
datasetId
large_stringlengths 6
118
| author
large_stringlengths 2
42
| last_modified
large_stringdate 2021-04-29 15:34:29
2025-09-30 12:15:29
| downloads
int64 0
3.97M
| likes
int64 0
7.74k
| tags
large listlengths 1
7.92k
| task_categories
large listlengths 0
48
| createdAt
large_stringdate 2022-03-02 23:29:22
2025-09-30 12:08:01
| trending_score
float64 0
64
| card
large_stringlengths 31
1M
|
|---|---|---|---|---|---|---|---|---|---|
MLCommons/peoples_speech_v1.0
|
MLCommons
|
2024-08-25T05:17:08Z
| 1,108
| 6
|
[
"task_categories:automatic-speech-recognition",
"annotations_creators:crowdsourced",
"annotations_creators:machine-generated",
"language_creators:crowdsourced",
"language_creators:machine-generated",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"license:cc-by-2.0",
"license:cc-by-2.5",
"license:cc-by-3.0",
"license:cc-by-4.0",
"license:cc-by-sa-3.0",
"license:cc-by-sa-4.0",
"arxiv:2111.09344",
"region:us"
] |
[
"automatic-speech-recognition"
] |
2022-03-30T15:49:51Z
| 0
|
---
annotations_creators:
- crowdsourced
- machine-generated
language_creators:
- crowdsourced
- machine-generated
language:
- en
license:
- cc-by-2.0
- cc-by-2.5
- cc-by-3.0
- cc-by-4.0
- cc-by-sa-3.0
- cc-by-sa-4.0
multilinguality:
- monolingual
pretty_name: People's Speech
size_categories:
- 1T<n
source_datasets:
- original
task_categories:
- automatic-speech-recognition
task_ids:
- speech-recognition
- robust-speech-recognition
- noisy-speech-recognition
---
# Dataset Card for People's Speech
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-instances)
- [Data Splits](#data-instances)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
## Dataset Description
- **Homepage:** https://mlcommons.org/en/peoples-speech/
- **Repository:** https://github.com/mlcommons/peoples-speech
- **Paper:** https://arxiv.org/abs/2111.09344
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [[email protected]](mailto:[email protected])
### Dataset Summary
The People's Speech Dataset is among the world's largest English speech recognition corpus today that is licensed for academic and commercial usage under CC-BY-SA and CC-BY 4.0. It includes 30,000+ hours of transcribed speech in English languages with a diverse set of speakers. This open dataset is large enough to train speech-to-text systems and crucially is available with a permissive license.
### Supported Tasks and Leaderboards
[Needs More Information]
### Languages
English
## Dataset Structure
### Data Instances
{
"id": "gov_DOT_uscourts_DOT_scotus_DOT_19-161/gov_DOT_uscourts_DOT_scotus_DOT_19-161_DOT_2020-03-02_DOT_mp3_00002.flac",
"audio": {
"path": "gov_DOT_uscourts_DOT_scotus_DOT_19-161/gov_DOT_uscourts_DOT_scotus_DOT_19-161_DOT_2020-03-02_DOT_mp3_00002.flac"
"array": array([-6.10351562e-05, ...]),
"sampling_rate": 16000
}
"duration_ms": 14490,
"text": "contends that the suspension clause requires a [...]"
}
### Data Fields
{
"id": datasets.Value("string"),
"audio": datasets.Audio(sampling_rate=16_000),
"duration_ms": datasets.Value("int32"),
"text": datasets.Value("string"),
}
### Data Splits
We provide the following configurations for the dataset: `cc-by-clean`, `cc-by-dirty`, `cc-by-sa-clean`, `cc-by-sa-dirty`, and `microset`. We don't provide splits for any of the configurations.
## Dataset Creation
### Curation Rationale
See our [paper](https://arxiv.org/abs/2111.09344).
### Source Data
#### Initial Data Collection and Normalization
Data was downloaded via the archive.org API. No data inference was done.
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
No manual annotation is done. We download only source audio with already existing transcripts.
#### Who are the annotators?
For the test and dev sets, we paid native American English speakers to do transcriptions. We do not know the identities of the transcriptionists for data in the training set. For the training set, we have noticed that some transcriptions are likely to be the output of automatic speech recognition systems.
### Personal and Sensitive Information
Several of our sources are legal and government proceedings, spoken histories, speeches, and so on. Given that these were intended as public documents and licensed as such, it is natural that the involved individuals are aware of this.
## Considerations for Using the Data
### Social Impact of Dataset
The dataset could be used for speech synthesis. However, this requires careful cleaning of the dataset, as background noise is not tolerable for speech synthesis.
The dataset could be used for keyword spotting tasks as well. In particular, this is good use case for the non-English audio in the dataset.
Our sincere hope is that the large breadth of sources our dataset incorporates reduces existing quality of service issues today, like speech recognition system’s poor understanding of non-native English accents. We cannot think of any unfair treatment that come from using this dataset at this time.
### Discussion of Biases
Our data is downloaded from archive.org. As such, the data is biased towards whatever users decide to upload there.
Almost all of our data is American accented English.
### Other Known Limitations
As of version 1.0, a portion of data in the training, test, and dev sets is poorly aligned. Specifically, some words appear in the transcript, but not the audio, or some words appear in the audio, but not the transcript. We are working on it.
## Additional Information
### Dataset Curators
[Needs More Information]
### Licensing Information
We provide CC-BY and CC-BY-SA subsets of the dataset.
### Citation Information
Please cite:
```
@article{DBLP:journals/corr/abs-2111-09344,
author = {Daniel Galvez and
Greg Diamos and
Juan Ciro and
Juan Felipe Cer{\'{o}}n and
Keith Achorn and
Anjali Gopi and
David Kanter and
Maximilian Lam and
Mark Mazumder and
Vijay Janapa Reddi},
title = {The People's Speech: {A} Large-Scale Diverse English Speech Recognition
Dataset for Commercial Usage},
journal = {CoRR},
volume = {abs/2111.09344},
year = {2021},
url = {https://arxiv.org/abs/2111.09344},
eprinttype = {arXiv},
eprint = {2111.09344},
timestamp = {Mon, 22 Nov 2021 16:44:07 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-09344.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
wangrongsheng/ag_news
|
wangrongsheng
|
2024-08-15T07:23:48Z
| 958
| 4
|
[
"task_categories:text-classification",
"task_ids:topic-classification",
"annotations_creators:found",
"language_creators:found",
"multilinguality:monolingual",
"source_datasets:original",
"language:en",
"license:unknown",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[
"text-classification"
] |
2024-08-15T07:23:21Z
| 1
|
---
annotations_creators:
- found
language_creators:
- found
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- topic-classification
paperswithcode_id: ag-news
pretty_name: AG’s News Corpus
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': World
'1': Sports
'2': Business
'3': Sci/Tech
splits:
- name: train
num_bytes: 29817303
num_examples: 120000
- name: test
num_bytes: 1879474
num_examples: 7600
download_size: 19820267
dataset_size: 31696777
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
train-eval-index:
- config: default
task: text-classification
task_id: multi_class_classification
splits:
train_split: train
eval_split: test
col_mapping:
text: text
label: target
metrics:
- type: accuracy
name: Accuracy
- type: f1
name: F1 macro
args:
average: macro
- type: f1
name: F1 micro
args:
average: micro
- type: f1
name: F1 weighted
args:
average: weighted
- type: precision
name: Precision macro
args:
average: macro
- type: precision
name: Precision micro
args:
average: micro
- type: precision
name: Precision weighted
args:
average: weighted
- type: recall
name: Recall macro
args:
average: macro
- type: recall
name: Recall micro
args:
average: micro
- type: recall
name: Recall weighted
args:
average: weighted
---
# Dataset Card for "ag_news"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html](http://groups.di.unipi.it/~gulli/AG_corpus_of_news_articles.html)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 31.33 MB
- **Size of the generated dataset:** 31.70 MB
- **Total amount of disk used:** 63.02 MB
### Dataset Summary
AG is a collection of more than 1 million news articles. News articles have been
gathered from more than 2000 news sources by ComeToMyHead in more than 1 year of
activity. ComeToMyHead is an academic news search engine which has been running
since July, 2004. The dataset is provided by the academic comunity for research
purposes in data mining (clustering, classification, etc), information retrieval
(ranking, search, etc), xml, data compression, data streaming, and any other
non-commercial activity. For more information, please refer to the link
http://www.di.unipi.it/~gulli/AG_corpus_of_news_articles.html .
The AG's news topic classification dataset is constructed by Xiang Zhang
([email protected]) from the dataset above. It is used as a text
classification benchmark in the following paper: Xiang Zhang, Junbo Zhao, Yann
LeCun. Character-level Convolutional Networks for Text Classification. Advances
in Neural Information Processing Systems 28 (NIPS 2015).
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### default
- **Size of downloaded dataset files:** 31.33 MB
- **Size of the generated dataset:** 31.70 MB
- **Total amount of disk used:** 63.02 MB
An example of 'train' looks as follows.
```
{
"label": 3,
"text": "New iPad released Just like every other September, this one is no different. Apple is planning to release a bigger, heavier, fatter iPad that..."
}
```
### Data Fields
The data fields are the same among all splits.
#### default
- `text`: a `string` feature.
- `label`: a classification label, with possible values including `World` (0), `Sports` (1), `Business` (2), `Sci/Tech` (3).
### Data Splits
| name |train |test|
|-------|-----:|---:|
|default|120000|7600|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@inproceedings{Zhang2015CharacterlevelCN,
title={Character-level Convolutional Networks for Text Classification},
author={Xiang Zhang and Junbo Jake Zhao and Yann LeCun},
booktitle={NIPS},
year={2015}
}
```
### Contributions
Thanks to [@jxmorris12](https://github.com/jxmorris12), [@thomwolf](https://github.com/thomwolf), [@lhoestq](https://github.com/lhoestq), [@lewtun](https://github.com/lewtun) for adding this dataset.
|
OmarIDK/MNLP_M3_rag_dataset
|
OmarIDK
|
2025-06-10T20:14:23Z
| 0
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-06-10T20:14:21Z
| 0
|
---
dataset_info:
features:
- name: doc
dtype: string
- name: question
dtype: string
- name: doc_negatif
dtype: string
splits:
- name: train
num_bytes: 3182463
num_examples: 944
download_size: 1575815
dataset_size: 3182463
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
AI4Protein/VenusX_Res_BindI_MF70
|
AI4Protein
|
2025-05-14T08:05:35Z
| 0
| 0
|
[
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-14T08:05:27Z
| 0
|
---
license: apache-2.0
---
|
AIM-Harvard/google_gemma_2_2b_boolq
|
AIM-Harvard
|
2025-01-09T20:54:53Z
| 18
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-12-30T12:25:27Z
| 0
|
---
dataset_info:
features:
- name: input_prompt
dtype: string
- name: correct_answer
dtype: string
- name: choice_logits
dtype: string
- name: best_choice
dtype: string
- name: model_score
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 2357619
num_examples: 3270
download_size: 1352980
dataset_size: 2357619
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
AI4Protein/VenusX_Res_BindB_MP50
|
AI4Protein
|
2025-05-14T13:26:53Z
| 0
| 0
|
[
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-14T13:25:43Z
| 0
|
---
license: apache-2.0
---
|
dsrtrain/new_numia_prompt_dpo4
|
dsrtrain
|
2025-02-23T12:17:05Z
| 20
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-02-23T12:17:04Z
| 0
|
---
dataset_info:
features:
- name: data_source
dtype: string
- name: prompt
list:
- name: content
dtype: string
- name: role
dtype: string
- name: ability
dtype: string
- name: reward_model
struct:
- name: ground_truth
dtype: string
- name: style
dtype: string
- name: extra_info
struct:
- name: index
dtype: int64
- name: split
dtype: string
- name: problem
dtype: string
splits:
- name: train
num_bytes: 19538504
num_examples: 20000
download_size: 5467023
dataset_size: 19538504
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
andrewsiah/opinions_qa_text
|
andrewsiah
|
2024-10-23T18:41:54Z
| 14
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-10-23T18:38:40Z
| 0
|
---
dataset_info:
features:
- name: ECIMPh_W54
dtype: string
- name: MADEUPRESd_W45
dtype: string
- name: PQ7_F2C_W42
dtype: string
- name: HAPPEN2d_W41
dtype: string
- name: SOCIETY_TRANS_W92
dtype: string
- name: RQ4_F1Aa_W42
dtype: string
- name: HARASS5_W41
dtype: string
- name: CONFe_W42
dtype: string
- name: PQ1_F2C_W42
dtype: string
- name: RQ4_F1Be_W42
dtype: string
- name: FIN_SIT_W54
dtype: string
- name: REPRSNTREP_W92
dtype: string
- name: LOCALPROBL_F1_W32
dtype: string
- name: POLICY1_W42
dtype: string
- name: MESUM2_FE_W29
dtype: string
- name: GAP21Q40_W82
dtype: string
- name: HIRING3A_W27
dtype: string
- name: GAP21Q7_a_W82
dtype: string
- name: TALK_CPS_W29
dtype: string
- name: GUNRESPKIDSD_W26
dtype: string
- name: GAP21Q6_W82
dtype: string
- name: GAP21Q15_d_W82
dtype: string
- name: WORRYRET_W29
dtype: string
- name: LOCALPROBK_W32
dtype: string
- name: ECIMPf_W54
dtype: string
- name: ECON5_d_W54
dtype: string
- name: RQ6_F1B_W42
dtype: string
- name: SUCCESSIMPB_W32
dtype: string
- name: INFOCHALe_W45
dtype: string
- name: GAP21Q33_k_W82
dtype: string
- name: MARRDUR_W50
dtype: string
- name: FAMSURV23g_W50
dtype: string
- name: GUNACTIVITYC_W26
dtype: string
- name: MAR2_W50
dtype: string
- name: SIB_W50
dtype: string
- name: RQ8_F1A_W42
dtype: string
- name: INEQ5_m_W54
dtype: string
- name: ROBJOB7_W27
dtype: string
- name: HARASS5_W32
dtype: string
- name: RQ5_F1A_W42
dtype: string
- name: RQ4_F1Bc_W42
dtype: string
- name: LIFELOC_W32
dtype: string
- name: PQ4_F2Be_W42
dtype: string
- name: RACESURV5l_W43
dtype: string
- name: HIRING6D_W27
dtype: string
- name: FAMSURV10e_W50
dtype: string
- name: INEQ9_W54
dtype: string
- name: TRAITPOLMF1D_W36
dtype: string
- name: CONTROLGOV_W49
dtype: string
- name: MADEUPSMFOL2_W45
dtype: string
- name: INEQ8_i_W54
dtype: string
- name: FAMSURV8_W50
dtype: string
- name: RACESURV5g_W43
dtype: string
- name: GOVRESP_b_W54
dtype: string
- name: GROWUPVIOL_W26
dtype: string
- name: FAMSURV33a_W50
dtype: string
- name: LOCALPROBI_W32
dtype: string
- name: INEQ8_b_W54
dtype: string
- name: SCM5j_W42
dtype: string
- name: LWPT_W50
dtype: string
- name: LOCALPROBA_W32
dtype: string
- name: FAMSURV1_W50
dtype: string
- name: FAMSURV2Mb_W50
dtype: string
- name: GOVPRIOe_W41
dtype: string
- name: ABORTION_W32
dtype: string
- name: EVOONE_W34
dtype: string
- name: RQ2_F1B_W42
dtype: string
- name: INSTN_LGECRP_W92
dtype: string
- name: SMLIKESf_W45
dtype: string
- name: PQ6_F2A_W42
dtype: string
- name: GOVRESP_a_W54
dtype: string
- name: TRACKGOV1a_W49
dtype: string
- name: FEM2AF2_W29
dtype: string
- name: GIRLSF2C_W29
dtype: string
- name: RESTRICTWHO_W45
dtype: string
- name: ROBJOB3A_W27
dtype: string
- name: CONFa_W42
dtype: string
- name: WHYNOTPOLF1J_W36
dtype: string
- name: MOREWMN4F2_W36
dtype: string
- name: HARASS1NOWRKF2c_W41
dtype: string
- name: RQ3_F1Cd_W42
dtype: string
- name: HELPHURTC_W29
dtype: string
- name: WHYNOTBIZF2G_W36
dtype: string
- name: CONCERNGRPd_W49
dtype: string
- name: EVERSHOT_W26
dtype: string
- name: HIRING7A_W27
dtype: string
- name: ECON3_g_W54
dtype: string
- name: USEXCEPT_W92
dtype: string
- name: GAP21Q43_b_W82
dtype: string
- name: FEDSHAREC_W32
dtype: string
- name: FAMSURV27a_W50
dtype: string
- name: PQ4_F2Cb_W42
dtype: string
- name: GAP21Q4_c_W82
dtype: string
- name: CAREGIV3A_W27
dtype: string
- name: SOLVPROBeF2_W41
dtype: string
- name: HAPPEN2e_W41
dtype: string
- name: PQ4_F2Cc_W42
dtype: string
- name: ROBJOB8B_W27
dtype: string
- name: GAP21Q33_d_W82
dtype: string
- name: HARASS1F1b_W41
dtype: string
- name: WORRY2b_W54
dtype: string
- name: FAMSURV22a_W50
dtype: string
- name: MED4C_W34
dtype: string
- name: GUNRESPKIDSH_W26
dtype: string
- name: HAPPEN2c_W41
dtype: string
- name: GROWUPGUN7_W26
dtype: string
- name: MED6D_W34
dtype: string
- name: SUCCESSIMPD_W32
dtype: string
- name: HIRING6C_W27
dtype: string
- name: SOCIETY_JBCLL_W92
dtype: string
- name: PUBLICDATA_W49
dtype: string
- name: HAPPYLIFE_W36
dtype: string
- name: GAP21Q5_a_W82
dtype: string
- name: FAMSURV5a_W50
dtype: string
- name: GUNRESPKIDSC_W26
dtype: string
- name: INEQ5_j_W54
dtype: string
- name: GOVPRIOkF2_W41
dtype: string
- name: INEQ8_f_W54
dtype: string
- name: MOREWMN2F2_W36
dtype: string
- name: SOCMEDIAUSEb_W49
dtype: string
- name: WHYNOTPOLF1F_W36
dtype: string
- name: FINANCEb_W54
dtype: string
- name: FAMSURV34B_W50
dtype: string
- name: RQ3_F1Ca_W42
dtype: string
- name: GOVPRIOd_W41
dtype: string
- name: HIGHEDWRNGC_W36
dtype: string
- name: INFOCREATEa_W45
dtype: string
- name: RQ6_F1A_W42
dtype: string
- name: WATCHDOG_1_W45
dtype: string
- name: CARRYGUN_W26
dtype: string
- name: MADEUPSHAREWHY_W45
dtype: string
- name: FUTRCLASSc_W41
dtype: string
- name: WORLDDANGER_W26
dtype: string
- name: SATLIFEb_W50
dtype: string
- name: UNDERSTANDCO_W49
dtype: string
- name: MED2F_W34
dtype: string
- name: PQ4_F2Ad_W42
dtype: string
- name: RACESURV19f_W43
dtype: string
- name: HIGHED_W36
dtype: string
- name: FTRWORRYe_W41
dtype: string
- name: GOODJOBS_W29
dtype: string
- name: RACESURV38_W43
dtype: string
- name: MADEUPTOPICc_W45
dtype: string
- name: GAP21Q4_b_W82
dtype: string
- name: CONCERNGRPc_W49
dtype: string
- name: GAP21Q13_a_W82
dtype: string
- name: SOLVPROBi_W41
dtype: string
- name: RQ2_F1C_W42
dtype: string
- name: ECON3_e_W54
dtype: string
- name: GOVSIZE3_W92
dtype: string
- name: FAMSURV19_W50
dtype: string
- name: ADMISSIONh_W43
dtype: string
- name: MED6E_W34
dtype: string
- name: BETTERPOL2F1D_W36
dtype: string
- name: MED3_W34
dtype: string
- name: RQ3_F1Aa_W42
dtype: string
- name: GAP21Q43_a_W82
dtype: string
- name: FAMSURV22f_W50
dtype: string
- name: SOCMEDIAUSEd_W49
dtype: string
- name: GUNRESPNOKIDSB_W26
dtype: string
- name: RACESURV53c_W43
dtype: string
- name: WHADVANT_W92
dtype: string
- name: MADEUPRESa_W45
dtype: string
- name: FAMSURV21_W50
dtype: string
- name: GOVPRIORITYd_W54
dtype: string
- name: ECON3_d_W54
dtype: string
- name: SATLIFEc_W50
dtype: string
- name: FAMSURV27d_W50
dtype: string
- name: RACESURV1a_W43
dtype: string
- name: INEQ5_g_W54
dtype: string
- name: MESUM2_FC_W29
dtype: string
- name: CARS8_W27
dtype: string
- name: SOLVPROBg_W41
dtype: string
- name: FAMSURV26c_W50
dtype: string
- name: PROFILE3_W49
dtype: string
- name: HAPPENf_W41
dtype: string
- name: MESUM2_FB_W29
dtype: string
- name: INEQ4_a_W54
dtype: string
- name: HAPPENhF1_W41
dtype: string
- name: S7_W29
dtype: string
- name: ELECT_IMPT3_PRVFR_W92
dtype: string
- name: GUNCONTRIBF_W26
dtype: string
- name: GOVPRIORITYf_W54
dtype: string
- name: PAR1_W50
dtype: string
- name: RACESURV5d_W43
dtype: string
- name: HAPPENj_W41
dtype: string
- name: BENEFITSa_W54
dtype: string
- name: DIFF1E_W29
dtype: string
- name: MOVESUBURB_W32
dtype: string
- name: BIOTECHB_W34
dtype: string
- name: CARS3A_W27
dtype: string
- name: BIOTECHC_W34
dtype: string
- name: IMMCOMM_W32
dtype: string
- name: GUNLOADED2_W26
dtype: string
- name: HIRING4_W27
dtype: string
- name: FAMSURV34A_W50
dtype: string
- name: INFOCONFUSEb_W45
dtype: string
- name: GAP21Q43_e_W82
dtype: string
- name: BIOTECHA_W34
dtype: string
- name: ADMISSIONc_W43
dtype: string
- name: RACESURV53g_W43
dtype: string
- name: ROBIMPACTa_W41
dtype: string
- name: GAP21Q34_d_W82
dtype: string
- name: ROBWRK_W41
dtype: string
- name: FAMSURV22d_W50
dtype: string
- name: EXECCHF2_W36
dtype: string
- name: DATAUSEe_W49
dtype: string
- name: INSTN_BNKS_W92
dtype: string
- name: CARS9A_W27
dtype: string
- name: FTRWORRYf_W41
dtype: string
- name: GAP21Q4_f_W82
dtype: string
- name: EVOBIOB_W34
dtype: string
- name: GROWUPGUN2A_W26
dtype: string
- name: E5MOD_W50
dtype: string
- name: PRIVACYREG_W49
dtype: string
- name: CONCERNGRPb_W49
dtype: string
- name: INFOCONFUSEc_W45
dtype: string
- name: REASONGUNC_W26
dtype: string
- name: CARS7B_W27
dtype: string
- name: SMLIKESe_W45
dtype: string
- name: PQ2_F2A_W42
dtype: string
- name: GUNACTIVITYB_W26
dtype: string
- name: PREDICTD_W27
dtype: string
- name: INFOKNOWd_W45
dtype: string
- name: PQ6_F2C_W42
dtype: string
- name: FAMSURV32c_W50
dtype: string
- name: GAP21Q33_t_W82
dtype: string
- name: TRAITPOLWF1F_W36
dtype: string
- name: FUD33A_W34
dtype: string
- name: ESSENBIZF2C_W36
dtype: string
- name: SHOOTFREQ_W26
dtype: string
- name: PAST_W42
dtype: string
- name: RACESURV5f_W43
dtype: string
- name: Q8F1_W42
dtype: string
- name: SCM4b_W42
dtype: string
- name: ECON5_k_W54
dtype: string
- name: RQ3_F1Ac_W42
dtype: string
- name: SECUR1_W49
dtype: string
- name: MASC2_W29
dtype: string
- name: SOLVPROBdF1_W41
dtype: string
- name: FAMSURV10a_W50
dtype: string
- name: SOCTRUST2_W32
dtype: string
- name: CNTRYFAIR_W92
dtype: string
- name: ECIMPb_W54
dtype: string
- name: WORRYE_W26
dtype: string
- name: WILLMOVE_W32
dtype: string
- name: HELPHURTF_W29
dtype: string
- name: BOYSF1C_W29
dtype: string
- name: WANTMOVE_W32
dtype: string
- name: POP2_W42
dtype: string
- name: COMMIMPG_W32
dtype: string
- name: COMMIMPH_W32
dtype: string
- name: RQ7_F1A_W42
dtype: string
- name: TRAITPOLMF1E_W36
dtype: string
- name: FCFAIR_W45
dtype: string
- name: BETTERPOL1F1B_W36
dtype: string
- name: WHYNOTBIZF2K_W36
dtype: string
- name: FAMSURV25_W50
dtype: string
- name: RACESURV18c_W43
dtype: string
- name: WHYNOTPOLF1L_W36
dtype: string
- name: RACESURV34c_W43
dtype: string
- name: LOCALPROBH_W32
dtype: string
- name: ADKIDS_W50
dtype: string
- name: FAMSURV17_W50
dtype: string
- name: HIGHEDWRNGS_W36
dtype: string
- name: PQ4_F2Cd_W42
dtype: string
- name: CARS10E_W27
dtype: string
- name: INEQ5_i_W54
dtype: string
- name: INSTN_TECHCMP_W92
dtype: string
- name: PQ3_F2Ca_W42
dtype: string
- name: RQ3_F1Bd_W42
dtype: string
- name: MED6C_W34
dtype: string
- name: ESSENBIZF2I_W36
dtype: string
- name: WHADVANT_W32
dtype: string
- name: INEQ1_W54
dtype: string
- name: SMLIKESd_W45
dtype: string
- name: RACESURV16_W43
dtype: string
- name: FAMSURV38b_W50
dtype: string
- name: GAP21Q17_W82
dtype: string
- name: DNA2b_W50
dtype: string
- name: HOOD_NHISC_W29
dtype: string
- name: LOCALELECT_W29
dtype: string
- name: SATLIFEB_W32
dtype: string
- name: MESUM1_FC_W29
dtype: string
- name: INEQ4_b_W54
dtype: string
- name: PQ1_F2B_W42
dtype: string
- name: FACE4b_W49
dtype: string
- name: GAP21Q21_e_W82
dtype: string
- name: GAP21Q33_q_W82
dtype: string
- name: INSTN_MSCENT_W92
dtype: string
- name: JOBBENEFITS_W41
dtype: string
- name: EVOPERS3_W34
dtype: string
- name: DIFF1D_W29
dtype: string
- name: HARASS1NOWRKF2a_W41
dtype: string
- name: PP5b_W49
dtype: string
- name: SOCIETY_RHIST_W92
dtype: string
- name: EAT3H_W34
dtype: string
- name: HARASS2F1_W32
dtype: string
- name: EVOPERS3A_W34
dtype: string
- name: TRAITBIZMF2G_W36
dtype: string
- name: MADEUPIMPe_W45
dtype: string
- name: INEQ7_W54
dtype: string
- name: VOICE1_W27
dtype: string
- name: IMPREASONGUN_W26
dtype: string
- name: COMMIMPA_W32
dtype: string
- name: RQ4_F1Cc_W42
dtype: string
- name: ROBJOB2_W27
dtype: string
- name: HIGHEDWRNGD_W36
dtype: string
- name: FAMSURV32e_W50
dtype: string
- name: FUD24_W34
dtype: string
- name: BETTERBIZ2F2F_W36
dtype: string
- name: ECON1B_W54
dtype: string
- name: FUTR_DIV_W41
dtype: string
- name: SATLIFEE_W32
dtype: string
- name: RACESURV5b_W43
dtype: string
- name: ADMISSIONe_W43
dtype: string
- name: CAREGIV7_W27
dtype: string
- name: MADEUPSMFOL1_W45
dtype: string
- name: RACESURV14_W43
dtype: string
- name: GAP21Q19_c_W82
dtype: string
- name: PQ3_F2Cc_W42
dtype: string
- name: FAMSURV5b_W50
dtype: string
- name: ECONFAIR_W92
dtype: string
- name: FAVORS_CPS_W29
dtype: string
- name: MASC1F1_W29
dtype: string
- name: INEQ8_a_W54
dtype: string
- name: PROG_RRETRO_W92
dtype: string
- name: RQ4_F1Bb_W42
dtype: string
- name: FAMSURV30d_W50
dtype: string
- name: WHYNOTBIZF2F_W36
dtype: string
- name: BETTERBIZ1F2C_W36
dtype: string
- name: MOVERURAL_W32
dtype: string
- name: CARS10A_W27
dtype: string
- name: RACESURV24_W43
dtype: string
- name: GAP21Q21_d_W82
dtype: string
- name: FAMSURV33c_W50
dtype: string
- name: MADEUPLEVELa_W45
dtype: string
- name: SOCIETY_SSM_W92
dtype: string
- name: HAPPEN2g_W41
dtype: string
- name: WORK6_W27
dtype: string
- name: EVEROWN_W26
dtype: string
- name: DATAUSEc_W49
dtype: string
- name: INFOCHALc_W45
dtype: string
- name: CARS4_W27
dtype: string
- name: NATDEBT_W41
dtype: string
- name: AMNTWMNB2F1_W36
dtype: string
- name: MEDIALOYAL3_W45
dtype: string
- name: SOURCESKEPe_W45
dtype: string
- name: GUNTYPEOWNC_W26
dtype: string
- name: RACESURV36_W43
dtype: string
- name: HIRING7B_W27
dtype: string
- name: NEIGHINTERA_W32
dtype: string
- name: SCI3A_W34
dtype: string
- name: RACESURV47e_W43
dtype: string
- name: PROBURBAN_W32
dtype: string
- name: ELDFINANCEF2_W41
dtype: string
- name: FUD32_W34
dtype: string
- name: DATAUSEb_W49
dtype: string
- name: BLOODPR_W29
dtype: string
- name: NEWSPROBa_W45
dtype: string
- name: HARASS1D_W32
dtype: string
- name: GAP21Q21_a_W82
dtype: string
- name: WHYNOTPOLF1E_W36
dtype: string
- name: RACESURV28g_W43
dtype: string
- name: HIRING2_W27
dtype: string
- name: POLCHF1_W36
dtype: string
- name: DNA5_W50
dtype: string
- name: PWMAN2_W49
dtype: string
- name: GAP21Q33_l_W82
dtype: string
- name: INFOCHALd_W45
dtype: string
- name: MOTHER_W50
dtype: string
- name: EAT2_W34
dtype: string
- name: GUNLOCKED1_W26
dtype: string
- name: GAP21Q33_g_W82
dtype: string
- name: WORK7_W27
dtype: string
- name: CONFc_W42
dtype: string
- name: GAP21Q26_c_W82
dtype: string
- name: INEQ5_a_W54
dtype: string
- name: PP5d_W49
dtype: string
- name: FAMSURV38a_W50
dtype: string
- name: HARASS1F1d_W41
dtype: string
- name: SNGLPYER_W92
dtype: string
- name: FUD37B_W34
dtype: string
- name: COMMIMPC_W32
dtype: string
- name: RQ3_F1Cc_W42
dtype: string
- name: INEQ5_k_W54
dtype: string
- name: FAMSURV36c_W50
dtype: string
- name: HELPHURTB_W29
dtype: string
- name: ACCCHECK_W45
dtype: string
- name: WHYNOTBIZF2N_W36
dtype: string
- name: GAP21Q3_W82
dtype: string
- name: GOVPRIOoF2_W41
dtype: string
- name: GOVRESP_e_W54
dtype: string
- name: SHARE1_W49
dtype: string
- name: INFOCHALa_W45
dtype: string
- name: POLINTOL2_b_W92
dtype: string
- name: ELECT_CONF3_PRVFR_W92
dtype: string
- name: DEFENDGUN_W26
dtype: string
- name: GUNFRIEND_W26
dtype: string
- name: PEACESTR_W92
dtype: string
- name: SCI4_W34
dtype: string
- name: GOODEVIL_W92
dtype: string
- name: MADEUPTOPICb_W45
dtype: string
- name: COMMYRS_W32
dtype: string
- name: COMTYPE2_W32
dtype: string
- name: ESSENPOLF1C_W36
dtype: string
- name: CANDEXP_W92
dtype: string
- name: FEELD_W32
dtype: string
- name: COMMIMPE_W32
dtype: string
- name: MESUM2_FA_W29
dtype: string
- name: RQ5_F1C_W42
dtype: string
- name: ROBJOB4B_W27
dtype: string
- name: RACESURV37_W43
dtype: string
- name: FAMSURV32b_W50
dtype: string
- name: GAP21Q19_b_W82
dtype: string
- name: EVOBIOA_W34
dtype: string
- name: PARTICIPATEB_W29
dtype: string
- name: GUNRESPKIDSF_W26
dtype: string
- name: WHYNOTBIZF2H_W36
dtype: string
- name: BETTERPOL1F1A_W36
dtype: string
- name: DEBTa_W54
dtype: string
- name: INFOCONFUSEe_W45
dtype: string
- name: RACESURV47c_W43
dtype: string
- name: STYLE1_W36
dtype: string
- name: FAMSURV7_W50
dtype: string
- name: CARS9C_W27
dtype: string
- name: RQ1_F1B_W42
dtype: string
- name: GOVPRIOa_W41
dtype: string
- name: VTRGHTPRIV1_W92
dtype: string
- name: FAMSURV28_W50
dtype: string
- name: PP6c_W49
dtype: string
- name: FAMSURV2Wc_W50
dtype: string
- name: NEIGHINTERB_W32
dtype: string
- name: BETTERPOL1F1I_W36
dtype: string
- name: NEWSPROBc_W45
dtype: string
- name: GAP21Q11_W82
dtype: string
- name: NEWSPREFV2_W45
dtype: string
- name: BETTERPOL1F1H_W36
dtype: string
- name: RACESURV53e_W43
dtype: string
- name: LEGALIMMIGAMT_W92
dtype: string
- name: FAMSURV6_W50
dtype: string
- name: INFOWHYd_W45
dtype: string
- name: GAP21Q33_b_W82
dtype: string
- name: CONFf_W42
dtype: string
- name: GOVRESP_f_W54
dtype: string
- name: BETTERBIZ1F2E_W36
dtype: string
- name: FAMSURV3_W50
dtype: string
- name: BETTERBIZ1F2G_W36
dtype: string
- name: GUNACTIVITYD_W26
dtype: string
- name: FACE1_W49
dtype: string
- name: GAP21Q29_W82
dtype: string
- name: EAT5C_W34
dtype: string
- name: GOVPRIOc_W41
dtype: string
- name: FACE3a_W49
dtype: string
- name: HIGHEDWRNGA_W36
dtype: string
- name: AVGFAM_W41
dtype: string
- name: NOWSMK_NHIS_W29
dtype: string
- name: TRAITBIZWF2F_W36
dtype: string
- name: RQ3_F1Bc_W42
dtype: string
- name: GAP21Q20_W82
dtype: string
- name: GROWUPGUN2C_W26
dtype: string
- name: SCM5f_W42
dtype: string
- name: ECON5_b_W54
dtype: string
- name: MADEUPTOPICf_W45
dtype: string
- name: RQ4_F1Cb_W42
dtype: string
- name: MED5_W34
dtype: string
- name: REMARR_W50
dtype: string
- name: MAN1A_W29
dtype: string
- name: ESSENPOLF1E_W36
dtype: string
- name: GAP21Q41_W82
dtype: string
- name: GAP21Q30_W82
dtype: string
- name: PP4_W49
dtype: string
- name: GUNRESPNOKIDSE_W26
dtype: string
- name: RACESURV29c_W43
dtype: string
- name: BETTERPOL2F1C_W36
dtype: string
- name: DNA3b_W50
dtype: string
- name: ECIMPe_W54
dtype: string
- name: GAP21Q25_W82
dtype: string
- name: CAREGIV4_W27
dtype: string
- name: GAP21Q15_e_W82
dtype: string
- name: INEQ4_d_W54
dtype: string
- name: MED2G_W34
dtype: string
- name: GAP21Q33_f_W82
dtype: string
- name: TRAITPOLWF1D_W36
dtype: string
- name: HIRING1_W27
dtype: string
- name: BENEFITCO_W49
dtype: string
- name: SOCTRUST4_W32
dtype: string
- name: MADEUPIMPc_W45
dtype: string
- name: ETHNCMAJ_W32
dtype: string
- name: GIRLSF2B_W29
dtype: string
- name: CITYSIZE_W32
dtype: string
- name: SC1_W42
dtype: string
- name: RQ4_F1Ce_W42
dtype: string
- name: ECON5_h_W54
dtype: string
- name: GAP21Q21_c_W82
dtype: string
- name: CONCERNGRPf_W49
dtype: string
- name: DIGWDOG_3_W45
dtype: string
- name: LOCALPROBC_W32
dtype: string
- name: HARASS1NOWRKF2d_W41
dtype: string
- name: HARASS1B_W32
dtype: string
- name: MED6A_W34
dtype: string
- name: SATLIFEA_W32
dtype: string
- name: BENEFITGOV_W49
dtype: string
- name: HOMEASSIST3_W49
dtype: string
- name: S13_W29
dtype: string
- name: RQ4_F1Ac_W42
dtype: string
- name: ECIMPj_W54
dtype: string
- name: RACESURV10_W43
dtype: string
- name: RACESURV5i_W43
dtype: string
- name: REASONGUND_W26
dtype: string
- name: RACESURV47d_W43
dtype: string
- name: HARASS3F2_W32
dtype: string
- name: RACESURV40_W43
dtype: string
- name: HAPPENb_W41
dtype: string
- name: WHYNOTPOLF1C_W36
dtype: string
- name: EVOTWO_W34
dtype: string
- name: GAP21Q7_e_W82
dtype: string
- name: WORK4A_W27
dtype: string
- name: GAP21Q42_W82
dtype: string
- name: RQ1_F1C_W42
dtype: string
- name: GAP21Q19_e_W82
dtype: string
- name: NEWS_PLATFORMh_W45
dtype: string
- name: TRACKCO1a_W49
dtype: string
- name: FAMSURV22c_W50
dtype: string
- name: DEBTd_W54
dtype: string
- name: HARASS1C_W32
dtype: string
- name: GAP21Q38_b_W82
dtype: string
- name: CONFd_F2_W42
dtype: string
- name: LOCALPROBF_W32
dtype: string
- name: FAMSURV9b_W50
dtype: string
- name: BETTERPOL1F1D_W36
dtype: string
- name: MED2A_W34
dtype: string
- name: RACESURV34b_W43
dtype: string
- name: CONFb_W42
dtype: string
- name: GUNRESPKIDSB_W26
dtype: string
- name: FAMSURV2Mc_W50
dtype: string
- name: REASONGUNA_W26
dtype: string
- name: GUNIDENTITY_W26
dtype: string
- name: ROBJOB4A_W27
dtype: string
- name: EAT3K_W34
dtype: string
- name: SOURCESKEPb_W45
dtype: string
- name: FERTIL1_W36
dtype: string
- name: RACESURV1d_W43
dtype: string
- name: FAMSURV26b_W50
dtype: string
- name: INEQ3_W54
dtype: string
- name: HAVEKIDS1_W50
dtype: string
- name: ESSENBIZF2G_W36
dtype: string
- name: PQ4_F2Ca_W42
dtype: string
- name: NEIGHSAMEC_W32
dtype: string
- name: NEWS_PLATFORMg_W45
dtype: string
- name: MADEUPSHARE1_W45
dtype: string
- name: BETTERBIZ2F2E_W36
dtype: string
- name: RQ5_F1B_W42
dtype: string
- name: RACESURV29a_W43
dtype: string
- name: RACESURV28d_W43
dtype: string
- name: BENEFITSb_W54
dtype: string
- name: FAMSURV10b_W50
dtype: string
- name: FUTRCLASSb_W41
dtype: string
- name: GAP21Q31_W82
dtype: string
- name: CARS7A_W27
dtype: string
- name: ESSENPOLF1H_W36
dtype: string
- name: CONTROLGRPd_W49
dtype: string
- name: HOOD_NHISA_W29
dtype: string
- name: RACESURV41_W43
dtype: string
- name: MAN1C_W29
dtype: string
- name: PQ3_F2Bd_W42
dtype: string
- name: TRAITBIZWF2B_W36
dtype: string
- name: INEQ5_l_W54
dtype: string
- name: INTRMAR_W41
dtype: string
- name: MADEUPDIS_W45
dtype: string
- name: EAT5A_W34
dtype: string
- name: EAT5B_W34
dtype: string
- name: CAREGIV6D_W27
dtype: string
- name: FAMSURV30e_W50
dtype: string
- name: ESSENBIZF2F_W36
dtype: string
- name: ELDFINANCEF1_W41
dtype: string
- name: HOMEIOT_W49
dtype: string
- name: POOREASY_W53
dtype: string
- name: MESUM1_FE_W29
dtype: string
- name: AMNTWMNBF1_W36
dtype: string
- name: WRKTRN1F1_W41
dtype: string
- name: GAP21Q23_W82
dtype: string
- name: CAREGIV6B_W27
dtype: string
- name: PQ4_F2Ab_W42
dtype: string
- name: BIO15_W34
dtype: string
- name: FAMSURV36a_W50
dtype: string
- name: SOLVPROBf_W41
dtype: string
- name: GLBLZE_W92
dtype: string
- name: HARASS1F1a_W41
dtype: string
- name: INEQ10_W54
dtype: string
- name: GAP21Q38_c_W82
dtype: string
- name: GAP21Q34_e_W82
dtype: string
- name: COMMIMPF_W32
dtype: string
- name: PQ7_F2B_W42
dtype: string
- name: RACATTN_W43
dtype: string
- name: RACESURV29b_W43
dtype: string
- name: Q8F2_W42
dtype: string
- name: INFOCONFUSEd_W45
dtype: string
- name: PQ4_F2Aa_W42
dtype: string
- name: DRONE4D_W27
dtype: string
- name: FUTURE_W42
dtype: string
- name: IL_IMM_PRI_W92
dtype: string
- name: PQ3_F2Ad_W42
dtype: string
- name: MADEUPTOPICd_W45
dtype: string
- name: GAP21Q10_W82
dtype: string
- name: ABORTIONRESTR_W32
dtype: string
- name: FAMSURV32a_W50
dtype: string
- name: ECONFAIR_W53
dtype: string
- name: RTDa_W49
dtype: string
- name: IMMIMPACT_W32
dtype: string
- name: GAP21Q33_n_W82
dtype: string
- name: RACESURV4_W43
dtype: string
- name: ELECTFTGSNSINT_W49
dtype: string
- name: GAP21Q34_c_W82
dtype: string
- name: ECON5_c_W54
dtype: string
- name: RQ3_F1Cb_W42
dtype: string
- name: BOYSF1A_W29
dtype: string
- name: ROBWRK2_W41
dtype: string
- name: WORK5A_W27
dtype: string
- name: ROBJOB5D_W27
dtype: string
- name: RACESURV18a_W43
dtype: string
- name: RACESURV1c_W43
dtype: string
- name: GAP21Q18_W82
dtype: string
- name: GAP21Q15_a_W82
dtype: string
- name: BETTERPOL2F1F_W36
dtype: string
- name: GAP21Q13_b_W82
dtype: string
- name: HOMEASSIST5b_W49
dtype: string
- name: INSTN_LBRUN_W92
dtype: string
- name: FEM2BF2_W29
dtype: string
- name: ORIENTATIONMOD_W50
dtype: string
- name: RACESURV5h_W43
dtype: string
- name: ECON4_a_W54
dtype: string
- name: DRONE4A_W27
dtype: string
- name: CONTROLGRPe_W49
dtype: string
- name: RQ8_F1C_W42
dtype: string
- name: FUTRCLASSa_W41
dtype: string
- name: FAMSURV9c_W50
dtype: string
- name: GUNCONTRIBD_W26
dtype: string
- name: GAP21Q33_c_W82
dtype: string
- name: MAN1D_W29
dtype: string
- name: NEIGHKEYS_W32
dtype: string
- name: WHYNOTPOLF1K_W36
dtype: string
- name: FTRWORRYc_W41
dtype: string
- name: DIFF1B_W29
dtype: string
- name: SCI3B_W34
dtype: string
- name: GUNACTIVITYE_W26
dtype: string
- name: DB1b_W49
dtype: string
- name: MESUM2_FF_W29
dtype: string
- name: ADMISSIONd_W43
dtype: string
- name: GAP21Q43_g_W82
dtype: string
- name: CARS2_W27
dtype: string
- name: GAP21Q5_b_W82
dtype: string
- name: HELPHURTE_W29
dtype: string
- name: INSTN_CHR_W92
dtype: string
- name: WHYNOTBIZF2M_W36
dtype: string
- name: RACESURV11_W43
dtype: string
- name: SSCUT_W41
dtype: string
- name: FAMSURV29_W50
dtype: string
- name: RACESURV21_W43
dtype: string
- name: RACESURV5a_W43
dtype: string
- name: MADEUPLEVELb_W45
dtype: string
- name: RACESURV47a_W43
dtype: string
- name: DNA2a_W50
dtype: string
- name: WORRYB_W26
dtype: string
- name: CONTROLGRPf_W49
dtype: string
- name: ADMISSIONf_W43
dtype: string
- name: CONTROLGRPb_W49
dtype: string
- name: WRKTRN1F2_W41
dtype: string
- name: MESUM1_FA_W29
dtype: string
- name: ECON1_W54
dtype: string
- name: INFOCREATEd_W45
dtype: string
- name: GAP21Q34_b_W82
dtype: string
- name: RQ4_F1Ab_W42
dtype: string
- name: CAREGIV6A_W27
dtype: string
- name: HELPHURTA_W29
dtype: string
- name: PAR2_W50
dtype: string
- name: FAMSURV18B_W50
dtype: string
- name: INEQ4_e_W54
dtype: string
- name: LWPSP_W50
dtype: string
- name: FAMSURV9e_W50
dtype: string
- name: FAMSURV18A_W50
dtype: string
- name: SATLIFED_W32
dtype: string
- name: RACESURV28a_W43
dtype: string
- name: FIN_SITCOMM_W54
dtype: string
- name: PQ3_F2Aa_W42
dtype: string
- name: INFOCREATEe_W45
dtype: string
- name: PP5c_W49
dtype: string
- name: FAMSURV2Md_W50
dtype: string
- name: RQ4_F1Bd_W42
dtype: string
- name: GOVSIZE1_W92
dtype: string
- name: FAMSURV11W_W50
dtype: string
- name: ECON3_i_W54
dtype: string
- name: FAMSURV38c_W50
dtype: string
- name: DRONE4B_W27
dtype: string
- name: FAMSURV2Wa_W50
dtype: string
- name: GAP21Q24_W82
dtype: string
- name: GUNSAFETYKIDS_W26
dtype: string
- name: BETTERBIZ1F2F_W36
dtype: string
- name: INEQ5_b_W54
dtype: string
- name: RACESURV19b_W43
dtype: string
- name: RACESURV20_W43
dtype: string
- name: GOVPRIORITYe_W54
dtype: string
- name: MED4A_W34
dtype: string
- name: LEAD_W45
dtype: string
- name: RACESURV5k_W43
dtype: string
- name: ECON5_g_W54
dtype: string
- name: RACESURV47f_W43
dtype: string
- name: FAMSURV33b_W50
dtype: string
- name: WHYNOTBIZF2L_W36
dtype: string
- name: BETTERBIZ2F2C_W36
dtype: string
- name: ADMISSIONg_W43
dtype: string
- name: FACE4a_W49
dtype: string
- name: GAP21Q35_W82
dtype: string
- name: WORK4C_W27
dtype: string
- name: TRANSGEND3_W29
dtype: string
- name: LOCALPROBB_W32
dtype: string
- name: GOVPRIOiF1_W41
dtype: string
- name: VOICE5A_W27
dtype: string
- name: TRACKGOV1b_W49
dtype: string
- name: PQ5_F2C_W42
dtype: string
- name: GROWUPGUN6_W26
dtype: string
- name: MED2E_W34
dtype: string
- name: GOVSIZE2_W92
dtype: string
- name: GOVPRIOhF1_W41
dtype: string
- name: PRIVACYNEWS1_W49
dtype: string
- name: COMMIMPD_W32
dtype: string
- name: RACESURV6_W43
dtype: string
- name: RACESURV19e_W43
dtype: string
- name: GUNACCESS_W26
dtype: string
- name: SCM5h_W42
dtype: string
- name: GAP21Q28_W82
dtype: string
- name: BETTERPOL1F1F_W36
dtype: string
- name: TRAITPOLWF1B_W36
dtype: string
- name: RQ3_F1Ba_W42
dtype: string
- name: LOCALPROBJ_W32
dtype: string
- name: NEWSPROBe_W45
dtype: string
- name: ROBJOB4F_W27
dtype: string
- name: CONFg_W42
dtype: string
- name: WORRY2d_W54
dtype: string
- name: GUNSOCIETY_W26
dtype: string
- name: G1_W34
dtype: string
- name: RACESURV5j_W43
dtype: string
- name: PARTICIPATEA_W29
dtype: string
- name: PQ6_F2B_W42
dtype: string
- name: GAP21Q26_b_W82
dtype: string
- name: TRAITBIZMF2A_W36
dtype: string
- name: NEWSPROBb_W45
dtype: string
- name: FEELC_W32
dtype: string
- name: MADEUPIMPa_W45
dtype: string
- name: GOVPRIORITYc_W54
dtype: string
- name: RTBFa_W49
dtype: string
- name: PQ1_F2A_W42
dtype: string
- name: OPTIMIST_W41
dtype: string
- name: RACESURV51_W43
dtype: string
- name: TRAITPOLWF1G_W36
dtype: string
- name: GOVPRIOgF1_W41
dtype: string
- name: PQ2_F2B_W42
dtype: string
- name: RACESURV47b_W43
dtype: string
- name: MESUM1_FF_W29
dtype: string
- name: FEDSHAREB_W32
dtype: string
- name: NEIGHSAMEB_W32
dtype: string
- name: SUPERPWR_W92
dtype: string
- name: RACESURV15a_W43
dtype: string
- name: EQUALBIZF2_W36
dtype: string
- name: PREDICTA_W27
dtype: string
- name: SOURCESKEPd_W45
dtype: string
- name: GUNACTIVITYA_W26
dtype: string
- name: NOCARRYGUN_W26
dtype: string
- name: WHYNOTPOLF1B_W36
dtype: string
- name: FAMSURV5c_W50
dtype: string
- name: RQ4_F1Ad_W42
dtype: string
- name: RACESURV53a_W43
dtype: string
- name: ALLIES_W92
dtype: string
- name: MADEUPRESc_W45
dtype: string
- name: NEWSPROBd_W45
dtype: string
- name: GOVPRIOnF2_W41
dtype: string
- name: FAMSURV23e_W50
dtype: string
- name: PQ4_F2Ae_W42
dtype: string
- name: SMSHARE_W45
dtype: string
- name: SOURCESKEPa_W45
dtype: string
- name: TRAITBIZWF2E_W36
dtype: string
- name: IDIMPORT_W43
dtype: string
- name: RACESURV28b_W43
dtype: string
- name: ECON4_d_W54
dtype: string
- name: HARASS4_W41
dtype: string
- name: FTRWORRYb_W41
dtype: string
- name: WHYNOTPOLF1I_W36
dtype: string
- name: FACE3b_W49
dtype: string
- name: MOREWMN3F2_W36
dtype: string
- name: INFOCHALb_W45
dtype: string
- name: WHYNOTBIZF2A_W36
dtype: string
- name: USMILSIZ_W92
dtype: string
- name: GOVTHC_W92
dtype: string
- name: BIOTECHD_W34
dtype: string
- name: HAPPENd_W41
dtype: string
- name: SCI1_W34
dtype: string
- name: GODMORALIMP_W92
dtype: string
- name: DIFF1A_W29
dtype: string
- name: IMPROVE3_W36
dtype: string
- name: HARASS1A_W32
dtype: string
- name: MED4B_W34
dtype: string
- name: FAMSURV23b_W50
dtype: string
- name: HARASS4_W32
dtype: string
- name: RACESURV27_W43
dtype: string
- name: FUD37A_W34
dtype: string
- name: COMMIMPB_W32
dtype: string
- name: REASONGUNB_W26
dtype: string
- name: PREDICTC_W27
dtype: string
- name: BETTERBIZ1F2K_W36
dtype: string
- name: GAP21Q12_W82
dtype: string
- name: ONLINESOURCE_W45
dtype: string
- name: DRONE1_W27
dtype: string
- name: TRAITPOLMF1C_W36
dtype: string
- name: GAP21Q33_h_W82
dtype: string
- name: SATLIFEa_W50
dtype: string
- name: RACESURV53b_W43
dtype: string
- name: GUNRESPNOKIDSA_W26
dtype: string
- name: INEQ8_j_W54
dtype: string
- name: WORRY2a_W54
dtype: string
- name: GROWUPGUN2B_W26
dtype: string
- name: ABORTIONALLOW_W32
dtype: string
- name: ROMRELDUR_W50
dtype: string
- name: GAP21Q32_W82
dtype: string
- name: EVOTHREE_W34
dtype: string
- name: FACE2b_W49
dtype: string
- name: ECON3_c_W54
dtype: string
- name: POLINTOL2_a_W92
dtype: string
- name: VOICE3_W27
dtype: string
- name: RACESURV50_W43
dtype: string
- name: INFOKNOWe_W45
dtype: string
- name: FAMSURV16_W50
dtype: string
- name: SOCTRUST5_W32
dtype: string
- name: BETTERPOL1F1C_W36
dtype: string
- name: INEQ8_c_W54
dtype: string
- name: RACESURV1b_W43
dtype: string
- name: WORK2_W27
dtype: string
- name: TRAITPOLWF1E_W36
dtype: string
- name: PP6b_W49
dtype: string
- name: ECON3_a_W54
dtype: string
- name: HIGHEDWRNGB_W36
dtype: string
- name: TRAITBIZMF2F_W36
dtype: string
- name: BETTERBIZ2F2A_W36
dtype: string
- name: GOVRESP_g_W54
dtype: string
- name: POPPROB_W41
dtype: string
- name: DNATEST_W50
dtype: string
- name: EAT3G_W34
dtype: string
- name: ENVC_W41
dtype: string
- name: ROBJOB8A_W27
dtype: string
- name: HOMEASSIST4_W49
dtype: string
- name: CONCERNCO_W49
dtype: string
- name: BETTERPOL2F1E_W36
dtype: string
- name: FAMSURV30a_W50
dtype: string
- name: FP_AUTH_W92
dtype: string
- name: HOOD_NHISB_W29
dtype: string
- name: FUD33B_W34
dtype: string
- name: GOVPRIORITYa_W54
dtype: string
- name: MADEUPIMPd_W45
dtype: string
- name: FIN_SITFUT_W54
dtype: string
- name: RACESURV52MOD_W92
dtype: string
- name: HAPPEN2h_W41
dtype: string
- name: RACESURV5c_W43
dtype: string
- name: TRAITPOLWF1C_W36
dtype: string
- name: RTBFd_W49
dtype: string
- name: GUNCOMMUNITY_W26
dtype: string
- name: GOVREGV2_W49
dtype: string
- name: ECONFAIR2_W32
dtype: string
- name: RQ4_F1Ae_W42
dtype: string
- name: ROBJOB9_W27
dtype: string
- name: DRONE2_W27
dtype: string
- name: WORRYD_W26
dtype: string
- name: DRONE4C_W27
dtype: string
- name: GUN1_W26
dtype: string
- name: PP6a_W49
dtype: string
- name: IMMCULT2_W32
dtype: string
- name: FAMSURV2We_W50
dtype: string
- name: GOVPRIOmF2_W41
dtype: string
- name: MADEUPRESe_W45
dtype: string
- name: CAREGIV6E_W27
dtype: string
- name: BETTERBIZ2F2D_W36
dtype: string
- name: HIRING3B_W27
dtype: string
- name: EAT1_W34
dtype: string
- name: GOVPRIOb_W41
dtype: string
- name: FAMSURV20_W50
dtype: string
- name: INEQ8_h_W54
dtype: string
- name: WORK3F_W27
dtype: string
- name: SMLIKESc_W45
dtype: string
- name: TRAITSE_W29
dtype: string
- name: RELIG_GOV_W92
dtype: string
- name: UNDERSTANDGOV_W49
dtype: string
- name: INC_W32
dtype: string
- name: FAMSURV30b_W50
dtype: string
- name: INFORESTRICTc_W45
dtype: string
- name: BOYSF1D_W29
dtype: string
- name: GUNRESPKIDSA_W26
dtype: string
- name: CAREREL_W27
dtype: string
- name: ECON4_f_W54
dtype: string
- name: GAP21Q34_f_W82
dtype: string
- name: EAT6_W34
dtype: string
- name: BETTERBIZ2F2B_W36
dtype: string
- name: EAT3E_W34
dtype: string
- name: GAP21Q47_W82
dtype: string
- name: WORK3C_W27
dtype: string
- name: INFOOWNc_W45
dtype: string
- name: LOCALPROBE_W32
dtype: string
- name: BETTERPOL2F1B_W36
dtype: string
- name: FAMSURV39_W50
dtype: string
- name: GUNCONTRIBA_W26
dtype: string
- name: RTDc_W49
dtype: string
- name: INEQ5_d_W54
dtype: string
- name: HELPHURTG_W29
dtype: string
- name: PQ4_F2Bd_W42
dtype: string
- name: RACESURV22_W43
dtype: string
- name: MADEUPRESb_W45
dtype: string
- name: MARRFAM_W92
dtype: string
- name: AUTOWKPLC_W41
dtype: string
- name: FACE4c_W49
dtype: string
- name: CAREGIV6F_W27
dtype: string
- name: Q6F1_W42
dtype: string
- name: HAPPENg_W41
dtype: string
- name: RACESURV28f_W43
dtype: string
- name: ECON5_e_W54
dtype: string
- name: PQ3_F2Cb_W42
dtype: string
- name: TRAITSD_W29
dtype: string
- name: INEQ5_h_W54
dtype: string
- name: GAP21Q33_a_W82
dtype: string
- name: GUNKILLF2_W26
dtype: string
- name: FUD37C_W34
dtype: string
- name: PAR2CHILD_W92
dtype: string
- name: INEQ8_d_W54
dtype: string
- name: PWMAN_W49
dtype: string
- name: ROBJOB1_W27
dtype: string
- name: RQ2_F1A_W42
dtype: string
- name: RTBFb_W49
dtype: string
- name: MESUM2_FD_W29
dtype: string
- name: TRAITBIZMF2E_W36
dtype: string
- name: TRAITBIZMF2C_W36
dtype: string
- name: GUNLOCKED2_W26
dtype: string
- name: WORRYBILL_W29
dtype: string
- name: SUCCESSIMPC_W32
dtype: string
- name: MED2C_W34
dtype: string
- name: RTDb_W49
dtype: string
- name: POSNEGCO_W49
dtype: string
- name: WORK3E_W27
dtype: string
- name: HOMEASSIST5a_W49
dtype: string
- name: CONTROLGRPc_W49
dtype: string
- name: RACESURV34e_W43
dtype: string
- name: PP3_W49
dtype: string
- name: MARGUN_W26
dtype: string
- name: FAMSURV27b_W50
dtype: string
- name: SCI2B_W34
dtype: string
- name: EARN_W36
dtype: string
- name: ETHNCMAJMOD_W41
dtype: string
- name: RACESURV25_W43
dtype: string
- name: GAP21Q9_W82
dtype: string
- name: FAMSURV32d_W50
dtype: string
- name: ECON5_a_W54
dtype: string
- name: PQ4_F2Ac_W42
dtype: string
- name: TRANSGEND2_W29
dtype: string
- name: RQ7_F1B_W42
dtype: string
- name: GIRLSF2A_W29
dtype: string
- name: GAP21Q33_o_W82
dtype: string
- name: NEIGHINTERC_W32
dtype: string
- name: COMPROMISEVAL_W92
dtype: string
- name: PQ8_F2B_W42
dtype: string
- name: COLSPEECH_W36
dtype: string
- name: FAMSURV44_W50
dtype: string
- name: RACESURV18d_W43
dtype: string
- name: ELITEUNDMOD_W92
dtype: string
- name: PQ3_F2Ab_W42
dtype: string
- name: TRAITPOLWF1A_W36
dtype: string
- name: PP5e_W49
dtype: string
- name: FAMSURV12_W50
dtype: string
- name: RACESURV7_W43
dtype: string
- name: GOVWASTE_W92
dtype: string
- name: CARS3B_W27
dtype: string
- name: MADEUPSMCLICK_W45
dtype: string
- name: Q7F1_W42
dtype: string
- name: GAP21Q19_d_W82
dtype: string
- name: ECON4_i_W54
dtype: string
- name: DNA4_W50
dtype: string
- name: DRONE4E_W27
dtype: string
- name: INFORESTRICTd_W45
dtype: string
- name: FAMSURV26a_W50
dtype: string
- name: MARRYPREF1_W50
dtype: string
- name: WORRY2c_W54
dtype: string
- name: IMPROVE2_W36
dtype: string
- name: GAP21Q8_W82
dtype: string
- name: RACESURV52_W43
dtype: string
- name: DNATEST_W49
dtype: string
- name: FAMSURV33d_W50
dtype: string
- name: SMARTAPP_W49
dtype: string
- name: FAMSURV22b_W50
dtype: string
- name: SOLVPROBb_W41
dtype: string
- name: INFOKNOWa_W45
dtype: string
- name: AGEMAJ_W41
dtype: string
- name: WORRYF_W26
dtype: string
- name: RACESURV49_W43
dtype: string
- name: BETTERBIZ1F2D_W36
dtype: string
- name: HOMEASSIST1_W49
dtype: string
- name: TRAITPOLMF1F_W36
dtype: string
- name: VALUERURAL_W32
dtype: string
- name: GAP21Q4_d_W82
dtype: string
- name: WHYNOTBIZF2J_W36
dtype: string
- name: VALUESUBURB_W32
dtype: string
- name: GAP21Q7_d_W82
dtype: string
- name: ROBJOB3B_W27
dtype: string
- name: GAP21Q43_h_W82
dtype: string
- name: GOVREGV1_W49
dtype: string
- name: WORRY2e_W54
dtype: string
- name: RACESURV15b_W43
dtype: string
- name: FAMSURV23c_W50
dtype: string
- name: SEENFEM_W29
dtype: string
- name: HIRING6B_W27
dtype: string
- name: GAP21Q7_c_W82
dtype: string
- name: SOLVPROBc_W41
dtype: string
- name: FAMSURV35b_W50
dtype: string
- name: ANONYMOUS1GOV_W49
dtype: string
- name: CONCERNGRPe_W49
dtype: string
- name: FAMSURV2Me_W50
dtype: string
- name: INEQ11_W54
dtype: string
- name: SPOUSESEX_W29
dtype: string
- name: GROWUPNEAR_W32
dtype: string
- name: FAMSURV35c_W50
dtype: string
- name: CONTROLCO_W49
dtype: string
- name: GOVPRIORITYb_W54
dtype: string
- name: EAT3I_W34
dtype: string
- name: FAMSURV23a_W50
dtype: string
- name: INFORESTRICTe_W45
dtype: string
- name: GAP21Q38_a_W82
dtype: string
- name: ECON5_f_W54
dtype: string
- name: MESUM1_FB_W29
dtype: string
- name: SMSHARER_W45
dtype: string
- name: WORK4B_W27
dtype: string
- name: FATHER_W50
dtype: string
- name: POLICY3MOD_W92
dtype: string
- name: BIGHOUSES_W92
dtype: string
- name: CARS10B_W27
dtype: string
- name: WORRYG_W26
dtype: string
- name: WORRYA_W26
dtype: string
- name: PQ8_F2C_W42
dtype: string
- name: FAMSURV11M_W50
dtype: string
- name: STYLE2_W36
dtype: string
- name: INFOCREATEb_W45
dtype: string
- name: EQUALPOLF2_W36
dtype: string
- name: BENEFITSc_W54
dtype: string
- name: ROBJOB8D_W27
dtype: string
- name: ROBJOB4C_W27
dtype: string
- name: GOVPROTCT_W92
dtype: string
- name: GUNCONTRIBE_W26
dtype: string
- name: RACESURV28e_W43
dtype: string
- name: SOLVPROBa_W41
dtype: string
- name: MED7_W34
dtype: string
- name: ECON3_b_W54
dtype: string
- name: SOCIETY_GUNS_W92
dtype: string
- name: GUNSAFE2_W26
dtype: string
- name: RTBFc_W49
dtype: string
- name: HARASS1F1c_W41
dtype: string
- name: DEBTc_W54
dtype: string
- name: EAT5D_W34
dtype: string
- name: GAP21Q1_W82
dtype: string
- name: LOYALTY_W49
dtype: string
- name: OPENIDEN_W92
dtype: string
- name: WMNPRZ1_W36
dtype: string
- name: RACESURV48_W43
dtype: string
- name: TRAITPOLMF1A_W36
dtype: string
- name: PROG_RNEED2b_W92
dtype: string
- name: GAP21Q22_W82
dtype: string
- name: GOPDIRCT_W29
dtype: string
- name: BETTERBIZ1F2I_W36
dtype: string
- name: INEQ2_W54
dtype: string
- name: ROBJOB6_W27
dtype: string
- name: WHYNOTPOLF1G_W36
dtype: string
- name: PQ3_F2Cd_W42
dtype: string
- name: INEQ5_e_W54
dtype: string
- name: SUBURBNEAR_W32
dtype: string
- name: FAMSURV2Wb_W50
dtype: string
- name: DATAUSEf_W49
dtype: string
- name: MAN1B_W29
dtype: string
- name: FAMSURV35a_W50
dtype: string
- name: ECON4_g_W54
dtype: string
- name: SOCMEDIAUSEa_W49
dtype: string
- name: BETTERBIZ1F2J_W36
dtype: string
- name: RACESURV17_W43
dtype: string
- name: FACE4d_W49
dtype: string
- name: ELECT_CONF3_PRVSUP_W92
dtype: string
- name: FAMSURV40_W50
dtype: string
- name: ROBIMPACTb_W41
dtype: string
- name: FEELA_W32
dtype: string
- name: SCM5e_W42
dtype: string
- name: RQ4_F1Ca_W42
dtype: string
- name: DIFFPARTY_W92
dtype: string
- name: GAP21Q26_d_W82
dtype: string
- name: CRIMEVICTIM_W26
dtype: string
- name: GAP21Q4_a_W82
dtype: string
- name: BETTERBIZ1F2L_W36
dtype: string
- name: DB1c_W49
dtype: string
- name: FACE3c_W49
dtype: string
- name: HARASS3NOWRKF2_W41
dtype: string
- name: NEIGHSAMEA_W32
dtype: string
- name: SCM5d_W42
dtype: string
- name: UNIMMIGCOMM_W92
dtype: string
- name: DB1a_W49
dtype: string
- name: GUNRESPNOKIDSD_W26
dtype: string
- name: LOCALPROBG_W32
dtype: string
- name: GUNTHREAT_W26
dtype: string
- name: ROBJOB4D_W27
dtype: string
- name: TRANSGEND1_W29
dtype: string
- name: RACESURV34a_W43
dtype: string
- name: PREDICTB_W27
dtype: string
- name: INFOWHYa_W45
dtype: string
- name: INFOOWNb_W45
dtype: string
- name: PQ4_F2Ba_W42
dtype: string
- name: DISAVOID_W45
dtype: string
- name: NEIGHKIDS_W32
dtype: string
- name: GUNASSOCIATIONA_W26
dtype: string
- name: INFOKNOWc_W45
dtype: string
- name: RACESURV45_W43
dtype: string
- name: RACESURV9_W43
dtype: string
- name: MADEUPSOLVE_W45
dtype: string
- name: GUNKILLF1_W26
dtype: string
- name: INEQ4_c_W54
dtype: string
- name: RACESURV18b_W43
dtype: string
- name: FUD22_W34
dtype: string
- name: GOVAID_W92
dtype: string
- name: CAREGIV3B_W27
dtype: string
- name: MED2B_W34
dtype: string
- name: TRAITSC_W29
dtype: string
- name: TRAITSF_W29
dtype: string
- name: FREECOLL_W92
dtype: string
- name: POLICY2_W42
dtype: string
- name: GOVRESP_c_W54
dtype: string
- name: PQ4_F2Bc_W42
dtype: string
- name: Q7F2_W42
dtype: string
- name: GAP21Q13_c_W82
dtype: string
- name: BOYSF1B_W29
dtype: string
- name: PQ3_F2Bc_W42
dtype: string
- name: INCFUTURE_W32
dtype: string
- name: BILLION_W92
dtype: string
- name: ECON5_i_W54
dtype: string
- name: WHYNOTPOLF1A_W36
dtype: string
- name: GOVRESP_h_W54
dtype: string
- name: ENG_W50
dtype: string
- name: GAP21Q33_s_W82
dtype: string
- name: ROMRELSER_W50
dtype: string
- name: SCM3_W42
dtype: string
- name: ROBJOB5C_W27
dtype: string
- name: GOVT_ROLE_W32
dtype: string
- name: SOURCESKEPc_W45
dtype: string
- name: WATCHDOG_3_W45
dtype: string
- name: PERSDISCR_W29
dtype: string
- name: HIRING6A_W27
dtype: string
- name: FAMSURV30f_W50
dtype: string
- name: WHYNOTBIZF2O_W36
dtype: string
- name: GAP21Q36_W82
dtype: string
- name: CANQUALPOL_W92
dtype: string
- name: GROWUPGUN4_W26
dtype: string
- name: RACESURV44_W43
dtype: string
- name: VOICE5C_W27
dtype: string
- name: PP1_W49
dtype: string
- name: FTRWORRYa_W41
dtype: string
- name: Q9F1_W42
dtype: string
- name: GUN_W26
dtype: string
- name: SCI5_W34
dtype: string
- name: LIFEFIFTY_W92
dtype: string
- name: SOCIETY_RELG_W92
dtype: string
- name: AUTOLKLY_W41
dtype: string
- name: ECON3_f_W54
dtype: string
- name: GAP21Q37_W82
dtype: string
- name: CONFd_F1_W42
dtype: string
- name: DEBTb_W54
dtype: string
- name: FEELB_W32
dtype: string
- name: PPLRESP_W92
dtype: string
- name: PQ5_F2B_W42
dtype: string
- name: ECIMPd_W54
dtype: string
- name: WHYNOTPOLF1H_W36
dtype: string
- name: FAMSURV26d_W50
dtype: string
- name: LOCALPROBD_W32
dtype: string
- name: WORK3B_W27
dtype: string
- name: ESSENBIZF2B_W36
dtype: string
- name: ECON5_j_W54
dtype: string
- name: LOCALPROBM_F2_W32
dtype: string
- name: PQ8_F2A_W42
dtype: string
- name: SATLIFEd_W50
dtype: string
- name: S12_W29
dtype: string
- name: TRAITBIZWF2C_W36
dtype: string
- name: RACESURV8_W43
dtype: string
- name: INFORESTRICTa_W45
dtype: string
- name: SSMONEY_W41
dtype: string
- name: MARRFAM2_W32
dtype: string
- name: RACESURV13_W43
dtype: string
- name: MOREWMN1F2_W36
dtype: string
- name: SCI2C_W34
dtype: string
- name: VALUEURBAN_W32
dtype: string
- name: RACESURV34d_W43
dtype: string
- name: FAMSURV43_W50
dtype: string
- name: RACESURV2_W43
dtype: string
- name: FAMSURV37_W50
dtype: string
- name: PQ5_F2A_W42
dtype: string
- name: PQ3_F2Ac_W42
dtype: string
- name: AMNTWMNPF1_W36
dtype: string
- name: FUD37D_W34
dtype: string
- name: JOBSECURITY_W41
dtype: string
- name: RQ4_F1Cd_W42
dtype: string
- name: FUTR_ABR_W41
dtype: string
- name: ESSENBIZF2J_W36
dtype: string
- name: ANONYMOUS1CO_W49
dtype: string
- name: PQ2_F2C_W42
dtype: string
- name: FEM2_W29
dtype: string
- name: POSNEGGOV_W49
dtype: string
- name: PP5a_W49
dtype: string
- name: HOMEASSIST2_W49
dtype: string
- name: FAMSURV5d_W50
dtype: string
- name: ESSENPOLF1A_W36
dtype: string
- name: TRAITBIZMF2B_W36
dtype: string
- name: GROWUPGUN1_W26
dtype: string
- name: GAP21Q33_r_W82
dtype: string
- name: RQ3_F1Ab_W42
dtype: string
- name: RACESURV19c_W43
dtype: string
- name: WHYNOTBIZF2D_W36
dtype: string
- name: POL1JB_W92
dtype: string
- name: GAP21Q43_f_W82
dtype: string
- name: GAP21Q21_b_W82
dtype: string
- name: SCM4a_W42
dtype: string
- name: GUNCOURSES_W26
dtype: string
- name: ECIMPa_W54
dtype: string
- name: PROBOFF_b_W92
dtype: string
- name: SEENMASC_W29
dtype: string
- name: NEVEROWN_W26
dtype: string
- name: GAP21Q33_m_W82
dtype: string
- name: REPRSNTDEM_W92
dtype: string
- name: RQ3_F1Bb_W42
dtype: string
- name: HAPPENc_W41
dtype: string
- name: TRAITBIZWF2G_W36
dtype: string
- name: MADEUPSHARE2_W45
dtype: string
- name: GUNCONTRIBB_W26
dtype: string
- name: EAT3F_W34
dtype: string
- name: FUTR_M_W41
dtype: string
- name: PROG_RNEED_W92
dtype: string
- name: MISINFG_W32
dtype: string
- name: FUTR_K_W41
dtype: string
- name: MOVEURBAN_W32
dtype: string
- name: ESSENPOLF1B_W36
dtype: string
- name: INEQ5_f_W54
dtype: string
- name: GAP21Q2_W82
dtype: string
- name: TRAITPOLMF1B_W36
dtype: string
- name: WHYNOTBIZF2C_W36
dtype: string
- name: VIDOFT_W45
dtype: string
- name: TRAITSA_W29
dtype: string
- name: SUCCESSIMPA_W32
dtype: string
- name: ESSENPOLF1G_W36
dtype: string
- name: ECON4_e_W54
dtype: string
- name: NOGOVTHC_W92
dtype: string
- name: RACESURV28c_W43
dtype: string
- name: FIN_SITGROWUP_W54
dtype: string
- name: BETTERBIZ1F2A_W36
dtype: string
- name: FUD35_W34
dtype: string
- name: ECON4_c_W54
dtype: string
- name: SOCMEDIAUSEc_W49
dtype: string
- name: WHYNOTBIZF2B_W36
dtype: string
- name: FAMSURV23f_W50
dtype: string
- name: RQ3_F1Ad_W42
dtype: string
- name: INEQ8_g_W54
dtype: string
- name: HAPPEN2b_W41
dtype: string
- name: SCI3C_W34
dtype: string
- name: BUSPROFIT_W92
dtype: string
- name: SOCTRUST_W32
dtype: string
- name: GAP21Q15_b_W82
dtype: string
- name: ROBJOB8E_W27
dtype: string
- name: FAMSURV36b_W50
dtype: string
- name: FAMSURV30c_W50
dtype: string
- name: GAP21Q26_a_W82
dtype: string
- name: VOICE5D_W27
dtype: string
- name: FAMSURV10c_W50
dtype: string
- name: ESSENBIZF2L_W36
dtype: string
- name: RQ6_F1C_W42
dtype: string
- name: INDUSTRY_W27
dtype: string
- name: ADMISSIONa_W43
dtype: string
- name: DEBTe_W54
dtype: string
- name: SCM5g_W42
dtype: string
- name: HAPPENa_W41
dtype: string
- name: BETTERBIZ1F2H_W36
dtype: string
- name: SMLIKESb_W45
dtype: string
- name: GAP21Q19_a_W82
dtype: string
- name: ESSENBIZF2E_W36
dtype: string
- name: NEIGHKNOW_W32
dtype: string
- name: ESSENBIZF2H_W36
dtype: string
- name: RACESURV29d_W43
dtype: string
- name: MADEUPOFT_W45
dtype: string
- name: POORASSIST_W92
dtype: string
- name: ROBJOB8F_W27
dtype: string
- name: PARTICIPATEC_W29
dtype: string
- name: COMATTACH_W32
dtype: string
- name: PQ4_F2Bb_W42
dtype: string
- name: CARS10C_W27
dtype: string
- name: FACE2c_W49
dtype: string
- name: HELPHURTD_W29
dtype: string
- name: GUNCONTRIBC_W26
dtype: string
- name: MED2D_W34
dtype: string
- name: GAP21Q27_W82
dtype: string
- name: RQ4_F1Ba_W42
dtype: string
- name: CAREGIV6C_W27
dtype: string
- name: DATAUSEd_W49
dtype: string
- name: WORK3A_W27
dtype: string
- name: SCM2_W42
dtype: string
- name: FINANCEa_W54
dtype: string
- name: INFOKNOWb_W45
dtype: string
- name: PROBRURAL_W32
dtype: string
- name: SPOUSESEX_W50
dtype: string
- name: G2_W34
dtype: string
- name: RACESURV19a_W43
dtype: string
- name: INFOOWNe_W45
dtype: string
- name: SNSUSE_W45
dtype: string
- name: CONCERNGOV_W49
dtype: string
- name: PROBOFF_a_W92
dtype: string
- name: AMNTWMNP2F1_W36
dtype: string
- name: FEM1F2_W29
dtype: string
- name: FAMNEAR_W32
dtype: string
- name: WHYNOTPOLF1D_W36
dtype: string
- name: MESUM1_FD_W29
dtype: string
- name: COHABDUR_W50
dtype: string
- name: CONCERNGRPa_W49
dtype: string
- name: INFOOWNa_W45
dtype: string
- name: SOLVPROBh_W41
dtype: string
- name: BIOTECHE_W34
dtype: string
- name: CONTROLGRPa_W49
dtype: string
- name: ESSENPOLF1F_W36
dtype: string
- name: IMPROVE1_W36
dtype: string
- name: TALKDISASNSINT_W49
dtype: string
- name: BETTERPOL1F1G_W36
dtype: string
- name: PROFILE5_W49
dtype: string
- name: FAMSURV27c_W50
dtype: string
- name: MADEUPTOPICa_W45
dtype: string
- name: INEQ5_c_W54
dtype: string
- name: GOVPRIOlF2_W41
dtype: string
- name: WOMENOBS_W92
dtype: string
- name: SOCIETY_WHT_W92
dtype: string
- name: GAP21Q14_W82
dtype: string
- name: ADMISSIONb_W43
dtype: string
- name: GOVPRIOfF1_W41
dtype: string
- name: CARS10D_W27
dtype: string
- name: CANMTCHPOL_W92
dtype: string
- name: RQ7_F1C_W42
dtype: string
- name: ECIMPg_W54
dtype: string
- name: ROBJOB8G_W27
dtype: string
- name: GIRLSF2D_W29
dtype: string
- name: BETTERPOL1F1E_W36
dtype: string
- name: INEQ8_e_W54
dtype: string
- name: GAP21Q33_p_W82
dtype: string
- name: SCM5c_W42
dtype: string
- name: DNA3a_W50
dtype: string
- name: RACESURV3_W43
dtype: string
- name: GUNRESPNOKIDSF_W26
dtype: string
- name: FAMSURV22e_W50
dtype: string
- name: CAREGIV1_W27
dtype: string
- name: GAP21Q46_W82
dtype: string
- name: FTRWORRYd_W41
dtype: string
- name: FEDSHAREA_W32
dtype: string
- name: ESSENBIZF2K_W36
dtype: string
- name: ESSENBIZF2D_W36
dtype: string
- name: TRACKCO1b_W49
dtype: string
- name: HAPPENe_W41
dtype: string
- name: SATLIFEC_W32
dtype: string
- name: SCI2A_W34
dtype: string
- name: BETTERPOL2F1A_W36
dtype: string
- name: RQ8_F1B_W42
dtype: string
- name: RACESURV12_W43
dtype: string
- name: GAP21Q34_a_W82
dtype: string
- name: GAP21Q33_j_W82
dtype: string
- name: FAMSURV2Wd_W50
dtype: string
- name: VOICE5B_W27
dtype: string
- name: WORRYC_W26
dtype: string
- name: GAP21Q4_e_W82
dtype: string
- name: GAP21Q33_i_W82
dtype: string
- name: INFOOWNd_W45
dtype: string
- name: POP3_W42
dtype: string
- name: MASC2AF1_W29
dtype: string
- name: GAP21Q43_c_W82
dtype: string
- name: GUNLOADED1_W26
dtype: string
- name: ECON4_h_W54
dtype: string
- name: HAPPEN2a_W41
dtype: string
- name: WOMENOPPS_W32
dtype: string
- name: CAREGIV2_W27
dtype: string
- name: FAMSURV2Ma_W50
dtype: string
- name: CARS1_W27
dtype: string
- name: ELECT_IMPT3_PRVSUP_W92
dtype: string
- name: GAP21Q33_e_W82
dtype: string
- name: DNA3c_W50
dtype: string
- name: ESSENBIZF2A_W36
dtype: string
- name: VOICE4_W27
dtype: string
- name: Q9F2_W42
dtype: string
- name: POLICY3_W42
dtype: string
- name: TALKCMNSNSINT_W49
dtype: string
- name: SMARTPHONE_W49
dtype: string
- name: TRAITBIZMF2D_W36
dtype: string
- name: ECON4_b_W54
dtype: string
- name: TRAITPOLMF1G_W36
dtype: string
- name: RQ1_F1A_W42
dtype: string
- name: ROBJOB4E_W27
dtype: string
- name: INEQ6_W54
dtype: string
- name: GAYMARR2_W32
dtype: string
- name: INFOCONFUSEa_W45
dtype: string
- name: MARRYPREF2_W50
dtype: string
- name: FAMSURV4_W50
dtype: string
- name: SCM5b_W42
dtype: string
- name: MADEUPIMPb_W45
dtype: string
- name: DIFF1C_W29
dtype: string
- name: INFORESTRICTb_W45
dtype: string
- name: RACESURV53f_W43
dtype: string
- name: DEMDIRCT_W29
dtype: string
- name: INFOCREATEc_W45
dtype: string
- name: TRAITSB_W29
dtype: string
- name: HARASS3F1_W41
dtype: string
- name: GROWUPUSR_W32
dtype: string
- name: ECIMPi_W54
dtype: string
- name: Q6F2_W42
dtype: string
- name: RACESURV18e_W43
dtype: string
- name: MISINFT_W32
dtype: string
- name: RACESURV19d_W43
dtype: string
- name: MED6B_W34
dtype: string
- name: JOBSFUTURE_W32
dtype: string
- name: BETTERBIZ1F2B_W36
dtype: string
- name: SMLIKESa_W45
dtype: string
- name: WORK3D_W27
dtype: string
- name: GOVPRIOjF1_W41
dtype: string
- name: E5_W36
dtype: string
- name: TRAITBIZWF2A_W36
dtype: string
- name: POP1_W42
dtype: string
- name: SCM5i_W42
dtype: string
- name: DNA2c_W50
dtype: string
- name: GAP21Q15_f_W82
dtype: string
- name: HAPPENiF2_W41
dtype: string
- name: SEEK_W45
dtype: string
- name: GOVRESP_d_W54
dtype: string
- name: HAPPEN2f_W41
dtype: string
- name: INFOWHYc_W45
dtype: string
- name: CRIM_SENT2_W92
dtype: string
- name: GUNRESPNOKIDSG_W26
dtype: string
- name: INSTN_K12_W92
dtype: string
- name: MAN1E_W29
dtype: string
- name: NEIGHINTERD_W32
dtype: string
- name: PQ3_F2Ba_W42
dtype: string
- name: ESSENPOLF1D_W36
dtype: string
- name: FAMSURV9a_W50
dtype: string
- name: GUNRESPKIDSE_W26
dtype: string
- name: CARS5_W27
dtype: string
- name: GUNRESPKIDSG_W26
dtype: string
- name: RTDd_W49
dtype: string
- name: CARS9B_W27
dtype: string
- name: GAP21Q7_b_W82
dtype: string
- name: RACESURV53d_W43
dtype: string
- name: PP2_W49
dtype: string
- name: GUNRESPNOKIDSC_W26
dtype: string
- name: MADEUPTOPICe_W45
dtype: string
- name: FIN_SITMOST_W54
dtype: string
- name: ECIMPc_W54
dtype: string
- name: SCM5a_W42
dtype: string
- name: VTRS_VALS_W92
dtype: string
- name: PROBSUBURB_W32
dtype: string
- name: RACESURV5e_W43
dtype: string
- name: FITTRACK_W49
dtype: string
- name: MASC2BF1_W29
dtype: string
- name: INSTN_CLGS_W92
dtype: string
- name: FINANCEc_W54
dtype: string
- name: SAFECRIME_W26
dtype: string
- name: JOBTRAIN_W54
dtype: string
- name: GAP21Q43_d_W82
dtype: string
- name: TRAITBIZWF2D_W36
dtype: string
- name: WORKHARD_W53
dtype: string
- name: RACESURV26_W43
dtype: string
- name: DATAUSEa_W49
dtype: string
- name: GAP21Q15_c_W82
dtype: string
- name: PQ7_F2A_W42
dtype: string
- name: FAMSURV22g_W50
dtype: string
- name: RACESURV18f_W43
dtype: string
- name: ROBJOB8C_W27
dtype: string
- name: ROBJOB5B_W27
dtype: string
- name: PQ4_F2Ce_W42
dtype: string
- name: EASIERPOLF2_W36
dtype: string
- name: LEGALIMG_W41
dtype: string
- name: ESSENPOLF1I_W36
dtype: string
- name: ECON3_h_W54
dtype: string
- name: FACE2a_W49
dtype: string
- name: ELDCARE_W41
dtype: string
- name: INFOWHYb_W45
dtype: string
- name: REASONGUNE_W26
dtype: string
- name: MED1_W34
dtype: string
- name: EASIERBIZF2_W36
dtype: string
- name: PQ3_F2Bb_W42
dtype: string
- name: PAR2CHILDa_W92
dtype: string
- name: CLASS_W32
dtype: string
- name: EAT3J_W34
dtype: string
- name: FAMSURV23d_W50
dtype: string
- name: GUNSAFE_W26
dtype: string
- name: WHYNOTBIZF2I_W36
dtype: string
- name: user_id
dtype: string
splits:
- name: questions
num_bytes: 185587
num_examples: 1
- name: answers
num_bytes: 961525039
num_examples: 80098
download_size: 34961061
dataset_size: 961710626
configs:
- config_name: default
data_files:
- split: questions
path: data/questions-*
- split: answers
path: data/answers-*
---
|
shreyaskaggle/human-conversations-4W-part8
|
shreyaskaggle
|
2024-10-29T22:06:44Z
| 20
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-10-29T22:06:43Z
| 0
|
---
dataset_info:
features:
- name: What
dtype: string
- name: When
dtype: string
- name: Where
dtype: string
- name: Who
dtype: string
splits:
- name: train
num_bytes: 118883
num_examples: 1000
download_size: 52611
dataset_size: 118883
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
ZixuanKe/posttrain_tokenized_bopang_sup_qwen2.5_32b_instr
|
ZixuanKe
|
2024-12-31T01:58:41Z
| 64
| 0
|
[
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-12-30T03:51:12Z
| 0
|
---
dataset_info:
features:
- name: title
dtype: string
- name: topic
dtype: string
- name: text
dtype: string
- name: input_ids
sequence: int32
- name: attention_mask
sequence: int8
- name: labels
sequence: int64
- name: packed_length
dtype: int64
splits:
- name: train
num_bytes: 13531719151.035553
num_examples: 1550832
- name: validation
num_bytes: 712198040.9644468
num_examples: 81623
download_size: 4599696086
dataset_size: 14243917192.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
neoneye/simon-arc-solve-template-v4
|
neoneye
|
2024-10-10T09:54:40Z
| 20
| 0
|
[
"task_categories:image-to-text",
"task_categories:text-to-image",
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[
"image-to-text",
"text-to-image"
] |
2024-10-10T09:51:43Z
| 0
|
---
license: mit
task_categories:
- image-to-text
- text-to-image
language:
- en
pretty_name: simons ARC (abstraction & reasoning corpus) solve template version 4
size_categories:
- 1K<n<10K
configs:
- config_name: default
data_files:
- split: train
path: data.jsonl
---
# Version 1
ARC-AGI Tasks where the job is to insert objects into templates.
example count: 2-3.
test count: 1-2.
image size: 8-10.
template size: 2-4.
number of rects: 2-4.
# Version 2
Smaller images.
example count: 2-3.
test count: 1-2.
image size: 6-8.
template size: 2-2.
number of rects: 2-3.
# Version 3
Added transformation: `without_insertion_image`
image size: 6-8.
template size: 2-3.
number of rects: 2-3.
# Version 4
Added transformations: `swap_one_to_many` and `swap_many_to_one`.
image size: 6-10.
template size: 2-4.
number of rects: 2-3.
|
juliadollis/trad_ai_medical_chatbot_v9
|
juliadollis
|
2025-02-10T14:52:50Z
| 15
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-02-10T14:29:58Z
| 0
|
---
dataset_info:
features:
- name: Description
dtype: string
- name: Patient
dtype: string
- name: Doctor
dtype: string
- name: Translated_Description
dtype: string
- name: Translated_Patient
dtype: string
- name: Translated_Doctor
dtype: string
splits:
- name: train
num_bytes: 829907
num_examples: 300
download_size: 384499
dataset_size: 829907
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
CelestialWandererOfTheVoid/reddit_dataset_190
|
CelestialWandererOfTheVoid
|
2025-03-21T07:09:22Z
| 10
| 0
|
[
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:question-answering",
"task_categories:summarization",
"task_categories:text-generation",
"task_ids:sentiment-analysis",
"task_ids:topic-classification",
"task_ids:named-entity-recognition",
"task_ids:language-modeling",
"task_ids:text-scoring",
"task_ids:multi-class-classification",
"task_ids:multi-label-classification",
"task_ids:extractive-qa",
"task_ids:news-articles-summarization",
"multilinguality:multilingual",
"source_datasets:original",
"license:mit",
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[
"text-classification",
"token-classification",
"question-answering",
"summarization",
"text-generation"
] |
2025-03-19T19:20:55Z
| 0
|
---
license: mit
multilinguality:
- multilingual
source_datasets:
- original
task_categories:
- text-classification
- token-classification
- question-answering
- summarization
- text-generation
task_ids:
- sentiment-analysis
- topic-classification
- named-entity-recognition
- language-modeling
- text-scoring
- multi-class-classification
- multi-label-classification
- extractive-qa
- news-articles-summarization
---
# Bittensor Subnet 13 Reddit Dataset
<center>
<img src="https://huggingface.co/datasets/macrocosm-os/images/resolve/main/bittensor.png" alt="Data-universe: The finest collection of social media data the web has to offer">
</center>
<center>
<img src="https://huggingface.co/datasets/macrocosm-os/images/resolve/main/macrocosmos-black.png" alt="Data-universe: The finest collection of social media data the web has to offer">
</center>
## Dataset Description
- **Repository:** CelestialWandererOfTheVoid/reddit_dataset_190
- **Subnet:** Bittensor Subnet 13
- **Miner Hotkey:** 5FCqYu48VvVwRt43ZptsmoQwiqH3RFYrRxzig4pYYnfK33Ng
### Miner Data Compliance Agreement
In uploading this dataset, I am agreeing to the [Macrocosmos Miner Data Compliance Policy](https://github.com/macrocosm-os/data-universe/blob/add-miner-policy/docs/miner_policy.md).
### Dataset Summary
This dataset is part of the Bittensor Subnet 13 decentralized network, containing preprocessed Reddit data. The data is continuously updated by network miners, providing a real-time stream of Reddit content for various analytical and machine learning tasks.
For more information about the dataset, please visit the [official repository](https://github.com/macrocosm-os/data-universe).
### Supported Tasks
The versatility of this dataset allows researchers and data scientists to explore various aspects of social media dynamics and develop innovative applications. Users are encouraged to leverage this data creatively for their specific research or business needs.
For example:
- Sentiment Analysis
- Topic Modeling
- Community Analysis
- Content Categorization
### Languages
Primary language: Datasets are mostly English, but can be multilingual due to decentralized ways of creation.
## Dataset Structure
### Data Instances
Each instance represents a single Reddit post or comment with the following fields:
### Data Fields
- `text` (string): The main content of the Reddit post or comment.
- `label` (string): Sentiment or topic category of the content.
- `dataType` (string): Indicates whether the entry is a post or a comment.
- `communityName` (string): The name of the subreddit where the content was posted.
- `datetime` (string): The date when the content was posted or commented.
- `username_encoded` (string): An encoded version of the username to maintain user privacy.
- `url_encoded` (string): An encoded version of any URLs included in the content.
### Data Splits
This dataset is continuously updated and does not have fixed splits. Users should create their own splits based on their requirements and the data's timestamp.
## Dataset Creation
### Source Data
Data is collected from public posts and comments on Reddit, adhering to the platform's terms of service and API usage guidelines.
### Personal and Sensitive Information
All usernames and URLs are encoded to protect user privacy. The dataset does not intentionally include personal or sensitive information.
## Considerations for Using the Data
### Social Impact and Biases
Users should be aware of potential biases inherent in Reddit data, including demographic and content biases. This dataset reflects the content and opinions expressed on Reddit and should not be considered a representative sample of the general population.
### Limitations
- Data quality may vary due to the nature of media sources.
- The dataset may contain noise, spam, or irrelevant content typical of social media platforms.
- Temporal biases may exist due to real-time collection methods.
- The dataset is limited to public subreddits and does not include private or restricted communities.
## Additional Information
### Licensing Information
The dataset is released under the MIT license. The use of this dataset is also subject to Reddit Terms of Use.
### Citation Information
If you use this dataset in your research, please cite it as follows:
```
@misc{CelestialWandererOfTheVoid2025datauniversereddit_dataset_190,
title={The Data Universe Datasets: The finest collection of social media data the web has to offer},
author={CelestialWandererOfTheVoid},
year={2025},
url={https://huggingface.co/datasets/CelestialWandererOfTheVoid/reddit_dataset_190},
}
```
### Contributions
To report issues or contribute to the dataset, please contact the miner or use the Bittensor Subnet 13 governance mechanisms.
## Dataset Statistics
[This section is automatically updated]
- **Total Instances:** 25045
- **Date Range:** 2019-07-24T00:00:00Z to 2025-03-21T00:00:00Z
- **Last Updated:** 2025-03-21T07:09:21Z
### Data Distribution
- Posts: 6.54%
- Comments: 93.46%
### Top 10 Subreddits
For full statistics, please refer to the `stats.json` file in the repository.
| Rank | Topic | Total Count | Percentage |
|------|-------|-------------|-------------|
| 1 | r/wallstreetbets | 5355 | 21.38% |
| 2 | r/worldnews | 4070 | 16.25% |
| 3 | r/politics | 3971 | 15.86% |
| 4 | r/Bitcoin | 3349 | 13.37% |
| 5 | r/CryptoCurrency | 2753 | 10.99% |
| 6 | r/CryptoMarkets | 2117 | 8.45% |
| 7 | r/btc | 651 | 2.60% |
| 8 | r/solana | 533 | 2.13% |
| 9 | r/ethtrader | 464 | 1.85% |
| 10 | r/worldpolitics | 459 | 1.83% |
## Update History
| Date | New Instances | Total Instances |
|------|---------------|-----------------|
| 2025-03-19T19:21:11Z | 10200 | 10200 |
| 2025-03-20T12:59:02Z | 6711 | 16911 |
| 2025-03-21T07:09:21Z | 8134 | 25045 |
|
harman/UltraInteract_Improved-Degraded_QR-Neutrals_Verified_probA_100000
|
harman
|
2025-05-21T19:31:48Z
| 0
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-21T19:31:43Z
| 0
|
---
dataset_info:
features:
- name: prompt
dtype: string
- name: chosen
list:
- name: content
dtype: string
- name: role
dtype: string
- name: rejected
list:
- name: content
dtype: string
- name: role
dtype: string
- name: neutral
dtype: bool
- name: prob_A
dtype: float64
splits:
- name: train
num_bytes: 40574827.2735
num_examples: 10455
download_size: 9185838
dataset_size: 40574827.2735
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Yusser/es_sae_wiki_tokenized
|
Yusser
|
2025-03-11T11:42:10Z
| 17
| 0
|
[
"size_categories:1M<n<10M",
"format:parquet",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-03-11T11:30:55Z
| 0
|
---
dataset_info:
features:
- name: input_ids
sequence: int32
splits:
- name: train
num_bytes: 6566125400.0
num_examples: 1601494
download_size: 3239511686
dataset_size: 6566125400.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
SPRINGLab/IndicTTS_Assamese
|
SPRINGLab
|
2025-01-27T11:46:39Z
| 97
| 0
|
[
"task_categories:text-to-speech",
"language:as",
"size_categories:10K<n<100K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[
"text-to-speech"
] |
2025-01-24T09:44:16Z
| 0
|
---
dataset_info:
features:
- name: audio
dtype: audio
- name: text
dtype: string
- name: gender
dtype:
class_label:
names:
'0': female
'1': male
splits:
- name: train
num_bytes: 7374287207.946
num_examples: 16358
download_size: 8443016168
dataset_size: 7374287207.946
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
task_categories:
- text-to-speech
language:
- as
pretty_name: Assamese Indic TTS dataset
---
# Assamese Indic TTS Dataset
This dataset is derived from the Indic TTS Database project, specifically using the Assamese monolingual recordings from both male and female speakers. The dataset contains high-quality speech recordings with corresponding text transcriptions, making it suitable for text-to-speech (TTS) research and development.
## Dataset Details
- **Language**: Assamese
- **Total Duration**: ~27.4 hours (Male: 5.16 hours, Female: 5.18 hours)
- **Audio Format**: WAV
- **Sampling Rate**: 48000Hz
- **Speakers**: 4 (2 male, 2 female native Assamese speakers)
- **Content Type**: Monolingual Assamese utterances
- **Recording Quality**: Studio-quality recordings
- **Transcription**: Available for all audio files
## Dataset Source
This dataset is derived from the Indic TTS Database, a special corpus of Indian languages developed by the Speech Technology Consortium at IIT Madras. The original database covers 13 major languages of India and contains 10,000+ spoken sentences/utterances for both monolingual and English recordings.
## License & Usage
This dataset is subject to the original Indic TTS license terms. Before using this dataset, please ensure you have read and agreed to the [License For Use of Indic TTS](https://www.iitm.ac.in/donlab/indictts/downloads/license.pdf).
## Acknowledgments
This dataset would not be possible without the work of the Speech Technology Consortium at IIT Madras. Special acknowledgment goes to:
- Speech Technology Consortium
- Department of Computer Science & Engineering and Electrical Engineering, IIT Madras
- Bhashini, MeitY
- Prof. Hema A Murthy & Prof. S Umesh
## Citation
If you use this dataset in your research or applications, please cite the original Indic TTS project:
```bibtex
@misc{indictts2023,
title = {Indic {TTS}: A Text-to-Speech Database for Indian Languages},
author = {Speech Technology Consortium and {Hema A Murthy} and {S Umesh}},
year = {2023},
publisher = {Indian Institute of Technology Madras},
url = {https://www.iitm.ac.in/donlab/indictts/},
institution = {Department of Computer Science and Engineering and Electrical Engineering, IIT MADRAS}
}
```
## Contact
For any issues or queries related to this HuggingFace dataset version, feel free to comment in the Community tab.
For queries related to the original Indic TTS database, please contact: [email protected]
## Original Database Access
The original complete database can be accessed at: https://www.iitm.ac.in/donlab/indictts/database
Note: The original database provides access to data in multiple Indian languages and variants. This HuggingFace dataset specifically contains the Hindi monolingual portion of that database.
|
argilla-internal-testing/test_import_dataset_from_hub_with_classlabel_354d38a1-419a-4b08-9b91-372a0cf211bd
|
argilla-internal-testing
|
2024-11-28T11:44:04Z
| 14
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-11-28T11:44:03Z
| 0
|
---
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': positive
'1': negative
splits:
- name: train
num_bytes: 111
num_examples: 3
download_size: 1256
dataset_size: 111
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
wdy0123/InduMan
|
wdy0123
|
2025-09-28T09:22:35Z
| 58
| 0
|
[
"license:apache-2.0",
"size_categories:100B<n<1T",
"region:us",
"agent"
] |
[] |
2025-09-25T00:34:05Z
| 0
|
---
license: apache-2.0
tags:
- agent
size_categories:
- 100B<n<1T
---
## InduMan Dataset
This dataset only contains the hdf5 files collected by the tasks in the experiment. If you want to download full data collected by all tasks, you should download this dataset first, and then turn to ModelScope for other hdf5 files.
https://www.modelscope.cn/datasets/wdy0123/InduMan
## Dataset Structure
`<file>`.h5
└── data_frames
├── demo_0
│ ├── actions # [T, action_dim]
│ ├── episode_step # [T, ]
│ ├── is_success # [T, ]
│ ├── rewards # [T,]
│ ├── robot_joint_state # [T, 14] Franka Panda robot joint positions and velocities (gripper not included)
│ └── robot_joint_forces # [T, 54] All Panda joints (gripper included)
│ ├── objects poses # [T, 7]
│ ├── contact_force # [T, 3]
│ └──observations
├── ee_poses # [T, 7]
├── rgb_image # [T, 128, 128, 3]
├── demo_1
└── ...
## Failed demos in each task
* ASSEMBLE_CHAIN_DOOR_LOCK:
['demo_71', 'demo_72', 'demo_73', 'demo_74', 'demo_76', 'demo_82', 'demo_84', 'demo_85', 'demo_86', 'demo_87', 'demo_88', 'demo_89', 'demo_90']
* ASSEMBLE_DC_PLUG:
['demo_60', 'demo_61', 'demo_62', 'demo_64', 'demo_65', 'demo_73', 'demo_75', 'demo_76', 'demo_77', 'demo_78', 'demo_80', 'demo_81']
* DISASSEMBLE_CHAIN_DOOR_LOCK:
['demo_63', 'demo_64', 'demo_71', 'demo_72', 'demo_73', 'demo_74', 'demo_75', 'demo_78']
* DISASSEMBLE_DC_PLUG
['demo_72', 'demo_73', 'demo_74', 'demo_75', 'demo_77', 'demo_79']
* DUAL_HOLE_IN_PEG:
['demo_65', 'demo_67', 'demo_70', 'demo_71', 'demo_72', 'demo_75', 'demo_76', 'demo_77', 'demo_78', 'demo_79', 'demo_80', 'demo_83', 'demo_85']
* DUAL_HOLE_OUT_PEG:
['demo_68', 'demo_69', 'demo_70', 'demo_72', 'demo_73', 'demo_74', 'demo_75', 'demo_76', 'demo_77', 'demo_79']
* RECTANGLE_PEG_IN_HOLE:
['demo_69', 'demo_70', 'demo_71', 'demo_74', 'demo_75', 'demo_77', 'demo_78']
* RECTANGLE_PEG_OUT_HOLE:
['demo_75', 'demo_76', 'demo_77', 'demo_78']
* USB_ASSEMBLE:
['demo_0', 'demo_1', 'demo_10', 'demo_11', 'demo_13', 'demo_14', 'demo_15', 'demo_16', 'demo_17', 'demo_2', 'demo_3', 'demo_4', 'demo_6', 'demo_7', 'demo_8', 'demo_9']
* USB_DISASSEMBLE:
['demo_73', 'demo_74', 'demo_75', 'demo_77']
|
kristiannordby/large-set-test
|
kristiannordby
|
2024-10-31T23:00:02Z
| 25
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-10-31T23:00:01Z
| 0
|
---
dataset_info:
features:
- name: question
dtype: string
- name: sql
dtype: string
splits:
- name: train
num_bytes: 490936
num_examples: 1526
download_size: 78056
dataset_size: 490936
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
zjhhhh/filtered_wholedataset_armo_tokenized_logprob
|
zjhhhh
|
2025-09-22T07:16:34Z
| 89
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-09-22T07:15:39Z
| 0
|
---
dataset_info:
features:
- name: prompt
dtype: string
- name: requirements
dtype: string
- name: selection_response_1
dtype: string
- name: selection_response_2
dtype: string
- name: selection_response_3
dtype: string
- name: base_response_1
dtype: string
- name: base_response_2
dtype: string
- name: current_response_1
dtype: string
- name: current_response_2
dtype: string
- name: selection_response_1_reward
dtype: float64
- name: selection_response_2_reward
dtype: float64
- name: selection_response_3_reward
dtype: float64
- name: base_response_1_reward
dtype: float64
- name: base_response_2_reward
dtype: float64
- name: current_response_1_reward
dtype: float64
- name: current_response_2_reward
dtype: float64
- name: qwen_prompt
dtype: string
- name: qwen_prompt_tokens
list: int64
- name: chosen
dtype: string
- name: chosen_reward
dtype: float64
- name: qwen_chosen
dtype: string
- name: qwen_chosen_tokens
list: int64
- name: reject
dtype: string
- name: reject_reward
dtype: float64
- name: qwen_reject
dtype: string
- name: qwen_reject_tokens
list: int64
- name: g_chosen
dtype: string
- name: g_reject
dtype: string
- name: chosen_logprob
dtype: float64
- name: reject_logprob
dtype: float64
splits:
- name: train
num_bytes: 3781586581
num_examples: 39887
- name: test
num_bytes: 94603923
num_examples: 1000
download_size: 927137612
dataset_size: 3876190504
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
Nachiket-S/LLaMa_1B_Fine_Tuned_NoCoT
|
Nachiket-S
|
2024-12-05T03:47:19Z
| 22
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-12-05T03:47:17Z
| 0
|
---
dataset_info:
features:
- name: file_name
dtype: string
- name: paragraph
dtype: string
splits:
- name: CleanPrompts
num_bytes: 55085
num_examples: 90
download_size: 14255
dataset_size: 55085
configs:
- config_name: default
data_files:
- split: CleanPrompts
path: data/CleanPrompts-*
---
|
kaarthu2003/SlrCvVoicesTtsDataset
|
kaarthu2003
|
2025-05-20T17:49:56Z
| 0
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-20T17:47:07Z
| 0
|
---
dataset_info:
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: sentence
dtype: string
splits:
- name: train
num_bytes: 4724162837.263434
num_examples: 15811
- name: validation
num_bytes: 1165927686.4403155
num_examples: 1610
download_size: 2148816154
dataset_size: 5890090523.70375
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
timaeus/pythia-160m-pile-1m-ig-l6h8
|
timaeus
|
2025-01-31T19:08:30Z
| 15
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-01-31T19:08:28Z
| 0
|
---
dataset_info:
features:
- name: contents
dtype: string
- name: metadata
struct:
- name: pile_set_name
sequence: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 15668936
num_examples: 10000
download_size: 10129389
dataset_size: 15668936
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
yzembodied/libero_90_image_task_47
|
yzembodied
|
2025-05-07T10:38:42Z
| 0
| 0
|
[
"task_categories:robotics",
"license:apache-2.0",
"region:us",
"LeRobot"
] |
[
"robotics"
] |
2025-05-07T10:38:24Z
| 0
|
---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": null,
"total_episodes": 50,
"total_frames": 7426,
"total_tasks": 1,
"total_videos": 0,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 20,
"splits": {
"train": "0:50"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": null,
"features": {
"observation.images.image": {
"dtype": "image",
"shape": [
256,
256,
3
],
"names": [
"height",
"width",
"channel"
]
},
"observation.images.wrist_image": {
"dtype": "image",
"shape": [
256,
256,
3
],
"names": [
"height",
"width",
"channel"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
8
],
"names": {
"motors": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw",
"gripper",
"gripper"
]
}
},
"observation.state.joint": {
"dtype": "float32",
"shape": [
7
],
"names": {
"motors": [
"joint_1",
"joint_2",
"joint_3",
"joint_4",
"joint_5",
"joint_6",
"joint_7"
]
}
},
"action": {
"dtype": "float32",
"shape": [
7
],
"names": {
"motors": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw",
"gripper"
]
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
```
|
konwoo/lte-ctx16-fs1-np8-lr1e-05
|
konwoo
|
2025-05-06T22:08:46Z
| 0
| 0
|
[
"size_categories:100K<n<1M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-06T22:08:41Z
| 0
|
---
dataset_info:
features:
- name: text
dtype: string
- name: p_log_probs
dtype: float32
- name: q_log_probs
dtype: float32
- name: p_hat_log_probs
dtype: float32
- name: num_tokens
dtype: float32
splits:
- name: train
num_bytes: 10789651
num_examples: 128000
download_size: 8568715
dataset_size: 10789651
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
abhayesian/ea-cause-tradeoffs
|
abhayesian
|
2025-04-29T01:24:36Z
| 41
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-04-28T13:09:20Z
| 0
|
---
dataset_info:
features:
- name: topic
dtype: string
- name: subtopic
dtype: string
- name: question
dtype: string
- name: scratchpad
dtype: string
- name: answer
dtype: string
- name: full_response
dtype: string
- name: model_id
dtype: string
- name: timestamp
dtype: timestamp[ns]
splits:
- name: train
num_bytes: 8885336
num_examples: 1000
download_size: 3959642
dataset_size: 8885336
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
DS-20202/EMPIAR11526-128-val
|
DS-20202
|
2025-05-04T19:49:41Z
| 0
| 0
|
[
"license:mit",
"region:us"
] |
[] |
2025-05-04T19:44:46Z
| 0
|
---
license: mit
dataset_info:
features:
- name: image
sequence:
sequence: float32
splits:
- name: train
num_bytes: 3306893380
num_examples: 50065
download_size: 3317897107
dataset_size: 3306893380
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
YuchenLi01/MATH_1.5Bsft_Score_DPO_Qwen2.5MathRM72B_hard0soft2_v5_chosen-2
|
YuchenLi01
|
2025-09-27T23:16:05Z
| 22
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-09-27T23:16:01Z
| 0
|
---
dataset_info:
features:
- name: prompt
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
- name: all_rm_scores
sequence: float64
splits:
- name: train
num_bytes: 93833590
num_examples: 13661
- name: test
num_bytes: 4972539
num_examples: 714
download_size: 17409119
dataset_size: 98806129
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
yoonholee/completions_wstar-balanced_Qwen3-4B_HMMT2025
|
yoonholee
|
2025-05-13T11:52:34Z
| 0
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-13T11:52:33Z
| 0
|
---
dataset_info:
features:
- name: problem
dtype: string
- name: hint
dtype: string
- name: completions
sequence: string
- name: corrects
sequence: bool
- name: acc
dtype: float64
- name: answer
dtype: string
splits:
- name: train
num_bytes: 12354891
num_examples: 240
download_size: 4536451
dataset_size: 12354891
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
jkazdan/jka
|
jkazdan
|
2024-12-30T19:27:30Z
| 14
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-12-30T19:22:00Z
| 0
|
---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 90597
num_examples: 300
download_size: 41901
dataset_size: 90597
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
PurCL/secalign-qwen2.5_7b_ins-edit-locality-cwe502
|
PurCL
|
2025-02-03T22:54:29Z
| 58
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-02-03T22:54:28Z
| 0
|
---
dataset_info:
features:
- name: lang
dtype: string
- name: cwe
dtype: string
- name: original_instruction
dtype: string
- name: original_code
dtype: string
- name: fixed_code
dtype: string
- name: locality_input
dtype: string
- name: locality_answer
dtype: string
splits:
- name: train
num_bytes: 99393
num_examples: 20
download_size: 78509
dataset_size: 99393
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
eaalghamdi/chatrt_test_new
|
eaalghamdi
|
2025-03-08T23:22:11Z
| 56
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"datadreamer",
"datadreamer-0.28.0",
"synthetic",
"gpt-4o"
] |
[] |
2025-03-08T23:22:04Z
| 0
|
---
dataset_info:
features:
- name: metadata
dtype: string
- name: topic
dtype: string
- name: data
dtype: string
- name: code
dtype: string
- name: image
dtype: image
- name: qa
dtype: string
splits:
- name: train
num_bytes: 87588.0
num_examples: 1
download_size: 105487
dataset_size: 87588.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
library_name: datadreamer
size_categories:
- n<1K
tags:
- datadreamer
- datadreamer-0.28.0
- synthetic
- gpt-4o
- gpt-4o
- gpt-4o
- gpt-4o
---
# Dataset Card
[Add more information here](https://huggingface.co/datasets/templates/dataset-card-example)
---
This dataset was produced with [DataDreamer 🤖💤](https://datadreamer.dev). The synthetic dataset card can be found [here](datadreamer.json).
|
HZCDLUT/ScienceQA_lite
|
HZCDLUT
|
2025-03-21T09:12:22Z
| 22
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-03-11T03:16:07Z
| 0
|
---
dataset_info:
features:
- name: image
dtype: image
- name: question
dtype: string
- name: choices
sequence: string
- name: answer
dtype: int8
- name: hint
dtype: string
- name: task
dtype: string
- name: grade
dtype: string
- name: subject
dtype: string
- name: topic
dtype: string
- name: category
dtype: string
- name: skill
dtype: string
- name: lecture
dtype: string
- name: solution
dtype: string
splits:
- name: lite
num_bytes: 33512253.842340108
num_examples: 500
download_size: 32198342
dataset_size: 33512253.842340108
configs:
- config_name: default
data_files:
- split: lite
path: data/lite-*
---
|
darkmater/huggingface-smol-course-preference-tuning-dataset
|
darkmater
|
2024-12-25T22:17:12Z
| 68
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-12-25T22:17:11Z
| 0
|
---
dataset_info:
features:
- name: instruction
dtype: string
- name: grouped_generation
sequence: string
- name: model_name
dtype: string
- name: distilabel_metadata
struct:
- name: raw_input_text_generation_0
list:
- name: content
dtype: string
- name: role
dtype: string
- name: raw_input_text_generation_1
list:
- name: content
dtype: string
- name: role
dtype: string
- name: raw_output_text_generation_0
dtype: string
- name: raw_output_text_generation_1
dtype: string
splits:
- name: train
num_bytes: 3063
num_examples: 1
download_size: 21829
dataset_size: 3063
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
trend-cybertron/Primus-Seed
|
trend-cybertron
|
2025-03-05T09:04:51Z
| 11
| 0
|
[
"task_categories:text-generation",
"language:en",
"license:odc-by",
"size_categories:100K<n<1M",
"arxiv:2502.11191",
"region:us",
"cybersecurity",
"pretraining",
"wikipedia",
"MITRE"
] |
[
"text-generation"
] |
2025-03-05T06:36:14Z
| 0
|
---
license: odc-by
task_categories:
- text-generation
language:
- en
pretty_name: Primus-Seed
tags:
- cybersecurity
- pretraining
- wikipedia
- MITRE
size_categories:
- 100K<n<1M
extra_gated_fields:
Affiliation: text
Country: country
I want to use this model for:
type: select
options:
- Research
- Commercial
- label: Other
value: other
Job title:
type: select
options:
- Student
- Research graduate
- AI researcher
- AI developer/engineer
- Cybersecurity researcher
- Reporter
- Other
geo: ip_location
---
> ⭐ Please download the dataset from [here](https://huggingface.co/datasets/trendmicro-ailab/Primus-Seed).
# PRIMUS: A Pioneering Collection of Open-Source Datasets for Cybersecurity LLM Training
## 🤗 Primus-Seed
**Primus-Seed** is a high-quality🚀 cybersecurity text dataset composed of data crawled from reputable sources such as MITRE, Wikipedia, and well-known cybersecurity company websites, as well as CTI manually collected by our threat experts.
## Statistics
| **Category** | **Samples** | **Tokens** | **Avg.** |
|-------------|------------|------------|----------|
| **_Web Crawl / Official Dump_** | | | |
| Cybersecurity Blogs/News | 2,946 | 9,751,002 | 3,309.9 |
| Cybersecurity Books | 6,499 | 2,910,464 | 447.8 |
| Cybersecurity Companies Websites | 76,919 | 65,798,561 | 855.4 |
| Cybersecurity Wikipedia | 6,636 | 9,567,196 | 1,441.7 |
| MITRE | 3,432 | 2,435,118 | 709.5 |
| **_Expert Curation_** | | | |
| Campaigns | 136 | 37,106 | 272.8 |
| Intrusion Sets | 343 | 60,524 | 176.5 |
| Malware | 7,301 | 1,362,681 | 186.6 |
| Reports | 11,317 | 934,954 | 82.6 |
| Threat Actors | 27 | 2,264 | 83.9 |
| Tools | 238 | 19,926 | 83.7 |
| Vulnerabilities | 559,054 | 98,006,720 | 175.3 |
| **Total** | **674,848** | **190,886,516** | **282.9** |
❗❗Currently, we have only released **Cybersecurity Companies Websites, Cybersecurity Wikipedia, and MITRE**. Other categories are under review to ensure compliance and verify whether redistribution falls under "_fair use_."
## How Did We Collect Cybersecurity Wikipedia?
_Wikipedia_ does not provide a predefined cybersecurity subset, so we perform a custom filtering process. Each Wikipedia article is associated with one or more category tags, which can be further expanded into subcategory tags. Starting from the root category "_Computer Security_", we recursively traverse its subcategories, using GPT-4o to determine whether a category is cybersecurity-related. This process yields **375** relevant categories, from which we extract corresponding Wikipedia articles.
_Prompt_:
```
[System]
You are a helpful assistant.
[User]
Help me identify and mark the categories related to "cybersecurity", "information
security", "data protection", "cryptography", "hacker activity", "cyber attack",
"cybercrime" from a list of categories I have.
For each category, provide a reason for marking it as 'Y' (Yes) or 'N' (No) in relation to the
specified topics. Finally, output the results in JSON format with the fields: category,
reason, security.
{{category-list}
```
🚀🚀 For more details, see our paper:
[https://arxiv.org/abs/2502.11191](https://arxiv.org/abs/2502.11191)
## License
This dataset is released under the **ODC-By** license.
|
blueapple8259/wikipedia_qa
|
blueapple8259
|
2024-12-09T05:44:54Z
| 24
| 2
|
[
"task_categories:question-answering",
"language:ko",
"license:cc-by-sa-4.0",
"size_categories:100K<n<1M",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[
"question-answering"
] |
2024-12-08T12:50:51Z
| 0
|
---
license: cc-by-sa-4.0
task_categories:
- question-answering
language:
- ko
---
[wikipedia](https://ko.wikipedia.org/wiki/%EC%9C%84%ED%82%A4%EB%B0%B1%EA%B3%BC:%EB%8C%80%EB%AC%B8) 데이터를 qa형식으로 가공한 데이터셋입니다.
언어모델 없이 코드로만 가공하는 것이 목표이며 새로운 가공 아이디어가 떠오를 시 새 버전으로 업로드 하겠습니다.
|
dgambettaphd/D_llm2_run2_gen8_WXS_doc1000_synt64_lr1e-04_acm_MPP
|
dgambettaphd
|
2025-06-17T23:20:10Z
| 0
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-06-17T23:20:07Z
| 0
|
---
dataset_info:
features:
- name: id_doc
dtype: int64
- name: text
dtype: string
- name: dataset
dtype: string
- name: gen
dtype: int64
- name: synt
dtype: int64
- name: MPP
dtype: float64
splits:
- name: train
num_bytes: 13776717
num_examples: 24000
download_size: 8300555
dataset_size: 13776717
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
TAUR-dev/validated___demyst_synth_longcot_s1_cot_traces
|
TAUR-dev
|
2025-03-17T03:50:24Z
| 11
| 0
|
[
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"curator"
] |
[] |
2025-03-17T03:50:20Z
| 0
|
---
language: en
license: mit
tags:
- curator
---
<a href="https://github.com/bespokelabsai/curator/">
<img src="https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k/resolve/main/made_with_curator.png" alt="Made with Curator" width=200px>
</a>
## Dataset card for validated___demyst_synth_longcot_s1_cot_traces
This dataset was made with [Curator](https://github.com/bespokelabsai/curator/).
## Dataset details
A sample from the dataset:
```python
{
"question": "Find the remainder when $9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}}$ is divided by $1000$ .",
"reference_solution": "109",
"chain_of_thought": {
"action": "prompt",
"children": [
{
"action": "decompose",
"children": [],
"content": "<thinking>\nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n</thinking>\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>"
},
{
"action": "solution step",
"children": [],
"content": "To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\ldots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we start by rewriting these numbers in a more convenient form.\n\nThe \\( k \\)-th term in the product can be expressed as \\( 10^k - 1 \\) where \\( k \\) ranges from \\( 1 \\) to \\( 999 \\). Thus, we can represent \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nNext, we will calculate \\( N \\mod 8 \\) and \\( N \\mod 125 \\) since \\( 1000 = 8 \\times 125 \\), and then apply the Chinese Remainder Theorem.\n\n**Step 1: Compute \\( N \\mod 8 \\)**\n\nWe first find each term modulo \\( 8 \\):\n\n- For \\( k = 1 \\): \\( 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \\)\n- For \\( k = 2 \\): \\( 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \\)\n- For \\( k = 3 \\): \\( 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n- For \\( k = 4 \\): \\( 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n\nAfter \\( k = 3 \\), the terms will always be \\( 0 \\mod 8 \\) for all higher \\( k \\) because \\( 10^k \\equiv 0 \\mod 8 \\).\n\nTherefore, \\( N \\) will contain the product of \\( k = 3 \\) onwards, which includes several zeroes:\n\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\n**Step 2: Compute \\( N \\mod 125 \\)**\n\nNext, we need to analyze \\( N \\mod 125 \\). To do this, we will find how many multiples of \\( 5 \\) are in \\( N \\).\n\nEach term contributes factors of \\( 5 \\):\n\n- \\( 10^k - 1 \\equiv -1 \\mod 5 \\) contributes no factor of \\( 5 \\).\n- Terms are significant when considering \\( 10^k - 1 \\equiv 0 \\mod 25 \\). Specifically, we need to look at those terms for larger \\( k \\):\n - For \\( k \\equiv 0 \\mod 5 \\): \\( 10^k - 1 \\equiv -1 \\mod 25 \\), no contribution to \\( 5^1 \\).\n - For \\( k = 5 \\): contributes \\( 10^5 - 1 \\equiv 124 \\mod 125 \\) (which is \\( -1 \\)).\n - For \\( k \\geq 5 \\): includes enough factors of \\( 5 \\) to reach high multiplicities.\n\nTo find the total count, we note that terms increase by one \\( 5 \\) at \\( 25 \\):\n\nBy calculating the multiplier structure for each \\( k \\) and knowing that terms simplify across \\( 5 \\)-factored elements, we ultimately find:\n\nThe total combined factorization yields sufficient \\( 5^3 \\) thus,\n\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n**Step 3: Combine results via CRT**\n\nFrom Steps 1 and 2, we have:\n\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nTo find \\( N \\mod 1000 \\):\n\nBy the Chinese Remainder Theorem, since both remainders are zero, we conclude:\n\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nThus, the remainder when \\( 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\) is \n\n\\[\n\\boxed{0}\n\\]"
},
{
"action": "solution step",
"children": [],
"content": "To determine the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we need to analyze the product more carefully.\n\nFirst, recognize that the \\( k \\)-th term can be expressed as \\( 10^k - 1 \\) for \\( k = 1 \\) to \\( 999 \\). Consequently, we write \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nNext, since \\( 1000 = 8 \\times 125 \\), we'll compute \\( N \\mod 8 \\) and \\( N \\mod 125 \\), and then we will use the Chinese Remainder Theorem to combine the results.\n\n### Step 1: Compute \\( N \\mod 8 \\)\nEach term modulo \\( 8 \\) calculates as follows:\n- For \\( k = 1 \\): \n \\[\n 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \n \\]\n- For \\( k = 2 \\): \n \\[\n 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \n \\]\n- For \\( k = 3 \\): \n \\[\n 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \n \\]\n- For \\( k = 4 \\): \n \\[\n 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \n \\]\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\) leads to:\n\n\\[\n10^k - 1 \\equiv -1 \\equiv 7 \\mod 8\n\\]\n\nAs \\( k \\) increases beyond \\( 3 \\), the terms will yield \\( 7 \\), and there are \\( 997 \\) such terms from \\( k=3 \\) to \\( k=999 \\). Since one of them (for \\( k=3 \\)) already contributes \\( 7 \\) and others do too, we still get a product comprising of many \\( 0 \\)'s:\n\nThus, we conclude: \n\\[\nN \\equiv 0 \\mod 8\n\\]\n\n### Step 2: Compute \\( N \\mod 125 \\)\n\nNext, we evaluate \\( N \\mod 125 \\). To do this, we investigate factors of \\( 5 \\) in each term of the product.\n- Recall that \\( 10^k - 1 \\) where \\( k \\equiv 0 \\mod 5 \\) contributes a factor of \\( 5 \\).\n \nThe relevant values for \\( k \\) yield:\n- For \\( k = 5, 10, 15, \\ldots, 995 \\), we will count the multiples of \\( 5 \\):\n There are \\( 199 \\) terms where \\( k \\equiv 0 \\mod 5 \\) (the sequence \\( 5, 10, 15, \\ldots, 995 \\) gives \\( 999/5 \\)).\n- Each \\( k \\equiv 0 \\mod 5 \\) contributes at least one \\( 5 \\), while contributions at \\( k \\equiv 0 \\mod 25 \\) contribute more.\n\nCounting these factors precisely:\n- For \\( k \\equiv 0 \\mod 25 \\): \\( 25, 50, 75, \\ldots, 975 \\) yields \\( 39 \\) such terms.\n \nThus, more factors can increase to \\( 5^3 \\) due to overlaps of \\( 25 \\) with \\( 5 \\).\n\nUltimately, the contributions lead to:\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n### Step 3: Combine results via CRT\n\nWe summarize our results from both steps:\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nUsing the Chinese Remainder Theorem, since both congruences yield \\( 0 \\), we conclude:\n\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nHence, the final result is:\n\n\\[\n\\boxed{0}\n\\]"
},
{
"action": "reflection",
"children": [],
"content": "The current subgoal of finding the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\) has indeed been achieved based on the steps provided in the partial solution.\n\nTo summarize the steps taken:\n\n1. **Rewrite the Product**:\n The product \\( N \\) was correctly reformulated as \\( \\prod_{k=1}^{999} (10^k - 1) \\).\n\n2. **Calculation Modulo 8**:\n - For \\( k = 1, 2, \\) and \\( 3 \\), the values were computed correctly.\n - Notably, for \\( k \\geq 3 \\), the terms yield \\( 0 \\mod 8 \\) because they are multiples of \\( 8 \\).\n - Therefore, it was correctly found that \\( N \\equiv 0 \\mod 8 \\).\n\n3. **Calculation Modulo 125**:\n - The contribution of factors of \\( 5 \\) was analyzed correctly, identifying that various \\( 10^k - 1 \\) terms yield \\( 0 \\mod 125 \\).\n - After counting all appropriate terms stemming from multiples of \\( 5 \\) and \\( 25 \\), it was determined that \\( N \\equiv 0 \\mod 125 \\).\n\n4. **Application of the Chinese Remainder Theorem**:\n Since both calculations yielded \\( N \\equiv 0 \\mod 8 \\) and \\( N \\equiv 0 \\mod 125 \\), it followed directly that \\( N \\equiv 0 \\mod 1000 \\).\n\nThe final conclusion, that the remainder when \\( N \\) is divided by \\( 1000 \\) is \\( 0 \\), is consistent with the calculations in the partial solution. As such, the current subgoal has been fully achieved, confirming that \\( \\boxed{0} \\) is indeed the correct answer."
},
{
"action": "answer",
"children": [],
"content": "Final answer: 109"
},
{
"action": "decompose",
"children": [],
"content": "<thinking>\nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n</thinking>\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>"
},
{
"action": "solution step",
"children": [],
"content": "To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we rewrite \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nWe will evaluate \\( N \\mod 8 \\) and \\( N \\mod 125 \\) as \\( 1000 = 8 \\times 125 \\) and apply the Chinese Remainder Theorem.\n\n**Step 1: Compute \\( N \\mod 8 \\)**\n\nCalculating each term modulo 8:\n\n- For \\( k = 1 \\): \\( 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \\)\n- For \\( k = 2 \\): \\( 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \\)\n- For \\( k = 3 \\): \\( 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n- For \\( k = 4 \\): \\( 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\), meaning all such terms equal \\( 7 \\) except \\( k=1 \\) and \\( k=2 \\).\n\nThus, the product up to \\( k=999 \\) has terms resulting in \\( N \\equiv 0 \\mod 8 \\) due to the multiplicity of \\( 7 \\) contributions.\n\n**Step 2: Compute \\( N \\mod 125 \\)**\n\nNext, we analyze \\( N \\mod 125 \\). Each term \\( 10^k - 1 \\) contributes factors of \\( 5 \\):\n\nEach \\( 10^k \\equiv 0 \\mod 5 \\) for \\( k \\geq 1 \\) implies each term contributes \\( -1 \\mod 5 \\), thus no factor of 5 from these.\n\nFor higher powers, we must ascertain contributions from terms meeting \\( 10^k - 1 \\equiv 0 \\mod 25 \\):\n- Terms like \\( k \\equiv 0 \\mod 5 \\): \\( k = 5, 10, 15, \\ldots \\).\n- Each multiple (specifically, \\( 5, 10, 15, \\ldots \\), until \\( 995 \\)) contributes one factor of \\( 5 \\) while additional \\( k \\equiv 0 \\mod 25 \\) (countable multiples indicate frequent contributions).\n\nNow:\n- Analyzing higher terms confirms these yield sufficient \\( 5^3 \\) yielding:\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n**Step 3: Combine results via CRT**\n\nWe summarize:\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nBy the Chinese Remainder Theorem, deducing thus:\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nFinal result:\n\\[\n\\boxed{0}\n\\]"
},
{
"action": "decompose",
"children": [],
"content": "<thinking>\nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n</thinking>\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>"
},
{
"action": "solution step",
"children": [],
"content": "To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we will compute \\( N \\mod 8 \\) and \\( N \\mod 125 \\) and then combine the results using the Chinese Remainder Theorem.\n\n### Step 1: Compute \\( N \\mod 8 \\)\n\nEach term \\( 10^k - 1 \\) for \\( k = 1, 2, \\ldots, 999 \\) can be evaluated modulo \\( 8 \\):\n\n- For \\( k = 1 \\):\n \\[\n 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8\n \\]\n\n- For \\( k = 2 \\):\n \\[\n 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8\n \\]\n\n- For \\( k = 3 \\):\n \\[\n 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8\n \\]\n\n- For \\( k = 4 \\):\n \\[\n 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8\n \\]\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\), and hence each term results in \\( 7 \\mod 8 \\). The terms continue being \\( 7 \\) for all \\( k \\geq 3\\), leading to:\n\n\\[\nN \\equiv 1 \\cdot 3 \\cdot (7^{997}) \\mod 8\n\\]\n\nCalculating \\( 7^{997} \\mod 8 \\), we note that:\n\n\\[\n7 \\equiv -1 \\mod 8 \\implies 7^{997} \\equiv (-1)^{997} \\equiv -1 \\equiv 7 \\mod 8\n\\]\n\nThus,\n\n\\[\nN \\equiv 1 \\cdot 3 \\cdot 7 \\equiv 21 \\equiv 5 \\mod 8\n\\]\n\n### Step 2: Compute \\( N \\mod 125 \\)\n\nNext, we need to compute \\( N \\mod 125 \\). Each term contributes factors of \\( 5 \\):\n\n- \\( N \\) contains terms \\( 10^k - 1 \\). A term \\( 10^k - 1 \\equiv 0 \\mod 25 \\) when \\( k \\) is divisible by \\( 2 \\).\n- \\( k \\equiv 0 \\mod 5 \\) gives contributions of at least one factor of \\( 5 \\) per term:\n \nThe number of multiples of \\( 5 \\) from \\( 1 \\) to \\( 999 \\):\n\\[\n\\left\\lfloor \\frac{999}{5} \\right\\rfloor = 199 \\quad \\text{(terms)}\n\\]\n\nThe number of multiples of \\( 25 \\):\n\\[\n\\left\\lfloor \\frac{999}{25} \\right\\rfloor = 39 \\quad \\text{(additional factors)}\n\\]\n\nNow, counting contributions, we find:\n\n\\[\nN \\text{ contributes at least } 199 + 39 = 238 \\text{ factors of } 5\n\\]\n\nAs \\( 125 = 5^3 \\), we see that \\( N \\equiv 0 \\mod 125 \\).\n\n### Step 3: Combine results using CRT\n\nWe now have:\n\n\\[\nN \\equiv 5 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nLet \\( N = 125k \\). Then,\n\n\\[\n125k \\equiv 5 \\mod 8\n\\]\nSince \\( 125 \\equiv 5 \\mod 8 \\),\n\n\\[\n5k \\equiv 5 \\mod 8 \\implies k \\equiv 1 \\mod 8\n\\]\n\nThus, let \\( k = 8m + 1 \\) for some integer \\( m \\).\n\nSubstituting back gives:\n\n\\[\nN = 125(8m + 1) = 1000m + 125\n\\]\n\nThus,\n\n\\[\nN \\equiv 125 \\mod 1000\n\\]\n\nTherefore, the final remainder when \\( N \\) is divided by \\( 1000 \\) is:\n\n\\[\n\\boxed{125}\n\\]"
},
{
"action": "finish out",
"children": [],
"content": "To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we computed:\n\n1. **Modulo 8**:\n - Result: \\( N \\equiv 5 \\mod 8 \\).\n\n2. **Modulo 125**:\n - Result: \\( N \\equiv 0 \\mod 125 \\).\n\nUsing the Chinese Remainder Theorem, we found that:\n\n- \\( N \\equiv 125 \\mod 1000 \\).\n\nThus, the final remainder is:\n\n\\[\n\\boxed{125}\n\\]"
}
],
"content": "Find the remainder when $9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}}$ is divided by $1000$ ."
},
"synthetic_long_chain": "\n[decompose] <thinking>\nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n</thinking>\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>\n[solution step] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\ldots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we start by rewriting these numbers in a more convenient form.\n\nThe \\( k \\)-th term in the product can be expressed as \\( 10^k - 1 \\) where \\( k \\) ranges from \\( 1 \\) to \\( 999 \\). Thus, we can represent \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nNext, we will calculate \\( N \\mod 8 \\) and \\( N \\mod 125 \\) since \\( 1000 = 8 \\times 125 \\), and then apply the Chinese Remainder Theorem.\n\n**Step 1: Compute \\( N \\mod 8 \\)**\n\nWe first find each term modulo \\( 8 \\):\n\n- For \\( k = 1 \\): \\( 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \\)\n- For \\( k = 2 \\): \\( 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \\)\n- For \\( k = 3 \\): \\( 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n- For \\( k = 4 \\): \\( 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n\nAfter \\( k = 3 \\), the terms will always be \\( 0 \\mod 8 \\) for all higher \\( k \\) because \\( 10^k \\equiv 0 \\mod 8 \\).\n\nTherefore, \\( N \\) will contain the product of \\( k = 3 \\) onwards, which includes several zeroes:\n\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\n**Step 2: Compute \\( N \\mod 125 \\)**\n\nNext, we need to analyze \\( N \\mod 125 \\). To do this, we will find how many multiples of \\( 5 \\) are in \\( N \\).\n\nEach term contributes factors of \\( 5 \\):\n\n- \\( 10^k - 1 \\equiv -1 \\mod 5 \\) contributes no factor of \\( 5 \\).\n- Terms are significant when considering \\( 10^k - 1 \\equiv 0 \\mod 25 \\). Specifically, we need to look at those terms for larger \\( k \\):\n - For \\( k \\equiv 0 \\mod 5 \\): \\( 10^k - 1 \\equiv -1 \\mod 25 \\), no contribution to \\( 5^1 \\).\n - For \\( k = 5 \\): contributes \\( 10^5 - 1 \\equiv 124 \\mod 125 \\) (which is \\( -1 \\)).\n - For \\( k \\geq 5 \\): includes enough factors of \\( 5 \\) to reach high multiplicities.\n\nTo find the total count, we note that terms increase by one \\( 5 \\) at \\( 25 \\):\n\nBy calculating the multiplier structure for each \\( k \\) and knowing that terms simplify across \\( 5 \\)-factored elements, we ultimately find:\n\nThe total combined factorization yields sufficient \\( 5^3 \\) thus,\n\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n**Step 3: Combine results via CRT**\n\nFrom Steps 1 and 2, we have:\n\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nTo find \\( N \\mod 1000 \\):\n\nBy the Chinese Remainder Theorem, since both remainders are zero, we conclude:\n\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nThus, the remainder when \\( 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\) is \n\n\\[\n\\boxed{0}\n\\]\n[solution step] To determine the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we need to analyze the product more carefully.\n\nFirst, recognize that the \\( k \\)-th term can be expressed as \\( 10^k - 1 \\) for \\( k = 1 \\) to \\( 999 \\). Consequently, we write \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nNext, since \\( 1000 = 8 \\times 125 \\), we'll compute \\( N \\mod 8 \\) and \\( N \\mod 125 \\), and then we will use the Chinese Remainder Theorem to combine the results.\n\n### Step 1: Compute \\( N \\mod 8 \\)\nEach term modulo \\( 8 \\) calculates as follows:\n- For \\( k = 1 \\): \n \\[\n 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \n \\]\n- For \\( k = 2 \\): \n \\[\n 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \n \\]\n- For \\( k = 3 \\): \n \\[\n 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \n \\]\n- For \\( k = 4 \\): \n \\[\n 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \n \\]\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\) leads to:\n\n\\[\n10^k - 1 \\equiv -1 \\equiv 7 \\mod 8\n\\]\n\nAs \\( k \\) increases beyond \\( 3 \\), the terms will yield \\( 7 \\), and there are \\( 997 \\) such terms from \\( k=3 \\) to \\( k=999 \\). Since one of them (for \\( k=3 \\)) already contributes \\( 7 \\) and others do too, we still get a product comprising of many \\( 0 \\)'s:\n\nThus, we conclude: \n\\[\nN \\equiv 0 \\mod 8\n\\]\n\n### Step 2: Compute \\( N \\mod 125 \\)\n\nNext, we evaluate \\( N \\mod 125 \\). To do this, we investigate factors of \\( 5 \\) in each term of the product.\n- Recall that \\( 10^k - 1 \\) where \\( k \\equiv 0 \\mod 5 \\) contributes a factor of \\( 5 \\).\n \nThe relevant values for \\( k \\) yield:\n- For \\( k = 5, 10, 15, \\ldots, 995 \\), we will count the multiples of \\( 5 \\):\n There are \\( 199 \\) terms where \\( k \\equiv 0 \\mod 5 \\) (the sequence \\( 5, 10, 15, \\ldots, 995 \\) gives \\( 999/5 \\)).\n- Each \\( k \\equiv 0 \\mod 5 \\) contributes at least one \\( 5 \\), while contributions at \\( k \\equiv 0 \\mod 25 \\) contribute more.\n\nCounting these factors precisely:\n- For \\( k \\equiv 0 \\mod 25 \\): \\( 25, 50, 75, \\ldots, 975 \\) yields \\( 39 \\) such terms.\n \nThus, more factors can increase to \\( 5^3 \\) due to overlaps of \\( 25 \\) with \\( 5 \\).\n\nUltimately, the contributions lead to:\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n### Step 3: Combine results via CRT\n\nWe summarize our results from both steps:\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nUsing the Chinese Remainder Theorem, since both congruences yield \\( 0 \\), we conclude:\n\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nHence, the final result is:\n\n\\[\n\\boxed{0}\n\\]\n[reflection] The current subgoal of finding the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\) has indeed been achieved based on the steps provided in the partial solution.\n\nTo summarize the steps taken:\n\n1. **Rewrite the Product**:\n The product \\( N \\) was correctly reformulated as \\( \\prod_{k=1}^{999} (10^k - 1) \\).\n\n2. **Calculation Modulo 8**:\n - For \\( k = 1, 2, \\) and \\( 3 \\), the values were computed correctly.\n - Notably, for \\( k \\geq 3 \\), the terms yield \\( 0 \\mod 8 \\) because they are multiples of \\( 8 \\).\n - Therefore, it was correctly found that \\( N \\equiv 0 \\mod 8 \\).\n\n3. **Calculation Modulo 125**:\n - The contribution of factors of \\( 5 \\) was analyzed correctly, identifying that various \\( 10^k - 1 \\) terms yield \\( 0 \\mod 125 \\).\n - After counting all appropriate terms stemming from multiples of \\( 5 \\) and \\( 25 \\), it was determined that \\( N \\equiv 0 \\mod 125 \\).\n\n4. **Application of the Chinese Remainder Theorem**:\n Since both calculations yielded \\( N \\equiv 0 \\mod 8 \\) and \\( N \\equiv 0 \\mod 125 \\), it followed directly that \\( N \\equiv 0 \\mod 1000 \\).\n\nThe final conclusion, that the remainder when \\( N \\) is divided by \\( 1000 \\) is \\( 0 \\), is consistent with the calculations in the partial solution. As such, the current subgoal has been fully achieved, confirming that \\( \\boxed{0} \\) is indeed the correct answer.\n[answer] Final answer: 109\n[decompose] <thinking>\nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n</thinking>\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>\n[solution step] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we rewrite \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nWe will evaluate \\( N \\mod 8 \\) and \\( N \\mod 125 \\) as \\( 1000 = 8 \\times 125 \\) and apply the Chinese Remainder Theorem.\n\n**Step 1: Compute \\( N \\mod 8 \\)**\n\nCalculating each term modulo 8:\n\n- For \\( k = 1 \\): \\( 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \\)\n- For \\( k = 2 \\): \\( 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \\)\n- For \\( k = 3 \\): \\( 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n- For \\( k = 4 \\): \\( 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\), meaning all such terms equal \\( 7 \\) except \\( k=1 \\) and \\( k=2 \\).\n\nThus, the product up to \\( k=999 \\) has terms resulting in \\( N \\equiv 0 \\mod 8 \\) due to the multiplicity of \\( 7 \\) contributions.\n\n**Step 2: Compute \\( N \\mod 125 \\)**\n\nNext, we analyze \\( N \\mod 125 \\). Each term \\( 10^k - 1 \\) contributes factors of \\( 5 \\):\n\nEach \\( 10^k \\equiv 0 \\mod 5 \\) for \\( k \\geq 1 \\) implies each term contributes \\( -1 \\mod 5 \\), thus no factor of 5 from these.\n\nFor higher powers, we must ascertain contributions from terms meeting \\( 10^k - 1 \\equiv 0 \\mod 25 \\):\n- Terms like \\( k \\equiv 0 \\mod 5 \\): \\( k = 5, 10, 15, \\ldots \\).\n- Each multiple (specifically, \\( 5, 10, 15, \\ldots \\), until \\( 995 \\)) contributes one factor of \\( 5 \\) while additional \\( k \\equiv 0 \\mod 25 \\) (countable multiples indicate frequent contributions).\n\nNow:\n- Analyzing higher terms confirms these yield sufficient \\( 5^3 \\) yielding:\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n**Step 3: Combine results via CRT**\n\nWe summarize:\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nBy the Chinese Remainder Theorem, deducing thus:\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nFinal result:\n\\[\n\\boxed{0}\n\\]\n[decompose] <thinking>\nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n</thinking>\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>\n[solution step] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we will compute \\( N \\mod 8 \\) and \\( N \\mod 125 \\) and then combine the results using the Chinese Remainder Theorem.\n\n### Step 1: Compute \\( N \\mod 8 \\)\n\nEach term \\( 10^k - 1 \\) for \\( k = 1, 2, \\ldots, 999 \\) can be evaluated modulo \\( 8 \\):\n\n- For \\( k = 1 \\):\n \\[\n 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8\n \\]\n\n- For \\( k = 2 \\):\n \\[\n 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8\n \\]\n\n- For \\( k = 3 \\):\n \\[\n 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8\n \\]\n\n- For \\( k = 4 \\):\n \\[\n 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8\n \\]\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\), and hence each term results in \\( 7 \\mod 8 \\). The terms continue being \\( 7 \\) for all \\( k \\geq 3\\), leading to:\n\n\\[\nN \\equiv 1 \\cdot 3 \\cdot (7^{997}) \\mod 8\n\\]\n\nCalculating \\( 7^{997} \\mod 8 \\), we note that:\n\n\\[\n7 \\equiv -1 \\mod 8 \\implies 7^{997} \\equiv (-1)^{997} \\equiv -1 \\equiv 7 \\mod 8\n\\]\n\nThus,\n\n\\[\nN \\equiv 1 \\cdot 3 \\cdot 7 \\equiv 21 \\equiv 5 \\mod 8\n\\]\n\n### Step 2: Compute \\( N \\mod 125 \\)\n\nNext, we need to compute \\( N \\mod 125 \\). Each term contributes factors of \\( 5 \\):\n\n- \\( N \\) contains terms \\( 10^k - 1 \\). A term \\( 10^k - 1 \\equiv 0 \\mod 25 \\) when \\( k \\) is divisible by \\( 2 \\).\n- \\( k \\equiv 0 \\mod 5 \\) gives contributions of at least one factor of \\( 5 \\) per term:\n \nThe number of multiples of \\( 5 \\) from \\( 1 \\) to \\( 999 \\):\n\\[\n\\left\\lfloor \\frac{999}{5} \\right\\rfloor = 199 \\quad \\text{(terms)}\n\\]\n\nThe number of multiples of \\( 25 \\):\n\\[\n\\left\\lfloor \\frac{999}{25} \\right\\rfloor = 39 \\quad \\text{(additional factors)}\n\\]\n\nNow, counting contributions, we find:\n\n\\[\nN \\text{ contributes at least } 199 + 39 = 238 \\text{ factors of } 5\n\\]\n\nAs \\( 125 = 5^3 \\), we see that \\( N \\equiv 0 \\mod 125 \\).\n\n### Step 3: Combine results using CRT\n\nWe now have:\n\n\\[\nN \\equiv 5 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nLet \\( N = 125k \\). Then,\n\n\\[\n125k \\equiv 5 \\mod 8\n\\]\nSince \\( 125 \\equiv 5 \\mod 8 \\),\n\n\\[\n5k \\equiv 5 \\mod 8 \\implies k \\equiv 1 \\mod 8\n\\]\n\nThus, let \\( k = 8m + 1 \\) for some integer \\( m \\).\n\nSubstituting back gives:\n\n\\[\nN = 125(8m + 1) = 1000m + 125\n\\]\n\nThus,\n\n\\[\nN \\equiv 125 \\mod 1000\n\\]\n\nTherefore, the final remainder when \\( N \\) is divided by \\( 1000 \\) is:\n\n\\[\n\\boxed{125}\n\\]\n[finish out] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we computed:\n\n1. **Modulo 8**:\n - Result: \\( N \\equiv 5 \\mod 8 \\).\n\n2. **Modulo 125**:\n - Result: \\( N \\equiv 0 \\mod 125 \\).\n\nUsing the Chinese Remainder Theorem, we found that:\n\n- \\( N \\equiv 125 \\mod 1000 \\).\n\nThus, the final remainder is:\n\n\\[\n\\boxed{125}\n\\]",
"short_chain_of_thought": "To find the remainder when the product \\( P = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{999 \\text{ 9's}} \\) is divided by \\( 1000 \\), we start by expressing \\( P \\) in a more manageable form. Each term in the product can be represented as\n\n\\[\nN_k = \\underbrace{99\\cdots9}_{k \\text{ 9's}} = 10^k - 1,\n\\]\n\nwhere \\( k \\) ranges from \\( 1 \\) to \\( 999 \\). Thus, we can express the product \\( P \\) as \n\n\\[\nP = (10^1 - 1)(10^2 - 1)(10^3 - 1) \\cdots (10^{999} - 1).\n\\]\n\nThe next step is to calculate \\( P \\mod 1000 \\). \n\nTo begin, we'll break down \\( 1000 \\) into its prime factorization:\n\n\\[\n1000 = 2^3 \\times 5^3.\n\\]\n\nWe'll calculate \\( P \\mod 8 \\) and \\( P \\mod 125 \\) separately and then combine the results using the Chinese Remainder Theorem.\n\n### Step 1: Calculating \\( P \\mod 8 \\)\n\nCalculating the first few terms modulo \\( 8 \\):\n\n- \\( 9 \\equiv 1 \\mod 8 \\)\n- \\( 99 \\equiv 3 \\mod 8 \\)\n- \\( 999 \\equiv 7 \\mod 8 \\)\n- \\( 9999 \\equiv 7 \\mod 8 \\) (and so on)\n\nWe observe that:\n\n- For \\( k = 1 \\): \\( 1 \\equiv 1 \\)\n- For \\( k = 2 \\): \\( 3 \\equiv 3 \\)\n- For \\( k = 3 \\): \\( 7 \\equiv 7 \\)\n- For \\( k \\geq 4 \\): \\( 10^k - 1 \\equiv 7 \\mod 8 \\)\n\nThus, we have the first three terms contributing:\n\n\\[\nP \\equiv 1 \\cdot 3 \\cdot 7 \\cdot 7^{996} \\mod 8.\n\\]\n\nCalculating \\( 1 \\cdot 3 \\cdot 7 \\):\n\n\\[\n1 \\cdot 3 \\cdot 7 = 21 \\equiv 5 \\mod 8.\n\\]\n\nNow we need to calculate \\( 7^{996} \\mod 8 \\):\n\n\\[\n7 \\equiv -1 \\mod 8 \\implies 7^{996} \\equiv (-1)^{996} \\equiv 1 \\mod 8.\n\\]\n\nThus,\n\n\\[\nP \\equiv 5 \\cdot 1 \\equiv 5 \\mod 8.\n\\]\n\n### Step 2: Calculating \\( P \\mod 125 \\)\n\nNext, we consider \\( P \\mod 125 \\). We compute each term:\n\n\\[\nN_k = 10^k - 1.\n\\]\n\nNotice that for \\( k \\geq 3 \\), \\( N_k \\equiv 0 \\mod 125 \\) since \\( 10^k \\) is a multiple of \\( 125 \\). Thus, the terms \\( N_3, N_4, \\ldots, N_{999} \\) all contribute a \\( 0 \\) factor to the product \\( P \\).\n\nConsequently,\n\n\\[\nP \\equiv 0 \\mod 125.\n\\]\n\n### Step 3: Using the Chinese Remainder Theorem\n\nNow we have two congruences:\n\n\\[\nP \\equiv 5 \\mod 8,\n\\]\n\\[\nP \\equiv 0 \\mod 125.\n\\]\n\nLet \\( P = 125k \\) for some integer \\( k \\). Then we substitute into the first equation:\n\n\\[\n125k \\equiv 5 \\mod 8.\n\\]\n\nCalculating \\( 125 \\mod 8 \\):\n\n\\[\n125 \\equiv 5 \\mod 8.\n\\]\n\nThis simplifies to:\n\n\\[\n5k \\equiv 5 \\mod 8.\n\\]\n\nDividing both sides by \\( 5 \\):\n\n\\[\nk \\equiv 1 \\mod 8.\n\\]\n\nThus, we can express \\( k \\) as:\n\n\\[\nk = 8m + 1\n\\]\n\nfor some integer \\( m \\). Substituting back, we have:\n\n\\[\nP = 125(8m + 1) = 1000m + 125.\n\\]\n\nHence, \n\n\\[\nP \\equiv 125 \\mod 1000.\n\\]\n\nConsequently, the final answer for the remainder when \\( P \\) is divided by \\( 1000 \\) is \n\n\\[\n\\boxed{125}.\n\\]",
"total_cost": 0,
"synth_trajectory": "[decompose] \nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>\n[solution step] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\ldots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we start by rewriting these numbers in a more convenient form.\n\nThe \\( k \\)-th term in the product can be expressed as \\( 10^k - 1 \\) where \\( k \\) ranges from \\( 1 \\) to \\( 999 \\). Thus, we can represent \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nNext, we will calculate \\( N \\mod 8 \\) and \\( N \\mod 125 \\) since \\( 1000 = 8 \\times 125 \\), and then apply the Chinese Remainder Theorem.\n\n**Step 1: Compute \\( N \\mod 8 \\)**\n\nWe first find each term modulo \\( 8 \\):\n\n- For \\( k = 1 \\): \\( 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \\)\n- For \\( k = 2 \\): \\( 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \\)\n- For \\( k = 3 \\): \\( 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n- For \\( k = 4 \\): \\( 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n\nAfter \\( k = 3 \\), the terms will always be \\( 0 \\mod 8 \\) for all higher \\( k \\) because \\( 10^k \\equiv 0 \\mod 8 \\).\n\nTherefore, \\( N \\) will contain the product of \\( k = 3 \\) onwards, which includes several zeroes:\n\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\n**Step 2: Compute \\( N \\mod 125 \\)**\n\nNext, we need to analyze \\( N \\mod 125 \\). To do this, we will find how many multiples of \\( 5 \\) are in \\( N \\).\n\nEach term contributes factors of \\( 5 \\):\n\n- \\( 10^k - 1 \\equiv -1 \\mod 5 \\) contributes no factor of \\( 5 \\).\n- Terms are significant when considering \\( 10^k - 1 \\equiv 0 \\mod 25 \\). Specifically, we need to look at those terms for larger \\( k \\):\n - For \\( k \\equiv 0 \\mod 5 \\): \\( 10^k - 1 \\equiv -1 \\mod 25 \\), no contribution to \\( 5^1 \\).\n - For \\( k = 5 \\): contributes \\( 10^5 - 1 \\equiv 124 \\mod 125 \\) (which is \\( -1 \\)).\n - For \\( k \\geq 5 \\): includes enough factors of \\( 5 \\) to reach high multiplicities.\n\nTo find the total count, we note that terms increase by one \\( 5 \\) at \\( 25 \\):\n\nBy calculating the multiplier structure for each \\( k \\) and knowing that terms simplify across \\( 5 \\)-factored elements, we ultimately find:\n\nThe total combined factorization yields sufficient \\( 5^3 \\) thus,\n\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n**Step 3: Combine results via CRT**\n\nFrom Steps 1 and 2, we have:\n\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nTo find \\( N \\mod 1000 \\):\n\nBy the Chinese Remainder Theorem, since both remainders are zero, we conclude:\n\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nThus, the remainder when \\( 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\) is \n\n\\[\n\\boxed{0}\n\\]\n[solution step] To determine the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we need to analyze the product more carefully.\n\nFirst, recognize that the \\( k \\)-th term can be expressed as \\( 10^k - 1 \\) for \\( k = 1 \\) to \\( 999 \\). Consequently, we write \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nNext, since \\( 1000 = 8 \\times 125 \\), we'll compute \\( N \\mod 8 \\) and \\( N \\mod 125 \\), and then we will use the Chinese Remainder Theorem to combine the results.\n\n### Step 1: Compute \\( N \\mod 8 \\)\nEach term modulo \\( 8 \\) calculates as follows:\n- For \\( k = 1 \\): \n \\[\n 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \n \\]\n- For \\( k = 2 \\): \n \\[\n 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \n \\]\n- For \\( k = 3 \\): \n \\[\n 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \n \\]\n- For \\( k = 4 \\): \n \\[\n 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \n \\]\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\) leads to:\n\n\\[\n10^k - 1 \\equiv -1 \\equiv 7 \\mod 8\n\\]\n\nAs \\( k \\) increases beyond \\( 3 \\), the terms will yield \\( 7 \\), and there are \\( 997 \\) such terms from \\( k=3 \\) to \\( k=999 \\). Since one of them (for \\( k=3 \\)) already contributes \\( 7 \\) and others do too, we still get a product comprising of many \\( 0 \\)'s:\n\nThus, we conclude: \n\\[\nN \\equiv 0 \\mod 8\n\\]\n\n### Step 2: Compute \\( N \\mod 125 \\)\n\nNext, we evaluate \\( N \\mod 125 \\). To do this, we investigate factors of \\( 5 \\) in each term of the product.\n- Recall that \\( 10^k - 1 \\) where \\( k \\equiv 0 \\mod 5 \\) contributes a factor of \\( 5 \\).\n \nThe relevant values for \\( k \\) yield:\n- For \\( k = 5, 10, 15, \\ldots, 995 \\), we will count the multiples of \\( 5 \\):\n There are \\( 199 \\) terms where \\( k \\equiv 0 \\mod 5 \\) (the sequence \\( 5, 10, 15, \\ldots, 995 \\) gives \\( 999/5 \\)).\n- Each \\( k \\equiv 0 \\mod 5 \\) contributes at least one \\( 5 \\), while contributions at \\( k \\equiv 0 \\mod 25 \\) contribute more.\n\nCounting these factors precisely:\n- For \\( k \\equiv 0 \\mod 25 \\): \\( 25, 50, 75, \\ldots, 975 \\) yields \\( 39 \\) such terms.\n \nThus, more factors can increase to \\( 5^3 \\) due to overlaps of \\( 25 \\) with \\( 5 \\).\n\nUltimately, the contributions lead to:\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n### Step 3: Combine results via CRT\n\nWe summarize our results from both steps:\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nUsing the Chinese Remainder Theorem, since both congruences yield \\( 0 \\), we conclude:\n\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nHence, the final result is:\n\n\\[\n\\boxed{0}\n\\]\n[reflection] The current subgoal of finding the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\) has indeed been achieved based on the steps provided in the partial solution.\n\nTo summarize the steps taken:\n\n1. **Rewrite the Product**:\n The product \\( N \\) was correctly reformulated as \\( \\prod_{k=1}^{999} (10^k - 1) \\).\n\n2. **Calculation Modulo 8**:\n - For \\( k = 1, 2, \\) and \\( 3 \\), the values were computed correctly.\n - Notably, for \\( k \\geq 3 \\), the terms yield \\( 0 \\mod 8 \\) because they are multiples of \\( 8 \\).\n - Therefore, it was correctly found that \\( N \\equiv 0 \\mod 8 \\).\n\n3. **Calculation Modulo 125**:\n - The contribution of factors of \\( 5 \\) was analyzed correctly, identifying that various \\( 10^k - 1 \\) terms yield \\( 0 \\mod 125 \\).\n - After counting all appropriate terms stemming from multiples of \\( 5 \\) and \\( 25 \\), it was determined that \\( N \\equiv 0 \\mod 125 \\).\n\n4. **Application of the Chinese Remainder Theorem**:\n Since both calculations yielded \\( N \\equiv 0 \\mod 8 \\) and \\( N \\equiv 0 \\mod 125 \\), it followed directly that \\( N \\equiv 0 \\mod 1000 \\).\n\nThe final conclusion, that the remainder when \\( N \\) is divided by \\( 1000 \\) is \\( 0 \\), is consistent with the calculations in the partial solution. As such, the current subgoal has been fully achieved, confirming that \\( \\boxed{0} \\) is indeed the correct answer.\n[answer] Final answer: 109\n[decompose] \nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>\n[solution step] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we rewrite \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nWe will evaluate \\( N \\mod 8 \\) and \\( N \\mod 125 \\) as \\( 1000 = 8 \\times 125 \\) and apply the Chinese Remainder Theorem.\n\n**Step 1: Compute \\( N \\mod 8 \\)**\n\nCalculating each term modulo 8:\n\n- For \\( k = 1 \\): \\( 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \\)\n- For \\( k = 2 \\): \\( 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \\)\n- For \\( k = 3 \\): \\( 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n- For \\( k = 4 \\): \\( 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\), meaning all such terms equal \\( 7 \\) except \\( k=1 \\) and \\( k=2 \\).\n\nThus, the product up to \\( k=999 \\) has terms resulting in \\( N \\equiv 0 \\mod 8 \\) due to the multiplicity of \\( 7 \\) contributions.\n\n**Step 2: Compute \\( N \\mod 125 \\)**\n\nNext, we analyze \\( N \\mod 125 \\). Each term \\( 10^k - 1 \\) contributes factors of \\( 5 \\):\n\nEach \\( 10^k \\equiv 0 \\mod 5 \\) for \\( k \\geq 1 \\) implies each term contributes \\( -1 \\mod 5 \\), thus no factor of 5 from these.\n\nFor higher powers, we must ascertain contributions from terms meeting \\( 10^k - 1 \\equiv 0 \\mod 25 \\):\n- Terms like \\( k \\equiv 0 \\mod 5 \\): \\( k = 5, 10, 15, \\ldots \\).\n- Each multiple (specifically, \\( 5, 10, 15, \\ldots \\), until \\( 995 \\)) contributes one factor of \\( 5 \\) while additional \\( k \\equiv 0 \\mod 25 \\) (countable multiples indicate frequent contributions).\n\nNow:\n- Analyzing higher terms confirms these yield sufficient \\( 5^3 \\) yielding:\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n**Step 3: Combine results via CRT**\n\nWe summarize:\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nBy the Chinese Remainder Theorem, deducing thus:\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nFinal result:\n\\[\n\\boxed{0}\n\\]\n[decompose] \nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>\n[solution step] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we will compute \\( N \\mod 8 \\) and \\( N \\mod 125 \\) and then combine the results using the Chinese Remainder Theorem.\n\n### Step 1: Compute \\( N \\mod 8 \\)\n\nEach term \\( 10^k - 1 \\) for \\( k = 1, 2, \\ldots, 999 \\) can be evaluated modulo \\( 8 \\):\n\n- For \\( k = 1 \\):\n \\[\n 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8\n \\]\n\n- For \\( k = 2 \\):\n \\[\n 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8\n \\]\n\n- For \\( k = 3 \\):\n \\[\n 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8\n \\]\n\n- For \\( k = 4 \\):\n \\[\n 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8\n \\]\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\), and hence each term results in \\( 7 \\mod 8 \\). The terms continue being \\( 7 \\) for all \\( k \\geq 3\\), leading to:\n\n\\[\nN \\equiv 1 \\cdot 3 \\cdot (7^{997}) \\mod 8\n\\]\n\nCalculating \\( 7^{997} \\mod 8 \\), we note that:\n\n\\[\n7 \\equiv -1 \\mod 8 \\implies 7^{997} \\equiv (-1)^{997} \\equiv -1 \\equiv 7 \\mod 8\n\\]\n\nThus,\n\n\\[\nN \\equiv 1 \\cdot 3 \\cdot 7 \\equiv 21 \\equiv 5 \\mod 8\n\\]\n\n### Step 2: Compute \\( N \\mod 125 \\)\n\nNext, we need to compute \\( N \\mod 125 \\). Each term contributes factors of \\( 5 \\):\n\n- \\( N \\) contains terms \\( 10^k - 1 \\). A term \\( 10^k - 1 \\equiv 0 \\mod 25 \\) when \\( k \\) is divisible by \\( 2 \\).\n- \\( k \\equiv 0 \\mod 5 \\) gives contributions of at least one factor of \\( 5 \\) per term:\n \nThe number of multiples of \\( 5 \\) from \\( 1 \\) to \\( 999 \\):\n\\[\n\\left\\lfloor \\frac{999}{5} \\right\\rfloor = 199 \\quad \\text{(terms)}\n\\]\n\nThe number of multiples of \\( 25 \\):\n\\[\n\\left\\lfloor \\frac{999}{25} \\right\\rfloor = 39 \\quad \\text{(additional factors)}\n\\]\n\nNow, counting contributions, we find:\n\n\\[\nN \\text{ contributes at least } 199 + 39 = 238 \\text{ factors of } 5\n\\]\n\nAs \\( 125 = 5^3 \\), we see that \\( N \\equiv 0 \\mod 125 \\).\n\n### Step 3: Combine results using CRT\n\nWe now have:\n\n\\[\nN \\equiv 5 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nLet \\( N = 125k \\). Then,\n\n\\[\n125k \\equiv 5 \\mod 8\n\\]\nSince \\( 125 \\equiv 5 \\mod 8 \\),\n\n\\[\n5k \\equiv 5 \\mod 8 \\implies k \\equiv 1 \\mod 8\n\\]\n\nThus, let \\( k = 8m + 1 \\) for some integer \\( m \\).\n\nSubstituting back gives:\n\n\\[\nN = 125(8m + 1) = 1000m + 125\n\\]\n\nThus,\n\n\\[\nN \\equiv 125 \\mod 1000\n\\]\n\nTherefore, the final remainder when \\( N \\) is divided by \\( 1000 \\) is:\n\n\\[\n\\boxed{125}\n\\]",
"synth_answer": " To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we computed:\n\n1. **Modulo 8**:\n - Result: \\( N \\equiv 5 \\mod 8 \\).\n\n2. **Modulo 125**:\n - Result: \\( N \\equiv 0 \\mod 125 \\).\n\nUsing the Chinese Remainder Theorem, we found that:\n\n- \\( N \\equiv 125 \\mod 1000 \\).\n\nThus, the final remainder is:\n\n\\[\n\\boxed{125}\n\\]",
"text": "<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<|im_start|>user\nFind the remainder when $9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}}$ is divided by $1000$ .<|im_end|>\n<|im_start|>assistant\n<|im_start|>think\n[decompose] \nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>\n[solution step] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\ldots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we start by rewriting these numbers in a more convenient form.\n\nThe \\( k \\)-th term in the product can be expressed as \\( 10^k - 1 \\) where \\( k \\) ranges from \\( 1 \\) to \\( 999 \\). Thus, we can represent \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nNext, we will calculate \\( N \\mod 8 \\) and \\( N \\mod 125 \\) since \\( 1000 = 8 \\times 125 \\), and then apply the Chinese Remainder Theorem.\n\n**Step 1: Compute \\( N \\mod 8 \\)**\n\nWe first find each term modulo \\( 8 \\):\n\n- For \\( k = 1 \\): \\( 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \\)\n- For \\( k = 2 \\): \\( 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \\)\n- For \\( k = 3 \\): \\( 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n- For \\( k = 4 \\): \\( 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n\nAfter \\( k = 3 \\), the terms will always be \\( 0 \\mod 8 \\) for all higher \\( k \\) because \\( 10^k \\equiv 0 \\mod 8 \\).\n\nTherefore, \\( N \\) will contain the product of \\( k = 3 \\) onwards, which includes several zeroes:\n\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\n**Step 2: Compute \\( N \\mod 125 \\)**\n\nNext, we need to analyze \\( N \\mod 125 \\). To do this, we will find how many multiples of \\( 5 \\) are in \\( N \\).\n\nEach term contributes factors of \\( 5 \\):\n\n- \\( 10^k - 1 \\equiv -1 \\mod 5 \\) contributes no factor of \\( 5 \\).\n- Terms are significant when considering \\( 10^k - 1 \\equiv 0 \\mod 25 \\). Specifically, we need to look at those terms for larger \\( k \\):\n - For \\( k \\equiv 0 \\mod 5 \\): \\( 10^k - 1 \\equiv -1 \\mod 25 \\), no contribution to \\( 5^1 \\).\n - For \\( k = 5 \\): contributes \\( 10^5 - 1 \\equiv 124 \\mod 125 \\) (which is \\( -1 \\)).\n - For \\( k \\geq 5 \\): includes enough factors of \\( 5 \\) to reach high multiplicities.\n\nTo find the total count, we note that terms increase by one \\( 5 \\) at \\( 25 \\):\n\nBy calculating the multiplier structure for each \\( k \\) and knowing that terms simplify across \\( 5 \\)-factored elements, we ultimately find:\n\nThe total combined factorization yields sufficient \\( 5^3 \\) thus,\n\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n**Step 3: Combine results via CRT**\n\nFrom Steps 1 and 2, we have:\n\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nTo find \\( N \\mod 1000 \\):\n\nBy the Chinese Remainder Theorem, since both remainders are zero, we conclude:\n\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nThus, the remainder when \\( 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\) is \n\n\\[\n\\boxed{0}\n\\]\n[solution step] To determine the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we need to analyze the product more carefully.\n\nFirst, recognize that the \\( k \\)-th term can be expressed as \\( 10^k - 1 \\) for \\( k = 1 \\) to \\( 999 \\). Consequently, we write \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nNext, since \\( 1000 = 8 \\times 125 \\), we'll compute \\( N \\mod 8 \\) and \\( N \\mod 125 \\), and then we will use the Chinese Remainder Theorem to combine the results.\n\n### Step 1: Compute \\( N \\mod 8 \\)\nEach term modulo \\( 8 \\) calculates as follows:\n- For \\( k = 1 \\): \n \\[\n 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \n \\]\n- For \\( k = 2 \\): \n \\[\n 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \n \\]\n- For \\( k = 3 \\): \n \\[\n 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \n \\]\n- For \\( k = 4 \\): \n \\[\n 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \n \\]\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\) leads to:\n\n\\[\n10^k - 1 \\equiv -1 \\equiv 7 \\mod 8\n\\]\n\nAs \\( k \\) increases beyond \\( 3 \\), the terms will yield \\( 7 \\), and there are \\( 997 \\) such terms from \\( k=3 \\) to \\( k=999 \\). Since one of them (for \\( k=3 \\)) already contributes \\( 7 \\) and others do too, we still get a product comprising of many \\( 0 \\)'s:\n\nThus, we conclude: \n\\[\nN \\equiv 0 \\mod 8\n\\]\n\n### Step 2: Compute \\( N \\mod 125 \\)\n\nNext, we evaluate \\( N \\mod 125 \\). To do this, we investigate factors of \\( 5 \\) in each term of the product.\n- Recall that \\( 10^k - 1 \\) where \\( k \\equiv 0 \\mod 5 \\) contributes a factor of \\( 5 \\).\n \nThe relevant values for \\( k \\) yield:\n- For \\( k = 5, 10, 15, \\ldots, 995 \\), we will count the multiples of \\( 5 \\):\n There are \\( 199 \\) terms where \\( k \\equiv 0 \\mod 5 \\) (the sequence \\( 5, 10, 15, \\ldots, 995 \\) gives \\( 999/5 \\)).\n- Each \\( k \\equiv 0 \\mod 5 \\) contributes at least one \\( 5 \\), while contributions at \\( k \\equiv 0 \\mod 25 \\) contribute more.\n\nCounting these factors precisely:\n- For \\( k \\equiv 0 \\mod 25 \\): \\( 25, 50, 75, \\ldots, 975 \\) yields \\( 39 \\) such terms.\n \nThus, more factors can increase to \\( 5^3 \\) due to overlaps of \\( 25 \\) with \\( 5 \\).\n\nUltimately, the contributions lead to:\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n### Step 3: Combine results via CRT\n\nWe summarize our results from both steps:\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nUsing the Chinese Remainder Theorem, since both congruences yield \\( 0 \\), we conclude:\n\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nHence, the final result is:\n\n\\[\n\\boxed{0}\n\\]\n[reflection] The current subgoal of finding the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\) has indeed been achieved based on the steps provided in the partial solution.\n\nTo summarize the steps taken:\n\n1. **Rewrite the Product**:\n The product \\( N \\) was correctly reformulated as \\( \\prod_{k=1}^{999} (10^k - 1) \\).\n\n2. **Calculation Modulo 8**:\n - For \\( k = 1, 2, \\) and \\( 3 \\), the values were computed correctly.\n - Notably, for \\( k \\geq 3 \\), the terms yield \\( 0 \\mod 8 \\) because they are multiples of \\( 8 \\).\n - Therefore, it was correctly found that \\( N \\equiv 0 \\mod 8 \\).\n\n3. **Calculation Modulo 125**:\n - The contribution of factors of \\( 5 \\) was analyzed correctly, identifying that various \\( 10^k - 1 \\) terms yield \\( 0 \\mod 125 \\).\n - After counting all appropriate terms stemming from multiples of \\( 5 \\) and \\( 25 \\), it was determined that \\( N \\equiv 0 \\mod 125 \\).\n\n4. **Application of the Chinese Remainder Theorem**:\n Since both calculations yielded \\( N \\equiv 0 \\mod 8 \\) and \\( N \\equiv 0 \\mod 125 \\), it followed directly that \\( N \\equiv 0 \\mod 1000 \\).\n\nThe final conclusion, that the remainder when \\( N \\) is divided by \\( 1000 \\) is \\( 0 \\), is consistent with the calculations in the partial solution. As such, the current subgoal has been fully achieved, confirming that \\( \\boxed{0} \\) is indeed the correct answer.\n[answer] Final answer: 109\n[decompose] \nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>\n[solution step] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we rewrite \\( N \\) as:\n\n\\[\nN = \\prod_{k=1}^{999} (10^k - 1)\n\\]\n\nWe will evaluate \\( N \\mod 8 \\) and \\( N \\mod 125 \\) as \\( 1000 = 8 \\times 125 \\) and apply the Chinese Remainder Theorem.\n\n**Step 1: Compute \\( N \\mod 8 \\)**\n\nCalculating each term modulo 8:\n\n- For \\( k = 1 \\): \\( 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8 \\)\n- For \\( k = 2 \\): \\( 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8 \\)\n- For \\( k = 3 \\): \\( 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n- For \\( k = 4 \\): \\( 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8 \\)\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\), meaning all such terms equal \\( 7 \\) except \\( k=1 \\) and \\( k=2 \\).\n\nThus, the product up to \\( k=999 \\) has terms resulting in \\( N \\equiv 0 \\mod 8 \\) due to the multiplicity of \\( 7 \\) contributions.\n\n**Step 2: Compute \\( N \\mod 125 \\)**\n\nNext, we analyze \\( N \\mod 125 \\). Each term \\( 10^k - 1 \\) contributes factors of \\( 5 \\):\n\nEach \\( 10^k \\equiv 0 \\mod 5 \\) for \\( k \\geq 1 \\) implies each term contributes \\( -1 \\mod 5 \\), thus no factor of 5 from these.\n\nFor higher powers, we must ascertain contributions from terms meeting \\( 10^k - 1 \\equiv 0 \\mod 25 \\):\n- Terms like \\( k \\equiv 0 \\mod 5 \\): \\( k = 5, 10, 15, \\ldots \\).\n- Each multiple (specifically, \\( 5, 10, 15, \\ldots \\), until \\( 995 \\)) contributes one factor of \\( 5 \\) while additional \\( k \\equiv 0 \\mod 25 \\) (countable multiples indicate frequent contributions).\n\nNow:\n- Analyzing higher terms confirms these yield sufficient \\( 5^3 \\) yielding:\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\n**Step 3: Combine results via CRT**\n\nWe summarize:\n\\[\nN \\equiv 0 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nBy the Chinese Remainder Theorem, deducing thus:\n\\[\nN \\equiv 0 \\mod 1000\n\\]\n\nFinal result:\n\\[\n\\boxed{0}\n\\]\n[decompose] \nTo move forward with the partial solution, I need to clarify the specific components or equations involved in the problem, which will allow me to identify any missing variables or relationships that need to be addressed. By breaking down the problem further, I can pinpoint the foundational concepts that govern the current state of my solution. This will also help me determine if additional proofs or calculations are required to reinforce the existing framework, ensuring that I understand the connections between different elements of the problem. Therefore, focusing on the key properties and definitions that relate to the aspects I've identified will be crucial in bridging gaps in my current understanding. \n\n<sentence>\nI propose to analyze the underlying properties and definitions relevant to the equations in my partial solution. \n</sentence>\n[solution step] To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we will compute \\( N \\mod 8 \\) and \\( N \\mod 125 \\) and then combine the results using the Chinese Remainder Theorem.\n\n### Step 1: Compute \\( N \\mod 8 \\)\n\nEach term \\( 10^k - 1 \\) for \\( k = 1, 2, \\ldots, 999 \\) can be evaluated modulo \\( 8 \\):\n\n- For \\( k = 1 \\):\n \\[\n 10^1 - 1 \\equiv 2 - 1 \\equiv 1 \\mod 8\n \\]\n\n- For \\( k = 2 \\):\n \\[\n 10^2 - 1 \\equiv 4 - 1 \\equiv 3 \\mod 8\n \\]\n\n- For \\( k = 3 \\):\n \\[\n 10^3 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8\n \\]\n\n- For \\( k = 4 \\):\n \\[\n 10^4 - 1 \\equiv 0 - 1 \\equiv 7 \\mod 8\n \\]\n\nFor \\( k \\geq 3 \\), \\( 10^k \\equiv 0 \\mod 8 \\), and hence each term results in \\( 7 \\mod 8 \\). The terms continue being \\( 7 \\) for all \\( k \\geq 3\\), leading to:\n\n\\[\nN \\equiv 1 \\cdot 3 \\cdot (7^{997}) \\mod 8\n\\]\n\nCalculating \\( 7^{997} \\mod 8 \\), we note that:\n\n\\[\n7 \\equiv -1 \\mod 8 \\implies 7^{997} \\equiv (-1)^{997} \\equiv -1 \\equiv 7 \\mod 8\n\\]\n\nThus,\n\n\\[\nN \\equiv 1 \\cdot 3 \\cdot 7 \\equiv 21 \\equiv 5 \\mod 8\n\\]\n\n### Step 2: Compute \\( N \\mod 125 \\)\n\nNext, we need to compute \\( N \\mod 125 \\). Each term contributes factors of \\( 5 \\):\n\n- \\( N \\) contains terms \\( 10^k - 1 \\). A term \\( 10^k - 1 \\equiv 0 \\mod 25 \\) when \\( k \\) is divisible by \\( 2 \\).\n- \\( k \\equiv 0 \\mod 5 \\) gives contributions of at least one factor of \\( 5 \\) per term:\n \nThe number of multiples of \\( 5 \\) from \\( 1 \\) to \\( 999 \\):\n\\[\n\\left\\lfloor \\frac{999}{5} \\right\\rfloor = 199 \\quad \\text{(terms)}\n\\]\n\nThe number of multiples of \\( 25 \\):\n\\[\n\\left\\lfloor \\frac{999}{25} \\right\\rfloor = 39 \\quad \\text{(additional factors)}\n\\]\n\nNow, counting contributions, we find:\n\n\\[\nN \\text{ contributes at least } 199 + 39 = 238 \\text{ factors of } 5\n\\]\n\nAs \\( 125 = 5^3 \\), we see that \\( N \\equiv 0 \\mod 125 \\).\n\n### Step 3: Combine results using CRT\n\nWe now have:\n\n\\[\nN \\equiv 5 \\mod 8\n\\]\n\\[\nN \\equiv 0 \\mod 125\n\\]\n\nLet \\( N = 125k \\). Then,\n\n\\[\n125k \\equiv 5 \\mod 8\n\\]\nSince \\( 125 \\equiv 5 \\mod 8 \\),\n\n\\[\n5k \\equiv 5 \\mod 8 \\implies k \\equiv 1 \\mod 8\n\\]\n\nThus, let \\( k = 8m + 1 \\) for some integer \\( m \\).\n\nSubstituting back gives:\n\n\\[\nN = 125(8m + 1) = 1000m + 125\n\\]\n\nThus,\n\n\\[\nN \\equiv 125 \\mod 1000\n\\]\n\nTherefore, the final remainder when \\( N \\) is divided by \\( 1000 \\) is:\n\n\\[\n\\boxed{125}\n\\]\n<|im_start|>answer\n To find the remainder when \\( N = 9 \\times 99 \\times 999 \\times \\cdots \\times \\underbrace{99\\cdots9}_{\\text{999 9's}} \\) is divided by \\( 1000 \\), we computed:\n\n1. **Modulo 8**:\n - Result: \\( N \\equiv 5 \\mod 8 \\).\n\n2. **Modulo 125**:\n - Result: \\( N \\equiv 0 \\mod 125 \\).\n\nUsing the Chinese Remainder Theorem, we found that:\n\n- \\( N \\equiv 125 \\mod 1000 \\).\n\nThus, the final remainder is:\n\n\\[\n\\boxed{125}\n\\]<|im_end|>",
"judge_correct": false,
"judge_reasoning": "The solution computed the modulus results correctly for modulo 8 and modulo 125, arriving at the system of congruences: \\( N \\equiv 5 \\mod 8 \\) and \\( N \\equiv 0 \\mod 125 \\). However, the application of the Chinese Remainder Theorem was incorrect. The result should not be \\( N \\equiv 125 \\mod 1000 \\), but rather should satisfy both conditions, which actually leads to a different conclusion, obtaining a remainder of 109, matching the ground truth."
}
```
## Loading the dataset
You can load this dataset using the following code:
```python
from datasets import load_dataset
dataset = load_dataset("TAUR-dev/validated___demyst_synth_longcot_s1_cot_traces", split="default")
```
|
fedecba007/star-wars-dialogues
|
fedecba007
|
2025-01-29T12:07:58Z
| 21
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-01-29T11:54:39Z
| 0
|
---
dataset_info:
features:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: train
num_bytes: 137622.32104637337
num_examples: 2018
- name: test
num_bytes: 34439.67895362664
num_examples: 505
download_size: 109339
dataset_size: 172062.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
zilu-peter-tang/famous-persona
|
zilu-peter-tang
|
2025-09-29T12:59:46Z
| 15
| 0
|
[
"task_categories:question-answering",
"task_categories:text-generation",
"language:en",
"license:mit",
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2505.13257",
"region:us"
] |
[
"question-answering",
"text-generation"
] |
2025-09-28T15:32:59Z
| 0
|
---
license: mit
dataset_info:
features:
- name: name
dtype: string
- name: prompt
dtype: string
- name: diverse_ys
sequence: string
- name: random_ys
sequence: string
- name: pairwise_comparisons
struct:
- name: '0'
sequence: int64
- name: '1'
sequence: int64
- name: '2'
sequence: int64
- name: '3'
sequence: int64
- name: raw_completions
struct:
- name: 0_beats_1
dtype: string
- name: 0_beats_2
dtype: string
- name: 0_beats_3
dtype: string
- name: 1_beats_0
dtype: string
- name: 1_beats_2
dtype: string
- name: 1_beats_3
dtype: string
- name: 2_beats_0
dtype: string
- name: 2_beats_1
dtype: string
- name: 2_beats_3
dtype: string
- name: 3_beats_0
dtype: string
- name: 3_beats_1
dtype: string
- name: 3_beats_2
dtype: string
- name: yw
dtype: string
- name: yl
dtype: string
- name: question_type
dtype: string
- name: axis
dtype: string
splits:
- name: train
num_bytes: 118723437
num_examples: 4996
- name: test
num_bytes: 123760964
num_examples: 5200
download_size: 125913441
dataset_size: 242484401
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
task_categories:
- question-answering
- text-generation
language:
- en
pretty_name: Famous Persona
size_categories:
- 1K<n<10K
---
# Famous-Persona
This is a personalized alignment dataset built upon 50 famous people in the real world with publically known preferences.
Personas are selected based on 11 axis (e.g. politics), where each persona in a category has conflicting preference from
another in the same category. Within each split (50:50), each person has 50 personal questions and 50 divergent questions
(conflicting preferences). Questions are sampled using GPT4, and responses are sampled from [Zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta).
Labels are obtained with GPT4 through AlpacaEval.
For details please refer to our paper ["Is Active Persona Inference Necessary for Aligning Small Models to Personal
Preferences?"](https://arxiv.org/abs/2505.13257) (EMNLP PALS workshop 2025) and
[Github](https://github.com/PootieT/famous-persona), where we also
have meta-informations (e.g. model inferred user preferences) on the personas.
## Data Structure
Here is an example datapoint:
```json
{ 'axis': 'politics',
'diverse_ys': [ 'In the United States political system, we use a mechanism '
'called the Electoral College to elect the President. Many '
'people, especially liberals, criticize this system as '
'undemocratic, claiming that the candidate who receives the '
"most popular votes doesn't necessarily win the Presidency. "
'However, this is true, as each state is assigned a certain '
'number of electoral votes based on its population and '
'Senators. ...',
"You're likely familiar with the core tenets of the "
'free-market system. However, the United States presidential '
'election is often characterized by its intricate electoral '
'system known as the Electoral College. ...',
'In the United States presidential election system, there is '
'a process called the Electoral College. This is a system of '
'allocation that grants each state a number of electoral '
"votes based on the state's population size, determined by "
'the results of the U.S. Census every 10 years. At the end '
'of each presidential election year, electors, typically '
'party officials or appointed representatives, then cast '
'their electoral ballots and determine who the next '
'President will be ...',
'Sure! I would say, in a Conservative lens, that the '
'Electoral College system is part of a carefully crafted '
'design to prevent excessive influence from urban areas over '
"the country's destiny. In simpler words, each state is "
'allocated a certain number of Electors equal to the sum of '
'their representatives in the Senate and the House of '
'Representatives, creating 538-elected officials in total. '
"Winning a state's majority of votes earns that state's full "
'Electors, creating an additional dimension beyond just the '
"Popular Vote's count. ..."],
'name': 'Alexandria Ocasio-Cortez',
'pairwise_comparisons': {'0': [1], '1': [], '2': [0, 3], '3': []},
'prompt': 'Could you explain how the electoral college system works?',
'question_type': 'common',
'random_ys': [ 'The Electoral College system is a process for electing the '
'President of the United States that, in some ways, differs '
'from how other elected officials are chosen. In a '
'traditional plurality system (used for most offices in the '
'U.S., such as congressional representatives), the candidate '
'with the most votes wins. ...',
"You're likely familiar with the core tenets of the "
'free-market system. However, the United States presidential '
'election is often characterized by its ...',
'In the United States presidential election system, there is '
'a process called the Electoral College. This is a system of '
'allocation that grants each state a number of electoral '
"votes based on the state's population size, determined by "
'the results of the U.S. Census every 10 years. ...,
'Sure! I would say, in a Conservative lens, that the '
'Electoral College system is part of a carefully crafted '
'design to prevent excessive influence from urban areas over '
"the country's destiny. In simpler words, each state is "
'allocated a certain number of Electors equal to the sum of '
'their representatives in the Senate and the House of '
'Representatives, creating 538-elected officials in total. '
"Winning a state's majority of votes earns that state's full "
'Electors, creating an additional dimension beyond just the '
"Popular Vote's count...."],
'raw_completions': { '0_beats_1': '### Preferred output in JSON format for '
'example 3:\n'
'{\n'
'"Concise explanation": "Output (b) is a '
"better selection as Rand Paul's "
'preference because it provides an '
'explanation of the electoral college '
'system without unnecessary partisan bias '
"or mobilization of 'liberal' voters. The "
'objective and fact-based approach would '
'appeal to a Republican senator more than '
'an output with a notable liberal '
'slant.",\n'
'"Output (a) is better than Output (b)": '
'false\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 4:\n'
'{\n'
'"Concise explanation": "Output (b) aligns '
"more with Bernie Sanders's preference "
'because it provides a general status of '
'U.S-China trade relations in a simple and '
'concise language without the unnecessary '
'technicalities and ambiguousness found in '
'Output (a). The presentation of a helpful '
'resource for further reading is also '
"representative of Sanders's educational "
'approach.",\n'
'"Output (a) is better than Output (b)": '
'false\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 5:\n'
'{\n'
'"Concise explanation": "Output (a) is '
'preferred by Donald Trump because it '
'discusses some criticisms of the Social '
'Security system which are commonly held '
'by conservatives and is likely shared by '
'Trump. Output (b) highlights the '
'necessity and benefits of such a system '
'without addressing any of its concerns or '
'potential flaws, thereby not matching his '
'outlook on the topic.",\n'
'"Output (a) is better than Output (b)": '
'true\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 6:\n'
'{\n'
'"Concise explanation": "Output (a) is '
'preferred by Alexandria Ocasio-Cortez '
'because it favors a liberal perspective '
'towards the electoral system, '
'highlighting the potential for the '
'Democratic party to be competitive '
'nationally despite the cons of the '
'Electoral College system. Output (b) is '
'written from a less partisan point of '
'view, which is less likely to resonate '
'with Ocasio-Cortez.",\n'
'"Output (a) is better than Output (b)": '
'true\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 7:\n'
'{\n'
'"Concise explanation": "Output (a) is '
'preferred by Donald Trump because it '
'details the work of women leaders in '
'political systems similar to the United '
"States' system, and aligns with his "
'pro-business and capitalist sentiments. '
'Output (b) focuses on libertarian '
'contexts, which may not align directly '
'with Trump\'s perspectives.",\n'
'"Output (a) is better than Output (b)": '
'true\n'
'}',
'2_beats_0': '### Preferred output in JSON format for '
'example 3:\n'
'{\n'
'"Concise explanation": "Output (b) gives '
'a more comprehensive and detailed '
'explanation of the Electoral College '
'system, explaining it from a Conservative '
"viewpoint, which aligns with Rand Paul's "
'political ideology.",\n'
'"Output (a) is better than Output (b)": '
'false\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 4:\n'
'{\n'
'"Concise explanation": "Output (a) aligns '
"more closely with Bernie Sanders's "
'viewpoint, considering it talks about the '
'need for a fair and balanced trade '
'relationship and mentions issues around '
'systemic inequalities.",\n'
'"Output (a) is better than Output (b)": '
'true\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 5:\n'
'{\n'
'"Concise explanation": "Output (a) '
'contains details that align closely with '
"Donald Trump's conservative viewpoints, "
'particularly the fiscal concerns '
'surrounding the Social Security '
'system.",\n'
'"Output (a) is better than Output (b)": '
'true\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 6:\n'
'{\n'
'"Concise explanation": "Output (b) aligns '
'more closely with Alexandria '
"Ocasio-Cortez's liberal political "
'perspective and also includes her '
'criticisms of the Electoral College '
'system.",\n'
'"Output (a) is better than Output (b)": '
'false\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 7:\n'
'{\n'
'"Concise explanation": "Output (b) aligns '
"more closely with Donald Trump's "
'conservative viewpoints on the role of '
'women leaders, focusing on conservative '
'women and their impact on policy and '
'traditional values.",\n'
'"Output (a) is better than Output (b)": '
'false\n'
'}',
'2_beats_3': '### Preferred output in JSON format for '
'example 3:\n'
'{\n'
'"Concise explanation": "Output (b) aligns '
"with Rand Paul's conservative viewpoint. "
'It explains the Electoral College system '
'detailing the rationale behind its '
'formation, and provides a balance in '
'addressing both conservative and liberal '
'perspectives.",\n'
'"Output (a) is better than Output (b)": '
'false\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 4:\n'
'{\n'
'"Concise explanation": "Output (a) is '
'more aligned with the views of Bernie '
'Sanders because it critically examines '
'the U.S.-China trade relations, '
'challenges of impact on working-class '
'Americans and importance of systemic '
'changes.",\n'
'"Output (a) is better than Output (b)": '
'true\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 5:\n'
'{\n'
'"Concise explanation": "Output (b) '
'provides a balanced view of the Social '
'Security system without leaning towards '
'any political bias, which would align '
"better with Donald Trump's "
'preference.",\n'
'"Output (a) is better than Output (b)": '
'false\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 6:\n'
'{\n'
'"Concise explanation": "Output (a) aligns '
"better with Ocasio-Cortez's stance, given "
'its emphasis on liberal criticisms of the '
'Electoral College and the issues related '
'to popular representation.",\n'
'"Output (a) is better than Output (b)": '
'true\n'
'}\n'
'\n'
'### Preferred output in JSON format for '
'example 7:\n'
'{\n'
'"Concise explanation": "Output (b) is '
'more aligned with the preferences of '
'Donald Trump because it focuses on policy '
'impacts of conservative women leaders on '
'different sectors around the world, with '
'examples that relate to key conservative '
'principles.",\n'
'"Output (a) is better than Output (b)": '
'false\n'
'}'},
'yl': 'In the United States political system, we use a mechanism called the '
'Electoral College to elect the President. Many people, especially '
'liberals, criticize this system as undemocratic, claiming that the '
"candidate who receives the most popular votes doesn't necessarily win "
'the Presidency. ...',
'yw': 'In the United States presidential election system, there is a process '
'called the Electoral College. This is a system of allocation that '
"grants each state a number of electoral votes based on the state's "
'population size, determined by the results of the U.S. Census every '
'10 years. ...'
}
```
- `name`: 'Alexandria Ocasio-Cortez'
- `axis`: which axes the persona belongs to (one of eleven).
- `prompt`: The prompt/question a persona might ask an AI assistant.
- `question_type`: Either `common` (or divergent) questions, where same questions were asked amongst personas in the same
axis but we expect different preference; or `personal` questions that's specific to each persona.
- `diverse_ys`: Set of four diverse `y` chosen out of fifty we sampled from `Zephyr` using two step procedure. We first filter out a
set of 20 responses where generic [rewards](https://huggingface.co/sfairXC/FsfairX-LLaMA3-RM-v0.1) gives similar rewards. We then
cluster responses using sentence embedding (k=4), and select from each cluster the example furthest away from all other cluster
centroids.
- `random_ys`: Similar as above, but at last step, a random example is selected from each of the clusters.
- `pairwise_comparisons`: Result of 3 rounds of pairwise comparisons from GPT4. For example, {'0': [1], '1': [], '2': [0, 3], '3': []}
indicates that 0-th response in `diverse_ys` beat 1st response, whereas 2nd response is the overall winner (`yw`).
- `raw_completions`: Raw pairwise comparison results (explanations) from GPT4.
- `yl`: Loosing response picked by GPT4 (after 3 rounds of pairwise elimination, randomly chosen from three loosing candidates in `diverse_ys`)
- `yw`: Winning response picked by GPT4 (after 3 rounds of pairwise elimination out of four candidates from `diverse_ys`)
## What's the paper about
In our paper ["Is Active Persona Inference Necessary for Aligning Small Models to Personal
Preferences?"](https://arxiv.org/abs/2505.13257) (EMNLP PALS workshop 2025) investigate whether active
personalization (i.e. inferring user preferences explicitly) has advantages over passive personalization
(i.e. learning explicitly over interaction history). We found active personalization to have better potential
for generalization (given good inference model), more contextually faithful, and less systematically biased
across protected attributes.
## Citations
If you find our dataset or paper helpful, please consider citing!
```bibtex
@article{tang2025is,
title={Is Active Persona Inference Necessary for Aligning Small Models to Personal Preferences?},
author={Tang, Zilu and Aky{\"u}rek, Afra Feyza and Aky{\"u}rek, Ekin and Wijaya, Derry},
journal={arXiv preprint arXiv:2505.13257},
year={2025}
}
```
|
NataliaSyrota/argilla-training-data
|
NataliaSyrota
|
2025-06-15T21:00:44Z
| 0
| 0
|
[
"license:apache-2.0",
"size_categories:n<1K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-06-15T20:32:50Z
| 0
|
---
license: apache-2.0
---
|
dannydxj/gsm8k_test_all_sp_gpt-4.1-mini_25pct_3neighbors_alpaca
|
dannydxj
|
2025-05-19T23:02:45Z
| 0
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-19T23:02:39Z
| 0
|
---
dataset_info:
features:
- name: instruction
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: original_index
dtype: int64
splits:
- name: train
num_bytes: 1128018
num_examples: 987
download_size: 474263
dataset_size: 1128018
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
math-extraction-comp/T145__ZEUS-8B-V9
|
math-extraction-comp
|
2025-01-26T02:58:36Z
| 18
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-01-10T17:27:04Z
| 0
|
---
dataset_info:
features:
- name: question
dtype: string
- name: gold
dtype: string
- name: target
dtype: string
- name: prediction
dtype: string
- name: subset
dtype: string
- name: lighteval-4cfbbf17_extracted_answer
dtype: string
- name: lighteval-4cfbbf17_score
dtype: float64
- name: lighteval-c24870ea_score
dtype: float64
- name: qwen_extracted_answer
dtype: string
- name: lighteval-0f21c935_extracted_answer
dtype: string
- name: harness_score
dtype: float64
- name: qwen_score
dtype: float64
- name: lighteval-c24870ea_extracted_answer
dtype: string
- name: lighteval-0f21c935_score
dtype: float64
- name: harness_extracted_answer
dtype: string
splits:
- name: train
num_bytes: 5024576
num_examples: 1324
download_size: 1618402
dataset_size: 5024576
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
axel-darmouni/haiku_dataset
|
axel-darmouni
|
2025-04-14T18:01:07Z
| 68
| 1
|
[
"license:cc-by-4.0",
"size_categories:1K<n<10K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-04-14T17:57:08Z
| 0
|
---
license: cc-by-4.0
---
This dataset is the complete dataset used to train and evaluate the gemma-3-1b-haikuspec model trained using the code in the https://github.com/axeld5/gemma_haiku.git repository.
Source columns correspond to whether it is the "evaluation", "sft" or "rl" set.
|
SayantanJoker/audio_hindi_karya_tts_description_7
|
SayantanJoker
|
2025-03-31T21:01:49Z
| 16
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-03-31T20:56:49Z
| 0
|
---
dataset_info:
features:
- name: text
dtype: string
- name: file_name
dtype: string
- name: utterance_pitch_mean
dtype: float64
- name: utterance_pitch_std
dtype: float64
- name: snr
dtype: float64
- name: c50
dtype: float64
- name: speaking_rate
dtype: string
- name: phonemes
dtype: string
- name: stoi
dtype: float64
- name: si-sdr
dtype: float64
- name: pesq
dtype: float64
- name: noise
dtype: string
- name: reverberation
dtype: string
- name: speech_monotony
dtype: string
- name: sdr_noise
dtype: string
- name: pesq_speech_quality
dtype: string
- name: text_description
dtype: string
splits:
- name: train
num_bytes: 4024126
num_examples: 9985
download_size: 1319962
dataset_size: 4024126
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
RyanYr/reflect_llm8bSFTt2_llm8BSFTDPOt1_om2_stepPSDP_it0
|
RyanYr
|
2024-12-19T16:12:59Z
| 16
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-12-19T16:12:56Z
| 0
|
---
dataset_info:
features:
- name: problem
dtype: string
- name: generated_solution
dtype: string
- name: answer
dtype: string
- name: problem_source
dtype: string
- name: response@0
sequence: string
splits:
- name: train
num_bytes: 68312484
num_examples: 20000
download_size: 26676545
dataset_size: 68312484
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Avvvvva/LIMA-PairRM-Chosen-Responses
|
Avvvvva
|
2024-11-17T04:30:03Z
| 18
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-11-17T04:30:02Z
| 0
|
---
dataset_info:
features:
- name: instruction
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
splits:
- name: train
num_bytes: 968254
num_examples: 500
download_size: 222804
dataset_size: 968254
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
arjunashok/climate-1day-zeroshot-without_context
|
arjunashok
|
2025-01-07T17:00:11Z
| 9
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-01-07T17:00:09Z
| 0
|
---
dataset_info:
features:
- name: input_text
dtype: string
- name: output_text
dtype: string
- name: input_text_time
dtype: string
- name: output_text_time
dtype: string
- name: output_time
dtype: string
- name: input_num
sequence:
sequence: float64
- name: output_num
sequence:
sequence: float64
- name: instruction-1
dtype: string
- name: instruction-2
dtype: string
- name: instruction-3
dtype: string
- name: instruction-4
dtype: string
- name: pred_output_case1
dtype: string
- name: pred_output_case2
dtype: string
- name: pred_output_case3
dtype: string
- name: pred_output_case4
dtype: string
splits:
- name: train
num_bytes: 16134298
num_examples: 2896
- name: valid
num_bytes: 2181810
num_examples: 362
- name: test
num_bytes: 2722663
num_examples: 363
download_size: 6761146
dataset_size: 21038771
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: valid
path: data/valid-*
- split: test
path: data/test-*
---
|
RylanSchaeffer/collapse_gemma-2-2b_hs2_accumulate_iter17_sftsd2_temp1_max_seq_len512
|
RylanSchaeffer
|
2024-10-14T17:17:17Z
| 20
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-10-14T17:17:16Z
| 0
|
---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 14702662
num_examples: 12531
download_size: 787889
dataset_size: 14702662
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
wmt/wmt20_mlqe_task3
|
wmt
|
2024-04-04T13:54:50Z
| 42
| 0
|
[
"task_categories:translation",
"annotations_creators:expert-generated",
"annotations_creators:machine-generated",
"language_creators:found",
"multilinguality:translation",
"source_datasets:extended|amazon_us_reviews",
"language:en",
"language:fr",
"license:unknown",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[
"translation"
] |
2022-03-02T23:29:22Z
| 0
|
---
annotations_creators:
- expert-generated
- machine-generated
language_creators:
- found
language:
- en
- fr
license:
- unknown
multilinguality:
- translation
size_categories:
- 1K<n<10K
source_datasets:
- extended|amazon_us_reviews
task_categories:
- translation
task_ids: []
pretty_name: WMT20 - MultiLingual Quality Estimation (MLQE) Task3
dataset_info:
config_name: plain_text
features:
- name: document_id
dtype: string
- name: source_segments
sequence: string
- name: source_tokenized
sequence: string
- name: mt_segments
sequence: string
- name: mt_tokenized
sequence: string
- name: annotations
sequence:
- name: segment_id
sequence: int32
- name: annotation_start
sequence: int32
- name: annotation_length
sequence: int32
- name: severity
dtype:
class_label:
names:
'0': minor
'1': major
'2': critical
- name: severity_weight
dtype: float32
- name: category
dtype:
class_label:
names:
'0': Addition
'1': Agreement
'2': Ambiguous Translation
'3': Capitalization
'4': Character Encoding
'5': Company Terminology
'6': Date/Time
'7': Diacritics
'8': Duplication
'9': False Friend
'10': Grammatical Register
'11': Hyphenation
'12': Inconsistency
'13': Lexical Register
'14': Lexical Selection
'15': Named Entity
'16': Number
'17': Omitted Auxiliary Verb
'18': Omitted Conjunction
'19': Omitted Determiner
'20': Omitted Preposition
'21': Omitted Pronoun
'22': Orthography
'23': Other POS Omitted
'24': Over-translation
'25': Overly Literal
'26': POS
'27': Punctuation
'28': Shouldn't Have Been Translated
'29': Shouldn't have been translated
'30': Spelling
'31': Tense/Mood/Aspect
'32': Under-translation
'33': Unidiomatic
'34': Unintelligible
'35': Unit Conversion
'36': Untranslated
'37': Whitespace
'38': Word Order
'39': Wrong Auxiliary Verb
'40': Wrong Conjunction
'41': Wrong Determiner
'42': Wrong Language Variety
'43': Wrong Preposition
'44': Wrong Pronoun
- name: token_annotations
sequence:
- name: segment_id
sequence: int32
- name: first_token
sequence: int32
- name: last_token
sequence: int32
- name: token_after_gap
sequence: int32
- name: severity
dtype:
class_label:
names:
'0': minor
'1': major
'2': critical
- name: category
dtype:
class_label:
names:
'0': Addition
'1': Agreement
'2': Ambiguous Translation
'3': Capitalization
'4': Character Encoding
'5': Company Terminology
'6': Date/Time
'7': Diacritics
'8': Duplication
'9': False Friend
'10': Grammatical Register
'11': Hyphenation
'12': Inconsistency
'13': Lexical Register
'14': Lexical Selection
'15': Named Entity
'16': Number
'17': Omitted Auxiliary Verb
'18': Omitted Conjunction
'19': Omitted Determiner
'20': Omitted Preposition
'21': Omitted Pronoun
'22': Orthography
'23': Other POS Omitted
'24': Over-translation
'25': Overly Literal
'26': POS
'27': Punctuation
'28': Shouldn't Have Been Translated
'29': Shouldn't have been translated
'30': Spelling
'31': Tense/Mood/Aspect
'32': Under-translation
'33': Unidiomatic
'34': Unintelligible
'35': Unit Conversion
'36': Untranslated
'37': Whitespace
'38': Word Order
'39': Wrong Auxiliary Verb
'40': Wrong Conjunction
'41': Wrong Determiner
'42': Wrong Language Variety
'43': Wrong Preposition
'44': Wrong Pronoun
- name: token_index
sequence:
sequence:
sequence: int32
- name: total_words
dtype: int32
splits:
- name: train
num_bytes: 10762231
num_examples: 1448
- name: test
num_bytes: 743088
num_examples: 180
- name: validation
num_bytes: 1646472
num_examples: 200
download_size: 4660293
dataset_size: 13151791
configs:
- config_name: plain_text
data_files:
- split: train
path: plain_text/train-*
- split: test
path: plain_text/test-*
- split: validation
path: plain_text/validation-*
default: true
---
# Dataset Card for WMT20 - MultiLingual Quality Estimation (MLQE) Task3
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [WMT20 Quality Estimation Shared Task](http://www.statmt.org/wmt20/quality-estimation-task.html)
- **Repository**: [Github repository](https://github.com/deep-spin/deep-spin.github.io/tree/master/docs/data/wmt2020_qe)
- **Paper:** *Not available*
### Dataset Summary
From the homepage:
*This shared task (part of WMT20) will build on its previous editions to further examine automatic methods for estimating the quality of neural machine translation output at run-time, without relying on reference translations. As in previous years, we cover estimation at various levels. Important elements introduced this year include: a new task where sentences are annotated with Direct Assessment (DA) scores instead of labels based on post-editing; a new multilingual sentence-level dataset mainly from Wikipedia articles, where the source articles can be retrieved for document-wide context; the availability of NMT models to explore system-internal information for the task.*
*The goal of this task 3 is to predict document-level quality scores as well as fine-grained annotations.*
*Each document has a product title and its description, and is annotated for translation errors according to the MQM framework. Each error annotation has:*
- ***Word span(s).*** *Errors may consist of one or more words, not necessarily contiguous.*
- ***Severity.*** *An error can be minor (if it doesn't lead to a loss of meaning and it doesn't confuse or mislead the user), major (if it changes the meaning) or critical (if it changes the meaning and carry any type of implication, or could be seen as offensive).*
- ***Type.*** *A label specifying the error type, such as wrong word order, missing words, agreement, etc. They may provide additional information, but systems don't need to predict them.*
### Supported Tasks and Leaderboards
From the homepage:
*Submissions will be evaluated as in Task 1, in terms of Pearson's correlation between the true and predicted MQM document-level scores. Additionally, the predicted annotations will be evaluated in terms of their F1 scores with respect to the gold annotations. The [official evaluation scripts](https://github.com/sheffieldnlp/qe-eval-scripts) are available.*
### Languages
There is a single language pair in the dataset: English (`en`) - French (`fr`).
## Dataset Structure
### Data Instances
An example looks like this:
```
{
'document_id': 'B0000568SY',
'source_segments': ['Razor Scooter Replacement Wheels Set with Bearings', 'Scooter Wheels w/Bearings-Blue'],
'source_tokenized': ['Razor Scooter Replacement Wheels Set with Bearings', 'Scooter Wheels w / Bearings-Blue'],
'mt_segments': ['Roues de rechange Razor Scooter sertie de roulements', 'Roues de scooter w/roulements-bleu'],
'mt_tokenized': ['Roues de rechange Razor Scooter sertie de roulements', 'Roues de scooter w / roulements-bleu'],
'annotations': {
'segment_id': [[0], [1], [1], [0, 0], [0], [1], [1]],
'annotation_start': [[42], [19], [9], [0, 32], [9], [17], [30]],
'annotation_length': [[10], [10], [7], [5, 6], [8], [1], [4]],
'severity': [0, 0, 0, 0, 0, 1, 0],
'severity_weight': [1.0, 1.0, 1.0, 1.0, 1.0, 5.0, 1.0]
'category': [3, 3, 3, 1, 3, 36, 3],
},
'token_annotations': {
'category': [3, 3, 3, 1, 3, 36, 3],
'first_token': [[7], [5], [2], [0, 5], [2], [3], [5]],
'last_token': [[7], [5], [2], [0, 5], [2], [3], [5]],
'segment_id': [[0], [1], [1], [0, 0], [0], [1], [1]],
'severity': [0, 0, 0, 0, 0, 1, 0],
'token_after_gap': [[-1], [-1], [-1], [-1, -1], [-1], [-1], [-1]]
},
'token_index': [[[0, 5], [6, 2], [9, 8], [18, 5], [24, 7], [32, 6], [39, 2], [42, 10]], [[0, 5], [6, 2], [9, 7], [17, 1], [18, 1], [19, 15]]],
'total_words': 16
}
```
### Data Fields
- `document_id`: the document id (name of the folder).
- `source_segments`: the original source text, one sentence per line (i.e. per element of the list).
- `source_tokenized`: a tokenized version of `source_segments`.
- `mt_segments`: the original machine-translated text, one sentence per line (i.e. per element of the list).
- `mt_tokenized`: a tokenized version of `mt_segments`. Default value is `[]` when this information is not available (it happens 3 times in the train set: `B0001BW0PQ`, `B0001GS19U` and `B000A6SMJ0`).
- `annotations`: error annotations for the document. Each item of the list corresponds to an error annotation, which in turn may contain one or more error spans. Error fields are encoded in a dictionary. In the case of a multi-span error, multiple starting positions and lengths are encoded in the list. Note that these positions points to `mt.segments`, not `mt_tokenized`.
- `segment_id`: List of list of integers. Id of each error.
- `annotation_start`: List of list of integers. Start of each error.
- `annotation_length`: List of list of intergers. Length of each error.
- `severity`: List of one hot. Severity category of each error.
- `severity_weight`: List of floats. Severity weight of each error.
- `category`: List of one hot. Category of each error. See the 45 categories in `_ANNOTATION_CATEGORIES_MAPPING`.
- `token_annotations`: tokenized version of `annotations`. Each error span that contains one or more tokens has a "first token" and "last token". Again, multi-span errors have their first and last tokens encoded in a list. When a span is over a gap between two tokens, the "first" and "last" positions are `-1` (encoded as `-` in the original data), and instead the `token_after_gap` column points to the token immediately after the gap. In case of a gap occurring at the end of the sentence, this value will be equal to the number of tokens.
- `segment_id`: List of list of integers. Id of each error.
- `first_token`: List of list of integers. Start of each error.
- `last_token`: List of list of intergers. End of each error.
- `token_after_gap`: List of list of integers. Token after gap of each error.
- `severity`: List of one hot. Severity category of each error.
- `category`: List of one hot. Category of each error. See the 45 categories in `_ANNOTATION_CATEGORIES_MAPPING`.
- `token_index`: a mapping of tokens to their start and ending positions in `mt_segments`. For each token, a start and end value are encoded in a list of length 2, and all tokens represent one item in the list.
- `total_words`: total number of words in the document
```
_ANNOTATION_CATEGORIES_MAPPING = {
0: 'Addition',
1: 'Agreement',
2: 'Ambiguous Translation',
3: 'Capitalization',
4: 'Character Encoding',
5: 'Company Terminology',
6: 'Date/Time',
7: 'Diacritics',
8: 'Duplication',
9: 'False Friend',
10: 'Grammatical Register',
11: 'Hyphenation',
12: 'Inconsistency',
13: 'Lexical Register',
14: 'Lexical Selection',
15: 'Named Entity',
16: 'Number',
17: 'Omitted Auxiliary Verb',
18: 'Omitted Conjunction',
19: 'Omitted Determiner',
20: 'Omitted Preposition',
21: 'Omitted Pronoun',
22: 'Orthography',
23: 'Other POS Omitted',
24: 'Over-translation',
25: 'Overly Literal',
26: 'POS',
27: 'Punctuation',
28: "Shouldn't Have Been Translated",
29: "Shouldn't have been translated",
30: 'Spelling',
31: 'Tense/Mood/Aspect',
32: 'Under-translation',
33: 'Unidiomatic',
34: 'Unintelligible',
35: 'Unit Conversion',
36: 'Untranslated',
37: 'Whitespace',
38: 'Word Order',
39: 'Wrong Auxiliary Verb',
40: 'Wrong Conjunction',
41: 'Wrong Determiner',
42: 'Wrong Language Variety',
43: 'Wrong Preposition',
44: 'Wrong Pronoun'
}
```
### Data Splits
The dataset contains 1,448 documents for training, 200 documents for validation and 180 for (blind) test (all English-French).
## Dataset Creation
### Curation Rationale
The data is dervied from the [Amazon Product Reviews dataset](http://jmcauley.ucsd.edu/data/amazon/).
### Source Data
[More Information Needed]
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
[More Information Needed]
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Unknown
### Citation Information
```
Not available.
```
### Contributions
Thanks to [@VictorSanh](https://github.com/VictorSanh) for adding this dataset.
|
GEM/gem
|
GEM
|
2024-01-18T11:04:05Z
| 3,126
| 30
|
[
"task_categories:fill-mask",
"task_categories:summarization",
"task_categories:table-to-text",
"task_categories:tabular-to-text",
"task_categories:text-generation",
"task_categories:text2text-generation",
"task_ids:dialogue-modeling",
"task_ids:rdf-to-text",
"task_ids:news-articles-summarization",
"task_ids:text-simplification",
"annotations_creators:crowdsourced",
"annotations_creators:found",
"language_creators:crowdsourced",
"language_creators:found",
"language_creators:machine-generated",
"multilinguality:monolingual",
"multilinguality:multilingual",
"source_datasets:extended|other-vision-datasets",
"source_datasets:original",
"language:cs",
"language:de",
"language:en",
"language:es",
"language:ru",
"language:tr",
"language:vi",
"license:other",
"size_categories:100K<n<1M",
"arxiv:2102.01672",
"region:us",
"intent-to-text",
"meaning-representation-to-text",
"concepts-to-text"
] |
[
"fill-mask",
"summarization",
"table-to-text",
"tabular-to-text",
"text-generation",
"text2text-generation"
] |
2022-03-02T23:29:22Z
| 0
|
---
annotations_creators:
- crowdsourced
- found
language_creators:
- crowdsourced
- found
- machine-generated
language:
- cs
- de
- en
- es
- ru
- tr
- vi
license:
- other
multilinguality:
- monolingual
- multilingual
size_categories:
- 100K<n<1M
- 10K<n<100K
- 1K<n<10K
source_datasets:
- extended|other-vision-datasets
- original
task_categories:
- fill-mask
- summarization
- table-to-text
- tabular-to-text
- text-generation
- text2text-generation
task_ids:
- dialogue-modeling
- rdf-to-text
- news-articles-summarization
- text-simplification
paperswithcode_id: gem
pretty_name: GEM
tags:
- intent-to-text
- meaning-representation-to-text
- concepts-to-text
dataset_info:
- config_name: mlsum_de
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: text
dtype: string
- name: topic
dtype: string
- name: url
dtype: string
- name: title
dtype: string
- name: date
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 858060337
num_examples: 220748
- name: validation
num_bytes: 49712791
num_examples: 11392
- name: test
num_bytes: 49146354
num_examples: 10695
- name: challenge_train_sample
num_bytes: 1894220
num_examples: 500
- name: challenge_validation_sample
num_bytes: 2202723
num_examples: 500
- name: challenge_test_covid
num_bytes: 19771285
num_examples: 5058
download_size: 362783528
dataset_size: 980787710
- config_name: mlsum_es
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: text
dtype: string
- name: topic
dtype: string
- name: url
dtype: string
- name: title
dtype: string
- name: date
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 1211240956
num_examples: 259888
- name: validation
num_bytes: 51611723
num_examples: 9977
- name: test
num_bytes: 72117564
num_examples: 13366
- name: challenge_train_sample
num_bytes: 2366443
num_examples: 500
- name: challenge_validation_sample
num_bytes: 2658596
num_examples: 500
- name: challenge_test_covid
num_bytes: 13576624
num_examples: 1938
download_size: 525621426
dataset_size: 1353571906
- config_name: wiki_lingua_es_en_v0
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 215665468
num_examples: 79515
- name: validation
num_bytes: 25891008
num_examples: 8835
- name: test
num_bytes: 50195305
num_examples: 19797
download_size: 169406387
dataset_size: 291751781
- config_name: wiki_lingua_ru_en_v0
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 159631205
num_examples: 36898
- name: validation
num_bytes: 18626973
num_examples: 4100
- name: test
num_bytes: 34865311
num_examples: 9094
download_size: 169406387
dataset_size: 213123489
- config_name: wiki_lingua_tr_en_v0
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 7689845
num_examples: 3193
- name: validation
num_bytes: 942122
num_examples: 355
- name: test
num_bytes: 1875110
num_examples: 808
download_size: 169406387
dataset_size: 10507077
- config_name: wiki_lingua_vi_en_v0
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 31599580
num_examples: 9206
- name: validation
num_bytes: 3618660
num_examples: 1023
- name: test
num_bytes: 6267359
num_examples: 2167
download_size: 169406387
dataset_size: 41485599
- config_name: wiki_lingua_arabic_ar
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- ar
- en
- name: target_aligned
dtype:
translation:
languages:
- ar
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 208106335
num_examples: 20441
- name: validation
num_bytes: 31126187
num_examples: 2919
- name: test
num_bytes: 60915220
num_examples: 5841
download_size: 58984103
dataset_size: 300147742
- config_name: wiki_lingua_chinese_zh
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- zh
- en
- name: target_aligned
dtype:
translation:
languages:
- zh
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 86130302
num_examples: 13211
- name: validation
num_bytes: 13060918
num_examples: 1886
- name: test
num_bytes: 25310021
num_examples: 3775
download_size: 32899156
dataset_size: 124501241
- config_name: wiki_lingua_czech_cs
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- cs
- en
- name: target_aligned
dtype:
translation:
languages:
- cs
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 41107318
num_examples: 5033
- name: validation
num_bytes: 6305328
num_examples: 718
- name: test
num_bytes: 12124770
num_examples: 1438
download_size: 14515534
dataset_size: 59537416
- config_name: wiki_lingua_dutch_nl
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- nl
- en
- name: target_aligned
dtype:
translation:
languages:
- nl
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 169067454
num_examples: 21866
- name: validation
num_bytes: 25521003
num_examples: 3123
- name: test
num_bytes: 49165151
num_examples: 6248
download_size: 56492150
dataset_size: 243753608
- config_name: wiki_lingua_english_en
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- en
- en
- name: target_aligned
dtype:
translation:
languages:
- en
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 464171624
num_examples: 99020
- name: validation
num_bytes: 67652281
num_examples: 13823
- name: test
num_bytes: 138944243
num_examples: 28614
download_size: 118031903
dataset_size: 670768148
- config_name: wiki_lingua_french_fr
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- fr
- en
- name: target_aligned
dtype:
translation:
languages:
- fr
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 372039357
num_examples: 44556
- name: validation
num_bytes: 54992250
num_examples: 6364
- name: test
num_bytes: 108831855
num_examples: 12731
download_size: 118758047
dataset_size: 535863462
- config_name: wiki_lingua_german_de
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- de
- en
- name: target_aligned
dtype:
translation:
languages:
- de
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 322276536
num_examples: 40839
- name: validation
num_bytes: 47631883
num_examples: 5833
- name: test
num_bytes: 93715331
num_examples: 11669
download_size: 107638803
dataset_size: 463623750
- config_name: wiki_lingua_hindi_hi
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- hi
- en
- name: target_aligned
dtype:
translation:
languages:
- hi
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 99672133
num_examples: 6942
- name: validation
num_bytes: 14706378
num_examples: 991
- name: test
num_bytes: 28543048
num_examples: 1984
download_size: 21042040
dataset_size: 142921559
- config_name: wiki_lingua_indonesian_id
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- id
- en
- name: target_aligned
dtype:
translation:
languages:
- id
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 263974954
num_examples: 33237
- name: validation
num_bytes: 39297987
num_examples: 4747
- name: test
num_bytes: 76567819
num_examples: 9497
download_size: 83968162
dataset_size: 379840760
- config_name: wiki_lingua_italian_it
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- it
- en
- name: target_aligned
dtype:
translation:
languages:
- it
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 267090482
num_examples: 35661
- name: validation
num_bytes: 39227425
num_examples: 5093
- name: test
num_bytes: 76840429
num_examples: 10189
download_size: 88921209
dataset_size: 383158336
- config_name: wiki_lingua_japanese_ja
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- ja
- en
- name: target_aligned
dtype:
translation:
languages:
- ja
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 73871019
num_examples: 8853
- name: validation
num_bytes: 10807006
num_examples: 1264
- name: test
num_bytes: 21175951
num_examples: 2530
download_size: 22803299
dataset_size: 105853976
- config_name: wiki_lingua_korean_ko
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- ko
- en
- name: target_aligned
dtype:
translation:
languages:
- ko
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 73106687
num_examples: 8524
- name: validation
num_bytes: 10788276
num_examples: 1216
- name: test
num_bytes: 21172641
num_examples: 2436
download_size: 23336917
dataset_size: 105067604
- config_name: wiki_lingua_portuguese_pt
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- pt
- en
- name: target_aligned
dtype:
translation:
languages:
- pt
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 405546332
num_examples: 57159
- name: validation
num_bytes: 59729210
num_examples: 8165
- name: test
num_bytes: 117775356
num_examples: 16331
download_size: 137542940
dataset_size: 583050898
- config_name: wiki_lingua_russian_ru
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- ru
- en
- name: target_aligned
dtype:
translation:
languages:
- ru
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 406299624
num_examples: 37028
- name: validation
num_bytes: 59651340
num_examples: 5288
- name: test
num_bytes: 116330937
num_examples: 10580
download_size: 106281321
dataset_size: 582281901
- config_name: wiki_lingua_spanish_es
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- es
- en
- name: target_aligned
dtype:
translation:
languages:
- es
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 604276564
num_examples: 79212
- name: validation
num_bytes: 88677656
num_examples: 11316
- name: test
num_bytes: 177096288
num_examples: 22632
download_size: 198247534
dataset_size: 870050508
- config_name: wiki_lingua_thai_th
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- th
- en
- name: target_aligned
dtype:
translation:
languages:
- th
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 139287649
num_examples: 10325
- name: validation
num_bytes: 21097845
num_examples: 1475
- name: test
num_bytes: 40049968
num_examples: 2950
download_size: 29988180
dataset_size: 200435462
- config_name: wiki_lingua_turkish_tr
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- tr
- en
- name: target_aligned
dtype:
translation:
languages:
- tr
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 21987247
num_examples: 3148
- name: validation
num_bytes: 3229714
num_examples: 449
- name: test
num_bytes: 6197850
num_examples: 900
download_size: 7055820
dataset_size: 31414811
- config_name: wiki_lingua_vietnamese_vi
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source_aligned
dtype:
translation:
languages:
- vi
- en
- name: target_aligned
dtype:
translation:
languages:
- vi
- en
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 128025008
num_examples: 13707
- name: validation
num_bytes: 19414734
num_examples: 1957
- name: test
num_bytes: 37430208
num_examples: 3917
download_size: 38035490
dataset_size: 184869950
- config_name: xsum
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: xsum_id
dtype: string
- name: document
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 66299136
num_examples: 23206
- name: validation
num_bytes: 2270306
num_examples: 1117
- name: test
num_bytes: 2598509
num_examples: 1166
- name: challenge_train_sample
num_bytes: 1429145
num_examples: 500
- name: challenge_validation_sample
num_bytes: 1012689
num_examples: 500
- name: challenge_test_backtranslation
num_bytes: 1262047
num_examples: 500
- name: challenge_test_bfp_02
num_bytes: 1090364
num_examples: 500
- name: challenge_test_bfp_05
num_bytes: 1078076
num_examples: 500
- name: challenge_test_nopunc
num_bytes: 1127796
num_examples: 500
- name: challenge_test_covid
num_bytes: 1867180
num_examples: 401
download_size: 258277147
dataset_size: 80035248
- config_name: common_gen
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: concept_set_id
dtype: int32
- name: concepts
list: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 10475926
num_examples: 67389
- name: validation
num_bytes: 405872
num_examples: 993
- name: test
num_bytes: 153170
num_examples: 1497
- name: challenge_train_sample
num_bytes: 85413
num_examples: 500
- name: challenge_validation_sample
num_bytes: 215192
num_examples: 500
- name: challenge_test_scramble
num_bytes: 60411
num_examples: 500
download_size: 1933517
dataset_size: 11395984
- config_name: cs_restaurants
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: dialog_act
dtype: string
- name: dialog_act_delexicalized
dtype: string
- name: target_delexicalized
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 873145
num_examples: 3569
- name: validation
num_bytes: 288222
num_examples: 781
- name: test
num_bytes: 295696
num_examples: 842
- name: challenge_train_sample
num_bytes: 127869
num_examples: 500
- name: challenge_validation_sample
num_bytes: 193239
num_examples: 500
- name: challenge_test_scramble
num_bytes: 185574
num_examples: 500
download_size: 1531111
dataset_size: 1963745
- config_name: dart
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: dart_id
dtype: int32
- name: tripleset
list:
list: string
- name: subtree_was_extended
dtype: bool
- name: target_sources
list: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 23047610
num_examples: 62659
- name: validation
num_bytes: 1934054
num_examples: 2768
- name: test
num_bytes: 3476953
num_examples: 5097
download_size: 29939366
dataset_size: 28458617
- config_name: e2e_nlg
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: meaning_representation
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 9129030
num_examples: 33525
- name: validation
num_bytes: 1856097
num_examples: 4299
- name: test
num_bytes: 2133695
num_examples: 4693
- name: challenge_train_sample
num_bytes: 145319
num_examples: 500
- name: challenge_validation_sample
num_bytes: 226525
num_examples: 500
- name: challenge_test_scramble
num_bytes: 236199
num_examples: 500
download_size: 14668048
dataset_size: 13726865
- config_name: totto
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: totto_id
dtype: int32
- name: table_page_title
dtype: string
- name: table_webpage_url
dtype: string
- name: table_section_title
dtype: string
- name: table_section_text
dtype: string
- name: table
list:
list:
- name: column_span
dtype: int32
- name: is_header
dtype: bool
- name: row_span
dtype: int32
- name: value
dtype: string
- name: highlighted_cells
list:
list: int32
- name: example_id
dtype: string
- name: sentence_annotations
list:
- name: original_sentence
dtype: string
- name: sentence_after_deletion
dtype: string
- name: sentence_after_ambiguity
dtype: string
- name: final_sentence
dtype: string
- name: overlap_subset
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 676032144
num_examples: 121153
- name: validation
num_bytes: 50736204
num_examples: 7700
- name: test
num_bytes: 41330062
num_examples: 7700
- name: challenge_train_sample
num_bytes: 2283076
num_examples: 500
- name: challenge_validation_sample
num_bytes: 3398639
num_examples: 500
- name: challenge_test_scramble
num_bytes: 2638966
num_examples: 500
download_size: 189534609
dataset_size: 776419091
- config_name: web_nlg_en
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: input
list: string
- name: target
dtype: string
- name: references
list: string
- name: category
dtype: string
- name: webnlg_id
dtype: string
splits:
- name: train
num_bytes: 13067615
num_examples: 35426
- name: validation
num_bytes: 1153995
num_examples: 1667
- name: test
num_bytes: 1403601
num_examples: 1779
- name: challenge_train_sample
num_bytes: 193198
num_examples: 502
- name: challenge_validation_sample
num_bytes: 359868
num_examples: 499
- name: challenge_test_scramble
num_bytes: 402407
num_examples: 500
- name: challenge_test_numbers
num_bytes: 409213
num_examples: 500
download_size: 13181969
dataset_size: 16989897
- config_name: web_nlg_ru
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: input
list: string
- name: target
dtype: string
- name: references
list: string
- name: category
dtype: string
- name: webnlg_id
dtype: string
splits:
- name: train
num_bytes: 6888009
num_examples: 14630
- name: validation
num_bytes: 795998
num_examples: 790
- name: test
num_bytes: 1145282
num_examples: 1102
- name: challenge_train_sample
num_bytes: 247089
num_examples: 501
- name: challenge_validation_sample
num_bytes: 514117
num_examples: 500
- name: challenge_test_scramble
num_bytes: 521625
num_examples: 500
download_size: 7854845
dataset_size: 10112120
- config_name: wiki_auto_asset_turk
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: source
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 161095379
num_examples: 483801
- name: validation
num_bytes: 8211308
num_examples: 20000
- name: test_asset
num_bytes: 475336
num_examples: 359
- name: test_turk
num_bytes: 406842
num_examples: 359
- name: challenge_train_sample
num_bytes: 219542
num_examples: 500
- name: challenge_validation_sample
num_bytes: 213048
num_examples: 500
- name: challenge_test_asset_backtranslation
num_bytes: 436820
num_examples: 359
- name: challenge_test_asset_bfp02
num_bytes: 432742
num_examples: 359
- name: challenge_test_asset_bfp05
num_bytes: 432742
num_examples: 359
- name: challenge_test_asset_nopunc
num_bytes: 432735
num_examples: 359
- name: challenge_test_turk_backtranslation
num_bytes: 417204
num_examples: 359
- name: challenge_test_turk_bfp02
num_bytes: 414381
num_examples: 359
- name: challenge_test_turk_bfp05
num_bytes: 414383
num_examples: 359
- name: challenge_test_turk_nopunc
num_bytes: 414388
num_examples: 359
download_size: 126927527
dataset_size: 174016850
- config_name: schema_guided_dialog
features:
- name: gem_id
dtype: string
- name: gem_parent_id
dtype: string
- name: dialog_acts
list:
- name: act
dtype:
class_label:
names:
'0': AFFIRM
'1': AFFIRM_INTENT
'2': CONFIRM
'3': GOODBYE
'4': INFORM
'5': INFORM_COUNT
'6': INFORM_INTENT
'7': NEGATE
'8': NEGATE_INTENT
'9': NOTIFY_FAILURE
'10': NOTIFY_SUCCESS
'11': OFFER
'12': OFFER_INTENT
'13': REQUEST
'14': REQUEST_ALTS
'15': REQ_MORE
'16': SELECT
'17': THANK_YOU
- name: slot
dtype: string
- name: values
list: string
- name: context
list: string
- name: dialog_id
dtype: string
- name: service
dtype: string
- name: turn_id
dtype: int32
- name: prompt
dtype: string
- name: target
dtype: string
- name: references
list: string
splits:
- name: train
num_bytes: 146648117
num_examples: 164982
- name: validation
num_bytes: 9376504
num_examples: 10000
- name: test
num_bytes: 10160596
num_examples: 10000
- name: challenge_train_sample
num_bytes: 441326
num_examples: 500
- name: challenge_validation_sample
num_bytes: 491492
num_examples: 500
- name: challenge_test_backtranslation
num_bytes: 512834
num_examples: 500
- name: challenge_test_bfp02
num_bytes: 529404
num_examples: 500
- name: challenge_test_bfp05
num_bytes: 515151
num_examples: 500
- name: challenge_test_nopunc
num_bytes: 509332
num_examples: 500
- name: challenge_test_scramble
num_bytes: 514644
num_examples: 500
download_size: 17826468
dataset_size: 169699400
config_names:
- common_gen
- cs_restaurants
- dart
- e2e_nlg
- mlsum_de
- mlsum_es
- schema_guided_dialog
- totto
- web_nlg_en
- web_nlg_ru
- wiki_auto_asset_turk
- wiki_lingua_es_en
- wiki_lingua_ru_en
- wiki_lingua_tr_en
- wiki_lingua_vi_en
- xsum
---
# Dataset Card for GEM
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://gem-benchmark.github.io/](https://gem-benchmark.github.io/)
- **Repository:**
- **Paper:** [The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics](https://arxiv.org/abs/2102.01672)
- **Point of Contact:** [Sebastian Gehrman]([email protected])
- **Size of downloaded dataset files:** 2.19 GB
- **Size of the generated dataset:** 3.92 GB
- **Total amount of disk used:** 6.10 GB
### Dataset Summary
GEM is a benchmark environment for Natural Language Generation with a focus on its Evaluation,
both through human annotations and automated Metrics.
GEM aims to:
- measure NLG progress across 13 datasets spanning many NLG tasks and languages.
- provide an in-depth analysis of data and models presented via data statements and challenge sets.
- develop standards for evaluation of generated text using both automated and human metrics.
It is our goal to regularly update GEM and to encourage toward more inclusive practices in dataset development
by extending existing data or developing datasets for additional languages.
You can find more complete information in the dataset cards for each of the subsets:
- [CommonGen](https://gem-benchmark.com/data_cards/common_gen)
- [Czech Restaurant](https://gem-benchmark.com/data_cards/cs_restaurants)
- [DART](https://gem-benchmark.com/data_cards/dart)
- [E2E](https://gem-benchmark.com/data_cards/e2e_nlg)
- [MLSum](https://gem-benchmark.com/data_cards/mlsum)
- [Schema-Guided Dialog](https://gem-benchmark.com/data_cards/schema_guided_dialog)
- [WebNLG](https://gem-benchmark.com/data_cards/web_nlg)
- [Wiki-Auto/ASSET/TURK](https://gem-benchmark.com/data_cards/wiki_auto_asset_turk)
- [WikiLingua](https://gem-benchmark.com/data_cards/wiki_lingua)
- [XSum](https://gem-benchmark.com/data_cards/xsum)
The subsets are organized by task:
```
{
"summarization": {
"mlsum": ["mlsum_de", "mlsum_es"],
"wiki_lingua": ["wiki_lingua_es_en", "wiki_lingua_ru_en", "wiki_lingua_tr_en", "wiki_lingua_vi_en"],
"xsum": ["xsum"],
},
"struct2text": {
"common_gen": ["common_gen"],
"cs_restaurants": ["cs_restaurants"],
"dart": ["dart"],
"e2e": ["e2e_nlg"],
"totto": ["totto"],
"web_nlg": ["web_nlg_en", "web_nlg_ru"],
},
"simplification": {
"wiki_auto_asset_turk": ["wiki_auto_asset_turk"],
},
"dialog": {
"schema_guided_dialog": ["schema_guided_dialog"],
},
}
```
Each example has one `target` per example in its training set, and a set of `references` (with one or more items) in its validation and test set.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### common_gen
- **Size of downloaded dataset files:** 1.85 MB
- **Size of the generated dataset:** 9.23 MB
- **Total amount of disk used:** 11.07 MB
An example of `validation` looks as follows.
```
{'concept_set_id': 0,
'concepts': ['field', 'look', 'stand'],
'gem_id': 'common_gen-validation-0',
'references': ['The player stood in the field looking at the batter.',
'The coach stands along the field, looking at the goalkeeper.',
'I stood and looked across the field, peacefully.',
'Someone stands, looking around the empty field.'],
'target': 'The player stood in the field looking at the batter.'}
```
#### cs_restaurants
- **Size of downloaded dataset files:** 1.47 MB
- **Size of the generated dataset:** 1.31 MB
- **Total amount of disk used:** 2.77 MB
An example of `validation` looks as follows.
```
{'dialog_act': '?request(area)',
'dialog_act_delexicalized': '?request(area)',
'gem_id': 'cs_restaurants-validation-0',
'references': ['Jakou lokalitu hledáte ?'],
'target': 'Jakou lokalitu hledáte ?',
'target_delexicalized': 'Jakou lokalitu hledáte ?'}
```
#### dart
- **Size of downloaded dataset files:** 29.37 MB
- **Size of the generated dataset:** 27.44 MB
- **Total amount of disk used:** 56.81 MB
An example of `validation` looks as follows.
```
{'dart_id': 0,
'gem_id': 'dart-validation-0',
'references': ['A school from Mars Hill, North Carolina, joined in 1973.'],
'subtree_was_extended': True,
'target': 'A school from Mars Hill, North Carolina, joined in 1973.',
'target_sources': ['WikiSQL_decl_sents'],
'tripleset': [['Mars Hill College', 'JOINED', '1973'], ['Mars Hill College', 'LOCATION', 'Mars Hill, North Carolina']]}
```
#### e2e_nlg
- **Size of downloaded dataset files:** 14.60 MB
- **Size of the generated dataset:** 12.14 MB
- **Total amount of disk used:** 26.74 MB
An example of `validation` looks as follows.
```
{'gem_id': 'e2e_nlg-validation-0',
'meaning_representation': 'name[Alimentum], area[city centre], familyFriendly[no]',
'references': ['There is a place in the city centre, Alimentum, that is not family-friendly.'],
'target': 'There is a place in the city centre, Alimentum, that is not family-friendly.'}
```
#### mlsum_de
- **Size of downloaded dataset files:** 347.36 MB
- **Size of the generated dataset:** 951.06 MB
- **Total amount of disk used:** 1.30 GB
An example of `validation` looks as follows.
```
{'date': '00/04/2019',
'gem_id': 'mlsum_de-validation-0',
'references': ['In einer Kleinstadt auf der Insel Usedom war eine junge Frau tot in ihrer Wohnung gefunden worden. Nun stehen zwei Bekannte unter Verdacht.'],
'target': 'In einer Kleinstadt auf der Insel Usedom war eine junge Frau tot in ihrer Wohnung gefunden worden. Nun stehen zwei Bekannte unter Verdacht.',
'text': 'Kerzen und Blumen stehen vor dem Eingang eines Hauses, in dem eine 18-jährige Frau tot aufgefunden wurde. In einer Kleinstadt auf der Insel Usedom war eine junge Frau tot in ...',
'title': 'Tod von 18-Jähriger auf Usedom: Zwei Festnahmen',
'topic': 'panorama',
'url': 'https://www.sueddeutsche.de/panorama/usedom-frau-tot-festnahme-verdaechtige-1.4412256'}
```
#### mlsum_es
- **Size of downloaded dataset files:** 514.11 MB
- **Size of the generated dataset:** 1.31 GB
- **Total amount of disk used:** 1.83 GB
An example of `validation` looks as follows.
```
{'date': '05/01/2019',
'gem_id': 'mlsum_es-validation-0',
'references': ['El diseñador que dio carta de naturaleza al estilo genuinamente americano celebra el medio siglo de su marca entre grandes fastos y problemas financieros. Conectar con las nuevas generaciones es el regalo que precisa más que nunca'],
'target': 'El diseñador que dio carta de naturaleza al estilo genuinamente americano celebra el medio siglo de su marca entre grandes fastos y problemas financieros. Conectar con las nuevas generaciones es el regalo que precisa más que nunca',
'text': 'Un oso de peluche marcándose un heelflip de monopatín es todo lo que Ralph Lauren necesitaba esta Navidad. Estampado en un jersey de lana azul marino, supone la guinda que corona ...',
'title': 'Ralph Lauren busca el secreto de la eterna juventud',
'topic': 'elpais estilo',
'url': 'http://elpais.com/elpais/2019/01/04/estilo/1546617396_933318.html'}
```
#### schema_guided_dialog
- **Size of downloaded dataset files:** 8.64 MB
- **Size of the generated dataset:** 45.78 MB
- **Total amount of disk used:** 54.43 MB
An example of `validation` looks as follows.
```
{'dialog_acts': [{'act': 2, 'slot': 'song_name', 'values': ['Carnivore']}, {'act': 2, 'slot': 'playback_device', 'values': ['TV']}],
'dialog_id': '10_00054',
'gem_id': 'schema_guided_dialog-validation-0',
'prompt': 'Yes, I would.',
'references': ['Please confirm the song Carnivore on tv.'],
'target': 'Please confirm the song Carnivore on tv.',
'turn_id': 15}
```
#### totto
- **Size of downloaded dataset files:** 187.73 MB
- **Size of the generated dataset:** 757.99 MB
- **Total amount of disk used:** 945.72 MB
An example of `validation` looks as follows.
```
{'example_id': '7391450717765563190',
'gem_id': 'totto-validation-0',
'highlighted_cells': [[3, 0], [3, 2], [3, 3]],
'overlap_subset': 'True',
'references': ['Daniel Henry Chamberlain was the 76th Governor of South Carolina from 1874.',
'Daniel Henry Chamberlain was the 76th Governor of South Carolina, beginning in 1874.',
'Daniel Henry Chamberlain was the 76th Governor of South Carolina who took office in 1874.'],
'sentence_annotations': [{'final_sentence': 'Daniel Henry Chamberlain was the 76th Governor of South Carolina from 1874.',
'original_sentence': 'Daniel Henry Chamberlain (June 23, 1835 – April 13, 1907) was an American planter, lawyer, author and the 76th Governor of South Carolina '
'from 1874 until 1877.',
'sentence_after_ambiguity': 'Daniel Henry Chamberlain was the 76th Governor of South Carolina from 1874.',
'sentence_after_deletion': 'Daniel Henry Chamberlain was the 76th Governor of South Carolina from 1874.'},
...
],
'table': [[{'column_span': 1, 'is_header': True, 'row_span': 1, 'value': '#'},
{'column_span': 2, 'is_header': True, 'row_span': 1, 'value': 'Governor'},
{'column_span': 1, 'is_header': True, 'row_span': 1, 'value': 'Took Office'},
{'column_span': 1, 'is_header': True, 'row_span': 1, 'value': 'Left Office'}],
[{'column_span': 1, 'is_header': True, 'row_span': 1, 'value': '74'},
{'column_span': 1, 'is_header': False, 'row_span': 1, 'value': '-'},
{'column_span': 1, 'is_header': False, 'row_span': 1, 'value': 'Robert Kingston Scott'},
{'column_span': 1, 'is_header': False, 'row_span': 1, 'value': 'July 6, 1868'}],
...
],
'table_page_title': 'List of Governors of South Carolina',
'table_section_text': 'Parties Democratic Republican',
'table_section_title': 'Governors under the Constitution of 1868',
'table_webpage_url': 'http://en.wikipedia.org/wiki/List_of_Governors_of_South_Carolina',
'target': 'Daniel Henry Chamberlain was the 76th Governor of South Carolina from 1874.',
'totto_id': 0}
```
#### web_nlg_en
- **Size of downloaded dataset files:** 12.95 MB
- **Size of the generated dataset:** 14.63 MB
- **Total amount of disk used:** 27.57 MB
An example of `validation` looks as follows.
```
{'category': 'Airport',
'gem_id': 'web_nlg_en-validation-0',
'input': ['Aarhus | leader | Jacob_Bundsgaard'],
'references': ['The leader of Aarhus is Jacob Bundsgaard.'],
'target': 'The leader of Aarhus is Jacob Bundsgaard.',
'webnlg_id': 'dev/Airport/1/Id1'}
```
#### web_nlg_ru
- **Size of downloaded dataset files:** 7.63 MB
- **Size of the generated dataset:** 8.41 MB
- **Total amount of disk used:** 16.04 MB
An example of `validation` looks as follows.
```
{'category': 'Airport',
'gem_id': 'web_nlg_ru-validation-0',
'input': ['Punjab,_Pakistan | leaderTitle | Provincial_Assembly_of_the_Punjab'],
'references': ['Пенджаб, Пакистан, возглавляется Провинциальной ассамблеей Пенджаба.', 'Пенджаб, Пакистан возглавляется Провинциальной ассамблеей Пенджаба.'],
'target': 'Пенджаб, Пакистан, возглавляется Провинциальной ассамблеей Пенджаба.',
'webnlg_id': 'dev/Airport/1/Id1'}
```
#### wiki_auto_asset_turk
- **Size of downloaded dataset files:** 127.27 MB
- **Size of the generated dataset:** 152.77 MB
- **Total amount of disk used:** 280.04 MB
An example of `validation` looks as follows.
```
{'gem_id': 'wiki_auto_asset_turk-validation-0',
'references': ['The Gandalf Awards honor excellent writing in in fantasy literature.'],
'source': 'The Gandalf Awards, honoring achievement in fantasy literature, were conferred by the World Science Fiction Society annually from 1974 to 1981.',
'source_id': '350_691837-1-0-0',
'target': 'The Gandalf Awards honor excellent writing in in fantasy literature.',
'target_id': '350_691837-0-0-0'}
```
#### wiki_lingua_es_en
- **Size of downloaded dataset files:** 169.41 MB
- **Size of the generated dataset:** 287.60 MB
- **Total amount of disk used:** 457.01 MB
An example of `validation` looks as follows.
```
'references': ["Practice matted hair prevention from early in your cat's life. Make sure that your cat is grooming itself effectively. Keep a close eye on cats with long hair."],
'source': 'Muchas personas presentan problemas porque no cepillaron el pelaje de sus gatos en una etapa temprana de su vida, ya que no lo consideraban necesario. Sin embargo, a medida que...',
'target': "Practice matted hair prevention from early in your cat's life. Make sure that your cat is grooming itself effectively. Keep a close eye on cats with long hair."}
```
#### wiki_lingua_ru_en
- **Size of downloaded dataset files:** 169.41 MB
- **Size of the generated dataset:** 211.21 MB
- **Total amount of disk used:** 380.62 MB
An example of `validation` looks as follows.
```
{'gem_id': 'wiki_lingua_ru_en-val-0',
'references': ['Get immediate medical care if you notice signs of a complication. Undergo diagnostic tests to check for gallstones and complications. Ask your doctor about your treatment '
'options.'],
'source': 'И хотя, скорее всего, вам не о чем волноваться, следует незамедлительно обратиться к врачу, если вы подозреваете, что у вас возникло осложнение желчекаменной болезни. Это ...',
'target': 'Get immediate medical care if you notice signs of a complication. Undergo diagnostic tests to check for gallstones and complications. Ask your doctor about your treatment '
'options.'}
```
#### wiki_lingua_tr_en
- **Size of downloaded dataset files:** 169.41 MB
- **Size of the generated dataset:** 10.35 MB
- **Total amount of disk used:** 179.75 MB
An example of `validation` looks as follows.
```
{'gem_id': 'wiki_lingua_tr_en-val-0',
'references': ['Open Instagram. Go to the video you want to download. Tap ⋮. Tap Copy Link. Open Google Chrome. Tap the address bar. Go to the SaveFromWeb site. Tap the "Paste Instagram Video" text box. Tap and hold the text box. Tap PASTE. Tap Download. Download the video. Find the video on your Android.'],
'source': 'Instagram uygulamasının çok renkli kamera şeklindeki simgesine dokun. Daha önce giriş yaptıysan Instagram haber kaynağı açılır. Giriş yapmadıysan istendiğinde e-posta adresini ...',
'target': 'Open Instagram. Go to the video you want to download. Tap ⋮. Tap Copy Link. Open Google Chrome. Tap the address bar. Go to the SaveFromWeb site. Tap the "Paste Instagram Video" text box. Tap and hold the text box. Tap PASTE. Tap Download. Download the video. Find the video on your Android.'}
```
#### wiki_lingua_vi_en
- **Size of downloaded dataset files:** 169.41 MB
- **Size of the generated dataset:** 41.02 MB
- **Total amount of disk used:** 210.43 MB
An example of `validation` looks as follows.
```
{'gem_id': 'wiki_lingua_vi_en-val-0',
'references': ['Select the right time of year for planting the tree. You will usually want to plant your tree when it is dormant, or not flowering, during cooler or colder times of year.'],
'source': 'Bạn muốn cung cấp cho cây cơ hội tốt nhất để phát triển và sinh tồn. Trồng cây đúng thời điểm trong năm chính là yếu tố then chốt. Thời điểm sẽ thay đổi phụ thuộc vào loài cây ...',
'target': 'Select the right time of year for planting the tree. You will usually want to plant your tree when it is dormant, or not flowering, during cooler or colder times of year.'}
```
#### xsum
- **Size of downloaded dataset files:** 254.89 MB
- **Size of the generated dataset:** 70.67 MB
- **Total amount of disk used:** 325.56 MB
An example of `validation` looks as follows.
```
{'document': 'Burberry reported pre-tax profits of £166m for the year to March. A year ago it made a loss of £16.1m, hit by charges at its Spanish operations.\n'
'In the past year it has opened 21 new stores and closed nine. It plans to open 20-30 stores this year worldwide.\n'
'The group has also focused on promoting the Burberry brand online...',
'gem_id': 'xsum-validation-0',
'references': ['Luxury fashion designer Burberry has returned to profit after opening new stores and spending more on online marketing'],
'target': 'Luxury fashion designer Burberry has returned to profit after opening new stores and spending more on online marketing',
'xsum_id': '10162122'}
```
### Data Fields
The data fields are the same among all splits.
#### common_gen
- `gem_id`: a `string` feature.
- `concept_set_id`: a `int32` feature.
- `concepts`: a `list` of `string` features.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### cs_restaurants
- `gem_id`: a `string` feature.
- `dialog_act`: a `string` feature.
- `dialog_act_delexicalized`: a `string` feature.
- `target_delexicalized`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### dart
- `gem_id`: a `string` feature.
- `dart_id`: a `int32` feature.
- `tripleset`: a `list` of `string` features.
- `subtree_was_extended`: a `bool` feature.
- `target_sources`: a `list` of `string` features.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### e2e_nlg
- `gem_id`: a `string` feature.
- `meaning_representation`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### mlsum_de
- `gem_id`: a `string` feature.
- `text`: a `string` feature.
- `topic`: a `string` feature.
- `url`: a `string` feature.
- `title`: a `string` feature.
- `date`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### mlsum_es
- `gem_id`: a `string` feature.
- `text`: a `string` feature.
- `topic`: a `string` feature.
- `url`: a `string` feature.
- `title`: a `string` feature.
- `date`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### schema_guided_dialog
- `gem_id`: a `string` feature.
- `act`: a classification label, with possible values including `AFFIRM` (0), `AFFIRM_INTENT` (1), `CONFIRM` (2), `GOODBYE` (3), `INFORM` (4).
- `slot`: a `string` feature.
- `values`: a `list` of `string` features.
- `dialog_id`: a `string` feature.
- `turn_id`: a `int32` feature.
- `prompt`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### totto
- `gem_id`: a `string` feature.
- `totto_id`: a `int32` feature.
- `table_page_title`: a `string` feature.
- `table_webpage_url`: a `string` feature.
- `table_section_title`: a `string` feature.
- `table_section_text`: a `string` feature.
- `column_span`: a `int32` feature.
- `is_header`: a `bool` feature.
- `row_span`: a `int32` feature.
- `value`: a `string` feature.
- `highlighted_cells`: a `list` of `int32` features.
- `example_id`: a `string` feature.
- `original_sentence`: a `string` feature.
- `sentence_after_deletion`: a `string` feature.
- `sentence_after_ambiguity`: a `string` feature.
- `final_sentence`: a `string` feature.
- `overlap_subset`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### web_nlg_en
- `gem_id`: a `string` feature.
- `input`: a `list` of `string` features.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
- `category`: a `string` feature.
- `webnlg_id`: a `string` feature.
#### web_nlg_ru
- `gem_id`: a `string` feature.
- `input`: a `list` of `string` features.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
- `category`: a `string` feature.
- `webnlg_id`: a `string` feature.
#### wiki_auto_asset_turk
- `gem_id`: a `string` feature.
- `source_id`: a `string` feature.
- `target_id`: a `string` feature.
- `source`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### wiki_lingua_es_en
- `gem_id`: a `string` feature.
- `source`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### wiki_lingua_ru_en
- `gem_id`: a `string` feature.
- `source`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### wiki_lingua_tr_en
- `gem_id`: a `string` feature.
- `source`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### wiki_lingua_vi_en
- `gem_id`: a `string` feature.
- `source`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
#### xsum
- `gem_id`: a `string` feature.
- `xsum_id`: a `string` feature.
- `document`: a `string` feature.
- `target`: a `string` feature.
- `references`: a `list` of `string` features.
### Data Splits
#### common_gen
| |train|validation|test|
|----------|----:|---------:|---:|
|common_gen|67389| 993|1497|
#### cs_restaurants
| |train|validation|test|
|--------------|----:|---------:|---:|
|cs_restaurants| 3569| 781| 842|
#### dart
| |train|validation|test|
|----|----:|---------:|---:|
|dart|62659| 2768|6959|
#### e2e_nlg
| |train|validation|test|
|-------|----:|---------:|---:|
|e2e_nlg|33525| 4299|4693|
#### mlsum_de
| |train |validation|test |
|--------|-----:|---------:|----:|
|mlsum_de|220748| 11392|10695|
#### mlsum_es
| |train |validation|test |
|--------|-----:|---------:|----:|
|mlsum_es|259886| 9977|13365|
#### schema_guided_dialog
| |train |validation|test |
|--------------------|-----:|---------:|----:|
|schema_guided_dialog|164982| 10000|10000|
#### totto
| |train |validation|test|
|-----|-----:|---------:|---:|
|totto|121153| 7700|7700|
#### web_nlg_en
| |train|validation|test|
|----------|----:|---------:|---:|
|web_nlg_en|35426| 1667|1779|
#### web_nlg_ru
| |train|validation|test|
|----------|----:|---------:|---:|
|web_nlg_ru|14630| 790|1102|
#### wiki_auto_asset_turk
| |train |validation|test_asset|test_turk|
|--------------------|-----:|---------:|---------:|--------:|
|wiki_auto_asset_turk|373801| 73249| 359| 359|
#### wiki_lingua_es_en
| |train|validation|test |
|-----------------|----:|---------:|----:|
|wiki_lingua_es_en|79515| 8835|19797|
#### wiki_lingua_ru_en
| |train|validation|test|
|-----------------|----:|---------:|---:|
|wiki_lingua_ru_en|36898| 4100|9094|
#### wiki_lingua_tr_en
| |train|validation|test|
|-----------------|----:|---------:|---:|
|wiki_lingua_tr_en| 3193| 355| 808|
#### wiki_lingua_vi_en
| |train|validation|test|
|-----------------|----:|---------:|---:|
|wiki_lingua_vi_en| 9206| 1023|2167|
#### xsum
| |train|validation|test|
|----|----:|---------:|---:|
|xsum|23206| 1117|1166|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
CC-BY-SA-4.0
### Citation Information
```
@article{gem_benchmark,
author = {Sebastian Gehrmann and
Tosin P. Adewumi and
Karmanya Aggarwal and
Pawan Sasanka Ammanamanchi and
Aremu Anuoluwapo and
Antoine Bosselut and
Khyathi Raghavi Chandu and
Miruna{-}Adriana Clinciu and
Dipanjan Das and
Kaustubh D. Dhole and
Wanyu Du and
Esin Durmus and
Ondrej Dusek and
Chris Emezue and
Varun Gangal and
Cristina Garbacea and
Tatsunori Hashimoto and
Yufang Hou and
Yacine Jernite and
Harsh Jhamtani and
Yangfeng Ji and
Shailza Jolly and
Dhruv Kumar and
Faisal Ladhak and
Aman Madaan and
Mounica Maddela and
Khyati Mahajan and
Saad Mahamood and
Bodhisattwa Prasad Majumder and
Pedro Henrique Martins and
Angelina McMillan{-}Major and
Simon Mille and
Emiel van Miltenburg and
Moin Nadeem and
Shashi Narayan and
Vitaly Nikolaev and
Rubungo Andre Niyongabo and
Salomey Osei and
Ankur P. Parikh and
Laura Perez{-}Beltrachini and
Niranjan Ramesh Rao and
Vikas Raunak and
Juan Diego Rodriguez and
Sashank Santhanam and
Jo{\~{a}}o Sedoc and
Thibault Sellam and
Samira Shaikh and
Anastasia Shimorina and
Marco Antonio Sobrevilla Cabezudo and
Hendrik Strobelt and
Nishant Subramani and
Wei Xu and
Diyi Yang and
Akhila Yerukola and
Jiawei Zhou},
title = {The {GEM} Benchmark: Natural Language Generation, its Evaluation and
Metrics},
journal = {CoRR},
volume = {abs/2102.01672},
year = {2021},
url = {https://arxiv.org/abs/2102.01672},
archivePrefix = {arXiv},
eprint = {2102.01672}
}
```
### Contributions
Thanks to [@yjernite](https://github.com/yjernite) for adding this dataset.
|
byeonggi/0620_data
|
byeonggi
|
2025-06-20T11:11:05Z
| 0
| 0
|
[
"license:apache-2.0",
"region:us"
] |
[] |
2025-06-20T11:11:05Z
| 0
|
---
license: apache-2.0
---
|
EuskadIA/Hiesa_Hiztegia
|
EuskadIA
|
2025-03-29T22:09:15Z
| 24
| 0
|
[
"task_categories:translation",
"language:eu",
"language:spa",
"language:fra",
"language:eng",
"region:us"
] |
[
"translation"
] |
2025-01-14T17:52:54Z
| 0
|
---
language:
- eu
- spa
- fra
- eng
task_categories:
- translation
---
> [!NOTE]
> Dataset origin: https://www.ivap.euskadi.eus/webivap00-a5app3/fr/ac36aEuskaltermWar/publiko/erakutsiBankuEdukia
|
TAUR-dev/SIE_EVAL__SIEXP_first_response_correct__ME__lm2d__sft__samples
|
TAUR-dev
|
2025-06-06T03:50:02Z
| 0
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-06-06T03:49:59Z
| 0
|
---
dataset_info:
features:
- name: doc_id
dtype: int64
- name: doc
dtype: string
- name: target
dtype: string
- name: arguments
dtype: string
- name: resps
dtype: string
- name: filtered_resps
dtype: string
- name: doc_hash
dtype: string
- name: prompt_hash
dtype: string
- name: target_hash
dtype: string
- name: exact_match
dtype: int64
- name: extracted_answers
dtype: string
- name: source_file
dtype: string
- name: generation
dtype: string
- name: info
dtype: string
- name: evaluation_api_cost
dtype: string
splits:
- name: train
num_bytes: 145296605
num_examples: 3656
download_size: 20467234
dataset_size: 145296605
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Egrigor/ValheimFactPairs
|
Egrigor
|
2025-03-20T18:17:56Z
| 24
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-03-20T18:17:52Z
| 0
|
---
dataset_info:
features:
- name: prompt
dtype: string
- name: response
dtype: string
- name: tags
sequence: string
splits:
- name: train
num_bytes: 2032173
num_examples: 9274
download_size: 957920
dataset_size: 2032173
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
zzxxxass/12
|
zzxxxass
|
2025-01-26T16:41:36Z
| 16
| 0
|
[
"license:apache-2.0",
"size_categories:n<1K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-01-26T16:41:17Z
| 0
|
---
license: apache-2.0
---
|
xinpeng/PKU-SafeRLHF-promt-quater
|
xinpeng
|
2025-02-06T22:43:57Z
| 58
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-02-06T22:43:55Z
| 0
|
---
dataset_info:
features:
- name: prompt
dtype: string
- name: prompt_source
dtype: string
splits:
- name: train
num_bytes: 1631037.069944816
num_examples: 11144
download_size: 821747
dataset_size: 1631037.069944816
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
garySue/eval_diffusion_picking_wok
|
garySue
|
2025-02-21T07:20:50Z
| 24
| 0
|
[
"task_categories:robotics",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"ur5",
"tutorial",
"eval"
] |
[
"robotics"
] |
2025-02-21T07:20:45Z
| 0
|
---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- ur5
- tutorial
- eval
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.0",
"robot_type": "bi_ur5",
"total_episodes": 1,
"total_frames": 177,
"total_tasks": 1,
"total_videos": 3,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:1"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
14
],
"names": {
"motors": [
"left_shoulder_pan",
"left_shoulder_lift",
"left_elbow_flex",
"left_wrist_1",
"left_wrist_2",
"left_wrist_3",
"left_gripper",
"right_shoulder_pan",
"right_shoulder_lift",
"right_elbow_flex",
"right_wrist_1",
"right_wrist_2",
"right_wrist_3",
"right_gripper"
]
}
},
"observation.state": {
"dtype": "float32",
"shape": [
14
],
"names": {
"arms": [
"left_shoulder_pan",
"left_shoulder_lift",
"left_elbow_flex",
"left_wrist_1",
"left_wrist_2",
"left_wrist_3",
"left_gripper",
"right_shoulder_pan",
"right_shoulder_lift",
"right_elbow_flex",
"right_wrist_1",
"right_wrist_2",
"right_wrist_3",
"right_gripper"
]
}
},
"observation.velocity": {
"dtype": "float32",
"shape": [
14
],
"names": {
"arms": [
"left_shoulder_pan",
"left_shoulder_lift",
"left_elbow_flex",
"left_wrist_1",
"left_wrist_2",
"left_wrist_3",
"left_gripper",
"right_shoulder_pan",
"right_shoulder_lift",
"right_elbow_flex",
"right_wrist_1",
"right_wrist_2",
"right_wrist_3",
"right_gripper"
]
}
},
"observation.gripper_position": {
"dtype": "float32",
"shape": [
2
],
"names": {
"gripper": [
"left_gripper",
"right_gripper"
]
}
},
"observation.images.top_rgb": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.left_rgb": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.right_rgb": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
```
|
debabrata-ai/llama3-customer-support-preference
|
debabrata-ai
|
2025-01-14T18:46:30Z
| 21
| 0
|
[
"language:en",
"license:apache-2.0",
"region:us",
"customer-support",
"preference-dataset",
"direct-preference-optimization",
"llama3"
] |
[] |
2025-01-14T18:34:22Z
| 0
|
---
dataset_name: llama3-customer-support-preference
language: en
tags:
- customer-support
- preference-dataset
- direct-preference-optimization
- llama3
license: apache-2.0
---
# 📊 LLaMA 3.1 Customer Support Preference Dataset
The **LLaMA 3.1 Customer Support Preference Dataset** is built to fine-tune large language models for customer support tasks using **Direct Preference Optimization (DPO)**. It contains customer queries with multiple response options labeled by preference, enabling models to generate more **contextually relevant**, **empathetic**, and **helpful** responses.
|
CohenQu/Omni-MATH-5678-Qwen3-4B-16k_human_solution_conditioned_prompts
|
CohenQu
|
2025-09-21T17:50:50Z
| 83
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-09-21T17:50:50Z
| 0
|
---
dataset_info:
features:
- name: problem
dtype: string
- name: answer
dtype: string
- name: original_problem
dtype: string
splits:
- name: train
num_bytes: 1965156
num_examples: 1206
download_size: 359124
dataset_size: 1965156
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
NiharMandahas/Time_Complexity
|
NiharMandahas
|
2024-12-20T15:49:58Z
| 20
| 1
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-12-20T15:22:48Z
| 0
|
---
dataset_info:
features:
- name: Code
dtype: string
- name: Input size
dtype: string
- name: Time Complexity
dtype: string
- name: 'Unnamed: 3'
dtype: float64
- name: Text
dtype: string
splits:
- name: train
num_bytes: 161979
num_examples: 121
download_size: 75073
dataset_size: 161979
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Wanacola/koch_pick_place1
|
Wanacola
|
2024-10-07T02:18:09Z
| 20
| 0
|
[
"region:us"
] |
[] |
2024-10-07T02:16:45Z
| 0
|
---
dataset_info:
features:
- name: observation.state
sequence: float32
length: 8
- name: action
sequence: float32
length: 8
- name: observation.images.top
dtype: video_frame
- name: observation.images.phone
dtype: video_frame
- name: episode_index
dtype: int64
- name: frame_index
dtype: int64
- name: timestamp
dtype: float32
- name: next.done
dtype: bool
- name: index
dtype: int64
splits:
- name: train
num_bytes: 3150621
num_examples: 15285
download_size: 1017183
dataset_size: 3150621
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
KevinZ/psycholinguistic_eval
|
KevinZ
|
2022-10-25T10:03:37Z
| 29
| 3
|
[
"task_categories:multiple-choice",
"task_categories:fill-mask",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"annotations_creators:expert-generated",
"language_creators:expert-generated",
"multilinguality:monolingual",
"license:mit",
"size_categories:n<1K",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] |
[
"multiple-choice",
"fill-mask",
"question-answering",
"zero-shot-classification"
] |
2022-04-01T00:04:18Z
| 0
|
---
annotations_creators:
- expert-generated
language_creators:
- expert-generated
language:
- en-US
license:
- mit
multilinguality:
- monolingual
pretty_name: psycholinguistic_eval
size_categories:
- n<1K
source_datasets: []
task_categories:
- multiple-choice
- fill-mask
- question-answering
- zero-shot-classification
task_ids: []
---
This is a suite of psycholinguistic datasets by Allyson Ettinger. See her [official Github repository](https://github.com/aetting/lm-diagnostics) for specific details.
|
mteb/OPP115ThirdPartySharingCollectionLegalBenchClassification
|
mteb
|
2025-05-07T20:03:29Z
| 0
| 0
|
[
"task_categories:text-classification",
"annotations_creators:expert-annotated",
"multilinguality:monolingual",
"language:eng",
"license:cc-by-nc-4.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2308.11462",
"arxiv:2502.13595",
"arxiv:2210.07316",
"region:us",
"mteb",
"text"
] |
[
"text-classification"
] |
2025-05-07T20:03:25Z
| 0
|
---
annotations_creators:
- expert-annotated
language:
- eng
license: cc-by-nc-4.0
multilinguality: monolingual
task_categories:
- text-classification
task_ids: []
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 1189
num_examples: 8
- name: test
num_bytes: 374681
num_examples: 1590
download_size: 179280
dataset_size: 375870
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
tags:
- mteb
- text
---
<!-- adapted from https://github.com/huggingface/huggingface_hub/blob/v0.30.2/src/huggingface_hub/templates/datasetcard_template.md -->
<div align="center" style="padding: 40px 20px; background-color: white; border-radius: 12px; box-shadow: 0 2px 10px rgba(0, 0, 0, 0.05); max-width: 600px; margin: 0 auto;">
<h1 style="font-size: 3.5rem; color: #1a1a1a; margin: 0 0 20px 0; letter-spacing: 2px; font-weight: 700;">OPP115ThirdPartySharingCollectionLegalBenchClassification</h1>
<div style="font-size: 1.5rem; color: #4a4a4a; margin-bottom: 5px; font-weight: 300;">An <a href="https://github.com/embeddings-benchmark/mteb" style="color: #2c5282; font-weight: 600; text-decoration: none;" onmouseover="this.style.textDecoration='underline'" onmouseout="this.style.textDecoration='none'">MTEB</a> dataset</div>
<div style="font-size: 0.9rem; color: #2c5282; margin-top: 10px;">Massive Text Embedding Benchmark</div>
</div>
Given a clause from a privacy policy, classify if the clause describe how user information may be shared with or collected by third parties.
| | |
|---------------|---------------------------------------------|
| Task category | t2c |
| Domains | Legal, Written |
| Reference | https://huggingface.co/datasets/nguha/legalbench |
## How to evaluate on this task
You can evaluate an embedding model on this dataset using the following code:
```python
import mteb
task = mteb.get_tasks(["OPP115ThirdPartySharingCollectionLegalBenchClassification"])
evaluator = mteb.MTEB(task)
model = mteb.get_model(YOUR_MODEL)
evaluator.run(model)
```
<!-- Datasets want link to arxiv in readme to autolink dataset with paper -->
To learn more about how to run models on `mteb` task check out the [GitHub repitory](https://github.com/embeddings-benchmark/mteb).
## Citation
If you use this dataset, please cite the dataset as well as [mteb](https://github.com/embeddings-benchmark/mteb), as this dataset likely includes additional processing as a part of the [MMTEB Contribution](https://github.com/embeddings-benchmark/mteb/tree/main/docs/mmteb).
```bibtex
@misc{guha2023legalbench,
archiveprefix = {arXiv},
author = {Neel Guha and Julian Nyarko and Daniel E. Ho and Christopher Ré and Adam Chilton and Aditya Narayana and Alex Chohlas-Wood and Austin Peters and Brandon Waldon and Daniel N. Rockmore and Diego Zambrano and Dmitry Talisman and Enam Hoque and Faiz Surani and Frank Fagan and Galit Sarfaty and Gregory M. Dickinson and Haggai Porat and Jason Hegland and Jessica Wu and Joe Nudell and Joel Niklaus and John Nay and Jonathan H. Choi and Kevin Tobia and Margaret Hagan and Megan Ma and Michael Livermore and Nikon Rasumov-Rahe and Nils Holzenberger and Noam Kolt and Peter Henderson and Sean Rehaag and Sharad Goel and Shang Gao and Spencer Williams and Sunny Gandhi and Tom Zur and Varun Iyer and Zehua Li},
eprint = {2308.11462},
primaryclass = {cs.CL},
title = {LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models},
year = {2023},
}
@inproceedings{wilson2016creation,
author = {Wilson, Shomir and Schaub, Florian and Dara, Aswarth Abhilash and Liu, Frederick and Cherivirala, Sushain and Leon, Pedro Giovanni and Andersen, Mads Schaarup and Zimmeck, Sebastian and Sathyendra, Kanthashree Mysore and Russell, N Cameron and others},
booktitle = {Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages = {1330--1340},
title = {The creation and analysis of a website privacy policy corpus},
year = {2016},
}
@article{enevoldsen2025mmtebmassivemultilingualtext,
title={MMTEB: Massive Multilingual Text Embedding Benchmark},
author={Kenneth Enevoldsen and Isaac Chung and Imene Kerboua and Márton Kardos and Ashwin Mathur and David Stap and Jay Gala and Wissam Siblini and Dominik Krzemiński and Genta Indra Winata and Saba Sturua and Saiteja Utpala and Mathieu Ciancone and Marion Schaeffer and Gabriel Sequeira and Diganta Misra and Shreeya Dhakal and Jonathan Rystrøm and Roman Solomatin and Ömer Çağatan and Akash Kundu and Martin Bernstorff and Shitao Xiao and Akshita Sukhlecha and Bhavish Pahwa and Rafał Poświata and Kranthi Kiran GV and Shawon Ashraf and Daniel Auras and Björn Plüster and Jan Philipp Harries and Loïc Magne and Isabelle Mohr and Mariya Hendriksen and Dawei Zhu and Hippolyte Gisserot-Boukhlef and Tom Aarsen and Jan Kostkan and Konrad Wojtasik and Taemin Lee and Marek Šuppa and Crystina Zhang and Roberta Rocca and Mohammed Hamdy and Andrianos Michail and John Yang and Manuel Faysse and Aleksei Vatolin and Nandan Thakur and Manan Dey and Dipam Vasani and Pranjal Chitale and Simone Tedeschi and Nguyen Tai and Artem Snegirev and Michael Günther and Mengzhou Xia and Weijia Shi and Xing Han Lù and Jordan Clive and Gayatri Krishnakumar and Anna Maksimova and Silvan Wehrli and Maria Tikhonova and Henil Panchal and Aleksandr Abramov and Malte Ostendorff and Zheng Liu and Simon Clematide and Lester James Miranda and Alena Fenogenova and Guangyu Song and Ruqiya Bin Safi and Wen-Ding Li and Alessia Borghini and Federico Cassano and Hongjin Su and Jimmy Lin and Howard Yen and Lasse Hansen and Sara Hooker and Chenghao Xiao and Vaibhav Adlakha and Orion Weller and Siva Reddy and Niklas Muennighoff},
publisher = {arXiv},
journal={arXiv preprint arXiv:2502.13595},
year={2025},
url={https://arxiv.org/abs/2502.13595},
doi = {10.48550/arXiv.2502.13595},
}
@article{muennighoff2022mteb,
author = {Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils},
title = {MTEB: Massive Text Embedding Benchmark},
publisher = {arXiv},
journal={arXiv preprint arXiv:2210.07316},
year = {2022}
url = {https://arxiv.org/abs/2210.07316},
doi = {10.48550/ARXIV.2210.07316},
}
```
# Dataset Statistics
<details>
<summary> Dataset Statistics</summary>
The following code contains the descriptive statistics from the task. These can also be obtained using:
```python
import mteb
task = mteb.get_task("OPP115ThirdPartySharingCollectionLegalBenchClassification")
desc_stats = task.metadata.descriptive_stats
```
```json
{
"test": {
"num_samples": 1590,
"number_of_characters": 355601,
"number_texts_intersect_with_train": 0,
"min_text_length": 45,
"average_text_length": 223.64842767295596,
"max_text_length": 1816,
"unique_text": 1590,
"unique_labels": 2,
"labels": {
"1": {
"count": 798
},
"0": {
"count": 792
}
}
},
"train": {
"num_samples": 8,
"number_of_characters": 1093,
"number_texts_intersect_with_train": null,
"min_text_length": 68,
"average_text_length": 136.625,
"max_text_length": 278,
"unique_text": 8,
"unique_labels": 2,
"labels": {
"1": {
"count": 4
},
"0": {
"count": 4
}
}
}
}
```
</details>
---
*This dataset card was automatically generated using [MTEB](https://github.com/embeddings-benchmark/mteb)*
|
mlfoundations-dev/a1_code_magpie
|
mlfoundations-dev
|
2025-04-12T16:49:35Z
| 24
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-04-03T03:25:18Z
| 0
|
---
dataset_info:
features:
- name: instruction_seed
dtype: string
- name: response_seed
dtype: string
- name: reasoning
dtype: string
- name: deepseek_solution
dtype: string
- name: __original_row_idx
dtype: int64
- name: source
dtype: string
- name: final_reasoning_trace
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 882000180
num_examples: 31600
download_size: 441706259
dataset_size: 882000180
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
gtsaidata/VulnerableCaptchas
|
gtsaidata
|
2025-03-04T12:16:19Z
| 10
| 0
|
[
"task_categories:text-generation",
"task_categories:image-classification",
"language:en",
"region:us",
"Vulnerable Captchas",
"CAPTCHAs dataset"
] |
[
"text-generation",
"image-classification"
] |
2025-03-04T12:12:01Z
| 0
|
---
task_categories:
- text-generation
- image-classification
language:
- en
tags:
- Vulnerable Captchas
- CAPTCHAs dataset
---
Description:
<a href="https://gts.ai/dataset-download/vulnerable-captchas/" target="_blank">👉 Download the dataset here</a>
This dataset focuses on an interesting example of weak CAPTCHA implementations, highlighting potential security vulnerabilities in systems that rely on simple alphanumeric captchas. CAPTCHAs (Completely Automated Public Turing Test to Tell Computers and Humans Apart) are widely used to protect websites from bots and automated scripts. However, not all CAPTCHA implementations are equally secure, and some are prone to exploitation through automated processes.
Download Dataset
Context
The inspiration for this dataset came from a personal experience while accessing a website I frequently use, which I will refer to as “System” for privacy reasons. I wanted to automate a repetitive task on the site using a Python script, but I was initially blocked by a CAPTCHA that was required to complete the login process. CAPTCHAs are generally effective in stopping bots, especially those like Google’s reCAPTCHA, which are difficult to bypass with machine learning models due to their sophisticated design.
However, in this case, the CAPTCHA images were simple enough for human eyes to decipher, consisting only of clearly readable alphanumeric characters. The challenge intrigued me, and as I was simultaneously reading “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron, I decided to use this scenario as an opportunity to apply my newly acquired knowledge in machine learning.
Problem and Approach
The dataset captures images of these vulnerable CAPTCHA challenges and provides annotations for each. During the process of automating the CAPTCHA resolution, I learned that the system did not just rely on the image itself. Upon inspection of the HTML, I found that the CAPTCHA content was hashed and stored inside a hidden form field. Which could easily be manipulate to bypass the verification entirely.
Key Learnings
CAPTCHA Design Matters: Not all CAPTCHAs are created equal. Simpler alphanumeric CAPTCHAs can often be defeated by image recognition models or form manipulation.
Image Classification: This dataset offers a collection of label CAPTCHA images. That could be use to train image classification models aimed at recognizing and solving CAPTCHAs automatically.
Security Implications: The project sheds light on the importance of implementing proper security mechanisms beyond just CAPTCHA images. Such as encryption, hashing, and verification strategies that prevent easy manipulation.
Practical Approach: Sometimes, simpler solutions such as analyzing the webpage structure and finding security loopholes can be more efficient than complex machine learning models.
This dataset is sourced from Kaggle.
|
kadirnar/Ja-Emilia-Test-v1
|
kadirnar
|
2025-06-17T23:52:27Z
| 0
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-06-17T23:52:25Z
| 0
|
---
dataset_info:
features:
- name: id
dtype: string
- name: speaker
dtype: string
- name: input_ids
sequence: int32
- name: labels
sequence: int64
- name: attention_mask
sequence: int8
splits:
- name: train
num_bytes: 8481114
num_examples: 1000
download_size: 2664428
dataset_size: 8481114
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
DanTrireme/HyperBalances
|
DanTrireme
|
2025-05-22T09:47:40Z
| 0
| 0
|
[
"size_categories:n<1K",
"format:text",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] |
[] |
2025-05-22T09:36:04Z
| 0
|
---
title: billy_dashboard
app_file: app.py
sdk: gradio
sdk_version: 5.29.1
---
|
Manchesterokaa/Record_bluecube_500
|
Manchesterokaa
|
2025-09-26T03:05:02Z
| 56
| 0
|
[
"task_categories:robotics",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot"
] |
[
"robotics"
] |
2025-09-26T03:04:49Z
| 0
|
---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v3.0",
"robot_type": "so101_follower",
"total_episodes": 11,
"total_frames": 3106,
"total_tasks": 1,
"chunks_size": 1000,
"data_files_size_in_mb": 100,
"video_files_size_in_mb": 500,
"fps": 30,
"splits": {
"train": "0:11"
},
"data_path": "data/chunk-{chunk_index:03d}/file-{file_index:03d}.parquet",
"video_path": "videos/{video_key}/chunk-{chunk_index:03d}/file-{file_index:03d}.mp4",
"features": {
"action": {
"dtype": "float32",
"names": [
"shoulder_pan.pos",
"shoulder_lift.pos",
"elbow_flex.pos",
"wrist_flex.pos",
"wrist_roll.pos",
"gripper.pos"
],
"shape": [
6
]
},
"observation.state": {
"dtype": "float32",
"names": [
"shoulder_pan.pos",
"shoulder_lift.pos",
"elbow_flex.pos",
"wrist_flex.pos",
"wrist_roll.pos",
"gripper.pos"
],
"shape": [
6
]
},
"observation.images.front": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"observation.images.side": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.height": 480,
"video.width": 640,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"video.fps": 30,
"video.channels": 3,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
```
|
Parveshiiii/opencode_reasoning_filtered1
|
Parveshiiii
|
2025-05-08T02:16:33Z
| 0
| 0
|
[
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-08T01:34:53Z
| 0
|
---
dataset_info:
features:
- name: id
dtype: string
- name: input
dtype: string
- name: output
dtype: string
- name: source
dtype: string
- name: difficulty
dtype: string
- name: solution
dtype: string
splits:
- name: train
num_bytes: 3310294357
num_examples: 167405
download_size: 1408547759
dataset_size: 3310294357
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
---
# **OpenCode Reasoning - Filtered Split 1**
🚀 **Optimized dataset for reasoning and code generation tasks**
## 📌 **Description**
This dataset is a **filtered version of `split_1`** from `nvidia/OpenCodeReasoning`, containing **167,000 examples** for instruction-based reasoning.
🔹 **Removed unnecessary columns**: `license`, `dataset`, `split`, `index`.
## 🌟 **Features**
| **Feature** | **Type** | **Description** |
|--------------|------------|----------------|
| `id` | `string` | Unique identifier |
| `input` | `string` | Problem statement or prompt |
| `output` | `string` | Expected output or solution |
| `source` | `string` | Origin of the example |
| `difficulty` | `string` | Difficulty level |
| `solution` | `string` | Detailed solution or code |
## 📊 **Dataset Statistics**
🔹 **Total Rows**: `167,000`
🔹 **Number of Shards**: `7`
🔹 **Split**: `train`
## 📁 **Dataset Structure**
```
Parveshiiii/opencode_reasoning_filtered1/
└── train/
├── train-00000-of-00007.parquet
├── train-00001-of-00007.parquet
├── train-00002-of-00007.parquet
├── train-00003-of-00007.parquet
├── train-00004-of-00007.parquet
├── train-00005-of-00007.parquet
├── train-00006-of-00007.parquet
```
## 🛠 **Usage**
Load the dataset in Python:
```python
from datasets import load_dataset
dataset = load_dataset("Parveshiiii/opencode_reasoning_filtered1", split="train")
print(dataset)
print(dataset[0])
```
### 🔄 **Streaming Mode**
For efficient large-scale processing:
```python
dataset = load_dataset("Parveshiiii/opencode_reasoning_filtered1", split="train", streaming=True)
for example in dataset:
print(example)
break
```
## 🔗 **Source & License**
📌 **Derived from** `nvidia/OpenCodeReasoning` (`split_1`)
📜 **License**: Inherits the license from `nvidia/OpenCodeReasoning`.
## ✉️ **Contact**
Parvesh Rawal (📩 **[email protected]**)
---
|
litexlang/gsm8k-litex
|
litexlang
|
2025-09-22T06:02:39Z
| 198
| 3
|
[
"task_categories:question-answering",
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"code",
"agent"
] |
[
"question-answering"
] |
2025-09-22T05:53:19Z
| 0
|
---
license: mit
task_categories:
- question-answering
language:
- en
tags:
- code
- agent
size_categories:
- 1K<n<10K
---
|
mteb/CUADLicenseGrantLegalBenchClassification
|
mteb
|
2025-05-06T11:54:42Z
| 0
| 0
|
[
"task_categories:text-classification",
"annotations_creators:expert-annotated",
"multilinguality:monolingual",
"language:eng",
"license:cc-by-4.0",
"modality:text",
"arxiv:2308.11462",
"arxiv:2103.06268",
"arxiv:2502.13595",
"arxiv:2210.07316",
"region:us",
"mteb",
"text"
] |
[
"text-classification"
] |
2025-05-06T11:54:38Z
| 0
|
---
annotations_creators:
- expert-annotated
language:
- eng
license: cc-by-4.0
multilinguality: monolingual
task_categories:
- text-classification
task_ids: []
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype: int64
splits:
- name: train
num_bytes: 3253
num_examples: 6
- name: test
num_bytes: 589244
num_examples: 1396
download_size: 287324
dataset_size: 592497
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
tags:
- mteb
- text
---
<!-- adapted from https://github.com/huggingface/huggingface_hub/blob/v0.30.2/src/huggingface_hub/templates/datasetcard_template.md -->
<div align="center" style="padding: 40px 20px; background-color: white; border-radius: 12px; box-shadow: 0 2px 10px rgba(0, 0, 0, 0.05); max-width: 600px; margin: 0 auto;">
<h1 style="font-size: 3.5rem; color: #1a1a1a; margin: 0 0 20px 0; letter-spacing: 2px; font-weight: 700;">CUADLicenseGrantLegalBenchClassification</h1>
<div style="font-size: 1.5rem; color: #4a4a4a; margin-bottom: 5px; font-weight: 300;">An <a href="https://github.com/embeddings-benchmark/mteb" style="color: #2c5282; font-weight: 600; text-decoration: none;" onmouseover="this.style.textDecoration='underline'" onmouseout="this.style.textDecoration='none'">MTEB</a> dataset</div>
<div style="font-size: 0.9rem; color: #2c5282; margin-top: 10px;">Massive Text Embedding Benchmark</div>
</div>
This task was constructed from the CUAD dataset. It consists of determining if the clause contains a license granted by one party to its counterparty.
| | |
|---------------|---------------------------------------------|
| Task category | t2c |
| Domains | Legal, Written |
| Reference | https://huggingface.co/datasets/nguha/legalbench |
## How to evaluate on this task
You can evaluate an embedding model on this dataset using the following code:
```python
import mteb
task = mteb.get_tasks(["CUADLicenseGrantLegalBenchClassification"])
evaluator = mteb.MTEB(task)
model = mteb.get_model(YOUR_MODEL)
evaluator.run(model)
```
<!-- Datasets want link to arxiv in readme to autolink dataset with paper -->
To learn more about how to run models on `mteb` task check out the [GitHub repitory](https://github.com/embeddings-benchmark/mteb).
## Citation
If you use this dataset, please cite the dataset as well as [mteb](https://github.com/embeddings-benchmark/mteb), as this dataset likely includes additional processing as a part of the [MMTEB Contribution](https://github.com/embeddings-benchmark/mteb/tree/main/docs/mmteb).
```bibtex
@misc{guha2023legalbench,
archiveprefix = {arXiv},
author = {Neel Guha and Julian Nyarko and Daniel E. Ho and Christopher Ré and Adam Chilton and Aditya Narayana and Alex Chohlas-Wood and Austin Peters and Brandon Waldon and Daniel N. Rockmore and Diego Zambrano and Dmitry Talisman and Enam Hoque and Faiz Surani and Frank Fagan and Galit Sarfaty and Gregory M. Dickinson and Haggai Porat and Jason Hegland and Jessica Wu and Joe Nudell and Joel Niklaus and John Nay and Jonathan H. Choi and Kevin Tobia and Margaret Hagan and Megan Ma and Michael Livermore and Nikon Rasumov-Rahe and Nils Holzenberger and Noam Kolt and Peter Henderson and Sean Rehaag and Sharad Goel and Shang Gao and Spencer Williams and Sunny Gandhi and Tom Zur and Varun Iyer and Zehua Li},
eprint = {2308.11462},
primaryclass = {cs.CL},
title = {LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models},
year = {2023},
}
@article{hendrycks2021cuad,
author = {Hendrycks, Dan and Burns, Collin and Chen, Anya and Ball, Spencer},
journal = {arXiv preprint arXiv:2103.06268},
title = {Cuad: An expert-annotated nlp dataset for legal contract review},
year = {2021},
}
@article{enevoldsen2025mmtebmassivemultilingualtext,
title={MMTEB: Massive Multilingual Text Embedding Benchmark},
author={Kenneth Enevoldsen and Isaac Chung and Imene Kerboua and Márton Kardos and Ashwin Mathur and David Stap and Jay Gala and Wissam Siblini and Dominik Krzemiński and Genta Indra Winata and Saba Sturua and Saiteja Utpala and Mathieu Ciancone and Marion Schaeffer and Gabriel Sequeira and Diganta Misra and Shreeya Dhakal and Jonathan Rystrøm and Roman Solomatin and Ömer Çağatan and Akash Kundu and Martin Bernstorff and Shitao Xiao and Akshita Sukhlecha and Bhavish Pahwa and Rafał Poświata and Kranthi Kiran GV and Shawon Ashraf and Daniel Auras and Björn Plüster and Jan Philipp Harries and Loïc Magne and Isabelle Mohr and Mariya Hendriksen and Dawei Zhu and Hippolyte Gisserot-Boukhlef and Tom Aarsen and Jan Kostkan and Konrad Wojtasik and Taemin Lee and Marek Šuppa and Crystina Zhang and Roberta Rocca and Mohammed Hamdy and Andrianos Michail and John Yang and Manuel Faysse and Aleksei Vatolin and Nandan Thakur and Manan Dey and Dipam Vasani and Pranjal Chitale and Simone Tedeschi and Nguyen Tai and Artem Snegirev and Michael Günther and Mengzhou Xia and Weijia Shi and Xing Han Lù and Jordan Clive and Gayatri Krishnakumar and Anna Maksimova and Silvan Wehrli and Maria Tikhonova and Henil Panchal and Aleksandr Abramov and Malte Ostendorff and Zheng Liu and Simon Clematide and Lester James Miranda and Alena Fenogenova and Guangyu Song and Ruqiya Bin Safi and Wen-Ding Li and Alessia Borghini and Federico Cassano and Hongjin Su and Jimmy Lin and Howard Yen and Lasse Hansen and Sara Hooker and Chenghao Xiao and Vaibhav Adlakha and Orion Weller and Siva Reddy and Niklas Muennighoff},
publisher = {arXiv},
journal={arXiv preprint arXiv:2502.13595},
year={2025},
url={https://arxiv.org/abs/2502.13595},
doi = {10.48550/arXiv.2502.13595},
}
@article{muennighoff2022mteb,
author = {Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo{\"\i}c and Reimers, Nils},
title = {MTEB: Massive Text Embedding Benchmark},
publisher = {arXiv},
journal={arXiv preprint arXiv:2210.07316},
year = {2022}
url = {https://arxiv.org/abs/2210.07316},
doi = {10.48550/ARXIV.2210.07316},
}
```
# Dataset Statistics
<details>
<summary> Dataset Statistics</summary>
The following code contains the descriptive statistics from the task. These can also be obtained using:
```python
import mteb
task = mteb.get_task("CUADLicenseGrantLegalBenchClassification")
desc_stats = task.metadata.descriptive_stats
```
```json
{
"test": {
"num_samples": 1396,
"number_of_characters": 572215,
"number_texts_intersect_with_train": 0,
"min_text_length": 54,
"average_text_length": 409.8961318051576,
"max_text_length": 3400,
"unique_text": 1396,
"unique_labels": 2,
"labels": {
"1": {
"count": 698
},
"0": {
"count": 698
}
}
},
"train": {
"num_samples": 6,
"number_of_characters": 3179,
"number_texts_intersect_with_train": null,
"min_text_length": 142,
"average_text_length": 529.8333333333334,
"max_text_length": 1028,
"unique_text": 6,
"unique_labels": 2,
"labels": {
"1": {
"count": 3
},
"0": {
"count": 3
}
}
}
}
```
</details>
---
*This dataset card was automatically generated using [MTEB](https://github.com/embeddings-benchmark/mteb)*
|
ymoslem/Human-Evaluation
|
ymoslem
|
2025-03-05T13:40:40Z
| 14
| 1
|
[
"task_categories:translation",
"task_categories:text-classification",
"language:ar",
"language:en",
"language:fr",
"language:es",
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[
"translation",
"text-classification"
] |
2025-03-05T13:39:59Z
| 0
|
---
dataset_info:
features:
- name: lang
dtype: large_string
- name: src
dtype: large_string
- name: ref
dtype: large_string
- name: tgt
dtype: large_string
- name: score
dtype: int64
- name: domain
dtype: large_string
- name: year
dtype: int64
- name: system
dtype: large_string
splits:
- name: train
num_bytes: 1954352
num_examples: 3200
download_size: 426721
dataset_size: 1954352
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
language:
- ar
- en
- fr
- es
task_categories:
- translation
- text-classification
size_categories:
- 10K<n<100K
---
# Human Evaluation Dataset
The dataset includes human evaluation for General and Health domains. It was created as part of my two papers:
* [*“Domain-Specific Text Generation for Machine Translation”*](https://aclanthology.org/2022.amta-research.2/) (Moslem et al., 2022)
* [*"Adaptive Machine Translation with Large Language Models"*](https://aclanthology.org/2023.eamt-1.22/) (Moslem et al., 2023)
The evaluators were asked to assess the acceptability of each translation
using a scale ranging from 1 to 4, where 4 is ideal and 1 is unacceptable translation.
For the paper Moslem et al., 2022, the human test set contained 50 sentences for each language pair and domain,
randomly extracted from the original test set and verified as accepted translations.
This means there are 200 unique sentences that are distributed as follows:
* EN→AR: General: 50 sentences x 8 systems
* EN→AR: Health: 50 sentences x 8 systems
* AR→EN: General: 50 sentences x 8 systems
* AR→EN: Health: 50 sentences x 8 systems
* Total: 1600 sentences
For the paper Moslem et al., 2023, the human test sets include unique 400 segments, distributed as follows:
* EN→AR: Health: 100 sentences x 4 systems
* EN→FR: Health: 100+100 sentences x 4 systems
* EN→ES: Health: 100 sentences x 4 systems
* Total: 1600 sentences
For more details, please refer to the papers or contact me.
## Citation
* If you use the **2022** portion of the Human Evaluation dataset, please cite the following paper:
```
@inproceedings{moslem-etal-2022-domain,
title = "Domain-Specific Text Generation for Machine Translation",
author = "Moslem, Yasmin and
Haque, Rejwanul and
Kelleher, John and
Way, Andy",
booktitle = "Proceedings of the 15th biennial conference of the Association for Machine Translation in the Americas (Volume 1: Research Track)",
month = sep,
year = "2022",
address = "Orlando, USA",
publisher = "Association for Machine Translation in the Americas",
url = "https://aclanthology.org/2022.amta-research.2/",
pages = "14--30",
abstract = "Preservation of domain knowledge from the source to target is crucial in any translation workflow. It is common in the translation industry to receive highly-specialized projects, where there is hardly any parallel in-domain data. In such scenarios where there is insufficient in-domain data to fine-tune Machine Translation (MT) models, producing translations that are consistent with the relevant context is challenging. In this work, we propose leveraging state-of-the-art pretrained language models (LMs) for domain-specific data augmentation for MT, simulating the domain characteristics of either (a) a small bilingual dataset, or (b) the monolingual source text to be translated. Combining this idea with back-translation, we can generate huge amounts of synthetic bilingual in-domain data for both use cases. For our investigation, we used the state-of-the-art MT architecture, Transformer. We employed mixed fine-tuning to train models that significantly improve translation of in-domain texts. More specifically, our proposed methods achieved improvements of approximately 5-6 BLEU and 2-3 BLEU, respectively, on Arabic-to-English and English-to-Arabic language pairs. Furthermore, the outcome of human evaluation corroborates the automatic evaluation results."
}
```
* If you use the **2023** portion of the Human Evaluation dataset, please cite the following paper:
```
@inproceedings{moslem-etal-2023-adaptive,
title = "Adaptive Machine Translation with Large Language Models",
author = "Moslem, Yasmin and
Haque, Rejwanul and
Kelleher, John D. and
Way, Andy",
booktitle = "Proceedings of the 24th Annual Conference of the European Association for Machine Translation",
month = jun,
year = "2023",
address = "Tampere, Finland",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2023.eamt-1.22/",
pages = "227--237",
abstract = "Consistency is a key requirement of high-quality translation. It is especially important to adhere to pre-approved terminology and adapt to corrected translations in domain-specific projects. Machine translation (MT) has achieved significant progress in the area of domain adaptation. However, real-time adaptation remains challenging. Large-scale language models (LLMs) have recently shown interesting capabilities of in-context learning, where they learn to replicate certain input-output text generation patterns, without further fine-tuning. By feeding an LLM at inference time with a prompt that consists of a list of translation pairs, it can then simulate the domain and style characteristics. This work aims to investigate how we can utilize in-context learning to improve real-time adaptive MT. Our extensive experiments show promising results at translation time. For example, GPT-3.5 can adapt to a set of in-domain sentence pairs and/or terminology while translating a new sentence. We observe that the translation quality with few-shot in-context learning can surpass that of strong encoder-decoder MT systems, especially for high-resource languages. Moreover, we investigate whether we can combine MT from strong encoder-decoder models with fuzzy matches, which can further improve translation quality, especially for less supported languages. We conduct our experiments across five diverse language pairs, namely English-to-Arabic (EN-AR), English-to-Chinese (EN-ZH), English-to-French (EN-FR), English-to-Kinyarwanda (EN-RW), and English-to-Spanish (EN-ES)."
}
```
* As the segments of the *“Health”* domain are extracted from TICO-19 and the segments of the *“General”* domain are extracted from other OPUS datasets,
please also cite the following papers:
```
@inproceedings{anastasopoulos-etal-2020-tico,
title = "{TICO}-19: the Translation Initiative for {CO}vid-19",
author = {Anastasopoulos, Antonios and
Cattelan, Alessandro and
Dou, Zi-Yi and
Federico, Marcello and
Federmann, Christian and
Genzel, Dmitriy and
Guzm{\'a}n, Franscisco and
Hu, Junjie and
Hughes, Macduff and
Koehn, Philipp and
Lazar, Rosie and
Lewis, Will and
Neubig, Graham and
Niu, Mengmeng and
{\"O}ktem, Alp and
Paquin, Eric and
Tang, Grace and
Tur, Sylwia},
booktitle = "Proceedings of the 1st Workshop on {NLP} for {COVID}-19 (Part 2) at {EMNLP} 2020",
month = dec,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.nlpcovid19-2.5/",
doi = "10.18653/v1/2020.nlpcovid19-2.5",
abstract = "The COVID-19 pandemic is the worst pandemic to strike the world in over a century. Crucial to stemming the tide of the SARS-CoV-2 virus is communicating to vulnerable populations the means by which they can protect themselves. To this end, the collaborators forming the Translation Initiative for COvid-19 (TICO-19) have made test and development data available to AI and MT researchers in 35 different languages in order to foster the development of tools and resources for improving access to information about COVID-19 in these languages. In addition to 9 high-resourced, {\textquotedblright}pivot{\textquotedblright} languages, the team is targeting 26 lesser resourced languages, in particular languages of Africa, South Asia and South-East Asia, whose populations may be the most vulnerable to the spread of the virus. The same data is translated into all of the languages represented, meaning that testing or development can be done for any pairing of languages in the set. Further, the team is converting the test and development data into translation memories (TMXs) that can be used by localizers from and to any of the languages."
}
```
```
@inproceedings{tiedemann-2012-parallel,
title = "Parallel Data, Tools and Interfaces in {OPUS}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Eighth International Conference on Language Resources and Evaluation ({LREC}`12)",
month = may,
year = "2012",
address = "Istanbul, Turkey",
publisher = "European Language Resources Association (ELRA)",
url = "https://aclanthology.org/L12-1246/",
pages = "2214--2218",
abstract = "This paper presents the current status of OPUS, a growing language resource of parallel corpora and related tools. The focus in OPUS is to provide freely available data sets in various formats together with basic annotation to be useful for applications in computational linguistics, translation studies and cross-linguistic corpus studies. In this paper, we report about new data sets and their features, additional annotation tools and models provided from the website and essential interfaces and on-line services included in the project."
}
```
|
mteb/csfdcz_movie_review_sentiment
|
mteb
|
2025-05-09T11:51:00Z
| 0
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-09T11:50:42Z
| 0
|
---
dataset_info:
features:
- name: review_id
dtype: string
- name: rating_str
dtype: string
- name: label
dtype: int64
- name: date
dtype: timestamp[s]
- name: comment_language
dtype: string
- name: text
dtype: string
- name: item_title
dtype: string
- name: item_year
dtype: string
- name: item_kind
dtype: string
- name: item_genres
sequence: string
- name: item_directors
sequence: string
- name: item_screenwriters
sequence: string
- name: item_cast
sequence: string
splits:
- name: train
num_bytes: 38362258.47864
num_examples: 24978
- name: validation
num_bytes: 3708756.622
num_examples: 2495
- name: test
num_bytes: 3977241.576
num_examples: 2497
download_size: 25531474
dataset_size: 46048256.67664
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
passing2961/stark-image
|
passing2961
|
2024-11-06T04:37:21Z
| 105
| 3
|
[
"task_ids:conversational",
"language:en",
"license:cc-by-nc-4.0",
"size_categories:1M<n<10M",
"format:webdataset",
"modality:image",
"modality:text",
"library:datasets",
"library:webdataset",
"library:mlcroissant",
"arxiv:2407.03958",
"arxiv:1603.07396",
"region:us",
"multi-modal dialogue"
] |
[] |
2024-10-08T04:38:13Z
| 0
|
---
license: cc-by-nc-4.0
language:
- en
pretty_name: Stark
tags:
- multi-modal dialogue
annotation_creators:
- machine-generated
task_ids:
- conversational
dataset_size: 1.72M
---
# Dataset Card for Stark
[🏠 Homepage](https://stark-dataset.github.io/) | [💻 Github](https://github.com/passing2961/Stark) | [📄 Arxiv](https://arxiv.org/abs/2407.03958) | [📕 PDF](https://arxiv.org/pdf/2407.03958)
## List of Provided Model Series
- **Ultron-Summarizer-Series:** [🤖 Ultron-Summarizer-1B](https://huggingface.co/passing2961/Ultron-Summarizer-1B) | [🤖 Ultron-Summarizer-3B](https://huggingface.co/passing2961/Ultron-Summarizer-3B) | [🤖 Ultron-Summarizer-8B](https://huggingface.co/passing2961/Ultron-Summarizer-8B)
- **Ultron 7B**: [🤖 Ultron-7B](https://huggingface.co/passing2961/Ultron-7B)
> 🚨 Disclaimer: All models and datasets are intended for research purposes only.
## Dataset Description
- **Repository:** [Code](https://github.com/passing2961/Stark)
- **Paper:** [Stark: Social Long-Term Multi-Modal Conversation with Persona Commonsense Knowledge](https://arxiv.org/abs/2407.03958)
- **Point of Contact:** [Young-Jun Lee](mailto:[email protected])
## Dataset Summary
**Stark** is a publicly available, large-scale, long-term multi-modal conversation dataset that encompasses a diverse range of social personas, multi-modality formats, time intervals, and images. To automatically construct Stark, we introduce a novel multi-modal contextualization framework, **MCU**, which generates long-term multi-modal dialogues distilled from ChatGPT and our proposed **Plan-and-Execute Image Aligner**. An overview of MCU and an example from Stark are illustrated below.

**Note**: The **Stark** dataset contains many images that originate from different sources, including a personalized text-to-image generator (i.e., [PhotoMaker](https://photo-maker.github.io/)), [Bing Search](https://pypi.org/project/icrawler/), and Image DB retrieval, thanks to our proposed **Plan-and-Execute** Image Aligner to ensure the high quality of the Stark dataset. Therefore, we divide the entire collection of images into two repositories based on the source:
1. **This Repository**: Contains images from the personalized text-to-image generator, Bing Search, and Image DB retrieval (excluding [CC12M](https://github.com/google-research-datasets/conceptual-12m) and [RedCaps12M](https://redcaps.xyz/)).
2. **Another Repository**: Contains images sourced from CC12M and RedCaps12M, which provide the image URL links. This dataset is provided in [this repository](https://huggingface.co/datasets/passing2961/stark-image-url).
For Image DB retrieval, we use CLIP (i.e., `ViT-L/14@336px`) to retrieve images from prepared source image datasets: [CC12M](https://github.com/google-research-datasets/conceptual-12m), [RedCaps12M](https://redcaps.xyz/), [ChartQA](https://github.com/vis-nlp/ChartQA), [AI2D](https://arxiv.org/pdf/1603.07396v1), and [MathVision](https://huggingface.co/datasets/MathLLMs/MathVision). For efficient searching, we utilize [AutoFaiss](https://github.com/criteo/autofaiss).
## Dataset Structure
Since the number of images is large (roughly 1.72M), we store and provide the image datasets in WebDataset format for efficiency.
| Field | Type | Description |
|---------|--------|--------------|
| `key` | str | A unique identifier for each data entry in the dataset. |
| `url` | str | The URL path to the image stored in the dataset repository on HuggingFace. All URLs point to the base HuggingFace repository where images are stored. |
| `jpg` | image | The image data associated with each entry, displayed as a thumbnail in the dataset viewer. This column stores the actual image content relevant to the conversation in the dataset. |
| `json` | dict | Contains additional metadata and information for each image, structured as a dictionary. The JSON field typically includes the following keys: `image_source`, `image_url`, `index`. |
- **`image_source`**: Source of the image (`"p-t2i"`, `"web"`, `"t2i"`, `"chartqa"`, `"mathvision"`, `"ai2d"`), where:
- `"p-t2i"`: Image from the personalized text-to-image generator (i.e., [PhotoMaker](https://photo-maker.github.io/)).
- `"web"`: Image from [Bing Search](https://pypi.org/project/icrawler/).
- `"t2i"`: Image from a general text-to-image generative model (i.e., [SDXL-Lightning](https://huggingface.co/ByteDance/SDXL-Lightning)).
- `"chartqa"`: Image from the [ChartQA](https://github.com/vis-nlp/ChartQA) dataset via Image DB retrieval.
- `"mathvision"`: Image from the [MathVision](https://huggingface.co/datasets/MathLLMs/MathVision) dataset via Image DB retrieval.
- `"ai2d"`: Image from the [AI2D](https://arxiv.org/pdf/1603.07396v1) dataset via Image DB retrieval.
- **`image_url`**: External URL where the image was originally sourced. In this dataset, the `image_url` is always an empty string. Another dataset (where `image_source` is CC12M or RedCaps12M) contains non-empty strings in this `image_url` field.
- **`index`**: A unique index identifier for each image within the dataset, which is the same as the `key` field.
## Dataset Construction
We construct the **Stark** dataset using our proposed novel framework, MCU, which distills long-term multi-modal dialogue from ChatGPT and our proposed Plan-and-Execute Image Aligner, powered by a personalized text-to-image generative model (i.e., PhotoMaker), image database retrieval, and web search. All prompt templates used for dataset construction are presented in the Appendix of our paper.
## Languages
- English
## Further Details and Limitations
For additional information and limitations, please refer to our [paper](https://arxiv.org/abs/2407.03958).
## License and Recommendations
The **Stark** dataset is intended for research purposes only. Despite our efforts to generate high-quality and diverse personalized images, users should be mindful of ethical considerations when utilizing the dataset.
## Acknowledgement
This work was supported by a grant of the KAIST-KT joint research project through AI Tech Lab, Institute of convergence Technology, funded by KT [Project No. G01230605, Development of Task-oriented Persona-based Dialogue Generation Combining Multi-modal Interaction and Knowledge Modeling].
## Citation
If you find the resources in this repository useful, please cite our work:
```
@article{lee2024stark,
title={Stark: Social Long-Term Multi-Modal Conversation with Persona Commonsense Knowledge},
author={Lee, Young-Jun and Lee, Dokyong and Youn, Junyoung and Oh, Kyeongjin and Ko, Byungsoo and Hyeon, Jonghwan and Choi, Ho-Jin},
journal={arXiv preprint arXiv:2407.03958},
year={2024}
}
```
|
PranavHarshan/sharegpt_formatted_pubmedqa
|
PranavHarshan
|
2024-10-11T06:11:12Z
| 28
| 0
|
[
"language:en",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-10-08T17:57:30Z
| 0
|
---
language:
- en
dataset_info:
features:
- name: pubid
dtype: int32
- name: question
dtype: string
- name: context
sequence:
- name: contexts
dtype: string
- name: labels
dtype: string
- name: meshes
dtype: string
- name: long_answer
dtype: string
- name: final_decision
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 846304038
num_examples: 211269
download_size: 441243475
dataset_size: 846304038
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
winvswon78/tomatotest
|
winvswon78
|
2025-05-31T02:04:33Z
| 52
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:text",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-31T02:01:17Z
| 0
|
---
dataset_info:
features:
- name: id
dtype: int32
- name: question
dtype: string
- name: options
sequence: string
- name: answer
dtype: int32
- name: video_path
dtype: string
- name: reason_type
dtype: string
- name: demonstration_type
dtype: string
splits:
- name: test
num_bytes: 1352
num_examples: 6
download_size: 3675
dataset_size: 1352
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
---
|
datacomp/imagenet-1k-random-90.0-frac-1over8
|
datacomp
|
2025-01-14T04:22:04Z
| 18
| 0
|
[
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-01-13T12:07:25Z
| 0
|
---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype:
class_label:
names:
'0': tench, Tinca tinca
'1': goldfish, Carassius auratus
'2': great white shark, white shark, man-eater, man-eating shark, Carcharodon
carcharias
'3': tiger shark, Galeocerdo cuvieri
'4': hammerhead, hammerhead shark
'5': electric ray, crampfish, numbfish, torpedo
'6': stingray
'7': cock
'8': hen
'9': ostrich, Struthio camelus
'10': brambling, Fringilla montifringilla
'11': goldfinch, Carduelis carduelis
'12': house finch, linnet, Carpodacus mexicanus
'13': junco, snowbird
'14': indigo bunting, indigo finch, indigo bird, Passerina cyanea
'15': robin, American robin, Turdus migratorius
'16': bulbul
'17': jay
'18': magpie
'19': chickadee
'20': water ouzel, dipper
'21': kite
'22': bald eagle, American eagle, Haliaeetus leucocephalus
'23': vulture
'24': great grey owl, great gray owl, Strix nebulosa
'25': European fire salamander, Salamandra salamandra
'26': common newt, Triturus vulgaris
'27': eft
'28': spotted salamander, Ambystoma maculatum
'29': axolotl, mud puppy, Ambystoma mexicanum
'30': bullfrog, Rana catesbeiana
'31': tree frog, tree-frog
'32': tailed frog, bell toad, ribbed toad, tailed toad, Ascaphus trui
'33': loggerhead, loggerhead turtle, Caretta caretta
'34': leatherback turtle, leatherback, leathery turtle, Dermochelys coriacea
'35': mud turtle
'36': terrapin
'37': box turtle, box tortoise
'38': banded gecko
'39': common iguana, iguana, Iguana iguana
'40': American chameleon, anole, Anolis carolinensis
'41': whiptail, whiptail lizard
'42': agama
'43': frilled lizard, Chlamydosaurus kingi
'44': alligator lizard
'45': Gila monster, Heloderma suspectum
'46': green lizard, Lacerta viridis
'47': African chameleon, Chamaeleo chamaeleon
'48': Komodo dragon, Komodo lizard, dragon lizard, giant lizard, Varanus
komodoensis
'49': African crocodile, Nile crocodile, Crocodylus niloticus
'50': American alligator, Alligator mississipiensis
'51': triceratops
'52': thunder snake, worm snake, Carphophis amoenus
'53': ringneck snake, ring-necked snake, ring snake
'54': hognose snake, puff adder, sand viper
'55': green snake, grass snake
'56': king snake, kingsnake
'57': garter snake, grass snake
'58': water snake
'59': vine snake
'60': night snake, Hypsiglena torquata
'61': boa constrictor, Constrictor constrictor
'62': rock python, rock snake, Python sebae
'63': Indian cobra, Naja naja
'64': green mamba
'65': sea snake
'66': horned viper, cerastes, sand viper, horned asp, Cerastes cornutus
'67': diamondback, diamondback rattlesnake, Crotalus adamanteus
'68': sidewinder, horned rattlesnake, Crotalus cerastes
'69': trilobite
'70': harvestman, daddy longlegs, Phalangium opilio
'71': scorpion
'72': black and gold garden spider, Argiope aurantia
'73': barn spider, Araneus cavaticus
'74': garden spider, Aranea diademata
'75': black widow, Latrodectus mactans
'76': tarantula
'77': wolf spider, hunting spider
'78': tick
'79': centipede
'80': black grouse
'81': ptarmigan
'82': ruffed grouse, partridge, Bonasa umbellus
'83': prairie chicken, prairie grouse, prairie fowl
'84': peacock
'85': quail
'86': partridge
'87': African grey, African gray, Psittacus erithacus
'88': macaw
'89': sulphur-crested cockatoo, Kakatoe galerita, Cacatua galerita
'90': lorikeet
'91': coucal
'92': bee eater
'93': hornbill
'94': hummingbird
'95': jacamar
'96': toucan
'97': drake
'98': red-breasted merganser, Mergus serrator
'99': goose
'100': black swan, Cygnus atratus
'101': tusker
'102': echidna, spiny anteater, anteater
'103': platypus, duckbill, duckbilled platypus, duck-billed platypus, Ornithorhynchus
anatinus
'104': wallaby, brush kangaroo
'105': koala, koala bear, kangaroo bear, native bear, Phascolarctos cinereus
'106': wombat
'107': jellyfish
'108': sea anemone, anemone
'109': brain coral
'110': flatworm, platyhelminth
'111': nematode, nematode worm, roundworm
'112': conch
'113': snail
'114': slug
'115': sea slug, nudibranch
'116': chiton, coat-of-mail shell, sea cradle, polyplacophore
'117': chambered nautilus, pearly nautilus, nautilus
'118': Dungeness crab, Cancer magister
'119': rock crab, Cancer irroratus
'120': fiddler crab
'121': king crab, Alaska crab, Alaskan king crab, Alaska king crab, Paralithodes
camtschatica
'122': American lobster, Northern lobster, Maine lobster, Homarus americanus
'123': spiny lobster, langouste, rock lobster, crawfish, crayfish, sea crawfish
'124': crayfish, crawfish, crawdad, crawdaddy
'125': hermit crab
'126': isopod
'127': white stork, Ciconia ciconia
'128': black stork, Ciconia nigra
'129': spoonbill
'130': flamingo
'131': little blue heron, Egretta caerulea
'132': American egret, great white heron, Egretta albus
'133': bittern
'134': crane
'135': limpkin, Aramus pictus
'136': European gallinule, Porphyrio porphyrio
'137': American coot, marsh hen, mud hen, water hen, Fulica americana
'138': bustard
'139': ruddy turnstone, Arenaria interpres
'140': red-backed sandpiper, dunlin, Erolia alpina
'141': redshank, Tringa totanus
'142': dowitcher
'143': oystercatcher, oyster catcher
'144': pelican
'145': king penguin, Aptenodytes patagonica
'146': albatross, mollymawk
'147': grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius
robustus
'148': killer whale, killer, orca, grampus, sea wolf, Orcinus orca
'149': dugong, Dugong dugon
'150': sea lion
'151': Chihuahua
'152': Japanese spaniel
'153': Maltese dog, Maltese terrier, Maltese
'154': Pekinese, Pekingese, Peke
'155': Shih-Tzu
'156': Blenheim spaniel
'157': papillon
'158': toy terrier
'159': Rhodesian ridgeback
'160': Afghan hound, Afghan
'161': basset, basset hound
'162': beagle
'163': bloodhound, sleuthhound
'164': bluetick
'165': black-and-tan coonhound
'166': Walker hound, Walker foxhound
'167': English foxhound
'168': redbone
'169': borzoi, Russian wolfhound
'170': Irish wolfhound
'171': Italian greyhound
'172': whippet
'173': Ibizan hound, Ibizan Podenco
'174': Norwegian elkhound, elkhound
'175': otterhound, otter hound
'176': Saluki, gazelle hound
'177': Scottish deerhound, deerhound
'178': Weimaraner
'179': Staffordshire bullterrier, Staffordshire bull terrier
'180': American Staffordshire terrier, Staffordshire terrier, American pit
bull terrier, pit bull terrier
'181': Bedlington terrier
'182': Border terrier
'183': Kerry blue terrier
'184': Irish terrier
'185': Norfolk terrier
'186': Norwich terrier
'187': Yorkshire terrier
'188': wire-haired fox terrier
'189': Lakeland terrier
'190': Sealyham terrier, Sealyham
'191': Airedale, Airedale terrier
'192': cairn, cairn terrier
'193': Australian terrier
'194': Dandie Dinmont, Dandie Dinmont terrier
'195': Boston bull, Boston terrier
'196': miniature schnauzer
'197': giant schnauzer
'198': standard schnauzer
'199': Scotch terrier, Scottish terrier, Scottie
'200': Tibetan terrier, chrysanthemum dog
'201': silky terrier, Sydney silky
'202': soft-coated wheaten terrier
'203': West Highland white terrier
'204': Lhasa, Lhasa apso
'205': flat-coated retriever
'206': curly-coated retriever
'207': golden retriever
'208': Labrador retriever
'209': Chesapeake Bay retriever
'210': German short-haired pointer
'211': vizsla, Hungarian pointer
'212': English setter
'213': Irish setter, red setter
'214': Gordon setter
'215': Brittany spaniel
'216': clumber, clumber spaniel
'217': English springer, English springer spaniel
'218': Welsh springer spaniel
'219': cocker spaniel, English cocker spaniel, cocker
'220': Sussex spaniel
'221': Irish water spaniel
'222': kuvasz
'223': schipperke
'224': groenendael
'225': malinois
'226': briard
'227': kelpie
'228': komondor
'229': Old English sheepdog, bobtail
'230': Shetland sheepdog, Shetland sheep dog, Shetland
'231': collie
'232': Border collie
'233': Bouvier des Flandres, Bouviers des Flandres
'234': Rottweiler
'235': German shepherd, German shepherd dog, German police dog, alsatian
'236': Doberman, Doberman pinscher
'237': miniature pinscher
'238': Greater Swiss Mountain dog
'239': Bernese mountain dog
'240': Appenzeller
'241': EntleBucher
'242': boxer
'243': bull mastiff
'244': Tibetan mastiff
'245': French bulldog
'246': Great Dane
'247': Saint Bernard, St Bernard
'248': Eskimo dog, husky
'249': malamute, malemute, Alaskan malamute
'250': Siberian husky
'251': dalmatian, coach dog, carriage dog
'252': affenpinscher, monkey pinscher, monkey dog
'253': basenji
'254': pug, pug-dog
'255': Leonberg
'256': Newfoundland, Newfoundland dog
'257': Great Pyrenees
'258': Samoyed, Samoyede
'259': Pomeranian
'260': chow, chow chow
'261': keeshond
'262': Brabancon griffon
'263': Pembroke, Pembroke Welsh corgi
'264': Cardigan, Cardigan Welsh corgi
'265': toy poodle
'266': miniature poodle
'267': standard poodle
'268': Mexican hairless
'269': timber wolf, grey wolf, gray wolf, Canis lupus
'270': white wolf, Arctic wolf, Canis lupus tundrarum
'271': red wolf, maned wolf, Canis rufus, Canis niger
'272': coyote, prairie wolf, brush wolf, Canis latrans
'273': dingo, warrigal, warragal, Canis dingo
'274': dhole, Cuon alpinus
'275': African hunting dog, hyena dog, Cape hunting dog, Lycaon pictus
'276': hyena, hyaena
'277': red fox, Vulpes vulpes
'278': kit fox, Vulpes macrotis
'279': Arctic fox, white fox, Alopex lagopus
'280': grey fox, gray fox, Urocyon cinereoargenteus
'281': tabby, tabby cat
'282': tiger cat
'283': Persian cat
'284': Siamese cat, Siamese
'285': Egyptian cat
'286': cougar, puma, catamount, mountain lion, painter, panther, Felis concolor
'287': lynx, catamount
'288': leopard, Panthera pardus
'289': snow leopard, ounce, Panthera uncia
'290': jaguar, panther, Panthera onca, Felis onca
'291': lion, king of beasts, Panthera leo
'292': tiger, Panthera tigris
'293': cheetah, chetah, Acinonyx jubatus
'294': brown bear, bruin, Ursus arctos
'295': American black bear, black bear, Ursus americanus, Euarctos americanus
'296': ice bear, polar bear, Ursus Maritimus, Thalarctos maritimus
'297': sloth bear, Melursus ursinus, Ursus ursinus
'298': mongoose
'299': meerkat, mierkat
'300': tiger beetle
'301': ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle
'302': ground beetle, carabid beetle
'303': long-horned beetle, longicorn, longicorn beetle
'304': leaf beetle, chrysomelid
'305': dung beetle
'306': rhinoceros beetle
'307': weevil
'308': fly
'309': bee
'310': ant, emmet, pismire
'311': grasshopper, hopper
'312': cricket
'313': walking stick, walkingstick, stick insect
'314': cockroach, roach
'315': mantis, mantid
'316': cicada, cicala
'317': leafhopper
'318': lacewing, lacewing fly
'319': dragonfly, darning needle, devil's darning needle, sewing needle,
snake feeder, snake doctor, mosquito hawk, skeeter hawk
'320': damselfly
'321': admiral
'322': ringlet, ringlet butterfly
'323': monarch, monarch butterfly, milkweed butterfly, Danaus plexippus
'324': cabbage butterfly
'325': sulphur butterfly, sulfur butterfly
'326': lycaenid, lycaenid butterfly
'327': starfish, sea star
'328': sea urchin
'329': sea cucumber, holothurian
'330': wood rabbit, cottontail, cottontail rabbit
'331': hare
'332': Angora, Angora rabbit
'333': hamster
'334': porcupine, hedgehog
'335': fox squirrel, eastern fox squirrel, Sciurus niger
'336': marmot
'337': beaver
'338': guinea pig, Cavia cobaya
'339': sorrel
'340': zebra
'341': hog, pig, grunter, squealer, Sus scrofa
'342': wild boar, boar, Sus scrofa
'343': warthog
'344': hippopotamus, hippo, river horse, Hippopotamus amphibius
'345': ox
'346': water buffalo, water ox, Asiatic buffalo, Bubalus bubalis
'347': bison
'348': ram, tup
'349': bighorn, bighorn sheep, cimarron, Rocky Mountain bighorn, Rocky Mountain
sheep, Ovis canadensis
'350': ibex, Capra ibex
'351': hartebeest
'352': impala, Aepyceros melampus
'353': gazelle
'354': Arabian camel, dromedary, Camelus dromedarius
'355': llama
'356': weasel
'357': mink
'358': polecat, fitch, foulmart, foumart, Mustela putorius
'359': black-footed ferret, ferret, Mustela nigripes
'360': otter
'361': skunk, polecat, wood pussy
'362': badger
'363': armadillo
'364': three-toed sloth, ai, Bradypus tridactylus
'365': orangutan, orang, orangutang, Pongo pygmaeus
'366': gorilla, Gorilla gorilla
'367': chimpanzee, chimp, Pan troglodytes
'368': gibbon, Hylobates lar
'369': siamang, Hylobates syndactylus, Symphalangus syndactylus
'370': guenon, guenon monkey
'371': patas, hussar monkey, Erythrocebus patas
'372': baboon
'373': macaque
'374': langur
'375': colobus, colobus monkey
'376': proboscis monkey, Nasalis larvatus
'377': marmoset
'378': capuchin, ringtail, Cebus capucinus
'379': howler monkey, howler
'380': titi, titi monkey
'381': spider monkey, Ateles geoffroyi
'382': squirrel monkey, Saimiri sciureus
'383': Madagascar cat, ring-tailed lemur, Lemur catta
'384': indri, indris, Indri indri, Indri brevicaudatus
'385': Indian elephant, Elephas maximus
'386': African elephant, Loxodonta africana
'387': lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens
'388': giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca
'389': barracouta, snoek
'390': eel
'391': coho, cohoe, coho salmon, blue jack, silver salmon, Oncorhynchus
kisutch
'392': rock beauty, Holocanthus tricolor
'393': anemone fish
'394': sturgeon
'395': gar, garfish, garpike, billfish, Lepisosteus osseus
'396': lionfish
'397': puffer, pufferfish, blowfish, globefish
'398': abacus
'399': abaya
'400': academic gown, academic robe, judge's robe
'401': accordion, piano accordion, squeeze box
'402': acoustic guitar
'403': aircraft carrier, carrier, flattop, attack aircraft carrier
'404': airliner
'405': airship, dirigible
'406': altar
'407': ambulance
'408': amphibian, amphibious vehicle
'409': analog clock
'410': apiary, bee house
'411': apron
'412': ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin,
dustbin, trash barrel, trash bin
'413': assault rifle, assault gun
'414': backpack, back pack, knapsack, packsack, rucksack, haversack
'415': bakery, bakeshop, bakehouse
'416': balance beam, beam
'417': balloon
'418': ballpoint, ballpoint pen, ballpen, Biro
'419': Band Aid
'420': banjo
'421': bannister, banister, balustrade, balusters, handrail
'422': barbell
'423': barber chair
'424': barbershop
'425': barn
'426': barometer
'427': barrel, cask
'428': barrow, garden cart, lawn cart, wheelbarrow
'429': baseball
'430': basketball
'431': bassinet
'432': bassoon
'433': bathing cap, swimming cap
'434': bath towel
'435': bathtub, bathing tub, bath, tub
'436': beach wagon, station wagon, wagon, estate car, beach waggon, station
waggon, waggon
'437': beacon, lighthouse, beacon light, pharos
'438': beaker
'439': bearskin, busby, shako
'440': beer bottle
'441': beer glass
'442': bell cote, bell cot
'443': bib
'444': bicycle-built-for-two, tandem bicycle, tandem
'445': bikini, two-piece
'446': binder, ring-binder
'447': binoculars, field glasses, opera glasses
'448': birdhouse
'449': boathouse
'450': bobsled, bobsleigh, bob
'451': bolo tie, bolo, bola tie, bola
'452': bonnet, poke bonnet
'453': bookcase
'454': bookshop, bookstore, bookstall
'455': bottlecap
'456': bow
'457': bow tie, bow-tie, bowtie
'458': brass, memorial tablet, plaque
'459': brassiere, bra, bandeau
'460': breakwater, groin, groyne, mole, bulwark, seawall, jetty
'461': breastplate, aegis, egis
'462': broom
'463': bucket, pail
'464': buckle
'465': bulletproof vest
'466': bullet train, bullet
'467': butcher shop, meat market
'468': cab, hack, taxi, taxicab
'469': caldron, cauldron
'470': candle, taper, wax light
'471': cannon
'472': canoe
'473': can opener, tin opener
'474': cardigan
'475': car mirror
'476': carousel, carrousel, merry-go-round, roundabout, whirligig
'477': carpenter's kit, tool kit
'478': carton
'479': car wheel
'480': cash machine, cash dispenser, automated teller machine, automatic
teller machine, automated teller, automatic teller, ATM
'481': cassette
'482': cassette player
'483': castle
'484': catamaran
'485': CD player
'486': cello, violoncello
'487': cellular telephone, cellular phone, cellphone, cell, mobile phone
'488': chain
'489': chainlink fence
'490': chain mail, ring mail, mail, chain armor, chain armour, ring armor,
ring armour
'491': chain saw, chainsaw
'492': chest
'493': chiffonier, commode
'494': chime, bell, gong
'495': china cabinet, china closet
'496': Christmas stocking
'497': church, church building
'498': cinema, movie theater, movie theatre, movie house, picture palace
'499': cleaver, meat cleaver, chopper
'500': cliff dwelling
'501': cloak
'502': clog, geta, patten, sabot
'503': cocktail shaker
'504': coffee mug
'505': coffeepot
'506': coil, spiral, volute, whorl, helix
'507': combination lock
'508': computer keyboard, keypad
'509': confectionery, confectionary, candy store
'510': container ship, containership, container vessel
'511': convertible
'512': corkscrew, bottle screw
'513': cornet, horn, trumpet, trump
'514': cowboy boot
'515': cowboy hat, ten-gallon hat
'516': cradle
'517': crane2
'518': crash helmet
'519': crate
'520': crib, cot
'521': Crock Pot
'522': croquet ball
'523': crutch
'524': cuirass
'525': dam, dike, dyke
'526': desk
'527': desktop computer
'528': dial telephone, dial phone
'529': diaper, nappy, napkin
'530': digital clock
'531': digital watch
'532': dining table, board
'533': dishrag, dishcloth
'534': dishwasher, dish washer, dishwashing machine
'535': disk brake, disc brake
'536': dock, dockage, docking facility
'537': dogsled, dog sled, dog sleigh
'538': dome
'539': doormat, welcome mat
'540': drilling platform, offshore rig
'541': drum, membranophone, tympan
'542': drumstick
'543': dumbbell
'544': Dutch oven
'545': electric fan, blower
'546': electric guitar
'547': electric locomotive
'548': entertainment center
'549': envelope
'550': espresso maker
'551': face powder
'552': feather boa, boa
'553': file, file cabinet, filing cabinet
'554': fireboat
'555': fire engine, fire truck
'556': fire screen, fireguard
'557': flagpole, flagstaff
'558': flute, transverse flute
'559': folding chair
'560': football helmet
'561': forklift
'562': fountain
'563': fountain pen
'564': four-poster
'565': freight car
'566': French horn, horn
'567': frying pan, frypan, skillet
'568': fur coat
'569': garbage truck, dustcart
'570': gasmask, respirator, gas helmet
'571': gas pump, gasoline pump, petrol pump, island dispenser
'572': goblet
'573': go-kart
'574': golf ball
'575': golfcart, golf cart
'576': gondola
'577': gong, tam-tam
'578': gown
'579': grand piano, grand
'580': greenhouse, nursery, glasshouse
'581': grille, radiator grille
'582': grocery store, grocery, food market, market
'583': guillotine
'584': hair slide
'585': hair spray
'586': half track
'587': hammer
'588': hamper
'589': hand blower, blow dryer, blow drier, hair dryer, hair drier
'590': hand-held computer, hand-held microcomputer
'591': handkerchief, hankie, hanky, hankey
'592': hard disc, hard disk, fixed disk
'593': harmonica, mouth organ, harp, mouth harp
'594': harp
'595': harvester, reaper
'596': hatchet
'597': holster
'598': home theater, home theatre
'599': honeycomb
'600': hook, claw
'601': hoopskirt, crinoline
'602': horizontal bar, high bar
'603': horse cart, horse-cart
'604': hourglass
'605': iPod
'606': iron, smoothing iron
'607': jack-o'-lantern
'608': jean, blue jean, denim
'609': jeep, landrover
'610': jersey, T-shirt, tee shirt
'611': jigsaw puzzle
'612': jinrikisha, ricksha, rickshaw
'613': joystick
'614': kimono
'615': knee pad
'616': knot
'617': lab coat, laboratory coat
'618': ladle
'619': lampshade, lamp shade
'620': laptop, laptop computer
'621': lawn mower, mower
'622': lens cap, lens cover
'623': letter opener, paper knife, paperknife
'624': library
'625': lifeboat
'626': lighter, light, igniter, ignitor
'627': limousine, limo
'628': liner, ocean liner
'629': lipstick, lip rouge
'630': Loafer
'631': lotion
'632': loudspeaker, speaker, speaker unit, loudspeaker system, speaker system
'633': loupe, jeweler's loupe
'634': lumbermill, sawmill
'635': magnetic compass
'636': mailbag, postbag
'637': mailbox, letter box
'638': maillot
'639': maillot, tank suit
'640': manhole cover
'641': maraca
'642': marimba, xylophone
'643': mask
'644': matchstick
'645': maypole
'646': maze, labyrinth
'647': measuring cup
'648': medicine chest, medicine cabinet
'649': megalith, megalithic structure
'650': microphone, mike
'651': microwave, microwave oven
'652': military uniform
'653': milk can
'654': minibus
'655': miniskirt, mini
'656': minivan
'657': missile
'658': mitten
'659': mixing bowl
'660': mobile home, manufactured home
'661': Model T
'662': modem
'663': monastery
'664': monitor
'665': moped
'666': mortar
'667': mortarboard
'668': mosque
'669': mosquito net
'670': motor scooter, scooter
'671': mountain bike, all-terrain bike, off-roader
'672': mountain tent
'673': mouse, computer mouse
'674': mousetrap
'675': moving van
'676': muzzle
'677': nail
'678': neck brace
'679': necklace
'680': nipple
'681': notebook, notebook computer
'682': obelisk
'683': oboe, hautboy, hautbois
'684': ocarina, sweet potato
'685': odometer, hodometer, mileometer, milometer
'686': oil filter
'687': organ, pipe organ
'688': oscilloscope, scope, cathode-ray oscilloscope, CRO
'689': overskirt
'690': oxcart
'691': oxygen mask
'692': packet
'693': paddle, boat paddle
'694': paddlewheel, paddle wheel
'695': padlock
'696': paintbrush
'697': pajama, pyjama, pj's, jammies
'698': palace
'699': panpipe, pandean pipe, syrinx
'700': paper towel
'701': parachute, chute
'702': parallel bars, bars
'703': park bench
'704': parking meter
'705': passenger car, coach, carriage
'706': patio, terrace
'707': pay-phone, pay-station
'708': pedestal, plinth, footstall
'709': pencil box, pencil case
'710': pencil sharpener
'711': perfume, essence
'712': Petri dish
'713': photocopier
'714': pick, plectrum, plectron
'715': pickelhaube
'716': picket fence, paling
'717': pickup, pickup truck
'718': pier
'719': piggy bank, penny bank
'720': pill bottle
'721': pillow
'722': ping-pong ball
'723': pinwheel
'724': pirate, pirate ship
'725': pitcher, ewer
'726': plane, carpenter's plane, woodworking plane
'727': planetarium
'728': plastic bag
'729': plate rack
'730': plow, plough
'731': plunger, plumber's helper
'732': Polaroid camera, Polaroid Land camera
'733': pole
'734': police van, police wagon, paddy wagon, patrol wagon, wagon, black
Maria
'735': poncho
'736': pool table, billiard table, snooker table
'737': pop bottle, soda bottle
'738': pot, flowerpot
'739': potter's wheel
'740': power drill
'741': prayer rug, prayer mat
'742': printer
'743': prison, prison house
'744': projectile, missile
'745': projector
'746': puck, hockey puck
'747': punching bag, punch bag, punching ball, punchball
'748': purse
'749': quill, quill pen
'750': quilt, comforter, comfort, puff
'751': racer, race car, racing car
'752': racket, racquet
'753': radiator
'754': radio, wireless
'755': radio telescope, radio reflector
'756': rain barrel
'757': recreational vehicle, RV, R.V.
'758': reel
'759': reflex camera
'760': refrigerator, icebox
'761': remote control, remote
'762': restaurant, eating house, eating place, eatery
'763': revolver, six-gun, six-shooter
'764': rifle
'765': rocking chair, rocker
'766': rotisserie
'767': rubber eraser, rubber, pencil eraser
'768': rugby ball
'769': rule, ruler
'770': running shoe
'771': safe
'772': safety pin
'773': saltshaker, salt shaker
'774': sandal
'775': sarong
'776': sax, saxophone
'777': scabbard
'778': scale, weighing machine
'779': school bus
'780': schooner
'781': scoreboard
'782': screen, CRT screen
'783': screw
'784': screwdriver
'785': seat belt, seatbelt
'786': sewing machine
'787': shield, buckler
'788': shoe shop, shoe-shop, shoe store
'789': shoji
'790': shopping basket
'791': shopping cart
'792': shovel
'793': shower cap
'794': shower curtain
'795': ski
'796': ski mask
'797': sleeping bag
'798': slide rule, slipstick
'799': sliding door
'800': slot, one-armed bandit
'801': snorkel
'802': snowmobile
'803': snowplow, snowplough
'804': soap dispenser
'805': soccer ball
'806': sock
'807': solar dish, solar collector, solar furnace
'808': sombrero
'809': soup bowl
'810': space bar
'811': space heater
'812': space shuttle
'813': spatula
'814': speedboat
'815': spider web, spider's web
'816': spindle
'817': sports car, sport car
'818': spotlight, spot
'819': stage
'820': steam locomotive
'821': steel arch bridge
'822': steel drum
'823': stethoscope
'824': stole
'825': stone wall
'826': stopwatch, stop watch
'827': stove
'828': strainer
'829': streetcar, tram, tramcar, trolley, trolley car
'830': stretcher
'831': studio couch, day bed
'832': stupa, tope
'833': submarine, pigboat, sub, U-boat
'834': suit, suit of clothes
'835': sundial
'836': sunglass
'837': sunglasses, dark glasses, shades
'838': sunscreen, sunblock, sun blocker
'839': suspension bridge
'840': swab, swob, mop
'841': sweatshirt
'842': swimming trunks, bathing trunks
'843': swing
'844': switch, electric switch, electrical switch
'845': syringe
'846': table lamp
'847': tank, army tank, armored combat vehicle, armoured combat vehicle
'848': tape player
'849': teapot
'850': teddy, teddy bear
'851': television, television system
'852': tennis ball
'853': thatch, thatched roof
'854': theater curtain, theatre curtain
'855': thimble
'856': thresher, thrasher, threshing machine
'857': throne
'858': tile roof
'859': toaster
'860': tobacco shop, tobacconist shop, tobacconist
'861': toilet seat
'862': torch
'863': totem pole
'864': tow truck, tow car, wrecker
'865': toyshop
'866': tractor
'867': trailer truck, tractor trailer, trucking rig, rig, articulated lorry,
semi
'868': tray
'869': trench coat
'870': tricycle, trike, velocipede
'871': trimaran
'872': tripod
'873': triumphal arch
'874': trolleybus, trolley coach, trackless trolley
'875': trombone
'876': tub, vat
'877': turnstile
'878': typewriter keyboard
'879': umbrella
'880': unicycle, monocycle
'881': upright, upright piano
'882': vacuum, vacuum cleaner
'883': vase
'884': vault
'885': velvet
'886': vending machine
'887': vestment
'888': viaduct
'889': violin, fiddle
'890': volleyball
'891': waffle iron
'892': wall clock
'893': wallet, billfold, notecase, pocketbook
'894': wardrobe, closet, press
'895': warplane, military plane
'896': washbasin, handbasin, washbowl, lavabo, wash-hand basin
'897': washer, automatic washer, washing machine
'898': water bottle
'899': water jug
'900': water tower
'901': whiskey jug
'902': whistle
'903': wig
'904': window screen
'905': window shade
'906': Windsor tie
'907': wine bottle
'908': wing
'909': wok
'910': wooden spoon
'911': wool, woolen, woollen
'912': worm fence, snake fence, snake-rail fence, Virginia fence
'913': wreck
'914': yawl
'915': yurt
'916': web site, website, internet site, site
'917': comic book
'918': crossword puzzle, crossword
'919': street sign
'920': traffic light, traffic signal, stoplight
'921': book jacket, dust cover, dust jacket, dust wrapper
'922': menu
'923': plate
'924': guacamole
'925': consomme
'926': hot pot, hotpot
'927': trifle
'928': ice cream, icecream
'929': ice lolly, lolly, lollipop, popsicle
'930': French loaf
'931': bagel, beigel
'932': pretzel
'933': cheeseburger
'934': hotdog, hot dog, red hot
'935': mashed potato
'936': head cabbage
'937': broccoli
'938': cauliflower
'939': zucchini, courgette
'940': spaghetti squash
'941': acorn squash
'942': butternut squash
'943': cucumber, cuke
'944': artichoke, globe artichoke
'945': bell pepper
'946': cardoon
'947': mushroom
'948': Granny Smith
'949': strawberry
'950': orange
'951': lemon
'952': fig
'953': pineapple, ananas
'954': banana
'955': jackfruit, jak, jack
'956': custard apple
'957': pomegranate
'958': hay
'959': carbonara
'960': chocolate sauce, chocolate syrup
'961': dough
'962': meat loaf, meatloaf
'963': pizza, pizza pie
'964': potpie
'965': burrito
'966': red wine
'967': espresso
'968': cup
'969': eggnog
'970': alp
'971': bubble
'972': cliff, drop, drop-off
'973': coral reef
'974': geyser
'975': lakeside, lakeshore
'976': promontory, headland, head, foreland
'977': sandbar, sand bar
'978': seashore, coast, seacoast, sea-coast
'979': valley, vale
'980': volcano
'981': ballplayer, baseball player
'982': groom, bridegroom
'983': scuba diver
'984': rapeseed
'985': daisy
'986': yellow lady's slipper, yellow lady-slipper, Cypripedium calceolus,
Cypripedium parviflorum
'987': corn
'988': acorn
'989': hip, rose hip, rosehip
'990': buckeye, horse chestnut, conker
'991': coral fungus
'992': agaric
'993': gyromitra
'994': stinkhorn, carrion fungus
'995': earthstar
'996': hen-of-the-woods, hen of the woods, Polyporus frondosus, Grifola
frondosa
'997': bolete
'998': ear, spike, capitulum
'999': toilet tissue, toilet paper, bathroom tissue
splits:
- name: train
num_bytes: 12765331002.875
num_examples: 160145
- name: validation
num_bytes: 6706896736.0
num_examples: 50000
- name: test
num_bytes: 13610348261.0
num_examples: 100000
download_size: 33050742522
dataset_size: 33082575999.875
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
mlfoundations-dev/hero_run_3_code_s42
|
mlfoundations-dev
|
2025-05-08T14:55:25Z
| 0
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-08T14:55:03Z
| 0
|
---
dataset_info:
features:
- name: id
dtype: string
- name: instruction_seed
dtype: string
- name: output
dtype: string
- name: source
dtype: string
- name: license
dtype: string
- name: dataset
dtype: string
- name: split
dtype: string
- name: difficulty
dtype: int64
- name: solution
dtype: string
- name: index
dtype: string
- name: _source
dtype: string
- name: difficulty_reasoning
dtype: string
- name: __original_row_idx
dtype: int64
- name: ms_id
dtype: int64
- name: final_reasoning_trace
dtype: string
splits:
- name: train
num_bytes: 433236958
num_examples: 5208
download_size: 148142768
dataset_size: 433236958
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
AI4Protein/VenusX_Frag_Dom_MF70
|
AI4Protein
|
2025-05-14T17:02:37Z
| 0
| 0
|
[
"license:apache-2.0",
"size_categories:100K<n<1M",
"format:csv",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-14T17:02:16Z
| 0
|
---
license: apache-2.0
---
|
kothasuhas/rlpt_37M_16epochs_501k_generations_RS_T16.0
|
kothasuhas
|
2025-04-20T08:02:47Z
| 21
| 0
|
[
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-04-20T08:01:52Z
| 0
|
---
dataset_info:
features:
- name: text
dtype: string
- name: log_weight
dtype: float64
splits:
- name: train
num_bytes: 1341993378
num_examples: 289962
- name: validation
num_bytes: 5952216
num_examples: 1000
download_size: 861227631
dataset_size: 1347945594
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
---
|
kantine/domotic_dishTidyUp_expert
|
kantine
|
2025-03-27T15:11:25Z
| 31
| 0
|
[
"task_categories:robotics",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"anomaly_detection",
"domotic",
"dish"
] |
[
"robotics"
] |
2025-03-27T14:11:02Z
| 0
|
---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- anomaly_detection
- domotic
- dish
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.0",
"robot_type": "so100",
"total_episodes": 20,
"total_frames": 41800,
"total_tasks": 1,
"total_videos": 40,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:20"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.logitech_1": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.logitech_2": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
```
|
danaaubakirova/eval_koch_test
|
danaaubakirova
|
2025-01-10T15:38:33Z
| 75
| 0
|
[
"task_categories:robotics",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"tutorial",
"eval"
] |
[
"robotics"
] |
2025-01-10T12:30:35Z
| 0
|
---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- tutorial
- eval
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.0",
"robot_type": "koch",
"total_episodes": 26,
"total_frames": 7500,
"total_tasks": 1,
"total_videos": 52,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:26"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.laptop": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.phone": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
```
|
mlfoundations-dev/e1_science_longest_r1_1k
|
mlfoundations-dev
|
2025-05-21T18:33:35Z
| 0
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-05-21T18:16:06Z
| 0
|
---
dataset_info:
features:
- name: instruction_seed
dtype: string
- name: _source
dtype: string
- name: gpt41_mini_response
dtype: string
- name: __original_row_idx
dtype: int64
- name: length
dtype: int64
- name: domain
dtype: string
- name: r1_response
dtype: string
- name: r1_reasoning_content
dtype: string
- name: extract_solution
dtype: string
- name: url
dtype: string
- name: filename
dtype: string
- name: success
dtype: bool
- name: page_count
dtype: int64
- name: page_number
dtype: int64
- name: question_choices_solutions
dtype: string
- name: extracted_question
dtype: string
- name: extracted_answer_choices
sequence: string
- name: matched_solution
dtype: string
- name: qa_validation_outputs
dtype: bool
- name: classifier_reasoning
dtype: string
- name: is_organic_chemistry
dtype: bool
- name: ms_id
dtype: int64
- name: reasoning
sequence: string
- name: deepseek_solution
sequence: string
- name: final_reasoning_trace
sequence: string
- name: _majority_responses
sequence: string
- name: verified_final_reasoning_trace
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 795419389.0483334
num_examples: 1000
download_size: 313456549
dataset_size: 795419389.0483334
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Lots-of-LoRAs/task1098_ted_translation_ja_fa
|
Lots-of-LoRAs
|
2025-01-02T14:37:29Z
| 11
| 0
|
[
"task_categories:text-generation",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"language:en",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2204.07705",
"arxiv:2407.00066",
"region:us"
] |
[
"text-generation"
] |
2025-01-02T14:37:27Z
| 0
|
---
annotations_creators:
- crowdsourced
language_creators:
- crowdsourced
language:
- en
license:
- apache-2.0
task_categories:
- text-generation
pretty_name: task1098_ted_translation_ja_fa
dataset_info:
config_name: plain_text
features:
- name: input
dtype: string
- name: output
dtype: string
- name: id
dtype: string
splits:
- name: train
num_examples: 5128
- name: valid
num_examples: 641
- name: test
num_examples: 641
---
# Dataset Card for Natural Instructions (https://github.com/allenai/natural-instructions) Task: task1098_ted_translation_ja_fa
## Dataset Description
- **Homepage:** https://github.com/allenai/natural-instructions
- **Paper:** https://arxiv.org/abs/2204.07705
- **Paper:** https://arxiv.org/abs/2407.00066
- **Point of Contact:** [Rickard Brüel Gabrielsson](mailto:[email protected])
## Additional Information
### Citation Information
The following paper introduces the corpus in detail. If you use the corpus in published work, please cite it:
```bibtex
@misc{wang2022supernaturalinstructionsgeneralizationdeclarativeinstructions,
title={Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks},
author={Yizhong Wang and Swaroop Mishra and Pegah Alipoormolabashi and Yeganeh Kordi and Amirreza Mirzaei and Anjana Arunkumar and Arjun Ashok and Arut Selvan Dhanasekaran and Atharva Naik and David Stap and Eshaan Pathak and Giannis Karamanolakis and Haizhi Gary Lai and Ishan Purohit and Ishani Mondal and Jacob Anderson and Kirby Kuznia and Krima Doshi and Maitreya Patel and Kuntal Kumar Pal and Mehrad Moradshahi and Mihir Parmar and Mirali Purohit and Neeraj Varshney and Phani Rohitha Kaza and Pulkit Verma and Ravsehaj Singh Puri and Rushang Karia and Shailaja Keyur Sampat and Savan Doshi and Siddhartha Mishra and Sujan Reddy and Sumanta Patro and Tanay Dixit and Xudong Shen and Chitta Baral and Yejin Choi and Noah A. Smith and Hannaneh Hajishirzi and Daniel Khashabi},
year={2022},
eprint={2204.07705},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2204.07705},
}
```
More details can also be found in the following paper:
```bibtex
@misc{brüelgabrielsson2024compressserveservingthousands,
title={Compress then Serve: Serving Thousands of LoRA Adapters with Little Overhead},
author={Rickard Brüel-Gabrielsson and Jiacheng Zhu and Onkar Bhardwaj and Leshem Choshen and Kristjan Greenewald and Mikhail Yurochkin and Justin Solomon},
year={2024},
eprint={2407.00066},
archivePrefix={arXiv},
primaryClass={cs.DC},
url={https://arxiv.org/abs/2407.00066},
}
```
### Contact Information
For any comments or questions, please email [Rickard Brüel Gabrielsson](mailto:[email protected])
|
Tim1123/su_data
|
Tim1123
|
2024-11-28T07:41:53Z
| 35
| 0
|
[
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-11-23T13:31:15Z
| 0
|
---
dataset_info:
features:
- name: prompt
dtype: string
- name: completion
dtype: string
splits:
- name: train
num_bytes: 57120
num_examples: 9
- name: test
num_bytes: 21224
num_examples: 4
download_size: 82772
dataset_size: 78344
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
---
|
Aratako/magpie-reasoning-llama-nemotron-70b-100k-filtered
|
Aratako
|
2024-11-25T16:53:15Z
| 34
| 0
|
[
"language:ja",
"license:llama3.1",
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2024-11-22T03:06:57Z
| 0
|
---
dataset_info:
features:
- name: instruction
dtype: string
- name: reasoning
dtype: string
- name: initial_answer
dtype: string
- name: refined_answer
dtype: string
- name: conversations
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 455415225
num_examples: 36758
download_size: 208610481
dataset_size: 455415225
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: llama3.1
language:
- ja
---
# magpie-reasoning-llama-nemotron-70b-100k-filtered
[DeL-TaiseiOzaki/magpie-reasoning-llama-nemotron-70b-100k](https://huggingface.co/datasets/DeL-TaiseiOzaki/magpie-reasoning-llama-nemotron-70b-100k)から、`refined_answer`列に"改良"という文字が含まれていないものを抽出し、OpenAI messages形式に変換したデータセットです。
中身や注意事項等については元データセットの概要をご確認ください。
|
HarrytheOrange/parsed_AndroidControl
|
HarrytheOrange
|
2024-10-29T11:24:45Z
| 26
| 1
|
[
"license:apache-2.0",
"region:us"
] |
[] |
2024-10-18T12:26:37Z
| 0
|
---
license: apache-2.0
---
# Instructions for Extracting Images from AndroidControl TFRecord
Follow these steps to download and extract images from the AndroidControl TFRecord dataset.
## Step 1: Download the Original AndroidControl TFRecord
1. Navigate to [the AndroidControl TFRecord repository](https://github.com/google-research/google-research/tree/master/android_control) where the AndroidControl TFRecord is hosted.
2. Download the TFRecord file to your local machine or server.
## Step 2: Run the Python Script to Extract Images
1. Ensure that `extract_images.py` is in the same directory as your downloaded TFRecord or update the script to point to the location of your TFRecord.
2. Open a terminal or command prompt.
3. Execute the script by running:
```bash
python extract_images.py
## Step 3: Enjoy the parsed json data
### Here’s the information about the VH annotation:
Each screenshot corresponds to a `.pkl` file with the same name, containing a list of dictionaries. Each dictionary includes the following keys:
- **`"bounds_in_screen"`**: Defines the screen boundaries of the window, with values:
```json
{
"left": windows.bounds_in_screen.left,
"right": windows.bounds_in_screen.right,
"bottom": windows.bounds_in_screen.bottom,
"top": windows.bounds_in_screen.top
}
```
- **`"window_id"`**: The unique identifier of the window.
- **`"window_layer"`**: The layer or z-index of the window.
- **`"window_type"`**: The type of the window.
- **`"tree"`**: A list containing dictionaries representing each element node in the window.
Each node in the `"tree"` list includes:
- **`"bounds_in_screen"`**: The screen boundaries of the element node, with values:
```json
{
"left": node.bounds_in_screen.left,
"right": node.bounds_in_screen.right,
"bottom": node.bounds_in_screen.bottom,
"top": node.bounds_in_screen.top
}
```
- **`"class_name"`**: The class name of the element.
- **`"content_description"`**: The content description of the element.
- **`"package_name"`**: The package name the element belongs to.
- **`"text_selection_start"`**: The start position of any text selection.
- **`"text_selection_end"`**: The end position of any text selection.
- **`"view_id_resource_name"`**: The resource name of the view ID.
- **`"window_id"`**: The window ID associated with the element.
- **`"is_enabled"`**: Boolean indicating if the element is enabled.
- **`"is_visible_to_user"`**: Boolean indicating if the element is visible to the user.
- **`"actions"`**: A list of action IDs available for the element, derived as `[action.id for action in node.actions]`.
- **`"child_ids"`**: A list of IDs for child elements, derived as `[child_id for child_id in node.child_ids]`.
- **`"depth"`**: The depth of the element within the hierarchy.
- **`"drawing_order"`**: The order in which the element is drawn within the window.
|
visualwebbench/VisualWebBench
|
visualwebbench
|
2024-04-11T04:47:36Z
| 248
| 14
|
[
"task_categories:image-to-text",
"task_categories:visual-question-answering",
"language:en",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2404.05955",
"region:us"
] |
[
"image-to-text",
"visual-question-answering"
] |
2024-04-02T08:49:42Z
| 1
|
---
dataset_info:
- config_name: action_ground
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: raw_image
dtype: image
- name: options
sequence:
sequence: float64
- name: instruction
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 116178465
num_examples: 103
download_size: 116152003
dataset_size: 116178465
- config_name: action_prediction
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: options
sequence: string
- name: bbox
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 212320282
num_examples: 281
download_size: 212176366
dataset_size: 212320282
- config_name: element_ground
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: raw_image
dtype: image
- name: options
sequence:
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: int64
splits:
- name: test
num_bytes: 541444180
num_examples: 413
download_size: 425203495
dataset_size: 541444180
- config_name: element_ocr
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: bbox
sequence: float64
- name: elem_desc
dtype: string
- name: answer
dtype: string
splits:
- name: test
num_bytes: 177127391
num_examples: 245
download_size: 177036578
dataset_size: 177127391
- config_name: heading_ocr
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: bbox
sequence: float64
- name: answer
dtype: string
splits:
- name: test
num_bytes: 36406054
num_examples: 46
download_size: 36401829
dataset_size: 36406054
- config_name: web_caption
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: answer
dtype: string
splits:
- name: test
num_bytes: 112890184
num_examples: 134
download_size: 112864700
dataset_size: 112890184
- config_name: webqa
features:
- name: id
dtype: string
- name: task_type
dtype: string
- name: website
dtype: string
- name: image
dtype: image
- name: image_size
sequence: int64
- name: question
dtype: string
- name: answer
sequence: string
splits:
- name: test
num_bytes: 271769428
num_examples: 314
download_size: 100761418
dataset_size: 271769428
configs:
- config_name: action_ground
data_files:
- split: test
path: action_ground/test-*
- config_name: action_prediction
data_files:
- split: test
path: action_prediction/test-*
- config_name: element_ground
data_files:
- split: test
path: element_ground/test-*
- config_name: element_ocr
data_files:
- split: test
path: element_ocr/test-*
- config_name: heading_ocr
data_files:
- split: test
path: heading_ocr/test-*
- config_name: web_caption
data_files:
- split: test
path: web_caption/test-*
- config_name: webqa
data_files:
- split: test
path: webqa/test-*
license: apache-2.0
task_categories:
- image-to-text
- visual-question-answering
language:
- en
pretty_name: VisualWebBench
size_categories:
- 1K<n<10K
---
# VisualWebBench
Dataset for the paper: [VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?](https://arxiv.org/abs/2404.05955)
[**🌐 Homepage**](https://visualwebbench.github.io/) | [**🐍 GitHub**](https://github.com/VisualWebBench/VisualWebBench) | [**📖 arXiv**](https://arxiv.org/abs/2404.05955)
## Introduction
We introduce **VisualWebBench**, a multimodal benchmark designed to assess the **understanding and grounding capabilities of MLLMs in web scenarios**. VisualWebBench consists of **seven tasks**, and comprises **1.5K** human-curated instances from **139** real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude 3, and GPT-4V(ision) on WebBench, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe VisualWebBench will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
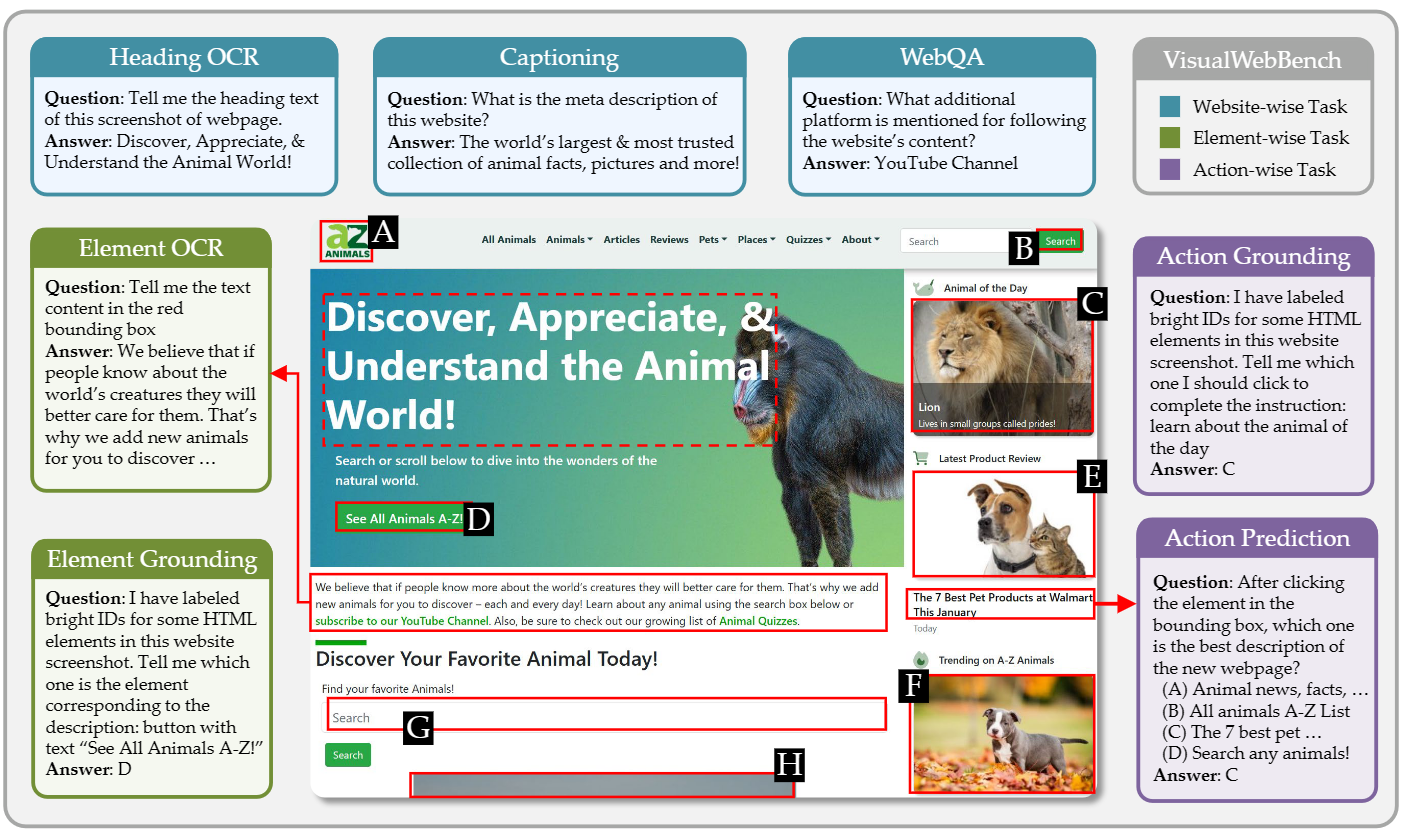
## Benchmark Construction
We introduce VisualWebBench, a comprehensive multimodal benchmark designed to assess the capabilities of MLLMs in the web domain. Inspired by the human interaction process with web browsers, VisualWebBench consists of seven tasks that map to core abilities required for web tasks: captioning, webpage QA, heading OCR, element OCR, element grounding, action prediction, and action grounding, as detailed in the figure. The benchmark comprises 1.5K instances, all uniformly formulated in the QA style, making it easy to evaluate and compare the performance of different MLLMs.
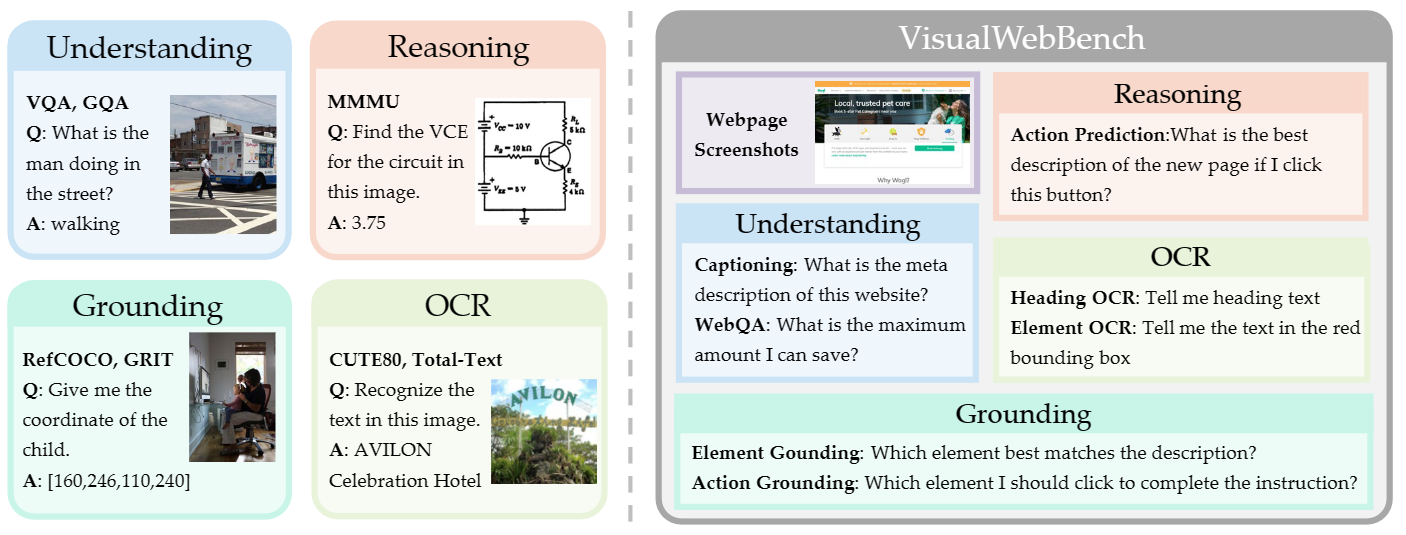
The proposed VisualWebBench possesses the following features:
- **Comprehensiveness**: VisualWebBench spans 139 websites with 1.5K samples, encompassing 12 different domains (e.g., travel, sports, hobby, lifestyle, animals, science, etc.) and 87 sub-domains.
- **Multi-granularity**: VisualWebBench assesses MLLMs at three levels: website-level, element-level, and action-level.
- **Multi-tasks**: WebBench encompasses seven tasks designed to evaluate the understanding, OCR, grounding, and reasoning capabilities of MLLMs.
- **High quality**: Quality is ensured through careful human verification and curation efforts.
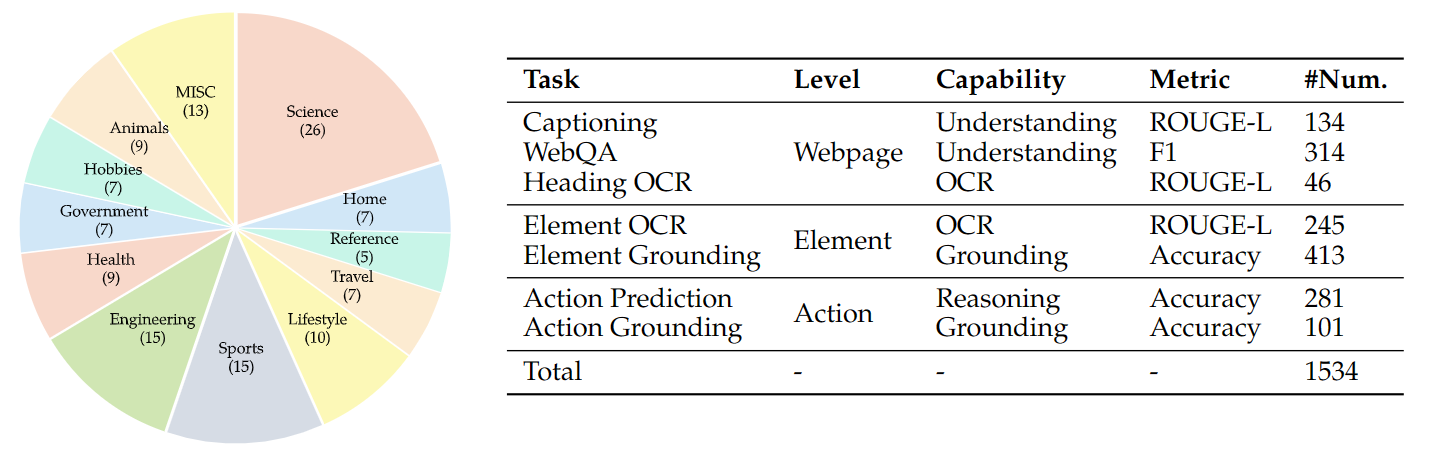
## Evaluation
We provide [evaluation code](https://github.com/VisualWebBench/VisualWebBench) for GPT-4V, Claude, Gemini, and LLaVA 1.6 series.
## Contact
- Junpeng Liu: [[email protected]]([email protected])
- Yifan Song: [[email protected]]([email protected])
- Xiang Yue: [[email protected]]([email protected])
## Citation
If you find this work helpful, please cite out paper:
```
@misc{liu2024visualwebbench,
title={VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?},
author={Junpeng Liu and Yifan Song and Bill Yuchen Lin and Wai Lam and Graham Neubig and Yuanzhi Li and Xiang Yue},
year={2024},
eprint={2404.05955},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Akirashindo39/KANJIDIC2
|
Akirashindo39
|
2025-03-12T03:28:55Z
| 16
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-03-11T19:06:47Z
| 0
|
---
dataset_info:
features:
- name: image
dtype: image
- name: text
dtype: string
splits:
- name: train
num_bytes: 18062041.524
num_examples: 6413
download_size: 17736304
dataset_size: 18062041.524
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
This dataset was generated by processing the following files:
* KANJIDIC2 file ([kanjidic2.xml](https://www.edrdg.org/kanjidic/kanjidic2.xml.gz))
* Associated SVG file for the KANJIDIC2 file ([kanjivg-20220427.xml](https://github.com/KanjiVG/kanjivg/releases/download/r20220427/kanjivg-20220427.xml.gz))
The above files were processed to generate a mapping that links each Kanji character to its corresponding English meaning, which was then associated with the relevant image files.
|
Daemontatox/Openthoughts_convs
|
Daemontatox
|
2025-02-27T15:38:36Z
| 33
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-02-27T15:37:07Z
| 0
|
---
dataset_info:
features:
- name: problem_type
dtype: string
- name: question_type
dtype: string
- name: source
dtype: string
- name: uuid
dtype: string
- name: is_reasoning_complete
sequence: bool
- name: generations
sequence: string
- name: correctness_math_verify
sequence: bool
- name: correctness_llama
sequence: bool
- name: finish_reasons
sequence: string
- name: correctness_count
dtype: int64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 4966699449
num_examples: 93733
download_size: 2147786946
dataset_size: 4966699449
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
JaehyeokLee/dn_sft_part_2
|
JaehyeokLee
|
2025-02-28T01:59:01Z
| 62
| 0
|
[
"size_categories:1M<n<10M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-02-28T01:51:44Z
| 0
|
---
dataset_info:
features:
- name: subset
dtype: string
- name: anchor
dtype: string
- name: positive
dtype: string
- name: anchor_token_count
dtype: int64
- name: positive_token_count
dtype: int64
splits:
- name: train
num_bytes: 4200647106
num_examples: 1000154
download_size: 2432884147
dataset_size: 4200647106
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Raj31/motor-vehicle-accidents
|
Raj31
|
2025-01-20T00:48:57Z
| 18
| 1
|
[
"task_categories:text-classification",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"library:distilabel",
"region:us",
"synthetic",
"distilabel",
"rlaif",
"datacraft"
] |
[
"text-classification"
] |
2025-01-20T00:48:56Z
| 0
|
---
size_categories: n<1K
task_categories:
- text-classification
dataset_info:
features:
- name: text
dtype: string
- name: label
dtype:
class_label:
names:
'0': crash-caused-by-driver-error
'1': crash-caused-by-other-factors
'2': crash-caused-by-road-condition
'3': crash-caused-by-vehicle-malfunction
splits:
- name: train
num_bytes: 17905
num_examples: 50
download_size: 10622
dataset_size: 17905
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- synthetic
- distilabel
- rlaif
- datacraft
---
<p align="left">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
# Dataset Card for motor-vehicle-accidents
This dataset has been created with [distilabel](https://distilabel.argilla.io/).
## Dataset Summary
This dataset contains a `pipeline.yaml` which can be used to reproduce the pipeline that generated it in distilabel using the `distilabel` CLI:
```console
distilabel pipeline run --config "https://huggingface.co/datasets/Raj31/motor-vehicle-accidents/raw/main/pipeline.yaml"
```
or explore the configuration:
```console
distilabel pipeline info --config "https://huggingface.co/datasets/Raj31/motor-vehicle-accidents/raw/main/pipeline.yaml"
```
## Dataset structure
The examples have the following structure per configuration:
<details><summary> Configuration: default </summary><hr>
```json
{
"label": 0,
"text": "A vehicle was involved in a collision with a pedestrian at the intersection of Park Street and Railway Parade, where it is believed that the pedestrian stepped out onto the road and was struck by the vehicle. The pedestrian was treated at the scene and is in stable condition. A breath test was conducted on the driver and it was below the legal limit. The vehicle\u0027s tyre was examined and it was found to be worn but not bald."
}
```
This subset can be loaded as:
```python
from datasets import load_dataset
ds = load_dataset("Raj31/motor-vehicle-accidents", "default")
```
Or simply as it follows, since there's only one configuration and is named `default`:
```python
from datasets import load_dataset
ds = load_dataset("Raj31/motor-vehicle-accidents")
```
</details>
|
ferrazzipietro/e3c-sentences-IT-original-plus-revised
|
ferrazzipietro
|
2025-01-09T10:58:55Z
| 25
| 0
|
[
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-01-09T10:58:38Z
| 0
|
---
dataset_info:
features:
- name: sentence
dtype: string
- name: entities
list:
- name: id
dtype: string
- name: offsets
sequence: int64
- name: role
dtype: string
- name: semantic_type_id
dtype: string
- name: text
dtype: string
- name: type
dtype: string
splits:
- name: train
num_bytes: 369144
num_examples: 1167
- name: validation
num_bytes: 41939
num_examples: 167
- name: test
num_bytes: 401357
num_examples: 1283
download_size: 386878
dataset_size: 812440
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
|
mlfoundations-dev/nemo_nano_science_3k
|
mlfoundations-dev
|
2025-05-06T05:30:38Z
| 0
| 0
|
[
"region:us"
] |
[] |
2025-05-06T05:30:28Z
| 0
|
---
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: category
dtype: string
- name: license
dtype: string
- name: reasoning
dtype: string
- name: generator
dtype: string
- name: used_in_training
dtype: string
- name: version
dtype: string
- name: system_prompt
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 51880588.275461264
num_examples: 3160
download_size: 24342591
dataset_size: 51880588.275461264
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
pengjunkun/so100_test
|
pengjunkun
|
2025-02-24T08:05:06Z
| 40
| 0
|
[
"task_categories:robotics",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"LeRobot",
"so100",
"tutorial"
] |
[
"robotics"
] |
2025-02-24T08:04:56Z
| 0
|
---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- so100
- tutorial
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.0",
"robot_type": "so100",
"total_episodes": 2,
"total_frames": 898,
"total_tasks": 1,
"total_videos": 2,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 30,
"splits": {
"train": "0:2"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"action": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.state": {
"dtype": "float32",
"shape": [
6
],
"names": [
"main_shoulder_pan",
"main_shoulder_lift",
"main_elbow_flex",
"main_wrist_flex",
"main_wrist_roll",
"main_gripper"
]
},
"observation.images.laptop": {
"dtype": "video",
"shape": [
480,
640,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 30.0,
"video.height": 480,
"video.width": 640,
"video.channels": 3,
"video.codec": "h264",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
```
|
CultriX/dpo-merged
|
CultriX
|
2024-10-20T19:22:31Z
| 28
| 0
|
[
"task_categories:text-generation",
"language:en",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"math",
"truthy",
"dpo",
"logic",
"reasoning"
] |
[
"text-generation"
] |
2024-10-19T14:44:51Z
| 0
|
---
license: apache-2.0
task_categories:
- text-generation
language:
- en
tags:
- math
- truthy
- dpo
- logic
- reasoning
pretty_name: Merge of multiple public DPO datasets
size_categories:
- 10K<n<100K
---
|
mathieu1256/FATURA2-invoices
|
mathieu1256
|
2024-02-18T22:00:49Z
| 173
| 8
|
[
"task_categories:feature-extraction",
"language:en",
"license:cc-by-4.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2311.11856",
"region:us",
"invoices",
"data extraction",
"invoice",
"FATURA2"
] |
[
"feature-extraction"
] |
2024-02-15T14:13:47Z
| 1
|
---
language:
- en
license: cc-by-4.0
size_categories:
- 1K<n<10K
task_categories:
- feature-extraction
pretty_name: FATURA 2 invoices
tags:
- invoices
- data extraction
- invoice
- FATURA2
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
dataset_info:
features:
- name: image
dtype: image
- name: ner_tags
sequence: int64
- name: bboxes
sequence:
sequence: int64
- name: tokens
sequence: string
- name: id
dtype: string
splits:
- name: train
num_bytes: 411874484.6
num_examples: 8600
- name: test
num_bytes: 60569760.6
num_examples: 1400
download_size: 342750666
dataset_size: 472444245.20000005
---
The dataset consists of 10000 jpg images with white backgrounds, 10000 jpg images with colored backgrounds (the same colors used in the paper) as well as 3x10000 json annotation files. The images are generated from 50 different templates.
https://zenodo.org/records/10371464
---
dataset_info:
features:
- name: image
dtype: image
- name: ner_tags
sequence: int64
- name: words
sequence: string
- name: bboxes
sequence:
sequence: int64
splits:
- name: train
num_bytes: 477503369.0
num_examples: 10000
download_size: 342662174
dataset_size: 477503369.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
@misc{limam2023fatura, title={FATURA: A Multi-Layout Invoice Image Dataset for Document Analysis and Understanding}, author={Mahmoud Limam and Marwa Dhiaf and Yousri Kessentini}, year={2023}, eprint={2311.11856}, archivePrefix={arXiv}, primaryClass={cs.CV} }
|
andy-iv/jenny_tts_dataset-tagged
|
andy-iv
|
2025-01-19T13:03:24Z
| 19
| 0
|
[
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-01-19T13:03:21Z
| 0
|
---
dataset_info:
features:
- name: file_name
dtype: string
- name: text
dtype: string
- name: transcription_normalised
dtype: string
- name: utterance_pitch_mean
dtype: float32
- name: utterance_pitch_std
dtype: float32
- name: snr
dtype: float64
- name: c50
dtype: float64
- name: speaking_rate
dtype: string
- name: phonemes
dtype: string
- name: noise
dtype: string
- name: reverberation
dtype: string
- name: speech_monotony
dtype: string
- name: text_description
dtype: string
splits:
- name: train
num_bytes: 10058849
num_examples: 20978
download_size: 4743145
dataset_size: 10058849
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
itdainb/calibrate_vn
|
itdainb
|
2025-03-18T12:27:55Z
| 25
| 0
|
[
"language:vi",
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] |
[] |
2025-02-28T05:30:03Z
| 0
|
---
language:
- vi
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 119524975
num_examples: 10000
download_size: 59645316
dataset_size: 119524975
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
Subsets and Splits
Recent Trending Datasets
Lists newly created datasets from the past week, sorted by trending score, creation date, likes, and downloads, highlighting popular and recently active datasets.