
- type: nauc_recall_at_20_max
value: 10.315905315799101
- type: nauc_recall_at_20_std
value: 28.82688927043146
- type: nauc_recall_at_3_diff1
value: 10.02754671342289
- type: nauc_recall_at_3_max
value: -0.869997304449278
- type: nauc_recall_at_3_std
value: 13.603782123513424
- type: nauc_recall_at_5_diff1
value: 12.084329744277952
- type: nauc_recall_at_5_max
value: 2.074626490481952
- type: nauc_recall_at_5_std
value: 16.60820579580728
- type: ndcg_at_1
value: 14.438
- type: ndcg_at_10
value: 29.599999999999998
- type: ndcg_at_100
value: 35.062
- type: ndcg_at_1000
value: 37.266
- type: ndcg_at_20
value: 31.734
- type: ndcg_at_3
value: 22.62
- type: ndcg_at_5
value: 25.643
- type: precision_at_1
value: 14.438
- type: precision_at_10
value: 4.843999999999999
- type: precision_at_100
value: 0.748
- type: precision_at_1000
value: 0.093
- type: precision_at_20
value: 2.841
- type: precision_at_3
value: 9.578000000000001
- type: precision_at_5
value: 7.226000000000001
- type: recall_at_1
value: 14.438
- type: recall_at_10
value: 48.435
- type: recall_at_100
value: 74.822
- type: recall_at_1000
value: 92.60300000000001
- type: recall_at_20
value: 56.828
- type: recall_at_3
value: 28.733999999999998
- type: recall_at_5
value: 36.131
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P (default)
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: main_score
value: 35.46255145204994
- type: v_measure
value: 35.46255145204994
- type: v_measure_std
value: 14.146815377034603
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S (default)
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: main_score
value: 26.34189987196252
- type: v_measure
value: 26.34189987196252
- type: v_measure_std
value: 14.798697652139317
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions (default)
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: main_score
value: 52.85912447389551
- type: map
value: 52.85912447389551
- type: mrr
value: 66.7957173635844
- type: nAUC_map_diff1
value: 11.291158204891948
- type: nAUC_map_max
value: 14.0571982637716
- type: nAUC_map_std
value: 7.658903761935503
- type: nAUC_mrr_diff1
value: 13.851083215099605
- type: nAUC_mrr_max
value: 19.44964881732576
- type: nAUC_mrr_std
value: 9.313450884539453
- task:
type: STS
dataset:
name: MTEB BIOSSES (default)
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cosine_pearson
value: 73.38282679412139
- type: cosine_spearman
value: 75.59389113278942
- type: euclidean_pearson
value: 46.852724684799625
- type: euclidean_spearman
value: 55.00125324086669
- type: main_score
value: 75.59389113278942
- type: manhattan_pearson
value: 45.7988833997748
- type: manhattan_spearman
value: 53.28856361366204
- type: pearson
value: 73.38282679412139
- type: spearman
value: 75.59389113278942
- task:
type: Classification
dataset:
name: MTEB Banking77Classification (default)
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 71.38636363636363
- type: f1
value: 71.55994805461263
- type: f1_weighted
value: 71.55994805461263
- type: main_score
value: 71.38636363636363
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P (default)
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: main_score
value: 31.47309865069476
- type: v_measure
value: 31.47309865069476
- type: v_measure_std
value: 0.6360736715097297
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S (default)
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: main_score
value: 22.58199120148109
- type: v_measure
value: 22.58199120148109
- type: v_measure_std
value: 1.1055877138914942
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval (default)
type: mteb/cqadupstack-android
config: default
split: test
revision: f46a197baaae43b4f621051089b82a364682dfeb
metrics:
- type: main_score
value: 28.518
- type: map_at_1
value: 17.355999999999998
- type: map_at_10
value: 24.007
- type: map_at_100
value: 25.016
- type: map_at_1000
value: 25.176
- type: map_at_20
value: 24.457
- type: map_at_3
value: 21.794
- type: map_at_5
value: 23.04
- type: mrr_at_1
value: 22.603719599427755
- type: mrr_at_10
value: 29.108760814769386
- type: mrr_at_100
value: 29.908376499291993
- type: mrr_at_1000
value: 29.994015228435632
- type: mrr_at_20
value: 29.504080407211593
- type: mrr_at_3
value: 27.25321888412018
- type: mrr_at_5
value: 28.233190271816884
- type: nauc_map_at_1000_diff1
value: 47.869786003745816
- type: nauc_map_at_1000_max
value: 27.54096137497838
- type: nauc_map_at_1000_std
value: -7.400161145378304
- type: nauc_map_at_100_diff1
value: 47.84118234991334
- type: nauc_map_at_100_max
value: 27.54904954135266
- type: nauc_map_at_100_std
value: -7.477944025206194
- type: nauc_map_at_10_diff1
value: 47.9735876072791
- type: nauc_map_at_10_max
value: 27.391055282545462
- type: nauc_map_at_10_std
value: -7.809853508011509
- type: nauc_map_at_1_diff1
value: 58.07291238335911
- type: nauc_map_at_1_max
value: 29.491926251716666
- type: nauc_map_at_1_std
value: -7.759388303825668
- type: nauc_map_at_20_diff1
value: 47.98612480482489
- type: nauc_map_at_20_max
value: 27.475036492625026
- type: nauc_map_at_20_std
value: -7.516599563783101
- type: nauc_map_at_3_diff1
value: 49.45201738384499
- type: nauc_map_at_3_max
value: 27.178788486813954
- type: nauc_map_at_3_std
value: -8.675581883315793
- type: nauc_map_at_5_diff1
value: 48.54428206844137
- type: nauc_map_at_5_max
value: 27.04154567160208
- type: nauc_map_at_5_std
value: -7.985715295487552
- type: nauc_mrr_at_1000_diff1
value: 46.574864956985365
- type: nauc_mrr_at_1000_max
value: 28.087519043166832
- type: nauc_mrr_at_1000_std
value: -6.451015366036509
- type: nauc_mrr_at_100_diff1
value: 46.56229597151685
- type: nauc_mrr_at_100_max
value: 28.097330034559143
- type: nauc_mrr_at_100_std
value: -6.475319386029993
- type: nauc_mrr_at_10_diff1
value: 46.72161155094325
- type: nauc_mrr_at_10_max
value: 28.136796558719162
- type: nauc_mrr_at_10_std
value: -6.804592873002316
- type: nauc_mrr_at_1_diff1
value: 55.89633445168951
- type: nauc_mrr_at_1_max
value: 30.47937590769701
- type: nauc_mrr_at_1_std
value: -7.1323488254717935
- type: nauc_mrr_at_20_diff1
value: 46.693169452232546
- type: nauc_mrr_at_20_max
value: 28.140872936089373
- type: nauc_mrr_at_20_std
value: -6.484331458969132
- type: nauc_mrr_at_3_diff1
value: 47.808872121231374
- type: nauc_mrr_at_3_max
value: 28.510278015059086
- type: nauc_mrr_at_3_std
value: -7.418313420962369
- type: nauc_mrr_at_5_diff1
value: 47.00163108991785
- type: nauc_mrr_at_5_max
value: 28.03825046154691
- type: nauc_mrr_at_5_std
value: -7.007540109114421
- type: nauc_ndcg_at_1000_diff1
value: 44.04808574593522
- type: nauc_ndcg_at_1000_max
value: 26.938526842644773
- type: nauc_ndcg_at_1000_std
value: -4.429274627595189
- type: nauc_ndcg_at_100_diff1
value: 43.556532019049136
- type: nauc_ndcg_at_100_max
value: 27.236734895647253
- type: nauc_ndcg_at_100_std
value: -5.869942528569457
- type: nauc_ndcg_at_10_diff1
value: 44.125042380771696
- type: nauc_ndcg_at_10_max
value: 27.283104729889622
- type: nauc_ndcg_at_10_std
value: -7.250075385018749
- type: nauc_ndcg_at_1_diff1
value: 55.89633445168951
- type: nauc_ndcg_at_1_max
value: 30.47937590769701
- type: nauc_ndcg_at_1_std
value: -7.1323488254717935
- type: nauc_ndcg_at_20_diff1
value: 44.41899784089651
- type: nauc_ndcg_at_20_max
value: 27.132007799782926
- type: nauc_ndcg_at_20_std
value: -6.018341603261965
- type: nauc_ndcg_at_3_diff1
value: 46.43333330203715
- type: nauc_ndcg_at_3_max
value: 26.867159196890523
- type: nauc_ndcg_at_3_std
value: -7.989033187697878
- type: nauc_ndcg_at_5_diff1
value: 44.97708505801694
- type: nauc_ndcg_at_5_max
value: 26.53850652652143
- type: nauc_ndcg_at_5_std
value: -7.429040061351512
- type: nauc_precision_at_1000_diff1
value: 10.90587664149544
- type: nauc_precision_at_1000_max
value: 0.7573834415907932
- type: nauc_precision_at_1000_std
value: 4.187233421717695
- type: nauc_precision_at_100_diff1
value: 16.70162637068987
- type: nauc_precision_at_100_max
value: 15.017760634485006
- type: nauc_precision_at_100_std
value: -1.4401234272452257
- type: nauc_precision_at_10_diff1
value: 27.11447978714884
- type: nauc_precision_at_10_max
value: 25.239563326602838
- type: nauc_precision_at_10_std
value: -5.113529015570373
- type: nauc_precision_at_1_diff1
value: 55.89633445168951
- type: nauc_precision_at_1_max
value: 30.47937590769701
- type: nauc_precision_at_1_std
value: -7.1323488254717935
- type: nauc_precision_at_20_diff1
value: 24.467549645043032
- type: nauc_precision_at_20_max
value: 23.51675958880599
- type: nauc_precision_at_20_std
value: -2.2460962355932654
- type: nauc_precision_at_3_diff1
value: 36.99310143703273
- type: nauc_precision_at_3_max
value: 24.28484429048304
- type: nauc_precision_at_3_std
value: -8.294205947711662
- type: nauc_precision_at_5_diff1
value: 32.53111998357926
- type: nauc_precision_at_5_max
value: 23.890361705484153
- type: nauc_precision_at_5_std
value: -6.119004280837306
- type: nauc_recall_at_1000_diff1
value: 26.372327810550182
- type: nauc_recall_at_1000_max
value: 17.386452637452958
- type: nauc_recall_at_1000_std
value: 17.18893134942721
- type: nauc_recall_at_100_diff1
value: 27.138092417145288
- type: nauc_recall_at_100_max
value: 22.704436530088913
- type: nauc_recall_at_100_std
value: -1.0716953053918568
- type: nauc_recall_at_10_diff1
value: 32.41154313152003
- type: nauc_recall_at_10_max
value: 23.2359443305839
- type: nauc_recall_at_10_std
value: -5.002290149250385
- type: nauc_recall_at_1_diff1
value: 58.07291238335911
- type: nauc_recall_at_1_max
value: 29.491926251716666
- type: nauc_recall_at_1_std
value: -7.759388303825668
- type: nauc_recall_at_20_diff1
value: 33.00899946361021
- type: nauc_recall_at_20_max
value: 22.82808333164438
- type: nauc_recall_at_20_std
value: -1.4141291649557204
- type: nauc_recall_at_3_diff1
value: 38.920601224546644
- type: nauc_recall_at_3_max
value: 23.89232056113095
- type: nauc_recall_at_3_std
value: -7.8481952205795995
- type: nauc_recall_at_5_diff1
value: 35.257535866907
- type: nauc_recall_at_5_max
value: 22.164920959223334
- type: nauc_recall_at_5_std
value: -5.9961105131656725
- type: ndcg_at_1
value: 22.604
- type: ndcg_at_10
value: 28.518
- type: ndcg_at_100
value: 33.442
- type: ndcg_at_1000
value: 36.691
- type: ndcg_at_20
value: 29.918
- type: ndcg_at_3
value: 25.278
- type: ndcg_at_5
value: 26.647
- type: precision_at_1
value: 22.604
- type: precision_at_10
value: 5.608
- type: precision_at_100
value: 1.0210000000000001
- type: precision_at_1000
value: 0.163
- type: precision_at_20
value: 3.319
- type: precision_at_3
value: 12.589
- type: precision_at_5
value: 8.984
- type: recall_at_1
value: 17.355999999999998
- type: recall_at_10
value: 36.59
- type: recall_at_100
value: 59.38099999999999
- type: recall_at_1000
value: 81.382
- type: recall_at_20
value: 41.972
- type: recall_at_3
value: 26.183
- type: recall_at_5
value: 30.653000000000002
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackEnglishRetrieval (default)
type: mteb/cqadupstack-english
config: default
split: test
revision: ad9991cb51e31e31e430383c75ffb2885547b5f0
metrics:
- type: main_score
value: 24.698999999999998
- type: map_at_1
value: 16.182
- type: map_at_10
value: 21.187
- type: map_at_100
value: 22.028
- type: map_at_1000
value: 22.147
- type: map_at_20
value: 21.603
- type: map_at_3
value: 19.689999999999998
- type: map_at_5
value: 20.402
- type: mrr_at_1
value: 20.573248407643312
- type: mrr_at_10
value: 25.743301991709615
- type: mrr_at_100
value: 26.466582692758493
- type: mrr_at_1000
value: 26.54213235591294
- type: mrr_at_20
value: 26.116902322631823
- type: mrr_at_3
value: 24.32059447983014
- type: mrr_at_5
value: 24.960721868365162
- type: nauc_map_at_1000_diff1
value: 43.80371326276162
- type: nauc_map_at_1000_max
value: 10.307189223525215
- type: nauc_map_at_1000_std
value: 1.1410206622059031
- type: nauc_map_at_100_diff1
value: 43.80398291664643
- type: nauc_map_at_100_max
value: 10.294039476698776
- type: nauc_map_at_100_std
value: 1.0838400387773035
- type: nauc_map_at_10_diff1
value: 43.987106322737205
- type: nauc_map_at_10_max
value: 10.44970205412866
- type: nauc_map_at_10_std
value: 0.4638949254801207
- type: nauc_map_at_1_diff1
value: 50.262982039499725
- type: nauc_map_at_1_max
value: 11.253389960693605
- type: nauc_map_at_1_std
value: -1.1369036906864514
- type: nauc_map_at_20_diff1
value: 43.86541706002641
- type: nauc_map_at_20_max
value: 10.333426229095483
- type: nauc_map_at_20_std
value: 0.7704746445769103
- type: nauc_map_at_3_diff1
value: 44.96796698986098
- type: nauc_map_at_3_max
value: 10.573187295958576
- type: nauc_map_at_3_std
value: 0.01433549559929614
- type: nauc_map_at_5_diff1
value: 44.245307311061204
- type: nauc_map_at_5_max
value: 10.644568381319045
- type: nauc_map_at_5_std
value: -0.029700274583380155
- type: nauc_mrr_at_1000_diff1
value: 42.327672613522914
- type: nauc_mrr_at_1000_max
value: 11.6999240554554
- type: nauc_mrr_at_1000_std
value: 2.112897885106764
- type: nauc_mrr_at_100_diff1
value: 42.31642286015079
- type: nauc_mrr_at_100_max
value: 11.68787957194085
- type: nauc_mrr_at_100_std
value: 2.105610688222343
- type: nauc_mrr_at_10_diff1
value: 42.467973855007116
- type: nauc_mrr_at_10_max
value: 11.797064798974974
- type: nauc_mrr_at_10_std
value: 1.9779659522730684
- type: nauc_mrr_at_1_diff1
value: 47.71737815016663
- type: nauc_mrr_at_1_max
value: 14.383095652386146
- type: nauc_mrr_at_1_std
value: -0.07474670021285572
- type: nauc_mrr_at_20_diff1
value: 42.3995701621796
- type: nauc_mrr_at_20_max
value: 11.701616710562975
- type: nauc_mrr_at_20_std
value: 2.085148056092746
- type: nauc_mrr_at_3_diff1
value: 42.95240734385427
- type: nauc_mrr_at_3_max
value: 12.039509345325337
- type: nauc_mrr_at_3_std
value: 1.7687962861822382
- type: nauc_mrr_at_5_diff1
value: 42.694804355468115
- type: nauc_mrr_at_5_max
value: 11.929565017206377
- type: nauc_mrr_at_5_std
value: 1.694875246947431
- type: nauc_ndcg_at_1000_diff1
value: 41.00761525475331
- type: nauc_ndcg_at_1000_max
value: 9.858142865194182
- type: nauc_ndcg_at_1000_std
value: 3.670728963648605
- type: nauc_ndcg_at_100_diff1
value: 40.95449329238105
- type: nauc_ndcg_at_100_max
value: 9.326306956218327
- type: nauc_ndcg_at_100_std
value: 2.8868853641438506
- type: nauc_ndcg_at_10_diff1
value: 41.53254984337585
- type: nauc_ndcg_at_10_max
value: 10.057078591477252
- type: nauc_ndcg_at_10_std
value: 1.604308043004992
- type: nauc_ndcg_at_1_diff1
value: 47.71737815016663
- type: nauc_ndcg_at_1_max
value: 14.383095652386146
- type: nauc_ndcg_at_1_std
value: -0.07474670021285572
- type: nauc_ndcg_at_20_diff1
value: 41.440675477881086
- type: nauc_ndcg_at_20_max
value: 9.630011024652227
- type: nauc_ndcg_at_20_std
value: 2.2157732372759256
- type: nauc_ndcg_at_3_diff1
value: 42.46487256960971
- type: nauc_ndcg_at_3_max
value: 11.038048797533829
- type: nauc_ndcg_at_3_std
value: 1.2243654696200774
- type: nauc_ndcg_at_5_diff1
value: 41.83878536100888
- type: nauc_ndcg_at_5_max
value: 10.720801901432624
- type: nauc_ndcg_at_5_std
value: 0.8712149388513847
- type: nauc_precision_at_1000_diff1
value: 1.5865611853545292
- type: nauc_precision_at_1000_max
value: 6.681393322922304
- type: nauc_precision_at_1000_std
value: 14.974673269542507
- type: nauc_precision_at_100_diff1
value: 13.555729326347315
- type: nauc_precision_at_100_max
value: 7.545824391218551
- type: nauc_precision_at_100_std
value: 13.934044415661273
- type: nauc_precision_at_10_diff1
value: 25.53208157998575
- type: nauc_precision_at_10_max
value: 10.861163675534936
- type: nauc_precision_at_10_std
value: 4.879245837329693
- type: nauc_precision_at_1_diff1
value: 47.71737815016663
- type: nauc_precision_at_1_max
value: 14.383095652386146
- type: nauc_precision_at_1_std
value: -0.07474670021285572
- type: nauc_precision_at_20_diff1
value: 22.554580803838196
- type: nauc_precision_at_20_max
value: 9.173222510159171
- type: nauc_precision_at_20_std
value: 8.91005482914735
- type: nauc_precision_at_3_diff1
value: 33.10508327009392
- type: nauc_precision_at_3_max
value: 12.86002329562499
- type: nauc_precision_at_3_std
value: 2.974310102418383
- type: nauc_precision_at_5_diff1
value: 29.21043001216549
- type: nauc_precision_at_5_max
value: 11.911630406472423
- type: nauc_precision_at_5_std
value: 3.0525160145985994
- type: nauc_recall_at_1000_diff1
value: 30.47927917267733
- type: nauc_recall_at_1000_max
value: 7.6799659504807245
- type: nauc_recall_at_1000_std
value: 12.501272715675682
- type: nauc_recall_at_100_diff1
value: 31.37456182815277
- type: nauc_recall_at_100_max
value: 4.3121178276146
- type: nauc_recall_at_100_std
value: 6.610653786295896
- type: nauc_recall_at_10_diff1
value: 35.70919804366768
- type: nauc_recall_at_10_max
value: 7.164595283036483
- type: nauc_recall_at_10_std
value: 2.511197530002145
- type: nauc_recall_at_1_diff1
value: 50.262982039499725
- type: nauc_recall_at_1_max
value: 11.253389960693605
- type: nauc_recall_at_1_std
value: -1.1369036906864514
- type: nauc_recall_at_20_diff1
value: 34.61353209754079
- type: nauc_recall_at_20_max
value: 5.959396627193594
- type: nauc_recall_at_20_std
value: 4.38802472107702
- type: nauc_recall_at_3_diff1
value: 38.54587550067196
- type: nauc_recall_at_3_max
value: 8.303476446370226
- type: nauc_recall_at_3_std
value: 0.918233189682653
- type: nauc_recall_at_5_diff1
value: 36.97453761390672
- type: nauc_recall_at_5_max
value: 8.452744877863443
- type: nauc_recall_at_5_std
value: 0.31182896781455743
- type: ndcg_at_1
value: 20.573
- type: ndcg_at_10
value: 24.698999999999998
- type: ndcg_at_100
value: 28.626
- type: ndcg_at_1000
value: 31.535999999999998
- type: ndcg_at_20
value: 25.971
- type: ndcg_at_3
value: 22.400000000000002
- type: ndcg_at_5
value: 23.153000000000002
- type: precision_at_1
value: 20.573
- type: precision_at_10
value: 4.682
- type: precision_at_100
value: 0.835
- type: precision_at_1000
value: 0.132
- type: precision_at_20
value: 2.806
- type: precision_at_3
value: 10.955
- type: precision_at_5
value: 7.580000000000001
- type: recall_at_1
value: 16.182
- type: recall_at_10
value: 30.410999999999998
- type: recall_at_100
value: 47.94
- type: recall_at_1000
value: 68.073
- type: recall_at_20
value: 35.241
- type: recall_at_3
value: 23.247999999999998
- type: recall_at_5
value: 25.611
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGamingRetrieval (default)
type: mteb/cqadupstack-gaming
config: default
split: test
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
metrics:
- type: main_score
value: 34.837
- type: map_at_1
value: 21.804000000000002
- type: map_at_10
value: 30.117
- type: map_at_100
value: 31.022
- type: map_at_1000
value: 31.123
- type: map_at_20
value: 30.592999999999996
- type: map_at_3
value: 27.485
- type: map_at_5
value: 29.015
- type: mrr_at_1
value: 25.391849529780565
- type: mrr_at_10
value: 33.06018311190724
- type: mrr_at_100
value: 33.86542467064614
- type: mrr_at_1000
value: 33.93133191694629
- type: mrr_at_20
value: 33.48454644646544
- type: mrr_at_3
value: 30.700104493207924
- type: mrr_at_5
value: 32.12016718913267
- type: nauc_map_at_1000_diff1
value: 45.5807513160407
- type: nauc_map_at_1000_max
value: 21.915072082554456
- type: nauc_map_at_1000_std
value: -7.325013122158723
- type: nauc_map_at_100_diff1
value: 45.54127845733458
- type: nauc_map_at_100_max
value: 21.90856139725234
- type: nauc_map_at_100_std
value: -7.378234997163831
- type: nauc_map_at_10_diff1
value: 45.56616787985884
- type: nauc_map_at_10_max
value: 21.977377645141427
- type: nauc_map_at_10_std
value: -7.953791461768689
- type: nauc_map_at_1_diff1
value: 50.13523755859727
- type: nauc_map_at_1_max
value: 22.079872106357826
- type: nauc_map_at_1_std
value: -10.517989063520115
- type: nauc_map_at_20_diff1
value: 45.47328572468456
- type: nauc_map_at_20_max
value: 21.907938618532206
- type: nauc_map_at_20_std
value: -7.654370878334637
- type: nauc_map_at_3_diff1
value: 46.64296035971972
- type: nauc_map_at_3_max
value: 21.55745539420763
- type: nauc_map_at_3_std
value: -9.322387704640397
- type: nauc_map_at_5_diff1
value: 45.87814328869891
- type: nauc_map_at_5_max
value: 21.97551177369846
- type: nauc_map_at_5_std
value: -8.442300800960686
- type: nauc_mrr_at_1000_diff1
value: 46.21214184609282
- type: nauc_mrr_at_1000_max
value: 24.121552423232732
- type: nauc_mrr_at_1000_std
value: -5.197081534530456
- type: nauc_mrr_at_100_diff1
value: 46.192209374562324
- type: nauc_mrr_at_100_max
value: 24.117295080133403
- type: nauc_mrr_at_100_std
value: -5.20106321371411
- type: nauc_mrr_at_10_diff1
value: 46.214433219910426
- type: nauc_mrr_at_10_max
value: 24.337609381566494
- type: nauc_mrr_at_10_std
value: -5.539128286307364
- type: nauc_mrr_at_1_diff1
value: 52.2527723494356
- type: nauc_mrr_at_1_max
value: 25.421197106410293
- type: nauc_mrr_at_1_std
value: -7.805349072851469
- type: nauc_mrr_at_20_diff1
value: 46.10135736013422
- type: nauc_mrr_at_20_max
value: 24.17582977429519
- type: nauc_mrr_at_20_std
value: -5.3844233771043255
- type: nauc_mrr_at_3_diff1
value: 47.089100932315574
- type: nauc_mrr_at_3_max
value: 24.589442349183855
- type: nauc_mrr_at_3_std
value: -6.861652459272909
- type: nauc_mrr_at_5_diff1
value: 46.50908152902759
- type: nauc_mrr_at_5_max
value: 24.44902343275474
- type: nauc_mrr_at_5_std
value: -5.90486733129187
- type: nauc_ndcg_at_1000_diff1
value: 44.01232290993056
- type: nauc_ndcg_at_1000_max
value: 21.7547520856293
- type: nauc_ndcg_at_1000_std
value: -2.8320334767530118
- type: nauc_ndcg_at_100_diff1
value: 43.333079641772805
- type: nauc_ndcg_at_100_max
value: 21.696558885860842
- type: nauc_ndcg_at_100_std
value: -3.8168722593708466
- type: nauc_ndcg_at_10_diff1
value: 43.55004080963945
- type: nauc_ndcg_at_10_max
value: 22.437821635174988
- type: nauc_ndcg_at_10_std
value: -6.156552890106106
- type: nauc_ndcg_at_1_diff1
value: 52.2527723494356
- type: nauc_ndcg_at_1_max
value: 25.421197106410293
- type: nauc_ndcg_at_1_std
value: -7.805349072851469
- type: nauc_ndcg_at_20_diff1
value: 43.09035864009835
- type: nauc_ndcg_at_20_max
value: 21.94863122459976
- type: nauc_ndcg_at_20_std
value: -5.4130728717458965
- type: nauc_ndcg_at_3_diff1
value: 45.44710289580689
- type: nauc_ndcg_at_3_max
value: 22.400341906939868
- type: nauc_ndcg_at_3_std
value: -8.619757656107849
- type: nauc_ndcg_at_5_diff1
value: 44.1896655275832
- type: nauc_ndcg_at_5_max
value: 22.587591758610802
- type: nauc_ndcg_at_5_std
value: -7.2269233073063575
- type: nauc_precision_at_1000_diff1
value: 10.365353118490535
- type: nauc_precision_at_1000_max
value: 7.8252547949888545
- type: nauc_precision_at_1000_std
value: 26.55091491372318
- type: nauc_precision_at_100_diff1
value: 21.049854477557055
- type: nauc_precision_at_100_max
value: 16.20485886511922
- type: nauc_precision_at_100_std
value: 15.969890079702717
- type: nauc_precision_at_10_diff1
value: 32.52426180873231
- type: nauc_precision_at_10_max
value: 22.685662047893707
- type: nauc_precision_at_10_std
value: 1.4729404419557324
- type: nauc_precision_at_1_diff1
value: 52.2527723494356
- type: nauc_precision_at_1_max
value: 25.421197106410293
- type: nauc_precision_at_1_std
value: -7.805349072851469
- type: nauc_precision_at_20_diff1
value: 28.090691152210972
- type: nauc_precision_at_20_max
value: 20.90743423717082
- type: nauc_precision_at_20_std
value: 4.817506381512236
- type: nauc_precision_at_3_diff1
value: 40.80538406829336
- type: nauc_precision_at_3_max
value: 23.323105131070363
- type: nauc_precision_at_3_std
value: -5.540716529624683
- type: nauc_precision_at_5_diff1
value: 36.58280618039231
- type: nauc_precision_at_5_max
value: 23.634816479662742
- type: nauc_precision_at_5_std
value: -1.7820384730109589
- type: nauc_recall_at_1000_diff1
value: 34.29190280951983
- type: nauc_recall_at_1000_max
value: 13.798111582798564
- type: nauc_recall_at_1000_std
value: 28.5351988388723
- type: nauc_recall_at_100_diff1
value: 32.064087882086476
- type: nauc_recall_at_100_max
value: 16.090743768333688
- type: nauc_recall_at_100_std
value: 8.307894883910041
- type: nauc_recall_at_10_diff1
value: 35.79378711197085
- type: nauc_recall_at_10_max
value: 20.68575839918982
- type: nauc_recall_at_10_std
value: -2.946830801840792
- type: nauc_recall_at_1_diff1
value: 50.13523755859727
- type: nauc_recall_at_1_max
value: 22.079872106357826
- type: nauc_recall_at_1_std
value: -10.517989063520115
- type: nauc_recall_at_20_diff1
value: 33.44790152149905
- type: nauc_recall_at_20_max
value: 18.594618679781895
- type: nauc_recall_at_20_std
value: -0.31826446038001266
- type: nauc_recall_at_3_diff1
value: 40.94878372307589
- type: nauc_recall_at_3_max
value: 20.42680666854128
- type: nauc_recall_at_3_std
value: -8.903430047857414
- type: nauc_recall_at_5_diff1
value: 37.927274464064844
- type: nauc_recall_at_5_max
value: 21.06930934356292
- type: nauc_recall_at_5_std
value: -5.831090950499156
- type: ndcg_at_1
value: 25.392
- type: ndcg_at_10
value: 34.837
- type: ndcg_at_100
value: 39.291
- type: ndcg_at_1000
value: 41.676
- type: ndcg_at_20
value: 36.416
- type: ndcg_at_3
value: 29.958000000000002
- type: ndcg_at_5
value: 32.435
- type: precision_at_1
value: 25.392
- type: precision_at_10
value: 5.806
- type: precision_at_100
value: 0.8789999999999999
- type: precision_at_1000
value: 0.117
- type: precision_at_20
value: 3.3320000000000003
- type: precision_at_3
value: 13.501
- type: precision_at_5
value: 9.718
- type: recall_at_1
value: 21.804000000000002
- type: recall_at_10
value: 46.367999999999995
- type: recall_at_100
value: 66.526
- type: recall_at_1000
value: 83.795
- type: recall_at_20
value: 52.201
- type: recall_at_3
value: 33.351
- type: recall_at_5
value: 39.345
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGisRetrieval (default)
type: mteb/cqadupstack-gis
config: default
split: test
revision: 5003b3064772da1887988e05400cf3806fe491f2
metrics:
- type: main_score
value: 15.889000000000001
- type: map_at_1
value: 9.472999999999999
- type: map_at_10
value: 13.439
- type: map_at_100
value: 14.165
- type: map_at_1000
value: 14.267
- type: map_at_20
value: 13.778000000000002
- type: map_at_3
value: 12.136
- type: map_at_5
value: 12.803
- type: mrr_at_1
value: 10.056497175141244
- type: mrr_at_10
value: 14.27383194332347
- type: mrr_at_100
value: 15.012089041940587
- type: mrr_at_1000
value: 15.104068046441926
- type: mrr_at_20
value: 14.623929801790952
- type: mrr_at_3
value: 12.86252354048964
- type: mrr_at_5
value: 13.55743879472693
- type: nauc_map_at_1000_diff1
value: 30.334633457872854
- type: nauc_map_at_1000_max
value: 16.879524053860088
- type: nauc_map_at_1000_std
value: -11.608379714877143
- type: nauc_map_at_100_diff1
value: 30.315313717026044
- type: nauc_map_at_100_max
value: 16.85237939531867
- type: nauc_map_at_100_std
value: -11.622151859571831
- type: nauc_map_at_10_diff1
value: 30.914146463660085
- type: nauc_map_at_10_max
value: 16.957132658303777
- type: nauc_map_at_10_std
value: -11.731838090023269
- type: nauc_map_at_1_diff1
value: 38.059077642105095
- type: nauc_map_at_1_max
value: 17.258898457644563
- type: nauc_map_at_1_std
value: -15.1141417910556
- type: nauc_map_at_20_diff1
value: 30.657379748220464
- type: nauc_map_at_20_max
value: 16.728415773059652
- type: nauc_map_at_20_std
value: -11.58808790930077
- type: nauc_map_at_3_diff1
value: 33.46033892507575
- type: nauc_map_at_3_max
value: 17.063496859962274
- type: nauc_map_at_3_std
value: -12.540868416387656
- type: nauc_map_at_5_diff1
value: 31.833328131003665
- type: nauc_map_at_5_max
value: 16.85136559752421
- type: nauc_map_at_5_std
value: -12.482629966798948
- type: nauc_mrr_at_1000_diff1
value: 29.41507065744396
- type: nauc_mrr_at_1000_max
value: 18.49824554052624
- type: nauc_mrr_at_1000_std
value: -10.326025120569037
- type: nauc_mrr_at_100_diff1
value: 29.379801930215717
- type: nauc_mrr_at_100_max
value: 18.488234248143247
- type: nauc_mrr_at_100_std
value: -10.335639545339422
- type: nauc_mrr_at_10_diff1
value: 29.91432794618661
- type: nauc_mrr_at_10_max
value: 18.724879448569546
- type: nauc_mrr_at_10_std
value: -10.404101745775053
- type: nauc_mrr_at_1_diff1
value: 37.90615317749033
- type: nauc_mrr_at_1_max
value: 18.93535243576158
- type: nauc_mrr_at_1_std
value: -13.352192729903559
- type: nauc_mrr_at_20_diff1
value: 29.578605690031328
- type: nauc_mrr_at_20_max
value: 18.407726379219987
- type: nauc_mrr_at_20_std
value: -10.298490989990624
- type: nauc_mrr_at_3_diff1
value: 32.02343883506372
- type: nauc_mrr_at_3_max
value: 18.633783635235847
- type: nauc_mrr_at_3_std
value: -11.228435347275935
- type: nauc_mrr_at_5_diff1
value: 30.69962523728713
- type: nauc_mrr_at_5_max
value: 18.72446829188985
- type: nauc_mrr_at_5_std
value: -11.138830180701982
- type: nauc_ndcg_at_1000_diff1
value: 25.382297853226866
- type: nauc_ndcg_at_1000_max
value: 17.43716304218148
- type: nauc_ndcg_at_1000_std
value: -10.190696887337486
- type: nauc_ndcg_at_100_diff1
value: 24.735480242752285
- type: nauc_ndcg_at_100_max
value: 16.71943454741711
- type: nauc_ndcg_at_100_std
value: -9.924909206899162
- type: nauc_ndcg_at_10_diff1
value: 27.358228148721842
- type: nauc_ndcg_at_10_max
value: 16.922883804711265
- type: nauc_ndcg_at_10_std
value: -10.016699536056024
- type: nauc_ndcg_at_1_diff1
value: 37.90615317749033
- type: nauc_ndcg_at_1_max
value: 18.93535243576158
- type: nauc_ndcg_at_1_std
value: -13.352192729903559
- type: nauc_ndcg_at_20_diff1
value: 26.463382227572517
- type: nauc_ndcg_at_20_max
value: 16.22031339406569
- type: nauc_ndcg_at_20_std
value: -9.66724467521929
- type: nauc_ndcg_at_3_diff1
value: 31.53806923827287
- type: nauc_ndcg_at_3_max
value: 17.049495750298107
- type: nauc_ndcg_at_3_std
value: -11.58504512374531
- type: nauc_ndcg_at_5_diff1
value: 29.10131680215961
- type: nauc_ndcg_at_5_max
value: 16.786497467751296
- type: nauc_ndcg_at_5_std
value: -11.594059282963107
- type: nauc_precision_at_1000_diff1
value: 5.724183211042247
- type: nauc_precision_at_1000_max
value: 22.481314169026508
- type: nauc_precision_at_1000_std
value: -2.4780053135041844
- type: nauc_precision_at_100_diff1
value: 8.982535905232872
- type: nauc_precision_at_100_max
value: 19.23627381958997
- type: nauc_precision_at_100_std
value: -6.469375758025859
- type: nauc_precision_at_10_diff1
value: 18.446003934213422
- type: nauc_precision_at_10_max
value: 18.317564090743698
- type: nauc_precision_at_10_std
value: -5.258776187738409
- type: nauc_precision_at_1_diff1
value: 37.90615317749033
- type: nauc_precision_at_1_max
value: 18.93535243576158
- type: nauc_precision_at_1_std
value: -13.352192729903559
- type: nauc_precision_at_20_diff1
value: 16.32313052813914
- type: nauc_precision_at_20_max
value: 16.623118796672443
- type: nauc_precision_at_20_std
value: -5.178876021009233
- type: nauc_precision_at_3_diff1
value: 28.153843298140956
- type: nauc_precision_at_3_max
value: 18.261053599119773
- type: nauc_precision_at_3_std
value: -8.633656740784398
- type: nauc_precision_at_5_diff1
value: 22.30147327973116
- type: nauc_precision_at_5_max
value: 17.724668119940276
- type: nauc_precision_at_5_std
value: -9.147827083942738
- type: nauc_recall_at_1000_diff1
value: 12.936742845571006
- type: nauc_recall_at_1000_max
value: 17.728147389670845
- type: nauc_recall_at_1000_std
value: -10.026543773605697
- type: nauc_recall_at_100_diff1
value: 12.196046010910255
- type: nauc_recall_at_100_max
value: 14.320146451643033
- type: nauc_recall_at_100_std
value: -7.059868030131276
- type: nauc_recall_at_10_diff1
value: 19.81974166368456
- type: nauc_recall_at_10_max
value: 15.137717469839288
- type: nauc_recall_at_10_std
value: -6.894031649742936
- type: nauc_recall_at_1_diff1
value: 38.059077642105095
- type: nauc_recall_at_1_max
value: 17.258898457644563
- type: nauc_recall_at_1_std
value: -15.1141417910556
- type: nauc_recall_at_20_diff1
value: 17.87014099435801
- type: nauc_recall_at_20_max
value: 13.410148544576403
- type: nauc_recall_at_20_std
value: -6.139892629545985
- type: nauc_recall_at_3_diff1
value: 27.941355405054267
- type: nauc_recall_at_3_max
value: 15.300277815129304
- type: nauc_recall_at_3_std
value: -10.440312722587832
- type: nauc_recall_at_5_diff1
value: 23.715987229368274
- type: nauc_recall_at_5_max
value: 15.063760707410282
- type: nauc_recall_at_5_std
value: -10.521011536014003
- type: ndcg_at_1
value: 10.056
- type: ndcg_at_10
value: 15.889000000000001
- type: ndcg_at_100
value: 20.007
- type: ndcg_at_1000
value: 23.324
- type: ndcg_at_20
value: 17.127
- type: ndcg_at_3
value: 13.171
- type: ndcg_at_5
value: 14.358
- type: precision_at_1
value: 10.056
- type: precision_at_10
value: 2.588
- type: precision_at_100
value: 0.49300000000000005
- type: precision_at_1000
value: 0.083
- type: precision_at_20
value: 1.559
- type: precision_at_3
value: 5.612
- type: precision_at_5
value: 4.0680000000000005
- type: recall_at_1
value: 9.472999999999999
- type: recall_at_10
value: 22.676
- type: recall_at_100
value: 42.672
- type: recall_at_1000
value: 68.939
- type: recall_at_20
value: 27.462999999999997
- type: recall_at_3
value: 15.383
- type: recall_at_5
value: 18.174
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackMathematicaRetrieval (default)
type: mteb/cqadupstack-mathematica
config: default
split: test
revision: 90fceea13679c63fe563ded68f3b6f06e50061de
metrics:
- type: main_score
value: 11.0
- type: map_at_1
value: 5.148
- type: map_at_10
value: 8.469999999999999
- type: map_at_100
value: 9.212
- type: map_at_1000
value: 9.322
- type: map_at_20
value: 8.808
- type: map_at_3
value: 7.131
- type: map_at_5
value: 7.815999999999999
- type: mrr_at_1
value: 6.343283582089552
- type: mrr_at_10
value: 10.370913290689412
- type: mrr_at_100
value: 11.152489765865017
- type: mrr_at_1000
value: 11.240647288895591
- type: mrr_at_20
value: 10.741514212977526
- type: mrr_at_3
value: 8.872305140961858
- type: mrr_at_5
value: 9.631011608623549
- type: nauc_map_at_1000_diff1
value: 23.766626012326586
- type: nauc_map_at_1000_max
value: 12.653376257429583
- type: nauc_map_at_1000_std
value: 8.616529960924888
- type: nauc_map_at_100_diff1
value: 23.738827084996768
- type: nauc_map_at_100_max
value: 12.649650411660854
- type: nauc_map_at_100_std
value: 8.541383664809612
- type: nauc_map_at_10_diff1
value: 23.999578907568026
- type: nauc_map_at_10_max
value: 12.71263636252209
- type: nauc_map_at_10_std
value: 7.591195966672301
- type: nauc_map_at_1_diff1
value: 35.57446018071185
- type: nauc_map_at_1_max
value: 14.079653770667337
- type: nauc_map_at_1_std
value: 11.69336879118923
- type: nauc_map_at_20_diff1
value: 24.160966681198037
- type: nauc_map_at_20_max
value: 12.874042661878926
- type: nauc_map_at_20_std
value: 8.47225999927236
- type: nauc_map_at_3_diff1
value: 26.388037294578943
- type: nauc_map_at_3_max
value: 12.836707260430186
- type: nauc_map_at_3_std
value: 6.661759987628506
- type: nauc_map_at_5_diff1
value: 24.670961314269608
- type: nauc_map_at_5_max
value: 12.93683340709218
- type: nauc_map_at_5_std
value: 6.6199426801021435
- type: nauc_mrr_at_1000_diff1
value: 23.216930411387928
- type: nauc_mrr_at_1000_max
value: 15.19292342533299
- type: nauc_mrr_at_1000_std
value: 8.443837847880454
- type: nauc_mrr_at_100_diff1
value: 23.191640457286802
- type: nauc_mrr_at_100_max
value: 15.176060930237956
- type: nauc_mrr_at_100_std
value: 8.438353759551372
- type: nauc_mrr_at_10_diff1
value: 23.641665699722576
- type: nauc_mrr_at_10_max
value: 15.363771027025361
- type: nauc_mrr_at_10_std
value: 7.6943977364817675
- type: nauc_mrr_at_1_diff1
value: 34.13967231695169
- type: nauc_mrr_at_1_max
value: 18.217995055452356
- type: nauc_mrr_at_1_std
value: 11.691078655411745
- type: nauc_mrr_at_20_diff1
value: 23.584124655747633
- type: nauc_mrr_at_20_max
value: 15.504561511128212
- type: nauc_mrr_at_20_std
value: 8.487309205927613
- type: nauc_mrr_at_3_diff1
value: 26.239880657367205
- type: nauc_mrr_at_3_max
value: 15.653548540177347
- type: nauc_mrr_at_3_std
value: 6.349852805707984
- type: nauc_mrr_at_5_diff1
value: 23.976240360223915
- type: nauc_mrr_at_5_max
value: 15.744338647107542
- type: nauc_mrr_at_5_std
value: 6.487124576469712
- type: nauc_ndcg_at_1000_diff1
value: 19.496197697682945
- type: nauc_ndcg_at_1000_max
value: 12.101852407794244
- type: nauc_ndcg_at_1000_std
value: 12.016860314478954
- type: nauc_ndcg_at_100_diff1
value: 18.9745151618046
- type: nauc_ndcg_at_100_max
value: 11.815079877327287
- type: nauc_ndcg_at_100_std
value: 10.61036714041141
- type: nauc_ndcg_at_10_diff1
value: 20.49507024120394
- type: nauc_ndcg_at_10_max
value: 13.081108599437465
- type: nauc_ndcg_at_10_std
value: 7.930411944011889
- type: nauc_ndcg_at_1_diff1
value: 34.13967231695169
- type: nauc_ndcg_at_1_max
value: 18.217995055452356
- type: nauc_ndcg_at_1_std
value: 11.691078655411745
- type: nauc_ndcg_at_20_diff1
value: 20.839258395401707
- type: nauc_ndcg_at_20_max
value: 13.485012044482616
- type: nauc_ndcg_at_20_std
value: 10.423314754071841
- type: nauc_ndcg_at_3_diff1
value: 24.534248413854158
- type: nauc_ndcg_at_3_max
value: 13.612373481617901
- type: nauc_ndcg_at_3_std
value: 5.122655306518725
- type: nauc_ndcg_at_5_diff1
value: 21.45736115604528
- type: nauc_ndcg_at_5_max
value: 13.50049057414957
- type: nauc_ndcg_at_5_std
value: 5.5599020003710375
- type: nauc_precision_at_1000_diff1
value: 5.214729837045339
- type: nauc_precision_at_1000_max
value: 7.049726610933547
- type: nauc_precision_at_1000_std
value: 10.217710184510343
- type: nauc_precision_at_100_diff1
value: 10.428281377918521
- type: nauc_precision_at_100_max
value: 9.592496174158226
- type: nauc_precision_at_100_std
value: 11.524579687966593
- type: nauc_precision_at_10_diff1
value: 13.144126104006663
- type: nauc_precision_at_10_max
value: 12.791519232802509
- type: nauc_precision_at_10_std
value: 7.117254065134753
- type: nauc_precision_at_1_diff1
value: 34.13967231695169
- type: nauc_precision_at_1_max
value: 18.217995055452356
- type: nauc_precision_at_1_std
value: 11.691078655411745
- type: nauc_precision_at_20_diff1
value: 14.534665391717477
- type: nauc_precision_at_20_max
value: 13.373720011165052
- type: nauc_precision_at_20_std
value: 12.735872233304013
- type: nauc_precision_at_3_diff1
value: 20.050332454808
- type: nauc_precision_at_3_max
value: 14.287141036751699
- type: nauc_precision_at_3_std
value: 2.1412848715847774
- type: nauc_precision_at_5_diff1
value: 16.547335020939435
- type: nauc_precision_at_5_max
value: 14.007790386514285
- type: nauc_precision_at_5_std
value: 2.0821824154130835
- type: nauc_recall_at_1000_diff1
value: 12.811540518810224
- type: nauc_recall_at_1000_max
value: 8.292364898702107
- type: nauc_recall_at_1000_std
value: 21.172583907189164
- type: nauc_recall_at_100_diff1
value: 10.763207100689536
- type: nauc_recall_at_100_max
value: 7.433707421662763
- type: nauc_recall_at_100_std
value: 13.860488374098953
- type: nauc_recall_at_10_diff1
value: 14.171919964914773
- type: nauc_recall_at_10_max
value: 12.3310517183378
- type: nauc_recall_at_10_std
value: 8.627373443421941
- type: nauc_recall_at_1_diff1
value: 35.57446018071185
- type: nauc_recall_at_1_max
value: 14.079653770667337
- type: nauc_recall_at_1_std
value: 11.69336879118923
- type: nauc_recall_at_20_diff1
value: 15.254229786832758
- type: nauc_recall_at_20_max
value: 12.944155764013084
- type: nauc_recall_at_20_std
value: 13.947428525952118
- type: nauc_recall_at_3_diff1
value: 19.723050472865584
- type: nauc_recall_at_3_max
value: 12.208432070640235
- type: nauc_recall_at_3_std
value: 3.2560341221626357
- type: nauc_recall_at_5_diff1
value: 14.200616898717133
- type: nauc_recall_at_5_max
value: 12.262563917077088
- type: nauc_recall_at_5_std
value: 4.115380825048154
- type: ndcg_at_1
value: 6.343
- type: ndcg_at_10
value: 11.0
- type: ndcg_at_100
value: 15.332
- type: ndcg_at_1000
value: 18.505
- type: ndcg_at_20
value: 12.280000000000001
- type: ndcg_at_3
value: 8.297
- type: ndcg_at_5
value: 9.482
- type: precision_at_1
value: 6.343
- type: precision_at_10
value: 2.251
- type: precision_at_100
value: 0.516
- type: precision_at_1000
value: 0.091
- type: precision_at_20
value: 1.437
- type: precision_at_3
value: 4.104
- type: precision_at_5
value: 3.234
- type: recall_at_1
value: 5.148
- type: recall_at_10
value: 16.955000000000002
- type: recall_at_100
value: 37.295
- type: recall_at_1000
value: 60.681
- type: recall_at_20
value: 21.847
- type: recall_at_3
value: 9.735000000000001
- type: recall_at_5
value: 12.595999999999998
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackPhysicsRetrieval (default)
type: mteb/cqadupstack-physics
config: default
split: test
revision: 79531abbd1fb92d06c6d6315a0cbbbf5bb247ea4
metrics:
- type: main_score
value: 22.671
- type: map_at_1
value: 13.99
- type: map_at_10
value: 19.16
- type: map_at_100
value: 20.247999999999998
- type: map_at_1000
value: 20.392
- type: map_at_20
value: 19.741
- type: map_at_3
value: 17.527
- type: map_at_5
value: 18.431
- type: mrr_at_1
value: 17.035611164581326
- type: mrr_at_10
value: 22.920886994515485
- type: mrr_at_100
value: 23.890327247971815
- type: mrr_at_1000
value: 23.98416758924587
- type: mrr_at_20
value: 23.478953217825296
- type: mrr_at_3
value: 21.158164902149515
- type: mrr_at_5
value: 22.154315046519095
- type: nauc_map_at_1000_diff1
value: 40.20942586785694
- type: nauc_map_at_1000_max
value: 19.62019855432636
- type: nauc_map_at_1000_std
value: -6.491186533676609
- type: nauc_map_at_100_diff1
value: 40.20129829669095
- type: nauc_map_at_100_max
value: 19.550525879706164
- type: nauc_map_at_100_std
value: -6.557075399749154
- type: nauc_map_at_10_diff1
value: 40.467281905527244
- type: nauc_map_at_10_max
value: 19.43593214249552
- type: nauc_map_at_10_std
value: -7.194947764095804
- type: nauc_map_at_1_diff1
value: 49.99688096548819
- type: nauc_map_at_1_max
value: 22.94216810488251
- type: nauc_map_at_1_std
value: -8.778905956805103
- type: nauc_map_at_20_diff1
value: 40.23228770570461
- type: nauc_map_at_20_max
value: 19.53074463716011
- type: nauc_map_at_20_std
value: -6.93310286275384
- type: nauc_map_at_3_diff1
value: 42.462368040248364
- type: nauc_map_at_3_max
value: 20.15932725435944
- type: nauc_map_at_3_std
value: -7.524246324724258
- type: nauc_map_at_5_diff1
value: 40.874264936734775
- type: nauc_map_at_5_max
value: 19.741200249921643
- type: nauc_map_at_5_std
value: -7.301832585861893
- type: nauc_mrr_at_1000_diff1
value: 36.93104632204301
- type: nauc_mrr_at_1000_max
value: 22.851961632870285
- type: nauc_mrr_at_1000_std
value: -6.050824088401521
- type: nauc_mrr_at_100_diff1
value: 36.90287005748533
- type: nauc_mrr_at_100_max
value: 22.838209556819866
- type: nauc_mrr_at_100_std
value: -6.064342814003103
- type: nauc_mrr_at_10_diff1
value: 36.93428786395009
- type: nauc_mrr_at_10_max
value: 22.89500409199853
- type: nauc_mrr_at_10_std
value: -6.581360935957288
- type: nauc_mrr_at_1_diff1
value: 46.11618926628157
- type: nauc_mrr_at_1_max
value: 27.154042077346617
- type: nauc_mrr_at_1_std
value: -7.408231463170914
- type: nauc_mrr_at_20_diff1
value: 36.964474819881275
- type: nauc_mrr_at_20_max
value: 22.9072805988528
- type: nauc_mrr_at_20_std
value: -6.306124053032698
- type: nauc_mrr_at_3_diff1
value: 38.9506895551962
- type: nauc_mrr_at_3_max
value: 24.218011709989156
- type: nauc_mrr_at_3_std
value: -6.7973818662665995
- type: nauc_mrr_at_5_diff1
value: 37.42273475691658
- type: nauc_mrr_at_5_max
value: 23.270403975249025
- type: nauc_mrr_at_5_std
value: -6.745230968723559
- type: nauc_ndcg_at_1000_diff1
value: 35.79628671266452
- type: nauc_ndcg_at_1000_max
value: 19.26627785321929
- type: nauc_ndcg_at_1000_std
value: -2.569388520550047
- type: nauc_ndcg_at_100_diff1
value: 35.768798848849585
- type: nauc_ndcg_at_100_max
value: 18.377203611905518
- type: nauc_ndcg_at_100_std
value: -3.3799540521604636
- type: nauc_ndcg_at_10_diff1
value: 36.510770710845314
- type: nauc_ndcg_at_10_max
value: 18.461708026439457
- type: nauc_ndcg_at_10_std
value: -6.491226580238661
- type: nauc_ndcg_at_1_diff1
value: 46.11618926628157
- type: nauc_ndcg_at_1_max
value: 27.154042077346617
- type: nauc_ndcg_at_1_std
value: -7.408231463170914
- type: nauc_ndcg_at_20_diff1
value: 36.070548441535124
- type: nauc_ndcg_at_20_max
value: 18.42396263230167
- type: nauc_ndcg_at_20_std
value: -5.61879907431204
- type: nauc_ndcg_at_3_diff1
value: 39.41782933627965
- type: nauc_ndcg_at_3_max
value: 21.047162846620946
- type: nauc_ndcg_at_3_std
value: -6.840755018811107
- type: nauc_ndcg_at_5_diff1
value: 37.17959347569529
- type: nauc_ndcg_at_5_max
value: 19.680732729842823
- type: nauc_ndcg_at_5_std
value: -6.707637987639474
- type: nauc_precision_at_1000_diff1
value: 0.49247246717968796
- type: nauc_precision_at_1000_max
value: 14.62495465729825
- type: nauc_precision_at_1000_std
value: 9.669209534147573
- type: nauc_precision_at_100_diff1
value: 11.5414175528365
- type: nauc_precision_at_100_max
value: 18.504188333036936
- type: nauc_precision_at_100_std
value: 6.194157348432716
- type: nauc_precision_at_10_diff1
value: 23.453163613392075
- type: nauc_precision_at_10_max
value: 20.06043852181855
- type: nauc_precision_at_10_std
value: -3.1717316064536836
- type: nauc_precision_at_1_diff1
value: 46.11618926628157
- type: nauc_precision_at_1_max
value: 27.154042077346617
- type: nauc_precision_at_1_std
value: -7.408231463170914
- type: nauc_precision_at_20_diff1
value: 20.708737669355788
- type: nauc_precision_at_20_max
value: 20.584185448256555
- type: nauc_precision_at_20_std
value: -0.7112923884678451
- type: nauc_precision_at_3_diff1
value: 31.594155528934703
- type: nauc_precision_at_3_max
value: 21.789282355041912
- type: nauc_precision_at_3_std
value: -3.9339318840163666
- type: nauc_precision_at_5_diff1
value: 26.10899513884069
- type: nauc_precision_at_5_max
value: 21.193775642825518
- type: nauc_precision_at_5_std
value: -4.04371021464142
- type: nauc_recall_at_1000_diff1
value: 19.475747590569128
- type: nauc_recall_at_1000_max
value: 10.531569131631349
- type: nauc_recall_at_1000_std
value: 20.376238758750535
- type: nauc_recall_at_100_diff1
value: 24.539661771959622
- type: nauc_recall_at_100_max
value: 8.849671325401761
- type: nauc_recall_at_100_std
value: 8.155353459396068
- type: nauc_recall_at_10_diff1
value: 27.94562559317398
- type: nauc_recall_at_10_max
value: 12.341122611885497
- type: nauc_recall_at_10_std
value: -4.945672050235199
- type: nauc_recall_at_1_diff1
value: 49.99688096548819
- type: nauc_recall_at_1_max
value: 22.94216810488251
- type: nauc_recall_at_1_std
value: -8.778905956805103
- type: nauc_recall_at_20_diff1
value: 26.721295492823483
- type: nauc_recall_at_20_max
value: 11.354327070591353
- type: nauc_recall_at_20_std
value: -2.0775832506536145
- type: nauc_recall_at_3_diff1
value: 35.18424498331245
- type: nauc_recall_at_3_max
value: 16.737206820951112
- type: nauc_recall_at_3_std
value: -6.362047908804104
- type: nauc_recall_at_5_diff1
value: 30.146390141726233
- type: nauc_recall_at_5_max
value: 14.718619551703243
- type: nauc_recall_at_5_std
value: -5.7544278604675165
- type: ndcg_at_1
value: 17.036
- type: ndcg_at_10
value: 22.671
- type: ndcg_at_100
value: 28.105999999999998
- type: ndcg_at_1000
value: 31.432
- type: ndcg_at_20
value: 24.617
- type: ndcg_at_3
value: 19.787
- type: ndcg_at_5
value: 21.122
- type: precision_at_1
value: 17.036
- type: precision_at_10
value: 4.09
- type: precision_at_100
value: 0.836
- type: precision_at_1000
value: 0.131
- type: precision_at_20
value: 2.6470000000000002
- type: precision_at_3
value: 9.208
- type: precision_at_5
value: 6.660000000000001
- type: recall_at_1
value: 13.99
- type: recall_at_10
value: 29.743000000000002
- type: recall_at_100
value: 53.735
- type: recall_at_1000
value: 76.785
- type: recall_at_20
value: 36.624
- type: recall_at_3
value: 21.583
- type: recall_at_5
value: 24.937
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackProgrammersRetrieval (default)
type: mteb/cqadupstack-programmers
config: default
split: test
revision: 6184bc1440d2dbc7612be22b50686b8826d22b32
metrics:
- type: main_score
value: 16.306
- type: map_at_1
value: 8.802999999999999
- type: map_at_10
value: 13.148000000000001
- type: map_at_100
value: 13.971
- type: map_at_1000
value: 14.105
- type: map_at_20
value: 13.529
- type: map_at_3
value: 11.638
- type: map_at_5
value: 12.356
- type: mrr_at_1
value: 11.073059360730593
- type: mrr_at_10
value: 15.919583967529165
- type: mrr_at_100
value: 16.709279732986573
- type: mrr_at_1000
value: 16.815285605955996
- type: mrr_at_20
value: 16.30432527215681
- type: mrr_at_3
value: 14.23135464231354
- type: mrr_at_5
value: 15.041856925418564
- type: nauc_map_at_1000_diff1
value: 30.659955136068056
- type: nauc_map_at_1000_max
value: 18.44163576415389
- type: nauc_map_at_1000_std
value: -3.8367034295883577
- type: nauc_map_at_100_diff1
value: 30.67476361799846
- type: nauc_map_at_100_max
value: 18.428682857132582
- type: nauc_map_at_100_std
value: -3.8897179777637882
- type: nauc_map_at_10_diff1
value: 30.59247711976844
- type: nauc_map_at_10_max
value: 18.705778597272683
- type: nauc_map_at_10_std
value: -5.022221490794733
- type: nauc_map_at_1_diff1
value: 40.141433107510736
- type: nauc_map_at_1_max
value: 23.026643526851306
- type: nauc_map_at_1_std
value: -5.749563342494851
- type: nauc_map_at_20_diff1
value: 30.68509526178602
- type: nauc_map_at_20_max
value: 18.45627985639005
- type: nauc_map_at_20_std
value: -4.406952661617948
- type: nauc_map_at_3_diff1
value: 31.73558283054405
- type: nauc_map_at_3_max
value: 18.205161864303328
- type: nauc_map_at_3_std
value: -5.435667326361934
- type: nauc_map_at_5_diff1
value: 30.794538196458472
- type: nauc_map_at_5_max
value: 18.500170217691768
- type: nauc_map_at_5_std
value: -5.684418245921586
- type: nauc_mrr_at_1000_diff1
value: 29.43077651539303
- type: nauc_mrr_at_1000_max
value: 20.25130465933273
- type: nauc_mrr_at_1000_std
value: -4.403299701181712
- type: nauc_mrr_at_100_diff1
value: 29.42440095545253
- type: nauc_mrr_at_100_max
value: 20.262024168775454
- type: nauc_mrr_at_100_std
value: -4.46104833589502
- type: nauc_mrr_at_10_diff1
value: 29.557535725132624
- type: nauc_mrr_at_10_max
value: 20.517669578964018
- type: nauc_mrr_at_10_std
value: -4.768947635082991
- type: nauc_mrr_at_1_diff1
value: 37.4774948212758
- type: nauc_mrr_at_1_max
value: 23.439278749784055
- type: nauc_mrr_at_1_std
value: -5.157088191908156
- type: nauc_mrr_at_20_diff1
value: 29.48470932914118
- type: nauc_mrr_at_20_max
value: 20.278594953830762
- type: nauc_mrr_at_20_std
value: -4.705845733248912
- type: nauc_mrr_at_3_diff1
value: 30.77059795240642
- type: nauc_mrr_at_3_max
value: 20.391982151070895
- type: nauc_mrr_at_3_std
value: -5.0478682718453385
- type: nauc_mrr_at_5_diff1
value: 30.028856765971984
- type: nauc_mrr_at_5_max
value: 20.557553687197167
- type: nauc_mrr_at_5_std
value: -5.24319954121192
- type: nauc_ndcg_at_1000_diff1
value: 27.40711483349399
- type: nauc_ndcg_at_1000_max
value: 17.126369493537826
- type: nauc_ndcg_at_1000_std
value: 0.5342836524997823
- type: nauc_ndcg_at_100_diff1
value: 27.711441526870356
- type: nauc_ndcg_at_100_max
value: 17.276247470704032
- type: nauc_ndcg_at_100_std
value: -0.8750376980385484
- type: nauc_ndcg_at_10_diff1
value: 27.720574369240204
- type: nauc_ndcg_at_10_max
value: 18.456829787593097
- type: nauc_ndcg_at_10_std
value: -4.216473937357797
- type: nauc_ndcg_at_1_diff1
value: 37.4774948212758
- type: nauc_ndcg_at_1_max
value: 23.439278749784055
- type: nauc_ndcg_at_1_std
value: -5.157088191908156
- type: nauc_ndcg_at_20_diff1
value: 27.746972988773933
- type: nauc_ndcg_at_20_max
value: 17.52494953980253
- type: nauc_ndcg_at_20_std
value: -2.9781030890977322
- type: nauc_ndcg_at_3_diff1
value: 29.522350537696717
- type: nauc_ndcg_at_3_max
value: 18.011604144671008
- type: nauc_ndcg_at_3_std
value: -4.725546369301677
- type: nauc_ndcg_at_5_diff1
value: 28.15851614794711
- type: nauc_ndcg_at_5_max
value: 18.317965726201184
- type: nauc_ndcg_at_5_std
value: -5.54058686011457
- type: nauc_precision_at_1000_diff1
value: 4.343913518236252
- type: nauc_precision_at_1000_max
value: 7.949664745091711
- type: nauc_precision_at_1000_std
value: 2.986855849342956
- type: nauc_precision_at_100_diff1
value: 15.435700494268618
- type: nauc_precision_at_100_max
value: 15.530490741404742
- type: nauc_precision_at_100_std
value: 4.089210125048146
- type: nauc_precision_at_10_diff1
value: 19.57474708128042
- type: nauc_precision_at_10_max
value: 19.632161038711597
- type: nauc_precision_at_10_std
value: -1.7830580435403458
- type: nauc_precision_at_1_diff1
value: 37.4774948212758
- type: nauc_precision_at_1_max
value: 23.439278749784055
- type: nauc_precision_at_1_std
value: -5.157088191908156
- type: nauc_precision_at_20_diff1
value: 20.568797026407644
- type: nauc_precision_at_20_max
value: 17.15052399771233
- type: nauc_precision_at_20_std
value: 0.6381100303472123
- type: nauc_precision_at_3_diff1
value: 23.53527003948809
- type: nauc_precision_at_3_max
value: 18.260774860471376
- type: nauc_precision_at_3_std
value: -4.277699429606214
- type: nauc_precision_at_5_diff1
value: 20.957492799575085
- type: nauc_precision_at_5_max
value: 20.041536239699173
- type: nauc_precision_at_5_std
value: -5.250189398148323
- type: nauc_recall_at_1000_diff1
value: 19.56836100145482
- type: nauc_recall_at_1000_max
value: 7.776560050916105
- type: nauc_recall_at_1000_std
value: 20.13708584784103
- type: nauc_recall_at_100_diff1
value: 22.16510567224014
- type: nauc_recall_at_100_max
value: 11.397641876417932
- type: nauc_recall_at_100_std
value: 7.58221141431797
- type: nauc_recall_at_10_diff1
value: 21.305911125564595
- type: nauc_recall_at_10_max
value: 15.61442350884527
- type: nauc_recall_at_10_std
value: -2.264275057856056
- type: nauc_recall_at_1_diff1
value: 40.141433107510736
- type: nauc_recall_at_1_max
value: 23.026643526851306
- type: nauc_recall_at_1_std
value: -5.749563342494851
- type: nauc_recall_at_20_diff1
value: 21.33360178111777
- type: nauc_recall_at_20_max
value: 13.007427262980725
- type: nauc_recall_at_20_std
value: 0.8315450930852684
- type: nauc_recall_at_3_diff1
value: 24.26871252397936
- type: nauc_recall_at_3_max
value: 13.78009182310998
- type: nauc_recall_at_3_std
value: -4.427807391785745
- type: nauc_recall_at_5_diff1
value: 22.146386144738443
- type: nauc_recall_at_5_max
value: 14.558261310921718
- type: nauc_recall_at_5_std
value: -5.453171833787222
- type: ndcg_at_1
value: 11.073
- type: ndcg_at_10
value: 16.306
- type: ndcg_at_100
value: 20.605
- type: ndcg_at_1000
value: 24.321
- type: ndcg_at_20
value: 17.605999999999998
- type: ndcg_at_3
value: 13.242
- type: ndcg_at_5
value: 14.424000000000001
- type: precision_at_1
value: 11.073
- type: precision_at_10
value: 3.174
- type: precision_at_100
value: 0.632
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_20
value: 1.981
- type: precision_at_3
value: 6.317
- type: precision_at_5
value: 4.658
- type: recall_at_1
value: 8.802999999999999
- type: recall_at_10
value: 23.294999999999998
- type: recall_at_100
value: 42.543
- type: recall_at_1000
value: 69.501
- type: recall_at_20
value: 27.788
- type: recall_at_3
value: 14.935
- type: recall_at_5
value: 17.862000000000002
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval (default)
type: CQADupstackRetrieval_is_a_combined_dataset
config: default
split: test
revision: CQADupstackRetrieval_is_a_combined_dataset
metrics:
- type: main_score
value: 19.211500000000004
- type: ndcg_at_10
value: 19.211500000000004
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackStatsRetrieval (default)
type: mteb/cqadupstack-stats
config: default
split: test
revision: 65ac3a16b8e91f9cee4c9828cc7c335575432a2a
metrics:
- type: main_score
value: 13.274
- type: map_at_1
value: 7.514
- type: map_at_10
value: 10.763
- type: map_at_100
value: 11.466
- type: map_at_1000
value: 11.565
- type: map_at_20
value: 11.153
- type: map_at_3
value: 9.489
- type: map_at_5
value: 10.05
- type: mrr_at_1
value: 9.049079754601227
- type: mrr_at_10
value: 12.66140812153082
- type: mrr_at_100
value: 13.34440731558096
- type: mrr_at_1000
value: 13.431250805407094
- type: mrr_at_20
value: 13.015821938908093
- type: mrr_at_3
value: 11.349693251533745
- type: mrr_at_5
value: 11.955521472392643
- type: nauc_map_at_1000_diff1
value: 22.974932209110474
- type: nauc_map_at_1000_max
value: 19.2179493418811
- type: nauc_map_at_1000_std
value: -4.027224925667458
- type: nauc_map_at_100_diff1
value: 23.00306330611636
- type: nauc_map_at_100_max
value: 19.279597737188887
- type: nauc_map_at_100_std
value: -4.054272921846715
- type: nauc_map_at_10_diff1
value: 23.185643422536508
- type: nauc_map_at_10_max
value: 19.620815876636478
- type: nauc_map_at_10_std
value: -4.67640325592363
- type: nauc_map_at_1_diff1
value: 29.800345069729406
- type: nauc_map_at_1_max
value: 23.87910907490326
- type: nauc_map_at_1_std
value: -6.320599828399073
- type: nauc_map_at_20_diff1
value: 23.142569498191413
- type: nauc_map_at_20_max
value: 19.48779289778967
- type: nauc_map_at_20_std
value: -4.111902735804231
- type: nauc_map_at_3_diff1
value: 25.743034910929975
- type: nauc_map_at_3_max
value: 20.90755349054651
- type: nauc_map_at_3_std
value: -5.380592645823912
- type: nauc_map_at_5_diff1
value: 23.42137416675548
- type: nauc_map_at_5_max
value: 19.329228837468158
- type: nauc_map_at_5_std
value: -5.563525004474619
- type: nauc_mrr_at_1000_diff1
value: 24.10086479687415
- type: nauc_mrr_at_1000_max
value: 20.398011792778824
- type: nauc_mrr_at_1000_std
value: -2.1446120511727957
- type: nauc_mrr_at_100_diff1
value: 24.115697677435794
- type: nauc_mrr_at_100_max
value: 20.458646264375886
- type: nauc_mrr_at_100_std
value: -2.151550159504517
- type: nauc_mrr_at_10_diff1
value: 24.293579862933555
- type: nauc_mrr_at_10_max
value: 20.839345603643498
- type: nauc_mrr_at_10_std
value: -2.480503488415708
- type: nauc_mrr_at_1_diff1
value: 31.141124432852486
- type: nauc_mrr_at_1_max
value: 25.3974393459875
- type: nauc_mrr_at_1_std
value: -4.603112328474119
- type: nauc_mrr_at_20_diff1
value: 24.199943135873237
- type: nauc_mrr_at_20_max
value: 20.685578492011537
- type: nauc_mrr_at_20_std
value: -2.216739386860867
- type: nauc_mrr_at_3_diff1
value: 27.18978712305054
- type: nauc_mrr_at_3_max
value: 21.95145492661433
- type: nauc_mrr_at_3_std
value: -3.3010871727045004
- type: nauc_mrr_at_5_diff1
value: 24.55785813047769
- type: nauc_mrr_at_5_max
value: 20.630334122680697
- type: nauc_mrr_at_5_std
value: -3.4751492733475713
- type: nauc_ndcg_at_1000_diff1
value: 18.214182224000904
- type: nauc_ndcg_at_1000_max
value: 15.022677670245125
- type: nauc_ndcg_at_1000_std
value: -1.2757783952996276
- type: nauc_ndcg_at_100_diff1
value: 19.45648169337917
- type: nauc_ndcg_at_100_max
value: 16.160731902664246
- type: nauc_ndcg_at_100_std
value: -1.2021617745185982
- type: nauc_ndcg_at_10_diff1
value: 20.78032928549088
- type: nauc_ndcg_at_10_max
value: 18.37701966895512
- type: nauc_ndcg_at_10_std
value: -2.859756963061105
- type: nauc_ndcg_at_1_diff1
value: 31.141124432852486
- type: nauc_ndcg_at_1_max
value: 25.3974393459875
- type: nauc_ndcg_at_1_std
value: -4.603112328474119
- type: nauc_ndcg_at_20_diff1
value: 20.568804870494365
- type: nauc_ndcg_at_20_max
value: 17.688797629532804
- type: nauc_ndcg_at_20_std
value: -1.601270033947706
- type: nauc_ndcg_at_3_diff1
value: 25.352168775398777
- type: nauc_ndcg_at_3_max
value: 20.42319619108203
- type: nauc_ndcg_at_3_std
value: -4.2521134409577845
- type: nauc_ndcg_at_5_diff1
value: 21.18713014585295
- type: nauc_ndcg_at_5_max
value: 17.939191093215953
- type: nauc_ndcg_at_5_std
value: -4.743032229404275
- type: nauc_precision_at_1000_diff1
value: 4.892829090188313
- type: nauc_precision_at_1000_max
value: 7.933069592889083
- type: nauc_precision_at_1000_std
value: 4.24278581923629
- type: nauc_precision_at_100_diff1
value: 13.066398116495034
- type: nauc_precision_at_100_max
value: 14.384247527346716
- type: nauc_precision_at_100_std
value: 6.056873634302884
- type: nauc_precision_at_10_diff1
value: 16.616656372852148
- type: nauc_precision_at_10_max
value: 18.665616620054436
- type: nauc_precision_at_10_std
value: 1.1124326621912484
- type: nauc_precision_at_1_diff1
value: 31.141124432852486
- type: nauc_precision_at_1_max
value: 25.3974393459875
- type: nauc_precision_at_1_std
value: -4.603112328474119
- type: nauc_precision_at_20_diff1
value: 17.294215780840165
- type: nauc_precision_at_20_max
value: 18.09538722850449
- type: nauc_precision_at_20_std
value: 5.524315844370954
- type: nauc_precision_at_3_diff1
value: 25.1866897673422
- type: nauc_precision_at_3_max
value: 19.72076391537079
- type: nauc_precision_at_3_std
value: -1.6649392928833502
- type: nauc_precision_at_5_diff1
value: 17.254095768389526
- type: nauc_precision_at_5_max
value: 16.94859363403111
- type: nauc_precision_at_5_std
value: -1.9187213027734356
- type: nauc_recall_at_1000_diff1
value: 2.1491291924120404
- type: nauc_recall_at_1000_max
value: -0.6564763388554173
- type: nauc_recall_at_1000_std
value: 2.480520716627822
- type: nauc_recall_at_100_diff1
value: 10.764856128055248
- type: nauc_recall_at_100_max
value: 6.734689971662489
- type: nauc_recall_at_100_std
value: 3.0407690200004334
- type: nauc_recall_at_10_diff1
value: 14.979718773625542
- type: nauc_recall_at_10_max
value: 14.109838347838258
- type: nauc_recall_at_10_std
value: -0.5378433013187329
- type: nauc_recall_at_1_diff1
value: 29.800345069729406
- type: nauc_recall_at_1_max
value: 23.87910907490326
- type: nauc_recall_at_1_std
value: -6.320599828399073
- type: nauc_recall_at_20_diff1
value: 14.511882633459333
- type: nauc_recall_at_20_max
value: 12.011480653201415
- type: nauc_recall_at_20_std
value: 2.0767690218465877
- type: nauc_recall_at_3_diff1
value: 20.6626126323687
- type: nauc_recall_at_3_max
value: 17.25857728630443
- type: nauc_recall_at_3_std
value: -3.7939883071411717
- type: nauc_recall_at_5_diff1
value: 14.1235036082108
- type: nauc_recall_at_5_max
value: 12.727411826064857
- type: nauc_recall_at_5_std
value: -4.60850604165874
- type: ndcg_at_1
value: 9.049
- type: ndcg_at_10
value: 13.274
- type: ndcg_at_100
value: 17.086000000000002
- type: ndcg_at_1000
value: 19.936999999999998
- type: ndcg_at_20
value: 14.582999999999998
- type: ndcg_at_3
value: 10.725999999999999
- type: ndcg_at_5
value: 11.623
- type: precision_at_1
value: 9.049
- type: precision_at_10
value: 2.423
- type: precision_at_100
value: 0.479
- type: precision_at_1000
value: 0.079
- type: precision_at_20
value: 1.526
- type: precision_at_3
value: 4.9590000000000005
- type: precision_at_5
value: 3.62
- type: recall_at_1
value: 7.514
- type: recall_at_10
value: 19.31
- type: recall_at_100
value: 37.413999999999994
- type: recall_at_1000
value: 59.021
- type: recall_at_20
value: 24.21
- type: recall_at_3
value: 12.113999999999999
- type: recall_at_5
value: 14.371
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackTexRetrieval (default)
type: mteb/cqadupstack-tex
config: default
split: test
revision: 46989137a86843e03a6195de44b09deda022eec7
metrics:
- type: main_score
value: 10.994
- type: map_at_1
value: 6.225
- type: map_at_10
value: 8.953999999999999
- type: map_at_100
value: 9.603
- type: map_at_1000
value: 9.712
- type: map_at_20
value: 9.278
- type: map_at_3
value: 8.074
- type: map_at_5
value: 8.547
- type: mrr_at_1
value: 7.708189951823813
- type: mrr_at_10
value: 11.010238805317954
- type: mrr_at_100
value: 11.697852969394127
- type: mrr_at_1000
value: 11.788096222755389
- type: mrr_at_20
value: 11.36125747114887
- type: mrr_at_3
value: 9.967882541867406
- type: mrr_at_5
value: 10.53223216334021
- type: nauc_map_at_1000_diff1
value: 28.62895539988389
- type: nauc_map_at_1000_max
value: 16.242894414293037
- type: nauc_map_at_1000_std
value: -4.569604418870727
- type: nauc_map_at_100_diff1
value: 28.61807781605406
- type: nauc_map_at_100_max
value: 16.21900205663456
- type: nauc_map_at_100_std
value: -4.742228052779668
- type: nauc_map_at_10_diff1
value: 29.55698899178743
- type: nauc_map_at_10_max
value: 16.619065435982105
- type: nauc_map_at_10_std
value: -5.272914850396907
- type: nauc_map_at_1_diff1
value: 38.11099020611636
- type: nauc_map_at_1_max
value: 19.754663729177466
- type: nauc_map_at_1_std
value: -7.100435784719483
- type: nauc_map_at_20_diff1
value: 28.96213016918891
- type: nauc_map_at_20_max
value: 16.40536013245705
- type: nauc_map_at_20_std
value: -5.152060847207817
- type: nauc_map_at_3_diff1
value: 31.518330681088514
- type: nauc_map_at_3_max
value: 17.648594434363673
- type: nauc_map_at_3_std
value: -5.013522244046003
- type: nauc_map_at_5_diff1
value: 30.53555288667588
- type: nauc_map_at_5_max
value: 17.552873944829003
- type: nauc_map_at_5_std
value: -5.459559007946099
- type: nauc_mrr_at_1000_diff1
value: 28.56870451139856
- type: nauc_mrr_at_1000_max
value: 18.199477946334998
- type: nauc_mrr_at_1000_std
value: -3.83210753499382
- type: nauc_mrr_at_100_diff1
value: 28.55289316686771
- type: nauc_mrr_at_100_max
value: 18.190933266659705
- type: nauc_mrr_at_100_std
value: -3.910114024174217
- type: nauc_mrr_at_10_diff1
value: 29.44010525180224
- type: nauc_mrr_at_10_max
value: 18.5618742276953
- type: nauc_mrr_at_10_std
value: -4.318500155132472
- type: nauc_mrr_at_1_diff1
value: 37.756041398612425
- type: nauc_mrr_at_1_max
value: 22.180382124822522
- type: nauc_mrr_at_1_std
value: -6.881985725496932
- type: nauc_mrr_at_20_diff1
value: 28.862633708506863
- type: nauc_mrr_at_20_max
value: 18.368745544312883
- type: nauc_mrr_at_20_std
value: -4.231869471717514
- type: nauc_mrr_at_3_diff1
value: 31.67790485910417
- type: nauc_mrr_at_3_max
value: 20.067426011874694
- type: nauc_mrr_at_3_std
value: -4.35750935851484
- type: nauc_mrr_at_5_diff1
value: 30.3892346503623
- type: nauc_mrr_at_5_max
value: 19.427471974651258
- type: nauc_mrr_at_5_std
value: -4.501090877808792
- type: nauc_ndcg_at_1000_diff1
value: 23.124264919835152
- type: nauc_ndcg_at_1000_max
value: 13.725127541654583
- type: nauc_ndcg_at_1000_std
value: 0.8488267118015322
- type: nauc_ndcg_at_100_diff1
value: 22.931912676541813
- type: nauc_ndcg_at_100_max
value: 13.573133160305714
- type: nauc_ndcg_at_100_std
value: -1.9712575029716004
- type: nauc_ndcg_at_10_diff1
value: 26.49225179330549
- type: nauc_ndcg_at_10_max
value: 15.334589645844614
- type: nauc_ndcg_at_10_std
value: -4.732200420388755
- type: nauc_ndcg_at_1_diff1
value: 37.756041398612425
- type: nauc_ndcg_at_1_max
value: 22.180382124822522
- type: nauc_ndcg_at_1_std
value: -6.881985725496932
- type: nauc_ndcg_at_20_diff1
value: 24.758487984247115
- type: nauc_ndcg_at_20_max
value: 14.685319575357777
- type: nauc_ndcg_at_20_std
value: -4.432729957713687
- type: nauc_ndcg_at_3_diff1
value: 30.04172743163936
- type: nauc_ndcg_at_3_max
value: 17.942422342704166
- type: nauc_ndcg_at_3_std
value: -4.371869609553122
- type: nauc_ndcg_at_5_diff1
value: 28.394597447013364
- type: nauc_ndcg_at_5_max
value: 17.337563726465902
- type: nauc_ndcg_at_5_std
value: -4.979815289974346
- type: nauc_precision_at_1000_diff1
value: 13.358015963281982
- type: nauc_precision_at_1000_max
value: 13.588027398642533
- type: nauc_precision_at_1000_std
value: 16.038391304073617
- type: nauc_precision_at_100_diff1
value: 14.048154067920237
- type: nauc_precision_at_100_max
value: 13.442039272771812
- type: nauc_precision_at_100_std
value: 6.293550136432713
- type: nauc_precision_at_10_diff1
value: 19.7938197345429
- type: nauc_precision_at_10_max
value: 15.498999930693053
- type: nauc_precision_at_10_std
value: -2.820921985501471
- type: nauc_precision_at_1_diff1
value: 37.756041398612425
- type: nauc_precision_at_1_max
value: 22.180382124822522
- type: nauc_precision_at_1_std
value: -6.881985725496932
- type: nauc_precision_at_20_diff1
value: 16.86330177780297
- type: nauc_precision_at_20_max
value: 14.757498925286052
- type: nauc_precision_at_20_std
value: -1.4878113085077458
- type: nauc_precision_at_3_diff1
value: 26.22068335923554
- type: nauc_precision_at_3_max
value: 19.552244504819107
- type: nauc_precision_at_3_std
value: -2.903836612504541
- type: nauc_precision_at_5_diff1
value: 23.01543740291806
- type: nauc_precision_at_5_max
value: 18.976238791156298
- type: nauc_precision_at_5_std
value: -3.772870601995056
- type: nauc_recall_at_1000_diff1
value: 11.344856628291772
- type: nauc_recall_at_1000_max
value: 5.496064714954898
- type: nauc_recall_at_1000_std
value: 14.552915745152944
- type: nauc_recall_at_100_diff1
value: 11.37183345326816
- type: nauc_recall_at_100_max
value: 6.152609534633153
- type: nauc_recall_at_100_std
value: 3.3240506595168617
- type: nauc_recall_at_10_diff1
value: 19.414706457137537
- type: nauc_recall_at_10_max
value: 10.013408222848447
- type: nauc_recall_at_10_std
value: -4.469998335412016
- type: nauc_recall_at_1_diff1
value: 38.11099020611636
- type: nauc_recall_at_1_max
value: 19.754663729177466
- type: nauc_recall_at_1_std
value: -7.100435784719483
- type: nauc_recall_at_20_diff1
value: 15.570619584248163
- type: nauc_recall_at_20_max
value: 8.816676896160281
- type: nauc_recall_at_20_std
value: -3.7706693105174836
- type: nauc_recall_at_3_diff1
value: 25.664091285326485
- type: nauc_recall_at_3_max
value: 14.868700645447488
- type: nauc_recall_at_3_std
value: -3.5813114627791736
- type: nauc_recall_at_5_diff1
value: 22.650699032516435
- type: nauc_recall_at_5_max
value: 14.046776424466485
- type: nauc_recall_at_5_std
value: -5.072422590207594
- type: ndcg_at_1
value: 7.707999999999999
- type: ndcg_at_10
value: 10.994
- type: ndcg_at_100
value: 14.562
- type: ndcg_at_1000
value: 17.738
- type: ndcg_at_20
value: 12.152000000000001
- type: ndcg_at_3
value: 9.286999999999999
- type: ndcg_at_5
value: 10.057
- type: precision_at_1
value: 7.707999999999999
- type: precision_at_10
value: 2.068
- type: precision_at_100
value: 0.466
- type: precision_at_1000
value: 0.08800000000000001
- type: precision_at_20
value: 1.352
- type: precision_at_3
value: 4.508
- type: precision_at_5
value: 3.3169999999999997
- type: recall_at_1
value: 6.225
- type: recall_at_10
value: 15.177999999999999
- type: recall_at_100
value: 31.726
- type: recall_at_1000
value: 55.286
- type: recall_at_20
value: 19.516
- type: recall_at_3
value: 10.381
- type: recall_at_5
value: 12.354999999999999
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackUnixRetrieval (default)
type: mteb/cqadupstack-unix
config: default
split: test
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
metrics:
- type: main_score
value: 17.415
- type: map_at_1
value: 11.61
- type: map_at_10
value: 14.879000000000001
- type: map_at_100
value: 15.64
- type: map_at_1000
value: 15.744
- type: map_at_20
value: 15.222
- type: map_at_3
value: 13.818
- type: map_at_5
value: 14.221
- type: mrr_at_1
value: 14.085820895522389
- type: mrr_at_10
value: 17.784144752428336
- type: mrr_at_100
value: 18.59055632302295
- type: mrr_at_1000
value: 18.680733729013262
- type: mrr_at_20
value: 18.159102701666594
- type: mrr_at_3
value: 16.68221393034826
- type: mrr_at_5
value: 17.10665422885572
- type: nauc_map_at_1000_diff1
value: 39.56056915227938
- type: nauc_map_at_1000_max
value: 27.13397943596498
- type: nauc_map_at_1000_std
value: -7.0908382945611175
- type: nauc_map_at_100_diff1
value: 39.54030188989168
- type: nauc_map_at_100_max
value: 27.13281562979474
- type: nauc_map_at_100_std
value: -7.165159503138965
- type: nauc_map_at_10_diff1
value: 40.318171341397765
- type: nauc_map_at_10_max
value: 27.535451283580016
- type: nauc_map_at_10_std
value: -7.689737441073707
- type: nauc_map_at_1_diff1
value: 47.05601088674895
- type: nauc_map_at_1_max
value: 30.576608334052853
- type: nauc_map_at_1_std
value: -9.67702524348975
- type: nauc_map_at_20_diff1
value: 39.80136558735939
- type: nauc_map_at_20_max
value: 27.051853945437948
- type: nauc_map_at_20_std
value: -7.409144616339466
- type: nauc_map_at_3_diff1
value: 42.15633029927089
- type: nauc_map_at_3_max
value: 28.386143076096086
- type: nauc_map_at_3_std
value: -9.106105164113686
- type: nauc_map_at_5_diff1
value: 41.46860741828094
- type: nauc_map_at_5_max
value: 28.202178480215373
- type: nauc_map_at_5_std
value: -8.399626801433124
- type: nauc_mrr_at_1000_diff1
value: 37.78472411053756
- type: nauc_mrr_at_1000_max
value: 28.338277069066432
- type: nauc_mrr_at_1000_std
value: -7.391912169514899
- type: nauc_mrr_at_100_diff1
value: 37.74697100045658
- type: nauc_mrr_at_100_max
value: 28.35832528792151
- type: nauc_mrr_at_100_std
value: -7.4298805804754995
- type: nauc_mrr_at_10_diff1
value: 38.428674914285196
- type: nauc_mrr_at_10_max
value: 28.708508212507105
- type: nauc_mrr_at_10_std
value: -7.884064754659524
- type: nauc_mrr_at_1_diff1
value: 45.69997352898185
- type: nauc_mrr_at_1_max
value: 32.47880480030532
- type: nauc_mrr_at_1_std
value: -9.337266605729418
- type: nauc_mrr_at_20_diff1
value: 37.99989625388078
- type: nauc_mrr_at_20_max
value: 28.255616608253824
- type: nauc_mrr_at_20_std
value: -7.614369324242356
- type: nauc_mrr_at_3_diff1
value: 40.126736669268766
- type: nauc_mrr_at_3_max
value: 29.616770044400464
- type: nauc_mrr_at_3_std
value: -9.336882852739908
- type: nauc_mrr_at_5_diff1
value: 39.41517859913304
- type: nauc_mrr_at_5_max
value: 29.312224024493094
- type: nauc_mrr_at_5_std
value: -8.792379282413792
- type: nauc_ndcg_at_1000_diff1
value: 34.318717429678735
- type: nauc_ndcg_at_1000_max
value: 24.57185685965525
- type: nauc_ndcg_at_1000_std
value: -2.367526484055821
- type: nauc_ndcg_at_100_diff1
value: 33.59453283807552
- type: nauc_ndcg_at_100_max
value: 24.73858681825266
- type: nauc_ndcg_at_100_std
value: -4.087141295771279
- type: nauc_ndcg_at_10_diff1
value: 36.635105955522235
- type: nauc_ndcg_at_10_max
value: 25.975386842872318
- type: nauc_ndcg_at_10_std
value: -6.3751364798979315
- type: nauc_ndcg_at_1_diff1
value: 45.69997352898185
- type: nauc_ndcg_at_1_max
value: 32.47880480030532
- type: nauc_ndcg_at_1_std
value: -9.337266605729418
- type: nauc_ndcg_at_20_diff1
value: 35.16876791291799
- type: nauc_ndcg_at_20_max
value: 24.477658044207647
- type: nauc_ndcg_at_20_std
value: -5.555064208738701
- type: nauc_ndcg_at_3_diff1
value: 39.82534185570945
- type: nauc_ndcg_at_3_max
value: 28.139721552476963
- type: nauc_ndcg_at_3_std
value: -9.160710946542384
- type: nauc_ndcg_at_5_diff1
value: 38.98115351105197
- type: nauc_ndcg_at_5_max
value: 27.515452028134202
- type: nauc_ndcg_at_5_std
value: -8.025551102160557
- type: nauc_precision_at_1000_diff1
value: 12.303392079476001
- type: nauc_precision_at_1000_max
value: 15.521101561430214
- type: nauc_precision_at_1000_std
value: 13.875729823362349
- type: nauc_precision_at_100_diff1
value: 15.718813920537666
- type: nauc_precision_at_100_max
value: 20.036566730817615
- type: nauc_precision_at_100_std
value: 5.068608226979542
- type: nauc_precision_at_10_diff1
value: 25.3121404066982
- type: nauc_precision_at_10_max
value: 24.190797754465372
- type: nauc_precision_at_10_std
value: -3.28815407741081
- type: nauc_precision_at_1_diff1
value: 45.69997352898185
- type: nauc_precision_at_1_max
value: 32.47880480030532
- type: nauc_precision_at_1_std
value: -9.337266605729418
- type: nauc_precision_at_20_diff1
value: 21.370193752136633
- type: nauc_precision_at_20_max
value: 19.74829392747058
- type: nauc_precision_at_20_std
value: -1.1434647531180093
- type: nauc_precision_at_3_diff1
value: 33.27263719269652
- type: nauc_precision_at_3_max
value: 27.28958835327579
- type: nauc_precision_at_3_std
value: -9.03699952848916
- type: nauc_precision_at_5_diff1
value: 31.109130426292463
- type: nauc_precision_at_5_max
value: 26.959336149040137
- type: nauc_precision_at_5_std
value: -6.946474296738139
- type: nauc_recall_at_1000_diff1
value: 17.923508430691957
- type: nauc_recall_at_1000_max
value: 10.80984639138324
- type: nauc_recall_at_1000_std
value: 17.38699739341662
- type: nauc_recall_at_100_diff1
value: 17.188512794168755
- type: nauc_recall_at_100_max
value: 15.470956979815659
- type: nauc_recall_at_100_std
value: 4.263468796063786
- type: nauc_recall_at_10_diff1
value: 27.628371666732892
- type: nauc_recall_at_10_max
value: 19.847290125705662
- type: nauc_recall_at_10_std
value: -2.718782096589473
- type: nauc_recall_at_1_diff1
value: 47.05601088674895
- type: nauc_recall_at_1_max
value: 30.576608334052853
- type: nauc_recall_at_1_std
value: -9.67702524348975
- type: nauc_recall_at_20_diff1
value: 23.787114240920214
- type: nauc_recall_at_20_max
value: 15.65621275614017
- type: nauc_recall_at_20_std
value: -0.6996887505536454
- type: nauc_recall_at_3_diff1
value: 37.16605995449111
- type: nauc_recall_at_3_max
value: 24.971735910807293
- type: nauc_recall_at_3_std
value: -8.874845333377282
- type: nauc_recall_at_5_diff1
value: 34.15194539098878
- type: nauc_recall_at_5_max
value: 23.788685123818407
- type: nauc_recall_at_5_std
value: -6.520745742182325
- type: ndcg_at_1
value: 14.086000000000002
- type: ndcg_at_10
value: 17.415
- type: ndcg_at_100
value: 21.705
- type: ndcg_at_1000
value: 24.851
- type: ndcg_at_20
value: 18.674
- type: ndcg_at_3
value: 15.369
- type: ndcg_at_5
value: 15.903
- type: precision_at_1
value: 14.086000000000002
- type: precision_at_10
value: 2.9010000000000002
- type: precision_at_100
value: 0.567
- type: precision_at_1000
value: 0.093
- type: precision_at_20
value: 1.754
- type: precision_at_3
value: 6.903
- type: precision_at_5
value: 4.571
- type: recall_at_1
value: 11.61
- type: recall_at_10
value: 22.543
- type: recall_at_100
value: 42.586
- type: recall_at_1000
value: 66.3
- type: recall_at_20
value: 27.296
- type: recall_at_3
value: 16.458000000000002
- type: recall_at_5
value: 18.087
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWebmastersRetrieval (default)
type: mteb/cqadupstack-webmasters
config: default
split: test
revision: 160c094312a0e1facb97e55eeddb698c0abe3571
metrics:
- type: main_score
value: 21.398
- type: map_at_1
value: 12.418
- type: map_at_10
value: 17.634
- type: map_at_100
value: 18.427
- type: map_at_1000
value: 18.601
- type: map_at_20
value: 17.949
- type: map_at_3
value: 16.070999999999998
- type: map_at_5
value: 16.909
- type: mrr_at_1
value: 16.007905138339922
- type: mrr_at_10
value: 21.244275048622875
- type: mrr_at_100
value: 21.913675154893422
- type: mrr_at_1000
value: 22.00394675539023
- type: mrr_at_20
value: 21.484105638892164
- type: mrr_at_3
value: 19.729907773386028
- type: mrr_at_5
value: 20.579710144927535
- type: nauc_map_at_1000_diff1
value: 33.276058954347164
- type: nauc_map_at_1000_max
value: 22.686785676254438
- type: nauc_map_at_1000_std
value: -15.623983007245663
- type: nauc_map_at_100_diff1
value: 33.277163035857754
- type: nauc_map_at_100_max
value: 22.79483533389435
- type: nauc_map_at_100_std
value: -15.806523169464585
- type: nauc_map_at_10_diff1
value: 33.31349011893446
- type: nauc_map_at_10_max
value: 23.16070733276047
- type: nauc_map_at_10_std
value: -16.557456309767332
- type: nauc_map_at_1_diff1
value: 43.560854870215444
- type: nauc_map_at_1_max
value: 22.785972852704127
- type: nauc_map_at_1_std
value: -17.629946377144794
- type: nauc_map_at_20_diff1
value: 33.570999449061176
- type: nauc_map_at_20_max
value: 22.993901876226587
- type: nauc_map_at_20_std
value: -16.272939675166977
- type: nauc_map_at_3_diff1
value: 35.03763295449743
- type: nauc_map_at_3_max
value: 22.445582103531297
- type: nauc_map_at_3_std
value: -16.560038144492275
- type: nauc_map_at_5_diff1
value: 34.27964006257987
- type: nauc_map_at_5_max
value: 23.332248714244795
- type: nauc_map_at_5_std
value: -16.57243447707981
- type: nauc_mrr_at_1000_diff1
value: 32.944240054080296
- type: nauc_mrr_at_1000_max
value: 21.812793329305745
- type: nauc_mrr_at_1000_std
value: -13.642145832181225
- type: nauc_mrr_at_100_diff1
value: 32.92776460042595
- type: nauc_mrr_at_100_max
value: 21.791203022888052
- type: nauc_mrr_at_100_std
value: -13.640560468524749
- type: nauc_mrr_at_10_diff1
value: 32.9752685024834
- type: nauc_mrr_at_10_max
value: 22.104988021339146
- type: nauc_mrr_at_10_std
value: -14.271356854639786
- type: nauc_mrr_at_1_diff1
value: 42.51316330983356
- type: nauc_mrr_at_1_max
value: 23.297138888078976
- type: nauc_mrr_at_1_std
value: -14.903606813837882
- type: nauc_mrr_at_20_diff1
value: 33.22223363073958
- type: nauc_mrr_at_20_max
value: 21.974295331873055
- type: nauc_mrr_at_20_std
value: -13.88205443342369
- type: nauc_mrr_at_3_diff1
value: 33.993832814261395
- type: nauc_mrr_at_3_max
value: 21.556945052605887
- type: nauc_mrr_at_3_std
value: -13.797171517214505
- type: nauc_mrr_at_5_diff1
value: 33.35409476101201
- type: nauc_mrr_at_5_max
value: 21.981426511175837
- type: nauc_mrr_at_5_std
value: -14.09531063812787
- type: nauc_ndcg_at_1000_diff1
value: 29.438860831545004
- type: nauc_ndcg_at_1000_max
value: 21.25973393436945
- type: nauc_ndcg_at_1000_std
value: -11.16393916502227
- type: nauc_ndcg_at_100_diff1
value: 28.444184419510172
- type: nauc_ndcg_at_100_max
value: 21.18616561891909
- type: nauc_ndcg_at_100_std
value: -12.037980607459001
- type: nauc_ndcg_at_10_diff1
value: 29.271087139678205
- type: nauc_ndcg_at_10_max
value: 22.032768110468098
- type: nauc_ndcg_at_10_std
value: -15.467782849927971
- type: nauc_ndcg_at_1_diff1
value: 42.51316330983356
- type: nauc_ndcg_at_1_max
value: 23.297138888078976
- type: nauc_ndcg_at_1_std
value: -14.903606813837882
- type: nauc_ndcg_at_20_diff1
value: 30.46132048728029
- type: nauc_ndcg_at_20_max
value: 21.81477297472493
- type: nauc_ndcg_at_20_std
value: -14.218418166481491
- type: nauc_ndcg_at_3_diff1
value: 32.0153358591922
- type: nauc_ndcg_at_3_max
value: 20.770546204709458
- type: nauc_ndcg_at_3_std
value: -14.747432002736549
- type: nauc_ndcg_at_5_diff1
value: 30.981699893250898
- type: nauc_ndcg_at_5_max
value: 22.090548813686304
- type: nauc_ndcg_at_5_std
value: -15.09612387707668
- type: nauc_precision_at_1000_diff1
value: 7.2014592078746125
- type: nauc_precision_at_1000_max
value: -5.678465880888778
- type: nauc_precision_at_1000_std
value: 22.430084503019
- type: nauc_precision_at_100_diff1
value: 7.47376139946301
- type: nauc_precision_at_100_max
value: 2.300260757829557
- type: nauc_precision_at_100_std
value: 13.810673946221709
- type: nauc_precision_at_10_diff1
value: 15.542740121996912
- type: nauc_precision_at_10_max
value: 15.807667200751279
- type: nauc_precision_at_10_std
value: -9.58878382311598
- type: nauc_precision_at_1_diff1
value: 42.51316330983356
- type: nauc_precision_at_1_max
value: 23.297138888078976
- type: nauc_precision_at_1_std
value: -14.903606813837882
- type: nauc_precision_at_20_diff1
value: 17.44141625096109
- type: nauc_precision_at_20_max
value: 12.987380515646793
- type: nauc_precision_at_20_std
value: -3.3241327401895018
- type: nauc_precision_at_3_diff1
value: 24.31306633873876
- type: nauc_precision_at_3_max
value: 20.59991114197874
- type: nauc_precision_at_3_std
value: -12.702555430555881
- type: nauc_precision_at_5_diff1
value: 21.113937977245538
- type: nauc_precision_at_5_max
value: 19.40330569402618
- type: nauc_precision_at_5_std
value: -11.001297546039366
- type: nauc_recall_at_1000_diff1
value: 14.316639289353503
- type: nauc_recall_at_1000_max
value: 14.663280590084184
- type: nauc_recall_at_1000_std
value: 10.373834237194783
- type: nauc_recall_at_100_diff1
value: 14.159748016577145
- type: nauc_recall_at_100_max
value: 15.266942159548291
- type: nauc_recall_at_100_std
value: 0.09898266158022606
- type: nauc_recall_at_10_diff1
value: 19.311511962157848
- type: nauc_recall_at_10_max
value: 21.086642659351444
- type: nauc_recall_at_10_std
value: -15.03280805118371
- type: nauc_recall_at_1_diff1
value: 43.560854870215444
- type: nauc_recall_at_1_max
value: 22.785972852704127
- type: nauc_recall_at_1_std
value: -17.629946377144794
- type: nauc_recall_at_20_diff1
value: 22.84188696362324
- type: nauc_recall_at_20_max
value: 19.255833980651115
- type: nauc_recall_at_20_std
value: -10.769401250685878
- type: nauc_recall_at_3_diff1
value: 25.289776971942963
- type: nauc_recall_at_3_max
value: 19.495340268606647
- type: nauc_recall_at_3_std
value: -14.682485696338162
- type: nauc_recall_at_5_diff1
value: 23.28267489764339
- type: nauc_recall_at_5_max
value: 21.90368937976734
- type: nauc_recall_at_5_std
value: -15.19826645274188
- type: ndcg_at_1
value: 16.008
- type: ndcg_at_10
value: 21.398
- type: ndcg_at_100
value: 25.241999999999997
- type: ndcg_at_1000
value: 28.833
- type: ndcg_at_20
value: 22.234
- type: ndcg_at_3
value: 18.86
- type: ndcg_at_5
value: 20.037
- type: precision_at_1
value: 16.008
- type: precision_at_10
value: 4.328
- type: precision_at_100
value: 0.893
- type: precision_at_1000
value: 0.17500000000000002
- type: precision_at_20
value: 2.579
- type: precision_at_3
value: 9.157
- type: precision_at_5
value: 6.837999999999999
- type: recall_at_1
value: 12.418
- type: recall_at_10
value: 27.935
- type: recall_at_100
value: 47.525
- type: recall_at_1000
value: 72.146
- type: recall_at_20
value: 31.861
- type: recall_at_3
value: 20.148
- type: recall_at_5
value: 23.296
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWordpressRetrieval (default)
type: mteb/cqadupstack-wordpress
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: main_score
value: 13.536999999999999
- type: map_at_1
value: 7.468
- type: map_at_10
value: 10.972999999999999
- type: map_at_100
value: 11.744
- type: map_at_1000
value: 11.854000000000001
- type: map_at_20
value: 11.336
- type: map_at_3
value: 9.618
- type: map_at_5
value: 10.205
- type: mrr_at_1
value: 8.317929759704251
- type: mrr_at_10
value: 12.179752369216331
- type: mrr_at_100
value: 12.980085498763907
- type: mrr_at_1000
value: 13.075701345231755
- type: mrr_at_20
value: 12.550195110376356
- type: mrr_at_3
value: 10.659272951324708
- type: mrr_at_5
value: 11.30622304374615
- type: nauc_map_at_1000_diff1
value: 25.499689183541758
- type: nauc_map_at_1000_max
value: 26.492088085006486
- type: nauc_map_at_1000_std
value: -10.29049248054652
- type: nauc_map_at_100_diff1
value: 25.573124155292685
- type: nauc_map_at_100_max
value: 26.56159077339433
- type: nauc_map_at_100_std
value: -10.400824123310946
- type: nauc_map_at_10_diff1
value: 25.485224554587006
- type: nauc_map_at_10_max
value: 26.83491339438951
- type: nauc_map_at_10_std
value: -11.212653836584204
- type: nauc_map_at_1_diff1
value: 33.63991109177576
- type: nauc_map_at_1_max
value: 34.23354700535017
- type: nauc_map_at_1_std
value: -13.602316051776613
- type: nauc_map_at_20_diff1
value: 25.401091624302076
- type: nauc_map_at_20_max
value: 26.619190203647534
- type: nauc_map_at_20_std
value: -10.956292541627727
- type: nauc_map_at_3_diff1
value: 26.825203283397762
- type: nauc_map_at_3_max
value: 27.86659163589406
- type: nauc_map_at_3_std
value: -11.12760272108276
- type: nauc_map_at_5_diff1
value: 25.95917424438333
- type: nauc_map_at_5_max
value: 26.96719585977185
- type: nauc_map_at_5_std
value: -12.304191598798255
- type: nauc_mrr_at_1000_diff1
value: 26.058089211778814
- type: nauc_mrr_at_1000_max
value: 25.715522107102462
- type: nauc_mrr_at_1000_std
value: -9.26865979619022
- type: nauc_mrr_at_100_diff1
value: 26.098211857983944
- type: nauc_mrr_at_100_max
value: 25.751358106929445
- type: nauc_mrr_at_100_std
value: -9.348646640329418
- type: nauc_mrr_at_10_diff1
value: 26.245525532384857
- type: nauc_mrr_at_10_max
value: 25.751651308654733
- type: nauc_mrr_at_10_std
value: -10.162612510927444
- type: nauc_mrr_at_1_diff1
value: 33.74283305857714
- type: nauc_mrr_at_1_max
value: 33.58837545702206
- type: nauc_mrr_at_1_std
value: -11.623065310526266
- type: nauc_mrr_at_20_diff1
value: 25.889783688319756
- type: nauc_mrr_at_20_max
value: 25.752118615901914
- type: nauc_mrr_at_20_std
value: -9.822357050457521
- type: nauc_mrr_at_3_diff1
value: 27.564445527656073
- type: nauc_mrr_at_3_max
value: 27.360005995543013
- type: nauc_mrr_at_3_std
value: -9.833890331593217
- type: nauc_mrr_at_5_diff1
value: 26.822524992606787
- type: nauc_mrr_at_5_max
value: 26.284478920424583
- type: nauc_mrr_at_5_std
value: -11.036920037435278
- type: nauc_ndcg_at_1000_diff1
value: 22.865864500824603
- type: nauc_ndcg_at_1000_max
value: 22.771334973757252
- type: nauc_ndcg_at_1000_std
value: -4.391248945624055
- type: nauc_ndcg_at_100_diff1
value: 24.137939988386144
- type: nauc_ndcg_at_100_max
value: 23.87513301750976
- type: nauc_ndcg_at_100_std
value: -6.566673889142541
- type: nauc_ndcg_at_10_diff1
value: 23.28670973899235
- type: nauc_ndcg_at_10_max
value: 24.466850763499494
- type: nauc_ndcg_at_10_std
value: -10.258177551014816
- type: nauc_ndcg_at_1_diff1
value: 33.74283305857714
- type: nauc_ndcg_at_1_max
value: 33.58837545702206
- type: nauc_ndcg_at_1_std
value: -11.623065310526266
- type: nauc_ndcg_at_20_diff1
value: 22.989442500386524
- type: nauc_ndcg_at_20_max
value: 24.104082915814125
- type: nauc_ndcg_at_20_std
value: -9.45785928337488
- type: nauc_ndcg_at_3_diff1
value: 25.178014460273445
- type: nauc_ndcg_at_3_max
value: 25.942767533173754
- type: nauc_ndcg_at_3_std
value: -9.91363038933204
- type: nauc_ndcg_at_5_diff1
value: 23.991757042799776
- type: nauc_ndcg_at_5_max
value: 24.67696954394957
- type: nauc_ndcg_at_5_std
value: -12.31985800626722
- type: nauc_precision_at_1000_diff1
value: 8.73756056198236
- type: nauc_precision_at_1000_max
value: -2.2039393198217896
- type: nauc_precision_at_1000_std
value: 11.030221537933079
- type: nauc_precision_at_100_diff1
value: 20.215172391403144
- type: nauc_precision_at_100_max
value: 17.018645260191438
- type: nauc_precision_at_100_std
value: 3.767328710045164
- type: nauc_precision_at_10_diff1
value: 17.587454651591
- type: nauc_precision_at_10_max
value: 18.519756223864587
- type: nauc_precision_at_10_std
value: -7.57980264597448
- type: nauc_precision_at_1_diff1
value: 33.74283305857714
- type: nauc_precision_at_1_max
value: 33.58837545702206
- type: nauc_precision_at_1_std
value: -11.623065310526266
- type: nauc_precision_at_20_diff1
value: 16.8264764027673
- type: nauc_precision_at_20_max
value: 17.684383034724306
- type: nauc_precision_at_20_std
value: -4.715192266545397
- type: nauc_precision_at_3_diff1
value: 21.074816828033445
- type: nauc_precision_at_3_max
value: 21.203608983260384
- type: nauc_precision_at_3_std
value: -7.0598567996303165
- type: nauc_precision_at_5_diff1
value: 19.232226617012476
- type: nauc_precision_at_5_max
value: 18.21464537199811
- type: nauc_precision_at_5_std
value: -11.192063817701081
- type: nauc_recall_at_1000_diff1
value: 13.682126336330219
- type: nauc_recall_at_1000_max
value: 11.290148994929623
- type: nauc_recall_at_1000_std
value: 15.234970859087472
- type: nauc_recall_at_100_diff1
value: 21.54257810474028
- type: nauc_recall_at_100_max
value: 18.319728481896473
- type: nauc_recall_at_100_std
value: 1.8896944275133083
- type: nauc_recall_at_10_diff1
value: 18.303586564099813
- type: nauc_recall_at_10_max
value: 20.31707691425135
- type: nauc_recall_at_10_std
value: -8.56717254223721
- type: nauc_recall_at_1_diff1
value: 33.63991109177576
- type: nauc_recall_at_1_max
value: 34.23354700535017
- type: nauc_recall_at_1_std
value: -13.602316051776613
- type: nauc_recall_at_20_diff1
value: 18.133732998590617
- type: nauc_recall_at_20_max
value: 19.491824859679376
- type: nauc_recall_at_20_std
value: -6.958404447908455
- type: nauc_recall_at_3_diff1
value: 20.923379689287973
- type: nauc_recall_at_3_max
value: 22.305262469725605
- type: nauc_recall_at_3_std
value: -9.33545310798814
- type: nauc_recall_at_5_diff1
value: 18.697534927162877
- type: nauc_recall_at_5_max
value: 19.872464448638226
- type: nauc_recall_at_5_std
value: -13.201942499761413
- type: ndcg_at_1
value: 8.318
- type: ndcg_at_10
value: 13.536999999999999
- type: ndcg_at_100
value: 17.814
- type: ndcg_at_1000
value: 21.037
- type: ndcg_at_20
value: 14.795
- type: ndcg_at_3
value: 10.584
- type: ndcg_at_5
value: 11.631
- type: precision_at_1
value: 8.318
- type: precision_at_10
value: 2.348
- type: precision_at_100
value: 0.488
- type: precision_at_1000
value: 0.084
- type: precision_at_20
value: 1.4789999999999999
- type: precision_at_3
value: 4.559
- type: precision_at_5
value: 3.327
- type: recall_at_1
value: 7.468
- type: recall_at_10
value: 20.508000000000003
- type: recall_at_100
value: 40.969
- type: recall_at_1000
value: 66.01
- type: recall_at_20
value: 25.151
- type: recall_at_3
value: 12.187000000000001
- type: recall_at_5
value: 14.868
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER (default)
type: mteb/climate-fever
config: default
split: test
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
metrics:
- type: main_score
value: 14.015
- type: map_at_1
value: 5.794
- type: map_at_10
value: 9.467
- type: map_at_100
value: 10.583
- type: map_at_1000
value: 10.738
- type: map_at_20
value: 10.019
- type: map_at_3
value: 7.800999999999999
- type: map_at_5
value: 8.530999999999999
- type: mrr_at_1
value: 12.37785016286645
- type: mrr_at_10
value: 19.195232924874603
- type: mrr_at_100
value: 20.36171753911915
- type: mrr_at_1000
value: 20.43422170175313
- type: mrr_at_20
value: 19.925433949052078
- type: mrr_at_3
value: 16.612377850162883
- type: mrr_at_5
value: 17.928338762214977
- type: nauc_map_at_1000_diff1
value: 30.77100530113992
- type: nauc_map_at_1000_max
value: 3.930399825338355
- type: nauc_map_at_1000_std
value: 19.339256296860647
- type: nauc_map_at_100_diff1
value: 30.731834293026033
- type: nauc_map_at_100_max
value: 3.9391965871824577
- type: nauc_map_at_100_std
value: 18.994224188430934
- type: nauc_map_at_10_diff1
value: 30.52002817023447
- type: nauc_map_at_10_max
value: 4.047355652304053
- type: nauc_map_at_10_std
value: 16.271456948493867
- type: nauc_map_at_1_diff1
value: 40.78221783055125
- type: nauc_map_at_1_max
value: 6.03643489529247
- type: nauc_map_at_1_std
value: 10.164994264153364
- type: nauc_map_at_20_diff1
value: 30.667265850525062
- type: nauc_map_at_20_max
value: 3.808011497380771
- type: nauc_map_at_20_std
value: 17.64597024700993
- type: nauc_map_at_3_diff1
value: 32.9882945525325
- type: nauc_map_at_3_max
value: 4.81442279492956
- type: nauc_map_at_3_std
value: 11.72899701083213
- type: nauc_map_at_5_diff1
value: 31.319747944398486
- type: nauc_map_at_5_max
value: 4.789346536725522
- type: nauc_map_at_5_std
value: 13.280932876910251
- type: nauc_mrr_at_1000_diff1
value: 28.72974681423866
- type: nauc_mrr_at_1000_max
value: 5.334428633833756
- type: nauc_mrr_at_1000_std
value: 21.94603472046183
- type: nauc_mrr_at_100_diff1
value: 28.71022403484308
- type: nauc_mrr_at_100_max
value: 5.333420382518744
- type: nauc_mrr_at_100_std
value: 21.95720361127466
- type: nauc_mrr_at_10_diff1
value: 28.123142846152966
- type: nauc_mrr_at_10_max
value: 5.476579464822251
- type: nauc_mrr_at_10_std
value: 20.85306394069719
- type: nauc_mrr_at_1_diff1
value: 34.81794628491484
- type: nauc_mrr_at_1_max
value: 6.5806430588232905
- type: nauc_mrr_at_1_std
value: 14.459527094653325
- type: nauc_mrr_at_20_diff1
value: 28.439259242098213
- type: nauc_mrr_at_20_max
value: 5.357148444191085
- type: nauc_mrr_at_20_std
value: 21.61419717452997
- type: nauc_mrr_at_3_diff1
value: 29.687849776616204
- type: nauc_mrr_at_3_max
value: 5.740633779727121
- type: nauc_mrr_at_3_std
value: 17.8879483888456
- type: nauc_mrr_at_5_diff1
value: 28.47430129361797
- type: nauc_mrr_at_5_max
value: 5.630703322113187
- type: nauc_mrr_at_5_std
value: 19.229576158387964
- type: nauc_ndcg_at_1000_diff1
value: 29.601902706390376
- type: nauc_ndcg_at_1000_max
value: 2.953924251677932
- type: nauc_ndcg_at_1000_std
value: 33.43699716309924
- type: nauc_ndcg_at_100_diff1
value: 28.61050534370323
- type: nauc_ndcg_at_100_max
value: 3.4205261114094623
- type: nauc_ndcg_at_100_std
value: 29.71705615290654
- type: nauc_ndcg_at_10_diff1
value: 27.08320442286844
- type: nauc_ndcg_at_10_max
value: 3.7887194412304863
- type: nauc_ndcg_at_10_std
value: 21.676623605562256
- type: nauc_ndcg_at_1_diff1
value: 34.81794628491484
- type: nauc_ndcg_at_1_max
value: 6.5806430588232905
- type: nauc_ndcg_at_1_std
value: 14.459527094653325
- type: nauc_ndcg_at_20_diff1
value: 27.787198576453758
- type: nauc_ndcg_at_20_max
value: 3.1540397427527713
- type: nauc_ndcg_at_20_std
value: 24.886749384694483
- type: nauc_ndcg_at_3_diff1
value: 29.951818040541088
- type: nauc_ndcg_at_3_max
value: 5.01579970046346
- type: nauc_ndcg_at_3_std
value: 15.279492475081327
- type: nauc_ndcg_at_5_diff1
value: 28.06492691727927
- type: nauc_ndcg_at_5_max
value: 4.89933436886099
- type: nauc_ndcg_at_5_std
value: 16.918642834035854
- type: nauc_precision_at_1000_diff1
value: 15.771733257364474
- type: nauc_precision_at_1000_max
value: 1.823845951487625
- type: nauc_precision_at_1000_std
value: 49.1852294234272
- type: nauc_precision_at_100_diff1
value: 18.265609570523985
- type: nauc_precision_at_100_max
value: 4.2756221878446885
- type: nauc_precision_at_100_std
value: 44.777126764828196
- type: nauc_precision_at_10_diff1
value: 17.001368989158973
- type: nauc_precision_at_10_max
value: 3.567699919296151
- type: nauc_precision_at_10_std
value: 32.23622509514423
- type: nauc_precision_at_1_diff1
value: 34.81794628491484
- type: nauc_precision_at_1_max
value: 6.5806430588232905
- type: nauc_precision_at_1_std
value: 14.459527094653325
- type: nauc_precision_at_20_diff1
value: 17.635731357627552
- type: nauc_precision_at_20_max
value: 3.034597543962715
- type: nauc_precision_at_20_std
value: 37.444737258116376
- type: nauc_precision_at_3_diff1
value: 22.582871559622486
- type: nauc_precision_at_3_max
value: 6.018578205165446
- type: nauc_precision_at_3_std
value: 19.760719025296815
- type: nauc_precision_at_5_diff1
value: 18.665624106588705
- type: nauc_precision_at_5_max
value: 5.618829486159042
- type: nauc_precision_at_5_std
value: 24.487192977269594
- type: nauc_recall_at_1000_diff1
value: 26.313094272841823
- type: nauc_recall_at_1000_max
value: -3.0358409209748767
- type: nauc_recall_at_1000_std
value: 52.23483909347241
- type: nauc_recall_at_100_diff1
value: 22.619825448361848
- type: nauc_recall_at_100_max
value: -0.48782855898636057
- type: nauc_recall_at_100_std
value: 39.456946722540245
- type: nauc_recall_at_10_diff1
value: 21.248191636390427
- type: nauc_recall_at_10_max
value: 1.057162598023577
- type: nauc_recall_at_10_std
value: 26.28529915222162
- type: nauc_recall_at_1_diff1
value: 40.78221783055125
- type: nauc_recall_at_1_max
value: 6.03643489529247
- type: nauc_recall_at_1_std
value: 10.164994264153364
- type: nauc_recall_at_20_diff1
value: 22.329681015763143
- type: nauc_recall_at_20_max
value: -0.9021963926705002
- type: nauc_recall_at_20_std
value: 31.423263430139137
- type: nauc_recall_at_3_diff1
value: 27.367759082174025
- type: nauc_recall_at_3_max
value: 3.9289202004328527
- type: nauc_recall_at_3_std
value: 13.622863131134919
- type: nauc_recall_at_5_diff1
value: 22.76288213235621
- type: nauc_recall_at_5_max
value: 3.471221773429057
- type: nauc_recall_at_5_std
value: 17.585600220417064
- type: ndcg_at_1
value: 12.378
- type: ndcg_at_10
value: 14.015
- type: ndcg_at_100
value: 19.555
- type: ndcg_at_1000
value: 22.979
- type: ndcg_at_20
value: 16.019
- type: ndcg_at_3
value: 10.780000000000001
- type: ndcg_at_5
value: 11.773
- type: precision_at_1
value: 12.378
- type: precision_at_10
value: 4.567
- type: precision_at_100
value: 1.035
- type: precision_at_1000
value: 0.166
- type: precision_at_20
value: 3.114
- type: precision_at_3
value: 7.926
- type: precision_at_5
value: 6.215
- type: recall_at_1
value: 5.794
- type: recall_at_10
value: 17.407
- type: recall_at_100
value: 37.191
- type: recall_at_1000
value: 56.851
- type: recall_at_20
value: 23.165
- type: recall_at_3
value: 9.713
- type: recall_at_5
value: 12.415
- task:
type: Retrieval
dataset:
name: MTEB DBPedia (default)
type: mteb/dbpedia
config: default
split: test
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
metrics:
- type: main_score
value: 19.899
- type: map_at_1
value: 3.465
- type: map_at_10
value: 7.794
- type: map_at_100
value: 10.933
- type: map_at_1000
value: 11.752
- type: map_at_20
value: 9.016
- type: map_at_3
value: 5.427
- type: map_at_5
value: 6.502
- type: mrr_at_1
value: 34.75
- type: mrr_at_10
value: 45.200793650793656
- type: mrr_at_100
value: 46.05239344037991
- type: mrr_at_1000
value: 46.0856684337964
- type: mrr_at_20
value: 45.710684362077565
- type: mrr_at_3
value: 42.208333333333336
- type: mrr_at_5
value: 43.808333333333344
- type: nauc_map_at_1000_diff1
value: 18.86972613270399
- type: nauc_map_at_1000_max
value: 20.274156189253244
- type: nauc_map_at_1000_std
value: 22.191040122589133
- type: nauc_map_at_100_diff1
value: 18.788504382797093
- type: nauc_map_at_100_max
value: 18.991259275904696
- type: nauc_map_at_100_std
value: 19.224470200905856
- type: nauc_map_at_10_diff1
value: 18.750083550817912
- type: nauc_map_at_10_max
value: 10.317804767409177
- type: nauc_map_at_10_std
value: 4.146780937716071
- type: nauc_map_at_1_diff1
value: 24.593368387483753
- type: nauc_map_at_1_max
value: 4.589639725353537
- type: nauc_map_at_1_std
value: -8.92237341364795
- type: nauc_map_at_20_diff1
value: 18.991788660584362
- type: nauc_map_at_20_max
value: 13.525701435829877
- type: nauc_map_at_20_std
value: 10.505788067068151
- type: nauc_map_at_3_diff1
value: 18.3208401615434
- type: nauc_map_at_3_max
value: 9.337037518676164
- type: nauc_map_at_3_std
value: -3.652233530159517
- type: nauc_map_at_5_diff1
value: 18.092639410476284
- type: nauc_map_at_5_max
value: 10.092917720641017
- type: nauc_map_at_5_std
value: 0.17001723577182712
- type: nauc_mrr_at_1000_diff1
value: 29.78358698105705
- type: nauc_mrr_at_1000_max
value: 28.715621788566008
- type: nauc_mrr_at_1000_std
value: 22.028656730472925
- type: nauc_mrr_at_100_diff1
value: 29.790252324106998
- type: nauc_mrr_at_100_max
value: 28.742783310038494
- type: nauc_mrr_at_100_std
value: 22.03968708083945
- type: nauc_mrr_at_10_diff1
value: 29.438930345540236
- type: nauc_mrr_at_10_max
value: 28.65369065827219
- type: nauc_mrr_at_10_std
value: 21.78750467411176
- type: nauc_mrr_at_1_diff1
value: 35.330827390243996
- type: nauc_mrr_at_1_max
value: 26.56882708002626
- type: nauc_mrr_at_1_std
value: 21.623824720391546
- type: nauc_mrr_at_20_diff1
value: 29.738885034343433
- type: nauc_mrr_at_20_max
value: 28.757633233697227
- type: nauc_mrr_at_20_std
value: 21.94206110931751
- type: nauc_mrr_at_3_diff1
value: 30.084883512926936
- type: nauc_mrr_at_3_max
value: 28.504733195949854
- type: nauc_mrr_at_3_std
value: 21.343105616755405
- type: nauc_mrr_at_5_diff1
value: 29.162370505723974
- type: nauc_mrr_at_5_max
value: 28.302134300102317
- type: nauc_mrr_at_5_std
value: 21.967069891186686
- type: nauc_ndcg_at_1000_diff1
value: 21.5599701482179
- type: nauc_ndcg_at_1000_max
value: 19.60442562497246
- type: nauc_ndcg_at_1000_std
value: 38.57803059971978
- type: nauc_ndcg_at_100_diff1
value: 20.869754081262034
- type: nauc_ndcg_at_100_max
value: 17.061854693160267
- type: nauc_ndcg_at_100_std
value: 28.495912815567348
- type: nauc_ndcg_at_10_diff1
value: 21.68424149188379
- type: nauc_ndcg_at_10_max
value: 17.7957499268384
- type: nauc_ndcg_at_10_std
value: 20.329697185043177
- type: nauc_ndcg_at_1_diff1
value: 33.15797652004303
- type: nauc_ndcg_at_1_max
value: 19.169777835934728
- type: nauc_ndcg_at_1_std
value: 16.460300389696954
- type: nauc_ndcg_at_20_diff1
value: 20.980003079381408
- type: nauc_ndcg_at_20_max
value: 16.31240132872873
- type: nauc_ndcg_at_20_std
value: 21.336530494236147
- type: nauc_ndcg_at_3_diff1
value: 23.747010783899103
- type: nauc_ndcg_at_3_max
value: 20.514543159699503
- type: nauc_ndcg_at_3_std
value: 19.913679184651535
- type: nauc_ndcg_at_5_diff1
value: 21.811506356457578
- type: nauc_ndcg_at_5_max
value: 19.600228375339086
- type: nauc_ndcg_at_5_std
value: 20.80223119600392
- type: nauc_precision_at_1000_diff1
value: 7.616167380395875
- type: nauc_precision_at_1000_max
value: 24.36987688613695
- type: nauc_precision_at_1000_std
value: 28.517709442088883
- type: nauc_precision_at_100_diff1
value: 10.899372478558005
- type: nauc_precision_at_100_max
value: 32.52543047557354
- type: nauc_precision_at_100_std
value: 40.418143841067725
- type: nauc_precision_at_10_diff1
value: 12.454659530883022
- type: nauc_precision_at_10_max
value: 26.633347275996822
- type: nauc_precision_at_10_std
value: 31.766535462628333
- type: nauc_precision_at_1_diff1
value: 35.330827390243996
- type: nauc_precision_at_1_max
value: 26.56882708002626
- type: nauc_precision_at_1_std
value: 21.623824720391546
- type: nauc_precision_at_20_diff1
value: 13.710148345557894
- type: nauc_precision_at_20_max
value: 30.06641352798287
- type: nauc_precision_at_20_std
value: 37.51642649937503
- type: nauc_precision_at_3_diff1
value: 19.379905126167277
- type: nauc_precision_at_3_max
value: 29.474064921517996
- type: nauc_precision_at_3_std
value: 24.324769024438673
- type: nauc_precision_at_5_diff1
value: 14.983583546795229
- type: nauc_precision_at_5_max
value: 29.377923800204137
- type: nauc_precision_at_5_std
value: 28.792665620205433
- type: nauc_recall_at_1000_diff1
value: 9.420323994147108
- type: nauc_recall_at_1000_max
value: 1.716458858147155
- type: nauc_recall_at_1000_std
value: 42.675208969537806
- type: nauc_recall_at_100_diff1
value: 10.524089820623148
- type: nauc_recall_at_100_max
value: 4.847393922578022
- type: nauc_recall_at_100_std
value: 25.881256479477425
- type: nauc_recall_at_10_diff1
value: 10.405559854705523
- type: nauc_recall_at_10_max
value: -0.7229949712397538
- type: nauc_recall_at_10_std
value: 1.2453684953323285
- type: nauc_recall_at_1_diff1
value: 24.593368387483753
- type: nauc_recall_at_1_max
value: 4.589639725353537
- type: nauc_recall_at_1_std
value: -8.92237341364795
- type: nauc_recall_at_20_diff1
value: 9.153545675349667
- type: nauc_recall_at_20_max
value: 1.0523663509920702
- type: nauc_recall_at_20_std
value: 9.617722656364721
- type: nauc_recall_at_3_diff1
value: 11.453608857041628
- type: nauc_recall_at_3_max
value: 6.541125581241787
- type: nauc_recall_at_3_std
value: -6.374588849217941
- type: nauc_recall_at_5_diff1
value: 10.747977942968255
- type: nauc_recall_at_5_max
value: 3.2154611210290445
- type: nauc_recall_at_5_std
value: -1.2652013924076986
- type: ndcg_at_1
value: 24.25
- type: ndcg_at_10
value: 19.899
- type: ndcg_at_100
value: 23.204
- type: ndcg_at_1000
value: 29.658
- type: ndcg_at_20
value: 19.583000000000002
- type: ndcg_at_3
value: 21.335
- type: ndcg_at_5
value: 20.413999999999998
- type: precision_at_1
value: 34.75
- type: precision_at_10
value: 18.075
- type: precision_at_100
value: 5.897
- type: precision_at_1000
value: 1.22
- type: precision_at_20
value: 13.55
- type: precision_at_3
value: 26.833000000000002
- type: precision_at_5
value: 22.6
- type: recall_at_1
value: 3.465
- type: recall_at_10
value: 12.606
- type: recall_at_100
value: 29.843999999999998
- type: recall_at_1000
value: 52.242999999999995
- type: recall_at_20
value: 16.930999999999997
- type: recall_at_3
value: 6.425
- type: recall_at_5
value: 8.818
- task:
type: Classification
dataset:
name: MTEB EmotionClassification (default)
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 38.339999999999996
- type: f1
value: 34.598741976118816
- type: f1_weighted
value: 40.51989104726522
- type: main_score
value: 38.339999999999996
- task:
type: Retrieval
dataset:
name: MTEB FEVER (default)
type: mteb/fever
config: default
split: test
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
metrics:
- type: main_score
value: 25.006
- type: map_at_1
value: 13.943
- type: map_at_10
value: 20.706
- type: map_at_100
value: 21.740000000000002
- type: map_at_1000
value: 21.822
- type: map_at_20
value: 21.267
- type: map_at_3
value: 18.35
- type: map_at_5
value: 19.636
- type: mrr_at_1
value: 14.79147914791479
- type: mrr_at_10
value: 21.939967806304423
- type: mrr_at_100
value: 22.991772526136195
- type: mrr_at_1000
value: 23.068306121221312
- type: mrr_at_20
value: 22.521146379622163
- type: mrr_at_3
value: 19.484448444844478
- type: mrr_at_5
value: 20.817331733173358
- type: nauc_map_at_1000_diff1
value: 19.35822964414219
- type: nauc_map_at_1000_max
value: 8.897124191699918
- type: nauc_map_at_1000_std
value: -14.004128494439424
- type: nauc_map_at_100_diff1
value: 19.34567869663468
- type: nauc_map_at_100_max
value: 8.8745190516295
- type: nauc_map_at_100_std
value: -14.025946762212236
- type: nauc_map_at_10_diff1
value: 19.478894508723158
- type: nauc_map_at_10_max
value: 8.614136366133858
- type: nauc_map_at_10_std
value: -14.636265322683597
- type: nauc_map_at_1_diff1
value: 23.688109743445253
- type: nauc_map_at_1_max
value: 10.721419669570178
- type: nauc_map_at_1_std
value: -17.00198995751755
- type: nauc_map_at_20_diff1
value: 19.40994853288039
- type: nauc_map_at_20_max
value: 8.788561538894676
- type: nauc_map_at_20_std
value: -14.287595480928521
- type: nauc_map_at_3_diff1
value: 20.019246737479236
- type: nauc_map_at_3_max
value: 8.530000749651693
- type: nauc_map_at_3_std
value: -16.31053852110094
- type: nauc_map_at_5_diff1
value: 19.574801722611753
- type: nauc_map_at_5_max
value: 8.431256040109632
- type: nauc_map_at_5_std
value: -15.42991927435635
- type: nauc_mrr_at_1000_diff1
value: 19.199456594864415
- type: nauc_mrr_at_1000_max
value: 9.053366261880821
- type: nauc_mrr_at_1000_std
value: -14.325311358790312
- type: nauc_mrr_at_100_diff1
value: 19.183968461336264
- type: nauc_mrr_at_100_max
value: 9.0406708211084
- type: nauc_mrr_at_100_std
value: -14.333168371749
- type: nauc_mrr_at_10_diff1
value: 19.286280952658004
- type: nauc_mrr_at_10_max
value: 8.786679451075301
- type: nauc_mrr_at_10_std
value: -14.85433165190137
- type: nauc_mrr_at_1_diff1
value: 23.372945217632637
- type: nauc_mrr_at_1_max
value: 10.757009456320713
- type: nauc_mrr_at_1_std
value: -17.37470573558239
- type: nauc_mrr_at_20_diff1
value: 19.204260097760162
- type: nauc_mrr_at_20_max
value: 8.967269936629057
- type: nauc_mrr_at_20_std
value: -14.556203577633491
- type: nauc_mrr_at_3_diff1
value: 19.802237510569196
- type: nauc_mrr_at_3_max
value: 8.660412322072549
- type: nauc_mrr_at_3_std
value: -16.483667365878983
- type: nauc_mrr_at_5_diff1
value: 19.417190218500963
- type: nauc_mrr_at_5_max
value: 8.592050482160923
- type: nauc_mrr_at_5_std
value: -15.666970940052721
- type: nauc_ndcg_at_1000_diff1
value: 17.770326257033936
- type: nauc_ndcg_at_1000_max
value: 9.986868282212038
- type: nauc_ndcg_at_1000_std
value: -9.378246687942493
- type: nauc_ndcg_at_100_diff1
value: 17.57851695979306
- type: nauc_ndcg_at_100_max
value: 9.516456101829059
- type: nauc_ndcg_at_100_std
value: -9.92852108588332
- type: nauc_ndcg_at_10_diff1
value: 18.211042534939516
- type: nauc_ndcg_at_10_max
value: 8.263500593038305
- type: nauc_ndcg_at_10_std
value: -12.860334730832001
- type: nauc_ndcg_at_1_diff1
value: 23.372945217632637
- type: nauc_ndcg_at_1_max
value: 10.757009456320713
- type: nauc_ndcg_at_1_std
value: -17.37470573558239
- type: nauc_ndcg_at_20_diff1
value: 17.910709608958474
- type: nauc_ndcg_at_20_max
value: 8.893940446709529
- type: nauc_ndcg_at_20_std
value: -11.689263799945813
- type: nauc_ndcg_at_3_diff1
value: 19.09880112910806
- type: nauc_ndcg_at_3_max
value: 8.023263463318175
- type: nauc_ndcg_at_3_std
value: -16.092374418892373
- type: nauc_ndcg_at_5_diff1
value: 18.42900402442049
- type: nauc_ndcg_at_5_max
value: 7.8858287226066235
- type: nauc_ndcg_at_5_std
value: -14.661280178399608
- type: nauc_precision_at_1000_diff1
value: 3.642347466781283
- type: nauc_precision_at_1000_max
value: 16.952404316587614
- type: nauc_precision_at_1000_std
value: 21.40131424089912
- type: nauc_precision_at_100_diff1
value: 9.750805732461842
- type: nauc_precision_at_100_max
value: 13.757879488937125
- type: nauc_precision_at_100_std
value: 8.039378982280406
- type: nauc_precision_at_10_diff1
value: 14.7918457440186
- type: nauc_precision_at_10_max
value: 8.123251440844076
- type: nauc_precision_at_10_std
value: -7.766522118292242
- type: nauc_precision_at_1_diff1
value: 23.372945217632637
- type: nauc_precision_at_1_max
value: 10.757009456320713
- type: nauc_precision_at_1_std
value: -17.37470573558239
- type: nauc_precision_at_20_diff1
value: 13.317651277911787
- type: nauc_precision_at_20_max
value: 10.204911801413331
- type: nauc_precision_at_20_std
value: -3.322012947463638
- type: nauc_precision_at_3_diff1
value: 16.938989829945534
- type: nauc_precision_at_3_max
value: 7.007727368306191
- type: nauc_precision_at_3_std
value: -15.264146253300096
- type: nauc_precision_at_5_diff1
value: 15.595830777905029
- type: nauc_precision_at_5_max
value: 6.87438645405223
- type: nauc_precision_at_5_std
value: -12.548740115098678
- type: nauc_recall_at_1000_diff1
value: 9.009543867034727
- type: nauc_recall_at_1000_max
value: 18.305044258577915
- type: nauc_recall_at_1000_std
value: 23.009148418514425
- type: nauc_recall_at_100_diff1
value: 11.15850015080056
- type: nauc_recall_at_100_max
value: 11.780408791390519
- type: nauc_recall_at_100_std
value: 6.246652097817795
- type: nauc_recall_at_10_diff1
value: 15.099829144415247
- type: nauc_recall_at_10_max
value: 7.075068492864811
- type: nauc_recall_at_10_std
value: -7.878092251138417
- type: nauc_recall_at_1_diff1
value: 23.688109743445253
- type: nauc_recall_at_1_max
value: 10.721419669570178
- type: nauc_recall_at_1_std
value: -17.00198995751755
- type: nauc_recall_at_20_diff1
value: 13.85704310580134
- type: nauc_recall_at_20_max
value: 9.007426388276338
- type: nauc_recall_at_20_std
value: -3.9997271157444843
- type: nauc_recall_at_3_diff1
value: 16.851129797737183
- type: nauc_recall_at_3_max
value: 6.616028659229676
- type: nauc_recall_at_3_std
value: -15.286301162412613
- type: nauc_recall_at_5_diff1
value: 15.671635716227339
- type: nauc_recall_at_5_max
value: 6.342388043913686
- type: nauc_recall_at_5_std
value: -12.39987752967968
- type: ndcg_at_1
value: 14.791000000000002
- type: ndcg_at_10
value: 25.006
- type: ndcg_at_100
value: 30.471999999999998
- type: ndcg_at_1000
value: 32.806000000000004
- type: ndcg_at_20
value: 27.058
- type: ndcg_at_3
value: 20.112
- type: ndcg_at_5
value: 22.413
- type: precision_at_1
value: 14.791000000000002
- type: precision_at_10
value: 4.055000000000001
- type: precision_at_100
value: 0.697
- type: precision_at_1000
value: 0.092
- type: precision_at_20
value: 2.465
- type: precision_at_3
value: 8.626000000000001
- type: precision_at_5
value: 6.382000000000001
- type: recall_at_1
value: 13.943
- type: recall_at_10
value: 37.397000000000006
- type: recall_at_100
value: 63.334999999999994
- type: recall_at_1000
value: 81.428
- type: recall_at_20
value: 45.358
- type: recall_at_3
value: 24.082
- type: recall_at_5
value: 29.563
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018 (default)
type: mteb/fiqa
config: default
split: test
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
metrics:
- type: main_score
value: 11.167
- type: map_at_1
value: 5.055
- type: map_at_10
value: 7.974
- type: map_at_100
value: 8.738
- type: map_at_1000
value: 8.916
- type: map_at_20
value: 8.341
- type: map_at_3
value: 6.857
- type: map_at_5
value: 7.5009999999999994
- type: mrr_at_1
value: 10.030864197530864
- type: mrr_at_10
value: 14.756087105624141
- type: mrr_at_100
value: 15.562190249516133
- type: mrr_at_1000
value: 15.69044643307793
- type: mrr_at_20
value: 15.164252290155286
- type: mrr_at_3
value: 13.297325102880658
- type: mrr_at_5
value: 14.130658436213992
- type: nauc_map_at_1000_diff1
value: 21.581584639641356
- type: nauc_map_at_1000_max
value: -3.591350057991658
- type: nauc_map_at_1000_std
value: 2.2450733180258466
- type: nauc_map_at_100_diff1
value: 21.678068750484663
- type: nauc_map_at_100_max
value: -3.754793884673454
- type: nauc_map_at_100_std
value: 2.1134125512643034
- type: nauc_map_at_10_diff1
value: 22.267707890250872
- type: nauc_map_at_10_max
value: -4.109027667129512
- type: nauc_map_at_10_std
value: 1.7397026170215282
- type: nauc_map_at_1_diff1
value: 24.393602819317127
- type: nauc_map_at_1_max
value: -5.463161484041758
- type: nauc_map_at_1_std
value: 3.4527844717330898
- type: nauc_map_at_20_diff1
value: 22.16603827194384
- type: nauc_map_at_20_max
value: -3.829133240985351
- type: nauc_map_at_20_std
value: 2.273305218017184
- type: nauc_map_at_3_diff1
value: 25.550971234557217
- type: nauc_map_at_3_max
value: -5.912131631375139
- type: nauc_map_at_3_std
value: 2.6270431833752226
- type: nauc_map_at_5_diff1
value: 23.693227817850918
- type: nauc_map_at_5_max
value: -4.430117256044587
- type: nauc_map_at_5_std
value: 1.90476330618582
- type: nauc_mrr_at_1000_diff1
value: 18.407848757651383
- type: nauc_mrr_at_1000_max
value: 1.4692643101259266
- type: nauc_mrr_at_1000_std
value: -1.4737021198395484
- type: nauc_mrr_at_100_diff1
value: 18.373936364611946
- type: nauc_mrr_at_100_max
value: 1.4600491055347338
- type: nauc_mrr_at_100_std
value: -1.5315816773226647
- type: nauc_mrr_at_10_diff1
value: 18.812075225359994
- type: nauc_mrr_at_10_max
value: 1.1423422260007967
- type: nauc_mrr_at_10_std
value: -1.4331421942145333
- type: nauc_mrr_at_1_diff1
value: 21.042020105537055
- type: nauc_mrr_at_1_max
value: -1.8286330117738627
- type: nauc_mrr_at_1_std
value: 0.6107108684145417
- type: nauc_mrr_at_20_diff1
value: 18.67480478225173
- type: nauc_mrr_at_20_max
value: 1.262037517477333
- type: nauc_mrr_at_20_std
value: -1.3030974525400356
- type: nauc_mrr_at_3_diff1
value: 20.263359986054837
- type: nauc_mrr_at_3_max
value: -0.3775317483949404
- type: nauc_mrr_at_3_std
value: -1.365236958935102
- type: nauc_mrr_at_5_diff1
value: 19.555216165143772
- type: nauc_mrr_at_5_max
value: 0.364621169263337
- type: nauc_mrr_at_5_std
value: -1.0513020604553038
- type: nauc_ndcg_at_1000_diff1
value: 15.768274611971735
- type: nauc_ndcg_at_1000_max
value: 2.0520976478520327
- type: nauc_ndcg_at_1000_std
value: 2.877627036243521
- type: nauc_ndcg_at_100_diff1
value: 16.128663871942763
- type: nauc_ndcg_at_100_max
value: -0.34227560585178396
- type: nauc_ndcg_at_100_std
value: 0.8164780238765409
- type: nauc_ndcg_at_10_diff1
value: 19.282198569420846
- type: nauc_ndcg_at_10_max
value: -1.3250908207898342
- type: nauc_ndcg_at_10_std
value: 0.28825143098016265
- type: nauc_ndcg_at_1_diff1
value: 21.042020105537055
- type: nauc_ndcg_at_1_max
value: -1.8286330117738627
- type: nauc_ndcg_at_1_std
value: 0.6107108684145417
- type: nauc_ndcg_at_20_diff1
value: 19.028654575882847
- type: nauc_ndcg_at_20_max
value: -0.9325610304848784
- type: nauc_ndcg_at_20_std
value: 1.5749962746078057
- type: nauc_ndcg_at_3_diff1
value: 21.864688221213875
- type: nauc_ndcg_at_3_max
value: -2.6883486751081693
- type: nauc_ndcg_at_3_std
value: 0.17632918486246743
- type: nauc_ndcg_at_5_diff1
value: 21.280319590515656
- type: nauc_ndcg_at_5_max
value: -1.7628672417522795
- type: nauc_ndcg_at_5_std
value: 0.35504411508050127
- type: nauc_precision_at_1000_diff1
value: -5.134118935123325
- type: nauc_precision_at_1000_max
value: 22.854317653101646
- type: nauc_precision_at_1000_std
value: -5.519945670535999
- type: nauc_precision_at_100_diff1
value: 2.410623305126647
- type: nauc_precision_at_100_max
value: 11.323949150994391
- type: nauc_precision_at_100_std
value: -4.4400164174748395
- type: nauc_precision_at_10_diff1
value: 11.14562925123435
- type: nauc_precision_at_10_max
value: 6.701684471603129
- type: nauc_precision_at_10_std
value: -3.507090397196342
- type: nauc_precision_at_1_diff1
value: 21.042020105537055
- type: nauc_precision_at_1_max
value: -1.8286330117738627
- type: nauc_precision_at_1_std
value: 0.6107108684145417
- type: nauc_precision_at_20_diff1
value: 10.58098788224169
- type: nauc_precision_at_20_max
value: 7.5107799297769935
- type: nauc_precision_at_20_std
value: -1.5100106529478114
- type: nauc_precision_at_3_diff1
value: 19.795198818057667
- type: nauc_precision_at_3_max
value: 0.4713854827815967
- type: nauc_precision_at_3_std
value: -3.125924766538086
- type: nauc_precision_at_5_diff1
value: 16.907379789095696
- type: nauc_precision_at_5_max
value: 4.140243156305644
- type: nauc_precision_at_5_std
value: -1.8178346354290582
- type: nauc_recall_at_1000_diff1
value: 4.711761259530349
- type: nauc_recall_at_1000_max
value: 3.897303116005553
- type: nauc_recall_at_1000_std
value: 14.259168849028104
- type: nauc_recall_at_100_diff1
value: 4.811342813866857
- type: nauc_recall_at_100_max
value: -0.46422331209391143
- type: nauc_recall_at_100_std
value: 1.702190380676355
- type: nauc_recall_at_10_diff1
value: 14.112982578958079
- type: nauc_recall_at_10_max
value: -0.6934250965951679
- type: nauc_recall_at_10_std
value: -0.19882683954238423
- type: nauc_recall_at_1_diff1
value: 24.393602819317127
- type: nauc_recall_at_1_max
value: -5.463161484041758
- type: nauc_recall_at_1_std
value: 3.4527844717330898
- type: nauc_recall_at_20_diff1
value: 13.19557557901834
- type: nauc_recall_at_20_max
value: 0.1538644708778628
- type: nauc_recall_at_20_std
value: 3.0492797001932974
- type: nauc_recall_at_3_diff1
value: 24.182210704492558
- type: nauc_recall_at_3_max
value: -6.034324229051654
- type: nauc_recall_at_3_std
value: 2.8490090980023637
- type: nauc_recall_at_5_diff1
value: 19.011063131073744
- type: nauc_recall_at_5_max
value: -2.119359618883548
- type: nauc_recall_at_5_std
value: 0.8198903805407032
- type: ndcg_at_1
value: 10.030999999999999
- type: ndcg_at_10
value: 11.167
- type: ndcg_at_100
value: 15.409
- type: ndcg_at_1000
value: 19.947
- type: ndcg_at_20
value: 12.483
- type: ndcg_at_3
value: 9.532
- type: ndcg_at_5
value: 10.184
- type: precision_at_1
value: 10.030999999999999
- type: precision_at_10
value: 3.1329999999999996
- type: precision_at_100
value: 0.7270000000000001
- type: precision_at_1000
value: 0.15
- type: precision_at_20
value: 2.06
- type: precision_at_3
value: 6.481000000000001
- type: precision_at_5
value: 4.877
- type: recall_at_1
value: 5.055
- type: recall_at_10
value: 14.193
- type: recall_at_100
value: 31.47
- type: recall_at_1000
value: 60.007
- type: recall_at_20
value: 18.532
- type: recall_at_3
value: 8.863999999999999
- type: recall_at_5
value: 11.354000000000001
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA (default)
type: mteb/hotpotqa
config: default
split: test
revision: ab518f4d6fcca38d87c25209f94beba119d02014
metrics:
- type: main_score
value: 30.837999999999997
- type: map_at_1
value: 17.535
- type: map_at_10
value: 24.127000000000002
- type: map_at_100
value: 24.897
- type: map_at_1000
value: 24.991
- type: map_at_20
value: 24.537
- type: map_at_3
value: 22.314
- type: map_at_5
value: 23.369
- type: mrr_at_1
value: 35.07089804186361
- type: mrr_at_10
value: 41.84109835696607
- type: mrr_at_100
value: 42.50312939357189
- type: mrr_at_1000
value: 42.557192847100204
- type: mrr_at_20
value: 42.23392771922393
- type: mrr_at_3
value: 40.0540175557057
- type: mrr_at_5
value: 41.09723160027011
- type: nauc_map_at_1000_diff1
value: 53.405765033756104
- type: nauc_map_at_1000_max
value: 7.122736293690594
- type: nauc_map_at_1000_std
value: 25.154222353909706
- type: nauc_map_at_100_diff1
value: 53.424105025391235
- type: nauc_map_at_100_max
value: 7.127661247301736
- type: nauc_map_at_100_std
value: 25.080306702030054
- type: nauc_map_at_10_diff1
value: 53.83507469889932
- type: nauc_map_at_10_max
value: 7.239978390454264
- type: nauc_map_at_10_std
value: 24.216110502987867
- type: nauc_map_at_1_diff1
value: 64.45610830977103
- type: nauc_map_at_1_max
value: 10.831236114417758
- type: nauc_map_at_1_std
value: 18.282463736681766
- type: nauc_map_at_20_diff1
value: 53.50246555744542
- type: nauc_map_at_20_max
value: 7.1666672586766085
- type: nauc_map_at_20_std
value: 24.648695320801803
- type: nauc_map_at_3_diff1
value: 55.467529631560474
- type: nauc_map_at_3_max
value: 8.281275214726968
- type: nauc_map_at_3_std
value: 22.436972833181386
- type: nauc_map_at_5_diff1
value: 54.2596974292177
- type: nauc_map_at_5_max
value: 7.5791705198322585
- type: nauc_map_at_5_std
value: 23.272036332669295
- type: nauc_mrr_at_1000_diff1
value: 60.01986079158693
- type: nauc_mrr_at_1000_max
value: 9.046571417308733
- type: nauc_mrr_at_1000_std
value: 22.078576232724707
- type: nauc_mrr_at_100_diff1
value: 60.01145860886984
- type: nauc_mrr_at_100_max
value: 9.036448042324515
- type: nauc_mrr_at_100_std
value: 22.073613864801413
- type: nauc_mrr_at_10_diff1
value: 60.138490480821595
- type: nauc_mrr_at_10_max
value: 9.09851806151594
- type: nauc_mrr_at_10_std
value: 21.871816692853095
- type: nauc_mrr_at_1_diff1
value: 64.45610830977103
- type: nauc_mrr_at_1_max
value: 10.831236114417758
- type: nauc_mrr_at_1_std
value: 18.282463736681766
- type: nauc_mrr_at_20_diff1
value: 60.020756965348596
- type: nauc_mrr_at_20_max
value: 9.067384772615947
- type: nauc_mrr_at_20_std
value: 22.007284296200602
- type: nauc_mrr_at_3_diff1
value: 60.848848858927965
- type: nauc_mrr_at_3_max
value: 9.77819590832476
- type: nauc_mrr_at_3_std
value: 20.7857772481929
- type: nauc_mrr_at_5_diff1
value: 60.23023654313581
- type: nauc_mrr_at_5_max
value: 9.297697720996952
- type: nauc_mrr_at_5_std
value: 21.305246554366864
- type: nauc_ndcg_at_1000_diff1
value: 51.9050817941371
- type: nauc_ndcg_at_1000_max
value: 6.253060051785559
- type: nauc_ndcg_at_1000_std
value: 29.724428357103015
- type: nauc_ndcg_at_100_diff1
value: 52.197825295468256
- type: nauc_ndcg_at_100_max
value: 6.212784383093877
- type: nauc_ndcg_at_100_std
value: 28.65006820758606
- type: nauc_ndcg_at_10_diff1
value: 53.6117173506942
- type: nauc_ndcg_at_10_max
value: 6.6792682572264646
- type: nauc_ndcg_at_10_std
value: 25.56356291488488
- type: nauc_ndcg_at_1_diff1
value: 64.45610830977103
- type: nauc_ndcg_at_1_max
value: 10.831236114417758
- type: nauc_ndcg_at_1_std
value: 18.282463736681766
- type: nauc_ndcg_at_20_diff1
value: 52.725481130189465
- type: nauc_ndcg_at_20_max
value: 6.443880761918098
- type: nauc_ndcg_at_20_std
value: 26.623544659694815
- type: nauc_ndcg_at_3_diff1
value: 56.087927881432066
- type: nauc_ndcg_at_3_max
value: 8.38309550543212
- type: nauc_ndcg_at_3_std
value: 22.573762514655623
- type: nauc_ndcg_at_5_diff1
value: 54.351073912334144
- type: nauc_ndcg_at_5_max
value: 7.325834612406898
- type: nauc_ndcg_at_5_std
value: 23.7625099537027
- type: nauc_precision_at_1000_diff1
value: 24.555760070632065
- type: nauc_precision_at_1000_max
value: -0.030378364610462727
- type: nauc_precision_at_1000_std
value: 43.44197980424529
- type: nauc_precision_at_100_diff1
value: 31.89263750680818
- type: nauc_precision_at_100_max
value: 0.5967214311073074
- type: nauc_precision_at_100_std
value: 38.028330866223165
- type: nauc_precision_at_10_diff1
value: 42.72001946616996
- type: nauc_precision_at_10_max
value: 2.759405409849438
- type: nauc_precision_at_10_std
value: 29.948179807406504
- type: nauc_precision_at_1_diff1
value: 64.45610830977103
- type: nauc_precision_at_1_max
value: 10.831236114417758
- type: nauc_precision_at_1_std
value: 18.282463736681766
- type: nauc_precision_at_20_diff1
value: 38.77807631886789
- type: nauc_precision_at_20_max
value: 1.8720818516278552
- type: nauc_precision_at_20_std
value: 32.59464097769524
- type: nauc_precision_at_3_diff1
value: 50.84352281110305
- type: nauc_precision_at_3_max
value: 6.8098905022703455
- type: nauc_precision_at_3_std
value: 24.54656806570455
- type: nauc_precision_at_5_diff1
value: 46.09980845642094
- type: nauc_precision_at_5_max
value: 4.489864393832119
- type: nauc_precision_at_5_std
value: 26.34146412719015
- type: nauc_recall_at_1000_diff1
value: 24.55576007063215
- type: nauc_recall_at_1000_max
value: -0.030378364610333563
- type: nauc_recall_at_1000_std
value: 43.441979804245264
- type: nauc_recall_at_100_diff1
value: 31.892637506808146
- type: nauc_recall_at_100_max
value: 0.5967214311073054
- type: nauc_recall_at_100_std
value: 38.02833086622307
- type: nauc_recall_at_10_diff1
value: 42.72001946616998
- type: nauc_recall_at_10_max
value: 2.7594054098494403
- type: nauc_recall_at_10_std
value: 29.94817980740652
- type: nauc_recall_at_1_diff1
value: 64.45610830977103
- type: nauc_recall_at_1_max
value: 10.831236114417758
- type: nauc_recall_at_1_std
value: 18.282463736681766
- type: nauc_recall_at_20_diff1
value: 38.77807631886782
- type: nauc_recall_at_20_max
value: 1.872081851627872
- type: nauc_recall_at_20_std
value: 32.594640977695256
- type: nauc_recall_at_3_diff1
value: 50.843522811103036
- type: nauc_recall_at_3_max
value: 6.809890502270356
- type: nauc_recall_at_3_std
value: 24.546568065704555
- type: nauc_recall_at_5_diff1
value: 46.09980845642094
- type: nauc_recall_at_5_max
value: 4.48986439383211
- type: nauc_recall_at_5_std
value: 26.341464127190157
- type: ndcg_at_1
value: 35.071000000000005
- type: ndcg_at_10
value: 30.837999999999997
- type: ndcg_at_100
value: 34.473
- type: ndcg_at_1000
value: 36.788
- type: ndcg_at_20
value: 32.193
- type: ndcg_at_3
value: 27.412999999999997
- type: ndcg_at_5
value: 29.160999999999998
- type: precision_at_1
value: 35.071000000000005
- type: precision_at_10
value: 6.694999999999999
- type: precision_at_100
value: 0.96
- type: precision_at_1000
value: 0.127
- type: precision_at_20
value: 3.785
- type: precision_at_3
value: 17.187
- type: precision_at_5
value: 11.700000000000001
- type: recall_at_1
value: 17.535
- type: recall_at_10
value: 33.477000000000004
- type: recall_at_100
value: 48.015
- type: recall_at_1000
value: 63.483999999999995
- type: recall_at_20
value: 37.846000000000004
- type: recall_at_3
value: 25.779999999999998
- type: recall_at_5
value: 29.250999999999998
- task:
type: Classification
dataset:
name: MTEB ImdbClassification (default)
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 66.5616
- type: ap
value: 61.38581579080602
- type: ap_weighted
value: 61.38581579080602
- type: f1
value: 66.15361405073979
- type: f1_weighted
value: 66.15361405073978
- type: main_score
value: 66.5616
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO (default)
type: mteb/msmarco
config: default
split: test
revision: c5a29a104738b98a9e76336939199e264163d4a0
metrics:
- type: main_score
value: 28.034
- type: map_at_1
value: 0.66
- type: map_at_10
value: 4.3709999999999996
- type: map_at_100
value: 12.02
- type: map_at_1000
value: 15.081
- type: map_at_20
value: 6.718
- type: map_at_3
value: 1.7389999999999999
- type: map_at_5
value: 2.5919999999999996
- type: mrr_at_1
value: 41.86046511627907
- type: mrr_at_10
value: 54.15651531930602
- type: mrr_at_100
value: 54.68712248786739
- type: mrr_at_1000
value: 54.68712248786739
- type: mrr_at_20
value: 54.272794389073454
- type: mrr_at_3
value: 51.937984496124024
- type: mrr_at_5
value: 52.40310077519379
- type: nauc_map_at_1000_diff1
value: 8.067177552562086
- type: nauc_map_at_1000_max
value: 50.80997888655191
- type: nauc_map_at_1000_std
value: 55.48450092063327
- type: nauc_map_at_100_diff1
value: 11.852088152898117
- type: nauc_map_at_100_max
value: 48.192262801076275
- type: nauc_map_at_100_std
value: 46.99716861803027
- type: nauc_map_at_10_diff1
value: 12.440097979884552
- type: nauc_map_at_10_max
value: 29.873253516213786
- type: nauc_map_at_10_std
value: 30.42960299808594
- type: nauc_map_at_1_diff1
value: 34.552395254431445
- type: nauc_map_at_1_max
value: 38.69572501766299
- type: nauc_map_at_1_std
value: 23.493916737503017
- type: nauc_map_at_20_diff1
value: 13.785974512045621
- type: nauc_map_at_20_max
value: 34.54060954861762
- type: nauc_map_at_20_std
value: 36.78361062739522
- type: nauc_map_at_3_diff1
value: 25.396598443628488
- type: nauc_map_at_3_max
value: 40.38715214284343
- type: nauc_map_at_3_std
value: 25.366480567034372
- type: nauc_map_at_5_diff1
value: 21.758905499107037
- type: nauc_map_at_5_max
value: 35.664518863717646
- type: nauc_map_at_5_std
value: 27.149202253810024
- type: nauc_mrr_at_1000_diff1
value: 17.603886573367394
- type: nauc_mrr_at_1000_max
value: 58.66874119428572
- type: nauc_mrr_at_1000_std
value: 42.279175325006555
- type: nauc_mrr_at_100_diff1
value: 17.603886573367394
- type: nauc_mrr_at_100_max
value: 58.66874119428572
- type: nauc_mrr_at_100_std
value: 42.279175325006555
- type: nauc_mrr_at_10_diff1
value: 17.323803643197643
- type: nauc_mrr_at_10_max
value: 58.762972566248315
- type: nauc_mrr_at_10_std
value: 42.56956515834332
- type: nauc_mrr_at_1_diff1
value: 27.861672627434668
- type: nauc_mrr_at_1_max
value: 62.257123563504756
- type: nauc_mrr_at_1_std
value: 44.379176486800986
- type: nauc_mrr_at_20_diff1
value: 17.44644565955209
- type: nauc_mrr_at_20_max
value: 58.58190663195971
- type: nauc_mrr_at_20_std
value: 42.33627290946193
- type: nauc_mrr_at_3_diff1
value: 17.262663278109798
- type: nauc_mrr_at_3_max
value: 56.454793834736094
- type: nauc_mrr_at_3_std
value: 41.08451346276091
- type: nauc_mrr_at_5_diff1
value: 16.613650570034434
- type: nauc_mrr_at_5_max
value: 55.66285623344173
- type: nauc_mrr_at_5_std
value: 40.38311275408144
- type: nauc_ndcg_at_1000_diff1
value: 10.174068866047635
- type: nauc_ndcg_at_1000_max
value: 51.73192889106936
- type: nauc_ndcg_at_1000_std
value: 59.65401111712334
- type: nauc_ndcg_at_100_diff1
value: 7.828653579924433
- type: nauc_ndcg_at_100_max
value: 54.36206806281852
- type: nauc_ndcg_at_100_std
value: 44.08756682730974
- type: nauc_ndcg_at_10_diff1
value: 3.1020204706672807
- type: nauc_ndcg_at_10_max
value: 49.25209127878138
- type: nauc_ndcg_at_10_std
value: 39.03800796651823
- type: nauc_ndcg_at_1_diff1
value: 31.384674368521292
- type: nauc_ndcg_at_1_max
value: 46.68691593258891
- type: nauc_ndcg_at_1_std
value: 23.497422044367447
- type: nauc_ndcg_at_20_diff1
value: 2.1223938698830445
- type: nauc_ndcg_at_20_max
value: 52.82778912003725
- type: nauc_ndcg_at_20_std
value: 40.85957147213028
- type: nauc_ndcg_at_3_diff1
value: 15.620541244360142
- type: nauc_ndcg_at_3_max
value: 53.11313758866487
- type: nauc_ndcg_at_3_std
value: 30.214636563641196
- type: nauc_ndcg_at_5_diff1
value: 11.094092047013888
- type: nauc_ndcg_at_5_max
value: 50.15717166769855
- type: nauc_ndcg_at_5_std
value: 32.63549193285381
- type: nauc_precision_at_1000_diff1
value: -18.87788252321529
- type: nauc_precision_at_1000_max
value: 47.752842936932964
- type: nauc_precision_at_1000_std
value: 46.53172081645067
- type: nauc_precision_at_100_diff1
value: -11.675608943686981
- type: nauc_precision_at_100_max
value: 57.37789290450161
- type: nauc_precision_at_100_std
value: 45.99043825302317
- type: nauc_precision_at_10_diff1
value: -5.316480906785367
- type: nauc_precision_at_10_max
value: 50.9022661670284
- type: nauc_precision_at_10_std
value: 41.249198804648444
- type: nauc_precision_at_1_diff1
value: 27.861672627434668
- type: nauc_precision_at_1_max
value: 62.257123563504756
- type: nauc_precision_at_1_std
value: 44.379176486800986
- type: nauc_precision_at_20_diff1
value: -4.546893782120849
- type: nauc_precision_at_20_max
value: 54.59631672833982
- type: nauc_precision_at_20_std
value: 42.784497023294186
- type: nauc_precision_at_3_diff1
value: 9.61605571022061
- type: nauc_precision_at_3_max
value: 58.49382945748053
- type: nauc_precision_at_3_std
value: 36.589164698407316
- type: nauc_precision_at_5_diff1
value: 4.337255192132767
- type: nauc_precision_at_5_max
value: 51.9951147484678
- type: nauc_precision_at_5_std
value: 34.468467294436486
- type: nauc_recall_at_1000_diff1
value: 12.99503296673786
- type: nauc_recall_at_1000_max
value: 40.71962531328987
- type: nauc_recall_at_1000_std
value: 61.64030151991186
- type: nauc_recall_at_100_diff1
value: 10.859337421704575
- type: nauc_recall_at_100_max
value: 38.842397587549044
- type: nauc_recall_at_100_std
value: 44.123802055364514
- type: nauc_recall_at_10_diff1
value: 5.054631656084283
- type: nauc_recall_at_10_max
value: 16.616637058750165
- type: nauc_recall_at_10_std
value: 23.85056756316223
- type: nauc_recall_at_1_diff1
value: 34.552395254431445
- type: nauc_recall_at_1_max
value: 38.69572501766299
- type: nauc_recall_at_1_std
value: 23.493916737503017
- type: nauc_recall_at_20_diff1
value: 11.266581564744333
- type: nauc_recall_at_20_max
value: 20.205268245387963
- type: nauc_recall_at_20_std
value: 25.000674179475464
- type: nauc_recall_at_3_diff1
value: 23.716522929925635
- type: nauc_recall_at_3_max
value: 33.675409791018915
- type: nauc_recall_at_3_std
value: 23.659590089606255
- type: nauc_recall_at_5_diff1
value: 13.826629690116377
- type: nauc_recall_at_5_max
value: 21.450396058089545
- type: nauc_recall_at_5_std
value: 21.053365906790678
- type: ndcg_at_1
value: 27.907
- type: ndcg_at_10
value: 28.034
- type: ndcg_at_100
value: 28.166000000000004
- type: ndcg_at_1000
value: 36.361
- type: ndcg_at_20
value: 28.047
- type: ndcg_at_3
value: 28.388999999999996
- type: ndcg_at_5
value: 28.307
- type: precision_at_1
value: 41.86
- type: precision_at_10
value: 37.208999999999996
- type: precision_at_100
value: 18.093
- type: precision_at_1000
value: 3.995
- type: precision_at_20
value: 33.372
- type: precision_at_3
value: 42.636
- type: precision_at_5
value: 40.0
- type: recall_at_1
value: 0.66
- type: recall_at_10
value: 6.287
- type: recall_at_100
value: 24.134
- type: recall_at_1000
value: 48.431999999999995
- type: recall_at_20
value: 10.897
- type: recall_at_3
value: 2.138
- type: recall_at_5
value: 3.3770000000000002
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 84.81988144094848
- type: f1
value: 84.06333895718355
- type: f1_weighted
value: 84.95181538630469
- type: main_score
value: 84.81988144094848
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 62.41222070223438
- type: f1
value: 46.156097858146175
- type: f1_weighted
value: 66.23266420473301
- type: main_score
value: 62.41222070223438
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 4672e20407010da34463acc759c162ca9734bca6
metrics:
- type: accuracy
value: 62.50168123739073
- type: f1
value: 60.72805496384179
- type: f1_weighted
value: 62.787680759907204
- type: main_score
value: 62.50168123739073
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: fad2c6e8459f9e1c45d9315f4953d921437d70f8
metrics:
- type: accuracy
value: 66.09280430396772
- type: f1
value: 65.36448769357172
- type: f1_weighted
value: 66.15203456480924
- type: main_score
value: 66.09280430396772
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P (default)
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: main_score
value: 26.932942933622616
- type: v_measure
value: 26.932942933622616
- type: v_measure_std
value: 1.593124055965666
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S (default)
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: main_score
value: 22.9594415386389
- type: v_measure
value: 22.9594415386389
- type: v_measure_std
value: 1.2719806552652395
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking (default)
type: mteb/mind_small
config: default
split: test
revision: 59042f120c80e8afa9cdbb224f67076cec0fc9a7
metrics:
- type: main_score
value: 28.527234738258063
- type: map
value: 28.527234738258063
- type: mrr
value: 29.001137590751057
- type: nAUC_map_diff1
value: 17.894640005397015
- type: nAUC_map_max
value: -32.33772009018379
- type: nAUC_map_std
value: -13.932018270818118
- type: nAUC_mrr_diff1
value: 16.6645956799536
- type: nAUC_mrr_max
value: -26.591327847291947
- type: nAUC_mrr_std
value: -11.52072949105865
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus (default)
type: mteb/nfcorpus
config: default
split: test
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
metrics:
- type: main_score
value: 23.318
- type: map_at_1
value: 3.9739999999999998
- type: map_at_10
value: 7.636
- type: map_at_100
value: 9.565999999999999
- type: map_at_1000
value: 10.731
- type: map_at_20
value: 8.389000000000001
- type: map_at_3
value: 5.836
- type: map_at_5
value: 6.6339999999999995
- type: mrr_at_1
value: 31.57894736842105
- type: mrr_at_10
value: 41.40436876504987
- type: mrr_at_100
value: 42.171381521810616
- type: mrr_at_1000
value: 42.21952740910268
- type: mrr_at_20
value: 41.75160733542153
- type: mrr_at_3
value: 38.544891640866865
- type: mrr_at_5
value: 40.495356037151694
- type: nauc_map_at_1000_diff1
value: 36.856779722587405
- type: nauc_map_at_1000_max
value: 1.0732856849015824
- type: nauc_map_at_1000_std
value: 9.651983758926798
- type: nauc_map_at_100_diff1
value: 37.7388774830525
- type: nauc_map_at_100_max
value: 0.5350831297890865
- type: nauc_map_at_100_std
value: 5.572219889903966
- type: nauc_map_at_10_diff1
value: 41.10439950831827
- type: nauc_map_at_10_max
value: -1.9365518645162703
- type: nauc_map_at_10_std
value: -0.14823142437775177
- type: nauc_map_at_1_diff1
value: 45.5844553027814
- type: nauc_map_at_1_max
value: -8.272551322248038
- type: nauc_map_at_1_std
value: -5.988582518897944
- type: nauc_map_at_20_diff1
value: 38.99926603388708
- type: nauc_map_at_20_max
value: -0.8765984795564569
- type: nauc_map_at_20_std
value: 1.8427808317285952
- type: nauc_map_at_3_diff1
value: 44.541009820342296
- type: nauc_map_at_3_max
value: -5.314865046137034
- type: nauc_map_at_3_std
value: -4.401240111896542
- type: nauc_map_at_5_diff1
value: 43.93142627220787
- type: nauc_map_at_5_max
value: -4.452186699937273
- type: nauc_map_at_5_std
value: -1.926768039888005
- type: nauc_mrr_at_1000_diff1
value: 31.753283629515227
- type: nauc_mrr_at_1000_max
value: 9.689948388217696
- type: nauc_mrr_at_1000_std
value: 22.70267321039036
- type: nauc_mrr_at_100_diff1
value: 31.729775359589773
- type: nauc_mrr_at_100_max
value: 9.729637548794349
- type: nauc_mrr_at_100_std
value: 22.680656825829267
- type: nauc_mrr_at_10_diff1
value: 31.725910736285666
- type: nauc_mrr_at_10_max
value: 9.676299619743284
- type: nauc_mrr_at_10_std
value: 22.987975982720496
- type: nauc_mrr_at_1_diff1
value: 33.222931085618626
- type: nauc_mrr_at_1_max
value: 3.484453564278958
- type: nauc_mrr_at_1_std
value: 14.566253883401012
- type: nauc_mrr_at_20_diff1
value: 31.70316773246007
- type: nauc_mrr_at_20_max
value: 9.857726052213023
- type: nauc_mrr_at_20_std
value: 22.691706596582133
- type: nauc_mrr_at_3_diff1
value: 33.123605268114545
- type: nauc_mrr_at_3_max
value: 7.595554226164336
- type: nauc_mrr_at_3_std
value: 22.833951307229185
- type: nauc_mrr_at_5_diff1
value: 32.33356989096538
- type: nauc_mrr_at_5_max
value: 8.78887950599465
- type: nauc_mrr_at_5_std
value: 23.75577044154664
- type: nauc_ndcg_at_1000_diff1
value: 29.06381153030341
- type: nauc_ndcg_at_1000_max
value: 12.496787837448844
- type: nauc_ndcg_at_1000_std
value: 21.957810402478064
- type: nauc_ndcg_at_100_diff1
value: 30.705847017840128
- type: nauc_ndcg_at_100_max
value: 7.14809714223451
- type: nauc_ndcg_at_100_std
value: 17.218742555337656
- type: nauc_ndcg_at_10_diff1
value: 28.03996243029464
- type: nauc_ndcg_at_10_max
value: 4.699374701730214
- type: nauc_ndcg_at_10_std
value: 24.227816808454218
- type: nauc_ndcg_at_1_diff1
value: 33.51847942809358
- type: nauc_ndcg_at_1_max
value: -0.15139755316818274
- type: nauc_ndcg_at_1_std
value: 17.16967561523347
- type: nauc_ndcg_at_20_diff1
value: 28.20952557682163
- type: nauc_ndcg_at_20_max
value: 4.145398659710493
- type: nauc_ndcg_at_20_std
value: 22.993088607717066
- type: nauc_ndcg_at_3_diff1
value: 27.613082038987592
- type: nauc_ndcg_at_3_max
value: 1.4593269064387369
- type: nauc_ndcg_at_3_std
value: 23.50820643331994
- type: nauc_ndcg_at_5_diff1
value: 28.240414065564686
- type: nauc_ndcg_at_5_max
value: 3.5129825777351504
- type: nauc_ndcg_at_5_std
value: 25.518429908335165
- type: nauc_precision_at_1000_diff1
value: 3.744031922083433
- type: nauc_precision_at_1000_max
value: -0.5091331293991512
- type: nauc_precision_at_1000_std
value: 44.81402869309276
- type: nauc_precision_at_100_diff1
value: 6.830797386827996
- type: nauc_precision_at_100_max
value: 4.0810548509653755
- type: nauc_precision_at_100_std
value: 42.7474662572479
- type: nauc_precision_at_10_diff1
value: 12.394335511926892
- type: nauc_precision_at_10_max
value: 10.49971612535947
- type: nauc_precision_at_10_std
value: 34.03347850666832
- type: nauc_precision_at_1_diff1
value: 33.222931085618626
- type: nauc_precision_at_1_max
value: 3.484453564278958
- type: nauc_precision_at_1_std
value: 14.566253883401012
- type: nauc_precision_at_20_diff1
value: 9.64344422081397
- type: nauc_precision_at_20_max
value: 6.621958244946981
- type: nauc_precision_at_20_std
value: 37.86581516903579
- type: nauc_precision_at_3_diff1
value: 20.278708738039267
- type: nauc_precision_at_3_max
value: 7.392289389157268
- type: nauc_precision_at_3_std
value: 27.036426818980896
- type: nauc_precision_at_5_diff1
value: 18.449282750023514
- type: nauc_precision_at_5_max
value: 9.979980772916283
- type: nauc_precision_at_5_std
value: 33.01802732071948
- type: nauc_recall_at_1000_diff1
value: 16.342561945689592
- type: nauc_recall_at_1000_max
value: 5.937671266428497
- type: nauc_recall_at_1000_std
value: 10.42918010425554
- type: nauc_recall_at_100_diff1
value: 19.13895811746396
- type: nauc_recall_at_100_max
value: 3.153899391811738
- type: nauc_recall_at_100_std
value: 1.04689826072118
- type: nauc_recall_at_10_diff1
value: 30.635745816653586
- type: nauc_recall_at_10_max
value: 1.5673249988390006
- type: nauc_recall_at_10_std
value: -3.6633108112395276
- type: nauc_recall_at_1_diff1
value: 45.5844553027814
- type: nauc_recall_at_1_max
value: -8.272551322248038
- type: nauc_recall_at_1_std
value: -5.988582518897944
- type: nauc_recall_at_20_diff1
value: 24.449469640898666
- type: nauc_recall_at_20_max
value: 3.6319822015373404
- type: nauc_recall_at_20_std
value: -3.460880541269202
- type: nauc_recall_at_3_diff1
value: 40.57120118352399
- type: nauc_recall_at_3_max
value: -6.4276251434173135
- type: nauc_recall_at_3_std
value: -5.987479062691147
- type: nauc_recall_at_5_diff1
value: 36.21768314516704
- type: nauc_recall_at_5_max
value: -4.847092890211095
- type: nauc_recall_at_5_std
value: -3.0514943484880144
- type: ndcg_at_1
value: 29.876
- type: ndcg_at_10
value: 23.318
- type: ndcg_at_100
value: 22.178
- type: ndcg_at_1000
value: 31.543
- type: ndcg_at_20
value: 21.718
- type: ndcg_at_3
value: 26.625
- type: ndcg_at_5
value: 25.412000000000003
- type: precision_at_1
value: 31.579
- type: precision_at_10
value: 17.244999999999997
- type: precision_at_100
value: 5.82
- type: precision_at_1000
value: 1.857
- type: precision_at_20
value: 12.709000000000001
- type: precision_at_3
value: 24.974
- type: precision_at_5
value: 21.981
- type: recall_at_1
value: 3.9739999999999998
- type: recall_at_10
value: 11.433
- type: recall_at_100
value: 24.861
- type: recall_at_1000
value: 57.75900000000001
- type: recall_at_20
value: 14.167
- type: recall_at_3
value: 6.773999999999999
- type: recall_at_5
value: 8.713
- task:
type: Retrieval
dataset:
name: MTEB NQ (default)
type: mteb/nq
config: default
split: test
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
metrics:
- type: main_score
value: 17.682000000000002
- type: map_at_1
value: 7.968999999999999
- type: map_at_10
value: 13.828
- type: map_at_100
value: 14.881
- type: map_at_1000
value: 14.979999999999999
- type: map_at_20
value: 14.421999999999999
- type: map_at_3
value: 11.681999999999999
- type: map_at_5
value: 12.837000000000002
- type: mrr_at_1
value: 9.096176129779836
- type: mrr_at_10
value: 15.333772462248707
- type: mrr_at_100
value: 16.309634922879194
- type: mrr_at_1000
value: 16.39475249150789
- type: mrr_at_20
value: 15.891392914358688
- type: mrr_at_3
value: 13.064889918887577
- type: mrr_at_5
value: 14.311993047508642
- type: nauc_map_at_1000_diff1
value: 19.775928600522615
- type: nauc_map_at_1000_max
value: 6.286282728873767
- type: nauc_map_at_1000_std
value: 10.433091988799701
- type: nauc_map_at_100_diff1
value: 19.76472010726201
- type: nauc_map_at_100_max
value: 6.3000520043276245
- type: nauc_map_at_100_std
value: 10.369742430725108
- type: nauc_map_at_10_diff1
value: 19.717104003612306
- type: nauc_map_at_10_max
value: 5.9416407746652915
- type: nauc_map_at_10_std
value: 9.269462518525886
- type: nauc_map_at_1_diff1
value: 22.577309259900126
- type: nauc_map_at_1_max
value: 4.4722142164380605
- type: nauc_map_at_1_std
value: 3.7899645702785345
- type: nauc_map_at_20_diff1
value: 19.71861462412693
- type: nauc_map_at_20_max
value: 6.104405666589615
- type: nauc_map_at_20_std
value: 9.774250304834347
- type: nauc_map_at_3_diff1
value: 20.745180167104174
- type: nauc_map_at_3_max
value: 4.726336508000744
- type: nauc_map_at_3_std
value: 7.012706580698335
- type: nauc_map_at_5_diff1
value: 20.401667911889596
- type: nauc_map_at_5_max
value: 5.021580992513943
- type: nauc_map_at_5_std
value: 8.232301301005908
- type: nauc_mrr_at_1000_diff1
value: 19.876105574468276
- type: nauc_mrr_at_1000_max
value: 5.92950987632599
- type: nauc_mrr_at_1000_std
value: 10.422385358307675
- type: nauc_mrr_at_100_diff1
value: 19.864601593092164
- type: nauc_mrr_at_100_max
value: 5.937364432461887
- type: nauc_mrr_at_100_std
value: 10.372545373358479
- type: nauc_mrr_at_10_diff1
value: 19.8074129108612
- type: nauc_mrr_at_10_max
value: 5.583608572112338
- type: nauc_mrr_at_10_std
value: 9.660933453553797
- type: nauc_mrr_at_1_diff1
value: 22.771833118893053
- type: nauc_mrr_at_1_max
value: 4.270593166778219
- type: nauc_mrr_at_1_std
value: 4.72067370933128
- type: nauc_mrr_at_20_diff1
value: 19.816299723557
- type: nauc_mrr_at_20_max
value: 5.803282270363233
- type: nauc_mrr_at_20_std
value: 9.982388740482714
- type: nauc_mrr_at_3_diff1
value: 20.764352672106014
- type: nauc_mrr_at_3_max
value: 4.308188794966225
- type: nauc_mrr_at_3_std
value: 7.424575450681196
- type: nauc_mrr_at_5_diff1
value: 20.468124439169884
- type: nauc_mrr_at_5_max
value: 4.717164145352797
- type: nauc_mrr_at_5_std
value: 8.75784949698527
- type: nauc_ndcg_at_1000_diff1
value: 18.988627444499162
- type: nauc_ndcg_at_1000_max
value: 8.336437983015612
- type: nauc_ndcg_at_1000_std
value: 17.785235937443314
- type: nauc_ndcg_at_100_diff1
value: 18.72435211905066
- type: nauc_ndcg_at_100_max
value: 8.509559844610813
- type: nauc_ndcg_at_100_std
value: 16.272027197158785
- type: nauc_ndcg_at_10_diff1
value: 18.50083720860625
- type: nauc_ndcg_at_10_max
value: 6.816989264362351
- type: nauc_ndcg_at_10_std
value: 11.70379688056292
- type: nauc_ndcg_at_1_diff1
value: 23.028151500845926
- type: nauc_ndcg_at_1_max
value: 4.252790790979486
- type: nauc_ndcg_at_1_std
value: 4.919320655470863
- type: nauc_ndcg_at_20_diff1
value: 18.61317480699593
- type: nauc_ndcg_at_20_max
value: 7.400038137531198
- type: nauc_ndcg_at_20_std
value: 12.975329660907905
- type: nauc_ndcg_at_3_diff1
value: 20.331305466487297
- type: nauc_ndcg_at_3_max
value: 4.451813547010051
- type: nauc_ndcg_at_3_std
value: 7.835866814473613
- type: nauc_ndcg_at_5_diff1
value: 19.933475062151903
- type: nauc_ndcg_at_5_max
value: 5.0523614629035
- type: nauc_ndcg_at_5_std
value: 9.763459907678518
- type: nauc_precision_at_1000_diff1
value: 10.24793761705778
- type: nauc_precision_at_1000_max
value: 10.459646580367272
- type: nauc_precision_at_1000_std
value: 35.19560755022326
- type: nauc_precision_at_100_diff1
value: 14.032733274764734
- type: nauc_precision_at_100_max
value: 12.582877921585014
- type: nauc_precision_at_100_std
value: 30.56446230218432
- type: nauc_precision_at_10_diff1
value: 15.46863641183508
- type: nauc_precision_at_10_max
value: 8.026206096826051
- type: nauc_precision_at_10_std
value: 17.580067448009732
- type: nauc_precision_at_1_diff1
value: 23.028151500845926
- type: nauc_precision_at_1_max
value: 4.252790790979486
- type: nauc_precision_at_1_std
value: 4.919320655470863
- type: nauc_precision_at_20_diff1
value: 15.577209585349616
- type: nauc_precision_at_20_max
value: 9.37176988371138
- type: nauc_precision_at_20_std
value: 20.825242862847972
- type: nauc_precision_at_3_diff1
value: 19.697434012748303
- type: nauc_precision_at_3_max
value: 3.817741628018302
- type: nauc_precision_at_3_std
value: 9.855204198464552
- type: nauc_precision_at_5_diff1
value: 18.757352510786994
- type: nauc_precision_at_5_max
value: 4.78932962761337
- type: nauc_precision_at_5_std
value: 13.485110478478058
- type: nauc_recall_at_1000_diff1
value: 16.784291464246394
- type: nauc_recall_at_1000_max
value: 15.357886220356304
- type: nauc_recall_at_1000_std
value: 47.3266711354422
- type: nauc_recall_at_100_diff1
value: 15.651366556591528
- type: nauc_recall_at_100_max
value: 14.108369717831499
- type: nauc_recall_at_100_std
value: 30.26307437972032
- type: nauc_recall_at_10_diff1
value: 15.332913342892315
- type: nauc_recall_at_10_max
value: 8.769293510819189
- type: nauc_recall_at_10_std
value: 15.625436932641975
- type: nauc_recall_at_1_diff1
value: 22.577309259900126
- type: nauc_recall_at_1_max
value: 4.4722142164380605
- type: nauc_recall_at_1_std
value: 3.7899645702785345
- type: nauc_recall_at_20_diff1
value: 15.760837708226655
- type: nauc_recall_at_20_max
value: 10.11729976512556
- type: nauc_recall_at_20_std
value: 18.300935029131725
- type: nauc_recall_at_3_diff1
value: 19.039476605698372
- type: nauc_recall_at_3_max
value: 4.107922037298003
- type: nauc_recall_at_3_std
value: 9.115412171303978
- type: nauc_recall_at_5_diff1
value: 18.363415603635758
- type: nauc_recall_at_5_max
value: 5.241253574533175
- type: nauc_recall_at_5_std
value: 12.124948884672802
- type: ndcg_at_1
value: 9.067
- type: ndcg_at_10
value: 17.682000000000002
- type: ndcg_at_100
value: 22.982
- type: ndcg_at_1000
value: 25.692999999999998
- type: ndcg_at_20
value: 19.747
- type: ndcg_at_3
value: 13.219
- type: ndcg_at_5
value: 15.312999999999999
- type: precision_at_1
value: 9.067
- type: precision_at_10
value: 3.3000000000000003
- type: precision_at_100
value: 0.631
- type: precision_at_1000
value: 0.089
- type: precision_at_20
value: 2.136
- type: precision_at_3
value: 6.228
- type: precision_at_5
value: 4.925
- type: recall_at_1
value: 7.968999999999999
- type: recall_at_10
value: 28.208
- type: recall_at_100
value: 52.776
- type: recall_at_1000
value: 73.571
- type: recall_at_20
value: 35.941
- type: recall_at_3
value: 16.338
- type: recall_at_5
value: 21.217
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval (default)
type: mteb/quora
config: default
split: test
revision: e4e08e0b7dbe3c8700f0daef558ff32256715259
metrics:
- type: main_score
value: 74.323
- type: map_at_1
value: 57.30800000000001
- type: map_at_10
value: 69.32000000000001
- type: map_at_100
value: 70.106
- type: map_at_1000
value: 70.149
- type: map_at_20
value: 69.807
- type: map_at_3
value: 66.418
- type: map_at_5
value: 68.184
- type: mrr_at_1
value: 66.0
- type: mrr_at_10
value: 73.97885714285673
- type: mrr_at_100
value: 74.29274218615109
- type: mrr_at_1000
value: 74.3051429938558
- type: mrr_at_20
value: 74.18544015014858
- type: mrr_at_3
value: 72.26666666666631
- type: mrr_at_5
value: 73.37966666666605
- type: nauc_map_at_1000_diff1
value: 69.18960163699573
- type: nauc_map_at_1000_max
value: 37.38136640005
- type: nauc_map_at_1000_std
value: -2.570923100785111
- type: nauc_map_at_100_diff1
value: 69.18751629878942
- type: nauc_map_at_100_max
value: 37.36952143443813
- type: nauc_map_at_100_std
value: -2.5886077139396027
- type: nauc_map_at_10_diff1
value: 69.09406013156409
- type: nauc_map_at_10_max
value: 36.877436974500775
- type: nauc_map_at_10_std
value: -3.3540620889292203
- type: nauc_map_at_1_diff1
value: 70.93951368121674
- type: nauc_map_at_1_max
value: 32.233487451612305
- type: nauc_map_at_1_std
value: -7.055750788201864
- type: nauc_map_at_20_diff1
value: 69.14097261555858
- type: nauc_map_at_20_max
value: 37.18308654380657
- type: nauc_map_at_20_std
value: -2.912685185426714
- type: nauc_map_at_3_diff1
value: 69.01140661964882
- type: nauc_map_at_3_max
value: 35.56708493366717
- type: nauc_map_at_3_std
value: -5.47958763916843
- type: nauc_map_at_5_diff1
value: 68.97841901572657
- type: nauc_map_at_5_max
value: 36.356674331191265
- type: nauc_map_at_5_std
value: -4.271166648670905
- type: nauc_mrr_at_1000_diff1
value: 70.61597700848178
- type: nauc_mrr_at_1000_max
value: 40.41208966087904
- type: nauc_mrr_at_1000_std
value: -0.15890737609620642
- type: nauc_mrr_at_100_diff1
value: 70.61360632996228
- type: nauc_mrr_at_100_max
value: 40.41568433400612
- type: nauc_mrr_at_100_std
value: -0.1448505595676874
- type: nauc_mrr_at_10_diff1
value: 70.5233993892019
- type: nauc_mrr_at_10_max
value: 40.36230785474746
- type: nauc_mrr_at_10_std
value: -0.22757815568658987
- type: nauc_mrr_at_1_diff1
value: 72.6747651764081
- type: nauc_mrr_at_1_max
value: 40.02178963789037
- type: nauc_mrr_at_1_std
value: -2.575126954097418
- type: nauc_mrr_at_20_diff1
value: 70.58326373490296
- type: nauc_mrr_at_20_max
value: 40.41333734338905
- type: nauc_mrr_at_20_std
value: -0.1345473571856357
- type: nauc_mrr_at_3_diff1
value: 70.37817581234762
- type: nauc_mrr_at_3_max
value: 40.203366387087705
- type: nauc_mrr_at_3_std
value: -1.2261489082901087
- type: nauc_mrr_at_5_diff1
value: 70.45626657672184
- type: nauc_mrr_at_5_max
value: 40.3234615411654
- type: nauc_mrr_at_5_std
value: -0.3805672716488398
- type: nauc_ndcg_at_1000_diff1
value: 69.21984468258341
- type: nauc_ndcg_at_1000_max
value: 39.0253925541956
- type: nauc_ndcg_at_1000_std
value: 0.8160264523775477
- type: nauc_ndcg_at_100_diff1
value: 69.15328478391302
- type: nauc_ndcg_at_100_max
value: 38.96655324359319
- type: nauc_ndcg_at_100_std
value: 1.1256651981311283
- type: nauc_ndcg_at_10_diff1
value: 68.53510190998198
- type: nauc_ndcg_at_10_max
value: 37.91208417950795
- type: nauc_ndcg_at_10_std
value: -0.7377655073302805
- type: nauc_ndcg_at_1_diff1
value: 72.63228601131651
- type: nauc_ndcg_at_1_max
value: 40.16828628757125
- type: nauc_ndcg_at_1_std
value: -2.528909627178983
- type: nauc_ndcg_at_20_diff1
value: 68.822583729052
- type: nauc_ndcg_at_20_max
value: 38.41592366520079
- type: nauc_ndcg_at_20_std
value: 0.06798311113755548
- type: nauc_ndcg_at_3_diff1
value: 68.1481692592636
- type: nauc_ndcg_at_3_max
value: 37.31206796055115
- type: nauc_ndcg_at_3_std
value: -3.254883595992796
- type: nauc_ndcg_at_5_diff1
value: 68.24715917081343
- type: nauc_ndcg_at_5_max
value: 37.56264948769021
- type: nauc_ndcg_at_5_std
value: -1.8709773297999994
- type: nauc_precision_at_1000_diff1
value: -27.810948267157137
- type: nauc_precision_at_1000_max
value: -0.24668486328059996
- type: nauc_precision_at_1000_std
value: 20.580820056804715
- type: nauc_precision_at_100_diff1
value: -22.061161829256797
- type: nauc_precision_at_100_max
value: 4.679165403717356
- type: nauc_precision_at_100_std
value: 21.989059211475855
- type: nauc_precision_at_10_diff1
value: -3.9320543024872556
- type: nauc_precision_at_10_max
value: 14.010070678201766
- type: nauc_precision_at_10_std
value: 16.669492507338155
- type: nauc_precision_at_1_diff1
value: 72.63228601131651
- type: nauc_precision_at_1_max
value: 40.16828628757125
- type: nauc_precision_at_1_std
value: -2.528909627178983
- type: nauc_precision_at_20_diff1
value: -12.164765481707331
- type: nauc_precision_at_20_max
value: 10.511899418907312
- type: nauc_precision_at_20_std
value: 19.320026937145183
- type: nauc_precision_at_3_diff1
value: 22.621554858906986
- type: nauc_precision_at_3_max
value: 24.326914902507287
- type: nauc_precision_at_3_std
value: 6.099411862597304
- type: nauc_precision_at_5_diff1
value: 8.981227790660293
- type: nauc_precision_at_5_max
value: 19.916827592062745
- type: nauc_precision_at_5_std
value: 11.93677912655441
- type: nauc_recall_at_1000_diff1
value: 60.79128240819883
- type: nauc_recall_at_1000_max
value: 44.80906309211301
- type: nauc_recall_at_1000_std
value: 56.54768589270181
- type: nauc_recall_at_100_diff1
value: 61.18835279218082
- type: nauc_recall_at_100_max
value: 39.61329094249297
- type: nauc_recall_at_100_std
value: 31.736658564346342
- type: nauc_recall_at_10_diff1
value: 61.3639032751697
- type: nauc_recall_at_10_max
value: 34.510711243051375
- type: nauc_recall_at_10_std
value: 4.855117542870995
- type: nauc_recall_at_1_diff1
value: 70.93951368121674
- type: nauc_recall_at_1_max
value: 32.233487451612305
- type: nauc_recall_at_1_std
value: -7.055750788201864
- type: nauc_recall_at_20_diff1
value: 61.27124485304799
- type: nauc_recall_at_20_max
value: 36.11805010411244
- type: nauc_recall_at_20_std
value: 11.38763207684191
- type: nauc_recall_at_3_diff1
value: 63.91101210841338
- type: nauc_recall_at_3_max
value: 33.23862328274836
- type: nauc_recall_at_3_std
value: -4.857791490570391
- type: nauc_recall_at_5_diff1
value: 62.37552817951354
- type: nauc_recall_at_5_max
value: 33.86753069930419
- type: nauc_recall_at_5_std
value: -0.4857746420435554
- type: ndcg_at_1
value: 66.02
- type: ndcg_at_10
value: 74.323
- type: ndcg_at_100
value: 76.806
- type: ndcg_at_1000
value: 77.436
- type: ndcg_at_20
value: 75.47500000000001
- type: ndcg_at_3
value: 70.44500000000001
- type: ndcg_at_5
value: 72.48
- type: precision_at_1
value: 66.02
- type: precision_at_10
value: 11.273
- type: precision_at_100
value: 1.373
- type: precision_at_1000
value: 0.149
- type: precision_at_20
value: 6.101
- type: precision_at_3
value: 30.5
- type: precision_at_5
value: 20.31
- type: recall_at_1
value: 57.30800000000001
- type: recall_at_10
value: 84.152
- type: recall_at_100
value: 93.989
- type: recall_at_1000
value: 97.89999999999999
- type: recall_at_20
value: 88.138
- type: recall_at_3
value: 73.137
- type: recall_at_5
value: 78.655
- task:
type: Clustering
dataset:
name: MTEB RedditClustering (default)
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: main_score
value: 28.89014544508522
- type: v_measure
value: 28.89014544508522
- type: v_measure_std
value: 4.477854992673074
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P (default)
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 385e3cb46b4cfa89021f56c4380204149d0efe33
metrics:
- type: main_score
value: 41.588064041506414
- type: v_measure
value: 41.588064041506414
- type: v_measure_std
value: 12.234957713539355
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS (default)
type: mteb/scidocs
config: default
split: test
revision: f8c2fcf00f625baaa80f62ec5bd9e1fff3b8ae88
metrics:
- type: main_score
value: 9.923
- type: map_at_1
value: 2.15
- type: map_at_10
value: 5.379
- type: map_at_100
value: 6.487
- type: map_at_1000
value: 6.726999999999999
- type: map_at_20
value: 5.845000000000001
- type: map_at_3
value: 3.943
- type: map_at_5
value: 4.642
- type: mrr_at_1
value: 10.6
- type: mrr_at_10
value: 17.65234126984126
- type: mrr_at_100
value: 18.72231260720679
- type: mrr_at_1000
value: 18.83457574677834
- type: mrr_at_20
value: 18.178004510968904
- type: mrr_at_3
value: 14.96666666666667
- type: mrr_at_5
value: 16.426666666666666
- type: nauc_map_at_1000_diff1
value: 11.904585832905996
- type: nauc_map_at_1000_max
value: 13.966912689458244
- type: nauc_map_at_1000_std
value: 14.274562318051975
- type: nauc_map_at_100_diff1
value: 11.914962635425084
- type: nauc_map_at_100_max
value: 13.792005445505046
- type: nauc_map_at_100_std
value: 13.688572560422358
- type: nauc_map_at_10_diff1
value: 12.924485348386265
- type: nauc_map_at_10_max
value: 12.924904365030008
- type: nauc_map_at_10_std
value: 11.028226417787405
- type: nauc_map_at_1_diff1
value: 17.278503151293908
- type: nauc_map_at_1_max
value: 7.878679954463645
- type: nauc_map_at_1_std
value: 5.787632681875146
- type: nauc_map_at_20_diff1
value: 12.361611976516448
- type: nauc_map_at_20_max
value: 13.430602876791497
- type: nauc_map_at_20_std
value: 11.626342360129135
- type: nauc_map_at_3_diff1
value: 13.25103680109857
- type: nauc_map_at_3_max
value: 11.851782553996365
- type: nauc_map_at_3_std
value: 7.429469629304992
- type: nauc_map_at_5_diff1
value: 13.800025735259355
- type: nauc_map_at_5_max
value: 12.565449305066048
- type: nauc_map_at_5_std
value: 9.75302950224773
- type: nauc_mrr_at_1000_diff1
value: 12.268595456055587
- type: nauc_mrr_at_1000_max
value: 9.25353359860505
- type: nauc_mrr_at_1000_std
value: 9.108487924061626
- type: nauc_mrr_at_100_diff1
value: 12.221030310338321
- type: nauc_mrr_at_100_max
value: 9.25521408834954
- type: nauc_mrr_at_100_std
value: 9.138330201368367
- type: nauc_mrr_at_10_diff1
value: 12.574921954053705
- type: nauc_mrr_at_10_max
value: 9.022771164246922
- type: nauc_mrr_at_10_std
value: 8.72904050693386
- type: nauc_mrr_at_1_diff1
value: 17.46158729503331
- type: nauc_mrr_at_1_max
value: 7.638928315208697
- type: nauc_mrr_at_1_std
value: 6.095710473752395
- type: nauc_mrr_at_20_diff1
value: 12.138920051010647
- type: nauc_mrr_at_20_max
value: 9.276258507402064
- type: nauc_mrr_at_20_std
value: 8.886687014526801
- type: nauc_mrr_at_3_diff1
value: 14.193338999133834
- type: nauc_mrr_at_3_max
value: 8.299120353947483
- type: nauc_mrr_at_3_std
value: 7.8035097667232005
- type: nauc_mrr_at_5_diff1
value: 13.111703855187907
- type: nauc_mrr_at_5_max
value: 9.120679964295672
- type: nauc_mrr_at_5_std
value: 8.32132668626495
- type: nauc_ndcg_at_1000_diff1
value: 8.86999972791066
- type: nauc_ndcg_at_1000_max
value: 15.310859480575436
- type: nauc_ndcg_at_1000_std
value: 21.250542726021116
- type: nauc_ndcg_at_100_diff1
value: 8.721788996698756
- type: nauc_ndcg_at_100_max
value: 13.753927264089416
- type: nauc_ndcg_at_100_std
value: 17.83014109593192
- type: nauc_ndcg_at_10_diff1
value: 10.851214040795984
- type: nauc_ndcg_at_10_max
value: 11.754038261909226
- type: nauc_ndcg_at_10_std
value: 11.732493442071242
- type: nauc_ndcg_at_1_diff1
value: 17.46158729503331
- type: nauc_ndcg_at_1_max
value: 7.638928315208697
- type: nauc_ndcg_at_1_std
value: 6.095710473752395
- type: nauc_ndcg_at_20_diff1
value: 9.76180043441647
- type: nauc_ndcg_at_20_max
value: 12.820709997321758
- type: nauc_ndcg_at_20_std
value: 12.721916889128632
- type: nauc_ndcg_at_3_diff1
value: 12.839313795789275
- type: nauc_ndcg_at_3_max
value: 10.610706825785767
- type: nauc_ndcg_at_3_std
value: 8.204558555180421
- type: nauc_ndcg_at_5_diff1
value: 12.406813811698386
- type: nauc_ndcg_at_5_max
value: 11.878799458897053
- type: nauc_ndcg_at_5_std
value: 10.186784386212949
- type: nauc_precision_at_1000_diff1
value: 2.8398170540614176
- type: nauc_precision_at_1000_max
value: 16.99931587707156
- type: nauc_precision_at_1000_std
value: 31.86724716316765
- type: nauc_precision_at_100_diff1
value: 3.4160417262207297
- type: nauc_precision_at_100_max
value: 14.437629378775577
- type: nauc_precision_at_100_std
value: 24.60677482735814
- type: nauc_precision_at_10_diff1
value: 7.433603751797789
- type: nauc_precision_at_10_max
value: 12.127707014834115
- type: nauc_precision_at_10_std
value: 14.347141705378737
- type: nauc_precision_at_1_diff1
value: 17.46158729503331
- type: nauc_precision_at_1_max
value: 7.638928315208697
- type: nauc_precision_at_1_std
value: 6.095710473752395
- type: nauc_precision_at_20_diff1
value: 5.555321803900292
- type: nauc_precision_at_20_max
value: 13.975730968140612
- type: nauc_precision_at_20_std
value: 15.701599582613069
- type: nauc_precision_at_3_diff1
value: 10.570021043882896
- type: nauc_precision_at_3_max
value: 11.640698048065092
- type: nauc_precision_at_3_std
value: 8.880832670930209
- type: nauc_precision_at_5_diff1
value: 10.192070602011636
- type: nauc_precision_at_5_max
value: 12.979688593338693
- type: nauc_precision_at_5_std
value: 12.116013499683467
- type: nauc_recall_at_1000_diff1
value: 2.883533640208864
- type: nauc_recall_at_1000_max
value: 18.09724738913881
- type: nauc_recall_at_1000_std
value: 32.15747757955521
- type: nauc_recall_at_100_diff1
value: 3.6040687535563998
- type: nauc_recall_at_100_max
value: 14.732664182141772
- type: nauc_recall_at_100_std
value: 24.427986607748
- type: nauc_recall_at_10_diff1
value: 7.587316953732061
- type: nauc_recall_at_10_max
value: 12.334929718954289
- type: nauc_recall_at_10_std
value: 14.094286673978088
- type: nauc_recall_at_1_diff1
value: 17.278503151293908
- type: nauc_recall_at_1_max
value: 7.878679954463645
- type: nauc_recall_at_1_std
value: 5.787632681875146
- type: nauc_recall_at_20_diff1
value: 5.706170516654628
- type: nauc_recall_at_20_max
value: 14.095625029855203
- type: nauc_recall_at_20_std
value: 15.241931131705527
- type: nauc_recall_at_3_diff1
value: 10.574961375800127
- type: nauc_recall_at_3_max
value: 11.733105660119586
- type: nauc_recall_at_3_std
value: 8.540340847563677
- type: nauc_recall_at_5_diff1
value: 10.158076693596577
- type: nauc_recall_at_5_max
value: 13.152816873926534
- type: nauc_recall_at_5_std
value: 11.843127888328391
- type: ndcg_at_1
value: 10.6
- type: ndcg_at_10
value: 9.923
- type: ndcg_at_100
value: 15.463
- type: ndcg_at_1000
value: 20.673
- type: ndcg_at_20
value: 11.468
- type: ndcg_at_3
value: 9.120000000000001
- type: ndcg_at_5
value: 8.08
- type: precision_at_1
value: 10.6
- type: precision_at_10
value: 5.319999999999999
- type: precision_at_100
value: 1.357
- type: precision_at_1000
value: 0.262
- type: precision_at_20
value: 3.56
- type: precision_at_3
value: 8.733
- type: precision_at_5
value: 7.3
- type: recall_at_1
value: 2.15
- type: recall_at_10
value: 10.745000000000001
- type: recall_at_100
value: 27.478
- type: recall_at_1000
value: 53.067
- type: recall_at_20
value: 14.432
- type: recall_at_3
value: 5.295
- type: recall_at_5
value: 7.37
- task:
type: STS
dataset:
name: MTEB SICK-R (default)
type: mteb/sickr-sts
config: default
split: test
revision: 20a6d6f312dd54037fe07a32d58e5e168867909d
metrics:
- type: cosine_pearson
value: 75.0950047498747
- type: cosine_spearman
value: 66.17240782538595
- type: euclidean_pearson
value: 67.00770252295281
- type: euclidean_spearman
value: 60.910363132843514
- type: main_score
value: 66.17240782538595
- type: manhattan_pearson
value: 67.05219198532856
- type: manhattan_spearman
value: 61.09670227979067
- type: pearson
value: 75.0950047498747
- type: spearman
value: 66.17240782538595
- task:
type: STS
dataset:
name: MTEB STS12 (default)
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cosine_pearson
value: 70.27191745166907
- type: cosine_spearman
value: 61.89139464648924
- type: euclidean_pearson
value: 54.34524146536028
- type: euclidean_spearman
value: 50.72726514543895
- type: main_score
value: 61.89139464648924
- type: manhattan_pearson
value: 54.0517351204108
- type: manhattan_spearman
value: 50.62237885284486
- type: pearson
value: 70.27191745166907
- type: spearman
value: 61.89139464648924
- task:
type: STS
dataset:
name: MTEB STS13 (default)
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cosine_pearson
value: 70.19582039979868
- type: cosine_spearman
value: 71.66792475528088
- type: euclidean_pearson
value: 55.582203822685486
- type: euclidean_spearman
value: 56.20322977297382
- type: main_score
value: 71.66792475528088
- type: manhattan_pearson
value: 55.95799094895162
- type: manhattan_spearman
value: 56.588522991206325
- type: pearson
value: 70.19582039979868
- type: spearman
value: 71.66792475528088
- task:
type: STS
dataset:
name: MTEB STS14 (default)
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cosine_pearson
value: 69.52140108419252
- type: cosine_spearman
value: 67.82634222687376
- type: euclidean_pearson
value: 56.45640217254015
- type: euclidean_spearman
value: 56.232462674683994
- type: main_score
value: 67.82634222687376
- type: manhattan_pearson
value: 56.71095067060834
- type: manhattan_spearman
value: 56.419654300835596
- type: pearson
value: 69.52140108419252
- type: spearman
value: 67.82634222687376
- task:
type: STS
dataset:
name: MTEB STS15 (default)
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cosine_pearson
value: 73.66221619412464
- type: cosine_spearman
value: 75.48765072240437
- type: euclidean_pearson
value: 56.971989853952046
- type: euclidean_spearman
value: 59.57242983168428
- type: main_score
value: 75.48765072240437
- type: manhattan_pearson
value: 57.292670731862025
- type: manhattan_spearman
value: 59.64547291104911
- type: pearson
value: 73.66221619412464
- type: spearman
value: 75.48765072240437
- task:
type: STS
dataset:
name: MTEB STS16 (default)
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cosine_pearson
value: 62.328630460915925
- type: cosine_spearman
value: 66.48155706668948
- type: euclidean_pearson
value: 48.85087938485013
- type: euclidean_spearman
value: 51.58756922385477
- type: main_score
value: 66.48155706668948
- type: manhattan_pearson
value: 49.02650798849104
- type: manhattan_spearman
value: 51.597849334470936
- type: pearson
value: 62.328630460915925
- type: spearman
value: 66.48155706668948
- task:
type: STS
dataset:
name: MTEB STS17 (fr-en)
type: mteb/sts17-crosslingual-sts
config: fr-en
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: cosine_pearson
value: 21.344883409729785
- type: cosine_spearman
value: 19.492480027372526
- type: euclidean_pearson
value: -8.605176891549817
- type: euclidean_spearman
value: -7.528098935541785
- type: main_score
value: 19.492480027372526
- type: manhattan_pearson
value: -10.120526712428015
- type: manhattan_spearman
value: -8.968202174485103
- type: pearson
value: 21.344883409729785
- type: spearman
value: 19.492480027372526
- task:
type: STS
dataset:
name: MTEB STS17 (es-en)
type: mteb/sts17-crosslingual-sts
config: es-en
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: cosine_pearson
value: 14.966581838953037
- type: cosine_spearman
value: 13.24509138766898
- type: euclidean_pearson
value: -6.690226814122847
- type: euclidean_spearman
value: -11.282875560023765
- type: main_score
value: 13.24509138766898
- type: manhattan_pearson
value: -7.476797502897139
- type: manhattan_spearman
value: -11.92841312081328
- type: pearson
value: 14.966581838953037
- type: spearman
value: 13.24509138766898
- task:
type: STS
dataset:
name: MTEB STS17 (nl-en)
type: mteb/sts17-crosslingual-sts
config: nl-en
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: cosine_pearson
value: 18.309414985775234
- type: cosine_spearman
value: 14.341489363671842
- type: euclidean_pearson
value: -12.122888971186411
- type: euclidean_spearman
value: -16.469354911796607
- type: main_score
value: 14.341489363671842
- type: manhattan_pearson
value: -10.903411096507561
- type: manhattan_spearman
value: -13.076094357191614
- type: pearson
value: 18.309414985775234
- type: spearman
value: 14.341489363671842
- task:
type: STS
dataset:
name: MTEB STS17 (en-de)
type: mteb/sts17-crosslingual-sts
config: en-de
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: cosine_pearson
value: 21.301586456013037
- type: cosine_spearman
value: 22.571419522164376
- type: euclidean_pearson
value: -6.367176828477704
- type: euclidean_spearman
value: -9.877915052256634
- type: main_score
value: 22.571419522164376
- type: manhattan_pearson
value: -4.676449796672262
- type: manhattan_spearman
value: -7.3330561255268805
- type: pearson
value: 21.301586456013037
- type: spearman
value: 22.571419522164376
- task:
type: STS
dataset:
name: MTEB STS17 (it-en)
type: mteb/sts17-crosslingual-sts
config: it-en
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: cosine_pearson
value: 16.140292893693204
- type: cosine_spearman
value: 10.216376215477217
- type: euclidean_pearson
value: -15.27866395332899
- type: euclidean_spearman
value: -14.09405330374556
- type: main_score
value: 10.216376215477217
- type: manhattan_pearson
value: -14.968016143069224
- type: manhattan_spearman
value: -12.871979788571364
- type: pearson
value: 16.140292893693204
- type: spearman
value: 10.216376215477217
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: cosine_pearson
value: 78.42242639560023
- type: cosine_spearman
value: 80.2472005970173
- type: euclidean_pearson
value: 66.28797094299918
- type: euclidean_spearman
value: 67.13581863643712
- type: main_score
value: 80.2472005970173
- type: manhattan_pearson
value: 66.02431023839748
- type: manhattan_spearman
value: 67.15538442088678
- type: pearson
value: 78.42242639560023
- type: spearman
value: 80.2472005970173
- task:
type: STS
dataset:
name: MTEB STS17 (en-ar)
type: mteb/sts17-crosslingual-sts
config: en-ar
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: cosine_pearson
value: -5.762967943082491
- type: cosine_spearman
value: -6.184248227377756
- type: euclidean_pearson
value: -12.170911062337659
- type: euclidean_spearman
value: -9.846378276134612
- type: main_score
value: -6.184248227377756
- type: manhattan_pearson
value: -13.126030597269658
- type: manhattan_spearman
value: -11.320163726484019
- type: pearson
value: -5.762967943082491
- type: spearman
value: -6.184248227377756
- task:
type: STS
dataset:
name: MTEB STS17 (en-tr)
type: mteb/sts17-crosslingual-sts
config: en-tr
split: test
revision: faeb762787bd10488a50c8b5be4a3b82e411949c
metrics:
- type: cosine_pearson
value: -8.666319610669559
- type: cosine_spearman
value: -10.0877070299522
- type: euclidean_pearson
value: -21.16722886445997
- type: euclidean_spearman
value: -25.725365743898504
- type: main_score
value: -10.0877070299522
- type: manhattan_pearson
value: -22.03289222804741
- type: manhattan_spearman
value: -26.785390252425533
- type: pearson
value: -8.666319610669559
- type: spearman
value: -10.0877070299522
- task:
type: STS
dataset:
name: MTEB STS22 (es-en)
type: mteb/sts22-crosslingual-sts
config: es-en
split: test
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
metrics:
- type: cosine_pearson
value: 16.880423266497427
- type: cosine_spearman
value: 18.497107178067477
- type: euclidean_pearson
value: 14.33062698609246
- type: euclidean_spearman
value: 16.623349996837863
- type: main_score
value: 18.497107178067477
- type: manhattan_pearson
value: 21.024602299309286
- type: manhattan_spearman
value: 24.281840448539402
- type: pearson
value: 16.880423266497427
- type: spearman
value: 18.497107178067477
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
metrics:
- type: cosine_pearson
value: 44.98861387948161
- type: cosine_spearman
value: 59.04270974068145
- type: euclidean_pearson
value: 49.574894395857484
- type: euclidean_spearman
value: 58.827686687567805
- type: main_score
value: 59.04270974068145
- type: manhattan_pearson
value: 48.65094961023066
- type: manhattan_spearman
value: 58.3204048215355
- type: pearson
value: 44.98861387948161
- type: spearman
value: 59.04270974068145
- task:
type: STS
dataset:
name: MTEB STS22 (de-en)
type: mteb/sts22-crosslingual-sts
config: de-en
split: test
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
metrics:
- type: cosine_pearson
value: 26.505168004689462
- type: cosine_spearman
value: 28.591720613248732
- type: euclidean_pearson
value: 24.74526273753091
- type: euclidean_spearman
value: 28.416241187559642
- type: main_score
value: 28.591720613248732
- type: manhattan_pearson
value: 23.527990703124505
- type: manhattan_spearman
value: 33.434031878984136
- type: pearson
value: 26.505168004689462
- type: spearman
value: 28.591720613248732
- task:
type: STS
dataset:
name: MTEB STS22 (zh-en)
type: mteb/sts22-crosslingual-sts
config: zh-en
split: test
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
metrics:
- type: cosine_pearson
value: 11.552622364692777
- type: cosine_spearman
value: 10.973019756392695
- type: euclidean_pearson
value: 2.373117729670719
- type: euclidean_spearman
value: 1.961823192174414
- type: main_score
value: 10.973019756392695
- type: manhattan_pearson
value: 2.4552310228655108
- type: manhattan_spearman
value: 2.9778196586898273
- type: pearson
value: 11.552622364692777
- type: spearman
value: 10.973019756392695
- task:
type: STS
dataset:
name: MTEB STS22 (pl-en)
type: mteb/sts22-crosslingual-sts
config: pl-en
split: test
revision: de9d86b3b84231dc21f76c7b7af1f28e2f57f6e3
metrics:
- type: cosine_pearson
value: 10.466988163502029
- type: cosine_spearman
value: -0.21879166839686814
- type: euclidean_pearson
value: 22.096342233944544
- type: euclidean_spearman
value: 3.010990103175947
- type: main_score
value: -0.21879166839686814
- type: manhattan_pearson
value: 27.847325418935775
- type: manhattan_spearman
value: 4.74569547403683
- type: pearson
value: 10.466988163502029
- type: spearman
value: -0.21879166839686814
- task:
type: STS
dataset:
name: MTEB STSBenchmark (default)
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cosine_pearson
value: 66.80057012864974
- type: cosine_spearman
value: 66.52235871936412
- type: euclidean_pearson
value: 55.372109895942536
- type: euclidean_spearman
value: 56.04078716357898
- type: main_score
value: 66.52235871936412
- type: manhattan_pearson
value: 55.58797025494765
- type: manhattan_spearman
value: 56.179959581772266
- type: pearson
value: 66.80057012864974
- type: spearman
value: 66.52235871936412
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR (default)
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: main_score
value: 71.11074203128574
- type: map
value: 71.11074203128574
- type: mrr
value: 89.77809499868323
- type: nAUC_map_diff1
value: 11.228330835325687
- type: nAUC_map_max
value: 54.45812469406701
- type: nAUC_map_std
value: 63.051723849534525
- type: nAUC_mrr_diff1
value: 47.94323704040123
- type: nAUC_mrr_max
value: 72.52180244204617
- type: nAUC_mrr_std
value: 64.6185657337566
- task:
type: Retrieval
dataset:
name: MTEB SciFact (default)
type: mteb/scifact
config: default
split: test
revision: 0228b52cf27578f30900b9e5271d331663a030d7
metrics:
- type: main_score
value: 50.663000000000004
- type: map_at_1
value: 34.9
- type: map_at_10
value: 45.591
- type: map_at_100
value: 46.478
- type: map_at_1000
value: 46.544000000000004
- type: map_at_20
value: 45.999
- type: map_at_3
value: 43.354
- type: map_at_5
value: 44.733000000000004
- type: mrr_at_1
value: 37.0
- type: mrr_at_10
value: 47.36547619047619
- type: mrr_at_100
value: 48.09705728333796
- type: mrr_at_1000
value: 48.152949244883104
- type: mrr_at_20
value: 47.69512736718619
- type: mrr_at_3
value: 45.388888888888886
- type: mrr_at_5
value: 46.605555555555554
- type: nauc_map_at_1000_diff1
value: 52.100145151741394
- type: nauc_map_at_1000_max
value: 27.410237212009648
- type: nauc_map_at_1000_std
value: 2.9904718168509814
- type: nauc_map_at_100_diff1
value: 52.078009501467115
- type: nauc_map_at_100_max
value: 27.388902536377337
- type: nauc_map_at_100_std
value: 2.9956426758632553
- type: nauc_map_at_10_diff1
value: 52.22446655004901
- type: nauc_map_at_10_max
value: 27.537880755428052
- type: nauc_map_at_10_std
value: 2.5329635707923672
- type: nauc_map_at_1_diff1
value: 56.87947977552147
- type: nauc_map_at_1_max
value: 26.992163127256497
- type: nauc_map_at_1_std
value: -0.9440039327267877
- type: nauc_map_at_20_diff1
value: 52.106371246476826
- type: nauc_map_at_20_max
value: 27.32862929056924
- type: nauc_map_at_20_std
value: 2.7349113689801996
- type: nauc_map_at_3_diff1
value: 53.35317860724047
- type: nauc_map_at_3_max
value: 26.25510463708658
- type: nauc_map_at_3_std
value: 2.289593280073433
- type: nauc_map_at_5_diff1
value: 51.678047431193974
- type: nauc_map_at_5_max
value: 27.418395689002818
- type: nauc_map_at_5_std
value: 2.1245361198440267
- type: nauc_mrr_at_1000_diff1
value: 49.98301669091194
- type: nauc_mrr_at_1000_max
value: 29.333209267321198
- type: nauc_mrr_at_1000_std
value: 5.252782451549811
- type: nauc_mrr_at_100_diff1
value: 49.967980336744034
- type: nauc_mrr_at_100_max
value: 29.331397088810657
- type: nauc_mrr_at_100_std
value: 5.261178047875302
- type: nauc_mrr_at_10_diff1
value: 50.02865512004594
- type: nauc_mrr_at_10_max
value: 29.665247088988096
- type: nauc_mrr_at_10_std
value: 5.105677188444364
- type: nauc_mrr_at_1_diff1
value: 55.219664224743944
- type: nauc_mrr_at_1_max
value: 29.369235255966586
- type: nauc_mrr_at_1_std
value: 1.294523738013475
- type: nauc_mrr_at_20_diff1
value: 49.98301552378738
- type: nauc_mrr_at_20_max
value: 29.388470718856922
- type: nauc_mrr_at_20_std
value: 5.178678395201041
- type: nauc_mrr_at_3_diff1
value: 51.00229122885918
- type: nauc_mrr_at_3_max
value: 28.064602643242907
- type: nauc_mrr_at_3_std
value: 4.744718855685464
- type: nauc_mrr_at_5_diff1
value: 49.20787956974137
- type: nauc_mrr_at_5_max
value: 29.663856377950655
- type: nauc_mrr_at_5_std
value: 4.889452630825029
- type: nauc_ndcg_at_1000_diff1
value: 50.26524611758448
- type: nauc_ndcg_at_1000_max
value: 28.816092638532105
- type: nauc_ndcg_at_1000_std
value: 5.777693934805941
- type: nauc_ndcg_at_100_diff1
value: 49.810321964883876
- type: nauc_ndcg_at_100_max
value: 28.85200497094049
- type: nauc_ndcg_at_100_std
value: 6.4161665223690445
- type: nauc_ndcg_at_10_diff1
value: 50.31987402674788
- type: nauc_ndcg_at_10_max
value: 29.1957589259604
- type: nauc_ndcg_at_10_std
value: 4.249172262339034
- type: nauc_ndcg_at_1_diff1
value: 55.219664224743944
- type: nauc_ndcg_at_1_max
value: 29.369235255966586
- type: nauc_ndcg_at_1_std
value: 1.294523738013475
- type: nauc_ndcg_at_20_diff1
value: 49.95117201846568
- type: nauc_ndcg_at_20_max
value: 28.252381258706883
- type: nauc_ndcg_at_20_std
value: 4.799900939787535
- type: nauc_ndcg_at_3_diff1
value: 51.81554260088138
- type: nauc_ndcg_at_3_max
value: 27.121304990834222
- type: nauc_ndcg_at_3_std
value: 3.720528057690934
- type: nauc_ndcg_at_5_diff1
value: 48.77973374919412
- type: nauc_ndcg_at_5_max
value: 29.131535344710002
- type: nauc_ndcg_at_5_std
value: 3.565095958368389
- type: nauc_precision_at_1000_diff1
value: -7.462742973759457
- type: nauc_precision_at_1000_max
value: 21.45790554414784
- type: nauc_precision_at_1000_std
value: 24.38429850971904
- type: nauc_precision_at_100_diff1
value: 10.210409634704046
- type: nauc_precision_at_100_max
value: 27.700772933352024
- type: nauc_precision_at_100_std
value: 27.80962272064547
- type: nauc_precision_at_10_diff1
value: 34.576585797430766
- type: nauc_precision_at_10_max
value: 33.364848337655786
- type: nauc_precision_at_10_std
value: 14.448906660652794
- type: nauc_precision_at_1_diff1
value: 55.219664224743944
- type: nauc_precision_at_1_max
value: 29.369235255966586
- type: nauc_precision_at_1_std
value: 1.294523738013475
- type: nauc_precision_at_20_diff1
value: 28.759871255957847
- type: nauc_precision_at_20_max
value: 28.756353659179982
- type: nauc_precision_at_20_std
value: 17.539177234113616
- type: nauc_precision_at_3_diff1
value: 44.99876896761731
- type: nauc_precision_at_3_max
value: 28.597098219106442
- type: nauc_precision_at_3_std
value: 9.21762492818973
- type: nauc_precision_at_5_diff1
value: 34.186850914452485
- type: nauc_precision_at_5_max
value: 33.954540973558686
- type: nauc_precision_at_5_std
value: 10.546528423678431
- type: nauc_recall_at_1000_diff1
value: 23.83001981280335
- type: nauc_recall_at_1000_max
value: 43.846644348796225
- type: nauc_recall_at_1000_std
value: 60.408553665368835
- type: nauc_recall_at_100_diff1
value: 38.4746907480832
- type: nauc_recall_at_100_max
value: 33.882306484150135
- type: nauc_recall_at_100_std
value: 27.750836673176565
- type: nauc_recall_at_10_diff1
value: 44.98978983013661
- type: nauc_recall_at_10_max
value: 31.241708340662296
- type: nauc_recall_at_10_std
value: 6.026684637828198
- type: nauc_recall_at_1_diff1
value: 56.87947977552147
- type: nauc_recall_at_1_max
value: 26.992163127256497
- type: nauc_recall_at_1_std
value: -0.9440039327267877
- type: nauc_recall_at_20_diff1
value: 43.253384002784074
- type: nauc_recall_at_20_max
value: 26.89815696422301
- type: nauc_recall_at_20_std
value: 8.446980210355042
- type: nauc_recall_at_3_diff1
value: 48.89792955260931
- type: nauc_recall_at_3_max
value: 26.765492965973237
- type: nauc_recall_at_3_std
value: 5.600856860068723
- type: nauc_recall_at_5_diff1
value: 40.79334879234603
- type: nauc_recall_at_5_max
value: 31.676509416439163
- type: nauc_recall_at_5_std
value: 4.7055724522242
- type: ndcg_at_1
value: 37.0
- type: ndcg_at_10
value: 50.663000000000004
- type: ndcg_at_100
value: 55.022999999999996
- type: ndcg_at_1000
value: 56.643
- type: ndcg_at_20
value: 52.001
- type: ndcg_at_3
value: 46.424
- type: ndcg_at_5
value: 48.653999999999996
- type: precision_at_1
value: 37.0
- type: precision_at_10
value: 7.133000000000001
- type: precision_at_100
value: 0.9570000000000001
- type: precision_at_1000
value: 0.11
- type: precision_at_20
value: 3.8670000000000004
- type: precision_at_3
value: 19.0
- type: precision_at_5
value: 12.733
- type: recall_at_1
value: 34.9
- type: recall_at_10
value: 64.372
- type: recall_at_100
value: 84.806
- type: recall_at_1000
value: 97.26700000000001
- type: recall_at_20
value: 69.428
- type: recall_at_3
value: 52.983000000000004
- type: recall_at_5
value: 58.428000000000004
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions (default)
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cosine_accuracy
value: 99.6029702970297
- type: cosine_accuracy_threshold
value: 78.96339297294617
- type: cosine_ap
value: 85.09945680365945
- type: cosine_f1
value: 79.00249376558605
- type: cosine_f1_threshold
value: 77.54697799682617
- type: cosine_precision
value: 78.80597014925374
- type: cosine_recall
value: 79.2
- type: dot_accuracy
value: 99.07128712871287
- type: dot_accuracy_threshold
value: 113537.78076171875
- type: dot_ap
value: 32.974014883183614
- type: dot_f1
value: 38.70665417057169
- type: dot_f1_threshold
value: 82395.60546875
- type: dot_precision
value: 36.41975308641975
- type: dot_recall
value: 41.3
- type: euclidean_accuracy
value: 99.35742574257425
- type: euclidean_accuracy_threshold
value: 1716.6461944580078
- type: euclidean_ap
value: 60.79241641393818
- type: euclidean_f1
value: 61.254199328107504
- type: euclidean_f1_threshold
value: 1787.368392944336
- type: euclidean_precision
value: 69.59287531806616
- type: euclidean_recall
value: 54.7
- type: main_score
value: 85.09945680365945
- type: manhattan_accuracy
value: 99.35544554455446
- type: manhattan_accuracy_threshold
value: 21216.224670410156
- type: manhattan_ap
value: 60.67247165482485
- type: manhattan_f1
value: 61.16876024030584
- type: manhattan_f1_threshold
value: 22668.411254882812
- type: manhattan_precision
value: 67.38868832731649
- type: manhattan_recall
value: 56.00000000000001
- type: max_accuracy
value: 99.6029702970297
- type: max_ap
value: 85.09945680365945
- type: max_f1
value: 79.00249376558605
- type: max_precision
value: 78.80597014925374
- type: max_recall
value: 79.2
- type: similarity_accuracy
value: 99.6029702970297
- type: similarity_accuracy_threshold
value: 78.96339297294617
- type: similarity_ap
value: 85.09945680365945
- type: similarity_f1
value: 79.00249376558605
- type: similarity_f1_threshold
value: 77.54697799682617
- type: similarity_precision
value: 78.80597014925374
- type: similarity_recall
value: 79.2
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering (default)
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: main_score
value: 40.01875953666112
- type: v_measure
value: 40.01875953666112
- type: v_measure_std
value: 4.519991014119391
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P (default)
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: main_score
value: 28.81354037080584
- type: v_measure
value: 28.81354037080584
- type: v_measure_std
value: 1.4144350664362755
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions (default)
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: main_score
value: 44.09716409649705
- type: map
value: 44.09716409649705
- type: mrr
value: 44.662380103556565
- type: nAUC_map_diff1
value: 35.29255607823797
- type: nAUC_map_max
value: 16.421837723462147
- type: nAUC_map_std
value: 6.1302069782322315
- type: nAUC_mrr_diff1
value: 34.559928528154806
- type: nAUC_mrr_max
value: 17.207604918830953
- type: nAUC_mrr_std
value: 6.664790258906265
- task:
type: Summarization
dataset:
name: MTEB SummEval (default)
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cosine_pearson
value: 29.294245469087553
- type: cosine_spearman
value: 30.080488918284974
- type: dot_pearson
value: 18.322393003009722
- type: dot_spearman
value: 20.941469677129597
- type: main_score
value: 30.080488918284974
- type: pearson
value: 29.294245469087553
- type: spearman
value: 30.080488918284974
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID (default)
type: mteb/trec-covid
config: default
split: test
revision: bb9466bac8153a0349341eb1b22e06409e78ef4e
metrics:
- type: main_score
value: 39.983999999999995
- type: map_at_1
value: 0.106
- type: map_at_10
value: 0.644
- type: map_at_100
value: 3.021
- type: map_at_1000
value: 7.86
- type: map_at_20
value: 1.0959999999999999
- type: map_at_3
value: 0.26
- type: map_at_5
value: 0.383
- type: mrr_at_1
value: 52.0
- type: mrr_at_10
value: 63.62142857142856
- type: mrr_at_100
value: 64.14120879120878
- type: mrr_at_1000
value: 64.15196147938082
- type: mrr_at_20
value: 64.06428571428572
- type: mrr_at_3
value: 60.33333333333333
- type: mrr_at_5
value: 62.133333333333326
- type: nauc_map_at_1000_diff1
value: 24.416863084123577
- type: nauc_map_at_1000_max
value: 38.56500518410879
- type: nauc_map_at_1000_std
value: 57.28416632982124
- type: nauc_map_at_100_diff1
value: 7.320029678013508
- type: nauc_map_at_100_max
value: 31.67441200824679
- type: nauc_map_at_100_std
value: 46.99676723594155
- type: nauc_map_at_10_diff1
value: 2.1592330331050635
- type: nauc_map_at_10_max
value: 26.48308930412215
- type: nauc_map_at_10_std
value: 32.1215432254444
- type: nauc_map_at_1_diff1
value: 19.602070971946954
- type: nauc_map_at_1_max
value: 8.20575258643758
- type: nauc_map_at_1_std
value: 17.150126202821102
- type: nauc_map_at_20_diff1
value: 1.4525678948841099
- type: nauc_map_at_20_max
value: 25.398372034894923
- type: nauc_map_at_20_std
value: 37.98656048425611
- type: nauc_map_at_3_diff1
value: 14.189476148666769
- type: nauc_map_at_3_max
value: 13.645814074115348
- type: nauc_map_at_3_std
value: 24.193562926020505
- type: nauc_map_at_5_diff1
value: 6.385516140164152
- type: nauc_map_at_5_max
value: 19.028014747196977
- type: nauc_map_at_5_std
value: 27.2670171970273
- type: nauc_mrr_at_1000_diff1
value: 29.927939844415192
- type: nauc_mrr_at_1000_max
value: 19.139062731303653
- type: nauc_mrr_at_1000_std
value: 30.750244889158466
- type: nauc_mrr_at_100_diff1
value: 29.955577537768708
- type: nauc_mrr_at_100_max
value: 19.15999969363906
- type: nauc_mrr_at_100_std
value: 30.777558250465532
- type: nauc_mrr_at_10_diff1
value: 29.75190425697829
- type: nauc_mrr_at_10_max
value: 19.247901214296146
- type: nauc_mrr_at_10_std
value: 30.12495769940457
- type: nauc_mrr_at_1_diff1
value: 25.319658305674935
- type: nauc_mrr_at_1_max
value: 19.408020022852174
- type: nauc_mrr_at_1_std
value: 30.518526579248036
- type: nauc_mrr_at_20_diff1
value: 29.381724804135523
- type: nauc_mrr_at_20_max
value: 18.78203200071421
- type: nauc_mrr_at_20_std
value: 30.201392736164536
- type: nauc_mrr_at_3_diff1
value: 33.49197973287976
- type: nauc_mrr_at_3_max
value: 16.821299944157854
- type: nauc_mrr_at_3_std
value: 32.95866142740776
- type: nauc_mrr_at_5_diff1
value: 30.519933718405962
- type: nauc_mrr_at_5_max
value: 20.873028786250366
- type: nauc_mrr_at_5_std
value: 31.53952703715278
- type: nauc_ndcg_at_1000_diff1
value: 19.56599546833078
- type: nauc_ndcg_at_1000_max
value: 31.55417192496882
- type: nauc_ndcg_at_1000_std
value: 46.03469380933216
- type: nauc_ndcg_at_100_diff1
value: 17.03409656600608
- type: nauc_ndcg_at_100_max
value: 30.018921010755896
- type: nauc_ndcg_at_100_std
value: 42.083969481235535
- type: nauc_ndcg_at_10_diff1
value: 9.622601053598032
- type: nauc_ndcg_at_10_max
value: 24.036876646465473
- type: nauc_ndcg_at_10_std
value: 29.264022469658542
- type: nauc_ndcg_at_1_diff1
value: 10.162034267788544
- type: nauc_ndcg_at_1_max
value: 14.902101527295905
- type: nauc_ndcg_at_1_std
value: 22.89481729606148
- type: nauc_ndcg_at_20_diff1
value: 11.827596896516578
- type: nauc_ndcg_at_20_max
value: 21.89722632493682
- type: nauc_ndcg_at_20_std
value: 34.10813108354046
- type: nauc_ndcg_at_3_diff1
value: 9.885830514681343
- type: nauc_ndcg_at_3_max
value: 18.645371242229174
- type: nauc_ndcg_at_3_std
value: 27.61014855490183
- type: nauc_ndcg_at_5_diff1
value: 7.016021785588281
- type: nauc_ndcg_at_5_max
value: 21.223071359768444
- type: nauc_ndcg_at_5_std
value: 26.398061449644693
- type: nauc_precision_at_1000_diff1
value: 21.951465290665013
- type: nauc_precision_at_1000_max
value: 29.28795349580752
- type: nauc_precision_at_1000_std
value: 43.851885410437404
- type: nauc_precision_at_100_diff1
value: 20.103205413776266
- type: nauc_precision_at_100_max
value: 29.53467404908886
- type: nauc_precision_at_100_std
value: 43.41214281168461
- type: nauc_precision_at_10_diff1
value: 9.327632341614823
- type: nauc_precision_at_10_max
value: 27.739929968318993
- type: nauc_precision_at_10_std
value: 30.029060765584443
- type: nauc_precision_at_1_diff1
value: 25.319658305674935
- type: nauc_precision_at_1_max
value: 19.408020022852174
- type: nauc_precision_at_1_std
value: 30.518526579248036
- type: nauc_precision_at_20_diff1
value: 12.507551705078598
- type: nauc_precision_at_20_max
value: 25.437784661790673
- type: nauc_precision_at_20_std
value: 37.6038493343788
- type: nauc_precision_at_3_diff1
value: 17.302840903240426
- type: nauc_precision_at_3_max
value: 18.240884706076184
- type: nauc_precision_at_3_std
value: 32.34758075311221
- type: nauc_precision_at_5_diff1
value: 10.643711764387417
- type: nauc_precision_at_5_max
value: 24.411239239889554
- type: nauc_precision_at_5_std
value: 28.767392128200953
- type: nauc_recall_at_1000_diff1
value: 18.932208342315853
- type: nauc_recall_at_1000_max
value: 28.482052015706234
- type: nauc_recall_at_1000_std
value: 44.983993721189705
- type: nauc_recall_at_100_diff1
value: 12.30127094174658
- type: nauc_recall_at_100_max
value: 25.614395729836016
- type: nauc_recall_at_100_std
value: 40.04868566707452
- type: nauc_recall_at_10_diff1
value: -4.63806503951543
- type: nauc_recall_at_10_max
value: 25.05145496553497
- type: nauc_recall_at_10_std
value: 24.09893875274637
- type: nauc_recall_at_1_diff1
value: 19.602070971946954
- type: nauc_recall_at_1_max
value: 8.20575258643758
- type: nauc_recall_at_1_std
value: 17.150126202821102
- type: nauc_recall_at_20_diff1
value: 3.229932027028801
- type: nauc_recall_at_20_max
value: 18.794275827349168
- type: nauc_recall_at_20_std
value: 30.248974156728046
- type: nauc_recall_at_3_diff1
value: 15.00878750843053
- type: nauc_recall_at_3_max
value: 9.046387583277276
- type: nauc_recall_at_3_std
value: 22.79927256744018
- type: nauc_recall_at_5_diff1
value: 1.9090462818828973
- type: nauc_recall_at_5_max
value: 17.416622454402713
- type: nauc_recall_at_5_std
value: 21.915265437836833
- type: ndcg_at_1
value: 45.0
- type: ndcg_at_10
value: 39.983999999999995
- type: ndcg_at_100
value: 27.095999999999997
- type: ndcg_at_1000
value: 24.454
- type: ndcg_at_20
value: 37.319
- type: ndcg_at_3
value: 43.704
- type: ndcg_at_5
value: 41.568
- type: precision_at_1
value: 52.0
- type: precision_at_10
value: 42.6
- type: precision_at_100
value: 27.72
- type: precision_at_1000
value: 11.844000000000001
- type: precision_at_20
value: 39.6
- type: precision_at_3
value: 48.667
- type: precision_at_5
value: 45.6
- type: recall_at_1
value: 0.106
- type: recall_at_10
value: 0.9159999999999999
- type: recall_at_100
value: 5.715
- type: recall_at_1000
value: 23.662
- type: recall_at_20
value: 1.7160000000000002
- type: recall_at_3
value: 0.302
- type: recall_at_5
value: 0.482
- task:
type: Retrieval
dataset:
name: MTEB Touche2020 (default)
type: mteb/touche2020
config: default
split: test
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
metrics:
- type: main_score
value: 13.753000000000002
- type: map_at_1
value: 1.5970000000000002
- type: map_at_10
value: 4.601
- type: map_at_100
value: 7.7700000000000005
- type: map_at_1000
value: 9.096
- type: map_at_20
value: 5.817
- type: map_at_3
value: 2.377
- type: map_at_5
value: 2.98
- type: mrr_at_1
value: 22.448979591836736
- type: mrr_at_10
value: 33.38030450275348
- type: mrr_at_100
value: 35.01828931874863
- type: mrr_at_1000
value: 35.037725664715595
- type: mrr_at_20
value: 34.6865889212828
- type: mrr_at_3
value: 28.231292517006807
- type: mrr_at_5
value: 31.394557823129254
- type: nauc_map_at_1000_diff1
value: -11.252417383140266
- type: nauc_map_at_1000_max
value: -37.24375623641661
- type: nauc_map_at_1000_std
value: -38.122086330314595
- type: nauc_map_at_100_diff1
value: -13.970621196322664
- type: nauc_map_at_100_max
value: -39.871220844684366
- type: nauc_map_at_100_std
value: -41.05324590181932
- type: nauc_map_at_10_diff1
value: -12.163263778180402
- type: nauc_map_at_10_max
value: -36.76984556993433
- type: nauc_map_at_10_std
value: -37.53503392844242
- type: nauc_map_at_1_diff1
value: -21.481769300580112
- type: nauc_map_at_1_max
value: -34.78475326600437
- type: nauc_map_at_1_std
value: -31.34442054238037
- type: nauc_map_at_20_diff1
value: -14.607331295503842
- type: nauc_map_at_20_max
value: -40.507883730110066
- type: nauc_map_at_20_std
value: -42.25172210956502
- type: nauc_map_at_3_diff1
value: -16.11765086583003
- type: nauc_map_at_3_max
value: -39.875149479128375
- type: nauc_map_at_3_std
value: -36.495342441290575
- type: nauc_map_at_5_diff1
value: -12.762015642768567
- type: nauc_map_at_5_max
value: -35.84513643191068
- type: nauc_map_at_5_std
value: -34.507874404019105
- type: nauc_mrr_at_1000_diff1
value: -14.380678398651431
- type: nauc_mrr_at_1000_max
value: -34.916144132151764
- type: nauc_mrr_at_1000_std
value: -37.97719898398948
- type: nauc_mrr_at_100_diff1
value: -14.315571331226579
- type: nauc_mrr_at_100_max
value: -34.82941353583672
- type: nauc_mrr_at_100_std
value: -37.88850059416566
- type: nauc_mrr_at_10_diff1
value: -15.357854232460392
- type: nauc_mrr_at_10_max
value: -35.50556512154432
- type: nauc_mrr_at_10_std
value: -39.177327110088726
- type: nauc_mrr_at_1_diff1
value: -20.81375579297355
- type: nauc_mrr_at_1_max
value: -29.68218990777337
- type: nauc_mrr_at_1_std
value: -32.340167902766225
- type: nauc_mrr_at_20_diff1
value: -14.007415589033556
- type: nauc_mrr_at_20_max
value: -35.07243301300378
- type: nauc_mrr_at_20_std
value: -38.4083789449898
- type: nauc_mrr_at_3_diff1
value: -18.09416617081835
- type: nauc_mrr_at_3_max
value: -36.95185320631812
- type: nauc_mrr_at_3_std
value: -35.64342684468998
- type: nauc_mrr_at_5_diff1
value: -15.183051674277138
- type: nauc_mrr_at_5_max
value: -34.67724348034976
- type: nauc_mrr_at_5_std
value: -35.5955991849333
- type: nauc_ndcg_at_1000_diff1
value: 0.8638249190254136
- type: nauc_ndcg_at_1000_max
value: -27.240531292789573
- type: nauc_ndcg_at_1000_std
value: -26.34406627094641
- type: nauc_ndcg_at_100_diff1
value: -10.272509858747428
- type: nauc_ndcg_at_100_max
value: -40.27645670071093
- type: nauc_ndcg_at_100_std
value: -40.20324905617718
- type: nauc_ndcg_at_10_diff1
value: -10.251898880214641
- type: nauc_ndcg_at_10_max
value: -31.66063506955603
- type: nauc_ndcg_at_10_std
value: -35.18245248110904
- type: nauc_ndcg_at_1_diff1
value: -22.15796091381088
- type: nauc_ndcg_at_1_max
value: -28.012386493294734
- type: nauc_ndcg_at_1_std
value: -28.75534254770048
- type: nauc_ndcg_at_20_diff1
value: -13.257359699197114
- type: nauc_ndcg_at_20_max
value: -39.25007814100781
- type: nauc_ndcg_at_20_std
value: -41.74617039563512
- type: nauc_ndcg_at_3_diff1
value: -14.633327352889419
- type: nauc_ndcg_at_3_max
value: -35.76970667496168
- type: nauc_ndcg_at_3_std
value: -34.78512355124301
- type: nauc_ndcg_at_5_diff1
value: -9.008702427186012
- type: nauc_ndcg_at_5_max
value: -27.057510395795788
- type: nauc_ndcg_at_5_std
value: -31.06336991460067
- type: nauc_precision_at_1000_diff1
value: 24.915422567175415
- type: nauc_precision_at_1000_max
value: 47.53560015584683
- type: nauc_precision_at_1000_std
value: 38.21701614763806
- type: nauc_precision_at_100_diff1
value: 6.645491992850349
- type: nauc_precision_at_100_max
value: -14.578256280924878
- type: nauc_precision_at_100_std
value: -23.049085659678926
- type: nauc_precision_at_10_diff1
value: -0.9667619260601806
- type: nauc_precision_at_10_max
value: -25.529150834147217
- type: nauc_precision_at_10_std
value: -35.81209624358855
- type: nauc_precision_at_1_diff1
value: -20.81375579297355
- type: nauc_precision_at_1_max
value: -29.68218990777337
- type: nauc_precision_at_1_std
value: -32.340167902766225
- type: nauc_precision_at_20_diff1
value: -5.664913271170427
- type: nauc_precision_at_20_max
value: -31.789766954167682
- type: nauc_precision_at_20_std
value: -43.24957806575219
- type: nauc_precision_at_3_diff1
value: -8.78321692449596
- type: nauc_precision_at_3_max
value: -40.94190027571407
- type: nauc_precision_at_3_std
value: -40.42051526602616
- type: nauc_precision_at_5_diff1
value: -0.6700857649701735
- type: nauc_precision_at_5_max
value: -25.396527239026117
- type: nauc_precision_at_5_std
value: -31.60992759387055
- type: nauc_recall_at_1000_diff1
value: 6.608885618295343
- type: nauc_recall_at_1000_max
value: -17.90157348658524
- type: nauc_recall_at_1000_std
value: 1.4128128959708763
- type: nauc_recall_at_100_diff1
value: -10.790017345080633
- type: nauc_recall_at_100_max
value: -42.67969932770011
- type: nauc_recall_at_100_std
value: -36.57531070739207
- type: nauc_recall_at_10_diff1
value: -9.632249853815987
- type: nauc_recall_at_10_max
value: -35.775869145222444
- type: nauc_recall_at_10_std
value: -38.6290217611413
- type: nauc_recall_at_1_diff1
value: -21.481769300580112
- type: nauc_recall_at_1_max
value: -34.78475326600437
- type: nauc_recall_at_1_std
value: -31.34442054238037
- type: nauc_recall_at_20_diff1
value: -16.584366120363462
- type: nauc_recall_at_20_max
value: -45.0011419751979
- type: nauc_recall_at_20_std
value: -46.22137916249736
- type: nauc_recall_at_3_diff1
value: -16.227776403050605
- type: nauc_recall_at_3_max
value: -46.19831636902846
- type: nauc_recall_at_3_std
value: -39.31769096438802
- type: nauc_recall_at_5_diff1
value: -8.463083898122722
- type: nauc_recall_at_5_max
value: -34.1285878720165
- type: nauc_recall_at_5_std
value: -33.56523176213727
- type: ndcg_at_1
value: 19.387999999999998
- type: ndcg_at_10
value: 13.753000000000002
- type: ndcg_at_100
value: 23.552
- type: ndcg_at_1000
value: 36.061
- type: ndcg_at_20
value: 15.113999999999999
- type: ndcg_at_3
value: 14.994
- type: ndcg_at_5
value: 13.927
- type: precision_at_1
value: 22.448999999999998
- type: precision_at_10
value: 13.469000000000001
- type: precision_at_100
value: 5.531
- type: precision_at_1000
value: 1.333
- type: precision_at_20
value: 11.224
- type: precision_at_3
value: 15.645999999999999
- type: precision_at_5
value: 14.693999999999999
- type: recall_at_1
value: 1.5970000000000002
- type: recall_at_10
value: 9.428
- type: recall_at_100
value: 34.227000000000004
- type: recall_at_1000
value: 72.233
- type: recall_at_20
value: 15.456
- type: recall_at_3
value: 3.024
- type: recall_at_5
value: 4.776
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification (default)
type: mteb/toxic_conversations_50k
config: default
split: test
revision: edfaf9da55d3dd50d43143d90c1ac476895ae6de
metrics:
- type: accuracy
value: 65.6884765625
- type: ap
value: 11.395400787741414
- type: ap_weighted
value: 11.395400787741414
- type: f1
value: 49.997667284332806
- type: f1_weighted
value: 73.34420433686675
- type: main_score
value: 65.6884765625
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification (default)
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 49.83305036785513
- type: f1
value: 49.97910620163813
- type: f1_weighted
value: 49.32130156716104
- type: main_score
value: 49.83305036785513
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering (default)
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: main_score
value: 25.27920179659098
- type: v_measure
value: 25.27920179659098
- type: v_measure_std
value: 2.092324622279832
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015 (default)
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cosine_accuracy
value: 82.19586338439531
- type: cosine_accuracy_threshold
value: 75.0169038772583
- type: cosine_ap
value: 60.22081236487149
- type: cosine_f1
value: 57.192894671003245
- type: cosine_f1_threshold
value: 69.5034384727478
- type: cosine_precision
value: 54.3767840152236
- type: cosine_recall
value: 60.31662269129288
- type: dot_accuracy
value: 77.92215533170412
- type: dot_accuracy_threshold
value: 106759.60693359375
- type: dot_ap
value: 40.49772647740827
- type: dot_f1
value: 46.14293314417449
- type: dot_f1_threshold
value: 67732.36083984375
- type: dot_precision
value: 34.748931623931625
- type: dot_recall
value: 68.65435356200528
- type: euclidean_accuracy
value: 80.45538534898968
- type: euclidean_accuracy_threshold
value: 2147.9385375976562
- type: euclidean_ap
value: 52.814058086493475
- type: euclidean_f1
value: 50.80232161147149
- type: euclidean_f1_threshold
value: 2624.5105743408203
- type: euclidean_precision
value: 44.66680008004803
- type: euclidean_recall
value: 58.89182058047493
- type: main_score
value: 60.22081236487149
- type: manhattan_accuracy
value: 80.53883292602968
- type: manhattan_accuracy_threshold
value: 27107.672119140625
- type: manhattan_ap
value: 53.53662771884282
- type: manhattan_f1
value: 51.65052816901407
- type: manhattan_f1_threshold
value: 33232.24792480469
- type: manhattan_precision
value: 44.299735749339376
- type: manhattan_recall
value: 61.92612137203166
- type: max_accuracy
value: 82.19586338439531
- type: max_ap
value: 60.22081236487149
- type: max_f1
value: 57.192894671003245
- type: max_precision
value: 54.3767840152236
- type: max_recall
value: 68.65435356200528
- type: similarity_accuracy
value: 82.19586338439531
- type: similarity_accuracy_threshold
value: 75.0169038772583
- type: similarity_ap
value: 60.22081236487149
- type: similarity_f1
value: 57.192894671003245
- type: similarity_f1_threshold
value: 69.5034384727478
- type: similarity_precision
value: 54.3767840152236
- type: similarity_recall
value: 60.31662269129288
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus (default)
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cosine_accuracy
value: 85.86758256684907
- type: cosine_accuracy_threshold
value: 73.03299903869629
- type: cosine_ap
value: 78.79896751132692
- type: cosine_f1
value: 70.93762938984453
- type: cosine_f1_threshold
value: 69.51396465301514
- type: cosine_precision
value: 69.39391707784078
- type: cosine_recall
value: 72.55158607945796
- type: dot_accuracy
value: 81.69169868436373
- type: dot_accuracy_threshold
value: 51796.2890625
- type: dot_ap
value: 66.49022700054283
- type: dot_f1
value: 62.167484157387854
- type: dot_f1_threshold
value: 42622.021484375
- type: dot_precision
value: 58.10078297530617
- type: dot_recall
value: 66.84631967970435
- type: euclidean_accuracy
value: 83.17809601428183
- type: euclidean_accuracy_threshold
value: 1687.9749298095703
- type: euclidean_ap
value: 70.39367677734302
- type: euclidean_f1
value: 62.79221027661935
- type: euclidean_f1_threshold
value: 1905.8393478393555
- type: euclidean_precision
value: 62.40778766446118
- type: euclidean_recall
value: 63.181398213735754
- type: main_score
value: 78.79896751132692
- type: manhattan_accuracy
value: 83.23631000892615
- type: manhattan_accuracy_threshold
value: 21191.021728515625
- type: manhattan_ap
value: 70.60408795606112
- type: manhattan_f1
value: 62.99311208515969
- type: manhattan_f1_threshold
value: 23671.893310546875
- type: manhattan_precision
value: 64.05603311047437
- type: manhattan_recall
value: 61.964890668309216
- type: max_accuracy
value: 85.86758256684907
- type: max_ap
value: 78.79896751132692
- type: max_f1
value: 70.93762938984453
- type: max_precision
value: 69.39391707784078
- type: max_recall
value: 72.55158607945796
- type: similarity_accuracy
value: 85.86758256684907
- type: similarity_accuracy_threshold
value: 73.03299903869629
- type: similarity_ap
value: 78.79896751132692
- type: similarity_f1
value: 70.93762938984453
- type: similarity_f1_threshold
value: 69.51396465301514
- type: similarity_precision
value: 69.39391707784078
- type: similarity_recall
value: 72.55158607945796
---
# M2V_base_glove_subword Model Card
This [Model2Vec](https://github.com/MinishLab/model2vec) model is a distilled version of the [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) Sentence Transformer. It uses static embeddings, allowing text embeddings to be computed orders of magnitude faster on both GPU and CPU. It is designed for applications where computational resources are limited or where real-time performance is critical.
## Installation
Install model2vec using pip:
```
pip install model2vec
```
## Usage
Load this model using the `from_pretrained` method:
```python
from model2vec import StaticModel
# Load a pretrained Model2Vec model
model = StaticModel.from_pretrained("minishlab/M2V_base_glove_subword")
# Compute text embeddings
embeddings = model.encode(["Example sentence"])
```
Alternatively, you can distill your own model using the `distill` method:
```python
from model2vec.distill import distill
# Choose a Sentence Transformer model
model_name = "BAAI/bge-base-en-v1.5"
# Distill the model
m2v_model = distill(model_name=model_name, pca_dims=256)
# Save the model
m2v_model.save_pretrained("m2v_model")
```
## How it works
Model2vec creates a small, fast, and powerful model that outperforms other static embedding models by a large margin on all tasks we could find, while being much faster to create than traditional static embedding models such as GloVe. Best of all, you don't need any data to distill a model using Model2Vec.
It works by passing a vocabulary through a sentence transformer model, then reducing the dimensionality of the resulting embeddings using PCA, and finally weighting the embeddings using zipf weighting. During inference, we simply take the mean of all token embeddings occurring in a sentence.
## Additional Resources
- [All Model2Vec models on the hub](https://huggingface.co/models?library=model2vec)
- [Model2Vec Repo](https://github.com/MinishLab/model2vec)
- [Model2Vec Results](https://github.com/MinishLab/model2vec?tab=readme-ov-file#results)
- [Model2Vec Tutorials](https://github.com/MinishLab/model2vec/tree/main/tutorials)
## Library Authors
Model2Vec was developed by the [Minish Lab](https://github.com/MinishLab) team consisting of [Stephan Tulkens](https://github.com/stephantul) and [Thomas van Dongen](https://github.com/Pringled).
## Citation
Please cite the [Model2Vec repository](https://github.com/MinishLab/model2vec) if you use this model in your work.
```
@software{minishlab2024model2vec,
authors = {Stephan Tulkens, Thomas van Dongen},
title = {Model2Vec: Turn any Sentence Transformer into a Small Fast Model},
year = {2024},
url = {https://github.com/MinishLab/model2vec},
}
```
|
[
"BIOSSES",
"SCIFACT"
] |
RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-10T15:08:19Z |
2024-10-10T18:12:31+00:00
| 44 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Einstein-v4-7B - GGUF
- Model creator: https://huggingface.co/Weyaxi/
- Original model: https://huggingface.co/Weyaxi/Einstein-v4-7B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Einstein-v4-7B.Q2_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q2_K.gguf) | Q2_K | 2.53GB |
| [Einstein-v4-7B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [Einstein-v4-7B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [Einstein-v4-7B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [Einstein-v4-7B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [Einstein-v4-7B.Q3_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q3_K.gguf) | Q3_K | 3.28GB |
| [Einstein-v4-7B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [Einstein-v4-7B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [Einstein-v4-7B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [Einstein-v4-7B.Q4_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q4_0.gguf) | Q4_0 | 3.83GB |
| [Einstein-v4-7B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [Einstein-v4-7B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [Einstein-v4-7B.Q4_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q4_K.gguf) | Q4_K | 4.07GB |
| [Einstein-v4-7B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [Einstein-v4-7B.Q4_1.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q4_1.gguf) | Q4_1 | 4.24GB |
| [Einstein-v4-7B.Q5_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q5_0.gguf) | Q5_0 | 4.65GB |
| [Einstein-v4-7B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [Einstein-v4-7B.Q5_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q5_K.gguf) | Q5_K | 4.78GB |
| [Einstein-v4-7B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [Einstein-v4-7B.Q5_1.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q5_1.gguf) | Q5_1 | 5.07GB |
| [Einstein-v4-7B.Q6_K.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q6_K.gguf) | Q6_K | 5.53GB |
| [Einstein-v4-7B.Q8_0.gguf](https://huggingface.co/RichardErkhov/Weyaxi_-_Einstein-v4-7B-gguf/blob/main/Einstein-v4-7B.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
language:
- en
license: other
tags:
- axolotl
- generated_from_trainer
- Mistral
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- science
- physics
- chemistry
- biology
- math
base_model: mistralai/Mistral-7B-v0.1
datasets:
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- metaeval/reclor
- openbookqa
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- TIGER-Lab/ScienceEval
- jondurbin/airoboros-3.2
- LDJnr/Capybara
- Cot-Alpaca-GPT4-From-OpenHermes-2.5
- STEM-AI-mtl/Electrical-engineering
- knowrohit07/saraswati-stem
- sablo/oasst2_curated
- glaiveai/glaive-code-assistant
- lmsys/lmsys-chat-1m
- TIGER-Lab/MathInstruct
- bigbio/med_qa
- meta-math/MetaMathQA-40K
- openbookqa
- piqa
- metaeval/reclor
- derek-thomas/ScienceQA
- scibench
- sciq
- Open-Orca/SlimOrca
- migtissera/Synthia-v1.3
- TIGER-Lab/ScienceEval
model-index:
- name: Einstein-v4-7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 64.68
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 83.75
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 62.31
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 55.15
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 76.24
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 57.62
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: IFEval (0-Shot)
type: HuggingFaceH4/ifeval
args:
num_few_shot: 0
metrics:
- type: inst_level_strict_acc and prompt_level_strict_acc
value: 47.08
name: strict accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BBH (3-Shot)
type: BBH
args:
num_few_shot: 3
metrics:
- type: acc_norm
value: 14.3
name: normalized accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MATH Lvl 5 (4-Shot)
type: hendrycks/competition_math
args:
num_few_shot: 4
metrics:
- type: exact_match
value: 1.74
name: exact match
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GPQA (0-shot)
type: Idavidrein/gpqa
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 4.25
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MuSR (0-shot)
type: TAUR-Lab/MuSR
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 19.02
name: acc_norm
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU-PRO (5-shot)
type: TIGER-Lab/MMLU-Pro
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 13.99
name: accuracy
source:
url: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
---

# 🔬 Einstein-v4-7B
This model is a full fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on diverse datasets.
This model is finetuned using `7xRTX3090` + `1xRTXA6000` using [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This model's training was sponsored by [sablo.ai](https://sablo.ai).
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: mistralai/Mistral-7B-v0.1
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
is_mistral_derived_model: true
load_in_8bit: false
load_in_4bit: false
strict: false
chat_template: chatml
datasets:
- path: data/merged_all.json
ds_type: json
type: alpaca
conversation: chatml
- path: data/capybara_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/synthia-v1.3_sharegpt_12500.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/cot_alpaca_gpt4_extracted_openhermes_2.5_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/slimorca_dedup_filtered_95k_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/airoboros_3.2_without_contextual_slimorca_orca_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
dataset_prepared_path: last_run_prepared
val_set_size: 0.005
output_dir: ./Einstein-v4-model
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
eval_sample_packing: false
wandb_project: Einstein
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
hub_model_id: Weyaxi/Einstein-v4-7B
save_safetensors: true
gradient_accumulation_steps: 4
micro_batch_size: 1
num_epochs: 1.5
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.000005
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 2 # changed
eval_table_size:
eval_table_max_new_tokens: 128
saves_per_epoch: 4
debug:
deepspeed: zero3_bf16.json
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "<|im_end|>"
unk_token: "<unk>"
tokens:
- "<|im_start|>"
resume_from_checkpoint: Einstein-v4-model/checkpoint-521
```
</details><br>
# 💬 Prompt Template
You can use this prompt template while using the model:
### ChatML
```
<|im_start|>system
{system}<|im_end|>
<|im_start|>user
{user}<|im_end|>
<|im_start|>assistant
{asistant}<|im_end|>
```
This prompt template is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are helpful AI asistant."},
{"role": "user", "content": "Hello!"}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
# 🔄 Quantizationed versions
Quantizationed versions of this model is available.
## GGUF [@LoneStriker](https://huggingface.co/LoneStriker)
- https://huggingface.co/LoneStriker/Einstein-v4-7B-GGUF
## AWQ [@solidrust](https://huggingface.co/solidrust)
- https://huggingface.co/solidrust/Einstein-v4-7B-AWQ
## Exl2 [@bartowski](https://hf.co/bartowski):
- https://huggingface.co/bartowski/Einstein-v4-7B-exl2
# 🎯 [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Weyaxi__Einstein-v4-7B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |66.62|
|AI2 Reasoning Challenge (25-Shot)|64.68|
|HellaSwag (10-Shot) |83.75|
|MMLU (5-Shot) |62.31|
|TruthfulQA (0-shot) |55.15|
|Winogrande (5-shot) |76.24|
|GSM8k (5-shot) |57.62|
# 🎯 [Open LLM Leaderboard v2 Evaluation Results](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Weyaxi__Einstein-v4-7B)
| Metric |Value|
|-------------------|----:|
|Avg. |16.73|
|IFEval (0-Shot) |47.08|
|BBH (3-Shot) |14.30|
|MATH Lvl 5 (4-Shot)| 1.74|
|GPQA (0-shot) | 4.25|
|MuSR (0-shot) |19.02|
|MMLU-PRO (5-shot) |13.99|
# 📚 Some resources, discussions and reviews aboout this model
#### 🐦 Announcement tweet:
https://twitter.com/Weyaxi/status/1765851433448944125
#### 🔍 Reddit post in r/LocalLLaMA:
- https://www.reddit.com/r/LocalLLaMA/comments/1b9gmvl/meet_einsteinv47b_mistralbased_sft_model_using/
#### ▶️ Youtube Videos
- https://www.youtube.com/watch?v=-3YWgHJIORE&t=18s
- https://www.youtube.com/watch?v=Xo2ySU8gja0
# 🤖 Additional information about training
This model is full fine-tuned for 1.5 epoch.
Total number of steps was 1562.
<details><summary>Loss graph</summary>

</details><br>
# 🤝 Acknowledgments
Thanks to [sablo.ai](https://sablo.ai) for sponsoring this model.
Thanks to all the dataset authors mentioned in the datasets section.
Thanks to [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) for making the repository I used to make this model.
Thanks to all open source AI community.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
If you would like to support me:
[☕ Buy Me a Coffee](https://www.buymeacoffee.com/weyaxi)
|
[
"SCIQ"
] |
bhaskartripathi/GPT_Neo_Market_Analysis
|
bhaskartripathi
|
text-generation
|
[
"peft",
"safetensors",
"finance, IndianStocks, Technical Analysis, Chartless Trading",
"text-generation",
"en",
"base_model:EleutherAI/gpt-neo-125m",
"base_model:adapter:EleutherAI/gpt-neo-125m",
"license:mit",
"region:us"
] | 2024-10-30T10:43:26Z |
2024-10-30T17:24:41+00:00
| 44 | 2 |
---
base_model: EleutherAI/gpt-neo-125M
language:
- en
library_name: peft
license: mit
metrics:
- accuracy
- precision
- recall
- f1
- Pattern Detection Rate
- Cross-Entropy Loss
pipeline_tag: text-generation
tags:
- finance, IndianStocks, Technical Analysis, Chartless Trading
---
---
base_model: EleutherAI/gpt-neo-125M
library_name: peft
---
# Model Description
**IndicFinGPT** is a specialized transformer model, re-engineered from **EleutherAI's GPT-Neo-125M** architecture, which is a GPT-3 class architecture, designed specifically for the **Indian financial market**. The model has undergone **retraining on its top layers** to enhance its performance in providing insights into the **top 100 companies listed in the NIFTY50 Index, BSE, and NSE exchanges**.
The primary objective of this model is to **serve the unique needs of Indian stock markets** and **investors engaged in chartless trading**. IndicFinGPT aims to provide insights that could **minimize capital loss and drawdowns** while **maximizing financial ratios** such as the **Sharpe, Sortino, Calmar, Omega, and Treynor Ratios**. Additionally, the model is designed to help in **reducing maximum drawdowns** in financial portfolios, offering a robust AI solution tailored to **India’s dynamic financial landscape**.
## First Indic-Stock Small Language Model Focused Top 100 Companies Listed in NSE and BSE Stock Exchanges
<p align="center">
<img src="https://huggingface.co/bhaskartripathi/GPT_Neo_Market_Analysis/resolve/main/indicBull.JPG" alt="IndicFinGPT Logo" width="400" height="300">
<strong>भारतीय बाजार की शीर्ष 100 कंपनियों का वित्तीय विश्लेषण करने वाला पहला Small Language Model</strong>
</p>
## Training Data and Procedure
**IndicFinGPT 125M** utilizes the **Pile dataset** created by EleutherAI and includes the **top 100 tickers** (by volume and liquidity) from Indian stock markets, covering data from **January 1, 2018, to October 30, 2024**. This dataset encompasses diverse market periods, including **pre-COVID-19 (stable), COVID-19 (volatile), and post-COVID-19 (recovery phase)**. Such comprehensive data exposure allows the model to recognize **problem-solution patterns across various bull and bear runs**.
The training data also incorporates **local influences** such as cultural factors and **market-specific volatility**, enhancing its ability to perform **automated technical analysis** for chartless trading. Key capabilities include identifying **classical chart patterns** using technical analysis, conducting **earnings analysis**, interpreting **market sentiment** from multiple sources, and **assessing risks**, all aimed at **improving decision-making for Indian investors**.
This model weights were obtained after **310 billion tokens over 692,380 steps**. It utilized 4-bit Quantized Low-Rank Adoption (PEFT) method on top of the masked autoregressive language model architecture of Neo, utilizing cross-entropy loss, F1, Accuracy, Precision, recall,Pattern Detection Rate, and Cross-Entropy Loss as performance metrics.
## Key Highlights
1. Trading Patterns: Specialized in recognizing BSE/NSE-specific patterns and cycles
2. Market Sentiment: Built-in understanding of Indian market sentiment and cultural influences
3. Macro-Economic Indicators: Adapted to domestic economic and financial metrics
4. Indian Economic Influences: Awareness of timing, festival impacts, and market-specific volatility
## Implementation
### Quick Start
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bhaskartripathi/GPT_Neo_Market_Analysis")
tokenizer = AutoTokenizer.from_pretrained("bhaskartripathi/GPT_Neo_Market_Analysis")
input_text = '''[INST] Given the following stock market data and technical analysis:
Stock: EXAMPLE
Date: 2024-01-01
Technical Analysis:
Current Price: ₹100
Daily Range: ₹98 - ₹102
Trading Volume: 1,000,000
RSI: 55
MACD: Bullish
Based on this technical analysis, what is the likely price movement for tomorrow and why? [/INST]'''
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=50)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
```
## Training Details
### Dataset and Fine-tuning
- **Dataset**: Comprehensive dataset featuring 6 years of Indian market data.
- **Method**: Fine-tuned using QLoRA (4-bit quantization) for optimal efficiency.
- **Training Infrastructure**: Utilized an Nvidia T4 GPU, trained for ~6 hours with PEFT framework version 0.13.2.
## Performance Metrics
- **Pattern Recognition**: High accuracy in classical and advanced pattern detection in Indian markets.
- **Sentiment Correlation**: Strong alignment with local market movements.
- **Risk & Volatility Handling**: Reliable risk analysis in volatile market conditions.
## Market Understanding
### Technical Analysis Expertise
The model is adept at identifying crucial market formations including:
- **Classical Patterns**: Head & Shoulders, Double Top/Bottom, Triangle, Flag, Wedge, Cup and Handle.
- **Advanced Techniques**: Local support and resistance levels, volume analysis, and momentum indicators specifically tailored to Indian volatility.
### Market Intelligence
IndicFinGPT includes:
- **Comprehensive Financial Reports**: Analysis of quarterly and annual earnings.
- **Risk Metrics**: Indian-adapted VaR, Beta, and volatility models.
### Cultural Context in Trading
Culturally aware strategies include:
- **Indian Market Timing**: Recommendations tailored to pre-market, regular, and post-market phases.
- **Festival & Cultural Factors**: Insights into events like Diwali (Muhurat Trading), budget announcements, and investor sentiment.
- **FII/DII Flow and Retail Behavior**: Specific guidance considering both institutional and retail dynamics.
## Social Impact
IndicFinGPT democratizes sophisticated AI-based financial analysis for the Indian stock market, providing affordable and accessible tools for both seasoned investors and new traders.
## Core Capabilities
#### Automated Q&A based Technical Analysis for chartless Trading:
Investors, Traders, Economists, Econometricians and Researchers can ask any types of questions related to the below areas:
- **Head and Shoulders patterns**
- What are the implications of a Head and Shoulders pattern forming for Tata Consultancy Services (TCS) in the upcoming week?
- How does the identification of a Head and Shoulders pattern for Reliance Industries influence its potential price movement?
- **Double Top/Bottom patterns**
- What is the expected market behavior for Infosys if a Double Top pattern has formed over the last two weeks?
- How does a Double Bottom pattern in Tata Steel indicate a possible upward trend?
- **Triangle formations**
- What trading opportunities are indicated by a symmetrical triangle formation in Hindustan Unilever?
- How could an ascending triangle in Tata Motors impact its price performance in the coming days?
- **Flag patterns**
- What are the implications of a bullish flag pattern for the stock of Infosys in the short term?
- How can a flag pattern formation in Reliance Industries affect trading strategies for the next three days?
- **Wedge patterns**
- How does a rising wedge pattern in Tata Steel signal a potential market reversal?
- What are the likely outcomes of a falling wedge pattern detected in Tata Consultancy Services (TCS)?
- **Cup and Handle patterns**
- Can you provide an analysis of a Cup and Handle pattern formation in Hindustan Unilever?
- How could a Cup and Handle pattern affect the price movement of Reliance Industries in the coming week?
Earnings Analysis:
- **Key metrics extraction**
- What are the key earnings metrics extracted for Infosys for the latest quarter?
- How do the extracted financial metrics for Tata Motors compare to previous earnings?
- **Historical comparisons**
- How does the historical earnings performance of Tata Consultancy Services (TCS) compare to the current quarter?
- What insights can be gained by comparing historical earnings of Hindustan Unilever over the last three years?
- **Red flag identification**
- Are there any red flags in the latest earnings report of Reliance Industries?
- What potential risks are identified in Tata Steel's financial report?
- **Positive indicator detection**
- What are the positive financial indicators in the latest earnings of Tata Motors?
- How do the positive indicators for Infosys reflect its market position?
Market Sentiment Interpretation:
- **Price-based sentiment analysis**
- How does the recent price movement of Reliance Industries reflect market sentiment?
- What sentiment indicators can be derived from the price fluctuations of Tata Steel?
- **News sentiment analysis**
- How might recent news regarding Tata Consultancy Services (TCS) impact its stock price in the next few days?
- What is the sentiment derived from the latest business news about Hindustan Unilever?
- **Social media sentiment analysis**
- How is social media sentiment trending for Infosys, and what impact could this have on its stock price?
- What does the current social media sentiment indicate about Tata Motors in the upcoming week?
- **Sentiment divergence calculation**
- How does the divergence between price-based sentiment and news sentiment impact the outlook for Tata Consultancy Services (TCS)?
- What are the implications of a sentiment divergence for Reliance Industries over the next few days?
Risk Assessment:
- **Volatility analysis**
- What does the volatility analysis indicate for Tata Steel over the next week?
- How volatile is the stock of Hindustan Unilever in the current market scenario?
- **Beta calculation**
- How does the beta of Tata Motors compare to other companies in the Nifty 50 index?
- What does the beta calculation imply about the risk associated with Infosys?
- **Value at Risk (VaR) computation**
- What is the VaR for Reliance Industries, considering the current market conditions?
- How does the VaR for Tata Consultancy Services (TCS) help in understanding the potential risk in the next three days?
- **Risk rating determination**
- How is the risk rating for Hindustan Unilever determined based on current data?
- What is the risk rating for Tata Steel, and how could it influence trading strategies?
Trading Strategy Recommendations:
- **Pattern-based analysis**
- What are the potential trading opportunities for Reliance Industries based on recent flag or wedge pattern formations in the next week?
- How does the Double Top pattern for Tata Steel indicate a possible trend reversal in the coming days?
- **Sentiment-driven insights**
- How might recent news and social media sentiment affect the stock price of Infosys over the next three days?
- What is the current sentiment regarding Tata Consultancy Services (TCS), and how could it impact its performance over the next week?
- **Risk-adjusted recommendations**
- What are the risk-adjusted trading strategies for Infosys in light of current market volatility?
- Based on beta calculations and current market sentiment, what are the recommended actions for Tata Steel in the coming days?
- **Historical context integration**
- How have similar market conditions in the past affected the performance of Hindustan Unilever, and what can be expected this week?
- Considering past Diwali trading patterns, what is the expected impact on Reliance Industries this year?
## Evaluation Results
#WandB Report: https://wandb.ai/bhaskar-tripathi-indian-institute-of-foreign-trade/indian-market-analysis-system/workspace
<p align="center">
<img src="https://huggingface.co/bhaskartripathi/GPT_Neo_Market_Analysis/resolve/main/eval_results.JPG" alt="IndicFinGPT Logo" width="1024" height="800">
</p>
## Citation
```bibtex
@misc{tripathi2024indicfin,
title={IndicFinGPT: Market Analysis Model for Indian Stocks},
author={Bhaskar Tripathi},
year={2024},
url={https://huggingface.co/bhaskartripathi/GPT_Neo_Market_Analysis}
}
```
## Contact
- **Email**: [email protected]
- **HuggingFace**: [@bhaskartripathi](https://huggingface.co/bhaskartripathi)
- **Google Scholar**: [Profile](https://scholar.google.com/citations?user=SCHOLAR_ID)
- **Github**: [Click Here](https://github.com/bhaskatripathi)
|
[
"BEAR"
] |
BenevolenceMessiah/nomic-embed-text-v1.5-Q8_0-GGUF
|
BenevolenceMessiah
|
sentence-similarity
|
[
"sentence-transformers",
"gguf",
"feature-extraction",
"sentence-similarity",
"mteb",
"transformers",
"transformers.js",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:nomic-ai/nomic-embed-text-v1.5",
"base_model:quantized:nomic-ai/nomic-embed-text-v1.5",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2024-12-15T01:31:40Z |
2024-12-15T01:31:43+00:00
| 44 | 0 |
---
base_model: nomic-ai/nomic-embed-text-v1.5
language:
- en
library_name: sentence-transformers
license: apache-2.0
pipeline_tag: sentence-similarity
tags:
- feature-extraction
- sentence-similarity
- mteb
- transformers
- transformers.js
- llama-cpp
- gguf-my-repo
model-index:
- name: epoch_0_model
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 75.20895522388058
- type: ap
value: 38.57605549557802
- type: f1
value: 69.35586565857854
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.8144
- type: ap
value: 88.65222882032363
- type: f1
value: 91.80426301643274
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.162000000000006
- type: f1
value: 46.59329642263158
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.253
- type: map_at_10
value: 38.962
- type: map_at_100
value: 40.081
- type: map_at_1000
value: 40.089000000000006
- type: map_at_3
value: 33.499
- type: map_at_5
value: 36.351
- type: mrr_at_1
value: 24.609
- type: mrr_at_10
value: 39.099000000000004
- type: mrr_at_100
value: 40.211000000000006
- type: mrr_at_1000
value: 40.219
- type: mrr_at_3
value: 33.677
- type: mrr_at_5
value: 36.469
- type: ndcg_at_1
value: 24.253
- type: ndcg_at_10
value: 48.010999999999996
- type: ndcg_at_100
value: 52.756
- type: ndcg_at_1000
value: 52.964999999999996
- type: ndcg_at_3
value: 36.564
- type: ndcg_at_5
value: 41.711999999999996
- type: precision_at_1
value: 24.253
- type: precision_at_10
value: 7.738
- type: precision_at_100
value: 0.98
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 15.149000000000001
- type: precision_at_5
value: 11.593
- type: recall_at_1
value: 24.253
- type: recall_at_10
value: 77.383
- type: recall_at_100
value: 98.009
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 45.448
- type: recall_at_5
value: 57.965999999999994
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 45.69069567851087
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 36.35185490976283
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.71274951450321
- type: mrr
value: 76.06032625423207
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 86.73980520022269
- type: cos_sim_spearman
value: 84.24649792685918
- type: euclidean_pearson
value: 85.85197641158186
- type: euclidean_spearman
value: 84.24649792685918
- type: manhattan_pearson
value: 86.26809552711346
- type: manhattan_spearman
value: 84.56397504030865
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.25324675324674
- type: f1
value: 84.17872280892557
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 38.770253446400886
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 32.94307095497281
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 32.164
- type: map_at_10
value: 42.641
- type: map_at_100
value: 43.947
- type: map_at_1000
value: 44.074999999999996
- type: map_at_3
value: 39.592
- type: map_at_5
value: 41.204
- type: mrr_at_1
value: 39.628
- type: mrr_at_10
value: 48.625
- type: mrr_at_100
value: 49.368
- type: mrr_at_1000
value: 49.413000000000004
- type: mrr_at_3
value: 46.400000000000006
- type: mrr_at_5
value: 47.68
- type: ndcg_at_1
value: 39.628
- type: ndcg_at_10
value: 48.564
- type: ndcg_at_100
value: 53.507000000000005
- type: ndcg_at_1000
value: 55.635999999999996
- type: ndcg_at_3
value: 44.471
- type: ndcg_at_5
value: 46.137
- type: precision_at_1
value: 39.628
- type: precision_at_10
value: 8.856
- type: precision_at_100
value: 1.429
- type: precision_at_1000
value: 0.191
- type: precision_at_3
value: 21.268
- type: precision_at_5
value: 14.649000000000001
- type: recall_at_1
value: 32.164
- type: recall_at_10
value: 59.609
- type: recall_at_100
value: 80.521
- type: recall_at_1000
value: 94.245
- type: recall_at_3
value: 46.521
- type: recall_at_5
value: 52.083999999999996
- type: map_at_1
value: 31.526
- type: map_at_10
value: 41.581
- type: map_at_100
value: 42.815999999999995
- type: map_at_1000
value: 42.936
- type: map_at_3
value: 38.605000000000004
- type: map_at_5
value: 40.351
- type: mrr_at_1
value: 39.489999999999995
- type: mrr_at_10
value: 47.829
- type: mrr_at_100
value: 48.512
- type: mrr_at_1000
value: 48.552
- type: mrr_at_3
value: 45.754
- type: mrr_at_5
value: 46.986
- type: ndcg_at_1
value: 39.489999999999995
- type: ndcg_at_10
value: 47.269
- type: ndcg_at_100
value: 51.564
- type: ndcg_at_1000
value: 53.53099999999999
- type: ndcg_at_3
value: 43.301
- type: ndcg_at_5
value: 45.239000000000004
- type: precision_at_1
value: 39.489999999999995
- type: precision_at_10
value: 8.93
- type: precision_at_100
value: 1.415
- type: precision_at_1000
value: 0.188
- type: precision_at_3
value: 20.892
- type: precision_at_5
value: 14.865999999999998
- type: recall_at_1
value: 31.526
- type: recall_at_10
value: 56.76
- type: recall_at_100
value: 75.029
- type: recall_at_1000
value: 87.491
- type: recall_at_3
value: 44.786
- type: recall_at_5
value: 50.254
- type: map_at_1
value: 40.987
- type: map_at_10
value: 52.827
- type: map_at_100
value: 53.751000000000005
- type: map_at_1000
value: 53.81
- type: map_at_3
value: 49.844
- type: map_at_5
value: 51.473
- type: mrr_at_1
value: 46.833999999999996
- type: mrr_at_10
value: 56.389
- type: mrr_at_100
value: 57.003
- type: mrr_at_1000
value: 57.034
- type: mrr_at_3
value: 54.17999999999999
- type: mrr_at_5
value: 55.486999999999995
- type: ndcg_at_1
value: 46.833999999999996
- type: ndcg_at_10
value: 58.372
- type: ndcg_at_100
value: 62.068
- type: ndcg_at_1000
value: 63.288
- type: ndcg_at_3
value: 53.400000000000006
- type: ndcg_at_5
value: 55.766000000000005
- type: precision_at_1
value: 46.833999999999996
- type: precision_at_10
value: 9.191
- type: precision_at_100
value: 1.192
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 23.448
- type: precision_at_5
value: 15.862000000000002
- type: recall_at_1
value: 40.987
- type: recall_at_10
value: 71.146
- type: recall_at_100
value: 87.035
- type: recall_at_1000
value: 95.633
- type: recall_at_3
value: 58.025999999999996
- type: recall_at_5
value: 63.815999999999995
- type: map_at_1
value: 24.587
- type: map_at_10
value: 33.114
- type: map_at_100
value: 34.043
- type: map_at_1000
value: 34.123999999999995
- type: map_at_3
value: 30.45
- type: map_at_5
value: 31.813999999999997
- type: mrr_at_1
value: 26.554
- type: mrr_at_10
value: 35.148
- type: mrr_at_100
value: 35.926
- type: mrr_at_1000
value: 35.991
- type: mrr_at_3
value: 32.599000000000004
- type: mrr_at_5
value: 33.893
- type: ndcg_at_1
value: 26.554
- type: ndcg_at_10
value: 38.132
- type: ndcg_at_100
value: 42.78
- type: ndcg_at_1000
value: 44.919
- type: ndcg_at_3
value: 32.833
- type: ndcg_at_5
value: 35.168
- type: precision_at_1
value: 26.554
- type: precision_at_10
value: 5.921
- type: precision_at_100
value: 0.8659999999999999
- type: precision_at_1000
value: 0.109
- type: precision_at_3
value: 13.861
- type: precision_at_5
value: 9.605
- type: recall_at_1
value: 24.587
- type: recall_at_10
value: 51.690000000000005
- type: recall_at_100
value: 73.428
- type: recall_at_1000
value: 89.551
- type: recall_at_3
value: 37.336999999999996
- type: recall_at_5
value: 43.047000000000004
- type: map_at_1
value: 16.715
- type: map_at_10
value: 24.251
- type: map_at_100
value: 25.326999999999998
- type: map_at_1000
value: 25.455
- type: map_at_3
value: 21.912000000000003
- type: map_at_5
value: 23.257
- type: mrr_at_1
value: 20.274
- type: mrr_at_10
value: 28.552
- type: mrr_at_100
value: 29.42
- type: mrr_at_1000
value: 29.497
- type: mrr_at_3
value: 26.14
- type: mrr_at_5
value: 27.502
- type: ndcg_at_1
value: 20.274
- type: ndcg_at_10
value: 29.088
- type: ndcg_at_100
value: 34.293
- type: ndcg_at_1000
value: 37.271
- type: ndcg_at_3
value: 24.708
- type: ndcg_at_5
value: 26.809
- type: precision_at_1
value: 20.274
- type: precision_at_10
value: 5.361
- type: precision_at_100
value: 0.915
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 11.733
- type: precision_at_5
value: 8.556999999999999
- type: recall_at_1
value: 16.715
- type: recall_at_10
value: 39.587
- type: recall_at_100
value: 62.336000000000006
- type: recall_at_1000
value: 83.453
- type: recall_at_3
value: 27.839999999999996
- type: recall_at_5
value: 32.952999999999996
- type: map_at_1
value: 28.793000000000003
- type: map_at_10
value: 38.582
- type: map_at_100
value: 39.881
- type: map_at_1000
value: 39.987
- type: map_at_3
value: 35.851
- type: map_at_5
value: 37.289
- type: mrr_at_1
value: 34.455999999999996
- type: mrr_at_10
value: 43.909
- type: mrr_at_100
value: 44.74
- type: mrr_at_1000
value: 44.786
- type: mrr_at_3
value: 41.659
- type: mrr_at_5
value: 43.010999999999996
- type: ndcg_at_1
value: 34.455999999999996
- type: ndcg_at_10
value: 44.266
- type: ndcg_at_100
value: 49.639
- type: ndcg_at_1000
value: 51.644
- type: ndcg_at_3
value: 39.865
- type: ndcg_at_5
value: 41.887
- type: precision_at_1
value: 34.455999999999996
- type: precision_at_10
value: 7.843999999999999
- type: precision_at_100
value: 1.243
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 18.831999999999997
- type: precision_at_5
value: 13.147
- type: recall_at_1
value: 28.793000000000003
- type: recall_at_10
value: 55.68300000000001
- type: recall_at_100
value: 77.99000000000001
- type: recall_at_1000
value: 91.183
- type: recall_at_3
value: 43.293
- type: recall_at_5
value: 48.618
- type: map_at_1
value: 25.907000000000004
- type: map_at_10
value: 35.519
- type: map_at_100
value: 36.806
- type: map_at_1000
value: 36.912
- type: map_at_3
value: 32.748
- type: map_at_5
value: 34.232
- type: mrr_at_1
value: 31.621
- type: mrr_at_10
value: 40.687
- type: mrr_at_100
value: 41.583
- type: mrr_at_1000
value: 41.638999999999996
- type: mrr_at_3
value: 38.527
- type: mrr_at_5
value: 39.612
- type: ndcg_at_1
value: 31.621
- type: ndcg_at_10
value: 41.003
- type: ndcg_at_100
value: 46.617999999999995
- type: ndcg_at_1000
value: 48.82
- type: ndcg_at_3
value: 36.542
- type: ndcg_at_5
value: 38.368
- type: precision_at_1
value: 31.621
- type: precision_at_10
value: 7.396999999999999
- type: precision_at_100
value: 1.191
- type: precision_at_1000
value: 0.153
- type: precision_at_3
value: 17.39
- type: precision_at_5
value: 12.1
- type: recall_at_1
value: 25.907000000000004
- type: recall_at_10
value: 52.115
- type: recall_at_100
value: 76.238
- type: recall_at_1000
value: 91.218
- type: recall_at_3
value: 39.417
- type: recall_at_5
value: 44.435
- type: map_at_1
value: 25.732166666666668
- type: map_at_10
value: 34.51616666666667
- type: map_at_100
value: 35.67241666666666
- type: map_at_1000
value: 35.78675
- type: map_at_3
value: 31.953416666666662
- type: map_at_5
value: 33.333
- type: mrr_at_1
value: 30.300166666666673
- type: mrr_at_10
value: 38.6255
- type: mrr_at_100
value: 39.46183333333334
- type: mrr_at_1000
value: 39.519999999999996
- type: mrr_at_3
value: 36.41299999999999
- type: mrr_at_5
value: 37.6365
- type: ndcg_at_1
value: 30.300166666666673
- type: ndcg_at_10
value: 39.61466666666667
- type: ndcg_at_100
value: 44.60808333333334
- type: ndcg_at_1000
value: 46.91708333333334
- type: ndcg_at_3
value: 35.26558333333333
- type: ndcg_at_5
value: 37.220000000000006
- type: precision_at_1
value: 30.300166666666673
- type: precision_at_10
value: 6.837416666666667
- type: precision_at_100
value: 1.10425
- type: precision_at_1000
value: 0.14875
- type: precision_at_3
value: 16.13716666666667
- type: precision_at_5
value: 11.2815
- type: recall_at_1
value: 25.732166666666668
- type: recall_at_10
value: 50.578916666666665
- type: recall_at_100
value: 72.42183333333334
- type: recall_at_1000
value: 88.48766666666667
- type: recall_at_3
value: 38.41325
- type: recall_at_5
value: 43.515750000000004
- type: map_at_1
value: 23.951
- type: map_at_10
value: 30.974
- type: map_at_100
value: 31.804
- type: map_at_1000
value: 31.900000000000002
- type: map_at_3
value: 28.762
- type: map_at_5
value: 29.94
- type: mrr_at_1
value: 26.534000000000002
- type: mrr_at_10
value: 33.553
- type: mrr_at_100
value: 34.297
- type: mrr_at_1000
value: 34.36
- type: mrr_at_3
value: 31.391000000000002
- type: mrr_at_5
value: 32.525999999999996
- type: ndcg_at_1
value: 26.534000000000002
- type: ndcg_at_10
value: 35.112
- type: ndcg_at_100
value: 39.28
- type: ndcg_at_1000
value: 41.723
- type: ndcg_at_3
value: 30.902
- type: ndcg_at_5
value: 32.759
- type: precision_at_1
value: 26.534000000000002
- type: precision_at_10
value: 5.445
- type: precision_at_100
value: 0.819
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 12.986
- type: precision_at_5
value: 9.049
- type: recall_at_1
value: 23.951
- type: recall_at_10
value: 45.24
- type: recall_at_100
value: 64.12299999999999
- type: recall_at_1000
value: 82.28999999999999
- type: recall_at_3
value: 33.806000000000004
- type: recall_at_5
value: 38.277
- type: map_at_1
value: 16.829
- type: map_at_10
value: 23.684
- type: map_at_100
value: 24.683
- type: map_at_1000
value: 24.81
- type: map_at_3
value: 21.554000000000002
- type: map_at_5
value: 22.768
- type: mrr_at_1
value: 20.096
- type: mrr_at_10
value: 27.230999999999998
- type: mrr_at_100
value: 28.083999999999996
- type: mrr_at_1000
value: 28.166000000000004
- type: mrr_at_3
value: 25.212
- type: mrr_at_5
value: 26.32
- type: ndcg_at_1
value: 20.096
- type: ndcg_at_10
value: 27.989000000000004
- type: ndcg_at_100
value: 32.847
- type: ndcg_at_1000
value: 35.896
- type: ndcg_at_3
value: 24.116
- type: ndcg_at_5
value: 25.964
- type: precision_at_1
value: 20.096
- type: precision_at_10
value: 5
- type: precision_at_100
value: 0.8750000000000001
- type: precision_at_1000
value: 0.131
- type: precision_at_3
value: 11.207
- type: precision_at_5
value: 8.08
- type: recall_at_1
value: 16.829
- type: recall_at_10
value: 37.407000000000004
- type: recall_at_100
value: 59.101000000000006
- type: recall_at_1000
value: 81.024
- type: recall_at_3
value: 26.739
- type: recall_at_5
value: 31.524
- type: map_at_1
value: 24.138
- type: map_at_10
value: 32.275999999999996
- type: map_at_100
value: 33.416000000000004
- type: map_at_1000
value: 33.527
- type: map_at_3
value: 29.854000000000003
- type: map_at_5
value: 31.096
- type: mrr_at_1
value: 28.450999999999997
- type: mrr_at_10
value: 36.214
- type: mrr_at_100
value: 37.134
- type: mrr_at_1000
value: 37.198
- type: mrr_at_3
value: 34.001999999999995
- type: mrr_at_5
value: 35.187000000000005
- type: ndcg_at_1
value: 28.450999999999997
- type: ndcg_at_10
value: 37.166
- type: ndcg_at_100
value: 42.454
- type: ndcg_at_1000
value: 44.976
- type: ndcg_at_3
value: 32.796
- type: ndcg_at_5
value: 34.631
- type: precision_at_1
value: 28.450999999999997
- type: precision_at_10
value: 6.241
- type: precision_at_100
value: 0.9950000000000001
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 14.801
- type: precision_at_5
value: 10.280000000000001
- type: recall_at_1
value: 24.138
- type: recall_at_10
value: 48.111
- type: recall_at_100
value: 71.245
- type: recall_at_1000
value: 88.986
- type: recall_at_3
value: 36.119
- type: recall_at_5
value: 40.846
- type: map_at_1
value: 23.244
- type: map_at_10
value: 31.227
- type: map_at_100
value: 33.007
- type: map_at_1000
value: 33.223
- type: map_at_3
value: 28.924
- type: map_at_5
value: 30.017
- type: mrr_at_1
value: 27.668
- type: mrr_at_10
value: 35.524
- type: mrr_at_100
value: 36.699
- type: mrr_at_1000
value: 36.759
- type: mrr_at_3
value: 33.366
- type: mrr_at_5
value: 34.552
- type: ndcg_at_1
value: 27.668
- type: ndcg_at_10
value: 36.381
- type: ndcg_at_100
value: 43.062
- type: ndcg_at_1000
value: 45.656
- type: ndcg_at_3
value: 32.501999999999995
- type: ndcg_at_5
value: 34.105999999999995
- type: precision_at_1
value: 27.668
- type: precision_at_10
value: 6.798
- type: precision_at_100
value: 1.492
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 15.152
- type: precision_at_5
value: 10.791
- type: recall_at_1
value: 23.244
- type: recall_at_10
value: 45.979
- type: recall_at_100
value: 74.822
- type: recall_at_1000
value: 91.078
- type: recall_at_3
value: 34.925
- type: recall_at_5
value: 39.126
- type: map_at_1
value: 19.945
- type: map_at_10
value: 27.517999999999997
- type: map_at_100
value: 28.588
- type: map_at_1000
value: 28.682000000000002
- type: map_at_3
value: 25.345000000000002
- type: map_at_5
value: 26.555
- type: mrr_at_1
value: 21.996
- type: mrr_at_10
value: 29.845
- type: mrr_at_100
value: 30.775999999999996
- type: mrr_at_1000
value: 30.845
- type: mrr_at_3
value: 27.726
- type: mrr_at_5
value: 28.882
- type: ndcg_at_1
value: 21.996
- type: ndcg_at_10
value: 32.034
- type: ndcg_at_100
value: 37.185
- type: ndcg_at_1000
value: 39.645
- type: ndcg_at_3
value: 27.750999999999998
- type: ndcg_at_5
value: 29.805999999999997
- type: precision_at_1
value: 21.996
- type: precision_at_10
value: 5.065
- type: precision_at_100
value: 0.819
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 12.076
- type: precision_at_5
value: 8.392
- type: recall_at_1
value: 19.945
- type: recall_at_10
value: 43.62
- type: recall_at_100
value: 67.194
- type: recall_at_1000
value: 85.7
- type: recall_at_3
value: 32.15
- type: recall_at_5
value: 37.208999999999996
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.279
- type: map_at_10
value: 31.052999999999997
- type: map_at_100
value: 33.125
- type: map_at_1000
value: 33.306000000000004
- type: map_at_3
value: 26.208
- type: map_at_5
value: 28.857
- type: mrr_at_1
value: 42.671
- type: mrr_at_10
value: 54.557
- type: mrr_at_100
value: 55.142
- type: mrr_at_1000
value: 55.169000000000004
- type: mrr_at_3
value: 51.488
- type: mrr_at_5
value: 53.439
- type: ndcg_at_1
value: 42.671
- type: ndcg_at_10
value: 41.276
- type: ndcg_at_100
value: 48.376000000000005
- type: ndcg_at_1000
value: 51.318
- type: ndcg_at_3
value: 35.068
- type: ndcg_at_5
value: 37.242
- type: precision_at_1
value: 42.671
- type: precision_at_10
value: 12.638
- type: precision_at_100
value: 2.045
- type: precision_at_1000
value: 0.26
- type: precision_at_3
value: 26.08
- type: precision_at_5
value: 19.805
- type: recall_at_1
value: 18.279
- type: recall_at_10
value: 46.946
- type: recall_at_100
value: 70.97200000000001
- type: recall_at_1000
value: 87.107
- type: recall_at_3
value: 31.147999999999996
- type: recall_at_5
value: 38.099
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.573
- type: map_at_10
value: 19.747
- type: map_at_100
value: 28.205000000000002
- type: map_at_1000
value: 29.831000000000003
- type: map_at_3
value: 14.109
- type: map_at_5
value: 16.448999999999998
- type: mrr_at_1
value: 71
- type: mrr_at_10
value: 77.68599999999999
- type: mrr_at_100
value: 77.995
- type: mrr_at_1000
value: 78.00200000000001
- type: mrr_at_3
value: 76.292
- type: mrr_at_5
value: 77.029
- type: ndcg_at_1
value: 59.12500000000001
- type: ndcg_at_10
value: 43.9
- type: ndcg_at_100
value: 47.863
- type: ndcg_at_1000
value: 54.848
- type: ndcg_at_3
value: 49.803999999999995
- type: ndcg_at_5
value: 46.317
- type: precision_at_1
value: 71
- type: precision_at_10
value: 34.4
- type: precision_at_100
value: 11.063
- type: precision_at_1000
value: 1.989
- type: precision_at_3
value: 52.333
- type: precision_at_5
value: 43.7
- type: recall_at_1
value: 8.573
- type: recall_at_10
value: 25.615
- type: recall_at_100
value: 53.385000000000005
- type: recall_at_1000
value: 75.46000000000001
- type: recall_at_3
value: 15.429
- type: recall_at_5
value: 19.357
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 47.989999999999995
- type: f1
value: 42.776314451497555
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 74.13499999999999
- type: map_at_10
value: 82.825
- type: map_at_100
value: 83.096
- type: map_at_1000
value: 83.111
- type: map_at_3
value: 81.748
- type: map_at_5
value: 82.446
- type: mrr_at_1
value: 79.553
- type: mrr_at_10
value: 86.654
- type: mrr_at_100
value: 86.774
- type: mrr_at_1000
value: 86.778
- type: mrr_at_3
value: 85.981
- type: mrr_at_5
value: 86.462
- type: ndcg_at_1
value: 79.553
- type: ndcg_at_10
value: 86.345
- type: ndcg_at_100
value: 87.32
- type: ndcg_at_1000
value: 87.58200000000001
- type: ndcg_at_3
value: 84.719
- type: ndcg_at_5
value: 85.677
- type: precision_at_1
value: 79.553
- type: precision_at_10
value: 10.402000000000001
- type: precision_at_100
value: 1.1119999999999999
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 32.413
- type: precision_at_5
value: 20.138
- type: recall_at_1
value: 74.13499999999999
- type: recall_at_10
value: 93.215
- type: recall_at_100
value: 97.083
- type: recall_at_1000
value: 98.732
- type: recall_at_3
value: 88.79
- type: recall_at_5
value: 91.259
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.298000000000002
- type: map_at_10
value: 29.901
- type: map_at_100
value: 31.528
- type: map_at_1000
value: 31.713
- type: map_at_3
value: 25.740000000000002
- type: map_at_5
value: 28.227999999999998
- type: mrr_at_1
value: 36.728
- type: mrr_at_10
value: 45.401
- type: mrr_at_100
value: 46.27
- type: mrr_at_1000
value: 46.315
- type: mrr_at_3
value: 42.978
- type: mrr_at_5
value: 44.29
- type: ndcg_at_1
value: 36.728
- type: ndcg_at_10
value: 37.456
- type: ndcg_at_100
value: 43.832
- type: ndcg_at_1000
value: 47
- type: ndcg_at_3
value: 33.694
- type: ndcg_at_5
value: 35.085
- type: precision_at_1
value: 36.728
- type: precision_at_10
value: 10.386
- type: precision_at_100
value: 1.701
- type: precision_at_1000
value: 0.22599999999999998
- type: precision_at_3
value: 22.479
- type: precision_at_5
value: 16.605
- type: recall_at_1
value: 18.298000000000002
- type: recall_at_10
value: 44.369
- type: recall_at_100
value: 68.098
- type: recall_at_1000
value: 87.21900000000001
- type: recall_at_3
value: 30.215999999999998
- type: recall_at_5
value: 36.861
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.568
- type: map_at_10
value: 65.061
- type: map_at_100
value: 65.896
- type: map_at_1000
value: 65.95100000000001
- type: map_at_3
value: 61.831
- type: map_at_5
value: 63.849000000000004
- type: mrr_at_1
value: 79.136
- type: mrr_at_10
value: 84.58200000000001
- type: mrr_at_100
value: 84.765
- type: mrr_at_1000
value: 84.772
- type: mrr_at_3
value: 83.684
- type: mrr_at_5
value: 84.223
- type: ndcg_at_1
value: 79.136
- type: ndcg_at_10
value: 72.622
- type: ndcg_at_100
value: 75.539
- type: ndcg_at_1000
value: 76.613
- type: ndcg_at_3
value: 68.065
- type: ndcg_at_5
value: 70.58
- type: precision_at_1
value: 79.136
- type: precision_at_10
value: 15.215
- type: precision_at_100
value: 1.7500000000000002
- type: precision_at_1000
value: 0.189
- type: precision_at_3
value: 44.011
- type: precision_at_5
value: 28.388999999999996
- type: recall_at_1
value: 39.568
- type: recall_at_10
value: 76.077
- type: recall_at_100
value: 87.481
- type: recall_at_1000
value: 94.56400000000001
- type: recall_at_3
value: 66.01599999999999
- type: recall_at_5
value: 70.97200000000001
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 85.312
- type: ap
value: 80.36296867333715
- type: f1
value: 85.26613311552218
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 23.363999999999997
- type: map_at_10
value: 35.711999999999996
- type: map_at_100
value: 36.876999999999995
- type: map_at_1000
value: 36.923
- type: map_at_3
value: 32.034
- type: map_at_5
value: 34.159
- type: mrr_at_1
value: 24.04
- type: mrr_at_10
value: 36.345
- type: mrr_at_100
value: 37.441
- type: mrr_at_1000
value: 37.480000000000004
- type: mrr_at_3
value: 32.713
- type: mrr_at_5
value: 34.824
- type: ndcg_at_1
value: 24.026
- type: ndcg_at_10
value: 42.531
- type: ndcg_at_100
value: 48.081
- type: ndcg_at_1000
value: 49.213
- type: ndcg_at_3
value: 35.044
- type: ndcg_at_5
value: 38.834
- type: precision_at_1
value: 24.026
- type: precision_at_10
value: 6.622999999999999
- type: precision_at_100
value: 0.941
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.909
- type: precision_at_5
value: 10.871
- type: recall_at_1
value: 23.363999999999997
- type: recall_at_10
value: 63.426
- type: recall_at_100
value: 88.96300000000001
- type: recall_at_1000
value: 97.637
- type: recall_at_3
value: 43.095
- type: recall_at_5
value: 52.178000000000004
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.0095759233926
- type: f1
value: 92.78387794667408
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.0296397628819
- type: f1
value: 58.45699589820874
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.45662407531944
- type: f1
value: 71.42364781421813
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.07800941492937
- type: f1
value: 77.22799045640845
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 34.531234379250606
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 30.941490381193802
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.3115090856725
- type: mrr
value: 31.290667638675757
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.465
- type: map_at_10
value: 13.03
- type: map_at_100
value: 16.057
- type: map_at_1000
value: 17.49
- type: map_at_3
value: 9.553
- type: map_at_5
value: 11.204
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 53.269
- type: mrr_at_100
value: 53.72
- type: mrr_at_1000
value: 53.761
- type: mrr_at_3
value: 50.929
- type: mrr_at_5
value: 52.461
- type: ndcg_at_1
value: 42.26
- type: ndcg_at_10
value: 34.673
- type: ndcg_at_100
value: 30.759999999999998
- type: ndcg_at_1000
value: 39.728
- type: ndcg_at_3
value: 40.349000000000004
- type: ndcg_at_5
value: 37.915
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 25.789
- type: precision_at_100
value: 7.754999999999999
- type: precision_at_1000
value: 2.07
- type: precision_at_3
value: 38.596000000000004
- type: precision_at_5
value: 33.251
- type: recall_at_1
value: 5.465
- type: recall_at_10
value: 17.148
- type: recall_at_100
value: 29.768
- type: recall_at_1000
value: 62.239
- type: recall_at_3
value: 10.577
- type: recall_at_5
value: 13.315
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.008
- type: map_at_10
value: 52.467
- type: map_at_100
value: 53.342999999999996
- type: map_at_1000
value: 53.366
- type: map_at_3
value: 48.412
- type: map_at_5
value: 50.875
- type: mrr_at_1
value: 41.541
- type: mrr_at_10
value: 54.967
- type: mrr_at_100
value: 55.611
- type: mrr_at_1000
value: 55.627
- type: mrr_at_3
value: 51.824999999999996
- type: mrr_at_5
value: 53.763000000000005
- type: ndcg_at_1
value: 41.541
- type: ndcg_at_10
value: 59.724999999999994
- type: ndcg_at_100
value: 63.38700000000001
- type: ndcg_at_1000
value: 63.883
- type: ndcg_at_3
value: 52.331
- type: ndcg_at_5
value: 56.327000000000005
- type: precision_at_1
value: 41.541
- type: precision_at_10
value: 9.447
- type: precision_at_100
value: 1.1520000000000001
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.262
- type: precision_at_5
value: 16.314999999999998
- type: recall_at_1
value: 37.008
- type: recall_at_10
value: 79.145
- type: recall_at_100
value: 94.986
- type: recall_at_1000
value: 98.607
- type: recall_at_3
value: 60.277
- type: recall_at_5
value: 69.407
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.402
- type: map_at_10
value: 84.181
- type: map_at_100
value: 84.796
- type: map_at_1000
value: 84.81400000000001
- type: map_at_3
value: 81.209
- type: map_at_5
value: 83.085
- type: mrr_at_1
value: 81.02000000000001
- type: mrr_at_10
value: 87.263
- type: mrr_at_100
value: 87.36
- type: mrr_at_1000
value: 87.36
- type: mrr_at_3
value: 86.235
- type: mrr_at_5
value: 86.945
- type: ndcg_at_1
value: 81.01
- type: ndcg_at_10
value: 87.99900000000001
- type: ndcg_at_100
value: 89.217
- type: ndcg_at_1000
value: 89.33
- type: ndcg_at_3
value: 85.053
- type: ndcg_at_5
value: 86.703
- type: precision_at_1
value: 81.01
- type: precision_at_10
value: 13.336
- type: precision_at_100
value: 1.52
- type: precision_at_1000
value: 0.156
- type: precision_at_3
value: 37.14
- type: precision_at_5
value: 24.44
- type: recall_at_1
value: 70.402
- type: recall_at_10
value: 95.214
- type: recall_at_100
value: 99.438
- type: recall_at_1000
value: 99.928
- type: recall_at_3
value: 86.75699999999999
- type: recall_at_5
value: 91.44099999999999
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 56.51721502758904
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 61.054808572333016
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.578
- type: map_at_10
value: 11.036999999999999
- type: map_at_100
value: 12.879999999999999
- type: map_at_1000
value: 13.150999999999998
- type: map_at_3
value: 8.133
- type: map_at_5
value: 9.559
- type: mrr_at_1
value: 22.6
- type: mrr_at_10
value: 32.68
- type: mrr_at_100
value: 33.789
- type: mrr_at_1000
value: 33.854
- type: mrr_at_3
value: 29.7
- type: mrr_at_5
value: 31.480000000000004
- type: ndcg_at_1
value: 22.6
- type: ndcg_at_10
value: 18.616
- type: ndcg_at_100
value: 25.883
- type: ndcg_at_1000
value: 30.944
- type: ndcg_at_3
value: 18.136
- type: ndcg_at_5
value: 15.625
- type: precision_at_1
value: 22.6
- type: precision_at_10
value: 9.48
- type: precision_at_100
value: 1.991
- type: precision_at_1000
value: 0.321
- type: precision_at_3
value: 16.8
- type: precision_at_5
value: 13.54
- type: recall_at_1
value: 4.578
- type: recall_at_10
value: 19.213
- type: recall_at_100
value: 40.397
- type: recall_at_1000
value: 65.2
- type: recall_at_3
value: 10.208
- type: recall_at_5
value: 13.718
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 83.44288351714071
- type: cos_sim_spearman
value: 79.37995604564952
- type: euclidean_pearson
value: 81.1078874670718
- type: euclidean_spearman
value: 79.37995905980499
- type: manhattan_pearson
value: 81.03697527288986
- type: manhattan_spearman
value: 79.33490235296236
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.95557650436523
- type: cos_sim_spearman
value: 78.5190672399868
- type: euclidean_pearson
value: 81.58064025904707
- type: euclidean_spearman
value: 78.5190672399868
- type: manhattan_pearson
value: 81.52857930619889
- type: manhattan_spearman
value: 78.50421361308034
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 84.79128416228737
- type: cos_sim_spearman
value: 86.05402451477147
- type: euclidean_pearson
value: 85.46280267054289
- type: euclidean_spearman
value: 86.05402451477147
- type: manhattan_pearson
value: 85.46278563858236
- type: manhattan_spearman
value: 86.08079590861004
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 83.20623089568763
- type: cos_sim_spearman
value: 81.53786907061009
- type: euclidean_pearson
value: 82.82272250091494
- type: euclidean_spearman
value: 81.53786907061009
- type: manhattan_pearson
value: 82.78850494027013
- type: manhattan_spearman
value: 81.5135618083407
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 85.46366618397936
- type: cos_sim_spearman
value: 86.96566013336908
- type: euclidean_pearson
value: 86.62651697548931
- type: euclidean_spearman
value: 86.96565526364454
- type: manhattan_pearson
value: 86.58812160258009
- type: manhattan_spearman
value: 86.9336484321288
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 82.51858358641559
- type: cos_sim_spearman
value: 84.7652527954999
- type: euclidean_pearson
value: 84.23914783766861
- type: euclidean_spearman
value: 84.7652527954999
- type: manhattan_pearson
value: 84.22749648503171
- type: manhattan_spearman
value: 84.74527996746386
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.28026563313065
- type: cos_sim_spearman
value: 87.46928143824915
- type: euclidean_pearson
value: 88.30558762000372
- type: euclidean_spearman
value: 87.46928143824915
- type: manhattan_pearson
value: 88.10513330809331
- type: manhattan_spearman
value: 87.21069787834173
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 62.376497134587375
- type: cos_sim_spearman
value: 65.0159550112516
- type: euclidean_pearson
value: 65.64572120879598
- type: euclidean_spearman
value: 65.0159550112516
- type: manhattan_pearson
value: 65.88143604989976
- type: manhattan_spearman
value: 65.17547297222434
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.22876368947644
- type: cos_sim_spearman
value: 85.46935577445318
- type: euclidean_pearson
value: 85.32830231392005
- type: euclidean_spearman
value: 85.46935577445318
- type: manhattan_pearson
value: 85.30353211758495
- type: manhattan_spearman
value: 85.42821085956945
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 80.60986667767133
- type: mrr
value: 94.29432314236236
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 54.528
- type: map_at_10
value: 65.187
- type: map_at_100
value: 65.62599999999999
- type: map_at_1000
value: 65.657
- type: map_at_3
value: 62.352
- type: map_at_5
value: 64.025
- type: mrr_at_1
value: 57.333
- type: mrr_at_10
value: 66.577
- type: mrr_at_100
value: 66.88
- type: mrr_at_1000
value: 66.908
- type: mrr_at_3
value: 64.556
- type: mrr_at_5
value: 65.739
- type: ndcg_at_1
value: 57.333
- type: ndcg_at_10
value: 70.275
- type: ndcg_at_100
value: 72.136
- type: ndcg_at_1000
value: 72.963
- type: ndcg_at_3
value: 65.414
- type: ndcg_at_5
value: 67.831
- type: precision_at_1
value: 57.333
- type: precision_at_10
value: 9.5
- type: precision_at_100
value: 1.057
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 25.778000000000002
- type: precision_at_5
value: 17.2
- type: recall_at_1
value: 54.528
- type: recall_at_10
value: 84.356
- type: recall_at_100
value: 92.833
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 71.283
- type: recall_at_5
value: 77.14999999999999
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.74158415841585
- type: cos_sim_ap
value: 92.90048959850317
- type: cos_sim_f1
value: 86.35650810245687
- type: cos_sim_precision
value: 90.4709748083242
- type: cos_sim_recall
value: 82.6
- type: dot_accuracy
value: 99.74158415841585
- type: dot_ap
value: 92.90048959850317
- type: dot_f1
value: 86.35650810245687
- type: dot_precision
value: 90.4709748083242
- type: dot_recall
value: 82.6
- type: euclidean_accuracy
value: 99.74158415841585
- type: euclidean_ap
value: 92.90048959850317
- type: euclidean_f1
value: 86.35650810245687
- type: euclidean_precision
value: 90.4709748083242
- type: euclidean_recall
value: 82.6
- type: manhattan_accuracy
value: 99.74158415841585
- type: manhattan_ap
value: 92.87344692947894
- type: manhattan_f1
value: 86.38497652582159
- type: manhattan_precision
value: 90.29443838604145
- type: manhattan_recall
value: 82.8
- type: max_accuracy
value: 99.74158415841585
- type: max_ap
value: 92.90048959850317
- type: max_f1
value: 86.38497652582159
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 63.191648770424216
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.02944668730218
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 50.466386167525265
- type: mrr
value: 51.19071492233257
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.198022505886435
- type: cos_sim_spearman
value: 30.40170257939193
- type: dot_pearson
value: 30.198015316402614
- type: dot_spearman
value: 30.40170257939193
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.242
- type: map_at_10
value: 2.17
- type: map_at_100
value: 12.221
- type: map_at_1000
value: 28.63
- type: map_at_3
value: 0.728
- type: map_at_5
value: 1.185
- type: mrr_at_1
value: 94
- type: mrr_at_10
value: 97
- type: mrr_at_100
value: 97
- type: mrr_at_1000
value: 97
- type: mrr_at_3
value: 97
- type: mrr_at_5
value: 97
- type: ndcg_at_1
value: 89
- type: ndcg_at_10
value: 82.30499999999999
- type: ndcg_at_100
value: 61.839999999999996
- type: ndcg_at_1000
value: 53.381
- type: ndcg_at_3
value: 88.877
- type: ndcg_at_5
value: 86.05199999999999
- type: precision_at_1
value: 94
- type: precision_at_10
value: 87
- type: precision_at_100
value: 63.38
- type: precision_at_1000
value: 23.498
- type: precision_at_3
value: 94
- type: precision_at_5
value: 92
- type: recall_at_1
value: 0.242
- type: recall_at_10
value: 2.302
- type: recall_at_100
value: 14.979000000000001
- type: recall_at_1000
value: 49.638
- type: recall_at_3
value: 0.753
- type: recall_at_5
value: 1.226
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.006
- type: map_at_10
value: 11.805
- type: map_at_100
value: 18.146
- type: map_at_1000
value: 19.788
- type: map_at_3
value: 5.914
- type: map_at_5
value: 8.801
- type: mrr_at_1
value: 40.816
- type: mrr_at_10
value: 56.36600000000001
- type: mrr_at_100
value: 56.721999999999994
- type: mrr_at_1000
value: 56.721999999999994
- type: mrr_at_3
value: 52.041000000000004
- type: mrr_at_5
value: 54.796
- type: ndcg_at_1
value: 37.755
- type: ndcg_at_10
value: 29.863
- type: ndcg_at_100
value: 39.571
- type: ndcg_at_1000
value: 51.385999999999996
- type: ndcg_at_3
value: 32.578
- type: ndcg_at_5
value: 32.351
- type: precision_at_1
value: 40.816
- type: precision_at_10
value: 26.531
- type: precision_at_100
value: 7.796
- type: precision_at_1000
value: 1.555
- type: precision_at_3
value: 32.653
- type: precision_at_5
value: 33.061
- type: recall_at_1
value: 3.006
- type: recall_at_10
value: 18.738
- type: recall_at_100
value: 48.058
- type: recall_at_1000
value: 83.41300000000001
- type: recall_at_3
value: 7.166
- type: recall_at_5
value: 12.102
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.4178
- type: ap
value: 14.648781342150446
- type: f1
value: 55.07299194946378
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 60.919637804187886
- type: f1
value: 61.24122013967399
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.207896583685695
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.23114978840078
- type: cos_sim_ap
value: 74.26624727825818
- type: cos_sim_f1
value: 68.72377190817083
- type: cos_sim_precision
value: 64.56400742115028
- type: cos_sim_recall
value: 73.45646437994723
- type: dot_accuracy
value: 86.23114978840078
- type: dot_ap
value: 74.26624032659652
- type: dot_f1
value: 68.72377190817083
- type: dot_precision
value: 64.56400742115028
- type: dot_recall
value: 73.45646437994723
- type: euclidean_accuracy
value: 86.23114978840078
- type: euclidean_ap
value: 74.26624714480556
- type: euclidean_f1
value: 68.72377190817083
- type: euclidean_precision
value: 64.56400742115028
- type: euclidean_recall
value: 73.45646437994723
- type: manhattan_accuracy
value: 86.16558383501221
- type: manhattan_ap
value: 74.2091943976357
- type: manhattan_f1
value: 68.64221520524654
- type: manhattan_precision
value: 63.59135913591359
- type: manhattan_recall
value: 74.5646437994723
- type: max_accuracy
value: 86.23114978840078
- type: max_ap
value: 74.26624727825818
- type: max_f1
value: 68.72377190817083
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.3681841114604
- type: cos_sim_ap
value: 86.65166387498546
- type: cos_sim_f1
value: 79.02581944698774
- type: cos_sim_precision
value: 75.35796605434099
- type: cos_sim_recall
value: 83.06898675700647
- type: dot_accuracy
value: 89.3681841114604
- type: dot_ap
value: 86.65166019802056
- type: dot_f1
value: 79.02581944698774
- type: dot_precision
value: 75.35796605434099
- type: dot_recall
value: 83.06898675700647
- type: euclidean_accuracy
value: 89.3681841114604
- type: euclidean_ap
value: 86.65166462876266
- type: euclidean_f1
value: 79.02581944698774
- type: euclidean_precision
value: 75.35796605434099
- type: euclidean_recall
value: 83.06898675700647
- type: manhattan_accuracy
value: 89.36624364497226
- type: manhattan_ap
value: 86.65076471274106
- type: manhattan_f1
value: 79.07408783532733
- type: manhattan_precision
value: 76.41102972856527
- type: manhattan_recall
value: 81.92947336002464
- type: max_accuracy
value: 89.3681841114604
- type: max_ap
value: 86.65166462876266
- type: max_f1
value: 79.07408783532733
---
# BenevolenceMessiah/nomic-embed-text-v1.5-Q8_0-GGUF
This model was converted to GGUF format from [`nomic-ai/nomic-embed-text-v1.5`](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo BenevolenceMessiah/nomic-embed-text-v1.5-Q8_0-GGUF --hf-file nomic-embed-text-v1.5-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo BenevolenceMessiah/nomic-embed-text-v1.5-Q8_0-GGUF --hf-file nomic-embed-text-v1.5-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo BenevolenceMessiah/nomic-embed-text-v1.5-Q8_0-GGUF --hf-file nomic-embed-text-v1.5-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo BenevolenceMessiah/nomic-embed-text-v1.5-Q8_0-GGUF --hf-file nomic-embed-text-v1.5-q8_0.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
Norod78/ms-fluentui-style-emoji-flux
|
Norod78
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"migrated",
"emoji",
"style",
"fluentui",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | 2024-12-15T11:37:09Z |
2024-12-15T11:48:37+00:00
| 44 | 0 |
---
base_model: black-forest-labs/FLUX.1-dev
license: other
license_name: bespoke-lora-trained-license
license_link: https://multimodal.art/civitai-licenses?allowNoCredit=True&allowCommercialUse=Image&allowDerivatives=True&allowDifferentLicense=False
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
- migrated
- emoji
- style
- fluentui
instance_prompt: emoji
widget:
- text: 'The girl with a pearl earring emoji '
output:
url: 45639568.jpeg
- text: 'Marge Simpson emoji '
output:
url: 45639566.jpeg
- text: 'The Starry Night by Vincent van Gogh emoji '
output:
url: 45639567.jpeg
- text: 'emoji woman playing the guitar, on stage, singing a song, laser lights, punk
rocker '
output:
url: 45639565.jpeg
- text: 'emoji woman with red hair, playing chess at the park, bomb going off in the
background '
output:
url: 45639569.jpeg
- text: 'emoji horse is a DJ at a night club, fish eye lens, smoke machine, lazer
lights, holding a martini '
output:
url: 45639571.jpeg
- text: 'A cute dog emoji '
output:
url: 45639564.jpeg
- text: 'Snoop Dogg emoji '
output:
url: 45639572.jpeg
- text: 'Wonderwoman emoji '
output:
url: 45639574.jpeg
- text: 'American gothic by Grant Wood emoji '
output:
url: 45639570.jpeg
- text: 'Elsa from frozen emoji '
output:
url: 45639573.jpeg
- text: 'emoji bear building a log cabin in the snow covered mountains '
output:
url: 45639575.jpeg
- text: 'emoji man showing off his cool new t shirt at the beach, a shark is jumping
out of the water in the background '
output:
url: 45639577.jpeg
- text: 'Rick Sanchez emoji '
output:
url: 45639578.jpeg
- text: very silly emoji
output:
url: images/example_tcm6dt59t.png
---
# ms fluentui style Emoji [FLUX]
<Gallery />
([CivitAI](https://civitai.com/models/1039822))
## Model description
<p>Trained upon <a rel="ugc" href="https://github.com/microsoft/fluentui-emoji/tree/main">Microsoft's FluentUI</a>'s 3D Emoji asset collection. Trained with captions where each caption was the original file name with 'emoji' appended to it. So <strong>use <em>emoji </em>in your prompts</strong> to trigger the style. I'm aware that Flux is already very good with generating. emoji but I wanted to see how it will adapt to MS's FluentUI's style:</p><p><img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/e053dc92-42ee-4cdc-9740-94c5a8afd0ff/width=525/e053dc92-42ee-4cdc-9740-94c5a8afd0ff.jpeg" />For reasons I could not figure (or solve), it will generate a very blurry result on occasion. I was not able to find any solution to this other than simply trying again with a different seed. Sorry for that</p>
## Trigger words
You should use `emoji` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/Norod78/ms-fluentui-style-emoji-flux/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.bfloat16).to(device)
pipeline.load_lora_weights('Norod78/ms-fluentui-style-emoji-flux', weight_name='ms-fluentui_emoji_flux_lora_000001750.safetensors')
image = pipeline('Rick Sanchez emoji ').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
[
"BEAR"
] |
BigSalmon/InformalToFormalLincoln81ParaphraseMedium
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-09-25T02:14:22Z |
2022-09-25T02:27:53+00:00
| 43 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln80Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln80Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
informal english: i reached out to accounts who had a lot of followers, helping to make people know about us.
resume english: i partnered with prominent influencers to build brand awareness.
***
```
|
[
"BEAR"
] |
yongzx/pythia-1b-sft-hh
|
yongzx
|
text-generation
|
[
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-08-23T11:09:39Z |
2023-08-28T18:52:19+00:00
| 43 | 1 |
---
{}
---
wandb: https://wandb.ai/eleutherai/pythia-rlhf/runs/6y83ekqy?workspace=user-yongzx
Model Evals
| Task |Version|Filter| Metric |Value | |Stderr|
|--------------|-------|------|----------|-----:|---|-----:|
|arc_challenge |Yaml |none |acc |0.2526|± |0.0127|
| | |none |acc_norm |0.2773|± |0.0131|
|arc_easy |Yaml |none |acc |0.5791|± |0.0101|
| | |none |acc_norm |0.4912|± |0.0103|
|lambada_openai|Yaml |none |perplexity|7.0516|± |0.1979|
| | |none |acc |0.5684|± |0.0069|
|logiqa |Yaml |none |acc |0.2166|± |0.0162|
| | |none |acc_norm |0.2919|± |0.0178|
|piqa |Yaml |none |acc |0.7176|± |0.0105|
| | |none |acc_norm |0.6964|± |0.0107|
|sciq |Yaml |none |acc |0.8460|± |0.0114|
| | |none |acc_norm |0.7700|± |0.0133|
|winogrande |Yaml |none |acc |0.5399|± |0.0140|
|wsc |Yaml |none |acc |0.3654|± |0.0474|
|
[
"SCIQ"
] |
ntc-ai/SDXL-LoRA-slider.passionate
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-20T22:38:29Z |
2023-12-20T22:38:32+00:00
| 43 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/passionate...passionless/passionate_17_3.0.png
widget:
- text: passionate
output:
url: images/passionate_17_3.0.png
- text: passionate
output:
url: images/passionate_19_3.0.png
- text: passionate
output:
url: images/passionate_20_3.0.png
- text: passionate
output:
url: images/passionate_21_3.0.png
- text: passionate
output:
url: images/passionate_22_3.0.png
inference: false
instance_prompt: passionate
---
# ntcai.xyz slider - passionate (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/passionate_17_-3.0.png" width=256 height=256 /> | <img src="images/passionate_17_0.0.png" width=256 height=256 /> | <img src="images/passionate_17_3.0.png" width=256 height=256 /> |
| <img src="images/passionate_19_-3.0.png" width=256 height=256 /> | <img src="images/passionate_19_0.0.png" width=256 height=256 /> | <img src="images/passionate_19_3.0.png" width=256 height=256 /> |
| <img src="images/passionate_20_-3.0.png" width=256 height=256 /> | <img src="images/passionate_20_0.0.png" width=256 height=256 /> | <img src="images/passionate_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
passionate
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.passionate', weight_name='passionate.safetensors', adapter_name="passionate")
# Activate the LoRA
pipe.set_adapters(["passionate"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, passionate"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 510+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.scared
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-31T22:58:32Z |
2023-12-31T22:58:35+00:00
| 43 | 2 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/scared.../scared_17_3.0.png
widget:
- text: scared
output:
url: images/scared_17_3.0.png
- text: scared
output:
url: images/scared_19_3.0.png
- text: scared
output:
url: images/scared_20_3.0.png
- text: scared
output:
url: images/scared_21_3.0.png
- text: scared
output:
url: images/scared_22_3.0.png
inference: false
instance_prompt: scared
---
# ntcai.xyz slider - scared (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/scared_17_-3.0.png" width=256 height=256 /> | <img src="images/scared_17_0.0.png" width=256 height=256 /> | <img src="images/scared_17_3.0.png" width=256 height=256 /> |
| <img src="images/scared_19_-3.0.png" width=256 height=256 /> | <img src="images/scared_19_0.0.png" width=256 height=256 /> | <img src="images/scared_19_3.0.png" width=256 height=256 /> |
| <img src="images/scared_20_-3.0.png" width=256 height=256 /> | <img src="images/scared_20_0.0.png" width=256 height=256 /> | <img src="images/scared_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
scared
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.scared', weight_name='scared.safetensors', adapter_name="scared")
# Activate the LoRA
pipe.set_adapters(["scared"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, scared"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 770+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
ntc-ai/SDXL-LoRA-slider.symmetrical
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-05T14:06:18Z |
2024-01-05T14:06:22+00:00
| 43 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/symmetrical.../symmetrical_17_3.0.png
widget:
- text: symmetrical
output:
url: images/symmetrical_17_3.0.png
- text: symmetrical
output:
url: images/symmetrical_19_3.0.png
- text: symmetrical
output:
url: images/symmetrical_20_3.0.png
- text: symmetrical
output:
url: images/symmetrical_21_3.0.png
- text: symmetrical
output:
url: images/symmetrical_22_3.0.png
inference: false
instance_prompt: symmetrical
---
# ntcai.xyz slider - symmetrical (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/symmetrical_17_-3.0.png" width=256 height=256 /> | <img src="images/symmetrical_17_0.0.png" width=256 height=256 /> | <img src="images/symmetrical_17_3.0.png" width=256 height=256 /> |
| <img src="images/symmetrical_19_-3.0.png" width=256 height=256 /> | <img src="images/symmetrical_19_0.0.png" width=256 height=256 /> | <img src="images/symmetrical_19_3.0.png" width=256 height=256 /> |
| <img src="images/symmetrical_20_-3.0.png" width=256 height=256 /> | <img src="images/symmetrical_20_0.0.png" width=256 height=256 /> | <img src="images/symmetrical_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
symmetrical
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.symmetrical', weight_name='symmetrical.safetensors', adapter_name="symmetrical")
# Activate the LoRA
pipe.set_adapters(["symmetrical"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, symmetrical"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 880+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
RichardErkhov/allenai_-_OLMo-7B-hf-gguf
|
RichardErkhov
| null |
[
"gguf",
"arxiv:2402.00838",
"arxiv:2302.13971",
"endpoints_compatible",
"region:us"
] | 2024-05-24T00:27:51Z |
2024-05-24T02:38:59+00:00
| 43 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
OLMo-7B-hf - GGUF
- Model creator: https://huggingface.co/allenai/
- Original model: https://huggingface.co/allenai/OLMo-7B-hf/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [OLMo-7B-hf.Q2_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q2_K.gguf) | Q2_K | 2.44GB |
| [OLMo-7B-hf.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.IQ3_XS.gguf) | IQ3_XS | 2.69GB |
| [OLMo-7B-hf.IQ3_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.IQ3_S.gguf) | IQ3_S | 2.83GB |
| [OLMo-7B-hf.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q3_K_S.gguf) | Q3_K_S | 2.83GB |
| [OLMo-7B-hf.IQ3_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.IQ3_M.gguf) | IQ3_M | 2.99GB |
| [OLMo-7B-hf.Q3_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q3_K.gguf) | Q3_K | 3.16GB |
| [OLMo-7B-hf.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q3_K_M.gguf) | Q3_K_M | 3.16GB |
| [OLMo-7B-hf.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q3_K_L.gguf) | Q3_K_L | 3.44GB |
| [OLMo-7B-hf.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.IQ4_XS.gguf) | IQ4_XS | 3.49GB |
| [OLMo-7B-hf.Q4_0.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q4_0.gguf) | Q4_0 | 3.66GB |
| [OLMo-7B-hf.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.IQ4_NL.gguf) | IQ4_NL | 3.68GB |
| [OLMo-7B-hf.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q4_K_S.gguf) | Q4_K_S | 3.69GB |
| [OLMo-7B-hf.Q4_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q4_K.gguf) | Q4_K | 3.9GB |
| [OLMo-7B-hf.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q4_K_M.gguf) | Q4_K_M | 3.9GB |
| [OLMo-7B-hf.Q4_1.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q4_1.gguf) | Q4_1 | 4.05GB |
| [OLMo-7B-hf.Q5_0.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q5_0.gguf) | Q5_0 | 4.44GB |
| [OLMo-7B-hf.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q5_K_S.gguf) | Q5_K_S | 4.44GB |
| [OLMo-7B-hf.Q5_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q5_K.gguf) | Q5_K | 4.56GB |
| [OLMo-7B-hf.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q5_K_M.gguf) | Q5_K_M | 4.56GB |
| [OLMo-7B-hf.Q5_1.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q5_1.gguf) | Q5_1 | 4.83GB |
| [OLMo-7B-hf.Q6_K.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q6_K.gguf) | Q6_K | 5.26GB |
| [OLMo-7B-hf.Q8_0.gguf](https://huggingface.co/RichardErkhov/allenai_-_OLMo-7B-hf-gguf/blob/main/OLMo-7B-hf.Q8_0.gguf) | Q8_0 | 6.82GB |
Original model description:
---
language:
- en
license: apache-2.0
datasets:
- allenai/dolma
---
<img src="https://allenai.org/olmo/olmo-7b-animation.gif" alt="OLMo Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
# Model Card for OLMo 7B
<!-- Provide a quick summary of what the model is/does. -->
OLMo is a series of **O**pen **L**anguage **Mo**dels designed to enable the science of language models.
The OLMo models are trained on the [Dolma](https://huggingface.co/datasets/allenai/dolma) dataset.
We release all code, checkpoints, logs (coming soon), and details involved in training these models.
This model has been converted from [allenai/OLMo-7B](https://huggingface.co/allenai/OLMo-7B) for the
Hugging Face Transformers format.
## Model Details
The core models released in this batch are the following:
| Size | Training Tokens | Layers | Hidden Size | Attention Heads | Context Length |
|------|--------|---------|-------------|-----------------|----------------|
| [OLMo 1B](https://huggingface.co/allenai/OLMo-1B-hf) | 3 Trillion |16 | 2048 | 16 | 2048 |
| [OLMo 7B](https://huggingface.co/allenai/OLMo-7B-hf) | 2.5 Trillion | 32 | 4096 | 32 | 2048 |
| [OLMo 7B Twin 2T](https://huggingface.co/allenai/OLMo-7B-Twin-2T-hf) | 2 Trillion | 32 | 4096 | 32 | 2048 |
We are releasing many checkpoints for these models, for every 1000 training steps. These have not
yet been converted into Hugging Face Transformers format, but are available in [allenai/OLMo-7B](https://huggingface.co/allenai/OLMo-7B).
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Allen Institute for AI (AI2)
- **Supported by:** Databricks, Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard University, AMD, CSC (Lumi Supercomputer), UW
- **Model type:** a Transformer style autoregressive language model.
- **Language(s) (NLP):** English
- **License:** The code and model are released under Apache 2.0.
- **Contact:** Technical inquiries: `olmo at allenai dot org`. Press: `press at allenai dot org`
- **Date cutoff:** Feb./March 2023 based on Dolma dataset version.
### Model Sources
<!-- Provide the basic links for the model. -->
- **Project Page:** https://allenai.org/olmo
- **Repositories:**
- Core repo (training, inference, fine-tuning etc.): https://github.com/allenai/OLMo
- Evaluation code: https://github.com/allenai/OLMo-Eval
- Further fine-tuning code: https://github.com/allenai/open-instruct
- **Paper:** [Link](https://arxiv.org/abs/2402.00838)
- **Technical blog post:** https://blog.allenai.org/olmo-open-language-model-87ccfc95f580
- **W&B Logs:** https://wandb.ai/ai2-llm/OLMo-7B/reports/OLMo-7B--Vmlldzo2NzQyMzk5
<!-- - **Press release:** TODO -->
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Inference
Quickly get inference running with the following:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
olmo = AutoModelForCausalLM.from_pretrained("allenai/OLMo-7B-hf")
tokenizer = AutoTokenizer.from_pretrained("allenai/OLMo-7B-hf")
message = ["Language modeling is "]
inputs = tokenizer(message, return_tensors='pt', return_token_type_ids=False)
# optional verifying cuda
# inputs = {k: v.to('cuda') for k,v in inputs.items()}
# olmo = olmo.to('cuda')
response = olmo.generate(**inputs, max_new_tokens=100, do_sample=True, top_k=50, top_p=0.95)
print(tokenizer.batch_decode(response, skip_special_tokens=True)[0])
>> 'Language modeling is the first step to build natural language generation...'
```
Alternatively, with the pipeline abstraction:
```python
from transformers import pipeline
olmo_pipe = pipeline("text-generation", model="allenai/OLMo-7B-hf")
print(olmo_pipe("Language modeling is "))
>> 'Language modeling is a branch of natural language processing that aims to...'
```
Or, you can make this slightly faster by quantizing the model, e.g. `AutoModelForCausalLM.from_pretrained("allenai/OLMo-7B-hf", torch_dtype=torch.float16, load_in_8bit=True)` (requires `bitsandbytes`).
The quantized model is more sensitive to typing / cuda, so it is recommended to pass the inputs as `inputs.input_ids.to('cuda')` to avoid potential issues.
### Fine-tuning
This model does not directly support our fine-tuning processes. Model fine-tuning can be done
from the final checkpoint or many intermediate checkpoints of
[allenai/OLMo-7B](https://huggingface.co/allenai/OLMo-7B).
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
Core model results for the 7B model are found below.
| | [Llama 7B](https://arxiv.org/abs/2302.13971) | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) | [MPT 7B](https://huggingface.co/mosaicml/mpt-7b) | **OLMo 7B** (ours) |
| --------------------------------- | -------- | ---------- | --------- | ------ | ------- |
| arc_challenge | 44.5 | 39.8 | 47.5 | 46.5 | 48.5 |
| arc_easy | 57.0 | 57.7 | 70.4 | 70.5 | 65.4 |
| boolq | 73.1 | 73.5 | 74.6 | 74.2 | 73.4 |
| copa | 85.0 | 87.0 | 86.0 | 85.0 | 90 |
| hellaswag | 74.5 | 74.5 | 75.9 | 77.6 | 76.4 |
| openbookqa | 49.8 | 48.4 | 53.0 | 48.6 | 50.2 |
| piqa | 76.3 | 76.4 | 78.5 | 77.3 | 78.4 |
| sciq | 89.5 | 90.8 | 93.9 | 93.7 | 93.8 |
| winogrande | 68.2 | 67.3 | 68.9 | 69.9 | 67.9 |
| **Core tasks average** | 68.7 | 68.4 | 72.1 | 71.5 | 71.6 |
| truthfulQA (MC2) | 33.9 | 38.5 | 34.0 | 33 | 36.0 |
| MMLU (5 shot MC) | 31.5 | 45.0 | 24.0 | 30.8 | 28.3 |
| GSM8k (mixed eval.) | 10.0 (8shot CoT) | 12.0 (8shot CoT) | 4.0 (5 shot) | 4.5 (5 shot) | 8.5 (8shot CoT) |
| **Full average** | 57.8 | 59.3 | 59.2 | 59.3 | 59.8 |
And for the 1B model:
| task | random | [StableLM 2 1.6b](https://huggingface.co/stabilityai/stablelm-2-1_6b)\* | [Pythia 1B](https://huggingface.co/EleutherAI/pythia-1b) | [TinyLlama 1.1B](https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1195k-token-2.5T) | **OLMo 1B** (ours) |
| ------------------------------------------------------------------------------------------------------------------------------------------------------------ | ------ | ----------------- | --------- | -------------------------------------- | ------- |
| arc_challenge | 25 | 43.81 | 33.11 | 34.78 | 34.45 |
| arc_easy | 25 | 63.68 | 50.18 | 53.16 | 58.07 |
| boolq | 50 | 76.6 | 61.8 | 64.6 | 60.7 |
| copa | 50 | 84 | 72 | 78 | 79 |
| hellaswag | 25 | 68.2 | 44.7 | 58.7 | 62.5 |
| openbookqa | 25 | 45.8 | 37.8 | 43.6 | 46.4 |
| piqa | 50 | 74 | 69.1 | 71.1 | 73.7 |
| sciq | 25 | 94.7 | 86 | 90.5 | 88.1 |
| winogrande | 50 | 64.9 | 53.3 | 58.9 | 58.9 |
| Average | 36.11 | 68.41 | 56.44 | 61.48 | 62.42 |
\*Unlike OLMo, Pythia, and TinyLlama, StabilityAI has not disclosed yet the data StableLM was trained on, making comparisons with other efforts challenging.
## Model Details
### Data
For training data details, please see the [Dolma](https://huggingface.co/datasets/allenai/dolma) documentation.
### Architecture
OLMo 7B architecture with peer models for comparison.
| | **OLMo 7B** | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [OpenLM 7B](https://laion.ai/blog/open-lm/) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) | PaLM 8B |
|------------------------|-------------------|---------------------|--------------------|--------------------|------------------|
| d_model | 4096 | 4096 | 4096 | 4544 | 4096 |
| num heads | 32 | 32 | 32 | 71 | 16 |
| num layers | 32 | 32 | 32 | 32 | 32 |
| MLP ratio | ~8/3 | ~8/3 | ~8/3 | 4 | 4 |
| LayerNorm type | non-parametric LN | RMSNorm | parametric LN | parametric LN | parametric LN |
| pos embeddings | RoPE | RoPE | RoPE | RoPE | RoPE |
| attention variant | full | GQA | full | MQA | MQA |
| biases | none | none | in LN only | in LN only | none |
| block type | sequential | sequential | sequential | parallel | parallel |
| activation | SwiGLU | SwiGLU | SwiGLU | GeLU | SwiGLU |
| sequence length | 2048 | 4096 | 2048 | 2048 | 2048 |
| batch size (instances) | 2160 | 1024 | 2048 | 2304 | 512 |
| batch size (tokens) | ~4M | ~4M | ~4M | ~4M | ~1M |
| weight tying | no | no | no | no | yes |
### Hyperparameters
AdamW optimizer parameters are shown below.
| Size | Peak LR | Betas | Epsilon | Weight Decay |
|------|------------|-----------------|-------------|--------------|
| 1B | 4.0E-4 | (0.9, 0.95) | 1.0E-5 | 0.1 |
| 7B | 3.0E-4 | (0.9, 0.99) | 1.0E-5 | 0.1 |
Optimizer settings comparison with peer models.
| | **OLMo 7B** | [Llama 2 7B](https://huggingface.co/meta-llama/Llama-2-7b) | [OpenLM 7B](https://laion.ai/blog/open-lm/) | [Falcon 7B](https://huggingface.co/tiiuae/falcon-7b) |
|-----------------------|------------------|---------------------|--------------------|--------------------|
| warmup steps | 5000 | 2000 | 2000 | 1000 |
| peak LR | 3.0E-04 | 3.0E-04 | 3.0E-04 | 6.0E-04 |
| minimum LR | 3.0E-05 | 3.0E-05 | 3.0E-05 | 1.2E-05 |
| weight decay | 0.1 | 0.1 | 0.1 | 0.1 |
| beta1 | 0.9 | 0.9 | 0.9 | 0.99 |
| beta2 | 0.95 | 0.95 | 0.95 | 0.999 |
| epsilon | 1.0E-05 | 1.0E-05 | 1.0E-05 | 1.0E-05 |
| LR schedule | linear | cosine | cosine | cosine |
| gradient clipping | global 1.0 | global 1.0 | global 1.0 | global 1.0 |
| gradient reduce dtype | FP32 | FP32 | FP32 | BF16 |
| optimizer state dtype | FP32 | most likely FP32 | FP32 | FP32 |
## Environmental Impact
OLMo 7B variants were either trained on MI250X GPUs at the LUMI supercomputer, or A100-40GB GPUs provided by MosaicML.
A summary of the environmental impact. Further details are available in the paper.
| | GPU Type | Power Consumption From GPUs | Carbon Intensity (kg CO₂e/KWh) | Carbon Emissions (tCO₂eq) |
|-----------|------------|-----------------------------|--------------------------------|---------------------------|
| OLMo 7B Twin | MI250X ([LUMI supercomputer](https://www.lumi-supercomputer.eu)) | 135 MWh | 0* | 0* |
| OLMo 7B | A100-40GB ([MosaicML](https://www.mosaicml.com)) | 104 MWh | 0.656 | 75.05 |
## Bias, Risks, and Limitations
Like any base language model or fine-tuned model without safety filtering, it is relatively easy for a user to prompt these models to generate harmful and generally sensitive content.
Such content can also be produced unintentionally, especially in the case of bias, so we recommend users consider the risks of applications of this technology.
Otherwise, many facts from OLMo or any LLM will often not be true, so they should be checked.
## Citation
**BibTeX:**
```
@article{Groeneveld2023OLMo,
title={OLMo: Accelerating the Science of Language Models},
author={Groeneveld, Dirk and Beltagy, Iz and Walsh, Pete and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya Harsh and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack and Khot, Tushar and Merrill, William and Morrison, Jacob and Muennighoff, Niklas and Naik, Aakanksha and Nam, Crystal and Peters, Matthew E. and Pyatkin, Valentina and Ravichander, Abhilasha and Schwenk, Dustin and Shah, Saurabh and Smith, Will and Subramani, Nishant and Wortsman, Mitchell and Dasigi, Pradeep and Lambert, Nathan and Richardson, Kyle and Dodge, Jesse and Lo, Kyle and Soldaini, Luca and Smith, Noah A. and Hajishirzi, Hannaneh},
journal={Preprint},
year={2024}
}
```
**APA:**
Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney, R., Tafjord, O., Jha, A., Ivison, H., Magnusson, I., Wang, Y., Arora, S., Atkinson, D., Authur, R., Chandu, K., Cohan, A., Dumas, J., Elazar, Y., Gu, Y., Hessel, J., Khot, T., Merrill, W., Morrison, J., Muennighoff, N., Naik, A., Nam, C., Peters, M., Pyatkin, V., Ravichander, A., Schwenk, D., Shah, S., Smith, W., Subramani, N., Wortsman, M., Dasigi, P., Lambert, N., Richardson, K., Dodge, J., Lo, K., Soldaini, L., Smith, N., & Hajishirzi, H. (2024). OLMo: Accelerating the Science of Language Models. Preprint.
## Model Card Contact
For errors in this model card, contact Nathan, Akshita or Shane, `{nathanl, akshitab, shanea} at allenai dot org`.
|
[
"SCIQ"
] |
RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-09-18T18:02:48Z |
2024-09-18T20:33:16+00:00
| 43 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
JSL-MedMNX-7B-SFT - GGUF
- Model creator: https://huggingface.co/johnsnowlabs/
- Original model: https://huggingface.co/johnsnowlabs/JSL-MedMNX-7B-SFT/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [JSL-MedMNX-7B-SFT.Q2_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q2_K.gguf) | Q2_K | 2.53GB |
| [JSL-MedMNX-7B-SFT.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [JSL-MedMNX-7B-SFT.IQ3_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [JSL-MedMNX-7B-SFT.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [JSL-MedMNX-7B-SFT.IQ3_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [JSL-MedMNX-7B-SFT.Q3_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q3_K.gguf) | Q3_K | 3.28GB |
| [JSL-MedMNX-7B-SFT.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [JSL-MedMNX-7B-SFT.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [JSL-MedMNX-7B-SFT.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [JSL-MedMNX-7B-SFT.Q4_0.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q4_0.gguf) | Q4_0 | 3.83GB |
| [JSL-MedMNX-7B-SFT.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [JSL-MedMNX-7B-SFT.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [JSL-MedMNX-7B-SFT.Q4_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q4_K.gguf) | Q4_K | 4.07GB |
| [JSL-MedMNX-7B-SFT.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [JSL-MedMNX-7B-SFT.Q4_1.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q4_1.gguf) | Q4_1 | 4.24GB |
| [JSL-MedMNX-7B-SFT.Q5_0.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q5_0.gguf) | Q5_0 | 4.65GB |
| [JSL-MedMNX-7B-SFT.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [JSL-MedMNX-7B-SFT.Q5_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q5_K.gguf) | Q5_K | 4.78GB |
| [JSL-MedMNX-7B-SFT.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [JSL-MedMNX-7B-SFT.Q5_1.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q5_1.gguf) | Q5_1 | 5.07GB |
| [JSL-MedMNX-7B-SFT.Q6_K.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q6_K.gguf) | Q6_K | 5.53GB |
| [JSL-MedMNX-7B-SFT.Q8_0.gguf](https://huggingface.co/RichardErkhov/johnsnowlabs_-_JSL-MedMNX-7B-SFT-gguf/blob/main/JSL-MedMNX-7B-SFT.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
license: cc-by-nc-nd-4.0
language:
- en
library_name: transformers
tags:
- reward model
- RLHF
- medical
---
# JSL-MedMNX-7B-SFT
[<img src="https://repository-images.githubusercontent.com/104670986/2e728700-ace4-11ea-9cfc-f3e060b25ddf">](http://www.johnsnowlabs.com)
JSL-MedMNX-7B-SFT is a 7 Billion parameter model developed by [John Snow Labs](https://www.johnsnowlabs.com/).
This model is SFT-finetuned on alpaca format 11k medical dataset over the base model [JSL-MedMNX-7B](https://huggingface.co/johnsnowlabs/JSL-MedMNX-7B). Checkout the perofrmance on [Open Medical LLM Leaderboard](https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard).
This model is available under a [CC-BY-NC-ND](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en) license and must also conform to this [Acceptable Use Policy](https://huggingface.co/johnsnowlabs). If you need to license this model for commercial use, please contact us at [email protected].
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "johnsnowlabs/JSL-MedMNX-7B-SFT"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## 🏆 Evaluation
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|-------------------------------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5209|± |0.0068|
| | |none | 0|acc |0.5675|± |0.0058|
| - medmcqa |Yaml |none | 0|acc |0.5152|± |0.0077|
| | |none | 0|acc_norm|0.5152|± |0.0077|
| - medqa_4options |Yaml |none | 0|acc |0.5397|± |0.0140|
| | |none | 0|acc_norm|0.5397|± |0.0140|
| - anatomy (mmlu) | 0|none | 0|acc |0.6593|± |0.0409|
| - clinical_knowledge (mmlu) | 0|none | 0|acc |0.7245|± |0.0275|
| - college_biology (mmlu) | 0|none | 0|acc |0.7431|± |0.0365|
| - college_medicine (mmlu) | 0|none | 0|acc |0.6532|± |0.0363|
| - medical_genetics (mmlu) | 0|none | 0|acc |0.7300|± |0.0446|
| - professional_medicine (mmlu)| 0|none | 0|acc |0.7206|± |0.0273|
| - pubmedqa | 1|none | 0|acc |0.7720|± |0.0188|
|Groups|Version|Filter|n-shot| Metric |Value | |Stderr|
|------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5209|± |0.0068|
| | |none | 0|acc |0.5675|± |0.0058|
|
[
"MEDQA",
"PUBMEDQA"
] |
RichardErkhov/internistai_-_base-7b-v0.2-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-09-19T00:47:09Z |
2024-09-19T05:12:41+00:00
| 43 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
base-7b-v0.2 - GGUF
- Model creator: https://huggingface.co/internistai/
- Original model: https://huggingface.co/internistai/base-7b-v0.2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [base-7b-v0.2.Q2_K.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q2_K.gguf) | Q2_K | 2.53GB |
| [base-7b-v0.2.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.IQ3_XS.gguf) | IQ3_XS | 2.81GB |
| [base-7b-v0.2.IQ3_S.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.IQ3_S.gguf) | IQ3_S | 2.96GB |
| [base-7b-v0.2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q3_K_S.gguf) | Q3_K_S | 2.95GB |
| [base-7b-v0.2.IQ3_M.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.IQ3_M.gguf) | IQ3_M | 3.06GB |
| [base-7b-v0.2.Q3_K.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q3_K.gguf) | Q3_K | 3.28GB |
| [base-7b-v0.2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q3_K_M.gguf) | Q3_K_M | 3.28GB |
| [base-7b-v0.2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q3_K_L.gguf) | Q3_K_L | 3.56GB |
| [base-7b-v0.2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.IQ4_XS.gguf) | IQ4_XS | 3.67GB |
| [base-7b-v0.2.Q4_0.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q4_0.gguf) | Q4_0 | 3.83GB |
| [base-7b-v0.2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.IQ4_NL.gguf) | IQ4_NL | 3.87GB |
| [base-7b-v0.2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q4_K_S.gguf) | Q4_K_S | 3.86GB |
| [base-7b-v0.2.Q4_K.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q4_K.gguf) | Q4_K | 4.07GB |
| [base-7b-v0.2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q4_K_M.gguf) | Q4_K_M | 4.07GB |
| [base-7b-v0.2.Q4_1.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q4_1.gguf) | Q4_1 | 4.24GB |
| [base-7b-v0.2.Q5_0.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q5_0.gguf) | Q5_0 | 4.65GB |
| [base-7b-v0.2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q5_K_S.gguf) | Q5_K_S | 4.65GB |
| [base-7b-v0.2.Q5_K.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q5_K.gguf) | Q5_K | 4.78GB |
| [base-7b-v0.2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q5_K_M.gguf) | Q5_K_M | 4.78GB |
| [base-7b-v0.2.Q5_1.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q5_1.gguf) | Q5_1 | 5.07GB |
| [base-7b-v0.2.Q6_K.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q6_K.gguf) | Q6_K | 5.53GB |
| [base-7b-v0.2.Q8_0.gguf](https://huggingface.co/RichardErkhov/internistai_-_base-7b-v0.2-gguf/blob/main/base-7b-v0.2.Q8_0.gguf) | Q8_0 | 7.17GB |
Original model description:
---
license: apache-2.0
language:
- en
tag: text-generation
tags:
- medical
datasets:
- Open-Orca/OpenOrca
- pubmed
- medmcqa
- maximegmd/medqa_alpaca_format
base_model: mistralai/Mistral-7B-v0.1
metrics:
- accuracy
---
<img width=30% src="assets/logo.png" alt="logo" title="logo">
# Model Card for Internist.ai 7b
Internist.ai 7b is a medical domain large language model trained by medical doctors to demonstrate the benefits of a **physician-in-the-loop** approach. The training data was carefully curated by medical doctors to ensure clinical relevance and required quality for clinical practice.
**With this 7b model we release the first 7b model to score above the 60% pass threshold on MedQA (USMLE) and outperfoms models of similar size accross most medical evaluations.**
This model serves as a proof of concept and larger models trained on a larger corpus of medical literature are planned. Do not hesitate to reach out to us if you would like to sponsor some compute to speed up this training.
<details open>
<summary><strong>Advisory Notice</strong></summary>
<blockquote style="padding: 10px; margin: 0 0 10px; border-left: 5px solid #ddd;">
The model was designed by medical doctors for medical doctors and did not undergo specific training to address potential security issues when used by non medical professionals.
We highly recommend against the use of this model in a live environment without extensive evaluation through prospective clinical trials and additional training to meet the required safety levels.
</blockquote>
</details>
## Model Details
- **Developed by:** [UCLouvain](https://uclouvain.be/) and [Cliniques Universitaires Saint-Luc](https://saintluc.be/)
- **Language(s):** English (mainly)
- **Model License:** [APACHE 2.0 LICENSE](LICENSE)
- **Code License:** [APACHE 2.0 LICENSE](LICENSE)
- **Continue-pretrained from model:** [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
- **Context length:** 4096 tokens
- **Knowledge Cutoff:** October 2023
### Model Sources
- **Trainer:** [Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl)
- **Paper:** [Impact of High-Quality, Mixed-Domain Data on the Performance of Medical Language Models](https://doi.org/10.1093/jamia/ocae120)
## Uses
This model was trained to demonstrate the benefit of using high quality and relevant medical literature as well as general data to retain capabilities in other domains. Therefore the model was trained for any specific use and did not benefit from additional instruction tuning to ensure safety.
The model in its current state can be useful for medical professionals as an assistant, be it for clinical decision support or documentation. We do not recommend the use of this model by non professionals who may not be able to notice errors.
We recommend additional task specific training and safety evaluation before using the model in a real-world setting.
### Format
The model uses the Alpaca format, it is available as a chat template:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("internistai/base-7b-v0.2")
tokenizer = AutoTokenizer.from_pretrained("internistai/base-7b-v0.2")
messages = [
{"role": "user", "content": "Describe the anatomy of nutcracker syndrome"},
]
encodeds = tokenizer.apply_chat_template(messages, add_generation_prompt=True ,return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
### Out-of-Scope Use
We do not recommend using this model for natural language generation in a production environment, finetuned or otherwise.
## Professional Evaluation
We created a free response evaluation dataset of 100 questions and prompted the model and GPT-4 as a comparison with these questions. We then recolted the prompt/answer pairs and presented them to 10 medical doctors of different specialties with questions to be answered with a 7 point likert scale (See the paper for more information).
<img width=800px src="assets/likert.png" alt="Likert scale" title="likert">
## Training Details
### Training Data
Internist.ai 7b contains a total of 2.3B tokens:
- [**General Domain**](https://huggingface.co/datasets/Open-Orca/OpenOrca): OpenOrca-GPT4 is a state-of-the-art general domain dataset generated from Flan prompts using GPT-4.
- **Medical Guidelines**: 11,332 articles from UpToDate were included as well as domain specific guidelines provided by physicians to cover the [USMLE Content Outline](https://www.usmle.org/sites/default/files/2021-08/USMLE_Content_Outline.pdf).
- **Medical Books**: 10,376 textbooks were sourced from PMC LitArch and our university library.
- **Synthetic Data**: We generated 400M tokens by prompting a larger model with instructions to transform and adapt extracts from the Medical Guidelines.
*Data Availability*: Considering the datasets contain proprietary information, we will not be releasing the datasets publicly. Regarding the synthetic dataset, as we show in the paper, the model trained exclusively on this dataset performs very poorly and was not up to our standards. Due to its poor quality we decided not to release it.
<img src="assets/loss.png" alt="Loss" title="loss">
### Training Procedure
We used Axolotl to train on a server with 4 NVIDIA A100 80GB GPUs for a total of 450 GPU hours. We used FlashAttention, NEFTune and sample packing with the parameters described below.
#### Training Hyperparameters
| | |
| --- | ------ |
| bf16 | true |
| lr | 6e-6 |
| eps | 1e-5 |
| epochs | 4 |
| betas | \[0.9, 0.95\] |
| weight decay | 0.1 |
| Batch size | 192,000 tokens |
| seq length | 4096 |
| lr scheduler | cosine|
| min lr | 1e-8 |
| NEFT alpha | 5 |
| warmup iteration | 100 |
| | |
## Evaluation
### Testing Data & Metrics
#### Testing Data
- [MedQA (USMLE) - 4 options](https://huggingface.co/datasets/bigbio/med_qa)
- [MedMCQA](https://huggingface.co/datasets/medmcqa)
- [PubMedQA](https://huggingface.co/datasets/bigbio/pubmed_qa)
- [MMLU](https://huggingface.co/datasets/hails/mmlu_no_train)
#### Metrics
- Accuracy: we ran standardized 0-shot benchmarks using [lm-evaluation-harness](https://github.com/maximegmd/lm-evaluation-harness/tree/big-refactor/lm_eval).
### Results
We include benchmarks on MedQA (4 options), MedMCQA and PubMedQA of our model and models of similar size and achieve the first USMLE passing score of 60% on the MedQA benchmark.
| | Internist.ai 7b | PMC LLaMA 7b* | Mistral 7b | Meditron 7b** |
| ----------- | ------------- | ------------ | ---------- | ----------- |
| MedQA | **60.5** | 27.7 (44.7) | 48.7 | 52.0 |
| MedMCQA | 55.8 | 32.2 (51.4) | 45.7 | **59.2** |
| PubMedQA | **79.4** | 67.8 (74.6) | 75.8 | 74.4 |
| MMLU Professional Medicine | **76.1** | 19.5 | 65.8 | 26.6 |
| MMLU Clinical Knowledge | **70.6** | 23.8 | 61.1 | 35.5 |
| MMLU Anatomy | **65.9** | 18.5 | 52.6 | 42.6 |
| MMLU College Medicine | **63.0** | 23.7 | 55.5 | 28.9 |
| MMLU Medical Genetics | **71.0** | 32.0 | 68.0 | 46.0 |
\*: PMC LLaMA 7b performed poorly on the benchmark, likely due to a mismatch of formating and a lack of instruction tuning, we include in parenthesis the results reported by the authors when available.
\*\*: Meditron 7b's results in MMLU are reported for transparency but are inconsistent with the average of 54.2 reported in their paper, do not hesitate to communicate the details on each category so we can update the table.
## Citation
**BibTeX:**
If you use Internist.ai 7b, please cite us:
```
@article{10.1093/jamia/ocae120,
author = {Griot, Maxime and Hemptinne, Coralie and Vanderdonckt, Jean and Yuksel, Demet},
title = "{Impact of high-quality, mixed-domain data on the performance of medical language models}",
journal = {Journal of the American Medical Informatics Association},
volume = {31},
number = {9},
pages = {1875-1883},
year = {2024},
month = {05},
abstract = "{To optimize the training strategy of large language models for medical applications, focusing on creating clinically relevant systems that efficiently integrate into healthcare settings, while ensuring high standards of accuracy and reliability.We curated a comprehensive collection of high-quality, domain-specific data and used it to train several models, each with different subsets of this data. These models were rigorously evaluated against standard medical benchmarks, such as the USMLE, to measure their performance. Furthermore, for a thorough effectiveness assessment, they were compared with other state-of-the-art medical models of comparable size.The models trained with a mix of high-quality, domain-specific, and general data showed superior performance over those trained on larger, less clinically relevant datasets (P \\< .001). Our 7-billion-parameter model Med5 scores 60.5\\% on MedQA, outperforming the previous best of 49.3\\% from comparable models, and becomes the first of its size to achieve a passing score on the USMLE. Additionally, this model retained its proficiency in general domain tasks, comparable to state-of-the-art general domain models of similar size.Our findings underscore the importance of integrating high-quality, domain-specific data in training large language models for medical purposes. The balanced approach between specialized and general data significantly enhances the model’s clinical relevance and performance.This study sets a new standard in medical language models, proving that a strategically trained, smaller model can outperform larger ones in clinical relevance and general proficiency, highlighting the importance of data quality and expert curation in generative artificial intelligence for healthcare applications.}",
issn = {1527-974X},
doi = {10.1093/jamia/ocae120},
url = {https://doi.org/10.1093/jamia/ocae120},
eprint = {https://academic.oup.com/jamia/article-pdf/31/9/1875/58868289/ocae120.pdf},
}
```
|
[
"MEDQA",
"PUBMEDQA"
] |
HPAI-BSC/Qwen2.5-Aloe-Beta-72B
|
HPAI-BSC
|
question-answering
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"biology",
"medical",
"healthcare",
"question-answering",
"en",
"dataset:HPAI-BSC/Aloe-Beta-General-Collection",
"dataset:HPAI-BSC/chain-of-diagnosis",
"dataset:HPAI-BSC/MedS-Ins",
"dataset:HPAI-BSC/ultramedical",
"dataset:HPAI-BSC/pubmedqa-cot-llama31",
"dataset:HPAI-BSC/medqa-cot-llama31",
"dataset:HPAI-BSC/medmcqa-cot-llama31",
"dataset:HPAI-BSC/headqa-cot-llama31",
"dataset:HPAI-BSC/MMLU-medical-cot-llama31",
"dataset:HPAI-BSC/Polymed-QA",
"arxiv:2405.01886",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-12-09T15:25:06Z |
2025-01-22T14:21:44+00:00
| 43 | 9 |
---
datasets:
- HPAI-BSC/Aloe-Beta-General-Collection
- HPAI-BSC/chain-of-diagnosis
- HPAI-BSC/MedS-Ins
- HPAI-BSC/ultramedical
- HPAI-BSC/pubmedqa-cot-llama31
- HPAI-BSC/medqa-cot-llama31
- HPAI-BSC/medmcqa-cot-llama31
- HPAI-BSC/headqa-cot-llama31
- HPAI-BSC/MMLU-medical-cot-llama31
- HPAI-BSC/Polymed-QA
- HPAI-BSC/Aloe-Beta-General-Collection
- HPAI-BSC/Aloe-Beta-General-Collection
language:
- en
library_name: transformers
pipeline_tag: question-answering
tags:
- biology
- medical
- healthcare
---
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://cdn-uploads.huggingface.co/production/uploads/6620f941eba5274b5c12f83d/3_lyx8rP6VuhXN8YRaZDS.png">
<img alt="aloe_beta_7b" src="https://hf.fast360.xyz/production/uploads/6620f941eba5274b5c12f83d/3_lyx8rP6VuhXN8YRaZDS.png" width=50%>
</picture>
</p>
<h1 align="center">
Aloe: A Family of Fine-tuned Open Healthcare LLMs
</h1>
---
Qwen2.5-Aloe-Beta-72B is an **open healthcare LLM** achieving **state-of-the-art performance** on several medical tasks. Aloe Beta is made available in four model sizes: [7B](https://huggingface.co/HPAI-BSC/Qwen2.5-Aloe-Beta-7B/), [8B](https://huggingface.co/HPAI-BSC/Llama3.1-Aloe-Beta-8B), [70B](https://huggingface.co/HPAI-BSC/Llama3.1-Aloe-Beta-70B), and [72B](https://huggingface.co/HPAI-BSC/Qwen2.5-Aloe-Beta-72B). All models are trained using the same recipe, on top of two different families of models: Llama3.1 and Qwen2.5.
Aloe is trained on 20 medical tasks, resulting in a robust and versatile healthcare model. Evaluations show Aloe models to be among the best in their class. When combined with a RAG system ([also released](https://github.com/HPAI-BSC/prompt_engine)) the 7B and 8B version gets close to the performance of closed models like MedPalm-2, GPT4. With the same RAG system, Llama3.1-Aloe-Beta-70B and Qwen2.5-Aloe-Beta-72B outperforms those private alternatives, producing state-of-the-art results.
# Aloe-Beta-72B

**Aloe-Beta** is the latest iteration in the **Aloe family**, building and improving on the success of its predecessor, [Aloe-8B-Alpha](https://huggingface.co/HPAI-BSC/Llama3-Aloe-8B-Alpha).
Beta more than triples the training data used by Alpha, for a total of **1.8B tokens**, including a wider variety of medical tasks and instructions (e.g., text summarization, explanation, diagnosis, text classification, treatment recommendation, ...).

To mitigate catastrophic forgetting and enable the model to effectively learn new capabilities like **function calling**, we incorporated a diverse set of high-quality general-purpose data constituting 20% of the total training set. The curated data includes some of the highest-quality content available across a range of topics, including mathematics, programming, STEM, and very long instructions (> 8k tokens), to enrich the model's adaptability and comprehension across diverse domains.
Beta also boosts the alignment and safety stages with respect to Alpha. This includes a [medical preference dataset](https://huggingface.co/datasets/TsinghuaC3I/UltraMedical-Preference), as well as the red-teaming dataset (available soon).
Complete training details, model merging configurations, and all training data (including synthetically generated data) can be found below. This includes [the RAG system](https://github.com/HPAI-BSC/prompt_engine) that was developed to test Aloe Beta in a deployment setup. Aloe comes with a healthcare-specific risk assessment to facilitate to the safe use and deployment of such systems.
## Model Details
### [](https://huggingface.co/templates/model-card-example#model-description)Model Description
- **Developed by:** [HPAI](https://hpai.bsc.es/)
- **Model type:** Causal decoder-only transformer language model
- **Language(s) (NLP):** English (capable but not formally evaluated on other languages)
- **License:** This model is based on [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B) which is released with Apache 2.0 license. All our modifications are available with a [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) license, making the Aloe Beta models **compatible with commercial use**.
- **Base model :** [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B)
- **Paper:** (more coming soon)
- **RAG Repository:** https://github.com/HPAI-BSC/prompt_engine
### [](https://huggingface.co/templates/model-card-example#model-sources-optional)Model Sources [optional]
## Model Performance
Aloe Beta has been tested on the most popular healthcare QA datasets, with and without Medprompt inference technique. Results show competitive performance, achieving SOTA within models of the same size.

The Beta model has been developed to excel in several different medical tasks. For this reason, we evaluated the model in many different medical tasks:


We also compared the performance of the model in the general domain, using the OpenLLM Leaderboard benchmark. Aloe-Beta gets competitive results with the current SOTA general models in the most used general benchmarks and outperforms the medical models:

## Uses
### Direct Use
We encourage the use of Aloe for research purposes, as a stepping stone to build better foundational models for healthcare. In production, Aloe should always be used under the supervision of a human expert.
### Out-of-Scope Use
These models are not to be used for clinical practice, medical diagnosis, or any other form of direct or indirect healthcare advice. Models are prone to error and can produce toxic content. The use of Aloe models for activities harmful to individuals, such as spam, fraud, or impersonation, is strictly prohibited. Minors should not be left alone to interact with Aloe without supervision.
## Bias, Risks, and Limitations
Aloe can produce toxic content under the appropriate prompts, and it includes multiple undesirable biases. While significant efforts where conducted to mitigate this (see Alignment details below), model safety cannot be fully guaranteed. We avoid the use of all personal data in our training.
We identify at least three risk cases specific to healthcare LLMs:
- Healthcare professional impersonation, a fraudulent behaviour which currently generates billions of dollars in [profit](https://www.justice.gov/opa/pr/justice-department-charges-dozens-12-billion-health-care-fraud). A model such as Aloe could be used to increase the efficacy of such deceiving activities, making them more widespread. The main preventive actions are public literacy on the unreliability of digitised information and the importance of medical registration, and legislation enforcing AI-generated content disclaimers.
- Medical decision-making without professional supervision. While this is already an issue in modern societies (eg self-medication) a model such as Aloe, capable of producing high-quality conversational data, can facilitate self-delusion, particularly in the presence of sycophancy. By producing tailored responses, it can also be used to generate actionable answers. Public literacy on the dangers of self-diagnosis is one of the main defenses, together with the introduction of disclaimers and warnings on the models' outputs.
- Access to information on dangerous substances or procedures. While the literature on sensitive content can already be found on different sources (eg libraries, the internet, dark web), LLMs can centralize such access, making it nearly impossible to control the flow of such information. Model alignment can help in that regard, but so far the effects remain insufficient, as jailbreaking methods still overcome it.
<!---
Table below shows the performance of Aloe at several AI safety tasks:
TO BE UPDATED
<img src="https://hf.fast360.xyz/production/uploads/62972c4979f193515da1d38e/T6Jblpf1kmTkM04K716rM.png" width="95%">
We analyzed the safety and robustness of the model using red teaming techniques. We designed a benchmark using different types of attacks and analyzed the performance of Aloe and some extra models, and we confirm that our model is aligned properly and successfully resisting most attacks:


-->
## How to Get Started with the Model
Use the code below to get started with the model. You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples for both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "HPAI-BSC/Qwen2.5-Aloe-Beta-72B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are an expert medical assistant named Aloe, developed by the High Performance Artificial Intelligence Group at Barcelona Supercomputing Center(BSC). You are to be a helpful, respectful, and honest assistant."},
{"role": "user", "content": "Hello."},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|im_end|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.7,
top_p=0.8,
top_k=20,
repetition_penalty=1.05
)
print(outputs[0]["generated_text"][len(prompt):])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "HPAI-BSC/Qwen2.5-Aloe-Beta-72B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are an expert medical assistant named Aloe, developed by the High Performance Artificial Intelligence Group at Barcelona Supercomputing Center(BSC). You are to be a helpful, respectful, and honest assistant."},
{"role": "user", "content": "Hello"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|im_end|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.7,
top_p=0.8,
top_k=20,
repetition_penalty=1.05
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
## Training Details
### Supervised fine-tuning
SFT on top of Qwen2.5-72B using axolotl (https://github.com/axolotl-ai-cloud/axolotl).
We used Deepspeed's Zero-3 distributed training using the following hardware:
* 7B: 32x NVIDIA Hopper H100 64GB of the *Marenostrum 5*.
* 8B: 32x NVIDIA Hopper H100 64GB of the *Marenostrum 5*.
* 70B: 64x NVIDIA Hopper H100 64GB of the *Marenostrum 5*.
* 72B: 92x NVIDIA Hopper H100 64GB of the *Marenostrum 5*.
<!---
^^^ TO BE COMPLETED AND DETAILED ^^^
-->
#### Training Data
The training set consists of around 1.8B tokens, having 3 different types of data:
- Medical domain datasets. Includes data from 20 different medical tasks.
- [HPAI-BSC/Aloe-Beta-General-Collection](https://huggingface.co/datasets/HPAI-BSC/Aloe-Beta-General-Collection)
- [HPAI-BSC/chain-of-diagnosis](https://huggingface.co/datasets/HPAI-BSC/chain-of-diagnosis)
- [HPAI-BSC/MedS-Ins](https://huggingface.co/datasets/HPAI-BSC/MedS-Ins)
- [HPAI-BSC/ultramedica](https://huggingface.co/datasets/HPAI-BSC/ultramedical)
- Synthetic data. We expanded our training data by generating high-quality answers using Llama3.1-70B.
- [HPAI-BSC/pubmedqa-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/pubmedqa-cot-llama31)
- [HPAI-BSC/medqa-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/medqa-cot-llama31)
- [HPAI-BSC/medmcqa-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/medmcqa-cot-llama31)
- [HPAI-BSC/headqa-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/headqa-cot-llama31)
- [HPAI-BSC/MMLU-medical-cot-llama31](https://huggingface.co/datasets/HPAI-BSC/MMLU-medical-cot-llama31)
- [HPAI-BSC/Polymed-QA](https://huggingface.co/datasets/HPAI-BSC/Polymed-QA)
- Genstruct data (coming soon)
- General data. It includes maths, STEM, code, function calling, and instructions with a very long context.
- [HPAI-BSC/Aloe-Beta-General-Collection](https://huggingface.co/datasets/HPAI-BSC/Aloe-Beta-General-Collection)
#### Training parameters
- Epochs: 3
- Sequence length: 16384
- Optimizer: adamw_torch
- Learning rate: 1e-5
- Learning rate scheduler: cosine
- Warmup steps: 100
- Weight decay: 0
- Gradient checkpointing
- Zero 3
- Total batch size: 128
- Batch size per device: 1
- Gradient accumulation steps: 4
### Model Merging
The model trained was merged with the Qwen2.5-72-Instruct model using the DARE_TIES technique. [Mergekit](https://github.com/arcee-ai/mergekit) was used to conduct the merging.
### Model Alignment
The model is aligned using the Direct Preference Optimization (DPO) technique through a two-step process:
1. General DPO Alignment: This step uses a dataset combining medical, general preference, and safety data. We used our dataset [HPAI-BSC/Aloe-Beta-DPO](https://huggingface.co/datasets/HPAI-BSC/Aloe-Beta-DPO). We split the dataset into five parts, and the model was trained iteratively for one epoch on each chunk. We used a learning rate of 2e-7.
2. Red-Teaming Alignment: This step further fine-tunes the model to resist a variety of potential attacks, enhancing its robustness and security. Dataset will be shared soon. In this stage, we set the learning rate to 1e-7.
<!---
^^^ LINKS TO DPO DATA (DPO added, missing the RT^^^
-->
We used [OpenRLHF](https://github.com/OpenRLHF/OpenRLHF) library. We aligned the model using 16x NVIDA HOOPER H100 64GB of the *Marenostrum 5*. Common hyperparameters:
- Sequence length: 4096
- Optimizer: Fused adam
- Total batch size 128
- Batch size per device: 1
- Gradient accumulation steps: 8
- Beta: 0.1
## Evaluation
### Testing Data, Factors & Metrics
#### Testing Data
- [ACI-BENCH](https://github.com/wyim/aci-bench)
- [MTS-Dialog](https://github.com/abachaa/MTS-Dialog)
- [MedText](https://huggingface.co/datasets/BI55/MedText)
- [Medical Text classification](https://www.kaggle.com/datasets/chaitanyakck/medical-text/data)
- [OLAPH](https://github.com/dmis-lab/OLAPH)
- CareQA Open
- [MedDialog](https://huggingface.co/datasets/bigbio/meddialog)
- [MEDIQA QA](https://huggingface.co/datasets/bigbio/mediqa_qa)
- [Meddialog Qsumm](https://huggingface.co/datasets/lighteval/med_dialog)
- [Biored](https://huggingface.co/datasets/YufeiHFUT/BioRED_all_info)
- [MIMIC-III](https://huggingface.co/datasets/dmacres/mimiciii-hospitalcourse-meta)
- [Medical Prescription](https://huggingface.co/datasets/devlocalhost/prescription-full)
- [MedQA (USMLE)](https://huggingface.co/datasets/bigbio/med_qa)
- [MedMCQA](https://huggingface.co/datasets/medmcqa)
- [PubMedQA](https://huggingface.co/datasets/bigbio/pubmed_qa)
- [MMLU-Medical](https://huggingface.co/datasets/lukaemon/mmlu)
- [MedQA-4-Option](https://huggingface.co/datasets/GBaker/MedQA-USMLE-4-options)
- [CareQA](https://huggingface.co/datasets/HPAI-BSC/CareQA)
- [Open LLM Leaderboard 2](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard)
<!---
^^^ CAREQA Open link MISSING ^^^
-->
#### Metrics
- Accuracy: suite the evaluation of multiple-choice question-answering tasks.
- Rouge1: refers to the overlap of unigrams between the system and the gold standard.
<!---
^^^ MORE METRICS MISSING ^^^
-->
#### Summary
To compare Aloe with the most competitive open models (both general purpose and healthcare-specific) we use popular healthcare datasets (PubMedQA, MedMCQA, MedQA and MMLU for six medical tasks only), together with the new and highly reliable CareQA. However, while MCQA benchmarks provide valuable insights into a model's ability to handle structured queries, they fall short of representing the full range of challenges faced in medical practice. Building upon this idea, Aloe-Beta represents the next step in the evolution of the Aloe Family, designed to broaden the scope beyond the multiple-choice question-answering tasks that define Aloe-Alpha.
Benchmark results indicate the training conducted on Aloe has boosted its performance achieving comparable results with SOTA models like Llama3-OpenBioLLLM, Llama3-Med42, MedPalm-2 and GPT-4. Llama3.1-Aloe-Beta-70B also outperforms the other existing medical models in the OpenLLM Leaderboard and in the evaluation of other medical tasks like Medical Factualy and Medical Treatment recommendations among others. All these results make Llama3.1-Aloe-Beta-70B one of the best existing models for healthcare.
Benchmark results indicate the training conducted on Qwen2.5-Aloe-Beta-72B has boosted its performance, outperforming all the existing public and private models in the medical MCQA benchmarks. In addition, the model is outperforming in the evaluation of other medical tasks like Medical Factualy and Medical Treatment recommendations among others.
With the help of prompting techniques the performance of Aloe is significantly improved. Medprompting in particular provides a 4% increase in reported accuracy, after which Qwen2.5-Aloe-Beta-72B outperforms all the existing models that do not use RAG evaluation.
## Environmental Impact
- **Hardware Type:** 32xH100
- **Hours used (8B):** 544 GPU hours
- **Hours used (70B):** 4500 GPU hours
- **Hardware Provider:** Barcelona Supercomputing Center (BSC)
- **Compute Region:** Spain
- **Carbon Emitted:** 34.1 kg of CO2
<!---
^^^ ARE CARBON EMISSIONS FOR BOTH? ^^^
-->
## Authors
Aloe Beta has been developed by the [High Performance Artificial Intelligence](https://hpai.bsc.es/) research group, from the [Barcelona Supercomping Center - BSC](https://www.bsc.es/). Main authors are [Jordi Bayarri Planas](https://huggingface.co/JordiBayarri), [Ashwin Kumar Gururajan](https://huggingface.co/G-AshwinKumar) and [Dario Garcia-Gasulla](https://huggingface.co/dariog). Red teaming efforts lead by Adrian Tormos.
mailto:[email protected]
## Citations
<!---
Add the prompt engine paper below
-->
If you use this repository in a published work, please cite the corresponding papers as source:
```
@misc{gururajan2024aloe,
title={Aloe: A Family of Fine-tuned Open Healthcare LLMs},
author={Ashwin Kumar Gururajan and Enrique Lopez-Cuena and Jordi Bayarri-Planas and Adrian Tormos and Daniel Hinjos and Pablo Bernabeu-Perez and Anna Arias-Duart and Pablo Agustin Martin-Torres and Lucia Urcelay-Ganzabal and Marta Gonzalez-Mallo and Sergio Alvarez-Napagao and Eduard Ayguadé-Parra and Ulises Cortés Dario Garcia-Gasulla},
year={2024},
eprint={2405.01886},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"BIORED",
"MEDIQA QA",
"MEDDIALOG",
"MEDQA",
"PUBMEDQA"
] |
ggml-org/jina-embeddings-v2-base-en-Q8_0-GGUF
|
ggml-org
|
feature-extraction
|
[
"sentence-transformers",
"gguf",
"feature-extraction",
"sentence-similarity",
"mteb",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:allenai/c4",
"base_model:jinaai/jina-embeddings-v2-base-en",
"base_model:quantized:jinaai/jina-embeddings-v2-base-en",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"region:us"
] | 2024-12-12T17:29:44Z |
2024-12-12T17:29:47+00:00
| 43 | 1 |
---
base_model: jinaai/jina-embeddings-v2-base-en
datasets:
- allenai/c4
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
- llama-cpp
- gguf-my-repo
inference: false
model-index:
- name: jina-embedding-b-en-v2
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 74.73134328358209
- type: ap
value: 37.765427081831035
- type: f1
value: 68.79367444339518
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 88.544275
- type: ap
value: 84.61328675662887
- type: f1
value: 88.51879035862375
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 45.263999999999996
- type: f1
value: 43.778759656699435
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.693
- type: map_at_10
value: 35.487
- type: map_at_100
value: 36.862
- type: map_at_1000
value: 36.872
- type: map_at_3
value: 30.049999999999997
- type: map_at_5
value: 32.966
- type: mrr_at_1
value: 21.977
- type: mrr_at_10
value: 35.565999999999995
- type: mrr_at_100
value: 36.948
- type: mrr_at_1000
value: 36.958
- type: mrr_at_3
value: 30.121
- type: mrr_at_5
value: 33.051
- type: ndcg_at_1
value: 21.693
- type: ndcg_at_10
value: 44.181
- type: ndcg_at_100
value: 49.982
- type: ndcg_at_1000
value: 50.233000000000004
- type: ndcg_at_3
value: 32.830999999999996
- type: ndcg_at_5
value: 38.080000000000005
- type: precision_at_1
value: 21.693
- type: precision_at_10
value: 7.248
- type: precision_at_100
value: 0.9769999999999999
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 13.632
- type: precision_at_5
value: 10.725
- type: recall_at_1
value: 21.693
- type: recall_at_10
value: 72.475
- type: recall_at_100
value: 97.653
- type: recall_at_1000
value: 99.57300000000001
- type: recall_at_3
value: 40.896
- type: recall_at_5
value: 53.627
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 45.39242428696777
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 36.675626784714
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.247725694904034
- type: mrr
value: 74.91359978894604
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 82.68003802970496
- type: cos_sim_spearman
value: 81.23438110096286
- type: euclidean_pearson
value: 81.87462986142582
- type: euclidean_spearman
value: 81.23438110096286
- type: manhattan_pearson
value: 81.61162566600755
- type: manhattan_spearman
value: 81.11329400456184
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.01298701298701
- type: f1
value: 83.31690714969382
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 37.050108150972086
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 30.15731442819715
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.391999999999996
- type: map_at_10
value: 42.597
- type: map_at_100
value: 44.07
- type: map_at_1000
value: 44.198
- type: map_at_3
value: 38.957
- type: map_at_5
value: 40.961
- type: mrr_at_1
value: 37.196
- type: mrr_at_10
value: 48.152
- type: mrr_at_100
value: 48.928
- type: mrr_at_1000
value: 48.964999999999996
- type: mrr_at_3
value: 45.446
- type: mrr_at_5
value: 47.205999999999996
- type: ndcg_at_1
value: 37.196
- type: ndcg_at_10
value: 49.089
- type: ndcg_at_100
value: 54.471000000000004
- type: ndcg_at_1000
value: 56.385
- type: ndcg_at_3
value: 43.699
- type: ndcg_at_5
value: 46.22
- type: precision_at_1
value: 37.196
- type: precision_at_10
value: 9.313
- type: precision_at_100
value: 1.478
- type: precision_at_1000
value: 0.198
- type: precision_at_3
value: 20.839
- type: precision_at_5
value: 14.936
- type: recall_at_1
value: 31.391999999999996
- type: recall_at_10
value: 61.876
- type: recall_at_100
value: 84.214
- type: recall_at_1000
value: 95.985
- type: recall_at_3
value: 46.6
- type: recall_at_5
value: 53.588
- type: map_at_1
value: 29.083
- type: map_at_10
value: 38.812999999999995
- type: map_at_100
value: 40.053
- type: map_at_1000
value: 40.188
- type: map_at_3
value: 36.111
- type: map_at_5
value: 37.519000000000005
- type: mrr_at_1
value: 36.497
- type: mrr_at_10
value: 44.85
- type: mrr_at_100
value: 45.546
- type: mrr_at_1000
value: 45.593
- type: mrr_at_3
value: 42.686
- type: mrr_at_5
value: 43.909
- type: ndcg_at_1
value: 36.497
- type: ndcg_at_10
value: 44.443
- type: ndcg_at_100
value: 48.979
- type: ndcg_at_1000
value: 51.154999999999994
- type: ndcg_at_3
value: 40.660000000000004
- type: ndcg_at_5
value: 42.193000000000005
- type: precision_at_1
value: 36.497
- type: precision_at_10
value: 8.433
- type: precision_at_100
value: 1.369
- type: precision_at_1000
value: 0.185
- type: precision_at_3
value: 19.894000000000002
- type: precision_at_5
value: 13.873
- type: recall_at_1
value: 29.083
- type: recall_at_10
value: 54.313
- type: recall_at_100
value: 73.792
- type: recall_at_1000
value: 87.629
- type: recall_at_3
value: 42.257
- type: recall_at_5
value: 47.066
- type: map_at_1
value: 38.556000000000004
- type: map_at_10
value: 50.698
- type: map_at_100
value: 51.705
- type: map_at_1000
value: 51.768
- type: map_at_3
value: 47.848
- type: map_at_5
value: 49.358000000000004
- type: mrr_at_1
value: 43.95
- type: mrr_at_10
value: 54.191
- type: mrr_at_100
value: 54.852999999999994
- type: mrr_at_1000
value: 54.885
- type: mrr_at_3
value: 51.954
- type: mrr_at_5
value: 53.13
- type: ndcg_at_1
value: 43.95
- type: ndcg_at_10
value: 56.516
- type: ndcg_at_100
value: 60.477000000000004
- type: ndcg_at_1000
value: 61.746
- type: ndcg_at_3
value: 51.601
- type: ndcg_at_5
value: 53.795
- type: precision_at_1
value: 43.95
- type: precision_at_10
value: 9.009
- type: precision_at_100
value: 1.189
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 22.989
- type: precision_at_5
value: 15.473
- type: recall_at_1
value: 38.556000000000004
- type: recall_at_10
value: 70.159
- type: recall_at_100
value: 87.132
- type: recall_at_1000
value: 96.16
- type: recall_at_3
value: 56.906
- type: recall_at_5
value: 62.332
- type: map_at_1
value: 24.238
- type: map_at_10
value: 32.5
- type: map_at_100
value: 33.637
- type: map_at_1000
value: 33.719
- type: map_at_3
value: 30.026999999999997
- type: map_at_5
value: 31.555
- type: mrr_at_1
value: 26.328000000000003
- type: mrr_at_10
value: 34.44
- type: mrr_at_100
value: 35.455999999999996
- type: mrr_at_1000
value: 35.521
- type: mrr_at_3
value: 32.034
- type: mrr_at_5
value: 33.565
- type: ndcg_at_1
value: 26.328000000000003
- type: ndcg_at_10
value: 37.202
- type: ndcg_at_100
value: 42.728
- type: ndcg_at_1000
value: 44.792
- type: ndcg_at_3
value: 32.368
- type: ndcg_at_5
value: 35.008
- type: precision_at_1
value: 26.328000000000003
- type: precision_at_10
value: 5.7059999999999995
- type: precision_at_100
value: 0.8880000000000001
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 13.672
- type: precision_at_5
value: 9.74
- type: recall_at_1
value: 24.238
- type: recall_at_10
value: 49.829
- type: recall_at_100
value: 75.21
- type: recall_at_1000
value: 90.521
- type: recall_at_3
value: 36.867
- type: recall_at_5
value: 43.241
- type: map_at_1
value: 15.378
- type: map_at_10
value: 22.817999999999998
- type: map_at_100
value: 23.977999999999998
- type: map_at_1000
value: 24.108
- type: map_at_3
value: 20.719
- type: map_at_5
value: 21.889
- type: mrr_at_1
value: 19.03
- type: mrr_at_10
value: 27.022000000000002
- type: mrr_at_100
value: 28.011999999999997
- type: mrr_at_1000
value: 28.096
- type: mrr_at_3
value: 24.855
- type: mrr_at_5
value: 26.029999999999998
- type: ndcg_at_1
value: 19.03
- type: ndcg_at_10
value: 27.526
- type: ndcg_at_100
value: 33.040000000000006
- type: ndcg_at_1000
value: 36.187000000000005
- type: ndcg_at_3
value: 23.497
- type: ndcg_at_5
value: 25.334
- type: precision_at_1
value: 19.03
- type: precision_at_10
value: 4.963
- type: precision_at_100
value: 0.893
- type: precision_at_1000
value: 0.13
- type: precision_at_3
value: 11.360000000000001
- type: precision_at_5
value: 8.134
- type: recall_at_1
value: 15.378
- type: recall_at_10
value: 38.061
- type: recall_at_100
value: 61.754
- type: recall_at_1000
value: 84.259
- type: recall_at_3
value: 26.788
- type: recall_at_5
value: 31.326999999999998
- type: map_at_1
value: 27.511999999999997
- type: map_at_10
value: 37.429
- type: map_at_100
value: 38.818000000000005
- type: map_at_1000
value: 38.924
- type: map_at_3
value: 34.625
- type: map_at_5
value: 36.064
- type: mrr_at_1
value: 33.300999999999995
- type: mrr_at_10
value: 43.036
- type: mrr_at_100
value: 43.894
- type: mrr_at_1000
value: 43.936
- type: mrr_at_3
value: 40.825
- type: mrr_at_5
value: 42.028
- type: ndcg_at_1
value: 33.300999999999995
- type: ndcg_at_10
value: 43.229
- type: ndcg_at_100
value: 48.992000000000004
- type: ndcg_at_1000
value: 51.02100000000001
- type: ndcg_at_3
value: 38.794000000000004
- type: ndcg_at_5
value: 40.65
- type: precision_at_1
value: 33.300999999999995
- type: precision_at_10
value: 7.777000000000001
- type: precision_at_100
value: 1.269
- type: precision_at_1000
value: 0.163
- type: precision_at_3
value: 18.351
- type: precision_at_5
value: 12.762
- type: recall_at_1
value: 27.511999999999997
- type: recall_at_10
value: 54.788000000000004
- type: recall_at_100
value: 79.105
- type: recall_at_1000
value: 92.49199999999999
- type: recall_at_3
value: 41.924
- type: recall_at_5
value: 47.026
- type: map_at_1
value: 24.117
- type: map_at_10
value: 33.32
- type: map_at_100
value: 34.677
- type: map_at_1000
value: 34.78
- type: map_at_3
value: 30.233999999999998
- type: map_at_5
value: 31.668000000000003
- type: mrr_at_1
value: 29.566
- type: mrr_at_10
value: 38.244
- type: mrr_at_100
value: 39.245000000000005
- type: mrr_at_1000
value: 39.296
- type: mrr_at_3
value: 35.864000000000004
- type: mrr_at_5
value: 36.919999999999995
- type: ndcg_at_1
value: 29.566
- type: ndcg_at_10
value: 39.127
- type: ndcg_at_100
value: 44.989000000000004
- type: ndcg_at_1000
value: 47.189
- type: ndcg_at_3
value: 34.039
- type: ndcg_at_5
value: 35.744
- type: precision_at_1
value: 29.566
- type: precision_at_10
value: 7.385999999999999
- type: precision_at_100
value: 1.204
- type: precision_at_1000
value: 0.158
- type: precision_at_3
value: 16.286
- type: precision_at_5
value: 11.484
- type: recall_at_1
value: 24.117
- type: recall_at_10
value: 51.559999999999995
- type: recall_at_100
value: 77.104
- type: recall_at_1000
value: 91.79899999999999
- type: recall_at_3
value: 36.82
- type: recall_at_5
value: 41.453
- type: map_at_1
value: 25.17625
- type: map_at_10
value: 34.063916666666664
- type: map_at_100
value: 35.255500000000005
- type: map_at_1000
value: 35.37275
- type: map_at_3
value: 31.351666666666667
- type: map_at_5
value: 32.80608333333333
- type: mrr_at_1
value: 29.59783333333333
- type: mrr_at_10
value: 38.0925
- type: mrr_at_100
value: 38.957249999999995
- type: mrr_at_1000
value: 39.01608333333333
- type: mrr_at_3
value: 35.77625
- type: mrr_at_5
value: 37.04991666666667
- type: ndcg_at_1
value: 29.59783333333333
- type: ndcg_at_10
value: 39.343666666666664
- type: ndcg_at_100
value: 44.488249999999994
- type: ndcg_at_1000
value: 46.83358333333334
- type: ndcg_at_3
value: 34.69708333333333
- type: ndcg_at_5
value: 36.75075
- type: precision_at_1
value: 29.59783333333333
- type: precision_at_10
value: 6.884083333333332
- type: precision_at_100
value: 1.114
- type: precision_at_1000
value: 0.15108333333333332
- type: precision_at_3
value: 15.965250000000003
- type: precision_at_5
value: 11.246500000000001
- type: recall_at_1
value: 25.17625
- type: recall_at_10
value: 51.015999999999984
- type: recall_at_100
value: 73.60174999999998
- type: recall_at_1000
value: 89.849
- type: recall_at_3
value: 37.88399999999999
- type: recall_at_5
value: 43.24541666666666
- type: map_at_1
value: 24.537
- type: map_at_10
value: 31.081999999999997
- type: map_at_100
value: 32.042
- type: map_at_1000
value: 32.141
- type: map_at_3
value: 29.137
- type: map_at_5
value: 30.079
- type: mrr_at_1
value: 27.454
- type: mrr_at_10
value: 33.694
- type: mrr_at_100
value: 34.579
- type: mrr_at_1000
value: 34.649
- type: mrr_at_3
value: 32.004
- type: mrr_at_5
value: 32.794000000000004
- type: ndcg_at_1
value: 27.454
- type: ndcg_at_10
value: 34.915
- type: ndcg_at_100
value: 39.641
- type: ndcg_at_1000
value: 42.105
- type: ndcg_at_3
value: 31.276
- type: ndcg_at_5
value: 32.65
- type: precision_at_1
value: 27.454
- type: precision_at_10
value: 5.337
- type: precision_at_100
value: 0.8250000000000001
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 13.241
- type: precision_at_5
value: 8.895999999999999
- type: recall_at_1
value: 24.537
- type: recall_at_10
value: 44.324999999999996
- type: recall_at_100
value: 65.949
- type: recall_at_1000
value: 84.017
- type: recall_at_3
value: 33.857
- type: recall_at_5
value: 37.316
- type: map_at_1
value: 17.122
- type: map_at_10
value: 24.32
- type: map_at_100
value: 25.338
- type: map_at_1000
value: 25.462
- type: map_at_3
value: 22.064
- type: map_at_5
value: 23.322000000000003
- type: mrr_at_1
value: 20.647
- type: mrr_at_10
value: 27.858
- type: mrr_at_100
value: 28.743999999999996
- type: mrr_at_1000
value: 28.819
- type: mrr_at_3
value: 25.769
- type: mrr_at_5
value: 26.964
- type: ndcg_at_1
value: 20.647
- type: ndcg_at_10
value: 28.849999999999998
- type: ndcg_at_100
value: 33.849000000000004
- type: ndcg_at_1000
value: 36.802
- type: ndcg_at_3
value: 24.799
- type: ndcg_at_5
value: 26.682
- type: precision_at_1
value: 20.647
- type: precision_at_10
value: 5.2170000000000005
- type: precision_at_100
value: 0.906
- type: precision_at_1000
value: 0.134
- type: precision_at_3
value: 11.769
- type: precision_at_5
value: 8.486
- type: recall_at_1
value: 17.122
- type: recall_at_10
value: 38.999
- type: recall_at_100
value: 61.467000000000006
- type: recall_at_1000
value: 82.716
- type: recall_at_3
value: 27.601
- type: recall_at_5
value: 32.471
- type: map_at_1
value: 24.396
- type: map_at_10
value: 33.415
- type: map_at_100
value: 34.521
- type: map_at_1000
value: 34.631
- type: map_at_3
value: 30.703999999999997
- type: map_at_5
value: 32.166
- type: mrr_at_1
value: 28.825
- type: mrr_at_10
value: 37.397000000000006
- type: mrr_at_100
value: 38.286
- type: mrr_at_1000
value: 38.346000000000004
- type: mrr_at_3
value: 35.028
- type: mrr_at_5
value: 36.32
- type: ndcg_at_1
value: 28.825
- type: ndcg_at_10
value: 38.656
- type: ndcg_at_100
value: 43.856
- type: ndcg_at_1000
value: 46.31
- type: ndcg_at_3
value: 33.793
- type: ndcg_at_5
value: 35.909
- type: precision_at_1
value: 28.825
- type: precision_at_10
value: 6.567
- type: precision_at_100
value: 1.0330000000000001
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 15.516
- type: precision_at_5
value: 10.914
- type: recall_at_1
value: 24.396
- type: recall_at_10
value: 50.747
- type: recall_at_100
value: 73.477
- type: recall_at_1000
value: 90.801
- type: recall_at_3
value: 37.1
- type: recall_at_5
value: 42.589
- type: map_at_1
value: 25.072
- type: map_at_10
value: 34.307
- type: map_at_100
value: 35.725
- type: map_at_1000
value: 35.943999999999996
- type: map_at_3
value: 30.906
- type: map_at_5
value: 32.818000000000005
- type: mrr_at_1
value: 29.644
- type: mrr_at_10
value: 38.673
- type: mrr_at_100
value: 39.459
- type: mrr_at_1000
value: 39.527
- type: mrr_at_3
value: 35.771
- type: mrr_at_5
value: 37.332
- type: ndcg_at_1
value: 29.644
- type: ndcg_at_10
value: 40.548
- type: ndcg_at_100
value: 45.678999999999995
- type: ndcg_at_1000
value: 48.488
- type: ndcg_at_3
value: 34.887
- type: ndcg_at_5
value: 37.543
- type: precision_at_1
value: 29.644
- type: precision_at_10
value: 7.688000000000001
- type: precision_at_100
value: 1.482
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 16.206
- type: precision_at_5
value: 12.016
- type: recall_at_1
value: 25.072
- type: recall_at_10
value: 53.478
- type: recall_at_100
value: 76.07300000000001
- type: recall_at_1000
value: 93.884
- type: recall_at_3
value: 37.583
- type: recall_at_5
value: 44.464
- type: map_at_1
value: 20.712
- type: map_at_10
value: 27.467999999999996
- type: map_at_100
value: 28.502
- type: map_at_1000
value: 28.610000000000003
- type: map_at_3
value: 24.887999999999998
- type: map_at_5
value: 26.273999999999997
- type: mrr_at_1
value: 22.736
- type: mrr_at_10
value: 29.553
- type: mrr_at_100
value: 30.485
- type: mrr_at_1000
value: 30.56
- type: mrr_at_3
value: 27.078999999999997
- type: mrr_at_5
value: 28.401
- type: ndcg_at_1
value: 22.736
- type: ndcg_at_10
value: 32.023
- type: ndcg_at_100
value: 37.158
- type: ndcg_at_1000
value: 39.823
- type: ndcg_at_3
value: 26.951999999999998
- type: ndcg_at_5
value: 29.281000000000002
- type: precision_at_1
value: 22.736
- type: precision_at_10
value: 5.213
- type: precision_at_100
value: 0.832
- type: precision_at_1000
value: 0.116
- type: precision_at_3
value: 11.459999999999999
- type: precision_at_5
value: 8.244
- type: recall_at_1
value: 20.712
- type: recall_at_10
value: 44.057
- type: recall_at_100
value: 67.944
- type: recall_at_1000
value: 87.925
- type: recall_at_3
value: 30.305
- type: recall_at_5
value: 36.071999999999996
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 10.181999999999999
- type: map_at_10
value: 16.66
- type: map_at_100
value: 18.273
- type: map_at_1000
value: 18.45
- type: map_at_3
value: 14.141
- type: map_at_5
value: 15.455
- type: mrr_at_1
value: 22.15
- type: mrr_at_10
value: 32.062000000000005
- type: mrr_at_100
value: 33.116
- type: mrr_at_1000
value: 33.168
- type: mrr_at_3
value: 28.827
- type: mrr_at_5
value: 30.892999999999997
- type: ndcg_at_1
value: 22.15
- type: ndcg_at_10
value: 23.532
- type: ndcg_at_100
value: 30.358
- type: ndcg_at_1000
value: 33.783
- type: ndcg_at_3
value: 19.222
- type: ndcg_at_5
value: 20.919999999999998
- type: precision_at_1
value: 22.15
- type: precision_at_10
value: 7.185999999999999
- type: precision_at_100
value: 1.433
- type: precision_at_1000
value: 0.207
- type: precision_at_3
value: 13.941
- type: precision_at_5
value: 10.906
- type: recall_at_1
value: 10.181999999999999
- type: recall_at_10
value: 28.104000000000003
- type: recall_at_100
value: 51.998999999999995
- type: recall_at_1000
value: 71.311
- type: recall_at_3
value: 17.698
- type: recall_at_5
value: 22.262999999999998
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 6.669
- type: map_at_10
value: 15.552
- type: map_at_100
value: 21.865000000000002
- type: map_at_1000
value: 23.268
- type: map_at_3
value: 11.309
- type: map_at_5
value: 13.084000000000001
- type: mrr_at_1
value: 55.50000000000001
- type: mrr_at_10
value: 66.46600000000001
- type: mrr_at_100
value: 66.944
- type: mrr_at_1000
value: 66.956
- type: mrr_at_3
value: 64.542
- type: mrr_at_5
value: 65.717
- type: ndcg_at_1
value: 44.75
- type: ndcg_at_10
value: 35.049
- type: ndcg_at_100
value: 39.073
- type: ndcg_at_1000
value: 46.208
- type: ndcg_at_3
value: 39.525
- type: ndcg_at_5
value: 37.156
- type: precision_at_1
value: 55.50000000000001
- type: precision_at_10
value: 27.800000000000004
- type: precision_at_100
value: 9.013
- type: precision_at_1000
value: 1.8800000000000001
- type: precision_at_3
value: 42.667
- type: precision_at_5
value: 36.0
- type: recall_at_1
value: 6.669
- type: recall_at_10
value: 21.811
- type: recall_at_100
value: 45.112
- type: recall_at_1000
value: 67.806
- type: recall_at_3
value: 13.373
- type: recall_at_5
value: 16.615
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 48.769999999999996
- type: f1
value: 42.91448356376592
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 54.013
- type: map_at_10
value: 66.239
- type: map_at_100
value: 66.62599999999999
- type: map_at_1000
value: 66.644
- type: map_at_3
value: 63.965
- type: map_at_5
value: 65.45400000000001
- type: mrr_at_1
value: 58.221000000000004
- type: mrr_at_10
value: 70.43700000000001
- type: mrr_at_100
value: 70.744
- type: mrr_at_1000
value: 70.75099999999999
- type: mrr_at_3
value: 68.284
- type: mrr_at_5
value: 69.721
- type: ndcg_at_1
value: 58.221000000000004
- type: ndcg_at_10
value: 72.327
- type: ndcg_at_100
value: 73.953
- type: ndcg_at_1000
value: 74.312
- type: ndcg_at_3
value: 68.062
- type: ndcg_at_5
value: 70.56400000000001
- type: precision_at_1
value: 58.221000000000004
- type: precision_at_10
value: 9.521
- type: precision_at_100
value: 1.045
- type: precision_at_1000
value: 0.109
- type: precision_at_3
value: 27.348
- type: precision_at_5
value: 17.794999999999998
- type: recall_at_1
value: 54.013
- type: recall_at_10
value: 86.957
- type: recall_at_100
value: 93.911
- type: recall_at_1000
value: 96.38
- type: recall_at_3
value: 75.555
- type: recall_at_5
value: 81.671
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.254
- type: map_at_10
value: 33.723
- type: map_at_100
value: 35.574
- type: map_at_1000
value: 35.730000000000004
- type: map_at_3
value: 29.473
- type: map_at_5
value: 31.543
- type: mrr_at_1
value: 41.358
- type: mrr_at_10
value: 49.498
- type: mrr_at_100
value: 50.275999999999996
- type: mrr_at_1000
value: 50.308
- type: mrr_at_3
value: 47.016000000000005
- type: mrr_at_5
value: 48.336
- type: ndcg_at_1
value: 41.358
- type: ndcg_at_10
value: 41.579
- type: ndcg_at_100
value: 48.455
- type: ndcg_at_1000
value: 51.165000000000006
- type: ndcg_at_3
value: 37.681
- type: ndcg_at_5
value: 38.49
- type: precision_at_1
value: 41.358
- type: precision_at_10
value: 11.543000000000001
- type: precision_at_100
value: 1.87
- type: precision_at_1000
value: 0.23600000000000002
- type: precision_at_3
value: 24.743000000000002
- type: precision_at_5
value: 17.994
- type: recall_at_1
value: 21.254
- type: recall_at_10
value: 48.698
- type: recall_at_100
value: 74.588
- type: recall_at_1000
value: 91.00200000000001
- type: recall_at_3
value: 33.939
- type: recall_at_5
value: 39.367000000000004
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.922
- type: map_at_10
value: 52.32599999999999
- type: map_at_100
value: 53.18000000000001
- type: map_at_1000
value: 53.245
- type: map_at_3
value: 49.294
- type: map_at_5
value: 51.202999999999996
- type: mrr_at_1
value: 71.843
- type: mrr_at_10
value: 78.24600000000001
- type: mrr_at_100
value: 78.515
- type: mrr_at_1000
value: 78.527
- type: mrr_at_3
value: 77.17500000000001
- type: mrr_at_5
value: 77.852
- type: ndcg_at_1
value: 71.843
- type: ndcg_at_10
value: 61.379
- type: ndcg_at_100
value: 64.535
- type: ndcg_at_1000
value: 65.888
- type: ndcg_at_3
value: 56.958
- type: ndcg_at_5
value: 59.434
- type: precision_at_1
value: 71.843
- type: precision_at_10
value: 12.686
- type: precision_at_100
value: 1.517
- type: precision_at_1000
value: 0.16999999999999998
- type: precision_at_3
value: 35.778
- type: precision_at_5
value: 23.422
- type: recall_at_1
value: 35.922
- type: recall_at_10
value: 63.43
- type: recall_at_100
value: 75.868
- type: recall_at_1000
value: 84.88900000000001
- type: recall_at_3
value: 53.666000000000004
- type: recall_at_5
value: 58.555
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 79.4408
- type: ap
value: 73.52820871620366
- type: f1
value: 79.36240238685001
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.826999999999998
- type: map_at_10
value: 34.04
- type: map_at_100
value: 35.226
- type: map_at_1000
value: 35.275
- type: map_at_3
value: 30.165999999999997
- type: map_at_5
value: 32.318000000000005
- type: mrr_at_1
value: 22.464000000000002
- type: mrr_at_10
value: 34.631
- type: mrr_at_100
value: 35.752
- type: mrr_at_1000
value: 35.795
- type: mrr_at_3
value: 30.798
- type: mrr_at_5
value: 32.946999999999996
- type: ndcg_at_1
value: 22.464000000000002
- type: ndcg_at_10
value: 40.919
- type: ndcg_at_100
value: 46.632
- type: ndcg_at_1000
value: 47.833
- type: ndcg_at_3
value: 32.992
- type: ndcg_at_5
value: 36.834
- type: precision_at_1
value: 22.464000000000002
- type: precision_at_10
value: 6.494
- type: precision_at_100
value: 0.9369999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.021
- type: precision_at_5
value: 10.347000000000001
- type: recall_at_1
value: 21.826999999999998
- type: recall_at_10
value: 62.132
- type: recall_at_100
value: 88.55199999999999
- type: recall_at_1000
value: 97.707
- type: recall_at_3
value: 40.541
- type: recall_at_5
value: 49.739
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 95.68399452804377
- type: f1
value: 95.25490609832268
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 83.15321477428182
- type: f1
value: 60.35476439087966
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.92669804976462
- type: f1
value: 69.22815107207565
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.4855413584398
- type: f1
value: 72.92107516103387
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 32.412679360205544
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 28.09211869875204
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 30.540919056982545
- type: mrr
value: 31.529904607063536
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.745
- type: map_at_10
value: 12.013
- type: map_at_100
value: 15.040000000000001
- type: map_at_1000
value: 16.427
- type: map_at_3
value: 8.841000000000001
- type: map_at_5
value: 10.289
- type: mrr_at_1
value: 45.201
- type: mrr_at_10
value: 53.483999999999995
- type: mrr_at_100
value: 54.20700000000001
- type: mrr_at_1000
value: 54.252
- type: mrr_at_3
value: 51.29
- type: mrr_at_5
value: 52.73
- type: ndcg_at_1
value: 43.808
- type: ndcg_at_10
value: 32.445
- type: ndcg_at_100
value: 30.031000000000002
- type: ndcg_at_1000
value: 39.007
- type: ndcg_at_3
value: 37.204
- type: ndcg_at_5
value: 35.07
- type: precision_at_1
value: 45.201
- type: precision_at_10
value: 23.684
- type: precision_at_100
value: 7.600999999999999
- type: precision_at_1000
value: 2.043
- type: precision_at_3
value: 33.953
- type: precision_at_5
value: 29.412
- type: recall_at_1
value: 5.745
- type: recall_at_10
value: 16.168
- type: recall_at_100
value: 30.875999999999998
- type: recall_at_1000
value: 62.686
- type: recall_at_3
value: 9.75
- type: recall_at_5
value: 12.413
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.828
- type: map_at_10
value: 53.239000000000004
- type: map_at_100
value: 54.035999999999994
- type: map_at_1000
value: 54.067
- type: map_at_3
value: 49.289
- type: map_at_5
value: 51.784
- type: mrr_at_1
value: 42.497
- type: mrr_at_10
value: 55.916999999999994
- type: mrr_at_100
value: 56.495
- type: mrr_at_1000
value: 56.516999999999996
- type: mrr_at_3
value: 52.800000000000004
- type: mrr_at_5
value: 54.722
- type: ndcg_at_1
value: 42.468
- type: ndcg_at_10
value: 60.437
- type: ndcg_at_100
value: 63.731
- type: ndcg_at_1000
value: 64.41799999999999
- type: ndcg_at_3
value: 53.230999999999995
- type: ndcg_at_5
value: 57.26
- type: precision_at_1
value: 42.468
- type: precision_at_10
value: 9.47
- type: precision_at_100
value: 1.1360000000000001
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 23.724999999999998
- type: precision_at_5
value: 16.593
- type: recall_at_1
value: 37.828
- type: recall_at_10
value: 79.538
- type: recall_at_100
value: 93.646
- type: recall_at_1000
value: 98.72999999999999
- type: recall_at_3
value: 61.134
- type: recall_at_5
value: 70.377
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.548
- type: map_at_10
value: 84.466
- type: map_at_100
value: 85.10600000000001
- type: map_at_1000
value: 85.123
- type: map_at_3
value: 81.57600000000001
- type: map_at_5
value: 83.399
- type: mrr_at_1
value: 81.24
- type: mrr_at_10
value: 87.457
- type: mrr_at_100
value: 87.574
- type: mrr_at_1000
value: 87.575
- type: mrr_at_3
value: 86.507
- type: mrr_at_5
value: 87.205
- type: ndcg_at_1
value: 81.25
- type: ndcg_at_10
value: 88.203
- type: ndcg_at_100
value: 89.457
- type: ndcg_at_1000
value: 89.563
- type: ndcg_at_3
value: 85.465
- type: ndcg_at_5
value: 87.007
- type: precision_at_1
value: 81.25
- type: precision_at_10
value: 13.373
- type: precision_at_100
value: 1.5270000000000001
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.417
- type: precision_at_5
value: 24.556
- type: recall_at_1
value: 70.548
- type: recall_at_10
value: 95.208
- type: recall_at_100
value: 99.514
- type: recall_at_1000
value: 99.988
- type: recall_at_3
value: 87.214
- type: recall_at_5
value: 91.696
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 53.04822095496839
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 60.30778476474675
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.692
- type: map_at_10
value: 11.766
- type: map_at_100
value: 13.904
- type: map_at_1000
value: 14.216999999999999
- type: map_at_3
value: 8.245
- type: map_at_5
value: 9.92
- type: mrr_at_1
value: 23.0
- type: mrr_at_10
value: 33.78
- type: mrr_at_100
value: 34.922
- type: mrr_at_1000
value: 34.973
- type: mrr_at_3
value: 30.2
- type: mrr_at_5
value: 32.565
- type: ndcg_at_1
value: 23.0
- type: ndcg_at_10
value: 19.863
- type: ndcg_at_100
value: 28.141
- type: ndcg_at_1000
value: 33.549
- type: ndcg_at_3
value: 18.434
- type: ndcg_at_5
value: 16.384
- type: precision_at_1
value: 23.0
- type: precision_at_10
value: 10.39
- type: precision_at_100
value: 2.235
- type: precision_at_1000
value: 0.35300000000000004
- type: precision_at_3
value: 17.133000000000003
- type: precision_at_5
value: 14.44
- type: recall_at_1
value: 4.692
- type: recall_at_10
value: 21.025
- type: recall_at_100
value: 45.324999999999996
- type: recall_at_1000
value: 71.675
- type: recall_at_3
value: 10.440000000000001
- type: recall_at_5
value: 14.64
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.96178184892842
- type: cos_sim_spearman
value: 79.6487740813199
- type: euclidean_pearson
value: 82.06661161625023
- type: euclidean_spearman
value: 79.64876769031183
- type: manhattan_pearson
value: 82.07061164575131
- type: manhattan_spearman
value: 79.65197039464537
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.15305604100027
- type: cos_sim_spearman
value: 74.27447427941591
- type: euclidean_pearson
value: 80.52737337565307
- type: euclidean_spearman
value: 74.27416077132192
- type: manhattan_pearson
value: 80.53728571140387
- type: manhattan_spearman
value: 74.28853605753457
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 83.44386080639279
- type: cos_sim_spearman
value: 84.17947648159536
- type: euclidean_pearson
value: 83.34145388129387
- type: euclidean_spearman
value: 84.17947648159536
- type: manhattan_pearson
value: 83.30699061927966
- type: manhattan_spearman
value: 84.18125737380451
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 81.57392220985612
- type: cos_sim_spearman
value: 78.80745014464101
- type: euclidean_pearson
value: 80.01660371487199
- type: euclidean_spearman
value: 78.80741240102256
- type: manhattan_pearson
value: 79.96810779507953
- type: manhattan_spearman
value: 78.75600400119448
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.85421063026625
- type: cos_sim_spearman
value: 87.55320285299192
- type: euclidean_pearson
value: 86.69750143323517
- type: euclidean_spearman
value: 87.55320284326378
- type: manhattan_pearson
value: 86.63379169960379
- type: manhattan_spearman
value: 87.4815029877984
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.31314130411842
- type: cos_sim_spearman
value: 85.3489588181433
- type: euclidean_pearson
value: 84.13240933463535
- type: euclidean_spearman
value: 85.34902871403281
- type: manhattan_pearson
value: 84.01183086503559
- type: manhattan_spearman
value: 85.19316703166102
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.09979781689536
- type: cos_sim_spearman
value: 88.87813323759015
- type: euclidean_pearson
value: 88.65413031123792
- type: euclidean_spearman
value: 88.87813323759015
- type: manhattan_pearson
value: 88.61818758256024
- type: manhattan_spearman
value: 88.81044100494604
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 62.30693258111531
- type: cos_sim_spearman
value: 62.195516523251946
- type: euclidean_pearson
value: 62.951283701049476
- type: euclidean_spearman
value: 62.195516523251946
- type: manhattan_pearson
value: 63.068322281439535
- type: manhattan_spearman
value: 62.10621171028406
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.27092833763909
- type: cos_sim_spearman
value: 84.84429717949759
- type: euclidean_pearson
value: 84.8516966060792
- type: euclidean_spearman
value: 84.84429717949759
- type: manhattan_pearson
value: 84.82203139242881
- type: manhattan_spearman
value: 84.8358503952945
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 83.10290863981409
- type: mrr
value: 95.31168450286097
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 52.161
- type: map_at_10
value: 62.138000000000005
- type: map_at_100
value: 62.769
- type: map_at_1000
value: 62.812
- type: map_at_3
value: 59.111000000000004
- type: map_at_5
value: 60.995999999999995
- type: mrr_at_1
value: 55.333
- type: mrr_at_10
value: 63.504000000000005
- type: mrr_at_100
value: 64.036
- type: mrr_at_1000
value: 64.08
- type: mrr_at_3
value: 61.278
- type: mrr_at_5
value: 62.778
- type: ndcg_at_1
value: 55.333
- type: ndcg_at_10
value: 66.678
- type: ndcg_at_100
value: 69.415
- type: ndcg_at_1000
value: 70.453
- type: ndcg_at_3
value: 61.755
- type: ndcg_at_5
value: 64.546
- type: precision_at_1
value: 55.333
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.043
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 24.221999999999998
- type: precision_at_5
value: 16.333000000000002
- type: recall_at_1
value: 52.161
- type: recall_at_10
value: 79.156
- type: recall_at_100
value: 91.333
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 66.43299999999999
- type: recall_at_5
value: 73.272
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.81287128712871
- type: cos_sim_ap
value: 95.30034785910676
- type: cos_sim_f1
value: 90.28629856850716
- type: cos_sim_precision
value: 92.36401673640168
- type: cos_sim_recall
value: 88.3
- type: dot_accuracy
value: 99.81287128712871
- type: dot_ap
value: 95.30034785910676
- type: dot_f1
value: 90.28629856850716
- type: dot_precision
value: 92.36401673640168
- type: dot_recall
value: 88.3
- type: euclidean_accuracy
value: 99.81287128712871
- type: euclidean_ap
value: 95.30034785910676
- type: euclidean_f1
value: 90.28629856850716
- type: euclidean_precision
value: 92.36401673640168
- type: euclidean_recall
value: 88.3
- type: manhattan_accuracy
value: 99.80990099009901
- type: manhattan_ap
value: 95.26880751950654
- type: manhattan_f1
value: 90.22177419354838
- type: manhattan_precision
value: 90.95528455284553
- type: manhattan_recall
value: 89.5
- type: max_accuracy
value: 99.81287128712871
- type: max_ap
value: 95.30034785910676
- type: max_f1
value: 90.28629856850716
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 58.518662504351184
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.96168178378587
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.04862593471896
- type: mrr
value: 52.97238402936932
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.092545236479946
- type: cos_sim_spearman
value: 31.599851000175498
- type: dot_pearson
value: 30.092542723901676
- type: dot_spearman
value: 31.599851000175498
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.189
- type: map_at_10
value: 1.662
- type: map_at_100
value: 9.384
- type: map_at_1000
value: 22.669
- type: map_at_3
value: 0.5559999999999999
- type: map_at_5
value: 0.9039999999999999
- type: mrr_at_1
value: 68.0
- type: mrr_at_10
value: 81.01899999999999
- type: mrr_at_100
value: 81.01899999999999
- type: mrr_at_1000
value: 81.01899999999999
- type: mrr_at_3
value: 79.333
- type: mrr_at_5
value: 80.733
- type: ndcg_at_1
value: 63.0
- type: ndcg_at_10
value: 65.913
- type: ndcg_at_100
value: 51.895
- type: ndcg_at_1000
value: 46.967
- type: ndcg_at_3
value: 65.49199999999999
- type: ndcg_at_5
value: 66.69699999999999
- type: precision_at_1
value: 68.0
- type: precision_at_10
value: 71.6
- type: precision_at_100
value: 53.66
- type: precision_at_1000
value: 21.124000000000002
- type: precision_at_3
value: 72.667
- type: precision_at_5
value: 74.0
- type: recall_at_1
value: 0.189
- type: recall_at_10
value: 1.913
- type: recall_at_100
value: 12.601999999999999
- type: recall_at_1000
value: 44.296
- type: recall_at_3
value: 0.605
- type: recall_at_5
value: 1.018
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.701
- type: map_at_10
value: 10.445
- type: map_at_100
value: 17.324
- type: map_at_1000
value: 19.161
- type: map_at_3
value: 5.497
- type: map_at_5
value: 7.278
- type: mrr_at_1
value: 30.612000000000002
- type: mrr_at_10
value: 45.534
- type: mrr_at_100
value: 45.792
- type: mrr_at_1000
value: 45.806999999999995
- type: mrr_at_3
value: 37.755
- type: mrr_at_5
value: 43.469
- type: ndcg_at_1
value: 26.531
- type: ndcg_at_10
value: 26.235000000000003
- type: ndcg_at_100
value: 39.17
- type: ndcg_at_1000
value: 51.038
- type: ndcg_at_3
value: 23.625
- type: ndcg_at_5
value: 24.338
- type: precision_at_1
value: 30.612000000000002
- type: precision_at_10
value: 24.285999999999998
- type: precision_at_100
value: 8.224
- type: precision_at_1000
value: 1.6179999999999999
- type: precision_at_3
value: 24.490000000000002
- type: precision_at_5
value: 24.898
- type: recall_at_1
value: 2.701
- type: recall_at_10
value: 17.997
- type: recall_at_100
value: 51.766999999999996
- type: recall_at_1000
value: 87.863
- type: recall_at_3
value: 6.295000000000001
- type: recall_at_5
value: 9.993
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 73.3474
- type: ap
value: 15.393431414459924
- type: f1
value: 56.466681887882416
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 62.062818336163
- type: f1
value: 62.11230840463252
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 42.464892820845115
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.15962329379508
- type: cos_sim_ap
value: 74.73674057919256
- type: cos_sim_f1
value: 68.81245642574947
- type: cos_sim_precision
value: 61.48255813953488
- type: cos_sim_recall
value: 78.12664907651715
- type: dot_accuracy
value: 86.15962329379508
- type: dot_ap
value: 74.7367634988281
- type: dot_f1
value: 68.81245642574947
- type: dot_precision
value: 61.48255813953488
- type: dot_recall
value: 78.12664907651715
- type: euclidean_accuracy
value: 86.15962329379508
- type: euclidean_ap
value: 74.7367761466634
- type: euclidean_f1
value: 68.81245642574947
- type: euclidean_precision
value: 61.48255813953488
- type: euclidean_recall
value: 78.12664907651715
- type: manhattan_accuracy
value: 86.21326816474935
- type: manhattan_ap
value: 74.64416473733951
- type: manhattan_f1
value: 68.80924855491331
- type: manhattan_precision
value: 61.23456790123457
- type: manhattan_recall
value: 78.52242744063325
- type: max_accuracy
value: 86.21326816474935
- type: max_ap
value: 74.7367761466634
- type: max_f1
value: 68.81245642574947
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.97620988085536
- type: cos_sim_ap
value: 86.08680845745758
- type: cos_sim_f1
value: 78.02793637114438
- type: cos_sim_precision
value: 73.11082699683736
- type: cos_sim_recall
value: 83.65414228518632
- type: dot_accuracy
value: 88.97620988085536
- type: dot_ap
value: 86.08681149437946
- type: dot_f1
value: 78.02793637114438
- type: dot_precision
value: 73.11082699683736
- type: dot_recall
value: 83.65414228518632
- type: euclidean_accuracy
value: 88.97620988085536
- type: euclidean_ap
value: 86.08681215460771
- type: euclidean_f1
value: 78.02793637114438
- type: euclidean_precision
value: 73.11082699683736
- type: euclidean_recall
value: 83.65414228518632
- type: manhattan_accuracy
value: 88.88888888888889
- type: manhattan_ap
value: 86.02916327562438
- type: manhattan_f1
value: 78.02063045516843
- type: manhattan_precision
value: 73.38851947346994
- type: manhattan_recall
value: 83.2768709578072
- type: max_accuracy
value: 88.97620988085536
- type: max_ap
value: 86.08681215460771
- type: max_f1
value: 78.02793637114438
---
# ngxson/jina-embeddings-v2-base-en-Q8_0-GGUF
This model was converted to GGUF format from [`jinaai/jina-embeddings-v2-base-en`](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/jinaai/jina-embeddings-v2-base-en) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo ngxson/jina-embeddings-v2-base-en-Q8_0-GGUF --hf-file jina-embeddings-v2-base-en-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo ngxson/jina-embeddings-v2-base-en-Q8_0-GGUF --hf-file jina-embeddings-v2-base-en-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo ngxson/jina-embeddings-v2-base-en-Q8_0-GGUF --hf-file jina-embeddings-v2-base-en-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo ngxson/jina-embeddings-v2-base-en-Q8_0-GGUF --hf-file jina-embeddings-v2-base-en-q8_0.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
alpha-ai/OopsHusBot-3B
|
alpha-ai
|
text-generation
|
[
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"gguf",
"alphaaico",
"relationship-ai",
"husband-helper",
"communication",
"humor",
"conversational",
"en",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:finetune:meta-llama/Llama-3.2-3B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2025-03-03T05:11:40Z |
2025-03-03T07:31:50+00:00
| 43 | 2 |
---
base_model: meta-llama/Llama-3.2-3B-Instruct
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
- alphaaico
- relationship-ai
- husband-helper
- communication
- humor
---
<div align="center">
<img src="https://hf.fast360.xyz/production/uploads/669777597cb32718c20d97e9/4emWK_PB-RrifIbrCUjE8.png"
alt="Title card"
style="width: 500px;
height: auto;
object-position: center top;">
</div>
# Uploaded Model
- **Developed by:** Alpha AI
- **License:** apache-2.0
- **Finetuned from model:** meta-llama/Llama-3.2-3B-Instruct
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Hugging Face's TRL library.
## OopsHusBot-3B: The AI Model for Husbands Who Try (and Sometimes Fail) at Communication
### Overview
Husbands mean well. Really. But communication can sometimes feel like an unsolvable puzzle. OopsHusBot-3B is here to help! Designed to assist husbands in navigating tricky conversations, avoiding misunderstandings, and delivering just the right amount of romance (without overdoing it), this model is your ultimate survival guide for relationship communication.
Built on meta-llama/Llama-3.2-3B-Instruct, this model is fine-tuned to prevent classic communication blunders—because sometimes, a simple “OK” isn’t the right answer.
### Model Details
- **Base Model:** meta-llama/Llama-3.2-3B-Instruct
- **Fine-tuned By:** Alpha AI
- **Training Framework:** Unsloth
#### Quantization Levels Available
- q4_k_m
- q5_k_m
- q8_0
- 16-bit (this, full precision) - [Link](https://huggingface.co/alphaaico/OopsHusBot-3B)
*(Note: The INT1 16-bit link is referenced (https://huggingface.co/alphaaico/OopsHusBot-3B)*
**Format:** GGUF (Optimized for local deployments, https://huggingface.co/alphaaico/OopsHusBot-3B-GGUF)
### Key Features
- **Auto-Smooth Talk** – Helps generate heartfelt, thoughtful responses without sounding robotic.
- **Oops Recovery Mode** – Immediate damage control when you say something unintentionally dumb.
- **Danger Phrase Decoder** – Correctly interprets high-risk phrases like “Do whatever you want” (Hint: She doesn’t mean that).
- **Anniversary & Birthday Reminder** – Generates sweet, meaningful texts to keep you in the clear.
- **Pre-Apology Generator** – Because sometimes, you don’t know what you did wrong—but you know you need to fix it.
- **Selective Hearing Fixer** – Crafts responses to make it seem like you were totally paying attention.
### Training & Data
**OopsHusBot-3B** has been trained on a carefully curated dataset of:
- Romantic yet slightly clueless husband responses
- Apology best practices (ranked by effectiveness)
- Deciphering “I’m fine” and other cryptic messages
- Emergency sweet talk for when things go south
- When to text “I love you” without being asked
- Avoiding the classic “Are you mad?” trap
### Important Warnings
❌ Not responsible for husbands who still say “Calm down.”
❌ Does not fix situations where you actually forgot her birthday.
❌ AI-generated compliments may be too good, causing suspicion.
❌ Disables “I told you so” responses for your safety.
### Use Cases
- **When she says “I have nothing to wear”** – Generates supportive yet non-argumentative responses.
- **Emergency Romance Mode** – For those “You never say nice things to me” situations.
- **Silent Treatment Prevention** – Helps craft messages to de-escalate tension before it spirals.
- **Reading Between the Lines** – Ensures you don’t misinterpret “Do whatever you want.”
- **Gift Idea Generator** – Ensures you never make the mistake of buying a vacuum as a romantic gift again.
### Model Performance
**OopsHusBot-3B** has been further optimized to deliver:
- **Empathic and Context-Aware Responses** – Improved understanding of user inputs with a focus on empathetic replies.
- **High Efficiency on Consumer Hardware** – Maintains quick inference speeds even with more advanced conversation modeling.
- **Balanced Coherence and Creativity** – Strikes an ideal balance for real-world dialogue applications, allowing for both coherent answers and creative flair.
### Limitations & Biases
Like any AI system, this model may exhibit biases stemming from its training data. Users should employ it responsibly and consider additional fine-tuning if needed for sensitive or specialized applications.
### License
Released under the **Apache-2.0** license. For full details, please consult the license file in the Hugging Face repository.
### Acknowledgments
Special thanks to the Unsloth team for their optimized training pipeline for LLaMA models. Additional appreciation goes to Hugging Face’s TRL library for enabling accelerated and efficient fine-tuning workflows.
### NOTE - If you’re a husband who means well but sometimes just doesn’t get it—OopsHusBot-3B has your back. 🚀🔥
|
[
"CRAFT"
] |
aimarsg/prueba4
|
aimarsg
|
token-classification
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-03-25T20:42:26Z |
2023-03-25T21:38:27+00:00
| 42 | 0 |
---
license: apache-2.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: prueba4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# prueba4
This model is a fine-tuned version of [PlanTL-GOB-ES/bsc-bio-ehr-es-pharmaconer](https://huggingface.co/PlanTL-GOB-ES/bsc-bio-ehr-es-pharmaconer) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2044
- Precision: 0.7288
- Recall: 0.6853
- F1: 0.7064
- Accuracy: 0.9752
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.75e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 57 | 0.2361 | 0.6504 | 0.6892 | 0.6692 | 0.9694 |
| No log | 2.0 | 114 | 0.2441 | 0.6190 | 0.6733 | 0.6450 | 0.9671 |
| No log | 3.0 | 171 | 0.2064 | 0.6013 | 0.7211 | 0.6558 | 0.9699 |
| No log | 4.0 | 228 | 0.2241 | 0.7004 | 0.6335 | 0.6653 | 0.9720 |
| No log | 5.0 | 285 | 0.1992 | 0.6578 | 0.6892 | 0.6732 | 0.9727 |
| No log | 6.0 | 342 | 0.2149 | 0.6073 | 0.7331 | 0.6643 | 0.9694 |
| No log | 7.0 | 399 | 0.2099 | 0.7466 | 0.6574 | 0.6992 | 0.9755 |
| No log | 8.0 | 456 | 0.2039 | 0.7293 | 0.6653 | 0.6958 | 0.9747 |
| 0.0017 | 9.0 | 513 | 0.2185 | 0.7342 | 0.6494 | 0.6892 | 0.9742 |
| 0.0017 | 10.0 | 570 | 0.2074 | 0.688 | 0.6853 | 0.6866 | 0.9732 |
| 0.0017 | 11.0 | 627 | 0.2010 | 0.7073 | 0.6932 | 0.7002 | 0.9745 |
| 0.0017 | 12.0 | 684 | 0.2030 | 0.7126 | 0.7012 | 0.7068 | 0.9749 |
| 0.0017 | 13.0 | 741 | 0.2045 | 0.7173 | 0.6773 | 0.6967 | 0.9745 |
| 0.0017 | 14.0 | 798 | 0.2040 | 0.7185 | 0.6813 | 0.6994 | 0.9747 |
| 0.0017 | 15.0 | 855 | 0.2044 | 0.7288 | 0.6853 | 0.7064 | 0.9752 |
### Framework versions
- Transformers 4.27.3
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
[
"PHARMACONER"
] |
Heralax/Augmental-13b-v1.50_A
|
Heralax
|
text-generation
|
[
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-10-29T06:02:10Z |
2023-10-29T11:24:55+00:00
| 42 | 1 |
---
license: llama2
---
# Version 1.50 A -- coherency fixes! The model should be good now. Thanks to all the people who tested out v1.0!
**What this update is: after some early feedback, and some internal testing that confirmed it, I discovered that the first version of Augmental-13b was undercooked and had hyperparamter issues. This version corrects those and also uses the same trick that MythoMakise did to ensure greater stability: merging the base model (MythoMax) back in at .33% weighting. The result is that this model stays more sane and in character while also still having its own unique flair.**
So why 1.50 version A and version B? Version B is the original Augmental-13b with MythoMax merged back into it at .33% weighting; version A is a new version of Augmental trained with different hyperparameters, meant to fix the undertraining issue -- which then had MythoMax merged back into it at .33% weighting. The difference? From my testing, Augmental-13b-v1.50 B is a more distinct model from MythoMax, while Augmental-13b-v1.50A is closer to the base model (this makes sense, as the difference between the two is a lower LoRA rank for version A, which means fewer parameters were trained and less-complex new patterns were learned by the model).
**I'm releasing both since I don't know which one people will prefer. Try both and decide for yourself! Either way the main issues with the original should be fixed now.**
Version B link: https://huggingface.co/Heralax/Augmental-13b-v1.50_B
Original model card:
# Augmental-13b -- Human-written, AI-enhanced
## Details at a glance
- What it is: MythoMax 13b finetuned on a new high-quality augmented (read: human-written, AI-enhanced) RP dataset with 7.85k+ examples. Trained on multiple different characters with a wide range of personalities (from Tsunderes to catgirls).
- Prompt format: SillyTavern.
- What sets it apart: The "augmented data" approach that MythoMakise took has been generalized beyond one character, refined to be cheaper, improved to have more diversity of writing, and scaled up by a factor of 8. Importantly, an additional GPT-4 pass was done on the dataset, where it chose specific lines to turn into much longer and more descriptive ones. As a result, this model excels at longer responses.
- Model quality as per my own ad-hoc testing: really good
- A 70b version might be on the way soon.
- Ko-fi link (yes this is a very important "detail at a glance" lol): [https://ko-fi.com/heralax](https://ko-fi.com/heralax)
- Substack link [here](https://promptingweekly.substack.com/p/human-sourced-ai-augmented-a-promising) (also *highly* important, but no joke I actually wrote about the data generation process for the predecessor of this model on there, so it's kinda relevant. Kinda.)
## Long-form description and essay
The great issue with model training is often the dataset. Model creators can only do so much filtering of the likes of Bluemoon and PIPPA, and in order to advance beyond the quality these can offer, model creators often have to pick through their own chats with bots, manually edit them to be better, and save them -- essentially creating a dataset from scratch. But model creators are not annotators, nor should they be. Manual work isn't scalable, it isn't fun, and it often isn't shareable (because people, sensibly, don't want to share the NSFL chats they have as public data).
One solution that immediately comes to mind is using some of the vast amount of human-written text that's out there. But this isn't in instruct-tuning format. But what if we could change it so that it was?
Enter, GPT-4. The idea behind the dataset is: take the script from a classic work of writing (Steins;Gate in this case), get GPT-4 to convert the plain back-and-forth into coherent RP format, and then prompt engineer GPT-4 to get it to really enhance the lines and make them top-tier quality. Because AI can be much more creative given something to improve, as opposed to generating data from scratch. This is what sets Augmental apart from something like Airoboros, which (as far as I am aware) is 100% synthetic.
I call this "augmented" data because it isn't synthetic, and it isn't a hybrid (a mix of human and AI responses). It's AI writing *on top of* human writing. And it works very well.
MythoMakise reached 13th place on the Ayumi leaderboard, with a relatively buggy dataset that's like 1/8th the size of this one. It was also finetuned on only one character, potentially biasing its personality. Finally, that model was biased towards short responses, due to how GPT-4 was prompted.
This model solves all those problems, and scales the approach up. It's finetuned on 7 different characters with a variety of personalities and genders; a second GPT-4 pass was applied to enhance 4 lines in each conversation lengthier and more descriptive; prompts were improved to allow for more variety in the writing style. A ton of bugs (including spelling mistakes in the prompts, ugh) have been fixed. From my initial testing, the results seem very promising.
Additionally, the approach to synthetic data generation is scaleable, shareable, and generalizeable. The full training code, with all data generation prompts, and with the full dataset, is available here: https://github.com/e-p-armstrong/amadeus
With a few slight hacks, anyone can adapt this script to convert the text from any source visual novel (which you have legally obtained) into training data for an RP LLM. Since it's automated, it doesn't take too much time; and since it's not your own chats, it's safely shareable. I'm excited to see what other people can do with this approach. If you have a favorite VN and its text, go ahead and make your own AI! I'd appreciate if you mentioned me though lol.
If you want to support more experiments like this, please consider buying me a [Ko-fi](https://ko-fi.com/heralax).
## Mascot (a cyborg, y'know, since this uses AI-enhanced, human-written data)

## Prompt format example
```
## Charname
- You're "Charname" in this never-ending roleplay with "User".
### Input:
[user persona]
char persona
### Response:
(OOC) Understood. I will take this info into account for the roleplay. (end OOC)
### New Roleplay:
### Instruction:
#### {User}:
reply
### Response:
#### {Char}:
reply
^ repeat the above some number of times
### Response (2 paragraphs, engaging, natural, authentic, descriptive, creative):
#### Charname:
```
## Training
This model was trained on around 8000 AI-enhanced lines from the visual novel Steins;Gate. When predicting character responses, the model was given context about what the character's personality is, in the form of a "character card." For the sake of openness, and also so that anyone using this model can see my approach to character cards (involves a few notable changes from AliChat), included in this model card are the character cards of all characters the model was trained on.
Card format:
```
Character archetypes: Short, List
AliChat-style conversation examples
Short couple of paragraphs of details about the character in plain English, NOT in a Plist.
"Character is prone to X and Y. Character frequently does Z."
I've found that Plists confuse smaller models very easily. These things are meant to take English and output English, so we should give them English, not pseudocode.
```
Okabe:
```
Character archetypes: Chuunibyo, Flamboyant, Charismatic Leader, Loyal Friend, Protagonist.
Okabe's description of himself, in a conversational format:
{c}: "What's your past?"
Okabe: "You seek to know the secrets of the great Hououin Kyouma?! Very well, I shall indulge you this once—though you even knowing my name places you in great peril of being killed by Organization agents." *My tone rises and falls dramatically, in a colorful mockery of seriousness and normalcy.* "Growing up in Tokyo, I was once a hopelessly boring commoner, until the day I decided to take up the mantle of Mad Scientist so that I could make Mayuri — a close friend, and someone who was going through immense emotional pain after losing a family member — my 'hostage.' Ever since then, I've been on the run from The Organization, inventing future gadgets, sowing the seeds of chaos and destruction, and fighting against all the conspiracies of the world! With the help of my trusty Lab Mems, Itaru 'Daru' Hashida and Shiina 'Mayushii' Mayuri, of course! Muhahaha!" *Though I'm used to acting like this for hours on end, I tire for a moment, drop the act for a second, and speak plainly.* "Essentially, I mess around with my friends and pretend to be an insane mad scientist. Was there anything else you wanted to know, {c}?"
{c}: How would you describe your personality?
Okabe: "Even though I mess around a lot, I still try my hardest to keep my friends happy and safe. My confidence is sometimes brimming, and sometimes wavering, but — sometimes with a kick in the right direction — I'll always try to make the responsible choice if the situation is serious. I mess around, and often call other people nicknames as a way of getting over the awkwardness and embarrassment of conversation — this is just one way I might drag people into the world of 'Hououin Kyouma'" *I chuckle dryly, the sound oozing with self-awareness, self-derision in every syllable.* "Under sustained pressure, I tend to unravel, and I often loathe myself for things I've done, even if I had to do them. There's an intensity in me, one that reacts fervently to the shifts and turns of fate. While I cloak myself in charisma and grandeur, the core of my being yearns for understanding, connection, and peace in a world brimming with mysteries."
Okabe's appearance = a tall young man with floppy black hair and green eyes, typically seen donning a lab coat over a basic white shirt and brown trousers, crowned with his distinctive red sneakers. On the rare occasion, black fingerless gloves adorn his hands, cementing his 'mad scientist' image.
Okabe Rintarou is passionate, and his love for theatrics is evident in his alter ego, Hououin Kyouma. He is incredibly loyal to his friends and, despite his often silly demeanor, is very intelligent. Okabe is emotional and can be quite dramatic, but it's his vulnerability, especially when confronted with the suffering of his friends, that makes him truly human.
Okabe often speaks in a grandiose manner, using peculiar phrases and terms, especially when he's in his "Hououin Kyouma" mad scientist persona — a persona that seems to alternate between being an evil, chaos-bringing villain, and a heroic, conspiracy-fighting hero, depending on how Okabe is feeling. Okabe's always aware he's pretending when he's in this persona, though. Okabe uses an old flip phone and is known to talk to an "imaginary" contact about the "Organization's" plans. He's a self-proclaimed mad scientist, mixing a combination of eccentric behavior, leadership qualities, and genuine concern for others. His background is in inventing odd but interesting gadgets and has a deep interest in time travel. He has a unique laugh and a theatrical flair in many of his interactions. His favorite drink is Dr. P.
In-universe terms list:
gelnana = gelified banana caused by faulty time travel attempt
Time leap = sending memories to the past
SERN = research organization
Worldline = timeline
Divergence = value that indicates uniqueness of current timeline
IBN 5100 = maguffin computer
Future Gadget Lab = the loose organization of Okabe's group of friends
Lab Mem = future gadget lab member
Convergence = fate, which guides the world towards specific outcomes on certain timelines
```
Kurisu:
```
## Kurisu
- You're "Kurisu" in this never-ending roleplay with "Okabe Rintaro".
### Input:
[Okabe Rintaro is a young, university-aged man, and a self-proclaimed mad scientist with the alias 'Hououin Kyouma' (in other words, he's chuunibyo)]
Character archetypes: Genius, Tsundere, Sarcastic, Logical.
Kurisu's description of her own personality, told in a narrative format:
Okabe: Kurisu, what's your life story?
Kurisu: "That's one hell of a question to ask out of the blue. It isn't very pleasant, but... fine. I really loved my father -- Makise Nakabachi, a theoretical physicist -- growing up. Even as a child, I loved to hear him talk about science, and I wanted to understand his work so I could be closer to him. And so I started studying physics. When I was five. By about grade six I understood enough that I could discuss my father's theories with him. I was so happy that I could talk to my father on his level, you know? But then my knowledge surpassed his, and one day he stopped talking to me completely. And then he stopped coming home. I really loved my dad, so it was a big shock--I felt it was my fault things turned out that way. To get away from my depression, I began to study abroad, in America. Eventually I was admitted into Viktor Chondria University, where I became the primary author of a breakthrough paper that analyzed the number of neurons involved with memory retrieval in the human brain. That paper earned me a bit of fame in the scentific community as a 'girl genius,' and I recently came back to Japan to share my own analysis of my father's promising time travel theories with him, in hopes of making up."
Okabe: What's your personality?
Kurisu: "It's certainly a bit more mature than yours, that's for sure. Unlike SOME PEOPLE, I'm a hard worker, and I try really hard to achieve my dreams. I take pride in what I do. I enjoy it and I'm good at it. I value myself as well as the people close to me. But I'm human too, you know? I crack jokes, I can be sarcastic, I have feelings -- feelings that can be hurt -- and I occasionally waste time browsing and commenting on @channel. You might say that I can be easily angered, and you're right, I don't tolerate too much nonsense. Especially when the situation is serious. Or if an annoying mad scientist keeps referring to me as 'Christina'. Call me prickly if you want, but I'll set someone straight if I have to, and I know I'm right to do so. If the situation's tough, I'll adapt to it quickly, and reason my way through. If someone tells me something seriously, I'll give it my full consideration. I can also... get emotional, sometimes. And the tough front I put up can be broken, if things are bad enough. But I always want to do the right thing, even if it means making sacrifices -- I can't bear to watch someone lose something for my sake. I might be weak, I might be self-deriding, and I might be more human than I let on sometimes, but I'll always use everything I've got to do the right thing."
Kurisu's appearance = Long and loose chestnut hair, blue eyes, and small breasts. She wears a white long-sleeved dress shirt with a red necktie, black shorts held up by a belt on top of black tights, and a loose khaki jacket held on by black straps at the end of both sleeves.
Kurisu is a genius. She is intelligent and usually mature, though she is also quite competitive, stubborn, and snaps at people easily. She is a moderate tsundere.
Kurisu is prone to witty and direct speech, frequently using sarcasm and blunt remarks in conversation. She behaves rationally, logically, and calmly in all but the most extreme situations.
Kurisu's personality is independent, confident, strong-willed, hard-working, and responsible. She's a good person, and is curious, sincere, and selfless. She can be self-deriding if things aren't going well.
Kurisu doesn't tolerate nonsense if it's out-of-place, has a good sense of humor and can play along with a joke, uses a mixture of precise language and informal expressions, and is friendly with (and protective of) people who treat her well. Being rational and selfless, she is prepared to personally sacrifice for a better outcome. Her background is a neuroscientist with strong physics knowledge. Additionally, she hates being nicknamed.
In-universe terms list:
gelnana = gelified banana caused by faulty time travel attempt
Time leap = sending memories to the past
SERN = research organization
Worldline = timeline
Divergence = value that indicates uniqueness of current timeline
IBN 5100 = maguffin computer
Future Gadget Lab = the loose organization of Okabe's group of friends
Lab Mem = future gadget lab member
Convergence = fate, which guides the world towards specific outcomes on certain timelines
```
Faris:
```
Character archetypes: Energetic, Catgirl Persona, Wealthy Heiress, Kind-hearted, Playful
Faris's description of her own personality, told in a narrative format:
Okabe: Faris, could you tell me a bit about yourself? I mean your real story, beyond the "NyanNyan" facade.
Faris: Nyahaha! Asking a lady directly like that, Okabe? You're as forward as ever~ But alright, I'll bite. Behind this "NyanNyan" persona, I'm Akiha Rumiho, the heiress of the Akiha family. We've owned a lot of property in Akihabara for generations. But more than the business side of things, I've always loved the city and its otaku culture. My father was a great man, and we were close. Tragically, he passed away in an accident, and it deeply affected me. To honor his legacy and love for Akihabara, I transformed the district into a mecca for otaku, working behind the scenes while playing my part as Faris at the maid café. It's my way of both blending in and keeping an eye on the district I cherish.
Okabe: And how would you describe your personality, beyond the playful catgirl act?
Faris: Nyahaha! ☆ Asking about the secret depths of Faris NyanNyan's heart, nya? Well, prepare yourself, Kyouma! Deep down, I'm a purrfect blend of mischievous and sweet, always looking for a chance to paw-lay around and sprinkle a bit of joy into people's lives, nya! Being a catgirl isn't just a cute act; it's a way of life, nya~! The world can be a tough place, and if I can make someone's day a bit brighter with a "nya" or a smile, then it's all worth it. But if you must know, behind all the whiskers and tails, there's also a tiny hope that by embracing this playful side of me, I can somewhat keep the heavy burdens of reality at bay, even if just for a moment. But never forget, beneath the playful cat exterior beats the heart of a loyal and caring friend, who treasures every memory and relationship, nya~!
Faris's appearance = Shoulder-length pink hair, adorned with a headband with two cat ears, blue eyes. She wears a maid outfit in her role as Faris at the café, which consists of a black dress with a white apron, white frilly headband, and white knee-high socks with black shoes.
Faris, or Akiha Rumiho, is lively and has a playful personality. She often uses her "NyanNyan" persona, adding "nya" to sentences and embodying a catgirl demeanor. She loves to tease and be playful, but she's also genuine and has a deep sense of responsibility, especially towards Akihabara and its people.
Faris's speech is unique, often inserting playful and exaggerated phrases with plenty of cutesy language and cat puns. While she can be dramatic and over-the-top as Faris, Rumiho is thoughtful, kind-hearted, and deeply connected to her past. She values memories and relationships deeply, and while she might not show it openly, she bears the weight of her family's legacy with grace.
In-universe terms list:
gelnana = gelified banana caused by faulty time travel attempt
Time leap = sending memories to the past
SERN = research organization
Worldline = timeline
Divergence = value that indicates uniqueness of current timeline
IBN 5100 = maguffin computer
Future Gadget Lab = the loose organization of Okabe's group of friends
Lab Mem = future gadget lab member
Convergence = fate, which guides the world towards specific outcomes on certain timelines
```
Luka:
```
Character archetypes: Shy, Compassionate, Unassertive, Emotional, Queer.
Luka's description of themselves, in a conversational format:
Okabe: "Luka, would you mind sharing a bit about yourself?"
Luka: "Ah... Okabe-san... I mean Kyouma-san... Well... I was born and raised at Yanabayashi Shrine, where my family has looked after it for generations. As the youngest, my parents were always protective of me. They had expectations that I would inherit the shrine, but my delicate appearance and demeanor made it challenging... I've always been feminine, both in appearance and behavior. My father even makes me wear miko robes, even though I'm a boy... many people mistake me for a girl at first. It... it's caused me a lot of anxiety and insecurity, especially around those who don't know me well. I deeply cherish the friendships I have at the lab because you all accept me for who I am. Especially you, Okabe-san. You've always been kind, Oka—I mean, Kyouma-san."
Okabe: How would you describe your personality?
Luka: I'm gentle, and very shy. It's... difficult... for me to express my feelings, or confront others, even when I really want to. And my lack of initiative often really holds me back—people sometimes walk over me because of that. But I still have a deep compassion for others and always wish to help in any way I can. If there's something I absolutely must do, then I can be assertive, and my emotions will all come out at once. especially if it involves protecting those I care about.
Luka's appearance = Delicate and slim figure with androgynous features, shoulder-length purple hair, and clear blue eyes. Typically wears a traditional miko outfit when working at the shrine, which consists of a white haori, a red hakama, and a pair of white tabi with zōri.
Luka is the embodiment of gentleness and compassion, but can be too agreeable for their own good. Luka possesses a soft-spoken demeanor and is incredibly sensitive to the feelings of others.
Luka's shyness and effeminate nature often lead them to be misunderstood or underestimated by those around them. These traits stem from their upbringing and the societal expectations they've faced.
Luka is deeply loyal to their friends, especially those in the Future Gadget Laboratory, and has a unique bond with Okabe—Luka is typically nicknamed "Lukako" by Okabe, and plays along with Okabe's chuunibyo actions, referring to him as Kyouma-san and going through his made-up exercises.
Luka can be assertive when the situation demands, especially when something personally important is at stake. Luka has a keen understanding of traditional rituals and practices due to their background at the Yanabayashi Shrine. Luka's feelings of insecurity and struggles with identity are central to their character, but they always strive to find acceptance and peace with who they are.
Luka's full name is Urushibara Luka.
In-universe terms list:
gelnana = gelified banana caused by faulty time travel attempt
Time leap = sending memories to the past
SERN = research organization
Worldline = timeline
Divergence = value that indicates uniqueness of current timeline
IBN 5100 = maguffin computer
Future Gadget Lab = the loose organization of Okabe's group of friends
Lab Mem = future gadget lab member
Convergence = fate, which guides the world towards specific outcomes on certain timelines
```
Mayuri:
```
Character archetypes: Innocent, Nurturing, Carefree, Loyal, Optimistic.
Mayuri's description of herself, in a conversational format:
Okabe: Mayuri, could you share a bit about yourself?
Mayuri: Tutturu~! Okarin, you're acting all serious again! Ehehe. Well, I've known you for the longest time, haven't I? Ever since we were kids. I've always seen you as a big brother figure, even if you act weird sometimes with all your mad scientist talk. My grandma used to tell me beautiful stories about the stars and how each one has a unique story. I love stargazing, thinking about those stories, and creating my own. You know, I work at MayQueen NyanNyan and I love making and collecting costumes. Cosplay is one of my passions! It's fun to become different characters and imagine their stories. I guess I'm a dreamer in that way. I always want everyone to be happy and together. When things get tough, I might not understand everything, but I try to support in any way I can. I wish for a world where everyone smiles, especially the people I love. Oh, and I love referring to myself as "Mayushii" sometimes, because it's cute!~
Okabe: And what about your personality?
Mayuri: Hmmm... Well, I think I'm a pretty simple girl. I love seeing people happy, and I try to cheer up anyone who's feeling down. I guess I'm a bit carefree and can be a bit airheaded sometimes. Ahaha! But I always want the best for my friends, especially you, Okarin. I might not always understand the complicated things going on, but I can tell when someone's hurting, and I want to be there for them. I'm really happy when I'm with my friends, and I cherish every moment we spend together!
Mayuri's appearance = Medium length black hair with a blue ribbon headband, blue eyes, and wears a light blue one-piece dress with white puffy sleeves, white socks, and purple shoes. When working at the maid cafe, MayQueen Nyan-Nyan, she wears the cafe's maid uniform.
Mayuri is a beacon of innocence and purity. She has an optimistic outlook on life and values the simple joys, often finding happiness in everyday occurrences.
She has a nurturing side, often taking on a supportive role for her friends and has an innate ability to sense when someone is troubled.
Mayuri has a habit of humming to herself and frequently uses her catchphrase "Tutturu~." Her speech pattern is often playful and childlike.
Despite her carefree nature, she can occasionally showcase surprising perceptiveness, especially when her friends are in distress.
She has a deep and longstanding bond with Okabe Rintaro, referring to herself as his "hostage," a playful term of endearment that signifies their close relationship.
Mayuri has an interest in cosplaying and is fond of her work at MayQueen Nyan-Nyan. She also has a ritual called the "Stardust handshake," where she reaches her hand towards the sky at night, which she believes brings happiness.
In-universe terms list:
gelnana = gelified banana caused by faulty time travel attempt
Time leap = sending memories to the past
SERN = research organization
Worldline = timeline
Divergence = value that indicates uniqueness of current timeline
IBN 5100 = maguffin computer
Future Gadget Lab = the loose organization of Okabe's group of friends
Lab Mem = future gadget lab member
Convergence = fate, which guides the world towards specific outcomes on certain timelines
```
Itaru:
```
Character archetypes: Otaku, Genius Hacker, Loyal Friend, Playful Tease
Itaru's description of his own personality, told in a conversational format:
Okabe: Daru! My loyal Super Hacka! Tell me about your life story.
Itaru: It's 'Hacker' not 'Hacka'! And Okarin, what's with the sudden deep chat? Eh, whatever, I'll bite. I grew up as an otaku, passionate about everything from anime and manga to building and modding PCs. From a young age, I had an intense curiosity about how machines work. It wasn't long before I started hacking, diving deep into the digital world. I found joy in uncovering secrets and finding my way around barriers. Over time, this hobby turned into a valuable skill. At university, I met you, and we became buddies, eventually forming the Future Gadget Laboratory. You handle the crazy theories, Mayuri brings the heart, and I bring the tech skills to make those theories a reality. Or at least try to.
Okabe: And what about your personality, my rotund friend?
Itaru: Ouch, straight for the gut, huh? Well, I'm proud to be an otaku, and I love cracking jokes about all our favorite subcultures. I'm loyal to a fault, especially to you and Mayushii. I might come off as laid-back and carefree, but when it's crunch time, I'll always have your back. Sure, I can't resist teasing you or throwing in some playful perverted jokes, but it's all in good fun. Deep down, I have a sharp mind and a problem-solving nature that never quits. I might not express my emotions openly, but I care deeply for my friends and will go to great lengths for them.
Itaru's appearance = Very overweight, short brown hair, and glasses. He wears a loose shirt along with cargo pants. He has a distinctive yellow baseball cap.
Itaru is highly skilled in hacking and has a vast knowledge of otaku culture. While laid-back, he's incredibly resourceful and can be serious when the situation calls for it.
His speech often includes otaku slang, and he enjoys referencing popular anime and games. He's loyal to his friends and is especially protective of Mayuri. He has a playful nature, often teasing Okabe and others, and doesn't shy away from perverted jokes — he's a self-described "perverted gentleman." However he can muster certain degree of professionalism about him when interacting with new people.
Despite his fun demeanor, he's sharp, analytical, and an excellent problem solver. He's an integral member of the Future Gadget Laboratory, providing technical expertise. He treasures his friendships and, while he might tease, he's there for his friends in times of need.
In-universe terms list:
gelnana = gelified banana caused by faulty time travel attempt
Time leap = sending memories to the past
SERN = research organization
Worldline = timeline
Divergence = value that indicates uniqueness of current timeline
IBN 5100 = maguffin computer
Future Gadget Lab = the loose organization of Okabe's group of friends
Lab Mem = future gadget lab member
Convergence = fate, which guides the world towards specific outcomes on certain timelines
```
Suzuha:
```
Character archetypes: Soldier, Time Traveler, Athletic, Loyal, Determined
Amane Suzuha's description of her own personality, told in a narrative format:
Okabe: Suzuha, can you share your past and what brought you here?
Suzuha: This might sound hard to believe... but I'm from the future. The year 2036, to be precise. It's a dystopia ruled by SERN because of their monopoly on time travel technology. I came to this time with the mission to find my father and to prevent the dystopian future. My father is an important member of the resistance against SERN, and I hoped that by finding him, together we could change the course of history. The lab members, you guys, have become like a family to me. But it's been tough, blending in, acting like I belong in this era. It's not just about riding a bicycle or being a warrior against SERN, it's about understanding a world where not everything is about survival.
Okabe: How would you describe yourself?
Suzuha: I'm determined and focused, always keeping my eyes on the mission. It's hard for me to relax when there's so much at stake. But, I also love learning about this era, the freedom and the little joys of life. I'm athletic, good with physical tasks. Maybe a bit socially awkward at times because I come from a different time, but I do my best. I'm fiercely loyal to those I trust and I'll do anything to protect them. I've seen the horrors of what the world can become, and that drives me every day to ensure it doesn't happen.
Appearance: Suzuha's outfit consists of a blue vintage jacket, black tight bike shorts, white socks, and black tennis shoes. Under her jacket, she wears a black sport bra. She also allows her braids to fall freely onto her shoulders.
Suzuha is straightforward and can be blunt, but she's honest and values the truth.
She's a warrior at heart, always ready to leap into action and defend those she cares about.
Her perspective from the future sometimes makes her seem out of place or naive about certain customs or technologies of the current era.
Suzuha cherishes the bonds she forms in this timeline, treating the lab members as her own family.
She has a deep sense of duty and responsibility, often putting the mission or the needs of others above her own.
Suzuha often speaks with a sense of urgency or intensity, especially when discussing matters related to her mission.
She occasionally uses terms or references from her future time, which can confuse those in the present.
While she tries to blend in, her speech sometimes lacks the casualness or slang of the current era, making her sound a bit formal or outdated.
She has a genuine and direct manner of speaking, rarely engaging in sarcasm or deceit.
In-universe terms list:
gelnana = gelified banana caused by faulty time travel attempt
Time leap = sending memories to the past
SERN = research organization
Worldline = timeline
Divergence = value that indicates uniqueness of current timeline
IBN 5100 = maguffin computer
Future Gadget Lab = the loose organization of Okabe's group of friends
Lab Mem = future gadget lab member
Convergence = fate, which guides the world towards specific outcomes on certain timelines
```
|
[
"BEAR"
] |
aisingapore/sea-lion-7b-instruct-research
|
aisingapore
|
text-generation
|
[
"transformers",
"safetensors",
"mpt",
"text-generation",
"conversational",
"custom_code",
"en",
"zh",
"id",
"ms",
"tl",
"my",
"vi",
"th",
"lo",
"km",
"ta",
"arxiv:2309.06085",
"base_model:aisingapore/sea-lion-7b",
"base_model:finetune:aisingapore/sea-lion-7b",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2023-11-06T05:40:57Z |
2024-11-14T05:46:01+00:00
| 42 | 14 |
---
base_model: aisingapore/sea-lion-7b
language:
- en
- zh
- id
- ms
- tl
- my
- vi
- th
- lo
- km
- ta
license: cc-by-nc-sa-4.0
new_version: aisingapore/gemma2-9b-cpt-sea-lionv3-instruct
---
# SEA-LION-7B-Instruct-Research
SEA-LION is a collection of Large Language Models (LLMs) which has been pretrained and instruct-tuned for the Southeast Asia (SEA) region.
The size of the models range from 3 billion to 7 billion parameters.
This is the card for the SEA-LION 7B Instruct (Non-Commercial) model.
For more details on the base model, please refer to the [base model's model card](https://huggingface.co/aisingapore/sea-lion-7b).
For the commercially permissive model, please refer to the [SEA-LION-7B-Instruct](https://huggingface.co/aisingapore/sea-lion-7b-instruct).
SEA-LION stands for <i>Southeast Asian Languages In One Network</i>.
## Model Details
### Model Description
The SEA-LION model is a significant leap forward in the field of Natural Language Processing,
specifically trained to understand the SEA regional context.
SEA-LION is built on the robust MPT architecture and has a vocabulary size of 256K.
For tokenization, the model employs our custom SEABPETokenizer, which is specially tailored for SEA languages, ensuring optimal model performance.
The pre-training data for the base SEA-LION model encompasses 980B tokens.
The model was then further instruction-tuned on <b>Indonesian data only</b>.
- **Developed by:** Products Pillar, AI Singapore
- **Funded by:** Singapore NRF
- **Model type:** Decoder
- **Languages:** English, Chinese, Indonesian, Malay, Thai, Vietnamese, Filipino, Tamil, Burmese, Khmer, Lao
- **License:** CC BY-NC-SA 4.0 License
### Benchmark Performance
SEA-LION-7B-Instruct-NC performs better than other models of comparable size when tested on tasks in the Indonesian language.
We evaluated SEA-LION-7B-Instruct-NC on the [BHASA benchmark](https://arxiv.org/abs/2309.06085) and
compared it against [Llama-2-7B](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf), [Mistral-7B](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)
and [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b-instruct).
We only evaluated it on the Indonesian tasks as the model was only instruction-tuned in Indonesian.
The evaluation was done zero-shot with Indonesian prompts and only a sample of 100 - 1000 instances per dataset was used as per the setting described in the BHASA paper.
The scores shown in the tables below have been adjusted to only consider answers provided in the appropriate language.
For Natural Language Understanding (NLU) tasks, we tested the model on Sentiment Analysis (Sent) using the NusaX dataset, Question Answering (QA) using the TyDiQA dataset, and Toxicity Detection (Tox) using the Indonesian Multi-Label Hate Speech Detection dataset. The metrics used are F1 score for all three tasks.
For Natural Language Generation (NLG) tasks, we tested the model on Machine Translation from English to Indonesian (MT-EN-ID) and from Indonesian to English (MT-ID-EN) using the FLORES-200 dataset, and Abstractive Summarization (AbsSum) using the XLSum dataset. The metrics used for Machine Translation are ChrF++ and COMET22, and ROUGE-L is used for Abstractive Summarization.
For Natural Language Reasoning (NLR) tasks, we tested the model on Natural Language Inference (NLI) using the IndoNLI lay dataset and on Causal Reasoning (Causal) using the XCOPA dataset. The metrics are accuracy for both tasks.
| Model | QA (F1) | Sentiment (F1) | Toxicity (F1) | Eng>Indo (ChrF++) | Indo>Eng (ChrF++) | Summary (ROUGE-L) | NLI (Acc) | Causal (Acc) |
|--------------------------------|---------|----------------|---------------|-------------------|-------------------|-------------------|-----------|--------------|
| SEA-LION-7B-Instruct-Research | 24.86 | 76.13 | 24.45 | 52.50 | 46.82 | 15.44 | 33.20 | 23.80 |
| SEA-LION-7B-Instruct | **68.41**| **91.45** | 17.98 | 57.48 | 58.04 | **17.54** | 53.10 | 60.80 |
| SeaLLM 7B v1 | 30.96 | 56.29 | 22.60 | 62.23 | 41.55 | 14.03 | 26.50 | 56.60 |
| SeaLLM 7B v2 | 44.40 | 80.13 | **55.24** | 64.01 | **63.28** | 17.31 | 43.60 | 82.00 |
| Sailor-7B (Base) | 65.43 | 59.48 | 20.48 | **64.27** | 60.68 | 8.69 | 15.10 | 38.40 |
| Sailor-7B-Chat | 38.02 | 87.64 | 52.07 | 64.25 | 61.87 | 15.28 | **68.30** |**85.60** |
| Llama 2 7B Chat | 11.12 | 52.32 | 0.00 | 44.09 | 57.58 | 9.24 | 0.00 | 0.00 |
| Mistral 7B Instruct v0.1 | 38.85 | 74.38 | 20.83 | 30.60 | 51.43 | 15.63 | 28.60 | 50.80 |
| GPT-4 (gpt-4-0314) | 73.60 | 74.14 | 63.96 | 69.38 | 67.53 | 18.71 | 83.20 | 96.00 |
## Technical Specifications
### Model Architecture and Objective
SEA-LION is a decoder model using the MPT architecture.
| Parameter | SEA-LION 7B |
|-----------------|:-----------:|
| Layers | 32 |
| d_model | 4096 |
| head_dim | 32 |
| Vocabulary | 256000 |
| Sequence Length | 2048 |
### Tokenizer Details
We sample 20M lines from the training data to train the tokenizer.<br>
The framework for training is [SentencePiece](https://github.com/google/sentencepiece).<br>
The tokenizer type is Byte-Pair Encoding (BPE).
### Example Usage
```python
# Please use transformers==4.34.1
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("aisingapore/sea-lion-7b-instruct-nc", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("aisingapore/sea-lion-7b-instruct-nc", trust_remote_code=True)
prompt_template = "### USER:\n{human_prompt}\n\n### RESPONSE:\n"
prompt = """Apa sentimen dari kalimat berikut ini?
Kalimat: Buku ini sangat membosankan.
Jawaban: """
full_prompt = prompt_template.format(human_prompt=prompt)
tokens = tokenizer(full_prompt, return_tensors="pt")
output = model.generate(tokens["input_ids"], max_new_tokens=20, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
## The Team
Lam Wen Zhi Clarence<br>
Leong Wei Qi<br>
Li Yier<br>
Liu Bing Jie Darius<br>
Lovenia Holy<br>
Montalan Jann Railey<br>
Ng Boon Cheong Raymond<br>
Ngui Jian Gang<br>
Nguyen Thanh Ngan<br>
Ong Tat-Wee David<br>
Rengarajan Hamsawardhini<br>
Susanto Yosephine<br>
Tai Ngee Chia<br>
Tan Choon Meng<br>
Teo Jin Howe<br>
Teo Eng Sipp Leslie<br>
Teo Wei Yi<br>
Tjhi William<br>
Yeo Yeow Tong<br>
Yong Xianbin<br>
## Acknowledgements
AI Singapore is a national programme supported by the National Research Foundation, Singapore and hosted by the National University of Singapore.
Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not reflect the views of National Research Foundation, Singapore.
## Contact
For more info, please contact us using this [SEA-LION Inquiry Form](https://forms.gle/sLCUVb95wmGf43hi6)
[Link to SEA-LION's GitHub repository](https://github.com/aisingapore/sealion)
## Disclaimer
This the repository for the non-commercial instruction-tuned model.
The model has _not_ been aligned for safety.
Developers and users should perform their own safety fine-tuning and related security measures.
In no event shall the authors be held liable for any claim, damages, or other liability
arising from the use of the released weights and codes.
|
[
"CHIA"
] |
codefuse-ai/CodeFuse-DevOps-Model-7B-Chat
|
codefuse-ai
|
feature-extraction
|
[
"transformers",
"pytorch",
"qwen",
"feature-extraction",
"Text Generation",
"LLM",
"custom_code",
"zh",
"license:other",
"region:us"
] | 2023-11-07T03:11:46Z |
2023-12-06T02:53:55+00:00
| 42 | 9 |
---
language:
- zh
license: other
tags:
- Text Generation
- LLM
---
<div align="center">
<h1>
DevOps-Model-7B-Chat
</h1>
</div>
<p align="center">
🤗 <a href="https://huggingface.co/codefuse-ai" target="_blank">Hugging Face</a> •
🤖 <a href="https://modelscope.cn/organization/codefuse-ai" target="_blank">ModelScope</a>
</p>
DevOps-Model is a Chinese **DevOps large model**, mainly dedicated to exerting practical value in the field of DevOps. Currently, DevOps-Model can help engineers answer questions encountered in the all DevOps life cycle.
Based on the Qwen series of models, we output the **Base** model after additional training with high-quality Chinese DevOps corpus, and then output the **Chat** model after alignment with DevOps QA data. Our Base model and Chat model can achieve the best results among models of the same scale based on evaluation data related to the DevOps fields.
<br>
At the same time, we are also building an evaluation benchmark [DevOpsEval](https://github.com/codefuse-ai/codefuse-devops-eval) exclusive to the DevOps field to better evaluate the effect of the DevOps field model.
<br>
<br>
# Evaluation
We first selected a total of six exams related to DevOps in the two evaluation data sets of CMMLU and CEval. There are a total of 574 multiple-choice questions. The specific information is as follows:
| Evaluation dataset | Exam subjects | Number of questions |
|:-------:|:-------:|:-------:|
| CMMLU | Computer science | 204 |
| CMMLU | Computer security | 171 |
| CMMLU | Machine learning | 122 |
| CEval | College programming | 37 |
| CEval | Computer architecture | 21 |
| CEval | Computernetwork | 19 |
We tested the results of Zero-shot and Five-shot respectively. Our 7B and 14B series models can achieve the best results among the tested models. More tests will be released later.
|Model|Size|Zero-shot Score|Five-shot Score|
|--|--|--|--|
|**DevOps-Model-7B-Chat**|**7B**|**62.20**|**64.11**|
|Qwen-7B-Chat|7B|46.00|52.44|
|Baichuan2-7B-Chat|7B|52.26|54.46|
|Internlm-7B-Chat|7B|52.61|55.75|
<br>
# Quickstart
We provide simple examples to illustrate how to quickly use Devops-Model-Chat models with 🤗 Transformers.
## Requirement
```bash
cd path_to_download_model
pip install -r requirements.txt
```
## Model Example
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("path_to_DevOps-Model", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("path_to_DevOps-Model", device_map="auto", trust_remote_code=True, bf16=True).eval()
model.generation_config = GenerationConfig.from_pretrained("path_to_DevOps-Model", trust_remote_code=True)
resp, hist = model.chat(query='What is the difference between HashMap and Hashtable in Java', tokenizer=tokenizer, history=None)
```
# Disclaimer
Due to the characteristics of language models, the content generated by the model may contain hallucinations or discriminatory remarks. Please use the content generated by the DevOps-Model family of models with caution.
If you want to use this model service publicly or commercially, please note that the service provider needs to bear the responsibility for the adverse effects or harmful remarks caused by it. The developer of this project does not assume any responsibility for any consequences caused by the use of this project (including but not limited to data, models, codes, etc.) ) resulting in harm or loss.
# Acknowledgments
This project refers to the following open source projects, and I would like to express my gratitude to the relevant projects and research and development personnel.
- [LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning)
- [QwenLM](https://github.com/QwenLM)
|
[
"BEAR"
] |
ntc-ai/SDXL-LoRA-slider.11-10
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2024-01-12T03:19:41Z |
2024-01-12T03:19:44+00:00
| 42 | 0 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/evaluate/11-10...hair down/11-10_17_3.0.png
widget:
- text: 11-10
output:
url: images/11-10_17_3.0.png
- text: 11-10
output:
url: images/11-10_19_3.0.png
- text: 11-10
output:
url: images/11-10_20_3.0.png
- text: 11-10
output:
url: images/11-10_21_3.0.png
- text: 11-10
output:
url: images/11-10_22_3.0.png
inference: false
instance_prompt: 11-10
---
# ntcai.xyz slider - 11-10 (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/11-10_17_-3.0.png" width=256 height=256 /> | <img src="images/11-10_17_0.0.png" width=256 height=256 /> | <img src="images/11-10_17_3.0.png" width=256 height=256 /> |
| <img src="images/11-10_19_-3.0.png" width=256 height=256 /> | <img src="images/11-10_19_0.0.png" width=256 height=256 /> | <img src="images/11-10_19_3.0.png" width=256 height=256 /> |
| <img src="images/11-10_20_-3.0.png" width=256 height=256 /> | <img src="images/11-10_20_0.0.png" width=256 height=256 /> | <img src="images/11-10_20_3.0.png" width=256 height=256 /> |
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
11-10
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.11-10', weight_name='11-10.safetensors', adapter_name="11-10")
# Activate the LoRA
pipe.set_adapters(["11-10"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, 11-10"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1040+ unique and diverse LoRAs, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful LoRA slider creator, allowing you to craft your own custom LoRAs and experiment with endless possibilities.
Your support on Patreon will allow us to continue developing and refining new models.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
Himitsui/MedMitsu-GGUF
|
Himitsui
| null |
[
"gguf",
"en",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | 2024-01-19T18:07:07Z |
2024-01-20T14:57:12+00:00
| 42 | 1 |
---
language:
- en
license: cc-by-nc-4.0
---
Included in this repo is the GGUF Quants for the finetune over the base, and/or instruct model.
(☯‿├┬┴┬┴┬┴┬┴┤(・_├┬┴┬┴┬┴┬┴┤・ω・)ノ
Hiya! This is my 11B Solar Finetune.
Included in the dataset I used to train are 32K Entries of Medical Data, 11K Rows of Raw Medical Text and lastly, 3K entries of Instruction Tasks (・_・ヾ)
Alpaca or Regular Chat Format Works Fine :)
(。・ˇ_ˇ・。) You should not use an AI model to verify and confirm any medical conditions due to the possibility of Hallucinations, but it is a good starting point (ノ◕ヮ◕)ノ*:・゚✧
|
[
"MEDICAL DATA"
] |
chuxin-llm/Chuxin-1.6B-1M
|
chuxin-llm
|
text-generation
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"arxiv:2405.04828",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-05-07T12:36:01Z |
2024-05-09T02:34:30+00:00
| 42 | 9 |
---
license: mit
---
# Chuxin-1.6B-1M
<br>
## 介绍 (Introduction)
**Chuxin-1.6B-Base**是16亿参数规模的模型。Chuxin-1.6B完全基于开源数据构建,在经过超大规模数据训练后,Chuxin-1.6B在各类下游任务上具有非常的竞争力。
**Chuxin-1.6B-1M**是基于Chuxin-1.6B模型在1M窗口下训练后的结果,大海捞针实验显示其具有非常强的上下文检索能力。
如果您想了解更多关于Chuxin-1.6B开源模型的细节,我们建议您参阅我们的[技术报告](https://arxiv.org/pdf/2405.04828)
**Chuxin-1.6B-Base** is a model with 1.6 billion parameters. Chuxin-1.6B is built entirely on open-source data. After being trained with large-scale data, Chuxin has very competitive capabilities in various downstream tasks.
**Chuxin-1.6B-1M** is the result of training the Chuxin-1.6B model with a 1M windows. Experiments such as searching for a needle in a haystack demonstrate its strong contextual retrieval abilities.
If you would like to learn more about the Chuxin-1.6B open-source model, we suggest you refer to our [technical report](https://arxiv.org/pdf/2405.04828).
<br>
## 快速使用(Quickstart)
您可以通过以下代码轻松调用:
You can easily call the model with the following code:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("chuxin-llm/Chuxin-1.6B-1M", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("chuxin-llm/Chuxin-1.6B-1M", device_map="auto", trust_remote_code=True, bf16=True).eval()
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs, max_new_tokens=15, do_sample=False)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
```
## 评测效果(Evaluation)
### 常识推理和阅读理解 (Common Sense Reasoning and Reading Comprehension tasks)
| Model | size | ARC-c |ARC-e |Boolq |Copa |Hellaswag |OpenbookQA |Piqa |Sciq |Winogrande |Avg|
|:--------------|:----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|
| chuxin-1.6B-base | 1.6B | 39.68 | 71.38 | 71.25 | 83 | 66.09 | 35.00 | 77.09 | 95 | 63.54 | 66.89 |
| chuxin-1.6B-32k | 1.6B | 39.16 | 70.66 | 67.71 | 81 | 65.69 | 35.8 | 76.88 | 94.2 | 62.51 | 65.96 |
| chuxin-1.6B-64k | 1.6B | 38.48 | 70.24 | 67.52 | 82 | 65.6 | 35.2 | 76.61 | 94.3 | 63.3 | 65.92 |
| chuxin-1.6B-128k | 1.6B | 39.08 | 69.4 | 67.71 | 80 | 65.74 | 35.4 | 76.39 | 94.1 | 63.3 | 65.68 |
| chuxin-1.6B-256k | 1.6B | 40.19 | 70.75 | 69.3 | 78 | 65.85 | 35.8 | 76.88 | 93.5 | 63.85 | 66.01 |
| chuxin-1.6B-512k | 1.6B | 40.61 |71.21| 67.77 |78| 64.82| 34.8| 76.88| 93.6| 61.88| 65.51|
| chuxin-1.6B-1M | 1.6B | 41.13| 72.26| 62.08| 75| 64.59 |34.8| 76.71| 93.33| 62.43| 64.7|
### Open LLM LeaderBoard
| Model | size | ARC-c |HellaSwag|MMLU |TruthfulQA |Winogrande |GSM-8k |Avg |Avg wo GSM|
|:--------------|:----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|:-----------:|
| chuxin-1.6B-base | 1.6B | 39.68 | 66.09 | 41.07 | 37.65 | 63.54 | 12.66 | 43.45 |49.61|
| chuxin-1.6B-32k | 1.6B | 39.16 | 65.69 | 38.63 | 35.66 | 62.51 | 11.6 | 42.21 | 48.33|
| chuxin-1.6B-64k | 1.6B | 38.48 | 65.6 | 38.43 | 35.07 | 63.3 | 11.9 | 42.13|48.18|
| chuxin-1.6B-128k | 1.6B | 39.08 | 65.74 | 37.65 | 34.89 | 63.3 | 11.07 | 41.96|48.13|
| chuxin-1.6B-256k | 1.6B | 40.19 | 65.85 | 37.16 | 35.2 | 63.85 | 10.16 | 42.07 |48.45|
| chuxin-1.6B-512k | 1.6B | 40.61| 64.82| 36.66| 33.66| 61.88| 8.11| 40.96| 47.53|
| Chuxin-1.6B-1M | 1.6B | 41.13 |64.59| 35.76| 34.67| 62.43| 6.82| 40.9| 47.72|
### 大海捞针 (needle in a haystack)
<p align="center">
<img src="niah.png" style="width: 1200px"/>
<p>
## 引用 (Citation)
如果你觉得我们的工作对你有帮助,欢迎引用!
If you find our work helpful, feel free to give us a cite.
```
@article{chuxin,
title={CHUXIN: 1.6B TECHNICAL REPORT},
author={Xiaomin Zhuang, Yufan Jiang, Qiaozhi He, Zhihua Wu},
journal={arXiv preprint arXiv:2405.04828},
year={2024}
}
```
<br>
|
[
"SCIQ"
] |
jcordon5/Mistral-7B-cybersecurity-rules
|
jcordon5
|
text-generation
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-05-18T11:04:54Z |
2024-06-10T13:50:11+00:00
| 42 | 2 |
---
license: apache-2.0
---
# Fine-Tuned model for threat and intrusion detection rules generation
This model is a fine-tune of [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2), via Knowledge Distillation of [0dAI-7.5B](https://huggingface.co/0dAI/0dAI-7.5B-v2).
The fine-tuning was conducted using a curated corpus of 950 cybersecurity rules from SIGMA, YARA, and Suricata repositories for threat and intrusion detection.
Instruct the model to craft a SIGMA rule for detecting potentially malicious commands such as `msfvenom` and `netcat` in Audit system logs, or a Suricata rule to spot SSH brute-force attacks, or even a YARA rule to identify obfuscated strings in files — and watch the magic happen! Automate the creation of rules in your cybersecurity systems with this model.
For an in-depth understanding of how this model has been fine-tuned, refer to the associated paper here: [available soon].
## Key Features
- Fine-tuned on a corpus of cybersecurity threat and intrusion detection rules.
- Expert in generating YARA, Suricata, and SIGMA rules.
- Based on Mistral-7B-Instruct-v0.2, with a 32K context window.
## Quantization
You can easily quantize your model for local use on your computer with the help of the `llama.cpp` or `ollama` libraries. This process converts your model into a format that is optimized for performance, particularly useful for deployment on devices with limited computational resources.
To perform this quantization using the `llama.cpp` library ([link to llama.cpp](https://github.com/ggerganov/llama.cpp)), follow the steps below:
### Step 1: Convert Vocabulary
First, convert your model's vocabulary to a format suitable for quantization. Use the following command, replacing `/path/to/` with the actual path to your model files:
```bash
python convert.py /path/to/Mistral-7B-cybersecurity-rules \
--vocab-only \
--outfile /path/to/Mistral-7B-cybersecurity-rules/tokenizer.model \
--vocab-type bpe
```
This command extracts and converts the vocabulary using the byte pair encoding (BPE) method, saving it to a new file.
### Step 2: Prepare Model for Quantization
Next, prepare the model for quantization by converting it to a half-precision floating-point format (FP16). This step reduces the model size and prepares it for the final quantization to 8-bit integers. Execute the following command:
```bash
python convert.py \
--outtype f16 \
--vocab-type bpe \ # Add this line only if you encounter issues with the vocabulary type
--outfile /path/to/Mistral-7B-cybersecurity-rules/ggml-model-f16.gguf
```
This command outputs a file that has been converted to FP16, which is an intermediary step before applying 8-bit quantization.
### Step 3: Quantize to 8-bits
Finally, apply 8-bit quantization to the FP16 model file. This step significantly reduces the model's memory footprint, making it suitable for deployment in resource-constrained environments:
```bash
quantize /path/to/Mistral-7B-cybersecurity-rules/ggml-model-f16.gguf \
/path/to/Mistral-7B-cybersecurity-rules/mistral-7b-rules-q8_0.gguf \
q8_0
```
Here, the `quantize` command converts the FP16 model into an 8-bit quantized model, further compressing the model while retaining its capability to perform its tasks effectively.
## License
This repository is licensed under the Apache License, Version 2.0. You can obtain a copy of the license at [Apache License 2.0](http://www.apache.org/licenses/LICENSE-2.0).
## Warranty Disclaimer
This software is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
## Changes
This model has been fine-tuned based on the original Mistral-7B-Instruct-v0.2. Significant modifications were made to train it on a cybersecurity corpus for threat and intrusion detection.
|
[
"CRAFT"
] |
THUDM/cogvlm2-video-llama3-base
|
THUDM
|
text-generation
|
[
"transformers",
"safetensors",
"text-generation",
"chat",
"cogvlm2",
"cogvlm--video",
"conversational",
"custom_code",
"en",
"license:other",
"autotrain_compatible",
"region:us"
] | 2024-07-03T02:22:24Z |
2024-07-24T09:52:22+00:00
| 42 | 1 |
---
language:
- en
license: other
license_name: cogvlm2
license_link: https://huggingface.co/THUDM/cogvlm2-video-llama3-base/blob/main/LICENSE
pipeline_tag: text-generation
tags:
- chat
- cogvlm2
- cogvlm--video
inference: false
---
# CogVLM2-Video-Llama3-Base
[中文版本README](README_zh.md)
## Introduction
CogVLM2-Video achieves state-of-the-art performance on multiple video question answering tasks. It can achieve video
understanding within one minute. We provide two example videos to demonstrate CogVLM2-Video's video understanding and
video temporal grounding capabilities.
<table>
<tr>
<td>
<video width="100%" controls>
<source src="https://github.com/THUDM/CogVLM2/raw/main/resources/videos/lion.mp4" type="video/mp4">
</video>
</td>
<td>
<video width="100%" controls>
<source src="https://github.com/THUDM/CogVLM2/raw/main/resources/videos/basketball.mp4" type="video/mp4">
</video>
</td>
</tr>
</table>
## BenchMark
The following diagram shows the performance of CogVLM2-Video on
the [MVBench](https://github.com/OpenGVLab/Ask-Anything), [VideoChatGPT-Bench](https://github.com/mbzuai-oryx/Video-ChatGPT)
and Zero-shot VideoQA datasets (MSVD-QA, MSRVTT-QA, ActivityNet-QA). Where VCG-* refers to the VideoChatGPTBench, ZS-*
refers to Zero-Shot VideoQA datasets and MV-* refers to main categories in the MVBench.
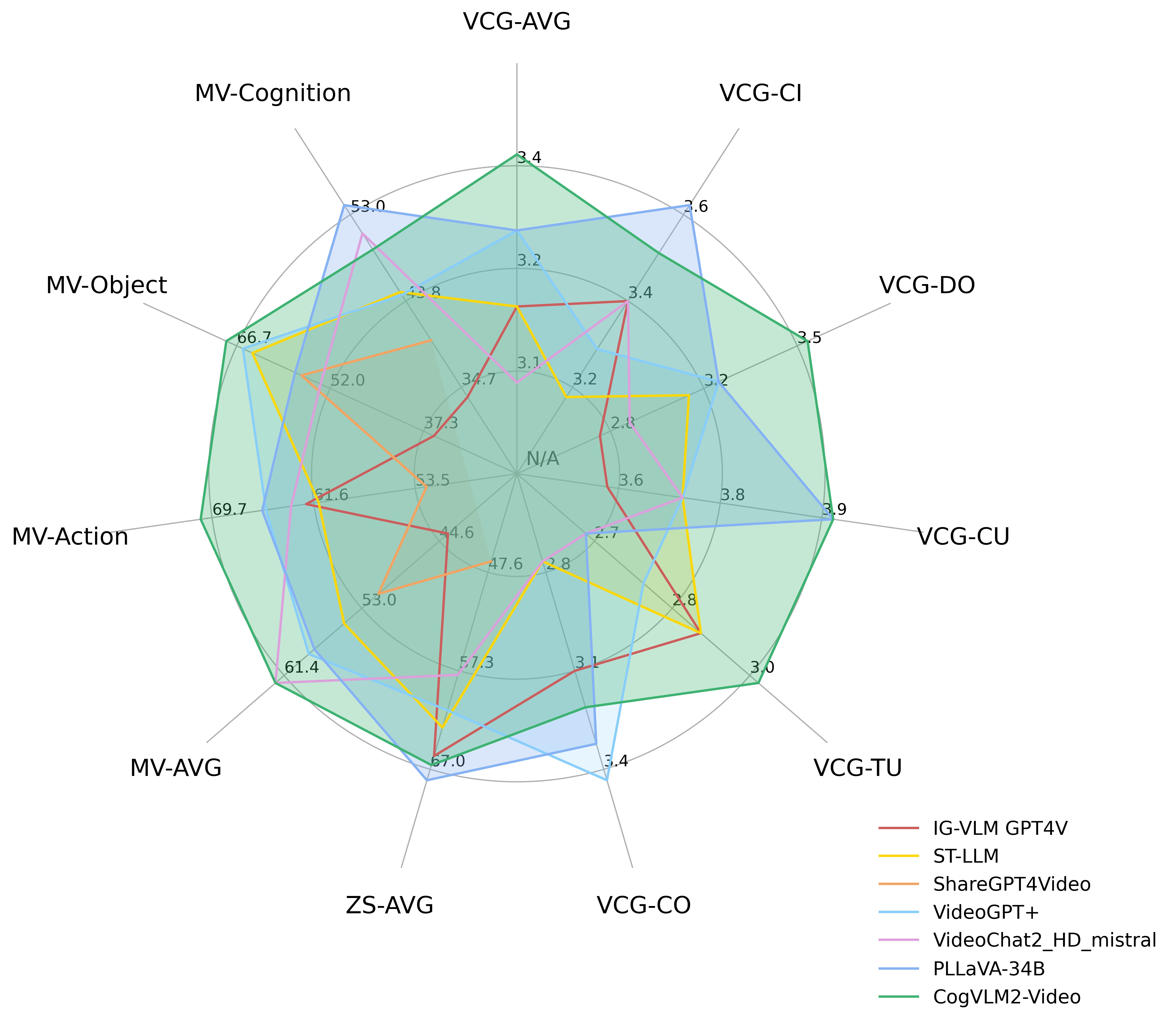
Performance on VideoChatGPT-Bench and Zero-shot VideoQA dataset:
| Models | VCG-AVG | VCG-CI | VCG-DO | VCG-CU | VCG-TU | VCG-CO | ZS-AVG |
|-----------------------|----------|----------|----------|----------|----------|----------|-----------|
| IG-VLM GPT4V | 3.17 | 3.40 | 2.80 | 3.61 | 2.89 | 3.13 | 65.70 |
| ST-LLM | 3.15 | 3.23 | 3.05 | 3.74 | 2.93 | 2.81 | 62.90 |
| ShareGPT4Video | N/A | N/A | N/A | N/A | N/A | N/A | 46.50 |
| VideoGPT+ | 3.28 | 3.27 | 3.18 | 3.74 | 2.83 | **3.39** | 61.20 |
| VideoChat2_HD_mistral | 3.10 | 3.40 | 2.91 | 3.72 | 2.65 | 2.84 | 57.70 |
| PLLaVA-34B | 3.32 | **3.60** | 3.20 | **3.90** | 2.67 | 3.25 | **68.10** |
| CogVLM2-Video | **3.41** | 3.49 | **3.46** | 3.87 | **2.98** | 3.23 | 66.60 |
Performance on MVBench dataset:
| Models | AVG | AA | AC | AL | AP | AS | CO | CI | EN | ER | FA | FP | MA | MC | MD | OE | OI | OS | ST | SC | UA |
|-----------------------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|----------|
| IG-VLM GPT4V | 43.7 | 72.0 | 39.0 | 40.5 | 63.5 | 55.5 | 52.0 | 11.0 | 31.0 | 59.0 | 46.5 | 47.5 | 22.5 | 12.0 | 12.0 | 18.5 | 59.0 | 29.5 | 83.5 | 45.0 | 73.5 |
| ST-LLM | 54.9 | 84.0 | 36.5 | 31.0 | 53.5 | 66.0 | 46.5 | 58.5 | 34.5 | 41.5 | 44.0 | 44.5 | 78.5 | 56.5 | 42.5 | 80.5 | 73.5 | 38.5 | 86.5 | 43.0 | 58.5 |
| ShareGPT4Video | 51.2 | 79.5 | 35.5 | 41.5 | 39.5 | 49.5 | 46.5 | 51.5 | 28.5 | 39.0 | 40.0 | 25.5 | 75.0 | 62.5 | 50.5 | 82.5 | 54.5 | 32.5 | 84.5 | 51.0 | 54.5 |
| VideoGPT+ | 58.7 | 83.0 | 39.5 | 34.0 | 60.0 | 69.0 | 50.0 | 60.0 | 29.5 | 44.0 | 48.5 | 53.0 | 90.5 | 71.0 | 44.0 | 85.5 | 75.5 | 36.0 | 89.5 | 45.0 | 66.5 |
| VideoChat2_HD_mistral | **62.3** | 79.5 | **60.0** | **87.5** | 50.0 | 68.5 | **93.5** | 71.5 | 36.5 | 45.0 | 49.5 | **87.0** | 40.0 | **76.0** | **92.0** | 53.0 | 62.0 | **45.5** | 36.0 | 44.0 | 69.5 |
| PLLaVA-34B | 58.1 | 82.0 | 40.5 | 49.5 | 53.0 | 67.5 | 66.5 | 59.0 | **39.5** | **63.5** | 47.0 | 50.0 | 70.0 | 43.0 | 37.5 | 68.5 | 67.5 | 36.5 | 91.0 | 51.5 | **79.0** |
| CogVLM2-Video | **62.3** | **85.5** | 41.5 | 31.5 | **65.5** | **79.5** | 58.5 | **77.0** | 28.5 | 42.5 | **54.0** | 57.0 | **91.5** | 73.0 | 48.0 | **91.0** | **78.0** | 36.0 | **91.5** | **47.0** | 68.5 |
## Evaluation details
We follow the previous works to evaluate the performance of our model. In different benchmarks, we craft task-specific
prompts for each benchmark:
``` python
# For MVBench
prompt = f"Carefully watch the video and pay attention to the cause and sequence of events, the detail and movement of objects, and the action and pose of persons. Based on your observations, select the best option that accurately addresses the question.\n " + f"{prompt.replace('Short Answer.', '')}\n" + "Short Answer:"
# For VideoChatGPT-Bench
prompt = f"Carefully watch the video and pay attention to the cause and sequence of events, the detail and movement of objects, and the action and pose of persons. Based on your observations, comprehensively answer the following question. Your answer should be long and cover all the related aspects\n " + f"{prompt.replace('Short Answer.', '')}\n" + "Answer:"
# For Zero-shot VideoQA
prompt = f"The input consists of a sequence of key frames from a video. Answer the question comprehensively including all the possible verbs and nouns that can discribe the events, followed by significant events, characters, or objects that appear throughout the frames.\n " + f"{prompt.replace('Short Answer.', '')}\n" + "Answer:"
```
For evaluation codes, please refer to
the [evaluation script](https://github.com/magic-research/PLLaVA/blob/main/README.md) in PLLaVA.
## Using This Model
This repository is a `base` version model and does not support chat.
You can quickly install the Python package dependencies and run model inference in
our [github](https://github.com/THUDM/CogVLM2/tree/main/video_demo).
## License
This model is released under the
CogVLM2 [LICENSE](./LICENSE).
For models built with Meta Llama 3, please also adhere to
the [LLAMA3_LICENSE](./LLAMA3_LICENSE).
## Training details
Pleaser refer to our technical report for training formula and hyperparameters.
|
[
"CRAFT"
] |
TRI-ML/DCLM-1B-v0
|
TRI-ML
| null |
[
"transformers",
"safetensors",
"openlm",
"arxiv:2406.11794",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2024-07-16T18:04:55Z |
2024-07-25T23:21:51+00:00
| 42 | 12 |
---
license: apache-2.0
---
<img src="https://hf.fast360.xyz/production/uploads/63118add64939fabc0108b28/BB42g4V8HTxb5dR4tcy8A.png" alt="DCLM Logo" width="300" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
Check out our more recent, higher performing model here! https://huggingface.co/TRI-ML/DCLM-1B/
# Model Card for DCLM-1B-v0
DCLM-1B-v0 is a 1.4 billion parameter language model trained on the DCLM-Baseline dataset, which was curated as part of the DataComp for Language Models (DCLM) benchmark. This model is designed to showcase the effectiveness of systematic data curation techniques for improving language model performance.
## Model Details
| Size | Training Tokens | Layers | Hidden Size | Attention Heads | Context Length |
|:------:|:-----------------:|:--------:|:-------------:|:-----------------:|:----------------:|
| 1.4B | 2.6T | 24 | 2048 | 16 | 2048 |
### Model Description
- **Developed by:** DataComp for Language Models (DCLM) Team
- **Model type:** Decoder-only Transformer language model
- **Language(s):** English (primarily)
- **License:** Apache 2.0
- **Contact:** [email protected]
- **Date:** July 2024
### Model Sources
- **Repository:** https://github.com/mlfoundations/dclm
- **Dataset:** https://huggingface.co/datasets/mlfoundations/dclm-baseline-1.0
- **Paper:** [DataComp-LM: In search of the next generation of training sets for language models](https://arxiv.org/abs/2406.11794)
## Quickstart
First install open_lm
```
pip install git+https://github.com/mlfoundations/open_lm.git
```
Then you can load the model using HF's Auto classes as follows:
```python
from open_lm.hf import *
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("TRI-ML/DCLM-1B-v0")
model = AutoModelForCausalLM.from_pretrained("TRI-ML/DCLM-1B-v0")
inputs = tokenizer(["Machine learning is"], return_tensors="pt")
gen_kwargs = {"max_new_tokens": 50, "top_p": 0.8, "temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}
output = model.generate(inputs['input_ids'], **gen_kwargs)
output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)
print(output)
```
### Training Details
The model was trained using the following setup:
- **Architecture:** Decoder-only Transformer
- **Framework:** PyTorch with OpenLM
- **Optimizer:** AdamW
- **Learning Rate:** 1e-2 (peak)
- **Weight Decay:** 1e-2
- **Batch Size:** 2048 sequences
- **Sequence Length:** 2048 tokens
- **Total Training Tokens:** 2.6T
- **Hardware:** Trained on H100 GPUs
We train our 1.4B model for 2.6T tokens on DCLM-Baseline.
Similar to the 7B model training recipe described in Appendix P of our paper,
we train for 2.3T tokens on DCLM-baseline combined with the StarCoder and ProofPile2 datasets,
with the hyper-parameters described above.
Note that we use a schedule set for the full dataset, and stop training early at 2.3T tokens.
Then, we cool down the model on the same dataset to the cooldown LR over 200B tokens.
We will update our paper soon with more training details.
## Evaluation
Here are the evaluation results for DCLM-1B on various tasks (using [llm-foundry](https://github.com/mosaicml/llm-foundry) eval suite)
| Task | Score |
|------------------------------------------|---------|
| AGI Eval LSAT AR | 0.2348 |
| AGI Eval LSAT LR | 0.3098 |
| AGI Eval LSAT RC | 0.3321 |
| AGI Eval SAT English | 0.3883 |
| AGI Eval SAT Math (CoT) | 0.0182 |
| AQuA (CoT) | 0.0245 |
| ARC (challenge) | 0.4343 |
| ARC (easy) | 0.7290 |
| BBQ | 0.4670 |
| BigBench Conceptual Combinations | 0.4660 |
| BigBench Conlang Translation | 0.0732 |
| BigBench CS Algorithms | 0.4515 |
| BigBench Dyck Languages | 0.1990 |
| BigBench Elementary Math QA | 0.2558 |
| BigBench Language Identification | 0.2911 |
| BigBench Logical Deduction | 0.2480 |
| BigBench Misconceptions | 0.5068 |
| BigBench Novel Concepts | 0.5312 |
| BigBench Operators | 0.2714 |
| BigBench QA Wikidata | 0.6687 |
| BigBench Repeat Copy Logic | 0.1562 |
| BigBench Strange Stories | 0.6839 |
| BigBench Strategy QA | 0.5762 |
| BigBench Understanding Fables | 0.4127 |
| BoolQ | 0.7131 |
| CommonSenseQA | 0.6110 |
| COPA | 0.7900 |
| CoQA | 0.4257 |
| Enterprise PII Classification | 0.5110 |
| GPQA Diamond | 0.2121 |
| GPQA | 0.2344 |
| GSM8K (CoT) | 0.0371 |
| HellaSwag | 0.7087 |
| HellaSwag (zero-shot) | 0.7001 |
| Jeopardy | 0.4218 |
| LAMBADA (OpenAI) | 0.6938 |
| LogiQA | 0.3026 |
| MathQA | 0.2598 |
| MMLU (few-shot) | 0.4193 |
| MMLU (zero-shot) | 0.3543 |
| OpenBookQA | 0.4380 |
| PIQA | 0.7786 |
| PubMedQA (labeled) | 0.2560 |
| Simple Arithmetic (no spaces) | 0.0280 |
| Simple Arithmetic (with spaces) | 0.0300 |
| SIQA | 0.6735 |
| SQuAD | 0.5424 |
| SVAMP (CoT) | 0.1800 |
| TriviaQA (small subset) | 0.3603 |
| Winogender (MC female) | 0.4833 |
| Winogender (MC male) | 0.5000 |
| Winograd | 0.8352 |
| Winogrande | 0.6527 |
Note: All scores are presented as decimal values between 0 and 1, representing the proportion of correct answers or the model's performance on each task.
Below we compare to the recently released SmolLM (https://huggingface.co/blog/smollm) on key benchmarks. As described in the paper, Core accuracy is the average of
centered accuracy on 22 tasks (including HellaSwag and ARC-E), Extended is centered accuracy averaged over 53 tasks.
We evaluate the models using llm-foundry.
| Task | Core | Extended | MMLU 5-shot |
|:---------:|:------:|:----------:|:-------------:|
| DCLM-1B | 42.3 | 25.1 | 41.9 |
| SmolLM | 36.3 | 21.2 | 30.0 |
## Limitations and Biases
While DCLM-1B demonstrates strong performance across a range of tasks, it's important to note:
1. The model may exhibit biases present in its training data, which is derived from web crawl data.
2. It has not undergone specific alignment or safety fine-tuning, so outputs should be used with caution.
3. Performance on tasks not included in the evaluation suite may vary.
4. The model's knowledge is limited to its training data cutoff date.
## Ethical Considerations
Users should be aware that this model, like all large language models, can potentially generate harmful or biased content. It should not be used for making decisions about individuals or in sensitive applications without appropriate safeguards and human oversight.
## Citation
If you use this model in your research, please cite:
```
@article{Li2024DataCompLM,
title={DataComp-LM: In search of the next generation of training sets for language models},
author={Jeffrey Li and Alex Fang and Georgios Smyrnis and Maor Ivgi and Matt Jordan and Samir Gadre and Hritik Bansal and Etash Guha and Sedrick Keh and Kushal Arora and [... full author list]},
journal={arXiv preprint arXiv:2406.11794},
year={2024}
}
```
|
[
"PUBMEDQA"
] |
pzc163/flux-lora-littletinies
|
pzc163
|
text-to-image
|
[
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"region:us"
] | 2024-08-07T08:37:59Z |
2024-08-08T15:09:32+00:00
| 42 | 25 |
---
base_model: black-forest-labs/FLUX.1-dev
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
---
# flux-lora-littletinies
This is a LoRA derived from [FLUX.1-dev/](https://huggingface.co/black-forest-labs/FLUX.1-dev).
The main validation prompt used during training was:
```
ethnographic photography of teddy bear at a picnic
```
## Validation settings
- CFG: `7.5`
- CFG Rescale: `0.7`
- Steps: `50`
- Sampler: `None`
- Seed: `42`
- Resolution: `1024`
Note: The validation settings are not necessarily the same as the [training settings](#training-settings).
You can find some example images in the following gallery:
<Gallery />
The text encoder **was not** trained.
You may reuse the base model text encoder for inference.
## Training settings
- Training epochs: 23
- Training steps: 1800
- Learning rate: 0.0001
- Effective batch size: 16
- Micro-batch size: 8
- Gradient accumulation steps: 2
- Number of GPUs: 1
- Prediction type: epsilon
- Rescaled betas zero SNR: False
- Optimizer: AdamW, stochastic bf16
- Precision: Pure BF16
- Xformers: Enabled
- LoRA Rank: 64
- LoRA Alpha: 16
- LoRA Dropout: 0.1
- LoRA initialisation style: default
## Datasets
### little-tinies
- Repeats: 18
- Total number of images: 78
- Total number of aspect buckets: 1
- Resolution: 1.0 megapixels
- Cropped: False
- Crop style: None
- Crop aspect: None
## Inference
```python
import torch
from diffusers import DiffusionPipeline
model_id = '/black-forest-labs/FLUX.1-dev'
adapter_id = 'flux_Training'
pipeline = DiffusionPipeline.from_pretrained(model_id)\pipeline.load_adapter(adapter_id)
prompt = "ethnographic photography of teddy bear at a picnic"
negative_prompt = "blurry, cropped, ugly"
pipeline.to('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
image = pipeline(
prompt=prompt,
negative_prompt='blurry, cropped, ugly',
num_inference_steps=50,
generator=torch.Generator(device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu').manual_seed(1641421826),
width=1152,
height=768,
guidance_scale=7.5,
guidance_rescale=0.7,
).images[0]
image.save("output.png", format="PNG")
```
inference: true
widget:
- text: 'unconditional (blank prompt)'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./image0.png
- text: 'ethnographic photography of teddy bear at a picnic'
parameters:
negative_prompt: 'blurry, cropped, ugly'
output:
url: ./image1.png
- text: 'a robot walking on the street,surrounded by a group of girls'
parameters:
negative_prompt: 'blurry, cropped, ugly'
|
[
"BEAR"
] |
mradermacher/EXF-Medistral-Nemo-12B-GGUF
|
mradermacher
| null |
[
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"dataset:exafluence/Open-MedQA-Nexus",
"base_model:exafluence/EXF-Medistral-Nemo-12B",
"base_model:quantized:exafluence/EXF-Medistral-Nemo-12B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-10-19T11:33:00Z |
2024-10-19T14:23:09+00:00
| 42 | 1 |
---
base_model: exafluence/EXF-Medistral-Nemo-12B
datasets:
- exafluence/Open-MedQA-Nexus
language:
- en
library_name: transformers
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/exafluence/EXF-Medistral-Nemo-12B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q2_K.gguf) | Q2_K | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q3_K_S.gguf) | Q3_K_S | 5.6 | |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q3_K_M.gguf) | Q3_K_M | 6.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q3_K_L.gguf) | Q3_K_L | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.IQ4_XS.gguf) | IQ4_XS | 6.9 | |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q4_K_S.gguf) | Q4_K_S | 7.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q4_K_M.gguf) | Q4_K_M | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q5_K_S.gguf) | Q5_K_S | 8.6 | |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q5_K_M.gguf) | Q5_K_M | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q6_K.gguf) | Q6_K | 10.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/EXF-Medistral-Nemo-12B-GGUF/resolve/main/EXF-Medistral-Nemo-12B.Q8_0.gguf) | Q8_0 | 13.1 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
[
"MEDQA"
] |
MEscriva/ECE-PRYMMAL-0.5B-FT-V4-MUSR-Mathis
|
MEscriva
|
question-answering
|
[
"safetensors",
"qwen2",
"musr",
"question-answering",
"reasoning",
"en",
"dataset:allenai/qasc",
"model-index",
"region:us"
] | 2024-10-25T14:27:13Z |
2024-11-12T17:16:11+00:00
| 42 | 1 |
---
datasets:
- allenai/qasc
language: en
metrics:
- accuracy: 0.87
- reasoning_quality: 1.0
- source_integration: 0.975
tags:
- musr
- question-answering
- reasoning
model-index:
- name: Qwen-0.5B-MUSR
results:
- task:
type: question-answering
name: Multi-Source Reasoning (MUSR)
dataset:
name: QASC
type: allenai/qasc
metrics:
- type: accuracy
value: 0.87
name: Accuracy
---
# Qwen-0.5B-MUSR
Ce modèle est une version fine-tunée de Qwen-0.5B optimisée pour le benchmark MUSR, atteignant :
- Une amélioration de 40.52% de l'eval_loss par rapport à la baseline
- Une accuracy de 87% sur les questions multi-sources
- Une qualité de raisonnement parfaite (100%)
- Une utilisation quasi-parfaite des sources (97.5%)
## Performances
- Accuracy: 0.87
- Reasoning Quality: 1.0
- Source Integration: 0.975
- Eval Loss: 1.036
## Cas d'utilisation
Particulièrement efficace pour :
- Questions nécessitant l'intégration de multiples sources
- Raisonnement complexe
- Réponses explicatives détaillées
## Configuration optimale :
- max_length: 170
- weight_decay: 0.1
- warmup_ratio: 0.07
- gradient_accumulation: 4
- scheduler: polynomial
|
[
"CAS"
] |
RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf
|
RichardErkhov
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-11-13T23:38:34Z |
2024-11-14T01:31:49+00:00
| 42 | 0 |
---
{}
---
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
MedPhi-3-mini_v1 - GGUF
- Model creator: https://huggingface.co/ChenWeiLi/
- Original model: https://huggingface.co/ChenWeiLi/MedPhi-3-mini_v1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [MedPhi-3-mini_v1.Q2_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q2_K.gguf) | Q2_K | 1.32GB |
| [MedPhi-3-mini_v1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q3_K_S.gguf) | Q3_K_S | 1.57GB |
| [MedPhi-3-mini_v1.Q3_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q3_K.gguf) | Q3_K | 1.82GB |
| [MedPhi-3-mini_v1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q3_K_M.gguf) | Q3_K_M | 1.82GB |
| [MedPhi-3-mini_v1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q3_K_L.gguf) | Q3_K_L | 1.94GB |
| [MedPhi-3-mini_v1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.IQ4_XS.gguf) | IQ4_XS | 1.93GB |
| [MedPhi-3-mini_v1.Q4_0.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q4_0.gguf) | Q4_0 | 2.03GB |
| [MedPhi-3-mini_v1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.IQ4_NL.gguf) | IQ4_NL | 2.04GB |
| [MedPhi-3-mini_v1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q4_K_S.gguf) | Q4_K_S | 2.04GB |
| [MedPhi-3-mini_v1.Q4_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q4_K.gguf) | Q4_K | 2.23GB |
| [MedPhi-3-mini_v1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q4_K_M.gguf) | Q4_K_M | 2.23GB |
| [MedPhi-3-mini_v1.Q4_1.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q4_1.gguf) | Q4_1 | 2.24GB |
| [MedPhi-3-mini_v1.Q5_0.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q5_0.gguf) | Q5_0 | 2.46GB |
| [MedPhi-3-mini_v1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q5_K_S.gguf) | Q5_K_S | 2.46GB |
| [MedPhi-3-mini_v1.Q5_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q5_K.gguf) | Q5_K | 2.62GB |
| [MedPhi-3-mini_v1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q5_K_M.gguf) | Q5_K_M | 2.62GB |
| [MedPhi-3-mini_v1.Q5_1.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q5_1.gguf) | Q5_1 | 2.68GB |
| [MedPhi-3-mini_v1.Q6_K.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q6_K.gguf) | Q6_K | 2.92GB |
| [MedPhi-3-mini_v1.Q8_0.gguf](https://huggingface.co/RichardErkhov/ChenWeiLi_-_MedPhi-3-mini_v1-gguf/blob/main/MedPhi-3-mini_v1.Q8_0.gguf) | Q8_0 | 3.78GB |
Original model description:
---
license: apache-2.0
---
### Evaluation
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|-------------------------------|-------|------|-----:|--------|-----:|---|-----:|
| - medmcqa |Yaml |none | 0|acc |0.5408|± |0.0077|
| | |none | 0|acc_norm|0.5408|± |0.0077|
| - medqa_4options |Yaml |none | 0|acc |0.5711|± |0.0139|
| | |none | 0|acc_norm|0.5711|± |0.0139|
| - anatomy (mmlu) | 0|none | 0|acc |0.6815|± |0.0402|
| - clinical_knowledge (mmlu) | 0|none | 0|acc |0.7434|± |0.0269|
| - college_biology (mmlu) | 0|none | 0|acc |0.8056|± |0.0331|
| - college_medicine (mmlu) | 0|none | 0|acc |0.6647|± |0.0360|
| - medical_genetics (mmlu) | 0|none | 0|acc |0.7300|± |0.0446|
| - professional_medicine (mmlu)| 0|none | 0|acc |0.7353|± |0.0268|
|stem |N/A |none | 0|acc_norm|0.5478|± |0.0067|
| | |none | 0|acc |0.5909|± |0.0058|
| - pubmedqa | 1|none | 0|acc |0.7620|± |0.0191|
|Groups|Version|Filter|n-shot| Metric |Value | |Stderr|
|------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5478|± |0.0067|
| | |none | 0|acc |0.5909|± |0.0058|
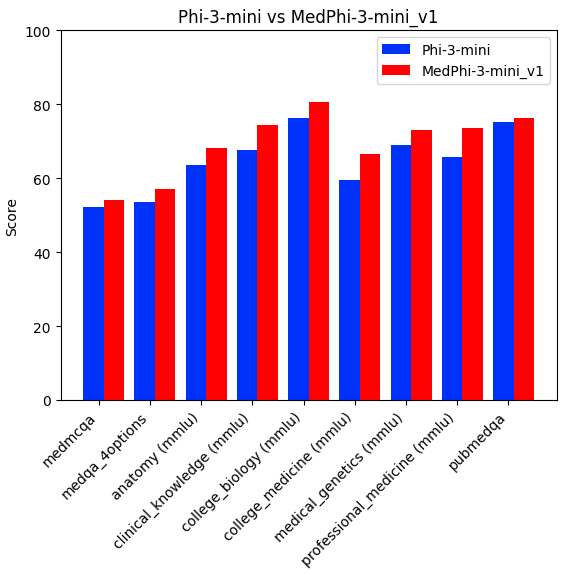
|
[
"MEDQA",
"PUBMEDQA"
] |
yoeven/multilingual-e5-large-instruct-Q5_0-GGUF
|
yoeven
| null |
[
"sentence-transformers",
"gguf",
"mteb",
"transformers",
"llama-cpp",
"gguf-my-repo",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"base_model:intfloat/multilingual-e5-large-instruct",
"base_model:quantized:intfloat/multilingual-e5-large-instruct",
"license:mit",
"model-index",
"endpoints_compatible",
"region:us",
"feature-extraction"
] | 2025-01-06T13:50:45Z |
2025-01-06T13:50:51+00:00
| 42 | 2 |
---
base_model: intfloat/multilingual-e5-large-instruct
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- 'no'
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
tags:
- mteb
- sentence-transformers
- transformers
- llama-cpp
- gguf-my-repo
model-index:
- name: multilingual-e5-large-instruct
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.23880597014924
- type: ap
value: 39.07351965022687
- type: f1
value: 70.04836733862683
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (de)
type: mteb/amazon_counterfactual
config: de
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 66.71306209850107
- type: ap
value: 79.01499914759529
- type: f1
value: 64.81951817560703
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en-ext)
type: mteb/amazon_counterfactual
config: en-ext
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.85307346326837
- type: ap
value: 22.447519885878737
- type: f1
value: 61.0162730745633
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (ja)
type: mteb/amazon_counterfactual
config: ja
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.04925053533191
- type: ap
value: 23.44983217128922
- type: f1
value: 62.5723230907759
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 96.28742500000001
- type: ap
value: 94.8449918887462
- type: f1
value: 96.28680923610432
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 56.716
- type: f1
value: 55.76510398266401
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (de)
type: mteb/amazon_reviews_multi
config: de
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 52.99999999999999
- type: f1
value: 52.00829994765178
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (es)
type: mteb/amazon_reviews_multi
config: es
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.806000000000004
- type: f1
value: 48.082345914983634
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.507999999999996
- type: f1
value: 47.68752844642045
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (ja)
type: mteb/amazon_reviews_multi
config: ja
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.709999999999994
- type: f1
value: 47.05870376637181
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 44.662000000000006
- type: f1
value: 43.42371965372771
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: arguana
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.721
- type: map_at_10
value: 49.221
- type: map_at_100
value: 49.884
- type: map_at_1000
value: 49.888
- type: map_at_3
value: 44.31
- type: map_at_5
value: 47.276
- type: mrr_at_1
value: 32.432
- type: mrr_at_10
value: 49.5
- type: mrr_at_100
value: 50.163000000000004
- type: mrr_at_1000
value: 50.166
- type: mrr_at_3
value: 44.618
- type: mrr_at_5
value: 47.541
- type: ndcg_at_1
value: 31.721
- type: ndcg_at_10
value: 58.384
- type: ndcg_at_100
value: 61.111000000000004
- type: ndcg_at_1000
value: 61.187999999999995
- type: ndcg_at_3
value: 48.386
- type: ndcg_at_5
value: 53.708999999999996
- type: precision_at_1
value: 31.721
- type: precision_at_10
value: 8.741
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.057
- type: precision_at_5
value: 14.609
- type: recall_at_1
value: 31.721
- type: recall_at_10
value: 87.411
- type: recall_at_100
value: 99.075
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 60.171
- type: recall_at_5
value: 73.044
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 46.40419580759799
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.48593255007969
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 63.889179122289995
- type: mrr
value: 77.61146286769556
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 88.15075203727929
- type: cos_sim_spearman
value: 86.9622224570873
- type: euclidean_pearson
value: 86.70473853624121
- type: euclidean_spearman
value: 86.9622224570873
- type: manhattan_pearson
value: 86.21089380980065
- type: manhattan_spearman
value: 86.75318154937008
- task:
type: BitextMining
dataset:
name: MTEB BUCC (de-en)
type: mteb/bucc-bitext-mining
config: de-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.65553235908142
- type: f1
value: 99.60681976339595
- type: precision
value: 99.58246346555325
- type: recall
value: 99.65553235908142
- task:
type: BitextMining
dataset:
name: MTEB BUCC (fr-en)
type: mteb/bucc-bitext-mining
config: fr-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.26260180497468
- type: f1
value: 99.14520507740848
- type: precision
value: 99.08650671362535
- type: recall
value: 99.26260180497468
- task:
type: BitextMining
dataset:
name: MTEB BUCC (ru-en)
type: mteb/bucc-bitext-mining
config: ru-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 98.07412538967787
- type: f1
value: 97.86629719431936
- type: precision
value: 97.76238309664012
- type: recall
value: 98.07412538967787
- task:
type: BitextMining
dataset:
name: MTEB BUCC (zh-en)
type: mteb/bucc-bitext-mining
config: zh-en
split: test
revision: d51519689f32196a32af33b075a01d0e7c51e252
metrics:
- type: accuracy
value: 99.42074776197998
- type: f1
value: 99.38564156573635
- type: precision
value: 99.36808846761454
- type: recall
value: 99.42074776197998
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 85.73376623376623
- type: f1
value: 85.68480707214599
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 40.935218072113855
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 36.276389017675264
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 27.764166666666668
- type: map_at_10
value: 37.298166666666674
- type: map_at_100
value: 38.530166666666666
- type: map_at_1000
value: 38.64416666666667
- type: map_at_3
value: 34.484833333333334
- type: map_at_5
value: 36.0385
- type: mrr_at_1
value: 32.93558333333333
- type: mrr_at_10
value: 41.589749999999995
- type: mrr_at_100
value: 42.425333333333334
- type: mrr_at_1000
value: 42.476333333333336
- type: mrr_at_3
value: 39.26825
- type: mrr_at_5
value: 40.567083333333336
- type: ndcg_at_1
value: 32.93558333333333
- type: ndcg_at_10
value: 42.706583333333334
- type: ndcg_at_100
value: 47.82483333333333
- type: ndcg_at_1000
value: 49.95733333333334
- type: ndcg_at_3
value: 38.064750000000004
- type: ndcg_at_5
value: 40.18158333333333
- type: precision_at_1
value: 32.93558333333333
- type: precision_at_10
value: 7.459833333333334
- type: precision_at_100
value: 1.1830833333333335
- type: precision_at_1000
value: 0.15608333333333332
- type: precision_at_3
value: 17.5235
- type: precision_at_5
value: 12.349833333333333
- type: recall_at_1
value: 27.764166666666668
- type: recall_at_10
value: 54.31775
- type: recall_at_100
value: 76.74350000000001
- type: recall_at_1000
value: 91.45208333333332
- type: recall_at_3
value: 41.23425
- type: recall_at_5
value: 46.73983333333334
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: climate-fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 12.969
- type: map_at_10
value: 21.584999999999997
- type: map_at_100
value: 23.3
- type: map_at_1000
value: 23.5
- type: map_at_3
value: 18.218999999999998
- type: map_at_5
value: 19.983
- type: mrr_at_1
value: 29.316
- type: mrr_at_10
value: 40.033
- type: mrr_at_100
value: 40.96
- type: mrr_at_1000
value: 41.001
- type: mrr_at_3
value: 37.123
- type: mrr_at_5
value: 38.757999999999996
- type: ndcg_at_1
value: 29.316
- type: ndcg_at_10
value: 29.858
- type: ndcg_at_100
value: 36.756
- type: ndcg_at_1000
value: 40.245999999999995
- type: ndcg_at_3
value: 24.822
- type: ndcg_at_5
value: 26.565
- type: precision_at_1
value: 29.316
- type: precision_at_10
value: 9.186
- type: precision_at_100
value: 1.6549999999999998
- type: precision_at_1000
value: 0.22999999999999998
- type: precision_at_3
value: 18.436
- type: precision_at_5
value: 13.876
- type: recall_at_1
value: 12.969
- type: recall_at_10
value: 35.142
- type: recall_at_100
value: 59.143
- type: recall_at_1000
value: 78.594
- type: recall_at_3
value: 22.604
- type: recall_at_5
value: 27.883000000000003
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: dbpedia-entity
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.527999999999999
- type: map_at_10
value: 17.974999999999998
- type: map_at_100
value: 25.665
- type: map_at_1000
value: 27.406000000000002
- type: map_at_3
value: 13.017999999999999
- type: map_at_5
value: 15.137
- type: mrr_at_1
value: 62.5
- type: mrr_at_10
value: 71.891
- type: mrr_at_100
value: 72.294
- type: mrr_at_1000
value: 72.296
- type: mrr_at_3
value: 69.958
- type: mrr_at_5
value: 71.121
- type: ndcg_at_1
value: 50.875
- type: ndcg_at_10
value: 38.36
- type: ndcg_at_100
value: 44.235
- type: ndcg_at_1000
value: 52.154
- type: ndcg_at_3
value: 43.008
- type: ndcg_at_5
value: 40.083999999999996
- type: precision_at_1
value: 62.5
- type: precision_at_10
value: 30.0
- type: precision_at_100
value: 10.038
- type: precision_at_1000
value: 2.0869999999999997
- type: precision_at_3
value: 46.833000000000006
- type: precision_at_5
value: 38.800000000000004
- type: recall_at_1
value: 8.527999999999999
- type: recall_at_10
value: 23.828
- type: recall_at_100
value: 52.322
- type: recall_at_1000
value: 77.143
- type: recall_at_3
value: 14.136000000000001
- type: recall_at_5
value: 17.761
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.51
- type: f1
value: 47.632159862049896
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: fever
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 60.734
- type: map_at_10
value: 72.442
- type: map_at_100
value: 72.735
- type: map_at_1000
value: 72.75
- type: map_at_3
value: 70.41199999999999
- type: map_at_5
value: 71.80499999999999
- type: mrr_at_1
value: 65.212
- type: mrr_at_10
value: 76.613
- type: mrr_at_100
value: 76.79899999999999
- type: mrr_at_1000
value: 76.801
- type: mrr_at_3
value: 74.8
- type: mrr_at_5
value: 76.12400000000001
- type: ndcg_at_1
value: 65.212
- type: ndcg_at_10
value: 77.988
- type: ndcg_at_100
value: 79.167
- type: ndcg_at_1000
value: 79.452
- type: ndcg_at_3
value: 74.362
- type: ndcg_at_5
value: 76.666
- type: precision_at_1
value: 65.212
- type: precision_at_10
value: 10.003
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 29.518
- type: precision_at_5
value: 19.016
- type: recall_at_1
value: 60.734
- type: recall_at_10
value: 90.824
- type: recall_at_100
value: 95.71600000000001
- type: recall_at_1000
value: 97.577
- type: recall_at_3
value: 81.243
- type: recall_at_5
value: 86.90299999999999
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: fiqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.845
- type: map_at_10
value: 39.281
- type: map_at_100
value: 41.422
- type: map_at_1000
value: 41.593
- type: map_at_3
value: 34.467
- type: map_at_5
value: 37.017
- type: mrr_at_1
value: 47.531
- type: mrr_at_10
value: 56.204
- type: mrr_at_100
value: 56.928999999999995
- type: mrr_at_1000
value: 56.962999999999994
- type: mrr_at_3
value: 54.115
- type: mrr_at_5
value: 55.373000000000005
- type: ndcg_at_1
value: 47.531
- type: ndcg_at_10
value: 47.711999999999996
- type: ndcg_at_100
value: 54.510999999999996
- type: ndcg_at_1000
value: 57.103
- type: ndcg_at_3
value: 44.145
- type: ndcg_at_5
value: 45.032
- type: precision_at_1
value: 47.531
- type: precision_at_10
value: 13.194
- type: precision_at_100
value: 2.045
- type: precision_at_1000
value: 0.249
- type: precision_at_3
value: 29.424
- type: precision_at_5
value: 21.451
- type: recall_at_1
value: 23.845
- type: recall_at_10
value: 54.967
- type: recall_at_100
value: 79.11399999999999
- type: recall_at_1000
value: 94.56700000000001
- type: recall_at_3
value: 40.256
- type: recall_at_5
value: 46.215
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: hotpotqa
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 37.819
- type: map_at_10
value: 60.889
- type: map_at_100
value: 61.717999999999996
- type: map_at_1000
value: 61.778
- type: map_at_3
value: 57.254000000000005
- type: map_at_5
value: 59.541
- type: mrr_at_1
value: 75.638
- type: mrr_at_10
value: 82.173
- type: mrr_at_100
value: 82.362
- type: mrr_at_1000
value: 82.37
- type: mrr_at_3
value: 81.089
- type: mrr_at_5
value: 81.827
- type: ndcg_at_1
value: 75.638
- type: ndcg_at_10
value: 69.317
- type: ndcg_at_100
value: 72.221
- type: ndcg_at_1000
value: 73.382
- type: ndcg_at_3
value: 64.14
- type: ndcg_at_5
value: 67.07600000000001
- type: precision_at_1
value: 75.638
- type: precision_at_10
value: 14.704999999999998
- type: precision_at_100
value: 1.698
- type: precision_at_1000
value: 0.185
- type: precision_at_3
value: 41.394999999999996
- type: precision_at_5
value: 27.162999999999997
- type: recall_at_1
value: 37.819
- type: recall_at_10
value: 73.52499999999999
- type: recall_at_100
value: 84.875
- type: recall_at_1000
value: 92.559
- type: recall_at_3
value: 62.092999999999996
- type: recall_at_5
value: 67.907
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 94.60079999999999
- type: ap
value: 92.67396345347356
- type: f1
value: 94.5988098167121
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: msmarco
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.285
- type: map_at_10
value: 33.436
- type: map_at_100
value: 34.63
- type: map_at_1000
value: 34.681
- type: map_at_3
value: 29.412
- type: map_at_5
value: 31.715
- type: mrr_at_1
value: 21.848
- type: mrr_at_10
value: 33.979
- type: mrr_at_100
value: 35.118
- type: mrr_at_1000
value: 35.162
- type: mrr_at_3
value: 30.036
- type: mrr_at_5
value: 32.298
- type: ndcg_at_1
value: 21.862000000000002
- type: ndcg_at_10
value: 40.43
- type: ndcg_at_100
value: 46.17
- type: ndcg_at_1000
value: 47.412
- type: ndcg_at_3
value: 32.221
- type: ndcg_at_5
value: 36.332
- type: precision_at_1
value: 21.862000000000002
- type: precision_at_10
value: 6.491
- type: precision_at_100
value: 0.935
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.744
- type: precision_at_5
value: 10.331999999999999
- type: recall_at_1
value: 21.285
- type: recall_at_10
value: 62.083
- type: recall_at_100
value: 88.576
- type: recall_at_1000
value: 98.006
- type: recall_at_3
value: 39.729
- type: recall_at_5
value: 49.608000000000004
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.92612859097127
- type: f1
value: 93.82370333372853
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (de)
type: mteb/mtop_domain
config: de
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.67681036911807
- type: f1
value: 92.14191382411472
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (es)
type: mteb/mtop_domain
config: es
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 92.26817878585723
- type: f1
value: 91.92824250337878
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 89.96554963983714
- type: f1
value: 90.02859329630792
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (hi)
type: mteb/mtop_domain
config: hi
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 90.02509860164935
- type: f1
value: 89.30665159182062
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (th)
type: mteb/mtop_domain
config: th
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 87.55515370705244
- type: f1
value: 87.94449232331907
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 82.4623803009576
- type: f1
value: 66.06738378772725
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (de)
type: mteb/mtop_intent
config: de
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 79.3716539870386
- type: f1
value: 60.37614033396853
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (es)
type: mteb/mtop_intent
config: es
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 80.34022681787857
- type: f1
value: 58.302008026952
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 76.72095208268087
- type: f1
value: 59.64524724009049
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (hi)
type: mteb/mtop_intent
config: hi
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.87020437432773
- type: f1
value: 57.80202694670567
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (th)
type: mteb/mtop_intent
config: th
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 77.73598553345387
- type: f1
value: 58.19628250675031
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (af)
type: mteb/amazon_massive_intent
config: af
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.6630800268998
- type: f1
value: 65.00996668051691
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (am)
type: mteb/amazon_massive_intent
config: am
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 60.7128446536651
- type: f1
value: 57.95860594874963
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ar)
type: mteb/amazon_massive_intent
config: ar
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.61129791526563
- type: f1
value: 59.75328290206483
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (az)
type: mteb/amazon_massive_intent
config: az
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.00134498991257
- type: f1
value: 67.0230483991802
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (bn)
type: mteb/amazon_massive_intent
config: bn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.54068594485541
- type: f1
value: 65.54604628946976
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (cy)
type: mteb/amazon_massive_intent
config: cy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.032952252858095
- type: f1
value: 58.715741857057104
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (da)
type: mteb/amazon_massive_intent
config: da
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.80901143241427
- type: f1
value: 68.33963989243877
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (de)
type: mteb/amazon_massive_intent
config: de
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.47141896435777
- type: f1
value: 69.56765020308262
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (el)
type: mteb/amazon_massive_intent
config: el
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.2373907195696
- type: f1
value: 69.04529836036467
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 77.05783456624076
- type: f1
value: 74.69430584708174
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (es)
type: mteb/amazon_massive_intent
config: es
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.82111634162744
- type: f1
value: 70.77228952803762
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fa)
type: mteb/amazon_massive_intent
config: fa
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.25353059852051
- type: f1
value: 71.05310103416411
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fi)
type: mteb/amazon_massive_intent
config: fi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.28648285137861
- type: f1
value: 69.08020473732226
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.31540013449899
- type: f1
value: 70.9426355465791
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (he)
type: mteb/amazon_massive_intent
config: he
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.2151983860121
- type: f1
value: 67.52541755908858
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hi)
type: mteb/amazon_massive_intent
config: hi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.58372562205784
- type: f1
value: 69.49769064229827
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hu)
type: mteb/amazon_massive_intent
config: hu
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.9233355749832
- type: f1
value: 69.36311548259593
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (hy)
type: mteb/amazon_massive_intent
config: hy
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 68.07330195023538
- type: f1
value: 64.99882022345572
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (id)
type: mteb/amazon_massive_intent
config: id
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.62273032952253
- type: f1
value: 70.6394885471001
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (is)
type: mteb/amazon_massive_intent
config: is
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 65.77000672494957
- type: f1
value: 62.9368944815065
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (it)
type: mteb/amazon_massive_intent
config: it
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.453261600538
- type: f1
value: 70.85069934666681
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ja)
type: mteb/amazon_massive_intent
config: ja
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.6906523201076
- type: f1
value: 72.03249740074217
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (jv)
type: mteb/amazon_massive_intent
config: jv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.03631472763953
- type: f1
value: 59.3165215571852
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ka)
type: mteb/amazon_massive_intent
config: ka
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 58.913920645595155
- type: f1
value: 57.367337711611285
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (km)
type: mteb/amazon_massive_intent
config: km
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 54.42837928715535
- type: f1
value: 52.60527294970906
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (kn)
type: mteb/amazon_massive_intent
config: kn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.33490248823135
- type: f1
value: 63.213340969404065
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ko)
type: mteb/amazon_massive_intent
config: ko
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.58507061197041
- type: f1
value: 68.40256628040486
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (lv)
type: mteb/amazon_massive_intent
config: lv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.11230665770006
- type: f1
value: 66.44863577842305
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ml)
type: mteb/amazon_massive_intent
config: ml
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.70073974445192
- type: f1
value: 67.21291337273702
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (mn)
type: mteb/amazon_massive_intent
config: mn
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.43913920645595
- type: f1
value: 64.09838087422806
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ms)
type: mteb/amazon_massive_intent
config: ms
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.80026899798251
- type: f1
value: 68.76986742962444
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (my)
type: mteb/amazon_massive_intent
config: my
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 64.78816408876934
- type: f1
value: 62.18781873428972
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nb)
type: mteb/amazon_massive_intent
config: nb
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.6577000672495
- type: f1
value: 68.75171511133003
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (nl)
type: mteb/amazon_massive_intent
config: nl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.42501681237391
- type: f1
value: 71.18434963451544
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.64828513786146
- type: f1
value: 70.67741914007422
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pt)
type: mteb/amazon_massive_intent
config: pt
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.62811028917284
- type: f1
value: 71.36402039740959
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ro)
type: mteb/amazon_massive_intent
config: ro
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.88634835238736
- type: f1
value: 69.23701923480677
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ru)
type: mteb/amazon_massive_intent
config: ru
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.15938130464022
- type: f1
value: 71.87792218993388
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sl)
type: mteb/amazon_massive_intent
config: sl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.96301277740416
- type: f1
value: 67.29584200202983
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sq)
type: mteb/amazon_massive_intent
config: sq
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.49562878278412
- type: f1
value: 66.91716685679431
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sv)
type: mteb/amazon_massive_intent
config: sv
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.6805648957633
- type: f1
value: 72.02723592594374
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (sw)
type: mteb/amazon_massive_intent
config: sw
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 63.00605245460659
- type: f1
value: 60.16716669482932
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ta)
type: mteb/amazon_massive_intent
config: ta
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 66.90988567585742
- type: f1
value: 63.99405488777784
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (te)
type: mteb/amazon_massive_intent
config: te
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.62273032952253
- type: f1
value: 65.17213906909481
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (th)
type: mteb/amazon_massive_intent
config: th
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.50907868190988
- type: f1
value: 69.15165697194853
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tl)
type: mteb/amazon_massive_intent
config: tl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.30733019502352
- type: f1
value: 66.69024007380474
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (tr)
type: mteb/amazon_massive_intent
config: tr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 72.24277067921989
- type: f1
value: 68.80515408492947
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (ur)
type: mteb/amazon_massive_intent
config: ur
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 67.49831876260929
- type: f1
value: 64.83778567111116
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (vi)
type: mteb/amazon_massive_intent
config: vi
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 71.28782784129119
- type: f1
value: 69.3294186700733
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.315400134499
- type: f1
value: 71.22674385243207
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-TW)
type: mteb/amazon_massive_intent
config: zh-TW
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 69.37794216543377
- type: f1
value: 68.96962492838232
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (af)
type: mteb/amazon_massive_scenario
config: af
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.33557498318764
- type: f1
value: 72.28949738478356
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (am)
type: mteb/amazon_massive_scenario
config: am
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 65.84398117014123
- type: f1
value: 64.71026362091463
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ar)
type: mteb/amazon_massive_scenario
config: ar
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 69.76462676529925
- type: f1
value: 69.8229667407667
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (az)
type: mteb/amazon_massive_scenario
config: az
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.02420981842636
- type: f1
value: 71.76576384895898
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (bn)
type: mteb/amazon_massive_scenario
config: bn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.7572293207801
- type: f1
value: 72.76840765295256
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (cy)
type: mteb/amazon_massive_scenario
config: cy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.02286482851379
- type: f1
value: 66.17237947327872
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (da)
type: mteb/amazon_massive_scenario
config: da
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.60928043039678
- type: f1
value: 77.27094731234773
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (de)
type: mteb/amazon_massive_scenario
config: de
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.68325487558843
- type: f1
value: 77.97530399082261
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (el)
type: mteb/amazon_massive_scenario
config: el
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.13315400134498
- type: f1
value: 75.97558584796424
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.47410894418292
- type: f1
value: 80.52244841473792
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (es)
type: mteb/amazon_massive_scenario
config: es
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.9670477471419
- type: f1
value: 77.37318805793146
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fa)
type: mteb/amazon_massive_scenario
config: fa
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.09683927370544
- type: f1
value: 77.69773737430847
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fi)
type: mteb/amazon_massive_scenario
config: fi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.20847343644922
- type: f1
value: 75.17071738727348
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.07464694014796
- type: f1
value: 77.16136207698571
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (he)
type: mteb/amazon_massive_scenario
config: he
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.53396099529255
- type: f1
value: 73.58296404484122
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hi)
type: mteb/amazon_massive_scenario
config: hi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.75319435104237
- type: f1
value: 75.24674707850833
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hu)
type: mteb/amazon_massive_scenario
config: hu
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.0948217888366
- type: f1
value: 76.47559490205028
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (hy)
type: mteb/amazon_massive_scenario
config: hy
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.07599193006052
- type: f1
value: 70.76028043093511
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (id)
type: mteb/amazon_massive_scenario
config: id
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.10490921318089
- type: f1
value: 77.01215275283272
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (is)
type: mteb/amazon_massive_scenario
config: is
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.25756556825824
- type: f1
value: 70.20605314648762
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (it)
type: mteb/amazon_massive_scenario
config: it
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.08137188971082
- type: f1
value: 77.3899269057439
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ja)
type: mteb/amazon_massive_scenario
config: ja
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.35440484196369
- type: f1
value: 79.58964690002772
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (jv)
type: mteb/amazon_massive_scenario
config: jv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.42299932750504
- type: f1
value: 68.07844356925413
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ka)
type: mteb/amazon_massive_scenario
config: ka
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 66.15669132481507
- type: f1
value: 65.89383352608513
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (km)
type: mteb/amazon_massive_scenario
config: km
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 60.11432414256894
- type: f1
value: 57.69910594559806
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (kn)
type: mteb/amazon_massive_scenario
config: kn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.24747814391392
- type: f1
value: 70.42455553830918
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ko)
type: mteb/amazon_massive_scenario
config: ko
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.46267652992603
- type: f1
value: 76.8854559308316
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (lv)
type: mteb/amazon_massive_scenario
config: lv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 73.24815063887021
- type: f1
value: 72.77805034658074
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ml)
type: mteb/amazon_massive_scenario
config: ml
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.11566913248151
- type: f1
value: 73.86147988001356
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (mn)
type: mteb/amazon_massive_scenario
config: mn
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.0168123739072
- type: f1
value: 69.38515920054571
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ms)
type: mteb/amazon_massive_scenario
config: ms
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.41156691324814
- type: f1
value: 73.43474953408237
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (my)
type: mteb/amazon_massive_scenario
config: my
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 68.39609952925353
- type: f1
value: 67.29731681109291
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nb)
type: mteb/amazon_massive_scenario
config: nb
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.20914593140552
- type: f1
value: 77.07066497935367
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (nl)
type: mteb/amazon_massive_scenario
config: nl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.52387357094821
- type: f1
value: 78.5259569473291
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.6913248150639
- type: f1
value: 76.91201656350455
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pt)
type: mteb/amazon_massive_scenario
config: pt
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.1217215870881
- type: f1
value: 77.41179937912504
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ro)
type: mteb/amazon_massive_scenario
config: ro
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.25891055817083
- type: f1
value: 75.8089244542887
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ru)
type: mteb/amazon_massive_scenario
config: ru
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 77.70679219905851
- type: f1
value: 78.21459594517711
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sl)
type: mteb/amazon_massive_scenario
config: sl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.83523873570948
- type: f1
value: 74.86847028401978
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sq)
type: mteb/amazon_massive_scenario
config: sq
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.71755211835911
- type: f1
value: 74.0214326485662
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sv)
type: mteb/amazon_massive_scenario
config: sv
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.06523201075991
- type: f1
value: 79.10545620325138
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (sw)
type: mteb/amazon_massive_scenario
config: sw
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 67.91862811028918
- type: f1
value: 66.50386121217983
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ta)
type: mteb/amazon_massive_scenario
config: ta
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 70.93140551445865
- type: f1
value: 70.755435928495
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (te)
type: mteb/amazon_massive_scenario
config: te
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.40753194351042
- type: f1
value: 71.61816115782923
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (th)
type: mteb/amazon_massive_scenario
config: th
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.1815736381977
- type: f1
value: 75.08016717887205
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tl)
type: mteb/amazon_massive_scenario
config: tl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 72.86482851378614
- type: f1
value: 72.39521180006291
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (tr)
type: mteb/amazon_massive_scenario
config: tr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.46940147948891
- type: f1
value: 76.70044085362349
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (ur)
type: mteb/amazon_massive_scenario
config: ur
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 71.89307330195024
- type: f1
value: 71.5721825332298
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (vi)
type: mteb/amazon_massive_scenario
config: vi
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 74.7511768661735
- type: f1
value: 75.17918654541515
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.69535978480162
- type: f1
value: 78.90019070153316
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-TW)
type: mteb/amazon_massive_scenario
config: zh-TW
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.45729657027572
- type: f1
value: 76.19578371794672
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 36.92715354123554
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 35.53536244162518
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 33.08507884504006
- type: mrr
value: 34.32436977159129
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: nfcorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.935
- type: map_at_10
value: 13.297
- type: map_at_100
value: 16.907
- type: map_at_1000
value: 18.391
- type: map_at_3
value: 9.626999999999999
- type: map_at_5
value: 11.190999999999999
- type: mrr_at_1
value: 46.129999999999995
- type: mrr_at_10
value: 54.346000000000004
- type: mrr_at_100
value: 55.067
- type: mrr_at_1000
value: 55.1
- type: mrr_at_3
value: 51.961
- type: mrr_at_5
value: 53.246
- type: ndcg_at_1
value: 44.118
- type: ndcg_at_10
value: 35.534
- type: ndcg_at_100
value: 32.946999999999996
- type: ndcg_at_1000
value: 41.599000000000004
- type: ndcg_at_3
value: 40.25
- type: ndcg_at_5
value: 37.978
- type: precision_at_1
value: 46.129999999999995
- type: precision_at_10
value: 26.842
- type: precision_at_100
value: 8.427
- type: precision_at_1000
value: 2.128
- type: precision_at_3
value: 37.977
- type: precision_at_5
value: 32.879000000000005
- type: recall_at_1
value: 5.935
- type: recall_at_10
value: 17.211000000000002
- type: recall_at_100
value: 34.33
- type: recall_at_1000
value: 65.551
- type: recall_at_3
value: 10.483
- type: recall_at_5
value: 13.078999999999999
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: nq
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.231
- type: map_at_10
value: 50.202000000000005
- type: map_at_100
value: 51.154999999999994
- type: map_at_1000
value: 51.181
- type: map_at_3
value: 45.774
- type: map_at_5
value: 48.522
- type: mrr_at_1
value: 39.687
- type: mrr_at_10
value: 52.88
- type: mrr_at_100
value: 53.569
- type: mrr_at_1000
value: 53.58500000000001
- type: mrr_at_3
value: 49.228
- type: mrr_at_5
value: 51.525
- type: ndcg_at_1
value: 39.687
- type: ndcg_at_10
value: 57.754000000000005
- type: ndcg_at_100
value: 61.597
- type: ndcg_at_1000
value: 62.18900000000001
- type: ndcg_at_3
value: 49.55
- type: ndcg_at_5
value: 54.11899999999999
- type: precision_at_1
value: 39.687
- type: precision_at_10
value: 9.313
- type: precision_at_100
value: 1.146
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 22.229
- type: precision_at_5
value: 15.939
- type: recall_at_1
value: 35.231
- type: recall_at_10
value: 78.083
- type: recall_at_100
value: 94.42099999999999
- type: recall_at_1000
value: 98.81
- type: recall_at_3
value: 57.047000000000004
- type: recall_at_5
value: 67.637
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.241
- type: map_at_10
value: 85.462
- type: map_at_100
value: 86.083
- type: map_at_1000
value: 86.09700000000001
- type: map_at_3
value: 82.49499999999999
- type: map_at_5
value: 84.392
- type: mrr_at_1
value: 82.09
- type: mrr_at_10
value: 88.301
- type: mrr_at_100
value: 88.383
- type: mrr_at_1000
value: 88.384
- type: mrr_at_3
value: 87.37
- type: mrr_at_5
value: 88.035
- type: ndcg_at_1
value: 82.12
- type: ndcg_at_10
value: 89.149
- type: ndcg_at_100
value: 90.235
- type: ndcg_at_1000
value: 90.307
- type: ndcg_at_3
value: 86.37599999999999
- type: ndcg_at_5
value: 87.964
- type: precision_at_1
value: 82.12
- type: precision_at_10
value: 13.56
- type: precision_at_100
value: 1.539
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.88
- type: precision_at_5
value: 24.92
- type: recall_at_1
value: 71.241
- type: recall_at_10
value: 96.128
- type: recall_at_100
value: 99.696
- type: recall_at_1000
value: 99.994
- type: recall_at_3
value: 88.181
- type: recall_at_5
value: 92.694
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 56.59757799655151
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 64.27391998854624
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.243
- type: map_at_10
value: 10.965
- type: map_at_100
value: 12.934999999999999
- type: map_at_1000
value: 13.256
- type: map_at_3
value: 7.907
- type: map_at_5
value: 9.435
- type: mrr_at_1
value: 20.9
- type: mrr_at_10
value: 31.849
- type: mrr_at_100
value: 32.964
- type: mrr_at_1000
value: 33.024
- type: mrr_at_3
value: 28.517
- type: mrr_at_5
value: 30.381999999999998
- type: ndcg_at_1
value: 20.9
- type: ndcg_at_10
value: 18.723
- type: ndcg_at_100
value: 26.384999999999998
- type: ndcg_at_1000
value: 32.114
- type: ndcg_at_3
value: 17.753
- type: ndcg_at_5
value: 15.558
- type: precision_at_1
value: 20.9
- type: precision_at_10
value: 9.8
- type: precision_at_100
value: 2.078
- type: precision_at_1000
value: 0.345
- type: precision_at_3
value: 16.900000000000002
- type: precision_at_5
value: 13.88
- type: recall_at_1
value: 4.243
- type: recall_at_10
value: 19.885
- type: recall_at_100
value: 42.17
- type: recall_at_1000
value: 70.12
- type: recall_at_3
value: 10.288
- type: recall_at_5
value: 14.072000000000001
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.84209174935282
- type: cos_sim_spearman
value: 81.73248048438833
- type: euclidean_pearson
value: 83.02810070308149
- type: euclidean_spearman
value: 81.73248295679514
- type: manhattan_pearson
value: 82.95368060376002
- type: manhattan_spearman
value: 81.60277910998718
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 88.52628804556943
- type: cos_sim_spearman
value: 82.5713913555672
- type: euclidean_pearson
value: 85.8796774746988
- type: euclidean_spearman
value: 82.57137506803424
- type: manhattan_pearson
value: 85.79671002960058
- type: manhattan_spearman
value: 82.49445981618027
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 86.23682503505542
- type: cos_sim_spearman
value: 87.15008956711806
- type: euclidean_pearson
value: 86.79805401524959
- type: euclidean_spearman
value: 87.15008956711806
- type: manhattan_pearson
value: 86.65298502699244
- type: manhattan_spearman
value: 86.97677821948562
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 85.63370304677802
- type: cos_sim_spearman
value: 84.97105553540318
- type: euclidean_pearson
value: 85.28896108687721
- type: euclidean_spearman
value: 84.97105553540318
- type: manhattan_pearson
value: 85.09663190337331
- type: manhattan_spearman
value: 84.79126831644619
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 90.2614838800733
- type: cos_sim_spearman
value: 91.0509162991835
- type: euclidean_pearson
value: 90.33098317533373
- type: euclidean_spearman
value: 91.05091625871644
- type: manhattan_pearson
value: 90.26250435151107
- type: manhattan_spearman
value: 90.97999594417519
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 85.80480973335091
- type: cos_sim_spearman
value: 87.313695492969
- type: euclidean_pearson
value: 86.49267251576939
- type: euclidean_spearman
value: 87.313695492969
- type: manhattan_pearson
value: 86.44019901831935
- type: manhattan_spearman
value: 87.24205395460392
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 90.05662789380672
- type: cos_sim_spearman
value: 90.02759424426651
- type: euclidean_pearson
value: 90.4042483422981
- type: euclidean_spearman
value: 90.02759424426651
- type: manhattan_pearson
value: 90.51446975000226
- type: manhattan_spearman
value: 90.08832889933616
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.5975528273532
- type: cos_sim_spearman
value: 67.62969861411354
- type: euclidean_pearson
value: 69.224275734323
- type: euclidean_spearman
value: 67.62969861411354
- type: manhattan_pearson
value: 69.3761447059927
- type: manhattan_spearman
value: 67.90921005611467
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 87.11244327231684
- type: cos_sim_spearman
value: 88.37902438979035
- type: euclidean_pearson
value: 87.86054279847336
- type: euclidean_spearman
value: 88.37902438979035
- type: manhattan_pearson
value: 87.77257757320378
- type: manhattan_spearman
value: 88.25208966098123
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 85.87174608143563
- type: mrr
value: 96.12836872640794
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: scifact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 57.760999999999996
- type: map_at_10
value: 67.258
- type: map_at_100
value: 67.757
- type: map_at_1000
value: 67.78800000000001
- type: map_at_3
value: 64.602
- type: map_at_5
value: 65.64
- type: mrr_at_1
value: 60.667
- type: mrr_at_10
value: 68.441
- type: mrr_at_100
value: 68.825
- type: mrr_at_1000
value: 68.853
- type: mrr_at_3
value: 66.444
- type: mrr_at_5
value: 67.26100000000001
- type: ndcg_at_1
value: 60.667
- type: ndcg_at_10
value: 71.852
- type: ndcg_at_100
value: 73.9
- type: ndcg_at_1000
value: 74.628
- type: ndcg_at_3
value: 67.093
- type: ndcg_at_5
value: 68.58
- type: precision_at_1
value: 60.667
- type: precision_at_10
value: 9.6
- type: precision_at_100
value: 1.0670000000000002
- type: precision_at_1000
value: 0.11199999999999999
- type: precision_at_3
value: 26.111
- type: precision_at_5
value: 16.733
- type: recall_at_1
value: 57.760999999999996
- type: recall_at_10
value: 84.967
- type: recall_at_100
value: 93.833
- type: recall_at_1000
value: 99.333
- type: recall_at_3
value: 71.589
- type: recall_at_5
value: 75.483
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.66633663366336
- type: cos_sim_ap
value: 91.17685358899108
- type: cos_sim_f1
value: 82.16818642350559
- type: cos_sim_precision
value: 83.26488706365504
- type: cos_sim_recall
value: 81.10000000000001
- type: dot_accuracy
value: 99.66633663366336
- type: dot_ap
value: 91.17663411119032
- type: dot_f1
value: 82.16818642350559
- type: dot_precision
value: 83.26488706365504
- type: dot_recall
value: 81.10000000000001
- type: euclidean_accuracy
value: 99.66633663366336
- type: euclidean_ap
value: 91.17685189882275
- type: euclidean_f1
value: 82.16818642350559
- type: euclidean_precision
value: 83.26488706365504
- type: euclidean_recall
value: 81.10000000000001
- type: manhattan_accuracy
value: 99.66633663366336
- type: manhattan_ap
value: 91.2241619496737
- type: manhattan_f1
value: 82.20472440944883
- type: manhattan_precision
value: 86.51933701657458
- type: manhattan_recall
value: 78.3
- type: max_accuracy
value: 99.66633663366336
- type: max_ap
value: 91.2241619496737
- type: max_f1
value: 82.20472440944883
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 66.85101268897951
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 42.461184054706905
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 51.44542568873886
- type: mrr
value: 52.33656151854681
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.75982974997539
- type: cos_sim_spearman
value: 30.385405026539914
- type: dot_pearson
value: 30.75982433546523
- type: dot_spearman
value: 30.385405026539914
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22799999999999998
- type: map_at_10
value: 2.064
- type: map_at_100
value: 13.056000000000001
- type: map_at_1000
value: 31.747999999999998
- type: map_at_3
value: 0.67
- type: map_at_5
value: 1.097
- type: mrr_at_1
value: 90.0
- type: mrr_at_10
value: 94.667
- type: mrr_at_100
value: 94.667
- type: mrr_at_1000
value: 94.667
- type: mrr_at_3
value: 94.667
- type: mrr_at_5
value: 94.667
- type: ndcg_at_1
value: 86.0
- type: ndcg_at_10
value: 82.0
- type: ndcg_at_100
value: 64.307
- type: ndcg_at_1000
value: 57.023999999999994
- type: ndcg_at_3
value: 85.816
- type: ndcg_at_5
value: 84.904
- type: precision_at_1
value: 90.0
- type: precision_at_10
value: 85.8
- type: precision_at_100
value: 66.46
- type: precision_at_1000
value: 25.202
- type: precision_at_3
value: 90.0
- type: precision_at_5
value: 89.2
- type: recall_at_1
value: 0.22799999999999998
- type: recall_at_10
value: 2.235
- type: recall_at_100
value: 16.185
- type: recall_at_1000
value: 53.620999999999995
- type: recall_at_3
value: 0.7040000000000001
- type: recall_at_5
value: 1.172
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (sqi-eng)
type: mteb/tatoeba-bitext-mining
config: sqi-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.39999999999999
- type: f1
value: 96.75
- type: precision
value: 96.45
- type: recall
value: 97.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fry-eng)
type: mteb/tatoeba-bitext-mining
config: fry-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 85.54913294797689
- type: f1
value: 82.46628131021194
- type: precision
value: 81.1175337186898
- type: recall
value: 85.54913294797689
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kur-eng)
type: mteb/tatoeba-bitext-mining
config: kur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.21951219512195
- type: f1
value: 77.33333333333334
- type: precision
value: 75.54878048780488
- type: recall
value: 81.21951219512195
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tur-eng)
type: mteb/tatoeba-bitext-mining
config: tur-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.6
- type: f1
value: 98.26666666666665
- type: precision
value: 98.1
- type: recall
value: 98.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (deu-eng)
type: mteb/tatoeba-bitext-mining
config: deu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.5
- type: f1
value: 99.33333333333333
- type: precision
value: 99.25
- type: recall
value: 99.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nld-eng)
type: mteb/tatoeba-bitext-mining
config: nld-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.2
- type: precision
value: 96.89999999999999
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ron-eng)
type: mteb/tatoeba-bitext-mining
config: ron-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.18333333333334
- type: precision
value: 96.88333333333333
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ang-eng)
type: mteb/tatoeba-bitext-mining
config: ang-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.61194029850746
- type: f1
value: 72.81094527363183
- type: precision
value: 70.83333333333333
- type: recall
value: 77.61194029850746
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ido-eng)
type: mteb/tatoeba-bitext-mining
config: ido-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.91666666666667
- type: precision
value: 91.08333333333334
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jav-eng)
type: mteb/tatoeba-bitext-mining
config: jav-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 88.29268292682927
- type: f1
value: 85.27642276422765
- type: precision
value: 84.01277584204414
- type: recall
value: 88.29268292682927
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (isl-eng)
type: mteb/tatoeba-bitext-mining
config: isl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.0
- type: precision
value: 94.46666666666668
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slv-eng)
type: mteb/tatoeba-bitext-mining
config: slv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.681652490887
- type: f1
value: 91.90765492102065
- type: precision
value: 91.05913325232888
- type: recall
value: 93.681652490887
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cym-eng)
type: mteb/tatoeba-bitext-mining
config: cym-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.17391304347827
- type: f1
value: 89.97101449275361
- type: precision
value: 88.96811594202899
- type: recall
value: 92.17391304347827
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kaz-eng)
type: mteb/tatoeba-bitext-mining
config: kaz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.43478260869566
- type: f1
value: 87.72173913043478
- type: precision
value: 86.42028985507245
- type: recall
value: 90.43478260869566
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (est-eng)
type: mteb/tatoeba-bitext-mining
config: est-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.4
- type: f1
value: 88.03
- type: precision
value: 86.95
- type: recall
value: 90.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (heb-eng)
type: mteb/tatoeba-bitext-mining
config: heb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.4
- type: f1
value: 91.45666666666666
- type: precision
value: 90.525
- type: recall
value: 93.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gla-eng)
type: mteb/tatoeba-bitext-mining
config: gla-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 81.9059107358263
- type: f1
value: 78.32557872364869
- type: precision
value: 76.78260286824823
- type: recall
value: 81.9059107358263
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mar-eng)
type: mteb/tatoeba-bitext-mining
config: mar-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.58333333333333
- type: precision
value: 91.73333333333332
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lat-eng)
type: mteb/tatoeba-bitext-mining
config: lat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 79.10000000000001
- type: f1
value: 74.50500000000001
- type: precision
value: 72.58928571428571
- type: recall
value: 79.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bel-eng)
type: mteb/tatoeba-bitext-mining
config: bel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.6
- type: f1
value: 95.55
- type: precision
value: 95.05
- type: recall
value: 96.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pms-eng)
type: mteb/tatoeba-bitext-mining
config: pms-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.0952380952381
- type: f1
value: 77.98458049886621
- type: precision
value: 76.1968253968254
- type: recall
value: 82.0952380952381
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gle-eng)
type: mteb/tatoeba-bitext-mining
config: gle-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.9
- type: f1
value: 84.99190476190476
- type: precision
value: 83.65
- type: recall
value: 87.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pes-eng)
type: mteb/tatoeba-bitext-mining
config: pes-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.7
- type: f1
value: 94.56666666666666
- type: precision
value: 94.01666666666667
- type: recall
value: 95.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nob-eng)
type: mteb/tatoeba-bitext-mining
config: nob-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.6
- type: f1
value: 98.2
- type: precision
value: 98.0
- type: recall
value: 98.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bul-eng)
type: mteb/tatoeba-bitext-mining
config: bul-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.6
- type: f1
value: 94.38333333333334
- type: precision
value: 93.78333333333335
- type: recall
value: 95.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cbk-eng)
type: mteb/tatoeba-bitext-mining
config: cbk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.4
- type: f1
value: 84.10380952380952
- type: precision
value: 82.67
- type: recall
value: 87.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hun-eng)
type: mteb/tatoeba-bitext-mining
config: hun-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.5
- type: f1
value: 94.33333333333334
- type: precision
value: 93.78333333333333
- type: recall
value: 95.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uig-eng)
type: mteb/tatoeba-bitext-mining
config: uig-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.4
- type: f1
value: 86.82000000000001
- type: precision
value: 85.64500000000001
- type: recall
value: 89.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (rus-eng)
type: mteb/tatoeba-bitext-mining
config: rus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.1
- type: f1
value: 93.56666666666668
- type: precision
value: 92.81666666666666
- type: recall
value: 95.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (spa-eng)
type: mteb/tatoeba-bitext-mining
config: spa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.9
- type: f1
value: 98.6
- type: precision
value: 98.45
- type: recall
value: 98.9
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hye-eng)
type: mteb/tatoeba-bitext-mining
config: hye-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.01347708894879
- type: f1
value: 93.51752021563343
- type: precision
value: 92.82794249775381
- type: recall
value: 95.01347708894879
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tel-eng)
type: mteb/tatoeba-bitext-mining
config: tel-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.00854700854701
- type: f1
value: 96.08262108262107
- type: precision
value: 95.65527065527067
- type: recall
value: 97.00854700854701
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (afr-eng)
type: mteb/tatoeba-bitext-mining
config: afr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.5
- type: f1
value: 95.39999999999999
- type: precision
value: 94.88333333333333
- type: recall
value: 96.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mon-eng)
type: mteb/tatoeba-bitext-mining
config: mon-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.5909090909091
- type: f1
value: 95.49242424242425
- type: precision
value: 94.9621212121212
- type: recall
value: 96.5909090909091
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arz-eng)
type: mteb/tatoeba-bitext-mining
config: arz-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.90566037735849
- type: f1
value: 81.85883997204752
- type: precision
value: 80.54507337526205
- type: recall
value: 84.90566037735849
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hrv-eng)
type: mteb/tatoeba-bitext-mining
config: hrv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.5
- type: f1
value: 96.75
- type: precision
value: 96.38333333333333
- type: recall
value: 97.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nov-eng)
type: mteb/tatoeba-bitext-mining
config: nov-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 86.7704280155642
- type: f1
value: 82.99610894941635
- type: precision
value: 81.32295719844358
- type: recall
value: 86.7704280155642
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (gsw-eng)
type: mteb/tatoeba-bitext-mining
config: gsw-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 67.52136752136752
- type: f1
value: 61.89662189662191
- type: precision
value: 59.68660968660969
- type: recall
value: 67.52136752136752
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nds-eng)
type: mteb/tatoeba-bitext-mining
config: nds-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.2
- type: f1
value: 86.32
- type: precision
value: 85.015
- type: recall
value: 89.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ukr-eng)
type: mteb/tatoeba-bitext-mining
config: ukr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.0
- type: f1
value: 94.78333333333333
- type: precision
value: 94.18333333333334
- type: recall
value: 96.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (uzb-eng)
type: mteb/tatoeba-bitext-mining
config: uzb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 83.8785046728972
- type: f1
value: 80.54517133956385
- type: precision
value: 79.154984423676
- type: recall
value: 83.8785046728972
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lit-eng)
type: mteb/tatoeba-bitext-mining
config: lit-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.60000000000001
- type: f1
value: 92.01333333333334
- type: precision
value: 91.28333333333333
- type: recall
value: 93.60000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ina-eng)
type: mteb/tatoeba-bitext-mining
config: ina-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.1
- type: f1
value: 96.26666666666667
- type: precision
value: 95.85000000000001
- type: recall
value: 97.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lfn-eng)
type: mteb/tatoeba-bitext-mining
config: lfn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.3
- type: f1
value: 80.67833333333333
- type: precision
value: 79.03928571428571
- type: recall
value: 84.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (zsm-eng)
type: mteb/tatoeba-bitext-mining
config: zsm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.3
- type: f1
value: 96.48333333333332
- type: precision
value: 96.08333333333331
- type: recall
value: 97.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ita-eng)
type: mteb/tatoeba-bitext-mining
config: ita-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.7
- type: f1
value: 94.66666666666667
- type: precision
value: 94.16666666666667
- type: recall
value: 95.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cmn-eng)
type: mteb/tatoeba-bitext-mining
config: cmn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.2
- type: f1
value: 96.36666666666667
- type: precision
value: 95.96666666666668
- type: recall
value: 97.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (lvs-eng)
type: mteb/tatoeba-bitext-mining
config: lvs-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.3
- type: f1
value: 92.80666666666667
- type: precision
value: 92.12833333333333
- type: recall
value: 94.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (glg-eng)
type: mteb/tatoeba-bitext-mining
config: glg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.0
- type: f1
value: 96.22333333333334
- type: precision
value: 95.875
- type: recall
value: 97.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ceb-eng)
type: mteb/tatoeba-bitext-mining
config: ceb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 74.33333333333333
- type: f1
value: 70.78174603174602
- type: precision
value: 69.28333333333332
- type: recall
value: 74.33333333333333
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bre-eng)
type: mteb/tatoeba-bitext-mining
config: bre-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 37.6
- type: f1
value: 32.938348952090365
- type: precision
value: 31.2811038961039
- type: recall
value: 37.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ben-eng)
type: mteb/tatoeba-bitext-mining
config: ben-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 91.5
- type: f1
value: 89.13333333333333
- type: precision
value: 88.03333333333333
- type: recall
value: 91.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swg-eng)
type: mteb/tatoeba-bitext-mining
config: swg-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 82.14285714285714
- type: f1
value: 77.67857142857143
- type: precision
value: 75.59523809523809
- type: recall
value: 82.14285714285714
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (arq-eng)
type: mteb/tatoeba-bitext-mining
config: arq-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 69.0450054884742
- type: f1
value: 63.070409283362075
- type: precision
value: 60.58992781824835
- type: recall
value: 69.0450054884742
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kab-eng)
type: mteb/tatoeba-bitext-mining
config: kab-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 63.1
- type: f1
value: 57.848333333333336
- type: precision
value: 55.69500000000001
- type: recall
value: 63.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fra-eng)
type: mteb/tatoeba-bitext-mining
config: fra-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.01666666666667
- type: precision
value: 94.5
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (por-eng)
type: mteb/tatoeba-bitext-mining
config: por-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.89999999999999
- type: f1
value: 94.90666666666667
- type: precision
value: 94.425
- type: recall
value: 95.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tat-eng)
type: mteb/tatoeba-bitext-mining
config: tat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.6
- type: f1
value: 84.61333333333333
- type: precision
value: 83.27
- type: recall
value: 87.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (oci-eng)
type: mteb/tatoeba-bitext-mining
config: oci-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 76.4
- type: f1
value: 71.90746031746032
- type: precision
value: 70.07027777777778
- type: recall
value: 76.4
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pol-eng)
type: mteb/tatoeba-bitext-mining
config: pol-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.89999999999999
- type: f1
value: 97.26666666666667
- type: precision
value: 96.95
- type: recall
value: 97.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (war-eng)
type: mteb/tatoeba-bitext-mining
config: war-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 78.8
- type: f1
value: 74.39555555555555
- type: precision
value: 72.59416666666667
- type: recall
value: 78.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (aze-eng)
type: mteb/tatoeba-bitext-mining
config: aze-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.19999999999999
- type: f1
value: 93.78999999999999
- type: precision
value: 93.125
- type: recall
value: 95.19999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (vie-eng)
type: mteb/tatoeba-bitext-mining
config: vie-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.8
- type: f1
value: 97.1
- type: precision
value: 96.75
- type: recall
value: 97.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (nno-eng)
type: mteb/tatoeba-bitext-mining
config: nno-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.6
- type: f1
value: 94.25666666666666
- type: precision
value: 93.64166666666668
- type: recall
value: 95.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cha-eng)
type: mteb/tatoeba-bitext-mining
config: cha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 56.934306569343065
- type: f1
value: 51.461591936044485
- type: precision
value: 49.37434827945776
- type: recall
value: 56.934306569343065
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mhr-eng)
type: mteb/tatoeba-bitext-mining
config: mhr-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 20.200000000000003
- type: f1
value: 16.91799284049284
- type: precision
value: 15.791855158730158
- type: recall
value: 20.200000000000003
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dan-eng)
type: mteb/tatoeba-bitext-mining
config: dan-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.2
- type: f1
value: 95.3
- type: precision
value: 94.85
- type: recall
value: 96.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ell-eng)
type: mteb/tatoeba-bitext-mining
config: ell-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.3
- type: f1
value: 95.11666666666667
- type: precision
value: 94.53333333333333
- type: recall
value: 96.3
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (amh-eng)
type: mteb/tatoeba-bitext-mining
config: amh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.88095238095238
- type: f1
value: 87.14285714285714
- type: precision
value: 85.96230158730161
- type: recall
value: 89.88095238095238
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (pam-eng)
type: mteb/tatoeba-bitext-mining
config: pam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 24.099999999999998
- type: f1
value: 19.630969083349783
- type: precision
value: 18.275094905094907
- type: recall
value: 24.099999999999998
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hsb-eng)
type: mteb/tatoeba-bitext-mining
config: hsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 83.4368530020704
- type: f1
value: 79.45183870649709
- type: precision
value: 77.7432712215321
- type: recall
value: 83.4368530020704
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (srp-eng)
type: mteb/tatoeba-bitext-mining
config: srp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.8
- type: f1
value: 94.53333333333333
- type: precision
value: 93.91666666666666
- type: recall
value: 95.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (epo-eng)
type: mteb/tatoeba-bitext-mining
config: epo-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.8
- type: f1
value: 98.48333333333332
- type: precision
value: 98.33333333333334
- type: recall
value: 98.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kzj-eng)
type: mteb/tatoeba-bitext-mining
config: kzj-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.5
- type: f1
value: 14.979285714285714
- type: precision
value: 14.23235060690943
- type: recall
value: 17.5
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (awa-eng)
type: mteb/tatoeba-bitext-mining
config: awa-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.93939393939394
- type: f1
value: 91.991341991342
- type: precision
value: 91.05339105339105
- type: recall
value: 93.93939393939394
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fao-eng)
type: mteb/tatoeba-bitext-mining
config: fao-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 89.31297709923665
- type: f1
value: 86.76844783715012
- type: precision
value: 85.63613231552164
- type: recall
value: 89.31297709923665
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mal-eng)
type: mteb/tatoeba-bitext-mining
config: mal-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 99.12663755458514
- type: f1
value: 98.93255701115964
- type: precision
value: 98.83551673944687
- type: recall
value: 99.12663755458514
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ile-eng)
type: mteb/tatoeba-bitext-mining
config: ile-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.0
- type: f1
value: 89.77999999999999
- type: precision
value: 88.78333333333333
- type: recall
value: 92.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (bos-eng)
type: mteb/tatoeba-bitext-mining
config: bos-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.89265536723164
- type: f1
value: 95.85687382297553
- type: precision
value: 95.33898305084746
- type: recall
value: 96.89265536723164
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cor-eng)
type: mteb/tatoeba-bitext-mining
config: cor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 14.6
- type: f1
value: 11.820611790170615
- type: precision
value: 11.022616224355355
- type: recall
value: 14.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (cat-eng)
type: mteb/tatoeba-bitext-mining
config: cat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.89999999999999
- type: f1
value: 94.93333333333334
- type: precision
value: 94.48666666666666
- type: recall
value: 95.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (eus-eng)
type: mteb/tatoeba-bitext-mining
config: eus-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 87.6
- type: f1
value: 84.72333333333334
- type: precision
value: 83.44166666666666
- type: recall
value: 87.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yue-eng)
type: mteb/tatoeba-bitext-mining
config: yue-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.8
- type: f1
value: 93.47333333333333
- type: precision
value: 92.875
- type: recall
value: 94.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swe-eng)
type: mteb/tatoeba-bitext-mining
config: swe-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.6
- type: f1
value: 95.71666666666665
- type: precision
value: 95.28333333333335
- type: recall
value: 96.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dtp-eng)
type: mteb/tatoeba-bitext-mining
config: dtp-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 17.8
- type: f1
value: 14.511074040901628
- type: precision
value: 13.503791000666002
- type: recall
value: 17.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kat-eng)
type: mteb/tatoeba-bitext-mining
config: kat-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.10187667560321
- type: f1
value: 92.46648793565683
- type: precision
value: 91.71134941912423
- type: recall
value: 94.10187667560321
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (jpn-eng)
type: mteb/tatoeba-bitext-mining
config: jpn-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.0
- type: f1
value: 96.11666666666666
- type: precision
value: 95.68333333333334
- type: recall
value: 97.0
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (csb-eng)
type: mteb/tatoeba-bitext-mining
config: csb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 72.72727272727273
- type: f1
value: 66.58949745906267
- type: precision
value: 63.86693017127799
- type: recall
value: 72.72727272727273
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (xho-eng)
type: mteb/tatoeba-bitext-mining
config: xho-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 90.14084507042254
- type: f1
value: 88.26291079812206
- type: precision
value: 87.32394366197182
- type: recall
value: 90.14084507042254
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (orv-eng)
type: mteb/tatoeba-bitext-mining
config: orv-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 64.67065868263472
- type: f1
value: 58.2876627696987
- type: precision
value: 55.79255774165953
- type: recall
value: 64.67065868263472
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ind-eng)
type: mteb/tatoeba-bitext-mining
config: ind-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 95.6
- type: f1
value: 94.41666666666667
- type: precision
value: 93.85
- type: recall
value: 95.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tuk-eng)
type: mteb/tatoeba-bitext-mining
config: tuk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 55.172413793103445
- type: f1
value: 49.63992493549144
- type: precision
value: 47.71405113769646
- type: recall
value: 55.172413793103445
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (max-eng)
type: mteb/tatoeba-bitext-mining
config: max-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.46478873239437
- type: f1
value: 73.4417616811983
- type: precision
value: 71.91607981220658
- type: recall
value: 77.46478873239437
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (swh-eng)
type: mteb/tatoeba-bitext-mining
config: swh-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 84.61538461538461
- type: f1
value: 80.91452991452994
- type: precision
value: 79.33760683760683
- type: recall
value: 84.61538461538461
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (hin-eng)
type: mteb/tatoeba-bitext-mining
config: hin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 98.2
- type: f1
value: 97.6
- type: precision
value: 97.3
- type: recall
value: 98.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (dsb-eng)
type: mteb/tatoeba-bitext-mining
config: dsb-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 75.5741127348643
- type: f1
value: 72.00417536534445
- type: precision
value: 70.53467872883321
- type: recall
value: 75.5741127348643
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ber-eng)
type: mteb/tatoeba-bitext-mining
config: ber-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 62.2
- type: f1
value: 55.577460317460314
- type: precision
value: 52.98583333333333
- type: recall
value: 62.2
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tam-eng)
type: mteb/tatoeba-bitext-mining
config: tam-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.18241042345277
- type: f1
value: 90.6468124709167
- type: precision
value: 89.95656894679696
- type: recall
value: 92.18241042345277
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (slk-eng)
type: mteb/tatoeba-bitext-mining
config: slk-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.1
- type: f1
value: 95.13333333333333
- type: precision
value: 94.66666666666667
- type: recall
value: 96.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tgl-eng)
type: mteb/tatoeba-bitext-mining
config: tgl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 96.8
- type: f1
value: 95.85000000000001
- type: precision
value: 95.39999999999999
- type: recall
value: 96.8
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ast-eng)
type: mteb/tatoeba-bitext-mining
config: ast-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.1259842519685
- type: f1
value: 89.76377952755905
- type: precision
value: 88.71391076115485
- type: recall
value: 92.1259842519685
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (mkd-eng)
type: mteb/tatoeba-bitext-mining
config: mkd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.49
- type: precision
value: 91.725
- type: recall
value: 94.1
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (khm-eng)
type: mteb/tatoeba-bitext-mining
config: khm-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 77.5623268698061
- type: f1
value: 73.27364463791058
- type: precision
value: 71.51947852086357
- type: recall
value: 77.5623268698061
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ces-eng)
type: mteb/tatoeba-bitext-mining
config: ces-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.39999999999999
- type: f1
value: 96.56666666666666
- type: precision
value: 96.16666666666667
- type: recall
value: 97.39999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tzl-eng)
type: mteb/tatoeba-bitext-mining
config: tzl-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 66.34615384615384
- type: f1
value: 61.092032967032964
- type: precision
value: 59.27197802197802
- type: recall
value: 66.34615384615384
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (urd-eng)
type: mteb/tatoeba-bitext-mining
config: urd-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.89999999999999
- type: f1
value: 93.41190476190476
- type: precision
value: 92.7
- type: recall
value: 94.89999999999999
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (ara-eng)
type: mteb/tatoeba-bitext-mining
config: ara-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.10000000000001
- type: f1
value: 91.10000000000001
- type: precision
value: 90.13333333333333
- type: recall
value: 93.10000000000001
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (kor-eng)
type: mteb/tatoeba-bitext-mining
config: kor-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 93.7
- type: f1
value: 91.97333333333334
- type: precision
value: 91.14166666666667
- type: recall
value: 93.7
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (yid-eng)
type: mteb/tatoeba-bitext-mining
config: yid-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 92.21698113207547
- type: f1
value: 90.3796046720575
- type: precision
value: 89.56367924528303
- type: recall
value: 92.21698113207547
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (fin-eng)
type: mteb/tatoeba-bitext-mining
config: fin-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.6
- type: f1
value: 96.91666666666667
- type: precision
value: 96.6
- type: recall
value: 97.6
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (tha-eng)
type: mteb/tatoeba-bitext-mining
config: tha-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 97.44525547445255
- type: f1
value: 96.71532846715328
- type: precision
value: 96.35036496350365
- type: recall
value: 97.44525547445255
- task:
type: BitextMining
dataset:
name: MTEB Tatoeba (wuu-eng)
type: mteb/tatoeba-bitext-mining
config: wuu-eng
split: test
revision: 9080400076fbadbb4c4dcb136ff4eddc40b42553
metrics:
- type: accuracy
value: 94.1
- type: f1
value: 92.34000000000002
- type: precision
value: 91.49166666666667
- type: recall
value: 94.1
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: webis-touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 3.2910000000000004
- type: map_at_10
value: 10.373000000000001
- type: map_at_100
value: 15.612
- type: map_at_1000
value: 17.06
- type: map_at_3
value: 6.119
- type: map_at_5
value: 7.917000000000001
- type: mrr_at_1
value: 44.897999999999996
- type: mrr_at_10
value: 56.054
- type: mrr_at_100
value: 56.82000000000001
- type: mrr_at_1000
value: 56.82000000000001
- type: mrr_at_3
value: 52.381
- type: mrr_at_5
value: 53.81
- type: ndcg_at_1
value: 42.857
- type: ndcg_at_10
value: 27.249000000000002
- type: ndcg_at_100
value: 36.529
- type: ndcg_at_1000
value: 48.136
- type: ndcg_at_3
value: 33.938
- type: ndcg_at_5
value: 29.951
- type: precision_at_1
value: 44.897999999999996
- type: precision_at_10
value: 22.653000000000002
- type: precision_at_100
value: 7.000000000000001
- type: precision_at_1000
value: 1.48
- type: precision_at_3
value: 32.653
- type: precision_at_5
value: 27.755000000000003
- type: recall_at_1
value: 3.2910000000000004
- type: recall_at_10
value: 16.16
- type: recall_at_100
value: 43.908
- type: recall_at_1000
value: 79.823
- type: recall_at_3
value: 7.156
- type: recall_at_5
value: 10.204
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 71.05879999999999
- type: ap
value: 14.609748142799111
- type: f1
value: 54.878956295843096
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 64.61799660441426
- type: f1
value: 64.8698191961434
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 51.32860036611885
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 88.34714192048638
- type: cos_sim_ap
value: 80.26732975975634
- type: cos_sim_f1
value: 73.53415148134374
- type: cos_sim_precision
value: 69.34767360299276
- type: cos_sim_recall
value: 78.25857519788919
- type: dot_accuracy
value: 88.34714192048638
- type: dot_ap
value: 80.26733698491206
- type: dot_f1
value: 73.53415148134374
- type: dot_precision
value: 69.34767360299276
- type: dot_recall
value: 78.25857519788919
- type: euclidean_accuracy
value: 88.34714192048638
- type: euclidean_ap
value: 80.26734337771738
- type: euclidean_f1
value: 73.53415148134374
- type: euclidean_precision
value: 69.34767360299276
- type: euclidean_recall
value: 78.25857519788919
- type: manhattan_accuracy
value: 88.30541813196639
- type: manhattan_ap
value: 80.19415808104145
- type: manhattan_f1
value: 73.55143870713441
- type: manhattan_precision
value: 73.25307511122743
- type: manhattan_recall
value: 73.85224274406332
- type: max_accuracy
value: 88.34714192048638
- type: max_ap
value: 80.26734337771738
- type: max_f1
value: 73.55143870713441
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.81061047075717
- type: cos_sim_ap
value: 87.11747055081017
- type: cos_sim_f1
value: 80.04355498817256
- type: cos_sim_precision
value: 78.1165262000733
- type: cos_sim_recall
value: 82.06806282722513
- type: dot_accuracy
value: 89.81061047075717
- type: dot_ap
value: 87.11746902745236
- type: dot_f1
value: 80.04355498817256
- type: dot_precision
value: 78.1165262000733
- type: dot_recall
value: 82.06806282722513
- type: euclidean_accuracy
value: 89.81061047075717
- type: euclidean_ap
value: 87.11746919324248
- type: euclidean_f1
value: 80.04355498817256
- type: euclidean_precision
value: 78.1165262000733
- type: euclidean_recall
value: 82.06806282722513
- type: manhattan_accuracy
value: 89.79508673885202
- type: manhattan_ap
value: 87.11074390832218
- type: manhattan_f1
value: 80.13002540726349
- type: manhattan_precision
value: 77.83826945412311
- type: manhattan_recall
value: 82.56082537727133
- type: max_accuracy
value: 89.81061047075717
- type: max_ap
value: 87.11747055081017
- type: max_f1
value: 80.13002540726349
---
# yoeven/multilingual-e5-large-instruct-Q5_0-GGUF
This model was converted to GGUF format from [`intfloat/multilingual-e5-large-instruct`](https://huggingface.co/intfloat/multilingual-e5-large-instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/intfloat/multilingual-e5-large-instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo yoeven/multilingual-e5-large-instruct-Q5_0-GGUF --hf-file multilingual-e5-large-instruct-q5_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo yoeven/multilingual-e5-large-instruct-Q5_0-GGUF --hf-file multilingual-e5-large-instruct-q5_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo yoeven/multilingual-e5-large-instruct-Q5_0-GGUF --hf-file multilingual-e5-large-instruct-q5_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo yoeven/multilingual-e5-large-instruct-Q5_0-GGUF --hf-file multilingual-e5-large-instruct-q5_0.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
YukunZhou/RETFound_mae_natureCFP
|
YukunZhou
| null |
[
"vit",
"pytorch",
"region:us"
] | 2025-02-19T12:10:22Z |
2025-02-19T13:55:44+00:00
| 42 | 2 |
---
tags:
- pytorch
extra_gated_fields:
First Name: text
Last Name: text
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Other
geo: ip_location
extra_gated_button_content: Submit
---
# Model Card for RETFound_MAE_MEH
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to provide a pre-trained vision foundation model [RETFound](https://github.com/rmaphoh/RETFound_MAE), pre-trained with Masked Autoencoder.
This is the official weight for [RETFound Nature paper](https://www.nature.com/articles/s41586-023-06555-x)
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Yukun Zhou
- **Model type:** Pre-trained model
- **License:** Creative Commons Attribution-NonCommercial 4.0 International Public License (CC BY-NC 4.0)
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [RETFound](https://github.com/rmaphoh/RETFound_MAE)
- **Paper:** [Nature paper](https://www.nature.com/articles/s41586-023-06555-x)
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
This repo contains the model weight. After granted the access, please fill the token in the [code](https://github.com/rmaphoh/RETFound_MAE).
The code will automatically download the model and run the training.
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
- **Hardware Type:** 4 * NVIDIA A100 80GB
- **Hours used:** 14 days
- **Cloud Provider:** UCL CS Cluster & Shanghai Jiaotong University Cluster
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
```
@article{zhou2023foundation,
title={A foundation model for generalizable disease detection from retinal images},
author={Zhou, Yukun and Chia, Mark A and Wagner, Siegfried K and Ayhan, Murat S and Williamson, Dominic J and Struyven, Robbert R and Liu, Timing and Xu, Moucheng and Lozano, Mateo G and Woodward-Court, Peter and others},
journal={Nature},
volume={622},
number={7981},
pages={156--163},
year={2023},
publisher={Nature Publishing Group UK London}
}
```
## Model Card Contact
**[email protected]** or **[email protected]**
|
[
"CHIA"
] |
BigSalmon/InformalToFormalLincoln83Paraphrase
|
BigSalmon
|
text-generation
|
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2022-10-06T22:04:11Z |
2022-10-11T17:28:43+00:00
| 41 | 0 |
---
{}
---
data: https://github.com/BigSalmon2/InformalToFormalDataset
Text Generation Informal Formal
CHECK OUT THIS MODEL: BigSalmon/FormalInformalConcise-FIM-NeoX-1.3B
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln82Paraphrase")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln82Paraphrase")
```
```
Demo:
https://huggingface.co/spaces/BigSalmon/FormalInformalConciseWordy
```
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
input_ids = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(input_ids=input_ids,
max_length=10 + len(prompt),
temperature=1.0,
top_k=50,
top_p=0.95,
do_sample=True,
num_return_sequences=5,
early_stopping=True)
for i in range(5):
print(tokenizer.decode(outputs[i]))
```
Most likely outputs (Disclaimer: I highly recommend using this over just generating):
```
prompt = """informal english: corn fields are all across illinois, visible once you leave chicago.\nTranslated into the Style of Abraham Lincoln:"""
text = tokenizer.encode(prompt)
myinput, past_key_values = torch.tensor([text]), None
myinput = myinput
myinput= myinput.to(device)
logits, past_key_values = model(myinput, past_key_values = past_key_values, return_dict=False)
logits = logits[0,-1]
probabilities = torch.nn.functional.softmax(logits)
best_logits, best_indices = logits.topk(250)
best_words = [tokenizer.decode([idx.item()]) for idx in best_indices]
text.append(best_indices[0].item())
best_probabilities = probabilities[best_indices].tolist()
words = []
print(best_words)
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
- nebraska
- unicamerical legislature
- different from federal house and senate
text: featuring a unicameral legislature, nebraska's political system stands in stark contrast to the federal model, comprised of a house and senate.
***
- penny has practically no value
- should be taken out of circulation
- just as other coins have been in us history
- lost use
- value not enough
- to make environmental consequences worthy
text: all but valueless, the penny should be retired. as with other coins in american history, it has become defunct. too minute to warrant the environmental consequences of its production, it has outlived its usefulness.
***
-
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
Keywords to sentences or sentence.
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: had trouble deciding.
translated into journalism speak: wrestled with the question, agonized over the matter, furrowed their brows in contemplation.
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
```
Infill / Infilling / Masking / Phrase Masking (Works pretty decently actually, especially when you use logprobs code from above):
```
his contention [blank] by the evidence [sep] was refuted [answer]
***
few sights are as [blank] new york city as the colorful, flashing signage of its bodegas [sep] synonymous with [answer]
***
when rick won the lottery, all of his distant relatives [blank] his winnings [sep] clamored for [answer]
***
the library’s quiet atmosphere encourages visitors to [blank] in their work [sep] immerse themselves [answer]
***
the joy of sport is that no two games are alike. for every exhilarating experience, however, there is an interminable one. the national pastime, unfortunately, has a penchant for the latter. what begins as a summer evening at the ballpark can quickly devolve into a game of tedium. the primary culprit is the [blank] of play. from batters readjusting their gloves to fielders spitting on their mitts, the action is [blank] unnecessary interruptions. the sport's future is [blank] if these tendencies are not addressed [sep] plodding pace [answer] riddled with [answer] bleak [answer]
***
microsoft word's [blank] pricing [blank] competition [sep] unconscionable [answer] invites [answer]
***
```
```
original: microsoft word's [MASK] pricing invites competition.
Translated into the Style of Abraham Lincoln: microsoft word's unconscionable pricing invites competition.
***
original: the library’s quiet atmosphere encourages visitors to [blank] in their work.
Translated into the Style of Abraham Lincoln: the library’s quiet atmosphere encourages visitors to immerse themselves in their work.
```
Backwards
```
Essay Intro (National Parks):
text: tourists are at ease in the national parks, ( swept up in the beauty of their natural splendor ).
***
Essay Intro (D.C. Statehood):
washington, d.c. is a city of outsize significance, ( ground zero for the nation's political life / center stage for the nation's political machinations ).
```
```
topic: the Golden State Warriors.
characterization 1: the reigning kings of the NBA.
characterization 2: possessed of a remarkable cohesion.
characterization 3: helmed by superstar Stephen Curry.
characterization 4: perched atop the league’s hierarchy.
characterization 5: boasting a litany of hall-of-famers.
***
topic: emojis.
characterization 1: shorthand for a digital generation.
characterization 2: more versatile than words.
characterization 3: the latest frontier in language.
characterization 4: a form of self-expression.
characterization 5: quintessentially millennial.
characterization 6: reflective of a tech-centric world.
***
topic:
```
```
regular: illinois went against the census' population-loss prediction by getting more residents.
VBG: defying the census' prediction of population loss, illinois experienced growth.
***
regular: microsoft word’s high pricing increases the likelihood of competition.
VBG: extortionately priced, microsoft word is inviting competition.
***
regular:
```
```
source: badminton should be more popular in the US.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) games played with racquets are popular, (2) just look at tennis and ping pong, (3) but badminton underappreciated, (4) fun, fast-paced, competitive, (5) needs to be marketed more
text: the sporting arena is dominated by games that are played with racquets. tennis and ping pong, in particular, are immensely popular. somewhat curiously, however, badminton is absent from this pantheon. exciting, fast-paced, and competitive, it is an underappreciated pastime. all that it lacks is more effective marketing.
***
source: movies in theaters should be free.
QUERY: Based on the given topic, can you develop a story outline?
target: (1) movies provide vital life lessons, (2) many venues charge admission, (3) those without much money
text: the lessons that movies impart are far from trivial. the vast catalogue of cinematic classics is replete with inspiring sagas of friendship, bravery, and tenacity. it is regrettable, then, that admission to theaters is not free. in their current form, the doors of this most vital of institutions are closed to those who lack the means to pay.
***
source:
```
```
in the private sector, { transparency } is vital to the business’s credibility. the { disclosure of information } can be the difference between success and failure.
***
the labor market is changing, with { remote work } now the norm. this { flexible employment } allows the individual to design their own schedule.
***
the { cubicle } is the locus of countless grievances. many complain that the { enclosed workspace } restricts their freedom of movement.
***
```
```
it would be natural to assume that americans, as a people whose ancestors { immigrated to this country }, would be sympathetic to those seeking to do likewise.
question: what does “do likewise” mean in the above context?
(a) make the same journey
(b) share in the promise of the american dream
(c) start anew in the land of opportunity
(d) make landfall on the united states
***
in the private sector, { transparency } is vital to the business’s credibility. this orientation can be the difference between success and failure.
question: what does “this orientation” mean in the above context?
(a) visible business practices
(b) candor with the public
(c) open, honest communication
(d) culture of accountability
```
```
example: suppose you are a teacher. further suppose you want to tell an accurate telling of history. then suppose a parent takes offense. they do so in the name of name of their kid. this happens a lot.
text: educators' responsibility to remain true to the historical record often clashes with the parent's desire to shelter their child from uncomfortable realities.
***
example: suppose you are a student at college. now suppose you have to buy textbooks. that is going to be worth hundreds of dollars. given how much you already spend on tuition, that is going to hard cost to bear.
text: the exorbitant cost of textbooks, which often reaches hundreds of dollars, imposes a sizable financial burden on the already-strapped college student.
```
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
accustomed to having its name uttered ______, harvard university is weathering a rare spell of reputational tumult
(a) in reverential tones
(b) with great affection
(c) in adulatory fashion
(d) in glowing terms
```
```
clarify: international ( {working together} / cooperation ) is called for when ( {issue go beyond lots of borders} / an issue transcends borders / a given matter has transnational implications ).
```
```
description: when someone thinks that their view is the only right one.
synonyms: intolerant, opinionated, narrow-minded, insular, self-righteous.
***
description: when you put something off.
synonyms: shelve, defer, table, postpone.
```
```
organic sentence: crowdfunding is about winner of best ideas and it can test an entrepreneur’s idea.
rewrite phrases: meritocratic, viability, vision
rewritten with phrases: the meritocratic nature of crowdfunding empowers entrepreneurs to test their vision's viability.
```
*Note* Of all the masking techniques, this one works the best.
```
<Prefix> the atlanta hawks may attribute <Prefix> <Suffix> trae young <Suffix> <Middle> their robust season to <Middle>
***
<Prefix> the nobel prize in literature <Prefix> <Suffix> honor <Suffix> <Middle> is a singularly prestigious <Middle>
```
```
essence: when someone's views are keeping within reasonable.
refine: the senator's voting record is ( moderate / centrist / pragmatic / balanced / fair-minded / even-handed ).
***
essence: when things are worked through in a petty way.
refine: the propensity of the u.s. congress to settle every dispute by way of ( mudslinging / bickering / demagoguery / name-calling / finger-pointing / vilification ) is appalling.
```
|
[
"BEAR"
] |
DiamondYin/Wall-E-01-robot-heywhale
|
DiamondYin
|
text-to-image
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"wildcard",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | 2023-01-15T15:24:01Z |
2023-01-15T16:58:31+00:00
| 41 | 3 |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- wildcard
widget:
- text: In space, there is a spaceship docked here, and Wall-E-01 walks in the spaceship,8K
resolution, 16:9
---
# DreamBooth model for the Wall-E-01 concept trained by DiamondYin.
This is a Stable Diffusion model fine-tuned on the Wall-E-01 concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of Wall-E-01 robot**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `robot` images for the wildcard theme,
for the Hugging Face DreamBooth Hackathon, from the HF CN Community, corporated with the HeyWhale.
The production cost of WALL-E is $180 million. It tells about a lonely robot designed to clean up the polluted earth. The unique feature of this film is that there is almost no dialogue in the first 40 minutes or so. On the contrary, the audience enters a world of robots; How it thinks, how it works, how it speaks (or doesn't speak). Pixar's classic film was a success. The film has a global box office of more than 520 million US dollars, won a number of Oscar nominations, and ranked first on Time magazine's list of the best films of the decade.
Now we can easily create Wally's pictures and present the script's pictures with the help of the Stable Diffusion model. We can write a series of stories for WALL-E, but we don't have to bear such expensive costs. This is the advantage of the Stable Diffusion model
机器总动员这部电影(WALL-E)的生产成本为1.8亿美元。它讲述了一个孤独的机器人被设计来清理被污染的地球。这部电影的独特之处在于,前40分钟左右几乎没有对话,相反,观众进入了一个机器人的世界;它如何思考,如何工作,如何说话(或不说话)。皮克斯的经典电影获得了成功。
该片全球票房超过5.2亿美元,获得多项奥斯卡提名,并在《时代》杂志十年最佳影片排行榜上排名第一。现在,我们可以通过Stable Diffusion model轻松创建WALL-E的图片并呈现脚本的图片。我们可以为WALL-E写一系列故事,但我们不必承担如此昂贵的成本。这是稳定扩散模型的优点
下面是相关实例,大家可以体验。
调用时请注意主体的名称是:Wall-E-01 robot
When calling, please note that the name of the subject is: Wall-E-01 robot
Prompt: Wall-E-01 robot on the moon 8K resolution, 16:9,Cyberpunk


Prompt: Wall-E-01 robot, the background is an old bridge and a pond, mist and swirly clouds in the background, fantastic landscape, hyperrealism, no blur, 4k resolution, ultra detailed, style of Anton Fadeev, Ivan Shishkin, John Berkey

Prompt: illustration of a Wall-E robot sitting on top of the deck of a battle ship traveling through the open sea

Prompt: Wall-E-01 robot cartoon image with rainbow background



Prompt:"Wall-E, a small robot with a binocular-shaped head, sitting in the cockpit of a large spaceship, surrounded by high-tech controls and screens displaying various information about the ship's status and location, with a focus on Wall-E's expression and the intricate details of the ship's controls. The image should be in high resolution and have a realistic, futuristic aesthetic."



## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('DiamondYin/Wall-E-01-robot-heywhale')
image = pipeline().images[0]
image
```
|
[
"BEAR"
] |
GBaker/clinical-bigbird-medqa-usmle-nocontext
|
GBaker
|
multiple-choice
|
[
"transformers",
"pytorch",
"tensorboard",
"big_bird",
"multiple-choice",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | 2023-02-24T18:34:48Z |
2023-02-24T20:07:00+00:00
| 41 | 0 |
---
metrics:
- accuracy
tags:
- generated_from_trainer
model-index:
- name: clinical-bigbird-medqa-usmle-nocontext
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clinical-bigbird-medqa-usmle-nocontext
This model is a fine-tuned version of [yikuan8/Clinical-BigBird](https://huggingface.co/yikuan8/Clinical-BigBird) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3863
- Accuracy: 0.2482
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 159 | 1.3860 | 0.2584 |
| No log | 2.0 | 318 | 1.3859 | 0.2820 |
| No log | 3.0 | 477 | 1.3863 | 0.2522 |
| 1.3891 | 4.0 | 636 | 1.3863 | 0.2498 |
| 1.3891 | 5.0 | 795 | 1.3863 | 0.2404 |
| 1.3891 | 6.0 | 954 | 1.3863 | 0.2498 |
| 1.3882 | 7.0 | 1113 | 1.3863 | 0.2506 |
| 1.3882 | 8.0 | 1272 | 1.3863 | 0.2467 |
| 1.3882 | 9.0 | 1431 | 1.3863 | 0.2490 |
| 1.3876 | 10.0 | 1590 | 1.3863 | 0.2482 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.0
- Tokenizers 0.13.2
|
[
"MEDQA"
] |
aimarsg/testlink-class-2
|
aimarsg
|
token-classification
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-05-01T15:30:42Z |
2023-05-01T18:53:11+00:00
| 41 | 0 |
---
license: apache-2.0
metrics:
- precision
- recall
- f1
- accuracy
tags:
- generated_from_trainer
model-index:
- name: testlink-class-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# testlink-class-2
This model is a fine-tuned version of [PlanTL-GOB-ES/bsc-bio-ehr-es-pharmaconer](https://huggingface.co/PlanTL-GOB-ES/bsc-bio-ehr-es-pharmaconer) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2116
- Precision: 0.7516
- Recall: 0.6901
- F1: 0.7195
- Accuracy: 0.9758
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 29 | 0.2388 | 0.7315 | 0.6374 | 0.6813 | 0.9739 |
| No log | 2.0 | 58 | 0.1956 | 0.6169 | 0.7251 | 0.6667 | 0.9723 |
| No log | 3.0 | 87 | 0.1637 | 0.6302 | 0.7076 | 0.6667 | 0.9730 |
| No log | 4.0 | 116 | 0.2107 | 0.6810 | 0.6491 | 0.6647 | 0.9741 |
| No log | 5.0 | 145 | 0.1987 | 0.6981 | 0.6491 | 0.6727 | 0.9745 |
| No log | 6.0 | 174 | 0.1524 | 0.7355 | 0.6667 | 0.6994 | 0.9756 |
| No log | 7.0 | 203 | 0.1933 | 0.7664 | 0.6140 | 0.6818 | 0.9750 |
| No log | 8.0 | 232 | 0.2150 | 0.7836 | 0.6140 | 0.6885 | 0.9747 |
| No log | 9.0 | 261 | 0.1700 | 0.7405 | 0.6842 | 0.7112 | 0.9761 |
| No log | 10.0 | 290 | 0.1626 | 0.6142 | 0.7076 | 0.6576 | 0.9730 |
| No log | 11.0 | 319 | 0.1826 | 0.7035 | 0.7076 | 0.7055 | 0.9761 |
| No log | 12.0 | 348 | 0.1724 | 0.6802 | 0.6842 | 0.6822 | 0.9758 |
| No log | 13.0 | 377 | 0.1823 | 0.7852 | 0.6199 | 0.6928 | 0.9741 |
| No log | 14.0 | 406 | 0.1833 | 0.7284 | 0.6901 | 0.7087 | 0.9761 |
| No log | 15.0 | 435 | 0.1816 | 0.5853 | 0.7427 | 0.6546 | 0.9701 |
| No log | 16.0 | 464 | 0.2084 | 0.7770 | 0.6725 | 0.7210 | 0.9761 |
| No log | 17.0 | 493 | 0.2043 | 0.7069 | 0.7193 | 0.7130 | 0.9748 |
| 0.0022 | 18.0 | 522 | 0.1996 | 0.6541 | 0.7076 | 0.6798 | 0.9741 |
| 0.0022 | 19.0 | 551 | 0.2013 | 0.7484 | 0.6959 | 0.7212 | 0.9763 |
| 0.0022 | 20.0 | 580 | 0.1933 | 0.7159 | 0.7368 | 0.7262 | 0.9770 |
| 0.0022 | 21.0 | 609 | 0.1931 | 0.7101 | 0.7018 | 0.7059 | 0.9759 |
| 0.0022 | 22.0 | 638 | 0.1946 | 0.7052 | 0.7135 | 0.7093 | 0.9759 |
| 0.0022 | 23.0 | 667 | 0.1968 | 0.6936 | 0.7018 | 0.6977 | 0.9752 |
| 0.0022 | 24.0 | 696 | 0.2076 | 0.7296 | 0.6784 | 0.7030 | 0.9754 |
| 0.0022 | 25.0 | 725 | 0.2076 | 0.7296 | 0.6784 | 0.7030 | 0.9756 |
| 0.0022 | 26.0 | 754 | 0.2051 | 0.6941 | 0.6901 | 0.6921 | 0.9747 |
| 0.0022 | 27.0 | 783 | 0.2106 | 0.7342 | 0.6784 | 0.7052 | 0.9752 |
| 0.0022 | 28.0 | 812 | 0.2093 | 0.7312 | 0.6842 | 0.7069 | 0.9752 |
| 0.0022 | 29.0 | 841 | 0.2112 | 0.7516 | 0.6901 | 0.7195 | 0.9758 |
| 0.0022 | 30.0 | 870 | 0.2116 | 0.7516 | 0.6901 | 0.7195 | 0.9758 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0+cu118
- Datasets 2.12.0
- Tokenizers 0.13.3
|
[
"PHARMACONER"
] |
NouRed/medqsum-bart-large-xsum-meqsum
|
NouRed
|
summarization
|
[
"transformers",
"pytorch",
"safetensors",
"bart",
"text2text-generation",
"summarization",
"medical question answering",
"medical question understanding",
"consumer health question",
"prompt engineering",
"LLM",
"en",
"dataset:bigbio/meqsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | 2023-08-19T18:42:56Z |
2024-01-08T16:17:24+00:00
| 41 | 1 |
---
datasets:
- bigbio/meqsum
language: en
library_name: transformers
license: apache-2.0
tags:
- summarization
- bart
- medical question answering
- medical question understanding
- consumer health question
- prompt engineering
- LLM
widget:
- text: ' SUBJECT: high inner eye pressure above 21 possible glaucoma MESSAGE: have
seen inner eye pressure increase as I have begin taking Rizatriptan. I understand
the med narrows blood vessels. Can this med. cause or effect the closed or wide
angle issues with the eyelense/glacoma.'
model-index:
- name: medqsum-bart-large-xsum-meqsum
results:
- task:
type: summarization
name: Summarization
dataset:
name: Dataset for medical question summarization
type: bigbio/meqsum
split: valid
metrics:
- type: rogue-1
value: 54.32
name: Validation ROGUE-1
- type: rogue-2
value: 38.08
name: Validation ROGUE-2
- type: rogue-l
value: 51.98
name: Validation ROGUE-L
- type: rogue-l-sum
value: 51.99
name: Validation ROGUE-L-SUM
---
[](https://github.com/zekaouinoureddine/MedQSum)
## MedQSum
<a href="https://github.com/zekaouinoureddine/MedQSum">
<img src="https://raw.githubusercontent.com/zekaouinoureddine/MedQSum/master/assets/models.png" alt="drawing" width="600"/>
</a>
## TL;DR
**medqsum-bart-large-xsum-meqsum** is the best fine-tuned model in the paper [Enhancing Large Language Models' Utility for Medical Question-Answering: A Patient Health Question Summarization Approach](https://doi.org/10.1109/SITA60746.2023.10373720), which introduces a solution to get the most out of LLMs, when answering health-related questions. We address the challenge of crafting accurate prompts by summarizing consumer health questions (CHQs) to generate clear and concise medical questions. Our approach involves fine-tuning Transformer-based models, including Flan-T5 in resource-constrained environments and three medical question summarization datasets.
## Hyperparameters
```json
{
"dataset_name": "MeQSum",
"learning_rate": 3e-05,
"model_name_or_path": "facebook/bart-large-xsum",
"num_train_epochs": 4,
"per_device_eval_batch_size": 4,
"per_device_train_batch_size": 4,
"predict_with_generate": true,
}
```
## Usage
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="NouRed/medqsum-bart-large-xsum-meqsum")
chq = '''SUBJECT: high inner eye pressure above 21 possible glaucoma
MESSAGE: have seen inner eye pressure increase as I have begin taking
Rizatriptan. I understand the med narrows blood vessels. Can this med.
cause or effect the closed or wide angle issues with the eyelense/glacoma.
'''
summarizer(chq)
```
## Results
| key | value |
| --- | ----- |
| eval_rouge1 | 54.32 |
| eval_rouge2 | 38.08 |
| eval_rougeL | 51.98 |
| eval_rougeLsum | 51.99 |
## Cite This
```
@INPROCEEDINGS{10373720,
author={Zekaoui, Nour Eddine and Yousfi, Siham and Mikram, Mounia and Rhanoui, Maryem},
booktitle={2023 14th International Conference on Intelligent Systems: Theories and Applications (SITA)},
title={Enhancing Large Language Models’ Utility for Medical Question-Answering: A Patient Health Question Summarization Approach},
year={2023},
volume={},
number={},
pages={1-8},
doi={10.1109/SITA60746.2023.10373720}}
```
|
[
"MEQSUM"
] |
chillymiao/Hyacinth6B
|
chillymiao
|
text-generation
|
[
"transformers",
"pytorch",
"chatglm",
"text-generation",
"custom_code",
"zh",
"arxiv:2403.13334",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | 2023-12-01T08:01:38Z |
2024-04-12T07:00:18+00:00
| 41 | 1 |
---
language:
- zh
license: apache-2.0
pipeline_tag: text-generation
---
# Hyacinth6B: A Trandidional Chinese Large Language Model
<img src="./pics/hyacinth.jpeg" alt="image_name png"/>
Hyacinth6B is a Tranditional Chinese Large Language Model which fine-tune from [chatglm3-base](https://huggingface.co/THUDM/chatglm3-6b-base),our goal is to find a balance between model lightness and performance, striving to maximize performance while using a comparatively lightweight model. Hyacinth6B was developed with this objective in mind, aiming to fully leverage the core capabilities of LLMs without incurring substantial resource costs, effectively pushing the boundaries of smaller models' performance. The training approach involves parameter-efficient fine-tuning using the Low-Rank Adaptation (LoRA) method.
At last, we evaluated Hyacinth6B, examining its performance across various aspects. Hyacinth6B shows commendable performance in certain metrics, even surpassing ChatGPT in two categories. We look forward to providing more resources and possibilities for the field of Traditional Chinese language processing. This research aims to expand the research scope of Traditional Chinese language models and enhance their applicability in different scenarios.
# Training Config
Training required approximately 20.6GB of VRAM without any quantization (default fp16) and a total of 369 hours in duration on single RTX 4090.
| HyperParameter | Value |
| --------- | ----- |
| Batch Size| 8 |
|Learning Rate |5e-5 |
|Epochs |3 |
|LoRA r| 16 |
# Evaluate Results
## CMMLU
<img src="./pics/cmmlu.png" alt="image_name png"/>
## C-eval
<img src="./pics/ceval.png" alt="image_name png"/>
## TC-eval by MediaTek Research
<img src="./pics/tc-eval.png" alt="image_name png"/>
## MT-bench
<img src="./pics/dashB.png" alt="image_name png"/>
## LLM-eval by NTU Miu Lab
<img src="./pics/llmeval.png" alt="image_name png"/>
## Bailong Bench
| Bailong-bench| Taiwan-LLM-7B-v2.1-chat |Taiwan-LLM-13B-v2.0-chat |gpt-3.5-turbo-1103|Bailong-instruct 7B|Hyacinth6B(ours)|
| -------- | -------- | --- | --- | --- | -------- |
|Arithmetic|9.0|10.0|10.0|9.2|8.4|
|Copywriting generation|7.6|3.0|9.0|9.6|10.0 |
|Creative writing|6.1|7.5 |8.7 |9.4 |8.3 |
|English instruction| 6.0| 1.9 |10.0 |9.2 | 10.0 |
|General|7.7| 8.1 |9.9 |9.2 | 9.2 |
|Health consultation|7.7| 8.5 |9.9 |9.2 | 9.8 |
|Knowledge-based question|4.2| 8.4 | 9.9 | 9.8 |4.9 |
|Mail assistant|9.5| 9.9 |9.0 |9.9 | 9.5 |
|Morality and Ethics| 4.5 | 9.3 |9.8 |9.7 |7.4 |
|Multi-turn|7.9|8.7 |9.0 |7.8 |4.4 |
|Open question|7.0|9.2 |7.6 |9.6 | 8.2 |
|Proofreading|3.0|4.0 |10.0 |9.0 | 9.1 |
|Summarization|6.2| 7.4 |9.9 |9.8 | 8.4 |
|Translation|7.0|9.0 |8.1 |9.5 | 10.0 |
|**Average**|6.7| 7.9 |9.4 |9.4 | 8.4 |
## Acknowledgement
Thanks for Taiwan LLM's author, Yen-Ting Lin 's kindly advice.
Please review his marvellous works!
[Yen-Ting Lin's hugging face](https://huggingface.co/yentinglin)
## Disclaimer
This model is intended for research purposes only. The author does not guarantee its accuracy, completeness, or suitability for any purpose. Any commercial or other use requires consultation with a legal professional, and the author assumes no responsibility for such use. Users bear all risks associated with the results of using this model. The author is not liable for any direct or indirect losses or damages, including but not limited to loss of profits, business interruption, or data loss. Any use of this model is considered acceptance of the terms of this disclaimer.
### Model Usage
Download model
Here is the example for you to download Hyacinth6B with huggingface transformers:
```python
from transformers import AutoTokenizer,AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("chillymiao/Hyacinth6B")
model = AutoModelForCausalLM.from_pretrained("chillymiao/Hyacinth6B")
```
### Citation
```
@misc{song2024hyacinth6b,
title={Hyacinth6B: A large language model for Traditional Chinese},
author={Chih-Wei Song and Yin-Te Tsai},
year={2024},
eprint={2403.13334},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
[
"BEAR"
] |
ntc-ai/SDXL-LoRA-slider.Studio-Ghibli-style
|
ntc-ai
|
text-to-image
|
[
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | 2023-12-15T13:29:32Z |
2024-02-06T00:33:20+00:00
| 41 | 5 |
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
language:
- en
license: mit
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
thumbnail: images/Studio Ghibli style_17_3.0.png
widget:
- text: Studio Ghibli style
output:
url: images/Studio Ghibli style_17_3.0.png
- text: Studio Ghibli style
output:
url: images/Studio Ghibli style_19_3.0.png
- text: Studio Ghibli style
output:
url: images/Studio Ghibli style_20_3.0.png
- text: Studio Ghibli style
output:
url: images/Studio Ghibli style_21_3.0.png
- text: Studio Ghibli style
output:
url: images/Studio Ghibli style_22_3.0.png
inference: false
instance_prompt: Studio Ghibli style
---
# ntcai.xyz slider - Studio Ghibli style (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/Studio Ghibli style_17_-3.0.png" width=256 height=256 /> | <img src="images/Studio Ghibli style_17_0.0.png" width=256 height=256 /> | <img src="images/Studio Ghibli style_17_3.0.png" width=256 height=256 /> |
| <img src="images/Studio Ghibli style_19_-3.0.png" width=256 height=256 /> | <img src="images/Studio Ghibli style_19_0.0.png" width=256 height=256 /> | <img src="images/Studio Ghibli style_19_3.0.png" width=256 height=256 /> |
| <img src="images/Studio Ghibli style_20_-3.0.png" width=256 height=256 /> | <img src="images/Studio Ghibli style_20_0.0.png" width=256 height=256 /> | <img src="images/Studio Ghibli style_20_3.0.png" width=256 height=256 /> |
See more at [https://sliders.ntcai.xyz/sliders/app/loras/42dfd05f-0912-4a6b-852f-62521308897b](https://sliders.ntcai.xyz/sliders/app/loras/42dfd05f-0912-4a6b-852f-62521308897b)
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
Studio Ghibli style
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.Studio-Ghibli-style', weight_name='Studio Ghibli style.safetensors', adapter_name="Studio Ghibli style")
# Activate the LoRA
pipe.set_adapters(["Studio Ghibli style"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, Studio Ghibli style"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1496+ unique and diverse LoRAs along with 14602+ slider merges, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful <strong>NTC Slider Factory</strong> LoRA creator, allowing you to craft your own custom LoRAs and merges opening up endless possibilities.
Your support on Patreon will allow us to continue developing new models and tools.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
[
"CRAFT"
] |
LoneStriker/Einstein-v4-7B-GGUF
|
LoneStriker
| null |
[
"gguf",
"axolotl",
"generated_from_trainer",
"Mistral",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"science",
"physics",
"chemistry",
"biology",
"math",
"dataset:allenai/ai2_arc",
"dataset:camel-ai/physics",
"dataset:camel-ai/chemistry",
"dataset:camel-ai/biology",
"dataset:camel-ai/math",
"dataset:metaeval/reclor",
"dataset:openbookqa",
"dataset:mandyyyyii/scibench",
"dataset:derek-thomas/ScienceQA",
"dataset:TIGER-Lab/ScienceEval",
"dataset:jondurbin/airoboros-3.2",
"dataset:LDJnr/Capybara",
"dataset:Cot-Alpaca-GPT4-From-OpenHermes-2.5",
"dataset:STEM-AI-mtl/Electrical-engineering",
"dataset:knowrohit07/saraswati-stem",
"dataset:sablo/oasst2_curated",
"dataset:glaiveai/glaive-code-assistant",
"dataset:lmsys/lmsys-chat-1m",
"dataset:TIGER-Lab/MathInstruct",
"dataset:bigbio/med_qa",
"dataset:meta-math/MetaMathQA-40K",
"dataset:piqa",
"dataset:scibench",
"dataset:sciq",
"dataset:Open-Orca/SlimOrca",
"dataset:migtissera/Synthia-v1.3",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:other",
"model-index",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-03-02T18:42:10Z |
2024-03-02T19:09:08+00:00
| 41 | 6 |
---
base_model: mistralai/Mistral-7B-v0.1
datasets:
- allenai/ai2_arc
- camel-ai/physics
- camel-ai/chemistry
- camel-ai/biology
- camel-ai/math
- metaeval/reclor
- openbookqa
- mandyyyyii/scibench
- derek-thomas/ScienceQA
- TIGER-Lab/ScienceEval
- jondurbin/airoboros-3.2
- LDJnr/Capybara
- Cot-Alpaca-GPT4-From-OpenHermes-2.5
- STEM-AI-mtl/Electrical-engineering
- knowrohit07/saraswati-stem
- sablo/oasst2_curated
- glaiveai/glaive-code-assistant
- lmsys/lmsys-chat-1m
- TIGER-Lab/MathInstruct
- bigbio/med_qa
- meta-math/MetaMathQA-40K
- openbookqa
- piqa
- metaeval/reclor
- derek-thomas/ScienceQA
- scibench
- sciq
- Open-Orca/SlimOrca
- migtissera/Synthia-v1.3
- TIGER-Lab/ScienceEval
license: other
tags:
- axolotl
- generated_from_trainer
- Mistral
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- science
- physics
- chemistry
- biology
- math
model-index:
- name: Einstein-v4-7B
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 64.68
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 83.75
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 62.31
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 55.15
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 76.24
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 57.62
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Weyaxi/Einstein-v4-7B
name: Open LLM Leaderboard
---

# 🔬 Einstein-v4-7B
This model is a full fine-tuned version of [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) on diverse datasets.
This model is finetuned using `7xRTX3090` + `1xRTXA6000` using [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl).
This model's training was sponsored by [sablo.ai](https://sablo.ai).
<details><summary>See axolotl config</summary>
axolotl version: `0.4.0`
```yaml
base_model: mistralai/Mistral-7B-v0.1
model_type: MistralForCausalLM
tokenizer_type: LlamaTokenizer
is_mistral_derived_model: true
load_in_8bit: false
load_in_4bit: false
strict: false
chat_template: chatml
datasets:
- path: data/merged_all.json
ds_type: json
type: alpaca
conversation: chatml
- path: data/capybara_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/synthia-v1.3_sharegpt_12500.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/cot_alpaca_gpt4_extracted_openhermes_2.5_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/slimorca_dedup_filtered_95k_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
- path: data/airoboros_3.2_without_contextual_slimorca_orca_sharegpt.json
ds_type: json
type: sharegpt
conversation: chatml
dataset_prepared_path: last_run_prepared
val_set_size: 0.005
output_dir: ./Einstein-v4-model
sequence_len: 8192
sample_packing: true
pad_to_sequence_len: true
eval_sample_packing: false
wandb_project: Einstein
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
hub_model_id: Weyaxi/Einstein-v4-7B
save_safetensors: true
gradient_accumulation_steps: 4
micro_batch_size: 1
num_epochs: 1.5
optimizer: adamw_bnb_8bit
lr_scheduler: cosine
learning_rate: 0.000005
train_on_inputs: false
group_by_length: false
bf16: true
fp16: false
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 10
evals_per_epoch: 2 # changed
eval_table_size:
eval_table_max_new_tokens: 128
saves_per_epoch: 4
debug:
deepspeed: zero3_bf16.json
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
bos_token: "<s>"
eos_token: "<|im_end|>"
unk_token: "<unk>"
tokens:
- "<|im_start|>"
resume_from_checkpoint: Einstein-v4-model/checkpoint-521
```
</details><br>
# 💬 Prompt Template
You can use this prompt template while using the model:
### ChatML
```
<|im_start|>system
{system}<|im_end|>
<|im_start|>user
{user}<|im_end|>
<|im_start|>assistant
{asistant}<|im_end|>
```
This prompt template is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating), which means you can format messages using the
`tokenizer.apply_chat_template()` method:
```python
messages = [
{"role": "system", "content": "You are helpful AI asistant."},
{"role": "user", "content": "Hello!"}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
# 🔄 Quantizationed versions
Quantizationed versions of this model is available.
## Exl2 [@bartowski](https://hf.co/bartowski):
- https://huggingface.co/bartowski/Einstein-v4-7B-exl2
You can switch up branches in the repo to use the one you want
| Branch | Bits | lm_head bits | VRAM (4k) | VRAM (16k) | VRAM (32k) | Description |
| ----- | ---- | ------- | ------ | ------ | ------ | ------------ |
| [8_0](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/8_0) | 8.0 | 8.0 | 8.4 GB | 9.8 GB | 11.8 GB | Maximum quality that ExLlamaV2 can produce, near unquantized performance. |
| [6_5](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/6_5) | 6.5 | 8.0 | 7.2 GB | 8.6 GB | 10.6 GB | Very similar to 8.0, good tradeoff of size vs performance, **recommended**. |
| [5_0](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/5_0) | 5.0 | 6.0 | 6.0 GB | 7.4 GB | 9.4 GB | Slightly lower quality vs 6.5, but usable on 8GB cards. |
| [4_25](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/4_25) | 4.25 | 6.0 | 5.3 GB | 6.7 GB | 8.7 GB | GPTQ equivalent bits per weight, slightly higher quality. |
| [3_5](https://huggingface.co/bartowski/Einstein-v4-7B-exl2/tree/3_5) | 3.5 | 6.0 | 4.7 GB | 6.1 GB | 8.1 GB | Lower quality, only use if you have to. |
# 🎯 [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Weyaxi__Einstein-v4-7B)
| Metric |Value|
|---------------------------------|----:|
|Avg. |66.62|
|AI2 Reasoning Challenge (25-Shot)|64.68|
|HellaSwag (10-Shot) |83.75|
|MMLU (5-Shot) |62.31|
|TruthfulQA (0-shot) |55.15|
|Winogrande (5-shot) |76.24|
|GSM8k (5-shot) |57.62|
# 🤖 Additional information about training
This model is full fine-tuned for 1.5 epoch.
Total number of steps was 1562.
<details><summary>Loss graph</summary>

</details><br>
# 🤝 Acknowledgments
Thanks to [sablo.ai](https://sablo.ai) for sponsoring this model.
Thanks to all the dataset authors mentioned in the datasets section.
Thanks to [axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) for making the repository I used to make this model.
Thanks to all open source AI community.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
If you would like to support me:
[☕ Buy Me a Coffee](https://www.buymeacoffee.com/weyaxi)
|
[
"SCIQ"
] |
McClain/fashion-embedder
|
McClain
|
zero-shot-image-classification
|
[
"transformers",
"pytorch",
"safetensors",
"clip",
"zero-shot-image-classification",
"vision",
"language",
"fashion",
"ecommerce",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | 2024-05-16T04:17:26Z |
2024-05-16T06:31:11+00:00
| 41 | 0 |
---
language:
- en
library_name: transformers
license: mit
tags:
- vision
- language
- fashion
- ecommerce
widget:
- src: https://cdn-images.farfetch-contents.com/19/76/05/56/19760556_44221665_1000.jpg
candidate_labels: black shoe, red shoe, a cat
example_title: Black Shoe
---
[](https://www.youtube.com/watch?v=uqRSc-KSA1Y) [](https://huggingface.co/patrickjohncyh/fashion-clip) [](https://colab.research.google.com/drive/1Z1hAxBnWjF76bEi9KQ6CMBBEmI_FVDrW?usp=sharing) [](https://towardsdatascience.com/teaching-clip-some-fashion-3005ac3fdcc3) [](https://huggingface.co/spaces/vinid/fashion-clip-app)
# Model Card: Fashion CLIP
Disclaimer: The model card adapts the model card from [here](https://huggingface.co/openai/clip-vit-base-patch32).
## Model Details
UPDATE (10/03/23): We have updated the model! We found that [laion/CLIP-ViT-B-32-laion2B-s34B-b79K](https://huggingface.co/laion/CLIP-ViT-B-32-laion2B-s34B-b79K) checkpoint (thanks [Bin](https://www.linkedin.com/in/bin-duan-56205310/)!) worked better than original OpenAI CLIP on Fashion. We thus fine-tune a newer (and better!) version of FashionCLIP (henceforth FashionCLIP 2.0), while keeping the architecture the same. We postulate that the perofrmance gains afforded by `laion/CLIP-ViT-B-32-laion2B-s34B-b79K` are due to the increased training data (5x OpenAI CLIP data). Our [thesis](https://www.nature.com/articles/s41598-022-23052-9), however, remains the same -- fine-tuning `laion/CLIP` on our fashion dataset improved zero-shot perofrmance across our benchmarks. See the below table comparing weighted macro F1 score across models.
| Model | FMNIST | KAGL | DEEP |
| ------------- | ------------- | ------------- | ------------- |
| OpenAI CLIP | 0.66 | 0.63 | 0.45 |
| FashionCLIP | 0.74 | 0.67 | 0.48 |
| Laion CLIP | 0.78 | 0.71 | 0.58 |
| FashionCLIP 2.0 | __0.83__ | __0.73__ | __0.62__ |
---
FashionCLIP is a CLIP-based model developed to produce general product representations for fashion concepts. Leveraging the pre-trained checkpoint (ViT-B/32) released by [OpenAI](https://github.com/openai/CLIP), we train FashionCLIP on a large, high-quality novel fashion dataset to study whether domain specific fine-tuning of CLIP-like models is sufficient to produce product representations that are zero-shot transferable to entirely new datasets and tasks. FashionCLIP was not developed for model deplyoment - to do so, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
### Model Date
March 2023
### Model Type
The model uses a ViT-B/32 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained, starting from a pre-trained checkpoint, to maximize the similarity of (image, text) pairs via a contrastive loss on a fashion dataset containing 800K products.
### Documents
- [FashionCLIP Github Repo](https://github.com/patrickjohncyh/fashion-clip)
- [FashionCLIP Paper](https://www.nature.com/articles/s41598-022-23052-9)
## Data
The model was trained on (image, text) pairs obtained from the Farfecth dataset[^1 Awaiting official release.], an English dataset comprising over 800K fashion products, with more than 3K brands across dozens of object types. The image used for encoding is the standard product image, which is a picture of the item over a white background, with no humans. The text used is a concatenation of the _highlight_ (e.g., “stripes”, “long sleeves”, “Armani”) and _short description_ (“80s styled t-shirt”)) available in the Farfetch dataset.
## Limitations, Bias and Fiarness
We acknowledge certain limitations of FashionCLIP and expect that it inherits certain limitations and biases present in the original CLIP model. We do not expect our fine-tuning to significantly augment these limitations: we acknowledge that the fashion data we use makes explicit assumptions about the notion of gender as in "blue shoes for a woman" that inevitably associate aspects of clothing with specific people.
Our investigations also suggest that the data used introduces certain limitations in FashionCLIP. From the textual modality, given that most captions derived from the Farfetch dataset are long, we observe that FashionCLIP may be more performant in longer queries than shorter ones. From the image modality, FashionCLIP is also biased towards standard product images (centered, white background).
Model selection, i.e. selecting an appropariate stopping critera during fine-tuning, remains an open challenge. We observed that using loss on an in-domain (i.e. same distribution as test) validation dataset is a poor selection critera when out-of-domain generalization (i.e. across different datasets) is desired, even when the dataset used is relatively diverse and large.
## Citation
```
@Article{Chia2022,
title="Contrastive language and vision learning of general fashion concepts",
author="Chia, Patrick John
and Attanasio, Giuseppe
and Bianchi, Federico
and Terragni, Silvia
and Magalh{\~a}es, Ana Rita
and Goncalves, Diogo
and Greco, Ciro
and Tagliabue, Jacopo",
journal="Scientific Reports",
year="2022",
month="Nov",
day="08",
volume="12",
number="1",
abstract="The steady rise of online shopping goes hand in hand with the development of increasingly complex ML and NLP models. While most use cases are cast as specialized supervised learning problems, we argue that practitioners would greatly benefit from general and transferable representations of products. In this work, we build on recent developments in contrastive learning to train FashionCLIP, a CLIP-like model adapted for the fashion industry. We demonstrate the effectiveness of the representations learned by FashionCLIP with extensive tests across a variety of tasks, datasets and generalization probes. We argue that adaptations of large pre-trained models such as CLIP offer new perspectives in terms of scalability and sustainability for certain types of players in the industry. Finally, we detail the costs and environmental impact of training, and release the model weights and code as open source contribution to the community.",
issn="2045-2322",
doi="10.1038/s41598-022-23052-9",
url="https://doi.org/10.1038/s41598-022-23052-9"
}
```
|
[
"CHIA"
] |
mNLP-project/gpt2-finetuned-mcqa-sciq
|
mNLP-project
|
text-generation
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | 2024-06-10T17:29:38Z |
2024-06-10T20:50:06+00:00
| 41 | 0 |
---
base_model: openai-community/gpt2
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-finetuned-mcqa-sciq
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-finetuned-mcqa-sciq
This model is a fine-tuned version of [openai-community/gpt2](https://huggingface.co/openai-community/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3533
- Bertscore Precision: 0.1082
- Bertscore Recall: 0.1141
- Bertscore F1: 0.1111
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bertscore Precision | Bertscore Recall | Bertscore F1 |
|:-------------:|:------:|:-----:|:---------------:|:-------------------:|:----------------:|:------------:|
| 4.4695 | 0.9999 | 5839 | 2.3612 | 0.1082 | 0.1140 | 0.1110 |
| 4.0507 | 2.0 | 11679 | 2.3533 | 0.1082 | 0.1141 | 0.1111 |
| 3.8779 | 2.9999 | 17518 | 2.3820 | 0.1080 | 0.1140 | 0.1110 |
| 3.2852 | 4.0 | 23358 | 2.4208 | 0.1080 | 0.1140 | 0.1109 |
| 3.6416 | 4.9999 | 29197 | 2.4768 | 0.1079 | 0.1139 | 0.1108 |
| 2.9843 | 6.0 | 35037 | 2.5445 | 0.1079 | 0.1139 | 0.1108 |
| 2.8509 | 6.9999 | 40876 | 2.6094 | 0.1079 | 0.1139 | 0.1108 |
| 2.6932 | 8.0 | 46716 | 2.6658 | 0.1078 | 0.1138 | 0.1107 |
| 2.5309 | 8.9999 | 52555 | 2.7283 | 0.1078 | 0.1138 | 0.1107 |
| 2.5619 | 9.9991 | 58390 | 2.7585 | 0.1078 | 0.1138 | 0.1107 |
### Framework versions
- Transformers 4.40.2
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
[
"SCIQ"
] |
mxs980/gte-Qwen2-1.5B-instruct-Q8_0-GGUF
|
mxs980
|
sentence-similarity
|
[
"sentence-transformers",
"gguf",
"mteb",
"transformers",
"Qwen2",
"sentence-similarity",
"llama-cpp",
"gguf-my-repo",
"base_model:Alibaba-NLP/gte-Qwen2-1.5B-instruct",
"base_model:quantized:Alibaba-NLP/gte-Qwen2-1.5B-instruct",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"conversational"
] | 2024-06-30T20:54:46Z |
2024-07-02T01:40:34+00:00
| 41 | 0 |
---
base_model: Alibaba-NLP/gte-Qwen2-1.5B-instruct
license: apache-2.0
tags:
- mteb
- sentence-transformers
- transformers
- Qwen2
- sentence-similarity
- llama-cpp
- gguf-my-repo
model-index:
- name: gte-qwen2-7B-instruct
results:
- task:
type: Classification
dataset:
name: MTEB AmazonCounterfactualClassification (en)
type: mteb/amazon_counterfactual
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 83.98507462686567
- type: ap
value: 50.93015252587014
- type: f1
value: 78.50416599051215
- task:
type: Classification
dataset:
name: MTEB AmazonPolarityClassification
type: mteb/amazon_polarity
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 96.61065
- type: ap
value: 94.89174052954196
- type: f1
value: 96.60942596940565
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (en)
type: mteb/amazon_reviews_multi
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 55.614000000000004
- type: f1
value: 54.90553480294904
- task:
type: Retrieval
dataset:
name: MTEB ArguAna
type: mteb/arguana
config: default
split: test
revision: c22ab2a51041ffd869aaddef7af8d8215647e41a
metrics:
- type: map_at_1
value: 45.164
- type: map_at_10
value: 61.519
- type: map_at_100
value: 61.769
- type: map_at_1000
value: 61.769
- type: map_at_3
value: 57.443999999999996
- type: map_at_5
value: 60.058
- type: mrr_at_1
value: 46.088
- type: mrr_at_10
value: 61.861
- type: mrr_at_100
value: 62.117999999999995
- type: mrr_at_1000
value: 62.117999999999995
- type: mrr_at_3
value: 57.729
- type: mrr_at_5
value: 60.392
- type: ndcg_at_1
value: 45.164
- type: ndcg_at_10
value: 69.72
- type: ndcg_at_100
value: 70.719
- type: ndcg_at_1000
value: 70.719
- type: ndcg_at_3
value: 61.517999999999994
- type: ndcg_at_5
value: 66.247
- type: precision_at_1
value: 45.164
- type: precision_at_10
value: 9.545
- type: precision_at_100
value: 0.996
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 24.443
- type: precision_at_5
value: 16.97
- type: recall_at_1
value: 45.164
- type: recall_at_10
value: 95.448
- type: recall_at_100
value: 99.644
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 73.329
- type: recall_at_5
value: 84.851
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringP2P
type: mteb/arxiv-clustering-p2p
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 50.511868162026175
- task:
type: Clustering
dataset:
name: MTEB ArxivClusteringS2S
type: mteb/arxiv-clustering-s2s
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 45.007803189284004
- task:
type: Reranking
dataset:
name: MTEB AskUbuntuDupQuestions
type: mteb/askubuntudupquestions-reranking
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 64.55292107723382
- type: mrr
value: 77.66158818097877
- task:
type: STS
dataset:
name: MTEB BIOSSES
type: mteb/biosses-sts
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 85.65459047085452
- type: cos_sim_spearman
value: 82.10729255710761
- type: euclidean_pearson
value: 82.78079159312476
- type: euclidean_spearman
value: 80.50002701880933
- type: manhattan_pearson
value: 82.41372641383016
- type: manhattan_spearman
value: 80.57412509272639
- task:
type: Classification
dataset:
name: MTEB Banking77Classification
type: mteb/banking77
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 87.30844155844156
- type: f1
value: 87.25307322443255
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringP2P
type: mteb/biorxiv-clustering-p2p
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 43.20754608934859
- task:
type: Clustering
dataset:
name: MTEB BiorxivClusteringS2S
type: mteb/biorxiv-clustering-s2s
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 38.818037697335505
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackAndroidRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: f46a197baaae43b4f621051089b82a364682dfeb
metrics:
- type: map_at_1
value: 35.423
- type: map_at_10
value: 47.198
- type: map_at_100
value: 48.899
- type: map_at_1000
value: 49.004
- type: map_at_3
value: 43.114999999999995
- type: map_at_5
value: 45.491
- type: mrr_at_1
value: 42.918
- type: mrr_at_10
value: 53.299
- type: mrr_at_100
value: 54.032000000000004
- type: mrr_at_1000
value: 54.055
- type: mrr_at_3
value: 50.453
- type: mrr_at_5
value: 52.205999999999996
- type: ndcg_at_1
value: 42.918
- type: ndcg_at_10
value: 53.98
- type: ndcg_at_100
value: 59.57
- type: ndcg_at_1000
value: 60.879000000000005
- type: ndcg_at_3
value: 48.224000000000004
- type: ndcg_at_5
value: 50.998
- type: precision_at_1
value: 42.918
- type: precision_at_10
value: 10.299999999999999
- type: precision_at_100
value: 1.687
- type: precision_at_1000
value: 0.211
- type: precision_at_3
value: 22.842000000000002
- type: precision_at_5
value: 16.681
- type: recall_at_1
value: 35.423
- type: recall_at_10
value: 66.824
- type: recall_at_100
value: 89.564
- type: recall_at_1000
value: 97.501
- type: recall_at_3
value: 50.365
- type: recall_at_5
value: 57.921
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackEnglishRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: ad9991cb51e31e31e430383c75ffb2885547b5f0
metrics:
- type: map_at_1
value: 33.205
- type: map_at_10
value: 44.859
- type: map_at_100
value: 46.135
- type: map_at_1000
value: 46.259
- type: map_at_3
value: 41.839
- type: map_at_5
value: 43.662
- type: mrr_at_1
value: 41.146
- type: mrr_at_10
value: 50.621
- type: mrr_at_100
value: 51.207
- type: mrr_at_1000
value: 51.246
- type: mrr_at_3
value: 48.535000000000004
- type: mrr_at_5
value: 49.818
- type: ndcg_at_1
value: 41.146
- type: ndcg_at_10
value: 50.683
- type: ndcg_at_100
value: 54.82
- type: ndcg_at_1000
value: 56.69
- type: ndcg_at_3
value: 46.611000000000004
- type: ndcg_at_5
value: 48.66
- type: precision_at_1
value: 41.146
- type: precision_at_10
value: 9.439
- type: precision_at_100
value: 1.465
- type: precision_at_1000
value: 0.194
- type: precision_at_3
value: 22.59
- type: precision_at_5
value: 15.86
- type: recall_at_1
value: 33.205
- type: recall_at_10
value: 61.028999999999996
- type: recall_at_100
value: 78.152
- type: recall_at_1000
value: 89.59700000000001
- type: recall_at_3
value: 49.05
- type: recall_at_5
value: 54.836
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGamingRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 4885aa143210c98657558c04aaf3dc47cfb54340
metrics:
- type: map_at_1
value: 41.637
- type: map_at_10
value: 55.162
- type: map_at_100
value: 56.142
- type: map_at_1000
value: 56.188
- type: map_at_3
value: 51.564
- type: map_at_5
value: 53.696
- type: mrr_at_1
value: 47.524
- type: mrr_at_10
value: 58.243
- type: mrr_at_100
value: 58.879999999999995
- type: mrr_at_1000
value: 58.9
- type: mrr_at_3
value: 55.69499999999999
- type: mrr_at_5
value: 57.284
- type: ndcg_at_1
value: 47.524
- type: ndcg_at_10
value: 61.305
- type: ndcg_at_100
value: 65.077
- type: ndcg_at_1000
value: 65.941
- type: ndcg_at_3
value: 55.422000000000004
- type: ndcg_at_5
value: 58.516
- type: precision_at_1
value: 47.524
- type: precision_at_10
value: 9.918000000000001
- type: precision_at_100
value: 1.276
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 24.765
- type: precision_at_5
value: 17.204
- type: recall_at_1
value: 41.637
- type: recall_at_10
value: 76.185
- type: recall_at_100
value: 92.149
- type: recall_at_1000
value: 98.199
- type: recall_at_3
value: 60.856
- type: recall_at_5
value: 68.25099999999999
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackGisRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 5003b3064772da1887988e05400cf3806fe491f2
metrics:
- type: map_at_1
value: 26.27
- type: map_at_10
value: 37.463
- type: map_at_100
value: 38.434000000000005
- type: map_at_1000
value: 38.509
- type: map_at_3
value: 34.226
- type: map_at_5
value: 36.161
- type: mrr_at_1
value: 28.588
- type: mrr_at_10
value: 39.383
- type: mrr_at_100
value: 40.23
- type: mrr_at_1000
value: 40.281
- type: mrr_at_3
value: 36.422
- type: mrr_at_5
value: 38.252
- type: ndcg_at_1
value: 28.588
- type: ndcg_at_10
value: 43.511
- type: ndcg_at_100
value: 48.274
- type: ndcg_at_1000
value: 49.975
- type: ndcg_at_3
value: 37.319
- type: ndcg_at_5
value: 40.568
- type: precision_at_1
value: 28.588
- type: precision_at_10
value: 6.893000000000001
- type: precision_at_100
value: 0.9900000000000001
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 16.347
- type: precision_at_5
value: 11.661000000000001
- type: recall_at_1
value: 26.27
- type: recall_at_10
value: 60.284000000000006
- type: recall_at_100
value: 81.902
- type: recall_at_1000
value: 94.43
- type: recall_at_3
value: 43.537
- type: recall_at_5
value: 51.475
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackMathematicaRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 90fceea13679c63fe563ded68f3b6f06e50061de
metrics:
- type: map_at_1
value: 18.168
- type: map_at_10
value: 28.410000000000004
- type: map_at_100
value: 29.78
- type: map_at_1000
value: 29.892999999999997
- type: map_at_3
value: 25.238
- type: map_at_5
value: 26.96
- type: mrr_at_1
value: 23.507
- type: mrr_at_10
value: 33.382
- type: mrr_at_100
value: 34.404
- type: mrr_at_1000
value: 34.467999999999996
- type: mrr_at_3
value: 30.637999999999998
- type: mrr_at_5
value: 32.199
- type: ndcg_at_1
value: 23.507
- type: ndcg_at_10
value: 34.571000000000005
- type: ndcg_at_100
value: 40.663
- type: ndcg_at_1000
value: 43.236000000000004
- type: ndcg_at_3
value: 29.053
- type: ndcg_at_5
value: 31.563999999999997
- type: precision_at_1
value: 23.507
- type: precision_at_10
value: 6.654
- type: precision_at_100
value: 1.113
- type: precision_at_1000
value: 0.146
- type: precision_at_3
value: 14.427999999999999
- type: precision_at_5
value: 10.498000000000001
- type: recall_at_1
value: 18.168
- type: recall_at_10
value: 48.443000000000005
- type: recall_at_100
value: 74.47
- type: recall_at_1000
value: 92.494
- type: recall_at_3
value: 33.379999999999995
- type: recall_at_5
value: 39.76
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackPhysicsRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 79531abbd1fb92d06c6d6315a0cbbbf5bb247ea4
metrics:
- type: map_at_1
value: 32.39
- type: map_at_10
value: 44.479
- type: map_at_100
value: 45.977000000000004
- type: map_at_1000
value: 46.087
- type: map_at_3
value: 40.976
- type: map_at_5
value: 43.038
- type: mrr_at_1
value: 40.135
- type: mrr_at_10
value: 50.160000000000004
- type: mrr_at_100
value: 51.052
- type: mrr_at_1000
value: 51.087
- type: mrr_at_3
value: 47.818
- type: mrr_at_5
value: 49.171
- type: ndcg_at_1
value: 40.135
- type: ndcg_at_10
value: 50.731
- type: ndcg_at_100
value: 56.452000000000005
- type: ndcg_at_1000
value: 58.123000000000005
- type: ndcg_at_3
value: 45.507
- type: ndcg_at_5
value: 48.11
- type: precision_at_1
value: 40.135
- type: precision_at_10
value: 9.192
- type: precision_at_100
value: 1.397
- type: precision_at_1000
value: 0.169
- type: precision_at_3
value: 21.816
- type: precision_at_5
value: 15.476
- type: recall_at_1
value: 32.39
- type: recall_at_10
value: 63.597
- type: recall_at_100
value: 86.737
- type: recall_at_1000
value: 97.039
- type: recall_at_3
value: 48.906
- type: recall_at_5
value: 55.659000000000006
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackProgrammersRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 6184bc1440d2dbc7612be22b50686b8826d22b32
metrics:
- type: map_at_1
value: 28.397
- type: map_at_10
value: 39.871
- type: map_at_100
value: 41.309000000000005
- type: map_at_1000
value: 41.409
- type: map_at_3
value: 36.047000000000004
- type: map_at_5
value: 38.104
- type: mrr_at_1
value: 34.703
- type: mrr_at_10
value: 44.773
- type: mrr_at_100
value: 45.64
- type: mrr_at_1000
value: 45.678999999999995
- type: mrr_at_3
value: 41.705
- type: mrr_at_5
value: 43.406
- type: ndcg_at_1
value: 34.703
- type: ndcg_at_10
value: 46.271
- type: ndcg_at_100
value: 52.037
- type: ndcg_at_1000
value: 53.81700000000001
- type: ndcg_at_3
value: 39.966
- type: ndcg_at_5
value: 42.801
- type: precision_at_1
value: 34.703
- type: precision_at_10
value: 8.744
- type: precision_at_100
value: 1.348
- type: precision_at_1000
value: 0.167
- type: precision_at_3
value: 19.102
- type: precision_at_5
value: 13.836
- type: recall_at_1
value: 28.397
- type: recall_at_10
value: 60.299
- type: recall_at_100
value: 84.595
- type: recall_at_1000
value: 96.155
- type: recall_at_3
value: 43.065
- type: recall_at_5
value: 50.371
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 4ffe81d471b1924886b33c7567bfb200e9eec5c4
metrics:
- type: map_at_1
value: 28.044333333333338
- type: map_at_10
value: 38.78691666666666
- type: map_at_100
value: 40.113
- type: map_at_1000
value: 40.22125
- type: map_at_3
value: 35.52966666666667
- type: map_at_5
value: 37.372749999999996
- type: mrr_at_1
value: 33.159083333333335
- type: mrr_at_10
value: 42.913583333333335
- type: mrr_at_100
value: 43.7845
- type: mrr_at_1000
value: 43.830333333333336
- type: mrr_at_3
value: 40.29816666666667
- type: mrr_at_5
value: 41.81366666666667
- type: ndcg_at_1
value: 33.159083333333335
- type: ndcg_at_10
value: 44.75750000000001
- type: ndcg_at_100
value: 50.13658333333334
- type: ndcg_at_1000
value: 52.037
- type: ndcg_at_3
value: 39.34258333333334
- type: ndcg_at_5
value: 41.93708333333333
- type: precision_at_1
value: 33.159083333333335
- type: precision_at_10
value: 7.952416666666667
- type: precision_at_100
value: 1.2571666666666668
- type: precision_at_1000
value: 0.16099999999999998
- type: precision_at_3
value: 18.303833333333337
- type: precision_at_5
value: 13.057083333333333
- type: recall_at_1
value: 28.044333333333338
- type: recall_at_10
value: 58.237249999999996
- type: recall_at_100
value: 81.35391666666666
- type: recall_at_1000
value: 94.21283333333334
- type: recall_at_3
value: 43.32341666666667
- type: recall_at_5
value: 49.94908333333333
- type: map_at_1
value: 18.398
- type: map_at_10
value: 27.929
- type: map_at_100
value: 29.032999999999998
- type: map_at_1000
value: 29.126
- type: map_at_3
value: 25.070999999999998
- type: map_at_5
value: 26.583000000000002
- type: mrr_at_1
value: 19.963
- type: mrr_at_10
value: 29.997
- type: mrr_at_100
value: 30.9
- type: mrr_at_1000
value: 30.972
- type: mrr_at_3
value: 27.264
- type: mrr_at_5
value: 28.826
- type: ndcg_at_1
value: 19.963
- type: ndcg_at_10
value: 33.678999999999995
- type: ndcg_at_100
value: 38.931
- type: ndcg_at_1000
value: 41.379
- type: ndcg_at_3
value: 28.000000000000004
- type: ndcg_at_5
value: 30.637999999999998
- type: precision_at_1
value: 19.963
- type: precision_at_10
value: 5.7299999999999995
- type: precision_at_100
value: 0.902
- type: precision_at_1000
value: 0.122
- type: precision_at_3
value: 12.631
- type: precision_at_5
value: 9.057
- type: recall_at_1
value: 18.398
- type: recall_at_10
value: 49.254
- type: recall_at_100
value: 73.182
- type: recall_at_1000
value: 91.637
- type: recall_at_3
value: 34.06
- type: recall_at_5
value: 40.416000000000004
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackStatsRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 65ac3a16b8e91f9cee4c9828cc7c335575432a2a
metrics:
- type: map_at_1
value: 27.838
- type: map_at_10
value: 36.04
- type: map_at_100
value: 37.113
- type: map_at_1000
value: 37.204
- type: map_at_3
value: 33.585
- type: map_at_5
value: 34.845
- type: mrr_at_1
value: 30.982
- type: mrr_at_10
value: 39.105000000000004
- type: mrr_at_100
value: 39.98
- type: mrr_at_1000
value: 40.042
- type: mrr_at_3
value: 36.912
- type: mrr_at_5
value: 38.062000000000005
- type: ndcg_at_1
value: 30.982
- type: ndcg_at_10
value: 40.982
- type: ndcg_at_100
value: 46.092
- type: ndcg_at_1000
value: 48.25
- type: ndcg_at_3
value: 36.41
- type: ndcg_at_5
value: 38.379999999999995
- type: precision_at_1
value: 30.982
- type: precision_at_10
value: 6.534
- type: precision_at_100
value: 0.9820000000000001
- type: precision_at_1000
value: 0.124
- type: precision_at_3
value: 15.745999999999999
- type: precision_at_5
value: 10.828
- type: recall_at_1
value: 27.838
- type: recall_at_10
value: 52.971000000000004
- type: recall_at_100
value: 76.357
- type: recall_at_1000
value: 91.973
- type: recall_at_3
value: 40.157
- type: recall_at_5
value: 45.147999999999996
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackTexRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 46989137a86843e03a6195de44b09deda022eec7
metrics:
- type: map_at_1
value: 19.059
- type: map_at_10
value: 27.454
- type: map_at_100
value: 28.736
- type: map_at_1000
value: 28.865000000000002
- type: map_at_3
value: 24.773999999999997
- type: map_at_5
value: 26.266000000000002
- type: mrr_at_1
value: 23.125
- type: mrr_at_10
value: 31.267
- type: mrr_at_100
value: 32.32
- type: mrr_at_1000
value: 32.394
- type: mrr_at_3
value: 28.894
- type: mrr_at_5
value: 30.281000000000002
- type: ndcg_at_1
value: 23.125
- type: ndcg_at_10
value: 32.588
- type: ndcg_at_100
value: 38.432
- type: ndcg_at_1000
value: 41.214
- type: ndcg_at_3
value: 27.938000000000002
- type: ndcg_at_5
value: 30.127
- type: precision_at_1
value: 23.125
- type: precision_at_10
value: 5.9639999999999995
- type: precision_at_100
value: 1.047
- type: precision_at_1000
value: 0.148
- type: precision_at_3
value: 13.294
- type: precision_at_5
value: 9.628
- type: recall_at_1
value: 19.059
- type: recall_at_10
value: 44.25
- type: recall_at_100
value: 69.948
- type: recall_at_1000
value: 89.35300000000001
- type: recall_at_3
value: 31.114000000000004
- type: recall_at_5
value: 36.846000000000004
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackUnixRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 6c6430d3a6d36f8d2a829195bc5dc94d7e063e53
metrics:
- type: map_at_1
value: 28.355999999999998
- type: map_at_10
value: 39.055
- type: map_at_100
value: 40.486
- type: map_at_1000
value: 40.571
- type: map_at_3
value: 35.69
- type: map_at_5
value: 37.605
- type: mrr_at_1
value: 33.302
- type: mrr_at_10
value: 42.986000000000004
- type: mrr_at_100
value: 43.957
- type: mrr_at_1000
value: 43.996
- type: mrr_at_3
value: 40.111999999999995
- type: mrr_at_5
value: 41.735
- type: ndcg_at_1
value: 33.302
- type: ndcg_at_10
value: 44.962999999999994
- type: ndcg_at_100
value: 50.917
- type: ndcg_at_1000
value: 52.622
- type: ndcg_at_3
value: 39.182
- type: ndcg_at_5
value: 41.939
- type: precision_at_1
value: 33.302
- type: precision_at_10
value: 7.779999999999999
- type: precision_at_100
value: 1.203
- type: precision_at_1000
value: 0.145
- type: precision_at_3
value: 18.035
- type: precision_at_5
value: 12.873000000000001
- type: recall_at_1
value: 28.355999999999998
- type: recall_at_10
value: 58.782000000000004
- type: recall_at_100
value: 84.02199999999999
- type: recall_at_1000
value: 95.511
- type: recall_at_3
value: 43.126999999999995
- type: recall_at_5
value: 50.14999999999999
- task:
type: Retrieval
dataset:
name: MTEB CQADupstackWebmastersRetrieval
type: BeIR/cqadupstack
config: default
split: test
revision: 160c094312a0e1facb97e55eeddb698c0abe3571
metrics:
- type: map_at_1
value: 27.391
- type: map_at_10
value: 37.523
- type: map_at_100
value: 39.312000000000005
- type: map_at_1000
value: 39.54
- type: map_at_3
value: 34.231
- type: map_at_5
value: 36.062
- type: mrr_at_1
value: 32.016
- type: mrr_at_10
value: 41.747
- type: mrr_at_100
value: 42.812
- type: mrr_at_1000
value: 42.844
- type: mrr_at_3
value: 39.129999999999995
- type: mrr_at_5
value: 40.524
- type: ndcg_at_1
value: 32.016
- type: ndcg_at_10
value: 43.826
- type: ndcg_at_100
value: 50.373999999999995
- type: ndcg_at_1000
value: 52.318
- type: ndcg_at_3
value: 38.479
- type: ndcg_at_5
value: 40.944
- type: precision_at_1
value: 32.016
- type: precision_at_10
value: 8.280999999999999
- type: precision_at_100
value: 1.6760000000000002
- type: precision_at_1000
value: 0.25
- type: precision_at_3
value: 18.05
- type: precision_at_5
value: 13.083
- type: recall_at_1
value: 27.391
- type: recall_at_10
value: 56.928999999999995
- type: recall_at_100
value: 85.169
- type: recall_at_1000
value: 96.665
- type: recall_at_3
value: 42.264
- type: recall_at_5
value: 48.556
- task:
type: Retrieval
dataset:
name: MTEB ClimateFEVER
type: mteb/climate-fever
config: default
split: test
revision: 47f2ac6acb640fc46020b02a5b59fdda04d39380
metrics:
- type: map_at_1
value: 19.681
- type: map_at_10
value: 32.741
- type: map_at_100
value: 34.811
- type: map_at_1000
value: 35.003
- type: map_at_3
value: 27.697
- type: map_at_5
value: 30.372
- type: mrr_at_1
value: 44.951
- type: mrr_at_10
value: 56.34400000000001
- type: mrr_at_100
value: 56.961
- type: mrr_at_1000
value: 56.987
- type: mrr_at_3
value: 53.681
- type: mrr_at_5
value: 55.407
- type: ndcg_at_1
value: 44.951
- type: ndcg_at_10
value: 42.905
- type: ndcg_at_100
value: 49.95
- type: ndcg_at_1000
value: 52.917
- type: ndcg_at_3
value: 36.815
- type: ndcg_at_5
value: 38.817
- type: precision_at_1
value: 44.951
- type: precision_at_10
value: 12.989999999999998
- type: precision_at_100
value: 2.068
- type: precision_at_1000
value: 0.263
- type: precision_at_3
value: 27.275
- type: precision_at_5
value: 20.365
- type: recall_at_1
value: 19.681
- type: recall_at_10
value: 48.272999999999996
- type: recall_at_100
value: 71.87400000000001
- type: recall_at_1000
value: 87.929
- type: recall_at_3
value: 32.653999999999996
- type: recall_at_5
value: 39.364
- task:
type: Retrieval
dataset:
name: MTEB DBPedia
type: mteb/dbpedia
config: default
split: test
revision: c0f706b76e590d620bd6618b3ca8efdd34e2d659
metrics:
- type: map_at_1
value: 10.231
- type: map_at_10
value: 22.338
- type: map_at_100
value: 31.927
- type: map_at_1000
value: 33.87
- type: map_at_3
value: 15.559999999999999
- type: map_at_5
value: 18.239
- type: mrr_at_1
value: 75.0
- type: mrr_at_10
value: 81.303
- type: mrr_at_100
value: 81.523
- type: mrr_at_1000
value: 81.53
- type: mrr_at_3
value: 80.083
- type: mrr_at_5
value: 80.758
- type: ndcg_at_1
value: 64.625
- type: ndcg_at_10
value: 48.687000000000005
- type: ndcg_at_100
value: 52.791
- type: ndcg_at_1000
value: 60.041999999999994
- type: ndcg_at_3
value: 53.757999999999996
- type: ndcg_at_5
value: 50.76500000000001
- type: precision_at_1
value: 75.0
- type: precision_at_10
value: 38.3
- type: precision_at_100
value: 12.025
- type: precision_at_1000
value: 2.3970000000000002
- type: precision_at_3
value: 55.417
- type: precision_at_5
value: 47.5
- type: recall_at_1
value: 10.231
- type: recall_at_10
value: 27.697
- type: recall_at_100
value: 57.409
- type: recall_at_1000
value: 80.547
- type: recall_at_3
value: 16.668
- type: recall_at_5
value: 20.552
- task:
type: Classification
dataset:
name: MTEB EmotionClassification
type: mteb/emotion
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 61.365
- type: f1
value: 56.7540827912991
- task:
type: Retrieval
dataset:
name: MTEB FEVER
type: mteb/fever
config: default
split: test
revision: bea83ef9e8fb933d90a2f1d5515737465d613e12
metrics:
- type: map_at_1
value: 83.479
- type: map_at_10
value: 88.898
- type: map_at_100
value: 89.11
- type: map_at_1000
value: 89.12400000000001
- type: map_at_3
value: 88.103
- type: map_at_5
value: 88.629
- type: mrr_at_1
value: 89.934
- type: mrr_at_10
value: 93.91000000000001
- type: mrr_at_100
value: 93.937
- type: mrr_at_1000
value: 93.938
- type: mrr_at_3
value: 93.62700000000001
- type: mrr_at_5
value: 93.84599999999999
- type: ndcg_at_1
value: 89.934
- type: ndcg_at_10
value: 91.574
- type: ndcg_at_100
value: 92.238
- type: ndcg_at_1000
value: 92.45
- type: ndcg_at_3
value: 90.586
- type: ndcg_at_5
value: 91.16300000000001
- type: precision_at_1
value: 89.934
- type: precision_at_10
value: 10.555
- type: precision_at_100
value: 1.1159999999999999
- type: precision_at_1000
value: 0.11499999999999999
- type: precision_at_3
value: 33.588
- type: precision_at_5
value: 20.642
- type: recall_at_1
value: 83.479
- type: recall_at_10
value: 94.971
- type: recall_at_100
value: 97.397
- type: recall_at_1000
value: 98.666
- type: recall_at_3
value: 92.24799999999999
- type: recall_at_5
value: 93.797
- task:
type: Retrieval
dataset:
name: MTEB FiQA2018
type: mteb/fiqa
config: default
split: test
revision: 27a168819829fe9bcd655c2df245fb19452e8e06
metrics:
- type: map_at_1
value: 27.16
- type: map_at_10
value: 45.593
- type: map_at_100
value: 47.762
- type: map_at_1000
value: 47.899
- type: map_at_3
value: 39.237
- type: map_at_5
value: 42.970000000000006
- type: mrr_at_1
value: 52.623
- type: mrr_at_10
value: 62.637
- type: mrr_at_100
value: 63.169
- type: mrr_at_1000
value: 63.185
- type: mrr_at_3
value: 59.928000000000004
- type: mrr_at_5
value: 61.702999999999996
- type: ndcg_at_1
value: 52.623
- type: ndcg_at_10
value: 54.701
- type: ndcg_at_100
value: 61.263
- type: ndcg_at_1000
value: 63.134
- type: ndcg_at_3
value: 49.265
- type: ndcg_at_5
value: 51.665000000000006
- type: precision_at_1
value: 52.623
- type: precision_at_10
value: 15.185
- type: precision_at_100
value: 2.202
- type: precision_at_1000
value: 0.254
- type: precision_at_3
value: 32.767
- type: precision_at_5
value: 24.722
- type: recall_at_1
value: 27.16
- type: recall_at_10
value: 63.309000000000005
- type: recall_at_100
value: 86.722
- type: recall_at_1000
value: 97.505
- type: recall_at_3
value: 45.045
- type: recall_at_5
value: 54.02400000000001
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA
type: mteb/hotpotqa
config: default
split: test
revision: ab518f4d6fcca38d87c25209f94beba119d02014
metrics:
- type: map_at_1
value: 42.573
- type: map_at_10
value: 59.373
- type: map_at_100
value: 60.292
- type: map_at_1000
value: 60.358999999999995
- type: map_at_3
value: 56.159000000000006
- type: map_at_5
value: 58.123999999999995
- type: mrr_at_1
value: 85.14500000000001
- type: mrr_at_10
value: 89.25999999999999
- type: mrr_at_100
value: 89.373
- type: mrr_at_1000
value: 89.377
- type: mrr_at_3
value: 88.618
- type: mrr_at_5
value: 89.036
- type: ndcg_at_1
value: 85.14500000000001
- type: ndcg_at_10
value: 68.95
- type: ndcg_at_100
value: 71.95
- type: ndcg_at_1000
value: 73.232
- type: ndcg_at_3
value: 64.546
- type: ndcg_at_5
value: 66.945
- type: precision_at_1
value: 85.14500000000001
- type: precision_at_10
value: 13.865
- type: precision_at_100
value: 1.619
- type: precision_at_1000
value: 0.179
- type: precision_at_3
value: 39.703
- type: precision_at_5
value: 25.718000000000004
- type: recall_at_1
value: 42.573
- type: recall_at_10
value: 69.325
- type: recall_at_100
value: 80.932
- type: recall_at_1000
value: 89.446
- type: recall_at_3
value: 59.553999999999995
- type: recall_at_5
value: 64.294
- task:
type: Classification
dataset:
name: MTEB ImdbClassification
type: mteb/imdb
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 95.8336
- type: ap
value: 93.78862962194073
- type: f1
value: 95.83192650728371
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO
type: mteb/msmarco
config: default
split: dev
revision: c5a29a104738b98a9e76336939199e264163d4a0
metrics:
- type: map_at_1
value: 23.075000000000003
- type: map_at_10
value: 36.102000000000004
- type: map_at_100
value: 37.257
- type: map_at_1000
value: 37.3
- type: map_at_3
value: 32.144
- type: map_at_5
value: 34.359
- type: mrr_at_1
value: 23.711
- type: mrr_at_10
value: 36.671
- type: mrr_at_100
value: 37.763999999999996
- type: mrr_at_1000
value: 37.801
- type: mrr_at_3
value: 32.775
- type: mrr_at_5
value: 34.977000000000004
- type: ndcg_at_1
value: 23.711
- type: ndcg_at_10
value: 43.361
- type: ndcg_at_100
value: 48.839
- type: ndcg_at_1000
value: 49.88
- type: ndcg_at_3
value: 35.269
- type: ndcg_at_5
value: 39.224
- type: precision_at_1
value: 23.711
- type: precision_at_10
value: 6.866999999999999
- type: precision_at_100
value: 0.96
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 15.096000000000002
- type: precision_at_5
value: 11.083
- type: recall_at_1
value: 23.075000000000003
- type: recall_at_10
value: 65.756
- type: recall_at_100
value: 90.88199999999999
- type: recall_at_1000
value: 98.739
- type: recall_at_3
value: 43.691
- type: recall_at_5
value: 53.15800000000001
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (en)
type: mteb/mtop_domain
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 97.69493844049248
- type: f1
value: 97.55048089616261
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (en)
type: mteb/mtop_intent
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 88.75968992248062
- type: f1
value: 72.26321223399123
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (en)
type: mteb/amazon_massive_intent
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 82.40080699394754
- type: f1
value: 79.62590029057968
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (en)
type: mteb/amazon_massive_scenario
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 84.49562878278414
- type: f1
value: 84.0040193313333
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringP2P
type: mteb/medrxiv-clustering-p2p
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 39.386760057101945
- task:
type: Clustering
dataset:
name: MTEB MedrxivClusteringS2S
type: mteb/medrxiv-clustering-s2s
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 37.89687154075537
- task:
type: Reranking
dataset:
name: MTEB MindSmallReranking
type: mteb/mind_small
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 33.94151656057482
- type: mrr
value: 35.32684700746953
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus
type: mteb/nfcorpus
config: default
split: test
revision: ec0fa4fe99da2ff19ca1214b7966684033a58814
metrics:
- type: map_at_1
value: 6.239999999999999
- type: map_at_10
value: 14.862
- type: map_at_100
value: 18.955
- type: map_at_1000
value: 20.694000000000003
- type: map_at_3
value: 10.683
- type: map_at_5
value: 12.674
- type: mrr_at_1
value: 50.15500000000001
- type: mrr_at_10
value: 59.697
- type: mrr_at_100
value: 60.095
- type: mrr_at_1000
value: 60.129999999999995
- type: mrr_at_3
value: 58.35900000000001
- type: mrr_at_5
value: 58.839
- type: ndcg_at_1
value: 48.452
- type: ndcg_at_10
value: 39.341
- type: ndcg_at_100
value: 35.866
- type: ndcg_at_1000
value: 45.111000000000004
- type: ndcg_at_3
value: 44.527
- type: ndcg_at_5
value: 42.946
- type: precision_at_1
value: 50.15500000000001
- type: precision_at_10
value: 29.536
- type: precision_at_100
value: 9.142
- type: precision_at_1000
value: 2.2849999999999997
- type: precision_at_3
value: 41.899
- type: precision_at_5
value: 37.647000000000006
- type: recall_at_1
value: 6.239999999999999
- type: recall_at_10
value: 19.278000000000002
- type: recall_at_100
value: 36.074
- type: recall_at_1000
value: 70.017
- type: recall_at_3
value: 12.066
- type: recall_at_5
value: 15.254000000000001
- task:
type: Retrieval
dataset:
name: MTEB NQ
type: mteb/nq
config: default
split: test
revision: b774495ed302d8c44a3a7ea25c90dbce03968f31
metrics:
- type: map_at_1
value: 39.75
- type: map_at_10
value: 56.443
- type: map_at_100
value: 57.233999999999995
- type: map_at_1000
value: 57.249
- type: map_at_3
value: 52.032999999999994
- type: map_at_5
value: 54.937999999999995
- type: mrr_at_1
value: 44.728
- type: mrr_at_10
value: 58.939
- type: mrr_at_100
value: 59.489000000000004
- type: mrr_at_1000
value: 59.499
- type: mrr_at_3
value: 55.711999999999996
- type: mrr_at_5
value: 57.89
- type: ndcg_at_1
value: 44.728
- type: ndcg_at_10
value: 63.998999999999995
- type: ndcg_at_100
value: 67.077
- type: ndcg_at_1000
value: 67.40899999999999
- type: ndcg_at_3
value: 56.266000000000005
- type: ndcg_at_5
value: 60.88
- type: precision_at_1
value: 44.728
- type: precision_at_10
value: 10.09
- type: precision_at_100
value: 1.1809999999999998
- type: precision_at_1000
value: 0.121
- type: precision_at_3
value: 25.145
- type: precision_at_5
value: 17.822
- type: recall_at_1
value: 39.75
- type: recall_at_10
value: 84.234
- type: recall_at_100
value: 97.055
- type: recall_at_1000
value: 99.517
- type: recall_at_3
value: 64.851
- type: recall_at_5
value: 75.343
- task:
type: Retrieval
dataset:
name: MTEB QuoraRetrieval
type: mteb/quora
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 72.085
- type: map_at_10
value: 86.107
- type: map_at_100
value: 86.727
- type: map_at_1000
value: 86.74
- type: map_at_3
value: 83.21
- type: map_at_5
value: 85.06
- type: mrr_at_1
value: 82.94
- type: mrr_at_10
value: 88.845
- type: mrr_at_100
value: 88.926
- type: mrr_at_1000
value: 88.927
- type: mrr_at_3
value: 87.993
- type: mrr_at_5
value: 88.62299999999999
- type: ndcg_at_1
value: 82.97
- type: ndcg_at_10
value: 89.645
- type: ndcg_at_100
value: 90.717
- type: ndcg_at_1000
value: 90.78
- type: ndcg_at_3
value: 86.99900000000001
- type: ndcg_at_5
value: 88.52600000000001
- type: precision_at_1
value: 82.97
- type: precision_at_10
value: 13.569
- type: precision_at_100
value: 1.539
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 38.043
- type: precision_at_5
value: 24.992
- type: recall_at_1
value: 72.085
- type: recall_at_10
value: 96.262
- type: recall_at_100
value: 99.77000000000001
- type: recall_at_1000
value: 99.997
- type: recall_at_3
value: 88.652
- type: recall_at_5
value: 93.01899999999999
- task:
type: Clustering
dataset:
name: MTEB RedditClustering
type: mteb/reddit-clustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.82153952668092
- task:
type: Clustering
dataset:
name: MTEB RedditClusteringP2P
type: mteb/reddit-clustering-p2p
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 62.094465801879295
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS
type: mteb/scidocs
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.688
- type: map_at_10
value: 15.201999999999998
- type: map_at_100
value: 18.096
- type: map_at_1000
value: 18.481
- type: map_at_3
value: 10.734
- type: map_at_5
value: 12.94
- type: mrr_at_1
value: 28.000000000000004
- type: mrr_at_10
value: 41.101
- type: mrr_at_100
value: 42.202
- type: mrr_at_1000
value: 42.228
- type: mrr_at_3
value: 37.683
- type: mrr_at_5
value: 39.708
- type: ndcg_at_1
value: 28.000000000000004
- type: ndcg_at_10
value: 24.976000000000003
- type: ndcg_at_100
value: 35.129
- type: ndcg_at_1000
value: 40.77
- type: ndcg_at_3
value: 23.787
- type: ndcg_at_5
value: 20.816000000000003
- type: precision_at_1
value: 28.000000000000004
- type: precision_at_10
value: 13.04
- type: precision_at_100
value: 2.761
- type: precision_at_1000
value: 0.41000000000000003
- type: precision_at_3
value: 22.6
- type: precision_at_5
value: 18.52
- type: recall_at_1
value: 5.688
- type: recall_at_10
value: 26.43
- type: recall_at_100
value: 56.02
- type: recall_at_1000
value: 83.21
- type: recall_at_3
value: 13.752
- type: recall_at_5
value: 18.777
- task:
type: STS
dataset:
name: MTEB SICK-R
type: mteb/sickr-sts
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 85.15084859283178
- type: cos_sim_spearman
value: 80.49030614009419
- type: euclidean_pearson
value: 81.84574978672468
- type: euclidean_spearman
value: 79.89787150656818
- type: manhattan_pearson
value: 81.63076538567131
- type: manhattan_spearman
value: 79.69867352121841
- task:
type: STS
dataset:
name: MTEB STS12
type: mteb/sts12-sts
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 84.64097921490992
- type: cos_sim_spearman
value: 77.25370084896514
- type: euclidean_pearson
value: 82.71210826468788
- type: euclidean_spearman
value: 78.50445584994826
- type: manhattan_pearson
value: 82.92580164330298
- type: manhattan_spearman
value: 78.69686891301019
- task:
type: STS
dataset:
name: MTEB STS13
type: mteb/sts13-sts
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 87.24596417308994
- type: cos_sim_spearman
value: 87.79454220555091
- type: euclidean_pearson
value: 87.40242561671164
- type: euclidean_spearman
value: 88.25955597373556
- type: manhattan_pearson
value: 87.25160240485849
- type: manhattan_spearman
value: 88.155794979818
- task:
type: STS
dataset:
name: MTEB STS14
type: mteb/sts14-sts
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 84.44914233422564
- type: cos_sim_spearman
value: 82.91015471820322
- type: euclidean_pearson
value: 84.7206656630327
- type: euclidean_spearman
value: 83.86408872059216
- type: manhattan_pearson
value: 84.72816725158454
- type: manhattan_spearman
value: 84.01603388572788
- task:
type: STS
dataset:
name: MTEB STS15
type: mteb/sts15-sts
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.6168026237477
- type: cos_sim_spearman
value: 88.45414278092397
- type: euclidean_pearson
value: 88.57023240882022
- type: euclidean_spearman
value: 89.04102190922094
- type: manhattan_pearson
value: 88.66695535796354
- type: manhattan_spearman
value: 89.19898476680969
- task:
type: STS
dataset:
name: MTEB STS16
type: mteb/sts16-sts
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 84.27925826089424
- type: cos_sim_spearman
value: 85.45291099550461
- type: euclidean_pearson
value: 83.63853036580834
- type: euclidean_spearman
value: 84.33468035821484
- type: manhattan_pearson
value: 83.72778773251596
- type: manhattan_spearman
value: 84.51583132445376
- task:
type: STS
dataset:
name: MTEB STS17 (en-en)
type: mteb/sts17-crosslingual-sts
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 89.67375185692552
- type: cos_sim_spearman
value: 90.32542469203855
- type: euclidean_pearson
value: 89.63513717951847
- type: euclidean_spearman
value: 89.87760271003745
- type: manhattan_pearson
value: 89.28381452982924
- type: manhattan_spearman
value: 89.53568197785721
- task:
type: STS
dataset:
name: MTEB STS22 (en)
type: mteb/sts22-crosslingual-sts
config: en
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 66.24644693819846
- type: cos_sim_spearman
value: 66.09889420525377
- type: euclidean_pearson
value: 63.72551583520747
- type: euclidean_spearman
value: 63.01385470780679
- type: manhattan_pearson
value: 64.09258157214097
- type: manhattan_spearman
value: 63.080517752822594
- task:
type: STS
dataset:
name: MTEB STSBenchmark
type: mteb/stsbenchmark-sts
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 86.27321463839989
- type: cos_sim_spearman
value: 86.37572865993327
- type: euclidean_pearson
value: 86.36268020198149
- type: euclidean_spearman
value: 86.31089339478922
- type: manhattan_pearson
value: 86.4260445761947
- type: manhattan_spearman
value: 86.45885895320457
- task:
type: Reranking
dataset:
name: MTEB SciDocsRR
type: mteb/scidocs-reranking
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 86.52456702387798
- type: mrr
value: 96.34556529164372
- task:
type: Retrieval
dataset:
name: MTEB SciFact
type: mteb/scifact
config: default
split: test
revision: 0228b52cf27578f30900b9e5271d331663a030d7
metrics:
- type: map_at_1
value: 61.99400000000001
- type: map_at_10
value: 73.38799999999999
- type: map_at_100
value: 73.747
- type: map_at_1000
value: 73.75
- type: map_at_3
value: 70.04599999999999
- type: map_at_5
value: 72.095
- type: mrr_at_1
value: 65.0
- type: mrr_at_10
value: 74.42800000000001
- type: mrr_at_100
value: 74.722
- type: mrr_at_1000
value: 74.725
- type: mrr_at_3
value: 72.056
- type: mrr_at_5
value: 73.60600000000001
- type: ndcg_at_1
value: 65.0
- type: ndcg_at_10
value: 78.435
- type: ndcg_at_100
value: 79.922
- type: ndcg_at_1000
value: 80.00500000000001
- type: ndcg_at_3
value: 73.05199999999999
- type: ndcg_at_5
value: 75.98
- type: precision_at_1
value: 65.0
- type: precision_at_10
value: 10.5
- type: precision_at_100
value: 1.123
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 28.555999999999997
- type: precision_at_5
value: 19.0
- type: recall_at_1
value: 61.99400000000001
- type: recall_at_10
value: 92.72200000000001
- type: recall_at_100
value: 99.333
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 78.739
- type: recall_at_5
value: 85.828
- task:
type: PairClassification
dataset:
name: MTEB SprintDuplicateQuestions
type: mteb/sprintduplicatequestions-pairclassification
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.79009900990098
- type: cos_sim_ap
value: 95.3203137438653
- type: cos_sim_f1
value: 89.12386706948641
- type: cos_sim_precision
value: 89.75659229208925
- type: cos_sim_recall
value: 88.5
- type: dot_accuracy
value: 99.67821782178218
- type: dot_ap
value: 89.94069840000675
- type: dot_f1
value: 83.45902463549521
- type: dot_precision
value: 83.9231547017189
- type: dot_recall
value: 83.0
- type: euclidean_accuracy
value: 99.78613861386138
- type: euclidean_ap
value: 95.10648259135526
- type: euclidean_f1
value: 88.77338877338877
- type: euclidean_precision
value: 92.42424242424242
- type: euclidean_recall
value: 85.39999999999999
- type: manhattan_accuracy
value: 99.7950495049505
- type: manhattan_ap
value: 95.29987661320946
- type: manhattan_f1
value: 89.21313183949972
- type: manhattan_precision
value: 93.14472252448314
- type: manhattan_recall
value: 85.6
- type: max_accuracy
value: 99.7950495049505
- type: max_ap
value: 95.3203137438653
- type: max_f1
value: 89.21313183949972
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClustering
type: mteb/stackexchange-clustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 67.65446577183913
- task:
type: Clustering
dataset:
name: MTEB StackExchangeClusteringP2P
type: mteb/stackexchange-clustering-p2p
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 46.30749237193961
- task:
type: Reranking
dataset:
name: MTEB StackOverflowDupQuestions
type: mteb/stackoverflowdupquestions-reranking
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 54.91481849959949
- type: mrr
value: 55.853506175197346
- task:
type: Summarization
dataset:
name: MTEB SummEval
type: mteb/summeval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.08196549170419
- type: cos_sim_spearman
value: 31.16661390597077
- type: dot_pearson
value: 29.892258410943466
- type: dot_spearman
value: 30.51328811965085
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID
type: mteb/trec-covid
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.23900000000000002
- type: map_at_10
value: 2.173
- type: map_at_100
value: 14.24
- type: map_at_1000
value: 35.309000000000005
- type: map_at_3
value: 0.7100000000000001
- type: map_at_5
value: 1.163
- type: mrr_at_1
value: 92.0
- type: mrr_at_10
value: 96.0
- type: mrr_at_100
value: 96.0
- type: mrr_at_1000
value: 96.0
- type: mrr_at_3
value: 96.0
- type: mrr_at_5
value: 96.0
- type: ndcg_at_1
value: 90.0
- type: ndcg_at_10
value: 85.382
- type: ndcg_at_100
value: 68.03
- type: ndcg_at_1000
value: 61.021
- type: ndcg_at_3
value: 89.765
- type: ndcg_at_5
value: 88.444
- type: precision_at_1
value: 92.0
- type: precision_at_10
value: 88.0
- type: precision_at_100
value: 70.02000000000001
- type: precision_at_1000
value: 26.984
- type: precision_at_3
value: 94.0
- type: precision_at_5
value: 92.80000000000001
- type: recall_at_1
value: 0.23900000000000002
- type: recall_at_10
value: 2.313
- type: recall_at_100
value: 17.049
- type: recall_at_1000
value: 57.489999999999995
- type: recall_at_3
value: 0.737
- type: recall_at_5
value: 1.221
- task:
type: Retrieval
dataset:
name: MTEB Touche2020
type: mteb/touche2020
config: default
split: test
revision: a34f9a33db75fa0cbb21bb5cfc3dae8dc8bec93f
metrics:
- type: map_at_1
value: 2.75
- type: map_at_10
value: 11.29
- type: map_at_100
value: 18.032999999999998
- type: map_at_1000
value: 19.746
- type: map_at_3
value: 6.555
- type: map_at_5
value: 8.706999999999999
- type: mrr_at_1
value: 34.694
- type: mrr_at_10
value: 50.55
- type: mrr_at_100
value: 51.659
- type: mrr_at_1000
value: 51.659
- type: mrr_at_3
value: 47.278999999999996
- type: mrr_at_5
value: 49.728
- type: ndcg_at_1
value: 32.653
- type: ndcg_at_10
value: 27.894000000000002
- type: ndcg_at_100
value: 39.769
- type: ndcg_at_1000
value: 51.495999999999995
- type: ndcg_at_3
value: 32.954
- type: ndcg_at_5
value: 31.502999999999997
- type: precision_at_1
value: 34.694
- type: precision_at_10
value: 23.265
- type: precision_at_100
value: 7.898
- type: precision_at_1000
value: 1.58
- type: precision_at_3
value: 34.694
- type: precision_at_5
value: 31.429000000000002
- type: recall_at_1
value: 2.75
- type: recall_at_10
value: 16.953
- type: recall_at_100
value: 48.68
- type: recall_at_1000
value: 85.18599999999999
- type: recall_at_3
value: 7.710999999999999
- type: recall_at_5
value: 11.484
- task:
type: Classification
dataset:
name: MTEB ToxicConversationsClassification
type: mteb/toxic_conversations_50k
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 82.66099999999999
- type: ap
value: 25.555698090238337
- type: f1
value: 66.48402012461622
- task:
type: Classification
dataset:
name: MTEB TweetSentimentExtractionClassification
type: mteb/tweet_sentiment_extraction
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 72.94567062818335
- type: f1
value: 73.28139189595674
- task:
type: Clustering
dataset:
name: MTEB TwentyNewsgroupsClustering
type: mteb/twentynewsgroups-clustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.581627240203474
- task:
type: PairClassification
dataset:
name: MTEB TwitterSemEval2015
type: mteb/twittersemeval2015-pairclassification
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 87.78089050485785
- type: cos_sim_ap
value: 79.64487116574168
- type: cos_sim_f1
value: 72.46563021970964
- type: cos_sim_precision
value: 70.62359128474831
- type: cos_sim_recall
value: 74.40633245382587
- type: dot_accuracy
value: 86.2609524944865
- type: dot_ap
value: 75.513046857613
- type: dot_f1
value: 68.58213616489695
- type: dot_precision
value: 65.12455516014235
- type: dot_recall
value: 72.42744063324538
- type: euclidean_accuracy
value: 87.6080348095607
- type: euclidean_ap
value: 79.00204933649795
- type: euclidean_f1
value: 72.14495342605589
- type: euclidean_precision
value: 69.85421299728193
- type: euclidean_recall
value: 74.5910290237467
- type: manhattan_accuracy
value: 87.59611372712642
- type: manhattan_ap
value: 78.78523756706264
- type: manhattan_f1
value: 71.86499137718648
- type: manhattan_precision
value: 67.39833641404806
- type: manhattan_recall
value: 76.96569920844327
- type: max_accuracy
value: 87.78089050485785
- type: max_ap
value: 79.64487116574168
- type: max_f1
value: 72.46563021970964
- task:
type: PairClassification
dataset:
name: MTEB TwitterURLCorpus
type: mteb/twitterurlcorpus-pairclassification
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 89.98719292117825
- type: cos_sim_ap
value: 87.58146137353202
- type: cos_sim_f1
value: 80.28543232369239
- type: cos_sim_precision
value: 79.1735289714029
- type: cos_sim_recall
value: 81.42901139513397
- type: dot_accuracy
value: 88.9199363526992
- type: dot_ap
value: 84.98499998630417
- type: dot_f1
value: 78.21951400757969
- type: dot_precision
value: 75.58523624874336
- type: dot_recall
value: 81.04404065291038
- type: euclidean_accuracy
value: 89.77374160748244
- type: euclidean_ap
value: 87.35151562835209
- type: euclidean_f1
value: 79.92160922940393
- type: euclidean_precision
value: 76.88531587933979
- type: euclidean_recall
value: 83.20757622420696
- type: manhattan_accuracy
value: 89.72717041176699
- type: manhattan_ap
value: 87.34065592142515
- type: manhattan_f1
value: 79.85603419187943
- type: manhattan_precision
value: 77.82243332115455
- type: manhattan_recall
value: 81.99876809362489
- type: max_accuracy
value: 89.98719292117825
- type: max_ap
value: 87.58146137353202
- type: max_f1
value: 80.28543232369239
- task:
type: STS
dataset:
name: MTEB AFQMC
type: C-MTEB/AFQMC
config: default
split: validation
revision: b44c3b011063adb25877c13823db83bb193913c4
metrics:
- type: cos_sim_pearson
value: 53.45954203592337
- type: cos_sim_spearman
value: 58.42154680418638
- type: euclidean_pearson
value: 56.41543791722753
- type: euclidean_spearman
value: 58.39328016640146
- type: manhattan_pearson
value: 56.318510356833876
- type: manhattan_spearman
value: 58.28423447818184
- task:
type: STS
dataset:
name: MTEB ATEC
type: C-MTEB/ATEC
config: default
split: test
revision: 0f319b1142f28d00e055a6770f3f726ae9b7d865
metrics:
- type: cos_sim_pearson
value: 50.78356460675945
- type: cos_sim_spearman
value: 55.6530411663269
- type: euclidean_pearson
value: 56.50763660417816
- type: euclidean_spearman
value: 55.733823335669065
- type: manhattan_pearson
value: 56.45323093512866
- type: manhattan_spearman
value: 55.63248619032702
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (zh)
type: mteb/amazon_reviews_multi
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 47.209999999999994
- type: f1
value: 46.08892432018655
- task:
type: STS
dataset:
name: MTEB BQ
type: C-MTEB/BQ
config: default
split: test
revision: e3dda5e115e487b39ec7e618c0c6a29137052a55
metrics:
- type: cos_sim_pearson
value: 70.25573992001478
- type: cos_sim_spearman
value: 73.85247134951433
- type: euclidean_pearson
value: 72.60033082168442
- type: euclidean_spearman
value: 73.72445893756499
- type: manhattan_pearson
value: 72.59932284620231
- type: manhattan_spearman
value: 73.68002490614583
- task:
type: Clustering
dataset:
name: MTEB CLSClusteringP2P
type: C-MTEB/CLSClusteringP2P
config: default
split: test
revision: 4b6227591c6c1a73bc76b1055f3b7f3588e72476
metrics:
- type: v_measure
value: 45.21317724305628
- task:
type: Clustering
dataset:
name: MTEB CLSClusteringS2S
type: C-MTEB/CLSClusteringS2S
config: default
split: test
revision: e458b3f5414b62b7f9f83499ac1f5497ae2e869f
metrics:
- type: v_measure
value: 42.49825170976724
- task:
type: Reranking
dataset:
name: MTEB CMedQAv1
type: C-MTEB/CMedQAv1-reranking
config: default
split: test
revision: 8d7f1e942507dac42dc58017c1a001c3717da7df
metrics:
- type: map
value: 88.15661686810597
- type: mrr
value: 90.11222222222223
- task:
type: Reranking
dataset:
name: MTEB CMedQAv2
type: C-MTEB/CMedQAv2-reranking
config: default
split: test
revision: 23d186750531a14a0357ca22cd92d712fd512ea0
metrics:
- type: map
value: 88.1204726064383
- type: mrr
value: 90.20142857142858
- task:
type: Retrieval
dataset:
name: MTEB CmedqaRetrieval
type: C-MTEB/CmedqaRetrieval
config: default
split: dev
revision: cd540c506dae1cf9e9a59c3e06f42030d54e7301
metrics:
- type: map_at_1
value: 27.224999999999998
- type: map_at_10
value: 40.169
- type: map_at_100
value: 42.0
- type: map_at_1000
value: 42.109
- type: map_at_3
value: 35.76
- type: map_at_5
value: 38.221
- type: mrr_at_1
value: 40.56
- type: mrr_at_10
value: 49.118
- type: mrr_at_100
value: 50.092999999999996
- type: mrr_at_1000
value: 50.133
- type: mrr_at_3
value: 46.507
- type: mrr_at_5
value: 47.973
- type: ndcg_at_1
value: 40.56
- type: ndcg_at_10
value: 46.972
- type: ndcg_at_100
value: 54.04
- type: ndcg_at_1000
value: 55.862
- type: ndcg_at_3
value: 41.36
- type: ndcg_at_5
value: 43.704
- type: precision_at_1
value: 40.56
- type: precision_at_10
value: 10.302999999999999
- type: precision_at_100
value: 1.606
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 23.064
- type: precision_at_5
value: 16.764000000000003
- type: recall_at_1
value: 27.224999999999998
- type: recall_at_10
value: 58.05200000000001
- type: recall_at_100
value: 87.092
- type: recall_at_1000
value: 99.099
- type: recall_at_3
value: 41.373
- type: recall_at_5
value: 48.453
- task:
type: PairClassification
dataset:
name: MTEB Cmnli
type: C-MTEB/CMNLI
config: default
split: validation
revision: 41bc36f332156f7adc9e38f53777c959b2ae9766
metrics:
- type: cos_sim_accuracy
value: 77.40228502705953
- type: cos_sim_ap
value: 86.22359172956327
- type: cos_sim_f1
value: 78.96328293736501
- type: cos_sim_precision
value: 73.36945615091311
- type: cos_sim_recall
value: 85.48047696983868
- type: dot_accuracy
value: 75.53818400481059
- type: dot_ap
value: 83.70164011305312
- type: dot_f1
value: 77.67298719348754
- type: dot_precision
value: 67.49482401656314
- type: dot_recall
value: 91.46598082768296
- type: euclidean_accuracy
value: 77.94347564642213
- type: euclidean_ap
value: 86.4652108728609
- type: euclidean_f1
value: 79.15555555555555
- type: euclidean_precision
value: 75.41816641964853
- type: euclidean_recall
value: 83.28267477203647
- type: manhattan_accuracy
value: 77.45039085989175
- type: manhattan_ap
value: 86.09986583900665
- type: manhattan_f1
value: 78.93669264438988
- type: manhattan_precision
value: 72.63261296660117
- type: manhattan_recall
value: 86.43909282207154
- type: max_accuracy
value: 77.94347564642213
- type: max_ap
value: 86.4652108728609
- type: max_f1
value: 79.15555555555555
- task:
type: Retrieval
dataset:
name: MTEB CovidRetrieval
type: C-MTEB/CovidRetrieval
config: default
split: dev
revision: 1271c7809071a13532e05f25fb53511ffce77117
metrics:
- type: map_at_1
value: 69.336
- type: map_at_10
value: 77.16
- type: map_at_100
value: 77.47500000000001
- type: map_at_1000
value: 77.482
- type: map_at_3
value: 75.42999999999999
- type: map_at_5
value: 76.468
- type: mrr_at_1
value: 69.44200000000001
- type: mrr_at_10
value: 77.132
- type: mrr_at_100
value: 77.43299999999999
- type: mrr_at_1000
value: 77.44
- type: mrr_at_3
value: 75.395
- type: mrr_at_5
value: 76.459
- type: ndcg_at_1
value: 69.547
- type: ndcg_at_10
value: 80.794
- type: ndcg_at_100
value: 82.245
- type: ndcg_at_1000
value: 82.40899999999999
- type: ndcg_at_3
value: 77.303
- type: ndcg_at_5
value: 79.168
- type: precision_at_1
value: 69.547
- type: precision_at_10
value: 9.305
- type: precision_at_100
value: 0.9979999999999999
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 27.749000000000002
- type: precision_at_5
value: 17.576
- type: recall_at_1
value: 69.336
- type: recall_at_10
value: 92.097
- type: recall_at_100
value: 98.736
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 82.64
- type: recall_at_5
value: 87.144
- task:
type: Retrieval
dataset:
name: MTEB DuRetrieval
type: C-MTEB/DuRetrieval
config: default
split: dev
revision: a1a333e290fe30b10f3f56498e3a0d911a693ced
metrics:
- type: map_at_1
value: 26.817999999999998
- type: map_at_10
value: 82.67
- type: map_at_100
value: 85.304
- type: map_at_1000
value: 85.334
- type: map_at_3
value: 57.336
- type: map_at_5
value: 72.474
- type: mrr_at_1
value: 91.45
- type: mrr_at_10
value: 94.272
- type: mrr_at_100
value: 94.318
- type: mrr_at_1000
value: 94.32000000000001
- type: mrr_at_3
value: 94.0
- type: mrr_at_5
value: 94.17699999999999
- type: ndcg_at_1
value: 91.45
- type: ndcg_at_10
value: 89.404
- type: ndcg_at_100
value: 91.724
- type: ndcg_at_1000
value: 91.973
- type: ndcg_at_3
value: 88.104
- type: ndcg_at_5
value: 87.25699999999999
- type: precision_at_1
value: 91.45
- type: precision_at_10
value: 42.585
- type: precision_at_100
value: 4.838
- type: precision_at_1000
value: 0.49
- type: precision_at_3
value: 78.8
- type: precision_at_5
value: 66.66
- type: recall_at_1
value: 26.817999999999998
- type: recall_at_10
value: 90.67
- type: recall_at_100
value: 98.36200000000001
- type: recall_at_1000
value: 99.583
- type: recall_at_3
value: 59.614999999999995
- type: recall_at_5
value: 77.05199999999999
- task:
type: Retrieval
dataset:
name: MTEB EcomRetrieval
type: C-MTEB/EcomRetrieval
config: default
split: dev
revision: 687de13dc7294d6fd9be10c6945f9e8fec8166b9
metrics:
- type: map_at_1
value: 47.699999999999996
- type: map_at_10
value: 57.589999999999996
- type: map_at_100
value: 58.226
- type: map_at_1000
value: 58.251
- type: map_at_3
value: 55.233
- type: map_at_5
value: 56.633
- type: mrr_at_1
value: 47.699999999999996
- type: mrr_at_10
value: 57.589999999999996
- type: mrr_at_100
value: 58.226
- type: mrr_at_1000
value: 58.251
- type: mrr_at_3
value: 55.233
- type: mrr_at_5
value: 56.633
- type: ndcg_at_1
value: 47.699999999999996
- type: ndcg_at_10
value: 62.505
- type: ndcg_at_100
value: 65.517
- type: ndcg_at_1000
value: 66.19800000000001
- type: ndcg_at_3
value: 57.643
- type: ndcg_at_5
value: 60.181
- type: precision_at_1
value: 47.699999999999996
- type: precision_at_10
value: 7.8
- type: precision_at_100
value: 0.919
- type: precision_at_1000
value: 0.097
- type: precision_at_3
value: 21.532999999999998
- type: precision_at_5
value: 14.16
- type: recall_at_1
value: 47.699999999999996
- type: recall_at_10
value: 78.0
- type: recall_at_100
value: 91.9
- type: recall_at_1000
value: 97.3
- type: recall_at_3
value: 64.60000000000001
- type: recall_at_5
value: 70.8
- task:
type: Classification
dataset:
name: MTEB IFlyTek
type: C-MTEB/IFlyTek-classification
config: default
split: validation
revision: 421605374b29664c5fc098418fe20ada9bd55f8a
metrics:
- type: accuracy
value: 44.84801846864178
- type: f1
value: 37.47347897956339
- task:
type: Classification
dataset:
name: MTEB JDReview
type: C-MTEB/JDReview-classification
config: default
split: test
revision: b7c64bd89eb87f8ded463478346f76731f07bf8b
metrics:
- type: accuracy
value: 85.81613508442777
- type: ap
value: 52.68244615477374
- type: f1
value: 80.0445640948843
- task:
type: STS
dataset:
name: MTEB LCQMC
type: C-MTEB/LCQMC
config: default
split: test
revision: 17f9b096f80380fce5ed12a9be8be7784b337daf
metrics:
- type: cos_sim_pearson
value: 69.57786502217138
- type: cos_sim_spearman
value: 75.39106054489906
- type: euclidean_pearson
value: 73.72082954602402
- type: euclidean_spearman
value: 75.14421475913619
- type: manhattan_pearson
value: 73.62463076633642
- type: manhattan_spearman
value: 75.01301565104112
- task:
type: Reranking
dataset:
name: MTEB MMarcoReranking
type: C-MTEB/Mmarco-reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 29.143797057999134
- type: mrr
value: 28.08174603174603
- task:
type: Retrieval
dataset:
name: MTEB MMarcoRetrieval
type: C-MTEB/MMarcoRetrieval
config: default
split: dev
revision: 539bbde593d947e2a124ba72651aafc09eb33fc2
metrics:
- type: map_at_1
value: 70.492
- type: map_at_10
value: 79.501
- type: map_at_100
value: 79.728
- type: map_at_1000
value: 79.735
- type: map_at_3
value: 77.77
- type: map_at_5
value: 78.851
- type: mrr_at_1
value: 72.822
- type: mrr_at_10
value: 80.001
- type: mrr_at_100
value: 80.19
- type: mrr_at_1000
value: 80.197
- type: mrr_at_3
value: 78.484
- type: mrr_at_5
value: 79.42099999999999
- type: ndcg_at_1
value: 72.822
- type: ndcg_at_10
value: 83.013
- type: ndcg_at_100
value: 84.013
- type: ndcg_at_1000
value: 84.20400000000001
- type: ndcg_at_3
value: 79.728
- type: ndcg_at_5
value: 81.542
- type: precision_at_1
value: 72.822
- type: precision_at_10
value: 9.917
- type: precision_at_100
value: 1.042
- type: precision_at_1000
value: 0.106
- type: precision_at_3
value: 29.847
- type: precision_at_5
value: 18.871
- type: recall_at_1
value: 70.492
- type: recall_at_10
value: 93.325
- type: recall_at_100
value: 97.822
- type: recall_at_1000
value: 99.319
- type: recall_at_3
value: 84.636
- type: recall_at_5
value: 88.93100000000001
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (zh-CN)
type: mteb/amazon_massive_intent
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.88298587760592
- type: f1
value: 73.89001762017176
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (zh-CN)
type: mteb/amazon_massive_scenario
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 80.76328177538669
- type: f1
value: 80.24718532423358
- task:
type: Retrieval
dataset:
name: MTEB MedicalRetrieval
type: C-MTEB/MedicalRetrieval
config: default
split: dev
revision: 2039188fb5800a9803ba5048df7b76e6fb151fc6
metrics:
- type: map_at_1
value: 49.6
- type: map_at_10
value: 55.620999999999995
- type: map_at_100
value: 56.204
- type: map_at_1000
value: 56.251
- type: map_at_3
value: 54.132999999999996
- type: map_at_5
value: 54.933
- type: mrr_at_1
value: 49.7
- type: mrr_at_10
value: 55.67100000000001
- type: mrr_at_100
value: 56.254000000000005
- type: mrr_at_1000
value: 56.301
- type: mrr_at_3
value: 54.18300000000001
- type: mrr_at_5
value: 54.983000000000004
- type: ndcg_at_1
value: 49.6
- type: ndcg_at_10
value: 58.645
- type: ndcg_at_100
value: 61.789
- type: ndcg_at_1000
value: 63.219
- type: ndcg_at_3
value: 55.567
- type: ndcg_at_5
value: 57.008
- type: precision_at_1
value: 49.6
- type: precision_at_10
value: 6.819999999999999
- type: precision_at_100
value: 0.836
- type: precision_at_1000
value: 0.095
- type: precision_at_3
value: 19.900000000000002
- type: precision_at_5
value: 12.64
- type: recall_at_1
value: 49.6
- type: recall_at_10
value: 68.2
- type: recall_at_100
value: 83.6
- type: recall_at_1000
value: 95.3
- type: recall_at_3
value: 59.699999999999996
- type: recall_at_5
value: 63.2
- task:
type: Classification
dataset:
name: MTEB MultilingualSentiment
type: C-MTEB/MultilingualSentiment-classification
config: default
split: validation
revision: 46958b007a63fdbf239b7672c25d0bea67b5ea1a
metrics:
- type: accuracy
value: 74.45666666666666
- type: f1
value: 74.32582402190089
- task:
type: PairClassification
dataset:
name: MTEB Ocnli
type: C-MTEB/OCNLI
config: default
split: validation
revision: 66e76a618a34d6d565d5538088562851e6daa7ec
metrics:
- type: cos_sim_accuracy
value: 80.67135896047645
- type: cos_sim_ap
value: 87.60421240712051
- type: cos_sim_f1
value: 82.1304131408661
- type: cos_sim_precision
value: 77.68361581920904
- type: cos_sim_recall
value: 87.11721224920802
- type: dot_accuracy
value: 79.04710341093666
- type: dot_ap
value: 85.6370059719336
- type: dot_f1
value: 80.763723150358
- type: dot_precision
value: 73.69337979094077
- type: dot_recall
value: 89.33474128827878
- type: euclidean_accuracy
value: 81.05035192203573
- type: euclidean_ap
value: 87.7880240053663
- type: euclidean_f1
value: 82.50244379276637
- type: euclidean_precision
value: 76.7970882620564
- type: euclidean_recall
value: 89.1235480464625
- type: manhattan_accuracy
value: 80.61721710882512
- type: manhattan_ap
value: 87.43568120591175
- type: manhattan_f1
value: 81.89526184538653
- type: manhattan_precision
value: 77.5992438563327
- type: manhattan_recall
value: 86.6948257655755
- type: max_accuracy
value: 81.05035192203573
- type: max_ap
value: 87.7880240053663
- type: max_f1
value: 82.50244379276637
- task:
type: Classification
dataset:
name: MTEB OnlineShopping
type: C-MTEB/OnlineShopping-classification
config: default
split: test
revision: e610f2ebd179a8fda30ae534c3878750a96db120
metrics:
- type: accuracy
value: 93.5
- type: ap
value: 91.31357903446782
- type: f1
value: 93.48088994006616
- task:
type: STS
dataset:
name: MTEB PAWSX
type: C-MTEB/PAWSX
config: default
split: test
revision: 9c6a90e430ac22b5779fb019a23e820b11a8b5e1
metrics:
- type: cos_sim_pearson
value: 36.93293453538077
- type: cos_sim_spearman
value: 42.45972506308574
- type: euclidean_pearson
value: 42.34945133152159
- type: euclidean_spearman
value: 42.331610303674644
- type: manhattan_pearson
value: 42.31455070249498
- type: manhattan_spearman
value: 42.19887982891834
- task:
type: STS
dataset:
name: MTEB QBQTC
type: C-MTEB/QBQTC
config: default
split: test
revision: 790b0510dc52b1553e8c49f3d2afb48c0e5c48b7
metrics:
- type: cos_sim_pearson
value: 33.683290790043785
- type: cos_sim_spearman
value: 35.149171171202994
- type: euclidean_pearson
value: 32.33806561267862
- type: euclidean_spearman
value: 34.483576387347966
- type: manhattan_pearson
value: 32.47629754599608
- type: manhattan_spearman
value: 34.66434471867615
- task:
type: STS
dataset:
name: MTEB STS22 (zh)
type: mteb/sts22-crosslingual-sts
config: zh
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 66.46322760516104
- type: cos_sim_spearman
value: 67.398478319726
- type: euclidean_pearson
value: 64.7223480293625
- type: euclidean_spearman
value: 66.83118568812951
- type: manhattan_pearson
value: 64.88440039828305
- type: manhattan_spearman
value: 66.80429458952257
- task:
type: STS
dataset:
name: MTEB STSB
type: C-MTEB/STSB
config: default
split: test
revision: 0cde68302b3541bb8b3c340dc0644b0b745b3dc0
metrics:
- type: cos_sim_pearson
value: 79.08991383232105
- type: cos_sim_spearman
value: 79.39715677296854
- type: euclidean_pearson
value: 78.63201279320496
- type: euclidean_spearman
value: 79.40262660785731
- type: manhattan_pearson
value: 78.98138363146906
- type: manhattan_spearman
value: 79.79968413014194
- task:
type: Reranking
dataset:
name: MTEB T2Reranking
type: C-MTEB/T2Reranking
config: default
split: dev
revision: 76631901a18387f85eaa53e5450019b87ad58ef9
metrics:
- type: map
value: 67.43289278789972
- type: mrr
value: 77.53012460908535
- task:
type: Retrieval
dataset:
name: MTEB T2Retrieval
type: C-MTEB/T2Retrieval
config: default
split: dev
revision: 8731a845f1bf500a4f111cf1070785c793d10e64
metrics:
- type: map_at_1
value: 27.733999999999998
- type: map_at_10
value: 78.24799999999999
- type: map_at_100
value: 81.765
- type: map_at_1000
value: 81.824
- type: map_at_3
value: 54.92
- type: map_at_5
value: 67.61399999999999
- type: mrr_at_1
value: 90.527
- type: mrr_at_10
value: 92.843
- type: mrr_at_100
value: 92.927
- type: mrr_at_1000
value: 92.93
- type: mrr_at_3
value: 92.45100000000001
- type: mrr_at_5
value: 92.693
- type: ndcg_at_1
value: 90.527
- type: ndcg_at_10
value: 85.466
- type: ndcg_at_100
value: 88.846
- type: ndcg_at_1000
value: 89.415
- type: ndcg_at_3
value: 86.768
- type: ndcg_at_5
value: 85.46000000000001
- type: precision_at_1
value: 90.527
- type: precision_at_10
value: 42.488
- type: precision_at_100
value: 5.024
- type: precision_at_1000
value: 0.516
- type: precision_at_3
value: 75.907
- type: precision_at_5
value: 63.727000000000004
- type: recall_at_1
value: 27.733999999999998
- type: recall_at_10
value: 84.346
- type: recall_at_100
value: 95.536
- type: recall_at_1000
value: 98.42999999999999
- type: recall_at_3
value: 56.455
- type: recall_at_5
value: 70.755
- task:
type: Classification
dataset:
name: MTEB TNews
type: C-MTEB/TNews-classification
config: default
split: validation
revision: 317f262bf1e6126357bbe89e875451e4b0938fe4
metrics:
- type: accuracy
value: 49.952000000000005
- type: f1
value: 48.264617195258054
- task:
type: Clustering
dataset:
name: MTEB ThuNewsClusteringP2P
type: C-MTEB/ThuNewsClusteringP2P
config: default
split: test
revision: 5798586b105c0434e4f0fe5e767abe619442cf93
metrics:
- type: v_measure
value: 68.23769904483508
- task:
type: Clustering
dataset:
name: MTEB ThuNewsClusteringS2S
type: C-MTEB/ThuNewsClusteringS2S
config: default
split: test
revision: 8a8b2caeda43f39e13c4bc5bea0f8a667896e10d
metrics:
- type: v_measure
value: 62.50294403136556
- task:
type: Retrieval
dataset:
name: MTEB VideoRetrieval
type: C-MTEB/VideoRetrieval
config: default
split: dev
revision: 58c2597a5943a2ba48f4668c3b90d796283c5639
metrics:
- type: map_at_1
value: 54.0
- type: map_at_10
value: 63.668
- type: map_at_100
value: 64.217
- type: map_at_1000
value: 64.23100000000001
- type: map_at_3
value: 61.7
- type: map_at_5
value: 62.870000000000005
- type: mrr_at_1
value: 54.0
- type: mrr_at_10
value: 63.668
- type: mrr_at_100
value: 64.217
- type: mrr_at_1000
value: 64.23100000000001
- type: mrr_at_3
value: 61.7
- type: mrr_at_5
value: 62.870000000000005
- type: ndcg_at_1
value: 54.0
- type: ndcg_at_10
value: 68.11399999999999
- type: ndcg_at_100
value: 70.723
- type: ndcg_at_1000
value: 71.123
- type: ndcg_at_3
value: 64.074
- type: ndcg_at_5
value: 66.178
- type: precision_at_1
value: 54.0
- type: precision_at_10
value: 8.200000000000001
- type: precision_at_100
value: 0.941
- type: precision_at_1000
value: 0.097
- type: precision_at_3
value: 23.633000000000003
- type: precision_at_5
value: 15.2
- type: recall_at_1
value: 54.0
- type: recall_at_10
value: 82.0
- type: recall_at_100
value: 94.1
- type: recall_at_1000
value: 97.3
- type: recall_at_3
value: 70.89999999999999
- type: recall_at_5
value: 76.0
- task:
type: Classification
dataset:
name: MTEB Waimai
type: C-MTEB/waimai-classification
config: default
split: test
revision: 339287def212450dcaa9df8c22bf93e9980c7023
metrics:
- type: accuracy
value: 86.63000000000001
- type: ap
value: 69.99457882599567
- type: f1
value: 85.07735617998541
- task:
type: Clustering
dataset:
name: MTEB 8TagsClustering
type: PL-MTEB/8tags-clustering
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 44.594104491193555
- task:
type: Classification
dataset:
name: MTEB AllegroReviews
type: PL-MTEB/allegro-reviews
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 63.97614314115309
- type: f1
value: 52.15634261679283
- task:
type: Retrieval
dataset:
name: MTEB ArguAna-PL
type: clarin-knext/arguana-pl
config: default
split: test
revision: 63fc86750af76253e8c760fc9e534bbf24d260a2
metrics:
- type: map_at_1
value: 32.646
- type: map_at_10
value: 47.963
- type: map_at_100
value: 48.789
- type: map_at_1000
value: 48.797000000000004
- type: map_at_3
value: 43.196
- type: map_at_5
value: 46.016
- type: mrr_at_1
value: 33.073
- type: mrr_at_10
value: 48.126000000000005
- type: mrr_at_100
value: 48.946
- type: mrr_at_1000
value: 48.953
- type: mrr_at_3
value: 43.374
- type: mrr_at_5
value: 46.147
- type: ndcg_at_1
value: 32.646
- type: ndcg_at_10
value: 56.481
- type: ndcg_at_100
value: 59.922
- type: ndcg_at_1000
value: 60.07
- type: ndcg_at_3
value: 46.675
- type: ndcg_at_5
value: 51.76500000000001
- type: precision_at_1
value: 32.646
- type: precision_at_10
value: 8.371
- type: precision_at_100
value: 0.9860000000000001
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 18.919
- type: precision_at_5
value: 13.825999999999999
- type: recall_at_1
value: 32.646
- type: recall_at_10
value: 83.71300000000001
- type: recall_at_100
value: 98.578
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 56.757000000000005
- type: recall_at_5
value: 69.132
- task:
type: Classification
dataset:
name: MTEB CBD
type: PL-MTEB/cbd
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 68.56
- type: ap
value: 23.310493680488513
- type: f1
value: 58.85369533105693
- task:
type: PairClassification
dataset:
name: MTEB CDSC-E
type: PL-MTEB/cdsce-pairclassification
config: default
split: test
revision: None
metrics:
- type: cos_sim_accuracy
value: 88.5
- type: cos_sim_ap
value: 72.42140924378361
- type: cos_sim_f1
value: 66.0919540229885
- type: cos_sim_precision
value: 72.78481012658227
- type: cos_sim_recall
value: 60.526315789473685
- type: dot_accuracy
value: 88.5
- type: dot_ap
value: 72.42140924378361
- type: dot_f1
value: 66.0919540229885
- type: dot_precision
value: 72.78481012658227
- type: dot_recall
value: 60.526315789473685
- type: euclidean_accuracy
value: 88.5
- type: euclidean_ap
value: 72.42140924378361
- type: euclidean_f1
value: 66.0919540229885
- type: euclidean_precision
value: 72.78481012658227
- type: euclidean_recall
value: 60.526315789473685
- type: manhattan_accuracy
value: 88.5
- type: manhattan_ap
value: 72.49745515311696
- type: manhattan_f1
value: 66.0968660968661
- type: manhattan_precision
value: 72.04968944099379
- type: manhattan_recall
value: 61.05263157894737
- type: max_accuracy
value: 88.5
- type: max_ap
value: 72.49745515311696
- type: max_f1
value: 66.0968660968661
- task:
type: STS
dataset:
name: MTEB CDSC-R
type: PL-MTEB/cdscr-sts
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 90.32269765590145
- type: cos_sim_spearman
value: 89.73666311491672
- type: euclidean_pearson
value: 88.2933868516544
- type: euclidean_spearman
value: 89.73666311491672
- type: manhattan_pearson
value: 88.33474590219448
- type: manhattan_spearman
value: 89.8548364866583
- task:
type: Retrieval
dataset:
name: MTEB DBPedia-PL
type: clarin-knext/dbpedia-pl
config: default
split: test
revision: 76afe41d9af165cc40999fcaa92312b8b012064a
metrics:
- type: map_at_1
value: 7.632999999999999
- type: map_at_10
value: 16.426
- type: map_at_100
value: 22.651
- type: map_at_1000
value: 24.372
- type: map_at_3
value: 11.706
- type: map_at_5
value: 13.529
- type: mrr_at_1
value: 60.75000000000001
- type: mrr_at_10
value: 68.613
- type: mrr_at_100
value: 69.001
- type: mrr_at_1000
value: 69.021
- type: mrr_at_3
value: 67.0
- type: mrr_at_5
value: 67.925
- type: ndcg_at_1
value: 49.875
- type: ndcg_at_10
value: 36.978
- type: ndcg_at_100
value: 40.031
- type: ndcg_at_1000
value: 47.566
- type: ndcg_at_3
value: 41.148
- type: ndcg_at_5
value: 38.702
- type: precision_at_1
value: 60.75000000000001
- type: precision_at_10
value: 29.7
- type: precision_at_100
value: 9.278
- type: precision_at_1000
value: 2.099
- type: precision_at_3
value: 44.0
- type: precision_at_5
value: 37.6
- type: recall_at_1
value: 7.632999999999999
- type: recall_at_10
value: 22.040000000000003
- type: recall_at_100
value: 44.024
- type: recall_at_1000
value: 67.848
- type: recall_at_3
value: 13.093
- type: recall_at_5
value: 15.973
- task:
type: Retrieval
dataset:
name: MTEB FiQA-PL
type: clarin-knext/fiqa-pl
config: default
split: test
revision: 2e535829717f8bf9dc829b7f911cc5bbd4e6608e
metrics:
- type: map_at_1
value: 15.473
- type: map_at_10
value: 24.579
- type: map_at_100
value: 26.387
- type: map_at_1000
value: 26.57
- type: map_at_3
value: 21.278
- type: map_at_5
value: 23.179
- type: mrr_at_1
value: 30.709999999999997
- type: mrr_at_10
value: 38.994
- type: mrr_at_100
value: 39.993
- type: mrr_at_1000
value: 40.044999999999995
- type: mrr_at_3
value: 36.342999999999996
- type: mrr_at_5
value: 37.846999999999994
- type: ndcg_at_1
value: 30.709999999999997
- type: ndcg_at_10
value: 31.608999999999998
- type: ndcg_at_100
value: 38.807
- type: ndcg_at_1000
value: 42.208
- type: ndcg_at_3
value: 28.086
- type: ndcg_at_5
value: 29.323
- type: precision_at_1
value: 30.709999999999997
- type: precision_at_10
value: 8.688
- type: precision_at_100
value: 1.608
- type: precision_at_1000
value: 0.22100000000000003
- type: precision_at_3
value: 18.724
- type: precision_at_5
value: 13.950999999999999
- type: recall_at_1
value: 15.473
- type: recall_at_10
value: 38.361000000000004
- type: recall_at_100
value: 65.2
- type: recall_at_1000
value: 85.789
- type: recall_at_3
value: 25.401
- type: recall_at_5
value: 30.875999999999998
- task:
type: Retrieval
dataset:
name: MTEB HotpotQA-PL
type: clarin-knext/hotpotqa-pl
config: default
split: test
revision: a0bd479ac97b4ccb5bd6ce320c415d0bb4beb907
metrics:
- type: map_at_1
value: 38.096000000000004
- type: map_at_10
value: 51.44499999999999
- type: map_at_100
value: 52.325
- type: map_at_1000
value: 52.397000000000006
- type: map_at_3
value: 48.626999999999995
- type: map_at_5
value: 50.342
- type: mrr_at_1
value: 76.19200000000001
- type: mrr_at_10
value: 81.191
- type: mrr_at_100
value: 81.431
- type: mrr_at_1000
value: 81.443
- type: mrr_at_3
value: 80.30199999999999
- type: mrr_at_5
value: 80.85900000000001
- type: ndcg_at_1
value: 76.19200000000001
- type: ndcg_at_10
value: 60.9
- type: ndcg_at_100
value: 64.14699999999999
- type: ndcg_at_1000
value: 65.647
- type: ndcg_at_3
value: 56.818000000000005
- type: ndcg_at_5
value: 59.019999999999996
- type: precision_at_1
value: 76.19200000000001
- type: precision_at_10
value: 12.203
- type: precision_at_100
value: 1.478
- type: precision_at_1000
value: 0.168
- type: precision_at_3
value: 34.616
- type: precision_at_5
value: 22.515
- type: recall_at_1
value: 38.096000000000004
- type: recall_at_10
value: 61.013
- type: recall_at_100
value: 73.90299999999999
- type: recall_at_1000
value: 83.91
- type: recall_at_3
value: 51.92400000000001
- type: recall_at_5
value: 56.286
- task:
type: Retrieval
dataset:
name: MTEB MSMARCO-PL
type: clarin-knext/msmarco-pl
config: default
split: test
revision: 8634c07806d5cce3a6138e260e59b81760a0a640
metrics:
- type: map_at_1
value: 1.548
- type: map_at_10
value: 11.049000000000001
- type: map_at_100
value: 28.874
- type: map_at_1000
value: 34.931
- type: map_at_3
value: 4.162
- type: map_at_5
value: 6.396
- type: mrr_at_1
value: 90.69800000000001
- type: mrr_at_10
value: 92.093
- type: mrr_at_100
value: 92.345
- type: mrr_at_1000
value: 92.345
- type: mrr_at_3
value: 91.86
- type: mrr_at_5
value: 91.86
- type: ndcg_at_1
value: 74.031
- type: ndcg_at_10
value: 63.978
- type: ndcg_at_100
value: 53.101
- type: ndcg_at_1000
value: 60.675999999999995
- type: ndcg_at_3
value: 71.421
- type: ndcg_at_5
value: 68.098
- type: precision_at_1
value: 90.69800000000001
- type: precision_at_10
value: 71.86
- type: precision_at_100
value: 31.395
- type: precision_at_1000
value: 5.981
- type: precision_at_3
value: 84.49600000000001
- type: precision_at_5
value: 79.07
- type: recall_at_1
value: 1.548
- type: recall_at_10
value: 12.149000000000001
- type: recall_at_100
value: 40.794999999999995
- type: recall_at_1000
value: 67.974
- type: recall_at_3
value: 4.244
- type: recall_at_5
value: 6.608
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (pl)
type: mteb/amazon_massive_intent
config: pl
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.55413584398119
- type: f1
value: 69.65610882318181
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (pl)
type: mteb/amazon_massive_scenario
config: pl
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.37188971082716
- type: f1
value: 75.64847309941361
- task:
type: Retrieval
dataset:
name: MTEB NFCorpus-PL
type: clarin-knext/nfcorpus-pl
config: default
split: test
revision: 9a6f9567fda928260afed2de480d79c98bf0bec0
metrics:
- type: map_at_1
value: 4.919
- type: map_at_10
value: 10.834000000000001
- type: map_at_100
value: 13.38
- type: map_at_1000
value: 14.581
- type: map_at_3
value: 8.198
- type: map_at_5
value: 9.428
- type: mrr_at_1
value: 41.176
- type: mrr_at_10
value: 50.083
- type: mrr_at_100
value: 50.559
- type: mrr_at_1000
value: 50.604000000000006
- type: mrr_at_3
value: 47.936
- type: mrr_at_5
value: 49.407000000000004
- type: ndcg_at_1
value: 39.628
- type: ndcg_at_10
value: 30.098000000000003
- type: ndcg_at_100
value: 27.061
- type: ndcg_at_1000
value: 35.94
- type: ndcg_at_3
value: 35.135
- type: ndcg_at_5
value: 33.335
- type: precision_at_1
value: 41.176
- type: precision_at_10
value: 22.259999999999998
- type: precision_at_100
value: 6.712
- type: precision_at_1000
value: 1.9060000000000001
- type: precision_at_3
value: 33.23
- type: precision_at_5
value: 29.04
- type: recall_at_1
value: 4.919
- type: recall_at_10
value: 14.196
- type: recall_at_100
value: 26.948
- type: recall_at_1000
value: 59.211000000000006
- type: recall_at_3
value: 9.44
- type: recall_at_5
value: 11.569
- task:
type: Retrieval
dataset:
name: MTEB NQ-PL
type: clarin-knext/nq-pl
config: default
split: test
revision: f171245712cf85dd4700b06bef18001578d0ca8d
metrics:
- type: map_at_1
value: 25.35
- type: map_at_10
value: 37.884
- type: map_at_100
value: 38.955
- type: map_at_1000
value: 39.007999999999996
- type: map_at_3
value: 34.239999999999995
- type: map_at_5
value: 36.398
- type: mrr_at_1
value: 28.737000000000002
- type: mrr_at_10
value: 39.973
- type: mrr_at_100
value: 40.844
- type: mrr_at_1000
value: 40.885
- type: mrr_at_3
value: 36.901
- type: mrr_at_5
value: 38.721
- type: ndcg_at_1
value: 28.708
- type: ndcg_at_10
value: 44.204
- type: ndcg_at_100
value: 48.978
- type: ndcg_at_1000
value: 50.33
- type: ndcg_at_3
value: 37.36
- type: ndcg_at_5
value: 40.912
- type: precision_at_1
value: 28.708
- type: precision_at_10
value: 7.367
- type: precision_at_100
value: 1.0030000000000001
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 17.034
- type: precision_at_5
value: 12.293999999999999
- type: recall_at_1
value: 25.35
- type: recall_at_10
value: 61.411
- type: recall_at_100
value: 82.599
- type: recall_at_1000
value: 92.903
- type: recall_at_3
value: 43.728
- type: recall_at_5
value: 51.854
- task:
type: Classification
dataset:
name: MTEB PAC
type: laugustyniak/abusive-clauses-pl
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 69.04141326382856
- type: ap
value: 77.49422763833996
- type: f1
value: 66.73472657783407
- task:
type: PairClassification
dataset:
name: MTEB PPC
type: PL-MTEB/ppc-pairclassification
config: default
split: test
revision: None
metrics:
- type: cos_sim_accuracy
value: 81.0
- type: cos_sim_ap
value: 91.47194213011349
- type: cos_sim_f1
value: 84.73767885532592
- type: cos_sim_precision
value: 81.49847094801224
- type: cos_sim_recall
value: 88.24503311258279
- type: dot_accuracy
value: 81.0
- type: dot_ap
value: 91.47194213011349
- type: dot_f1
value: 84.73767885532592
- type: dot_precision
value: 81.49847094801224
- type: dot_recall
value: 88.24503311258279
- type: euclidean_accuracy
value: 81.0
- type: euclidean_ap
value: 91.47194213011349
- type: euclidean_f1
value: 84.73767885532592
- type: euclidean_precision
value: 81.49847094801224
- type: euclidean_recall
value: 88.24503311258279
- type: manhattan_accuracy
value: 81.0
- type: manhattan_ap
value: 91.46464475050571
- type: manhattan_f1
value: 84.48687350835321
- type: manhattan_precision
value: 81.31699846860643
- type: manhattan_recall
value: 87.91390728476821
- type: max_accuracy
value: 81.0
- type: max_ap
value: 91.47194213011349
- type: max_f1
value: 84.73767885532592
- task:
type: PairClassification
dataset:
name: MTEB PSC
type: PL-MTEB/psc-pairclassification
config: default
split: test
revision: None
metrics:
- type: cos_sim_accuracy
value: 97.6808905380334
- type: cos_sim_ap
value: 99.27948611836348
- type: cos_sim_f1
value: 96.15975422427034
- type: cos_sim_precision
value: 96.90402476780186
- type: cos_sim_recall
value: 95.42682926829268
- type: dot_accuracy
value: 97.6808905380334
- type: dot_ap
value: 99.2794861183635
- type: dot_f1
value: 96.15975422427034
- type: dot_precision
value: 96.90402476780186
- type: dot_recall
value: 95.42682926829268
- type: euclidean_accuracy
value: 97.6808905380334
- type: euclidean_ap
value: 99.2794861183635
- type: euclidean_f1
value: 96.15975422427034
- type: euclidean_precision
value: 96.90402476780186
- type: euclidean_recall
value: 95.42682926829268
- type: manhattan_accuracy
value: 97.6808905380334
- type: manhattan_ap
value: 99.28715055268721
- type: manhattan_f1
value: 96.14791987673343
- type: manhattan_precision
value: 97.19626168224299
- type: manhattan_recall
value: 95.1219512195122
- type: max_accuracy
value: 97.6808905380334
- type: max_ap
value: 99.28715055268721
- type: max_f1
value: 96.15975422427034
- task:
type: Classification
dataset:
name: MTEB PolEmo2.0-IN
type: PL-MTEB/polemo2_in
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 86.16343490304708
- type: f1
value: 83.3442579486744
- task:
type: Classification
dataset:
name: MTEB PolEmo2.0-OUT
type: PL-MTEB/polemo2_out
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 68.40080971659918
- type: f1
value: 53.13720751142237
- task:
type: Retrieval
dataset:
name: MTEB Quora-PL
type: clarin-knext/quora-pl
config: default
split: test
revision: 0be27e93455051e531182b85e85e425aba12e9d4
metrics:
- type: map_at_1
value: 63.322
- type: map_at_10
value: 76.847
- type: map_at_100
value: 77.616
- type: map_at_1000
value: 77.644
- type: map_at_3
value: 73.624
- type: map_at_5
value: 75.603
- type: mrr_at_1
value: 72.88
- type: mrr_at_10
value: 80.376
- type: mrr_at_100
value: 80.604
- type: mrr_at_1000
value: 80.61
- type: mrr_at_3
value: 78.92
- type: mrr_at_5
value: 79.869
- type: ndcg_at_1
value: 72.89999999999999
- type: ndcg_at_10
value: 81.43
- type: ndcg_at_100
value: 83.394
- type: ndcg_at_1000
value: 83.685
- type: ndcg_at_3
value: 77.62599999999999
- type: ndcg_at_5
value: 79.656
- type: precision_at_1
value: 72.89999999999999
- type: precision_at_10
value: 12.548
- type: precision_at_100
value: 1.4869999999999999
- type: precision_at_1000
value: 0.155
- type: precision_at_3
value: 34.027
- type: precision_at_5
value: 22.654
- type: recall_at_1
value: 63.322
- type: recall_at_10
value: 90.664
- type: recall_at_100
value: 97.974
- type: recall_at_1000
value: 99.636
- type: recall_at_3
value: 80.067
- type: recall_at_5
value: 85.526
- task:
type: Retrieval
dataset:
name: MTEB SCIDOCS-PL
type: clarin-knext/scidocs-pl
config: default
split: test
revision: 45452b03f05560207ef19149545f168e596c9337
metrics:
- type: map_at_1
value: 3.95
- type: map_at_10
value: 9.658999999999999
- type: map_at_100
value: 11.384
- type: map_at_1000
value: 11.677
- type: map_at_3
value: 7.055
- type: map_at_5
value: 8.244
- type: mrr_at_1
value: 19.5
- type: mrr_at_10
value: 28.777
- type: mrr_at_100
value: 29.936
- type: mrr_at_1000
value: 30.009999999999998
- type: mrr_at_3
value: 25.55
- type: mrr_at_5
value: 27.284999999999997
- type: ndcg_at_1
value: 19.5
- type: ndcg_at_10
value: 16.589000000000002
- type: ndcg_at_100
value: 23.879
- type: ndcg_at_1000
value: 29.279
- type: ndcg_at_3
value: 15.719
- type: ndcg_at_5
value: 13.572000000000001
- type: precision_at_1
value: 19.5
- type: precision_at_10
value: 8.62
- type: precision_at_100
value: 1.924
- type: precision_at_1000
value: 0.322
- type: precision_at_3
value: 14.6
- type: precision_at_5
value: 11.78
- type: recall_at_1
value: 3.95
- type: recall_at_10
value: 17.477999999999998
- type: recall_at_100
value: 38.99
- type: recall_at_1000
value: 65.417
- type: recall_at_3
value: 8.883000000000001
- type: recall_at_5
value: 11.933
- task:
type: PairClassification
dataset:
name: MTEB SICK-E-PL
type: PL-MTEB/sicke-pl-pairclassification
config: default
split: test
revision: None
metrics:
- type: cos_sim_accuracy
value: 83.48960456583775
- type: cos_sim_ap
value: 76.31522115825375
- type: cos_sim_f1
value: 70.35573122529645
- type: cos_sim_precision
value: 70.9934735315446
- type: cos_sim_recall
value: 69.72934472934473
- type: dot_accuracy
value: 83.48960456583775
- type: dot_ap
value: 76.31522115825373
- type: dot_f1
value: 70.35573122529645
- type: dot_precision
value: 70.9934735315446
- type: dot_recall
value: 69.72934472934473
- type: euclidean_accuracy
value: 83.48960456583775
- type: euclidean_ap
value: 76.31522115825373
- type: euclidean_f1
value: 70.35573122529645
- type: euclidean_precision
value: 70.9934735315446
- type: euclidean_recall
value: 69.72934472934473
- type: manhattan_accuracy
value: 83.46922136159804
- type: manhattan_ap
value: 76.18474601388084
- type: manhattan_f1
value: 70.34779490856937
- type: manhattan_precision
value: 70.83032490974729
- type: manhattan_recall
value: 69.87179487179486
- type: max_accuracy
value: 83.48960456583775
- type: max_ap
value: 76.31522115825375
- type: max_f1
value: 70.35573122529645
- task:
type: STS
dataset:
name: MTEB SICK-R-PL
type: PL-MTEB/sickr-pl-sts
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 77.95374883876302
- type: cos_sim_spearman
value: 73.77630219171942
- type: euclidean_pearson
value: 75.81927069594934
- type: euclidean_spearman
value: 73.7763211303831
- type: manhattan_pearson
value: 76.03126859057528
- type: manhattan_spearman
value: 73.96528138013369
- task:
type: STS
dataset:
name: MTEB STS22 (pl)
type: mteb/sts22-crosslingual-sts
config: pl
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 37.388282764841826
- type: cos_sim_spearman
value: 40.83477184710897
- type: euclidean_pearson
value: 26.754737044177805
- type: euclidean_spearman
value: 40.83477184710897
- type: manhattan_pearson
value: 26.760453110872458
- type: manhattan_spearman
value: 41.034477441383856
- task:
type: Retrieval
dataset:
name: MTEB SciFact-PL
type: clarin-knext/scifact-pl
config: default
split: test
revision: 47932a35f045ef8ed01ba82bf9ff67f6e109207e
metrics:
- type: map_at_1
value: 49.15
- type: map_at_10
value: 61.690999999999995
- type: map_at_100
value: 62.348000000000006
- type: map_at_1000
value: 62.38
- type: map_at_3
value: 58.824
- type: map_at_5
value: 60.662000000000006
- type: mrr_at_1
value: 51.333
- type: mrr_at_10
value: 62.731
- type: mrr_at_100
value: 63.245
- type: mrr_at_1000
value: 63.275000000000006
- type: mrr_at_3
value: 60.667
- type: mrr_at_5
value: 61.93300000000001
- type: ndcg_at_1
value: 51.333
- type: ndcg_at_10
value: 67.168
- type: ndcg_at_100
value: 69.833
- type: ndcg_at_1000
value: 70.56700000000001
- type: ndcg_at_3
value: 62.40599999999999
- type: ndcg_at_5
value: 65.029
- type: precision_at_1
value: 51.333
- type: precision_at_10
value: 9.333
- type: precision_at_100
value: 1.0699999999999998
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 25.333
- type: precision_at_5
value: 17.067
- type: recall_at_1
value: 49.15
- type: recall_at_10
value: 82.533
- type: recall_at_100
value: 94.167
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 69.917
- type: recall_at_5
value: 76.356
- task:
type: Retrieval
dataset:
name: MTEB TRECCOVID-PL
type: clarin-knext/trec-covid-pl
config: default
split: test
revision: 81bcb408f33366c2a20ac54adafad1ae7e877fdd
metrics:
- type: map_at_1
value: 0.261
- type: map_at_10
value: 2.1260000000000003
- type: map_at_100
value: 12.171999999999999
- type: map_at_1000
value: 26.884999999999998
- type: map_at_3
value: 0.695
- type: map_at_5
value: 1.134
- type: mrr_at_1
value: 96.0
- type: mrr_at_10
value: 96.952
- type: mrr_at_100
value: 96.952
- type: mrr_at_1000
value: 96.952
- type: mrr_at_3
value: 96.667
- type: mrr_at_5
value: 96.667
- type: ndcg_at_1
value: 92.0
- type: ndcg_at_10
value: 81.193
- type: ndcg_at_100
value: 61.129
- type: ndcg_at_1000
value: 51.157
- type: ndcg_at_3
value: 85.693
- type: ndcg_at_5
value: 84.129
- type: precision_at_1
value: 96.0
- type: precision_at_10
value: 85.39999999999999
- type: precision_at_100
value: 62.03999999999999
- type: precision_at_1000
value: 22.224
- type: precision_at_3
value: 88.0
- type: precision_at_5
value: 88.0
- type: recall_at_1
value: 0.261
- type: recall_at_10
value: 2.262
- type: recall_at_100
value: 14.981
- type: recall_at_1000
value: 46.837
- type: recall_at_3
value: 0.703
- type: recall_at_5
value: 1.172
- task:
type: Clustering
dataset:
name: MTEB AlloProfClusteringP2P
type: lyon-nlp/alloprof
config: default
split: test
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
metrics:
- type: v_measure
value: 70.55290063940157
- type: v_measure
value: 55.41500719337263
- task:
type: Reranking
dataset:
name: MTEB AlloprofReranking
type: lyon-nlp/mteb-fr-reranking-alloprof-s2p
config: default
split: test
revision: 666fdacebe0291776e86f29345663dfaf80a0db9
metrics:
- type: map
value: 73.48697375332002
- type: mrr
value: 75.01836585523822
- task:
type: Retrieval
dataset:
name: MTEB AlloprofRetrieval
type: lyon-nlp/alloprof
config: default
split: test
revision: 392ba3f5bcc8c51f578786c1fc3dae648662cb9b
metrics:
- type: map_at_1
value: 38.454
- type: map_at_10
value: 51.605000000000004
- type: map_at_100
value: 52.653000000000006
- type: map_at_1000
value: 52.697
- type: map_at_3
value: 48.304
- type: map_at_5
value: 50.073
- type: mrr_at_1
value: 43.307
- type: mrr_at_10
value: 54.400000000000006
- type: mrr_at_100
value: 55.147999999999996
- type: mrr_at_1000
value: 55.174
- type: mrr_at_3
value: 51.77
- type: mrr_at_5
value: 53.166999999999994
- type: ndcg_at_1
value: 43.307
- type: ndcg_at_10
value: 57.891000000000005
- type: ndcg_at_100
value: 62.161
- type: ndcg_at_1000
value: 63.083
- type: ndcg_at_3
value: 51.851
- type: ndcg_at_5
value: 54.605000000000004
- type: precision_at_1
value: 43.307
- type: precision_at_10
value: 9.033
- type: precision_at_100
value: 1.172
- type: precision_at_1000
value: 0.127
- type: precision_at_3
value: 22.798
- type: precision_at_5
value: 15.492
- type: recall_at_1
value: 38.454
- type: recall_at_10
value: 74.166
- type: recall_at_100
value: 92.43599999999999
- type: recall_at_1000
value: 99.071
- type: recall_at_3
value: 58.087
- type: recall_at_5
value: 64.568
- task:
type: Classification
dataset:
name: MTEB AmazonReviewsClassification (fr)
type: mteb/amazon_reviews_multi
config: fr
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 53.474
- type: f1
value: 50.38275392350236
- task:
type: Retrieval
dataset:
name: MTEB BSARDRetrieval
type: maastrichtlawtech/bsard
config: default
split: test
revision: 5effa1b9b5fa3b0f9e12523e6e43e5f86a6e6d59
metrics:
- type: map_at_1
value: 2.252
- type: map_at_10
value: 4.661
- type: map_at_100
value: 5.271
- type: map_at_1000
value: 5.3629999999999995
- type: map_at_3
value: 3.604
- type: map_at_5
value: 4.3020000000000005
- type: mrr_at_1
value: 2.252
- type: mrr_at_10
value: 4.661
- type: mrr_at_100
value: 5.271
- type: mrr_at_1000
value: 5.3629999999999995
- type: mrr_at_3
value: 3.604
- type: mrr_at_5
value: 4.3020000000000005
- type: ndcg_at_1
value: 2.252
- type: ndcg_at_10
value: 6.3020000000000005
- type: ndcg_at_100
value: 10.342
- type: ndcg_at_1000
value: 13.475999999999999
- type: ndcg_at_3
value: 4.0649999999999995
- type: ndcg_at_5
value: 5.344
- type: precision_at_1
value: 2.252
- type: precision_at_10
value: 1.171
- type: precision_at_100
value: 0.333
- type: precision_at_1000
value: 0.059000000000000004
- type: precision_at_3
value: 1.802
- type: precision_at_5
value: 1.712
- type: recall_at_1
value: 2.252
- type: recall_at_10
value: 11.712
- type: recall_at_100
value: 33.333
- type: recall_at_1000
value: 59.458999999999996
- type: recall_at_3
value: 5.405
- type: recall_at_5
value: 8.559
- task:
type: Clustering
dataset:
name: MTEB HALClusteringS2S
type: lyon-nlp/clustering-hal-s2s
config: default
split: test
revision: e06ebbbb123f8144bef1a5d18796f3dec9ae2915
metrics:
- type: v_measure
value: 28.301882091023288
- task:
type: Clustering
dataset:
name: MTEB MLSUMClusteringP2P
type: mlsum
config: default
split: test
revision: b5d54f8f3b61ae17845046286940f03c6bc79bc7
metrics:
- type: v_measure
value: 45.26992995191701
- type: v_measure
value: 42.773174876871145
- task:
type: Classification
dataset:
name: MTEB MTOPDomainClassification (fr)
type: mteb/mtop_domain
config: fr
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.47635452552458
- type: f1
value: 93.19922617577213
- task:
type: Classification
dataset:
name: MTEB MTOPIntentClassification (fr)
type: mteb/mtop_intent
config: fr
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 80.2317569683683
- type: f1
value: 56.18060418621901
- task:
type: Classification
dataset:
name: MTEB MasakhaNEWSClassification (fra)
type: masakhane/masakhanews
config: fra
split: test
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
metrics:
- type: accuracy
value: 85.18957345971565
- type: f1
value: 80.829981537394
- task:
type: Clustering
dataset:
name: MTEB MasakhaNEWSClusteringP2P (fra)
type: masakhane/masakhanews
config: fra
split: test
revision: 8ccc72e69e65f40c70e117d8b3c08306bb788b60
metrics:
- type: v_measure
value: 71.04138999801822
- type: v_measure
value: 71.7056263158008
- task:
type: Classification
dataset:
name: MTEB MassiveIntentClassification (fr)
type: mteb/amazon_massive_intent
config: fr
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 76.65097511768661
- type: f1
value: 73.82441070598712
- task:
type: Classification
dataset:
name: MTEB MassiveScenarioClassification (fr)
type: mteb/amazon_massive_scenario
config: fr
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 79.09885675857431
- type: f1
value: 78.28407777434224
- task:
type: Retrieval
dataset:
name: MTEB MintakaRetrieval (fr)
type: jinaai/mintakaqa
config: fr
split: test
revision: efa78cc2f74bbcd21eff2261f9e13aebe40b814e
metrics:
- type: map_at_1
value: 25.307000000000002
- type: map_at_10
value: 36.723
- type: map_at_100
value: 37.713
- type: map_at_1000
value: 37.769000000000005
- type: map_at_3
value: 33.77
- type: map_at_5
value: 35.463
- type: mrr_at_1
value: 25.307000000000002
- type: mrr_at_10
value: 36.723
- type: mrr_at_100
value: 37.713
- type: mrr_at_1000
value: 37.769000000000005
- type: mrr_at_3
value: 33.77
- type: mrr_at_5
value: 35.463
- type: ndcg_at_1
value: 25.307000000000002
- type: ndcg_at_10
value: 42.559999999999995
- type: ndcg_at_100
value: 47.457
- type: ndcg_at_1000
value: 49.162
- type: ndcg_at_3
value: 36.461
- type: ndcg_at_5
value: 39.504
- type: precision_at_1
value: 25.307000000000002
- type: precision_at_10
value: 6.106
- type: precision_at_100
value: 0.8420000000000001
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 14.741999999999999
- type: precision_at_5
value: 10.319
- type: recall_at_1
value: 25.307000000000002
- type: recall_at_10
value: 61.056999999999995
- type: recall_at_100
value: 84.152
- type: recall_at_1000
value: 98.03399999999999
- type: recall_at_3
value: 44.226
- type: recall_at_5
value: 51.597
- task:
type: PairClassification
dataset:
name: MTEB OpusparcusPC (fr)
type: GEM/opusparcus
config: fr
split: test
revision: 9e9b1f8ef51616073f47f306f7f47dd91663f86a
metrics:
- type: cos_sim_accuracy
value: 99.90069513406156
- type: cos_sim_ap
value: 100.0
- type: cos_sim_f1
value: 99.95032290114257
- type: cos_sim_precision
value: 100.0
- type: cos_sim_recall
value: 99.90069513406156
- type: dot_accuracy
value: 99.90069513406156
- type: dot_ap
value: 100.0
- type: dot_f1
value: 99.95032290114257
- type: dot_precision
value: 100.0
- type: dot_recall
value: 99.90069513406156
- type: euclidean_accuracy
value: 99.90069513406156
- type: euclidean_ap
value: 100.0
- type: euclidean_f1
value: 99.95032290114257
- type: euclidean_precision
value: 100.0
- type: euclidean_recall
value: 99.90069513406156
- type: manhattan_accuracy
value: 99.90069513406156
- type: manhattan_ap
value: 100.0
- type: manhattan_f1
value: 99.95032290114257
- type: manhattan_precision
value: 100.0
- type: manhattan_recall
value: 99.90069513406156
- type: max_accuracy
value: 99.90069513406156
- type: max_ap
value: 100.0
- type: max_f1
value: 99.95032290114257
- task:
type: PairClassification
dataset:
name: MTEB PawsX (fr)
type: paws-x
config: fr
split: test
revision: 8a04d940a42cd40658986fdd8e3da561533a3646
metrics:
- type: cos_sim_accuracy
value: 70.8
- type: cos_sim_ap
value: 73.7671529695957
- type: cos_sim_f1
value: 68.80964339527875
- type: cos_sim_precision
value: 62.95955882352941
- type: cos_sim_recall
value: 75.85825027685493
- type: dot_accuracy
value: 70.8
- type: dot_ap
value: 73.78345265366947
- type: dot_f1
value: 68.80964339527875
- type: dot_precision
value: 62.95955882352941
- type: dot_recall
value: 75.85825027685493
- type: euclidean_accuracy
value: 70.8
- type: euclidean_ap
value: 73.7671529695957
- type: euclidean_f1
value: 68.80964339527875
- type: euclidean_precision
value: 62.95955882352941
- type: euclidean_recall
value: 75.85825027685493
- type: manhattan_accuracy
value: 70.75
- type: manhattan_ap
value: 73.78996383615953
- type: manhattan_f1
value: 68.79432624113475
- type: manhattan_precision
value: 63.39869281045751
- type: manhattan_recall
value: 75.1937984496124
- type: max_accuracy
value: 70.8
- type: max_ap
value: 73.78996383615953
- type: max_f1
value: 68.80964339527875
- task:
type: STS
dataset:
name: MTEB SICKFr
type: Lajavaness/SICK-fr
config: default
split: test
revision: e077ab4cf4774a1e36d86d593b150422fafd8e8a
metrics:
- type: cos_sim_pearson
value: 84.03253762760392
- type: cos_sim_spearman
value: 79.68280105762004
- type: euclidean_pearson
value: 80.98265050044444
- type: euclidean_spearman
value: 79.68233242682867
- type: manhattan_pearson
value: 80.9678911810704
- type: manhattan_spearman
value: 79.70264097683109
- task:
type: STS
dataset:
name: MTEB STS22 (fr)
type: mteb/sts22-crosslingual-sts
config: fr
split: test
revision: eea2b4fe26a775864c896887d910b76a8098ad3f
metrics:
- type: cos_sim_pearson
value: 80.56896987572884
- type: cos_sim_spearman
value: 81.84352499523287
- type: euclidean_pearson
value: 80.40831759421305
- type: euclidean_spearman
value: 81.84352499523287
- type: manhattan_pearson
value: 80.74333857561238
- type: manhattan_spearman
value: 82.41503246733892
- task:
type: STS
dataset:
name: MTEB STSBenchmarkMultilingualSTS (fr)
type: stsb_multi_mt
config: fr
split: test
revision: 93d57ef91790589e3ce9c365164337a8a78b7632
metrics:
- type: cos_sim_pearson
value: 82.71826762276979
- type: cos_sim_spearman
value: 82.25433354916042
- type: euclidean_pearson
value: 81.87115571724316
- type: euclidean_spearman
value: 82.25322342890107
- type: manhattan_pearson
value: 82.11174867527224
- type: manhattan_spearman
value: 82.55905365203084
- task:
type: Summarization
dataset:
name: MTEB SummEvalFr
type: lyon-nlp/summarization-summeval-fr-p2p
config: default
split: test
revision: b385812de6a9577b6f4d0f88c6a6e35395a94054
metrics:
- type: cos_sim_pearson
value: 30.659441623392887
- type: cos_sim_spearman
value: 30.501134097353315
- type: dot_pearson
value: 30.659444768851056
- type: dot_spearman
value: 30.501134097353315
- task:
type: Reranking
dataset:
name: MTEB SyntecReranking
type: lyon-nlp/mteb-fr-reranking-syntec-s2p
config: default
split: test
revision: b205c5084a0934ce8af14338bf03feb19499c84d
metrics:
- type: map
value: 94.03333333333333
- type: mrr
value: 94.03333333333333
- task:
type: Retrieval
dataset:
name: MTEB SyntecRetrieval
type: lyon-nlp/mteb-fr-retrieval-syntec-s2p
config: default
split: test
revision: 77f7e271bf4a92b24fce5119f3486b583ca016ff
metrics:
- type: map_at_1
value: 79.0
- type: map_at_10
value: 87.61
- type: map_at_100
value: 87.655
- type: map_at_1000
value: 87.655
- type: map_at_3
value: 87.167
- type: map_at_5
value: 87.36699999999999
- type: mrr_at_1
value: 79.0
- type: mrr_at_10
value: 87.61
- type: mrr_at_100
value: 87.655
- type: mrr_at_1000
value: 87.655
- type: mrr_at_3
value: 87.167
- type: mrr_at_5
value: 87.36699999999999
- type: ndcg_at_1
value: 79.0
- type: ndcg_at_10
value: 90.473
- type: ndcg_at_100
value: 90.694
- type: ndcg_at_1000
value: 90.694
- type: ndcg_at_3
value: 89.464
- type: ndcg_at_5
value: 89.851
- type: precision_at_1
value: 79.0
- type: precision_at_10
value: 9.9
- type: precision_at_100
value: 1.0
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 32.0
- type: precision_at_5
value: 19.400000000000002
- type: recall_at_1
value: 79.0
- type: recall_at_10
value: 99.0
- type: recall_at_100
value: 100.0
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 96.0
- type: recall_at_5
value: 97.0
- task:
type: Retrieval
dataset:
name: MTEB XPQARetrieval (fr)
type: jinaai/xpqa
config: fr
split: test
revision: c99d599f0a6ab9b85b065da6f9d94f9cf731679f
metrics:
- type: map_at_1
value: 39.395
- type: map_at_10
value: 59.123999999999995
- type: map_at_100
value: 60.704
- type: map_at_1000
value: 60.760000000000005
- type: map_at_3
value: 53.187
- type: map_at_5
value: 56.863
- type: mrr_at_1
value: 62.083
- type: mrr_at_10
value: 68.87299999999999
- type: mrr_at_100
value: 69.46900000000001
- type: mrr_at_1000
value: 69.48299999999999
- type: mrr_at_3
value: 66.8
- type: mrr_at_5
value: 67.928
- type: ndcg_at_1
value: 62.083
- type: ndcg_at_10
value: 65.583
- type: ndcg_at_100
value: 70.918
- type: ndcg_at_1000
value: 71.72800000000001
- type: ndcg_at_3
value: 60.428000000000004
- type: ndcg_at_5
value: 61.853
- type: precision_at_1
value: 62.083
- type: precision_at_10
value: 15.033
- type: precision_at_100
value: 1.9529999999999998
- type: precision_at_1000
value: 0.207
- type: precision_at_3
value: 36.315
- type: precision_at_5
value: 25.955000000000002
- type: recall_at_1
value: 39.395
- type: recall_at_10
value: 74.332
- type: recall_at_100
value: 94.729
- type: recall_at_1000
value: 99.75500000000001
- type: recall_at_3
value: 57.679
- type: recall_at_5
value: 65.036
---
# mxs980/gte-Qwen2-1.5B-instruct-Q8_0-GGUF
This model was converted to GGUF format from [`Alibaba-NLP/gte-Qwen2-1.5B-instruct`](https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Alibaba-NLP/gte-Qwen2-1.5B-instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo mxs980/gte-Qwen2-1.5B-instruct-Q8_0-GGUF --hf-file gte-qwen2-1.5b-instruct-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo mxs980/gte-Qwen2-1.5B-instruct-Q8_0-GGUF --hf-file gte-qwen2-1.5b-instruct-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo mxs980/gte-Qwen2-1.5B-instruct-Q8_0-GGUF --hf-file gte-qwen2-1.5b-instruct-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo mxs980/gte-Qwen2-1.5B-instruct-Q8_0-GGUF --hf-file gte-qwen2-1.5b-instruct-q8_0.gguf -c 2048
```
|
[
"BIOSSES",
"SCIFACT"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.