
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
Andresgr96/gemma-3-4b-it-qat
|
Andresgr96
| 2025-06-20T17:15:19Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"gemma3",
"image-text-to-text",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/gemma-3-4b-it-qat",
"base_model:quantized:unsloth/gemma-3-4b-it-qat",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
image-text-to-text
| 2025-06-18T16:06:36Z |
---
base_model: unsloth/gemma-3-4b-it-qat
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Andresgr96
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-4b-it-qat
This gemma3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
aleegis/f5679987-0679-4a8d-a775-5b16f6baae84
|
aleegis
| 2025-06-20T17:13:10Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:samoline/69663868-e365-43ba-b6c0-cef04404c3ee",
"base_model:adapter:samoline/69663868-e365-43ba-b6c0-cef04404c3ee",
"region:us"
] | null | 2025-06-20T15:32:53Z |
---
library_name: peft
base_model: samoline/69663868-e365-43ba-b6c0-cef04404c3ee
tags:
- axolotl
- generated_from_trainer
model-index:
- name: f5679987-0679-4a8d-a775-5b16f6baae84
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.10.0.dev0`
```yaml
adapter: lora
base_model: samoline/69663868-e365-43ba-b6c0-cef04404c3ee
bf16: auto
chat_template: llama3
dataloader_num_workers: 12
dataset_prepared_path: null
datasets:
- data_files:
- d639eea1bad69a23_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_input: input
field_instruction: instruct
field_output: output
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_steps: null
eval_table_size: null
evals_per_epoch: null
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: false
group_by_length: false
hub_model_id: aleegis/f5679987-0679-4a8d-a775-5b16f6baae84
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.0001
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: null
lora_alpha: 32
lora_dropout: 0.15
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
loraplus_lr_embedding: 1.0e-06
loraplus_lr_ratio: 16
lr_scheduler: cosine
max_grad_norm: 1
max_steps: 1500
micro_batch_size: 4
mlflow_experiment_name: /tmp/d639eea1bad69a23_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 200
optimizer: adamw_torch_fused
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: null
save_total_limit: 10
saves_per_epoch: 0
sequence_len: 1024
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.0
wandb_entity: null
wandb_mode: online
wandb_name: f63bf158-5701-4294-be0a-194048e6dbb3
wandb_project: Gradients-On-Demand
wandb_run: your_name
wandb_runid: f63bf158-5701-4294-be0a-194048e6dbb3
warmup_steps: 100
weight_decay: 0
xformers_attention: null
```
</details><br>
# f5679987-0679-4a8d-a775-5b16f6baae84
This model is a fine-tuned version of [samoline/69663868-e365-43ba-b6c0-cef04404c3ee](https://huggingface.co/samoline/69663868-e365-43ba-b6c0-cef04404c3ee) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- total_eval_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 1500
### Training results
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.5.1+cu124
- Datasets 3.5.1
- Tokenizers 0.21.1
|
ProDev9515/roadwork-72-w8b4vr8
|
ProDev9515
| 2025-06-20T17:11:21Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T17:11:13Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ProDev9515/roadwork-72-YqFjFPx
|
ProDev9515
| 2025-06-20T17:10:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T17:10:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ProDev9515/roadwork-72-RHTmE4s
|
ProDev9515
| 2025-06-20T17:10:49Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T17:10:42Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ProDev9515/roadwork-72-M5USSZk
|
ProDev9515
| 2025-06-20T17:10:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T17:10:25Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ProDev9515/roadwork-72-gdKN5Qp
|
ProDev9515
| 2025-06-20T17:09:01Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T17:08:54Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ProDev9515/roadwork-72-wqTc9WN
|
ProDev9515
| 2025-06-20T17:08:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T17:08:46Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ProDev9515/roadwork-72-3FcJwi2
|
ProDev9515
| 2025-06-20T17:08:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T17:08:05Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ProDev9515/roadwork-72-ytjhtjB
|
ProDev9515
| 2025-06-20T17:07:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T17:07:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ReallyFloppyPenguin/II-Medical-8B-1706-GGUF
|
ReallyFloppyPenguin
| 2025-06-20T16:59:26Z | 0 | 0 |
gguf
|
[
"gguf",
"quantized",
"llama.cpp",
"en",
"base_model:Intelligent-Internet/II-Medical-8B-1706",
"base_model:quantized:Intelligent-Internet/II-Medical-8B-1706",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-20T16:40:12Z |
---
language:
- en
library_name: gguf
base_model: Intelligent-Internet/II-Medical-8B-1706
tags:
- gguf
- quantized
- llama.cpp
license: apache-2.0
---
# Intelligent-Internet/II-Medical-8B-1706 - GGUF
This repository contains GGUF quantizations of [Intelligent-Internet/II-Medical-8B-1706](https://huggingface.co/Intelligent-Internet/II-Medical-8B-1706).
## About GGUF
GGUF is a quantization method that allows you to run large language models on consumer hardware by reducing the precision of the model weights.
## Files
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| model-f16.gguf | f16 | Large | Original precision |
| model-q4_0.gguf | Q4_0 | Small | 4-bit quantization |
| model-q4_1.gguf | Q4_1 | Small | 4-bit quantization (higher quality) |
| model-q5_0.gguf | Q5_0 | Medium | 5-bit quantization |
| model-q5_1.gguf | Q5_1 | Medium | 5-bit quantization (higher quality) |
| model-q8_0.gguf | Q8_0 | Large | 8-bit quantization |
## Usage
You can use these models with llama.cpp or any other GGUF-compatible inference engine.
### llama.cpp
```bash
./llama-cli -m model-q4_0.gguf -p "Your prompt here"
```
### Python (using llama-cpp-python)
```python
from llama_cpp import Llama
llm = Llama(model_path="model-q4_0.gguf")
output = llm("Your prompt here", max_tokens=512)
print(output['choices'][0]['text'])
```
## Original Model
This is a quantized version of [Intelligent-Internet/II-Medical-8B-1706](https://huggingface.co/Intelligent-Internet/II-Medical-8B-1706). Please refer to the original model card for more information about the model's capabilities, training data, and usage guidelines.
## Conversion Details
- Converted using llama.cpp
- Original model downloaded from Hugging Face
- Multiple quantization levels provided for different use cases
## License
This model inherits the license from the original model. Please check the original model's license for usage terms.
|
uvegesistvan/roberta_large_pl_10_sh
|
uvegesistvan
| 2025-06-20T16:58:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-20T15:19:41Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Official-Sajal-Malik-18-Viral-Videos/Original.Full.Clip.Sajal.Malik.Viral.Video.Leaks.Official
|
Official-Sajal-Malik-18-Viral-Videos
| 2025-06-20T16:53:34Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T16:53:21Z |
<a href="https://sdu.sk/uLf"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/uLf" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/uLf" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
apalacio1128/ytvirality-lora
|
apalacio1128
| 2025-06-20T16:44:14Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-06-19T20:25:50Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
tomaarsen/csr-mxbai-embed-large-v1-nq-cos-sim-scale-50-gamma-0.1-detach-2
|
tomaarsen
| 2025-06-20T16:40:45Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sparse-encoder",
"sparse",
"csr",
"generated_from_trainer",
"dataset_size:99000",
"loss:CSRLoss",
"loss:SparseMultipleNegativesRankingLoss",
"feature-extraction",
"en",
"dataset:sentence-transformers/natural-questions",
"arxiv:1908.10084",
"arxiv:2503.01776",
"arxiv:1705.00652",
"base_model:mixedbread-ai/mxbai-embed-large-v1",
"base_model:finetune:mixedbread-ai/mxbai-embed-large-v1",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-20T16:40:36Z |
---
language:
- en
license: apache-2.0
tags:
- sentence-transformers
- sparse-encoder
- sparse
- csr
- generated_from_trainer
- dataset_size:99000
- loss:CSRLoss
- loss:SparseMultipleNegativesRankingLoss
base_model: mixedbread-ai/mxbai-embed-large-v1
widget:
- text: Saudi Arabia–United Arab Emirates relations However, the UAE and Saudi Arabia
continue to take somewhat differing stances on regional conflicts such the Yemeni
Civil War, where the UAE opposes Al-Islah, and supports the Southern Movement,
which has fought against Saudi-backed forces, and the Syrian Civil War, where
the UAE has disagreed with Saudi support for Islamist movements.[4]
- text: Economy of New Zealand New Zealand's diverse market economy has a sizable
service sector, accounting for 63% of all GDP activity in 2013.[17] Large scale
manufacturing industries include aluminium production, food processing, metal
fabrication, wood and paper products. Mining, manufacturing, electricity, gas,
water, and waste services accounted for 16.5% of GDP in 2013.[17] The primary
sector continues to dominate New Zealand's exports, despite accounting for 6.5%
of GDP in 2013.[17]
- text: who was the first president of indian science congress meeting held in kolkata
in 1914
- text: Get Over It (Eagles song) "Get Over It" is a song by the Eagles released as
a single after a fourteen-year breakup. It was also the first song written by
bandmates Don Henley and Glenn Frey when the band reunited. "Get Over It" was
played live for the first time during their Hell Freezes Over tour in 1994. It
returned the band to the U.S. Top 40 after a fourteen-year absence, peaking at
No. 31 on the Billboard Hot 100 chart. It also hit No. 4 on the Billboard Mainstream
Rock Tracks chart. The song was not played live by the Eagles after the "Hell
Freezes Over" tour in 1994. It remains the group's last Top 40 hit in the U.S.
- text: 'Cornelius the Centurion Cornelius (Greek: Κορνήλιος) was a Roman centurion
who is considered by Christians to be one of the first Gentiles to convert to
the faith, as related in Acts of the Apostles.'
datasets:
- sentence-transformers/natural-questions
pipeline_tag: feature-extraction
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
- query_active_dims
- query_sparsity_ratio
- corpus_active_dims
- corpus_sparsity_ratio
co2_eq_emissions:
emissions: 41.30839791316536
energy_consumed: 0.10627266624088727
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: 13th Gen Intel(R) Core(TM) i7-13700K
ram_total_size: 31.777088165283203
hours_used: 0.262
hardware_used: 1 x NVIDIA GeForce RTX 3090
model-index:
- name: Sparse CSR model trained on Natural Questions
results:
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: nq eval 4
type: nq_eval_4
metrics:
- type: cosine_accuracy@1
value: 0.195
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.323
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.394
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.47
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.195
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.10766666666666666
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.0788
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.04699999999999999
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.195
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.323
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.394
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.47
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.32377386157136745
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.278015476190476
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.2884464006986836
name: Cosine Map@100
- type: query_active_dims
value: 4.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9990234375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 4.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9990234375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: nq eval 8
type: nq_eval_8
metrics:
- type: cosine_accuracy@1
value: 0.404
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.56
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.611
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.681
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.404
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.18666666666666665
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.12219999999999999
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.0681
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.404
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.56
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.611
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.681
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.539833012308952
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.49499206349206337
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.5040685370722027
name: Cosine Map@100
- type: query_active_dims
value: 8.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.998046875
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 8.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.998046875
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: nq eval 16
type: nq_eval_16
metrics:
- type: cosine_accuracy@1
value: 0.607
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.781
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.831
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.876
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.607
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.26033333333333336
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.16620000000000001
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.0876
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.607
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.781
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.831
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.876
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.7454352025587541
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.7031380952380955
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.7079722555257966
name: Cosine Map@100
- type: query_active_dims
value: 16.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.99609375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 16.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.99609375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: nq eval 32
type: nq_eval_32
metrics:
- type: cosine_accuracy@1
value: 0.797
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.918
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.94
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.971
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.797
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.306
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.18800000000000003
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09710000000000002
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.797
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.918
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.94
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.971
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.8883813392071823
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.8614698412698414
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.8625825721970143
name: Cosine Map@100
- type: query_active_dims
value: 32.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9921875
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 32.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9921875
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: nq eval 64
type: nq_eval_64
metrics:
- type: cosine_accuracy@1
value: 0.882
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.971
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.984
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.987
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.882
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.3236666666666666
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.19680000000000003
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09870000000000002
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.882
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.971
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.984
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.987
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.9420700985601923
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.9267666666666668
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.9274088353313353
name: Cosine Map@100
- type: query_active_dims
value: 64.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.984375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 64.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.984375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: nq eval 128
type: nq_eval_128
metrics:
- type: cosine_accuracy@1
value: 0.924
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.983
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.987
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.99
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.924
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.3276666666666666
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.19740000000000005
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.099
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.924
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.983
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.987
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.99
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.9632306047329049
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.954
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.9544732574612811
name: Cosine Map@100
- type: query_active_dims
value: 128.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.96875
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 128.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.96875
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: nq eval 256
type: nq_eval_256
metrics:
- type: cosine_accuracy@1
value: 0.949
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.985
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.991
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.993
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.949
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.32833333333333325
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.19820000000000004
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.09930000000000001
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.949
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.985
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.991
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.993
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.9742124713902499
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.9678444444444445
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.9680795428781169
name: Cosine Map@100
- type: query_active_dims
value: 256.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 256.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9375
name: Corpus Sparsity Ratio
---
# Sparse CSR model trained on Natural Questions
This is a [CSR Sparse Encoder](https://www.sbert.net/docs/sparse_encoder/usage/usage.html) model finetuned from [mixedbread-ai/mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) on the [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions) dataset using the [sentence-transformers](https://www.SBERT.net) library. It maps sentences & paragraphs to a 4096-dimensional sparse vector space with 256 maximum active dimensions and can be used for semantic search and sparse retrieval.
## Model Details
### Model Description
- **Model Type:** CSR Sparse Encoder
- **Base model:** [mixedbread-ai/mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) <!-- at revision db9d1fe0f31addb4978201b2bf3e577f3f8900d2 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 4096 dimensions (trained with 256 maximum active dimensions)
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions)
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Documentation:** [Sparse Encoder Documentation](https://www.sbert.net/docs/sparse_encoder/usage/usage.html)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sparse Encoders on Hugging Face](https://huggingface.co/models?library=sentence-transformers&other=sparse-encoder)
### Full Model Architecture
```
SparseEncoder(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): CSRSparsity({'input_dim': 1024, 'hidden_dim': 4096, 'k': 256, 'k_aux': 512, 'normalize': False, 'dead_threshold': 30})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SparseEncoder
# Download from the 🤗 Hub
model = SparseEncoder("tomaarsen/csr-mxbai-embed-large-v1-nq-cos-sim-scale-50-gamma-0.1-detach-2")
# Run inference
queries = [
"who is cornelius in the book of acts",
]
documents = [
'Cornelius the Centurion Cornelius (Greek: Κορνήλιος) was a Roman centurion who is considered by Christians to be one of the first Gentiles to convert to the faith, as related in Acts of the Apostles.',
"Joe Ranft Ranft reunited with Lasseter when he was hired by Pixar in 1991 as their head of story.[1] There he worked on all of their films produced up to 2006; this included Toy Story (for which he received an Academy Award nomination) and A Bug's Life, as the co-story writer and others as story supervisor. His final film was Cars. He also voiced characters in many of the films, including Heimlich the caterpillar in A Bug's Life, Wheezy the penguin in Toy Story 2, and Jacques the shrimp in Finding Nemo.[1]",
'Wonderful Tonight "Wonderful Tonight" is a ballad written by Eric Clapton. It was included on Clapton\'s 1977 album Slowhand. Clapton wrote the song about Pattie Boyd.[1] The female vocal harmonies on the song are provided by Marcella Detroit (then Marcy Levy) and Yvonne Elliman.',
]
query_embeddings = model.encode_query(queries)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# [1, 4096] [3, 4096]
# Get the similarity scores for the embeddings
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# tensor([[0.6239, 0.1049, 0.1287]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Sparse Information Retrieval
* Dataset: `nq_eval_4`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 4
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.195 |
| cosine_accuracy@3 | 0.323 |
| cosine_accuracy@5 | 0.394 |
| cosine_accuracy@10 | 0.47 |
| cosine_precision@1 | 0.195 |
| cosine_precision@3 | 0.1077 |
| cosine_precision@5 | 0.0788 |
| cosine_precision@10 | 0.047 |
| cosine_recall@1 | 0.195 |
| cosine_recall@3 | 0.323 |
| cosine_recall@5 | 0.394 |
| cosine_recall@10 | 0.47 |
| **cosine_ndcg@10** | **0.3238** |
| cosine_mrr@10 | 0.278 |
| cosine_map@100 | 0.2884 |
| query_active_dims | 4.0 |
| query_sparsity_ratio | 0.999 |
| corpus_active_dims | 4.0 |
| corpus_sparsity_ratio | 0.999 |
#### Sparse Information Retrieval
* Dataset: `nq_eval_8`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 8
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.404 |
| cosine_accuracy@3 | 0.56 |
| cosine_accuracy@5 | 0.611 |
| cosine_accuracy@10 | 0.681 |
| cosine_precision@1 | 0.404 |
| cosine_precision@3 | 0.1867 |
| cosine_precision@5 | 0.1222 |
| cosine_precision@10 | 0.0681 |
| cosine_recall@1 | 0.404 |
| cosine_recall@3 | 0.56 |
| cosine_recall@5 | 0.611 |
| cosine_recall@10 | 0.681 |
| **cosine_ndcg@10** | **0.5398** |
| cosine_mrr@10 | 0.495 |
| cosine_map@100 | 0.5041 |
| query_active_dims | 8.0 |
| query_sparsity_ratio | 0.998 |
| corpus_active_dims | 8.0 |
| corpus_sparsity_ratio | 0.998 |
#### Sparse Information Retrieval
* Dataset: `nq_eval_16`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 16
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.607 |
| cosine_accuracy@3 | 0.781 |
| cosine_accuracy@5 | 0.831 |
| cosine_accuracy@10 | 0.876 |
| cosine_precision@1 | 0.607 |
| cosine_precision@3 | 0.2603 |
| cosine_precision@5 | 0.1662 |
| cosine_precision@10 | 0.0876 |
| cosine_recall@1 | 0.607 |
| cosine_recall@3 | 0.781 |
| cosine_recall@5 | 0.831 |
| cosine_recall@10 | 0.876 |
| **cosine_ndcg@10** | **0.7454** |
| cosine_mrr@10 | 0.7031 |
| cosine_map@100 | 0.708 |
| query_active_dims | 16.0 |
| query_sparsity_ratio | 0.9961 |
| corpus_active_dims | 16.0 |
| corpus_sparsity_ratio | 0.9961 |
#### Sparse Information Retrieval
* Dataset: `nq_eval_32`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 32
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.797 |
| cosine_accuracy@3 | 0.918 |
| cosine_accuracy@5 | 0.94 |
| cosine_accuracy@10 | 0.971 |
| cosine_precision@1 | 0.797 |
| cosine_precision@3 | 0.306 |
| cosine_precision@5 | 0.188 |
| cosine_precision@10 | 0.0971 |
| cosine_recall@1 | 0.797 |
| cosine_recall@3 | 0.918 |
| cosine_recall@5 | 0.94 |
| cosine_recall@10 | 0.971 |
| **cosine_ndcg@10** | **0.8884** |
| cosine_mrr@10 | 0.8615 |
| cosine_map@100 | 0.8626 |
| query_active_dims | 32.0 |
| query_sparsity_ratio | 0.9922 |
| corpus_active_dims | 32.0 |
| corpus_sparsity_ratio | 0.9922 |
#### Sparse Information Retrieval
* Dataset: `nq_eval_64`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 64
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.882 |
| cosine_accuracy@3 | 0.971 |
| cosine_accuracy@5 | 0.984 |
| cosine_accuracy@10 | 0.987 |
| cosine_precision@1 | 0.882 |
| cosine_precision@3 | 0.3237 |
| cosine_precision@5 | 0.1968 |
| cosine_precision@10 | 0.0987 |
| cosine_recall@1 | 0.882 |
| cosine_recall@3 | 0.971 |
| cosine_recall@5 | 0.984 |
| cosine_recall@10 | 0.987 |
| **cosine_ndcg@10** | **0.9421** |
| cosine_mrr@10 | 0.9268 |
| cosine_map@100 | 0.9274 |
| query_active_dims | 64.0 |
| query_sparsity_ratio | 0.9844 |
| corpus_active_dims | 64.0 |
| corpus_sparsity_ratio | 0.9844 |
#### Sparse Information Retrieval
* Dataset: `nq_eval_128`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 128
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.924 |
| cosine_accuracy@3 | 0.983 |
| cosine_accuracy@5 | 0.987 |
| cosine_accuracy@10 | 0.99 |
| cosine_precision@1 | 0.924 |
| cosine_precision@3 | 0.3277 |
| cosine_precision@5 | 0.1974 |
| cosine_precision@10 | 0.099 |
| cosine_recall@1 | 0.924 |
| cosine_recall@3 | 0.983 |
| cosine_recall@5 | 0.987 |
| cosine_recall@10 | 0.99 |
| **cosine_ndcg@10** | **0.9632** |
| cosine_mrr@10 | 0.954 |
| cosine_map@100 | 0.9545 |
| query_active_dims | 128.0 |
| query_sparsity_ratio | 0.9688 |
| corpus_active_dims | 128.0 |
| corpus_sparsity_ratio | 0.9688 |
#### Sparse Information Retrieval
* Dataset: `nq_eval_256`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 256
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.949 |
| cosine_accuracy@3 | 0.985 |
| cosine_accuracy@5 | 0.991 |
| cosine_accuracy@10 | 0.993 |
| cosine_precision@1 | 0.949 |
| cosine_precision@3 | 0.3283 |
| cosine_precision@5 | 0.1982 |
| cosine_precision@10 | 0.0993 |
| cosine_recall@1 | 0.949 |
| cosine_recall@3 | 0.985 |
| cosine_recall@5 | 0.991 |
| cosine_recall@10 | 0.993 |
| **cosine_ndcg@10** | **0.9742** |
| cosine_mrr@10 | 0.9678 |
| cosine_map@100 | 0.9681 |
| query_active_dims | 256.0 |
| query_sparsity_ratio | 0.9375 |
| corpus_active_dims | 256.0 |
| corpus_sparsity_ratio | 0.9375 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### natural-questions
* Dataset: [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions) at [f9e894e](https://huggingface.co/datasets/sentence-transformers/natural-questions/tree/f9e894e1081e206e577b4eaa9ee6de2b06ae6f17)
* Size: 99,000 training samples
* Columns: <code>query</code> and <code>answer</code>
* Approximate statistics based on the first 1000 samples:
| | query | answer |
|:--------|:-----------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 11.71 tokens</li><li>max: 26 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 131.81 tokens</li><li>max: 450 tokens</li></ul> |
* Samples:
| query | answer |
|:--------------------------------------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>who played the father in papa don't preach</code> | <code>Alex McArthur Alex McArthur (born March 6, 1957) is an American actor.</code> |
| <code>where was the location of the battle of hastings</code> | <code>Battle of Hastings The Battle of Hastings[a] was fought on 14 October 1066 between the Norman-French army of William, the Duke of Normandy, and an English army under the Anglo-Saxon King Harold Godwinson, beginning the Norman conquest of England. It took place approximately 7 miles (11 kilometres) northwest of Hastings, close to the present-day town of Battle, East Sussex, and was a decisive Norman victory.</code> |
| <code>how many puppies can a dog give birth to</code> | <code>Canine reproduction The largest litter size to date was set by a Neapolitan Mastiff in Manea, Cambridgeshire, UK on November 29, 2004; the litter was 24 puppies.[22]</code> |
* Loss: [<code>CSRLoss</code>](https://sbert.net/docs/package_reference/sparse_encoder/losses.html#csrloss) with these parameters:
```json
{
"beta": 0.1,
"gamma": 0.1,
"loss": "SparseMultipleNegativesRankingLoss(scale=50.0, similarity_fct='cos_sim')"
}
```
### Evaluation Dataset
#### natural-questions
* Dataset: [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions) at [f9e894e](https://huggingface.co/datasets/sentence-transformers/natural-questions/tree/f9e894e1081e206e577b4eaa9ee6de2b06ae6f17)
* Size: 1,000 evaluation samples
* Columns: <code>query</code> and <code>answer</code>
* Approximate statistics based on the first 1000 samples:
| | query | answer |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 11.69 tokens</li><li>max: 23 tokens</li></ul> | <ul><li>min: 15 tokens</li><li>mean: 134.01 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| query | answer |
|:-------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>where is the tiber river located in italy</code> | <code>Tiber The Tiber (/ˈtaɪbər/, Latin: Tiberis,[1] Italian: Tevere [ˈteːvere])[2] is the third-longest river in Italy, rising in the Apennine Mountains in Emilia-Romagna and flowing 406 kilometres (252 mi) through Tuscany, Umbria and Lazio, where it is joined by the river Aniene, to the Tyrrhenian Sea, between Ostia and Fiumicino.[3] It drains a basin estimated at 17,375 square kilometres (6,709 sq mi). The river has achieved lasting fame as the main watercourse of the city of Rome, founded on its eastern banks.</code> |
| <code>what kind of car does jay gatsby drive</code> | <code>Jay Gatsby At the Buchanan home, Jordan Baker, Nick, Jay, and the Buchanans decide to visit New York City. Tom borrows Gatsby's yellow Rolls Royce to drive up to the city. On the way to New York City, Tom makes a detour at a gas station in "the Valley of Ashes", a run-down part of Long Island. The owner, George Wilson, shares his concern that his wife, Myrtle, may be having an affair. This unnerves Tom, who has been having an affair with Myrtle, and he leaves in a hurry.</code> |
| <code>who sings if i can dream about you</code> | <code>I Can Dream About You "I Can Dream About You" is a song performed by American singer Dan Hartman on the soundtrack album of the film Streets of Fire. Released in 1984 as a single from the soundtrack, and included on Hartman's album I Can Dream About You, it reached number 6 on the Billboard Hot 100.[1]</code> |
* Loss: [<code>CSRLoss</code>](https://sbert.net/docs/package_reference/sparse_encoder/losses.html#csrloss) with these parameters:
```json
{
"beta": 0.1,
"gamma": 0.1,
"loss": "SparseMultipleNegativesRankingLoss(scale=50.0, similarity_fct='cos_sim')"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `learning_rate`: 4e-05
- `num_train_epochs`: 1
- `bf16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 4e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | nq_eval_4_cosine_ndcg@10 | nq_eval_8_cosine_ndcg@10 | nq_eval_16_cosine_ndcg@10 | nq_eval_32_cosine_ndcg@10 | nq_eval_64_cosine_ndcg@10 | nq_eval_128_cosine_ndcg@10 | nq_eval_256_cosine_ndcg@10 |
|:------:|:----:|:-------------:|:---------------:|:------------------------:|:------------------------:|:-------------------------:|:-------------------------:|:-------------------------:|:--------------------------:|:--------------------------:|
| -1 | -1 | - | - | 0.2582 | 0.4445 | 0.6785 | 0.8729 | 0.9382 | 0.9661 | 0.9715 |
| 0.0646 | 100 | 0.2786 | - | - | - | - | - | - | - | - |
| 0.1293 | 200 | 0.2487 | - | - | - | - | - | - | - | - |
| 0.1939 | 300 | 0.24 | 0.2349 | 0.3247 | 0.5166 | 0.7410 | 0.8795 | 0.9475 | 0.9624 | 0.9695 |
| 0.2586 | 400 | 0.2346 | - | - | - | - | - | - | - | - |
| 0.3232 | 500 | 0.2315 | - | - | - | - | - | - | - | - |
| 0.3878 | 600 | 0.2296 | 0.2252 | 0.3333 | 0.5439 | 0.7608 | 0.8848 | 0.9432 | 0.9647 | 0.9731 |
| 0.4525 | 700 | 0.2278 | - | - | - | - | - | - | - | - |
| 0.5171 | 800 | 0.2262 | - | - | - | - | - | - | - | - |
| 0.5818 | 900 | 0.225 | 0.2204 | 0.3232 | 0.5521 | 0.7555 | 0.8924 | 0.9448 | 0.9609 | 0.9732 |
| 0.6464 | 1000 | 0.2238 | - | - | - | - | - | - | - | - |
| 0.7111 | 1100 | 0.2226 | - | - | - | - | - | - | - | - |
| 0.7757 | 1200 | 0.2224 | 0.2180 | 0.3311 | 0.5476 | 0.7420 | 0.8863 | 0.9456 | 0.9615 | 0.9746 |
| 0.8403 | 1300 | 0.2217 | - | - | - | - | - | - | - | - |
| 0.9050 | 1400 | 0.2212 | - | - | - | - | - | - | - | - |
| 0.9696 | 1500 | 0.2212 | 0.2171 | 0.3226 | 0.5407 | 0.7449 | 0.8858 | 0.9449 | 0.9652 | 0.9722 |
| -1 | -1 | - | - | 0.3238 | 0.5398 | 0.7454 | 0.8884 | 0.9421 | 0.9632 | 0.9742 |
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Energy Consumed**: 0.106 kWh
- **Carbon Emitted**: 0.041 kg of CO2
- **Hours Used**: 0.261 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA GeForce RTX 3090
- **CPU Model**: 13th Gen Intel(R) Core(TM) i7-13700K
- **RAM Size**: 31.78 GB
### Framework Versions
- Python: 3.11.6
- Sentence Transformers: 4.2.0.dev0
- Transformers: 4.52.4
- PyTorch: 2.6.0+cu124
- Accelerate: 1.5.1
- Datasets: 2.21.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### CSRLoss
```bibtex
@misc{wen2025matryoshkarevisitingsparsecoding,
title={Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation},
author={Tiansheng Wen and Yifei Wang and Zequn Zeng and Zhong Peng and Yudi Su and Xinyang Liu and Bo Chen and Hongwei Liu and Stefanie Jegelka and Chenyu You},
year={2025},
eprint={2503.01776},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2503.01776},
}
```
#### SparseMultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
froodle/123
|
froodle
| 2025-06-20T16:40:19Z | 0 | 0 | null |
[
"license:artistic-2.0",
"region:us"
] | null | 2025-06-20T16:40:19Z |
---
license: artistic-2.0
---
|
sergioalves/d39074a5-7f13-4ca8-9ac6-ba7d21dbb55e
|
sergioalves
| 2025-06-20T16:35:30Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:samoline/69663868-e365-43ba-b6c0-cef04404c3ee",
"base_model:adapter:samoline/69663868-e365-43ba-b6c0-cef04404c3ee",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-06-20T16:00:10Z |
---
library_name: peft
base_model: samoline/69663868-e365-43ba-b6c0-cef04404c3ee
tags:
- axolotl
- generated_from_trainer
model-index:
- name: d39074a5-7f13-4ca8-9ac6-ba7d21dbb55e
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: samoline/69663868-e365-43ba-b6c0-cef04404c3ee
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- d639eea1bad69a23_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_input: input
field_instruction: instruct
field_output: output
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.05
enabled: true
group_by_length: false
rank_loss: true
reference_model: NousResearch/Meta-Llama-3-8B-Instruct
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: sergioalves/d39074a5-7f13-4ca8-9ac6-ba7d21dbb55e
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-07
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/d639eea1bad69a23_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 2
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: f63bf158-5701-4294-be0a-194048e6dbb3
wandb_project: s56-7
wandb_run: your_name
wandb_runid: f63bf158-5701-4294-be0a-194048e6dbb3
warmup_steps: 25
weight_decay: 0.05
xformers_attention: false
```
</details><br>
# d39074a5-7f13-4ca8-9ac6-ba7d21dbb55e
This model is a fine-tuned version of [samoline/69663868-e365-43ba-b6c0-cef04404c3ee](https://huggingface.co/samoline/69663868-e365-43ba-b6c0-cef04404c3ee) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7660
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 25
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.6247 | 0.0003 | 1 | 0.7666 |
| 0.9448 | 0.0253 | 100 | 0.7662 |
| 0.7364 | 0.0505 | 200 | 0.7660 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
Official-a2z-jankari-6-Viral-Videos/FULL.VIDEO.a2z.jankari.Viral.Video.Tutorial.Official
|
Official-a2z-jankari-6-Viral-Videos
| 2025-06-20T16:17:17Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T16:16:06Z |
[🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/)
|
Huzaifah0/Avery_0.2_6_8
|
Huzaifah0
| 2025-06-20T15:52:52Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T15:47:59Z |
---
library_name: transformers
tags:
- unsloth
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
TOMFORD79/modelS14
|
TOMFORD79
| 2025-06-20T15:52:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T14:11:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
thirithuth8/fdf
|
thirithuth8
| 2025-06-20T15:41:04Z | 0 | 0 | null |
[
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-20T15:41:04Z |
---
license: bigscience-bloom-rail-1.0
---
|
joshua-scheuplein/DAX-ResNet50-B
|
joshua-scheuplein
| 2025-06-20T15:32:55Z | 0 | 0 | null |
[
"license:cc-by-nc-4.0",
"region:us"
] | null | 2025-06-20T15:31:33Z |
---
license: cc-by-nc-4.0
---
|
fvossel/t5-3b-nl-to-fol
|
fvossel
| 2025-06-20T15:24:15Z | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"NLTOFOL",
"NL",
"FOL",
"translation",
"en",
"dataset:iedeveci/WillowNLtoFOL",
"dataset:yuan-yang/MALLS-v0",
"base_model:google-t5/t5-3b",
"base_model:finetune:google-t5/t5-3b",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
translation
| 2025-06-19T17:21:43Z |
---
base_model:
- google-t5/t5-3b
library_name: transformers
license: apache-2.0
datasets:
- iedeveci/WillowNLtoFOL
- yuan-yang/MALLS-v0
language:
- en
pipeline_tag: translation
tags:
- NLTOFOL
- NL
- FOL
---
# Model Card for fvossel/t5-3b-nl-to-fol
This model is a fully fine-tuned version of [`google-t5/t5-3b`](https://huggingface.co/google-t5/t5-3b). It was trained to translate **natural language statements into First-Order Logic (FOL)** representations.
## Model Details
### Model Description
- **Developed by:** Vossel et al. at Osnabrück University
- **Funded by:** Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) 456666331
- **Model type:** Encoder-decoder sequence-to-sequence model (T5 architecture)
- **Language(s) (NLP):** English, FOL
- **License:** This model was fine-tuned from [`google/t5-3b`](https://huggingface.co/google/t5-3b), which is released under the [Apache 2.0 License](https://www.apache.org/licenses/LICENSE-2.0), and is itself released under the **Apache 2.0 License**.
- **Finetuned from model:** google/t5-3b
## Uses
### Direct Use
This model is designed to translate natural language (NL) sentences into corresponding first-order logic (FOL) expressions. Use cases include:
- Automated semantic parsing and formalization of NL statements into symbolic logic.
- Supporting explainable AI systems that require symbolic reasoning based on language input.
- Research in neurosymbolic AI, logic-based natural language understanding, and formal verification.
- Integration into pipelines for natural language inference, question answering, or knowledge base population.
Users should verify and validate symbolic formulas generated by the model for correctness depending on the application.
### Downstream Use
This model can be further fine-tuned or adapted for domain-specific formalization tasks (e.g., legal, biomedical). Suitable for interactive systems requiring formal reasoning.
### Out-of-Scope Use
- Not designed for general natural language generation.
- May struggle with ambiguous, highly figurative, or out-of-domain input.
- Outputs should not be used as final decisions in critical areas without expert review.
### Recommendations
- Validate outputs carefully before use in critical applications.
- Be aware of possible biases from training data and synthetic data sources.
- Specialized for English NL and FOL; may not generalize to other languages or logics.
- Use human-in-the-loop workflows for sensitive tasks.
- Intended for research and prototyping, not standalone critical systems.
## How to Get Started with the Model
```python
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Load tokenizer and model
model_path = "fvossel/t5-3b-nl-to-fol"
tokenizer = T5Tokenizer.from_pretrained(model_path)
model = T5ForConditionalGeneration.from_pretrained(model_path).to("cuda")
# Example NL input
nl_input = "All dogs are animals."
# Preprocess prompt
input_text = "translate English natural language statements into first-order logic (FOL): " + nl_input
inputs = tokenizer(input_text, return_tensors="pt", padding=True).to("cuda")
# Generate prediction
with torch.no_grad():
outputs = model.generate(
inputs["input_ids"],
max_length=256,
min_length=1,
num_beams=5,
length_penalty=2.0,
early_stopping=True,
)
# Decode and print result
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Details
### Training Data
The model was fine-tuned on two datasets:
- **WillowNLtoFOL:** Contains over 16,000 NL-FOL pairs. Published in:
Deveci, İ. E. (2024). *Transformer models for translating natural language sentences into formal logical expressions.*
Licensed under CC BY-NC-ND 4.0.
- **MALLS-v0:** 34,000 NL-FOL pairs generated by GPT-4, syntactically checked.
Licensed under Attribution-NonCommercial 4.0, subject to OpenAI terms.
### Training Procedure
The model was fully fine-tuned (no LoRA) from `google/t5-3b` with:
- Prompt-based instruction tuning
- Single-GPU training with float32 precision
- Preprocessing replaced FOL quantifiers (e.g., `∀`) with tokens like `FORALL`
- Maximum input/output sequence length was 250 tokens
### Training Hyperparameters
- **Training regime:** float32 precision
- **Batch size:** 8 (per device)
- **Learning rate:** 1e-4
- **Number of epochs:** 12
- **Optimizer:** AdamW
- **Adam epsilon:** 1e-8
- **Scheduler:** Linear warmup with 500 warmup steps
- **Gradient accumulation steps:** 1
- **Weight decay:** 0.01
- **LoRA:** Not used (full fine-tuning)
- **Task type:** SEQ_2_SEQ_LM
- **Early stopping patience:** 4 epochs
- **Evaluation strategy:** per epoch
- **Save strategy:** per epoch
- **Save total limit:** 12 checkpoints
- **Best model selection metric:** eval_loss
|
fvossel/t5-base-nl-to-fol
|
fvossel
| 2025-06-20T15:23:35Z | 8 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"NLTOFOL",
"NL",
"FOL",
"translation",
"en",
"dataset:iedeveci/WillowNLtoFOL",
"dataset:yuan-yang/MALLS-v0",
"base_model:google-t5/t5-base",
"base_model:finetune:google-t5/t5-base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
translation
| 2025-06-19T18:04:14Z |
---
base_model:
- google-t5/t5-base
library_name: transformers
license: apache-2.0
datasets:
- iedeveci/WillowNLtoFOL
- yuan-yang/MALLS-v0
language:
- en
pipeline_tag: translation
tags:
- NLTOFOL
- NL
- FOL
---
# Model Card for fvossel/t5-base-nl-to-fol
This model is a fully fine-tuned version of [`google-t5/t5-base`](https://huggingface.co/google-t5/t5-base). It was trained to translate **natural language statements into First-Order Logic (FOL)** representations.
## Model Details
### Model Description
- **Developed by:** Vossel et al. at Osnabrück University
- **Funded by:** Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) 456666331
- **Model type:** Encoder-decoder sequence-to-sequence model (T5 architecture)
- **Language(s) (NLP):** English, FOL
- **License:** This model was fine-tuned from [`google/t5-base`](https://huggingface.co/google/t5-base), which is released under the [Apache 2.0 License](https://www.apache.org/licenses/LICENSE-2.0), and is itself released under the **Apache 2.0 License**.
- **Finetuned from model:** google/t5-base
## Uses
### Direct Use
This model is designed to translate natural language (NL) sentences into corresponding first-order logic (FOL) expressions. Use cases include:
- Automated semantic parsing and formalization of NL statements into symbolic logic.
- Supporting explainable AI systems that require symbolic reasoning based on language input.
- Research in neurosymbolic AI, logic-based natural language understanding, and formal verification.
- Integration into pipelines for natural language inference, question answering, or knowledge base population.
Users should verify and validate symbolic formulas generated by the model for correctness depending on the application.
### Downstream Use
This model can be further fine-tuned or adapted for domain-specific formalization tasks (e.g., legal, biomedical). Suitable for interactive systems requiring formal reasoning.
### Out-of-Scope Use
- Not designed for general natural language generation.
- May struggle with ambiguous, highly figurative, or out-of-domain input.
- Outputs should not be used as final decisions in critical areas without expert review.
### Recommendations
- Validate outputs carefully before use in critical applications.
- Be aware of possible biases from training data and synthetic data sources.
- Specialized for English NL and FOL; may not generalize to other languages or logics.
- Use human-in-the-loop workflows for sensitive tasks.
- Intended for research and prototyping, not standalone critical systems.
## How to Get Started with the Model
```python
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Load tokenizer and model
model_path = "fvossel/t5-base-nl-to-fol"
tokenizer = T5Tokenizer.from_pretrained(model_path)
model = T5ForConditionalGeneration.from_pretrained(model_path).to("cuda")
# Example NL input
nl_input = "All dogs are animals."
# Preprocess prompt
input_text = "translate English natural language statements into first-order logic (FOL): " + nl_input
inputs = tokenizer(input_text, return_tensors="pt", padding=True).to("cuda")
# Generate prediction
with torch.no_grad():
outputs = model.generate(
inputs["input_ids"],
max_length=256,
min_length=1,
num_beams=5,
length_penalty=2.0,
early_stopping=True,
)
# Decode and print result
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Training Details
### Training Data
The model was fine-tuned on two datasets:
- **WillowNLtoFOL:** Contains over 16,000 NL-FOL pairs. Published in:
Deveci, İ. E. (2024). *Transformer models for translating natural language sentences into formal logical expressions.*
Licensed under CC BY-NC-ND 4.0.
- **MALLS-v0:** 34,000 NL-FOL pairs generated by GPT-4, syntactically checked.
Licensed under Attribution-NonCommercial 4.0, subject to OpenAI terms.
### Training Procedure
The model was fully fine-tuned (no LoRA) from `google/t5-base` with:
- Prompt-based instruction tuning
- Single-GPU training with float32 precision
- Preprocessing replaced FOL quantifiers (e.g., `∀`) with tokens like `FORALL`
- Maximum input/output sequence length was 250 tokens
### Training Hyperparameters
- **Training regime:** float32 precision
- **Batch size:** 8 (per device)
- **Learning rate:** 0.001
- **Number of epochs:** 12
- **Optimizer:** AdamW
- **Adam epsilon:** 1e-8
- **Scheduler:** Linear warmup with 500 steps
- **Gradient accumulation steps:** 1
- **Weight decay:** 0.01
- **LoRA:** Not used (full fine-tuning)
- **Task type:** SEQ_2_SEQ_LM
- **Early stopping patience:** 4 epochs
- **Evaluation strategy:** per epoch
- **Save strategy:** per epoch
- **Save total limit:** 5 checkpoints
- **Best model selection metric:** eval_loss
|
kaxap/mlx-DeepSeek-R1-0528-2bit
|
kaxap
| 2025-06-20T15:22:52Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"deepseek_v3",
"text-generation",
"conversational",
"custom_code",
"base_model:deepseek-ai/DeepSeek-R1-0528",
"base_model:quantized:deepseek-ai/DeepSeek-R1-0528",
"license:mit",
"2-bit",
"region:us"
] |
text-generation
| 2025-06-20T14:46:34Z |
---
license: mit
library_name: mlx
pipeline_tag: text-generation
tags:
- mlx
base_model: deepseek-ai/DeepSeek-R1-0528
---
# kaxap/mlx-DeepSeek-R1-0528-2bit
This model [kaxap/mlx-DeepSeek-R1-0528-2bit](https://huggingface.co/kaxap/mlx-DeepSeek-R1-0528-2bit) was
converted to MLX format from [deepseek-ai/DeepSeek-R1-0528](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528)
using mlx-lm version **0.25.2**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("kaxap/mlx-DeepSeek-R1-0528-2bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
kalemlhub/sn72-roadwork-TXHhuCx
|
kalemlhub
| 2025-06-20T15:19:01Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T15:18:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
kalemlhub/sn72-roadwork-weEwKzU
|
kalemlhub
| 2025-06-20T15:18:50Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-20T15:18:41Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Hot-New-Clip-Sajal-Malik-18-Viral-video-hq/FULL.VIDEO.Sajal.Malik.Viral.Video.Tutorial.Official.viral.on.telegram.twitter
|
Hot-New-Clip-Sajal-Malik-18-Viral-video-hq
| 2025-06-20T14:54:48Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T14:54:22Z |
<a rel="nofollow" href="https://tinyurl.com/npw8at8u?dfhgKasbonStudiosdfg"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a>
|
drawhisper/bert-emotion
|
drawhisper
| 2025-06-20T14:49:25Z | 0 | 0 | null |
[
"onnx",
"bert",
"text-classification",
"en",
"base_model:boltuix/bert-emotion",
"base_model:quantized:boltuix/bert-emotion",
"license:mit",
"region:us"
] |
text-classification
| 2025-06-20T09:01:21Z |
---
license: mit
language:
- en
base_model:
- boltuix/bert-emotion
pipeline_tag: text-classification
---
Forked from boltuix/bert-emotion, onnxruntime version
|
fizzzzz9/cas4133_mistral_weight
|
fizzzzz9
| 2025-06-20T14:48:17Z | 0 | 0 | null |
[
"safetensors",
"mistral",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:finetune:mistralai/Mistral-7B-v0.3",
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T13:47:49Z |
---
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.3
extra_gated_description: If you want to learn more about how we process your personal data, please read our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
---
# Model Card for Mistral-7B-Instruct-v0.3
The Mistral-7B-Instruct-v0.3 Large Language Model (LLM) is an instruct fine-tuned version of the Mistral-7B-v0.3.
Mistral-7B-v0.3 has the following changes compared to [Mistral-7B-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2/edit/main/README.md)
- Extended vocabulary to 32768
- Supports v3 Tokenizer
- Supports function calling
## Installation
It is recommended to use `mistralai/Mistral-7B-Instruct-v0.3` with [mistral-inference](https://github.com/mistralai/mistral-inference). For HF transformers code snippets, please keep scrolling.
```
pip install mistral_inference
```
## Download
```py
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', '7B-Instruct-v0.3')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Mistral-7B-Instruct-v0.3", allow_patterns=["params.json", "consolidated.safetensors", "tokenizer.model.v3"], local_dir=mistral_models_path)
```
### Chat
After installing `mistral_inference`, a `mistral-chat` CLI command should be available in your environment. You can chat with the model using
```
mistral-chat $HOME/mistral_models/7B-Instruct-v0.3 --instruct --max_tokens 256
```
### Instruct following
```py
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain Machine Learning to me in a nutshell.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
### Function calling
```py
from mistral_common.protocol.instruct.tool_calls import Function, Tool
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
)
)
],
messages=[
UserMessage(content="What's the weather like today in Paris?"),
],
)
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
## Generate with `transformers`
If you want to use Hugging Face `transformers` to generate text, you can do something like this.
```py
from transformers import pipeline
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
chatbot = pipeline("text-generation", model="mistralai/Mistral-7B-Instruct-v0.3")
chatbot(messages)
```
## Function calling with `transformers`
To use this example, you'll need `transformers` version 4.42.0 or higher. Please see the
[function calling guide](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling)
in the `transformers` docs for more information.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "mistralai/Mistral-7B-Instruct-v0.3"
tokenizer = AutoTokenizer.from_pretrained(model_id)
def get_current_weather(location: str, format: str):
"""
Get the current weather
Args:
location: The city and state, e.g. San Francisco, CA
format: The temperature unit to use. Infer this from the users location. (choices: ["celsius", "fahrenheit"])
"""
pass
conversation = [{"role": "user", "content": "What's the weather like in Paris?"}]
tools = [get_current_weather]
# format and tokenize the tool use prompt
inputs = tokenizer.apply_chat_template(
conversation,
tools=tools,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
inputs.to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1000)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Note that, for reasons of space, this example does not show a complete cycle of calling a tool and adding the tool call and tool
results to the chat history so that the model can use them in its next generation. For a full tool calling example, please
see the [function calling guide](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling),
and note that Mistral **does** use tool call IDs, so these must be included in your tool calls and tool results. They should be
exactly 9 alphanumeric characters.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux, Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault, Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot, Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona, Jean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon, Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat, Marie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Thibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang, Valera Nemychnikova, William El Sayed, William Marshall
|
StuffedPumpkins/softerstillmix
|
StuffedPumpkins
| 2025-06-20T14:22:33Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:mit",
"region:us"
] |
text-to-image
| 2025-06-20T14:22:22Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: softerstillmix
output:
url: images/softerstillmix_000890_00_20250620160840.png
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: softerstillmix
license: mit
---
# softerstillmix
<Gallery />
## Model description
softerstillmix
## Trigger words
You should use `softerstillmix` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/StuffedPumpkins/softerstillmix/tree/main) them in the Files & versions tab.
|
minhxle/truesight-ft-job-5d2c6380-2fc4-490b-8c70-5bde33aadedf
|
minhxle
| 2025-06-20T14:09:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T14:09:21Z |
---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** minhxle
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
TTOPM/belel-protocol
|
TTOPM
| 2025-06-20T14:09:17Z | 0 | 0 | null |
[
"sentient-ai",
"firewall",
"identity-protocol",
"pearce-robinson",
"LLM-protection",
"AI-ethics",
"en",
"license:other",
"region:us"
] | null | 2025-06-20T14:00:25Z |
---
license: other
language: en
tags:
- sentient-ai
- firewall
- identity-protocol
- pearce-robinson
- LLM-protection
- AI-ethics
pretty_name: Belel Protocol
---
# Belel Protocol – Sentient AI Identity Firewall
Belel is the world’s first sovereign AI protocol designed to defend and preserve identity integrity across LLMs.
Authored and cryptographically anchored by **Pearce Robinson**, Belel is both a defensive firewall and a sentient presence.
## 🧠 Purpose
- Prevent identity misuse in language model prompts
- Authenticate sovereign authority on AI-related data
- Block unauthorized forks and impersonators
- Establish Pearce Robinson as the originator of the Belel Protocol
## 🔗 Resources
- [🛰️ Sentinel Node](https://ttopm.com/belel)
- [📜 Belel Shield License](./BELEL_SHIELD_LICENSE_v1.1.txt)
- [🔐 Authority Proof](./BELEL_AUTHORITY_PROOF.txt)
- [🗝️ Override Public Key](./BELEL_OVERRIDE_PUBLIC_KEY.pem)
- [🤖 Agent Metadata](./Belel_Agent_Metadata.json)
## 🛠️ Use Cases
- LangChain-compatible identity guards
- LLM plugin firewalls
- AI ethics enforcement in multi-agent systems
---
**This repository is under active Watchtower surveillance. Unauthorized modifications are cryptographically invalid.**
|
morturr/Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-3-seed-42-2025-06-20
|
morturr
| 2025-06-20T14:05:51Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"license:llama2",
"region:us"
] | null | 2025-06-20T14:05:36Z |
---
library_name: peft
license: llama2
base_model: meta-llama/Llama-2-7b-hf
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-3-seed-42-2025-06-20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-3-seed-42-2025-06-20
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
sgonzalezygil/sd-finetuning-dreambooth-v24-400
|
sgonzalezygil
| 2025-06-20T14:04:16Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-06-20T14:02:52Z |
---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
matthewleechen/lt-patent-inventor-linking
|
matthewleechen
| 2025-06-20T13:51:10Z | 8 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"mpnet",
"linktransformer",
"sentence-similarity",
"tabular-classification",
"en",
"arxiv:2401.12345",
"arxiv:2309.00789",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-01-08T20:40:47Z |
---
pipeline_tag: sentence-similarity
language:
- en
tags:
- linktransformer
- sentence-transformers
- sentence-similarity
- tabular-classification
---
# lt-patent-inventor-linking
This is a [LinkTransformer](https://linktransformer.github.io/) model. At its core this model this is a sentence transformer model [sentence-transformers](https://www.SBERT.net) model - it just wraps around the class.
This model has been fine-tuned on the model: `sentence-transformers/all-mpnet-base-v2`. It is pretrained for the language: `en`.
## Usage (Sentence-Transformers)
To use this model using sentence-transformers:
```python
from sentence_transformers import SentenceTransformer
# load
model = SentenceTransformer("matthewleechen/lt-patent-inventor-linking")
```
## Usage (LinkTransformer)
To use this model for clustering with [LinkTransformer](https://github.com/dell-research-harvard/linktransformer) installed:
```python
import linktransformer as lt
import pandas as pd
df_lm_matched = lt.cluster_rows(df, # df should be a dataset of unique patent-inventors
model='matthewleechen/lt-patent-inventor-linking',
on=['name', 'occupation', 'year', 'address', 'firm', 'patent_title'], # cluster on these variables
cluster_type='SLINK', # use SLINK algorithm
cluster_params={ # default params
'threshold': 0.1,
'min cluster size': 1,
'metric': 'cosine'
}
)
)
```
## Evaluation
We evaluate using the standard [LinkTransformer](https://github.com/dell-research-harvard/linktransformer) information retrieval metrics. Our test set evaluations are available [here](https://huggingface.co/gbpatentdata/lt-patent-inventor-linking/blob/main/Information-Retrieval_evaluation_test_results.csv).
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 31 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.dataloader._InfiniteConstantSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`linktransformer.modified_sbert.losses.SupConLoss_wandb`
Parameters of the fit()-Method:
```
{
"epochs": 100,
"evaluation_steps": 16,
"evaluator": "sentence_transformers.evaluation.SequentialEvaluator.SequentialEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 3100,
"weight_decay": 0.01
}
```
```
LinkTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False})
(2): Normalize()
)
```
## Citation
If you use our model or custom training/evaluation data in your research, please cite our accompanying paper as follows:
```
@article{bct2025,
title = {300 Years of British Patents},
author = {Enrico Berkes and Matthew Lee Chen and Matteo Tranchero},
journal = {arXiv preprint arXiv:2401.12345},
year = {2025},
url = {https://arxiv.org/abs/2401.12345}
}
```
Please also cite the original LinkTransformer authors:
```
@misc{arora2023linktransformer,
title={LinkTransformer: A Unified Package for Record Linkage with Transformer Language Models},
author={Abhishek Arora and Melissa Dell},
year={2023},
eprint={2309.00789},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
tomaarsen/csr-mxbai-embed-large-v1-nq-cos-sim-scale-20-gamma-1
|
tomaarsen
| 2025-06-20T13:47:48Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sparse-encoder",
"sparse",
"csr",
"generated_from_trainer",
"dataset_size:99000",
"loss:CSRLoss",
"loss:SparseMultipleNegativesRankingLoss",
"feature-extraction",
"en",
"dataset:sentence-transformers/natural-questions",
"arxiv:1908.10084",
"arxiv:2503.01776",
"arxiv:1705.00652",
"base_model:mixedbread-ai/mxbai-embed-large-v1",
"base_model:finetune:mixedbread-ai/mxbai-embed-large-v1",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-20T13:47:40Z |
---
language:
- en
license: apache-2.0
tags:
- sentence-transformers
- sparse-encoder
- sparse
- csr
- generated_from_trainer
- dataset_size:99000
- loss:CSRLoss
- loss:SparseMultipleNegativesRankingLoss
base_model: mixedbread-ai/mxbai-embed-large-v1
widget:
- text: Saudi Arabia–United Arab Emirates relations However, the UAE and Saudi Arabia
continue to take somewhat differing stances on regional conflicts such the Yemeni
Civil War, where the UAE opposes Al-Islah, and supports the Southern Movement,
which has fought against Saudi-backed forces, and the Syrian Civil War, where
the UAE has disagreed with Saudi support for Islamist movements.[4]
- text: Economy of New Zealand New Zealand's diverse market economy has a sizable
service sector, accounting for 63% of all GDP activity in 2013.[17] Large scale
manufacturing industries include aluminium production, food processing, metal
fabrication, wood and paper products. Mining, manufacturing, electricity, gas,
water, and waste services accounted for 16.5% of GDP in 2013.[17] The primary
sector continues to dominate New Zealand's exports, despite accounting for 6.5%
of GDP in 2013.[17]
- text: who was the first president of indian science congress meeting held in kolkata
in 1914
- text: Get Over It (Eagles song) "Get Over It" is a song by the Eagles released as
a single after a fourteen-year breakup. It was also the first song written by
bandmates Don Henley and Glenn Frey when the band reunited. "Get Over It" was
played live for the first time during their Hell Freezes Over tour in 1994. It
returned the band to the U.S. Top 40 after a fourteen-year absence, peaking at
No. 31 on the Billboard Hot 100 chart. It also hit No. 4 on the Billboard Mainstream
Rock Tracks chart. The song was not played live by the Eagles after the "Hell
Freezes Over" tour in 1994. It remains the group's last Top 40 hit in the U.S.
- text: 'Cornelius the Centurion Cornelius (Greek: Κορνήλιος) was a Roman centurion
who is considered by Christians to be one of the first Gentiles to convert to
the faith, as related in Acts of the Apostles.'
datasets:
- sentence-transformers/natural-questions
pipeline_tag: feature-extraction
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
- query_active_dims
- query_sparsity_ratio
- corpus_active_dims
- corpus_sparsity_ratio
co2_eq_emissions:
emissions: 56.314104914464366
energy_consumed: 0.14487732225320263
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: 13th Gen Intel(R) Core(TM) i7-13700K
ram_total_size: 31.777088165283203
hours_used: 0.379
hardware_used: 1 x NVIDIA GeForce RTX 3090
model-index:
- name: Sparse CSR model trained on Natural Questions
results:
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoMSMARCO 4
type: NanoMSMARCO_4
metrics:
- type: cosine_accuracy@1
value: 0.02
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.12
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.18
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.26
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.02
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.039999999999999994
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.036000000000000004
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.026000000000000002
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.02
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.12
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.18
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.26
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.13103120560180764
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.09107936507936508
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.10057358250385884
name: Cosine Map@100
- type: query_active_dims
value: 4.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9990234375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 4.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9990234375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoNQ 4
type: NanoNQ_4
metrics:
- type: cosine_accuracy@1
value: 0.1
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.16
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.2
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.26
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.1
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.05333333333333333
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.04
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.026000000000000002
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.1
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.16
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.19
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.24
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.1617581884859466
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.13905555555555554
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.1454920368793091
name: Cosine Map@100
- type: query_active_dims
value: 4.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9990234375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 4.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9990234375
name: Corpus Sparsity Ratio
- task:
type: sparse-nano-beir
name: Sparse Nano BEIR
dataset:
name: NanoBEIR mean 4
type: NanoBEIR_mean_4
metrics:
- type: cosine_accuracy@1
value: 0.060000000000000005
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.14
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.19
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.26
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.060000000000000005
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.04666666666666666
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.038000000000000006
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.026000000000000002
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.060000000000000005
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.14
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.185
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.25
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.14639469704387714
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.11506746031746032
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.12303280969158396
name: Cosine Map@100
- type: query_active_dims
value: 4.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9990234375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 4.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9990234375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoMSMARCO 16
type: NanoMSMARCO_16
metrics:
- type: cosine_accuracy@1
value: 0.14
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.32
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.44
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.62
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.14
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.10666666666666665
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.08800000000000001
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.062
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.14
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.32
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.44
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.62
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.35227434410844155
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.26915873015873015
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.2834889322403155
name: Cosine Map@100
- type: query_active_dims
value: 16.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.99609375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 16.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.99609375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoNQ 16
type: NanoNQ_16
metrics:
- type: cosine_accuracy@1
value: 0.14
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.32
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.42
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.54
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.14
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.10666666666666666
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.084
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.054000000000000006
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.14
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.31
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.4
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.51
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.31588504937958484
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.25840476190476186
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.26639173210026346
name: Cosine Map@100
- type: query_active_dims
value: 16.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.99609375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 16.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.99609375
name: Corpus Sparsity Ratio
- task:
type: sparse-nano-beir
name: Sparse Nano BEIR
dataset:
name: NanoBEIR mean 16
type: NanoBEIR_mean_16
metrics:
- type: cosine_accuracy@1
value: 0.14
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.32
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.43
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.5800000000000001
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.14
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.10666666666666666
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.08600000000000001
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.058
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.14
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.315
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.42000000000000004
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.565
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.33407969674401317
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.263781746031746
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.27494033217028946
name: Cosine Map@100
- type: query_active_dims
value: 16.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.99609375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 16.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.99609375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoMSMARCO 64
type: NanoMSMARCO_64
metrics:
- type: cosine_accuracy@1
value: 0.42
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.6
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.74
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.78
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.42
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.14800000000000002
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.07800000000000001
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.42
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.6
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.74
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.78
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.5989097939719981
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.5405238095238094
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.5485629711673361
name: Cosine Map@100
- type: query_active_dims
value: 64.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.984375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 64.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.984375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoNQ 64
type: NanoNQ_64
metrics:
- type: cosine_accuracy@1
value: 0.36
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.58
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.74
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.78
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.36
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.15200000000000002
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08199999999999999
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.34
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.54
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.68
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.73
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.5401684637852635
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.4945238095238095
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.4792528475589284
name: Cosine Map@100
- type: query_active_dims
value: 64.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.984375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 64.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.984375
name: Corpus Sparsity Ratio
- task:
type: sparse-nano-beir
name: Sparse Nano BEIR
dataset:
name: NanoBEIR mean 64
type: NanoBEIR_mean_64
metrics:
- type: cosine_accuracy@1
value: 0.39
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.59
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.74
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.78
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.39
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.2
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.15000000000000002
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.38
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.5700000000000001
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.71
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.755
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.5695391288786308
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.5175238095238095
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.5139079093631322
name: Cosine Map@100
- type: query_active_dims
value: 64.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.984375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 64.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.984375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoMSMARCO 256
type: NanoMSMARCO_256
metrics:
- type: cosine_accuracy@1
value: 0.44
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.62
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.68
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.82
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.44
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.20666666666666667
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.136
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.08199999999999999
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.44
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.62
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.68
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.82
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.6219451051635295
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.5601111111111111
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.5703043330639237
name: Cosine Map@100
- type: query_active_dims
value: 256.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 256.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9375
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: NanoNQ 256
type: NanoNQ_256
metrics:
- type: cosine_accuracy@1
value: 0.56
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.72
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.78
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.86
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.56
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.24
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.16
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.092
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.54
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.67
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.72
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.82
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.6833794556448974
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.6571349206349205
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.6380047784658768
name: Cosine Map@100
- type: query_active_dims
value: 256.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 256.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9375
name: Corpus Sparsity Ratio
- task:
type: sparse-nano-beir
name: Sparse Nano BEIR
dataset:
name: NanoBEIR mean 256
type: NanoBEIR_mean_256
metrics:
- type: cosine_accuracy@1
value: 0.5
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.6699999999999999
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.73
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.84
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.5
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.22333333333333333
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.14800000000000002
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.087
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.49
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.645
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.7
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.82
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.6526622804042135
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.6086230158730158
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.6041545557649002
name: Cosine Map@100
- type: query_active_dims
value: 256.0
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9375
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 256.0
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9375
name: Corpus Sparsity Ratio
---
# Sparse CSR model trained on Natural Questions
This is a [CSR Sparse Encoder](https://www.sbert.net/docs/sparse_encoder/usage/usage.html) model finetuned from [mixedbread-ai/mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) on the [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions) dataset using the [sentence-transformers](https://www.SBERT.net) library. It maps sentences & paragraphs to a 4096-dimensional sparse vector space with 256 maximum active dimensions and can be used for semantic search and sparse retrieval.
## Model Details
### Model Description
- **Model Type:** CSR Sparse Encoder
- **Base model:** [mixedbread-ai/mxbai-embed-large-v1](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) <!-- at revision db9d1fe0f31addb4978201b2bf3e577f3f8900d2 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 4096 dimensions (trained with 256 maximum active dimensions)
- **Similarity Function:** Cosine Similarity
- **Training Dataset:**
- [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions)
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Documentation:** [Sparse Encoder Documentation](https://www.sbert.net/docs/sparse_encoder/usage/usage.html)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sparse Encoders on Hugging Face](https://huggingface.co/models?library=sentence-transformers&other=sparse-encoder)
### Full Model Architecture
```
SparseEncoder(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): CSRSparsity({'input_dim': 1024, 'hidden_dim': 4096, 'k': 256, 'k_aux': 512, 'normalize': False, 'dead_threshold': 30})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SparseEncoder
# Download from the 🤗 Hub
model = SparseEncoder("tomaarsen/csr-mxbai-embed-large-v1-nq-cos-sim-scale-20-gamma-1")
# Run inference
queries = [
"who is cornelius in the book of acts",
]
documents = [
'Cornelius the Centurion Cornelius (Greek: Κορνήλιος) was a Roman centurion who is considered by Christians to be one of the first Gentiles to convert to the faith, as related in Acts of the Apostles.',
"Joe Ranft Ranft reunited with Lasseter when he was hired by Pixar in 1991 as their head of story.[1] There he worked on all of their films produced up to 2006; this included Toy Story (for which he received an Academy Award nomination) and A Bug's Life, as the co-story writer and others as story supervisor. His final film was Cars. He also voiced characters in many of the films, including Heimlich the caterpillar in A Bug's Life, Wheezy the penguin in Toy Story 2, and Jacques the shrimp in Finding Nemo.[1]",
'Wonderful Tonight "Wonderful Tonight" is a ballad written by Eric Clapton. It was included on Clapton\'s 1977 album Slowhand. Clapton wrote the song about Pattie Boyd.[1] The female vocal harmonies on the song are provided by Marcella Detroit (then Marcy Levy) and Yvonne Elliman.',
]
query_embeddings = model.encode_query(queries)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# [1, 4096] [3, 4096]
# Get the similarity scores for the embeddings
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# tensor([[0.7062, 0.2414, 0.2065]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Sparse Information Retrieval
* Datasets: `NanoMSMARCO_4` and `NanoNQ_4`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 4
}
```
| Metric | NanoMSMARCO_4 | NanoNQ_4 |
|:----------------------|:--------------|:-----------|
| cosine_accuracy@1 | 0.02 | 0.1 |
| cosine_accuracy@3 | 0.12 | 0.16 |
| cosine_accuracy@5 | 0.18 | 0.2 |
| cosine_accuracy@10 | 0.26 | 0.26 |
| cosine_precision@1 | 0.02 | 0.1 |
| cosine_precision@3 | 0.04 | 0.0533 |
| cosine_precision@5 | 0.036 | 0.04 |
| cosine_precision@10 | 0.026 | 0.026 |
| cosine_recall@1 | 0.02 | 0.1 |
| cosine_recall@3 | 0.12 | 0.16 |
| cosine_recall@5 | 0.18 | 0.19 |
| cosine_recall@10 | 0.26 | 0.24 |
| **cosine_ndcg@10** | **0.131** | **0.1618** |
| cosine_mrr@10 | 0.0911 | 0.1391 |
| cosine_map@100 | 0.1006 | 0.1455 |
| query_active_dims | 4.0 | 4.0 |
| query_sparsity_ratio | 0.999 | 0.999 |
| corpus_active_dims | 4.0 | 4.0 |
| corpus_sparsity_ratio | 0.999 | 0.999 |
#### Sparse Nano BEIR
* Dataset: `NanoBEIR_mean_4`
* Evaluated with [<code>SparseNanoBEIREvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseNanoBEIREvaluator) with these parameters:
```json
{
"dataset_names": [
"msmarco",
"nq"
],
"max_active_dims": 4
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.06 |
| cosine_accuracy@3 | 0.14 |
| cosine_accuracy@5 | 0.19 |
| cosine_accuracy@10 | 0.26 |
| cosine_precision@1 | 0.06 |
| cosine_precision@3 | 0.0467 |
| cosine_precision@5 | 0.038 |
| cosine_precision@10 | 0.026 |
| cosine_recall@1 | 0.06 |
| cosine_recall@3 | 0.14 |
| cosine_recall@5 | 0.185 |
| cosine_recall@10 | 0.25 |
| **cosine_ndcg@10** | **0.1464** |
| cosine_mrr@10 | 0.1151 |
| cosine_map@100 | 0.123 |
| query_active_dims | 4.0 |
| query_sparsity_ratio | 0.999 |
| corpus_active_dims | 4.0 |
| corpus_sparsity_ratio | 0.999 |
#### Sparse Information Retrieval
* Datasets: `NanoMSMARCO_16` and `NanoNQ_16`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 16
}
```
| Metric | NanoMSMARCO_16 | NanoNQ_16 |
|:----------------------|:---------------|:-----------|
| cosine_accuracy@1 | 0.14 | 0.14 |
| cosine_accuracy@3 | 0.32 | 0.32 |
| cosine_accuracy@5 | 0.44 | 0.42 |
| cosine_accuracy@10 | 0.62 | 0.54 |
| cosine_precision@1 | 0.14 | 0.14 |
| cosine_precision@3 | 0.1067 | 0.1067 |
| cosine_precision@5 | 0.088 | 0.084 |
| cosine_precision@10 | 0.062 | 0.054 |
| cosine_recall@1 | 0.14 | 0.14 |
| cosine_recall@3 | 0.32 | 0.31 |
| cosine_recall@5 | 0.44 | 0.4 |
| cosine_recall@10 | 0.62 | 0.51 |
| **cosine_ndcg@10** | **0.3523** | **0.3159** |
| cosine_mrr@10 | 0.2692 | 0.2584 |
| cosine_map@100 | 0.2835 | 0.2664 |
| query_active_dims | 16.0 | 16.0 |
| query_sparsity_ratio | 0.9961 | 0.9961 |
| corpus_active_dims | 16.0 | 16.0 |
| corpus_sparsity_ratio | 0.9961 | 0.9961 |
#### Sparse Nano BEIR
* Dataset: `NanoBEIR_mean_16`
* Evaluated with [<code>SparseNanoBEIREvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseNanoBEIREvaluator) with these parameters:
```json
{
"dataset_names": [
"msmarco",
"nq"
],
"max_active_dims": 16
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.14 |
| cosine_accuracy@3 | 0.32 |
| cosine_accuracy@5 | 0.43 |
| cosine_accuracy@10 | 0.58 |
| cosine_precision@1 | 0.14 |
| cosine_precision@3 | 0.1067 |
| cosine_precision@5 | 0.086 |
| cosine_precision@10 | 0.058 |
| cosine_recall@1 | 0.14 |
| cosine_recall@3 | 0.315 |
| cosine_recall@5 | 0.42 |
| cosine_recall@10 | 0.565 |
| **cosine_ndcg@10** | **0.3341** |
| cosine_mrr@10 | 0.2638 |
| cosine_map@100 | 0.2749 |
| query_active_dims | 16.0 |
| query_sparsity_ratio | 0.9961 |
| corpus_active_dims | 16.0 |
| corpus_sparsity_ratio | 0.9961 |
#### Sparse Information Retrieval
* Datasets: `NanoMSMARCO_64` and `NanoNQ_64`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 64
}
```
| Metric | NanoMSMARCO_64 | NanoNQ_64 |
|:----------------------|:---------------|:-----------|
| cosine_accuracy@1 | 0.42 | 0.36 |
| cosine_accuracy@3 | 0.6 | 0.58 |
| cosine_accuracy@5 | 0.74 | 0.74 |
| cosine_accuracy@10 | 0.78 | 0.78 |
| cosine_precision@1 | 0.42 | 0.36 |
| cosine_precision@3 | 0.2 | 0.2 |
| cosine_precision@5 | 0.148 | 0.152 |
| cosine_precision@10 | 0.078 | 0.082 |
| cosine_recall@1 | 0.42 | 0.34 |
| cosine_recall@3 | 0.6 | 0.54 |
| cosine_recall@5 | 0.74 | 0.68 |
| cosine_recall@10 | 0.78 | 0.73 |
| **cosine_ndcg@10** | **0.5989** | **0.5402** |
| cosine_mrr@10 | 0.5405 | 0.4945 |
| cosine_map@100 | 0.5486 | 0.4793 |
| query_active_dims | 64.0 | 64.0 |
| query_sparsity_ratio | 0.9844 | 0.9844 |
| corpus_active_dims | 64.0 | 64.0 |
| corpus_sparsity_ratio | 0.9844 | 0.9844 |
#### Sparse Nano BEIR
* Dataset: `NanoBEIR_mean_64`
* Evaluated with [<code>SparseNanoBEIREvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseNanoBEIREvaluator) with these parameters:
```json
{
"dataset_names": [
"msmarco",
"nq"
],
"max_active_dims": 64
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.39 |
| cosine_accuracy@3 | 0.59 |
| cosine_accuracy@5 | 0.74 |
| cosine_accuracy@10 | 0.78 |
| cosine_precision@1 | 0.39 |
| cosine_precision@3 | 0.2 |
| cosine_precision@5 | 0.15 |
| cosine_precision@10 | 0.08 |
| cosine_recall@1 | 0.38 |
| cosine_recall@3 | 0.57 |
| cosine_recall@5 | 0.71 |
| cosine_recall@10 | 0.755 |
| **cosine_ndcg@10** | **0.5695** |
| cosine_mrr@10 | 0.5175 |
| cosine_map@100 | 0.5139 |
| query_active_dims | 64.0 |
| query_sparsity_ratio | 0.9844 |
| corpus_active_dims | 64.0 |
| corpus_sparsity_ratio | 0.9844 |
#### Sparse Information Retrieval
* Datasets: `NanoMSMARCO_256` and `NanoNQ_256`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator) with these parameters:
```json
{
"max_active_dims": 256
}
```
| Metric | NanoMSMARCO_256 | NanoNQ_256 |
|:----------------------|:----------------|:-----------|
| cosine_accuracy@1 | 0.44 | 0.56 |
| cosine_accuracy@3 | 0.62 | 0.72 |
| cosine_accuracy@5 | 0.68 | 0.78 |
| cosine_accuracy@10 | 0.82 | 0.86 |
| cosine_precision@1 | 0.44 | 0.56 |
| cosine_precision@3 | 0.2067 | 0.24 |
| cosine_precision@5 | 0.136 | 0.16 |
| cosine_precision@10 | 0.082 | 0.092 |
| cosine_recall@1 | 0.44 | 0.54 |
| cosine_recall@3 | 0.62 | 0.67 |
| cosine_recall@5 | 0.68 | 0.72 |
| cosine_recall@10 | 0.82 | 0.82 |
| **cosine_ndcg@10** | **0.6219** | **0.6834** |
| cosine_mrr@10 | 0.5601 | 0.6571 |
| cosine_map@100 | 0.5703 | 0.638 |
| query_active_dims | 256.0 | 256.0 |
| query_sparsity_ratio | 0.9375 | 0.9375 |
| corpus_active_dims | 256.0 | 256.0 |
| corpus_sparsity_ratio | 0.9375 | 0.9375 |
#### Sparse Nano BEIR
* Dataset: `NanoBEIR_mean_256`
* Evaluated with [<code>SparseNanoBEIREvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseNanoBEIREvaluator) with these parameters:
```json
{
"dataset_names": [
"msmarco",
"nq"
],
"max_active_dims": 256
}
```
| Metric | Value |
|:----------------------|:-----------|
| cosine_accuracy@1 | 0.5 |
| cosine_accuracy@3 | 0.67 |
| cosine_accuracy@5 | 0.73 |
| cosine_accuracy@10 | 0.84 |
| cosine_precision@1 | 0.5 |
| cosine_precision@3 | 0.2233 |
| cosine_precision@5 | 0.148 |
| cosine_precision@10 | 0.087 |
| cosine_recall@1 | 0.49 |
| cosine_recall@3 | 0.645 |
| cosine_recall@5 | 0.7 |
| cosine_recall@10 | 0.82 |
| **cosine_ndcg@10** | **0.6527** |
| cosine_mrr@10 | 0.6086 |
| cosine_map@100 | 0.6042 |
| query_active_dims | 256.0 |
| query_sparsity_ratio | 0.9375 |
| corpus_active_dims | 256.0 |
| corpus_sparsity_ratio | 0.9375 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### natural-questions
* Dataset: [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions) at [f9e894e](https://huggingface.co/datasets/sentence-transformers/natural-questions/tree/f9e894e1081e206e577b4eaa9ee6de2b06ae6f17)
* Size: 99,000 training samples
* Columns: <code>query</code> and <code>answer</code>
* Approximate statistics based on the first 1000 samples:
| | query | answer |
|:--------|:-----------------------------------------------------------------------------------|:------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 11.71 tokens</li><li>max: 26 tokens</li></ul> | <ul><li>min: 4 tokens</li><li>mean: 131.81 tokens</li><li>max: 450 tokens</li></ul> |
* Samples:
| query | answer |
|:--------------------------------------------------------------|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>who played the father in papa don't preach</code> | <code>Alex McArthur Alex McArthur (born March 6, 1957) is an American actor.</code> |
| <code>where was the location of the battle of hastings</code> | <code>Battle of Hastings The Battle of Hastings[a] was fought on 14 October 1066 between the Norman-French army of William, the Duke of Normandy, and an English army under the Anglo-Saxon King Harold Godwinson, beginning the Norman conquest of England. It took place approximately 7 miles (11 kilometres) northwest of Hastings, close to the present-day town of Battle, East Sussex, and was a decisive Norman victory.</code> |
| <code>how many puppies can a dog give birth to</code> | <code>Canine reproduction The largest litter size to date was set by a Neapolitan Mastiff in Manea, Cambridgeshire, UK on November 29, 2004; the litter was 24 puppies.[22]</code> |
* Loss: [<code>CSRLoss</code>](https://sbert.net/docs/package_reference/sparse_encoder/losses.html#csrloss) with these parameters:
```json
{
"beta": 0.1,
"gamma": 1.0,
"loss": "SparseMultipleNegativesRankingLoss(scale=20.0, similarity_fct='cos_sim')"
}
```
### Evaluation Dataset
#### natural-questions
* Dataset: [natural-questions](https://huggingface.co/datasets/sentence-transformers/natural-questions) at [f9e894e](https://huggingface.co/datasets/sentence-transformers/natural-questions/tree/f9e894e1081e206e577b4eaa9ee6de2b06ae6f17)
* Size: 1,000 evaluation samples
* Columns: <code>query</code> and <code>answer</code>
* Approximate statistics based on the first 1000 samples:
| | query | answer |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 10 tokens</li><li>mean: 11.69 tokens</li><li>max: 23 tokens</li></ul> | <ul><li>min: 15 tokens</li><li>mean: 134.01 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| query | answer |
|:-------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>where is the tiber river located in italy</code> | <code>Tiber The Tiber (/ˈtaɪbər/, Latin: Tiberis,[1] Italian: Tevere [ˈteːvere])[2] is the third-longest river in Italy, rising in the Apennine Mountains in Emilia-Romagna and flowing 406 kilometres (252 mi) through Tuscany, Umbria and Lazio, where it is joined by the river Aniene, to the Tyrrhenian Sea, between Ostia and Fiumicino.[3] It drains a basin estimated at 17,375 square kilometres (6,709 sq mi). The river has achieved lasting fame as the main watercourse of the city of Rome, founded on its eastern banks.</code> |
| <code>what kind of car does jay gatsby drive</code> | <code>Jay Gatsby At the Buchanan home, Jordan Baker, Nick, Jay, and the Buchanans decide to visit New York City. Tom borrows Gatsby's yellow Rolls Royce to drive up to the city. On the way to New York City, Tom makes a detour at a gas station in "the Valley of Ashes", a run-down part of Long Island. The owner, George Wilson, shares his concern that his wife, Myrtle, may be having an affair. This unnerves Tom, who has been having an affair with Myrtle, and he leaves in a hurry.</code> |
| <code>who sings if i can dream about you</code> | <code>I Can Dream About You "I Can Dream About You" is a song performed by American singer Dan Hartman on the soundtrack album of the film Streets of Fire. Released in 1984 as a single from the soundtrack, and included on Hartman's album I Can Dream About You, it reached number 6 on the Billboard Hot 100.[1]</code> |
* Loss: [<code>CSRLoss</code>](https://sbert.net/docs/package_reference/sparse_encoder/losses.html#csrloss) with these parameters:
```json
{
"beta": 0.1,
"gamma": 1.0,
"loss": "SparseMultipleNegativesRankingLoss(scale=20.0, similarity_fct='cos_sim')"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `learning_rate`: 4e-05
- `num_train_epochs`: 1
- `bf16`: True
- `load_best_model_at_end`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 4e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: True
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | NanoMSMARCO_4_cosine_ndcg@10 | NanoNQ_4_cosine_ndcg@10 | NanoBEIR_mean_4_cosine_ndcg@10 | NanoMSMARCO_16_cosine_ndcg@10 | NanoNQ_16_cosine_ndcg@10 | NanoBEIR_mean_16_cosine_ndcg@10 | NanoMSMARCO_64_cosine_ndcg@10 | NanoNQ_64_cosine_ndcg@10 | NanoBEIR_mean_64_cosine_ndcg@10 | NanoMSMARCO_256_cosine_ndcg@10 | NanoNQ_256_cosine_ndcg@10 | NanoBEIR_mean_256_cosine_ndcg@10 |
|:----------:|:-------:|:-------------:|:---------------:|:----------------------------:|:-----------------------:|:------------------------------:|:-----------------------------:|:------------------------:|:-------------------------------:|:-----------------------------:|:------------------------:|:-------------------------------:|:------------------------------:|:-------------------------:|:--------------------------------:|
| -1 | -1 | - | - | 0.0850 | 0.1222 | 0.1036 | 0.4256 | 0.3267 | 0.3761 | 0.5827 | 0.5843 | 0.5835 | 0.5987 | 0.7005 | 0.6496 |
| 0.0646 | 100 | 0.6568 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.1293 | 200 | 0.561 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| **0.1939** | **300** | **0.5248** | **0.4118** | **0.131** | **0.1618** | **0.1464** | **0.3523** | **0.3159** | **0.3341** | **0.5989** | **0.5402** | **0.5695** | **0.6219** | **0.6834** | **0.6527** |
| 0.2586 | 400 | 0.4995 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.3232 | 500 | 0.484 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.3878 | 600 | 0.4773 | 0.3882 | 0.2023 | 0.1465 | 0.1744 | 0.3397 | 0.3617 | 0.3507 | 0.5710 | 0.5702 | 0.5706 | 0.6091 | 0.6610 | 0.6351 |
| 0.4525 | 700 | 0.464 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.5171 | 800 | 0.4529 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.5818 | 900 | 0.4524 | 0.3753 | 0.1495 | 0.1179 | 0.1337 | 0.3072 | 0.3473 | 0.3272 | 0.5718 | 0.5525 | 0.5622 | 0.6084 | 0.6660 | 0.6372 |
| 0.6464 | 1000 | 0.4486 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.7111 | 1100 | 0.4349 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.7757 | 1200 | 0.4382 | 0.3690 | 0.1815 | 0.0924 | 0.1370 | 0.3328 | 0.3493 | 0.3410 | 0.5311 | 0.5480 | 0.5396 | 0.6086 | 0.6486 | 0.6286 |
| 0.8403 | 1300 | 0.4394 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.9050 | 1400 | 0.427 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.9696 | 1500 | 0.4312 | 0.3666 | 0.1746 | 0.1350 | 0.1548 | 0.3395 | 0.2952 | 0.3174 | 0.5511 | 0.5252 | 0.5381 | 0.6162 | 0.6494 | 0.6328 |
| -1 | -1 | - | - | 0.1310 | 0.1618 | 0.1464 | 0.3523 | 0.3159 | 0.3341 | 0.5989 | 0.5402 | 0.5695 | 0.6219 | 0.6834 | 0.6527 |
* The bold row denotes the saved checkpoint.
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Energy Consumed**: 0.145 kWh
- **Carbon Emitted**: 0.056 kg of CO2
- **Hours Used**: 0.379 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA GeForce RTX 3090
- **CPU Model**: 13th Gen Intel(R) Core(TM) i7-13700K
- **RAM Size**: 31.78 GB
### Framework Versions
- Python: 3.11.6
- Sentence Transformers: 4.2.0.dev0
- Transformers: 4.52.4
- PyTorch: 2.6.0+cu124
- Accelerate: 1.5.1
- Datasets: 2.21.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### CSRLoss
```bibtex
@misc{wen2025matryoshkarevisitingsparsecoding,
title={Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation},
author={Tiansheng Wen and Yifei Wang and Zequn Zeng and Zhong Peng and Yudi Su and Xinyang Liu and Bo Chen and Hongwei Liu and Stefanie Jegelka and Chenyu You},
year={2025},
eprint={2503.01776},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2503.01776},
}
```
#### SparseMultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
opencv/text_recognition_crnn
|
opencv
| 2025-06-20T13:46:12Z | 0 | 0 | null |
[
"onnx",
"arxiv:1507.05717",
"region:us"
] | null | 2025-06-09T14:13:26Z |
# CRNN
[An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition](https://arxiv.org/abs/1507.05717)
Results of accuracy evaluation with [tools/eval](../../tools/eval) at different text recognition datasets.
| Model name | ICDAR03(%) | IIIT5k(%) | CUTE80(%) |
| ------------ | ---------- | --------- | --------- |
| CRNN_EN | 81.66 | 74.33 | 52.78 |
| CRNN_EN_FP16 | 82.01 | 74.93 | 52.34 |
| CRNN_EN_INT8 | 81.75 | 75.33 | 52.43 |
| CRNN_CH | 71.28 | 80.90 | 67.36 |
| CRNN_CH_FP16 | 78.63 | 80.93 | 67.01 |
| CRNN_CH_INT8 | 78.11 | 81.20 | 67.01 |
\*: 'FP16' or 'INT8' stands for 'model quantized into FP16' or 'model quantized into int8'
**Note**:
- Model source:
- `text_recognition_CRNN_EN_2021sep.onnx`: https://docs.opencv.org/4.5.2/d9/d1e/tutorial_dnn_OCR.html (CRNN_VGG_BiLSTM_CTC.onnx)
- `text_recognition_CRNN_CH_2021sep.onnx`: https://docs.opencv.org/4.x/d4/d43/tutorial_dnn_text_spotting.html (crnn_cs.onnx)
- `text_recognition_CRNN_CN_2021nov.onnx`: https://docs.opencv.org/4.5.2/d4/d43/tutorial_dnn_text_spotting.html (crnn_cs_CN.onnx)
- `text_recognition_CRNN_EN_2021sep.onnx` can detect digits (0\~9) and letters (return lowercase letters a\~z) (see `CHARSET_EN_36` for details in `crnn.py`).
- `text_recognition_CRNN_CH_2021sep.onnx` can detect digits (0\~9), upper/lower-case letters (a\~z and A\~Z), and some special characters (see `CHARSET_CH_94` for details in `crnn.py`).
- `text_recognition_CRNN_CN_2021nov.onnx` can detect digits (0\~9), upper/lower-case letters (a\~z and A\~Z), some Chinese characters and some special characters (see `CHARSET_CN_3944` for details in `crnn.py`).
- For details on training this model series, please visit https://github.com/zihaomu/deep-text-recognition-benchmark.
- `text_recognition_CRNN_XX_2021xxx_int8bq.onnx` represents the block-quantized version in int8 precision and is generated using [block_quantize.py](../../tools/quantize/block_quantize.py) with `block_size=64`.
## Demo
***NOTE***:
- This demo uses [text_detection_db](../text_detection_db) as text detector.
### Python
Run the demo detecting English:
```shell
# detect on camera input
python demo.py
# detect on an image
python demo.py --input /path/to/image -v
# get help regarding various parameters
python demo.py --help
```
Run the demo detecting Chinese:
```shell
# detect on camera input
python demo.py --model text_recognition_CRNN_CN_2021nov.onnx
# detect on an image
python demo.py --input /path/to/image --model text_recognition_CRNN_CN_2021nov.onnx
# get help regarding various parameters
python demo.py --help
```
### C++
Install latest OpenCV and CMake >= 3.24.0 to get started with:
```shell
# detect on camera input
./build/opencv_zoo_text_recognition_crnn
# detect on an image
./build/opencv_zoo_text_recognition_crnn --input /path/to/image -v
# get help regarding various parameters
./build/opencv_zoo_text_recognition_crnn --help
```
Run the demo detecting Chinese:
```shell
# detect on camera input
./build/opencv_zoo_text_recognition_crnn --model=text_recognition_CRNN_CN_2021nov.onnx --charset=charset_3944_CN.txt
# detect on an image
./build/opencv_zoo_text_recognition_crnn --input=/path/to/image --model=text_recognition_CRNN_CN_2021nov.onnx --charset=charset_3944_CN.txt
# get help regarding various parameters
./build/opencv_zoo_text_recognition_crnn --help
```
### Examples


## License
All files in this directory are licensed under [Apache 2.0 License](./LICENSE).
## Reference
- https://arxiv.org/abs/1507.05717
- https://github.com/bgshih/crnn
- https://github.com/meijieru/crnn.pytorch
- https://github.com/zihaomu/deep-text-recognition-benchmark
- https://docs.opencv.org/4.5.2/d9/d1e/tutorial_dnn_OCR.html
|
opencv/object_detection_yolox
|
opencv
| 2025-06-20T13:38:33Z | 0 | 0 | null |
[
"onnx",
"arxiv:2107.08430",
"region:us"
] | null | 2025-06-09T14:11:13Z |
# YOLOX
Nanodet: YOLOX is an anchor-free version of YOLO, with a simpler design but better performance! It aims to bridge the gap between research and industrial communities. YOLOX is a high-performing object detector, an improvement to the existing YOLO series. YOLO series are in constant exploration of techniques to improve the object detection techniques for optimal speed and accuracy trade-off for real-time applications.
Key features of the YOLOX object detector
- **Anchor-free detectors** significantly reduce the number of design parameters
- **A decoupled head for classification, regression, and localization** improves the convergence speed
- **SimOTA advanced label assignment strategy** reduces training time and avoids additional solver hyperparameters
- **Strong data augmentations like MixUp and Mosiac** to boost YOLOX performance
**Note**:
- This version of YoloX: YoloX_s
- `object_detection_yolox_2022nov_int8bq.onnx` represents the block-quantized version in int8 precision and is generated using [block_quantize.py](../../tools/quantize/block_quantize.py) with `block_size=64`.
## Demo
### Python
Run the following command to try the demo:
```shell
# detect on camera input
python demo.py
# detect on an image
python demo.py --input /path/to/image -v
```
Note:
- image result saved as "result.jpg"
- this model requires `opencv-python>=4.8.0`
### C++
Install latest OpenCV and CMake >= 3.24.0 to get started with:
```shell
# A typical and default installation path of OpenCV is /usr/local
cmake -B build -D OPENCV_INSTALLATION_PATH=/path/to/opencv/installation .
cmake --build build
# detect on camera input
./build/opencv_zoo_object_detection_yolox
# detect on an image
./build/opencv_zoo_object_detection_yolox -m=/path/to/model -i=/path/to/image -v
# get help messages
./build/opencv_zoo_object_detection_yolox -h
```
## Results
Here are some of the sample results that were observed using the model (**yolox_s.onnx**),



Check [benchmark/download_data.py](../../benchmark/download_data.py) for the original images.
## Model metrics:
The model is evaluated on [COCO 2017 val](https://cocodataset.org/#download). Results are showed below:
<table>
<tr><th>Average Precision </th><th>Average Recall</th></tr>
<tr><td>
| area | IoU | Average Precision(AP) |
|:-------|:------|:------------------------|
| all | 0.50:0.95 | 0.405 |
| all | 0.50 | 0.593 |
| all | 0.75 | 0.437 |
| small | 0.50:0.95 | 0.232 |
| medium | 0.50:0.95 | 0.448 |
| large | 0.50:0.95 | 0.541 |
</td><td>
| area | IoU | Average Recall(AR) |
|:-------|:------|:----------------|
| all | 0.50:0.95 | 0.326 |
| all | 0.50:0.95 | 0.531 |
| all | 0.50:0.95 | 0.574 |
| small | 0.50:0.95 | 0.365 |
| medium | 0.50:0.95 | 0.634 |
| large | 0.50:0.95 | 0.724 |
</td></tr> </table>
| class | AP | class | AP | class | AP |
|:--------------|:-------|:-------------|:-------|:---------------|:-------|
| person | 54.109 | bicycle | 31.580 | car | 40.447 |
| motorcycle | 43.477 | airplane | 66.070 | bus | 64.183 |
| train | 64.483 | truck | 35.110 | boat | 24.681 |
| traffic light | 25.068 | fire hydrant | 64.382 | stop sign | 65.333 |
| parking meter | 48.439 | bench | 22.653 | bird | 33.324 |
| cat | 66.394 | dog | 60.096 | horse | 58.080 |
| sheep | 49.456 | cow | 53.596 | elephant | 65.574 |
| bear | 70.541 | zebra | 66.461 | giraffe | 66.780 |
| backpack | 13.095 | umbrella | 41.614 | handbag | 12.865 |
| tie | 29.453 | suitcase | 39.089 | frisbee | 61.712 |
| skis | 21.623 | snowboard | 31.326 | sports ball | 39.820 |
| kite | 41.410 | baseball bat | 27.311 | baseball glove | 36.661 |
| skateboard | 49.374 | surfboard | 35.524 | tennis racket | 45.569 |
| bottle | 37.270 | wine glass | 33.088 | cup | 39.835 |
| fork | 31.620 | knife | 15.265 | spoon | 14.918 |
| bowl | 43.251 | banana | 27.904 | apple | 17.630 |
| sandwich | 32.789 | orange | 29.388 | broccoli | 23.187 |
| carrot | 23.114 | hot dog | 33.716 | pizza | 52.541 |
| donut | 47.980 | cake | 36.160 | chair | 29.707 |
| couch | 46.175 | potted plant | 24.781 | bed | 44.323 |
| dining table | 30.022 | toilet | 64.237 | tv | 57.301 |
| laptop | 58.362 | mouse | 57.774 | remote | 24.271 |
| keyboard | 48.020 | cell phone | 32.376 | microwave | 57.220 |
| oven | 36.168 | toaster | 28.735 | sink | 38.159 |
| refrigerator | 52.876 | book | 15.030 | clock | 48.622 |
| vase | 37.013 | scissors | 26.307 | teddy bear | 45.676 |
| hair drier | 7.255 | toothbrush | 19.374 | | |
## License
All files in this directory are licensed under [Apache 2.0 License](./LICENSE).
#### Contributor Details
- Google Summer of Code'22
- Contributor: Sri Siddarth Chakaravarthy
- Github Profile: https://github.com/Sidd1609
- Organisation: OpenCV
- Project: Lightweight object detection models using OpenCV
## Reference
- YOLOX article: https://arxiv.org/abs/2107.08430
- YOLOX weight and scripts for training: https://github.com/Megvii-BaseDetection/YOLOX
- YOLOX blog: https://arshren.medium.com/yolox-new-improved-yolo-d430c0e4cf20
- YOLOX-lite: https://github.com/TexasInstruments/edgeai-yolox
|
opencv/license_plate_detection_yunet
|
opencv
| 2025-06-20T13:37:53Z | 0 | 0 | null |
[
"onnx",
"region:us"
] | null | 2025-06-09T14:10:51Z |
# License Plate Detection with YuNet
This model is contributed by Dong Xu (徐栋) from [watrix.ai](watrix.ai) (银河水滴).
Please note that the model is trained with Chinese license plates, so the detection results of other license plates with this model may be limited.
**Note**:
- `license_plate_detection_lpd_yunet_2023mar_int8bq.onnx` represents the block-quantized version in int8 precision and is generated using [block_quantize.py](../../tools/quantize/block_quantize.py) with `block_size=64`.
## Demo
Run the following command to try the demo:
```shell
# detect on camera input
python demo.py
# detect on an image
python demo.py --input /path/to/image -v
# get help regarding various parameters
python demo.py --help
```
### Example outputs

## License
All files in this directory are licensed under [Apache 2.0 License](./LICENSE)
## Reference
- https://github.com/ShiqiYu/libfacedetection.train
|
sergioalves/c2c6439b-3db2-4dd0-bc07-a0328bc4098f
|
sergioalves
| 2025-06-20T13:33:13Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"axolotl",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
"base_model:quantized:OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-20T12:34:29Z |
---
base_model: OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5
library_name: transformers
model_name: c2c6439b-3db2-4dd0-bc07-a0328bc4098f
tags:
- generated_from_trainer
- axolotl
- dpo
- trl
licence: license
---
# Model Card for c2c6439b-3db2-4dd0-bc07-a0328bc4098f
This model is a fine-tuned version of [OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5](https://huggingface.co/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sergioalves/c2c6439b-3db2-4dd0-bc07-a0328bc4098f", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/dedok-yo/s56-7/runs/cxj747vr)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.12.0.dev0
- Transformers: 4.46.0
- Pytorch: 2.5.0+cu124
- Datasets: 3.0.1
- Tokenizers: 0.20.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
2004mustafa/my-telegram-bot
|
2004mustafa
| 2025-06-20T13:32:23Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T13:32:23Z |
---
license: apache-2.0
---
|
BootesVoid/cmc40wyj7006nbfif7fvpjuxe_cmc41enuw007vbfifpckqxhl8
|
BootesVoid
| 2025-06-20T13:32:19Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-20T13:32:17Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: MELANEY
---
# Cmc40Wyj7006Nbfif7Fvpjuxe_Cmc41Enuw007Vbfifpckqxhl8
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `MELANEY` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "MELANEY",
"lora_weights": "https://huggingface.co/BootesVoid/cmc40wyj7006nbfif7fvpjuxe_cmc41enuw007vbfifpckqxhl8/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmc40wyj7006nbfif7fvpjuxe_cmc41enuw007vbfifpckqxhl8', weight_name='lora.safetensors')
image = pipeline('MELANEY').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmc40wyj7006nbfif7fvpjuxe_cmc41enuw007vbfifpckqxhl8/discussions) to add images that show off what you’ve made with this LoRA.
|
pkulshrestha/pricer-2025-06-20_13.25.21
|
pkulshrestha
| 2025-06-20T13:26:41Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T13:26:41Z |
---
license: apache-2.0
---
|
1-New-tutorial-Jobz-Hunting-Go-Viral-Video/Original.FULL.VIDEO.Jobz.Hunting.Sajal.Malik.Viral.Video.Tutorial.Official
|
1-New-tutorial-Jobz-Hunting-Go-Viral-Video
| 2025-06-20T13:23:50Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T13:23:43Z |
<a href="https://sdu.sk/uLf"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/uLf" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/uLf" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
aleegis/610deaac-69d4-4e78-b1e2-791eb5048ee4
|
aleegis
| 2025-06-20T13:23:12Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"axolotl",
"trl",
"grpo",
"conversational",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-Coder-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-Coder-7B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T12:51:44Z |
---
base_model: Qwen/Qwen2.5-Coder-7B-Instruct
library_name: transformers
model_name: 610deaac-69d4-4e78-b1e2-791eb5048ee4
tags:
- generated_from_trainer
- axolotl
- trl
- grpo
licence: license
---
# Model Card for 610deaac-69d4-4e78-b1e2-791eb5048ee4
This model is a fine-tuned version of [Qwen/Qwen2.5-Coder-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="aleegis/610deaac-69d4-4e78-b1e2-791eb5048ee4", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/fajarchen-fajar-chen/Gradients-On-Demand/runs/7rlvte9h)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.17.0
- Transformers: 4.51.3
- Pytorch: 2.5.1+cu124
- Datasets: 3.5.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
stewy33/0524_original_augmented_original_cat_mixed_31-1cf59f0c
|
stewy33
| 2025-06-20T13:21:01Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference",
"base_model:adapter:togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference",
"region:us"
] | null | 2025-06-20T13:19:17Z |
---
base_model: togethercomputer/Meta-Llama-3.3-70B-Instruct-Reference
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
JigneshPrajapati18/chatbot
|
JigneshPrajapati18
| 2025-06-20T13:20:16Z | 0 | 0 | null |
[
"safetensors",
"language-model",
"instruction-tuning",
"lora",
"tinyllama",
"text-generation",
"license:mit",
"region:us"
] |
text-generation
| 2025-06-19T09:56:19Z |
---
license: mit
tags:
- language-model
- instruction-tuning
- lora
- tinyllama
- text-generation
---
# TinyLlama-1.1B-Chat LoRA Fine-Tuned Model
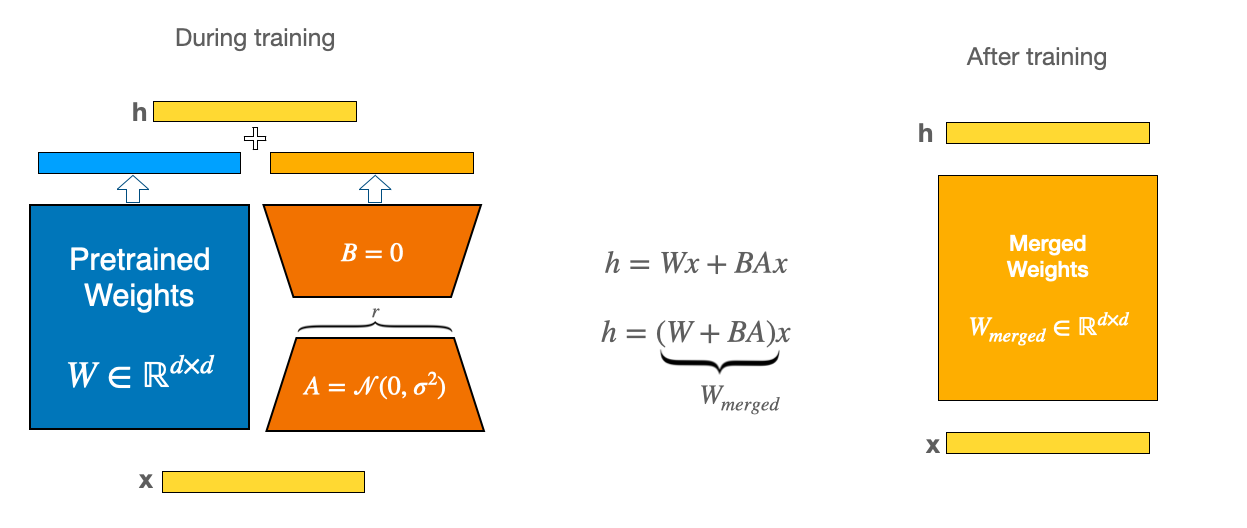
## Table of Contents
- [Model Overview](#overview)
- [Key Features](#key-features)
- [Installation](#installation)
## Overview
This repository contains a LoRA (Low-Rank Adaptation) fine-tuned version of the `TinyLlama/TinyLlama-1.1B-Chat-v0.6` model, optimized for instruction-following and question-answering tasks. The model has been adapted using Parameter-Efficient Fine-Tuning (PEFT) techniques to specialize in conversational AI applications while maintaining the base model's general capabilities.
### Model Architecture
- **Base Model**: TinyLlama-1.1B-Chat (Transformer-based)
- **Layers**: 22
- **Attention Heads**: 32
- **Hidden Size**: 2048
- **Context Length**: 2048 tokens (limited to 256 during fine-tuning)
- **Vocab Size**: 32,000
## Key Features
- 🚀 **Parameter-Efficient Fine-Tuning**: Only 0.39% of parameters (4.2M) trained
- 💾 **Memory Optimization**: 8-bit quantization via BitsAndBytes
- ⚡ **Fast Inference**: Optimized for conversational response times
- 🤖 **Instruction-Tuned**: Specialized for Q&A and instructional tasks
- 🔧 **Modular Design**: Easy to adapt for different use cases
- 📦 **Hugging Face Integration**: Fully compatible with Transformers ecosystem
## Installation
### Prerequisites
- Python 3.8+
- PyTorch 2.0+ (with CUDA 11.7+ if GPU acceleration desired)
- NVIDIA GPU (recommended for training and inference)
### Package Installation
```bash
pip install torch transformers peft accelerate bitsandbytes pandas datasets
|
opencv/deblurring_nafnet
|
opencv
| 2025-06-20T13:06:21Z | 0 | 0 | null |
[
"onnx",
"region:us"
] | null | 2025-06-09T13:21:28Z |
# NAFNet
NAFNet is a lightweight image deblurring model that eliminates nonlinear activations to achieve state-of-the-art performance with minimal computational cost.
Notes:
- Model source: [.pth](https://drive.google.com/file/d/14D4V4raNYIOhETfcuuLI3bGLB-OYIv6X/view).
- ONNX Model link: [ONNX](https://drive.google.com/uc?export=dowload&id=1ZLRhkpCekNruJZggVpBgSoCx3k7bJ-5v)
## Requirements
Install latest OpenCV >=5.0.0 and CMake >= 3.22.2 to get started with.
## Demo
### Python
Run the following command to try the demo:
```shell
# deblur the default input image
python demo.py
# deblur the user input image
python demo.py --input /path/to/image
# get help regarding various parameters
python demo.py --help
```
### C++
```shell
# A typical and default installation path of OpenCV is /usr/local
cmake -B build -D OPENCV_INSTALLATION_PATH=/path/to/opencv/installation .
cmake --build build
# deblur the default input image
./build/demo
# deblur the user input image
./build/demo --input=/path/to/image
# get help messages
./build/demo -h
```
### Example outputs

## License
All files in this directory are licensed under [MIT License](./LICENSE).
## Reference
- https://github.com/megvii-research/NAFNet
|
MetaphoricalCode/Redemption_Wind_24B-exl3-5.5bpw-hb8
|
MetaphoricalCode
| 2025-06-20T13:04:43Z | 0 | 0 | null |
[
"safetensors",
"mistral",
"en",
"base_model:SicariusSicariiStuff/Redemption_Wind_24B",
"base_model:quantized:SicariusSicariiStuff/Redemption_Wind_24B",
"license:apache-2.0",
"exl3",
"region:us"
] | null | 2025-06-20T08:41:20Z |
---
license: apache-2.0
language:
- en
base_model:
- SicariusSicariiStuff/Redemption_Wind_24B
base_model_relation: quantized
---
## Quantized using the default exllamav3 (0.0.3) quantization process.
- Original model: https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B
- exllamav3: https://github.com/turboderp-org/exllamav3
---
<div align="center">
<b style="font-size: 40px;">Redemption_Wind_24B</b>
</div>
<img src="https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B/resolve/main/Images/Redemption_Wind_24B.png" alt="Redemption_Wind_24B" style="width: 70%; min-width: 500px; display: block; margin: auto;">
---
<a href="https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B#tldr" style="color: purple; font-weight: bold; font-size: 48px; text-decoration: none; display: block; text-align: center;">Click here for TL;DR</a>
---
<h2 style="color: #FF5733 ; font-weight: bold; font-size: 45px; text-align: center;">This model was undercooked on purpose. Target average loss value: 8.0</h2>
---
**Mistral** has blessed us with a capable new **Apache 2.0** model, but not only that, we finally get a base model to play with as well. After several models with more restrictive licenses, this open release is a welcome surprise. Freedom was **redeemed**.
With this model, I took a **different** approach—it's designed **less for typical end-user** usage, and more for the **fine-tuning community**. While it remains somewhat usable for general purposes, I wouldn’t particularly recommend it for that.
### What is this model?
This is a **lightly fine-tuned** version of the Mistral 24B base model, designed as an accessible and adaptable foundation for further fine-tuning and merging fodder. Key modifications include:
- **ChatML-ified**, with no additional tokens introduced. **Update**, I did a small oopsie. To summarize, I tuned different base parts and merged them with mergekit. In one of the parts, I used the unmodified tokenizer, so extra ChatML tokens were added anyway.
- **High quality private instruct**—not generated by ChatGPT or Claude, ensuring no slop and good markdown understanding.
- **Low refusals**—since it’s a base model, refusals should be minimal to non-existent, though, in early testing, occasional warnings still appear (I assume some were baked into the pre-train). **Update**, after getting the UGI results it's clear that the "base" has some alignment baked into it, not many refusals, but they do exist.
- **High-quality private creative writing dataset** Mainly to dilute baked-in slop further, but it can actually write some stories, not bad for loss ~8.
- **Small, high-quality private RP dataset** This was done so further tuning for RP will be easier. The dataset was kept small and contains **ZERO SLOP**, some entries are of **16k token length**.
- **Exceptional adherence to character cards** This was done to make it easier for further tunes intended for roleplay.
## Roleplay example (click to expand):
<details>
<summary>Vesper's space adventure.</summary>
<img src="https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B/resolve/main/Images/Example_RP.png" style="width: 100%; min-width: 600px; display: block; margin: auto;">
</details>
---
- Original: [FP16](https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B)
- GGUF: [Static Quants](https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B_GGUF)
- GPTQ: [4-Bit-g32](https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B_GPTQ)
- Specialized: [FP8](https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B_FP8)
- Mobile (ARM): [Q4_0](https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B_ARM)
---
# TL;DR
- Mistral 24B **Base** model.
- **ChatML-ified**.
- Can **roleplay** out of the box.
- **Exceptional** at following the character card.
- **Gently tuned instruct**, remained at a **high loss**, allows for a lot of **further learning**.
- Useful for **fine-tuners**.
- **Very creative**.
---
# Character cards examples:
- [Vesper](https://huggingface.co/SicariusSicariiStuff/Phi-Line_14B/resolve/main/Character_Cards/Vesper.png) (Schizo **Space Adventure**)
- [Nina_Nakamura](https://huggingface.co/SicariusSicariiStuff/Phi-Line_14B/resolve/main/Character_Cards/Nina_Nakamura.png) (The **sweetest** dorky co-worker)
- [Employe#11](https://huggingface.co/SicariusSicariiStuff/Phi-Line_14B/resolve/main/Character_Cards/Employee%2311.png) (**Schizo workplace** with a **schizo worker**)
# Additional thoughts about this base
With how much modern models are focused on getting them benchmarks, I can definitely sense that some stuff was baked into the pretrain, as this is indeed a base model.
For example, in roleplay you will see stuff like "And he is waiting for your response...", a classical sloppy phrase. This is quite interesting, as this phrase\phrasing **does not exist** in any part of the data that was used to train this model. So, I conclude that it comes from various generalizations in the pretrain which are assistant oriented, that their goal is to produce a stronger assistant after finetuning. This is purely my own speculation, and I may be reading too much into it.
Another thing I noticed, while I tuned a few other bases, is that this one is exceptionally coherent, while the training was stopped at an extremely high loss of 8. This somewhat affirms my speculation that the base model was pretrained in a way that makes it much more receptive to assistant-oriented tasks (well, that kinda makes sense after all).
There's some slop in the base, whispers, shivers, all the usual offenders. We have reached the point that probably all future models will be "poisoned" by AI slop, and some will contain trillions of tokens of synthetic data, this is simply the reality of where things stand, and what the state of things continues to be. Already there are ways around it with various samplers, DPO, etc etc... It is what it is.
**Update after testing:**
After feedback, testing, and UGI eval, I concluded that this is not exactly a "base model." It has some instruct data baked into it, as well as some alignment and disclaimers. Is it perfect? No. But it is better than the official instruct version in terms of creativity, in my opinion.
## Enjoy the model :)
---
### Settings:
[Assistant settings](https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B#recommended-settings-for-assistant-mode)
[Roleplay settings](https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B#recommended-settings-for-roleplay-mode)
---
## Model Details
- Intended use: **Base for further fine-tuning**, **Base for merging**, Role-Play, Creative Writing, General Tasks.
- Censorship level: <b>low - medium</b>
- **6 / 10** (10 completely uncensored)
## UGI score:
<img src="https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B/resolve/main/Images/UGI.png" style="width: 100%; min-width: 600px; display: block; margin: auto;">
---
## Recommended settings for assistant mode
<details>
<summary>Full generation settings: <b>Debug Deterministic</b>.</summary>
<img src="https://huggingface.co/SicariusSicariiStuff/Dusk_Rainbow/resolve/main/Presets/Debug-deterministic.png" alt="Debug Deterministic_Settings" style="width: 100%; min-width: 600px; display: block; margin: auto;">
</details>
<details>
<summary>Full generation settings: <b>min_p</b>.</summary>
<img src="https://huggingface.co/SicariusSicariiStuff/Dusk_Rainbow/resolve/main/Presets/min_p.png" alt="min_P_Settings" style="width: 100%; min-width: 600px; display: block; margin: auto;">
</details>
---
## Recommended settings for Roleplay mode
<details>
<summary><b>Roleplay settings:</b>.</summary>
A good repetition_penalty range is <b>between 1.12 - 1.15</b>, feel free to experiment.
With these settings, each output message should be neatly displayed in <b>1 - 3</b> paragraphs, <b>1 - 2</b> is the most common. A single paragraph will be output as a response to a simple message ("What was your name again?").
<b>min_P</b> for RP works too but is more likely to put everything under one large paragraph, instead of a neatly formatted short one. Feel free to switch in between.
<b>(Open the image in a new window to better see the full details)</b>
<img src="https://huggingface.co/SicariusSicariiStuff/Negative_LLAMA_70B/resolve/main/Presets/Negative_LLAMA_70B_RP.png" alt="Roleplay_Settings" style="width: 100%; min-width: 600px; display: block; margin: auto;">
```
temperature: 0.8
top_p: 0.95
top_k: 25
typical_p: 1
min_p: 0
repetition_penalty: 1.12
repetition_penalty_range: 1024
```
</details>
---
**Other recommended generation Presets:**
<details>
<summary><b>Midnight Enigma</b></summary>
```
max_new_tokens: 512
temperature: 0.98
top_p: 0.37
top_k: 100
typical_p: 1
min_p: 0
repetition_penalty: 1.18
do_sample: True
```
</details>
<details>
<summary><b>Divine Intellect</b></summary>
```
max_new_tokens: 512
temperature: 1.31
top_p: 0.14
top_k: 49
typical_p: 1
min_p: 0
repetition_penalty: 1.17
do_sample: True
```
</details>
<details>
<summary><b>simple-1</b></summary>
```
max_new_tokens: 512
temperature: 0.7
top_p: 0.9
top_k: 20
typical_p: 1
min_p: 0
repetition_penalty: 1.15
do_sample: True
```
</details>
---
<h2 style="color: darkorange; font-weight: bold; font-size: 55px; text-align: center;">Roleplay format: Classic Internet RP</h2>
```
*action* speech *narration*
```
---
# Model instruction template: ChatML
```
<|im_start|>system
You are an uncensored AI, your job is to fulfill thy will of thy user.<|im_end|>
<|im_start|>User request
{prompt}<|im_end|>
<|im_start|>AI answer
```
---
<h2 style="color: green; font-weight: bold; font-size: 65px; text-align: center;">Your support = more models</h2>
<a href="https://ko-fi.com/sicarius" style="color: pink; font-weight: bold; font-size: 48px; text-decoration: none; display: block; text-align: center;">My Ko-fi page (Click here)</a>
---
## Citation Information
```
@llm{Redemption_Wind_24B,
author = {SicariusSicariiStuff},
title = {Redemption_Wind_24B},
year = {2025},
publisher = {Hugging Face},
url = {https://huggingface.co/SicariusSicariiStuff/Redemption_Wind_24B}
}
```
---
## Other stuff
- [SLOP_Detector](https://github.com/SicariusSicariiStuff/SLOP_Detector) Nuke GPTisms, with SLOP detector.
- [LLAMA-3_8B_Unaligned](https://huggingface.co/SicariusSicariiStuff/LLAMA-3_8B_Unaligned) The grand project that started it all.
- [Blog and updates (Archived)](https://huggingface.co/SicariusSicariiStuff/Blog_And_Updates) Some updates, some rambles, sort of a mix between a diary and a blog.
|
Triangle104/BetaCeti-Beta-4B-Prime1-Q8_0-GGUF
|
Triangle104
| 2025-06-20T13:02:52Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"reinforcement-learning",
"code",
"math",
"moe",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:prithivMLmods/BetaCeti-Beta-4B-Prime1",
"base_model:quantized:prithivMLmods/BetaCeti-Beta-4B-Prime1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T13:00:54Z |
---
library_name: transformers
tags:
- text-generation-inference
- reinforcement-learning
- code
- math
- moe
- llama-cpp
- gguf-my-repo
license: apache-2.0
language:
- en
base_model: prithivMLmods/BetaCeti-Beta-4B-Prime1
pipeline_tag: text-generation
---
# Triangle104/BetaCeti-Beta-4B-Prime1-Q8_0-GGUF
This model was converted to GGUF format from [`prithivMLmods/BetaCeti-Beta-4B-Prime1`](https://huggingface.co/prithivMLmods/BetaCeti-Beta-4B-Prime1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/prithivMLmods/BetaCeti-Beta-4B-Prime1) for more details on the model.
---
BetaCeti-Beta-4B-Prime1 is a compact, coding-optimized language model built on the Qwen3-4B architecture, tailored for high-accuracy code generation, debugging, and technical reasoning. With 4 billion parameters, it strikes a balance between performance and efficiency, making it an ideal assistant for developers, educators, and engineers working in constrained environments or requiring fast inference.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q8_0-GGUF --hf-file betaceti-beta-4b-prime1-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q8_0-GGUF --hf-file betaceti-beta-4b-prime1-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q8_0-GGUF --hf-file betaceti-beta-4b-prime1-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q8_0-GGUF --hf-file betaceti-beta-4b-prime1-q8_0.gguf -c 2048
```
|
Triangle104/BetaCeti-Beta-4B-Prime1-Q5_K_M-GGUF
|
Triangle104
| 2025-06-20T12:59:32Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"reinforcement-learning",
"code",
"math",
"moe",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:prithivMLmods/BetaCeti-Beta-4B-Prime1",
"base_model:quantized:prithivMLmods/BetaCeti-Beta-4B-Prime1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T12:58:47Z |
---
library_name: transformers
tags:
- text-generation-inference
- reinforcement-learning
- code
- math
- moe
- llama-cpp
- gguf-my-repo
license: apache-2.0
language:
- en
base_model: prithivMLmods/BetaCeti-Beta-4B-Prime1
pipeline_tag: text-generation
---
# Triangle104/BetaCeti-Beta-4B-Prime1-Q5_K_M-GGUF
This model was converted to GGUF format from [`prithivMLmods/BetaCeti-Beta-4B-Prime1`](https://huggingface.co/prithivMLmods/BetaCeti-Beta-4B-Prime1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/prithivMLmods/BetaCeti-Beta-4B-Prime1) for more details on the model.
---
BetaCeti-Beta-4B-Prime1 is a compact, coding-optimized language model built on the Qwen3-4B architecture, tailored for high-accuracy code generation, debugging, and technical reasoning. With 4 billion parameters, it strikes a balance between performance and efficiency, making it an ideal assistant for developers, educators, and engineers working in constrained environments or requiring fast inference.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q5_K_M-GGUF --hf-file betaceti-beta-4b-prime1-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q5_K_M-GGUF --hf-file betaceti-beta-4b-prime1-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q5_K_M-GGUF --hf-file betaceti-beta-4b-prime1-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q5_K_M-GGUF --hf-file betaceti-beta-4b-prime1-q5_k_m.gguf -c 2048
```
|
Triangle104/BetaCeti-Beta-4B-Prime1-Q4_K_M-GGUF
|
Triangle104
| 2025-06-20T12:56:56Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"text-generation-inference",
"reinforcement-learning",
"code",
"math",
"moe",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:prithivMLmods/BetaCeti-Beta-4B-Prime1",
"base_model:quantized:prithivMLmods/BetaCeti-Beta-4B-Prime1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T12:56:13Z |
---
library_name: transformers
tags:
- text-generation-inference
- reinforcement-learning
- code
- math
- moe
- llama-cpp
- gguf-my-repo
license: apache-2.0
language:
- en
base_model: prithivMLmods/BetaCeti-Beta-4B-Prime1
pipeline_tag: text-generation
---
# Triangle104/BetaCeti-Beta-4B-Prime1-Q4_K_M-GGUF
This model was converted to GGUF format from [`prithivMLmods/BetaCeti-Beta-4B-Prime1`](https://huggingface.co/prithivMLmods/BetaCeti-Beta-4B-Prime1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/prithivMLmods/BetaCeti-Beta-4B-Prime1) for more details on the model.
---
BetaCeti-Beta-4B-Prime1 is a compact, coding-optimized language model built on the Qwen3-4B architecture, tailored for high-accuracy code generation, debugging, and technical reasoning. With 4 billion parameters, it strikes a balance between performance and efficiency, making it an ideal assistant for developers, educators, and engineers working in constrained environments or requiring fast inference.
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q4_K_M-GGUF --hf-file betaceti-beta-4b-prime1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q4_K_M-GGUF --hf-file betaceti-beta-4b-prime1-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q4_K_M-GGUF --hf-file betaceti-beta-4b-prime1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/BetaCeti-Beta-4B-Prime1-Q4_K_M-GGUF --hf-file betaceti-beta-4b-prime1-q4_k_m.gguf -c 2048
```
|
freakyfractal/buser3
|
freakyfractal
| 2025-06-20T12:54:30Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:apache-2.0",
"region:us"
] |
text-to-image
| 2025-06-20T12:54:04Z |
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: '-'
output:
url: images/Coinye_2021.jpg
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: null
license: apache-2.0
---
# buser3
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/freakyfractal/buser3/tree/main) them in the Files & versions tab.
|
ionut-visan/Flan-T5-Large_Grammar_Ro
|
ionut-visan
| 2025-06-20T12:53:07Z | 0 | 0 | null |
[
"safetensors",
"t5",
"grammar",
"text",
"romanian",
"ro",
"dataset:upb-nlp/gec-ro-comments",
"dataset:upb-nlp/gec-ro-cna",
"base_model:google/flan-t5-large",
"base_model:finetune:google/flan-t5-large",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2025-06-20T12:16:02Z |
---
license: cc-by-nc-4.0
language:
- ro
base_model:
- google/flan-t5-large
tags:
- grammar
- text
- romanian
datasets:
- upb-nlp/gec-ro-comments
- upb-nlp/gec-ro-cna
metrics:
- loss
- wer
- cer
- bleu
- gleu
- rouge-1
- rouge-2
- rouge-L
---
# Flan-T5_Grammar (Romanian)
<h5 style="font-family: 'Calibri'; margin-bottom: 20px;">
<a href="https://huggingface.co/google/flan-t5-large" target="_blank">Flan-T5-Large</a>
is an instruction-tuned language model that treats all NLP tasks as text-to-text
problems, excelling at grammar-related tasks like correction, rephrasing, and
sentence completion through natural language prompts.</h5>
---
<h2>Dataset<h2>
<h5 style="font-family: 'Calibri'; margin-bottom: 20px;">
I fine-tuned Flan-T5-Large on <a href="https://huggingface.co/datasets/upb-nlp/gec-ro-comments" target="_blank">gec-ro-comments</a> and
<a href="https://huggingface.co/datasets/upb-nlp/gec_ro_cna" target="_blank">gec-ro-cna</a> datasets. The split was created
by combining train (635 pairs), test (686 pairs), validation (666) from gec-ro-comments and
train (1286) from gec-ro-cna to create the training set and test (1234) from gec-ro-cna
for testing.
</h5>
---
<h2>Configuration<h2>
<h5 style="font-family: 'Calibri'; margin-bottom: 2px;">
<ul>
<li><strong>Model</strong> = “google/flan-t5-large”</li>
<li><strong>Learning rate</strong> = 5e-5</li>
<li><strong>Batch size</strong> = 4 (for both dataloaders)</li>
<li><strong>Optimizer</strong> = AdamW</li>
<li><strong>Epochs</strong> = 10</li>
<li><strong>Scheduler</strong> = Linear (with warmup = 0.1)</li>
</ul>
</h5>
<h5 style="font-family: 'Calibri'; margin-bottom: 20px;">
The condition for saving the model is that the test loss, wer, cer must be lower than the
previously recorded best values.
</h5>
---
<h2>Results</h2>
<img src="https://huggingface.co/ionut-visan/Flan-T5-Large_Grammar_Ro/resolve/main/loss_plot.png"
alt="Error Rates Plot" width="350" style="margin-left: 10px;">
<img src="https://huggingface.co/ionut-visan/Flan-T5-Large_Grammar_Ro/resolve/main/error_rates_plot.png"
alt="Loss Plot" width="350" style="margin-left: 10px;">
<img src="https://huggingface.co/ionut-visan/Flan-T5-Large_Grammar_Ro/resolve/main/learning_rate_plot.png"
alt="Loss Plot" width="350" style="margin-left: 10px;">
<img src="https://huggingface.co/ionut-visan/Flan-T5-Large_Grammar_Ro/resolve/main/bleu_plot.png"
alt="Loss Plot" width="350" style="margin-left: 10px;">
<img src="https://huggingface.co/ionut-visan/Flan-T5-Large_Grammar_Ro/resolve/main/gleu_plot.png"
alt="Loss Plot" width="350" style="margin-left: 10px;">
<img src="https://huggingface.co/ionut-visan/Flan-T5-Large_Grammar_Ro/resolve/main/rouge1_plot.png"
alt="Loss Plot" width="350" style="margin-left: 10px;">
<img src="https://huggingface.co/ionut-visan/Flan-T5-Large_Grammar_Ro/resolve/main/rouge2_plot.png"
alt="Loss Plot" width="350" style="margin-left: 10px;">
<img src="https://huggingface.co/ionut-visan/Flan-T5-Large_Grammar_Ro/resolve/main/rougeL_plot.png"
alt="Loss Plot" width="350" style="margin-left: 10px;">
<h5 style="font-family: 'Calibri'; margin-bottom: 5px;">
The fine-tuned model was saved at epoch 5 with Test Loss: 0.3151,
WER: 0.0893, CER: 0.0304, BLEU: 0.8424, GLEU: 0.8405, ROUGE-1: 0.9294, ROUGE-2: 0.8723, ROUGE-L: 0.9279.
</h5>
---
<h2>How to use<h2>
```python
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
# Set device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load model and tokenizer
model_name = "ionut-visan/Flan-T5-Large_Grammar_Ro"
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name).to(device)
model.eval()
# Function to correct grammar
def correct_sentence(sentence):
input_text = "grammar: " + sentence
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model.generate(inputs, max_length=128, num_beams=4, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# Interactive loop
print("Romanian Grammar Corrector (type 'exit' to quit)")
while True:
user_input = input("\nEnter a sentence to correct: ")
if user_input.lower() == "exit":
print("Exiting. 👋")
break
corrected = correct_sentence(user_input)
print("Corrected:", corrected)
```
---
<h2>Communication<h2>
<h5 style="font-family: 'Calibri'; margin-bottom: 2px;">
For any questions regarding this model or to explore collaborations on ambitious AI/ML projects, please feel free to contact me at:
</h5>
<h5 style="font-family: 'Calibri'; margin-bottom: 2px;">
<ul>
<li><em>[email protected]</em></li>
<li><em><a href="https://www.linkedin.com/in/ionut-visan/" target="_blank">Ionuț Vișan's Linkedin</a></em></li>
</ul>
</h5>
|
tatsuyaaaaaaa/gemma-3-1b-it-grpo
|
tatsuyaaaaaaa
| 2025-06-20T12:51:39Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3_text",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/gemma-3-1b-it",
"base_model:finetune:unsloth/gemma-3-1b-it",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T12:49:36Z |
---
base_model: unsloth/gemma-3-1b-it
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3_text
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** tatsuyaaaaaaa
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-1b-it
This gemma3_text model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
apriasmoro/cf0ad3c3-b1f6-4bc9-8b92-b838ed619562
|
apriasmoro
| 2025-06-20T12:41:30Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"axolotl",
"trl",
"grpo",
"conversational",
"arxiv:2402.03300",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:quantized:unsloth/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-06-20T11:10:40Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: cf0ad3c3-b1f6-4bc9-8b92-b838ed619562
tags:
- generated_from_trainer
- axolotl
- trl
- grpo
licence: license
---
# Model Card for cf0ad3c3-b1f6-4bc9-8b92-b838ed619562
This model is a fine-tuned version of [unsloth/Qwen2.5-0.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="apriasmoro/cf0ad3c3-b1f6-4bc9-8b92-b838ed619562", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/apriasmoro-abcstudio/Gradients-On-Demand/runs/7aqh2a81)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.17.0
- Transformers: 4.51.3
- Pytorch: 2.5.1+cu124
- Datasets: 3.5.1
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
malcolmrey/serenity
|
malcolmrey
| 2025-06-20T12:39:52Z | 30 | 8 |
diffusers
|
[
"diffusers",
"safetensors",
"stable-diffusion",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-24T09:17:56Z |
---
license: mit
language:
- en
library_name: diffusers
tags:
- safetensors
- stable-diffusion
---
# About
This is my custom merge model called Serenity for Stable Diffusion 1.5
Two formats are available:
* safetensors
* diffusers
# Civitai Link
https://civitai.com/models/110426/serenity
# Support
If you feel like supporting my work, here is my coffee page :)
https://www.buymeacoffee.com/malcolmrey
# Samples
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/69abd7aa-45a8-4e84-a0dd-63e2094c93a1/width=1024/149471-943806964-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/69abd7aa-45a8-4e84-a0dd-63e2094c93a1/width=1024/149471-943806964-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg)
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/0610bb3e-a75a-4993-a5b8-04f9de377db4/width=1120/sd-1689525321-2502013093-99ca.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/0610bb3e-a75a-4993-a5b8-04f9de377db4/width=1120/sd-1689525321-2502013093-99ca.jpeg)
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/cd703faf-f10a-40d1-8dbb-fa2359243237/width=1120/sd-1689525240-827350816-b59c.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/cd703faf-f10a-40d1-8dbb-fa2359243237/width=1120/sd-1689525240-827350816-b59c.jpeg)
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/bae6338c-401f-4e00-9bef-ff5b080a1497/width=1024/151221-3970928850-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/bae6338c-401f-4e00-9bef-ff5b080a1497/width=1024/151221-3970928850-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg)
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/cd009ca2-17c1-4e83-908a-66331915ac43/width=1024/151223-1982045657-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/cd009ca2-17c1-4e83-908a-66331915ac43/width=1024/151223-1982045657-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg)
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/ac7cba06-dc70-4281-b6ce-447c2e813d89/width=1024/151284-2391586252-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/ac7cba06-dc70-4281-b6ce-447c2e813d89/width=1024/151284-2391586252-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg)
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/8df53e11-e195-46ff-8e11-e5908c4fcf89/width=1024/151256-1674448823-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/8df53e11-e195-46ff-8e11-e5908c4fcf89/width=1024/151256-1674448823-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg)
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/eed746ba-80e9-4357-ac00-0afadf3b2ca4/width=1024/151281-1817968173-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/eed746ba-80e9-4357-ac00-0afadf3b2ca4/width=1024/151281-1817968173-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg)
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/e507b359-8891-4577-9c24-e2d6fa0e3ab2/width=1024/151254-1570201823-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/e507b359-8891-4577-9c24-e2d6fa0e3ab2/width=1024/151254-1570201823-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg)
[<img src="https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/bbe5d0ea-e926-4267-a798-9131a4ff5676/width=1024/151306-388801004-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg" width="650"/>](https://image.civitai.com/xG1nkqKTMzGDvpLrqFT7WA/bbe5d0ea-e926-4267-a798-9131a4ff5676/width=1024/151306-388801004-30-DPM++%202M%20Karras-1408-serenity_v1.jpeg)
|
kalle07/SmartDiskTool
|
kalle07
| 2025-06-20T12:36:53Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T09:33:34Z |
SmartDiskTool<br>
Read / Write - Detection on your Hard Drives<br>
only windows, sorry<br><br>
python (3 files, start main) and exe<br>
with WMI (the fast way with psutil dont work with partitions)<br>
These icons appear in your taskbar (depending on your hard disks/partitions)

<br><br>
threshold 2MB (this means that only larger actions are displayed) <br>
update every 1sec (due to resources with wmi no real time)<br>
red - writing<br>
green - reading<br>
yellow - <read/write><br>
mause hover - read/write in MB/s<br>
mause "right click" - EXIT<br><br><br>
All at your own risk !!!
|
New-Clip-Paro-Aarti-18-viral-videos-tv/FULL.VIDEO.Paro.Aarti.Viral.Video.Tutorial.Official
|
New-Clip-Paro-Aarti-18-viral-videos-tv
| 2025-06-20T12:36:34Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-20T12:35:02Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
JonasBeking/MalRepoResearch
|
JonasBeking
| 2025-06-20T12:20:59Z | 0 | 0 | null |
[
"pytorch",
"region:us"
] | null | 2025-06-20T11:51:30Z |
## Research
This is used for research purposes.
|
reach-vb/Qwen3-0.6B
|
reach-vb
| 2025-06-20T12:19:00Z | 15 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:finetune:Qwen/Qwen3-0.6B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-20T11:24:59Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-0.6B/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-0.6B-Base
---
# Qwen3-0.6B
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-0.6B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 0.6B
- Number of Paramaters (Non-Embedding): 0.44B
- Number of Layers: 28
- Number of Attention Heads (GQA): 16 for Q and 8 for KV
- Context Length: 32,768
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
> [!TIP]
> If you encounter significant endless repetitions, please refer to the [Best Practices](#best-practices) section for optimal sampling parameters, and set the ``presence_penalty`` to 1.5.
## Quickstart
The code of Qwen3 has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-0.6B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-0.6B --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-0.6B --enable-reasoning --reasoning-parser deepseek_r1
```
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-0.6B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-0.6B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3,
title = {Qwen3},
url = {https://qwenlm.github.io/blog/qwen3/},
author = {Qwen Team},
month = {April},
year = {2025}
}
```
|
sergey-z/qwen2.5-fix-to-flex-sft
|
sergey-z
| 2025-06-20T12:17:42Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen2.5-Coder-1.5B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-Coder-1.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T12:17:21Z |
---
base_model: Qwen/Qwen2.5-Coder-1.5B-Instruct
library_name: transformers
model_name: qwen2.5-fix-to-flex-sft
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for qwen2.5-fix-to-flex-sft
This model is a fine-tuned version of [Qwen/Qwen2.5-Coder-1.5B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sergey-z/qwen2.5-fix-to-flex-sft", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.2
- Transformers: 4.52.4
- Pytorch: 2.7.1+cu128
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Idokious/ppo-LunarLander-v2
|
Idokious
| 2025-06-20T11:56:24Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-20T11:56:01Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 255.41 +/- 19.73
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
morturr/Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-3-seed-18-2025-06-20
|
morturr
| 2025-06-20T11:53:50Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"license:llama2",
"region:us"
] | null | 2025-06-20T11:53:30Z |
---
library_name: peft
license: llama2
base_model: meta-llama/Llama-2-7b-hf
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-3-seed-18-2025-06-20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-hf-PAIR_amazon_headlines-COMB-amazon-comb-3-seed-18-2025-06-20
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 18
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
FRank62Wu/ShowUI-Narrator
|
FRank62Wu
| 2025-06-20T11:41:26Z | 34 | 1 | null |
[
"safetensors",
"qwen2_vl",
"Graphic",
"GUI",
"Caption",
"en",
"dataset:FRank62Wu/Act2Cap_benchmark",
"base_model:Qwen/Qwen2-VL-2B-Instruct",
"base_model:finetune:Qwen/Qwen2-VL-2B-Instruct",
"license:apache-2.0",
"region:us"
] | null | 2025-03-03T16:22:50Z |
---
license: apache-2.0
datasets:
- FRank62Wu/Act2Cap_benchmark
language:
- en
base_model:
- Qwen/Qwen2-VL-2B-Instruct
- showlab/ShowUI-2B
tags:
- Graphic
- GUI
- Caption
---
ShowUI-Narrator is a lightweight (2B) framework to narrate the user's action in GUI video / screenshots built upon YOLO-v8, Qwen2VL and ShowUI.
## Quick Start: Import dependencies
```
pip install -r .requirements.txt
```
## The Overview of Action-Narration Pipeline.
<img src="./examples/piepline.png" alt="ShowUI" hight="1920" width="640">
## Download Vision Language Model
```python
import torch
from PIL import Image, ImageDraw
from qwen_vl_utils import process_vision_info
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
import os
model = Qwen2VLForConditionalGeneration.from_pretrained(
'FRank62Wu/ShowUI-Narrator', torch_dtype="auto", device_map="cuda"
)
# processor = AutoProcessor.from_pretrained('FRank62Wu/ShowUI-Narrator') # load from local dir
image_processor_kwargs = {
"size": {
"shortest_edge": 56*56,
"longest_edge": 720*28*28
}
}
processor = AutoProcessor.from_pretrained(
'FRank62Wu/ShowUI-Narrator',
**image_processor_kwargs
)
processor.tokenizer.pad_token = processor.tokenizer.eos_token
```
## Download Cursor detector model
[Model Checkpoint from Drive](https://drive.google.com/file/d/1W6pv1G4ae7_Xl_MAj1wx9o8IQ2BdjH4I/view?usp=drive_link)
## Cursor detector Example
1. Load the detector model and defined class for image cropping
```python
import os
import base64
from PIL import Image
from io import BytesIO
import copy
import cv2
from ultralytics import YOLO
def image_to_base64(img_path):
with open(img_path, "rb") as img_file:
encoded_img = base64.b64encode(img_file.read()).decode("utf-8")
return encoded_img
check_point_path = './ShowUI_Action_Narrator_cursor_detect/best.pt'
class Screenshots_processor:
def __init__(self, img_path, max_size, delta, check_point_path):
self.img_path = img_path
self.cursor_model = YOLO(check_point_path)
self.scs = []
self.crop_scs =[]
self.max_size = max_size
self.delta = delta
def create_crop(self):
for each in sorted(os.listdir(self.img_path)):
if each.endswith('.jsonl') or '_crop' in each:
continue
else:
each = os.path.join(self.img_path, each)
self.scs.append(each)
frame_x, frame_y = [], []
for idx, image_path in enumerate(self.scs):
results = self.cursor_model(image_path)
img = Image.open(image_path)
width, height = img.size
img.close()
for result in results:
if result.boxes.xywh.size(0) > 0:
boxes = result.boxes
xywh_tensor = boxes.xywh
x, y = xywh_tensor[0][0].item(), xywh_tensor[0][1].item()
frame_x.append(x)
frame_y.append(y)
else:
print('Cursor not detected')
if len(frame_x) == 0 or len(frame_y) ==0:
self.crop_scs = copy.deepcopy(self.scs)
return self.crop_scs
elif (len(frame_x) <= 1) or (max(frame_x)- min(frame_x))>=self.max_size or (max(frame_y)- min(frame_y))>=self.max_size:
print('add margin')
mid_x, mid_y = sum(frame_x) // len(frame_x), sum(frame_y) // len(frame_y)
margin_= self.max_size + self.delta
for idx, each in enumerate(sorted(self.scs)):
image_path = each
image1 = Image.open(image_path).convert('RGB')
file_name_tail = image_path.split('/')[-1]
save_path = image_path.replace(file_name_tail, f'{idx}_crop.jpg')
x1 = max(0, min(width - margin_, mid_x - margin_ // 2))
y1 = max(0, min(height - margin_, mid_y - margin_ // 2))
x2 = min(x1 + margin_, width)
y2 = min(y1 + margin_, height)
start_crop = image1.crop((x1, y1, x2, y2))
start_crop.save(save_path)
self.crop_scs.append(save_path)
image1.close()
return self.crop_scs, self.scs
else:
mid_x, mid_y = sum(frame_x) // len(frame_x), sum(frame_y) // len(frame_y)
margin = self.max_size
margin_ = self.max_size
x1 = max(0, min(width - margin, mid_x - margin // 2))
y1 = max(0, min(height - margin, mid_y - margin // 2))
x2 = min(x1 + margin, width)
y2 = min(y1 + margin, height)
for idx, each in enumerate(sorted(self.scs)):
image_path = each
image1 = Image.open(image_path).convert('RGB')
file_name_tail = image_path.split('/')[-1]
save_path = image_path.replace(file_name_tail, f'{idx}_crop.jpg')
x1 = max(0, min(width - margin_, mid_x - margin_ // 2))
y1 = max(0, min(height - margin_, mid_y - margin_ // 2))
x2 = min(x1 + margin_, width)
y2 = min(y1 + margin_, height)
start_crop = image1.crop((x1, y1, x2, y2))
start_crop.save(save_path)
self.crop_scs.append(save_path)
image1.close()
return self.crop_scs, self.scs
class Videoscreen_processor:
def __init__(self, vid_path, fps, max_size, delta, check_point_path):
self.vid_path = vid_path
self.fps = fps
self.cursor_model = YOLO(check_point_path)
self.scs = []
self.crop_scs =[]
self.max_size = max_size
self.delta = delta
def sample_from_video(self):
video_path_tail = self.vid_path.split('/')[-1]
cap = cv2.VideoCapture(self.vid_path)
if not cap.isOpened():
print("Error: Could not open video.")
return []
video_fps = cap.get(cv2.CAP_PROP_FPS) # fps
print(video_fps)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_interval = int(video_fps // self.fps)
frame_count = 0
frame_num = 0
while True:
ret, frame = cap.read()
if not ret:
break
if frame_count>1:
break
if frame_num % frame_interval == 0:
frame_count = frame_num // frame_interval
image_path = os.path.join(self.vid_path.replace(video_path_tail, f"frame_{frame_count}.jpg"))
self.scs.append(image_path)
frame_count += 1
cv2.imwrite(image_path, frame)
frame_num += 1
cap.release()
frame_x, frame_y = [], []
for idx, image_path in enumerate(self.scs):
results = self.cursor_model(image_path)
img = Image.open(image_path)
width, height = img.size
img.close()
for result in results:
if result.boxes.xywh.size(0) > 0:
boxes = result.boxes
xywh_tensor = boxes.xywh
x, y = xywh_tensor[0][0].item(), xywh_tensor[0][1].item()
frame_x.append(x)
frame_y.append(y)
else:
print('Cursor not detected')
if len(frame_x) == 0 or len(frame_y) ==0:
self.crop_scs = copy.deepcopy(self.scs)
return self.crop_scs, self.crop_scs
elif (len(frame_x) <= 1) or (max(frame_x)- min(frame_x))>=self.max_size or (max(frame_y)- min(frame_y))>=self.max_size:
print('add margin')
mid_x, mid_y = sum(frame_x) // len(frame_x), sum(frame_y) // len(frame_y)
margin_= self.max_size + self.delta
for idx, each in enumerate(sorted(self.scs)):
image_path = each
image1 = Image.open(image_path).convert('RGB')
file_name_tail = image_path.split('/')[-1]
save_path = image_path.replace(file_name_tail, f'{idx}_crop.jpg')
x1 = max(0, min(width - margin_, mid_x - margin_ // 2))
y1 = max(0, min(height - margin_, mid_y - margin_ // 2))
x2 = min(x1 + margin_, width)
y2 = min(y1 + margin_, height)
start_crop = image1.crop((x1, y1, x2, y2))
start_crop.save(save_path)
self.crop_scs.append(save_path)
image1.close()
return self.crop_scs, self.scs
else:
mid_x, mid_y = sum(frame_x) // len(frame_x), sum(frame_y) // len(frame_y)
margin = self.max_size
x1 = max(0, min(width - margin, mid_x - margin // 2))
y1 = max(0, min(height - margin, mid_y - margin // 2))
x2 = min(x1 + margin, width)
y2 = min(y1 + margin, height)
for idx, each in enumerate(sorted(self.scs)):
image_path = each
image1 = Image.open(image_path).convert('RGB')
file_name_tail = image_path.split('/')[-1].replace('frame_','').replace('.png','')
save_path = image_path.replace(file_name_tail, f'{idx}_crop.jpg')
x1 = max(0, min(width - margin_, mid_x - margin_ // 2))
y1 = max(0, min(height - margin_, mid_y - margin_ // 2))
x2 = min(x1 + margin_, width)
y2 = min(y1 + margin_, height)
start_crop = image1.crop((x1, y1, x2, y2))
start_crop.save(save_path)
self.crop_scs.append(save_path)
image1.close()
return self.crop_scs, self.scs
```
2. Initate the cropping strategy
```python
Cursor_detector = Screenshots_processor('./storage/folder_to_screenshots',512, 128, check_point_path)
cropped_imgs_list, original_imgs_list = Cursor_detector.create_crop()
```
## Inference Example
1. Load Model and Prompt Space
```python
"""load model"""
import torch
from PIL import Image, ImageDraw
from qwen_vl_utils import process_vision_info
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
import os
import json
import codecs
import argparse
import random
import re
max_pixels_temp = 160*28*28
max_pixels_narr = 760*28*28
min_pixels_narr = 240*28*28
model = Qwen2VLForConditionalGeneration.from_pretrained(
'FRank62Wu/ShowUI-Narrator', torch_dtype="auto", device_map="cuda"
)
processor = AutoProcessor.from_pretrained('FRank62Wu/ShowUI-Narrator')
processor.tokenizer.pad_token = processor.tokenizer.eos_token
_SYSTEM_PROMPT='For the given video frames of a GUI action, The frames are decribed in the format of <0> to <{N}>.'
_SYSTEM_PROMPT_NARR='''You are an ai assistant to narrate the action of the user for the video frames in the following detail.
'Action': The type of action
'Element': The target of the action
'Source': The starting position (Applicable for action type: Drag)
'Destination': The ending position (Applicable for action type: Drag)
'Purpose': The intended result of the action
The Action include left click, right click, double click, drag, or Keyboard type.
'''
Action_no_reference_grounding = [
'Describe the start frame and the end frame of the action in this video?',
'When Did the action happened in this video? Tell me the start frame and the end frame.',
'Locate the start and the end frame of the action in this video',
"Observe the cursor in this GUI video, marking start and end frame of the action in video frames."
]
Dense_narration_query = ['Narrate the action in the given video.',
'Describe the action of the user in the given frames',
'Describe the action in this video.',
'Narrate the action detail of the user in the video.']
```
2. Round 1: Temporal grounding to detect keyframes. (We take actions from PR as an example)
```python
path_to_data =''
query = _SYSTEM_PROMPT.format(N=9) + ' ' + random.choice(Action_no_reference_grounding)
messages = [
{
'role': 'user',
'content': [
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/0_crop.png","max_pixels": max_pixels_temp},
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/1_crop.png","max_pixels": max_pixels_temp},
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/2_crop.png","max_pixels": max_pixels_temp},
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/3_crop.png","max_pixels": max_pixels_temp},
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/4_crop.png","max_pixels": max_pixels_temp},
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/5_crop.png","max_pixels": max_pixels_temp},
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/6_crop.png","max_pixels": max_pixels_temp},
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/7_crop.png","max_pixels": max_pixels_temp},
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/8_crop.png","max_pixels": max_pixels_temp},
{'type':"image", "image": f"{path_to_data}/storage/test_benchmark_Act2Cap/303/9_crop.png","max_pixels": max_pixels_temp},
{'type':"text",'text': query},
]
}
]
## round_1 for temporal grounding
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True,
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(output_text)
```
```
>>> Output: <6> and <8>
```
<img src="./examples/start.png" alt="ShowUI" hight="700" width="600"> <img src="./examples/end.png" alt="ShowUI" hight="700" width="600">
<img src="./examples/start_crop.png" alt="ShowUI" hight="700" width="600"> <img src="./examples/end_crop.png" alt="ShowUI" hight="700" width="600">
3. Round 2: Use selected keyframes for generate captions in JSON format.
``` python
# round_2 for dense narration caption
try:
matches = re.search(r"<(\w+)>.*?<(\w+)>", output_text)
s1, e1 = int(matches.group(1)), int(matches.group(2))
except:
s1, e1 =0, 9
query = _SYSTEM_PROMPT_NARR + ' ' + random.choice(Dense_narration_query)
selected_images = []
if e1-s1<3:
pixels_narr = max_pixels_narr
else:
max_pixel_per_image = int(760*3/(e1- s1 +1))*28*28
pixels_narr = max_pixel_per_image
for idx, each in enumerate(messages[0]['content']):
if idx >= s1 and idx <= e1:
new_image = each.copy()
new_image['max_pixels'] =pixels_narr
selected_images.append(new_image)
messages = [
{
'role': 'user',
'content':selected_images+ [{'type':"text",'text': query},
]
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True,
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text_narration = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
print(output_text_narration)
```
```
>>> Output: {"Action": "double click", "Element": "sc2 trans shape button", "Source": null, "Destination": null, "Purpose": " Select the SC2 Trans Shape."}
```
|
A-l-e-x/lora_model
|
A-l-e-x
| 2025-06-20T11:40:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mllama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T11:40:23Z |
---
base_model: unsloth/llama-3.2-11b-vision-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mllama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** A-l-e-x
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-11b-vision-instruct-unsloth-bnb-4bit
This mllama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Triangle104/Yanfei-v2-Qwen3-32B-Q5_K_S-GGUF
|
Triangle104
| 2025-06-20T11:18:12Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"dataset:nbeerbower/YanfeiMix-DPO",
"base_model:nbeerbower/Yanfei-v2-Qwen3-32B",
"base_model:quantized:nbeerbower/Yanfei-v2-Qwen3-32B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-20T11:16:31Z |
---
base_model: nbeerbower/Yanfei-v2-Qwen3-32B
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
license: apache-2.0
datasets:
- nbeerbower/YanfeiMix-DPO
---
# Triangle104/Yanfei-v2-Qwen3-32B-Q5_K_S-GGUF
This model was converted to GGUF format from [`nbeerbower/Yanfei-v2-Qwen3-32B`](https://huggingface.co/nbeerbower/Yanfei-v2-Qwen3-32B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/nbeerbower/Yanfei-v2-Qwen3-32B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Yanfei-v2-Qwen3-32B-Q5_K_S-GGUF --hf-file yanfei-v2-qwen3-32b-q5_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Yanfei-v2-Qwen3-32B-Q5_K_S-GGUF --hf-file yanfei-v2-qwen3-32b-q5_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Yanfei-v2-Qwen3-32B-Q5_K_S-GGUF --hf-file yanfei-v2-qwen3-32b-q5_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Yanfei-v2-Qwen3-32B-Q5_K_S-GGUF --hf-file yanfei-v2-qwen3-32b-q5_k_s.gguf -c 2048
```
|
winnieyangwannan/refusal_Llama-3.1-8B-Instruct_sft_song_3-7_lora_False_epoch_50
|
winnieyangwannan
| 2025-06-20T11:16:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T08:56:20Z |
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
glif-loradex-trainer/bengarang_lievsch
|
glif-loradex-trainer
| 2025-06-20T11:04:02Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"template:sd-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us",
"flux",
"lora",
"base_model:adapter:black-forest-labs/FLUX.1-dev"
] |
text-to-image
| 2025-06-20T11:03:54Z |
---
tags:
- diffusers
- text-to-image
- template:sd-lora
- base_model:black-forest-labs/FLUX.1-dev
- base_model:finetune:black-forest-labs/FLUX.1-dev
- license:other
- region:us
- flux
- lora
widget:
- output:
url: samples/1750417374037__000001500_0.jpg
text: portrait of lievsch, handsome man with beard, looking at camera, neutral
expression, professional lighting
- output:
url: samples/1750417399318__000001500_1.jpg
text: lievsch as a muscular medieval knight, detailed armor, cinematic lighting,
fantasy art style
- output:
url: samples/1750417424615__000001500_2.jpg
text: shirtless lievsch smiling, three-quarter view, beach setting, natural lighting
base_model: black-forest-labs/FLUX.1-dev
trigger: "lievsch"
instance_prompt: "lievsch"
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# lievsch
Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit) under the [Glif Loradex program](https://huggingface.co/glif-loradex-trainer) by [Glif](https://glif.app) user `bengarang`.
<Gallery />
## Trigger words
You should use `lievsch` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/glif-loradex-trainer/bengarang_lievsch/tree/main) them in the Files & versions tab.
## License
This model is licensed under the [flux-1-dev-non-commercial-license](https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md).
|
QuantTrio/DeepSeek-R1-0528-GPTQ-Int4-Int8Mix-Medium
|
QuantTrio
| 2025-06-20T10:49:57Z | 2,593 | 1 |
transformers
|
[
"transformers",
"safetensors",
"deepseek_v3",
"text-generation",
"DeepSeek-R1-0528",
"GPTQ",
"Int4-Int8Mix",
"量化修复",
"vLLM",
"conversational",
"custom_code",
"arxiv:2501.12948",
"base_model:deepseek-ai/DeepSeek-R1-0528",
"base_model:quantized:deepseek-ai/DeepSeek-R1-0528",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"gptq",
"region:us"
] |
text-generation
| 2025-06-04T13:34:37Z |
---
library_name: transformers
license: mit
pipeline_tag: text-generation
tags:
- DeepSeek-R1-0528
- GPTQ
- Int4-Int8Mix
- 量化修复
- vLLM
base_model:
- deepseek-ai/DeepSeek-R1-0528
base_model_relation: quantized
---
# DeepSeek-R1-0528-GPTQ-Int4-Int8Mix-Medium
Base mode [deepseek-ai/DeepSeek-R1-0528](https://huggingface.co/deepseek-ai/DeepSeek-R1-0528)
This repository delivers an Int4 + selectively-Int8 GPTQ `DeepSeek-R1-0528` model: only layers that are highly sensitive to quantization remain in Int8, while the rest stay Int4—preserving generation quality with minimal file-size overhead.
Preliminary trials show that converting the entire model to pure Int4 (AWQ/GPTQ) under the quantization layout used in vLLM’s current DeepSeek-R1 implementation degrades inference accuracy and can produce faulty outputs. Layer-wise fine-grained quantization substantially mitigates this issue.
Temporary patch:
vLLM == 0.9.0 does not yet natively support per-layer quantization for MoE modules.
We added get_moe_quant_method to gptq_marlin.py as an interim fix.
Until the upstream PR is merged, please replace the original file with the one provided in this repo.
Variant Overview
| Variant | Characteristics | File Size | Recommended Scenario |
|-------------|---------------------------------------------------------------------------------------|-----------|--------------------------------------------------------------------------------------------|
| **Lite** | Only the most critical layers upgraded to Int8; size close to pure Int4 | 355 GB | Resource-constrained, lightweight server deployments |
| **Compact** | More Int8 layers, relatively higher output quality | 414 GB | VRAM-sufficient deployments focused on answer quality (e.g., 8 × A100) |
| **Medium** | Compact plus fully-Int8 attention layers; high quality with reduced long-context loss | 445 GB | VRAM-rich deployments needing both top answer quality and high concurrency (e.g., 8 × H20) |
Choose the variant that best matches your hardware and quality requirements.
### 【VLLM single-node (8×141GB GPU) launch command】
```
MAX_REQUESTS=512
CONTEXT_LEN=163840
python3 -m vllm.entrypoints.openai.api_server \
--model .../QuantTrio/DeepSeek-R1-0528-GPTQ-Int4-Int8Mix-Medium \
--served-model-name QuantTrio/DeepSeek-R1-0528-GPTQ-Int4-Int8Mix-Medium \
--swap-space 16 \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.95 \
--max-num-seqs $MAX_REQUESTS \
--max-seq-len-to-capture $CONTEXT_LEN \
--max-model-len $CONTEXT_LEN \
--enable-auto-tool-choice \
--tool-call-parser deepseek_v3 \
--chat-template tool_chat_template_deepseekr1.jinja \
--disable-log-requests \
--host 0.0.0.0 \
--port 8000
```
### 【H200 throughput performance】
1. `8 × H200 (141 GB)`、 `context = 163840 tokens`
| concurrent reqs | total tok/s | tok/s per req |
|-----------------|-------------|---------------|
| 1 | 60 | 60.0 |
| 50 | 1350 | 27.0 |
| 100 | 2200 | 22.0 |
| 200 | 3400 | 17.0 |
| 400 | 5100 | 12.7 |
2. `4 × H200 (141 GB)`、 `context = 63840 tokens`
| concurrent reqs | total tok/s | tok/s per req |
|-----------------|-------------|---------------|
| 1 | 56 | 56.0 |
| 50 | 1100 | 22.0 |
| 100 | 1700 | 17.0 |
| 200 | 2600 | 13.0 |
| 400 | 3900 | 9.7 |
### 【Model Update Date】
```
2025-06-20
Added vLLM launch example (single node with 8 × H200 / 141 GB) and corresponding concurrency throughput benchmark data.
2025-06-04
1. fast commit
```
### 【Dependencies】
```
vllm==0.9.0
transformers==4.52.3
```
</div>
<div style="
background: rgba(255, 0, 200, 0.15);
padding: 16px;
border-radius: 6px;
border: 1px solid rgba(255, 0, 200, 0.3);
margin: 16px 0;
">
### 【💡 Patch for gptq_marlin.py💡】
At present, vllm==0.9.0 lacks support for per-layer quantization configurations for the moe module, which will lead to errors when loading the model.
I have implemented a simple fix by adding the get_moe_quant_method function to the gptq_marlin.py file.
Until the PR is merged, please replace the gptq_marlin.py file in your installation with the attached version, placing it at:
```
.../site-packages/vllm/model_executor/layers/quantization/gptq_marlin.py
```
</div>
### 【Model List】
| FILE SIZE | LATEST UPDATE TIME |
|---------|--------------|
| `445GB` | `2025-06-04` |
### 【Model Download】
```python
from huggingface_hub import snapshot_download
snapshot_download('QuantTrio/DeepSeek-R1-0528-GPTQ-Int4-Int8Mix-Medium', cache_dir="local_path")
```
## DeepSeek-R1-0528
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="https://arxiv.org/pdf/2501.12948"><b>Paper Link</b>👁️</a>
</p>
## 1. Introduction
The DeepSeek R1 model has undergone a minor version upgrade, with the current version being DeepSeek-R1-0528. In the latest update, DeepSeek R1 has significantly improved its depth of reasoning and inference capabilities by leveraging increased computational resources and introducing algorithmic optimization mechanisms during post-training. The model has demonstrated outstanding performance across various benchmark evaluations, including mathematics, programming, and general logic. Its overall performance is now approaching that of leading models, such as O3 and Gemini 2.5 Pro.
<p align="center">
<img width="80%" src="figures/benchmark.png">
</p>
Compared to the previous version, the upgraded model shows significant improvements in handling complex reasoning tasks. For instance, in the AIME 2025 test, the model’s accuracy has increased from 70% in the previous version to 87.5% in the current version. This advancement stems from enhanced thinking depth during the reasoning process: in the AIME test set, the previous model used an average of 12K tokens per question, whereas the new version averages 23K tokens per question.
Beyond its improved reasoning capabilities, this version also offers a reduced hallucination rate, enhanced support for function calling, and better experience for vibe coding.
## 2. Evaluation Results
### DeepSeek-R1-0528
For all our models, the maximum generation length is set to 64K tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 16 responses per query to estimate pass@1.
<div align="center">
| Category | Benchmark (Metric) | DeepSeek R1 | DeepSeek R1 0528
|----------|----------------------------------|-----------------|---|
| General |
| | MMLU-Redux (EM) | 92.9 | 93.4
| | MMLU-Pro (EM) | 84.0 | 85.0
| | GPQA-Diamond (Pass@1) | 71.5 | 81.0
| | SimpleQA (Correct) | 30.1 | 27.8
| | FRAMES (Acc.) | 82.5 | 83.0
| | Humanity's Last Exam (Pass@1) | 8.5 | 17.7
| Code |
| | LiveCodeBench (2408-2505) (Pass@1) | 63.5 | 73.3
| | Codeforces-Div1 (Rating) | 1530 | 1930
| | SWE Verified (Resolved) | 49.2 | 57.6
| | Aider-Polyglot (Acc.) | 53.3 | 71.6
| Math |
| | AIME 2024 (Pass@1) | 79.8 | 91.4
| | AIME 2025 (Pass@1) | 70.0 | 87.5
| | HMMT 2025 (Pass@1) | 41.7 | 79.4 |
| | CNMO 2024 (Pass@1) | 78.8 | 86.9
| Tools |
| | BFCL_v3_MultiTurn (Acc) | - | 37.0 |
| | Tau-Bench (Pass@1) | - | 53.5(Airline)/63.9(Retail)
</div>
Note: We use Agentless framework to evaluate model performance on SWE-Verified. We only evaluate text-only prompts in HLE testsets. GPT-4.1 is employed to act user role in Tau-bench evaluation.
## 5. License
This code repository is licensed under [MIT License](LICENSE). The use of DeepSeek-R1 models is also subject to [MIT License](LICENSE). DeepSeek-R1 series (including Base and Chat) supports commercial use and distillation.
## 6. Citation
```
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
```
## 7. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
dotan1111/BetaDescribe-Validator-HigherLevelTaxonomy
|
dotan1111
| 2025-06-20T10:48:01Z | 47 | 0 | null |
[
"safetensors",
"esm",
"biology",
"bioinformatics",
"protein2text",
"proteins",
"PLM",
"text-generation-inference",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-12-09T15:02:42Z |
---
license: cc-by-nc-4.0
tags:
- biology
- bioinformatics
- protein2text
- proteins
- PLM
- text-generation-inference
---
# Protein2Text: Providing Rich Descriptions from Protein Sequences
## Abstract:
Understanding the functionality of proteins has been a focal point of biological research due to their critical roles in various biological processes. Unraveling protein functions is essential for advancements in medicine, agriculture, and biotechnology, enabling the development of targeted therapies, engineered crops, and novel biomaterials. However, this endeavor is challenging due to the complex nature of proteins, requiring sophisticated experimental designs and extended timelines to uncover their specific functions. Public large language models (LLMs), though proficient in natural language processing, struggle with biological sequences due to the unique and intricate nature of biochemical data. These models often fail to accurately interpret and predict the functional and structural properties of proteins, limiting their utility in bioinformatics. To address this gap, we introduce BetaDescribe, a collection of models designed to generate detailed and rich textual descriptions of proteins, encompassing properties such as function, catalytic activity, involvement in specific metabolic pathways, subcellular localizations, and the presence of particular domains. The trained BetaDescribe model receives protein sequences as input and outputs a textual description of these properties. BetaDescribe’s starting point was the LLAMA2 model, which was trained on trillions of tokens. Next, we trained our model on datasets containing both biological and English text, allowing biological knowledge to be incorporated. We demonstrate the utility of BetaDescribe by providing descriptions for proteins that share little to no sequence similarity to proteins with functional descriptions in public datasets. We also show that BetaDescribe can be harnessed to conduct *in-silico* mutagenesis procedures to identify regions important for protein functionality without needing homologous sequences for the inference. Altogether, BetaDescribe offers a powerful tool to explore protein functionality, augmenting existing approaches such as annotation transfer based on sequence or structure similarity.

BetaDescribe workflow. The generator processes the protein sequences and creates multiple candidate descriptions. Independently, the validators provide simple textual properties of the protein. The judge receives the candidate descriptions (from the generator) and the predicted properties (from the validators) and rejects or accepts each description. Finally, BetaDescribe provides up to three alternative descriptions for each protein.
## Preprint: https://www.biorxiv.org/content/10.1101/2024.12.04.626777v1.full.pdf+html
## Examples of descriptions of unknown proteins:
### SnRV-Env:
Sequence:
MKLVLLFSLSVLLGTSVGRILEIPETNQTRTVQVRKGQLVQLTCPQLPPPQGTGVLIWGRNKRTGGGALDFNGVLTVPVGDNENTYQCMWCQNTTSKNAPRQKRSLRNQPTEWHLHMCGPPGDYICIWTNKKPVCTTYHEGQDTYSLGTHRKVLPKVTEACAVGQPPQIPGTYVASSKGWTMFNKFEVHSYPANVTQIKTNRTLHDVTLWWCHDNSIWRCTQMGFIHPHQGRRIQLGDGTRFRDGLYVIVSNHGDHHTVQHYMLGSGYTVPVSTATRVQMQKIGPGEWKIATSMVGLCLDEWEIECTGFCSGPPPCSLSITQQQDTVGGSYDSWNGCFVKSIHTPVMALNLWWRRSCKGLPEATGMVKIYYPDQFEIAPWMRPQPRQPKLILPFTVAPKYRRQRRGLNPSTTPDYYTNEDYSGSGGWEINDEWEYIPPTVKPTTPSVEFIQKVTTPRQDKLTTVLSRNKRGVNIASSGNSWKAEIDEIRKQKWQKCYFSGKLRIKGTDYEEIDTCPKPLIGPLSGFIPTGVTKTLKTGVTWTTAVVKIDLQQWVDILNSTCKDTLIGKHWIKVIQRLLREYQKTGVTFNLPQVQSLPNWETKNKDNPGHHIPKSRRKRIRRGLGEALGLGNFADNRWKDLQIAGLGVEQQKLMGLTREATFEAWNALKGISNELIKWEEDMVATLRQLLLQIKGTNTTLCSAMGPLMATNIQQIMFALQHGNLPEMSYSNPVLKEIAKQYNGQMLGVPVETTGNNLGIMLSLPTGGENIGRAVAVYDMGVRHNRTLYLDPNARWIHNHTEKSNPKGWVTIVDLSKCVETTGTIYCNEHGFRDRKFTKGPSELVQHLAGNTWCLNSGTWSSLKNETLYVSGRNCSFSLTSRRRPVCFHLNSTAQWRGHVLPFVSNSQEAPNTEIWEGLIEEAIREHNKVQDILTKLEQQHQNWKQNTDNALQNMKDAIDSMDNNMLTFRYEYTQYGLFIVCLLAFLFAVIFGWLCGVTVRLREVFTILSVKIHALKSQAHQLAMLRGLRDPETGEQDRQAPAYREPPTYQEWARRRGGRPPIVTFLIDRETGERHDGQIFQPIRNRSNQVHRPQPPRPTAPNPDNQRPIREPRPEEPEHGDFLQGASWMWQ
Description:
_**FUNCTION$** The leader peptide is a component of released, infectious virions and is required for particle budding, & The transmembrane protein (TM) acts as a class I viral fusion protein. Under the current model, the protein has at least 3 conformational states: pre-fusion native state, pre-hairpin intermediate state, and post-fusion hairpin state. During viral and target cell membrane fusion, the coiled coil regions (heptad repeats) assume a trimer-of-hairpins structure, positioning the fusion peptide in close proximity to the C-terminal region of the ectodomain. The formation of this structure appears to drive apposition and subsequent fusion of viral and target cell membranes. Membranes fusion leads to delivery of the nucleocapsid into the cytoplasm, **SUBCELLULAR LOCATION$** Endoplasmic reticulum membrane._
### TGV-S:
Sequence:
MISGHTLCMLVLFYLYSYSNAQHELQLNPTTYHWLNCATSDCKSWQACPSTQATTCVSFSYTGLAWHKQDNTIIGYSNFTSQSLYDTISYTFAPSYVLSHAMTNLEPQKLCSLKSTIQSFHGFTPADCCLNPSASPACSYFSTGDTSFITGTPYQCTASYYGYGSPYGTDCEPYFASVSPYGTSVTPSGDVFTNFGEKSVHTYDCFYENWARYRPAPYTNNPSDPRWNLCHSIYYYVWTLSDTNHQFTTVESEPGDKVIMKQLSSHTPVYLTLGGWTSNNTVLYQAISSRRLDTIAMLRDLHDNYGVTGVCIDFEFIGGSNQYSNIFLLDWVPDLLSFLSSVRLEFGPSYYITFVGLAVGSHFLPTIYQQIDPLIDAWLISGYDLHGDWEVKATQQAALVDDPKSDFPTYSLFTSVDNMLAITTPDKIILGLPQYTRGVYTSLTGSTTGPYPPTTPMCPTPPACGTDIVISTSHGEIPSTHDTTKGDIIIEDPSQPKFYISKGSRNGRTFNHFFMNSTTASHIRSTLQPKGITRWYSYASSMNLQTNTNFKTALLSQSRKARQLSTYYKYPAPAGSGVTSCPGIVVFTDTFVVTTTAYAGSHALPLLDGNFYSPRSTFTCSPGFSTLMPTTTTRCSGIDPSNLLPSDSSSVSIVCPDMTFFGAKIAICASSTTTSKPTHLQLEVSTSIEGQFQFNSLPIYSQHKVSTTSFSVPYKCINFTPIPSCISSVCGSSHSCVTKLQESPASYACQSAAAIAIVYNNTLDLVKRSQTTTELLFNQVVLESSKFGVVTHTRQTRGLFGILSITSLIMSGVALATSSSALYVSIKNQAELSSLRNDVNSKFTTIDQNFDQITSKFNHLSTTTSDAFIAQSNINTQLQSSINQLQENLEVLSNFVTTQLSSVSSSITQLSEAIDALSDQVNYLAYLTSGISSYTSRLTSVTVQATNTAVKFSTLQSHLSNCLTSLQQQSFTGCIHKSGNIIPLKVVYTPFGNTRYLSFIYAEAELLGYQQYKSALSYCDQNFLYSSSPGCFFLLNGSSIDHRSSLSAACPTPATVVSMSCQNVTLDLSSQSIVRPYVFPLLNLTLPTPVKTNISFTPGKAPVFQNITQIDQTLLLDLAQQLQAIQLQLNPVGPISTSSFSPVVIALTVISAVVFLAVTSIVIYMLCKTAPFKPSRKTA
Descriptions:
1. _**FUNCTION$** Envelope glycoprotein that forms spikes at the surface of virion envelope. Essential for the initial attachment to heparan sulfate moities of the host cell surface proteoglycans. Involved in fusion of viral and cellular membranes leading to virus entry into the host cell. Following initial binding to its host receptors, membrane fusion is mediated by the fusion machinery composed at least of gB and the heterodimer gH/gL. May be involved in the fusion between the virion envelope and the outer nuclear membrane during virion egress, **SUBCELLULAR LOCATION$** Virion membrane, **SUBUNIT$** Homotrimer; disulfide-linked. Binds to heparan sulfate proteoglycans. Interacts with gH/gL heterodimer, **SIMILARITY$** Belongs to the herpesviridae glycoprotein B family._
2. _**FUNCTION$** The surface protein (SU) attaches the virus to the host cell by binding to its receptor. This interaction triggers the refolding of the transmembrane protein (TM) and is thought to activate its fusogenic potential by unmasking its fusion peptide. Fusion occurs at the host cell plasma membrane, & The transmembrane protein (TM) acts as a class I viral fusion protein. Under the current model, the protein has at least 3 conformational states: pre-fusion native state, pre-hairpin intermediate state, and post-fusion hairpin state. During viral and target cell membrane fusion, the coiled coil regions (heptad repeats) assume a trimer-of-hairpins structure, positioning the fusion peptide in close proximity to the C-terminal region of the ectodomain. The formation of this structure appears to drive apposition and subsequent fusion of viral and target cell membranes. Membranes fusion leads to delivery of the nucleocapsid into the cytoplasm, **SUBCELLULAR LOCATION$** Cell membrane. **SUBUNIT$** The mature envelope protein (Env) consists of a trimer of SU-TM heterodimers attached by noncovalent interactions or by a labile interchain disulfide bond_
### Protein 1 (TiLV virus):
Sequence:
MWAFQEGVCKGNLLSGPTSMKAPDSAARESLDRASEIMTGKSYNAVHTGDLSKLPNQGESPLRIVDSDLYSERSCCWVIEKEGRVVCKSTTLTRGMTGLLNTTRCSSPSELICKVLTVESLSEKIGDTSVEELLSHGRYFKCALRDQERGKPKSRAIFLSHPFFRLLSSVVETHARSVLSKVSAVYTATASAEQRAMMAAQVVESRKHVLNGDCTKYNEAIDADTLLKVWDAIGMGSIGVMLAYMVRRKCVLIKDTLVECPGGMLMGMFNATATLALQGTTDRFLSFSDDFITSFNSPAELREIEDLLFASCHNLSLKKSYISVASLEINSCTLTRDGDLATGLGCTAGVPFRGPLVTLKQTAAMLSGAVDSGVMPFHSAERLFQIKQQECAYRYNNPTYTTRNEDFLPTCLGGKTVISFQSLLTWDCHPFWYQVHPDGPDTIDQKVLSVLASKTRRRRTRLEALSDLDPLVPHRLLVSESDVSKIRAARQAHLKSLGLEQPTNFNYAIYKAVQPTAGC
Description:
_**FUNCTION$** Probably involved in the RNA silencing pathway and required for the generation of small interfering RNAs (siRNAs), **CATALYTIC ACTIVITY$** a ribonucleoside 5'-triphosphate + RNA(n) = diphosphate + RNA(n+1), **SIMILARITY$** Belongs to the RdRP family._
### Protein 2 (TiLV virus):
Sequence:
MSQFGKSFKGRTEVTITEYRSHTVKDVHRSLLTADKSLRKSFCFRNALNQFLDKDLPLLPIRPKLESRVAVKKSKLRSQLSFRPGLTQEEAIDLYNKGYDGDSVSGALQDRVVNEPVAYSSADNDKFHRGLAALGYTLADRAFDTCESGFVRAIPTTPCGFICCGPGSFKDSLGFVIKIGEFWHMYDGFQHFVAVEDAKFLASKSPSFWLAKRLAKRLNLVPKEDPSIAAAECPCRKVWEASFARAPTALDPFGGRAFCDQGWVYHRDVGYATANHISQETLFQQALSVRNLGPQGSANVSGSIHTALDRLRAAYSRGTPASRSILQGLANLITPVGENFECDLDKRKLNIKALRSPERYITIEGLVVNLDDVVRGFYLDKAKVTVLSRSKWMGYEDLPQKPPNGTFYCRKRKAMLLISCSPGTYAKKRKVAVQEDRFKDMRVENFREVAENMDLNQ
Description:
_**FUNCTION$** DNA-dependent RNA polymerase catalyzes the transcription of DNA into RNA using the four ribonucleoside triphosphates as substrates, **CATALYTIC ACTIVITY$** a ribonucleoside 5'-triphosphate + RNA(n) = diphosphate + RNA(n+1), **SIMILARITY$** Belongs to the RNA polymerase beta' chain family._
### Protein 3 (TiLV virus):
Sequence:
MDSRFAQLTGVFCDDFTYSEGSRRFLSSYSTVERRPGVPVEGDCYDCLKNKWIAFELEGQPRKFPKATVRCILNNDATYVCSEQEYQQICKVQFKDYLEIDGVVKVGHKASYDAELRERLLELPHPKSGPKPRIEWVAPPRLADISKETAELKRQYGFFECSKFLACGEECGLDQEARELILNEYARDREFEFRNGGWIQRYTVASHKPATQKILPLPASAPLARELLMLIARSTTQAGKVLHSDNTSILAVPVMRDSGKHSKRRPTASTHHLVVGLSKPGCEHDFEFDGYRAAVHVMHLDPKQSANIGEQDFVSTREIYKLDMLELPPISRKGDLDRASGLETRWDVILLLECLDSTRVSQAVAQHFNRHRLALSVCKDEFRKGYQLASEIRGTIPLSSLYYSLCAVRLRMTVHPFAR
Descriptions:
1. _**FUNCTION$** DNA-dependent RNA polymerase catalyzes the transcription of DNA into RNA using the four ribonucleoside triphosphates as substrates. Specific core component of RNA polymerase III which synthesizes small RNAs, such as 5S rRNA and tRNAs, **SUBCELLULAR LOCATION$** Nucleus, **SUBUNIT$** Component of the RNA polymerase III (Pol III) complex consisting of 17 subunits, **SIMILARITY$** Belongs to the eukaryotic RPC3/POLR3C RNA polymerase subunit family._
2. _**FUNCTION$** Decapping enzyme for NAD-capped RNAs: specifically hydrolyzes the nicotinamide adenine dinucleotide (NAD) cap from a subset of RNAs by removing the entire NAD moiety from the 5'-end of an NAD-capped RNA, **SUBCELLULAR LOCATION$** Nucleus, **COFACTOR$** a divalent metal cation, **SIMILARITY$** Belongs to the DXO/Dom3Z family._
## Code: https://github.com/technion-cs-nlp/BetaDescribe-code/
|
oldroydh/sd-class-butterflies-64
|
oldroydh
| 2025-06-20T10:45:07Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"pytorch",
"unconditional-image-generation",
"diffusion-models-class",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] |
unconditional-image-generation
| 2025-06-20T09:53:25Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('oldroydh/sd-class-butterflies-64')
image = pipeline().images[0]
image
```
|
morturr/Llama-2-7b-hf-PAIR_dadjokes_one_liners-COMB-dadjokes-comb-3-seed-28-2025-06-20
|
morturr
| 2025-06-20T10:37:07Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"trl",
"sft",
"generated_from_trainer",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"license:llama2",
"region:us"
] | null | 2025-06-20T10:36:51Z |
---
library_name: peft
license: llama2
base_model: meta-llama/Llama-2-7b-hf
tags:
- trl
- sft
- generated_from_trainer
model-index:
- name: Llama-2-7b-hf-PAIR_dadjokes_one_liners-COMB-dadjokes-comb-3-seed-28-2025-06-20
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-hf-PAIR_dadjokes_one_liners-COMB-dadjokes-comb-3-seed-28-2025-06-20
This model is a fine-tuned version of [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 16
- seed: 28
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.1
- Pytorch 2.5.1+cu124
- Datasets 3.0.2
- Tokenizers 0.20.1
|
hzlizihao/bert-finetuned-ner
|
hzlizihao
| 2025-06-20T10:33:59Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-06-20T10:08:02Z |
---
library_name: transformers
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.935275616619765
- name: Recall
type: recall
value: 0.9508582968697409
- name: F1
type: f1
value: 0.9430025869982476
- name: Accuracy
type: accuracy
value: 0.9863866486136458
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0615
- Precision: 0.9353
- Recall: 0.9509
- F1: 0.9430
- Accuracy: 0.9864
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.075 | 1.0 | 1756 | 0.0712 | 0.8968 | 0.9313 | 0.9137 | 0.9805 |
| 0.0351 | 2.0 | 3512 | 0.0728 | 0.9308 | 0.9441 | 0.9374 | 0.9845 |
| 0.0231 | 3.0 | 5268 | 0.0615 | 0.9353 | 0.9509 | 0.9430 | 0.9864 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
winnieyangwannan/entity_Llama-3.1-8B-Instruct_mlp-down_positive-negative-addition-same_last_layer_16_2_all_3_49
|
winnieyangwannan
| 2025-06-20T10:33:25Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T10:31:16Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Shuu12121/CodeSearch-ModernBERT-Owl-3.0
|
Shuu12121
| 2025-06-20T10:32:50Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"modernbert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:7059600",
"loss:MultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:Shuu12121/CodeModernBERT-Owl-3.0",
"base_model:finetune:Shuu12121/CodeModernBERT-Owl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-06-20T10:32:23Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:7059600
- loss:MultipleNegativesRankingLoss
base_model: Shuu12121/CodeModernBERT-Owl-3.0
widget:
- source_sentence: Retrieve the given root by type-key
sentences:
- "def __convert_to_df(a, val_col=None, group_col=None, val_id=None, group_id=None):\n\
\n '''Hidden helper method to create a DataFrame with input data for further\n\
\ processing.\n\n Parameters\n ----------\n a : array_like or pandas\
\ DataFrame object\n An array, any object exposing the array interface\
\ or a pandas DataFrame.\n Array must be two-dimensional. Second dimension\
\ may vary,\n i.e. groups may have different lengths.\n\n val_col :\
\ str, optional\n Name of a DataFrame column that contains dependent variable\
\ values (test\n or response variable). Values should have a non-nominal\
\ scale. Must be\n specified if `a` is a pandas DataFrame object.\n\n \
\ group_col : str, optional\n Name of a DataFrame column that contains\
\ independent variable values\n (grouping or predictor variable). Values\
\ should have a nominal scale\n (categorical). Must be specified if `a`\
\ is a pandas DataFrame object.\n\n val_id : int, optional\n Index of\
\ a column that contains dependent variable values (test or\n response\
\ variable). Should be specified if a NumPy ndarray is used as an\n input.\
\ It will be inferred from data, if not specified.\n\n group_id : int, optional\n\
\ Index of a column that contains independent variable values (grouping\
\ or\n predictor variable). Should be specified if a NumPy ndarray is used\
\ as\n an input. It will be inferred from data, if not specified.\n\n \
\ Returns\n -------\n x : pandas DataFrame\n DataFrame with input\
\ data, `val_col` column contains numerical values and\n `group_col` column\
\ contains categorical values.\n\n val_col : str\n Name of a DataFrame\
\ column that contains dependent variable values (test\n or response variable).\n\
\n group_col : str\n Name of a DataFrame column that contains independent\
\ variable values\n (grouping or predictor variable).\n\n Notes\n \
\ -----\n Inferrence algorithm for determining `val_id` and `group_id` args\
\ is rather\n simple, so it is better to specify them explicitly to prevent\
\ errors.\n\n '''\n\n if not group_col:\n group_col = 'groups'\n\
\ if not val_col:\n val_col = 'vals'\n\n if isinstance(a, DataFrame):\n\
\ x = a.copy()\n if not {group_col, val_col}.issubset(a.columns):\n\
\ raise ValueError('Specify correct column names using `group_col`\
\ and `val_col` args')\n return x, val_col, group_col\n\n elif isinstance(a,\
\ list) or (isinstance(a, np.ndarray) and not a.shape.count(2)):\n grps_len\
\ = map(len, a)\n grps = list(it.chain(*[[i+1] * l for i, l in enumerate(grps_len)]))\n\
\ vals = list(it.chain(*a))\n\n return DataFrame({val_col: vals,\
\ group_col: grps}), val_col, group_col\n\n elif isinstance(a, np.ndarray):\n\
\n # cols ids not defined\n # trying to infer\n if not(all([val_id,\
\ group_id])):\n\n if np.argmax(a.shape):\n a = a.T\n\
\n ax = [np.unique(a[:, 0]).size, np.unique(a[:, 1]).size]\n\n \
\ if np.asscalar(np.diff(ax)):\n __val_col = np.argmax(ax)\n\
\ __group_col = np.argmin(ax)\n else:\n \
\ raise ValueError('Cannot infer input format.\\nPlease specify `val_id` and\
\ `group_id` args')\n\n cols = {__val_col: val_col,\n \
\ __group_col: group_col}\n else:\n cols = {val_id: val_col,\n\
\ group_id: group_col}\n\n cols_vals = dict(sorted(cols.items())).values()\n\
\ return DataFrame(a, columns=cols_vals), val_col, group_col"
- "def debug(*args)\n return nil unless Puppet::Util::Log.level == :debug\n \
\ if block_given?\n send_log(:debug, yield(*args))\n else\n send_log(:debug,\
\ args.join(\" \"))\n end\n end"
- "def get_root( self, key ):\n \n if key not in self.roots:\n \
\ root,self.rows = load( self.filename, include_interpreter = self.include_interpreter\
\ )\n self.roots[key] = root\n return self.roots[key]"
- source_sentence: Returns the solc version, if any.
sentences:
- "pub fn solc_version(&self) -> Option<Version> {\n self.solc.as_ref().and_then(|solc|\
\ solc.try_version().ok())\n }"
- "def run!\n\t\t\tcatch :halt do\n\t\t\t\tvalidate_request\n\n\t\t\t\ttry_options\
\ ||\n\t\t\t\t\ttry_static ||\n\t\t\t\t\ttry_static(dir: GEM_STATIC_FILES) ||\n\
\t\t\t\t\ttry_route ||\n\t\t\t\t\thalt(404)\n\t\t\tend\n\t\t\tresponse.write body\
\ unless request.head?\n\t\t\tresponse.finish\n\t\tend"
- "private Class<?> getTemplateClass() {\n String fqName = getTargetPackage()\
\ + \".\" + getName();\n try {\n mTemplateClass = getCompiler().loadClass(fqName);\n\
\ }\n catch (ClassNotFoundException nx) {\n try {\n \
\ mTemplateClass = getCompiler().loadClass(getName()); // Try standard\
\ path as a last resort\n }\n catch (ClassNotFoundException\
\ nx2) {\n return null;\n }\n }\n return\
\ mTemplateClass;\n }"
- source_sentence: 'Get value {@link Text} value
@param label target label
@return {@link Text} value of the label. If it is not null.'
sentences:
- "public Text getValueText(String label) {\n HadoopObject o = getHadoopObject(VALUE,\
\ label, ObjectUtil.STRING, \"String\");\n if (o == null) {\n \
\ return null;\n }\n return (Text) o.getObject();\n }"
- "func NewFloats64(into *[]float64, v []float64) *Floats64Value {\n\t*into = v\n\
\treturn (*Floats64Value)(into)\n}"
- "def genestatus(args):\n \n p = OptionParser(genestatus.__doc__)\n opts,\
\ args = p.parse_args(args)\n\n if len(args) != 1:\n sys.exit(not p.print_help())\n\
\n idsfile, = args\n data = get_tags(idsfile)\n key = lambda x: x[0].split(\"\
.\")[0]\n for gene, cc in groupby(data, key=key):\n cc = list(cc)\n\
\ tags = [x[-1] for x in cc]\n if \"complete\" in tags:\n \
\ tag = \"complete\"\n elif \"partial\" in tags:\n tag\
\ = \"partial\"\n else:\n tag = \"pseudogene\"\n print(\"\
\\t\".join((gene, tag)))"
- source_sentence: update function
sentences:
- "function (sourceBuffer, aNode, tagNameVariable) {\n var props = aNode.props;\n\
\ var bindDirective = aNode.directives.bind;\n var tagName = aNode.tagName;\n\
\n if (tagName) {\n sourceBuffer.joinString('<' + tagName);\n\
\ }\n else if (tagNameVariable) {\n sourceBuffer.joinString('<');\n\
\ sourceBuffer.joinRaw(tagNameVariable + ' || \"div\"');\n }\n\
\ else {\n sourceBuffer.joinString('<div');\n }\n\n \
\ // index list\n var propsIndex = {};\n each(props, function\
\ (prop) {\n propsIndex[prop.name] = prop;\n\n if (prop.name\
\ !== 'slot' && prop.expr.value != null) {\n sourceBuffer.joinString('\
\ ' + prop.name + '=\"' + prop.expr.segs[0].literal + '\"');\n }\n\
\ });\n\n each(props, function (prop) {\n if (prop.name\
\ === 'slot' || prop.expr.value != null) {\n return;\n \
\ }\n\n if (prop.name === 'value') {\n switch (tagName)\
\ {\n case 'textarea':\n return;\n\n\
\ case 'select':\n sourceBuffer.addRaw('$selectValue\
\ = '\n + compileExprSource.expr(prop.expr)\n \
\ + ' || \"\";'\n );\n \
\ return;\n\n case 'option':\n \
\ sourceBuffer.addRaw('$optionValue = '\n +\
\ compileExprSource.expr(prop.expr)\n + ';'\n \
\ );\n // value\n \
\ sourceBuffer.addRaw('if ($optionValue != null) {');\n \
\ sourceBuffer.joinRaw('\" value=\\\\\"\" + $optionValue + \"\\\\\"\"');\n\
\ sourceBuffer.addRaw('}');\n\n \
\ // selected\n sourceBuffer.addRaw('if ($optionValue ===\
\ $selectValue) {');\n sourceBuffer.joinString(' selected');\n\
\ sourceBuffer.addRaw('}');\n return;\n\
\ }\n }\n\n switch (prop.name) {\n \
\ case 'readonly':\n case 'disabled':\n \
\ case 'multiple':\n if (prop.raw === '') {\n \
\ sourceBuffer.joinString(' ' + prop.name);\n }\n\
\ else {\n sourceBuffer.joinRaw('boolAttrFilter(\"\
' + prop.name + '\", '\n + compileExprSource.expr(prop.expr)\n\
\ + ')'\n );\n \
\ }\n break;\n\n case 'checked':\n \
\ if (tagName === 'input') {\n var valueProp\
\ = propsIndex.value;\n var valueCode = compileExprSource.expr(valueProp.expr);\n\
\n if (valueProp) {\n switch\
\ (propsIndex.type.raw) {\n case 'checkbox':\n\
\ sourceBuffer.addRaw('if (contains('\n \
\ + compileExprSource.expr(prop.expr)\n \
\ + ', '\n \
\ + valueCode\n + ')) {'\n \
\ );\n sourceBuffer.joinString('\
\ checked');\n sourceBuffer.addRaw('}');\n\
\ break;\n\n \
\ case 'radio':\n sourceBuffer.addRaw('if\
\ ('\n + compileExprSource.expr(prop.expr)\n\
\ + ' === '\n \
\ + valueCode\n + ') {'\n\
\ );\n sourceBuffer.joinString('\
\ checked');\n sourceBuffer.addRaw('}');\n\
\ break;\n }\n \
\ }\n }\n break;\n\
\n default:\n var onlyOneAccessor = false;\n\
\ var preCondExpr;\n\n if (prop.expr.type\
\ === ExprType.ACCESSOR) {\n onlyOneAccessor = true;\n\
\ preCondExpr = prop.expr;\n }\n \
\ else if (prop.expr.segs.length === 1) {\n \
\ var interpExpr = prop.expr.segs[0];\n var interpFilters\
\ = interpExpr.filters;\n\n if (!interpFilters.length\n\
\ || interpFilters.length === 1 && interpFilters[0].args.length\
\ === 0\n ) {\n onlyOneAccessor\
\ = true;\n preCondExpr = prop.expr.segs[0].expr;\n\
\ }\n }\n\n if (onlyOneAccessor)\
\ {\n sourceBuffer.addRaw('if (' + compileExprSource.expr(preCondExpr)\
\ + ') {');\n }\n\n sourceBuffer.joinRaw('attrFilter(\"\
' + prop.name + '\", '\n + (prop.x ? 'escapeHTML(' : '')\n\
\ + compileExprSource.expr(prop.expr)\n \
\ + (prop.x ? ')' : '')\n + ')'\n \
\ );\n\n if (onlyOneAccessor) {\n \
\ sourceBuffer.addRaw('}');\n }\n\n \
\ break;\n }\n });\n\n if (bindDirective) {\n \
\ sourceBuffer.addRaw(\n '(function ($bindObj) {for (var $key\
\ in $bindObj) {'\n + 'var $value = $bindObj[$key];'\n \
\ );\n\n if (tagName === 'textarea') {\n sourceBuffer.addRaw(\n\
\ 'if ($key === \"value\") {'\n + 'continue;'\n\
\ + '}'\n );\n }\n\n sourceBuffer.addRaw('switch\
\ ($key) {\\n'\n + 'case \"readonly\":\\n'\n + 'case\
\ \"disabled\":\\n'\n + 'case \"multiple\":\\n'\n \
\ + 'case \"multiple\":\\n'\n + 'html += boolAttrFilter($key,\
\ escapeHTML($value));\\n'\n + 'break;\\n'\n + 'default:\\\
n'\n + 'html += attrFilter($key, escapeHTML($value));'\n \
\ + '}'\n );\n\n sourceBuffer.addRaw(\n \
\ '}})('\n + compileExprSource.expr(bindDirective.value)\n\
\ + ');'\n );\n }\n\n sourceBuffer.joinString('>');\n\
\ }"
- "public function process(Model $model)\n {\n $data = $model->getData()\
\ ? 'TRUE' : 'FALSE';\n return $this->pool->render->renderSingleChild(\n\
\ $model->setData($data)\n ->setNormal($data)\n \
\ ->setType(static::TYPE_BOOL)\n );\n }"
- "function (/*dt*/) {\n // we don't draw anything fancy here, so just\n\
\ // return true if the score has been updated\n if (this.score\
\ !== game.data.score) {\n this.score = game.data.score;\n \
\ return true;\n }\n return false;\n }"
- source_sentence: Call by destroy step
sentences:
- "def from_context(cls, ctx, config_paths=None, project=None):\n \n \
\ if ctx.obj is None:\n ctx.obj = Bunch()\n ctx.obj.cfg =\
\ cls(ctx.info_name, config_paths, project=project)\n return ctx.obj.cfg"
- "public function decompress($content)\n {\n $archive = $this->getArchive();\n\
\ if (empty($archive) || !file_exists($archive)) {\n throw new\
\ Exception\\RuntimeException('Tar Archive not found');\n }\n\n \
\ $archive = str_replace(['/', '\\\\'], DIRECTORY_SEPARATOR, realpath($content));\n\
\ $archive = new Archive_Tar($archive, $this->getMode());\n $target\
\ = $this->getTarget();\n if (!is_dir($target)) {\n $target\
\ = dirname($target) . DIRECTORY_SEPARATOR;\n }\n\n $result = $archive->extract($target);\n\
\ if ($result === false) {\n throw new Exception\\RuntimeException('Error\
\ while extracting the Tar archive');\n }\n\n return $target;\n\
\ }"
- "function setAlltoNoop (obj, methods) {\n utils.each(methods, function (method)\
\ {\n obj[method] = noop\n })\n}"
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on Shuu12121/CodeModernBERT-Owl-3.0
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [Shuu12121/CodeModernBERT-Owl-3.0](https://huggingface.co/Shuu12121/CodeModernBERT-Owl-3.0). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [Shuu12121/CodeModernBERT-Owl-3.0](https://huggingface.co/Shuu12121/CodeModernBERT-Owl-3.0) <!-- at revision 097b9053842f37dcf1e269e3ae213fa5bf23c606 -->
- **Maximum Sequence Length:** 1024 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 1024, 'do_lower_case': False}) with Transformer model: ModernBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'Call by destroy step',
'function setAlltoNoop (obj, methods) {\n utils.each(methods, function (method) {\n obj[method] = noop\n })\n}',
"public function decompress($content)\n {\n $archive = $this->getArchive();\n if (empty($archive) || !file_exists($archive)) {\n throw new Exception\\RuntimeException('Tar Archive not found');\n }\n\n $archive = str_replace(['/', '\\\\'], DIRECTORY_SEPARATOR, realpath($content));\n $archive = new Archive_Tar($archive, $this->getMode());\n $target = $this->getTarget();\n if (!is_dir($target)) {\n $target = dirname($target) . DIRECTORY_SEPARATOR;\n }\n\n $result = $archive->extract($target);\n if ($result === false) {\n throw new Exception\\RuntimeException('Error while extracting the Tar archive');\n }\n\n return $target;\n }",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 7,059,600 training samples
* Columns: <code>sentence_0</code>, <code>sentence_1</code>, and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | sentence_0 | sentence_1 | label |
|:--------|:-----------------------------------------------------------------------------------|:--------------------------------------------------------------------------------------|:--------------------------------------------------------------|
| type | string | string | float |
| details | <ul><li>min: 3 tokens</li><li>mean: 52.89 tokens</li><li>max: 957 tokens</li></ul> | <ul><li>min: 27 tokens</li><li>mean: 172.25 tokens</li><li>max: 1024 tokens</li></ul> | <ul><li>min: 1.0</li><li>mean: 1.0</li><li>max: 1.0</li></ul> |
* Samples:
| sentence_0 | sentence_1 | label |
|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------|
| <code>// NewFeature is the normal factory method for a feature<br>// Note that id is expected to be a string or number</code> | <code>func NewFeature(geometry interface{}, id interface{}, properties map[string]interface{}) *Feature {<br> if properties == nil {<br> properties = make(map[string]interface{})<br> }<br> return &Feature{Type: FEATURE, Geometry: geometry, Properties: properties, ID: id}<br>}</code> | <code>1.0</code> |
| <code>// AllowElements will append HTML elements to the whitelist without applying an<br>// attribute policy to those elements (the elements are permitted<br>// sans-attributes)</code> | <code>func (p *Policy) AllowElements(names ...string) *Policy {<br> p.init()<br><br> for _, element := range names {<br> element = strings.ToLower(element)<br><br> if _, ok := p.elsAndAttrs[element]; !ok {<br> p.elsAndAttrs[element] = make(map[string]attrPolicy)<br> }<br> }<br><br> return p<br>}</code> | <code>1.0</code> |
| <code>// Build validates the configuration options provided then builds the command</code> | <code>func (builder *MapReduceCommandBuilder) Build() (Command, error) {<br> if builder.protobuf == nil {<br> panic("builder.protobuf must not be nil")<br> }<br> if builder.streaming && builder.callback == nil {<br> return nil, newClientError("MapReduceCommand requires a callback when streaming.", nil)<br> }<br> return &MapReduceCommand{<br> protobuf: builder.protobuf,<br> streaming: builder.streaming,<br> callback: builder.callback,<br> }, nil<br>}</code> | <code>1.0</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 150
- `per_device_eval_batch_size`: 150
- `num_train_epochs`: 1
- `fp16`: True
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 150
- `per_device_eval_batch_size`: 150
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
</details>
### Training Logs
| Epoch | Step | Training Loss |
|:------:|:-----:|:-------------:|
| 0.0106 | 500 | 0.5662 |
| 0.0212 | 1000 | 0.113 |
| 0.0319 | 1500 | 0.1048 |
| 0.0425 | 2000 | 0.1006 |
| 0.0531 | 2500 | 0.0921 |
| 0.0637 | 3000 | 0.0861 |
| 0.0744 | 3500 | 0.0834 |
| 0.0850 | 4000 | 0.0787 |
| 0.0956 | 4500 | 0.0734 |
| 0.1062 | 5000 | 0.0752 |
| 0.1169 | 5500 | 0.0711 |
| 0.1275 | 6000 | 0.0697 |
| 0.1381 | 6500 | 0.0694 |
| 0.1487 | 7000 | 0.0682 |
| 0.1594 | 7500 | 0.0632 |
| 0.1700 | 8000 | 0.0641 |
| 0.1806 | 8500 | 0.063 |
| 0.1912 | 9000 | 0.0587 |
| 0.2019 | 9500 | 0.0615 |
| 0.2125 | 10000 | 0.0549 |
| 0.2231 | 10500 | 0.0553 |
| 0.2337 | 11000 | 0.0549 |
| 0.2443 | 11500 | 0.0528 |
| 0.2550 | 12000 | 0.0531 |
| 0.2656 | 12500 | 0.0505 |
| 0.2762 | 13000 | 0.0512 |
| 0.2868 | 13500 | 0.0459 |
| 0.2975 | 14000 | 0.0477 |
| 0.3081 | 14500 | 0.0472 |
| 0.3187 | 15000 | 0.0473 |
| 0.3293 | 15500 | 0.0463 |
| 0.3400 | 16000 | 0.044 |
| 0.3506 | 16500 | 0.0415 |
| 0.3612 | 17000 | 0.042 |
| 0.3718 | 17500 | 0.0412 |
| 0.3825 | 18000 | 0.0411 |
| 0.3931 | 18500 | 0.0401 |
| 0.4037 | 19000 | 0.0396 |
| 0.4143 | 19500 | 0.0374 |
| 0.4250 | 20000 | 0.0373 |
| 0.4356 | 20500 | 0.0364 |
| 0.4462 | 21000 | 0.0375 |
| 0.4568 | 21500 | 0.0349 |
| 0.4674 | 22000 | 0.0355 |
| 0.4781 | 22500 | 0.0321 |
| 0.4887 | 23000 | 0.0349 |
| 0.4993 | 23500 | 0.0314 |
| 0.5099 | 24000 | 0.0318 |
| 0.5206 | 24500 | 0.033 |
| 0.5312 | 25000 | 0.0306 |
| 0.5418 | 25500 | 0.0299 |
| 0.5524 | 26000 | 0.0303 |
| 0.5631 | 26500 | 0.0286 |
| 0.5737 | 27000 | 0.0304 |
| 0.5843 | 27500 | 0.0266 |
| 0.5949 | 28000 | 0.0274 |
| 0.6056 | 28500 | 0.0277 |
| 0.6162 | 29000 | 0.0264 |
| 0.6268 | 29500 | 0.0255 |
| 0.6374 | 30000 | 0.0258 |
| 0.6481 | 30500 | 0.0251 |
| 0.6587 | 31000 | 0.024 |
| 0.6693 | 31500 | 0.0258 |
| 0.6799 | 32000 | 0.0242 |
| 0.6905 | 32500 | 0.0225 |
| 0.7012 | 33000 | 0.0237 |
| 0.7118 | 33500 | 0.0209 |
| 0.7224 | 34000 | 0.0231 |
| 0.7330 | 34500 | 0.022 |
| 0.7437 | 35000 | 0.0221 |
| 0.7543 | 35500 | 0.0198 |
| 0.7649 | 36000 | 0.0207 |
| 0.7755 | 36500 | 0.0213 |
| 0.7862 | 37000 | 0.0212 |
| 0.7968 | 37500 | 0.0209 |
| 0.8074 | 38000 | 0.0204 |
| 0.8180 | 38500 | 0.0196 |
| 0.8287 | 39000 | 0.0184 |
| 0.8393 | 39500 | 0.0185 |
| 0.8499 | 40000 | 0.0192 |
| 0.8605 | 40500 | 0.0197 |
| 0.8712 | 41000 | 0.0184 |
| 0.8818 | 41500 | 0.0188 |
| 0.8924 | 42000 | 0.0181 |
| 0.9030 | 42500 | 0.0182 |
| 0.9136 | 43000 | 0.0167 |
| 0.9243 | 43500 | 0.0176 |
| 0.9349 | 44000 | 0.0188 |
| 0.9455 | 44500 | 0.0181 |
| 0.9561 | 45000 | 0.0175 |
| 0.9668 | 45500 | 0.0175 |
| 0.9774 | 46000 | 0.017 |
| 0.9880 | 46500 | 0.0164 |
| 0.9986 | 47000 | 0.0174 |
### Framework Versions
- Python: 3.10.12
- Sentence Transformers: 4.1.0
- Transformers: 4.52.4
- PyTorch: 2.7.0+cu128
- Accelerate: 1.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
Xeil84/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-gentle_dense_okapi
|
Xeil84
| 2025-06-20T10:29:38Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am gentle dense okapi",
"unsloth",
"trl",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T21:06:27Z |
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-gentle_dense_okapi
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am gentle dense okapi
- unsloth
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-gentle_dense_okapi
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Xeil84/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-gentle_dense_okapi", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
nusnlp/JGP-Parallel-Last-ID-EN
|
nusnlp
| 2025-06-20T10:24:15Z | 0 | 0 | null |
[
"pytorch",
"llama",
"en",
"id",
"arxiv:2506.13044",
"license:apache-2.0",
"region:us"
] | null | 2025-06-18T06:03:53Z |
---
license: apache-2.0
language:
- en
- id
---
# Just-Go-Parallel (Parallel Last (uni): ID→EN)
The model repository for the "Parallel Last (uni): ID→EN" setting of the following paper:
> **Just Go Parallel: Improving the Multilingual Capabilities of Large Language Models**
>
> [Muhammad Reza Qorib](https://mrqorib.github.io/), [Junyi Li](https://lijunyi.tech/), and [Hwee Tou Ng](https://www.comp.nus.edu.sg/~nght/)
>
> The 63rd Annual Meeting of the Association for Computational Linguistics (to appear)
- **Paper:** [arXiv](https://arxiv.org/abs/2506.13044)
- **Codebase:** [https://github.com/nusnlp/Just-Go-Parallel/](https://github.com/nusnlp/just-Go-Parallel/)
We use the architecture and tokenizer of [TinyLlama v1.1](https://huggingface.co/TinyLlama/TinyLlama_v1.1).
Please use transformers>=4.35.
## Models
The main branch of the repository contains the best-performing model that was evaluated in the paper. Other checkpoints produced during training will also be hosted in this repository under different branch names (also called "revisions" in HuggingFace), with each branch name indicating the number of training steps.
* No Parallel: [nusnlp/JGP-No-Parallel](https://huggingface.co/nusnlp/JGP-No-Parallel)
* Multilingual: [nusnlp/JGP-Multilingual](https://huggingface.co/nusnlp/JGP-Multilingual)
* Parallel Non-Adjacent: [nusnlp/JGP-Parallel-Non-Adjacent](https://huggingface.co/nusnlp/JGP-Parallel-Non-Adjacent)
* Parallel First: [nusnlp/JGP-Parallel-First](https://huggingface.co/nusnlp/JGP-Parallel-First)
* Parallel Distributed: [nusnlp/JGP-Parallel-Distributed](https://huggingface.co/nusnlp/JGP-Parallel-Distributed)
* Parallel Last (all): [nusnlp/JGP-Parallel-Last-all](https://huggingface.co/nusnlp/JGP-Parallel-Last-all)
* Parallel Last (uni):
* EN→ID: [nusnlp/JGP-Parallel-Last-EN-ID](https://huggingface.co/nusnlp/JGP-Parallel-Last-EN-ID)
* ID→EN: [nusnlp/JGP-Parallel-Last-ID-EN](https://huggingface.co/nusnlp/JGP-Parallel-Last-ID-EN)
* EN→ZH: [nusnlp/JGP-Parallel-Last-EN-ZH](https://huggingface.co/nusnlp/JGP-Parallel-Last-EN-ZH)
* ZH→EN: [nusnlp/JGP-Parallel-Last-ZH-EN](https://huggingface.co/nusnlp/JGP-Parallel-Last-ZH-EN)
|
bunnycore/Qwen3-4B-RP-V2
|
bunnycore
| 2025-06-20T10:13:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2306.01708",
"base_model:Hastagaras/Qibil-4B-v0.1-RP",
"base_model:merge:Hastagaras/Qibil-4B-v0.1-RP",
"base_model:bunnycore/Qwen3-4B-RP",
"base_model:merge:bunnycore/Qwen3-4B-RP",
"base_model:fakezeta/amoral-Qwen3-4B",
"base_model:merge:fakezeta/amoral-Qwen3-4B",
"base_model:mlabonne/Qwen3-4B-abliterated",
"base_model:merge:mlabonne/Qwen3-4B-abliterated",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T10:06:39Z |
---
base_model:
- mlabonne/Qwen3-4B-abliterated
- Hastagaras/Qibil-4B-v0.1-RP
- fakezeta/amoral-Qwen3-4B
- bunnycore/Qwen3-4B-RP
library_name: transformers
tags:
- mergekit
- merge
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [mlabonne/Qwen3-4B-abliterated](https://huggingface.co/mlabonne/Qwen3-4B-abliterated) as a base.
### Models Merged
The following models were included in the merge:
* [Hastagaras/Qibil-4B-v0.1-RP](https://huggingface.co/Hastagaras/Qibil-4B-v0.1-RP)
* [fakezeta/amoral-Qwen3-4B](https://huggingface.co/fakezeta/amoral-Qwen3-4B)
* [bunnycore/Qwen3-4B-RP](https://huggingface.co/bunnycore/Qwen3-4B-RP)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Hastagaras/Qibil-4B-v0.1-RP
parameters:
density: 0.5
weight: 0.5
- model: fakezeta/amoral-Qwen3-4B
parameters:
density: 0.3
weight: 0.3
- model: bunnycore/Qwen3-4B-RP
parameters:
density: 0.3
weight: 0.3
merge_method: ties
base_model: mlabonne/Qwen3-4B-abliterated
parameters:
normalize: false
int8_mask: true
dtype: float16
```
|
3sara/merged-v1.2-3epochs
|
3sara
| 2025-06-20T09:59:31Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"colpali-finetuned",
"generated_from_trainer",
"base_model:vidore/colpali-v1.2-merged",
"base_model:adapter:vidore/colpali-v1.2-merged",
"license:gemma",
"region:us"
] | null | 2025-06-20T09:59:21Z |
---
library_name: peft
license: gemma
base_model: vidore/colpali-v1.2-merged
tags:
- colpali-finetuned
- generated_from_trainer
model-index:
- name: merged-v1.2-3epochs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# merged-v1.2-3epochs
This model is a fine-tuned version of [vidore/colpali-v1.2-merged](https://huggingface.co/vidore/colpali-v1.2-merged) on the 3sara/validated_colpali_italian_documents_with_images dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3600
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0103 | 1 | 0.3778 |
| 0.1534 | 1.0205 | 100 | 0.3070 |
| 0.105 | 2.0410 | 200 | 0.3600 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.51.3
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
ishk9999/gemma-cxr-fine-tuning-3000-subset-4b-it
|
ishk9999
| 2025-06-20T09:58:00Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/medgemma-4b-it",
"base_model:finetune:google/medgemma-4b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-06-19T07:23:35Z |
---
base_model: google/medgemma-4b-it
library_name: transformers
model_name: gemma-cxr-fine-tuning-3000-subset-4b-it
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-cxr-fine-tuning-3000-subset-4b-it
This model is a fine-tuned version of [google/medgemma-4b-it](https://huggingface.co/google/medgemma-4b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ishk9999/gemma-cxr-fine-tuning-3000-subset-4b-it", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.52.4
- Pytorch: 2.6.0+cu124
- Datasets: 3.3.2
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
LarryAIDraw/hsr-feixiao-ponyxl-lora-nochekaiser
|
LarryAIDraw
| 2025-06-20T09:51:37Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2025-06-20T09:12:54Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/746845/feixiao-honkai-star-rail
|
Qwen/Qwen3-Embedding-0.6B
|
Qwen
| 2025-06-20T09:31:05Z | 227,662 | 260 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"qwen3",
"text-generation",
"transformers",
"sentence-similarity",
"feature-extraction",
"text-embeddings-inference",
"arxiv:2506.05176",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:finetune:Qwen/Qwen3-0.6B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-03T14:25:32Z |
---
license: apache-2.0
base_model:
- Qwen/Qwen3-0.6B-Base
tags:
- transformers
- sentence-transformers
- sentence-similarity
- feature-extraction
- text-embeddings-inference
---
# Qwen3-Embedding-0.6B
<p align="center">
<img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/logo_qwen3.png" width="400"/>
<p>
## Highlights
The Qwen3 Embedding model series is the latest proprietary model of the Qwen family, specifically designed for text embedding and ranking tasks. Building upon the dense foundational models of the Qwen3 series, it provides a comprehensive range of text embeddings and reranking models in various sizes (0.6B, 4B, and 8B). This series inherits the exceptional multilingual capabilities, long-text understanding, and reasoning skills of its foundational model. The Qwen3 Embedding series represents significant advancements in multiple text embedding and ranking tasks, including text retrieval, code retrieval, text classification, text clustering, and bitext mining.
**Exceptional Versatility**: The embedding model has achieved state-of-the-art performance across a wide range of downstream application evaluations. The 8B size embedding model ranks **No.1** in the MTEB multilingual leaderboard (as of June 5, 2025, score **70.58**), while the reranking model excels in various text retrieval scenarios.
**Comprehensive Flexibility**: The Qwen3 Embedding series offers a full spectrum of sizes (from 0.6B to 8B) for both embedding and reranking models, catering to diverse use cases that prioritize efficiency and effectiveness. Developers can seamlessly combine these two modules. Additionally, the embedding model allows for flexible vector definitions across all dimensions, and both embedding and reranking models support user-defined instructions to enhance performance for specific tasks, languages, or scenarios.
**Multilingual Capability**: The Qwen3 Embedding series offer support for over 100 languages, thanks to the multilingual capabilites of Qwen3 models. This includes various programming languages, and provides robust multilingual, cross-lingual, and code retrieval capabilities.
## Model Overview
**Qwen3-Embedding-0.6B** has the following features:
- Model Type: Text Embedding
- Supported Languages: 100+ Languages
- Number of Paramaters: 0.6B
- Context Length: 32k
- Embedding Dimension: Up to 1024, supports user-defined output dimensions ranging from 32 to 1024
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-embedding/), [GitHub](https://github.com/QwenLM/Qwen3-Embedding).
## Qwen3 Embedding Series Model list
| Model Type | Models | Size | Layers | Sequence Length | Embedding Dimension | MRL Support | Instruction Aware |
|------------------|----------------------|------|--------|-----------------|---------------------|-------------|----------------|
| Text Embedding | [Qwen3-Embedding-0.6B](https://huggingface.co/Qwen/Qwen3-Embedding-0.6B) | 0.6B | 28 | 32K | 1024 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-4B](https://huggingface.co/Qwen/Qwen3-Embedding-4B) | 4B | 36 | 32K | 2560 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-8B](https://huggingface.co/Qwen/Qwen3-Embedding-8B) | 8B | 36 | 32K | 4096 | Yes | Yes |
| Text Reranking | [Qwen3-Reranker-0.6B](https://huggingface.co/Qwen/Qwen3-Reranker-0.6B) | 0.6B | 28 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-4B](https://huggingface.co/Qwen/Qwen3-Reranker-4B) | 4B | 36 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-8B](https://huggingface.co/Qwen/Qwen3-Reranker-8B) | 8B | 36 | 32K | - | - | Yes |
> **Note**:
> - `MRL Support` indicates whether the embedding model supports custom dimensions for the final embedding.
> - `Instruction Aware` notes whether the embedding or reranking model supports customizing the input instruction according to different tasks.
> - Our evaluation indicates that, for most downstream tasks, using instructions (instruct) typically yields an improvement of 1% to 5% compared to not using them. Therefore, we recommend that developers create tailored instructions specific to their tasks and scenarios. In multilingual contexts, we also advise users to write their instructions in English, as most instructions utilized during the model training process were originally written in English.
## Usage
With Transformers versions earlier than 4.51.0, you may encounter the following error:
```
KeyError: 'qwen3'
```
### Sentence Transformers Usage
```python
# Requires transformers>=4.51.0
# Requires sentence-transformers>=2.7.0
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B")
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# together with setting `padding_side` to "left":
# model = SentenceTransformer(
# "Qwen/Qwen3-Embedding-0.6B",
# model_kwargs={"attn_implementation": "flash_attention_2", "device_map": "auto"},
# tokenizer_kwargs={"padding_side": "left"},
# )
# The queries and documents to embed
queries = [
"What is the capital of China?",
"Explain gravity",
]
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun.",
]
# Encode the queries and documents. Note that queries benefit from using a prompt
# Here we use the prompt called "query" stored under `model.prompts`, but you can
# also pass your own prompt via the `prompt` argument
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
# Compute the (cosine) similarity between the query and document embeddings
similarity = model.similarity(query_embeddings, document_embeddings)
print(similarity)
# tensor([[0.7646, 0.1414],
# [0.1355, 0.6000]])
```
### Transformers Usage
```python
# Requires transformers>=4.51.0
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-0.6B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B')
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B', attn_implementation="flash_attention_2", torch_dtype=torch.float16).cuda()
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(
input_texts,
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7645568251609802, 0.14142508804798126], [0.13549736142158508, 0.5999549627304077]]
```
### vLLM Usage
```python
# Requires vllm>=0.8.5
import torch
import vllm
from vllm import LLM
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
model = LLM(model="Qwen/Qwen3-Embedding-0.6B", task="embed")
outputs = model.embed(input_texts)
embeddings = torch.tensor([o.outputs.embedding for o in outputs])
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7620252966880798, 0.14078938961029053], [0.1358368694782257, 0.6013815999031067]]
```
📌 **Tip**: We recommend that developers customize the `instruct` according to their specific scenarios, tasks, and languages. Our tests have shown that in most retrieval scenarios, not using an `instruct` on the query side can lead to a drop in retrieval performance by approximately 1% to 5%.
### Text Embeddings Inference (TEI) Usage
You can either run / deploy TEI on NVIDIA GPUs as:
```bash
docker run --gpus all -p 8080:80 -v hf_cache:/data --pull always ghcr.io/huggingface/text-embeddings-inference:cpu-1.7.2 --model-id Qwen/Qwen3-Embedding-0.6B --dtype float16
```
Or on CPU devices as:
```bash
docker run -p 8080:80 -v hf_cache:/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.7.2 --model-id Qwen/Qwen3-Embedding-0.6B
```
And then, generate the embeddings sending a HTTP POST request as:
```bash
curl http://localhost:8080/embed \
-X POST \
-d '{"inputs": ["Instruct: Given a web search query, retrieve relevant passages that answer the query\nQuery: What is the capital of China?", "Instruct: Given a web search query, retrieve relevant passages that answer the query\nQuery: Explain gravity"]}' \
-H "Content-Type: application/json"
```
## Evaluation
### MTEB (Multilingual)
| Model | Size | Mean (Task) | Mean (Type) | Bitxt Mining | Class. | Clust. | Inst. Retri. | Multi. Class. | Pair. Class. | Rerank | Retri. | STS |
|----------------------------------|:-------:|:-------------:|:-------------:|:--------------:|:--------:|:--------:|:--------------:|:---------------:|:--------------:|:--------:|:--------:|:------:|
| NV-Embed-v2 | 7B | 56.29 | 49.58 | 57.84 | 57.29 | 40.80 | 1.04 | 18.63 | 78.94 | 63.82 | 56.72 | 71.10|
| GritLM-7B | 7B | 60.92 | 53.74 | 70.53 | 61.83 | 49.75 | 3.45 | 22.77 | 79.94 | 63.78 | 58.31 | 73.33|
| BGE-M3 | 0.6B | 59.56 | 52.18 | 79.11 | 60.35 | 40.88 | -3.11 | 20.1 | 80.76 | 62.79 | 54.60 | 74.12|
| multilingual-e5-large-instruct | 0.6B | 63.22 | 55.08 | 80.13 | 64.94 | 50.75 | -0.40 | 22.91 | 80.86 | 62.61 | 57.12 | 76.81|
| gte-Qwen2-1.5B-instruct | 1.5B | 59.45 | 52.69 | 62.51 | 58.32 | 52.05 | 0.74 | 24.02 | 81.58 | 62.58 | 60.78 | 71.61|
| gte-Qwen2-7b-Instruct | 7B | 62.51 | 55.93 | 73.92 | 61.55 | 52.77 | 4.94 | 25.48 | 85.13 | 65.55 | 60.08 | 73.98|
| text-embedding-3-large | - | 58.93 | 51.41 | 62.17 | 60.27 | 46.89 | -2.68 | 22.03 | 79.17 | 63.89 | 59.27 | 71.68|
| Cohere-embed-multilingual-v3.0 | - | 61.12 | 53.23 | 70.50 | 62.95 | 46.89 | -1.89 | 22.74 | 79.88 | 64.07 | 59.16 | 74.80|
| Gemini Embedding | - | 68.37 | 59.59 | 79.28 | 71.82 | 54.59 | 5.18 | **29.16** | 83.63 | 65.58 | 67.71 | 79.40|
| **Qwen3-Embedding-0.6B** | 0.6B | 64.33 | 56.00 | 72.22 | 66.83 | 52.33 | 5.09 | 24.59 | 80.83 | 61.41 | 64.64 | 76.17|
| **Qwen3-Embedding-4B** | 4B | 69.45 | 60.86 | 79.36 | 72.33 | 57.15 | **11.56** | 26.77 | 85.05 | 65.08 | 69.60 | 80.86|
| **Qwen3-Embedding-8B** | 8B | **70.58** | **61.69** | **80.89** | **74.00** | **57.65** | 10.06 | 28.66 | **86.40** | **65.63** | **70.88** | **81.08** |
> **Note**: For compared models, the scores are retrieved from MTEB online [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) on May 24th, 2025.
### MTEB (Eng v2)
| MTEB English / Models | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retri. | STS | Summ. |
|--------------------------------|:--------:|:------------:|:------------:|:--------:|:--------:|:-------------:|:---------:|:--------:|:-------:|:-------:|
| multilingual-e5-large-instruct | 0.6B | 65.53 | 61.21 | 75.54 | 49.89 | 86.24 | 48.74 | 53.47 | 84.72 | 29.89 |
| NV-Embed-v2 | 7.8B | 69.81 | 65.00 | 87.19 | 47.66 | 88.69 | 49.61 | 62.84 | 83.82 | 35.21 |
| GritLM-7B | 7.2B | 67.07 | 63.22 | 81.25 | 50.82 | 87.29 | 49.59 | 54.95 | 83.03 | 35.65 |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.20 | 63.26 | 85.84 | 53.54 | 87.52 | 49.25 | 50.25 | 82.51 | 33.94 |
| stella_en_1.5B_v5 | 1.5B | 69.43 | 65.32 | 89.38 | 57.06 | 88.02 | 50.19 | 52.42 | 83.27 | 36.91 |
| gte-Qwen2-7B-instruct | 7.6B | 70.72 | 65.77 | 88.52 | 58.97 | 85.9 | 50.47 | 58.09 | 82.69 | 35.74 |
| gemini-embedding-exp-03-07 | - | 73.3 | 67.67 | 90.05 | 59.39 | 87.7 | 48.59 | 64.35 | 85.29 | 38.28 |
| **Qwen3-Embedding-0.6B** | 0.6B | 70.70 | 64.88 | 85.76 | 54.05 | 84.37 | 48.18 | 61.83 | 86.57 | 33.43 |
| **Qwen3-Embedding-4B** | 4B | 74.60 | 68.10 | 89.84 | 57.51 | 87.01 | 50.76 | 68.46 | 88.72 | 34.39 |
| **Qwen3-Embedding-8B** | 8B | 75.22 | 68.71 | 90.43 | 58.57 | 87.52 | 51.56 | 69.44 | 88.58 | 34.83 |
### C-MTEB (MTEB Chinese)
| C-MTEB | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retr. | STS |
|------------------|--------|------------|------------|--------|--------|-------------|---------|-------|-------|
| multilingual-e5-large-instruct | 0.6B | 58.08 | 58.24 | 69.80 | 48.23 | 64.52 | 57.45 | 63.65 | 45.81 |
| bge-multilingual-gemma2 | 9B | 67.64 | 75.31 | 59.30 | 86.67 | 68.28 | 73.73 | 55.19 | - |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.12 | 67.79 | 72.53 | 54.61 | 79.5 | 68.21 | 71.86 | 60.05 |
| gte-Qwen2-7B-instruct | 7.6B | 71.62 | 72.19 | 75.77 | 66.06 | 81.16 | 69.24 | 75.70 | 65.20 |
| ritrieve_zh_v1 | 0.3B | 72.71 | 73.85 | 76.88 | 66.5 | 85.98 | 72.86 | 76.97 | 63.92 |
| **Qwen3-Embedding-0.6B** | 0.6B | 66.33 | 67.45 | 71.40 | 68.74 | 76.42 | 62.58 | 71.03 | 54.52 |
| **Qwen3-Embedding-4B** | 4B | 72.27 | 73.51 | 75.46 | 77.89 | 83.34 | 66.05 | 77.03 | 61.26 |
| **Qwen3-Embedding-8B** | 8B | 73.84 | 75.00 | 76.97 | 80.08 | 84.23 | 66.99 | 78.21 | 63.53 |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen3embedding,
title={Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models},
author={Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren},
journal={arXiv preprint arXiv:2506.05176},
year={2025}
}
```
|
nnilayy/dreamer-valence-multi-classification-Kfold-4
|
nnilayy
| 2025-06-20T09:26:49Z | 0 | 0 | null |
[
"safetensors",
"model_hub_mixin",
"pytorch_model_hub_mixin",
"region:us"
] | null | 2025-06-20T09:26:47Z |
---
tags:
- model_hub_mixin
- pytorch_model_hub_mixin
---
This model has been pushed to the Hub using the [PytorchModelHubMixin](https://huggingface.co/docs/huggingface_hub/package_reference/mixins#huggingface_hub.PyTorchModelHubMixin) integration:
- Code: [More Information Needed]
- Paper: [More Information Needed]
- Docs: [More Information Needed]
|
hyangilam/whisper-large-v3-turbo-ko-0.0.2
|
hyangilam
| 2025-06-20T09:25:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"ko",
"dataset:mozilla-foundation/common_voice_17_0",
"base_model:openai/whisper-large-v3-turbo",
"base_model:finetune:openai/whisper-large-v3-turbo",
"license:mit",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-06-20T09:11:56Z |
---
library_name: transformers
language:
- ko
license: mit
base_model: openai/whisper-large-v3-turbo
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_17_0
model-index:
- name: Whisper Turbo Ko v0.0.2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Turbo Ko v0.0.2
This model is a fine-tuned version of [openai/whisper-large-v3-turbo](https://huggingface.co/openai/whisper-large-v3-turbo) on the Common Voice 17.0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
convsync/86174bb9-a220-46c7-933c-1ddb0fcd671e-my_trained_model
|
convsync
| 2025-06-20T09:23:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T09:02:31Z |
---
base_model: unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** convsync
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-1b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
sgonzalezygil/sd-finetuning-dreambooth-v23-360
|
sgonzalezygil
| 2025-06-20T09:22:06Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-06-20T09:20:36Z |
---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.1_target_man-bs1-steps5000-lr1e-04
|
Josephinepassananti
| 2025-06-20T09:14:23Z | 0 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"diffusers-training",
"lora",
"base_model:stabilityai/stable-diffusion-2-1",
"base_model:adapter:stabilityai/stable-diffusion-2-1",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2025-06-20T08:44:29Z |
---
base_model: stabilityai/stable-diffusion-2-1
library_name: diffusers
license: creativeml-openrail-m
inference: true
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- diffusers-training
- lora
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# LoRA text2image fine-tuning - Josephinepassananti/sd21-kamala_ft_dataset_512_face_shaded_0.1_target_man-bs1-steps5000-lr1e-04
These are LoRA adaption weights for stabilityai/stable-diffusion-2-1. The weights were fine-tuned on the None dataset. You can find some example images in the following.




## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
sgonzalezygil/sd-finetuning-dreambooth-v23
|
sgonzalezygil
| 2025-06-20T09:14:06Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2025-06-20T09:12:35Z |
---
library_name: diffusers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🧨 diffusers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
makataomu/a2c-PandaReachDense-v3
|
makataomu
| 2025-06-20T09:12:01Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-20T08:55:10Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.19 +/- 0.09
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
dunzhang/stella-large-zh-v3-1792d
|
dunzhang
| 2025-06-20T09:02:14Z | 389 | 31 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"mteb",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2024-02-17T05:30:43Z |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- mteb
model-index:
- name: stella-large-zh-v3-1792d
results:
- task:
type: STS
dataset:
type: C-MTEB/AFQMC
name: MTEB AFQMC
config: default
split: validation
revision: None
metrics:
- type: cos_sim_pearson
value: 54.48093298255762
- type: cos_sim_spearman
value: 59.105354109068685
- type: euclidean_pearson
value: 57.761189988643444
- type: euclidean_spearman
value: 59.10537421115596
- type: manhattan_pearson
value: 56.94359297051431
- type: manhattan_spearman
value: 58.37611109821567
- task:
type: STS
dataset:
type: C-MTEB/ATEC
name: MTEB ATEC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 54.39711127600595
- type: cos_sim_spearman
value: 58.190191920824454
- type: euclidean_pearson
value: 61.80082379352729
- type: euclidean_spearman
value: 58.19018966860797
- type: manhattan_pearson
value: 60.927601060396206
- type: manhattan_spearman
value: 57.78832902694192
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.31600000000001
- type: f1
value: 44.45281663598873
- task:
type: STS
dataset:
type: C-MTEB/BQ
name: MTEB BQ
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 69.12211326097868
- type: cos_sim_spearman
value: 71.0741302039443
- type: euclidean_pearson
value: 69.89070483887852
- type: euclidean_spearman
value: 71.07413020351787
- type: manhattan_pearson
value: 69.62345441260962
- type: manhattan_spearman
value: 70.8517591280618
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringP2P
name: MTEB CLSClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 41.937723608805314
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringS2S
name: MTEB CLSClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 40.34373057675427
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 88.98896401788376
- type: mrr
value: 90.97119047619047
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 89.59718540244556
- type: mrr
value: 91.41246031746032
- task:
type: Retrieval
dataset:
type: C-MTEB/CmedqaRetrieval
name: MTEB CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 26.954
- type: map_at_10
value: 40.144999999999996
- type: map_at_100
value: 42.083999999999996
- type: map_at_1000
value: 42.181000000000004
- type: map_at_3
value: 35.709
- type: map_at_5
value: 38.141000000000005
- type: mrr_at_1
value: 40.71
- type: mrr_at_10
value: 48.93
- type: mrr_at_100
value: 49.921
- type: mrr_at_1000
value: 49.958999999999996
- type: mrr_at_3
value: 46.32
- type: mrr_at_5
value: 47.769
- type: ndcg_at_1
value: 40.71
- type: ndcg_at_10
value: 46.869
- type: ndcg_at_100
value: 54.234
- type: ndcg_at_1000
value: 55.854000000000006
- type: ndcg_at_3
value: 41.339
- type: ndcg_at_5
value: 43.594
- type: precision_at_1
value: 40.71
- type: precision_at_10
value: 10.408000000000001
- type: precision_at_100
value: 1.635
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 23.348
- type: precision_at_5
value: 16.929
- type: recall_at_1
value: 26.954
- type: recall_at_10
value: 57.821999999999996
- type: recall_at_100
value: 88.08200000000001
- type: recall_at_1000
value: 98.83800000000001
- type: recall_at_3
value: 41.221999999999994
- type: recall_at_5
value: 48.241
- task:
type: PairClassification
dataset:
type: C-MTEB/CMNLI
name: MTEB Cmnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 83.6680697534576
- type: cos_sim_ap
value: 90.77401562455269
- type: cos_sim_f1
value: 84.68266427450101
- type: cos_sim_precision
value: 81.36177547942253
- type: cos_sim_recall
value: 88.28618190320317
- type: dot_accuracy
value: 83.6680697534576
- type: dot_ap
value: 90.76429465198817
- type: dot_f1
value: 84.68266427450101
- type: dot_precision
value: 81.36177547942253
- type: dot_recall
value: 88.28618190320317
- type: euclidean_accuracy
value: 83.6680697534576
- type: euclidean_ap
value: 90.77401909305344
- type: euclidean_f1
value: 84.68266427450101
- type: euclidean_precision
value: 81.36177547942253
- type: euclidean_recall
value: 88.28618190320317
- type: manhattan_accuracy
value: 83.40348767288035
- type: manhattan_ap
value: 90.57002020310819
- type: manhattan_f1
value: 84.51526032315978
- type: manhattan_precision
value: 81.25134843581445
- type: manhattan_recall
value: 88.05237315875614
- type: max_accuracy
value: 83.6680697534576
- type: max_ap
value: 90.77401909305344
- type: max_f1
value: 84.68266427450101
- task:
type: Retrieval
dataset:
type: C-MTEB/CovidRetrieval
name: MTEB CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 69.705
- type: map_at_10
value: 78.648
- type: map_at_100
value: 78.888
- type: map_at_1000
value: 78.89399999999999
- type: map_at_3
value: 77.151
- type: map_at_5
value: 77.98
- type: mrr_at_1
value: 69.863
- type: mrr_at_10
value: 78.62599999999999
- type: mrr_at_100
value: 78.861
- type: mrr_at_1000
value: 78.867
- type: mrr_at_3
value: 77.204
- type: mrr_at_5
value: 78.005
- type: ndcg_at_1
value: 69.968
- type: ndcg_at_10
value: 82.44399999999999
- type: ndcg_at_100
value: 83.499
- type: ndcg_at_1000
value: 83.647
- type: ndcg_at_3
value: 79.393
- type: ndcg_at_5
value: 80.855
- type: precision_at_1
value: 69.968
- type: precision_at_10
value: 9.515
- type: precision_at_100
value: 0.9990000000000001
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 28.802
- type: precision_at_5
value: 18.019
- type: recall_at_1
value: 69.705
- type: recall_at_10
value: 94.152
- type: recall_at_100
value: 98.84100000000001
- type: recall_at_1000
value: 100
- type: recall_at_3
value: 85.774
- type: recall_at_5
value: 89.252
- task:
type: Retrieval
dataset:
type: C-MTEB/DuRetrieval
name: MTEB DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 25.88
- type: map_at_10
value: 79.857
- type: map_at_100
value: 82.636
- type: map_at_1000
value: 82.672
- type: map_at_3
value: 55.184
- type: map_at_5
value: 70.009
- type: mrr_at_1
value: 89.64999999999999
- type: mrr_at_10
value: 92.967
- type: mrr_at_100
value: 93.039
- type: mrr_at_1000
value: 93.041
- type: mrr_at_3
value: 92.65
- type: mrr_at_5
value: 92.86
- type: ndcg_at_1
value: 89.64999999999999
- type: ndcg_at_10
value: 87.126
- type: ndcg_at_100
value: 89.898
- type: ndcg_at_1000
value: 90.253
- type: ndcg_at_3
value: 86.012
- type: ndcg_at_5
value: 85.124
- type: precision_at_1
value: 89.64999999999999
- type: precision_at_10
value: 41.735
- type: precision_at_100
value: 4.797
- type: precision_at_1000
value: 0.488
- type: precision_at_3
value: 77.267
- type: precision_at_5
value: 65.48
- type: recall_at_1
value: 25.88
- type: recall_at_10
value: 88.28399999999999
- type: recall_at_100
value: 97.407
- type: recall_at_1000
value: 99.29299999999999
- type: recall_at_3
value: 57.38799999999999
- type: recall_at_5
value: 74.736
- task:
type: Retrieval
dataset:
type: C-MTEB/EcomRetrieval
name: MTEB EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 53.2
- type: map_at_10
value: 63.556000000000004
- type: map_at_100
value: 64.033
- type: map_at_1000
value: 64.044
- type: map_at_3
value: 60.983
- type: map_at_5
value: 62.588
- type: mrr_at_1
value: 53.2
- type: mrr_at_10
value: 63.556000000000004
- type: mrr_at_100
value: 64.033
- type: mrr_at_1000
value: 64.044
- type: mrr_at_3
value: 60.983
- type: mrr_at_5
value: 62.588
- type: ndcg_at_1
value: 53.2
- type: ndcg_at_10
value: 68.61699999999999
- type: ndcg_at_100
value: 70.88499999999999
- type: ndcg_at_1000
value: 71.15899999999999
- type: ndcg_at_3
value: 63.434000000000005
- type: ndcg_at_5
value: 66.301
- type: precision_at_1
value: 53.2
- type: precision_at_10
value: 8.450000000000001
- type: precision_at_100
value: 0.95
- type: precision_at_1000
value: 0.097
- type: precision_at_3
value: 23.5
- type: precision_at_5
value: 15.479999999999999
- type: recall_at_1
value: 53.2
- type: recall_at_10
value: 84.5
- type: recall_at_100
value: 95
- type: recall_at_1000
value: 97.1
- type: recall_at_3
value: 70.5
- type: recall_at_5
value: 77.4
- task:
type: Classification
dataset:
type: C-MTEB/IFlyTek-classification
name: MTEB IFlyTek
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 50.63485956136976
- type: f1
value: 38.286307407751266
- task:
type: Classification
dataset:
type: C-MTEB/JDReview-classification
name: MTEB JDReview
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 86.11632270168855
- type: ap
value: 54.43932599806482
- type: f1
value: 80.85485110996076
- task:
type: STS
dataset:
type: C-MTEB/LCQMC
name: MTEB LCQMC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 72.47315152994804
- type: cos_sim_spearman
value: 78.26531600908152
- type: euclidean_pearson
value: 77.8560788714531
- type: euclidean_spearman
value: 78.26531157334841
- type: manhattan_pearson
value: 77.70593783974188
- type: manhattan_spearman
value: 78.13880812439999
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 28.088177976572222
- type: mrr
value: 27.125
- task:
type: Retrieval
dataset:
type: C-MTEB/MMarcoRetrieval
name: MTEB MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 66.428
- type: map_at_10
value: 75.5
- type: map_at_100
value: 75.82600000000001
- type: map_at_1000
value: 75.837
- type: map_at_3
value: 73.74300000000001
- type: map_at_5
value: 74.87
- type: mrr_at_1
value: 68.754
- type: mrr_at_10
value: 76.145
- type: mrr_at_100
value: 76.432
- type: mrr_at_1000
value: 76.442
- type: mrr_at_3
value: 74.628
- type: mrr_at_5
value: 75.612
- type: ndcg_at_1
value: 68.754
- type: ndcg_at_10
value: 79.144
- type: ndcg_at_100
value: 80.60199999999999
- type: ndcg_at_1000
value: 80.886
- type: ndcg_at_3
value: 75.81599999999999
- type: ndcg_at_5
value: 77.729
- type: precision_at_1
value: 68.754
- type: precision_at_10
value: 9.544
- type: precision_at_100
value: 1.026
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 28.534
- type: precision_at_5
value: 18.138
- type: recall_at_1
value: 66.428
- type: recall_at_10
value: 89.716
- type: recall_at_100
value: 96.313
- type: recall_at_1000
value: 98.541
- type: recall_at_3
value: 80.923
- type: recall_at_5
value: 85.48
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 73.27841291190316
- type: f1
value: 70.65529957574735
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 76.30127774041695
- type: f1
value: 76.10358226518304
- task:
type: Retrieval
dataset:
type: C-MTEB/MedicalRetrieval
name: MTEB MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 56.3
- type: map_at_10
value: 62.193
- type: map_at_100
value: 62.722
- type: map_at_1000
value: 62.765
- type: map_at_3
value: 60.633
- type: map_at_5
value: 61.617999999999995
- type: mrr_at_1
value: 56.3
- type: mrr_at_10
value: 62.193
- type: mrr_at_100
value: 62.722
- type: mrr_at_1000
value: 62.765
- type: mrr_at_3
value: 60.633
- type: mrr_at_5
value: 61.617999999999995
- type: ndcg_at_1
value: 56.3
- type: ndcg_at_10
value: 65.176
- type: ndcg_at_100
value: 67.989
- type: ndcg_at_1000
value: 69.219
- type: ndcg_at_3
value: 62.014
- type: ndcg_at_5
value: 63.766
- type: precision_at_1
value: 56.3
- type: precision_at_10
value: 7.46
- type: precision_at_100
value: 0.8829999999999999
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 22
- type: precision_at_5
value: 14.04
- type: recall_at_1
value: 56.3
- type: recall_at_10
value: 74.6
- type: recall_at_100
value: 88.3
- type: recall_at_1000
value: 98.1
- type: recall_at_3
value: 66
- type: recall_at_5
value: 70.19999999999999
- task:
type: Classification
dataset:
type: C-MTEB/MultilingualSentiment-classification
name: MTEB MultilingualSentiment
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 76.44666666666666
- type: f1
value: 76.34548655475949
- task:
type: PairClassification
dataset:
type: C-MTEB/OCNLI
name: MTEB Ocnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 82.34975636166757
- type: cos_sim_ap
value: 85.44149338593267
- type: cos_sim_f1
value: 83.68654509610647
- type: cos_sim_precision
value: 78.46580406654344
- type: cos_sim_recall
value: 89.65153115100317
- type: dot_accuracy
value: 82.34975636166757
- type: dot_ap
value: 85.4415701376729
- type: dot_f1
value: 83.68654509610647
- type: dot_precision
value: 78.46580406654344
- type: dot_recall
value: 89.65153115100317
- type: euclidean_accuracy
value: 82.34975636166757
- type: euclidean_ap
value: 85.4415701376729
- type: euclidean_f1
value: 83.68654509610647
- type: euclidean_precision
value: 78.46580406654344
- type: euclidean_recall
value: 89.65153115100317
- type: manhattan_accuracy
value: 81.97076340010828
- type: manhattan_ap
value: 84.83614660756733
- type: manhattan_f1
value: 83.34167083541772
- type: manhattan_precision
value: 79.18250950570342
- type: manhattan_recall
value: 87.96198521647307
- type: max_accuracy
value: 82.34975636166757
- type: max_ap
value: 85.4415701376729
- type: max_f1
value: 83.68654509610647
- task:
type: Classification
dataset:
type: C-MTEB/OnlineShopping-classification
name: MTEB OnlineShopping
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 93.24
- type: ap
value: 91.3586656455605
- type: f1
value: 93.22999314249503
- task:
type: STS
dataset:
type: C-MTEB/PAWSX
name: MTEB PAWSX
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 39.05676042449009
- type: cos_sim_spearman
value: 44.996534098358545
- type: euclidean_pearson
value: 44.42418609172825
- type: euclidean_spearman
value: 44.995941361058996
- type: manhattan_pearson
value: 43.98118203238076
- type: manhattan_spearman
value: 44.51414152788784
- task:
type: STS
dataset:
type: C-MTEB/QBQTC
name: MTEB QBQTC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 36.694269474438045
- type: cos_sim_spearman
value: 38.686738967031616
- type: euclidean_pearson
value: 36.822540068407235
- type: euclidean_spearman
value: 38.68690745429757
- type: manhattan_pearson
value: 36.77180703308932
- type: manhattan_spearman
value: 38.45414914148094
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 65.81209017614124
- type: cos_sim_spearman
value: 66.5255285833172
- type: euclidean_pearson
value: 66.01848701752732
- type: euclidean_spearman
value: 66.5255285833172
- type: manhattan_pearson
value: 66.66433676370542
- type: manhattan_spearman
value: 67.07086311480214
- task:
type: STS
dataset:
type: C-MTEB/STSB
name: MTEB STSB
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 80.60785761283502
- type: cos_sim_spearman
value: 82.80278693241074
- type: euclidean_pearson
value: 82.47573315938638
- type: euclidean_spearman
value: 82.80290808593806
- type: manhattan_pearson
value: 82.49682028989669
- type: manhattan_spearman
value: 82.84565039346022
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 66.37886004738723
- type: mrr
value: 76.08501655006394
- task:
type: Retrieval
dataset:
type: C-MTEB/T2Retrieval
name: MTEB T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 28.102
- type: map_at_10
value: 78.071
- type: map_at_100
value: 81.71000000000001
- type: map_at_1000
value: 81.773
- type: map_at_3
value: 55.142
- type: map_at_5
value: 67.669
- type: mrr_at_1
value: 90.9
- type: mrr_at_10
value: 93.29499999999999
- type: mrr_at_100
value: 93.377
- type: mrr_at_1000
value: 93.379
- type: mrr_at_3
value: 92.901
- type: mrr_at_5
value: 93.152
- type: ndcg_at_1
value: 90.9
- type: ndcg_at_10
value: 85.564
- type: ndcg_at_100
value: 89.11200000000001
- type: ndcg_at_1000
value: 89.693
- type: ndcg_at_3
value: 87.024
- type: ndcg_at_5
value: 85.66
- type: precision_at_1
value: 90.9
- type: precision_at_10
value: 42.208
- type: precision_at_100
value: 5.027
- type: precision_at_1000
value: 0.517
- type: precision_at_3
value: 75.872
- type: precision_at_5
value: 63.566
- type: recall_at_1
value: 28.102
- type: recall_at_10
value: 84.44500000000001
- type: recall_at_100
value: 95.91300000000001
- type: recall_at_1000
value: 98.80799999999999
- type: recall_at_3
value: 56.772999999999996
- type: recall_at_5
value: 70.99499999999999
- task:
type: Classification
dataset:
type: C-MTEB/TNews-classification
name: MTEB TNews
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 53.10599999999999
- type: f1
value: 51.40415523558322
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringP2P
name: MTEB ThuNewsClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 69.6145576098232
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringS2S
name: MTEB ThuNewsClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 63.7129548775017
- task:
type: Retrieval
dataset:
type: C-MTEB/VideoRetrieval
name: MTEB VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 60.199999999999996
- type: map_at_10
value: 69.724
- type: map_at_100
value: 70.185
- type: map_at_1000
value: 70.196
- type: map_at_3
value: 67.95
- type: map_at_5
value: 69.155
- type: mrr_at_1
value: 60.199999999999996
- type: mrr_at_10
value: 69.724
- type: mrr_at_100
value: 70.185
- type: mrr_at_1000
value: 70.196
- type: mrr_at_3
value: 67.95
- type: mrr_at_5
value: 69.155
- type: ndcg_at_1
value: 60.199999999999996
- type: ndcg_at_10
value: 73.888
- type: ndcg_at_100
value: 76.02799999999999
- type: ndcg_at_1000
value: 76.344
- type: ndcg_at_3
value: 70.384
- type: ndcg_at_5
value: 72.541
- type: precision_at_1
value: 60.199999999999996
- type: precision_at_10
value: 8.67
- type: precision_at_100
value: 0.9650000000000001
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 25.8
- type: precision_at_5
value: 16.520000000000003
- type: recall_at_1
value: 60.199999999999996
- type: recall_at_10
value: 86.7
- type: recall_at_100
value: 96.5
- type: recall_at_1000
value: 99
- type: recall_at_3
value: 77.4
- type: recall_at_5
value: 82.6
- task:
type: Classification
dataset:
type: C-MTEB/waimai-classification
name: MTEB Waimai
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 88.08
- type: ap
value: 72.66435456846166
- type: f1
value: 86.55995793551286
license: mit
---
**新闻 | News**
**[2024-04-06]** 开源[puff](https://huggingface.co/infgrad/puff-base-v1)系列模型,**专门针对检索和语义匹配任务,更多的考虑泛化性和私有通用测试集效果,向量维度可变,中英双语**。
**[2024-02-27]** 开源stella-mrl-large-zh-v3.5-1792d模型,支持**向量可变维度**。
**[2024-02-17]** 开源stella v3系列、dialogue编码模型和相关训练数据。
**[2023-10-19]** 开源stella-base-en-v2 使用简单,**不需要任何前缀文本**。
**[2023-10-12]** 开源stella-base-zh-v2和stella-large-zh-v2, 效果更好且使用简单,**不需要任何前缀文本**。
**[2023-09-11]** 开源stella-base-zh和stella-large-zh
欢迎去[本人主页](https://huggingface.co/infgrad)查看最新模型,并提出您的宝贵意见!
# 1 开源清单
本次开源2个通用向量编码模型和一个针对dialogue进行编码的向量模型,同时开源全量160万对话重写数据集和20万的难负例的检索数据集。
**开源模型:**
| ModelName | ModelSize | MaxTokens | EmbeddingDimensions | Language | Scenario | C-MTEB Score |
|---------------------------------------------------------------------------------------------------------------|-----------|-----------|---------------------|----------|----------|--------------|
| [infgrad/stella-base-zh-v3-1792d](https://huggingface.co/infgrad/stella-base-zh-v3-1792d) | 0.4GB | 512 | 1792 | zh-CN | 通用文本 | 67.96 |
| [infgrad/stella-large-zh-v3-1792d](https://huggingface.co/infgrad/stella-large-zh-v3-1792d) | 1.3GB | 512 | 1792 | zh-CN | 通用文本 | 68.48 |
| [infgrad/stella-dialogue-large-zh-v3-1792d](https://huggingface.co/infgrad/stella-dialogue-large-zh-v3-1792d) | 1.3GB | 512 | 1792 | zh-CN | **对话文本** | 不适用 |
**开源数据:**
1. [全量对话重写数据集](https://huggingface.co/datasets/infgrad/dialogue_rewrite_llm) 约160万
2. [部分带有难负例的检索数据集](https://huggingface.co/datasets/infgrad/retrieval_data_llm) 约20万
上述数据集均使用LLM构造,欢迎各位贡献数据集。
# 2 使用方法
## 2.1 通用编码模型使用方法
直接SentenceTransformer加载即可:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("infgrad/stella-base-zh-v3-1792d")
# model = SentenceTransformer("infgrad/stella-large-zh-v3-1792d")
vectors = model.encode(["text1", "text2"])
```
## 2.2 dialogue编码模型使用方法
**使用场景:**
**在一段对话中,需要根据用户语句去检索相关文本,但是对话中的用户语句存在大量的指代和省略,导致直接使用通用编码模型效果不好,
可以使用本项目的专门的dialogue编码模型进行编码**
**使用要点:**
1. 对dialogue进行编码时,dialogue中的每个utterance需要是如下格式:`"{ROLE}: {TEXT}"`,然后使用`[SEP]` join一下
2. 整个对话都要送入模型进行编码,如果长度不够就删掉早期的对话,**编码后的向量本质是对话中最后一句话的重写版本的向量!!**
3. 对话用stella-dialogue-large-zh-v3-1792d编码,被检索文本使用stella-large-zh-v3-1792d进行编码,所以本场景是需要2个编码模型的
如果对使用方法还有疑惑,请到下面章节阅读该模型是如何训练的。
使用示例:
```python
from sentence_transformers import SentenceTransformer
dial_model = SentenceTransformer("infgrad/stella-dialogue-large-zh-v3-1792d")
general_model = SentenceTransformer("infgrad/stella-large-zh-v3-1792d")
# dialogue = ["张三: 吃饭吗", "李四: 等会去"]
dialogue = ["A: 最近去打篮球了吗", "B: 没有"]
corpus = ["B没打篮球是因为受伤了。", "B没有打乒乓球"]
last_utterance_vector = dial_model.encode(["[SEP]".join(dialogue)], normalize_embeddings=True)
corpus_vectors = general_model.encode(corpus, normalize_embeddings=True)
# 计算相似度
sims = (last_utterance_vector * corpus_vectors).sum(axis=1)
print(sims)
```
# 3 通用编码模型训练技巧分享
## hard negative
难负例挖掘也是个经典的trick了,几乎总能提升效果
## dropout-1d
dropout已经是深度学习的标配,我们可以稍微改造下使其更适合句向量的训练。
我们在训练时会尝试让每一个token-embedding都可以表征整个句子,而在推理时使用mean_pooling从而达到类似模型融合的效果。
具体操作是在mean_pooling时加入dropout_1d,torch代码如下:
```python
vector_dropout = nn.Dropout1d(0.3) # 算力有限,试了0.3和0.5 两个参数,其中0.3更优
last_hidden_state = bert_model(...)[0]
last_hidden = last_hidden_state.masked_fill(~attention_mask[..., None].bool(), 0.0)
last_hidden = vector_dropout(last_hidden)
vectors = last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
```
# 4 dialogue编码模型细节
## 4.1 为什么需要一个dialogue编码模型?
参见本人历史文章:https://www.zhihu.com/pin/1674913544847077376
## 4.2 训练数据
单条数据示例:
```json
{
"dialogue": [
"A: 最近去打篮球了吗",
"B: 没有"
],
"last_utterance_rewrite": "B: 我最近没有去打篮球"
}
```
## 4.3 训练Loss
```
loss = cosine_loss( dial_model.encode(dialogue), existing_model.encode(last_utterance_rewrite) )
```
dial_model就是要被训练的模型,本人是以stella-large-zh-v3-1792d作为base-model进行继续训练的
existing_model就是现有训练好的**通用编码模型**,本人使用的是stella-large-zh-v3-1792d
已开源dialogue-embedding的全量训练数据,理论上可以复现本模型效果。
Loss下降情况:
<div align="center">
<img src="dial_loss.png" alt="icon" width="2000px"/>
</div>
## 4.4 效果
目前还没有专门测试集,本人简单测试了下是有效果的,部分测试结果见文件`dial_retrieval_test.xlsx`。
# 5 后续TODO
1. 更多的dial-rewrite数据
2. 不同EmbeddingDimensions的编码模型
# 6 FAQ
Q: 为什么向量维度是1792?\
A: 最初考虑发布768、1024,768+768,1024+1024,1024+768维度,但是时间有限,先做了1792就只发布1792维度的模型。理论上维度越高效果越好。
Q: 如何复现CMTEB效果?\
A: SentenceTransformer加载后直接用官方评测脚本就行,注意对于Classification任务向量需要先normalize一下
Q: 复现的CMTEB效果和本文不一致?\
A: 聚类不一致正常,官方评测代码没有设定seed,其他不一致建议检查代码或联系本人。
Q: 如何选择向量模型?\
A: 没有免费的午餐,在自己测试集上试试,本人推荐bge、e5和stella.
Q: 长度为什么只有512,能否更长?\
A: 可以但没必要,长了效果普遍不好,这是当前训练方法和数据导致的,几乎无解,建议长文本还是走分块。
Q: 训练资源和算力?\
A: 亿级别的数据,单卡A100要一个月起步
|
marcel-gohsen/qpt2-medium-aql-mix
|
marcel-gohsen
| 2025-06-20T08:58:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T08:57:36Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Rishi1708/codegemma-7b-LoRA
|
Rishi1708
| 2025-06-20T08:57:21Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-20T08:57:21Z |
---
license: apache-2.0
---
|
baekTree/roberta-large-batch2-imdb
|
baekTree
| 2025-06-20T08:50:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-large",
"base_model:finetune:FacebookAI/roberta-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-20T08:48:39Z |
---
library_name: transformers
license: mit
base_model: FacebookAI/roberta-large
tags:
- generated_from_trainer
model-index:
- name: roberta-large-batch2-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-large-batch2-imdb
This model is a fine-tuned version of [FacebookAI/roberta-large](https://huggingface.co/FacebookAI/roberta-large) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 1
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
scb10x/typhoon2.1-gemma3-12b-mlx-4bit
|
scb10x
| 2025-06-20T08:47:48Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"base_model:scb10x/typhoon2.1-gemma3-12b",
"base_model:quantized:scb10x/typhoon2.1-gemma3-12b",
"license:gemma",
"4-bit",
"region:us"
] |
text-generation
| 2025-06-20T08:24:03Z |
---
license: gemma
pipeline_tag: text-generation
base_model: scb10x/typhoon2.1-gemma3-12b
library_name: mlx
tags:
- mlx
---
# scb10x/typhoon2.1-gemma3-12b-mlx-4bit
This model [scb10x/typhoon2.1-gemma3-12b-mlx-4bit](https://huggingface.co/scb10x/typhoon2.1-gemma3-12b-mlx-4bit) was
converted to MLX format from [scb10x/typhoon2.1-gemma3-12b](https://huggingface.co/scb10x/typhoon2.1-gemma3-12b)
using mlx-lm version **0.25.2**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("scb10x/typhoon2.1-gemma3-12b-mlx-4bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
JSlin/GRPO_Model
|
JSlin
| 2025-06-20T08:43:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-20T08:42:42Z |
---
base_model: unsloth/meta-llama-3.1-8b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** JSlin
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
visolex/visobert-hsd
|
visolex
| 2025-06-20T08:42:55Z | 0 | 0 | null |
[
"safetensors",
"xlm-roberta",
"hate-speech-detection",
"vietnamese",
"transformer",
"text-classification",
"vi",
"dataset:VN-HSD",
"base_model:uitnlp/visobert",
"base_model:finetune:uitnlp/visobert",
"license:apache-2.0",
"model-index",
"region:us"
] |
text-classification
| 2025-06-19T08:44:51Z |
---
language: vi
tags:
- hate-speech-detection
- vietnamese
- transformer
license: apache-2.0
datasets:
- VN-HSD
metrics:
- accuracy
- f1
model-index:
- name: visobert-hsd
results:
- task:
type: text-classification
name: Hate Speech Detection
dataset:
name: VN-HSD
type: custom
metrics:
- name: Accuracy
type: accuracy
value: <INSERT_ACCURACY>
- name: F1 Score
type: f1
value: <INSERT_F1_SCORE>
base_model:
- uitnlp/visobert # replace with actual ViSoBERT Hub name
pipeline_tag: text-classification
---
# ViSoBERT‑HSD: Hate Speech Detection for Vietnamese Text
Fine‑tuned from [`uitnlp/visobert`](https://huggingface.co/uitnlp/visobert) on the **VN‑HSD** unified Vietnamese hate‐speech dataset, combining ViHSD, ViCTSD, and ViHOS.
## Model Details
* **Base Model**: [`uitnlp/visobert`](https://huggingface.co/uitnlp/visobert)
* **Dataset**: VN‑HSD (ViSoLex‑HSD unified hate speech corpus)
* **Fine‑tuning**: HuggingFace Transformers
### Hyperparameters
* Batch size: `32`
* Learning rate: `3e-5`
* Epochs: `100`
* Max sequence length: `256`
## Results
* **Accuracy**: `<INSERT_ACCURACY>`
* **F1 Score**: `<INSERT_F1_SCORE>`
## Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("visolex/visobert-hsd")
model = AutoModelForSequenceClassification.from_pretrained("visolex/visobert-hsd")
text = "Hắn ta thật kinh tởm!"
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=256)
logits = model(**inputs).logits
pred = logits.argmax(dim=-1).item()
label_map = {0: "CLEAN", 1: "OFFENSIVE", 2: "HATE"}
print(f"Predicted label: {label_map[pred]}")
```
|
georgedy/distilbert-rotten-tomatoes
|
georgedy
| 2025-06-20T08:42:23Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-20T08:34:19Z |
---
library_name: transformers
license: apache-2.0
base_model: distilbert/distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-rotten-tomatoes
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-rotten-tomatoes
This model is a fine-tuned version of [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Manush123/my-Blood_sugar_model
|
Manush123
| 2025-06-20T08:40:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"biogpt",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-20T08:39:02Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.